WO2024166539A1 - 核酸集合体医薬 - Google Patents
核酸集合体医薬 Download PDFInfo
- Publication number
- WO2024166539A1 WO2024166539A1 PCT/JP2023/045425 JP2023045425W WO2024166539A1 WO 2024166539 A1 WO2024166539 A1 WO 2024166539A1 JP 2023045425 W JP2023045425 W JP 2023045425W WO 2024166539 A1 WO2024166539 A1 WO 2024166539A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- bases
- sequence
- nucleic acid
- mir
- hairpin
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images

Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- A61P35/02—Antineoplastic agents specific for leukemia
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
Definitions
- the present invention relates to a cell death-inducing composition containing a hairpin nucleic acid, a pharmaceutical composition containing the same, and an anticancer agent containing the hairpin nucleic acid.
- Nucleic acid medicines are molecular targeted therapeutic drugs that are based on nucleic acid molecules and specifically bind to target nucleic acids or proteins to suppress their function. Nucleic acid medicines have attracted attention as new medicines for diseases that were previously difficult to treat, and in fact, in the 2010s, technological new drugs such as Givlaari, which target the liver as a disease site, were born both in Japan and overseas (Non-Patent Document 1). However, practical application of nucleic acid medicines, especially for cancer, has yet to be achieved.
- Nucleic acid drugs that have been marketed so far have mainly been antisense nucleic acids and siRNAs that inhibit the translation and splicing process of target mRNA by hybridizing with a sequence-specific manner.
- decoy nucleic acids are capable of capturing and/or inactivating nucleic acid-binding proteins such as transcription factors that are difficult to develop drugs for, and are promising nucleic acid molecules as anticancer drugs.
- decoy nucleic acids have low cell selectivity, leading to high off-target effects and a tendency to be toxic to normal cells.
- decoy nucleic acids since their target is limited to diseases with specific target proteins, they have been unsuitable for developing drugs that are effective against many diseases.
- miRNAs are non-coding RNAs with a length of approximately 20 to 25 bases, and are known to suppress the translation and transcription of multiple target genes.
- a miRNA called miR-21 is highly expressed in many diseases, including cancer, and is therefore expected to be a therapeutic target applicable to a wide range of diseases.
- a medicine targeting miR-21 with sufficient cell selectivity has yet to be developed.
- Non-Patent Document 2 In conventional nucleic acid drug discovery, the immunotoxicity of the nucleic acid drug itself has been viewed as a problem. This immunotoxicity is the result of the defense mechanism against foreign nucleic acids such as viruses (nucleic acid immunity) recognizing the nucleic acid drug as a foreign substance, and to avoid it, additional effort is required, such as chemical modification of the nucleic acid or selection of the sequence (Non-Patent Document 2).
- the objective of the present invention is to provide a composition for treating a disease involving cells expressing miR-21 by specifically inducing nucleic acid immunity in cells expressing miR-21.
- the present inventors previously reported a technology that induces cell-specific nucleic acid immunity and can be applied as a nucleic acid medicine (PCT/JP2022/026323).
- the present inventors applied the above technology that they developed themselves to develop a nucleic acid medicine targeting miR-21.
- the present invention is based on these novel findings, etc., and provides the following.
- a cell death-inducing composition comprising a pair of hairpin nucleic acids, the pair consisting of an initiating hairpin nucleic acid comprising a structure represented by general formula (I) and an extended hairpin nucleic acid comprising a structure represented by general formula (II), which specifically induces cell death in cells expressing miR-21.
- X1 is a protruding region consisting of a sequence of 4 to 20 bases
- Y1 and Y'1 are stem regions each consisting of a sequence of 10 to 20 bases capable of hybridizing to each other within a molecule
- Z1 is a loop region consisting of a sequence of 7 to 12 bases that does not contain a CG sequence or a GGG sequence
- the whole of X1 and the whole or part of Y1 constitute a miR-21-binding domain capable of hybridizing to the whole or part of the base sequence of miR-21
- All or a portion of Y'1 constitutes an extended hairpin-binding domain capable of hybridizing to all or a portion of miR-21.
- X2 is a protruding region consisting of a sequence of 4 to 20 bases
- Y2 and Y'2 are stem regions each consisting of a sequence of 10 to 20 bases capable of hybridizing to each other within a molecule
- Z2 is a loop region consisting of a sequence of 7 to 12 bases, all or a part of Y'2 constitutes the miR-21 domain
- All of Y2 and all or part of X2 constitute an initiating hairpin-binding domain miR-21 domain capable of hybridizing with all or part of the extended hairpin-binding domain.
- [2] The cell death-inducing composition described in [1], wherein the left end is the 5' end in formula (I) and formula (II).
- [3] The cell death-inducing composition described in [1] or [2], wherein the miR-21 binding domain comprises the base sequence represented by sequence number 2, and the miR-21 domain comprises the base sequence represented by sequence number 3.
- [4] The cell death-inducing composition described in any of [1] to [3], wherein the initiator hairpin nucleic acid forms a single-stranded structure in the presence of miR-21 under physiological conditions in a mammal.
- [5] The cell death-inducing composition according to any one of [1] to [4], wherein the GC content of Z1 is 40% or more and 60% or less.
- [6] The cell death-inducing composition according to any one of [1] to [5], wherein the purine base content of Z1 is 40% or more and 60% or less.
- [7] The cell death-inducing composition described in any one of [1] to [6], wherein the hairpin nucleic acid is composed of DNA and/or RNA nucleotides.
- [8] The cell death-inducing composition according to any one of [1] to [7], which contains one or more modified nucleotides and/or non-natural nucleotides.
- [9] The cell death-inducing composition described in [8], wherein the modified nucleotide or the non-natural nucleotide contains a base into which a substituent has been introduced.
- a pharmaceutical composition comprising the cell death-inducing composition according to any one of [1] to [10] as an active ingredient.
- cancer is one or more cancers selected from the group consisting of breast cancer, colon cancer, pancreatic cancer, lung cancer, prostate cancer, liver cancer, gastric cancer, brain tumor, thyroid cancer, oral cancer, acute myeloid leukemia, chronic lymphocytic leukemia, and glioblastoma.
- An anticancer agent for preventing or treating cancer including cells expressing miR-21, comprising a pair of hairpin nucleic acids consisting of an initiating hairpin nucleic acid comprising a structure represented by general formula (I) and an extended hairpin nucleic acid comprising a structure represented by general formula (II).
- X1 is a protruding region consisting of a sequence of 4 to 20 bases
- Y1 and Y'1 are stem regions each consisting of a sequence of 10 to 20 bases capable of hybridizing to each other within a molecule
- Z1 is a loop region consisting of a sequence of 7 to 12 bases that does not contain a CG sequence or a GGG sequence
- the whole of X1 and the whole or part of Y1 constitute a miR-21-binding domain capable of hybridizing to the whole or part of the base sequence of miR-21
- All or a portion of Y'1 constitutes an extended hairpin-binding domain capable of hybridizing to all or a portion of miR-21.
- X2 is a protruding region consisting of a sequence of 4 to 20 bases
- Y2 and Y'2 are stem regions each consisting of a sequence of 10 to 20 bases capable of hybridizing to each other within a molecule
- Z2 is a loop region consisting of a sequence of 7 to 12 bases, all or a part of Y'2 constitutes the miR-21 domain
- All of Y2 and all or part of X2 constitute an initiating hairpin-binding domain miR-21 domain capable of hybridizing with all or part of the extended hairpin-binding domain.
- the cell death-inducing composition of the present invention can induce cell death specifically in cells that express miR-21.
- the pharmaceutical composition of the present invention can treat diseases involving cells that express miR-21.
- the anticancer agent of the present invention can treat cancers that contain cells that express miR-21.
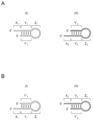
- A shows the structure of a set of a 5'-end overhanging initiating hairpin nucleic acid ((I)) and a 3'-end overhanging extended hairpin nucleic acid ((II)).
- B shows the structure of a set of a 3'-end overhanging initiating hairpin nucleic acid ((I)) and a 5'-end overhanging extended hairpin nucleic acid ((II)).
- X represents the overhanging region
- Y and Y' represent the stem regions
- Z represents the loop region.
- FIG. 1 shows the HCR efficiency in three different sets of hairpin nucleic acids (HP-o, HP-a, and HP-b).
- FIG. 1 shows the HCR efficiency in two different sets of hairpin nucleic acids (HP-c and HP-d).
- This is a diagram showing the change in relative cell viability in HeLa cells by the introduction of a set of hairpin nucleic acids.
- “sc” indicates the result when a hairpin nucleic acid having a scrambled sequence was introduced.
- "***" indicates that the p-value is less than 0.001.
- the first aspect of the present invention is a cell death-inducing composition comprising a hairpin nucleic acid.
- the cell death-inducing composition of the present invention comprises an initiation hairpin nucleic acid and an extended hairpin nucleic acid as essential components.
- the cell death-inducing composition of the present invention can specifically induce cell death in cells expressing miR-21, and can also be an active ingredient of the pharmaceutical composition of the present invention.
- hairpin nucleic acid refers to a single-stranded nucleic acid capable of forming a hairpin structure.
- hairpin structure refers to a secondary structure of a nucleic acid formed by a single-stranded nucleic acid, the secondary structure comprising a set of a stem structure Y, a loop structure Z, and a protruding region X. Schematic diagrams of a hairpin nucleic acid are shown in Figures 1A and 1B.
- the hairpin nucleic acid as used herein comprises, in order, a protruding region X, a stem region Y, a loop region Z, and a stem region Y'.
- 5'-end overhanging type (Fig. 1A(I) and B(II)) refers to a type of hairpin nucleic acid that includes a overhanging region X at the 5'-end.
- a 5'-end overhanging type hairpin nucleic acid includes, in order from the 5'-end, a overhanging region X, a stem region Y, a loop region Z, and a stem region Y'.
- 3'-end overhanging type (Fig. 1A(II) and B(I))” refers to a type of hairpin nucleic acid that includes a overhanging region X at the 3'-end.
- a 3'-end overhanging type hairpin nucleic acid includes, in order from the 5'-end, a stem region Y', a loop region Z, a stem region Y, and a overhanging region X.
- the “stem structure” is a structure in which two stem regions (Y and Y') containing base sequences that can hybridize with each other form a double strand.
- the "loop structure” is a loop-shaped structure formed by a loop region (Z) consisting of a single-stranded nucleic acid.
- protruding region (X) refers to a protruding end that recognizes the single-stranded portion of miR-21 or the HCR product in the HCR.
- protruding end refers to a nucleic acid region consisting of a single strand adjacent to either or both of the free ends (ends not adjacent to the loop region Z) of the stem region (Y or Y').
- the length of the protruding region X is not particularly limited in the present specification, but may be, for example, 4 bases or more, 5 bases or more, 6 bases or more, 7 bases or more, or 8 bases or more.
- the protruding region X may be, for example, 20 bases or less, 19 bases or less, 18 bases or less, 17 bases or less, 16 bases or less, 15 bases or less, 14 bases or less, 13 bases or less, 12 bases or less, 11 bases or less, 10 bases or less, or 9 bases or less.
- the length of the protruding region X may be, for example, 4 to 20 bases.
- stem regions (Y and Y') refer to nucleic acid regions that hybridize with each other in a molecule to form a stem structure. At least both ends of each stem region are composed of complementary bases.
- the length of each stem region is not particularly limited, but may be, for example, 10 bases or more, 11 bases or more, 12 bases or more, 13 bases or more, or 14 bases or more.
- the length of each stem region may be, for example, 20 bases or less, 19 bases or less, 18 bases or less, 17 bases or less, 16 bases or less, or 15 bases or less.
- the length of each stem region may be, for example, 10 to 20 bases.
- “Stem region Y (Y)” refers to a stem region adjacent to protruding region X.
- “Stem region Y' (Y')” refers to a stem region that is not adjacent to protruding region X.
- loop region (Z) refers to a nucleic acid region located between the two stem regions in a single-stranded nucleic acid.
- the length of loop region Z is not particularly limited, but is, for example, 7 or more bases or 8 or more bases. Loop region Z can also be, for example, 12 or less bases, 11 or less bases, 10 or less bases, or 9 or less bases. Specifically, the length of loop region Z can be, for example, 7 to 12 bases.
- miR-21 refers to miRNA having a full-length 22-base sequence as shown in SEQ ID NO:1, as well as its mutants, homologs, modifications, and derivatives. miR-21 is known to be upregulated in many cancers, and is known to be involved in cell proliferation, cell death, DNA damage response, etc.
- Hybridization Chain Reaction refers to an extension reaction of a double-stranded nucleic acid molecule that occurs by the chain-like hybridization of multiple cleaved hairpin nucleic acids.
- Figure 2 shows a typical HCR process.
- the initiating hairpin nucleic acid recognizes the target miR-21 at the protruding region X1 , hybridizes to form a miR-21 sequence-initiating hairpin nucleic acid complex ( Figure 2 (1)).
- the hairpin structure of the initiating hairpin nucleic acid is cleaved by the extension of hybridization with miR-21.
- this miR-21 sequence-initiating hairpin nucleic acid complex is the starting point for the formation of the HCR product.
- the protruding region X2 of the extended hairpin nucleic acid recognizes and hybridizes to the single-stranded portion (extended hairpin binding domain) of the initiating hairpin nucleic acid that has become free due to the cleavage, forming a miR-21 sequence-initiating-extended hairpin nucleic acid complex ( Figure 2 (2)).
- the hairpin structure of the extended hairpin nucleic acid is cleaved by the extension of hybridization between the start hairpin nucleic acid and the extended hairpin binding domain.
- step 3 the start hairpin nucleic acid recognizes and cleaves the miR-21-like sequence of the single-stranded portion (miR-21 domain) of the extended hairpin nucleic acid in the miR-21 sequence-start-extended hairpin nucleic acid complex formed in step 2, and further hybridizes with the miR-21 sequence-start-extended hairpin nucleic acid complex to form a miR-21 sequence-start-extended-start hairpin nucleic acid complex ( Figure 2 (3)).
- steps 2 and 3 are alternately repeated, whereby the start hairpin nucleic acid and the extended hairpin nucleic acid hybridize in succession to extend the double-stranded nucleic acid, forming a high molecular weight polymer (HCR product) ( Figures 2 (4) and (5)).
- the HCR product forms a linear double-stranded nucleic acid.
- hybridization chain structure refers to a nucleic acid structure contained in the linear double-stranded nucleic acid formed by the above-mentioned HCR.
- the hybridization chain structure contains a pathogen-associated molecular pattern and induces nucleic acid immunity via a pattern recognition receptor.
- nucleic acid immunity refers to a natural immune response based on the recognition of nucleic acids. Nucleic acid immunity is induced by the recognition of non-self nucleic acids and/or damaged self-derived nucleic acids by pattern recognition receptors.
- Pattern recognition receptor is a general term for receptor proteins involved in the induction of the innate immune system that recognize structural patterns found in non-self molecules and/or damaged self-derived molecules. In this specification, unless otherwise specified, it refers to receptor proteins that recognize nucleic acid molecules. The structural patterns recognized by pattern recognition receptors are called pathogen-associated molecular patterns (PAMPs).
- PAMPs pathogen-associated molecular patterns
- Portureogen-associated molecular pattern refers to a molecular pattern that is present in viruses, prokaryotes and/or protostomes but is not present in the environment in which pattern recognition receptors are present in normal vertebrates. In this specification, it particularly refers to a structural pattern that is present in the nucleic acid molecules of viruses, prokaryotes and/or protostomes but is not present in the nucleic acid molecules of vertebrates.
- “Complementary” refers to a relationship in which nucleic acid bases can form base pairs with each other through hydrogen bonds. This includes so-called Watson-Crick base pairs (natural base pairs) or Hoogsteen base pairs.
- Hybridize or “capable of hybridizing” refers to polynucleotides having complementary base sequences base pairing to form a completely or partially complementary double strand.
- multiple refers to a number of 2 or more. Specifically, for example, it refers to 2 to 60, 2 to 45, 2 to 30, 2 to 14, 2 to 10, 2 to 8, 2 to 6, 2 to 5, 2 to 4, or 2 to 3. In this specification, “several” refers to 2 to 3.
- physiological conditions refers to any conditions that are identical to or similar to the pH and temperature conditions within the body of an individual mammal.
- physiological conditions include both in vitro and in vivo conditions.
- Specific physiological conditions include, for example, conditions in an aqueous buffer solution at approximately pH 7.4 (pH 6.8 to pH 7.8) and approximately 37°C (35°C to 40°C).
- GC content refers to the ratio of the total number of guanines (G) and cytosines (C) to the total number of bases in a target base sequence.
- G guanines
- C cytosines
- loop region Z1 it refers to the ratio of the total number of Gs and Cs to the total number of bases in loop region Z1 .
- purine base refers to a base having a purine skeleton, and broadly includes bases containing derivatives of purine, a heterocyclic compound represented by the chemical formula C5N4H4 .
- purine bases include adenine (A), guanine (G), hypoxanthine, xanthine, etc.
- pyrimidine base refers to a base having a pyrimidine skeleton, and broadly includes bases containing derivatives of pyrimidine, a heterocyclic compound represented by the chemical formula C4H4N2 .
- Specific examples of pyrimidine bases include cytosine (C), thymine (T), and uracil (U).
- purine content refers to the ratio of the total number of purine bases to the total number of bases in a target base sequence.
- loop region Z1 it refers to the ratio of the total number of purine bases to the total number of bases in loop region Z1 .
- cell death refers to the death of a cell.
- Cell death is broadly divided into programmed cell death and accidental cell death, and cell death in this specification includes both of these.
- Examples of programmed cell death include apoptosis, autophagy, and necroptosis.
- Apoptosis refers to programmed cell death characterized by the formation of aggregates (apoptotic bodies) in which fragmented nuclei are wrapped in cell membranes. In the process of apoptosis, for example, phenomena such as cell fragmentation, nuclear fragmentation, membrane blebbing, and chromatin condensation are observed.
- autophagy is particularly called macroautophagy and refers to programmed cell death that occurs during nutritional stress.
- necroptosis refers to programmed cell death in which necrosis-like phenomena such as the release of cell contents outside the cell are observed.
- necroptosis includes all of them.
- Accidental cell death refers to cell death caused by mechanical damage to the cell or stress on the outside or inside of the cell. Accidental cell death is also called necrosis.
- a particular gene is "highly expressed” means that its expression level is markedly or significantly increased compared to its expression level in normal cells.
- Statistically significant means that there is a significant difference between the measured value of the test subject and the control value when the difference between them is statistically processed.
- the risk rate (significance level) of the obtained value is small, specifically, less than 5% (p ⁇ 0.05), less than 1% (p ⁇ 0.01), or less than 0.1% (p ⁇ 0.001).
- the "p (value)” shown here indicates the probability that the test statistic will become that value by chance in a distribution based on the null hypothesis in a statistical test. Therefore, the smaller the "p", the lower the probability that the test statistic will become that value, meaning that the null hypothesis is more likely to be rejected.
- the statistical processing test method is not particularly limited and may be any known test method that can determine the presence or absence of significance. For example, the Student's t-test, covariate analysis of variance, etc. can be used.
- the cell death-inducing composition of the present invention comprises a pair of hairpin nucleic acids.
- a set of hairpin nucleic acids consists of an initiating hairpin nucleic acid and an extended hairpin nucleic acid. More specifically, a set of hairpin nucleic acids consists of a 5'-end overhanging initiating hairpin nucleic acid and a 3'-end overhanging extended hairpin nucleic acid, or a 3'-end overhanging initiating hairpin nucleic acid and a 5'-end overhanging extended hairpin nucleic acid. Each of these will be specifically described below.
- the "initial hairpin nucleic acid (FIG. 1(I))” is a hairpin nucleic acid that includes a structure represented by general formula (I) and contains a miR-21-binding domain and an extended hairpin-binding domain (FIG. 2).
- X1 is a protruding region consisting of a sequence of 4 to 20 bases
- Y1 and Y'1 are stem regions each consisting of a sequence of 10 to 20 bases capable of hybridizing to each other within a molecule
- Z1 is a loop region consisting of a sequence of 7 to 12 bases that does not contain a CG sequence or a GGG sequence
- the whole of X1 and the whole or part of Y1 constitute a miR-21-binding domain capable of hybridizing to the whole or part of the base sequence of miR-21
- All or a portion of Y'1 constitutes an extended hairpin-binding domain capable of hybridizing to all or a portion of miR-21.
- a base or base sequence not constituting the miR-21 binding domain may be contained at the protruding end
- a base or base sequence not constituting the stem region Y'1 and/or the extended hairpin binding domain may be contained at the free end of the stem region Y'1 .
- miR-21 binding domain refers to a nucleic acid region in the starting hairpin nucleic acid that hybridizes with miR-21. Specifically, for example, the miR-21 binding domain includes the entire overhang region X1 and the entire or part of the subsequent stem region Y1 ( Figure 2). The miR-21 binding domain can hybridize with the entire or part of the base sequence of miR-21, and the base sequence of this domain is complementary to miR-21 at least at both ends of the domain.
- extended hairpin binding domain refers to a nucleic acid region in an initiating hairpin nucleic acid that hybridizes with an extended hairpin nucleic acid.
- the extended hairpin binding domain comprises all or a portion of the stem region Y'1 ( Figure 2).
- the extended hairpin binding domain is capable of hybridizing with the initiating hairpin binding domain of an extended hairpin nucleic acid, and the base sequences of the domains are complementary to each other, at least at both termini of each domain.
- the miR-21 binding domain of the initiating hairpin nucleic acid can contain the base sequence represented by SEQ ID NO:2, or a base sequence in which one or several bases have been deleted, substituted or added to the base sequence represented by SEQ ID NO:2, regardless of whether it is a 5'-end overhang type (an initiating hairpin nucleic acid in which the left end is the 5' end in formula (I)) or a 3'-end overhang type (an initiating hairpin nucleic acid in which the left end is the 3' end in formula (I)).
- SEQ ID NO:2 a base sequence in which one or several bases have been deleted, substituted or added to the base sequence represented by SEQ ID NO:2, regardless of whether it is a 5'-end overhang type (an initiating hairpin nucleic acid in which the left end is the 5' end in formula (I)) or a 3'-end overhang type (an initiating hairpin nucleic acid in which the left end is the 3' end in formula (I)).
- the base sequence of the loop region Z1 of the starting hairpin nucleic acid herein is not particularly limited as long as it does not contain a CG sequence or a GGG sequence.
- the GC content in the loop region Z1 of the starting hairpin nucleic acid is not particularly limited. For example, it can be 0% or more, 10% or more, 20% or more, 25% or more, 30% or more, 34% or more, 35% or more, 36% or more, 40% or more, or 44% or more.
- the upper limit is also not particularly limited.
- it can be 100% or less, 92% or less, 91% or less, 90% or less, 89% or less, 88% or less, 87% or less, 86% or less, 85% or less, 84% or less, 82% or less, 80% or less, 78% or less, 77% or less, 75% or less, 73% or less, 70% or less, 67% or less, 66% or less, 65% or less, 64% or less, 63% or less, 62% or less, 61% or less, 60% or less, 59% or less, or 58% or less.
- the range may be 0% or more and 92% or less, 20% or more and 90% or less, 34% or more and 80% or less, 40% or more and 60% or less, or 44% or more and 58% or less.
- the content of purine bases in the loop region Z1 of the starting hairpin nucleic acid is not particularly limited. For example, it can be 0% or more, 10% or more, 20% or more, 25% or more, 30% or more, 34% or more, 35% or more, 36% or more, 40% or more, or 44% or more. There is also no particular limit to the upper limit.
- it can be 100% or less, 92% or less, 91% or less, 90% or less, 89% or less, 88% or less, 87% or less, 86% or less, 85% or less, 84% or less, 82% or less, 80% or less, 78% or less, 77% or less, 75% or less, 73% or less, 70% or less, 67% or less, 66% or less, 65% or less, 64% or less, 63% or less, 62% or less, 61% or less, 60% or less, 59% or less, 58% or less, or 57% or less.
- the range may be 0% or more and 92% or less, 20% or more and 90% or less, 34% or more and 80% or less, 40% or more and 60% or less, or 44% or more and 57% or less.
- the loop region Z1 of the starting hairpin nucleic acid may be a base sequence that does not contain a reverse sequence of a complementary base sequence within the same loop region for any base sequence consisting of two or more consecutive bases.
- the base sequence "ATGCATGC” does not fall under this type of base sequence because, for "AT” consisting of the 1st and 2nd bases from the left end, "AT” is contained at the 5th to 6th bases, which is a reverse sequence of "TA”, which is a complementary base sequence, for "ATG” consisting of the 1st to 3rd bases from the left end, and "CAT” is contained at the 4th to 6th bases, which is a reverse sequence of "TAC”, which is a complementary base sequence.
- the base sequence "AGTCAGTC” does not contain a reverse sequence of a complementary base sequence, regardless of how the consecutive base sequence is selected, and therefore falls under this type of base sequence.
- a base sequence containing multiple AT sequences, TA sequences, or GC sequences is not included in this type of base sequence.
- the loop region Z1 of the starting hairpin nucleic acid may consist of, for example, any of the following base sequences: (i) a base sequence containing two or more sequence units with two or more consecutive identical bases; (ii) a base sequence that does not contain a sequence of two or more consecutive identical bases; or (iii) a base sequence that contains two or more sequence units of three or more bases that do not contain any identical bases.
- base sequences (i) to (iii) is explained below.
- the number of bases contained in the sequence unit is not particularly limited as long as it is 2 or more. For example, it may be 3 or more, 4 or more, 5 or more, or 6 or more.
- the number of bases may be the same or different between the sequence units.
- the first sequence unit may consist of 3 bases
- the second sequence unit may consist of 2 to 4 bases (e.g., 2 bases, 3 bases, 4 bases).
- the number of sequence units is not particularly limited as long as it is two or more. For example, it may be three or more, four or more, five or more, or six.
- the type of base contained in each sequence unit is not particularly limited. Two or more sequence units may be composed of the same base, or two or more sequence units may be composed of different bases. For example, it may contain two or more sequence units composed of purine bases, may contain two or more sequence units composed of pyrimidine bases, or may contain a sequence unit composed of purine bases and a sequence unit composed of pyrimidine bases. When it contains two or more sequence units, it is preferable that any two sequence units are not composed of complementary bases.
- it may contain two or more sequence units consisting of G, two or more sequence units consisting of C, two or more sequence units consisting of T, two or more sequence units consisting of A, one or more sequence units consisting of G and one or more sequence units consisting of T, one or more sequence units consisting of G and one or more sequence units consisting of A, one or more sequence units consisting of C and one or more sequence units consisting of T, or one or more sequence units consisting of C and one or more sequence units consisting of A.
- sequence units may be adjacent to each other, or may contain one or more bases between them.
- sequence units may contain one or more bases, two or more bases, three or more bases, four or more bases, five or more bases, six or more bases, seven or more bases, or eight bases.
- the base sequence between sequence units is not particularly limited as long as the bases at both ends are different from the bases constituting the adjacent sequence units and do not include a sequence with two or more consecutive identical bases. That is, for example, the base adjacent to a sequence unit consisting of T may be any other than T. Also, for example, the bases adjacent to both a sequence unit consisting of A and a sequence unit consisting of T may be any other than A and T. For example, the base adjacent to a sequence unit consisting of purine bases may be either a purine base or a pyrimidine base.
- the sequence between the sequence units may be made up of all different bases.
- it may contain both purine bases and pyrimidine bases, or it may contain only either purine bases or pyrimidine bases.
- it may be any of the following sequences: AC, CA, TG, GT, GC, AG, GA, TC, CT, TA, and AT.
- the bases at both ends of loop region Z1 may be bases constituting a sequence unit, or either one or both may not be bases constituting a sequence unit.
- the bases at both ends of loop region Z1 are C, and the C at the left end is a base constituting a sequence unit called CCC, and the C at the right end is a base not constituting a sequence unit.
- An example of the base sequence of (i) is a base sequence in which the bases at both ends of the loop region Z1 are bases constituting a sequence unit, the base sequence includes one sequence unit consisting of a purine base and one sequence unit consisting of a pyrimidine base, and the two sequence units include two different bases between each other.
- the base sequence of (i) may include CCTGAA, CCTGAAA, CCTGAAAA, CCCTGAA, CCCTGAAA, CCCTGAAAA, CCCCTGAA, CCCCTGAAA, CCCCTGAAAA, TTGACC, TTGACCC, TTTGACC, TTTGACCC, TTTGACCCC, TTTTGACC, TTTTGACCC, TTTTGACCCC, AATGCCC, AATGCCC, AATGCCC, AAATGCC, AAATGCCC, AAATGCCCC, AAAATGCC, AAAATGCCC, AAAATGCCCC, AAGTCC, AAGTCCC, AAGTCCCC, AAAGTCC, AAAGTCCC, AAAGTCCCC, AAAAGTCC, AAAAGTCCC, AAAAGTCCC, AAAAGTCCCC, CCAGTT, CCAGTTT, CCAGTTTT, CCCAGTTT, CCCAGTTTT, CCCAGTTT, CCCAGTTTT, CCCAGTTT, CCCAGTTTT, CC
- the base sequence of (ii) is not particularly limited as long as it is a base sequence that does not contain a sequence of two or more consecutive identical bases.
- it can be constructed by including one or more sequence units of two or more bases that do not contain the same base so as not to include a sequence of two or more consecutive identical bases.
- the number of bases included in the sequence unit is not particularly limited as long as it is two or more bases.
- it may be three or more bases (three bases, four bases, etc.), and in particular when a modified base is included, it may be four or more bases, for example, five or more bases or six or more bases.
- the number of bases may be the same or different between each sequence unit.
- the first sequence unit may be composed of three bases
- the second sequence unit may be composed of three to four bases (for example, three bases, four bases).
- the number of sequence units is not particularly limited as long as it is one or more. For example, it may be two, three, or four.
- the type of base contained in each sequence unit is not particularly limited. Two or more sequence units may have the same base sequence, or two or more sequence units may have different base sequences. When two or more sequence units are included, it is preferable that any two sequence units are not in an inverse complementary relationship with each other (a base sequence and a complementary base sequence are in an inverse sequence relationship).
- each sequence unit may be, for example, a sequence unit consisting of A and T, a sequence unit consisting of A and C, a sequence unit consisting of A and G, a sequence unit consisting of T and C, a sequence unit consisting of T and G, a sequence unit consisting of a GC sequence, or a sequence unit as described later in (iii).
- sequence units may be sequence units having common constituent bases, or may have different constituent bases.
- sequence units include AT sequences, TA sequences, AC sequences, CA sequences, AG sequences, GA sequences, TC sequences, CT sequences, TG sequences, GT sequences, GC sequences, and sequence units exemplified for the base sequence of (iii).
- sequence units may be adjacent to each other, or may contain one base between them. Usually, when there are two bases between them, the two bases constitute a different sequence unit.
- the bases between the sequence units are not particularly limited, so long as they are selected so that no sequence of two or more consecutive identical bases appears. In other words, there are no particular limitations as long as the base is different from the adjacent base.
- the base adjacent to a sequence unit whose last base is a purine base may be either a purine base or a pyrimidine base.
- the base adjacent to a sequence unit whose first base is a purine base may be either a purine base or a pyrimidine base.
- the base sequence of (iii) is not particularly limited as long as it is a base sequence containing two or more sequence units of three or more bases that do not contain the same base.
- the number of bases contained in the sequence unit is not particularly limited as long as it is three or more bases. For example, it may be three or four bases, and in particular when a modified base is contained, it may be four or more bases, for example, five or more bases or six or more bases.
- the number of bases may be the same or different between each sequence unit.
- the first sequence unit may consist of four bases
- the second sequence unit may consist of three to four bases (e.g., three or four bases).
- sequence units is not particularly limited as long as it is two or more. For example, it may be two, three, or four.
- the type of base contained in each sequence unit is not particularly limited. Two or more sequence units may have the same base sequence, or two or more sequence units may have different base sequences. When two or more sequence units are included, it is preferable that any two sequence units are not complementary to each other.
- each sequence unit may be, for example, a sequence unit consisting of A, T, and G, a sequence unit consisting of A, T, and C, a sequence unit consisting of C, T, and G, a sequence unit consisting of A, C, and G, or a sequence unit consisting of A, T, C, and G.
- sequence units When two or more sequence units have different base sequences, they may be sequence units having common constituent bases, or may have different constituent bases.
- sequence units include AGT sequences, GTC sequences, TCA sequences, CAG sequences, and their reverse sequences (TGA sequences, CTG sequences, ACT sequences, GAC sequences), AGTC sequences, GTCA sequences, TCAG sequences, CAGT sequences, and their reverse sequences (CTGA sequences, ACTG sequences, GACT sequences, TGAC sequences), etc.
- sequence units may be adjacent to each other, or may contain one or more bases between them. Specifically, for example, one or more bases, two or more bases, three or more bases, four or more bases, or five or more bases may be contained between the sequence units.
- the base sequence between sequence units is not particularly limited.
- the base adjacent to a sequence unit whose last base is a purine base may be a purine base or a pyrimidine base.
- the base adjacent to a sequence unit whose first base is a purine base may be a purine base or a pyrimidine base.
- the sequence between the sequence units may be made up of all different bases.
- it may include both purine bases and pyrimidine bases, or it may include only either purine bases or pyrimidine bases.
- it may be any of the following sequences: AC, CA, TG, GT, GC, AG, GA, TC, CT, TA, and AT.
- the bases at both ends of loop region Z1 may be bases constituting a sequence unit, or either one or both may not be bases constituting a sequence unit.
- the bases at both ends of loop region Z1 are A, and the A at the left end is a base constituting a sequence unit called AGT, and the A at the right end is a base not constituting a sequence unit.
- the base sequence of (iii) is, for example, a base sequence in which at least one end of the loop region Z1 is a base constituting a sequence unit, and which contains two adjacent identical sequence units each consisting of four bases.
- the base sequence of (iii) may include AGTCAGTC, GTCAGTCA, TCAGTCAG, CAGTCAGT, or their reverse sequences (CTGACTGA, TGACTGAC, GACTGACT, ACTGACTG), etc.
- the starting hairpin nucleic acid is one in which the hairpin structure is cleaved to form a single-stranded structure in the presence of miR-21 under physiological conditions in a mammal. Whether or not the hairpin structure is cleaved under physiological conditions can be confirmed using methods known in the art. For example, it can be determined by a cell-free system, an in vitro experimental system using a cell system, an in vivo experimental system, in silico analysis using the free energy change in the hairpin structure formation reaction as an indicator, or a combination of these. Specific in vitro experimental systems, in vivo experimental systems, and in silico analysis methods that can be used for determination may include, but are not limited to, the methods exemplified in the examples of the present application.
- hairpin structure forming reaction refers to a reaction in which a single-stranded nucleic acid in a hairpin nucleic acid changes from a linear form to a hairpin form to form a hairpin structure.
- free energy change refers to the net amount of energy supplied from the external environment to a reaction system through a certain reaction when the temperature and pressure conditions are constant. In this specification, it particularly refers to the net amount of energy supplied from the external environment in a hairpin structure formation reaction. For example, if the reaction product is more thermodynamically stable than the starting material, the reaction system loses energy through the reaction, and the free energy change will be negative.
- the free energy change of the present invention includes, for example, both the Gibbs free energy change ( ⁇ G) and the Helmholtz free energy change ( ⁇ F).
- the free energy change in the hairpin structure formation reaction is not particularly limited. In general, the lower the free energy change in the hairpin structure formation reaction, the more difficult it is for the hairpin structure to cleave, and the higher the free energy change, the easier it is for the hairpin structure to cleave.
- the free energy change is, for example, -20 to -10 kcal/mol. Specifically, for example, -20 kcal/mol or more, -19 kcal/mol or more, -18 kcal/mol or more, -17.5 kcal/mol or more, -17 kcal/mol or more, or -16.5 kcal/mol or more.
- the free energy change is, for example, -10 kcal/mol or less, -11 kcal/mol or less, -12 kcal/mol or less, -12.5 kcal/mol or less, -13 kcal/mol or less, -13.5 kcal/mol or less, -14 kcal/mol or less, -14.5 kcal/mol or less, or -15 kcal/mol or less.
- the amount of free energy change can be determined using known software, such as NUPAK, which is used to predict the stability of higher-order structures of nucleic acids.
- the starting hairpin nucleic acid comprises the following base sequence: (1) A base sequence selected from the group consisting of SEQ ID NOs: 4, 6, 15, and 17. (2) A base sequence in which one or more bases have been deleted, substituted, or added compared to (1). (3) A base sequence that hybridizes under highly stringent conditions with a base sequence complementary to any one of the base sequences selected from the group consisting of SEQ ID NOs: 4, 6, 15, and 17.
- Whether or not a nucleic acid can hybridize can be determined using a method known in the art. For example, it can be determined based on base identity. Usually, a second nucleic acid having a base sequence that is completely complementary to the base sequence of a first nucleic acid and has a certain level of base identity can hybridize with the first nucleic acid. Specifically, for example, the base identity is 70% or more, 80% or more, 90% or more, 95% or more, 96% or more, 97% or more, 98% or more, 99% or more, or 100%.
- base identity refers to the ratio (%) of identical bases in one polynucleotide to the total number of bases in the other polynucleotide when the base sequences of two polynucleotides are aligned and, if necessary, gaps are introduced into either base sequence to maximize the base identity between the two polynucleotides.
- the percent identity can be easily determined using known programs such as the homology search program BLAST (Basic local alignment search tool; Altschul, S. F. et al, J. Mol. Biol., 215, 403-410, 1990) search.
- a second nucleic acid having a base sequence in which multiple bases are replaced with other bases in a base sequence completely complementary to the base sequence of a first nucleic acid can usually hybridize with the first nucleic acid.
- hybridization is possible when 2 to 60, 2 to 45, 2 to 30, 2 to 14, 2 to 12, 2 to 10, for example, 2 to 8, 2 to 6, 2 to 5, 2 to 4, or 2 to 3 bases are replaced.
- Hybridization conditions are not particularly limited, and may be various stringent conditions, such as low stringency conditions and high stringency conditions.
- Low stringency conditions refer to conditions under which nucleic acids are likely to hybridize.
- Low stringency conditions refer to low temperature and high salt concentration conditions in washing after hybridization. For example, in washing after hybridization, washing is performed at 42°C to 50°C using a buffer containing 5xSSC and 0.1% SDS.
- High stringency conditions refer to environmental conditions under which nonspecific hybridization is unlikely to occur. Under high stringency conditions, a hybrid can be formed with a nucleic acid having a target base sequence, but a hybrid cannot be substantially formed with a nucleic acid having a nonspecific base sequence.
- high stringency conditions refer to low salt concentration and high temperature conditions.
- the low salt concentration referred to here specifically means, for example, 15 to 750 mM, preferably 15 to 500 mM, 15 to 300 mM, or 15 to 200 mM.
- the high temperature referred to here specifically means, for example, 50 to 68°C, or 55 to 70°C.
- Specific highly stringent conditions include, for example, washing at 65°C with 0.1xSSC and 0.1% SDS.
- 1xSSC contains 150 mM sodium chloride and 15 mM sodium citrate.
- Extended hairpin nucleic acid refers to a hairpin nucleic acid that contains a structure represented by general formula (II) and hybridizes with an initiating hairpin nucleic acid.
- the extended hairpin nucleic acid contains an initiating hairpin binding domain and a miR-21 domain.
- X2 is a protruding region consisting of a sequence of 4 to 20 bases
- Y2 and Y'2 are stem regions each consisting of a sequence of 10 to 20 bases capable of hybridizing to each other within a molecule
- Z2 is a loop region consisting of a sequence of 7 to 12 bases, all or a part of Y'2 constitutes the miR-21 domain
- All of Y2 and all or part of X2 constitute an initiating hairpin-binding domain miR-21 domain capable of hybridizing with all or part of the extended hairpin-binding domain.
- a base or base sequence not constituting the initiation hairpin binding domain may be contained at the protruding end
- a base or base sequence not constituting the stem region Y'2 and/or the miR-21 domain may be contained at the free end of the stem region Y'2 .
- initial hairpin binding domain refers to a nucleic acid region in an extended hairpin nucleic acid that hybridizes with an initial hairpin nucleic acid.
- the initial hairpin binding domain includes the entire overhang region X2 and the entire or part of the subsequent stem region Y2 ( Figure 2).
- the initial hairpin binding domain is capable of hybridizing with the extended hairpin binding domain of the initial hairpin nucleic acid, and the base sequences of both domains are complementary to each other at least at both ends of each domain.
- miR-21 domain refers to a nucleic acid region in an extended hairpin nucleic acid having a base sequence capable of hybridizing with a base sequence complementary to that of miR-21.
- the miR-21 domain includes all or part of stem region Y'2 ( Figure 2).
- the miR-21 domain is capable of hybridizing with the miR-21-binding domain of an initiating hairpin nucleic acid, and the base sequences of both domains are complementary to each other at least at both termini of each domain.
- the base sequence of the miR-21 domain of the extended hairpin nucleic acid can include the base sequence represented by SEQ ID NO: 3, or a base sequence in which one or several bases have been deleted, substituted or added to the base sequence represented by SEQ ID NO: 3, regardless of whether it is a 3'-end overhang type (initial hairpin nucleic acid in which the left end is the 5' end in formula (II)) or a 5'-end overhang type (initial hairpin nucleic acid in which the left end is the 3' end in formula (II)).
- the extended hairpin nucleic acid preferably forms a single-stranded structure by cleaving the hairpin structure in the presence of the starting hairpin nucleic acid under physiological conditions in a mammal.
- the extended hairpin nucleic acid comprises the following base sequence: (1) A base sequence represented by any one selected from the group consisting of SEQ ID NOs: 5, 7, 16, and 18. (2) A base sequence in which one or more bases have been deleted, substituted, or added compared to (1). (3) A base sequence that hybridizes under highly stringent conditions with a base sequence complementary to any one selected from the group consisting of SEQ ID NOs: 5, 7, 16, and 18. The determination of whether or not a single-stranded structure is formed, the amount of free energy change, the base sequence that hybridizes under highly stringent conditions, etc. are similar to those described above for the starting hairpin nucleic acid.
- the base sequence of miR-21 and the base sequences described above for the initiating hairpin nucleic acid and the extended hairpin nucleic acid are shown in Table 1.
- a typical HCR reaction is explained again using the domains of hairpin nucleic acid.
- miR-21 binds to the miR-21 binding domain of the starting hairpin nucleic acid
- the hairpin structure (particularly the stem structure) of the starting hairpin nucleic acid dissociates (step 1 (1) in Figure 2).
- the extended hairpin binding domain of the starting hairpin nucleic acid and the extended hairpin binding domain of the starting hairpin nucleic acid can hybridize (step 2 (2) in Figure 2).
- the hairpin structure (particularly the stem structure) of the extended hairpin nucleic acid dissociates (step 2 in Figure 2).
- step 2 the miR-21 domain of this extended hairpin nucleic acid and the miR-21 binding domain of the starting hairpin nucleic acid can hybridize (step 3 (3) in Figure 2).
- This reaction is linked to form a linear double-stranded nucleic acid (HCR product) with a hybridization linkage structure ( Figures 2 (4) and (5)).
- each domain constituting the hairpin nucleic acid is not particularly limited. For example, it may be 4 bases or more, 5 bases or more, 6 bases or more, 7 bases or more, 8 bases or more, 9 bases or more, 10 bases or more, 11 bases or more, 12 bases or more, 13 bases or more, 14 bases or more, 15 bases or more, 16 bases or more, 17 bases or more, 18 bases or more, 19 bases or more, 20 bases or more, 21 bases or more, or 22 bases or more.
- each domain may be, for example, 55 bases or less, 50 bases or less, 40 bases or less, 30 bases or less, 25 bases or less, 24 bases or less, or 23 bases or less.
- each domain is not particularly limited as long as it contains a base sequence that can hybridize to the target nucleic acid.
- each domain can contain one or more bases that are unrelated to the base sequence of the target nucleic acid.
- the miR-21-binding domain of the initiating hairpin nucleic acid and the initiating hairpin-binding domain of the extended hairpin nucleic acid preferably comprise the entire protruding region X and the entire or part of the subsequent stem region Y.
- these domains may be a continuous region comprising the entire protruding region X, stem region Y, and loop region Z, and a part of stem region Y', or a continuous region comprising the protruding region X and a part of stem region Y.
- the base sequence of the stem region capable of hybridizing with miR-21 or the extended hairpin-binding domain of the initiating hairpin nucleic acid is 2 or more bases, 3 or more bases, 4 or more bases, 5 or more bases, 6 or more bases, 7 or more bases, 8 or more bases, 9 or more bases, 10 or more bases, 11 or more bases, 12 or more bases, 13 or more bases, 14 or more bases, 15 or more bases, or 16 or more bases.
- the extended hairpin binding domain of the starting hairpin nucleic acid and the miR-21 domain of the extended hairpin nucleic acid preferably include all or a part of the stem region Y'.
- these domains may be a continuous region including a part of the stem region Y, the whole of the loop region Z, and the whole of the stem region Y', or may be a continuous region including only a part of the stem region Y'.
- the hairpin nucleic acid has a protruding end adjacent to the stem region Y', it may include all or a part of the protruding end.
- the base sequence of the stem region Y' that can hybridize with the miR-21 domain of the extended hairpin nucleic acid or the miR-21 binding domain of the starting hairpin nucleic acid is 4 bases or more, 5 bases or more, 6 bases or more, 7 bases or more, 8 bases or more, 9 bases or more, 10 bases or more, 11 bases or more, 12 bases or more, 13 bases or more, 14 bases or more, 15 bases or more, or 16 bases or more.
- the hairpin nucleic acid of the present invention forms a linear double-stranded nucleic acid having a hybridization linkage structure in the presence of miR-21.
- the hybridization linkage structure can induce nucleic acid immunity.
- the specific structure of the hybridization chain structure is not particularly limited as long as it is a double-stranded structure of nucleic acid capable of inducing nucleic acid immunity.
- the hybridization chain structure includes a pathogen-associated molecular pattern that is recognized by a pattern recognition receptor present on a biological membrane or in the cytoplasm.
- pattern recognition receptors that can recognize nucleic acids present on biological membranes include Toll-like receptors, including TLR3, TLR7, TLR8, and TLR9. These are present on the biological membranes of endosomes and lysosomes, and recognize nucleic acid molecules that have entered cells.
- pattern recognition receptors that can recognize nucleic acids present in the cytoplasm include RIG-I-like receptors (e.g., RIG-I, MDA5, LGP2, etc.), cGAS, and AIM2.
- TLR3 is known to recognize double-stranded RNA of 40 base pairs or more
- TLR7 and TLR8 are known to recognize double-stranded RNA rich in polyuracil or guanine and uracil
- TLR9 is known to recognize unmethylated single-stranded DNA containing a sequence rich in cytosine and guanine, such as 5'-GTCGTT-3'.
- RIG-I protein is known to recognize double-stranded RNA containing blunt ends and having triphosphate at the 5' end.
- AIM2 protein is known to recognize double-stranded DNA.
- the hybridization sequence structure may, for example, have a pathogen-associated molecular pattern that is recognized by a pattern recognition receptor present in the cytoplasm, or may have a pathogen-associated molecular pattern that is recognized by a pattern recognition receptor that recognizes double-stranded nucleic acids (e.g., double-stranded DNA and/or double-stranded RNA).
- the pathogen-associated molecular pattern may, for example, be a double-stranded structure recognized by cGAS, or may be a double-stranded structure recognized by MDA5.
- cGAS cyclic GMP-AMP synthase
- An exemplary amino acid sequence of cGAS is shown in SEQ ID NO: 14.
- cGAS binds to foreign double-stranded nucleic acid (e.g., viral nucleic acid, etc.) or abnormal self double-stranded nucleic acid (e.g., nucleic acid leaked from the nucleus in aging cells, etc.)
- foreign double-stranded nucleic acid e.g., viral nucleic acid, etc.
- abnormal self double-stranded nucleic acid e.g., nucleic acid leaked from the nucleus in aging cells, etc.
- STING Stimulator of interferon genes
- Nucleic acids recognized by cGAS include long double-stranded DNA that does not form a chromatin structure and short double-stranded DNA with ends that contain unpaired guanosines. It is also known that the immune response pathway mediated by cGAS is easily induced when a large amount of nucleic acid molecules enters a cell, or when double-stranded nucleic acids containing oxidized DNA molecules enter the cell.
- the hybridization chain structure has a specific length.
- the median length of the HCR products formed may be, for example, 100 base pairs or more, 150 base pairs or more, 200 base pairs or more, 250 base pairs or more, 300 base pairs or more, 350 base pairs or more, 400 base pairs or more, 450 base pairs or more, 500 base pairs or more, or 550 base pairs or more. It is preferable that a certain amount of double-stranded structures of 500 base pairs or more are formed.
- 5% or more, 6% or more, 7% or more, 8% or more, 9% or more, 10% or more, 11% or more, 12% or more, 13% or more, 14% or more, 15% or more, 16% or more, 17% or more, 18% or more, 19% or more, 20% or more, 21% or more, 22% or more, 23% or more, 24% or more, or 25% or more of the HCR products have double-stranded structures of 500 base pairs or more.
- Each hairpin nucleic acid constituting the cell death inducing composition of the present invention may be composed of DNA and/or RNA nucleotides.
- each hairpin nucleic acid may contain natural and/or non-natural nucleotides as the constitutive nucleotides.
- the types, numbers, positions, etc. of the natural and non-natural nucleotides contained are not particularly limited.
- Nucleotide refers to a compound that contains a phosphate group covalently linked to the sugar portion of the nucleoside.
- a “nucleoside” is a base and sugar combination.
- the nucleobase (also known as base) portion of the nucleoside is usually a heterocyclic base moiety.
- the phosphate group can be linked to the 2', 3', or 5' hydroxyl portion of the sugar.
- Oligonucleotides are formed by the covalent linkage of adjacent nucleosides to one another to form a linear polymeric oligonucleotide. Within the oligonucleotide structure, the phosphate groups are generally considered to form the internucleoside linkages of the oligonucleotide.
- nucleotides include deoxyribonucleotides found in DNA and ribonucleotides found in RNA.
- deoxyribonucleotides and ribonucleotides are sometimes referred to as “DNA nucleotides” and “RNA nucleotides,” respectively.
- nucleosides include the deoxyribonucleosides found in DNA and the ribonucleosides found in RNA.
- deoxyribonucleosides and ribonucleosides are sometimes referred to as “DNA nucleosides” and “RNA nucleosides,” respectively.
- Non-natural nucleotide refers to any nucleotide other than naturally occurring nucleotides, including modified nucleotides and nucleotide mimetics.
- non-natural nucleoside refers to any nucleoside other than naturally occurring nucleosides, including modified nucleosides and nucleoside mimetics.
- modified nucleotide refers to a nucleotide having one or more of a modified sugar moiety, a modified internucleoside linkage, and a modified nucleobase.
- modified nucleoside refers to a nucleoside having a modified sugar moiety and/or a modified nucleobase.
- Nucleic acids including non-natural oligonucleotides, may be preferred over natural forms due to properties such as, for example, enhanced cellular uptake, enhanced affinity for nucleic acid targets, increased stability in the presence of nucleases, or increased inhibitory activity.
- modified internucleoside linkage refers to an internucleoside linkage that has a substitution or any change from a naturally occurring internucleoside linkage (i.e., a phosphodiester linkage). Modified internucleoside linkages include internucleoside linkages that contain a phosphorus atom and internucleoside linkages that do not contain a phosphorus atom.
- Representative phosphorus-containing internucleoside linkages include, but are not limited to, phosphodiester linkages, phosphorothioate linkages, phosphorodithioate linkages, phosphotriester linkages, methylphosphonate linkages, methylthiophosphonate linkages, boranophosphate linkages, and phosphoroamidate linkages.
- a phosphorothioate linkage refers to an internucleoside linkage in which the non-bridging oxygen atom of the phosphodiester linkage is replaced with a sulfur atom. Methods for preparing phosphorus-containing and non-phosphorus-containing linkages are well known.
- Modified internucleoside linkages are preferably linkages that are more nuclease-resistant than naturally occurring internucleoside linkages.
- modified nucleobase refers to any nucleobase other than adenine, cytosine, guanine, thymine, or uracil.
- unmodified nucleobase or “unmodified base” (natural nucleobase) refers to the purine bases adenine (A) and guanine (G), and the pyrimidine bases thymine (T), cytosine (C), and uracil (U).
- modified nucleobases include bases into which a substituent has been introduced. There is no particular limitation on the type of base into which a substituent is introduced. It may be either a pyrimidine base or a purine base.
- the position into which the substituent is introduced there is also no particular limitation on the position into which the substituent is introduced.
- it may be the 3'-position, 4'-position, 5'-position, 6'-position, or a combination thereof, and if it is a purine base, it may be the 2'-position, 6'-position, 7'-position, 8'-position, or a combination thereof.
- modified bases include, for example, 5-methylcytosine, 5-hydroxymethylcytosine, 5-formylated cytosine, 5-carboxylated cytosine, 5-fluorocytosine, 5-bromocytosine, 5-iodocytosine, or N4-methylcytosine; 2-aminoadenine, N6-methyladenine, 7-deazaadenine, 8-haloadenine, 8-aminoadenine, 8-thioladenine, 8-thioalkyladenine, 8-hydroxyladenine, or 8-bromoadenine; 2-thio-thymine; N2-methylguanine, 6-methylguanine, 7-methylguanine, 8 ...
- chiruguanine 7-deazaguanine, 7-methylguanine, 8-haloguanine, 8-aminoguanine, 8-thiolguanine, 8-thioalkylguanine, 8-hydroxylguanine, or 8-bromoguanine; 5-methyluracil, N3-methyluracil, 6-methyluracil, 5-fluorouracil, 5-bromouracil, 5-iodouracil, 5-hydroxyuracil, pseudouracil, or methylpseudouracil; hypoxanthine or xanthine; and derivatives thereof.
- modified sugar refers to a sugar having a substitution and/or any change from a natural sugar moiety (i.e., a sugar moiety found in DNA (2'-H) or RNA (2'-OH)).
- Nucleic acids herein may optionally contain one or more modified nucleosides, including modified sugars.
- Sugar modifications may confer enhanced nuclease stability, increased binding affinity, or some other beneficial biological property to the nucleic acid.
- a nucleoside may contain a chemically modified ribofuranose ring moiety.
- Examples of chemically modified ribofuranose rings include, but are not limited to, the addition of substituents (including 5' and 2' substituents), bridging non-geminal ring atoms to form bicyclic nucleic acids (bridged nucleic acids, BNAs), replacement of ribosyl ring oxygen atoms with S, N(R), or C( R1 )( R2 ), where R, R1 , and R2 each independently represent H, C1 - C12 alkyl, or a protecting group, and combinations thereof.
- nucleosides having modified sugar moieties include, but are not limited to, nucleosides containing 5'-vinyl, 5'-methyl, 4'-S, 2'-F (2'-fluoro), 2' -OCH3 (2'-OMe or 2'-O-methyl), and 2'-O( CH2 ) 2OCH3 substituents.
- 2'-modified sugar herein is meant a furanosyl sugar modified at the 2' position.
- bicyclic nucleoside refers to a modified nucleoside that contains a bicyclic sugar moiety. Nucleic acids that contain a bicyclic sugar moiety are commonly referred to as bridged nucleic acids (BNAs). Nucleosides that contain a bicyclic sugar moiety are sometimes referred to herein as “bridged nucleosides.”
- a bicyclic sugar may be a sugar in which the 2' and 4' carbon atoms are bridged by two or more atoms.
- bicyclic sugars are known to those of skill in the art.
- One subgroup of bicyclic sugar-containing nucleic acids (BNAs) is those having the 2'- and 4'-carbon atoms bridged by 4'-( CH2 ) p -O-2', 4'-( CH2 ) p - CH2-2 ', 4'-( CH2 ) p -S-2', 4'-( CH2 ) p -OCO-2', 4'-(CH2) n - N ( R3 )-O-( CH2 ) m -2' (wherein p, m and n represent integers of 1 to 4, 0 to 2 and 1 to 3, respectively; and R3 represents a hydrogen atom, an alkyl group, an alkenyl group, a cycloalkyl group, an aryl group, an a
- R1 and R2 are typically hydrogen atoms, but may be any other substituent.
- each substituent may be the same or different from each other.
- R1 and R2 include, independently, a protecting group for a hydroxyl group for nucleic acid synthesis, an alkyl group, an alkenyl group, a cycloalkyl group, an aryl group, an aralkyl group, an acyl group, a sulfonyl group, a silyl group, a phosphate group, a phosphate group protected by a protecting group for nucleic acid synthesis, or -P( R4 ) R5 (wherein R4 and R5 may be the same or different and each represent a hydroxyl group, a hydroxyl group protected by a protecting group for nucleic acid synthesis, a mercapto group, a mercapto group protected by a protecting group for nucleic acid synthesis, an amino group, an alkoxy group having 1 to 5 carbon atoms, an alkylthio group having 1 to 5 carbon atoms, a cyanoalkoxy group having 1 to 6 carbon atoms,
- Non-limiting examples of such BNAs include methyleneoxy (4'- CH2 -O-2') BNAs (also known as LNA (Locked Nucleic Acid®), 2',4'-BNAs), e.g., ⁇ -L-methyleneoxy (4'- CH2 -O-2') BNAs or ⁇ -D-methyleneoxy (4'- CH2 -O-2') BNAs, ethyleneoxy (4'-( CH2 ) 2 -O-2') BNAs (also known as ENAs), ⁇ -D-thio (4'- CH2 -S-2') BNAs, aminooxy (4'- CH2 -ON( R3 )-2') BNAs, oxyamino (4'- CH2 -N( R3 )-O-2') BNAs (also known as 2',4'-BNA NC ), 2',4'-BNA coc , 3'-amino-2',4'-BNA, 5'-methyl BNA
- nucleobase moieties (natural, modified, or a combination thereof) may be maintained for hybridization with an appropriate nucleic acid target.
- nucleoside mimetics include structures used to replace sugars, sugars and bases, or sugars, bases and linkages at one or more positions of an oligomeric compound.
- Nucleoside mimetics include, for example, morpholino, cyclohexenyl, cyclohexyl, tetrahydropyranyl, bicyclic or tricyclic sugar mimetics, e.g., nucleoside mimetics having non-furanose sugar units.
- Nucleotide mimetics include structures used to replace nucleosides and linkages at one or more positions of an oligomeric compound.
- Peptide nucleic acids are nucleotide mimetics with a backbone in which N-(2-aminoethyl)glycine is linked by amide bonds in place of sugars.
- “Mimetic” refers to groups that replace the sugar, nucleobase, and/or internucleoside linkage. Generally, a mimetic is used in place of a sugar or sugar-internucleoside linkage combination, and the nucleobase is maintained for hybridization to a selected target.
- modification are not particularly limited.
- different modifications can be made independently to nucleotides in the same nucleic acid molecule.
- multiple types of modifications may be made to one nucleotide.
- a nucleotide may contain a modified internucleoside bond (e.g., phosphorothioate bond) and a modified sugar (e.g., 2'-O-methyl modified sugar or bicyclic sugar) for the purpose of providing resistance to enzymatic cleavage.
- a modified nucleic acid base e.g., 5-methylcytosine
- a modified sugar e.g., 2'-O-methyl modified sugar or bicyclic sugar
- one or more of the starting hairpin nucleic acid and the extended hairpin nucleic acid do not contain natural nucleosides and unmodified nucleotides over the entire length.
- the non-natural nucleosides and modified nucleotides contained in one or more of the starting hairpin nucleic acid and the extended hairpin nucleic acid are less than half of the entire length.
- both the starting hairpin nucleic acid and the extended hairpin nucleic acid do not contain natural nucleosides and unmodified nucleotides.
- all of the nucleotides in the overhang region X may be non-natural nucleosides and/or modified nucleotides, and the internucleoside bond connecting the overhang region X and the stem region Y may be a modified internucleoside bond.
- a person skilled in the art can determine a suitable embodiment for the selection of modifications by referring to the explanations in literature related to nucleic acid medicines (e.g., WO 2007/143315, etc.). Furthermore, the purpose of the modification is not particularly limited. For example, modifications can be performed for the stabilization, detection, and pharmacological function of hairpin nucleic acids and HCR products.
- the initiation hairpin nucleic acid and extension hairpin nucleic acid that make up the cell death-inducing composition may contain multiple types of hairpin nucleic acids.
- nucleic acid molecules herein can be made by any method, for example, by chemical synthesis (e.g., using an automated synthesizer) or by enzymatic processes (e.g., but not limited to, polymerase, ligase, or restriction enzyme reactions), in whole or in part.
- chemical synthesis e.g., using an automated synthesizer
- enzymatic processes e.g., but not limited to, polymerase, ligase, or restriction enzyme reactions
- the cell death-inducing composition of the present invention is intended to induce cell death. Therefore, in addition to the above-mentioned hairpin nucleic acid, the active ingredient may contain one or more active ingredients capable of inducing cell death. Specific active ingredients include, for example, compounds that induce cell death, drugs based on promoting or suppressing gene expression, and drugs based on promoting or inhibiting function at the protein level.
- the cell death-inducing composition of the present invention does not necessarily induce cell death only in cells containing HCR products.
- the hybridization chain structure is one that is recognized by cGAS
- the secondary messenger 2'-5'-cGAMP synthesized by cGAS may move through gap junctions to adjacent cells, etc., and induce cell death in those cells as well.
- an immune response can be induced in association with cell death of cells containing HCR products. This immune response can promote secondary cell death (e.g., immunogenic cell death) in cells with similar abnormalities that do not contain HCR products.
- the cell death-inducing composition herein can induce cell death in cells that express miR-21 and pattern recognition receptors such as cGAS, as well as in other cells that express miR-21.
- the second aspect of the present invention is a pharmaceutical composition.
- the pharmaceutical composition of the present invention contains the cell death-inducing composition according to the first aspect as an active ingredient, and induces an HCR response at a target site containing miR-21.
- cell death can be induced specifically in miR-21-expressing cells at a target site.
- composition The components of the pharmaceutical composition of this embodiment will be described.
- the pharmaceutical composition of the present invention contains a carrier as an optional component in addition to the active ingredient, which is an essential component. Each component will be specifically described below.
- the pharmaceutical composition of the present invention contains an effective amount of the cell death-inducing composition described in the first aspect as an essential active ingredient.
- the composition of the cell death-inducing composition is described in detail in the first aspect, so a detailed description is omitted here.
- one or more other active ingredients may be included.
- An effective amount refers to the amount necessary for the cell death-inducing composition to function as an active ingredient, and which causes little or no harmful side effects to the subject to which it is applied. This effective amount may vary depending on various conditions, such as information about the subject, the route of administration, and the number of administrations. It is ultimately determined by the judgment of the person administering, which may be a physician, veterinarian, or pharmacist.
- an effective amount can be determined so that a sufficient amount of hybridization chain structure to activate cGAS is formed in the cell.
- effective amounts include, but are not limited to, amounts of nucleic acid in target cells of 0.01 nM to 20 nM, 0.05 nM to 15 nM, 0.08 nM to 12 nM, 0.09 nM to 11 nM, 0.1 nM to 10 nM, 0.11 nM to 10 nM, 0.2 nM to 10 nM, 0.5 nM to 10 nM, 0.8 nM to 10 nM, 0.9 nM
- concentration of each hairpin nucleic acid can be, for example, 1.5 times or more, 2 times or more, 2.5 times or more, 3 times or more, 3.5 times or more, 4 times or more, 4.5 times or more, 5 times or more, 5.5 times or more, 6 times or more, 6.5 times or more, 7 times or more
- the term "subject” refers to an object to which the cell death-inducing composition and pharmaceutical composition of the present invention are applied.
- Subjects include individuals, as well as organs, tissues, and cells.
- the subject may be any animal, including humans. Examples of subjects other than humans include various livestock, poultry, pets, and laboratory animals.
- the subject may be an individual having abnormal protein expression or abnormal cells, or an individual in need of treatment or prevention of a disease.
- subject information refers to various individual information about the living body to which the method is applied. For example, if the subject is a human, this includes age, weight, sex, diet, health condition, disease progression and severity, drug sensitivity, and the presence or absence of concomitant medication.
- the pharmaceutical composition of the present invention may be a so-called combined preparation that contains other active ingredients to the extent that the pharmacological effect of the hairpin nucleic acid, which is the active ingredient, is not lost.
- the "other active ingredients” referred to here include, for example, drugs that target miR-21-expressing cells and induce cell death through a mechanism of action different from that of the cell death-inducing composition of the first embodiment.
- the other active ingredients may also be drugs that have a pharmacological effect different from that of the cell death-inducing composition of the first embodiment. For example, antibiotics may be included.
- composition of the present invention may contain a pharma- ceutically acceptable carrier.
- pharmaceutically acceptable carrier refers to additives commonly used in the field of formulation technology. Examples include solvents, bases, emulsifiers, suspending agents, surfactants, pH adjusters, stabilizers, flavorings, excipients, vehicles, preservatives, binders, diluents, isotonicity agents, sedatives, buffers, coating agents, lubricants, colorants, thickeners, dissolution aids, and other additives.
- Solvents include any solvent, such as water or other pharma- ceutically acceptable aqueous solutions, or pharma-ceutically acceptable organic solvents (e.g., vegetable oils, etc.).
- Aqueous solutions include, for example, physiological saline, isotonic solutions containing glucose or other adjuvants, phosphate buffer, and sodium acetate buffer.
- Adjuvants include, for example, D-sorbitol, D-mannose, D-mannitol, sodium chloride, other low-concentration nonionic surfactants, polyoxyethylene sorbitan fatty acid esters, etc.
- the above-mentioned carriers are used to prevent or inhibit the degradation of the cell death-inducing composition, which is the active ingredient, by enzymes in the body, as well as to facilitate formulation and administration methods and maintain the dosage form and efficacy, and may be used appropriately as needed.
- the dosage form of the pharmaceutical composition of the present invention is not particularly limited as long as it is a form that can deliver the cell death-inducing composition described in the first aspect, which is an active ingredient, to a target site without inactivating the composition through degradation or the like, and can exert the pharmacological effect of the active ingredient in the body.
- the administration form of the pharmaceutical composition of the present invention can be broadly divided into oral administration and parenteral administration. If the administration method is parenteral administration, the preferred dosage form is a liquid that can be administered directly to the target site or systemically via the circulatory system.
- An example of a liquid is an injection.
- An injection can be formulated by appropriately combining the above-mentioned excipients, elixirs, emulsifiers, suspending agents, surfactants, stabilizers, pH regulators, etc., and mixing them in a unit dosage form required for generally accepted pharmaceutical practice.
- Other examples include ointments, plasters, cataplasms, transdermal agents, lotions, inhalants, aerosols, eye drops, and suppositories.
- each of the above dosage forms are not particularly limited as long as they are within the range of dosage forms known in the art.
- the pharmaceutical composition of the present invention may be formulated according to conventional methods in the art.
- the cell death-inducing composition of the present invention has excellent properties as a pharmaceutical, such as excellent solubility in water, Japanese Pharmacopoeia Dissolution Test Fluid 2, or Japanese Pharmacopoeia Disintegration Test Fluid 2, excellent pharmacokinetics (e.g., drug half-life in blood, brain transferability, metabolic stability, CYP inhibition), low toxicity (e.g., superior as a pharmaceutical in terms of acute toxicity, chronic toxicity, genotoxicity, reproductive toxicity, cardiotoxicity, drug interactions, carcinogenicity, phototoxicity, etc.), and few side effects (e.g., suppression of hypersedation, avoidance of lamellar necrosis).
- excellent pharmacokinetics e.g., drug half-life in blood, brain transferability, metabolic stability, CYP inhibition
- low toxicity e.g., superior as a pharmaceutical in terms of acute toxicity, chronic toxicity, genotoxicity, reproductive toxicity, cardiotoxicity, drug interactions, carcinogenicity, phototoxicity, etc.
- few side effects
- Dosage form and dosage there is no particular limitation on the preferred dosage form of the pharmaceutical composition of the present invention.
- it may be administered orally or parenterally. It is usually administered parenterally.
- parenteral administration examples include intramuscular administration, intravenous administration, intra-arterial administration, intraperitoneal administration, subcutaneous administration (including continuous subcutaneous implantation), intradermal administration, tracheal/bronchial administration, rectal administration, administration by blood transfusion, intratumoral administration, juxtatumoral administration (e.g., intradermal or subcutaneous administration in the vicinity of a tumor), intraventricular administration, intrathecal administration, intranasal administration, and intramuscular administration. Administration may be by intramuscular injection, intravenous drip administration, or continuous subcutaneous implantation. Subcutaneous administration also includes self-injection by the patient.
- the pharmaceutical composition of the present invention exerts an additive inhibitory effect within cells even when administered repeatedly. Furthermore, when administering repeatedly, the effectiveness can be improved by leaving a certain interval between administrations (e.g., half a day or more).
- Target Diseases The target diseases to which the pharmaceutical composition of the present invention can be applied are not particularly limited as long as they are diseases in which miR-21 is highly expressed, but are typically malignant tumors (cancers) and inflammatory diseases.
- malignant tumors include, for example, breast cancer, colon cancer, pancreatic cancer, lung cancer, prostate cancer, liver cancer, stomach cancer, brain tumor, thyroid cancer, oral cancer, acute myeloid leukemia, chronic lymphocytic leukemia, glioblastoma, esophageal cancer, hepatocellular carcinoma, glioma, cervical cancer, bladder cancer, laryngeal cancer, pancreatic ductal adenocarcinoma, head and neck squamous cell carcinoma, oral squamous cell carcinoma, ovarian cancer, bile duct cancer, renal cell carcinoma, skin cancer, endometrial cancer, bile duct cancer, kidney cancer, malignant melanoma, rectal cancer, etc.
- cancers include their metastatic pathologies.
- an anticancer drug containing the cell death-inducing composition of the present invention as an active ingredient can be prepared by using a composition similar to that of the pharmaceutical composition of this embodiment.
- the anticancer drug of the present invention can optionally contain other anticancer drugs.
- an anti-inflammatory agent containing the cell death-inducing composition of the present invention as an active ingredient can be prepared in the same manner as the pharmaceutical composition of this embodiment.
- inflammatory disease refers to a disease characterized by high levels of inflammation or degeneration in tissues.
- inflammatory diseases include both chronic inflammatory diseases and acute inflammatory diseases.
- Specific examples of inflammatory diseases include atopic dermatitis, contact dermatitis, allergic contact dermatitis, arthritis, etc.
- Example 1 Evaluation of HCR efficiency using a cell-free system (the purpose) In a cell-free experimental system, the relationship between the structure of the hairpin nucleic acid and HCR efficiency will be examined.
- miR-21 was added to a final concentration of 50 nM in 100 ⁇ L of TE buffer solution (containing 500 mM NaCl and 1.25 mM MgCl 2 ) containing the starting hairpin nucleic acid (HP(1)) and the extended hairpin nucleic acid (HP(2)) at a concentration of 500 nM, and the mixture was incubated at 37 ° C for 2 hours.
- TE buffer solution containing 500 mM NaCl and 1.25 mM MgCl 2
- HP(1) starting hairpin nucleic acid
- HP(2) extended hairpin nucleic acid
- HCR was induced in all three types of hairpin nucleic acid sets evaluated. In all cases, when miR-21 was not added, there were many monomeric hairpin nucleic acid molecules, and when miR-21 was added, the amount of monomers was significantly reduced and HCR products with large molecular weights were observed. In the hairpin nucleic acid sets HP-a and HP-b, the amount of monomers was more significantly reduced and more HCR products were formed in the presence of miR-21 compared to the comparative hairpin nucleic acid set (HP-o). This suggests that the hairpin nucleic acid sets HP-a and HP-b have a significantly higher efficiency of forming HCR products.
- Example 2 Evaluation of HCR efficiency using a cell-free system (2) (the purpose) In a cell-free experimental system, the relationship between the structure of the hairpin nucleic acid and HCR efficiency will be examined.
- the HCR efficiency was evaluated as follows. For each hairpin nucleic acid set, miR-21 was added to a TE buffer solution containing HP(1) and HP(2) at a concentration of 1 ⁇ M, and the mixture was allowed to stand at room temperature. As a control, a mixture without miR-21 was used. After standing, the reaction solution was analyzed by 1% agarose gel electrophoresis. GelRed (Biotium) was used to stain the gel.
- Example 3 Evaluation of cell death promotion efficiency by HCR (the purpose) We confirmed that HCR promotes cell death in human cells and investigated its efficiency.
- reaction solution was added to the dish, and after 2 hours, the medium was replaced with 200 ⁇ L of DMEM solution containing 10% FBS and 0.5% penicillin-streptomycin. After 24 hours, the medium was replaced with 100 ⁇ L of DMEM solution containing 9% FBS, 0.45% penicillin-streptomycin, and 10% Presto Blue (Invitrogen).
- the relative cell viability was calculated as a relative value, with the cell viability when a hairpin nucleic acid with a scrambled sequence was introduced as the hairpin nucleic acid being set at 100%. The experiment was performed in triplicate.
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Genetics & Genomics (AREA)
- Medicinal Chemistry (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Biomedical Technology (AREA)
- Biotechnology (AREA)
- General Chemical & Material Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Epidemiology (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Hematology (AREA)
- Pain & Pain Management (AREA)
- Rheumatology (AREA)
- Oncology (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024576151A JPWO2024166539A1 (https=) | 2023-02-07 | 2023-12-19 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2023-016897 | 2023-02-07 | ||
| JP2023016897 | 2023-02-07 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024166539A1 true WO2024166539A1 (ja) | 2024-08-15 |
Family
ID=92262961
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2023/045425 Ceased WO2024166539A1 (ja) | 2023-02-07 | 2023-12-19 | 核酸集合体医薬 |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2024166539A1 (https=) |
| WO (1) | WO2024166539A1 (https=) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110313030A1 (en) * | 2005-10-07 | 2011-12-22 | California Institute Of Technology | Pkr activation via hybridization chain reaction |
| WO2023013329A1 (ja) * | 2021-08-04 | 2023-02-09 | 国立大学法人東京大学 | ヘアピン核酸組成物 |
| WO2024005045A1 (ja) * | 2022-06-28 | 2024-01-04 | 国立大学法人東京大学 | ヘアピン核酸組成物 |
-
2023
- 2023-12-19 JP JP2024576151A patent/JPWO2024166539A1/ja active Pending
- 2023-12-19 WO PCT/JP2023/045425 patent/WO2024166539A1/ja not_active Ceased
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110313030A1 (en) * | 2005-10-07 | 2011-12-22 | California Institute Of Technology | Pkr activation via hybridization chain reaction |
| WO2023013329A1 (ja) * | 2021-08-04 | 2023-02-09 | 国立大学法人東京大学 | ヘアピン核酸組成物 |
| WO2024005045A1 (ja) * | 2022-06-28 | 2024-01-04 | 国立大学法人東京大学 | ヘアピン核酸組成物 |
Non-Patent Citations (3)
| Title |
|---|
| MORIHIRO KUNIHIKO, OSUMI HIRAKI, MORITA SHUNTO, HATTORI TAKARA, BABA MANAMI, HARADA NAOKI, OHASHI RIUKO, OKAMOTO AKIMITSU: "Oncolytic Hairpin DNA Pair: Selective Cytotoxic Inducer through MicroRNA-Triggered DNA Self-Assembly", JOURNAL OF THE AMERICAN CHEMICAL SOCIETY, AMERICAN CHEMICAL SOCIETY, vol. 145, no. 1, 11 January 2023 (2023-01-11), pages 135 - 142, XP093199473, ISSN: 0002-7863, DOI: 10.1021/jacs.2c08974 * |
| MORIHIRO KUNIHIKO: "MicroRNA-responsive DNA decoy therapeutics based on DNA nanotechnology", KURATA SCHOLARSHIP RESEARCH REPORT, vol. 50, no. 49, 1 January 2018 (2018-01-01), pages 1384, XP093199470 * |
| OSUMI, HIROKI: "Poster no. 057: Multiple decoy construction system responding to microRNA", THE 20TH LIFE SCIENCE SYMPOSIUM IN THE UNIVERSITY OF TOKYO, 21 October 2020 (2020-10-21), XP009552429 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2024166539A1 (https=) | 2024-08-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20240141362A1 (en) | Modified oligonucleotides with increased stability | |
| US20220307019A1 (en) | Double-stranded nucleic acid complex and use thereof | |
| US9738895B2 (en) | Oligomeric compounds and methods | |
| JP2026012736A (ja) | 結合修飾オリゴマー化合物及びその使用 | |
| WO2021195533A2 (en) | Synthesis of modified oligonucleotides with increased stability | |
| JP5816556B2 (ja) | 治療剤のためのunaオリゴマー構造 | |
| AU2022202991A1 (en) | Organic compositions to treat KRAS-related diseases | |
| CN113015802B (zh) | Pnpla3表达的调节剂 | |
| CN108513588A (zh) | Kras表达的调节剂 | |
| WO2016115490A1 (en) | Compounds and methods for modulation of dux4 | |
| KR20220069103A (ko) | 최소 플루오린 함량을 갖는 작은 간섭 rna의 화학적 변형 | |
| JP2021502411A (ja) | 標的遺伝子の発現を抑制するためのジチオリン酸結合を含む核酸 | |
| JP2023539341A (ja) | Dux4阻害剤およびその使用方法 | |
| CN111902537A (zh) | Dnm2表达的调节剂 | |
| US20240043837A1 (en) | Modulation of signal transducer and activator of transcription 3 (stat3) expression | |
| JP2025156522A (ja) | 修飾ヘテロ核酸 | |
| WO2013056670A1 (zh) | 小干扰RNA及其应用和抑制plk1基因表达的方法 | |
| CN120752341A (zh) | 靶向sod1的寡核苷酸 | |
| JP6974872B2 (ja) | ヘテロ二本鎖型antimiR | |
| WO2024005045A1 (ja) | ヘアピン核酸組成物 | |
| WO2024166539A1 (ja) | 核酸集合体医薬 | |
| KR20240014533A (ko) | 신규한 유전자 침묵 기술로서의 짧은 듀플렉스 dna 및 이의 용도 | |
| KR20240014532A (ko) | 신규한 유전자 침묵 기술로서의 비대칭의 짧은 듀플렉스 dna 및 이의 용도 | |
| EP3906930A1 (en) | Rnai molecule for treating cancer | |
| WO2024228398A1 (ja) | グアニン四重鎖構造を誘導するための核酸剤 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 23921358 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2024576151 Country of ref document: JP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 23921358 Country of ref document: EP Kind code of ref document: A1 |