WO2020250730A1 - 不正検知装置、不正検知方法および不正検知プログラム - Google Patents
不正検知装置、不正検知方法および不正検知プログラム Download PDFInfo
- Publication number
- WO2020250730A1 WO2020250730A1 PCT/JP2020/021566 JP2020021566W WO2020250730A1 WO 2020250730 A1 WO2020250730 A1 WO 2020250730A1 JP 2020021566 W JP2020021566 W JP 2020021566W WO 2020250730 A1 WO2020250730 A1 WO 2020250730A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- target data
- learning
- fraud detection
- mixed model
- Prior art date
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q20/00—Payment architectures, schemes or protocols
- G06Q20/38—Payment protocols; Details thereof
- G06Q20/40—Authorisation, e.g. identification of payer or payee, verification of customer or shop credentials; Review and approval of payers, e.g. check credit lines or negative lists
- G06Q20/401—Transaction verification
- G06Q20/4016—Transaction verification involving fraud or risk level assessment in transaction processing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/088—Non-supervised learning, e.g. competitive learning
Definitions
- the present invention relates to a fraud detection device, a fraud detection method, and a fraud detection program that detect fraudulent transactions in the business of a financial institution.
- Non-Patent Document 1 describes a data clustering algorithm (DBSCAN: Density-based spatial clustering of applications with noise), which is an example of unsupervised learning, as a method of learning such a model.
- DBSCAN Density-based spatial clustering of applications with noise
- an object of the present invention is to provide a fraud detection device, a fraud detection method, and a fraud detection program that can learn a model so as to improve the accuracy of detecting fraudulent transactions even when imbalanced data is used. To do.
- the fraud detection device is a fraud detection device that detects fraudulent transactions in the business of a financial institution, and is a target data extraction unit that extracts target data by excluding normal transaction data from transaction data in business by learning without a teacher. And, among the target data, the first learning unit that learns the first hierarchical mixed model using the learning data that uses the data indicating fraudulent transactions as a positive example and the remaining data other than the positive example as a negative example. It is characterized in that it is provided with a data exclusion unit that excludes the target data in which the training data as a negative example is determined to be a negative example by the first hierarchical mixed model from the target data.
- the fraud detection method is a fraud detection method for detecting fraudulent transactions in the business of a financial institution, and the target data is extracted by excluding the normal transaction data from the transaction data in the business by learning without a teacher, and the target data is Of these, the first-tier mixed model is trained using the training data in which the data indicating fraudulent transactions is a positive example and the remaining data other than the positive example is a negative example, and the first-tier mixed model is used from the target data.
- the model is characterized in that the training data as a negative example excludes the target data determined to be a negative example.
- the fraud detection program is a fraud detection program applied to a computer that detects fraudulent transactions in the business of a financial institution, and targets the computer by excluding normal transaction data from the transaction data in the business by learning without a teacher.
- Target data extraction processing to extract data, among the target data, the first hierarchical mixed model is created using the training data in which the data indicating fraudulent transactions is a positive example and the remaining data other than the positive example is a negative example. It is characterized in that the first learning process to be learned and the data exclusion process for excluding the target data for which the training data as a negative example is determined to be a negative example are executed by the first hierarchical mixed model from the target data. ..
- the model can be learned so as to improve the accuracy of detecting fraudulent transactions even when imbalanced data is used.
- FIG. 1 is a block diagram showing a configuration example of the first embodiment of the fraud detection device according to the present invention.
- the fraud detection device 100 of the present embodiment includes a storage unit 10, a target data extraction unit 20, a first learning unit 30, and a data exclusion unit 40.
- the fraud detection device 100 of the present embodiment is a device that detects fraudulent transactions (for example, fraudulent remittance, fraudulent use of an account, etc.) in the business of a financial institution from acquired electronic data.
- the storage unit 10 stores transaction data used for determining whether or not the transaction is fraudulent.
- This transaction data includes, for example, deposit / withdrawal information, date and time, amount of money, and other information used in transactions performed by each financial institution.
- the format of the transaction data is arbitrary and may be determined according to the target financial institution. Further, the storage unit 10 may store various parameters necessary for the first learning unit 30, which will be described later, to learn the model.
- the storage unit 10 is realized by, for example, a magnetic disk or the like.
- the target data extraction unit 20 excludes transaction data judged to be normal by unsupervised learning (hereinafter referred to as normal transaction data) from transaction data in the business of a financial institution, and the first learning unit 30 described later. Extracts the data used for learning (hereinafter referred to as target data).
- the method in which the target data extraction unit 20 performs unsupervised learning is arbitrary.
- the target data extraction unit 20 may extract the target data using, for example, the algorithm described in Non-Patent Document 1 described above.
- the number of cases where the positive example data is judged to be a positive example is described as TP (True Positive)
- the number of cases where the negative example data is judged to be a negative example is described as TN (True Negative).
- the number of cases in which the data of the positive example is judged to be a negative case is described as FN (False Negative)
- the number of cases in which the data of the negative case is judged to be a positive case is described as FP (False Positive).
- the target data extraction unit 20 excludes the data corresponding to the TP classified as the normal transaction data by unsupervised learning, and sets the data corresponding to other data including the TN classified as the fraudulent transaction data as the target data. Extract.
- the first learning unit 30 uses the learning data in which the data indicating fraudulent transaction is a positive example and the remaining data other than the positive example is a negative example, and is hierarchical. Learn a mixed type model. In order to distinguish it from the explanation described later, the hierarchical mixed model learned by the first learning unit 30 is referred to as a first hierarchical mixed model.
- the first learning unit 30 generates a hierarchical mixed model by heterogeneous mixed machine learning using the generated learning data, for example.
- the method in which the first learning unit 30 learns the hierarchical mixed model is not limited to heterogeneous mixed machine learning.
- the hierarchical mixed model is represented by a tree structure, and has a structure in which components are arranged in leaf nodes and a gate function (gate tree function) indicating branching conditions is arranged in other upper nodes.
- the branching condition of the portal function is described using explanatory variables.
- FIG. 2 is an explanatory diagram showing an example of a discrimination model based on a hierarchical mixed model.
- the data exclusion unit 40 excludes the target data in which the learning data as a negative example is classified as a negative example by the first hierarchical mixed model from the target data. That is, the data exclusion unit 40 excludes the data corresponding to the negative example data (TNh) predicted to be the negative example from the target data.
- TNh negative example data
- the data exclusion unit 40 discriminates the data classified in the leaf node by using the discriminant arranged in each leaf node of the hierarchical mixed model.
- the data exclusion unit 40 also discriminates the data classified into the other leaf nodes in the same manner, and aggregates the discrimination results of the data classified into each leaf node.
- the data exclusion unit 40 calculates the ratio at which the classified data is predicted to be a negative example for each leaf node (that is, the condition under which the data is classified). When the calculated ratio is equal to or higher than a predetermined threshold value, the data exclusion unit 40 determines that the data corresponding to the condition for classifying into the node is excluded from the target data.
- the above processing by the data exclusion unit 40 corresponds to the processing of excluding normal transaction data from the data determined to be fraudulent transaction data by unsupervised learning.
- excluding the normal transaction data from the target data in this way, it is possible to increase the ratio of the fraudulent transaction data to the entire target data, so that it becomes easier to detect the fraudulent transaction.
- the learning process by the first learning unit 30 and the exclusion process by the data exclusion unit 40 may be repeated. Specifically, each time the first learning unit 30 generates a first hierarchical mixed model, the data exclusion unit 40 specifies a condition to be excluded, and data corresponding to the condition is extracted from the target data. You may decide to exclude it. That is, even if the data exclusion unit 40 specifies a condition for excluding the target data each time the first hierarchical mixed model is trained and excludes the data corresponding to any of the conditions from the target data. Good. By repeating the process in this way, it is possible to increase the data to be excluded.
- the target data extraction unit 20, the first learning unit 30, and the data exclusion unit 40 are computer processors (for example, CPU (Central Processing Unit), GPU (Graphics Processing Unit), which operate according to a program (fraud detection program). It is realized by FPGA (field-programmable gate array)).
- CPU Central Processing Unit
- GPU Graphics Processing Unit
- FPGA field-programmable gate array
- the program may be stored in the storage unit 10, and the processor may read the program and operate as the target data extraction unit 20, the first learning unit 30, and the data exclusion unit 40 according to the program.
- the function of the fraud detection device may be provided in the SaaS (Software as a Service) format.
- the target data extraction unit 20, the first learning unit 30, and the data exclusion unit 40 may each be realized by dedicated hardware. Further, a part or all of each component of each device may be realized by a general-purpose or dedicated circuit (circuitry), a processor, or a combination thereof. These may be composed of a single chip or may be composed of a plurality of chips connected via a bus. A part or all of each component of each device may be realized by a combination of the above-mentioned circuit or the like and a program.
- the plurality of information processing devices and circuits may be centrally arranged or distributed. It may be arranged.
- the information processing device, the circuit, and the like may be realized as a form in which each of the client-server system, the cloud computing system, and the like is connected via a communication network.
- FIG. 3 is a flowchart showing an operation example of the fraud detection device of the present embodiment.
- the target data extraction unit 20 extracts the target data by excluding the normal transaction data from the transaction data in the business of the financial institution by unsupervised learning (step S11).
- the first learning unit 30 learns the first hierarchical mixed model by using the extracted target data in which the data indicating fraudulent transaction is a positive example and the remaining data is a negative example (step).
- S12 The data exclusion unit 40 excludes the data (TN) that is completely determined to be a negative example from the training data from the target data by the first hierarchical mixed model (step S13).
- the target data extraction unit 20 extracts the target data by excluding the normal transaction data from the transaction data in the business of the financial institution by unsupervised learning, and the first learning unit 30 extracts the target data.
- the first hierarchical mixed model is trained using the training data in which the data indicating fraudulent transactions is a positive example and the remaining data is a negative example among the target data.
- the data exclusion unit 40 excludes the data (TN) that is completely determined to be a negative example from the training data by the first hierarchical mixed model. Therefore, even when imbalanced data is used, the model can be learned so as to improve the accuracy of detecting fraudulent transactions.
- FIG. 4 is a block diagram showing a configuration example of a second embodiment of the fraud detection device according to the present invention.
- the fraud detection device 200 of the present embodiment includes a storage unit 10, a target data extraction unit 20, a first learning unit 30, a data exclusion unit 40, a second learning unit 50, a score calculation unit 60, and a visualization unit. It is equipped with 70.
- the fraud detection device 200 of the present embodiment is different from the fraud detection device 100 of the first embodiment in that it further includes a second learning unit 50, a score calculation unit 60, and a visualization unit 70.
- Other configurations are the same as in the first embodiment.
- the second learning unit 50 uses learning data in which, among the target data excluded by the data exclusion unit 40 and remains, data indicating fraudulent transactions is a positive example, and the remaining data other than the positive example is a negative example. , Learn a hierarchical mixed model. In order to distinguish it from the hierarchical mixed model learned by the first learning unit 30, the learning model generated by the second learning unit 50 is referred to as a second hierarchical mixed model.
- the score calculation unit 60 calculates the data discrimination result for each leaf node in the hierarchical mixed model. Specifically, the score calculation unit 60 calculates the ratio of the target data (that is, the ratio of TP) in which the learning data as a positive example is determined to be a regular example by the second hierarchical mixed model as a score.
- the score calculation unit 60 discriminates the data classified in the leaf node by using the discriminant arranged in each leaf node, similarly to the data exclusion unit 40 in the first embodiment. ..
- the score calculation unit 60 calculates the ratio of TP as a score for each leaf node (that is, the condition for classifying the data).
- the score calculation unit 60 specifies a node condition in which the calculated score is equal to or higher than a predetermined threshold value as a condition having a high probability of fraudulent transaction.
- the learning process by the second learning unit 50 and the data identification process by the score calculation unit 60 may be repeatedly performed. Specifically, each time the second learning unit 50 generates a second hierarchical mixed model, the score calculation unit 60 may specify a condition with a high probability of fraudulent transactions. By repeating the process in this way, it is possible to increase the conditions with high probability of fraudulent transactions.
- the visualization unit 70 visualizes the ratio of the target data aggregated for each score to the total target data. Specifically, the visualization unit 70 aggregates the number of data corresponding to the condition of the node in which the scores corresponding to the predetermined values or ranges are aggregated. Then, the visualization unit 70 calculates the ratio of the total number of cases to the total number of cases.
- the visualization unit 70 For example, suppose that the ratio of data contained in a node whose score is calculated to be 100% is visualized. In this case, the visualization unit 70 totals the number of data that matches the condition of the node calculated that the ratio of TP is 100%. Further, for example, it is assumed that the ratio of data is visualized for each score in increments of 10%. In this case, the visualization unit 70 aggregates the number of data that matches the node conditions calculated such that the ratio of TP is 100% to 90%, 100% to 80%, and so on.
- FIG. 5 is an explanatory diagram showing an example in which the ratio is totaled for each score.
- the learning process by the second learning unit 50 and the data identification process by the score calculation unit 60 are repeated 300 times, 600 times, 900 times, 1200 times, and 6000 times, respectively. Is shown.
- the number of data matching the condition that the score is calculated to be 100% is totaled for each of the normal transaction data and the fraudulent transaction data. Is shown.
- 6000 times an example in which the score is aggregated for each of normal transaction data and fraudulent transaction data in increments of 10% is shown.
- the number of fraudulent transaction data extracted increases. Furthermore, if the score is allowed to include not only 100% but also a certain percentage of normal transaction data, more candidates for fraudulent transaction data can be extracted. That is, it can be said that the fraud rate (ratio) can be increased by setting the threshold value high, and many candidates for fraudulent transaction data can be extracted by setting the threshold value low.
- the visualization unit 70 visualizes the calculated ratio on a display device (not shown).
- the visualization unit 70 may visualize the ratio of the number of data in association with the area, for example.
- FIG. 6 is an explanatory diagram showing an example of visualizing the ratio of the target data.
- the target data D2 extracted by unsupervised learning out of the entire transaction data D1 is displayed as a circle according to the area. Further, among the target data D2, the data D3 is excluded by the data exclusion unit 40.
- the visualization unit 70 may, for example, visualize the proportion of data having a high score in a more conspicuous manner than the proportion of data having a low score.
- the visualization unit 70 visualizes the proportion of data having a large score with a black ellipse D13, and visualizes it as an ellipse D12 and an ellipse D11 in which the shading density is reduced as the score becomes lower. An example is shown.
- prediction accuracy can be classified together with interpretability. For example, a person in charge of a financial institution will be able to prioritize confirmation from fraudulent transaction data contained in an area having a higher score.
- the target data extraction unit 20, the first learning unit 30, the data exclusion unit 40, the second learning unit 50, the score calculation unit 60, and the visualization unit 70 are computers that operate according to a program (fraud detection program). It is realized by the processor.
- FIG. 7 is a flowchart showing an operation example of the fraud detection device of the present embodiment.
- the process from step S11 to step S13 from extracting the target data from the transaction data to excluding the normal transaction data is the same as the process illustrated in FIG.
- the second learning unit 50 uses learning data in which, among the target data excluded by the data exclusion unit 40 and remains, the data indicating fraudulent transaction is a positive example, and the remaining data other than the positive example is a negative example.
- Learn a second-tier mixed model (step S21).
- the score calculation unit 60 calculates the ratio of the target data for which the learning data as a positive example is determined to be a regular example as a score by the second hierarchical mixed model (step S22).
- the visualization unit 70 visualizes the ratio of the target data aggregated for each score to the total target data (step S23).
- the second learning unit 50 uses the data indicating fraudulent transactions as a positive example and the remaining data other than the positive example as a negative example among the target data that remains after being excluded.
- the training data is used to train a second-tier mixed model.
- the score calculation unit 60 calculates the ratio of the target data for which the training data as a positive example is determined to be a regular example by the second hierarchical mixed model as a score, and the visualization unit 70 aggregates each score. Visualize the ratio of the target data to the total target data. Therefore, in addition to the effect of the first embodiment, the prediction accuracy can be classified together with the interpretability. Therefore, for example, a person in charge of a financial institution can check the ratio of fraudulent transaction data.
- the target data extraction unit 20 identifies normal transaction data from 82,663 transaction data by unsupervised learning, excludes the normal transaction data from the transaction data, and extracts the target data.
- FIG. 8 is an explanatory diagram showing an example of the result of identifying the normal transaction data.
- 70,404 out of 82,183 normal transaction data are predicted to be normal transaction data, and the recall rate (Recall) is 85.67%.
- the recall rate (Recall) is 99.58%.
- 70,406 cases predicted as normal transaction data include 2 cases of fraudulent transaction data, and the precision rate is 99.99%.
- 12,259 cases predicted as fraudulent transaction data 11,779 normal transaction data are included, and the precision rate is 3.90%.
- the accuracy of the entire data is calculated to be 85.75%.
- the first learning unit 30 learns the first hierarchical mixed model with 12,257 data predicted to be fraudulent transaction data, with TN as a positive example and other as a negative example.
- FIG. 9 is an explanatory diagram showing an example of correspondence between the learning result by unsupervised learning and the learning result of the first hierarchical mixed model.
- TP, FN, FP and TN are calculated, respectively.
- the calculated TP, FN, FP and TN are shown by TPh, FNh, FPh and TNh, respectively, in order to distinguish them from the results shown in FIG.
- the data exclusion unit 40 excludes the data corresponding to TNh from the target data.
- FIG. 10 is an explanatory diagram showing an example of the result of excluding the target data.
- FIG. 10 (a) shows the overall accuracy
- FIG. 10 (b) shows the prediction accuracy.
- the number of data was reduced by about 50% (reduced to 6,528 cases) and the precision rate was improved to 7.31%.
- the prediction accuracy has also improved to 7.09%.
- the second learning unit 50 uses the learning data in which the data indicating fraudulent transactions is a positive example and the remaining data other than the positive example is a negative example for the excluded and remaining data, and is a second hierarchical mixed model.
- FIG. 11 is an explanatory diagram showing an example of correspondence between the target data after data exclusion and the learning result of the second hierarchical mixed model.
- TP, FN, FP and TN are calculated, respectively.
- the calculated TP, FN, FP and TN are represented by TPx, FNx, FPx and TNx, respectively, to distinguish them from the results shown in FIGS. 8 and 9.
- the score calculation unit 60 calculates the score for each node, and the visualization unit 70 identifies and visualizes a portion having a high ratio of TPx as a portion with high accuracy.
- the visualization unit 70 visualizes the content illustrated in FIG. 6 from the results illustrated in FIG. 5, for example.
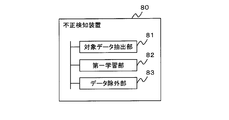
- FIG. 12 is a block diagram showing an outline of the fraud detection device according to the present invention.
- the fraud detection device 80 according to the present invention is a fraud detection device (for example, fraud detection device 100) that detects fraudulent transactions in the business of a financial institution (for example, a bank), and is financed by unsupervised learning (for example, DBSCAN).
- the target data extraction unit 81 (for example, the target data extraction unit 20) that extracts the target data by excluding the normal transaction data from the transaction data in the business of the institution, and the data indicating the fraudulent transaction among the target data are taken as regular examples.
- the hierarchical mixed model includes a data exclusion unit 83 (for example, a data exclusion unit 40) that excludes the target data (TNh) for which the training data as a negative example is determined to be a negative example.
- the model can be learned so as to improve the accuracy of detecting fraudulent transactions even when using imbalanced data.
- the fraud detection device 80 learns that among the target data that remains after being excluded, the data indicating fraudulent transaction is used as a positive example, and the remaining data other than the positive example is used as a negative example.
- the second learning unit (for example, the second learning unit 50) that learns the second-layer mixed model and the second-layer mixed model determined that the training data as a positive example was a regular example.
- a score calculation unit (for example, score calculation unit 60) that calculates the ratio of the target data (TP) as a score
- a visualization unit for example, visualization
- a unit 70 may be provided.
- prediction accuracy can be classified together with interpretability. For example, a person in charge of a financial institution will be able to prioritize confirmation from fraudulent transaction data contained in an area having a higher score.
- the score calculation unit discriminates the training data classified into each leaf node by using the discrimination formula arranged in each leaf node of the second hierarchical mixed model, and positive for each leaf node.
- the ratio of the target data for which the learning data as an example is determined to be a positive example may be calculated as a score, and the condition of the node where the calculated score is equal to or higher than the predetermined threshold may be specified as the condition with high probability of fraudulent transaction. ..
- the data exclusion unit 83 discriminates the training data classified into each leaf node by using the discrimination formula arranged in each leaf node of the first hierarchical mixed model, and the classified training data is completely obtained.
- a negative example and a predicted ratio may be calculated for each leaf node, and data corresponding to the conditions for classifying into leaf nodes whose calculated ratio is equal to or higher than a predetermined threshold may be excluded from the target data.
- the data exclusion unit 83 specifies a condition for excluding the target data each time the first hierarchical mixed model is trained, and excludes data corresponding to any of the conditions from the target data. You may.
- FIG. 13 is a schematic block diagram showing a configuration of a computer according to at least one embodiment.
- the computer 1000 includes a processor 1001, a main storage device 1002, an auxiliary storage device 1003, and an interface 1004.
- the fraud detection device is mounted on the computer 1000.
- the operation of each processing unit described above is stored in the auxiliary storage device 1003 in the form of a program (fraud detection program).
- the processor 1001 reads a program from the auxiliary storage device 1003, deploys it to the main storage device 1002, and executes the above processing according to the program.
- the auxiliary storage device 1003 is an example of a non-temporary tangible medium.
- non-temporary tangible media include magnetic disks, magneto-optical disks, CD-ROMs (Compact Disc Read-only memory), DVD-ROMs (Read-only memory), which are connected via interface 1004. Examples include semiconductor memory.
- the program may be for realizing a part of the above-mentioned functions. Further, the program may be a so-called difference file (difference program) that realizes the above-mentioned function in combination with another program already stored in the auxiliary storage device 1003.
- difference file difference program
- Storage unit 20
- Target data extraction unit 30
- Data exclusion unit 50
- Second learning unit 60
- Score calculation unit 70
- Visualization unit 100,200 Fraud detection device
Landscapes
- Engineering & Computer Science (AREA)
- Business, Economics & Management (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Accounting & Taxation (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Strategic Management (AREA)
- Computer Security & Cryptography (AREA)
- Mathematical Physics (AREA)
- Finance (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Evolutionary Computation (AREA)
- General Business, Economics & Management (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Medical Informatics (AREA)
- Financial Or Insurance-Related Operations Such As Payment And Settlement (AREA)
Abstract
金融機関の業務における不正取引を検知する不正検知装置80であって、教師なし学習により金融機関の業務における取引データから正常取引データを除外して対象データを抽出する対象データ抽出部81と、対象データのうち、不正取引を示すデータを正例とし、その正例以外の残りのデータを負例とする学習データを用いて、第一階層型混合モデルを学習する第一学習部82と、対象データから、第一階層型混合モデルにより、負例とした学習データが負例と判別された対象データを除外するデータ除外部83とを備えている。
Description
本発明は、金融機関の業務において不正な取引を検知する不正検知装置、不正検知方法および不正検知プログラムに関する。
金融機関の業務において、不正送金や口座の不正利用といった不正取引を自動で検出できるように、取引データから不正取引を検出する仕組みが各種提案されている。例えば、このような不正取引を検出する方法として、金融機関の業務で発生するトランザクションデータに基づいて、不正取引を検出するモデルを学習する方法が挙げられる。
例えば、非特許文献1には、このようなモデルを学習する方法として、教師なし学習の一例であるデータクラスタリングアルゴリズム(DBSCAN:Density-based spatial clustering of applications with noise)が記載されている。
Martin Ester , Hans-peter Kriegel , Jorg Sander , Xiaowei Xu,A density-based algorithm for discovering clusters in large spatial databases with noise,AAAI Press,p226--231,1996
一方、金融機関の業務において発生する不正取引の数は、通常の取引(正常取引)の数に比べて圧倒的に少ない。すなわち、不正取引のデータと正常取引のデータとは不均衡であると言える。そのため、例えば、非特許文献1に記載されたアルゴリズムを用いて不正取引を予測しようとしたとしても、不均衡データの問題により、予測精度が非常に低下したり、偏ったりしてしまうという問題がある。
そのため、金融機関の業務において発生する不正取引のような、正常取引に比べて極めて少ないデータ(不均衡データ)を用いて、その不正取引を検知するモデルを学習する場合であっても、そのモデルの予測精度を向上できることが好ましい。
そこで、本発明は、不均衡データを用いる場合であっても、不正取引を検知する精度を向上させるようにモデルを学習できる不正検知装置、不正検知方法および不正検知プログラムを提供することを目的とする。
本発明による不正検知装置は、金融機関の業務における不正取引を検知する不正検知装置であって、教師なし学習により業務における取引データから正常取引データを除外して対象データを抽出する対象データ抽出部と、対象データのうち、不正取引を示すデータを正例とし、その正例以外の残りのデータを負例とする学習データを用いて、第一階層型混合モデルを学習する第一学習部と、対象データから、第一階層型混合モデルにより、負例とした学習データが負例と判別された対象データを除外するデータ除外部とを備えたことを特徴とする。
本発明による不正検知方法は、金融機関の業務における不正取引を検知する不正検知方法であって、教師なし学習により業務における取引データから正常取引データを除外して対象データを抽出し、対象データのうち、不正取引を示すデータを正例とし、その正例以外の残りのデータを負例とする学習データを用いて、第一階層型混合モデルを学習し、対象データから、第一階層型混合モデルにより、負例とした学習データが負例と判別された対象データを除外することを特徴とする。
本発明による不正検知プログラムは、金融機関の業務における不正取引を検知するコンピュータに適用される不正検知プログラムであって、コンピュータに、教師なし学習により業務における取引データから正常取引データを除外して対象データを抽出する対象データ抽出処理、対象データのうち、不正取引を示すデータを正例とし、その正例以外の残りのデータを負例とする学習データを用いて、第一階層型混合モデルを学習する第一学習処理、および、対象データから、第一階層型混合モデルにより、負例とした学習データが負例と判別された対象データを除外するデータ除外処理を実行させることを特徴とする。
本発明によれば、不均衡データを用いる場合であっても、不正取引を検知する精度を向上させるようにモデルを学習できる。
以下、本発明の実施形態を図面を参照して説明する。
実施形態1.
図1は、本発明による不正検知装置の第一の実施形態の構成例を示すブロック図である。本実施形態の不正検知装置100は、記憶部10と、対象データ抽出部20と、第一学習部30と、データ除外部40とを備えている。本実施形態の不正検知装置100は、取得される電子データから、金融機関の業務における不正取引(例えば、不正送金や、口座の不正利用など)を検知する装置である。
図1は、本発明による不正検知装置の第一の実施形態の構成例を示すブロック図である。本実施形態の不正検知装置100は、記憶部10と、対象データ抽出部20と、第一学習部30と、データ除外部40とを備えている。本実施形態の不正検知装置100は、取得される電子データから、金融機関の業務における不正取引(例えば、不正送金や、口座の不正利用など)を検知する装置である。
記憶部10は、不正取引か否かの判断に用いられる取引データを記憶する。この取引データには、例えば、入出金の情報や、日時、金額など、各金融機関において行われる取引で利用される情報が含まれる。なお、取引データのフォーマットは任意であり、対象とする金融機関等に応じて定めておけばよい。また、記憶部10は、後述する第一学習部30がモデルを学習するために必要な各種パラメータを記憶していてもよい。記憶部10は、例えば、磁気ディスク等により実現される。
対象データ抽出部20は、金融機関の業務における取引データから、教師なし学習により、正常と判断される取引データ(以下、正常取引データと記す。)を除外して、後述する第一学習部30が、学習に用いるデータ(以下、対象データと記す。)を抽出する。なお、対象データ抽出部20が教師なし学習を行う方法は任意である。対象データ抽出部20は、例えば、上述する非特許文献1に記載されたアルゴリズムを用いて対象データを抽出してもよい。
以下の説明では、正例のデータを正例と判断した件数をTP(True Positive )と記し、負例のデータを負例と判断した件数をTN(True Negative )と記す。また、正例のデータを負例と判断した件数をFN(False Negative)と記し、負例のデータを正例と判断した件数をFP(False Positive)と記す。
すなわち、対象データ抽出部20は、教師なし学習により、正常取引データと分類されたTPに該当するデータを除外して、不正取引データに分類されたTN含むそれ以外に該当するデータを対象データとして抽出する。
第一学習部30は、対象データ抽出部20によって抽出された対象データのうち、不正取引を示すデータを正例とし、正例以外の残りのデータを負例とする学習データを用いて、階層型混合モデルを学習する。なお、後述する説明と区別するために、第一学習部30によって学習される階層型混合モデルのことを、第一階層型混合モデルと記す。
第一学習部30は、例えば、生成された学習データを用いて異種混合機械学習により階層型混合モデルを生成する。ただし、同様の技術であれば、第一学習部30が階層型混合モデルを学習する方法は、異種混合機械学習に限定されない。
階層型混合モデルは、木構造で表され、葉ノードにコンポーネントが配されるとともに、他の上位ノードに分岐条件を示す門関数(門木関数)が配される構造を有する。門関数の分岐条件は説明変数を用いて記述される。階層型混合モデルにデータが入力されると、入力されたデータは、門関数で分岐され、根ノードおよび各節ノードを辿って複数のコンポーネントのいずれかに割り当てられる。
図2は、階層型混合モデルによる判別モデルの例を示す説明図である。図2に示す例では、条件1~3に基づいて、入力されたデータが4種類のいずれかの葉ノードに分類され、各葉ノードに配された判別式Y1~Y4に基づいて判別されることを示す。例えば、条件1を満たすデータ(条件1=trueを満たすデータ)が入力された場合、そのデータは、判別式Y1が配される葉ノードに分類され、判別式Y1=F1(X)に基づいて判別が行われる。
データ除外部40は、対象データから、負例とされた学習データが第一階層型混合モデルにより負例と分類された対象データを除外する。すなわち、データ除外部40は、負例と予測された負例のデータ(TNh)に該当するデータを対象データから除外する。
具体的には、データ除外部40は、階層型混合モデルの各葉ノードに配された判別式を用いて、その葉ノードに分類されたデータの判別を行う。データ除外部40は、他の葉ノードに分類されたデータについても同様に判別を行い、各葉ノードに分類されたデータの判別結果を集計する。データ除外部40は、葉ノード(すなわち、データが分類される条件)ごとに、分類されたデータが負例と予測された割合を算出する。算出した割合が予め定めた閾値以上の場合、データ除外部40は、そのノードに分類するための条件に該当するデータを対象データから除外すると判断する。
データ除外部40による上記処理は、教師なし学習により、不正取引データと判別されたデータの中から、正常取引データを除外する処理に対応する。このように正常取引データを対象データから除外することで、対象データ全体に対する不正取引データの割合を高めることが可能になるため、不正取引をより検知しやすくなる。さらに、不正取引データと正常取引データの不均衡度合いを低減させた学習データ群を生成できるため、不正取引を検知する精度を向上させるようにモデルを学習できるようになる。
また、第一学習部30による学習処理と、データ除外部40による除外処理が繰り返し行われてもよい。具体的には、第一学習部30によって第一階層型混合モデルが生成されるごとに、データ除外部40が、除外対象とする条件を特定して、その条件に該当するデータを対象データから除外すると決定してもよい。すなわち、データ除外部40は、第一階層型混合モデルが学習されるごとに、対象データを除外するための条件を特定し、その条件のいずれかに該当するデータを対象データから除外してもよい。このように繰り返し処理を行うことで、除外対象とするデータを増加させることが可能になる。
対象データ抽出部20と、第一学習部30と、データ除外部40とは、プログラム(不正検知プログラム)に従って動作するコンピュータのプロセッサ(例えば、CPU(Central Processing Unit )、GPU(Graphics Processing Unit)、FPGA(field-programmable gate array ))によって実現される。
例えば、プログラムは、記憶部10に記憶され、プロセッサは、そのプログラムを読み込み、プログラムに従って、対象データ抽出部20、第一学習部30およびデータ除外部40として動作してもよい。また、不正検知装置の機能がSaaS(Software as a Service )形式で提供されてもよい。
対象データ抽出部20と、第一学習部30と、データ除外部40とは、それぞれが専用のハードウェアで実現されていてもよい。また、各装置の各構成要素の一部又は全部は、汎用または専用の回路(circuitry )、プロセッサ等やこれらの組合せによって実現されもよい。これらは、単一のチップによって構成されてもよいし、バスを介して接続される複数のチップによって構成されてもよい。各装置の各構成要素の一部又は全部は、上述した回路等とプログラムとの組合せによって実現されてもよい。
また、不正検知装置の各構成要素の一部又は全部が複数の情報処理装置や回路等により実現される場合には、複数の情報処理装置や回路等は、集中配置されてもよいし、分散配置されてもよい。例えば、情報処理装置や回路等は、クライアントサーバシステム、クラウドコンピューティングシステム等、各々が通信ネットワークを介して接続される形態として実現されてもよい。
次に、本実施形態の不正検知装置の動作を説明する。図3は、本実施形態の不正検知装置の動作例を示すフローチャートである。対象データ抽出部20は、教師なし学習により金融機関の業務における取引データから正常取引データを除外して対象データを抽出する(ステップS11)。第一学習部30は、抽出された対象データのうち、不正取引を示すデータを正例とし、残りのデータを負例とする学習データを用いて、第一階層型混合モデルを学習する(ステップS12)。データ除外部40は、第一階層型混合モデルにより、学習データのうち、完全に負例と判別されたデータ(TN)を対象データから除外する(ステップS13)。
以上のように、本実施形態では、対象データ抽出部20が、教師なし学習により金融機関の業務における取引データから正常取引データを除外して対象データを抽出し、第一学習部30が、抽出された対象データのうち、不正取引を示すデータを正例とし、残りのデータを負例とする学習データを用いて、第一階層型混合モデルを学習する。そして、データ除外部40が、第一階層型混合モデルにより、学習データのうち、完全に負例と判別されたデータ(TN)を対象データから除外する。よって、不均衡データを用いる場合であっても、不正取引を検知する精度を向上させるようにモデルを学習できる。
実施形態2.
次に、本発明による不正検知装置の第二の実施形態を説明する。第二の実施形態では、不正取引の確度に応じて、予測結果を可視化する方法を説明する。図4は、本発明による不正検知装置の第二の実施形態の構成例を示すブロック図である。本実施形態の不正検知装置200は、記憶部10と、対象データ抽出部20と、第一学習部30と、データ除外部40と、第二学習部50と、スコア算出部60と、可視化部70とを備えている。
次に、本発明による不正検知装置の第二の実施形態を説明する。第二の実施形態では、不正取引の確度に応じて、予測結果を可視化する方法を説明する。図4は、本発明による不正検知装置の第二の実施形態の構成例を示すブロック図である。本実施形態の不正検知装置200は、記憶部10と、対象データ抽出部20と、第一学習部30と、データ除外部40と、第二学習部50と、スコア算出部60と、可視化部70とを備えている。
すなわち、本実施形態の不正検知装置200は、第一の実施形態の不正検知装置100と比較し、第二学習部50、スコア算出部60および可視化部70をさらに備えている点において異なる。それ以外の構成は、第一の実施形態と同様である。
第二学習部50は、データ除外部40により除外されて残った対象データのうち、不正取引を示すデータを正例とし、その正例以外の残りのデータを負例とする学習データを用いて、階層型混合モデルを学習する。なお、第一学習部30によって学習される階層型混合モデルと区別するため、第二学習部50が生成した学習モデルを第二階層型混合モデルと記す。
スコア算出部60は、階層型混合モデルにおける葉ノードごとに、データの判別結果を算出する。具体的には、スコア算出部60は、第二階層型混合モデルにより、正例とした学習データが正例と判別された対象データの割合(すなわち、TPの割合)をスコアとして算出する。
具体的には、スコア算出部60は、第一の実施形態におけるデータ除外部40と同様に、各葉ノードに配された判別式を用いて、その葉ノードに分類されたデータの判別を行う。スコア算出部60は、葉ノード(すなわち、データが分類される条件)ごとに、TPの割合をスコアとして算出する。スコア算出部60は、算出したスコアが予め定めた閾値以上になるノードの条件を不正取引の確度が高い条件として特定する。
また、第二学習部50による学習処理と、スコア算出部60によるデータ特定処理が繰り返し行われてもよい。具体的には、第二学習部50によって第二階層型混合モデルが生成されるごとに、スコア算出部60が、不正取引の確度が高い条件を特定してもよい。このように繰り返し処理を行うことで、不正取引の確度の高い条件を増加させることが可能になる。
可視化部70は、スコアごとに集計された対象データの、全体の対象データに対する割合を可視化する。具体的には、可視化部70は、予め定めた値または範囲に該当するスコアが集計されたノードの条件に該当するデータの件数を集計する。そして、可視化部70は、全体の件数に対する集計された件数の割合を算出する。
例えば、スコアが100%と算出されたノードに含まれるデータの割合を可視化するとする。この場合、可視化部70は、TPの割合が100%と算出されたノードの条件に合致するデータの件数を集計する。また、例えば、10%刻みのスコアごとにデータの割合を可視化するとする。この場合、可視化部70は、TPの割合が100%~90%、100%~80%、…、と算出されたノードの条件に合致するデータの件数を集計する。
図5は、スコアごとに割合を集計した例を示す説明図である。図5に示す例では、第二学習部50による学習処理と、スコア算出部60によるデータ特定処理が、それぞれ、300回、600回、900回、1200回、および、6000回繰り返し行われた結果を示す。また、図5では、300回、600回、900回および1200回の場合に、スコアが100%と算出された条件に合致するデータの件数を、正常取引データと不正取引データごとに集計した例を示す。さらに、6000回の場合には、スコアを10%刻みで正常取引データと不正取引データごとに集計した例を示す。
図5に例示するように、繰り返し回数が増加するにしたがって、不正取引データの抽出件数は増加する。さらに、スコアを100%だけでなく、一定割合の正常取引データが含まれることを許容した場合、より不正取引データの候補を抽出することができるようになる。すなわち、閾値を高く設定することにより不正率(割合)を高めることができ、閾値を低く設定することで、多くの不正取引データの候補を抽出できるようになると言える。
可視化部70は、算出した割合を表示装置(図示せず)に可視化する。可視化部70は、例えば、面積に対応付けてデータ数の割合を可視化してもよい。図6は、対象データの割合を可視化した例を示す説明図である。図6に示す例では、取引データ全体D1のうち、教師なし学習によって抽出された対象データD2が、面積に応じた円で表示されている。また、対象データD2のうち、データ除外部40によってデータD3が除外される。
こうして除外された残ったデータの中に、不正取引データが含まれていることになる。可視化部70は、例えば、スコアの大きいデータの割合を、低いデータの割合よりも目立つ態様で可視化してもよい。図6では、可視化部70が、スコアの大きいデータの割合を、黒の楕円D13で可視化し、スコアが低くなるにしたがって、網掛けの濃さを薄くした楕円D12、楕円D11のように可視化した例を示す。
このように可視化することで、予測精度を解釈性と併せて分類できるようになる。例えば、金融機関の担当者は、よりスコアの大きい領域に含まれる不正取引データから優先的に確認することができるようになる。
対象データ抽出部20と、第一学習部30と、データ除外部40と、第二学習部50と、スコア算出部60と、可視化部70とは、プログラム(不正検知プログラム)に従って動作するコンピュータのプロセッサによって実現される。
次に、本実施形態の不正検知装置の動作を説明する。図7は、本実施形態の不正検知装置の動作例を示すフローチャートである。なお、取引データから対象データを抽出して、されに正常取引データを除外するまでのステップS11からステップS13までの処理は、図4に例示する処理と同様である。
第二学習部50は、データ除外部40によって除外されて残った対象データのうち、不正取引を示すデータを正例とし、その正例以外の残りのデータを負例とする学習データを用いて、第二階層型混合モデルを学習する(ステップS21)。スコア算出部60は、第二階層型混合モデルにより、正例とした学習データが正例と判別された対象データの割合をスコアとして算出する(ステップS22)。そして、可視化部70は、スコアごとに集計された対象データの、全体の対象データに対する割合を可視化する(ステップS23)。
以上のように、本実施形態では、第二学習部50が、除外されて残った対象データのうち、不正取引を示すデータを正例とし、その正例以外の残りのデータを負例とする学習データを用いて、第二階層型混合モデルを学習する。そして、スコア算出部60が、第二階層型混合モデルにより、正例とした学習データが正例と判別された対象データの割合をスコアとして算出し、可視化部70が、スコアごとに集計された対象データの、全体の対象データに対する割合を可視化する。よって、第一の実施形態の効果に加え、予測精度を解釈性と併せて分類することが可能になる。そのため、例えば、金融機関の担当者が、不正取引データの割合を確認することが可能になる。
次に、本発明による不正検知装置を用いて不正取引データを検知する具体例を説明する。本具体例では、ある金融機関の取引データが82,663件存在し、そのうち480件が不正取引データである(すなわち、正常取引データが82,183件である)ものとする。
まず、対象データ抽出部20が、教師なし学習により、82,663件の取引データから正常取引データを特定し、その正常取引データを取引データから除外して対象データを抽出する。図8は、正常取引データを特定した結果の例を示す説明図である。図8に示す例では、正常取引データ82,183件のうち、70,404件を正常取引データと予測し、再現率(Recall)が85.67%である。また、不正取引データ480件のうち、478件を不正取引データと予測し、再現率(Recall)が99.58%である。
さらに、図8に示す例では、正常取引データと予測した70,406件に、2件の不正取引データが含まれており、適合率が99.99%である。また、不正取引データと予測した12,259件のうち、11,779件の正常取引データが含まれており、適合率が3.90%である。その結果、データ全体の精度(正解率:Accuracy)は、85.75%と算出される。本具体例では、不正取引データと予測された12,257件(適合率:3.90%)に含まれる正常取引データの割合を減らし、適合率を向上させることを目指す。
第一学習部30は、不正取引データと予測された12,257件のデータで、TNを正例、それ以外を負例として第一階層型混合モデルを学習する。図9は、教師なし学習による学習結果と、第一階層型混合モデルの学習結果との対応例を示す説明図である。第一階層型混合モデルを学習した結果、それぞれ、TP、FN、FPおよびTNが算出される。図9では、図8に示す結果と区別するため、算出されたTP、FN、FPおよびTNを、それぞれ、TPh、FNh、FPhおよびTNhで示している。データ除外部40は、学習の結果、TNhに該当するデータを対象データから除外する。
図10は、対象データを除外した結果の例を示す説明図である。図10(a)は、全体の精度を示し、図10(b)は、予測精度を示す。図10に例示するように、学習処理および除外処理を3,600回行った結果、データ数を約50%程度削減(6,528件に削減)して適合率が7.31%まで向上し、予測精度も7.09%まで向上している。
第二学習部50は、除外されて残ったデータについて、不正取引を示すデータを正例とし、その正例以外の残りのデータを負例とする学習データを用いて、第二階層型混合モデルを学習する。図11は、データ除外後の対象データと第二階層型混合モデルの学習結果との対応例を示す説明図である。第二階層型混合モデルを学習した結果、それぞれ、TP、FN、FPおよびTNが算出される。図11では、図8および図9に示す結果と区別するため、算出されたTP、FN、FPおよびTNを、それぞれ、TPx、FNx、FPxおよびTNxで示している。
スコア算出部60は、ノードごとにスコアを算出し、可視化部70は、TPxの割合が高いものを確度が高い部分として特定し、可視化する。可視化部70は、例えば、図5に例示する結果から図6に例示する内容を可視化する。
次に、本発明の概要を説明する。図12は、本発明による不正検知装置の概要を示すブロック図である。本発明による不正検知装置80は、金融機関(例えば、銀行など)の業務における不正取引を検知する不正検知装置(例えば、不正検知装置100)であって、教師なし学習(例えば、DBSCAN)により金融機関の業務における取引データから正常取引データを除外して対象データを抽出する対象データ抽出部81(例えば、対象データ抽出部20)と、対象データのうち、不正取引を示すデータを正例とし、その正例以外の残りのデータを負例とする学習データを用いて、第一階層型混合モデルを学習する第一学習部82(例えば、第一学習部30)と、対象データから、第一階層型混合モデルにより、負例とした学習データが負例と判別された対象データ(TNh)を除外するデータ除外部83(例えば、データ除外部40)とを備えている。
そのような構成により、不均衡データを用いる場合であっても、不正取引を検知する精度を向上させるようにモデルを学習できる。
また、不正検知装置80(例えば、不正検知装置200)は、除外されて残った対象データのうち、不正取引を示すデータを正例とし、その正例以外の残りのデータを負例とする学習データを用いて、第二階層型混合モデルを学習する第二学習部(例えば、第二学習部50)と、第二階層型混合モデルにより、正例とした学習データが正例と判別された対象データ(TP)の割合をスコアとして算出するスコア算出部(例えば、スコア算出部60)と、スコアごとに集計された対象データの、全体の対象データに対する割合を可視化する可視化部(例えば、可視化部70)とを備えていてもよい。
そのような構成によれば、予測精度を解釈性と併せて分類できるようになる。例えば、金融機関の担当者は、よりスコアの大きい領域に含まれる不正取引データから優先的に確認することができるようになる。
具体的には、スコア算出部は、第二階層型混合モデルの各葉ノードに配された判別式を用いて、各葉ノードに分類された学習データの判別を行い、葉ノードごとに、正例とした学習データが正例と判別された対象データの割合をスコアとして算出し、算出したスコアが予め定めた閾値以上になるノードの条件を不正取引の確度が高い条件として特定してもよい。
また、データ除外部83は、第一階層型混合モデルの各葉ノードに配された判別式を用いて、各葉ノードに分類された学習データの判別を行い、分類された学習データが完全に負例と予測された割合を葉ノードごとに算出し、算出した割合が予め定めた閾値以上である葉ノードに分類するための条件に該当するデータを対象データから除外してもよい。
より詳しくは、データ除外部83は、第一階層型混合モデルが学習されるごとに、対象データを除外するための条件を特定し、その条件のいずれかに該当するデータを対象データから除外してもよい。
図13は、少なくとも1つの実施形態に係るコンピュータの構成を示す概略ブロック図である。コンピュータ1000は、プロセッサ1001、主記憶装置1002、補助記憶装置1003、インタフェース1004を備える。
不正検知装置は、コンピュータ1000に実装される。そして、上述した各処理部の動作は、プログラム(不正検知プログラム)の形式で補助記憶装置1003に記憶されている。プロセッサ1001は、プログラムを補助記憶装置1003から読み出して主記憶装置1002に展開し、当該プログラムに従って上記処理を実行する。
なお、少なくとも1つの実施形態において、補助記憶装置1003は、一時的でない有形の媒体の一例である。一時的でない有形の媒体の他の例としては、インタフェース1004を介して接続される磁気ディスク、光磁気ディスク、CD-ROM(Compact Disc Read-only memory )、DVD-ROM(Read-only memory)、半導体メモリ等が挙げられる。また、このプログラムが通信回線によってコンピュータ1000に配信される場合、配信を受けたコンピュータ1000が当該プログラムを主記憶装置1002に展開し、上記処理を実行してもよい。
また、当該プログラムは、前述した機能の一部を実現するためのものであってもよい。さらに、当該プログラムは、前述した機能を補助記憶装置1003に既に記憶されている他のプログラムとの組み合わせで実現するもの、いわゆる差分ファイル(差分プログラム)であってもよい。
以上、実施形態及び実施例を参照して本願発明を説明したが、本願発明は上記実施形態および実施例に限定されるものではない。本願発明の構成や詳細には、本願発明のスコープ内で当業者が理解し得る様々な変更をすることができる。
この出願は、2019年6月11日に出願された日本特許出願2019-108517を基礎とする優先権を主張し、その開示の全てをここに取り込む。
10 記憶部
20 対象データ抽出部
30 第一学習部
40 データ除外部
50 第二学習部
60 スコア算出部
70 可視化部
100,200 不正検知装置
20 対象データ抽出部
30 第一学習部
40 データ除外部
50 第二学習部
60 スコア算出部
70 可視化部
100,200 不正検知装置
Claims (9)
- 金融機関の業務における不正取引を検知する不正検知装置であって、
教師なし学習により前記業務における取引データから正常取引データを除外して対象データを抽出する対象データ抽出部と、
前記対象データのうち、不正取引を示すデータを正例とし、当該正例以外の残りのデータを負例とする学習データを用いて、第一階層型混合モデルを学習する第一学習部と、
前記対象データから、前記第一階層型混合モデルにより、負例とした学習データが負例と判別された対象データを除外するデータ除外部とを備えた
ことを特徴とする不正検知装置。 - 除外されて残った対象データのうち、不正取引を示すデータを正例とし、当該正例以外の残りのデータを負例とする学習データを用いて、第二階層型混合モデルを学習する第二学習部と、
前記第二階層型混合モデルにより、正例とした学習データが正例と判別された対象データの割合をスコアとして算出するスコア算出部と、
前記スコアごとに集計された対象データの、全体の対象データに対する割合を可視化する可視化部とを備えた
請求項1記載の不正検知装置。 - スコア算出部は、第二階層型混合モデルの各葉ノードに配された判別式を用いて、当該各葉ノードに分類された学習データの判別を行い、葉ノードごとに、正例とした学習データが正例と判別された対象データの割合をスコアとして算出し、算出したスコアが予め定めた閾値以上になるノードの条件を不正取引の確度が高い条件として特定する
請求項2記載の不正検知装置。 - データ除外部は、第一階層型混合モデルの各葉ノードに配された判別式を用いて、当該各葉ノードに分類された学習データの判別を行い、分類された学習データが負例と予測された割合を葉ノードごとに算出し、算出した割合が予め定めた閾値以上である葉ノードに分類するための条件に該当するデータを対象データから除外する
請求項1から請求項3のうちのいずれか1項に記載の不正検知装置。 - データ除外部は、第一階層型混合モデルが学習されるごとに、対象データを除外するための条件を特定し、当該条件のいずれかに該当するデータを対象データから除外する
請求項4記載の不正検知装置。 - 金融機関の業務における不正取引を検知する不正検知方法であって、
教師なし学習により前記業務における取引データから正常取引データを除外して対象データを抽出し、
前記対象データのうち、不正取引を示すデータを正例とし、当該正例以外の残りのデータを負例とする学習データを用いて、第一階層型混合モデルを学習し、
前記対象データから、前記第一階層型混合モデルにより、負例とした学習データが負例と判別された対象データを除外する
ことを特徴とする不正検知方法。 - 除外されて残った対象データのうち、不正取引を示すデータを正例とし、当該正例以外の残りのデータを負例とする学習データを用いて、第二階層型混合モデルを学習し、
前記第二階層型混合モデルにより、正例とした学習データが正例と判別された対象データの割合をスコアとして算出し、
前記スコアごとに集計された対象データの、全体の対象データに対する割合を可視化する
請求項6記載の不正検知方法。 - 金融機関の業務における不正取引を検知するコンピュータに適用される不正検知プログラムであって、
前記コンピュータに、
教師なし学習により前記業務における取引データから正常取引データを除外して対象データを抽出する対象データ抽出処理、
前記対象データのうち、不正取引を示すデータを正例とし、当該正例以外の残りのデータを負例とする学習データを用いて、第一階層型混合モデルを学習する第一学習処理、および、
前記対象データから、前記第一階層型混合モデルにより、負例とした学習データが負例と判別された対象データを除外するデータ除外処理
を実行させるための不正検知プログラム。 - コンピュータに、
除外されて残った対象データのうち、不正取引を示すデータを正例とし、当該正例以外の残りのデータを負例とする学習データを用いて、第二階層型混合モデルを学習する第二学習処理、
前記第二階層型混合モデルにより、正例とした学習データが正例と判別された対象データの割合をスコアとして算出するスコア算出処理、および、
前記スコアごとに集計された対象データの、全体の対象データに対する割合を可視化する可視化処理を実行させる
請求項8記載の不正検知プログラム。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021526009A JP7173332B2 (ja) | 2019-06-11 | 2020-06-01 | 不正検知装置、不正検知方法および不正検知プログラム |
| EP20822519.3A EP3985589A4 (en) | 2019-06-11 | 2020-06-01 | FRAUD DETECTION DEVICE, FRAUD DETECTION PROCESS AND FRAUD DETECTION PROGRAM |
| US17/617,393 US20220180369A1 (en) | 2019-06-11 | 2020-06-01 | Fraud detection device, fraud detection method, and fraud detection program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019108517 | 2019-06-11 | ||
| JP2019-108517 | 2019-06-11 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020250730A1 true WO2020250730A1 (ja) | 2020-12-17 |
Family
ID=73781987
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/021566 WO2020250730A1 (ja) | 2019-06-11 | 2020-06-01 | 不正検知装置、不正検知方法および不正検知プログラム |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20220180369A1 (ja) |
| EP (1) | EP3985589A4 (ja) |
| JP (1) | JP7173332B2 (ja) |
| WO (1) | WO2020250730A1 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112927061A (zh) * | 2021-03-26 | 2021-06-08 | 深圳前海微众银行股份有限公司 | 用户操作检测方法及程序产品 |
| WO2022195630A1 (en) * | 2021-03-18 | 2022-09-22 | Abhishek Gupta | Fraud detection system and method thereof |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6933780B1 (ja) * | 2019-12-26 | 2021-09-08 | 楽天グループ株式会社 | 不正検知システム、不正検知方法、及びプログラム |
| JP7373001B2 (ja) | 2022-03-16 | 2023-11-01 | ヤフー株式会社 | 判定システム、判定方法、およびプログラム |
| CN115577287B (zh) * | 2022-09-30 | 2023-05-30 | 湖南工程学院 | 数据处理方法、设备及计算机可读存储介质 |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005181928A (ja) * | 2003-12-24 | 2005-07-07 | Fuji Xerox Co Ltd | 機械学習システム及び機械学習方法、並びにコンピュータ・プログラム |
| JP2018073258A (ja) * | 2016-11-02 | 2018-05-10 | 日本電信電話株式会社 | 検知装置、検知方法および検知プログラム |
| WO2018131219A1 (ja) * | 2017-01-11 | 2018-07-19 | 株式会社東芝 | 異常検知装置、異常検知方法、および記憶媒体 |
| JP2019061565A (ja) * | 2017-09-27 | 2019-04-18 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカPanasonic Intellectual Property Corporation of America | 異常診断方法および異常診断装置 |
| JP2019067270A (ja) * | 2017-10-03 | 2019-04-25 | 富士通株式会社 | 分類プログラム、分類方法、および分類装置 |
| JP2019108517A (ja) | 2017-12-15 | 2019-07-04 | 住友ベークライト株式会社 | 熱硬化性樹脂組成物、その硬化物、積層板、金属ベース基板およびパワーモジュール |
| US20200019883A1 (en) * | 2018-07-16 | 2020-01-16 | Invoca, Inc. | Performance score determiner for binary signal classifiers |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20160086185A1 (en) * | 2014-10-15 | 2016-03-24 | Brighterion, Inc. | Method of alerting all financial channels about risk in real-time |
| US20180350006A1 (en) * | 2017-06-02 | 2018-12-06 | Visa International Service Association | System, Method, and Apparatus for Self-Adaptive Scoring to Detect Misuse or Abuse of Commercial Cards |
-
2020
- 2020-06-01 JP JP2021526009A patent/JP7173332B2/ja active Active
- 2020-06-01 EP EP20822519.3A patent/EP3985589A4/en not_active Withdrawn
- 2020-06-01 WO PCT/JP2020/021566 patent/WO2020250730A1/ja unknown
- 2020-06-01 US US17/617,393 patent/US20220180369A1/en active Pending
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005181928A (ja) * | 2003-12-24 | 2005-07-07 | Fuji Xerox Co Ltd | 機械学習システム及び機械学習方法、並びにコンピュータ・プログラム |
| JP2018073258A (ja) * | 2016-11-02 | 2018-05-10 | 日本電信電話株式会社 | 検知装置、検知方法および検知プログラム |
| WO2018131219A1 (ja) * | 2017-01-11 | 2018-07-19 | 株式会社東芝 | 異常検知装置、異常検知方法、および記憶媒体 |
| JP2019061565A (ja) * | 2017-09-27 | 2019-04-18 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカPanasonic Intellectual Property Corporation of America | 異常診断方法および異常診断装置 |
| JP2019067270A (ja) * | 2017-10-03 | 2019-04-25 | 富士通株式会社 | 分類プログラム、分類方法、および分類装置 |
| JP2019108517A (ja) | 2017-12-15 | 2019-07-04 | 住友ベークライト株式会社 | 熱硬化性樹脂組成物、その硬化物、積層板、金属ベース基板およびパワーモジュール |
| US20200019883A1 (en) * | 2018-07-16 | 2020-01-16 | Invoca, Inc. | Performance score determiner for binary signal classifiers |
Non-Patent Citations (2)
| Title |
|---|
| MARTIN ESTERHANS-PETER KRIEGELJORG SANDERXIAOWEI XU: "AAAI Press", 1996, article "A density-based algorithm for discovering clusters in large spatial databases with noise", pages: 226 - 231 |
| See also references of EP3985589A4 |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022195630A1 (en) * | 2021-03-18 | 2022-09-22 | Abhishek Gupta | Fraud detection system and method thereof |
| CN112927061A (zh) * | 2021-03-26 | 2021-06-08 | 深圳前海微众银行股份有限公司 | 用户操作检测方法及程序产品 |
| CN112927061B (zh) * | 2021-03-26 | 2024-03-12 | 深圳前海微众银行股份有限公司 | 用户操作检测方法及程序产品 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2020250730A1 (ja) | 2020-12-17 |
| US20220180369A1 (en) | 2022-06-09 |
| EP3985589A4 (en) | 2022-07-20 |
| JP7173332B2 (ja) | 2022-11-16 |
| EP3985589A1 (en) | 2022-04-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2020250730A1 (ja) | 不正検知装置、不正検知方法および不正検知プログラム | |
| De Roux et al. | Tax fraud detection for under-reporting declarations using an unsupervised machine learning approach | |
| CN107633265B (zh) | 用于优化信用评估模型的数据处理方法及装置 | |
| Yeh et al. | Going-concern prediction using hybrid random forests and rough set approach | |
| CN107103171B (zh) | 机器学习模型的建模方法及装置 | |
| WO2017133188A1 (zh) | 一种特征集确定的方法及装置 | |
| CN110111113B (zh) | 一种异常交易节点的检测方法及装置 | |
| Alden et al. | Detection of financial statement fraud using evolutionary algorithms | |
| CN110570312B (zh) | 样本数据获取方法、装置、计算机设备和可读存储介质 | |
| CN111539733A (zh) | 基于全中心损失函数的欺诈交易识别方法、系统、装置 | |
| WO2021111540A1 (ja) | 評価方法、評価プログラム、および情報処理装置 | |
| CN109102396A (zh) | 一种用户信用评级方法、计算机设备及可读介质 | |
| WO2020044814A1 (ja) | モデル更新装置、モデル更新方法およびモデル更新プログラム | |
| US20200285958A1 (en) | Counter data generation for data profiling using only true samples | |
| Torky et al. | Explainable AI model for recognizing financial crisis roots based on Pigeon optimization and gradient boosting model | |
| CN112750038B (zh) | 交易风险的确定方法、装置和服务器 | |
| CN112200402B (zh) | 一种基于风险画像的风险量化方法、装置及设备 | |
| CN112329862A (zh) | 基于决策树的反洗钱方法及系统 | |
| CN115081950A (zh) | 企业成长性评估建模方法、系统、计算机及可读存储介质 | |
| Mokheleli et al. | Machine learning approach for credit score predictions | |
| Yang et al. | An evidential reasoning rule-based ensemble learning approach for evaluating credit risks with customer heterogeneity | |
| US20200285895A1 (en) | Method, apparatus and computer program for selecting a subset of training transactions from a plurality of training transactions | |
| Tatusch et al. | Predicting erroneous financial statements using a density-based clustering approach | |
| Caplescu et al. | Will they repay their debt? Identification of borrowers likely to be charged off | |
| Lee et al. | Application of machine learning in credit risk scorecard |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20822519 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021526009 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020822519 Country of ref document: EP Effective date: 20220111 |