WO2021176514A1 - 学習処理プログラム、情報処理装置及び学習処理方法 - Google Patents
学習処理プログラム、情報処理装置及び学習処理方法 Download PDFInfo
- Publication number
- WO2021176514A1 WO2021176514A1 PCT/JP2020/008681 JP2020008681W WO2021176514A1 WO 2021176514 A1 WO2021176514 A1 WO 2021176514A1 JP 2020008681 W JP2020008681 W JP 2020008681W WO 2021176514 A1 WO2021176514 A1 WO 2021176514A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- learning
- feature amount
- determination
- input
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images

















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/211—Selection of the most significant subset of features
- G06F18/2113—Selection of the most significant subset of features by ranking or filtering the set of features, e.g. using a measure of variance or of feature cross-correlation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G06F18/2155—Generating training patterns; Bootstrap methods, e.g. bagging or boosting characterised by the incorporation of unlabelled data, e.g. multiple instance learning [MIL], semi-supervised techniques using expectation-maximisation [EM] or naïve labelling
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/217—Validation; Performance evaluation; Active pattern learning techniques
- G06F18/2178—Validation; Performance evaluation; Active pattern learning techniques based on feedback of a supervisor
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/40—Software arrangements specially adapted for pattern recognition, e.g. user interfaces or toolboxes therefor
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/771—Feature selection, e.g. selecting representative features from a multi-dimensional feature space
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
- G06V10/7753—Incorporation of unlabelled data, e.g. multiple instance learning [MIL]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/778—Active pattern-learning, e.g. online learning of image or video features
- G06V10/7784—Active pattern-learning, e.g. online learning of image or video features based on feedback from supervisors
- G06V10/7788—Active pattern-learning, e.g. online learning of image or video features based on feedback from supervisors the supervisor being a human, e.g. interactive learning with a human teacher
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/50—Context or environment of the image
- G06V20/56—Context or environment of the image exterior to a vehicle by using sensors mounted on the vehicle
Definitions
- the present invention relates to a learning processing program, an information processing device, and a learning processing method.
- anomaly detection (hereinafter, also simply referred to as anomaly detection) using a judgment model generated by machine learning has been performed.
- anomaly detection is used, for example, in fields such as rough road detection based on automobile sensor data and visual inspection of products in factories.
- the feature quantity vectors of the data to be determined for abnormality (hereinafter, also referred to as the determination target data) are distributed in the feature space, and the determination target data is normal. Identify the data with a large distance from the feature vector corresponding to the state data. Then, in the abnormality detection, each of the identified determination target data is detected as data in an abnormal state and presented to the user (see, for example, Non-Patent Document 1).
- the user may manually label the learning data. Therefore, depending on the number of learning data that needs to be labeled, the man-hours required by the user for labeling may become enormous.
- the above-mentioned determination model determines the state of each data by using, for example, the distance of the feature amount vector in the feature space. Therefore, in the determination model as described above, there is a possibility that the data of the abnormal state implicitly desired by the user cannot always be detected.
- the user performs, for example, active learning that gives feedback to the learning data. Specifically, for example, the user labels a part of the data output from the determination model as the data in the abnormal state as to whether or not the data is in the abnormal state, and further, the labeled data. Supervised learning by using.
- the user when performing active learning as described above, the user needs to comprehensively grasp the abnormal state of the data that needs to be detected in advance. Therefore, for example, if the user does not fully understand the abnormal state of the data, the above-mentioned active learning cannot be performed.
- the feature quantities in the training data set for each of the data contained in the training data set are used using a determination model generated by training using the unlabeled training data set.
- the degree of deviation is calculated, and based on the degree of deviation, one or more data included in the training data set or related data related to the one or more data is selected and output, and the user for the one or more data.
- Accepts the input of the judgment result by, and based on the received judgment result determines the adjustment standard for adjusting the feature amount of each of the data included in the training data set, causes the computer to execute the process, and uses the judgment model.
- the determination target data is determined, the feature amount of the determination target data is adjusted based on the adjustment reference.
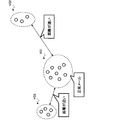
- FIG. 1 is a diagram illustrating a configuration of an information processing system 10.
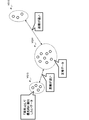
- FIG. 2 is a diagram illustrating a specific example of processing in the learning stage of the determination model.
- FIG. 3 is a diagram illustrating a specific example of abnormality detection by the determination model.
- FIG. 4 is a diagram illustrating a specific example of abnormality detection by the determination model.
- FIG. 5 is a diagram illustrating a specific example of processing in the learning stage of the determination model.
- FIG. 6 is a diagram illustrating a hardware configuration of the information processing device 1.
- FIG. 7 is a block diagram of the function of the information processing device 1.
- FIG. 8 is a flowchart illustrating an outline of the learning process according to the first embodiment.
- FIG. 8 is a flowchart illustrating an outline of the learning process according to the first embodiment.
- FIG. 9 is a flowchart illustrating an outline of the inference process according to the first embodiment.
- FIG. 10 is a diagram illustrating an outline of a learning process according to the first embodiment.
- FIG. 11 is a diagram illustrating a specific example of coordinate transformation of the feature vector by the adjuster.
- FIG. 12 is a diagram illustrating a specific example of coordinate transformation of the feature vector by the adjuster.
- FIG. 13 is a diagram illustrating a specific example of coordinate transformation of the feature vector by the adjuster.
- FIG. 14 is a flowchart illustrating the details of the learning process according to the first embodiment.
- FIG. 15 is a flowchart illustrating the details of the learning process according to the first embodiment.
- FIG. 16 is a flowchart illustrating the details of the learning process according to the first embodiment.
- FIG. 17 is a flowchart illustrating the details of the inference process according to the first embodiment.
- FIG. 18 is a diagram illustrating details of the learning process according to the first embodiment.
- FIG. 19 is a diagram illustrating details of the learning process according to the first embodiment.
- FIG. 20 is a diagram illustrating details of the learning process according to the first embodiment.
- FIG. 1 is a diagram illustrating a configuration of an information processing system 10.
- the information processing system 10 includes an information processing device 1 and a user terminal 2 in which a user inputs information or the like.
- the user terminal 2 is, for example, a PC (Personal Computer) used by the user, and is connected via a network NW such as an Internet network of the information processing device 1.
- NW such as an Internet network of the information processing device 1.
- the user terminal 2 accepts input of learning data 131 used for generating a determination model (not shown) for performing abnormality detection, for example. Then, when the user terminal 2 receives the input of the learning data 131, the user terminal 2 transmits the learning data 131 to the information processing device 1.
- each of the learning data 131 may be, for example, each of the image data included in the moving image data captured by the camera mounted on the automobile. Further, each of the learning data 131 is, for example, time-series data (time-series data corresponding to the video data cut out for each predetermined window size) indicating changes in the video data captured by the camera mounted on the automobile. It may be each.
- the information processing device 1 When the information processing device 1 receives the learning data 131 transmitted from the user terminal 2, for example, the received learning data 131 is stored in the information storage area 130. Then, in the learning stage, the information processing device 1 learns the learning data 131 stored in the information storage area 130 to generate a determination model for detecting an abnormality in the data.
- the information processing apparatus 1 determines the determination target data as a determination model. Enter in. Then, the information processing device 1 outputs the value output from the determination model in connection with the input of the determination target data as information indicating whether or not the determination target data is data in an abnormal state.
- FIG. 2 is a diagram illustrating a specific example of processing in the learning stage of the determination model.
- the user When generating the determination model as described above, the user manually labels the learning data 131 after collecting the learning data 131 (S101) as shown in FIG. 2 (S102). Then, after selecting the learning method (S103), the user generates a determination model by using the labeled learning data 131 (S104). After that, the user confirms that, for example, the determination accuracy and the like satisfy the criteria (S105).
- the state of each determination target data is determined in the inference stage, for example, by using the distance of the feature amount vector in the feature space. Therefore, in the determination model as described above, there is a possibility that the determination target data in the abnormal state implicitly desired by the user cannot always be detected.
- abnormality detection by the determination model will be described.
- each feature amount vector (each feature amount vector included in the vector group VG1, the vector group VG2, and the vector group VG3) corresponding to the learning data 131 learned in the learning stage is distributed in the feature space. Indicates the state.
- the mail corresponding to each feature vector included in the vector group VG2 is, for example, a mail described by an expression far from the natural sentence, and the mail corresponding to each feature vector included in the vector group VG3. Is, for example, an email written in natural text. Therefore, in this case, as shown in FIG. 3, the determination model uses each feature amount vector included in the vector group VG2 from each feature amount vector (each feature amount vector corresponding to the normal mail) included in the vector group VG1. It is distributed at a distant position, and each feature amount vector included in the vector group VG3 is distributed at a position close to each feature amount vector corresponding to the normal mail.
- the determination model may detect, for example, a spam mail described by an expression resembling a natural sentence as an abnormal state mail. It may not be possible. Further, in this case, the determination model may detect, for example, a normal mail described by an expression far from the natural sentence as a mail in an abnormal state. That is, in the determination model in which the learning is performed as described above, there is a possibility that the determination target data in the abnormal state implicitly desired by the user cannot always be detected.
- the user performs active learning that gives feedback to the learning data 131. Specifically, for example, among the learning data 131 input to the determination model, the user labels the learning data 131 determined to be in the abnormal state as to whether or not the learning data 131 is in the abnormal state. Performed manually. Then, the user performs supervised learning by using the labeled learning data 131.
- the user when performing active learning as described above, the user needs to comprehensively grasp the abnormal state of the data that needs to be detected in advance. Therefore, for example, if the user does not fully understand the abnormal state of the data, the above-mentioned active learning cannot be performed. Further, when the determination model determines that the data in the abnormal state is the data in the normal state, the user cannot detect such data.
- the user regenerates the judgment model as shown in FIG. Due to the necessity, it becomes necessary to perform each work including labeling again, and the work man-hours by the user may become larger (NO in S106, S102, etc.).
- the information processing device 1 in the present embodiment uses a determination model generated by learning using a plurality of unlabeled learning data 131 (hereinafter, also referred to as a learning data set) in the learning stage. , The degree of deviation of the feature amount in the training data set for each of the training data 131 included in the training data set is calculated.
- the information processing apparatus 1 selects related data related to the data of one or more training data 131 included in the training data set or the data of one or more training data 131 included in the training data set based on the degree of deviation. Output. After that, the information processing device 1 accepts the input of the determination result by the user for the output one or more learning data 131. Subsequently, the information processing apparatus 1 determines an adjustment standard for adjusting each feature amount of the learning data 131 included in the learning data set based on the received determination result.
- the information processing device 1 adjusts the feature amount of the judgment target data according to the adjustment standard, and then makes a judgment on the judgment target data.
- the information processing device 1 is included in the learning data set by, for example, receiving input of only the determination result corresponding to a part of the learning data 131 included in the learning data set from the user and using the received determination result.
- An adjustment standard for adjusting the feature amount of all the learning data 131 is determined.
- the information processing apparatus 1 determines, for example, a matrix for performing coordinate transformation of the feature amount vector of each learning data 131 in the feature space as an adjustment reference based on the determination result.
- the information processing device 1 can suppress the user's work man-hours associated with labeling, and also generate a determination model capable of detecting the abnormal state data implicitly desired by the user. Becomes possible.
- FIG. 6 is a diagram illustrating a hardware configuration of the information processing device 1.
- the information processing device 1 has a CPU 101 which is a processor, a memory 102, an external interface (I / O unit) 103, and a storage medium 104.
- the parts are connected to each other via the bus 105.
- the storage medium 104 has, for example, a program storage area (not shown) for storing a program 110 for performing a process of generating and adjusting a determination model (hereinafter, also simply referred to as a learning process). Further, the storage medium 104 has, for example, an information storage area 130 for storing information used when performing a learning process.
- the storage medium 104 may be, for example, an HDD (Hard Disk Drive) or an SSD (Solid State Drive).
- the CPU 101 executes the program 110 loaded from the storage medium 104 into the memory 102 to perform the learning process.
- the external interface 103 communicates with the user terminal 2 via, for example, the network NW.
- FIG. 7 is a block diagram of the function of the information processing device 1.
- the data receiving unit 111 and the data management unit 112 are formed by organically collaborating with the hardware such as the CPU 101 and the memory 102 of the information processing device 1 and the program 110.
- the model generation unit 113, the deviation degree calculation unit 114, the information output unit 115, the input reception unit 116, the feature amount adjustment unit 117, and the data determination unit 118 are realized.
- the information processing device 1 stores the learning data 131 and the determination target data 132 in the information storage area 130.
- the data receiving unit 111 receives, for example, a learning data set including a plurality of learning data 131 from the user terminal 2. Specifically, the data receiving unit 111 receives, for example, a learning data set composed of a plurality of unlabeled learning data 131. Then, the data management unit 112 stores the learning data set received by the data receiving unit 111 in the information storage area 130.
- the model generation unit 113 generates a determination model by using a plurality of learning data 131 included in the learning data set stored in the information storage area 130.
- the deviation degree calculation unit 114 deviates from the feature amount in the learning data set for each of the learning data 131 included in the learning data set stored in the information storage area 130. Calculate the degree.
- the information output unit 115 selects one or more learning data 131 included in the learning data set based on the degree of deviation calculated by the degree of deviation calculation unit 114. Specifically, the information output unit 115 selects, for example, one or more learning data 131 in order from the one with the highest degree of deviation calculated by the degree of deviation calculation unit 114. Then, the information output unit 115 outputs, for example, one or more selected learning data 131 to the user terminal 2.
- the input receiving unit 116 receives the input of the determination result by the user for one or more data output by the information output unit 115. Specifically, the input receiving unit 116 receives, for example, the determination result input by the user via the user terminal 2.
- each of the one or more data output by the information output unit 115 is data in an abnormal state and has a high priority (hereinafter, also referred to as first data). Indicates whether the data is in an abnormal state and has a low priority (hereinafter, also referred to as the second data) or the data in the normal state (hereinafter, also referred to as the third data). Accepts input of judgment result.
- the feature amount adjusting unit 117 determines an adjustment standard for adjusting each feature amount of the learning data 131 included in the learning data set stored in the information storage area 130 based on the determination result received by the input receiving unit 116. .. Specifically, when the feature amount adjusting unit 117 distributes the feature amount vectors corresponding to each of the learning data 131 included in the learning data stored in the information storage area 130 in the feature amount space, each learning in the feature amount space
- the matrix for performing coordinate conversion of the feature vector of the data 131 is determined as an adjustment reference.
- the feature amount adjusting unit 117 may, for example, reduce the degree of deviation corresponding to each of the learning data 131 indicating that the determination result received by the input receiving unit 116 is the first data. An adjustment standard for adjusting each feature amount of the learning data 131 included in the set is determined.
- the data receiving unit 111 receives, for example, the determination target data 132 for determining by the determination model from the user terminal 2. Then, the data management unit 112 stores, for example, the determination target data 132 received by the data receiving unit 111 in the information storage area 130.
- the data determination unit 118 inputs the determination target data 132 received by the data reception unit 111 into the determination model generated by the model generation unit 113.
- the determination model adjusts the feature amount extracted from the determination target data 132 received by the data receiving unit 111 by using the adjustment reference determined by the feature amount adjusting unit 117. Then, the determination model determines the determination target data 132 received by the data receiving unit 111 by using the adjusted feature amount. Specifically, the determination model determines, for example, whether or not the determination target data 132 received by the data receiving unit 111 is data in an abnormal state.
- the information output unit 115 outputs, for example, a determination result (for example, a determination result as to whether or not the determination target data 132 is data in an abnormal state) made by the data determination unit 118 to the user terminal 2.
- a determination result for example, a determination result as to whether or not the determination target data 132 is data in an abnormal state
- FIG. 8 is a flowchart illustrating an outline of the learning process according to the first embodiment.
- FIG. 9 is a flowchart illustrating an outline of the inference process according to the first embodiment.
- FIG. 10 is a diagram illustrating an outline of the learning process according to the first embodiment.
- the information processing device 1 waits until, for example, the model learning timing is reached (NO in S1).
- the model learning timing may be, for example, the timing at which the user inputs information to the effect that the determination model is learned via the user terminal 2.
- the information processing device 1 is included in the learning data set by using the determination model generated by the learning using the learning data set without the label.
- the degree of deviation of the feature amount in the training data set for each of the training data 131 is calculated (S2).
- the information processing apparatus 1 selects and outputs one or more data included in the learning data set based on the degree of deviation calculated in the process of S2 (S3).
- the information processing device 1 waits until it receives the input of the determination result by the user for one or more data output in the process of S3 (NO in S4).
- the information processing apparatus 1 receives the learning included in the learning data set based on the accepted determination result.
- An adjustment standard for adjusting each feature amount of the data 131 is determined (S5).
- the information processing device 1 waits until, for example, the user inputs the determination target data 132 via the user terminal 2 (NO in S11).
- the information processing apparatus 1 uses the determination model and the adjustment reference determined in the process of S5 to input the determination target data in the process of S11. A determination is made for 132 (S12).
- the information processing device 1 outputs the determination result for the determination target data 132 input in the process of S11 (S13).
- the information processing device 1 in the present embodiment accepts and accepts the input of only the determination result corresponding to a part of the learning data 131 included in the learning data set from the user. By using the determination result, the feature amounts of all the training data 131 included in the training data set are adjusted. Specifically, as shown in FIG. 10, the information processing apparatus 1 generates an adjuster that transforms the coordinates of the feature amount vector of each learning data 131 in the feature space as one of the functions constituting the determination model (). S108).
- the information processing device 1 determines whether or not the determination target data 132 is data in an abnormal state by using a determination model including an adjuster.
- the information processing device 1 can generate a determination model that can detect even the data of the abnormal state implicitly desired by the user while suppressing the work man-hours of the user associated with labeling.
- the information processing apparatus 1 in the present embodiment generates the regulator as described above, it is not necessary to regenerate the generated determination model.
- the user can suppress not only the work man-hours required for labeling the learning data 131 but also the work man-hours required for regenerating the determination model.
- coordinate conversion of the feature vector by the adjuster will be described.
- FIGS. 11 to 13 are diagrams illustrating a specific example of coordinate conversion of a feature vector by an adjuster.
- both the learning data 131 in the normal state and the learning data 131 in the abnormal state will be learned in the learning stage.
- the example shown in FIG. 11 shows a state in which each feature amount vector (each feature amount vector included in the vector group VG11) corresponding to the learning data 131 in the normal state is distributed in the feature space. Further, in the example shown in FIG. 11, each feature amount vector (each feature amount vector included in each of the vector group VG12 and the vector group VG13) corresponding to the learning data 131 in the abnormal state is distributed in the feature space. Is shown. Then, in the example shown in FIG. 11, each feature amount vector included in the vector group V13 is distributed closer to each feature amount vector included in the vector group V11 than each feature amount vector included in the vector group V12. Has been done.
- the determination result in which the input is received from the user in the processing of S4 determines that the determination target data 132 corresponding to the feature amount vector included in the vector group VG13 corresponds to the feature amount vector included in the vector group VG12.
- the information processing apparatus 1 indicates that each feature quantity vector included in the vector group V11 and each feature quantity vector included in the vector group V13, as shown in FIG. Generate an adjuster that performs coordinate conversion so that the distance between the two is larger than the distance between each feature vector included in the vector group V11 and each feature vector included in the vector group V12.
- the user can use the adjuster, for example, as shown in FIG. 13, without labeling each of the feature quantity vectors included in the vector group VG12 and the vector group VG13, and the vector group VG12. It is possible to generate a determination model that detects the determination target data 132 corresponding to the feature amount vector included in the vector group VG13 as an abnormality rather than the determination target data 132 corresponding to the feature amount vector included in.
- FIGS. 18 to 20 are diagrams for explaining the details of the learning process in the first embodiment.
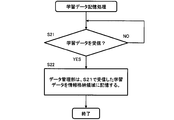
- FIG. 14 is a flowchart illustrating the learning data storage process according to the first embodiment.
- the data receiving unit 111 of the information processing device 1 waits until, for example, receives the learning data 131 (learning data 131 included in the learning data set) from the user terminal 2 (NO in S21).
- FIG. 15 is a flowchart illustrating the model generation process according to the first embodiment.
- the model generation unit 113 of the information processing device 1 waits until the model generation timing is reached (NO in S31).
- the model generation timing may be, for example, the timing at which the user inputs information to the effect that the generation of the determination model is started via the user terminal 2.
- the model generation unit 113 corresponds to each of a part of the learning data 131 stored in the information storage area 130 (hereinafter, referred to as the first learning data 131a).
- the feature amount to be used is specified (S32).
- the first learning data 131a may be, for example, learning data 131 determined by the user to be in a normal state.
- the model generation unit 113 After that, the model generation unit 113 generates a determination model by using each of the feature quantities specified in the process of S32 (S33).
- the deviation degree calculation unit 114 of the information processing device 1 uses the determination model generated in the process of S33 to use a part of the learning data 131 stored in the information storage area 130 (hereinafter, the second learning data 131b).
- the degree of deviation of the feature amount corresponding to each of (called) is calculated (S24).
- the second learning data 131b may be, for example, learning data 131 different from the first learning data 131a, and may be learning data 131 determined to be in an abnormal state by the user.
- the second learning data 131b is, for example, learning data 131 different from the first learning data 131a, and the learning data 131 determined to be in an abnormal state by the user and the learning data 131 determined to be in a normal state. It may include both of.
- the deviation degree calculation unit 114 calculates the deviation degree of the feature amount corresponding to each of the second learning data 131b from the value output from the determination model in response to inputting each of the second learning data 131b. calculate. That is, the deviation degree calculation unit 114 calculates, for each second learning data 131b, a value indicating the deviation state of the feature amount vector with respect to the other second learning data 131b in the feature space as the deviation degree.
- the degree of deviation of the feature amount corresponding to each learning data 131 will be described.
- FIG. 18 is a diagram illustrating a specific example of the degree of deviation of the feature amount corresponding to each learning data 131.
- the horizontal axis corresponds to the time
- the vertical axis corresponds to the degree of deviation of the feature amount of the learning data 131 (learning data 131 acquired at each time) corresponding to each time.
- the time series data for each minute corresponds to each of the learning data 131.
- the learning data 131 having a degree of deviation of 0 indicates that the data is in a normal state.
- the learning data 131 having a degree of deviation of not 0 indicates that the data is in an abnormal state.
- the information output unit 115 of the information processing device 1 selects and outputs one or more second learning data 131b in descending order of the degree of deviation calculated in the process of S34 (S35). Specifically, the information output unit 115 outputs, for example, one or more second learning data 131b itself to the user terminal 2. Further, the information output unit 115 outputs, for example, related data indicating at least a part of the contents of one or more second learning data 131b to the user terminal 2.
- S35 a specific example of the processing of S35 will be described.
- FIG. 19 is a specific example for explaining a specific example of the processing of S35.
- the graph shown in FIG. 19 shows that the data sets DG1, DG2, and DG3 exist as a set of learning data 131 in which the degree of deviation of the feature amount is not 0.
- the information output unit 115 selects and outputs, for example, the data set DG3 having the largest average value of the deviation degree at each time among the data sets DG1, DG2, and DG3.
- the input receiving unit 116 of the information processing device 1 waits until the input of the determination result by the user for one or more second learning data 131b output by the information output unit 115 is received (NO in S41).
- each of the one or more second learning data 131b output by the information output unit 115 is in an abnormal state and has a high priority, the first data and the abnormal state. It accepts input of a determination result indicating which of the second data, which is data and has a low priority, and the third data, which is in a normal state, corresponds to.
- the user when the user detects the existence of the second learning data 131b corresponding to the new abnormality, the user may determine the second learning data 131b as the first data. Further, in this case, the user may input a score indicating the degree of abnormality and the priority for each of the one or more second learning data 131b output by the information output unit 115.
- the feature amount adjusting unit 117 of the information processing apparatus 1 receives the determination result for one or more second learning data 131b. Determines whether or not satisfies a predetermined condition (S42).
- the feature amount adjusting unit 117 determines whether or not the number or ratio of the second learning data 131b determined as the first data among the one or more second learning data 131b is equal to or more than the threshold value. Make a judgment.
- the feature amount adjusting unit 117 uses the determination result received in the process of S31.
- the adjustment standard for adjusting the feature amount of the learning data 131 (first learning data 131a and second learning data 131b) stored in the information storage area 130 is determined (S43).
- the feature amount adjusting unit 117 performs distance learning on the learning data 131 stored in the information storage area 130 by using, for example, the determination result received in the process of S31. Then, the feature amount adjusting unit 117 determines the adjustment standard so that each feature amount of the learning data 131 stored in the information storage area 130 follows the learning result of the distance learning.
- the processing of S43 will be described.
- the feature amount adjusting unit 117 performs distance learning so that the distance between each of the first and second data and the third data becomes large, for example. Further, the feature amount adjusting unit 117 performs distance learning so that the distance between the first data and the third data is larger than the distance between the second data and the third data, for example. Further, the feature amount adjusting unit 117 performs distance learning so that the distance between different third data becomes small, for example.
- the feature amount adjusting unit 117 performs distance learning by solving the optimization problems shown in the following equations (1) to (4), for example.
- the above equation (1) is an equation showing that the distance between each of the first and second data and the third data is increased
- the equation (2) is an equation showing that the distance between different third data is decreased. It is an equation showing that (the distance between different third data is set to be equal to or less than the threshold value), and the equation (3) sets the distance between the first data and the third data as the distance between the second data and the third data. It is an equation showing that it is made larger than, and the equation (4) is an equation showing that the matrix M is a semi-regular value matrix.
- X i indicates the i-th learning data 131
- X j indicates the j-th learning data 131
- N is the th of the learning data 131.
- 3 Indicates a set of data
- a + indicates a set of the first data of the training data 131
- a ⁇ indicates a set of the second data of the training data 131
- M corresponds to the adjustment criterion.
- the matrix M to be used is shown.
- the feature amount adjusting unit 117 decomposes the matrix M, which is the optimum solution of the optimization problem shown in the equations (1) to (4), as shown in the following equation (5).
- the feature amount adjusting unit 117 performs coordinate conversion of the feature amount vector corresponding to each of the learning data 131 in the feature amount space by following the following equation (6).
- the feature amount adjusting unit 117 performs coordinate conversion of the feature amount vector corresponding to each of the learning data 131 described in FIG. 19, for example.
- the feature amount adjusting unit 117 can suppress the degree of deviation of the feature amount corresponding to each of the second learning data 131b.
- the deviation degree calculation unit 114 uses the determination model generated in the process of S33 and the adjustment reference determined in the process of S43 in each of the second learning data 131b stored in the information storage area 130. The degree of deviation of the corresponding feature amount is calculated (S44).
- the information output unit 115 selects and outputs one or more second learning data 131b in descending order of the degree of deviation calculated in the process of S44 (S45). After that, the input receiving unit 116 performs the processing after S41.
- the information processing apparatus 1 ends the learning process.
- FIG. 17 is a flowchart illustrating the inference process according to the first embodiment.
- the data receiving unit 111 waits until, for example, the user inputs the determination target data 132 via the user terminal 2 (NO in S51).
- the data determination unit 118 of the information processing apparatus 1 uses the determination model generated in the process of S33 and the adjustment reference determined in the process of S43. , The determination target data 132 input in the process of S51 is determined (S52).
- the determination model adjusts the feature amount extracted from the determination target data 132 input in the process of S51 by using the adjustment standard determined in the process of S43. That is, in this case, the determination model performs coordinate conversion by using the adjustment reference (matrix) determined in the process of S43 for the feature amount vector corresponding to the determination target data 132 in the feature space. Then, the determination model determines whether or not the determination target data 132 input in the process of S51 is the data in the abnormal state by using the adjusted feature amount.
- the feature amount extracted from the determination target data 132 input in the processing of S51 is adjusted by the processing of S43. Adjust by using all of the criteria.
- the information output unit 115 outputs the determination result for the determination target data 132 input in the process of S51 (S53).
- the information processing apparatus 1 in the present embodiment learns using the determination model generated by learning using a plurality of unlabeled learning data 131 (learning data sets).
- the degree of deviation of the feature amount in the training data set for each of the training data 131 included in the data set is calculated.
- the information processing apparatus 1 selects related data related to the data of one or more training data 131 included in the training data set or the data of one or more training data 131 included in the training data set based on the degree of deviation. Output. After that, the information processing device 1 accepts the input of the determination result by the user for the output one or more learning data 131. Subsequently, the information processing apparatus 1 determines an adjustment standard for adjusting each feature amount of the learning data 131 included in the learning data set based on the received determination result.
- the information processing device 1 adjusts the feature amount of the determination target data according to the adjustment standard, and then determines the determination target data 132.
- the information processing device 1 in the present embodiment accepts and accepts the input of only the determination result corresponding to a part of the learning data 131 included in the learning data set from the user. By using the determination result, the feature amounts of all the training data 131 included in the training data set are adjusted. Specifically, the information processing device 1 generates an adjustment reference (adjuster) for performing coordinate conversion of the feature amount vector of each learning data 131 in the feature space as one of the functions constituting the determination model.
- an adjustment reference adjuster
- the information processing device 1 determines whether or not the determination target data 132 is data in an abnormal state by using a determination model including an adjuster.
- the information processing device 1 can generate a determination model that can detect even the data of the abnormal state implicitly desired by the user while suppressing the work man-hours of the user associated with labeling.
- the information processing apparatus 1 in the present embodiment generates the regulator as described above, it is not necessary to regenerate the generated determination model.
- the user can suppress not only the work man-hours required for labeling the learning data 131 but also the work man-hours required for regenerating the determination model.
- Information processing device 2 User terminal 130: Information storage area 131: Learning data NW: Network
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- General Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Databases & Information Systems (AREA)
- Software Systems (AREA)
- Medical Informatics (AREA)
- Computing Systems (AREA)
- Multimedia (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Human Computer Interaction (AREA)
- Mathematical Physics (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Image Analysis (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP20923361.8A EP4116892A4 (en) | 2020-03-02 | 2020-03-02 | LEARNING PROCESSING PROGRAM, INFORMATION PROCESSING DEVICE AND LEARNING PROCESSING METHOD |
| PCT/JP2020/008681 WO2021176514A1 (ja) | 2020-03-02 | 2020-03-02 | 学習処理プログラム、情報処理装置及び学習処理方法 |
| JP2022504775A JP7368776B2 (ja) | 2020-03-02 | 2020-03-02 | 学習処理プログラム、情報処理装置及び学習処理方法 |
| US17/895,121 US12450309B2 (en) | 2020-03-02 | 2022-08-25 | Storage medium, information processing device, and training processing method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2020/008681 WO2021176514A1 (ja) | 2020-03-02 | 2020-03-02 | 学習処理プログラム、情報処理装置及び学習処理方法 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US17/895,121 Continuation US12450309B2 (en) | 2020-03-02 | 2022-08-25 | Storage medium, information processing device, and training processing method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021176514A1 true WO2021176514A1 (ja) | 2021-09-10 |
Family
ID=77613946
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/008681 Ceased WO2021176514A1 (ja) | 2020-03-02 | 2020-03-02 | 学習処理プログラム、情報処理装置及び学習処理方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US12450309B2 (https=) |
| EP (1) | EP4116892A4 (https=) |
| JP (1) | JP7368776B2 (https=) |
| WO (1) | WO2021176514A1 (https=) |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2806374B1 (en) * | 2013-05-24 | 2022-07-06 | Tata Consultancy Services Limited | Method and system for automatic selection of one or more image processing algorithm |
| JP5943358B2 (ja) * | 2014-09-30 | 2016-07-05 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | 学習装置、処理装置、予測システム、学習方法、処理方法、およびプログラム |
| KR101880901B1 (ko) * | 2017-08-09 | 2018-07-23 | 펜타시큐리티시스템 주식회사 | 기계 학습 방법 및 장치 |
| CN110633745B (zh) * | 2017-12-12 | 2022-11-29 | 腾讯科技(深圳)有限公司 | 一种基于人工智能的图像分类训练方法、装置及存储介质 |
| JP7040065B2 (ja) * | 2018-01-31 | 2022-03-23 | 富士通株式会社 | 検出プログラム、検出方法および検出装置 |
| CN111105008A (zh) * | 2018-10-29 | 2020-05-05 | 富士通株式会社 | 模型训练方法、数据识别方法和数据识别装置 |
| US11514329B2 (en) * | 2019-03-27 | 2022-11-29 | General Electric Company | Data-driven deep learning model generalization analysis and improvement |
-
2020
- 2020-03-02 JP JP2022504775A patent/JP7368776B2/ja active Active
- 2020-03-02 EP EP20923361.8A patent/EP4116892A4/en active Pending
- 2020-03-02 WO PCT/JP2020/008681 patent/WO2021176514A1/ja not_active Ceased
-
2022
- 2022-08-25 US US17/895,121 patent/US12450309B2/en active Active
Non-Patent Citations (2)
| Title |
|---|
| KYOKO SUDO , KAORU WAKABAYASHI , KENICHI ARAKAWA , TAKAYUKI YASUNO : "Detecting anomalous sequences in long duration monitoring videos", IPSJ SIG TECHNICAL REPORTS, vol. 2005, no. 112, 2005, pages 77 - 82, XP055955552, ISSN: 0919-6072 * |
| OKADA, SHOGO; KANDA, KENICHI; OHMOTO, YOSHIMASA; NISHIDA, TOYOAKI: "Image classification system based on interaction with human", PROCEEDINGS OF THE 24TH ANNUAL CONFERENCE OF JSAI; JUNE 9-11, 2010, vol. 24, 2010, pages 1 - 3, XP009538589, ISSN: 1347-9881, DOI: 10.11517/pjsai.JSAI2010.0_2G2OS96 * |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4116892A1 (en) | 2023-01-11 |
| US20220405526A1 (en) | 2022-12-22 |
| JP7368776B2 (ja) | 2023-10-25 |
| US12450309B2 (en) | 2025-10-21 |
| EP4116892A4 (en) | 2023-03-29 |
| JPWO2021176514A1 (https=) | 2021-09-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11694109B2 (en) | Data processing apparatus for accessing shared memory in processing structured data for modifying a parameter vector data structure | |
| US20220245405A1 (en) | Deterioration suppression program, deterioration suppression method, and non-transitory computer-readable storage medium | |
| US10628709B2 (en) | Image recognition device and image recognition method | |
| CN113435409A (zh) | 图像识别模型的训练方法、装置、存储介质及电子设备 | |
| KR102748213B1 (ko) | 국부적으로 해석 가능한 모델에 기반한 강화 학습 | |
| WO2018121737A1 (zh) | 关键点预测、网络训练及图像处理方法和装置、电子设备 | |
| US11481647B1 (en) | Determining high impact features for a prediction of a machine learning model | |
| US12307376B2 (en) | Training spectral inference neural networks using bilevel optimization | |
| JP6645441B2 (ja) | 情報処理システム、情報処理方法、及び、プログラム | |
| CN114445682A (zh) | 训练模型的方法、装置、电子设备、存储介质及产品 | |
| CN114241411A (zh) | 基于目标检测的计数模型处理方法、装置及计算机设备 | |
| He et al. | Sgfm: Conditional flow matching for time series anomaly detection with state space models | |
| CN116152613B (zh) | 对抗图像生成方法、装置、电子设备及存储介质 | |
| US11688175B2 (en) | Methods and systems for the automated quality assurance of annotated images | |
| EP3701431B1 (en) | Increasing security of neural networks by discretizing neural network inputs | |
| US12387459B2 (en) | System and method for image de-identification to humans while remaining recognizable by machines | |
| EP4027270A1 (en) | Determination model generation program, information processing apparatus, and determination model generation method | |
| WO2021176514A1 (ja) | 学習処理プログラム、情報処理装置及び学習処理方法 | |
| CN117473291B (zh) | 谐振腔参数的确定方法、装置、设备及存储介质 | |
| CN118485309A (zh) | 基于溯源信息的乳制品质量数据处理方法及系统 | |
| US20210279609A1 (en) | Failure prediction apparatus and learning device | |
| JP7331938B2 (ja) | 学習装置、推定装置、学習方法及び学習プログラム | |
| JP2021111027A (ja) | 情報出力プログラム、情報出力装置及び情報出力方法 | |
| JP7401747B2 (ja) | 類別プログラム、類別装置及び類別方法 | |
| KR102779724B1 (ko) | 군중 계수의 추정 방법, 군중 계수의 추정을 위한 모델의 훈련 방법, 및 이를 수행하기 위한 전자 장치 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20923361 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022504775 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020923361 Country of ref document: EP Effective date: 20221004 |