WO2022093992A1 - Chroma coding enhancement in cross-component sample adaptive offset with virtual boundary - Google Patents
Chroma coding enhancement in cross-component sample adaptive offset with virtual boundary Download PDFInfo
- Publication number
- WO2022093992A1 WO2022093992A1 PCT/US2021/056897 US2021056897W WO2022093992A1 WO 2022093992 A1 WO2022093992 A1 WO 2022093992A1 US 2021056897 W US2021056897 W US 2021056897W WO 2022093992 A1 WO2022093992 A1 WO 2022093992A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- component
- samples
- subset
- video
- sample
- Prior art date
Links
- 230000003044 adaptive effect Effects 0.000 title description 17
- 238000000034 method Methods 0.000 claims abstract description 75
- 238000012545 processing Methods 0.000 claims description 53
- 238000003860 storage Methods 0.000 claims description 20
- 230000004044 response Effects 0.000 claims description 3
- 241000023320 Luma <angiosperm> Species 0.000 description 154
- OSWPMRLSEDHDFF-UHFFFAOYSA-N methyl salicylate Chemical compound COC(=O)C1=CC=CC=C1O OSWPMRLSEDHDFF-UHFFFAOYSA-N 0.000 description 154
- 230000008569 process Effects 0.000 description 37
- 238000010586 diagram Methods 0.000 description 35
- 239000013598 vector Substances 0.000 description 33
- 208000037170 Delayed Emergence from Anesthesia Diseases 0.000 description 20
- 239000000872 buffer Substances 0.000 description 20
- 238000000638 solvent extraction Methods 0.000 description 19
- 238000005192 partition Methods 0.000 description 17
- 238000013139 quantization Methods 0.000 description 17
- 238000004891 communication Methods 0.000 description 15
- 230000011664 signaling Effects 0.000 description 15
- 230000006835 compression Effects 0.000 description 9
- 238000007906 compression Methods 0.000 description 9
- 238000005259 measurement Methods 0.000 description 8
- 238000013461 design Methods 0.000 description 7
- 230000005540 biological transmission Effects 0.000 description 6
- 238000001914 filtration Methods 0.000 description 6
- 230000003252 repetitive effect Effects 0.000 description 6
- 230000002123 temporal effect Effects 0.000 description 6
- 230000008901 benefit Effects 0.000 description 4
- 239000011449 brick Substances 0.000 description 4
- 238000013500 data storage Methods 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 238000005303 weighing Methods 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 3
- 238000010276 construction Methods 0.000 description 3
- 238000005516 engineering process Methods 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 230000006978 adaptation Effects 0.000 description 2
- 108010063123 alfare Proteins 0.000 description 2
- 238000003491 array Methods 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- 230000001143 conditioned effect Effects 0.000 description 2
- 230000006837 decompression Effects 0.000 description 2
- 238000006073 displacement reaction Methods 0.000 description 2
- 101100520660 Drosophila melanogaster Poc1 gene Proteins 0.000 description 1
- 241000985610 Forpus Species 0.000 description 1
- 101100520663 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) ADD66 gene Proteins 0.000 description 1
- 101100520662 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) PBA1 gene Proteins 0.000 description 1
- 238000004422 calculation algorithm Methods 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000009499 grossing Methods 0.000 description 1
- 238000012432 intermediate storage Methods 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 235000015096 spirit Nutrition 0.000 description 1
- 230000001360 synchronised effect Effects 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/186—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being a colour or a chrominance component
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/117—Filters, e.g. for pre-processing or post-processing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/132—Sampling, masking or truncation of coding units, e.g. adaptive resampling, frame skipping, frame interpolation or high-frequency transform coefficient masking
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/136—Incoming video signal characteristics or properties
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/167—Position within a video image, e.g. region of interest [ROI]
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/172—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a picture, frame or field
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/90—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using coding techniques not provided for in groups H04N19/10-H04N19/85, e.g. fractals
- H04N19/96—Tree coding, e.g. quad-tree coding
Definitions
- the present application generally relates to video coding and compression, and more specifically, to methods and apparatus on improving the chroma coding efficiency.
- Digital video is supported by a variety of electronic devices, such as digital televisions, laptop or desktop computers, tablet computers, digital cameras, digital recording devices, digital media players, video gaming consoles, smart phones, video teleconferencing devices, video streaming devices, etc.
- the electronic devices transmit, receive, encode, decode, and/or store digital video data by implementing video compression/decompression standards.
- Some well-known video coding standards include Versatile Video Coding (VVC), High Efficiency Video Coding (HEVC, also known as H.265 or MPEG-H Part 2) and Advanced Video Coding (AVC, also known as H.264 or MPEG-4 Part 10), which are jointly developed by ISO/IEC MPEG and ITU-T VCEG.
- Audio Video Coding which refers to digital audio and digital video compression standard, is another video compression standard series developed by the Audio and Video Coding Standard Workgroup of China.
- Video compression typically includes performing spatial (intra frame) prediction and/or temporal (inter frame) prediction to reduce or remove redundancy inherent in the video data.
- a video frame is partitioned into one or more slices, each slice having multiple video blocks, which may also be referred to as coding tree units (CTUs).
- Each CTU may contain one coding unit (CU) or recursively split into smaller CUs until the predefined minimum CU size is reached.
- Each CU also named leaf CU
- TUs transform units
- PUs prediction units
- Each CU can be coded in either intra, inter or IBC modes.
- Video blocks in an intra coded (I) slice of a video frame are encoded using spatial prediction with respect to reference samples in neighboring blocks within the same video frame.
- Video blocks in an inter coded (P or B) slice of a video frame may use spatial prediction with respect to reference samples in neighboring blocks within the same video frame or temporal prediction with respect to reference samples in other previous and/or future reference video frames.
- the process of finding the reference block may be accomplished by block matching algorithm.
- Residual data representing pixel differences between the current block to be coded and the predictive block is referred to as a residual block or prediction errors.
- An inter-coded block is encoded according to a motion vector that points to a reference block in a reference frame forming the predictive block, and the residual block. The process of determining the motion vector is typically referred to as motion estimation.
- An intra coded block is encoded according to an intra prediction mode and the residual block.
- the residual block is transformed from the pixel domain to a transform domain, e.g., frequency domain, resulting in residual transform coefficients, which may then be quantized.
- the quantized transform coefficients initially arranged in a two-dimensional array, may be scanned to produce a one-dimensional vector of transform coefficients, and then entropy encoded into a video bitstream to achieve even more compression.
- the encoded video bitstream is then saved in a computer-readable storage medium (e.g., flash memory) to be accessed by another electronic device with digital video capability or directly transmitted to the electronic device wired or wirelessly.
- the electronic device then performs video decompression (which is an opposite process to the video compression described above) by, e.g., parsing the encoded video bitstream to obtain syntax elements from the bitstream and reconstructing the digital video data to its original format from the encoded video bitstream based at least in part on the syntax elements obtained from the bitstream, and renders the reconstructed digital video data on a display of the electronic device.
- video decompression which is an opposite process to the video compression described above
- the present application describes implementations related to video data encoding and decoding and, more particularly, to methods and apparatus on improving the coding efficiency of chroma coding, including improving the coding efficiency by exploring cross-component relationship between luma and chroma components.
- a method of decoding video signal comprises: receiving, from the video signal, a picture frame that includes a first component and a second component; determining a classifier for the second component from a set of samples of the first component associated with a respective sample of the second component; in response to a determination that the set of samples of the first component associated with the respective sample of the second component is divided by a virtual boundary, obtaining an updated set of samples of the first component by copying one or more central subsets of the set of samples of the first component to a first boundary position and a second boundary position of the set of samples of the first component, wherein the one or more central subsets are at a same side of the virtual boundary relative to the respective sample of the second component; determining a sample offset for the respective sample of the second component according to the classifier based on the updated set of samples of the first component; and modifying the value of the respective sample of the second component based on the determined sample offset.
- an electronic apparatus includes one or more processing units, memory and a plurality of programs stored in the memory.
- the programs when executed by the one or more processing units, cause the electronic apparatus to perform the method of coding video data as described above.
- a non-transitory computer readable storage medium stores a plurality of programs for execution by an electronic apparatus having one or more processing units.
- the programs when executed by the one or more processing units, cause the electronic apparatus to perform the method of coding video data as described above.
- FIG. 1 is a block diagram illustrating an exemplary video encoding and decoding system in accordance with some implementations of the present disclosure.
- FIG. 2 is a block diagram illustrating an exemplary video encoder in accordance with some implementations of the present disclosure.
- FIG. 3 is a block diagram illustrating an exemplary video decoder in accordance with some implementations of the present disclosure.
- FIGS. 4A through 4E are block diagrams illustrating how a frame is recursively partitioned into multiple video blocks of different sizes and shapes in accordance with some implementations of the present disclosure.
- FIG. 5 is a block diagram depicting the four gradient patterns used in Sample Adaptive Offset (SAO) in accordance with some implementations of the present disclosure.
- SAO Sample Adaptive Offset
- FIG. 6A is a block diagram illustrating the system and process of CrossComponent Sample Adaptive Offset (CCSAO) according to some implementations of the present disclosure.
- CCSAO CrossComponent Sample Adaptive Offset
- FIG. 6B is a block diagram illustrating the system and process of CCSAO applied in parallel with Enhanced Sample Adaptive Offset (ESAO) in the AVS standard according to some implementations of the present disclosure.
- ESAO Enhanced Sample Adaptive Offset
- FIG. 6C is a block diagram illustrating the system and process of CCSAO applied after SAO according to some implementations of the present disclosure.
- FIG. 6D is a block diagram illustrating the system and process of CCSAO applied in parallel with Cross-Component Adaptive Loop Filter (CCALF) according to some implementations of the present disclosure.
- CCALF Cross-Component Adaptive Loop Filter
- FIG. 7 is a block diagram illustrating a sample process using CCSAO in accordance with some implementations of the present disclosure.
- FIG. 8 is a block diagram illustrating that CCSAO process is interleaved to vertical and horizontal deblocking filter (DBF) in accordance with some implementations of the present disclosure.
- DPF vertical and horizontal deblocking filter
- FIG. 9 is a flowchart illustrating an exemplary process of decoding video signal using cross-component correlation in accordance with some implementations of the present disclosure.
- FIG. 10A is a block diagram showing a classifier using different luma sample position for classification in accordance with some implementations of the present disclosure.
- FIG. 10B illustrates some examples of different shapes for luma candidates, in accordance with some implementations of the present disclosure.
- FIG. 11 is a block diagram of a sample process illustrating that besides luma, the other cross-component collocated and neighboring chroma samples are also fed into
- FIG. 12 illustrates exemplary classifiers by replacing the collocated luma sample value with a value obtained by weighing collocated and neighboring luma samples in accordance with some implementations of the present disclosure.
- FIG. 13A is a block diagram illustrating CCS AO is not applied on the current chroma sample if any of the collocated and neighboring luma samples used for classification is outside the current picture in accordance with some implementations of the present disclosure.
- FIG. 13B is a block diagram illustrating CCSAO is applied on the current chroma sample if any of the collocated and neighboring luma samples used for classification is outside the current picture in accordance with some implementations of the present disclosure.
- FIG. 14 is a block diagram illustrating CCSAO is not applied on the current chroma sample if a corresponding selected collocated or neighboring luma sample used for classification is outside a virtual space defined by a virtual boundary (VB) in accordance with some implementations of the present disclosure.
- VB virtual boundary
- FIG. 15 shows repetitive or mirror padding is applied on the luma samples that are outside the virtual boundary in accordance with some implementations of the present disclosure.
- FIG. 16 shows additional 1 luma line buffer is required if all 9 collocated neighboring luma samples are used for classification in accordance with some implementations of the present disclosure.
- FIG. 17 shows an illustration in AVS that 9 luma candidates CCSAO crossing VB may increase 2 additional luma line buffers in accordance with some implementations of the present disclosure.
- FIG. 18 shows an illustration in VVC that 9 luma candidates CCSAO crossing VB may increase 1 additional luma line buffer in accordance with some implementations of the present disclosure.
- FIGs. 19A-19C show in AVS and VVC, CCSAO is disabled for a chroma sample if any of the chroma sample’s luma candidates is across VB (outside the current chroma sample VB) in accordance with some implementations of the present disclosure.
- FIGs. 20A-20C show in AVS and VVC, CCSAO is enabled using repetitive padding for a chroma sample if any of the chroma sample’s luma candidates is across VB (outside the current chroma sample VB) in accordance with some implementations of the present disclosure.
- FIGs. 21A-21C show in AVS and VVC, CCSAO is enabled using mirror padding for a chroma sample if any of the chroma sample’s luma candidates is across VB (outside the current chroma sample VB) in accordance with some implementations of the present disclosure.
- FIGs. 22A-22B show that CCSAO is enabled using double sided symmetric padding for different CCSAO sample shapes in accordance with some implementations of the present disclosure.
- FIG. 23 shows the restrictions of using a limited number of luma candidates for classification in accordance with some implementations of the present disclosure.
- FIG. 24 shows the CCSAO applied region is not aligned to the coding tree block (CTB)Zcoding tree unit (CTU) boundary in accordance with some implementations of the present disclosure.
- CTB coding tree block
- CTU coding tree unit
- FIG. 25 shows that the CCSAO applied region frame partition can be fixed with CCSAO parameters in accordance with some implementations of the present disclosure.
- FIG. 26 shows that the CCSAO applied region can be Binary-tree (BT)/ Quadtree (QT)ZTemary-tree (TT) split from frame/slice/CTB level in accordance with some implementations of the present disclosure.
- FIG. 27 is a block diagram illustrating that the SAG classification methods disclosed in the present disclosure serve as a post prediction filter in accordance with some implementations of the present disclosure.
- FIG. 28 is a block diagram illustrating that for post prediction SAO filter, each component can use the current and neighboring samples for classification in accordance with some implementations of the present disclosure.
- FIG. 29 is a flowchart illustrating an exemplary process of decoding video signal using cross-component correlation when Virtual Boundary is present in accordance with some implementations of the present disclosure.
- the first generation AVS standard includes Chinese national standard “Information Technology, Advanced Audio Video Coding, Part 2: Video” (known as AVS1) and “Information Technology, Advanced Audio Video Coding Part 16: Radio Television Video” (known as AVS+). It can offer around 50% bit-rate saving at the same perceptual quality compared to MPEG-2 standard.
- the second generation AVS standard includes the series of Chinese national standard “Information Technology, Efficient Multimedia Coding” (knows as AVS2), which is mainly targeted at the transmission of extra HD TV programs. The coding efficiency of the AVS2 is double of that of the AVS+. Meanwhile, the AVS2 standard video part was submitted by Institute of Electrical and Electronics Engineers (IEEE) as one international standard for applications.
- the AVS3 standard is one new generation video coding standard for UHD video application aiming at surpassing the coding efficiency of the latest international standard HEVC, which provides approximately 30% bit-rate savings over the HEVC standard.
- HEVC latest international standard
- the AVS3-P2 baseline was finished, which provides approximately 30% bit-rate savings over the HEVC standard.
- HPM high performance model
- the AVS3 standard is built upon the block-based hybrid video coding framework.
- FIG. 1 is a block diagram illustrating an exemplary system 10 for encoding and decoding video blocks in parallel in accordance with some implementations of the present disclosure.
- system 10 includes a source device 12 that generates and encodes video data to be decoded at a later time by a destination device 14.
- Source device 12 and destination device 14 may comprise any of a wide variety of electronic devices, including desktop or laptop computers, tablet computers, smart phones, set-top boxes, digital televisions, cameras, display devices, digital media players, video gaming consoles, video streaming device, or the like.
- source device 12 and destination device 14 are equipped with wireless communication capabilities.
- destination device 14 may receive the encoded video data to be decoded via a link 16.
- Link 16 may comprise any type of communication medium or device capable of moving the encoded video data from source device 12 to destination device 14.
- link 16 may comprise a communication medium to enable source device 12 to transmit the encoded video data directly to destination device 14 in real-time.
- the encoded video data may be modulated according to a communication standard, such as a wireless communication protocol, and transmitted to destination device 14.
- the communication medium may comprise any wireless or wired communication medium, such as a radio frequency (RF) spectrum or one or more physical transmission lines.
- the communication medium may form part of a packet-based network, such as a local area network, a wide-area network, or a global network such as the Internet.
- the communication medium may include routers, switches, base stations, or any other equipment that may be useful to facilitate communication from source device 12 to destination device 14.
- the encoded video data may be transmitted from output interface 22 to a storage device 32. Subsequently, the encoded video data in storage device 32 may be accessed by destination device 14 via input interface 28.
- Storage device 32 may include any of a variety of distributed or locally accessed data storage media such as a hard drive, Blu-ray discs, DVDs, CD-ROMs, flash memory, volatile or non-volatile memory, or any other suitable digital storage media for storing encoded video data.
- storage device 32 may correspond to a fde server or another intermediate storage device that may hold the encoded video data generated by source device 12. Destination device 14 may access the stored video data from storage device 32 via streaming or downloading.
- the fde server may be any type of computer capable of storing encoded video data and transmitting the encoded video data to destination device 14.
- Exemplary fde servers include a web server (e.g., for a website), an FTP server, network attached storage (NAS) devices, or a local disk drive.
- Destination device 14 may access the encoded video data through any standard data connection, including a wireless channel (e.g., a Wi-Fi connection), a wired connection (e.g., DSL, cable modem, etc.), or a combination of both that is suitable for accessing encoded video data stored on a fde server.
- the transmission of encoded video data from storage device 32 may be a streaming transmission, a download transmission, or a combination of both.
- source device 12 includes a video source 18, a video encoder 20 and an output interface 22.
- Video source 18 may include a source such as a video capture device, e.g., a video camera, a video archive containing previously captured video, a video feed interface to receive video from a video content provider, and/or a computer graphics system for generating computer graphics data as the source video, or a combination of such sources.
- a video capture device e.g., a video camera, a video archive containing previously captured video, a video feed interface to receive video from a video content provider, and/or a computer graphics system for generating computer graphics data as the source video, or a combination of such sources.
- source device 12 and destination device 14 may form camera phones or video phones.
- the implementations described in the present application may be applicable to video coding in general, and may be applied to wireless and/or wired applications.
- the captured, pre-captured, or computer-generated video may be encoded by video encoder 20.
- the encoded video data may be transmitted directly to destination device 14 via output interface 22 of source device 12.
- the encoded video data may also (or alternatively) be stored onto storage device 32 for later access by destination device 14 or other devices, for decoding and/or playback.
- Output interface 22 may further include a modem and/or a transmitter.
- Destination device 14 includes an input interface 28, a video decoder 30, and a display device 34.
- Input interface 28 may include a receiver and/or a modem and receive the encoded video data over link 16.
- the encoded video data communicated over link 16, or provided on storage device 32 may include a variety of syntax elements generated by video encoder 20 for use by video decoder 30 in decoding the video data. Such syntax elements may be included within the encoded video data transmitted on a communication medium, stored on a storage medium, or stored a file server.
- destination device 14 may include a display device 34, which can be an integrated display device and an external display device that is configured to communicate with destination device 14.
- Display device 34 displays the decoded video data to a user, and may comprise any of a variety of display devices such as a liquid crystal display (LCD), a plasma display, an organic light emitting diode (OLED) display, or another type of display device.
- LCD liquid crystal display
- OLED organic light emitting diode
- Video encoder 20 and video decoder 30 may operate according to proprietary or industry standards, such as VVC, HEVC, MPEG-4, Part 10, Advanced Video Coding (AVC), AVS, or extensions of such standards. It should be understood that the present application is not limited to a specific video coding/decoding standard and may be applicable to other video coding/decoding standards. It is generally contemplated that video encoder 20 of source device 12 may be configured to encode video data according to any of these current or future standards. Similarly, it is also generally contemplated that video decoder 30 of destination device 14 may be configured to decode video data according to any of these current or future standards.
- Video encoder 20 and video decoder 30 each may be implemented as any of a variety of suitable encoder circuitry, such as one or more microprocessors, digital signal processors (DSPs), application specific integrated circuits (ASICs), field programmable gate arrays (FPGAs), discrete logic, software, hardware, firmware or any combinations thereof.
- DSPs digital signal processors
- ASICs application specific integrated circuits
- FPGAs field programmable gate arrays
- an electronic device may store instructions for the software in a suitable, non-transitory computer-readable medium and execute the instructions in hardware using one or more processors to perform the video coding/decoding operations disclosed in the present disclosure.
- Each of video encoder 20 and video decoder 30 may be included in one or more encoders or decoders, either of which may be integrated as part of a combined encoder/decoder (CODEC) in a respective device.
- CDEC combined encoder/decoder
- FIG. 2 is a block diagram illustrating an exemplary video encoder 20 in accordance with some implementations described in the present application.
- Video encoder 20 may perform intra and inter predictive coding of video blocks within video frames. Intra predictive coding relies on spatial prediction to reduce or remove spatial redundancy in video data within a given video frame or picture. Inter predictive coding relies on temporal prediction to reduce or remove temporal redundancy in video data within adjacent video frames or pictures of a video sequence.
- video encoder 20 includes video data memory 40, prediction processing unit 41, decoded picture buffer (DPB) 64, summer 50, transform processing unit 52, quantization unit 54, and entropy encoding unit 56.
- Prediction processing unit 41 further includes motion estimation unit 42, motion compensation unit 44, partition unit 45, intra prediction processing unit 46, and intra block copy (BC) unit 48.
- video encoder 20 also includes inverse quantization unit 58, inverse transform processing unit 60, and summer 62 for video block reconstruction.
- An in-loop filter 63 such as a deblocking filter may be positioned between summer 62 and DPB 64 to filter block boundaries to remove blockiness artifacts from reconstructed video.
- Video encoder 20 may take the form of a fixed or programmable hardware unit or may be divided among one or more of the illustrated fixed or programmable hardware units.
- Video data memory 40 may store video data to be encoded by the components of video encoder 20.
- the video data in video data memory 40 may be obtained, for example, from video source 18.
- DPB 64 is a buffer that stores reference video data for use in encoding video data by video encoder 20 (e.g., in intra or inter predictive coding modes).
- Video data memory 40 and DPB 64 may be formed by any of a variety of memory devices.
- video data memory 40 may be on-chip with other components of video encoder 20, or off-chip relative to those components.
- partition unit 45 within prediction processing unit 41 partitions the video data into video blocks.
- This partitioning may also include partitioning a video frame into slices, tiles, or other larger coding units (CUs) according to a predefined splitting structures such as quad-tree structure associated with the video data.
- the video frame may be divided into multiple video blocks (or sets of video blocks referred to as tiles).
- Prediction processing unit 41 may select one of a plurality of possible predictive coding modes, such as one of a plurality of intra predictive coding modes or one of a plurality of inter predictive coding modes, for the current video block based on error results (e.g., coding rate and the level of distortion).
- Prediction processing unit 41 may provide the resulting intra or inter prediction coded block to summer 50 to generate a residual block and to summer 62 to reconstruct the encoded block for use as part of a reference frame subsequently. Prediction processing unit 41 also provides syntax elements, such as motion vectors, intra-mode indicators, partition information, and other such syntax information, to entropy encoding unit 56. [0062] In order to select an appropriate intra predictive coding mode for the current video block, intra prediction processing unit 46 within prediction processing unit 41 may perform intra predictive coding of the current video block relative to one or more neighboring blocks in the same frame as the current block to be coded to provide spatial prediction.
- Motion estimation unit 42 and motion compensation unit 44 within prediction processing unit 41 perform inter predictive coding of the current video block relative to one or more predictive blocks in one or more reference frames to provide temporal prediction.
- Video encoder 20 may perform multiple coding passes, e.g., to select an appropriate coding mode for each block of video data.
- motion estimation unit 42 determines the inter prediction mode for a current video frame by generating a motion vector, which indicates the displacement of a prediction unit (PU) of a video block within the current video frame relative to a predictive block within a reference video frame, according to a predetermined pattern within a sequence of video frames.
- Motion estimation performed by motion estimation unit 42, is the process of generating motion vectors, which estimate motion for video blocks.
- a motion vector may indicate the displacement of a PU of a video block within a current video frame or picture relative to a predictive block within a reference frame (or other coded unit) relative to the current block being coded within the current frame (or other coded unit).
- Intra BC unit 48 may determine vectors, e.g., block vectors, for intra BC coding in a manner similar to the determination of motion vectors by motion estimation unit 42 for inter prediction, or may utilize motion estimation unit 42 to determine the block vector.
- a predictive block is a block of a reference frame that is deemed as closely matching the PU of the video block to be coded in terms of pixel difference, which may be determined by sum of absolute difference (SAD), sum of square difference (SSD), or other difference metrics.
- video encoder 20 may calculate values for subinteger pixel positions of reference frames stored in DPB 64. For example, video encoder 20 may interpolate values of one-quarter pixel positions, one-eighth pixel positions, or other fractional pixel positions of the reference frame. Therefore, motion estimation unit 42 may perform a motion search relative to the full pixel positions and fractional pixel positions and output a motion vector with fractional pixel precision.
- Motion estimation unit 42 calculates a motion vector for a PU of a video block in an inter prediction coded frame by comparing the position of the PU to the position of a predictive block of a reference frame selected from a first reference frame list (List 0) or a second reference frame list (List 1), each of which identifies one or more reference frames stored in DPB 64. Motion estimation unit 42 sends the calculated motion vector to motion compensation unit 44 and then to entropy encoding unit 56.
- Motion compensation performed by motion compensation unit 44, may involve fetching or generating the predictive block based on the motion vector determined by motion estimation unit 42.
- motion compensation unit 44 may locate a predictive block to which the motion vector points in one of the reference frame lists, retrieve the predictive block from DPB 64, and forward the predictive block to summer 50.
- Summer 50 then forms a residual video block of pixel difference values by subtracting pixel values of the predictive block provided by motion compensation unit 44 from the pixel values of the current video block being coded.
- the pixel difference values forming the residual vide block may include luma or chroma difference components or both.
- Motion compensation unit 44 may also generate syntax elements associated with the video blocks of a video frame for use by video decoder 30 in decoding the video blocks of the video frame.
- the syntax elements may include, for example, syntax elements defining the motion vector used to identify the predictive block, any flags indicating the prediction mode, or any other syntax information described herein. Note that motion estimation unit 42 and motion compensation unit 44 may be highly integrated, but are illustrated separately for conceptual purposes.
- intra BC unit 48 may generate vectors and fetch predictive blocks in a manner similar to that described above in connection with motion estimation unit 42 and motion compensation unit 44, but with the predictive blocks being in the same frame as the current block being coded and with the vectors being referred to as block vectors as opposed to motion vectors.
- intra BC unit 48 may determine an intra-prediction mode to use to encode a current block.
- intra BC unit 48 may encode a current block using various intra-prediction modes, e.g., during separate encoding passes, and test their performance through rate-distortion analysis. Next, intra BC unit 48 may select, among the various tested intra-prediction modes, an appropriate intraprediction mode to use and generate an intra-mode indicator accordingly.
- intra BC unit 48 may calculate rate-distortion values using a rate-distortion analysis for the various tested intra-prediction modes, and select the intra-prediction mode having the best ratedistortion characteristics among the tested modes as the appropriate intra-prediction mode to use.
- Rate-distortion analysis generally determines an amount of distortion (or error) between an encoded block and an original, unencoded block that was encoded to produce the encoded block, as well as a bitrate (i.e., a number of bits) used to produce the encoded block.
- Intra BC unit 48 may calculate ratios from the distortions and rates for the various encoded blocks to determine which intra-prediction mode exhibits the best rate-distortion value for the block.
- intra BC unit 48 may use motion estimation unit 42 and motion compensation unit 44, in whole or in part, to perform such functions for Intra BC prediction according to the implementations described herein.
- a predictive block may be a block that is deemed as closely matching the block to be coded, in terms of pixel difference, which may be determined by sum of absolute difference (SAD), sum of squared difference (SSD), or other difference metrics, and identification of the predictive block may include calculation of values for sub-integer pixel positions.
- video encoder 20 may form a residual video block by subtracting pixel values of the predictive block from the pixel values of the current video block being coded, forming pixel difference values.
- the pixel difference values forming the residual video block may include both luma and chroma component differences.
- Intra prediction processing unit 46 may intra-predict a current video block, as an alternative to the inter-prediction performed by motion estimation unit 42 and motion compensation unit 44, or the intra block copy prediction performed by intra BC unit 48, as described above.
- intra prediction processing unit 46 may determine an intra prediction mode to use to encode a current block. To do so, intra prediction processing unit 46 may encode a current block using various intra prediction modes, e.g., during separate encoding passes, and intra prediction processing unit 46 (or a mode select unit, in some examples) may select an appropriate intra prediction mode to use from the tested intra prediction modes.
- Intra prediction processing unit 46 may provide information indicative of the selected intra-prediction mode for the block to entropy encoding unit 56. Entropy encoding unit 56 may encode the information indicating the selected intra-prediction mode in the bitstream.
- summer 50 forms a residual video block by subtracting the predictive block from the current video block.
- the residual video data in the residual block may be included in one or more transform units (TUs) and is provided to transform processing unit 52.
- Transform processing unit 52 transforms the residual video data into residual transform coefficients using a transform, such as a discrete cosine transform (DCT) or a conceptually similar transform.
- DCT discrete cosine transform
- Transform processing unit 52 may send the resulting transform coefficients to quantization unit 54.
- Quantization unit 54 quantizes the transform coefficients to further reduce bit rate. The quantization process may also reduce the bit depth associated with some or all of the coefficients. The degree of quantization may be modified by adjusting a quantization parameter.
- quantization unit 54 may then perform a scan of a matrix including the quantized transform coefficients.
- entropy encoding unit 56 may perform the scan.
- entropy encoding unit 56 entropy encodes the quantized transform coefficients into a video bitstream using, e.g., context adaptive variable length coding (CAVLC), context adaptive binary arithmetic coding (CABAC), syntax-based context-adaptive binary arithmetic coding (SBAC), probability interval partitioning entropy (PIPE) coding or another entropy encoding methodology or technique.
- CAVLC context adaptive variable length coding
- CABAC context adaptive binary arithmetic coding
- SBAC syntax-based context-adaptive binary arithmetic coding
- PIPE probability interval partitioning entropy
- the encoded bitstream may then be transmitted to video decoder 30, or archived in storage device 32 for later transmission to or retrieval by video decoder 30.
- Entropy encoding unit 56 may also entropy encode the motion vectors and the other syntax elements for the current video frame being coded.
- Inverse quantization unit 58 and inverse transform processing unit 60 apply inverse quantization and inverse transformation, respectively, to reconstruct the residual video block in the pixel domain for generating a reference block for prediction of other video blocks.
- motion compensation unit 44 may generate a motion compensated predictive block from one or more reference blocks of the frames stored in DPB 64. Motion compensation unit 44 may also apply one or more interpolation filters to the predictive block to calculate sub-integer pixel values for use in motion estimation.
- Summer 62 adds the reconstructed residual block to the motion compensated predictive block produced by motion compensation unit 44 to produce a reference block for storage in DPB 64.
- the reference block may then be used by intra BC unit 48, motion estimation unit 42 and motion compensation unit 44 as a predictive block to inter predict another video block in a subsequent video frame.
- FIG. 3 is a block diagram illustrating an exemplary video decoder 30 in accordance with some implementations of the present application.
- Video decoder 30 includes video data memory 79, entropy decoding unit 80, prediction processing unit 81, inverse quantization unit 86, inverse transform processing unit 88, summer 90, and DPB 92.
- Prediction processing unit 81 further includes motion compensation unit 82, intra prediction processing unit 84, and intra BC unit 85.
- Video decoder 30 may perform a decoding process generally reciprocal to the encoding process described above with respect to video encoder 20 in connection with FIG. 2.
- motion compensation unit 82 may generate prediction data based on motion vectors received from entropy decoding unit 80
- intraprediction unit 84 may generate prediction data based on intra-prediction mode indicators received from entropy decoding unit 80.
- a unit of video decoder 30 may be tasked to perform the implementations of the present application. Also, in some examples, the implementations of the present disclosure may be divided among one or more of the units of video decoder 30.
- intra BC unit 85 may perform the implementations of the present application, alone, or in combination with other units of video decoder 30, such as motion compensation unit 82, intra prediction processing unit 84, and entropy decoding unit 80.
- video decoder 30 may not include intra BC unit 85 and the functionality of intra BC unit 85 may be performed by other components of prediction processing unit 81, such as motion compensation unit 82.
- Video data memory 79 may store video data, such as an encoded video bitstream, to be decoded by the other components of video decoder 30.
- the video data stored in video data memory 79 may be obtained, for example, from storage device 32, from a local video source, such as a camera, via wired or wireless network communication of video data, or by accessing physical data storage media (e.g., a flash drive or hard disk).
- Video data memory 79 may include a coded picture buffer (CPB) that stores encoded video data from an encoded video bitstream.
- Decoded picture buffer (DPB) 92 of video decoder 30 stores reference video data for use in decoding video data by video decoder 30 (e.g., in intra or inter predictive coding modes).
- Video data memory 79 and DPB 92 may be formed by any of a variety of memory devices, such as dynamic random access memory (DRAM), including synchronous DRAM (SDRAM), magneto-resistive RAM (MRAM), resistive RAM (RRAM), or other types of memory devices.
- DRAM dynamic random access memory
- SDRAM synchronous DRAM
- MRAM magneto-resistive RAM
- RRAM resistive RAM
- video data memory 79 and DPB 92 are depicted as two distinct components of video decoder 30 in FIG. 3. But it will be apparent to one skilled in the art that video data memory 79 and DPB 92 may be provided by the same memory device or separate memory devices.
- video data memory 79 may be on-chip with other components of video decoder 30, or off-chip relative to those components.
- video decoder 30 receives an encoded video bitstream that represents video blocks of an encoded video frame and associated syntax elements.
- Video decoder 30 may receive the syntax elements at the video frame level and/or the video block level.
- Entropy decoding unit 80 of video decoder 30 entropy decodes the bitstream to generate quantized coefficients, motion vectors or intra-prediction mode indicators, and other syntax elements. Entropy decoding unit 80 then forwards the motion vectors and other syntax elements to prediction processing unit 81.
- intra prediction processing unit 84 of prediction processing unit 81 may generate prediction data for a video block of the current video frame based on a signaled intra prediction mode and reference data from previously decoded blocks of the current frame.
- motion compensation unit 82 of prediction processing unit 81 produces one or more predictive blocks for a video block of the current video frame based on the motion vectors and other syntax elements received from entropy decoding unit 80.
- Each of the predictive blocks may be produced from a reference frame within one of the reference frame lists.
- Video decoder 30 may construct the reference frame lists, List 0 and List 1, using default construction techniques based on reference frames stored in DPB 92.
- intra BC unit 85 of prediction processing unit 81 produces predictive blocks for the current video block based on block vectors and other syntax elements received from entropy decoding unit 80.
- the predictive blocks may be within a reconstructed region of the same picture as the current video block defined by video encoder 20.
- Motion compensation unit 82 and/or intra BC unit 85 determines prediction information for a video block of the current video frame by parsing the motion vectors and other syntax elements, and then uses the prediction information to produce the predictive blocks for the current video block being decoded. For example, motion compensation unit 82 uses some of the received syntax elements to determine a prediction mode (e.g., intra or inter prediction) used to code video blocks of the video frame, an inter prediction frame type (e.g., B or P), construction information for one or more of the reference frame lists for the frame, motion vectors for each inter predictive encoded video block of the frame, inter prediction status for each inter predictive coded video block of the frame, and other information to decode the video blocks in the current video frame.
- a prediction mode e.g., intra or inter prediction
- an inter prediction frame type e.g., B or P
- intra BC unit 85 may use some of the received syntax elements, e.g., a flag, to determine that the current video block was predicted using the intra BC mode, construction information of which video blocks of the frame are within the reconstructed region and should be stored in DPB 92, block vectors for each intra BC predicted video block of the frame, intra BC prediction status for each intra BC predicted video block of the frame, and other information to decode the video blocks in the current video frame.
- a flag e.g., a flag
- Motion compensation unit 82 may also perform interpolation using the interpolation fdters as used by video encoder 20 during encoding of the video blocks to calculate interpolated values for sub-integer pixels of reference blocks. In this case, motion compensation unit 82 may determine the interpolation fdters used by video encoder 20 from the received syntax elements and use the interpolation fdters to produce predictive blocks. [0086] Inverse quantization unit 86 inverse quantizes the quantized transform coefficients provided in the bitstream and entropy decoded by entropy decoding unit 80 using the same quantization parameter calculated by video encoder 20 for each video block in the video frame to determine a degree of quantization. Inverse transform processing unit 88 applies an inverse transform, e.g., an inverse DCT, an inverse integer transform, or a conceptually similar inverse transform process, to the transform coefficients in order to reconstruct the residual blocks in the pixel domain.
- an inverse transform e.g., an inverse DCT, an inverse integer transform, or
- summer 90 reconstructs decoded video block for the current video block by summing the residual block from inverse transform processing unit 88 and a corresponding predictive block generated by motion compensation unit 82 and intra BC unit 85.
- An in-loop filter 91 may be positioned between summer 90 and DPB 92 to further process the decoded video block.
- the in-loop filtering 91 such as deblocking filter, sample adaptive offset (SAO) and adaptive in-loop filter (ALF) may be applied on the reconstructed CU before it is put in the reference picture store.
- DPB 92 stores reference frames used for subsequent motion compensation of next video blocks.
- DPB 92 or a memory device separate from DPB 92, may also store decoded video for later presentation on a display device, such as display device 34 of FIG. 1.
- a video sequence typically includes an ordered set of frames or pictures.
- Each frame may include three sample arrays, denoted SL, SCb, and SCr.
- SL is a two-dimensional array of luma samples.
- SCb is a two-dimensional array of Cb chroma samples.
- SCr is a two-dimensional array of Cr chroma samples.
- a frame may be monochrome and therefore includes only one two-dimensional array of luma samples.
- the AVS3 standard is built upon the block-based hybrid video coding framework.
- the input video signal is processed block by block (called coding units (CUs)).
- CUs coding units
- one coding tree unit (CTU) is split into CUs to adapt to varying local characteristics based on quad/binary /extended-quad-tree.
- the concept of multiple partition unit type in the HEVC is removed, i.e., the separation of CU, prediction unit (PU) and transform unit (TU) does not exist in the AV S3. Instead, each CU is always used as the basic unit for both prediction and transform without further partitions.
- one CTU is firstly partitioned based on a quad-tree structure. Then, each quad-tree leaf node can be further partitioned based on a binary and extended-quad-tree structure.
- video encoder 20 (or more specifically partition unit 45) generates an encoded representation of a frame by first partitioning the frame into a set of coding tree units (CTUs).
- a video frame may include an integer number of CTUs ordered consecutively in a raster scan order from left to right and from top to bottom.
- Each CTU is a largest logical coding unit and the width and height of the CTU are signaled by the video encoder 20 in a sequence parameter set, such that all the CTUs in a video sequence have the same size being one of 128x 128, 64x64, 32x32, and 16x 16.
- the present application is not necessarily limited to a particular size. As shown in FIG.
- each CTU may comprise one coding tree block (CTB) of luma samples, two corresponding coding tree blocks of chroma samples, and syntax elements used to code the samples of the coding tree blocks.
- the syntax elements describe properties of different types of units of a coded block of pixels and how the video sequence can be reconstructed at the video decoder 30, including inter or intra prediction, intra prediction mode, motion vectors, and other parameters.
- a CTU may comprise a single coding tree block and syntax elements used to code the samples of the coding tree block.
- a coding tree block may be an NxN block of samples.
- video encoder 20 may recursively perform tree partitioning such as binary-tree partitioning, ternary-tree partitioning, quad-tree partitioning or a combination of both on the coding tree blocks of the CTU and divide the CTU into smaller coding units (CUs).
- tree partitioning such as binary-tree partitioning, ternary-tree partitioning, quad-tree partitioning or a combination of both on the coding tree blocks of the CTU and divide the CTU into smaller coding units (CUs).
- the 64x64 CTU 400 is first divided into four smaller CU, each having a block size of 32x32.
- CU 410 and CU 420 are each divided into four CUs of 16x16 by block size.
- the two 16x16 CUs 430 and 440 are each further divided into four CUs of 8x8 by block size.
- each leaf node of the quad-tree corresponding to one CU of a respective size ranging from 32x32 to 8x8.
- each CU may comprise a coding block (CB) of luma samples and two corresponding coding blocks of chroma samples of a frame of the same size, and syntax elements used to code the samples of the coding blocks.
- CB coding block
- a CU may comprise a single coding block and syntax structures used to code the samples of the coding block.
- quad-tree partitioning depicted in FIGS. 4C and 4D is only for illustrative purposes and one CTU can be split into CUs to adapt to varying local characteristics based on quad/temary/binary-tree partitions.
- one CTU is partitioned by a quad-tree structure and each quad-tree leaf CU can be further partitioned by a binary and ternary tree structure.
- FIG. 4E there are five splitting/partitioning types in the AVS3, i.e., quaternary partitioning, horizontal binary partitioning, vertical binary partitioning, horizontal extended quad-tree partitioning, and vertical extended quad-tree partitioning.
- video encoder 20 may further partition a coding block of a CU into one or more MxN prediction blocks (PB).
- a prediction block is a rectangular (square or non-square) block of samples on which the same prediction, inter or intra, is applied.
- a prediction unit (PU) of a CU may comprise a prediction block of luma samples, two corresponding prediction blocks of chroma samples, and syntax elements used to predict the prediction blocks.
- a PU may comprise a single prediction block and syntax structures used to predict the prediction block.
- Video encoder 20 may generate predictive luma, Cb, and Cr blocks for luma, Cb, and Cr prediction blocks of each PU of the CU.
- Video encoder 20 may use intra prediction or inter prediction to generate the predictive blocks for a PU. If video encoder 20 uses intra prediction to generate the predictive blocks of a PU, video encoder 20 may generate the predictive blocks of the PU based on decoded samples of the frame associated with the PU. If video encoder 20 uses inter prediction to generate the predictive blocks of a PU, video encoder 20 may generate the predictive blocks of the PU based on decoded samples of one or more frames other than the frame associated with the PU.
- video encoder 20 may generate a luma residual block for the CU by subtracting the CU’s predictive luma blocks from its original luma coding block such that each sample in the CU’s luma residual block indicates a difference between a luma sample in one of the CU's predictive luma blocks and a corresponding sample in the CU's original luma coding block.
- video encoder 20 may generate a Cb residual block and a Cr residual block for the CU, respectively, such that each sample in the CU's Cb residual block indicates a difference between a Cb sample in one of the CU's predictive Cb blocks and a corresponding sample in the CU's original Cb coding block and each sample in the CU's Cr residual block may indicate a difference between a Cr sample in one of the CU's predictive Cr blocks and a corresponding sample in the CU's original Cr coding block.
- video encoder 20 may use quad-tree partitioning to decompose the luma, Cb, and Cr residual blocks of a CU into one or more luma, Cb, and Cr transform blocks.
- a transform block is a rectangular (square or non-square) block of samples on which the same transform is applied.
- a transform unit (TU) of a CU may comprise a transform block of luma samples, two corresponding transform blocks of chroma samples, and syntax elements used to transform the transform block samples.
- each TU of a CU may be associated with a luma transform block, a Cb transform block, and a Cr transform block.
- the luma transform block associated with the TU may be a sub-block of the CU's luma residual block.
- the Cb transform block may be a sub-block of the CU's Cb residual block.
- the Cr transform block may be a sub-block of the CU's Cr residual block.
- a TU may comprise a single transform block and syntax structures used to transform the samples of the transform block.
- Video encoder 20 may apply one or more transforms to a luma transform block of a TU to generate a luma coefficient block for the TU.
- a coefficient block may be a two-dimensional array of transform coefficients.
- a transform coefficient may be a scalar quantity.
- Video encoder 20 may apply one or more transforms to a Cb transform block of a TU to generate a Cb coefficient block for the TU.
- Video encoder 20 may apply one or more transforms to a Cr transform block of a TU to generate a Cr coefficient block for the TU.
- After generating a coefficient block (e.g., a luma coefficient block, a Cb coefficient block or a Cr coefficient block)
- video encoder 20 may quantize the coefficient block.
- Quantization generally refers to a process in which transform coefficients are quantized to possibly reduce the amount of data used to represent the transform coefficients, providing further compression.
- video encoder 20 may entropy encode syntax elements indicating the quantized transform coefficients.
- video encoder 20 may perform Context-Adaptive Binary Arithmetic Coding (CABAC) on the syntax elements indicating the quantized transform coefficients.
- CABAC Context-Adaptive Binary Arithmetic Coding
- video encoder 20 may output a bitstream that includes a sequence of bits that forms a representation of coded frames and associated data, which is either saved in storage device 32 or transmitted to destination device 14.
- video decoder 30 may parse the bitstream to obtain syntax elements from the bitstream. Video decoder 30 may reconstruct the frames of the video data based at least in part on the syntax elements obtained from the bitstream. The process of reconstructing the video data is generally reciprocal to the encoding process performed by video encoder 20. For example, video decoder 30 may perform inverse transforms on the coefficient blocks associated with TUs of a current CU to reconstruct residual blocks associated with the TUs of the current CU. Video decoder 30 also reconstructs the coding blocks of the current CU by adding the samples of the predictive blocks for PUs of the current CU to corresponding samples of the transform blocks of the TUs of the current CU. After reconstructing the coding blocks for each CU of a frame, video decoder 30 may reconstruct the frame.
- SAO is a process that modifies the decoded samples by conditionally adding an offset value to each sample after the application of the deblocking filter, based on values in look-up tables transmitted by the encoder.
- SAO filtering is performed on a region basis, based on a filtering type selected per CTB by a syntax element sao-type-idx.
- a value of 0 for sao-type-idx indicates that the SAO filter is not applied to the CTB, and the values 1 and 2 signal the use of the band offset and edge offset filtering types, respectively.
- the selected offset value directly depends on the sample amplitude.
- the full sample amplitude range is uniformly split into 32 segments called bands, and the sample values belonging to four of these bands (which are consecutive within the 32 bands) are modified by adding transmitted values denoted as band offsets, which can be positive or negative.
- band offsets transmitted values denoted as band offsets, which can be positive or negative.
- the main reason for using four consecutive bands is that in the smooth areas where banding artifacts can appear, the sample amplitudes in a CTB tend to be concentrated in only few of the bands.
- the design choice of using four offsets is unified with the edge offset mode of operation which also uses four offset values.
- a syntax element sao-eo-class with values from 0 to 3 signals whether a horizontal, vertical or one of two diagonal gradient directions is used for the edge offset classification in the CTB.
- FIG. 5 is a block diagram depicting the four gradient patterns used in SAG in accordance with some implementations of the present disclosure.
- the four gradient patterns 502, 504, 506, and 508 are for the respective sao-eo-class in the edge offset mode.
- Sample labelled “p” indicates a center sample to be considered.
- Each sample in the CTB is classified into one of five Edgeldx categories by comparing the sample value p located at some position with the values nO and nl of two samples located at neighboring positions as shown in FIG. 5. This classification is done for each sample based on decoded sample values, so no additional signaling is required for the Edgeldx classification.
- an offset value from a transmitted look-up table is added to the sample value. The offset values are always positive for categories 1 and 2 and negative for categories 3 and 4.
- Table 1 illustrates a sample Edgeldx categories in SAO edge classes.
- Table 1 A sample Edgeldx categories in SAO edge classes.
- SAO types 1 and 2 a total of four amplitude offset values are transmitted to the decoder for each CTB.
- type 1 the sign is also encoded.
- the offset values and related syntax elements such as sao-type-idx and sao-eo-class are determined by the encoder - typically using criteria that optimize rate-distortion performance.
- the SAO parameters can be indicated to be inherited from the left or above CTB using a merge flag to make the signaling efficient.
- SAO is a nonlinear filtering operation which allows additional refinement of the reconstructed signal, and it can enhance the signal representation in both smooth areas and around edges.
- SAO Sample Adaptive Offset
- SAO is used in the HEVC, VVC, AVS2 and AVS3 standards.
- SAO is replaced by a coding tool called Enhanced Sample Adaptive Offset (ESAO).
- ESAO Enhanced Sample Adaptive Offset
- CCS AO disclosed herein can also be applied in parallel with ESAO.
- CCS AO can be applied in parallel with Constrained Directional Enhancement Filter (CDEF) in the AVI standard.
- CDEF Constrained Directional Enhancement Filter
- the luma Y, chroma Cb and chroma Cr sample offset values are decided independently. That is, for example, the current chroma sample offset is decided by only the current and neighboring chroma sample values, without taking collocated or neighboring luma samples into consideration.
- luma samples preserve more original picture detail information than chroma samples, and they can benefit the decision of the current chroma sample offset.
- chroma samples usually lose high frequency details after color conversion from RGB to Y CbCr, or after quantization and deblocking filter, introducing luma samples with high frequency detail preserved for chroma offset decision can benefit the chroma sample reconstruction.
- CCS AO Cross-Component Sample Adaptive Offset
- FIG. 6A is a block diagram illustrating the system and process of CCSAO according to some implementations of the present disclosure.
- the luma samples after luma deblocking filter (DBF Y) is used to determine additional offsets for chroma Cb and Cr after SAO Cb and SAO Cr.
- the current chroma sample 602 is first classified using collocated 604 and neighboring (white) luma samples 606, and the corresponding CCSAO offset value of the corresponding class is added to the current chroma sample value.
- CCSAO can also be applied in parallel with other coding tools, for example, ESAO in the AVS standard, or CDEF in the AVI standard.
- FIG. 6B is a block diagram illustrating the system and process of CCSAO applied in parallel with ESAO in the AVS standard according to some implementations of the present disclosure.
- FIG. 6C is a block diagram illustrating the system and process of CCSAO applied after SAO according to some implementations of the present disclosure.
- FIG. 6C shows that the location of CCSAO can be after SAO, i.e., the location of Cross-Component Adaptive Loop Filter (CCALF) in the VVC standard.
- CCALF Cross-Component Adaptive Loop Filter
- the SAO Y/Cb/Cr can be replaced by ESAO, for example, in the AVS3 standard.
- FIG. 6D is a block diagram illustrating the system and process of CCSAO applied in parallel with CCALF according to some implementations of the present disclosure.
- FIG. 6D shows that CCSAO can be applied in parallel with CCALF.
- the locations of CCALF and CCSAO can be switched.
- the SAG Y/Cb/Cr blocks can be replaced by ESAO Y/Cb/Cr (in AVS3) or CDEF (in AVI).
- the current chroma sample classification is reusing the SAO type (EO or BO), class, and category of the collocated luma sample.
- the corresponding CCSAO offset can be signaled or derived from the decoder itself.
- h_Y be the collocated luma SAO offset
- h_Cb and h_Cr be the CCSAO Cb and Cr offset, respectively.
- h_Cb (or h_Cr) w * h_Y where w can be selected in a limited table. For example, +-1/4, +- 1/2, 0, +-1, +-2, +-4...etc., where
- the comparison score [-8, 8] of the collocated luma samples (Y0) and neighboring 8 luma samples are used, which yields 17 classes in total.
- the abovementioned classification methods can be combined. For example, comparison score combined with SAO BO (32 bands classification) is used to increase diversity, which yields 17 * 32 classes in total.
- the Cb and Cr can use the same class to reduce the complexity or saving bits.
- FIG 7 is a block diagram illustrating a sample process using CCSAO in accordance with some implementations of the present disclosure.
- FIG 7 shows the input of CCSAO can introduce the input of vertical and horizontal DBF, to simplify the class determination, or increase flexibility.
- Y0 DBF V, Y0 DBF H, and Y0 be collocated luma samples at the input of DBF V, DBF H, and SAO, respectively.
- Max Y0 max (Y0 DBF V, Y0 DBF H, Y0 DBF)
- Max Yi max (Yi DBF V, Yi DBF H, Yi DBF)
- FIG 8 is a block diagram illustrating that CCSAO process is interleaved to vertical and horizontal DBF in accordance with some implementations of the present disclosure.
- CCSAO blocks in FIG 6, 7 and 8 can be selective. For example, using YO DBF V and Yi DBF V for the first CCSAO V, which applies the same sample processing as in FIG 6, while using the input of DBF V luma samples as CCSAO input.
- CCSAO syntax implemented is shown in Table 2 below.
- the other chroma component offset can be derived by plus or minus sign, or weighting to save bits overhead.
- h_Cb and h_Cr be the offset of CCSAO Cb and Cr, respectively.
- w +- 1 w
- candidates h_Cr can be derived from h_Cb without explicit signaling h_Cr itself.
- h_Cr w * h_Cb
- FIG. 9 is a flowchart illustrating an exemplary process 900 of decoding video signal using cross-component correlation in accordance with some implementations of the present disclosure.
- the video decoder 30, receives the video signal that includes a first component and a second component (910).
- the first component is a luma component
- the second component is a chroma component of the video signal.
- the video decoder 30 also receives a plurality of offsets associated with the second component (920).
- the video decoder 30 then utilizes a characteristic measurement of the first component to obtain a classification category associated with the second component (930). For example, in FIG 6, the current chroma sample 602 is first classified using collocated 604 and neighboring (white) luma samples 606, and the corresponding CCSAO offset value is added to the current chroma sample.
- the video decoder 30 further selects a first offset from the plurality of offsets for the second component according to the classification category (940).
- the video decoder 30 additionally modifies the second component based on the selected first offset (950).
- utilizing the characteristic measurement of the first component to obtain the classification category associated with the second component (930) includes: utilizing a respective sample of the first component to obtain a respective classification category of a respective each sample of the second component, wherein the respective sample of the first component is a respective collocated sample of the first component to the respective each sample of the second component.
- the current chroma sample classification is reusing the SAG type (EO or BO), class, and category of the collocated luma sample.
- utilizing the characteristic measurement of the first component to obtain the classification category associated with the second component (930) includes: utilizing a respective sample of the first component to obtain a respective classification category of a respective each sample of the second component, wherein the respective sample of the first component is reconstructed before being deblocked or is reconstructed after being deblocked.
- the first component is being deblocked at a deblocking filter (DBF).
- the first component is being deblocked at a luma deblocking filter (DBF Y).
- DBF deblocking filter
- DBF Y luma deblocking filter
- the CCSAO input can also be before DBF Y.
- the characteristic measurement is derived by dividing the range of sample values of the first component into several bands and selecting a band based on the intensity value of a sample in the first component.
- the characteristic measurement is derived from Band Offset (BO).
- the characteristic measurement is derived based on the direction and strength of the edge information of a sample in the first component. In some embodiments, the characteristic measurement is derived from Edge Offset (EO).
- EO Edge Offset
- modifying the second component (950) comprises directly adding the selected first offset to the second component. For example, the corresponding CCSAO offset value is added to the current chroma component sample.
- modifying the second component (950) comprises mapping the selected first offset to a second offset and adding the mapped second offset to the second component. For example, for signaling CCSAO Cb and Cr offset values, if one additional chroma offset is signaled, the other chroma component offset can be derived by using a plus or minus sign, or weighting to save bits overhead.
- receiving the video signal (910) comprises receiving a syntax element that indicates whether the method of decoding video signal using CCSAO is enabled for the video signal in the Sequence Parameter Set (SPS).
- SPS Sequence Parameter Set
- cc_sao_enabled_flag indicates whether CCSAO is enabled in the sequence level.
- receiving the video signal (910) comprises receiving a syntax element that indicates whether the method of decoding video signal using CCSAO is enabled for the second component on the slice level.
- slice_cc_sao_cb_flag or slice_cc_sao_cr_flag indicates whether CCSAO is enabled in the respective slice for Cb or Cr.
- receiving the plurality of offsets associated with the second component (920) comprises receiving different offsets for different Coding Tree Units (CTUs).
- CTUs Coding Tree Units
- cc_sao_offset_sign_flag indicates a sign for an offset
- cc_sao_offset_abs indicates the CCSAO Cb and Cr offset values of the current CTU.
- receiving the plurality of offsets associated with the second component (920) comprises receiving a syntax element that indicates whether the received offsets of a CTU are the same as that of one of a neighboring CTU of the CTU, wherein the neighboring CTU is either a left or atop neighboring CTU.
- cc_sao_merge_up_flag indicates whether CCSAO offset is merged from the left or up CTU.
- the video signal further includes a third component and the method of decoding the video signal using CCSAO further includes: receiving a second plurality of offsets associated with a third component; utilizing the characteristic measurement of the first component to obtain a second classification category associated with the third component; selecting a third offset from the second plurality of offsets for the third component according to the second classification category; and modifying the third component based on the selected third offset.
- FIG. 11 is a block diagram of a sample process illustrating that besides luma, the other cross-component collocated (1102) and neighboring (white) chroma samples are also fed into CCSAO classification in accordance with some implementations of the present disclosure.
- FIG. 6A, 6B and FIG. 11 show the input of CCSAO classification.
- current chroma sample is 1104
- the cross-component collocated chroma sample is 1102
- the collocated luma sample is 1106.
- a classifier example uses the collocated luma sample value (Y0) for classification.
- Uet band num be the number of equally divided bands of luma dynamic range
- bit depth be the sequence bit depth
- the class index for the current chroma sample is:
- Class (CO) (Y0 * band num) » bit depth
- the classification takes rounding into account, for example:
- Class (CO) ((Y0 * band num) + (1 « bit depth)) » bit depth [00135]
- Some band num and bit depth examples are listed below in Table 3. Table 3 shows three classification examples when the number of bands is different for each of the classification examples.
- Table 3 Exemplary band num and bit depth for each class index.
- a classifier uses different luma sample position for CO classification.
- FIG. 10A is a block diagram showing a classifier using different luma sample position for CO classification in accordance with some implementations of the present disclosure, for example, using the neighboring Y7 but not Y0 for CO classification.
- different classifiers can be switched in Sequence Parameter Set (SPS)/ Adaptation parameter set (APS)/ Picture parameter set (PPS)/ Picture header (PH)/ Slice header (SH) /Coding tree unit (CTU) / Coding unit (CU) levels.
- SPS Sequence Parameter Set
- PPS Picture parameter set
- PH Picture header
- SH Slice header
- CTU Coding tree unit
- CU Coding unit
- FIG. 10B illustrates some examples of different shapes for luma candidates, in accordance with some implementations of the present disclosure.
- a constraint can be applied to the shapes.
- the total number of luma candidates must be the power of 2, as shown in FIG. 10B (b) (c) (d).
- the number of luma candidates must be horizontal and vertical symmetric relative to the chroma sample (in the center), as shown in FIG. 10B (a) (c) (d) (e).
- the CO position and CO band num can be combined and switched in SPS/APS/PPS/PH/SH/CTU/CU levels. Different combinations can be different classifiers as shown in Table 5 below.
- the collocated luma sample value (Y 0) is replaced by a value (Y p) obtained by weighing collocated and neighboring luma samples.
- FIG. 12 illustrates exemplary classifiers by replacing the collocated luma sample value with a value obtained by weighing collocated and neighboring luma samples in accordance with some implementations of the present disclosure.
- the collocated luma sample value (Y0) can be replaced by a phase corrected value (Yp) obtained by weighing neighboring luma samples. Different Yp can be a different classifier.
- different Yp is applied on different chroma format.
- the Yp of (a) is used for the 420 chroma format
- the Yp of (b) is used for the 422 chroma format
- Y0 is used for the 444 chroma format.
- another classifier is the comparison score [-8, 8] of the collocated luma samples (Y0) and neighboring 8 luma samples, which yields 17 classes in total as shown below.
- a variation (Cl’) only counts comparison score [0, 8], and this yields 8 classes.
- (Cl, Cl’) is a classifier group and a PH/SH level flag can be signaled to switch between Cl and Cl’.
- different classifiers are combined to yield a general classifier. For example, for different pictures (different POC values), different classifiers are applied as shown in Table 6-1 below.
- Table 6-1 Different general classifiers are applied to different pictures [00145]
- another classifier example (C3) is using a bitmask for classification as shown in Table 6-2.
- a 10-bit bitmask is signaled in SPS/APS/PPS/PH/SH/Region/CTU/CU/Subblock levels to indicate the classifier.
- bitmask 11 1100 0000 means that for a given 10-bit luma sample value, only most significant bit (MSB): 4 bits are used for classification, and that yields 16 classes in total.
- MSB most significant bit
- bitmask 10 0100 0001 means that only 3 bits are used for classification, and that yields 8 classes in total.
- the luma position and C3 bitmask can be combined and switched in SPS/APS/PPS/PH/SH/Region/CTU/CU/Subblock levels. Different combinations can be different classifiers.
- a “max number of Is” of the bitmask restriction can be applied to restrict the corresponding number of offsets. For example, restricting “max number of Is” of the bitmask to 4 in SPS, and that yields the max offsets in the sequence to be 16.
- bitmask in different POC can be different, but the “max number of Is” shall not exceed 4 (total classes shall not exceed 16).
- the “max number of Is” value can be signaled and switched in SPS/APS/PPS/PH/SH/Region/CTU/CU/Subblock levels.
- Table 6-2 Classifier example uses a bitmask for classification (bit mask position is underscored)
- a classifier example (C2) uses the difference (Y n) of collocated and neighboring luma samples.
- FIG. 12 (c) shows an example of Yn, which has a dynamic range of [-1024, 1023] when bit depth is 10.
- C2 band_num be the number of equally divided bands of Yn dynamic range
- Class (C2) (Yn + (1 « bit_depth) * band_num) » (bit_depth + 1).
- CO and C2 are combined to yield a general classifier.
- different classifiers are applied as shown in Table 7 below.
- classifiers CO, Cl, Cl’, C2
- different classifiers are applied as shown in Table 8 below.
- plural classifiers are used in the same POC.
- the current frame is divided by several regions, and each region uses the same classifier.
- 3 different classifiers are used in POCO, and which classifier (0, 1, or 2) is used is signaled in CTU level as shown in Table 9 below.
- the maximum number of plural classifiers can be fixed or signaled in SPS/APS/PPS/PH/SH/CTU/CU levels.
- the fixed (pre-defined) maximum number of plural classifiers is 4.
- 4 different classifiers are used in POCO, and which classifier (0, 1, or 2) is used is signaled in the CTU level.
- Truncated-unary (TU) code can be used to indicate the classifier used for each chroma CTB.
- Truncated-unary (TU) code is used to indicate the classifier used for each chroma
- Cb and Cr CTB offset set indices is given for 1280x720 sequence POCO (number of CTUs in a frame is 10x6 if the CTU size is 128x128).
- POCO Cb uses 4 offset sets and Cr uses 1 offset set.
- Table 11 when the offset set index is 0: CCSAO is not applied; when the offset set index is 1: set 0 is applied; when the offset set index is 2: set 1 is applied; when the offset set index is 3: set 2 is applied; when the offset set index is 4: set 3 is applied.
- Type means the position of the chosen collocated luma sample (Yi). Different offset sets can have different types, band_num and corresponding offsets.
- Table 11 An example of Cb and Cr CTB offset set indices is given for 1280x720 sequence POCO (number of CTUs in a frame is 10x6 if the CTU size is 128x128)
- a restriction can be applied on the CO classification, for example, restricting band_num to be only power of 2 values.
- a syntax band num shift is signaled. Decoder can use shift operation to avoid multiplication.
- Class (CO) (YO » band num shift) » bit depth
- Another operation example is taking rounding into account to reduce error.
- Class (CO) ((YO + (1 « (band num shift - 1))) » band num shift) » bit depth
- band num max 16
- the classifiers applied to Cb and Cr are different.
- the Cb and Cr offsets for all classes can be signaled separately.
- different signaled offsets are applied to different chroma components as shown in Table 14 below.
- the max offset value is fixed or signaled in Sequence Parameter Set (SPS)/ Adaptation parameter set (APS)/ Picture parameter set (PPS)/ Picture header (PH)/ Slice header (SH).
- SPS Sequence Parameter Set
- APS Adaptation parameter set
- PPS Picture parameter set
- PH Picture header
- SH Slice header
- the offset signaling can use Differential pulse-code modulation (DPCM). For example, offsets ⁇ 3, 3, 2, 1, -1 ⁇ can be signaled as ⁇ 3, 0, -1, -1, -2 ⁇ .
- DPCM Differential pulse-code modulation
- the offsets can be stored in APS or a memory buffer for the next picture/slice reuse. An index can be signaled to indicate which stored previous frame offsets are used for the current picture.
- the classifiers of Cb and Cr are the same.
- the Cb and Cr offsets for all classes can be signaled jointly, for example, as shown in Table 15 below.
- the classifier of Cb and Cr can be the same.
- the Cb and Cr offsets for all classes can be signaled jointly, with a sign flag difference, for example, as shown in Table 16 below. According to Table 16, when Cb offsets are (3, 3, 2, -1), the derived Cr offsets are (-3, -3, -2, 1).
- the sign flag can be signaled for each class, for example, as shown in Table 17 below. According to Table 17, when Cb offsets are (3, 3, 2, -1), the derived Cr offsets are (-3, 3, 2, 1) according to the respective signed flag.
- the Cb and Cr offsets for all classes can be signaled jointly with a sign flag signaled for each class [00166]
- the classifiers of Cb and Cr can be the same.
- the Cb and Cr offsets for all classes can be signaled jointly, with a weight difference, for example, as shown in Table 18 below.
- the weight (w) can be selected in a limited table, for example, +- 1/4, +-1/2, 0, +-1, +-2, +-4. . . etc., where
- Cb offsets are (3, 3, 2, -1)
- the derived Cr offsets are (-6, -6, -4, 2) according to the respective signed flag.
- the weight can be signaled for each class, for example, as shown in Table 19 below. According to Table 19, when Cb offsets are (3, 3, 2, -1), the derived Cr offsets are (-6, 12, 0, -1) according to the respective signed flag.
- the previously decoded offsets can be stored for use of future frames.
- An index can be signaled to indicate which previously decoded offsets set is used for the current frame, to reduce offsets signaling overhead.
- Table 20 An index can be signaled to indicate which previously decoded offsets set is used for the current frame
- the reuse offsets set idx for Cb and Cr can be different
- Table 21 An index can be signaled to indicate which previously decoded offsets set is used for the current frame, and the index can be different for Cb and Cr components.
- the offset can be quantized before signaling.
- the decoded offset is dequantized before applying it as shown in Table 23 below. For example, for a 12-bit sequence, the decoded offsets are left shifted (dequantized) by 2.
- R(x, y) be the input chroma sample value before CCSAO
- R’(x, y) Clip3( 0, (1 « bit depth) - 1, R(x, y) + offset )
- each chroma sample value R(x, y) is classified using the indicated classifier of the current picture.
- the corresponding offset of the derived class index is added to each chroma sample value R(x, y).
- a clip function Clip 3 is applied to the (R(x, y) + offset) to make the output chroma sample value R’(x, y) within the bit depth dynamic range, for example, range 0 to ( 1 « bit depth) - 1 .
- FIG. 13 A is a block diagram illustrating CCSAO is not applied on the current chroma sample if any of the collocated and neighboring luma samples used for classification is outside the current picture in accordance with some implementations of the present disclosure.
- CCSAO is not applied on the left 1 column chroma components of the current picture.
- Cl is used, CCSAO is not applied on the left 1 column and the top 1 row chroma components of the current picture, as shown in FIG. 13A(b).
- FIG. 13B is a block diagram illustrating CCSAO is applied on the current chroma sample if any of the collocated and neighboring luma samples used for classification is outside the current picture in accordance with some implementations of the present disclosure.
- a variation is, if any of the collocated and neighboring luma samples used for classification is outside the current picture, the missed samples are used repetitively as shown in FIG. 13B(a), or the missed samples are mirror padded to create samples for classification as shown in FIG. 13B(b), and CCSAO can be applied on the current chroma samples.
- FIG. 14 is a block diagram illustrating CCSAO is not applied on the current chroma sample if a corresponding selected collocated or neighboring luma sample used for classification is outside a virtual space defined by a virtual boundary in accordance with some implementations of the present disclosure.
- a virtual boundary is a virtual line that separates the space within a picture frame.
- CCSAO is not applied on the chroma samples that have selected corresponding luma position outside a virtual space defined by the virtual boundary.
- FIG. 14 shows an example with a virtual boundary for CO classifier with 9 luma position candidates.
- CCSAO is not applied on the chroma samples for which the corresponding selected luma position is outside a virtual space surrounded by the virtual boundary.
- CCSAO is not applied to the chroma sample 1402 when the selected Y7 luma sample position is on the other side of the horizontal virtual boundary 1406 which is located 4 pixel lines from the bottom side of the frame.
- CCSAO is not applied to the chroma sample 1404 when the selected Y5 luma sample position is located on the other side of the vertical virtual boundary 1408 which is located y pixel lines from the right side of the frame.
- FIG. 15 shows repetitive or mirror padding can be applied on the luma samples that are outside the virtual boundary in accordance with some implementations of the present disclosure.
- FIG. 15 (a) shows an example of repetitive padding. If the original Y7 is chosen to be the classifier which is located on the bottom side of the VB 1502, the Y4 luma sample value is used for classification (copied to the Y7 position), instead of the original Y7 luma sample value.
- FIG. 15 (b) shows an example of mirror padding. If Y7 is chosen to be the classifier which is located on the bottom side of the VB 1504, the Y 1 luma sample value which is symmetric to the Y7 value relative to the Y0 luma sample is used for classification, instead of the original Y7 luma sample value.
- the padding methods give more chroma samples possibility to apply CCSAO so more coding gain can be achieved.
- FIG. 16 shows additional 1 luma line buffer, i.e., the whole line luma samples of line -5 above the current VB 1602, may be required if all 9 collocated neighboring luma samples are used for classification in accordance with some implementations of the present disclosure.
- FIG. 10B (a) shows an example using only 6 luma candidates for classification, which reduces the line buffer and does not need any additional boundary check in Fig. 13 A and Fig. 13 B.
- using luma samples for CCSAO classification may increase the luma line buffer and hence increase the decoder hardware implementation cost.
- FIG. 17 shows an illustration in AVS that 9 luma candidates CCSAO crossing VB 1702 may increase 2 additional luma line buffers in accordance with some implementations of the present disclosure.
- DBF/SAO/ALF are processed at the current CTU row.
- DBF/SAO/ALF are processed at the next CTU row.
- luma line -4 to -1 pre DBF samples, line -5 pre SAO samples, and chroma line -3 to - 1 pre DBF samples, line -4 pre SAO samples are stored as line buffers for next CTU row DBF/SAO/ALF processing.
- luma and chroma samples not in the line buffer are not available.
- CCSAO requires pre SAO luma sample lines -7, -6, and -5 for classification.
- Pre SAO luma sample lines -7, -6 are not in the line buffer so they are not available.
- luma VB (line -4) and chroma VB (line -3) can be different (not aligned).
- FIG. 18 shows an illustration in VVC that 9 luma candidates CCSAO crossing VB 1802 may increase 1 additional luma line buffer in accordance with some implementations of the present disclosure.
- VB can be different in different standard.
- luma VB is line -4 and chroma VB is line -2, so 9 candidate CCSAO may increase 1 luma line buffer.
- CCSAO is disabled for a chroma sample if any of the chroma sample’s luma candidates is across VB (outside the current chroma sample VB).
- FIGs. 19A-19C show in AVS and VVC, CCSAO is disabled for a chroma sample if any of the chroma sample’s luma candidates is across VB 1902 (outside the current chroma sample VB) in accordance with some implementations of the present disclosure.
- FIG. 14 also shows some examples of this implementation.
- repetitive padding is used for CCSAO from a luma line close to and on the other side of the VB, for example, the luma line -4, for “cross VB” luma candidates.
- FIGs. 20A-20C show in AVS and VVC, CCSAO is enabled using repetitive padding for a chroma sample if any of the chroma sample’s luma candidates is across VB 2002 (outside the current chroma sample VB) in accordance with some implementations of the present disclosure.
- FIG. 14 (a) also shows some examples of this implementation.
- mirror padding is used for CCSAO from below luma VB for “cross VB” luma candidates.
- FIGs. 21A-21C show in AVS and
- VVC VVC
- CCSAO is enabled using mirror padding for a chroma sample if any of the chroma sample’s luma candidates is across VB 2102 (outside the current chroma sample VB) in accordance with some implementations of the present disclosure.
- FIG. 14 (b) and 13B (b) also show some examples of this implementation.
- FIGs. 22A-22B show that CCSAO is enabled using double sided symmetric padding for some examples of different CCSAO shapes (for example, 9 luma candidates (FIG. 22A) and 8 luma candidates (FIG. 22B)) in accordance with some implementations of the present disclosure.
- CCSAO is enabled using double sided symmetric padding for some examples of different CCSAO shapes (for example, 9 luma candidates (FIG. 22A) and 8 luma candidates (FIG. 22B)) in accordance with some implementations of the present disclosure.
- double-sided symmetric padding is applied for both sides of the luma sample set. For example, in FIG.
- luma samples Y0, Y 1 , and Y 2 are outside of the VB 2202, so both Y 0, Yl, Y2 and Y6, Y7, Y8 are padded using Y3, Y4, Y5.
- luma sample Y0 is outside of the VB 2202, so Y0 is padded using Y2, and Y7 is padded using Y5.
- the padding methods give more chroma samples possibility to apply CCSAO so more coding gain can be achieved.
- the samples below VB are processed at the current CTU row, so the above special handling (Solution 1, 2, 3, 4) is not applied at the bottom picture (or slice, tile, brick) boundary CTU row.
- a frame of 1920x1080 is divided by CTUs of 128x128.
- a frame contains 15x9 CTUs (round up).
- the bottom CTU row is the 15th CTU row.
- the decoding process is CTU row by CTU row, and CTU by CTU for each CTU row. Deblocking needs to be applied along horizontal CTU boundaries between the current and next CTU row.
- FIG. 23 shows the restrictions of using a limited number of luma candidates for classification in accordance with some implementations of the present disclosure.
- FIG. 23 (a) shows the restriction of using only 6 luma candidates for classification.
- FIG. 23 (b) shows the restriction of using only 4 luma candidates for classification.
- applied region is implemented.
- the CCSAO applied region unit can be CTB based. That is, the on/off control, CCSAO parameters (offsets, luma candidate positions, band_num, bitmask. . .etc. used for classification, offset set index) are the same in one CTB.
- the applied region can be not aligned to the CTB boundary.
- the applied region is not aligned to chroma CTB boundary but shifted.
- the syntaxes on/off control, CCSAO parameters
- FIG. 24 shows the CCSAO applied region is not aligned to the CTB/CTU boundary 2406 in accordance with some implementations of the present disclosure.
- the applied region is not aligned to chroma CTB/CTU boundary 2406 but top-left shifted (4, 4) samples to VB 2408.
- This not- aligned CTB boundary design benefits the deblocking process since the same deblocking parameters are used for each 8x8 deblocking process region.
- the CCSAO applied region unit can be variant (larger or smaller than CTB size) as shown in Table 24.
- the mask size can be different for different components.
- the mask size can be switched in SPS/APS/PPS/PH/SH/Region/CTU/CU/Subblock levels. For example, in PH, a series of mask on/off flags and offset set indices are signaled to indicate each CCSAO region information.
- the CCSAO applied region frame partition can be fixed. For example, partition the frame into N regions.
- FIG. 25 shows that the CCSAO applied region frame partition can be fixed with CCSAO parameters in accordance with some implementations of the present disclosure.
- each region can have its own region on/off control flag and CCSAO parameters. Also, if the region size is larger than CTB size, it can have both CTB on/off control flags and region on/off control flag.
- FIG. 25 (a) and (b) show some examples of partitioning the frame into N regions.
- FIG. 25 (a) shows vertical partitioning of 4 regions.
- FIG. 25 (b) shows square partitioning of 4 regions.
- different CCSAO applied region can share the same region on/off control and CCSAO parameters.
- region 0 ⁇ 2 shares the same parameters and region 3—15 shares the same parameters.
- FIG. 25 (c) also shows the region on/off control flag and CCSAO parameters can be signaled in a Hilbert scan order.
- the CCSAO applied region unit can be quad- tree/binary-tree/temary-tree split from picture/slice/CTB level. Similar to the CTB split, a series of split flags are signaled to indicate the CCSAO applied region partition.
- FIG. 26 shows that the CCSAO applied region can be Binary -tree (BT)/ Quad-tree (QT)/Temary-tree (TT) split from frame/slice/CTB level in accordance with some implementations of the present disclosure.
- CCSAO syntax implemented is shown in Table 25 below.
- patch is similar with slice
- patch header is similar with the slice header.
- FLC stands for fixed length code.
- TU stands for truncated unary code.
- EGk stands for exponential-golomb code with order k, where k can be fixed.
- Table 25 A exemplary CCSAO syntax [00198] If a higher-level flag is off, the lower level flags can be inferred from the off state of the flag and do not need to be signaled. For example, if ph_cc_sao_cb_flag is false in this picture, ph_cc_sao_cb_band_num_minusl, ph cc sao cb luma type, cc_sao_cb_offset_sign_flag, cc_sao_cb_offset_abs, ctb_cc_sao_cb_flag, cc_sao_cb_merge_left_flag, and cc_sao_cb_merge_up_flag are not present and inferred to be false.
- the SPS ccsao enabled flag is conditioned on the SPS SAO enabled flag as shown in Table 26 below.
- ph cc sao cb ctb control flag, ph_cc_sao_cr_ctb_control_flag indicate whether to enable Cb/Cr CTB on/off control granularity. If ph cc sao cb ctb control flag, ph cc sao cr ctb control flag are enabled, ctb_cc_sao_cb_flag and ctb_cc_sao_cr_flag can be further signaled.
- CCSAO whether CCSAO is applied in the current picture depends on ph cc sao cb flag, ph cc sao cr flag, without further signaling ctb cc sao cb flag and ctb cc sao cr flag at CTB level.
- a flag can be further signaled to distinguish if the center collocated luma position is used (Y 0 position in FIG. 10) for classification for a chroma sample, to reduce bit overhead.
- a flag can be further signaled with the same mechanism.
- cc_sao_cb_typeO_flag is further signaled to distinguish if the center collocated luma position is used as shown in Table 27 below. If the center collocated luma position is not used, cc_sao_cb_type_idc is used to indicate which of the remaining 8 neighboring luma positions is used.
- FIG. 27 is a block diagram illustrating that the SAO classification methods disclosed in the present disclosure serve as a post prediction filter in accordance with some implementations of the present disclosure.
- each component for each Y, U, and V component, a corresponding classifier is chosen. And for each component prediction sample, it is first classified, and a corresponding offset is added. For example, each component can use the current and neighboring samples for classification.
- Y uses the current Y and neighboring Y samples
- U/V uses the current U/V samples for classification as shown in Table 28 below.
- FIG. 28 is a block diagram illustrating that for post prediction SAO filter, each component can use the current and neighboring samples for classification in accordance with some implementations of the present disclosure.
- Table 28 A corresponding classifier is chosen for each Y, U, and V component
- the refined prediction samples (Ypred’, Upred’, Vpred’) are updated by adding the corresponding class offset and are used for intra, inter, or other prediction thereafter.
- Ypred’ clip3(0, (1 « bit_depth)-l, Ypred + h_Y[i])
- Upred’ clip3(0, (1 « bit_depth)-l, Upred + h_U[i])
- Vpred’ clip3(0, (1 « bit_depth)-l, Vpred + h_V[i])
- the cross-component (Y) can be used for further offset classification.
- the additional cross-component offset (h’_U, h’_V) can be added on the current component offset (h_U, h_V), for example, as shown in Table 29 below.
- the cross-component (Y) can be used for further offset classification [00209]
- the refined prediction samples (Upred”, Vpred”) are updated by adding the corresponding class offset and are used for intra, inter, or other prediction thereafter.
- Upred clip3(0, (1 « bit_depth)-l, Upred’ + h’_U[i])
- Vpred clip3(0, (1 « bit_depth)-l, Vpred’ + h’_V[i])
- the intra and inter prediction can use different SAO filter offsets.
- FIG. 29 is a flowchart illustrating an exemplary process 2900 of decoding video signal using cross-component correlation when VB is present in accordance with some implementations of the present disclosure.
- the video decoder 30 receives, from the video signal, a picture frame that includes a first component and a second component (2910).
- the video decoder 30, determines a classifier for the second component from a set of samples of the first component associated with a respective sample of the second component (2920).
- the video decoder 30 obtains an updated set of samples of the first component by copying one or more central subsets of the set of samples of the first component to a first boundary position and a second boundary position of the set of samples of the first component, wherein the one or more central subsets are at a same side of the virtual boundary relative to the respective sample of the second component (2930-2).
- the video decoder 30 determines a sample offset for the respective sample of the second component according to the classifier based on the updated set of samples of the first component (2940). [00218] The video decoder 30 modifies the value of the respective sample of the second component based on the determined sample offset (2950).
- obtaining the updated set of samples of the first component by copying one or more central subsets of the set of samples of the first component to the first boundary position and the second boundary position of the set of samples of the first component comprises: in accordance with a determination that: a first subset of the set of samples of the first component associated with the respective sample of the second component is located on the different side of the virtual boundary relative to the respective sample of the second component, and a remaining subset of the set of samples of the first component associated with the respective sample of the second component is located on a same side of the virtual boundary relative to the respective sample of the second component, copying a second subset of the one or more central subsets from the remaining subset of the set of samples of the first component to replace the first subset at the first boundary position; and copying the second subset of the one or more central subsets from the remaining subset of the set of samples of the first component to replace a third subset in the remaining subset at a second side.
- the third subset and the first subset are symmetrical relative to a collocated sample of the first component associated with the respective sample of the second component.
- the second subset from the remaining subset of the set of samples of the first component is from a closest row to the first subset.
- the second subset from the remaining subset of the set of samples of the first component is from a closest row to the third subset.
- obtaining the updated set of samples of the first component by copying one or more central subsets of the set of samples of the first component to the first boundary position and the second boundary position of the set of samples of the first component comprises: in accordance with a determination that: a first subset of the set of samples of the first component associated with the respective sample of the second component is located on the different side of the virtual boundary relative to the respective sample of the second component, and a remaining subset of the set of samples of the first component associated with the respective sample of the second component is located on a same side of the virtual boundary relative to the respective sample of the second component, copying a second subset of the one or more central subsets from the remaining subset of the set of samples of the first component to replace the first subset at the first boundary position; and copying a third subset of the one or more central subsets from the remaining subset of the set of samples of the first component to replace a fourth subset in the remaining subset at a second side.
- the fourth subset and the first subset are symmetrical relative to a collocated sample of the first component associated with the respective sample of the second component.
- the second subset from the remaining subset of the set of samples of the first component is from a closest row to the first subset.
- the third subset from the remaining subset of the set of samples of the first component is from a closest row to the fourth subset.
- the set of samples of the first component is horizontal, or vertical symmetric relative to a collocated sample of the first component associated with the respective sample of the second component.
- the virtual boundary includes a first virtual boundary within a first block of the first component and a second virtual boundary within a second block of the second component.
- the virtual boundary includes a first virtual boundary within a first Coding Tree Block (CTB) of the first component and a second virtual boundary within a second CTB of the second component, and the first virtual boundary is not aligned with the second virtual boundary within a Coding Tree Unit (CTU).
- CTU Coding Tree Unit
- the virtual boundary is parallel with a block boundary and separated from the block boundary by at least one row or column of samples.
- a subset of the one or more samples of the first component is located on a different side of the virtual boundary relative to the respective sample of the second component, and the subset of the one or more samples of the first component is within a boundary coding tree unit (CTU) row at a processing bottom of the picture frame, determining to modify the value of the respective sample of the second component of the current block of the picture frame within the virtual boundary according to the classifier.
- CTU boundary coding tree unit
- the samples below VB are processed at the current CTU row, so the special handling (Solution 1, 2, 3, 4) is not applied at the bottom picture (or slice, tile, brick) boundary CTU row.
- Computer- readable media may include computer-readable storage media, which corresponds to a tangible medium such as data storage media, or communication media including any medium that facilitates transfer of a computer program from one place to another, e.g., according to a communication protocol.
- computer-readable media generally may correspond to (1) tangible computer-readable storage media which is non-transitory or (2) a communication medium such as a signal or carrier wave.
- Data storage media may be any available media that can be accessed by one or more computers or one or more processors to retrieve instructions, code and/or data structures for implementation of the implementations described in the present application.
- a computer program product may include a computer- readable medium.
- first, second, etc. may be used herein to describe various elements, these elements should not be limited by these terms. These terms are only used to distinguish one element from another.
- a first electrode could be termed a second electrode, and, similarly, a second electrode could be termed a first electrode, without departing from the scope of the implementations.
- the first electrode and the second electrode are both electrodes, but they are not the same electrode.
- Reference throughout this specification to "one example,” “an example,” “exemplary example,” or the like in the singular or plural means that one or more particular features, structures, or characteristics described in connection with an example is included in at least one example of the present disclosure.
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
- Color Television Systems (AREA)
Abstract
An electronic apparatus performs a method of decoding video data. The method comprises: receiving, from the video signal, a picture frame that includes a first component and a second component; determining a classifier for the second component from a set of samples of the first component associated with a respective sample of the second component; when the set of samples of the first component associated with the respective sample of the second component is divided by a virtual boundary, copying one or more central subsets of the set of samples of the first component to a first boundary position and a second boundary position of the set of samples of the first component; determining a sample offset for the respective sample of the second component according to the classifier; and modifying the value of the respective sample of the second component based on the determined sample offset.
Description
CHROMA CODING ENHANCEMENT IN CROSS-COMPONENT SAMPLE ADAPTIVE OFFSET WITH VIRTUAL BOUNDARY
RELATED APPLICATIONS
[0001] The present application claims priority to US Provisional Patent Application No. 63/106,357, entitled “Cross-component Sample Adaptive Offset” fded October 28, 2020, which is incorporated by reference in its entirety.
TECHNICAL FIELD
[0002] The present application generally relates to video coding and compression, and more specifically, to methods and apparatus on improving the chroma coding efficiency.
BACKGROUND
[0003] Digital video is supported by a variety of electronic devices, such as digital televisions, laptop or desktop computers, tablet computers, digital cameras, digital recording devices, digital media players, video gaming consoles, smart phones, video teleconferencing devices, video streaming devices, etc. The electronic devices transmit, receive, encode, decode, and/or store digital video data by implementing video compression/decompression standards. Some well-known video coding standards include Versatile Video Coding (VVC), High Efficiency Video Coding (HEVC, also known as H.265 or MPEG-H Part 2) and Advanced Video Coding (AVC, also known as H.264 or MPEG-4 Part 10), which are jointly developed by ISO/IEC MPEG and ITU-T VCEG. AOMedia Video 1 (AVI) was developed by Alliance for Open Media (AOM) as a successor to its preceding standard VP9. Audio Video Coding (AVS), which refers to digital audio and digital video compression standard, is another video compression standard series developed by the Audio and Video Coding Standard Workgroup of China.
[0004] Video compression typically includes performing spatial (intra frame) prediction and/or temporal (inter frame) prediction to reduce or remove redundancy inherent
in the video data. For block-based video coding, a video frame is partitioned into one or more slices, each slice having multiple video blocks, which may also be referred to as coding tree units (CTUs). Each CTU may contain one coding unit (CU) or recursively split into smaller CUs until the predefined minimum CU size is reached. Each CU (also named leaf CU) contains one or multiple transform units (TUs) and each CU also contains one or multiple prediction units (PUs). Each CU can be coded in either intra, inter or IBC modes. Video blocks in an intra coded (I) slice of a video frame are encoded using spatial prediction with respect to reference samples in neighboring blocks within the same video frame. Video blocks in an inter coded (P or B) slice of a video frame may use spatial prediction with respect to reference samples in neighboring blocks within the same video frame or temporal prediction with respect to reference samples in other previous and/or future reference video frames.
[0005] Spatial or temporal prediction based on a reference block that has been previously encoded, e.g., a neighboring block, results in a predictive block for a current video block to be coded. The process of finding the reference block may be accomplished by block matching algorithm. Residual data representing pixel differences between the current block to be coded and the predictive block is referred to as a residual block or prediction errors. An inter-coded block is encoded according to a motion vector that points to a reference block in a reference frame forming the predictive block, and the residual block. The process of determining the motion vector is typically referred to as motion estimation. An intra coded block is encoded according to an intra prediction mode and the residual block. For further compression, the residual block is transformed from the pixel domain to a transform domain, e.g., frequency domain, resulting in residual transform coefficients, which may then be quantized. The quantized transform coefficients, initially arranged in a two-dimensional array, may be scanned to produce a one-dimensional vector of transform coefficients, and then entropy encoded into a video bitstream to achieve even more compression.
[0006] The encoded video bitstream is then saved in a computer-readable storage medium (e.g., flash memory) to be accessed by another electronic device with digital video
capability or directly transmitted to the electronic device wired or wirelessly. The electronic device then performs video decompression (which is an opposite process to the video compression described above) by, e.g., parsing the encoded video bitstream to obtain syntax elements from the bitstream and reconstructing the digital video data to its original format from the encoded video bitstream based at least in part on the syntax elements obtained from the bitstream, and renders the reconstructed digital video data on a display of the electronic device.
[0007] With digital video quality going from high definition, to 4Kx2K or even 8Kx4K, the amount of vide data to be encoded/decoded grows exponentially. It is a constant challenge in terms of how the video data can be encoded/decoded more efficiently while maintaining the image quality of the decoded video data.
SUMMARY
[0008] The present application describes implementations related to video data encoding and decoding and, more particularly, to methods and apparatus on improving the coding efficiency of chroma coding, including improving the coding efficiency by exploring cross-component relationship between luma and chroma components.
[0009] According to a first aspect of the present application, a method of decoding video signal comprises: receiving, from the video signal, a picture frame that includes a first component and a second component; determining a classifier for the second component from a set of samples of the first component associated with a respective sample of the second component; in response to a determination that the set of samples of the first component associated with the respective sample of the second component is divided by a virtual boundary, obtaining an updated set of samples of the first component by copying one or more central subsets of the set of samples of the first component to a first boundary position and a second boundary position of the set of samples of the first component, wherein the one or more central subsets are at a same side of the virtual boundary relative to the respective sample of the second component; determining a sample offset for the respective sample of the
second component according to the classifier based on the updated set of samples of the first component; and modifying the value of the respective sample of the second component based on the determined sample offset.
[0010] According to a second aspect of the present application, an electronic apparatus includes one or more processing units, memory and a plurality of programs stored in the memory. The programs, when executed by the one or more processing units, cause the electronic apparatus to perform the method of coding video data as described above.
[0011] According to a third aspect of the present application, a non-transitory computer readable storage medium stores a plurality of programs for execution by an electronic apparatus having one or more processing units. The programs, when executed by the one or more processing units, cause the electronic apparatus to perform the method of coding video data as described above.
BRIEF DESCRIPTION OF DRAWINGS
[0012] The accompanying drawings, which are included to provide a further understanding of the implementations and are incorporated herein and constitute a part of the specification, illustrate the described implementations and together with the description serve to explain the underlying principles. Like reference numerals refer to corresponding parts.
[0013] FIG. 1 is a block diagram illustrating an exemplary video encoding and decoding system in accordance with some implementations of the present disclosure.
[0014] FIG. 2 is a block diagram illustrating an exemplary video encoder in accordance with some implementations of the present disclosure.
[0015] FIG. 3 is a block diagram illustrating an exemplary video decoder in accordance with some implementations of the present disclosure.
[0016] FIGS. 4A through 4E are block diagrams illustrating how a frame is recursively partitioned into multiple video blocks of different sizes and shapes in accordance with some implementations of the present disclosure.
[0017] FIG. 5 is a block diagram depicting the four gradient patterns used in Sample Adaptive Offset (SAO) in accordance with some implementations of the present disclosure.
[0018] FIG. 6A is a block diagram illustrating the system and process of CrossComponent Sample Adaptive Offset (CCSAO) according to some implementations of the present disclosure.
[0019] FIG. 6B is a block diagram illustrating the system and process of CCSAO applied in parallel with Enhanced Sample Adaptive Offset (ESAO) in the AVS standard according to some implementations of the present disclosure.
[0020] FIG. 6C is a block diagram illustrating the system and process of CCSAO applied after SAO according to some implementations of the present disclosure.
[0021] FIG. 6D is a block diagram illustrating the system and process of CCSAO applied in parallel with Cross-Component Adaptive Loop Filter (CCALF) according to some implementations of the present disclosure.
[0022] FIG. 7 is a block diagram illustrating a sample process using CCSAO in accordance with some implementations of the present disclosure.
[0023] FIG. 8 is a block diagram illustrating that CCSAO process is interleaved to vertical and horizontal deblocking filter (DBF) in accordance with some implementations of the present disclosure.
[0024] FIG. 9 is a flowchart illustrating an exemplary process of decoding video signal using cross-component correlation in accordance with some implementations of the present disclosure.
[0025] FIG. 10A is a block diagram showing a classifier using different luma sample position for classification in accordance with some implementations of the present disclosure. [0026] FIG. 10B illustrates some examples of different shapes for luma candidates, in accordance with some implementations of the present disclosure.
[0027] FIG. 11 is a block diagram of a sample process illustrating that besides luma, the other cross-component collocated and neighboring chroma samples are also fed into
CCSAO classification in accordance with some implementations of the present disclosure.
[0028] FIG. 12 illustrates exemplary classifiers by replacing the collocated luma sample value with a value obtained by weighing collocated and neighboring luma samples in accordance with some implementations of the present disclosure.
[0029] FIG. 13A is a block diagram illustrating CCS AO is not applied on the current chroma sample if any of the collocated and neighboring luma samples used for classification is outside the current picture in accordance with some implementations of the present disclosure.
[0030] FIG. 13B is a block diagram illustrating CCSAO is applied on the current chroma sample if any of the collocated and neighboring luma samples used for classification is outside the current picture in accordance with some implementations of the present disclosure.
[0031] FIG. 14 is a block diagram illustrating CCSAO is not applied on the current chroma sample if a corresponding selected collocated or neighboring luma sample used for classification is outside a virtual space defined by a virtual boundary (VB) in accordance with some implementations of the present disclosure.
[0032] FIG. 15 shows repetitive or mirror padding is applied on the luma samples that are outside the virtual boundary in accordance with some implementations of the present disclosure.
[0033] FIG. 16 shows additional 1 luma line buffer is required if all 9 collocated neighboring luma samples are used for classification in accordance with some implementations of the present disclosure.
[0034] FIG. 17 shows an illustration in AVS that 9 luma candidates CCSAO crossing VB may increase 2 additional luma line buffers in accordance with some implementations of the present disclosure.
[0035] FIG. 18 shows an illustration in VVC that 9 luma candidates CCSAO crossing VB may increase 1 additional luma line buffer in accordance with some implementations of the present disclosure.
[0036] FIGs. 19A-19C show in AVS and VVC, CCSAO is disabled for a chroma sample if any of the chroma sample’s luma candidates is across VB (outside the current chroma sample VB) in accordance with some implementations of the present disclosure.
[0037] FIGs. 20A-20C show in AVS and VVC, CCSAO is enabled using repetitive padding for a chroma sample if any of the chroma sample’s luma candidates is across VB (outside the current chroma sample VB) in accordance with some implementations of the present disclosure.
[0038] FIGs. 21A-21C show in AVS and VVC, CCSAO is enabled using mirror padding for a chroma sample if any of the chroma sample’s luma candidates is across VB (outside the current chroma sample VB) in accordance with some implementations of the present disclosure.
[0039] FIGs. 22A-22B show that CCSAO is enabled using double sided symmetric padding for different CCSAO sample shapes in accordance with some implementations of the present disclosure.
[0040] FIG. 23 shows the restrictions of using a limited number of luma candidates for classification in accordance with some implementations of the present disclosure.
[0041] FIG. 24 shows the CCSAO applied region is not aligned to the coding tree block (CTB)Zcoding tree unit (CTU) boundary in accordance with some implementations of the present disclosure.
[0042] FIG. 25 shows that the CCSAO applied region frame partition can be fixed with CCSAO parameters in accordance with some implementations of the present disclosure.
[0043] FIG. 26 shows that the CCSAO applied region can be Binary-tree (BT)/ Quadtree (QT)ZTemary-tree (TT) split from frame/slice/CTB level in accordance with some implementations of the present disclosure.
[0044] FIG. 27 is a block diagram illustrating that the SAG classification methods disclosed in the present disclosure serve as a post prediction filter in accordance with some implementations of the present disclosure.
[0045] FIG. 28 is a block diagram illustrating that for post prediction SAO filter, each component can use the current and neighboring samples for classification in accordance with some implementations of the present disclosure.
[0046] FIG. 29 is a flowchart illustrating an exemplary process of decoding video signal using cross-component correlation when Virtual Boundary is present in accordance with some implementations of the present disclosure.
DETAILED DESCRIPTION
[0047] Reference will now be made in detail to specific implementations, examples of which are illustrated in the accompanying drawings. In the following detailed description, numerous non-limiting specific details are set forth in order to assist in understanding the subject matter presented herein. But it will be apparent to one of ordinary skill in the art that various alternatives may be used without departing from the scope of claims and the subject matter may be practiced without these specific details. For example, it will be apparent to one of ordinary skill in the art that the subject matter presented herein can be implemented on many types of electronic devices with digital video capabilities.
[0048] The first generation AVS standard includes Chinese national standard “Information Technology, Advanced Audio Video Coding, Part 2: Video” (known as AVS1) and “Information Technology, Advanced Audio Video Coding Part 16: Radio Television Video” (known as AVS+). It can offer around 50% bit-rate saving at the same perceptual quality compared to MPEG-2 standard. The second generation AVS standard includes the series of Chinese national standard “Information Technology, Efficient Multimedia Coding” (knows as AVS2), which is mainly targeted at the transmission of extra HD TV programs. The coding efficiency of the AVS2 is double of that of the AVS+. Meanwhile, the AVS2 standard video part was submitted by Institute of Electrical and Electronics Engineers (IEEE)
as one international standard for applications. The AVS3 standard is one new generation video coding standard for UHD video application aiming at surpassing the coding efficiency of the latest international standard HEVC, which provides approximately 30% bit-rate savings over the HEVC standard. In March 2019, at the 68-th AVS meeting, the AVS3-P2 baseline was finished, which provides approximately 30% bit-rate savings over the HEVC standard. Currently, one reference software, called high performance model (HPM), is maintained by the AVS group to demonstrate a reference implementation of the AVS3 standard. Like the HEVC, the AVS3 standard is built upon the block-based hybrid video coding framework.
[0049] FIG. 1 is a block diagram illustrating an exemplary system 10 for encoding and decoding video blocks in parallel in accordance with some implementations of the present disclosure. As shown in FIG. 1, system 10 includes a source device 12 that generates and encodes video data to be decoded at a later time by a destination device 14. Source device 12 and destination device 14 may comprise any of a wide variety of electronic devices, including desktop or laptop computers, tablet computers, smart phones, set-top boxes, digital televisions, cameras, display devices, digital media players, video gaming consoles, video streaming device, or the like. In some implementations, source device 12 and destination device 14 are equipped with wireless communication capabilities.
[0050] In some implementations, destination device 14 may receive the encoded video data to be decoded via a link 16. Link 16 may comprise any type of communication medium or device capable of moving the encoded video data from source device 12 to destination device 14. In one example, link 16 may comprise a communication medium to enable source device 12 to transmit the encoded video data directly to destination device 14 in real-time. The encoded video data may be modulated according to a communication standard, such as a wireless communication protocol, and transmitted to destination device 14. The communication medium may comprise any wireless or wired communication medium, such as a radio frequency (RF) spectrum or one or more physical transmission lines. The communication medium may form part of a packet-based network, such as a local area
network, a wide-area network, or a global network such as the Internet. The communication medium may include routers, switches, base stations, or any other equipment that may be useful to facilitate communication from source device 12 to destination device 14.
[0051] In some other implementations, the encoded video data may be transmitted from output interface 22 to a storage device 32. Subsequently, the encoded video data in storage device 32 may be accessed by destination device 14 via input interface 28. Storage device 32 may include any of a variety of distributed or locally accessed data storage media such as a hard drive, Blu-ray discs, DVDs, CD-ROMs, flash memory, volatile or non-volatile memory, or any other suitable digital storage media for storing encoded video data. In a further example, storage device 32 may correspond to a fde server or another intermediate storage device that may hold the encoded video data generated by source device 12. Destination device 14 may access the stored video data from storage device 32 via streaming or downloading. The fde server may be any type of computer capable of storing encoded video data and transmitting the encoded video data to destination device 14. Exemplary fde servers include a web server (e.g., for a website), an FTP server, network attached storage (NAS) devices, or a local disk drive. Destination device 14 may access the encoded video data through any standard data connection, including a wireless channel (e.g., a Wi-Fi connection), a wired connection (e.g., DSL, cable modem, etc.), or a combination of both that is suitable for accessing encoded video data stored on a fde server. The transmission of encoded video data from storage device 32 may be a streaming transmission, a download transmission, or a combination of both.
[0052] As shown in FIG. 1, source device 12 includes a video source 18, a video encoder 20 and an output interface 22. Video source 18 may include a source such as a video capture device, e.g., a video camera, a video archive containing previously captured video, a video feed interface to receive video from a video content provider, and/or a computer graphics system for generating computer graphics data as the source video, or a combination of such sources. As one example, if video source 18 is a video camera of a security surveillance system, source device 12 and destination device 14 may form camera phones or
video phones. However, the implementations described in the present application may be applicable to video coding in general, and may be applied to wireless and/or wired applications.
[0053] The captured, pre-captured, or computer-generated video may be encoded by video encoder 20. The encoded video data may be transmitted directly to destination device 14 via output interface 22 of source device 12. The encoded video data may also (or alternatively) be stored onto storage device 32 for later access by destination device 14 or other devices, for decoding and/or playback. Output interface 22 may further include a modem and/or a transmitter.
[0054] Destination device 14 includes an input interface 28, a video decoder 30, and a display device 34. Input interface 28 may include a receiver and/or a modem and receive the encoded video data over link 16. The encoded video data communicated over link 16, or provided on storage device 32, may include a variety of syntax elements generated by video encoder 20 for use by video decoder 30 in decoding the video data. Such syntax elements may be included within the encoded video data transmitted on a communication medium, stored on a storage medium, or stored a file server.
[0055] In some implementations, destination device 14 may include a display device 34, which can be an integrated display device and an external display device that is configured to communicate with destination device 14. Display device 34 displays the decoded video data to a user, and may comprise any of a variety of display devices such as a liquid crystal display (LCD), a plasma display, an organic light emitting diode (OLED) display, or another type of display device.
[0056] Video encoder 20 and video decoder 30 may operate according to proprietary or industry standards, such as VVC, HEVC, MPEG-4, Part 10, Advanced Video Coding (AVC), AVS, or extensions of such standards. It should be understood that the present application is not limited to a specific video coding/decoding standard and may be applicable to other video coding/decoding standards. It is generally contemplated that video encoder 20 of source device 12 may be configured to encode video data according to any of these current
or future standards. Similarly, it is also generally contemplated that video decoder 30 of destination device 14 may be configured to decode video data according to any of these current or future standards.
[0057] Video encoder 20 and video decoder 30 each may be implemented as any of a variety of suitable encoder circuitry, such as one or more microprocessors, digital signal processors (DSPs), application specific integrated circuits (ASICs), field programmable gate arrays (FPGAs), discrete logic, software, hardware, firmware or any combinations thereof. When implemented partially in software, an electronic device may store instructions for the software in a suitable, non-transitory computer-readable medium and execute the instructions in hardware using one or more processors to perform the video coding/decoding operations disclosed in the present disclosure. Each of video encoder 20 and video decoder 30 may be included in one or more encoders or decoders, either of which may be integrated as part of a combined encoder/decoder (CODEC) in a respective device.
[0058] FIG. 2 is a block diagram illustrating an exemplary video encoder 20 in accordance with some implementations described in the present application. Video encoder 20 may perform intra and inter predictive coding of video blocks within video frames. Intra predictive coding relies on spatial prediction to reduce or remove spatial redundancy in video data within a given video frame or picture. Inter predictive coding relies on temporal prediction to reduce or remove temporal redundancy in video data within adjacent video frames or pictures of a video sequence.
[0059] As shown in FIG. 2, video encoder 20 includes video data memory 40, prediction processing unit 41, decoded picture buffer (DPB) 64, summer 50, transform processing unit 52, quantization unit 54, and entropy encoding unit 56. Prediction processing unit 41 further includes motion estimation unit 42, motion compensation unit 44, partition unit 45, intra prediction processing unit 46, and intra block copy (BC) unit 48. In some implementations, video encoder 20 also includes inverse quantization unit 58, inverse transform processing unit 60, and summer 62 for video block reconstruction. An in-loop filter 63, such as a deblocking filter may be positioned between summer 62 and DPB 64 to filter
block boundaries to remove blockiness artifacts from reconstructed video. Another in-loop filter 63 may also be used in addition to the deblocking filter to filter the output of summer 62. Further in-loop filtering 63, such as sample adaptive offset (SAO) and adaptive in-loop filter (ALF) may be applied on the reconstructed CU before it is put in the reference picture store and used as reference to code future video blocks. Video encoder 20 may take the form of a fixed or programmable hardware unit or may be divided among one or more of the illustrated fixed or programmable hardware units.
[0060] Video data memory 40 may store video data to be encoded by the components of video encoder 20. The video data in video data memory 40 may be obtained, for example, from video source 18. DPB 64 is a buffer that stores reference video data for use in encoding video data by video encoder 20 (e.g., in intra or inter predictive coding modes). Video data memory 40 and DPB 64 may be formed by any of a variety of memory devices. In various examples, video data memory 40 may be on-chip with other components of video encoder 20, or off-chip relative to those components.
[0061] As shown in FIG. 2, after receiving video data, partition unit 45 within prediction processing unit 41 partitions the video data into video blocks. This partitioning may also include partitioning a video frame into slices, tiles, or other larger coding units (CUs) according to a predefined splitting structures such as quad-tree structure associated with the video data. The video frame may be divided into multiple video blocks (or sets of video blocks referred to as tiles). Prediction processing unit 41 may select one of a plurality of possible predictive coding modes, such as one of a plurality of intra predictive coding modes or one of a plurality of inter predictive coding modes, for the current video block based on error results (e.g., coding rate and the level of distortion). Prediction processing unit 41 may provide the resulting intra or inter prediction coded block to summer 50 to generate a residual block and to summer 62 to reconstruct the encoded block for use as part of a reference frame subsequently. Prediction processing unit 41 also provides syntax elements, such as motion vectors, intra-mode indicators, partition information, and other such syntax information, to entropy encoding unit 56.
[0062] In order to select an appropriate intra predictive coding mode for the current video block, intra prediction processing unit 46 within prediction processing unit 41 may perform intra predictive coding of the current video block relative to one or more neighboring blocks in the same frame as the current block to be coded to provide spatial prediction. Motion estimation unit 42 and motion compensation unit 44 within prediction processing unit 41 perform inter predictive coding of the current video block relative to one or more predictive blocks in one or more reference frames to provide temporal prediction. Video encoder 20 may perform multiple coding passes, e.g., to select an appropriate coding mode for each block of video data.
[0063] In some implementations, motion estimation unit 42 determines the inter prediction mode for a current video frame by generating a motion vector, which indicates the displacement of a prediction unit (PU) of a video block within the current video frame relative to a predictive block within a reference video frame, according to a predetermined pattern within a sequence of video frames. Motion estimation, performed by motion estimation unit 42, is the process of generating motion vectors, which estimate motion for video blocks. A motion vector, for example, may indicate the displacement of a PU of a video block within a current video frame or picture relative to a predictive block within a reference frame (or other coded unit) relative to the current block being coded within the current frame (or other coded unit). The predetermined pattern may designate video frames in the sequence as P frames or B frames. Intra BC unit 48 may determine vectors, e.g., block vectors, for intra BC coding in a manner similar to the determination of motion vectors by motion estimation unit 42 for inter prediction, or may utilize motion estimation unit 42 to determine the block vector.
[0064] A predictive block is a block of a reference frame that is deemed as closely matching the PU of the video block to be coded in terms of pixel difference, which may be determined by sum of absolute difference (SAD), sum of square difference (SSD), or other difference metrics. In some implementations, video encoder 20 may calculate values for subinteger pixel positions of reference frames stored in DPB 64. For example, video encoder 20
may interpolate values of one-quarter pixel positions, one-eighth pixel positions, or other fractional pixel positions of the reference frame. Therefore, motion estimation unit 42 may perform a motion search relative to the full pixel positions and fractional pixel positions and output a motion vector with fractional pixel precision.
[0065] Motion estimation unit 42 calculates a motion vector for a PU of a video block in an inter prediction coded frame by comparing the position of the PU to the position of a predictive block of a reference frame selected from a first reference frame list (List 0) or a second reference frame list (List 1), each of which identifies one or more reference frames stored in DPB 64. Motion estimation unit 42 sends the calculated motion vector to motion compensation unit 44 and then to entropy encoding unit 56.
[0066] Motion compensation, performed by motion compensation unit 44, may involve fetching or generating the predictive block based on the motion vector determined by motion estimation unit 42. Upon receiving the motion vector for the PU of the current video block, motion compensation unit 44 may locate a predictive block to which the motion vector points in one of the reference frame lists, retrieve the predictive block from DPB 64, and forward the predictive block to summer 50. Summer 50 then forms a residual video block of pixel difference values by subtracting pixel values of the predictive block provided by motion compensation unit 44 from the pixel values of the current video block being coded. The pixel difference values forming the residual vide block may include luma or chroma difference components or both. Motion compensation unit 44 may also generate syntax elements associated with the video blocks of a video frame for use by video decoder 30 in decoding the video blocks of the video frame. The syntax elements may include, for example, syntax elements defining the motion vector used to identify the predictive block, any flags indicating the prediction mode, or any other syntax information described herein. Note that motion estimation unit 42 and motion compensation unit 44 may be highly integrated, but are illustrated separately for conceptual purposes.
[0067] In some implementations, intra BC unit 48 may generate vectors and fetch predictive blocks in a manner similar to that described above in connection with motion
estimation unit 42 and motion compensation unit 44, but with the predictive blocks being in the same frame as the current block being coded and with the vectors being referred to as block vectors as opposed to motion vectors. In particular, intra BC unit 48 may determine an intra-prediction mode to use to encode a current block. In some examples, intra BC unit 48 may encode a current block using various intra-prediction modes, e.g., during separate encoding passes, and test their performance through rate-distortion analysis. Next, intra BC unit 48 may select, among the various tested intra-prediction modes, an appropriate intraprediction mode to use and generate an intra-mode indicator accordingly. For example, intra BC unit 48 may calculate rate-distortion values using a rate-distortion analysis for the various tested intra-prediction modes, and select the intra-prediction mode having the best ratedistortion characteristics among the tested modes as the appropriate intra-prediction mode to use. Rate-distortion analysis generally determines an amount of distortion (or error) between an encoded block and an original, unencoded block that was encoded to produce the encoded block, as well as a bitrate (i.e., a number of bits) used to produce the encoded block. Intra BC unit 48 may calculate ratios from the distortions and rates for the various encoded blocks to determine which intra-prediction mode exhibits the best rate-distortion value for the block. [0068] In other examples, intra BC unit 48 may use motion estimation unit 42 and motion compensation unit 44, in whole or in part, to perform such functions for Intra BC prediction according to the implementations described herein. In either case, for Intra block copy, a predictive block may be a block that is deemed as closely matching the block to be coded, in terms of pixel difference, which may be determined by sum of absolute difference (SAD), sum of squared difference (SSD), or other difference metrics, and identification of the predictive block may include calculation of values for sub-integer pixel positions.
[0069] Whether the predictive block is from the same frame according to intra prediction, or a different frame according to inter prediction, video encoder 20 may form a residual video block by subtracting pixel values of the predictive block from the pixel values of the current video block being coded, forming pixel difference values. The pixel difference
values forming the residual video block may include both luma and chroma component differences.
[0070] Intra prediction processing unit 46 may intra-predict a current video block, as an alternative to the inter-prediction performed by motion estimation unit 42 and motion compensation unit 44, or the intra block copy prediction performed by intra BC unit 48, as described above. In particular, intra prediction processing unit 46 may determine an intra prediction mode to use to encode a current block. To do so, intra prediction processing unit 46 may encode a current block using various intra prediction modes, e.g., during separate encoding passes, and intra prediction processing unit 46 (or a mode select unit, in some examples) may select an appropriate intra prediction mode to use from the tested intra prediction modes. Intra prediction processing unit 46 may provide information indicative of the selected intra-prediction mode for the block to entropy encoding unit 56. Entropy encoding unit 56 may encode the information indicating the selected intra-prediction mode in the bitstream.
[0071] After prediction processing unit 41 determines the predictive block for the current video block via either inter prediction or intra prediction, summer 50 forms a residual video block by subtracting the predictive block from the current video block. The residual video data in the residual block may be included in one or more transform units (TUs) and is provided to transform processing unit 52. Transform processing unit 52 transforms the residual video data into residual transform coefficients using a transform, such as a discrete cosine transform (DCT) or a conceptually similar transform.
[0072] Transform processing unit 52 may send the resulting transform coefficients to quantization unit 54. Quantization unit 54 quantizes the transform coefficients to further reduce bit rate. The quantization process may also reduce the bit depth associated with some or all of the coefficients. The degree of quantization may be modified by adjusting a quantization parameter. In some examples, quantization unit 54 may then perform a scan of a matrix including the quantized transform coefficients. Alternatively, entropy encoding unit 56 may perform the scan.
[0073] Following quantization, entropy encoding unit 56 entropy encodes the quantized transform coefficients into a video bitstream using, e.g., context adaptive variable length coding (CAVLC), context adaptive binary arithmetic coding (CABAC), syntax-based context-adaptive binary arithmetic coding (SBAC), probability interval partitioning entropy (PIPE) coding or another entropy encoding methodology or technique. The encoded bitstream may then be transmitted to video decoder 30, or archived in storage device 32 for later transmission to or retrieval by video decoder 30. Entropy encoding unit 56 may also entropy encode the motion vectors and the other syntax elements for the current video frame being coded.
[0074] Inverse quantization unit 58 and inverse transform processing unit 60 apply inverse quantization and inverse transformation, respectively, to reconstruct the residual video block in the pixel domain for generating a reference block for prediction of other video blocks. As noted above, motion compensation unit 44 may generate a motion compensated predictive block from one or more reference blocks of the frames stored in DPB 64. Motion compensation unit 44 may also apply one or more interpolation filters to the predictive block to calculate sub-integer pixel values for use in motion estimation.
[0075] Summer 62 adds the reconstructed residual block to the motion compensated predictive block produced by motion compensation unit 44 to produce a reference block for storage in DPB 64. The reference block may then be used by intra BC unit 48, motion estimation unit 42 and motion compensation unit 44 as a predictive block to inter predict another video block in a subsequent video frame.
[0076] FIG. 3 is a block diagram illustrating an exemplary video decoder 30 in accordance with some implementations of the present application. Video decoder 30 includes video data memory 79, entropy decoding unit 80, prediction processing unit 81, inverse quantization unit 86, inverse transform processing unit 88, summer 90, and DPB 92. Prediction processing unit 81 further includes motion compensation unit 82, intra prediction processing unit 84, and intra BC unit 85. Video decoder 30 may perform a decoding process generally reciprocal to the encoding process described above with respect to video encoder
20 in connection with FIG. 2. For example, motion compensation unit 82 may generate prediction data based on motion vectors received from entropy decoding unit 80, while intraprediction unit 84 may generate prediction data based on intra-prediction mode indicators received from entropy decoding unit 80.
[0077] In some examples, a unit of video decoder 30 may be tasked to perform the implementations of the present application. Also, in some examples, the implementations of the present disclosure may be divided among one or more of the units of video decoder 30. For example, intra BC unit 85 may perform the implementations of the present application, alone, or in combination with other units of video decoder 30, such as motion compensation unit 82, intra prediction processing unit 84, and entropy decoding unit 80. In some examples, video decoder 30 may not include intra BC unit 85 and the functionality of intra BC unit 85 may be performed by other components of prediction processing unit 81, such as motion compensation unit 82.
[0078] Video data memory 79 may store video data, such as an encoded video bitstream, to be decoded by the other components of video decoder 30. The video data stored in video data memory 79 may be obtained, for example, from storage device 32, from a local video source, such as a camera, via wired or wireless network communication of video data, or by accessing physical data storage media (e.g., a flash drive or hard disk). Video data memory 79 may include a coded picture buffer (CPB) that stores encoded video data from an encoded video bitstream. Decoded picture buffer (DPB) 92 of video decoder 30 stores reference video data for use in decoding video data by video decoder 30 (e.g., in intra or inter predictive coding modes). Video data memory 79 and DPB 92 may be formed by any of a variety of memory devices, such as dynamic random access memory (DRAM), including synchronous DRAM (SDRAM), magneto-resistive RAM (MRAM), resistive RAM (RRAM), or other types of memory devices. For illustrative purpose, video data memory 79 and DPB 92 are depicted as two distinct components of video decoder 30 in FIG. 3. But it will be apparent to one skilled in the art that video data memory 79 and DPB 92 may be provided by the same memory device or separate memory devices. In some examples, video data memory
79 may be on-chip with other components of video decoder 30, or off-chip relative to those components.
[0079] During the decoding process, video decoder 30 receives an encoded video bitstream that represents video blocks of an encoded video frame and associated syntax elements. Video decoder 30 may receive the syntax elements at the video frame level and/or the video block level. Entropy decoding unit 80 of video decoder 30 entropy decodes the bitstream to generate quantized coefficients, motion vectors or intra-prediction mode indicators, and other syntax elements. Entropy decoding unit 80 then forwards the motion vectors and other syntax elements to prediction processing unit 81.
[0080] When the video frame is coded as an intra predictive coded (I) frame or for intra coded predictive blocks in other types of frames, intra prediction processing unit 84 of prediction processing unit 81 may generate prediction data for a video block of the current video frame based on a signaled intra prediction mode and reference data from previously decoded blocks of the current frame.
[0081] When the video frame is coded as an inter-predictive coded (i.e., B or P) frame, motion compensation unit 82 of prediction processing unit 81 produces one or more predictive blocks for a video block of the current video frame based on the motion vectors and other syntax elements received from entropy decoding unit 80. Each of the predictive blocks may be produced from a reference frame within one of the reference frame lists. Video decoder 30 may construct the reference frame lists, List 0 and List 1, using default construction techniques based on reference frames stored in DPB 92.
[0082] In some examples, when the video block is coded according to the intra BC mode described herein, intra BC unit 85 of prediction processing unit 81 produces predictive blocks for the current video block based on block vectors and other syntax elements received from entropy decoding unit 80. The predictive blocks may be within a reconstructed region of the same picture as the current video block defined by video encoder 20.
[0083] Motion compensation unit 82 and/or intra BC unit 85 determines prediction information for a video block of the current video frame by parsing the motion vectors and
other syntax elements, and then uses the prediction information to produce the predictive blocks for the current video block being decoded. For example, motion compensation unit 82 uses some of the received syntax elements to determine a prediction mode (e.g., intra or inter prediction) used to code video blocks of the video frame, an inter prediction frame type (e.g., B or P), construction information for one or more of the reference frame lists for the frame, motion vectors for each inter predictive encoded video block of the frame, inter prediction status for each inter predictive coded video block of the frame, and other information to decode the video blocks in the current video frame.
[0084] Similarly, intra BC unit 85 may use some of the received syntax elements, e.g., a flag, to determine that the current video block was predicted using the intra BC mode, construction information of which video blocks of the frame are within the reconstructed region and should be stored in DPB 92, block vectors for each intra BC predicted video block of the frame, intra BC prediction status for each intra BC predicted video block of the frame, and other information to decode the video blocks in the current video frame.
[0085] Motion compensation unit 82 may also perform interpolation using the interpolation fdters as used by video encoder 20 during encoding of the video blocks to calculate interpolated values for sub-integer pixels of reference blocks. In this case, motion compensation unit 82 may determine the interpolation fdters used by video encoder 20 from the received syntax elements and use the interpolation fdters to produce predictive blocks. [0086] Inverse quantization unit 86 inverse quantizes the quantized transform coefficients provided in the bitstream and entropy decoded by entropy decoding unit 80 using the same quantization parameter calculated by video encoder 20 for each video block in the video frame to determine a degree of quantization. Inverse transform processing unit 88 applies an inverse transform, e.g., an inverse DCT, an inverse integer transform, or a conceptually similar inverse transform process, to the transform coefficients in order to reconstruct the residual blocks in the pixel domain.
[0087] After motion compensation unit 82 or intra BC unit 85 generates the predictive block for the current video block based on the vectors and other syntax elements, summer 90
reconstructs decoded video block for the current video block by summing the residual block from inverse transform processing unit 88 and a corresponding predictive block generated by motion compensation unit 82 and intra BC unit 85. An in-loop filter 91 may be positioned between summer 90 and DPB 92 to further process the decoded video block. The in-loop filtering 91, such as deblocking filter, sample adaptive offset (SAO) and adaptive in-loop filter (ALF) may be applied on the reconstructed CU before it is put in the reference picture store. The decoded video blocks in a given frame are then stored in DPB 92, which stores reference frames used for subsequent motion compensation of next video blocks. DPB 92, or a memory device separate from DPB 92, may also store decoded video for later presentation on a display device, such as display device 34 of FIG. 1.
[0088] In a typical video coding process, a video sequence typically includes an ordered set of frames or pictures. Each frame may include three sample arrays, denoted SL, SCb, and SCr. SL is a two-dimensional array of luma samples. SCb is a two-dimensional array of Cb chroma samples. SCr is a two-dimensional array of Cr chroma samples. In other instances, a frame may be monochrome and therefore includes only one two-dimensional array of luma samples.
[0089] Like the HEVC, the AVS3 standard is built upon the block-based hybrid video coding framework. The input video signal is processed block by block (called coding units (CUs)). Different from the HEVC which partitions blocks only based on quad-trees, in the AVS3, one coding tree unit (CTU) is split into CUs to adapt to varying local characteristics based on quad/binary /extended-quad-tree. Additionally, the concept of multiple partition unit type in the HEVC is removed, i.e., the separation of CU, prediction unit (PU) and transform unit (TU) does not exist in the AV S3. Instead, each CU is always used as the basic unit for both prediction and transform without further partitions. In the tree partition structure of the AVS3, one CTU is firstly partitioned based on a quad-tree structure. Then, each quad-tree leaf node can be further partitioned based on a binary and extended-quad-tree structure.
[0090] As shown in FIG. 4A, video encoder 20 (or more specifically partition unit 45) generates an encoded representation of a frame by first partitioning the frame into a set of
coding tree units (CTUs). A video frame may include an integer number of CTUs ordered consecutively in a raster scan order from left to right and from top to bottom. Each CTU is a largest logical coding unit and the width and height of the CTU are signaled by the video encoder 20 in a sequence parameter set, such that all the CTUs in a video sequence have the same size being one of 128x 128, 64x64, 32x32, and 16x 16. But it should be noted that the present application is not necessarily limited to a particular size. As shown in FIG. 4B, each CTU may comprise one coding tree block (CTB) of luma samples, two corresponding coding tree blocks of chroma samples, and syntax elements used to code the samples of the coding tree blocks. The syntax elements describe properties of different types of units of a coded block of pixels and how the video sequence can be reconstructed at the video decoder 30, including inter or intra prediction, intra prediction mode, motion vectors, and other parameters. In monochrome pictures or pictures having three separate color planes, a CTU may comprise a single coding tree block and syntax elements used to code the samples of the coding tree block. A coding tree block may be an NxN block of samples.
[0091] To achieve a better performance, video encoder 20 may recursively perform tree partitioning such as binary-tree partitioning, ternary-tree partitioning, quad-tree partitioning or a combination of both on the coding tree blocks of the CTU and divide the CTU into smaller coding units (CUs). As depicted in FIG. 4C, the 64x64 CTU 400 is first divided into four smaller CU, each having a block size of 32x32. Among the four smaller CUs, CU 410 and CU 420 are each divided into four CUs of 16x16 by block size. The two 16x16 CUs 430 and 440 are each further divided into four CUs of 8x8 by block size. FIG. 4D depicts a quad-tree data structure illustrating the end result of the partition process of the CTU 400 as depicted in FIG. 4C, each leaf node of the quad-tree corresponding to one CU of a respective size ranging from 32x32 to 8x8. Eike the CTU depicted in FIG. 4B, each CU may comprise a coding block (CB) of luma samples and two corresponding coding blocks of chroma samples of a frame of the same size, and syntax elements used to code the samples of the coding blocks. In monochrome pictures or pictures having three separate color planes, a CU may comprise a single coding block and syntax structures used to code the samples of the
coding block. It should be noted that the quad-tree partitioning depicted in FIGS. 4C and 4D is only for illustrative purposes and one CTU can be split into CUs to adapt to varying local characteristics based on quad/temary/binary-tree partitions. In the multi-type tree structure, one CTU is partitioned by a quad-tree structure and each quad-tree leaf CU can be further partitioned by a binary and ternary tree structure. As shown in FIG. 4E, there are five splitting/partitioning types in the AVS3, i.e., quaternary partitioning, horizontal binary partitioning, vertical binary partitioning, horizontal extended quad-tree partitioning, and vertical extended quad-tree partitioning.
[0092] In some implementations, video encoder 20 may further partition a coding block of a CU into one or more MxN prediction blocks (PB). A prediction block is a rectangular (square or non-square) block of samples on which the same prediction, inter or intra, is applied. A prediction unit (PU) of a CU may comprise a prediction block of luma samples, two corresponding prediction blocks of chroma samples, and syntax elements used to predict the prediction blocks. In monochrome pictures or pictures having three separate color planes, a PU may comprise a single prediction block and syntax structures used to predict the prediction block. Video encoder 20 may generate predictive luma, Cb, and Cr blocks for luma, Cb, and Cr prediction blocks of each PU of the CU.
[0093] Video encoder 20 may use intra prediction or inter prediction to generate the predictive blocks for a PU. If video encoder 20 uses intra prediction to generate the predictive blocks of a PU, video encoder 20 may generate the predictive blocks of the PU based on decoded samples of the frame associated with the PU. If video encoder 20 uses inter prediction to generate the predictive blocks of a PU, video encoder 20 may generate the predictive blocks of the PU based on decoded samples of one or more frames other than the frame associated with the PU.
[0094] After video encoder 20 generates predictive luma, Cb, and Cr blocks for one or more PUs of a CU, video encoder 20 may generate a luma residual block for the CU by subtracting the CU’s predictive luma blocks from its original luma coding block such that each sample in the CU’s luma residual block indicates a difference between a luma sample in
one of the CU's predictive luma blocks and a corresponding sample in the CU's original luma coding block. Similarly, video encoder 20 may generate a Cb residual block and a Cr residual block for the CU, respectively, such that each sample in the CU's Cb residual block indicates a difference between a Cb sample in one of the CU's predictive Cb blocks and a corresponding sample in the CU's original Cb coding block and each sample in the CU's Cr residual block may indicate a difference between a Cr sample in one of the CU's predictive Cr blocks and a corresponding sample in the CU's original Cr coding block.
[0095] Furthermore, as illustrated in FIG. 4C, video encoder 20 may use quad-tree partitioning to decompose the luma, Cb, and Cr residual blocks of a CU into one or more luma, Cb, and Cr transform blocks. A transform block is a rectangular (square or non-square) block of samples on which the same transform is applied. A transform unit (TU) of a CU may comprise a transform block of luma samples, two corresponding transform blocks of chroma samples, and syntax elements used to transform the transform block samples. Thus, each TU of a CU may be associated with a luma transform block, a Cb transform block, and a Cr transform block. In some examples, the luma transform block associated with the TU may be a sub-block of the CU's luma residual block. The Cb transform block may be a sub-block of the CU's Cb residual block. The Cr transform block may be a sub-block of the CU's Cr residual block. In monochrome pictures or pictures having three separate color planes, a TU may comprise a single transform block and syntax structures used to transform the samples of the transform block.
[0096] Video encoder 20 may apply one or more transforms to a luma transform block of a TU to generate a luma coefficient block for the TU. A coefficient block may be a two-dimensional array of transform coefficients. A transform coefficient may be a scalar quantity. Video encoder 20 may apply one or more transforms to a Cb transform block of a TU to generate a Cb coefficient block for the TU. Video encoder 20 may apply one or more transforms to a Cr transform block of a TU to generate a Cr coefficient block for the TU. [0097] After generating a coefficient block (e.g., a luma coefficient block, a Cb coefficient block or a Cr coefficient block), video encoder 20 may quantize the coefficient
block. Quantization generally refers to a process in which transform coefficients are quantized to possibly reduce the amount of data used to represent the transform coefficients, providing further compression. After video encoder 20 quantizes a coefficient block, video encoder 20 may entropy encode syntax elements indicating the quantized transform coefficients. For example, video encoder 20 may perform Context-Adaptive Binary Arithmetic Coding (CABAC) on the syntax elements indicating the quantized transform coefficients. Finally, video encoder 20 may output a bitstream that includes a sequence of bits that forms a representation of coded frames and associated data, which is either saved in storage device 32 or transmitted to destination device 14.
[0098] After receiving a bitstream generated by video encoder 20, video decoder 30 may parse the bitstream to obtain syntax elements from the bitstream. Video decoder 30 may reconstruct the frames of the video data based at least in part on the syntax elements obtained from the bitstream. The process of reconstructing the video data is generally reciprocal to the encoding process performed by video encoder 20. For example, video decoder 30 may perform inverse transforms on the coefficient blocks associated with TUs of a current CU to reconstruct residual blocks associated with the TUs of the current CU. Video decoder 30 also reconstructs the coding blocks of the current CU by adding the samples of the predictive blocks for PUs of the current CU to corresponding samples of the transform blocks of the TUs of the current CU. After reconstructing the coding blocks for each CU of a frame, video decoder 30 may reconstruct the frame.
[0099] SAO is a process that modifies the decoded samples by conditionally adding an offset value to each sample after the application of the deblocking filter, based on values in look-up tables transmitted by the encoder. SAO filtering is performed on a region basis, based on a filtering type selected per CTB by a syntax element sao-type-idx. A value of 0 for sao-type-idx indicates that the SAO filter is not applied to the CTB, and the values 1 and 2 signal the use of the band offset and edge offset filtering types, respectively. In the band offset mode specified by sao-type-idx equal to 1, the selected offset value directly depends on the sample amplitude. In this mode, the full sample amplitude range is uniformly split into
32 segments called bands, and the sample values belonging to four of these bands (which are consecutive within the 32 bands) are modified by adding transmitted values denoted as band offsets, which can be positive or negative. The main reason for using four consecutive bands is that in the smooth areas where banding artifacts can appear, the sample amplitudes in a CTB tend to be concentrated in only few of the bands. In addition, the design choice of using four offsets is unified with the edge offset mode of operation which also uses four offset values. In the edge offset mode specified by sao-type-idx equal to 2, a syntax element sao-eo-class with values from 0 to 3 signals whether a horizontal, vertical or one of two diagonal gradient directions is used for the edge offset classification in the CTB.
[00100] FIG. 5 is a block diagram depicting the four gradient patterns used in SAG in accordance with some implementations of the present disclosure. The four gradient patterns 502, 504, 506, and 508 are for the respective sao-eo-class in the edge offset mode. Sample labelled “p” indicates a center sample to be considered. Two samples labeled “nO” and “nl” specify two neighboring samples along the (a) horizontal (sao-eo-class = 0), (b) vertical (sao-eo-class = 1), (c) 135° diagonal (sao-eo-class = 2), and (d) 45° (sao-eo-class = 3) gradient patterns. Each sample in the CTB is classified into one of five Edgeldx categories by comparing the sample value p located at some position with the values nO and nl of two samples located at neighboring positions as shown in FIG. 5. This classification is done for each sample based on decoded sample values, so no additional signaling is required for the Edgeldx classification. Depending on the Edgeldx category at the sample position, for Edgeldx categories from 1 to 4, an offset value from a transmitted look-up table is added to the sample value. The offset values are always positive for categories 1 and 2 and negative for categories 3 and 4. Thus the filter generally has a smoothing effect in the edge offset mode. Table 1 below illustrates a sample Edgeldx categories in SAO edge classes.

Table 1 : A sample Edgeldx categories in SAO edge classes.
[00101] For SAO types 1 and 2, a total of four amplitude offset values are transmitted to the decoder for each CTB. For type 1, the sign is also encoded. The offset values and related syntax elements such as sao-type-idx and sao-eo-class are determined by the encoder - typically using criteria that optimize rate-distortion performance. The SAO parameters can be indicated to be inherited from the left or above CTB using a merge flag to make the signaling efficient. In summary, SAO is a nonlinear filtering operation which allows additional refinement of the reconstructed signal, and it can enhance the signal representation in both smooth areas and around edges.
[00102] In some embodiments, methods and systems are disclosed herein to improve the coding efficiency or reduce the complexity of Sample Adaptive Offset (SAO) by introducing cross-component information. SAO is used in the HEVC, VVC, AVS2 and AVS3 standards. Although the existing SAO design in the HEVC, VVC, AVS2 and AVS3 standards is used as the basic SAO method in the following descriptions, to a person skilled in the art of video coding, the cross-component methods described in the disclosure can also be applied to other loop filter designs or other coding tools with the similar design spirits. For example, in the AVS3 standard, SAO is replaced by a coding tool called Enhanced Sample Adaptive Offset (ESAO). However, the CCS AO disclosed herein can also be applied in parallel with ESAO. In another example, CCS AO can be applied in parallel with Constrained Directional Enhancement Filter (CDEF) in the AVI standard.
[00103] For the existing SAO design in the HEVC, VVC, AVS2 and AVS3 standards, the luma Y, chroma Cb and chroma Cr sample offset values are decided independently. That is, for example, the current chroma sample offset is decided by only the current and
neighboring chroma sample values, without taking collocated or neighboring luma samples into consideration. However, luma samples preserve more original picture detail information than chroma samples, and they can benefit the decision of the current chroma sample offset. Furthermore, since chroma samples usually lose high frequency details after color conversion from RGB to Y CbCr, or after quantization and deblocking filter, introducing luma samples with high frequency detail preserved for chroma offset decision can benefit the chroma sample reconstruction. Hence, further gain can be expected by exploring cross-component correlation, for example, by using the methods and systems of Cross-Component Sample Adaptive Offset (CCS AO).
[00104] FIG. 6A is a block diagram illustrating the system and process of CCSAO according to some implementations of the present disclosure. The luma samples after luma deblocking filter (DBF Y) is used to determine additional offsets for chroma Cb and Cr after SAO Cb and SAO Cr. For example, the current chroma sample 602 is first classified using collocated 604 and neighboring (white) luma samples 606, and the corresponding CCSAO offset value of the corresponding class is added to the current chroma sample value.
[00105] In some embodiments, CCSAO can also be applied in parallel with other coding tools, for example, ESAO in the AVS standard, or CDEF in the AVI standard. FIG. 6B is a block diagram illustrating the system and process of CCSAO applied in parallel with ESAO in the AVS standard according to some implementations of the present disclosure. [00106] FIG. 6C is a block diagram illustrating the system and process of CCSAO applied after SAO according to some implementations of the present disclosure. In some embodiments, FIG. 6C shows that the location of CCSAO can be after SAO, i.e., the location of Cross-Component Adaptive Loop Filter (CCALF) in the VVC standard. In some embodiments, the SAO Y/Cb/Cr can be replaced by ESAO, for example, in the AVS3 standard.
[00107] FIG. 6D is a block diagram illustrating the system and process of CCSAO applied in parallel with CCALF according to some implementations of the present disclosure.
In some embodiments, FIG. 6D shows that CCSAO can be applied in parallel with CCALF.
In some embodiments, in FIG. 6D, the locations of CCALF and CCSAO can be switched. In some embodiments, in FIG. 6A to FIG. 6D, or throughout the present disclosure, the SAG Y/Cb/Cr blocks can be replaced by ESAO Y/Cb/Cr (in AVS3) or CDEF (in AVI).
[00108] In some embodiments, the current chroma sample classification is reusing the SAO type (EO or BO), class, and category of the collocated luma sample. The corresponding CCSAO offset can be signaled or derived from the decoder itself. For example, let h_Y be the collocated luma SAO offset, h_Cb and h_Cr be the CCSAO Cb and Cr offset, respectively. h_Cb (or h_Cr) = w * h_Y where w can be selected in a limited table. For example, +-1/4, +- 1/2, 0, +-1, +-2, +-4...etc., where |w| only includes the power-of-2 values.
[00109] In some embodiments, the comparison score [-8, 8] of the collocated luma samples (Y0) and neighboring 8 luma samples are used, which yields 17 classes in total.
Initial Class = 0
Loop over neighboring 8 luma samples (Yi, i=l to 8) if Y0 > Yi Class += 1 else if Y0 < Yi Class -= 1
[00110] In some embodiments, the abovementioned classification methods can be combined. For example, comparison score combined with SAO BO (32 bands classification) is used to increase diversity, which yields 17 * 32 classes in total. In some embodiments, the Cb and Cr can use the same class to reduce the complexity or saving bits.
[00111] FIG 7 is a block diagram illustrating a sample process using CCSAO in accordance with some implementations of the present disclosure. Specifically, FIG 7 shows the input of CCSAO can introduce the input of vertical and horizontal DBF, to simplify the class determination, or increase flexibility. For example, let Y0 DBF V, Y0 DBF H, and Y0 be collocated luma samples at the input of DBF V, DBF H, and SAO, respectively. Yi DBF V, Yi DBF H, and Yi are neighbouring 8 luma samples at the input of DBF V, DBF H, and SAO, respectively, where i = 1 to 8.
Max Y0 = max (Y0 DBF V, Y0 DBF H, Y0 DBF)
Max Yi = max (Yi DBF V, Yi DBF H, Yi DBF) And feed max YO and max Yi to CCSAO classification.
[00112] FIG 8 is a block diagram illustrating that CCSAO process is interleaved to vertical and horizontal DBF in accordance with some implementations of the present disclosure. In some embodiments, CCSAO blocks in FIG 6, 7 and 8 can be selective. For example, using YO DBF V and Yi DBF V for the first CCSAO V, which applies the same sample processing as in FIG 6, while using the input of DBF V luma samples as CCSAO input.
[00113] In some embodiments, CCSAO syntax implemented is shown in Table 2 below.

Table 2: An example of CCSAO syntax
[00114] In some embodiments, for signaling CCSAO Cb and Cr offset values, if one additional chroma offset is signaled, the other chroma component offset can be derived by plus or minus sign, or weighting to save bits overhead. For example, let h_Cb and h_Cr be the offset of CCSAO Cb and Cr, respectively. With explicit signaling w, wherein w = +- 1 w | with limited | w | candidates, h_Cr can be derived from h_Cb without explicit signaling h_Cr itself.
h_Cr = w * h_Cb
[00115] FIG. 9 is a flowchart illustrating an exemplary process 900 of decoding video signal using cross-component correlation in accordance with some implementations of the present disclosure.
[00116] The video decoder 30, receives the video signal that includes a first component and a second component (910). In some embodiments, the first component is a luma component, and the second component is a chroma component of the video signal.
[00117] The video decoder 30 also receives a plurality of offsets associated with the second component (920).
[00118] The video decoder 30 then utilizes a characteristic measurement of the first component to obtain a classification category associated with the second component (930). For example, in FIG 6, the current chroma sample 602 is first classified using collocated 604 and neighboring (white) luma samples 606, and the corresponding CCSAO offset value is added to the current chroma sample.
[00119] The video decoder 30 further selects a first offset from the plurality of offsets for the second component according to the classification category (940).
[00120] The video decoder 30 additionally modifies the second component based on the selected first offset (950).
[00121] In some embodiments, utilizing the characteristic measurement of the first component to obtain the classification category associated with the second component (930) includes: utilizing a respective sample of the first component to obtain a respective classification category of a respective each sample of the second component, wherein the respective sample of the first component is a respective collocated sample of the first component to the respective each sample of the second component. For example, the current chroma sample classification is reusing the SAG type (EO or BO), class, and category of the collocated luma sample.
[00122] In some embodiments, utilizing the characteristic measurement of the first component to obtain the classification category associated with the second component (930)
includes: utilizing a respective sample of the first component to obtain a respective classification category of a respective each sample of the second component, wherein the respective sample of the first component is reconstructed before being deblocked or is reconstructed after being deblocked. In some embodiment, the first component is being deblocked at a deblocking filter (DBF). In some embodiment, the first component is being deblocked at a luma deblocking filter (DBF Y). For example, alternative to FIGS. 6 or 7, the CCSAO input can also be before DBF Y.
[00123] In some embodiments, the characteristic measurement is derived by dividing the range of sample values of the first component into several bands and selecting a band based on the intensity value of a sample in the first component. In some embodiments, the characteristic measurement is derived from Band Offset (BO).
[00124] In some embodiments, the characteristic measurement is derived based on the direction and strength of the edge information of a sample in the first component. In some embodiments, the characteristic measurement is derived from Edge Offset (EO).
[00125] In some embodiments, modifying the second component (950) comprises directly adding the selected first offset to the second component. For example, the corresponding CCSAO offset value is added to the current chroma component sample.
[00126] In some embodiments, modifying the second component (950) comprises mapping the selected first offset to a second offset and adding the mapped second offset to the second component. For example, for signaling CCSAO Cb and Cr offset values, if one additional chroma offset is signaled, the other chroma component offset can be derived by using a plus or minus sign, or weighting to save bits overhead.
[00127] In some embodiments, receiving the video signal (910) comprises receiving a syntax element that indicates whether the method of decoding video signal using CCSAO is enabled for the video signal in the Sequence Parameter Set (SPS). In some embodiments, cc_sao_enabled_flag indicates whether CCSAO is enabled in the sequence level.
[00128] In some embodiments, receiving the video signal (910) comprises receiving a syntax element that indicates whether the method of decoding video signal using CCSAO is
enabled for the second component on the slice level. In some embodiments, slice_cc_sao_cb_flag or slice_cc_sao_cr_flag indicates whether CCSAO is enabled in the respective slice for Cb or Cr.
[00129] In some embodiments, receiving the plurality of offsets associated with the second component (920) comprises receiving different offsets for different Coding Tree Units (CTUs). In some embodiments, for a CTU, cc_sao_offset_sign_flag indicates a sign for an offset, and cc_sao_offset_abs indicates the CCSAO Cb and Cr offset values of the current CTU.
[00130] In some embodiments, receiving the plurality of offsets associated with the second component (920) comprises receiving a syntax element that indicates whether the received offsets of a CTU are the same as that of one of a neighboring CTU of the CTU, wherein the neighboring CTU is either a left or atop neighboring CTU. For example, cc_sao_merge_up_flag indicates whether CCSAO offset is merged from the left or up CTU. [00131] In some embodiments, the video signal further includes a third component and the method of decoding the video signal using CCSAO further includes: receiving a second plurality of offsets associated with a third component; utilizing the characteristic measurement of the first component to obtain a second classification category associated with the third component; selecting a third offset from the second plurality of offsets for the third component according to the second classification category; and modifying the third component based on the selected third offset.
[00132] FIG. 11 is a block diagram of a sample process illustrating that besides luma, the other cross-component collocated (1102) and neighboring (white) chroma samples are also fed into CCSAO classification in accordance with some implementations of the present disclosure. FIG. 6A, 6B and FIG. 11 show the input of CCSAO classification. In FIG. 11, current chroma sample is 1104, the cross-component collocated chroma sample is 1102, and the collocated luma sample is 1106.
[00133] In some embodiments, a classifier example (CO) uses the collocated luma sample value (Y0) for classification. Uet band num be the number of equally divided bands
of luma dynamic range, and bit depth be the sequence bit depth, the class index for the current chroma sample is:
Class (CO) = (Y0 * band num) » bit depth
[00134] In some embodiments, the classification takes rounding into account, for example:
Class (CO) = ((Y0 * band num) + (1 « bit depth)) » bit depth [00135] Some band num and bit depth examples are listed below in Table 3. Table 3 shows three classification examples when the number of bands is different for each of the classification examples.



Table 3 : Exemplary band num and bit depth for each class index.
[00136] In some embodiments, a classifier uses different luma sample position for CO classification. FIG. 10A is a block diagram showing a classifier using different luma sample position for CO classification in accordance with some implementations of the present disclosure, for example, using the neighboring Y7 but not Y0 for CO classification.
[00137] In some embodiments, different classifiers can be switched in Sequence Parameter Set (SPS)/ Adaptation parameter set (APS)/ Picture parameter set (PPS)/ Picture header (PH)/ Slice header (SH) /Coding tree unit (CTU) / Coding unit (CU) levels. For example, in FIG. 10, using Y0 for POCO but using Y7 for POC1, as shown in Table 4 below.

Table 4: Different classifiers are applied to different pictures
[00138] In some embodiments, FIG. 10B illustrates some examples of different shapes for luma candidates, in accordance with some implementations of the present disclosure. For example, a constraint can be applied to the shapes. In some instances, the total number of luma candidates must be the power of 2, as shown in FIG. 10B (b) (c) (d). In some instances, the number of luma candidates must be horizontal and vertical symmetric relative to the chroma sample (in the center), as shown in FIG. 10B (a) (c) (d) (e).
[00139] In some embodiments, the CO position and CO band num can be combined and switched in SPS/APS/PPS/PH/SH/CTU/CU levels. Different combinations can be different classifiers as shown in Table 5 below.

Table 5 : Different classifier and band number combinations are applied to different pictures [00140] In some embodiments, the collocated luma sample value (Y 0) is replaced by a value (Y p) obtained by weighing collocated and neighboring luma samples. FIG. 12 illustrates exemplary classifiers by replacing the collocated luma sample value with a value obtained by weighing collocated and neighboring luma samples in accordance with some implementations of the present disclosure. The collocated luma sample value (Y0) can be
replaced by a phase corrected value (Yp) obtained by weighing neighboring luma samples. Different Yp can be a different classifier.
[00141] In some embodiments, different Yp is applied on different chroma format. For example, in FIG. 12, the Yp of (a) is used for the 420 chroma format, the Yp of (b) is used for the 422 chroma format, and Y0 is used for the 444 chroma format.
[00142] In some embodiments, another classifier (Cl) is the comparison score [-8, 8] of the collocated luma samples (Y0) and neighboring 8 luma samples, which yields 17 classes in total as shown below.
Initial Class (Cl) = 0, Loop over neighboring 8 luma samples (Yi, i=l to 8) if Y0 > Yi Class += 1 else if Y0 < Yi Class -= 1
[00143] In some embodiments, a variation (Cl’) only counts comparison score [0, 8], and this yields 8 classes. (Cl, Cl’) is a classifier group and a PH/SH level flag can be signaled to switch between Cl and Cl’.
Initial Class (Cl’) = 0, Loop over neighboring 8 luma samples (Yi, i=l to 8) if Y0 > Yi Class += 1
[00144] In some embodiments, different classifiers are combined to yield a general classifier. For example, for different pictures (different POC values), different classifiers are applied as shown in Table 6-1 below.

Table 6-1: Different general classifiers are applied to different pictures
[00145] In some embodiments, another classifier example (C3) is using a bitmask for classification as shown in Table 6-2. A 10-bit bitmask is signaled in SPS/APS/PPS/PH/SH/Region/CTU/CU/Subblock levels to indicate the classifier. For example, bitmask 11 1100 0000 means that for a given 10-bit luma sample value, only most significant bit (MSB): 4 bits are used for classification, and that yields 16 classes in total.
Another example bitmask 10 0100 0001 means that only 3 bits are used for classification, and that yields 8 classes in total.
[00146] In some embodiments, the luma position and C3 bitmask can be combined and switched in SPS/APS/PPS/PH/SH/Region/CTU/CU/Subblock levels. Different combinations can be different classifiers.
[00147] In some embodiments, a “max number of Is” of the bitmask restriction can be applied to restrict the corresponding number of offsets. For example, restricting “max number of Is” of the bitmask to 4 in SPS, and that yields the max offsets in the sequence to be 16.
The bitmask in different POC can be different, but the “max number of Is” shall not exceed 4 (total classes shall not exceed 16). The “max number of Is” value can be signaled and switched in SPS/APS/PPS/PH/SH/Region/CTU/CU/Subblock levels.


Table 6-2: Classifier example uses a bitmask for classification (bit mask position is underscored)
[00148] All abovementioned classifies (CO, Cl, Cl’, C2, C3) can be combined. For example, see Table 6-3 below.

Table 6-3 : Different classifiers are combined
[00149] In some embodiments, a classifier example (C2) uses the difference (Y n) of collocated and neighboring luma samples. FIG. 12 (c) shows an example of Yn, which has a dynamic range of [-1024, 1023] when bit depth is 10. Let C2 band_num be the number of equally divided bands of Yn dynamic range,
Class (C2) = (Yn + (1 « bit_depth) * band_num) » (bit_depth + 1).
[00150] In some embodiments, CO and C2 are combined to yield a general classifier. For example, for different pictures (different POC), different classifiers are applied as shown in Table 7 below.

Table 7 : Different general classifiers are applied to different pictures
[00151] In some embodiments, all above mentioned classifiers (CO, Cl, Cl’, C2) are combined. For example, for different pictures (different POCs), different classifiers are applied as shown in Table 8 below.

Table 8: Different general classifiers are applied to different pictures
[00152] In some embodiments, plural classifiers are used in the same POC. The current frame is divided by several regions, and each region uses the same classifier. For example, 3 different classifiers are used in POCO, and which classifier (0, 1, or 2) is used is signaled in CTU level as shown in Table 9 below.

Table 9: Different general classifiers are applied to different regions in the same picture
[00153] In some embodiments, the maximum number of plural classifiers (plural classifiers can also be called alternative offset sets) can be fixed or signaled in SPS/APS/PPS/PH/SH/CTU/CU levels. In one example, the fixed (pre-defined) maximum number of plural classifiers is 4. In that case, 4 different classifiers are used in POCO, and which classifier (0, 1, or 2) is used is signaled in the CTU level. Truncated-unary (TU) code can be used to indicate the classifier used for each chroma CTB. For example, as shown in Table 10 below, when TU code is 0: CCS AO is not applied; when TU code is 10: set 0 is applied; when TU code is 110, set 1 is applied; when TU code is 1110: set 2 is applied; when TU code is 1111: set 3 is applied. Fixed-length code, golomb-rice code, and exponential- golomb code can also be used to indicate the classifier (offset set index) for CTB. 3 different classifiers are used in POC 1.

Table 10: Truncated-unary (TU) code is used to indicate the classifier used for each chroma
CTB
[00154] An example of Cb and Cr CTB offset set indices is given for 1280x720 sequence POCO (number of CTUs in a frame is 10x6 if the CTU size is 128x128). POCO Cb uses 4 offset sets and Cr uses 1 offset set. As shown in Table 11 below, when the offset set index is 0: CCSAO is not applied; when the offset set index is 1: set 0 is applied; when the
offset set index is 2: set 1 is applied; when the offset set index is 3: set 2 is applied; when the offset set index is 4: set 3 is applied. Type means the position of the chosen collocated luma sample (Yi). Different offset sets can have different types, band_num and corresponding offsets.

Table 11: An example of Cb and Cr CTB offset set indices is given for 1280x720 sequence POCO (number of CTUs in a frame is 10x6 if the CTU size is 128x128)
[00155] In some embodiments, the maximum band num can be fixed or signaled in SPS/APS/PPS/PH/SH/CTU/CU levels. For example, fixing max band_num=16 in the decoder and for each frame, 4 bits are signaled to indicate the CO band_num in a frame. Some other maximum band num examples are listed below in Table 12.


Table 12: Maximum band num and band num bit examples
[00156] In some embodiments, a restriction can be applied on the CO classification, for example, restricting band_num to be only power of 2 values. Instead of explicitly signaling band num, a syntax band num shift is signaled. Decoder can use shift operation to avoid multiplication.
Class (CO) = (YO » band num shift) » bit depth
[00157] Another operation example is taking rounding into account to reduce error.
Class (CO) = ((YO + (1 « (band num shift - 1))) » band num shift) » bit depth
[00158] For example, if band num max is 16, the possible band num shift candidates are 0, 1, 2, 3, 4, corresponding to band_num = 1, 2, 4, 8, 16, as shown in Table 13.



Table 13: Band num and corresponding band num shift candidates
[00159] In some embodiments, the classifiers applied to Cb and Cr are different. The Cb and Cr offsets for all classes can be signaled separately. For example, different signaled offsets are applied to different chroma components as shown in Table 14 below.

Table 14: The Cb and Cr offsets for all classes can be signaled separately
[00160] In some embodiments, the max offset value is fixed or signaled in Sequence Parameter Set (SPS)/ Adaptation parameter set (APS)/ Picture parameter set (PPS)/ Picture header (PH)/ Slice header (SH). For example, the max offset is between [-15, 15],
[00161] In some embodiments, the offset signaling can use Differential pulse-code modulation (DPCM). For example, offsets {3, 3, 2, 1, -1} can be signaled as {3, 0, -1, -1, -2}.
[00162] In some embodiments, the offsets can be stored in APS or a memory buffer for the next picture/slice reuse. An index can be signaled to indicate which stored previous frame offsets are used for the current picture.
[00163] In some embodiments, the classifiers of Cb and Cr are the same. The Cb and Cr offsets for all classes can be signaled jointly, for example, as shown in Table 15 below.

Table 15: The Cb and Cr offsets for all classes can be signaled jointly
[00164] In some embodiments, the classifier of Cb and Cr can be the same. The Cb and Cr offsets for all classes can be signaled jointly, with a sign flag difference, for example, as shown in Table 16 below. According to Table 16, when Cb offsets are (3, 3, 2, -1), the derived Cr offsets are (-3, -3, -2, 1).

Table 16: The Cb and Cr offsets for all classes can be signaled jointly with a sign flag difference
[00165] In some embodiments, the sign flag can be signaled for each class, for example, as shown in Table 17 below. According to Table 17, when Cb offsets are (3, 3, 2, -1), the derived Cr offsets are (-3, 3, 2, 1) according to the respective signed flag.

Table 17: The Cb and Cr offsets for all classes can be signaled jointly with a sign flag signaled for each class
[00166] In some embodiments, the classifiers of Cb and Cr can be the same. The Cb and Cr offsets for all classes can be signaled jointly, with a weight difference, for example, as shown in Table 18 below. The weight (w) can be selected in a limited table, for example, +- 1/4, +-1/2, 0, +-1, +-2, +-4. . . etc., where |w| only includes the power-of-2 values. According to Table 18, when Cb offsets are (3, 3, 2, -1), the derived Cr offsets are (-6, -6, -4, 2) according to the respective signed flag.

Table 18: The Cb and Cr offsets for all classes can be signaled jointly with a weight difference
[00167] In some embodiments, the weight can be signaled for each class, for example, as shown in Table 19 below. According to Table 19, when Cb offsets are (3, 3, 2, -1), the derived Cr offsets are (-6, 12, 0, -1) according to the respective signed flag.

Table 19: The Cb and Cr offsets for all classes can be signaled jointly with a weight signaled for each class
[00168] In some embodiments, if plural classifiers are used in the same POC, different offset sets are signaled separately or jointly.
[00169] In some embodiments, the previously decoded offsets can be stored for use of future frames. An index can be signaled to indicate which previously decoded offsets set is used for the current frame, to reduce offsets signaling overhead. For example, POCO offsets can be reused by POC2 with signaling offsets set idx = 0 as shown in Table 20 below.

Table 20: An index can be signaled to indicate which previously decoded offsets set is used for the current frame
[00170] In some embodiments, the reuse offsets set idx for Cb and Cr can be different,
For example, as shown in Table 21 below.


Table 21: An index can be signaled to indicate which previously decoded offsets set is used for the current frame, and the index can be different for Cb and Cr components.
[00171] In some embodiments, the offset signaling can use additional syntax including start and length, to reduce signaling overhead. For example, when band_num=256, only offsets of band_idx=37~44 are signaled. In the example below in Table 22, the syntax of start and length both are 8 bits fixed-length coded that should match band num bits.

Table 22: the offset signaling uses additional syntax including start and length
[00172] In some embodiments, if a sequence bit depth is higher than 10 (or a certain bit depth), the offset can be quantized before signaling. On the decoder side, the decoded offset is dequantized before applying it as shown in Table 23 below. For example, for a 12-bit sequence, the decoded offsets are left shifted (dequantized) by 2.


Table 23 : The decoded offset is dequantized before applying it
[00173] In some embodiments, the offset can be calculated as CcSaoOffsetVal=( 1 - 2 * ccsao offset sign flag ) * (ccsao offset abs « ( BitDepth - Min( 10, BitDepth ) ) )
[00174] In some embodiments, a sample processing is described below. Let R(x, y) be the input chroma sample value before CCSAO, R’(x, y) be the output chroma sample value after CCSAO: offset = ccsao offset [class index of R(x, y)]
R’(x, y) = Clip3( 0, (1 « bit depth) - 1, R(x, y) + offset )
[00175] According the above equations, each chroma sample value R(x, y) is classified using the indicated classifier of the current picture. The corresponding offset of the derived class index is added to each chroma sample value R(x, y). A clip function Clip 3 is applied to the (R(x, y) + offset) to make the output chroma sample value R’(x, y) within the bit depth dynamic range, for example, range 0 to ( 1 « bit depth) - 1 .
[00176] In some embodiments, a boundary processing is described below. If any of the collocated and neighboring luma samples used for classification is outside the current picture, CCSAO is not applied on the current chroma sample. FIG. 13 A is a block diagram illustrating CCSAO is not applied on the current chroma sample if any of the collocated and neighboring luma samples used for classification is outside the current picture in accordance with some implementations of the present disclosure. For example, in FIG. 13A(a), if a classifier is used,
CCSAO is not applied on the left 1 column chroma components of the current picture. For example, if Cl’ is used, CCSAO is not applied on the left 1 column and the top 1 row chroma components of the current picture, as shown in FIG. 13A(b).
[00177] FIG. 13B is a block diagram illustrating CCSAO is applied on the current chroma sample if any of the collocated and neighboring luma samples used for classification is outside the current picture in accordance with some implementations of the present disclosure. In some embodiments, a variation is, if any of the collocated and neighboring luma samples used for classification is outside the current picture, the missed samples are used repetitively as shown in FIG. 13B(a), or the missed samples are mirror padded to create samples for classification as shown in FIG. 13B(b), and CCSAO can be applied on the current chroma samples.
[00178] FIG. 14 is a block diagram illustrating CCSAO is not applied on the current chroma sample if a corresponding selected collocated or neighboring luma sample used for classification is outside a virtual space defined by a virtual boundary in accordance with some implementations of the present disclosure. In some embodiments, a virtual boundary (VB) is a virtual line that separates the space within a picture frame. In some embodiments, if a virtual boundary (VB) is applied in the current frame, CCSAO is not applied on the chroma samples that have selected corresponding luma position outside a virtual space defined by the virtual boundary. FIG. 14 shows an example with a virtual boundary for CO classifier with 9 luma position candidates. For each CTU, CCSAO is not applied on the chroma samples for which the corresponding selected luma position is outside a virtual space surrounded by the virtual boundary. For example, in FIG. 14(a), CCSAO is not applied to the chroma sample 1402 when the selected Y7 luma sample position is on the other side of the horizontal virtual boundary 1406 which is located 4 pixel lines from the bottom side of the frame. For example, in FIG. 14(b), CCSAO is not applied to the chroma sample 1404 when the selected Y5 luma sample position is located on the other side of the vertical virtual boundary 1408 which is located y pixel lines from the right side of the frame.
[00179] FIG. 15 shows repetitive or mirror padding can be applied on the luma samples that are outside the virtual boundary in accordance with some implementations of the present disclosure. FIG. 15 (a) shows an example of repetitive padding. If the original Y7 is chosen to be the classifier which is located on the bottom side of the VB 1502, the Y4 luma sample value is used for classification (copied to the Y7 position), instead of the original Y7 luma sample value. FIG. 15 (b) shows an example of mirror padding. If Y7 is chosen to be the classifier which is located on the bottom side of the VB 1504, the Y 1 luma sample value which is symmetric to the Y7 value relative to the Y0 luma sample is used for classification, instead of the original Y7 luma sample value. The padding methods give more chroma samples possibility to apply CCSAO so more coding gain can be achieved.
[00180] In some embodiments, a restriction can be applied to reduce the CCSAO required line buffer, and to simplify the boundary processing condition check. FIG. 16 shows additional 1 luma line buffer, i.e., the whole line luma samples of line -5 above the current VB 1602, may be required if all 9 collocated neighboring luma samples are used for classification in accordance with some implementations of the present disclosure. FIG. 10B (a) shows an example using only 6 luma candidates for classification, which reduces the line buffer and does not need any additional boundary check in Fig. 13 A and Fig. 13 B.
[00181] In some embodiments, using luma samples for CCSAO classification may increase the luma line buffer and hence increase the decoder hardware implementation cost. FIG. 17 shows an illustration in AVS that 9 luma candidates CCSAO crossing VB 1702 may increase 2 additional luma line buffers in accordance with some implementations of the present disclosure. For luma and chroma samples above Virtual Boundary (VB) 1702, DBF/SAO/ALF are processed at the current CTU row. For luma and chroma samples below VB 1702, DBF/SAO/ALF are processed at the next CTU row. In AVS decoder hardware design, luma line -4 to -1 pre DBF samples, line -5 pre SAO samples, and chroma line -3 to - 1 pre DBF samples, line -4 pre SAO samples are stored as line buffers for next CTU row DBF/SAO/ALF processing. When processing the next CTU row, luma and chroma samples not in the line buffer are not available. However, for example, at chroma line -3 (b) position,
the chroma sample is processed at the next CTU row, but CCSAO requires pre SAO luma sample lines -7, -6, and -5 for classification. Pre SAO luma sample lines -7, -6 are not in the line buffer so they are not available. And adding pre SAO luma samples line -7 and -6 to the line buffer will increase the decoder hardware implementation cost. In some examples, luma VB (line -4) and chroma VB (line -3) can be different (not aligned).
[00182] Similar as FIG. 17, FIG. 18 shows an illustration in VVC that 9 luma candidates CCSAO crossing VB 1802 may increase 1 additional luma line buffer in accordance with some implementations of the present disclosure. VB can be different in different standard. In VVC, luma VB is line -4 and chroma VB is line -2, so 9 candidate CCSAO may increase 1 luma line buffer.
[00183] In some embodiments, in a first solution, CCSAO is disabled for a chroma sample if any of the chroma sample’s luma candidates is across VB (outside the current chroma sample VB). FIGs. 19A-19C show in AVS and VVC, CCSAO is disabled for a chroma sample if any of the chroma sample’s luma candidates is across VB 1902 (outside the current chroma sample VB) in accordance with some implementations of the present disclosure. FIG. 14 also shows some examples of this implementation.
[00184] In some embodiments, in a second solution, repetitive padding is used for CCSAO from a luma line close to and on the other side of the VB, for example, the luma line -4, for “cross VB” luma candidates. FIGs. 20A-20C show in AVS and VVC, CCSAO is enabled using repetitive padding for a chroma sample if any of the chroma sample’s luma candidates is across VB 2002 (outside the current chroma sample VB) in accordance with some implementations of the present disclosure. FIG. 14 (a) also shows some examples of this implementation.
[00185] In some embodiments, in a third solution, mirror padding is used for CCSAO from below luma VB for “cross VB” luma candidates. FIGs. 21A-21C show in AVS and
VVC, CCSAO is enabled using mirror padding for a chroma sample if any of the chroma sample’s luma candidates is across VB 2102 (outside the current chroma sample VB) in
accordance with some implementations of the present disclosure. FIG. 14 (b) and 13B (b) also show some examples of this implementation.
[00186] In some embodiments, in a fourth solution, “double sided symmetric padding” is used for applying CCSAO. FIGs. 22A-22B show that CCSAO is enabled using double sided symmetric padding for some examples of different CCSAO shapes (for example, 9 luma candidates (FIG. 22A) and 8 luma candidates (FIG. 22B)) in accordance with some implementations of the present disclosure. For a luma sample set with a collocated centered luma sample of a chroma sample, if one side of the luma sample set is outside the VB 2202, double-sided symmetric padding is applied for both sides of the luma sample set. For example, in FIG. 22A, luma samples Y0, Y 1 , and Y 2 are outside of the VB 2202, so both Y 0, Yl, Y2 and Y6, Y7, Y8 are padded using Y3, Y4, Y5. For example, in FIG. 22B, luma sample Y0 is outside of the VB 2202, so Y0 is padded using Y2, and Y7 is padded using Y5.
[00187] The padding methods give more chroma samples possibility to apply CCSAO so more coding gain can be achieved.
[00188] In some embodiments, at the bottom picture (or slice, tile, brick) boundary CTU row, the samples below VB are processed at the current CTU row, so the above special handling (Solution 1, 2, 3, 4) is not applied at the bottom picture (or slice, tile, brick) boundary CTU row. For example, a frame of 1920x1080 is divided by CTUs of 128x128. A frame contains 15x9 CTUs (round up). The bottom CTU row is the 15th CTU row. The decoding process is CTU row by CTU row, and CTU by CTU for each CTU row. Deblocking needs to be applied along horizontal CTU boundaries between the current and next CTU row. CTB VB is applied for each CTU row since inside one CTU, at the bottom 4/2 luma/chroma line, DBF samples (VVC case) are processed at the next CTU row and are not available for CCSAO at the current CTU row. However, at the bottom CTU row of the picture frame, the bottom 4/2 luma/chroma line DBF samples are available at the current CTU row since there is no next CTU row left and they are DBF processed at the current CTU row.
[00189] In some embodiments, a restriction can be applied to reduce the CCSAO required line buffer, and to simplify boundary processing condition check as explained in FIG. 16. FIG. 23 shows the restrictions of using a limited number of luma candidates for classification in accordance with some implementations of the present disclosure. FIG. 23 (a) shows the restriction of using only 6 luma candidates for classification. FIG. 23 (b) shows the restriction of using only 4 luma candidates for classification.
[00190] In some embodiments, applied region is implemented. The CCSAO applied region unit can be CTB based. That is, the on/off control, CCSAO parameters (offsets, luma candidate positions, band_num, bitmask. . .etc. used for classification, offset set index) are the same in one CTB.
[00191] In some embodiments, the applied region can be not aligned to the CTB boundary. For example, the applied region is not aligned to chroma CTB boundary but shifted. The syntaxes (on/off control, CCSAO parameters) are still signaled for each CTB, but the truly applied region is not aligned to the CTB boundary. FIG. 24 shows the CCSAO applied region is not aligned to the CTB/CTU boundary 2406 in accordance with some implementations of the present disclosure. For example, the applied region is not aligned to chroma CTB/CTU boundary 2406 but top-left shifted (4, 4) samples to VB 2408. This not- aligned CTB boundary design benefits the deblocking process since the same deblocking parameters are used for each 8x8 deblocking process region.
[00192] In some embodiments, the CCSAO applied region unit (mask size) can be variant (larger or smaller than CTB size) as shown in Table 24. The mask size can be different for different components. The mask size can be switched in SPS/APS/PPS/PH/SH/Region/CTU/CU/Subblock levels. For example, in PH, a series of mask on/off flags and offset set indices are signaled to indicate each CCSAO region information.


Table 24: CCS AO applied region unit (mask size) can be variant
[00193] In some embodiments, the CCSAO applied region frame partition can be fixed. For example, partition the frame into N regions. FIG. 25 shows that the CCSAO applied region frame partition can be fixed with CCSAO parameters in accordance with some implementations of the present disclosure.
[00194] In some embodiments, each region can have its own region on/off control flag and CCSAO parameters. Also, if the region size is larger than CTB size, it can have both CTB on/off control flags and region on/off control flag. FIG. 25 (a) and (b) show some examples of partitioning the frame into N regions. FIG. 25 (a) shows vertical partitioning of 4 regions. FIG. 25 (b) shows square partitioning of 4 regions.
[00195] In some embodiments, different CCSAO applied region can share the same region on/off control and CCSAO parameters. For example, in FIG. 25 (c), region 0~2 shares the same parameters and region 3—15 shares the same parameters. FIG. 25 (c) also shows the region on/off control flag and CCSAO parameters can be signaled in a Hilbert scan order.
[00196] In some embodiments, the CCSAO applied region unit can be quad- tree/binary-tree/temary-tree split from picture/slice/CTB level. Similar to the CTB split, a series of split flags are signaled to indicate the CCSAO applied region partition. FIG. 26 shows that the CCSAO applied region can be Binary -tree (BT)/ Quad-tree (QT)/Temary-tree (TT) split from frame/slice/CTB level in accordance with some implementations of the present disclosure.
[00197] In some embodiments, CCSAO syntax implemented is shown in Table 25 below. In AVS3, the term patch is similar with slice, and patch header is similar with the slice
header. FLC stands for fixed length code. TU stands for truncated unary code. EGk stands for exponential-golomb code with order k, where k can be fixed.

Table 25 : A exemplary CCSAO syntax
[00198] If a higher-level flag is off, the lower level flags can be inferred from the off state of the flag and do not need to be signaled. For example, if ph_cc_sao_cb_flag is false in this picture, ph_cc_sao_cb_band_num_minusl, ph cc sao cb luma type, cc_sao_cb_offset_sign_flag, cc_sao_cb_offset_abs, ctb_cc_sao_cb_flag, cc_sao_cb_merge_left_flag, and cc_sao_cb_merge_up_flag are not present and inferred to be false.
[00199] In some embodiments, the SPS ccsao enabled flag is conditioned on the SPS SAO enabled flag as shown in Table 26 below.

Table 26: the SPS ccsao enabled flag is conditioned on the SPS SAO enabled flag
[00200] In some embodiments, ph cc sao cb ctb control flag, ph_cc_sao_cr_ctb_control_flag indicate whether to enable Cb/Cr CTB on/off control granularity. If ph cc sao cb ctb control flag, ph cc sao cr ctb control flag are enabled, ctb_cc_sao_cb_flag and ctb_cc_sao_cr_flag can be further signaled. Otherwise, whether CCSAO is applied in the current picture depends on ph cc sao cb flag, ph cc sao cr flag, without further signaling ctb cc sao cb flag and ctb cc sao cr flag at CTB level.
[00201] In some embodiments, for ph cc sao cb type and ph cc sao cr type, a flag can be further signaled to distinguish if the center collocated luma position is used (Y 0 position in FIG. 10) for classification for a chroma sample, to reduce bit overhead. Similarly, if cc sao cb type and cc sao cr type are signaled in CTB level, a flag can be further signaled with the same mechanism. For example, if the number of the CO luma position candidates is 9, cc_sao_cb_typeO_flag is further signaled to distinguish if the center collocated luma position is used as shown in Table 27 below. If the center collocated luma
position is not used, cc_sao_cb_type_idc is used to indicate which of the remaining 8 neighboring luma positions is used.

Table 27 : cc_sao_cb_typeO_flag is signaled to distinguish if the center collocated luma position is used
[00202] In some embodiments, an extension to the intra and inter post prediction SAO filter is illustrated further below. In some embodiments, the SAO classification methods disclosed in the present disclosure can serve as a post prediction filter, and the prediction can be intra, inter, or other prediction tools such as Intra Block Copy. FIG. 27 is a block diagram illustrating that the SAO classification methods disclosed in the present disclosure serve as a post prediction filter in accordance with some implementations of the present disclosure.
[00203] In some embodiments, for each Y, U, and V component, a corresponding classifier is chosen. And for each component prediction sample, it is first classified, and a corresponding offset is added. For example, each component can use the current and neighboring samples for classification. Y uses the current Y and neighboring Y samples, and U/V uses the current U/V samples for classification as shown in Table 28 below. FIG. 28 is a block diagram illustrating that for post prediction SAO filter, each component can use the current and neighboring samples for classification in accordance with some implementations of the present disclosure.

Table 28: A corresponding classifier is chosen for each Y, U, and V component
[00204] In some embodiments, the refined prediction samples (Ypred’, Upred’, Vpred’) are updated by adding the corresponding class offset and are used for intra, inter, or other prediction thereafter.
[00205] Ypred’ = clip3(0, (1 « bit_depth)-l, Ypred + h_Y[i])
[00206] Upred’ = clip3(0, (1 « bit_depth)-l, Upred + h_U[i])
[00207] Vpred’ = clip3(0, (1 « bit_depth)-l, Vpred + h_V[i])
[00208] In some embodiments, for chroma U and V components, besides the current chroma component, the cross-component (Y) can be used for further offset classification. The additional cross-component offset (h’_U, h’_V) can be added on the current component offset (h_U, h_V), for example, as shown in Table 29 below.
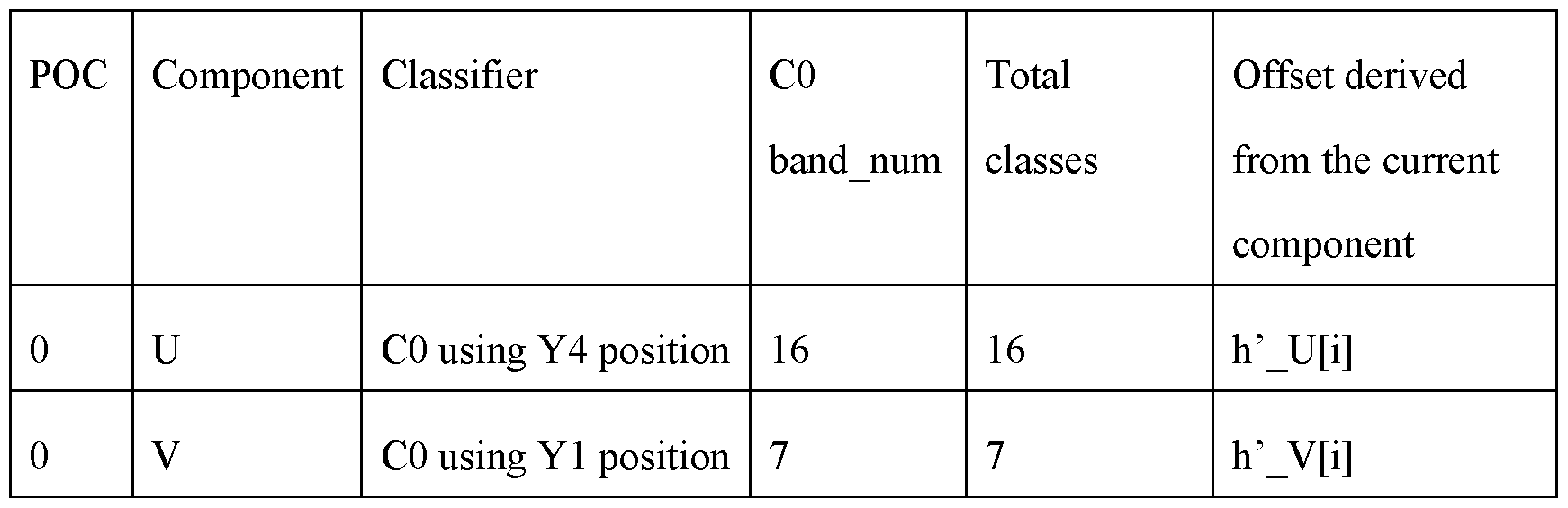
Table 29: For chroma U and V components, besides the current chroma component, the cross-component (Y) can be used for further offset classification
[00209] In some embodiments, the refined prediction samples (Upred”, Vpred”) are updated by adding the corresponding class offset and are used for intra, inter, or other prediction thereafter.
[00210] Upred” = clip3(0, (1 « bit_depth)-l, Upred’ + h’_U[i])
[00211] Vpred” = clip3(0, (1 « bit_depth)-l, Vpred’ + h’_V[i])
[00212] In some embodiments, the intra and inter prediction can use different SAO filter offsets.
[00213] FIG. 29 is a flowchart illustrating an exemplary process 2900 of decoding video signal using cross-component correlation when VB is present in accordance with some implementations of the present disclosure.
[00214] The video decoder 30 (as shown in FIG. 3), receives, from the video signal, a picture frame that includes a first component and a second component (2910).
[00215] The video decoder 30, determines a classifier for the second component from a set of samples of the first component associated with a respective sample of the second component (2920).
[00216] In response to a determination that the set of samples of the first component associated with the respective sample of the second component is divided by a virtual boundary (2930-1): the video decoder 30 obtains an updated set of samples of the first component by copying one or more central subsets of the set of samples of the first component to a first boundary position and a second boundary position of the set of samples of the first component, wherein the one or more central subsets are at a same side of the virtual boundary relative to the respective sample of the second component (2930-2).
[00217] The video decoder 30 determines a sample offset for the respective sample of the second component according to the classifier based on the updated set of samples of the first component (2940).
[00218] The video decoder 30 modifies the value of the respective sample of the second component based on the determined sample offset (2950).
[00219] In some embodiments, obtaining the updated set of samples of the first component by copying one or more central subsets of the set of samples of the first component to the first boundary position and the second boundary position of the set of samples of the first component (2930-2) comprises: in accordance with a determination that: a first subset of the set of samples of the first component associated with the respective sample of the second component is located on the different side of the virtual boundary relative to the respective sample of the second component, and a remaining subset of the set of samples of the first component associated with the respective sample of the second component is located on a same side of the virtual boundary relative to the respective sample of the second component, copying a second subset of the one or more central subsets from the remaining subset of the set of samples of the first component to replace the first subset at the first boundary position; and copying the second subset of the one or more central subsets from the remaining subset of the set of samples of the first component to replace a third subset in the remaining subset at a second side.
[00220] In some embodiments, the third subset and the first subset are symmetrical relative to a collocated sample of the first component associated with the respective sample of the second component.
[00221] In some embodiments, the second subset from the remaining subset of the set of samples of the first component is from a closest row to the first subset.
[00222] In some embodiments, the second subset from the remaining subset of the set of samples of the first component is from a closest row to the third subset.
[00223] In some embodiments, obtaining the updated set of samples of the first component by copying one or more central subsets of the set of samples of the first component to the first boundary position and the second boundary position of the set of samples of the first component (2930-2) comprises: in accordance with a determination that:
a first subset of the set of samples of the first component associated with the respective sample of the second component is located on the different side of the virtual boundary relative to the respective sample of the second component, and a remaining subset of the set of samples of the first component associated with the respective sample of the second component is located on a same side of the virtual boundary relative to the respective sample of the second component, copying a second subset of the one or more central subsets from the remaining subset of the set of samples of the first component to replace the first subset at the first boundary position; and copying a third subset of the one or more central subsets from the remaining subset of the set of samples of the first component to replace a fourth subset in the remaining subset at a second side.
[00224] In some embodiments, the fourth subset and the first subset are symmetrical relative to a collocated sample of the first component associated with the respective sample of the second component.
[00225] In some embodiments, the second subset from the remaining subset of the set of samples of the first component is from a closest row to the first subset.
[00226] In some embodiments, the third subset from the remaining subset of the set of samples of the first component is from a closest row to the fourth subset.
[00227] In some embodiments, the set of samples of the first component is horizontal, or vertical symmetric relative to a collocated sample of the first component associated with the respective sample of the second component.
[00228] In some embodiments, the virtual boundary includes a first virtual boundary within a first block of the first component and a second virtual boundary within a second block of the second component.
[00229] In some embodiments, the virtual boundary includes a first virtual boundary within a first Coding Tree Block (CTB) of the first component and a second virtual boundary within a second CTB of the second component, and the first virtual boundary is not aligned with the second virtual boundary within a Coding Tree Unit (CTU).
[00230] In some embodiments, the virtual boundary is parallel with a block boundary and separated from the block boundary by at least one row or column of samples.
[00231] In some embodiments, in accordance with a determination that the set of one or more samples of the first component associated with the respective sample of the second component is divided by the virtual boundary, a subset of the one or more samples of the first component is located on a different side of the virtual boundary relative to the respective sample of the second component, and the subset of the one or more samples of the first component is within a boundary coding tree unit (CTU) row at a processing bottom of the picture frame, determining to modify the value of the respective sample of the second component of the current block of the picture frame within the virtual boundary according to the classifier. For example, at the bottom picture (or slice, tile, brick) boundary CTU row, the samples below VB are processed at the current CTU row, so the special handling (Solution 1, 2, 3, 4) is not applied at the bottom picture (or slice, tile, brick) boundary CTU row.
[00232] Further embodiments also include various subsets of the above embodiments combined or otherwise re-arranged in various other embodiments.
[00233] In one or more examples, the functions described may be implemented in hardware, software, firmware, or any combination thereof. If implemented in software, the functions may be stored on or transmitted over, as one or more instructions or code, a computer-readable medium and executed by a hardware-based processing unit. Computer- readable media may include computer-readable storage media, which corresponds to a tangible medium such as data storage media, or communication media including any medium that facilitates transfer of a computer program from one place to another, e.g., according to a communication protocol. In this manner, computer-readable media generally may correspond to (1) tangible computer-readable storage media which is non-transitory or (2) a communication medium such as a signal or carrier wave. Data storage media may be any available media that can be accessed by one or more computers or one or more processors to retrieve instructions, code and/or data structures for implementation of the implementations
described in the present application. A computer program product may include a computer- readable medium.
[00234] The terminology used in the description of the implementations herein is for the purpose of describing particular implementations only and is not intended to limit the scope of claims. As used in the description of the implementations and the appended claims, the singular forms “a,” “an,” and “the” are intended to include the plural forms as well, unless the context clearly indicates otherwise. It will also be understood that the term “and/or” as used herein refers to and encompasses any and all possible combinations of one or more of the associated listed items. It will be further understood that the terms “comprises” and/or “comprising,” when used in this specification, specify the presence of stated features, elements, and/or components, but do not preclude the presence or addition of one or more other features, elements, components, and/or groups thereof.
[00235] It will also be understood that, although the terms first, second, etc. may be used herein to describe various elements, these elements should not be limited by these terms. These terms are only used to distinguish one element from another. For example, a first electrode could be termed a second electrode, and, similarly, a second electrode could be termed a first electrode, without departing from the scope of the implementations. The first electrode and the second electrode are both electrodes, but they are not the same electrode. [00236] Reference throughout this specification to "one example," "an example," "exemplary example," or the like in the singular or plural means that one or more particular features, structures, or characteristics described in connection with an example is included in at least one example of the present disclosure. Thus, the appearances of the phrases "in one example" or "in an example," "in an exemplary example," or the like in the singular or plural in various places throughout this specification are not necessarily all referring to the same example. Furthermore, the particular features, structures, or characteristics in one or more examples may include combined in any suitable manner.
[00237] The description of the present application has been presented for purposes of illustration and description, and is not intended to be exhaustive or limited to the invention in
the form disclosed. Many modifications, variations, and alternative implementations will be apparent to those of ordinary skill in the art having the benefit of the teachings presented in the foregoing descriptions and the associated drawings. The embodiment was chosen and described in order to best explain the principles of the invention, the practical application, and to enable others skilled in the art to understand the invention for various implementations and to best utilize the underlying principles and various implementations with various modifications as are suited to the particular use contemplated. Therefore, it is to be understood that the scope of claims is not to be limited to the specific examples of the implementations disclosed and that modifications and other implementations are intended to be included within the scope of the appended claims.
Claims
1. A method of decoding a video signal, comprising: receiving, from the video signal, a picture frame that includes a first component and a second component; determining a classifier for the second component from a set of samples of the first component associated with a respective sample of the second component; in response to a determination that the set of samples of the first component associated with the respective sample of the second component is divided by a virtual boundary, obtaining an updated set of samples of the first component by copying one or more central subsets of the set of samples of the first component to a first boundary position and a second boundary position of the set of samples of the first component, wherein the one or more central subsets are at a same side of the virtual boundary relative to the respective sample of the second component; determining a sample offset for the respective sample of the second component according to the classifier based on the updated set of samples of the first component; and modifying a value of the respective sample of the second component based on the determined sample offset.
2. The method of claim 1, wherein obtaining the updated set of samples of the first component by copying the one or more central subsets of the set of samples of the first component to the first boundary position and the second boundary position of the set of samples of the first component comprises: in accordance with a determination that: a first subset of the set of samples of the first component associated with the respective sample of the second component is located on a different side of the virtual boundary relative to the respective sample of the second component, and
66
a remaining subset of the set of samples of the first component associated with the respective sample of the second component is located on a same side of the virtual boundary relative to the respective sample of the second component, copying a second subset of the one or more central subsets from the remaining subset of the set of samples of the first component to replace the first subset at the first boundary position; and copying the second subset of the one or more central subsets from the remaining subset of the set of samples of the first component to replace a third subset in the remaining subset at a second side.
3. The method of claim 2, wherein the third subset and the first subset are symmetrical relative to a collocated sample of the first component associated with the respective sample of the second component.
4. The method of claim 2, wherein the second subset from the remaining subset of the set of samples of the first component is from a closest row to the first subset.
5. The method of claim 2, wherein the second subset from the remaining subset of the set of samples of the first component is from a closest row to the third subset.
6. The method of claim 1, wherein obtaining the updated set of samples of the first component by copying the one or more central subsets of the set of samples of the first component to the first boundary position and the second boundary position of the set of samples of the first component comprises: in accordance with a determination that: a first subset of the set of samples of the first component associated with the respective sample of the second component is located on a different
67
side of the virtual boundary relative to the respective sample of the second component, and a remaining subset of the set of samples of the first component associated with the respective sample of the second component is located on a same side of the virtual boundary relative to the respective sample of the second component, copying a second subset of the one or more central subsets from the remaining subset of the set of samples of the first component to replace the first subset at the first boundary position; and copying a third subset of the one or more central subsets from the remaining subset of the set of samples of the first component to replace a fourth subset in the remaining subset at a second side.
7. The method of claim 6, wherein the fourth subset and the first subset are symmetrical relative to a collocated sample of the first component associated with the respective sample of the second component.
8. The method of claim 6, wherein the second subset from the remaining subset of the set of samples of the first component is from a closest row to the first subset.
9. The method of claim 6, wherein the third subset from the remaining subset of the set of samples of the first component is from a closest row to the fourth subset.
10. The method of claim 1, wherein the set of samples of the first component is horizontal, or vertical symmetric relative to a collocated sample of the first component associated with the respective sample of the second component.
68
11. The method of claim 1, wherein the virtual boundary includes a first virtual boundary within a first block of the first component and a second virtual boundary within a second block of the second component.
12. The method of claim 1, wherein the virtual boundary includes a first virtual boundary within a first Coding Tree Block (CTB) of the first component and a second virtual boundary within a second CTB of the second component, and the first virtual boundary is not aligned with the second virtual boundary within a Coding Tree Unit (CTU).
13. The method of claim 1, wherein the virtual boundary is parallel with a block boundary and separated from the block boundary by at least one row or column of samples.
14. An electronic apparatus comprising: one or more processing units; memory coupled to the one or more processing units; and a plurality of programs stored in the memory that, when executed by the one or more processing units, cause the electronic apparatus to perform the method of claims 1-13.
15. A non-transitory computer readable storage medium storing a plurality of programs for execution by an electronic apparatus having one or more processing units, wherein the plurality of programs, when executed by the one or more processing units, cause the electronic apparatus to perform the method of claims 1-13.
69
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP21887464.2A EP4238311A4 (en) | 2020-10-28 | 2021-10-27 | ENHANCEMENT OF CHROMINANCE CODING IN ADAPTIVE INTER-COMPONENT SAMPLE SHIFT WITH VIRTUAL BOUNDARY |
| CN202180073769.4A CN116671105A (en) | 2020-10-28 | 2021-10-27 | Chroma Codec Enhancement in Adaptive Offset Across Component Samples with Virtual Boundaries |
| US18/308,811 US12177456B2 (en) | 2020-10-28 | 2023-04-28 | Chroma coding enhancement in cross-component sample adaptive offset with virtual boundary |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063106357P | 2020-10-28 | 2020-10-28 | |
| US63/106,357 | 2020-10-28 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US18/308,811 Continuation US12177456B2 (en) | 2020-10-28 | 2023-04-28 | Chroma coding enhancement in cross-component sample adaptive offset with virtual boundary |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2022093992A1 true WO2022093992A1 (en) | 2022-05-05 |
| WO2022093992A8 WO2022093992A8 (en) | 2023-06-15 |
Family
ID=81383160
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2021/056897 WO2022093992A1 (en) | 2020-10-28 | 2021-10-27 | Chroma coding enhancement in cross-component sample adaptive offset with virtual boundary |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US12177456B2 (en) |
| EP (1) | EP4238311A4 (en) |
| CN (1) | CN116671105A (en) |
| WO (1) | WO2022093992A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12177456B2 (en) | 2020-10-28 | 2024-12-24 | Beijing Dajia Internet Information Technology Co., Ltd. | Chroma coding enhancement in cross-component sample adaptive offset with virtual boundary |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20170244975A1 (en) * | 2014-10-28 | 2017-08-24 | Mediatek Singapore Pte. Ltd. | Method of Guided Cross-Component Prediction for Video Coding |
| KR20190042579A (en) * | 2016-08-31 | 2019-04-24 | 퀄컴 인코포레이티드 | Cross-component filter |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022093992A1 (en) | 2020-10-28 | 2022-05-05 | Beijing Dajia Internet Information | Chroma coding enhancement in cross-component sample adaptive offset with virtual boundary |
-
2021
- 2021-10-27 WO PCT/US2021/056897 patent/WO2022093992A1/en active Application Filing
- 2021-10-27 EP EP21887464.2A patent/EP4238311A4/en active Pending
- 2021-10-27 CN CN202180073769.4A patent/CN116671105A/en active Pending
-
2023
- 2023-04-28 US US18/308,811 patent/US12177456B2/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20170244975A1 (en) * | 2014-10-28 | 2017-08-24 | Mediatek Singapore Pte. Ltd. | Method of Guided Cross-Component Prediction for Video Coding |
| KR20190042579A (en) * | 2016-08-31 | 2019-04-24 | 퀄컴 인코포레이티드 | Cross-component filter |
Non-Patent Citations (4)
| Title |
|---|
| B. BROSS, J. CHEN, S. LIU, Y.-K. WANG: "Versatile Video Coding (Draft 10)", 131. MPEG MEETING; 20200629 - 20200703; ONLINE; (MOTION PICTURE EXPERT GROUP OR ISO/IEC JTC1/SC29/WG11), 25 June 2020 (2020-06-25), pages 1 - 529, XP030289298 * |
| J. CHEN, Y. YE, S. KIM: "Algorithm description for Versatile Video Coding and Test Model 10 (VTM 10)", 19. JVET MEETING; 20200622 - 20200701; TELECONFERENCE; (THE JOINT VIDEO EXPLORATION TEAM OF ISO/IEC JTC1/SC29/WG11 AND ITU-T SG.16 ), no. JVET-S2002, 12 August 2020 (2020-08-12), pages 1 - 97, XP030289619 * |
| KIRAN MISRA , FRANK BOSSEN , ANDREW SEGALL: "Cross-Component Adaptive Loop Filter for chroma", 15. JVET MEETING; 20190703 - 20190712; GOTHENBURG; (THE JOINT VIDEO EXPLORATION TEAM OF ISO/IEC JTC1/SC29/WG11 AND ITU-T SG.16 ), 7 July 2019 (2019-07-07), Gothenburg SE, pages 1 - 9, XP030220123 * |
| See also references of EP4238311A4 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12177456B2 (en) | 2020-10-28 | 2024-12-24 | Beijing Dajia Internet Information Technology Co., Ltd. | Chroma coding enhancement in cross-component sample adaptive offset with virtual boundary |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4238311A4 (en) | 2024-05-29 |
| WO2022093992A8 (en) | 2023-06-15 |
| CN116671105A (en) | 2023-08-29 |
| EP4238311A1 (en) | 2023-09-06 |
| US12177456B2 (en) | 2024-12-24 |
| US20230262235A1 (en) | 2023-08-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12149687B2 (en) | Chroma coding enhancement in cross-component sample adaptive offset | |
| US20230388509A1 (en) | Chroma coding enhancement in cross-component sample adaptive offset | |
| US11800124B2 (en) | Chroma coding enhancement in cross-component sample adaptive offset | |
| US20230396781A1 (en) | Coding enhancement in cross-component sample adaptive offset | |
| EP3959878A1 (en) | Chroma coding enhancement in cross-component correlation | |
| US20250039420A1 (en) | Chroma coding enhancement in cross-component sample adaptive offset | |
| US20240007662A1 (en) | Coding enhancement in cross-component sample adaptive offset | |
| US20230308652A1 (en) | Chroma coding enhancement in cross-component sample adaptive offset with virtual boundary | |
| EP4349014A1 (en) | Coding enhancement in cross-component sample adaptive offset | |
| US20230209093A1 (en) | Chroma coding enhancement in cross-component sample adaptive offset | |
| US12177456B2 (en) | Chroma coding enhancement in cross-component sample adaptive offset with virtual boundary | |
| US20230379480A1 (en) | Chroma coding enhancement in cross-component sample adaptive offset | |
| US20230336785A1 (en) | Coding enhancement in cross-component sample adaptive offset | |
| EP4349013A1 (en) | Coding enhancement in cross-component sample adaptive offset | |
| US12219163B2 (en) | Chroma coding enhancement in cross-component sample adaptive offset | |
| US20250047848A1 (en) | Chroma coding enhancement in cross-component sample adaptive offset | |
| CN116569551A (en) | Chroma coding enhancement in cross-component sample adaptive offset |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21887464 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 202180073769.4 Country of ref document: CN |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2021887464 Country of ref document: EP Effective date: 20230530 |