WO2020033899A1 - Modified oligonucleotides targeting snps - Google Patents
Modified oligonucleotides targeting snps Download PDFInfo
- Publication number
- WO2020033899A1 WO2020033899A1 PCT/US2019/046013 US2019046013W WO2020033899A1 WO 2020033899 A1 WO2020033899 A1 WO 2020033899A1 US 2019046013 W US2019046013 W US 2019046013W WO 2020033899 A1 WO2020033899 A1 WO 2020033899A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- nucleotide
- snp
- position nucleotide
- rna
- nucleotides
- Prior art date
Links
- JRZONRPMOSGDHY-UHFFFAOYSA-N CC(C)P(NCCCOCCOCCOCCOCC(COP(C(C)C)(O)=O)O)(O)=O Chemical compound CC(C)P(NCCCOCCOCCOCCOCC(COP(C(C)C)(O)=O)O)(O)=O JRZONRPMOSGDHY-UHFFFAOYSA-N 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
- A61K31/7105—Natural ribonucleic acids, i.e. containing only riboses attached to adenine, guanine, cytosine or uracil and having 3'-5' phosphodiester links
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/14—Type of nucleic acid interfering N.A.
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/312—Phosphonates
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/351—Conjugate
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2320/00—Applications; Uses
- C12N2320/10—Applications; Uses in screening processes
- C12N2320/11—Applications; Uses in screening processes for the determination of target sites, i.e. of active nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2320/00—Applications; Uses
- C12N2320/30—Special therapeutic applications
- C12N2320/34—Allele or polymorphism specific uses
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2330/00—Production
- C12N2330/30—Production chemically synthesised
Definitions
- RNA interference represents a simple and effective tool for inhibiting the function of genes.
- RNA silencing agents have received particular interest as research tools and therapeutic agents for their ability to knock down expression of a particular protein with a high degree of sequence specificity.
- sequence specificity of RNA silencing agents is particularly useful for the treatment of diseases caused by dominant mutations in heterozygotes bearing one mutant and one wild-type copy of a particular gene.
- RNA silencing agents that can preferentially silence mutant, disease-causing allele expression while not or only minimally effecting expression of the wild-type allele.
- the present invention is based on the surprising discovery of novel oligonucleotides that enhance silencing of the expression of a gene containing a single nucleotide polymorphism (SNP) (e.g., a heterozygous SNP) relative to the expression of the corresponding wild-type gene in a heterozygote, e.g., by up to more than 100 times.
- SNP single nucleotide polymorphism
- an oligonucleotide e.g., a dsRNA
- a SNP-containing nucleic acid for degradation wherein the oligonucleotide (e.g., a double-stranded RNA (dsRNA)) does not target, or targets to a lesser degree, the corresponding wild-type (non-SNP-containing) nucleic acid for degradation.
- an oligonucleotide (e.g., a dsRNA) of the invention is: 1) complementary to a SNP position in a target nucleic acid; and 2) contains a mismatch at a particular position of the target nucleic acid relative to the SNP.
- an oligonucleotide (e.g., a dsRNA) of the invention also contains a two mismatches relative to the corresponding wild-type target nucleic acid sequence: 1) at the wild-type SNP position; and 2) at the particular position of the target nucleic acid sequence relative to the wild-type SNP position.
- an exemplary oligonucleotide e.g., dsRNA contains one mismatch relative to a SNP-containing target and two mismatches relative to the corresponding wild-type sequence, thus resulting in preferential cleavage of the SNP-containing target relative to the corresponding wild-type sequence.
- MM mismatch
- the oligonucleotide is complementary to a region of a gene comprising an allelic polymorphism, wherein the oligonucleotide comprises an SNP position nucleotide at any one of positions 2 to 6 from the 5’ end; and a mismatch position nucleotide located 2-11 nucleotides from the SNP position nucleotide that is a mismatch with a nucleotide in the gene.
- the oligonucleotide is RNA.
- the RNA further comprises at least one vinyl phosphonate (VP) modification in an intersubunit linkage having the formula:
- a YP motif is inserted next to the SNP position nucleotide or next to the MM position nucleotide.
- oligonucleotide is selected from the group consisting of siRNA, miRNA, shRNA, CRISPR guide, DNA, antisense oligonucleotide (ASO), gapmer, mixmer, miRNA inhibitor, splice-switching oligonucleotide (SSO), phosphorodiamidate morpholino oligomer (PMO), and peptide nucleic acid (PNA).
- ASO antisense oligonucleotide
- SSO splice-switching oligonucleotide
- PMO phosphorodiamidate morpholino oligomer
- PNA peptide nucleic acid
- the RNA is an antisense oligonucleotide (ASO) or a dsRNA.
- ASO antisense oligonucleotide
- dsRNA dsRNA
- the dsRNA comprises a first strand of about 15-35 nucleotides that is complementary to the region of the gene comprising an allelic polymorphism, and a second strand of about 15-35 nucleotides that is complementary to at least a portion of the first strand, wherein the first strand comprises the SNP position nucleotide in a seed region (e.g., at position 2-6 from the 5’ end) that is complementary to the allelic polymorphism, and wherein the first strand comprises the MM position nucleotide located 2-6 nucleotides from the SNP position nucleotide that is a mismatch with a nucleotide in the gene.
- a seed region e.g., at position 2-6 from the 5’ end
- the SNP position nucleotide is located at position 2, 4 or 6 from the 5’ end of the RNA, and the MM position nucleotide is located 2-6 nucleotides from the SNP position nucleotide.
- the MM position nucleotide is located within 2, 3, 4 or 6 nucleotides of the SNP position nucleotide. In certain exemplary embodiments, the MM position nucleotide is located within 5 nucleotides of the SNP position nucleotide.
- the dsRNA is blunt-ended.
- the dsRNA comprises at least one single-stranded nucleotide overhang.
- the dsRNA comprises naturally occurring nucleotides.
- the dsRNA comprises at least one modified nucleotide. In certain exemplary embodiments, each nucleotide of the dsRNA is modified.
- the at least one modified nucleotide is selected from the group consisting of a 2'-0-methyl modified nucleotide, a nucleotide comprising a 5'- phosphorothioate group, a terminal nucleotide linked to a cholesteryl derivative and a terminal nucleotide linked to a dodecanoic acid bisdecylamide group.
- the modified nucleotide is selected from the group consisting of a 2'-deoxy-2'-fluoro modified nucleotide, a 2'-deoxy-modified nucleotide, a locked nucleotide, an abasic nucleotide, a 2'-amino-modified nucleotide, a 2'-alkyl-modified nucleotide, a morpholino nucleotide, a phosphoramidate, and a non-natural base comprising nucleotide.
- the dsRNA comprises at least one 2'-0-methyl modified nucleotide and a 5 '-phosphorothioate group.
- the first strand comprises at least three 2'-0-methyl modified nucleotides. In certain exemplary embodiments, the first strand comprises a 2'-0-methyl modified nucleotide on either side of the SNP position nucleotide.
- the dsRNA comprises a hydrophobic moiety.
- the region of a gene comprising the allelic polymorphism comprises a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 1-10.
- the first strand comprises
- an RNA described herein (e.g., the first strand of a dsRNA) comprises a SNP position nucleotide (referenced from the 5’ end) - MM position nucleotide (referenced from the 5’ end) combination selected from the group consisting of 2-7, 4- 7, 4-8, 4-15, 6-5, 6-8, 6-11, 6-14, 6-16, 3-5, 3-7 and 3-8.
- the SNP position nucleotide is complementary to an allelic polymorphism of an htt SNP selected from the group consisting of rs363l25, rs362273, rs362307, rs362336, rs36233l, rs362272, rs362306, rs362268, rs362267, and rs363099.
- the RNA further comprises a 5’ stabilizing moiety selected from the group consisting of phosphate, vinyl phosphonate, C5-methyl (R or S or racemic), C5-methyl on vinyl, and reduced vinyl.
- the RNA further comprises a conjugate moiety selected from the group consisting of alkyl chain, vitamin, peptide, glycosphingolipid, polyunsaturated fatty acid, secosteroid, steroid hormone, and steroid lipid.
- a dsRNA comprising a first strand of about 15-35 nucleotides that is complementary to a region of a gene comprising an allelic polymorphism, and a second strand of about 15-35 nucleotides that is complementary to at least a portion of the first strand, wherein the first strand comprises a SNP position nucleotide at any one of positions in the seed region (e.g., one of positions 2 to 6 from the 5’ end) that is complementary to the allelic polymorphism, and wherein the first strand comprises a MM position nucleotide located 2-6 nucleotides from the SNP position nucleotide that is a mismatch with a nucleotide in the gene, is provided.
- a dsRNA comprising a first strand of about 15-35 nucleotides that is complementary to a region of a gene comprising an allelic polymorphism, and a second strand of about 15-35 nucleotides that is complementary to at least a portion of the first strand, wherein the first strand comprises a SNP position nucleotide at position 2, 4 or 6 from the 5’ end that is complementary to the allelic polymorphism, and wherein the first strand comprises a MM position nucleotide located 2-6 nucleotides from the SNP position nucleotide that is a mismatch with a nucleotide in the gene, is provided.
- the RNA further comprises at least one vinyl phosphonate modification in an intersubunit linkage having the formula:
- a YP motif is inserted next to the SNP position nucleotide or next to the MM position nucleotide.
- the SNP position nucleotide is at position 2 from the 5’ end, at position 4 from the 5’ end, or at position 6 from the 5’ end of the first strand.
- the MM position nucleotide is located within 2 nucleotides of the SNP position nucleotide, is located within 3 nucleotides of the SNP position nucleotide, is located within 4 nucleotides of the SNP position nucleotide, is located within 5 nucleotides of the SNP position nucleotide, or is located within 6 nucleotides of the SNP position nucleotide.
- the SNP position nucleotide is located 4 nucleotides from the 5’ end, and the MM position nucleotide is located 7 nucleotides from the 5’ end. In other exemplary embodiments, the SNP position nucleotide is located 6 nucleotides from the 5’ end, and the MM position nucleotide is located 11 nucleotides from the 5’ end.
- a dsRNA comprising a first strand of about 15-35 nucleotides that is complementary to a region of a gene comprising an allelic polymorphism, and a second strand of about 15-35 nucleotides that is complementary to at least a portion of the first strand, wherein the first strand comprises a SNP position nucleotide at a position 6 from the 5’ end that is complementary to the allelic polymorphism, and wherein the first strand comprises a MM position nucleotide located at position 11 from the 5’ end is a mismatch with a nucleotide in the gene, is provided.
- the RNA further comprises at least one vinyl phosphonate modification in an intersubunit linkage having the formula:
- a VP motif is inserted next to the SNP position nucleotide or next to the MM position nucleotide.
- the first strand comprises a 2'-0-methyl modified nucleotide on either side of the SNP position nucleotide. In certain exemplary embodiments, the first strand comprises at least three 2'-0-methyl modified nucleotides.
- the dsRNA comprises a 5'-phosphorothioate group.
- the gene comprising an allelic polymorphism is the Huntingtin (htt) gene.
- the region of a gene comprising the allelic polymorphism comprises a nucleic acid sequence selected from the group consisting of SEQ ID NOs: 1-10.
- the first strand comprises
- RNA described herein a pharmaceutically acceptable carrier is provided.
- a method of inhibiting expression of a gene comprising an allelic polymorphism in a cell comprising contacting the cell with the described herein is provided.
- a method of treating a disease or disorder characterized or caused by a gene comprising an allelic polymorphism in a subject in need thereof comprising administering to a subject a therapeutically effective amount of an RNA having a 5’ end, a 3’ end, and a seed region, that is complementary to a region of a gene comprising an allelic polymorphism, wherein the RNA comprises a SNP position nucleotide at position in the seed region that is complementary to the allelic polymorphism, and a MM position nucleotide located 2-11 nucleotides from the SNP position nucleotide that is a mismatch with a nucleotide in the gene, provided.
- the RNA further comprises at least one vinyl phosphonate modification in an intersubunit linkage having the formula:
- a YP motif is inserted next to the SNP position nucleotide or next to the MM position nucleotide.
- the RNA is an ASO or a dsRNA.
- the dsRNA comprises a first strand of about 15-35 nucleotides that is complementary to the region of the gene comprising an allelic polymorphism, and a second strand of about 15-35 nucleotides that is complementary to at least a portion of the first strand, wherein the first strand comprises the SNP position nucleotide within the seed region (e.g, any one of positions 2 to 6 from the 5’ end, such as position 2, 4 or 6 from the 5’ end) that is complementary to the allelic polymorphism, and wherein the first strand comprises the MM position nucleotide located 2-6 nucleotides from the SNP position nucleotide that is a mismatch with a nucleotide in the gene.
- the first strand comprises the SNP position nucleotide within the seed region (e.g, any one of positions 2 to 6 from the 5’ end, such as position 2, 4 or 6 from the 5’ end) that is complementary to the allelic polymorphism
- said dsRNA is administered to the brain of the subject. In certain exemplary embodiments, said dsRNA is administered by intrastriatal infusion. In certain exemplary embodiments, a decrease in expression of the gene in the striatum is achieved. In certain exemplary embodiments, a decrease in expression of the gene in the cortex is achieved.
- the gene comprising an allelic polymorphism is the Huntingtin (htt) gene.
- the disease is Huntington’s disease.
- the SNP position nucleotide is located at position 2, 4 or 6 from the 5’ end of the RNA, and the MM position nucleotide is located 2-6 nucleotides from the SNP position nucleotide.
- a di-branched oligonucleotide compound comprising two RNAs, wherein the RNAs are connected to one another by one or more moieties selected from a linker, a spacer and a branching point, wherein each RNA has a 5’ end, a 3’ end and a seed region, wherein each RNA is complementary to a region of a gene comprising an allelic polymorphism, and wherein each RNA comprises a SNP position nucleotide at a position within the seed region, the SNP position nucleotide being complementary to the allelic polymorphism, and a MM position nucleotide located 2-11 nucleotides from the SNP position nucleotide that is a mismatch with a nucleotide in the gene, is provided.
- the RNA further comprises at least one vinyl phosphonate modification in an intersubunit linkage having the formula:
- a YP motif is inserted next to the SNP position nucleotide or next to the MM position nucleotide.
- the di-branched oligonucleotide compound has an hsi- RNA structure.
- the SNP position nucleotide is complementary to an allelic polymorphism of an htt SNP selected from the group consisting of rs363l25, rs362273, rs362307, rs362336, rs36233l, rs362272, rs362306, rs362268, rs362267, and rs363099.
- a di-branched oligonucleotide compound comprising two or more nucleic acid sequences, wherein the nucleic acid sequences (N) are connected to one another by one or more moieties selected from a linker (L), a spacer (S) and optionally a branching point (B), wherein each nucleic acid sequence is double-stranded and comprises a sense strand and an antisense strand, wherein the sense strand and the antisense strand each have a 5’ end and a 3’ end, wherein the sense strand and the antisense strand each comprises one or more chemically-modified nucleotides, wherein each antisense strand has a seed region, wherein each antisense strand is complementary to a region of a gene comprising an allelic polymorphism, and wherein each antisense strand comprises a SNP position nucleotide at a position within the seed region, the SNP position nucleotide being complementary to the
- the RNA further comprises at least one vinyl phosphonate modification in an intersubunit linkage having the formula:
- a VP motif is inserted next to the SNP position nucleotide or next to the MM position nucleotide.
- the sense strands and the antisense strands each comprise >80% chemically-modified nucleotides.
- each antisense strand comprises at least 15 contiguous nucleotides, and wherein each sense strand comprises at least 15 contiguous nucleotides and has complementarity to the antisense strand.
- the compound further comprises a hydrophobic moiety attached to the terminal 5’position of the branched oligonucleotide compound.
- each double-stranded nucleic acid sequence is independently connected to a linker, spacer or branching point at the 3’ end or at the 5’ end of the sense strand or the antisense strand.
- the SNP position nucleotide is complementary to an allelic polymorphism of an htt SNP selected from the group consisting of rs363 l25, rs362273, rs362307, rs362336, rs36233 l, rs362272, rs362306, rs362268, rs362267, and rs363099.
- a nucleic acid having a 5’ end, a 3’ end and a seed region, that is complementary to a region of a gene comprising an allelic polymorphism wherein the nucleic acid comprises a SNP position nucleotide at a position within the seed region, wherein the SNP position nucleotide is complementary to the allelic polymorphism, a MM position that is a mismatch with a nucleotide in the gene, and at least one modified nucleotide (X) on either side of the SNP position nucleotide, wherein each X is located within four, three or two nucleotides from the SNP position nucleotide, is provided.
- X modified nucleotide
- the RNA further comprises at least one vinyl phosphonate modification in an intersubunit linkage having the formula:
- a YP motif is inserted next to the SNP position nucleotide or next to the MM position nucleotide.
- X comprises a sugar modification selected from the group consisting of 2’-0-methyl (2’-OMe), 2’-fluoro (2’-F), 2’-ribo, 2’-deoxyribo, 2'-F-4'- thioarabino (2’-F-ANA), 2-0-(2-methoxyethyl) (2’-MOE), 4’-S-RNA, locked nucleic acid (LNA), 4’-S-F-ANA, 2’-0-allyl, 2’-0-ethylamine, 2-cyanoethyl-RNA (CNet-RNA), tricyclo-DNA, cyclohexenyl nucleic acid (CeNA), arabino nucleic acid (ANA), and hexitol nucleic acid (HNA).
- an X is positioned immediately 5’ to the SNP position nucleotide or immediately 3’ to the SNP position nucleotide. In certain exemplary embodiments, an X is positioned immediately 5’ to the SNP position nucleotide and immediately 3’ to the SNP position nucleotide.
- the SNP position nucleotide is present from position 2 to position 6 from the 5’ end.
- the MM position nucleotide is located 2-11 nucleotides from the SNP position nucleotide.
- the MM position nucleotide is located 2-6 nucleotides from the SNP position nucleotide.
- nucleic acid having a 5’ end, a 3’ end and a seed region, that is complementary to a region of a gene comprising an allelic polymorphism, wherein the nucleic acid comprises a SNP position nucleotide at a position within the seed region, wherein the SNP position nucleotide is complementary to the allelic polymorphism, a MM position that is a mismatch with a nucleotide in the gene, and at least one modified nucleotide (Y) on either side of the MM position nucleotide, wherein each Y is located within four, three or two nucleotides from the MM position nucleotide, is provided.
- the RNA further comprises at least one vinyl phosphonate modification in an intersubunit linkage having the formula:
- a YP motif is inserted next to the SNP position nucleotide or next to the MM position nucleotide.
- a Y is positioned immediately 5’ to the MM position nucleotide or immediately 3’ to the MM position nucleotide. In certain exemplary embodiments, a Y is positioned immediately 5’ to the MM position nucleotide and immediately 3’ to the MM position nucleotide.
- the SNP position nucleotide is present from position 2 to position 6 from the 5’ end. In certain exemplary embodiments, the MM position nucleotide is located 2-11 nucleotides from the SNP position nucleotide. In certain exemplary embodiments, the MM position nucleotide is located 2-6 nucleotides from the SNP position nucleotide.
- a nucleic acid having a 5’ end, a 3’ end and a seed region, that is complementary to a region of a gene comprising an allelic polymorphism wherein the nucleic acid comprises a SNP position nucleotide at a position within the seed region, wherein the SNP position nucleotide is complementary to the allelic polymorphism, a MM position that is a mismatch with a nucleotide in the gene, and at least one modified nucleotide (X) on either side of the SNP position nucleotide, wherein each X is located within four, three or two nucleotides from the SNP position nucleotide, and at least one modified nucleotide (Y) on either side of the MM position nucleotide, wherein each Y is located within four, three or two nucleotides from the MM position nucleotide, is provided.
- X modified nucleotide
- the RNA further comprises at least one vinyl phosphonate modification in an intersubunit linkage having the formula:
- a YP motif is inserted next to the SNP position nucleotide or next to the MM position nucleotide.
- X comprises a sugar modification selected from the group consisting of 2’-OMe, 2’-F, 2’-ribo, 2’-deoxyribo, 2’-F-ANA, 2’-MOE, 4’-S-RNA, LNA, 4’-S-F-ANA, 2’-0-allyl, 2’-0-ethylamine, CNet-RNA, tricyclo-DNA, CeNA, ANA, and HNA.
- Y comprises a sugar modification selected from the group consisting of 2’-OMe, 2’-F, 2’-ribo, 2’-deoxyribo, 2’-F-ANA, 2’-MOE, 4’-S-RNA, LNA, 4’-S-F- ANA, 2’-0-allyl, 2’-0-ethylamine, CNet-RNA, tricyclo-DNA, CeNA, ANA, and HNA.
- an X is positioned immediately 5’ to the SNP position nucleotide or immediately 3’ to the SNP position nucleotide. In certain exemplary embodiments, an X is positioned immediately 5’ to the SNP position nucleotide and immediately 3’ to the SNP position nucleotide.
- a Y is positioned immediately 5’ to the MM position nucleotide or immediately 3’ to the MM position nucleotide. In certain exemplary embodiments, a Y is positioned immediately 5’ to the MM position nucleotide and immediately 3’ to the MM position nucleotide.
- the SNP position nucleotide is present from position 2 to position 6 from the 5’ end.
- the MM position nucleotide is located 2-11 nucleotides from the SNP position nucleotide.
- the MM position nucleotide is located 2-6 nucleotides from the SNP position nucleotide.
- X and Y are the same.
- FIG. 1 depicts psiCHECK reporter plasmids containing either a wild-type region of htt or the same region of htt with the SNP, rs362273.
- FIG. 2 depicts a bar graph showing luciferase activity following a psiCHECK reporter plasmid assay in HeLa cells transfected with hsiRNAs with the SNP nucleotide at varying positions. This primary screen yielded multiple efficacious hydrophobically modified siRNA (hsiRNA) sequences.
- hsiRNA hydrophobically modified siRNA
- FIG. 3 depicts dose response curves showing the silencing effects of three exemplary hsiRNAs of the invention on psiCHECK reporter plasmids.
- FIG. 4 depicts a dose response curve showing the efficacy of two hsiRNAs on silencing htt mRNA.
- FIG. 5 depicts bar graphs showing luciferase activity following a psiCHECK reporter plasmid assay in HeLa cells transfected with hsiRNAs having a second mismatch at varying positions.
- FIG. 6 depicts dose response curves comparing silencing effects of SNP2 hsiRNA with (mm2-7) or without (mm2-0) an additional mismatch.
- FIG. 7 depicts dose response curves comparing silencing effects of SNP4 hsiRNAs with or without an additional mismatch.
- FIG. 8 depicts dose response curves comparing silencing effects of SNP6 hsiRNAs with or without an additional mismatch.
- FIG. 9 depicts dose response curves comparing silencing effects of SNP4 or SNP6 hsiRNAs with an additional mismatch (SNP4-7 and SNP6-11 , respectively), compared to the same hsiRNAs without an additional mismatch (SNP4-0 and SNP4-11).
- HeLa cells transfected with one of two reporter plasmids were revers transfected with hsiRNAs by passive uptake, and treated for 72 hours reporter expression was measured with a dual luciferase assay.
- FIG. 10 depicts dose response curves of htt mRNA expression that measures silencing efficacy of hsiRNAs with additional mismatches.
- FIG. 11 schematically depicts an hsiRNA and exemplary modifications according to certain embodiments of the invention.
- FIG. 12A - FIG. 12C depict the SNP2, SNP4 and SNP6 hsiRNA libraries, respectively. Antisense strands are depicted 5’ to 3’, with the SNP site in red and the mismatch in blue.
- FIG. 13 depicts antisense and sense strand sequences and modification patterns for various hsiRNA constructs according to certain embodiments.
- mm4-7 and mm6-l 1 demonstrated superior SNP discrimination, and were selected for further screening.
- FIG. 14 depicts an exemplary SNP-selective compound designed as a di-siRNA.
- FIG. 15 depicts backbone linkages according to certain exemplary embodiments.
- Oligonucleotide backbones may comprise one or any combination of phosphates, phosphorothioates (a racemic mixture or stereospecific), diphosphorothioates, phosphoramidates, peptide nucleic acids (PNAs), boranophosphates, 2’-5’-pliospliodiesters, amides, phosphonoacetates, morpholinos and the like
- FIG. 16 depicts sugar modifications according to certain exemplary embodiments.
- Sugar modifications include one or any combination of 2’-0-methyl, 2’-fluoro, 2’-ribo, 2’-deoxyribo, 2’-F-ANA, MOE, 4’-S-RNA, LNA, 4’-S-F-ANA, 2’-0-allyl, 2’-0-ethylamine, CNet-RNA, tricyclo-DNA, CeNA, ANA, HNA and the like.
- FIG. 17 depicts intemucleotide bonds according to certain exemplary embodiments. Potential intemucleotide bonds can be between the first two nucleotides at the 5’ or 3’ ends of any given oligonucleotide strand can be stabilized with any of the moieties depicted.
- FIG. 18 depicts 5’ stabilization modifications according to certain exemplary embodiments.
- a suitable 5’ stabilization modification can be a phosphate, no phosphate, a vinyl phosphonate, a C5-methyl (R or S or racemic), a C5-methyl on vinyl, reduced vinyl (e.g., three carbon alkyl) or the like.
- FIG. 19 depicts conjugates moieties according to certain exemplary embodiments.
- a suitable conjugated moiety can be any length alkyl chain, a vitamin, a ligand, a peptide or a bioactive conjugate, e.g., a glycosphingolipid, a polyunsaturated fatty acid, a secosteroid, a steroid hormone, a steroid lipid, or the like.
- FIG. 20 graphically depicts that the activity of a SNP discriminating scaffold that comprises a SNP position nucleotide at position 6 from the 5’ end, and a mismatch position nucleotide located at position 11 from the 5’ end, is sequence-independent.
- FIG. 21 illustrates a representative synthesis of the vinyl phosphonate (YP)-modified intersubunit linkage described herein.
- FIG. 22 depicts a method for preparing oligonucleotides having a YP-modified intersubunit linkage.
- FIG. 23 is a pictoral representation of a VP-modified RNA according to certain exemplary embodiments.
- FIG. 24 illustrates the sequences of VP -modified oligonucleotides synthesized according to certain exemplary embodiments.
- FIG. 25 is a summary of a comparative study of siRNA efficacy.
- FIG. 26 is a schematic of hsiRNA antisense scaffolds aligned to HTT sequence surrounding SNP site rs362273 wherein the green box depicts the position of the SNP site.
- FIGS. 27A and 27B illustrate the effect of adding a mismatch in the siRNA sequence improves allelic discrimination without impairing the silencing of the mutant allele.
- FIGS. 28A and 28B depict YP -modified sequences prepared by a synthesizer.
- FIG. 29 demonstrates another method for preparing the YP -modified oligonucleotides provided herein.
- FIG. 30 demonstrates the effect a VP-modified linkage has on target/non-target discrimination of SNP-selective siRNAs.
- FIG. 31 illustrates an example di-branched siRNA chemical scaffold.
- FIG. 32A is a western blot performed to measure HTT protein levels.
- FIG. 32B shows protein levels normalized to vinculin.
- FIG. 33 depicts dose response curves comparing silencing effects for oligonucleotides targeting G at the SNP site instead of A.
- FIG. 34 illustrates example sequences introducing single mismatches in sequences previously chosen for dose response.
- FIG. 35 illustrates a number of exemplary oligonucleotide backbone modifications.
- FIG. 36 shows oligonucleotide branching motifs according to certain exemplary embodiments.
- the double-helices represent oligonucleotides.
- the combination of different linkers, spacer(s) and branching points allows generation of a wide diversity of branched hsiRNA structures.
- FIG. 37 shows branched oligonucleotides of the invention with conjugated bioactive moieties.
- FIG. 38 shows exemplary amidite linkers, spacers and branching moieties.
- FIG. 39 is a schematic of hsiRNA antisense scaffolds aligned to HTT sequence surrounding alternative SNP site rs362273.
- FIG. 40 depicts bar graphs showing luciferase activity following a psiCHECK reporter plasmid assay in HeLa cells transfected with the hsiRNAs of FIG. 39. The number following “SNP” represents the position of the SNP in the siRNA.
- FIG. 41 depicts dose response curves comparing silencing effects for oligonucleotides of FIG. 39 targeting C or T at the SNP3 site.
- FIG. 42 depicts bar graphs showing luciferase activity following a psiCHECK reporter plasmid assay in HeLa cells transfected with hsiRNAs of FIG. 39 which were modified to feature a second mismatch at varying positions.
- FIG. 43 illustrates example modified intersubunit linkers.
- FIG. 44A shows a representative example for preparing a monomer for the modified phosphinate-containing oligonucleotides provided herein.
- FIG 44B shows a representative example for preparing another monomer for the modified phosphinate-containing oligonucleotides provided herein.
- FIG. 44C shows a representative example for preparing a modified phosphinate- containing oligonucleotides provided herein.
- FIG. 45 illustrates exemplary SNPs within the HTT gene (SEQ ID NOs: 1-10 (numbered from top to bottom)).
- FIG. 46 is a flow chart illustrating a methodology for generating and selecting SNP- discriminating siR As.
- FIG. 47 illustrates a naming convention denoting the position of an SNP within an siRNA.
- compositions comprising oligonucleotide, e.g., RNA, silencing agents, e.g., RNAs such as double-stranded RNAs (“dsRNAs”), antisense oligonucleotides (“ASOs”) and the like, that are useful for silencing allelic polymorphisms located within a gene encoding a mutant protein.
- silencing agents e.g., RNAs such as double-stranded RNAs (“dsRNAs”), antisense oligonucleotides (“ASOs”) and the like, that are useful for silencing allelic polymorphisms located within a gene encoding a mutant protein.
- an oligonucleotide e.g., an RNA, silencing agent is a dsRNA agent provided herein, that destroys a corresponding mutant mRNA (e.g., a SNP-containing mRNA) with nucleotide specificity and selectivity.
- a dsRNA agent provided herein, that destroys a corresponding mutant mRNA (e.g., a SNP-containing mRNA) with nucleotide specificity and selectivity.
- RNA, silencing agents e.g., dsRNA agents disclosed herein target mRNA corresponding to polymorphic regions of a mutant gene, resulting in cleavage of mutant mRNA, and preventing synthesis of the corresponding mutant protein e.g., a gain of function mutant protein such as the huntingtin protein.
- “A” represents a nucleoside comprising the base adenine (e.g., adenosine or a chemically-modified derivative thereof)
- “G” represents a nucleoside comprising the base guanine (e.g., guanosine or a chemically-modified derivative thereof)
- “U” represents a nucleoside comprising the base uracil (e.g., uridine or a chemically-modified derivative thereof)
- “C” represents a nucleoside comprising the base adenine (e.g., cytidine or a chemically-modified derivative thereof)
- capping group refers to a chemical moiety that replaces a hydrogen atom in a functional group such as an alcohol (ROH), a carboxylic acid (RC0 2 H), or an amine (RNH 2 ).
- a functional group such as an alcohol (ROH), a carboxylic acid (RC0 2 H), or an amine (RNH 2 ).
- capping groups include: alkyl (e.g., methyl, tertiary- butyl); alkenyl (e.g., vinyl, allyl); carboxyl (e.g., acetyl, benzoyl); carbamoyl; phosphate; and phosphonate (e.g., vinylphosphonate).
- alkyl e.g., methyl, tertiary- butyl
- alkenyl e.g., vinyl, allyl
- carboxyl e.g., acetyl, benzoyl
- carbamoyl phosphate
- nucleotide analog or“altered nucleotide” or“modified nucleotide” refers to a non-standard nucleotide, including non-naturally occurring ribonucleotides or deoxyribonucleotides.
- exemplary nucleotide analogs are modified at any position so as to alter certain chemical properties of the nucleotide yet retain the ability of the nucleotide analog to perform its intended function.
- positions of the nucleotide which may be derivatized include the 5 position, e.g., 5-(2-amino)propyl uridine, 5-bromo uridine, 5-propyne uridine, 5- propenyl uridine, and the like; the 6 position, e.g., 6-(2-amino)propyl uridine; the 8-position for adenosine and/or guanosines, e.g., 8-bromo guanosine, 8-chloro guanosine, 8-f uoroguanosine, etc.
- 5 position e.g., 5-(2-amino)propyl uridine, 5-bromo uridine, 5-propyne uridine, 5- propenyl uridine, and the like
- the 6 position e.g., 6-(2-amino)propyl uridine
- the 8-position for adenosine and/or guanosines
- Nucleotide analogs also include deaza nucleotides, e.g., 7-deaza-adenosine; O- and N- modified (e.g., alkylated, e.g., N6-methyl adenosine, or as otherwise known in the art) nucleotides; and other heterocyclically modified nucleotide analogs such as those described in Herdewijn, Antisense Nucleic Acid Drug Dev., 2000 Aug. 10(4):297-310.
- oligonucleotide refers to a short polymer of nucleotides and/or nucleotide analogs.
- RNA analog refers to an polynucleotide (e.g., a chemically synthesized polynucleotide) having at least one altered or modified nucleotide as compared to a corresponding unaltered or unmodified RNA but retaining the same or similar nature or function as the corresponding unaltered or unmodified RNA.
- the oligonucleotides may be linked with linkages which result in a lower rate of hydrolysis of the RNA analog as compared to an RNA molecule with phosphodiester linkages.
- RNA analogues include sugar- and/or backbone-modified ribonucleotides and/or deoxyribonucleotides. Such alterations or modifications can further include addition of non nucleotide material, such as to the end(s) of the RNA or internally (at one or more nucleotides of the RNA).
- An RNA analog need only be sufficiently similar to natural RNA that it has the ability to mediate (mediates) RNA interference.
- exemplary oligonucleotides include, but are not limited to, siRNAs, miRNAs, shRNAs, CRISPR guides, DNA oligonucleotides, antisense oligonucleotides, AAV oligonucleotides, gapmers, mixmers, miRNA inhibitors, SSOs, PMOs, PNAs and the like.
- RNA interference refers to a selective intracellular degradation of RNA. RNAi occurs in cells naturally to remove foreign RNAs (e.g., viral RNAs). Natural RNAi proceeds via fragments cleaved from free dsRNA which direct the degradative mechanism to other similar RNA sequences. Alternatively, RNAi can be initiated by the hand of man, for example, to silence the expression of target genes.
- RNAi agent e.g., an RNA silencing agent, having a strand which is“sequence sufficiently complementary to a target mRNA sequence to direct target-specific RNA interference (RNAi)” means that the strand has a sequence sufficient to trigger the destruction of the target mRNA by the RNAi machinery or process.
- RNAi target-specific RNA interference
- RNA molecules which are substantially free of other cellular material, or culture medium when produced by recombinant techniques, or substantially free of chemical precursors or other chemicals when chemically synthesized.
- RNA silencing refers to a group of sequence-specific regulatory mechanisms (e.g. RNA interference (RNAi), transcriptional gene silencing (TGS), post- transcriptional gene silencing (PTGS), quelling, co-suppression, translational repression and the like) mediated by RNA molecules which result in the inhibition or“silencing” of the expression of a corresponding protein-coding gene.
- RNA silencing has been observed in many types of organisms, including plants, animals, and fungi.
- the term“discriminatory RNA silencing” refers to the ability of an RNA molecule to substantially inhibit the expression of a“first” or“target” polynucleotide sequence while not substantially inhibiting the expression of a“second” or“non-target” polynucleotide sequence, e.g., when both polynucleotide sequences are present in the same cell.
- the target polynucleotide sequence corresponds to a target gene
- the non-target polynucleotide sequence corresponds to a non-target gene.
- the target polynucleotide sequence corresponds to a target allele, while the non-target polynucleotide sequence corresponds to a non-target allele.
- the target polynucleotide sequence is the DNA sequence encoding the regulatory region (e.g., promoter or enhancer elements) of a target gene.
- the target polynucleotide sequence is a target mRNA encoded by a target gene.
- a gene“involved” in a disease or disorder includes a gene, the normal or aberrant expression or function of which effects or causes the disease or disorder or at least one symptom of said disease or disorder.
- the term “target gene” e.g., the mutant allele of a heterozygous polymorphism, e.g., a heterozygous SNP
- This silencing can be achieved by RNA silencing, e.g., by cleaving the mRNA of the target gene or translational repression of the target gene.
- non-target gene is a gene whose expression is not to be substantially silenced.
- the polynucleotide sequences of the target and non-target gene can differ by one or more nucleotides.
- the target and non-target genes can differ by one or more polymorphisms (e.g., single nucleotide polymorphisms or SNPs).
- the target and non-target genes can share less than 100% sequence identity.
- the non-target gene may be a homolog (e.g., an ortholog or paralog) of the target gene.
- A“target allele” is an allele (e.g., a SNP allele) whose expression is to be selectively inhibited or“silenced.” This silencing can be achieved by RNA silencing, e.g., by cleaving the mRNA of the target gene or target allele by a siRNA.
- the term“non-target allele” is an allele (e.g., the corresponding wild-type allele) whose expression is not to be substantially silenced.
- the target and non-target alleles can correspond to the same target gene.
- the target allele corresponds to, or is associated with, a target gene
- the non-target allele corresponds to, or is associated with, a non-target gene.
- the polynucleotide sequences of the target and non-target alleles can differ by one or more nucleotides.
- the target and non-target alleles can differ by one or more allelic polymorphisms (e.g., one or more SNPs).
- the target and non-target alleles can share less than 100% sequence identity.
- polymorphism refers to a variation (e.g., one or more deletions, insertions, or substitutions) in a gene sequence that is identified or detected when the same gene sequence from different sources or subjects (but from the same organism) are compared.
- a polymorphism can be identified when the same gene sequence from different subjects are compared. Identification of such polymorphisms is routine in the art, the methodologies being similar to those used to detect, for example, breast cancer point mutations. Identification can be made, for example, from DNA extracted from a subject's lymphocytes, followed by amplification of polymorphic regions using specific primers to said polymorphic region. Alternatively, the polymorphism can be identified when two alleles of the same gene are compared.
- the polymorphism is a single nucleotide polymorphism (SNP).
- SNP single nucleotide polymorphism
- a variation in sequence between two alleles of the same gene within an organism is referred to herein as an “allelic polymorphism.”
- the allelic polymorphism corresponds to a SNP allele.
- the allelic polymorphism may comprise a single nucleotide variation between the two alleles of a SNP, also referred to herein as a heterozygous SNP.
- the polymorphism can be at a nucleotide within a coding region but, due to the degeneracy of the genetic code, no change in amino acid sequence is encoded.
- polymorphic sequences can encode a different amino acid at a particular position, but the change in the amino acid does not affect protein function.
- Polymorphic regions can also be found in non-encoding regions of the gene.
- the polymorphism is found in a coding region of the gene or in an untranslated region (e.g., a 5' UTR or 3' UTR) of the gene.
- the term“allelic frequency” is a measure (e.g., proportion or percentage) of the relative frequency of an allele (e.g., a SNP allele) at a single locus in a population of individuals. For example, where a population of individuals carry n loci of a particular chromosomal locus (and the gene occupying the locus) in each of their somatic cells, then the allelic frequency of an allele is the fraction or percentage of loci that the allele occupies within the population. In particular embodiments, the allelic frequency of an allele (e.g. a SNP allele) is at least 10% (e.g., at least 15%, 20%, 25%, 30%, 35%, 40% or more) in a sample population.
- an allele e.g., a SNP allele
- the term“gain-of-function mutation,” as used herein, refers to any mutation in a gene in which the protein encoded by said gene (i.e., the mutant protein) acquires a function not normally associated with the protein (i.e., the wild-type protein) causes or contributes to a disease or disorder.
- the gain-of-function mutation can be a deletion, addition, or substitution of a nucleotide or nucleotides in the gene which gives rise to the change in the function of the encoded protein.
- the gain-of-function mutation changes the function of the mutant protein or causes interactions with other proteins.
- the gain-of-function mutation causes a decrease in or removal of normal wild-type protein, for example, by interaction of the altered, mutant protein with said normal, wild-type protein.
- the term“gain-of-function disorder” refers to a disorder characterized by a gain-of-function mutation.
- the gain-of-function disorder is a neurodegenerative disease caused by a gain-of-function mutation, e.g., polyglutamine disorders and/or trinucleotide repeat diseases, for example, Huntington’s disease.
- the gain-of-function disorder is caused by a gain-of-function in an oncogene, the mutated gene product being a gain-of-function mutant, e.g., cancers caused by a mutation in the ret oncogene (e.g., ret-l), for example, endocrine tumors, medullary thyroid tumors, parathyroid hormone tumors, multiple endocrine neoplasia type2, and the like.
- Additional exemplary gain-of-function disorders include, but are not limited to, Alzheimer’s disease, amyotrophic lateral sclerosis (ALS), human immunodeficiency disorder (HIV), and slow channel congenital myasthenic syndrome (SCCMS).
- trinucleotide repeat diseases refers to any disease or disorder characterized by an expanded trinucleotide repeat region located within a gene, the expanded trinucleotide repeat region being causative of the disease or disorder.
- examples of trinucleotide repeat diseases include, but are not limited to, spino-cerebellar ataxia type 12 spino-cerebellar ataxia type 8, fragile X syndrome, fragile XE Mental Retardation, Friedreich’s ataxia and myotonic dystrophy.
- Preferred trinucleotide repeat diseases for treatment according to the present invention are those characterized or caused by an expanded trinucleotide repeat region at the 5' end of the coding region of a gene, the gene encoding a mutant protein which causes or is causative of the disease or disorder.
- Certain trinucleotide diseases for example, fragile X syndrome, where the mutation is not associated with a coding region may not be suitable for treatment according to the methodologies of the present invention, as there is no suitable mRNA to be targeted by RNAi.
- disease such as Friedreich’s ataxia may be suitable for treatment according to the methodologies of the invention because, although the causative mutation is not within a coding region (i.e., lies within an intron), the mutation may be within, for example, an mRNA precursor (e.g., a pre-spliced mRNA precursor).
- an mRNA precursor e.g., a pre-spliced mRNA precursor
- polyglutamine disorder refers to any disease or disorder characterized by an expanded of a (CAG) n repeats at the 5' end of the coding region (thus encoding an expanded polyglutamine region in the encoded protein).
- CAG a progressive degeneration of nerve cells.
- polyglutamine disorders include, but are not limited to, Huntington’s disease, spino-cerebellar ataxia type 1, spino-cerebellar ataxia type 2, spino-cerebellar ataxia type 3 (also known as Machado- Joseph disease), and spino-cerebellar ataxia type 6, spino-cerebellar ataxia type 7, dentatoiubral-pallidoluysian atrophy and the like.
- SNP disorder refers to a disorder characterized by a the presence of an SNP, e.g., a heterozygous SNP.
- SNP disorders include, but are not limited to, phenylketonuria, cystic fibrosis, sickle-cell anemia, albinism, Huntington’s disease, myotonic dystrophy type 1, hypercholesterolemia (autosomal dominant, type B), neurofibromatosis (type 1), polycystic kidney disease (1 and 2), hemophilia A, Duchenne’s muscular dystrophy, X-linked hypophosphatemic rickets, Rett’s syndrome, non-obstructive spermatogenic failure and the like.
- An exemplary heterozygous SNP disorder is Huntington’s disease.
- a double-stranded RNA comprising a first strand of about 15-35 nucleotides that is complementary to a region of a gene comprising an allelic polymorphism, and a second strand of about 15-35 nucleotides that is complementary to at least a portion of the first strand, wherein the first strand comprises a single nucleotide polymorphism (SNP) position nucleotide at a position 2 to 7 from the 5’ end that is complementary to the allelic polymorphism; and a mismatch (MM) position nucleotide located 2-11 nucleotides from the SNP position nucleotide that is a mismatch with a nucleotide in the gene.
- SNP single nucleotide polymorphism
- MM mismatch
- the MM position is located 2 to 10 nucleotides from the SNP position.
- the SNP position nucleotide is any one of positions 2 to 6 from the 5’ end.
- the SNP position nucleotide is at a position 2, 4 or 6 from the 5’ end and the mismatch (MM) position nucleotide is located 2-6 nucleotides from the SNP position nucleotide.
- the SNP position nucleotide is any one of positions 2 to 6 from the 5’ end and the nucleotide is located 2-6 nucleuotdes from the SNP position nucleotide.
- a“single nucleotide polymorphism position nucleotide” or a“SNP position nucleotide” refers to the position of an RNA described herein (e.g., the first strand of a dsRNA) that corresponds to the polymorphic position of a target nucleic acid sequence (i.e., either the mutant nucleotide corresponding to the SNP allele or the wild-type nucleotide corresponding to the wild-type allele).
- a strand may be labeled “SNP2,” “SNP3,” or“SNP3” to denote the position of the SNP as being 2, 3, or 4 nucleotides from the 5’ end of the strand.
- a SNP position nucleotide is within a seed region. In certain exemplary embodiments, a SNP position nucleotide is located from position 2 to position 7 from the 5’ end, from position 2 to position 6 from the 5’ end, or from position 2 to position 5 from the 5’ end. In certain exemplary embodiments, a SNP position nucleotide is located at position 2 from the 5’ end, at position 3 from the 5’ end, at position 4 from the 5’ end, at position 5 from the 5’ end, at position 6 from the 5’ end, or at position 7 from the 5’ end of an RNA described herein (e.g., the first strand of a dsRNA).
- an RNA described herein e.g., the first strand of a dsRNA
- a SNP position nucleotide is located at a position set forth in Tables 5-7.
- the term“seed region” refers to a six -nucleotide stretch corresponding to positions 2-7 from the 5’ end of an RNA strand. siRNA recognition of the target mRNA is believed to be conferred by the seed region of its antisense strand.
- a“mismatch position nucleotide” or a“MM position nucleotide” refers to the position of an RNA described herein (e.g., the first strand of a dsRNA) that is in a position that does not correspond to the SNP position nucleotide.
- a MM position nucleotide can be defined by its position from the 5’ end or the 3’ end of an RNA described herein (e.g., the 5’ or the 3’ end of first strand of a dsRNA), or defined by its position relative to a SNP position nucleotide of an RNA described herein (e.g., a first strand of a dsRNA).
- a MM position nucleotide is located 2-11 nucleotides, 2-10 nucleotides, 2-9 nucleotides, 2-8 nucleotides, 2-7 nucleotides, or 2-6 nucleotides from a SNP position nucleotide.
- a MM position nucleotide is located 11 nucleotides, 10 nucleotides, 9 nucleotides, 8 nucleotides, 7 nucleotides, 6 nucleotides, 5 nucleotides, 4 nucleotides, 3 nucleotides or 2 nucleotides from a SNP position nucleotide.
- a MM position nucleotide is located at a position set forth in Tables 5-7.
- an RNA described herein (e.g., the first strand of a dsRNA) is homologous to an allelic polymorphism except for one mismatched oligonucleotide at a particular position relative to the nucleotide corresponding to the allelic polymorphism.
- the mismatch is within about 6 nucleotides of the SNP position nucleotide, within about 5 nucleotides of the SNP position nucleotide, within about 4 nucleotides of the SNP position nucleotide, within about 3 nucleotide of the SNP position nucleotide, within about 2 nucleotide of the SNP position nucleotide, or within about 1 nucleotide of the SNP position nucleotide.
- the mismatch is not adjacent to a SNP position nucleotide.
- a SNP position nucleotide is at position 2, 3, 4, 5, or 6 from the 5’ end. In an embodiment, a SNP position nucleotide is at position 2 from the 5’ end. In an embodiment, is at position 3 from the 5’ end. In an embodiment, a SNP position nucleotide is at position 4 from the 5’ end. In an embodiment, a SNP position nucleotide is at position 5 from the 5’ end. In an embodiment, a SNP position nucleotide is at position 6 from the 5’ end.
- an RNA described herein (e.g., the first strand of a dsRNA) comprises a MM position nucleotide at position 5, 7, 8, 11, 14, 15 or 16 from the 5’ end.
- an RNA described herein (e.g., the first strand of a dsRNA) comprises a MM position nucleotide 1, 2, 3, 4, 5, 8, 9, 10 or 11 nucleotides from the SNP position nucleotide.
- an RNA described herein (e.g., the first strand of a dsRNA) comprises a SNP position nucleotide (referenced from the 5’ end) - MM position nucleotide (referenced from the 5’ end) combination selected from the group consisting of 2-7, 4- 7, 4-8, 4-15, 6-5, 6-8, 6-11, 6-14, 6-16, 3-5, 3-7 and 3-8.
- an RNA described herein (e.g., the first strand of a dsRNA) comprises an SNP position nucleotide at position 6 from the 5’ end and a MM position nucleotide at position 11 from the 5’ end.
- an RNA described herein (e.g., the first strand of a dsRNA) comprises an SNP position nucleotide at position 4 from the 5’ end and a mismatch at position 7 from the 5’ end.
- the double-stranded RNAs provided herein selectively silence a mutant allele having an allelic polymorphism.
- the double-stranded RNAs provided herein silence a mutant allele having an allelic polymorphism and do not affect the wild-type allele of the same gene.
- the double-stranded RNAs provided herein silence a mutant allele having an allelic polymorphism and silence the wild-type allele of the same gene to a lesser extent than the mutant allele.
- the present invention provides a method of treating a subject having or at risk of having a disease characterized or caused by a mutant protein associated with an allelic polymorphism by administering to the subject an effective amount of an RNAi agent targeting an allelic polymorphism within a gene encoding a mutant protein (e.g., huntingtin protein), such that sequence-specific interference of a gene occurs resulting in an effective treatment for the disease.
- an RNAi agent targeting an allelic polymorphism within a gene encoding a mutant protein e.g., huntingtin protein
- RNA silencing agents disclosed herein preferentially silence a mutant allele comprising a polymorphism more efficiently than the corresponding wild-type allele.
- dsRNAs disclosed herein silence the allele comprising a polymorphism about 20%, about 30%, about 40%, about 50%, about 60%, about 70%, about 80%, or about 90% more than the corresponding wild-type allele.
- RNA silencing agents disclosed herein silence the allele comprising a polymorphism at least about 50% more than the corresponding wild-type allele.
- dsRNAs disclosed herein silence the allele comprising a polymorphism at least about 5 times, about 10 times, about 15 times, about 20 times, about 25 times, about 30 times, about 35 times, about 40 times, about 45 times, about 50 times, about 55 times, about 60 times, about 65 times, about 70 times, about 75 times, about 80 times, about 85 times, about 90 times, about 95 times, about 100 times, about 110 times, about 120 times, about 130 times, about 140 times, about 150 times, about 160 times, about 170 times, about 180 times, about 190 times, about 200 times, about 250 times, about 300 times, about 350 times, about 400 times, about 450 times, or up to about 500 times the level of silencing of the corresponding wild-type allele.
- the term“antisense strand” of an RNA silencing agent refers to a strand that is substantially complementary to a section of about 10-50 nucleotides, e.g., about 15-30, 16-25, 18-23 or 19-22 nucleotides of the mRNA of the gene targeted for silencing.
- the antisense strand or first strand has sequence sufficiently complementary to the desired target mRNA sequence to direct target-specific silencing, e.g., complementarity sufficient to trigger the destruction of the desired target mRNA by the RNAi machinery or process (RNAi interference) or complementarity sufficient to trigger translational repression of the desired target mRNA.
- RNA silencing agent e.g., an siRNA or RNA silencing agent
- antisense and sense strands can also be referred to as first or second strands, the first or second strand having complementarity to the target sequence and the respective second or first strand having complementarity to said first or second strand.
- miRNA duplex intermediates or siRNA- like duplexes include a miRNA strand having sufficient complementarity to a section of about 10- 50 nucleotides of the mRNA of the gene targeted for silencing and a miRNA* strand having sufficient complementarity to form a duplex with the miRNA strand.
- the term“antisense oligonucleotide” or“ASO” refers to a nucleic acid
- RNA e.g., an RNA
- a target RNA e.g., a SNP- containing mRNA or a SNP-containing pre-mRNA
- an RNA e.g., a SNP- containing mRNA or a SNP-containing pre-mRNA
- an effective manner e.g., in a manner effective to inhibit translation of a target mRNA and/or splicing of a target pre-mRNA.
- An antisense oligonucleotide having a“sequence sufficiently complementary to a target RNA” means that the antisense agent has a sequence sufficient to mask a binding site for a protein that would otherwise modulate splicing and/or that the antisense agent has a sequence sufficient to mask a binding site for a ribosome and/or that the antisense agent has a sequence sufficient to alter the three-dimensional structure of the targeted RNA to prevent splicing and/or translation.
- the“5' end,” as in the 5' end of an antisense strand refers to the 5' terminal nucleotides, e.g., between one and about 5 nucleotides at the 5' terminus of the antisense strand.
- the“3' end,” as in the 3' end of a sense strand refers to the region, e.g., a region of between one and about 5 nucleotides, that is complementary to the nucleotides of the 5' end of the complementary antisense strand.
- base pair refers to the interaction between pairs of nucleotides
- the term“bond strength” or“base pair strength” refers to the strength of the base pair.
- the term“mismatched base pair” refers to a base pair consisting of non complementary or non-Watson-Crick base pairs, for example, not normal complementary G:C, A:T or A:U base pairs.
- the term“ambiguous base pair” (also known as a non- discriminatory base pair) refers to a base pair formed by a universal nucleotide.
- Linkers useful in conjugated compounds of the invention include glycol chains (e.g., polyethylene glycol), alkyl chains, peptides, RNA, DNA, and combinations thereof.
- glycol chains e.g., polyethylene glycol
- alkyl chains e.g., polyethylene glycol
- peptides e.g., RNA, DNA, and combinations thereof.
- TEG triethylene glycol
- an oligonucleotide e.g., an siRNA
- an siRNA is a duplex consisting of a sense strand and complementary antisense strand, the antisense strand having sufficient complementary to an target mRNA containing an allelic polymorphism to mediate RNAi.
- the siRNA molecule has a length from about 10-50 or more nucleotides, i.e., each strand comprises 10-50 nucleotides (or nucleotide analogs).
- the siRNA molecule has a length from about 15-35, e.g., about 15, about 16, about 17, about 18, about 19, about 20, about 21, about 22, about 23, about 24, about 25, about 26, about 27, about 28, about 29, about 30, about 31, about 32, about 33, about 34 or about 35 nucleotides in each strand, wherein one of the strands is sufficiently complementary to a target region.
- the strands are aligned such that there are at least 1, 2, or 3 bases at the end of the strands which do not align (i.e., for which no complementary bases occur in the opposing strand) such that an overhang of 1, 2 or 3 residues occurs at one or both ends of the duplex when strands are annealed.
- the siRNA molecule has a length from about 10-50 or more nucleotides, i.e., each strand comprises 10-50 nucleotides (or nucleotide analogs).
- the siRNA molecule has a length from about 15-35, e.g., about 15, about 16, about 17, about 18, about 19, about 20, about 21, about 22, about 23, about 24, about 25, about 26, about 27, about 28, about 29, about 30, about 31, about 32, about 33, about 34 or about 35 nucleotides in each strand, wherein one of the strands is substantially complementary to a target sequence containing an allelic polymorphism, and the other strand is complementary or substantially complementary to the first strand.
- siRNA molecule in fully complementary to a target sequence containing an allelic polymorphism except for one additional mismatch, also known as secondary mismatch.
- siRNAs can be designed by using any method known in the art, for instance, by using the following protocol:
- the siRNA may be specific for a target sequence which contains an allelic polymorphism.
- the first strand is substantially complementary to the target sequence containing an allelic polymorphism having one mismatch to the target sequence containing an allelic polymorphism, and the other strand is substantially complementary to the first strand.
- the target sequence is outside a coding region of the target gene.
- Exemplary target sequences are selected from the 5' untranslated region (5'-UTR) or an intronic region of a target gene. Cleavage of mRNA at these sites should eliminate translation of corresponding mutant protein.
- Target sequences from other regions of the htt gene are also suitable for targeting.
- a sense strand is designed based on the target sequence. Further, siRNAs with lower G/C content (35-55%) may be more active than those with G/C content higher than 55%. Thus in one embodiment, the invention includes nucleic acid molecules having 35-55% G/C content.
- the sense strand of the siRNA is designed based on the sequence of the selected target site and the position of the allelic polymorphism.
- the RNA silencing agents of the invention do not elicit a PKR response (i.e., are of a sufficiently short length).
- longer RNA silencing agents may be useful, for example, in cell types incapable of generating a PKR response or in situations where the PKR response has been down-regulated or dampened by alternative means.
- the siRNA molecules of the invention have sufficient complementarity with the target sequence such that the siRNA can mediate RNAi.
- siRNA containing nucleotide sequences sufficiently identical to a target sequence portion of the target gene to effect RISC- mediated cleavage of the target gene are used.
- the sense strand of the siRNA is designed have to have a sequence sufficiently identical to a portion of the target which contains an allelic polymorphism.
- the invention has the advantage of being able to tolerate certain sequence variations to enhance efficiency and specificity of RNAi.
- the sense strand has 1 mismatched nucleotide with a target region containing an allelic polymorphism, such as a target region that differs by at least one base pair between a wild-type and mutant allele, e.g., a target region comprising the gain-of-function mutation, and the other strand is identical or substantially identical to the first strand.
- a target region containing an allelic polymorphism such as a target region that differs by at least one base pair between a wild-type and mutant allele, e.g., a target region comprising the gain-of-function mutation
- the mismatch is 4 nucleotides upstream, 3 nucleotides upstream nucleotide corresponding to the allelic polymorphism, 2 nucleotides upstream nucleotide corresponding to the allelic polymorphism, 1 nucleotide upstream, 1 nucleotide downstream nucleotide corresponding to the allelic polymorphism, 2 nucleotides downstream nucleotide corresponding to the allelic polymorphism, 3 nucleotides downstream nucleotide corresponding to the allelic polymorphism, 4 nucleotides downstream nucleotide corresponding to the allelic polymorphism, or 5 nucleotides downstream nucleotide corresponding to the allelic polymorphism.
- the mismatch is not adjacent to the nucleotide corresponding to the allelic polymorphism.
- siRNA sequences with small insertions or deletions of 1 or 2 nucleotides may also be effective for mediating RNAi.
- siRNA sequences with nucleotide analog substitutions or insertions can be effective for inhibition.
- Sequence identity may be determined by sequence comparison and alignment algorithms known in the art. To determine the percent identity of two nucleic acid sequences (or of two amino acid sequences), the sequences are aligned for optimal comparison purposes (e.g., gaps can be introduced in the first sequence or second sequence for optimal alignment). The nucleotides (or amino acid residues) at corresponding nucleotide (or amino acid) positions are then compared. When a position in the first sequence is occupied by the same residue as the corresponding position in the second sequence, then the molecules are identical at that position.
- the comparison of sequences and determination of percent identity between two sequences can be accomplished using a mathematical algorithm.
- the alignment generated over a certain portion of the sequence aligned having sufficient identity but not over portions having low degree of identity i.e., a local alignment.
- An exemplary, non-limiting example of a local alignment algorithm utilized for the comparison of sequences is the algorithm of Karlin and Altschul (1990) Proc. Natl. Acad. Sci. USA 87:2264-68, modified as in Karlin and Altschul (1993) Proc. Natl. Acad. Sci. USA 90:5873-77. Such an algorithm is incorporated into the BLAST programs (version 2.0) of Altschul, et al. (1990) J. Mol. Biol. 215:403-10.
- the alignment is optimized by introducing appropriate gaps and percent identity is determined over the length of the aligned sequences (i.e., a gapped alignment).
- Gapped BLAST can be utilized as described in Altschul et al., (1997) Nucleic Acids Res. 25(l7):3389-3402.
- the alignment is optimized by introducing appropriate gaps and percent identity is determined over the entire length of the sequences aligned (i.e., a global alignment).
- An exemplary, non-limiting example of a mathematical algorithm utilized for the global comparison of sequences is the algorithm of Myers and Miller, CABIOS (1989).
- the antisense or guide strand of the siRNA is routinely the same length as the sense strand and includes complementary nucleotides.
- the guide and sense strands are fully complementary, i.e., the strands are blunt-ended when aligned or annealed.
- the strands of the siRNA can be paired in such a way as to have a 3' overhang of 1 to 4, e.g., 2, nucleotides. Overhangs can comprise (or consist of) nucleotides corresponding to the target gene sequence (or complement thereof).
- overhangs can comprise (or consist of) deoxyribonucleotides, for example dTs, or nucleotide analogs, or other suitable non-nucleotide material.
- the nucleic acid molecules may have a 3' overhang of 2 nucleotides, such as TT.
- the overhanging nucleotides may be either RNA or DNA. As noted above, it is desirable to choose a target region wherein the mutant:wild-type mismatch is a purine:purine mismatch.
- the siRNA may be defined functionally as a nucleotide sequence (or oligonucleotide sequence) that is capable of hybridizing with the target sequence (e.g., 400 mM NaCl, 40 mM PIPES pH 6.4, 1 mM EDTA, 50 °C or 70 °C hybridization for 12-16 hours; followed by washing).
- the target sequence e.g., 400 mM NaCl, 40 mM PIPES pH 6.4, 1 mM EDTA, 50 °C or 70 °C hybridization for 12-16 hours; followed by washing.
- Additional exemplary hybridization conditions include hybridization at 70 °C in lxSSC or 50 °C in lxSSC, 50% formamide followed by washing at 70 °C in 0.3xSSC or hybridization at 70 °C in 4xSSC or 50 °C in 4xSSC, 50% formamide followed by washing at 67 °C in lxSSC.
- the hybridization temperature for hybrids anticipated to be less than 50 base pairs in length should be 5-10 °C less than the melting temperature (Tm) of the hybrid, where Tm is determined according to the following equations.
- Tm(°C) 2(# of A+T bases)+4(# of G+C bases).
- Tm(°C) 8l.5+l6.6(log l0[Na+])+0.4l(% G+C)-(600/N)
- N is the number of bases in the hybrid
- Negative control siRNAs should have the same nucleotide composition as the selected siRNA, but without significant sequence complementarity to the appropriate genome. Such negative controls may be designed by randomly scrambling the nucleotide sequence of the selected siRNA. A homology search can be performed to ensure that the negative control lacks homology to any other gene in the appropriate genome. In addition, negative control siRNAs can be designed by introducing one or more base mismatches into the sequence.
- siRNAs destroy target mRNAs (e.g., wild-type or mutant huntingtin mRNA)
- target cDNA e.g., huntingtin cDNA
- Radiolabeled with 32 P newly synthesized target mRNAs (e.g., huntingtin mRNA) are detected autoradiographically on an agarose gel. The presence of cleaved target mRNA indicates mRNA nuclease activity.
- Suitable controls include omission of siRNA and use of non-target cDNA.
- control siRNAs are selected having the same nucleotide composition as the selected siRNA, but without significant sequence complementarity to the appropriate target gene.
- Such negative controls can be designed by randomly scrambling the nucleotide sequence of the selected siRNA. A homology search can be performed to ensure that the negative control lacks homology to any other gene in the appropriate genome.
- negative control siRNAs can be designed by introducing one or more base mismatches into the sequence.
- siRNAs may be designed to target any of the target sequences described supra. Said siRNAs comprise an antisense strand which is sufficiently complementary with the target sequence to mediate silencing of the target sequence.
- the RNA silencing agent is a siRNA.
- siRNA-like molecules of the invention have a sequence (i.e., have a strand having a sequence) that is“sufficiently complementary” to a target sequence of an mRNA (e.g. an htt mRNA) to direct gene silencing either by RNAi or translational repression.
- siRNA-like molecules are designed in the same way as siRNA molecules, but the degree of sequence identity between the sense strand and target RNA approximates that observed between an miRNA and its target.
- the miRNA sequence has partial complementarity with the target gene sequence.
- the miRNA sequence has partial complementarity with one or more short sequences (complementarity sites) dispersed within the target mRNA (e.g., within the 3'-UTR of the target mRNA) (Hutvagner and Zamore, Science, 2002; Zeng et ah, Mol.
- the capacity of a siRNA-like duplex to mediate RNAi or translational repression may be predicted by the distribution of non-identical nucleotides between the target gene sequence and the nucleotide sequence of the silencing agent at the site of complementarity.
- at least one non-identical nucleotide is present in the central portion of the complementarity site so that duplex formed by the miRNA guide strand and the target mRNA contains a central“bulge” (Doench J G et ah, Genes & Dev., 2003).
- 2, 3, 4, 5, or 6 contiguous or non-contiguous non-identical nucleotides are introduced.
- the non-identical nucleotide may be selected such that it forms a wobble base pair (e.g., G:U) or a mismatched base pair (G:A, C:A, C:U, G:G, A:A, C:C, U:U).
- the“bulge” is centered at nucleotide positions 12 and 13 from the 5' end of the miRNA molecule.
- an RNA silencing agent (or any portion thereof) of the invention as described supra may be modified such that the activity of the agent is further improved.
- the RNA silencing agents described in above may be modified with any of the modifications described infra.
- the modifications can, in part, serve to further enhance target discrimination, to enhance stability of the agent (e.g., to prevent degradation), to promote cellular uptake, to enhance the target efficiency, to improve efficacy in binding (e.g., to the targets), to improve patient tolerance to the agent, and/or to reduce toxicity.
- the RNA silencing agents of the invention may be substituted with a destabilizing nucleotide to enhance single nucleotide target discrimination (see U.S. application Ser. No. 11/698,689, filed Jan. 25, 2007 and U.S. Provisional Application No. 60/762,225 filed Jan. 25, 2006, both of which are incorporated herein by reference).
- a modification may be sufficient to abolish the specificity of the RNA silencing agent for a non-target mRNA (e.g. wild- type mRNA), without appreciably affecting the specificity of the RNA silencing agent for a target mRNA (e.g. gain-of-function mutant mRNA).
- the RNA silencing agents of the invention are modified by the introduction of at least one universal nucleotide in the antisense strand thereof.
- Universal nucleotides comprise base portions that are capable of base pairing indiscriminately with any of the four conventional nucleotide bases (e.g. A, G, C, U).
- a universal nucleotide is typically utilized because it has relatively minor effect on the stability of the RNA duplex or the duplex formed by the guide strand of the RNA silencing agent and the target mRNA.
- Exemplary universal nucleotide include those having an inosine base portion or an inosine analog base portion selected from the group consisting of deoxyinosine (e.g.
- the universal nucleotide is an inosine residue or a naturally occurring analog thereof.
- the RNA silencing agents of the invention are modified by the introduction of at least one destabilizing nucleotide within 11 nucleotides from a specificity- determining nucleotide (e.g., within 11 nucleotides from the nucleotide which recognizes the disease-related polymorphism (e.g., a SNP position nucleotide)).
- the destabilizing nucleotide may be introduced at a position that is within 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, or 1 nucleotide(s) from a specificity-determining nucleotide.
- the destabilizing nucleotide is introduced at a position which is 3 nucleotides from the specificity- determining nucleotide (i.e., such that there are 2 stabilizing nucleotides between the destabilizing nucleotide and the specificity-determining nucleotide).
- the destabilizing nucleotide may be introduced in the strand or strand portion that does not contain the specificity-determining nucleotide.
- the destabilizing nucleotide is introduced in the same strand or strand portion that contains the specificity-determining nucleotide.
- RNA silencing agents of the invention are modified by the introduction of a modified intersubunit linkage of Formula 1:
- D is selected from the group consisting of O, OCH 2 , OCH, CH 2 , and CH;
- C is selected from the group consisting of 0 , OH, OR 1 , NH , NH 2 , S , and SH;
- A is selected from the group consisting of O and CH 2 ;
- R 1 is a protecting group
- the intersubunit is bridging two optionally modified nucleosides.
- Formula VIII is a modified intersubunit linkage of Formula 2:
- D is O.
- the modified intersubunit linkage of Formula VIII is a modified intersubunit linkage of Formula 3:
- D is CH 2 .
- the modified intersubunit linkage of Formula VIII is a modified intersubunit linkage of Formula 4:
- the modified intersubunit linkage is a modified intersubunit linkage of Formula 5:
- D is OCH 2 .
- the modified intersubunit linkage is a modified intersubunit linkage of Formula 6:
- the modified intersubunit linkage of Formula YII is a modified intersubunit linkage of Formula 7:
- the RNA silencing agents of the invention are modified by the introduction of one or more of the intersubunit linkers of FIG. 43.
- an intersubunit linker of FIG. 43 is inserted between the SNP position nucleotide and a nucleotide at a position directly adjacent to and on either side of the SNP position nucleotide of the antisense strand.
- RNA silencing agents of the invention are modified by the introduction of one or more vinyl phosphonate (VP) motifs in the intersubunit linker having the following formula:
- a VP motif is inserted at any position(s) of an oligonucleotide, e.g., an RNA.
- an oligonucleotide having a length of 20 nucleotides e.g., a VP motif can be inserted at position 1-2, 2-3, 3-4, 4-5, 5-6, 6-7, 7-8, 8-9, 9-10, 10-11, 11-12, 12-13, 13-14, 14-15, 15-16, 16-17, 17-18, 18-19 or 19-20 and at any combinations of these.
- a VP motif is inserted at one or more of positions 1-2, 5-6, 6-7, 10-11, 18-19 and/or 19-20 of the antisense strand.
- a VP motif is inserted at one or more of positions 1-2, 6-7, 10-11 and/or 19-20 of the antisense strand.
- a VP motif is inserted next to (i.e., between a SNP position nucleotide and a nucleotide at a position directly adjacent to and on either side of) the SNP position nucleotide of the antisense strand.
- a VP motif is inserted next to (i.e., between a MM position nucleotide and a nucleotide at a position directly adjacent to and on either side of) the MM position nucleotide of the antisense strand.
- RNA silencing agents of the invention may be altered to facilitate enhanced efficacy and specificity in mediating RNAi according to asymmetry design rules (see U.S. Patent Nos. 8,309,704, 7,750,144, 8,304,530, 8,329,892 and 8,309,705).
- Such alterations facilitate entry of the antisense strand of the siRNA (e.g., a siRNA designed using the methods of the invention or an siRNA produced from a shRNA) into RISC in favor of the sense strand, such that the antisense strand preferentially guides cleavage or translational repression of a target mRNA, and thus increasing or improving the efficiency of target cleavage and silencing.
- siRNA e.g., a siRNA designed using the methods of the invention or an siRNA produced from a shRNA
- the asymmetry of an RNA silencing agent is enhanced by lessening the base pair strength between the antisense strand 5' end (AS 5') and the sense strand 3' end (S 3') of the RNA silencing agent relative to the bond strength or base pair strength between the antisense strand 3' end (AS 3') and the sense strand 5' end (S’5) of said RNA silencing agent.
- the asymmetry of an RNA silencing agent of the invention may be enhanced such that there are fewer G:C base pairs between the 5' end of the first or antisense strand and the 3' end of the sense strand portion than between the 3' end of the first or antisense strand and the 5' end of the sense strand portion.
- the asymmetry of an RNA silencing agent of the invention may be enhanced such that there is at least one mismatched base pair between the 5' end of the first or antisense strand and the 3' end of the sense strand portion.
- the mismatched base pair is selected from the group consisting of G:A, C:A, C:U, G:G, A:A, C:C and U:U.
- the asymmetry of an RNA silencing agent of the invention may be enhanced such that there is at least one wobble base pair, e.g., G:U, between the 5' end of the first or antisense strand and the 3' end of the sense strand portion.
- the asymmetry of an RNA silencing agent of the invention may be enhanced such that there is at least one base pair comprising a rare nucleotide, e.g., inosine (I).
- the base pair is selected from the group consisting of an I:A, I:U and I:C.
- the asymmetry of an RNA silencing agent of the invention may be enhanced such that there is at least one base pair comprising a modified nucleotide.
- the modified nucleotide is selected from the group consisting of 2-amino-G, 2- amino-A, 2,6-diamino-G, and 2,6-diamino-A.
- the RNA silencing agents of the invention are altered at one or more intersubunit linkages in an oligonucleotide by the introduction of a vinyl phosphonate (VP) motif having the following formula:
- RNA silencing agents of the present invention can be modified to improve stability in serum or in growth medium for cell cultures.
- the 3 '-residues may be stabilized against degradation, e.g., they may be selected such that they consist of purine nucleotides, particularly adenosine or guanosine nucleotides.
- substitution of pyrimidine nucleotides by modified analogues, e.g., substitution of uridine by 2'-deoxythymidine is tolerated and does not affect the efficiency of RNA interference.
- RNA silencing agents that include first and second strands wherein the second strand and/or first strand is modified by the substitution of internal nucleotides with modified nucleotides, such that in vivo stability is enhanced as compared to a corresponding unmodified RNA silencing agent.
- an“internal” nucleotide is one occurring at any position other than the 5' end or 3' end of nucleic acid molecule, polynucleotide or oligonucleotide.
- An internal nucleotide can be within a single-stranded molecule or within a strand of a duplex or double-stranded molecule.
- the sense strand and/or antisense strand is modified by the substitution of at least one internal nucleotide. In another embodiment, the sense strand and/or antisense strand is modified by the substitution of at least 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25 or more internal nucleotides. In another embodiment, the sense strand and/or antisense strand is modified by the substitution of at least 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95% or more of the internal nucleotides.
- the sense strand and/or antisense strand is modified by the substitution of all of the internal nucleotides.
- the RNA silencing agents may contain at least one modified nucleotide analogue.
- the nucleotide analogues may be located at positions where the target-specific silencing activity, e.g., the RNAi mediating activity or translational repression activity is not substantially effected, e.g., in a region at the 5'-end and/or the 3'-end of the siRNA molecule.
- the ends may be stabilized by incorporating modified nucleotide analogues.
- RNA silencing agents of the invention are altered at one or more intersubunit linkages in an oligonucleotide by the introduction of a vinyl phosphonate (VP) motif having the following formula:
- oligonucleotide types e.g., gapmers, mixmers, miRNA inhibitors, splice- switching oligonucleotides (“SSOs”), phosphorodiamidate morpholino oligonucleotides (“PMOs”), peptide nucleic acids (“PNAs”) and the like
- SSOs splice- switching oligonucleotides
- PMOs phosphorodiamidate morpholino oligonucleotides
- PNAs peptide nucleic acids
- Exemplary nucleotide analogues include sugar- and/or backbone-modified ribonucleotides (i.e., include modifications to the phosphate-sugar backbone).
- the phosphodiester linkages of natural RNA may be modified to include at least one of a nitrogen or sulfur heteroatom.
- the phosphoester group connecting to adjacent ribonucleotides is replaced by a modified group, e.g., of phosphothioate group.
- the 2' OH-group is replaced by a group selected from H, OR, R, halo, SH, SR, NH 2 , NHR, NR 2 or ON, wherein R is Ci-Ce alkyl, alkenyl or alkynyl and halo is F, Cl, Br or I.
- the modifications are 2'-fluoro, 2'-amino and/or 2'-thio modifications.
- Particularly exemplary modifications include 2'-fluoro-cytidine, 2'-fluoro-uridine, 2'-fluoro-adenosine, 2'-fluoro-guanosine, 2'-amino-cytidine, 2'-amino-uridine, 2'-amino- adenosine, 2'-amino-guanosine, 2,6-diaminopurine, 4-thio-uridine, and/or 5-amino-allyl-uridine.
- the 2'-fluoro ribonucleotides are every uridine and cytidine.
- Additional exemplary modifications include 5-bromo-uridine, 5-iodo-uridine, 5-methyl-cytidine, ribo-thymidine, 2-aminopurine, 2'-amino-butyryl-pyrene-uridine, 5-fluoro-cytidine, and 5-fluoro- uridine.
- 2'-deoxy-nucleotides and 2'-Ome nucleotides can also be used within modified RNA- silencing agents moieties of the instant invention.
- Additional modified residues include, deoxy- abasic, inosine, N3-methyl-uridine, N6,N6-dimethyl-adenosine, pseudouridine, purine ribonucleoside and ribavirin.
- the 2' moiety is a methyl group such that the linking moiety is a 2'-0-methyl oligonucleotide.
- the RNA silencing agent of the invention comprises locked nucleic acids (LNAs).
- LNAs comprise sugar-modified nucleotides that resist nuclease activities (are highly stable) and possess single nucleotide discrimination for mRNA (Elmen et ah, Nucleic Acids Res., (2005), 33(1): 439-447; Braasch et al. (2003) Biochemistry 42:7967-7975, Petersen et al. (2003) Trends Biotechnol 21 :74-81). These molecules have 2'-0,4'-C-ethylene-bridged nucleic acids, with possible modifications such as 2'-deoxy-2"-fluorouridine.
- LNAs increase the specificity of oligonucleotides by constraining the sugar moiety into the 3'-endo conformation, thereby pre-organizing the nucleotide for base pairing and increasing the melting temperature of the oligonucleotide by as much as 10 °C per base.
- the RNA silencing agent of the invention comprises peptide nucleic acids (PNAs).
- PNAs comprise modified nucleotides in which the sugar-phosphate portion of the nucleotide is replaced with a neutral 2-amino ethylglycine moiety capable of forming a polyamide backbone which is highly resistant to nuclease digestion and imparts improved binding specificity to the molecule (Nielsen, et al., Science, (2001), 254: 1497-1500).
- nucleobase-modified ribonucleotides i.e., ribonucleotides, containing at least one non-naturally occurring nucleobase instead of a naturally occurring nucleobase, are used.
- Bases may be modified to block the activity of adenosine deaminase.
- modified nucleobases include, but are not limited to, uridine and/or cytidine modified at the 5-position, e.g., 5-(2-amino)propyl uridine, 5-bromo uridine; adenosine and/or guanosines modified at the 8 position, e.g., 8-bromo guanosine; deaza nucleotides, e.g., 7- deaza-adenosine; O- and N-alkylated nucleotides, e.g., N6-methyl adenosine are suitable. It should be noted that the above modifications may be combined.
- cross-linking can be employed to alter the pharmacokinetics of the RNA silencing agent, for example, to increase half-life in the body.
- the invention includes RNA silencing agents having two complementary strands of nucleic acid, wherein the two strands are crosslinked.
- the invention also includes RNA silencing agents which are conjugated or unconjugated (e.g., at its 3' terminus) to another moiety (e.g. a non-nucleic acid moiety such as a peptide), an organic compound (e.g., a dye), or the like).
- Modifying siRNA derivatives in this way may improve cellular uptake or enhance cellular targeting activities of the resulting siRNA derivative as compared to the corresponding siRNA, are useful for tracing the siRNA derivative in the cell, or improve the stability of the siRNA derivative compared to the corresponding siRNA.
- Other exemplary modifications include: (a) 2' modification, e.g., provision of a 2' OMe moiety on a U in a sense or antisense strand, but especially on a sense strand, or provision of a 2' OMe moiety in a 3' overhang, e.g., at the 3' terminus (3' terminus means at the 3' atom of the molecule or at the most 3' moiety, e.g., the most 3' P or 2' position, as indicated by the context); (b) modification of the backbone, e.g., with the replacement of an 0 with an S, in the phosphate backbone, e.g., the provision of a phosphorothioate modification, on the U or the A or both, especially on an antisense strand; e.g., with the replacement of a P with an S; (c) replacement of the U with a C5 amino linker; (d) replacement of an A with a G (in most
- RNA silencing agents may be modified with chemical moieties, for example, to enhance cellular uptake by target cells (e.g., neuronal cells).
- target cells e.g., neuronal cells
- the invention includes RNA silencing agents which are conjugated or unconjugated (e.g., at its 3' terminus) to another moiety (e.g. a non-nucleic acid moiety such as a peptide), an organic compound (e.g., a dye), or the like.
- the conjugation can be accomplished by methods known in the art, e.g., using the methods of Lambert et ah, Drug Deliv.
- a modification to the RNA silencing agents of the invention comprise a vinyl phosphonate (VP) motif in one or more intersubunit linkers of an oligonucleotide, wherein the VP motif has the following formula:
- an RNA silencing agent of invention is conjugated to a lipophilic moiety.
- the lipophilic moiety is a ligand that includes a cationic group.
- the lipophilic moiety is attached to one or both strands of an siRNA.
- the lipophilic moiety is attached to one end of the sense strand of the siRNA. In another exemplary embodiment, the lipophilic moiety is attached to the 3' end of the sense strand. In certain embodiments, the lipophilic moiety is selected from the group consisting of cholesterol, vitamin E, vitamin K, vitamin A, folic acid, or a cationic dye (e.g., Cy3). In an exemplary embodiment, the lipophilic moiety is a cholesterol.
- lipophilic moieties include cholic acid, adamantane acetic acid, 1 -pyrene butyric acid, dihydrotestosterone, l,3-Bis- 0(hexadecyl)glyeerol, geranyloxyhexyl group, hexadecylglycerol, borneol, menthol, 1,3- propanediol, heptadecyl group, palmitic acid, myristic acid, 03-(oleoyl)lithocholic acid, 03- (oleoyl)cholenic acid, dimethoxytrityl, or phenoxazine.
- RNA silencing agent of the invention can be tethered to an RNA silencing agent of the invention.
- Ligands and associated modifications can also increase sequence specificity and consequently decrease off-site targeting.
- a tethered ligand can include one or more modified bases or sugars that can function as intercalators. In certain exemplary embodiments, these are located in an internal region, such as in a bulge of RNA silencing agent/target duplex.
- the intercalator can be an aromatic, e.g., a polycyclic aromatic or heterocyclic aromatic compound.
- a polycyclic intercalator can have stacking capabilities, and can include systems with 2, 3, or 4 fused rings.
- the universal bases described herein can be included on a ligand.
- the ligand can include a cleaving group that contributes to target gene inhibition by cleavage of the target nucleic acid.
- the cleaving group can be, for example, a bleomycin (e.g., bleomycin-A5, bleomycin-A2, or bleomycin-B2), pyrene, phenanthroline (e.g., O-phenanthroline), a polyamine, a tripeptide (e.g., lys-tyr-lys tripeptide), or metal ion chelating group.
- a bleomycin e.g., bleomycin-A5, bleomycin-A2, or bleomycin-B2
- phenanthroline e.g., O-phenanthroline
- polyamine e.g., a tripeptide (e.g., lys-tyr-lys tripeptide), or metal ion chelating group.
- the metal ion chelating group can include, e.g., an Lu(III) or EU(III) macrocyclic complex, a Zn(II) 2,9-dimethylphenanthroline derivative, a Cu(II) terpyridine, or acridine, which can promote the selective cleavage of target RNA at the site of the bulge by free metal ions, such as Lu(III).
- a peptide ligand can be tethered to a RNA silencing agent to promote cleavage of the target RNA, e.g., at the bulge region.
- l,8-dimethyl- l,3,6,8,l0,l3-hexaazacyclotetradecane can be conjugated to a peptide (e.g., by an amino acid derivative) to promote target RNA cleavage.
- a tethered ligand can be an aminoglycoside ligand, which can cause an RNA silencing agent to have improved hybridization properties or improved sequence specificity.
- Exemplary aminoglycosides include glycosylated polylysine, galactosylated polylysine, neomycin B, tobramycin, kanamycin A, and acridine conjugates of aminoglycosides, such as Neo-N-acridine, Neo-S-acridine, Neo-C-acridine, Tobra-N-acridine, and KanaA-N-acridine.
- Use of an acridine analog can increase sequence specificity.
- neomycin B has a high affinity for RNA as compared to DNA, but low sequence-specificity.
- an acridine analog, neo-5 -acridine has an increased affinity for the HIV Rev-response element (RRE).
- the guanidine analog (the guanidinoglycoside) of an aminoglycoside ligand is tethered to an RNA silencing agent.
- the amine group on the amino acid is exchanged for a guanidine group.
- Attachment of a guanidine analog can enhance cell permeability of an RNA silencing agent.
- a tethered ligand can be a poly-arginine peptide, peptoid or peptidomimetic, which can enhance the cellular uptake of an oligonucleotide agent.
- Exemplary ligands are coupled, typically covalently, either directly or indirectly via an intervening tether, to a ligand-conjugated carrier.
- the ligand is attached to the carrier via an intervening tether.
- a ligand alters the distribution, targeting or lifetime of an RNA silencing agent into which it is incorporated.
- a ligand provides an enhanced affinity for a selected target, e.g., molecule, cell or cell type, compartment, e.g., a cellular or organ compartment, tissue, organ or region of the body, as, e.g., compared to a species absent such a ligand.
- Exemplary ligands can improve transport, hybridization, and specificity properties and may also improve nuclease resistance of the resultant natural or modified RNA silencing agent, or a polymeric molecule comprising any combination of monomers described herein and/or natural or modified ribonucleotides.
- Ligands in general can include therapeutic modifiers, e.g., for enhancing uptake; diagnostic compounds or reporter groups e.g., for monitoring distribution; cross-linking agents; nuclease-resistance conferring moieties; and natural or unusual nucleobases.
- Lipophiles examples include lipophiles, lipids, steroids (e.g., uvaol, hecigenin, diosgenin), terpenes (e.g., triterpenes, e.g., sarsasapogenin, Friedelin, epifriedelanol derivatized lithocholic acid), vitamins (e.g., folic acid, vitamin A, biotin, pyridoxal), carbohydrates, proteins, protein binding agents, integrin targeting molecules, polycationics, peptides, polyamines, and peptide mimics.
- steroids e.g., uvaol, hecigenin, diosgenin
- terpenes e.g., triterpenes, e.g., sarsasapogenin, Friedelin, epifriedelanol derivatized lithocholic acid
- vitamins e.g., folic acid, vitamin A, biotin,
- Ligands can include a naturally occurring substance, (e.g., human serum albumin (HSA), low- density lipoprotein (LDL), or globulin); carbohydrate (e.g., a dextran, pullulan, chitin, chitosan, inulin, cyclodextrin or hyaluronic acid); amino acid, or a lipid.
- HSA human serum albumin
- LDL low- density lipoprotein
- globulin carbohydrate
- carbohydrate e.g., a dextran, pullulan, chitin, chitosan, inulin, cyclodextrin or hyaluronic acid
- amino acid or a lipid.
- the ligand may also be a recombinant or synthetic molecule, such as a synthetic polymer, e.g., a synthetic polyamino acid.
- polyamino acids examples include polyamino acid is a polylysine (PLL), poly L-aspartic acid, poly L-glutamic acid, styrene-maleic acid anhydride copolymer, poly(L-lactide-co-glycolied) copolymer, divinyl ether-maleic anhydride copolymer, N-(2-hydroxypropyl)methacrylamide copolymer (HMPA), polyethylene glycol (PEG), polyvinyl alcohol (PVA), polyurethane, poly(2- ethylacryllic acid), N-isopropylacrylamide polymers, or polyphosphazine.
- PLL polylysine
- poly L-aspartic acid poly L-glutamic acid
- styrene-maleic acid anhydride copolymer poly(L-lactide-co-glycolied) copolymer
- divinyl ether-maleic anhydride copolymer divinyl ether
- polyamines include: polyethylenimine, polylysine (PLL), spermine, spermidine, polyamine, pseudopeptide-polyamine, peptidomimetic polyamine, dendrimer polyamine, arginine, amidine, protamine, cationic lipid, cationic porphyrin, quaternary salt of a polyamine, or an alpha helical peptide.
- Ligands can also include targeting groups, e.g., a cell or tissue targeting agent, e.g., a lectin, glycoprotein, lipid or protein, e.g., an antibody, that binds to a specified cell type such as a kidney cell.
- a cell or tissue targeting agent e.g., a lectin, glycoprotein, lipid or protein, e.g., an antibody, that binds to a specified cell type such as a kidney cell.
- a targeting group can be a thyrotropin, melanotropin, lectin, glycoprotein, surfactant protein A, mucin carbohydrate, multivalent lactose, multivalent galactose, N-acetyl- galactosamine, N-acetyl-glucosamine, multivalent mannose, multivalent fucose, glycosylated polyaminoacids, multivalent galactose, transferrin, bisphosphonate, polyglutamate, polyaspartate, a lipid, cholesterol, a steroid, bile acid, folate, vitamin B12, biotin, or an RGD peptide or RGD peptide mimetic.
- ligands include dyes, intercalating agents (e.g. acridines and substituted acridines), cross-linkers (e.g. psoralene, mitomycin C), porphyrins (TPPC4, texaphyrin, Sapphyrin), polycyclic aromatic hydrocarbons (e.g., phenazine, dihydrophenazine, phenanthroline, pyrenes), lys-tyr-lys tripeptide, aminoglycosides, guanidium aminoglycodies, artificial endonucleases (e.g.
- intercalating agents e.g. acridines and substituted acridines
- cross-linkers e.g. psoralene, mitomycin C
- porphyrins TPPC4, texaphyrin, Sapphyrin
- polycyclic aromatic hydrocarbons e.g., phenazine, dihydrophenazine, phen
- EDTA lipophilic molecules
- cholesterol and thio analogs thereof
- cholic acid cholanic acid, lithocholic acid, adamantane acetic acid, 1 -pyrene butyric acid, dihydrotestosterone, glycerol (e.g., esters (e.g., mono, bis, or tris fatty acid esters, e.g., Cio, Cn,
- Ci2 Ci3, Ci4, Ci5, Ci6, C17, Ci8, C19, or C 20 fatty acids
- ethers thereof e.g., Cio, Cn, Ci 2 , C13,
- Ci4 C15, Ci6, Cn, Ci8, C19, or C 20 alkyl; e.g., l,3-bis-0(hexadecyl)glycerol, 1 ,3-bis-
- biotin e.g., aspirin, naproxen, vitamin E, folic acid
- transport/absorption facilitators e.g., aspirin, naproxen, vitamin E, folic acid
- synthetic ribonucleases e.g., imidazole, bisimidazole, histamine, imidazole clusters, acridine-imidazole conjugates, Eu 3+ complexes of tetraazamacrocycles
- dinitrophenyl HRP or AP.
- Ligands can be proteins, e.g., glycoproteins, or peptides, e.g., molecules having a specific affinity for a co-ligand, or antibodies e.g., an antibody, that binds to a specified cell type such as a cancer cell, endothelial cell, or bone cell.
- Ligands may also include hormones and hormone receptors. They can also include non-peptidic species, such as lipids, lectins, carbohydrates, vitamins, cofactors, multivalent lactose, multivalent galactose, N-acetyl-galactosamine, N-acetyl- glucosamine multivalent mannose, or multivalent fucose.
- the ligand can be, for example, a lipopolysaccharide, an activator of p38 MAP kinase, or an activator of NF-KB.
- the ligand can be a substance, e.g., a drug, which can increase the uptake of the RNA silencing agent into the cell, for example, by disrupting the cell's cytoskeleton, e.g., by disrupting the cell’s microtubules, micro filaments, and/or intermediate filaments.
- the drug can be, for example, taxon, vincristine, vinblastine, cytochalasin, nocodazole, japlakinolide, latrunculin A, phalloidin, swinholide A, indanocine, or myoservin.
- the ligand can increase the uptake of the RNA silencing agent into the cell by activating an inflammatory response, for example.
- Exemplary ligands that would have such an effect include tumor necrosis factor alpha (TNFa), interleukin- 1 beta, or gamma interferon.
- the ligand is a lipid or lipid-based molecule.
- a lipid or lipid-based molecule typically binds a serum protein, e.g., human serum albumin (HSA).
- HSA human serum albumin
- An HSA binding ligand allows for distribution of the conjugate to a target tissue, e.g., a non-kidney target tissue of the body.
- the target tissue can be the liver, including parenchymal cells of the liver.
- Other molecules that can bind HSA can also be used as ligands. For example, naproxen or aspirin can be used.
- a lipid or lipid-based ligand can (a) increase resistance to degradation of the conjugate, (b) increase targeting or transport into a target cell or cell membrane, and/or (c) can be used to adjust binding to a serum protein, e.g., HSA.
- a lipid based ligand can be used to modulate, e.g., control the binding of the conjugate to a target tissue.
- the lipid based ligand binds HSA.
- the affinity not be so strong that the HSA- ligand binding cannot be reversed.
- the lipid based ligand binds HSA weakly or not at all.
- the ligand is a moiety, e.g., a vitamin, which is taken up by a target cell, e.g., a proliferating cell.
- a target cell e.g., a proliferating cell.
- vitamins include vitamin A, E and K.
- Other exemplary vitamins include are B vitamin, e.g., folic acid, B12, riboflavin, biotin, pyridoxal or other vitamins or nutrients taken up by cancer cells.
- HSA and low density lipoprotein (LDL) low density lipoprotein
- the ligand is a cell-permeation agent, typically a helical cell-permeation agent.
- the agent is amphipathic.
- An exemplary agent is a peptide such as tat or antennopedia. If the agent is a peptide, it can be modified, including a peptidylmimetic, invertomers, non-peptide or pseudo-peptide linkages, and use ofD-amino acids.
- the helical agent is typically an alpha-helical agent, which typically has a lipophilic face and a lipophobic face.
- the ligand can be a peptide or peptidomimetic.
- a peptidomimetic also referred to herein as an oligopeptidomimetic is a molecule capable of folding into a defined three-dimensional structure similar to a natural peptide.
- the attachment of peptide and peptidomimetics to oligonucleotide agents can affect pharmacokinetic distribution of the RNA silencing agent, such as by enhancing cellular recognition and absorption.
- the peptide or peptidomimetic moiety can be about 5-50 amino acids long, e.g., about 5, 10, 15, 20, 25, 30, 35, 40, 45, or 50 amino acids long.
- a peptide or peptidomimetic can be, for example, a cell permeation peptide, cationic peptide, amphipathic peptide, or hydrophobic peptide (e.g., consisting primarily of Tyr, Trp or Phe).
- the peptide moiety can be a dendrimer peptide, constrained peptide or crosslinked peptide.
- the peptide moiety can be an L-peptide or D-peptide.
- the peptide moiety can include a hydrophobic membrane translocation sequence (MTS).
- a peptide or peptidomimetic can be encoded by a random sequence of DNA, such as a peptide identified from a phage-display library, or one-bead-one-compound (OBOC) combinatorial library (Lam et ah, Nature 354:82-84, 1991).
- the peptide or peptidomimetic tethered to an RNA silencing agent via an incorporated monomer unit is a cell targeting peptide such as an arginine-glycine- aspartic acid (RGD)-peptide, or RGD mimic.
- RGD arginine-glycine- aspartic acid
- a peptide moiety can range in length from about 5 amino acids to about 40 amino acids.
- the peptide moieties can have a structural modification, such as to increase stability or direct conformational properties. Any of the structural modifications described below can be utilized.
- the RNA molecule is conjugated to one or more hydrophobic moieties (see PCT Pub. No. WO 2018/031933, which is incorporated herein by reference).
- the hydrophobic moiety has an affinity for low density lipoprotein and/or intermediate density lipoprotein.
- the hydrophobic moiety is a saturated or unsaturated moiety having fewer than three double bonds.
- the hydrophobic moiety has an affinity for high density lipoprotein.
- the hydrophobic moiety is a polyunsaturated moiety having at three or more double bonds (e.g., having three, four, five, six, seven, eight, nine or ten double bonds).
- the hydrophobic moiety is a polyunsaturated moiety having three double bonds.
- the hydrophobic moiety is a polyunsaturated moiety having four double bonds.
- the hydrophobic moiety is a polyunsaturated moiety having five double bonds.
- the hydrophobic moiety is a polyunsaturated moiety having six double bonds.
- the hydrophobic moiety is selected from the group consisting of fatty acids, steroids, secosteroids, lipids, gangliosides and nucleoside analogs, and endocannabinoids.
- the hydrophobic moiety is a neuromodulatory lipid, e.g., an endocannabinoid.
- endocannabinoids include: anandamide, arachidonoylethanolamine, 2-Arachidonyl glyceryl ether (noladin ether), 2-Arachidonyl glyceryl ether (noladin ether), 2-Arachidonoylglycerol, and N-Arachidonoyl dopamine.
- the hydrophobic moiety is an omega-3 fatty acid.
- omega-3 fatty acids include, but are not limited to: hexadecatrienoic acid (HTA), alpha-linolenic acid (ALA), stearidonic acid (SDA), eicosatrienoic acid (ETE), eicosatetraenoic acid (ETA), eicosapentaenoic acid (EPA, Timnodonic acid), heneicosapentaenoic acid (HP A), docosapentaenoic acid (DP A, clupanodonic acid), docosahexaenoic acid (DHA, cervonic acid), tetracosapentaenoic acid, and tetracosahexaenoic acid (nisinic acid).
- HTA hexadecatrienoic acid
- ALA alpha-linolenic acid
- SDA stearidonic acid
- ETE e
- the hydrophobic moiety is an omega-6 fatty acid.
- omega-6 fatty acids include, but are not limited to: linoleic acid, gamma-linolenic acid (GLA), eicosadienoic acid, dihomo-gamma-linolenic acid (DGLA), arachidonic acid (AA), docosadienoic acid, adrenic acid, docosapentaenoic acid (osbond acid), tetracosatetraenoic acid, and tetracosapentaenoic acid.
- GLA gamma-linolenic acid
- DGLA dihomo-gamma-linolenic acid
- AA arachidonic acid
- docosadienoic acid adrenic acid
- docosapentaenoic acid osbond acid
- tetracosatetraenoic acid tetracosapentaenoic
- the hydrophobic moiety is an omega-9 fatty acid.
- omega-9 fatty acids include, but are not limited to: oleic acid, eicosenoic acid, Mead acid, erucic acid, and nervonic acid.
- the hydrophobic moiety is a conjugated linolenic acid.
- conjugated linolenic acids include, but are not limited to: a-calendic acid, b- calendic acid, jacaric acid, a-eleostearic acid, b-eleostearic acid, catalpic acid, and punicic acid.
- the hydrophobic moiety is a saturated fatty acid.
- saturated fatty acids include, but are not limited to: caprylic acid, capric acid, docosanoic acid, lauric acid, myristic acid, palmitic acid, stearic acid, arachidic acid, behenic acid, lignoceric acid, and cerotic acid.
- the hydrophobic moiety is an acid selected from the group consisting of: rumelenic acid, a-parinaric acid, b-parinaric acid, bosseopentaenoic acid, pinolenic acid, and podocarpic acid.
- the hydrophobic moiety is selected from the group consisting of: docosanoic acid (DCA), docosahexaenoic acid (DHA), and eicosapentaenoic acid (EPA).
- DCA docosanoic acid
- DHA docosahexaenoic acid
- EPA eicosapentaenoic acid
- the hydrophobic moiety is docosanoic acid (DCA).
- the hydrophobic moiety is DHA.
- the hydrophobic moiety is EPA.
- the hydrophobic moiety is a secosteroid. In a particular embodiment, the hydrophobic moiety is calciferol. In another embodiment, the hydrophobic moiety is a steroid other than cholesterol.
- the hydrophobic moiety is not cholesterol.
- the hydrophobic moiety is an alkyl chain, a vitamin, a peptide, or a bioactive conjugate, including but not limited to: glycosphingolipids, polyunsaturated fatty acids, secosteroids, steroid hormones, or sterol lipids.
- a double-stranded RNA provided herein comprises one or more chemically-modified nucleotides.
- the double-stranded RNA comprises alternating 2’-methoxy-nucleotides and 2’-fluoro-nucleotides.
- one or more nucleotides of the double-stranded RNA are connected to adjacent nucleotides via phosphorothioate linkages.
- the mismatch nucleotide and the nucleotide(s) adjacent to the mismatch nucleotide are 2’- methoxy-ribonucleotides .
- nucleotides at positions 1 and 2 from the 3’ end of the double-stranded RNAs provided herein are connected to adjacent nucleotides via phosphorothioate linkages.
- nucleotides at positions 1 and 2 from the 3’ end of the double-stranded RNAs and the nucleotides at positions 1 and 2 from the 5’ end of the double-stranded RNAs are connected to adjacent nucleotides via phosphorothioate linkages.
- the first oligonucleotide comprises at least 16 contiguous nucleotides, a 5’ end, a 3’ end, and has complementarity to a target, wherein:
- the first oligonucleotide comprises alternating 2’-methoxy-nucleotides and 2’-fluoro- nucleotides;
- nucleotides at positions 2 and 14 from the 5’ end are not 2’-methoxy-nucleotides
- nucleotides are connected via phosphodiester or phosphorothioate linkages
- nucleotides at positions 1-6 from the 3’ end, or positions 1-7 from the 3’ end are connected to adjacent nucleotides via phosphorothioate linkages.
- the first oligonucleotide comprises alternating 2’-methoxy-ribonucleotides and 2’- fluoro-ribonucleotides, wherein each nucleotide is a 2’-methoxy-ribonucleotide or a 2’-fluoro- ribonucleotide; and the nucleotides at positions 2 and 14 from the 5’ end of the first oligonucleotide are not 2’-methoxy-ribonucleotides;
- the second oligonucleotide comprises alternating 2’-methoxy-ribonucleotides and 2’- fluoro-ribonucleotides, wherein each nucleotide is a 2’-methoxy-ribonucleotide or a 2’-fluoro- ribonucleotide; and the nucleotides at positions 2 and 14 from the 5’ end of the second oligonucleotide are 2’-methoxy-ribonucleotides;
- nucleotides of the first oligonucleotide are connected to adjacent nucleotides via phosphodiester or phosphorothioate linkages, wherein the nucleotides at positions 1-6 from the 3’ end, or positions 1-7 from the 3’ end are connected to adjacent nucleotides via phosphorothioate linkages;
- nucleotides of the second oligonucleotide are connected to adjacent nucleotides via phosphodiester or phosphorothioate linkages, wherein the nucleotides at positions 1 and 2 from the 3’ end are connected to adjacent nucleotides via phosphorothioate linkages.
- the first oligonucleotide has 3-7 more ribonucleotides than the second oligonucleotide.
- the double-stranded RNA comprises 11-16 base pair duplexes, wherein the nucleotides of each base pair duplex have different chemical modifications (e.g., one nucleotide has a 2’-fluoro modification and the other nucleotide has a 2’-methoxy).
- the first oligonucleotide has 3-7 more ribonucleotides than the second oligonucleotide. In another embodiment.
- the first oligonucleotide is the antisense strand and the second oligonucleotide is the sense strand. See PCT Pub. No. WO 2016/161388, which is incorporated herein by reference.
- the first or second oligonucleotide comprises one or more VP intersubunit modifications having the following formula:
- RNA silencing agents as disclosed above may be connected to one another by one or more moieties independently selected from a linker, a spacer and a branching point, forming a branched oligonucleotide containing two or more RNA silencing agents.
- FIG. 31 illustrates an exemplary di-siRNA di-branched scaffolding for delivering two siRNAs.
- the nucleic acids of the branched oligonucleotide each comprise an antisense strand (or portions thereof), wherein the antisense strand has sufficient complementary to a heterozygous single nucleotide polymorphism to mediate an RNA-mediated silencing mechanism (e.g. RNAi).
- RNA-mediated silencing mechanism e.g. RNAi
- a third type of branched oligonucleotides including nucleic acids of both types, that is, a nucleic acid comprising an antisense strand (or portions thereof) and an oligonucleotide comprising a sense strand (or portions thereof).
- the branched oligonucleotides may have two to eight RNA silencing agents attached through a linker.
- the linker may be hydrophobic.
- branched oligonucleotides of the present application have two to three oligonucleotides.
- the oligonucleotides independently have substantial chemical stabilization (e.g., at least 40% of the constituent bases are chemically-modified).
- the oligonucleotides have full chemical stabilization (i.e., all of the constituent bases are chemically-modified).
- branched oligonucleotides comprise one or more single-stranded phosphorothioated tails, each independently having two to twenty nucleotides.
- each single-stranded tail has eight to ten nucleotides.
- branched oligonucleotides are characterized by three properties:
- branched oligonucleotides have 2 or 3 branches. It is believed that the increased overall size of the branched structures promotes increased uptake. Also, without being bound by a particular theory of activity, multiple adjacent branches (e.g., 2 or 3) are believed to allow each branch to act cooperatively and thus dramatically enhance rates of internalization, trafficking and release.
- nucleic acids attached at the branching points are single stranded and consist of miRNA inhibitors, gapmers, mixmers, SSOs, PMOs, or PNAs. These single strands can be attached at their 3’ or 5’ end. Combinations of siRNA and single stranded oligonucleotides could also be used for dual function.
- short nucleic acids complementary to the gapmers, mixmers, miRNA inhibitors, SSOs, PMOs, and PNAs are used to carry these active single-stranded nucleic acids and enhance distribution and cellular internalization.
- the short duplex region has a low melting temperature (T m ⁇ 37 °C) for fast dissociation upon internalization of the branched structure into the cell.
- Di-siRNA branched oligonucleotides may comprise chemically diverse conjugates.
- Conjugated bioactive ligands may be used to enhance cellular specificity and to promote membrane association, internalization, and serum protein binding.
- bioactive moieties to be used for conjugation include DHAg2, DHA, GalNAc, and cholesterol. These moieties can be attached to Di-siRNA either through the connecting linker or spacer, or added via an additional linker or spacer attached to another free siRNA end.
- Branched oligonucleotides have unexpectedly uniform distribution throughout the spinal cord and brain. Moreover, branched oligonucleotides exhibit unexpectedly efficient systemic delivery to a variety of tissues, and very high levels of tissue accumulation.
- Branched oligonucleotides comprise a variety of therapeutic nucleic acids, including ASOs, miRNAs, miRNA inhibitors, splice switching, PMOs, PNAs. In some embodiments, branched oligonucleotides further comprise conjugated hydrophobic moieties and exhibit unprecedented silencing and efficacy in vitro and in vivo.
- each linker is independently selected from an ethylene glycol chain, an alkyl chain, a peptide, RNA, DNA, a phosphate, a phosphonate, a phosphoramidate, an ester, an amide, a triazole, and combinations thereof; wherein any carbon or oxygen atom of the linker is optionally replaced with a nitrogen atom, bears a hydroxyl substituent, or bears an oxo substituent.
- each linker is an ethylene glycol chain.
- each linker is an alkyl chain.
- each linker is a peptide.
- each linker is RNA.
- each linker is DNA. In another embodiment, each linker is a phosphate. In another embodiment, each linker is a phosphonate. In another embodiment, each linker is a phosphoramidate. In another embodiment, each linker is an ester. In another embodiment, each linker is an amide. In another embodiment, each linker is a triazole. In another embodiment, each linker is a structure selected from the formulas of FIG. 37.
- L is selected from an ethylene glycol chain, an alkyl chain, a peptide, RNA, DNA, a phosphate, a phosphonate, a phosphoramidate, an ester, an amide, a triazole, and combinations thereof, wherein formula (I) optionally further comprises one or more branch point B, and one or more spacer S; wherein B is independently for each occurrence a polyvalent organic species or derivative thereof; S is independently for each occurrence selected from an ethylene glycol chain, an alkyl chain, a peptide, RNA, DNA, a phosphate, a phosphonate, a phosphoramidate, an ester, an amide, a triazole, and combinations thereof; N is an RNA duplex comprising a sense strand and an antisense strand, wherein the antisense strand comprises a region of complementarity which is substantially complementary to a region of a gene comprising an allelic polymorphism, wherein the antisense
- the SNP position nucleotide is at a position 2, 4 or 6 from the 5’ end and the mismatch (MM) position nucleotide is located 2-6 nucleotides from the SNP position nucleotide.
- the sense strand and antisense strand each independently comprise one or more chemical modifications; and n is 2, 3, 4, 5, 6, 7 or 8.
- the compound of formula (I) has a structure selected from formulas (I-l)-(I-9) of Table 1.
- the compound of formula (I) is formula (1-1). In another embodiment, the compound of formula (I) is formula (1-2). In another embodiment, the compound of formula (I) is formula (1-3). In another embodiment, the compound of formula (I) is formula (1-4). In another embodiment, the compound of formula (I) is formula (1-5). In another embodiment, the compound of formula (I) is formula (1-6). In another embodiment, the compound of formula (I) is formula (1-7). In another embodiment, the compound of formula (I) is formula (1-8). In another embodiment, the compound of formula (I) is formula (1-9).
- each linker is independently selected from an ethylene glycol chain, an alkyl chain, a peptide, RNA, DNA, a phosphate, a phosphonate, a phosphoramidate, an ester, an amide, a triazole, and combinations thereof; wherein any carbon or oxygen atom of the linker is optionally replaced with a nitrogen atom, bears a hydroxyl substituent, or bears an oxo substituent.
- each linker is an ethylene glycol chain.
- each linker is an alkyl chain.
- each linker is a peptide.
- each linker is RNA. In another embodiment of the compound of formula (I), each linker is DNA. In another embodiment of the compound of formula (I), each linker is a phosphate. In another embodiment, each linker is a phosphonate. In another embodiment of the compound of formula (I), each linker is a phosphoramidate. In another embodiment of the compound of formula (I), each linker is an ester. In another embodiment of the compound of formula (I), each linker is an amide. In another embodiment of the compound of formula (I), each linker is a triazole. In another embodiment of the compound of formula (I), each linker is a structure selected from the formulas of FIG 36.
- B is a polyvalent organic species. In another embodiment of the compound of formula (I), B is a derivative of a polyvalent organic species. In one embodiment of the compound of formula (I), B is a triol or tetrol derivative. In another embodiment, B is a tri- or tetra-carboxylic acid derivative. In another embodiment, B is an amine derivative. In another embodiment, B is a tri- or tetra-amine derivative. In another embodiment, B is an amino acid derivative. In another embodiment of the compound of formula (I), B is selected from the formulas of FIG. 38.
- Polyvalent organic species are moieties comprising carbon and three or more valencies (i.e., points of attachment with moieties such as S, L or N, as defined above).
- Non-limiting examples of polyvalent organic species include triols (e.g., glycerol, phloroglucinol, and the like), tetrols (e.g., ribose, pentaerythritol, l,2,3,5-tetrahydroxybenzene, and the like), tri-carboxylic acids (e.g., citric acid, l,3,5-cyclohexanetricarboxylic acid, trimesic acid, and the like), tetra- carboxylic acids (e.g., ethylenediaminetetraacetic acid, pyromellitic acid, and the like), tertiary amines (e.g., tripropargylamine, triethanolamine, and the like), triamines (e.g., di
- each nucleic acid comprises one or more chemically-modified nucleotides. In an embodiment of the compound of formula (I), each nucleic acid consists of chemically-modified nucleotides. In certain embodiments of the compound of formula (I), >95%, >90%, >85%, >80%, >75%, >70%, >65%, >60%, >55% or >50% of each nucleic acid comprises chemically-modified nucleotides.
- each antisense strand independently comprises a 5’ terminal group R selected from the groups of Table 2:
- R is Ri. In another embodiment, R is R 2 . In another embodiment, R is R 3 . In another embodiment, R is R 4. In another embodiment, R is R 5. In another embodiment, R is Re . In another embodiment, R is R 7. In another embodiment, R is 3 ⁇ 4 .
- X for each occurrence, independently, is selected from adenosine, guanosine, uridine, cytidine, and chemically-modified derivatives thereof
- Y for each occurrence, independently, is selected from adenosine, guanosine, uridine, cytidine, and chemically-modified derivatives thereof
- - represents a phosphodiester internucleoside linkage
- represents a phosphorothioate intemucleoside linkage
- — represents, individually for each occurrence, a base-pairing interaction or a mismatch.
- the structure of formula (II) does not contain mismatches. In one embodiment, the structure of formula (II) contains 1 mismatch. In another embodiment, the compound of formula (II) contains 2 mismatches. In another embodiment, the compound of formula (II) contains 3 mismatches. In another embodiment, the compound of formula (II) contains 4 mismatches. In an embodiment, each nucleic acid consists of chemically-modified nucleotides.
- >95%, >90%, >85%, >80%, >75%, >70%, >65%, >60%, >55% or >50% of X’s of the structure of formula (II) are chemically-modified nucleotides. In other embodiments, >95%, >90%, >85%, >80%, >75%, >70%, >65%, >60%, >55% or >50% of X’s of the structure of formula (II) are chemically-modified nucleotides.
- the compound of formula (I) has the structure of formula (III):
- X for each occurrence, independently, is a nucleotide comprising a 2’-deoxy-2’- fluoro modification
- X for each occurrence, independently, is a nucleotide comprising a 2’-0- methyl modification
- Y for each occurrence, independently, is a nucleotide comprising a 2’- deoxy-2’-fluoro modification
- Y for each occurrence, independently, is a nucleotide comprising a 2’-0-methyl modification.
- X is chosen from the group consisting of 2’-deoxy-2’-fluoro modified adenosine, guanosine, uridine or cytidine. In an embodiment, X is chosen from the group consisting of 2’-0-methyl modified adenosine, guanosine, uridine or cytidine. In an embodiment, Y is chosen from the group consisting of 2’-deoxy-2’-fluoro modified adenosine, guanosine, uridine or cytidine. In an embodiment, Y is chosen from the group consisting of 2’-0-methyl modified adenosine, guanosine, uridine or cytidine.
- the structure of formula (III) does not contain mismatches. In one embodiment, the structure of formula (III) contains 1 mismatch. In another embodiment, the compound of formula (III) contains 2 mismatches. In another embodiment, the compound of formula (III) contains 3 mismatches. In another embodiment, the compound of formula (III) contains 4 mismatches.
- the compound of formula (I) has the structure of formula (IV):
- X for each occurrence, independently, is selected from adenosine, guanosine, uridine, cytidine, and chemically-modified derivatives thereof
- Y for each occurrence, independently, is selected from adenosine, guanosine, uridine, cytidine, and chemically-modified derivatives thereof
- - represents a phosphodiester internucleoside linkage
- represents a phosphorothioate intemucleoside linkage
- — represents, individually for each occurrence, a base-pairing interaction or a mismatch.
- the structure of formula (IV) does not contain mismatches. In one embodiment, the structure of formula (IV) contains 1 mismatch. In another embodiment, the compound of formula (IV) contains 2 mismatches. In another embodiment, the compound of formula (IV) contains 3 mismatches. In another embodiment, the compound of formula (IV) contains 4 mismatches. In an embodiment, each nucleic acid consists of chemically-modified nucleotides.
- >95%, >90%, >85%, >80%, >75%, >70%, >65%, >60%, >55% or >50% of X’s of the structure of formula (II) are chemically-modified nucleotides. In other embodiments, >95%, >90%, >85%, >80%, >75%, >70%, >65%, >60%, >55% or >50% of X’s of the structure of formula (II) are chemically-modified nucleotides.
- the compound of formula (I) has the structure of formula (Y):
- X for each occurrence, independently, is a nucleotide comprising a 2’-deoxy-2’-fluoro modification
- X for each occurrence, independently, is a nucleotide comprising a 2’-0-methyl modification
- Y for each occurrence, independently, is a nucleotide comprising a 2’-deoxy-2’- fluoro modification
- Y for each occurrence, independently, is a nucleotide comprising a 2’- O-methyl modification.
- X is chosen from the group consisting of 2’ -deoxy-2’ -fluoro modified adenosine, guanosine, uridine or cytidine. In an embodiment, X is chosen from the group consisting of 2’-0-methyl modified adenosine, guanosine, uridine or cytidine. In an embodiment, Y is chosen from the group consisting of 2’ -deoxy-2’ -fluoro modified adenosine, guanosine, uridine or cytidine. In an embodiment, Y is chosen from the group consisting of 2’-0-methyl modified adenosine, guanosine, uridine or cytidine.
- the structure of formula (Y) does not contain mismatches. In one embodiment, the structure of formula (Y) contains 1 mismatch. In another embodiment, the compound of formula (V) contains 2 mismatches. In another embodiment, the compound of formula (V) contains 3 mismatches. In another embodiment, the compound of formula (V) contains 4 mismatches.
- L has the structure of Ll :
- R is R 3 and n is 2.
- L has the structure of LL In an embodiment of the structure of formula (III), L has the structure of LL In an embodiment of the structure of formula (IV), L has the structure of LL In an embodiment of the structure of formula (V), L has the structure of LL In an embodiment of the structure of formula (VI), L has the structure of LL In an embodiment of the structure of formula (VI), L has the structure of LL
- L has the structure of L2:
- L2 is R 3 and n is 2.
- L has the structure of L2.
- L has the structure of L2.
- L has the structure of L2.
- L has the structure of L2.
- L has the structure of L2.
- a delivery system for therapeutic nucleic acids having the structure of formula (VI):
- L is selected from an ethylene glycol chain, an alkyl chain, a peptide, RNA, DNA, a phosphate, a phosphonate, a phosphoramidate, an ester, an amide, a triazole, and combinations thereof, wherein formula (VI) optionally further comprises one or more branch point B, and one or more spacer S; wherein B is independently for each occurrence a polyvalent organic species or derivative thereof; S is independently for each occurrence selected from an ethylene glycol chain, an alkyl chain, a peptide, RNA, DNA, a phosphate, a phosphonate, a phosphoramidate, an ester, an amide, a triazole, and combinations thereof; each cNA, independently, is a carrier nucleic acid comprising one or more chemical modifications; and n is 2, 3, 4, 5, 6, 7 or 8.
- L is an ethylene glycol chain. In another embodiment of the delivery system, L is an alkyl chain. In another embodiment of the delivery system, L is a peptide. In another embodiment of the delivery system, L is RNA. In another embodiment of the delivery system, L is DNA. In another embodiment of the delivery system, L is a phosphate. In another embodiment of the delivery system, L is a phosphonate. In another embodiment of the delivery system, L is a phosphoramidate. In another embodiment of the delivery system, L is an ester. In another embodiment of the delivery system, L is an amide. In another embodiment of the delivery system, L is a triazole.
- S is an ethylene glycol chain. In another embodiment, S is an alkyl chain. In another embodiment of the delivery system, S is a peptide. In another embodiment, S is RNA. In another embodiment of the delivery system, S is DNA. In another embodiment of the delivery system, S is a phosphate. In another embodiment of the delivery system, S is a phosphonate. In another embodiment of the delivery system, S is a phosphoramidate. In another embodiment of the delivery system, S is an ester. In another embodiment, S is an amide. In another embodiment, S is a triazole.
- n is 2. In another embodiment of the delivery system, n is 3. In another embodiment of the delivery system, n is 4. In another embodiment of the delivery system, n is 5. In another embodiment of the delivery system, n is 6. In another embodiment of the delivery system, n is 7. In another embodiment of the delivery system, n is 8.
- each cNA comprises >95%, >90%, >85%, >80%, >75%, >70%, >65%, >60%, >55% or >50% chemically-modified nucleotides.
- the compound of formula (VI) has a structure selected from formulas
- the compound of formula (VI) is the structure of formula (VI- 1). In an embodiment, the compound of formula (VI) is the structure of formula (VI-2). In an embodiment, the compound of formula (VI) is the structure of formula (VI-3). In an embodiment, the compound of formula (VI) is the structure of formula (VI-4). In an embodiment, the compound of formula (VI) is the structure of formula (VI-5). In an embodiment, the compound of formula (VI) is the structure of formula (VI-6). In an embodiment, the compound of formula (VI) is the structure of formula (VI-7). In an embodiment, the compound of formula (VI) is the structure of formula (VI-1). In an embodiment, the compound of formula (VI) is the structure of formula (VI-1). In an embodiment, the compound of formula (VI) is the structure of formula (VI-2). In an embodiment, the compound of formula (VI) is the structure of formula (VI-3). In an embodiment, the compound of formula (VI-4). In an embodiment, the compound of formula (VI) is the structure of formula (VI-5). In an embodiment, the
- the compound of formula (VI) is the structure of formula (VI-9).
- the compound of formulas (VI) (including, e.g., formulas (Vl-l)-(VI-
- each cNA independently comprises at least 15 contiguous nucleotides. In an embodiment, each cNA independently consists of chemically-modified nucleotides.
- the delivery system further comprises n therapeutic nucleic acids (NA), wherein each NA comprises a region of complementarity which is substantially complementary to a region of a gene comprising an allelic polymorphism, wherein the antisense strand comprises: a single nucleotide polymorphism (SNP) position nucleotide at a position 2 to 7 from the 5’ end that is complementary to the allelic polymorphism; and a mismatch (MM) position nucleotide located 2-11 nucleotide from the SNP position nucleotide that is a mismatch with a nucleotide in the gene.
- SNP single nucleotide polymorphism
- MM mismatch
- the SNP position nucleotide is at a position 2, 4 or 6 from the 5’ end and the mismatch (MM) position nucleotide is located 2-6 nucleotides from the SNP position nucleotide.
- each NA is hybridized to at least one cNA.
- the delivery system is comprised of 2 NAs.
- the delivery system is comprised of 3 NAs.
- the delivery system is comprised of 4 NAs.
- the delivery system is comprised of 5 NAs.
- the delivery system is comprised of 6 NAs.
- the delivery system is comprised of 7 NAs.
- the delivery system is comprised of 8 NAs.
- each NA independently comprises at least 16 contiguous nucleotides.
- each NA independently comprises 16-20 contiguous nucleotides. In an embodiment, each NA independently comprises 16 contiguous nucleotides. In another embodiment, each NA independently comprises 17 contiguous nucleotides. In another embodiment, each NA independently comprises 18 contiguous nucleotides. In another embodiment, each NA independently comprises 19 contiguous nucleotides. In another embodiment, each NA independently comprises 20 contiguous nucleotides.
- each NA comprises an unpaired overhang of at least 2 nucleotides. In another embodiment, each NA comprises an unpaired overhang of at least 3 nucleotides. In another embodiment, each NA comprises an unpaired overhang of at least 4 nucleotides. In another embodiment, each NA comprises an unpaired overhang of at least 5 nucleotides. In another embodiment, each NA comprises an unpaired overhang of at least 6 nucleotides. In an embodiment, the nucleotides of the overhang are connected via phosphorothioate linkages.
- each NA is selected from the group consisting of: DNA, siRNAs, antagomiRs, miRNAs, gapmers, mixmers, or guide RNAs.
- each NA is a DNA.
- each NA is a siRNA.
- each NA is an antagomiR.
- each NA is a miRNA.
- each NA is a gapmer.
- each NA is a mixmer.
- each NA independently, is a guide RNA.
- each NA is the same. In an embodiment, each NA is not the same.
- the delivery system further comprising n therapeutic nucleic acids (NA) has a structure selected from formulas (I), (II), (III), (IV), (Y), (VI), and embodiments thereof described herein.
- the delivery system has a structure selected from formulas (I), (II), (III), (IV), (Y), (VI), and embodiments thereof described herein further comprising 2 therapeutic nucleic acids (NA).
- the delivery system has a structure selected from formulas (I), (II), (III), (IV), (V), (VI), and embodiments thereof described herein further comprising 3 therapeutic nucleic acids (NA).
- the delivery system has a structure selected from formulas (I), (II), (III), (IV), (Y), (VI), and embodiments thereof described herein further comprising 4 therapeutic nucleic acids (NA). In one embodiment, the delivery system has a structure selected from formulas (I), (II), (III), (IV), (Y), (VI), and embodiments thereof described herein further comprising 5 therapeutic nucleic acids (NA). In one embodiment, the delivery system has a structure selected from formulas (I), (II), (III), (IV), (Y), (VI), and embodiments thereof described herein further comprising 6 therapeutic nucleic acids (NA).
- the delivery system has a structure selected from formulas (I), (II), (III), (IV), (Y), (VI), and embodiments thereof described herein further comprising 7 therapeutic nucleic acids (NA). In one embodiment, the delivery system has a structure selected from formulas (I),
- the delivery system has a structure selected from formulas (I), (II),
- the delivery system has a structure selected from formulas (I), (II), (III),
- the delivery system has a structure selected from formulas (I), (II), (III), (IV), (Y), (VI), further comprising a linker of structure L2 wherein R is R3 and n is 2.
- compositions and Methods of Administration comprising a therapeutically effective amount of one or more compound, oligonucleotide, or nucleic acid as described herein, and a pharmaceutically acceptable carrier.
- the pharmaceutical composition comprises one or more double-stranded, chemically-modified nucleic acid as described herein, and a pharmaceutically acceptable carrier.
- the pharmaceutical composition comprises one double-stranded, chemically-modified nucleic acid as described herein, and a pharmaceutically acceptable carrier.
- the pharmaceutical composition comprises two double-stranded, chemically-modified nucleic acids as described herein, and a pharmaceutically acceptable carrier.
- the pharmaceutical composition comprises a double-stranded RNA molecule comprising about 15-35 nucleotides complementary to a region of a gene encoding a heterozygous SNP mutant protein, said region comprising an allelic polymorphism, and a second strand comprising about 15-35 nucleotides complementary to the first strand, wherein the dsRNA molecule comprises a mismatch that is not in the position of the allelic polymorphism; and the mismatch and the nucleotide corresponding to the polymorphism are not in the center of the dsRNA molecule.
- the mismatch is 4 nucleotides upstream, 3 nucleotides upstream nucleotide corresponding to the allelic polymorphism, 2 nucleotides upstream nucleotide corresponding to the allelic polymorphism, 1 nucleotide upstream, 1 nucleotide downstream nucleotide corresponding to the allelic polymorphism, 2 nucleotides downstream nucleotide corresponding to the allelic polymorphism, 3 nucleotides downstream nucleotide corresponding to the allelic polymorphism, 4 nucleotides downstream nucleotide corresponding to the allelic polymorphism, or 5 nucleotides downstream nucleotide corresponding to the allelic polymorphism.
- the mismatch is not adjacent to the nucleotide corresponding to the allelic polymorphism.
- the double-stranded RNA comprises a nucleotide corresponding to the allelic polymorphism which is in position 2, 3, 4, 5, or 6 from the 5’ end.
- the nucleotide corresponding to the allelic polymorphism is in position 2 from the 5’ end.
- the nucleotide corresponding to the allelic polymorphism is in position 3 from the 5’ end.
- the nucleotide corresponding to the allelic polymorphism is in position 4 from the 5’ end.
- the nucleotide corresponding to the allelic polymorphism is in position 5 from the 5’ end.
- the nucleotide corresponding to the allelic polymorphism is in position 6 from the 5’ end.
- the double-stranded RNA selectively silences a mutant allele having an allelic polymorphism, e.g., a heterozygous SNP.
- the double-stranded RNA silences a mutant allele having an allelic polymorphism and does not affect the wild-type allele of the same gene.
- the double-stranded RNA provided herein silences a mutant allele having an allelic polymorphism and silences the wild-type allele of the same gene to a lesser extent than the mutant allele.
- a pharmaceutical composition of the invention is formulated to be compatible with its intended route of administration.
- routes of administration include parenteral, e.g., intravenous (IV), intradermal, subcutaneous (SC or SQ), intraperitoneal, intramuscular, oral (e.g., inhalation), transdermal (topical), and transmucosal administration.
- Solutions or suspensions used for parenteral, intradermal, or subcutaneous application can include the following components: a sterile diluent such as water for injection, saline solution, fixed oils, polyethylene glycols, glycerine, propylene glycol or other synthetic solvents; antibacterial agents such as benzyl alcohol or methyl parabens; antioxidants such as ascorbic acid or sodium bisulfite; chelating agents such as ethylenediaminetetraacetic acid; buffers such as acetates, citrates or phosphates and agents for the adjustment of tonicity such as sodium chloride or dextrose. pH can be adjusted with acids or bases, such as hydrochloric acid or sodium hydroxide.
- the parenteral preparation can be enclosed in ampoules, disposable syringes or multiple dose vials made of glass or plastic.
- compositions suitable for injectable use include sterile aqueous solutions (where water soluble) or dispersions and sterile powders for the extemporaneous preparation of sterile injectable solutions or dispersion.
- suitable carriers include physiological saline, bacteriostatic water, Cremophor ELTM (BASF, Parsippany, N.J.) or phosphate buffered saline (PBS).
- the composition must be sterile and should be fluid to the extent that easy syringability exists. It must be stable under the conditions of manufacture and storage and must be preserved against the contaminating action of microorganisms such as bacteria and fungi.
- the carrier can be a solvent or dispersion medium containing, for example, water, ethanol, polyol (for example, glycerol, propylene glycol, and liquid polyethylene glycol, and the like), and suitable mixtures thereof.
- the proper fluidity can be maintained, for example, by the use of a coating such as lecithin, by the maintenance of the required particle size in the case of dispersion and by the use of surfactants.
- Prevention of the action of microorganisms can be achieved by various antibacterial and antifungal agents, for example, parabens, chlorobutanol, phenol, ascorbic acid, thimerosal, and the like.
- isotonic agents for example, sugars, polyalcohols such as mannitol, sorbitol, sodium chloride in the composition.
- Prolonged absorption of the injectable compositions can be brought about by including in the composition an agent which delays absorption, for example, aluminum monostearate and gelatin.
- Sterile injectable solutions can be prepared by incorporating the active compound in the required amount in an appropriate solvent with one or a combination of ingredients enumerated above, as required, followed by fdtered sterilization.
- dispersions are prepared by incorporating the active compound into a sterile vehicle which contains a basic dispersion medium and the required other ingredients from those enumerated above.
- typical methods of preparation are vacuum drying and freeze-drying which yields a powder of the active ingredient plus any additional desired ingredient from a previously sterile-filtered solution thereof.
- the dosage of such compounds should typically lie within a range of circulating concentrations that include the ED50 with little or no toxicity.
- the dosage may vary within this range depending upon the dosage form employed and the route of administration utilized.
- the therapeutically effective dose can be estimated initially from cell culture assays.
- a dose may be formulated in animal models to achieve a circulating plasma concentration range that includes the EC50 (i.e., the concentration of the test compound which achieves a half-maximal response) as determined in cell culture.
- EC50 i.e., the concentration of the test compound which achieves a half-maximal response
- levels in plasma may be measured, for example, by high performance liquid chromatography.
- the present invention provides for both prophylactic and therapeutic methods of treating a subject at risk of (or susceptible to) a disease or disorder caused, in whole or in part, by an allelic polymorphism (e.g., a heterozygous SNP).
- a disease or disorder is a trinucleotide repeat disease or disorder.
- the disease or disorder is a polyglutamine disorder.
- the methods comprise administering a therapeutically effective amount of a double-stranded RNA molecule provided herein.
- the disease or disorder is a disorder associated with the expression of huntingtin and in which alteration of huntingtin, especially the amplification of CAG repeat copy number, leads to a defect in the huntingtin gene (structure or function) or huntingtin protein (structure or function or expression), such that clinical manifestations include those seen in Huntington’s disease patients.
- the double-stranded RNAs disclosed herein are homologous to an allelic polymorphism except for one mismatched oligonucleotide at a particular position relative to the nucleotide corresponding to the allelic polymorphism.
- the mismatch is within about 6 nucleotides of the nucleotide corresponding to the allelic polymorphism, within about 5 nucleotides of the nucleotide corresponding to the allelic polymorphism, within about 4 nucleotides of the nucleotide corresponding to the allelic polymorphism within about 3 nucleotide of the nucleotide corresponding to the allelic polymorphism, within about 2 nucleotide of the nucleotide corresponding to the allelic polymorphism, or within about 1 nucleotides of the nucleotide corresponding to the allelic polymorphism.
- the mismatch is not adjacent to the nucleotide corresponding to the allelic polymorphism.
- the double-stranded RNA comprises a nucleotide corresponding to the allelic polymorphism which is in position 2, 3, 4, 5, or 6 from the 5’ end. In an embodiment, the nucleotide corresponding to the allelic polymorphism is in position 2 from the 5’ end. In an embodiment, the nucleotide corresponding to the allelic polymorphism is in position
- nucleotide corresponding to the allelic polymorphism is in position 4 from the 5’ end. In an embodiment, the nucleotide corresponding to the allelic polymorphism is in position 5 from the 5’ end. In an embodiment, the nucleotide corresponding to the allelic polymorphism is in position 6 from the 5’ end.
- the dsRNA comprises a nucleotide corresponding to a polymorphism at position 6 from the 5’ end and a mismatch at position 11 from the 5’ end. In an embodiment of the methods, the dsRNA comprises a nucleotide corresponding to a polymorphism at position 4 from the 5’ end and a mismatch at position 7 from the 5’ end.
- the double-stranded RNA selectively silences a mutant allele having an allelic polymorphism.
- the double-stranded RNA silences a mutant allele having an allelic polymorphism and does not affect the wild-type allele of the same gene.
- the double-stranded RNA silences a mutant allele having an allelic polymorphism and silences the wild-type allele of the same gene to a lesser extent than the mutant allele.
- the dsRNA comprises one or more YP intersubunit linkage modifications wherein the intersubunit linkage has the following formula:
- the dsRNA comprises one or more of the intersubunit linkage modifications depicted in FIG. 43.
- “Treatment,” or“treating,” as used herein is defined as the application or administration of a therapeutic agent (e.g., a RNA agent or vector or transgene encoding same) to a patient, or application or administration of a therapeutic agent to an isolated tissue or cell line from a patient, who has the disease or disorder, a symptom of disease or disorder or a predisposition toward a disease or disorder, with the purpose to cure, heal, alleviate, relieve, alter, remedy, ameliorate, improve or affect the disease or disorder, the symptoms of the disease or disorder, or the predisposition toward disease.
- a therapeutic agent e.g., a RNA agent or vector or transgene encoding same
- the invention provides a method for preventing in a subject, a disease or disorder as described above, by administering to the subject a therapeutic agent (e.g., an RNAi agent or vector or transgene encoding same).
- a therapeutic agent e.g., an RNAi agent or vector or transgene encoding same.
- Subjects at risk for the disease can be identified by, for example, any or a combination of diagnostic or prognostic assays as described herein.
- Administration of a prophylactic agent can occur prior to the manifestation of symptoms characteristic of the disease or disorder, such that the disease or disorder is prevented or, alternatively, delayed in its progression.
- the modulatory method of the invention involves contacting a cell expressing a gain-of-function mutant with a therapeutic agent (e.g., a RNAi agent or vector or transgene encoding same) that is specific for one or more target sequences within the gene, such that sequence specific interference with the gene is achieved.
- a therapeutic agent e.g., a RNAi agent or vector or transgene encoding same
- These methods can be performed in vitro (e.g., by culturing the cell with the agent) or, alternatively, in vivo (e.g., by administering the agent to a subject).
- RNA silencing agent modified for enhanced uptake into neural cells can be administered at a unit dose less than about 1.4 mg per kg of bodyweight, or less than 10, 5, 2, 1, 0.5, 0.1, 0.05, 0.01, 0.005, 0.001, 0.0005, 0.0001, 0.00005 or 0.00001 mg per kg of bodyweight, and less than 200 nmole of RNA agent (e.g., about 4.4 x 10 16 copies) per kg of bodyweight, or less than 1500, 750, 300, 150, 75, 15, 7.5, 1.5, 0.75, 0.15, 0.075, 0.015, 0.0075, 0.0015, 0.00075 or 0.00015 nmole of RNA silencing agent per kg of bodyweight.
- RNA agent e.g., about 4.4 x 10 16 copies
- the unit dose for example, can be administered by injection (e.g., intravenous or intramuscular, intrathecally, or directly into the brain), an inhaled dose, or a topical application.
- dosages are less than 2, 1 or 0.1 mg/kg of body weight.
- Delivery of an RNA silencing agent directly to an organ can be at a dosage on the order of about 0.00001 mg to about 3 mg per organ, or about 0.0001-0.001 mg per organ, about 0.03-3.0 mg per organ, about 0.1 -3.0 mg per organ or about 0.3-3.0 mg per organ.
- the dosage can be an amount effective to treat or prevent a neurological disease or disorder (e.g., Huntington’s disease).
- a neurological disease or disorder e.g., Huntington’s disease.
- the unit dose is administered less frequently than once a day, e.g., less than every 2, 4, 8 or 30 days.
- the unit dose is not administered with a frequency (e.g., not a regular frequency).
- the unit dose may be administered a single time.
- the effective dose is administered with other traditional therapeutic modalities.
- a subject is administered an initial dose, and one or more maintenance doses of an RNA silencing agent.
- the maintenance dose or doses are generally lower than the initial dose, e.g., one-half less of the initial dose.
- a maintenance regimen can include treating the subject with a dose or doses ranging from 0.01 pg to 1.4 mg/kg of body weight per day, e.g., 10, 1, 0.1, 0.01, 0.001, or 0.00001 mg per kg of bodyweight per day.
- the maintenance doses are typically administered no more than once every 5, 10, or 30 days. Further, the treatment regimen may last for a period of time which will vary depending upon the nature of the particular disease, its severity and the overall condition of the patient.
- the dosage may be delivered no more than once per day, e.g., no more than once per 24, 36, 48 or more hours, e.g., no more than once every 5 or 8 days.
- the patient can be monitored for changes in his condition and for alleviation of the symptoms of the disease state.
- the dosage of the compound may either be increased in the event the patient does not respond significantly to current dosage levels, or the dose maybe decreased if an alleviation of the symptoms of the disease state is observed, if the disease state has been ablated, or if undesired side-effects are observed.
- RNA silencing agents are designed to target polymorphisms (e.g., heterozygous single nucleotide polymorphisms) in the mutant human huntingtin protein (htt) for the treatment of Huntington’s disease.
- htt human huntingtin protein
- a method of treating or managing Huntington’s disease comprising administering to a patient in need of such treatment or management a therapeutically effective amount of a compound, oligonucleotide, or nucleic acid as described herein, or a pharmaceutical composition comprising said compound, oligonucleotide, or nucleic acid.
- Huntington’s disease inherited as an autosomal dominant disease, causes impaired cognition and motor disease. Patients can live more than a decade with severe debilitation, before premature death from starvation or infection. The disease begins in the fourth or fifth decade for most cases, but a subset of patients manifest disease in teenage years.
- the genetic mutation for Huntington’s disease is a lengthened CAG repeat in the huntingtin gene. The CAG repeat varies in number from 8 to 35 copies in normal individuals (Kremer et ah, 1994).
- the genetic mutation (e.g., an increase in length of the CAG repeats from less than 36 in the normal huntingtin gene to greater than 36 in the disease) is associated with the synthesis of a mutant huntingtin protein, which has greater than 36 consecutive polyglutamine residues (Aronin et ah, 1995).
- individuals with 36 or more CAG repeats will get Huntington's disease.
- Prototypic for as many as twenty other diseases with a lengthened CAG as the underlying mutation, Huntington’s disease still has no effective therapy.
- a variety of interventions—such as interruption of apoptotic pathways, addition of reagents to boost mitochondrial efficiency, and blockade of NMDA receptors— have shown promise in cell cultures and mouse model of Huntington’s disease.
- the disease gene linked to Huntington’s disease is termed Huntingtin or ( htt ).
- the huntingtin locus is large, spanning 180 kb and consisting of 67 exons.
- the huntingtin gene is widely expressed and is required for normal development. It is expressed as 2 alternatively polyadenylated forms displaying different relative abundance in various fetal and adult tissues.
- the larger transcript is approximately 13.7 kb and is expressed predominantly in adult and fetal brain whereas the smaller transcript of approximately 10.3 kb is more widely expressed.
- the two transcripts differ with respect to their 3' untranslated regions (Lin et ah, 1993). Both messages are predicted to encode a 348 kilodalton protein containing 3144 amino acids.
- the genetic defect leading to Huntington’s disease is believed to confer a new property on the mRNA or alter the function of the protein.
- Huntington’s disease complies with the central dogma of genetics: a mutant gene serves as a template for production of a mutant mRNA; the mutant mRNA then directs synthesis of a mutant protein (Aronin et ah, 1995; DiFiglia et ah, 1997). Mutant huntingtin (protein) likely accumulates in selective neurons in the striatum and cortex, disrupts as yet determined cellular activities, and causes neuronal dysfunction and death (Aronin et ah, 1999; Laforet et ah, 2001). Because a single copy of a mutant gene suffices to cause Huntington’s disease, the most parsimonious treatment would render the mutant gene ineffective. Theoretical approaches might include stopping gene transcription of mutant huntingtin, destroying mutant mRNA, and blocking translation. Each has the same outcome— loss of mutant huntingtin.
- Exemplary SNPs in the huntingtin gene sequence suitable for targeting according to certain exemplary embodiments are disclosed in Table 4 below.
- Genomic sequence for each SNP site can be found in, for example, the publicly available“SNP Entrez” database maintained by the NCBI.
- the frequency of heterozygosity for each SNP site for HD patient and control DNA is further illustrated in Table 4. Targeting combinations of frequently heterozygous SNPs allows the treatment of a large percentage of the individuals in a HD population using a relatively small number of allele-specific RNA silencing agents.
- RNA silencing agents of the invention are capable of targeting one or more of the SNP sites listed in Table 4. In one embodiment, RNA silencing agents of the invention are capable of targeting rs363l25 SNP site of the Huntingtin mRNA. In another embodiment, RNA silencing agents of the invention are capable of targeting rs362273 SNP site of the Huntingtin mRNA. In another embodiment, RNA silencing agents of the invention are capable of targeting rs362307 SNP site of the Huntingtin mRNA. In another embodiment, RNA silencing agents of the invention are capable of targeting rs362336 SNP site of the Huntingtin mRNA.
- RNA silencing agents of the invention are capable of targeting rs362331 SNP site of the Huntingtin mRNA. In another embodiment, RNA silencing agents of the invention are capable of targeting rs362272 SNP site of the Huntingtin mRNA. In another embodiment, RNA silencing agents of the invention are capable of targeting rs362306 SNP site of the Huntingtin mRNA. In another embodiment, RNA silencing agents of the invention are capable of targeting rs362268 SNP site of the Huntingtin mRNA. In another embodiment, RNA silencing agents of the invention are capable of targeting rs362267 SNP site of the Huntingtin mRNA.
- RNA silencing agents of the invention are capable of targeting rs363099 SNP site of the Huntingtin mRNA.
- SNP sites targeted by RNA silencing agents are associated with Huntington’s Disease.
- SNP sites targeted by RNA silencing agents are significantly associated with Huntington’s Disease.
- RNA silencing agents include one or more of the sequences of Tables 5-7:
- RNA silencing agents of the invention may be directly introduced into a cell (e.g., a neural cell) (i.e., intracellular ly); or introduced extracellularly into a cavity, interstitial space, into the circulation of an organism, introduced orally, or may be introduced by bathing a cell or organism in a solution containing the nucleic acid.
- a cell e.g., a neural cell
- intracellular ly i.e., intracellular ly
- extracellularly into a cavity, interstitial space, into the circulation of an organism, introduced orally, or may be introduced by bathing a cell or organism in a solution containing the nucleic acid.
- vascular or extravascular circulation, the blood or lymph system, and the cerebrospinal fluid are sites where the nucleic acid may be introduced.
- RNA silencing agents of the invention can be introduced using nucleic acid delivery methods known in art including injection of a solution containing the nucleic acid, bombardment by particles covered by the nucleic acid, soaking the cell or organism in a solution of the nucleic acid, or electroporation of cell membranes in the presence of the nucleic acid.
- nucleic acid delivery methods known in art including injection of a solution containing the nucleic acid, bombardment by particles covered by the nucleic acid, soaking the cell or organism in a solution of the nucleic acid, or electroporation of cell membranes in the presence of the nucleic acid.
- Other methods known in the art for introducing nucleic acids to cells may be used, such as lipid-mediated carrier transport, chemical- mediated transport, and cationic liposome transfection such as calcium phosphate, and the like.
- the nucleic acid may be introduced along with other components that perform one or more of the following activities: enhance nucleic acid uptake by the cell or other wise increase inhibition of the
- RNA may be introduced along with components that perform one or more of the following activities: enhance RNA uptake by the cell, inhibit annealing of single strands, stabilize the single strands, or other-wise increase inhibition of the target gene.
- RNA may be directly introduced into the cell (i.e., intracellularly), or introduced extracellularly into a cavity, interstitial space, into the circulation of an organism, introduced orally, or may be introduced by bathing a cell or organism in a solution containing the RNA.
- Vascular or extravascular circulation, the blood or lymph system, and the cerebrospinal fluid are sites where the RNA may be introduced.
- the cell having the target gene may be from the germ line or somatic, totipotent or pluripotent, dividing or non-dividing, parenchyma or epithelium, immortalized or transformed, or the like.
- the cell may be a stem cell or a differentiated cell.
- Cell types that are differentiated include adipocytes, fibroblasts, myocytes, cardiomyocytes, endothelium, neurons, glia, blood cells, megakaryocytes, lymphocytes, macrophages, neutrophils, eosinophils, basophils, mast cells, leukocytes, granulocytes, keratinocytes, chondrocytes, osteoblasts, osteoclasts, hepatocytes, and cells of the endocrine or exocrine glands.
- this process may provide partial or complete loss of function for the target gene.
- a reduction or loss of gene expression in at least 50%, 60%, 70%, 80%, 90%, 95% or 99% or more of targeted cells is exemplary.
- Inhibition of gene expression refers to the absence (or observable decrease) in the level of protein and/or mRNA product from a target gene. Specificity refers to the ability to inhibit the target gene without manifest effects on other genes of the cell.
- RNA solution hybridization nuclease protection, Northern hybridization, reverse transcription, gene expression monitoring with a microarray, antibody binding, enzyme linked immunosorbent assay (ELISA), Western blotting, radioimmunoassay (RIA), other immunoassays, fluorescence activated cell analysis (FACS) and the like.
- biochemical techniques such as RNA solution hybridization, nuclease protection, Northern hybridization, reverse transcription, gene expression monitoring with a microarray, antibody binding, enzyme linked immunosorbent assay (ELISA), Western blotting, radioimmunoassay (RIA), other immunoassays, fluorescence activated cell analysis (FACS) and the like.
- RNA-mediated inhibition in a cell line or whole organism gene expression is conveniently assayed by use of a reporter or drug resistance gene whose protein product is easily assayed.
- reporter genes include acetohydroxyacid synthase (AHAS), alkaline phosphatase (AP), beta galactosidase (LacZ), beta glucoronidase (GUS), chloramphenicol acetyltransferase (CAT), green fluorescent protein (GFP), horseradish peroxidase (HRP), luciferase (Luc), nopaline synthase (NOS), octopine synthase (OCS), and derivatives thereof.
- AHAS acetohydroxyacid synthase
- AP alkaline phosphatase
- LacZ beta galactosidase
- GUS beta glucoronidase
- CAT chloramphenicol acetyltransferase
- GFP green fluorescent protein
- HRP horserad
- RNAi agent Multiple selectable markers are available that confer resistance to ampicillin, bleomycin, chloramphenicol, gentarnycin, hygromycin, kanamycin, lincomycin, methotrexate, phosphinothricin, puromycin, and tetracyclin.
- quantitation of the amount of gene expression allows one to determine a degree of inhibition which is greater than 10%, 33%, 50%, 90%, 95% or 99% as compared to a cell not treated according to the present invention.
- Lower doses of injected material and longer times after administration of RNAi agent may result in inhibition in a smaller fraction of cells (e.g., at least 10%, 20%, 50%, 75%, 90%, or 95% of targeted cells).
- Quantization of gene expression in a cell may show similar amounts of inhibition at the level of accumulation of target mRNA or translation of target protein.
- the efficiency of inhibition may be determined by assessing the amount of gene product in the cell.
- mRNA may be detected with a hybridization probe having a nucleotide sequence outside the region used for the inhibitory double-stranded RNA, or translated polypeptide may be detected with an antibody raised against the polypeptide sequence of that region.
- the RNA may be introduced in an amount which allows delivery of at least one copy per cell. Higher doses (e.g., at least 5, 10, 100, 500 or 1000 copies per cell) of material may yield more effective inhibition; lower doses may also be useful for specific applications.
- an RNAi agent of the invention e.g., an siRNA targeting a polymorphism in a mutant gene
- an RNAi agent of the invention is tested for its ability to specifically degrade mutant mRNA (e.g., mutant htt mRNA and/or the production of mutant huntingtin protein) in cells, in particular, in neurons (e.g., striatal or cortical neuronal clonal lines and/or primary neurons).
- mutant mRNA e.g., mutant htt mRNA and/or the production of mutant huntingtin protein
- cells in particular, in neurons (e.g., striatal or cortical neuronal clonal lines and/or primary neurons).
- cells e.g., striatal or cortical neuronal clonal lines and/or primary neurons.
- Other readily transfectable cells for example, HeLa cells or COS cells.
- Cells are transfected with human wild-type or mutant cDNAs (e.g., human
- Standard siRNA, modified siRNA or vectors able to produce siRNA from U-looped mRNA are co-transfected.
- Selective reduction in mutant mRNA (e.g., mutant huntingtin mRNA) and/or mutant protein (e.g., mutant huntingtin) is measured.
- Reduction of mutant mRNA or protein can be compared to levels of normal mRNA or protein.
- Exogenously-introduced normal mRNA or protein (or endogenous normal mRNA or protein) can be assayed for comparison purposes.
- RNAi agents e.g., siRNAs
- a composition that includes an RNA agent, e.g., a dsRNA agent, of the invention can be delivered to the nervous system of a subject by a variety of routes.
- routes include intrathecal, parenchymal (e.g., in the brain), nasal, and ocular delivery.
- the composition can also be delivered systemically, e.g., by intravenous, subcutaneous or intramuscular injection, which is particularly useful for delivery of the RNA agents, e.g., dsRNA agents, to peripheral neurons.
- An exemplary route of delivery is directly to the brain, e.g., into the ventricles or the hypothalamus of the brain, or into the lateral or dorsal areas of the brain.
- compositions can include one or more species of an RNA agent, e.g., a dsRNA agent, and a pharmaceutically acceptable carrier.
- the pharmaceutical compositions of the present invention may be administered in a number of ways depending upon whether local or systemic treatment is desired and upon the area to be treated. Administration may be topical (including ophthalmic, intranasal, transdermal), oral or parenteral. Parenteral administration includes intravenous drip, subcutaneous, intraperitoneal or intramuscular injection, intrathecal, or intraventricular (e.g., intracerebroventricular) administration.
- an RNA silencing agent of the invention is delivered across the Blood-Brain-Barrier (BBB) suing a variety of suitable compositions and methods described herein.
- BBB Blood-Brain-Barrier
- the route of delivery can be dependent on the disorder of the patient.
- a subject diagnosed with Huntington’s disease can be administered an anti-htt RNA agent, e.g., a dsRNA agent, of the invention directly into the brain (e.g., into the globus pallidus or the corpus striatum of the basal ganglia, and near the medium spiny neurons of the corpus striatum).
- a patient can be administered a second therapy, e.g., a palliative therapy and/or disease-specific therapy.
- the secondary therapy can be, for example, symptomatic (e.g., for alleviating symptoms), neuroprotective (e.g., for slowing or halting disease progression), or restorative (e.g., for reversing the disease process).
- symptomatic therapies can include the drugs haloperidol, carbamazepine, or valproate.
- Other therapies can include psychotherapy, physiotherapy, speech therapy, communicative and memory aids, social support services, and dietary advice.
- RNA agent e.g., a dsRNA agent
- a pharmaceutical composition containing an RNA agent e.g., a dsRNA agent
- the pharmaceutical composition can be delivered by injection directly into the brain.
- the injection can be by stereotactic injection into a particular region of the brain (e.g., the substantia nigra, cortex, hippocampus, striatum, or globus pallidus).
- the RNA agent e.g., a dsRNA agent
- the RNA agent e.g., a dsRNA agent
- the RNA agent e.g., a dsRNA agent
- a cannula or other delivery device having one end implanted in a tissue, e.g., the brain, e.g., the substantia nigra, cortex, hippocampus, striatum or globus pallidus of the brain.
- the cannula can be connected to a reservoir of RNA agent, e.g., dsRNA agent.
- the flow or delivery can be mediated by a pump, e.g., an osmotic pump or minipump, such as an Alzet pump (Durect, Cupertino, CA).
- a pump and reservoir are implanted in an area distant from the tissue, e.g., in the abdomen, and delivery is effected by a conduit leading from the pump or reservoir to the site of release.
- Delivery is effected by a conduit leading from the pump or reservoir to the site of release.
- Devices for delivery to the brain are described, for example, in U.S. Pat. Nos. 6,093,180, and 5,814,014.
- RNA agent e.g., a dsRNA agent
- an RNA agent can be further modified such that it is capable of traversing the blood brain barrier.
- the RNA agent e.g., a dsRNA agent
- modified RNA agents e.g., dsRNA agents
- exosomes are used to deliver an RNA agent, e.g., a dsRNA agent, of the invention.
- Exosomes can cross the BBB and deliver siRNAs, antisense oligonucleotides, chemotherapeutic agents and proteins specifically to neurons after systemic injection (See, Alvarez-Erviti L, Seow Y, Yin H, Betts C, Lakhal S, Wood MJ. (2011). Delivery of siRNA to the mouse brain by systemic injection of targeted exosomes. Nat Biotechnol. 2011 Apr;29(4):34l-5. doi: l0.
- one or more lipophilic molecules are used to allow delivery of an RNA agent, e.g., a dsRNA agent, of the invention past the BBB (Alvarez-Ervit (2011)).
- the RNA silencing agent would then be activated, e.g., by enzyme degradation of the lipophilic disguise to release the drug into its active form.
- one or more receptor-mediated permeabilizing compounds can be used to increase the permeability of the BBB to allow delivery of an RNA silencing agent of the invention.
- These drugs increase the permeability of the BBB temporarily by increasing the osmotic pressure in the blood which loosens the tight junctions between the endothelial cells ((El- Andaloussi (2012)). By loosening the tight junctions normal intravenous injection of an RNA silencing agent can be performed.
- nanoparticle-based delivery systems are used to deliver an RNA agent, e.g., a dsRNA agent, of the invention across the BBB.
- RNA agent e.g., a dsRNA agent
- nanoparticles refer to polymeric nanoparticles that are typically solid, biodegradable, colloidal systems that have been widely investigated as drug or gene carriers (S. P. Egusquiaguirre, M. Igartua, R. M. Hernandez, and J. L. Pedraz,“Nanoparticle delivery systems for cancer therapy: advances in clinical and preclinical research,” Clinical and Translational Oncology, vol. 14, no. 2, pp. 83-93, 2012).
- Natural polymers for siRNA delivery include, but are not limited to, cyclodextrin, chitosan, and atelocollagen (Y. Wang, Z. Li, Y. Han, L. H. Liang, and A. Ji,“Nanoparticle-based delivery system for application of siRNA in vivo,” Current Drug Metabolism, vol. 11, no. 2, pp. 182-196, 2010).
- Synthetic polymers include, but are not limited to, polyethyleneimine (PEI), poly(dl-lactide-co-glycolide) (PLGA), and dendrimers, which have been intensively investigated (X. Yuan, S. Naguib, and Z.
- RNA agent e.g., a dsRNA agent
- an RNA agent can be administered ocularly, such as to treat retinal disorder, e.g., a retinopathy.
- the pharmaceutical compositions can be applied to the surface of the eye or nearby tissue, e.g., the inside of the eyelid. They can be applied topically, e.g., by spraying, in drops, as an eyewash, or an ointment. Ointments or droppable liquids may be delivered by ocular delivery systems known in the art such as applicators or eye droppers.
- compositions can include mucomimetics such as hyaluronic acid, chondroitin sulfate, hydroxypropyl methylcellulose or poly( vinyl alcohol), preservatives such as sorbic acid, EDTA or benzyl chronium chloride, and the usual quantities of diluents and/or carriers.
- the pharmaceutical composition can also be administered to the interior of the eye, and can be introduced by a needle or other delivery device which can introduce it to a selected area or structure.
- the composition containing the RNA silencing agent can also be applied via an ocular patch.
- an RNA agent e.g., a dsRNA agent
- topical delivery can refer to the direct application of an RNA agent, e.g., a dsRNA agent, to any surface of the body, including the eye, a mucous membrane, surfaces of a body cavity, or to any internal surface.
- Formulations for topical administration may include transdermal patches, ointments, lotions, creams, gels, drops, sprays, and liquids. Conventional pharmaceutical carriers, aqueous, powder or oily bases, thickeners and the like may be necessary or desirable.
- Topical administration can also be used as a means to selectively deliver the RNA agent, e.g., a dsRNA agent, to the epidermis or dermis of a subject, or to specific strata thereof, or to an underlying tissue.
- compositions for intrathecal or intraventricular (e.g., intracerebroventricular) administration may include sterile aqueous solutions which may also contain buffers, diluents and other suitable additives.
- Compositions for intrathecal or intraventricular administration typically do not include a transfection reagent or an additional lipophilic moiety besides, for example, the lipophilic moiety attached to the RNA agent, e.g., a dsRNA agent.
- Formulations for parenteral administration may include sterile aqueous solutions which may also contain buffers, diluents and other suitable additives.
- Intraventricular injection may be facilitated by an intraventricular catheter, for example, attached to a reservoir.
- the total concentration of solutes should be controlled to render the preparation isotonic.
- RNA agent e.g., a dsRNA agent
- Pulmonary delivery compositions can be delivered by inhalation of a dispersion so that the composition within the dispersion can reach the lung where it can be readily absorbed through the alveolar region directly into blood circulation. Pulmonary delivery can be effective both for systemic delivery and for localized delivery to treat diseases of the lungs.
- an RNA agent e.g., a dsRNA agent, administered by pulmonary delivery has been modified such that it is capable of traversing the blood brain barrier.
- Pulmonary delivery can be achieved by different approaches, including the use of nebulized, aerosolized, micellular and dry powder-based formulations. Delivery can be achieved with liquid nebulizers, aerosol-based inhalers, and dry powder dispersion devices. Metered-dose devices are exemplary. One of the benefits of using an atomizer or inhaler is that the potential for contamination is minimized because the devices are self-contained. Dry powder dispersion devices, for example, deliver drugs that may be readily formulated as dry powders. An RNA silencing agent composition may be stably stored as lyophilized or spray-dried powders by itself or in combination with suitable powder carriers.
- the delivery of a composition for inhalation can be mediated by a dosing timing element which can include a timer, a dose counter, time measuring device, or a time indicator which when incorporated into the device enables dose tracking, compliance monitoring, and/or dose triggering to a patient during administration of the aerosol medicament.
- a dosing timing element which can include a timer, a dose counter, time measuring device, or a time indicator which when incorporated into the device enables dose tracking, compliance monitoring, and/or dose triggering to a patient during administration of the aerosol medicament.
- the types of pharmaceutical excipients that are useful as carriers include stabilizers such as human serum albumin (HSA), bulking agents such as carbohydrates, amino acids and polypeptides; pH adjusters or buffers; salts such as sodium chloride; and the like. These carriers may be in a crystalline or amorphous form or may be a mixture of the two.
- HSA human serum albumin
- bulking agents such as carbohydrates, amino acids and polypeptides
- pH adjusters or buffers such as sodium chloride
- salts such as sodium chloride
- Bulking agents that are particularly valuable include compatible carbohydrates, polypeptides, amino acids or combinations thereof.
- suitable carbohydrates include monosaccharides such as galactose, D-mannose, sorbose, and the like; disaccharides, such as lactose, trehalose, and the like; cyclodextrins, such as 2-hydroxypropyl-.beta.-cyclodextrin; and polysaccharides, such as raffinose, maltodextrins, dextrans, and the like; alditols, such as mannitol, xylitol, and the like.
- An exemplary group of carbohydrates includes lactose, trehalose, raffinose maltodextrins, and mannitol.
- Suitable polypeptides include aspartame.
- Amino acids include alanine and glycine, with glycine being exemplary.
- Suitable pH adjusters or buffers include organic salts prepared from organic acids and bases, such as sodium citrate, sodium ascorbate, and the like; sodium citrate is exemplary.
- RNA agent e.g., a dsRNA agent
- An RNA agent can be administered by oral and nasal delivery.
- drugs administered through these membranes have a rapid onset of action, provide therapeutic plasma levels, avoid first pass effect of hepatic metabolism, and avoid exposure of the drug to the hostile gastrointestinal (GI) environment. Additional advantages include easy access to the membrane sites so that the drug can be applied, localized and removed easily.
- an RNA silencing agent administered by oral or nasal delivery has been modified to be capable of traversing the blood-brain barrier.
- unit doses or measured doses of a composition that include RNA agents are dispensed by an implanted device.
- the device can include a sensor that monitors a parameter within a subject.
- the device can include a pump, such as an osmotic pump and, optionally, associated electronics.
- FIG. 46 is a flow chart illustrating a methodology for generating and selecting SNP- discriminating siRNAs that was implemented in the instance of HTT, but is also applicable to SNPs in other genes.
- a primary screen is conducted to determine which position the SNP is placed at causes the greatest discrimination. Then, the mismatch position(s) yielding best results are selected, and affinity for non-target alleles is further reduced in a secondary screening where chemical and structural optimizations to the siRNA molecule with improved selectivity and/or potency are selected.
- the psiCHECK reporter plasmid described herein contains SNP rs362273 and a partial flanking region from exon 57 of htt, within a Rluc 3’ UTR.
- the wild-type psiCHECK reporter plasmid contains the same region of htt without the SNP (FIG. 1).
- hsiRNAs Hydrophobically modified RNAs
- Huntingtin (htt) mRNA containing the mutant SNP (2273-1 (A)) were screened for efficacy with the psiCheck reporter plasmid system.
- the number following SNP represents the position of the SNP in the siRNA (FIG. 47).
- FIG. 2 shows that placing the SNP in position 2, 4 or 6 provided the greatest SNP discrimination, without losing efficacy against the mutant allele.
- HeLa cells transfected with one of two reporter plasmids were reverse transfected with 1.5 mM hsiRNAs by passive uptake, and treated for 72 hours. Luciferase activity was measured at 72 hours post transfection (FIG. 2).
- the hsiRNAs were further tested for allelic discrimination in a dose response dual luciferase assay in HeLa cells (FIG. 3). Multiple hsiRNAs preferentially silenced the reporter plasmid containing the mutant SNP as compared to the wild-type reporter plasmid. HeLa cells transfected with one of two reporter plasmids were reverse transfected with 1.5 mM hsiRNAs by passive uptake, and treated for 72 hours. Reporter plasmid expression was measured at 72 hours post transfection (FIG. 3).
- Example 2 SNP Discrimination in the Endogenous Htt mRNA
- FIG. 4 shows that two hsiRNAs, SNP4-0 and SNP6-0, were highly effective at silencing the htt mRNA containing the correct SNP.
- the mRNA levels were measured using Quantigene 2.0 bDNA assay after treating HeLa cells with hsiRNAs via passive uptake for 72 hours. Human htt mRNA levels were normalized to human HPRT.
- Example 3 Designing hsiRNAs with a Second Mismatch for Greater Allelic Discrimination
- a primary screen of the efficacy of the hsiRNAs in FIG. 12 showed that the position of the second mismatch, relative to the position of the nucleotide corresponding to the SNP, resulted in varying levels of SNP discrimination in HeLa cells.
- HeLa cells transfected with one of two psiCHECK reporter plasmids were reverse transfected with 1.5 mM hsiRNAs by passive uptake, and treated for 72 hours. Luciferase activity was measured at 72 hours post transfection.
- FIG. 5 shows that multiple hsiRNAs discriminately silenced the reporter plasmid containing the SNP mutation as compared to the wild-type reporter plasmid.
- hsiRNAs containing the second mismatch
- HeLa cells transfected with one of two reporter plasmids were reverse transfected with hsiRNAs by passive uptake, and treated for 72 hours. Reporter expression measured with a dual-luciferase assay.
- FIGs. 6-8 show the IC50 values of the hsiRNAs with two mismatches for silencing the reporter plasmid containing the SNP mutation versus the wild-type reporter plasmid.
- the SNP6-11 hsiRNA (hsiRNA molecule with the nucleotide corresponding to the polymorphism at position 6 from the 5’ end and the mismatch at position 11 from the 5’ end) and the SNP4-7 hsiRNA (hsiRNA molecule with the nucleotide corresponding to the polymorphism at position 4 from the 5’ end and the mismatch at position 7 from the 5’ end) were shown to be the most efficacious (see FIGs. 7-9). Surprisingly, altering the modification pattern around the SNP rescues efficacy lost by introducing the second mismatch without impairing discrimination.
- oligonucleotide types e.g., gapmers, mixmers, miRNA inhibitors, splice- switching oligonucleotides (“SSOs”), phosphorodiamidate morpholino oligonucleotides (“PMOs”), peptide nucleic acids (“PNAs”) and the like
- SSOs splice- switching oligonucleotides
- PMOs phosphorodiamidate morpholino oligonucleotides
- PNAs peptide nucleic acids
- an oligonucleotide described herein may be designed as a di-siRNA (see, e.g., FIG. 14).
- An oligonucleotide described herein may include one or more different backbone linkages (see, e.g., FIG. 15).
- An oligonucleotide described herein may include a variety of sugar modifications (see, e.g., FIG. 16).
- An oligonucleotide described herein may include a variety of intemucleotide bonds (see, e.g., FIG. 17).
- An oligonucleotide described herein may include one or more 5’ stabilization modifications (see, e.g., FIG. 18).
- An oligonucleotide described herein may include one or more conjugated moieties (see, e.g., FIG. 19). Illustrated in FIG. 35 are a number of exemplary oligonucleotide backbone modifications.
- An oligonucleotide described herein can effectively be used to target a G at the SNP site simply by changing the base at the SNP position.
- compound SNP6-11 was synthesized a second time, this time to target a G at the SNP site instead of an A. This allowed for selectively silencing either allele, a strategy that is very useful for patients with different heterozygosities at the same SNP site.
- one or more abasic nucleotides are utilized at an SNP position nucleotide, at a MM position nucleotide, at the 5' end, at the 3' end, or any combination of these.
- hsiRNAs are synthesized with varying sugar modifications around the mismatch to improve allele specificity, e.g., 2’FANA instead of 2’F; triple 2’F or triple 2’OMe around SNP/mismatch position.
- Example 5 HTT Mouse Model
- BAC97-HD refer to a transgenic mouse comprising a human bacterial artificial chromosome (BAC) transgenic insert containing the entire pathogenic 170 kb human Huntingtin (htt) genomic locus that was modified by replacing the human htt exon 1 with a loxP-flanked human mutant htt exon 1 sequence containing 97 mixed CAA-CAG repeats encoding a continuous polyglutamine (polyQ) stretch.
- BAC human bacterial artificial chromosome
- Lead compound (SNP6-11) was synthesized into the di-branched chemical scaffold having the structure illustrated in FIG. 31 and subsequently tested in vivo via 40 nmol bilateral intracerebro ventricular (ICY) injection (20nmols to each side) in BAC97-HD female mice at 8 weeks of age.
- the mice had two copies of normal mouse htt gene with a G at SNP rs362273 and a transgenic insert of pathogenic human htt gene with an A at SNP rs362273A.
- a nonsense sequence with no target matches in the RNA transcriptome was also synthesized into the same di- branched scaffold and injected in the mice as a negative control (NTC).
- FIG. 32A is a western blot performed on collected striatum tissue, and protein levels normalized to vinculin are presented in FIG. 32B.
- hsiRNAs Hydrophobically modified RNAs designed to be complimentary to the Huntingtin (htt) mRNA containing a U to G mismatch or a C to A mismatch in rs362273 were used. Both the 6- 11 hsiRNA complementary to a U to G mismatch and the 6-11 hsiRNA complementary to a C to A mismatch preferentially cleaved the target SNP (FIG. 20).
- anhydrous CH2CI2 (25 mL) solution containing CBr 4 (7.3 g, 22.1 mmol) was added PPI13 (11.6 g, 44.2 mmol) at 0 °C and stirred for 0.5 h at 0 °C.
- anhydrous CH2CI2 solution (25 mL) of compound 5a was added dropwise (10 min) at 0 °C and stirred for 2 h at 0 °C. After diluting with CH2CI2, the organic solution was washed by aq. sat. NH4CI, dried over MgS0 4 , filtered, and evaporated.
- FIG. 22 A representative synthesis of an oligonucleotide having a vinyl phosphinate modified intersubunit linkages is illustrated in FIG. 22. Examples of VP-modified sequences that were synthesized can be found in FIGS. 28A and 28B.
- RNA oligonucleotides having one vinyl phosphonate linkage was performed on MerMade 12 automated RNA synthesizer (BioAutomation) using 0.1 M anhydrous
- RNA phosphoramidite synthesis cycle which consists of (i) detritylation, (ii) coupling, (iii) capping, and (iv) iodine oxidation.
- RNA oligonucleotide synthesis cholesterol 3'-lcaa CPG 500 A (ChemGenes) was used, and RNA synthesis was conducted in the same condition as the condition used for VP-modified RNAs. After the chemical chain elongation, deprotection and cleavage from the solid support were conducted by NH 4 OH-EtOH (3: 1, v/v) for 48 hours at 26 °C. In the case of vinyl phosphonate modified
- RNA on solid support was first treated with TMSBr-pyridine-C ⁇ Ch (3: 1 : 18, v/v/v) for 1 h at ambient temperature in RNA synthesis column. Solid support was then washed by water (1 mL x 3), CH3CN (1 mL x 3) and CH2CI2 (1 mL x 3) by flowing solution thorough synthesis column, and then dried under vacuum. After transferring the solid support to screw-capped sample tube, base treatment by NH 4 OH-EtOH (3: 1, v/v) for 48 h at 26 °C was conducted.
- RNA oligonucleotide without cholesterol conjugate was purified by standard anion exchange HPLC, whereas RNAs with cholesterol-conjugate were purified by reversed-phase HPLC. Obtained all purified RNAs were desalted by Sephadex G-25 (GE Healthcare) and characterized by electrospray ionization mass spectrometry (ESI-MS) analysis.
- ESI-MS electrospray ionization mass spectrometry
- FIGS. 23 and 24 provide visual representations of the VP -modified siRNA studied herein.
- FIG. 25 exemplifies the effect that one or more vinyl phosphonate modifications in an intersubunit linkage at varying positions on the guide strand has on silencing. As can be seen from the data in FIG. 25, RISC is very sensitive to VP modification, and having a mismatch base pair at various positions can disrupt siRNA potency.
- FIGS. 26, 27A, and 27B also illustrate the ability of VP -modified siRNA to silence the mutant allele.
- adding a mismatch in the siRNA sequence could improve allelic discrimination without affecting mutant allele silencing.
- FIG. 30 demonstrates that the introduction of a VP -modified linkage next to the SNP site significantly enhanced target/non-target discrimination of SNP-selective siRNAs.
- Compounds containing primary (position 6) and secondary (position 11) SNPs were synthesized with or without a VP- modification between positions 5 and 6.
- the presence of a VP- modification had no impact on“on target” activity, but fully eliminated any detectable silencing for non-target mRNAs.
- the method for generating the data in FIGS. 25, 26, 27A, and 27B is described below.
- Example 10 Primary screen yields multiple efficacious siRNA sequences for SNP rs362307 heterozygosity
- siRNAs designed to be complimentary the the HTT mRNA containing an alternative mutant SNP (rs362307) (FIG. 39) were all screened with reporter plasmids containing the target region for the SNP of interest (FIG. 40).
- HeLa cells transfected with one of two reporter plasmids were reverse transfected with l .5uM hsiRNAs by passive uptake, and treated for 72 hours.
- the number following SNP represents the position of the SNP in the siRNA. It was expected that this SNP would be more difficult to target based on the high G/C content of the region around it.
- Example 11 When applied to SNP rs362307, a secondary mismatch continues to improve allelic discrimination
- Example 12 Measuring SNP discrimination in sequences including an SNP
- psiCHECK reporter plasmids containing either a wild-type region of htt or the same region of htt with the SNP of the sequence are prepared and tested using a dual-luciferase.
- HeLa cells transfected with one of two reporter plasmids are reverse transfected with hsiRNAs by passive uptake, and treated for 72 hours.
- Luciferase activities are measured in the assays with or without the additional mismatch, and are then plotted in dose response curves and compared to reveal sequences yielding the best results in terms of discrimination and efficacy of silencing.
- Example 13 Synthesis of a Phosphinate-Modified Intersubunit Linkage
- FIGS. 44A-44C A method for preparing a phosphinate-modified intersubunit linkage of the invention is summarized in FIGS. 44A-44C.
- This method involves Jones oxidation from a free alcohol to the corresponding ketone followed by a Wittig olefination to achieve the exomethylene moiety shown in intermediate compound 3.
- Protecting of the amide with BOM followed by hydroboration-oxidation results in the free alcohol intermediate 5.
- Mesylation followed by a modified Finkelstein reaction produces the iodinated intermediate 7, which then undergoes further functionalization to achieve the methyl phosphinate monomer 9.
- To achieve monomer 18, various protection and deprotection steps are employed to achieve intermediate 13.
- IBX oxidation produces the corresponding ketone followed by Wittig olefmation to access the methylene.
- hydroboration-oxidation followed by mesylation and Finkelstein reaction results in monomer 18.
Landscapes
- Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- Biophysics (AREA)
- Medicinal Chemistry (AREA)
- Pharmacology & Pharmacy (AREA)
- Epidemiology (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
Description







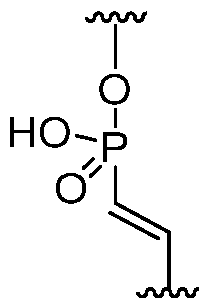







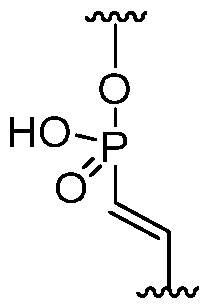



















Claims








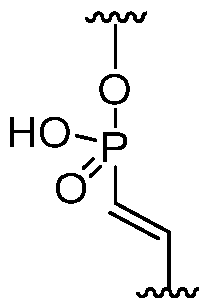

Priority Applications (11)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| MX2021001590A MX2021001590A (en) | 2018-08-10 | 2019-08-09 | Modified oligonucleotides targeting snps. |
| CA3109133A CA3109133A1 (en) | 2018-08-10 | 2019-08-09 | Modified oligonucleotides targeting snps |
| BR112021002440-9A BR112021002440A2 (en) | 2018-08-10 | 2019-08-09 | modified oligonucleotides targeting snps |
| JP2021507003A JP2021533762A (en) | 2018-08-10 | 2019-08-09 | Modified oligonucleotides that target SNPs |
| EA202190483A EA202190483A1 (en) | 2019-03-28 | 2019-08-09 | Modified oligonucleotides targeting SNP |
| SG11202101288TA SG11202101288TA (en) | 2018-08-10 | 2019-08-09 | Modified oligonucleotides targeting snps |
| EP19847586.5A EP3833763A4 (en) | 2018-08-10 | 2019-08-09 | Modified oligonucleotides targeting snps |
| CN201980066120.2A CN112805383A (en) | 2018-08-10 | 2019-08-09 | Modified oligonucleotides targeting SNPs |
| KR1020217006987A KR20210093227A (en) | 2018-08-10 | 2019-08-09 | Modified oligonucleotides targeting SNPs |
| AU2019316640A AU2019316640A1 (en) | 2018-08-10 | 2019-08-09 | Modified oligonucleotides targeting SNPs |
| IL280724A IL280724A (en) | 2018-08-10 | 2021-02-08 | Chemically modified oligonucleotides targeting snps |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862717287P | 2018-08-10 | 2018-08-10 | |
| US62/717,287 | 2018-08-10 | ||
| US201962825429P | 2019-03-28 | 2019-03-28 | |
| US62/825,429 | 2019-03-28 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020033899A1 true WO2020033899A1 (en) | 2020-02-13 |
Family
ID=69414459
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2019/046013 WO2020033899A1 (en) | 2018-08-10 | 2019-08-09 | Modified oligonucleotides targeting snps |
Country Status (12)
| Country | Link |
|---|---|
| US (2) | US11827882B2 (en) |
| EP (1) | EP3833763A4 (en) |
| JP (1) | JP2021533762A (en) |
| KR (1) | KR20210093227A (en) |
| CN (1) | CN112805383A (en) |
| AU (1) | AU2019316640A1 (en) |
| BR (1) | BR112021002440A2 (en) |
| CA (1) | CA3109133A1 (en) |
| IL (1) | IL280724A (en) |
| MX (1) | MX2021001590A (en) |
| SG (1) | SG11202101288TA (en) |
| WO (1) | WO2020033899A1 (en) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11702659B2 (en) | 2021-06-23 | 2023-07-18 | University Of Massachusetts | Optimized anti-FLT1 oligonucleotide compounds for treatment of preeclampsia and other angiogenic disorders |
| US11753638B2 (en) | 2016-08-12 | 2023-09-12 | University Of Massachusetts | Conjugated oligonucleotides |
| EP3946369A4 (en) * | 2019-03-26 | 2023-10-18 | University Of Massachusetts | Modified oligonucleotides with increased stability |
| US11827882B2 (en) | 2018-08-10 | 2023-11-28 | University Of Massachusetts | Modified oligonucleotides targeting SNPs |
| US11896669B2 (en) | 2016-01-31 | 2024-02-13 | University Of Massachusetts | Branched oligonucleotides |
| US12024706B2 (en) | 2019-08-09 | 2024-07-02 | University Of Massachusetts | Modified oligonucleotides targeting SNPs |
| US12049627B2 (en) | 2017-06-23 | 2024-07-30 | University Of Massachusetts | Two-tailed self-delivering siRNA |
| US12077755B2 (en) | 2015-08-14 | 2024-09-03 | University Of Massachusetts | Bioactive conjugates for oligonucleotide delivery |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021041247A1 (en) * | 2019-08-23 | 2021-03-04 | University Of Massachusetts | O-methyl rich fully stabilized oligonucleotides |
| EP4158028A4 (en) | 2020-05-28 | 2024-10-02 | Univ Massachusetts | Oligonucleotides for sars-cov-2 modulation |
| AR125230A1 (en) | 2021-03-29 | 2023-06-28 | Alnylam Pharmaceuticals Inc | COMPOSITIONS OF ANTI-HUNTINGTIN (HTT) RNAi AGENTS AND THEIR METHODS OF USE |
| WO2024002007A1 (en) * | 2022-06-27 | 2024-01-04 | 大睿生物医药科技(上海)有限公司 | Double-stranded rna comprising nucleotide analog capable of reducing off-target toxicity |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20120136039A1 (en) * | 2009-04-08 | 2012-05-31 | University Of Massachusetts | Single nucleotide polymorphism (snp) targeting therapies for the treatment of huntington's disease |
| US20170051286A1 (en) * | 2014-05-01 | 2017-02-23 | Larry J. Smith | METHODS AND MODIFICATIONS THAT PRODUCE ssRNAi COMPOUNDS WITH ENHANCED ACTIVITY, POTENCY AND DURATION OF EFFECT |
| US20180094263A1 (en) * | 2015-04-03 | 2018-04-05 | University Of Massachusetts | Oligonucleotide compounds for targeting huntingtin mrna |
Family Cites Families (145)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4522811A (en) | 1982-07-08 | 1985-06-11 | Syntex (U.S.A.) Inc. | Serial injection of muramyldipeptides and liposomes enhances the anti-infective activity of muramyldipeptides |
| US5240848A (en) | 1988-11-21 | 1993-08-31 | Monsanto Company | Dna sequences encoding human vascular permeability factor having 189 amino acids |
| US5328470A (en) | 1989-03-31 | 1994-07-12 | The Regents Of The University Of Michigan | Treatment of diseases by site-specific instillation of cells or site-specific transformation of cells and kits therefor |
| US5332671A (en) | 1989-05-12 | 1994-07-26 | Genetech, Inc. | Production of vascular endothelial cell growth factor and DNA encoding same |
| US5219739A (en) | 1989-07-27 | 1993-06-15 | Scios Nova Inc. | DNA sequences encoding bVEGF120 and hVEGF121 and methods for the production of bovine and human vascular endothelial cell growth factors, bVEGF120 and hVEGF121 |
| US5194596A (en) | 1989-07-27 | 1993-03-16 | California Biotechnology Inc. | Production of vascular endothelial cell growth factor |
| JPH05503841A (en) | 1989-11-16 | 1993-06-24 | デューク ユニバーシティ | Particle-mediated transformation of animal tissue cells |
| US5672697A (en) | 1991-02-08 | 1997-09-30 | Gilead Sciences, Inc. | Nucleoside 5'-methylene phosphonates |
| US6291438B1 (en) | 1993-02-24 | 2001-09-18 | Jui H. Wang | Antiviral anticancer poly-substituted phenyl derivatized oligoribonucleotides and methods for their use |
| US5858988A (en) | 1993-02-24 | 1999-01-12 | Wang; Jui H. | Poly-substituted-phenyl-oligoribo nucleotides having enhanced stability and membrane permeability and methods of use |
| TW404844B (en) | 1993-04-08 | 2000-09-11 | Oxford Biosciences Ltd | Needleless syringe |
| CA2190998A1 (en) | 1994-06-01 | 1995-12-07 | Sudhir Agrawal | Branched oligonucleotides as pathogen-inhibitory agents |
| US6383814B1 (en) | 1994-12-09 | 2002-05-07 | Genzyme Corporation | Cationic amphiphiles for intracellular delivery of therapeutic molecules |
| WO1996033761A1 (en) | 1995-04-28 | 1996-10-31 | Medtronic, Inc. | Intraparenchymal infusion catheter system |
| US5684143A (en) | 1996-02-21 | 1997-11-04 | Lynx Therapeutics, Inc. | Oligo-2'-fluoronucleotide N3'->P5' phosphoramidates |
| US5735814A (en) | 1996-04-30 | 1998-04-07 | Medtronic, Inc. | Techniques of treating neurodegenerative disorders by brain infusion |
| US5898031A (en) | 1996-06-06 | 1999-04-27 | Isis Pharmaceuticals, Inc. | Oligoribonucleotides for cleaving RNA |
| US5849902A (en) | 1996-09-26 | 1998-12-15 | Oligos Etc. Inc. | Three component chimeric antisense oligonucleotides |
| US6177403B1 (en) | 1996-10-21 | 2001-01-23 | The Trustees Of The University Of Pennsylvania | Compositions, methods, and apparatus for delivery of a macromolecular assembly to an extravascular tissue of an animal |
| US6042820A (en) | 1996-12-20 | 2000-03-28 | Connaught Laboratories Limited | Biodegradable copolymer containing α-hydroxy acid and α-amino acid units |
| US6472375B1 (en) | 1998-04-16 | 2002-10-29 | John Wayne Cancer Institute | DNA vaccine and methods for its use |
| EP1016726A1 (en) | 1998-12-30 | 2000-07-05 | Introgene B.V. | Gene therapy to promote angiogenesis |
| EP1240337B1 (en) | 1999-12-24 | 2006-08-23 | Genentech, Inc. | Methods and compositions for prolonging elimination half-times of bioactive compounds |
| US20070026394A1 (en) | 2000-02-11 | 2007-02-01 | Lawrence Blatt | Modulation of gene expression associated with inflammation proliferation and neurite outgrowth using nucleic acid based technologies |
| US8202979B2 (en) | 2002-02-20 | 2012-06-19 | Sirna Therapeutics, Inc. | RNA interference mediated inhibition of gene expression using chemically modified short interfering nucleic acid |
| EP2385123B1 (en) | 2001-09-28 | 2018-04-25 | Max-Planck-Gesellschaft zur Förderung der Wissenschaften e.V. | Microrna molecules |
| US20060009409A1 (en) | 2002-02-01 | 2006-01-12 | Woolf Tod M | Double-stranded oligonucleotides |
| US20050096284A1 (en) | 2002-02-20 | 2005-05-05 | Sirna Therapeutics, Inc. | RNA interference mediated treatment of polyglutamine (polyQ) repeat expansion diseases using short interfering nucleic acid (siNA) |
| US9181551B2 (en) | 2002-02-20 | 2015-11-10 | Sirna Therapeutics, Inc. | RNA interference mediated inhibition of gene expression using chemically modified short interfering nucleic acid (siNA) |
| WO2003092594A2 (en) | 2002-04-30 | 2003-11-13 | Duke University | Adeno-associated viral vectors and methods for their production from hybrid adenovirus and for their use |
| ES2534294T3 (en) | 2002-07-19 | 2015-04-21 | Beth Israel Deaconess Medical Center | Methods to treat preeclampsia |
| US20050106731A1 (en) * | 2002-08-05 | 2005-05-19 | Davidson Beverly L. | siRNA-mediated gene silencing with viral vectors |
| US20040241854A1 (en) | 2002-08-05 | 2004-12-02 | Davidson Beverly L. | siRNA-mediated gene silencing |
| US7956176B2 (en) | 2002-09-05 | 2011-06-07 | Sirna Therapeutics, Inc. | RNA interference mediated inhibition of gene expression using chemically modified short interfering nucleic acid (siNA) |
| AU2003290597A1 (en) | 2002-11-05 | 2004-06-03 | Isis Pharmaceuticals, Inc. | Modified oligonucleotides for use in rna interference |
| US7250496B2 (en) | 2002-11-14 | 2007-07-31 | Rosetta Genomics Ltd. | Bioinformatically detectable group of novel regulatory genes and uses thereof |
| EP1560931B1 (en) | 2002-11-14 | 2011-07-27 | Dharmacon, Inc. | Functional and hyperfunctional sirna |
| US7790867B2 (en) | 2002-12-05 | 2010-09-07 | Rosetta Genomics Inc. | Vaccinia virus-related nucleic acids and microRNA |
| US6913890B2 (en) | 2002-12-18 | 2005-07-05 | Palo Alto Research Center Incorporated | Process for preparing albumin protein conjugated oligonucleotide probes |
| AU2003299864A1 (en) | 2002-12-27 | 2004-07-29 | P. Radhakrishnan | Sirna compounds and methods for the downregulation of gene expression |
| US20040198640A1 (en) | 2003-04-02 | 2004-10-07 | Dharmacon, Inc. | Stabilized polynucleotides for use in RNA interference |
| US7851615B2 (en) | 2003-04-17 | 2010-12-14 | Alnylam Pharmaceuticals, Inc. | Lipophilic conjugated iRNA agents |
| EP1620544B1 (en) | 2003-04-17 | 2018-09-19 | Alnylam Pharmaceuticals Inc. | MODIFIED iRNA AGENTS |
| US8309704B2 (en) | 2003-06-02 | 2012-11-13 | University Of Massachusetts | Methods and compositions for enhancing the efficacy and specificity of RNAi |
| AU2004248136B2 (en) | 2003-06-02 | 2011-09-15 | University Of Massachusetts | Methods and compositions for controlling efficacy of RNA silencing |
| US7750144B2 (en) | 2003-06-02 | 2010-07-06 | University Of Massachusetts | Methods and compositions for enhancing the efficacy and specificity of RNA silencing |
| WO2005060697A2 (en) | 2003-12-19 | 2005-07-07 | Chiron Corporation | Cell transfecting formulations of small interfering rna, related compositions and methods of making and use |
| US20050176045A1 (en) * | 2004-02-06 | 2005-08-11 | Dharmacon, Inc. | SNP discriminatory siRNA |
| US20060078542A1 (en) | 2004-02-10 | 2006-04-13 | Mah Cathryn S | Gel-based delivery of recombinant adeno-associated virus vectors |
| EP2365077B1 (en) | 2004-03-12 | 2013-05-08 | Alnylam Pharmaceuticals, Inc. | iRNA agents targeting VEGF |
| JP4635046B2 (en) | 2004-04-20 | 2011-02-16 | マリナ・バイオテック・インコーポレーテッド | Methods and compositions for enhancing delivery of double stranded RNA or double stranded hybrid nucleic acids for modulating gene expression in mammalian cells |
| WO2005116204A1 (en) | 2004-05-11 | 2005-12-08 | Rnai Co., Ltd. | Polynucleotide causing rna interfere and method of regulating gene expression with the use of the same |
| CA2568735A1 (en) | 2004-06-03 | 2005-12-22 | Isis Pharmaceuticals, Inc. | Double strand compositions comprising differentially modified strands for use in gene modulation |
| JP5136766B2 (en) | 2004-12-15 | 2013-02-06 | ユニバーシティ オブ ノース カロライナ アット チャペル ヒル | Chimera vector |
| US20070161591A1 (en) | 2005-08-18 | 2007-07-12 | University Of Massachusetts | Methods and compositions for treating neurological disease |
| EP1941059A4 (en) | 2005-10-28 | 2010-11-03 | Alnylam Pharmaceuticals Inc | Compositions and methods for inhibiting expression of huntingtin gene |
| JP5336853B2 (en) | 2005-11-02 | 2013-11-06 | プロチバ バイオセラピューティクス インコーポレイティッド | Modified siRNA molecules and methods of use thereof |
| AU2006311912A1 (en) | 2005-11-04 | 2007-05-18 | Mdrna, Inc. | Peptide-dicer substrate RNA conjugates as delivery vehicles for siRNA |
| US20070259827A1 (en) | 2006-01-25 | 2007-11-08 | University Of Massachusetts | Compositions and methods for enhancing discriminatory RNA interference |
| US9198981B2 (en) | 2006-02-01 | 2015-12-01 | The University Of Kentucky | Modulation of angiogenesis |
| US8362229B2 (en) | 2006-02-08 | 2013-01-29 | Quark Pharmaceuticals, Inc. | Tandem siRNAS |
| JPWO2007094218A1 (en) | 2006-02-16 | 2009-07-02 | 国立大学法人岐阜大学 | Modified oligonucleotide |
| US20100184209A1 (en) | 2006-02-17 | 2010-07-22 | Dharmacon, Inc. | Compositions and methods for inhibiting gene silencing by rna interference |
| US20090306178A1 (en) | 2006-03-27 | 2009-12-10 | Balkrishen Bhat | Conjugated double strand compositions for use in gene modulation |
| EP2046993A4 (en) | 2006-07-07 | 2010-11-17 | Univ Massachusetts | Rna silencing compositions and methods for the treatment of huntington's disease |
| US20080039415A1 (en) | 2006-08-11 | 2008-02-14 | Gregory Robert Stewart | Retrograde transport of sirna and therapeutic uses to treat neurologic disorders |
| US8809514B2 (en) | 2006-09-22 | 2014-08-19 | Ge Healthcare Dharmacon, Inc. | Tripartite oligonucleotide complexes and methods for gene silencing by RNA interference |
| JP5876637B2 (en) | 2006-10-18 | 2016-03-02 | マリーナ バイオテック,インコーポレイテッド | Nicked or gapped nucleic acid molecules and their use |
| US8906874B2 (en) | 2006-11-09 | 2014-12-09 | Gradalis, Inc. | Bi-functional shRNA targeting Stathmin 1 and uses thereof |
| EP2120966A4 (en) | 2006-11-27 | 2013-06-19 | Enzon Pharmaceuticals Inc | Polymeric short interfering rna conjugates |
| EP2126081A2 (en) | 2007-03-02 | 2009-12-02 | MDRNA, Inc. | Nucleic acid compounds for inhibiting hif1a gene expression and uses thereof |
| WO2008154482A2 (en) | 2007-06-08 | 2008-12-18 | Sirnaomics, Inc. | Sirna compositions and methods of use in treatment of ocular diseases |
| WO2009002944A1 (en) | 2007-06-22 | 2008-12-31 | Isis Pharmaceuticals, Inc. | Double strand compositions comprising differentially modified strands for use in gene modulation |
| CA2735166C (en) | 2007-08-27 | 2020-12-01 | Boston Biomedical, Inc. | Compositions of asymmetric interfering rna and uses thereof |
| CN101199858A (en) | 2007-10-18 | 2008-06-18 | 广州拓谱基因技术有限公司 | Multiple target point small interference RNA cocktail agent for treating ophthalmic disease and preparing method thereof |
| TW200927177A (en) | 2007-10-24 | 2009-07-01 | Nat Inst Of Advanced Ind Scien | Lipid-modified double-stranded RNA having potent RNA interference effect |
| CA2708173C (en) | 2007-12-04 | 2016-02-02 | Alnylam Pharmaceuticals, Inc. | Targeting lipids |
| US9029524B2 (en) | 2007-12-10 | 2015-05-12 | California Institute Of Technology | Signal activated RNA interference |
| US20110081362A1 (en) | 2008-01-31 | 2011-04-07 | The Brigham And Women's Hospital, Inc. | Treatment of cancer |
| CN104975020B (en) | 2008-02-11 | 2020-01-17 | 菲奥医药公司 | Modified RNAi polynucleotides and uses thereof |
| US9217155B2 (en) | 2008-05-28 | 2015-12-22 | University Of Massachusetts | Isolation of novel AAV'S and uses thereof |
| US8815818B2 (en) | 2008-07-18 | 2014-08-26 | Rxi Pharmaceuticals Corporation | Phagocytic cell delivery of RNAI |
| CA2731779A1 (en) | 2008-07-24 | 2010-01-28 | Rxi Pharmaceuticals Corporation | Rnai constructs and uses therof |
| WO2010033246A1 (en) | 2008-09-22 | 2010-03-25 | Rxi Pharmaceuticals Corporation | Rna interference in skin indications |
| WO2010048585A2 (en) | 2008-10-24 | 2010-04-29 | Isis Pharmaceuticals, Inc. | Oligomeric compounds and methods |
| US9074211B2 (en) | 2008-11-19 | 2015-07-07 | Rxi Pharmaceuticals Corporation | Inhibition of MAP4K4 through RNAI |
| WO2010078536A1 (en) | 2009-01-05 | 2010-07-08 | Rxi Pharmaceuticals Corporation | Inhibition of pcsk9 through rnai |
| US9023820B2 (en) | 2009-01-26 | 2015-05-05 | Protiva Biotherapeutics, Inc. | Compositions and methods for silencing apolipoprotein C-III expression |
| US9745574B2 (en) | 2009-02-04 | 2017-08-29 | Rxi Pharmaceuticals Corporation | RNA duplexes with single stranded phosphorothioate nucleotide regions for additional functionality |
| KR101141544B1 (en) | 2009-03-13 | 2012-05-03 | 한국과학기술원 | Multi-conjugate of siRNA and preparing method thereof |
| US8734809B2 (en) | 2009-05-28 | 2014-05-27 | University Of Massachusetts | AAV's and uses thereof |
| GB0910723D0 (en) | 2009-06-22 | 2009-08-05 | Sylentis Sau | Novel drugs for inhibition of gene expression |
| PT2470656E (en) | 2009-08-27 | 2015-07-16 | Idera Pharmaceuticals Inc | Composition for inhibiting gene expression and uses thereof |
| US20150025122A1 (en) | 2009-10-12 | 2015-01-22 | Larry J. Smith | Methods and Compositions for Modulating Gene Expression Using Oligonucleotide Based Drugs Administered in vivo or in vitro |
| EP3561060A1 (en) | 2010-02-08 | 2019-10-30 | Ionis Pharmaceuticals, Inc. | Selective reduction of allelic variants |
| WO2011109698A1 (en) | 2010-03-04 | 2011-09-09 | Rxi Pharmaceuticals Corporation | Formulations and methods for targeted delivery to phagocyte cells |
| EP2550001B1 (en) | 2010-03-24 | 2019-05-22 | Phio Pharmaceuticals Corp. | Rna interference in ocular indications |
| WO2011119887A1 (en) | 2010-03-24 | 2011-09-29 | Rxi Pharmaceuticals Corporation | Rna interference in dermal and fibrotic indications |
| EP2550000A4 (en) | 2010-03-24 | 2014-03-26 | Advirna Inc | Reduced size self-delivering rnai compounds |
| US8993738B2 (en) | 2010-04-28 | 2015-03-31 | Isis Pharmaceuticals, Inc. | Modified nucleosides, analogs thereof and oligomeric compounds prepared therefrom |
| WO2012005898A2 (en) | 2010-06-15 | 2012-01-12 | Alnylam Pharmaceuticals, Inc. | Chinese hamster ovary (cho) cell transcriptome, corresponding sirnas and uses thereof |
| CN102946908B (en) * | 2010-06-18 | 2015-04-22 | Lsip基金运营联合公司 | Inhibitor of expression of dominant allele |
| US8586301B2 (en) | 2010-06-30 | 2013-11-19 | Stratos Genomics, Inc. | Multiplexed identification of nucleic acid sequences |
| EP2616543A1 (en) | 2010-09-15 | 2013-07-24 | Alnylam Pharmaceuticals, Inc. | MODIFIED iRNA AGENTS |
| WO2012078637A2 (en) | 2010-12-06 | 2012-06-14 | Immune Disease Institute, Inc. | Composition and method for oligonucleotide delivery |
| CA2816155C (en) | 2010-12-17 | 2020-10-27 | Arrowhead Research Corporation | Galactose cluster-pharmacokinetic modulator targeting moiety for sirna |
| SG193280A1 (en) | 2011-03-03 | 2013-10-30 | Quark Pharmaceuticals Inc | Oligonucleotide modulators of the toll-like receptor pathway |
| GB201105137D0 (en) | 2011-03-28 | 2011-05-11 | Isis Innovation | Therapeutic molecules for use in the suppression of Parkinson's disease |
| EP3564393A1 (en) | 2011-06-21 | 2019-11-06 | Alnylam Pharmaceuticals, Inc. | Assays and methods for determining activity of a therapeutic agent in a subject |
| EP3358013B1 (en) | 2012-05-02 | 2020-06-24 | Sirna Therapeutics, Inc. | Short interfering nucleic acid (sina) compositions |
| DK2853597T3 (en) | 2012-05-22 | 2019-04-08 | Olix Pharmaceuticals Inc | RNA INTERFERENCE-INducing NUCLEIC ACID MOLECULES WITH CELL PENETENING EQUIPMENT AND USE THEREOF |
| US9480752B2 (en) | 2012-07-10 | 2016-11-01 | Baseclick Gmbh | Anandamide-modified nucleic acid molecules |
| CA2884608A1 (en) | 2012-09-14 | 2014-03-20 | Rana Therapeutics, Inc. | Multimeric oligonucleotide compounds |
| WO2014047649A1 (en) | 2012-09-24 | 2014-03-27 | The Regents Of The University Of California | Methods for arranging and packing nucleic acids for unusual resistance to nucleases and targeted delivery for gene therapy |
| US20150291958A1 (en) | 2012-11-15 | 2015-10-15 | Roche Innovation Center Copenhagen A/S | Anti apob antisense conjugate compounds |
| US20140200124A1 (en) | 2013-01-15 | 2014-07-17 | Karen Michelle JAMES | Physical Therapy Device and Methods for Use Thereof |
| PL2992098T3 (en) | 2013-05-01 | 2019-09-30 | Ionis Pharmaceuticals, Inc. | Compositions and methods for modulating hbv and ttr expression |
| JP7011389B2 (en) | 2013-06-12 | 2022-01-26 | オンコイミューニン,インコーポレイティド | Systemic in vivo delivery of oligonucleotides |
| CA2915443A1 (en) | 2013-06-16 | 2014-12-24 | National University Corporation Tokyo Medical And Dental University | Double-stranded antisense nucleic acid with exon-skipping effect |
| US9862350B2 (en) | 2013-08-12 | 2018-01-09 | Tk Holdings Inc. | Dual chambered passenger airbag |
| WO2015057847A1 (en) | 2013-10-16 | 2015-04-23 | Cerulean Pharma Inc. | Conjugates, particles, compositions, and related methods |
| DK3066219T3 (en) | 2013-11-08 | 2019-03-11 | Ionis Pharmaceuticals Inc | METHODS FOR DETECTING OIGONUCLEOTIDES |
| EP3099795A4 (en) | 2014-01-27 | 2018-01-17 | The Board of Trustees of the Leland Stanford Junior University | Oligonucleotides and methods for treatment of cardiomyopathy using rna interference |
| EP3132044B1 (en) | 2014-04-18 | 2020-04-08 | University of Massachusetts | Exosomal loading using hydrophobically modified oligonucleotides |
| EP3146049B1 (en) | 2014-05-22 | 2020-02-26 | Alnylam Pharmaceuticals, Inc. | Angiotensinogen (agt) irna compositions and methods of use thereof |
| US10588980B2 (en) | 2014-06-23 | 2020-03-17 | Novartis Ag | Fatty acids and their use in conjugation to biomolecules |
| MX2017004039A (en) | 2014-10-10 | 2017-07-24 | Hoffmann La Roche | Galnac phosphoramidites, nucleic acid conjugates thereof and their use. |
| HUE057431T2 (en) | 2015-04-03 | 2022-05-28 | Univ Massachusetts | Oligonucleotide compounds for treatment of preeclampsia and other angiogenic disorders |
| WO2016161388A1 (en) | 2015-04-03 | 2016-10-06 | University Of Massachusetts | Fully stabilized asymmetric sirna |
| EP3280805B1 (en) | 2015-04-10 | 2020-12-16 | HudsonAlpha Institute For Biotechnology | Method for blocking mirna |
| KR20180039621A (en) | 2015-06-15 | 2018-04-18 | 엠펙 엘에이, 엘엘씨 | The defined multijunctional oligonucleotides |
| MA43072A (en) | 2015-07-22 | 2018-05-30 | Wave Life Sciences Ltd | COMPOSITIONS OF OLIGONUCLEOTIDES AND RELATED PROCESSES |
| EP3334499A4 (en) | 2015-08-14 | 2019-04-17 | University of Massachusetts | Bioactive conjugates for oligonucleotide delivery |
| CN105194689A (en) | 2015-10-10 | 2015-12-30 | 湖南中楚博生物科技有限公司 | SiRNA-based double-coupled compound |
| US10478503B2 (en) | 2016-01-31 | 2019-11-19 | University Of Massachusetts | Branched oligonucleotides |
| MA45328A (en) | 2016-04-01 | 2019-02-06 | Avidity Biosciences Llc | NUCLEIC ACID-POLYPEPTIDE COMPOSITIONS AND USES THEREOF |
| WO2017174572A1 (en) | 2016-04-04 | 2017-10-12 | F. Hoffmann-La Roche Ag | Nucleic acid sample preparation methods |
| US10036024B2 (en) * | 2016-06-03 | 2018-07-31 | Purdue Research Foundation | siRNA compositions that specifically downregulate expression of a variant of the PNPLA3 gene and methods of use thereof for treating a chronic liver disease or alcoholic liver disease (ALD) |
| CA3033368A1 (en) | 2016-08-12 | 2018-02-15 | University Of Massachusetts | Conjugated oligonucleotides |
| CA3035293A1 (en) | 2016-09-01 | 2018-03-08 | Proqr Therapeutics Ii B.V. | Chemically modified single-stranded rna-editing oligonucleotides |
| US11603532B2 (en) | 2017-06-02 | 2023-03-14 | Wave Life Sciences Ltd. | Oligonucleotide compositions and methods of use thereof |
| US10844377B2 (en) | 2017-06-23 | 2020-11-24 | University Of Massachusetts | Two-tailed self-delivering siRNA |
| CA3071086A1 (en) | 2017-08-18 | 2019-02-21 | The Procter & Gamble Company | Cleaning agent |
| KR20210093227A (en) | 2018-08-10 | 2021-07-27 | 유니버시티 오브 매사추세츠 | Modified oligonucleotides targeting SNPs |
| JP2022523467A (en) | 2019-01-18 | 2022-04-25 | ユニバーシティ・オブ・マサチューセッツ | Anchors that modify dynamic pharmacokinetics |
-
2019
- 2019-08-09 KR KR1020217006987A patent/KR20210093227A/en unknown
- 2019-08-09 CN CN201980066120.2A patent/CN112805383A/en active Pending
- 2019-08-09 JP JP2021507003A patent/JP2021533762A/en active Pending
- 2019-08-09 SG SG11202101288TA patent/SG11202101288TA/en unknown
- 2019-08-09 BR BR112021002440-9A patent/BR112021002440A2/en unknown
- 2019-08-09 EP EP19847586.5A patent/EP3833763A4/en active Pending
- 2019-08-09 AU AU2019316640A patent/AU2019316640A1/en active Pending
- 2019-08-09 WO PCT/US2019/046013 patent/WO2020033899A1/en active Search and Examination
- 2019-08-09 CA CA3109133A patent/CA3109133A1/en active Pending
- 2019-08-09 MX MX2021001590A patent/MX2021001590A/en unknown
- 2019-08-09 US US16/537,374 patent/US11827882B2/en active Active
-
2021
- 2021-02-08 IL IL280724A patent/IL280724A/en unknown
-
2023
- 2023-08-09 US US18/446,929 patent/US20240132888A1/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20120136039A1 (en) * | 2009-04-08 | 2012-05-31 | University Of Massachusetts | Single nucleotide polymorphism (snp) targeting therapies for the treatment of huntington's disease |
| US20170051286A1 (en) * | 2014-05-01 | 2017-02-23 | Larry J. Smith | METHODS AND MODIFICATIONS THAT PRODUCE ssRNAi COMPOUNDS WITH ENHANCED ACTIVITY, POTENCY AND DURATION OF EFFECT |
| US20180094263A1 (en) * | 2015-04-03 | 2018-04-05 | University Of Massachusetts | Oligonucleotide compounds for targeting huntingtin mrna |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12077755B2 (en) | 2015-08-14 | 2024-09-03 | University Of Massachusetts | Bioactive conjugates for oligonucleotide delivery |
| US11896669B2 (en) | 2016-01-31 | 2024-02-13 | University Of Massachusetts | Branched oligonucleotides |
| US11753638B2 (en) | 2016-08-12 | 2023-09-12 | University Of Massachusetts | Conjugated oligonucleotides |
| US12049627B2 (en) | 2017-06-23 | 2024-07-30 | University Of Massachusetts | Two-tailed self-delivering siRNA |
| US11827882B2 (en) | 2018-08-10 | 2023-11-28 | University Of Massachusetts | Modified oligonucleotides targeting SNPs |
| EP3946369A4 (en) * | 2019-03-26 | 2023-10-18 | University Of Massachusetts | Modified oligonucleotides with increased stability |
| US11820985B2 (en) | 2019-03-26 | 2023-11-21 | University Of Massachusetts | Modified oligonucleotides with increased stability |
| US12024706B2 (en) | 2019-08-09 | 2024-07-02 | University Of Massachusetts | Modified oligonucleotides targeting SNPs |
| US11702659B2 (en) | 2021-06-23 | 2023-07-18 | University Of Massachusetts | Optimized anti-FLT1 oligonucleotide compounds for treatment of preeclampsia and other angiogenic disorders |
Also Published As
| Publication number | Publication date |
|---|---|
| MX2021001590A (en) | 2021-07-02 |
| IL280724A (en) | 2021-03-25 |
| JP2021533762A (en) | 2021-12-09 |
| AU2019316640A1 (en) | 2021-03-18 |
| KR20210093227A (en) | 2021-07-27 |
| SG11202101288TA (en) | 2021-03-30 |
| US20200123543A1 (en) | 2020-04-23 |
| EP3833763A1 (en) | 2021-06-16 |
| US20240132888A1 (en) | 2024-04-25 |
| CN112805383A (en) | 2021-05-14 |
| EP3833763A4 (en) | 2023-07-19 |
| BR112021002440A2 (en) | 2021-05-04 |
| US11827882B2 (en) | 2023-11-28 |
| CA3109133A1 (en) | 2020-02-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11827882B2 (en) | Modified oligonucleotides targeting SNPs | |
| US11279930B2 (en) | O-methyl rich fully stabilized oligonucleotides | |
| US12024706B2 (en) | Modified oligonucleotides targeting SNPs | |
| US11820985B2 (en) | Modified oligonucleotides with increased stability | |
| US20210115442A1 (en) | O-methyl rich fully stabilized oligonucleotides | |
| US20200362341A1 (en) | Oligonucleotides for tissue specific apoe modulation | |
| WO2008005562A2 (en) | Rna silencing compositions and methods for the treatment of huntington's disease | |
| US20220090069A1 (en) | Oligonucleotides for htt-1a modulation | |
| CN115666659A (en) | Synthesis of modified oligonucleotides with increased stability | |
| US20230193281A1 (en) | Oligonucleotides for sod1 modulation | |
| WO2021173984A2 (en) | Oligonucleotides for prnp modulation | |
| EA047511B1 (en) | MODIFIED OLIGONUCLEOTIDES TARGETING SNPs |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19847586 Country of ref document: EP Kind code of ref document: A1 |
|
| DPE2 | Request for preliminary examination filed before expiration of 19th month from priority date (pct application filed from 20040101) | ||
| ENP | Entry into the national phase |
Ref document number: 3109133 Country of ref document: CA |
|
| ENP | Entry into the national phase |
Ref document number: 2021507003 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01A Ref document number: 112021002440 Country of ref document: BR |
|
| ENP | Entry into the national phase |
Ref document number: 2019847586 Country of ref document: EP Effective date: 20210310 |
|
| ENP | Entry into the national phase |
Ref document number: 2019316640 Country of ref document: AU Date of ref document: 20190809 Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 112021002440 Country of ref document: BR Kind code of ref document: A2 Effective date: 20210209 |