WO2023190136A1 - 学習システム、決定システム、及び予測システム、並びに学習方法、決定方法、及び予測方法 - Google Patents
学習システム、決定システム、及び予測システム、並びに学習方法、決定方法、及び予測方法 Download PDFInfo
- Publication number
- WO2023190136A1 WO2023190136A1 PCT/JP2023/011772 JP2023011772W WO2023190136A1 WO 2023190136 A1 WO2023190136 A1 WO 2023190136A1 JP 2023011772 W JP2023011772 W JP 2023011772W WO 2023190136 A1 WO2023190136 A1 WO 2023190136A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- biomarker
- sequence
- sequences
- learning
- score
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images






Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N7/00—Computing arrangements based on specific mathematical models
- G06N7/01—Probabilistic graphical models, e.g. probabilistic networks
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/20—Allele or variant detection, e.g. single nucleotide polymorphism [SNP] detection
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B25/00—ICT specially adapted for hybridisation; ICT specially adapted for gene or protein expression
- G16B25/20—Polymerase chain reaction [PCR]; Primer or probe design; Probe optimisation
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B40/00—ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding
- G16B40/10—Signal processing, e.g. from mass spectrometry [MS] or from PCR
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B40/00—ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding
- G16B40/20—Supervised data analysis
Definitions
- the present invention relates to a technique for measuring the value of a biomarker.
- methylation occurs in DNA (deoxyribonucleic acid). Methylation refers to a modification in which a methyl molecule chemically binds to cytosine. Cytosine (C), together with guanine (G), adenine (A), and thymine (T), constitutes four essential nucleobases that make up DNA. Any sequence of nucleobases is called a “nucleotide sequence,” and nucleotide sequences that encode important information such as proteins are called “genomic sequences" or “genes.”
- methylation is particularly common where cytosine follows guanine on the DNA strand (called "CpG sites"). Methylation status influences gene activation or repression, and the methylation status of CpG sites in certain genes forms important biomarkers for many diseases.
- data obtained from a combination of several biomarker candidate sequences is used to create a quantitative model for disease diagnosis. Therefore, it is important to measure DNA methylation as a biomarker.
- Patent Document 1 describes selecting and evaluating a biomarker set from representative biomarker data. Furthermore, Non-Patent Document 1 describes the measurement and mitigation of PCR bias (PCR: polymerase chain reaction).
- each "signal” is a gene or sequence of interest.
- the number of such sequences is very small, so the derived signal is weak. Therefore, it is possible to increase the number of sequences and amplify the signal by copying the original sequence many times.
- G1_pre the signal intensity of gene 1 before PCR
- G1_post the signal intensity after PCR
- gene 1 has some sequences with CpG as unmethylated, which are converted to another sequence containing uracil. Similarly, sequences where CpGs are methylated are not converted. This is common and seen in a mixture of liver and stomach DNA. In such a mixture, genes important to the liver may be unmethylated in hepatocytes but methylated (and thus repressed) in gastric cells.
- the strength of the pre-PCR signal and the strength of the post-PCR signal are set as G1_U_Pre and G1_U_post (if not methylated), and G1_M_Pre and G1_M_post (if methylated), and the decoded sequence is G1_M_Pre and G1_M_post.
- the present invention is particularly important in cases where simultaneous and highly accurate measurements of DNA methylation from multiple genes are required, such as in liquid biopsies.
- certain cancer cell genes are known to exhibit high methylation compared to the same genes in healthy cells.
- Problem 2 means that in such cases the measurement underestimates the true methylation ratio from the mixture of cancer and normal DNA (negative bias).
- Problems 1 and 3 further exacerbate the degree of underestimation.
- the present invention has been made in view of the above circumstances, and one form thereof provides a learning system and a learning method for learning measurement error characteristics of biomarker sequences. Further, one form of the present invention provides a determination system and determination method that determines a sequence set by reflecting learned error characteristics, and predicts measurement error characteristics of gene sequences using data obtained by the learning system or learning method. A prediction system and a prediction method are provided.
- a learning system is a learning system for learning the relationship between measurement protocol variables and resultant error characteristics of a biomarker array, the learning system comprising a processor, the processor comprising: Enter calibration data designed to ensure that appropriate data are available for the variables, use a probabilistic model to learn the characteristics of the error distribution across each measurement protocol for the variables of interest, and the probabilistic model
- the first parameter is initialized with appropriately selected a priori parameters to model the error of and a third parameter initialized with appropriately selected a priori parameters to model overall PCR bias.
- a learning system is a system that learns a relationship between measurement protocol variables and resulting error characteristics of a biomarker sequence (defined as template-to-product ratio).
- a "variable of significance” is a variable that is known by laboratory experts to affect signal amplification performance;
- the PCR device is calibrated.
- the PCR temperature and the number of PCR cycles as shown in FIG. 2, which will be described later, are examples of "important variables.” If the temperature is too high, the DNA will degrade and the reactions necessary to replicate the target gene sequence will not occur.
- the same parameter may be used as the "appropriately selected a priori parameter”.
- “input of calibration data” for example, in the case of PCR temperature, it is necessary that appropriate display is possible within the temperature range used in normal PCR.
- the second parameter separately acquires counts of methylated sequences and unmethylated sequences of the gene after bisulfite conversion, and uses the acquired counts as These are parameters modeled using a multinomial distribution that allows prior variables to be determined separately for each methylated sequence and non-methylated sequence.
- the second aspect is to specify a specific aspect of the second parameter in order to deal with problem 2 mentioned above, by modeling and correcting the error of bisulfite conversion, and correcting the methylation of the biomarker sequence. It allows for evaluation.
- better a priori variables can be selected from empirical data analysis. Note that the counts obtained in the second aspect can be modeled based on factors such as the GC ratio (guanine to cytosine ratio) of the base sequence.
- the third parameter is an individual count of the counts calculated by a multinomial distribution when a plurality of sequences are simultaneously amplified using a universal primer.
- This parameter is subject to a configuration data constraint such that the sum of the values follows a Gaussian distribution.
- the third aspect is to define a specific aspect of the second parameter in order to deal with the problem 3 mentioned above.
- the sum of each count in multiple distributed counts follows a Gaussian distribution.
- the count values of individual markers are not independent, but the amplification method is such that the total value is approximately constant, so modeling using multinomial distribution as described above is suitable. .
- modeling is performed for the count value of the number of markers x 2.
- a decision system is a decision system comprising a processor, the processor inputting the nucleotide sequence and measurement protocol information of the biomarker sequence of interest for use in the multiplexed panel;
- the learned error characteristics and metadata associated with the error characteristics are input from the learning system according to any one of the third aspects, and the nucleotide sequence and measurement protocol information are input using predetermined criteria.
- the learned error characteristics, and the metadata to output a first score for the set of possible biomarker sequences, and consider the value of the first score for each set to determine the biomarker sequence. Decide on the set.
- a decision system uses the output from the system according to the first aspect to decide whether to use a biomarker sequence in a multiplex panel.
- the first score is a score derived from measurement accuracy, and is a "low error score" which has a higher value as the measurement error is smaller.
- the processor inputs a second score for each biomarker sequence to be determined, and inputs a first score for each biomarker sequence in the biomarker sequence set.
- the best subset of multiplexed panels is selected by optimizing the balance between the first score and the second score.
- the decision system according to the fifth aspect enhances the fourth aspect to enable a more balanced selection of biomarker sequences by considering the ultimate goal of the multiplex panel.
- the second score is, for example, a higher score (relevance score) as the degree of association with the disease to be predicted is greater.
- the "balance between the first score and the second score" is calculated by calculating the third score defined by the arithmetic mean or geometric mean of the first score and the second score, and Optimization can be achieved by maximizing the score.
- a prediction system is a prediction system for predicting measurement error characteristics of a gene sequence, comprising a processor, the processor comprising a nucleotide sequence and a nucleotide sequence of a biomarker sequence of interest to be used in a multiplexed panel.
- the measurement protocol information is input, the learned error characteristics and the metadata associated with the error characteristics are input from the learning system according to any one of the first to third aspects, and the error characteristics between the two gene sequences are input.
- the metric for calculating similarity measures is used to calculate the similarity between the new biomarker sequences and the biomarker sequences previously included in the calibration data, and to apply the calculated similarity to other relevant Used in combination with the input and learned error characteristics to predict error characteristics when measuring biomarker sequences not included in the calibration data.
- the prediction system according to the sixth aspect allows the learning systems according to the first to third aspects to be used for biomarker sequences that were not included in the calibration data.
- other related input means, for example, metadata corresponding to a biomarker sequence.
- the gene type is "promoter or enhancer”
- the CpG type is "island, shore, shelf”
- the CG abundance is "high, low”
- the combination can be represented as a vector "promoter, island, low”.
- the prediction system according to the seventh aspect is the sixth aspect, wherein the processor uses the predicted error characteristics to determine which biomarker sequences are most similar to those available in the calibration data that are not included in the calibration data. information on the obtained biomarker sequence is reflected in the determination of a biomarker sequence set in the determination system according to the fourth or fifth aspect.
- using the determination system according to the fourth or fifth aspect it is possible to use a biomarker sequence that is not included in the calibration data in selecting a biomarker sequence set.
- a learning method is a learning method performed by a learning system that includes a processor and learns a relationship between a measurement protocol variable and an error characteristic that occurs as a result of a biomarker array. enters calibration data designed to ensure that adequate data are available for the variables of interest (calibration data entry step) and uses a probabilistic model to estimate the error distribution across each measurement protocol for the variables of interest. After learning the characteristics (learning step), the probabilistic model uses the interaction of the first parameter initialized with appropriately selected a priori parameters and the amplification of the biomarker sequence to model the error of the bisulfite conversion.
- the second parameter was initialized with an appropriately selected a priori parameter to model the dependence and the second parameter was initialized with an appropriately selected a priori parameter to model overall PCR bias. and a third parameter.
- the eighth aspect defines a learning method corresponding to the first aspect described above.
- the second parameter separately acquires counts of methylated sequences and unmethylated sequences of the gene after bisulfite conversion, and These are parameters modeled using a multinomial distribution that allows prior variables to be determined separately for each methylated sequence and non-methylated sequence.
- the ninth aspect defines a learning method corresponding to the second aspect described above.
- the third parameter is an individual count of the counts calculated by a multinomial distribution when a plurality of sequences are simultaneously amplified using a universal primer.
- This parameter is subject to a configuration data constraint such that the sum of the values follows a Gaussian distribution.
- the tenth aspect defines a learning method corresponding to the third aspect described above.
- a determination method is a determination method performed by a determination system comprising a processor, wherein the processor determines the nucleotide sequence and measurement protocol information of a biomarker sequence of interest to be used in a multiplexed panel.
- input sequence information input step
- input learned error characteristics and metadata associated with the error characteristics obtained as a result of the learning method according to any one of the eighth to tenth aspects learning result input step
- using the input nucleotide sequences using predetermined criteria, measurement protocol information, learned error characteristics, and metadata to create a first set of possible biomarker sequences.
- a score is output (score output step), and a biomarker sequence set is determined by considering the first score value for each set (sequence set determination step).
- the eleventh aspect defines a determination method corresponding to the fourth aspect described above.
- the prediction method according to the fourteenth aspect is the thirteenth aspect, wherein the processor uses the predicted error characteristics to determine which biomarker sequences are available in the calibration data that are most similar to biomarker sequences not included in the calibration data.
- the obtained biomarker sequence is acquired (sequence acquisition step), and the information on the acquired biomarker sequence is reflected in the determination of a biomarker sequence set in the determination method according to the eleventh or twelfth aspect (information reflection step).
- the fourteenth aspect defines a prediction method corresponding to the seventh aspect described above.
- a wet experiment protocol 20 is used to obtain calibration data consisting of important measurement protocol variables such as PCR temperature and number of PCR cycles. It is necessary to create a . Preferably, this calibration data is designed such that appropriate data is available for variables of interest. Finally, the sequence measurement results are stored in a calibration data DB 30 (DB) along with protocol information (hereinafter, the database may be referred to as "DB"). Note that in FIG. 2, a part of the calibration data creation procedure is omitted for clarity.
- the present invention characterizes the measurement error of biomarker sequences by detailing the operation of probabilistic models and estimating the "template-to-product” ratio.
- “Template” refers to the initial amount of a biomarker sequence (amount before PCR amplification)
- product refers to the final amount of the same biomarker sequence after PCR amplification (amount after PCR amplification).
- the processor 110 may include a display control section, a communication control section, an output control section, etc. (not shown).
- the learning system 100 may include a display device (for example, a liquid crystal monitor) and an operation device (for example, a mouse and a keyboard) that are not shown.
- the display device can display calibration data, error distribution data, etc., and the user can perform operations necessary to execute the learning method (learning program) according to the present invention via the operation unit. I can do it.
- FIG. 3 described above shows blood sample data 11, which is any biological data including tissue samples.
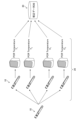
- blood sample data 11 is measured using the measurement procedure that includes STEP 1 and STEP 2 described above, plus DNA sequencing. It has several influencing variables (variables of importance). Since it is necessary to obtain data from several values of such variables, the relevant variables are first identified and measurements are taken over a range of these values. For example, if the number of PCR cycles is the only variable of interest, data can be generated for the same blood sample for 5, 10, and 15 PCR cycles. This is so-called calibration data.
- the learning system 100 is tuned through a set of hyperparameters (hyperparameters 40) according to an optimization method (such as a loss function for minimization). Such tuning is done by ascertaining the final performance of the system and selecting hyperparameters that maximize it.
- the learning system 100 described above may be accompanied by a decision system 200 (decision system) and a prediction system 300 (prediction system), as shown in FIG. Adding these decision and prediction systems to the learning system 100 is a recommended option.
- the decision system 200 and the prediction system 300 the best subset of candidate biomarkers can be found by the decision system 200 using, for example, the error characteristics learned by the learning system 100 (including the learning result input step and the score (by carrying out the determination method according to the invention, including an input step, a subset selection step, etc.), thereby informing the selection criteria of the biomarker sequences (including an information reflection step, etc.) prediction system 300), can help effectively utilize the learning system 100.
- the sequence information input unit 212 (processor) of the determination system 200 inputs the nucleotide sequence of the biomarker sequence of interest and measurement protocol information (sequence information input step), and the learning result input unit 214 (processor) inputs the learned error characteristics and metadata associated with the error characteristics from the learning system 100 (learning result input step).
- the score output unit 216 (processor) independently considers the learned measurement error characteristics, and generates a score (measurement error score; first (one example of a score) can be assigned to each biomarker sequence (score output step).
- the sequence set determining unit 218 can sum up the scores (first score) from the order of each biomarker and determine whether to use the combination (biomarker sequence set) (sequence set determining step).
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Theoretical Computer Science (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biophysics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Biotechnology (AREA)
- Evolutionary Biology (AREA)
- General Health & Medical Sciences (AREA)
- Data Mining & Analysis (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Molecular Biology (AREA)
- Evolutionary Computation (AREA)
- Chemical & Material Sciences (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Bioethics (AREA)
- Analytical Chemistry (AREA)
- Public Health (AREA)
- Epidemiology (AREA)
- Databases & Information Systems (AREA)
- General Physics & Mathematics (AREA)
- Genetics & Genomics (AREA)
- Signal Processing (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Computing Systems (AREA)
- Mathematical Optimization (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Probability & Statistics with Applications (AREA)
- Pure & Applied Mathematics (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Algebra (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202380031812.XA CN118974834A (zh) | 2022-03-30 | 2023-03-24 | 学习系统、确定系统和预测系统以及学习方法、确定方法和预测方法 |
| EP23780146.9A EP4503038A4 (en) | 2022-03-30 | 2023-03-24 | Learning system, decision system, and prediction system, and learning method, decision method, and prediction method |
| JP2024512336A JPWO2023190136A1 (https=) | 2022-03-30 | 2023-03-24 | |
| US18/900,009 US20250022539A1 (en) | 2022-03-30 | 2024-09-27 | Learning system, determination system, prediction system, learning method, determination method, and prediction method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022-056626 | 2022-03-30 | ||
| JP2022056626 | 2022-03-30 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/900,009 Continuation US20250022539A1 (en) | 2022-03-30 | 2024-09-27 | Learning system, determination system, prediction system, learning method, determination method, and prediction method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2023190136A1 true WO2023190136A1 (ja) | 2023-10-05 |
Family
ID=88201403
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2023/011772 Ceased WO2023190136A1 (ja) | 2022-03-30 | 2023-03-24 | 学習システム、決定システム、及び予測システム、並びに学習方法、決定方法、及び予測方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20250022539A1 (https=) |
| EP (1) | EP4503038A4 (https=) |
| JP (1) | JPWO2023190136A1 (https=) |
| CN (1) | CN118974834A (https=) |
| WO (1) | WO2023190136A1 (https=) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11610648B2 (en) * | 2019-04-18 | 2023-03-21 | Life Technologies Corporation | Methods for context based compression of genomic data for immuno-oncology biomarkers |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017523437A (ja) | 2014-06-10 | 2017-08-17 | クレッシェンド バイオサイエンス インコーポレイテッド | 体軸性脊椎関節炎の疾患活動性を測定およびモニタリングするためのバイオマーカーおよび方法 |
| WO2020008192A2 (en) * | 2018-07-03 | 2020-01-09 | Chronomics Limited | Phenotype prediction |
| JP2021521536A (ja) * | 2018-04-13 | 2021-08-26 | フリーノーム・ホールディングス・インコーポレイテッドFreenome Holdings, Inc. | 生体試料の多検体アッセイのための機械学習実装 |
-
2023
- 2023-03-24 JP JP2024512336A patent/JPWO2023190136A1/ja active Pending
- 2023-03-24 CN CN202380031812.XA patent/CN118974834A/zh active Pending
- 2023-03-24 EP EP23780146.9A patent/EP4503038A4/en active Pending
- 2023-03-24 WO PCT/JP2023/011772 patent/WO2023190136A1/ja not_active Ceased
-
2024
- 2024-09-27 US US18/900,009 patent/US20250022539A1/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017523437A (ja) | 2014-06-10 | 2017-08-17 | クレッシェンド バイオサイエンス インコーポレイテッド | 体軸性脊椎関節炎の疾患活動性を測定およびモニタリングするためのバイオマーカーおよび方法 |
| JP2021521536A (ja) * | 2018-04-13 | 2021-08-26 | フリーノーム・ホールディングス・インコーポレイテッドFreenome Holdings, Inc. | 生体試料の多検体アッセイのための機械学習実装 |
| WO2020008192A2 (en) * | 2018-07-03 | 2020-01-09 | Chronomics Limited | Phenotype prediction |
Non-Patent Citations (2)
| Title |
|---|
| JUSTIN D. SILVERMAN ET AL., MEASURING AND MITIGATING PCR BIAS IN MICROBIOME DATA, 22 March 2022 (2022-03-22), Retrieved from the Internet <URL:https://www.biorxiv.org/content/10.1101/604025v1> |
| See also references of EP4503038A4 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4503038A4 (en) | 2025-07-30 |
| CN118974834A (zh) | 2024-11-15 |
| EP4503038A1 (en) | 2025-02-05 |
| US20250022539A1 (en) | 2025-01-16 |
| JPWO2023190136A1 (https=) | 2023-10-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Vandesompele et al. | Reference gene validation software for improved normalization | |
| García-Ortega et al. | How many genes are expressed in a transcriptome? Estimation and results for RNA-Seq | |
| JP2021503922A (ja) | ターゲットシーケンシングのためのモデル | |
| JP2005531853A (ja) | Snp遺伝子型クラスタリングのためのシステムおよび方法 | |
| Iqbal et al. | Integrated COVID-19 Predictor: Differential expression analysis to reveal potential biomarkers and prediction of coronavirus using RNA-Seq profile data | |
| ES2937408T3 (es) | Método y producto informático de análisis de ADN fetal por secuenciación masiva | |
| JP7275334B2 (ja) | 個人の生物学的ステータスを予測するためのシステム、方法および遺伝子シグネチャ | |
| US20250022539A1 (en) | Learning system, determination system, prediction system, learning method, determination method, and prediction method | |
| Foroozandeh Shahraki et al. | Robust chromatin state annotation | |
| Wong et al. | A comparison study for DNA motif modeling on protein binding microarray | |
| JPWO2023190136A5 (https=) | ||
| Mboning et al. | BayesAge: A maximum likelihood algorithm to predict epigenetic age | |
| US20200105374A1 (en) | Mixture model for targeted sequencing | |
| Lijoi et al. | A Bayesian nonparametric approach for comparing clustering structures in EST libraries | |
| Aliferi et al. | Predicting chronological age from DNA methylation data: a machine learning approach for small datasets and limited predictors | |
| Jung et al. | Identifying Differentially Expressed Genes in Meta‐Analysis via Bayesian Model‐Based Clustering | |
| Chong et al. | SeqControl: process control for DNA sequencing | |
| Okamoto et al. | Probabilistic Fine-mapping of putative causal genes | |
| Bradley et al. | Hierarchical Bayesian modeling identifies key considerations in the development of quantitative loop-mediated isothermal amplification assays | |
| Alsharif | DeepRice6mA: A convolutional neural network approach for 6mA site prediction in the rice Genome | |
| Yang et al. | Regression trees for interval‐censored failure time data based on censoring unbiased transformations and pseudo‐observations | |
| Forrest et al. | MMRT: MultiMut Recursive Tree for predicting functional effects of high-order protein variants from low-order variants | |
| Chowdhury et al. | Robust genomic prediction and heritability estimation using density power divergence | |
| Eck et al. | Determining the relationship of gene expression and global mRNA stability in Drosophila melanogaster and Escherichia coli using linear models | |
| KR20200085144A (ko) | 모체 시료 중 태아 분획을 결정하는 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 23780146 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2024512336 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202380031812.X Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2023780146 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2023780146 Country of ref document: EP Effective date: 20241030 |