WO2015153800A2 - Compositions for modulating sod-1 expression - Google Patents
Compositions for modulating sod-1 expression Download PDFInfo
- Publication number
- WO2015153800A2 WO2015153800A2 PCT/US2015/023934 US2015023934W WO2015153800A2 WO 2015153800 A2 WO2015153800 A2 WO 2015153800A2 US 2015023934 W US2015023934 W US 2015023934W WO 2015153800 A2 WO2015153800 A2 WO 2015153800A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- compound
- modified
- sugar
- tds
- internucleoside linkage
- Prior art date
Links
- 239000000203 mixture Substances 0.000 title claims abstract description 34
- 230000014509 gene expression Effects 0.000 title abstract description 37
- 101150062190 sod1 gene Proteins 0.000 title description 5
- 150000001875 compounds Chemical class 0.000 claims abstract description 389
- 238000000034 method Methods 0.000 claims abstract description 52
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims abstract description 42
- 201000010099 disease Diseases 0.000 claims abstract description 33
- 108010021188 Superoxide Dismutase-1 Proteins 0.000 claims abstract description 18
- 102000008221 Superoxide Dismutase-1 Human genes 0.000 claims abstract description 18
- 239000002777 nucleoside Substances 0.000 claims description 303
- 235000000346 sugar Nutrition 0.000 claims description 302
- 108091034117 Oligonucleotide Proteins 0.000 claims description 293
- 125000003835 nucleoside group Chemical group 0.000 claims description 190
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 claims description 100
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 claims description 100
- 150000003833 nucleoside derivatives Chemical class 0.000 claims description 94
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 claims description 89
- 150000004713 phosphodiesters Chemical class 0.000 claims description 81
- 230000000295 complement effect Effects 0.000 claims description 61
- 229930024421 Adenine Natural products 0.000 claims description 53
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 claims description 53
- 229960000643 adenine Drugs 0.000 claims description 53
- 229940113082 thymine Drugs 0.000 claims description 50
- 125000003729 nucleotide group Chemical group 0.000 claims description 46
- 239000002773 nucleotide Substances 0.000 claims description 43
- 241001465754 Metazoa Species 0.000 claims description 26
- 125000002619 bicyclic group Chemical group 0.000 claims description 21
- 125000004400 (C1-C12) alkyl group Chemical group 0.000 claims description 17
- LRSASMSXMSNRBT-UHFFFAOYSA-N 5-methylcytosine Chemical compound CC1=CNC(=O)N=C1N LRSASMSXMSNRBT-UHFFFAOYSA-N 0.000 claims description 17
- 208000015122 neurodegenerative disease Diseases 0.000 claims description 16
- 150000003839 salts Chemical class 0.000 claims description 14
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 13
- 230000004770 neurodegeneration Effects 0.000 claims description 13
- 125000006239 protecting group Chemical group 0.000 claims description 13
- 239000003085 diluting agent Substances 0.000 claims description 10
- 239000003814 drug Substances 0.000 claims description 10
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 claims description 9
- 238000004519 manufacturing process Methods 0.000 claims description 4
- 208000024891 symptom Diseases 0.000 claims description 3
- 239000003937 drug carrier Substances 0.000 claims description 2
- 230000000692 anti-sense effect Effects 0.000 abstract description 187
- 108020004999 messenger RNA Proteins 0.000 abstract description 129
- 108090000623 proteins and genes Proteins 0.000 abstract description 44
- 102000004169 proteins and genes Human genes 0.000 abstract description 18
- 208000035475 disorder Diseases 0.000 abstract description 9
- 230000003247 decreasing effect Effects 0.000 abstract description 2
- 208000034189 Sclerosis Diseases 0.000 abstract 1
- 101710139715 Superoxide dismutase [Cu-Zn] Proteins 0.000 description 303
- 102100038836 Superoxide dismutase [Cu-Zn] Human genes 0.000 description 301
- 241000764238 Isis Species 0.000 description 236
- ABEXEQSGABRUHS-UHFFFAOYSA-N 16-methylheptadecyl 16-methylheptadecanoate Chemical compound CC(C)CCCCCCCCCCCCCCCOC(=O)CCCCCCCCCCCCCCC(C)C ABEXEQSGABRUHS-UHFFFAOYSA-N 0.000 description 225
- 238000005417 image-selected in vivo spectroscopy Methods 0.000 description 225
- 238000012739 integrated shape imaging system Methods 0.000 description 225
- 102000039446 nucleic acids Human genes 0.000 description 179
- 108020004707 nucleic acids Proteins 0.000 description 179
- 150000007523 nucleic acids Chemical class 0.000 description 173
- 230000005764 inhibitory process Effects 0.000 description 130
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Chemical class Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 106
- 210000004027 cell Anatomy 0.000 description 97
- RXRFPTFLAMOTBU-PMWOLJKMSA-A 5qy760i44w Chemical compound [Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].[Na+].N1([C@H]2C[C@@H]([C@H](O2)COP([O-])(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(NC(=O)C(C)=C2)=O)COP([O-])(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C(C)=C2)=O)COP([O-])(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C(C)=C2)=O)COP([O-])(=S)O[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C(C)=C2)=O)COP([O-])(=S)O[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP([O-])(=S)O[C@H]2[C@H]([C@@H](O[C@@H]2COP([O-])(=S)O[C@H]2[C@H]([C@@H](O[C@@H]2COP([O-])(=S)O[C@H]2[C@H]([C@@H](O[C@@H]2COP([O-])(=S)O[C@H]2[C@H]([C@@H](O[C@@H]2COP([O-])(=S)O[C@H]2[C@H]([C@@H](O[C@@H]2CO)N2C(N=C(N)C(C)=C2)=O)OCCOC)N2C(N=C(N)C(C)=C2)=O)OCCOC)N2C3=C(C(NC(N)=N3)=O)N=C2)OCCOC)N2C(NC(=O)C(C)=C2)=O)OCCOC)N2C(N=C(N)C(C)=C2)=O)OCCOC)OP([O-])(=S)OC[C@H]2O[C@H](C[C@@H]2OP([S-])(=O)OC[C@H]2O[C@H](C[C@@H]2OP([O-])(=S)OC[C@H]2O[C@H](C[C@@H]2OP([O-])(=S)OC[C@H]2O[C@H](C[C@@H]2OP([O-])(=S)OC[C@@H]2[C@H]([C@H]([C@@H](O2)N2C3=NC=NC(N)=C3N=C2)OCCOC)OP([O-])(=S)OC[C@@H]2[C@H]([C@H]([C@@H](O2)N2C(N=C(N)C(C)=C2)=O)OCCOC)OP([O-])(=S)OC[C@@H]2[C@H]([C@H]([C@@H](O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OCCOC)OP([O-])(=S)OC[C@@H]2[C@H]([C@H]([C@@H](O2)N2C(N=C(N)C(C)=C2)=O)OCCOC)OP([O-])(=S)OC[C@@H]2[C@@H](O)[C@H]([C@@H](O2)N2C3=NC=NC(N)=C3N=C2)OCCOC)N2C(N=C(N)C(C)=C2)=O)N2C3=C(C(NC(N)=N3)=O)N=C2)N2C3=NC=NC(N)=C3N=C2)N2C(N=C(N)C(C)=C2)=O)C=C(C)C(=O)NC1=O RXRFPTFLAMOTBU-PMWOLJKMSA-A 0.000 description 58
- 229920002477 rna polymer Polymers 0.000 description 52
- 241000700159 Rattus Species 0.000 description 48
- -1 hybridization) Chemical class 0.000 description 44
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical class NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 37
- 230000008685 targeting Effects 0.000 description 37
- 230000000694 effects Effects 0.000 description 36
- 230000004048 modification Effects 0.000 description 35
- 238000012986 modification Methods 0.000 description 35
- 238000011282 treatment Methods 0.000 description 34
- 239000000523 sample Substances 0.000 description 33
- 210000000278 spinal cord Anatomy 0.000 description 33
- 210000001519 tissue Anatomy 0.000 description 31
- 238000002474 experimental method Methods 0.000 description 29
- 231100000673 dose–response relationship Toxicity 0.000 description 26
- 206010002026 amyotrophic lateral sclerosis Diseases 0.000 description 25
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 23
- 239000002953 phosphate buffered saline Substances 0.000 description 23
- 239000005549 deoxyribonucleoside Substances 0.000 description 22
- 210000005230 lumbar spinal cord Anatomy 0.000 description 21
- 239000003550 marker Substances 0.000 description 21
- 241000699670 Mus sp. Species 0.000 description 20
- 239000000126 substance Substances 0.000 description 20
- 230000009261 transgenic effect Effects 0.000 description 20
- 238000011529 RT qPCR Methods 0.000 description 17
- 238000009396 hybridization Methods 0.000 description 17
- 230000002829 reductive effect Effects 0.000 description 17
- 102100039289 Glial fibrillary acidic protein Human genes 0.000 description 16
- 101710193519 Glial fibrillary acidic protein Proteins 0.000 description 16
- 210000005046 glial fibrillary acidic protein Anatomy 0.000 description 16
- 102100040121 Allograft inflammatory factor 1 Human genes 0.000 description 15
- 101000890626 Homo sapiens Allograft inflammatory factor 1 Proteins 0.000 description 15
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 15
- 238000000338 in vitro Methods 0.000 description 15
- 239000008177 pharmaceutical agent Substances 0.000 description 15
- 108020004414 DNA Proteins 0.000 description 14
- 102000053602 DNA Human genes 0.000 description 14
- 229940104302 cytosine Drugs 0.000 description 14
- 239000008194 pharmaceutical composition Substances 0.000 description 14
- 238000004520 electroporation Methods 0.000 description 13
- 230000002401 inhibitory effect Effects 0.000 description 13
- 125000001424 substituent group Chemical group 0.000 description 13
- 238000011824 transgenic rat model Methods 0.000 description 13
- 125000000882 C2-C6 alkenyl group Chemical group 0.000 description 12
- 125000003601 C2-C6 alkynyl group Chemical group 0.000 description 12
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 12
- 241000699666 Mus <mouse, genus> Species 0.000 description 11
- 229910052739 hydrogen Inorganic materials 0.000 description 11
- 239000001257 hydrogen Substances 0.000 description 11
- YIMATHOGWXZHFX-WCTZXXKLSA-N (2r,3r,4r,5r)-5-(hydroxymethyl)-3-(2-methoxyethoxy)oxolane-2,4-diol Chemical compound COCCO[C@H]1[C@H](O)O[C@H](CO)[C@H]1O YIMATHOGWXZHFX-WCTZXXKLSA-N 0.000 description 10
- 238000004458 analytical method Methods 0.000 description 10
- 230000003140 astrocytic effect Effects 0.000 description 10
- 229910052799 carbon Inorganic materials 0.000 description 10
- 150000002243 furanoses Chemical group 0.000 description 10
- 125000000623 heterocyclic group Chemical group 0.000 description 10
- 230000002025 microglial effect Effects 0.000 description 10
- 238000002360 preparation method Methods 0.000 description 10
- 230000009467 reduction Effects 0.000 description 10
- 101710163270 Nuclease Proteins 0.000 description 9
- 125000002252 acyl group Chemical group 0.000 description 9
- 239000000074 antisense oligonucleotide Substances 0.000 description 9
- 238000012230 antisense oligonucleotides Methods 0.000 description 9
- 238000003556 assay Methods 0.000 description 9
- 238000003182 dose-response assay Methods 0.000 description 9
- 238000001727 in vivo Methods 0.000 description 9
- 238000003753 real-time PCR Methods 0.000 description 9
- 239000000243 solution Substances 0.000 description 9
- 238000012453 sprague-dawley rat model Methods 0.000 description 9
- 238000006467 substitution reaction Methods 0.000 description 9
- 125000006710 (C2-C12) alkenyl group Chemical group 0.000 description 8
- 125000006711 (C2-C12) alkynyl group Chemical group 0.000 description 8
- 229910052736 halogen Inorganic materials 0.000 description 8
- 150000002367 halogens Chemical class 0.000 description 8
- 238000002347 injection Methods 0.000 description 8
- 239000007924 injection Substances 0.000 description 8
- 229940035893 uracil Drugs 0.000 description 8
- 102100034343 Integrase Human genes 0.000 description 7
- 108091028043 Nucleic acid sequence Proteins 0.000 description 7
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 7
- 125000000217 alkyl group Chemical group 0.000 description 7
- 230000027455 binding Effects 0.000 description 7
- 230000006870 function Effects 0.000 description 7
- 125000004573 morpholin-4-yl group Chemical group N1(CCOCC1)* 0.000 description 7
- 230000002441 reversible effect Effects 0.000 description 7
- 238000011830 transgenic mouse model Methods 0.000 description 7
- 241000282693 Cercopithecidae Species 0.000 description 6
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 6
- 238000003776 cleavage reaction Methods 0.000 description 6
- 125000000956 methoxy group Chemical group [H]C([H])([H])O* 0.000 description 6
- 125000002743 phosphorus functional group Chemical group 0.000 description 6
- 238000011160 research Methods 0.000 description 6
- 230000007017 scission Effects 0.000 description 6
- 238000003786 synthesis reaction Methods 0.000 description 6
- 238000012360 testing method Methods 0.000 description 6
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 5
- 241000699660 Mus musculus Species 0.000 description 5
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 5
- 230000001154 acute effect Effects 0.000 description 5
- 125000003545 alkoxy group Chemical group 0.000 description 5
- 230000015572 biosynthetic process Effects 0.000 description 5
- 230000015556 catabolic process Effects 0.000 description 5
- 239000003153 chemical reaction reagent Substances 0.000 description 5
- 238000006731 degradation reaction Methods 0.000 description 5
- 230000001747 exhibiting effect Effects 0.000 description 5
- 230000007659 motor function Effects 0.000 description 5
- 230000003389 potentiating effect Effects 0.000 description 5
- 239000000651 prodrug Substances 0.000 description 5
- 229940002612 prodrug Drugs 0.000 description 5
- 230000002861 ventricular Effects 0.000 description 5
- 125000004642 (C1-C12) alkoxy group Chemical group 0.000 description 4
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 4
- 230000008901 benefit Effects 0.000 description 4
- 230000004071 biological effect Effects 0.000 description 4
- 125000004432 carbon atom Chemical group C* 0.000 description 4
- 230000001413 cellular effect Effects 0.000 description 4
- 230000004700 cellular uptake Effects 0.000 description 4
- 210000003169 central nervous system Anatomy 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 238000011161 development Methods 0.000 description 4
- 125000005647 linker group Chemical group 0.000 description 4
- 125000004430 oxygen atom Chemical group O* 0.000 description 4
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 4
- 108090000765 processed proteins & peptides Proteins 0.000 description 4
- 239000000047 product Substances 0.000 description 4
- 230000004044 response Effects 0.000 description 4
- 239000000758 substrate Substances 0.000 description 4
- 230000001225 therapeutic effect Effects 0.000 description 4
- 238000013519 translation Methods 0.000 description 4
- 125000003903 2-propenyl group Chemical group [H]C([*])([H])C([H])=C([H])[H] 0.000 description 3
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 3
- 125000000824 D-ribofuranosyl group Chemical group [H]OC([H])([H])[C@@]1([H])OC([H])(*)[C@]([H])(O[H])[C@]1([H])O[H] 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- 101000664887 Homo sapiens Superoxide dismutase [Cu-Zn] Proteins 0.000 description 3
- 241000282567 Macaca fascicularis Species 0.000 description 3
- 238000002123 RNA extraction Methods 0.000 description 3
- HMNZFMSWFCAGGW-XPWSMXQVSA-N [3-[hydroxy(2-hydroxyethoxy)phosphoryl]oxy-2-[(e)-octadec-9-enoyl]oxypropyl] (e)-octadec-9-enoate Chemical compound CCCCCCCC\C=C\CCCCCCCC(=O)OCC(COP(O)(=O)OCCO)OC(=O)CCCCCCC\C=C\CCCCCCCC HMNZFMSWFCAGGW-XPWSMXQVSA-N 0.000 description 3
- 125000004103 aminoalkyl group Chemical group 0.000 description 3
- IQFYYKKMVGJFEH-UHFFFAOYSA-N beta-L-thymidine Natural products O=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1 IQFYYKKMVGJFEH-UHFFFAOYSA-N 0.000 description 3
- 210000004556 brain Anatomy 0.000 description 3
- 238000011260 co-administration Methods 0.000 description 3
- 210000004748 cultured cell Anatomy 0.000 description 3
- 229940079593 drug Drugs 0.000 description 3
- 125000001153 fluoro group Chemical group F* 0.000 description 3
- 238000009472 formulation Methods 0.000 description 3
- 125000003843 furanosyl group Chemical group 0.000 description 3
- 230000006872 improvement Effects 0.000 description 3
- 238000010348 incorporation Methods 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 3
- 210000002161 motor neuron Anatomy 0.000 description 3
- 210000003205 muscle Anatomy 0.000 description 3
- 238000006384 oligomerization reaction Methods 0.000 description 3
- 229910052698 phosphorus Inorganic materials 0.000 description 3
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 238000003757 reverse transcription PCR Methods 0.000 description 3
- 239000002342 ribonucleoside Substances 0.000 description 3
- 238000007920 subcutaneous administration Methods 0.000 description 3
- 150000008163 sugars Chemical class 0.000 description 3
- 229910052717 sulfur Inorganic materials 0.000 description 3
- 229940104230 thymidine Drugs 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- JEOQACOXAOEPLX-WCCKRBBISA-N (2s)-2-amino-5-(diaminomethylideneamino)pentanoic acid;1,3-thiazolidine-4-carboxylic acid Chemical compound OC(=O)C1CSCN1.OC(=O)[C@@H](N)CCCN=C(N)N JEOQACOXAOEPLX-WCCKRBBISA-N 0.000 description 2
- 0 *[C@](COC(CO)[C@@]1*)[C@]1O Chemical compound *[C@](COC(CO)[C@@]1*)[C@]1O 0.000 description 2
- 108020005345 3' Untranslated Regions Proteins 0.000 description 2
- 108020003589 5' Untranslated Regions Proteins 0.000 description 2
- 108091093088 Amplicon Proteins 0.000 description 2
- 102100021569 Apoptosis regulator Bcl-2 Human genes 0.000 description 2
- 241000182988 Assa Species 0.000 description 2
- 102100026596 Bcl-2-like protein 1 Human genes 0.000 description 2
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 2
- 108020004705 Codon Proteins 0.000 description 2
- 108020004635 Complementary DNA Proteins 0.000 description 2
- 108010072220 Cyclophilin A Proteins 0.000 description 2
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical group OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 2
- 238000002965 ELISA Methods 0.000 description 2
- 102100031780 Endonuclease Human genes 0.000 description 2
- 108010042407 Endonucleases Proteins 0.000 description 2
- 208000034826 Genetic Predisposition to Disease Diseases 0.000 description 2
- 102100036263 Glutamyl-tRNA(Gln) amidotransferase subunit C, mitochondrial Human genes 0.000 description 2
- 101000971171 Homo sapiens Apoptosis regulator Bcl-2 Proteins 0.000 description 2
- 101001001786 Homo sapiens Glutamyl-tRNA(Gln) amidotransferase subunit C, mitochondrial Proteins 0.000 description 2
- MHAJPDPJQMAIIY-UHFFFAOYSA-N Hydrogen peroxide Chemical compound OO MHAJPDPJQMAIIY-UHFFFAOYSA-N 0.000 description 2
- 206010061218 Inflammation Diseases 0.000 description 2
- 101710203526 Integrase Proteins 0.000 description 2
- 101100366155 Macaca fascicularis SOD1 gene Proteins 0.000 description 2
- 241000282560 Macaca mulatta Species 0.000 description 2
- 108700011259 MicroRNAs Proteins 0.000 description 2
- 208000008238 Muscle Spasticity Diseases 0.000 description 2
- 238000000636 Northern blotting Methods 0.000 description 2
- 108700026244 Open Reading Frames Proteins 0.000 description 2
- 241000283973 Oryctolagus cuniculus Species 0.000 description 2
- 206010033799 Paralysis Diseases 0.000 description 2
- 102100034539 Peptidyl-prolyl cis-trans isomerase A Human genes 0.000 description 2
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 2
- 108091034057 RNA (poly(A)) Proteins 0.000 description 2
- 238000013381 RNA quantification Methods 0.000 description 2
- 108091028664 Ribonucleotide Proteins 0.000 description 2
- 108020004459 Small interfering RNA Proteins 0.000 description 2
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 2
- 108091081024 Start codon Proteins 0.000 description 2
- OUUQCZGPVNCOIJ-UHFFFAOYSA-M Superoxide Chemical compound [O-][O] OUUQCZGPVNCOIJ-UHFFFAOYSA-M 0.000 description 2
- 102000019197 Superoxide Dismutase Human genes 0.000 description 2
- 108010012715 Superoxide dismutase Proteins 0.000 description 2
- 230000005856 abnormality Effects 0.000 description 2
- DZBUGLKDJFMEHC-UHFFFAOYSA-N acridine Chemical compound C1=CC=CC2=CC3=CC=CC=C3N=C21 DZBUGLKDJFMEHC-UHFFFAOYSA-N 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 125000000304 alkynyl group Chemical group 0.000 description 2
- VREFGVBLTWBCJP-UHFFFAOYSA-N alprazolam Chemical compound C12=CC(Cl)=CC=C2N2C(C)=NN=C2CN=C1C1=CC=CC=C1 VREFGVBLTWBCJP-UHFFFAOYSA-N 0.000 description 2
- 150000001412 amines Chemical class 0.000 description 2
- 239000000427 antigen Substances 0.000 description 2
- 102000036639 antigens Human genes 0.000 description 2
- 108091007433 antigens Proteins 0.000 description 2
- 125000004429 atom Chemical group 0.000 description 2
- 230000037396 body weight Effects 0.000 description 2
- 238000010804 cDNA synthesis Methods 0.000 description 2
- 150000001721 carbon Chemical group 0.000 description 2
- 108091092328 cellular RNA Proteins 0.000 description 2
- 210000004289 cerebral ventricle Anatomy 0.000 description 2
- 230000001055 chewing effect Effects 0.000 description 2
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical group C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 230000009260 cross reactivity Effects 0.000 description 2
- 125000004122 cyclic group Chemical group 0.000 description 2
- 230000007850 degeneration Effects 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 150000002148 esters Chemical class 0.000 description 2
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 2
- 208000019995 familial amyotrophic lateral sclerosis Diseases 0.000 description 2
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 125000001072 heteroaryl group Chemical class 0.000 description 2
- 102000056070 human SOD1 Human genes 0.000 description 2
- BHEPBYXIRTUNPN-UHFFFAOYSA-N hydridophosphorus(.) (triplet) Chemical compound [PH] BHEPBYXIRTUNPN-UHFFFAOYSA-N 0.000 description 2
- 125000004435 hydrogen atom Chemical class [H]* 0.000 description 2
- 206010020745 hyperreflexia Diseases 0.000 description 2
- 230000004054 inflammatory process Effects 0.000 description 2
- 238000001802 infusion Methods 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- 238000007913 intrathecal administration Methods 0.000 description 2
- 238000001990 intravenous administration Methods 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 239000000178 monomer Substances 0.000 description 2
- 230000035772 mutation Effects 0.000 description 2
- 238000007911 parenteral administration Methods 0.000 description 2
- 230000000144 pharmacologic effect Effects 0.000 description 2
- RDOWQLZANAYVLL-UHFFFAOYSA-N phenanthridine Chemical compound C1=CC=C2C3=CC=CC=C3C=NC2=C1 RDOWQLZANAYVLL-UHFFFAOYSA-N 0.000 description 2
- 125000004437 phosphorous atom Chemical group 0.000 description 2
- 229920000642 polymer Polymers 0.000 description 2
- 238000003752 polymerase chain reaction Methods 0.000 description 2
- 229920001184 polypeptide Polymers 0.000 description 2
- 230000002265 prevention Effects 0.000 description 2
- 102000004196 processed proteins & peptides Human genes 0.000 description 2
- 230000000750 progressive effect Effects 0.000 description 2
- 238000011321 prophylaxis Methods 0.000 description 2
- 238000011552 rat model Methods 0.000 description 2
- 230000029058 respiratory gaseous exchange Effects 0.000 description 2
- 239000002336 ribonucleotide Substances 0.000 description 2
- 125000002652 ribonucleotide group Chemical group 0.000 description 2
- 208000018198 spasticity Diseases 0.000 description 2
- 230000000087 stabilizing effect Effects 0.000 description 2
- 230000009747 swallowing Effects 0.000 description 2
- 125000001412 tetrahydropyranyl group Chemical group 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 150000003573 thiols Chemical class 0.000 description 2
- 210000000115 thoracic cavity Anatomy 0.000 description 2
- 230000002110 toxicologic effect Effects 0.000 description 2
- 231100000759 toxicological effect Toxicity 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- 125000000876 trifluoromethoxy group Chemical group FC(F)(F)O* 0.000 description 2
- 229920002554 vinyl polymer Polymers 0.000 description 2
- 125000000008 (C1-C10) alkyl group Chemical group 0.000 description 1
- 108010052418 (N-(2-((4-((2-((4-(9-acridinylamino)phenyl)amino)-2-oxoethyl)amino)-4-oxobutyl)amino)-1-(1H-imidazol-4-ylmethyl)-1-oxoethyl)-6-(((-2-aminoethyl)amino)methyl)-2-pyridinecarboxamidato) iron(1+) Proteins 0.000 description 1
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 1
- BCOSEZGCLGPUSL-UHFFFAOYSA-N 2,3,3-trichloroprop-2-enoyl chloride Chemical compound ClC(Cl)=C(Cl)C(Cl)=O BCOSEZGCLGPUSL-UHFFFAOYSA-N 0.000 description 1
- VEPOHXYIFQMVHW-XOZOLZJESA-N 2,3-dihydroxybutanedioic acid (2S,3S)-3,4-dimethyl-2-phenylmorpholine Chemical compound OC(C(O)C(O)=O)C(O)=O.C[C@H]1[C@@H](OCCN1C)c1ccccc1 VEPOHXYIFQMVHW-XOZOLZJESA-N 0.000 description 1
- JTTIOYHBNXDJOD-UHFFFAOYSA-N 2,4,6-triaminopyrimidine Chemical compound NC1=CC(N)=NC(N)=N1 JTTIOYHBNXDJOD-UHFFFAOYSA-N 0.000 description 1
- OALHHIHQOFIMEF-UHFFFAOYSA-N 3',6'-dihydroxy-2',4',5',7'-tetraiodo-3h-spiro[2-benzofuran-1,9'-xanthene]-3-one Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC(I)=C(O)C(I)=C1OC1=C(I)C(O)=C(I)C=C21 OALHHIHQOFIMEF-UHFFFAOYSA-N 0.000 description 1
- FVFVNNKYKYZTJU-UHFFFAOYSA-N 6-chloro-1,3,5-triazine-2,4-diamine Chemical compound NC1=NC(N)=NC(Cl)=N1 FVFVNNKYKYZTJU-UHFFFAOYSA-N 0.000 description 1
- 208000035657 Abasia Diseases 0.000 description 1
- 208000000187 Abnormal Reflex Diseases 0.000 description 1
- 241000023308 Acca Species 0.000 description 1
- 206010067484 Adverse reaction Diseases 0.000 description 1
- 206010003694 Atrophy Diseases 0.000 description 1
- 208000031648 Body Weight Changes Diseases 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 102000011727 Caspases Human genes 0.000 description 1
- 108010076667 Caspases Proteins 0.000 description 1
- 102100034330 Chromaffin granule amine transporter Human genes 0.000 description 1
- 108020004394 Complementary RNA Proteins 0.000 description 1
- 208000019505 Deglutition disease Diseases 0.000 description 1
- 206010013642 Drooling Diseases 0.000 description 1
- 206010013887 Dysarthria Diseases 0.000 description 1
- IAYPIBMASNFSPL-UHFFFAOYSA-N Ethylene oxide Chemical group C1CO1 IAYPIBMASNFSPL-UHFFFAOYSA-N 0.000 description 1
- 108700024394 Exon Proteins 0.000 description 1
- 108060002716 Exonuclease Proteins 0.000 description 1
- 208000001308 Fasciculation Diseases 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 101000641221 Homo sapiens Chromaffin granule amine transporter Proteins 0.000 description 1
- 101000908713 Homo sapiens Dihydrofolate reductase Proteins 0.000 description 1
- 101000724418 Homo sapiens Neutral amino acid transporter B(0) Proteins 0.000 description 1
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 206010022095 Injection Site reaction Diseases 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 208000034819 Mobility Limitation Diseases 0.000 description 1
- 208000007101 Muscle Cramp Diseases 0.000 description 1
- 208000010428 Muscle Weakness Diseases 0.000 description 1
- 206010028347 Muscle twitching Diseases 0.000 description 1
- 208000021642 Muscular disease Diseases 0.000 description 1
- 206010028372 Muscular weakness Diseases 0.000 description 1
- 201000009623 Myopathy Diseases 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 208000005736 Nervous System Malformations Diseases 0.000 description 1
- 102100028267 Neutral amino acid transporter B(0) Human genes 0.000 description 1
- 108091005461 Nucleic proteins Proteins 0.000 description 1
- 239000012807 PCR reagent Substances 0.000 description 1
- 241000282579 Pan Species 0.000 description 1
- 108091093037 Peptide nucleic acid Proteins 0.000 description 1
- PCNDJXKNXGMECE-UHFFFAOYSA-N Phenazine Natural products C1=CC=CC2=NC3=CC=CC=C3N=C21 PCNDJXKNXGMECE-UHFFFAOYSA-N 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- 208000008630 Sialorrhea Diseases 0.000 description 1
- 108091027967 Small hairpin RNA Proteins 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 201000008754 Tenosynovial giant cell tumor Diseases 0.000 description 1
- DHXVGJBLRPWPCS-UHFFFAOYSA-N Tetrahydropyran Chemical compound C1CCOCC1 DHXVGJBLRPWPCS-UHFFFAOYSA-N 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical class OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 230000007059 acute toxicity Effects 0.000 description 1
- 231100000403 acute toxicity Toxicity 0.000 description 1
- 230000006838 adverse reaction Effects 0.000 description 1
- 125000003342 alkenyl group Chemical group 0.000 description 1
- 125000002877 alkyl aryl group Chemical group 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 150000001413 amino acids Chemical class 0.000 description 1
- 125000003277 amino group Chemical group 0.000 description 1
- 108010025592 aminoadipoyl-cysteinyl-allylglycine Proteins 0.000 description 1
- 125000005122 aminoalkylamino group Chemical group 0.000 description 1
- 125000002344 aminooxy group Chemical group [H]N([H])O[*] 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 238000000137 annealing Methods 0.000 description 1
- PYKYMHQGRFAEBM-UHFFFAOYSA-N anthraquinone Natural products CCC(=O)c1c(O)c2C(=O)C3C(C=CC=C3O)C(=O)c2cc1CC(=O)OC PYKYMHQGRFAEBM-UHFFFAOYSA-N 0.000 description 1
- 150000004056 anthraquinones Chemical class 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 125000003710 aryl alkyl group Chemical group 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 230000037444 atrophy Effects 0.000 description 1
- 238000002869 basic local alignment search tool Methods 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- ZYGHJZDHTFUPRJ-UHFFFAOYSA-N benzo-alpha-pyrone Natural products C1=CC=C2OC(=O)C=CC2=C1 ZYGHJZDHTFUPRJ-UHFFFAOYSA-N 0.000 description 1
- HMFHBZSHGGEWLO-TXICZTDVSA-N beta-D-ribose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-TXICZTDVSA-N 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 230000004579 body weight change Effects 0.000 description 1
- 239000006227 byproduct Substances 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 210000001638 cerebellum Anatomy 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 235000012000 cholesterol Nutrition 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 239000003184 complementary RNA Substances 0.000 description 1
- 235000001671 coumarin Nutrition 0.000 description 1
- 125000000332 coumarinyl group Chemical class O1C(=O)C(=CC2=CC=CC=C12)* 0.000 description 1
- 238000002425 crystallisation Methods 0.000 description 1
- 230000008025 crystallization Effects 0.000 description 1
- 125000000596 cyclohexenyl group Chemical group C1(=CCCCC1)* 0.000 description 1
- 125000000113 cyclohexyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C([H])([H])C1([H])[H] 0.000 description 1
- 230000007123 defense Effects 0.000 description 1
- 230000002939 deleterious effect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 208000035647 diffuse type tenosynovial giant cell tumor Diseases 0.000 description 1
- 238000007323 disproportionation reaction Methods 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 239000000975 dye Substances 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 102000013165 exonuclease Human genes 0.000 description 1
- 210000003414 extremity Anatomy 0.000 description 1
- 125000004785 fluoromethoxy group Chemical group [H]C([H])(F)O* 0.000 description 1
- 229940014144 folate Drugs 0.000 description 1
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 1
- 235000019152 folic acid Nutrition 0.000 description 1
- 239000011724 folic acid Substances 0.000 description 1
- 239000012634 fragment Substances 0.000 description 1
- 210000005153 frontal cortex Anatomy 0.000 description 1
- 150000004820 halides Chemical class 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 210000003494 hepatocyte Anatomy 0.000 description 1
- 231100000304 hepatotoxicity Toxicity 0.000 description 1
- 125000005842 heteroatom Chemical group 0.000 description 1
- 125000000592 heterocycloalkyl group Chemical group 0.000 description 1
- 210000000548 hind-foot Anatomy 0.000 description 1
- 210000001320 hippocampus Anatomy 0.000 description 1
- 210000005260 human cell Anatomy 0.000 description 1
- 230000035859 hyperreflexia Effects 0.000 description 1
- 238000003119 immunoblot Methods 0.000 description 1
- 238000003365 immunocytochemistry Methods 0.000 description 1
- 238000003364 immunohistochemistry Methods 0.000 description 1
- 238000001114 immunoprecipitation Methods 0.000 description 1
- 238000005462 in vivo assay Methods 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 239000000138 intercalating agent Substances 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000000185 intracerebroventricular administration Methods 0.000 description 1
- 238000007917 intracranial administration Methods 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 230000003907 kidney function Effects 0.000 description 1
- 150000002632 lipids Chemical group 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 238000007449 liver function test Methods 0.000 description 1
- 230000007056 liver toxicity Effects 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 210000004705 lumbosacral region Anatomy 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 239000002207 metabolite Substances 0.000 description 1
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical class CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 1
- 210000003470 mitochondria Anatomy 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 125000002950 monocyclic group Chemical group 0.000 description 1
- 210000000337 motor cortex Anatomy 0.000 description 1
- CJWXCNXHAIFFMH-AVZHFPDBSA-N n-[(2s,3r,4s,5s,6r)-2-[(2r,3r,4s,5r)-2-acetamido-4,5,6-trihydroxy-1-oxohexan-3-yl]oxy-3,5-dihydroxy-6-methyloxan-4-yl]acetamide Chemical compound C[C@H]1O[C@@H](O[C@@H]([C@@H](O)[C@H](O)CO)[C@@H](NC(C)=O)C=O)[C@H](O)[C@@H](NC(C)=O)[C@@H]1O CJWXCNXHAIFFMH-AVZHFPDBSA-N 0.000 description 1
- 231100000417 nephrotoxicity Toxicity 0.000 description 1
- 230000007658 neurological function Effects 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 230000009437 off-target effect Effects 0.000 description 1
- 229940124276 oligodeoxyribonucleotide Drugs 0.000 description 1
- 210000000287 oocyte Anatomy 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 125000001181 organosilyl group Chemical group [SiH3]* 0.000 description 1
- 230000004792 oxidative damage Effects 0.000 description 1
- 230000010627 oxidative phosphorylation Effects 0.000 description 1
- 125000004043 oxo group Chemical group O=* 0.000 description 1
- 229910052760 oxygen Inorganic materials 0.000 description 1
- 230000008506 pathogenesis Effects 0.000 description 1
- 238000003359 percent control normalization Methods 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 230000003285 pharmacodynamic effect Effects 0.000 description 1
- 150000003904 phospholipids Chemical class 0.000 description 1
- PTMHPRAIXMAOOB-UHFFFAOYSA-L phosphoramidate Chemical compound NP([O-])([O-])=O PTMHPRAIXMAOOB-UHFFFAOYSA-L 0.000 description 1
- 239000011574 phosphorus Substances 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 230000006461 physiological response Effects 0.000 description 1
- 210000002975 pon Anatomy 0.000 description 1
- 159000000001 potassium salts Chemical class 0.000 description 1
- 230000000063 preceeding effect Effects 0.000 description 1
- 230000000069 prophylactic effect Effects 0.000 description 1
- QQONPFPTGQHPMA-UHFFFAOYSA-N propylene Natural products CC=C QQONPFPTGQHPMA-UHFFFAOYSA-N 0.000 description 1
- 230000004952 protein activity Effects 0.000 description 1
- 238000002731 protein assay Methods 0.000 description 1
- 230000011514 reflex Effects 0.000 description 1
- 125000006853 reporter group Chemical group 0.000 description 1
- 210000001995 reticulocyte Anatomy 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 125000006413 ring segment Chemical group 0.000 description 1
- 102220020162 rs397508045 Human genes 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- 210000002027 skeletal muscle Anatomy 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 125000000547 substituted alkyl group Chemical group 0.000 description 1
- 125000000472 sulfonyl group Chemical group *S(*)(=O)=O 0.000 description 1
- 125000004962 sulfoxyl group Chemical group 0.000 description 1
- 125000004434 sulfur atom Chemical group 0.000 description 1
- 101150075675 tatC gene Proteins 0.000 description 1
- 238000011191 terminal modification Methods 0.000 description 1
- 208000002918 testicular germ cell tumor Diseases 0.000 description 1
- 229940124597 therapeutic agent Drugs 0.000 description 1
- 125000004001 thioalkyl group Chemical group 0.000 description 1
- 230000036962 time dependent Effects 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 239000012096 transfection reagent Substances 0.000 description 1
- 238000011820 transgenic animal model Methods 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 125000000391 vinyl group Chemical group [H]C([*])=C([H])[H] 0.000 description 1
- 230000003313 weakening effect Effects 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
- C12N15/1137—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing against enzymes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
- A61K31/711—Natural deoxyribonucleic acids, i.e. containing only 2'-deoxyriboses attached to adenine, guanine, cytosine or thymine and having 3'-5' phosphodiester links
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P21/00—Drugs for disorders of the muscular or neuromuscular system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/02—Drugs for disorders of the nervous system for peripheral neuropathies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/28—Drugs for disorders of the nervous system for treating neurodegenerative disorders of the central nervous system, e.g. nootropic agents, cognition enhancers, drugs for treating Alzheimer's disease or other forms of dementia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y115/00—Oxidoreductases acting on superoxide as acceptor (1.15)
- C12Y115/01—Oxidoreductases acting on superoxide as acceptor (1.15) with NAD or NADP as acceptor (1.15.1)
- C12Y115/01001—Superoxide dismutase (1.15.1.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/11—Antisense
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/31—Chemical structure of the backbone
- C12N2310/315—Phosphorothioates
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/321—2'-O-R Modification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/32—Chemical structure of the sugar
- C12N2310/323—Chemical structure of the sugar modified ring structure
- C12N2310/3231—Chemical structure of the sugar modified ring structure having an additional ring, e.g. LNA, ENA
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/33—Chemical structure of the base
- C12N2310/334—Modified C
- C12N2310/3341—5-Methylcytosine
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/34—Spatial arrangement of the modifications
- C12N2310/341—Gapmers, i.e. of the type ===---===
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/34—Spatial arrangement of the modifications
- C12N2310/346—Spatial arrangement of the modifications having a combination of backbone and sugar modifications
Definitions
- compositions and methods for reducing expression of superoxide dismutase 1 , soluble (SOD-1) mPvNA and protein in an animal are useful to treat, prevent, or ameliorate neurodegenerative diseases, including amyotrophic lateral sclerosis (ALS) by inhibiting expression of SOD-1 in an animal.
- ALS amyotrophic lateral sclerosis
- the soluble SOD-1 enzyme (also known as Cu/Zn superoxide dismutase) is one of the superoxide dismutases that provide defense against oxidative damage of biomolecules by catalyzing the dismutation of superoxide to hydrogen peroxide (H202) (Fridovich, Annu. Rev. Biochem., 1995, 64, 97-112).
- H202 hydrogen peroxide
- the superoxide anion (02-) is a potentially harmful cellular by-product produced primarily by errors of oxidative phosphorylation in mitochondria (Turrens, J. Physiol. 2003, 552, 335-344)
- ALS amyotrophic lateral sclerosis
- Lou Gehrig's disease a disorder characterized by a selective degeneration of upper and lower motor neurons
- mutant SOD1 The toxicity of mutant SOD1 is believed to arise from an initial misfolding (gain of function) reducing nuclear protection from the active enzyme (loss of function in the nuclei), a process that may be involved in
- ALS is a devastating progressive neurodegenerative disease affecting as many as 30,000 Americans at any given time.
- the progressive degeneration of the motor neurons in ALS eventually leads to their death.
- compositions for modulating expression of superoxide dismutase 1, soluble (SOD-1) mRNA and protein are provided herein.
- compounds useful for modulating expression of SOD-1 mRNA and protein are antisense compounds.
- the antisense compounds are modified oligonucleotides.
- modulation can occur in a cell or tissue.
- the cell or tissue is in an animal.
- the animal is a human.
- SOD-1 mRNA levels are reduced.
- SOD-1 protein levels are reduced. Such reduction can occur in a time-dependent manner or in a dose-dependent manner.
- SOD-1 related diseases, disorders, and conditions are neurodegenerative diseases.
- neurodegenerative diseases, disorders, and conditions include amyotrophic lateral sclerosis (ALS).
- Such diseases, disorders, and conditions can have one or more risk factors, causes, or outcomes in common.
- Certain risk factors and causes for development of ALS include growing older, having a personal or family history, or genetic predisposition. However, the majority of ALS cases are sporadic and no known risk factors are known.
- Certain symptoms and outcomes associated with development of ALS include but are not limited to: fasciculations, cramps, tight and stiff muscles (spasticity), muscle weakness affecting an arm or a leg, slurred and nasal speech, difficulty walking, difficulty chewing or swallowing (dysphagia), difficulty speaking or forming words (dysarthria), weakness or atrophy, spasticity, exaggerated reflexes (hyperreflexia), and presence of Babinski's sign.
- ALS As ALS progresses, symptoms and outcomes by include weakening of other limbs, perhaps accompanied by twitching, muscle cramping, and exaggerated, faster reflexes; problems with chewing, swallowing, and breathing; drooling may occur; eventual paralysis; and death.
- methods of treatment include administering an SOD-1 antisense compound to an individual in need thereof. In certain embodiments, methods of treatment include administering an SOD-1 modified oligonucleotide to an individual in need thereof.
- 2'-deoxynucleoside (also 2'-deoxyribonucleoside) means a nucleoside comprising 2'-H furanosyl sugar moiety, as found in naturally occurring deoxyribonucleosides (DNA).
- a 2'- deoxynucleoside may comprise a modified nucleobase or may comprise an RNA nucleobase (e.g., uracil).
- 2'-deoxyribose sugar means a 2'-H furanosyl sugar moiety, as found in naturally occurring deoxyribonucleic acids (DNA).
- 2'-0-methoxyethyl refers to an O-methoxy-ethyl modification of the 2' position of a furanose ring.
- a 2'-0- methoxyethylribose modified sugar is a modified sugar.
- 2'-0-methoxyethylribose modified nucleoside means a nucleoside comprising a 2' -MOE modified sugar moiety.
- 2 '-substituted nucleoside means a nucleoside comprising a substituent at the 2 '-position of the furanose ring other than H or OH.
- 2' substituted nucleosides include nucleosides with bicyclic sugar modifications.
- 5-methylcytosine means a cytosine modified with a methyl group attached to the 5 position.
- a 5- methylcytosine is a modified nucleobase.
- “About” means within ⁇ 10% of a value. For example, if it is stated, “the compounds affected at least about 50% inhibition of SOD-1", it is implied that the SOD-1 levels are inhibited within a range of 45% and 55%.
- administering concomitantly refers to the co-administration of two pharmaceutical agents in any manner in which the pharmacological effects of both are manifest in the patient at the same time.
- Concomitant administration does not require that both pharmaceutical agents be administered in a single pharmaceutical composition, in the same dosage form, or by the same route of administration.
- the effects of both pharmaceutical agents need not manifest themselves at the same time. The effects need only be overlapping for a period of time and need not be coextensive.
- administering means providing a pharmaceutical agent to an animal, and includes, but is not limited to administering by a medical professional and self-administering.
- “Amelioration” refers to a lessening, slowing, stopping, or reversing of at least one indicator of the severity of a condition or disease.
- the severity of indicators may be determined by subjective or objective measures, which are known to those skilled in the art.
- Animal refers to a human or non-human animal, including, but not limited to, mice, rats, rabbits, dogs, cats, pigs, and non-human primates, including, but not limited to, monkeys and chimpanzees.
- Antibody refers to a molecule characterized by reacting specifically with an antigen in some way, where the antibody and the antigen are each defined in terms of the other. Antibody may refer to a complete antibody molecule or any fragment or region thereof, such as the heavy chain, the light chain, Fab region, and Fc region.
- Antisense activity means any detectable or measurable activity attributable to the hybridization of an antisense compound to its target nucleic acid. In certain embodiments, antisense activity is a decrease in the amount or expression of a target nucleic acid or protein encoded by such target nucleic acid.
- Antisense compound means an oligomeric compound that is capable of undergoing hybridization to a target nucleic acid through hydrogen bonding.
- antisense compounds include single- stranded and double-stranded compounds, such as, antisense oligonucleotides, siRNAs, shRNAs, ssRNAs, and occupancy-based compounds.
- Antisense inhibition means reduction of target nucleic acid levels in the presence of an antisense compound complementary to a target nucleic acid compared to target nucleic acid levels or in the absence of the antisense compound.
- Antisense mechanisms are all those mechanisms involving hybridization of a compound with a target nucleic acid, wherein the outcome or effect of the hybridization is either target degradation or target occupancy with concomitant stalling of the cellular machinery involving, for example, transcription or splicing.
- Antisense oligonucleotide means a single-stranded oligonucleotide having a nucleobase sequence that permits hybridization to a corresponding segment of a target nucleic acid.
- Base complementarity refers to the capacity for the precise base pairing of nucleobases of an oligonucleotide with corresponding nucleobases in a target nucleic acid (i.e., hybridization), and is mediated by Watson-Crick, Hoogsteen or reversed Hoogsteen hydrogen binding between corresponding nucleobases.
- Bicyclic sugar means a furanose ring modified by the bridging of two atoms.
- a bicyclic sugar is a modified sugar.
- BNA Bicyclic nucleic acid
- BNA a nucleoside or nucleotide wherein the furanose portion of the nucleoside or nucleotide includes a bridge connecting two carbon atoms on the furanose ring, thereby forming a bicyclic ring system.
- Cap structure or "terminal cap moiety” means chemical modifications, which have been incorporated at either terminus of an antisense compound.
- cEt or “constrained ethyl” or “cEt modified sugar” means a bicyclic nucleoside having a sugar moiety comprising a bridge connecting the 4 '-carbon and the 2 '-carbon, wherein the bridge has the formula: 4'-CH(CH 3 )-0-2'.
- a cEt modified sugar is a modified sugar.
- cEt modified nucleoside means a bicyclic nucleoside having a sugar moiety comprising a bridge connecting the 4'-carbon and the 2'-carbon, wherein the bridge has the formula: 4'-CH(CH 3 )-0-2'.
- a cEt modified sugar is a modified sugar.
- “Chemically distinct region” refers to a region of an antisense compound that is in some way chemically different than another region of the same antisense compound. For example, a region having 2'- O-methoxyethyl nucleosides is chemically distinct from a region having nucleosides without 2'-0- methoxyethyl modifications.
- Chimeric antisense compound means an antisense compound that has at least two chemically distinct regions, each position having a plurality of subunits.
- Co-administration means administration of two or more pharmaceutical agents to an individual.
- the two or more pharmaceutical agents may be in a single pharmaceutical composition, or may be in separate pharmaceutical compositions.
- Each of the two or more pharmaceutical agents may be administered through the same or different routes of administration.
- Co-administration encompasses parallel or sequential administration.
- “Complementarity” means the capacity for pairing between nucleobases of a first nucleic acid and a second nucleic acid.
- Contiguous nucleobases means nucleobases immediately adjacent to each other.
- Designing or “designed to” refer to the process of designing an oligomeric compound that specifically hybridizes with a selected nucleic acid molecule.
- “Diluent” means an ingredient in a composition that lacks pharmacological activity, but is pharmaceutically necessary or desirable.
- the diluent may be a liquid, e.g. saline solution.
- Dose means a specified quantity of a pharmaceutical agent provided in a single administration, or in a specified time period.
- a dose may be administered in one, two, or more boluses, tablets, or injections.
- the desired dose requires a volume not easily accommodated by a single injection, therefore, two or more injections may be used to achieve the desired dose.
- the pharmaceutical agent is administered by infusion over an extended period of time or continuously. Doses may be stated as the amount of pharmaceutical agent per hour, day, week, or month.
- Effective amount in the context of modulating an activity or of treating or preventing a condition means the administration of that amount of pharmaceutical agent to a subject in need of such modulation, treatment, or prophylaxis, either in a single dose or as part of a series, that is effective for modulation of that effect, or for treatment or prophylaxis or improvement of that condition.
- the effective amount may vary among individuals depending on the health and physical condition of the individual to be treated, the taxonomic group of the individuals to be treated, the formulation of the composition, assessment of the individual's medical condition, and other relevant factors.
- “Expression” includes all the functions by which a gene's coded information is converted into structures present and operating in a cell. Such structures include, but are not limited to the products of transcription and translation.
- “Fully complementary” or “100% complementary” means each nucleobase of a first nucleic acid has a complementary nucleobase in a second nucleic acid.
- a first nucleic acid is an antisense compound and a target nucleic acid is a second nucleic acid.
- Gapmer means a chimeric antisense compound in which an internal region having a plurality of nucleosides that support RNase H cleavage is positioned between external regions having one or more nucleosides, wherein the nucleosides comprising the internal region are chemically distinct from the nucleoside or nucleosides comprising the external regions.
- the internal region may be referred to as a "gap” and the external regions may be referred to as the "wings.”
- Gap-narrowed means a chimeric antisense compound having a gap segment of 9 or fewer contiguous 2'-deoxyribonucleosides positioned between and immediately adjacent to 5' and 3' wing segments having from 1 to 6 nucleosides.
- Gap-widened means a chimeric antisense compound having a gap segment of 12 or more contiguous 2'-deoxyribonucleosides positioned between and immediately adjacent to 5' and 3' wing segments having from 1 to 6 nucleosides.
- Hybridization means the annealing of complementary nucleic acid molecules.
- complementary nucleic acid molecules include, but are not limited to, an antisense compound and a target nucleic acid.
- complementary nucleic acid molecules include, but are not limited to, an oligonucleotide and a nucleic acid target.
- Identifying an animal having a SOD-1 associated disease means identifying an animal having been diagnosed with a SOD-1 associated disease or predisposed to develop a SOD-1 associated disease.
- Individuals predisposed to develop a SOD-1 associated disease include those having one or more risk factors for developing a SOD-1 associated disease, including, growing older, having a personal or family history, or genetic predisposition of one or more SOD-1 associated diseases. Such identification may be accomplished by any method including evaluating an individual's medical history and standard clinical tests or assessments, such as genetic testing.
- “Individual” means a human or non-human animal selected for treatment or therapy.
- “Inhibiting SOD-1” means reducing the level or expression of a SOD-1 m NA and/or protein.
- SOD-1 mRNA and/or protein levels are inhibited in the presence of an antisense compound targeting SOD-1, including a modified oligonucleotide targeting SOD-1, as compared to expression of SOD-1 mRNA and/or protein levels in the absence of a SOD-1 antisense compound, such as a modified oligonucleotide.
- “Inhibiting the expression or activity” refers to a reduction or blockade of the expression or activity and does not necessarily indicate a total elimination of expression or activity.
- Internucleoside linkage refers to the chemical bond between nucleosides.
- Linked nucleosides means adjacent nucleosides linked together by an internucleoside linkage.
- mis or non-complementary nucleobase refers to the case when a nucleobase of a first nucleic acid is not capable of pairing with the corresponding nucleobase of a second or target nucleic acid.
- Mated backbone means a pattern of internucleoside linkages including at least two different internucleoside linkages.
- an oligonucleotide with a mixed backbone may include at least one phosphodiester linkage and at least one phosphorothioate linkage.
- Modified internucleoside linkage refers to a substitution or any change from a naturally occurring internucleoside bond (i.e., a phosphodiester internucleoside bond).
- Modified nucleobase means any nucleobase other than adenine, cytosine, guanine, thymidine, or uracil.
- An "unmodified nucleobase” means the purine bases adenine (A) and guanine (G), and the pyrimidine bases thymine (T), cytosine (C), and uracil (U).
- modified nucleoside means a nucleoside having, independently, a modified sugar moiety and/or modified nucleobase.
- Modified nucleotide means a nucleotide having, independently, a modified sugar moiety, modified internucleoside linkage, and/or modified nucleobase.
- Modified oligonucleotide means an oligonucleotide comprising at least one modified
- Modified sugar means substitution and/or any change from a natural sugar moiety.
- “Monomer” means a single unit of an oligomer. Monomers include, but are not limited to, nucleosides and nucleotides, whether naturally occurring or modified.
- Microtif means the pattern of unmodified and modified nucleosides in an antisense compound.
- Natural sugar moiety means a sugar moiety found in DNA (2'-H) or RNA (2' -OH).
- Naturally occurring internucleoside linkage means a 3' to 5' phosphodiester linkage.
- Non-complementary nucleobase refers to a pair of nucleobases that do not form hydrogen bonds with one another or otherwise support hybridization.
- Nucleic acid refers to molecules composed of monomeric nucleotides.
- a nucleic acid includes, but is not limited to, ribonucleic acids (RNA), deoxyribonucleic acids (DNA), single-stranded nucleic acids, double-stranded nucleic acids, small interfering ribonucleic acids (siRNA), and microRNAs (miRNA).
- RNA ribonucleic acids
- DNA deoxyribonucleic acids
- siRNA small interfering ribonucleic acids
- miRNA microRNAs
- Nucleobase means a heterocyclic moiety capable of pairing with a base of another nucleic acid.
- nucleobase complementarity refers to a nucleobase that is capable of base pairing with another nucleobase.
- adenine (A) is complementary to thymine (T).
- adenine (A) is complementary to uracil (U).
- complementary nucleobase refers to a nucleobase of an antisense compound that is capable of base pairing with a nucleobase of its target nucleic acid.
- nucleobase at a certain position of an antisense compound is capable of hydrogen bonding with a nucleobase at a certain position of a target nucleic acid
- the position of hydrogen bonding between the oligonucleotide and the target nucleic acid is considered to be complementary at that nucleobase pair.
- Nucleobase sequence means the order of contiguous nucleobases independent of any sugar, linkage, and/or nucleobase modification.
- Nucleoside means a nucleobase linked to a sugar.
- Nucleoside mimetic includes those structures used to replace the sugar or the sugar and the base and not necessarily the linkage at one or more positions of an oligomeric compound such as for example nucleoside mimetics having morpholino, cyclohexenyl, cyclohexyl, tetrahydropyranyl, bicyclo, or tricyclo sugar mimetics, e.g., non furanose sugar units.
- Sugar surrogate overlaps with the slightly broader term nucleoside mimetic but is intended to indicate replacement of the sugar unit (furanose ring) only.
- the tetrahydropyranyl rings provided herein are illustrative of an example of a sugar surrogate wherein the furanose sugar group has been replaced with a tetrahydropyranyl ring system.
- Mimetic refers to groups that are substituted for a sugar, a nucleobase, and/or internucleoside linkage. Generally, a mimetic is used in place of the sugar or sugar-internucleoside linkage combination, and the nucleobase is maintained for hybridization to a selected target.
- Nucleotide means a nucleoside having a phosphate group covalently linked to the sugar portion of the nucleoside.
- Off-target effect refers to an unwanted or deleterious biological effect associated with modulation of RNA or protein expression of a gene other than the intended target nucleic acid.
- Oligomer means a polymer of linked monomelic subunits which is capable of hybridizing to at least a region of a nucleic acid molecule.
- Oligonucleotide means a polymer of linked nucleosides each of which can be modified or unmodified, independent one from another.
- Parenteral administration means administration through injection (e.g., bolus injection) or infusion.
- Parenteral administration includes subcutaneous administration, intravenous administration, intramuscular administration, intraarterial administration, intraperitoneal administration, or intracranial administration, e.g., intrathecal or intracerebroventricular administration.
- peptide means a molecule formed by linking at least two amino acids by amide bonds.
- peptide refers to polypeptides and proteins.
- “Pharmaceutical agent” means a substance that provides a therapeutic benefit when administered to an individual.
- a modified oligonucleotide targeted to SOD-1 is a pharmaceutical agent.
- “Pharmaceutical composition” means a mixture of substances suitable for administering to a subject.
- a pharmaceutical composition may comprise a modified oligonucleotide and a sterile aqueous solution.
- “Pharmaceutically acceptable derivative” encompasses pharmaceutically acceptable salts, conjugates, prodrugs or isomers of the compounds described herein.
- “Pharmaceutically acceptable salts” means physiologically and pharmaceutically acceptable salts of antisense compounds, i.e. , salts that retain the desired biological activity of the parent oligonucleotide and do not impart undesired toxicological effects thereto.
- Phosphorothioate linkage means a linkage between nucleosides where the phosphodiester bond is modified by replacing one of the non-bridging oxygen atoms with a sulfur atom.
- a phosphorothioate linkage is a modified internucleoside linkage.
- Portion means a defined number of contiguous (i.e., linked) nucleobases of a nucleic acid. In certain embodiments, a portion is a defined number of contiguous nucleobases of a target nucleic acid. In certain embodiments, a portion is a defined number of contiguous nucleobases of an antisense compound.
- Prevent or “preventing” refers to delaying or forestalling the onset or development of a disease, disorder, or condition for a period of time from minutes to days, weeks to months, or indefinitely.
- Prodrug means a therapeutic agent that is prepared in an inactive form that is converted to an active form (i.e., drug) within the body or cells thereof by the action of endogenous enzymes or other chemicals and/or conditions.
- “Prophylactically effective amount” refers to an amount of a pharmaceutical agent that provides a prophylactic or preventative benefit to an animal.
- Regular is defined as a portion of the target nucleic acid having at least one identifiable structure, function, or characteristic.
- “Ribonucleotide” means a nucleotide having a hydroxy at the 2' position of the sugar portion of the nucleotide. Ribonucleotides may be modified with any of a variety of substituents.
- Salts mean a physiologically and pharmaceutically acceptable salts of antisense compounds, i.e., salts that retain the desired biological activity of the parent oligonucleotide and do not impart undesired toxicological effects thereto.
- “Segments” are defined as smaller or sub-portions of regions within a target nucleic acid.
- Side effects means physiological responses attributable to a treatment other than desired effects.
- side effects include, without limitation, injection site reactions, liver function test abnormalities, renal function abnormalities, liver toxicity, renal toxicity, central nervous system abnormalities, and myopathies.
- Single-stranded oligonucleotide means an oligonucleotide which is not hybridized to a
- Sites are defined as unique nucleobase positions within a target nucleic acid.
- SOD-1 means the mammalian gene superoxide dismutase 1, soluble (SOD-1), including the human gene superoxide dismutase 1, soluble (SOD-1).
- SOD-1 associated disease means any disease associated with any SOD-1 nucleic acid or expression product thereof. Such diseases may include a neurodegenerative disease. Such neurodegenerative diseases may include amyotrophic lateral sclerosis (ALS).
- ALS amyotrophic lateral sclerosis
- SOD-1 mRNA means any messenger RNA expression product of a DNA sequence encoding SOD-
- SOD-1 nucleic acid means any nucleic acid encoding SOD-1. For example, in certain embodiments
- a SOD-1 nucleic acid includes a DNA sequence encoding SOD-1, an RNA sequence transcribed from DNA encoding SOD-1 (including genomic DNA comprising introns and exons), and a mRNA sequence encoding SOD-1.
- SOD-1 mRNA means a mRNA encoding a SOD-1 protein.
- SOD-1 protein means the polypeptide expression product of a SOD-1 nucleic acid.
- Specifically hybridizable refers to an antisense compound having a sufficient degree of complementarity between an oligonucleotide and a target nucleic acid to induce a desired effect, while exhibiting minimal or no effects on non-target nucleic acids under conditions in which specific binding is desired, i.e., under physiological conditions in the case of in vivo assays and therapeutic treatments.
- Stringent hybridization conditions or “stringent conditions” refer to conditions under which an oligomeric compound will hybridize to its target sequence, but to a minimal number of other sequences.
- Subject means a human or non-human animal selected for treatment or therapy.
- oligonucleotide with a mixed backbone may include at least one 2'-0- methoxyethyl modified nucleoside, and/or one cEt modified nucleoside, and/or one 2'-deoxynucleoside.
- Target refers to a protein, the modulation of which is desired.
- Target gene refers to a gene encoding a target.
- Targeting or “targeted” means the process of design and selection of an antisense compound that will specifically hybridize to a target nucleic acid and induce a desired effect.
- Target nucleic acid means a nucleic acid capable of being targeted by antisense compounds.
- Target region means a portion of a target nucleic acid to which one or more antisense compounds is targeted.
- Target segment means the sequence of nucleotides of a target nucleic acid to which an antisense compound is targeted.
- 5' target site refers to the 5 '-most nucleotide of a target segment.
- 3' target site refers to the 3 '-most nucleotide of a target segment.
- “Therapeutically effective amount” means an amount of a pharmaceutical agent that provides a therapeutic benefit to an individual.
- Treat” or “treating” or “treatment” refers administering a composition to effect an alteration or improvement of the disease or condition.
- Unmodified nucleobases mean the purine bases adenine (A) and guanine (G), and the pyrimidine bases thymine (T), cytosine (C) and uracil (U).
- Unmodified nucleotide means a nucleotide composed of naturally occuring nucleobases, sugar moieties, and internucleoside linkages.
- an unmodified nucleotide is an RNA nucleotide (i.e. ⁇ -D-ribonucleosides) or a DNA nucleotide (i.e. ⁇ -D-deoxyribonucleoside).
- Wild segment means a plurality of nucleosides modified to impart to an oligonucleotide properties such as enhanced inhibitory activity, increased binding affinity for a target nucleic acid, or resistance to degradation by in vivo nucleases.
- Certain embodiments provide methods, compounds, and compositions for inhibiting SOD-1 m NA and protein expression. Certain embodiments provide methods, compounds, and composition for decreasing SOD-1 mRNA and protein levels.
- Certain embodiments provide antisense compounds targeted to a SOD-1 nucleic acid.
- the SOD-1 nucleic acid is the sequence set forth in GENBANK Accession No. NM 000454.4 (incorporated herein as SEQ ID NO: 1), GENBANK Accession No. NT 011512.10 truncated from nucleotides 18693000 to 18704000 (incorporated herein as SEQ ID NO: 2), and the complement of
- Certain embodiments provide methods for the treatment, prevention, or amelioration of diseases, disorders, and conditions associated with SOD-1 in an individual in need thereof. Also contemplated are methods for the preparation of a medicament for the treatment, prevention, or amelioration of a disease, disorder, or condition associated with SOD-1.
- SOD-1 associated diseases, disorders, and conditions include neurodegenerative diseases.
- SOD-1 associated diseases include amyotrophic lateral sclerosis (ALS).
- Embodiment 1 A compound, comprising a modified oligonucleotide consisting of 12 to 30 linked nucleosides and having a nucleobase sequence comprising at least 8, at least 9, at least 10, at least 11, at least 12, at least 13, at least 14, at least 15, at least 16, at least 17, at least 18, at least 19, or at least 20 consecutive nucleobases of any of the nucleobase sequences of SEQ ID NOs: 118-1461.
- Embodiment 2 A compound, comprising a modified oligonucleotide consisting of 12 to 30 linked nucleosides and having a nucleobase sequence comprising at least 8, at least 9, at least 10, at least 11, at least 12, at least 13, at least 14, at least 15, at least 16, at least 17, at least 18, at least 19, or at least
- Embodiment 3 The compound of any preceding embodiment, wherein the modified oligonucleotide has a mixed backbone.
- Embodiment 4 The compound of embodiment 3, wherein the mixed backbone motif is any of the following:
- sooossssssssssssoss soossssssssooss
- o a phosphodiester internucleoside linkage.
- Embodiment 5 The compound of any preceding embodiment, wherein the modified oligonucleotide has a sugar chemistry motif of any of the following:
- Embodiment 6 The compound of any preceding embodiment, wherein the nucleobase sequence of the modified oligonucleotide is at least 80%, at least 81%, at least 82%, at least 83%, at least 84%, at least 85%, at least 86%, at least 87%, at least 88%, at least 89%, at least 90%, at least 91%, at least 92%, at least 93%, at least 94%, at least 95%, at least 96%, at least 97%, at least 98%, at least 99%, or 100% complementary to SEQ ID NO: 1 or SEQ ID NO: 2.
- Embodiment 7 The compound of any preceding embodiment, consisting of a single-stranded modified oligonucleotide.
- Embodiment 8 The compound of any preceding embodiment, wherein at least one internucleoside linkage is a modified internucleoside linkage.
- Embodiment 9 The compound of embodiment 8, wherein at least one modified internucleoside linkage is a phosphorothioate internucleoside linkage.
- Embodiment 10 The compound of embodiment 9, wherein each modified internucleoside linkage is a phosphorothioate internucleoside linkage.
- Embodiment 11 The compound of any preceding embodiment, wherein at least one internucleoside linkage is a phosphodiester internucleoside linkage.
- Embodiment 12 The compound of any preceding embodiment, wherein at least one internucleoside linkage is a phosphorothioate linkage and at least one internucleoside linkage is a phosphodiester linkage.
- Embodiment 13 The compound of any preceding embodiment, wherein at least one nucleoside comprises a modified nucleobase.
- Embodiment 14 The compound of embodiment 13, wherein the modified nucleobase is a 5- methylcytosine.
- Embodiment 15 The compound of any preceding embodiment, wherein at least one nucleoside of the modified oligonucleotide comprises a modified sugar.
- Embodiment 16 The compound of embodiment 15, wherein the at least one modified sugar is a bicyclic sugar.
- Embodiment 17 The compound of embodiment 16, wherein the bicyclic sugar comprises a chemical link between the 2' and 4' position of the sugar 4'-CH 2 -N(R)-0-2' bridge wherein R is, independently, H, C1-C12 alkyl, or a protecting group.
- Embodiment 18 The compound of embodiment 17, wherein the bicyclic sugar comprises a 4'-CH 2 - N(R)-0-2' bridge wherein R is, independently, H, C1-C12 alkyl, or a protecting group.
- Embodiment 19 The compound of embodiment 15, wherein at least one modified sugar comprises a 2 ' -O -methoxyethyl grou .
- Embodiment 20 The compound of embodiment 15, wherein the modified sugar comprises a 2'- 0(CH 2 ) 2 -OCH 3 group.
- Embodiment 21 The compound of any preceding embodiment, wherein the modified oligonucleotide comprises:
- a 3' wing segment consisting of 5 linked nucleosides
- each nucleoside of each wing segment comprises a modified sugar
- Embodiment 22 The compound of any preceding embodiment, wherein the modified oligonucleotide comprises:
- a 3' wing segment consisting of 5 linked nucleosides
- each nucleoside of each wing segment comprises a modified sugar
- Embodiment 23 The compound of any preceding embodiment, wherein the modified oligonucleotide comprises:
- a 3' wing segment consisting of 5 linked nucleosides
- each nucleoside of each wing segment comprises a modified sugar.
- Embodiment 24 The compound of any preceding embodiment, wherein the modified oligonucleotide comprises:
- a 3' wing segment consisting of 5 linked nucleosides
- each nucleoside of each wing segment comprises a modified sugar
- Embodiment 25 The compound of any preceding embodiment, wherein the modified oligonucleotide comprises:
- a 3' wing segment consisting of 7 linked nucleosides
- each nucleoside of each wing segment comprises a modified sugar
- Embodiment 26 The compound of any preceding embodiment, wherein the modified oligonucleotide comprises:
- a 3' wing segment consisting of 6 linked nucleosides
- each nucleoside of each wing segment comprises a modified sugar
- Embodiment 27 The compound of any preceding embodiment, wherein the modified oligonucleotide comprises:
- a 3' wing segment consisting of 5 linked nucleosides
- each nucleoside of each wing segment comprises a modified sugar
- Embodiment 28 The compound of any preceding embodiment, wherein the modified oligonucleotide consists of 12, 13, 14, 15, 16, 17, 18, 19, or 20 linked nucleosides.
- Embodiment 30 A compound consisting of a modified oligonucleotide according to the following formula:
- Embodiment 34 A compound consisting of a modified oligonucleotide according to the following formula:
- Embodiment 35 A compound consisting of a modified oligonucleotide according to the following formula:
- Embodiment 36 A compound consisting of a modified oligonucleotide according to the following formula:
- Embodiment 37 A compound consisting of a modified oligonucleotide according to the following formula: mCes Aeo Ges Geo Aes Tds Ads mCds Ads Tds Tds Tds mCds Tds Ads mCeo Aes Geo mCes Te; wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- Embodiment 38 A compound consisting of a modified oligonucleotide according to the following formula: Tes Teo Aeo Aes Tds Gds Tds Tds Tds Ads Tds mCds Ako Gko Ges Aes Te; wherein,
- A an adenine
- mC a S'-methylcytosine
- G a guanine
- d a 2 , -deoxyribose sugar
- o a phosphodiester internucleoside linkage.
- Embodiment 39 A compound consisting of a modified oligonucleotide according to the following formula: Ges Geo Aeo Teo Ads mCds Ads Tds Tds Tds mCds Tds Ads mCko Aks Ges mCe; wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- Embodiment 40 A compound consisting of a modified oligonucleotide according to the following formula: Ges Geo Aeo Teo Aes mCds Ads Tds Tds Tds mCds Tds Ads mCko Aks Ges mCe; wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- d a 2'-deoxyribose sugar
- s a phosphorothioate internucleoside linkage
- o a phosphodiester internucleoside linkage.
- Embodiment 41 A compound consisting of a modified oligonucleotide according to the following formula: Ges Geo Aeo Teo Aks mCds Ads Tds Tds Tds mCds Tds Ads mCko Aes Ges mCe; wherein,
- A an adenine
- mC a S'-methylcytosine
- G a guanine
- e a 2' -O-methoxyethylribose modified sugar
- d a 2 , -deoxyribose sugar
- o a phosphodiester internucleoside linkage.
- Embodiment 42 A compound consisting of a modified oligonucleotide according to the following formula: Aes Gko Teo Gks Tds Tds Tds Ads Ads Tds Gds Tds Tko Teo Aks Tes mCe; wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- e a -O-methoxyethylribose modified sugar
- o a phosphodiester internucleoside linkage.
- Embodiment 43 A compound consisting of a modified oligonucleotide according to the following formula: Aes Gko Teo Gks Tds Tds Tds Ads Ads Tds Gds Tds Teo Teo Aes Tes mCe; wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- e a 2' -O-methoxyethylribose modified sugar
- k a cEt modified sugar
- d a 2'-deoxyribose sugar
- o a phosphodiester internucleoside linkage.
- Embodiment 44 A compound consisting of a modified oligonucleotide according to the following formula: Aes Geo Tko Gks Tds Tds Tds Ads Ads Tds Gds Tds Teo Teo Aes Tes mCe; wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- Embodiment 45 A compound consisting of a modified oligonucleotide according to the following formula: mCes mCeo Geo Teo mCeo Gds mCds mCds mCds Tds Tds mCds Ads Gds mCds Aeo mCeo Ges mCes Ae, wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- Embodiment 46 A compound consisting of a modified oligonucleotide according to the following formula: mCes mCeo Geo Teo mCes Gds mCds mCds mCds Tds Tds mCds Ads Ges mCeo Aeo mCeo Ges mCes Ae, wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- e a 2'-0-methoxyethylribose modified sugar
- d a 2'-deoxyribose sugar
- o a phosphodiester internucleoside linkage.
- Embodiment 47 A compound consisting of a modified oligonucleotide according to the following formula: mCes mCeo Geo Teo mCes Gds mCds mCds mCds Tds Tds mCds Ads Gds mCds Aeo mCeo Geo mCes Ae, wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- Embodiment 48 A compound consisting of a modified oligonucleotide according to the following formula: Aes mCeo Aeo mCeo mCes Tds Tds mCds Ads mCds Tds Gds Gds Tds mCds mCeo Aeo Teo Tes Ae, wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- Embodiment 49 A compound consisting of a modified oligonucleotide according to the following formula: Ges Geo mCeo Geo Aes Tds mCds mCds mCds Ads Ads Tds Tds Ads mCds Aeo mCeo mCeo Aes mCe, wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- e a 2'-0-methoxyethylribose modified sugar
- d a 2'-deoxyribose sugar
- o a phosphodiester internucleoside linkage.
- Embodiment 50 A compound consisting of a modified oligonucleotide according to the following formula: Ges Geo mCeo Geo Aes Tes mCds mCds mCds Ads Ads Tds Tds Ads mCeo Aeo mCeo mCes Aes mCe, wherein,
- A an adenine
- mC a S'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- Embodiment 51 A compound consisting of a modified oligonucleotide according to the following formula: Ges Geo mCeo Geo Aes Tds mCds mCds mCds Ads Ads Tds Tds Aes mCeo Aeo mCeo mCes Aes mCe, wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- Embodiment 52 A compound consisting of a modified oligonucleotide according to the following formula: Ges Geo mCeo Geo Aeo Tes mCds mCds mCds Ads Ads Tds Tds Ads mCds Aeo mCeo mCes Aes mCe, wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- T a thymine
- e a 2'-0-methoxyethylribose modified sugar
- o a phosphodiester internucleoside linkage.
- Embodiment 53 A compound consisting of a modified oligonucleotide according to the following formula: Ges Teo mCeo Geo mCes mCds mCds Tds Tds mCds Ads Gds mCds Ads mCds Geo mCeo Aeo mCes Ae, wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- Embodiment 54 A compound consisting of a modified oligonucleotide according to the following formula: Tes mCeo Geo mCeo mCes mCds Tds Tds mCds Ads Gds mCds Ads mCds Gds mCeo Aeo mCeo Aes mCe, wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- Embodiment 55 A compound consisting of a modified oligonucleotide according to the following formula: Ges Aes Aes Aes Tes Tds Gds Ads Tds Gds Ads Tds Gds mCds mCds mCes Tes Ges mCes Ae, wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- T a thymine
- e a 2'-0-methoxyethylribose modified sugar
- s a phosphorothioate internucleoside linkage.
- Embodiment 56 A composition comprising the compound of any preceding embodiment or salt thereof and at least one of a pharmaceutically acceptable carrier or diluent.
- Embodiment 57 A method comprising administering to an animal the compound or composition of any preceding embodiment.
- Embodiment 58 The method of embodiment 57, wherein the animal is a human.
- Embodiment 59 The method of embodiment 57, wherein administering the compound prevents, treats, ameliorates, or slows progression of a SOD-1 associated disease.
- Embodiment 60 The method of embodiment 59, wherein the SOD-1 associated disease is a neurodegenerative disease.
- Embodiment 61 The method of embodiment 60, wherein the SOD-1 associated disease is ALS.
- Embodiment 62 Use of the compound or composition of any preceding embodiment for the manufacture of a medicament for treating a neurodegenerative disorder.
- Embodiment 63 Use of the compound or composition of any preceding embodiment for the manufacture of a medicament for treating ALS.
- Embodiment 64 The compound or composition of any preceding embodiment wherein the modified oligonucleotide does not have the nucleobase sequence of SEQ ID NO: 21.
- Embodiment 65 The compound or composition of any preceding embodiment wherein the modified oligonucleotide does not have the nucleobase sequence of any of SEQ ID NOs: 21-118.
- Embodiment 66 A compound comprising a modified oligonucleotide consisting of 12 to 30 linked nucleosides and having a nucleobase sequence, wherein the nucleobase sequence comprises an at least 12 consecutive nucleobase portion complementary to an equal number of nucleobases of nucleotides 665 to 684 of SEQ ID NO: 1, wherein the modified oligonucleotide is at least 80% complementary to SEQ ID NO: 1.
- Embodiment 67 The compound of embodiment 66, wherein the modified oligonucleotide is 100% complementary to SEQ ID NO: 1.
- Embodiment 68 The compound of embodiment 66, wherein the modified oligonucleotide is a single- stranded modified oligonucleotide.
- Embodiment 69 The compound of embodiments 66-68 wherein at least one internucleoside linkage is a modified internucleoside linkage.
- Embodiment 70 The compound of embodiment 69, wherein at least one modified internucleoside linkage is a phosphorothioate internucleoside linkage.
- Embodiment 71 The compound of embodiment 70, wherein each modified internucleoside linkage is a phosphorothioate internucleoside linkage.
- Embodiment 72 The compound of embodiments 66-69, wherein at least one internucleoside linkage is a phosphodiester internucleoside linkage.
- Embodiment 73 The compound of embodiments 66-71 and 72-73, wherein at least one internucleoside linkage is a phosphorothioate linkage and at least one internucleoside linkage is a phosphodiester linkage.
- Embodiment 74 The compound of embodiments 66-73, wherein at least one nucleoside comprises a modified nucleobase.
- Embodiment 75 The compound of embodiment 74, wherein the modified nucleobase is a 5- methylcytosine.
- Embodiment 76 The compound of embodiments 66-75, wherein at least one nucleoside of the modified oligonucleotide comprises a modified sugar.
- Embodiment 77 The compound of embodiment 76, wherein the at least one modified sugar is a bicyclic sugar.
- Embodiment 78 The compound of embodiment 77, wherein the bicyclic sugar comprises a 4'- CH(R)-0-2' bridge wherein R is, independently, H, C 1 -C 12 alkyl, or a protecting group.
- Embodiment 79 The compound of embodiment 78, wherein R is methyl.
- Embodiment 80 The compound of embodiment 78, wherein R is H.
- Embodiment 81 The compound of embodiment 76, wherein the at least one modified sugar comprises a 2'-0-methoxyethyl group.
- Oligomeric compounds include, but are not limited to, oligonucleotides, oligonucleosides, oligonucleotide analogs, oligonucleotide mimetics, antisense compounds, antisense oligonucleotides, modified oligonucleotides, and siRNAs.
- An oligomeric compound may be "antisense" to a target nucleic acid, meaning that is is capable of undergoing hybridization to a target nucleic acid through hydrogen bonding.
- an antisense compound has a nucleobase sequence that, when written in the 5' to 3' direction, comprises the reverse complement of the target segment of a target nucleic acid to which it is targeted.
- an oligonucleotide has a nucleobase sequence that, when written in the 5' to 3' direction, comprises the reverse complement of the target segment of a target nucleic acid to which it is targeted.
- an antisense compound targeted to a SOD-1 nucleic acid is 12 to 30 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 12 to 25 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 12 to 22 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 14 to 20 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 15 to 25 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 18 to 22 subunits in length.
- an antisense compound targeted to a SOD-1 nucleic acid is 19 to 21 subunits in length.
- the antisense compound is 8 to 80, 12 to 50, 13 to 30, 13 to 50, 14 to 30, 14 to 50, 15 to 30, 15 to 50, 16 to 30, 16 to 50, 17 to 30, 17 to 50, 18 to 30, 18 to 50, 19 to 30, 19 to 50, or 20 to 30 linked subunits in length.
- an antisense compound targeted to a SOD-1 nucleic acid is 12 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 13 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 14 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 15 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 16 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 17 subunits in length.
- an antisense compound targeted to a SOD-1 nucleic acid is 18 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 19 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 20 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 21 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 22 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 23 subunits in length.
- an antisense compound targeted to a SOD-1 nucleic acid is 24 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 25 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 26 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 27 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 28 subunits in length. In certain embodiments, an antisense compound targeted to a SOD-1 nucleic acid is 29 subunits in length.
- an antisense compound targeted to a SOD-1 nucleic acid is 30 subunits in length.
- the antisense compound targeted to a SOD-1 nucleic acid is 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, or 80 linked subunits in length, or a range defined by any two of the above values.
- the antisense compound is a modified
- oligonucleotide, and the linked subunits are nucleosides.
- oligonucleotides targeted to a SOD-1 nucleic acid may be shortened or truncated.
- a single subunit may be deleted from the 5' end (5' truncation), or alternatively from the 3' end (3' truncation).
- a shortened or truncated antisense compound targeted to a SOD-1 nucleic acid may have two subunits deleted from the 5' end, or alternatively may have two subunits deleted from the 3' end, of the antisense compound.
- the deleted nucleosides may be dispersed throughout the antisense compound, for example, in an antisense compound having one nucleoside deleted from the 5' end and one nucleoside deleted from the 3' end.
- the additional subunit may be located at the 5' or 3' end of the antisense compound.
- the added subunits may be adjacent to each other, for example, in an antisense compound having two subunits added to the 5' end (5' addition), or alternatively to the 3' end (3' addition), of the antisense compound.
- the added subunits may be dispersed throughout the antisense compound, for example, in an antisense compound having one subunit added to the 5' end and one subunit added to the 3' end.
- an antisense compound such as a modified oligonucleotide
- an antisense compound such as a modified oligonucleotide
- a series of oligonucleotides 13-25 nucleobases in length were tested for their ability to induce cleavage of a target RNA in an oocyte injection model.
- Oligonucleotides 25 nucleobases in length with 8 or 11 mismatch bases near the ends of the oligonucleotides were able to direct specific cleavage of the target mRNA, albeit to a lesser extent than oligonucleotides that contained no mismatches. Similarly, target specific cleavage was achieved using 13 nucleobase
- oligonucleotides including those with 1 or 3 mismatches.
- Gautschi et al demonstrated the ability of an oligonucleotide having 100% complementarity to the bcl-2 mRNA and having 3 mismatches to the bcl-xL mRNA to reduce the expression of both bcl-2 and bcl-xL in vitro and in vivo. Furthermore, this oligonucleotide demonstrated potent anti-tumor activity in vivo.
- Maher and Dolnick (Nuc. Acid. Res. 16:3341-3358,1988) tested a series of tandem 14 nucleobase oligonucleotides, and a 28 and 42 nucleobase oligonucleotides comprised of the sequence of two or three of the tandem oligonucleotides, respectively, for their ability to arrest translation of human DHFR in a rabbit reticulocyte assay.
- Each of the three 14 nucleobase oligonucleotides alone was able to inhibit translation, albeit at a more modest level than the 28 or 42 nucleobase oligonucleotides.
- antisense compounds targeted to a SOD-1 nucleic acid have chemically modified subunits arranged in patterns, or motifs, to confer to the antisense compounds properties such as enhanced inhibitory activity, increased binding affinity for a target nucleic acid, or resistance to degradation by in vivo nucleases.
- Chimeric antisense compounds typically contain at least one region modified so as to confer increased resistance to nuclease degradation, increased cellular uptake, increased binding affinity for the target nucleic acid, and/or increased inhibitory activity.
- a second region of a chimeric antisense compound may optionally serve as a substrate for the cellular endonuclease RNase H, which cleaves the RNA strand of an RNA:DNA duplex.
- Antisense compounds having a gapmer motif are considered chimeric antisense compounds.
- a gapmer an internal region having a plurality of nucleotides that supports RNaseH cleavage is positioned between external regions having a plurality of nucleotides that are chemically distinct from the nucleosides of the internal region.
- the gap segment In the case of an oligonucleotide having a gapmer motif, the gap segment generally serves as the substrate for endonuclease cleavage, while the wing segments comprise modified nucleosides.
- the regions of a gapmer are differentiated by the types of sugar moieties comprising each distinct region.
- wings may include several modified sugar moieties, including, for example 2'-MOE.
- wings may include several modified and unmodified sugar moieties.
- wings may include various combinations of 2'-MOE nucleosides and 2'-deoxynucleosides.
- Each distinct region may comprise uniform sugar moieties, variant, or alternating sugar moieties.
- the wing-gap-wing motif is frequently described as "X-Y-Z", where "X” represents the length of the 5' wing, "Y” represents the length of the gap, and “Z” represents the length of the 3' wing.
- "X” and “Z” may comprise uniform, variant, or alternating sugar moieties.
- "X" and “Y” may include one or more 2'-deoxynucleosides.
- “Y” may comprise 2'-deoxynucleosides.
- a gapmer described as "X-Y-Z” has a configuration such that the gap is positioned immediately adjacent to each of the 5' wing and the 3' wing. Thus, no intervening nucleotides exist between the 5' wing and gap, or the gap and the 3 ' wing.
- Any of the antisense compounds described herein can have a gapmer motif.
- "X" and “Z” are the same; in other embodiments they are different.
- gapmers provided herein include, for example 20-mers having a motif of 5-
- gapmers provided herein include, for example 19-mers having a motif of 5- 9-5.
- gapmers provided herein include, for example 18-mers having a motif of 5-
- gapmers provided herein include, for example 18-mers having a motif of 4-
- gapmers provided herein include, for example 18-mers having a motif of 5-
- gapmers provided herein include, for example 18-mers having a motif of 6-
- gapmers provided herein include, for example 18-mers having a motif of 6- 8-5.
- the modified oligonucleotide contains at least one 2'-0-methoxyethyl modified nucleoside , at least one cEt modified nucleoside , and at least one 2'-deoxynucleoside. In certain embodiments, the modified oligonucleotide has a sugar chemistry motif of any of the following:
- d a 2'-deoxyribose sugar, Target Nucleic Acids, Target Regions and Nucleotide Sequences
- Nucleotide sequences that encode SOD-1 include, without limitation, the following: GENBANK Accession No. NM 000454.4 (incorporated herein as SEQ ID NO: 1), GENBANK Accession No.
- NT 011512.10 truncated from nucleotides 18693000 to 18704000 (incorporated herein as SEQ ID NO: 2), and the complement of GENBANK Accession No. NW 001114168.1 truncated from nucleotides 2258000 to 2271000 (incorporated herein as SEQ ID NO: 3).
- antisense compounds defined by a SEQ ID NO may comprise, independently, one or more modifications to a sugar moiety, an internucleoside linkage, or a nucleobase.
- Antisense compounds described by Isis Number (Isis No) indicate a combination of nucleobase sequence and motif.
- a target region is a structurally defined region of the target nucleic acid.
- a target region may encompass a 3' UTR, a 5' UTR, an exon, an intron, an exon/intron junction, a coding region, a translation initiation region, translation termination region, or other defined nucleic acid region.
- the structurally defined regions for SOD-1 can be obtained by accession number from sequence databases such as NCBI and such information is incorporated herein by reference.
- a target region may encompass the sequence from a 5' target site of one target segment within the target region to a 3' target site of another target segment within the same target region.
- Targeting includes determination of at least one target segment to which an antisense compound hybridizes, such that a desired effect occurs.
- the desired effect is a reduction in mRNA target nucleic acid levels.
- the desired effect is reduction of levels of protein encoded by the target nucleic acid or a phenotypic change associated with the target nucleic acid.
- a target region may contain one or more target segments. Multiple target segments within a target region may be overlapping. Alternatively, they may be non-overlapping. In certain embodiments, target segments within a target region are separated by no more than about 300 nucleotides. In certain emodiments, target segments within a target region are separated by a number of nucleotides that is, is about, is no more than, is no more than about, 250, 200, 150, 100, 90, 80, 70, 60, 50, 40, 30, 20, or 10 nucleotides on the target nucleic acid, or is a range defined by any two of the preceeding values.
- target segments within a target region are separated by no more than, or no more than about, 5 nucleotides on the target nucleic acid. In certain embodiments, target segments are contiguous. Contemplated are target regions defined by a range having a starting nucleic acid that is any of the 5' target sites or 3' target sites listed herein.
- Suitable target segments may be found within a 5' UTR, a coding region, a 3' UTR, an intron, an exon, or an exon/intron junction.
- Target segments containing a start codon or a stop codon are also suitable target segments.
- a suitable target segment may specifcally exclude a certain structurally defined region such as the start codon or stop codon.
- the determination of suitable target segments may include a comparison of the sequence of a target nucleic acid to other sequences throughout the genome.
- the BLAST algorithm may be used to identify regions of similarity amongst different nucleic acids. This comparison can prevent the selection of antisense compound sequences that may hybridize in a non-specific manner to sequences other than a selected target nucleic acid (i.e., non-target or off-target sequences).
- SOD-1 mRNA levels are indicative of inhibition of SOD-1 expression.
- Reductions in levels of a SOD-1 protein are also indicative of inhibition of target mRNA expression.
- Phenotypic changes are indicative of inhibition of SOD-1 expression.
- Improvement in neurological function is indicative of inhibition of SOD-1 expression.
- Improved motor function is indicative of inhibition of SOD-1 expression.
- hybridization occurs between an antisense compound disclosed herein and a SOD-1 nucleic acid.
- the most common mechanism of hybridization involves hydrogen bonding (e.g.,
- Hybridization can occur under varying conditions. Stringent conditions are sequence-dependent and are determined by the nature and composition of the nucleic acid molecules to be hybridized.
- the antisense compounds provided herein are specifically hybridizable with a SOD-1 nucleic acid.
- An antisense compound and a target nucleic acid are complementary to each other when a sufficient number of nucleobases of the antisense compound can hydrogen bond with the corresponding nucleobases of the target nucleic acid, such that a desired effect will occur (e.g., antisense inhibition of a target nucleic acid, such as a SOD- 1 nucleic acid).
- Non-complementary nucleobases between an antisense compound and a SOD-1 nucleic acid may be tolerated provided that the antisense compound remains able to specifically hybridize to a target nucleic acid.
- an antisense compound may hybridize over one or more segments of a SOD-1 nucleic acid such that intervening or adjacent segments are not involved in the hybridization event (e.g., a loop structure, mismatch or hairpin structure).
- the antisense compounds provided herein, or a specified portion thereof are, or are at least, 70%, 80%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%o, 99%), or 100% complementary to a SOD-1 nucleic acid, a target region, target segment, or specified portion thereof. Percent complementarity of an antisense compound with a target nucleic acid can be determined using routine methods.
- an antisense compound in which 18 of 20 nucleobases of the antisense compound are complementary to a target region, and would therefore specifically hybridize, would represent 90 percent complementarity.
- the remaining noncomplementary nucleobases may be clustered or interspersed with complementary nucleobases and need not be contiguous to each other or to complementary nucleobases.
- Percent complementarity of an antisense compound with a region of a target nucleic acid can be determined routinely using BLAST programs (basic local alignment search tools) and PowerBLAST programs known in the art (Altschul et al., J. Mol. Biol., 1990, 215, 403 410; Zhang and Madden, Genome Res., 1997, 7, 649 656). Percent homology, sequence identity or
- complementarity can be determined by, for example, the Gap program (Wisconsin Sequence Analysis Package, Version 8 for Unix, Genetics Computer Group, University Research Park, Madison Wis.), using default settings, which uses the algorithm of Smith and Waterman (Adv. Appl. Math., 1981, 2, 482 489).
- the antisense compounds provided herein, or specified portions thereof are fully complementary ⁇ i.e., 100%> complementary) to a target nucleic acid, or specified portion thereof.
- an antisense compound may be fully complementary to a SOD-1 nucleic acid, or a target region, or a target segment or target sequence thereof.
- "fully complementary" means each nucleobase of an antisense compound is capable of precise base pairing with the corresponding nucleobases of a target nucleic acid.
- a 20 nucleobase antisense compound is fully complementary to a target sequence that is 400 nucleobases long, so long as there is a corresponding 20 nucleobase portion of the target nucleic acid that is fully complementary to the antisense compound.
- Fully complementary can also be used in reference to a specified portion of the first and /or the second nucleic acid.
- a 20 nucleobase portion of a 30 nucleobase antisense compound can be "fully complementary" to a target sequence that is 400 nucleobases long.
- the 20 nucleobase portion of the 30 nucleobase oligonucleotide is fully complementary to the target sequence if the target sequence has a corresponding 20 nucleobase portion wherein each nucleobase is complementary to the 20 nucleobase portion of the antisense compound.
- the entire 30 nucleobase antisense compound may or may not be fully complementary to the target sequence, depending on whether the remaining 10 nucleobases of the antisense compound are also complementary to the target sequence.
- non-complementary nucleobase may be at the 5' end or 3' end of the antisense compound.
- the non-complementary nucleobase or nucleobases may be at an internal position of the antisense compound.
- two or more non-complementary nucleobases may be contiguous (i.e., linked) or non-contiguous.
- a non-complementary nucleobase is located in the wing segment of a gapmer oligonucleotide.
- antisense compounds that are, or are up to 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 nucleobases in length comprise no more than 4, no more than 3, no more than 2, or no more than 1 non-complementary nucleobase(s) relative to a target nucleic acid, such as a SOD-1 nucleic acid, or specified portion thereof.
- antisense compounds that are, or are up to 11, 12, 13, 14, 15, 16, 17, 18,
- nucleobases in length comprise no more than 6, no more than 5, no more than 4, no more than 3, no more than 2, or no more than 1 non-complementary nucleobase(s) relative to a target nucleic acid, such as a SOD-1 nucleic acid, or specified portion thereof.
- the antisense compounds provided herein also include those which are complementary to a portion of a target nucleic acid.
- portion refers to a defined number of contiguous (i.e. linked) nucleobases within a region or segment of a target nucleic acid.
- a “portion” can also refer to a defined number of contiguous nucleobases of an antisense compound.
- the antisense compounds are complementary to at least an 8 nucleobase portion of a target segment.
- the antisense compounds are complementary to at least a 9 nucleobase portion of a target segment.
- the antisense compounds are complementary to at least a 10 nucleobase portion of a target segment.
- the antisense compounds are complementary to at least an 11 nucleobase portion of a target segment. In certain embodiments, the antisense compounds, are complementary to at least a 12 nucleobase portion of a target segment. In certain embodiments, the antisense compounds, are complementary to at least a 13 nucleobase portion of a target segment. In certain embodiments, the antisense compounds, are complementary to at least a 14 nucleobase portion of a target segment. In certain embodiments, the antisense compounds, are complementary to at least a 15 nucleobase portion of a target segment. Also contemplated are antisense compounds that are complementary to at least a 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, or more nucleobase portion of a target segment, or a range defined by any two of these values.
- the antisense compounds provided herein may also have a defined percent identity to a particular nucleotide sequence, SEQ ID NO, or compound represented by a specific Isis number, or portion thereof.
- an antisense compound is identical to the sequence disclosed herein if it has the same nucleobase pairing ability.
- a RNA which contains uracil in place of thymidine in a disclosed DNA sequence would be considered identical to the DNA sequence since both uracil and thymidine pair with adenine.
- Shortened and lengthened versions of the antisense compounds described herein as well as compounds having non-identical bases relative to the antisense compounds provided herein also are contemplated.
- the non-identical bases may be adjacent to each other or dispersed throughout the antisense compound. Percent identity of an antisense compound is calculated according to the number of bases that have identical base pairing relative to the sequence to which it is being compared.
- the antisense compounds, or portions thereof are at least 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99% or 100% identical to one or more of the antisense compounds or SEQ ID NOs, or a portion thereof, disclosed herein.
- a portion of the antisense compound is compared to an equal length portion of the target nucleic acid.
- an 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 nucleobase portion is compared to an equal length portion of the target nucleic acid.
- a portion of the oligonucleotide is compared to an equal length portion of the target nucleic acid.
- an 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 nucleobase portion is compared to an equal length portion of the target nucleic acid.
- a nucleoside is a base-sugar combination.
- the nucleobase (also known as base) portion of the nucleoside is normally a heterocyclic base moiety.
- Nucleotides are nucleosides that further include a phosphate group covalently linked to the sugar portion of the nucleoside. For those nucleosides that include a pentofuranosyl sugar, the phosphate group can be linked to the 2', 3 Or 5' hydroxyl moiety of the sugar. Oligonucleotides are formed through the covalent linkage of adjacent nucleosides to one another, to form a linear polymeric oligonucleotide.
- the phosphate groups are commonly referred to as forming the internucleoside linkages of the oligonucleotide.
- Modifications to antisense compounds encompass substitutions or changes to internucleoside linkages, sugar moieties, or nucleobases. Modified antisense compounds are often preferred over native forms because of desirable properties such as, for example, enhanced cellular uptake, enhanced affinity for nucleic acid target, increased stability in the presence of nucleases, or increased inhibitory activity.
- Chemically modified nucleosides may also be employed to increase the binding affinity of a shortened or truncated oligonucleotide for its target nucleic acid. Consequently, comparable results can often be obtained with shorter antisense compounds that have such chemically modified nucleosides.
- RNA and DNA The naturally occuring internucleoside linkage of RNA and DNA is a 3' to 5' phosphodiester linkage.
- Antisense compounds having one or more modified, i.e. non-naturally occurring, internucleoside linkages are often selected over antisense compounds having naturally occurring internucleoside linkages because of desirable properties such as, for example, enhanced cellular uptake, enhanced affinity for target nucleic acids, and increased stability in the presence of nucleases.
- Oligonucleotides having modified internucleoside linkages include internucleoside linkages that retain a phosphorus atom as well as internucleoside linkages that do not have a phosphorus atom.
- Representative phosphorus containing internucleoside linkages include, but are not limited to,
- modified oligonucleotides targeted to a SOD-1 nucleic acid comprise one or more modified internucleoside linkages.
- the modified internucleoside linkages are interspersed throughout the antisense compound.
- the modified internucleoside linkages are phosphorothioate linkages.
- each internucleoside linkage of a modified oligonucleotide is a phosphorothioate internucleoside linkage.
- the modified oligonucleotides targeted to a SOD-1 nucleic acid comprise one or more phosphodiester internucleoside linkages. In certain embodiments, modified oligonucleotides targeted to a SOD-1 nucleic acid comprise at least one phosphorothioate internucleoside linkage and at least one phosphodiester internucleoside linkage. In certain embodiments, the modified oligonucleotide has a mixed backbone motif of the following:
- sooosssssssssssooss sooossssssssooss, sooossssssssooss,
- Antisense compounds of the invention can optionally contain one or more nucleosides wherein the sugar group has been modified.
- Such sugar modified nucleosides may impart enhanced nuclease stability, increased binding affinity, or some other beneficial biological property to the antisense compounds.
- nucleosides comprise chemically modified ribofuranose ring moieties.
- Examples of chemically modified ribofuranose rings include without limitation, addition of substitutent groups (including 5' and 2' substituent groups, bridging of non- geminal ring atoms to form bicyclic nucleic acids (BNA), replacement of the ribosyl ring oxygen atom with S, N(R), or C(Ri)(R 2 ) (R, Ri and R 2 are each independently H, C 1 -C 12 alkyl or a protecting group) and combinations thereof.
- substitutent groups including 5' and 2' substituent groups, bridging of non- geminal ring atoms to form bicyclic nucleic acids (BNA)
- BNA bicyclic nucleic acids
- R, Ri and R 2 are each independently H, C 1 -C 12 alkyl or a protecting group
- Examples of chemically modified sugars include 2'-F- 5'-methyl substituted nucleoside (see PCT International Application WO 2008/101157 Published on 8/21/08 for other disclosed 5',2'-bis substituted nucleosides) or replacement of the ribosyl ring oxygen atom with S with further substitution at the 2'-position (see published U.S. Patent
- nucleosides having modified sugar moieties include without limitation nucleosides comprising 5 * -vinyl, 5 * -methyl (R or S), 4'-S, 2'-F, 2'-OCH 3 , 2'-OCH 2 CH 3 , 2'- OCH 2 CH 2 F and 2'-0(CH 2 ) 2 OCH substituent groups.
- bicyclic nucleosides refer to modified nucleosides comprising a bicyclic sugar moiety.
- BNAs bicyclic nucleic acids
- examples of bicyclic nucleic acids (BNAs) include without limitation nucleosides comprising a bridge between the 4' and the 2' ribosyl ring atoms.
- antisense compounds provided herein include one or more BNA nucleosides wherein the bridge comprises one of the formulas: 4'-(CH 2 )-0-2' (LNA); 4'-(CH 2 )-S-2'; 4 , -(CH 2 ) 2 -0-2' (ENA); 4'-CH(CH 3 )-0-2' and 4 * -CH(CH 2 0CH 3 )-0-2 * (and analogs thereof see U.S. Patent 7,399,845, issued on July 15, 2008); 4 , -C(CH 3 )(CH 3 )-0-2' (and analogs thereof see PCT/US2008/068922 published as
- Each of the foregoing bicyclic nucleosides can be prepared having one or more stereochemical sugar configurations including for example a-L-ribofuranose and ⁇ -D-ribofuranose (see PCT international application PCT/DK98/00393, published on March 25, 1999 as WO 99/14226).
- nucleosides refer to nucleosides comprising modified sugar moieties that are not bicyclic sugar moieties.
- sugar moiety, or sugar moiety analogue, of a nucleoside may be modified or substituted at any position.
- “4 '-2' bicyclic nucleoside” or “4' to 2' bicyclic nucleoside” refers to a bicyclic nucleoside comprising a furanose ring comprising a bridge connecting two carbon atoms of the furanose ring connects the 2' carbon atom and the 4' carbon atom of the sugar ring.
- the bridge of a bicyclic sugar moiety is , -[C(R a )(Rb)] n - , -[C(R a )(R b )]n-0-, -C(R a R b )-N(R)-0- or -C(R a R b )-0-N(R)-.
- the bridge is 4'-CH 2 -2', 4 , -(CH 2 ) 2 -2', 4'-(CH 2 ) 3 -2', 4'-CH 2 -0-2', 4 , -(CH 2 ) 2 -0-2', 4'-CH 2 -0-N( )-2' and 4'-CH 2 - N(R)-0-2'- wherein each R is, independently, H, a protecting group or Ci-C 12 alkyl.
- bicyclic nucleosides are further defined by isomeric configuration.
- a nucleoside comprising a 4'-(CH 2 )-0-2' bridge may be in the a-L configuration or in the ⁇ -D configuration.
- a-L-methyleneoxy (4'-CH 2 -0-2') BNA's have been incorporated into antisense oligonucleotides that showed antisense activity (Frieden et al, Nucleic Acids
- bicyclic nucleosides include those having a 4' to 2' bridge wherein such bridges include without limitation, a-L-4'-(CH 2 )-0-2', P-D-4'-CH 2 -0-2', 4 , -(CH 2 ) 2 -0-2', 4'- CH 2 -0-N(R)-2', 4'-CH 2 -N(R)-0-2', 4'-CH(CH 3 )-0-2', 4'-CH 2 -S-2', 4'-CH 2 -N(R)-2', 4'-CH 2 - CH(CH 3 )-2', and 4'-(CH 2 ) 3 -2', wherein R is H, a protecting group or Ci-Ci 2 alkyl.
- bicyclic nucleosides have the formula:
- Bx is a heterocyclic base moiety
- Rc is Ci-Ci 2 alkyl or an amino protecting group
- T a and Tb are each, independently H, a hydroxyl protecting group, a conjugate group, a reactive phosphorus group, a phosphorus moiety or a covalent attachment to a support medium.
- bicyclic nucleosides have the formula:
- Bx is a heterocyclic base moiety
- T a and Tb are each, independently H, a hydroxyl protecting group, a conjugate group, a reactive phosphorus group, a phosphorus moiety or a covalent attachment to a support medium;
- Z a is Ci-C 6 alkyl, C 2 -C 6 alkenyl, C 2 -C 6 alkynyl, substituted Ci-C 6 alkyl, substituted C 2 -C 6 alkenyl, substituted C 2 -C 6 alkynyl, acyl, substituted acyl, substituted amide, thiol or substituted thiol.
- bicyclic nucleosides have the formula:
- Bx is a heterocyclic base moiety
- T a and T b are each, independently H, a hydroxyl protecting group, a conjugate group, a reactive phosphorus group, a phosphorus moiety or a covalent attachment to a support medium;
- bicyclic nucleosides have the formula:
- Bx is a heterocyclic base moiety
- T a and Tb are each, independently H, a hydroxyl protecting group, a conjugate group, a reactive phosphorus group, a phosphorus moiety or a covalent attachment to a support medium;
- R d is Ci-C 6 alkyl, substituted Ci-C 6 alkyl, C 2 -C 6 alkenyl, substituted C 2 -C 6 alkenyl, C 2 -C 6 alkynyl or substituted C 2 -C 6 alkynyl;
- each q a , qb, q c and qa is, independently, H, halogen, Ci-C 6 alkyl, substituted Ci-C 6 alkyl, C 2 - C 6 alkenyl, substituted C 2 -C 6 alkenyl, C 2 -C 6 alkynyl or substituted C 2 -C 6 alkynyl, Ci-C 6 alkoxyl, substituted Ci-C 6 alkoxyl, acyl, substituted acyl, Ci-C 6 aminoalkyl or substituted Ci-C 6 aminoalkyl;
- bicyclic nucleosides have the formula:
- Bx is a heterocyclic base moiety
- T a and T b are each, independently H, a hydroxyl protecting group, a conjugate group, a reactive phosphorus group, a phosphorus moiety or a covalent attachment to a support medium;
- q g and q h are each, independently, H, halogen, C1-C12 alkyl or substituted C1-C12 alkyl.
- bicyclic nucleosides have the formula:
- Bx is a heterocyclic base moiety
- bicyclic nucleosides include, but are not limited to, (A) a-L- methyleneoxy (4'-CH 2 -0-2') BNA , (B) ⁇ -D-methyleneoxy (4'-CH 2 -0-2') BNA , (C) ethyleneoxy (4'-(CH 2 )2-0-2') BNA, (D) aminooxy (4'-CH 2 -0-N(R)-2') BNA, (E) oxyamino (4'-CH 2 -N(R)-0- 2') BNA, (F) methyl(methyleneoxy) (4'-CH(CH 3 )-0-2') BNA (also referred to as constrained ethyl or cEt), (G) methylene-thio (4'-CH 2 -S-2') BNA, (H) methylene-amino (4'-CH 2 -N(R)-2') BNA, (I) methyl carbocyclic (4'-CH 2 ,
- modified tetrahydropyran nucleoside or “modified THP nucleoside” means a nucleoside having a six-membered tetrahydropyran "sugar” substituted for the pentofuranosyl residue in normal nucleosides and can be referred to as a sugar surrogate.
- Modified THP nucleosides include, but are not limited to, what is referred to in the art as hexitol nucleic acid (HNA), anitol nucleic acid (ANA), manitol nucleic acid (MNA) (see Leumann, Bioorg. Med.
- HNA hexitol nucleic acid
- ANA anitol nucleic acid
- MNA manitol nucleic acid
- sugar surrogates are selected having the formula:
- Bx is a heterocyclic base moiety
- T 3 and T 4 are each, independently, an internucleoside linking group linking the
- internucleoside linking group linking the tetrahydropyran nucleoside analog to an oligomeric compound or oligonucleotide and the other of T 3 and T 4 is H, a hydroxyl protecting group, a linked conjugate group or a 5' or 3'-terminal group;
- qi > q 2 , q3, 1 4 , q 5 , q6 and q 7 are each independently, H, Ci-C 6 alkyl, substituted Ci-C 6 alkyl, C 2 -C6 alkenyl, substituted C2-C6 alkenyl, C2-C6 alkynyl or substituted C2-C6 alkynyl; and
- q ls q 2 , q 3 , q 4 , q 5 , q 6 and q 7 are each H. In certain embodiments, at least one of qi, q 2 , q 3 , q 4 , q 5 , q 6 and q 7 is other than H. In certain embodiments, at least one of qi, q 2 , q 3 , q 4 , q 5 , q 6 and q 7 is methyl.
- THP nucleosides are provided wherein one of Ri and R2 is F. In certain embodiments, Ri is fluoro and R2 is H; Ri is methoxy and R2 is H, and Ri is methoxyethoxy and R 2 is H.
- sugar surrogates comprise rings having more than 5 atoms and more than one heteroatom.
- nucleosides comprising morpholino sugar moieties and their use in oligomeric compounds has been reported (see for example: Braasch et al, Biochemistry, 2002, 41, 4503-4510; and U.S. Patents 5,698,685; 5,166,315; 5,185,444; and 5,034,506).
- morpholino means a sugar surrogate having the following formula:
- morpholinos may be modified, for example by adding or altering various substituent groups from the above morpholino structure.
- sugar surrogates are referred to herein as "modifed morpholinos.”
- Patent Application US2005-0130923, published on June 16, 2005) or alternatively 5 '-substitution of a bicyclic nucleic acid see PCT International Application WO 2007/134181, published on 1 1/22/07 wherein a 4'-CH 2 - 0-2' bicyclic nucleoside is further substituted at the 5' position with a 5'-methyl or a 5'-vinyl group).
- PCT International Application WO 2007/134181 published on 1 1/22/07 wherein a 4'-CH 2 - 0-2' bicyclic nucleoside is further substituted at the 5' position with a 5'-methyl or a 5'-vinyl group.
- carbocyclic bicyclic nucleosides along with their oligomerization and biochemical studies have also been described (see, e.g., Srivastava et al, J. Am. Chem. Soc. 2007, 129(26), 8362-8379).
- antisense compounds comprise one or more modified cyclohexenyl nucleosides, which is a nucleoside having a six-membered cyclohexenyl in place of the
- Modified cyclohexenyl nucleosides include, but are not limited to those described in the art (see for example commonly owned, published PCT Application WO 2010/036696, published on April 10, 2010, Robeyns et al, J. Am. Chem. Soc, 2008, 130(6), 1979-1984; Horvath et al, Tetrahedron Letters, 2007, 48, 3621-3623; Nauwelaerts et al, J. Am. Chem. Soc, 2007, 129(30), 9340-9348; Gu et al.,, Nucleosides,
- Bx is a heterocyclic base moiety
- T 3 and T 4 are each, independently, an internucleoside linking group linking the cyclohexenyl nucleoside analog to an antisense compound or one of T and T 4 is an internucleoside linking group linking the tetrahydropyran nucleoside analog to an antisense compound and the other of T 3 and T 4 is H, a hydroxyl protecting group, a linked conjugate group, or a 5'-or 3'-terminal group; and
- qi, q 2 , q 3 , q 4 , q 5 , q 6 , q7, qs and q are each, independently, H, Ci-C 6 alkyl, substituted Ci-C 6 alkyl, C 2 -C 6 alkenyl, substituted C 2 -C 6 alkenyl, C 2 -C 6 alkynyl, substituted C 2 -C 6 alkynyl or other sugar substituent group .
- 2 '-modified sugar means a furanosyl sugar modified at the 2' position.
- modifications include substituents selected from: a halide, including, but not limited to substituted and unsubstituted alkoxy, substituted and unsubstituted thioalkyl, substituted and unsubstituted amino alkyl, substituted and unsubstituted alkyl, substituted and unsubstituted allyl, and substituted and unsubstituted alkynyl.
- 2'- substituent groups can also be selected from: Ci-Ci 2 alkyl, substituted alkyl, alkenyl, alkynyl, alkaryl, aralkyl, O-alkaryl or O-aralkyl, SH, SCH 3 , OCN, CI, Br, CN, F, CF 3 , OCF 3 , SOCH 3 , S0 2 CH 3 , ON0 2 , N0 2 , N 3 , NH 2 , heterocycloalkyl, heterocycloalkaryl, aminoalkylamino, polyalkylamino, substituted silyl, an R A cleaving group, a reporter group, an intercalator, a group for improving pharmacokinetic properties, or a group for improving the pharmacodynamic properties of an antisense compound, and other substituents having similar properties.
- modifed nucleosides comprise a 2'- MOE side chain (Baker et al, J. Biol. Chem., 1997, 272, 11944-12000).
- 2 * -MOE substitution have been described as having improved binding affinity compared to unmodified nucleosides and to other modified nucleosides, such as 2'- O-methyl, O-propyl, and O-aminopropyl.
- Oligonucleotides having the 2'-MOE substituent also have been shown to be antisense inhibitors of gene expression with promising features for in vivo use (Martin, Helv. Chim. Acta, 1995, 78, 486- 504; Altmann et al., Chimia, 1996, 50, 168-176; Altmann et al., Biochem. Soc. Trans., 1996, 24, 630-637; and Altmann et al., Nucleosides Nucleotides, 1997, 16, 917-926).
- 2 '-modified or “2 '-substituted” refers to a nucleoside comprising a sugar comprising a substituent at the 2' position other than H or OH.
- 2'-F refers to a nucleoside comprising a sugar comprising a fluoro group at the 2' position of the sugar ring.
- MOE or "2'-MOE” or “2'-OCH 2 CH 2 OCH 3 " or “2'-0-methoxyethyl” each refers to a nucleoside comprising a sugar comprising a -OCH 2 CH 2 OCH 3 group at the 2' position of the sugar ring.
- Methods for the preparations of modified sugars are well known to those skilled in the art. Some representative U.S.
- oligonucleotide refers to a compound comprising a plurality of linked nucleosides. In certain embodiments, one or more of the plurality of nucleosides is modified. In certain embodiments, an oligonucleotide comprises one or more ribonucleo sides (R A) and/or deoxyribonucleosides (DNA).
- nucleobase moieties In nucleotides having modified sugar moieties, the nucleobase moieties (natural, modified or a combination thereof) are maintained for hybridization with an appropriate nucleic acid target.
- antisense compounds comprise one or more nucleosides having modified sugar moieties.
- the modified sugar moiety is 2'-MOE.
- the 2'-MOE modified nucleosides are arranged in a gapmer motif.
- the modified sugar moiety is a bicyclic nucleoside having a (4'-CH(CH 3 )-0-2') bridging group.
- the (4'-CH(CH 3 )-0-2') modified nucleosides are arranged throughout the wings of a gapmer motif.
- Oligonucleotides may be admixed with pharmaceutically acceptable active or inert substances for the preparation of pharmaceutical compositions or formulations.
- Compositions and methods for the formulation of pharmaceutical compositions are dependent upon a number of criteria, including, but not limited to, route of administration, extent of disease, or dose to be administered.
- An antisense compound targeted to a SOD-1 nucleic acid can be utilized in pharmaceutical compositions by combining the antisense compound with a suitable pharmaceutically acceptable diluent or carrier.
- a pharmaceutically acceptable diluent includes phosphate -buffered saline (PBS).
- PBS is a diluent suitable for use in compositions to be delivered parenterally.
- employed in the methods described herein is a pharmaceutical composition comprising an antisense compound targeted to a SOD-1 nucleic acid and a pharmaceutically acceptable diluent.
- the composition comprising an antisense compound targeted to a SOD-1 nucleic acid and a pharmaceutically acceptable diluent.
- the composition comprising an antisense compound targeted to a SOD-1 nucleic acid and a pharmaceutically acceptable diluent.
- compositions comprising antisense compounds encompass any pharmaceutically acceptable salts, esters, or salts of such esters, or any other oligonucleotide which, upon administration to an animal, including a human, is capable of providing (directly or indirectly) the biologically active metabolite or residue thereof. Accordingly, for example, the disclosure is also drawn to pharmaceutically acceptable salts of antisense compounds, prodrugs, pharmaceutically acceptable salts of such prodrugs, and other bioequivalents. Suitable pharmaceutically acceptable salts include, but are not limited to, sodium and potassium salts.
- a prodrug can include the incorporation of additional nucleosides at one or both ends of an antisense compound which are cleaved by endogenous nucleases within the body, to form the active antisense compound.
- Antisense compounds may be covalently linked to one or more moieties or conjugates which enhance the activity, cellular distribution or cellular uptake of the resulting oligonucleotides.
- Typical conjugate groups include cholesterol moieties and lipid moieties.
- Additional conjugate groups include carbohydrates, phospholipids, biotin, phenazine, folate, phenanthridine, anthraquinone, acridine, fluoresceins, rhodamines, coumarins, and dyes.
- Antisense compounds can also be modified to have one or more stabilizing groups that are generally attached to one or both termini of antisense compounds to enhance properties such as, for example, nuclease stability. Included in stabilizing groups are cap structures. These terminal modifications protect the antisense compound having terminal nucleic acid from exonuclease degradation, and can help in delivery and/or localization within a cell. The cap can be present at the 5'-terminus (5'-cap), or at the 3'-terminus (3'- cap), or can be present on both termini. Cap structures are well known in the art and include, for example, inverted deoxy abasic caps. Further 3' and 5 '-stabilizing groups that can be used to cap one or both ends of an antisense compound to impart nuclease stability include those disclosed in WO 03/004602 published on
- SOD-1 nucleic acids can be tested in vitro in a variety of cell types.
- Cell types used for such analyses are available from commerical vendors (e.g. American Type Culture Collection, Manassus, VA; Zen-Bio, Inc., Research Triangle Park, NC; Clonetics Corporation, Walkersville, MD) and are cultured according to the vendor's instructions using commercially available reagents (e.g. Invitrogen Life Technologies, Carlsbad, CA).
- Illustrative cell types include, but are not limited to, HepG2 cells, Hep3B cells, primary hepatocytes, A431 cells, and SH-SY5Y cells.
- oligonucleotides which can be modified appropriately for treatment with other antisense compounds.
- Cells may be treated with oligonucleotides when the cells reach approximately 60-80% confluency in culture.
- oligonucleotides include the cationic lipid transfection reagent LIPOFECTIN (Invitrogen, Carlsbad, CA). Oligonucleotides may be mixed with LIPOFECTIN in OPTI-MEM 1 (Invitrogen, Carlsbad, CA) to achieve the desired final concentration of oligonucleotide and a LIPOFECTIN concentration that may range from 2 to 12 ug/mL per 100 nM oligonucleotide.
- LIPOFECTIN cationic lipid transfection reagent
- Oligonucleotides may be mixed with LIPOFECTIN in OPTI-MEM 1 (Invitrogen, Carlsbad, CA) to achieve the desired final concentration of oligonucleotide and a LIPOFECTIN concentration that may range from 2 to 12 ug/mL per 100 nM oligonucleotide.
- LIPOFECT AMINE (Invitrogen, Carlsbad, CA). Oligonucleotide is mixed with LIPOFECT AMINE in OPTI-MEM 1 reduced serum medium (Invitrogen, Carlsbad, CA) to achieve the desired concentration of oligonucleotide and a LIPOFECTAMINE concentration that may range from 2 to 12 ug/mL per 100 nM oligonucleotide.
- oligonucleotides are introduced into cultured cells.
- Cells are treated with oligonucleotides by routine methods.
- Cells may be harvested 16-24 hours after oligonucleotide treatment, at which time RNA or protein levels of target nucleic acids are measured by methods known in the art and described herein.
- RNA or protein levels of target nucleic acids are measured by methods known in the art and described herein.
- the data are presented as the average of the replicate treatments.
- the concentration of oligonucleotide used varies from cell line to cell line. Methods to determine the optimal oligonucleotide concentration for a particular cell line are well known in the art.
- Oligonucleotides are typically used at concentrations ranging from 1 nM to 300 nM when transfected with LIPOFECTAMINE. Oligonucleotides are used at higher concentrations ranging from 625 to 20,000 nM when transfected using electroporation.
- RNA analysis can be performed on total cellular RNA or poly(A)+ mRNA. Methods of RNA isolation are well known in the art. RNA is prepared using methods well known in the art, for example, using the TRIZOL Reagent (Invitrogen, Carlsbad, CA) according to the manufacturer's recommended protocols.
- Target nucleic acid levels can be quantitated by, e.g., Northern blot analysis, competitive polymerase chain reaction (PCR), or quantitaive real-time PCR.
- RNA analysis can be performed on total cellular RNA or poly(A)+ mRNA. Methods of RNA isolation are well known in the art. Northern blot analysis is also routine in the art. Quantitative real-time PCR can be conveniently accomplished using the commercially available ABI PRISM 7600, 7700, or 7900 Sequence Detection System, available from PE- Applied Biosystems, Foster City, CA and used according to manufacturer's instructions.
- Quantitation of target RNA levels may be accomplished by quantitative real-time PCR using the ABI PRISM 7600, 7700, or 7900 Sequence Detection System (PE-Applied Biosystems, Foster City, CA) according to manufacturer's instructions. Methods of quantitative real-time PCR are well known in the art.
- RNA Prior to real-time PCR, the isolated RNA is subjected to a reverse transcriptase (RT) reaction, which produces complementary DNA (cDNA) that is then used as the substrate for the real-time PCR amplification.
- RT and real-time PCR reactions are performed sequentially in the same sample well.
- RT and real-time PCR reagents may be obtained from Invitrogen (Carlsbad, CA). RT real-time -PCR reactions are carried out by methods well known to those skilled in the art.
- Gene (or RNA) target quantities obtained by real time PCR are normalized using either the expression level of a gene whose expression is constant, such as cyclophilin A, or by quantifying total RNA using RIBOGREEN (Invitrogen, Inc. Carlsbad, CA). Cyclophilin A expression is quantified by real time PCR, by being run simultaneously with the target, multiplexing, or separately. Total RNA is quantified using RIBOGREEN RNA quantification reagent (Invetrogen, Inc. Eugene, OR). Methods of RNA quantification by RIBOGREEN are SOD-lght in Jones, L.J., et al, (Analytical Biochemistry, 1998, 265, 368-374). A
- CYTOFLUOR 4000 instrument PE Applied Biosystems is used to measure RIBOGREEN fluorescence.
- Probes and primers are designed to hybridize to a SOD-1 nucleic acid.
- Methods for designing realtime PCR probes and primers are well known in the art, and may include the use of software such as PRIMER EXPRESS Software (Applied Biosystems, Foster City, CA).
- Antisense inhibition of SOD-1 nucleic acids can be assessed by measuring SOD-1 protein levels. Protein levels of SOD-1 can be evaluated or quantitated in a variety of ways well known in the art, such as immunoprecipitation, Western blot analysis (immunoblotting), enzyme-linked immunosorbent assay (ELISA), quantitative protein assays, protein activity assays (for example, caspase activity assays), immunohistochemistry, immunocytochemistry or fluorescence-activated cell sorting (FACS).
- Antibodies directed to a target can be identified and obtained from a variety of sources, such as the MSRS catalog of antibodies (Aerie Corporation, Birmingham, MI), or can be prepared via conventional monoclonal or polyclonal antibody generation methods well known in the art. In certain embodiments, the compounds herein provide improved reduction in protein levels. In vivo testing of antisense compounds
- Antisense compounds for example, modified oligonucleotides, are tested in animals to assess their ability to inhibit expression of SOD-1 and produce phenotypic changes, such as, improved motor function.
- motor function is measured by walking initiation analysis, rotarod, grip strength, pole climb, open field performance, balance beam, hindpaw footprint testing in the animal. Testing may be performed in normal animals, or in experimental disease models.
- oligonucleotides are formulated in a pharmaceutically acceptable diluent, such as phosphate -buffered saline. Administration includes parenteral routes of administration, such as intraperitoneal, intravenous, and subcutaneous.
- Oligonucleotide dosage and dosing frequency depends upon multiple factors such as, but not limited to, route of administration and animal body weight. Following a period of treatment with oligonucleotides, RNA is isolated from CNS tissue or CSF and changes in SOD-1 nucleic acid expression are measured. Certain Indications
- provided herein are methods, compounds, and compositions of treating an individual comprising administering one or more pharmaceutical compositions described herein.
- the individual has a neurodegenerative disease.
- the individual is at risk for developing a neurodegenerative disease, including, but not limited to, amyotrophic lateral sclerosis (ALS).
- ALS amyotrophic lateral sclerosis
- the individual has been identified as having a SOD-1 associated disease.
- methods for prophylactically reducing SOD-1 expression in an individual Certain embodiments include treating an individual in need thereof by administering to an individual a therapeutically effective amount of an antisense compound targeted to a SOD-1 nucleic acid.
- administration of a therapeutically effective amount of an antisense compound targeted to a SOD-1 nucleic acid is accompanied by monitoring of SOD-1 levels in an individual, to determine an individual's response to administration of the antisense compound.
- An individual's response to administration of the antisense compound may be used by a physician to determine the amount and duration of therapeutic intervention.
- administering results in reduction of SOD-1 expression by at least 15, 20, 25, 30, 35, 40, 45, 50, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, or 100%, or a range defined by any two of these values.
- administering results in improved motor function in an animal.
- administration of a SOD-1 antisense compound improves motor function by at least 15, 20, 25, 30, 35, 40, 45, 50, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, or 100%, or a range defined by any two of these values.
- compositions comprising an antisense compound targeted to SOD-1 are used for the preparation of a medicament for treating a patient suffering or susceptible to a neurodegenerative disease including amyotrophic lateral sclerosis (ALS).
- ALS amyotrophic lateral sclerosis
- Antisense oligonucleotides targeting human SOD-1 were described in an earlier publication (see WO 2005/040180, incorporated by reference herein, in its entirety).
- oligonucleotides ISIS 333611, ISIS 146144, ISIS 146145, ISIS 150437, ISIS 150441, ISIS 150443, ISIS 150444, ISIS 150445, ISIS 150446, ISIS 150447, ISIS 150448, ISIS 150449, ISIS 150452, ISIS 150454, ISIS 150458, ISIS 150460, ISIS 150462-150467, ISIS 150470, ISIS 150472, ISIS 150474, ISIS 150475, ISIS 150476, ISIS 150479-150483, ISIS 150488, ISIS 150489, ISIS 150490, ISIS 150491-150493, ISIS 150495-150498, ISIS 150511, ISIS 333605, ISIS 333606, ISIS 333609-333617, ISIS 333619, ISIS 333620-333
- ISIS 333611 a 5-10-5 MOE gapmer, having a sequence of (from 5' to 3') CCGTCGCCCTTCAGCACGCA (incorporated herein as SEQ ID NO: 21), wherein each internucleoside linkage is a phosphorothioate linkage, each cytosine is a 5-methylcytosine, and each of nucleosides 1-5 and 16-20 (from 5' to 3') comprise a 2'-0-methoxyethyl moiety was used as a comparator compound.
- ISIS 333611 was selected as a comparator compound because it exhibited high levels of dose-dependent inhibition in various studies as described in WO 2005/040180. Additionally, phase 1 human clinical trials were completed using ISIS 333611. See, MILLER et al., "An antisense oligonucleotide against SOD1 delivered intrathecally for patients with SOD1 familial amyotrophic lateral sclerosis: a phase 1, randomised, first-in- man study" Lancet Neurol. (2013) 12(5): 435-442. Thus, ISIS 333611 was deemed a highly efficacious and potent compound with an acceptable safety profile (such that it was tested in human patients).
- the compounds described herein benefit from one or more improved properties relative to the antisense compounds described in WO 2005/040180. Some of the improved properties are demonstrated in the examples provided herein.
- compounds described herein are more efficacious, potent, and/or tolerable in various in vitro and in vivo studies than comparator compounds described herein, including ISIS 333611.
- ISIS 666853, ISIS 666859, ISIS 666919, ISIS 666921, ISIS 666922, ISIS 666869, ISIS 666870, and ISIS 666867 are more efficacious and/or potent in various in vitro and in vivo studies than comparator compounds described herein, including ISIS 333611.
- ISIS 666853, ISIS 666859, ISIS 666919, ISIS 666921, ISIS 666922, ISIS 666869, ISIS 666870, and ISIS 666867 are more tolerable in one or more tolerability assays in animals than comparator compounds described herein, including ISIS 333611. This is despite 333611 being sufficiently well tolerated to progress to human clinical trials.
- certain compounds described herein are more efficacious than comparator compounds by virtue of an in vitro IC50 of less than 2 ⁇ , less than 1.9 ⁇ , less than 1.8 ⁇ , less than 1.7 ⁇ , less than 1.6 ⁇ , less than 1.5 ⁇ , less than 1.4 ⁇ , less than 1.3 ⁇ , less than 1.2 ⁇ , less than 1.1 ⁇ , less than 1 ⁇ , less than 0.9 ⁇ , less than 0.8 ⁇ , less than 0.7 ⁇ , less than 0.6 ⁇ , or less than 0.5 ⁇ less than 0.4 ⁇ , less than 0.3 ⁇ , less than 0.2 ⁇ , less than 0.1 ⁇ , when tested in human cells, for example, in the HepG2 A431 or SH-SY5Y cell lines (For example, see Examples 6-11).
- certain compounds described herein are more efficacious than comparator compounds by virtue of their ability to inhibit SOD-1 expression in vivo.
- the compounds inhibit SOD-1 in lumbar spinal cord and cervical spinal cord by at least 60%, at least 65%, at least 70%), at least 75%, at least 80%, at least 85%, at least 90% or at least 95% in, for example, a transgenic animal model.
- certain compounds described herein are more tolerable than comparator compounds on the basis of reduced microglial marker levels (e.g.,IBAl), reduced astrocytic marker levels (e.g., GFAP), and/or FOB scores in rats, mice, and/or monkeys. See, for example, Examples 14, 15, 18, and 19.
- reduced microglial marker levels e.g.,IBAl
- reduced astrocytic marker levels e.g., GFAP
- FOB scores in rats, mice, and/or monkeys. See, for example, Examples 14, 15, 18, and 19.
- ISIS 666853 achieved 81% inhibition in lumbar spinal cord and 74% in cervical spinal cord of an SOD-1 transgenic rat model when dosed with 30 ⁇ , of 16.67 mg/ml solution of oligonucleotide diluted in PBS (500 ⁇ g final dose), whereas ISIS 33361 1 achieved 51% inhibition in lumbar spinal cord and 47% inhibition in cervical spinal cord.
- ISIS 666853 achieved a FOB score of 0 whereas ISIS 33361 1 achieved a FOB score of 4 in Sprague-Dawley rats after 3 hours when treated with 3 mg of oligonucleotide.
- Microglial marker (IBA1) levels and astrocytic marker (GFAP) levels were also reduced in ISIS 666853 treated rats as compared to ISIS 33361 1 treated rats.
- ISIS 666853 achieved an ED 50 of
- ISIS 666853 achieved an ED 5 o of 136 and 188 in lumbar tissue and cortex tissue (respectively)
- ISIS 333611 achieved an ED 5 o of 401 and 786 in lumbar tissue and cortex tissue (respectively) in SOD-1 transgenic mice when treated with an intracerebral ventricular bolus of 10, 30, 100, 300, or 700 ⁇ g of oligonucleotide.
- ISIS 666853 achieved a FOB score of 1.25 whereas ISIS 333611 achieved a FOB score of 6.5 in C57bl6 mice after 3 hours when treated with 700 ⁇ g of oligonucleotide.
- Microglial marker (IBA1) levels and astrocytic marker (GFAP) levels were also reduced in ISIS 666853 treated mice as compared to ISIS 333611 treated mice.
- ISIS 666859 achieved 79% inhibition in lumbar spinal cord and 64% inhibition in cervical spinal cord of an SOD-1 transgenic rat model when dosed with 30 of 16.67 mg/ml solution of oligonucleotide diluted in PBS (500 ⁇ g final dose), whereas ISIS 333611 achieved 51% inhibition in lumbar spinal cord and 47% inhibition in cervical spinal cord.
- ISIS 666859 achieved a FOB score of 1 whereas ISIS 33361 1 achieved a FOB score of 4 in Sprague-Dawley rats after 3 hours when treated with 3 mg of oligonucleotide.
- Microglial marker (IBA1) levels and astrocytic marker (GFAP) levels were also reduced in ISIS 666859 treated rats as compared to ISIS 333611 treated rats.
- ISIS 666859 achieved an ED 5 o of 74.0 and 358.8 in lumbar tissue and cervical tissue (respectively) in SOD-1 transgenic rats when treated intrathecally with 10, 30, 100, 300, or 3000 ⁇ g of oligonucleotide.
- ED 50 in lumbar and cervical tissues could not be calculated in ISIS 333611 treated transgenic rats because the highest concentration tested (3000 ⁇ g) filed to inhibit human SOD-1 mRNA greater than 55-65%.
- Example 16 at doses of 1 mg and 3 mg ISIS 666859 achieved 3 hour FOB scores of 0.0 and 2.1 (respectively) whereas ISIS 333611 achieved FOB scores of 3.0 and 4.9 (respectively). At doses of 1 mg and 3 mg ISIS 666859 achieved 8 week FOB scores of 0.0 and 0.3 (respectively) whereas ISIS 333611 achieved FOB scores of 0.0 and 1.2 (respectively).
- ISIS 666859 achieved an ED 5 o of 106 and 206 in lumbar tissue and cortex tissue (respectively)
- ISIS 333611 achieved an ED 5 o of 401 and 786 in lumbar tissue and cortex tissue (respectively) in SOD-1 transgenic mice when treated with an intracerebral ventricular bolus of 10, 30, 100, 300, or 700 ⁇ g of oligonucleotide.
- ISIS 666859 achieved a FOB score of 1.75 whereas ISIS 333611 achieved a FOB score of 6.5 in C57bl6 mice after 3 hours when treated with 700 ⁇ g of oligonucleotide.
- Microglial marker (IBA1) levels and astrocytic marker (GFAP) levels were also reduced in ISIS 666859 treated mice as compared to ISIS 333611 treated mice.
- ISIS 666919 achieved 76% inhibition in lumbar spinal cord and 68% in cervical spinal cord of an SOD-1 transgenic rat model when dosed with 30 of 16.67 mg/ml solution of oligonucleotide diluted in PBS (500 ⁇ g final dose), whereas ISIS 333611 achieved 51% inhibition in lumbar spinal cord and 47% inhibition in cervical spinal cord.
- ISIS 666919 achieved a FOB score of 2 whereas ISIS 33361 1 achieved a FOB score of 4 in Sprague-Dawley rats after 3 hours when treated with 3 mg of oligonucleotide.
- Microglial marker (IBA1) levels and astrocytic marker (GFAP) levels were also reduced in ISIS 666919 treated rats as compared to ISIS 333611 treated rats.
- ISIS 666919 achieved an ED 5 o of 104.1 and 613.5 in lumbar tissue and cervical tissue (respectively) in SOD-1 transgenic rats when treated intrathecally with 10, 30, 100, 300, or 3000 ⁇ g of oligonucleotide.
- ED 50 in lumbar and cervical tissues could not be calculated in ISIS 333611 treated transgenic rats because the highest concentration tested (3000 ⁇ g) filed to inhibit human SOD-1 mRNA greater than 55-65%.
- Example 16 at doses of 1 mg and 3 mg ISIS 666919 achieved 3 hour FOB scores of 1.3 and 3.5 (respectively) whereas ISIS 333611 achieved FOB scores of 3.0 and 4.9 (respectively). At doses of 1 mg and 3 mg ISIS 666919 achieved 8 week FOB scores of 0.0 and 0.1 (respectively) whereas ISIS 333611 achieved FOB scores of 0.0 and 1.2 (respectively).
- ISIS 666919 achieved an ED 5 o of 168 in lumbar tissue
- ISIS 333611 achieved an ED50 of 401 in lumbar tissue in SOD-1 transgenic mice when treated with an intracerebral ventricular bolus of 10, 30, 100, 300, or 700 ⁇ g of oligonucleotide.
- ISIS 666919 achieved a FOB score of 0.0
- ISIS 333611 achieved a FOB score of 6.5 in C57bl6 mice after 3 hours when treated with 700 ⁇ g of oligonucleotide.
- Microglial marker (IBA1) levels and astrocytic marker (GFAP) levels were also reduced in ISIS 666919 treated mice as compared to ISIS 333611 treated mice.
- ISIS 66621 achieved 71% inhibition in lumbar spinal cord and 65% in cervical spinal cord of an SOD-1 transgenic rat model when dosed with 30 of 16.67 mg/ml solution of oligonucleotide diluted in PBS (500 ⁇ g final dose), whereas ISIS 333611 achieved 51% inhibition in lumbar spinal cord and 47% inhibition in cervical spinal cord.
- ISIS 666921 achieved a FOB score of 2 whereas ISIS 33361 1 achieved a FOB score of 4 in Sprague-Dawley rats after 3 hours when treated with 3 mg of oligonucleotide.
- Microglial marker (IBA1) levels and astrocytic marker (GFAP) levels were also reduced in ISIS 666919 treated rats as compared to ISIS 333611 treated rats.
- ISIS 666922 achieved 67% inhibition in lumbar spinal cord and 62% in cervical spinal cord of an SOD-1 transgenic rat model when dosed with 30 ⁇ , of 16.67 mg/ml solution of oligonucleotide diluted in PBS (500 ⁇ g final dose), whereas ISIS 333611 achieved 51% inhibition in lumbar spinal cord and 47% inhibition in cervical spinal cord.
- ISIS 666922 achieved a FOB score of 3
- ISIS 33361 1 achieved a FOB score of 4 in Sprague-Dawley rats after 3 hours when treated with 3 mg of oligonucleotide.
- Microglial marker (IBA1) levels and astrocytic marker (GFAP) levels were also reduced in ISIS 666919 treated rats as compared to ISIS 333611 treated rats.
- ISIS 666869 achieved 82% inhibition in lumbar spinal cord and 81% in cervical spinal cord of an SOD-1 transgenic rat model when dosed with 30 of 16.67 mg/ml solution of oligonucleotide diluted in PBS (500 ⁇ g final dose), whereas ISIS 333611 achieved 51% inhibition in lumbar spinal cord and 47% inhibition in cervical spinal cord.
- ISIS 666870 achieved 76% inhibition in lumbar spinal cord and 68% in cervical spinal cord of an SOD-1 transgenic rat model when dosed with 30 of 16.67 mg/ml solution of oligonucleotide diluted in PBS (500 ⁇ g final dose), whereas ISIS 333611 achieved 51% inhibition in lumbar spinal cord and 47% inhibition in cervical spinal cord.
- ISIS 666870 achieved an ED 50 of 139.4 and 1111 in lumbar tissue and cervical tissue (respectively) in SOD-1 transgenic rats when treated intrathecally with 10, 30, 100, 300, or 3000 ⁇ g of oligonucleotide.
- ED 5 o in lumbar and cervical tissues could not be calculated in ISIS 333611 treated transgenic rats because the highest concentration tested (3000 ⁇ g) filed to inhibit human SOD-1 mRNA greater than 55-65%.
- ISIS 666870 achieved an ED 5 o of 148 and 409 in lumbar tissue and cortex tissue (respectively)
- ISIS 333611 achieved an ED 5 o of 401 and 786 in lumbar tissue and cortex tissue (respectively) in SOD-1 transgenic mice when treated with an intracerebral ventricular bolus of 10, 30, 100, 300, or 700 ⁇ g of oligonucleotide.
- ISIS 666870 achieved a FOB score of 4.75 whereas ISIS 333611 achieved a FOB score of 6.5 in C57bl6 mice after 3 hours when treated with 700 ⁇ g of oligonucleotide.
- ISIS 666867
- ISIS 666867 achieved 59% inhibition in lumbar spinal cord and 48% in cervical spinal cord of an SOD-1 transgenic rat model when dosed with 30 ⁇ _, of 16.67 mg/ml solution of oligonucleotide diluted in PBS (500 ⁇ g final dose), whereas ISIS 333611 achieved 51% inhibition in lumbar spinal cord and 47% inhibition in cervical spinal cord.
- ISIS 666853 is characterized as a 5-10-5 MOE gapmer, having a sequence of (from 5' to 3') CAGGATACATTTCTACAGCT (incorporated herein as SEQ ID NO: 725), wherein each of nucleosides 1-5 and 16-20 are 2'-0-methoxyethylribose modified nucleosides, and each of nucleosides 6- 15 are 2'-deoxynucleosides, wherein the internucleoside linkages between nucleosides 2 to 3, 4 to 5, 16 to 17, and 18 to 19 are phosphodiester linkages and the internucleoside linkages between nucleosides 1 to 2, 3 to 4, 5 to 6, 6 to 7, 7 to 8, 8 to 9, 9 to 10, 10 to 11, 11 to 12, 12 to 13, 13 to 14, 14 to 15, 15 to 16, 17 to 18, and 19 to 20 are phosphorothioate linkages, and wherein each cytosine is a 5'-methylcytosine.
- ISIS 666853 is described by the following chemical notation: mCes Aeo Ges Geo Aes Tds Ads mCds Ads Tds Tds Tds mCds Tds Ads mCeo Aes Geo mCes Te; wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- ISIS 666859 is characterized as a modified oligonucleotide having the nucleobase sequence (from 5' to 3') TTAATGTTTATCAGGAT (incorporated herein as SEQ ID NO: 1351), consisting of seventeen nucleosides, wherein each of nucleosides 1-4 and 15-17 are 2'-0-methoxyethylribose nucleosides, wherein each of nucleosides 13 and 14 are cEt modified nucleosides, wherein each of nucleosides 5-12 are 2'-deoxyribonucleosides, wherein the internucleoside linkages between nucleosides 2 to
- 3 to 4, 13 to 14, 14 to 15 are phosphodiester linkages and the internucleoside linkages between nucleosides 1 to 2, 4 to 5, 5 to 6, 6 to 7, 7 to 8, 8 to 9, 9 to 10, 10 to 11, 11 to 12, 12 to 13, 15 to 16, and 16 to 17 are phosphorothioate linkages, and wherein each cytosine is a 5'-methylcytosine.
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- ISIS 666859 is described by the following chemical structure:
- ISIS 666919 is characterized as a modified oligonucleotide having the nucleobase sequence (from 5 ' to 3 ') GGATACATTTCTACAGC (incorporated herein as SEQ ID NO: 1342), consisting of seventeen nucleosides, wherein each of nucleosides 1-4 and 16-17 are 2'-0-methoxyethylribose modified nucleosides, wherein each of nucleosides 14 and 15 are cEt modified nucleosides, wherein each of nucleosides 5-13 are 2'-deoxyribonucleosides, wherein the internucleoside linkages between nucleosides 2 to 3, 3 to 4, 4 to 5, and 14 to 15 are phosphodiester linkages and the internucleoside linkages between nucleosides 1 to 2, 5 to 6, 6 to 7, 7 to 8, 8 to 9, 9 to 10, 10 to 11, 11 to 12, 12 to 13, 13 to 14, 15 to 16, and 16 to 17 are phosphorothio
- ISIS 666919 is described by the following chemical notation: Ges Geo Aeo Teo Ads mCds Ads Tds Tds Tds mCds Tds Ads mCko Aks Ges mCe; wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- ISIS 666919 is described by the following chemical structure:
- ISIS 666921 is characterized as a modified oligonucleotide having the nucleobase sequence (from 5' to 3') GGATACATTTCTACAGC (incorporated herein as SEQ ID NO: 1342), consisting of seventeen nucleosides, wherein each of nucleosides 1-5 and 16-17 are 2'-0-methoxyethylribose modified nucleosides, wherein each of nucleosides 14-15 are cEt modified nucleosides, wherein each of nucleosides 6-13 are 2'-deoxyribonucleosides, wherein the internucleoside linkages between nucleosides 2 to 3, 3 to 4, 4 to 5, and 14 to 15 are phosphodiester linkages and the internucleoside linkages between nucleosides 1 to 2, 5 to 6, 6 to 7, 7 to 8, 8 to 9, 9 to 10, 10 to 11, 11 to 12, 12 to 13, 13 to 14, 15 to 16, and 16 to 17 are phosphorothioate linkages
- ISIS 666921 is described by the following chemical notation: Ges Geo Aeo Teo Aes mCds Ads Tds Tds Tds mCds Tds Ads mCko Aks Ges mCe; wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- ISIS 666921 is described by the following chemical structure:
- ISIS 666922 is characterized as a modified oligonucleotide having the nucleobase sequence (from 5' to 3') GGATACATTTCTACAGC (incorporated herein as SEQ ID NO: 1342), consisting of seventeen nucleosides, wherein each of nucleosides 1-4 and 15-17 are 2'-0-methoxyethylribose modified nucleosides, wherein each of nucleosides 5 and 14 are cEt modified nucleosides, wherein each of nucleosides 6-13 are 2'-deoxyribonucleosides, wherein the internucleoside linkages between nucleosides 2 to 3, 3 to 4, 4 to 5, and 14 to 15 are phosphodiester linkages and the internucleoside linkages between nucleosides 1 to 2, 5 to 6, 6 to 7, 7 to 8, 8 to 9, 9 to 10, 10 to 11, 11 to 12, 12 to 13, 13 to 14, 15 to 16, and 16 to 17 are phosphorothioate link
- ISIS 666922 is described by the following chemical notation: Ges Geo Aeo
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- ISIS 666922 is described by the following chemical structure:
- ISIS 666869 is characterized as a modified oligonucleotide having the nucleobase sequence (from 5' to 3') AGTGTTTAATGTTTATC (incorporated herein as SEQ ID NO: 1173), consisting of seventeen nucleosides, wherein each of nucleosides 1, 3, 14, and 16-17 are 2'-0- methoxyethylribose modified nucleosides, wherein each of nucleosides 2, 4, 13, and 15 are cEt modified nucleosides, wherein each of nucleosides 5-12 are 2'-deoxyribonucleosides, wherein the internucleoside linkages between nucleosides 2 to 3, 3 to 4, 13 to 14, and 14 to 15 are phosphodiester linkages and the internucleoside linkages between nucleosides 1 to 2, 4 to 5, 5 to 6, 6 to 7, 7 to 8, 8 to 9, 9 to 10, 10 to 11, 11 to 12, 12 to 13, 15 to 16, and 16 to 17 are phosphoroth
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- ISIS 666870 is characterized as a modified oligonucleotide having the nucleobase sequence (from 5' to 3') AGTGTTTAATGTTTATC (incorporated herein as SEQ ID NO: 1173), consisting of seventeen nucleosides, wherein each of nucleosides 1, 3, 13-17 are 2'-0-methoxyethylribose modified nucleosides, wherein each of nucleosides 2 and 4 are cEt modified nucleosides, wherein each of nucleosides 5-12 are 2'-deoxyribonucleosides, wherein the internucleoside linkages between nucleosides 2 to 3, 3 to 4, 13 to 14, and 14 to 15 are phosphodiester linkages and the internucleoside linkages between nucleosides 1 to 2, 4 to 5, 5 to 6, 6 to 7, 7 to 8, 8 to 9, 9 to 10, 10 to 11, 11 to 12, 12 to 13, 15 to 16, and 16 to 17 are phosphorothioate link
- ISIS 666870 is described by the following chemical notation: Aes Gko Teo Gks Tds Tds Tds Ads Ads Tds Gds Tds Teo Teo Aes Tes mCe; wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- ISIS 666867 is characterized as a modified oligonucleotide having the nucleobase sequence (from 5' to 3') AGTGTTTAATGTTTATC (incorporated herein as SEQ ID NO: 1173), consisting of seventeen nucleosides, wherein each of nucleosides 1-2 and 13-17 are 2'-0-methoxyethylribose modified nucleosides, wherein each of nucleosides 3 and 4 are cEt modified nucleosides, wherein each of nucleosides 5-12 are 2'-deoxyribonucleosides, wherein the internucleoside linkages between nucleosides 2 to 3, 3 to 4, 13 to 14, and 14 to 15 are phosphodiester linkages and the internucleoside linkages between nucleosides 1 to 2, 4 to 5, 5 to 6, 6 to 7, 7 to 8, 8 to 9, 9 to 10, 10 to 11, 11 to 12, 12 to 13, 15 to 16, and 16 to 17 are phosphorothioate
- ISIS 666867 is described by the following chemical notation: Aes Geo Tko Gks Tds Tds Tds Ads Ads Tds Gds Tds Teo Teo Aes Tes mCe; wherein,
- A an adenine
- mC a 5'-methylcytosine
- G a guanine
- o a phosphodiester internucleoside linkage.
- ISIS 666867 is described by the following chemical structure:
- Example 1 Inhibition of human superoxide dismutase 1, soluble (SOD-1) in HepG2 cells by MOE gapmers
- Modified oligonucleotides were designed targeting a superoxide dismutase 1, soluble (SOD-1) nucleic acid and were tested for their effects on SOD-1 m NA in vitro.
- ISIS 333611 previously disclosed in WO 2005/040180, was also designated as a benchmark or comparator oligonucleotide. ISIS 333611 was recently tested in human clinical trials. See, MILLER et al., "An antisense oligonucleotide against SOD1 delivered intrathecally for patients with SOD1 familial amyotrophic lateral sclerosis: a phase 1, randomised, first-in-man study" Lancet Neurol. (2013) 12(5): 435-442.
- the modified oligonucleotides were tested in a series of experiments that had similar culture conditions. The results for each experiment are presented in separate tables shown below. Cultured HepG2 cells at a density of 20,000 cells per well were transfected using electroporation with 7,000 nM modified oligonucleotide. After a treatment period of approximately 24 hours, RNA was isolated from the cells and SOD-1 mRNA levels were measured by quantitative real-time PCR.
- Human primer probe set RTS3898 forward sequence CTCTCAGGAGACCATTGCATCA, designated herein as SEQ ID NO: 11 ; reverse sequence TCCTGTCTTTGTACTTTCTTCATTTCC;
- SEQ ID NO: 12 probe sequence CCGCACACTGGTGGTCCATGAAAA, designated herein as SEQ ID NO: 13
- SEQ ID NO: 14 probe sequence CCGCACACTGGTGGTCCATGAAAA
- SEQ ID NO: 15 probe sequence ACGAAGGCCGTGTGCGTGCTGX, designated herein as SEQ ID NO: 16
- SOD-1 mRNA levels were adjusted according to total RNA content, as measured by
- RIBOGREEN® Results are presented as percent inhibition of SOD-1, relative to untreated control cells, 'n.d.' indicates that inhibition levels were not measured using the particular primer probe set.
- the newly designed modified oligonucleotides in the Tables below were designed as 5-10-5 MOE gapmers.
- the 5-10-5 MOE gapmers are 20 nucleosides in length, wherein the central gap segment is comprised of ten 2'-deoxyribonucleosides and is flanked by wing segments on the 5' direction and the 3' directions comprising five nucleosides each.
- Each nucleoside in the 5' wing segment and each nucleoside in the 3' wing segment has a 2' -MOE modification.
- the internucleoside linkages throughout each gapmer are phosphorothioate linkages. All cytosine residues throughout each gapmer are 5-methylcytosines.
- Start site indicates the 5 '-most nucleoside to which the gapmer is targeted in the human gene sequence.
- “Stop site” indicates the 3 '-most nucleoside to which the gapmer is targeted human gene sequence.
- Each gapmer listed in the Tables below is targeted to either the human SOD-1 mRNA, designated herein as SEQ ID NO: 1 (GENBANK Accession No. NM 000454.4) or the human SOD-1 genomic sequence, designated herein as SEQ ID NO: 2 (GENBANK Accession No. NT 011512.10 truncated from nucleotides 18693000 to
- 'n/a' indicates that the modified oligonucleotide does not target that particular gene sequence with 100% complementarity.
Abstract
Description






























































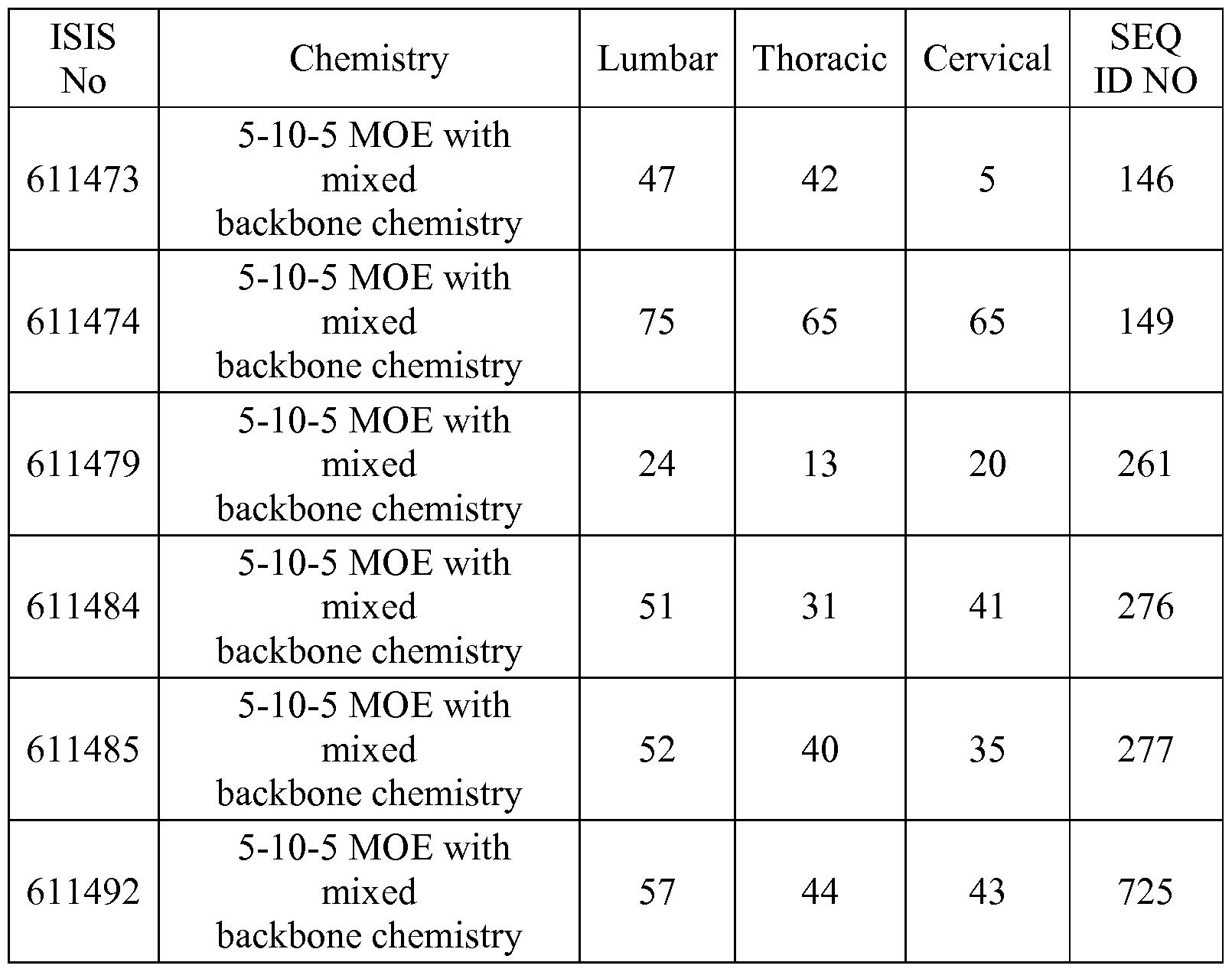

















Claims








Priority Applications (32)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP15773965.7A EP3126499B1 (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| KR1020237018802A KR20230085222A (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| KR1020227017808A KR20220077933A (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| EP22178713.8A EP4137573A3 (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| PL15773965T PL3126499T3 (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| NZ724100A NZ724100A (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| MYPI2016703576A MY175665A (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| JP2016560543A JP6622214B2 (en) | 2014-04-01 | 2015-04-01 | Composition for modulating SOD-1 expression |
| RS20201004A RS60707B1 (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| SI201531274T SI3126499T1 (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| LTEP15773965.7T LT3126499T (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| AU2015240761A AU2015240761B2 (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating SOD-1 expression |
| ES15773965T ES2818236T3 (en) | 2014-04-01 | 2015-04-01 | Compositions to modulate SOD-1 expression |
| RU2016142532A RU2704619C2 (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating expression of sod-1 |
| DK15773965.7T DK3126499T3 (en) | 2014-04-01 | 2015-04-01 | COMPOSITIONS FOR MODULATION OF SOD-1 EXPRESSION |
| CN201580024405.1A CN106459972B (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating SOD-1 expression |
| SG11201608109TA SG11201608109TA (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| CA2942394A CA2942394A1 (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| EP20176637.5A EP3757214B1 (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| KR1020217024143A KR20210097225A (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| KR1020167030062A KR102285629B1 (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
| US15/301,004 US10385341B2 (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating SOD-1 expression |
| BR112016021848-5A BR112016021848B1 (en) | 2014-04-01 | 2015-04-01 | ANTI-SENSE COMPOUND OR PHARMACEUTICALLY ACCEPTABLE SALT THEREOF, PHARMACEUTICAL COMPOSITION AND USES THEREOF |
| MX2016012922A MX2016012922A (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression. |
| IL247714A IL247714B (en) | 2014-04-01 | 2016-09-08 | Compositions for modulating sod-1 expression |
| US16/513,297 US10669546B2 (en) | 2014-04-01 | 2019-07-16 | Compositions for modulating SOD-1 expression |
| AU2019268063A AU2019268063A1 (en) | 2014-04-01 | 2019-11-19 | Compositions for modulating sod-1 expression |
| IL273404A IL273404B (en) | 2014-04-01 | 2020-03-18 | Compositions for modulating sod-1 expression |
| US16/849,583 US10968453B2 (en) | 2014-04-01 | 2020-04-15 | Compositions for modulating SOD-1 expression |
| HRP20201078TT HRP20201078T1 (en) | 2014-04-01 | 2020-07-09 | Compositions for modulating sod-1 expression |
| CY20201100794T CY1123288T1 (en) | 2014-04-01 | 2020-08-25 | COMPOSITIONS FOR MODULATING SOD-1 EXPRESSION |
| AU2022200002A AU2022200002A1 (en) | 2014-04-01 | 2022-01-03 | Compositions for modulating sod-1 expression |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201461973803P | 2014-04-01 | 2014-04-01 | |
| US61/973,803 | 2014-04-01 |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US15/301,004 A-371-Of-International US10385341B2 (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating SOD-1 expression |
| US16/513,297 Division US10669546B2 (en) | 2014-04-01 | 2019-07-16 | Compositions for modulating SOD-1 expression |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2015153800A2 true WO2015153800A2 (en) | 2015-10-08 |
| WO2015153800A3 WO2015153800A3 (en) | 2015-12-03 |
Family
ID=54241435
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2015/023934 WO2015153800A2 (en) | 2014-04-01 | 2015-04-01 | Compositions for modulating sod-1 expression |
Country Status (26)
| Country | Link |
|---|---|
| US (3) | US10385341B2 (en) |
| EP (3) | EP4137573A3 (en) |
| JP (4) | JP6622214B2 (en) |
| KR (4) | KR102285629B1 (en) |
| CN (2) | CN106459972B (en) |
| AU (3) | AU2015240761B2 (en) |
| BR (1) | BR112016021848B1 (en) |
| CA (1) | CA2942394A1 (en) |
| CL (3) | CL2016002509A1 (en) |
| CY (1) | CY1123288T1 (en) |
| DK (2) | DK3126499T3 (en) |
| ES (2) | ES2926869T3 (en) |
| HR (2) | HRP20220798T1 (en) |
| HU (2) | HUE059109T2 (en) |
| IL (2) | IL247714B (en) |
| LT (2) | LT3757214T (en) |
| MX (2) | MX2016012922A (en) |
| MY (2) | MY192634A (en) |
| NZ (1) | NZ724100A (en) |
| PL (2) | PL3126499T3 (en) |
| PT (2) | PT3126499T (en) |
| RS (2) | RS60707B1 (en) |
| RU (1) | RU2704619C2 (en) |
| SG (3) | SG11201608109TA (en) |
| SI (2) | SI3757214T1 (en) |
| WO (1) | WO2015153800A2 (en) |
Cited By (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20170152517A1 (en) * | 2014-07-31 | 2017-06-01 | Association Institut De Myologie | Treatment of amyotrophic lateral sclerosis |
| WO2017218454A1 (en) | 2016-06-14 | 2017-12-21 | Biogen Ma Inc. | Hydrophobic interaction chromatography for purification of oligonucleotides |
| WO2017223258A1 (en) | 2016-06-24 | 2017-12-28 | Biogen Ma Inc. | Synthesis of thiolated oligonucleotides without a capping step |
| US10385341B2 (en) | 2014-04-01 | 2019-08-20 | Biogen Ma Inc. | Compositions for modulating SOD-1 expression |
| WO2020117772A1 (en) | 2018-12-06 | 2020-06-11 | Biogen Ma Inc. | Neurofilament protein for guiding therapeutic intervention in amyotrophic lateral sclerosis |
| WO2020123783A1 (en) * | 2018-12-14 | 2020-06-18 | Biogen Ma Inc. | Compositions and methods for treating and preventing amyotrophic lateral sclerosis |
| WO2020222182A1 (en) * | 2019-05-01 | 2020-11-05 | Black Swan Pharmaceuticals, Inc. | Treatment for sod1 associated disease |
| WO2020227618A2 (en) | 2019-05-08 | 2020-11-12 | Biogen Ma Inc. | Convergent liquid phase syntheses of oligonucleotides |
| EP3631470A4 (en) * | 2017-05-26 | 2021-03-24 | University of Miami | Determining onset of amyotrophic lateral sclerosis |
| US11434502B2 (en) | 2017-10-16 | 2022-09-06 | Voyager Therapeutics, Inc. | Treatment of amyotrophic lateral sclerosis (ALS) |
| US11474113B2 (en) | 2018-01-25 | 2022-10-18 | Biosen MA Inc. | Methods of treating spinal muscular atrophy |
| US11542506B2 (en) | 2014-11-14 | 2023-01-03 | Voyager Therapeutics, Inc. | Compositions and methods of treating amyotrophic lateral sclerosis (ALS) |
| US11603542B2 (en) | 2017-05-05 | 2023-03-14 | Voyager Therapeutics, Inc. | Compositions and methods of treating amyotrophic lateral sclerosis (ALS) |
| US11873495B2 (en) | 2018-06-27 | 2024-01-16 | Ionis Pharmaceuticals, Inc. | Compounds and methods for reducing LRRK2 expression |
| US20240026363A1 (en) * | 2022-06-15 | 2024-01-25 | Arrowhead Pharmaceuticals, Inc. | RNAi Agents for Inhibiting Expression of Superoxide Dismutase 1 (SOD1), Compositions Thereof, and Methods of Use |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107207556B (en) | 2014-11-14 | 2020-12-08 | 沃雅戈治疗公司 | Regulatory polynucleotides |
| JP7066635B2 (en) | 2016-05-18 | 2022-05-13 | ボイジャー セラピューティクス インコーポレイテッド | Modulatory polynucleotide |
| WO2019079242A1 (en) | 2017-10-16 | 2019-04-25 | Voyager Therapeutics, Inc. | Treatment of amyotrophic lateral sclerosis (als) |
| US20220025366A1 (en) | 2018-11-21 | 2022-01-27 | Ionis Pharmaceuticals, Inc. | Compounds and methods for reducing prion expression |
| JP2022520885A (en) * | 2019-03-26 | 2022-04-01 | ラトガース,ザ ステート ユニバーシティ オブ ニュー ジャージー | Compositions and Methods for Treating Neurodegenerative Diseases |
| EP3966328A4 (en) * | 2019-05-06 | 2023-10-18 | University Of Massachusetts | Anti-c9orf72 oligonucleotides and related methods |
| WO2020243292A1 (en) * | 2019-05-28 | 2020-12-03 | Ionis Pharmaceuticals, Inc. | Compounds and methods for reducing fus expression |
| KR20230146048A (en) | 2021-02-12 | 2023-10-18 | 알닐람 파마슈티칼스 인코포레이티드 | Superoxide dismutase 1 (SOD1) IRNA compositions and methods of using them to treat or prevent superoxide dismutase 1- (SOD1-)-related neurodegenerative diseases |
| BR112023019877A2 (en) | 2021-03-31 | 2023-11-07 | Biogen Ma Inc | TREATMENT OF AMIOTROPHIC LATERAL SCLEROSIS |
| TW202304473A (en) | 2021-04-01 | 2023-02-01 | 美商百健Ma公司 | Nucleic acid delivery to the central nervous system |
| CN114369130B (en) * | 2021-12-28 | 2023-10-03 | 杭州天龙药业有限公司 | Modified thio-oligonucleotides and their use |
| KR20240038469A (en) | 2022-09-16 | 2024-03-25 | 김정훈 | Apparatus and method for providing promotion service based on user's contents |
Citations (49)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4981957A (en) | 1984-07-19 | 1991-01-01 | Centre National De La Recherche Scientifique | Oligonucleotides with modified phosphate and modified carbohydrate moieties at the respective chain termini |
| US5034506A (en) | 1985-03-15 | 1991-07-23 | Anti-Gene Development Group | Uncharged morpholino-based polymers having achiral intersubunit linkages |
| US5118800A (en) | 1983-12-20 | 1992-06-02 | California Institute Of Technology | Oligonucleotides possessing a primary amino group in the terminal nucleotide |
| US5166315A (en) | 1989-12-20 | 1992-11-24 | Anti-Gene Development Group | Sequence-specific binding polymers for duplex nucleic acids |
| US5185444A (en) | 1985-03-15 | 1993-02-09 | Anti-Gene Deveopment Group | Uncharged morpolino-based polymers having phosphorous containing chiral intersubunit linkages |
| US5319080A (en) | 1991-10-17 | 1994-06-07 | Ciba-Geigy Corporation | Bicyclic nucleosides, oligonucleotides, process for their preparation and intermediates |
| WO1994014226A1 (en) | 1992-12-14 | 1994-06-23 | Honeywell Inc. | Motor system with individually controlled redundant windings |
| US5359044A (en) | 1991-12-13 | 1994-10-25 | Isis Pharmaceuticals | Cyclobutyl oligonucleotide surrogates |
| US5446137A (en) | 1993-12-09 | 1995-08-29 | Syntex (U.S.A.) Inc. | Oligonucleotides containing 4'-substituted nucleotides |
| US5466786A (en) | 1989-10-24 | 1995-11-14 | Gilead Sciences | 2'modified nucleoside and nucleotide compounds |
| US5514785A (en) | 1990-05-11 | 1996-05-07 | Becton Dickinson And Company | Solid supports for nucleic acid hybridization assays |
| US5519134A (en) | 1994-01-11 | 1996-05-21 | Isis Pharmaceuticals, Inc. | Pyrrolidine-containing monomers and oligomers |
| US5567811A (en) | 1990-05-03 | 1996-10-22 | Amersham International Plc | Phosphoramidite derivatives, their preparation and the use thereof in the incorporation of reporter groups on synthetic oligonucleotides |
| US5576427A (en) | 1993-03-30 | 1996-11-19 | Sterling Winthrop, Inc. | Acyclic nucleoside analogs and oligonucleotide sequences containing them |
| US5591722A (en) | 1989-09-15 | 1997-01-07 | Southern Research Institute | 2'-deoxy-4'-thioribonucleosides and their antiviral activity |
| US5597909A (en) | 1994-08-25 | 1997-01-28 | Chiron Corporation | Polynucleotide reagents containing modified deoxyribose moieties, and associated methods of synthesis and use |
| US5610300A (en) | 1992-07-01 | 1997-03-11 | Ciba-Geigy Corporation | Carbocyclic nucleosides containing bicyclic rings, oligonucleotides therefrom, process for their preparation, their use and intermediates |
| US5627053A (en) | 1994-03-29 | 1997-05-06 | Ribozyme Pharmaceuticals, Inc. | 2'deoxy-2'-alkylnucleotide containing nucleic acid |
| US5639873A (en) | 1992-02-05 | 1997-06-17 | Centre National De La Recherche Scientifique (Cnrs) | Oligothionucleotides |
| US5646265A (en) | 1990-01-11 | 1997-07-08 | Isis Pharmceuticals, Inc. | Process for the preparation of 2'-O-alkyl purine phosphoramidites |
| US5670633A (en) | 1990-01-11 | 1997-09-23 | Isis Pharmaceuticals, Inc. | Sugar modified oligonucleotides that detect and modulate gene expression |
| US5698685A (en) | 1985-03-15 | 1997-12-16 | Antivirals Inc. | Morpholino-subunit combinatorial library and method |
| WO1998039352A1 (en) | 1997-03-07 | 1998-09-11 | Takeshi Imanishi | Novel bicyclonucleoside and oligonucleotide analogues |
| WO1999014226A2 (en) | 1997-09-12 | 1999-03-25 | Exiqon A/S | Bi- and tri-cyclic nucleoside, nucleotide and oligonucleotide analogues |
| WO2001049687A2 (en) | 1999-12-30 | 2001-07-12 | K. U. Leuven Research & Development | Cyclohexene nucleic acids |
| WO2003004602A2 (en) | 2001-07-03 | 2003-01-16 | Isis Pharmaceuticals, Inc. | Nuclease resistant chimeric oligonucleotides |
| US6525191B1 (en) | 1999-05-11 | 2003-02-25 | Kanda S. Ramasamy | Conformationally constrained L-nucleosides |
| US6600032B1 (en) | 1998-08-07 | 2003-07-29 | Isis Pharmaceuticals, Inc. | 2′-O-aminoethyloxyethyl-modified oligonucleotides |
| US6670461B1 (en) | 1997-09-12 | 2003-12-30 | Exiqon A/S | Oligonucleotide analogues |
| US6770748B2 (en) | 1997-03-07 | 2004-08-03 | Takeshi Imanishi | Bicyclonucleoside and oligonucleotide analogue |
| US20040171570A1 (en) | 2002-11-05 | 2004-09-02 | Charles Allerson | Polycyclic sugar surrogate-containing oligomeric compounds and compositions for use in gene modulation |
| WO2004106356A1 (en) | 2003-05-27 | 2004-12-09 | Syddansk Universitet | Functionalized nucleotide derivatives |
| WO2005021570A1 (en) | 2003-08-28 | 2005-03-10 | Gene Design, Inc. | Novel artificial nucleic acids of n-o bond crosslinkage type |
| WO2005040180A2 (en) | 2003-09-26 | 2005-05-06 | Isis Pharmaceuticals, Inc. | Antisense modulation of superoxide dismutase 1, soluble (sod-1) expression |
| US20050130923A1 (en) | 2003-09-18 | 2005-06-16 | Balkrishen Bhat | 4'-thionucleosides and oligomeric compounds |
| WO2005121371A2 (en) | 2004-06-03 | 2005-12-22 | Isis Pharmaceuticals, Inc. | Double strand compositions comprising differentially modified strands for use in gene modulation |
| WO2006047842A2 (en) | 2004-11-08 | 2006-05-11 | K.U. Leuven Research And Development | Modified nucleosides for rna interference |
| US7053207B2 (en) | 1999-05-04 | 2006-05-30 | Exiqon A/S | L-ribo-LNA analogues |
| WO2006066203A2 (en) | 2004-12-16 | 2006-06-22 | Alsgen, Llc | Small interfering rna (sirna) molecules for modulating superoxide dismutase (sod) |
| WO2007134181A2 (en) | 2006-05-11 | 2007-11-22 | Isis Pharmaceuticals, Inc. | 5'-modified bicyclic nucleic acid analogs |
| US20080039618A1 (en) | 2002-11-05 | 2008-02-14 | Charles Allerson | Polycyclic sugar surrogate-containing oligomeric compounds and compositions for use in gene modulation |
| US7399845B2 (en) | 2006-01-27 | 2008-07-15 | Isis Pharmaceuticals, Inc. | 6-modified bicyclic nucleic acid analogs |
| WO2008101157A1 (en) | 2007-02-15 | 2008-08-21 | Isis Pharmaceuticals, Inc. | 5'-substituted-2'-f modified nucleosides and oligomeric compounds prepared therefrom |
| WO2008150729A2 (en) | 2007-05-30 | 2008-12-11 | Isis Pharmaceuticals, Inc. | N-substituted-aminomethylene bridged bicyclic nucleic acid analogs |
| WO2008154401A2 (en) | 2007-06-08 | 2008-12-18 | Isis Pharmaceuticals, Inc. | Carbocyclic bicyclic nucleic acid analogs |
| WO2009006478A2 (en) | 2007-07-05 | 2009-01-08 | Isis Pharmaceuticals, Inc. | 6-disubstituted bicyclic nucleic acid analogs |
| US20090130195A1 (en) | 2007-10-17 | 2009-05-21 | Mildred Acevedo-Duncan | Prostate carcinogenesis predictor |
| WO2009102427A2 (en) | 2008-02-11 | 2009-08-20 | Rxi Pharmaceuticals Corp. | Modified rnai polynucleotides and uses thereof |
| WO2010036696A1 (en) | 2008-09-24 | 2010-04-01 | Isis Pharmaceuticals, Inc. | Cyclohexenyl nucleic acid analogs |
Family Cites Families (172)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3687808A (en) | 1969-08-14 | 1972-08-29 | Univ Leland Stanford Junior | Synthetic polynucleotides |
| US5132418A (en) | 1980-02-29 | 1992-07-21 | University Patents, Inc. | Process for preparing polynucleotides |
| US4500707A (en) | 1980-02-29 | 1985-02-19 | University Patents, Inc. | Nucleosides useful in the preparation of polynucleotides |
| US4469863A (en) | 1980-11-12 | 1984-09-04 | Ts O Paul O P | Nonionic nucleic acid alkyl and aryl phosphonates and processes for manufacture and use thereof |
| US4973679A (en) | 1981-03-27 | 1990-11-27 | University Patents, Inc. | Process for oligonucleo tide synthesis using phosphormidite intermediates |
| US4415732A (en) | 1981-03-27 | 1983-11-15 | University Patents, Inc. | Phosphoramidite compounds and processes |
| US5023243A (en) | 1981-10-23 | 1991-06-11 | Molecular Biosystems, Inc. | Oligonucleotide therapeutic agent and method of making same |
| US4476301A (en) | 1982-04-29 | 1984-10-09 | Centre National De La Recherche Scientifique | Oligonucleotides, a process for preparing the same and their application as mediators of the action of interferon |
| DE3329892A1 (en) | 1983-08-18 | 1985-03-07 | Köster, Hubert, Prof. Dr., 2000 Hamburg | METHOD FOR PRODUCING OLIGONUCLEOTIDES |
| USRE34036E (en) | 1984-06-06 | 1992-08-18 | National Research Development Corporation | Data transmission using a transparent tone-in band system |
| US5550111A (en) | 1984-07-11 | 1996-08-27 | Temple University-Of The Commonwealth System Of Higher Education | Dual action 2',5'-oligoadenylate antiviral derivatives and uses thereof |
| US5367066A (en) | 1984-10-16 | 1994-11-22 | Chiron Corporation | Oligonucleotides with selectably cleavable and/or abasic sites |
| FR2575751B1 (en) | 1985-01-08 | 1987-04-03 | Pasteur Institut | NOVEL ADENOSINE DERIVATIVE NUCLEOSIDES, THEIR PREPARATION AND THEIR BIOLOGICAL APPLICATIONS |
| US5235033A (en) | 1985-03-15 | 1993-08-10 | Anti-Gene Development Group | Alpha-morpholino ribonucleoside derivatives and polymers thereof |
| US5405938A (en) | 1989-12-20 | 1995-04-11 | Anti-Gene Development Group | Sequence-specific binding polymers for duplex nucleic acids |
| DE3788914T2 (en) | 1986-09-08 | 1994-08-25 | Ajinomoto Kk | Compounds for cleaving RNA at a specific position, oligomers used in the preparation of these compounds and starting materials for the synthesis of these oligomers. |
| US5276019A (en) | 1987-03-25 | 1994-01-04 | The United States Of America As Represented By The Department Of Health And Human Services | Inhibitors for replication of retroviruses and for the expression of oncogene products |
| US5264423A (en) | 1987-03-25 | 1993-11-23 | The United States Of America As Represented By The Department Of Health And Human Services | Inhibitors for replication of retroviruses and for the expression of oncogene products |
| AU598946B2 (en) | 1987-06-24 | 1990-07-05 | Howard Florey Institute Of Experimental Physiology And Medicine | Nucleoside derivatives |
| US5188897A (en) | 1987-10-22 | 1993-02-23 | Temple University Of The Commonwealth System Of Higher Education | Encapsulated 2',5'-phosphorothioate oligoadenylates |
| US4924624A (en) | 1987-10-22 | 1990-05-15 | Temple University-Of The Commonwealth System Of Higher Education | 2,',5'-phosphorothioate oligoadenylates and plant antiviral uses thereof |
| EP0348458B1 (en) | 1987-11-30 | 1997-04-09 | University Of Iowa Research Foundation | Dna molecules stabilized by modifications of the 3'-terminal phosphodiester linkage and their use as nucleic acid probes and as therapeutic agents to block the expression of specifically targeted genes |
| US5403711A (en) | 1987-11-30 | 1995-04-04 | University Of Iowa Research Foundation | Nucleic acid hybridization and amplification method for detection of specific sequences in which a complementary labeled nucleic acid probe is cleaved |
| WO1989009221A1 (en) | 1988-03-25 | 1989-10-05 | University Of Virginia Alumni Patents Foundation | Oligonucleotide n-alkylphosphoramidates |
| US5278302A (en) | 1988-05-26 | 1994-01-11 | University Patents, Inc. | Polynucleotide phosphorodithioates |
| US5216141A (en) | 1988-06-06 | 1993-06-01 | Benner Steven A | Oligonucleotide analogs containing sulfur linkages |
| US5175273A (en) | 1988-07-01 | 1992-12-29 | Genentech, Inc. | Nucleic acid intercalating agents |
| US5194599A (en) | 1988-09-23 | 1993-03-16 | Gilead Sciences, Inc. | Hydrogen phosphonodithioate compositions |
| WO1990005181A1 (en) | 1988-11-07 | 1990-05-17 | Cl-Pharma Aktiengesellschaft | PURIFICATION OF Cu/Zn SUPEROXIDEDISMUTASE________________________ |
| US5256775A (en) | 1989-06-05 | 1993-10-26 | Gilead Sciences, Inc. | Exonuclease-resistant oligonucleotides |
| US5134066A (en) | 1989-08-29 | 1992-07-28 | Monsanto Company | Improved probes using nucleosides containing 3-dezauracil analogs |
| US5399676A (en) | 1989-10-23 | 1995-03-21 | Gilead Sciences | Oligonucleotides with inverted polarity |
| US5721218A (en) | 1989-10-23 | 1998-02-24 | Gilead Sciences, Inc. | Oligonucleotides with inverted polarity |
| US5264564A (en) | 1989-10-24 | 1993-11-23 | Gilead Sciences | Oligonucleotide analogs with novel linkages |
| US5264562A (en) | 1989-10-24 | 1993-11-23 | Gilead Sciences, Inc. | Oligonucleotide analogs with novel linkages |
| US5177198A (en) | 1989-11-30 | 1993-01-05 | University Of N.C. At Chapel Hill | Process for preparing oligoribonucleoside and oligodeoxyribonucleoside boranophosphates |
| US5130302A (en) | 1989-12-20 | 1992-07-14 | Boron Bilogicals, Inc. | Boronated nucleoside, nucleotide and oligonucleotide compounds, compositions and methods for using same |
| US5459255A (en) | 1990-01-11 | 1995-10-17 | Isis Pharmaceuticals, Inc. | N-2 substituted purines |
| US5587361A (en) | 1991-10-15 | 1996-12-24 | Isis Pharmaceuticals, Inc. | Oligonucleotides having phosphorothioate linkages of high chiral purity |
| US5859221A (en) | 1990-01-11 | 1999-01-12 | Isis Pharmaceuticals, Inc. | 2'-modified oligonucleotides |
| US5587470A (en) | 1990-01-11 | 1996-12-24 | Isis Pharmaceuticals, Inc. | 3-deazapurines |
| US5457191A (en) | 1990-01-11 | 1995-10-10 | Isis Pharmaceuticals, Inc. | 3-deazapurines |
| US7101993B1 (en) | 1990-01-11 | 2006-09-05 | Isis Pharmaceuticals, Inc. | Oligonucleotides containing 2′-O-modified purines |
| US6005087A (en) | 1995-06-06 | 1999-12-21 | Isis Pharmaceuticals, Inc. | 2'-modified oligonucleotides |
| US5623065A (en) | 1990-08-13 | 1997-04-22 | Isis Pharmaceuticals, Inc. | Gapped 2' modified oligonucleotides |
| US5681941A (en) | 1990-01-11 | 1997-10-28 | Isis Pharmaceuticals, Inc. | Substituted purines and oligonucleotide cross-linking |
| US5149797A (en) | 1990-02-15 | 1992-09-22 | The Worcester Foundation For Experimental Biology | Method of site-specific alteration of rna and production of encoded polypeptides |
| US5220007A (en) | 1990-02-15 | 1993-06-15 | The Worcester Foundation For Experimental Biology | Method of site-specific alteration of RNA and production of encoded polypeptides |
| US5321131A (en) | 1990-03-08 | 1994-06-14 | Hybridon, Inc. | Site-specific functionalization of oligodeoxynucleotides for non-radioactive labelling |
| US5470967A (en) | 1990-04-10 | 1995-11-28 | The Dupont Merck Pharmaceutical Company | Oligonucleotide analogs with sulfamate linkages |
| US5536638A (en) | 1990-04-18 | 1996-07-16 | N.V. Innogenetics S.A. | Hybridization probes derived from the spacer region between the 16S and 23S rRNA genes for the detection of Neisseria gonorrhoeae |
| US5541307A (en) | 1990-07-27 | 1996-07-30 | Isis Pharmaceuticals, Inc. | Backbone modified oligonucleotide analogs and solid phase synthesis thereof |
| US5608046A (en) | 1990-07-27 | 1997-03-04 | Isis Pharmaceuticals, Inc. | Conjugated 4'-desmethyl nucleoside analog compounds |
| US5489677A (en) | 1990-07-27 | 1996-02-06 | Isis Pharmaceuticals, Inc. | Oligonucleoside linkages containing adjacent oxygen and nitrogen atoms |
| US5677437A (en) | 1990-07-27 | 1997-10-14 | Isis Pharmaceuticals, Inc. | Heteroatomic oligonucleoside linkages |
| US5610289A (en) | 1990-07-27 | 1997-03-11 | Isis Pharmaceuticals, Inc. | Backbone modified oligonucleotide analogues |
| WO1992002258A1 (en) | 1990-07-27 | 1992-02-20 | Isis Pharmaceuticals, Inc. | Nuclease resistant, pyrimidine modified oligonucleotides that detect and modulate gene expression |
| US5623070A (en) | 1990-07-27 | 1997-04-22 | Isis Pharmaceuticals, Inc. | Heteroatomic oligonucleoside linkages |
| US5618704A (en) | 1990-07-27 | 1997-04-08 | Isis Pharmacueticals, Inc. | Backbone-modified oligonucleotide analogs and preparation thereof through radical coupling |
| US5378825A (en) | 1990-07-27 | 1995-01-03 | Isis Pharmaceuticals, Inc. | Backbone modified oligonucleotide analogs |
| US5602240A (en) | 1990-07-27 | 1997-02-11 | Ciba Geigy Ag. | Backbone modified oligonucleotide analogs |
| US5386023A (en) | 1990-07-27 | 1995-01-31 | Isis Pharmaceuticals | Backbone modified oligonucleotide analogs and preparation thereof through reductive coupling |
| US5223618A (en) | 1990-08-13 | 1993-06-29 | Isis Pharmaceuticals, Inc. | 4'-desmethyl nucleoside analog compounds |
| EP0541722B1 (en) | 1990-08-03 | 1995-12-20 | Sterling Winthrop Inc. | Compounds and methods for inhibiting gene expression |
| US5177196A (en) | 1990-08-16 | 1993-01-05 | Microprobe Corporation | Oligo (α-arabinofuranosyl nucleotides) and α-arabinofuranosyl precursors thereof |
| US5214134A (en) | 1990-09-12 | 1993-05-25 | Sterling Winthrop Inc. | Process of linking nucleosides with a siloxane bridge |
| US5561225A (en) | 1990-09-19 | 1996-10-01 | Southern Research Institute | Polynucleotide analogs containing sulfonate and sulfonamide internucleoside linkages |
| WO1992005186A1 (en) | 1990-09-20 | 1992-04-02 | Gilead Sciences | Modified internucleoside linkages |
| US5432272A (en) | 1990-10-09 | 1995-07-11 | Benner; Steven A. | Method for incorporating into a DNA or RNA oligonucleotide using nucleotides bearing heterocyclic bases |
| US6582908B2 (en) | 1990-12-06 | 2003-06-24 | Affymetrix, Inc. | Oligonucleotides |
| US5948903A (en) | 1991-01-11 | 1999-09-07 | Isis Pharmaceuticals, Inc. | Synthesis of 3-deazapurines |
| US5672697A (en) | 1991-02-08 | 1997-09-30 | Gilead Sciences, Inc. | Nucleoside 5'-methylene phosphonates |
| US7015315B1 (en) | 1991-12-24 | 2006-03-21 | Isis Pharmaceuticals, Inc. | Gapped oligonucleotides |
| US5571799A (en) | 1991-08-12 | 1996-11-05 | Basco, Ltd. | (2'-5') oligoadenylate analogues useful as inhibitors of host-v5.-graft response |
| US5594121A (en) | 1991-11-07 | 1997-01-14 | Gilead Sciences, Inc. | Enhanced triple-helix and double-helix formation with oligomers containing modified purines |
| TW393513B (en) | 1991-11-26 | 2000-06-11 | Isis Pharmaceuticals Inc | Enhanced triple-helix and double-helix formation with oligomers containing modified pyrimidines |
| WO1993010820A1 (en) | 1991-11-26 | 1993-06-10 | Gilead Sciences, Inc. | Enhanced triple-helix and double-helix formation with oligomers containing modified pyrimidines |
| US5484908A (en) | 1991-11-26 | 1996-01-16 | Gilead Sciences, Inc. | Oligonucleotides containing 5-propynyl pyrimidines |
| US5792608A (en) | 1991-12-12 | 1998-08-11 | Gilead Sciences, Inc. | Nuclease stable and binding competent oligomers and methods for their use |
| US5700922A (en) | 1991-12-24 | 1997-12-23 | Isis Pharmaceuticals, Inc. | PNA-DNA-PNA chimeric macromolecules |
| US5633360A (en) | 1992-04-14 | 1997-05-27 | Gilead Sciences, Inc. | Oligonucleotide analogs capable of passive cell membrane permeation |
| US5434257A (en) | 1992-06-01 | 1995-07-18 | Gilead Sciences, Inc. | Binding compentent oligomers containing unsaturated 3',5' and 2',5' linkages |
| US5652355A (en) | 1992-07-23 | 1997-07-29 | Worcester Foundation For Experimental Biology | Hybrid oligonucleotide phosphorothioates |
| US6784290B1 (en) | 1992-10-05 | 2004-08-31 | Isis Pharmaceuticals, Inc. | Antisense oligonucleotide inhibition of ras |
| US5476925A (en) | 1993-02-01 | 1995-12-19 | Northwestern University | Oligodeoxyribonucleotides including 3'-aminonucleoside-phosphoramidate linkages and terminal 3'-amino groups |
| US5843641A (en) | 1993-02-26 | 1998-12-01 | Massachusetts Institute Of Technology | Methods for the daignosis, of familial amyotrophic lateral sclerosis |
| GB9304618D0 (en) | 1993-03-06 | 1993-04-21 | Ciba Geigy Ag | Chemical compounds |
| GB9304620D0 (en) | 1993-03-06 | 1993-04-21 | Ciba Geigy Ag | Compounds |
| ATE160572T1 (en) | 1993-03-31 | 1997-12-15 | Sanofi Sa | OLIGONUCLEOTIDES WITH AMIDE CHAINS THAT USE PHOSPHOESTER CHAINS |
| US5502177A (en) | 1993-09-17 | 1996-03-26 | Gilead Sciences, Inc. | Pyrimidine derivatives for labeled binding partners |
| US5801154A (en) | 1993-10-18 | 1998-09-01 | Isis Pharmaceuticals, Inc. | Antisense oligonucleotide modulation of multidrug resistance-associated protein |
| US5457187A (en) | 1993-12-08 | 1995-10-10 | Board Of Regents University Of Nebraska | Oligonucleotides containing 5-fluorouracil |
| EP0733059B1 (en) | 1993-12-09 | 2000-09-13 | Thomas Jefferson University | Compounds and methods for site-directed mutations in eukaryotic cells |
| US5596091A (en) | 1994-03-18 | 1997-01-21 | The Regents Of The University Of California | Antisense oligonucleotides comprising 5-aminoalkyl pyrimidine nucleotides |
| US5625050A (en) | 1994-03-31 | 1997-04-29 | Amgen Inc. | Modified oligonucleotides and intermediates useful in nucleic acid therapeutics |
| US5646269A (en) | 1994-04-28 | 1997-07-08 | Gilead Sciences, Inc. | Method for oligonucleotide analog synthesis |
| US5525711A (en) | 1994-05-18 | 1996-06-11 | The United States Of America As Represented By The Secretary Of The Department Of Health And Human Services | Pteridine nucleotide analogs as fluorescent DNA probes |
| US5877021A (en) | 1995-07-07 | 1999-03-02 | Ribozyme Pharmaceuticals, Inc. | B7-1 targeted ribozymes |
| US5652356A (en) | 1995-08-17 | 1997-07-29 | Hybridon, Inc. | Inverted chimeric and hybrid oligonucleotides |
| US5994517A (en) | 1995-11-22 | 1999-11-30 | Paul O. P. Ts'o | Ligands to enhance cellular uptake of biomolecules |
| AU1430097A (en) | 1996-01-16 | 1997-08-11 | Ribozyme Pharmaceuticals, Inc. | Synthesis of methoxy nucleosides and enzymatic nucleic acid molecules |
| WO1997031012A1 (en) | 1996-02-22 | 1997-08-28 | The Regents Of The University Of Michigan | Gene specific universal mammalian sequence-tagged sites |
| US6077833A (en) | 1996-12-31 | 2000-06-20 | Isis Pharmaceuticals, Inc. | Oligonucleotide compositions and methods for the modulation of the expression of B7 protein |
| USRE44779E1 (en) | 1997-03-07 | 2014-02-25 | Santaris Pharma A/S | Bicyclonucleoside and oligonucleotide analogues |
| US6352829B1 (en) | 1997-05-21 | 2002-03-05 | Clontech Laboratories, Inc. | Methods of assaying differential expression |
| US5994076A (en) | 1997-05-21 | 1999-11-30 | Clontech Laboratories, Inc. | Methods of assaying differential expression |
| US7572582B2 (en) | 1997-09-12 | 2009-08-11 | Exiqon A/S | Oligonucleotide analogues |
| US20030228597A1 (en) | 1998-04-13 | 2003-12-11 | Cowsert Lex M. | Identification of genetic targets for modulation by oligonucleotides and generation of oligonucleotides for gene modulation |
| US6300319B1 (en) | 1998-06-16 | 2001-10-09 | Isis Pharmaceuticals, Inc. | Targeted oligonucleotide conjugates |
| CN1273478C (en) | 1999-02-12 | 2006-09-06 | 三共株式会社 | Novel nucleosides and oligonucleotide analogues |
| US5998148A (en) | 1999-04-08 | 1999-12-07 | Isis Pharmaceuticals Inc. | Antisense modulation of microtubule-associated protein 4 expression |
| US9029523B2 (en) | 2000-04-26 | 2015-05-12 | Ceres, Inc. | Promoter, promoter control elements, and combinations, and uses thereof |
| JP4151751B2 (en) | 1999-07-22 | 2008-09-17 | 第一三共株式会社 | New bicyclonucleoside analogues |
| US6303374B1 (en) | 2000-01-18 | 2001-10-16 | Isis Pharmaceuticals Inc. | Antisense modulation of caspase 3 expression |
| US7491805B2 (en) | 2001-05-18 | 2009-02-17 | Sirna Therapeutics, Inc. | Conjugates and compositions for cellular delivery |
| WO2001077384A2 (en) | 2000-04-07 | 2001-10-18 | Epigenomics Ag | Detection of single nucleotide polymorphisms (snp's) and cytosine-methylations |
| US20020106348A1 (en) | 2000-07-12 | 2002-08-08 | Peng Huang | Cancer therapeutics involving the administration of 2-methoxyestradiol and an agent that increases intracellular superoxide anion |
| EP1314734A1 (en) | 2000-08-29 | 2003-05-28 | Takeshi Imanishi | Novel nucleoside analogs and oligonucleotide derivatives containing these analogs |
| NZ525336A (en) | 2000-10-20 | 2006-03-31 | Expression Diagnostics Inc | Leukocyte expression profiling |
| US6426220B1 (en) | 2000-10-30 | 2002-07-30 | Isis Pharmaceuticals, Inc. | Antisense modulation of calreticulin expression |
| AU2002236489A1 (en) | 2000-11-14 | 2002-05-27 | University Of Iowa Research Foundation | Reduction of antioxidant enzyme levels in tumor cells using antisense oligonucleotides |
| DK2813582T3 (en) | 2000-12-01 | 2017-07-31 | Max-Planck-Gesellschaft Zur Förderung Der Wss E V | Small RNA molecules that mediate RNA interference |
| EP1355672A2 (en) | 2000-12-01 | 2003-10-29 | Cell Works Inc. | Conjugates of glycosylated/galactosylated peptide, bifunctional linker, and nucleotidic monomers/polymers, and related compositions and methods of use |
| CA2790034A1 (en) | 2001-06-21 | 2003-01-03 | Isis Pharmaceuticals, Inc. | Antisense modulation of superoxide dismutase 1, soluble expression |
| US20030158403A1 (en) | 2001-07-03 | 2003-08-21 | Isis Pharmaceuticals, Inc. | Nuclease resistant chimeric oligonucleotides |
| US20030175906A1 (en) | 2001-07-03 | 2003-09-18 | Muthiah Manoharan | Nuclease resistant chimeric oligonucleotides |
| WO2003020739A2 (en) | 2001-09-04 | 2003-03-13 | Exiqon A/S | Novel lna compositions and uses thereof |
| JP2003319198A (en) | 2002-04-19 | 2003-11-07 | Orion Denki Kk | X-ray protector apparatus |
| ES2334125T3 (en) * | 2002-11-04 | 2010-03-05 | University Of Massachusetts | SPECIFIC ARN INTERFERENCE OF ALELOS. |
| EP2305813A3 (en) | 2002-11-14 | 2012-03-28 | Dharmacon, Inc. | Fuctional and hyperfunctional sirna |
| US7655785B1 (en) | 2002-11-14 | 2010-02-02 | Rosetta Genomics Ltd. | Bioinformatically detectable group of novel regulatory oligonucleotides and uses thereof |
| WO2006006948A2 (en) | 2002-11-14 | 2006-01-19 | Dharmacon, Inc. | METHODS AND COMPOSITIONS FOR SELECTING siRNA OF IMPROVED FUNCTIONALITY |
| US7723509B2 (en) | 2003-04-17 | 2010-05-25 | Alnylam Pharmaceuticals | IRNA agents with biocleavable tethers |
| US7683036B2 (en) * | 2003-07-31 | 2010-03-23 | Regulus Therapeutics Inc. | Oligomeric compounds and compositions for use in modulation of small non-coding RNAs |
| US7888497B2 (en) | 2003-08-13 | 2011-02-15 | Rosetta Genomics Ltd. | Bioinformatically detectable group of novel regulatory oligonucleotides and uses thereof |
| US20050118625A1 (en) | 2003-10-02 | 2005-06-02 | Mounts William M. | Nucleic acid arrays for detecting gene expression associated with human osteoarthritis and human proteases |
| US20050244851A1 (en) | 2004-01-13 | 2005-11-03 | Affymetrix, Inc. | Methods of analysis of alternative splicing in human |
| US20060148740A1 (en) | 2005-01-05 | 2006-07-06 | Prosensa B.V. | Mannose-6-phosphate receptor mediated gene transfer into muscle cells |
| WO2007089607A2 (en) | 2006-01-26 | 2007-08-09 | University Of Massachusetts | Rna silencing agents for use in therapy and nanotransporters for efficient delivery of same |
| US7569686B1 (en) | 2006-01-27 | 2009-08-04 | Isis Pharmaceuticals, Inc. | Compounds and methods for synthesis of bicyclic nucleic acid analogs |
| US7666854B2 (en) | 2006-05-11 | 2010-02-23 | Isis Pharmaceuticals, Inc. | Bis-modified bicyclic nucleic acid analogs |
| ATE540118T1 (en) | 2006-10-18 | 2012-01-15 | Isis Pharmaceuticals Inc | ANTISENSE COMPOUNDS |
| US8088904B2 (en) | 2007-08-15 | 2012-01-03 | Isis Pharmaceuticals, Inc. | Tetrahydropyran nucleic acid analogs |
| WO2009067647A1 (en) | 2007-11-21 | 2009-05-28 | Isis Pharmaceuticals, Inc. | Carbocyclic alpha-l-bicyclic nucleic acid analogs |
| EP4074344A1 (en) | 2007-12-04 | 2022-10-19 | Arbutus Biopharma Corporation | Targeting lipids |
| WO2009100320A2 (en) | 2008-02-07 | 2009-08-13 | Isis Pharmaceuticals, Inc. | Bicyclic cyclohexitol nucleic acid analogs |
| WO2009126933A2 (en) | 2008-04-11 | 2009-10-15 | Alnylam Pharmaceuticals, Inc. | Site-specific delivery of nucleic acids by combining targeting ligands with endosomolytic components |
| EP2356129B1 (en) | 2008-09-24 | 2013-04-03 | Isis Pharmaceuticals, Inc. | Substituted alpha-l-bicyclic nucleosides |
| EP2462153B1 (en) | 2009-08-06 | 2015-07-29 | Isis Pharmaceuticals, Inc. | Bicyclic cyclohexose nucleic acid analogs |
| WO2011123621A2 (en) | 2010-04-01 | 2011-10-06 | Alnylam Pharmaceuticals Inc. | 2' and 5' modified monomers and oligonucleotides |
| AU2011237426A1 (en) * | 2010-04-07 | 2012-11-22 | Isis Pharmaceuticals, Inc. | Modulation of CETP expression |
| WO2011133871A2 (en) * | 2010-04-22 | 2011-10-27 | Alnylam Pharmaceuticals, Inc. | 5'-end derivatives |
| WO2011133876A2 (en) | 2010-04-22 | 2011-10-27 | Alnylam Pharmaceuticals, Inc. | Oligonucleotides comprising acyclic and abasic nucleosides and analogs |
| WO2012037254A1 (en) | 2010-09-15 | 2012-03-22 | Alnylam Pharmaceuticals, Inc. | MODIFIED iRNA AGENTS |
| EP3467109A1 (en) | 2011-02-08 | 2019-04-10 | Ionis Pharmaceuticals, Inc. | Oligomeric compounds comprising bicyclic nucleotides and uses thereof |
| DK3505528T3 (en) * | 2011-04-21 | 2021-02-08 | Ionis Pharmaceuticals Inc | MODULATION OF HEPATITIS B VIRUS (HBV) EXPRESSION |
| WO2013033230A1 (en) | 2011-08-29 | 2013-03-07 | Isis Pharmaceuticals, Inc. | Oligomer-conjugate complexes and their use |
| EP2839006B1 (en) | 2012-04-20 | 2018-01-03 | Ionis Pharmaceuticals, Inc. | Oligomeric compounds comprising bicyclic nucleotides and uses thereof |
| JP2016522674A (en) | 2012-05-16 | 2016-08-04 | ラナ セラピューティクス インコーポレイテッド | Compositions and methods for regulating gene expression |
| WO2014059353A2 (en) | 2012-10-11 | 2014-04-17 | Isis Pharmaceuticals, Inc. | Oligomeric compounds comprising bicyclic nucleosides and uses thereof |
| RU2015119411A (en) | 2012-11-15 | 2017-01-10 | Рош Инновейшен Сентер Копенгаген А/С | ANTI-SENSE COMPOUNDS CONJUGATES AIMED AT APOLIPOPROTEIN IN |
| US9127276B2 (en) | 2013-05-01 | 2015-09-08 | Isis Pharmaceuticals, Inc. | Conjugated antisense compounds and their use |
| SI3039146T1 (en) | 2013-08-27 | 2020-10-30 | Research Institute At Nationwide Children's Hospital | Products and methods for treatment of amyotrophic lateral sclerosis |
| US9344563B2 (en) | 2013-09-19 | 2016-05-17 | Verizon Patent And Licensing Inc. | System for and method of recycling numbers seamlessly |
| SG11201608109TA (en) | 2014-04-01 | 2016-10-28 | Ionis Pharmaceuticals Inc | Compositions for modulating sod-1 expression |
| HUE052709T2 (en) * | 2014-05-01 | 2021-05-28 | Ionis Pharmaceuticals Inc | Conjugates of modified antisense oligonucleotides and their use for modulating pkk expression |
| CA2955285C (en) | 2014-07-31 | 2023-09-26 | Association Institut De Myologie | Treatment of amyotrophic lateral sclerosis |
| RU2020108189A (en) | 2014-11-14 | 2020-03-11 | Вояджер Терапьютикс, Инк. | COMPOSITIONS AND METHODS OF TREATMENT OF LATERAL AMYOTROPHIC SCLEROSIS (ALS) |
| US10808247B2 (en) | 2015-07-06 | 2020-10-20 | Phio Pharmaceuticals Corp. | Methods for treating neurological disorders using a synergistic small molecule and nucleic acids therapeutic approach |
| KR20180026739A (en) | 2015-07-06 | 2018-03-13 | 알엑스아이 파마슈티칼스 코포레이션 | A nucleic acid molecule targeting superoxide dismutase 1 (SOD1) |
| JP2020518258A (en) | 2017-05-05 | 2020-06-25 | ボイジャー セラピューティクス インコーポレイテッドVoyager Therapeutics,Inc. | Amyotrophic lateral sclerosis (ALS) treatment composition and method |
| WO2020023737A1 (en) * | 2018-07-25 | 2020-01-30 | Ionis Pharmaceuticals, Inc. | Compounds and methods for reducing atxn2 expression |
-
2015
- 2015-04-01 SG SG11201608109TA patent/SG11201608109TA/en unknown
- 2015-04-01 PT PT157739657T patent/PT3126499T/en unknown
- 2015-04-01 SI SI201531852T patent/SI3757214T1/en unknown
- 2015-04-01 MY MYPI2019006915A patent/MY192634A/en unknown
- 2015-04-01 WO PCT/US2015/023934 patent/WO2015153800A2/en active Application Filing
- 2015-04-01 PL PL15773965T patent/PL3126499T3/en unknown
- 2015-04-01 DK DK15773965.7T patent/DK3126499T3/en active
- 2015-04-01 SG SG10201910844SA patent/SG10201910844SA/en unknown
- 2015-04-01 KR KR1020167030062A patent/KR102285629B1/en active IP Right Grant
- 2015-04-01 RS RS20201004A patent/RS60707B1/en unknown
- 2015-04-01 CA CA2942394A patent/CA2942394A1/en active Pending
- 2015-04-01 RU RU2016142532A patent/RU2704619C2/en active
- 2015-04-01 MY MYPI2016703576A patent/MY175665A/en unknown
- 2015-04-01 HR HRP20220798TT patent/HRP20220798T1/en unknown
- 2015-04-01 CN CN201580024405.1A patent/CN106459972B/en active Active
- 2015-04-01 ES ES20176637T patent/ES2926869T3/en active Active
- 2015-04-01 SG SG10201906520RA patent/SG10201906520RA/en unknown
- 2015-04-01 RS RS20220767A patent/RS63487B1/en unknown
- 2015-04-01 KR KR1020237018802A patent/KR20230085222A/en not_active Application Discontinuation
- 2015-04-01 DK DK20176637.5T patent/DK3757214T3/en active
- 2015-04-01 PT PT201766375T patent/PT3757214T/en unknown
- 2015-04-01 EP EP22178713.8A patent/EP4137573A3/en active Pending
- 2015-04-01 HU HUE20176637A patent/HUE059109T2/en unknown
- 2015-04-01 SI SI201531274T patent/SI3126499T1/en unknown
- 2015-04-01 US US15/301,004 patent/US10385341B2/en active Active
- 2015-04-01 PL PL20176637.5T patent/PL3757214T3/en unknown
- 2015-04-01 ES ES15773965T patent/ES2818236T3/en active Active
- 2015-04-01 LT LTEP20176637.5T patent/LT3757214T/en unknown
- 2015-04-01 LT LTEP15773965.7T patent/LT3126499T/en unknown
- 2015-04-01 HU HUE15773965A patent/HUE050704T2/en unknown
- 2015-04-01 AU AU2015240761A patent/AU2015240761B2/en active Active
- 2015-04-01 NZ NZ724100A patent/NZ724100A/en unknown
- 2015-04-01 CN CN202010286289.3A patent/CN111440798A/en active Pending
- 2015-04-01 EP EP20176637.5A patent/EP3757214B1/en active Active
- 2015-04-01 EP EP15773965.7A patent/EP3126499B1/en active Active
- 2015-04-01 KR KR1020217024143A patent/KR20210097225A/en not_active Application Discontinuation
- 2015-04-01 KR KR1020227017808A patent/KR20220077933A/en not_active Application Discontinuation
- 2015-04-01 MX MX2016012922A patent/MX2016012922A/en active IP Right Grant
- 2015-04-01 JP JP2016560543A patent/JP6622214B2/en active Active
- 2015-04-01 BR BR112016021848-5A patent/BR112016021848B1/en active IP Right Grant
-
2016
- 2016-09-08 IL IL247714A patent/IL247714B/en active IP Right Grant
- 2016-09-30 MX MX2020007166A patent/MX2020007166A/en unknown
- 2016-10-03 CL CL2016002509A patent/CL2016002509A1/en unknown
-
2018
- 2018-07-12 CL CL2018001897A patent/CL2018001897A1/en unknown
-
2019
- 2019-07-16 US US16/513,297 patent/US10669546B2/en active Active
- 2019-08-01 JP JP2019141933A patent/JP2019201664A/en not_active Withdrawn
- 2019-09-03 CL CL2019002535A patent/CL2019002535A1/en unknown
- 2019-11-19 AU AU2019268063A patent/AU2019268063A1/en not_active Abandoned
-
2020
- 2020-03-18 IL IL273404A patent/IL273404B/en unknown
- 2020-04-15 US US16/849,583 patent/US10968453B2/en active Active
- 2020-07-09 HR HRP20201078TT patent/HRP20201078T1/en unknown
- 2020-08-25 CY CY20201100794T patent/CY1123288T1/en unknown
-
2021
- 2021-02-01 JP JP2021014429A patent/JP7198298B2/en active Active
-
2022
- 2022-01-03 AU AU2022200002A patent/AU2022200002A1/en active Pending
- 2022-12-16 JP JP2022200959A patent/JP2023027299A/en active Pending
Patent Citations (59)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5118800A (en) | 1983-12-20 | 1992-06-02 | California Institute Of Technology | Oligonucleotides possessing a primary amino group in the terminal nucleotide |
| US4981957A (en) | 1984-07-19 | 1991-01-01 | Centre National De La Recherche Scientifique | Oligonucleotides with modified phosphate and modified carbohydrate moieties at the respective chain termini |
| US5698685A (en) | 1985-03-15 | 1997-12-16 | Antivirals Inc. | Morpholino-subunit combinatorial library and method |
| US5034506A (en) | 1985-03-15 | 1991-07-23 | Anti-Gene Development Group | Uncharged morpholino-based polymers having achiral intersubunit linkages |
| US5185444A (en) | 1985-03-15 | 1993-02-09 | Anti-Gene Deveopment Group | Uncharged morpolino-based polymers having phosphorous containing chiral intersubunit linkages |
| US5591722A (en) | 1989-09-15 | 1997-01-07 | Southern Research Institute | 2'-deoxy-4'-thioribonucleosides and their antiviral activity |
| US5466786B1 (en) | 1989-10-24 | 1998-04-07 | Gilead Sciences | 2' Modified nucleoside and nucleotide compounds |
| US5792847A (en) | 1989-10-24 | 1998-08-11 | Gilead Sciences, Inc. | 2' Modified Oligonucleotides |
| US5466786A (en) | 1989-10-24 | 1995-11-14 | Gilead Sciences | 2'modified nucleoside and nucleotide compounds |
| US5166315A (en) | 1989-12-20 | 1992-11-24 | Anti-Gene Development Group | Sequence-specific binding polymers for duplex nucleic acids |
| US5646265A (en) | 1990-01-11 | 1997-07-08 | Isis Pharmceuticals, Inc. | Process for the preparation of 2'-O-alkyl purine phosphoramidites |
| US5670633A (en) | 1990-01-11 | 1997-09-23 | Isis Pharmaceuticals, Inc. | Sugar modified oligonucleotides that detect and modulate gene expression |
| US5567811A (en) | 1990-05-03 | 1996-10-22 | Amersham International Plc | Phosphoramidite derivatives, their preparation and the use thereof in the incorporation of reporter groups on synthetic oligonucleotides |
| US5514785A (en) | 1990-05-11 | 1996-05-07 | Becton Dickinson And Company | Solid supports for nucleic acid hybridization assays |
| US5393878A (en) | 1991-10-17 | 1995-02-28 | Ciba-Geigy Corporation | Bicyclic nucleosides, oligonucleotides, process for their preparation and intermediates |
| US5319080A (en) | 1991-10-17 | 1994-06-07 | Ciba-Geigy Corporation | Bicyclic nucleosides, oligonucleotides, process for their preparation and intermediates |
| US5359044A (en) | 1991-12-13 | 1994-10-25 | Isis Pharmaceuticals | Cyclobutyl oligonucleotide surrogates |
| US5639873A (en) | 1992-02-05 | 1997-06-17 | Centre National De La Recherche Scientifique (Cnrs) | Oligothionucleotides |
| US5610300A (en) | 1992-07-01 | 1997-03-11 | Ciba-Geigy Corporation | Carbocyclic nucleosides containing bicyclic rings, oligonucleotides therefrom, process for their preparation, their use and intermediates |
| US5700920A (en) | 1992-07-01 | 1997-12-23 | Novartis Corporation | Carbocyclic nucleosides containing bicyclic rings, oligonucleotides therefrom, process for their preparation, their use and intermediates |
| WO1994014226A1 (en) | 1992-12-14 | 1994-06-23 | Honeywell Inc. | Motor system with individually controlled redundant windings |
| US5576427A (en) | 1993-03-30 | 1996-11-19 | Sterling Winthrop, Inc. | Acyclic nucleoside analogs and oligonucleotide sequences containing them |
| US5446137B1 (en) | 1993-12-09 | 1998-10-06 | Behringwerke Ag | Oligonucleotides containing 4'-substituted nucleotides |
| US5446137A (en) | 1993-12-09 | 1995-08-29 | Syntex (U.S.A.) Inc. | Oligonucleotides containing 4'-substituted nucleotides |
| US5519134A (en) | 1994-01-11 | 1996-05-21 | Isis Pharmaceuticals, Inc. | Pyrrolidine-containing monomers and oligomers |
| US5627053A (en) | 1994-03-29 | 1997-05-06 | Ribozyme Pharmaceuticals, Inc. | 2'deoxy-2'-alkylnucleotide containing nucleic acid |
| US5597909A (en) | 1994-08-25 | 1997-01-28 | Chiron Corporation | Polynucleotide reagents containing modified deoxyribose moieties, and associated methods of synthesis and use |
| WO1998039352A1 (en) | 1997-03-07 | 1998-09-11 | Takeshi Imanishi | Novel bicyclonucleoside and oligonucleotide analogues |
| US6268490B1 (en) | 1997-03-07 | 2001-07-31 | Takeshi Imanishi | Bicyclonucleoside and oligonucleotide analogues |
| US6770748B2 (en) | 1997-03-07 | 2004-08-03 | Takeshi Imanishi | Bicyclonucleoside and oligonucleotide analogue |
| WO1999014226A2 (en) | 1997-09-12 | 1999-03-25 | Exiqon A/S | Bi- and tri-cyclic nucleoside, nucleotide and oligonucleotide analogues |
| US7034133B2 (en) | 1997-09-12 | 2006-04-25 | Exiqon A/S | Oligonucleotide analogues |
| US6670461B1 (en) | 1997-09-12 | 2003-12-30 | Exiqon A/S | Oligonucleotide analogues |
| US6794499B2 (en) | 1997-09-12 | 2004-09-21 | Exiqon A/S | Oligonucleotide analogues |
| US6600032B1 (en) | 1998-08-07 | 2003-07-29 | Isis Pharmaceuticals, Inc. | 2′-O-aminoethyloxyethyl-modified oligonucleotides |
| US7053207B2 (en) | 1999-05-04 | 2006-05-30 | Exiqon A/S | L-ribo-LNA analogues |
| US6525191B1 (en) | 1999-05-11 | 2003-02-25 | Kanda S. Ramasamy | Conformationally constrained L-nucleosides |
| WO2001049687A2 (en) | 1999-12-30 | 2001-07-12 | K. U. Leuven Research & Development | Cyclohexene nucleic acids |
| WO2003004602A2 (en) | 2001-07-03 | 2003-01-16 | Isis Pharmaceuticals, Inc. | Nuclease resistant chimeric oligonucleotides |
| US20040171570A1 (en) | 2002-11-05 | 2004-09-02 | Charles Allerson | Polycyclic sugar surrogate-containing oligomeric compounds and compositions for use in gene modulation |
| US20080039618A1 (en) | 2002-11-05 | 2008-02-14 | Charles Allerson | Polycyclic sugar surrogate-containing oligomeric compounds and compositions for use in gene modulation |
| WO2004106356A1 (en) | 2003-05-27 | 2004-12-09 | Syddansk Universitet | Functionalized nucleotide derivatives |
| WO2005021570A1 (en) | 2003-08-28 | 2005-03-10 | Gene Design, Inc. | Novel artificial nucleic acids of n-o bond crosslinkage type |
| US7427672B2 (en) | 2003-08-28 | 2008-09-23 | Takeshi Imanishi | Artificial nucleic acids of n-o bond crosslinkage type |
| US20050130923A1 (en) | 2003-09-18 | 2005-06-16 | Balkrishen Bhat | 4'-thionucleosides and oligomeric compounds |
| WO2005040180A2 (en) | 2003-09-26 | 2005-05-06 | Isis Pharmaceuticals, Inc. | Antisense modulation of superoxide dismutase 1, soluble (sod-1) expression |
| WO2005121371A2 (en) | 2004-06-03 | 2005-12-22 | Isis Pharmaceuticals, Inc. | Double strand compositions comprising differentially modified strands for use in gene modulation |
| WO2006047842A2 (en) | 2004-11-08 | 2006-05-11 | K.U. Leuven Research And Development | Modified nucleosides for rna interference |
| WO2006066203A2 (en) | 2004-12-16 | 2006-06-22 | Alsgen, Llc | Small interfering rna (sirna) molecules for modulating superoxide dismutase (sod) |
| US7399845B2 (en) | 2006-01-27 | 2008-07-15 | Isis Pharmaceuticals, Inc. | 6-modified bicyclic nucleic acid analogs |
| US20070287831A1 (en) | 2006-05-11 | 2007-12-13 | Isis Pharmaceuticals, Inc | 5'-modified bicyclic nucleic acid analogs |
| WO2007134181A2 (en) | 2006-05-11 | 2007-11-22 | Isis Pharmaceuticals, Inc. | 5'-modified bicyclic nucleic acid analogs |
| WO2008101157A1 (en) | 2007-02-15 | 2008-08-21 | Isis Pharmaceuticals, Inc. | 5'-substituted-2'-f modified nucleosides and oligomeric compounds prepared therefrom |
| WO2008150729A2 (en) | 2007-05-30 | 2008-12-11 | Isis Pharmaceuticals, Inc. | N-substituted-aminomethylene bridged bicyclic nucleic acid analogs |
| WO2008154401A2 (en) | 2007-06-08 | 2008-12-18 | Isis Pharmaceuticals, Inc. | Carbocyclic bicyclic nucleic acid analogs |
| WO2009006478A2 (en) | 2007-07-05 | 2009-01-08 | Isis Pharmaceuticals, Inc. | 6-disubstituted bicyclic nucleic acid analogs |
| US20090130195A1 (en) | 2007-10-17 | 2009-05-21 | Mildred Acevedo-Duncan | Prostate carcinogenesis predictor |
| WO2009102427A2 (en) | 2008-02-11 | 2009-08-20 | Rxi Pharmaceuticals Corp. | Modified rnai polynucleotides and uses thereof |
| WO2010036696A1 (en) | 2008-09-24 | 2010-04-01 | Isis Pharmaceuticals, Inc. | Cyclohexenyl nucleic acid analogs |
Non-Patent Citations (49)
| Title |
|---|
| "GENBANK", Database accession no. NW 001114168.1 |
| ALBAEK ET AL., J. ORG. CHEM., vol. 71, 2006, pages 7731 - 7740 |
| ALTMANN ET AL., BIOCHEM. SOC. TRANS., vol. 24, 1996, pages 630 - 637 |
| ALTMANN ET AL., CHIMIA, vol. 50, 1996, pages 168 - 176 |
| ALTMANN ET AL., NUCLEOSIDES NUCLEOTIDES, vol. 16, 1997, pages 917 - 926 |
| ALTSCHUL ET AL., J. MOL. BIOL., vol. 215, 1990, pages 403 410 |
| BAKER ET AL., J. BIOL. CHEM., vol. 272, 1997, pages 11944 - 12000 |
| BRAASCH ET AL., BIOCHEMISTRY, vol. 41, 2002, pages 4503 - 4510 |
| BRAASCH ET AL., CHEM. BIOL., vol. 8, 2001, pages 1 - 7 |
| CHATTOPADHYAYA ET AL., J. ORG. CHEM., vol. 74, 2009, pages 118 - 134 |
| ELAYADI ET AL., CURR. OPINION INVENS. DRUGS, vol. 2, 2001, pages 558 - 561 |
| FRANK, MG, BRAIN BEHAV. IMMUN., vol. 21, 2007, pages 47 - 59 |
| FRIDOVICH, ANNU. REV. BIOCHEM., vol. 64, 1995, pages 97 - 112 |
| FRIEDEN ET AL., NUCLEIC ACIDS RESEARCH, vol. 21, 2003, pages 6365 - 6372 |
| FRIER ET AL., NUCLEIC ACIDS RESEARCH, vol. 25, no. 22, 1997, pages 4429 - 4443 |
| GAUTSCHI ET AL., J. NATL. CANCER INST., vol. 93, March 2001 (2001-03-01), pages 463 - 471 |
| GU ET AL., NUCLEOSIDES, NUCLEOTIDES & NUCLEIC ACIDS, vol. 24, no. 5-7, 2005, pages 993 - 998 |
| GU ET AL., OLIGONUCLEOTIDES, vol. 13, no. 6, 2003, pages 479 - 489 |
| GU ET AL., TETRAHEDRON, vol. 60, no. 9, 2004, pages 2111 - 2123 |
| HORVATH ET AL., TETRAHEDRON LETTERS, vol. 48, 2007, pages 3621 - 3623 |
| JONES, L.J. ET AL., ANALYTICAL BIOCHEMISTRY, vol. 265, 1998, pages 368 - 374 |
| KOSHKIN ET AL., TETRAHEDRON, vol. 54, 1998, pages 3607 - 3630 |
| KUMAR ET AL., BIOORG. MED. CHEM. LETT., vol. 8, 1998, pages 2219 - 2222 |
| LEUMANN, BIOORG. MED. CHEM., vol. 10, 2002, pages 841 - 854 |
| LEUMANN, CHRISTIAN J., BIOORG. & MED. CHEM., vol. 10, 2002, pages 841 - 854 |
| MAHERDOLNICK, NUC. ACID. RES., vol. 16, 1988, pages 3341 - 3358 |
| MARTIN, HELV. CHIM. ACTA, vol. 78, 1995, pages 486 - 504 |
| MILLER ET AL.: "An antisense oligonucleotide against SOD 1 delivered intrathecally for patients with SOD1 familial amyotrophic lateral sclerosis: a phase 1, randomised, first-in-man study", LANCET NEUROL., vol. 12, no. 5, 2013, pages 435 - 442 |
| MILLER ET AL.: "An antisense oligonucleotide against SOD1 delivered intrathecally for patients with SOD1 familial amyotrophic lateral sclerosis: a phase 1, randomised, first-in-man study", LANCET NEUROL., vol. 12, no. 5, 2013, pages 435 - 442 |
| NAUWELAERTS ET AL., J. AM. CHEM. SOC., vol. 129, no. 30, 2007, pages 9340 - 9348 |
| NAUWELAERTS ET AL., NUCLEIC ACIDS RESEARCH, vol. 33, no. 8, 2005, pages 2452 - 2463 |
| ORUM ET AL., CURR. OPINION MOL. THER., vol. 3, 2001, pages 239 - 243 |
| ROBEYNS ET AL., ACTA CRYSTALLOGRAPHICA, SECTION F: STRUCTURAL BIOLOGY AND CRYSTALLIZATION COMMUNICATIONS, vol. F61, no. 6, 2005, pages 585 - 586 |
| ROBEYNS ET AL., J. AM. CHEM. SOC., vol. 130, no. 6, 2008, pages 1979 - 1984 |
| ROSEN, NATURE, vol. 362, 1993, pages 59 - 62 |
| ROWLAND, N. ENGL. J. MED., vol. 344, 2001, pages 1688 - 1700 |
| SAU, HUM. MOL. GENET., vol. 16, 2007, pages 1604 - 1618 |
| SINGH ET AL., CHEM. COMMUN., vol. 4, 1998, pages 455 - 456 |
| SINGH ET AL., J. ORG. CHEM., vol. 63, 1998, pages 10035 - 10039 |
| SMITHWATERMAN, ADV. APPL. MATH., vol. 2, 1981, pages 482 489 |
| TURRENS, J. PHYSIOL., vol. 552, 2003, pages 335 - 344 |
| VERBEURE ET AL., NUCLEIC ACIDS RESEARCH, vol. 29, no. 24, 2001, pages 4941 - 4947 |
| WAHLESTEDT ET AL., PROC. NATL. ACAD. SCI. U. S. A., vol. 97, 2000, pages 5633 - 5638 |
| WANG ET AL., J. AM. CHEM., vol. 122, 2000, pages 8595 - 8602 |
| WANG ET AL., J. ORG. CHEM., vol. 66, 2001, pages 8478 - 82 |
| WANG ET AL., J. ORG. CHEM., vol. 68, 2003, pages 4499 - 4505 |
| WANG ET AL., NUCLEOSIDES, NUCLEOTIDES & NUCLEIC ACIDS, vol. 20, no. 4-7, 2001, pages 785 - 788 |
| WOOLF ET AL., PROC. NATL. ACAD. SCI. USA, vol. 89, 1992, pages 7305 - 7309 |
| ZHANGMADDEN, GENOME RES., vol. 7, 1997, pages 649 656 |
Cited By (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10968453B2 (en) | 2014-04-01 | 2021-04-06 | Biogen Ma Inc. | Compositions for modulating SOD-1 expression |
| US10385341B2 (en) | 2014-04-01 | 2019-08-20 | Biogen Ma Inc. | Compositions for modulating SOD-1 expression |
| US10669546B2 (en) | 2014-04-01 | 2020-06-02 | Biogen Ma Inc. | Compositions for modulating SOD-1 expression |
| US10590420B2 (en) | 2014-07-31 | 2020-03-17 | Association Institut De Myologie | Treatment of amyotrophic lateral sclerosis |
| EP3174981B1 (en) * | 2014-07-31 | 2020-03-25 | Association Institut de Myologie | Treatment of amyotrophic lateral sclerosis |
| US20170152517A1 (en) * | 2014-07-31 | 2017-06-01 | Association Institut De Myologie | Treatment of amyotrophic lateral sclerosis |
| US11542506B2 (en) | 2014-11-14 | 2023-01-03 | Voyager Therapeutics, Inc. | Compositions and methods of treating amyotrophic lateral sclerosis (ALS) |
| WO2017218454A1 (en) | 2016-06-14 | 2017-12-21 | Biogen Ma Inc. | Hydrophobic interaction chromatography for purification of oligonucleotides |
| US20210269467A1 (en) * | 2016-06-14 | 2021-09-02 | Biogen Ma Inc. | Hydrophobic interaction chromatography for purification of oligonucleotides |
| WO2017223258A1 (en) | 2016-06-24 | 2017-12-28 | Biogen Ma Inc. | Synthesis of thiolated oligonucleotides without a capping step |
| US11603542B2 (en) | 2017-05-05 | 2023-03-14 | Voyager Therapeutics, Inc. | Compositions and methods of treating amyotrophic lateral sclerosis (ALS) |
| EP3631470A4 (en) * | 2017-05-26 | 2021-03-24 | University of Miami | Determining onset of amyotrophic lateral sclerosis |
| US11434502B2 (en) | 2017-10-16 | 2022-09-06 | Voyager Therapeutics, Inc. | Treatment of amyotrophic lateral sclerosis (ALS) |
| US11474113B2 (en) | 2018-01-25 | 2022-10-18 | Biosen MA Inc. | Methods of treating spinal muscular atrophy |
| US11873495B2 (en) | 2018-06-27 | 2024-01-16 | Ionis Pharmaceuticals, Inc. | Compounds and methods for reducing LRRK2 expression |
| CN113365640A (en) * | 2018-12-06 | 2021-09-07 | 比奥根Ma公司 | Neurofilament proteins that direct therapeutic intervention in amyotrophic lateral sclerosis |
| WO2020117772A1 (en) | 2018-12-06 | 2020-06-11 | Biogen Ma Inc. | Neurofilament protein for guiding therapeutic intervention in amyotrophic lateral sclerosis |
| WO2020123783A1 (en) * | 2018-12-14 | 2020-06-18 | Biogen Ma Inc. | Compositions and methods for treating and preventing amyotrophic lateral sclerosis |
| WO2020222182A1 (en) * | 2019-05-01 | 2020-11-05 | Black Swan Pharmaceuticals, Inc. | Treatment for sod1 associated disease |
| WO2020227618A2 (en) | 2019-05-08 | 2020-11-12 | Biogen Ma Inc. | Convergent liquid phase syntheses of oligonucleotides |
| US20240026363A1 (en) * | 2022-06-15 | 2024-01-25 | Arrowhead Pharmaceuticals, Inc. | RNAi Agents for Inhibiting Expression of Superoxide Dismutase 1 (SOD1), Compositions Thereof, and Methods of Use |
| US11912997B2 (en) | 2022-06-15 | 2024-02-27 | Arrowhead Pharmaceuticals, Inc. | RNAi agents for inhibiting expression of Superoxide Dismutase 1 (SOD1), compositions thereof, and methods of use |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10968453B2 (en) | Compositions for modulating SOD-1 expression | |
| EP3283080B1 (en) | Compositions for modulating c9orf72 expression | |
| AU2015231130C1 (en) | Compositions for modulating Ataxin 2 expression | |
| CA2918600C (en) | Compositions for modulating tau expression | |
| WO2016112132A1 (en) | Compositions for modulating expression of c9orf72 antisense transcript | |
| WO2016167780A1 (en) | Compositions for modulating expression of c9orf72 antisense transcript | |
| EP3055414A2 (en) | Compositions for modulating c9orf72 expression | |
| WO2014062691A2 (en) | Compositions for modulating c9orf72 expression | |
| EP2906696A1 (en) | Methods for modulating c9orf72 expression | |
| WO2015057727A1 (en) | Compositions for modulating expression of c9orf72 antisense transcript | |
| WO2015143245A1 (en) | Methods for modulating ataxin 2 expression | |
| EP3265098A1 (en) | Compositions for modulating mecp2 expression | |
| EP3265564B1 (en) | Methods for modulating mecp2 expression |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 15773965 Country of ref document: EP Kind code of ref document: A2 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 247714 Country of ref document: IL |
|
| ENP | Entry into the national phase |
Ref document number: 2942394 Country of ref document: CA |
|
| ENP | Entry into the national phase |
Ref document number: 2015240761 Country of ref document: AU Date of ref document: 20150401 Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 122023000354 Country of ref document: BR |
|
| ENP | Entry into the national phase |
Ref document number: 2016560543 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 15301004 Country of ref document: US Ref document number: MX/A/2016/012922 Country of ref document: MX |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 20167030062 Country of ref document: KR Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2016142532 Country of ref document: RU Kind code of ref document: A |
|
| REEP | Request for entry into the european phase |
Ref document number: 2015773965 Country of ref document: EP |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01A Ref document number: 112016021848 Country of ref document: BR |
|
| WWE | Wipo information: entry into national phase |
Ref document number: NC2016/0003727 Country of ref document: CO Ref document number: 2015773965 Country of ref document: EP |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 15773965 Country of ref document: EP Kind code of ref document: A2 |
|
| ENP | Entry into the national phase |
Ref document number: 112016021848 Country of ref document: BR Kind code of ref document: A2 Effective date: 20160922 |