WO2022074737A1 - 処理装置、処理方法及びプログラムが格納された非一時的なコンピュータ可読媒体 - Google Patents
処理装置、処理方法及びプログラムが格納された非一時的なコンピュータ可読媒体 Download PDFInfo
- Publication number
- WO2022074737A1 WO2022074737A1 PCT/JP2020/037881 JP2020037881W WO2022074737A1 WO 2022074737 A1 WO2022074737 A1 WO 2022074737A1 JP 2020037881 W JP2020037881 W JP 2020037881W WO 2022074737 A1 WO2022074737 A1 WO 2022074737A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- entity
- processing
- vector
- atom
- query
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/042—Knowledge-based neural networks; Logical representations of neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
- G06N5/022—Knowledge engineering; Knowledge acquisition
- G06N5/025—Extracting rules from data
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
Definitions
- the present invention relates to a non-temporary computer-readable medium in which a processing device, a processing method, and a program are stored.
- predicates define the nature of the facts of interest.
- a fact that holds in the real world is represented by an atom that is a pair of a predicate corresponding to the nature of the fact and a set of entities related to the fact.
- Non-Patent Document 1 an atom set expressing a fact established in the real world is accepted as an input. However, in the entity set included in the atom of the atom set, the order between the entities is not considered. Next, a predetermined calculation is performed with the atom set as an input, and an entity feature vector summarizing the information of the atom set is calculated for each entity appearing in the atom set. Then, using the entity feature vector, processing peculiar to each entity such as classification of the category to which the entity belongs is performed.
- Non-Patent Document 1 since the order between the entities that are arguments is not defined in the set of input atoms, the predicates that the entities included in the arguments have different roles. When an atom set containing is input, it is not possible to perform processing considering the different roles of the entity.
- the object of the present disclosure is to solve such a problem, and even if the entities included in the arguments of the atoms have different roles with respect to the input atom set, the entity's It is an object of the present invention to provide a non-temporary computer-readable medium in which a processing device, a processing method, and a program capable of performing processing considering different roles are stored.
- the processing device takes as an input a set of atoms that are a pair of a predicate and an associative array of entities that are arguments of the predescriptor, and for each of the entities, a key in the associative array of the atom.
- the entity preprocessing unit that calculates the entity feature vector that reflects the information corresponding to the correspondence with the entity, and the query that instructs the content of the process are accepted, and the process specified by the query is performed using the entity feature vector. It is provided with a post-processing unit to perform.
- a set of atoms which is a pair of a predicate and an associative array of an entity which is an argument of the predescriptive word is input, and the associative array is used for each of the entities. It is characterized by calculating an entity feature vector that reflects the correspondence between the key and the entity, (b) accepting a query instructing the content of the process, and performing the process instructed by the query using the entity feature vector. And.
- the program according to the present disclosure inputs the set of atoms which are a pair of (a) a predicate and an associative array of an entity which is an argument of the predicate to a computer, and the associative with each of the above entities.
- An entity feature vector that reflects information according to the correspondence between the key in the array and the entity is calculated, (b) a query instructing the content of processing is accepted, and the query is instructed using the entity feature vector. Let the computer do the processing.
- the processing device even if the entities included in the argument of the atom have different roles, the processing device, the processing method, and the program that can realize the processing reflecting the different roles of the entities in the atom are stored.
- a non-temporary computer-readable medium can be provided.
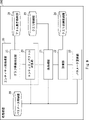
- FIG. It is a block diagram which illustrates the structure of the processing apparatus which concerns on Embodiment 1.
- FIG. It is a block diagram which more concretely exemplified the structure of the processing apparatus which concerns on Embodiment 1.
- FIG. It is a block diagram which more concretely illustrated the structure of the entity vector calculation part which concerns on Embodiment 1.
- FIG. It is a figure which shows an example of the operation of the entity vector calculation part which concerns on Embodiment 1.
- FIG. It is a figure which shows an example of the operation of the post-processing part which concerns on Embodiment 1.
- FIG. It is a figure which shows another example of the operation of the post-processing part which concerns on Embodiment 1.
- FIG. It is a flow diagram which illustrates the operation of the processing apparatus which concerns on Embodiment 1.
- FIG. It is a block diagram which illustrates the structure of the processing apparatus which concerns on Embodiment 2.
- the "associative array” is an array that stores data such as numerical values and character strings, and data in which keys such as numerical values and character strings are associated with elements in the array. Refers to the format. A normal array can be regarded as an associative array by treating the position of the element in the array as the key of the element.
- the "entity” is an entity, thing, person, concept, numerical value, etc. that appears in an event, and is given a distinguishable name.
- entities include “Obama”, “U.S.” (proprietary noun), "Human” (noun representing a concept / type), and the like.
- an entity may have an "attribute” in addition to a distinguishable name. Attributes are expressed in a format that can be summarized into a vector through preprocessing, such as symbols, character strings, numbers, vectors, and matrices, and represent the properties of an entity. For example, the entity "Obama” can have an attribute of 185.4 cm, which is a numerical value representing height. Even if the entity does not have an attribute, it can be treated as having an attribute represented by the symbol "no attribute”.
- the "predicate” defines the facts or relationships that hold between entities by the meaning and nature of the facts or relationships.
- the predicate may be in any form, such as a symbol, a character string, a numerical value, a vector, a matrix, etc., which can express the meaning or property of a fact or relationship between entities and can be summarized into a vector through preprocessing.
- “isIn, ⁇ X, Y ⁇ ” means "Y belongs to X" and is a predicate that defines the relationship between the entities X and Y.
- atom is defined by a combination of a predicate and an associative array of entities that are arguments of the predicate, and the facts or relationships defined by the predicate between the entities included in the associative array.
- the key associated with each entity in the associative array represents a role in the facts or relationships defined by the predicate of the entity.
- the key may be in any form, such as a symbol, a string, a number, a vector, a matrix, etc., which can represent the role of the entity and can be summarized into a vector through preprocessing.
- the key of the associative array of the entity which is the argument of the predicate is also referred to as the argument key of the predicate.
- the "query” represents the processing to be performed by the processing device and the instruction input regarding the output of the processing device.
- the query may include information about the entity involved in performing the process in order to identify the content of the process.
- the output of the processing device indicated by the query may be in any format such as a symbol, a character string, a numerical value, a vector, a matrix, or the like, which can be obtained by performing predetermined post-processing from the vector or the numerical value.
- ⁇ classification, ⁇ entity: Tokyo, class: [city, person, country] ⁇ > is an example of a query that causes a process to classify the category to which an entity belongs.
- classification is a label indicating that the process of classifying the category to which the entity belongs is performed.
- ⁇ entity: Tokyo, class: [city, person, country] ⁇ is an associative array that stores auxiliary information necessary for executing processing.
- Tokyo, which is the value corresponding to entity is the entity to be classified
- the array [city, person, country], which is the value corresponding to class is a candidate city, person, of three categories to which the entity can belong. It is an array that stores country.
- FIG. 1 is a block diagram illustrating the configuration of the processing apparatus according to the first embodiment.
- the processing apparatus 100 accepts an atom set and a query as inputs, and outputs a result of performing the processing instructed by the query using the information contained in the atom set. ..
- the processing device 100 includes an entity pre-processing unit 10 and a post-processing unit 11.
- the entity pre-processing unit 10 and the post-processing unit 11 have functions as an entity pre-processing means and a post-processing means, respectively.
- the entity preprocessing unit 10 takes a set of atoms that are a pair of a predicate and an associative array of the entity that is an argument of the predicate as an input, and reflects the correspondence between the key and the entity in the associative array for each entity. Compute the entity feature vector.
- the entity preprocessing unit 10 takes a set of atoms as an input and reflects information according to the correspondence between each key in the associative array of atoms and the entity for each entity without updating the parameters. Output the entity feature vector.
- the post-processing unit 11 receives the query instructing the content of the processing, and performs the processing instructed by the query using the entity feature vector. For example, the post-processing unit 11 accepts the entity feature vector and the query as inputs, performs the process instructed by the query using the information included in the entity feature vector, and outputs the result of the process.
- the entity preprocessing unit 10 provides information according to the correspondence between each key and the entity in the associative array of the entities that are the arguments of the atoms included in the input atom set. Since the reflected entity feature vector is output, even if the entities included in the argument of the atom have different roles, by distinguishing the role as the key of the associative array, the entity in the atom in the post-processing unit 11 It is possible to realize processing specific to each entity that reflects the different roles of.
- the entity preprocessing unit 10 since the entity preprocessing unit 10 does not update the parameters in order to calculate the entity feature vector, even if a different atom set is input, the entity preprocessing unit 10 is the same for each atom set. Parameters can be used to calculate a consistent entity feature vector. As a result, even in the post-processing unit 11, by using the entity feature vector, it is possible to perform consistent processing even for an atom set containing different entities.
- FIG. 2 is a block diagram illustrating more specifically the configuration of the processing apparatus according to the first embodiment.
- the processing device 100 further includes an atom set storage unit 12, a query storage unit 13, and a parameter storage unit 16.
- the atom set storage unit 12, the query storage unit 13, and the parameter storage unit 16 have functions as an atom set storage unit, a query storage unit, and a parameter storage unit, respectively.
- the entity preprocessing unit 10 includes a graph structure extraction unit 14 and an entity vector calculation unit 15 inside.
- the graph structure extraction unit 14 and the entity vector calculation unit 15 have functions as a graph structure extraction means and an entity vector calculation means, respectively.
- the parameter storage unit 16 stores the parameters used by the entity vector calculation unit 15 and the parameters used by the post-processing unit 11.
- FIG. 3 is a block diagram more specifically illustrating the configuration of the entity vector calculation unit according to the first embodiment.
- the entity vector calculation unit 15 includes an input vector calculation unit 17 and a graph neural network calculation unit 18.
- the input vector calculation unit 17 and the graph neural network calculation unit 18 have functions as an input vector calculation means and a graph neural network calculation means, respectively.
- the graph structure extraction unit 14 takes a set of atoms as an input and constructs a graph structure including information on the correspondence between each key and an entity in an associative array. Specifically, the graph structure extraction unit 14 extracts the graph structure from the atom set extracted from the atom set storage unit 12.
- the graph structure includes the node corresponding to the entity for all or part of the entity contained in the atom set.
- the graph structure also includes nodes corresponding to all or part of the atoms contained in the atom set.
- the graph structure is between the node corresponding to the atom and the node corresponding to the entity for all or part of the pair of the atom contained in the atom set and the entity contained in the argument of the atom. Includes a labeled edge with a label corresponding to the pair of the predicate corresponding to the atom and the argument key of the associative array corresponding to the entity in the atom.
- FIG. 4 is a diagram showing an example of the operation of the graph structure extraction unit 14 according to the first embodiment. Note that the one-way arrows and graph structures in the figure merely indicate the relationships between the data, do not exclude the bidirectional relationships between the data, and are data structures based on a specific graph structure. Is not assumed.
- Atom A1 ⁇ isIn, ⁇ area: Asia, country: Japan ⁇ >
- Atom A2 ⁇ isCapitalSince, ⁇ country: Japan, city: Tokyo, year: 1868 ⁇ >
- Atom A3 ⁇
- the four atoms of isCapitalSince, ⁇ country: Japan, city: Kyoto, year: 794 ⁇ > and Atom A4: ⁇ ”E1 is a big city.
- ⁇ “E1”: Tokyo ⁇ > are the atom set storage 12 Taken from.
- the graph structure extraction unit 14 includes a node corresponding to Asia, Japan, Tokyo, and Kyoto, and a node corresponding to each of the four atoms, and outputs a graph structure including the following labeled edges. ..
- Atom A1 --Asia Label: (isIn, area)
- Atom A1-Japan label: (isIn, country)
- Atom A2-Japan Label: (isCapitalSince, country)
- Atom A2-Tokyo Label: (isCapitalSince, city)
- Atom A2- 1868 Label: (isCapitalSince, year)
- Atom A3 --Japan Label: (isCapitalSince, country)
- Atom A3-Kyoto Label: (isCapitalSince, city)
- Atom A3-794 Label: (isCapitalSince, year)
- Atom A4 --Tokyo Label: (“E1 is a big city”, “E1”)
- the entity vector calculation unit 15 accepts the graph structure and calculates the entity feature vector for each entity. Specifically, in the present embodiment, the entity vector calculation unit 15 uses the graph structure output from the graph structure extraction unit 14 and the parameters stored in the parameter storage unit 16 to correspond to the nodes in the graph structure. For each entity in which is exists, the entity feature vector containing the correspondence between the argument key of the associative array in the atom set and the entity of the entity is output.
- the entity vector calculation unit 15 inputs the graph structure to the input vector calculation unit 17, and calculates the input vector corresponding to each node and each edge of the graph structure. Then, the input vector corresponding to each node and each edge is input to the graph neural network calculation unit 18, and the graph neural network output vector corresponding to each node is calculated. At this time, the graph structure may be additionally input to the graph neural network calculation unit 18. Subsequently, the entity vector calculation unit 15 identifies a node corresponding to the entity in the graph structure, and outputs the graph neural network output vector corresponding to the node as the entity feature vector corresponding to the entity.
- the parameters stored in the parameter storage unit 16 may be used for the calculation by the input vector calculation unit 17 and the calculation by the graph neural network calculation unit 18.
- FIG. 5 is a diagram showing an example of the operation of the entity vector calculation unit 15 according to the present embodiment. Note that the one-way arrows and graph structure in the figure merely indicate the relationships between the data, do not exclude the bidirectional relationships between the data, and the data structure based on a specific graph structure. It is not an assumption.
- the entity vector calculation unit 15 receives the graph structure output by the graph structure extraction unit 14 as an input.
- the graph structure consists of the nodes corresponding to the entities Asia and Japan, the nodes corresponding to Atom A1: ⁇ isIn, ⁇ area: Asia, country: Japan ⁇ >, and the following edge 1 which is a labeled edge. Includes edge 2.
- Edge 1 Atom A1-Asia (Label: (isIn, area))
- Edge 2 Atom A1-Japan (Label: (isIn, country))
- the entity vector calculation unit 15 inputs the graph structure to the input vector calculation unit 17.
- the input vector calculation unit 17 extracts the attributes Asia and the attribute Japan , which are the attributes of the entity, with respect to the entities Asia and Japan included in the graph structure, and Asia and Japan from the attributes. Calculate v Asia and v Japan as entity input vectors corresponding to.
- the calculation of the entity input vector is realized, for example, by preprocessing the attribute and converting it into a vector format, performing an operation on the vector, a matrix operation, a calculation using a neural network, or a combination of calculations.
- the input vector calculation unit 17 calculates vA1 as an atom input vector for the atom A1 which is an atom included in the graph structure.
- the atom input vector is converted into a vector format by preprocessing isIn, which is a predicate corresponding to the atom, and is calculated on a vector, a matrix operation, or a calculation using a neural network, or Calculated by their combination.
- the vector stored in the parameter storage unit 16 may be used as it is, regardless of the calculation by the method of the present embodiment.
- the input vector calculation unit 17 calculates v (isIn, area) and v (isIn, country) as edge input vectors for the edges 1 and 2 included in the graph structure.
- the calculation of the edge input vector takes out the labels (isIn, area) and (isIn, country) in the example of FIG.
- the predicate isIn constituting the label and a part or all of the argument keys area and country are preprocessed and converted into a vector format.
- the input vector calculation unit 17 is realized by an operation on a vector, a matrix operation, a calculation using a neural network, or a combination of calculations.
- the entity vector calculation unit 15 sets the entity input vector, the atom input vector, and the edge input vector as an input vector in association with the corresponding entity, the atom, and the entity, and makes a graph. Input to the neural network calculation unit 18.
- the graph neural network calculation unit 18 calculates the graph neural network output vectors o Asia , o A1 , and o Japan from the above input vector using the graph neural network.
- the entity vector calculation unit 15 inputs the graph neural network output vectors o Asia and o Japan output to the node to Asia and Japan, which are the entities included in the graph structure. It is output as a feature vector eAsia and eJapan .
- the post-processing unit 11 first reads the query from the query storage unit 13 and specifies the content of the processing instructed by the query.
- the post-processing unit 11 retrieves the entity feature vector of the entity calculated by the entity vector calculation unit 15 for all or part of the entity related to the query processing. Then, the post-processing unit 11 performs the calculation with the extracted entity feature vector as an input according to the processing instructed by the query.
- the calculation is realized by, for example, an operation on a vector, a matrix operation, a process such as a neural network, or a combination of the operation and the process.
- the post-processing unit 11 takes out a vector that is a calculation result, and outputs the result of performing predetermined post-processing on the vector.
- FIG. 6 is a diagram showing an example of the operation of the post-processing unit 11 according to the present embodiment. Note that the one-way arrows in the figure merely indicate the relationships between the data, and do not exclude the bidirectional relationships between the data.
- the post-processing unit 11 retrieves the following query from the query storage unit 13. ⁇ link_prediction, ⁇ pred: ”E1 is a big city”, “E1”: Kyoto ⁇ >
- the query is represented by a pair of the symbol link_prediction, which represents the content of the instruction, and an associative array, which contains the information necessary to execute the processing according to the instruction.
- the value "E1 is a big city.”
- Corresponding to the key pred in the associative array is a predicate, and the value Kyoto corresponding to the key "E1" in the associative array is an entity.
- the query is the formation of an atom ⁇ "E1 is a big city", ⁇ "E1": Kyoto ⁇ >, which is a pair of a predicate and an associative array ⁇ "E1": Kyoto ⁇ consisting of the entity and the corresponding key "E1".
- the content of the process of evaluating the score which is the accuracy of the degree, is instructed.
- the post-processing unit 11 sets e Kyoto , which is an entity feature vector calculated for the entity by the entity vector calculation unit 15, for Kyoto, which is an entity related to the execution of the process. Take it out.
- the post-processing unit 11 performs the processing instructed by the query. Therefore, the post-processing unit 11 replaces the predicate "E1 is a big city.” With a bag-of-words vector, converts it into a vector sequence, and inputs it into the recurrent neural network to input the vector r pred . Convert to. Then, the post-processing unit 11 calculates the inner product value s of eKyoto and rpred and outputs it as the result of processing.
- FIG. 7 is a diagram showing another example of the operation of the post-processing unit 11 according to the present embodiment. Note that the one-way arrows in the figure merely indicate the relationships between the data, and do not exclude the bidirectional relationships between the data.
- the post-processing unit 11 retrieves the following query from the query storage unit 13. ⁇ classification, ⁇ entity: Tokyo, class: [city, person, country] ⁇ > The query is represented by a pair of the symbol classification, which represents the content of the instruction, and an associative array, which contains the information necessary to execute the processing according to the instruction.
- the value corresponding to the key entity is Tokyo, which is an entity
- the value corresponding to the key class is an array consisting of the entity categories city, person, and country.
- the query instructs the content of the process that the entity Tokyo outputs the predicted value of the probability of belonging to the category for each of the categories belonging to the array of categories.
- the post-processing unit 11 retrieves the entity feature vector eTokyo calculated by the entity vector calculation unit 15 for the entity Tokyo from the entity Tokyo.
- the post-processing unit 11 performs the processing instructed by the query. Therefore, the post-processing unit 11 extracts the corresponding vectors c city , c person , and c country from the parameter storage unit 16 for each of the categories belonging to the array of categories, and puts them in each of the vectors corresponding to the categories.
- the vector which is the internal product value with eTokyo , the sperson , and the scountry are calculated. Further, the post-processing unit 11 applies the softmax function to the calculated three internal product values, and calculates the three values P city , P person , and P country such that the total is 1. Output as a predicted value of the probability that Tokyo belongs to category city, category person, and category country respectively.
- FIG. 8 is a flow chart illustrating the operation of the processing apparatus according to the first embodiment.
- FIGS. 1 to 7 will be referred to as appropriate.
- the processing method is implemented by operating the processing device 100. Therefore, the description of the processing method in the first embodiment is replaced with the following description of the operation of the processing device 100.
- step A1 the atom set stored in the atom set storage unit 12 is taken out.
- the graph structure extraction unit 14 constructs and outputs a graph structure that reflects the information on the correspondence between the argument key and the entity in the associative array of the atoms included in the atom set from the atom set extracted in step A1.
- Step A2 That is, a graph structure including information on the correspondence between each key and an entity in an associative array is constructed by using a set of atoms as an input.
- the entity vector calculation unit 15 takes the graph structure constructed in step A2 as an input, and calculates the entity feature vector for each entity including the node corresponding to the graph structure (step A3).
- the entity input vector, the atom input vector, and the edge input vector may be calculated for the entity, the atom, and the edge, respectively, included in the graph structure.
- the graph neural network output vector may be calculated by using the entity input vector, the atom input vector, and the edge input vector as inputs. In this way, the graph structure may be accepted and the entity feature vector for each entity may be calculated.
- the set of atoms which is a pair of the predicate and the associative array of the entity which is the argument of the predicate is input, and the key and the entity in the associative array are used for each entity. Calculate the entity feature vector that reflects the correspondence.
- step A4 the query stored in the query storage unit 13 is fetched.
- the post-processing unit 11 specifies the processing content instructed by the query extracted in step A4, and executes the specified processing content using the entity feature vector calculated in step A3 (step A5).
- the query instructing the content of the processing is accepted, and the processing instructed by the query is performed using the entity feature vector.
- the post-processing unit 11 outputs the result of the processing executed in step A5 (step A6).
- a graph structure is constructed from the atom set, reflecting information on the correspondence between the argument key and the entity in the associative array of the atoms included in the atom set. Then, based on the graph structure, the entity feature vector is calculated for each entity that appears as an argument of the atom in the atom set. After that, the process specified by the query is executed using the entity feature vector. Therefore, according to the first embodiment, even when the entities included in the arguments of the atom of the atom set have different roles, the roles are distinguished as the keys of the associative array. This allows the computer to perform processing specific to each entity that reflects the different roles of the entities in the atom.
- the parameters are not updated in order to calculate the entity feature vector, even if different atom sets are input, the same parameters are used for each atom set consistently. Entity feature vector can be calculated. Therefore, consistent processing can be performed even for atom sets containing different entities.
- Non-Patent Document 1 when the entities included in the arguments of the atom of the atom set have different roles, it is not possible to make the computer perform the processing for distinguishing the roles. ..
- the atom set illustrated in FIG. 4 when the atom set illustrated in FIG. 4 is input, in the technique disclosed in Non-Patent Document 1, three entities Japan, Kyoto appear as arguments of atom A3 in order to calculate a vector used for post-processing. Do not distinguish between the roles of, 794. Since the entities Kyoto and 794 appear only in the atom A3 in the input atom set, if the roles in the atom A3 cannot be distinguished from each other, the characteristics of the entities Kyoto and the 794 in the atom set cannot be distinguished from each other. ..
- the edges connecting the entities Kyoto and the 794 are described as (isCapitalSince, city) and (isCapitalSince, year), respectively.
- the input vector calculation unit 17 can calculate different edge input vectors for these edges.
- the entities Kyoto and 794 can be distinguished from each other by the edge input vector corresponding to the connecting edge. Therefore, for example, by inputting these graph structures and input vectors into the graph neural network calculation unit 18, different graph neural network output vectors can be calculated for the entities Kyoto and 794, and used as the entity feature vector. can. Therefore, for example, when classifying the categories to which the entities Kyoto and 794 belong in the post-processing, it is possible to process using different vectors for each entity. Therefore, different categories such as place names and eras can be appropriately output for each entity.
- the input atom set is queried for processing that reflects the correspondence between the argument key and the entity in the associative array of the entity that is the argument of the atom included in the atom set. It can be executed by the instruction by. In addition, the process can be executed without using the parameters associated with the entity that appears as an argument of the atom contained in the atom set.
- the program in the first embodiment may be any program that causes a computer to execute steps A1 to A6 shown in FIG. By installing and executing this program on a computer, the processing apparatus 100 and the processing method according to the first embodiment can be realized.
- the computer processor functions as a graph structure extraction unit 14, an entity vector calculation unit 15, an input vector calculation unit 17, a graph neural network calculation unit 18, and a post-processing unit 11 to perform processing.
- the atom set storage unit 12, the query storage unit 13, and the parameter storage unit 16 store the data files constituting them in a storage device such as a hard disk provided in the computer. It has been realized. Further, the atom set storage unit 12, the query storage unit 13, and the parameter storage unit 16 may be constructed on a computer different from the computer that executes the program in the first embodiment.
- each computer may function as one of the graph structure extraction unit 14, the entity vector calculation unit 15, the input vector calculation unit 17, the graph neural network calculation unit 18, and the post-processing unit 11, respectively. good.
- FIG. 9 is a block diagram illustrating the configuration of the processing apparatus according to the second embodiment.
- the processing device 200 in the second embodiment shown in FIG. 9 Similar to the processing device in the first embodiment, the processing device 200 in the second embodiment shown in FIG. 9 also inputs an atom set and performs the processing instructed by the query. Further, the processing apparatus 200 evaluates the processing result after executing the processing, and updates the parameters for executing the processing based on the similarity between the processing result and the query target which is the desired processing result.
- the processing device 200 includes an entity pre-processing unit 20, a post-processing unit 21, an evaluation unit 22, and a parameter updating unit 23. That is, the processing apparatus 200 according to the second embodiment partially includes the configuration of the processing apparatus 100 according to the first embodiment.
- the entity pre-processing unit 20, the post-processing unit 21, the evaluation unit 22, and the parameter updating unit 23 have functions as an entity pre-processing unit, a post-processing unit, an evaluation unit, and a parameter updating unit, respectively.
- the processing device 200 includes an atom set storage unit 24, a query storage unit 25, and a parameter storage unit 29.
- the atom set storage unit 24, the query storage unit 25, and the parameter storage unit 29 have functions as an atom set storage unit, a query storage unit, and a parameter storage unit, respectively.
- the entity preprocessing unit 20 includes a graph structure extraction unit 27 and an entity vector calculation unit 28 inside.
- the graph structure extraction unit 27 and the entity vector calculation unit 28 have functions as a graph structure extraction means and an entity vector calculation means, respectively.
- the parameter storage unit 29 stores the parameters used by the entity vector calculation unit 28 and the parameters used by the post-processing unit 21, as in the first embodiment.
- the processing device 200 includes a query target storage unit 26.
- the query target storage unit 26 has a function as a query target storage means.
- the graph structure extraction unit 27 extracts the graph structure from the atom set stored in the atom set storage unit 24, as in the first embodiment.
- the entity vector calculation unit 28 calculates the entity feature vector for each of the entities included in the graph structure, as in the first embodiment.
- the post-processing unit 21 reads the query from the query storage unit 25, executes the processing instructed by the query using the entity feature vector, and outputs the processing result, as in the first embodiment.
- the evaluation unit 22 extracts the query target corresponding to the query from the query target storage unit 26.
- a query goal represents the desired processing result as a result of the processing indicated by the corresponding query.
- the evaluation unit 22 compares the processing result output from the post-processing unit 21 with the query target extracted from the query target storage unit 26, and the processing result is similar to the query target. Output the degree.
- an index such as how small the distance between the processing result and the query target may be used as the similarity. For example, the smaller the distance, the greater the similarity.
- the evaluation unit 22 compares the processing result output by the post-processing unit 21 with the query target which is a desirable processing result, and calculates the degree of similarity between the processing result output by the post-processing unit 21 and the query target. do.
- the parameter update unit 23 updates the parameters used in the processing device 200 based on the degree of similarity between the processing result output by the post-processing unit 21 and the query target. For example, the parameter updating unit 23 updates the parameters stored in the parameter storage unit 29 by using the gradient method so that the similarity output from the evaluation unit 22 becomes high.
- FIG. 10 is a flow chart showing the operation of the processing apparatus according to the second embodiment.
- FIG. 9 will be referred to as appropriate.
- the processing method is implemented by operating the processing device 200. Therefore, the description of the processing method in the second embodiment is replaced with the following description of the operation of the processing device 200.
- step B1 the atom set stored in the atom set storage unit is taken out.
- the graph structure extraction unit 27 constructs and outputs a graph structure that reflects the information on the correspondence between the argument key and the entity in the associative array of the atoms included in the atom set from the atom set extracted in step B1. (Step B2).
- the entity vector calculation unit 28 takes the graph structure constructed in step B2 as an input, and calculates the entity feature vector for each entity including the node corresponding to the graph structure (step B3).
- step B4 the query stored in the query storage unit 25 is fetched.
- the post-processing unit 21 specifies the processing content specified by the query extracted in step B4, and executes the specified processing content using the entity feature vector calculated in step B3 (step B5).
- the post-processing unit 21 outputs the result of the processing executed in step B5 (step B6).
- step B7 the query target stored in the query target storage unit 26 is fetched.
- step B8 calculate the similarity between the processing result output in step B6, the query target extracted in step B7, and the processing result (step B8). That is, the processing result up to step B6 is compared with the query target which is a desirable processing result, and the similarity between the processing result up to step B6 and the query target is calculated.
- the parameters stored in the parameter storage unit are updated based on the similarity calculated in step B8 (step B9). Specifically, the parameters used in the processing up to step B6 are updated so that the similarity between the processing result up to step B6 and the query target becomes large.
- the similarity between the processing result and the query target which is a desirable processing result, is calculated from the processing result in the post-processing unit 21 and the query target fetched from the query target storage unit 26. Will be done. Then, the parameters stored in the parameter storage unit 29 are updated based on the similarity. Therefore, it is possible to output a result close to the desired processing result given as a query target without manually setting or adjusting the parameters used in the entity vector calculation unit 28 and the post-processing unit 21 in advance.
- the parameters can be learned so that the processing result is close to the desired result given as the query target.
- the program in the second embodiment may be any program as long as it causes a computer to execute steps B1 to B9 shown in FIG. By installing this program on a computer and executing it, the processing apparatus 200 and the processing method according to the second embodiment can be realized.
- the computer processor functions as a graph structure extraction unit 27, an entity vector calculation unit 28, a post-processing unit 21, an evaluation unit 22, and a parameter update unit 23, and performs processing.
- the atom set storage unit 24, the query storage unit 25, the query target storage unit 26, and the parameter storage unit 29 are stored in a storage device such as a hard disk provided in the computer. It is realized by storing the file. Further, the atom set storage unit 24, the query storage unit 25, the query target storage unit 26, and the parameter storage unit 29 are constructed on a computer different from the computer that executes the program in the second embodiment. May be.
- each computer may function as a graph structure extraction unit 27, an entity vector calculation unit 28, a post-processing unit 21, an evaluation unit 22, and a parameter update unit 23, respectively.
- FIG. 11 is a block diagram showing an example of a computer that realizes the processing apparatus according to the first and second embodiments.
- the computer 110 includes a CPU (Central Processing Unit) 111, a main memory 112, a storage device 113, an input interface 114, a display controller 115, a data reader / writer 116, and a communication interface 117. And. Each of these parts is connected to each other via a bus 121 so as to be capable of data communication. Further, the computer 110 may include a GPU (Graphics Processing Unit) or an FPGA (Field-Programmable Gate Array) in addition to the CPU 111 or in place of the CPU 111.
- a GPU Graphics Processing Unit
- FPGA Field-Programmable Gate Array
- the CPU 111 expands the program (code) in the present embodiment stored in the storage device 113 into the main memory 112, and executes these in a predetermined order to perform various operations.
- the main memory 112 is typically a volatile storage device such as a DRAM (Dynamic Random Access Memory).
- the program in the present embodiment is provided in a state of being stored in a computer-readable recording medium 120.
- the program in the present embodiment may be distributed on the Internet connected via the communication interface 117.
- the storage device 113 include a semiconductor storage device such as a flash memory in addition to a hard disk drive.
- the input interface 114 mediates data transmission between the CPU 111 and an input device 118 such as a keyboard and mouse.
- the display controller 115 is connected to the display device 119 and controls the display on the display device 119.
- the data reader / writer 116 mediates the data transmission between the CPU 111 and the recording medium 120, reads the program from the recording medium 120, and writes the processing result in the computer 110 to the recording medium 120.
- the communication interface 117 mediates data transmission between the CPU 111 and another computer.
- the recording medium 120 include a general-purpose semiconductor storage device such as CF (Compact Flash (registered trademark)) and SD (Secure Digital), a magnetic recording medium such as a flexible disk, or a CD-.
- CF Compact Flash
- SD Secure Digital
- a magnetic recording medium such as a flexible disk
- CD- Compact Disk Read Only Memory
- optical recording media such as ROM (Compact Disk Read Only Memory).
- the processing device in the present embodiment can also be realized by using the hardware corresponding to each part instead of the computer in which the program is installed. Further, the processing device may be partially realized by a program and the rest may be realized by hardware.
- Entity preprocessing means to calculate the vector
- a post-processing means that accepts a query instructing the content of processing and performs the processing instructed by the query using the entity feature vector.
- the entity preprocessing means A graph structure extraction means for constructing a graph structure including information on the correspondence between each key and the entity in the associative array by using the set of atoms as an input.
- An entity vector calculation means that accepts the graph structure and calculates the entity feature vector for each entity.
- the processing apparatus according to Appendix 1. (Appendix 3)
- the entity vector calculation means An input vector calculation means for calculating an entity input vector, an atom input vector, and an edge input vector for the entity, the atom, and the edge included in the graph structure, respectively.
- a graph neural network calculation means for calculating a graph neural network output vector using the entity input vector, the atom input vector, and the edge input vector as inputs.
- Appendix 2 The processing apparatus according to Appendix 2.
- Entity feature vector is calculated and (B) Accepting a query instructing the content of processing, and performing the processing instructed by the query using the entity feature vector.
- a processing method characterized by that. (Appendix 6) The above (a) is as a part of the process. (A1) Using the set of the atoms as an input, a graph structure including information on the correspondence between each key in the associative array and the entity is constructed. (A2) Accepting the graph structure and calculating the entity feature vector for each entity. The processing method according to Appendix 5, characterized in that. (Appendix 7) The above (a2) is as a part of the process.
- the entity input vector, the atom input vector, and the edge input vector are calculated for the entity, the atom, and the edge included in the graph structure, respectively.
- a graph neural network output vector is calculated by using the entity input vector, the atom input vector, and the edge input vector as inputs.
- (Appendix 8) After (b) above, (C) The processing result of (b) is compared with the query target which is a desirable processing result, and the similarity between the processing result of (b) and the query target is calculated.
- the graph structure is accepted, and the entity feature vector for each entity is calculated.
- Appendix 11 In the above (a2), as a part of the processing, The entity input vector, the atom input vector, and the edge input vector are calculated for the entity, the atom, and the edge included in the graph structure, respectively.
- the graph neural network output vector is calculated by using the entity input vector, the atom input vector, and the edge input vector as inputs.
- a non-temporary computer-readable medium containing the program according to Appendix 10 which causes a computer to execute such a thing.
- Entity pre-processing unit 11 Post-processing unit 12 Atom set storage unit 13 Query storage unit 14 Graph structure extraction unit 15 Entity vector calculation unit 16 Parameter storage unit 17 Input vector calculation unit 18 Graph neural network calculation unit 20 Entity pre-processing unit 21 After Processing unit 22 Evaluation unit 23 Parameter update unit 24 Atom set storage unit 25 Query storage unit 26 Query target storage unit 27 Graph structure extraction unit 28 Entity vector calculation unit 29 Parameter storage unit 100
- Processing device 110 Computer 111 CPU 112 Main memory 113 Storage device 114 Input interface 115 Display controller 116 Data reader / writer 117 Communication interface 118 Input device 119 Display device 120 Recording medium 121 Bus 200 Processing device
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Mathematical Physics (AREA)
- Computing Systems (AREA)
- Molecular Biology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Health & Medical Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US18/027,299 US12591763B2 (en) | 2020-10-06 | 2020-10-06 | Processing a query using an entity feature vector |
| JP2022555005A JP7494929B2 (ja) | 2020-10-06 | 2020-10-06 | 処理装置、処理方法及びプログラム |
| PCT/JP2020/037881 WO2022074737A1 (ja) | 2020-10-06 | 2020-10-06 | 処理装置、処理方法及びプログラムが格納された非一時的なコンピュータ可読媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/037881 WO2022074737A1 (ja) | 2020-10-06 | 2020-10-06 | 処理装置、処理方法及びプログラムが格納された非一時的なコンピュータ可読媒体 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2022074737A1 true WO2022074737A1 (ja) | 2022-04-14 |
Family
ID=81126737
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/037881 Ceased WO2022074737A1 (ja) | 2020-10-06 | 2020-10-06 | 処理装置、処理方法及びプログラムが格納された非一時的なコンピュータ可読媒体 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US12591763B2 (https=) |
| JP (1) | JP7494929B2 (https=) |
| WO (1) | WO2022074737A1 (https=) |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20200312300A1 (en) * | 2019-03-29 | 2020-10-01 | Microsoft Technology Licensing, Llc | Training utterance generation |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12361044B2 (en) * | 2022-04-06 | 2025-07-15 | Relativity Oda Llc | System and method for automatic identification of legal entities |
-
2020
- 2020-10-06 JP JP2022555005A patent/JP7494929B2/ja active Active
- 2020-10-06 US US18/027,299 patent/US12591763B2/en active Active
- 2020-10-06 WO PCT/JP2020/037881 patent/WO2022074737A1/ja not_active Ceased
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20200312300A1 (en) * | 2019-03-29 | 2020-10-01 | Microsoft Technology Licensing, Llc | Training utterance generation |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7494929B2 (ja) | 2024-06-04 |
| US12591763B2 (en) | 2026-03-31 |
| JPWO2022074737A1 (https=) | 2022-04-14 |
| US20240013028A1 (en) | 2024-01-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113505244B (zh) | 基于深度学习的知识图谱构建方法、系统、设备及介质 | |
| CN115878904A (zh) | 基于深度学习的知识产权个性化推荐方法、系统及介质 | |
| CN113656587B (zh) | 文本分类方法、装置、电子设备及存储介质 | |
| JP5881048B2 (ja) | 情報処理システム、及び、情報処理方法 | |
| US12361278B2 (en) | Automated generation and integration of an optimized regular expression | |
| CN115017879B (zh) | 文本对比方法、计算机设备及计算机存储介质 | |
| CN114328894A (zh) | 文档处理方法、装置、电子设备及介质 | |
| CN117272142A (zh) | 一种日志异常检测方法、系统及电子设备 | |
| CN120104873B (zh) | 一种人岗精准匹配智能推荐的方法及系统 | |
| CN115204142A (zh) | 开放关系抽取方法、设备及存储介质 | |
| WO2022044053A1 (en) | Generating a knowledge base from mathematical formulae in technical documents | |
| CN113761151A (zh) | 同义词挖掘、问答方法、装置、计算机设备和存储介质 | |
| CN115114401B (zh) | 面向数据智能的孪生网络结构搜索方法及语义匹配方法 | |
| US20220229982A1 (en) | Information processing apparatus, information learning apparatus, information processing method, information learning method and program | |
| CN119128076B (zh) | 一种基于课程学习的司法类案检索方法及系统 | |
| JP7494929B2 (ja) | 処理装置、処理方法及びプログラム | |
| CN112613072A (zh) | 基于档案大数据的信息管理方法、管理系统及管理云平台 | |
| CN117669711A (zh) | 一种用于不确定知识图谱嵌入的工具包 | |
| CN111860662B (zh) | 一种相似性检测模型的训练方法及装置、应用方法及装置 | |
| Shen et al. | Using Chinese natural language to configure authorization policies in attribute-based access control system | |
| JP6980616B2 (ja) | 計算機システム及び学習方法 | |
| KR20220008520A (ko) | 중요 문서 파일 판별 학습 장치, 중요 문서 파일 판별 학습 방법, 중요 문서 파일 판별 장치 및 중요 문서 파일 판별 방법 | |
| CN118916617B (zh) | 基于多标签因果关系的信息分级预警方法、装置和设备 | |
| US12314325B1 (en) | Appartus and method of generating a data structure for operational inefficiency | |
| CN113378993B (zh) | 基于人工智能的分类方法、装置、设备及存储介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20956686 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 18027299 Country of ref document: US |
|
| ENP | Entry into the national phase |
Ref document number: 2022555005 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20956686 Country of ref document: EP Kind code of ref document: A1 |
|
| WWG | Wipo information: grant in national office |
Ref document number: 18027299 Country of ref document: US |