WO2015088543A1 - Modeling subterranean fluid viscosity - Google Patents
Modeling subterranean fluid viscosity Download PDFInfo
- Publication number
- WO2015088543A1 WO2015088543A1 PCT/US2013/074810 US2013074810W WO2015088543A1 WO 2015088543 A1 WO2015088543 A1 WO 2015088543A1 US 2013074810 W US2013074810 W US 2013074810W WO 2015088543 A1 WO2015088543 A1 WO 2015088543A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- relaxation
- nmr
- time
- distributions
- time distributions
- Prior art date
Links
Classifications
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01V—GEOPHYSICS; GRAVITATIONAL MEASUREMENTS; DETECTING MASSES OR OBJECTS; TAGS
- G01V3/00—Electric or magnetic prospecting or detecting; Measuring magnetic field characteristics of the earth, e.g. declination, deviation
- G01V3/18—Electric or magnetic prospecting or detecting; Measuring magnetic field characteristics of the earth, e.g. declination, deviation specially adapted for well-logging
- G01V3/32—Electric or magnetic prospecting or detecting; Measuring magnetic field characteristics of the earth, e.g. declination, deviation specially adapted for well-logging operating with electron or nuclear magnetic resonance
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N24/00—Investigating or analyzing materials by the use of nuclear magnetic resonance, electron paramagnetic resonance or other spin effects
- G01N24/08—Investigating or analyzing materials by the use of nuclear magnetic resonance, electron paramagnetic resonance or other spin effects by using nuclear magnetic resonance
- G01N24/081—Making measurements of geologic samples, e.g. measurements of moisture, pH, porosity, permeability, tortuosity or viscosity
Definitions
- This specification relates to modeling subterranean fluid viscosity based on nuclear magnetic resonance (NMR) data associated with a subterranean region.
- NMR nuclear magnetic resonance
- nuclear magnetic resonance (NMR) tools have been used to explore the subsurface based on the magnetic interactions with subsurface material.
- NMR tools include a magnet assembly that produces a static magnetic field, and a coil assembly that generates radio frequency (RF) control signals and detects magnetic resonance phenomena in the subsurface material. Properties of the subsurface material can be identified from the detected phenomena.
- RF radio frequency
- FIG. 1A is a diagram of an example well system.
- FIG. IB is a diagram of an example well system that includes an NMR logging tool in a wireline logging environment.
- FIG. 1C is a diagram of an example well system that includes an NMR logging tool in a logging while drilling (LWD) environment.
- LWD logging while drilling
- FIG. 2 is a diagram of an example mapping function.
- FIG. 3 is a diagram of an example process for modeling the viscosity of a subterranean formation.
- FIG. 4 includes plots of example T 2 distributions for each of several spin-echo times (TEs).
- FIG. 5 includes plots of an example training database that includes 21 samples measured using one spin-echo time.
- FIGS. 6A-B includes plots comparing the measured viscosities and predicted viscosities from an example radial basis function (RBF) model.
- FIGS. 7A-B include plots showing the predictive performance of example RBF models trained using T 2 distributions acquired with the same TE, and used to predict viscosities based on T 2 distributions acquired with different TEs.
- FIGS. 8A-B include plots comparing results of the example RBF model with and without the inclusion of the apparent hydrogen index during model training.
- FIGS. 9A-B include plots comparing the viscosity predictions of the example RBF model and the viscosity predictions of the regularized RBF model.
- FIG. 10 is a diagram of an example principal component analysis process.
- FIG. 11 is a plot that shows variance accounted for by example sets of principal components.
- FIG. 12 is a plot that shows an example of the first two principle components of the T 2 distributions from the sample database and a corresponding model-application envelope.
- FIG. 13 is a plot that shows several example live and dead oil samples plotted according to two identified principle components.
- FIG. 14 is a plot that shows an example of the deviation of predictions made using an RBF model trained with T 2 distributions of dead oil applied to the T 2 distributions of live oil.
- FIG. 15 is a diagram of an example process for predicting the viscosity of a subterranean formation.
- FIG. 16 includes plots that show the application of an example process for predicting the viscosity of subterranean fluid.
- FIG. 17 shows a diagram of an example computer system.
- FIG. 1A is a diagram of an example well system 100a.
- the example well system 100a includes an NMR logging system 108 and a subterranean region 120 beneath the ground surface 106.
- a well system can include additional or different features that are not shown in FIG. 1A.
- the well system 100a may include additional drilling system components, wireline logging system components, etc.
- the subterranean region 120 can include all or part of one or more subterranean formations or zones.
- the example subterranean region 120 shown in FIG. 1A includes multiple subsurface layers 122 and a wellbore 104 penetrated through the subsurface layers 122.
- the subsurface layers 122 can include sedimentary layers, rock layers, sand layers, or combinations of these and other types of subsurface layers.
- One or more of the subsurface layers can contain fluids, such as brine, oil, gas, etc.
- the example wellbore 104 shown in FIG. 1A is a vertical wellbore
- the NMR logging system 108 can be implemented in other wellbore orientations.
- the NMR logging system 108 may be adapted for horizontal wellbores, slant wellbores, curved wellbores, vertical wellbores, or combinations of these.
- the example NMR logging system 108 includes a logging tool 102, surface equipment 1 12, and a computing subsystem 110.
- the logging tool 102 is a downhole logging tool that operates while disposed in the wellbore 104.
- the example surface equipment 1 12 shown in FIG. 1A operates at or above the surface 106, for example, near the well head 105, to control the logging tool 102 and possibly other downhole equipment or other components of the well system 100.
- the example computing subsystem 1 10 can receive and analyze logging data from the logging tool 102.
- An NMR logging system can include additional or different features, and the features of an NMR logging system can be arranged and operated as represented in FIG. 1A or in another manner.
- all or part of the computing subsystem 110 can be implemented as a component of, or can be integrated with one or more components of, the surface equipment 1 12, the logging tool 102 or both. In some cases, the computing subsystem 110 can be implemented as one or more computing structures separate from the surface equipment 1 12 and the logging tool 102.
- the computing subsystem 110 is embedded in the logging tool 102, and the computing subsystem 1 10 and the logging tool 102 can operate concurrently while disposed in the wellbore 104.
- the computing subsystem 1 10 is shown above the surface 106 in the example shown in FIG. 1A, all or part of the computing subsystem 110 may reside below the surface 106, for example, at or near the location of the logging tool 102.
- the well system 100a can include communication or telemetry equipment that allows communication among the computing subsystem 110, the logging tool 102, and other components of the NMR logging system 108.
- the components of the NMR logging system 108 can each include one or more transceivers or similar apparatus for wired or wireless data communication among the various components.
- the NMR logging system 108 can include systems and apparatus for wireline telemetry, wired pipe telemetry, mud pulse telemetry, acoustic telemetry, electromagnetic telemetry, or a combination of these and other types of telemetry.
- the logging tool 102 receives commands, status signals, or other types of information from the computing subsystem 1 10 or another source.
- the computing subsystem 110 receives logging data, status signals, or other types of information from the logging tool 102 or another source.
- NMR logging operations can be performed in connection with various types of downhole operations at various stages in the lifetime of a well system.
- Structural attributes and components of the surface equipment 1 12 and logging tool 102 can be adapted for various types of NMR logging operations.
- NMR logging may be performed during drilling operations, during wireline logging operations, or in other contexts.
- the surface equipment 1 12 and the logging tool 102 may include, or may operate in connection with drilling equipment, wireline logging equipment, or other equipment for other types of operations.
- NMR logging operations are performed during wireline logging operations.
- FIG. IB shows an example well system 100b that includes the NMR logging tool 102 in a wireline logging environment.
- the surface equipment 112 includes a platform above the surface 106 equipped with a derrick 132 that supports a wireline cable 134 that extends into the wellbore 104.
- Wireline logging operations can be performed, for example, after a drill string is removed from the wellbore 104, to allow the wireline logging tool 102 to be lowered by wireline or logging cable into the wellbore 104.
- FIG. 1C shows an example well system 100c that includes the NMR logging tool 102 in a logging while drilling (LWD) environment. Drilling is commonly carried out using a string of drill pipes connected together to form a drill string 140 that is lowered through a rotary table into the wellbore 104. In some cases, a drilling rig 142 at the surface 106 supports the drill string 140, as the drill string 140 is operated to drill a wellbore penetrating the subterranean region 120.
- the drill string 140 may include, for example, a kelly, drill pipe, a bottom hole assembly, and other components.
- the bottom hole assembly on the drill string may include drill collars, drill bits, the logging tool 102, and other components.
- the logging tools may include measuring while drilling (MWD) tools, LWD tools, and others.
- the logging tool 102 includes an NMR tool for obtaining NMR measurements from the subterranean region 120. As shown, for example, in FIG. IB, the logging tool 102 can be suspended in the wellbore 104 by a coiled tubing, wireline cable, or another structure that connects the tool to a surface control unit or other components of the surface equipment 112.
- the logging tool 102 is lowered to the bottom of a region of interest and subsequently pulled upward (e.g., at a substantially constant speed) through the region of interest.
- the logging tool 102 can be deployed in the wellbore 104 on jointed drill pipe, hard wired drill pipe, or other deployment hardware.
- the logging tool 102 collects data during drilling operations as it moves downward through the region of interest.
- the logging tool 102 collects data while the drill string 140 is moving, for example, while it is being tripped in or tripped out of the wellbore 104.
- the logging tool 102 collects data at discrete logging points in the wellbore 104.
- the logging tool 102 can move upward or downward incrementally to each logging point at a series of depths in the wellbore 104.
- instruments in the logging tool 102 perform measurements on the subterranean region 120.
- the measurement data can be communicated to the computing subsystem 110 for storage, processing, and analysis.
- Such data may be gathered and analyzed during drilling operations (e.g., during logging while drilling (LWD) operations), during wireline logging operations, or during other types of activities.
- LWD logging while drilling
- the computing subsystem 110 can receive and analyze the measurement data from the logging tool 102 to detect properties of various subsurface layers 122. For example, the computing subsystem 1 10 can identify the density, material content, or other properties of the subsurface layers 122 based on the NMR measurements acquired by the logging tool 102 in the wellbore 104.
- the logging tool 102 obtains NMR signals by polarizing nuclear spins in the formation 120 and pulsing the nuclei with a radio frequency (RF) magnetic field.
- RF radio frequency
- Various pulse sequences i.e., series of radio frequency pulses, delays, and other operations
- CPMG Carr Purcell Meiboom Gill
- ORPS Optimized Refocusing Pulse Sequence
- the acquired spin-echo signals may be processed (e.g., inverted, transformed, etc.) to a relaxation-time distribution (e.g., a distribution of transverse relaxation times T 2 or a distribution of longitudinal relaxation times T , or both).
- the relaxation-time distribution can be used to determine various physical properties of the formation by solving one or more inverse problems.
- relaxation-time distributions are acquired for multiple logging points and used to train a model of the subterranean region.
- relaxation-time distributions are acquired for multiple logging points and used to predict properties of the subterranean region.
- Inverse problems encountered in well logging and geophysical applications may involve predicting the physical properties of some underlying system given a set of measurements (e.g., a set of relaxation-time distributions).
- a set of measurements e.g., a set of relaxation-time distributions.
- the different cases in the database represent different states of the underlying physical system.
- y ⁇ x values represent samples of the function that one wants to approximate (e.g., by a model), and x ⁇ l values are the distinct points at which the function is given.
- the database is used to construct a mapping function such that, given measurements x that are not in the database, one can predict the properties F(x) of the physical system that is consistent with the measurements.
- the mapping function can solve the inverse problem of predicting the physical properties of the system from the measurements.
- mapping functions can be used to solve the inverse problem of predicting the viscosity of fluid (e.g., oil, etc.) in a subterranean formation based on measurements obtained using NMR. In some cases, mapping can be used to develop a correlation that links fluid viscosity measurements with NMR measurements. A mapping function can be developed, for example, based on training data obtained through in situ measurements or ex situ
- RBFs Radial Basis Functions
- PCA Principal Component Analysis
- FIG. 3 An example process 300 for modeling the viscosity of fluid in a subterranean formation from NMR measurements is shown in FIG. 3.
- the example process 300 shown in FIG. 3 includes a model training sub-process 310 and a viscosity prediction sub-process 340.
- the model training sub-process 310 can be used to develop a mapping function based on a database of NMR and viscosity measurements; the viscosity prediction sub-process 340 can be used to predict viscosity based on one or more NMR measurements and the developed mapping function.
- the process 300 can include additional or different sub-processes or other operations, and the operations can be configured as shown or in another manner.
- the example model training sub-process 310 includes generating a training database of relaxation distributions obtained from NMR measurements of fluids associated with one or more subterranean formations (312). Each distribution can be normalized to a common normalizing value (314). In some cases, each of the relaxation distributions can be reduced to a subset of key components (i.e., the "principal" components of the database) through principal component analysis. Measured viscosity values can be obtained by laboratory core plug viscosity measurements, measurements of fluids extracted from the subterranean region, measurement of fluids within the wellbore, or other types of
- the normalized distributions and the measured viscosity values can be used to train the RBF model (318). Training the RBF model generates model coefficients (320); the resulting RBF model and its coefficients can be used as a mapping function that predicts the viscosity of fluid in a subterranean formation based on input relaxation-time distributions.
- the viscosity prediction sub-process 340 includes obtaining an input relaxation-time distribution from NMR logging of a subterranean formation (342), and normalizing the distribution to the same normalizing value that was used to normalize the training dataset (344). In some cases, the distribution is also converted to the same subset of principal components identified during model training. The processed relaxation-time distribution can then be used as an input in the RBF model, using the modeling coefficients identified during model training (346), resulting in a viscosity estimate (348).
- NMR signals are obtained in situ (e.g., by using NMR logging tools to obtain measurements of formations under the earth's surface).
- NMR signals can be obtained ex situ (e.g., by using NMR tools to obtain measurements of reservoir fluid samples and/or core plug samples that have been removed from the earth's surface).
- the NMR signals (obtained in situ or ex situ) can be converted into relaxation-time distributions.
- each NMR signal is a spin-echo train that includes a series of multi-exponential decays, and the relaxation-time distribution can be a histogram of the decay rates extracted from the spin-echo train.
- an NMR tool acquires multiple echo-time (TE) data of heavy oil samples. That is, multiple NMR signals are acquired in order to produce multiple relaxation-time distributions, each corresponding to a particular TE.
- Various pulse sequences i.e., series of radio frequency pulses
- CPMG Carr Purcell Meiboom Gill
- ORPS Optimized Refocusing Pulse Sequence
- the NMR measurements can be carried out in a non-uniform static magnetic field.
- NMR measurements are obtained by NMR tools that use magnetic field gradients and uniform static magnetic fields. In a gradient field, the measured T 2 M can be expressed as
- the second term on the right side of the above equation may be much smaller than the first term.
- the NMR signals (obtained in situ or ex situ) can be converted into relaxation-time distributions. NMR signal inversion is dependent on the inter-echo spacing TE used to acquire the signal.
- the inter-echo spacing can be controlled by the NMR measurement system, for example, by controlling the duration of the pulses and the timing between pulses in the pulse sequence executed by the NMR measurement system.
- each NMR signal is a spin-echo train that includes a series of multi-exponential decays
- the relaxation-time distribution can be a histogram of the decay rates extracted from the spin-echo train.
- the inter-echo spacing TE dictates the upper limit of the fast T 2 component that can be measured by a particular NMR system.
- the decay of NMR signals can be described by a multi-exponential decay function.
- an NMR signal can be described as multiple components resulting from multiple difference relaxation times in the measured region.
- the signal amplitude of the first echo may be expressed approximately by:
- each of the components has a respective amplitude of and a characteristic relaxation time T 2 i .
- the apparent hydrogen index (HI app ) can be expressed as
- Multiple TEs can be used to acquired NMR data, and can result in multiple apparent T 2 distributions, each corresponding to a particular TE.
- Example T 2 distributions 402a-e for each of several TEs is shown in FIG. 4, where the horizontal axis 404 represents the range of T 2 times and the vertical axis 404 represents the relative frequency of occurrence of each T 2 time.
- Other NMR inversion techniques can be used to obtain other relaxation-time distributions.
- the relaxation-time distributions can include distributions of transverse relaxation times or longitudinal relaxation times obtained from NMR data.
- the sum of the amplitudes of each distribution is normalized to a common normalizing value.
- the normalizing value can be 1 or another constant value.
- the values in the distribution can be multiplied or scaled uniformly so that the amplitudes in the normalized distribution sum to the normalizing value.
- the relaxation-time distributions of the training database can be normalized to the common normalizing value. This may be beneficial in some circumstances, as viscosity may depend primarily on the shape of the T 2 distribution rather than on the amplitude of the distribution.
- the RBF model can be developed such that it considers the shape of the shape of the T 2 distribution rather than on the amplitude of the distribution.
- the relaxation-time distribution can be normalized according to various common normalizing values. For instance, in some implementations, the relaxation-time distributions can be normalized to a common normalizing value of one (i.e., normalized such that each relaxation-time distribution has a unit integral). In some implementations, the relaxation-time distribution can be normalized to other common normalizing values (e.g., 0.5, 1.5, 2, 2.5, and so forth).
- Viscosity values can be obtained using different means other than NMR for the subterranean formations (316 of FIG. 3). For the purposes of model training, these measured viscosity values can be obtained independently and treated as "ground truth" values, and can be used to determine correlations between the measured NMR signals and corresponding viscosity values. In some implementations, these viscosity values are obtained ex situ using any of a variety of viscosity measurement instruments and techniques. For example, in some implementations, a core sample from the formation is removed from the earth's surface, and fluid from the core sample is measured using a viscometer or another type of system. In another example, a reservoir fluid sample is removed from the earth's surface, and the reservoir fluid sample is measured using a viscometer or another type of system.
- the training database and the measured viscosity values can be used to train an RBF model.
- a radial basis function (RBF) is a function in the form of where
- An RBF model F( ) can be represented as a linear combination of radial basis functions.
- the RBF model can be used to approximate the physical system /(x) to a certain degree of accuracy, for example, assuming the underlying physical system f(x) is smooth and continuous.
- the RBF model F(x) is derived by interpolating an input-output data set
- the input data set can include, for example, the database of relaxation-time distributions, the corresponding TEs and other information for each of the distributions.
- the output data set can include the measured viscosity
- RBFs is a set of weighted RBFs, N, w and are model coefficients, and
- the centers correspond to the inputted training parameters which may include, for example, the database of relaxation- time distributions, principle components of the normalized relaxation-time distributions, the corresponding TEs for each of the distributions, the measured viscosities, or combinations of these and other input training parameters.
- the RBF model can be represented as:
- the function ⁇ can be a Gaussian function or another type of smooth function.
- the function ⁇ is a Gaussian, the matrix associated with the interpolation is well-conditioned, and the RBF inversion has a unique solution.
- the coefficients of the RBF model can be determined by interpolation of the training datasets.
- the coefficients W can be determined by requiring that the interpolation equations be satisfied exactly.
- the coefficients can be a linear combination of the function values
- the RBF model and model coefficients can be used to predict viscosity based on an input relaxation-time distribution.
- An input relaxation-time distribution can be obtained from an input NMR signal, for example, using NMR signal inversion.
- this input NMR signal is obtained independently from the NMR signals used to train the model.
- the input NMR signal can be obtained from a subterranean formation that contains oil or other fluids having unknown viscosity.
- the input NMR signal is inverted to produce a relaxation-time distribution using an NMR inversion process similar to the NMR signal inversion described above.
- the input relaxation-time distribution can then be normalized to the same common normalizing value used in model training. In some cases, the input relaxation-time distribution can then be remapped to a new coordinate system identified during principal component analysis of the model training.
- the processed relaxation-time distribution data and corresponding TE value can be provided as inputs to the RBF model, using the model coefficients identified during model training (346 of FIG. 3). For example, if is the input relaxation-time distribution and the corresponding TE value, the estimated viscosity F(x) can be determined by:
- an example input database includes 21 samples, each measured using TEs of 0.1 ms, 0.4 ms, 0.6 ms, 0.9 ms, and 1.2 ms.
- each sample can be removed from the training database one at a time, and its viscosity can be predicted using an RBF model trained using the remaining samples. This process can be repeated for all the samples in the database.
- FIGS. 6A and 6B show the comparisons between the measured viscosities and predicted viscosities from the RBF model. For clarity, the results from each TE are plotted separately even though all the data were used together for the RBF model. As shown in FIG. 6A, plots 600 compare the measured viscosities 602a-e and the predicted viscosities 604a-e for each of the 21 samples. In FIG. 6B, plots 610 show this comparison as a scatter plot. Using this example training database, the viscosity predicted using the RBF model is generally well within one order of magnitude or less of the measured viscosity.
- a model trained with data acquired using multiple TEs provides viscosity estimates that are more accurate than a model trained with data acquired using only a single TE.
- FIGS. 7A-B illustrate an example of an advantage of using training data acquired using a range of different TE acquisitions.
- an example RBF model is trained using T 2 distributions acquired with the same TE, and the model is used to predict viscosities based on T 2 distributions acquired with different TEs. Referring to FIG.
- the RBF model was trained using T 2 distributions acquired with a TE of 0.1 ms, then used to predict viscosities based on T 2 distributions acquired with TEs of 0.4 ms, 0.6 ms, 0.9 ms, and 1.2 ms.
- a comparison between the measured viscosity and the predicted viscosity is shown in plots 700.
- the RBF model was trained using T 2 distributions acquired with a TE of 0.9 ms, then used to predict viscosities based on T 2 distributions acquired with TEs of 0.1 ms, 0.4 ms, 0.6 ms, and 1.2 ms.
- FIGS. 7A-B illustrate that models trained using a single TE can more accurately predict viscosity values based on T 2 distributions acquired with the same TE, and the models provide less accurate predictions of viscosity values based on T 2 distributions acquired with different TEs.
- training a model with training data from multiple TE values can improve the prediction accuracy of the model.
- the input data set used to train the model may additionally include each T 2 distribution's apparent hydrogen index value, HI app (TEj).
- the apparent hydrogen index value HI app (TEj) can be calculated as the integral of a T 2 distribution's amplitude, normalized by the apparent porosity determined from the shortest TE measurement.
- the T 2 distributions with larger inter-echo times (TEs) fail to detect very fast relaxation components.
- Hl app (TEj) can be used as another input parameter to compensate these missing components.
- the normalized T 2 distribution patterns may already contain some information about the missing signal amplitude. Because the apparent hydrogen index can depend on this missing signal amplitude, the apparent hydrogen index can serve as an optional input parameter during model training.
- FIGS. 8A-B show a comparison of results of an example RBF model with (plot 800 of FIG. 8 A) and without (810 of FIG. 8B) the inclusion of the apparent hydrogen index (HI app ) during model training.
- the example RBF models are trained with T 2 distributions derived from measurements acquired using TEs of 0.1 ms, 0.4 ms, 0.9 ms and 1.2 ms, and T 2 distributions derived from measurements acquired using a TE of 0.6ms are used to predict the viscosities.
- the performance of the RBF model training using HI app is better than the one trained without HI app .
- the degree of benefit in training a model using HI app depends on the number of fast relaxation components in the sample.
- a T 2 distribution is affected by noise in the measurement and the inversion process, and these uncertainties can affect the accuracy of the RBF model.
- the T 2 distribution can be divided into a number of segments, where Pi (TEj) is the partial porosity of the i th segment for a T 2 distribution derived from a measurement acquired using TEj .
- the T 2 distribution can be divided based on various criteria. For example, in some implementations, the T 2 distribution is divided into segments based on previously acquired T 2 distributions of substances expected to be in a particular reservoir. Thus, the T 2 distributions can be segmented in a manner that accentuates differences between various substances expected to be within a particular reservoir.
- the input parameters of the RBF can be described as:
- N the number of segments from the T 2 distribution.
- the RBF model in order to mitigate the effects of over-fitting, can be regularized according to a cost function that penalizes oscillatory behavior.
- the measurement data with noise can be described by:
- the RBF model can be obtained by minimizing the following cost function:
- parameter ⁇ controls the balance between fitting the data and avoiding the penalty, and can be assigned different values depending on the desired fitting behavior.
- the value of parameter ⁇ can be determined using generalized cross-validation methods in order to assess the accuracy of the resulting RBF model.
- Example cross-validation methods include K-fold cross validation, repeated random sub-sampling validation, and leave-one-out cross- validation.
- FIGS. 9A-B show a comparison between the viscosity predictions of the example RBF model, without regularization (FIG. 9A) and with regularization (FIG. 9B).
- the predictions based on the regularized RBF model exhibit a lesser degree of over- fitting compared to that of the non-regularized RBF model.
- the viscosities 902 predicted by the non-regularized RBF model exhibit a greater degree of oscillatory behavior compared to the viscosities 904 predicted by the regularized RBF model in plot 910 of FIG. 9B.
- Regularizing the RBF model can also increase the accuracy of the prediction by reducing the relative error of the predictions.
- plots 920 and 930 of FIGS. 9A-B show the relative error of the predicted viscosities for the non- regularized RBF model and the regularized RBF model, respectively. Regularizing the RBF model can also reduce the overall spread of the predictions.
- plots 940 and 950 of FIGS. 9A-B compare the predicted viscosities to the measured viscosities as a scatter plot.
- the effects of noise can be lessened by using Principal Component Analysis (PCA) to reduce the training database of relaxation-time distributions to a subset of key components.
- PCA Principal Component Analysis
- PCA provides a rank ordering of variances in the data. The rank ordering can be structured such that principal components with larger associated variances represent important structure (signal), while those with lower variances represent noise or less significant information.
- Principal Component Analysis transforms a set of data vectors from an initial coordinate system to a new coordinate system.
- the new coordinate system can be defined such that when the data vectors are expressed in the new coordinate system, all (or substantially all) significant variations among the data vectors are described by a reduced number of vector components.
- the data vectors may have the same number of components in both coordinate systems, most of the vector components in the new coordinate system can be ignored or neglected; the retained vector components form a set of principal components that can be used to analyze the data.
- the k principal component is the k component of a transformed data vector in the new coordinate system. The proportion of the total variance accounted for by k th principal component can be:
- each of the eigenvalues quantifies the variance of the corresponding principal component.
- an example principal component analysis process 1000 can be used to generate sets of principal components from relaxation-time distributions, where each set of principal components represents a respective one of the relaxation-time distributions.
- the process 1000 can include additional or different operations, and the operation can be performed in the order shown or in another order.
- a dataset matrix X is formed from the relaxation-time distributions.
- Each of the n relaxation-time distributions has p elements, so the dataset matrix X can be an n x p matrix (n rows, p columns), in which each of the relaxation-time distributions forms a respective row.
- the training dataset of relaxation-time distributions can be represented in another manner, using any suitable data format, data structure, or data type.
- the relaxation-time distributions can include distributions of transverse relaxation times or longitudinal relaxation times obtained from NMR data.
- the area integration of each distribution is normalized to a common normalizing value.
- the normalizing value can be 1 or another constant value.
- the values in the distribution can be multiplied or scaled uniformly so that the area of the scaled distribution is equal to the normalizing value.
- the eigenvectors of the covariance matrix C of dataset matrix X are determined.
- a transformation matrix W L is formed, where W L is a p x I matrix whose columns are eigenvectors of the covariance matrix C.
- the transformation matrix W L can be formed from the I eigenvectors that correspond to the I largest eigenvalues of the covariance matrix C.
- the eigenvectors and eigenvalues of the covariance matrix C can be determined, for example, by conventional techniques for computing matrix eigenvectors and eigenvalues.
- sets of principal components are extracted from the transformed matrix T.
- the transformed matrix T is an n x I matrix, and the i th row contains a set of principal components corresponding to the i th relaxation-time distribution in the dataset matrix X.
- the matrix element T(i, k) (the element at the k th column and i th row), can represent the k th principal component of the i th relaxation-time distribution.
- the data vectors in the initial coordinate system can be the T 2 distributions of the database obtained from NMR measurements, and each data vector can have 27 or 54 components.
- the relaxation-time bins are evenly spaced along the logarithmically-scaled axis; or the bins may be spaced in another manner.
- the first three principal components i.e., the first three components of the transformed data vectors
- another number of transformed components can be retained for use in training (or using) the viscosity model (1010); the other 24 (or 51) components can be disregarded because they primarily represent noise or redundancy.
- the same transformation can then be applied to NMR logging data extracted from another formation, for example, to predict the viscosity of fluid in the other formation.
- each element T input (i, k) (the element at the k th column, i th row), represents the k th principal component of the i th input relaxation- time distribution, and W L represents the transformation matrix identified during model training.
- plot 1100 shows that for an example database of T 2 distributions, the first three principal components 1 102a-c account for over 90% of the variances (as shown by line 1104 that plots the cumulative variance after each additional principal component is added).
- line 1104 that plots the cumulative variance after each additional principal component is added.
- the components having lower variances can be discarded.
- noise-to-signal ratio noise-to-signal ratio
- NMR logging data is adequately stacked to reduce the noise to 1 pu. Assuming the average porosity is around 30 pu, the noise-to-signal ratio is about 3 percent.
- three principal components of the T 2 distribution are retained.
- a greater number of principal components can be retained for use in training or using the viscosity model. For example, in some implementations, four, five, six, or more principal components are retained.
- N, w it and q are the model coefficients identified during model training.
- FIG. 12 shows a plot 1200 of the first two principle components of the T 2
- the outer polygon 1202 is the boundary for the first two components in the example database, and shows where the input parameter space of the RBF model is populated by the sample database. Because the RBF training uses
- the polygon enclosure 1202 can delineate the valid input data range where the model can yield a reliable interpolated prediction result.
- this model-application envelope 1202 to expand this model-application envelope 1202, more data that fall outside of an existing polygon envelope 1202 can be included.
- this model-application envelope 1202 can be used to generate a binary prediction reliability indicator.
- NMR signals that are obtained ex situ are used to train the RBF model, while NMR signals obtained in situ are subsequently used to predict viscosity based on the trained RBF model.
- Measurements of in situ fluids are typically conducted on live oil, while measurements of ex situ fluids are typically conducted on dead oil.
- Live oil is subject to the higher pressures of the subterranean formation, and typically contains gas dissolved in solution.
- Dead oil is subject to much lower pressures (e.g., conditions at the earth's surface), and typically contains a much lower degree of gas dissolved in solution.
- an RBF model can be configured to account for these and other differences between the samples used to train the RBF model and the samples that the RBF model later uses to predict viscosity.
- an RBF model trained on dead oil can be configured to predict the viscosity of live oil.
- a relaxation-time distribution for live oil can be mapped to its corresponding relaxation-time distribution for dead oil.
- an RBF model developed with dead oil samples can be used to predict the properties of live oil.
- Live oil can be correlated to dead oil in various ways. For example, in some implementations, given a number of samples of T 2 distributions of live oil and their corresponding T 2 distributions of dead oil, principle component analysis can be applied to the T 2 distributions of live oil and dead oil. Referring to FIG. 13, plot 1300 shows several example live oil samples 1302 and dead oil samples 1304 plotted according to two identified principle components.
- the transformation T from the principle components of live oil to the principle components of dead oil can be approximated with a linear transformation or nonlinear transformation. For example, if a linear transformation is used, T can be solved with a standard linear regression method.
- T can be modeled as a linear combination of radial basis functions, similar to the RBF model for the correlation of viscosities and T 2 distributions (as discussed above).
- the correlation of viscosities and the T 2 distribution of live oil can be described as the following:
- T(X live ) is the transformation
- T of the principle components of a relaxation-time distribution of a live oil sample
- X PC A ⁇ Transformations can be incorporated into the RBF model as shown above or in another manner.
- the predicted value from the RBF model can deviate from the true value.
- the degree of the deviation can be modeled given a number of samples which include the T 2 distributions of live oil, and the true viscosities of dead oil.
- An example of this deviation is illustrated in plot 1400 of FIG. 14.
- the deviation between the predicted viscosity 1402 and the measured viscosity 1404 can be approximated with linear or nonlinear regression, and then a correction of the deviation can be inferred.
- C is the correction of the deviation
- the correlation of viscosities and T 2 distribution of live oil can be described as the following:
- X PC A represents the principle components of a relaxation-time distribution of a live oil sample. Corrections can be incorporated into the RBF model as shown above or in another manner.
- the predicted value from the RBF model is correlated to the viscosity of the dead oil.
- the RBF model predicts apparent oil viscosities based on live oil or in situ logging data, and the apparent oil viscosities may need be converted to live oil viscosities in some instances.
- Apparent oil viscosity can be converted into live oil viscosity in various ways. For example, in some implementations, Bergman's correlation, or many other similar empirical correlations, can be used to obtain the live oil viscosities from the apparent oil viscosities, for example, if the gas-oil ratio (GOR) of the live oil is known. In some implementations, however, these correlations are not applicable for heavy oils.
- GOR gas-oil ratio
- an RBF model or a regression model can be used to convert the apparent oil viscosity to the live oil viscosity. For example, these models can be based on the live and dead oil viscosities of known samples.
- FIG. 15 An example process 1500 for predicting the viscosity of oil from MR measurements is shown in FIG. 15. The example process 1500 is similar in many respects to the example process 300 shown in FIG. 3.
- relaxation-time distributions are obtained (1512), normalized (1514), and converted to a set of principal components (1516).
- the principal components are used by the RBF interpolation (1528) to generate coefficients (1530).
- the RBF interpolation process (1528) can operate based on additional inputs, such as, for example, the apparent hydrogen index (1526), the apparent oil viscosity (1524), or a combination of these and other training data.
- the apparent oil viscosity can be obtained from measured viscosities of dead oil and live oil (1518), for example, based on a regression method (1522), an RBF method (1520), or a combination of these and others.
- the input relaxation-time distributions (1542) are normalized and converted to a set of principal components (1546).
- each distribution is normalized to the same normalizing value that was used at 1514 in the model training sub-process 1510; and the principal components are obtained by applying the same transformation that was used at 1516 in the model training sub-process 1510.
- the bulk density or neutron density or both can be used for the apparent hydrogen indices (1544), in some instances.
- the principal components are provided as input to the radial basis function model 1548, and the resulting viscosity for live oil (1550) can be used to predict viscosity values in situ.
- FIG. 16 shows example data from applying the example process 1500 shown in FIG. 15.
- the left curve 1602 shows the total porosities from the NMR measurement
- the set of curves 1604 in the middle panel shows the T 2 distributions
- the third curve 1606 shows the viscosities predicted by the RBF model.
- the three solid lines 1608a-c are indicators for 1 ms, 10 ms, and 100 ms of the T 2 distributions, respectively.
- the left dashed line 1610 is the cut-off of the oil signals
- the right dashed line 1612 is the T 2 geometric mean of the oil.
- the dashed line 1614 provides an indicator of reliability of the prediction; in this example, the indicator shows that the predictions are reliable.
- the dashed line 1614 can represent a binary indicator for reliability. In some examples, predictions outside the dashed line 1614 can be considered unreliable, while predictions inside the dashed line 1614 can be considered reliable.
- This example process 1500 allows for the prediction of oil viscosity in situ, based on training data obtained either in situ or ex situ.
- Process 1500 is one example of how the above-described techniques can be employed in combination to enhance the predictive accuracy of the RBF model. Other combinations of the above techniques can be used.
- Some embodiments of subject matter and operations described in this specification can be implemented in digital electronic circuitry, or in computer software, firmware, or hardware, including the structures disclosed in this specification and their structural equivalents, or in combinations of one or more of them.
- Some embodiments of subject matter described in this specification can be implemented as one or more computer programs, i.e., one or more modules of computer program instructions encoded on computer storage medium for execution by, or to control the operation of, data processing apparatus.
- a computer storage medium can be, or can be included in, a computer-readable storage device, a computer-readable storage substrate, a random or serial access memory array or device, or a combination of one or more of them.
- a computer storage medium is not a propagated signal
- a computer storage medium can be a source or destination of computer program instructions encoded in an artificially generated propagated signal.
- the computer storage medium can also be, or be included in, one or more separate physical components or media (e.g., multiple CDs, disks, or other storage devices).
- the term "data processing apparatus” encompasses all kinds of apparatus, devices, and machines for processing data, including by way of example a programmable processor, a computer, a system on a chip, or multiple ones, or combinations, of the foregoing.
- the apparatus can include special purpose logic circuitry, e.g., an FPGA (field programmable gate array) or an ASIC (application specific integrated circuit).
- the apparatus can also include, in addition to hardware, code that creates an execution environment for the computer program in question, e.g., code that constitutes processor firmware, a protocol stack, a database management system, an operating system, a cross-platform runtime environment, a virtual machine, or a combination of one or more of them.
- the apparatus and execution environment can realize various different computing model infrastructures, such as web services, or distributed computing and grid computing infrastructures.
- a computer program (also known as a program, software, software application, script, or code) can be written in any form of programming language, including compiled or interpreted languages, declarative or procedural languages.
- a computer program may, but need not, correspond to a file in a file system.
- a program can be stored in a portion of a file that holds other programs or data (e.g., one or more scripts stored in a markup language document), in a single file dedicated to the program in question, or in multiple coordinated files (e.g., files that store one or more modules, sub programs, or portions of code).
- a computer program can be deployed to be executed on one computer or on multiple computers that are located at one site or distributed across multiple sites and interconnected by a communication network.
- Some of the processes and logic flows described in this specification can be performed by one or more programmable processors executing one or more computer programs to perform actions by operating on input data and generating output.
- the processes and logic flows can also be performed by, and apparatus can also be implemented as, special purpose logic circuitry, e.g., an FPGA (field programmable gate array) or an ASIC
- processors suitable for the execution of a computer program include, by way of example, both general and special purpose microprocessors, and processors of any kind of digital computer.
- a processor will receive instructions and data from a read only memory or a random access memory or both.
- a computer includes a processor for performing actions in accordance with instructions and one or more memory devices for storing instructions and data.
- a computer may also include, or be operatively coupled to receive data from or transfer data to, or both, one or more mass storage devices for storing data, e.g., magnetic, magneto optical disks, or optical disks.
- mass storage devices for storing data, e.g., magnetic, magneto optical disks, or optical disks.
- a computer need not have such devices.
- Devices suitable for storing computer program instructions and data include all forms of non-volatile memory, media and memory devices, including by way of example semiconductor memory devices (e.g., EPROM, EEPROM, flash memory devices, and others), magnetic disks (e.g., internal hard disks, removable disks, and others), magneto optical disks , and CD-ROM and DVD-ROM disks.
- semiconductor memory devices e.g., EPROM, EEPROM, flash memory devices, and others
- magnetic disks e.g., internal hard disks, removable disks, and others
- magneto optical disks e.g., CD-ROM and DVD-ROM disks.
- the processor and the memory can be supplemented by, or incorporated in, special purpose logic circuitry.
- a computer having a display device (e.g., a monitor, or another type of display device) for displaying information to the user and a keyboard and a pointing device (e.g., a mouse, a trackball, a tablet, a touch sensitive screen, or another type of pointing device) by which the user can provide input to the computer.
- a display device e.g., a monitor, or another type of display device
- a keyboard and a pointing device e.g., a mouse, a trackball, a tablet, a touch sensitive screen, or another type of pointing device
- Other kinds of devices can be used to provide for interaction with a user as well; for example, feedback provided to the user can be any form of sensory feedback, e.g., visual feedback, auditory feedback, or tactile feedback, and input from the user can be received in any form, including acoustic, speech, or tactile input.
- a computer can interact with a user by sending documents to and receiving documents from a device that is used
- a computer system may include a single computing device, or multiple computers that operate in proximity or generally remote from each other and typically interact through a communication network.
- Examples of communication networks include a local area network ("LAN”) and a wide area network (“WAN”), an inter-network (e.g., the Internet), a network comprising a satellite link, and peer-to-peer networks (e.g., ad hoc peer-to-peer networks).
- LAN local area network
- WAN wide area network
- Internet inter-network
- peer-to-peer networks e.g., ad hoc peer-to-peer networks.
- a relationship of client and server may arise by virtue of computer programs running on the respective computers and having a client-server relationship to each other.
- FIG. 17 shows an example computer system 1700.
- the system 1700 includes a processor 1710, a memory 1720, a storage device 1730, and an input/output device 1740.
- Each of the components 1710, 1720, 1730, and 1740 can be interconnected, for example, using a system bus 1750.
- the processor 1710 is capable of processing instructions for execution within the system 1700.
- the processor 1710 is a single- threaded processor, a multi-threaded processor, or another type of processor.
- the processor 1710 is capable of processing instructions stored in the memory 1720 or on the storage device 1730.
- the memory 1720 and the storage device 1730 can store information within the system 1700.
- the input/output device 1740 provides input/output operations for the system 1700.
- the input/output device 1740 can include one or more network interface devices, e.g., an Ethernet card, a serial communication device, e.g., an RS- 232 port, and/or a wireless interface device, e.g., an 802.1 1 card, a 3G wireless modem, a 4G wireless modem, etc.
- the input/output device can include driver devices configured to receive input data and send output data to other input/output devices, e.g., keyboard, printer and display devices 1760.
- mobile computing devices, mobile communication devices, and other devices can be used.
Abstract
Description




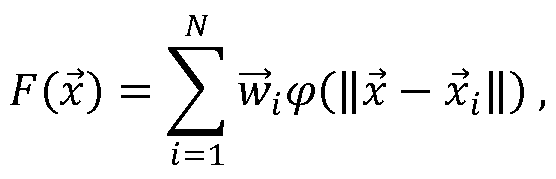

Claims
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/399,025 US10061052B2 (en) | 2013-12-12 | 2013-12-12 | Modeling subterranean fluid viscosity |
| MX2016005259A MX2016005259A (en) | 2013-12-12 | 2013-12-12 | Modeling subterranean fluid viscosity. |
| PCT/US2013/074810 WO2015088543A1 (en) | 2013-12-12 | 2013-12-12 | Modeling subterranean fluid viscosity |
| EP13884958.3A EP2895892A4 (en) | 2013-12-12 | 2013-12-12 | Modeling subterranean fluid viscosity |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/US2013/074810 WO2015088543A1 (en) | 2013-12-12 | 2013-12-12 | Modeling subterranean fluid viscosity |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2015088543A1 true WO2015088543A1 (en) | 2015-06-18 |
Family
ID=53371635
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2013/074810 WO2015088543A1 (en) | 2013-12-12 | 2013-12-12 | Modeling subterranean fluid viscosity |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US10061052B2 (en) |
| EP (1) | EP2895892A4 (en) |
| MX (1) | MX2016005259A (en) |
| WO (1) | WO2015088543A1 (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108291440A (en) * | 2015-11-11 | 2018-07-17 | 斯伦贝谢技术有限公司 | Estimate Nuclear Magnetic Resonance Measurement quality |
| CN108897975A (en) * | 2018-08-03 | 2018-11-27 | 新疆工程学院 | Coalbed gas logging air content prediction technique based on deepness belief network |
| US10408773B2 (en) | 2014-11-25 | 2019-09-10 | Halliburton Energy Services, Inc. | Predicting total organic carbon (TOC) using a radial basis function (RBF) model and nuclear magnetic resonance (NMR) data |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2017095390A1 (en) * | 2015-12-01 | 2017-06-08 | Halliburton Energy Services, Inc. | Oil viscosity prediction |
| CA2963129C (en) * | 2016-04-12 | 2020-05-26 | Syncrude Canada Ltd. In Trust For The Owners Of The Syncrude Project As Such Owners Exist Now And In The Future | Low-field time-domain nmr measurement of oil sands process streams |
| CN112761627B (en) * | 2020-12-31 | 2023-09-29 | 中国海洋石油集团有限公司 | Crude oil viscosity calculation method for offshore sandstone oil reservoir stratum |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1003053A2 (en) | 1998-11-19 | 2000-05-24 | Schlumberger Holdings Limited | Formation evaluation using magnetic resonance logging measurements |
| US20050242807A1 (en) | 2004-04-30 | 2005-11-03 | Robert Freedman | Method for determining properties of formation fluids |
| US20060055403A1 (en) | 2004-04-30 | 2006-03-16 | Schlumberger Technology Corporation | Method for determining characteristics of earth formations |
| US20080206887A1 (en) | 2007-02-23 | 2008-08-28 | Baker Hughes Incorporated | Methods for identification and quantification of multicomponent-fluid and estimating fluid gas/ oil ratio from nmr logs |
| US20110025324A1 (en) | 2007-01-18 | 2011-02-03 | Halliburton Energy Services, Inc. | Simultaneous relaxation time inversion |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6650114B2 (en) * | 2001-06-28 | 2003-11-18 | Baker Hughes Incorporated | NMR data acquisition with multiple interecho spacing |
| US6972564B2 (en) | 2001-11-06 | 2005-12-06 | Baker Hughes Incorporated | Objective oriented methods for NMR log acquisitions for estimating earth formation and fluid properties |
| US20080036457A1 (en) | 2005-03-18 | 2008-02-14 | Baker Hughes Incorporated | NMR Echo Train Compression |
| WO2006132861A1 (en) | 2005-06-03 | 2006-12-14 | Baker Hughes Incorporated | Pore-scale geometric models for interpetation of downhole formation evaluation data |
| US7538547B2 (en) * | 2006-12-26 | 2009-05-26 | Schlumberger Technology Corporation | Method and apparatus for integrating NMR data and conventional log data |
| US8022698B2 (en) | 2008-01-07 | 2011-09-20 | Baker Hughes Incorporated | Joint compression of multiple echo trains using principal component analysis and independent component analysis |
| US8004279B2 (en) | 2008-05-23 | 2011-08-23 | Baker Hughes Incorporated | Real-time NMR distribution while drilling |
| US20100138157A1 (en) | 2008-12-01 | 2010-06-03 | Chevron U.S.A. Inc. | Method for processing borehole logs to enhance the continuity of physical property measurements of a subsurface region |
| US8400147B2 (en) * | 2009-04-22 | 2013-03-19 | Schlumberger Technology Corporation | Predicting properties of live oils from NMR measurements |
| US8427145B2 (en) * | 2010-03-24 | 2013-04-23 | Schlumberger Technology Corporation | System and method for emulating nuclear magnetic resonance well logging tool diffusion editing measurements on a bench-top nuclear magnetic resonance spectrometer for laboratory-scale rock core analysis |
| US9081117B2 (en) | 2010-09-15 | 2015-07-14 | Baker Hughes Incorporated | Method and apparatus for predicting petrophysical properties from NMR data in carbonate rocks |
| US9528874B2 (en) | 2011-08-16 | 2016-12-27 | Gushor, Inc. | Reservoir sampling tools and methods |
| US8912916B2 (en) * | 2012-02-15 | 2014-12-16 | Baker Hughes Incorporated | Non-uniform echo train decimation |
| US20130257424A1 (en) * | 2012-03-27 | 2013-10-03 | Schlumberger Technology Corporation | Magnetic resonance rock analysis |
-
2013
- 2013-12-12 WO PCT/US2013/074810 patent/WO2015088543A1/en active Application Filing
- 2013-12-12 US US14/399,025 patent/US10061052B2/en active Active
- 2013-12-12 MX MX2016005259A patent/MX2016005259A/en unknown
- 2013-12-12 EP EP13884958.3A patent/EP2895892A4/en not_active Withdrawn
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1003053A2 (en) | 1998-11-19 | 2000-05-24 | Schlumberger Holdings Limited | Formation evaluation using magnetic resonance logging measurements |
| US20050242807A1 (en) | 2004-04-30 | 2005-11-03 | Robert Freedman | Method for determining properties of formation fluids |
| US20060055403A1 (en) | 2004-04-30 | 2006-03-16 | Schlumberger Technology Corporation | Method for determining characteristics of earth formations |
| US7309983B2 (en) | 2004-04-30 | 2007-12-18 | Schlumberger Technology Corporation | Method for determining characteristics of earth formations |
| US20110025324A1 (en) | 2007-01-18 | 2011-02-03 | Halliburton Energy Services, Inc. | Simultaneous relaxation time inversion |
| US20080206887A1 (en) | 2007-02-23 | 2008-08-28 | Baker Hughes Incorporated | Methods for identification and quantification of multicomponent-fluid and estimating fluid gas/ oil ratio from nmr logs |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP2895892A4 * |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10408773B2 (en) | 2014-11-25 | 2019-09-10 | Halliburton Energy Services, Inc. | Predicting total organic carbon (TOC) using a radial basis function (RBF) model and nuclear magnetic resonance (NMR) data |
| CN108291440A (en) * | 2015-11-11 | 2018-07-17 | 斯伦贝谢技术有限公司 | Estimate Nuclear Magnetic Resonance Measurement quality |
| US11091997B2 (en) | 2015-11-11 | 2021-08-17 | Schlumberger Technology Corporation | Estimating nuclear magnetic resonance measurement quality |
| CN108291440B (en) * | 2015-11-11 | 2022-03-29 | 斯伦贝谢技术有限公司 | Estimating nuclear magnetic resonance measurement quality |
| CN108897975A (en) * | 2018-08-03 | 2018-11-27 | 新疆工程学院 | Coalbed gas logging air content prediction technique based on deepness belief network |
| CN108897975B (en) * | 2018-08-03 | 2022-10-28 | 新疆工程学院 | Method for predicting gas content of coal bed gas logging based on deep belief network |
Also Published As
| Publication number | Publication date |
|---|---|
| US20160231451A1 (en) | 2016-08-11 |
| MX2016005259A (en) | 2017-01-05 |
| EP2895892A1 (en) | 2015-07-22 |
| EP2895892A4 (en) | 2015-11-11 |
| US10061052B2 (en) | 2018-08-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10324222B2 (en) | Methods and systems employing NMR-based prediction of pore throat size distributions | |
| Maleki et al. | Prediction of shear wave velocity using empirical correlations and artificial intelligence methods | |
| US11636240B2 (en) | Reservoir performance system | |
| Khan et al. | Machine learning derived correlation to determine water saturation in complex lithologies | |
| US10061052B2 (en) | Modeling subterranean fluid viscosity | |
| CA2573467A1 (en) | Computer-based method for while-drilling modeling and visualization of layered subterranean earth formations | |
| US20220187492A1 (en) | Physics-driven deep learning inversion coupled to fluid flow simulators | |
| US10408773B2 (en) | Predicting total organic carbon (TOC) using a radial basis function (RBF) model and nuclear magnetic resonance (NMR) data | |
| US11734603B2 (en) | Method and system for enhancing artificial intelligence predictions using well data augmentation | |
| US10197697B2 (en) | Modeling subterranean formation permeability | |
| US20160231461A1 (en) | Nuclear magnetic resonance (nmr) porosity integration in a probabilistic multi-log interpretation methodology | |
| Aifa | Neural network applications to reservoirs: Physics-based models and data models | |
| Zhao* et al. | TOC estimation in the Barnett Shale from triple combo logs using support vector machine | |
| US20210073631A1 (en) | Dual neural network architecture for determining epistemic and aleatoric uncertainties | |
| US20230289499A1 (en) | Machine learning inversion using bayesian inference and sampling | |
| US20170138871A1 (en) | Estimating Subterranean Fluid Viscosity Based on Nuclear Magnetic Resonance (NMR) Data | |
| Horne | Prediction of multilateral inflow control valve flow performance using machine learning | |
| Cao et al. | Acoustic log prediction on the basis of kernel Extreme learning machine for wells in GJH survey, Erdos basin | |
| US20230288589A1 (en) | Method for predicting a geophysical model of a subterranean region of interest | |
| US20230012429A1 (en) | Constrained Natural Fracture Parameter Hydrocarbon Reservoir Development | |
| Bhattacharya | Unsupervised time series clustering, class-based ensemble machine learning, and petrophysical modeling for predicting shear sonic wave slowness in heterogeneous rocks | |
| Otchere | Data Science and Machine Learning Applications in Subsurface Engineering | |
| US20230280494A1 (en) | Proper layout of data in gpus for accelerating line solve pre-conditioner used in iterative linear solvers in reservoir simulation | |
| US20230288592A1 (en) | Method for predicting a seismic model | |
| US20230193751A1 (en) | Method and system for generating formation property volume using machine learning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 14399025 Country of ref document: US |
|
| REEP | Request for entry into the european phase |
Ref document number: 2013884958 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2013884958 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: MX/A/2016/005259 Country of ref document: MX |
|
| WWE | Wipo information: entry into national phase |
Ref document number: IDP00201602925 Country of ref document: ID |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01A Ref document number: 112016010762 Country of ref document: BR |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 112016010762 Country of ref document: BR Kind code of ref document: A2 Effective date: 20160512 |