CN109086807B - Semi-supervised optical flow learning method based on void convolution stacking network - Google Patents
Semi-supervised optical flow learning method based on void convolution stacking network Download PDFInfo
- Publication number
- CN109086807B CN109086807B CN201810779483.8A CN201810779483A CN109086807B CN 109086807 B CN109086807 B CN 109086807B CN 201810779483 A CN201810779483 A CN 201810779483A CN 109086807 B CN109086807 B CN 109086807B
- Authority
- CN
- China
- Prior art keywords
- network
- optical flow
- layers
- stacking
- semi
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G06F18/2155—Generating training patterns; Bootstrap methods, e.g. bagging or boosting characterised by the incorporation of unlabelled data, e.g. multiple instance learning [MIL], semi-supervised techniques using expectation-maximisation [EM] or naïve labelling
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Software Systems (AREA)
- Mathematical Physics (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Computing Systems (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Image Analysis (AREA)
Abstract
The invention provides a semi-supervised learning optical flow method based on a convolutional neural network, belonging to the field of network design. The method provided by the invention can be used for training mixed data with labels and without labels, designing an occlusion perception loss function, combining an end point error cost function for supervised learning with a data item and a smooth item for unsupervised learning to construct a semi-supervised learning optical flow model, adopting a stacked network structure on a network architecture, introducing cavity convolution into a convolutional layer to increase the receptive field, and designing an occlusion perception layer to estimate an occlusion area, wherein the network can carry out semi-supervised optical flow learning end to end. The method provided by the invention can improve the optical flow estimation precision, and also provides a shielding perception loss function to semi-supervise the training network, and a stacked network structure is designed on the network architecture so as to further improve the network performance.
Description
Technical Field
The invention provides an optical flow estimation method, particularly relates to a semi-supervised optical flow learning method based on a void convolution stack network, and belongs to the field of network design.
Background
The optical flow estimation can be used as a supervised learning problem, and the supervised learning method based on the convolutional neural network has a good effect on solving the optical flow estimation problem, but the supervised learning optical flow method still has many problems. Firstly, real world data truth values are difficult to obtain, a large amount of labeled data is lacking to become a limitation of a supervised learning optical flow method, secondly, in order to avoid loss of motion information, pooling operation is not performed in many existing full convolution network architectures, however, detail information of images is still lost by convolution operation, and the problems are still fatal to pixel-level tasks. Meanwhile, the occlusion problem is also an urgent problem to be solved in the optical flow estimation.
Aiming at the problems, the invention provides a semi-supervised learning optical flow model based on a convolutional neural network, which introduces cavity convolution in a network convolution layer to increase the receptive field, designs a layer of shielding sensing layer to blend a shielding area into a network training process to improve the optical flow estimation precision, further provides a shielding sensing loss function to semi-supervise the training network, and finally designs a stacked network structure on a network architecture to further improve the network performance.
Disclosure of Invention
The invention provides a semi-supervised optical flow learning method based on a hole convolution stack network, which aims to train mixed data with labels and without labels, design a shielding perception loss function, combine an end point error cost function for supervised learning with a data item and a smooth item for unsupervised learning, construct a semi-supervised learning optical flow model named SA-Net, adopt a stack network structure on a network architecture, introduce hole convolution into a convolution layer to increase the perception field of a convolution kernel, and design a shielding perception layer to estimate a shielding area, wherein the network can carry out end-to-end semi-supervised learning optical flow.
The purpose of the invention is realized as follows:
step one, constructing a 1 st optical flow learning sub-network, and naming the optical flow learning sub-network as SA-Net _1, wherein the SA-Net _1 optical flow learning network adopts a full convolution architecture and is composed of 2 parts of contraction and expansion, the contraction part firstly extracts feature maps from 2 images by adopting 4 layers of standard convolution operation, then the 2 feature maps are input into related layers for feature matching and merging, optical flow features are extracted through 4 layers of cavity convolution layers, the expansion part comprises 4 layers of deconvolution layers, and the optical flow extracted by the contraction part is restored to the resolution of an original image.
And step two, constructing a 2 nd optical flow learning sub-network, which is named as SA-Net _2, wherein the SA-Net _2 optical flow learning network adopts a full convolution architecture and consists of 2 parts of contraction and expansion, an input layer inputs 2 images into the network after stacking, the network extracts optical flows between image pairs through 4 layers of standard convolution layers and 4 layers of cavity convolution layers, a contraction part consists of 4 layers of deconvolution layers, and the optical flows extracted by the contraction part are restored to the resolution of the original images.
And step three, constructing 2 stacking networks, connecting 2 SA-Net _2 sub-networks after the SA-Net _1 sub-network to form a 1 st stacking network, deforming the 2 nd image to the 1 st image at the connection part of each sub-network by adopting a deformation technology, taking the deformed images and the 1 st image as the input of the next sub-network, and calculating the optical flow increment of the 2 images. The 2 nd stacking network and the 1 st stacking network share network architecture and parameters, 2 images at the t moment and the t +1 moment are input into the input end of the 1 st stacking network, forward optical flow between image pairs is extracted, meanwhile, the images at the t moment and the t +1 moment are input into the 2 nd stacking network in a switching order, and reverse optical flow between the image pairs is extracted.
And step four, training 2 stacking networks, wherein only the 1 st stacking network is required to be trained, the 2 nd network shares the updated network weight, when the subnetworks at the corresponding positions of the 2 stacking networks are synchronously trained, each 1 layer of the expansion part respectively outputs forward optical flows and reverse optical flows with different resolutions, the forward optical flows and the reverse optical flows of each layer are simultaneously input into the shielding perception layer, the shielding area is judged through the consistency check function, and the positive and negative consistency check is stopped until the forward optical flows are restored to the original resolution.
And step five, designing a shielding perception loss function, and performing semi-supervised learning on the network. The end point error cost function for supervised learning is combined with the data item and the smooth item for unsupervised learning, so that the labeled data and the unlabeled data can be trained, wherein the data item is designed with a constant assumption based on image structure texture decomposition and Census transformation, the smooth item is designed by isotropic diffusion based on image driving, and the loss function can be used for semi-supervised training network end to end through back propagation.
And step six, in the training stage, firstly inputting a large amount of label-free data at the input end of the network, obtaining total loss by summing the loss weights, then training the network by using a back propagation algorithm to obtain an initial network weight, and then training the network by using a small amount of labeled data to obtain a final network model.
And step seven, testing by using the trained model, inputting the image pair, and outputting the corresponding optical flow.
Compared with the prior art, the invention has the advantages that:
the method provided by the invention introduces cavity convolution in the network convolution layer to increase the receptive field, designs a layer of shielding sensing layer to fuse the shielding area into the network training process to improve the optical flow estimation precision, further provides a shielding sensing loss function to semi-supervise the training network, and also designs a stacked network structure on the network architecture to further improve the network performance.
Drawings
FIG. 1 is a flow chart of the present invention.
FIG. 2 is a diagram of the learning subnetwork SA-Net _1 architecture of the present invention.
FIG. 3 is a diagram of the learning subnetwork SA-Net _2 architecture of the present invention.
Fig. 4 is a diagram of a stacked learning network architecture according to the present invention.
FIG. 5 is a schematic diagram of the hole convolution according to the present invention.
FIG. 6 is a schematic diagram of an occlusion region error according to the present invention.
FIG. 7 is a diagram of the architecture of the semi-supervised learning optical flow network SA-Net according to the present invention.
Detailed Description
The invention is described in more detail below with reference to the accompanying drawings.
Step one, as shown in fig. 2, 1 optical flow learning subnetwork SA-Net _1 is constructed, firstly, feature maps of images at time t and time t +1 are respectively extracted from a contraction part through 4 layers of standard convolution layers, a network is helped to match the feature maps through a related layer, and a corresponding relation between the feature maps is found, wherein a related function of the related layer is defined as follows:

wherein The characteristic diagrams at time t and time t +1 are shown, respectively, and pi indicates a blob of size K × K centered on pixel x.
The characteristic diagrams at time t and time t +1 are shown, respectively, and pi indicates a blob of size K × K centered on pixel x.
The method comprises the steps of respectively taking 2 blobs which are centered at x1 and x2 in 2 images, multiplying the blobs at corresponding positions and then adding the blobs, carrying out correlation operation on the whole image by a correlation layer, simultaneously merging the features of the 2 images, and then extracting features of higher levels by 4 layers of hole convolution layers, wherein a hole convolution schematic diagram can be shown in a figure 5, and the figure 5 shows 1 hole convolution kernel with the size of 3 x 3 and the interval of 1. The convolution kernel size of the standard convolution layer is 3 × 3, the step size is 2, the cavity convolution kernel size is 3 × 3, the step size is 1, the interval value increases exponentially from small to large and is respectively 2, 4, 8 and 16, the ReLU layer is arranged next to each convolution layer and the cavity convolution layer, and other parameter settings and details can be shown in FIG. 2. The expansion part of the network is composed of 4 layers of deconvolution layers, the convolution kernel size is 3 x 3, the step length is 2, each layer of deconvolution layer is connected with a ReLU layer, and the feature diagram is restored to the original image resolution size through a series of deconvolution operations, so that the final optical flow is obtained.
And step two, as shown in FIG. 3, constructing a 2 nd optical flow learning subnetwork SA-Net _2, inputting images at the time t and the time t +1 into a network in a stacking mode, wherein firstly, a contraction part is composed of 4 layers of standard convolutional layers and 4 layers of cavity convolutional layers, the network extracts optical flow information through the standard convolutional layers and the cavity convolutional layers, an expansion part is composed of 4 layers of deconvolution layers, and the optical flow is restored to the resolution of the original image. The convolution kernel size of the standard convolution layer is 3 x 3, the step size is 2, the convolution kernel size of the cavity convolution layer is 3 x 3, the step size is 1, the intervals increase in an exponential mode and are respectively 2, 4, 8 and 12, the convolution kernel size of the deconvolution layer is 5 x 5, the step size is 2, and each convolution layer is connected with the nonlinear ReLU layer. Since the SA-Net _1 and SA-Net _2 sub-networks do not contain a fully connected layer, the input to both networks can be an image of any size.
Step three, training 2 stacked learning networks with the same architecture simultaneously, and learning a forward optical flow and a backward optical flow between two images in a semi-supervised mode, wherein each stacked learning network is formed by stacking 1 SA-Net _1 sub-network and 2 SA-Net _2 sub-networks, in order to evaluate the result of the previous sub-network and update the calculation increment of the whole network more easily, a deformation operation is added between each stacked sub-network, the output optical flow of the previous sub-network is used for performing a deformation operation on the image at the t +1 th moment, and the obtained image can be represented by the following formula:

wherein It+1, Representing the pre-and post-warped images, respectively, u, v representing the optical flow values at pixels x, y, respectively.
Representing the pre-and post-warped images, respectively, u, v representing the optical flow values at pixels x, y, respectively.
Will be deformed the images at the moment t and their brightness errors are used as the input of the next sub-networkNetwork learning
the images at the moment t and their brightness errors are used as the input of the next sub-networkNetwork learning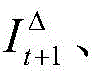 Incremental optical flow between images at time t. The morphing operation is realized by a guided bilinear interpolation algorithm, so that the stacked network can be trained end to end. In the training stage, only the 1 st stacking network needs to be trained, the 2 nd stacking network shares the weight of the stacking network, the training strategy adopted by the stacking network is to train the SA-Net _1 sub-network firstly, provide a good initial value for the next two sub-networks, keep the weight of the SA-Net _1 unchanged, train the next stacking sub-network SA-Net _2, then fix the weight of the previous 2 sub-networks unchanged, train the 3 rd stacking sub-network, and update the weight. The SA-Net increases the depth of the network in a network stacking mode, and increases the iteration times during network training, so that the overall performance of the network is improved.
Incremental optical flow between images at time t. The morphing operation is realized by a guided bilinear interpolation algorithm, so that the stacked network can be trained end to end. In the training stage, only the 1 st stacking network needs to be trained, the 2 nd stacking network shares the weight of the stacking network, the training strategy adopted by the stacking network is to train the SA-Net _1 sub-network firstly, provide a good initial value for the next two sub-networks, keep the weight of the SA-Net _1 unchanged, train the next stacking sub-network SA-Net _2, then fix the weight of the previous 2 sub-networks unchanged, train the 3 rd stacking sub-network, and update the weight. The SA-Net increases the depth of the network in a network stacking mode, and increases the iteration times during network training, so that the overall performance of the network is improved.
Step four, as shown in fig. 6, in the non-shielded area, a pixel point returns to the original pixel position after being subjected to forward optical flow mapping and reverse optical flow mapping, and in the shielded area, the pixel point position of the pixel point after being subjected to the forward optical flow mapping and the reverse optical flow mapping has a deviation from the original pixel point position, and the shielded area is a concentrated area where such errors occur, so that the shielded area with a large optical flow estimation error can be obtained by performing positive and negative consistency check on the forward optical flow and the reverse optical flow. The positive and negative consistency check discriminant function is as follows:

wherein And
And representing the forward and reverse optical flows at pixel x, respectively, with epsilon being the threshold of the discriminant function.
representing the forward and reverse optical flows at pixel x, respectively, with epsilon being the threshold of the discriminant function.
Defining an occlusion tagging function OxWhen the discriminant function is greater thanWhen the threshold value is reached, the optical flow solution of the area has larger error, the area is judged to be shielded, and O is usedx1. When the discriminant function is smaller than the threshold value, the optical flow solution of the area is accurate, the area is judged to be a non-shielding area, and O is enabledx0. During training, consistency check is carried out on each 1-layer forward optical flow and reverse optical flow of 2 stacked network expansion parts, and an occlusion area is estimated to be used in a network training process. The sheltered area participates in the network training process, and the optical flow precision is improved.
And fifthly, designing a shielding perception loss function for restraining pixels in the shielding area, wherein the shielding perception loss function is suitable for a semi-supervised learning optical flow network, the loss function is only applied to a training stage, and the semi-supervised learning optical flow network is trained through back propagation. Compared with the supervised learning optical flow model, the semi-supervised learning optical flow model is not limited by difficulty in acquiring the true value of the optical flow, can learn the optical flow with or without supervision, and is more suitable for solving the problem of motion information extraction in the real world.
Loss function ElossThe following were used:
Eloss=αEepe+(1-α)(Edata+γEsmooth), (4)
wherein EepeAs an end point error cost function, EdataConstraining the cost function for the data item, EsmoothAnd motion smoothing constraint, wherein alpha and gamma are weights, alpha is 1 when the input data are labeled data, and alpha is 0 when the input data are unlabeled data.
End point error cost function EepeThe following were used:

where m and n are the width and height, respectively, of the input image, ui,jAnd vi,jRespectively, predicted optical flow values, ui′,jAnd vi′,jIs the corresponding optical flow true value.
Data item cost function EdataThe following were used:

wherein κxIs the optical flow at pixel point x, N is the number of pixel points, T (x) represents the value of texture quantity at pixel point x, C (x) represents the value of Census transformation at pixel point x, and phi is the robust penalty function (x)2+δ2)α,δ=0.001,OxRepresenting an occlusion flag function.
Image texture algorithm decomposes an image into a part I containing geometric informationS(x) And a part I containing image texture informationT(x) Namely, the following formula:
I(x)=IS(x)+IT(x), (7)
wherein the texture part I of the imageT(x) Hardly affected by light intensity changes such as illumination and shadows.
Census transform is a nonlinear transform, has conservation property under the condition of severe and monotonous illumination, represents pixels in a certain rectangular transform window in an image by a string of binary sequences, and is applied to data item constraints after being simply improved, and the concrete realization formula is as follows:


wherein W (p) represents a rectangular transformation window with p as a central pixel point, q is other points in the rectangular transformation window, I (p), I (q) are the gray values of p, q pixel points respectively, σ is a threshold value of the discriminant.
σ is a threshold value of the discriminant.
The motion smoothing cost function is as follows:

wherein And
And the gradient values of the optical flow in the horizontal direction and the vertical direction, respectively.
the gradient values of the optical flow in the horizontal direction and the vertical direction, respectively.
And step six, inputting a small amount of labeled data and a large amount of unlabeled data at the input end of the network, summing the different loss weights to obtain the total loss, and training the semi-supervised learning network by using a back propagation algorithm.
And step seven, inputting labeled data and unlabeled data in the trained model, testing the semi-supervised learning optical flow network, and outputting corresponding dense optical flow.
Claims (5)
1. A semi-supervised optical flow learning method based on a hole convolution stacking network is characterized by comprising the following steps:
step one, constructing a 1 st optical flow learning sub-network, and naming the optical flow learning sub-network as SA-Net _1, wherein the SA-Net _1 optical flow learning network adopts a full convolution architecture and is composed of 2 parts of contraction and expansion, the contraction part firstly extracts feature maps from 2 images by adopting 4 layers of standard convolution operation respectively, then 2 feature maps are input into related layers for feature matching and merging, optical flow features are extracted through 4 layers of cavity convolution layers, the expansion part comprises 4 layers of deconvolution layers, and the optical flow extracted by the contraction part is restored to the resolution of an original image;
step two, constructing a 2 nd optical flow learning sub-network, which is named as SA-Net _2, wherein the SA-Net _2 optical flow learning network adopts a full convolution architecture and consists of 2 parts of contraction and expansion, an input layer inputs 2 images into the network after stacking, the network extracts optical flows between image pairs through 4 layers of standard convolution layers and 4 layers of cavity convolution layers, a contraction part consists of 4 layers of reverse convolution layers, and the optical flows extracted by the contraction part are restored to the resolution ratio of the original images;
step three, constructing 2 stacking networks, connecting 2 SA-Net _2 sub-networks after the SA-Net _1 sub-network to form a 1 st stacking network, deforming the 2 nd image to the 1 st image at the connection part of each sub-network by adopting a deformation technology, taking the deformed images and the 1 st image as the input of the next sub-network, and calculating the optical flow increment of the 2 images; the 2 nd stacking network and the 1 st stacking network share network architecture and parameters, 2 images at the t moment and the t +1 moment are input into the input end of the 1 st stacking network, forward optical flow between image pairs is extracted, meanwhile, the images at the t moment and the t +1 moment are input into the 2 nd stacking network in a switching order, and reverse optical flow between the image pairs is extracted;
step four, training 2 stacking networks, wherein only the 1 st stacking network is required to be trained, the 2 nd network shares the updated network weight, when the subnetworks at the corresponding positions of the 2 stacking networks are synchronously trained, each 1 layer of the expansion part respectively outputs forward optical flows and reverse optical flows with different resolutions, the forward optical flows and the reverse optical flows of each layer are simultaneously input into the shielding perception layer, the shielding area is judged through the consistency check function, and the positive and negative consistency check is stopped until the forward optical flows are restored to the original resolution;
designing a shielding perception loss function, wherein a semi-supervised learning network can be designed, an end point error cost function for supervised learning is combined with a data item and a smooth item for unsupervised learning, so that the labeled data can be trained, and the unlabeled data can also be trained, wherein the data item is a constant hypothesis designed based on image structure texture decomposition and Census transformation, the smooth item is designed by adopting isotropic diffusion based on image driving, and the loss function is end-to-end through back propagation to the semi-supervised training network;
step six, in the training stage, firstly inputting a large amount of label-free data at the input end of the network, obtaining total loss by summing loss weights, then training the network by using a back propagation algorithm to obtain an initial network weight, and then training the network by using a small amount of labeled data to obtain a final network model;
step seven, testing by using the trained model, inputting the image pair and outputting the corresponding optical flow;
loss function E described in step fivelossThe following were used:
Eloss=αEepe+(1-α)(Edata+γEsmooth), (4)
wherein EepeAs an end point error cost function, EdataConstraining the cost function for the data item, EsmoothAnd motion smoothing constraint, wherein alpha and gamma are weights, alpha is 1 when the input data are labeled data, and alpha is 0 when the input data are unlabeled data.
2. The semi-supervised optical flow learning method based on the hole convolution stacking network as recited in claim 1, wherein: the process of extracting the feature map in the step one is as follows:
respectively extracting feature maps of images at the t moment and the t +1 moment by 4 layers of standard convolutional layers, helping a network to match the feature maps by a related layer, and finding out the corresponding relation between the feature maps, wherein the related function of the related layer is defined as follows:

wherein The characteristic diagrams at time t and time t +1 are shown, respectively, and pi indicates a blob of size K × K centered on pixel x.
The characteristic diagrams at time t and time t +1 are shown, respectively, and pi indicates a blob of size K × K centered on pixel x.
3. The semi-supervised optical flow learning method based on the hole convolution stacking network as recited in claim 1, wherein: the deformation operation process described in step three is as follows: and (3) performing deformation operation on the image at the t +1 th moment by using the output optical flow of the previous sub-network, wherein the obtained image can be represented by the following formula:

wherein It+1, Representing the pre-and post-warped images, respectively, u, v representing the optical flow values at pixels x, y, respectively.
Representing the pre-and post-warped images, respectively, u, v representing the optical flow values at pixels x, y, respectively.
4. The semi-supervised optical flow learning method based on the hole convolution stacking network as recited in claim 1, wherein: the process of distinguishing the occlusion region by the consistency check function in the fourth step is as follows:
the positive and negative consistency check function formula is as follows

Wherein And
And respectively representing a forward optical flow and a reverse optical flow at a pixel x, wherein epsilon is a threshold value of a discriminant function;
respectively representing a forward optical flow and a reverse optical flow at a pixel x, wherein epsilon is a threshold value of a discriminant function;
defining an occlusion tagging function OxWhen the discriminant function is larger than the threshold value, the optical flow solution of the area has larger error, the area is judged to be shielded, and O is usedx1 is ═ 1; when the discriminant function is smaller than the threshold value, the optical flow solution of the area is accurate, the area is judged to be a non-shielding area, and O is enabledx0; during training, consistency check is carried out on each 1-layer forward optical flow and reverse optical flow of 2 stacked network expansion parts, and an occlusion area is estimated to be used in a network training process.
5. The method of claim 4A semi-supervised optical flow learning method based on a hole convolution stacking network is characterized by comprising the following steps: the end point error cost function EepeThe following were used:

where m and n are the width and height, respectively, of the input image, ui,jAnd vi,jRespectively, predicted optical flow values, ui′,jAnd vi′,jIs the corresponding true value of the optical flow;
said data item cost function EdataThe following were used:

wherein κxIs the optical flow at pixel point x, N is the number of pixel points, T (x) represents the value of texture quantity at pixel point x, C (x) represents the value of Census transformation at pixel point x, and phi is the robust penalty function (x)2+δ2)α,δ=0.001,OxRepresenting an occlusion flag function;
the motion smoothing cost function is as follows:

wherein And
And the gradient values of the optical flow in the horizontal direction and the vertical direction, respectively.
the gradient values of the optical flow in the horizontal direction and the vertical direction, respectively.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810779483.8A CN109086807B (en) | 2018-07-16 | 2018-07-16 | Semi-supervised optical flow learning method based on void convolution stacking network |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810779483.8A CN109086807B (en) | 2018-07-16 | 2018-07-16 | Semi-supervised optical flow learning method based on void convolution stacking network |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN109086807A CN109086807A (en) | 2018-12-25 |
| CN109086807B true CN109086807B (en) | 2022-03-18 |
Family
ID=64838001
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810779483.8A Active CN109086807B (en) | 2018-07-16 | 2018-07-16 | Semi-supervised optical flow learning method based on void convolution stacking network |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN109086807B (en) |
Families Citing this family (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109741383A (en) * | 2018-12-26 | 2019-05-10 | 西安电子科技大学 | Picture depth estimating system and method based on empty convolution sum semi-supervised learning |
| CN109816611B (en) * | 2019-01-31 | 2021-02-12 | 北京市商汤科技开发有限公司 | Video repair method and device, electronic equipment and storage medium |
| CN110533051B (en) * | 2019-08-02 | 2023-01-17 | 中国民航大学 | Automatic detection method for contraband in X-ray security inspection image based on convolutional neural network |
| CN110599428B (en) * | 2019-09-24 | 2023-06-20 | 北京航空航天大学青岛研究院 | Heterogeneous hybrid network for optical flow estimation and embedding method thereof |
| CN111325774B (en) * | 2020-02-14 | 2023-04-18 | 上海交通大学 | Optical flow unsupervised loss calculation method based on geometric relation |
| CN111507185B (en) * | 2020-03-11 | 2020-11-24 | 杭州电子科技大学 | Tumble detection method based on stack cavity convolution network |
| CN111524166B (en) | 2020-04-22 | 2023-06-30 | 北京百度网讯科技有限公司 | Video frame processing method and device |
| CN111462191B (en) * | 2020-04-23 | 2022-07-19 | 武汉大学 | Non-local filter unsupervised optical flow estimation method based on deep learning |
| CN111582483B (en) * | 2020-05-14 | 2022-12-13 | 哈尔滨工程大学 | Unsupervised learning optical flow estimation method based on space and channel combined attention mechanism |
| US20220051102A1 (en) * | 2020-08-14 | 2022-02-17 | Tencent America LLC | Method and apparatus for multi-rate neural image compression with stackable nested model structures and micro-structured weight unification |
| CN114119445A (en) * | 2020-08-27 | 2022-03-01 | 北京晟易机器人科技有限公司 | Pad voidage calculation method based on automatic X-ray imaging |
| CN112465872B (en) * | 2020-12-10 | 2022-08-26 | 南昌航空大学 | Image sequence optical flow estimation method based on learnable occlusion mask and secondary deformation optimization |
| CN112950639B (en) * | 2020-12-31 | 2024-05-10 | 山西三友和智慧信息技术股份有限公司 | SA-Net-based MRI medical image segmentation method |
| CN112785523B (en) * | 2021-01-22 | 2023-10-17 | 北京大学 | Semi-supervised image rain removing method and device for sub-band network bridging |
| CN115759202B (en) * | 2022-11-22 | 2023-11-28 | 江苏济远医疗科技有限公司 | Variable cavity convolution dense image super-resolution method |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107679477A (en) * | 2017-09-27 | 2018-02-09 | 深圳市未来媒体技术研究院 | Face depth and surface normal Forecasting Methodology based on empty convolutional neural networks |
| CN107808389A (en) * | 2017-10-24 | 2018-03-16 | 上海交通大学 | Unsupervised methods of video segmentation based on deep learning |
| US9953236B1 (en) * | 2017-03-10 | 2018-04-24 | TuSimple | System and method for semantic segmentation using dense upsampling convolution (DUC) |
| CN107967515A (en) * | 2016-10-19 | 2018-04-27 | 三星电子株式会社 | The method and apparatus quantified for neutral net |
| CN108256562A (en) * | 2018-01-09 | 2018-07-06 | 深圳大学 | Well-marked target detection method and system based on Weakly supervised space-time cascade neural network |
-
2018
- 2018-07-16 CN CN201810779483.8A patent/CN109086807B/en active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107967515A (en) * | 2016-10-19 | 2018-04-27 | 三星电子株式会社 | The method and apparatus quantified for neutral net |
| US9953236B1 (en) * | 2017-03-10 | 2018-04-24 | TuSimple | System and method for semantic segmentation using dense upsampling convolution (DUC) |
| CN107679477A (en) * | 2017-09-27 | 2018-02-09 | 深圳市未来媒体技术研究院 | Face depth and surface normal Forecasting Methodology based on empty convolutional neural networks |
| CN107808389A (en) * | 2017-10-24 | 2018-03-16 | 上海交通大学 | Unsupervised methods of video segmentation based on deep learning |
| CN108256562A (en) * | 2018-01-09 | 2018-07-06 | 深圳大学 | Well-marked target detection method and system based on Weakly supervised space-time cascade neural network |
Non-Patent Citations (3)
| Title |
|---|
| Learning Optical Flow via Dilated Networks and Occlusion Reasoning;Yi Zhu 等;《arXiv:1805.02733v1》;20180507;第1-5页 * |
| Scene Flow Estimation Based on Adaptive Anisotropic Total Variation Flow-Driven Method;Xuezhi Xiang 等;《Mathematical Problems in Engineering》;20180520;第1-11页 * |
| 基于光流场分析与深度学习的视频监控系统;刘勇;《湘南学院学报》;20170430;第38卷(第2期);第18-23页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN109086807A (en) | 2018-12-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109086807B (en) | Semi-supervised optical flow learning method based on void convolution stacking network | |
| CN109271933B (en) | Method for estimating three-dimensional human body posture based on video stream | |
| CN110232394B (en) | Multi-scale image semantic segmentation method | |
| CN108537746B (en) | Fuzzy variable image blind restoration method based on deep convolutional network | |
| CN111582483B (en) | Unsupervised learning optical flow estimation method based on space and channel combined attention mechanism | |
| CN115601549B (en) | River and lake remote sensing image segmentation method based on deformable convolution and self-attention model | |
| CN110674742B (en) | Remote sensing image road extraction method based on DLinkNet | |
| CN110163801B (en) | Image super-resolution and coloring method, system and electronic equipment | |
| CN113837938B (en) | Super-resolution method for reconstructing potential image based on dynamic vision sensor | |
| CN111640060A (en) | Single image super-resolution reconstruction method based on deep learning and multi-scale residual dense module | |
| CN113538401B (en) | Crowd counting method and system combining cross-modal information in complex scene | |
| CN113870335A (en) | Monocular depth estimation method based on multi-scale feature fusion | |
| CN113284251B (en) | Cascade network three-dimensional reconstruction method and system with self-adaptive view angle | |
| CN110363068A (en) | A kind of high-resolution pedestrian image generation method based on multiple dimensioned circulation production confrontation network | |
| CN111353988B (en) | KNN dynamic self-adaptive double-image convolution image segmentation method and system | |
| CN113077505A (en) | Optimization method of monocular depth estimation network based on contrast learning | |
| CN111354030A (en) | Method for generating unsupervised monocular image depth map embedded into SENET unit | |
| CN114677479A (en) | Natural landscape multi-view three-dimensional reconstruction method based on deep learning | |
| CN113449612A (en) | Three-dimensional target point cloud identification method based on sub-flow sparse convolution | |
| Zhang et al. | Multiscale adaptation fusion networks for depth completion | |
| CN116109689A (en) | Edge-preserving stereo matching method based on guide optimization aggregation | |
| CN115272438A (en) | High-precision monocular depth estimation system and method for three-dimensional scene reconstruction | |
| CN116030537B (en) | Three-dimensional human body posture estimation method based on multi-branch attention-seeking convolution | |
| CN112115786A (en) | Monocular vision odometer method based on attention U-net | |
| CN116402874A (en) | Spacecraft depth complementing method based on time sequence optical image and laser radar data |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |