WO2018176035A1 - Method and system of building hospital-scale chest x-ray database for entity extraction and weakly-supervised classification and localization of common thorax diseases - Google Patents
Method and system of building hospital-scale chest x-ray database for entity extraction and weakly-supervised classification and localization of common thorax diseases Download PDFInfo
- Publication number
- WO2018176035A1 WO2018176035A1 PCT/US2018/024354 US2018024354W WO2018176035A1 WO 2018176035 A1 WO2018176035 A1 WO 2018176035A1 US 2018024354 W US2018024354 W US 2018024354W WO 2018176035 A1 WO2018176035 A1 WO 2018176035A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- chest
- image
- ray
- disease
- diseases
- Prior art date
Links
- 201000010099 disease Diseases 0.000 title claims abstract description 84
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 title claims abstract description 84
- 230000004807 localization Effects 0.000 title claims abstract description 43
- 238000000034 method Methods 0.000 title claims description 51
- 210000000038 chest Anatomy 0.000 title claims description 32
- 238000000605 extraction Methods 0.000 title description 2
- 208000026216 Thoracic disease Diseases 0.000 claims abstract description 22
- 238000003058 natural language processing Methods 0.000 claims abstract description 8
- 238000011176 pooling Methods 0.000 claims description 29
- 230000007704 transition Effects 0.000 claims description 16
- 238000013527 convolutional neural network Methods 0.000 claims description 13
- 230000004913 activation Effects 0.000 claims description 12
- 238000001994 activation Methods 0.000 claims description 12
- 206010003598 Atelectasis Diseases 0.000 claims description 7
- 206010035664 Pneumonia Diseases 0.000 claims description 7
- 208000007123 Pulmonary Atelectasis Diseases 0.000 claims description 7
- 208000006029 Cardiomegaly Diseases 0.000 claims description 6
- 238000003384 imaging method Methods 0.000 claims description 6
- 230000008595 infiltration Effects 0.000 claims description 6
- 238000001764 infiltration Methods 0.000 claims description 6
- 238000013145 classification model Methods 0.000 claims description 4
- 206010063045 Effusion Diseases 0.000 claims description 3
- 210000003484 anatomy Anatomy 0.000 claims description 2
- 238000013500 data storage Methods 0.000 claims description 2
- 238000004458 analytical method Methods 0.000 claims 2
- 238000011976 chest X-ray Methods 0.000 abstract description 15
- 230000007170 pathology Effects 0.000 description 31
- 238000001514 detection method Methods 0.000 description 22
- 238000005516 engineering process Methods 0.000 description 11
- 238000012545 processing Methods 0.000 description 10
- 238000004891 communication Methods 0.000 description 7
- 238000013135 deep learning Methods 0.000 description 7
- 238000003745 diagnosis Methods 0.000 description 6
- 230000014509 gene expression Effects 0.000 description 6
- 201000003144 pneumothorax Diseases 0.000 description 6
- 230000008569 process Effects 0.000 description 6
- 230000000007 visual effect Effects 0.000 description 6
- 238000013459 approach Methods 0.000 description 5
- 230000006870 function Effects 0.000 description 5
- 230000001575 pathological effect Effects 0.000 description 5
- 230000011218 segmentation Effects 0.000 description 5
- 238000002474 experimental method Methods 0.000 description 4
- 230000003287 optical effect Effects 0.000 description 4
- 238000012549 training Methods 0.000 description 4
- 208000002151 Pleural effusion Diseases 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 238000004195 computer-aided diagnosis Methods 0.000 description 3
- 238000010276 construction Methods 0.000 description 3
- 238000002372 labelling Methods 0.000 description 3
- 230000006855 networking Effects 0.000 description 3
- 239000007787 solid Substances 0.000 description 3
- 238000012360 testing method Methods 0.000 description 3
- 210000000115 thoracic cavity Anatomy 0.000 description 3
- 238000013528 artificial neural network Methods 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 230000036541 health Effects 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 210000004072 lung Anatomy 0.000 description 2
- 238000013507 mapping Methods 0.000 description 2
- 230000005055 memory storage Effects 0.000 description 2
- 230000002093 peripheral effect Effects 0.000 description 2
- 208000011580 syndromic disease Diseases 0.000 description 2
- 241000700196 Galea musteloides Species 0.000 description 1
- 208000029523 Interstitial Lung disease Diseases 0.000 description 1
- 208000019693 Lung disease Diseases 0.000 description 1
- 208000011623 Obstructive Lung disease Diseases 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 239000008186 active pharmaceutical agent Substances 0.000 description 1
- 210000004027 cell Anatomy 0.000 description 1
- 230000002490 cerebral effect Effects 0.000 description 1
- 238000010219 correlation analysis Methods 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000002059 diagnostic imaging Methods 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 1
- 238000010191 image analysis Methods 0.000 description 1
- 238000003709 image segmentation Methods 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 210000001165 lymph node Anatomy 0.000 description 1
- 208000010949 lymph node disease Diseases 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 238000005065 mining Methods 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 230000035479 physiological effects, processes and functions Effects 0.000 description 1
- 238000007781 pre-processing Methods 0.000 description 1
- 230000002685 pulmonary effect Effects 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 238000013341 scale-up Methods 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 238000012358 sourcing Methods 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 238000013526 transfer learning Methods 0.000 description 1
- 238000010200 validation analysis Methods 0.000 description 1
Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H30/00—ICT specially adapted for the handling or processing of medical images
- G16H30/40—ICT specially adapted for the handling or processing of medical images for processing medical images, e.g. editing
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B6/00—Apparatus or devices for radiation diagnosis; Apparatus or devices for radiation diagnosis combined with radiation therapy equipment
- A61B6/52—Devices using data or image processing specially adapted for radiation diagnosis
- A61B6/5211—Devices using data or image processing specially adapted for radiation diagnosis involving processing of medical diagnostic data
- A61B6/5217—Devices using data or image processing specially adapted for radiation diagnosis involving processing of medical diagnostic data extracting a diagnostic or physiological parameter from medical diagnostic data
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G06F18/2155—Generating training patterns; Bootstrap methods, e.g. bagging or boosting characterised by the incorporation of unlabelled data, e.g. multiple instance learning [MIL], semi-supervised techniques using expectation-maximisation [EM] or naïve labelling
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/0002—Inspection of images, e.g. flaw detection
- G06T7/0012—Biomedical image inspection
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/0002—Inspection of images, e.g. flaw detection
- G06T7/0012—Biomedical image inspection
- G06T7/0014—Biomedical image inspection using an image reference approach
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H15/00—ICT specially adapted for medical reports, e.g. generation or transmission thereof
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H30/00—ICT specially adapted for the handling or processing of medical images
- G16H30/20—ICT specially adapted for the handling or processing of medical images for handling medical images, e.g. DICOM, HL7 or PACS
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H50/00—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics
- G16H50/20—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics for computer-aided diagnosis, e.g. based on medical expert systems
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H50/00—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics
- G16H50/70—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics for mining of medical data, e.g. analysing previous cases of other patients
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B5/00—Measuring for diagnostic purposes; Identification of persons
- A61B5/08—Detecting, measuring or recording devices for evaluating the respiratory organs
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61B—DIAGNOSIS; SURGERY; IDENTIFICATION
- A61B5/00—Measuring for diagnostic purposes; Identification of persons
- A61B5/72—Signal processing specially adapted for physiological signals or for diagnostic purposes
- A61B5/7235—Details of waveform analysis
- A61B5/7264—Classification of physiological signals or data, e.g. using neural networks, statistical classifiers, expert systems or fuzzy systems
- A61B5/7267—Classification of physiological signals or data, e.g. using neural networks, statistical classifiers, expert systems or fuzzy systems involving training the classification device
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10116—X-ray image
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/30—Subject of image; Context of image processing
- G06T2207/30004—Biomedical image processing
- G06T2207/30061—Lung
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2210/00—Indexing scheme for image generation or computer graphics
- G06T2210/12—Bounding box
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V2201/00—Indexing scheme relating to image or video recognition or understanding
- G06V2201/03—Recognition of patterns in medical or anatomical images
Definitions
- This application related to classifying and localizing thorax diseases using medical imaging and machine intelligence.
- the chest X-ray is one of the most commonly accessible radiological examinations for screening and diagnosis of many lung diseases.
- a tremendous number of X-ray imaging studies accompanied by radiological reports are accumulated and stored in many modern hospitals' Picture Archiving and Communication Systems (PACS).
- PACS Picture Archiving and Communication Systems
- this type of hospital-size knowledge database containing invaluable imaging informatics i.e., loosely labeled
- CAD computer-aided diagnosis
- ChestX-ray8 which comprises 108,948 frontal view X-ray images of 32,717 unique patients with the text mined eight disease image labels (where each image can have multi-labels), from the associated radiological reports using natural language processing.
- ChestX-ray8 comprises 108,948 frontal view X-ray images of 32,717 unique patients with the text mined eight disease image labels (where each image can have multi-labels), from the associated radiological reports using natural language processing.
- We demonstrate that these commonly occurring thoracic diseases can be detected and spatially-located via a unified weakly supervised multi-label image classification and disease localization framework, which is validated using our disclosed dataset.
- FIG. 1 illustrates eight common thoracic diseases observed in chest X-rays that validate a challenging task of fully-automated diagnosis.
- FTG. 2 is a circular diagram that shows the proportions of images with multi-labels in each of eight pathology classes and the labels' co-occurrence statistics.
- FTG. 3 is a dependency graph of text: "clear of focal airspace disease, pneumothorax, or pleural effusion".
- FTG. 4 is an overall flow-chart of a disclosed unified DCNN framework and disease localization process.
- FIG. 5 is a comparison of multi-label classification performance with different model initializations.
- FIG. 6 is a comparison of a multi-label classification performance with different pooling strategies.
- FIG. 7 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Atelectasis" Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
- FIG. 8 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Cardiomegaly” Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
- FIG. 9 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Effusion" Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
- FIG. 10 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Infiltration" Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
- FIG. 11 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Mass" Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
- FIG. 12 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Nodule" Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
- FIG. 13 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Pneumonia" Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
- FIG. 14 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Pneumothorax" Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
- FIG. 15 is a flowchart illustrating exemplary method steps disclosed herein.
- FIG. 16 is a schematic representation of an exemplary computing system disclosed herein.
- Region- level ImageNet pre-trained convolutional neural networks (CNN) based detectors are used to parse an input image and output a list of attributes or "visually-grounded high-level concepts" (including objects, actions, scenes and so on) in.
- Visual question answering (VQA) requires more detailed parsing and complex reasoning on the image contents to answer the paired natural language questions. A new dataset containing 250k natural images, 760k questions and 10M text answers is provided to address this new challenge.
- databases such as "Flickr30k Entities”, “Visual7W” and “Visual Genome” (as detailed as 94,000 images and 4,100,000 region-grounded captions) are introduced to construct and learn the spatially-dense and increasingly difficult semantic links between textual descriptions and image regions through the object-level grounding.
- FIG. 1 shows eight illustrative examples and the actual pathological findings are often significantly smaller (thus harder to detect). Fully dense annotation of region-level bounding boxes (for grounding the pathological findings) would normally be needed in computer vision datasets but may be completely nonviable for the time being. Consequently, we formulate and verify a weakly- supervised multi-label image classification and disease localization framework to address this difficulty.
- ChestX-ray8 which comprises 108,948 frontal-view X-ray images of 32,717 (collected from the year of 1992 to 2015) unique patients with the text-mined eight common disease labels, mined from the text radiological reports via NLP techniques.
- ChestX-ray8 comprises 108,948 frontal-view X-ray images of 32,717 (collected from the year of 1992 to 2015) unique patients with the text-mined eight common disease labels, mined from the text radiological reports via NLP techniques.
- these commonly occurred thoracic diseases can be detected and even spatially-located via a unified weakly- supervised multi-label image classification and disease localization formulation.
- each radiological report will be either linked with one or more keywords or marked with 'Normal' as the background category.
- the ChestX-ray8 database is composed of 108,948 frontal-view X-ray images (from 32,717 patients) and each image is labeled with one or multiple pathology keywords or "Normal" otherwise.
- FIG. 2 illustrates the correlation of the resulted keywords. It reveals some connections between different pathologies, which agree with radiologists' domain knowledge, e.g., Infiltration is often associated with Atelectasis and Effusion. To some extent, this is similar with understanding the interactions and relationships among objects or concepts in natural images.
- DNorm is a machine learning method for disease recognition and normalization. It maps every mention of keywords in a report to a unique concept ID in the Systematized Nomenclature of Medicine Clinical Terms (or SNOMED-CT), which is a
- MetaMap is another prominent tool to detect bio-concepts from the biomedical text corpus. Different from DNorm, it is an ontology-based approach for the detection of Unified Medical Language System (UMLS) Metathesaurus. In this work, we only consider the semantic types of Diseases or Syndromes and Findings (namely 'dsyn' and 'fndg' respectively). To maximize the recall of our automatic disease detection, we merge the results of DNorm and MetaMap. Table 5 shows the corresponding SNOMED-CT concepts that are relevant to the eight target diseases (these mappings are developed by searching the disease names in the UMLS terminology service, and verified by a board certified radiologist).
- UMLS Unified Medical Language System
- Negation and Uncertainty The disease detection algorithm locates every keyword mentioned in the radiology report no matter if it is truly present or negated. To eliminate the noisy labeling, we need to rule out those negated pathological statements and, more importantly, uncertain mentions of findings and diseases, e.g., "suggesting obstructive lung disease”.
- Radiology report is "normal” if it meets one of the following criteria: » If there is no disease detected in the report. Note that here we not only consider 8 diseases of interest in this paper, but all diseases detected in the reports. » If the report contains text- mined concepts of "normal” or "normal size” (CUIs C0205307 and C0332506 in the SNOMED-CT concepts respectively).
- B-Boxes hand labeled bounding boxes
- Reading and diagnosing Chest X-ray images may seem to be simple task for radiologists but, in fact, it is a complex reasoning problem which often requires careful observation and good knowledge of anatomical principles, physiology and pathology. Such factors increase the difficulty of developing a consistent and automated technique for reading chest X-ray images while simultaneously considering all common thoracic diseases.
- DCNN Deep Convolutional Neural Network
- FIG. 4 illustrates the DCNN architecture we adapted, with similarity to several previous weakly- supervised object localization methods.
- ImageNet pre-trained models
- FIG. 4 we perform the network surgery on the pre-trained models (using ImageNet), e.g., AlexNet, GoogLeNet, VGGNet-16, and ResNet-50, by leaving out the fully-connected layers and the final classification layers. Instead we insert a transition layer, a global pooling layer, a prediction layer and a loss layer in the end (after the last convolutional layer).
- ImageNet imageNet
- AlexNet AlexNet
- GoogLeNet GoogLeNet
- VGGNet-16 VGGNet-16
- ResNet-50 ResNet-50
- Multi-label Setup There are several options of image-label representation and the choices of multi-label classification loss functions.
- y c indicates the presence with respect to according pathology in the image while an all-zero vector [0,0,0,0,0,0,0,0] represents the status of "Normal" (no pathology is found in the scope of any of 8 disease categories as listed).
- This definition transits the multi-label classification problem into a regression-like loss setting.
- Transition Layer Due to the large variety of pre-trained DCNN architectures we adopt, a transition layer is usually required to transform the activations from previous layers into a uniform dimension of output, S x S x D,S £ ⁇ 8, 16,32 ⁇ .
- the transition layer helps pass down the weights from pre- trained DCNN models in a standard form, which is critical for using this layers' activations to further generate the heatmap in pathology localization step.
- Multi-label Classification Loss Layer We first experiment 3 standard loss functions for the regression task instead of using the softmax loss for traditional multi-class classification model, i.e., Hinge Loss (HL), Euclidean Loss (EL) and Cross Entropy Loss (CEL).
- Hinge Loss HL
- Euclidean Loss EL
- Cross Entropy Loss CEL
- the weighted CEL W-CEL
- INI are the total number of Ts and in a batch of image labels.
- the global pooling and the predication layer are designed not only to be part of the DCNN for classification but also to generate the likelihood map of pathologies, namely a heatmap.
- the location with a peak in the heatmap generally corresponds to the presence of disease pattern with a high probability.
- the upper part of FIG. 4 demonstrates the process of producing this heatmap.
- the pooling layer plays an important role that chooses what information to be passed down. Besides the conventional max pooling and average pooling, we also utilize the Log-Sum-Exp (LSE) pooling proposed in.
- LSE pooled value x p is defined as
- the pooled value ranges from the maximum in S (when r ⁇ ) to average (r ⁇ 0). It serves as an adjustable option between max pooling and average pooling. Since the LSE function suffers from overflow/underflow problems, the following equivalent is used while implementing the LSE pooling layer in our own DCNN architecture,
- Bounding Box Generation The heatmap produced from our multi-label classification framework indicates the approximate spatial location of one particular thoracic disease class each time. Due to the simplicity of intensity distributions in these resulting heatmaps, applying an ad- hoc thresholding based B-Box generation method for this task is found to be sufficient. The intensities in heatmaps are first normalized to [0,255] and then thresholded by ⁇ 60, 180 ⁇ individually. Finally, B-Boxes are generated to cover the isolated regions in the resulting binary maps.
- CNN Setting Our multi-label CNN architecture is implemented using Caffe framework.
- the ImageNet pre-trained models i.e., AlexNet, GoogLeNet, VGGNet-16 and ResNet-50 are obtained from the Caffe model zoo.
- Our unified DCNN takes the weights from those models and only the transition layers and prediction layers are trained from scratch.
- FIG. 5 demonstrates the multi-label classification ROC curves on 8 pathology classes by initializing the DCNN framework with 4 different pre-trained models of AlexNet, GoogLeNet, VGG and ResNet-50.
- the corresponding Area-Under-Curve (AUC) values are given in Table 4.
- the quantitative performance varies greatly, in which the model based on ResNet-50 achieves the best results.
- the weighted loss provides better overall performance than CEL, especially for those classes with relative fewer positive instances, e.g. AUC for "Cardiomegaly” is increased from 0.7262 to 0.8141 and from 0.5164 to 0.6333 for "Pneumonia”.
- Table 4 illustrates the localization accuracy (Acc.) and Average False Positive (AFP) number for each disease type, with T(IoBB) £ ⁇ 0.1, 0.25, 0.5, 0.75, 0.9 ⁇ . See below for qualitative exemplary disease localization results for each of 8 pathology classes.
- ChestX-ray8 can enable the data-hungry deep neural network paradigms to create clinically meaningful applications, including common disease pattern mining, disease correlation analysis, automated radiological report generation, etc.
- ChestX-ray8 will be extended to cover more disease classes and integrated with other clinical information, e.g., follow-up studies across time and patient history.
- the ChestX-ray8 dataset will be made publicly accessible upon institutional approval (in progress) and publication. In some embodiments, only the semantic types of Diseases or Syndromes and Findings
- negation/uncertainty defined on the syntactic level. More specifically, we utilize the syntactic dependency information because it is close to the semantic relationship between words and thus has become prevalent in biomedical text processing. We defined our rules on the dependency graph, by utilizing the dependency label and direction information between words. Table 6 shows the rules we defined for negation/uncertainty detection on the syntactic level.
- Table 7 illustrates the localization accuracy (Acc.) and Average False Positive (AFP) number for each disease type, with loll > T(IoU) only and T(IoU) E
- FIGS. 7-14 illustrate localization results from each of 8 disease classes together with associated report and mined disease keywords. The heatmaps overlay on the original images are shown on the right. Correct bounding boxes (in green), false positives (in red) and the groundtruth (in blue) are plotted over the original image on the left.
- the peak at the lower part of the left lung region indicates the presence of "atelectasis", which confer the statement of "...stable abnormal study including left basilar infilrate/atelectasis, " presented in the impression section of the associated radiological report.
- the heatmap itself is already more informative than just the presence indication of certain disease in an image.
- image refers to a visual image such as presented on a display device, or image data stored in one or more computer-readable media devices such as random access memory (RAM), hard disks, hard drives, CDs, DVDs.
- RAM random access memory
- Such data can be stored in a variety of formats such as JEPG, TIFF, BMP, PNG, GIF, and others.
- FIG. 15 is a flow diagram including several exemplary steps, yet any combination of these steps, in any logical order, can be performed to carry out many different methods, all of which methods are intended to be supported and encompassed by this disclosure.
- FIG. 15 is a flow diagram including several exemplary steps, yet any combination of these steps, in any logical order, can be performed to carry out many different methods, all of which methods are intended to be supported and encompassed by this disclosure.
- Various other steps or variations of the illustrated steps can also be included in various methods as part of the disclosed technology.
- the attached figures may not show the various ways in which the disclosed methods can be used in conjunction with other methods.
- values, procedures, or apparatus' are referred to as “lowest”, “best”, “minimum,” or the like. It will be appreciated that such descriptions are intended to indicate that a selection among many used functional alternatives can be made, and such selections need not be better, smaller, or otherwise preferable to other selections.
- the terms “a”, “an”, and “at least one” encompass one or more of the specified element. That is, if two of a particular element are present, one of these elements is also present and thus “an” element is present.
- the terms “a plurality of and “plural” mean two or more of the specified element.
- the term “and/or” used between the last two of a list of elements means any one or more of the listed elements.
- the phrase “A, B, and/or C” means “A”, “B,”, “C”, “A and B”, “A and C", “B and C”, or “A, B, and C.”
- the term “coupled” generally means physically coupled or linked and does not exclude the presence of intermediate elements between the coupled items absent specific contrary language.
- FIG. 16 illustrates an exemplary system that includes a processor, memory/data storage/database, user interfaces, communications, x-ray image acquisition module, and applications configured to perform methods and operations disclosed herein.
- the disclosed technology can be implemented at least in part in the general context of computer executable instructions, such as program modules, being executed by a personal computer (PC), a mobile computing device, tablet computer, or other computational and/or control device.
- program modules include routines, programs, objects, components, data structures, etc., that perform particular tasks or implement particular abstract data types.
- the disclosed technology may be implemented with other computer system configurations, including hand held devices, multiprocessor systems, microprocessor-based or programmable consumer electronics, network PCs, minicomputers, mainframe computers, and the like.
- the disclosed technology may also be practiced in distributed computing environments where tasks are performed by remote processing devices that are linked through a communications network.
- program modules may be located in both local and remote memory storage devices.
- An exemplary system for implementing the disclosed technology can include a general purpose computing device in the form of an exemplary PC, including one or more processing units, a system memory, and a system bus that couples various system components including the system memory to the one or more processing units.
- the system bus may be any of several types of bus structures including a memory bus or memory controller, a peripheral bus, and a local bus using any of a variety of bus architectures.
- the exemplary system memory includes read only memory (ROM) and random access memory (RAM).
- ROM read only memory
- RAM random access memory
- a basic input/output system (BIOS) containing the basic routines that help with the transfer of information between elements within the PC, is stored in ROM.
- An exemplary PC can further include one or more storage devices such as a hard disk drive for reading from and writing to a hard disk, a magnetic disk drive for reading from or writing to a removable magnetic disk, an optical disk drive for reading from or writing to a removable optical disk (such as a CD-ROM or other optical media), and a solid state drive.
- a hard disk drive for reading from and writing to a hard disk
- a magnetic disk drive for reading from or writing to a removable magnetic disk
- an optical disk drive for reading from or writing to a removable optical disk (such as a CD-ROM or other optical media)
- a solid state drive Such storage devices can be connected to the system bus by a hard disk drive interface, a magnetic disk drive interface, an optical drive interface, or a solid state drive interface, respectively.
- the drives and their associated computer readable media provide nonvolatile storage of computer-readable instructions, data structures, program modules, and other data for the PC.
- PCs computer-readable media which can store data that is accessible by a PC
- a number of program modules may be stored in the storage devices including an operating system, one or more application programs, other program modules, and program data.
- a user may enter commands and information into the PC through one or more input devices such as a keyboard and a pointing device such as a mouse.
- Other input devices may include a digital camera, microphone, joystick, game pad, scanner, or the like.
- serial port interface that is coupled to the system bus, but may be connected by other interfaces such as a parallel port, game port, or universal serial bus (USB).
- a monitor or other type of display device is also connected to the system bus via an interface, such as a video adapter.
- Other peripheral output devices such as speakers and printers (not shown), may be included.
- the PC may operate in a networked environment using logical connections to one or more remote computers.
- a remote computer may be another PC, a server, a router, a network PC, or a peer device or other common network node, and typically includes many or all of the elements described above relative to the PC.
- the local computer and/or the remote computer can be connected to a logical a local area network (LAN) and a wide area network (WAN).
- LAN local area network
- WAN wide area network
- Such networking environments may include wide computer networks, intranets, and the Internet.
- the PC When used in a LAN networking environment, the PC is connected to the LAN through a network interface. When used in a WAN networking environment, the PC typically includes a modem or other means for establishing communications over the WAN, such as the Internet. In a networked environment, program modules depicted relative to the personal computer, or portions thereof, may be stored in the remote memory storage device or other locations on the LAN or WAN. The network connections shown are exemplary, and other means of establishing a communications link between the computers may be used.
- the memory generally includes computer-executable instructions for performing aspects of the disclosed methods in respective memory portions.
- Computer-executable instructions for data acquisition and/or other aspects of the disclosed methods can be stored in a specific memory portion for use with an X-ray machine or other equipment.
- Acquired and processed data can be displayed using computer-executable instructions stored at the memory portion.
- data acquisition, processing, and instrument control can be provided at any portion of the system, or distribution at one or more processing devices using a LAN or WAN.
Landscapes
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- General Health & Medical Sciences (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Public Health (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- Biomedical Technology (AREA)
- Evolutionary Computation (AREA)
- Life Sciences & Earth Sciences (AREA)
- Primary Health Care (AREA)
- Epidemiology (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Radiology & Medical Imaging (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- Databases & Information Systems (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Pathology (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Computational Linguistics (AREA)
- Multimedia (AREA)
- Quality & Reliability (AREA)
- Physiology (AREA)
- High Energy & Nuclear Physics (AREA)
- Optics & Photonics (AREA)
- Heart & Thoracic Surgery (AREA)
- Surgery (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Apparatus For Radiation Diagnosis (AREA)
Abstract
A new chest X-ray database, referred to as "ChestX-ray8", is disclosed herein, which comprises over 100,000 frontal view X-ray images of over 32,000 unique patients with the text- mined eight disease image labels (where each image can have multi-labels), from the associated radiological reports using natural language processing. We demonstrate that these commonly occurring thoracic diseases can be detected and spatially-located via a unified weakly supervised multi-label image classification and disease localization framework, which is validated using our disclosed dataset.
Description
METHOD AND SYSTEM OF BUILDING HOSPITAL-SCALE CHEST
X-RAY DATABASE FOR ENTITY EXTRACTION AND WEAKLY-SUPERVISED CLASSIFICATION AND LOCALIZATION OF
COMMON THORAX DISEASES
CROSS-REFERENCE TO RELATED APPLICATIONS
This application claims priority to U.S. Provisional Patent Application No. 62/476,029, filed March 24, 2017, which is incorporated by reference herein in its entirety. STATEMENT OF GOVERNMENT SUPPORT
This invention was made with Government support by the National Institutes of Health, National Cancer Institute, Clinical Center. The United States Government has certain rights in the invention. FIELD
This application related to classifying and localizing thorax diseases using medical imaging and machine intelligence.
BACKGROUND
The chest X-ray is one of the most commonly accessible radiological examinations for screening and diagnosis of many lung diseases. A tremendous number of X-ray imaging studies accompanied by radiological reports are accumulated and stored in many modern hospitals' Picture Archiving and Communication Systems (PACS). On the other side, it is still an open question how this type of hospital-size knowledge database containing invaluable imaging informatics (i.e., loosely labeled) can be used to facilitate the data-hungry deep learning paradigms in building truly large-scale high precision computer-aided diagnosis (CAD) systems.
SUMMARY
Disclosed herein is new chest X-ray database, referred to as "ChestX-ray8", which comprises 108,948 frontal view X-ray images of 32,717 unique patients with the text mined eight disease image labels (where each image can have multi-labels), from the associated radiological reports using natural language processing. We demonstrate that these commonly occurring thoracic diseases can be detected and spatially-located via a unified weakly supervised multi-label image
classification and disease localization framework, which is validated using our disclosed dataset. The initial quantitative results are described herein, and furthermore deep convolutional neural network based "reading chest X-rays" (e.g., recognizing and locating the common disease patterns trained with only image-level labels) can also be performed with fully- automated high precision CAD systems.
The foregoing and other features and advantages of the disclosed technology will become more apparent from the following detailed description, which proceeds with reference to the accompanying figures. BRIEF DESCRIPTION OF THE FIGURES
FIG. 1 illustrates eight common thoracic diseases observed in chest X-rays that validate a challenging task of fully-automated diagnosis.
FTG. 2 is a circular diagram that shows the proportions of images with multi-labels in each of eight pathology classes and the labels' co-occurrence statistics.
FTG. 3 is a dependency graph of text: "clear of focal airspace disease, pneumothorax, or pleural effusion".
FTG. 4 is an overall flow-chart of a disclosed unified DCNN framework and disease localization process.
FIG. 5 is a comparison of multi-label classification performance with different model initializations.
FIG. 6 is a comparison of a multi-label classification performance with different pooling strategies.
FIG. 7 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Atelectasis" Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
FIG. 8 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Cardiomegaly" Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
FIG. 9 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Effusion" Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
FIG. 10 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Infiltration" Class. Correct bounding box (in green), false positives (in
red) and the ground truth (in blue) are plotted over the original image.
FIG. 11 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Mass" Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
FIG. 12 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Nodule" Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
FIG. 13 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Pneumonia" Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
FIG. 14 is a sample of a chest x-ray radiology report, with mined disease keywords and localization result from the "Pneumothorax" Class. Correct bounding box (in green), false positives (in red) and the ground truth (in blue) are plotted over the original image.
FIG. 15 is a flowchart illustrating exemplary method steps disclosed herein.
FIG. 16 is a schematic representation of an exemplary computing system disclosed herein.
DETAILED DESCRIPTION
As described herein, rapid and tremendous progress has been evidenced in a range of computer vision problems via deep learning and large-scale annotated image datasets. Drastically improved quantitative performances in object recognition, detection, and segmentation are demonstrated in comparison to previous shallow methodologies built upon hand-crafted image features. Deep neural network representations further make the joint language and vision learning tasks more feasible to solve, in image captioning, visual question answering and knowledge-guided transfer learning, and so on. However, the intriguing and strongly observable performance gaps of the current state-of-the-art object detection and segmentation methods, evaluated between using PASCAL VOC and employing Microsoft (MS) COCO, demonstrate that there is still significant room for performance improvement when underlying challenges (represented by different datasets) become greater. For example, MS COCO is composed of 80 object categories from 200k images, with 1.2M instances (350k are people) where every instance is segmented and many instances are small objects. Comparing to PASCAL VOC of only 20 classes and 11,530 images containing
27,450 annotated objects with bounding-boxes (BBox), an alternative object detection approaches achieve 0.413 in MS COCO versus 0.884 in PASCAL VOC, under mean Average Precision (mAP).
Deep learning yields similar rises in performance in the medical image analysis domain for object (often human anatomical or pathological structures in radiology imaging) detection and segmentation tasks. Recent notable work includes (but is not limit to) an overview review on the future promise of deep learning and a collection of important medical applications on lymph node and interstitial lung disease detection and classification; cerebral microbleed detection; pulmonary nodule detection in CT images; automated pancreas segmentation; cell image segmentation and tracking, predicting spinal radiological scores, and extensions of multi-modal imaging
segmentation. A significant limitation is that all proposed methods are evaluated on some small-to- middle scale problems of (at most) several hundred patients. It remains unclear how well the current deep learning techniques can scale up to tens of thousands of patient studies.
In the era of deep learning in computer vision, research efforts on building various annotated image datasets with different characteristics play important roles on the better definition of the forthcoming problems, challenges and subsequently possible technological progresses. Particularly, here we focus on the relationship and joint learning of image (chest X-rays) and text (X-ray reports). The previous representative image caption generation work utilize Flickr8K, Flickr30K and MS COCO datasets that hold 8,000, 31,000 and 123,000 images respectively and every image is annotated by five sentences via Amazon Mechanical Turk (AMT). The text generally describes annotator's attention of objects and activity occurring on an image in a straightforward manner. Region- level ImageNet pre-trained convolutional neural networks (CNN) based detectors are used to parse an input image and output a list of attributes or "visually-grounded high-level concepts" (including objects, actions, scenes and so on) in. Visual question answering (VQA) requires more detailed parsing and complex reasoning on the image contents to answer the paired natural language questions. A new dataset containing 250k natural images, 760k questions and 10M text answers is provided to address this new challenge. Additionally, databases such as "Flickr30k Entities", "Visual7W" and "Visual Genome" (as detailed as 94,000 images and 4,100,000 region-grounded captions) are introduced to construct and learn the spatially-dense and increasingly difficult semantic links between textual descriptions and image regions through the object-level grounding.
Though one could argue that the high-level analogy exists between image caption generation, visual question answering, and imaging based disease diagnosis, there are at least three factors making truly large-scale medical image based diagnosis (e.g., involving tens of thousands of patients) tremendously more formidable. 1, Generic, open-ended image-level anatomy and pathology labels cannot be obtained through crowd-sourcing, such as AMT, which is prohibitively implausible for non- medically trained annotators. Therefore we exploit to mine the per- image
(possibly multiple) common thoracic pathology labels from the image- attached chest X-ray radiological reports using Natural Language Processing (NLP) techniques. Radiologists tend to write more abstract and complex logical reasoning sentences than the plain describing texts in. 2, The spatial dimensions of a chest X-ray are usually 2000x3000 pixels. Local pathological image regions can show hugely varying sizes or extents but often very small comparing to the full image scale. FIG. 1 shows eight illustrative examples and the actual pathological findings are often significantly smaller (thus harder to detect). Fully dense annotation of region-level bounding boxes (for grounding the pathological findings) would normally be needed in computer vision datasets but may be completely nonviable for the time being. Consequently, we formulate and verify a weakly- supervised multi-label image classification and disease localization framework to address this difficulty. 3, So far, all image captioning and VQA techniques in computer vision strongly depend on the ImageNet pre-trained deep CNN models which already perform very well in a large number of object classes and serves a good baseline for further model fine-tuning. However, this situation does not apply to the medical image diagnosis domain. Thus we have to learn the deep image recognition and localization models while constructing the weakly-labeled medical image database.
To tackle these issues, we propose a new chest X-ray database, namely "ChestX-ray8", which comprises 108,948 frontal-view X-ray images of 32,717 (collected from the year of 1992 to 2015) unique patients with the text-mined eight common disease labels, mined from the text radiological reports via NLP techniques. In particular, we demonstrate that these commonly occurred thoracic diseases can be detected and even spatially-located via a unified weakly- supervised multi-label image classification and disease localization formulation.
There have been recent efforts on creating openly available annotated medical image databases with the studied patient numbers ranging from a few hundreds to two thousands.
Particularly for chest X-rays, the largest public dataset is Openl that contains 3,955 radiology reports from the Indiana Network for Patient Care and 7,470 associated chest x-rays from the hospitals picture archiving and communication system (PACS). This database is utilized in as a problem of caption generation but no quantitative disease detection results are reported. Our newly proposed chest X-ray database is at least one order of magnitude larger than Openl (Refer to Table 1). To achieve the better clinical relevance, we focus to exploit the quantitative performance on weakly-supervised multi-label image classification and disease localization of common thoracic diseases, in analogy to the intermediate step of "detecting attributes" in or "visual grounding" for.
In this section, we describe the approach for building a hospital-scale chest X-ray image database, namely "ChestX-ray8", mined from our institute's PACS system. First, we short-list eight common thoracic pathology keywords that are frequently observed and diagnosed, i.e., Atelectasis, Cardiomegaly, Effusion, Infiltration, Mass, Nodule, Pneumonia and Pneumathorax (FIG. 1), based on radiologists' feedback. Given those 8 text keywords, we search the PACS system to pull out all the related radiological reports (together with images) as our target corpus. A variety of Natural Language Processing (NLP) techniques are adopted for detecting the pathology keywords and removal of negation and uncertainty. Each radiological report will be either linked with one or more keywords or marked with 'Normal' as the background category. As a result, the ChestX-ray8 database is composed of 108,948 frontal-view X-ray images (from 32,717 patients) and each image is labeled with one or multiple pathology keywords or "Normal" otherwise. FIG. 2 illustrates the correlation of the resulted keywords. It reveals some connections between different pathologies, which agree with radiologists' domain knowledge, e.g., Infiltration is often associated with Atelectasis and Effusion. To some extent, this is similar with understanding the interactions and relationships among objects or concepts in natural images.
Overall, our approach produces labels using the reports in two passes. In the first iteration, we detected all the disease concept in the corpus. The main body of each chest X-ray report is generally structured as "Comparison", "Indication", "Findings", and "Impression" sections. Here, we focus on detecting disease concepts in the Findings and Impression sections. If a report contains neither of these two sections, the full-length report will then be considered. In the second pass, we code the reports as "Normal" if they do not contain any diseases (not limited to 8 predefined pathologies).
Pathology Detection: We mine the radiology reports for disease concepts using two tools, DNorm and MetaMap. DNorm is a machine learning method for disease recognition and normalization. It maps every mention of keywords in a report to a unique concept ID in the Systematized Nomenclature of Medicine Clinical Terms (or SNOMED-CT), which is a
standardized vocabulary of clinical terminology for the electronic exchange of clinical health information.
MetaMap is another prominent tool to detect bio-concepts from the biomedical text corpus. Different from DNorm, it is an ontology-based approach for the detection of Unified Medical Language System (UMLS) Metathesaurus. In this work, we only consider the semantic types of Diseases or Syndromes and Findings (namely 'dsyn' and 'fndg' respectively). To maximize the recall of our automatic disease detection, we merge the results of DNorm and MetaMap. Table 5
shows the corresponding SNOMED-CT concepts that are relevant to the eight target diseases (these mappings are developed by searching the disease names in the UMLS terminology service, and verified by a board certified radiologist).
Negation and Uncertainty: The disease detection algorithm locates every keyword mentioned in the radiology report no matter if it is truly present or negated. To eliminate the noisy labeling, we need to rule out those negated pathological statements and, more importantly, uncertain mentions of findings and diseases, e.g., "suggesting obstructive lung disease".
Although many text processing systems can handle the negation/uncertainty detection problem, most of them exploit regular expressions on the text directly. One of the disadvantages to use regular expressions for negation/uncertainty detection is that they cannot capture various syntactic constructions for multiple subjects. For example, in the phrase of "clear of A and B", the regular expression can capture "A" as a negation but not "B", particularly when both "A" and "B" are long and complex noun phrases ("clear of focal airspace disease, pneumothorax, or pleural effusion" in FIG. 3).
To overcome this complication, we hand-craft a number of novel rules of
negation/uncertainty defined on the syntactic level in this work. More specifically, we utilize the syntactic dependency information because it is close to the semantic relationship between words and thus has become prevalent in biomedical text processing. We defined our rules on the dependency graph, by utilizing the dependency label and direction information between words.
As the first step of preprocessing, we split and tokenize the reports into sentences using
NLTK. Next we parse each sentence by the Bllip parser using David McClosky' s biomedical model. The syntactic dependencies are then obtained from "CCProcessed" dependencies output by applying Stanford dependencies converter on the parse tree. The "CCProcessed" representation propagates conjunct dependencies thus simplifies coordinations. As a result, we can use fewer rules to match more complex constructions. For an example as shown in FIG. 3, we could use "clear→ prep_of→ DISEASE" to detect three negations from the text (neg, focal airspace disease), (neg, pneumothorax), and (neg, pleural effusion).
Furthermore, we label a radiology report as "normal" if it meets one of the following criteria: » If there is no disease detected in the report. Note that here we not only consider 8 diseases of interest in this paper, but all diseases detected in the reports.
» If the report contains text- mined concepts of "normal" or "normal size" (CUIs C0205307 and C0332506 in the SNOMED-CT concepts respectively).
To validate our method, we perform the following experiments. Given the fact that no gold- standard labels exist for our dataset, we resort to some existing annotated corpora as an alternative. Using the OpenI API, we retrieve a total of 3,851 unique radiology reports where each OpenI report is assigned with its key findings/disease names by human annotators. Given our focus on the eight diseases, a subset of OpenI reports and their human annotations are used as the gold standard for evaluating our method. Table 1 summarizes the statistics of the subset of OpenI reports. Table 2 shows the results of our method using OpenI, measured in precision (P), recall (R), and Fl-score. Higher precision of 0.90, higher recall of 0.91, and higher Fl-score of 0.90 are achieved compared to the existing MetaMap approach (with NegEx enabled). For all diseases, our method obtains higher precisions, particularly in "pneumothorax" (0.90 vs. 0.32) and "infiltration" (0.74 vs. 0.25). This indicates that the usage of negation and uncertainty detection on syntactic level successfully removes false positive cases. More importantly, the higher precisions meet our expectation to generate a Chest X-ray corpus with accurate semantic labels, to lay a solid foundation for the later processes.


Comparing to the popular ImageNet classification problem, significantly smaller spatial extents of many diseases inside the typical X-ray image dimensions of 3000 x 2000 pixels impose challenges in both the capacity of computing hardware and the design of deep learning paradigm. In ChestX-ray8, X-rays images are directly extracted from the DICOM file and resized as 1024x1024 bitmap images without significantly losing the detail contents, compared with image sizes of 512 x 512 in OpenI dataset. Their intensity ranges are rescaled using the default window settings stored in the DICOM header files.
As part of the ChestX-ray8 database, a small number of images with pathology are provided with hand labeled bounding boxes (B-Boxes), which can be used as the ground truth to evaluate the disease localization performance. Furthermore, it could also be adopted for one/low-shot learning setup, in which only one or several samples are needed to initialize the learning and the system will then evolve by itself with more unlabeled data. We leave this as future work.
In our labeling process, we first select 200 instances for each pathology (1,600 instances total), consisting of 983 images. Given an image and a disease keyword, a board certified radiologist identified only the corresponding disease instance in the image and labeled it with a B-Box. The B- Box is then outputted as an XML file. If one image contains multiple disease instances, each disease instance is labeled separately and stored into individual XML files. As an application of the proposed ChestX-ray8 database and benchmarking, we will demonstrate the detection and localization of thoracic diseases in the following.
Reading and diagnosing Chest X-ray images may seem to be simple task for radiologists
but, in fact, it is a complex reasoning problem which often requires careful observation and good knowledge of anatomical principles, physiology and pathology. Such factors increase the difficulty of developing a consistent and automated technique for reading chest X-ray images while simultaneously considering all common thoracic diseases.
As an important application of ChestX-ray8 dataset, we present a unified weakly- supervised multi-label image classification and pathology localization framework, which can detect the presence of multiple pathologies and subsequently generate bounding boxes around the
corresponding pathologies. In details, we tailor Deep Convolutional Neural Network (DCNN) architectures for weakly-supervised object localization, by considering large image capacity, various multi-label CNN losses and different pooling strategies.
One goal is to first detect if one or multiple pathologies are presented in each X-ray image and later we can locate them using the activation and weights extracted from the network. We tackle this problem by training a multi-label DCNN classification model. FIG. 4 illustrates the DCNN architecture we adapted, with similarity to several previous weakly- supervised object localization methods. As shown in FIG. 4, we perform the network surgery on the pre-trained models (using ImageNet), e.g., AlexNet, GoogLeNet, VGGNet-16, and ResNet-50, by leaving out the fully-connected layers and the final classification layers. Instead we insert a transition layer, a global pooling layer, a prediction layer and a loss layer in the end (after the last convolutional layer). A combination of deep activations from the transition layer (a set of spatial image features) and the weights of prediction inner-product layer (trained feature weighting) can enable us to find the plausible spatial locations of diseases.
Multi-label Setup: There are several options of image-label representation and the choices of multi-label classification loss functions. Here, we define a 8-dimensional label vector y =
 ε {0, 1 },C = 8 for each image. yc indicates the presence with respect to according pathology in the image while an all-zero vector [0,0,0,0,0,0,0,0] represents the status of "Normal" (no pathology is found in the scope of any of 8 disease categories as listed). This definition transits the multi-label classification problem into a regression-like loss setting.
ε {0, 1 },C = 8 for each image. yc indicates the presence with respect to according pathology in the image while an all-zero vector [0,0,0,0,0,0,0,0] represents the status of "Normal" (no pathology is found in the scope of any of 8 disease categories as listed). This definition transits the multi-label classification problem into a regression-like loss setting.
Transition Layer: Due to the large variety of pre-trained DCNN architectures we adopt, a transition layer is usually required to transform the activations from previous layers into a uniform dimension of output, S x S x D,S £ { 8, 16,32} . D represents the dimension of features at spatial location E { l,...,S} , which can be varied in different model settings, e.g., D = 1024 for
GoogLeNet and D = 2048 for ResNet. The transition layer helps pass down the weights from pre-
trained DCNN models in a standard form, which is critical for using this layers' activations to further generate the heatmap in pathology localization step.
Multi-label Classification Loss Layer: We first experiment 3 standard loss functions for the regression task instead of using the softmax loss for traditional multi-class classification model, i.e., Hinge Loss (HL), Euclidean Loss (EL) and Cross Entropy Loss (CEL). However, we find that the model has difficulty learning positive instances (images with pathologies) and the image labels are rather sparse, meaning there are extensively more 'O's than Ts. This is due to our one-hot-like image labeling strategy and the unbalanced numbers of pathology and "Normal" classes. Therefore, we introduce the positive/negative balancing factor βρ,βΝ to enforce the learning of positive examples. For example, the weighted CEL (W-CEL) is defined as follows,

where is set to
 while vis set to
while vis set to
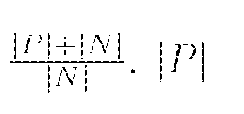
and INI are the total number of Ts and in a batch of image labels.
Global Pooling Layer and Prediction Layer: In our multi-label image classification network, the global pooling and the predication layer are designed not only to be part of the DCNN for classification but also to generate the likelihood map of pathologies, namely a heatmap. The location with a peak in the heatmap generally corresponds to the presence of disease pattern with a high probability. The upper part of FIG. 4 demonstrates the process of producing this heatmap. By performing a global pooling after the transition layer, the weights learned in the prediction layer can function as the weights of spatial maps from the transition layer. Therefore, we can produce weighted spatial activation maps for each disease class (with a size of S x S x C) by multiplying the activation from transition layer (with a size of S x S x D) and the weights of prediction layer (with a size of D x C).
The pooling layer plays an important role that chooses what information to be passed down. Besides the conventional max pooling and average pooling, we also utilize the Log-Sum-Exp (LSE) pooling proposed in. The LSE pooled value xpis defined as

where is the activation value at is one location in the pooling region S, and S

where

Bounding Box Generation: The heatmap produced from our multi-label classification framework indicates the approximate spatial location of one particular thoracic disease class each time. Due to the simplicity of intensity distributions in these resulting heatmaps, applying an ad- hoc thresholding based B-Box generation method for this task is found to be sufficient. The intensities in heatmaps are first normalized to [0,255] and then thresholded by {60, 180} individually. Finally, B-Boxes are generated to cover the isolated regions in the resulting binary maps.
Experiments
Data: We evaluate and validate the unified disease classification and localization framework using the proposed ChestX-ray8 database. In total, 108,948 frontal-view X-ray images are in the database, of which 24,636 images contain one or more pathologies. The remaining 84,312 images are normal cases. For the pathology classification and localization task, we randomly shuffled the entire dataset into three subgroups for CNN fine-tuning via Stochastic Gradient Descent (SGD): i.e. training (70%), validation (10%) and testing (20%). We only report the 8 thoracic disease recognition performance on the testing set in our experiments. Furthermore, for the 983 images with 1,600 annotated B-Boxes of pathologies, these boxes are only used as the ground truth to evaluate the disease localization accuracy in testing (not for training purpose).
CNN Setting: Our multi-label CNN architecture is implemented using Caffe framework. The ImageNet pre-trained models, i.e., AlexNet, GoogLeNet, VGGNet-16 and ResNet-50 are obtained from the Caffe model zoo. Our unified DCNN takes the weights from those models and only the transition layers and prediction layers are trained from scratch.
Due to the large image size and the limit of GPU memory, it is necessary to reduce the
image batchsize to load the entire model and keep activations in GPU while we increase the iter- size to accumulate the gradients for more iterations. The combination of both may vary in different CNN models but we set batchsize x iter_size = 80 as a constant. Furthermore, the total training iterations are customized for different CNN models to prevent over-fitting. More complex models like ResNet-50 actually take less iterations (e.g., 10,000 iterations) to reach the convergence. The DCNN models are trained using a Dev-Box linux server with 4 Titan X GPUs.
Multi-label Disease Classification: FIG. 5 demonstrates the multi-label classification ROC curves on 8 pathology classes by initializing the DCNN framework with 4 different pre-trained models of AlexNet, GoogLeNet, VGG and ResNet-50. The corresponding Area-Under-Curve (AUC) values are given in Table 4. The quantitative performance varies greatly, in which the model based on ResNet-50 achieves the best results. The "Cardiomegaly" (AUC=0.8141) and "Pneumothorax" (AUC=0.7891) classes are consistently well-recognized compared to other groups while the detection ratios can be relatively lower for pathologies which contain small objects, e.g., "Mass" (AUC=0.5609) and "Nodule" classes. Mass is difficult to detect due to its huge within-class appearance variation. The lower performance on "Pneumonia" (AUC=0.6333) is probably because of lack of total instances in our patient population (less than 1% X-rays labeled as Pneumonia). This finding is consistent with the comparison on object detection performance, degrading from
PASCAL VOC to MS COCO where many small annotated objects appear.


Next, we examine the influence of different pooling strategies when using ResNet-50 to initialize the DCNN framework. As discussed above, three types of pooling schemes are experimented: average looping, LSE pooling and max pooling. The hyper-parameter r in LSE pooling varies in {0.1, 0.5, 1, 5, 8, 10, 12}. As illustrated in FIG. 6, average pooling and max pooling achieve approximately equivalent performance in this classification task. The performance of LSE pooling start declining first when r starts increasing and reach the bottom when r = 5. Then it reaches the overall best performance around r = 10. LSE pooling behaves like a weighed pooling method or a transition scheme between average and max pooling under different r values. Overall, LSE pooling (r = 10) reports the best performance (consistently higher than mean and max pooling).
Last, we demonstrate the performance improvement by using the positive/negative instances balanced loss functions (Eq. 1). As shown in Table 4, the weighted loss (WCEL) provides better overall performance than CEL, especially for those classes with relative fewer positive instances, e.g. AUC for "Cardiomegaly" is increased from 0.7262 to 0.8141 and from 0.5164 to 0.6333 for "Pneumonia".
Disease Localization: Leveraging the fine-tuned DCNN models for multi-label disease classification, we can calculate the disease heatmaps using the activations of the transition layer and the weights from the prediction layer, and even generate the B-Boxes for each pathology candidate. The computed bounding boxes are evaluated against the hand annotated ground truth (GT) boxes (included in ChestX-ray8). Although the total number of B-Box annotations (1,600 instances) is relatively small compared to the entire dataset, it may be still sufficient to get a reasonable estimate on how the proposed framework performs on the weakly-supervised disease localization task. To
examine the accuracy of computerized B-Boxes versus the GT B-Boxes, two types of measurement are used, i.e, the standard Intersection over Union ratio (IoU) or the Intersection over the detected B-Box area ratio (IoBB) (similar to Area of Precision or Purity). Due to the relatively low spatial resolution of heatmaps (32 x 32) in contrast to the original image dimensions (1024 x 1024), the computed B-Boxes are often larger than the according GT B-Boxes. Therefore, we define a correct localization by requiring either IoU > T(IoU) or IoBB > T(IoBB). Refer to the supplementary material for localization performance under varying T(IoU). Table 4 illustrates the localization accuracy (Acc.) and Average False Positive (AFP) number for each disease type, with T(IoBB) £ {0.1, 0.25, 0.5, 0.75, 0.9}. See below for qualitative exemplary disease localization results for each of 8 pathology classes.
Constructing hospital-scale radiology image databases with computerized diagnostic performance benchmarks has not been addressed until this work. We attempt to build a "machine- human annotated" comprehensive chest X-ray database that presents the realistic clinical and methodological challenges of handling at least tens of thousands of patients (somewhat similar to "ImageNet" in natural images). We also conduct extensive quantitative performance benchmarking on eight common thoracic pathology classification and weakly- supervised localization using ChestX-ray8 database. Building large-scale, fully- automated high precision medical diagnosis systems can be performed using the disclosed technology. ChestX-ray8 can enable the data-hungry deep neural network paradigms to create clinically meaningful applications, including common disease pattern mining, disease correlation analysis, automated radiological report generation, etc. For future work, ChestX-ray8 will be extended to cover more disease classes and integrated with other clinical information, e.g., follow-up studies across time and patient history. The ChestX-ray8 dataset will be made publicly accessible upon institutional approval (in progress) and publication. In some embodiments, only the semantic types of Diseases or Syndromes and Findings
(namely 'dsyn' and 'fndg' respectively) are considered. Table 5 shows the corresponding
SNOMED-CT concepts that are relevant to the target diseases (these mappings are developed by searching the disease names in the UMLS terminology service, and verified by a board certificated radiologist.
 Although many text processing systems can handle the negation/uncertainty detection problem, most of them exploit regular expressions on the text directly. One of the disadvantages to use regular expressions for negation/uncertainty detection is that they cannot capture various syntactic constructions for multiple subjects. For example, in the phrase of "clear of A and B", the regular expression can capture "A" as a negation but not "B", particularly when both "A" and "B" are long and complex noun phrases.
Although many text processing systems can handle the negation/uncertainty detection problem, most of them exploit regular expressions on the text directly. One of the disadvantages to use regular expressions for negation/uncertainty detection is that they cannot capture various syntactic constructions for multiple subjects. For example, in the phrase of "clear of A and B", the regular expression can capture "A" as a negation but not "B", particularly when both "A" and "B" are long and complex noun phrases.
To overcome this complication, we developed a number of novel rules of
negation/uncertainty defined on the syntactic level. More specifically, we utilize the syntactic dependency information because it is close to the semantic relationship between words and thus has become prevalent in biomedical text processing. We defined our rules on the dependency graph, by
utilizing the dependency label and direction information between words. Table 6 shows the rules we defined for negation/uncertainty detection on the syntactic level.

Table 6. Rules and corresponding examples for negation and uncertainty detection.
Table 7 illustrates the localization accuracy (Acc.) and Average False Positive (AFP) number for each disease type, with loll > T(IoU) only and T(IoU) E
{0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7}.

Table 7. Pathology localization accuracy and average false positive number for 8 disease classes with TiloU) ranged from 0.1 to 0.7.
FIGS. 7-14 illustrate localization results from each of 8 disease classes together with associated report and mined disease keywords. The heatmaps overlay on the original images are shown on the right. Correct bounding boxes (in green), false positives (in red) and the groundtruth (in blue) are plotted over the original image on the left.
In order to quantitatively demonstrate how informative those heatmaps are, a simple two- level thresholding based bounding box generator is adopted here to catch the peaks in the heatmap and later generated bounding boxes can be evaluated against the ground truth. Each heatmap will approximately result in 1-3 bounding boxes. The localization accuracy and AFP (shown in Table 7) can be further optimized by adopting a more sophisticated bounding box generation method, e.g. selective search or Edgebox. With this technology, is can be possible to compute the exact spatial location of disease patterns, or to just obtain some instructive location information for future applications, e.g. automated radiological report generation. Take the case shown in FIG. 7 for an example. The peak at the lower part of the left lung region indicates the presence of "atelectasis", which confer the statement of "...stable abnormal study including left basilar infilrate/atelectasis, ..." presented in the impression section of the associated radiological report. By combining with other information, e.g. a lung region mask, the heatmap itself is already more informative than just the presence indication of certain disease in an image.
As used herein, "image" refers to a visual image such as presented on a display device, or image data stored in one or more computer-readable media devices such as random access memory (RAM), hard disks, hard drives, CDs, DVDs. Such data can be stored in a variety of formats such as JEPG, TIFF, BMP, PNG, GIF, and others.
For purposes of this description, certain aspects, advantages, and novel features of the embodiments of this disclosure are described herein. The disclosed methods, apparatuses, and systems should not be construed as limiting in any way. Instead, the present disclosure is directed toward all novel and nonobvious features and aspects of the various disclosed embodiments, alone and in various combinations and sub-combinations with one another. The methods, apparatuses, and systems are not limited to any specific aspect or feature or combination thereof, nor do the disclosed embodiments require that any one or more specific advantages be present or problems be solved.
Characteristics and features described in conjunction with a particular aspect, embodiment, or example of the disclosed technology are to be understood to be applicable to any other aspect, embodiment or example described herein unless incompatible therewith. All of the features disclosed in this specification (including any accompanying claims, abstract and drawings), and/or
all of the steps of any method or process so disclosed, may be combined in any combination, except combinations where at least some of such features and/or steps are mutually exclusive. The invention is not restricted to the details of any foregoing embodiments. The invention extends to any novel one, or any novel combination, of the features disclosed in this specification (including any accompanying claims, abstract and drawings), or to any novel one, or any novel combination, of the steps of any method or process so disclosed.
Although the operations of some of the disclosed methods are described in a particular, sequential order for convenient presentation, it should be understood that this manner of description encompasses rearrangement, unless a particular ordering is required by specific language. For example, operations described sequentially may in some cases be rearranged or performed concurrently. For example, FIG. 15 is a flow diagram including several exemplary steps, yet any combination of these steps, in any logical order, can be performed to carry out many different methods, all of which methods are intended to be supported and encompassed by this disclosure. Various other steps or variations of the illustrated steps, can also be included in various methods as part of the disclosed technology. Moreover, for the sake of simplicity, the attached figures may not show the various ways in which the disclosed methods can be used in conjunction with other methods.
In some examples, values, procedures, or apparatus' are referred to as "lowest", "best", "minimum," or the like. It will be appreciated that such descriptions are intended to indicate that a selection among many used functional alternatives can be made, and such selections need not be better, smaller, or otherwise preferable to other selections.
As used herein, the terms "a", "an", and "at least one" encompass one or more of the specified element. That is, if two of a particular element are present, one of these elements is also present and thus "an" element is present. The terms "a plurality of and "plural" mean two or more of the specified element. As used herein, the term "and/or" used between the last two of a list of elements means any one or more of the listed elements. For example, the phrase "A, B, and/or C" means "A", "B,", "C", "A and B", "A and C", "B and C", or "A, B, and C." As used herein, the term "coupled" generally means physically coupled or linked and does not exclude the presence of intermediate elements between the coupled items absent specific contrary language.
The following discussion is intended to provide a brief description of an exemplary computing/data acquisition/application environment in which the disclosed technology may be implemented. FIG. 16 illustrates an exemplary system that includes a processor, memory/data storage/database, user interfaces, communications, x-ray image acquisition module, and
applications configured to perform methods and operations disclosed herein. Although not required, the disclosed technology can be implemented at least in part in the general context of computer executable instructions, such as program modules, being executed by a personal computer (PC), a mobile computing device, tablet computer, or other computational and/or control device. Generally, program modules include routines, programs, objects, components, data structures, etc., that perform particular tasks or implement particular abstract data types. Moreover, the disclosed technology may be implemented with other computer system configurations, including hand held devices, multiprocessor systems, microprocessor-based or programmable consumer electronics, network PCs, minicomputers, mainframe computers, and the like. The disclosed technology may also be practiced in distributed computing environments where tasks are performed by remote processing devices that are linked through a communications network. In a distributed computing environment, program modules may be located in both local and remote memory storage devices.
An exemplary system for implementing the disclosed technology can include a general purpose computing device in the form of an exemplary PC, including one or more processing units, a system memory, and a system bus that couples various system components including the system memory to the one or more processing units. The system bus may be any of several types of bus structures including a memory bus or memory controller, a peripheral bus, and a local bus using any of a variety of bus architectures. The exemplary system memory includes read only memory (ROM) and random access memory (RAM). A basic input/output system (BIOS), containing the basic routines that help with the transfer of information between elements within the PC, is stored in ROM.
An exemplary PC can further include one or more storage devices such as a hard disk drive for reading from and writing to a hard disk, a magnetic disk drive for reading from or writing to a removable magnetic disk, an optical disk drive for reading from or writing to a removable optical disk (such as a CD-ROM or other optical media), and a solid state drive. Such storage devices can be connected to the system bus by a hard disk drive interface, a magnetic disk drive interface, an optical drive interface, or a solid state drive interface, respectively. The drives and their associated computer readable media provide nonvolatile storage of computer-readable instructions, data structures, program modules, and other data for the PC. Other types of computer-readable media which can store data that is accessible by a PC, such as magnetic cassettes, flash memory cards, digital video disks, CDs, DVDs, RAMs, ROMs, and the like, may also be used in the exemplary operating environment.
A number of program modules may be stored in the storage devices including an operating system, one or more application programs, other program modules, and program data. A user may enter commands and information into the PC through one or more input devices such as a keyboard and a pointing device such as a mouse. Other input devices may include a digital camera, microphone, joystick, game pad, scanner, or the like. These and other input devices are often connected to the one or more processing units through a serial port interface that is coupled to the system bus, but may be connected by other interfaces such as a parallel port, game port, or universal serial bus (USB). A monitor or other type of display device is also connected to the system bus via an interface, such as a video adapter. Other peripheral output devices, such as speakers and printers (not shown), may be included.
The PC may operate in a networked environment using logical connections to one or more remote computers. In some examples, one or more network or communication connections are included. A remote computer may be another PC, a server, a router, a network PC, or a peer device or other common network node, and typically includes many or all of the elements described above relative to the PC. The local computer and/or the remote computer can be connected to a logical a local area network (LAN) and a wide area network (WAN). Such networking environments may include wide computer networks, intranets, and the Internet.
When used in a LAN networking environment, the PC is connected to the LAN through a network interface. When used in a WAN networking environment, the PC typically includes a modem or other means for establishing communications over the WAN, such as the Internet. In a networked environment, program modules depicted relative to the personal computer, or portions thereof, may be stored in the remote memory storage device or other locations on the LAN or WAN. The network connections shown are exemplary, and other means of establishing a communications link between the computers may be used.
The memory generally includes computer-executable instructions for performing aspects of the disclosed methods in respective memory portions. Computer-executable instructions for data acquisition and/or other aspects of the disclosed methods can be stored in a specific memory portion for use with an X-ray machine or other equipment. Acquired and processed data can be displayed using computer-executable instructions stored at the memory portion. As noted above, data acquisition, processing, and instrument control can be provided at any portion of the system, or distribution at one or more processing devices using a LAN or WAN.
In view of the many possible embodiments to which the principles of the disclosed technology may be applied, it should be recognized that the illustrated embodiments are only
examples and should not be taken as limiting the scope of the disclosure. Rather, the scope of the disclosure is at least as broad as the following claims. We therefore claim all that comes within the scope of the following claims.
Claims
1. A method comprising:
providing a chest x-ray image of a subject; and
by a computing system, determining the presence and anatomical locations of one or more thoracic diseases in the subject based on analysis of the chest x-ray image of the subject applying a unified weakly supervised multi-label image classification and disease localization framework to the chest x-ray image of the subject.
2. The method of claim 1, further comprising generating an automated radiological report corresponding to the x-ray image of the subject based in the determined presence and anatomical locations of the one or more thoracic diseases in the subject.
3. The method of claim 1 or claim 2, wherein the determining utilizes a database containing a plurality of chest x-ray images and a plurality of corresponding thoracic diseases and locations associated with the plurality of chest x-ray images, the plurality of corresponding thoracic diseases and locations having been text-mined from radiological reports corresponding to the plurality of chest x-ray images using natural language processing.
4. The method of any one of claims 1-3, wherein the one or more thoracic diseases comprise Atelectasis, Cardiomegaly, Effusion, Infiltration, Mass, Nodule, Pneumonia, and Pneumathorax.
5. The method of any one of claims 1-4, wherein the anatomical locations of the one or more thoracic diseases are identified with one or more bounding boxes localized relative to the chest x-ray images.
6. The method of any one of claims 1-5, wherein Deep Convolutional Neural Network (DCNN) architectures are used for weakly- supervised object localization.
7. The method of any one of claims 1-6, wherein the unified weakly supervised multi- label image classification and disease localization framework comprises a multi-label DCNN classification model, wherein the DCNN comprises a transition layer, a global pooling layer, a
prediction layer and a multi-label classification loss layer in the end after a last convolutional layer.
8 The method of claim 7, wherein spatial locations of diseases are determined using a combination of deep activations from the transition layer and weights of the prediction layer.
9. The method of claims 7 or claim 8, wherein the transition layer transforms the activations from previous layers into a uniform dimension of output.
10. A system comprising:
a computer processor;
a data storage device that stores a database comprising:
a plurality of chest x-ray images; and
disease labels and locations associated with each chest x-ray image; wherein the disease labels and locations are mined from radiological reports associated with the chest x-ray images, the disease labels identifying thoracic diseases indicated by the corresponding chest x-ray images, and the locations identifying anatomical areas in the chest x- ray images where the indicated thoracic diseases are located; and
an image acquisition module configured to receive or generate a chest x-ray image of a subject;
wherein the computer processor is operable to determine presence and anatomical locations of one or more thoracic diseases in the subject based on automated analysis of the chest x-ray image of the subject using a unified weakly supervised multi-label image classification and disease localization framework.
11. The system of claim 10, wherein the system is further operable to generate a radiological report corresponding to the x-ray image of the subject based on the determined presence and anatomical locations of the one or more thoracic diseases in the subject.
12. The system of claim 10 or claim 11, wherein the thoracic diseases comprise
Atelectasis, Cardiomegaly, Effusion, Infiltration, Mass, Nodule, Pneumonia, and Pneumathorax.
13. The system of any one of claims 10-12, wherein the anatomical locations of the one or more thoracic diseases are identified with one or more bounding boxes localized relative to the chest x-ray images.
14. The system of any one of claims 10-13, wherein the system uses Deep Convolutional Neural Network (DCNN) architectures for weakly-supervised object localization.
15. The system of any one of claims 10-14, wherein the unified weakly supervised multi-label image classification and disease localization framework comprises a multi-label DCNN classification model, wherein the DCNN comprises a transition layer, a global pooling layer, a prediction layer and a multi-label classification loss layer.
16. The system of any one of claims 10-15, wherein spatial locations of diseases are determined using a combination of deep activations from the transition layer and weights of the prediction layer.
17. The system of any one of claims 10-16, wherein the image acquisition module comprises an x-ray imaging device that generates the chest x-ray of the subject.
18. A computer readable storage device comprises computer-executable instructions for performing the method of any one of claims 1-9.
19. The database of any one of claims 10-17.
20. The method of any one of claims 1-9, further comprising treating the subject for the determined thoracic diseases.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US16/495,012 US11583239B2 (en) | 2017-03-24 | 2018-03-26 | Method and system of building hospital-scale chest X-ray database for entity extraction and weakly-supervised classification and localization of common thorax diseases |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201762476029P | 2017-03-24 | 2017-03-24 | |
| US62/476,029 | 2017-03-24 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2018176035A1 true WO2018176035A1 (en) | 2018-09-27 |
Family
ID=63585802
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2018/024354 WO2018176035A1 (en) | 2017-03-24 | 2018-03-26 | Method and system of building hospital-scale chest x-ray database for entity extraction and weakly-supervised classification and localization of common thorax diseases |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US11583239B2 (en) |
| WO (1) | WO2018176035A1 (en) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109685102A (en) * | 2018-11-13 | 2019-04-26 | 平安科技(深圳)有限公司 | Breast lesion image classification method, device, computer equipment and storage medium |
| CN110287970A (en) * | 2019-06-25 | 2019-09-27 | 电子科技大学 | A kind of Weakly supervised object positioning method based on CAM and cover |
| CN111436212A (en) * | 2018-11-14 | 2020-07-21 | 库雷人工智能科技私人有限公司 | Application of deep learning for medical imaging assessment |
| CN112116571A (en) * | 2020-09-14 | 2020-12-22 | 中国科学院大学宁波华美医院 | X-ray lung disease automatic positioning method based on weak supervised learning |
| EP3971779A4 (en) * | 2019-06-17 | 2022-08-10 | Quibim, S.L. | Method and system for identifying anomalies in x-rays |
| US11416757B2 (en) | 2019-11-04 | 2022-08-16 | International Business Machines Corporation | Classifier training using noisy samples |
| US11636385B2 (en) | 2019-11-04 | 2023-04-25 | International Business Machines Corporation | Training an object detector using raw and unlabeled videos and extracted speech |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11341631B2 (en) * | 2017-08-09 | 2022-05-24 | Shenzhen Keya Medical Technology Corporation | System and method for automatically detecting a physiological condition from a medical image of a patient |
| US11436720B2 (en) * | 2018-12-28 | 2022-09-06 | Shanghai United Imaging Intelligence Co., Ltd. | Systems and methods for generating image metric |
| KR102078876B1 (en) * | 2019-09-03 | 2020-02-20 | 주식회사 루닛 | Method and system for detecting pneumothorax |
| US10755413B1 (en) * | 2020-02-24 | 2020-08-25 | Qure.Ai Technologies Private Limited | Method and system for medical imaging evaluation |
| US11308612B2 (en) * | 2020-04-17 | 2022-04-19 | Qure.Ai Technologies Private Limited | Systems and methods for detection of infectious respiratory diseases |
| CN111553890B (en) * | 2020-04-22 | 2021-01-08 | 上海全景云医学影像诊断有限公司 | X-ray positive chest radiography multi-task detection method based on incremental learning |
| CN111513702A (en) * | 2020-04-30 | 2020-08-11 | 何中煜 | Method for detecting electrocardiographic data and storage medium |
| US11244755B1 (en) | 2020-10-02 | 2022-02-08 | International Business Machines Corporation | Automatic generation of medical imaging reports based on fine grained finding labels |
| US11763081B2 (en) | 2020-10-02 | 2023-09-19 | Merative Us L.P. | Extracting fine grain labels from medical imaging reports |
| CN112382360B (en) * | 2020-12-03 | 2024-05-31 | 卫宁健康科技集团股份有限公司 | Diagnostic report automatic generation system, storage medium and electronic equipment |
| US11928186B2 (en) | 2021-11-01 | 2024-03-12 | International Business Machines Corporation | Combined deep learning and knowledge driven reasoning for artificial intelligence classification |
| CN117636099B (en) * | 2024-01-23 | 2024-04-12 | 数据空间研究院 | Medical image and medical report pairing training model |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106372390A (en) * | 2016-08-25 | 2017-02-01 | 姹ゅ钩 | Deep convolutional neural network-based lung cancer preventing self-service health cloud service system |
| US20180144209A1 (en) * | 2016-11-22 | 2018-05-24 | Lunit Inc. | Object recognition method and apparatus based on weakly supervised learning |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110035208A1 (en) * | 2009-08-05 | 2011-02-10 | Hale Charles R | System and Method for Extracting Radiological Information Utilizing Radiological Domain Report Ontology and Natural Language Processing |
| EP3215968B1 (en) * | 2014-11-07 | 2023-08-23 | Koninklijke Philips N.V. | Optimized anatomical structure of interest labelling |
| US9842390B2 (en) * | 2015-02-06 | 2017-12-12 | International Business Machines Corporation | Automatic ground truth generation for medical image collections |
-
2018
- 2018-03-26 US US16/495,012 patent/US11583239B2/en active Active
- 2018-03-26 WO PCT/US2018/024354 patent/WO2018176035A1/en active Application Filing
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106372390A (en) * | 2016-08-25 | 2017-02-01 | 姹ゅ钩 | Deep convolutional neural network-based lung cancer preventing self-service health cloud service system |
| US20180144209A1 (en) * | 2016-11-22 | 2018-05-24 | Lunit Inc. | Object recognition method and apparatus based on weakly supervised learning |
Non-Patent Citations (6)
| Title |
|---|
| SHIN HOO-CHANG ET AL.: "Interleaved text/image deep mining on a large-scale radiology database for automated image interpretation", JOURNAL OF MACHINE LEARNING RESEARCH, vol. 17, 1 June 2016 (2016-06-01), pages 1 - 31, XP055544301 * |
| SHIN HOO-CHANG ET AL.: "Learning to Read Chest X-Rays: Recurrent Neural Cascade Model for Automated Image Annotation", IEEE CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR, 27 June 2016 (2016-06-27), Las Vegas, NV, pages 2497 - 2506, XP055544272 * |
| SUZUKI KENJI: "Pixel-based machine learning in medical imaging", INTERNATIONAL JOURNAL OF BIOMEDICAL LEARNING, vol. 2012, 28 February 2012 (2012-02-28), pages 18, XP055263162 * |
| WANGX ET AL.: "ChestX-ray8: Hospital-scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases", IEEE CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR, 21 July 2017 (2017-07-21), Honolulu, HI, XP055544283 * |
| XUE Z. ET AL.: "Chest X-ray image view classification", IEEE SYMPOSIUM ON COMPUTER-BASED MEDICAL SYSTEMS, 1 July 2015 (2015-07-01), XP055370934 * |
| ZAKIROV A.N. ET AL.: "Advanced approaches to computer-aided detection of thoracic diseases on chest X-rays", APPLIED MATHEMATICAL SCIENCES, vol. 9, no. 88, 1 January 2015 (2015-01-01), pages 4361 - 4369, XP055544304 * |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109685102A (en) * | 2018-11-13 | 2019-04-26 | 平安科技(深圳)有限公司 | Breast lesion image classification method, device, computer equipment and storage medium |
| CN111436212A (en) * | 2018-11-14 | 2020-07-21 | 库雷人工智能科技私人有限公司 | Application of deep learning for medical imaging assessment |
| EP3971779A4 (en) * | 2019-06-17 | 2022-08-10 | Quibim, S.L. | Method and system for identifying anomalies in x-rays |
| CN110287970A (en) * | 2019-06-25 | 2019-09-27 | 电子科技大学 | A kind of Weakly supervised object positioning method based on CAM and cover |
| CN110287970B (en) * | 2019-06-25 | 2021-07-27 | 电子科技大学 | Weak supervision object positioning method based on CAM and covering |
| US11416757B2 (en) | 2019-11-04 | 2022-08-16 | International Business Machines Corporation | Classifier training using noisy samples |
| US11636385B2 (en) | 2019-11-04 | 2023-04-25 | International Business Machines Corporation | Training an object detector using raw and unlabeled videos and extracted speech |
| US11842278B2 (en) | 2019-11-04 | 2023-12-12 | International Business Machines Corporation | Object detector trained via self-supervised training on raw and unlabeled videos |
| CN112116571A (en) * | 2020-09-14 | 2020-12-22 | 中国科学院大学宁波华美医院 | X-ray lung disease automatic positioning method based on weak supervised learning |
Also Published As
| Publication number | Publication date |
|---|---|
| US20200093455A1 (en) | 2020-03-26 |
| US11583239B2 (en) | 2023-02-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11583239B2 (en) | Method and system of building hospital-scale chest X-ray database for entity extraction and weakly-supervised classification and localization of common thorax diseases | |
| Wang et al. | Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases | |
| Monshi et al. | Deep learning in generating radiology reports: A survey | |
| US10929420B2 (en) | Structured report data from a medical text report | |
| US11176188B2 (en) | Visualization framework based on document representation learning | |
| Wu et al. | Comparison of chest radiograph interpretations by artificial intelligence algorithm vs radiology residents | |
| Qayyum et al. | Medical image retrieval using deep convolutional neural network | |
| US10496884B1 (en) | Transformation of textbook information | |
| RU2703679C2 (en) | Method and system for supporting medical decision making using mathematical models of presenting patients | |
| CN111095426A (en) | Computer-aided diagnosis using deep neural networks | |
| Hamida et al. | A Novel COVID‐19 Diagnosis Support System Using the Stacking Approach and Transfer Learning Technique on Chest X‐Ray Images | |
| WO2017151759A1 (en) | Category discovery and image auto-annotation via looped pseudo-task optimization | |
| US11244755B1 (en) | Automatic generation of medical imaging reports based on fine grained finding labels | |
| Tataru et al. | Deep Learning for abnormality detection in Chest X-Ray images | |
| US11763081B2 (en) | Extracting fine grain labels from medical imaging reports | |
| Stanescu et al. | Creating new medical ontologies for image annotation: a case study | |
| RU2720363C2 (en) | Method for generating mathematical models of a patient using artificial intelligence techniques | |
| US20220375576A1 (en) | Apparatus and method for diagnosing a medical condition from a medical image | |
| Lin et al. | EDICNet: An end-to-end detection and interpretable malignancy classification network for pulmonary nodules in computed tomography | |
| US20220083878A1 (en) | Label inference system | |
| US20240028831A1 (en) | Apparatus and a method for detecting associations among datasets of different types | |
| Wang et al. | An interpretable deep learning system for automatic intracranial hemorrhage diagnosis with CT image | |
| US11928186B2 (en) | Combined deep learning and knowledge driven reasoning for artificial intelligence classification | |
| Peng et al. | Text mining and deep learning for disease classification | |
| Shin et al. | Interleaved text/image deep mining on a large-scale radiology image database |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 18770267 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 18770267 Country of ref document: EP Kind code of ref document: A1 |