WO2014089241A2 - Molecular profiling for cancer - Google Patents
Molecular profiling for cancer Download PDFInfo
- Publication number
- WO2014089241A2 WO2014089241A2 PCT/US2013/073184 US2013073184W WO2014089241A2 WO 2014089241 A2 WO2014089241 A2 WO 2014089241A2 US 2013073184 W US2013073184 W US 2013073184W WO 2014089241 A2 WO2014089241 A2 WO 2014089241A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- gene
- cancer
- panel
- treatment
- benefit
- Prior art date
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
- C12Q1/6886—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material for cancer
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
- G01N33/57484—Immunoassay; Biospecific binding assay; Materials therefor for cancer involving compounds serving as markers for tumor, cancer, neoplasia, e.g. cellular determinants, receptors, heat shock/stress proteins, A-protein, oligosaccharides, metabolites
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B25/00—ICT specially adapted for hybridisation; ICT specially adapted for gene or protein expression
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B25/00—ICT specially adapted for hybridisation; ICT specially adapted for gene or protein expression
- G16B25/10—Gene or protein expression profiling; Expression-ratio estimation or normalisation
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B40/00—ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H50/00—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics
- G16H50/20—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics for computer-aided diagnosis, e.g. based on medical expert systems
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H70/00—ICT specially adapted for the handling or processing of medical references
- G16H70/40—ICT specially adapted for the handling or processing of medical references relating to drugs, e.g. their side effects or intended usage
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/106—Pharmacogenomics, i.e. genetic variability in individual responses to drugs and drug metabolism
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/112—Disease subtyping, staging or classification
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/154—Methylation markers
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/156—Polymorphic or mutational markers
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/16—Primer sets for multiplex assays
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02A—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE
- Y02A90/00—Technologies having an indirect contribution to adaptation to climate change
- Y02A90/10—Information and communication technologies [ICT] supporting adaptation to climate change, e.g. for weather forecasting or climate simulation
Definitions
- Disease states in patients are typically treated with treatment regimens or therapies that are selected based on clinical based criteria; that is, a treatment therapy or regimen is selected for a patient based on the determination that the patient has been diagnosed with a particular disease (which diagnosis has been made from classical diagnostic assays).
- a treatment therapy or regimen is selected for a patient based on the determination that the patient has been diagnosed with a particular disease (which diagnosis has been made from classical diagnostic assays).
- Some treatment regimens have been determined using molecular profiling in combination with clinical characterization of a patient such as observations made by a physician (such as a code from the International Classification of Diseases, for example, and the dates such codes were determined), laboratory test results, x-rays, biopsy results, statements made by the patient, and any other medical information typically relied upon by a physician to make a diagnosis in a specific disease.
- a physician such as a code from the International Classification of Diseases, for example, and the dates such codes were determined
- laboratory test results x-rays
- biopsy results biopsy results
- statements made by the patient and any other medical information typically relied upon by a physician to make a diagnosis in a specific disease.
- any other medical information typically relied upon by a physician to make a diagnosis in a specific disease such as observations made by a physician (such as a code from the International Classification of Diseases, for example, and the dates such codes were determined), laboratory test results, x-rays, biopsy results, statements made by the patient, and
- Patients with refractory or metastatic cancer are of particular concern for treating physicians.
- the majority of patients with metastatic or refractory cancer eventually run out of treatment options or may suffer a cancer type with no real treatment options.
- some patients have very limited options after their tumor has progressed in spite of front line, second line and sometimes third line and beyond) therapies.
- molecular profiling of their cancer may provide the only viable option for prolonging life.
- additional targets or specific therapeutic agents can be identified assessment of a comprehensive number of targets or molecular findings examining molecular mechanisms, genes, gene expressed proteins, and/or combinations of such in a patient's tumor. Identifying multiple agents that can treat multiple targets or underlying mechanisms would provide cancer patients with a viable therapeutic alternative on a personalized basis so as to avoid standar therapies, which may simply not work or identify therapies that would not otherwise be considered by the treating physician.
- the present invention provides methods and system for molecular profiling, using the results from molecular profiling to identify treatments for individuals.
- the treatments were not identified initially as a treatment for the disease or disease lineage.
- the invention provides a method of identifying one or more candidate treatment for a cancer in a subject in need thereof, comprising: (a) determining a molecular profile for a sample from the subject by assessing a panel of gene or gene products, wherein the panel of gene or gene products are assessed as indicated in Table 21, FIG. 33A or FIG. 33B; and (b) identifying one or more treatment that is beneficially associated with the molecular profile of the subject, and optionally one or more treatment associated with lack of benefit, according to the determining in (a) and one or more rules in Table 22, thereby identifying the one or more candidate treatment.
- the panel of gene or gene products may comprise 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28,
- EGFR EGFR
- ER ERBB2
- ERBB4 FBXW7, FGFR1 , FGFR2, FLT3, GNA1 1, GNAQ, GNAS, HER2,
- HNF1A HNF1A
- HRAS IDH1, JAK2, JAK3, KDR (VEGFR2)
- KRAS KRAS
- MGMT MLH1
- MPL NOTCH1 ,
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 or 2 of cMET and HER2.
- Assessing the panel of gene or gene products may comprise using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9,
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16, 17, 18, 19,
- HRAS IDH1 , JAK2, KDR (VEGFR2), KRAS, MLH1 , MPL, NOTCH 1, NRAS, PDGFRA, PIK3CA,
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 or 2 of cMET and HER2; using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15 or
- TOPOl, TS, TUBB3 comprises using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 or 1 1 of CDH1, ERBB4, FBXW7, HNF1A, JAK3, NPM1, PTPN1 1 , RB I , SMAD4, SMARCB 1 and STK1 1.
- sequence analysis can be performed using Next Generation Sequencing.
- the panel of gene or gene products comprises the androgen receptor (AR).
- the one or more candidate treatment can be an antiandrogen.
- the antiandrogen may suppress androgen production and/or inhibits androgens from binding to AR.
- the antiandrogen can be one or more of abarelix, bicalutamide, flutamide, gonadorelin, goserelin, leuprolide, nilutamide, a 5- alpha-reductase inhibitor, finasteride, dutasteride, bexlosteride, izonsteride, turosteride, and epristeride.
- the cancer can be androgen independent.
- the one or more candidate treatment comprises one or more of a CYP17 inhibitor, CYP17A1 inhibitor, chemotherapeutic agent, antiandrogen, an endocrine disruptor, immunotherapy, and bone-targeting radiopharmaceutical.
- the cancer may comprise an acute lymphoblastic leukemia; acute myeloid leukemia; adrenocortical carcinoma; AIDS- related cancer; AIDS-related lymphoma; anal cancer; appendix cancer; astrocytomas; atypical teratoid/rhabdoid tumor; basal cell carcinoma; bladder cancer; brain stem glioma; brain tumor, brain stem glioma, central nervous system atypical teratoid/rhabdoid tumor, central nervous system embryonal tumors, astrocytomas, craniopharyngioma, ependymoblastoma, ependymoma, medulloblastoma, medulloepithelioma, pineal parenchymal tumors of intermediate differentiation, supratentorial primitive neuroectodermal tumors and pineoblastoma; breast cancer; bronchial tumors; Burkitt
- gastrointestinal carcinoid tumor gastrointestinal stromal cell tumor; gastrointestinal stromal tumor (GIST); gestational trophoblastic tumor; glioma; hairy cell leukemia; head and neck cancer; heart cancer; Hodgkin lymphoma; hypopharyngeal cancer; infraocular melanoma; islet cell tumors; Kaposi sarcoma; kidney cancer; Langerhans cell histiocytosis; laryngeal cancer; lip cancer; liver cancer; malignant fibrous histiocytoma bone cancer; medulloblastoma; medulloepithelioma; melanoma; Merkel cell carcinoma; Merkel cell skin carcinoma; mesothelioma; metastatic squamous neck cancer with occult primary; mouth cancer; multiple endocrine neoplasia syndromes; multiple myeloma; multiple myeloma/plasma cell neoplasm; mycosis fungoides; my
- pleuropulmonary blastoma primary central nervous system (CNS) lymphoma; primary hepatocellular liver cancer; prostate cancer; rectal cancer; renal cancer; renal cell (kidney) cancer; renal cell cancer; respiratory tract cancer; retinoblastoma; rhabdomyosarcoma; salivary gland cancer; Sezary syndrome; small cell lung cancer; small intestine cancer; soft tissue sarcoma; squamous cell carcinoma; squamous neck cancer; stomach (gastric) cancer; supratentorial primitive neuroectodermal tumors; T-cell lymphoma; testicular cancer; throat cancer; thymic carcinoma; thymoma; thyroid cancer; transitional cell cancer; transitional cell cancer of the renal pelvis and ureter; trophoblastic tumor; ureter cancer; urethral cancer; uterine cancer; uterine sarcoma; vaginal cancer; vulvar cancer; Waldenstrom macroglobulinemia; or Wilm's tumor.
- cholangiocarcinoma colorectal adenocarcinoma, extrahepatic bile duct adenocarcinoma, female genital tract malignancy, gastric adenocarcinoma, gastroesophageal adenocarcinoma, gastrointestinal stromal tumor (GIST), glioblastoma, head and neck squamous carcinoma, leukemia, liver hepatocellular carcinoma, low grade glioma, lung bronchioloalveolar carcinoma (BAC), non-small cell lung cancer (NSCLC), lung small cell cancer (SCLC), lymphoma, male genital tract malignancy, malignant solitary fibrous tumor of the pleura (M SFT), melanoma, multiple myeloma, neuroendocrine tumor, nodal diffuse large B-cell lymphoma, non epithelial ovarian cancer (non-EOC), ovarian surface epithelial carcinoma, pancreatic adenocarcinoma
- the invention provides a method of identifying one or more candidate treatment for an ovarian cancer in a subject in need thereof, comprising: (a) determining a molecular profile for a sample from the subject by assessing a panel of gene or gene products, wherein the panel of gene or gene products are assessed as indicated in Table 7, FIG. 33C or FIG. 33D; and (b) identifying one or more treatment that is beneficially associated with the molecular profile of the subject, and optionally one or more treatment associated with lack of benefit, according to the determining in (a) and one or more rules in Table 8, thereby identifying the one or more candidate treatment.
- the panel of gene or gene products can include 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57 or 58, of: ABL1, AKT1, ALK, APC, AR, ATM, BRAF, CDH1, cKIT, cMET, CSF1R, CTN B 1, EGFR, ER, ERBB2, ERBB4, FBXW7, FGFR1, FGFR2, FLT3, GNA11, GNAQ, GNAS, HER2, HNF1A, HRAS, IDH1, JAK2, JAK3, KDR (VEGFR2), KRAS, MGMT, MLH1, MPL, NOTCH1, NPM1, NRAS, PDGFRA, PGP, PIK3CA, PR, PTEN,
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 or 2 of cMET and HER2. Assessing the panel of gene or gene products may comprise using IHC to assess 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1 , 12, 13, 14, 15 or 16 of: AR, cMET, ER, HER2, MGMT, PGP, PR, PTEN, RRMl, SPARCm, SPARCp, TLE3, TOP2A, TOPOl , TS, TUBB3.
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33 or 34 of: ABL1 , AKT1 , ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTN B 1, EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA1 1 , GNAQ, GNAS, HRAS, IDH1 , JAK2, KDR (VEGFR2), KRAS, MLH1 , MPL, NOTCH 1 , NRAS, PDGFRA, PIK3CA, PTEN, RET, SMO, TP53, VHL.
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 or 2 of cMET and HER2; using IHC to assess 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1 , 12, 13, 14, 15 or 16 of: AR, cMET, ER, HER2, MGMT, PGP, PR, PTEN, RRMl , SPARCm, SPARCp, TLE3, TOP2A, TOPO l , TS, TUBB3; and/or using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33 or 34 of: ABL1, AKT1, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNB1 , EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA1 1, GNAQ, GNAS, HRAS, IDH1 , JAK2, KDR (VEGFR2), KRAS,
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 or 1 1 of CDH1, ERBB4, FBXW7, HNF 1A, JAK3, NPM1, PTPN1 1 , RB I, SMAD4, SMARCB 1 and STK1 1.
- the sequence analysis comprises Next Generation Sequencing.
- the invention provides a method of identifying one or more candidate treatment for a breast cancer in a subject in need thereof, comprising: (a) determining a molecular profile for a sample from the subject by assessing a panel of gene or gene products, wherein the panel of gene or gene products are assessed as indicated in Table 9, FIG. 33K or FIG. 33L; and (b) identifying one or more treatment that is beneficially associated with the molecular profile of the subject, and optionally one or more treatment associated with lack of benefit, according to the determining in (a) and one or more rules in Table 10, thereby identifying the one or more candidate treatment.
- the panel of gene or gene products can include 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41 , 42, 43, 44, 45, 46, 47, 48, 49, 50, 51 , 52, 53, 54, 55, 56, 57 or 58, of: ABL1 , AKT1 , ALK, APC, AR, ATM, BRAF, CDH1 , cKIT, cMET, CSF1R, CTNNB 1 , EGFR, ER, ERBB2, ERBB4, FBXW7, FGFR1 , FGFR2, FLT3, GNA1 1, GNAQ, GNAS, HER2, HNF1A, HRAS, IDH1, JAK2, JAK3, KDR (VEGFR2), KRAS, MGMT, MLH1 , MPL, NOTCH1 , NPM1, NRAS,
- Assessing the panel of gene or gene products may comprise using ISH to assess 1, 2 or 3, of: cMET, HER2, TOP2A. Assessing the panel of gene or gene products may comprise using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1 , 12, 13, 14, 15 or 16 of: AR, cMET, ER, HER2, MGMT, PGP, PR, PTEN, RRMl , SPARCm, SPARCp, TLE3, TOPOl, TS, TUBB3. Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24,
- ABL1 ABL1 , AKT1, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNB l, EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA11, GNAQ, GNAS, HRAS, IDHl, JAK2, KDR (VEGFR2), KRAS, MLHl, MPL, NOTCHl, NRAS, PDGFRA, PIK3CA, PTEN, RET, SMO, TP53, VHL.
- Assessing the panel of gene or gene products may comprise using ISH to assess 1, 2 or 3, of: cMET, HER2, TOP2A; using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 or 16 of: AR, cMET, ER, HER2, MGMT, PGP, PR, PTEN, RRMl, SPARCm, SPARCp, TLE3, TOPOl, TS, TUBB3; and/or using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 or 34 of: ABL1, AKT1, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNBl, EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA11, GNAQ, GNAS, HRAS, IDHl, JAK2, KDR (VEGFR2), KRAS, MLHl, MPL, NOTCHl,
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 or 11 of CDH1, ERBB4, FBXW7, HNFIA, JAK3, NPM1, PTPN1 1, RBI, SMAD4, SMARCB 1 and STK1 1.
- the sequence analysis comprises Next Generation Sequencing.
- the invention provides a method of identifying one or more candidate treatment for a skin cancer (melanoma) in a subject in need thereof, comprising: (a) determining a molecular profile for a sample from the subject by assessing a panel of gene or gene products, wherein the panel of gene or gene products are assessed as indicated in Table 11, FIG. 33E or FIG. 33F; and (b) identifying one or more treatment that is beneficially associated with the molecular profile of the subject, and optionally one or more treatment associated with lack of benefit, according to the determining in (a) and one or more rules in Table 12, thereby identifying the one or more candidate treatment.
- the panel of gene or gene products can include 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 or 2 of: cMET, HER2. Assessing the panel of gene or gene products may comprise using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 or 16 of: AR, cMET, ER, HER2, MGMT, PGP, PR, PTEN, RRMl, SPARCm, SPARCp, TLE3, TOP2A, TOPOl, TS, TUBB3.
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 or 34 of: ABL1 , AKT1, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNB l, EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA11, GNAQ, GNAS, HRAS, IDHl, JAK2, KDR (VEGFR2), KRAS, MLHl, MPL, NOTCHl, NRAS, PDGFRA, PIK3CA, PTEN, RET, SMO, TP53, VHL.
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 or 2 of: cMET, HER2; using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 or 16 of: AR, cMET, ER, HER2, MGMT, PGP, PR, PTEN, RRMl, SPARCm, SPARCp, TLE3, TOP2A, TOPOl, TS, TUBB3; and/or using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 or 34 of: ABL1, AKT1, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTN B1, EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA11, GNAQ, GNAS, HRAS, IDHl, JAK2, KDR (VEGFR2), KRAS, MLHl, MPL, NOTCHl,
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 or 11 of CDH1, ERBB4, FBXW7, HNFIA, JAK3, NPM1, PTPN1 1, RBI, SMAD4, SMARCB 1 and STK1 1.
- the sequence analysis comprises Next Generation Sequencing.
- the sequence analysis of BRAF comprises PCR, e.g., the FDA approved cobas PCR assay.
- the invention provides a method of identifying one or more candidate treatment for a uveal melanoma cancer in a subject in need thereof, comprising: (a) determining a molecular profile for a sample from the subject by assessing a panel of gene or gene products, wherein the panel of gene or gene products are assessed as indicated in Table 13, FIG. 33G or FIG. 33H; and (b) identifying one or more treatment that is beneficially associated with the molecular profile of the subject, and optionally one or more treatment associated with lack of benefit, according to the determining in (a) and one or more rules in Table 14, thereby identifying the one or more candidate treatment.
- the panel of gene or gene products can include 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57 or 58, of: ABL1, AKT1, ALK, APC, AR, ATM, BRAF, CDH1, cKIT, cMET, CSF1R, CTNNB1, EGFR, ER, ERBB2, ERBB4, FBXW7, FGFR1, FGFR2, FLT3, GNA11, GNAQ, GNAS, HER2, HNFIA, HRAS, IDHl, JAK2, JAK3, KDR (VEGFR2), KRAS, MGMT, MLHl, MPL, NOTCHl, NPM1, NRAS, PDGFRA, PGP, PIK3CA, PR, P
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 or 2, of: cMET, HER2. Assessing the panel of gene or gene products may comprise using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 or 16 of: AR, cMET, ER, HER2, MGMT, PGP, PR, PTEN, RRMl, SPARCm, SPARCp, TLE3, TOP2A, TOPOl, TS, TUBB3.
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 or 34 of: ABL1 , AKT1, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNB 1, EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA11, GNAQ, GNAS, HRAS, IDHl, JAK2, KDR (VEGFR2), KRAS, MLHl, MPL, NOTCHl, NRAS, PDGFRA, PIK3CA, PTEN, RET, SMO, TP53, VHL.
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 or 2, of: cMET, HER2; using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 or 16 of: AR, cMET, ER, HER2, MGMT, PGP, PR, PTEN, RRMl, SPARCm, SPARCp, TLE3, TOP2A, TOPOl, TS, TUBB3; and/or using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 or 34 of: ABL1, AKT1, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNB1, EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA11, GNAQ, GNAS, HRAS, IDH1, JAK2, KDR (VEGFR2), KRAS, MLH1, MPL, NOTCH1, NRAS,
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 or 11 of CDH1, ERBB4, FBXW7, HNF1A, JAK3, NPM1, PTPN1 1, RBI, SMAD4, SMARCB l and STK1 1.
- the sequence analysis comprises Next Generation Sequencing.
- the sequence analysis of BRAF comprises PCR, e.g., the FDA approved cobas PCR assay.
- the invention provides a method of identifying one or more candidate treatment for a colorectal cancer in a subject in need thereof, comprising: (a) determining a molecular profile for a sample from the subject by assessing a panel of gene or gene products, wherein the panel of gene or gene products are assessed as indicated in Table 15, FIG. 33M or FIG. 33N; and (b) identifying one or more treatment that is beneficially associated with the molecular profile of the subject, and optionally one or more treatment associated with lack of benefit, according to the determining in (a) and one or more rules in Table 16, thereby identifying the one or more candidate treatment.
- the panel of gene or gene products can include 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57 or 58, of: ABL1, AKT1, AL , APC, AR, ATM, BRAF, CDH1, cKIT, cMET, CSF1R, CTNNB 1, EGFR, ER, ERBB2, ERBB4, FBXW7, FGFR1, FGFR2, FLT3, GNA11, GNAQ, GNAS, HER2, HNFIA, HRAS, IDH1, JAK2, JAK3, KDR (VEGFR2), KRAS, MGMT, MLH1, MPL, NOTCH1, NPM1, NRAS, PDGFRA, PGP, PIK3CA, PR, PTEN,
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 or 2 of: cMET, HER2. Assessing the panel of gene or gene products may comprise using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 or 16 of: AR, cMET, ER, HER2, MGMT, PGP, PR, PTEN, RRM1, SPARCm, SPARCp, TLE3, TOP2A, TOPOl, TS, TUBB3.
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 or 34 of: ABL1, AKT1, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNB1, EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA11, GNAQ, GNAS, HRAS, IDH1, JAK2, KDR (VEGFR2), KRAS, MLH1, MPL, NOTCH 1, NRAS, PDGFRA, PIK3CA, PTEN, RET, SMO, TP53, VHL.
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 or 2 of: cMET, HER2; using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 or 16 of: AR, cMET, ER, HER2, MGMT, PGP, PR, PTEN, RRM1, SPARCm, SPARCp, TLE3, TOP2A, TOPOl, TS, TUBB3; and/or using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 or 34 of: ABL1, AKT1, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNB1, EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA11, GNAQ, GNAS, HRAS, IDH1, JAK2, KDR (VEGFR2), KRAS, MLH1, MPL, NOTCH1, NRAS,
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 or 11 of CDH1, ERBB4, FBXW7, HNFIA, JAK3, NPM1, PTPN1 1, RBI, SMAD4, SMARCB l and STK1 1.
- the sequence analysis comprises Next Generation Sequencing.
- the invention provides a method of identifying one or more candidate treatment for a lung cancer in a subject in need thereof, comprising: (a) determining a molecular profile for a sample from the subject by assessing a panel of gene or gene products, wherein the panel of gene or gene products are assessed as indicated in Table 17, FIG. 331 or FIG. 33 J; and (b) identifying one or more treatment that is beneficially associated with the molecular profile of the subject, and optionally one or more treatment associated with lack of benefit, according to the determining in (a) and one or more rules in Table 18, thereby identifying the one or more candidate treatment.
- the panel of gene or gene products can include 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58 or 59 of: ABL1, AKT1, ALK, APC, AR, ATM, BRAF, CDH1, c IT, cMET, CSF1R, CTNNBl, EGFR, ER, ERBB2, ERBB4, FBXW7, FGFRl, FGFR2, FLT3, GNAl 1, GNAQ, GNAS, HER2, HNF1A, HRAS, IDHl, JAK2, JAK3, KDR (VEGFR2), KRAS, MGMT, MLH1, MPL, NOTCH1, NPM1, NRAS, PDGFRA, PGP, PIK3CA, PR,
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 , 2, 3 or 4, of: ALK, cMET, HER2, ROS 1. Assessing the panel of gene or gene products may comprise using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 or 17 of: AR, cMET, EGFR (H-score), ER, HER2, MGMT, PGP, PR, PTEN, RRM1, SPARCm, SPARCp, TLE3, TOP2A, TOPOl, TS, TUBB3.
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 or 34 of: ABL1, AKT1, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNB l, EGFR, ERBB2, FGFRl, FGFR2, FLT3, GNAl 1, GNAQ, GNAS, HRAS, IDHl, JAK2, KDR (VEGFR2), KRAS, MLH1, MPL, NOTCH 1, NRAS, PDGFRA, PIK3CA, PTEN, RET, SMO, TP53, VHL.
- Assessing the panel of gene or gene products may comprise using ISH to assess 1, 2, 3 or 4, of: ALK, cMET, HER2, ROS1 ; using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 or 17 of: AR, cMET, EGFR (H-score), ER, HER2, MGMT, PGP, PR, PTEN, RRM1, SPARCm, SPARCp, TLE3, TOP2A, TOPOl, TS, TUBB3; and/or using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 or 34 of: ABL1, AKT1, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNBl, EGFR, ERBB2, FGFRl, FGFR2, FLT3, GNAl 1, GNAQ, GNAS, HRAS, IDHl, JAK2, KDR (VE
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10 or 1 1 of CDH1, ERBB4, FBXW7, HNF1A, JAK3, NPM1, PTPN11, RBI, SMAD4, SMARCBl and STK1 1.
- the sequence analysis comprises Next Generation Sequencing.
- the lung cancer can include without limitation a non-small cell lung cancer (NSCLC) or a bronchioloalveolar cancer (BAC).
- the invention provides a method of identifying one or more candidate treatment for a glioma brain cancer in a subject in need thereof, comprising: (a) determining a molecular profile for a sample from the subject by assessing a panel of gene or gene products, wherein the panel of gene or gene products are assessed as indicated in Table 21, FIG. 330 or FIG. 33P; and (b) identifying one or more treatment that is beneficially associated with the molecular profile of the subject, and optionally one or more treatment associated with lack of benefit, according to the determining in (a) and one or more rules in Table 19, thereby identifying the one or more candidate treatment.
- the panel of gene or gene products can include 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60 or 61, of: ABLl, AKTl, ALK, APC, AR, ATM, BRAF, CDH1, cKIT, cMET, CSF1R, CTN B1, EGFR, EGFRvIII, ER, ERBB2, ERBB4, FBXW7, FGFR1, FGFR2, FLT3, GNA1 1, GNAQ, GNAS, HER2, HNF1A, HRAS, IDH1, IDH2, JAK2, JAK3, KDR (VEGFR2), KRAS, MGMT-Me, MLH1, MPL, NOTCH1, NPM1, NR
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 or 2 of: cMET, HER2. Assessing the panel of gene or gene products may comprise using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 or 15, of: AR, cMET, ER, HER2, PGP, PR, PTEN, RRMl, SPARCm, SPARCp, TLE3, TOP2A, TOPOl, TS, TUBB3. Assessing the panel of gene or gene products may comprise assessing methylation of the MGMT promoter region. Assessing methylation of the MGMT promoter region can be performed using pyro sequencing and/or methylation specific PCR (MS-PCR). Assessing the panel of gene or gene products may comprise sequence analysis of IDH2.
- MS-PCR methylation specific PCR
- Sequence analysis of IDH2 can be performed using Sanger sequencing or Next Generation Sequencing.
- Assessing the panel of gene or gene products may comprise detection of the EGFRvIII variant.
- the EGFRvIII variant can be detected by fragment analysis.
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 or 34 of: ABLl, AKTl, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNB 1, EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA11, GNAQ, GNAS, HRAS, IDH1, JAK2, KDR (VEGFR2), KRAS, MLH1, MPL, NOTCH 1, NRAS, PDGFRA, PIK3CA, PTEN, RET, SMO, TP53, VHL.
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 or 2 of: cMET, HER2; using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 or 15, of: AR, cMET, ER, HER2, PGP, PR, PTEN, RRMl, SPARCm, SPARCp, TLE3, TOP2A, TOPOl, TS, TUBB3; using pyrosequencing to detect methylation of the MGMT promoter; using Sanger sequencing to assess the sequence of IDH2; using fragment analysis to detect the EGFRvIII variant; and/or using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 or 34 of: ABLl, AKTl, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNB1, EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10 or 1 1 of CDHl , ERBB4, FBXW7, HNF1A, JAK3, NPM1, PTPN1 1, RB I , SMAD4, SMARCB 1 and STK1 1.
- the sequence analysis comprises Next Generation Sequencing.
- the invention provides a method of identifying one or more candidate treatment for a gastrointestinal stromal tumor (GIST) cancer in a subject in need thereof, comprising: (a) determining a molecular profile for a sample from the subject by assessing a panel of gene or gene products, wherein the panel of gene or gene products are assessed as indicated in Table 21; and (b) identifying one or more treatment that is beneficially associated with the molecular profile of the subject, and optionally one or more treatment associated with lack of benefit, according to the determining in (a) and one or more rules in Table 20, thereby identifying the one or more candidate treatment.
- GIST gastrointestinal stromal tumor
- the panel of gene or gene products can include 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41 , 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57 or 58, of: ABL1 , AKT1 , ALK, APC, AR, ATM, BRAF, CDH1 , cKIT, cMET, CSF1R, CTNNB 1 , EGFR, ER, ERBB2, ERBB4, FBXW7, FGFR1 , FGFR2, FLT3, GNA1 1, GNAQ, GNAS, HER2, HNF1A, HRAS, IDH1, JAK2, JAK3, KDR (VEGFR2), KRAS, MGMT, MLH1 , MPL, NOTCH1 , NPM1, NRAS,
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 or 2 of: cMET, HER2. Assessing the panel of gene or gene products may comprise using IHC to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15 or 16 of: AR, cMET, ER, HER2, MGMT, PGP, PR, PTEN, RRMl , SPARCm, SPARCp, TLE3, TOP2A, TOPO l, TS, TUBB3.
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33 or 34 of: ABL1 , AKT1 , ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNB 1, EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA1 1 , GNAQ, GNAS, HRAS, IDH1 , JAK2, KDR (VEGFR2), KRAS, MLH1 , MPL, NOTCH 1 , NRAS, PDGFRA, PIK3CA, PTEN, RET, SMO, TP53, VHL.
- Assessing the panel of gene or gene products may comprise using ISH to assess 1 or 2 of: cMET, HER2; using IHC to assess 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15 or 16 of: AR, cMET, ER, HER2, MGMT, PGP, PR, PTEN, RRMl, SPARCm, SPARCp, TLE3, TOP2A, TOPO l , TS, TUBB3; and/or using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33 or 34 of: ABL1, AKT1, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNB1 , EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA1 1, GNAQ, GNAS, HRAS, IDH1 , JAK2, KDR (VEGFR2), KRAS, ML
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 or 1 1 of CDH1, ERBB4, FBXW7, HNF 1A, JAK3, NPM1 , PTPN1 1 , RBI, SMAD4, SMARCB l and STK1 1.
- the sequence analysis comprises Next Generation Sequencing.
- the invention provides a method of identifying one or more candidate treatment for a cancer in a subject in need thereof, comprising: (a) determining a molecular profile for a sample from the subject by assessing a panel of gene or gene products, wherein the panel of gene or gene products are assessed using IHC for 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16 or 17 of AR, cMET, EGFR (including H-score for SCLC), ER, HER2, MGMT, PGP, PR, PTEN, RRM1, SPARCm, SPARCp, TLE3, TOPO l , TOP2A, TS, TUBB3; FISH or CISH for 1 , 2, 3, 4, or 5 of ALK, cMET, HER2, ROS 1 , TOP2A; Mutational Analysis of 1, 2, 3 or 4 of BRAF (e.g., cobas® PCR), IDH2 (e.g., Sanger), IDH2 (e.g., Sanger), IDH2 (e.
- MGMT promoter methylation e.g., by PyroSequencing
- EGFR e.g., fragment analysis to detect EGFRvIII
- Mutational Analysis e.g., by Next- Generation Sequencing
- the methods may further comprising additional molecular profiling according to FIG. 33Q.
- the invention provides a method of identifying one or more candidate treatment for a prostate cancer in a subject in need thereof, comprising: (a) determining a molecular profile for a sample from the subject on a panel of gene or gene products, wherein the panel of gene or gene products comprises immunohistochemistry (IHC) of AR, MRP1 , TOPO l , TLE3, EGFR, TS, PGP, TUBB3, RRM1, PTEN and/or MGMT; in situ hybridization (ISH) of EGFR and/or cMYC; and/or sequencing of TP53, PTEN, CTNNBl , PIK3CA, RB I , ATM, cMET, K/HRAS, ERBB4, ALK, BRAF and/or cKIT; and (b) identifying one or more treatment that is beneficially associated with the molecular profile of the subject, and optionally one or more treatment associated with lack of benefit, according to the determining in (a) and one or more
- the rules can include one or more of: imatinib for patients with high cKIT or PDGFRA; cetuximab for patients with EGFR positivity; cabozantinib for patients with cMET aberrations; PAM pathway inhibitors (e.g., BEZ234, everolimus) for patients with PIK3CA pathway activation; HDAC inhibitors for patients with cMYC amplification; 5-FU for patients with low TS; gemcitabine for patients with low RRMl ; temozolomide for patients with low MGMT; cabazitaxel for patients with low TUBB3 or PGP, or high TLE3; and anti-androgen agents (e.g., enzalutamide) for patients with high AR.
- PAM pathway inhibitors e.g., BEZ234, everolimus
- HDAC inhibitors for patients with cMYC amplification
- 5-FU for patients with low TS
- gemcitabine for patients with low RRMl
- the invention provides a method of identifying one or more candidate treatment for a cancer in a subject in need thereof, comprising: a) determining a molecular profile for a sample from the subject by sequencing a panel of gene or gene products, wherein the panel of gene or gene products comprises one or more gene in Table 24; and b) identifying one or more treatment that is beneficially associated with the molecular profile of the subject, and optionally one or more treatment associated with lack of benefit, according to the determining in (a) and one or more rules in Table 25 or any of Tables 7- 22, thereby identifying the one or more candidate treatment.
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35, 36, 37, 38, 39, 40, 41 , 42, 43, 44, or 45 of ABLl , AKT1 , AL , APC, ATM, BRAF, CDH1 , CSF1R, CTN B 1 , EGFR, ERBB2 (HER2), ERBB4, FBXW7, FGFR1 , FGFR2, FLT3, GNA1 1 , GNAQ, GNAS, HNF1A, HRAS, IDH1, JAK2, JAK3, KDR (VEGFR2), KIT, KRAS, MET, MLH1 , MPL, NOTCH1 , NPM1, NRAS, PDGFRA, PIK3CA, PTEN, PTPN1 1, RBI, RET, SMAD4,
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 or 34 of: ABLl, AKT1, ALK, APC, ATM, BRAF, cKIT, cMET, CSF1R, CTNNB 1 , EGFR, ERBB2, FGFR1, FGFR2, FLT3, GNA1 1 , GNAQ, GNAS, HRAS, IDH1 , JAK2, KDR (VEGFR2), KRAS, MLH1 , MPL, NOTCH 1 , NRAS, PDGFRA, PIK3CA, PTEN, RET, SMO, TP53, VHL.
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1 , 12, 13, 14 or 15 of ABLl , APC, BRAF, EGFR, FLT3, GNAQ, IDH1 , JAK2, cKIT, KRAS, MPL, NPM1 , NRAS, PDGFRA, VHL.
- Assessing the panel of gene or gene products may comprise using sequence analysis to assess 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13 or 14 of ABLl, APC, BRAF, EGFR, FLT3, GNAQ, IDH1 , JAK2, cKIT, KRAS, MPL, NRAS, PDGFRA, VHL.
- identifying the one or more treatment that is beneficially associated with the molecular profile of the subject, and optionally the one or more treatment associated with lack of benefit can comprise: a) correlating the molecular profile with the one or more rules, wherein the one or more rules comprise a mapping of treatments whose efficacy has been previously determined in individuals having cancers that have different levels of, overexpress, underexpress, and/or have mutations in one or more members of the panel of gene or gene products; and b) identifying one or more treatment that is associated with treatment benefit based on the correlating in (a); and c) optionally identifying one or more treatment that is associated with lack of treatment benefit based on the correlating in (a).
- the mapping of treatments can be any of those included in Tables 3-5, 7-23, FTGs. 33A-Q, FIGs. 35A-I, or FIGs. 36A-F.
- the methods of the invention above may further comprise identifying one or more candidate clinical trial for the subject based on the molecular profiling.
- the invention provides a method of identifying one or more candidate clinical trial for a subject having a cancer, comprising: (a) determining a molecular profile for a sample from the subject on a panel of gene or gene products; and (b) identifying one or more clinical trial associated with the molecular profile of the subject according to the determining in (a) and one or more biomarker- clinical trial association rules, thereby identifying the one or more candidate clinical trial.
- the molecular profile can include IHC for 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1 , 12, 13, 14, 15, 16 or 17 of AR, cMET, EGFR (including H-score for NSCLC), ER, HER2, MGMT, Pgp, PR, PTEN, RRM1 , SPARCm, SPARCp, TLE3, TOPO l , TOP2A, TS, TUBB3; FISH or CISH for 1 , 2, 3, 4, or 5 of ALK, cMET, HER2, ROS 1 , TOP2A; Mutational Analysis of 1, 2, 3 or 4 of BRAF (e.g., cobas® PCR), IDH2 (e.g., Sanger
- MGMT promoter methylation e.g., by PyroSequencing
- EGFR e.g., fragment analysis to detect EGFRvIII
- Mutational Analysis e.g., by Next- Generation Sequencing
- Identifying the one or more clinical trial associated with the molecular profile of the subject according to the methods above can comprise: 1) matching to clinical trials for non-standard of care treatments for the patient's cancer (e.g., off NCCN compendium treatments) indicated as potentially beneficial according to the biomarker - drug association rules herein; 2) matching to clinical trials based on biomarker eligibility requirements of the trial; and/or 3) matching to clinical trials based on the molecular profile of the patient, biology of the disease and/or associated signaling pathways.
- non-standard of care treatments for the patient's cancer e.g., off NCCN compendium treatments
- biomarker - drug association rules e.g., off NCCN compendium treatments
- matching to clinical trials based on the molecular profile of the patient, biology of the disease and/or associated signaling pathways comprises: 1) matching trials with therapeutic agents directly targeting a gene and/or gene product in the molecular profile; 2) matching trials with therapeutic agents that target another gene or gene product in a biological pathway that directly target a gene and/or gene product in the molecular profile; 3) matching trials with therapeutic agents that target another gene or gene product in a biological pathway that indirectly target a gene and/or gene product in the molecular profile. Identifying the one or more candidate clinical trial can be performed according to one or more biomarker-clinical trial association rules in Tables 28-29.
- additional genes and/or gene products may be assessed according to the methods of the invention.
- the molecular profiles above may comprise one or more additional gene or gene product listed in Table 2, Table 6 or Table 25. Additional genes and/or gene products can be assessed as evidence becomes available linking such genes and/or gene products to a therapeutic efficacy.
- the one or more additional gene or gene product listed in Table 2, Table 6 or Table 25 can be assessed by any appropriate laboratory technique such as described herein, including without limitation next generation sequencing.
- the sample used to perform molecular profiling in the methods of the invention can include one or more of a formalin- fixed paraffin-embedded (FFPE) tissue, fixed tissue, core needle biopsy, fine needle aspirate, unstained slides, fresh frozen (FF) tissue, formalin samples, tissue comprised in a solution that preserves nucleic acid or protein molecules, and/or a bodily fluid sample.
- FFPE formalin- fixed paraffin-embedded
- the sample comprises cells from a solid tumor.
- the sample comprises a bodily fluid.
- the bodily fluid can be a malignant fluid.
- the bodily fluid can be a pleural or peritoneal fluid.
- the bodily fluid comprises peripheral blood, sera, plasma, ascites, urine, cerebrospinal fluid (CSF), sputum, saliva, bone marrow, synovial fluid, aqueous humor, amniotic fluid, cerumen, breast milk, broncheoalveolar lavage fluid, semen, prostatic fluid, cowper's fluid or pre-ejaculatory fluid, female ejaculate, sweat, fecal matter, hair, tears, cyst fluid, pleural and peritoneal fluid, pericardial fluid, lymph, chyme, chyle, bile, interstitial fluid, menses, pus, sebum, vomit, vaginal secretions, mucosal secretion, stool water, pancreatic juice, lavage fluids from sinus cavities, bronchopulmonary aspirates, blastocyl cavity fluid, or umbilical cord blood.
- the sample may comprise a microvesicle population. In such cases, one or more members of the panel of gene or gene products may be associated
- the one or more candidate treatment can be selected from those listed in any of Tables 3-5, 7-22, 28, 29, 33, 36 or 37 herein.
- the methods of the invention may provide a prioritized list of one or more candidate treatment.
- the cancer that is profiled according to the methods of the invention can be of any stage or progression.
- the subject has not previously been treated with the one or more candidate treatment associated with treatment benefit.
- the cancer comprises a metastatic cancer.
- the cancer comprises a recurrent cancer.
- the cancer is refractory to a prior treatment.
- the prior treatment can be the standard of care for the cancer, e.g., as based on the available evidence and or guidelines such as the NCCN compendium.
- the cancer may be refractory to all known standard of care treatments. Alternately, the subject has not previously been treated for the cancer.
- the one or more candidate treatment can be administered to the subject.
- progression free survival (PFS) or disease free survival (DFS) for the subject is extended by administration of the one or more candidate treatment to the subject.
- the subject's lifespan can be extended by administration of the one or more candidate treatment to the subject.
- the molecular profile can be compared to the one or more rules using a computer.
- the one or more rules may be comprised within a computer database.
- the invention provides a method of generating a molecular profiling report comprising preparing a report comprising results of the molecular profile determined by any of the methods of the invention, e.g., as described above. Illustrative reports are shown in FIGs. 37A-37Y, FIGs. 38A-38AA and FIGs. 39A-39Y.
- the report further comprises a list of the one or more candidate treatment that is associated with benefit for treating the cancer.
- the report may further comprise identification of the one or more candidate treatment as standard of care or not for the cancer lineage.
- the report can also comprise a list of one or more treatment that is associated with lack of benefit for treating the cancer.
- the report can also comprise a list of one or more treatment that is associated with indeterminate benefit for treating the cancer.
- the report comprises a listing of members of the panel of genes or gene products assessed with description of each.
- the report comprises a listing of members of the panel of genes or gene products assessed by one or more of ISH, IHC, Next Generation sequencing, Sanger sequencing, PCR, pyrosequencing and fragment analysis.
- the report comprises a list of clinical trials for which the subject is eligible based on the molecular profile.
- the report comprises a list of evidence supporting the identification of certain treatments as likely to benefit the patient, not benefit the patient, or having indeterminate benefit.
- the report may comprise: 1) a list of the genes and/or gene products in the molecular profile; 2) a description of the molecular profile of the genes and/or gene products as determined for the subject; 3) a treatment associated with one or more of the genes and/or gene products in the molecular profile; and 4) and an indication whether each treatment is likely to benefit the patient, not benefit the patient, or has indeterminate benefit.
- the description of the molecular profile of the genes and/or gene products as determined for the subject can comprise the technique used to assess the gene and/or gene products and the results of the assessment.
- the invention provides a method of generating a molecular profiling report comprising preparing a report comprising results of the molecular profile determined by the methods for identifying one or more candidate clinical trial as provided herein, e.g., as provided above.
- the report can include a list of the one or more identified candidate clinical trial.
- the molecular profile reports of the invention can be computer generated reports. Such reports may be provided as a printed report and/or as a computer file.
- the molecular profile report can be made accessible via a web portal.
- the reports can be transmitted over a network. In some embodiments, the results of some or all of the molecular profiling are transmitted over a network before the report is compiled.
- the invention contemplates use of a reagent in carrying out the methods of the invention.
- the invention contemplates use of a reagent in the manufacture of a reagent or kit for carrying out the method of the invention.
- the invention provides a kit comprising a reagent for carrying out the method of the invention.
- the reagent can be any reagent useful for carrying out one or more of the molecular profiling methods provided herein.
- the reagent can include without limitation one or more of a reagent for extracting nucleic acid from a sample, a reagent for performing ISH, a reagent for performing IHC, a reagent for performing PCR, a reagent for performing Sanger sequencing, a reagent for performing next generation sequencing, a reagent for a DNA microarray, a reagent for performing pyrosequencing, a nucleic acid probe, a nucleic acid primer, an antibody, a reagent for performing bisulfite treatment of nucleic acid.
- a reagent for extracting nucleic acid from a sample a reagent for performing ISH, a reagent for performing IHC, a reagent for performing PCR, a reagent for performing Sanger sequencing, a reagent for performing next generation sequencing, a reagent for a DNA microarray, a reagent for performing pyrosequencing, a nucleic acid probe, a nucle
- the invention provides a report generated by the methods of report generation as described herein, e.g., as described above. Illustrative reports are shown in FIGs. 37A-37Y,
- the invention provides a computer system for generating the report provided by the invention.
- the invention provides a system for identifying one or more candidate treatment for a cancer comprising: a host server; a user interface for accessing the host server to access and input data; a processor for processing the inputted data; a memory coupled to the processor for storing the processed data and instructions for: i) accessing a molecular profile generated by the method of the invention, e.g., as described above; ii) identifying one or more candidate treatment that is associated with likely treatment benefit by comparing the molecular profiling results to the one or more rules; iii) optionally identifying one or more tteatment that is associated with likely lack of treatment benefit by comparing the molecular profiling results to the one or more rules; and iv) optionally identifying one or more treatment that is associated with indeterminate treatment benefit by comparing the molecular profiling results to the one or more rules; and a display for displaying the identified one or more candidate treatment that is associated with likely treatment benefit and the optional one or more treatment that is
- the invention provides a system for identifying one or more candidate clinical trial for a cancer comprising: a host server; a user interface for accessing the host server to access and input data; a processor for processing the inputted data; a memory coupled to the processor for storing the processed data and instructions for: accessing a molecular profile generated by the methods of identifying one or more candidate clinical trial provided by the invention; and identifying one or more candidate candidate clinical trial by comparing the molecular profiling results to the one or more rules; and a display for displaying the identified one or more candidate candidate clinical trial.
- the display may comprise a report as described above.
- the invention provides a computer medium comprising one or more rules from any of Tables 7, 9, 11, 13, 15, 17, 21 and 28.
- the computer medium comprises one or more rules selected from: performing IHC on RRM1 to determine likely benefit or lack of benefit from an antimetabolite and/or gemcitabine; performing IHC on TS to determine likely benefit or lack of benefit from a TOPO l inhibitor, irinotecan and/or topotecan; performing IHC on TS to determine likely benefit or lack of benefit from an antimetabolite, fluorouracil, capecitabine, and/or pemetrexed;
- the computer medium can comprise one or more rules selected from Table 28.
- the computer medium may comprise a partial set of rules provided in any of Tables 7, 9, 11, 13, 15, 17, 21 and 28.
- the computer medium may comprise the full set of rules provided in any of Tables 7, 9, 11, 13, 15, 17, 21 and 28.
- FIG. 1 illustrates a block diagram of an exemplary embodiment of a system for determining individualized medical intervention for a particular disease state that utilizes molecular profiling of a patient's biological specimen that is non disease specific.
- FIG. 2 is a flowchart of an exemplary embodiment of a method for determining individualized medical intervention for a particular disease state that utilizes molecular profiling of a patient's biological specimen that is non disease specific.
- FIGS. 3A through 3D illustrate an exemplary patient profile report in accordance with step 80 of FIG. 2.
- FIG. 4 is a flowchart of an exemplary embodiment of a method for identifying a drug therapy/agent capable of interacting with a target.
- FIGS. 5-14 are flowcharts and diagrams illustrating various parts of an information-based personalized medicine drug discovery system and method in accordance with the present invention.
- FIGS. 15-25 are computer screen print outs associated with various parts of the information- based personalized medicine drug discovery system and method shown in FIGS. 5-14.
- FIGs. 26-31 herein are incorporated by reference from FIGs. 26-31, respectively, from
- FIGs. 32A-B illustrate a diagram showing a biomarker centric (FIG. 32A) and therapeutic centric (FIG. 32B) approach to identifying a therapeutic agent.
- FIGs. 33A-33Q illustrate molecular intelligence (MI) profiles comprising biomarkers and associated therapeutic agents that can be assessed to identify candidate therapeutic agents.
- the indicated MI Plus profiles include additional cancer markers to be assessed by mutational analysis for diagnostic, prognostic and related purposes.
- NextGen refers to Next Generation Sequencing.
- PyroSeq refers to pyrosequencing.
- SangerSeq refers to Sanger dye termination sequencing.
- FIG. 33A and FIG. 33B illustrate an MI profile and and MI PLUS profile, respectively, for any solid tumor.
- FIG. 33C and FIG. 33D illustrate an MI profile and and MI PLUS profile, respectively, for an ovarian cancer.
- FIG. 33E and FIG. 33F illustrate an MI profile and and MI PLUS profile, respectively, for a melanoma.
- FIG. 33G and FIG. 33H illustrate an MI profile and and MI PLUS profile, respectively, for a uveal melanoma.
- FIG. 331 and FIG. 33J illustrate an MI profile and and MI PLUS profile, respectively, for a non-small cell lung cancer (NSCLC).
- FIG. 33K and FIG. 33L illustrate an MI profile and and MI PLUS profile, respectively, for a breast cancer.
- FIG. 33M and FIG. 33N illustrate an MI profile and and MI PLUS profile, respectively, for a colorectal cancer (CRC).
- FIG. 330 and FIG. 33P illustrate an MI profile and and MI PLUS profile, respectively, for a glioma.
- FIG. 33Q illustrates individual marker profiling that can be added to any of the molecular profiles in FIGs. 33A-33P.
- FIGs. 34A-34C illustrate biomarkers assessed using a molecular profiling approach as outlined in FIGs. FIGs. 33A-33Q, Tables 7-24, and accompanying text herein.
- FIG. 34A illustrates biomarkers that are assessed. The biomarkers that are assessed according to the Next Generation sequencing panel in FIG. 34A are shown in FIG. 34B.
- FIG. 34C illustrates sample requirements that can be used to perform molecular profiling on a patient tumor sample according to the panels in FIGs. 34A-34B.
- FIGs. 35A-35I illustrate biomarkers and associated therapeutic agents that can be assessed to identify candidate therapeutic agents.
- NextGen refers to Next Generation Sequencing.
- FIGs. 36A-F illustrate how molecular profiles for any cancer, e.g., for assessment of solid tumors, can be altered depending on sample availability.
- FIG. 36A illustrates a core comprehensive molecular profile for cancer.
- FIG. 36B illustrates lineage specific components of the comprehensive molecular profile for cancer.
- FIG. 36C illustrates drugs and clinical trials corresponding to the profiling shown in FIGs. 36A-B.
- FIG. 36D illustrates a comprehensive molecular profile that can be used instead of the profile shown in FIGs. 36A-B when insufficient sample is present to perform RT-PCR.
- FIG. 36E illustrates additional molecular profiling that can be performed.
- TOP2A IHC and PGP IHC can be used instead of TOP2A FISH when the sample is insufficient for FISH testing.
- FIG. 36F provides illustrative biomarker tests that can be prioritized for various lineages, e.g., when insufficient sample is available for comprehensive molecular profiling.
- FIGs. 37A-37Y illustrate an exemplary patient report based on molecular profiling for a patient having a history of anaplastic astrocytoma, a WHO grade III type of astrocytoma, a high grade glioma.
- FIGs. 38A-38AA illustrate an exemplary patient report based on molecular intelligence molecular profiling for a patient having a history of lung adenocarcinoma.
- FIGs. 39A-39Y illustrate an exemplary patient report based on molecular profiling for a non- small cell lung cancer with stand alone mutational analysis.
- FIG. 40 illustrates progression free survival (PFS) using therapy selected by molecular profiling (period B) with PFS for the most recent therapy on which the patient has just progressed (period A). If PFS(B) / PFS(A) ratio > 1.3, then molecular profiling selected therapy was defined as having benefit for patient.
- FIG. 41 is a schematic of methods for identifying treatments by molecular profiling if a target is identified.
- FIG. 42 illustrates the distribution of the patients in the study as performed in Example 1.
- FIG. 43 is graph depicting the results of the study with patients having PFS ratio > 1.3 was 18/66 (27%).
- FIG. 44 is a waterfall plot of all the patients for maximum % change of summed diameters of target lesions with respect to baseline diameter.
- FIG. 45 illustrates the relationship between what clinician selected as what she/he would use to treat the patient before knowing what the molecular profiling results suggested. There were no matches for the 18 patients with PFS ratio > 1.3.
- FIG. 46 is a schematic of the overall survival for the 18 patients with PFS ratio > 1.3 versus all 66 patients.
- FIG. 47 illustrates a molecular profiling system that performs analysis of a cancer sample using a variety of components that measure expression levels, chromosomal aberrations and mutations.
- the molecular "blueprint" of the cancer is used to generate a prioritized ranking of druggable targets and/or drug associated targets in tumor and their associated therapies.
- FIG. 48 shows an example output of microarray profiling results and calls made using a cutoff value.
- FIGs. 49A-B illustrate a workflow chart for identifying a therapeutic for an individual having breast cancer.
- the workflow of FIG. 49A feeds into the workflow of FIG. 49B as indicated.
- FIGs. 50 illustrates biomarkers used for identifying a therapeutic for an individual having breast cancer such as when following the workflow of FIGs. 49A-B.
- the figure illustrates a biomarker centric view of the workflow described above in different cancer settings.
- FIG. 51 illustrates the percentage of HER2 positive breast cancers that are likely to respond to treatment with trastuzumab (Herceptin®), which is about 30%. Characteristics of the tumor that can be identified by molecular profiling are shown as well.
- the present invention provides methods and systems for identifying therapeutic agents for use in treatments on an individualized basis by using molecular profiling.
- the molecular profiling approach provides a method for selecting a candidate treatment for an individual that could favorably change the clinical course for the individual with a condition or disease, such as cancer.
- the molecular profiling approach provides clinical benefit for individuals, such as identifying drug target(s) that provide a longer progression free survival (PFS), longer disease free survival (DFS), longer overall survival (OS) or extended lifespan.
- PFS progression free survival
- DFS disease free survival
- OS overall survival
- Methods and systems of the invention are directed to molecular profiling of cancer on an individual basis that can provide alternatives for treatment that may be convention or alternative to conventional treatment regimens.
- alternative treatment regimes can be selected through molecular profiling methods of the invention where, a disease is refractory to current therapies, e.g., after a cancer has developed resistance to a standard-of-care treatment.
- Illustrative schemes for using molecular profiling to identify a treatment regime are shown in FIGs. 2, 49A-B and 50, each of which is described in further detail herein.
- molecular profiling provides a personalized approach to selecting candidate treatments that are likely to benefit a cancer.
- the molecular profiling method is used to identify therapies for patients with poor prognosis, such as those with metastatic disease or those whose cancer has progressed on standard front line therapies, or whose cancer has progressed on multiple chemotherapeutic or hormonal regimens.
- NCCN CompendiumTM contains authoritative, scientifically derived information designed to support decision-making about the appropriate use of drugs and biologies in patients with cancer.
- the NCCN CompendiumTM is recognized by the Centers for Medicare and Medicaid Services
- CMS CMR
- United Healthcare as an authoritative reference for oncology coverage policy.
- On- compendium treatments are those recommended by such guides.
- the biostatistical methods used to validate the results of clinical trials rely on minimizing differences between patients, and are based on declaring the likelihood of error that one approach is better than another for a patient group defined only by light microscopy and stage, not by individual differences in tumors.
- the molecular profiling methods of the invention exploit such individual differences.
- the methods can provide candidate treatments that can be then selected by a physician for treating a patient.
- Example 1 In a study of such an approach presented in Example 1 herein, the results were profound: in 66 consecutive patients, the treating oncologist never managed to identify the molecular target selected by the test, and 27% of patients whose treatment was guided by molecular profiling managed a remission 1.3x longer than their previous best response. At present, such results are virtually unheard of result in the salvage therapy setting.
- Molecular profiling can be used to provide a comprehensive view of the biological state of a sample.
- molecular profiling is used for whole tumor profiling. Accordingly, a number of molecular approaches are used to assess the state of a tumor.
- the whole tumor profiling can be used for selecting a candidate treatment for a tumor.
- Molecular profiling can be used to select candidate therapeutics on any sample for any stage of a disease.
- the methods of the invention are used to profile a newly diagnosed cancer.
- the candidate treatments indicated by the molecular profiling can be used to select a therapy for treating the newly diagnosed cancer.
- the methods of the invention are used to profile a cancer that has already been treated, e.g., with one or more standard-of-care therapy.
- the cancer is refractory to the prior treatment/s.
- the cancer may be refractory to the standard of care treatments for the cancer.
- the cancer can be a metastatic cancer or other recurrent cancer.
- the treatments can be on-compendium or off-compendium treatments.
- Molecular profiling can be performed by any known means for detecting a molecule in a biological sample.
- Molecular profiling comprises methods that include but are not limited to, nucleic acid sequencing, such as a DNA sequencing or mRNA sequencing; immunohistochemistry (IHC); in situ hybridization (ISH); fluorescent in situ hybridization (FISH); chromogenic in situ hybridization (CISH); PCR amplification (e.g., qPCR or RT-PCR); various types of microarray (mRNA expression arrays, low density arrays, protein arrays, etc); various types of sequencing (Sanger, pyrosequencing, etc); comparative genomic hybridization (CGH); NextGen sequencing; Northern blot; Southern blot; immunoassay; and any other appropriate technique to assay the presence or quantity of a biological molecule of interest.
- any one or more of these methods can be used concurrently or subsequent to each other for assessing target genes disclosed herein.
- Molecular profiling of individual samples is used to select one or more candidate treatments for a disorder in a subject, e.g., by identifying targets for drugs that may be effective for a given cancer.
- the candidate treatment can be a treatment known to have an effect on cells that differentially express genes as identified by molecular profiling techniques, an experimental drug, a government or regulatory approved drug or any combination of such drugs, which may have been studied and approved for a particular indication that is the same as or different from the indication of the subject from whom a biological sample is obtain and molecularly profiled.
- one or more decision rules can be put in place to prioritize the selection of certain therapeutic agent for treatment of an individual on a personalized basis.
- Rules of the invention aide prioritizing treatment, e.g., direct results of molecular profiling, anticipated efficacy of therapeutic agent, prior history with the same or other treatments, expected side effects, availability of therapeutic agent, cost of therapeutic agent, drug-drug interactions, and other factors considered by a treating physician. Based on the recommended and prioritized therapeutic agent targets, a physician can decide on the course of treatment for a particular individual.
- molecular profiling methods and systems of the invention can select candidate treatments based on individual characteristics of diseased cells, e.g., tumor cells, and other personalized factors in a subject in need of treatment, as opposed to relying on a traditional one-size fits all approach that is conventionally used to treat individuals suffering from a disease, especially cancer.
- the recommended treatments are those not typically used to treat the disease or disorder inflicting the subject.
- the recommended treatments are used after standard-of-care therapies are no longer providing adequate efficacy.
- the treating physician can use the results of the molecular profiling methods to optimize a treatment regimen for a patient.
- the candidate treatment identified by the methods of the invention can be used to treat a patient; however, such treatment is not required of the methods. Indeed, the analysis of molecular profiling results and identification of candidate treatments based on those results can be automated and does not require physician involvement.
- Nucleic acids include deoxyribonucleotides or ribonucleotides and polymers thereof in either single- or double-stranded form, or complements thereof. Nucleic acids can contain known nucleotide analogs or modified backbone residues or linkages, which are synthetic, naturally occurring, and non- naturally occurring, which have similar binding properties as the reference nucleic acid, and which are metabolized in a manner similar to the reference nucleotides. Examples of such analogs include, without limitation, phosphorothioates, phosphoramidates, methyl phosphonates, chiral-methyl phosphonates, 2- O-methyl ribonucleotides, peptide-nucleic acids (PNAs).
- PNAs peptide-nucleic acids
- Nucleic acid sequence can encompass conservatively modified variants thereof (e.g., degenerate codon substitutions) and complementary sequences, as well as the sequence explicitly indicated. Specifically, degenerate codon substitutions may be achieved by generating sequences in which the third position of one or more selected (or all) codons is substituted with mixed-base and/or deoxyinosine residues (Batzer et al., Nucleic Acid Res. 19:5081 (1991); Ohtsuka et al., J. Biol. Chem. 260:2605-2608 (1985); Rossolini et al., Mol. Cell Probes 8:91 -98 (1994)).
- the term nucleic acid can be used interchangeably with gene, cDNA, mRNA, oligonucleotide, and polynucleotide.
- a particular nucleic acid sequence may implicitly encompass the particular sequence and "splice variants" and nucleic acid sequences encoding truncated forms.
- a particular protein encoded by a nucleic acid can encompass any protein encoded by a splice variant or truncated form of that nucleic acid.
- “Splice variants,” as the name suggests, are products of alternative splicing of a gene. After transcription, an initial nucleic acid transcript may be spliced such that different (alternate) nucleic acid splice products encode different polypeptides. Mechanisms for the production of splice variants vary, but include alternate splicing of exons.
- Alternate polypeptides derived from the same nucleic acid by read- through transcription are also encompassed by this definition. Any products of a splicing reaction, including recombinant forms of the splice products, are included in this definition. Nucleic acids can be truncated at the 5' end or at the 3' end. Polypeptides can be truncated at the N-terminal end or the C- terminal end. Truncated versions of nucleic acid or polypeptide sequences can be naturally occurring or created using recombinant techniques.
- nucleotide variant refers to changes or alterations to the reference human gene or cDNA sequence at a particular locus, including, but not limited to, nucleotide base deletions, insertions, inversions, and substitutions in the coding and non- coding regions.
- Deletions may be of a single nucleotide base, a portion or a region of the nucleotide sequence of the gene, or of the entire gene sequence. Insertions may be of one or more nucleotide bases.
- the genetic variant or nucleotide variant may occur in transcriptional regulatory regions, untranslated regions of mRNA, exons, introns, exon/intron junctions, etc.
- the genetic variant or nucleotide variant can potentially result in stop codons, frame shifts, deletions of amino acids, altered gene transcript splice forms or altered amino acid sequence.
- An allele or gene allele comprises generally a naturally occurring gene having a reference sequence or a gene containing a specific nucleotide variant.
- a haplotype refers to a combination of genetic (nucleotide) variants in a region of an mRNA or a genomic DNA on a chromosome found in an individual.
- a haplotype includes a number of genetically linked polymorphic variants which are typically inherited together as a unit.
- amino acid variant is used to refer to an amino acid change to a reference human protein sequence resulting from genetic variants or nucleotide variants to the reference human gene encoding the reference protein.
- amino acid variant is intended to encompass not only single amino acid substitutions, but also amino acid deletions, insertions, and other significant changes of amino acid sequence in the reference protein.
- genotyping means the nucleotide characters at a particular nucleotide variant marker (or locus) in either one allele or both alleles of a gene (or a particular chromosome region). With respect to a particular nucleotide position of a gene of interest, the nucleotide(s) at that locus or equivalent thereof in one or both alleles form the genotype of the gene at that locus. A genotype can be homozygous or heterozygous. Accordingly, “genotyping” means determining the genotype, that is, the nucleotide(s) at a particular gene locus. Genotyping can also be done by determining the amino acid variant at a particular position of a protein which can be used to deduce the corresponding nucleotide variant(s).
- locus refers to a specific position or site in a gene sequence or protein. Thus, there may be one or more contiguous nucleotides in a particular gene locus, or one or more amino acids at a particular locus in a polypeptide. Moreover, a locus may refer to a particular position in a gene where one or more nucleotides have been deleted, inserted, or inverted.
- protein and “peptide” are used interchangeably herein to refer to an amino acid chain in which the amino acid residues are linked by covalent peptide bonds.
- the amino acid chain can be of any length of at least two amino acids, including full-length proteins.
- polypeptide, protein, and peptide also encompass various modified forms thereof, including but not limited to glycosylated forms, phosphorylated forms, etc.
- a polypeptide, protein or peptide can also be referred to as a gene product.
- biomarker or “marker” comprises a gene and/or gene product depending on the context.
- label and “detectable label” can refer to any composition detectable by
- Such labels include biotin for staining with labeled streptavidin conjugate, magnetic beads (e.g., DYNABEADSTM), fluorescent dyes (e.g., fluorescein, Texas red, rhodamine, green fluorescent protein, and the like), radiolabels (e.g., H, I, S, C, or P), enzymes (e.g., horse radish peroxidase, alkaline phosphatase and others commonly used in an ELISA), and calorimetric labels such as colloidal gold or colored glass or plastic (e.g., polystyrene, polypropylene, latex, etc) beads.
- fluorescent dyes e.g., fluorescein, Texas red, rhodamine, green fluorescent protein, and the like
- radiolabels e.g., H, I, S, C, or P
- enzymes e.g., horse radish peroxidase, alkaline phosphatase and others commonly used
- Patents teaching the use of such labels include U.S. Pat. Nos. 3,817,837; 3,850,752; 3,939,350; 3,996,345; 4,277,437; 4,275, 149; and 4,366,241.
- Means of detecting such labels are well known to those of skill in the art.
- radiolabels may be detected using photographic film or scintillation counters
- fluorescent markers may be detected using a photodetector to detect emitted light.
- Enzymatic labels are typically detected by providing the enzyme with a substrate and detecting the reaction product produced by the action of the enzyme on the substrate, and calorimetric labels are detected by simply visualizing the colored label.
- Labels can include, e.g., ligands that bind to labeled antibodies, fluorophores, chemiluminescent agents, enzymes, and antibodies which can serve as specific binding pair members for a labeled ligand.
- ligands that bind to labeled antibodies, fluorophores, chemiluminescent agents, enzymes, and antibodies which can serve as specific binding pair members for a labeled ligand.
- An introduction to labels, labeling procedures and detection of labels is found in Polak and Van Noorden Introduction to Immunocytochemistry, 2nd ed., Springer Verlag, NY (1997); and in Haugland Handbook of Fluorescent Probes and Research Chemicals, a combined handbook and catalogue Published by Molecular Probes, Inc. (1996).
- Detectable labels include, but are not limited to, nucleotides (labeled or unlabelled), compomers, sugars, peptides, proteins, antibodies, chemical compounds, conducting polymers, binding moieties such as biotin, mass tags, calorimetric agents, light emitting agents, chemiluminescent agents, light scattering agents, fluorescent tags, radioactive tags, charge tags (electrical or magnetic charge), volatile tags and hydrophobic tags, biomolecules (e.g., members of a binding pair antibody/antigen, antibody/antibody, antibody/antibody fragment, antibody/antibody receptor, antibody/protein A or protein G, hapten/anti- hapten, biotin/avidin, biotin/streptavidin, folic acid/folate binding protein, vitamin B 12/intrinsic factor, chemical reactive group/complementary chemical reactive group (e.g., sulfhydryl/maleimide, sulfhydryl/haloacetyl derivative, amine/is
- antibody encompasses naturally occurring antibodies as well as non- naturally occurring antibodies, including, for example, single chain antibodies, chimeric, bifunctional and humanized antibodies, as well as antigen-binding fragments thereof, (e.g., Fab', F(ab') 2 , Fab, Fv and rlgG). See also, Pierce Catalog and Handbook, 1994-1995 (Pierce Chemical Co., Rockford, 111.). See also, e.g., Kuby, J., Immunology, 3.sup.rd Ed., W. H. Freeman & Co., New York (1998).
- Such non- naturally occurring antibodies can be constructed using solid phase peptide synthesis, can be produced recombinantly or can be obtained, for example, by screening combinatorial libraries consisting of variable heavy chains and variable light chains as described by Huse et al., Science 246: 1275- 1281 (1989), which is incorporated herein by reference.
- These and other methods of making, for example, chimeric, humanized, CDR-grafted, single chain, and bifunctional antibodies are well known to those skilled in the art. See, e.g., Winter and Harris, Immunol.
- antibodies can include both polyclonal and monoclonal antibodies.
- Antibodies also include genetically engineered forms such as chimeric antibodies (e.g., humanized murine antibodies) and heteroconjugate antibodies (e.g., bispecific antibodies).
- the term also refers to recombinant single chain Fv fragments (scFv).
- the term also includes bivalent or bispecific molecules, diabodies, triabodies, and tetrabodies. Bivalent and bispecific molecules are described in, e.g., Kostelny et al. (1992) J Immunol 148: 1547, Pack and Pluckthun (1992) Biochemistry 31 : 1579, Holliger et al.
- an antibody typically has a heavy and light chain.
- Each heavy and light chain contains a constant region and a variable region, (the regions are also known as "domains").
- Light and heavy chain variable regions contain four framework regions interrupted by three hyper-variable regions, also called complementarity-determining regions (CDRs).
- CDRs complementarity-determining regions
- the extent of the framework regions and CDRs have been defined.
- the sequences of the framework regions of different light or heavy chains are relatively conserved within a species.
- the framework region of an antibody that is the combined framework regions of the constituent light and heavy chains, serves to position and align the CDRs in three dimensional spaces.
- the CDRs are primarily responsible for binding to an epitope of an antigen.
- the CDRs of each chain are typically referred to as CDR1 , CDR2, and CDR3, numbered sequentially starting from the N-terminus, and are also typically identified by the chain in which the particular CDR is located.
- a VH CDR3 is located in the variable domain of the heavy chain of the antibody in which it is found
- a VL CDRl is the CDR1 from the variable domain of the light chain of the antibody in which it is found.
- References to VH refer to the variable region of an immunoglobulin heavy chain of an antibody, including the heavy chain of an Fv, scFv, or Fab.
- References to VL refer to the variable region of an immunoglobulin light chain, including the light chain of an Fv, scFv, dsFv or Fab.
- single chain Fv or “scFv” refers to an antibody in which the variable domains of the heavy chain and of the light chain of a traditional two chain antibody have been joined to form one chain.
- a linker peptide is inserted between the two chains to allow for proper folding and creation of an active binding site.
- a “chimeric antibody” is an immunoglobulin molecule in which (a) the constant region, or a portion thereof, is altered, replaced or exchanged so that the antigen binding site (variable region) is linked to a constant region of a different or altered class, effector function and/or species, or an entirely different molecule which confers new properties to the chimeric antibody, e.g., an enzyme, toxin, hormone, growth factor, drug, etc.; or (b) the variable region, or a portion thereof, is altered, replaced or exchanged with a variable region having a different or altered antigen specificity.
- a "humanized antibody” is an immunoglobulin molecule that contains minimal sequence derived from non-human immunoglobulin.
- Humanized antibodies include human immunoglobulins (recipient antibody) in which residues from a complementary determining region (CDR) of the recipient are replaced by residues from a CDR of a non-human species (donor antibody) such as mouse, rat or rabbit having the desired specificity, affinity and capacity.
- CDR complementary determining region
- donor antibody such as mouse, rat or rabbit having the desired specificity, affinity and capacity.
- Fv framework residues of the human immunoglobulin are replaced by corresponding non-human residues.
- Humanized antibodies may also comprise residues which are found neither in the recipient antibody nor in the imported CDR or framework sequences.
- a humanized antibody will comprise substantially all of at least one, and typically two, variable domains, in which all or substantially all of the CDR regions correspond to those of a non-human immunoglobulin and all or substantially all of the framework (FR) regions are those of a human immunoglobulin consensus sequence.
- the humanized antibody optimally also will comprise at least a portion of an immunoglobulin constant region (Fc), typically that of a human immunoglobulin (Jones et al., Nature 321 :522-525 (1986); Riechmann et al, Nature 332:323-327 (1988); and Presta, Curr. Op. Struct. Biol. 2:593-596 (1992)).
- Humanization can be essentially performed following the method of Winter and co-workers (Jones et al., Nature 321 :522-525 (1986); Riechmann et al., Nature 332:323-327 (1988); Verhoeyen et al., Science 239: 1534- 1536 (1988)), by substituting rodent CDRs or CDR sequences for the corresponding sequences of a human antibody.
- rodent CDRs or CDR sequences for the corresponding sequences of a human antibody.
- such humanized antibodies are chimeric antibodies (U.S. Pat. No. 4,816,567), wherein substantially less than an intact human variable domain has been substituted by the corresponding sequence from a non-human species.
- epitopes and "antigenic determinant” refer to a site on an antigen to which an antibody binds.
- Epitopes can be formed both from contiguous amino acids or noncontiguous amino acids juxtaposed by tertiary folding of a protein. Epitopes formed from contiguous amino acids are typically retained on exposure to denaturing solvents whereas epitopes formed by tertiary folding are typically lost on treatment with denaturing solvents.
- An epitope typically includes at least 3, and more usually, at least 5 or 8- 10 amino acids in a unique spatial conformation. Methods of determining spatial conformation of epitopes include, for example, x-ray crystallography and 2-dimensional nuclear magnetic resonance. See, e.g., Epitope Mapping Protocols in Methods in Molecular Biology, Vol. 66, Glenn E. Morris, Ed (1996).
- primer refers to a relatively short nucleic acid fragment or sequence. They can comprise DNA, RNA, or a hybrid thereof, or chemically modified analog or derivatives thereof. Typically, they are single-stranded. However, they can also be double-stranded having two complementing strands which can be separated by denaturation. Normally, primers, probes and oligonucleotides have a length of from about 8 nucleotides to about 200 nucleotides, preferably from about 12 nucleotides to about 100 nucleotides, and more preferably about 18 to about 50 nucleotides. They can be labeled with detectable markers or modified using conventional manners for various molecular biological applications.
- nucleic acids e.g., genomic DNAs, cDNAs, mRNAs, or fragments thereof
- isolated nucleic acid can be a nucleic acid molecule having only a portion of the nucleic acid sequence in the chromosome but not one or more other portions present on the same chromosome.
- an isolated nucleic acid can include naturally occurring nucleic acid sequences that flank the nucleic acid in the naturally existing chromosome (or a viral equivalent thereof).
- An isolated nucleic acid can be substantially separated from other naturally occurring nucleic acids that are on a different chromosome of the same organism.
- An isolated nucleic acid can also be a composition in which the specified nucleic acid molecule is significantly enriched so as to constitute at least 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95%, or at least 99% of the total nucleic acids in the composition.
- An isolated nucleic acid can be a hybrid nucleic acid having the specified nucleic acid molecule covalently linked to one or more nucleic acid molecules that are not the nucleic acids naturally flanking the specified nucleic acid.
- an isolated nucleic acid can be in a vector.
- the specified nucleic acid may have a nucleotide sequence that is identical to a naturally occurring nucleic acid or a modified form or mutein thereof having one or more mutations such as nucleotide substitution, deletion/insertion, inversion, and the like.
- An isolated nucleic acid can be prepared from a recombinant host cell (in which the nucleic acids have been recombinantly amplified and/or expressed), or can be a chemically synthesized nucleic acid having a naturally occurring nucleotide sequence or an artificially modified form thereof.
- isolated polypeptide as used herein is defined as a polypeptide molecule that is present in a form other than that found in nature. Thus, an isolated polypeptide can be a non-naturally occurring polypeptide.
- an isolated polypeptide can be a "hybrid polypeptide.”
- An isolated polypeptide can also be a polypeptide derived from a naturally occurring polypeptide by additions or deletions or substitutions of amino acids.
- An isolated polypeptide can also be a "purified polypeptide” which is used herein to mean a composition or preparation in which the specified polypeptide molecule is significantly enriched so as to constitute at least 10% of the total protein content in the composition.
- a “purified polypeptide” can be obtained from natural or recombinant host cells by standard purification techniques, or by chemically synthesis, as will be apparent to skilled artisans.
- hybrid protein means a non-naturally occurring polypeptide or isolated polypeptide having a specified polypeptide molecule covalently linked to one or more other polypeptide molecules that do not link to the specified polypeptide in nature.
- a “hybrid protein” may be two naturally occurring proteins or fragments thereof linked together by a covalent linkage.
- a “hybrid protein” may also be a protein formed by covalently linking two artificial polypeptides together. Typically but not necessarily, the two or more polypeptide molecules are linked or "fused” together by a peptide bond forming a single non-branched polypeptide chain.
- high stringency hybridization conditions when used in connection with nucleic acid hybridization, includes hybridization conducted overnight at 42 °C in a solution containing 50% formamide, 5 *SSC (750 mM NaCl, 75 mM sodium citrate), 50 mM sodium phosphate, pH 7.6,
- hybridization conditions when used in connection with nucleic acid hybridization, includes
- hybridization conducted overnight at 37 °C in a solution containing 50% formamide, 5xSSC (750 mM NaCl, 75 mM sodium citrate), 50 mM sodium phosphate, pH 7.6, 5xDenhardt's solution, 10% dextran sulfate, and 20 microgram/ml denatured and sheared salmon sperm DNA, with hybridization filters washed in l xSSC at about 50 °C. It is noted that many other hybridization methods, solutions and temperatures can be used to achieve comparable stringent hybridization conditions as will be apparent to skilled artisans.
- test sequence For the purpose of comparing two different nucleic acid or polypeptide sequences, one sequence (test sequence) may be described to be a specific percentage identical to another sequence (comparison sequence).
- the percentage identity can be determined by the algorithm of Karlin and Altschul, Proc. Natl. Acad. Sci. USA, 90:5873-5877 (1993), which is incorporated into various BLAST programs. The percentage identity can be determined by the "BLAST 2 Sequences" tool, which is available at the National Center for Biotechnology Information (NCBI) website. See Tatusova and Madden, FEMS Microbiol. Lett, 174(2):247-250 (1999).
- the BLASTN program is used with default parameters (e.g., Match: 1 ; Mismatch: -2; Open gap: 5 penalties; extension gap: 2 penalties; gap x dropoff: 50; expect: 10; and word size: 1 1, with filter).
- the BLASTP program can be employed using default parameters (e.g., Matrix: BLOSUM62; gap open: 1 1 ; gap extension: 1 ; x dropoff: 15; expect: 10.0; and wordsize: 3, with filter).
- Percent identity of two sequences is calculated by aligning a test sequence with a comparison sequence using BLAST, determining the number of amino acids or nucleotides in the aligned test sequence that are identical to amino acids or nucleotides in the same position of the comparison sequence, and dividing the number of identical amino acids or nucleotides by the number of amino acids or nucleotides in the comparison sequence.
- BLAST is used to compare two sequences, it aligns the sequences and yields the percent identity over defined, aligned regions. If the two sequences are aligned across their entire length, the percent identity yielded by the BLAST is the percent identity of the two sequences.
- BLAST does not align the two sequences over their entire length, then the number of identical amino acids or nucleotides in the unaligned regions of the test sequence and comparison sequence is considered to be zero and the percent identity is calculated by adding the number of identical amino acids or nucleotides in the aligned regions and dividing that number by the length of the comparison sequence.
- BLAST programs can be used to compare sequences, e.g., BLAST 2.1.2 or BLAST+ 2.2.22.
- a subject or individual can be any animal which may benefit from the methods of the invention, including, e.g., humans and non-human mammals, such as primates, rodents, horses, dogs and cats.
- Subjects include without limitation a eukaryotic organisms, most preferably a mammal such as a primate, e.g., chimpanzee or human, cow; dog; cat; a rodent, e.g., guinea pig, rat, mouse; rabbit; or a bird; reptile; or fish.
- Subjects specifically intended for treatment using the methods described herein include humans.
- a subject may be referred to as an individual or a patient.
- Treatment of a disease or individual according to the invention is an approach for obtaining beneficial or desired medical results, including clinical results, but not necessarily a cure.
- beneficial or desired clinical results include, but are not limited to, alleviation or amelioration of one or more symptoms, diminishment of extent of disease, stabilized (i.e., not worsening) state of disease, preventing spread of disease, delay or slowing of disease progression, amelioration or palliation of the disease state, and remission (whether partial or total), whether detectable or undetectable.
- Treatment also includes prolonging survival as compared to expected survival if not receiving treatment or if receiving a different treatment.
- a treatment can include administration of a therapeutic agent, which can be an agent that exerts a cytotoxic, cytostatic, or immunomodulatory effect on diseased cells, e.g., cancer cells, or other cells that may promote a diseased state, e.g., activated immune cells.
- Therapeutic agents selected by the methods of the invention are not limited. Any therapeutic agent can be selected where a link can be made between molecular profiling and potential efficacy of the agent.
- Therapeutic agents include without limitation drugs, pharmaceuticals, small molecules, protein therapies, antibody therapies, viral therapies, gene therapies, and the like.
- Cancer treatments or therapies include apoptosis- mediated and non-apoptosis mediated cancer therapies including, without limitation, chemotherapy, hormonal therapy, radiotherapy, immunotherapy, and combinations thereof.
- Chemotherapeutic agents comprise therapeutic agents and combinations of therapeutic agents that treat, cancer cells, e.g., by killing those cells.
- chemotherapeutic drugs include without limitation alkylating agents (e.g., nitrogen mustard derivatives, ethylenimines, alkylsulfonates, hydrazines and triazines, nitrosureas, and metal salts), plant alkaloids (e.g., vinca alkaloids, taxanes, podophyllotoxins, and camptothecan analogs), antitumor antibiotics (e.g., anthracyclines, chromomycins, and the like), antimetabolites (e.g., folic acid antagonists, pyrimidine antagonists, purine antagonists, and adenosine deaminase inhibitors), topoisomerase I inhibitors, topoisomerase II inhibitors, and miscellaneous antineoplastics (e.g., ribonucleotide reductas
- a biomarker refers generally to a molecule, including without limitation a gene or product thereof, nucleic acids (e.g., DNA, RNA), protein/peptide/polypeptide, carbohydrate structure, lipid, glycolipid, characteristics of which can be detected in a tissue or cell to provide information that is predictive, diagnostic, prognostic and/or theranostic for sensitivity or resistance to candidate treatment.
- nucleic acids e.g., DNA, RNA
- protein/peptide/polypeptide e.g., carbohydrate structure
- lipid e.g., glycolipid
- a sample as used herein includes any relevant biological sample that can be used for molecular profiling, e.g., sections of tissues such as biopsy or tissue removed during surgical or other procedures, bodily fluids, autopsy samples, and frozen sections taken for histological purposes.
- samples include blood and blood fractions or products (e.g., serum, buffy coat, plasma, platelets, red blood cells, and the like), sputum, malignant effusion, cheek cells tissue, cultured cells (e.g., primary cultures, explants, and transformed cells), stool, urine, other biological or bodily fluids (e.g., prostatic fluid, gastric fluid, intestinal fluid, renal fluid, lung fluid, cerebrospinal fluid, and the like), etc.
- blood and blood fractions or products e.g., serum, buffy coat, plasma, platelets, red blood cells, and the like
- sputum e.g., malignant effusion
- cheek cells tissue e.g., cultured cells (e.g., primary cultures, explants
- the sample can comprise biological material that is a fresh frozen & formalin fixed paraffin embedded (FFPE) block, formalin- fixed paraffin embedded, or is within an RNA preservative + formalin fixative. More than one sample of more than one type can be used for each patient. In a preferred embodiment, the sample comprises a fixed tumor sample.
- FFPE fresh frozen & formalin fixed paraffin embedded
- the sample used in the methods described herein can be a formalin fixed paraffin embedded (FFPE) sample.
- the FFPE sample can be one or more of fixed tissue, unstained slides, bone marrow core or clot, core needle biopsy, malignant fluids and fine needle aspirate (FNA).
- the fixed tissue comprises a tumor containing formalin fixed paraffin embedded (FFPE) block from a surgery or biopsy.
- the unstained slides comprise unstained, charged, unbaked slides from a paraffin block.
- bone marrow core or clot comprises a decalcified core.
- a formalin fixed core and/or clot can be paraffin-embedded.
- the core needle biopsy comprises 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10 or more, e.g., 3-4, paraffin embedded biopsy samples.
- An 18 gauge needle biopsy can be used.
- the malignant fluid can comprise a sufficient volume of fresh pleural/ascitic fluid to produce a 5x5x2mm cell pellet.
- the fluid can be formalin fixed in a paraffin block.
- the core needle biopsy comprises 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 or more, e.g., 4-6, paraffin embedded aspirates.
- a sample may be processed according to techniques understood by those in the art.
- a sample can be without limitation fresh, frozen or fixed cells or tissue.
- a sample comprises formalin-fixed paraffin-embedded (FFPE) tissue, fresh tissue or fresh frozen (FF) tissue.
- FFPE formalin-fixed paraffin-embedded
- a sample can comprise cultured cells, including primary or immortalized cell lines derived from a subject sample.
- a sample can also refer to an extract from a sample from a subject.
- a sample can comprise DNA, RNA or protein extracted from a tissue or a bodily fluid. Many techniques and commercial kits are available for such purposes.
- the fresh sample from the individual can be treated with an agent to preserve RNA prior to further processing, e.g., cell lysis and extraction.
- Samples can include frozen samples collected for other purposes. Samples can be associated with relevant information such as age, gender, and clinical symptoms present in the subject; source of the sample; and methods of collection and storage of the sample.
- a sample is typically obtained from
- a biopsy comprises the process of removing a tissue sample for diagnostic or prognostic evaluation, and to the tissue specimen itself.
- Any biopsy technique known in the art can be applied to the molecular profiling methods of the present invention.
- the biopsy technique applied can depend on the tissue type to be evaluated (e.g., colon, prostate, kidney, bladder, lymph node, liver, bone marrow, blood cell, lung, breast, etc.), the size and type of the tumor (e.g., solid or suspended, blood or ascites), among other factors.
- Representative biopsy techniques include, but are not limited to, excisional biopsy, incisional biopsy, needle biopsy, surgical biopsy, and bone marrow biopsy.
- An "excisional biopsy” refers to the removal of an entire tumor mass with a small margin of normal tissue surrounding it.
- biopsy refers to the removal of a wedge of tissue that includes a cross-sectional diameter of the tumor.
- Molecular profiling can use a "core-needle biopsy” of the tumor mass, or a “fine-needle aspiration biopsy” which generally obtains a suspension of cells from within the tumor mass. Biopsy techniques are discussed, for example, in Harrison's Principles of Internal Medicine, asper, et al., eds., 16th ed., 2005, Chapter 70, and throughout Part V.
- PCR Polymerase chain reaction
- the sample can comprise vesicles.
- Methods of the invention can include assessing one or more vesicles, including assessing vesicle populations.
- a vesicle, as used herein, is a membrane vesicle that is shed from cells.
- Vesicles or membrane vesicles include without limitation: circulating microvesicles (cMVs), microvesicle, exosome, nanovesicle, dexosome, bleb, blebby, prostasome, microparticle, intralurnenal vesicle, membrane fragment, intralumenal endosomal vesicle, endosomal-like vesicle, exocytosis vehicle, endosome vesicle, endosomal vesicle, apoptotic body, multivesicular body, secretory vesicle, phospholipid vesicle, liposomal vesicle, argosome, texasome, secresome, tolerosome, melanosome, oncosome, or exocytosed vehicle.
- cMVs circulating microvesicles
- Vesicles may be produced by different cellular processes, the methods of the invention are not limited to or reliant on any one mechanism, insofar as such vesicles are present in a biological sample and are capable of being characterized by the methods disclosed herein. Unless otherwise specified, methods that make use of a species of vesicle can be applied to other types of vesicles. Vesicles comprise spherical structures with a lipid bilayer similar to cell membranes which surrounds an inner compartment which can contain soluble components, sometimes referred to as the payload. In some embodiments, the methods of the invention make use of exosomes, which are small secreted vesicles of about 40-100 nm in diameter. For a review of membrane vesicles, including types and characterizations, see Thery et al, Nat Rev Immunol. 2009 Aug;9(8):581-93. Some properties of different types of vesicles include those in Table 1:
- PPS phosphatidylserine
- EM electron microscopy
- Vesicles include shed membrane bound particles, or "microparticles," that are derived from either the plasma membrane or an internal membrane. Vesicles can be released into the extracellular environment from cells.
- Cells releasing vesicles include without limitation cells that originate from, or are derived from, the ectoderm, endoderm, or mesoderm. The cells may have undergone genetic, environmental, and/or any other variations or alterations.
- the cell can be tumor cells.
- a vesicle can reflect any changes in the source cell, and thereby reflect changes in the originating cells, e.g., cells having various genetic mutations.
- a vesicle is generated intracellularly when a segment of the cell membrane spontaneously invaginates and is ultimately exocytosed (see for example, Keller et al, Immunol. Lett. 107 (2): 102-8 (2006)).
- Vesicles also include cell-derived structures bounded by a lipid bilayer membrane arising from both herniated evagination (blebbing) separation and sealing of portions of the plasma membrane or from the export of any intracellular membrane-bounded vesicular structure containing various membrane-associated proteins of tumor origin, including surface- bound molecules derived from the host circulation that bind selectively to the tumor-derived proteins together with molecules contained in the vesicle lumen, including but not limited to tumor-derived microRNAs or intracellular proteins.
- a vesicle shed into circulation or bodily fluids from tumor cells may be referred to as a "circulating tumor-derived vesicle.”
- a vesicle shed into circulation or bodily fluids from tumor cells may be referred to as a "circulating tumor-derived vesicle.”
- a vesicle When such vesicle is an exosome, it may be referred to as a circulating-tumor derived exosome (CTE).
- CTE circulating-tumor derived exosome
- a vesicle can be derived from a specific cell of origin.
- CTE as with a cell-of-origin specific vesicle, typically have one or more unique biomarkers that permit isolation of the CTE or cell-of-origin specific vesicle, e.g., from a bodily fluid and sometimes in a specific manner.
- a cell or tissue specific markers are used to identify the cell of origin. Examples of such cell or tissue specific markers are disclosed herein and can further be accessed in the Tissue-specific Gene Expression and Regulation (TiGER) Database, available at bioinfo.wilmer.jhu.edu/tiger/; Liu et al. (2008) TiGER: a database for tissue-specific gene expression and regulation. BMC Bioinformatics. 9:271 ;
- TissueDistributionDBs available at genome.dkfz-heidelberg.de/menu/tissue_db/index.html.
- a vesicle can have a diameter of greater than about 10 nm, 20 nm, or 30 nm.
- a vesicle can have a diameter of greater than 40 nm, 50 nm, 100 nm, 200 nm, 500 nm, 1000 nm or greater than 10,000 nm.
- a vesicle can have a diameter of about 30- 1000 nm, about 30-800 nm, about 30-200 nm, or about 30- 100 nm.
- the vesicle has a diameter of less than 10,000 nm, 1000 nm, 800 nm, 500 nm, 200 nm, 100 nm, 50 nm, 40 nm, 30 nm, 20 nm or less than 10 nm.
- the term "about" in reference to a numerical value means that variations of 10% above or below the numerical value are within the range ascribed to the specified value. Typical sizes for various types of vesicles are shown in Table 1. Vesicles can be assessed to measure the diameter of a single vesicle or any number of vesicles.
- the range of diameters of a vesicle population or an average diameter of a vesicle population can be determined.
- Vesicle diameter can be assessed using methods known in the art, e.g., imaging technologies such as electron microscopy.
- a diameter of one or more vesicles is determined using optical particle detection. See, e.g., U.S. Patent 7,751 ,053, entitled “Optical Detection and Analysis of Particles" and issued July 6, 2010; and U.S. Patent 7,399,600, entitled “Optical Detection and Analysis of Particles" and issued July 15, 2010.
- vesicles are directly assayed from a biological sample without prior isolation, purification, or concentration from the biological sample.
- the amount of vesicles in the sample can by itself provide a biosignature that provides a diagnostic, prognostic or theranostic determination.
- the vesicle in the sample may be isolated, captured, purified, or concentrated from a sample prior to analysis.
- isolation, capture or purification as used herein comprises partial isolation, partial capture or partial purification apart from other components in the sample.
- Vesicle isolation can be performed using various techniques as described herein or known in the art, including without limitation size exclusion chromatography, density gradient centrifugation, differential centrifugation, nanomembrane ultrafiltration, immuno absorbent capture, affinity purification, affinity capture, immunoassay, immunoprecipitation, microfluidic separation, flow cytometry or combinations thereof.
- Vesicles can be assessed to provide a phenotypic characterization by comparing vesicle characteristics to a reference.
- surface antigens on a vesicle are assessed.
- a vesicle or vesicle population carrying a specific marker can be referred to as a positive (biomarker+) vesicle or vesicle population.
- a DLL4+ population refers to a vesicle population associated with DLL4.
- a DLL4- population would not be associated with DLL4.
- the surface antigens can provide an indication of the anatomical origin and/or cellular of the vesicles and other phenotypic information, e.g., tumor status.
- vesicles found in a patient sample can be assessed for surface antigens indicative of colorectal origin and the presence of cancer, thereby identifying vesicles associated with colorectal cancer cells.
- the surface antigens may comprise any informative biological entity that can be detected on the vesicle membrane surface, including without limitation surface proteins, lipids, carbohydrates, and other membrane components.
- positive detection of colon derived vesicles expressing tumor antigens can indicate that the patient has colorectal cancer.
- methods of the invention can be used to characterize any disease or condition associated with an anatomical or cellular origin, by assessing, for example, disease-specific and cell-specific biomarkers of one or more vesicles obtained from a subject.
- one or more vesicle payloads are assessed to provide a phenotypic
- the payload with a vesicle comprises any informative biological entity that can be detected as encapsulated within the vesicle, including without limitation proteins and nucleic acids, e.g., genomic or cDNA, mRNA, or functional fragments thereof, as well as microRNAs (miRs).
- methods of the invention are directed to detecting vesicle surface antigens (in addition or exclusive to vesicle payload) to provide a phenotypic characterization.
- vesicles can be characterized by using binding agents (e.g., antibodies or aptamers) that are specific to vesicle surface antigens, and the bound vesicles can be further assessed to identify one or more payload components disclosed therein.
- the levels of vesicles with surface antigens of interest or with payload of interest can be compared to a reference to characterize a phenotype.
- overexpression in a sample of cancer- related surface antigens or vesicle payload e.g., a tumor associated mRNA or microRNA, as compared to a reference, can indicate the presence of cancer in the sample.
- the biomarkers assessed can be present or absent, increased or reduced based on the selection of the desired target sample and comparison of the target sample to the desired reference sample.
- target samples include: disease; treated/not-treated; different time points, such as a in a longitudinal study; and non-limiting examples of reference sample: non-disease; normal; different time points; and sensitive or resistant to candidate treatment(s).
- molecular profiling of the invention comprises analysis of microvesicles, such as circulating microvesicles.
- MicroRNAs comprise one class biomarkers assessed via methods of the invention.
- MicroRNAs also referred to herein as miRNAs or miRs, are short RNA strands approximately 21 -23 nucleotides in length.
- MiRNAs are encoded by genes that are transcribed from DNA but are not translated into protein and thus comprise non-coding RNA.
- the miRs are processed from primary transcripts known as pri-miRNA to short stem-loop structures called pre-miRNA and finally to the resulting single strand miRNA.
- the pre-miRNA typically forms a structure that folds back on itself in self-complementary regions.
- Mature miRNA molecules are partially complementary to one or more messenger RNA (mRNA) molecules and can function to regulate translation of proteins. Identified sequences of miRNA can be accessed at publicly available databases, such as www.microRNA.org, www.mirbase.org, or www.mirz.unibas.ch/cgi/miRNA.cgi.
- miRNAs are generally assigned a number according to the naming convention " mir-[number]." The number of a miRNA is assigned according to its order of discovery relative to previously identified miRNA species. For example, if the last published miRNA was mir-121, the next discovered miRNA will be named mir- 122, etc. When a miRNA is discovered that is homologous to a known miRNA from a different organism, the name can be given an optional organism identifier, of the form [organism identifier]- mir-[number]. Identifiers include hsa for Homo sapiens and mmu for Mus Musculus. For example, a human homolog to mir- 121 might be referred to as hsa-mir- 121 whereas the mouse homolog can be referred to as mmu-mir- 121.
- Mature microRNA is commonly designated with the prefix “miR” whereas the gene or precursor miRNA is designated with the prefix “mir.”
- mir- 121 is a precursor for miR- 121.
- the genes/precursors can be delineated by a numbered suffix.
- mir-121-1 and mir- 121-2 can refer to distinct genes or precursors that are processed into miR- 121.
- Lettered suffixes are used to indicate closely related mature sequences.
- mir-121 a and mir- 121b can be processed to closely related miRNAs miR-121a and miR- 121b, respectively.
- any microRNA (miRNA or miR) designated herein with the prefix mir-* or miR-* is understood to encompass both the precursor and/or mature species, unless otherwise explicitly stated otherwise.
- miR- 121 would be the predominant product whereas miR- 121 * is the less common variant found on the opposite arm of the precursor.
- the miRs can be distinguished by the suffix "5p" for the variant from the 5' arm of the precursor and the suffix "3p" for the variant from the 3' arm.
- miR- 121 -5p originates from the 5' arm of the precursor whereas miR- 121 -3p originates from the 3 ' arm.
- miR- 121 -5p may be referred to as miR- 121 -s
- miR-121-3p may be referred to as miR- 121-as.
- Plant miRNAs follow a different naming convention as described in Meyers et al., Plant Cell. 2008 20(12):3186-3190.
- miRNAs are involved in gene regulation, and miRNAs are part of a growing class of non-coding RNAs that is now recognized as a major tier of gene control.
- miRNAs can interrupt translation by binding to regulatory sites embedded in the 3'-UTRs of their target mRNAs, leading to the repression of translation.
- Target recognition involves complementary base pairing of the target site with the miRNA's seed region (positions 2-8 at the miRNA's 5' end), although the exact extent of seed complementarity is not precisely determined and can be modified by 3' pairing.
- miRNAs function like small interfering RNAs (siRNA) and bind to perfectly complementary mRNA sequences to destroy the target transcript.
- miRNAs Characterization of a number of miRNAs indicates that they influence a variety of processes, including early development, cell proliferation and cell death, apoptosis and fat metabolism. For example, some miRNAs, such as lin-4, let-7, mir- 14, mir-23, and bantam, have been shown to play critical roles in cell differentiation and tissue development. Others are believed to have similarly important roles because of their differential spatial and temporal expression patterns.
- the miRNA database available at miRBase comprises a searchable database of published miRNA sequences and annotation. Further information about miRBase can be found in the following articles, each of which is incorporated by reference in its entirety herein: Griffiths-Jones et al., miRBase: tools for microRNA genomics. NAR 2008 36(Database Issue):D154-D158; Griffiths-Jones et al., miRBase: microRNA sequences, targets and gene nomenclature. NAR 2006 34(Database
- microRNAs are known to be involved in cancer and other diseases and can be assessed in order to characterize a phenotype in a sample. See, e.g., Ferracin et al., Micromarkers: miRNAs in cancer diagnosis and prognosis, Exp Rev Mol Diag, Apr 2010, Vol. 10, No. 3, Pages 297- 308; Fabbri, miRNAs as molecular biomarkers of cancer, Exp Rev Mol Diag, May 2010, Vol. 10, No. 4, Pages 435-444. [00129] In an embodiment, molecular profiling of the invention comprises analysis of microRNA.
- BIOMARKERS FOR THERANOSTICS and filed March 1 , 201 1 ; and WO/201 1/127219, entitled “CIRCULATING BIOMARKERS FOR DISEASE” and filed April 6, 201 1, each of which applications are incorporated by reference herein in their entirety.
- Circulating biomarkers include biomarkers that are detectable in body fluids, such as blood, plasma, serum.
- body fluids such as blood, plasma, serum.
- circulating cancer biomarkers include cardiac troponin T (cTnT), prostate specific antigen (PSA) for prostate cancer and CA125 for ovarian cancer.
- Circulating biomarkers according to the invention include any appropriate biomarker that can be detected in bodily fluid, including without limitation protein, nucleic acids, e.g., DNA, mRNA and microRNA, lipids, carbohydrates and metabolites.
- Circulating biomarkers can include biomarkers that are not associated with cells, such as biomarkers that are membrane associated, embedded in membrane fragments, part of a biological complex, or free in solution.
- circulating biomarkers are biomarkers that are associated with one or more vesicles present in the biological fluid of a subject.
- Circulating biomarkers have been identified for use in characterization of various phenotypes, such as detection of a cancer. See, e.g., Ahmed N, et al., Proteomic -based identification of haptoglobin- 1 precursor as a novel circulating biomarker of ovarian cancer. Br. J. Cancer 2004; Mathelin et al., Circulating proteinic biomarkers and breast cancer, Gynecol Obstet Fertil. 2006 Jul-Aug;34(7-8):638-46. Epub 2006 Jul 28; Ye et al., Recent technical strategies to identify diagnostic biomarkers for ovarian cancer. Expert Rev Proteomics.
- molecular profiling of the invention comprises analysis of circulating biomarkers.
- the methods and systems of the invention comprise expression profiling, which includes assessing differential expression of one or more target genes disclosed herein.
- Differential expression can include overexpression and/or underexpression of a biological product, e.g., a gene, mRNA or protein, compared to a control (or a reference).
- the control can include similar cells to the sample but without the disease (e.g., expression profiles obtained from samples from healthy individuals).
- a control can be a previously determined level that is indicative of a drug target efficacy associated with the particular disease and the particular drug target.
- the control can be derived from the same patient, e.g., a normal adj cent portion of the same organ as the diseased cells, the control can be derived from healthy tissues from other patients, or previously determined thresholds that are indicative of a disease responding or not-responding to a particular drug target.
- the control can also be a control found in the same sample, e.g. a housekeeping gene or a product thereof (e.g., mRNA or protein).
- a control nucleic acid can be one which is known not to differ depending on the cancerous or non-cancerous state of the cell.
- the expression level of a control nucleic acid can be used to normalize signal levels in the test and reference populations.
- Illustrative control genes include, but are not limited to, e.g., ⁇ -actin,
- differential expression can vary. For example, a gene copy number may be increased in a cell, thereby resulting in increased expression of the gene. Alternately, transcription of the gene may be modified, e.g., by chromatin remodeling, differential methylation, differential expression or activity of transcription factors, etc. Translation may also be modified, e.g., by differential expression of factors that degrade mRNA, translate mRNA, or silence translation, e.g., microRNAs or siRNAs. In some embodiments, differential expression comprises differential activity. For example, a protein may carry a mutation that increases the activity of the protein, such as constitutive activation, thereby contributing to a diseased state. Molecular profiling that reveals changes in activity can be used to guide treatment selection.
- Methods of gene expression profiling include methods based on hybridization analysis of
- RT-PCR Reverse transcription polymerase chain reaction
- PCR polymerase chain reaction
- a RNA strand is reverse transcribed into its DNA complement (i.e., complementary DNA, or cDNA) using the enzyme reverse transcriptase, and the resulting cDNA is amplified using PCR.
- Real-time polymerase chain reaction is another PCR variant, which is also referred to as quantitative PCR, Q-PCR, qRT-PCR, or sometimes as RT-PCR.
- Either the reverse transcription PCR method or the real-time PCR method can be used for molecular profiling according to the invention, and RT-PCR can refer to either unless otherwise specified or as understood by one of skill in the art.
- RT-PCR can be used to determine RNA levels, e.g., mRNA or miRNA levels, of the biomarkers of the invention. RT-PCR can be used to compare such RNA levels of the biomarkers of the invention in different sample populations, in normal and tumor tissues, with or without drug treatment, to characterize patterns of gene expression, to discriminate between closely related RNAs, and to analyze RNA structure.
- RNA levels e.g., mRNA or miRNA levels
- the first step is the isolation of RNA, e.g., mRNA, from a sample.
- the starting material can be total RNA isolated from human tumors or tumor cell lines, and corresponding normal tissues or cell lines, respectively.
- RNA can be isolated from a sample, e.g., tumor cells or tumor cell lines, and compared with pooled DNA from healthy donors. If the source of mRNA is a primary tumor, mRNA can be extracted, for example, from frozen or archived paraffin-embedded and fixed (e.g. formalin- fixed) tissue samples.
- RNA isolation can be performed using purification kit, buffer set and protease from commercial manufacturers, such as Qiagen, according to the manufacturer's instructions (QIAGEN Inc., Valencia, CA). For example, total RNA from cells in culture can be isolated using Qiagen RNeasy mini- columns. Numerous RNA isolation kits are commercially available and can be used in the methods of the invention.
- the first step is the isolation of miRNA from a target sample.
- the starting material is typically total RNA isolated from human tumors or tumor cell lines, and corresponding normal tissues or cell lines, respectively.
- RNA can be isolated from a variety of primary tumors or tumor cell lines, with pooled DNA from healthy donors. If the source of miRNA is a primary tumor, miRNA can be extracted, for example, from frozen or archived paraffin-embedded and fixed (e.g.
- RNA isolation can be performed using purification kit, buffer set and protease from commercial manufacturers, such as Qiagen, according to the manufacturer's instructions. For example, total RNA from cells in culture can be isolated using Qiagen RNeasy mini-columns. Numerous miRNA isolation kits are commercially available and can be used in the methods of the invention.
- RNA comprises mRNA, miRNA or other types of RNA
- gene expression profiling by RT-PCR can include reverse transcription of the RNA template into cDNA, followed by amplification in a PCR reaction.
- Commonly used reverse transcriptases include, but are not limited to, avilo myeloblastosis virus reverse transcriptase (AMV-RT) and Moloney murine leukemia virus reverse transcriptase (MMLV-RT).
- AMV-RT avilo myeloblastosis virus reverse transcriptase
- MMLV-RT Moloney murine leukemia virus reverse transcriptase
- the reverse transcription step is typically primed using specific primers, random hexamers, or oligo-dT primers, depending on the circumstances and the goal of expression profiling.
- extracted RNA can be reverse -transcribed using a GeneAmp RNA PCR kit (Perkin Elmer, Calif, USA), following the manufacturer's instructions.
- the derived cDNA can then be used as
- the PCR step can use a variety of thermostable DNA-dependent DNA polymerases, it typically employs the Taq DNA polymerase, which has a 5'-3' nuclease activity but lacks a 3'-5' proofreading endonuclease activity.
- TaqMan PCR typically uses the 5'-nuc lease activity of Taq or Tth polymerase to hydrolyze a hybridization probe bound to its target amplicon, but any enzyme with equivalent 5' nuclease activity can be used.
- Two oligonucleotide primers are used to generate an amplicon typical of a PCR reaction.
- a third oligonucleotide, or probe is designed to detect nucleotide sequence located between the two PCR primers.
- the probe is non-extendible by Taq DNA polymerase enzyme, and is labeled with a reporter fluorescent dye and a quencher fluorescent dye. Any laser-induced emission from the reporter dye is quenched by the quenching dye when the two dyes are located close together as they are on the probe.
- the Taq DNA polymerase enzyme cleaves the probe in a template-dependent manner. The resultant probe fragments disassociate in solution, and signal from the released reporter dye is free from the quenching effect of the second fluorophore.
- One molecule of reporter dye is liberated for each new molecule synthesized, and detection of the unquenched reporter dye provides the basis for quantitative interpretation of the data.
- TaqManTM RT-PCR can be performed using commercially available equipment, such as, for example, ABI PRISM 7700TM Sequence Detection SystemTM (Perkin-Elmer-Applied Biosystems, Foster City, Calif, USA), or LightCycler (Roche Molecular Biochemicals, Mannheim, Germany).
- the 5' nuclease procedure is run on a real-time quantitative PCR device such as the ABI PRISM 7700 Sequence Detection System.
- the system consists of a thermocycler, laser, charge- coupled device (CCD), camera and computer.
- the system amplifies samples in a 96-well format on a thermocycler.
- laser-induced fluorescent signal is collected in real-time through fiber optic cables for all 96 wells, and detected at the CCD.
- the system includes software for running the instrument and for analyzing the data.
- TaqMan data are initially expressed as Ct, or the threshold cycle.
- Ct threshold cycle
- RT-PCR is usually performed using an internal standard.
- the ideal internal standard is expressed at a constant level among different tissues, and is unaffected by the experimental treatment.
- RNAs most frequently used to normalize patterns of gene expression are mRNAs for the housekeeping genes glyceraldehyde-3-phosphate- dehydrogenase (GAPDH) and ⁇ -actin.
- GPDH glyceraldehyde-3-phosphate- dehydrogenase
- ⁇ -actin glyceraldehyde-3-phosphate- dehydrogenase
- Real time quantitative PCR (also quantitative real time polymerase chain reaction, QRT-PCR or Q-PCR) is a more recent variation of the RT-PCR technique.
- Q-PCR can measure PCR product accumulation through a dual-labeled fluorigenic probe (i.e., TaqMan probe).
- Real time PCR is compatible both with quantitative competitive PCR, where internal competitor for each target sequence is used for normalization, and with quantitative comparative PCR using a normalization gene contained within the sample, or a housekeeping gene for RT-PCR. See, e.g. Held et al. (1996) Genome Research 6:986-994.
- Protein-based detection techniques are also useful for molecular profiling, especially when the nucleotide variant causes amino acid substitutions or deletions or insertions or frame shift that affect the protein primary, secondary or tertiary structure.
- protein sequencing techniques may be used.
- a protein or fragment thereof corresponding to a gene can be synthesized by recombinant expression using a DNA fragment isolated from an individual to be tested.
- a cDNA fragment of no more than 100 to 150 base pairs encompassing the polymorphic locus to be determined is used.
- the amino acid sequence of the peptide can then be determined by conventional protein sequencing methods.
- HPLC-microscopy tandem mass spectrometry technique can be used for determining the amino acid sequence variations.
- proteolytic digestion is performed on a protein, and the resulting peptide mixture is separated by reversed-phase chromatographic separation. Tandem mass spectrometry is then performed and the data collected is analyzed. See Gatlin et al., Anal. Chem., 72:757-763 (2000).
- the biomarkers of the invention can also be identified, confirmed, and/or measured using the microarray technique.
- the expression profile biomarkers can be measured in cancer samples using microarray technology.
- polynucleotide sequences of interest are plated, or arrayed, on a microchip substrate.
- the arrayed sequences are then hybridized with specific DNA probes from cells or tissues of interest.
- the source of mRNA can be total RNA isolated from a sample, e.g., human tumors or tumor cell lines and corresponding normal tissues or cell lines.
- RNA can be isolated from a variety of primary tumors or tumor cell lines. If the source of mRNA is a primary tumor, mRNA can be extracted, for example, from frozen or archived paraffin-embedded and fixed (e.g. formalin- fixed) tissue samples, which are routinely prepared and preserved in everyday clinical practice.
- the expression profile of biomarkers can be measured in either fresh or paraffin-embedded tumor tissue, or body fluids using microarray technology.
- polynucleotide sequences of interest are plated, or arrayed, on a microchip substrate.
- the arrayed sequences are then hybridized with specific DNA probes from cells or tissues of interest.
- the source of miRNA typically is total RNA isolated from human tumors or tumor cell lines, including body fluids, such as serum, urine, tears, and exosomes and corresponding normal tissues or cell lines.
- body fluids such as serum, urine, tears, and exosomes and corresponding normal tissues or cell lines.
- RNA can be isolated from a variety of sources. If the source of miRNA is a primary tumor, miRNA can be extracted, for example, from frozen tissue samples, which are routinely prepared and preserved in everyday clinical practice.
- cDNA microarray technology allows for identification of gene expression levels in a biologic sample.
- cDNAs or oligonucleotides, each representing a given gene are immobilized on a substrate, e.g., a small chip, bead or nylon membrane, tagged, and serve as probes that will indicate whether they are expressed in biologic samples of interest.
- a substrate e.g., a small chip, bead or nylon membrane
- PCR amplified inserts of cDNA clones are applied to a substrate in a dense array.
- at least 100, 200, 300, 400, 500, 600, 700, 800, 900, 1,000, 1 ,500, 2,000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10,000, 15,000, 20,000, 25,000, 30,000, 35,000, 40,000, 45,000 or at least 50,000 nucleotide sequences are applied to the substrate.
- Each sequence can correspond to a different gene, or multiple sequences can be arrayed per gene.
- the microarrayed genes, immobilized on the microchip, are suitable for hybridization under stringent conditions.
- Fluorescently labeled cDNA probes may be generated through incorporation of fluorescent nucleotides by reverse transcription of RNA extracted from tissues of interest. Labeled cDNA probes applied to the chip hybridize with specificity to each spot of DNA on the array. After stringent washing to remove non-specifically bound probes, the chip is scanned by confocal laser microscopy or by another detection method, such as a CCD camera. Quantitation of hybridization of each arrayed element allows for assessment of corresponding mRNA abundance. With dual color fluorescence, separately labeled cDNA probes generated from two sources of RNA are hybridized pairwise to the array. The relative abundance of the transcripts from the two sources corresponding to each specified gene is thus determined simultaneously.
- the miniaturized scale of the hybridization affords a convenient and rapid evaluation of the expression pattern for large numbers of genes.
- Such methods have been shown to have the sensitivity required to detect rare transcripts, which are expressed at a few copies per cell, and to reproducibly detect at least approximately two-fold differences in the expression levels (Schena et al. (1996) Proc. Natl. Acad. Sci. USA 93(2): 106- 149).
- Microarray analysis can be performed by commercially available equipment following manufacturer's protocols, including without limitation the Affymetrix GeneChip technology (Affymetrix, Santa Clara, CA), Agilent (Agilent Technologies, Inc., Santa Clara, CA), or Illumina (Illumina, Inc., San Diego, CA) microarray technology.
- the system can analyze more than 41 ,000 unique human genes and transcripts represented, all with public domain annotations.
- the system is used according to the manufacturer's instructions.
- the Illumina Whole Genome DASL assay (Illumina Inc., San Diego, CA) is used.
- the system offers a method to simultaneously profile over 24,000 transcripts from minimal RNA input, from both fresh frozen (FF) and formalin- fixed paraffin embedded (FFPE) tissue sources, in a high throughput fashion.
- Microarray expression analysis comprises identifying whether a gene or gene product is up- regulated or down-regulated relative to a reference. The identification can be performed using a statistical test to determine statistical significance of any differential expression observed. In some embodiments, statistical significance is determined using a parametric statistical test.
- the parametric statistical test can comprise, for example, a fractional factorial design, analysis of variance (ANOVA), a t-test, least squares, a Pearson correlation, simple linear regression, nonlinear regression, multiple linear regression, or multiple nonlinear regression.
- the parametric statistical test can comprise a one-way analysis of variance, two-way analysis of variance, or repeated measures analysis of variance. In other embodiments, statistical significance is determined using a nonparametric statistical test.
- Examples include, but are not limited to, a Wilcoxon signed-rank test, a Mann- Whitney test, a Kruskal-Wallis test, a Friedman test, a Spearman ranked order correlation coefficient, a Kendall Tau analysis, and a nonparametric regression test.
- statistical significance is determined at a p-value of less than about 0.05, 0.01, 0.005, 0.001, 0.0005, or 0.0001.
- the p-values can also be corrected for multiple comparisons, e.g., using a Bonferroni correction, a modification thereof, or other technique known to those in the art, e.g., the Hochberg correction, Holm-Bonferroni correction, Sidak correction, or Dunnett's correction.
- the degree of differential expression can also be taken into account.
- a gene can be considered as differentially expressed when the fold-change in expression compared to control level is at least 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0, 2.2, 2.5, 2.7, 3.0, 4, 5, 6, 7, 8, 9 or 10-fold different in the sample versus the control.
- the differential expression takes into account both overexpression and underexpression.
- a gene or gene product can be considered up or down-regulated if the differential expression meets a statistical threshold, a fold-change threshold, or both.
- the criteria for identifying differential expression can comprise both a p-value of 0.001 and fold change of at least 1.5-fold (up or down).
- One of skill will understand that such statistical and threshold measures can be adapted to determine differential expression by any molecular profiling technique disclosed herein.
- Microarrays include without limitation DNA microarrays, such as cDNA microarrays, oligonucleotide microarrays and SNP microarrays, microRNA arrays, protein microarrays, antibody microarrays, tissue microarrays, cellular microarrays (also called transfection microarrays), chemical compound microarrays, and carbohydrate arrays (glycoarrays).
- DNA microarrays such as cDNA microarrays, oligonucleotide microarrays and SNP microarrays, microRNA arrays, protein microarrays, antibody microarrays, tissue microarrays, cellular microarrays (also called transfection microarrays), chemical compound microarrays, and carbohydrate arrays (glycoarrays).
- DNA arrays typically comprise addressable nucleotide sequences that can bind to sequences present in a sample.
- MicroRNA arrays e.g., the MMChips array from the University of Louisville or commercial systems from Agilent, can be used to detect microRNAs.
- Protein microarrays can be used to identify protein-protein interactions, including without limitation identifying substrates of protein kinases, transcription factor protein-activation, or to identify the targets of biologically active small molecules. Protein arrays may comprise an array of different protein molecules, commonly antibodies, or nucleotide sequences that bind to proteins of interest.
- Antibody microarrays comprise antibodies spotted onto the protein chip that are used as capture molecules to detect proteins or other biological materials from a sample, e.g., from cell or tissue lysate solutions.
- antibody arrays can be used to detect biomarkers from bodily fluids, e.g., serum or urine, for diagnostic applications.
- Tissue microarrays comprise separate tissue cores assembled in array fashion to allow multiplex histological analysis.
- Cellular microarrays, also called transfection microarrays comprise various capture agents, such as antibodies, proteins, or lipids, which can interact with cells to facilitate their capture on addressable locations.
- Chemical compound microarrays comprise arrays of chemical compounds and can be used to detect protein or other biological materials that bind the compounds.
- Carbohydrate arrays (glycoarrays) comprise arrays of carbohydrates and can detect, e.g., protein that bind sugar moieties.
- Certain embodiments of the current methods comprise a multi-well reaction vessel, including without limitation, a multi-well plate or a multi-chambered microfluidic device, in which a multiplicity of amplification reactions and, in some embodiments, detection are performed, typically in parallel.
- one or more multiplex reactions for generating amplicons are performed in the same reaction vessel, including without limitation, a multi-well plate, such as a 96-well, a 384-well, a 1536-well plate, and so forth; or a microfluidic device, for example but not limited to, a TaqManTM Low Density Array (Applied Biosystems, Foster City, CA).
- a massively parallel amplifying step comprises a multi-well reaction vessel, including a plate comprising multiple reaction wells, for example but not limited to, a 24-well plate, a 96-well plate, a 384-well plate, or a 1536-well plate; or a multi-chamber microfluidics device, for example but not limited to a low density array wherein each chamber or well comprises an appropriate primer(s), primer set(s), and/or reporter probe(s), as appropriate.
- amplification steps occur in a series of parallel single-plex, two-plex, three- plex, four-plex, five-plex, or six-plex reactions, although higher levels of parallel multiplexing are also within the intended scope of the current teachings.
- These methods can comprise PCR methodology, such as RT-PCR, in each of the wells or chambers to amplify and/or detect nucleic acid molecules of interest.
- Low density arrays can include arrays that detect 10s or 100s of molecules as opposed to 1000s of molecules. These arrays can be more sensitive than high density arrays.
- a low density array such as a TaqManTM Low Density Array is used to detect one or more gene or gene product in Table 2, Table 6 or Table 25.
- the low density array can be used to detect at least 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 40, 50, 60, 70, 80, 90 or 100 genes or gene products in Table 2, Table 6 or Table 25.
- the disclosed methods comprise a microfluidics device, "lab on a chip,” or micrototal analytical system (pTAS).
- sample preparation is performed using a microfluidics device.
- an amplification reaction is performed using a microfluidics device.
- a sequencing or PCR reaction is performed using a microfluidic device.
- the nucleotide sequence of at least a part of an amplified product is obtained using a microfluidics device.
- detecting comprises a microfluidic device, including without limitation, a low density array, such as a TaqManTM Low Density Array.
- microfluidic devices can be found in, among other places, Published PCT Application Nos. WO/0185341 and WO 04/01 1666; Kartalov and Quake, Nucl. Acids Res. 32:2873-79, 2004; and Fiorini and Chiu, Bio Techniques 38:429-46, 2005.
- microfluidic device can be used in the methods of the invention.
- microfluidic devices that may be used, or adapted for use with molecular profiling, include but are not limited to those described in U.S. Pat. Nos. 7,591,936, 7,581 ,429, 7,579, 136, 7,575,722, 7,568,399, 7,552,741, 7,544,506, 7,541,578, 7,518,726, 7,488,596, 7,485,214, 7,467,928, 7,452,713, 7,452,509, 7,449,096, 7,431 ,887, 7,422,725, 7,422,669, 7,419,822, 7,419,639, 7,413,709, 7,411 , 184, 7,402,229, 7,390,463, 7,381 ,471 , 7,357,864, 7,351,592, 7,351 ,380, 7,338,637, 7,329,391, 7,323, 140, 7,261 ,824, 7,258,
- Another example for use with methods disclosed herein is described in Chen et ah, "Microfluidic isolation and transcriptome analysis of serum vesicles, " Lab on a Chip, Dec. 8, 2009 DOI: 10.1039/b916199f.
- This method is a sequencing approach that combines non-gel-based signature sequencing with in vitro cloning of millions of templates on separate microbeads.
- a microbead library of DNA templates is constructed by in vitro cloning. This is followed by the assembly of a planar array of the template-containing microbeads in a flow cell at a high density. The free ends of the cloned templates on each microbead are analyzed simultaneously, using a fluorescence-based signature sequencing method that does not require DNA fragment separation. This method has been shown to simultaneously and accurately provide, in a single operation, hundreds of thousands of gene signature sequences from a cDNA library.
- MPSS data has many uses. The expression levels of nearly all transcripts can be quantitatively determined; the abundance of signatures is representative of the expression level of the gene in the analyzed tissue. Quantitative methods for the analysis of tag frequencies and detection of differences among libraries have been published and incorporated into public databases for SAGETM data and are applicable to MPSS data. The availability of complete genome sequences permits the direct comparison of signatures to genomic sequences and further extends the utility of MPSS data. Because the targets for MPSS analysis are not pre-selected (like on a microarray), MPSS data can characterize the full complexity of transcriptomes. This is analogous to sequencing millions of ESTs at once, and genomic sequence data can be used so that the source of the MPSS signature can be readily identified by computational means.
- Serial analysis of gene expression is a method that allows the simultaneous and quantitative analysis of a large number of gene transcripts, without the need of providing an individual hybridization probe for each transcript.
- a short sequence tag e.g., about 10-14 bp
- many transcripts are linked together to form long serial molecules, that can be sequenced, revealing the identity of the multiple tags simultaneously.
- the expression pattern of any population of transcripts can be quantitatively evaluated by determining the abundance of individual tags, and identifying the gene corresponding to each tag. See, e.g. Velculescu et al. (1995) Science 270:484-487; and Velculescu et al. (1997) Cell 88:243-51.
- Any method capable of determining a DNA copy number profile of a particular sample can be used for molecular profiling according to the invention as long as the resolution is sufficient to identify the biomarkers of the invention.
- the skilled artisan is aware of and capable of using a number of different platforms for assessing whole genome copy number changes at a resolution sufficient to identify the copy number of the one or more biomarkers of the invention. Some of the platforms and techniques are described in the embodiments below.
- the copy number profile analysis involves amplification of whole genome DNA by a whole genome amplification method.
- the whole genome amplification method can use a strand displacing polymerase and random primers.
- the copy number profile analysis involves hybridization of whole genome amplified DNA with a high density array.
- the high density array has 5,000 or more different probes.
- the high density array has 5,000, 10,000, 20,000, 50,000, 100,000, 200,000, 300,000, 400,000, 500,000, 600,000, 700,000, 800,000, 900,000, or 1,000,000 or more different probes.
- each of the different probes on the array is an oligonucleotide having from about 15 to 200 bases in length.
- each of the different probes on the array is an oligonucleotide having from about 15 to 200, 15 to 150, 15 to 100, 15 to 75, 15 to 60, or 20 to 55 bases in length.
- a microarray is employed to aid in determining the copy number profile for a sample, e.g., cells from a tumor.
- Microarrays typically comprise a plurality of oligomers (e.g., DNA or RNA polynucleotides or oligonucleotides, or other polymers), synthesized or deposited on a substrate (e.g., glass support) in an array pattern.
- the support-bound oligomers are "probes", which function to hybridize or bind with a sample material (e.g., nucleic acids prepared or obtained from the tumor samples), in hybridization experiments.
- the sample can be bound to the microarray substrate and the oligomer probes are in solution for the hybridization.
- the array surface is contacted with one or more targets under conditions that promote specific, high- affinity binding of the target to one or more of the probes.
- the sample nucleic acid is labeled with a detectable label, such as a fluorescent tag, so that the hybridized sample and probes are detectable with scanning equipment.
- a detectable label such as a fluorescent tag
- the substrates used for arrays are surface-derivatized glass or silica, or polymer membrane surfaces (see e.g., in Z. Guo, et al., Nucleic Acids Res, 22, 5456-65 (1994); U. Maskos, E. M. Southern, Nucleic Acids Res, 20, 1679-84 (1992), and E. M. Southern, et al., Nucleic Acids Res, 22, 1368-73 (1994), each incorporated by reference herein). Modification of surfaces of array substrates can be accomplished by many techniques.
- siliceous or metal oxide surfaces can be derivatized with bifunctional silanes, i.e., silanes having a first functional group enabling covalent binding to the surface (e.g., Si-halogen or Si-alkoxy group, as in— SiCl 3 or ⁇ Si(OCH 3 ) 3 , respectively) and a second functional group that can impart the desired chemical and/or physical modifications to the surface to covalently or non-covalently attach ligands and/or the polymers or monomers for the biological probe array.
- Silylated derivatizations and other surface derivatizations that are known in the art (see for example U.S. Pat. No. 5,624,711 to Sundberg, U.S. Pat. No. 5,266,222 to Willis, and U.S. Pat. No.
- Nucleic acid arrays that are useful in the present invention include, but are not limited to, those that are commercially available from Affymetrix (Santa Clara, Calif.) under the brand name GeneChipTM. Example arrays are shown on the website at affymetrix.com. Another microarray supplier is Illumina, Inc., of San Diego, Calif, with example arrays shown on their website at illumina.com. [00172] In some embodiments, the inventive methods provide for sample preparation. Depending on the microarray and experiment to be performed, sample nucleic acid can be prepared in a number of ways by methods known to the skilled artisan. In some aspects of the invention, prior to or concurrent with genotyping (analysis of copy number profiles), the sample may be amplified any number of mechanisms.
- PCR Technology Principles and Applications for DNA Amplification (Ed. H. A. Erlich, Freeman Press, NY, N.Y., 1992); PCR Protocols: A Guide to Methods and Applications (Eds. Innis, et al., Academic Press, San Diego, Calif, 1990); Mattila et al., Nucleic Acids Res. 19, 4967 (1991); Eckert et al., PCR Methods and Applications 1 , 17 (1991); PCR (Eds. McPherson et al., IRL Press, Oxford); and U.S. Pat. Nos.
- the sample may be amplified on the array (e.g., U.S. Pat. No. 6,300,070 which is incorporated herein by reference)
- LCR ligase chain reaction
- PCR ligase chain reaction
- CP-PCR consensus sequence primed polymerase chain reaction
- nucleic acid based sequence amplification See, U.S. Pat. Nos. 5,409,818, 5,554,517, and 6,063,603, each of which is incorporated herein by reference).
- Other amplification methods that may be used are described in, U.S. Pat. Nos. 5,242,794, 5,494,810, 4,988,617 and in U.S. Ser. No. 09/854,317, each of which is incorporated herein by reference.
- Hybridization assay procedures and conditions used in the methods of the invention will vary depending on the application and are selected in accordance with the general binding methods known including those referred to in: Maniatis et al. Molecular Cloning: A Laboratory Manual (2.sup.nd Ed. Cold Spring Harbor, N.Y., 1989); Berger and Kimmel Methods in Enzymology, Vol. 152, Guide to Molecular Cloning Techniques (Academic Press, Inc., San Diego, Calif, 1987); Young and Davism, P.N.A.S, 80: 1 194 (1983). Methods and apparatus for carrying out repeated and controlled hybridization reactions have been described in U.S. Pat. Nos. 5,871,928, 5,874,219, 6,045,996 and 6,386,749, 6,391 ,623 each of which are incorporated herein by reference.
- the methods of the invention may also involve signal detection of hybridization between ligands in after (and/or during) hybridization. See U.S. Pat. Nos. 5,143,854, 5,578,832; 5,631,734; 5,834,758; 5,936,324; 5,981 ,956; 6,025,601; 6, 141,096; 6, 185,030; 6,201,639; 6,218,803; and 6,225,625, in U.S. Ser. No. 10/389,194 and in PCT Application PCT/US99/06097 (published as W099/47964), each of which also is hereby incorporated by reference in its entirety for all purposes.
- Protein-based detection molecular profiling techniques include immunoaffinity assays based on antibodies selectively immunoreactive with mutant gene encoded protein according to the present invention. These techniques include without limitation immunoprecipitation, Western blot analysis, molecular binding assays, enzyme-linked immunosorbent assay (ELISA), enzyme-linked
- an optional method of detecting the expression of a biomarker in a sample comprises contacting the sample with an antibody against the biomarker, or an immunoreactive fragment of the antibody thereof, or a recombinant protein containing an antigen binding region of an antibody against the biomarker; and then detecting the binding of the biomarker in the sample.
- Methods for producing such antibodies are known in the art.
- Antibodies can be used to immunoprecipitate specific proteins from solution samples or to immunoblot proteins separated by, e.g., polyacrylamide gels. Immunocytochemical methods can also be used in detecting specific protein polymorphisms in tissues or cells.
- antibody-based techniques can also be used including, e.g., ELISA, radioimmunoassay (RIA), immunoradiometric assays (IRMA) and immuno enzymatic assays (IEMA), including sandwich assays using monoclonal or polyclonal antibodies. See, e.g., U.S. Pat. Nos. 4,376, 1 10 and 4,486,530, both of which are incorporated herein by reference.
- the sample may be contacted with an antibody specific for a biomarker under conditions sufficient for an antibody-biomarker complex to form, and then detecting said complex.
- the presence of the biomarker may be detected in a number of ways, such as by Western blotting and ELISA procedures for assaying a wide variety of tissues and samples, including plasma or serum.
- a wide range of immunoassay techniques using such an assay format are available, see, e.g., U.S. Pat. Nos. 4,016,043, 4,424,279 and 4,018,653. These include both single-site and two-site or "sandwich" assays of the non-competitive types, as well as in the traditional competitive binding assays. These assays also include direct binding of a labelled antibody to a target biomarker.
- a typical forward assay an unlabelled antibody is immobilized on a solid substrate, and the sample to be tested brought into contact with the bound molecule.
- a second antibody specific to the antigen, labelled with a reporter molecule capable of producing a detectable signal is then added and incubated, allowing time sufficient for the formation of another complex of antibody-antigen-labelled antibody. Any unreacted material is washed away, and the presence of the antigen is determined by observation of a signal produced by the reporter molecule.
- the results may either be qualitative, by simple observation of the visible signal, or may be quantitated by comparing with a control sample containing known amounts of biomarker.
- Variations on the forward assay include a simultaneous assay, in which both sample and labelled antibody are added simultaneously to the bound antibody. These techniques are well known to those skilled in the art, including any minor variations as will be readily apparent.
- a first antibody having specificity for the biomarker is either covalently or passively bound to a solid surface.
- the solid surface is typically glass or a polymer, the most commonly used polymers being cellulose, polyacrylamide, nylon, polystyrene, polyvinyl chloride or polypropylene.
- the solid supports may be in the form of tubes, beads, discs of microplates, or any other surface suitable for conducting an immunoassay.
- the binding processes are well-known in the art and generally consist of cross-linking covalently binding or physically adsorbing, the polymer-antibody complex is washed in preparation for the test sample. An aliquot of the sample to be tested is then added to the solid phase complex and incubated for a period of time sufficient (e.g. 2-40 minutes or overnight if more convenient) and under suitable conditions (e.g. from room temperature to 40°C such as between 25°C and 32°C inclusive) to allow binding of any subunit present in the antibody. Following the incubation period, the antibody subunit solid phase is washed and dried and incubated with a second antibody specific for a portion of the biomarker. The second antibody is linked to a reporter molecule which is used to indicate the binding of the second antibody to the molecular marker.
- An alternative method involves immobilizing the target biomarkers in the sample and then exposing the immobilized target to specific antibody which may or may not be labelled with a reporter molecule. Depending on the amount of target and the strength of the reporter molecule signal, a bound target may be detectable by direct labelling with the antibody. Alternatively, a second labelled antibody, specific to the first antibody is exposed to the target-first antibody complex to form a target-first antibody-second antibody tertiary complex. The complex is detected by the signal emitted by the reporter molecule.
- reporter molecule as used in the present specification, is meant a molecule which, by its chemical nature, provides an analytically identifiable signal which allows the detection of antigen-bound antibody.
- the most commonly used reporter molecules in this type of assay are either enzymes, fluorophores or radionuclide containing molecules (i.e. radioisotopes) and chemiluminescent molecules.
- an enzyme is conjugated to the second antibody, generally by means of glutaraldehyde or periodate.
- glutaraldehyde or periodate As will be readily recognized, however, a wide variety of different conjugation techniques exist, which are readily available to the skilled artisan.
- Commonly used enzymes include horseradish peroxidase, glucose oxidase, ⁇ -galactosidase and alkaline phosphatase, amongst others.
- the substrates to be used with the specific enzymes are generally chosen for the production, upon hydrolysis by the corresponding enzyme, of a detectable color change. Examples of suitable enzymes include alkaline phosphatase and peroxidase. It is also possible to employ fluorogenic substrates, which yield a fluorescent product rather than the chromogenic substrates noted above. In all cases, the enzyme-labelled antibody is added to the first antibody-molecular marker complex, allowed to bind, and then the excess reagent is washed away.
- a solution containing the appropriate substrate is then added to the complex of antibody-antigen-antibody.
- the substrate will react with the enzyme linked to the second antibody, giving a qualitative visual signal, which may be further quantitated, usually spectrophotometrically, to give an indication of the amount of biomarker which was present in the sample.
- fluorescent compounds such as fluorescein and rhodamine, may be chemically coupled to antibodies without altering their binding capacity.
- the fluorochrome-labelled antibody When activated by illumination with light of a particular wavelength, the fluorochrome-labelled antibody adsorbs the light energy, inducing a state to excitability in the molecule, followed by emission of the light at a characteristic color visually detectable with a light microscope.
- the fluorescent labelled antibody is allowed to bind to the first antibody-molecular marker complex. After washing off the unbound reagent, the remaining tertiary complex is then exposed to the light of the appropriate wavelength, the fluorescence observed indicates the presence of the molecular marker of interest.
- Immunofluorescence and EIA techniques are both very well established in the art. However, other reporter molecules, such as radioisotope, chemiluminescent or bioluminescent molecules, may also be employed.
- IHC is a process of localizing antigens (e.g., proteins) in cells of a tissue binding antibodies specifically to antigens in the tissues.
- the antigen-binding antibody can be conjugated or fused to a tag that allows its detection, e.g., via visualization.
- the tag is an enzyme that can catalyze a color-producing reaction, such as alkaline phosphatase or horseradish peroxidase.
- the enzyme can be fused to the antibody or non-covalently bound, e.g., using a biotin-avadin system.
- the antibody can be tagged with a fluorophore, such as fluorescein, rhodamine, DyLight Fluor or Alexa Fluor.
- the antigen-binding antibody can be directly tagged or it can itself be recognized by a detection antibody that carries the tag. Using IHC, one or more proteins may be detected.
- the expression of a gene product can be related to its staining intensity compared to control levels. In some embodiments, the gene product is considered differentially expressed if its staining varies at least 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0, 2.2, 2.5, 2.7, 3.0, 4, 5, 6, 7, 8, 9 or 10-fold in the sample versus the control.
- IHC comprises the application of antigen-antibody interactions to histochemical techniques.
- a tissue section is mounted on a slide and is incubated with antibodies (polyclonal or monoclonal) specific to the antigen (primary reaction).
- the antigen-antibody signal is then amplified using a second antibody conjugated to a complex of peroxidase antiperoxidase (PAP), avidin-biotin- peroxidase (ABC) or avidin-biotin alkaline phosphatase.
- PAP peroxidase antiperoxidase
- ABSC avidin-biotin- peroxidase
- avidin-biotin alkaline phosphatase avidin-biotin alkaline phosphatase.
- Immunofluorescence is an alternate approach to visualize antigens.
- the primary antigen-antibody signal is amplified using a second antibody conjugated to a fluorochrome.
- the fluorochrome emits its own light at a longer wavelength (fluorescence), thus allowing localization of antibody-antigen complexes.
- Molecular profiling methods also comprise measuring epigenetic change, i.e., modification in a gene caused by an epigenetic mechanism, such as a change in methylation status or histone acetylation.
- epigenetic change will result in an alteration in the levels of expression of the gene which may be detected (at the RNA or protein level as appropriate) as an indication of the epigenetic change.
- the epigenetic change results in silencing or down regulation of the gene, referred to as "epigenetic silencing.”
- the most frequently investigated epigenetic change in the methods of the invention involves determining the DNA methylation status of a gene, where an increased level of methylation is typically associated with the relevant cancer (since it may cause down regulation of gene expression).
- methylation Aberrant methylation, which may be referred to as hypermethylation, of the gene or genes can be detected.
- the methylation status is determined in suitable CpG islands which are often found in the promoter region of the gene(s).
- the term "methylation,” “methylation state” or “methylation status” may refers to the presence or absence of 5-methylcytosine at one or a plurality of CpG dinucleotides within a DNA sequence. CpG dinucleotides are typically concentrated in the promoter regions and exons of human genes.
- Diminished gene expression can be assessed in terms of DNA methylation status or in terms of expression levels as determined by the methylation status of the gene.
- One method to detect epigenetic silencing is to determine that a gene which is expressed in normal cells is less expressed or not expressed in tumor cells. Accordingly, the invention provides for a method of molecular profiling comprising detecting epigenetic silencing.
- the HeavyMethylTMassay in the embodiment thereof implemented herein, is an assay, wherein methylation specific blocking probes (also referred to herein as blockers) covering CpG positions between, or covered by the amplification primers enable methylation-specific selective amplification of a nucleic acid sample;
- HeavyMethylTMMethyLightTM is a variation of the MethyLightTM assay wherein the MethyLightTM assay is combined with methylation specific blocking probes covering CpG positions between the amplification primers;
- Ms-SNuPE Metalhylation-sensitive Single Nucleotide Primer Extension
- MSP Metal-specific PCR
- COBRA Combined Bisulfite Restriction Analysis
- MCA Metal-associated CpG Island Amplification
- DNA methylation analysis include sequencing, methylation-specific PCR (MS-PCR), melting curve methylation-specific PCR (McMS-PCR), MLPA with or without bisulfite treatment, QAMA, MSRE-PCR, MethyLight, ConLight-MSP, bisulfite conversion-specific methylation- specific PCR (BS-MSP), COBRA (which relies upon use of restriction enzymes to reveal methylation dependent sequence differences in PCR products of sodium bisulfite-treated DNA), methylation-sensitive single-nucleotide primer extension conformation (MS-SNuPE), methylation-sensitive single-strand conformation analysis (MS-SSCA), Melting curve combined bisulfite restriction analysis (McCOBRA), PyroMethA, HeavyMethyl, MALDI-TOF, MassARRAY, Quantitative analysis of methylated alleles (QAMA), enzymatic regional methylation assay (ERMA), QBSUPT, MethylQuant, Quantit
- Molecular profiling comprises methods for genotyping one or more biomarkers by determining whether an individual has one or more nucleotide variants (or amino acid variants) in one or more of the genes or gene products. Genotyping one or more genes according to the methods of the invention in some embodiments, can provide more evidence for selecting a treatment.
- the biomarkers of the invention can be analyzed by any method useful for determining alterations in nucleic acids or the proteins they encode. According to one embodiment, the ordinary skilled artisan can analyze the one or more genes for mutations including deletion mutants, insertion mutants, frame shift mutants, nonsense mutants, missense mutant, and splice mutants.
- Nucleic acid used for analysis of the one or more genes can be isolated from cells in the sample according to standard methodologies (Sambrook et al., 1989). The nucleic acid, for example, may be genomic DNA or fractionated or whole cell RNA, or miRNA acquired from exosomes or cell surfaces. Where RNA is used, it may be desired to convert the RNA to a complementary DNA.
- the RNA is whole cell RNA; in another, it is poly-A RNA; in another, it is exosomal RNA.
- the nucleic acid is amplified.
- the specific nucleic acid of interest is identified in the sample directly using amplification or with a second, known nucleic acid following amplification.
- the identified product is detected.
- the detection may be performed by visual means (e.g., ethidium bromide staining of a gel).
- the detection may involve indirect identification of the product via
- Various types of defects are known to occur in the biomarkers of the invention. Alterations include without limitation deletions, insertions, point mutations, and duplications. Point mutations can be silent or can result in stop codons, frame shift mutations or amino acid substitutions. Mutations in and outside the coding region of the one or more genes may occur and can be analyzed according to the methods of the invention.
- the target site of a nucleic acid of interest can include the region wherein the sequence varies.
- Examples include, but are not limited to, polymorphisms which exist in different forms such as single nucleotide variations, nucleotide repeats, multibase deletion (more than one nucleotide deleted from the consensus sequence), multibase insertion (more than one nucleotide inserted from the consensus sequence), microsatellite repeats (small numbers of nucleotide repeats with a typical 5- 1000 repeat units), di-nucleotide repeats, tri-nucleotide repeats, sequence rearrangements (including translocation and duplication), chimeric sequence (two sequences from different gene origins are fused together), and the like.
- sequence polymorphisms the most frequent polymorphisms in the human genome are single -base variations, also called single-nucleotide polymorphisms (SNPs). SNPs are abundant, stable and widely distributed across the genome.
- Molecular profiling includes methods for haplotyping one or more genes.
- the haplotype is a set of genetic determinants located on a single chromosome and it typically contains a particular combination of alleles (all the alternative sequences of a gene) in a region of a chromosome.
- the haplotype is phased sequence information on individual chromosomes.
- phased SNPs on a chromosome define a haplotype.
- a combination of haplotypes on chromosomes can determine a genetic profile of a cell. It is the haplotype that determines a linkage between a specific genetic marker and a disease mutation. Haplotyping can be done by any methods known in the art.
- additional variant(s) that are in linkage disequilibrium with the variants and/or haplotypes of the present invention can be identified by a haplotyping method known in the art, as will be apparent to a skilled artisan in the field of genetics and haplotyping.
- the additional variants that are in linkage disequilibrium with a variant or haplotype of the present invention can also be useful in the various applications as described below.
- genomic DNA and mRNA/cDNA can be used, and both are herein referred to generically as "gene.”
- nucleotide variants Numerous techniques for detecting nucleotide variants are known in the art and can all be used for the method of this invention.
- the techniques can be protein-based or nucleic acid-based. In either case, the techniques used must be sufficiently sensitive so as to accurately detect the small nucleotide or amino acid variations.
- a probe is used which is labeled with a detectable marker.
- any suitable marker known in the art can be used, including but not limited to, radioactive isotopes, fluorescent compounds, biotin which is detectable using streptavidin, enzymes (e.g., alkaline phosphatase), substrates of an enzyme, ligands and antibodies, etc. See Jablonski et al, Nucleic Acids Res., 14:61 15-6128 (1986); Nguyen et al.,
- target DNA sample i.e., a sample containing genomic DNA, cDNA, mRNA and/or miRNA, corresponding to the one or more genes must be obtained from the individual to be tested.
- Any tissue or cell sample containing the genomic DNA, miRNA, mRNA, and/or cDNA (or a portion thereof) corresponding to the one or more genes can be used.
- a tissue sample containing cell nucleus and thus genomic DNA can be obtained from the individual.
- Blood samples can also be useful except that only white blood cells and other lymphocytes have cell nucleus, while red blood cells are without a nucleus and contain only mRNA or miRNA.
- miRNA and mRNA are also useful as either can be analyzed for the presence of nucleotide variants in its sequence or serve as template for cDNA synthesis.
- the tissue or cell samples can be analyzed directly without much processing.
- nucleic acids including the target sequence can be extracted, purified, and/or amplified before they are subject to the various detecting procedures discussed below.
- cDNAs or genomic DNAs from a cDNA or genomic DNA library constructed using a tissue or cell sample obtained from the individual to be tested are also useful.
- sequencing of the target genomic DNA or cDNA particularly the region encompassing the nucleotide variant locus to be detected.
- Various sequencing techniques are generally known and widely used in the art including the Sanger method and Gilbert chemical method.
- the pyrosequencing method monitors DNA synthesis in real time using a luminometric detection system. Pyrosequencing has been shown to be effective in analyzing genetic polymorphisms such as single-nucleotide polymorphisms and can also be used in the present invention. See Nordstrom et al., Biotechnol. Appl. Biochem., 31(2): 107- 1 12 (2000); Ahmadian et al., Anal. Biochem., 280: 103- 1 10 (2000).
- Nucleic acid variants can be detected by a suitable detection process.
- suitable detection process Non limiting examples of methods of detection, quantification, sequencing and the like are; mass detection of mass modified amplicons (e.g., matrix-assisted laser desorption ionization (MALDI) mass spectrometry and electrospray (ES) mass spectrometry), a primer extension method (e.g., iPLEXTM; Sequenom, Inc.), microsequencing methods (e.g., a modification of primer extension methodology), ligase sequence determination methods (e.g., U.S. Pat. Nos. 5,679,524 and 5,952,174, and WO 01/27326), mismatch sequence determination methods (e.g., U.S. Pat.
- MALDI matrix-assisted laser desorption ionization
- ES electrospray
- the amount of a nucleic acid species is determined by mass spectrometry, primer extension, sequencing (e.g., any suitable method, for example nanopore or pyrosequencing), Quantitative PCR (Q-PCR or QRT-PCR), digital PCR, combinations thereof, and the like.
- sequence analysis refers to determining a nucleotide sequence, e.g., that of an amplification product.
- the entire sequence or a partial sequence of a polynucleotide, e.g., DNA or mRNA, can be determined, and the determined nucleotide sequence can be referred to as a "read” or "sequence read.”
- linear amplification products may be analyzed directly without further amplification in some embodiments (e.g., by using single -molecule sequencing methodology).
- linear amplification products may be subject to further amplification and then analyzed (e.g., using sequencing by ligation or pyrosequencing methodology).
- Reads may be subject to different types of sequence analysis. Any suitable sequencing method can be used to detect, and determine the amount of, nucleotide sequence species, amplified nucleic acid species, or detectable products generated from the foregoing. Examples of certain sequencing methods are described hereafter.
- a sequence analysis apparatus or sequence analysis component(s) includes an apparatus, and one or more components used in conjunction with such apparatus, that can be used by a person of ordinary skill to determine a nucleotide sequence resulting from processes described herein (e.g., linear and/or exponential amplification products).
- Examples of sequencing platforms include, without limitation, the 454 platform (Roche) (Margulies, M. et al.
- Next-generation sequencing can be used in the methods of the invention, e.g., to determine mutations, copy number, or expression levels, as appropriate.
- the methods can be used to perform whole genome sequencing or sequencing of specific sequences of interest, such as a gene of interest or a fragment thereof.
- Sequencing by ligation is a nucleic acid sequencing method that relies on the sensitivity of DNA ligase to base-pairing mismatch.
- DNA ligase joins together ends of DNA that are correctly base paired.
- Combining the ability of DNA ligase to join together only correctly base paired DNA ends, with mixed pools of fluorescently labeled oligonucleotides or primers, enables sequence determination by fluorescence detection.
- Longer sequence reads may be obtained by including primers containing cleavable linkages that can be cleaved after label identification. Cleavage at the linker removes the label and regenerates the 5' phosphate on the end of the ligated primer, preparing the primer for another round of ligation.
- primers may be labeled with more than one fluorescent label, e.g., at least 1, 2, 3, 4, or 5 fluorescent labels.
- Sequencing by ligation generally involves the following steps.
- Clonal bead populations can be prepared in emulsion microreactors containing target nucleic acid template sequences, amplification reaction components, beads and primers.
- templates are denatured and bead enrichment is performed to separate beads with extended templates from undesired beads (e.g., beads with no extended templates).
- the template on the selected beads undergoes a 3' modification to allow covalent bonding to the slide, and modified beads can be deposited onto a glass slide.
- Deposition chambers offer the ability to segment a slide into one, four or eight chambers during the bead loading process.
- primers hybridize to the adapter sequence.
- a set of four color dye-labeled probes competes for ligation to the sequencing primer. Specificity of probe ligation is achieved by interrogating every 4th and 5th base during the ligation series. Five to seven rounds of ligation, detection and cleavage record the color at every 5th position with the number of rounds determined by the type of library used. Following each round of ligation, a new complimentary primer offset by one base in the 5' direction is laid down for another series of ligations. Primer reset and ligation rounds (5-7 ligation cycles per round) are repeated sequentially five times to generate 25-35 base pairs of sequence for a single tag. With mate-paired sequencing, this process is repeated for a second tag.
- Pyrosequencing is a nucleic acid sequencing method based on sequencing by synthesis, which relies on detection of a pyrophosphate released on nucleotide incorporation.
- sequencing by synthesis involves synthesizing, one nucleotide at a time, a DNA strand complimentary to the strand whose sequence is being sought.
- Target nucleic acids may be immobilized to a solid support, hybridized with a sequencing primer, incubated with DNA polymerase, ATP sulfurylase, luciferase, apyrase, adenosine 5' phosphosulfate and luciferin. Nucleotide solutions are sequentially added and removed.
- Certain single-molecule sequencing embodiments are based on the principal of sequencing by synthesis, and use single-pair Fluorescence Resonance Energy Transfer (single pair FRET) as a mechanism by which photons are emitted as a result of successful nucleotide incorporation.
- the emitted photons often are detected using intensified or high sensitivity cooled charge-couple-devices in conjunction with total internal reflection microscopy (TI M). Photons are only emitted when the introduced reaction solution contains the correct nucleotide for incorporation into the growing nucleic acid chain that is synthesized as a result of the sequencing process.
- FRET FRET based single-molecule sequencing
- energy is transferred between two fluorescent dyes, sometimes polymethine cyanine dyes Cy3 and Cy5, through long-range dipole interactions.
- the donor is excited at its specific excitation wavelength and the excited state energy is transferred, non-radiatively to the acceptor dye, which in turn becomes excited.
- the acceptor dye eventually returns to the ground state by radiative emission of a photon.
- the two dyes used in the energy transfer process represent the "single pair" in single pair FRET. Cy3 often is used as the donor fluorophore and often is incorporated as the first labeled nucleotide.
- Cy5 often is used as the acceptor fluorophore and is used as the nucleotide label for successive nucleotide additions after incorporation of a first Cy3 labeled nucleotide.
- the fluorophores generally are within 10 nanometers of each for energy transfer to occur successfully.
- An example of a system that can be used based on single-molecule sequencing generally involves hybridizing a primer to a target nucleic acid sequence to generate a complex; associating the complex with a solid phase; iteratively extending the primer by a nucleotide tagged with a fluorescent molecule; and capturing an image of fluorescence resonance energy transfer signals after each iteration (e.g., U.S. Pat. No. 7,169,314; Braslavsky et al., PNAS 100(7): 3960-3964 (2003)).
- Such a system can be used to directly sequence amplification products (linearly or exponentially amplified products) generated by processes described herein.
- the amplification products can be hybridized to a primer that contains sequences complementary to immobilized capture sequences present on a solid support, a bead or glass slide for example. Hybridization of the primer-amplification product complexes with the immobilized capture sequences, immobilizes amplification products to solid supports for single pair FRET based sequencing by synthesis.
- the primer often is fluorescent, so that an initial reference image of the surface of the slide with immobilized nucleic acids can be generated. The initial reference image is useful for determining locations at which true nucleotide incorporation is occurring.
- Fluorescence signals detected in array locations not initially identified in the "primer only" reference image are discarded as non-specific fluorescence.
- the bound nucleic acids often are sequenced in parallel by the iterative steps of, a) polymerase extension in the presence of one fluorescently labeled nucleotide, b) detection of fluorescence using appropriate microscopy, TIRM for example, c) removal of fluorescent nucleotide, and d) return to step a with a different fluorescently labeled nucleotide.
- nucleotide sequencing may be by solid phase single nucleotide sequencing methods and processes.
- Solid phase single nucleotide sequencing methods involve contacting target nucleic acid and solid support under conditions in which a single molecule of sample nucleic acid hybridizes to a single molecule of a solid support.
- Such conditions can include providing the solid support molecules and a single molecule of target nucleic acid in a "microreactor.”
- Such conditions also can include providing a mixture in which the target nucleic acid molecule can hybridize to solid phase nucleic acid on the solid support.
- Single nucleotide sequencing methods useful in the embodiments described herein are described in U.S. Provisional Patent Application Ser. No. 61/021 ,871 filed Jan. 17, 2008.
- nanopore sequencing detection methods include (a) contacting a target nucleic acid for sequencing ("base nucleic acid,” e.g., linked probe molecule) with sequence-specific detectors, under conditions in which the detectors specifically hybridize to substantially complementary subsequences of the base nucleic acid; (b) detecting signals from the detectors and (c) determining the sequence of the base nucleic acid according to the signals detected.
- the detectors hybridized to the base nucleic acid are disassociated from the base nucleic acid (e.g., sequentially dissociated) when the detectors interfere with a nanopore structure as the base nucleic acid passes through a pore, and the detectors disassociated from the base sequence are detected.
- a detector disassociated from a base nucleic acid emits a detectable signal, and the detector hybridized to the base nucleic acid emits a different detectable signal or no detectable signal.
- nucleotides in a nucleic acid e.g., linked probe molecule
- nucleotide representatives specific nucleotide sequences corresponding to specific nucleotides
- nucleotide representatives may be arranged in a binary or higher order arrangement (e.g., Soni and Meller, Clinical Chemistry 53(1 1): 1996-2001 (2007)).
- a nucleic acid is not expanded, does not give rise to an expanded nucleic acid, and directly serves a base nucleic acid (e.g., a linked probe molecule serves as a non-expanded base nucleic acid), and detectors are directly contacted with the base nucleic acid.
- a first detector may hybridize to a first subsequence and a second detector may hybridize to a second subsequence, where the first detector and second detector each have detectable labels that can be distinguished from one another, and where the signals from the first detector and second detector can be distinguished from one another when the detectors are disassociated from the base nucleic acid.
- detectors include a region that hybridizes to the base nucleic acid (e.g., two regions), which can be about 3 to about 100 nucleotides in length (e.g., about 4, 5, 6, 7, 8, 9, 10, 1 1 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 25, 30, 35, 40, 50, 55, 60, 65, 70, 75, 80, 85, 90, or 95 nucleotides in length).
- a detector also may include one or more regions of nucleotides that do not hybridize to the base nucleic acid.
- a detector is a molecular beacon.
- a detector often comprises one or more detectable labels independently selected from those described herein.
- Each detectable label can be detected by any convenient detection process capable of detecting a signal generated by each label (e.g., magnetic, electric, chemical, optical and the like).
- a CD camera can be used to detect signals from one or more distinguishable quantum dots linked to a detector.
- reads may be used to construct a larger nucleotide sequence, which can be facilitated by identifying overlapping sequences in different reads and by using identification sequences in the reads.
- sequence analysis methods and software for constructing larger sequences from reads are known to the person of ordinary skill (e.g., Venter et al., Science 291 : 1304- 1351 (2001)).
- Specific reads, partial nucleotide sequence constructs, and full nucleotide sequence constructs may be compared between nucleotide sequences within a sample nucleic acid (i.e., internal comparison) or may be compared with a reference sequence (i.e., reference comparison) in certain sequence analysis embodiments.
- Primer extension polymorphism detection methods typically are carried out by hybridizing a complementary oligonucleotide to a nucleic acid carrying the polymorphic site.
- the oligonucleotide typically hybridizes adjacent to the polymorphic site.
- adjacent refers to the 3' end of the extension oligonucleotide being sometimes 1 nucleotide from the 5' end of the polymorphic site, often 2 or 3, and at times 4, 5, 6, 7, 8, 9, or 10 nucleotides from the 5' end of the polymorphic site, in the nucleic acid when the extension oligonucleotide is hybridized to the nucleic acid.
- extension oligonucleotide then is extended by one or more nucleotides, often 1 , 2, or 3 nucleotides, and the number and/or type of nucleotides that are added to the extension oligonucleotide determine which polymorphic variant or variants are present. Oligonucleotide extension methods are disclosed, for example, in U.S. Pat. Nos. 4,656, 127; 4,851 ,331 ; 5,679,524; 5,834, 189; 5,876,934; 5,908,755; 5,912,1 18; 5,976,802;
- the extension products can be detected in any manner, such as by fluorescence methods (see, e.g., Chen & Kwok, Nucleic Acids Research 25: 347-353 (1997) and Chen et al., Proc. Natl. Acad. Sci. USA 94/20: 10756- 10761 (1997)) or by mass spectrometric methods (e.g., MALDI-TOF mass spectrometry) and other methods described herein.
- fluorescence methods see, e.g., Chen & Kwok, Nucleic Acids Research 25: 347-353 (1997) and Chen et al., Proc. Natl. Acad. Sci. USA 94/20: 10756- 10761 (1997)
- mass spectrometric methods e.g., MALDI-TOF mass spectrometry
- Oligonucleotide extension methods using mass spectrometry are described, for example, in U.S. Pat. Nos. 5,547,835; 5,605,798; 5,691, 141 ; 5,849,542; 5,869,242;
- Microsequencing detection methods often incorporate an amplification process that proceeds the extension step.
- the amplification process typically amplifies a region from a nucleic acid sample that comprises the polymorphic site.
- Amplification can be carried out using methods described above, or for example using a pair of oligonucleotide primers in a polymerase chain reaction (PCR), in which one oligonucleotide primer typically is complementary to a region 3' of the polymorphism and the other typically is complementary to a region 5' of the polymorphism.
- PCR primer pair may be used in methods disclosed in U.S. Pat. Nos.
- PCR primer pairs may also be used in any commercially available machines that perform PCR, such as any of the GeneAmpTM Systems available from Applied Biosystems.
- Other appropriate sequencing methods include multiplex polony sequencing (as described in Shendure et al., Accurate Multiplex Polony Sequencing of an Evolved Bacterial Genome, Sciencexpress, Aug. 4, 2005, pg 1 available at www.sciencexpress.org/4 Aug.
- Whole genome sequencing may also be used for discriminating alleles of RNA transcripts, in some embodiments.
- Examples of whole genome sequencing methods include, but are not limited to, nanopore-based sequencing methods, sequencing by synthesis and sequencing by ligation, as described above.
- Nucleic acid variants can also be detected using standard electrophoretic techniques. Although the detection step can sometimes be preceded by an amplification step, amplification is not required in the embodiments described herein. Examples of methods for detection and quantification of a nucleic acid using electrophoretic techniques can be found in the art.
- a non-limiting example comprises running a sample (e.g., mixed nucleic acid sample isolated from maternal serum, or amplification nucleic acid species, for example) in an agarose or polyacrylamide gel. The gel may be labeled (e.g., stained) with ethidium bromide (see, Sambrook and Russell, Molecular Cloning: A Laboratory Manual 3d ed., 2001).
- the presence of a band of the same size as the standard control is an indication of the presence of a target nucleic acid sequence, the amount of which may then be compared to the control based on the intensity of the band, thus detecting and quantifying the target sequence of interest.
- restriction enzymes capable of distinguishing between maternal and paternal alleles may be used to detect and quantify target nucleic acid species.
- oligonucleotide probes specific to a sequence of interest are used to detect the presence of the target sequence of interest.
- oligonucleotides can also be used to indicate the amount of the target nucleic acid molecules in comparison to the standard control, based on the intensity of signal imparted by the probe.
- Sequence-specific probe hybridization can be used to detect a particular nucleic acid in a mixture or mixed population comprising other species of nucleic acids. Under sufficiently stringent hybridization conditions, the probes hybridize specifically only to substantially complementary sequences. The stringency of the hybridization conditions can be relaxed to tolerate varying amounts of sequence mismatch.
- a number of hybridization formats are known in the art, which include but are not limited to, solution phase, solid phase, or mixed phase hybridization assays. The following articles provide an overview of the various hybridization assay formats: Singer et al, Biotechniques 4:230, 1986; Haase et al., Methods in Virology, pp.
- Hybridization complexes can be detected by techniques known in the art.
- Nucleic acid probes capable of specifically hybridizing to a target nucleic acid e.g., mRNA or DNA
- a target nucleic acid e.g., mRNA or DNA
- the labeled probe used to detect the presence of hybridized nucleic acids.
- One commonly used method of detection is autoradiography, using probes labeled with 3 H, 125 1, 35 S, 14 C, 32 P, 33 P, or the like.
- radioactive isotope depends on research preferences due to ease of synthesis, stability, and half-lives of the selected isotopes.
- Other labels include compounds (e.g., biotin and digoxigenin), which bind to antiligands or antibodies labeled with fluorophores, chemiluminescent agents, and enzymes.
- probes can be conjugated directly with labels such as fluorophores, chemiluminescent agents or enzymes.
- the choice of label depends on sensitivity required, ease of conjugation with the probe, stability requirements, and available instrumentation.
- fragment analysis referred to herein as "FA"
- Fragment analysis includes techniques such as restriction fragment length polymorphism (RFLP) and/or (amplified fragment length polymorphism). If a nucleotide variant in the target DNA corresponding to the one or more genes results in the elimination or creation of a restriction enzyme recognition site, then digestion of the target DNA with that particular restriction enzyme will generate an altered restriction fragment length pattern. Thus, a detected RFLP or AFLP will indicate the presence of a particular nucleotide variant.
- RFLP restriction fragment length polymorphism
- AFLP amplified fragment length polymorphism
- Terminal restriction fragment length polymorphism works by PCR amplification of DNA using primer pairs that have been labeled with fluorescent tags. The PCR products are digested using RFLP enzymes and the resulting patterns are visualized using a DNA sequencer. The results are analyzed either by counting and comparing bands or peaks in the TRFLP profile, or by comparing bands from one or more TRFLP runs in a database.
- the sequence changes directly involved with an RFLP can also be analyzed more quickly by PCR. Amplification can be directed across the altered restriction site, and the products digested with the restriction enzyme. This method has been called Cleaved Amplified Polymorphic Sequence (CAPS). Alternatively, the amplified segment can be analyzed by Allele specific oligonucleotide (ASO) probes, a process that is sometimes assessed using a Dot blot.
- ASO Allele specific oligonucleotide
- a variation on AFLP is cDNA-AFLP, which can be used to quantify differences in gene expression levels.
- SSCA single -stranded conformation polymorphism assay
- Denaturing gel-based techniques such as clamped denaturing gel electrophoresis (CDGE) and denaturing gradient gel electrophoresis (DGGE) detect differences in migration rates of mutant sequences as compared to wild- type sequences in denaturing gel.
- CDGE clamped denaturing gel electrophoresis
- DGGE denaturing gradient gel electrophoresis
- CDGE clamped denaturing gel electrophoresis
- DGGE denaturing gradient gel electrophoresis
- DSCA double-strand conformation analysis
- the presence or absence of a nucleotide variant at a particular locus in the one or more genes of an individual can also be detected using the amplification refractory mutation system (ARMS) technique.
- ARMS amplification refractory mutation system
- European Patent No. 0,332,435 Newton et al., Nucleic Acids Res., 17:2503-2515 (1989); Fox et al., Br. J. Cancer, 77: 1267-1274 (1998); Robertson et al., Eur. Respir. J., 12:477-482 (1998).
- a primer is synthesized matching the nucleotide sequence immediately 5' upstream from the locus being tested except that the 3'-end nucleotide which corresponds to the nucleotide at the locus is a predetermined nucleotide.
- the 3'-end nucleotide can be the same as that in the mutated locus.
- the primer can be of any suitable length so long as it hybridizes to the target DNA under stringent conditions only when its 3'-end nucleotide matches the nucleotide at the locus being tested.
- the primer has at least 12 nucleotides, more preferably from about 18 to 50 nucleotides.
- the primer can be further extended upon hybridizing to the target DNA template, and the primer can initiate a PCR amplification reaction in conjunction with another suitable PCR primer.
- primer extension cannot be achieved.
- ARMS techniques developed in the past few years can be used. See e.g., Gibson et al., Clin. Chem. 43 : 1336- 1341 (1997).
- nucleotide primer extension method Similar to the ARMS technique is the mini sequencing or single nucleotide primer extension method, which is based on the incorporation of a single nucleotide.
- An oligonucleotide primer matching the nucleotide sequence immediately 5' to the locus being tested is hybridized to the target DNA, mRNA or miRNA in the presence of labeled dideoxyribonucleotides.
- a labeled nucleotide is incorporated or linked to the primer only when the dideoxyribonucleotides matches the nucleotide at the variant locus being detected.
- the identity of the nucleotide at the variant locus can be revealed based on the detection label attached to the incorporated dideoxyribonucleotides.
- OLA oligonucleotide ligation assay
- two oligonucleotides can be synthesized, one having the sequence just 5' upstream from the locus with its 3' end nucleotide being identical to the nucleotide in the variant locus of the particular gene, the other having a nucleotide sequence matching the sequence immediately 3' downstream from the locus in the gene.
- the oligonucleotides can be labeled for the purpose of detection.
- the two oligonucleotides Upon hybridizing to the target gene under a stringent condition, the two oligonucleotides are subject to ligation in the presence of a suitable ligase. The ligation of the two oligonucleotides would indicate that the target DNA has a nucleotide variant at the locus being detected.
- Detection of small genetic variations can also be accomplished by a variety of hybridization- based approaches. Allele-specific oligonucleotides are most useful. See Conner et al, Proc. Natl. Acad. Sci. USA, 80:278-282 (1983); Saiki et al, Proc. Natl. Acad. Sci. USA, 86:6230-6234 (1989).
- Oligonucleotide probes hybridizing specifically to a gene allele having a particular gene variant at a particular locus but not to other alleles can be designed by methods known in the art.
- the probes can have a length of, e.g., from 10 to about 50 nucleotide bases.
- the target DNA and the oligonucleotide probe can be contacted with each other under conditions sufficiently stringent such that the nucleotide variant can be distinguished from the wild-type gene based on the presence or absence of hybridization.
- the probe can be labeled to provide detection signals.
- the allele-specific oligonucleotide probe can be used as a PCR amplification primer in an "allele-specific PCR" and the presence or absence of a PCR product of the expected length would indicate the presence or absence of a particular nucleotide variant.
- RNA probe can be prepared spanning the nucleotide variant site to be detected and having a detection marker. See Giunta et al., Diagn. Mol.
- RNA probe can be hybridized to the target DNA or mRNA forming a heteroduplex that is then subject to the ribonuclease RNase A digestion.
- RNase A digests the RNA probe in the heteroduplex only at the site of mismatch. The digestion can be determined on a denaturing electrophoresis gel based on size variations.
- mismatches can also be detected by chemical cleavage methods known in the art. See e.g., Roberts et al., Nucleic Acids Res., 25:3377-3378 (1997).
- a probe in the mutS assay, can be prepared matching the gene sequence surrounding the locus at which the presence or absence of a mutation is to be detected, except that a predetermined nucleotide is used at the variant locus.
- the E. coli mutS protein Upon annealing the probe to the target DNA to form a duplex, the E. coli mutS protein is contacted with the duplex. Since the mutS protein binds only to heteroduplex sequences containing a nucleotide mismatch, the binding of the mutS protein will be indicative of the presence of a mutation. See Modrich et al., Ann. Rev. Genet., 25:229-253 (1991).
- the "sunrise probes” or “molecular beacons” use the fluorescence resonance energy transfer (FRET) property and give rise to high sensitivity.
- FRET fluorescence resonance energy transfer
- a probe spanning the nucleotide locus to be detected are designed into a hairpin-shaped structure and labeled with a quenching fluorophore at one end and a reporter fluorophore at the other end.
- HANDS homo-tag assisted non-dimer system
- Dye-labeled oligonucleotide ligation assay is a FRET-based method, which combines the OLA assay and PCR. See Chen et al., Genome Res. 8:549-556 (1998).
- TaqMan is another FRET-based method for detecting nucleotide variants.
- a TaqMan probe can be oligonucleotides designed to have the nucleotide sequence of the gene spanning the variant locus of interest and to differentially hybridize with different alleles. The two ends of the probe are labeled with a quenching fluorophore and a reporter fluorophore, respectively.
- the TaqMan probe is incorporated into a PCR reaction for the amplification of a target gene region containing the locus of interest using Taq polymerase.
- Taq polymerase exhibits 5'-3' exonuclease activity but has no 3'-5' exonuclease activity
- the TaqMan probe is annealed to the target DNA template, the 5'-end of the TaqMan probe will be degraded by Taq polymerase during the PCR reaction thus separating the reporting fluorophore from the quenching fluorophore and releasing fluorescence signals.
- the detection in the present invention can also employ a chemiluminescence-based technique.
- an oligonucleotide probe can be designed to hybridize to either the wild-type or a variant gene locus but not both.
- the probe is labeled with a highly chemiluminescent acridinium ester. Hydrolysis of the acridinium ester destroys chemiluminescence.
- the hybridization of the probe to the target DNA prevents the hydrolysis of the acridinium ester. Therefore, the presence or absence of a particular mutation in the target DNA is determined by measuring chemiluminescence changes. See Nelson et al., Nucleic Acids Res., 24:4998-5003 (1996).
- the detection of genetic variation in the gene in accordance with the present invention can also be based on the "base excision sequence scanning" (BESS) technique.
- BESS base excision sequence scanning
- the BESS method is a PCR-based mutation scanning method.
- BESS T-Scan and BESS G-Tracker are generated which are analogous to T and G ladders of dideoxy sequencing. Mutations are detected by comparing the sequence of normal and mutant DNA. See, e.g., Hawkins et al., Electrophoresis, 20: 1 171 -1 176 (1999).
- Mass spectrometry can be used for molecular profiling according to the invention. See Graber et al., Curr. Opin. Biotechnol., 9: 14- 18 (1998).
- a target nucleic acid is immobilized to a solid-phase support.
- a primer is annealed to the target immediately 5' upstream from the locus to be analyzed.
- Primer extension is carried out in the presence of a selected mixture of deoxyribonucleotides and dideoxyribonucleotides.
- the resulting mixture of newly extended primers is then analyzed by MALDI-TOF. See e.g., Monforte et al., Nat. Med., 3:360-362 (1997).
- microchip or microarray technologies are also applicable to the detection method of the present invention.
- a large number of different oligonucleotide probes are immobilized in an array on a substrate or carrier, e.g., a silicon chip or glass slide.
- Target nucleic acid sequences to be analyzed can be contacted with the immobilized oligonucleotide probes on the microchip. See Lipshutz et al., Biotechniques, 19:442-447 (1995); Chee et al., Science, 274:610-614 (1996); Kozal et al., Nat. Med. 2:753-759 (1996); Hacia et al., Nat.
- PCR-based techniques combine the amplification of a portion of the target and the detection of the mutations. PCR amplification is well known in the art and is disclosed in U.S. Pat. Nos. 4,683,195 and 4,800,159, both which are incorporated herein by reference.
- the amplification can be achieved by, e.g., in vivo plasmid multiplication, or by purifying the target DNA from a large amount of tissue or cell samples.
- in vivo plasmid multiplication or by purifying the target DNA from a large amount of tissue or cell samples.
- tissue or cell samples See generally, Sambrook et al., Molecular Cloning: A Laboratory Manual, 2 nd ed., Cold Spring Harbor Laboratory, Cold Spring Harbor, N.Y., 1989.
- many sensitive techniques have been developed in which small genetic variations such as single -nucleotide substitutions can be detected without having to amplify the target DNA in the sample.
- branched DNA or dendrimers that can hybridize to the target DNA.
- the branched or dendrimer DNAs provide multiple hybridization sites for hybridization probes to attach thereto thus amplifying the detection signals. See Detmer et al., J. Clin.
- the InvaderTM assay is another technique for detecting single nucleotide variations that can be used for molecular profiling according to the invention.
- the InvaderTM assay uses a novel linear signal amplification technology that improves upon the long turnaround times required of the typical PCR DNA sequenced-based analysis. See Cooksey et al., Antimicrobial Agents and Chemotherapy 44: 1296- 1301 (2000). This assay is based on cleavage of a unique secondary structure formed between two overlapping oligonucleotides that hybridize to the target sequence of interest to form a "flap.” Each "flap" then generates thousands of signals per hour.
- the InvaderTM system uses two short DNA probes, which are hybridized to a DNA target.
- the structure formed by the hybridization event is recognized by a special cleavase enzyme that cuts one of the probes to release a short DNA "flap.” Each released "flap” then binds to a fluorescently-labeled probe to form another cleavage structure.
- the cleavase enzyme cuts the labeled probe, the probe emits a detectable fluorescence signal. See e.g. Lyamichev et al., Nat. Biotechnol., 17:292-296 (1999).
- the rolling circle method is another method that avoids exponential amplification.
- Lizardi et al. Nature Genetics, 19:225-232 (1998) (which is incorporated herein by reference).
- SniperTM a commercial embodiment of this method, is a sensitive, high-throughput SNP scoring system designed for the accurate fluorescent detection of specific variants.
- two linear, allele-specific probes are designed.
- the two allele-specific probes are identical with the exception of the 3'- base, which is varied to complement the variant site.
- target DNA is denatured and then hybridized with a pair of single, allele-specific, open-circle oligonucleotide probes.
- SERRS surface- enhanced resonance Raman scattering
- fluorescence correlation spectroscopy single- molecule electrophoresis.
- SERRS surface- enhanced resonance Raman scattering
- fluorescence correlation spectroscopy is based on the spatio- temporal correlations among fluctuating light signals and trapping single molecules in an electric field. See Eigen et al., Proc. Natl.
- the electrophoretic velocity of a fluorescently tagged nucleic acid is determined by measuring the time required for the molecule to travel a predetermined distance between two laser beams. See Castro et al., Anal. Chem., 67:3181 -3186 (1995).
- the allele-specific oligonucleotides can also be used in in situ hybridization using tissues or cells as samples.
- the oligonucleotide probes which can hybridize differentially with the wild-type gene sequence or the gene sequence harboring a mutation may be labeled with radioactive isotopes, fluorescence, or other detectable markers.
- In situ hybridization techniques are well known in the art and their adaptation to the present invention for detecting the presence or absence of a nucleotide variant in the one or more gene of a particular individual should be apparent to a skilled artisan apprised of this disclosure.
- the presence or absence of one or more genes nucleotide variant or amino acid variant in an individual can be determined using any of the detection methods described above.
- the result can be cast in a transmittable form that can be communicated or transmitted to other researchers or physicians or genetic counselors or patients.
- a transmittable form can vary and can be tangible or intangible.
- the result with regard to the presence or absence of a nucleotide variant of the present invention in the individual tested can be embodied in descriptive statements, diagrams, photographs, charts, images or any other visual forms. For example, images of gel electrophoresis of PCR products can be used in explaining the results.
- Diagrams showing where a variant occurs in an individual's gene are also useful in indicating the testing results.
- the statements and visual forms can be recorded on a tangible media such as papers, computer readable media such as floppy disks, compact disks, etc., or on an intangible media, e.g., an electronic media in the form of email or website on internet or intranet.
- the result with regard to the presence or absence of a nucleotide variant or amino acid variant in the individual tested can also be recorded in a sound form and transmitted through any suitable media, e.g., analog or digital cable lines, fiber optic cables, etc., via telephone, facsimile, wireless mobile phone, internet phone and the like.
- the information and data on a test result can be produced anywhere in the world and transmitted to a different location.
- the information and data on a test result may be generated and cast in a transmittable form as described above.
- the test result in a transmittable form thus can be imported into the U.S.
- the present invention also encompasses a method for producing a transmittable form of information on the genotype of the two or more suspected cancer samples from an individual.
- the method comprises the steps of (1) determining the genotype of the DNA from the samples according to methods of the present invention; and (2) embodying the result of the determining step in a transmittable form.
- the transmittable form is the product of the production method.
- In situ hybridization assays are well known and are generally described in Angerer et al., Methods Enzymol. 152:649-660 (1987).
- cells e.g., from a biopsy, are fixed to a solid support, typically a glass slide. If DNA is to be probed, the cells are denatured with heat or alkali. The cells are then contacted with a hybridization solution at a moderate temperature to permit annealing of specific probes that are labeled.
- the probes are preferably labeled, e.g., with radioisotopes or fluorescent reporters, or enzymatically.
- FISH fluorescence in situ hybridization
- CISH chromogenic in situ hybridization
- CISH uses conventional peroxidase or alkaline phosphatase reactions visualized under a standard bright-field microscope.
- In situ hybridization can be used to detect specific gene sequences in tissue sections or cell preparations by hybridizing the complementary strand of a nucleotide probe to the sequence of interest.
- Fluorescent in situ hybridization uses a fluorescent probe to increase the sensitivity of in situ hybridization.
- FISH is a cytogenetic technique used to detect and localize specific polynucleotide sequences in cells.
- FISH can be used to detect DNA sequences on chromosomes.
- FISH can also be used to detect and localize specific RNAs, e.g., mRNAs, within tissue samples.
- RNAs e.g., mRNAs
- FISH uses fluorescent probes that bind to specific nucleotide sequences to which they show a high degree of sequence similarity. Fluorescence microscopy can be used to find out whether and where the fluorescent probes are bound.
- FISH can help define the spatial-temporal patterns of specific gene copy number and/or gene expression within cells and tissues.
- FISH probes can be used to detect chromosome translocations. Dual color, single fusion probes can be useful in detecting cells possessing a specific chromosomal translocation.
- the DNA probe hybridization targets are located on one side of each of the two genetic breakpoints.
- "Extra signal" probes can reduce the frequency of normal cells exhibiting an abnormal FISH pattern due to the random co-localization of probe signals in a normal nucleus. One large probe spans one breakpoint, while the other probe flanks the breakpoint on the other gene. Dual color, break apart probes are useful in cases where there may be multiple translocation partners associated with a known genetic breakpoint.
- This labeling scheme features two differently colored probes that hybridize to targets on opposite sides of a breakpoint in one gene. Dual color, dual fusion probes can reduce the number of normal nuclei exhibiting abnormal signal patterns. The probe offers advantages in detecting low levels of nuclei possessing a simple balanced translocation. Large probes span two breakpoints on different chromosomes. Such probes are available as Vysis probes from Abbott Laboratories, Abbott Park, IL.
- CISH or chromogenic in situ hybridization
- CISH methodology can be used to evaluate gene amplification, gene deletion, chromosome translocation, and chromosome number.
- CISH can use conventional enzymatic detection methodology, e.g., horseradish peroxidase or alkaline phosphatase reactions, visualized under a standard bright-field microscope.
- a probe that recognizes the sequence of interest is contacted with a sample.
- An antibody or other binding agent that recognizes the probe can be used to target an enzymatic detection system to the site of the probe.
- the antibody can recognize the label of a FISH probe, thereby allowing a sample to be analyzed using both FISH and CISH detection.
- CISH can be used to evaluate nucleic acids in multiple settings, e.g., formalin-fixed, paraffin-embedded (FFPE) tissue, blood or bone marrow smear, metaphase chromosome spread, and/or fixed cells.
- FFPE paraffin-embedded
- CISH is performed following the methodology in the SPoT-Light® HER2 CISH Kit available from Life Technologies (Carlsbad, CA) or similar CISH products available from Life Technologies.
- the SPoT-Light® HER2 CISH Kit itself is FDA approved for in vitro diagnostics and can be used for molecular profiling of HER2.
- CISH can be used in similar applications as FISH.
- FISH fluorescence In situ hybridization
- SISH Silver-enhanced in situ hybridization
- Modifications of the in situ hybridization techniques can be used for molecular profiling according to the invention. Such modifications comprise simultaneous detection of multiple targets, e.g., Dual ISH, Dual color CISH, bright field double in situ hybridization (BDISH). See e.g., the FDA approved INFORM HER2 Dual ISH DNA Probe Cocktail kit from Ventana Medical Systems, Inc. (Tucson, AZ); DuoCISHTM, a dual color CISH kit developed by Dako Denmark AJS (Denmark).
- targets e.g., Dual ISH, Dual color CISH, bright field double in situ hybridization (BDISH).
- BDISH bright field double in situ hybridization
- Comparative Genomic Hybridization comprises a molecular cytogenetic method of screening tumor samples for genetic changes showing characteristic patterns for copy number changes at chromosomal and subchromosomal levels. Alterations in patterns can be classified as DNA gains and losses.
- CGH employs the kinetics of in situ hybridization to compare the copy numbers of different DNA or RNA sequences from a sample, or the copy numbers of different DNA or RNA sequences in one sample to the copy numbers of the substantially identical sequences in another sample.
- the DNA or RNA is isolated from a subject cell or cell population. The comparisons can be qualitative or quantitative.
- Procedures are described that permit determination of the absolute copy numbers of DNA sequences throughout the genome of a cell or cell population if the absolute copy number is known or determined for one or several sequences.
- the different sequences are discriminated from each other by the different locations of their binding sites when hybridized to a reference genome, usually metaphase chromosomes but in certain cases interphase nuclei.
- the copy number information originates from comparisons of the intensities of the hybridization signals among the different locations on the reference genome.
- the methods, techniques and applications of CGH are known, such as described in U.S. Pat. No. 6,335, 167, and in U.S. App. Ser. No. 60/804,818, the relevant parts of which are herein incorporated by reference.
- CGH used to compare nucleic acids between diseased and healthy tissues.
- the method comprises isolating DNA from disease tissues (e.g., tumors) and reference tissues (e.g., healthy tissue) and labeling each with a different "color" or fluor.
- the two samples are mixed and hybridized to normal metaphase chromosomes.
- the hybridization mixing is done on a slide with thousands of DNA probes.
- detection system can be used that basically determine the color ratio along the chromosomes to determine DNA regions that might be gained or lost in the diseased samples as compared to the reference.
- the methods of the invention provide a candidate treatment selection for a subject in need thereof.
- Molecular profiling can be used to identify one or more candidate therapeutic agents for an individual suffering from a condition in which one or more of the biomarkers disclosed herein are targets for treatment.
- the method can identify one or more chemotherapy treatments for a cancer.
- the invention provides a method comprising: performing an immunohistochemistry (IHC) analysis on a sample from the subject to determine an IHC expression profile on at least five proteins; performing a microarray analysis on the sample to determine a microarray expression profile on at least ten genes; performing a fluorescent in-situ hybridization (FISH) analysis on the sample to determine a FISH mutation profile on at least one gene; performing DNA sequencing on the sample to determine a sequencing mutation profile on at least one gene; and comparing the IHC expression profile, microarray expression profile, FISH mutation profile and sequencing mutation profile against a rules database, wherein the rules database comprises a mapping of treatments whose biological activity is known against diseased cells that: i) overexpress or underexpress one or more proteins included in the IHC expression profile; ii) overexpress or underexpress one or more genes included in the microarray expression profile; iii) have zero or more mutations in one or more genes included in the FISH mutation profile; and/or iv) have zero or more
- the disease can be a cancer.
- the molecular profiling steps can be performed in any order. In some embodiments, not all of the molecular profiling steps are performed. As a non-limiting example, microarray analysis is not performed if the sample quality does not meet a threshold value, as described herein. In another example, sequencing is performed only if FISH analysis meets a threshold value. Any relevant biomarker can be assessed using one or more of the molecular profiling techniques described herein or known in the art. The marker need only have some direct or indirect association with a treatment to be useful.
- Molecular profiling comprises the profiling of at least one gene (or gene product) for each assay technique that is performed. Different numbers of genes can be assayed with different techniques. Any marker disclosed herein that is associated directly or indirectly with a target therapeutic can be assessed. For example, any "draggable target" comprising a target that can be modulated with a therapeutic agent such as a small molecule or binding agent such as an antibody, is a candidate for inclusion in the molecular profiling methods of the invention.
- the target can also be indirectly drug associated, such as a component of a biological pathway that is affected by the associated drug.
- the molecular profiling can be based on either the gene, e.g., DNA sequence, and/or gene product, e.g., mRNA or protein.
- Such nucleic acid and/or polypeptide can be profiled as applicable as to presence or absence, level or amount, activity, mutation, sequence, haplotype, rearrangement, copy number, or other measurable characteristic.
- a single gene and/or one or more corresponding gene products is assayed by more than one molecular profiling technique.
- a gene or gene product (also referred to herein as “marker” or “biomarker”), e.g., an mRNA or protein, is assessed using applicable techniques (e.g., to assess DNA, RNA, protein), including without limitation FISH, microarray, IHC, sequencing or immunoassay.
- any of the markers disclosed herein can be assayed by a single molecular profiling technique or by multiple methods disclosed herein (e.g., a single marker is profiled by one or more of IHC, FISH, sequencing, microarray, etc.).
- a single marker is profiled by one or more of IHC, FISH, sequencing, microarray, etc.
- at least about 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95 or at least about 100 genes or gene products are profiled by at least one technique, a plurality of techniques, or using a combination of FISH, microarray, IHC, and sequencing.
- At least about 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10,000, 1 1 ,000, 12,000, 13,000, 14,000, 15,000, 16,000, 17,000, 18,000, 19,000, 20,000, 21 ,000, 22,000, 23,000, 24,000, 25,000, 26,000, 27,000, 28,000, 29,000, 30,000, 31 ,000, 32,000, 33,000, 34,000, 35,000, 36,000, 37,000, 38,000, 39,000, 40,000, 41,000, 42,000, 43,000, 44,000, 45,000, 46,000, 47,000, 48,000, 49,000, or at least 50,000 genes or gene products are profiled using various techniques.
- the number of markers assayed can depend on the technique used. For example, microarray and massively parallel sequencing lend themselves to high throughput analysis. Because molecular profiling queries molecular characteristics of the tumor itself, this approach provides information on therapies that might not otherwise be considered based on the lineage of the tumor.
- a sample from a subject in need thereof is profiled using methods which include but are not limited to IHC expression profiling, microarray expression profiling, FISH mutation profiling, and/or sequencing mutation profiling (such as by PCR, RT-PCR, pyro sequencing) for one or more of the following: ABCC 1 , ABCG2, ACE2, ADA, ADH1 C, ADH4, AGT, AR, AREG, ASNS, BCL2, BCRP, BDCAl, beta III tubulin, BIRC5, B-RAF, BRCAl, BRCA2, CA2, caveolin, CD20, CD25, CD33, CD52, CDA, CDKN2A, CD N1A, CDKN1 B, CDK2, CDW52, CES2, CK 14, CK 17, CK 5/6, c- KIT, c-Met, c-Myc, COX-2, Cyclin Dl, DCK, DHFR, DNMT1 , DNMT3A, DNMT3
- Table 2 provides a listing of gene and corresponding protein symbols and names of many of the molecular profiling targets that are analyzed according to the methods of the invention. As understood by those of skill in the art, genes and proteins have developed a number of alternative names in the scientific literature. Thus, the listing in Table 2 comprises an illustrative but not exhaustive compilation. A further listing of gene aliases and descriptions can be found using a variety of online databases, including
- GeneCards® www.genecards.org
- HUGO Gene Nomenclature www.genenames.org
- UniProtKB/Swiss-Prot www.uniprot.org
- ABCC1 ATP -binding cassette, sub-family C MRP1, Multidrug resistance-associated protein M P1 (CFTR MRP), member 1 ABCC1 1
- ADH1C alcohol dehydrogenase 1C (class I)
- ADH1G Alcohol dehydrogenase 1 C (class I)
- ADH4 alcohol dehydrogenase 4 (class II), pi ADH4 Alcohol dehydrogenase 4
- AGT angiotensinogen (serpin peptidase ANGT, AGT Angiotensinogen precursor
- ALK anaplastic lymphoma receptor ALK ALK tyrosine kinase receptor precursor tyrosine kinase
- BRCA1 breast cancer 1 early onset BRCA1 Breast cancer type 1 susceptibility protein
- BRCA2 breast cancer 2 early onset BRCA2 Breast cancer type 2 susceptibility protein
- CA2 carbonic anhydrase II CA2 Carbonic anhydrase 2
- additional molecular profiling methods are performed. These can include without limitation PCR, RT-PCR, Q-PCR, SAGE, MPSS, immunoassays and other techniques to assess biological systems described herein or known to those of skill in the art.
- the choice of genes and gene products to be assayed can be updated over time as new treatments and new drug targets are identified.
- molecular profiling is not limited to those techniques disclosed herein but comprises any methodology conventional for assessing nucleic acid or protein levels, sequence information, or both.
- a gene or gene product is assessed by a single molecular profiling technique.
- a gene and/or gene product is assessed by multiple molecular profiling techniques.
- a gene sequence can be assayed by one or more of FISH and pyrosequencing analysis, the mRNA gene product can be assayed by one or more of RT-PCR and microarray, and the protein gene product can be assayed by one or more of IHC and immunoassay.
- Genes and gene products that are known to play a role in cancer and can be assayed by any of the molecular profiling techniques of the invention include without limitation 2AR, A DISINTEGRIN, ACTIVATOR OF THYROID AND RETINOIC ACID RECEPTOR (ACTR), ADAM 1 1,
- ADIPOGENESIS INHIBITORY FACTOR (ADIF), ALPHA 6 INTEGRIN SUBUNIT, ALPHA V INTEGRIN SUBUNIT, ALPHA-CATENIN, AMPLIFIED IN BREAST CANCER 1 (AIB l),
- AMPLIFIED IN BREAST CANCER 3 (AIB3), AMPLIFIED IN BREAST CANCER 4 (AIB4), AMYLOID PRECURSOR PROTEIN SECRETASE (APPS), AP-2 GAMMA, APPS, ATP-BINDING CASSETTE TRANSPORTER (ABCT), PLACENTA- SPECIFIC (ABCP), ATP-BINDING CASSETTE SUBFAMILY C MEMBER (ABCCl), BAG-1, BASIGIN (BSG), BCEI, B-CELL DIFFERENTIATION FACTOR (BCDF), B-CELL LEUKEMIA 2 (BCL-2), B-CELL STIMULATORY FACTOR-2 (BSF-2), BCL- 1 , BCL-2-AS SOCIATED X PROTEIN (BAX), BCRP, BETA 1 INTEGRIN SUBUNIT, BETA 3 INTEGRIN SUBUNIT, BETA 5 INTEGRIN SUBUNIT, BETA-2 INTERFERON, B
- METALLOPROTEINASE INDUCER EMMPRIN
- FIBRONECTIN RECEPTOR BETA
- JUNCTION PROTEIN 43 kDa
- GAP JUNCTION PROTEIN ALPHA- 1 GJA1
- GAP JUNCTION PROTEIN BETA-2 GJB2
- GCP1 GAP JUNCTION A, GELATINASE B, GELATINASE (72 kDa), GELATINASE (92 kDa)
- GLIOSTATIN GLUCOCORTICOID RECEPTOR INTERACTING
- PROTEIN 1 (GRIP1), GLUTATHIONE S-TRANSFERASE p, GM-CSF, GRANULOCYTE
- STIMULATING FACTOR GROWTH FACTOR RECEPTOR BOUND-7 (GRB-7), GSTp, HAP, HEAT-SHOCK COGNATE PROTEIN 70 (HSC70), HEAT-STABLE ANTIGEN, HEPATOCYTE GROWTH FACTOR (HGF), HEPATOCYTE GROWTH FACTOR RECEPTOR (HGFR),
- HEPATOCYTE- STIMULATING FACTOR III HPF III
- HER-2 HEPATOCYTE- STIMULATING FACTOR III
- HER2/NEU HERMES ANTIGEN
- HET HHM
- HUMORAL HYPERCALCEMIA OF MALIGNANCY HHM
- ICERE- 1 INT-1
- INTERCELLULAR ADHESION MOLECULE- 1 ICM-1
- INTERFERON-GAMMA-INDUCING FACTOR IGIF
- INTERLEUKIN- 1 ALPHA IL-1A
- INTERLEUKIN- 1 BETA IL-1B
- INTERLEUKIN-11 (IL-11), INTERLEUKIN- 17 (IL-17), INTERLEUKIN- 18 (IL-18), INTERLEUKIN - 6 (IL-6), INTERLEUKIN- 8 (IL-8), INVERSELY CORRELATED WITH ESTROGEN RECEPTOR EXPRESSION-1 (ICERE- 1), KAI1, KDR, KERATIN 8, KERATIN 18, KERATIN 19, KISS-1, LEUKEMIA INHIBITORY FACTOR (LIF), LIF, LOST IN INFLAMMATORY BREAST CANCER (LIBC), LOT ("LOST ON TRANSFORMATION”), LYMPHOCYTE HOMING RECEPTOR,
- MACROPHAGE-COLONY STIMULATING FACTOR MAGE-3, MAMMAGLOBIN, MASPIN, MC56, M-CSF, MDC, MDNCF, MDR, MELANOMA CELL ADHESION MOLECULE (MCAM), MEMBRANE METALLOENDOPEPTIDASE (MME), MEMBRANE-ASSOCIATED NEUTRAL ENDOPEPTIDASE (NEP), CYSTEINE-RICH PROTEIN (MDC), METASTASIN (MTS-1), MLN64, MMP1, MMP2, MMP3, MMP7, MMP9, MMP1 1, MMP13, MMP14, MMP15, MMP16, MMP17, MOESIN, MONOCYTE ARGININE- SERPIN, MONOCYTE-DERIVED NEUTROPHIL
- CHEMOTACTIC FACTOR MONOCYTE-DERIVED PLASMINOGEN ACTIVATOR INHIBITOR, MTS-1, MUC-1, MUC 18, MUCIN LIKE CANCER ASSOCIATED ANTIGEN (MCA), MUCIN, MUC- 1, MULTIDRUG RESISTANCE PROTEIN 1 (MDR, MDR1), MULTIDRUG RESISTANCE
- RECEPTOR COACTIVATOR-3 SRC-3
- STEROID RECEPTOR RNA ACTIVATOR SRA
- STROMELY SIN- 1 STROMELYSIN-3
- TENASCIN-C T-C
- TESTES-SPECIFIC PROTEASE 50 THROMBOSPONDIN I
- THROMBOSPONDIN II THYMIDINE PHOSPHORYLASE (TP)
- THYROID HORMONE RECEPTOR ACTIVATOR MOLECULE 1 (TRAM-1), TIGHT JUNCTION PROTEIN 1 (TJP1), TIMP1, TIMP2, TIMP3, TIMP4, TISSUE-TYPE PLASMINOGEN ACTIVATOR, TN-C, TP53, tPA, TRANSCRIPTIONAL INTERMEDIARY FACTOR 2 (TIF2), TREFOIL FACTOR 1 (TFF1), TSG 101 , TSP- 1 , TSP1 , TSP-2, TSP2, TSP50, TUMOR CELL COLLAGENASE
- STIMULATING FACTOR TSF
- TUMOR-ASSOCIATED EPITHELIAL MUCIN uPA
- uPAR UROKINASE
- UROKINASE-TYPE PLASMINOGEN ACTIVATOR
- UROKINASE-TYPE TUMOR-ASSOCIATED EPITHELIAL MUCIN, uPA, uPAR, UROKINASE, UROKINASE-TYPE PLASMINOGEN ACTIVATOR, UROKINASE-TYPE
- PLASMINOGEN ACTIVATOR RECEPTOR (uPAR), UVOMORULIN, VASCULAR ENDOTHELIAL GROWTH FACTOR, VASCULAR ENDOTHELIAL GROWTH FACTOR RECEPTOR-2 (VEGFR2), VASCULAR ENDOTHELIAL GROWTH FACTOR-A, VASCULAR PERMEABILITY FACTOR, VEGFR2, VERY LATE T-CELL ANTIGEN BETA (VLA-BETA), VIMENTIN, VITRONECTIN RECEPTOR ALPHA POLYPEPTIDE (VNRA), VITRONECTIN RECEPTOR, VON WILLEBRAND FACTOR, VPF, VWF, WNT-1 , ZAC, ZO- 1 , and ZONULA OCCLUDENS- 1.
- the gene products used for IHC expression profiling include without limitation one or more of AR, BCRP, BCRP1 , BRCA1 , CAV- 1 , CK 5/6, CK14, CK17, c-Kit, cMET, cMYC, COX2, Cyclin Dl , ECAD, EGFR, ER, ERCC l , Her2/Neu, IGF1R, IGFRBP 1 , IGFRBP2, IGFRBP3, IGFRBP4, IGFRBP5, IGFRBP6, IGFRBP7, Ki67, MGMT, MRP1 , P53, P95, PDGFR, PDGFRA, PGP (MDR1), PR, PTEN, RRMl, SPARC, TLE3, TOPI , TOP2, TOP2A, TS, and TUBB3.
- the IHC is performed on AR, BCRP, CAV- 1, CK 5/6, CK14, CK17, c-Kit, COX2, Cyclin D l , ECAD, EGFR, ER, ERCCl, Her2/Neu, IGF1R, Ki67, MGMT, MRPl, P53, P95, PDGFRa, PGP (MDR1), PR, PTEN, RRMl, SPARC, TLE3, TOP I, TOP2A, TS, and TUBB3.
- IHC analysis includes one or more of c-Met, EML4-ALK fusion, hENT- 1, IGF-1R, MMR, i 6, p21 , p27, PARP- 1 , PI3K, and TLE3.
- IHC profiling of EGFR can also be performed.
- IHC is also used to detect or test for various gene products, including without limitation one or more of the following: EGFR, SPARC, C-kit, ER, PR, Androgen receptor, PGP, RRMl, TOPOl, BRCP 1 , MRPl , MGMT, PDGFR, DCK, ERCC l ,
- IHC is used to detect on or more of the following proteins, including without limitation: ADA, AR, ASNA, BCL2, BRCA2, c-Met, CD33, CDW52, CES2, DNMT1, EGFR, EML4-ALK fusion, ERBB2, ERCC3, ESR1, FOLR2, GART, GSTP1 , HDAC1 , hENT- 1, HIF1A, HSPCA, IGF- 1R, IL2RA, KIT, MLH1 , MMR, MS4A1, MASH2, NFKB2, NFKBIA, OGFR, pi 6, p21, p27, PARP- 1 , PI3K, PDGFC, PDGFRA, PDGFRB, PGR, POLA, PTEN, PTGS2, RAF1 , RARA, RXRB, SPARC, SSTR1 , SSTR1 , SSTR1 , TK1, TLE3, TNF, TOPI , TOPI , TOPI , TOPI , TOPI
- the proteins can be detected by IHC using monoclonal or polyclonal antibodies. In some embodiments, both are used.
- SPARC can be detected by anti-SPARC monoclonal (SPARC mono, SPARC m) and/or anti-SPARC polyclonal (SPARC poly, SPARC p) antibodies.
- IHC analysis according to the methods of the invention includes one or more of AR, c-Kit, COX2, CAV- 1 , CK 5/6, CK14, CK17, ECAD, ER, Her2/Neu, Ki67, MRPl , P53, PDGFR, PGP, PR, PTEN, SPARC, TLE3 and TS. All of these genes can be examined.
- additional IHC assays can be performed.
- the additional IHC comprises that of p95, or p95, Cyclin D l and EGFR.
- IHC can also be performed on IGFRBP3, IGFRBP4, IGFRBP5, or other forms of IGFRBP (e.g., IGFRBPl, IGFRBP2, IGFRBP6, IGFRBP7).
- the additional IHC comprises that of one or more of BCRP, ERCC l , MGMT, P95, RRMl, TOP2A, and TOPI .
- the additional IHC comprises that of one or more of BCRP, Cyclin D l , EGFR, ERCCl , MGMT, P95, RRMl, TOP2A, and TOPI . Any useful subset or all of these genes can be examined.
- the additional IHC can be selected on the basis of molecular characteristics of the tumor so that IHC is only performed where it is likely to indicate a candidate therapy for treating the cancer.
- the molecular characteristics of the tumor determined can be determined by IHC combined with one or more of FISH, DNA microarray and mutation analysis.
- the genes and/or gene products used for IHC analysis can be at least 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 40, 50, 60, 70, 80, 90, 100 or all of the genes and/or gene products listed in Table 2.
- Microarray expression profiling can be used to simultaneously measure the expression of one or more genes or gene products, including without limitation ABCC1, ABCG2, ADA, AR, ASNS, BCL2, BIRC5, BRCAl, BRCA2, CD33, CD52, CDA, CES2, DCK, DHFR, DNMT1 , DNMT3A, DNMT3B, ECGF1, EGFR, EPHA2, ERBB2, ERCC 1 , ERCC3, ESR1 , FLT1, FOLR2, FY , GART, GNRH1, GSTP 1 , HCK, HDAC 1, HIF1A, HSP90AA1, IGFBP3, IGFBP4, IGFBP5, IL2RA, KDR, KIT, LCK, LY , MET, MGMT, MLH1 , MS4A1 , MSH2, NFKB 1 , NFKB2, NFKBIA, OGFR, PARP 1 , PDGFC, PDGFRA, PDGFRB, PDGFC,
- the genes used for the microarray expression profiling comprise one or more of: EGFR, SPARC, C-kit, ER, PR, Androgen receptor, PGP, RRMl, TOPOl, BRCP1 , MRP 1 , MGMT, PDGFR, DCK, ERCC1 , Thymidylate synthase, Her2/neu, TOP02A, ADA, AR, ASNA, BCL2, BRCA2, CD33, CDW52, CES2, DNMT1 , EGFR, ERBB2, ERCC3, ESR1, FOLR2, GART, GSTP1 , HDAC1, HIF1A, HSPCA, IL2RA, KIT, MLH1, MS4A1 , MASH2, NFKB2, NFKBIA, OGFR, PDGFC, PDGFRA, PDGFRB, PGR, POLA, PTEN, PTGS2, RAF l , RARA, RXRB, SPARC, SSTRl , TKl
- microarray expression profiling can be performed using a low density microarray, an expression microarray, a comparative genomic hybridization (CGH) microarray, a single nucleotide polymorphism (SNP) microarray, a proteomic array an antibody array, or other array as disclosed herein or known to those of skill in the art.
- CGH comparative genomic hybridization
- SNP single nucleotide polymorphism
- proteomic array an antibody array, or other array as disclosed herein or known to those of skill in the art.
- high throughput expression arrays are used.
- Such systems include without limitation commercially available systems from
- Microarray expression profding can be used to simultaneously measure the expression of one or more genes or gene products, including without limitation ABCC1, ABCG2, ADA, AR, ASNS, BCL2, BIRC5, BRCAl, BRCA2, CD33, CD52, CDA, CES2, DCK, DHFR, DNMTl , DNMT3A, DNMT3B, ECGF1, EGFR, EPHA2, ERBB2, ERCC 1, ERCC3, ESR1 , FLT1, FOLR2, FYN, GART, GNRH1, GSTP 1 , HCK, HDAC1 , HIF1A, HSP90AA1, IGFBP3, IGFBP4, IGFBP5, IL2RA, KDR, KIT, LCK, LYN, MET, MGMT, MLH1 , MS4A1 , MSH2, NFKB 1 , NFKB2, NFKBIA, OGFR, PARP L PDGFC, PDGFRA, PDGFRB, PGP
- Expression profiling can be performed using PCR, e.g., real-time PCR (qPCR or RT-PCR).
- RT-PCR can be used to measure the expression of one or more genes or gene products, including without limitation ABCC1 , ABCG2, ACE2, ADA, ADH1 C, ADH4, AGT, AR, AREG, ASNS, BCL2, BCRP, BDCAl , beta III tubulin, BIRC5, B-RAF, BRCAl , BRCA2, CA2, caveolin, CD20, CD25, CD33, CD52, CDA, CDKN2A, CDKNIA, CDKNIB, CDK2, CDW52, CES2, CK 14, CK 17, CK 5/6, c-KIT, c-Met, c- Myc, COX-2, Cyclin D l , DCK, DHFR, DNMTl, DNMT3A, DNMT3B, E-Cadherin, ECGF1, EGFR, EML4-
- the genes assessed by RT-PCR can include AREG, BRCA1 , EGFR, ERBB3, ERCC 1 , EREG, PGP (MDR- 1), RRM1 , TOPO l , TOP02A, TS, TUBB3 and VEGFR2.
- the genes and/or gene products used for real-time PCR analysis can be at least 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 40, 50, 60, 70, 80, 90, 100 or all of the genes and/or gene products listed in Table 2.
- the PCR can be performed in a high throughput fashion, e.g., using multiplex amplification, microfluidics, and/or using a low density microarray.
- FISH analysis can be used to profile one or more of HER2, CMET, PIK3CA, EGFR, TOP2A, CMYC and EML4-ALK fusion.
- FISH is used to detect or test for one or more of the following genes, including without limitation: EGFR, SPARC, C-kit, ER, PR, AR, PGP, RRM1 , TOPOl, BRCP1, MRP 1 , MGMT, PDGFR, DCK, ERCC1 , TS, HER2, or TOP02A.
- FISH is used to detect or test for one or more of EML4-ALK fusion and IGF- 1R.
- FISH is used to detect or test various biomarkers, including without limitation one or more of the following: ADA, AR, ASNA, BCL2, BRCA2, c-Met, CD33, CDW52, CES2, DNMT1 , EGFR, EML4-ALK fusion, ERBB2, ERCC3, ESR1 , FOLR2, GART, GSTP1, HDAC1, hENT- 1, HIF1A, HSPCA, IGF- 1R, IL2RA, KIT, MLH1 , MMR, MS4A1 , MASH2, NFKB2, NFKBIA, OGFR, p l 6, p21, p27, PARP-1, PI3K, PDGFC, PDGFRA, PDGFRB, PGR, POLA, PTEN, PTGS2, RAF l, RARA, RXRB, SPARC, SSTR1, TK1 , TLE3, TNF, TOPI, TOP2A, TOP2B, TXNRD
- FISH is used to detect or test for HER2, and depending on the results of the HER2 analysis and other molecular profiling techniques, additional FISH testing may be performed.
- the additional FISH testing can comprise that of CMYC and/or TOP2A.
- FISH testing may indicate that a cancer is HER2+.
- the cancer may be a breast cancer.
- HER2+ cancers may then be followed up by FISH testing for CMYC and TOP2A, whereas HER2- cancers are followed up with FISH testing for CMYC.
- triple negative breast cancer i.e., ER-/PR-/HER2-
- additional FISH testing may not be performed.
- the decision whether to perform additional FISH testing can be guided by whether the additional FISH testing is likely to reveal information about candidate therapies for the cancer.
- the additional FISH can be selected on the basis of molecular characteristics of the tumor so that FISH is only performed where it is likely to indicate a candidate therapy for treating the cancer.
- the molecular characteristics of the tumor determined can be determined by one or more of IHC, FISH, DNA microarray and sequence analysis.
- the genes and/or gene products used for FISH analysis can be at least 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 40, 50, 60, 70, 80, 90, 100 or all of the genes and/or gene products listed in Table 2.
- the genes used for the mutation profiling comprise one or more of PIK3CA, EGFR, cKIT, KRAS, NRAS and BRAF.
- Mutation profiling can be determined by sequencing, including Sanger sequencing, array sequencing, pyrosequencing, NextGen sequencing, etc. Sequence analysis may reveal that genes harbor activating mutations so that drugs that inhibit activity are indicated for treatment. Alternately, sequence analysis may reveal that genes harbor mutations that inhibit or eliminate activity, thereby indicating treatment for compensating therapies. In embodiments, sequence analysis comprises that of exon 9 and 1 1 of c-KIT. Sequencing may also be performed on EGFR-kinase domain exons 18, 19, 20, and 21.
- Mutations, amplifications or misregulations of EGFR or its family members are implicated in about 30% of all epithelial cancers. Sequencing can also be performed on PI3K, encoded by the PIK3CA gene. This gene is a found mutated in many cancers.
- Sequencing analysis can also comprise assessing mutations in one or more ABCC1, ABCG2, ADA, AR, ASNS, BCL2, BIRC5, BRCA1, BRCA2, CD33, CD52, CDA, CES2, DCK, DHFR, DNMTl , DNMT3A, DNMT3B, ECGF1, EGFR, EPHA2, ERBB2, ERCC 1, ERCC3, ESR1 , FLT1, FOLR2, FYN, GART, GNRH1, GSTP 1 , HCK, HDAC 1, HIF1A, HSP90AA1, IGFBP3, IGFBP4, IGFBP5, IL2RA, KDR, KIT, LCK, LYN, MET, MGMT, MLH1 , MS4A1 , MSH2, NFKB 1, NFKB2, NFKBIA, NRAS, OGFR, PARP1 , PDGFC, PDGFRA, PDGFRB, PGP, PGR, POLA1, PTEN, PTGS2,
- genes can also be assessed by sequence analysis: ALK, EML4, hENT-1, IGF-1R, HSP90AA1, MMR, pl6, p21 , p27, PARP-1, PI3K and TLE3.
- the genes and/or gene products used for mutation or sequence analysis can be at least 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 40, 50, 60, 70, 80, 90, 100 or all of the genes and/or gene products listed in Table 2, Table 6 or Table 25.
- mutational analysis is performed on PIK3CA.
- the decision whether to perform mutational analysis on PIK3CA can be guided by whether this testing is likely to reveal information about candidate therapies for the cancer.
- the PIK3CA mutational analysis can be selected on the basis of molecular characteristics of the tumor so that the analysis is only performed where it is likely to indicate a candidate therapy for treating the cancer.
- the molecular characteristics of the tumor determined can be determined by one or more of IHC, FISH, DNA microarray and sequence analysis.
- PIK3CA is analyzed for a HER2+ cancer.
- the cancer can be a breast cancer.
- the invention provides a method of identifying a candidate treatment for a subject in need thereof by using molecular profiling of sets of known biomarkers.
- the method can identify a chemotherapeutic agent for an individual with a cancer.
- the method comprises: obtaining a sample from the subject; performing an immunohistochemistry (IHC) analysis on the sample to determine an IHC expression profile on one or more, e.g.
- IHC immunohistochemistry
- the disease can be a cancer.
- the molecular profiling steps can be performed in any order. In some embodiments, not all of the molecular profiling steps are performed. As a non-limiting example, microarray analysis is not performed if the sample quality does not meet a threshold value, as described herein.
- the IHC expression profiling is performed on at least 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, or 95% of the gene products above.
- the microarray expression profiling is performed on at least 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, or 95% of the genes listed above.
- the IHC expression profiling is performed on all of the gene products above.
- the microarray profiling is performed on all of the genes listed above.
- the FISH profiling is performed on all of the gene products above.
- the sequence profiling is performed on all of the genes listed above.
- the invention provides a method of identifying a candidate treatment for a subject in need thereof by using molecular profiling of defined sets of known biomarkers.
- the method can identify a chemotherapeutic agent for an individual with a cancer.
- the method comprises: obtaining a sample from the subject, wherein the sample comprises formalin- fixed paraffin-embedded (FFPE) tissue or fresh frozen tissue, and wherein the sample comprises cancer cells; performing an immunohistochemistry (IHC) analysis on the sample to determine an IHC expression profile on at least: SPARC, PGP, Her2/neu, ER, PR, c-kit, AR, CD52, PDGFR, TOP2A, TS, ERCC1 , RRM1 , BCRP, TOPOl, PTEN, MGMT, MRPl , c-Met, EML4-ALK fusion, hENT- 1 , IGF- IR, MMR, pl6, p21 , p27, PARP- 1 , PI3K, and TLE3; performing a microarray analysis on the sample to determine a microarray expression profile on at least: ABCC1, ABCG2, ADA, AR, ASNS, BCL2, BIRC5, BRCA1 , BRCA2, CD33, CD52,
- the IHC expression profile, microarray expression profile, FISH mutation profile and sequencing mutation profile are compared against a rules database, wherein the rules database comprises a mapping of treatments whose biological activity is known against diseased cells that: i) overexpress or underexpress one or more proteins included in the IHC expression profile; ii) overexpress or underexpress one or more genes included in the microarray expression profile; iii) have zero or more mutations in one or more genes included in the FISH mutation profile; or iv) have zero or more mutations in one or more genes included in the sequencing mutation profile; and identifying the treatment if the comparison against the rules database indicates that the treatment should have biological activity against the disease; and the comparison against the rules database does not contraindicate the treatment for treating the disease.
- the rules database comprises a mapping of treatments whose biological activity is known against diseased cells that: i) overexpress or underexpress one or more proteins included in the IHC expression profile; ii) overexpress or underexpress one or more genes included in the microarra
- the disease can be a cancer.
- the molecular profiling steps can be performed in any order. In some embodiments, not all of the molecular profiling steps are performed.
- microarray analysis is not performed if the sample quality does not meet a threshold value, as described herein.
- the biological material is mRNA and the quality control test comprises a A260/A280 ratio and/or a Ct value of RT-PCR using a housekeeping gene, e.g., RPL13a.
- the mRNA does not pass the quality control test if the A260/A280 ratio ⁇ 1.5 or the RPL13a Ct value is > 30. In that case, microarray analysis may not be performed. Alternately, microarray results may be attenuated, e.g., given a lower priority as compared to the results of other molecular profiling techniques.
- molecular profiling is always performed on certain genes or gene products, whereas the profiling of other genes or gene products is optional.
- IHC expression profiling may be performed on at least SPARC, TOP2A and/or PTEN.
- microarray expression profiling may be performed on at least CD52.
- genes in addition to those listed above are used to identify a treatment.
- the group of genes used for the IHC expression profiling can further comprise DCK, EGFR, BRCA1, CK 14, CK 17, CK 5/6, E-Cadherin, p95, PARP- 1 , SPARC and TLE3.
- the group of genes used for the IHC expression profiling further comprises Cox-2 and/or Ki-67.
- HSPCA is assayed by microarray analysis.
- FISH mutation is performed on c-Myc and TOP2A.
- sequencing is performed on PI3K.
- the methods of the invention can be used in any setting wherein differential expression or mutation analysis have been linked to efficacy of various treatments.
- the methods are used to identify candidate treatments for a subject having a cancer.
- the sample used for molecular profiling preferably comprises cancer cells.
- the percentage of cancer in a sample can be determined by methods known to those of skill in the art, e.g., using pathology techniques. Cancer cells can also be enriched from a sample, e.g., using microdissection techniques or the like.
- a sample may be required to have a certain threshold of cancer cells before it is used for molecular profiling.
- the threshold can be at least about 5, 10, 20, 30, 40, 50, 60, 70, 80, 90 or 95% cancer cells.
- the threshold can depend on the analysis method. For example, a technique that reveals expression in individual cells may require a lower threshold that a technique that used a sample extracted from a mixture of different cells.
- the diseased sample is compared to a normal sample taken from the same patient, e.g., adjacent but non-cancer tissue.
- the methods of the invention are used detect gene fusions, such as those listed in U.S. Patent Application 12/658,770, filed February 12, 2010; International PCT Patent Application PCT/US2010/000407, filed February 1 1, 2010; and International PCT Patent Application
- a fusion gene is a hybrid gene created by the juxtaposition of two previously separate genes. This can occur by chromosomal translocation or inversion, deletion or via trans-splicing. The resulting fusion gene can cause abnormal temporal and spatial expression of genes, leading to abnormal expression of cell growth factors, angiogenesis factors, tumor promoters or other factors contributing to the neoplastic transformation of the cell and the creation of a tumor.
- such fusion genes can be oncogenic due to the juxtaposition of: 1) a strong promoter region of one gene next to the coding region of a cell growth factor, tumor promoter or other gene promoting oncogenesis leading to elevated gene expression, or 2) due to the fusion of coding regions of two different genes, giving rise to a chimeric gene and thus a chimeric protein with abnormal activity. Fusion genes are characteristic of many cancers. Once a therapeutic intervention is associated with a fusion, the presence of that fusion in any type of cancer identifies the therapeutic intervention as a candidate therapy for treating the cancer.
- fusion genes e.g., those described in U.S. Patent Application 12/658,770, filed February 12, 2010; International PCT Patent Application PCT/US2010/000407, filed February 1 1 , 2010; and International PCT Patent Application PCT/US2010/54366, filed October 27, 2010 or elsewhere herein, can be used to guide therapeutic selection.
- the BCR-ABL gene fusion is a characteristic molecular aberration in -90% of chronic myelogenous leukemia (CML) and in a subset of acute leukemias (Kurzrock et al., Annals of Internal Medicine 2003; 138:819-830).
- the BCR-ABL results from a translocation between chromosomes 9 and 22, commonly referred to as the Philadelphia chromosome or Philadelphia translocation.
- the translocation brings together the 5' region of the BCR gene and the 3 ' region of ABL1, generating a chimeric BCR-ABL1 gene, which encodes a protein with constitutively active tyrosine kinase activity (Mittleman et al., Nature Reviews Cancer 2007; 7:233-245).
- Philadelphia chromosome Philadelphia chromosome are treated with imatinib and other targeted therapies.
- Imatinib binds to the site of the constitutive tyrosine kinase activity of the fusion protein and prevents its activity. Imatinib treatment has led to molecular responses (disappearance of BCR-ABL+ blood cells) and improved progression-free survival in BCR-ABL+ CML patients (Kantarjian et al, Clinical Cancer Research 2007; 13: 1089-1097).
- IGH-MYC Another fusion gene, IGH-MYC, is a defining feature of -80% of Burkitt's lymphoma (Ferry et al. Oncologist 2006; 1 1 :375-83).
- the causal event for this is a translocation between chromosomes 8 and 14, bringing the c-Myc oncogene adjacent to the strong promoter of the immunoglobulin heavy chain gene, causing c-myc overexpression (Mittleman et al., Nature Reviews Cancer 2007; 7:233-245).
- the c- myc rearrangement is a pivotal event in lymphomagenesis as it results in a perpetually proliferative state. It has wide ranging effects on progression through the cell cycle, cellular differentiation, apoptosis, and cell adhesion (Ferry et al. Oncologist 2006; 1 1 :375-83).
- the gene fusions can be used to characterize neoplasms and cancers and guide therapy using the subject methods described herein.
- TMPRSS2-ERG, TMPRSS2-ETV and SLC45A3-ELK4 fusions can be detected to characterize prostate cancer; and ETV6- NTRK3 and ODZ4-NRG1 can be used to characterize breast cancer.
- EML4-ALK, RLF-MYCL1, TGF-ALK, or CD74-ROS 1 fusions can be used to characterize a lung cancer.
- the ACSL3-ETV1, C150RF21 -ETV1, FLJ35294-ETV1 , HERV-ETV1 , TMPRSS2-ERG, TMPRSS2-ETV1/4/5, TMPRSS2- ETV4/5, SLC5A3-ERG, SLC5A3-ETV1 , SLC5A3-ETV5 or KLK2-ETV4 fusions can be used to characterize a prostate cancer.
- the GOPC-ROS 1 fusion can be used to characterize a brain cancer.
- the CHCHD7-PLAG 1 , CTNNB 1 -PLAG 1 , FHIT-HMGA2, HMGA2-NFIB, LIFR-PLAG1 , or TCEA1 - PLAG1 fusions can be used to characterize a head and neck cancer.
- the ALPHA-TFEB, NONO-TFE3, PRCC-TFE3, SFPQ-TFE3, CLTC-TFE3, or MALAT1 -TFEB fusions can be used to characterize a renal cell carcinoma (RCC).
- the AKAP9-BRAF, CCDC6-RET, ERCl-RETM, GOLGA5-RET, HOOK3-RET, HRH4-RET, KTN1-RET, NCOA4-RET, PCMl-RET, PRKARA 1 A-RET, RFG-RET, RFG9-RET, Ria- RET, TGF-NTRK1, TPM3-NTRK1, TPM3-TPR, TPR-MET, TPR-NTRK1 , TRIM24-RET, TRIM27- RET or TRIM33-RET fusions can be used to characterize a thyroid cancer and/or papillary thyroid carcinoma; and the PAX8-PPARy fusion can be analyzed to characterize a follicular thyroid cancer.
- Fusions that are associated with hematological malignancies include without limitation TTL-ETV6, CDK6-MLL, CDK6-TLX3, ETV6-FLT3, ETV6-RUNX1, ETV6-TTL, MLL-AFF1, MLL-AFF3, MLL- AFF4, MLL-GAS7, TCBA1-ETV6, TCF3-PBX1 or TCF3-TFPT, which are characteristic of acute lymphocytic leukemia (ALL); BCL11B-TLX3, IL2-TNFRFS17, NUP214-ABL1, NUP98-CCDC28A, TAL1-STIL, or ETV6-ABL2, which are characteristic of T-cell acute lymphocytic leukemia (T-ALL); ATIC-ALK, KIAA1618-ALK, MSN-ALK, MYH9-ALK, NPM1 -ALK, TGF-ALK or TPM3-ALK, which are characteristic of anaplastic large cell lymphoma (
- the fusion genes and gene products can be detected using one or more techniques described herein.
- the sequence of the gene or corresponding mRNA is determined, e.g., using Sanger sequencing, NextGen sequencing, pyrosequencing, DNA microarrays, etc.
- Chromosomal abnormalities can be assessed using FISH or PCR techniques, among others.
- a break apart probe can be used for FISH detection of ALK fusions such as EML4-ALK, KIF5B-ALK and/or TFG-ALK.
- PCR can be used to amplify the fusion product, wherein amplification or lack thereof indicates the presence or absence of the fusion, respectively.
- the fusion protein fusion is detected.
- Appropriate methods for protein analysis include without limitation mass
- electrophoresis e.g., 2D gel electrophoresis or SDS-PAGE
- antibody related techniques including immunoassay, protein array or immunohistochemistry.
- the techniques can be combined.
- indication of an ALK fusion by FISH can be confirmed for ALK expression using IHC, or vice versa.
- the systems and methods allow identification of one or more therapeutic targets whose projected efficacy can be linked to therapeutic efficacy, ultimately based on the molecular profiling.
- Illustrative schemes for using molecular profiling to identify a treatment regime are shown in FIGs. 2, 49A-B and 50, each of which is described in further detail herein.
- the invention comprises use of molecular profiling results to suggest associations with treatment responses.
- the appropriate biomarkers for molecular profiling are selected on the basis of the subject's tumor type. These suggested biomarkers can be used to modify a default list of biomarkers.
- the molecular profiling is independent of the source material.
- rules are used to provide the suggested chemotherapy treatments based on the molecular profiling test results.
- the rules are generated from abstracts of the peer reviewed clinical oncology literature. Expert opinion rules can be used but are optional.
- clinical citations are assessed for their relevance to the methods of the invention using a hierarchy derived from the evidence grading system used by the United States Preventive Services Taskforce.
- the "best evidence" can be used as the basis for a rule.
- the simplest rules are constructed in the format of "if biomarker positive then treatment option one, else treatment option two.” Treatment options comprise no treatment with a specific drug, treatment with a specific drug or treatment with a combination of drugs.
- more complex rules are constructed that involve the interaction of two or more biomarkers. In such cases, the more complex interactions are typically supported by clinical studies that analyze the interaction between the biomarkers included in the rule.
- a report can be generated that describes the association of the chemotherapy response and the biomarker and a summary statement of the best evidence supporting the treatments selected.
- the treating physician will decide on the best course of treatment.
- molecular profiling might reveal that the EGFR gene is amplified or overexpressed, thus indicating selection of a treatment that can block EGFR activity, such as the monoclonal antibody inhibitors cetuximab and panitumumab, or small molecule kinase inhibitors effective in patients with activating mutations in EGFR such as gefmnib, erlotinib, and lapatinib.
- a treatment that can block EGFR activity such as the monoclonal antibody inhibitors cetuximab and panitumumab, or small molecule kinase inhibitors effective in patients with activating mutations in EGFR such as gefmnib, erlotinib, and lapatinib.
- Other anti-EGFR monoclonal antibodies in clinical development include zalutumumab, nimotuzumab, and matuzumab.
- the candidate treatment selected can depend on the setting revealed by molecular profiling.
- kinase inhibitors are often prescribed with EGFR is found to have activating mutations.
- molecular profiling may also reveal that some or all of these treatments are likely to be less effective.
- patients taking gefitinib or erlotinib eventually develop drug resistance mutations in EGFR. Accordingly, the presence of a drug resistance mutation would contraindicate selection of the small molecule kinase inhibitors.
- this example can be expanded to guide the selection of other candidate treatments that act against genes or gene products whose differential expression is revealed by molecular profiling.
- candidate agents known to be effective against diseased cells carrying certain nucleic acid variants can be selected if molecular profiling reveals such variants.
- Imatinib is a 2-phenylaminopyrimidine derivative that functions as a specific inhibitor of a number of tyrosine kinase enzymes. It occupies the tyrosine kinase active site, leading to a decrease in kinase activity. Imatinib has been shown to block the activity of Abelson cytoplasmic tyrosine kinase (ABL), c-Kit and the platelet- derived growth factor receptor (PDGFR).
- ABL Abelson cytoplasmic tyrosine kinase
- PDGFR platelet- derived growth factor receptor
- imatinib can be indicated as a candidate therapeutic for a cancer determined by molecular profiling to overexpress ABL, c-KIT or PDGFR.
- Imatinib can be indicated as a candidate therapeutic for a cancer determined by molecular profiling to have mutations in ABL, c-KIT or PDGFR that alter their activity, e.g., constitutive kinase activity of ABLs caused by the BCR-ABL mutation.
- imatinib mesylate appears to have utility in the treatment of a variety of dermatological diseases.
- Cancer therapies that can be identified as candidate treatments by the methods of the invention include without limitation: 13-cis-Retinoic Acid, 2-CdA, 2-Chlorodeoxyadenosine, 5-Azacitidine, 5- Fluorouracil, 5-FU, 6-Mercaptopurine, 6-MP, 6-TG, 6-Thioguanine, Abraxane, Accutane®,
- Actinomycin-D Adriamycin®, Adrucil®, Afinitor®, Agrylin®, Ala-Cort®, Aldesleukin, Alemtuzumab, ALIMTA, Alitretinoin, Alkaban-AQ®, Alkeran®, All-transretinoic Acid, Alpha Interferon, Altretamine, Amethopterin, Amifostine, Aminoglutethimide, Anagrelide, Anandron®, Anastrozole,
- Daunomycin Dactinomycin, Darbepoetin Alfa, Dasatinib, Daunomycin Daunorubicin, Daunorubicin Hydrochloride, Daunorubicin Liposomal, DaunoXome®, Decadron, Decitabine, Delta- Cortef®, Deltasone®, Denileukin, Diftitox, DepoCytTM, Dexamethasone, Dexamethasone Acetate Dexamethasone Sodium Phosphate, Dexasone, Dexrazoxane, DHAD, DIC, Diodex Docetaxel, Doxil®, Doxorubicin, Doxorubicin Liposomal, DroxiaTM, DTIC, DTIC-Dome®, Duralone®, Efudex®, EligardTM, EllenceTM, EloxatinTM, Elspar®, Emcyt®, Epirubicin, Epoe
- Prolifeprospan 20 with Carmustine Implant Purinethol®, Raloxifene, Revlimid®, Rheumatrex®, Rituxan®, Rituximab, Roferon-A® (Interferon Alfa-2a), Rubex®, Rubidomycin hydrochloride, Sandostatin®, Sandostatin LAR®, Sargramostim, Solu-Cortef®, Solu-Medrol®, Sorafenib,
- SPRYCELTM SPRYCELTM, STI-571, Streptozocin, SU1 1248, Sunitinib, Sutent®, Tamoxifen, Tarceva®, Targretin®, Taxol®, Taxotere®, Temodar®, Temozolomide, Temsirolimus, Teniposide, TESPA, Thalidomide, Thalomid®, TheraCys®, Thioguanine, Thioguanine Tabloid®, Thiophosphoamide, Thioplex®, Thiotepa, TICE®, Toposar®, Topotecan, Toremifene, Torisel®, Tositumomab, Trastuzumab, Treanda®, Tretinoin, TrexallTM, Trisenox®, TSPA, TYKERB®, VCR, VectibixTM, Velban®, Velcade®, VePesid®, Vesanoid®, ViadurTM
- the candidate treatments identified according to the subject methods can be chosen from the class of therapeutic agents identified as Anthracyclines and related substances, Anti-androgens, Anti- estrogens, Antigrowth hormones (e.g., Somatostatin analogs), Combination therapy (e.g., vincristine, bcnu, melphalan, cyclophosphamide, prednisone (VBMCP)), DNA methyltransferase inhibitors, Endocrine therapy - Enzyme inhibitor, Endocrine therapy - other hormone antagonists and related agents, Folic acid analogs (e.g., methotrexate), Folic acid analogs (e.g., pemetrexed), Gonadotropin releasing hormone analogs, Gonadotropin-releasing hormones, Monoclonal antibodies (EGFR-Targeted - e.g., panitumumab, cetuximab), Monoclonal antibodies (Her2-Targeted - e.g., trastu
- the candidate treatments identified according to the subject methods are chosen from at least the groups of treatments consisting of 5-fluorouracil, abarelix, alemtuzumab, aminoglutethimide, anastrozole, asparaginase, aspirin, ATRA, azacitidine, bevacizumab, bexarotene, bicalutamide, calcitriol, capecitabine, carboplatin, celecoxib, cetuximab, chemotherapy, cholecalciferol, cisplatin, cytarabine, dasatinib, daunorubicin, decitabine, doxorubicin, epirubicin, erlotinib, etoposide, exemestane, flutamide, fulvestrant, gefitinib, gemcitabine, gonadorelin, goserelin, hydroxyurea, imatinib, irinotecan, lapatinib,
- a database is created that maps treatments and molecular profiling results.
- the treatment information can include the projected efficacy of a therapeutic agent against cells having certain attributes that can be measured by molecular profiling.
- the molecular profiling can include differential expression or mutations in certain genes, proteins, or other biological molecules of interest.
- the database can include both positive and negative mappings between treatments and molecular profiling results.
- the mapping is created by reviewing the literature for links between biological agents and therapeutic agents. For example, a journal article, patent publication or patent application publication, scientific presentation, etc can be reviewed for potential mappings.
- mapping can include results of in vivo, e.g., animal studies or clinical trials, or in vitro experiments, e.g., cell culture. Any mappings that are found can be entered into the database, e.g., cytotoxic effects of a therapeutic agent against cells expressing a gene or protein. In this manner, the database can be continuously updated. It will be appreciated that the methods of the invention are updated as well.
- the rules can be generated by evidence-based literature review. Biomarker research continues to provide a better understanding of the clinical behavior and biology of cancer. This body of literature can be maintained in an up-to-date data repository incorporating recent clinical studies relevant to treatment options and potential clinical outcomes. The studies can be ranked so that only those with the strongest or most reliable evidence are selected for rules generation. For example, the rules generation can employ the grading system from the current methods of the U.S. Preventive Services Task Force.
- the literature evidence can be reviewed and evaluated based on the strength of clinical evidence supporting associations between biomarkers and treatments in the literature study. This process can be performed by a staff of scientists, physicians and other skilled reviewers. The process can also be automated in whole or in part by using language search and heuristics to identify relevant literature.
- the rules can be generated by a review of a plurality of literature references, e.g., tens, hundreds, thousands or more literature articles.
- the invention provides a method of generating a set of evidence-based associations, comprising: (a) searching one or more literature database by a computer using an evidence- based medicine search filter to identify articles comprising a gene or gene product thereof, a disease, and one or more therapeutic agent; (b) filtering the articles identified in (a) to compile evidence-based associations comprising the expected benefit and/or the expected lack of benefit of the one or more therapeutic agent for treating the disease given the status of the gene or gene product; (c) adding the evidence-based associations compiled in (b) to the set of evidence-based associations; and (d) repeating steps (a)-(c) for an additional gene or gene product thereof.
- the status of the gene can include one or more assessments as described herein which relate to a biological state, e.g., one or more of an expression level, a copy number, and a mutation.
- the genes or gene products thereof can be one or more genes or gene products thereof selected from Table 2, Table 6 or Table 25.
- the method can be repeated for 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 40, 50 or more of the genes or gene products thereof in Table 2, Table 6 or Table 25.
- the disease can be a disease described here, e.g., in embodiment the disease comprises a cancer.
- the one or more literature database can be selected from the group consisting of the National Library of Medicine's (NLM's) MEDLINETM database of citations, a patent literature database, and a combination thereof.
- Evidence-based medicine or evidence-based practice (EBP) aims to apply the best available evidence gained from the scientific method to clinical decision making. This approach assesses the strength of evidence of the risks and benefits of treatments (including lack of treatment) and diagnostic tests. Evidence quality can be assessed based on the source type (from meta-analyses and systematic reviews of double-blind, placebo-controlled clinical trials at the top end, down to conventional wisdom at the bottom), as well as other factors including statistical validity, clinical relevance, currency, and peer-review acceptance.
- Evidence-based medicine filters are searches that have been developed to facilitate searches in specific areas of clinical medicine related to evidence-based medicine (diagnosis, etiology, meta-analysis, prognosis and therapy).
- the evidence-based medicine filter used in the invention can be selected from the group consisting of a generic evidence-based medicine filter, a McMaster University optimal search strategy evidence-based medicine filter, a University of York statistically developed search evidence-based medicine filter, and a University of California San Francisco systemic review evidence-based medicine filter. See e.g., US Patent Publication 20080215570; Shojania and Bero. Taking advantage of the explosion of systematic reviews: an efficient MEDLINE search strategy. Eff Clin Pract. 2001 Iul-Aug;4(4): 157-62; Ingui and Rogers. Searching for clinical prediction rales in MEDLINE. J Am Med Inform Assoc.
- a generic filter can be a customized filter based on an algorithm to identify the desired references from the one or more literature database.
- the method can use one or more approach as described in US Patent 5168533 to Kato et al., US Patent 6886010 to Kostoff, or US Patent Application Publication No.
- the further filtering of articles identified by the evidence-based medicine filter can be performed using a computer, by one or more expert user, or combination thereof.
- the one or more expert can be a trained scientist or physician.
- the set of evidence-based associations comprise one or more of the rules in any of Tables 3-4, 7-25 or 27.
- the set of evidence-based associations can include at least 5, 10, 25, 50 or 100 rules in Tables 3-4, 7-25 or 27.
- the set of evidence-based associations comprises or consists of all of the rules in any of Tables 3-4, 7-25 or 27.
- the invention provides a computer readable medium comprising the set of evidence-based associations generated by the subject methods.
- the invention further provides a computer readable medium comprising one or more rules in any of Tables 3-4, 7-25 or 27 herein.
- the computer readable medium comprises at least 5, 10, 25, 50 or 100 rules in any of Tables 3-4, 7-25 or 27.
- the computer readable medium can comprise all rules in any of Tables 3-4, 7-25 or 27., e.g., all rules in Tables 3-4, 7-25 or 27.
- the rules for the mappings can contain a variety of supplemental information.
- the database contains prioritization criteria. For example, a treatment with more projected efficacy in a given setting can be preferred over a treatment projected to have lesser efficacy.
- a mapping derived from a certain setting e.g., a clinical trial, may be prioritized over a mapping derived from another setting, e.g., cell culture experiments.
- a treatment with strong literature support may be prioritized over a treatment supported by more preliminary results.
- a treatment generally applied to the type of disease in question e.g., cancer of a certain tissue origin, may be prioritized over a treatment that is not indicated for that particular disease.
- Mappings can include both positive and negative correlations between a treatment and a molecular profiling result.
- one mapping might suggest use of a kinase inhibitor like erlotinib against a tumor having an activating mutation in EGFR, whereas another mapping might suggest against that treatment if the EGFR also has a drug resistance mutation.
- a treatment might be indicated as effective in cells that overexpress a certain gene or protein but indicated as not effective if the gene or protein is underexpressed.
- the selection of a candidate treatment for an individual can be based on molecular profiling results from any one or more of the methods described. Alternatively, selection of a candidate treatment for an individual can be based on molecular profiling results from more than one of the methods described. For example, selection of treatment for an individual can be based on molecular profiling results from FISH alone, IHC alone, or microarray analysis alone. In other embodiments, selection of treatment for an individual can be based on molecular profiling results from IHC, FISH, and microarray analysis; IHC and FISH; IHC and microarray analysis, or FISH and microarray analysis. Selection of treatment for an individual can also be based on molecular profiling results from sequencing or other methods of mutation detection.
- Molecular profiling results may include mutation analysis along with one or more methods, such as IHC, immunoassay, and/or microarray analysis. Different combinations and sequential results can be used. For example, treatment can be prioritized according the results obtained by molecular profiling. In an embodiment, the prioritization is based on the following algorithm: 1) IHC/FISH and microarray indicates same target as a first priority; 2) IHC positive result alone next priority; or 3) microarray positive result alone as last priority. Sequencing can also be used to guide selection. In some embodiments, sequencing reveals a drug resistance mutation so that the effected drug is not selected even if techniques including IHC, microarray and/or FISH indicate differential expression of the target molecule. Any such contraindication, e.g., differential expression or mutation of another gene or gene product may override selection of a treatment.
- contraindication e.g., differential expression or mutation of another gene or gene product may override selection of a treatment.
- Table 3 An illustrative listing of microarray expression results versus predicted treatments is presented in Table 3.
- molecular profiling is performed to determine whether a gene or gene product is differentially expressed in a sample as compared to a control.
- the expression status of the gene or gene product is used to select agents that are predicted to be efficacious or not.
- Table 3 shows that overexpression of the ADA gene or protein points to pentostatin as a possible treatment.
- underexpression of the ADA gene or protein implicates resistance to cytarabine, suggesting that cytarabine is not an optimal treatment.
- DNMT1 Overexpressed azacitidine, decitabine
- DNMT3A Overexpressed azacitidine, decitabine
- DNMT3B Overexpressed azacitidine, decitabine
- HER- 2 (ERBB2) Overexpressed trastuzumab, lapatinib
- MRP1 (ABCC1) Overexpressed etoposide, paclitaxel, docetaxel, vinblastine, vinorelbine, topotecan, teniposide
- etoposide epirubicin
- paclitaxel docetaxel
- vinblastine vinorelbine
- topotecan teniposide
- VEGFR1 (Fltl) Overexpressed sorafenib, sunitinib,
- VEGFR2 Overexpressed sorafenib, sunitinib,
- Table 4 presents a selection of illustrative rules for treatment selection.
- the table is ordered by groups of related therapeutic agents. Each row describes a rule that maps the information derived from molecular profiling with an indication of benefit or lack of benefit for the therapeutic agent.
- the database contains a mapping of treatments whose biological activity is known against cancer cells that have alterations in certain genes or gene products, including gene copy alterations, chromosomal abnormalities, overexpression of or underexpression of one or more genes or gene products, or have various mutations.
- a Lineage is presented as applicable which corresponds to a type of cancer associated with use of the agent.
- the agents can be used for all cancers.
- Agents with Benefit are listed along with a Benefit Summary Statement that describes molecular profiling information that relates to the predicted beneficial agent.
- agents with Lack of Benefit are listed along with a Lack of Benefit Summary Statement that describes molecular profiling information that relates to the lack of benefit associated with the agent.
- molecular profiling Criteria are shown. In the criteria, results from analysis using DNA microarray (DMA), IHC, FISH, and mutation analysis (MA) for one or more biomarkers is listed. For microarray analysis, expression can be reported as over (overexpressed) or under (underexpressed). When these criteria are met according to the application of the molecular profiling techniques to a sample, then the therapeutic agent or agents are predicted to have a benefit or lack of benefit as indicated in the corresponding row.
- DMA HIF1A sorafenib, been overexpressed. sunitinib
- DMA VEGFR2 benefit from overexpressed. sunitinib.
- DMA KIT addition, over overexpressed. expression of DMA: PDGFRA
- VEGFR2 VEGFR2, c- overexpressed.
- Kit, PDGFRA DMA VHL and PDGFRB, underexpressed. and under MA: c-kit mutated expression of - Exon 9
- DMA HIF1A sorafenib, been overexpressed. sunitinib
- DMA VEGFR2 benefit from overexpressed. sunitinib.
- DMA KIT addition, over overexpressed. expression of DMA: PDGFRA
- VEGFR2 VEGFR2, c- overexpressed.
- Kit, PDGFRA DMA VHL. MA: and PDGFRB c-kit mutated - have been Exon 9 associated with
- DMA KIT sunitinib.
- DMA PDGFRA expression of overexpressed.
- HIF1A, DMA PDGFRB
- VEGFRl VEGFRl
- Kit, PDGFRA DMA VHL and PDGFRB, underexpressed. and under MA: c-kit mutated expression of - Exon 9
- DMA KIT sunitinib.
- DMA PDGFRA expression of overexpressed.
- HIF1A DMA: PDGFRB VEGFR1, c- overexpressed.
- Kit PDGFRA DMA: VHL.
- MA and PDGFRB c-kit mutated - have been Exon 9, associated with
- DMA KIT sunitinib.
- DMA PDGFRA expression of overexpressed.
- HIF1A DMA: PDGFRB VEGFR2, c- overexpressed.
- Kit PDGFRA DMA: VHL and PDGFRB, underexpressed.
- MA c-kit mutated expression of - Exon 9 VHL have
- DMA KIT sunitinib.
- DMA PDGFRA expression of overexpressed.
- HIF1A DMA: PDGFRB VEGFR2, c- overexpressed.
- Kit PDGFRA DMA: VHL.
- MA and PDGFRB c-kit mutated - have been Exon 9
- DMA PDGFRA addition, over overexpressed. expression of DMA: PDGFRB HIF1A, c-Kit, overexpressed. PDGFRA and DMA: VHL PDGFRB, and underexpressed. under MA: c-kit mutated expression of - Exon 9 VHL have
- DMA PDGFRA addition, over overexpressed. expression of DMA: PDGFRB HIF1A, c-Kit, overexpressed. PDGFRA and DMA: VHL.
- MA PDGFRB have c-kit mutated - been Exon 9 associated with
- DMA HIF1A sorafenib, been overexpressed. sunitinib
- DMA VEGFR2 benefit from overexpressed. sunitinib.
- DMA KIT addition, over overexpressed. expression of DMA: PDGFRA HIF1A, overexpressed. VEGFR1 , DMA: PDGFRB. VEGFR2, c- DMA: VHL Kit and underexpressed. PDGFRA, and MA: c-kit mutated under - Exon 9 expression of
- the efficacy of various therapeutic agents given particular assay results is derived from reviewing, analyzing and rendering conclusions on empirical evidence, such as that is available the medical literature or other medical knowledge base.
- the results are used to guide the selection of certain therapeutic agents in a prioritized list for use in treatment of an individual.
- molecular profiling results e.g., differential expression or mutation of a gene or gene product
- the results can be compared against the database to guide treatment selection.
- the set of rules in the database can be updated as new treatments and new treatment data become available.
- the rules database is updated continuously.
- the rules database is updated on a periodic basis.
- any relevant correlative or comparative approach can be used to compare the molecular profiling results to the rules database.
- a gene or gene product is identified as differentially expressed by molecular profiling.
- the rules database is queried to select entries for that gene or gene product.
- Treatment selection information selected from the rules database is extracted and used to select a treatment.
- the information e.g., to recommend or not recommend a particular treatment, can be dependent on whether the gene or gene product is over or underexpressed, or has other abnormalities at the genetic or protein levels as compared to a reference.
- multiple rules and treatments may be pulled from a database comprising the comprehensive rules set depending on the results of the molecular profiling.
- the treatment options are presented in a prioritized list.
- the treatment options are presented without prioritization information. In either case, an individual, e.g., the treating physician or similar caregiver may choose from the available options.
- the methods described herein are used to prolong survival of a subject by providing personalized treatment.
- the subject has been previously treated with one or more therapeutic agents to treat the disease, e.g., a cancer.
- the cancer may be refractory to one of these agents, e.g., by acquiring drug resistance mutations.
- the cancer is metastatic.
- the subject has not previously been treated with one or more therapeutic agents identified by the method. Using molecular profiling, candidate treatments can be selected regardless of the stage, anatomical location, or anatomical origin of the cancer cells.
- Progression-free survival denotes the chances of staying free of disease progression for an individual or a group of individuals suffering from a disease, e.g., a cancer, after initiating a course of treatment. It can refer to the percentage of individuals in a group whose disease is likely to remain stable (e.g., not show signs of progression) after a specified duration of time. Progression-free survival rates are an indication of the effectiveness of a particular treatment.
- disease-free survival (DFS) denotes the chances of staying free of disease after initiating a particular treatment for an individual or a group of individuals suffering from a cancer. It can refer to the percentage of individuals in a group who are likely to be free of disease after a specified duration of time. Disease-free survival rates are an indication of the effectiveness of a particular treatment. Treatment strategies can be compared on the basis of the PFS or DFS that is achieved in similar groups of patients. Disease-free survival is often used with the term overall survival when cancer survival is described.
- the candidate treatment selected by molecular profiling according to the invention can be compared to a non-molecular profiling selected treatment by comparing the progression free survival (PFS) using therapy selected by molecular profiling (period B) with PFS for the most recent therapy on which the patient has just progressed (period A). See FIG. 40.
- PFS progression free survival
- period B therapy selected by molecular profiling
- period A therapy selected by molecular profiling
- a PFS(B)/PFS(A) ratio > 1.3 was used to indicate that the molecular profiling selected therapy provides benefit for patient (Robert Temple, Clinical measurement in drug evaluation. Edited by Wu Ningano and G. T. Thicker John Wiley and Sons Ltd. 1995; Von Hoff, D.D. Clin Can Res. 4: 1079, 1999: Dhani et al.
- the PFS from a treatment selected by molecular profiling can be extended by at least 100%, 150%, 200%, 300%, 400%, 500%, 600%, 700%, 800%, 900%, or at least about 1000% as compared to a non-molecular profiling selected treatment.
- the PFS ratio (PFS on molecular profiling selected therapy or new treatment / PFS on prior therapy or treatment) is at least about 1.3.
- the PFS ratio is at least about 1.1 , 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, or 2.0.
- the PFS ratio is at least about 3, 4, 5, 6, 7, 8, 9 or 10.
- the DFS can be compared in patients whose treatment is selected with or without molecular profiling.
- DFS from a treatment selected by molecular profiling is extended by at least 10%, 15%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, or at least 90% as compared to a non- molecular profiling selected treatment.
- the DFS from a treatment selected by molecular profiling can be extended by at least 100%, 150%, 200%, 300%, 400%, 500%, 600%, 700%, 800%, 900%, or at least about 1000% as compared to a non-molecular profiling selected treatment.
- the DFS ratio (DFS on molecular profiling selected therapy or new treatment / DFS on prior therapy or treatment) is at least about 1.3. In yet other embodiments, the DFS ratio is at least about 1.1 , 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, or 2.0. In yet other embodiments, the DFS ratio is at least about 3, 4, 5, 6, 7, 8, 9 or 10.
- the candidate treatment of the invention will not increase the PFS ratio or the DFS ratio in the patient, nevertheless molecular profiling provides invaluable patient benefit. For example, in some instances no preferable treatment has been identified for the patient. In such cases, molecular profiling provides a method to identify a candidate treatment where none is currently identified.
- the molecular profiling may extend PFS, DFS or lifespan by at least 1 week, 2 weeks, 3 weeks, 4 weeks, 1 month, 5 weeks, 6 weeks, 7 weeks, 8 weeks, 2 months, 9 weeks, 10 weeks, 1 1 weeks, 12 weeks, 3 months, 4 months, 5 months, 6 months, 7 months, 8 months, 9 months, 10 months, 1 1 months, 12 months, 13 months, 14 months, 15 months, 16 months, 17 months, 18 months, 19 months, 20 months, 21 months, 22 months, 23 months, 24 months or 2 years.
- the molecular profiling may extend PFS, DFS or lifespan by at least 2 1 ⁇ 2 years, 3 years, 4 years, 5 years, or more. In some embodiments, the methods of the invention improve outcome so that patient is in remission.
- a complete response comprises a complete disappearance of the disease: no disease is evident on examination, scans or other tests.
- a partial response (PR) refers to some disease remaining in the body, but there has been a decrease in size or number of the lesions by 30% or more.
- Stable disease refers to a disease that has remained relatively unchanged in size and number of lesions. Generally, less than a 50% decrease or a slight increase in size would be described as stable disease.
- Progressive disease (PD) means that the disease has increased in size or number on treatment.
- molecular profiling according to the invention results in a complete response or partial response.
- the methods of the invention result in stable disease.
- the invention is able to achieve stable disease where non-molecular profiling results in progressive disease.
- Computer software products of the invention typically include computer readable medium having computer-executable instructions for performing the logic steps of the method of the invention.
- Suitable computer readable medium include floppy disk, CD-ROM/DVD/DVD-ROM, hard-disk drive, flash memory, ROM/RAM, magnetic tapes and etc.
- the computer executable instructions may be written in a suitable computer language or combination of several languages. Basic computational biology methods are described in, for example Setubal and Meidanis et al., Introduction to Computational Biology Methods (PWS Publishing Company, Boston, 1997); Salzberg, Searles, Kasif, (Ed.),
- the present invention may also make use of various computer program products and software for a variety of purposes, such as probe design, management of data, analysis, and instrument operation. See, U.S. Pat. Nos. 5,593,839, 5,795,716, 5,733,729, 5,974, 164, 6,066,454, 6,090,555, 6,185,561 , 6, 188,783, 6,223,127, 6,229,91 1 and 6,308, 170.
- the present invention relates to embodiments that include methods for providing genetic information over networks such as the Internet as shown in U.S. Ser. Nos. 10/197,621,
- one or more molecular profiling techniques can be performed in one location, e.g., a city, state, country or continent, and the results can be transmitted to a different city, state, country or continent. Treatment selection can then be made in whole or in part in the second location.
- the methods of the invention comprise transmittal of information between different locations.
- the various system components discussed herein may include one or more of the following: a host server or other computing systems including a processor for processing digital data; a memory coupled to the processor for storing digital data; an input digitizer coupled to the processor for inputting digital data; an application program stored in the memory and accessible by the processor for directing processing of digital data by the processor; a display device coupled to the processor and memory for displaying information derived from digital data processed by the processor; and a plurality of databases.
- a host server or other computing systems including a processor for processing digital data; a memory coupled to the processor for storing digital data; an input digitizer coupled to the processor for inputting digital data; an application program stored in the memory and accessible by the processor for directing processing of digital data by the processor; a display device coupled to the processor and memory for displaying information derived from digital data processed by the processor; and a plurality of databases.
- Various databases used herein may include: patient data such as family history, demography and environmental data, biological sample data, prior treatment and protocol data, patient clinical data, molecular profiling data of biological samples, data on therapeutic drug agents and/or investigative drugs, a gene library, a disease library, a drug library, patient tracking data, file management data, financial management data, billing data and/or like data useful in the operation of the system.
- user computer may include an operating system (e.g., Windows NT, 95/98/2000, OS2, UNIX, Linux, Solaris, MacOS, etc.) as well as various conventional support software and drivers typically associated with computers.
- the computer may include any suitable personal computer, network computer, workstation, minicomputer, mainframe or the like.
- User computer can be in a home or medical/business environment with access to a network. In an illustrative embodiment, access is through a network or the Internet through a commercially-available web-browser software package.
- the term "network” shall include any electronic communications means which incorporates both hardware and software components of such. Communication among the parties may be accomplished through any suitable communication channels, such as, for example, a telephone network, an extranet, an intranet, Internet, point of interaction device, personal digital assistant (e.g., Palm Pilot®, Blackberry®), cellular phone, kiosk, etc.), online communications, satellite communications, off-line communications, wireless communications, transponder communications, local area network (LAN), wide area network (WAN), networked or linked devices, keyboard, mouse and/or any suitable communication or data input modality.
- a telephone network an extranet, an intranet, Internet, point of interaction device, personal digital assistant (e.g., Palm Pilot®, Blackberry®), cellular phone, kiosk, etc.)
- online communications satellite communications
- off-line communications wireless communications
- transponder communications local area network (LAN), wide area network (WAN), networked or linked devices
- keyboard, mouse and/or any suitable communication or data input modality.
- the system is frequently described herein as being implemented with TCP/IP communications protocols, the system may also be implemented using IPX, Appletalk, IP-6, NetBIOS, OSI or any number of existing or future protocols.
- IPX IPX
- Appletalk IP-6
- NetBIOS NetBIOS
- OSI any number of existing or future protocols.
- the network is in the nature of a public network, such as the Internet, it may be advantageous to presume the network to be insecure and open to eavesdroppers. Specific information related to the protocols, standards, and application software used in connection with the Internet is generally known to those skilled in the art and, as such, need not be detailed herein.
- the various system components may be independently, separately or collectively suitably coupled to the network via data links which includes, for example, a connection to an Internet Service Provider (ISP) over the local loop as is typically used in connection with standard modem
- ISP Internet Service Provider
- the network may be implemented as other types of networks, such as an interactive television (ITV) network.
- ITV interactive television
- the system contemplates the use, sale or distribution of any goods, services or information over any network having similar functionality described herein.
- transmit may include sending electronic data from one system component to another over a network connection.
- data may include encompassing information such as commands, queries, files, data for storage, and the like in digital or any other form.
- the system contemplates uses in association with web services, utility computing, pervasive and individualized computing, security and identity solutions, autonomic computing, commodity computing, mobility and wireless solutions, open source, biometrics, grid computing and/or mesh computing.
- Any databases discussed herein may include relational, hierarchical, graphical, or object-oriented structure and or any other database configurations.
- Common database products that may be used to implement the databases include DB2 by IBM (White Plains, NY), various database products available from Oracle Corporation (Redwood Shores, CA), Microsoft Access or Microsoft SQL Server by Microsoft Corporation (Redmond, Washington), or any other suitable database product.
- the databases may be organized in any suitable manner, for example, as data tables or lookup tables. Each record may be a single file, a series of files, a linked series of data fields or any other data structure. Association of certain data may be accomplished through any desired data association technique such as those known or practiced in the art. For example, the association may be accomplished either manually or automatically.
- Automatic association techniques may include, for example, a database search, a database merge, GREP, AGREP, SQL, using a key field in the tables to speed searches, sequential searches through all the tables and files, sorting records in the file according to a known order to simplify lookup, and/or the like.
- the association step may be accomplished by a database merge function, for example, using a "key field" in pre-selected databases or data sectors.
- a "key field" partitions the database according to the high-level class of objects defined by the key field. For example, certain types of data may be designated as a key field in a plurality of related data tables and the data tables may then be linked on the basis of the type of data in the key field.
- the data corresponding to the key field in each of the linked data tables is preferably the same or of the same type.
- data tables having similar, though not identical, data in the key fields may also be linked by using AGREP, for example.
- any suitable data storage technique may be used to store data without a standard format.
- Data sets may be stored using any suitable technique, including, for example, storing individual files using an ISO/IEC 7816-4 file structure; implementing a domain whereby a dedicated file is selected that exposes one or more elementary files containing one or more data sets; using data sets stored in individual files using a hierarchical filing system; data sets stored as records in a single file (including compression, SQL accessible, hashed vione or more keys, numeric, alphabetical by first tuple, etc.); Binary Large Object (BLOB); stored as ungrouped data elements encoded using ISO/IEC 7816-6 data elements; stored as ungrouped data elements encoded using ISO/IEC Abstract Syntax Notation (ASN.1) as in ISO/IEC 8824 and 8825; and/or other proprietary techniques that may include fractal compression methods, image compression methods, etc.
- BLOB Binary Large Object
- the ability to store a wide variety of information in different formats is facilitated by storing the information as a BLOB.
- any binary information can be stored in a storage space associated with a data set.
- the BLOB method may store data sets as ungrouped data elements formatted as a block of binary via a fixed memory offset using either fixed storage allocation, circular queue techniques, or best practices with respect to memory management (e.g., paged memory, least recently used, etc.).
- the ability to store various data sets that have different formats facilitates the storage of data by multiple and unrelated owners of the data sets.
- a first data set which may be stored may be provided by a first party
- a second data set which may be stored may be provided by an unrelated second party
- a third data set which may be stored may be provided by a third party unrelated to the first and second party.
- Each of these three illustrative data sets may contain different information that is stored using different data storage formats and/or techniques. Further, each data set may contain subsets of data that also may be distinct from other subsets.
- the data can be stored without regard to a common format.
- the data set e.g., BLOB
- the annotation may comprise a short header, trailer, or other appropriate indicator related to each data set that is configured to convey information useful in managing the various data sets.
- the annotation may be called a "condition header", “header”, “nailer”, or “status”, herein, and may comprise an indication of the status of the data set or may include an identifier correlated to a specific issuer or owner of the data. Subsequent bytes of data may be used to indicate for example, the identity of the issuer or owner of the data, user, transaction/membership account identifier or the like.
- the data set annotation may also be used for other types of status information as well as various other purposes.
- the data set annotation may include security information establishing access levels.
- the access levels may, for example, be configured to permit only certain individuals, levels of employees, companies, or other entities to access data sets, or to permit access to specific data sets based on the transaction, issuer or owner of data, user or the like.
- the security information may restrict/permit only certain actions such as accessing, modifying, and/or deleting data sets.
- the data set annotation indicates that only the data set owner or the user are permitted to delete a data set, various identified users may be permitted to access the data set for reading, and others are altogether excluded from accessing the data set.
- access restriction parameters may also be used allowing various entities to access a data set with various permission levels as appropriate.
- the data, including the header or trailer may be received by a standalone interaction device configured to add, delete, modify, or augment the data in accordance with the header or trailer.
- any databases, systems, devices, servers or other components of the system may consist of any combination thereof at a single location or at multiple locations, wherein each database or system includes any of various suitable security features, such as firewalls, access codes, encryption, decryption, compression, decompression, and/or the like.
- the computing unit of the web client may be further equipped with an Internet browser connected to the Internet or an intranet using standard dial-up, cable, DSL or any other Internet protocol known in the art. Transactions originating at a web client may pass through a firewall in order to prevent unauthorized access from users of other networks. Further, additional firewalls may be deployed between the varying components of CMS to further enhance security.
- Firewall may include any hardware and/or software suitably configured to protect CMS components and/or enterprise computing resources from users of other networks. Further, a firewall may be configured to limit or restrict access to various systems and components behind the firewall for web clients connecting through a web server. Firewall may reside in varying configurations including Stateful Inspection, Proxy based and Packet Filtering among others. Firewall may be integrated within an web server or any other CMS components or may further reside as a separate entity.
- the computers discussed herein may provide a suitable website or other Internet-based graphical user interface which is accessible by users.
- the Microsoft Internet Information Server (IIS), Microsoft Transaction Server (MTS), and Microsoft SQL Server are used in conjunction with the Microsoft operating system, Microsoft NT web server software, a Microsoft SQL Server database system, and a Microsoft Commerce Server.
- components such as Access or Microsoft SQL Server, Oracle, Sybase, Informix MySQL, Interbase, etc., may be used to provide an Active Data Object (ADO) compliant database management system.
- ADO Active Data Object
- Any of the communications, inputs, storage, databases or displays discussed herein may be facilitated through a website having web pages.
- the term "web page" as it is used herein is not meant to limit the type of documents and applications that might be used to interact with the user.
- a typical website might include, in addition to standard HTML documents, various forms, Java applets, JavaScript, active server pages (ASP), common gateway interface scripts (CGI), extensible markup language (XML), dynamic HTML, cascading style sheets (CSS), helper applications, plug-ins, and the like.
- a server may include a web service that receives a request from a web server, the request including a URL (http://yahoo.com/stockquotes/ge) and an IP address (123.56.789.234).
- the web server retrieves the appropriate web pages and sends the data or applications for the web pages to the IP address.
- Web services are applications that are capable of interacting with other applications over a communications means, such as the internet. Web services are typically based on standards or protocols such as XML, XSLT, SOAP, WSDL and UDDI. Web services methods are well known in the art, and are covered in many standard texts. See, e.g., ALE NGHIEM, IT WEB SERVICES: A ROADMAP FOR THE ENTERPRISE (2003), hereby incorporated by reference.
- the web-based clinical database for the system and method of the present invention preferably has the ability to upload and store clinical data files in native formats and is searchable on any clinical parameter.
- the database is also scalable and may use an EAV data model (metadata) to enter clinical annotations from any study for easy integration with other studies.
- the web-based clinical database is flexible and may be XML and XSLT enabled to be able to add user customized questions dynamically. Further, the database includes exportability to CDISC ODM.
- the system and method may be described herein in terms of functional block components, screen shots, optional selections and various processing steps. It should be appreciated that such functional blocks may be realized by any number of hardware and/or software components configured to perform the specified functions.
- the system may employ various integrated circuit components, e.g., memory elements, processing elements, logic elements, look-up tables, and the like, which may carry out a variety of functions under the control of one or more microprocessors or other control devices.
- the software elements of the system may be implemented with any programming or scripting language such as C, C++, Macromedia Cold Fusion, Microsoft Active Server Pages, Java, COBOL, assembler, PERL, Visual Basic, SQL Stored Procedures, extensible markup language (XML), with the various algorithms being implemented with any combination of data structures, objects, processes, routines or other programming elements.
- the system may employ any number of conventional techniques for data transmission, signaling, data processing, network control, and the like.
- the system could be used to detect or prevent security issues with a client-side scripting language, such as JavaScript, VBScript or the like.
- the term "end user”, “consumer”, “customer”, “client”, “treating physician”, “hospital”, or “business” may be used interchangeably with each other, and each shall mean any person, entity, machine, hardware, software or business.
- Each participant is equipped with a computing device in order to interact with the system and facilitate online data access and data input.
- the customer has a computing unit in the form of a personal computer, although other types of computing units may be used including laptops, notebooks, hand held computers, set-top boxes, cellular telephones, touch-tone telephones and the like.
- the owner/operator of the system and method of the present invention has a computing unit implemented in the form of a computer-server, although other implementations are contemplated by the system including a computing center shown as a main frame computer, a minicomputer, a PC server, a network of computers located in the same of different geographic locations, or the like. Moreover, the system contemplates the use, sale or distribution of any goods, services or information over any network having similar functionality described herein.
- each client customer may be issued an "account” or "account number".
- the account or account number may include any device, code, number, letter, symbol, digital certificate, smart chip, digital signal, analog signal, biometric or other identifier/indicia suitably configured to allow the consumer to access, interact with or communicate with the system (e.g., one or more of an authorization/access code, personal identification number (PIN), Internet code, other identification code, and/or the like).
- the account number may optionally be located on or associated with a charge card, credit card, debit card, prepaid card, embossed card, smart card, magnetic stripe card, bar code card, transponder, radio frequency card or an associated account.
- the system may include or interface with any of the foregoing cards or devices, or a fob having a transponder and RFID reader in RF communication with the fob.
- the system may include a fob embodiment, the invention is not to be so limited.
- system may include any device having a transponder which is configured to communicate with RFID reader via RF communication.
- Typical devices may include, for example, a key ring, tag, card, cell phone, wristwatch or any such form capable of being presented for interrogation.
- the system, computing unit or device discussed herein may include a "pervasive computing device," which may include a traditionally non-computerized device that is embedded with a computing unit.
- the account number may be distributed and stored in any form of plastic, electronic, magnetic, radio frequency, wireless, audio and/or optical device capable of transmitting or downloading data from itself to a second device.
- the system may be embodied as a customization of an existing system, an add-on product, upgraded software, a standalone system, a distributed system, a method, a data processing system, a device for data processing, and/or a computer program product. Accordingly, the system may take the form of an entirely software embodiment, an entirely hardware embodiment, or an embodiment combining aspects of both software and hardware. Furthermore, the system may take the form of a computer program product on a computer -readable storage medium having computer-readable program code means embodied in the storage medium. Any suitable computer-readable storage medium may be used, including hard disks, CD-ROM, optical storage devices, magnetic storage devices, and/or the like.
- These computer program instructions may be loaded onto a general purpose computer, special purpose computer, or other programmable data processing apparatus to produce a machine, such that the instructions that execute on the computer or other programmable data processing apparatus create means for implementing the functions specified in the flowchart block or blocks.
- These computer program instructions may also be stored in a computer-readable memory that can direct a computer or other programmable data processing apparatus to function in a particular manner, such that the instructions stored in the computer-readable memory produce an article of manufacture including instruction means which implement the function specified in the flowchart block or blocks.
- the computer program instructions may also be loaded onto a computer or other programmable data processing apparatus to cause a series of operational steps to be performed on the computer or other programmable apparatus to produce a computer-implemented process such that the instructions which execute on the computer or other programmable apparatus provide steps for implementing the functions specified in the flowchart block or blocks.
- steps as illustrated and described may be combined into single web pages and/or windows but have been expanded for the sake of simplicity.
- steps illustrated and described as single process steps may be separated into multiple web pages and/or windows but have been combined for simplicity.
- FIG. 1 illustrates a block diagram of an illustrative embodiment of a system 10 for determining individualized medical intervention for a particular disease state that uses molecular profiling of a patient's biological specimen.
- System 10 includes a user interface 12, a host server 14 including a processor 16 for processing data, a memory 18 coupled to the processor, an application program 20 stored in the memory 18 and accessible by the processor 16 for directing processing of the data by the processor 16, a plurality of internal databases 22 and external databases 24, and an interface with a wired or wireless communications network 26 (such as the Internet, for example).
- System 10 may also include an input digitizer 28 coupled to the processor 16 for inputting digital data from data that is received from user interface 12.
- User interface 12 includes an input device 30 and a display 32 for inputting data into system 10 and for displaying information derived from the data processed by processor 16.
- User interface 12 may also include a printer 34 for printing the information derived from the data processed by the processor 16 such as patient reports that may include test results for targets and proposed drug therapies based on the test results.
- Internal databases 22 may include, but are not limited to, patient biological sample/specimen information and tracking, clinical data, patient data, patient tracking, file management, study protocols, patient test results from molecular profiling, and billing information and tracking.
- External databases 24 nay include, but are not limited to, drug libraries, gene libraries, disease libraries, and public and private databases such as UniGene, OMIM, GO, TIGR, GenBank, KEGG and Biocarta.
- FIG. 2 shows a flowchart of an illustrative embodiment of a method 50 for determining individualized medical intervention for a particular disease state that uses molecular profiling of a patient's biological specimen that is non disease specific.
- at least one test is performed for at least one target from a biological sample of a diseased patient in step 52.
- a target is defined as any molecular finding that may be obtained from molecular testing.
- a target may include one or more genes, one or more gene expressed proteins, one or more molecular mechanisms, and/or combinations of such.
- the expression level of a target can be determined by the analysis of mR A levels or the target or gene, or protein levels of the gene.
- Tests for finding such targets may include, but are not limited, fluorescent in-situ hybridization (FISH), in-situ hybridization (ISH), and other molecular tests known to those skilled in the art.
- FISH fluorescent in-situ hybridization
- ISH in-situ hybridization
- PCR-based methods such as real-time PCR or quantitative PCR can be used.
- microarray analysis such as a comparative genomic hybridization (CGH) micro array, a single nucleotide polymorphism (SNP) microarray, a proteomic array, or antibody array analysis can also be used in the methods disclosed herein.
- CGH comparative genomic hybridization
- SNP single nucleotide polymorphism
- proteomic array or antibody array analysis
- microarray analysis comprises identifying whether a gene is up-regulated or down-regulated relative to a reference with a significance of p ⁇ 0.001.
- Tests or analyses of targets can also comprise immunohistochemical (IHC) analysis.
- IHC analysis comprises determining whether 30% or more of a sample is stained, if the staining intensity is +2 or greater, or both.
- the methods disclosed herein also including profiling more than one target.
- the expression of a plurality of genes can be identified.
- identification of a plurality of targets in a sample can be by one method or by various means.
- the expression of a first gene can be determined by one method and the expression level of a second gene determined by a different method.
- the same method can be used to detect the expression level of the first and second gene.
- the first method can be IHC and the second by microarray analysis, such as detecting the gene expression of a gene.
- molecular profiling can also including identifying a genetic variant, such as a mutation, polymorphism (such as a SNP), deletion, or insertion of a target.
- identifying a SNP in a gene can be determined by microarray analysis, real-time PCR, or sequencing. Other methods disclosed herein can also be used to identify variants of one or more targets.
- step 54 an IHC analysis in step 54
- microanalysis in step 56 a microanalysis in step 56
- other molecular tests know to those skilled in the art in step 58.
- Biological samples are obtained from diseased patients by taking a biopsy of a tumor, conducting minimally invasive surgery if no recent tumor is available, obtaining a sample of the patient's blood, or a sample of any other biological fluid including, but not limited to, cell extracts, nuclear extracts, cell lysates or biological products or substances of biological origin such as excretions, blood, sera, plasma, urine, sputum, tears, feces, saliva, membrane extracts, and the like.
- step 60 a determination is made as to whether one or more of the targets that were tested for in step 52 exhibit a change in expression compared to a normal reference for that particular target.
- an IHC analysis may be performed in step 54 and a determination as to whether any targets from the IHC analysis exhibit a change in expression is made in step 64 by determining whether 30% or more of the biological sample cells were +2 or greater staining for the particular target. It will be understood by those skilled in the art that there will be instances where +1 or greater staining will indicate a change in expression in that staining results may vary depending on the technician performing the test and type of target being tested.
- a micro array analysis may be performed in step 56 and a determination as to whether any targets from the micro array analysis exhibit a change in expression is made in step 66 by identifying which targets are up-regulated or down-regulated by determining whether the fold change in expression for a particular target relative to a normal tissue of origin reference is significant at p ⁇ 0.001.
- a change in expression may also be evidenced by an absence of one or more genes, gene expressed proteins, molecular mechanisms, or other molecular findings.
- At least one non- disease specific agent is identified that interacts with each target having a changed expression in step 70.
- An agent may be any drug or compound having a therapeutic effect.
- a non-disease specific agent is a therapeutic drug or compound not previously associated with treating the patient's diagnosed disease that is capable of interacting with the target from the patient's biological sample that has exhibited a change in expression.
- a patient profile report may be provided which includes the patient's test results for various targets and any proposed therapies based on those results.
- An illustrative patient profile report 100 is shown in FIGS. 3A-3D.
- Patient profile report 100 shown in FIG. 3A identifies the targets tested 102, those targets tested that exhibited significant changes in expression 104, and proposed non-disease specific agents for interacting with the targets 106.
- Patient profile report 100 shown in FIG. 3B identifies the results 108 of immunohistochemical analysis for certain gene expressed proteins 110 and whether a gene expressed protein is a molecular target 112 by determining whether 30% or more of the tumor cells were +2 or greater staining.
- Report 100 also identifies immunohistochemical tests that were not performed 114.
- Patient profile report 100 shown in FIG. 3C identifies the genes analyzed 116 with a micro array analysis and whether the genes were under expressed or over expressed 118 compared to a reference.
- patient profile report 100 shown in FIG. 3D identifies the clinical history 120 of the patient and the specimens that were submitted 122 from the patient.
- Molecular profiling techniques can be performed anywhere, e.g., a foreign country, and the results sent by network to an appropriate party, e.g., the patient, a physician, lab or other party located remotely.
- FIG. 4 shows a flowchart of an illustrative embodiment of a method 200 for identifying a drug therapy/agent capable of interacting with a target.
- a molecular target is identified which exhibits a change in expression in a number of diseased individuals.
- a drug therapy/agent is administered to the diseased individuals.
- any changes in the molecular target identified in step 202 are identified in step 206 in order to determine if the drug therapy/agent administered in step 204 interacts with the molecular targets identified in step 202.
- the drug therapy/agent administered in step 204 may be approved for treating patients exhibiting a change in expression of the identified molecular target instead of approving the drug therapy/agent for a particular disease.
- FIGS. 5-14 are flowcharts and diagrams illustrating various parts of an information-based personalized medicine drug discovery system and method in accordance with the present invention.
- FIG. 5 is a diagram showing an illustrative clinical decision support system of the information-based personalized medicine drug discovery system and method of the present invention. Data obtained through clinical research and clinical care such as clinical trial data, biomedical/molecular imaging data, genomics/proteomics/chemical library/literature/expert curation, biospecimen tracking/LIMS, family history/environmental records, and clinical data are collected and stored as databases and datamarts within a data warehouse.
- FIG. 6 is a diagram showing the flow of information through the clinical decision support system of the information-based personalized medicine drug discovery system and method of the present invention using web services.
- a user interacts with the system by entering data into the system via form-based entry/upload of data sets, formulating queries and executing data analysis jobs, and acquiring and evaluating representations of output data.
- the data warehouse in the web based system is where data is extracted, transformed, and loaded from various database systems.
- the data warehouse is also where common formats, mapping and transformation occurs.
- the web based system also includes datamarts which are created based on data views of interest.
- FIG. 7 A flow chart of an illustrative clinical decision support system of the information-based personalized medicine drug discovery system and method of the present invention is shown in FIG. 7.
- the clinical information management system includes the laboratory information management system and the medical information contained in the data warehouses and databases includes medical information libraries, such as drug libraries, gene libraries, and disease libraries, in addition to literature text mining. Both the information management systems relating to particular patients and the medical information databases and data warehouses come together at a data junction center where diagnostic information and therapeutic options can be obtained.
- a financial management system may also be incorporated in the clinical decision support system of the information-based personalized medicine drug discovery system and method of the present invention.
- FIG. 8 is a diagram showing an illustrative biospecimen tracking and management system which may be used as part of the information-based personalized medicine drug discovery system and method of the present invention.
- FIG. 8 shows two host medical centers which forward specimens to a tissue/blood bank. The specimens may go through laboratory analysis prior to shipment. Research may also be conducted on the samples via micro array, genotyping, and proteomic analysis. This information can be redistributed to the tissue/blood bank.
- FIG. 9 depicts a flow chart of an illustrative biospecimen tracking and management system which may be used with the information-based personalized medicine drug discovery system and method of the present invention. The host medical center obtains samples from patients and then ships the patient samples to a molecular profiling laboratory which may also perform RNA and DNA isolation and analysis.
- FIG. 10 A diagram showing a method for maintaining a clinical standardized vocabulary for use with the information-based personalized medicine drug discovery system and method of the present invention is shown in FIG. 10.
- FIG. 10 illustrates how physician observations and patient information associated with one physician's patient may be made accessible to another physician to enable the other physician to use the data in making diagnostic and therapeutic decisions for their patients.
- FIG. 11 shows a schematic of an illustrative microarray gene expression database which may be used as part of the information-based personalized medicine drug discovery system and method of the present invention.
- the micro array gene expression database includes both external databases and internal databases which can be accessed via the web based system.
- External databases may include, but are not limited to, UniGene, GO, TIG , GenBank, KEGG.
- the internal databases may include, but are not limited to, tissue tracking, LIMS, clinical data, and patient tracking.
- FIG. 12 shows a diagram of an illustrative micro array gene expression database data warehouse which may be used as part of the information-based personalized medicine drug discovery system and method of the present invention.
- Laboratory data, clinical data, and patient data may all be housed in the micro array gene expression database data warehouse and the data may in turn be accessed by public/private release and used by data analysis tools.
- FIG. 13 Another schematic showing the flow of information through an information-based personalized medicine drug discovery system and method of the present invention is shown in FIG. 13. Like FIG. 7, the schematic includes clinical information management, medical and literature information management, and financial management of the information-based personalized medicine drug discovery system and method of the present invention.
- FIG. 14 is a schematic showing an illustrative network of the information-based personalized medicine drug discovery system and method of the present invention. Patients, medical practitioners, host medical centers, and labs all share and exchange a variety of information in order to provide a patient with a proposed therapy or agent based on various identified targets.
- FIGS. 15-25 are computer screen print outs associated with various parts of the information- based personalized medicine drug discovery system and method shown in FIGS. 5-14.
- FIGS. 15 and 16 show computer screens where physician information and insurance company information is entered on behalf of a client.
- FIGS. 17-19 show computer screens in which information can be entered for ordering analysis and tests on patient samples.
- FIG. 20 is a computer screen showing micro array analysis results of specific genes tested with patient samples. This information and computer screen is similar to the information detailed in the patient profile report shown in FIG. 3C.
- FIG. 22 is a computer screen that shows immunohistochemistry test results for a particular patient for various genes. This information is similar to the information contained in the patient profile report shown in FIG. 3B.
- FIG. 21 is a computer screen showing selection options for finding particular patients, ordering tests and/or results, issuing patient reports, and tracking current cases/patients.
- FIG. 23 is a computer screen which outlines some of the steps for creating a patient profile report as shown in FIGS. 3A through 3D.
- FIG. 24 shows a computer screen for ordering an
- FIG. 25 shows a computer screen for entering information regarding a primary tumor site for micro array analysis. It will be understood by those skilled in the art that any number and variety of computer screens may be used to enter the information necessary for using the information-based personalized medicine drug discovery system and method of the present invention and to obtain information resulting from using the information-based personalized medicine drug discovery system and method of the present invention.
- FIGS. 26-31 represent tables that show the frequency of a significant change in expression of certain genes and/or gene expressed proteins by tumor type, i.e. the number of times that a gene and/or gene expressed protein was flagged as a target by tumor type as being significantly overexpressed or underexpressed.
- the tables show the total number of times a gene and/or gene expressed protein was overexpressed or underexpressed in a particular tumor type and whether the change in expression was determined by immunohistochemistry analysis (FIG. 26, FIG. 28) or gene expression analysis (FIGS. 27, 30).
- the tables also identify the total number of times an overexpression of any gene expressed protein occurred in a particular tumor type using immunohistochemistry and the total number of times an overexpression or underexpression of any gene occurred in a particular tumor type using gene microarray analysis.
- the systems of the invention can be used to automate the steps of identifying a molecular profile to assess a cancer.
- the invention provides a method of generating a report comprising a molecular profile. The method comprises: performing a search on an electronic medium to obtain a data set, wherein the data set comprises a plurality of scientific publications corresponding to plurality of cancer biomarkers; and analyzing the data set to identify a rule set linking a characteristic of each of the plurality of cancer biomarkers with an expected benefit of a plurality of treatment options, thereby identifying the cancer biomarkers included within a molecular profile.
- the method can further comprise performing molecular profiling on a sample from a subject to assess the characteristic of each of the plurality of cancer biomarkers, and compiling a report comprising the assessed characteristics into a list, thereby generating a report that identifies a molecular profile for the sample.
- the report can further comprise a list describing the expected benefit of the plurality of treatment options based on the assessed characteristics, thereby identifying candidate treatment options for the subject.
- the sample from the subject may comprise cancer cells.
- the cancer can be any cancer disclosed herein or known in the art.
- the characteristic of each of the plurality of cancer biomarkers can be any useful characteristic for molecular profiling as disclosed herein or known in the art. Such characteristics include without limitation mutations (point mutations, insertions, deletions, rearrangements, etc), epigenetic
- the method further comprises identifying a priority list as amongst said plurality of cancer biomarkers.
- the priority list can be sorted according to any appropriate priority criteria.
- the priority list is sorted according to strength of evidence in the plurality of scientific publications linking the cancer biomarkers to the expected benefit.
- the priority list is sorted according to strength of the expected benefit.
- the priority list is sorted according to strength of the expected benefit.
- the candidate treatment options can be sorted according to the priority list, thereby identifying a ranked list of treatment options for the subject.
- the candidate treatment options can be categorized by expected benefit to the subject. For example, the candidate treatment options can categorized as those that are expected to provide benefit, those that are not expected to provide benefit, or those whose expected benefit cannot be determined.
- the candidate treatment options can include regulatory approved and/or on-compendium treatments for the cancer.
- the candidate treatment options can include regulatory approved but off-label treatments for the cancer, such as a treatment that has been approved for a cancer of another lineage.
- the candidate treatment options can include treatments that are under development, such as in ongoing clinical trials.
- the report may identify treatments as approved, on- or off-compendium, in clinical trials, and the like.
- the method further comprises analyzing the data set to select a laboratory technique to assess the characteristics of the biomarkers, thereby designating a technique that can be used to assess the characteristic for each of the plurality of biomarkers.
- the laboratory technique is chosen based on its applicability to assess the characteristic of each of the biomarkers.
- the laboratory techniques can be those disclosed herein, including without limitation FISH for gene copy number or mutation analysis, IHC for protein expression levels, RT-PCR for mutation or expression analysis, sequencing or fragment analysis for mutation analysis. Sequencing includes any useful sequencing method disclosed herein or known in the art, including without limitation Sanger sequencing, pyrosequencing, or next generation sequencing methods.
- the invention provides a method comprising: performing a search on an electronic medium to obtain a data set comprising a plurality of scientific publications corresponding to plurality of cancer biomarkers; analyzing the data set to select a method to assess a characteristic of each of the cancer biomarkers, thereby designating a method for characterizing each of the biomarkers; further analyzing the data set to select a rule set that identifies a priority list as amongst the biomarkers;
- the present invention provides methods and systems for analyzing diseased tissue using molecular profiling as previously described above. Because the methods rely on analysis of the characteristics of the tumor under analysis, the methods can be applied in for any tumor or any stage of disease, such an advanced stage of disease or a metastatic tumor of unknown origin. As described herein, a tumor or cancer sample is analyzed for molecular characteristics in order to predict or identify a candidate therapeutic treatment.
- the molecular characteristics can include the expression of genes or gene products, assessment of gene copy number, or mutational analysis. Any relevant determinable characteristic that can assist in prediction or identification of a candidate therapeutic can be included within the methods of the invention.
- the biomarker patterns or biomarker signature sets can be determined for tumor types, diseased tissue types, or diseased cells including without limitation adipose, adrenal cortex, adrenal gland, adrenal gland - medulla, appendix, bladder, blood vessel, bone, bone cartilage, brain, breast, cartilage, cervix, colon, colon sigmoid, dendritic cells, skeletal muscle, endometrium, esophagus, fallopian tube, fibroblast, gallbladder, kidney, larynx, liver, lung, lymph node, melanocytes, mesothelial lining, myoepithelial cells, osteoblasts, ovary, pancreas, parotid, prostate, salivary gland, sinus tissue, skeletal muscle, skin, small intestine, smooth muscle, stomach, synovium, joint lining tissue, tendon, testis, thymus, thyroid, uterus, and uterus corpus.
- the methods of the present invention can be used for selecting a treatment of any cancer or tumor type, including but not limited to breast cancer (including HER2+ breast cancer, HER2- breast cancer, ER/PR+, HER2- breast cancer, or triple negative breast cancer), pancreatic cancer, cancer of the colon and/or rectum, leukemia, skin cancer, bone cancer, prostate cancer, liver cancer, lung cancer, brain cancer, cancer of the larynx, gallbladder, parathyroid, thyroid, adrenal, neural tissue, head and neck, stomach, bronchi, kidneys, basal cell carcinoma, squamous cell carcinoma of both ulcerating and papillary type, metastatic skin carcinoma, osteo sarcoma, Ewing's sarcoma, veticulum cell sarcoma, myeloma, giant cell tumor, small-cell lung tumor, islet cell carcinoma, primary brain tumor, acute and chronic lymphocytic and granulocytic tumors, hairy-cell tumor, adenoma, hyperplasia,
- the cancer or tumor can comprise, without limitation, a carcinoma, a sarcoma, a lymphoma or leukemia, a germ cell tumor, a blastoma, or other cancers.
- Carcinomas that can be assessed using the subject methods include without limitation epithelial neoplasms, squamous cell neoplasms, squamous cell carcinoma, basal cell neoplasms basal cell carcinoma, transitional cell papillomas and carcinomas, adenomas and
- adenocarcinomas glands
- adenoma adenocarcinoma
- adenocarcinoma linitis plastica insulinoma, glucagonoma, gastrinoma, vipoma
- cholangiocarcinoma hepatocellular carcinoma
- adenoid cystic carcinoma carcinoid tumor of appendix, prolactinoma, oncocytoma
- hurthle cell adenoma renal cell carcinoma, grawitz tumor
- multiple endocrine adenomas endometrioid adenoma, adnexal and skin appendage neoplasms, mucoepidermoid neoplasms, cystic, mucinous and serous neoplasms, cystadenoma, pseudomyxoma peritonei, ductal, lobular and medullary neoplasms, acinar cell neoplasms, complex epithelial
- pheochromocytoma glomus tumor, nevi and melanomas, melanocytic nevus, malignant melanoma, melanoma, nodular melanoma, dysplastic nevus, lentigo maligna melanoma, superficial spreading melanoma, and malignant acral lentiginous melanoma.
- Sarcoma that can be assessed using the subject methods include without limitation Askin's tumor, botryodies, chondrosarcoma, Ewing's sarcoma, malignant hemangio endothelioma, malignant schwannoma, osteosarcoma, soft tissue sarcomas including: alveolar soft part sarcoma, angiosarcoma, cystosarcoma phyllodes, dermatofibrosarcoma, desmoid tumor, desmoplastic small round cell tumor, epithelioid sarcoma, extraskeletal chondrosarcoma, extraskeletal osteosarcoma, fibrosarcoma, hemangiopericytoma, hemangiosarcoma, kaposi's sarcoma, leiomyosarcoma, liposarcoma, lymphangiosarcoma, lymphosarcoma, malignant fibrous histiocytoma, neurofibrosarcoma, rhabdom
- Lymphoma and leukemia that can be assessed using the subject methods include without limitation chronic lymphocytic leukemia/small lymphocytic lymphoma, B-cell prolymphocytic leukemia, lymphoplasmacytic lymphoma (such as Waldenstrom macroglobulinemia), splenic marginal zone lymphoma, plasma cell myeloma,
- follicular lymphoma mantle cell lymphoma, diffuse large B cell lymphoma, mediastinal (thymic) large B cell lymphoma, intravascular large B cell lymphoma, primary effusion lymphoma, burkitt lymphoma/leukemia, T cell prolymphocytic leukemia, T cell large granular lymphocytic leukemia, aggressive NK cell leukemia, adult T cell leukemia/lymphoma, extranodal NK/T cell lymphoma, nasal type, enteropathy-type T cell lymphoma, hepatosplenic T cell lymphoma, blastic NK cell lymphoma, mycosis fungoides / sezary syndrome, primary cutaneous CD30
- angioimmunoblastic T cell lymphoma peripheral T cell lymphoma, unspecified, anaplastic large cell lymphoma, classical Hodgkin lymphomas (nodular sclerosis, mixed cellularity, lymphocyte-rich, lymphocyte depleted or not depleted), and nodular lymphocyte-predominant Hodgkin lymphoma.
- Germ cell tumors that can be assessed using the subject methods include without limitation germinoma, dysgerminoma, seminoma, nongerminomatous germ cell tumor, embryonal carcinoma, endodermal sinus turmor, choriocarcinoma, teratoma, polyembryoma, and gonadoblastoma.
- Blastoma includes without limitation nephroblastoma, medulloblastoma, and retinoblastoma.
- Other cancers include without limitation labial carcinoma, larynx carcinoma, hypopharynx carcinoma, tongue carcinoma, salivary gland carcinoma, gastric carcinoma, adenocarcinoma, thyroid cancer (medullary and papillary thyroid carcinoma), renal carcinoma, kidney parenchyma carcinoma, cervix carcinoma, uterine corpus carcinoma, endometrium carcinoma, chorion carcinoma, testis carcinoma, urinary carcinoma, melanoma, brain tumors such as glioblastoma, astrocytoma, meningioma, medulloblastoma and peripheral neuroectodermal tumors, gall bladder carcinoma, bronchial carcinoma, multiple myeloma, basalioma, teratoma, retinoblastoma, choroidea melanoma, seminoma, rhabdomyosarcom
- the cancer may be a acute myeloid leukemia (AML), breast carcinoma, cholangiocarcinoma, colorectal adenocarcinoma, extrahepatic bile duct adenocarcinoma, female genital tract malignancy, gastric adenocarcinoma, gastroesophageal adenocarcinoma, gastrointestinal stromal tumors (GIST), glioblastoma, head and neck squamous carcinoma, leukemia, liver hepatocellular carcinoma, low grade glioma, lung bronchioloalveolar carcinoma (BAC), lung non-small cell lung cancer (NSCLC), lung small cell cancer (SCLC), lymphoma, male genital tract malignancy, malignant solitary fibrous tumor of the pleura (MSFT), melanoma, multiple myeloma, neuroendocrine tumor, nodal diffuse large B-cell lymphoma, non epithelial ova
- AML acute myeloid
- the cancer may be a lung cancer including non-small cell lung cancer and small cell lung cancer (including small cell carcinoma (oat cell cancer), mixed small cell/large cell carcinoma, and combined small cell carcinoma), colon cancer, breast cancer, prostate cancer, liver cancer, pancreas cancer, brain cancer, kidney cancer, ovarian cancer, stomach cancer, skin cancer, bone cancer, gastric cancer, breast cancer, pancreatic cancer, glioma, glioblastoma, hepatocellular carcinoma, papillary renal carcinoma, head and neck squamous cell carcinoma, leukemia, lymphoma, myeloma, or a solid tumor.
- non-small cell lung cancer and small cell lung cancer including small cell carcinoma (oat cell cancer), mixed small cell/large cell carcinoma, and combined small cell carcinoma
- colon cancer breast cancer, prostate cancer, liver cancer, pancreas cancer, brain cancer, kidney cancer, ovarian cancer, stomach cancer, skin cancer, bone cancer, gastric cancer, breast cancer, pancreatic cancer, glioma, glioblastom
- the cancer comprises an acute lymphoblastic leukemia; acute myeloid leukemia; adrenocortical carcinoma; AIDS-related cancers; AIDS-related lymphoma; anal cancer; appendix cancer; astrocytomas; atypical teratoid/rhabdoid tumor; basal cell carcinoma; bladder cancer; brain stem glioma; brain tumor (including brain stem glioma, central nervous system atypical teratoid/rhabdoid tumor, central nervous system embryonal tumors, astrocytomas, craniopharyngioma, ependymoblastoma, ependymoma, medulloblastoma, medulloepithelioma, pineal parenchymal tumors of intermediate differentiation, supratentorial primitive neuroectodermal tumors and pineoblastoma); breast cancer; bronchial tumors; Burkitt lymphoma; cancer of unknown primary site
- craniopharyngioma cutaneous T-cell lymphoma; endocrine pancreas islet cell tumors; endometrial cancer; ependymoblastoma; ependymoma; esophageal cancer; esthesioneuroblastoma; Ewing sarcoma; extracranial germ cell tumor; extragonadal germ cell tumor; extrahepatic bile duct cancer; gallbladder cancer; gastric (stomach) cancer; gastrointestinal carcinoid tumor; gastrointestinal stromal cell tumor; gastrointestinal stromal tumor (GIST); gestational trophoblastic tumor; glioma; hairy cell leukemia; head and neck cancer; heart cancer; Hodgkin lymphoma; hypopharyngeal cancer; intraocular melanoma; islet cell tumors; Kaposi sarcoma; kidney cancer; Langerhans cell histiocytosis; laryngeal cancer; lip cancer; liver cancer; mal
- melanoma Merkel cell carcinoma; Merkel cell skin carcinoma; mesothelioma; metastatic squamous neck cancer with occult primary; mouth cancer; multiple endocrine neoplasia syndromes; multiple myeloma; multiple myeloma/plasma cell neoplasm; mycosis fungoides; myelodysplastic syndromes;
- myeloproliferative neoplasms nasal cavity cancer; nasopharyngeal cancer; neuroblastoma; Non-Hodgkin lymphoma; nonmelanoma skin cancer; non-small cell lung cancer; oral cancer; oral cavity cancer;
- oropharyngeal cancer osteosarcoma; other brain and spinal cord tumors; ovarian cancer; ovarian epithelial cancer; ovarian germ cell tumor; ovarian low malignant potential tumor; pancreatic cancer; papillomatosis; paranasal sinus cancer; parathyroid cancer; pelvic cancer; penile cancer; pharyngeal cancer; pineal parenchymal tumors of intermediate differentiation; pineoblastoma; pituitary tumor; plasma cell neoplasm/multiple myeloma; pleuropulmonary blastoma; primary central nervous system (CNS) lymphoma; primary hepatocellular liver cancer; prostate cancer; rectal cancer; renal cancer; renal cell (kidney) cancer; renal cell cancer; respiratory tract cancer; retinoblastoma; rhabdomyosarcoma; salivary gland cancer; Sezary syndrome; small cell lung cancer; small intestine cancer; soft tissue sarcoma; squamous cell carcinoma; squamous
- the methods of the invention can be used to determine biomarker patterns or biomarker signature sets in a number of tumor types, diseased tissue types, or diseased cells including accessory, sinuses, middle and inner ear, adrenal glands, appendix, hematopoietic system, bones and joints, spinal cord, breast, cerebellum, cervix uteri, connective and soft tissue, corpus uteri, esophagus, eye, nose, eyeball, fallopian tube, extrahepatic bile ducts, other mouth, intrahepatic bile ducts, kidney, appendix-colon, larynx, lip, liver, lung and bronchus, lymph nodes, cerebral, spinal, nasal cartilage, excl.
- the molecular profiling methods are used to identify a treatment for a cancer of unknown primary (CUP). Approximately 40,000 CUP cases are reported annually in the US. Most of these are metastatic and/or poorly differentiated tumors. Because molecular profiling can identify a candidate treatment depending only upon the diseased sample, the methods of the invention can be used in the CUP setting. Moreover, molecular profiling can be used to create signatures of known tumors, which can then be used to classify a CUP and identify its origin.
- CUP cancer of unknown primary
- the invention provides a method of identifying the origin of a CUP, the method comprising performing molecular profiling on a panel of diseased samples to determine a panel of molecular profiles that correlate with the origin of each diseased sample, performing molecular profiling on a CUP sample, and correlating the molecular profile of the CUP sample with the molecular profiling of the panel of diseased samples, thereby identifying the origin of the CUP sample.
- the identification of the origin of the CUP sample can be made by matching the molecular profile of the CUP sample with the molecular profiles that correlate most closely from the panel of disease samples.
- the molecular profiling can use any of the techniques described herein, e.g., IHC, FISH, microarray and sequencing.
- the diseased samples and CUP samples can be derived from a patient sample, e.g., a biopsy sample, including a fine needle biopsy.
- DNA microarray and IHC profiling are performed on the panel of diseased samples, DNA microarray is performed on the CUP samples, and then IHC is performed on the CUP sample for a subset of the most informative genes as indicated by the DNA microarray analysis. This approach can identify the origin of the CUP sample while avoiding the expense of performing unnecessary IHC testing.
- the IHC can be used to confirm the microarray findings.
- the biomarker patterns or biomarker signature sets of the cancer or tumor can be used to determine a therapeutic agent or therapeutic protocol that is capable of interacting with the biomarker pattern or signature set.
- a therapeutic agent or therapeutic protocol can be identified which is capable of interacting with the biomarker pattern or signature set.
- biomarker patterns or biomarker signature sets for advanced stage breast cancer are just one example of the extensive number of biomarker patterns or biomarker signature sets for a number of advanced stage diseases or cancers that can be identified from the tables depicted in FIGS. 26-31.
- a number of non disease specific therapies or therapeutic protocols may be identified for treating patients with these biomarker patterns or biomarker signature sets by using method steps of the present invention described above such as depicted in FIGS. 1-2 and FIGS. 5-14.
- the biomarker patterns and/or biomarker signature sets disclosed in the table depicted in FIGS. 26 and 28, and the tables depicted in FIGS. 27 and 30 may be used for a number of purposes including, but not limited to, specific cancer/disease detection, specific cancer/disease treatment, and identification of new drug therapies or protocols for specific cancers/diseases.
- the biomarker patterns and/or biomarker signature sets disclosed in the table depicted in FIGS. 26 and 28, and the tables depicted in FIGS. 27 and 30 can also represent drug resistant expression profiles for the specific tumor type or cancer type.
- the biomarker patterns and/or biomarker signature sets disclosed in the table depicted in FIGS. 26 and 28, and the tables depicted in FIGS. 27 and 30 represent advanced stage drug resistant profiles.
- the biomarker patterns and/or biomarker signature sets can comprise at least one biomarker.
- the biomarker patterns or signature sets can comprise at least 2, 3, 4, 5, 6, 7, 8, 9, or 10 biomarkers.
- the biomarker signature sets or biomarker patterns can comprise at least 15, 20, 30, 40, 50, or 60 biomarkers.
- the biomarker signature sets or biomarker patterns can comprise at least 70, 80, 90, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10,000, 15,000, 20,000, 25,000, 30,000, 35,000, 40,000, 45,000 or 50,000 biomarkers.
- Analysis of the one or more biomarkers can be by one or more methods. For example, analysis of 2 biomarkers can be performed using microarrays. Alternatively, one biomarker may be analyzed by IHC and another by microarray. Any such combinations of methods and biomarkers are contemplated herein.
- the one or more biomarkers can be selected from the group consisting of, but not limited to: Her2/Neu, ER, PR, c-kit, EGFR, MLH1 , MSH2, CD20, p53, Cyclin Dl , bcl2, COX-2, Androgen receptor, CD52, PDGFR, AR, CD25, VEGF, HSP90, PTEN, RRM1 , SPARC, Survivin, TOP2A, BCL2, HIF1A, AR, ESR1, PDGFRA, KIT, PDGFRB, CDW52, ZAP70, PGR, SPARC, GART, GSTP1 , NFKBIA, MSH2, TXNRD1, HDAC1 , PDGFC, PTEN, CD33, TYMS, RXRB, ADA, TNF, ERCC3, RAF 1 , VEGF, TOPI , TOP2A, BRCA2, TK1 , FOLR2, TOP2B, MLH1, IL2RA,
- a biological sample from an individual can be analyzed to determine a biomarker pattern or biomarker signature set that comprises a biomarker such as HSP90, Survivin, RRMl, SSTRS3, DNMT3B, VEGFA, SSTR4, RRM2, SRC, RRM2B, HSP90AA1, STR2, FLT1 , SSTR5, YES 1, BRCA1 , RRMl, DHFR, KDR, EPHA2, RXRG, or LCK.
- the biomarker SPARC, HSP90, TOP2A, PTEN, Survivin, or RRMl forms part of the biomarker pattern or biomarker signature set.
- the biomarker MGMT, SSTRS3, DNMT3B, VEGFA, SSTR4, RRM2, SRC, RRM2B, HSP90AA1 , STR2, FLT1, SSTR5, YES1, BRCA1, RRMl, DHFR, KDR, EPHA2, RXRG, CD52, or LCK is included in a biomarker pattern or biomarker signature set.
- the biomarker hENTl, cMet, P21 , PARP- 1 , TLE3 or IGF1R is included in a biomarker pattern or biomarker signature set.
- the expression level of HSP90, Survivin, RRMl , SSTRS3, DNMT3B, VEGFA, SSTR4, RRM2, SRC, RRM2B, HSP90AA1 , STR2, FLT1, SSTR5, YES 1, BRCA1, RRMl , DHFR, KDR, EPHA2, RXRG, or LCK can be determined and used to identify a therapeutic for an individual.
- the expression level of the biomarker can be used to form a biomarker pattern or biomarker signature set. Determining the expression level can be by analyzing the levels of mRNA or protein, such as by microarray analysis or IHC.
- the expression level of a biomarker is performed by IHC, such as for SPARC, TOP2A, or PTEN, and used to identify a therapeutic for an individual.
- the results of the IHC can be used to form a biomarker pattern or biomarker signature set.
- a biological sample from an individual or subject is analyzed for the expression level of CD52, such as by determining the mRNA expression level by methods including, but not limited to, microarray analysis.
- the expression level of CD52 can be used to identify a therapeutic for the individual.
- the expression level of CD52 can be used to form a biomarker pattern or biomarker signature set.
- the biomarkers hENTl, cMet, P21, PARP- 1 , TLE3 and/or IGF1R are assessed to identify a therapeutic for the individual.
- the molecular profiling of one or more targets can be used to determine or identify a therapeutic for an individual.
- the expression level of one or more biomarkers can be used to determine or identify a therapeutic for an individual.
- the one or more biomarkers such as those disclosed herein, can be used to form a biomarker pattern or biomarker signature set, which is used to identify a therapeutic for an individual.
- the therapeutic identified is one that the individual has not previously been treated with. For example, a reference biomarker pattern has been established for a particular therapeutic, such that individuals with the reference biomarker pattern will be responsive to that therapeutic.
- an individual with a biomarker pattern that differs from the reference for example the expression of a gene in the biomarker pattern is changed or different from that of the reference, would not be administered that therapeutic.
- an individual exhibiting a biomarker pattern that is the same or substantially the same as the reference is advised to be treated with that therapeutic.
- the individual has not previously been treated with that therapeutic and thus a new therapeutic has been identified for the individual.
- Molecular profiling according to the invention can take on a biomarker-centric or a therapeutic- centric point of view.
- the biomarker-centric approach focuses on sets of biomarkers that are expected to be informative for a tumor of a given tumor lineage
- the therapeutic-centric point approach identifies candidate therapeutics using biomarker panels that are lineage independent.
- panels of specific biomarkers are run on different tumor types. See FIG. 32A.
- This approach provides a method of identifying a candidate therapeutic by collecting a sample from a subject with a cancer of known origin, and performing molecular profiling on the cancer for specific biomarkers depending on the origin of the cancer.
- FIG. 32A shows biomarker panels for breast cancer, ovarian cancer, colorectal cancer, lung cancer, and a "complete" profile to run on any cancer.
- markers shown in italics are assessed using mutational analysis (e.g., sequencing approaches), marker shown underlined are analyzed by FISH, and the remainder are analyzed using IHC.
- DNA microarray profiling can be performed on any sample. The candidate therapeutic is selected based on the molecular profiling results according to the subject methods.
- Another advantage is that this approach can focus on identifying therapeutics conventionally used to treat cancers of the specific lineage.
- the biomarkers assessed are not dependent on the origin of the tumor. See FIG. 32B.
- This approach provides a method of identifying a candidate therapeutic by collecting a sample from a subject with a cancer, and performing molecular profiling on the cancer for a panel of biomarkers without regards to the origin of the cancer.
- the molecular profiling can be performed using any of the various techniques disclosed herein. As an example, in FIG. 32B, markers shown in italics are assessed using mutational analysis (e.g., sequencing approaches), marker shown underlined are analyzed by FISH, and the remainder are analyzed using IHC.
- DNA microarray profiling can be performed on any sample.
- the candidate therapeutic is selected based on the molecular profiling results according to the subject methods.
- An advantage to the therapeutic -marker centric approach is that the most promising therapeutics are identified only taking into account the molecular characteristics of the tumor itself.
- Another advantage is that the method can be preferred for a cancer of unidentified primary origin (CUP).
- CUP unidentified primary origin
- a hybrid of biomarker-centric and therapeutic-centric points of view is used to identify a candidate therapeutic.
- This method comprises identifying a candidate therapeutic by collecting a sample from a subject with a cancer of known origin, and performing molecular profiling on the cancer for a comprehensive panel of biomarkers, wherein a portion of the markers assessed depend on the origin of the cancer. For example, consider a breast cancer. A comprehensive biomarker panel is run on the breast cancer, e.g., the complete panel as shown in FIG. 32B, but additional sequencing analysis is performed on one or more additional markers, e.g., BRCA1 or any other marker with mutations informative for theranosis or prognosis of the breast cancer.
- additional markers e.g., BRCA1 or any other marker with mutations informative for theranosis or prognosis of the breast cancer.
- Theranosis can be used to refer to the likely efficacy of a therapeutic treatment.
- Prognosis refers to the likely outcome of an illness.
- the hybrid approach can be used to identify a candidate therapeutic for any cancer having additional biomarkers that provide theranostic or prognostic information, including the cancers disclosed herein.
- Methods for providing a theranosis of disease include selecting candidate therapeutics for various cancers by assessing a sample from a subject in need thereof (i.e., suffering from a particular cancer).
- the sample is assessed by performing an immunohistochemistry (IHC) to determine of the presence or level of: AR, BCRP, c-KIT, ER, ERCC1 , HER2, IGF 1R, MET (also referred to herein as cMet), MGMT, MRP1, PDGFR, PGP, PR, PTEN, RRMl, SPARC, TOPO l , TOP2A, TS, COX-2, CK5/6, CK14, CK17, Ki67, p53, CAV- 1, CYCLIN Dl, EGFR, E-cadherin, p95, TLE3 or a combination thereof; performing a microarray analysis on the sample to determine a microarray expression profile on one or more (such as at least five, 10, 15, 20, 25, 30, 40, 50,
- Assessment can further comprise determining a fluorescent in-situ hybridization (FISH) profile of EGFR, HER2, cMYC, TOP2A, MET, or a combination thereof, comparing the FISH profile against a rules database comprising a mapping of candidate treatments predetermined as effective against a cancer cell having a mutation profile for EGFR, HER2, cMYC, TOP2A, MET, or a combination thereof, and determining a candidate treatment if the comparison of the FISH profile against the rules database indicates that the candidate treatment has biological activity against the cancer.
- FISH fluorescent in-situ hybridization
- the FISH analysis can be performed based on the origin of the sample. This can avoid unnecessary laboratory procedures and concomitant expenses by targeting analysis of genes that are known to play a role in a particular disorder, e.g., a particular type of cancer.
- EGFR, HER2, cMYC, and TOP2A are assessed for breast cancer.
- EGFR and MET are assessed for lung cancer.
- FISH analysis of all of EGFR, HER2, cMYC, TOP2A, MET can be performed on a sample. The complete panel may be assessed, e.g., when a sample is of unknown or mixed origin, to provide a comprehensive view of an unusual sample, or when economies of scale dictate that it is more efficient to perform FISH on the entire panel than to make individual assessments.
- the sample is assessed by performing nucleic acid sequencing on the sample to determine a presence of a mutation of KRAS, BRAF, NRAS, PIK3CA (also referred to as PI3K), c-Kit, EGFR, or a combination thereof, comparing the results obtained from the sequencing against a rules database comprising a mapping of candidate treatments predetermined as effective against a cancer cell having a mutation profile for KRAS, BRAF, NRAS, PIK3CA, c-Kit, EGFR, or a combination thereof; and determining a candidate treatment if the comparison of the sequencing to the mutation profile indicates that the candidate treatment has biological activity against the cancer.
- the nucleic acid sequencing can be performed based on the origin of the sample. This can avoid unnecessary laboratory procedures and concomitant expenses by targeting analysis of genes that are known to play a role in a particular disorder, e.g., a particular type of cancer.
- the sequences of PIK3CA and c-KIT are assessed for breast cancer.
- the sequences of KRAS and BRAF are assessed for GI cancers such as colorectal cancer.
- the sequences of KRAS, BRAF and EGFR are assessed for lung cancer.
- sequencing of all of KRAS, BRAF, NRAS, PIK3CA, c-Kit, EGFR can be performed on a sample.
- the complete panel may be sequenced, e.g., when a sample is of unknown or mixed origin, to provide a comprehensive view of an unusual sample, or when economies of scale dictate that it is more efficient to sequence the entire panel than to make individual assessments.
- genes and gene products used for molecular profiling e.g., by microarray, IHC, FISH, sequencing, and/or PCR (e.g., qPCR), can be selected from those listed in Table 2, Table 6 or Table 25.
- IHC is performed for one or more, e.g., 2, 3, 4, 5, 6,7, 8, 9, 10, 15, 20 or more, of: AR, BCRP, CAV-1, CD20, CD52, CK 5/6, CK14, CK17, c-kit, CMET, COX-2, Cyclin D l , E-Cad, EGFR, ER, ERCC1, HER-2, IGF1R, Ki67, MGMT, MRP 1 , P53, p95, PDGFR, PGP, PR, PTEN, RRM1 , SPARC, TLE3, TOPOl, TOP02A, TS, TUBB3; expression analysis (e.g., microarray or RT-PCR) is performed on one or more, e.g.
- expression analysis e.g., microarray or RT-PCR
- Assessing one or more biomarkers disclosed herein can be used for characterizing any of the cancers disclosed herein. Characterizing includes the diagnosis of a disease or condition, the prognosis of a disease or condition, the determination of a disease stage or a condition stage, a drug efficacy, a physiological condition, organ distress or organ rejection, disease or condition progression, therapy- related association to a disease or condition, or a specific physiological or biological state.
- a cancer in a subject can be characterized by obtaining a biological sample from a subject and analyzing one or more biomarkers from the sample.
- characterizing a cancer for a subject or individual may include detecting a disease or condition (including pre -symptomatic early stage detecting), determining the prognosis, diagnosis, or theranosis of a disease or condition, or determining the stage or progression of a disease or condition.
- Characterizing a cancer can also include identifying appropriate treatments or treatment efficacy for specific diseases, conditions, disease stages and condition stages, predictions and likelihood analysis of disease progression, particularly disease recurrence, metastatic spread or disease relapse. Characterizing can also be identifying a distinct type or subtype of a cancer.
- the products and processes described herein allow assessment of a subject on an individual basis, which can provide benefits of more efficient and economical decisions in treatment.
- characterizing a cancer includes predicting whether a subject is likely to respond to a treatment for the cancer.
- a "responder” responds to or is predicted to respond to a treatment and a “non-responder” does not respond or is predicted to not respond to the treatment.
- Biomarkers can be analyzed in the subject and compared to biomarker profiles of previous subjects that were known to respond or not to a treatment. If the biomarker profile in a subject more closely aligns with that of previous subjects that were known to respond to the treatment, the subject can be characterized, or predicted, as a responder to the treatment. Similarly, if the biomarker profile in the subject more closely aligns with that of previous subjects that did not respond to the treatment, the subject can be characterized, or predicted as a non-responder to the treatment.
- the sample used for characterizing a cancer can be any disclosed herein, including without limitation a tissue sample, tumor sample, or a bodily fluid.
- Bodily fluids that can be used included without limitation peripheral blood, sera, plasma, ascites, urine, cerebrospinal fluid (CSF), sputum, saliva, bone marrow, synovial fluid, aqueous humor, amniotic fluid, cerumen, breast milk,
- the sample comprises vesicles.
- the biomarkers can be associated with the vesicles.
- vesicles are isolated from the sample and the biomarkers associated with the vesicles are assessed.
- Molecular profiling can be used to guide treatment selection for cancers at any stage of disease or prior treatment.
- Molecular profiling comprises assessment of DNA mutations, gene rearrangements, gene copy number variation, RNA expression, protein expression, as well as assessment of other biological entities and phenomena that can inform clinical decision making.
- the methods herein are used to guide selection of candidate treatments using the standard of care treatments for a particular type or lineage of cancer.
- Profiling of biomarkers that implicate standard-of-care treatments may be used to assist in treatment selection for a newly diagnosed cancer having multiple treatment options. Such profiling may be referred to herein as "select" profiling.
- Standard-of-care treatments may comprise NCCN on-compendium treatments or other standard treatments used for a cancer of a given lineage.
- profiles can be updated as the standard of care and/or availability of experimental agents for a given disease lineage change.
- molecular profiling is performed for additional biomarkers to identify treatments as beneficial or not beyond that go beyond the standard-of-care for a particular lineage or stage of the cancer.
- Such "comprehensive" profiling can be performed to assess a wide panel of druggable or drug-associated biomarker targets for any biological sample or specimen of interest.
- select profiles generally comprise subsets of the comprehensive profile. The comprehensive profile can also be used to guide selection of candidate treatments for any cancer at any point of care.
- the comprehensive profile may also be preferable when standard-of-care treatments not expected to provide further benefit, such as in the salvage treatment setting for recurrent cancer or wherein all standard treatments have been exhausted.
- the comprehensive profile may be used to assist in treatment selection when standard therapies are not an option for any reason including, without limitation, when standard treatments have been exhausted for the patient.
- the comprehensive profile may be used to assist in treatment selection for highly aggressive or rare tumors with uncertain treatment regimens.
- a comprehensive profile can be used to identify a candidate treatment for a newly diagnosed case or when the patient has exhausted standard of care therapies or has an aggressive disease.
- molecular profiling according to the invention has indeed identified beneficial therapies for a cancer patient when all standard-of-care treatments were exhausted the treating physician was unsure ofwhat treatment to select next.
- a comprehensive molecular profiling can be used to select a therapy for any appropriate indication independent of the nature of the indication (e.g., source, stage, prior treatment, etc).
- a comprehensive molecular profile is tailored for a particular indication. For example, biomarkers associated with treatments that are known to be ineffective for a cancer from a particular lineage or anatomical origin may not be assessed as part of a comprehensive molecular profile for that particular cancer. Similarly, biomarkers associated with treatments that have been previously used and failed for a particular patient may not be assessed as part of a comprehensive molecular profile for that particular patient.
- biomarkers associated with treatments that are only known to be effective for a cancer from a particular anatomical origin may only be assessed as part of a comprehensive molecular profile for that particular cancer.
- the comprehensive molecular profile can be updated to reflect advancements, e.g., new treatments, new biomarker-drug associations, and the like, as available.
- the invention provides molecular intelligence (MI) molecular profiles using a variety of techniques to assess panels of biomarkers in order to select or not select a candidate therapeutic for treating a cancer.
- Such techniques comprise IHC for expression profiling, CISH/FISH for DNA copy number, and Sanger, Pyrosequencing, PC , RFLP, fragment analysis and Next Generation sequencing for mutational analysis.
- Such profiles are described in FIGs. 33A-33Q.
- the profiling is performed using the rules for the biomarker - drag associations for the various cancer lineages as described for FIGs. 33A-33Q and Tables 7-24.
- MI profiles for all solid tumors or that have additional analyses based on tumor lineage include NextGen analysis of a panel of biomarkers linked to known therapies and clinical trials.
- the MI profiles can further be expanded to "MI PLUS" profiles that include sequencing of set of genes that are known to be involved in cancer and have alternative clinical utilities including predictive, prognostic or diagnostic uses.
- the biomarkers which comprise the molecular intelligence molecular profiles can include genes or gene products that are known to be associated directly with a particular drug or class of drugs.
- the biomarkers can also be genes or gene products that interact with such drug associated targets, e.g., as members of a common pathway.
- the biomarkers can be selected from Table 2.
- the genes and/or gene products included in the molecular intelligence (MI) molecular profiles are selected from Table 6.
- ALK ALK rearrangements may indicate the fusion of ALK (anaplastic lymphoma
- EML4-ALK fusion results in the pathologic expression of a fusion protein with constitutively active ALK kinase, resulting in aberrant activation of downstream signaling pathways including RAS- ERK, JAK3-STAT3 and PI3K-AKT.
- Patients with ALK rearrangements such as EML4-ALK are likely to respond to the ALK-targeted agent crizotinib.
- AR The androgen receptor (AR) is a member of the nuclear hormone receptor
- Prostate tumor dependency on androgens / AR signaling is the basis for hormone withdrawal, or androgen ablation therapy, to treat men with prostate cancer.
- Androgen receptor antagonists as well as agents which block androgen production are indicated for the treatment of AR expressing prostate cancers.
- AREG AREG also known as amphiregulin, is a ligand of the epidermal growth factor receptor. Overexpression of AREG in primary colorectal cancer patients has been associated with increased clinical benefit from cetuximab in KRAS wildtype patients.
- BRAF BRAF encodes a protein belonging to the raf/mil family of serine/threonine protein kinases. This protein plays a role in regulating the MAP kinase/ERK signaling pathway initiated by EGFR activation, which affects cell division, differentiation, and secretion. Patients with mutated BRAF genes have a reduced likelihood of response to EGFR targeted monoclonal antibodies, such as cetuximab in colorectal cancer.
- a BRAF enzyme inhibitor, vemurafenib was approved by FDA to treat unresectable or metastatic melanoma patients harboring BRAF V600E mutations.
- BRCA1 BRCA1 breast cancer type 1 susceptibility gene
- breast cancer type 1 susceptibility gene is a gene involved in cell growth, cell division, and DNA-damage repair. Low expression of the BRCA1 gene has been associated with clinical benefit from cisplatin and carboplatin in cancers of the lung and ovary.
- c-kit c-Kit is a cytokine receptor expressed on the surface of hematopoietic stem cells as well as other cell types. This receptor binds to stem cell factor (SCF, a cell growth factor).
- SCF stem cell factor
- c-Kit is a receptor tyrosine kinase, ligand binding causes receptor dimerization and initiates a phosphorylation cascade resulting in changes in gene expression. These changes affect cell proliferation, apoptosis, chemotaxis and adhesion.
- c-Kit is inhibited by multi-targeted agents including imatinib, sunitinib and sorafenib.
- cMET C-Met is a tyrosine kinase receptor for hepatocyte growth factor (HGF) or scatter factor (SF) and is overexpressed and amplified in a wide range of tumors.
- HGF hepatocyte growth factor
- SF scatter factor
- cMET overexpression has been associated with a more aggressive biology and a worse prognosis in many human malignancies.
- Amplification or overexpression of cMET has been implicated in the development of acquired resistance to erlotinib and gefitinib in SCLC.
- EGFR EGFR epidermal growth factor receptor
- Sensitizing mutations are commonly detected in SCLC and patients harboring such mutations may respond to EGFR-targeted tyrosine kinase inhibitors including erlotinib and gefitinib.
- Lung cancer patients overexpressing EGFR protein are known to respond to the EGFR monoclonal antibody, cetuximab. Increased gene expression of EGFR is associated with response to irinotecan containing regimen in colorectal cancer patients.
- ER The estrogen receptor (ER) is a member of the nuclear hormone family of
- Estrogen receptors overexpressing breast cancers are referred to as "ER positive.” Estrogen binding to ER on cancer cells leads to cancer cell proliferation. Breast tumors over-expressing ER are indicated for treatment with hormone-based anti- estrogen therapy.
- ERBB3 ERBB3 encodes for HER3, a member of the epidermal growth factor receptor
- EGFR EGFR
- ERBB3 ERBB3 is a target for drug development.
- ERCC1 Nucleotide excision repair is a DNA repair mechanism necessary for the repair of DNA damage from a vast variety of sources including chemicals and ultraviolet (UV) light from the sun.
- ERCC 1 excision repair cross- complementation group 1 is an important enzyme in the NER pathway. Platinum- based drugs induce DNA cross-links that interfere with DNA replication. Tumors with low ERCC1 expression and, hence, less DNA repair capacity, are more likely to benefit from platinum-based DNA damaging agents.
- EREG EREG also known as epiregulin, is a ligand of the epidermal growth factor
- GNA11 G proteins are a family of heterotrimeric proteins coupling seven-transmembrane domain receptor. These heterotrimeric proteins are composed of three subunits: Galpha, Gbeta, and Ggamma.
- the GNA1 1 gene encodes the alpha- 1 1 subunit (Galphal 1).
- Galphal 1 alpha- 1 1 subunit
- GNAQ G proteins are a family of heterotrimeric proteins coupling seven-transmembrane domain receptors. G proteins are potential drivers of MAPK activation. In uveal melanomas 46-53% of patients exhibit a GNAQ mutation which encodes the q class of G-protein alpha subunit. Clinical trials are underway with HDAC inhibitors and MEK inhibitors in patients harboring GNAQ mutations.
- Her2/Neu ErbB2/Her2 encodes a member of the epidermal growth factor (EGF) receptor family of receptor tyrosine kinases.
- Her2 has no ligand-binding domain of its own and, therefore, cannot bind growth factors. It does, however, bind tightly to other ligand-bound EGF receptor family members to form a heterodimer and enhances kinase-mediated activation of downstream signaling pathways leading to cell proliferation.
- Her2 is overexpressed in 15-30% of newly diagnosed breast cancers and is also expressed in various other cancers.
- Her2 is a target for the monoclonal antibodies trastuzumab and pertuzumab which bind to the receptor extracellularly; the kinase inhibitor lapatinib binds and blocks the receptor intracellularly.
- IDH2 IDH2 encodes for the mitochondrial form of isocitrate dehydrogenase, a key
- IDH2 mutation is mutually exclusive of IDH1 mutation, and has been found in 2% of gliomas and 10% of AML, as well as in cartilaginous tumors and cholangiocarcinoma. In gliomas, IDH2 mutations are associated with lower grade astrocytomas, oligodendrogliomas (grade II/III), as well as secondary glioblastoma (transformed from a lower grade glioma), and are associated with a better prognosis.
- IDH2 mutation may associate with a better response to alkylating agent temozolomide. IDH mutations have also been suggested to associate with a benefit from using hypomethylating agents in cancers including AML. Various clinical trials investigating agents which target this gene and/or its downstream or upstream effectors may be available, which include the following: NCTO 1534845, NCTO 1537744. Germline IDH2 mutation has been indicated to associate with a rare inherited neurometabolic disorder D-2-hydroxyglutaric aciduria.
- KRAS Proto-oncogene of the Kirsten murine sarcoma virus is a signaling
- Mutations at activating hotspots are associated with resistance to EGFR tyrosine kinase inhibitors (erlotinib, gefitinib) and monoclonal antibodies (cetuximab, panitumumab).
- MGMT O-6-methylguanine-DNA methyltransferase encodes a DNA repair enzyme. Loss of MGMT expression leads to compromised DNA repair in cells and may play a significant role in cancer formation. Low MGMT expression has been correlated with response to alkylating agents like temozolomide and dacarbazine. MGMT expression can be downregulated by promoter hyper methylation.
- NRAS NRAS is an oncogene and a member of the (GTPase) ras family, which includes
- KRAS and HRAS This biomarker has been detected in multiple cancers including melanoma, colorectal cancer, AML and bladder cancer. Evidence suggests that an acquired mutation in NRAS may be associated with resistance to vemurafenib in melanoma patients. In other cancers, e.g., colorectal cancer, NRAS mutation is associated with resistance to EGFR-targeted monoclonal antibodies.
- PGP P-glycoprotein (MDR1, ABCB1) is an ATP-dependent, transmembrane drug efflux pump with broad substrate specificity, which pumps antitumor drugs out of cells. Its expression is often induced by chemotherapy drugs and is thought to be a major mechanism of chemotherapy resistance. Overexpression of PGP is associated with resistance to anthracylines (doxorubicin, epirubicin). PGP remains the most important and dominant representative of Multi-Drug Resistance phenotype and is correlated with disease state and resistant phenotype.
- PIK3CA mutations have been associated with benefit from mTOR inhibitors (everolimus, temsirolimus).
- mTOR inhibitors everolimus, temsirolimus.
- Evidence suggests that breast cancer patients with activation of the PI3K pathway due to PTEN loss or PIK3CA mutation/am lification have a significantly shorter survival following trastuzumab treatment.
- PIK3CA mutated (exon 20) colorectal cancer patients are less likely to respond to EGFR targeted monoclonal antibody therapy.
- the progesterone receptor (PR or PGR) is an intracellular steroid receptor that specifically binds progesterone, an important hormone that fuels breast cancer growth. PR positivity in a tumor indicates that the tumor is more likely to be responsive to hormone therapy by anti-estrogens, aromatase inhibitors and progestogens.
- PTEN PTEN phosphatase and tensin homolog
- Loss of PTEN protein is one of the most common occurrences in multiple advanced human cancers.
- PTEN is an important mediator in signaling downstream of EGFR, and its loss is associated with reduced benefit to trastuzumab and EGFR-targeted therapies.
- Intra-tumoral PTEN loss has been associated with benefit from mTOR inhibitors (everolimus, temsirolimus).
- the RET proto-oncogene is a member of the cadherin superfamily and encodes a receptor tyrosine kinase cell-surface molecule involved in numerous cellular mechanisms including cell proliferation, neuronal navigation, cell migration, and cell differentiation upon binding with glial cell derived neurotrophic factor family ligands.
- Gain of function mutations in RET are associated with the development of various types of human cancers.
- Vandetanib is a tyrosine kinase inhibitor that can inhibit several receptors, including VEGFR, EGFR, and RET.
- ROS1 ROS1 (c-ros oncogene 1, receptor tyrosine kinase) is a tyrosine kinase that plays a role in epithelial cell differentiation and regionalization of the proximal epididymal epithelium.
- ROS1 may activate several downstream signaling pathways related to cell differentiation, proliferation, growth and survival including the PI3 kinase- mTOR signaling pathway.
- TKI inhibitors such as crizotinib or other ROS1 inhibitor compounds can have benefit when mutations or rearrangements in ROS1 are identified.
- RRM1 Ribonucleotide reductase subunit Ml (RRM1) is a component of the
- ribonucleotide reductase holoenzyme consisting of Ml and M2 subunits.
- the ribonucleotide reductase is a rate-limiting enzyme involved in the production of nucleotides required for DNA synthesis.
- Gemcitabine is a deoxycitidine analogue which inhibits ribonucleotide reductase activity. High RRM1 level is associated with resistance to gemcitabine.
- SPARC SPARC secreted protein acidic and rich in cysteine
- SPARC over-expression improves the response to the anticancer drug, nab-paclitaxel.
- the improved response is thought to be related to SPARC' S role in accumulating albumin and albumin-targeted agents within tumor tissue.
- TLE3 TLE3 is a member of the trans ducin- like enhancer of split (TLE) family of proteins that have been implicated in tumorigenesis. It acts downstream of APC and beta- catenin to repress transcription of a number of oncogenes, which influence growth and microtubule stability. Studies indicate that TLE3 expression is associated with response to taxane therapy in various cancers, e.g., breast, ovarian and lung cancers.
- TOPOIIA is an enzyme that alters the supercoiling of double-stranded DNA and allows chromosomal segregation into daughter cells. Due to its essential role in DNA synthesis and repair, and frequent overexpression in tumors, TOPOIIA is an ideal target for antineoplastic agents. In breast cancer, co-amplification of TOPOIIA and HER2 has been associated with benefit from anthracycline-based therapy. In HER2 negative breast cancers, patients with low gene expression of TOPOIIA may derive benefit from anthracycline-based therapy.
- TOPOl Topoisomerase I is an enzyme that alters the supercoiling of double-stranded DNA.
- TOPOI acts by transiently cutting one strand of the DNA to relax the coil and extend the DNA molecule. Higher expression of TOPOI has been associated with response to TOPOI inhibitors including irinotecan and topotecan.
- TS Thymidylate synthase is an enzyme involved in DNA synthesis that generates thymidine monophosphate (dTMP), which is subsequently phosphorylated to thymidine triphosphate for use in DNA synthesis and repair.
- dTMP thymidine monophosphate
- Low levels of TS are predictive of response to fluoropyrimidines and other folate analogues.
- TUBB3 Class III ⁇ -Tubulin (TUBB3) is part of a class of proteins that provide the
- microtubules major structural components of the cytoskeleton. Due to their importance in maintaining structural integrity of the cell, microtubules are ideal targets for anti-cancer agents. Low expression of TUBB3 is associated with potential clinical benefit to taxanes and vinca alkaloids in certain tumor types.
- VEGFR2 VEGFR2 VEGFR2, vascular endothelial growth factor 2 is one of three main subtypes of
- VEGFR This protein is an important signaling protein in angiogenesis. Evidence suggests that increased levels of VEGFR2 may be predictive of response to anti- angiogenic drugs.
- Tables 7, 9, 11, 13, 15, 17 and 21 present views of the information that can be gathered and reported for the MI and MI Plus molecular profiles. Profiles for various lineages are indicated by the table headers. Modifications made dependent on cancer lineage are indicated as appropriate.
- the columns headed "Agent/Biomarker Status Reported" provide either candidate agents (e.g., drugs) or biomarker status to be included in the report. Where agents are indicated, the association of the agent with the indicated biomarker is included in the report. Where a status is indicated (e.g., mutational status, protein expression status, gene copy number status), the biomarker status is indicated in the report instead of drug associations.
- the candidate agents may comprise those undergoing clinical trials, as indicated. Platform abbreviations are as used throughout the application, e.g., IHC: immunohistochemistry; FISH:
- CISH colorimetric in situ hybridization
- NGS next generation sequencing
- PCR polymerase chain reaction
- the invention provides molecular intelligence (MI) profiles for an ovarian cancer comprising assessment of one or more, e.g., 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41 , 42, 43, 44, 45, 46, 47, 48, 49, 50, 51 , 52, 53, 54, 55, 56, 57 or 58, of: ABL1 , AKT1 , ALK, APC, AR, ATM, BRAF, CDHl, cKIT, cMET, CSFIR, CTNNB l, EGFR, ER, ERBB2, ERBB4, FBXW7, FGFRl , FGFR2, FLT3, GNA1 1, GNAQ, GNAS, HER2, HNF1A, HRAS, IDH1 , JAK2, JAK3, KDR (VEGFR
- MI molecular intelligence
- the invention further provides a method of selecting a candidate treatment for an ovarian cancer comprising assessment of one or more members of the ovarian cancer molecular profile using one or more molecular profiling technique presented herein, e.g., ISH (e.g., FISH, CISH), IHC, RT-PCR, expression array, mutation analysis (e.g., NextGen sequencing, Sanger sequencing, pyrosequencing, Fragment analysis (FA, e.g., RFLP), PCR), etc.
- ISH is used to assess one or more, e.g., 1 or 2, of: cMET, HER2. Any useful ISH technique can be used.
- FISH can be used to assess cMET and/or HER2; or CISH can be used to assess cMET and/or HER2.
- protein analysis such as IHC is used to assess one or more, e.g., 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15 or 16 of: AR, cMET, ER, HER2, MGMT, PGP, PR, PTEN, RRMl, SPARCm, SPARCp, TLE3, TOP2A, TOPOl, TS, TUBB3.
- m and "p" as in SPARC (m/p) refer to IHC performed with monoclonal ("m") or polyclonal ("p”) primary antibodies.
- sequence analysis is used to assess one or more, e.g., 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44 or 45 of: ABLl, AKT1, ALK, APC, ATM, BRAF, CDH1, cKIT, cMET, CSF1R, CTNNB1, EGFR, ERBB2, ERBB4, FBXW7, FGFR1, FGFR2, FLT3, GNA1 1, GNAQ, GNAS, FfNFlA, HRAS, IDHl, JAK2, JAK3, KDR (VEGFR2), KRAS, MLH1, MPL, NOTCH1, NPM1, NRAS, PDGFRA, PIK3CA, PTEN, PTPN11, RB I, RET, SMAD4, SMARCBl, SMO, STK1 1, TP53,
- the sequence analysis can be performed on one or more, e.g., 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13 or 14 of ABLl, APC, BRAF, EGFR, FLT3, GNAQ, IDHl, JAK2, cKIT, KRAS, MPL, NRAS, PDGFRA, VHL.
- the sequence analysis can also be performed on one or more, e.g., 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 or 15 of ABLl, APC, BRAF, EGFR, FLT3, GNAQ, IDHl, JAK2, cKIT, KRAS, MPL, NPM1, NRAS, PDGFRA, VHL.
- the sequencing may be performed using Next Generation sequencing technology or other technologies as described herein.
- the molecular profile can be based on assessing the biomarkers as illustrated in FIGs. 33C-D or Table 7 below.
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Immunology (AREA)
- Biotechnology (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Organic Chemistry (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Pathology (AREA)
- Analytical Chemistry (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Public Health (AREA)
- Theoretical Computer Science (AREA)
- Evolutionary Biology (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Microbiology (AREA)
- Biochemistry (AREA)
- Epidemiology (AREA)
- Hematology (AREA)
- Urology & Nephrology (AREA)
- Hospice & Palliative Care (AREA)
- Oncology (AREA)
- Databases & Information Systems (AREA)
- Cell Biology (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Medicinal Chemistry (AREA)
- Evolutionary Computation (AREA)
- General Physics & Mathematics (AREA)
- Primary Health Care (AREA)
Abstract
Description










































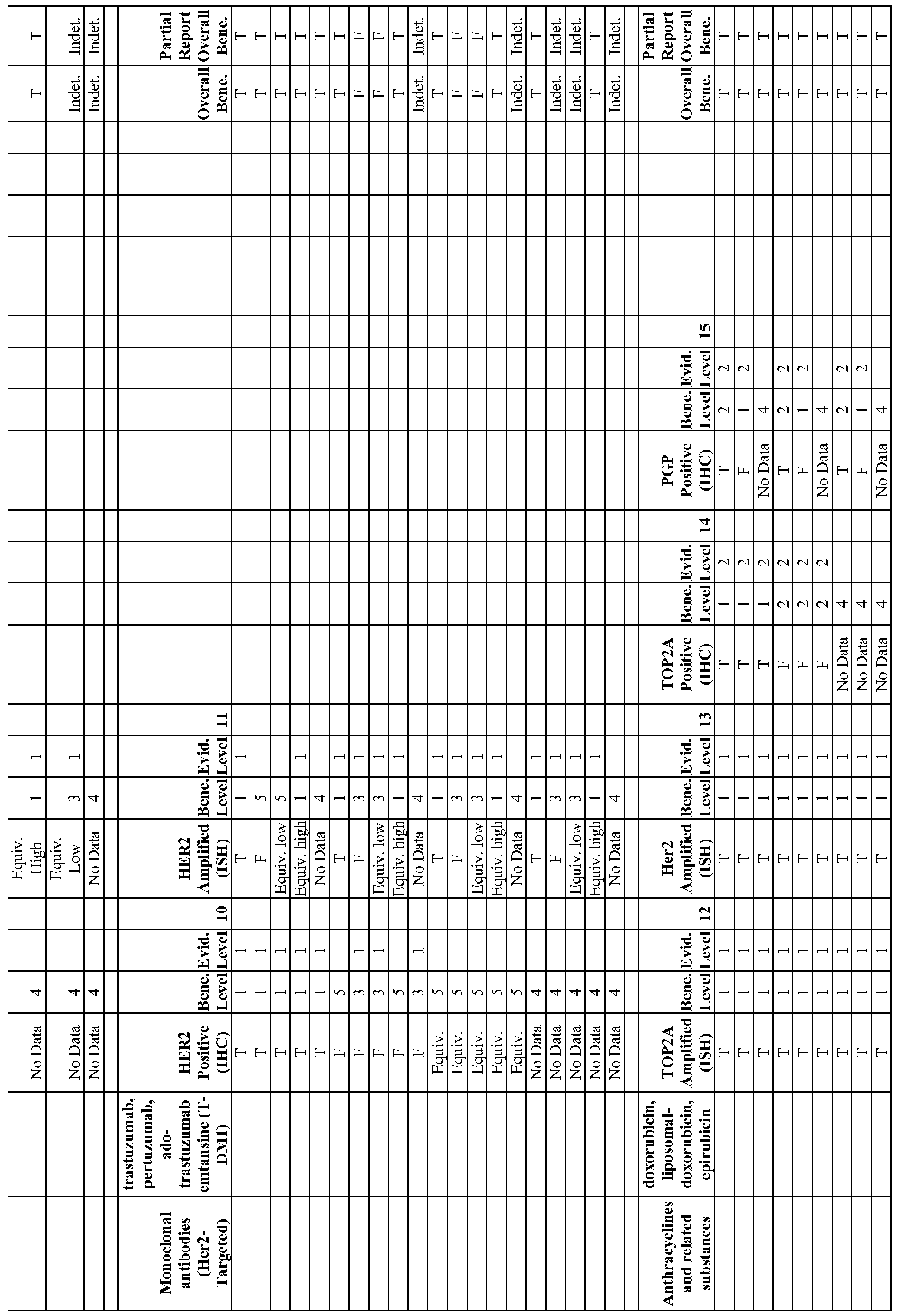



































































Claims
Priority Applications (9)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP13860539.9A EP2929350A4 (en) | 2012-12-04 | 2013-12-04 | Molecular profiling for cancer |
| CA2893745A CA2893745A1 (en) | 2012-12-04 | 2013-12-04 | Molecular profiling for cancer |
| US14/648,988 US20150307947A1 (en) | 2012-12-04 | 2013-12-04 | Molecular profiling for cancer |
| AU2013355260A AU2013355260B2 (en) | 2012-12-04 | 2013-12-04 | Molecular profiling for cancer |
| IL239147A IL239147B (en) | 2012-12-04 | 2015-06-02 | Molecular profiling for cancer |
| US16/597,061 US20200299774A1 (en) | 2012-12-04 | 2019-10-09 | Molecular profiling for cancer |
| AU2019250106A AU2019250106A1 (en) | 2012-12-04 | 2019-10-14 | Molecular profiling for cancer |
| US16/902,164 US20210062269A1 (en) | 2012-12-04 | 2020-06-15 | Databases, data structures, data processing systems, and computer programs for identifying a candidate treatment |
| AU2022200781A AU2022200781A1 (en) | 2012-12-04 | 2022-02-07 | Molecular profiling for cancer |
Applications Claiming Priority (22)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201261733396P | 2012-12-04 | 2012-12-04 | |
| US61/733,396 | 2012-12-04 | ||
| US201361757701P | 2013-01-28 | 2013-01-28 | |
| US61/757,701 | 2013-01-28 | ||
| US201361759986P | 2013-02-01 | 2013-02-01 | |
| US61/759,986 | 2013-02-01 | ||
| US201361830018P | 2013-05-31 | 2013-05-31 | |
| US61/830,018 | 2013-05-31 | ||
| US201361847057P | 2013-07-16 | 2013-07-16 | |
| US61/847,057 | 2013-07-16 | ||
| US201361865957P | 2013-08-14 | 2013-08-14 | |
| US61/865,957 | 2013-08-14 | ||
| US201361878536P | 2013-09-16 | 2013-09-16 | |
| US61/878,536 | 2013-09-16 | ||
| US201361879498P | 2013-09-18 | 2013-09-18 | |
| US61/879,498 | 2013-09-18 | ||
| US201361885456P | 2013-10-01 | 2013-10-01 | |
| US61/885,456 | 2013-10-01 | ||
| US201361887971P | 2013-10-07 | 2013-10-07 | |
| US61/887,971 | 2013-10-07 | ||
| US201361904398P | 2013-11-14 | 2013-11-14 | |
| US61/904,398 | 2013-11-14 |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US14/648,988 A-371-Of-International US20150307947A1 (en) | 2012-12-04 | 2013-12-04 | Molecular profiling for cancer |
| US16/597,061 Continuation US20200299774A1 (en) | 2012-12-04 | 2019-10-09 | Molecular profiling for cancer |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| WO2014089241A2 true WO2014089241A2 (en) | 2014-06-12 |
| WO2014089241A3 WO2014089241A3 (en) | 2014-08-28 |
| WO2014089241A9 WO2014089241A9 (en) | 2015-08-20 |
Family
ID=50884139
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2013/073184 WO2014089241A2 (en) | 2012-12-04 | 2013-12-04 | Molecular profiling for cancer |
Country Status (6)
| Country | Link |
|---|---|
| US (3) | US20150307947A1 (en) |
| EP (1) | EP2929350A4 (en) |
| AU (3) | AU2013355260B2 (en) |
| CA (1) | CA2893745A1 (en) |
| IL (1) | IL239147B (en) |
| WO (1) | WO2014089241A2 (en) |
Cited By (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9259399B2 (en) | 2007-11-07 | 2016-02-16 | Cornell University | Targeting CDK4 and CDK6 in cancer therapy |
| WO2016123515A1 (en) * | 2015-01-30 | 2016-08-04 | The Regents Of The University Of Michigan | Methods and biomarkers for detection and treatment of langerhans cell histiocytosis |
| WO2016145298A1 (en) * | 2015-03-12 | 2016-09-15 | The Regents Of The University Of California | METHODS FOR TREATING CANCER WITH RORgamma INHIBITORS |
| CN105950750A (en) * | 2016-06-08 | 2016-09-21 | 福州市传染病医院 | Genetic group and kit for liver cancer diagnosis and prognosis evaluation |
| WO2017046394A1 (en) * | 2015-09-17 | 2017-03-23 | Astrazeneca Ab | Novel biomarkers and methods of treating cancer |
| US9857328B2 (en) | 2014-12-18 | 2018-01-02 | Agilome, Inc. | Chemically-sensitive field effect transistors, systems and methods for manufacturing and using the same |
| US9859394B2 (en) | 2014-12-18 | 2018-01-02 | Agilome, Inc. | Graphene FET devices, systems, and methods of using the same for sequencing nucleic acids |
| US10006910B2 (en) | 2014-12-18 | 2018-06-26 | Agilome, Inc. | Chemically-sensitive field effect transistors, systems, and methods for manufacturing and using the same |
| US10020300B2 (en) | 2014-12-18 | 2018-07-10 | Agilome, Inc. | Graphene FET devices, systems, and methods of using the same for sequencing nucleic acids |
| WO2019178606A1 (en) | 2018-03-16 | 2019-09-19 | Gopath Laboratories Llc | Methods for personalized detection of the recurrence of cancer or metastasis and/or evaluation of treatment response |
| US10429342B2 (en) | 2014-12-18 | 2019-10-01 | Edico Genome Corporation | Chemically-sensitive field effect transistor |
| US10494670B2 (en) | 2014-12-18 | 2019-12-03 | Agilome, Inc. | Graphene FET devices, systems, and methods of using the same for sequencing nucleic acids |
| US10590425B2 (en) | 2015-06-29 | 2020-03-17 | Caris Science, Inc. | Therapeutic oligonucleotides |
| WO2020113237A1 (en) | 2018-11-30 | 2020-06-04 | Caris Mpi, Inc. | Next-generation molecular profiling |
| EP3510175A4 (en) * | 2016-09-08 | 2020-06-24 | Curematch, Inc. | Optimizing therapeutic options in personalized medicine |
| US10731166B2 (en) | 2016-03-18 | 2020-08-04 | Caris Science, Inc. | Oligonucleotide probes and uses thereof |
| US10811539B2 (en) | 2016-05-16 | 2020-10-20 | Nanomedical Diagnostics, Inc. | Graphene FET devices, systems, and methods of using the same for sequencing nucleic acids |
| CN111816315A (en) * | 2020-05-28 | 2020-10-23 | 上海生物信息技术研究中心 | Pancreatic duct cancer state evaluation model construction method and application |
| US10941176B2 (en) | 2015-07-28 | 2021-03-09 | Caris Science, Inc. | Therapeutic oligonucleotides |
| CN113454733A (en) * | 2019-03-12 | 2021-09-28 | 豪夫迈·罗氏有限公司 | Multi-instance learner for prognostic tissue pattern recognition |
| US11293017B2 (en) | 2016-05-25 | 2022-04-05 | Caris Science, Inc. | Oligonucleotide probes and uses thereof |
| US11320436B2 (en) | 2020-07-16 | 2022-05-03 | Immunovia Ab | Methods, arrays and uses thereof |
| US11515004B2 (en) | 2015-05-22 | 2022-11-29 | Csts Health Care Inc. | Thermodynamic measures on protein-protein interaction networks for cancer therapy |
| US11525832B2 (en) | 2007-03-27 | 2022-12-13 | Immunovia Ab | Protein signature/markers for the detection of adenocarcinoma |
| US11842805B2 (en) | 2019-12-02 | 2023-12-12 | Caris Mpi, Inc. | Pan-cancer platinum response predictor |
| WO2024137798A1 (en) * | 2022-12-20 | 2024-06-27 | Mayo Foundation For Medical Education And Research | Compositions and methods for detecting esophageal cancer |
Families Citing this family (48)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8338109B2 (en) | 2006-11-02 | 2012-12-25 | Mayo Foundation For Medical Education And Research | Predicting cancer outcome |
| EP2806054A1 (en) | 2008-05-28 | 2014-11-26 | Genomedx Biosciences Inc. | Systems and methods for expression-based discrimination of distinct clinical disease states in prostate cancer |
| US10407731B2 (en) | 2008-05-30 | 2019-09-10 | Mayo Foundation For Medical Education And Research | Biomarker panels for predicting prostate cancer outcomes |
| US9495515B1 (en) | 2009-12-09 | 2016-11-15 | Veracyte, Inc. | Algorithms for disease diagnostics |
| US10236078B2 (en) | 2008-11-17 | 2019-03-19 | Veracyte, Inc. | Methods for processing or analyzing a sample of thyroid tissue |
| US9074258B2 (en) | 2009-03-04 | 2015-07-07 | Genomedx Biosciences Inc. | Compositions and methods for classifying thyroid nodule disease |
| WO2010129934A2 (en) | 2009-05-07 | 2010-11-11 | Veracyte, Inc. | Methods and compositions for diagnosis of thyroid conditions |
| US10446272B2 (en) | 2009-12-09 | 2019-10-15 | Veracyte, Inc. | Methods and compositions for classification of samples |
| CN110016499B (en) | 2011-04-15 | 2023-11-14 | 约翰·霍普金斯大学 | Safety sequencing system |
| US10513737B2 (en) | 2011-12-13 | 2019-12-24 | Decipher Biosciences, Inc. | Cancer diagnostics using non-coding transcripts |
| DK3435084T3 (en) | 2012-08-16 | 2023-05-30 | Mayo Found Medical Education & Res | PROSTATE CANCER PROGNOSIS USING BIOMARKERS |
| ES2701742T3 (en) | 2012-10-29 | 2019-02-25 | Univ Johns Hopkins | Papanicolaou test for ovarian and endometrial cancers |
| EP3626308A1 (en) | 2013-03-14 | 2020-03-25 | Veracyte, Inc. | Methods for evaluating copd status |
| US11976329B2 (en) | 2013-03-15 | 2024-05-07 | Veracyte, Inc. | Methods and systems for detecting usual interstitial pneumonia |
| AU2014290044B2 (en) * | 2013-07-17 | 2020-10-29 | Foundation Medicine, Inc. | Methods of treating urothelial carcinomas |
| JPWO2015079647A1 (en) * | 2013-11-28 | 2017-03-16 | 日本電気株式会社 | Information processing apparatus and information processing method |
| CA2951514A1 (en) | 2014-06-18 | 2015-12-23 | Clear Gene, Inc. | Methods, compositions, and devices for rapid analysis of biological markers |
| US11091810B2 (en) * | 2015-01-27 | 2021-08-17 | BioSpyder Technologies, Inc. | Focal gene expression profiling of stained FFPE tissues with spatial correlation to morphology |
| EP3770274A1 (en) | 2014-11-05 | 2021-01-27 | Veracyte, Inc. | Systems and methods of diagnosing idiopathic pulmonary fibrosis on transbronchial biopsies using machine learning and high dimensional transcriptional data |
| WO2017027653A1 (en) | 2015-08-11 | 2017-02-16 | The Johns Hopkins University | Assaying ovarian cyst fluid |
| AU2016321204B2 (en) | 2015-09-08 | 2022-12-01 | Cold Spring Harbor Laboratory | Genetic copy number determination using high throughput multiplex sequencing of smashed nucleotides |
| US10823738B2 (en) * | 2015-12-07 | 2020-11-03 | George Mason Research Foundation, Inc. | Methods for breast cancer treatment |
| US11401558B2 (en) | 2015-12-18 | 2022-08-02 | Clear Gene, Inc. | Methods, compositions, kits and devices for rapid analysis of biological markers |
| US10431331B1 (en) * | 2016-02-28 | 2019-10-01 | Allscripts Software, Llc | Computer-executable application that is configured to process cross-clinical genomics data |
| EP3791897A1 (en) * | 2016-02-29 | 2021-03-17 | Madrigal Pharmaceuticals, Inc. | Hsp90 inhibitor drug conjugates |
| WO2017185062A1 (en) * | 2016-04-22 | 2017-10-26 | University Of Southern California | Predictive biomarkers for tas-102 efficacy |
| WO2017189647A1 (en) * | 2016-04-26 | 2017-11-02 | Memorial Sloan Kettering Cancer Center | Methods and compositions for the treatment of myelodysplastic syndrome |
| EP3504348B1 (en) | 2016-08-24 | 2022-12-14 | Decipher Biosciences, Inc. | Use of genomic signatures to predict responsiveness of patients with prostate cancer to post-operative radiation therapy |
| CU20190051A7 (en) | 2016-11-17 | 2020-01-03 | Univ Texas | COMPOUNDS WITH ANTITUMOR ACTIVITY AGAINST CANCER CELLS THAT HAVE MUTATIONS IN EXON 20 OF EGFR OR HER2 |
| US11873532B2 (en) | 2017-03-09 | 2024-01-16 | Decipher Biosciences, Inc. | Subtyping prostate cancer to predict response to hormone therapy |
| WO2018205035A1 (en) | 2017-05-12 | 2018-11-15 | Genomedx Biosciences, Inc | Genetic signatures to predict prostate cancer metastasis and identify tumor agressiveness |
| US20220205043A1 (en) * | 2017-06-02 | 2022-06-30 | Myriad Genetics, Inc. | Detecting cancer risk |
| US11217329B1 (en) | 2017-06-23 | 2022-01-04 | Veracyte, Inc. | Methods and systems for determining biological sample integrity |
| WO2019067092A1 (en) | 2017-08-07 | 2019-04-04 | The Johns Hopkins University | Methods and materials for assessing and treating cancer |
| KR20200041387A (en) * | 2017-09-08 | 2020-04-21 | 에프. 호프만-라 로슈 아게 | How to diagnose and treat cancer |
| WO2019133752A1 (en) * | 2017-12-28 | 2019-07-04 | Development Center For Biotechnology | A method for predicting drug efficacy |
| WO2019199684A1 (en) * | 2018-04-09 | 2019-10-17 | The Regents Of The University Of Michigan | Methods and systems for biocellular marker detection and diagnosis using a microfluidic profiling device |
| US11042699B1 (en) * | 2019-01-29 | 2021-06-22 | Massachusetts Mutual Life Insurance Company | Systems, devices, and methods for software coding |
| TWI798532B (en) * | 2019-03-25 | 2023-04-11 | 大陸商深圳微芯生物科技股份有限公司 | Use of kdm5a gene and atrx gene |
| US11049590B1 (en) | 2020-02-12 | 2021-06-29 | Peptilogics, Inc. | Artificial intelligence engine architecture for generating candidate drugs |
| US20210358571A1 (en) * | 2020-05-13 | 2021-11-18 | Tempus Labs, Inc. | Systems and methods for predicting pathogenic status of fusion candidates detected in next generation sequencing data |
| US20220059196A1 (en) * | 2020-08-24 | 2022-02-24 | Peptilogics, Inc. | Artificial intelligence engine for generating candidate drugs using experimental validation and peptide drug optimization |
| TW202309094A (en) * | 2021-05-18 | 2023-03-01 | 美商健生生物科技公司 | Methods for identifying cancer patients for combination treatment |
| EP4399330A1 (en) * | 2021-09-10 | 2024-07-17 | Foundation Medicine, Inc. | Gene fusions in sarcoma |
| WO2023108140A1 (en) * | 2021-12-09 | 2023-06-15 | Endeavor Biomedicines, Inc. | Method of treating cancer having an activated hedgehog pathway |
| CN114438218B (en) * | 2022-04-01 | 2022-08-09 | 普瑞基准科技(北京)有限公司 | Gene Panel for detecting various tumors, kit and application |
| WO2023235822A1 (en) * | 2022-06-03 | 2023-12-07 | Foundation Medicine, Inc. | Igf1r activation mutations and uses thereof |
| CN116381237B (en) * | 2023-02-28 | 2024-06-11 | 杭州凯保罗生物科技有限公司 | Early thyroid cancer prediction system and application thereof |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2003082072A2 (en) * | 2002-02-13 | 2003-10-09 | Nadia Harbeck | Methods for selecting treatment regimens and predicting outcomes in cancer patients |
| US20100144836A1 (en) * | 2007-01-09 | 2010-06-10 | Oncomethylome Sciences Sa | Methods for Detecting Epigenetic Modifications |
| WO2010123982A2 (en) * | 2009-04-21 | 2010-10-28 | Fox Chase Cancer Center | Gene expression signatures associated with response to imatinib mesylate in gastrointestinal stromal tumors and use thereof for predicting patient response to therapy and identification of agents which have efficacy for the treatment of cancer |
| WO2012092336A2 (en) * | 2010-12-28 | 2012-07-05 | Caris Mpi, Inc. | Molecular profiling for cancer |
| WO2012170715A1 (en) * | 2011-06-07 | 2012-12-13 | Caris Mpi, Inc. | Molecular profiling for cancer |
| US20140018254A1 (en) * | 2008-09-16 | 2014-01-16 | Caris Mpi, Inc. | Theranostic and diagnostic methods using sparc and hsp90 |
-
2013
- 2013-12-04 EP EP13860539.9A patent/EP2929350A4/en not_active Ceased
- 2013-12-04 WO PCT/US2013/073184 patent/WO2014089241A2/en active Application Filing
- 2013-12-04 US US14/648,988 patent/US20150307947A1/en not_active Abandoned
- 2013-12-04 AU AU2013355260A patent/AU2013355260B2/en active Active
- 2013-12-04 CA CA2893745A patent/CA2893745A1/en not_active Abandoned
-
2015
- 2015-06-02 IL IL239147A patent/IL239147B/en active IP Right Grant
-
2019
- 2019-10-09 US US16/597,061 patent/US20200299774A1/en not_active Abandoned
- 2019-10-14 AU AU2019250106A patent/AU2019250106A1/en not_active Abandoned
-
2020
- 2020-06-15 US US16/902,164 patent/US20210062269A1/en not_active Abandoned
-
2022
- 2022-02-07 AU AU2022200781A patent/AU2022200781A1/en not_active Abandoned
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2003082072A2 (en) * | 2002-02-13 | 2003-10-09 | Nadia Harbeck | Methods for selecting treatment regimens and predicting outcomes in cancer patients |
| US20100144836A1 (en) * | 2007-01-09 | 2010-06-10 | Oncomethylome Sciences Sa | Methods for Detecting Epigenetic Modifications |
| US20140018254A1 (en) * | 2008-09-16 | 2014-01-16 | Caris Mpi, Inc. | Theranostic and diagnostic methods using sparc and hsp90 |
| WO2010123982A2 (en) * | 2009-04-21 | 2010-10-28 | Fox Chase Cancer Center | Gene expression signatures associated with response to imatinib mesylate in gastrointestinal stromal tumors and use thereof for predicting patient response to therapy and identification of agents which have efficacy for the treatment of cancer |
| WO2012092336A2 (en) * | 2010-12-28 | 2012-07-05 | Caris Mpi, Inc. | Molecular profiling for cancer |
| WO2012170715A1 (en) * | 2011-06-07 | 2012-12-13 | Caris Mpi, Inc. | Molecular profiling for cancer |
Cited By (40)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11525832B2 (en) | 2007-03-27 | 2022-12-13 | Immunovia Ab | Protein signature/markers for the detection of adenocarcinoma |
| US9259399B2 (en) | 2007-11-07 | 2016-02-16 | Cornell University | Targeting CDK4 and CDK6 in cancer therapy |
| US9859394B2 (en) | 2014-12-18 | 2018-01-02 | Agilome, Inc. | Graphene FET devices, systems, and methods of using the same for sequencing nucleic acids |
| US9857328B2 (en) | 2014-12-18 | 2018-01-02 | Agilome, Inc. | Chemically-sensitive field effect transistors, systems and methods for manufacturing and using the same |
| US10607989B2 (en) | 2014-12-18 | 2020-03-31 | Nanomedical Diagnostics, Inc. | Graphene FET devices, systems, and methods of using the same for sequencing nucleic acids |
| US10006910B2 (en) | 2014-12-18 | 2018-06-26 | Agilome, Inc. | Chemically-sensitive field effect transistors, systems, and methods for manufacturing and using the same |
| US10020300B2 (en) | 2014-12-18 | 2018-07-10 | Agilome, Inc. | Graphene FET devices, systems, and methods of using the same for sequencing nucleic acids |
| US10429381B2 (en) | 2014-12-18 | 2019-10-01 | Agilome, Inc. | Chemically-sensitive field effect transistors, systems, and methods for manufacturing and using the same |
| US10429342B2 (en) | 2014-12-18 | 2019-10-01 | Edico Genome Corporation | Chemically-sensitive field effect transistor |
| US10494670B2 (en) | 2014-12-18 | 2019-12-03 | Agilome, Inc. | Graphene FET devices, systems, and methods of using the same for sequencing nucleic acids |
| WO2016123515A1 (en) * | 2015-01-30 | 2016-08-04 | The Regents Of The University Of Michigan | Methods and biomarkers for detection and treatment of langerhans cell histiocytosis |
| WO2016145298A1 (en) * | 2015-03-12 | 2016-09-15 | The Regents Of The University Of California | METHODS FOR TREATING CANCER WITH RORgamma INHIBITORS |
| US10959984B2 (en) | 2015-03-12 | 2021-03-30 | The Regents Of The University Of California | Methods for treating cancer with RORγ inhibitors |
| US11515004B2 (en) | 2015-05-22 | 2022-11-29 | Csts Health Care Inc. | Thermodynamic measures on protein-protein interaction networks for cancer therapy |
| US10590425B2 (en) | 2015-06-29 | 2020-03-17 | Caris Science, Inc. | Therapeutic oligonucleotides |
| US11091765B2 (en) | 2015-06-29 | 2021-08-17 | Caris Science, Inc. | Therapeutic oligonucleotides |
| US10941176B2 (en) | 2015-07-28 | 2021-03-09 | Caris Science, Inc. | Therapeutic oligonucleotides |
| US11725023B2 (en) | 2015-07-28 | 2023-08-15 | Caris Science, Inc. | Therapeutic oligonucleotides |
| US11685953B2 (en) | 2015-09-17 | 2023-06-27 | Astrazeneca Ab | Biomarkers and methods of treating cancer |
| WO2017046394A1 (en) * | 2015-09-17 | 2017-03-23 | Astrazeneca Ab | Novel biomarkers and methods of treating cancer |
| US10731166B2 (en) | 2016-03-18 | 2020-08-04 | Caris Science, Inc. | Oligonucleotide probes and uses thereof |
| US11332748B2 (en) | 2016-03-18 | 2022-05-17 | Caris Science, Inc. | Oligonucleotide probes and uses thereof |
| US10811539B2 (en) | 2016-05-16 | 2020-10-20 | Nanomedical Diagnostics, Inc. | Graphene FET devices, systems, and methods of using the same for sequencing nucleic acids |
| US11293017B2 (en) | 2016-05-25 | 2022-04-05 | Caris Science, Inc. | Oligonucleotide probes and uses thereof |
| CN105950750A (en) * | 2016-06-08 | 2016-09-21 | 福州市传染病医院 | Genetic group and kit for liver cancer diagnosis and prognosis evaluation |
| EP3510175A4 (en) * | 2016-09-08 | 2020-06-24 | Curematch, Inc. | Optimizing therapeutic options in personalized medicine |
| US11434534B2 (en) | 2016-09-08 | 2022-09-06 | Curematch, Inc. | Optimizing therapeutic options in personalized medicine |
| EP3752604A4 (en) * | 2018-03-16 | 2021-04-21 | Gopath Laboratories LLC | Methods for personalized detection of the recurrence of cancer or metastasis and/or evaluation of treatment response |
| WO2019178606A1 (en) | 2018-03-16 | 2019-09-19 | Gopath Laboratories Llc | Methods for personalized detection of the recurrence of cancer or metastasis and/or evaluation of treatment response |
| EP4369356A2 (en) | 2018-11-30 | 2024-05-15 | Caris MPI, Inc. | Next-generation molecular profiling |
| US11315673B2 (en) | 2018-11-30 | 2022-04-26 | Caris Mpi, Inc. | Next-generation molecular profiling |
| WO2020113237A1 (en) | 2018-11-30 | 2020-06-04 | Caris Mpi, Inc. | Next-generation molecular profiling |
| CN113454733A (en) * | 2019-03-12 | 2021-09-28 | 豪夫迈·罗氏有限公司 | Multi-instance learner for prognostic tissue pattern recognition |
| US11901077B2 (en) | 2019-03-12 | 2024-02-13 | Hoffmann-La Roche Inc. | Multiple instance learner for prognostic tissue pattern identification |
| CN113454733B (en) * | 2019-03-12 | 2024-04-05 | 豪夫迈·罗氏有限公司 | Multi-instance learner for prognostic tissue pattern recognition |
| US11842805B2 (en) | 2019-12-02 | 2023-12-12 | Caris Mpi, Inc. | Pan-cancer platinum response predictor |
| CN111816315B (en) * | 2020-05-28 | 2023-10-13 | 上海市生物医药技术研究院 | Pancreatic duct cancer state assessment model construction method and application |
| CN111816315A (en) * | 2020-05-28 | 2020-10-23 | 上海生物信息技术研究中心 | Pancreatic duct cancer state evaluation model construction method and application |
| US11320436B2 (en) | 2020-07-16 | 2022-05-03 | Immunovia Ab | Methods, arrays and uses thereof |
| WO2024137798A1 (en) * | 2022-12-20 | 2024-06-27 | Mayo Foundation For Medical Education And Research | Compositions and methods for detecting esophageal cancer |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2019250106A1 (en) | 2019-10-31 |
| AU2013355260B2 (en) | 2019-07-25 |
| EP2929350A4 (en) | 2016-11-16 |
| IL239147A0 (en) | 2015-07-30 |
| EP2929350A2 (en) | 2015-10-14 |
| US20210062269A1 (en) | 2021-03-04 |
| US20200299774A1 (en) | 2020-09-24 |
| US20150307947A1 (en) | 2015-10-29 |
| WO2014089241A9 (en) | 2015-08-20 |
| WO2014089241A3 (en) | 2014-08-28 |
| IL239147B (en) | 2020-03-31 |
| CA2893745A1 (en) | 2014-06-12 |
| AU2013355260A1 (en) | 2014-06-12 |
| AU2022200781A1 (en) | 2022-02-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20210062269A1 (en) | Databases, data structures, data processing systems, and computer programs for identifying a candidate treatment | |
| US20210263034A1 (en) | Data processing system for identifying a therapeutic agent | |
| US20190330700A1 (en) | Molecular Profiling of Immune Modulators | |
| AU2010315400B2 (en) | Molecular profiling for personalized medicine | |
| US20170039328A1 (en) | Molecular profiling for cancer | |
| EP3301446B1 (en) | Molecular profiling of tumors | |
| US20170228522A1 (en) | Molecular profiling of tumors | |
| US20150024952A1 (en) | Molecular profiling for cancer | |
| WO2018175501A1 (en) | Genomic stability profiling | |
| US20230123908A1 (en) | Molecular profiling of tumors | |
| AU2018240195B2 (en) | Genomic stability profiling |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 13860539 Country of ref document: EP Kind code of ref document: A2 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 239147 Country of ref document: IL Ref document number: 14648988 Country of ref document: US |
|
| ENP | Entry into the national phase |
Ref document number: 2893745 Country of ref document: CA |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2013860539 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: 2013355260 Country of ref document: AU Date of ref document: 20131204 Kind code of ref document: A |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 13860539 Country of ref document: EP Kind code of ref document: A2 |