WO2021068954A1 - High level syntax for video coding tools - Google Patents
High level syntax for video coding tools Download PDFInfo
- Publication number
- WO2021068954A1 WO2021068954A1 PCT/CN2020/120287 CN2020120287W WO2021068954A1 WO 2021068954 A1 WO2021068954 A1 WO 2021068954A1 CN 2020120287 W CN2020120287 W CN 2020120287W WO 2021068954 A1 WO2021068954 A1 WO 2021068954A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- picture
- video
- block
- flag
- resolution
- Prior art date
Links
Images































Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/70—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by syntax aspects related to video coding, e.g. related to compression standards
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/103—Selection of coding mode or of prediction mode
- H04N19/105—Selection of the reference unit for prediction within a chosen coding or prediction mode, e.g. adaptive choice of position and number of pixels used for prediction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/117—Filters, e.g. for pre-processing or post-processing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/119—Adaptive subdivision aspects, e.g. subdivision of a picture into rectangular or non-rectangular coding blocks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/132—Sampling, masking or truncation of coding units, e.g. adaptive resampling, frame skipping, frame interpolation or high-frequency transform coefficient masking
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/136—Incoming video signal characteristics or properties
- H04N19/137—Motion inside a coding unit, e.g. average field, frame or block difference
- H04N19/139—Analysis of motion vectors, e.g. their magnitude, direction, variance or reliability
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/174—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a slice, e.g. a line of blocks or a group of blocks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/176—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a block, e.g. a macroblock
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/46—Embedding additional information in the video signal during the compression process
- H04N19/463—Embedding additional information in the video signal during the compression process by compressing encoding parameters before transmission
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/513—Processing of motion vectors
- H04N19/517—Processing of motion vectors by encoding
- H04N19/52—Processing of motion vectors by encoding by predictive encoding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/577—Motion compensation with bidirectional frame interpolation, i.e. using B-pictures
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/60—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using transform coding
Definitions
- This patent document relates to video coding techniques, devices and systems.
- Devices, systems and methods related to digital video coding, and specifically, to adaptive loop filtering for video coding are described.
- the described methods may be applied to both the existing video coding standards (e.g., High Efficiency Video Coding (HEVC) ) and future video coding standards (e.g., Versatile Video Coding (VVC) ) or codecs.
- HEVC High Efficiency Video Coding
- VVC Versatile Video Coding
- Video coding standards have evolved primarily through the development of the well-known ITU-T and ISO/IEC standards.
- the ITU-T produced H. 261 and H. 263, ISO/IEC produced MPEG-1 and MPEG-4 Visual, and the two organizations jointly produced the H. 262/MPEG-2 Video and H. 264/MPEG-4 Advanced Video Coding (AVC) and H. 265/HEVC standards.
- AVC H. 264/MPEG-4 Advanced Video Coding
- H. 265/HEVC High Efficiency Video Coding
- the video coding standards are based on the hybrid video coding structure wherein temporal prediction plus transform coding are utilized.
- Joint Video Exploration Team JVET was founded by VCEG and MPEG jointly in 2015.
- JVET Joint Exploration Model
- the disclosed technology may be used to provide a method for video processing which includes determining, for a conversion between a video region of a picture of a video and a coded representation of the video, enablement status of a coding tool used to represent the video region in the coded representation; and performing the conversion according to the determination; wherein a first flag is included in a picture header to indicate the enablement status of the coding tool for the picture.
- the above-described method is embodied in the form of processor-executable code and stored in a computer-readable program medium.
- a device that is configured or operable to perform the above-described method.
- the device may include a processor that is programmed to implement this method.
- a video decoder apparatus may implement a method as described herein.
- FIG. 1 shows an example of adaptive streaming of two Representations of a same content coded at different resolutions.
- FIG. 2 shows an example of an adaptive streaming of two Representations of the same content coded at different resolutions.
- FIG. 3 shows examples of open GOP prediction structures of the two Representations.
- FIG. 4 shows an example of Representation switching at an open GOP position.
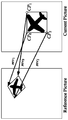
- FIG. 5 shows an example of a decoding process for RASL pictures by using a resampled reference picture from other bitstream as a reference.
- FIGS. 6A to 6C show examples of MCTS-based RWMR viewport-dependent 360° streaming.
- FIG. 7 shows examples of collocated sub-picture Representations of different IRAP intervals and different sizes.
- FIG. 8 illustrates an example of segments received when a viewing orientation change causes a resolution change.
- FIG. 9 illustrates an example of a viewing orientation change which is slightly upwards and towards the right cube face as compared to FIG. 6.
- FIG. 10 shows an example of an implementation in which sub-picture representations for two sub-picture locations are presented.
- FIGS. 11 and 12 illustrate ARC encoder and decoder implementations, respectively.
- FIG. 13 shows an example of tile group-based resampling for ARC.
- FIG. 14 shows an example of adaptive resolution change.
- FIG. 15 shows an example of ATMVP motion prediction for a CU.
- FIGS. 16A and 16B show examples of a simplified 4-paramter affine motion model and a simplified 6-parmaeter affine motion model, respectively.
- FIG. 17 shows an example of affine MVF per sub-block.
- FIG. 18A and 18B show examples of a 4-paramenter affine model and 6-parameter affine model, respectively.
- FIG. 19 shows MVP (Motion Vector Difference) for AF_INTER for inherited affine candidates.
- FIG. 20 shows MVP for AF_INTER for constructed affine candidates.
- FIG. 21A and 21B show five neighboring blocks and CPMV predictor derivation, respectively.
- FIG. 22 shows an example of a candidates position for affine merge mode.
- FIG. 23 shows a flowchart of example method for video processing in accordance with the disclosed technology.
- FIGS. 24A and 24B block diagrams of examples of a hardware platform for implementing a visual media decoding or a visual media encoding technique described in the present document.
- FIG. 25 is a block diagram that illustrates an example video coding system.
- FIG. 26 is a block diagram that illustrates an encoder in accordance with some embodiments of the disclosed technology.
- FIG. 27 is a block diagram that illustrates a decoder in accordance with some embodiments of the disclosed technology.
- FIG. 28 shows a flowchart for an example method of video processing based on some implementations of the disclosed technology.
- AVC and HEVC do not have the ability to change resolution without having to introduce an IDR or intra random access point (IRAP) picture; such ability can be referred to as adaptive resolution change (ARC) .
- ARC adaptive resolution change
- - Rate adaption in video telephony and conferencing For adapting the coded video to the changing network conditions, when the network condition gets worse so that available bandwidth becomes lower, the encoder may adapt to it by encoding smaller resolution pictures.
- changing picture resolution can be done only after an IRAP picture; this has several issues.
- An IRAP picture at reasonable quality will be much larger than an inter-coded picture and will be correspondingly more complex to decode: this costs time and resource. This is a problem if the resolution change is requested by the decoder for loading reasons. It can also break low-latency buffer conditions, forcing an audio re-sync, and the end-to-end delay of the stream will increase, at least temporarily. This can give a poor user experience.
- the Dynamic Adaptive Streaming over HTTP (DASH) specification includes a feature named @mediaStreamStructureId. This enables switching between different representations at open-GOP random access points with non-decodable leading pictures, e.g., CRA pictures with associated RASL pictures in HEVC.
- CRA pictures with associated RASL pictures in HEVC.
- switching between the two representations at a CRA picture with associated RASL pictures can be performed, and the RASL pictures associated with the switching-at CRA pictures can be decoded with acceptable quality hence enabling seamless switching.
- the @mediaStreamStructureId feature would also be usable for switching between DASH representations with different spatial resolutions.
- ARC is also known as Dynamic resolution conversion.
- ARC may also be regarded as a special case of Reference Picture Resampling (RPR) such as H. 263 Annex P.
- RPR Reference Picture Resampling
- This mode describes an algorithm to warp the reference picture prior to its use for prediction. It can be useful for resampling a reference picture having a different source format than the picture being predicted. It can also be used for global motion estimation, or estimation of rotating motion, by warping the shape, size, and location of the reference picture.
- the syntax includes warping parameters to be used as well as a resampling algorithm.
- the simplest level of operation for the reference picture resampling mode is an implicit factor of 4 resampling as only an FIR filter needs to be applied for the upsampling and downsampling processes. In this case, no additional signaling overhead is required as its use is understood when the size of a new picture (indicated in the picture header) is different from that of the previous picture.
- the spatial resolution may differ from the nominal resolution by a factor 0.5, applied to both dimensions.
- the spatial resolution may increase or decrease, yielding scaling ratios of 0.5 and 2.0.
- the cropping areas are scaled in proportion to spatial resolutions.
- the reference pictures are simply re-scaled as needed and inter prediction is applied as usual.
- the down-sampling points are at even sample positions and are co-sited.
- the same filter is used for luma and chroma.
- the combined up-and down-sampling will not change phase or the position of chroma sampling points.
- pic_width_in_luma_samples specifies the width of each decoded picture in units of luma samples. pic_width_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
- pic_height_in_luma_samples specifies the height of each decoded picture in units of luma samples. pic_height_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY. ] ]
- num_pic_size_in_luma_samples_minus1 plus 1 specifies the number of picture sizes (width and height) in units of luma samples that may be present in the coded video sequence.
- pic_width_in_luma_samples [i] specifies the i-th width of decoded pictures in units of luma samples that may be present in the coded video sequence.
- pic_width_in_luma_samples [i ] shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
- pic_height_in_luma_samples [i] specifies the i-th height of decoded pictures in units of luma samples that may be present in the coded video sequence.
- pic_height_in_luma_samples [i] shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
- pic_size_idx specifies the index to the i-th picture size in the sequence parameter set.
- the width of pictures that refer to the picture parameter set is pic_width_in_luma_samples [pic_size_idx] in luma samples.
- the height of pictures that refer to the picture parameter set is pic_height_in_luma_samples [pic_size_idx] in luma samples.
- sub-picture track is defined as follows in Omnidirectional Media Format (OMAF) : track that is with spatial relationships to other track (s) and that represents that represents a spatial subset of the original video content, which has been split into spatial subsets before video encoding at the content production side.
- OMAF Omnidirectional Media Format
- a sub-picture track for HEVC can be constructed by rewriting the parameter sets and slice segment headers for a motion-constrained tile set so that it becomes a self-standing HEVC bitstream.
- a sub-picture Representation can be defined as a DASH Representation that carries a sub-picture track.
- JVET-M0261 used the term sub-picture as a spatial partitioning unit for VVC, summarized as follows:
- Pictures are divided into sub-pictures, tile groups and tiles.
- a sub-picture is a rectangular set of tile groups that starts with a tile group that has tile_group_address equal to 0.
- Each sub-picture may refer to its own PPS and may hence have its own tile partitioning.
- Sub-pictures are treated like pictures in the decoding process.
- the reference pictures for decoding the sub-picture are generated by extracting the area collocating with the current sub-picture from the reference pictures in the decoded picture buffer.
- the extracted area shall be a decoded sub-picture, i.e. inter prediction takes place between sub-pictures of the same size and the same location within the picture.
- a tile group is a sequence of tiles in tile raster scan of a sub-picture.
- sub-picture can be understood as defined in JVET-M0261.
- a track that encapsulates a sub-picture sequence as defined in JVET-M0261 has very similar properties as a sub-picture track defined in OMAF, the examples given below apply in both cases.
- Section 5.13 ( "Support for Adaptive Streaming" ) of MPEG N17074 includes the following requirement for VVC:
- the standard shall support fast representation switching in the case of adaptive streaming services that offer multiple representations of the same content, each having different properties (e.g. spatial resolution or sample bit depth) .
- the standard shall enable the use of efficient prediction structures (e.g. so-called open groups of pictures) without compromising from the fast and seamless representation switching capability between representations of different properties, such as different spatial resolutions.
- Content generation for adaptive bitrate streaming includes generations of different Representations, which can have different spatial resolutions.
- the client requests Segments from the Representations and can hence decide at which resolution and bitrate the content is received.
- the Segments of different Representations are concatenated, decoded, and played.
- the client should be able to achieve seamless playout with one decoder instance. Closed GOP structures (starting with an IDR picture) are conventionally used as illustrated in FIG. 1.
- FIG. 1 shows adaptive streaming of two Representations of the same content coded at different resolutions.
- Open GOP prediction structures starting with CRA pictures
- CRA pictures open GOP prediction structures
- an average bitrate reduction of 5.6%in terms of luma Bjontegaard delta bitrate was achieved with an IRAP picture interval of 24 pictures.
- Open GOP prediction structures reportedly also reduce subjectively visible quality pumping.
- FIG. 2 shows adaptive streaming of two Representations of the same content coded at different resolutions.
- the Segments use either closed GOP or open GOP prediction structures.
- the Segments starting with a CRA picture contain RASL pictures for which at least one reference picture is in the previous Segment. This is illustrated in FIG. 3 which shows open GOP prediction structures of the two Representations.
- picture 0 in both bitstreams resides in the previous Segment and is used as reference for predicting the RASL pictures.
- FIG. 4 shows Representation switching at an open GOP position. It can be observed that the reference picture ( "picture 0" ) for RASL pictures has not been decoded. Consequently, RASL pictures are not decodable and there will be a gap in the playout of the video.
- FIG. 5 shows a decoding process for RASL picture by using resampled reference picture from the other bitstream as reference.
- RWMR 360° streaming offers an increased effective spatial resolution on the viewport.
- Schemes where tiles covering the viewport originate from a 6K (6144 ⁇ 3072) ERP picture or an equivalent CMP resolution, illustrated in Figure 6, with "4K" decoding capacity (HEVC Level 5.1) were included in clauses D. 6.3 and D. 6.4 of OMAF and also adopted in the VR Industry Forum Guidelines. Such resolutions are asserted to be suitable for head-mounted displays using quad-HD (2560 ⁇ 1440) display panel.
- Encoding The content is encoded at two spatial resolutions with cube face size 1536 ⁇ 1536 and 768 ⁇ 768, respectively. In both bitstreams a 6 ⁇ 4 tile grid is used and a motion-constrained tile set (MCTS) is coded for each tile position.
- MCTS motion-constrained tile set
- Each MCTS sequence is encapsulated as a sub-picture track and made available as a sub-picture Representation in DASH.
- Merging MCTSs to a bitstream to be decoded The received MCTSs of a single time instance are merged into a coded picture of 1920 ⁇ 4608, which conforms to HEVC Level 5.1. Another option for the merged picture is to have 4 tile columns of width 768, two tile columns of width 384, and three tile rows of height 768 luma samples, resulting into a picture of 3840 ⁇ 2304 luma samples.
- FIG. 6 shows examples of MCTS-based RWMR viewport-dependent 360° streaming.
- FIG. 6A shows examples of coded bitstreams
- FIG. 6B shows examples of MCTSs selected for streaming
- FIG. 6C shows an example of a picture merged from MCTSs.
- Sub-picture Representations are merged to coded pictures for decoding, and hence the VCL NAL unit types are aligned in all selected sub-picture Representations.
- FIG. 7 shows examples of collocated sub-picture Representations of different IRAP intervals and different sizes.
- FIG. 8 presents an example where a sub-picture location is firstly selected to be received at the lower resolution (384 ⁇ 384) .
- a change in the viewing orientation causes a new selection of the sub-picture locations to be received at the higher resolution (768 ⁇ 768) .
- the segments received when a viewing orientation change causes a resolution change are at the start of Segment 4.
- the viewing orientation change occurs so that Segment 4 is received from the short-IRAP-interval sub-picture Representations.
- the viewing orientation is stable and thus, the long-IRAP-interval version can be used starting from Segment 5 onwards.
- FIG. 9 illustrates a viewing orientation change from FIG. 6 slightly upwards and towards the right cube face. Cube face partitions that have a different resolution as earlier are indicated with "C" . It can be observed that the resolution changed in 6 out of 24 cube face partitions. However, as discussed above, Segments starting with an IRAP picture need to be received for all 24 cube face partitions in response to the viewing orientation change. Updating all sub-picture locations with Segments starting with an IRAP picture is inefficient in terms of streaming rate-distortion performance.
- the ability to use open GOP prediction structures with sub-picture Representations of RWMR 360° streaming is desirable to improve rate-distortion performance and to avoid visible picture quality pumping caused by closed GOP prediction structures.
- the VVC design should allow merging of a sub-picture originating from a random-access picture and another sub-picture originating from a non-random-access picture into the same coded picture conforming to VVC.
- the VVC design should enable the use of open GOP prediction structure in sub-picture representations without compromising from the fast and seamless representation switching capability between sub-picture representations of different properties, such as different spatial resolutions, while enabling merging of sub-picture representations into a single VVC bitstream.
- FIG. 10 The example of the design goals can be illustrated with FIG. 10, in which sub-picture Representations for two sub-picture locations are presented. For both sub-picture locations, a separate version of the content is coded for each combination among two resolutions and two random access intervals. Some of the Segments start with an open GOP prediction structure. A viewing orientation change causes the resolution of sub-picture location 1 to be switched at the start of Segment 4. Since Segment 4 starts with a CRA picture, which is associated with RASL pictures, those reference pictures of the RASL pictures that are in Segment 3 need to be resampled. It is remarked that this resampling applies to sub-picture location 1 while decoded sub-pictures of some other sub-picture locations are not resampled.
- the viewing orientation change does not cause changes in the resolution of sub-picture location 2 and thus decoded sub-pictures of sub-picture location 2 are not resampled.
- the Segment for sub-picture location 1 contains a sub-picture originating from a CRA picture
- the Segment for sub-picture location 2 contains a sub-picture originating from a non-random-access picture. It is suggested that merging of these sub-pictures into a coded picture is allowed in VVC.
- JCTVC-F158 proposed adaptive resolution change mainly for video conferencing.
- the following sub-sections are copied from JCTVC-F158 and present the use cases where adaptive resolution change is asserted to be useful.
- the IDR is typically sent at low quality, using a similar number of bits to a P frame, and it takes a significant time to return to full quality for the given resolution.
- the quality can be very low indeed and there is often a visible blurring before the image is “refocused” .
- the Intra frame is doing very little useful work in compression terms: it is just a method of re-starting the stream.
- Video conferences also often have a feature whereby the person speaking is shown full-screen and other participants are shown in smaller resolution windows. To support this efficiently, often the smaller pictures are sent at lower resolution. This resolution is then increased when the participant becomes the speaker and is full-screened. Sending an intra frame at this point causes an unpleasant hiccup in the video stream. This effect can be quite noticeable and unpleasant if speakers alternate rapidly.
- VVC version 1 The following is high-level design choices are proposed for VVC version 1:
- VVC version 1 1. It is proposed to include a reference picture resampling process in VVC version 1 for the following use cases:
- VVC design is proposed to allow merging of a sub-picture originating from a random-access picture and another sub-picture originating from a non-random-access picture into the same coded picture conforming to VVC. This is asserted to enable efficient handling of viewing orientation changes in mixed-quality and mixed-resolution viewport-adaptive 360° streaming.
- VVC version 1 It is proposed to include sub-picture-wise resampling process in VVC version 1. This is asserted to enable efficient prediction structure for more efficient handling of viewing orientation changes in mixed-resolution viewport-adaptive 360° streaming.
- Section 5.13 ( "Support for Adaptive Streaming" ) of MPEG N17074 includes the following requirement for VVC:
- the standard shall support fast representation switching in the case of adaptive streaming services that offer multiple representations of the same content, each having different properties (e.g. spatial resolution or sample bit depth) .
- the standard shall enable the use of efficient prediction structures (e.g. so-called open groups of pictures) without compromising from the fast and seamless representation switching capability between representations of different properties, such as different spatial resolutions.
- JVET-M0259 discusses how to meet this requirement by resampling of reference pictures of leading pictures.
- JVET-M0259 discusses how to address this use case by resampling certain independently coded picture regions of reference pictures of leading pictures.
- sps_max_rpr specifies the maximum number of active reference pictures in reference picture list 0 or 1 for any tile group in the CVS that have pic_width_in_luma_samples and pic_height_in_luma_samples not equal to pic_width_in_luma_samples and pic_height_in_luma_samples, respectively, of the current picture.
- max_width_in_luma_samples specifies that it is a requirement of bitstream conformance that pic_width_in_luma_samples in any active PPS for any picture of a CVS for which this SPS is active is less than or equal to max_width_in_luma_samples.
- max_height_in_luma_samples specifies that it is a requirement of bitstream conformance that pic_height_in_luma_samples in any active PPS for any picture of a CVS for which this SPS is active is less than or equal to max_height_in_luma_samples.
- the decoding process operates as follows for the current picture CurrPic:
- Variables and functions relating to picture order count are derived as specified in clause 8.3.1. This needs to be invoked only for the first tile group of a picture.
- the reference picture used as input to the resampling process is marked as "unused for reference” .
- the current decoded picture is marked as "used for short-term reference" .
- SHVC resampling process (HEVC clause H. 8.1.4.2) is proposed with the following additions:
- Adaptive resolution change as a concept in video compression standards, has been around since at least 1996; in particular H. 263+ related proposals towards reference picture resampling (RPR, Annex P) and Reduced Resolution Update (Annex Q) . It has recently gained a certain prominence, first with proposals by Cisco during the JCT-VC time, then in the context of VP9 (where it is moderately widely deployed nowadays) , and more recently in the context of VVC.
- ARC allows reducing the number of samples required to be coded for a given picture, and upsampling the resulting reference picture to a higher resolution when such is desirable.
- ARC of particular interest is considered in two scenarios:
- Intra coded pictures such as IDR pictures are often considerably larger than inter pictures. Downsampling pictures intended to be intra coded, regardless of reason, may provide a better input for future prediction. It’s also clearly advantageous from a rate control viewpoint, at least in low delay applications.
- ARC may become handy even for non-intra coded pictures, such as in scene transitions without a hard transition point.
- ARC can be implemented as reference picture resampling.
- Implementing reference picture resampling has two major aspects: the resampling filters, and the signaling of the resampling information in the bitstream. This document focusses on the latter and touches the former to the extent there is an implementation experience. More study of suitable filter design is encouraged, and Tencent will carefully consider and, when appropriate, support any proposals in that regard that substantially improve the strawman design provided.
- FIGS. 11 and 12 illustrate Tencent’s ARC encoder and decoder implementations, respectively. Implementations of the disclosed technology enable to change the picture width and height, on a per picture granularity irrespective of the picture type.
- the input image data is down-sampled to the selected picture size for the current picture encoding.
- the decoded picture is stored in the decoded picture buffer (DPB) .
- the reference picture (s) in the DPB is/are up-/down-scaled according the spatial ratio between the picture size of the reference and the current picture size.
- the decoded picture is stored in the DPB without resampling.
- the reference picture in the DPB is up-/down-scaled in relation to the spatial ratio between the currently decoded picture and the reference, when used for motion compensation.
- the decoded picture is up-sampled to the original picture size or the desired output picture size when bumped out for display.
- motion vectors are scaled in relation to picture size ratio as well as picture order count difference.
- ARC parameters is used herein as a combination of any parameters required to make ARC work.
- the implementations proposed herein are to allow, at least conceptually, different ARC parameters for different parts of a picture. It is proposed that the appropriate syntax structure as per the current VVC draft would be a rectangular tile group (TG) . Those using scan-order TGs would be restricted to use ARC only to a full picture, or to the extent scan order TGs are included in a rectangular TG. That can easily be specified by a bitstream constraint.
- TG rectangular tile group
- TGs may have different ARC parameters
- the appropriate place for ARC parameters would be either in the TG header or in a parameter set with the scope of a TG, and referenced by the TG header-the Adaptation Parameter Set in the current VVC draft, or a more detailed reference (an index) into a table in a higher parameter set.
- a zoom factor can be directly coded into the TG header, without using any parameter set values.
- the use of the PPS for the reference is counter-indicated if the per tile group signaling of ARC parameters is a design criterion.
- max_pic_width_in_luma_samples specifies the maximum width of decoded pictures in units of luma samples in the bitstream.
- max_pic_width_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
- the value of dec_pic_width_in_luma_samples [i] cannot be greater than the value of max_pic_width_in_luma_samples.
- max_pic_height_in_luma_samples specifies the maximum height of decoded pictures in units of luma samples.
- max_pic_height_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
- the value of dec_pic_height_in_luma_samples [i] cannot be greater than the value of max_pic_height_in_luma_samples.
- adaptive_pic_resolution_change_flag 1 specifies that an output picture size (output_pic_width_in_luma_samples, output_pic_height_in_luma_samples) , an indication of the number of decoded picture sizes (num_dec_pic_size_in_luma_samples_minus1) and at least one decoded picture size (dec_pic_width_in_luma_samples [i] , dec_pic_height_in_luma_samples [i ] ) are present in the SPS.
- a reference picture size reference_pic_width_in_luma_samples, reference_pic_height_in_luma_samples is present conditioned on the value of reference_pic_size_present_flag.
- output_pic_width_in_luma_samples specifies the width of the output picture in units of luma samples. output_pic_width_in_luma_samples shall not be equal to 0.
- output_pic_height_in_luma_samples specifies the height of the output picture in units of luma samples. output_pic_height_in_luma_samples shall not be equal to 0.
- reference_pic_size_present_flag 1 specifies that reference_pic_width_in_luma_samples and reference_pic_height_in_luma_samples are present.
- reference_pic_width_in_luma_samples specifies the width of the reference picture in units of luma samples. output_pic_width_in_luma_samples shall not be equal to 0. If not present, the value of reference_pic_width_in_luma_samples is inferred to be equal to dec_pic_width_in_luma_samples [i] .
- reference_pic_height_in_luma_samples specifies the height of the reference picture in units of luma samples. output_pic_height_in_luma_samples shall not be equal to 0. If not present, the value of reference_pic_height_in_luma_samples is inferred to be equal to dec_pic_height_in_luma_samples [i] .
- the size of the output picture shall be equal to the values of output_pic_width_in_luma_samples and output_pic_height_in_luma_samples.
- the size of the reference picture shall be equal to the values of reference_pic_width_in_luma_samples and _pic_height_in_luma_samples, when the reference picture is used for motion compensation.
- num_dec_pic_size_in_luma_samples_minus1 plus 1 specifies the number of the decoded picture size (dec_pic_width_in_luma_samples [i] , dec_pic_height_in_luma_samples [i] ) in units of luma samples in the coded video sequence.
- dec_pic_width_in_luma_samples [i] specifies the i-th width of the decoded picture sizes in units of luma samples in the coded video sequence.
- dec_pic_width_in_luma_samples [i] shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
- dec_pic_height_in_luma_samples [i] specifies the i-th height of the decoded picture sizes in units of luma samples in the coded video sequence.
- dec_pic_height_in_luma_samples [i] shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
- the i-th decoded picture size (dec_pic_width_in_luma_samples [i] , dec_pic_height_in_luma_samples [i] ) may be equal to the decoded picture size of the decoded picture in the coded video sequence.
- Table 8 Tile group header syntax
- dec_pic_size_idx specifies that the width of the decoded picture shall be equal to pic_width_in_luma_samples [dec_pic_size_idx] and the height of the decoded picture shall be equal to pic_height _in_luma_samples [dec_pic_size_idx] .
- the proposed design conceptually includes four different filter sets: down-sampling filter from the original picture to the input picture, up-/down-sampling filters to rescale reference pictures for motion estimation/compensation, and up-sampling filter from the decoded picture to the output picture.
- the first and last ones can be left as non-normative matters.
- up-/down-sampling filters need to be explicitly signaled in an appropriate parameter set, or pre-defined.
- SHVC SHM ver. 12.4
- SHVC SHM ver. 12.4
- 2D separable filter a 12-tap and 2D separable filter
- the phase of the down-sampling filter is set equal to zero by default.
- 8-tap interpolation filters are used, with 16-phases, to shift the phase and align the luma and chroma pixel positions to the original positions.
- Table 11 provides the 12-tap filter coefficients for down-sampling process. The same filter coefficients are used for both luma and chroma for down-sampling.
- tile group header is the correct place for something like dec_pic_size_idx as proposed above, for reasons already stated.
- a single ue (v) codepoint dec_pic_size_idx, conditionally present in the tile group header, is used to indicate the employed ARC parameters.
- the parameter dec_pic_size_idx can be moved into whatever header that starts a sub-picture. It may continue to be a tile group header.
- FIG. 13 shows an example of tile group-based resampling for ARC.
- the right picture which is made up of four sub-pictures (expressed perhaps as four rectangular tile groups in the bitstream syntax) .
- the bottom right TG is subsampled to half the size. It needs to be discussed what to do with the samples outside the relevant area, marked as “Half” .
- the basic ARC to be included in the “baseline/main” profiles is proposed. Sub-profiling may be used to remove them if not needed for certain application scenarios. Certain restrictions may be acceptable. In that regard, it is noted that certain H. 263+ profiles and “recommended modes” (which pre-dated profiles) included a restriction for Annex P to be used only as “implicit factor of 4” , i.e. dyadic downsampling in both dimensions. That was enough to support fast start (get the I frame over quickly) in video conferencing.
- the design is such that all filtering can be done “on the fly” and that there is no, or only negligible, increases in memory bandwidth. Insofar, it doesn’t seem there is a need to punt ARC into exotic profiles.
- a list of picture resolutions is signalled in the SPS, and an index to the list is signalled in the PPS to specify the size of an individual picture.
- the decoded picture before resampling is cropped (as necessary) and outputted, i.e., a resampled picture is not for output, only for inter prediction reference.
- both the resampled version and the original, resampled version of the reference picture are stored in the DPB, and thus both would affect the DPB fullness.
- a resampled reference picture is marked as "unused for reference” when the corresponding un-resampled reference picture is marked as "unused for reference” .
- the RPL signalling syntax is kept unchanged, while the RPL construction process is modified as follows: When a reference picture needs to be included into a RPL entry, and a version of that reference picture with the same resolution as the current picture is not in the DPB, the picture resampling process is invoked and the resampled version of that reference picture is included into the RPL entry.
- the number of resampled reference pictures that may be present in the DPB should be limited, e.g., to be less than or equal to 2.
- Another option is that, when resampling and quarter-pel interpolation need to be done, the two filters are combined and the operation is applied at once.
- temporal motion vector scaling is applied as needed.
- the ARC software was implemented on top of VTM-4.0.1, with the following changes:
- a picture-based resampling scheme was implemented for resampling reference pictures. After a picture is decoded, the reconstructed picture may be resampled to a different spatial resolution. The original reconstructed picture and the resampled reconstructed picture are both stored in the DPB and are available for reference by future pictures in decoding order.
- the up-sampling filter 4-tap +/-quarter-phase DCTIF with taps (-4, 54, 16, -2) /64
- the down-sampling filter the h11 filter with taps (1, 0, -3, 0, 10, 16, 10, 0, -3, 0, 1) /32
- the reference picture lists of the current picture i.e., L0 and L1
- the reference pictures may be available in both their original sizes or the resampled sizes.
- TMVP and ATMVP may be enabled; however, when the original coding resolutions of the current picture and a reference picture are different, TMVP and ATMVP are disabled for that reference picture.
- the decoder when outputting a picture, the decoder outputs the highest available resolution.
- the decoded picture before resampling is cropped (as necessary) and outputted, i.e., a resampled picture is not for output, only for inter prediction reference.
- the ARC resampling filters needs to be designed to optimize the use of the resampled pictures for inter prediction, and such filters may not be optimal for picture outputting/displaying purpose, while video terminal devices usually have optimized output zooming/scaling functionalities already implemented.
- Resampling of a decoded picture can be either picture-based or block-based.
- block-based resampling is preferred over picture-based resampling. It is recommend that these two approaches are discussed and the JVET makes a decision on which of these two is to be specified for ARC support in VVC.
- a reference picture may need to be resampled multiple times since multiple pictures may refer to the same reference picture, and .
- inverse resampling needs to be applied when the reference picture needs to be outputted, since it's better to output un-resampled pictures, as discussed above. This is a problem since resampling process is not a lossless operation.
- both the resampled version and the original, resampled version of the reference picture are stored in the DPB, and thus both would affect the DPB fullness.
- a resampled reference picture is marked as "unused for reference” when the corresponding un-resampled reference picture is marked as "unused for reference” .
- the reference picture lists (RPLs) of each tile group contain reference pictures that have the same resolution as the current picture. While there is no need for a change to the RPL signalling syntax, the RPL construction process is modified to ensure what is said in the previous sentence, as follows: When a reference picture needs to be included into a RPL entry while a version of that reference picture with the same resolution as the current picture is not yet available, the picture resampling process is invoked and the resampled version of that reference picture is included.
- the number of resampled reference pictures that may be present in the DPB should be limited, e.g., to be less than or equal to 2.
- temporal MV usage e.g. merge mode and ATMVP
- scaling temporal MV to the current resolution as needed.
- a reference block is resampled whenever needed, and no resampled picture is stored in the DPB.
- the main issue here is the additional decoder complexity. This is because a block in a reference picture may be referred to multiple times by multiple blocks in another picture and by blocks in multiple pictures.
- the reference block is resampled by invocation of the interpolation filter such that the reference block has the integer-pel resolution.
- the interpolation process is invoked again to obtain the resampled reference block in the quarter-pel resolution. Therefore, for each motion compensation operation for the current block from a reference block involving different resolutions, up to two, instead of one, interpolation filtering operations are needed. Without ARC support, up to only one interpolation filter operation (i.e., for generation of the reference block in the quarter-pel resolution) is needed.
- block blkA in the current picture picA refers to a reference block blkB in a reference picture picB
- block blkA shall be a uni-predicted block.
- the worst-case number of interpolation operations needed to decode a block is limited to two. If a block refers to a block from a different-resolution picture, the number of interpolation operations needed is two as discussed above. This is the same as in the case when the block refers to a reference block from a same-resolution picture and coded as a bi-predicted block since the number of interpolation operations is also two (i.e., one for getting the quarter-pel resolution for each reference block) .
- the corresponding positions of every pixel of predictors are calculated first, and then the interpolation is applied only one time. That is, two interpolation operations (i.e. one for resampling and one for quarter-pel interpolation) are combined into only one interpolation operation.
- the sub-pel interpolation filters in the current VVC can be reused, but, in this case, the granularity of interpolation should be enlarged but the interpolation operation times are reduced from two to one.
- temporal MV usage e.g. merge mode and ATMVP
- scaling temporal MV to the current resolution as needed.
- JVET-M0135 [1] to start the discussion on ARC, it is proposed that for the starting point of ARC, consider only the resampling ratio of 2x (meaning 2 x 2 for upsampling and 1/2 x 1/2 for downsampling) . From further discussion on this topic after the Marrakech meeting, it is found that supporting only the resampling ratio of 2x is very limited, as in some cases a smaller difference between resampled and un-resampled resolutions would be more beneficial.
- the DPB may contains decoded pictures of different spatial resolutions within the same CVS.
- counting DPB size and fullness in units decoded picture no longer works.
- PicSizeInSamplesY pic_width_in_luma_samples *pic_height_in_luma_samples
- MaxDpbSize maximum number of reference picture that may present in the DPB
- MinPicSizeInSampleY (Width of the smallest picture resolution in the bitstream) * (Height of the smallest resolution in the bitstream)
- MaxDpbSize is modified as follows (based on the HEVC equation) :
- PictureSizeUnit is an integer value that specifies how big a decoded picture size is relative to the MinPicSizeInSampleY.
- the definition of PictureSizeUnit depends on what resampling ratios are supported for ARC in VVC.
- the PictureSizeUnit is defined as follows:
- the PictureSizeUnit is defined as follows:
- MinPictureSizeUnit be the smallest possible value of PictureSizeUnit. That is, if ARC supports only resampling ratio of 2, MinPictureSizeUnit is 1; if ARC supports resampling ratios of 1.5 and 2, MinPictureSizeUnit is 4; likewise, the same principle is used to determine the value of MinPictureSizeUnit.
- the value range of sps_max_dec_pic_buffering_minus1 [i] is specified to range from 0 to (MinPictureSizeUnit * (MaxDpbSize –1) ) .
- MinPictureSizeUnit is the smallest possible value of PictureSizeUnit.
- the DPB fullness operation is specified based on PictureSizeUnit as follows:
- the HRD is initialized at decoding unit 0, with both the CPB and the DPB being set to be empty (the DPB fullness is set equal to 0) .
- the DPB fullness is set equal to 0.
- the DPB fullness is decrement by the value of PictureSizeUnit associated with the removed picture.
- the DPB fullness is increment by the value of PictureSizeUnit associated with the inserted picture.
- the implemented resampling filters were simply taken from previously available filters described in JCTVC-H0234 [3] .
- Other resampling filters should be tested and used if they provide better performance and/or lower complexity. It is proposed that various resampling filters to be tested to strike a trade-off between complexity and performance. Such tests can be done in a CE.
- TMVP and ATMVP are disabled when the original coding resolutions of current picture and reference picture are different.
- the standard shall support fast representation switching in the case of adaptive streaming services that offer multiple representations of the same content, each having different properties (e.g. spatial resolution or sample bit depth) . ”
- allowing resolution change within a coded video sequence without inserting an I picture can not only adapt the video data to dynamic channel conditions or user preference seamlessly, but also remove the beating effect caused by I pictures.
- FIG. 14 A hypothetical example of adaptive resolution change is shown in FIG. 14 where the current picture is predicted from reference pictures of different sizes.
- This contribution proposes high level syntax to signal adaptive resolution change as well as modifications to the current motion compensated prediction process in the VTM. These modifications are limited to motion vector scaling and subpel location derivations with no changes in the existing motion compensation interpolators. This would allow the existing motion compensation interpolators to be reused and not require new processing blocks to support adaptive resolution change which would introduce additional cost.
- pic_width_in_luma_samples specifies the width of each decoded picture in units of luma samples. pic_width_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
- pic_height_in_luma_samples specifies the height of each decoded picture in units of luma samples. pic_height_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY. ] ]
- max_pic_width_in_luma_samples specifies the maximum width of decoded pictures referring to the SPS in units of luma samples.
- max_pic_width_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
- max_pic_height_in_luma_samples specifies the maximum height of decoded pictures referring to the SPS in units of luma samples.
- max_pic_height_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
- pic_size_different_from_max_flag 1 specifies that the PPS signals different picture width or picture height from the max_pic_width_in_luma_samples and max_pic_height_in_luma_sample in the referred SPS.
- pic_size_different_from_max_flag 0 specifies that pic_width_in_luma_samples and pic_height_in_luma_sample are the same as max_pic_width_in_luma_samples and max_pic_height_in_luma_sample in the referred SPS.
- pic_width_in_luma_samples specifies the width of each decoded picture in units of luma samples.
- pic_width_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
- pic_width_in_luma_samples is not present, it is inferred to be equal to max_pic_width_in_luma_samples
- pic_height_in_luma_samples specifies the height of each decoded picture in units of luma samples.
- pic_height_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
- pic_height_in_luma_samples is not present, it is inferred to be equal to max_pic_height_in_luma_samples.
- horizontal and vertical scaling ratios shall be in the range of 1/8 to 2, inclusive for every active reference picture.
- the scaling ratios are defined as follows:
- horizontal_scaling_ratio ( (reference_pic_width_in_luma_samples ⁇ 14) + (pic_width _in_luma_samples/2) ) /pic_width_in_luma_samples
- vertical_scaling_ratio ( (reference_pic_height_in_luma_samples ⁇ 14) + (pic_height_i n_luma_samples/2) ) /pic_height_in_luma_samples
- a picture When there is a resolution change within a CVS, a picture may have a different size from one or more of its reference pictures.
- This proposal normalizes all motion vectors to the current picture grid instead of their corresponding reference picture grids. This is asserted to be beneficial to keep the design consistent and make resolution changes transparent to the motion vector prediction process. Otherwise, neighboring motion vectors pointing to reference pictures with different sizes cannot be used directly for spatial motion vector prediction due to the different scale.
- the scaling range is limited to [1/8, 2] , i.e. the upscaling is limited to 1: 8 and downscaling is limited to 2: 1. Note that upscaling refers to the case where the reference picture is smaller than the current picture, while downscaling refers to the case where the reference picture is larger than the current picture. In the following sections, the scaling process is described in more detail.
- the scaling process includes two parts:
- the subpel location (x ⁇ ', y ⁇ ') in the reference picture pointed to by a motion vector (mvX, mvY) in units of 1/16th pel is specified as follows:
- the horizontal location in the reference picture is the horizontal location in the reference picture.
- the reference location of the upper left corner pixel of the current block is at (x ⁇ ', y ⁇ ') .
- the other reference subple/pel locations are calculated relative to (x ⁇ ', y ⁇ ') with horizontal and vertical step sizes. Those step sizes are derived with 1/1024-pel accuracy from the above horizontal and vertical scaling factors as follows:
- x′ i and y′ j have to be broken up into full-pel parts and fractional-pel parts:
- the existing motion compensation interpolators can be used without any additional changes.
- the full-pel location will be used to fetch the reference block patch from the reference picture and the fractional-pel location will be used to select the proper interpolation filter.
- chroma motion vectors When the chroma format is 4: 2: 0, chroma motion vectors have 1/32-pel accuracy.
- the scaling process of chroma motion vectors and chroma reference blocks is almost the same as for luma blocks except a chroma format related adjustment.
- mvX and mvY are the original luma motion vector but now should be examined with 1/32-pel accuracy.
- x c ′ and y c ′ are further scaled down to keep 1/1024 pel accuracy
- chroma pixel at (i, j) relative to the upper left corner pixel its reference pixel’s horizontal and vertical coordinates are derived by
- fractional-pel parts used to select interpolation filters are equal to:
- tile_group_temporal_mvp_enabled_flag When tile_group_temporal_mvp_enabled_flag is equal to 1, the current picture and its collocated picture shall have the same size.
- decoder motion vector refinement When resolution change is allowed within a sequence, decoder motion vector refinement shall be turned off.
- sps_bdof_enabled_flag When resolution change is allowed within a sequence, sps_bdof_enabled_flag shall be equal to 0.
- CTB Coding Tree Block
- ALF Adaptive Loop Filter
- Adaptive parameter set was adopted in VTM4.
- Each APS contains one set of signalled ALF filters, up to 32 APSs are supported.
- slice-level temporal filter is tested.
- a tile group can re-use the ALF information from an APS to reduce the overhead.
- the APSs are updated as a first-in-first-out (FIFO) buffer.
- For luma component when ALF is applied to a luma CTB, the choice among 16 fixed, 5 temporal or 1 signaled filter sets is indicated. Only the filter set index is signalled. For one slice, only one new set of 25 filters can be signaled. If a new set is signalled for a slice, all the luma CTBs in the same slice share that set. Fixed filter sets can be used to predict the new slice-level filter set and can be used as candidate filter sets for a luma CTB as well. The number of filters is 64 in total.
- chroma component when ALF is applied to a chroma CTB, if a new filter is signalled for a slice, the CTB used the new filter, otherwise, the most recent temporal chroma filter satisfying the temporal scalability constrain is applied.
- the APSs are updated as a first-in-first-out (FIFO) buffer.
- the motion vectors temporal motion vector prediction is modified by fetching multiple sets of motion information (including motion vectors and reference indices) from blocks smaller than the current CU.
- the sub-CUs are square N ⁇ N blocks (N is set to 8 by default) .
- ATMVP predicts the motion vectors of the sub-CUs within a CU in two steps.
- the first step is to identify the corresponding block in a reference picture with a so-called temporal vector.
- the reference picture is called the motion source picture.
- the second step is to split the current CU into sub-CUs and obtain the motion vectors as well as the reference indices of each sub-CU from the block corresponding to each sub-CU, as shown in FIG. 15 which shows an example of ATMVP motion prediction for a CU.
- a reference picture and the corresponding block is determined by the motion information of the spatial neighbouring blocks of the current CU.
- the merge candidate from block A0 (the left block) in the merge candidate list of the current CU is used.
- the first available motion vector from block A0 referring to the collocated reference picture are set to be the temporal vector. This way, in ATMVP, the corresponding block may be more accurately identified, compared with TMVP, wherein the corresponding block (sometimes called collocated block) is always in a bottom-right or center position relative to the current CU.
- a corresponding block of the sub-CU is identified by the temporal vector in the motion source picture, by adding to the coordinate of the current CU the temporal vector.
- the motion information of its corresponding block (the smallest motion grid that covers the center sample) is used to derive the motion information for the sub-CU.
- the motion information of a corresponding N ⁇ N block is identified, it is converted to the motion vectors and reference indices of the current sub-CU, in the same way as TMVP of HEVC, wherein motion scaling and other procedures apply.
- FIGS. 16a and 16b show a simplified 4-paramter affine motion model and a simplified 6-parmaeter affine motion model, respectively. As shown FIGS. 16a and 16b, the affine motion field of the block is described by two control point motion vectors (CPMVs) for the 4-parameter affine model and 3 CPMVs for the 6-parameter affine model.
- CPMVs control point motion vectors
- the motion vector field (MVF) of a block is described by the following equations with the 4-parameter affine model (wherein the 4-parameter are defined as the variables a, b, e and f) in equation (1) and 6-parameter affine model (wherein the 4-parameter are defined as the variables a, b, c, d, e and f) in equation (2) respectively:
- control point motion vectors (CPMV)
- (x, y) represents the coordinate of a representative point relative to the top-left sample within current block
- (mvh (x, y) , mvv (x, y) ) is the motion vector derived for a sample located at (x, y) .
- the CP motion vectors may be signaled (like in the affine AMVP mode) or derived on-the-fly (like in the affine merge mode) .
- w and h are the width and height of the current block.
- the division is implemented by right-shift with a rounding operation.
- the representative point is defined to be the center position of a sub-block, e.g., when the coordinate of the left-top corner of a sub-block relative to the top-left sample within current block is (xs, ys) , the coordinate of the representative point is defined to be (xs+2, ys+2) .
- the representative point is utilized to derive the motion vector for the whole sub-block.
- sub-block based affine transform prediction is applied.
- the motion vector of the center sample of each sub-block is calculated according to Equation 25 and Equation 26, and rounded to 1/16 fraction accuracy.
- the motion compensation interpolation filters for 1/16-pel are applied to generate the prediction of each sub-block with derived motion vector.
- the interpolation filters for 1/16-pel are introduced by the affine mode.
- the high accuracy motion vector of each sub-block is rounded and saved as the same accuracy as the normal motion vector.
- AFFINE_INTER Similar to the translational motion model, there are also two modes for signaling the side information due affine prediction. They are AFFINE_INTER and AFFINE_MERGE modes.
- AF_INTER mode can be applied.
- An affine flag in CU level is signaled in the bitstream to indicate whether AF_INTER mode is used.
- an affine AMVP candidate list is constructed with three types of affine motion predictors in the following order, wherein each candidate includes the estimated CPMVs of the current block.
- the differences of the best CPMVs found at the encoder side (such as mv 0 mv 1 mv 2 in FIGS. 18a and 18b and the estimated CPMVs are signaled.
- the index of affine AMVP candidate from which the estimated CPMVs are derived is further signaled.
- the checking order is similar to that of spatial MVPs in HEVC AMVP list construction.
- a left inherited affine motion predictor is derived from the first block in ⁇ A1, A0 ⁇ that is affine coded and has the same reference picture as in current block.
- an above inherited affine motion predictor is derived from the first block in ⁇ B1, B0, B2 ⁇ that is affine coded and has the same reference picture as in current block.
- the five blocks A1, A0, B1, B0, B2 are depicted in FIG. 19.
- the CPMVs of the coding unit covering the neighboring block are used to derive predictors of CPMVs of current block. For example, if A1 is coded with non-affine mode and A0 is coded with 4-parameter affine mode, the left inherited affine MV predictor will be derived from A0. In this case, the CPMVs of a CU covering A0, as denoted by for the top-left CPMV and for the top-right CPMV in FIG.
- top-left with coordinate (x0, y0)
- top-right with coordinate (x1, y1)
- bottom-right positions with coordinate (x2, y2)
- a constructed affine motion predictor consists of control-point motion vectors (CPMVs) that are derived from neighboring inter coded blocks, as shown in FIG. 20, which have the same reference picture.
- CPMVs control-point motion vectors
- the number of CPMVs is 2, otherwise if the current affine motion model is 6-parameter affine, the number of CPMVs is 3.
- the top-left CPMV is derived by the MV at the first block in the group ⁇ A, B, C ⁇ that is inter coded and has the same reference picture as in current block.
- the top-right CPMV is derived by the MV at the first block in the group ⁇ D, E ⁇ that is inter coded and has the same reference picture as in current block.
- the bottom-left CPMV is derived by the MV at the first block in the group ⁇ F, G ⁇ that is inter coded and has the same reference picture as in current block.
- a constructed affine motion predictor is inserted into the candidate list only if both and are founded, that is, and are used as the estimated CPMVs for top-left (with coordinate (x0, y0) ) , top-right (with coordinate (x1, y1) ) positions of current block.
- a constructed affine motion predictor is inserted into the candidate list only if and are all founded, that is, and are used as the estimated CPMVs for top-left (with coordinate (x0, y0) ) , top-right (with coordinate (x1, y1) ) and bottom-right (with coordinate (x2, y2) ) positions of current block.
- MVD Motion Vector Difference
- two motion vectors e.g., mvA(xA, yA) and mvB (xB, yB)
- newMV mvA + mvB and the two components of newMV is set to (xA + xB) and (yA + yB) , respectively.
- FIG. 21 shows candidates for AF_MERGE.
- the selection order for the candidate block is from left, above, above right, left bottom to above left as shown in FIG. 21a (denoted by A, B, C, D, E in order) .
- the neighbor left bottom block is coded in affine mode as denoted by A0 in FIG. 21b
- the Control Point (CP) motion vectors mv 0 N , mv 1 N and mv 2 N of the top left corner, above right corner and left bottom corner of the neighboring CU/PU which contains the block A are fetched.
- the motion vector mv 0 C , mv 1 C and mv 2 C (which is only used for the 6-parameter affine model) of the top left corner/top right/bottom left on the current CU/PU is calculated based on mv 0 N , mv 1 N and mv 2 N .
- sub-block e.g. 4 ⁇ 4 block in VTM located at the top-left corner stores mv0
- the sub-block located at the top-right corner stores mv1 if the current block is affine coded.
- the sub-block located at the bottom-left corner stores mv2; otherwise (with the 4-parameter affine model) , LB stores mv2’.
- Other sub-blocks store the MVs used for MC.
- the MVF of the current CU is generated.
- an affine flag is signaled in the bitstream when there is at least one neighbor block is coded in affine mode.
- an affine merge candidate list is constructed with following steps:
- Inherited affine candidate means that the candidate is derived from the affine motion model of its valid neighbor affine coded block.
- the maximum two inherited affine candidates are derived from affine motion model of the neighboring blocks and inserted into the candidate list.
- the scan order is ⁇ A0, A1 ⁇ ; for the above predictor, the scan order is ⁇ B0, B1, B2 ⁇ .
- Constructed affine candidate means the candidate is constructed by combining the neighbor motion information of each control point.
- the motion information for the control points is derived firstly from the specified spatial neighbors and temporal neighbor shown in FIG. 22 which shows an example of a candidates position for affine merge mode.
- T is temporal position for predicting CP4.
- the coordinates of CP1, CP2, CP3 and CP4 is (0, 0) , (W, 0) , (H, 0) and (W, H) , respectively, where W and H are the width and height of current block.
- the motion information of each control point is obtained according to the following priority order:
- the checking priority is B2->B3->A2.
- B2 is used if it is available. Otherwise, if B2 is available, B3 is used. If both B2 and B3 are unavailable, A2 is used. If all the three candidates are unavailable, the motion information of CP1 cannot be obtained.
- the checking priority is B1->B0.
- the checking priority is A1->A0.
- the three control points can be selected from one of the following four combinations ( ⁇ CP1, CP2, CP4 ⁇ , ⁇ CP1, CP2, CP3 ⁇ , ⁇ CP2, CP3, CP4 ⁇ , ⁇ CP1, CP3, CP4 ⁇ ) .
- Combinations ⁇ CP1, CP2, CP3 ⁇ , ⁇ CP2, CP3, CP4 ⁇ , ⁇ CP1, CP3, CP4 ⁇ will be converted to a 6-parameter motion model represented by top-left, top-right and bottom-left control points.
- the two control points can be selected from one of the two combinations ( ⁇ CP1, CP2 ⁇ , ⁇ CP1, CP3 ⁇ ) .
- the two combinations will be converted to a 4-parameter motion model represented by top-left and top-right control points.
- the reference indices of list X for each CP are checked, if they are all the same, then this combination has valid CPMVs for list X. If the combination does not have valid CPMVs for both list 0 and list 1, then this combination is marked as invalid. Otherwise, it is valid, and the CPMVs are put into the sub-block merge list.
- ARC When applied in VVC, ARC may have the following issues:
- VVC Video Coding Coding
- LMCS Luma Mapping Chroma Scaling
- DMVR Decoder Side Motion-vector Refinement
- BDOF Bi-Directional Optical Flow
- Affine prediction Triangular Prediction Mode
- SMVD Symmetrical Motion Vector Difference
- MMVD Merge Motion Vector Difference
- inter-intra prediction a.k.a. Combined Inter-picture merge and Intra-picture Prediction CIIP in VVC
- LIC Localized Illumination Compensation
- HMVP History-based Motion Vector Prediction
- Embodiments of the disclosed technology overcome the drawbacks of existing implementations.
- the examples of the disclosed technology provided below are discussed to facilitate the understanding of the disclosed technology and should be interpreted in a way to limit the disclosed technology. Unless explicitly indicated to the contrary, the various features described in these examples can be combined.
- Shift (x, n) (x+ offset0) >>n.
- offset0 and/or offset1 are set to (1 ⁇ n) >>1 or (1 ⁇ (n-1) ) . In another example, offset0 and/or offset1 are set to 0.
- Clip3 (min, max, x) is defined as
- Floor (x) is defined as the largest integer less than or equal to x.
- Ceil (x) is the smallest integer greater than or equal to x.
- Log2 (x) is defined as the base-2 logarithm of x.
- the derivation of MV offsets in MMVD/SMVD and/or refined motion vectors in decoder side derivation process may depend on the resolution of reference pictures associated with current block and the resolution of current picture.
- the second MV offset referring to a second reference picture may be scaled from a first MV offset referring to a first reference picture.
- the scaling factor may depend on the resolutions of the first and second reference pictures.
- the motion candidate list construction process may be constructed according to the reference picture resolution associated with the spatial/temporal/history motion candidates.
- a merge candidate referring to a reference picture with a higher resolution may have a higher priority than a merge candidate referring to a reference picture with a lower resolution.
- resolution W0*H0 is lower than resolution W1*H1 if W0 ⁇ W1 and H0 ⁇ H1.
- a merge candidate referring to a reference picture with a higher resolution may be put before a merge candidate referring to a reference picture with a lower resolution in the merge candidate list.
- a motion vector referring to a reference picture with a resolution lower than the resolution of the current picture cannot be in the merge candidate list.
- whether to and/or how to update the history buffer may depend on reference picture resolution associated with the decoded motion candidate.
- ALF parameters signaled in a video unit such as APS may be associated with one or multiple picture dimensions.
- a video unit such as APS signaling ALF parameters may be associated with one or multiple picture dimensions.
- a picture may only apply ALF parameters signaled in a video unit such as APS, associated with the same dimensions.
- the resolution/index of PPS/indication of resolution may be signaled in the ALF APS.
- ALF parameter may only inherit/be predicted from that used for a picture with the same resolution.
- ALF parameters associated with a first corresponding dimensions may inherit or be predicted from ALF parameters associated with a second corresponding dimensions.
- the first corresponding dimensions must be the same as the second corresponding dimensions.
- the first corresponding dimensions may be different to the second corresponding dimensions.
- LMCS parameters signaled in a video unit such as APS may be associated with one or multiple picture dimensions.
- a video unit such as APS signaling LMCS parameters may be associated with one or multiple picture dimensions.
- a picture may only apply LMCS parameters signaled in a video unit such as APS, associated with the same dimensions.
- the resolution/index of PPS/indication of resolution may be signaled in the LMCS APS.
- LMCS parameter may only inherit/be predicted from that used for a picture with the same resolution.
- LMCS parameters associated with a first corresponding dimensions may inherit or be predicted from LMCS parameters associated with a second corresponding dimensions.
- the first corresponding dimensions must be the same as the second corresponding dimensions.
- the first corresponding dimensions may be different to the second corresponding dimensions.
- TPM triangular prediction mode
- GEO inter prediction with geometry partitioning
- a may depend on whether resolution of one of the two reference pictures and resolution of current picture.
- b may depend on whether resolutions of the two reference pictures are same or not.
- a coding tool may be disabled if two reference pictures are associated with different resolution.
- the coding tool X may be disabled.
- such a coding tool may be always disabled if RPR (reference picture resampling is enabled in slice/picture header/sequence parameter set) .
- coding tool X may be disabled for a block if the block refers to at least one reference picture with different dimensions to the current picture.
- the information related to the coding tool X may not be signaled.
- motion information of such block may not be inserted into the HMVP table.
- coding tool X is applied in a block, the block cannot refer to a reference picture with different dimensions to the current picture.
- a merge candidate referring to a reference picture with different dimensions to the current picture may be skipped or not put into the merge candidate list.
- the reference index corresponds to a reference picture with different dimensions to the current picture may be skipped or not allowed to be signaled.
- the coding tool X may be applied after scaling the two reference blocks or pictures according to resolution of the current picture and resolutions of the reference pictures.
- the coding tool X may be applied after scaling the two MVs or MVDs according to resolution of the current picture and resolutions of the reference pictures.
- whether to disable or enabled the coding tool X may depend on the resolutions of the reference picture associated with the reference picture list and/or current reference picture.
- the coding tool X may be disabled for one reference picture list but enabled for the other reference picture list.
- the coding tool X may be disabled for one reference picture but enabled for the other reference picture.
- the two reference pictures may be from different or same reference picture list.
- enabling/disabling the coding tool is determined regardless the reference picture in another reference picture list different than list L.
- it may be determined by the reference picture of list L and current picture.
- the tool may be disabled for list L if the associated reference picture for list L is different from current picture.
- enabling/disabling the coding tool is determined by resolutions of all reference pictures and/or current picture.
- the coding tool X may be disabled if at least one of the reference pictures has different resolution as current picture.
- the coding tool X may be still enabled.
- the coding tool X may be disabled.
- the coding tool X may be anyone below.
- Reference picture list of a picture may contain no more than K different resolutions.
- K is equal to 2.
- no more than K different resolutions may be allowed in a GOP
- no more than K different resolutions may be allowed between two pictures with same certain temporal layer id (denoted as tid) .
- Resolution change may be allowed for Intra picture only.
- Bi-prediction may be converted to uni-prediction in the decoding process if one or two reference pictures of one block are with different resolution as the current picture.
- the prediction from list X with the corresponding reference picture with different resolution as the current picture may be discarded.
- Whether to enable or disable inter-prediction from reference pictures in different resolution may depend on the motion vector precision and/or resolution ratios.
- the inter-prediction may be still applied.
- the inter-prediction may be still applied.
- bi-prediction may be disallowed when both reference pictures are with different resolutions from the current picture.
- bi-prediction may be enabled when one reference picture is with different resolution from the current picture and the other is with the same resolution.
- uni-prediction may be disallowed for a block when the reference picture is with different resolution from the current picture and the block dimension satisfy certain conditions.
- a first flag (e.g., pic_disable_X_flag) to indicate whether a coding tool X is disabled may be signaled in picture header.
- Whether to enable the coding tool for a slice/tile/brick/subpicture/other video unit smaller than a picture may be controlled by this flag in picture header and/or slice types.
- the coding tool X is disabled.
- the coding tool X is enabled.
- ii In one example, it is enabled/disabled for all samples within the picture.
- the signaling of the first flag may further depend on a syntax element or multiple syntax elements in SPS/VPS/DPS/PPS.
- the signaling of the flag may depend on the enabling flag of the coding tool X in SPS.
- a second flag (e.g., sps_X_slice_present_flag) to indicate the presence of the first flag in a picture header may be signaled in SPS.
- the second flag may be conditionally signaled when the coding tool X is enabled for a sequence (e.g., sps_X_enabled_flag is true) .
- the first flag may be signaled in picture header.
- the first and/or the second flag is coded with 1-bit.
- the coding tool X may be:
- the coding tool X is the PROF.
- the coding tool X is the DMVR.
- the coding tool X is the BDOF.
- the coding tool X is the cross-component ALF.
- the coding tool X is the GEO.
- the coding tool X is the TPM.
- the coding tool X is the MTS.
- Whether a block can refer to a reference picture with different dimensions to the current picture may depend on the width (WB) and/or height (HB) of the block, and/or block prediction mode (i.e., bi-prediction or uni-prediction) .
- WB width
- HB height
- block prediction mode i.e., bi-prediction or uni-prediction
- FIG. 23 shows a flowchart of an exemplary method for video processing.
- the method 2300 includes, at step 2310, deriving during conversion between a current video block and a bitstream representation of the current video block, motion vector offsets based on a resolution of reference pictures associated with the current video block and a resolution of a current picture.
- the method 2300 further includes, at step 2320, performing the conversion using the motion vector offsets.
- the deriving motion vector offset includes: deriving a first motion vector offset referring to a first reference picture; and deriving a second motion vector offset referring to a second reference picture based on the first motion vector offset.
- the method further comprises: performing, for the current video block, a motion candidate list construction process based on a reference picture resolution associated with a spatial, temporal, or history motion candidates. In some implementations, whether to or how to update a look up table depends on a reference picture resolution associated with a decoded motion candidate.
- the method further comprises: performing, for the current picture, a filtering operation with adaptive loop filter (ALF) parameters associated with corresponding dimensions.
- the ALF parameters include first ALF parameters associated with first corresponding dimensions and second ALF parameters associated with second corresponding dimensions, the second ALF parameters being inherited or predicted from the first ALF parameters.
- the method further comprises reshaping samples in the current picture with LMCS (Luma Mapping Chroma Scaling) parameters associated with corresponding dimensions.
- the LMCS parameters include first LMCS parameters associated with first corresponding dimensions and second LMCS parameters associated with second corresponding dimensions, the second LMCS parameters being inherited or predicted from the first LMCS parameters.
- the ALF parameters or the LMCS parameters signaled in a video unit is associated with one or multiple picture dimensions.
- the method further comprises disabling a coding tool for the current video block when the current video block refers to at least one reference picture with different dimensions to the current picture.
- the method further includes skipping or omitting a merge candidate referring to a reference picture with different dimensions from dimensions of the current picture.
- the method further includes applying a coding tool after scaling two reference blocks or two reference pictures based on the resolution of the reference pictures and the resolution of the current picture or after scaling two MVs or MVDs (Motion Vector Differences) based on the resolution of the reference pictures and the resolution of the current picture.
- the current picture includes no more than K different resolutions, K being a natural number.
- the K different resolutions are allowed for N consecutive pictures, N being a natural number.
- the method further includes applying a resolution change to the current picture that is an Intra picture. In some implementations, the method further includes converting a bi-prediction to a uni-prediction when one or two reference pictures of the current video block has a different resolution from that of the current picture. In some implementations, the method further includes enabling or disabling an inter-prediction from the reference pictures in different resolutions depending on at least one of a motion vector precision or a resolution ratio between a current block dimension and a reference block dimension.
- the method further includes applying a bi-prediction depending on whether both reference pictures or one reference picture is with different resolution from that of the current picture.
- whether the current video block refers to a reference picture with different dimensions from that of the current picture depends on at least one of a size of the current video block or a block prediction mode.
- the performing of the conversion includes generating the current video block from the bitstream representation.
- the performing of the conversion includes generating the bitstream representation from the current video block.
- FIG. 24A is a block diagram of a video processing apparatus 2400.
- the apparatus 2400 may be used to implement one or more of the methods described herein.
- the apparatus 2400 may be embodied in a smartphone, tablet, computer, Internet of Things (IoT) receiver, and so on.
- the apparatus 2400 may include one or more processors 2402, one or more memories 2404 and video processing hardware 2406.
- the processor (s) 2402 may be configured to implement one or more methods (including, but not limited to, methods 2300) described in the present document.
- the memory (memories) 2404 may be used for storing data and code used for implementing the methods and techniques described herein.
- the video processing hardware 2406 may be used to implement, in hardware circuitry, some techniques described in the present document. In some embodiments, the hardware 2406 may be entirely or partly in the processor 2401, e.g., as a graphics processor.
- FIG. 24B is a block diagram showing an example video processing system 2410 in which various techniques disclosed herein may be implemented.
- the system 2410 may include input 2412 for receiving video content.
- the video content may be received in a raw or uncompressed format, e.g., 8 or 10 bit multi-component pixel values, or may be in a compressed or encoded format.
- the input 2412 may represent a network interface, a peripheral bus interface, or a storage interface. Examples of network interface include wired interfaces such as Ethernet, passive optical network (PON) , etc. and wireless interfaces such as Wi-Fi or cellular interfaces.
- PON passive optical network
- the system 2410 may include a coding component 2414 that may implement the various coding or encoding methods described in the present document.
- the coding component 2414 may reduce the average bitrate of video from the input 2412 to the output of the coding component 2414 to produce a coded representation of the video.
- the coding techniques are therefore sometimes called video compression or video transcoding techniques.
- the output of the coding component 2414 may be either stored, or transmitted via a communication connected, as represented by the component 2416.
- the stored or communicated bitstream (or coded) representation of the video received at the input 2412 may be used by the component 2418 for generating pixel values or displayable video that is sent to a display interface 2420.
- the process of generating user-viewable video from the bitstream representation is sometimes called video decompression.
- certain video processing operations are referred to as “coding” operations or tools, it will be appreciated that the coding tools or operations are used at an encoder and corresponding decoding tools or operations that reverse the results of the coding will be
- peripheral bus interface or a display interface may include universal serial bus (USB) or high definition multimedia interface (HDMI) or Displayport, and so on.
- storage interfaces include SATA (serial advanced technology attachment) , PCI, IDE interface, and the like.
- the video coding methods may be implemented using an apparatus that is implemented on a hardware platform as described with respect to FIG. 24A or 24B.
- FIG. 25 is a block diagram that illustrates an example video coding system 100 that may utilize the techniques of this disclosure.
- video coding system 100 may include a source device 110 and a destination device 120.
- Source device 110 generates encoded video data which may be referred to as a video encoding device.
- Destination device 120 may decode the encoded video data generated by source device 110 which may be referred to as a video decoding device.
- Source device 110 may include a video source 112, a video encoder 114, and an input/output (I/O) interface 116.
- Video source 112 may include a source such as a video capture device, an interface to receive video data from a video content provider, and/or a computer graphics system for generating video data, or a combination of such sources.
- the video data may comprise one or more pictures.
- Video encoder 114 encodes the video data from video source 112 to generate a bitstream.
- the bitstream may include a sequence of bits that form a coded representation of the video data.
- the bitstream may include coded pictures and associated data.
- the coded picture is a coded representation of a picture.
- the associated data may include sequence parameter sets, picture parameter sets, and other syntax structures.
- I/O interface 116 may include a modulator/demodulator (modem) and/or a transmitter.
- the encoded video data may be transmitted directly to destination device 120 via I/O interface 116 through network 130a.
- the encoded video data may also be stored onto a storage medium/server 130b for access by destination device 120.
- Destination device 120 may include an I/O interface 126, a video decoder 124, and a display device 122.
- I/O interface 126 may include a receiver and/or a modem. I/O interface 126 may acquire encoded video data from the source device 110 or the storage medium/server 130b. Video decoder 124 may decode the encoded video data. Display device 122 may display the decoded video data to a user. Display device 122 may be integrated with the destination device 120, or may be external to destination device 120 which be configured to interface with an external display device.
- Video encoder 114 and video decoder 124 may operate according to a video compression standard, such as the High Efficiency Video Coding (HEVC) standard, Versatile Video Coding (VVC) standard and other current and/or further standards.
- HEVC High Efficiency Video Coding
- VVC Versatile Video Coding
- FIG. 26 is a block diagram illustrating an example of video encoder 200, which may be video encoder 114 in the system 100 illustrated in FIG. 25.
- Video encoder 200 may be configured to perform any or all of the techniques of this disclosure.
- video encoder 200 includes a plurality of functional components. The techniques described in this disclosure may be shared among the various components of video encoder 200.
- a processor may be configured to perform any or all of the techniques described in this disclosure.
- the functional components of video encoder 200 may include a partition unit 201, a predication unit 202 which may include a mode select unit 203, a motion estimation unit 204, a motion compensation unit 205 and an intra prediction unit 206, a residual generation unit 207, a transform unit 208, a quantization unit 209, an inverse quantization unit 210, an inverse transform unit 211, a reconstruction unit 212, a buffer 213, and an entropy encoding unit 214.
- a partition unit 201 may include a mode select unit 203, a motion estimation unit 204, a motion compensation unit 205 and an intra prediction unit 206, a residual generation unit 207, a transform unit 208, a quantization unit 209, an inverse quantization unit 210, an inverse transform unit 211, a reconstruction unit 212, a buffer 213, and an entropy encoding unit 214.
- video encoder 200 may include more, fewer, or different functional components.
- predication unit 202 may include an intra block copy (IBC) unit.
- the IBC unit may perform predication in an IBC mode in which at least one reference picture is a picture where the current video block is located.
- IBC intra block copy
- motion estimation unit 204 and motion compensation unit 205 may be highly integrated, but are represented in the example of FIG. 26 separately for purposes of explanation.
- Partition unit 201 may partition a picture into one or more video blocks.
- Video encoder 200 and video decoder 300 may support various video block sizes.
- Mode select unit 203 may select one of the coding modes, intra or inter, e.g., based on error results, and provide the resulting intra-or inter-coded block to a residual generation unit 207 to generate residual block data and to a reconstruction unit 212 to reconstruct the encoded block for use as a reference picture.
- Mode select unit 203 may select a combination of intra and inter predication (CIIP) mode in which the predication is based on an inter predication signal and an intra predication signal.
- CIIP intra and inter predication
- Mode select unit 203 may also select a resolution for a motion vector (e.g., a sub-pixel or integer pixel precision) for the block in the case of inter-predication.
- motion estimation unit 204 may generate motion information for the current video block by comparing one or more reference frames from buffer 213 to the current video block.
- Motion compensation unit 205 may determine a predicted video block for the current video block based on the motion information and decoded samples of pictures from buffer 213 other than the picture associated with the current video block.
- Motion estimation unit 204 and motion compensation unit 205 may perform different operations for a current video block, for example, depending on whether the current video block is in an I slice, a P slice, or a B slice.
- motion estimation unit 204 may perform uni-directional prediction for the current video block, and motion estimation unit 204 may search reference pictures of list 0 or list 1 for a reference video block for the current video block. Motion estimation unit 204 may then generate a reference index that indicates the reference picture in list 0 or list 1 that contains the reference video block and a motion vector that indicates a spatial displacement between the current video block and the reference video block. Motion estimation unit 204 may output the reference index, a prediction direction indicator, and the motion vector as the motion information of the current video block. Motion compensation unit 205 may generate the predicted video block of the current block based on the reference video block indicated by the motion information of the current video block.
- motion estimation unit 204 may perform bi-directional prediction for the current video block, motion estimation unit 204 may search the reference pictures in list 0 for a reference video block for the current video block and may also search the reference pictures in list 1 for another reference video block for the current video block. Motion estimation unit 204 may then generate reference indexes that indicate the reference pictures in list 0 and list 1 containing the reference video blocks and motion vectors that indicate spatial displacements between the reference video blocks and the current video block. Motion estimation unit 204 may output the reference indexes and the motion vectors of the current video block as the motion information of the current video block. Motion compensation unit 205 may generate the predicted video block of the current video block based on the reference video blocks indicated by the motion information of the current video block.
- motion estimation unit 204 may output a full set of motion information for decoding processing of a decoder.
- motion estimation unit 204 may do not output a full set of motion information for the current video. Rather, motion estimation unit 204 may signal the motion information of the current video block with reference to the motion information of another video block. For example, motion estimation unit 204 may determine that the motion information of the current video block is sufficiently similar to the motion information of a neighboring video block.
- motion estimation unit 204 may indicate, in a syntax structure associated with the current video block, a value that indicates to the video decoder 300 that the current video block has the same motion information as the another video block.
- motion estimation unit 204 may identify, in a syntax structure associated with the current video block, another video block and a motion vector difference (MVD) .
- the motion vector difference indicates a difference between the motion vector of the current video block and the motion vector of the indicated video block.
- the video decoder 300 may use the motion vector of the indicated video block and the motion vector difference to determine the motion vector of the current video block.
- video encoder 200 may predictively signal the motion vector.
- Two examples of predictive signaling techniques that may be implemented by video encoder 200 include advanced motion vector predication (AMVP) and merge mode signaling.
- AMVP advanced motion vector predication
- merge mode signaling merge mode signaling
- Intra prediction unit 206 may perform intra prediction on the current video block. When intra prediction unit 206 performs intra prediction on the current video block, intra prediction unit 206 may generate prediction data for the current video block based on decoded samples of other video blocks in the same picture.
- the prediction data for the current video block may include a predicted video block and various syntax elements.
- Residual generation unit 207 may generate residual data for the current video block by subtracting (e.g., indicated by the minus sign) the predicted video block (s) of the current video block from the current video block.
- the residual data of the current video block may include residual video blocks that correspond to different sample components of the samples in the current video block.
- residual generation unit 207 may not perform the subtracting operation.
- Transform processing unit 208 may generate one or more transform coefficient video blocks for the current video block by applying one or more transforms to a residual video block associated with the current video block.
- quantization unit 209 may quantize the transform coefficient video block associated with the current video block based on one or more quantization parameter (QP) values associated with the current video block.
- QP quantization parameter
- Inverse quantization unit 210 and inverse transform unit 211 may apply inverse quantization and inverse transforms to the transform coefficient video block, respectively, to reconstruct a residual video block from the transform coefficient video block.
- Reconstruction unit 212 may add the reconstructed residual video block to corresponding samples from one or more predicted video blocks generated by the predication unit 202 to produce a reconstructed video block associated with the current block for storage in the buffer 213.
- loop filtering operation may be performed reduce video blocking artifacts in the video block.
- Entropy encoding unit 214 may receive data from other functional components of the video encoder 200. When entropy encoding unit 214 receives the data, entropy encoding unit 214 may perform one or more entropy encoding operations to generate entropy encoded data and output a bitstream that includes the entropy encoded data.
- FIG. 27 is a block diagram illustrating an example of video decoder 300 which may be video decoder 114 in the system 100 illustrated in FIG. 25.
- the video decoder 300 may be configured to perform any or all of the techniques of this disclosure.
- the video decoder 300 includes a plurality of functional components.
- the techniques described in this disclosure may be shared among the various components of the video decoder 300.
- a processor may be configured to perform any or all of the techniques described in this disclosure.
- video decoder 300 includes an entropy decoding unit 301, a motion compensation unit 302, an intra prediction unit 303, an inverse quantization unit 304, an inverse transformation unit 305, and a reconstruction unit 306 and a buffer 307.
- Video decoder 300 may, in some examples, perform a decoding pass generally reciprocal to the encoding pass described with respect to video encoder 200 (e.g., FIG. 26) .
- Entropy decoding unit 301 may retrieve an encoded bitstream.
- the encoded bitstream may include entropy coded video data (e.g., encoded blocks of video data) .
- Entropy decoding unit 301 may decode the entropy coded video data, and from the entropy decoded video data, motion compensation unit 302 may determine motion information including motion vectors, motion vector precision, reference picture list indexes, and other motion information. Motion compensation unit 302 may, for example, determine such information by performing the AMVP and merge mode.
- Motion compensation unit 302 may produce motion compensated blocks, possibly performing interpolation based on interpolation filters. Identifiers for interpolation filters to be used with sub-pixel precision may be included in the syntax elements.
- Motion compensation unit 302 may use interpolation filters as used by video encoder 20 during encoding of the video block to calculate interpolated values for sub-integer pixels of a reference block. Motion compensation unit 302 may determine the interpolation filters used by video encoder 200 according to received syntax information and use the interpolation filters to produce predictive blocks.
- Motion compensation unit 302 may uses some of the syntax information to determine sizes of blocks used to encode frame (s) and/or slice (s) of the encoded video sequence, partition information that describes how each macroblock of a picture of the encoded video sequence is partitioned, modes indicating how each partition is encoded, one or more reference frames (and reference frame lists) for each inter-encoded block, and other information to decode the encoded video sequence.
- Intra prediction unit 303 may use intra prediction modes for example received in the bitstream to form a prediction block from spatially adjacent blocks.
- Inverse quantization unit 303 inverse quantizes, i.e., de-quantizes, the quantized video block coefficients provided in the bitstream and decoded by entropy decoding unit 301.
- Inverse transform unit 303 applies an inverse transform.
- Reconstruction unit 306 may sum the residual blocks with the corresponding prediction blocks generated by motion compensation unit 202 or intra-prediction unit 303 to form decoded blocks. If desired, a deblocking filter may also be applied to filter the decoded blocks in order to remove blockiness artifacts. The decoded video blocks are then stored in buffer 307, which provides reference blocks for subsequent motion compensation.
- Some embodiments of the disclosed technology include making a decision or determination to enable a video processing tool or mode.
- the encoder when the video processing tool or mode is enabled, the encoder will use or implement the tool or mode in the processing of a block of video, but may not necessarily modify the resulting bitstream based on the usage of the tool or mode. That is, a conversion from the block of video to the bitstream representation of the video will use the video processing tool or mode when it is enabled based on the decision or determination.
- the decoder when the video processing tool or mode is enabled, the decoder will process the bitstream with the knowledge that the bitstream has been modified based on the video processing tool or mode. That is, a conversion from the bitstream representation of the video to the block of video will be performed using the video processing tool or mode that was enabled based on the decision or determination.
- Some embodiments of the disclosed technology include making a decision or determination to disable a video processing tool or mode.
- the encoder will not use the tool or mode in the conversion of the block of video to the bitstream representation of the video.
- the decoder will process the bitstream with the knowledge that the bitstream has not been modified using the video processing tool or mode that was disabled based on the decision or determination.
- video processing may refer to video encoding, video decoding, video compression or video decompression.
- video compression algorithms may be applied during conversion from pixel representation of a video to a corresponding bitstream representation or vice versa.
- the bitstream representation of a current video block may, for example, correspond to bits that are either co-located or spread in different places within the bitstream, as is defined by the syntax.
- a macroblock may be encoded in terms of transformed and coded error residual values and also using bits in headers and other fields in the bitstream.
- a method for video processing comprising: deriving, during conversion between a current video block and a bitstream representation of the current video block, motion vector offsets based on a resolution of reference pictures associated with the current video block and a resolution of a current picture; and performing the conversion using the motion vector offsets.
- the deriving motion vector offset includes: deriving a first motion vector offset referring to a first reference picture; and deriving a second motion vector offset referring to a second reference picture based on the first motion vector offset.
- the ALF parameters include first ALF parameters associated with first corresponding dimensions and second ALF parameters associated with second corresponding dimensions, the second ALF parameters being inherited or predicted from the first ALF parameters.
- the LMCS parameters include first LMCS parameters associated with first corresponding dimensions and second LMCS parameters associated with second corresponding dimensions, the second LMCS parameters being inherited or predicted from the first LMCS parameters.
- An apparatus in a video system comprising a processor and a non-transitory memory with instructions thereon, wherein the instructions upon execution by the processor, cause the processor to implement the method in any one of clauses 1 to 21.
- a computer program product stored on a non-transitory computer readable media including program code for carrying out the method in any one of clauses 1 to 21.
- a method for video processing comprising: determining (2810) , for a conversion between a video region of a picture of a video and a coded representation of the video, enablement status of a coding tool used to represent the video region in the coded representation; and performing (2820) the conversion according to the determination; wherein a first flag is included in a picture header to indicate the enablement status of the coding tool for the picture.
- a signaling of the first flag depends on one or more syntax elements in a sequence parameter set (SPS) , a video parameter set (VPS) , a dependency parameter set (DPS) , or a picture parameter set (PPS) that is associated with the video region.
- SPS sequence parameter set
- VPN video parameter set
- DPS dependency parameter set
- PPS picture parameter set
- coding tool is a decoder-side motion vector refinement (DMVR) in which motion information is refined by using prediction blocks.
- DMVR decoder-side motion vector refinement
- the coding tool is a geometry partitioning (GEO) in which prediction samples are generated with weighting values, the prediction samples based on partitioning of the video region according to a non-horizontal or a non-vertical line.
- GEO geometry partitioning
- the coding tool is a triangular prediction mode (TPM) in which prediction samples are generated with weighting values, the prediction samples based on partitioning of the video region into two triangular partitions.
- TPM triangular prediction mode
- a video processing apparatus comprising a processor configured to implement a method recited in any one or more of clauses 1 to 21.
- a computer readable medium storing program code that, when executed, causes a processor to implement a method recited in any one or more of clauses 1 to 21.
- a computer readable medium that stores a coded representation or a bitstream representation generated according to any of the above described methods.
- Implementations of the subject matter and the functional operations described in this patent document can be implemented in various systems, digital electronic circuitry, or in computer software, firmware, or hardware, including the structures disclosed in this specification and their structural equivalents, or in combinations of one or more of them. Implementations of the subject matter described in this specification can be implemented as one or more computer program products, i.e., one or more modules of computer program instructions encoded on a tangible and non-transitory computer readable medium for execution by, or to control the operation of, data processing apparatus.
- the computer readable medium can be a machine-readable storage device, a machine-readable storage substrate, a memory device, a composition of matter effecting a machine-readable propagated signal, or a combination of one or more of them.
- data processing unit or “data processing apparatus” encompasses all apparatus, devices, and machines for processing data, including by way of example a programmable processor, a computer, or multiple processors or computers.
- the apparatus can include, in addition to hardware, code that creates an execution environment for the computer program in question, e.g., code that constitutes processor firmware, a protocol stack, a database management system, an operating system, or a combination of one or more of them.
- a computer program (also known as a program, software, software application, script, or code) can be written in any form of programming language, including compiled or interpreted languages, and it can be deployed in any form, including as a stand-alone program or as a module, component, subroutine, or other unit suitable for use in a computing environment.
- a computer program does not necessarily correspond to a file in a file system.
- a program can be stored in a portion of a file that holds other programs or data (e.g., one or more scripts stored in a markup language document) , in a single file dedicated to the program in question, or in multiple coordinated files (e.g., files that store one or more modules, sub programs, or portions of code) .
- a computer program can be deployed to be executed on one computer or on multiple computers that are located at one site or distributed across multiple sites and interconnected by a communication network.
- the processes and logic flows described in this specification can be performed by one or more programmable processors executing one or more computer programs to perform functions by operating on input data and generating output.
- the processes and logic flows can also be performed by, and apparatus can also be implemented as, special purpose logic circuitry, e.g., an FPGA (field programmable gate array) or an ASIC (application specific integrated circuit) .
- processors suitable for the execution of a computer program include, by way of example, both general and special purpose microprocessors, and any one or more processors of any kind of digital computer.
- a processor will receive instructions and data from a read only memory or a random access memory or both.
- the essential elements of a computer are a processor for performing instructions and one or more memory devices for storing instructions and data.
- a computer will also include, or be operatively coupled to receive data from or transfer data to, or both, one or more mass storage devices for storing data, e.g., magnetic, magneto optical disks, or optical disks.
- mass storage devices for storing data, e.g., magnetic, magneto optical disks, or optical disks.
- a computer need not have such devices.
- Computer readable media suitable for storing computer program instructions and data include all forms of nonvolatile memory, media and memory devices, including by way of example semiconductor memory devices, e.g., EPROM, EEPROM, and flash memory devices.
- semiconductor memory devices e.g., EPROM, EEPROM, and flash memory devices.
- the processor and the memory can be supplemented by, or incorporated in, special purpose logic circuitry.
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
A method of video processing are described. The method includes determining, for a conversion between a video region of a picture of a video and a coded representation of the video, enablement status of a coding tool used to represent the video region in the coded representation; and performing the conversion according to the determination; wherein a first flag is included in a picture header to indicate the enablement status of the coding tool for the picture.
Description
CROSS REFERENCE TO RELATED APPLICATIONS
Under the applicable patent law and/or rules pursuant to the Paris Convention, this application is made to timely claim the priority to and benefits of International Patent Application No. PCT/CN2019/110905, filed on October 12, 2019. For all purposes under the law, the entire disclosures of the aforementioned applications are incorporated by reference as part of the disclosure of this application.
This patent document relates to video coding techniques, devices and systems.
In spite of the advances in video compression, digital video still accounts for the largest bandwidth use on the internet and other digital communication networks. As the number of connected user devices capable of receiving and displaying video increases, it is expected that the bandwidth demand for digital video usage will continue to grow.
SUMMARY
Devices, systems and methods related to digital video coding, and specifically, to adaptive loop filtering for video coding are described. The described methods may be applied to both the existing video coding standards (e.g., High Efficiency Video Coding (HEVC) ) and future video coding standards (e.g., Versatile Video Coding (VVC) ) or codecs.
Video coding standards have evolved primarily through the development of the well-known ITU-T and ISO/IEC standards. The ITU-T produced H. 261 and H. 263, ISO/IEC produced MPEG-1 and MPEG-4 Visual, and the two organizations jointly produced the H. 262/MPEG-2 Video and H. 264/MPEG-4 Advanced Video Coding (AVC) and H. 265/HEVC standards. Since H. 262, the video coding standards are based on the hybrid video coding structure wherein temporal prediction plus transform coding are utilized. To explore the future video coding technologies beyond HEVC, Joint Video Exploration Team (JVET) was founded by VCEG and MPEG jointly in 2015. Since then, many new methods have been adopted by JVET and put into the reference software named Joint Exploration Model (JEM) . In April 2018, the Joint Video Expert Team (JVET) between VCEG (Q6/16) and ISO/IEC JTC1 SC29/WG11 (MPEG) was created to work on the VVC standard targeting at 50%bitrate reduction compared to HEVC.
In one representative aspect, the disclosed technology may be used to provide a method for video processing which includes determining, for a conversion between a video region of a picture of a video and a coded representation of the video, enablement status of a coding tool used to represent the video region in the coded representation; and performing the conversion according to the determination; wherein a first flag is included in a picture header to indicate the enablement status of the coding tool for the picture.
In yet another representative aspect, the above-described method is embodied in the form of processor-executable code and stored in a computer-readable program medium.
In yet another representative aspect, a device that is configured or operable to perform the above-described method is disclosed. The device may include a processor that is programmed to implement this method.
In yet another representative aspect, a video decoder apparatus may implement a method as described herein.
The above and other aspects and features of the disclosed technology are described in greater detail in the drawings, the description and the claims.
FIG. 1 shows an example of adaptive streaming of two Representations of a same content coded at different resolutions.
FIG. 2 shows an example of an adaptive streaming of two Representations of the same content coded at different resolutions.
FIG. 3 shows examples of open GOP prediction structures of the two Representations.
FIG. 4 shows an example of Representation switching at an open GOP position.
FIG. 5 shows an example of a decoding process for RASL pictures by using a resampled reference picture from other bitstream as a reference.
FIGS. 6A to 6C show examples of MCTS-based RWMR viewport-dependent 360° streaming.
FIG. 7 shows examples of collocated sub-picture Representations of different IRAP intervals and different sizes.
FIG. 8 illustrates an example of segments received when a viewing orientation change causes a resolution change.
FIG. 9 illustrates an example of a viewing orientation change which is slightly upwards and towards the right cube face as compared to FIG. 6.
FIG. 10 shows an example of an implementation in which sub-picture representations for two sub-picture locations are presented.
FIGS. 11 and 12 illustrate ARC encoder and decoder implementations, respectively.
FIG. 13 shows an example of tile group-based resampling for ARC.
FIG. 14 shows an example of adaptive resolution change.
FIG. 15 shows an example of ATMVP motion prediction for a CU.
FIGS. 16A and 16B show examples of a simplified 4-paramter affine motion model and a simplified 6-parmaeter affine motion model, respectively.
FIG. 17 shows an example of affine MVF per sub-block.
FIG. 18A and 18B show examples of a 4-paramenter affine model and 6-parameter affine model, respectively.
FIG. 19 shows MVP (Motion Vector Difference) for AF_INTER for inherited affine candidates.
FIG. 20 shows MVP for AF_INTER for constructed affine candidates.
FIG. 21A and 21B show five neighboring blocks and CPMV predictor derivation, respectively.
FIG. 22 shows an example of a candidates position for affine merge mode.
FIG. 23 shows a flowchart of example method for video processing in accordance with the disclosed technology.
FIGS. 24A and 24B block diagrams of examples of a hardware platform for implementing a visual media decoding or a visual media encoding technique described in the present document.
FIG. 25 is a block diagram that illustrates an example video coding system.
FIG. 26 is a block diagram that illustrates an encoder in accordance with some embodiments of the disclosed technology.
FIG. 27 is a block diagram that illustrates a decoder in accordance with some embodiments of the disclosed technology.
FIG. 28 shows a flowchart for an example method of video processing based on some implementations of the disclosed technology.
The techniques and devices disclosed in this document provide coding tools with adaptive resolution conversion. AVC and HEVC do not have the ability to change resolution without having to introduce an IDR or intra random access point (IRAP) picture; such ability can be referred to as adaptive resolution change (ARC) . There are use cases or application scenarios that would benefit from an ARC feature, including the following:
- Rate adaption in video telephony and conferencing: For adapting the coded video to the changing network conditions, when the network condition gets worse so that available bandwidth becomes lower, the encoder may adapt to it by encoding smaller resolution pictures. Currently, changing picture resolution can be done only after an IRAP picture; this has several issues. An IRAP picture at reasonable quality will be much larger than an inter-coded picture and will be correspondingly more complex to decode: this costs time and resource. This is a problem if the resolution change is requested by the decoder for loading reasons. It can also break low-latency buffer conditions, forcing an audio re-sync, and the end-to-end delay of the stream will increase, at least temporarily. This can give a poor user experience.
- Active speaker changes in multi-party video conferencing: For multi-party video conferencing, it is common that the active speaker is shown in bigger video size than the video for the rest of conference participants. When the active speaker changes, picture resolution for each participant may also need to be adjusted. The need to have ARC feature becomes more important when such change in active speaker happens frequently.
- Fast start in streaming: For streaming application, it is common that the application would buffer up to certain length of decoded picture before start displaying. Starting the bitstream with smaller resolution would allow the application to have enough pictures in the buffer to start displaying faster.
Adaptive stream switching in streaming: The Dynamic Adaptive Streaming over HTTP (DASH) specification includes a feature named @mediaStreamStructureId. This enables switching between different representations at open-GOP random access points with non-decodable leading pictures, e.g., CRA pictures with associated RASL pictures in HEVC. When two different representations of the same video have different bitrates but the same spatial resolution while they have the same value of @mediaStreamStructureId, switching between the two representations at a CRA picture with associated RASL pictures can be performed, and the RASL pictures associated with the switching-at CRA pictures can be decoded with acceptable quality hence enabling seamless switching. With ARC, the @mediaStreamStructureId feature would also be usable for switching between DASH representations with different spatial resolutions.
ARC is also known as Dynamic resolution conversion.
ARC may also be regarded as a special case of Reference Picture Resampling (RPR) such as H. 263 Annex P.
1.1 Reference picture resampling in H. 263 Annex P
This mode describes an algorithm to warp the reference picture prior to its use for prediction. It can be useful for resampling a reference picture having a different source format than the picture being predicted. It can also be used for global motion estimation, or estimation of rotating motion, by warping the shape, size, and location of the reference picture. The syntax includes warping parameters to be used as well as a resampling algorithm. The simplest level of operation for the reference picture resampling mode is an implicit factor of 4 resampling as only an FIR filter needs to be applied for the upsampling and downsampling processes. In this case, no additional signaling overhead is required as its use is understood when the size of a new picture (indicated in the picture header) is different from that of the previous picture.
1.2 Contributions on ARC to VVC
1.2.1. JVET-M0135
A preliminary design of ARC as described below, with some parts taken from JCTVC-F158, is suggested to be a place holder just to trigger the discussion.
2.2.1.1 Description of basic tools
The basic tools constraints for supporting ARC are as follows:
- The spatial resolution may differ from the nominal resolution by a factor 0.5, applied to both dimensions. The spatial resolution may increase or decrease, yielding scaling ratios of 0.5 and 2.0.
- The aspect ratios and chroma formats of the video format are not changed.
- The cropping areas are scaled in proportion to spatial resolutions.
- The reference pictures are simply re-scaled as needed and inter prediction is applied as usual.
2.2.1.2 Scaling operations
It is proposed to use simple, zero-phase separable down-and up-scaling filters. Note that these filters are for prediction only; a decoder may use more sophisticated scaling for output purposes.
The following 1: 2 down-scaling filter is used, which has zero phase and 5 taps:
(-1, 9, 16, 9, -1) /32
The down-sampling points are at even sample positions and are co-sited. The same filter is used for luma and chroma.
For 2: 1 up-sampling, additional samples at odd grid positions are generated using the half-pel motion compensation interpolation filter coefficients in the latest VVC WD.
The combined up-and down-sampling will not change phase or the position of chroma sampling points.
2.2.1.2 Resolution description in parameter set
The signaling of picture resolution in the SPS is changed as shown below. Among changes, deleted parts are marked with double brackets (e.g., [ [a] ] denotes the deletion of the character “a” )
Table 1: Sequence parameter set RBSP syntax and semantics

[ [pic_width_in_luma_samples specifies the width of each decoded picture in units of luma samples. pic_width_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
pic_height_in_luma_samples specifies the height of each decoded picture in units of luma samples. pic_height_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY. ] ]
num_pic_size_in_luma_samples_minus1 plus 1 specifies the number of picture sizes (width and height) in units of luma samples that may be present in the coded video sequence.
pic_width_in_luma_samples [i] specifies the i-th width of decoded pictures in units of luma samples that may be present in the coded video sequence. pic_width_in_luma_samples [i ] shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
pic_height_in_luma_samples [i] specifies the i-th height of decoded pictures in units of luma samples that may be present in the coded video sequence. pic_height_in_luma_samples [i] shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
Table 2: Picture parameter set RBSP syntax and semantics

pic_size_idx specifies the index to the i-th picture size in the sequence parameter set. The width of pictures that refer to the picture parameter set is pic_width_in_luma_samples [pic_size_idx] in luma samples. Likewise, the height of pictures that refer to the picture parameter set is pic_height_in_luma_samples [pic_size_idx] in luma samples.
1.2.2. JVET-M0259
1.2.2.1. Background: sub-pictures
The terms sub-picture track is defined as follows in Omnidirectional Media Format (OMAF) : track that is with spatial relationships to other track (s) and that represents that represents a spatial subset of the original video content, which has been split into spatial subsets before video encoding at the content production side. A sub-picture track for HEVC can be constructed by rewriting the parameter sets and slice segment headers for a motion-constrained tile set so that it becomes a self-standing HEVC bitstream. A sub-picture Representation can be defined as a DASH Representation that carries a sub-picture track.
JVET-M0261 used the term sub-picture as a spatial partitioning unit for VVC, summarized as follows:
1. Pictures are divided into sub-pictures, tile groups and tiles.
2. A sub-picture is a rectangular set of tile groups that starts with a tile group that has tile_group_address equal to 0.
3. Each sub-picture may refer to its own PPS and may hence have its own tile partitioning.
4. Sub-pictures are treated like pictures in the decoding process.
5. The reference pictures for decoding the sub-picture are generated by extracting the area collocating with the current sub-picture from the reference pictures in the decoded picture buffer. The extracted area shall be a decoded sub-picture, i.e. inter prediction takes place between sub-pictures of the same size and the same location within the picture.
6. A tile group is a sequence of tiles in tile raster scan of a sub-picture.
In this contribution, the term, sub-picture, can be understood as defined in JVET-M0261. However, a track that encapsulates a sub-picture sequence as defined in JVET-M0261 has very similar properties as a sub-picture track defined in OMAF, the examples given below apply in both cases.
1.2.2.2. Use cases
1.2.2.2.1. Adaptive resolution change in streaming
Requirement for the support of adaptive streaming
Section 5.13 ( "Support for Adaptive Streaming" ) of MPEG N17074 includes the following requirement for VVC: The standard shall support fast representation switching in the case of adaptive streaming services that offer multiple representations of the same content, each having different properties (e.g. spatial resolution or sample bit depth) . The standard shall enable the use of efficient prediction structures (e.g. so-called open groups of pictures) without compromising from the fast and seamless representation switching capability between representations of different properties, such as different spatial resolutions.
Example of the open GOP prediction structure with representation switching
Content generation for adaptive bitrate streaming includes generations of different Representations, which can have different spatial resolutions. The client requests Segments from the Representations and can hence decide at which resolution and bitrate the content is received. At the client, the Segments of different Representations are concatenated, decoded, and played. The client should be able to achieve seamless playout with one decoder instance. Closed GOP structures (starting with an IDR picture) are conventionally used as illustrated in FIG. 1. FIG. 1 shows adaptive streaming of two Representations of the same content coded at different resolutions.
Open GOP prediction structures (starting with CRA pictures) enable better compression performance than the respective closed GOP prediction structures. For example, an average bitrate reduction of 5.6%in terms of luma Bjontegaard delta bitrate was achieved with an IRAP picture interval of 24 pictures. For convenience, the simulations conditions and results of [2] are summarized in Section YY.
Open GOP prediction structures reportedly also reduce subjectively visible quality pumping.
A challenge in the use of open GOPs in streaming is that RASL pictures cannot be decoded with correct reference pictures after switching Representations. This challenge in relation to the Representations is presented in FIG. 2 which shows adaptive streaming of two Representations of the same content coded at different resolutions. In FIG. 2, the Segments use either closed GOP or open GOP prediction structures.
The Segments starting with a CRA picture contain RASL pictures for which at least one reference picture is in the previous Segment. This is illustrated in FIG. 3 which shows open GOP prediction structures of the two Representations. In FIG. 3, picture 0 in both bitstreams resides in the previous Segment and is used as reference for predicting the RASL pictures.
The Representation switching marked with a dashed rectangle in in Figure 2 is illustrated below in FIG. 4 which shows Representation switching at an open GOP position. It can be observed that the reference picture ( "picture 0" ) for RASL pictures has not been decoded. Consequently, RASL pictures are not decodable and there will be a gap in the playout of the video.
However, it has been found to be subjectively acceptable to decode RASL pictures with resampled reference pictures, see Section 4. Resampling of "picture 0" and using it as a reference picture for decoding the RASL pictures is illustrated in Figure 5. FIG. 5 shows a decoding process for RASL picture by using resampled reference picture from the other bitstream as reference.
2.2.2.2.2. Viewport change in region-wise mixed-resolution (RWMR) 360° video streaming
Background: HEVC-based RWMR streaming
RWMR 360° streaming offers an increased effective spatial resolution on the viewport. Schemes where tiles covering the viewport originate from a 6K (6144×3072) ERP picture or an equivalent CMP resolution, illustrated in Figure 6, with "4K" decoding capacity (HEVC Level 5.1) were included in clauses D. 6.3 and D. 6.4 of OMAF and also adopted in the VR Industry Forum Guidelines. Such resolutions are asserted to be suitable for head-mounted displays using quad-HD (2560×1440) display panel.
Encoding: The content is encoded at two spatial resolutions with cube face size 1536×1536 and 768×768, respectively. In both bitstreams a 6×4 tile grid is used and a motion-constrained tile set (MCTS) is coded for each tile position.
Encapsulation: Each MCTS sequence is encapsulated as a sub-picture track and made available as a sub-picture Representation in DASH.
Selection of streamed MCTSs: 12 MCTSs from the high-resolution bitstream are selected and the complementary 12 MCTSs are extracted from the low-resolution bitstream. Thus, a hemi-sphere (180°×180°) of the streamed content originates from the high-resolution bitstream.
Merging MCTSs to a bitstream to be decoded: The received MCTSs of a single time instance are merged into a coded picture of 1920×4608, which conforms to HEVC Level 5.1. Another option for the merged picture is to have 4 tile columns of width 768, two tile columns of width 384, and three tile rows of height 768 luma samples, resulting into a picture of 3840×2304 luma samples.
FIG. 6 shows examples of MCTS-based RWMR viewport-dependent 360° streaming. FIG. 6A shows examples of coded bitstreams, FIG. 6B shows examples of MCTSs selected for streaming, and FIG. 6C shows an example of a picture merged from MCTSs.
Background: several Representations of different IRAP intervals for viewport-dependent 360° streaming
When viewing orientation changes in HEVC-based viewport-dependent 360° streaming, a new selection of sub-picture Representations can take effect at the next IRAP-aligned Segment boundary. Sub-picture Representations are merged to coded pictures for decoding, and hence the VCL NAL unit types are aligned in all selected sub-picture Representations.
To provide a trade-off between the response time to react to viewing orientation changes and the rate-distortion performance when the viewing orientation is stable, multiple versions of the content can be coded at different IRAP intervals. This is illustrated in Figure 7 for one set of collocated sub-picture Representations for encoding presented in Figure 6 and discussed in more details in Section 3 of H. Chen, H. Yang, J. Chen, “Separate list for sub-block merge candidates, ” JVET-L0368, Oct. 2018.
FIG. 7 shows examples of collocated sub-picture Representations of different IRAP intervals and different sizes.
FIG. 8 presents an example where a sub-picture location is firstly selected to be received at the lower resolution (384×384) . A change in the viewing orientation causes a new selection of the sub-picture locations to be received at the higher resolution (768×768) . In the example of FIG. 8, the segments received when a viewing orientation change causes a resolution change are at the start of Segment 4. In this example, the viewing orientation change occurs so that Segment 4 is received from the short-IRAP-interval sub-picture Representations. After that, the viewing orientation is stable and thus, the long-IRAP-interval version can be used starting from Segment 5 onwards.
Drawback of updating all sub-picture locations
Since the viewing orientation moves gradually in typical viewing situations, the resolution changes in only a subset of the sub-picture locations in RWMR viewport-dependent streaming. FIG. 9 illustrates a viewing orientation change from FIG. 6 slightly upwards and towards the right cube face. Cube face partitions that have a different resolution as earlier are indicated with "C" . It can be observed that the resolution changed in 6 out of 24 cube face partitions. However, as discussed above, Segments starting with an IRAP picture need to be received for all 24 cube face partitions in response to the viewing orientation change. Updating all sub-picture locations with Segments starting with an IRAP picture is inefficient in terms of streaming rate-distortion performance.
In addition, the ability to use open GOP prediction structures with sub-picture Representations of RWMR 360° streaming is desirable to improve rate-distortion performance and to avoid visible picture quality pumping caused by closed GOP prediction structures.
Proposed design examples
The following design goals are proposed:
1. The VVC design should allow merging of a sub-picture originating from a random-access picture and another sub-picture originating from a non-random-access picture into the same coded picture conforming to VVC.
2. The VVC design should enable the use of open GOP prediction structure in sub-picture representations without compromising from the fast and seamless representation switching capability between sub-picture representations of different properties, such as different spatial resolutions, while enabling merging of sub-picture representations into a single VVC bitstream.
The example of the design goals can be illustrated with FIG. 10, in which sub-picture Representations for two sub-picture locations are presented. For both sub-picture locations, a separate version of the content is coded for each combination among two resolutions and two random access intervals. Some of the Segments start with an open GOP prediction structure. A viewing orientation change causes the resolution of sub-picture location 1 to be switched at the start of Segment 4. Since Segment 4 starts with a CRA picture, which is associated with RASL pictures, those reference pictures of the RASL pictures that are in Segment 3 need to be resampled. It is remarked that this resampling applies to sub-picture location 1 while decoded sub-pictures of some other sub-picture locations are not resampled. In this example, the viewing orientation change does not cause changes in the resolution of sub-picture location 2 and thus decoded sub-pictures of sub-picture location 2 are not resampled. In the first picture of Segment 4, the Segment for sub-picture location 1 contains a sub-picture originating from a CRA picture, while the Segment for sub-picture location 2 contains a sub-picture originating from a non-random-access picture. It is suggested that merging of these sub-pictures into a coded picture is allowed in VVC.
2.2.2.2.3. Adaptive resolution change in video conferencing
JCTVC-F158 proposed adaptive resolution change mainly for video conferencing. The following sub-sections are copied from JCTVC-F158 and present the use cases where adaptive resolution change is asserted to be useful.
Seamless network adaption and error resilience
Applications such as video conferencing and streaming over packets networks frequently require that the encoded stream adapt to changing network conditions, especially when bit rates are too high and data is being lost. Such applications typically have a return channel allowing the encoder to detect the errors and perform adjustments. The encoder has two main tools at its disposal: bit rate reduction and changing the resolution, either temporal or spatial. Temporal resolution changes can be effectively achieved by coding using hierarchical prediction structures. However, for best quality spatial resolution changes are needed as well as part of a well-designed encoder for video communications.
Changing spatial resolution within AVC requires an IDR frame is sent and the stream is reset. This causes significant problems. An IDR frame at reasonable quality will be much larger than an Inter picture, and will be correspondingly more complex to decode: this costs time and resource. This is a problem if the resolution change is requested by the decoder for loading reasons. It can also break low-latency buffer conditions, forcing an audio re-sync, and the end-to-end delay of the stream will increase, at least temporarily. This gives a poor user experience.
To minimize these problems, the IDR is typically sent at low quality, using a similar number of bits to a P frame, and it takes a significant time to return to full quality for the given resolution. To get low enough delay, the quality can be very low indeed and there is often a visible blurring before the image is “refocused” . In effect, the Intra frame is doing very little useful work in compression terms: it is just a method of re-starting the stream.
So, there is a requirement for methods in HEVC which allow resolution to be changed, especially in challenging network conditions, with minimal impact on subjective experience.
Fast start
It would be useful to have a “fast start” mode where the first frame is sent at reduced resolution and resolution is increased over the next few frames, in order to reduce delay and get to normal quality more quickly without unacceptable image blurring at the beginning.
Conference “compose”
Video conferences also often have a feature whereby the person speaking is shown full-screen and other participants are shown in smaller resolution windows. To support this efficiently, often the smaller pictures are sent at lower resolution. This resolution is then increased when the participant becomes the speaker and is full-screened. Sending an intra frame at this point causes an unpleasant hiccup in the video stream. This effect can be quite noticeable and unpleasant if speakers alternate rapidly.
2.2.2.3. Proposed design goals
The following is high-level design choices are proposed for VVC version 1:
1. It is proposed to include a reference picture resampling process in VVC version 1 for the following use cases:
- Usage of efficient prediction structures (e.g. so-called open groups of pictures) in adaptive streaming without compromising from the fast and seamless representation switching capability between representations of different properties, such as different spatial resolutions.
- Adapting low-delay conversational video content to network conditions and application-originated resolution changes without significant delay or delay variation.
2. The VVC design is proposed to allow merging of a sub-picture originating from a random-access picture and another sub-picture originating from a non-random-access picture into the same coded picture conforming to VVC. This is asserted to enable efficient handling of viewing orientation changes in mixed-quality and mixed-resolution viewport-adaptive 360° streaming.
3. It is proposed to include sub-picture-wise resampling process in VVC version 1. This is asserted to enable efficient prediction structure for more efficient handling of viewing orientation changes in mixed-resolution viewport-adaptive 360° streaming.
2.2.3. JVET-N0048
The use cases and design goals for adaptive resolution changing (ARC) were discussed in detail in JVET-M0259. A summary is provided below:
1. Real-time communication
The following use cases for adaptive resolution change were originally included in JCTVC-F158:
a. Seamless network adaption and error resilience (through dynamic adaptive resolution changes)
b. Fast start (gradual increase of resolution at session start or reset)
c. Conference “compose” (person speaking is given a higher resolution)
2. Adaptive streaming
Section 5.13 ( "Support for Adaptive Streaming" ) of MPEG N17074 includes the following requirement for VVC: The standard shall support fast representation switching in the case of adaptive streaming services that offer multiple representations of the same content, each having different properties (e.g. spatial resolution or sample bit depth) . The standard shall enable the use of efficient prediction structures (e.g. so-called open groups of pictures) without compromising from the fast and seamless representation switching capability between representations of different properties, such as different spatial resolutions.
JVET-M0259 discusses how to meet this requirement by resampling of reference pictures of leading pictures.
3. 360-degree viewport-dependent streaming
JVET-M0259 discusses how to address this use case by resampling certain independently coded picture regions of reference pictures of leading pictures.
This contribution proposes an adaptive resolution coding approach, which is asserted to meet all the use cases and design goals above. 360-degree viewport-dependent streaming and conference "compose" uses cases are handled by this proposal together with JVET-N0045 (proposing independent sub-picture layers) .
Proposed specification text
Signaling
Table 3: sps_max_rpr
| seq_parameter_set_rbsp () { | Descriptor |
| … | |
| sps_max_rpr | ue (v) |
| … |
sps_max_rpr specifies the maximum number of active reference pictures in reference picture list 0 or 1 for any tile group in the CVS that have pic_width_in_luma_samples and pic_height_in_luma_samples not equal to pic_width_in_luma_samples and pic_height_in_luma_samples, respectively, of the current picture.
Tables 4 and 5: Picture width and height


max_width_in_luma_samples specifies that it is a requirement of bitstream conformance that pic_width_in_luma_samples in any active PPS for any picture of a CVS for which this SPS is active is less than or equal to max_width_in_luma_samples.
max_height_in_luma_samples specifies that it is a requirement of bitstream conformance that pic_height_in_luma_samples in any active PPS for any picture of a CVS for which this SPS is active is less than or equal to max_height_in_luma_samples.
High-level decoding process
The decoding process operates as follows for the current picture CurrPic:
1. The decoding of NAL units is specified in clause 8.2.
2. The processes in clause 8.3 specify the following decoding processes using syntax elements in the tile group header layer and above:
– Variables and functions relating to picture order count are derived as specified in clause 8.3.1. This needs to be invoked only for the first tile group of a picture.
– At the beginning of the decoding process for each tile group of a non-IDR picture, the decoding process for reference picture lists construction specified in clause 8.3.2 is invoked for derivation of reference picture list 0 (RefPicList [0] ) and reference picture list 1 (RefPicList [1] ) .
– The decoding process for reference picture marking in clause 8.3.3 is invoked, wherein reference pictures may be marked as "unused for reference" or "used for long-term reference" . This needs to be invoked only for the first tile group of a picture.
– For each active reference picture in RefPicList [0] and RefPicList [1] that has pic_width_in_luma_samples or pic_height_in_luma_samples not equal to pic_width_in_luma_samples or pic_height_in_luma_samples, respectively, of CurrPic, the following applies:
– The resampling process in clause X. Y. Z is invoked [Ed. (MH) : details of invocation parameters to be added] with the output having the same reference picture marking and picture order count as the input.
– The reference picture used as input to the resampling process is marked as "unused for reference" .
The invocation of the decoding processes for coding tree units, scaling, transform, in-loop filtering, etc. can be further discussed.
After all tile groups of the current picture have been decoded, the current decoded picture is marked as "used for short-term reference" .
Resampling process
SHVC resampling process (HEVC clause H. 8.1.4.2) is proposed with the following additions:
If sps_ref_wraparound_enabled_flag is equal to 0, the sample value tempArray [n] with n = 0.. 7, is derived as follows:

Otherwise, the sample value tempArray [n] with n = 0.. 7, is derived as follows:
refOffset = (sps_ref_wraparound_offset_minus1+1) *MinCbSizeY
tempArray [n] = (f
L [xPhase, 0] *rlPicSample
L [ClipH (refOffset, refW, xRef-3) , yPosRL] + f
L [xPhase, 1] *rlPicSample
L [ClipH (refOffset, refW, xRef-2) , yPosRL] + f
L [xPhase, 2] *rlPicSample
L [ClipH (refOffset, refW, xRef-1) , yPosRL] + f
L [xPhase, 3] *rlPicSample
L [ClipH (refOffset, refW, xRef) , yPosRL] + f
L [xPhase, 4] *rlPicSample
L [ClipH (refOffset, refW, xRef+1) , yPosRL] + f
L [xPhase, 5] *rlPicSample
L [ClipH (refOffset, refW, xRef+2) , yPosRL] + f
L [xPhase, 6] *rlPicSample
L [ClipH (refOffset, refW, xRef+3) , yPosRL] + f
L [xPhase, 7] *rlPicSample
L [ClipH (refOffset, refW, xRef+4) , yPosRL] ) >>shift1
If sps_ref_wraparound_enabled_flag is equal to 0, the sample value tempArray [n] with n = 0.. 3, is derived as follows:

Otherwise, the sample value tempArray [n] with n = 0.. 3, is derived as follows:
refOffset = (sps_ref_wraparound_offset_minus1+1) *MinCbSizeY) /SubWidthC
tempArray [n] = (f
C [xPhase, 0] *rlPicSample
C [ClipH (refOffset, refWC, xRef-1) , yPosRL] + f
C [xPhase, 1] *rlPicSample
C [ClipH (refOffset, refWC, xRef) , yPosRL] + f
C [xPhase, 2] *rlPicSample
C [ClipH (refOffset, refWC, xRef+1) , yPosRL] + f
C [xPhase, 3] *rlPicSample
C [ClipH (refOffset, refWC, xRef+2) , yPosRL] ) >>shift1
2.2.4. JVET-N0052
Adaptive resolution change, as a concept in video compression standards, has been around since at least 1996; in particular H. 263+ related proposals towards reference picture resampling (RPR, Annex P) and Reduced Resolution Update (Annex Q) . It has recently gained a certain prominence, first with proposals by Cisco during the JCT-VC time, then in the context of VP9 (where it is moderately widely deployed nowadays) , and more recently in the context of VVC. ARC allows reducing the number of samples required to be coded for a given picture, and upsampling the resulting reference picture to a higher resolution when such is desirable.
ARC of particular interest is considered in two scenarios:
1) Intra coded pictures, such as IDR pictures are often considerably larger than inter pictures. Downsampling pictures intended to be intra coded, regardless of reason, may provide a better input for future prediction. It’s also clearly advantageous from a rate control viewpoint, at least in low delay applications.
2) When operating the codec near its breaking point, as at least some cable and satellite operators routinely seem to do, ARC may become handy even for non-intra coded pictures, such as in scene transitions without a hard transition point.
3) Looking perhaps a bit too much forward: is the concept of a fixed resolution generally defensible? With the departure of CRTs and the ubiquity of scaling engines in rendering devices, the hard bind between rendering and coding resolution is a thing of the past. Also, it is noted that there is certain research available that suggests that most people are not able to concentrate on fine details (associated perhaps with high resolution) when there is a lot of activity going on in the video sequence, even if that activity is elsewhere spatially. If that were true and generally accepted, fine granularity resolution changes may be a better rate control mechanism than adaptive QP. This point is now for discussion. Doing away with the concept of fixed resolution bitstreams has a myriad of system layer and implementation implications, which (at least at the level of their existence, if not their detailed nature) are well aware of.
Technically, ARC can be implemented as reference picture resampling. Implementing reference picture resampling has two major aspects: the resampling filters, and the signaling of the resampling information in the bitstream. This document focusses on the latter and touches the former to the extent there is an implementation experience. More study of suitable filter design is encouraged, and Tencent will carefully consider and, when appropriate, support any proposals in that regard that substantially improve the strawman design provided.
Overview of Tencent’s ARC implementation
FIGS. 11 and 12 illustrate Tencent’s ARC encoder and decoder implementations, respectively. Implementations of the disclosed technology enable to change the picture width and height, on a per picture granularity irrespective of the picture type. At the encoder, the input image data is down-sampled to the selected picture size for the current picture encoding. After the first input picture is encoded as intra-picture, the decoded picture is stored in the decoded picture buffer (DPB) . When the consequent picture is down-sampled with a different sampling ratio and encoded as inter-picture, the reference picture (s) in the DPB is/are up-/down-scaled according the spatial ratio between the picture size of the reference and the current picture size. At the decoder, the decoded picture is stored in the DPB without resampling. However, the reference picture in the DPB is up-/down-scaled in relation to the spatial ratio between the currently decoded picture and the reference, when used for motion compensation. The decoded picture is up-sampled to the original picture size or the desired output picture size when bumped out for display. In motion estimation/compensation process, motion vectors are scaled in relation to picture size ratio as well as picture order count difference.
Signaling of ARC parameters
The term ARC parameters is used herein as a combination of any parameters required to make ARC work. In the easiest case, that could be a zoom factor, or an index into a table with defined zoom factors. It could be a target resolution (for example in sample or max CU size granularity) , or an index into a table providing a target resolution, like what was proposed in JVET-M0135. Also included would be filter selectors or even filter parameters (all the way up to filter coefficients) of the up/down-sampling filters in use.
From the outset, the implementations proposed herein are to allow, at least conceptually, different ARC parameters for different parts of a picture. It is proposed that the appropriate syntax structure as per the current VVC draft would be a rectangular tile group (TG) . Those using scan-order TGs would be restricted to use ARC only to a full picture, or to the extent scan order TGs are included in a rectangular TG. That can easily be specified by a bitstream constraint.
As different TGs may have different ARC parameters, the appropriate place for ARC parameters would be either in the TG header or in a parameter set with the scope of a TG, and referenced by the TG header-the Adaptation Parameter Set in the current VVC draft, or a more detailed reference (an index) into a table in a higher parameter set. Of these three choices, it is proposed, at this point, to use the TG header to code a reference to a table entry including the ARC parameters, and that table be located in the SPS, with maximum table values coded in the (forthcoming) DPS. A zoom factor can be directly coded into the TG header, without using any parameter set values. The use of the PPS for the reference, as proposed in JVET-M0135, is counter-indicated if the per tile group signaling of ARC parameters is a design criterion.
As for the table entries themselves, the following options are available:
- coding down-sample factors, either one for both dimension or independently in X and Y dimension? That’s mostly a (HW-) implementation discussion, and some would perhaps prefer an outcome where the zoom factor in X dimension is fairly flexible, but in Y dimension is fixed to 1, or has very few choices. It is suggested that the syntax is the wrong place for expressing such constraints and, if they were desirable, the constraints expressed as requirements for conformance are preferred. In other words, keep the syntax flexible.
- Coding target resolutions are proposed below. There could be more or less complex constraints about those resolutions in relation to the current resolution, expressed perhaps in bitstream conformance requirements.
- Down-sampling per tile group is preferred to allow for picture composition/extraction. However, it is not critical from a signaling viewpoint. If the group were making the unwise decision of allowing ARC only at picture granularity, a requirement for bitstream conformance that all TGs use the same ARC parameters can be included.
- Control information related to ARC. In our design below, that includes the reference picture size.
- Flexibility in filter design is needed? Anything bigger than a handful of codepoints? If yes, put those into APS? In some implementations, if down-sample filter changes and ALF stays, it is proposed that bitstream has to eat the overhead.
For now, in order to keep proposed technology aligned and simple (to the extent possible) , the following is proposed:
- Fixed filter design
- Target resolutions in a table in the SPS, with bitstream constraints TBD.
- Minimum/Maximum target resolution in DPS to facilitate cap exchange/negotiation.
The resulting syntax could look as follows:
Table 6: Decoder parameter set RBSP syntax

max_pic_width_in_luma_samples specifies the maximum width of decoded pictures in units of luma samples in the bitstream. max_pic_width_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY. The value of dec_pic_width_in_luma_samples [i] cannot be greater than the value of max_pic_width_in_luma_samples.
max_pic_height_in_luma_samples specifies the maximum height of decoded pictures in units of luma samples. max_pic_height_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY. The value of dec_pic_height_in_luma_samples [i] cannot be greater than the value of max_pic_height_in_luma_samples.
Table 7: Sequence parameter set RBSP syntax

adaptive_pic_resolution_change_flag equal to 1 specifies that an output picture size (output_pic_width_in_luma_samples, output_pic_height_in_luma_samples) , an indication of the number of decoded picture sizes (num_dec_pic_size_in_luma_samples_minus1) and at least one decoded picture size (dec_pic_width_in_luma_samples [i] , dec_pic_height_in_luma_samples [i ] ) are present in the SPS. A reference picture size (reference_pic_width_in_luma_samples, reference_pic_height_in_luma_samples) is present conditioned on the value of reference_pic_size_present_flag.
output_pic_width_in_luma_samples specifies the width of the output picture in units of luma samples. output_pic_width_in_luma_samples shall not be equal to 0.
output_pic_height_in_luma_samples specifies the height of the output picture in units of luma samples. output_pic_height_in_luma_samples shall not be equal to 0.
reference_pic_size_present_flag equal 1 specifies that reference_pic_width_in_luma_samples and reference_pic_height_in_luma_samples are present.
reference_pic_width_in_luma_samples specifies the width of the reference picture in units of luma samples. output_pic_width_in_luma_samples shall not be equal to 0. If not present, the value of reference_pic_width_in_luma_samples is inferred to be equal to dec_pic_width_in_luma_samples [i] .
reference_pic_height_in_luma_samples specifies the height of the reference picture in units of luma samples. output_pic_height_in_luma_samples shall not be equal to 0. If not present, the value of reference_pic_height_in_luma_samples is inferred to be equal to dec_pic_height_in_luma_samples [i] .
NOTE1 –The size of the output picture shall be equal to the values of output_pic_width_in_luma_samples and output_pic_height_in_luma_samples. The size of the reference picture shall be equal to the values of reference_pic_width_in_luma_samples and _pic_height_in_luma_samples, when the reference picture is used for motion compensation.
num_dec_pic_size_in_luma_samples_minus1 plus 1 specifies the number of the decoded picture size (dec_pic_width_in_luma_samples [i] , dec_pic_height_in_luma_samples [i] ) in units of luma samples in the coded video sequence.
dec_pic_width_in_luma_samples [i] specifies the i-th width of the decoded picture sizes in units of luma samples in the coded video sequence. dec_pic_width_in_luma_samples [i] shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
dec_pic_height_in_luma_samples [i] specifies the i-th height of the decoded picture sizes in units of luma samples in the coded video sequence. dec_pic_height_in_luma_samples [i] shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
NOTE2 –The i-th decoded picture size (dec_pic_width_in_luma_samples [i] , dec_pic_height_in_luma_samples [i] ) may be equal to the decoded picture size of the decoded picture in the coded video sequence.
Table 8: Tile group header syntax


dec_pic_size_idx specifies that the width of the decoded picture shall be equal to pic_width_in_luma_samples [dec_pic_size_idx] and the height of the decoded picture shall be equal to pic_height _in_luma_samples [dec_pic_size_idx] .
Filters
The proposed design conceptually includes four different filter sets: down-sampling filter from the original picture to the input picture, up-/down-sampling filters to rescale reference pictures for motion estimation/compensation, and up-sampling filter from the decoded picture to the output picture. The first and last ones can be left as non-normative matters. In the scope of specification, up-/down-sampling filters need to be explicitly signaled in an appropriate parameter set, or pre-defined.
Our implementation uses the down-sampling filters of SHVC (SHM ver. 12.4) , which is a 12-tap and 2D separable filter, for down-sampling to resize the reference picture to be used for motion compensation. In the current implementation, only dyadic sampling is supported. Therefore, the phase of the down-sampling filter is set equal to zero by default. For up-sampling, 8-tap interpolation filters are used, with 16-phases, to shift the phase and align the luma and chroma pixel positions to the original positions.
Tables 9 and 10 provide the 8-tap filter coefficients fL [p, x] with p = 0.. 15 and x = 0.. 7 used for the luma up-sampling process, and the 4-tap filter coefficients fC [p, x] with p = 0.. 15 and x = 0.. 3 used for the chroma up-sampling process.
Table 11 provides the 12-tap filter coefficients for down-sampling process. The same filter coefficients are used for both luma and chroma for down-sampling.
Table 9: Luma up-sampling filter with 16 phases


Table 10: Chroma up-sampling filter with 16 phases

Table 11: Down-sampling filter coefficient for luma and chroma

It is anticipated that (perhaps significant) subjective and objective gains can be expected when using filters adaptive to content and/or to scaling factors.
Tile Group boundary discussions
As it is perhaps true with a lot of tile group related work, our implementation is not quite finished with respect to tile group (TG) based ARC. Our preference is to revisit that implementation once the discussion of spatial composition and extraction, in the compressed domain, of multiple sub-pictures into a composed picture has yielded at least a working draft. That, however, does not prevent from extrapolating the outcome to some extent, and to adapt our signaling design accordingly.
For now, the tile group header is the correct place for something like dec_pic_size_idx as proposed above, for reasons already stated. A single ue (v) codepoint dec_pic_size_idx, conditionally present in the tile group header, is used to indicate the employed ARC parameters. In order to match the implementation which is ARC per picture only, in spec-space, it is needed to code a single tile group only, or to make it a condition of bitstream compliance that all TG headers of a given coded picture have the same value of dec_pic_size_idx (when present) .
The parameter dec_pic_size_idx can be moved into whatever header that starts a sub-picture. It may continue to be a tile group header.
Beyond these syntactical considerations, some additional work is needed to enable tile group or sub-picture based ARC. The perhaps most difficult part is how to address the issue of unneeded samples in a picture where a sub-picture has been resampled to a lower size.
FIG. 13 shows an example of tile group-based resampling for ARC. Consider the right picture, which is made up of four sub-pictures (expressed perhaps as four rectangular tile groups in the bitstream syntax) . To the left, the bottom right TG is subsampled to half the size. It needs to be discussed what to do with the samples outside the relevant area, marked as “Half” .
Many (most? all? ) previous video coding standards had in common that spatial extraction of parts of a picture in the compressed domain was not supported. That implied that each sample of a picture is represented by one or more syntax elements, and each syntax elements impacts at least one sample. To keep that up, it may be needed to populate the area around the samples covered by the downsampled TG labelled “Half” somehow. H. 263+ Annex P solved that problem by padding; in fact, the sample values of the padded samples could be signaled in the bitstream (within certain strict limits) .
An alternative that would perhaps constitute a significant departure from previous assumptions but may be needed in any case to support sub-bitstream extraction (and composition) based on rectangular parts of a picture, would be to relax the current understanding that each sample of a reconstructed picture needs to be represented by something in the coded picture (even if that something is only a skipped block) .
Implementation considerations, system implications and Profiles/Levels
The basic ARC to be included in the “baseline/main” profiles is proposed. Sub-profiling may be used to remove them if not needed for certain application scenarios. Certain restrictions may be acceptable. In that regard, it is noted that certain H. 263+ profiles and “recommended modes” (which pre-dated profiles) included a restriction for Annex P to be used only as “implicit factor of 4” , i.e. dyadic downsampling in both dimensions. That was enough to support fast start (get the I frame over quickly) in video conferencing.
The design is such that all filtering can be done “on the fly” and that there is no, or only negligible, increases in memory bandwidth. Insofar, it doesn’t seem there is a need to punt ARC into exotic profiles.
Complex tables and such may not be meaningfully used in capability exchange, as it was argued in Marrakech in conjunction with JVET-M0135. The number of options is simply to big to allow for meaningful cross-vendor interop, assuming offer-answer and similar limited-depth handshakes. Insofar, realistically, to support ARC in a meaningful way in a capability exchange scenario, we have to fallback to a handful, at most interop points. For example: no ARC, ARC with implicit factor of 4, full ARC. As an alternative, it is possible to spec the required support for all ARC and leave the restrictions in bitstream complexity to higher level SDOs. That’s a strategic discussion to be done at some point anyway (beyond what already discussed in the sub-profiling and flags context) .
As for levels: The basic design principle needs to be that, as a condition of bitstream conformance, the sample count of an upsampled pictures needs to fit into level of bitstream no matter how much upsampling is signaled in bitstream, and that all samples need to fit into the upsampled coded picture. It is noted that this was not the case in H263+; there, it was possible that certain samples were not present.
2.2.5. JVET-N0118
The following aspects are proposed:
1. A list of picture resolutions is signalled in the SPS, and an index to the list is signalled in the PPS to specify the size of an individual picture.
2. For any picture that is to be outputted, the decoded picture before resampling is cropped (as necessary) and outputted, i.e., a resampled picture is not for output, only for inter prediction reference.
3. Support 1.5x and 2x resampling ratios. No support of arbitrary resampling ratio. Further study the need of one or two more other resampling ratios.
4. Between picture-level resampling and block-level resampling, the proponents prefer block-level resampling.
a. However, if picture-level resampling is chosen, the following aspects are proposed:
i. When a reference picture is resampled, both the resampled version and the original, resampled version of the reference picture are stored in the DPB, and thus both would affect the DPB fullness.
ii. A resampled reference picture is marked as "unused for reference" when the corresponding un-resampled reference picture is marked as "unused for reference" .
iii. The RPL signalling syntax is kept unchanged, while the RPL construction process is modified as follows: When a reference picture needs to be included into a RPL entry, and a version of that reference picture with the same resolution as the current picture is not in the DPB, the picture resampling process is invoked and the resampled version of that reference picture is included into the RPL entry.
iv. The number of resampled reference pictures that may be present in the DPB should be limited, e.g., to be less than or equal to 2.
b. Otherwise (block-level resampling is chosen) , the following are suggested:
i. To limit the worst-case decoder complexity, it is proposed that bi-prediction of a block from a reference picture with a different resolution than the current picture is disallowed.
ii. Another option is that, when resampling and quarter-pel interpolation need to be done, the two filters are combined and the operation is applied at once.
5. Regardless of which of the picture-based and block-based resampling approaches is chosen, it is proposed that temporal motion vector scaling is applied as needed.
2.2.5.1. Implementation
The ARC software was implemented on top of VTM-4.0.1, with the following changes:
- A list of supported resolutions is signalled in SPS.
- The spatial resolution signalling was moved from SPS to PPS.
- A picture-based resampling scheme was implemented for resampling reference pictures. After a picture is decoded, the reconstructed picture may be resampled to a different spatial resolution. The original reconstructed picture and the resampled reconstructed picture are both stored in the DPB and are available for reference by future pictures in decoding order.
- The implemented resampling filters are based on the filters tested in JCTVC-H0234, as follows:
-- The up-sampling filter: 4-tap +/-quarter-phase DCTIF with taps (-4, 54, 16, -2) /64
-- The down-sampling filter: the h11 filter with taps (1, 0, -3, 0, 10, 16, 10, 0, -3, 0, 1) /32
- When constructing the reference picture lists of the current picture (i.e., L0 and L1) , only the reference pictures with the same resolution as the current picture are used. Note that the reference pictures may be available in both their original sizes or the resampled sizes.
- TMVP and ATVMP may be enabled; however, when the original coding resolutions of the current picture and a reference picture are different, TMVP and ATMVP are disabled for that reference picture.
- For convenience and simplicity of the starting-point software implementation, when outputting a picture, the decoder outputs the highest available resolution.
On signaling of picture sizes and picture output
1. On the list of spatial resolutions of coded pictures in the bitstream
Currently all coded pictures in a CVS have the same resolution. Thus, it is straightforward to signal just one resolution (i.e., picture width and height) in the SPS. With ARC support, instead of one resolution, a list of picture resolutions needs to be signaled. It is proposed that this list is signaled in the SPS, and an index to the list is signaled in the PPS to specify the size of an individual picture.
2. On picture output
It is proposed that, for any picture that is to be outputted, the decoded picture before resampling is cropped (as necessary) and outputted, i.e., a resampled picture is not for output, only for inter prediction reference. The ARC resampling filters needs to be designed to optimize the use of the resampled pictures for inter prediction, and such filters may not be optimal for picture outputting/displaying purpose, while video terminal devices usually have optimized output zooming/scaling functionalities already implemented.
2.2.5.3. On resampling
Resampling of a decoded picture can be either picture-based or block-based. For the final ARC design in VVC, block-based resampling is preferred over picture-based resampling. It is recommend that these two approaches are discussed and the JVET makes a decision on which of these two is to be specified for ARC support in VVC.
Picture-based resampling
In picture-based resampling for ARC, a picture is resampled only once for a particular resolution, which is then stored in the DPB, while the un-resampled version of the same picture is also kept in the DPB.
Employing picture-based resampling for ARC has two issues: 1) additional DPB buffer is required for storing resampled reference pictures, and 2) additional memory bandwidth is required since due to increased operations of reading reference picture data from the DPB and writing reference picture data into the DPB.
Keeping only one version of a reference picture in the DPB would not be a good idea for picture-based resampling. If only the un-resampled version is kept, a reference picture may need to be resampled multiple times since multiple pictures may refer to the same reference picture, and . On the other hand, if a reference picture is resampled and the resampled version only is kept, then inverse resampling needs to be applied when the reference picture needs to be outputted, since it's better to output un-resampled pictures, as discussed above. This is a problem since resampling process is not a lossless operation. Take a picture A and downsample it then upsample it to get A' with the same resolution as A, A and A' would not be the same; A' would contain less information than A since some high frequency information has been lost during the downsampling and upsampling processes.
To deal with the issues of additional DPB buffer and memory bandwidth, it is proposed that, if the ARC design in VVC uses picture-based resampling, the following applies:
1. When a reference picture is resampled, both the resampled version and the original, resampled version of the reference picture are stored in the DPB, and thus both would affect the DPB fullness.
2. A resampled reference picture is marked as "unused for reference" when the corresponding un-resampled reference picture is marked as "unused for reference" .
3. The reference picture lists (RPLs) of each tile group contain reference pictures that have the same resolution as the current picture. While there is no need for a change to the RPL signalling syntax, the RPL construction process is modified to ensure what is said in the previous sentence, as follows: When a reference picture needs to be included into a RPL entry while a version of that reference picture with the same resolution as the current picture is not yet available, the picture resampling process is invoked and the resampled version of that reference picture is included.
4. The number of resampled reference pictures that may be present in the DPB should be limited, e.g., to be less than or equal to 2.
Furthermore, to enable temporal MV usage (e.g. merge mode and ATMVP) for the case that the temporal MV comes from the reference frame with different resolution than the current one, it is proposed that, scaling temporal MV to the current resolution as needed.
Block-based ARC resampling
In block-based resampling for ARC, a reference block is resampled whenever needed, and no resampled picture is stored in the DPB.
The main issue here is the additional decoder complexity. This is because a block in a reference picture may be referred to multiple times by multiple blocks in another picture and by blocks in multiple pictures.
When a block in a reference picture is referred to by a block in the current picture and the resolutions of the reference picture and the current picture are different, the reference block is resampled by invocation of the interpolation filter such that the reference block has the integer-pel resolution. When the motion vector is in quarter-pel, the interpolation process is invoked again to obtain the resampled reference block in the quarter-pel resolution. Therefore, for each motion compensation operation for the current block from a reference block involving different resolutions, up to two, instead of one, interpolation filtering operations are needed. Without ARC support, up to only one interpolation filter operation (i.e., for generation of the reference block in the quarter-pel resolution) is needed.
To limit the worst-case complexity, it is proposed that, if the ARC design in VVC uses block-based resampling, the following apply:
- Bi-prediction of a block from a reference picture with a different resolution than the current picture is disallowed.
- To be more more precise, the constraint is as follow: For the current block blkA in the current picture picA refers to a reference block blkB in a reference picture picB, when picA and picB have different resolutions, block blkA shall be a uni-predicted block.
With this constraint, the worst-case number of interpolation operations needed to decode a block is limited to two. If a block refers to a block from a different-resolution picture, the number of interpolation operations needed is two as discussed above. This is the same as in the case when the block refers to a reference block from a same-resolution picture and coded as a bi-predicted block since the number of interpolation operations is also two (i.e., one for getting the quarter-pel resolution for each reference block) .
To simplify the implementation, another variation is proposed that if the ARC design in VVC uses block-based resampling, the following apply:
- If the reference frame and current frame have different resolutions, the corresponding positions of every pixel of predictors are calculated first, and then the interpolation is applied only one time. That is, two interpolation operations (i.e. one for resampling and one for quarter-pel interpolation) are combined into only one interpolation operation. The sub-pel interpolation filters in the current VVC can be reused, but, in this case, the granularity of interpolation should be enlarged but the interpolation operation times are reduced from two to one.
- To enable temporal MV usage (e.g. merge mode and ATMVP) for the case that the temporal MV comes from the reference frame with different resolution than the current one, it is proposed that, scaling temporal MV to the current resolution as needed.
Resampling ratios
In JVET-M0135 [1] , to start the discussion on ARC, it is proposed that for the starting point of ARC, consider only the resampling ratio of 2x (meaning 2 x 2 for upsampling and 1/2 x 1/2 for downsampling) . From further discussion on this topic after the Marrakech meeting, it is found that supporting only the resampling ratio of 2x is very limited, as in some cases a smaller difference between resampled and un-resampled resolutions would be more beneficial.
Although support of arbitrary resampling ratio may be desirable, it support seemed difficult. This is because to support arbitrary resampling ratio, the number of resampling filters that have to be defined and implemented seemed to be too many and to impose a significant burden on decoder implementations.
It is proposed that more than one but a small number of resampling ratios need to be supported, but at least 1.5x and 2x resampling ratios, and arbitrary resampling ratio is not supported.
2.2.5.4. Max DPB buffer size and buffer fullness
With ARC, the DPB may contains decoded pictures of different spatial resolutions within the same CVS. For DPB management and related aspects, counting DPB size and fullness in units decoded picture no longer works.
Below are discussions of some specific aspects that need to be addressed and possible solutions in the final VVC specification if ARC is supported:
1. Rather than using the value of PicSizeInSamplesY (i.e., PicSizeInSamplesY =pic_width_in_luma_samples *pic_height_in_luma_samples) for deriving MaxDpbSize (i.e., maximum number of reference picture that may present in the DPB) , derivation of MaxDpbSize is based on the value of MinPicSizeInSamplesY. MinPicSizeInSampleY defined as follows:
MinPicSizeInSampleY = (Width of the smallest picture resolution in the bitstream) * (Height of the smallest resolution in the bitstream)
The derivation of MaxDpbSize is modified as follows (based on the HEVC equation) :


2. Each decoded picture is associated with a value called PictureSizeUnit. PictureSizeUnit is an integer value that specifies how big a decoded picture size is relative to the MinPicSizeInSampleY. The definition of PictureSizeUnit depends on what resampling ratios are supported for ARC in VVC.
For example, if ARC supports only the resampling ratio of 2, the PictureSizeUnit is defined as follows:
- Decoded pictures having the smallest resolution in the bitstream are associated with PictureSizeUnit of 1.
- Decoded pictures having the resolution that is 2 by 2 of the smallest resolution in the bitstream is associated with PictureSizeUnit of 4 (i.e., 1 *4) .
For another example, if ARC supports both the resampling ratios of 1.5 and 2, the PictureSizeUnit is defined as follows:
- Decoded pictures having the smallest resolution in the bitstream is associated with PictureSizeUnit of 4.
- Decoded pictures having the resolution that is 1.5 by 1.5 of the smallest resolution in the bitstream is associated with PictureSizeUnit of 9 (i.e., 2.25 *4) .
- Decoded pictures having the resolution that is 2 by 2 of the smallest resolution in the bitstream is associated with PictureSizeUnit of 16 (i.e., 4 *4) .
For other resampling rations supported by ARC, the same principle as given by the examples above should be used to determine the value of PictureSizeUnit for each picture size.
3. Let the variable MinPictureSizeUnit be the smallest possible value of PictureSizeUnit. That is, if ARC supports only resampling ratio of 2, MinPictureSizeUnit is 1; if ARC supports resampling ratios of 1.5 and 2, MinPictureSizeUnit is 4; likewise, the same principle is used to determine the value of MinPictureSizeUnit.
4. The value range of sps_max_dec_pic_buffering_minus1 [i] is specified to range from 0 to (MinPictureSizeUnit * (MaxDpbSize –1) ) . The variable MinPictureSizeUnit is the smallest possible value of PictureSizeUnit.
5. The DPB fullness operation is specified based on PictureSizeUnit as follows:
- The HRD is initialized at decoding unit 0, with both the CPB and the DPB being set to be empty (the DPB fullness is set equal to 0) .
- When the DPB is flushed (i.e., all pictures are removed from the DPB) , the DPB fullness is set equal to 0.
- When a picture is removed from the DPB, the DPB fullness is decrement by the value of PictureSizeUnit associated with the removed picture.
- When a picture is inserted into the DPB, the DPB fullness is increment by the value of PictureSizeUnit associated with the inserted picture.
2.2.5.5. Resampling filters
In the software implementation, the implemented resampling filters were simply taken from previously available filters described in JCTVC-H0234 [3] . Other resampling filters should be tested and used if they provide better performance and/or lower complexity. It is proposed that various resampling filters to be tested to strike a trade-off between complexity and performance. Such tests can be done in a CE.
2.2.5.6. Miscellaneous necessary modifications to existing tools
To support ARC, some modifications and /or additional operations may be needed to some of the existing coding tools. For example, in the ARC software implementation picture-based resampling, for simplicity, TMVP and ATMVP are disabled when the original coding resolutions of current picture and reference picture are different.
2.2.6. JVET-N0279
According to “Requirements for a Future Video Coding Standard” , “the standard shall support fast representation switching in the case of adaptive streaming services that offer multiple representations of the same content, each having different properties (e.g. spatial resolution or sample bit depth) . ” In real-time video communication, allowing resolution change within a coded video sequence without inserting an I picture can not only adapt the video data to dynamic channel conditions or user preference seamlessly, but also remove the beating effect caused by I pictures. A hypothetical example of adaptive resolution change is shown in FIG. 14 where the current picture is predicted from reference pictures of different sizes.
This contribution proposes high level syntax to signal adaptive resolution change as well as modifications to the current motion compensated prediction process in the VTM. These modifications are limited to motion vector scaling and subpel location derivations with no changes in the existing motion compensation interpolators. This would allow the existing motion compensation interpolators to be reused and not require new processing blocks to support adaptive resolution change which would introduce additional cost.
2.2.6.1. Adaptive Resolution Change Signaling
Table 12: SPS

[ [pic_width_in_luma_samples specifies the width of each decoded picture in units of luma samples. pic_width_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
pic_height_in_luma_samples specifies the height of each decoded picture in units of luma samples. pic_height_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY. ] ]
max_pic_width_in_luma_samples specifies the maximum width of decoded pictures referring to the SPS in units of luma samples. max_pic_width_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
max_pic_height_in_luma_samples specifies the maximum height of decoded pictures referring to the SPS in units of luma samples. max_pic_height_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY.
Table 13: PPS

pic_size_different_from_max_flag equal to 1 specifies that the PPS signals different picture width or picture height from the max_pic_width_in_luma_samples and max_pic_height_in_luma_sample in the referred SPS. pic_size_different_from_max_flag equal to 0 specifies that pic_width_in_luma_samples and pic_height_in_luma_sample are the same as max_pic_width_in_luma_samples and max_pic_height_in_luma_sample in the referred SPS.
pic_width_in_luma_samples specifies the width of each decoded picture in units of luma samples. pic_width_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY. When pic_width_in_luma_samples is not present, it is inferred to be equal to max_pic_width_in_luma_samples
pic_height_in_luma_samples specifies the height of each decoded picture in units of luma samples. pic_height_in_luma_samples shall not be equal to 0 and shall be an integer multiple of MinCbSizeY. When pic_height_in_luma_samples is not present, it is inferred to be equal to max_pic_height_in_luma_samples.
It is a requirement of bitstream conformance that horizontal and vertical scaling ratios shall be in the range of 1/8 to 2, inclusive for every active reference picture. The scaling ratios are defined as follows:
horizontal_scaling_ratio= ( (reference_pic_width_in_luma_samples<<14) + (pic_width _in_luma_samples/2) ) /pic_width_in_luma_samples
vertical_scaling_ratio= ( (reference_pic_height_in_luma_samples<<14) + (pic_height_i n_luma_samples/2) ) /pic_height_in_luma_samples
Table 14

Reference Picture Scaling Process
When there is a resolution change within a CVS, a picture may have a different size from one or more of its reference pictures. This proposal normalizes all motion vectors to the current picture grid instead of their corresponding reference picture grids. This is asserted to be beneficial to keep the design consistent and make resolution changes transparent to the motion vector prediction process. Otherwise, neighboring motion vectors pointing to reference pictures with different sizes cannot be used directly for spatial motion vector prediction due to the different scale.
When a resolution change happens, both the motion vectors and reference blocks have to be scaled while doing motion compensated prediction. The scaling range is limited to [1/8, 2] , i.e. the upscaling is limited to 1: 8 and downscaling is limited to 2: 1. Note that upscaling refers to the case where the reference picture is smaller than the current picture, while downscaling refers to the case where the reference picture is larger than the current picture. In the following sections, the scaling process is described in more detail.
Luma Block
The scaling factors and their fixed-point representations are defined as
The scaling process includes two parts:
1. Map the upper left corner pixel of the current block to the reference picture;
2. Use the horizontal and vertical step sizes to address the reference locations of the current block’s other pixels.
If the coordinate of the upper left corner pixel of the current block is (x, y) , the subpel location (x^', y^') in the reference picture pointed to by a motion vector (mvX, mvY) in units of 1/16th pel is specified as follows:
The horizontal location in the reference picture is
x′= ( (x<<4) +mvX) ·hori_scale_fp ---- [Equation 3]
and x' is further scaled down to only keep 10 fractional bits
x′=Sign (x′) · ( (Abs (x′) + (1<<7) ) >>8) ---- [Equation 4]
Similarly, the vertical location in the reference picture is
y′= ( (y<<4) +mvY) ·vert_scale_fp ---- [Equation 5]
and y' is further scaled down to
y′=Sign (y′) · ( (Abs (y′) + (1<<7) ) >>8) ---- [Equation 6]
At this point, the reference location of the upper left corner pixel of the current block is at (x^', y^') . The other reference subple/pel locations are calculated relative to (x^', y^') with horizontal and vertical step sizes. Those step sizes are derived with 1/1024-pel accuracy from the above horizontal and vertical scaling factors as follows:
x_step = (hori_scale_fp + 8) >> 4 ---- [Equation 7]
y_step = (vert_scale_fp+ 8) >> 4. ---- [Equation 8]
As an example, if a pixel in the current block is i-column and j-row away from the upper left corner pixel, its corresponding reference pixel’s horizontal and vertical coordinates are derived by
x′
i=x′+i*x_step ---- [Equation 9]
y′
j=y′+j*y_step ---- [Equation 10]
In subpel interpolation, x′
i and y′
j have to be broken up into full-pel parts and fractional-pel parts:
- The full-pel parts for addressing reference block are equal to
(x′
i+32) >>10 ---- [Equation 11]
(y′
j+32) >>10 ---- [Equation 12]
- The fractional-pel parts used to select interpolation filters are equal to
Δx= ( (x′
i+32) >>6) &15 ---- [Equation 13]
Δy= ( (y′
j+32) >>6) &15. ---- [Equation 14]
Once the full-pel and fractional-pel locations within a reference picture are determined, the existing motion compensation interpolators can be used without any additional changes. The full-pel location will be used to fetch the reference block patch from the reference picture and the fractional-pel location will be used to select the proper interpolation filter.
Chroma Block
When the chroma format is 4: 2: 0, chroma motion vectors have 1/32-pel accuracy. The scaling process of chroma motion vectors and chroma reference blocks is almost the same as for luma blocks except a chroma format related adjustment.
When the coordinate of the upper left corner pixel of the current chroma block is (xc, yc) , the initial horizontal and vertical locations in the reference chroma picture are
x
c′= ( (x
c<<5) +mvX) ·hori_scale_fp ---- [Equation 15]
y
c′= ( (y
c<<5) +mvY) ·vert_scale_fp ---- [Equation 16]
where mvX and mvY are the original luma motion vector but now should be examined with 1/32-pel accuracy.
x
c′ and y
c′ are further scaled down to keep 1/1024 pel accuracy
x
c′=Sign (x
c′) · ( (Abs (x
c′) + (1<<8) ) >>9) ---- [Equation 17]
y
c′=Sign (y
c′) · ( (Abs (y
c′) + (1<<8) ) >>9) ---- [Equation 18]
Compared to the associated luma equations, the above right shift is increased by one extra bit.
The step sizes used are the same as for luma. For a chroma pixel at (i, j) relative to the upper left corner pixel, its reference pixel’s horizontal and vertical coordinates are derived by
In subpel interpolation,
 and
and
 are also broken up into full-pel parts and fractional-pel parts:
are also broken up into full-pel parts and fractional-pel parts:
The full-pel parts for addressing reference block are equal to:
The fractional-pel parts used to select interpolation filters are equal to:
Interaction with Other Coding Tools
Because of the extra complexity and memory bandwidth associated with the interaction of some coding tools with reference picture scaling, it is recommended to add the following restrictions to the VVC specification:
When tile_group_temporal_mvp_enabled_flag is equal to 1, the current picture and its collocated picture shall have the same size.
When resolution change is allowed within a sequence, decoder motion vector refinement shall be turned off.
When resolution change is allowed within a sequence, sps_bdof_enabled_flag shall be equal to 0.
2.3. Coding Tree Block (CTB) -based Adaptive Loop Filter (ALF) in JVET-N0415
Slice-level temporal filter
Adaptive parameter set (APS) was adopted in VTM4. Each APS contains one set of signalled ALF filters, up to 32 APSs are supported. In the proposal, slice-level temporal filter is tested. A tile group can re-use the ALF information from an APS to reduce the overhead. The APSs are updated as a first-in-first-out (FIFO) buffer.
CTB based ALF
For luma component, when ALF is applied to a luma CTB, the choice among 16 fixed, 5 temporal or 1 signaled filter sets is indicated. Only the filter set index is signalled. For one slice, only one new set of 25 filters can be signaled. If a new set is signalled for a slice, all the luma CTBs in the same slice share that set. Fixed filter sets can be used to predict the new slice-level filter set and can be used as candidate filter sets for a luma CTB as well. The number of filters is 64 in total.
For chroma component, when ALF is applied to a chroma CTB, if a new filter is signalled for a slice, the CTB used the new filter, otherwise, the most recent temporal chroma filter satisfying the temporal scalability constrain is applied.
As the slice-level temporal filter, the APSs are updated as a first-in-first-out (FIFO) buffer.
2.4. Alternative temporal motion vector prediction (a.k.a. subblock-based temporal merging candidate in VVC)
In the alternative temporal motion vector prediction (ATMVP) method, the motion vectors temporal motion vector prediction (TMVP) is modified by fetching multiple sets of motion information (including motion vectors and reference indices) from blocks smaller than the current CU. As shown in Figure 14, the sub-CUs are square N×N blocks (N is set to 8 by default) .
ATMVP predicts the motion vectors of the sub-CUs within a CU in two steps. The first step is to identify the corresponding block in a reference picture with a so-called temporal vector. The reference picture is called the motion source picture. The second step is to split the current CU into sub-CUs and obtain the motion vectors as well as the reference indices of each sub-CU from the block corresponding to each sub-CU, as shown in FIG. 15 which shows an example of ATMVP motion prediction for a CU.
In the first step, a reference picture and the corresponding block is determined by the motion information of the spatial neighbouring blocks of the current CU. To avoid the repetitive scanning process of neighbouring blocks, the merge candidate from block A0 (the left block) in the merge candidate list of the current CU is used. The first available motion vector from block A0 referring to the collocated reference picture are set to be the temporal vector. This way, in ATMVP, the corresponding block may be more accurately identified, compared with TMVP, wherein the corresponding block (sometimes called collocated block) is always in a bottom-right or center position relative to the current CU.
In the second step, a corresponding block of the sub-CU is identified by the temporal vector in the motion source picture, by adding to the coordinate of the current CU the temporal vector. For each sub-CU, the motion information of its corresponding block (the smallest motion grid that covers the center sample) is used to derive the motion information for the sub-CU. After the motion information of a corresponding N×N block is identified, it is converted to the motion vectors and reference indices of the current sub-CU, in the same way as TMVP of HEVC, wherein motion scaling and other procedures apply.
2.5. Affine motion prediction
In HEVC, only translation motion model is applied for motion compensation prediction (MCP) . While in the real world, there are many kinds of motion, e.g. zoom in/out, rotation, perspective motions and the other irregular motions. In VVC, a simplified affine transform motion compensation prediction is applied with 4-parameter affine model and 6-parameter affine model. FIGS. 16a and 16b show a simplified 4-paramter affine motion model and a simplified 6-parmaeter affine motion model, respectively. As shown FIGS. 16a and 16b, the affine motion field of the block is described by two control point motion vectors (CPMVs) for the 4-parameter affine model and 3 CPMVs for the 6-parameter affine model.
The motion vector field (MVF) of a block is described by the following equations with the 4-parameter affine model (wherein the 4-parameter are defined as the variables a, b, e and f) in equation (1) and 6-parameter affine model (wherein the 4-parameter are defined as the variables a, b, c, d, e and f) in equation (2) respectively:


where (mvh0, mvh0) is motion vector of the top-left corner control point, and (mvh1, mvh1) is motion vector of the top-right corner control point and (mvh2, mvh2) is motion vector of the bottom-left corner control point, all of the three motion vectors are called control point motion vectors (CPMV) , (x, y) represents the coordinate of a representative point relative to the top-left sample within current block and (mvh (x, y) , mvv (x, y) ) is the motion vector derived for a sample located at (x, y) . The CP motion vectors may be signaled (like in the affine AMVP mode) or derived on-the-fly (like in the affine merge mode) . w and h are the width and height of the current block. In practice, the division is implemented by right-shift with a rounding operation. In VTM, the representative point is defined to be the center position of a sub-block, e.g., when the coordinate of the left-top corner of a sub-block relative to the top-left sample within current block is (xs, ys) , the coordinate of the representative point is defined to be (xs+2, ys+2) . For each sub-block (i.e., 4x4 in VTM) , the representative point is utilized to derive the motion vector for the whole sub-block.
In order to further simplify the motion compensation prediction, sub-block based affine transform prediction is applied. To derive motion vector of each M×N (both M and N are set to 4 in current VVC) sub-block, the motion vector of the center sample of each sub-block, as shown in FIG. 17, is calculated according to Equation 25 and Equation 26, and rounded to 1/16 fraction accuracy. Then the motion compensation interpolation filters for 1/16-pel are applied to generate the prediction of each sub-block with derived motion vector. The interpolation filters for 1/16-pel are introduced by the affine mode.
After MCP, the high accuracy motion vector of each sub-block is rounded and saved as the same accuracy as the normal motion vector.
2.5.1. Signaling of affine prediction
Similar to the translational motion model, there are also two modes for signaling the side information due affine prediction. They are AFFINE_INTER and AFFINE_MERGE modes.
2.5.2. AF_INTER mode
For CUs with both width and height larger than 8, AF_INTER mode can be applied. An affine flag in CU level is signaled in the bitstream to indicate whether AF_INTER mode is used.
In this mode, for each reference picture list (List 0 or List 1) , an affine AMVP candidate list is constructed with three types of affine motion predictors in the following order, wherein each candidate includes the estimated CPMVs of the current block. The differences of the best CPMVs found at the encoder side (such as mv
0 mv
1 mv
2 in FIGS. 18a and 18b and the estimated CPMVs are signaled. In addition, the index of affine AMVP candidate from which the estimated CPMVs are derived is further signaled.
1) Inherited affine motion predictors
The checking order is similar to that of spatial MVPs in HEVC AMVP list construction. First, a left inherited affine motion predictor is derived from the first block in {A1, A0} that is affine coded and has the same reference picture as in current block. Second, an above inherited affine motion predictor is derived from the first block in {B1, B0, B2} that is affine coded and has the same reference picture as in current block. The five blocks A1, A0, B1, B0, B2 are depicted in FIG. 19.
Once a neighboring block is found to be coded with affine mode, the CPMVs of the coding unit covering the neighboring block are used to derive predictors of CPMVs of current block. For example, if A1 is coded with non-affine mode and A0 is coded with 4-parameter affine mode, the left inherited affine MV predictor will be derived from A0. In this case, the CPMVs of a CU covering A0, as denoted by
 for the top-left CPMV and
for the top-left CPMV and
 for the top-right CPMV in FIG. 18b are utilized to derive the estimated CPMVs of current block, denoted by
for the top-right CPMV in FIG. 18b are utilized to derive the estimated CPMVs of current block, denoted by

 for the top-left (with coordinate (x0, y0) ) , top-right (with coordinate (x1, y1) ) and bottom-right positions (with coordinate (x2, y2) ) of current block.
for the top-left (with coordinate (x0, y0) ) , top-right (with coordinate (x1, y1) ) and bottom-right positions (with coordinate (x2, y2) ) of current block.
2) Constructed affine motion predictors
A constructed affine motion predictor consists of control-point motion vectors (CPMVs) that are derived from neighboring inter coded blocks, as shown in FIG. 20, which have the same reference picture. If the current affine motion model is 4-paramter affine, the number of CPMVs is 2, otherwise if the current affine motion model is 6-parameter affine, the number of CPMVs is 3. The top-left CPMV
 is derived by the MV at the first block in the group {A, B, C} that is inter coded and has the same reference picture as in current block. The top-right CPMV
is derived by the MV at the first block in the group {A, B, C} that is inter coded and has the same reference picture as in current block. The top-right CPMV
 is derived by the MV at the first block in the group {D, E} that is inter coded and has the same reference picture as in current block. The bottom-left CPMV
is derived by the MV at the first block in the group {D, E} that is inter coded and has the same reference picture as in current block. The bottom-left CPMV
 is derived by the MV at the first block in the group {F, G} that is inter coded and has the same reference picture as in current block.
is derived by the MV at the first block in the group {F, G} that is inter coded and has the same reference picture as in current block.
- If the current affine motion model is 4-parameter affine, then a constructed affine motion predictor is inserted into the candidate list only if both
 and
and
 are founded, that is,
are founded, that is,
 and
and
 are used as the estimated CPMVs for top-left (with coordinate (x0, y0) ) , top-right (with coordinate (x1, y1) ) positions of current block.
are used as the estimated CPMVs for top-left (with coordinate (x0, y0) ) , top-right (with coordinate (x1, y1) ) positions of current block.
- If the current affine motion model is 6-parameter affine, then a constructed affine motion predictor is inserted into the candidate list only if
 and
and
 are all founded, that is,
are all founded, that is,
 and
and
 are used as the estimated CPMVs for top-left (with coordinate (x0, y0) ) , top-right (with coordinate (x1, y1) ) and bottom-right (with coordinate (x2, y2) ) positions of current block.
are used as the estimated CPMVs for top-left (with coordinate (x0, y0) ) , top-right (with coordinate (x1, y1) ) and bottom-right (with coordinate (x2, y2) ) positions of current block.
No pruning process is applied when inserting a constructed affine motion predictor into the candidate list.
3) Normal AMVP motion predictors
The following applies until the number of affine motion predictors reaches the maximum.
i. Derive an affine motion predictor by setting all CPMVs equal to
 if available.
if available.
ii. Derive an affine motion predictor by setting all CPMVs equal to
 if available.
if available.
iii. Derive an affine motion predictor by setting all CPMVs equal to
 if available.
if available.
iv. Derive an affine motion predictor by setting all CPMVs equal to HEVC TMVP if available.
v. Derive an affine motion predictor by setting all CPMVs to zero MV.
Note that
 is already derived in constructed affine motion predictor.
is already derived in constructed affine motion predictor.
In AF_INTER mode, when 4/6-parameter affine mode is used, 2/3 control points are required, and therefore 2/3 MVD (Motion Vector Difference) needs to be coded for these control points, as shown in F IGS. 18a and 18b. In JVET-K0337, it is proposed to derive the MV as follows, i.e., mvd
1 and mvd
2 are predicted from mvd
0.
Wherein
 mvd
i and mv
1 are the predicted motion vector, motion vector difference and motion vector of the top-left pixel (i = 0) , top-right pixel (i = 1) or left-bottom pixel (i = 2) respectively, as shown in FIG. 18b. Please note that the addition of two motion vectors (e.g., mvA(xA, yA) and mvB (xB, yB) ) is equal to summation of two components separately, that is, newMV = mvA + mvB and the two components of newMV is set to (xA + xB) and (yA + yB) , respectively.
mvd
i and mv
1 are the predicted motion vector, motion vector difference and motion vector of the top-left pixel (i = 0) , top-right pixel (i = 1) or left-bottom pixel (i = 2) respectively, as shown in FIG. 18b. Please note that the addition of two motion vectors (e.g., mvA(xA, yA) and mvB (xB, yB) ) is equal to summation of two components separately, that is, newMV = mvA + mvB and the two components of newMV is set to (xA + xB) and (yA + yB) , respectively.
2.5.2.1. AF_MERGE mode
When a CU is applied in AF_MERGE mode, it gets the first block coded with affine mode from the valid neighbor reconstructed blocks. FIG. 21 shows candidates for AF_MERGE. The selection order for the candidate block is from left, above, above right, left bottom to above left as shown in FIG. 21a (denoted by A, B, C, D, E in order) . For example, if the neighbor left bottom block is coded in affine mode as denoted by A0 in FIG. 21b, the Control Point (CP) motion vectors mv
0
N, mv
1
N and mv
2
N of the top left corner, above right corner and left bottom corner of the neighboring CU/PU which contains the block A are fetched. And the motion vector mv
0
C, mv
1
C and mv
2
C (which is only used for the 6-parameter affine model) of the top left corner/top right/bottom left on the current CU/PU is calculated based on mv
0
N, mv
1
N and mv
2
N. It should be noted that in VTM-2.0, sub-block (e.g. 4×4 block in VTM) located at the top-left corner stores mv0, the sub-block located at the top-right corner stores mv1 if the current block is affine coded. If the current block is coded with the 6-parameter affine model, the sub-block located at the bottom-left corner stores mv2; otherwise (with the 4-parameter affine model) , LB stores mv2’. Other sub-blocks store the MVs used for MC.
After the CPMV of the current CU mv0C, mv1C and mv2C are derived, according to the simplified affine motion model Equation 25 and Equation 26, the MVF of the current CU is generated. In order to identify whether the current CU is coded with AF_MERGE mode, an affine flag is signaled in the bitstream when there is at least one neighbor block is coded in affine mode.
In JVET-L0142 and JVET-L0632, an affine merge candidate list is constructed with following steps:
1) Insert inherited affine candidates
Inherited affine candidate means that the candidate is derived from the affine motion model of its valid neighbor affine coded block. The maximum two inherited affine candidates are derived from affine motion model of the neighboring blocks and inserted into the candidate list. For the left predictor, the scan order is {A0, A1} ; for the above predictor, the scan order is {B0, B1, B2} .
2) Insert constructed affine candidates
If the number of candidates in affine merge candidate list is less than MaxNumAffineCand (e.g., 5) , constructed affine candidates are inserted into the candidate list. Constructed affine candidate means the candidate is constructed by combining the neighbor motion information of each control point.
a) The motion information for the control points is derived firstly from the specified spatial neighbors and temporal neighbor shown in FIG. 22 which shows an example of a candidates position for affine merge mode. CPk (k=1, 2, 3, 4) represents the k-th control point. A0, A1, A2, B0, B1, B2 and B3 are spatial positions for predicting CPk (k=1, 2, 3) . T is temporal position for predicting CP4.
The coordinates of CP1, CP2, CP3 and CP4 is (0, 0) , (W, 0) , (H, 0) and (W, H) , respectively, where W and H are the width and height of current block.
The motion information of each control point is obtained according to the following priority order:
- For CP1, the checking priority is B2->B3->A2. B2 is used if it is available. Otherwise, if B2 is available, B3 is used. If both B2 and B3 are unavailable, A2 is used. If all the three candidates are unavailable, the motion information of CP1 cannot be obtained.
- For CP2, the checking priority is B1->B0.
- For CP3, the checking priority is A1->A0.
- For CP4, T is used.
b) Secondly, the combinations of controls points are used to construct an affine merge candidate.
- Motion information of three control points is needed to construct a 6-parameter affine candidate. The three control points can be selected from one of the following four combinations ( {CP1, CP2, CP4} , {CP1, CP2, CP3} , {CP2, CP3, CP4} , {CP1, CP3, CP4} ) . Combinations {CP1, CP2, CP3} , {CP2, CP3, CP4} , {CP1, CP3, CP4} will be converted to a 6-parameter motion model represented by top-left, top-right and bottom-left control points.
- Motion information of two control points is needed to construct a 4-parameter affine candidate. The two control points can be selected from one of the two combinations ( {CP1, CP2} , {CP1, CP3} ) . The two combinations will be converted to a 4-parameter motion model represented by top-left and top-right control points.
- The combinations of constructed affine candidates are inserted into to candidate list as following order:
{CP1, CP2, CP3} , {CP1, CP2, CP4} , {CP1, CP3, CP4} , {CP2, CP3, CP4} , {CP1, CP2} , {CP1, CP3}
i. For each combination, the reference indices of list X for each CP are checked, if they are all the same, then this combination has valid CPMVs for list X. If the combination does not have valid CPMVs for both list 0 and list 1, then this combination is marked as invalid. Otherwise, it is valid, and the CPMVs are put into the sub-block merge list.
3) Padding with zero motion vectors
If the number of candidates in affine merge candidate list is less than 5, zero motion vectors with zero reference indices are insert into the candidate list, until the list is full.
More specifically, for the sub-block merge candidate list, a 4-parameter merge candidate with MVs set to (0, 0) and prediction direction set to uni-prediction from list 0 (for P slice) and bi-prediction (for B slice) .
Drawbacks of existing implementations
When applied in VVC, ARC may have the following issues:
It is unclear to apply coding tools in VVC such as ALF, Luma Mapping Chroma Scaling (LMCS) , Decoder Side Motion-vector Refinement (DMVR) , Bi-Directional Optical Flow (BDOF) , Affine prediction, Triangular Prediction Mode (TPM) , Symmetrical Motion Vector Difference (SMVD) , Merge Motion Vector Difference (MMVD) , inter-intra prediction (a.k.a. Combined Inter-picture merge and Intra-picture Prediction CIIP in VVC) , Localized Illumination Compensation (LIC) and History-based Motion Vector Prediction (HMVP) .
Exemplary methods for coding tools with adaptive resolution conversion
Embodiments of the disclosed technology overcome the drawbacks of existing implementations. The examples of the disclosed technology provided below are discussed to facilitate the understanding of the disclosed technology and should be interpreted in a way to limit the disclosed technology. Unless explicitly indicated to the contrary, the various features described in these examples can be combined.
In the following discussion, SatShift (x, n) is defined as
Shift (x, n) is defined as Shift (x, n) = (x+ offset0) >>n.
In one example, offset0 and/or offset1 are set to (1<<n) >>1 or (1<< (n-1) ) . In another example, offset0 and/or offset1 are set to 0.
In another example, offset0=offset1= ( (1<<n) >>1) -1 or ( (1<< (n-1) ) ) -1.
Clip3 (min, max, x) is defined as

Floor (x) is defined as the largest integer less than or equal to x.
Ceil (x) is the smallest integer greater than or equal to x.
Log2 (x) is defined as the base-2 logarithm of x.
Some aspects of the implementations of the disclosed technology are listed in the below.
1. The derivation of MV offsets in MMVD/SMVD and/or refined motion vectors in decoder side derivation process may depend on the resolution of reference pictures associated with current block and the resolution of current picture.
a. For example, the second MV offset referring to a second reference picture may be scaled from a first MV offset referring to a first reference picture. The scaling factor may depend on the resolutions of the first and second reference pictures.
2. The motion candidate list construction process may be constructed according to the reference picture resolution associated with the spatial/temporal/history motion candidates.
a. In one example, a merge candidate referring to a reference picture with a higher resolution may have a higher priority than a merge candidate referring to a reference picture with a lower resolution. In the discussion, resolution W0*H0 is lower than resolution W1*H1 if W0 < W1 and H0<H1.
b. For example, a merge candidate referring to a reference picture with a higher resolution may be put before a merge candidate referring to a reference picture with a lower resolution in the merge candidate list.
c. For example, a motion vector referring to a reference picture with a resolution lower than the resolution of the current picture cannot be in the merge candidate list.
d. In one example, whether to and/or how to update the history buffer (look up table) may depend on reference picture resolution associated with the decoded motion candidate.
i. In one example, if one reference picture associated with the decoded motion candidate is with different resolution, such motion candidate is disallowed to update the history buffer.
3. It is proposed that a picture should be filtered with ALF parameters associated with corresponding dimensions.
a. In one example, ALF parameters signaled in a video unit such as APS may be associated with one or multiple picture dimensions.
b. In one example, a video unit such as APS signaling ALF parameters may be associated with one or multiple picture dimensions.
c. For example, a picture may only apply ALF parameters signaled in a video unit such as APS, associated with the same dimensions.
d. The resolution/index of PPS/indication of resolution may be signaled in the ALF APS.
e. It is restricted that ALF parameter may only inherit/be predicted from that used for a picture with the same resolution.
4. It is proposed that ALF parameters associated with a first corresponding dimensions may inherit or be predicted from ALF parameters associated with a second corresponding dimensions.
a. In one example, the first corresponding dimensions must be the same as the second corresponding dimensions.
b. In one example, the first corresponding dimensions may be different to the second corresponding dimensions.
5. It is proposed that samples in a picture should be reshaped with LMCS parameters associated with corresponding dimensions.
a. In one example, LMCS parameters signaled in a video unit such as APS may be associated with one or multiple picture dimensions.
b. In one example, a video unit such as APS signaling LMCS parameters may be associated with one or multiple picture dimensions.
c. For example, a picture may only apply LMCS parameters signaled in a video unit such as APS, associated with the same dimensions.
d. The resolution/index of PPS/indication of resolution may be signaled in the LMCS APS.
e. It is restricted that LMCS parameter may only inherit/be predicted from that used for a picture with the same resolution.
6. It is proposed that LMCS parameters associated with a first corresponding dimensions may inherit or be predicted from LMCS parameters associated with a second corresponding dimensions.
a. In one example, the first corresponding dimensions must be the same as the second corresponding dimensions.
b. In one example, the first corresponding dimensions may be different to the second corresponding dimensions.
7. Whether to and/or how to enable TPM (triangular prediction mode) /GEO (inter prediction with geometry partitioning) or other coding tools that may split one block to two or multiple sub-partitions may depend on the associated reference picture information of the two or multiple sub-partitions.
a. In one example, it may depend on whether resolution of one of the two reference pictures and resolution of current picture.
i. In one example, if at least one of the two reference pictures are associated with different resolution compared to the current picture, such a coding tool is disabled.
b. In one example, it may depend on whether resolutions of the two reference pictures are same or not.
i. In one example, if two reference pictures are associated with different resolution, such a coding tool may be disabled.
ii. In one example, if both two reference pictures are associated with different resolution compared to the current picture, such a coding tool is disabled.
iii. Alternatively, if both two reference pictures are associated with different resolution compared to the current picture but the two reference pictures are with same resolution, such a coding tool may still be disabled.
iv. Alternatively, if at least one of the reference pictures has different resolution as current picture, and the reference pictures are with different resolution, the coding tool X may be disabled.
c. Alternatively, furthermore, it may depend on whether the two reference pictures are the same reference picture.
d. Alternatively, furthermore, it may depend on whether the two reference pictures are in the same reference list or not.
e. Alternatively, such a coding tool may be always disabled if RPR (reference picture resampling is enabled in slice/picture header/sequence parameter set) .
8. It is proposed that coding tool X may be disabled for a block if the block refers to at least one reference picture with different dimensions to the current picture.
a. In one example, the information related to the coding tool X may not be signaled.
b. In one example, motion information of such block may not be inserted into the HMVP table.
c. Alternatively, if coding tool X is applied in a block, the block cannot refer to a reference picture with different dimensions to the current picture.
i. In one example, a merge candidate referring to a reference picture with different dimensions to the current picture may be skipped or not put into the merge candidate list.
ii. In one example, the reference index corresponds to a reference picture with different dimensions to the current picture may be skipped or not allowed to be signaled.
d. Alternatively, the coding tool X may be applied after scaling the two reference blocks or pictures according to resolution of the current picture and resolutions of the reference pictures.
e. Alternatively, the coding tool X may be applied after scaling the two MVs or MVDs according to resolution of the current picture and resolutions of the reference pictures.
f. In one example, for a block (e.g., bi-prediction coded block or a block with multiple-hypothesis from the same reference picture list with different reference pictures or different MVs; or a block with multiple-hypothesis from different reference picture lists) , whether to disable or enabled the coding tool X may depend on the resolutions of the reference picture associated with the reference picture list and/or current reference picture.
i. In one example, the coding tool X may be disabled for one reference picture list but enabled for the other reference picture list.
ii. In one example, the coding tool X may be disabled for one reference picture but enabled for the other reference picture. Here, the two reference pictures may be from different or same reference picture list.
iii. In on example, for each reference picture list L, enabling/disabling the coding tool is determined regardless the reference picture in another reference picture list different than list L.
1. In one example, it may be determined by the reference picture of list L and current picture.
2. In one example, the tool may be disabled for list L if the associated reference picture for list L is different from current picture.
iv. Alternatively, enabling/disabling the coding tool is determined by resolutions of all reference pictures and/or current picture.
1. In one example, if at least one of the reference pictures has different resolution as current picture, the coding tool X may be disabled.
2. In one example, if at least one of the reference pictures has different resolution as current picture, but the reference pictures are with the same resolution, the coding tool X may be still enabled.
3. In one example, if at least one of the reference pictures has different resolution as current picture, and the reference pictures are with different resolution, the coding tool X may be disabled.
g. The coding tool X may be anyone below.
iii. DMVR
iv. BDOF
v. Affine prediction
vi. Triangular Prediction Mode
vii. SMVD
viii. MMVD
ix. Inter-intra prediction in VVC
x. LIC
xi. HMVP
xii. Multiple Transform Set (MTS)
xiii. Sub-Block Transform (SBT)
xiv. PROF and/or other decode side motion/prediction refinement methods
xv. LFNST (low frequency non-square transform)
xvi. Filtering methods (e.g., deblocking filter/SAO/ALF)
xvii. GEO/TPM/cross-component ALF
9. Reference picture list of a picture may contain no more than K different resolutions.
a. In one example, K is equal to 2.
10. No more than K different resolutions may be allowed for N consecutive (in decoding order or display order) pictures.
a. In one example, N = 3, K = 3.
b. In one example, N = 10, K = 3.
c. In one example, no more than K different resolutions may be allowed in a GOP
d. In one example, no more than K different resolutions may be allowed between two pictures with same certain temporal layer id (denoted as tid) .
i. For example, K = 3, tid = 0.
11. Resolution change may be allowed for Intra picture only.
12. Bi-prediction may be converted to uni-prediction in the decoding process if one or two reference pictures of one block are with different resolution as the current picture.
a. In one example, the prediction from list X with the corresponding reference picture with different resolution as the current picture may be discarded.
13. Whether to enable or disable inter-prediction from reference pictures in different resolution may depend on the motion vector precision and/or resolution ratios.
a. In one example, if the scaled motion vector according to the resolution ratios point to integer positions, the inter-prediction may be still applied.
b. In one example, if the scaled motion vector according to the resolution ratios point to a sub-pel position (e.g., 1/4-pel) which is allowed for the cases without ARC, the inter-prediction may be still applied.
c. Alternatively, bi-prediction may be disallowed when both reference pictures are with different resolutions from the current picture.
d. Alternatively, bi-prediction may be enabled when one reference picture is with different resolution from the current picture and the other is with the same resolution.
e. Alternatively, uni-prediction may be disallowed for a block when the reference picture is with different resolution from the current picture and the block dimension satisfy certain conditions.
14. A first flag (e.g., pic_disable_X_flag) to indicate whether a coding tool X is disabled may be signaled in picture header.
a. Whether to enable the coding tool for a slice/tile/brick/subpicture/other video unit smaller than a picture may be controlled by this flag in picture header and/or slice types.
b. In one example, when the first flag is true, the coding tool X is disabled.
i. Alternatively, when the first flag is false, the coding tool X is enabled.
ii. In one example, it is enabled/disabled for all samples within the picture.
c. In one example, the signaling of the first flag may further depend on a syntax element or multiple syntax elements in SPS/VPS/DPS/PPS.
i. In one example, the signaling of the flag may depend on the enabling flag of the coding tool X in SPS.
ii. Alternatively, furthermore, a second flag (e.g., sps_X_slice_present_flag) to indicate the presence of the first flag in a picture header may be signaled in SPS.
1) Alternatively, furthermore, the second flag may be conditionally signaled when the coding tool X is enabled for a sequence (e.g., sps_X_enabled_flag is true) .
2) Alternatively, furthermore, only the second flag indicates the first flag is present, the first flag may be signaled in picture header.
d. In one example, the first and/or the second flag is coded with 1-bit.
e. The coding tool X may be:
i. In one example, the coding tool X is the PROF.
ii. In one example, the coding tool X is the DMVR.
iii. In one example, the coding tool X is the BDOF.
iv. In one example, the coding tool X is the cross-component ALF.
v. In one example, the coding tool X is the GEO.
vi. In one example, the coding tool X is the TPM.
vii. In one example, the coding tool X is the MTS.
15. Whether a block can refer to a reference picture with different dimensions to the current picture may depend on the width (WB) and/or height (HB) of the block, and/or block prediction mode (i.e., bi-prediction or uni-prediction) .
a. In one example, a block can refer to a reference picture with different dimensions to the current picture if WB>=T1 and HB>=T2. E.g. T1=T2=8.
b. In one example, a block can refer to a reference picture with different dimensions to the current picture if WB *HB >=T. E.g. T=64.
c. In one example, a block can refer to a reference picture with different dimensions to the current picture if Min (WB, HB) >=T. E.g. T=8.
d. In one example, a block can refer to a reference picture with different dimensions to the current picture if Max (WB, HB) >=T. E.g. T=8.
e. In one example, a block can refer to a reference picture with different dimensions to the current picture if WB<=T1 and HB<=T2. E.g. T1=T2=64.
f. In one example, a block can refer to a reference picture with different dimensions to the current picture if WB *HB <=T. E.g. T=4096.
g. In one example, a block can refer to a reference picture with different dimensions to the current picture if Min (WB, HB) <=T. E.g. T=64.
h. In one example, a block can refer to a reference picture with different dimensions to the current picture if Max (WB, HB) <=T. E.g. T=64.
i. Alternatively, a block is disallowed to refer to a reference picture with different dimensions to the current picture if WB<=T1 and/or HB<=T2. E.g. T1=T2=8.
j. Alternatively, a block is disallowed to refer to a reference picture with different dimensions to the current picture if WB<=T1 and/or HB<=T2. E.g. T1=T2=8.
FIG. 23 shows a flowchart of an exemplary method for video processing. Referring to FIG. 23, the method 2300 includes, at step 2310, deriving during conversion between a current video block and a bitstream representation of the current video block, motion vector offsets based on a resolution of reference pictures associated with the current video block and a resolution of a current picture. The method 2300 further includes, at step 2320, performing the conversion using the motion vector offsets.
In some implementations, the deriving motion vector offset includes: deriving a first motion vector offset referring to a first reference picture; and deriving a second motion vector offset referring to a second reference picture based on the first motion vector offset. In some implementations, the method further comprises: performing, for the current video block, a motion candidate list construction process based on a reference picture resolution associated with a spatial, temporal, or history motion candidates. In some implementations, whether to or how to update a look up table depends on a reference picture resolution associated with a decoded motion candidate. In some implementations, the method further comprises: performing, for the current picture, a filtering operation with adaptive loop filter (ALF) parameters associated with corresponding dimensions. In some implementations, the ALF parameters include first ALF parameters associated with first corresponding dimensions and second ALF parameters associated with second corresponding dimensions, the second ALF parameters being inherited or predicted from the first ALF parameters.
In some implementations, the method further comprises reshaping samples in the current picture with LMCS (Luma Mapping Chroma Scaling) parameters associated with corresponding dimensions. In some implementations, the LMCS parameters include first LMCS parameters associated with first corresponding dimensions and second LMCS parameters associated with second corresponding dimensions, the second LMCS parameters being inherited or predicted from the first LMCS parameters. In some implementations, the ALF parameters or the LMCS parameters signaled in a video unit is associated with one or multiple picture dimensions. In some implementations, the method further comprises disabling a coding tool for the current video block when the current video block refers to at least one reference picture with different dimensions to the current picture. In some implementations, the method further includes skipping or omitting a merge candidate referring to a reference picture with different dimensions from dimensions of the current picture. In some implementations, the method further includes applying a coding tool after scaling two reference blocks or two reference pictures based on the resolution of the reference pictures and the resolution of the current picture or after scaling two MVs or MVDs (Motion Vector Differences) based on the resolution of the reference pictures and the resolution of the current picture. In some implementations, the current picture includes no more than K different resolutions, K being a natural number. In some implementations, the K different resolutions are allowed for N consecutive pictures, N being a natural number.
In some implementations, the method further includes applying a resolution change to the current picture that is an Intra picture. In some implementations, the method further includes converting a bi-prediction to a uni-prediction when one or two reference pictures of the current video block has a different resolution from that of the current picture. In some implementations, the method further includes enabling or disabling an inter-prediction from the reference pictures in different resolutions depending on at least one of a motion vector precision or a resolution ratio between a current block dimension and a reference block dimension. Suppose the current block dimension is W*H, the reference block dimension may be W1*H1 and the resolution ratio may refer to W1/W, H1/H, (W1*H1) / (W*H) , max (W1/W, H1/H) , or min (W1/W, H1/H) , etc. In some implementations, the method further includes applying a bi-prediction depending on whether both reference pictures or one reference picture is with different resolution from that of the current picture. In some implementations, whether the current video block refers to a reference picture with different dimensions from that of the current picture depends on at least one of a size of the current video block or a block prediction mode. In some implementations, the performing of the conversion includes generating the current video block from the bitstream representation. In some implementations, the performing of the conversion includes generating the bitstream representation from the current video block.
FIG. 24A is a block diagram of a video processing apparatus 2400. The apparatus 2400 may be used to implement one or more of the methods described herein. The apparatus 2400 may be embodied in a smartphone, tablet, computer, Internet of Things (IoT) receiver, and so on. The apparatus 2400 may include one or more processors 2402, one or more memories 2404 and video processing hardware 2406. The processor (s) 2402 may be configured to implement one or more methods (including, but not limited to, methods 2300) described in the present document. The memory (memories) 2404 may be used for storing data and code used for implementing the methods and techniques described herein. The video processing hardware 2406 may be used to implement, in hardware circuitry, some techniques described in the present document. In some embodiments, the hardware 2406 may be entirely or partly in the processor 2401, e.g., as a graphics processor.
FIG. 24B is a block diagram showing an example video processing system 2410 in which various techniques disclosed herein may be implemented. Various implementations may include some or all of the components of the system 24100. The system 2410 may include input 2412 for receiving video content. The video content may be received in a raw or uncompressed format, e.g., 8 or 10 bit multi-component pixel values, or may be in a compressed or encoded format. The input 2412 may represent a network interface, a peripheral bus interface, or a storage interface. Examples of network interface include wired interfaces such as Ethernet, passive optical network (PON) , etc. and wireless interfaces such as Wi-Fi or cellular interfaces.
The system 2410 may include a coding component 2414 that may implement the various coding or encoding methods described in the present document. The coding component 2414 may reduce the average bitrate of video from the input 2412 to the output of the coding component 2414 to produce a coded representation of the video. The coding techniques are therefore sometimes called video compression or video transcoding techniques. The output of the coding component 2414 may be either stored, or transmitted via a communication connected, as represented by the component 2416. The stored or communicated bitstream (or coded) representation of the video received at the input 2412 may be used by the component 2418 for generating pixel values or displayable video that is sent to a display interface 2420. The process of generating user-viewable video from the bitstream representation is sometimes called video decompression. Furthermore, while certain video processing operations are referred to as “coding” operations or tools, it will be appreciated that the coding tools or operations are used at an encoder and corresponding decoding tools or operations that reverse the results of the coding will be performed by a decoder.
Examples of a peripheral bus interface or a display interface may include universal serial bus (USB) or high definition multimedia interface (HDMI) or Displayport, and so on. Examples of storage interfaces include SATA (serial advanced technology attachment) , PCI, IDE interface, and the like. The techniques described in the present document may be embodied in various electronic devices such as mobile phones, laptops, smartphones or other devices that are capable of performing digital data processing and/or video display.
In some embodiments, the video coding methods may be implemented using an apparatus that is implemented on a hardware platform as described with respect to FIG. 24A or 24B.
FIG. 25 is a block diagram that illustrates an example video coding system 100 that may utilize the techniques of this disclosure.
As shown in FIG. 25, video coding system 100 may include a source device 110 and a destination device 120. Source device 110 generates encoded video data which may be referred to as a video encoding device. Destination device 120 may decode the encoded video data generated by source device 110 which may be referred to as a video decoding device.
I/O interface 126 may include a receiver and/or a modem. I/O interface 126 may acquire encoded video data from the source device 110 or the storage medium/server 130b. Video decoder 124 may decode the encoded video data. Display device 122 may display the decoded video data to a user. Display device 122 may be integrated with the destination device 120, or may be external to destination device 120 which be configured to interface with an external display device.
FIG. 26 is a block diagram illustrating an example of video encoder 200, which may be video encoder 114 in the system 100 illustrated in FIG. 25.
The functional components of video encoder 200 may include a partition unit 201, a predication unit 202 which may include a mode select unit 203, a motion estimation unit 204, a motion compensation unit 205 and an intra prediction unit 206, a residual generation unit 207, a transform unit 208, a quantization unit 209, an inverse quantization unit 210, an inverse transform unit 211, a reconstruction unit 212, a buffer 213, and an entropy encoding unit 214.
In other examples, video encoder 200 may include more, fewer, or different functional components. In an example, predication unit 202 may include an intra block copy (IBC) unit. The IBC unit may perform predication in an IBC mode in which at least one reference picture is a picture where the current video block is located.
Furthermore, some components, such as motion estimation unit 204 and motion compensation unit 205 may be highly integrated, but are represented in the example of FIG. 26 separately for purposes of explanation.
Mode select unit 203 may select one of the coding modes, intra or inter, e.g., based on error results, and provide the resulting intra-or inter-coded block to a residual generation unit 207 to generate residual block data and to a reconstruction unit 212 to reconstruct the encoded block for use as a reference picture. In some example, Mode select unit 203 may select a combination of intra and inter predication (CIIP) mode in which the predication is based on an inter predication signal and an intra predication signal. Mode select unit 203 may also select a resolution for a motion vector (e.g., a sub-pixel or integer pixel precision) for the block in the case of inter-predication.
To perform inter prediction on a current video block, motion estimation unit 204 may generate motion information for the current video block by comparing one or more reference frames from buffer 213 to the current video block. Motion compensation unit 205 may determine a predicted video block for the current video block based on the motion information and decoded samples of pictures from buffer 213 other than the picture associated with the current video block.
Motion estimation unit 204 and motion compensation unit 205 may perform different operations for a current video block, for example, depending on whether the current video block is in an I slice, a P slice, or a B slice.
In some examples, motion estimation unit 204 may perform uni-directional prediction for the current video block, and motion estimation unit 204 may search reference pictures of list 0 or list 1 for a reference video block for the current video block. Motion estimation unit 204 may then generate a reference index that indicates the reference picture in list 0 or list 1 that contains the reference video block and a motion vector that indicates a spatial displacement between the current video block and the reference video block. Motion estimation unit 204 may output the reference index, a prediction direction indicator, and the motion vector as the motion information of the current video block. Motion compensation unit 205 may generate the predicted video block of the current block based on the reference video block indicated by the motion information of the current video block.
In other examples, motion estimation unit 204 may perform bi-directional prediction for the current video block, motion estimation unit 204 may search the reference pictures in list 0 for a reference video block for the current video block and may also search the reference pictures in list 1 for another reference video block for the current video block. Motion estimation unit 204 may then generate reference indexes that indicate the reference pictures in list 0 and list 1 containing the reference video blocks and motion vectors that indicate spatial displacements between the reference video blocks and the current video block. Motion estimation unit 204 may output the reference indexes and the motion vectors of the current video block as the motion information of the current video block. Motion compensation unit 205 may generate the predicted video block of the current video block based on the reference video blocks indicated by the motion information of the current video block.
In some examples, motion estimation unit 204 may output a full set of motion information for decoding processing of a decoder.
In some examples, motion estimation unit 204 may do not output a full set of motion information for the current video. Rather, motion estimation unit 204 may signal the motion information of the current video block with reference to the motion information of another video block. For example, motion estimation unit 204 may determine that the motion information of the current video block is sufficiently similar to the motion information of a neighboring video block.
In one example, motion estimation unit 204 may indicate, in a syntax structure associated with the current video block, a value that indicates to the video decoder 300 that the current video block has the same motion information as the another video block.
In another example, motion estimation unit 204 may identify, in a syntax structure associated with the current video block, another video block and a motion vector difference (MVD) . The motion vector difference indicates a difference between the motion vector of the current video block and the motion vector of the indicated video block. The video decoder 300 may use the motion vector of the indicated video block and the motion vector difference to determine the motion vector of the current video block.
As discussed above, video encoder 200 may predictively signal the motion vector. Two examples of predictive signaling techniques that may be implemented by video encoder 200 include advanced motion vector predication (AMVP) and merge mode signaling.
Intra prediction unit 206 may perform intra prediction on the current video block. When intra prediction unit 206 performs intra prediction on the current video block, intra prediction unit 206 may generate prediction data for the current video block based on decoded samples of other video blocks in the same picture. The prediction data for the current video block may include a predicted video block and various syntax elements.
In other examples, there may be no residual data for the current video block for the current video block, for example in a skip mode, and residual generation unit 207 may not perform the subtracting operation.
Transform processing unit 208 may generate one or more transform coefficient video blocks for the current video block by applying one or more transforms to a residual video block associated with the current video block.
After transform processing unit 208 generates a transform coefficient video block associated with the current video block, quantization unit 209 may quantize the transform coefficient video block associated with the current video block based on one or more quantization parameter (QP) values associated with the current video block.
After reconstruction unit 212 reconstructs the video block, loop filtering operation may be performed reduce video blocking artifacts in the video block.
FIG. 27 is a block diagram illustrating an example of video decoder 300 which may be video decoder 114 in the system 100 illustrated in FIG. 25.
The video decoder 300 may be configured to perform any or all of the techniques of this disclosure. In the example of FIG. 27, the video decoder 300 includes a plurality of functional components. The techniques described in this disclosure may be shared among the various components of the video decoder 300. In some examples, a processor may be configured to perform any or all of the techniques described in this disclosure.
In the example of FIG. 27, video decoder 300 includes an entropy decoding unit 301, a motion compensation unit 302, an intra prediction unit 303, an inverse quantization unit 304, an inverse transformation unit 305, and a reconstruction unit 306 and a buffer 307. Video decoder 300 may, in some examples, perform a decoding pass generally reciprocal to the encoding pass described with respect to video encoder 200 (e.g., FIG. 26) .
Some embodiments of the disclosed technology include making a decision or determination to enable a video processing tool or mode. In an example, when the video processing tool or mode is enabled, the encoder will use or implement the tool or mode in the processing of a block of video, but may not necessarily modify the resulting bitstream based on the usage of the tool or mode. That is, a conversion from the block of video to the bitstream representation of the video will use the video processing tool or mode when it is enabled based on the decision or determination. In another example, when the video processing tool or mode is enabled, the decoder will process the bitstream with the knowledge that the bitstream has been modified based on the video processing tool or mode. That is, a conversion from the bitstream representation of the video to the block of video will be performed using the video processing tool or mode that was enabled based on the decision or determination.
Some embodiments of the disclosed technology include making a decision or determination to disable a video processing tool or mode. In an example, when the video processing tool or mode is disabled, the encoder will not use the tool or mode in the conversion of the block of video to the bitstream representation of the video. In another example, when the video processing tool or mode is disabled, the decoder will process the bitstream with the knowledge that the bitstream has not been modified using the video processing tool or mode that was disabled based on the decision or determination.
In the present document, the term “video processing” may refer to video encoding, video decoding, video compression or video decompression. For example, video compression algorithms may be applied during conversion from pixel representation of a video to a corresponding bitstream representation or vice versa. The bitstream representation of a current video block may, for example, correspond to bits that are either co-located or spread in different places within the bitstream, as is defined by the syntax. For example, a macroblock may be encoded in terms of transformed and coded error residual values and also using bits in headers and other fields in the bitstream.
The following first set of clauses may be implemented in some embodiments.
1. A method for video processing, comprising: deriving, during conversion between a current video block and a bitstream representation of the current video block, motion vector offsets based on a resolution of reference pictures associated with the current video block and a resolution of a current picture; and performing the conversion using the motion vector offsets.
2. The method of clause 1, wherein the deriving motion vector offset includes: deriving a first motion vector offset referring to a first reference picture; and deriving a second motion vector offset referring to a second reference picture based on the first motion vector offset.
3. The method of clause 1, further comprising: performing, for the current video block, a motion candidate list construction process based on a reference picture resolution associated with a spatial, temporal, or history motion candidates.
4. The method of clause 1, wherein whether to or how to update a look up table depends on a reference picture resolution associated with a decoded motion candidate.
5. The method of clause 1, further comprising: performing, for the current picture, a filtering operation with adaptive loop filter (ALF) parameters associated with corresponding dimensions.
6. The method of clause 5, wherein the ALF parameters include first ALF parameters associated with first corresponding dimensions and second ALF parameters associated with second corresponding dimensions, the second ALF parameters being inherited or predicted from the first ALF parameters.
7. The method of clause 1, further comprising reshaping samples in the current picture with LMCS (Luma Mapping Chroma Scaling) parameters associated with corresponding dimensions.
8. The method of clause 7, wherein the LMCS parameters include first LMCS parameters associated with first corresponding dimensions and second LMCS parameters associated with second corresponding dimensions, the second LMCS parameters being inherited or predicted from the first LMCS parameters.
9. The method of clause 5 or 7, wherein the ALF parameters or the LMCS parameters signaled in a video unit is associated with one or multiple picture dimensions.
10. The method of clause 1, further comprising disabling a coding tool for the current video block when the current video block refers to at least one reference picture with different dimensions to the current picture.
11. The method of clause 10, further including skipping or omitting a merge candidate referring to a reference picture with different dimensions from dimensions of the current picture.
12. The method of clause 1, further including applying a coding tool after scaling two reference blocks or two reference pictures based on the resolution of the reference pictures and the resolution of the current picture or after scaling two MVs or MVDs (Motion Vector Differences) based on the resolution of the reference pictures and the resolution of the current picture.
13. The method of clause 1, wherein the current picture includes no more than K different resolutions, K being a natural number.
14. The method of clause 13, wherein the K different resolutions are allowed for N consecutive pictures, N being a natural number.
15. The method of clause 1, further including applying a resolution change to the current picture that is an Intra picture.
16. The method of clause 1, further including converting a bi-prediction to a uni-prediction when one or two reference pictures of the current video block has a different resolution from that of the current picture.
17. The method of clause 1, further including enabling or disabling an inter-prediction from the reference pictures in different resolutions depending on at least one of a motion vector precision or a resolution ratio between a current block dimension and a reference block dimension.
18. The method of clause 1, further including applying a bi-prediction depending on whether both reference pictures or one reference picture is with different resolution from that of the current picture.
19. The method of clause 1, wherein whether the current video block refers to a reference picture with different dimensions from that of the current picture depends on at least one of a size of the current video block or a block prediction mode.
20. The method of clause 1, wherein the performing of the conversion includes generating the current video block from the bitstream representation.
21. The method of clause 1, wherein the performing of the conversion includes generating the bitstream representation from the current video block.
22. An apparatus in a video system comprising a processor and a non-transitory memory with instructions thereon, wherein the instructions upon execution by the processor, cause the processor to implement the method in any one of clauses 1 to 21.
23. A computer program product stored on a non-transitory computer readable media, the computer program product including program code for carrying out the method in any one of clauses 1 to 21.
The second set of clauses describe certain features and aspects of the disclosed techniques in the previous section (e.g., item 14) .
1. A method (e.g. method 2800 as shown in FIG. 28) for video processing, comprising: determining (2810) , for a conversion between a video region of a picture of a video and a coded representation of the video, enablement status of a coding tool used to represent the video region in the coded representation; and performing (2820) the conversion according to the determination; wherein a first flag is included in a picture header to indicate the enablement status of the coding tool for the picture.
2. The method of clause 1, wherein the enablement status indicates that the coding is either disabled or enabled for the video region depending on the first flag and/or a slice type of the video.
3. The method of clause 1, wherein the determining determines that the coding tool is disabled in a case that the first flag is true.
4. The method of clause 1, wherein the determining determines that the coding tool is disabled in a case that the first flag is false.
5. The method of clause 1, wherein the determining determines that the coding tool is enabled in a case that the first flag is false.
6. The method of clause 1, wherein the determining determines that the coding tool is enabled in a case that the first flag is true.
7. The method of clause 1, wherein the coding tool is disabled or enabled for all samples within the picture.
8. The method of clause 1, wherein a signaling of the first flag depends on one or more syntax elements in a sequence parameter set (SPS) , a video parameter set (VPS) , a dependency parameter set (DPS) , or a picture parameter set (PPS) that is associated with the video region.
9. The method of clause 8, wherein the signaling of the first flag depends on an indication indicating an enablement of the coding tool in the sequence parameter set (SPS) .
10. The method of clause 8, wherein a second flag to indicate a presence of the first flag in the picture header is signaled in the sequence parameter set (SPS) .
11. The method of clause 8, wherein a second flag to indicate a presence of the first flag in the picture header is signaled in a case that the coding tool is enabled for a sequence of the video.
12. The method of clause 8, wherein the first flag is signaled in the picture header in a case that the second flag to indicate a presence of the first flag indicates the presence of the first flag.
13. The method of any of clauses 1 to 12, wherein the first flag and/or the second flag is coded with 1 bit.
14. The method of any of clauses 1 to 13, wherein the coding tool is a prediction refinement with optical flow (PROF) in which one or more initial affine predictions are refined based on an optical flow calculation.
15. The method of any of clauses 1 to 13, wherein the coding tool is a decoder-side motion vector refinement (DMVR) in which motion information is refined by using prediction blocks.
16. The method of any of clauses 1 to 13, wherein the coding tool is bi-directional optical flow (BDOF) in which one or more initial predictions are refined using an optical flow calculation.
17. The method of any of clauses 1 to 13, wherein the coding tool is a cross-component adaptive loop filter (CCALF) in which a linear filter is applied to chroma samples based on luma information.
18. The method of any of clauses 1 to 13, wherein the coding tool is a geometry partitioning (GEO) in which prediction samples are generated with weighting values, the prediction samples based on partitioning of the video region according to a non-horizontal or a non-vertical line.
19. The method of any of clauses 1 to 13, wherein the coding tool is a triangular prediction mode (TPM) in which prediction samples are generated with weighting values, the prediction samples based on partitioning of the video region into two triangular partitions.
20. The method of any of clauses 1 to 19, wherein the conversion includes encoding the video into the bitstream representation.
21. The method of any of clauses 1 to 19, wherein the conversion includes decoding the bitstream representation to generate the video.
22. A video processing apparatus comprising a processor configured to implement a method recited in any one or more of clauses 1 to 21.
23. A computer readable medium storing program code that, when executed, causes a processor to implement a method recited in any one or more of clauses 1 to 21.
24. A computer readable medium that stores a coded representation or a bitstream representation generated according to any of the above described methods.
From the foregoing, it will be appreciated that specific embodiments of the presently disclosed technology have been described herein for purposes of illustration, but that various modifications may be made without deviating from the scope of the disclosed technology. Accordingly, the presently disclosed technology is not limited except as by the appended claims.
Implementations of the subject matter and the functional operations described in this patent document can be implemented in various systems, digital electronic circuitry, or in computer software, firmware, or hardware, including the structures disclosed in this specification and their structural equivalents, or in combinations of one or more of them. Implementations of the subject matter described in this specification can be implemented as one or more computer program products, i.e., one or more modules of computer program instructions encoded on a tangible and non-transitory computer readable medium for execution by, or to control the operation of, data processing apparatus. The computer readable medium can be a machine-readable storage device, a machine-readable storage substrate, a memory device, a composition of matter effecting a machine-readable propagated signal, or a combination of one or more of them. The term “data processing unit” or “data processing apparatus” encompasses all apparatus, devices, and machines for processing data, including by way of example a programmable processor, a computer, or multiple processors or computers. The apparatus can include, in addition to hardware, code that creates an execution environment for the computer program in question, e.g., code that constitutes processor firmware, a protocol stack, a database management system, an operating system, or a combination of one or more of them.
A computer program (also known as a program, software, software application, script, or code) can be written in any form of programming language, including compiled or interpreted languages, and it can be deployed in any form, including as a stand-alone program or as a module, component, subroutine, or other unit suitable for use in a computing environment. A computer program does not necessarily correspond to a file in a file system. A program can be stored in a portion of a file that holds other programs or data (e.g., one or more scripts stored in a markup language document) , in a single file dedicated to the program in question, or in multiple coordinated files (e.g., files that store one or more modules, sub programs, or portions of code) . A computer program can be deployed to be executed on one computer or on multiple computers that are located at one site or distributed across multiple sites and interconnected by a communication network.
The processes and logic flows described in this specification can be performed by one or more programmable processors executing one or more computer programs to perform functions by operating on input data and generating output. The processes and logic flows can also be performed by, and apparatus can also be implemented as, special purpose logic circuitry, e.g., an FPGA (field programmable gate array) or an ASIC (application specific integrated circuit) .
Processors suitable for the execution of a computer program include, by way of example, both general and special purpose microprocessors, and any one or more processors of any kind of digital computer. Generally, a processor will receive instructions and data from a read only memory or a random access memory or both. The essential elements of a computer are a processor for performing instructions and one or more memory devices for storing instructions and data. Generally, a computer will also include, or be operatively coupled to receive data from or transfer data to, or both, one or more mass storage devices for storing data, e.g., magnetic, magneto optical disks, or optical disks. However, a computer need not have such devices. Computer readable media suitable for storing computer program instructions and data include all forms of nonvolatile memory, media and memory devices, including by way of example semiconductor memory devices, e.g., EPROM, EEPROM, and flash memory devices. The processor and the memory can be supplemented by, or incorporated in, special purpose logic circuitry.
It is intended that the specification, together with the drawings, be considered exemplary only, where exemplary means an example. As used herein, the singular forms “a” , “an” and “the” are intended to include the plural forms as well, unless the context clearly indicates otherwise. Additionally, the use of “or” is intended to include “and/or” , unless the context clearly indicates otherwise.
While this patent document contains many specifics, these should not be construed as limitations on the scope of any invention or of what may be claimed, but rather as descriptions of features that may be specific to particular embodiments of particular inventions. Certain features that are described in this patent document in the context of separate embodiments can also be implemented in combination in a single embodiment. Conversely, various features that are described in the context of a single embodiment can also be implemented in multiple embodiments separately or in any suitable subcombination. Moreover, although features may be described above as acting in certain combinations and even initially claimed as such, one or more features from a claimed combination can in some cases be excised from the combination, and the claimed combination may be directed to a subcombination or variation of a subcombination.
Similarly, while operations are depicted in the drawings in a particular order, this should not be understood as requiring that such operations be performed in the particular order shown or in sequential order, or that all illustrated operations be performed, to achieve desirable results. Moreover, the separation of various system components in the embodiments described in this patent document should not be understood as requiring such separation in all embodiments.
Only a few implementations and examples are described and other implementations, enhancements and variations can be made based on what is described and illustrated in this patent document.
Claims (24)
- A method for video processing, comprising:determining, for a conversion between a video region of a picture of a video and a coded representation of the video, enablement status of a coding tool used to represent the video region in the coded representation; andperforming the conversion according to the determination;wherein a first flag is included in a picture header to indicate the enablement status of the coding tool for the picture.
- The method of claim 1, wherein the enablement status indicates that the coding is either disabled or enabled for the video region depending on the first flag and/or a slice type of the video.
- The method of claim 1, wherein the determining determines that the coding tool is disabled in a case that the first flag is true.
- The method of claim 1, wherein the determining determines that the coding tool is disabled in a case that the first flag is false.
- The method of claim 1, wherein the determining determines that the coding tool is enabled in a case that the first flag is false.
- The method of claim 1, wherein the determining determines that the coding tool is enabled in a case that the first flag is true.
- The method of claim 1, wherein the coding tool is disabled or enabled for all samples within the picture.
- The method of claim 1, wherein a signaling of the first flag depends on one or more syntax elements in a sequence parameter set (SPS) , a video parameter set (VPS) , a dependency parameter set (DPS) , or a picture parameter set (PPS) that is associated with the video region.
- The method of claim 8, wherein the signaling of the first flag depends on an indication indicating an enablement of the coding tool in the sequence parameter set (SPS) .
- The method of claim 8, wherein a second flag to indicate a presence of the first flag in the picture header is signaled in the sequence parameter set (SPS) .
- The method of claim 8, wherein a second flag to indicate a presence of the first flag in the picture header is signaled in a case that the coding tool is enabled for a sequence of the video.
- The method of claim 8, wherein the first flag is signaled in the picture header in a case that the second flag to indicate a presence of the first flag indicates the presence of the first flag.
- The method of any of claims 1 to 12, wherein the first flag and/or the second flag is coded with 1 bit.
- The method of any of claims 1 to 13, wherein the coding tool is a prediction refinement with optical flow (PROF) in which one or more initial affine predictions are refined based on an optical flow calculation.
- The method of any of claims 1 to 13, wherein the coding tool is a decoder-side motion vector refinement (DMVR) in which motion information is refined by using prediction blocks.
- The method of any of claims 1 to 13, wherein the coding tool is bi-directional optical flow (BDOF) in which one or more initial predictions are refined using an optical flow calculation.
- The method of any of claims 1 to 13, wherein the coding tool is a cross-component adaptive loop filter (CCALF) in which a linear filter is applied to chroma samples based on luma information.
- The method of any of claims 1 to 13, wherein the coding tool is a geometry partitioning (GEO) in which prediction samples are generated with weighting values, the prediction samples based on partitioning of the video region according to a non-horizontal or a non-vertical line.
- The method of any of claims 1 to 13, wherein the coding tool is a triangular prediction mode (TPM) in which prediction samples are generated with weighting values, the prediction samples based on partitioning of the video region into two triangular partitions.
- The method of any of claims 1 to 19, wherein the conversion includes encoding the video into the bitstream representation.
- The method of any of claims 1 to 19, wherein the conversion includes decoding the bitstream representation to generate the video.
- A video processing apparatus comprising a processor configured to implement a method recited in any one or more of claims 1 to 21.
- A computer readable medium storing program code that, when executed, causes a processor to implement a method recited in any one or more of claims 1 to 21.
- A computer readable medium that stores a coded representation or a bitstream representation generated according to any of the above described methods.
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022521585A JP7628533B2 (en) | 2019-10-12 | 2020-10-12 | High-Level Syntax for Video Coding Tools |
| KR1020227010809A KR102762340B1 (en) | 2019-10-12 | 2020-10-12 | High-level syntax for video coding tools |
| CN202080071639.2A CN114556916B (en) | 2019-10-12 | 2020-10-12 | Advanced syntax for video codec tools |
| EP20873612.4A EP4029245A4 (en) | 2019-10-12 | 2020-10-12 | HIGH-LEVEL SYNTAX FOR VIDEO CODING TOOLS |
| US17/717,549 US11689747B2 (en) | 2019-10-12 | 2022-04-11 | High level syntax for video coding tools |
| JP2024158878A JP2024177195A (en) | 2019-10-12 | 2024-09-13 | High-Level Syntax for Video Coding Tools |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2019110905 | 2019-10-12 | ||
| CNPCT/CN2019/110905 | 2019-10-12 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US17/717,549 Continuation US11689747B2 (en) | 2019-10-12 | 2022-04-11 | High level syntax for video coding tools |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021068954A1 true WO2021068954A1 (en) | 2021-04-15 |
Family
ID=75436985
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2020/120287 WO2021068954A1 (en) | 2019-10-12 | 2020-10-12 | High level syntax for video coding tools |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US11689747B2 (en) |
| EP (1) | EP4029245A4 (en) |
| JP (1) | JP2024177195A (en) |
| CN (1) | CN114556916B (en) |
| WO (1) | WO2021068954A1 (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20230021722A1 (en) * | 2021-07-20 | 2023-01-26 | Mediatek Inc. | Apparatus and method for performing motion vector refinement to get more precise motion vectors |
| WO2023061334A1 (en) * | 2021-10-11 | 2023-04-20 | Beijing Bytedance Network Technology Co., Ltd. | Method, device, and medium for video processing |
| TWI861479B (en) | 2021-07-20 | 2024-11-11 | 聯發科技股份有限公司 | Motion vector refinement apparatus and method |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113383548A (en) | 2019-02-03 | 2021-09-10 | 北京字节跳动网络技术有限公司 | Interaction between MV precision and MV differential coding |
| EP3909239A4 (en) | 2019-02-14 | 2022-04-20 | Beijing Bytedance Network Technology Co., Ltd. | SIZE-SELECTIVE APPLICATION OF DECODER-SIDE FINISHING TOOLS |
| CA3165461A1 (en) | 2019-12-20 | 2021-06-24 | Lg Electronics Inc. | Prediction weighted table-based image/video coding method and apparatus |
| WO2021125702A1 (en) * | 2019-12-20 | 2021-06-24 | 엘지전자 주식회사 | Image/video coding method and device based on weighted prediction |
| US11863789B2 (en) * | 2020-03-31 | 2024-01-02 | Tencent America LLC | Method for signaling rectangular slice partitioning in coded video stream |
| US12015785B2 (en) * | 2020-12-04 | 2024-06-18 | Ofinno, Llc | No reference image quality assessment based decoder side inter prediction |
| CA3142044A1 (en) * | 2020-12-14 | 2022-06-14 | Comcast Cable Communications, Llc | Methods and systems for improved content encoding |
| US11683514B2 (en) * | 2020-12-22 | 2023-06-20 | Tencent America LLC | Method and apparatus for video coding for machine |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018113658A1 (en) * | 2016-12-22 | 2018-06-28 | Mediatek Inc. | Method and apparatus of motion refinement for video coding |
| WO2018119167A1 (en) * | 2016-12-21 | 2018-06-28 | Arris Enterprises Llc | Constrained position dependent intra prediction combination (pdpc) |
| US20180359483A1 (en) * | 2017-06-13 | 2018-12-13 | Qualcomm Incorporated | Motion vector prediction |
| WO2019129130A1 (en) * | 2017-12-31 | 2019-07-04 | 华为技术有限公司 | Image prediction method and device and codec |
Family Cites Families (55)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8340177B2 (en) | 2004-07-12 | 2012-12-25 | Microsoft Corporation | Embedded base layer codec for 3D sub-band coding |
| US8442108B2 (en) | 2004-07-12 | 2013-05-14 | Microsoft Corporation | Adaptive updates in motion-compensated temporal filtering |
| US8374238B2 (en) | 2004-07-13 | 2013-02-12 | Microsoft Corporation | Spatial scalability in 3D sub-band decoding of SDMCTF-encoded video |
| US20130094774A1 (en) | 2011-10-13 | 2013-04-18 | Sharp Laboratories Of America, Inc. | Tracking a reference picture based on a designated picture on an electronic device |
| TWI603611B (en) * | 2011-12-21 | 2017-10-21 | Jvc Kenwood Corp | Motion picture encoding apparatus, motion picture encoding method, and recording medium for moving picture encoding program |
| US9525861B2 (en) | 2012-03-14 | 2016-12-20 | Qualcomm Incorporated | Disparity vector prediction in video coding |
| WO2013153822A1 (en) | 2012-04-13 | 2013-10-17 | Sharp Kabushiki Kaisha | Devices for sending and receiving a long-term reference picture indicator |
| US9380289B2 (en) * | 2012-07-20 | 2016-06-28 | Qualcomm Incorporated | Parameter sets in video coding |
| US9161039B2 (en) * | 2012-09-24 | 2015-10-13 | Qualcomm Incorporated | Bitstream properties in video coding |
| US20140098851A1 (en) * | 2012-10-04 | 2014-04-10 | Qualcomm Incorporated | Indication of video properties |
| WO2014166119A1 (en) | 2013-04-12 | 2014-10-16 | Mediatek Inc. | Stereo compatibility high level syntax |
| JP6587046B2 (en) * | 2013-07-08 | 2019-10-09 | サン パテント トラスト | Image encoding method, image decoding method, image encoding device, and image decoding device |
| WO2015006967A1 (en) | 2013-07-19 | 2015-01-22 | Mediatek Singapore Pte. Ltd. | Simplified view synthesis prediction for 3d video coding |
| EP3025498B1 (en) | 2013-08-13 | 2019-01-16 | HFI Innovation Inc. | Method of deriving default disparity vector in 3d and multiview video coding |
| US9294766B2 (en) * | 2013-09-09 | 2016-03-22 | Apple Inc. | Chroma quantization in video coding |
| US20150160390A1 (en) | 2013-12-10 | 2015-06-11 | Apple Inc. | Display Having Polarizer with Unpolarized Strip |
| WO2015100710A1 (en) | 2014-01-02 | 2015-07-09 | Mediatek Singapore Pte. Ltd. | Existence of inter-view reference picture and availability of 3dvc coding tools |
| US10158884B2 (en) * | 2014-03-19 | 2018-12-18 | Qualcomm Incorporated | Simplified merge list construction process for 3D-HEVC |
| US10432928B2 (en) * | 2014-03-21 | 2019-10-01 | Qualcomm Incorporated | Using a current picture as a reference for video coding |
| US20150326875A1 (en) | 2014-05-06 | 2015-11-12 | Mediatek Inc. | Video processing method for determining position of reference block of resized reference frame and related video processing apparatus |
| CN105187824A (en) | 2014-06-10 | 2015-12-23 | 杭州海康威视数字技术股份有限公司 | Image coding method and device, and image decoding method and device |
| KR102051193B1 (en) | 2014-09-12 | 2019-12-02 | 브이아이디 스케일, 인크. | Inter-component de-correlation for video coding |
| US10924743B2 (en) | 2015-02-06 | 2021-02-16 | Microsoft Technology Licensing, Llc | Skipping evaluation stages during media encoding |
| US10979732B2 (en) | 2016-10-04 | 2021-04-13 | Qualcomm Incorporated | Adaptive motion vector precision for video coding |
| US10542280B2 (en) | 2017-01-09 | 2020-01-21 | QUALCOMM Incorpated | Encoding optimization with illumination compensation and integer motion vector restriction |
| KR20200051596A (en) * | 2017-09-15 | 2020-05-13 | 소니 주식회사 | Image processing apparatus and method |
| CN117499684A (en) * | 2017-09-20 | 2024-02-02 | 韩国电子通信研究院 | Method and apparatus for encoding/decoding images |
| GB2567249A (en) | 2017-10-09 | 2019-04-10 | Canon Kk | New sample sets and new down-sampling schemes for linear component sample prediction |
| US11265551B2 (en) | 2018-01-18 | 2022-03-01 | Qualcomm Incorporated | Decoder-side motion vector derivation |
| CA3092638A1 (en) * | 2018-03-01 | 2019-09-06 | Arris Enterprises Llc | System and method of motion information storage for video coding and signaling |
| US20190306502A1 (en) * | 2018-04-02 | 2019-10-03 | Qualcomm Incorporated | System and method for improved adaptive loop filtering |
| CN112655214A (en) * | 2018-04-12 | 2021-04-13 | 艾锐势有限责任公司 | Motion information storage for video coding and signaling |
| WO2019234578A1 (en) | 2018-06-05 | 2019-12-12 | Beijing Bytedance Network Technology Co., Ltd. | Asymmetric weighted bi-predictive merges |
| US11070813B2 (en) * | 2018-06-29 | 2021-07-20 | Intel Corporation | Global motion estimation and modeling for accurate global motion compensation for efficient video processing or coding |
| TWI815974B (en) | 2018-09-23 | 2023-09-21 | 大陸商北京字節跳動網絡技術有限公司 | Modification of motion vector with adaptive motion vector resolution |
| TW202029755A (en) | 2018-09-26 | 2020-08-01 | 美商Vid衡器股份有限公司 | Bi-prediction for video coding |
| WO2020084465A1 (en) | 2018-10-22 | 2020-04-30 | Beijing Bytedance Network Technology Co., Ltd. | Simplified coding of generalized bi-directional index |
| CN117880513A (en) | 2018-10-22 | 2024-04-12 | 北京字节跳动网络技术有限公司 | Restriction of decoder-side motion vector derivation based on codec information |
| WO2020084507A1 (en) | 2018-10-23 | 2020-04-30 | Beijing Bytedance Network Technology Co., Ltd. | Harmonized local illumination compensation and modified inter prediction coding |
| WO2020084508A1 (en) | 2018-10-23 | 2020-04-30 | Beijing Bytedance Network Technology Co., Ltd. | Harmonization between local illumination compensation and inter prediction coding |
| SG11202104480RA (en) | 2018-11-05 | 2021-05-28 | Beijing Bytedance Network Technology Co Ltd | Interpolation for inter prediction with refinement |
| EP3864842A4 (en) | 2018-11-07 | 2021-12-08 | Huawei Technologies Co., Ltd. | Header parameter set for video coding |
| WO2020098803A1 (en) | 2018-11-15 | 2020-05-22 | Beijing Bytedance Network Technology Co., Ltd. | Harmonization between affine mode and other inter coding tools |
| CN113039790B (en) | 2018-11-17 | 2023-04-14 | 北京字节跳动网络技术有限公司 | Method, apparatus and non-transitory computer readable medium for video processing |
| CN117915083A (en) | 2018-11-29 | 2024-04-19 | 北京字节跳动网络技术有限公司 | Interaction between intra copy mode and inter prediction tools |
| CN113316935A (en) | 2019-01-15 | 2021-08-27 | 北京字节跳动网络技术有限公司 | Motion candidate list using local illumination compensation |
| WO2020147747A1 (en) | 2019-01-15 | 2020-07-23 | Beijing Bytedance Network Technology Co., Ltd. | Weighted prediction in video coding |
| WO2020147805A1 (en) | 2019-01-17 | 2020-07-23 | Beijing Bytedance Network Technology Co., Ltd. | Deblocking filtering using motion prediction |
| SG11202109950UA (en) | 2019-03-11 | 2021-10-28 | Vid Scale Inc | Methods and apparatus for sub-picture adaptive resolution change |
| US20200296405A1 (en) | 2019-03-14 | 2020-09-17 | Qualcomm Incorporated | Affine motion compensation refinement using optical flow |
| WO2020192611A1 (en) | 2019-03-22 | 2020-10-01 | Beijing Bytedance Network Technology Co., Ltd. | Interaction between merge list construction and other tools |
| CN117499641A (en) | 2019-05-10 | 2024-02-02 | 北京字节跳动网络技术有限公司 | Conditional use of simplified quadratic transforms for video processing |
| WO2020228660A1 (en) | 2019-05-11 | 2020-11-19 | Beijing Bytedance Network Technology Co., Ltd. | Selective use of coding tools in video processing |
| JP7400088B2 (en) * | 2019-09-24 | 2023-12-18 | ホアウェイ・テクノロジーズ・カンパニー・リミテッド | Time identifier limitations for SEI messages |
| MX2022004380A (en) * | 2019-10-10 | 2022-08-08 | Huawei Tech Co Ltd | An encoder, a decoder and corresponding methods for simplifying signalling picture header. |
-
2020
- 2020-10-12 EP EP20873612.4A patent/EP4029245A4/en active Pending
- 2020-10-12 CN CN202080071639.2A patent/CN114556916B/en active Active
- 2020-10-12 WO PCT/CN2020/120287 patent/WO2021068954A1/en unknown
-
2022
- 2022-04-11 US US17/717,549 patent/US11689747B2/en active Active
-
2024
- 2024-09-13 JP JP2024158878A patent/JP2024177195A/en active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018119167A1 (en) * | 2016-12-21 | 2018-06-28 | Arris Enterprises Llc | Constrained position dependent intra prediction combination (pdpc) |
| WO2018113658A1 (en) * | 2016-12-22 | 2018-06-28 | Mediatek Inc. | Method and apparatus of motion refinement for video coding |
| US20180359483A1 (en) * | 2017-06-13 | 2018-12-13 | Qualcomm Incorporated | Motion vector prediction |
| WO2019129130A1 (en) * | 2017-12-31 | 2019-07-04 | 华为技术有限公司 | Image prediction method and device and codec |
Non-Patent Citations (2)
| Title |
|---|
| S WENGER (STEWE), A. SEGALL (SHARPLABS), M.M. HANNUKSELA (NOKIA), HENDRY (HUAWEI), S. MCCARTHY (DOLBY), Y.-C. SUN (ALIBABA-INC): "JVET AHG report: Layered coding and resolution adaptivity (AHG19)", 14. JVET MEETING; 20190319 - 20190327; GENEVA; (THE JOINT VIDEO EXPLORATION TEAM OF ISO/IEC JTC1/SC29/WG11 AND ITU-T SG.16 ), 19 March 2019 (2019-03-19), XP030203566 * |
| See also references of EP4029245A4 * |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20230021722A1 (en) * | 2021-07-20 | 2023-01-26 | Mediatek Inc. | Apparatus and method for performing motion vector refinement to get more precise motion vectors |
| TWI861479B (en) | 2021-07-20 | 2024-11-11 | 聯發科技股份有限公司 | Motion vector refinement apparatus and method |
| WO2023061334A1 (en) * | 2021-10-11 | 2023-04-20 | Beijing Bytedance Network Technology Co., Ltd. | Method, device, and medium for video processing |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2024177195A (en) | 2024-12-19 |
| EP4029245A4 (en) | 2022-11-23 |
| CN114556916A (en) | 2022-05-27 |
| KR20220073752A (en) | 2022-06-03 |
| US11689747B2 (en) | 2023-06-27 |
| CN114556916B (en) | 2023-11-17 |
| EP4029245A1 (en) | 2022-07-20 |
| US20220248061A1 (en) | 2022-08-04 |
| JP2022552511A (en) | 2022-12-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11575887B2 (en) | Selective use of coding tools in video processing | |
| US11671602B2 (en) | Signaling for reference picture resampling | |
| US11689747B2 (en) | High level syntax for video coding tools | |
| WO2020228833A1 (en) | Adaptive resolution change in video coding | |
| KR102637881B1 (en) | Usage and signaling of tablet video coding tools | |
| KR102762340B1 (en) | High-level syntax for video coding tools | |
| JP7628533B2 (en) | High-Level Syntax for Video Coding Tools |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20873612 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2022521585 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020873612 Country of ref document: EP Effective date: 20220412 |