WO2013129580A1 - 近似最近傍探索装置、近似最近傍探索方法およびそのプログラム - Google Patents
近似最近傍探索装置、近似最近傍探索方法およびそのプログラム Download PDFInfo
- Publication number
- WO2013129580A1 WO2013129580A1 PCT/JP2013/055440 JP2013055440W WO2013129580A1 WO 2013129580 A1 WO2013129580 A1 WO 2013129580A1 JP 2013055440 W JP2013055440 W JP 2013055440W WO 2013129580 A1 WO2013129580 A1 WO 2013129580A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- query
- point
- distance
- search
- hash
- Prior art date
Links
Images


























Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/50—Information retrieval; Database structures therefor; File system structures therefor of still image data
- G06F16/58—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
- G06F16/583—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content
Definitions
- the present invention relates to an approximate nearest neighbor search apparatus, an approximate nearest neighbor search method, and a program thereof, and more specifically, an approximate nearest neighbor search apparatus, an approximate nearest neighbor search method, and an approximate nearest neighbor using fast distance estimation by hashing with a codebook. It relates to a search program.
- Nearest neighbor search is a method of searching data (points) that are most similar to a query, that is, the data having the shortest distance (nearest point) from data (points) expressed by vectors.
- Nearest neighbor search is a basic and effective technique for processing large-scale data, and because it is basic, it has a wide range of applicability to excellent methods. Even those that the inventors are involved in can be applied to object recognition (for example, see Non-Patent Document 1), document image search (for example, Non-Patent Document 2), character recognition (for example, Non-Patent Document 3) and Face recognition (for example, refer nonpatent literature 4) can be mentioned. Both have been shown to operate very fast on relatively large amounts of data.
- the above-mentioned technique can be said to be an image recognition technique in a broad sense, but the application field of nearest neighbor search is not limited to that, but extends to statistical classification, code logic, data compression, recommendation system, spell checker, and the like. Considering practical applications, the nearest neighbor search requires high speed. If the speed increases, it will be possible to process a larger amount of data in the same time than before, and it will be possible to use it for applications that have been given up in the past due to processing time constraints.
- the approximate nearest neighbor search is a technique that can significantly reduce the processing time by introducing an approximation to the nearest neighbor search and allowing a search error. Since a search error occurs, there is no guarantee that the true nearest neighbor will be found, but it is used for applications that only need to have a certain degree of search accuracy. Improvement in search accuracy and speeding up are conflicting requirements, and it is generally not easy to satisfy both at the same time.
- Kise "Memory-based recognition of camera-captured characters," Proceedings of the 9th IAPR International Works on Document Analysis Systems (DAS2010), pp.89-96, June 2010. Keisuke Maekawa, Yuzuko Utsumi, Masakazu Iwamura, Koichi Kise, “Realization of Matching in 1 Million Face Image Database in 34 ms -Large-scale Fast Face Image Search Using Approximate Nearest Neighbor Search-”, IEICE Technology Research report, vol.111, no.353, pp.95-100, Dec. 2011. S. Arya, DM Mount, NS photographer, R.
- the approximate nearest neighbor search indexing is performed by dividing the data space into a number of regions in advance.
- the present invention particularly relates to a technique using a hash.
- the data space is basically linearly divided along a plurality of axes, and data is registered in a hash table for each divided area (bin). Then, a high-speed search is realized by extracting from the hash table the points that have entered the query area or its neighboring areas, and obtaining the nearest neighbors from the extracted points.
- a bin product area (bucket) is a unit of division.
- the approximate nearest neighbor search is composed of two steps.
- a bin or bucket having a high probability of including the nearest point is specified.
- a point belonging to this point is called a nearest neighbor candidate.
- the point having the smallest distance from the query is calculated.
- the “approximate” element is included only in the first step. Therefore, this processing affects the search accuracy and processing time of the approximate nearest neighbor search.
- the processing time required for the distance calculation is greatly reduced by limiting the distance calculation target to the nearest neighbor candidate.
- this is a double-edged sword, and although the speed can be increased by reducing the number of nearest neighbor candidates, the search accuracy decreases. This is because the true nearest neighbor point leaks from the nearest neighbor candidate and the probability of failure in nearest neighbor search increases. Therefore, what is required in the first-stage processing is that the true nearest neighbor point is not leaked while the number of nearest neighbor candidates is reduced. Moreover, it is necessary to select the nearest neighbor candidate at high speed.
- the policy taken by the inventors to satisfy these requirements is to use the same distance measure used in the second stage when selecting the nearest neighbor candidates. Thereby, even if the number of nearest neighbor candidates is reduced, the probability that a true nearest neighbor point is included in the nearest neighbors is difficult to decrease. However, such processing usually requires a large calculation cost.
- an approximate nearest neighbor search method capable of executing the above-described processing at high speed is desired.
- the present invention has been made in view of the above circumstances, and provides a new approximate nearest neighbor search method that combines high search accuracy and high speed by appropriately narrowing down the nearest neighbor candidates. Is.
- a hash index for each point is calculated by applying a hash function for calculating the index of the multidimensional hash table, and a plurality of points are calculated by bins of the multidimensional hash table.
- a hash index is calculated by applying a hash function to each point, and multiple points divided into a plurality of regions by an orthonormal basis are obtained.
- a database storage unit in which each point is registered in a multidimensional hash table by projecting each point to an area corresponding to the index in the dimensional space, and when the query is input, the hash function is applied to the query.
- a search range in which a position of the query in the space is determined, an estimated value of a distance between the query and each area in the space is determined, and one or more areas are determined as search areas based on the estimated value
- a determination unit and a nearest point determination unit that calculates a distance between each point in the search area and the query, and calculates a point closest to the query as a nearest neighbor point of the query.
- Search range determining unit the position of the representative point representing the area determined with reference to the index of a region in which each point belongs and provides the approximate nearest neighbor searching and wherein the
- the present invention applies a hash function for calculating an index of a multidimensional hash table when a plurality of points represented by vector data are input, and calculates a hash index for each point.
- Each point is stored in the multidimensional hash table by calculating and projecting each point to an area corresponding to the hash index in the multidimensional space divided into a plurality of areas by bins of the multidimensional hash table Accessing the database storage, and when a query is input, applying the hash function to the query to determine the position of the query in the space, and determining the distance between the query and each region in the space
- a search range determination process for determining an estimated value and determining at least one area to be searched based on the estimated value.
- the search range determining step refers to an index of each area to obtain a position of a representative point representing the area, and estimates the difference between the position of the query and the position of each representative point Provided is an approximate nearest neighbor search method characterized by a value.
- the present invention calculates a hash index for each point by applying a hash function for calculating an index of a multidimensional hash table when a plurality of points represented by vector data are input.
- Access the database storage unit that stores each point in the multidimensional hash table by projecting each point to the area corresponding to the hash index in the multidimensional space divided into multiple areas by the bin of the multidimensional hash table
- the hash function is applied to the query to determine the position of the query in the space, and an estimate of the distance between the query and each region in the space is determined.
- Processing as a search range determination unit for determining at least one region to be searched based on the estimated value, and the search The distance between each point in the power region and the query is calculated, and the computer is caused to execute processing as a nearest neighbor point determination unit that calculates the closest point to the query as the nearest neighbor point of the query.
- a representative point of the region is obtained with reference to the index of the region, the estimated value is determined based on a distance between the query and each representative point, and the region to be searched cannot be applied by applying a branch and bound method.
- Provided is an approximate nearest neighbor search program characterized in that a region to be searched is determined by excluding a region.
- the program product is provided. The inventions from the above three viewpoints are all related to the description of “first improvement: hash-based point-to-bucket distance estimation” in the embodiments described later.
- the search range determining unit refers to the index of each region to obtain a representative point of that region, and determines the estimated value based on the distance between the query and each representative point. Therefore, without calculating the distance between the query and each region, the estimated value is determined using the index, the region to be searched (search region) is determined based on the estimated value, and the nearest neighbor determining unit determines the distance.
- the points to be calculated can be narrowed down.
- the method of the present invention that estimates the point-to-bucket distance can improve the accuracy of distance estimation with the same data structure.
- the branch and bound method is applied to exclude regions that cannot be search regions, so that the search regions can be determined in a short time.
- individual data registered in the database and data of a query (search question) used for searching the database are expressed as at least one point.
- Each point has an attribute indicating the characteristics of the data or query, and the attribute is expressed by vector data.
- Hashing is a well-known method for retrieving data at high speed on a memory.
- the hash function receives a vector data and outputs a scalar value.
- the scalar value is a discrete value used to refer to a hash table that is a kind of data table, and is called a hash value, a hash index, or simply an index. It can be said that the hash function divides the output space by the discrete values that the index can take.
- a hash function can also be said to project vector data (points) as an input into an output multidimensional space.
- each vector data is projected into a multidimensional space.
- ⁇ hash functions are used to project vector data onto a vector space of ⁇ dimension ( ⁇ is an integer of 2 or more), for example.
- ⁇ is an integer of 2 or more
- Each point is composed of ⁇ bases by applying ⁇ hash functions, is divided into a plurality of bins along each base, and any bin is specified by the index of each hash function Projected into space. Since the registration of each point in each bin is represented using a hash table, there are ⁇ hash tables ( ⁇ dimensions). However, a single hash function may be used by combining several dimensions. In this case, there are fewer than ⁇ hash tables.
- the approximate nearest neighbor search method according to the present invention can be applied to object recognition, document image search, character recognition, face recognition, statistical classification, code logic, data compression, recommendation system, spell checker, and the like.
- the 2nd graph which shows the relationship between the precision in the optimal parameter, and processing time compared with the conventional method.
- it is explanatory drawing which shows the example of the division
- it is explanatory drawing which shows a mode that a search radius is changed according to the density of a query periphery.
- It is a graph which shows the accuracy of distance estimation by BDH and k-means BDH of the present invention in comparison with SH of the conventional method with the horizontal axis as the code length and the vertical axis as the correlation coefficient.
- BDH it is a graph which shows the average rank of the nearest point in the distance on a hash when code length is changed compared with SH of a conventional method.
- this invention is a graph which shows the relationship between the search precision of k-means
- it is a graph which shows the relationship between the parameter c regarding the number of nearest neighbor candidates, and processing time.
- it is a figure which shows two algorithms which identify the bucket within the search radius R at high speed.
- each point is registered in each of M sets of multidimensional hash tables corresponding to each hash function group using M sets (M is a natural number of 2 or more) of hash functions.
- the function group may be a combination of a plurality of hash functions. In this way, for example, when ⁇ hash functions ( ⁇ > M) are divided into one hash function group without being divided, if the number of bins in each hash table is s, it corresponds to s bins. Since it is necessary to prepare ⁇ sets of data storage areas, the order of the hash table size is O (s ⁇ ).
- O (s ⁇ / M ) is a notation method of an approximate calculation amount necessary for solving the problem, and the calculation amount when s is determined is the order of s to the ⁇ power, that is, as ⁇ + bs ( ⁇ ⁇ 1). + ... + ls 2 + ms + n or less.
- a, b,..., L, m, and n are constants. This aspect is related to the description of “second improvement: hash table division” in an embodiment described later.
- the M sets of hash tables may be defined so that the number of dimensions of each hash is substantially equal.
- the basis selection method at this time may be determined so that the sum of the variances of the basis is substantially equal.
- the sum of the variances of the data in the respective base directions and the basis of each set of hash tables divided so that the sum of the variances is as equal as possible. Determine the assignment.
- the distance in the base direction having a large variance tends to be large, and the distance in the base direction having a small dispersion tends to be small. Therefore, summing the sum of the variances of the hash tables has the effect of aligning the distances calculated for each hash table.
- the search radius R used for selection of the distance calculation target or censoring of the distance calculation (processing for replacing the distance with a constant value when the distance calculation target point does not exist in the search range) as in the embodiment of the present specification. If the tables are shared, it is considered that each hash table divided into M sets contributes to the determination of the nearest neighbor candidates by equalizing the sum of the variance of each hash table. It is not necessary to set a parameter instead of R, and the calculation can be performed easily. This aspect is related to the description of “second improvement: hash table division” in an embodiment described later.
- the multi-dimensional hash table is a combination of hash tables corresponding to each dimension.
- Each hash table divides a base corresponding to each dimension into bins, and each bin has a uniform width.
- the position error between the point that will be registered in each bin and the representative point that represents each bin is obtained for each bin, and the width of each bin is adjusted so that the sum of these errors becomes smaller May be.
- the processing time of distance calculation with each point in the search area varies depending on the number of data registered in the bucket of the search area. This variation can be suppressed.
- This aspect relates to the description of “third improvement: division of data space suitable for distance estimation” in an embodiment described later.
- each hash table calculates the representative point for each cluster by clustering each point into predetermined n clusters, and represents the average distance from each point belonging to each cluster to the representative point of that cluster.
- the width of each bin may be determined so that the variance is smaller than a predetermined threshold. In this way, by determining the width of each bin so that the variance of each point in the bin is equal to or less than the threshold, the number of points registered in each bin can be leveled within an appropriate range.
- This aspect relates to the description of “third improvement: division of data space suitable for distance estimation” in an embodiment described later.
- the search range determination unit may determine a probability density function from the distribution of vector data in each base direction, and determine the estimated value using the probability density function for weighting the distance. In this way, appropriate leveling is possible even for complex distributions by using the probability density function.
- This aspect relates to the description of “fourth improvement: distance estimation based on probability density function” in an embodiment described later.
- the search range determination unit may set a region having a representative point within a range of a search radius R determined in advance centering on a query as the search region. In this way, the search area can be determined by setting the search radius R in advance.
- This aspect is related to the description of “fifth improvement: expansion of search radius considering data density around query” in an embodiment described later.
- the search range determination unit searches a region having a representative point within the range of the search radius R around the query as the search region, and searches until the number of points included in the search region reaches a predetermined number
- the radius R may be gradually increased.
- the number of points included in the search area that is, the number of candidates for the nearest neighbor point
- the processing time required for calculating the distance to each point in the search area can be made substantially constant. This aspect is related to the description of “fifth improvement: expansion of search radius considering data density around query” in an embodiment described later.
- the database storage unit projects each point in a ⁇ -dimensional space in which the basis is determined by principal component analysis
- the search range determination unit is configured to determine the distance between the query and each representative point in each base direction.
- Each distance component is calculated as the estimated value, and in the course of calculating each distance component, a constraint condition is that the sum of the distance components is within a determined search radius R, and a large eigenvalue is calculated in the principal component analysis.
- the search area may be determined by pruning an area that cannot be the search area by applying a branch and bound method that determines whether the representative point of each area is within the radius R in the order of the bases.
- the search area can be determined in a short time.
- This aspect is related to the description of “first improvement: point-to-bucket distance estimation based on hash” in an embodiment described later.
- the database storage unit calculates ⁇ indexes by applying ⁇ ( ⁇ is an integer of 2 or more) hash functions to each point, and is composed of ⁇ bases. It is generated by projecting each point into a ⁇ -dimensional space that is divided into bins and each bin is specified by each index, and the registration of each point in each bin is represented using a hash table. May be. This aspect is related to the description of “first improvement: point-to-bucket distance estimation based on hash” in an embodiment described later.
- the database storage unit projects each point in a ⁇ -dimensional space, and the multi-dimensional hash table selects M sets of subspaces spanned by P orthogonal bases among ⁇ orthogonal bases spanning the ⁇ -dimensional space.
- the subspace is divided into subspaces using the k-means method, and the subspace having a larger variance in each region is set to have a larger number of divisions.
- the estimated value may be determined so that an estimation error of a square distance between a point existing in each region and a query is minimized in each base direction according to a probability density function obtained from the distribution of vector data in the direction of .
- This aspect relates to the description of “sixth improvement” in the embodiment described later.
- Preferred embodiments of the present invention include combinations of any of the plurality of embodiments shown here.
- FIG. 20 is a block diagram showing an image recognition apparatus as an application example of the approximate nearest neighbor search apparatus of the present invention.
- the approximate nearest neighbor search according to the present invention is realized by the computer processing image data using hardware resources such as a storage device on the image recognition apparatus shown in FIG.
- the hardware of the image recognition apparatus includes, for example, a CPU, a storage device such as a hard disk device storing a program indicating a processing procedure executed by the CPU, a RAM that provides a work area to the CPU, and an input / output that inputs and outputs data. It consists of a circuit. More specifically, the image recognition apparatus may be realized by a personal computer having the above configuration. Or it may be comprised from the microcomputer which is integrated in an apparatus and has the said structure.
- the feature point extraction unit 11 is a block that extracts a feature vector from a pattern of an object included in input image data using a known method.
- a feature vector represents a local feature of an image, and a plurality of feature vectors each representing a plurality of local features are extracted from one image.
- the CPU When registering image data in the image database 15, the CPU attaches an image ID for identifying the image and stores it in the image database 15, and further associates a feature vector extracted from the image with the image ID in a hash table.
- Register at 15h Specifically, the hash function is applied to classify each feature vector into one of a plurality of bins and register the bins in the bins. That is, an index is calculated by applying a hash function to each feature vector, and an image database 15 in which each feature vector is registered in a bin or bucket corresponding to the index is created.
- the hash function used at the time of registration is the same as the hash function used by the search range determination unit 13 for calculating the index.
- the image recognition apparatus selects the image closest to the query image from among the images stored in the image database 15. Is output as a recognition result.
- the search for the closest image is realized by comparing feature vectors and searching for the nearest vector for each feature vector of the query. An approximate nearest neighbor search is applied to this nearest neighbor vector search.
- the CPU as the feature point extraction unit 11 extracts a feature vector from the query.
- the extracted feature vector is called a query vector
- the feature vector registered in the hash table 15h is called a reference vector.
- the CPU obtains an index by applying the hash function described above to each query vector. Then, the CPU refers to the bin of the hash table 15h specified by the obtained index, and sets the reference vector registered in the bin as the nearest candidate for the query vector.
- the process of applying a hash function to a query vector to refer to a bin and using the reference vector registered in the bin as the nearest neighbor candidate corresponds to the first stage process of the approximate nearest neighbor search.
- the hash function is determined in advance in consideration of balance so that the number of reference vectors registered in each bin is reduced while the reference vector includes a reference vector having a high probability of being the nearest bin.
- the CPU sets the image ID associated with the reference vector as a recognition result candidate.
- the CPU determines the nearest neighbor vector among the reference vectors as the nearest neighbor point determination unit 17. Specifically, the CPU performs distance calculation between the query vector and the reference vector registered in the reference destination bin. Then, the reference vector closest to the query vector is determined as the nearest neighbor vector.
- the image ID associated with the reference vector is set as a recognition result candidate.
- the nearest neighbor determination unit 17 corresponds to a configuration that embodies the second step of the approximate nearest neighbor search.
- the CPU obtains the nearest reference vector for each of a plurality of query vectors extracted from the query, and uses the image ID associated with the reference vector as a recognition result candidate.
- the voting unit 19 the CPU performs voting on image IDs that are candidates for recognition results for each query vector.
- a voting table 21 is provided for storing the number of votes for each image ID (image 1 to image n) at the time of voting.
- a search range determination unit 13 that applies a hash function to a query vector
- a hash table 15 h that systematizes and stores feature vectors
- a nearest neighbor point determination unit that determines a nearest neighbor vector among reference vectors registered in the same bin.
- Reference numeral 17 denotes a configuration related to the approximate nearest neighbor search, which can be said to be an element constituting the nearest neighbor search device. Since the image recognition apparatus in FIG. 20 outputs an image as a recognition result, for example, the nearest neighbor determination unit 17 outputs an image ID associated with the nearest neighbor vector.
- the component as an approximate nearest neighbor search device determines and outputs the nearest feature vector from the feature vectors registered in the hash table for the input feature vector.
- a component that stores an image ID associated with a feature vector and a component that outputs an image ID associated with a nearest neighbor vector are not included.
- the image recognition apparatus in FIG. 20 is an application example of nearest neighbor search, and data handled by the nearest neighbor search apparatus is not limited to feature vectors.
- ANN Approximate Nearest Neighbor
- ANN is based on binary trees. In constructing a tree, the data space is divided into two equal parts, and division is repeated until one point enters the leaf. When a query is given, the tree is traced, and the distance registered with the data registered in the reached leaf is calculated. If the distance is r, the search area is the area where the closest part of each divided area falls within the radius r / (1 + ⁇ ) from the query.
- FLANN> Fast Library for Approximate Nearest Neighbors is a library that provides an approximate nearest neighbor search method suitable for a given database and its parameter tuning. This library includes an exhaustive search in addition to randamized kd-tree (for example, see Non-Patent Document 12) and hierarchical k-means (for example, see Non-Patent Document 13), which have high performance among the proposed methods. Is adopted.
- Randamized kd-tree is a technique for selecting re-neighbor candidates from multiple trees.
- a tree structure is formed by dividing a space into two parts while sequentially changing elements of data of interest.
- the processing time required for the tree traversal and a lot of useless distance calculations are performed. Therefore, the principal component analysis is performed in the randamized kd-tree, and the kd-tree is constructed by focusing on only the upper D-dimensional base that contributes to the distance calculation.
- Hierarchical k-means as its name suggests, points belonging to each node at each node are clustered by k-means, and the space is divided into clusters at each hierarchy.
- LSH> Locality Sensitive Hashing is one of the most representative techniques among approximate nearest neighbor search techniques using a hash.
- LSH that can be used in the vector space (refer to, for example, Non-Patent Document 8) related to the present invention will be described.
- LSH uses a plurality of hash functions to select points that are considered to be in the vicinity of the query, and performs distance calculation only for those points.
- the data space is divided into a plurality of randomly generated bases at equal intervals, thereby dividing the space into regions called buckets for indexing.
- FIG. 21 is an explanatory diagram of LSH, which is one method of conventional approximate nearest neighbor search.
- FIG. 21A shows a state in which the data space is equally divided by the bins of the hash table along the directions of two bases a 1 and a 2 that are randomly generated.
- Each region divided along the axis a 1 is a bin indexed by the hash function h j1 related to the base a 1
- each region divided along the axis a 2 is a hash function h j2 related to the base a 2 Is a bin indexed by.
- Each axis shows the index value.
- a cell-like region where these two types of bins intersect, that is, a product region where bins of each dimension of the two-dimensional hash table intersect is a bucket.
- the numerical value of each bucket has shown the value of the index of hash function hj1 and hj2 .
- FIG. 21B shows the state of the search area obtained by three projections.
- LSH of Non-Patent Document 8 a hash function group as shown in the following equation is used.
- x is an arbitrary point
- a i is a vector in which the value of each dimension element is independently selected from a Gaussian distribution
- W is a hash width
- b i is uniformly selected from the interval [0, W]. It is a real number.
- a hash function that is sensitive to locality is a hash function that has a high probability of taking the same hash value (index) at points close to each other and a low probability of taking the same hash value at points far away from each other.
- a hash function group H j is created by combining k hash functions h ji .
- the bucket is obtained by applying the hash function group H j to the query.
- This bucket is a target area for distance calculation related to one function group H j .
- L (L sets) of such hash function groups H j are created, and an area obtained by combining the L areas is finally set as a target area for distance calculation with the query.
- SH An outline of typical spectral hashing (SH) among techniques using a binary code hash function will be described.
- SH is a technique that is said to provide good performance among those using a hash.
- SH selects several principal components of the data space from the top and performs projection onto the Hamming space. Then, a candidate having a distance (Hamming distance) in the projected Hamming space that is equal to or smaller than a threshold is set as the nearest neighbor candidate. That is, paying attention only to the upper principal component basis, each sample is converted into a binary code, and the nearest neighbor candidate is selected according to the Hamming distance from the query.
- the SH encoding assumes a uniform distribution of the data space, divides the space so that the divided area is divided as close to a rectangular parallelepiped as possible, and gives a binary code to each bucket.
- FIG. 22 is an explanatory diagram of SH, which is a conventional approximate nearest neighbor search method, and shows a state in which the data space is projected onto a two-dimensional Hamming space composed of two principal component bases pv 1 and pv 2 .
- SH which is a conventional approximate nearest neighbor search method
- Each axis has an index indicated by a binary code.
- the sign of each bucket is a combination of the indices of the axes pv 1 and pv 2 .
- the query belongs to the bucket denoted by reference numeral 111.
- the gray area represents a search area for a query when the upper limit of the Hamming distance is 1.
- buckets of reference numerals 110, 101, and 011 that differ from reference numeral 111 by only one reference code are search areas. Since SH projects the data space onto the principal component basis, it can be said that the original distance is easily maintained after the projection, but since the distance in the projected space is represented by the Hamming distance, an error from the Euclidean distance occurs. For example, there is a problem that the region 011 far from the bucket 111 onto which the query is projected in FIG.
- the nearest neighbor candidate is extracted from the approximate hypersphere region centered on the query by obtaining the distance between the bucket to which the query belongs and the bucket to which each point belongs.
- FIG. 23 is an explanatory diagram showing a procedure for determining the distance of each bucket in the method of Sato et al., which is a conventional method of approximate nearest neighbor search.
- the numerical values attached to the vertical axis and the horizontal axis are indexes.
- Each cell-shaped section is a bucket as a bin product area.
- the sequence of numbers 11 to 33 assigned to each bucket is a combination of bin indexes that make up the bucket. This sequence of numbers can be considered as a position vector indicating the position of the bucket in the data space.
- a distance D between the buckets is defined from the index sequence, that is, the position vector of the bucket.
- the search for the nearest point may be performed by referring to the data included in the bucket in order from the bucket having the smallest bucket distance. In this way, a search for a hypersphere region centered on the query can be realized. Only points with a small approximate distance from the query can be targeted for distance calculation.
- FIG. 23 shows an example when the index of the bin is ⁇ 2, 2> when the hash function is applied to the query.
- the distance between the points registered in the bucket with the same index as the query is calculated.
- a bucket with a bucket distance of 1 is searched.
- the buckets are indexes ⁇ 1, 2>, ⁇ 2, 1>, ⁇ 2, 3>, ⁇ 3, 2>. These buckets are searched in order. If it is determined that a sufficient number of buckets have been searched, the search is terminated. On the other hand, if it is determined that the number of buckets is still insufficient, the search range is expanded to farther buckets.
- the buckets are the indexes ⁇ 1,1>, ⁇ 3,1>, ⁇ 3,3>, ⁇ 1,3>.
- the accuracy of the approximate distance decreases when the dimension of the projection space is smaller than the dimension of the data space.
- the hash size increases exponentially with respect to the hash dimension number ⁇ , an enormous hash size is required to maintain accuracy for high-dimensional data. It is difficult to increase the dimension number ⁇ of the hash for high-dimensional data, and as a result, it is not possible to obtain a sufficient approximate distance accuracy for high-dimensional data.
- the hash size becomes too large, it is necessary to refer to many buckets in order to maintain the accuracy of nearest neighbor search, and it takes a lot of time to extract the nearest neighbor candidate. ⁇ 6.
- G. At this time, the expected value (estimated distance) of the distance from the query to the point belonging to each area is the distance to the centroid of the area.
- IVFADC nearest neighbor selection IVFADC uses simple vector quantization for coarse quantization (eg H. Jegou, M. Douze, and C. Schmid, "Product quantization for nearest neighbor search," IEEE Trans. TPAMI, vol. .33, no.1, pp.117-128, 2011).
- coarse quantization eg H. Jegou, M. Douze, and C. Schmid, "Product quantization for nearest neighbor search," IEEE Trans. TPAMI, vol. .33, no.1, pp.117-128, 2011.
- G the calculation cost for selecting the nearest neighbor candidate
- O O
- IMI nearest neighbor candidate selection Therefore, IMI has been proposed as an improved method of IVFADV (for example, A. Babenko and V. Lempitsky, "The inverted multi-index," Proc. IEEE Conference on Computer Vision and Pattern Recognition ( CVPR), pp. 3069-3076, 2012).
- product quantization is performed by dividing the vector x into two partial vectors U 1 (x) and U 2 (x).
- the set of partial centroids obtained is C 1 , C 2 , and the number of elements
- is g.
- estimated square distance F ij to the point belonging to the query q and c ij (Q) is the distance from the query to the i-th element of the m-th partial centroid Is expressed by the following equation. Therefore, the problem of selecting centroids in order of proximity to the query is the two partial distance lists This results in a problem of searching for a combination of i and j where the sum F ij is small. In IMI, this problem is solved by using a combinatorial search method called Multi-Sequence algorithm.
- the algorithm Each time the algorithm generates the combination of subscripts with the shortest distance at a given time, it adds subscript candidates as subscript pairs that may generate the next smallest combination of distances. Repeat the process of selecting the next combination. Then, the search is terminated when the obtained number of nearest neighbor candidates reaches point L.
- the space division number G is equal, the product quantization is less accurate than the vector quantization.
- the Multi-Sequence algorithm can be applied and the calculation cost is reduced. Since the nearest neighbor candidates can be obtained, the search speed can be increased.
- the inverted multi-index it is reported that a solution can be obtained at a higher speed than that of IVFADC. The conventional representative nearest neighbor search method has been described above.
- the distance from the query can be estimated based on the index.
- the distance in the space after projection cannot sufficiently hold the distance in the original space, and the estimated distance cannot sufficiently hold the magnitude relationship of the true distance. In that case, in order to increase the accuracy of the search, it is necessary to secure many nearest neighbor candidates, and a solution cannot be obtained at high speed.
- the inventors pay attention to the method of Sato et al.
- the approximate distance well reflects the magnitude relationship of the true distance
- This makes it possible to estimate the distance with higher accuracy and higher speed than the conventional method, and as a result, the overall speed of the approximate nearest neighbor search can be increased.
- the present invention provides a distance estimation method and an adaptive search range determination method. Special attention.
- Bucket Distance Hashing an approximate nearest neighbor search method to which the first point-to-bucket distance estimation and the second hash table partitioning are applied is referred to as Bucket Distance Hashing or BDH.
- BDH space division suitable for distance estimation
- k-means BDH a method in which k-means BDH is combined with distance estimation based on a probability density function, which is the fourth improvement point, is called k-means BDH P.
- k-meansmeanBDH PC a technique in which the adaptive search range which is the fifth improvement point is combined with k-meansmeanBDH P.
- the first improved method mainly relates to improvement in accuracy of distance estimation. Sato et al. Estimated the distance between buckets to which the query and data belong, that is, the bucket-to-bucket distance. Here, a method for improving the accuracy of distance estimation with the same data structure by estimating the distance from the exact query position to the bucket to which each data belongs, that is, the distance of the point-to-bucket, is proposed.
- This technique uses the same equation (5) as the technique of Sato et al.
- the representative point is determined by calculating the expected value of the coordinate of p 1 and the coordinate of the point belonging to the same bucket as p 2 .
- the representative point is determined so that the coordinate of the representative point becomes an expected value of the coordinates of the point belonging to the bucket. That is, the representative point is the center of gravity of the bucket.
- the Euclidean distance between the two points of the coordinates of p 1 and the coordinates of the representative point of the bucket to which p 2 belongs is calculated, and this is used as the approximate distance.
- the expected value of the Euclidean square distance in the base i direction is as follows. From the assumption that each base is independent, the expected value of the Euclidean square distance in v-dimensional space is as follows.
- the distance between the buckets B (p 2 ) to which the points p 1 and p 2 belong, that is, the point-to-bucket distance is expressed as follows.
- (h i (p 2 ) +1/2) represents the coordinates in the ⁇ i direction of the center of gravity of the bucket B (p 2 ), and the distance in Expression (7) is the distance between the query and the center of gravity of the bucket. be equivalent to. Since the position of the query is specified, distance estimation with higher accuracy than Expression (6) is realized.
- the error variance of the estimated distance is 1 / W 2 compared to the method of Sato et al. That estimates the bucket-to-bucket distance.
- the distance of the expression (7) is multiplied by W, and is rewritten as the following expression.
- BD i (p 1 , B (p 2 )) represents the distance in the base direction of the i-th dimension between the point p 1 and the center of gravity of the bucket B (p 2 ).
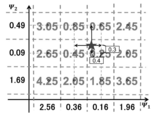
- FIG. 2 is an explanatory diagram showing an example of distance estimation according to this embodiment. It is a figure corresponding to FIG. 1 which shows the distance estimation in the method of the conventional Sato et al.
- the star in FIG. 2 represents a query. If the distance between the bucket centers is 1, the left and right direction query is 0.6 from the center of the left bucket and 0.4 from the center of the right bucket, and the vertical direction is 0.7 from the center of the upper bucket. Located at 0.3 from the center of the lower bucket.
- the number on the axis (2.56, 0.36, etc.) represents the weight of the bucket distance in the horizontal direction and the vertical direction, and the number in the bucket (3.05, 0.85, etc.) represents the weight of the distance between the estimated query and each bucket.
- the weight is the Euclidean square distance.
- FIG. 3 is an explanatory view showing a different example of distance estimation according to this embodiment.
- the dimension number ⁇ 2 of the hash function.
- This is an example of a search space and query different from those in FIG.
- a circle centered on the query in FIG. 3 represents the size of the search radius, a bucket whose bucket center is within the circle is a search area, and the search area is shown in gray.
- a bucket within a search radius R given as a parameter is referred to. Since the search range is within the circle centered on the query instead of the center of the bucket containing the query (a hypersphere when the dimension ⁇ of the hash is expanded to an arbitrary natural number), Sato performs the bucket-to-bucket distance estimation.
- Distance estimation can be performed with higher accuracy than those methods.
- the process of selecting a bucket within the search radius R is more complicated than the method of Sato et al.
- the reason is that the estimated distance is limited to an integer in the method of Sato et al., But is a real number in BDH, so it takes a long time to handle the estimated distance strictly.
- the present invention proposes an algorithm for quickly identifying buckets within the search radius R.
- FIG. 18 shows two algorithms based on the branch and bound method for quickly identifying buckets within the search radius R in this embodiment. “Algorithm 1” and “Algorithm 2”.
- ⁇ coordinate values are required to obtain the distance from the query to the representative point of a bucket.
- H (x) ⁇ h 1 (x), h 2 (x)... H ⁇ (x) ⁇ .
- the distance to the bucket can be found by adding ⁇ times.
- the ⁇ bases are selected by principal component analysis and are arranged in descending order of the eigenvalues. Therefore, the data has a large variance in the upper base direction (the subscript number is young). Therefore, the most efficient method for searching for buckets within the radius R is to evaluate in the order of subscript numbers as described below.
- Algorithm 2 takes two arguments. I indicating the dimension of the hash value to be determined, and the distance D for the (i ⁇ 1) th dimension already determined. In the 1st to 7th lines, if the last base (the stage at which the ⁇ -th hash value is determined) has not been reached (1st line), k i (the number of divisions of the i-th base, that is, the bucket in the i-th base direction) Try the hash value (index) of the number of bins that make up (second line).
- BD ij is a one-dimensional distance (distance component in the i-th base direction) in the i-th base when the hash value j (j-th bin) is selected
- D + BD ij + mD i is i hash values. Is the distance to the nearest bucket at a determined stage, and only when it is smaller than the search radius R, recursively calls itself and proceeds to the next base (lines 3-5). Lines 9 to 13 are executed only when the last ⁇ th base is reached. If there is a bucket within the search radius, the hash is subtracted.
- Hash table partitioning> The technique of Sato et al. Has a problem that high-speed data cannot be searched at high speed. This is a problem caused by the relationship between the number of dimensions of the hash and the number of buckets included in the hash table (hereinafter referred to as hash size).
- hash size the number of dimensions of the hash and the number of buckets included in the hash table.
- the hash dimension number ⁇ In order to maintain the accuracy of the estimated distance, it is necessary to increase the hash dimension number ⁇ in accordance with the data dimension number. However, if the dimension number ⁇ of the hash is increased, the hash size becomes enormous and falls into a situation where it cannot fit in the memory.
- the estimated distance of the high-dimensional hash is obtained by dividing the high-dimensional hash table and integrating the estimated distances obtained from the low-dimensional hash table. Suggest a method.
- the estimated distance from query q to any point p Can be expressed as This is equal to the estimated distance determined by the ⁇ -dimensional hash.
- the advantage of dividing the hash table is that the hash size can be drastically reduced even when a hash of the same number of dimensions is expressed as compared to the case of using one hash table.
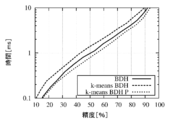
- FIG. 4 is a graph showing the relationship between accuracy and processing time when the dimension number ⁇ of the multidimensional hash of the conventional Sato et al. Method is changed.
- the data used here is 64 dimensions or 128 dimensions
- FIG. 4A shows the case of 64 dimensions
- FIG. 4B shows the case of 128 dimensions.
- Artificial data and queries based on a normal distribution of 10 million points are both 2000 points generated under the same conditions.
- the computer used was an Opteron (tm) 6174 (2.2 GHz) CPU, 256 [GB] memory, and the experiment was performed on a single core.
- tm 6174 (2.2 GHz) CPU, 256 [GB] memory
- Data is extracted from artificial data following normal distribution of 64, 128, and 256 dimensions (dispersion is uniformly selected from 100 to 400 for each base) and each frame image of the video distributed by Instance Search task of TRECVID2010 SIFT features (128 dimensions, for SIFT, DG Lowe, "Distinctive image features from scale-invariant keypoints," International journal of computer vision, vol.60, no.2, pp.91-110, 2004 .)) was prepared for 10 million each.
- the query uses 2000 points created under the same conditions as the database, and the average is the result.
- FIG. 5 shows the relationship between accuracy and processing time for artificial data results.
- FIG. 5A shows experimental results of 64-dimensional artificial data
- FIG. 5B shows experimental results of 128-dimensional artificial data
- FIG. 5C shows experimental results of 256-dimensional artificial data.
- Table 1 shows the memory usage at this time.
- the result of the image data is shown in FIG. 5 and 6, the horizontal axis represents accuracy, and the vertical axis represents processing time.
- the single hash of the legend is a case where the hash table is not divided in the present invention, and the divided hash is a case where the hash table is divided.
- BDH is improved by three additional approaches.
- the first is the proposal of space division suitable for distance estimation
- the second is the proposal of distance estimation based on the probability density function
- the third is the expansion of the search area considering the data density around the query. The details will be described below.
- V i is a unit vector in the direction of the i-th basis.
- a bucket is defined by this vector. That is, an area where a certain vector is closest is defined as a bucket range.
- This vector is called a representative vector.
- the data space is divided into ⁇ i v k i regions. Therefore, the distance component between the point p and the representative value C ij in the i-th base direction, that is, the base distance BD i is
- X represents a set of data
- X n represents n-th data
- BE i represents an error in the i-th principal component direction.
- the representative value ⁇ C ij ⁇ in each base is obtained by the k-means method having the same objective function as the present invention. What is important here is how many representative values in each base are set. In order to solve this problem, all bases are divided by the same number, but in the actual data, the variance of the data projected onto the principal component basis differs greatly depending on the principal component basis, and it is not efficient to handle it equally. . Naturally, if the number of representative vectors is the same, it is better that the estimation error is smaller.
- FIG. 7 is an explanatory diagram showing a comparative example of equal division and adaptive base division according to this embodiment.
- the estimated distance BD i (p, j) in the i-th principal component direction is expressed as the expected value of the square base distance as follows.
- the feature of the distance estimation proposed here is that the fitness to a general complex distribution is higher than that of the distance estimation of BDH, and at the same time, the calculation cost is low and it is suitable for high-speed processing.
- ⁇ Fifth improvement Expansion of search radius considering data density around query>
- a search area is generally determined according to a search radius R given as a parameter.
- R search radius
- well-known literature e.g., W. Dong, Z. Wang, W. Josephson, M. Charikar, and K. Li, "Modeling LSH for performance tuning," Proceeding of the 17th ACM conference on Information and knowledge management, pp .669-678 2008.
- FIG. 8 is an explanatory diagram showing how the search radius is changed according to the density around the query as an example of this embodiment.
- the dimension number of hash ⁇ 2.
- the reference bucket is obtained by calculating the distance on the hash for all buckets (for example, H. Jegou, M. Douze, and C. Schmid, "Product quantization for nearest neighbor search," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol.33, no.1, pp.117-128, 2011.) and implementation has a hash structure to calculate the distance on the hash for all sample points
- the processing time is also required for specifying the nearest neighbor candidate such as the one that determines a point less than the search radius (SH or its improved method).
- Algorithm 1 a distance mD i obtained by adding the minimum values that can be taken in each of the ⁇ i hash functions is calculated and a bucket existing within a radius R from the query is searched.
- Algorithm 3 and “Algorithm 4” also use the condition that the distance MD i obtained by adding the maximum possible values is calculated and exists beyond the radius L from the query.
- the distance MDi obtained by adding the minimum value mD i for the ⁇ i dimension and the maximum possible value is calculated in the first to fourth lines. In the 5th to 6th lines, initial values of L and U which are lower and upper limits of the search radius are set. In the seventh to eleventh lines, the function of algorithm 4 is called and the search is continued while the search radius is increased by ⁇ until the nearest neighbor candidate becomes c points or more.
- the computer used in the experiment was an Opteron (tm) 6174 (2.2 GHz) CPU and 256 [GB] memory, and the experiment was performed with a single core.
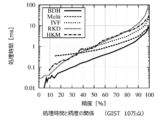
- SIFT features were extracted from images obtained every 10 seconds from the video distributed by the Instance Search task of TRECVID2010, and duplicate vectors were removed.
- the horizontal axis is the code length [bit]
- the vertical axis is the correlation coefficient.
- the horizontal axis is the code length [bit]
- the vertical axis is the rank of the nearest point. It can be seen that the average rank of the nearest points is higher in BDH than SH in any code length.
- the ranking of the nearest neighbors is about 1/8 at 20 bits, about 1/8 at 40 bits, and about 1/13 at 80 bits compared to SH.
- k-means BDH is obtained by applying a spatial partitioning method using k-means according to the third improvement point
- k-means BDH P uses a probability density function which is the fourth improvement point for k-means BDH.
- the distance estimation is applied.
- the performance is lower than that of BDH, but improvement is seen by combining the probability density function.
- k-means BDH P (method for fixing the search radius R) of only the fourth improvement point (distance estimation based on the probability density function) that was the fastest in FIG.
- a comparison of k-means BDH PC with 5 improvement points (method of fixing the nearest neighbor candidate number c) is performed. The result of the comparison is shown in FIG. By reflecting the data density around the query, it was confirmed that the speed was increased by about twice, and a sufficient effect was obtained.
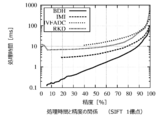
- each search parameter is ⁇ for ANN, SH for Hamming distance R, and k-means BDH PC nearest neighbor number c.
- the comparison results are shown in FIG.
- the processing time of k-means ⁇ BDH PC is about 1/10 for ANN and about 1/6 to 1/12 for SH, compared with the same accuracy, and the speed is greatly increased. I understand that.
- bucket number G is
- the number of buckets increases, but it takes time to search for adjacent buckets. Therefore, a large M cannot be used easily, and if the vector has a high dimension, the M used for indexing becomes relatively small with respect to the total number of dimensions, and the approximation cannot be obtained without obtaining the accuracy of distance estimation. The performance of the nearest neighbor search is degraded.
- the number of buckets is the data set size
- M sets of P sets of orthogonal bases are selected from the orthogonal bases V, and the data space is expressed as a direct product of M P-dimensional subspaces.
- V m be P orthogonal bases that span the mth subspace.
- a centroid set C m is obtained for each subspace using the k-means algorithm to minimize the quantization error. This is equivalent to performing product quantization by dividing the vector projected onto the PM dimensional space spanned by the base into M P dimensional partial vectors.
- the hash function H ( ⁇ ) is as follows.
- Bucket distance an estimated amount of distance that minimizes the estimation error is derived, and the bucket distance is defined. Assuming that there is no correlation between the bases (if the principal component basis is used, non-correlation up to the second order is guaranteed), the error in the estimated distance in each base direction can be minimized independently.
- the minimization problem is defined as follows: The data x follows the probability density function P (x), and if the event that exists in a certain region z is Z, the distribution of the data in the region z is expressed as P (x
- Equation (24) Var [] is a function that returns an unbiased variance with the argument regarded as a sample of the population. Note that the estimated amount obtained here is not the distance from the center of gravity of the region. From the above results, the bucket distance F H in which the hash value list is H is defined as follows. In the following formula (26), u m p is the p-th principal component basis of the m-th subspace.
- FIG. 24 shows the distribution of points in the data space, and u 1 and u 2 represent the first and second principal component bases. When the bases of bases are quantized independently as in Normal of FIG. 24A, these often have a correlation, resulting in waste of quantization. Therefore, as in the case of PCA in FIG.
- the relationship between accuracy and processing time is verified by first examining the relationship between accuracy and processing time without limiting memory usage, and then applying memory reduction to set an upper limit on the amount of memory that can be used. Verified.
- the problem setting is a K-neighbor search problem that searches for K points close to the query.
- 11 Feature point extraction unit
- 13 Search range determination unit
- 15 Image database
- 15h Hash table
- 17 Nearest neighbor determination unit
- 19 Voting unit
- 21 Voting table
- 23 Image selection unit
Landscapes
- Engineering & Computer Science (AREA)
- Library & Information Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
最近傍候補の数を適切に絞り込むことにより、高い探索精度と高速性を兼ね備えた近似最近傍探索を実現する。 ベクトルデータで表現される複数の点が入力されたとき、各点にハッシュ関数をそれぞれ適用してハッシュのインデックスを算出し、前記多次元ハッシュテーブルのビンによって複数の領域に分割された多次元空間内に各点を射影することにより各点を多次元ハッシュテーブルに格納してなるデータベース格納部と、クエリが入力されたとき、そのクエリに前記ハッシュ関数を適用して前記空間内でのクエリの位置を決定し、クエリと前記空間内の各領域との距離の推定値を決定し、その推定値に基づいて探索すべき領域を決定する探索範囲決定部と、前記探索領域内の各点とクエリとの距離を計算し、クエリに最も近い点をクエリの最近傍点として算出する最近傍点決定部とを備え、前記探索範囲決定部は、各領域のインデックスを参照してその領域の代表点を求め、前記クエリと各代表点との距離に基づいて前記推定値を決定し、分枝限定法を適用して前記探索すべき領域になり得ない領域を除外して前記探索すべき領域を決定する近似最近傍探索装置を適用する。
Description
この発明は、近似最近傍探索装置、近似最近傍探索方法およびそのプログラムに関し、より詳細にはコードブック付きハッシングによる高速距離推定を用いた近似最近傍探索装置、近似最近傍探索方法および近似最近傍探索プログラムに関する。
近年の情報処理において大規模データの処理は不可欠であり、年々その重要度が増している。この要因のひとつはハードウェアである。すなわち、計算機環境の高性能化、低価格化、記憶媒体の大容量化によって大容量のデータを扱えるようになり、さらに言えば現実的な時間で処理できるようになったことである。他の要因と言えるのはコンテンツとニーズである。すなわち、一般の人々が写真や動画、音楽などの様々なコンテンツを自ら制作し、Flickr(URL: http://www.flickr.com/ 参照)やYouTube(URL: http://www.youtube.com/ 参照)などのサイトにアップロードするようになったことに加えて、それらの中から自分の興味に合致するものを高速で発見したいという欲求が生じたことである。このような写真や動画に限らず、人類が扱うことができるデータの総量は猛烈な勢いで増え続けているため、大規模データの処理技術の開発は喫緊の課題である。
この課題の一つの答えになるのが最近傍探索である。最近傍探索はベクトルで表現されるデータ(点)の中から、クエリと最も類似している、即ち最も距離が小さいデータ(最近傍点)を探す手法である。最近傍探索は、大規模データの処理を実現する基本的で有効な技術であり、基本的であるが故に優れた手法には幅広い応用可能性がある。発明者らが携わっているものだけでも応用先として物体認識(例えば、非特許文献1参照)、文書画像検索(例えば、非特許文献2参照)、文字認識(例えば、非特許文献3参照)および顔認識(例えば、非特許文献4参照)を挙げることができる。いずれも比較的大規模なデータに対して非常に高速に動作することが示されている。前述の技術は、広い意味での画像認識技術といえるが、最近傍探索の応用分野はそれに留まらず、統計分類、符号論理、データ圧縮、レコメンデーションシステム、スペルチェッカ等におよぶ。
実応用を考えると、最近傍探索には高速性が求められる。高速化が進めば、同じ時間でこれまで以上に大規模なデータを処理することができ、従来は処理時間の制約から導入を諦めていた用途にも使用できるようになる。
実応用を考えると、最近傍探索には高速性が求められる。高速化が進めば、同じ時間でこれまで以上に大規模なデータを処理することができ、従来は処理時間の制約から導入を諦めていた用途にも使用できるようになる。
この要求を満たすために生み出されたのが近似最近傍探索である。近似最近傍探索とは、最近傍探索に近似を導入し、探索誤りを許容することで処理時間を大幅に削減することができる技術である。探索誤りが生じるため、必ずしも真の最近傍点がみつかる保証はないが、ある程度の探索精度が得られればよいアプリケーションに使用される。探索精度の向上と高速化は相反する要求であり、一般に両者を同時に満足することは容易でない。
これまでに提案された代表的な近似最近傍探索手法について述べる。木構造を用いた手法として、Approximate Nearest Neighbor(あるいはANN、例えば、非特許文献5参照)およびFast Library for Approximate Nearest Neighbors(あるいはFLANN、例えば、非特許文献6参照)などが知られている。また、ハッシュ法を用いた手法としてLocality Sensitive Hashing(あるいはLSH例えば、非特許文献7、8および9参照)、Spectral Hashing(あるいはSH、例えば、非特許文献10参照)ならびに佐藤らの手法(例えば、非特許文献11参照)などが知られている。
さらに、FLANNに採用されているパラメータチューニングの手法としてrandamized kd-tree(例えば、非特許文献12参照)や階層的k-means(例えば、非特許文献13参照)が知られている。
さらに、FLANNに採用されているパラメータチューニングの手法としてrandamized kd-tree(例えば、非特許文献12参照)や階層的k-means(例えば、非特許文献13参照)が知られている。
黄瀬浩一、野口和人、岩村雅一、"参照特徴ベクトルの増加による低品質画像の高速・高精度認識、"電子情報通信学会論文誌D、vol.J93-D,no.8,pp.1353-1363,Aug. 2010.
K. Takeda, K. Kise, and M. Iwamura, "Real-time document image retrieval for a 10 million pages database with a memory efficient and stability improved llah," Proc. International Conference on Document Analysis and Recognition(ICDAR2011), pp.1054-1058, Sept. 2011.
M. Iwamura, T. Tsuji, and K. Kise, "Memory-based recognition of camera-captured characters," Proceedings of the 9th IAPR International Workshop on Document Analysis Systems(DAS2010), pp.89-96, June 2010.
前川敬介、内海ゆづ子、岩村雅一、黄瀬浩一、"100万顔画像データベースに対する34msでの照合の実現~近似最近傍探索を用いた大規模高速顔画像検索~、"電子情報通信学会技術研究報告、vol.111,no.353,pp.95-100,Dec. 2011.
S. Arya, D.M. Mount, N.S. Netanyahu, R. Silverman, and A.Y. Wu, "An optimal algorithm for approximate nearest neighbor searching in fixed dimensions," Journal of the ACM, vol.45, no.6, pp.891-923, Nov. 1998.
M. Muja and D.G. Lowe, "Fast approximate nearest neighbors with automatic algorithm configuration," International Conference on Computer Vision Theory and Application (VISSAPP'09), pp.331-340, INSTICC Press, 2009.
P. Indyk and R. Motwani, "Approximate nearest neighbors: towards removing the curse of dimensionality," Proceedings of the thirtieth annual ACM symposium on Theory of computing, pp.604-613 1998.
M. Datar, N. Immorlica, P. Indyk, and V.S. Mirrokni, "Locality-sensitive hashing scheme based on p-stable distributions," Proceedings of the twentieth annual symposium on Computational geometry, pp.253-262 2004.
A. Andoni and P. Indyk, "Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions," Annual IEEE Symposium on Foundations of Computer Science, pp.459-468 2006.
Y. Weiss, A. Torralba, and R. Fergus, "Spectral Hashing," Advances in Neural Information Processing Systems, pp.1753-1760, 2008.
佐藤智一、武藤大志、岩村雅一、黄瀬浩一、"バケット距離に基づく近似最近傍探索、"第3回データ工学と情報マネジメントに関するフォーラム論文集、pp.1-6,Feb. 2011.
C. Silpa-Anan and R. Hartley, "Optimised kd-trees for fast image descriptor matching," IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2008), pp.1-8 2008.
B. Leibe, K. Mikolajczyk, and B. Schiele, "Efficient clustering and matching for object class recognition," Proc. BMVC, pp.1-10, 2006.
近似最近傍探索では予めデータ空間を多数の領域に分割してインデクシングを施す。この発明は、特にハッシュを使用する手法に係るものである。ハッシュを用いた近似最近傍探索は、基本的にデータ空間を複数の軸に沿って線形分割し、分割された領域(ビン)ごとにデータをハッシュテーブルに登録する。そして、クエリの入った領域または、その近傍の領域に入った点をハッシュテーブルから抽出し、その中から最近傍点を求めることで、高速な探索を実現している。複数のハッシュテーブルを用いる場合はビンの積領域(バケット)が分割の単位になる。
一般に近似最近傍探索は二段階の処理から成り、一段目で最近傍点が含まれる確率の高いビンまたはバケットを特定する。そこに属する点を最近傍候補と呼ぶことにする。二段目では最近傍候補に含まれる点のうち、最もクエリからの距離が小さい点を算出する。つまり、「近似」の要素が入るのは一段目の処理のみである。従って、この処理が近似最近傍探索の探索精度と処理時間を左右する。
一般に近似最近傍探索は二段階の処理から成り、一段目で最近傍点が含まれる確率の高いビンまたはバケットを特定する。そこに属する点を最近傍候補と呼ぶことにする。二段目では最近傍候補に含まれる点のうち、最もクエリからの距離が小さい点を算出する。つまり、「近似」の要素が入るのは一段目の処理のみである。従って、この処理が近似最近傍探索の探索精度と処理時間を左右する。
一段目の最近傍候補の特定では距離計算の対象を最近傍候補に限定することで距離計算に要する処理時間を大幅に削減する。しかし、これは諸刃の剣であり、最近傍候補の数を減らすことで高速化を図れるものの、探索精度が低下してしまう。それは最近傍候補から真の最近傍点が漏れてしまい、最近傍探索に失敗する確率が上昇するためである。従って、一段目の処理において求められるのは最近傍候補の数を絞りつつも真の最近傍点を漏らさないことである。しかも最近傍候補の選定は高速に行う必要がある。
これらの要求を満足するために発明者らが採った方針は、最近傍候補の選定の際に二段目で使用するのと同じ距離尺度を用いることである。これにより、最近傍候補の数を絞っても真の最近傍点が最近傍候補に含まれる確率は減少し難い。しかし、このような処理には通常大きな計算コストが必要になる。この課題を解決するためには、前述の処理を高速に実行できる近似最近傍探索の手法が望まれている。
この発明は、以上のような事情を考慮してなされたものであって、最近傍候補を適切に絞り込むことにより、高い探索精度と高速性を兼ね備えた新たな近似最近傍探索の手法を提供するものである。
この発明は、以上のような事情を考慮してなされたものであって、最近傍候補を適切に絞り込むことにより、高い探索精度と高速性を兼ね備えた新たな近似最近傍探索の手法を提供するものである。
ベクトルデータで表現される複数の点が入力されたとき、多次元ハッシュテーブルのインデックス算出用のハッシュ関数をそれぞれ適用して各点についてハッシュインデックスを算出し、前記多次元ハッシュテーブルのビンによって複数の領域に分割された多次元空間内の前記ハッシュインデックスに応じた領域に各点を射影することにより各点を多次元ハッシュテーブルに格納してなるデータベース格納部と、クエリが入力されたとき、そのクエリに前記ハッシュ関数を適用して前記多次元空間内でのクエリの位置を決定し、クエリと前記空間内の各領域との距離の推定値を決定し、その推定値に基づいて少なくとも1つの探索すべき領域を決定する探索範囲決定部と、前記探索すべき領域内の各点とクエリとの距離を計算し、クエリに最も近い点をクエリの最近傍点として算出する最近傍点決定部とを備え、前記探索範囲決定部は、各領域のインデックスを参照してその領域の代表点を求め、前記クエリと各代表点との距離に基づいて前記推定値を決定し、分枝限定法を適用して前記探索すべき領域になり得ない領域を除外して前記探索すべき領域を決定することを特徴とする近似最近傍探索装置を提供する。
言い換えればこの発明は、ベクトルデータで表現される複数の点が入力されたとき、各点にハッシュ関数をそれぞれ適用してハッシュのインデックスを算出し、正規直交基底によって複数の領域に分割された多次元空間内の前記インデックスに応じた領域に各点を射影することにより各点が多次元ハッシュテーブルに登録されてなるデータベース格納部と、クエリが入力されたとき、そのクエリに前記ハッシュ関数を適用して前記空間内でのクエリの位置を決定し、クエリと前記空間内の各領域との距離の推定値を決定し、その推定値に基づいて1以上の領域を探索領域として決定する探索範囲決定部と、前記探索領域内の各点とクエリとの距離を計算し、クエリに最も近い点をクエリの最近傍点として算出する最近傍点決定部とを備え、前記探索範囲決定部は、各点が属する領域のインデックスを参照してその領域を代表する代表点の位置を求め、前記推定値を決定することを特徴とする近似最近傍探索装置を提供する。
言い換えればこの発明は、ベクトルデータで表現される複数の点が入力されたとき、各点にハッシュ関数をそれぞれ適用してハッシュのインデックスを算出し、正規直交基底によって複数の領域に分割された多次元空間内の前記インデックスに応じた領域に各点を射影することにより各点が多次元ハッシュテーブルに登録されてなるデータベース格納部と、クエリが入力されたとき、そのクエリに前記ハッシュ関数を適用して前記空間内でのクエリの位置を決定し、クエリと前記空間内の各領域との距離の推定値を決定し、その推定値に基づいて1以上の領域を探索領域として決定する探索範囲決定部と、前記探索領域内の各点とクエリとの距離を計算し、クエリに最も近い点をクエリの最近傍点として算出する最近傍点決定部とを備え、前記探索範囲決定部は、各点が属する領域のインデックスを参照してその領域を代表する代表点の位置を求め、前記推定値を決定することを特徴とする近似最近傍探索装置を提供する。
また、異なる観点から、この発明は、コンピュータが、ベクトルデータで表現される複数の点が入力されたとき、多次元ハッシュテーブルのインデックス算出用のハッシュ関数をそれぞれ適用して各点についてハッシュインデックスを算出し、前記多次元ハッシュテーブルのビンによって複数の領域に分割された多次元空間内の前記ハッシュインデックスに応じた領域に各点を射影することにより各点を多次元ハッシュテーブルに格納してなるデータベース格納部にアクセスするステップと、クエリが入力されたとき、そのクエリに前記ハッシュ関数を適用して前記空間内でのクエリの位置を決定し、クエリと前記空間内の各領域との距離の推定値を決定し、その推定値に基づいて少なくとも1つの探索すべき領域を決定する探索範囲決定ステップと、前記探索すべき領域内の各点とクエリとの距離を計算し、クエリに最も近い点をクエリの最近傍点として算出するステップとを備え、前記探索範囲決定ステップは、各領域のインデックスを参照してその領域の代表点を求め、前記クエリと各代表点との距離に基づいて前記推定値を決定し、分枝限定法を適用して前記探索すべき領域になり得ない領域を除外して前記探索すべき領域を決定することを特徴とする近似最近傍探索方法を提供する。
言い換えれば、コンピュータが、ベクトルデータで表現される複数の点が入力されたとき、各点にハッシュ関数をそれぞれ適用してハッシュのインデックスを算出し、正規直交基底によって複数の領域に分割された多次元空間内の前記インデックスに応じた領域に各点を射影することにより各点が多次元ハッシュテーブルに登録されてなるデータベース格納部にアクセスするステップと、クエリが入力されたとき、そのクエリに前記ハッシュ関数を適用して前記空間内でのクエリの位置を決定し、クエリと前記空間内の各領域との距離の推定値を決定し、その推定値に基づいて1以上の領域を探索領域として決定する探索範囲決定ステップと、前記探索領域内の各点とクエリとの距離を計算し、クエリに最も近い点をクエリの最近傍点として算出するステップとを備え、前記探索範囲決定ステップは、各領域のインデックスを参照してその領域を代表する代表点の位置を求め、前記クエリの位置と各代表点の位置との差を前記推定値とすることを特徴とする近似最近傍探索方法を提供する。
言い換えれば、コンピュータが、ベクトルデータで表現される複数の点が入力されたとき、各点にハッシュ関数をそれぞれ適用してハッシュのインデックスを算出し、正規直交基底によって複数の領域に分割された多次元空間内の前記インデックスに応じた領域に各点を射影することにより各点が多次元ハッシュテーブルに登録されてなるデータベース格納部にアクセスするステップと、クエリが入力されたとき、そのクエリに前記ハッシュ関数を適用して前記空間内でのクエリの位置を決定し、クエリと前記空間内の各領域との距離の推定値を決定し、その推定値に基づいて1以上の領域を探索領域として決定する探索範囲決定ステップと、前記探索領域内の各点とクエリとの距離を計算し、クエリに最も近い点をクエリの最近傍点として算出するステップとを備え、前記探索範囲決定ステップは、各領域のインデックスを参照してその領域を代表する代表点の位置を求め、前記クエリの位置と各代表点の位置との差を前記推定値とすることを特徴とする近似最近傍探索方法を提供する。
さらに異なる観点から、この発明は、ベクトルデータで表現される複数の点が入力されたとき、多次元ハッシュテーブルのインデックス算出用のハッシュ関数をそれぞれ適用して各点についてハッシュインデックスを算出し、前記多次元ハッシュテーブルのビンによって複数の領域に分割された多次元空間内のハッシュインデックスに応じた領域に各点を射影することにより各点を多次元ハッシュテーブルに格納してなるデータベース格納部にアクセスする処理と、クエリが入力されたとき、そのクエリに前記ハッシュ関数を適用して前記空間内でのクエリの位置を決定し、クエリと前記空間内の各領域との距離の推定値を決定し、その推定値に基づいて少なくとも1つの探索すべき領域を決定する探索範囲決定部としての処理と、前記探索すべき領域内の各点とクエリとの距離を計算し、クエリに最も近い点をクエリの最近傍点として算出する最近傍点決定部としての処理をコンピュータに実行させ、前記探索範囲決定部は、各領域のインデックスを参照してその領域の代表点を求め、前記クエリと各代表点との距離に基づいて前記推定値を決定し、分枝限定法を適用して前記探索すべき領域になり得ない領域を除外して前記探索すべき領域を決定することを特徴とする近似最近傍探索プログラムを提供する。あるいは、そのプログラム製品を提供する。
上述の3つの観点からの発明は、いずれも後述の実施形態における「第1の改良点:ハッシュに基づく点対バケットの距離推定」の記載に関連する。
上述の3つの観点からの発明は、いずれも後述の実施形態における「第1の改良点:ハッシュに基づく点対バケットの距離推定」の記載に関連する。
この発明の近似最近傍探索装置において、探索範囲決定部は、各領域のインデックスを参照してその領域の代表点を求め、前記クエリと各代表点との距離に基づいて前記推定値を決定するので、クエリと各領域との距離計算を行わずとも、インデックスを用いて前記推定値を決定し、その推定値に基づいて探索すべき領域(探索領域)を決定し、最近傍点決定部が距離計算を行うべき点を絞り込むことができる。また、バケット対バケットの距離推定を行う佐藤らの手法に比べて、点対バケットの距離を推定するこの発明の手法は同じデータ構造のまま距離推定の精度を向上させることができる。さらに、分枝限定法を適用して探索領域になり得ない領域を除外するので、短時間で探索領域を決定できる。
この発明において、データベースに登録される個々のデータおよびデータベースの検索に用いられるクエリ(検索質問)のデータは、少なくとも一つの点として表現される。各点は、前記データあるいはクエリの特徴を示す属性を有しており、その属性はベクトルデータで表現される。ハッシュは、メモリ上でデータを高速に検索するための公知の手法である。ハッシュ関数は、ベクトルデータを入力としてスカラー値を出力する。そのスカラー値はデータテーブルの一種であるハッシュテーブルを参照するために用いる離散値であり、ハッシュ値、ハッシュインデックスあるいは単にインデックスと呼ぶ。ハッシュ関数は出力の空間をインデックスがとり得る離散値の分だけ分割するものといえる。ハッシュ関数はまた、入力としてのベクトルデータ(点)を出力の多次元空間に射影するものといえる。この発明において、各ベクトルデータは多次元空間に射影される。一つのハッシュ関数の出力は一つのスカラー値であるから、ベクトルデータを例えばν次元(νは2以上の整数)のベクトル空間に射影するためにν個のハッシュ関数を用いる。各点は、ν個のハッシュ関数を適用することによって、ν個の基底で構成され各基底に沿って複数のビンに分割されかつ各ハッシュ関数のインデックスによって何れかのビンが特定されるν次元空間に射影される。各ビンへの各点の登録がハッシュテーブルを用いて表されるので、ハッシュテーブルはν個(ν次元)ある。ただし、いくつかの次元をまとめて一つのハッシュ関数を用いる場合もあり得る。この場合、ハッシュテーブルはν個よりも少ない。
この発明による近似最近傍探索の手法は、物体認識、文書画像検索、文字認識、顔認識、統計分類、符号論理、データ圧縮、レコメンデーションシステム、スペルチェッカ等に適用できる。
この発明による近似最近傍探索の手法は、物体認識、文書画像検索、文字認識、顔認識、統計分類、符号論理、データ圧縮、レコメンデーションシステム、スペルチェッカ等に適用できる。
この明細書では一つのハッシュ関数によって分割される各領域をビンと呼ぶ。また、複数のハッシュ関数によってそれぞれ生成されたビンの積領域、即ち複数のハッシュ関数により分割された各領域をバケットと呼ぶ。
この発明に係る近似最近傍探索は、コンピュータが記憶装置等のハードウェア資源を用いつつデータを処理することによって実現される。
この発明に係る近似最近傍探索は、コンピュータが記憶装置等のハードウェア資源を用いつつデータを処理することによって実現される。
この発明について詳述する前に、この発明の好ましい態様について説明する。
前記データベース格納部は、M組(Mは2以上の自然数)のハッシュ関数群を用いて各ハッシュ関数群に対応するM組の多次元ハッシュテーブルのそれぞれに各点が登録されてなり、各ハッシュ関数群は複数のハッシュ関数を組み合わせたものであってもよい。このようにすれば、例えばν個のハッシュ関数(ν>M)を分割することなく1つのハッシュ関数群とする場合、各ハッシュテーブルのビンの数をsとすると、s個のビンに対応するデータ格納領域をν組用意する必要があるため、ハッシュテーブルのサイズのオーダーはO(sν)となるところ、ハッシュ関数をM組に分割することによってそのオーダーをO(sν/M)に抑えることができる。即ち、ハッシュテーブルを分割することによって、近似最近傍探索の処理に要する記憶容量を節約することができる。なお、O(sν)は、問題を解くために必要なおおよその計算量の表記方法であって、sが定まったときの計算量がsのν乗のオーダー、即ち、asν+bs(ν-1)+…+ls2+ms+n以下で収まることを表す。ここで、a,b,…,l,m,nは定数である。
この態様は、後述する実施形態における「第2の改良点: ハッシュテーブルの分割」の記載に関連する。
前記データベース格納部は、M組(Mは2以上の自然数)のハッシュ関数群を用いて各ハッシュ関数群に対応するM組の多次元ハッシュテーブルのそれぞれに各点が登録されてなり、各ハッシュ関数群は複数のハッシュ関数を組み合わせたものであってもよい。このようにすれば、例えばν個のハッシュ関数(ν>M)を分割することなく1つのハッシュ関数群とする場合、各ハッシュテーブルのビンの数をsとすると、s個のビンに対応するデータ格納領域をν組用意する必要があるため、ハッシュテーブルのサイズのオーダーはO(sν)となるところ、ハッシュ関数をM組に分割することによってそのオーダーをO(sν/M)に抑えることができる。即ち、ハッシュテーブルを分割することによって、近似最近傍探索の処理に要する記憶容量を節約することができる。なお、O(sν)は、問題を解くために必要なおおよその計算量の表記方法であって、sが定まったときの計算量がsのν乗のオーダー、即ち、asν+bs(ν-1)+…+ls2+ms+n以下で収まることを表す。ここで、a,b,…,l,m,nは定数である。
この態様は、後述する実施形態における「第2の改良点: ハッシュテーブルの分割」の記載に関連する。
さらに、M組のハッシュテーブルは、それぞれのハッシュの次元数が略等しくなるように定められてもよい。このときの基底の選択方法は、基底の分散の和が略等しくなるように定められてもよい。具体的には、分割されたM組のハッシュテーブルのそれぞれにおいて各基底方向のデータの分散の合計し、それらの分散の和がなるべく等しくなるように分割されたハッシュテーブルの各組への基底の割り当てを決定する。一般に分散が大きい基底方向の距離は大きくなり易く、分散が小さい基底方向の距離は小さくなり易い傾向がある。そのため、各ハッシュテーブルの分散の和を合計することはハッシュテーブル毎に計算される距離の大きさを揃える効果がある。本明細書の実施例のように距離計算対象の選択や距離計算の打ち切り(距離計算対象の点が探索範囲内に存在しない場合は距離を一定値で置き換える処理)に用いる探索半径Rを各ハッシュテーブルで共通にした場合は、各ハッシュテーブルの分散の和を均一化することによって、M組に分割された各ハッシュテーブルは同じくらい最近傍候補の決定に寄与すると考えられるため、ハッシュテーブル毎にRに代わるパラメータを設定する必要がなく簡便に計算することができる。
この態様は、後述する実施形態における「第2の改良点: ハッシュテーブルの分割」の記載に関連する。
この態様は、後述する実施形態における「第2の改良点: ハッシュテーブルの分割」の記載に関連する。
また、前記多次元ハッシュテーブルは、各次元に対応するハッシュテーブルを組み合わせてなり、各ハッシュテーブルは各次元に対応する基底をビンで分割し、各ビンの幅は、すべてのビンが等幅とした場合に各ビンに登録されることになる点と、各ビンを代表する代表点との位置の誤差を各ビンについて求め、それらの誤差の和がより小さくなるように各ビンの幅が調整されてもよい。このようにすれば、等分割のビン幅に比べて各点の距離の推定値の真の距離に対する誤差を小さくし、より良い精度で探索領域を決定することができる。各ビンに登録されたベクトルデータの数に多少があると探索領域のバケットに登録されたデータ数の多少によって探索領域内の各点との距離計算の処理時間にバラツキが生じるが、後述する平準化によってそのバラツキが抑えられる。
この態様は、後述する実施形態における「第3の改良点:距離推定に適したデータ空間の分割」の記載に関連する。
この態様は、後述する実施形態における「第3の改良点:距離推定に適したデータ空間の分割」の記載に関連する。
さらに、各ハッシュテーブルは、各点を予め定められたn個のクラスタにクラスタリングしてクラスタごとの代表点を算出し、それぞれのクラスタに属する各点からそのクラスタの代表点までの平均距離を表す分散が予め定められた閾値よりも小さくなるように各ビンの幅が決定されてもよい。このようにすれば、ビンの各点の分散が閾値以下になるように各ビンの幅を決定することにより、各ビンに登録される点の数を適切な範囲に平準化することができる。
この態様は、後述する実施形態における「第3の改良点:距離推定に適したデータ空間の分割」の記載に関連する。
この態様は、後述する実施形態における「第3の改良点:距離推定に適したデータ空間の分割」の記載に関連する。
さらに、前記探索範囲決定部は、各基底の方向におけるベクトルデータの分布から確率密度関数を求め、その確率密度関数を距離の重み付けに用いて前記推定値を決定してもよい。このようにすれば、確率密度関数を用いることによって複雑な分布に対しても適切な平準化が可能になる。
この態様は、後述する実施形態における「第4の改良点:確率密度関数に基づく距離推定」の記載に関連する。
また、前記探索範囲決定部は、クエリを中心として予め定められた探索半径Rの範囲内に代表点のある領域を前記探索領域とするものであってもよい。このようにすれば、探索半径Rを予め定めておくことによって、探索領域を決定することができる。
この態様は、後述する実施形態における「第5の改良点:クエリ周辺のデータ密度を考慮した探索半径の拡張」の記載に関連する。
この態様は、後述する実施形態における「第4の改良点:確率密度関数に基づく距離推定」の記載に関連する。
また、前記探索範囲決定部は、クエリを中心として予め定められた探索半径Rの範囲内に代表点のある領域を前記探索領域とするものであってもよい。このようにすれば、探索半径Rを予め定めておくことによって、探索領域を決定することができる。
この態様は、後述する実施形態における「第5の改良点:クエリ周辺のデータ密度を考慮した探索半径の拡張」の記載に関連する。
あるいは、前記探索範囲決定部は、クエリを中心として探索半径Rの範囲内に代表点のある領域を前記探索領域とし、その探索領域に含まれる点の数が予め定められた数に達するまで探索半径Rを漸次大きくするものであってもよい。このようにすれば、クエリが入るバケットおよびその周辺のバケットに登録されたデータに多少があっても、探索領域に含まれる点の数、即ち最近傍点の候補数が予め定められ数になるように探索領域を決定するので、近似最近傍探索の精度を安定させることができる。また、探索領域内の各点との距離計算に要する処理時間を略一定にすることができる。
この態様は、後述する実施形態における「第5の改良点:クエリ周辺のデータ密度を考慮した探索半径の拡張」の記載に関連する。
この態様は、後述する実施形態における「第5の改良点:クエリ周辺のデータ密度を考慮した探索半径の拡張」の記載に関連する。
さらに、前記データベース格納部は、主成分分析により基底が決定されたν次元空間に各点が射影されてなり、前記探索範囲決定部は、前記クエリと各代表点との距離の各基底方向における距離成分をそれぞれ算出して前記推定値とし、各距離成分の算出の過程において、各距離成分の和が定められた探索半径R内であることを制約条件とし、前記主成分分析において大きな固有値を有する基底の順に各領域の代表点が半径R内にあるかを判断する分枝限定法を適用して前記探索領域になり得ない領域を刈り込み、前記探索領域を決定してもよい。このようにすれば、分散の大きな基底方向から順に代表点が半径R以遠の領域を刈り込んで前記探索領域から除外するので、各領域が探索半径R内にあるかを総当たり的に判断する場合に比べると短時間で探索領域を決定することができる。
この態様は、後述する実施形態における「第1の改良点:ハッシュに基づく点対バケットの距離推定」の記載に関連する。
この態様は、後述する実施形態における「第1の改良点:ハッシュに基づく点対バケットの距離推定」の記載に関連する。
前記データベース格納部は、各点にν個(νは2以上の整数)のハッシュ関数をそれぞれ適用してν個のインデックスを算出し、ν個の基底で構成され、各基底に沿って複数のビンに分割されかつ各インデックスによって何れかのビンが特定されるν次元空間に各点を射影することにより生成され、各ビンへの各点の登録がハッシュテーブルを用いて表されたものであってもよい。
この態様は、後述する実施形態における「第1の改良点:ハッシュに基づく点対バケットの距離推定」の記載に関連する。
この態様は、後述する実施形態における「第1の改良点:ハッシュに基づく点対バケットの距離推定」の記載に関連する。
前記データベース格納部は、ν次元空間に各点が射影され、前記多次元ハッシュテーブルは、前記ν次元空間を張るν本の直交基底のうちP本の直交基底が張る部分空間をM組選択し、各部分空間にk-means法を用いてその部分空間が分割され、かつ、各領域内の分散が大きい部分空間ほど分割の数が大きく設定されてなり、前記検索範囲決定部は、各基底の方向におけるベクトルデータの分布から求めた確率密度関数に従って各領域に存在する点とクエリとの二乗距離の推定誤差が各基底方向においてそれぞれ最小化されるように前記推定値を決定してもよい。
この態様は、後述する実施形態における「第6の改良点」の記載に関連する。
この発明の好ましい態様は、ここで示した複数の態様のうち何れかを組み合わせたものも含む。
この態様は、後述する実施形態における「第6の改良点」の記載に関連する。
この発明の好ましい態様は、ここで示した複数の態様のうち何れかを組み合わせたものも含む。
《この発明を実行するハードウェアの構成例》
ここでは、近似最近傍探索の具体的な応用の一態様として画像認識装置について述べる。
図20は、この発明の近似最近傍探索装置の応用例としての画像認識装置示すブロック図である。この発明に係る近似最近傍探索は、図20に示す画像認識装置上でコンピュータが記憶装置等のハードウェア資源を用いつつ画像データを処理することによって実現される。画像認識装置のハードウェアは、例えば、CPUと、前記CPUが実行する処理手順を示すプログラムを格納したハードディスク装置などの記憶装置、前記CPUにワークエリアを提供するRAM、データを入出力する入出力回路などから構成される。より具体的には、上記構成を有するパーソナルコンピュータによって画像認識装置が実現されてもよい。あるいは、機器に組み込まれ、上記構成を有するマイクロコンピュータから構成されてもよい。
ここでは、近似最近傍探索の具体的な応用の一態様として画像認識装置について述べる。
図20は、この発明の近似最近傍探索装置の応用例としての画像認識装置示すブロック図である。この発明に係る近似最近傍探索は、図20に示す画像認識装置上でコンピュータが記憶装置等のハードウェア資源を用いつつ画像データを処理することによって実現される。画像認識装置のハードウェアは、例えば、CPUと、前記CPUが実行する処理手順を示すプログラムを格納したハードディスク装置などの記憶装置、前記CPUにワークエリアを提供するRAM、データを入出力する入出力回路などから構成される。より具体的には、上記構成を有するパーソナルコンピュータによって画像認識装置が実現されてもよい。あるいは、機器に組み込まれ、上記構成を有するマイクロコンピュータから構成されてもよい。
図20で、例えばデジタルカメラで撮影された画像のデータが、通信あるいは記憶媒体を介して画像認識装置に入力される。特徴点抽出部11は、入力された画像のデータに含まれる対象物のパターンから公知の手法を用いて特徴ベクトルを抽出するブロックである。図20の構成では、特徴ベクトルは画像の局所的な特徴を表し、1つの画像から複数箇所の局所特徴をそれぞれ表す複数の特徴ベクトルを抽出するものとしている。なお、別の態様として、一つの画像を一つの特徴ベクトルで表す手法もある。
探索範囲決定部13は、各特徴ベクトルにハッシュ関数を適用して後述するハッシュテーブル15hのインデックスを算出し、ハッシュテーブル15hが有するビン(複数のハッシュ関数を用いる場合はバケット)を参照する処理を行う。
探索範囲決定部13は、各特徴ベクトルにハッシュ関数を適用して後述するハッシュテーブル15hのインデックスを算出し、ハッシュテーブル15hが有するビン(複数のハッシュ関数を用いる場合はバケット)を参照する処理を行う。
画像データベース15に画像のデータを登録するとき、前記CPUはその画像を識別する画像IDを付して画像データベース15に格納し、さらにその画像から抽出された特徴ベクトルを画像IDと関連付けてハッシュテーブル15hに登録する。詳細には、前記ハッシュ関数を適用して各特徴ベクトルを複数のビンの何れかに分類し、そのビンに登録しておく。つまり、各特徴ベクトルにハッシュ関数を適用してインデックスを算出し、各特徴ベクトルが前記インデックスに応じたビンまたはバケットに登録された画像データベース15を作成する。登録時に用いるハッシュ関数は、探索範囲決定部13がインデックスの算出に用いるハッシュ関数と同一である。
以上のようにして画像データベース15に画像が登録された後、クエリとして画像のデータが入力されると、画像認識装置は、画像データベース15に格納された画像の中からクエリの画像に最も近い画像を探索し、認識結果として出力する。ここで、最も近い画像の探索は、特徴ベクトルどうしを比較し、クエリの各特徴ベクトルについて、最近傍のベクトルを探索することにより実現される。この最近傍ベクトルの探索に近似最近傍探索が適用される。
クエリとしての画像が与えられると、特徴点抽出部11として前記CPUは、クエリから特徴ベクトルを抽出する。以下、抽出された特徴ベクトルをクエリベクトルと呼び、ハッシュテーブル15hに登録されている特徴ベクトルを参照ベクトルと呼ぶ。
探索範囲決定部13として前記CPUは各クエリベクトルに前述したハッシュ関数を適用してインデックスを得る。そして前記CPUは、得られたインデックスで特定されるハッシュテーブル15hのビンを参照し、そのビンに登録されている参照ベクトルをクエリベクトルに対する最近傍の候補とする。このようにクエリベクトルにハッシュ関数を適用してビンを参照し、そのビンに登録された参照ベクトルを最近傍の候補とする処理は、近似最近傍探索の一段目の処理に該当する。最近傍候補、即ち距離計算の対象を絞り込む処理である。探索範囲決定部13およびハッシュテーブル15hは、近似最近傍探索の一段目の処理を具現化する構成といえる。ハッシュ関数は、参照先のビンが最近傍である確率が高い参照ベクトルを含む一方で、各ビンに登録される参照ベクトルの数が少なくなるようにバランスを考慮して、予め定められる。
探索範囲決定部13として前記CPUは各クエリベクトルに前述したハッシュ関数を適用してインデックスを得る。そして前記CPUは、得られたインデックスで特定されるハッシュテーブル15hのビンを参照し、そのビンに登録されている参照ベクトルをクエリベクトルに対する最近傍の候補とする。このようにクエリベクトルにハッシュ関数を適用してビンを参照し、そのビンに登録された参照ベクトルを最近傍の候補とする処理は、近似最近傍探索の一段目の処理に該当する。最近傍候補、即ち距離計算の対象を絞り込む処理である。探索範囲決定部13およびハッシュテーブル15hは、近似最近傍探索の一段目の処理を具現化する構成といえる。ハッシュ関数は、参照先のビンが最近傍である確率が高い参照ベクトルを含む一方で、各ビンに登録される参照ベクトルの数が少なくなるようにバランスを考慮して、予め定められる。
参照先のビンに唯一つの参照ベクトルが登録されている場合、前記CPUは、その参照ベクトルに対応付けられた画像IDを認識結果の候補とする。一方、参照先のビンに複数の参照ベクトルが登録されている場合、最近傍点決定部17として前記CPUは、それらの参照ベクトルのうちで最近傍ベクトルを決定する。詳細には、前記CPUは、クエリベクトルと参照先のビンに登録された参照ベクトルとの距離計算をそれぞれ行う。そして、クエリベクトルに最も距離の近い参照ベクトルを最近傍ベクトルとして決定する。その参照ベクトルに関連付けられた画像IDを認識結果の候補とする。最近傍点決定部17は、近似最近傍探索の二段目の処理を具現化する構成に該当する。
前記CPUは、一つのクエリが与えられると、そのクエリから抽出された複数のクエリベクトルのそれぞれについて最近傍の参照ベクトルを求め、その参照ベクトルに関連付けられた画像IDを認識結果の候補とする。
投票部19として前記CPUは、各クエリベクトルについて認識結果の候補とされた画像IDの投票を行う。投票の際に各画像ID(画像1から画像n)の得票数を記憶する投票テーブル21が設けられている。このように投票による多数決処理を経て認識結果を得る利点は、いくつかのクエリベクトルが誤った画像IDに対応付けられても、最終的に正しい認識結果が得られる可能性が高いことである。画像の撮影、特徴ベクトルの抽出の各過程は幾何学的歪み、解像度変換、明暗の変化等に伴う誤差要因を含んでいる。また、近似最近傍探索それ自体が処理時間とのトレードオフとして探索誤りを許容するために誤差要因を含む。よって、全てのクエリベクトルが正しい画像IDに対応付けられるとは限らない。高精度の画像認識を実現するうえでこのような多数決処理は有効である。
画像選択部23として前記CPUは、投票テーブル21を参照して最大得票数を得た画像IDに係る画像を最終的な認識結果とする。
投票部19として前記CPUは、各クエリベクトルについて認識結果の候補とされた画像IDの投票を行う。投票の際に各画像ID(画像1から画像n)の得票数を記憶する投票テーブル21が設けられている。このように投票による多数決処理を経て認識結果を得る利点は、いくつかのクエリベクトルが誤った画像IDに対応付けられても、最終的に正しい認識結果が得られる可能性が高いことである。画像の撮影、特徴ベクトルの抽出の各過程は幾何学的歪み、解像度変換、明暗の変化等に伴う誤差要因を含んでいる。また、近似最近傍探索それ自体が処理時間とのトレードオフとして探索誤りを許容するために誤差要因を含む。よって、全てのクエリベクトルが正しい画像IDに対応付けられるとは限らない。高精度の画像認識を実現するうえでこのような多数決処理は有効である。
画像選択部23として前記CPUは、投票テーブル21を参照して最大得票数を得た画像IDに係る画像を最終的な認識結果とする。
以上が画像認識装置の構成である。このうち、クエリベクトルにハッシュ関数を適用する探索範囲決定部13、特徴ベクトルを体系化して格納するハッシュテーブル15h、同一ビンに登録された参照ベクトルのうちで最近傍ベクトルを決定する最近傍点決定部17は、近似最近傍探索に係る構成であり、最近傍探索装置を構成する要素といえる。なお、図20の画像認識装置は認識結果として画像を出力するものであるため、例えば最近傍点決定部17は最近傍ベクトルに関連付けられた画像IDを出力する。このうち、近似最近傍探索装置としての構成部分は、入力された特徴ベクトルに対してハッシュテーブルに登録された特徴ベクトルの中から最近傍の特徴ベクトルを決定して出力するものである。特徴ベクトルに関連付けて画像IDを格納する構成部分および最近傍ベクトルに関連付けられた画像IDを出力する構成部分は含まない。なお、図20の画像認識装置は最近傍探索の応用例であって、最近傍探索装置が扱うデータは特徴ベクトルに限定されるものではない。
《従来の代表的な近似最近傍探索手法》
次に、従来の代表的な近似最近傍探索手法について述べる。これにより、後述するこの発明の実施形態がより理解しやすくなるであろう。
〈1. ANN〉
木構造を用いる手法の中で最も代表的なものの一つがApproximate Nearest Neighbor(ANN)である。ANNは2分木をベースとしている。木の構築ではデータ空間を階層的に2等分していき、葉に入る点が1つになるまで分割を繰り返す。クエリが与えられると、木を辿り、到達した葉に登録されているデータと距離計算を行う。その距離がrであるとすると、分割された各領域の最も近いところがクエリから半径r/(1+ε)に入る領域を探索領域とする。εは近似度パラメータであり、ε=0であれば、rより近い点が存在する可能性のある領域を全て探索するので、必ず真の最近傍点を得ることができる。
次に、従来の代表的な近似最近傍探索手法について述べる。これにより、後述するこの発明の実施形態がより理解しやすくなるであろう。
〈1. ANN〉
木構造を用いる手法の中で最も代表的なものの一つがApproximate Nearest Neighbor(ANN)である。ANNは2分木をベースとしている。木の構築ではデータ空間を階層的に2等分していき、葉に入る点が1つになるまで分割を繰り返す。クエリが与えられると、木を辿り、到達した葉に登録されているデータと距離計算を行う。その距離がrであるとすると、分割された各領域の最も近いところがクエリから半径r/(1+ε)に入る領域を探索領域とする。εは近似度パラメータであり、ε=0であれば、rより近い点が存在する可能性のある領域を全て探索するので、必ず真の最近傍点を得ることができる。
〈2. FLANN〉
Fast Library for Approximate Nearest Neighbors(FLANN)は与えたデータベースに合った近似最近傍探索手法とそのパラメータチューニングを提供するライブラリである。このライブラリには、提案されている手法の中で高い性能を持つrandamized kd-tree(例えば、非特許文献12参照)と階層的k-means(例えば、非特許文献13参照)に加えて全数探索が採用されている。
Fast Library for Approximate Nearest Neighbors(FLANN)は与えたデータベースに合った近似最近傍探索手法とそのパラメータチューニングを提供するライブラリである。このライブラリには、提案されている手法の中で高い性能を持つrandamized kd-tree(例えば、非特許文献12参照)と階層的k-means(例えば、非特許文献13参照)に加えて全数探索が採用されている。
randamized kd-treeは複数の木から再近傍候補を選択する手法である。ANNのような通常のkd-treeを用いた方法では、着目するデータの要素を順に変えながら空間を2分割していくことで木構造を構成する。このとき、高次元データに対しては高い精度を得ようとすると構造的に最近傍点が含まれる確率の低い葉にまで探索範囲広げる必要がある。しかし、これでは木の巡回に要する処理時間や多くの無駄な距離計算をすることになる。そこで、randamized kd-treeでは主成分分析を行い、距離計算への寄与度が高い上位D次元の基底にのみ着目してkd-treeを構成する。このとき、各階層での基底選択をランダムに行い複数の木を構成する。従って、探索時には一つ一つの木の探索範囲が小さくても複数の木を辿ることで高い精度を確保することが可能になり、通常のkd-treeよりも高い性能を得ることができる。
階層的k-meansはその名の通り、各ノードで自身に所属する点をk-meansによってクラスタリングし、各階層で空間をクラスタごとに分割する。
階層的k-meansはその名の通り、各ノードで自身に所属する点をk-meansによってクラスタリングし、各階層で空間をクラスタごとに分割する。
〈3. LSH〉
Locality Sensitive Hashing(LSH)はハッシュを利用した近似最近傍探索手法の中で最も代表的な手法の一つである。ここではLSHの中でもこの発明に関連する、ベクトル空間で用いることができるLSH(例えば、非特許文献8参照)について述べる。LSHは、複数のハッシュ関数を利用して、クエリの近傍にあると考えられる点を選出し、それらの点に対してのみ距離計算を行う。即ち、データ空間をランダムに生成された複数の基底の方向に等間隔に分割することで、空間をバケットと呼ばれる領域に分割してインデクシングを施す。
Locality Sensitive Hashing(LSH)はハッシュを利用した近似最近傍探索手法の中で最も代表的な手法の一つである。ここではLSHの中でもこの発明に関連する、ベクトル空間で用いることができるLSH(例えば、非特許文献8参照)について述べる。LSHは、複数のハッシュ関数を利用して、クエリの近傍にあると考えられる点を選出し、それらの点に対してのみ距離計算を行う。即ち、データ空間をランダムに生成された複数の基底の方向に等間隔に分割することで、空間をバケットと呼ばれる領域に分割してインデクシングを施す。
図21は、従来の近似最近傍探索の一手法であるLSHの説明図である。図21(a)は、データ空間がランダムに生成された2つの基底a1およびa2の方向に沿ってそれぞれハッシュテーブルのビンで等分割された様子を示している。軸a1に沿って分割された各領域は基底a1に係るハッシュ関数hj1によってインデクシングされたビンであり、軸a2に沿って分割された各領域は基底a2に係るハッシュ関数hj2によってインデクシングされたビンである。各軸にインデックスの値を示している。そして、それら2種類のビンが交差するセル状の1つ1つの領域、即ち2次元ハッシュテーブルの各次元のビンが交差する積領域がバケットである。各バケットの数値は、ハッシュ関数hj1およびhj2のインデックスの値を示している。
探索時にはクエリと同じバケットに属する点を最近傍候補とする。しかし、これだけでは真の最近傍点を候補から漏らす可能性が高いため、この処理を数回繰り返すことで候補を増やして精度を上げる工夫をしている。図21(b)は3回の射影によって得られた探索領域の様子を表す。
非特許文献8のLSHでは次式のようなハッシュ関数群を用いる。

ただし、xは任意の点、aiは各次元の要素の値がガウス分布から独立に選ばれたベクトル、Wはハッシュ幅であり、biは区間[0,W]から一様に選ばれた実数である。そして、最近傍候補はクエリqに対して∃(gj(q)=gj(p))j=1,…,Lとなる点pである。LSHが近似最近傍点を求めることができるのは局所性に鋭敏な(Locality Sensitive)ハッシュ関数を用いているためである。局所性に鋭敏なハッシュ関数とは、距離が近い点同士は同じハッシュ値(インデックス)を取る確率が高く、距離が遠い点同士は同じハッシュ値を取る確率が低いハッシュ関数である。
式(2)のごとく、LSHではハッシュ関数hjiをk個組み合わせてハッシュ関数群Hjを作る。これは、k次元のハッシュテーブルに対応する。図21(a)の灰色の領域は、k=2(射影空間が2次元)のときクエリにhj1とhj2の2つのハッシュ関数を適用して求めたビンの積領域(共通の領域)、言い換えるとクエリにハッシュ関数群Hjを適用して求めたバケットである。このバケットが一つの関数群Hjに係る距離計算の対象領域である。このようなハッシュ関数群HjをL個(L組)作り、最終的にL個の領域を組み合わせた領域をクエリとの距離計算の対象領域とする。図21(b)はL=3の場合を示している。LSHは、上記の手順で距離計算の対象を削減して処理を高速化する。
LSHはデータの分布に依らないランダムな斜交基底に射影を行うため、データ空間における距離を射影空間が保持するという観点から効率的でない。
LSHはデータの分布に依らないランダムな斜交基底に射影を行うため、データ空間における距離を射影空間が保持するという観点から効率的でない。
〈4. SH〉
バイナリ符号のハッシュ関数を用いた手法の中でも代表的なSpectral Hashing(SH)の概要について述べる。SHはハッシュを用いたもの中で良い性能が得られるといわれている手法である。SHはデータ空間の主成分を上からいくつか選択し、ハミング空間への射影を行う。そして、射影されたハミング空間における距離(ハミング距離)が閾値以下のものを最近傍候補とする。即ち、上位の主成分基底にのみ着目して各サンプルをバイナリ符号に変換し、クエリとのハミング距離によって最近傍候補を選択する。SHの符号化はデータ空間の一様分布を仮定し、分割された領域がなるべく直方体に近い形で分割されるように空間を分割し、各バケットにバイナリ符号を与える。
バイナリ符号のハッシュ関数を用いた手法の中でも代表的なSpectral Hashing(SH)の概要について述べる。SHはハッシュを用いたもの中で良い性能が得られるといわれている手法である。SHはデータ空間の主成分を上からいくつか選択し、ハミング空間への射影を行う。そして、射影されたハミング空間における距離(ハミング距離)が閾値以下のものを最近傍候補とする。即ち、上位の主成分基底にのみ着目して各サンプルをバイナリ符号に変換し、クエリとのハミング距離によって最近傍候補を選択する。SHの符号化はデータ空間の一様分布を仮定し、分割された領域がなるべく直方体に近い形で分割されるように空間を分割し、各バケットにバイナリ符号を与える。
図22は、従来の近似最近傍探索の一手法であるSHの説明図であり、データ空間が2つの主成分基底pv1およびpv2からなる2次元のハミング空間に射影された様子を示したものである。各軸にインデックスをバイナリ符号で示している。各バケットの符号は、軸pv1および軸pv2のインデックスを組み合わせたものである。クエリは符号111のバケットに属する。灰色の領域はハミング距離の上限を1とした場合のクエリに対する探索領域を表したものである。即ち、符号111のバケットに加えて、符号111と1つの符号のみが異なる符号110、101、011のバケットが探索領域となる。
SHはデータ空間を主成分基底に射影するため、射影後も元の距離が保持されやすいといえるが、射影した空間での距離がハミング距離で表されるため、ユークリッド距離との誤差が生じる。例えば、図22でクエリが射影されるバケット111から遠い011の領域が最近傍候補となるといった問題がある。
SHはデータ空間を主成分基底に射影するため、射影後も元の距離が保持されやすいといえるが、射影した空間での距離がハミング距離で表されるため、ユークリッド距離との誤差が生じる。例えば、図22でクエリが射影されるバケット111から遠い011の領域が最近傍候補となるといった問題がある。
〈5. 佐藤らの手法〉
佐藤らの手法(例えば、非特許文献11参照)は、クエリが入ったバケットの重心から各バケットの重心までの距離(バケット距離)の概算値を求めてクエリから各点の距離の推定値とし、クエリからの距離が小さい点を探し出そうという手法である。
佐藤らの手法では、データ空間を任意の正規直交基底に対して共通の分割幅で等分した空間に射影し、これを多次元ハッシュによって表現する。この処理は、データをスカラー量子化することに等しく、射影空間上の距離は、元のデータ空間の距離(真の距離)をよく反映したデータ構造となっている。探索時には、クエリが属するバケットと各点が属するバケットとの距離を求めることで、クエリを中心とする近似的な超球領域から最近傍候補を抽出する。
佐藤らの手法(例えば、非特許文献11参照)は、クエリが入ったバケットの重心から各バケットの重心までの距離(バケット距離)の概算値を求めてクエリから各点の距離の推定値とし、クエリからの距離が小さい点を探し出そうという手法である。
佐藤らの手法では、データ空間を任意の正規直交基底に対して共通の分割幅で等分した空間に射影し、これを多次元ハッシュによって表現する。この処理は、データをスカラー量子化することに等しく、射影空間上の距離は、元のデータ空間の距離(真の距離)をよく反映したデータ構造となっている。探索時には、クエリが属するバケットと各点が属するバケットとの距離を求めることで、クエリを中心とする近似的な超球領域から最近傍候補を抽出する。
図23は、従来の近似最近傍探索の一手法である佐藤らの手法において各バケットの距離を定める手順を示す説明図である。図23で、射影空間は縦軸と横軸の2つの正規直交基底で分割されている。即ち、ハッシュの次元数ν=2である。縦横の各基底に対して共通の分割幅でビンに分割されている。縦軸と横軸に付された数値はインデックスである。セル状になっている一つ一つの区画がビンの積領域としてのバケットである。各バケットに振られている数字の並び11~33は、バケットを作るビンのインデックスを組み合わせたものである。この数字の並びはデータ空間内のバケットの位置を示す位置ベクトルとして考えることができる。このインデックスの並びつまりバケットの位置ベクトルから、バケット間の距離Dが定義される。
クエリが入ったバケットが分かれば、そのバケットから他の何れかのバケットまでの距離はバケットのインデックスを用いて知ることができる。よって、最近傍点の探索は、バケット距離の小さいバケットから順にバケットに含まれるデータを参照していけばよい。このようにすれば、クエリを中心とした超球領域の探索が実現できる。そして、クエリからの距離の概算値が小さい点のみを距離計算対象とすることができる。
いま、xを任意の点、Ψiを正規直交基底、Wを分割幅(ビンの幅)とすると、ν次元ハッシュ関数Hは次のようになる。


ここで、B(p)を任意の点pが属するバケットの重心であるとすると、2点p1,p2がそれぞれ属するバケットのバケット距離は次のように表される。

図23を例に探索領域の選択について説明する。図23は、クエリにハッシュ関数を適用したときのビンのインデックスが〈2,2〉のときの例である。まず、クエリと同じインデックスのバケットに登録されている点と距離計算を行う。次に、バケット距離1のバケットを探索する。図23ではインデックス〈1,2〉、〈2,1〉、〈2,3〉、〈3,2〉のバケットである。これらのバケットを順に探索していく。十分な数のバケットを探索したと判断すれば、探索を終了する。一方、まだバケットの数が不十分であると判断すればさらに遠いバケットに探索範囲を広げていく。図23では、インデックス〈1,1〉、〈3,1〉、〈3,3〉、〈1,3〉のバケットである。
図1は、従来の佐藤らの手法における距離推定の一例を示す説明図である。図1で、縦軸と横軸は、図23と同様に二次元の正規直交基底である。星印はクエリを表す。図23と異なり、各軸の数字はクエリを基準(原点)としたときの左右方向および上下方向におけるバケット距離の重みを表している。図1では、重みはクエリの入ったビンからのユークリッド2乗距離としている。また、バケット内の数字は推定されたバケット間の距離を表す。バケット間の距離は、左右方向および上下方向の重みの和である。探索したバケットの数が十分か否かの判定として、探索時には探索半径Rを与え、D(B(q),B(p))≦Rを満たす点pを最近傍候補とする。仮に探索半径をR=2とすれば、推定距離が2以下の9つのバケットが最近傍候補として選択される。Rはクエリに応じて決めてもよい。
この手法では、データ空間の次元数に対して射影空間の次元数が小さいと概算距離の精度が低下する。しかし、ハッシュサイズはハッシュの次元数νに対して指数関数的に大きくなるため、高次元データに対して精度を保持するためには膨大なハッシュサイズが必要となる。高次元データに対してハッシュの次元数νを大きくすることは難しく、結果的に高次元データに対して十分な概算距離の精度を得ることができない。また、ハッシュサイズが大きくなりすぎると、最近傍探索の精度を維持するために多くのバケットを参照する必要があり、最近傍候補の抽出処理に多くの時間がかかる。
〈6.IVFADCとIMI〉
Inverted File with Asymmetric Distance Calculation(IVFADC)やその改良手法であるInveted Multi-Index(IMI)は、k-means法によってデータ空間を粗く量子化(粗量子化)することで、空間を分割(インデクシング)する。このとき粗量子化により得られる各クラスター(分割された領域)の代表値(セントロイド)の集合をCとし、クラスターの総数、即ちセントロイドの総数を|C|=Gとする。このとき、クエリから各領域に属する点までの距離の期待値(推定距離)はその領域のセントロイドまでの距離である。従って、クエリに近いセントロイドを求め、その領域に属する点を最近傍候補とすれば効率がよい。
1.IVFADCの最近傍候補選択
IVFADCは粗量子化に単純なベクトル量子化を用いる(例えば、H. Jegou, M. Douze, and C. Schmid, "Product quantization for nearest neighbor search," IEEE Trans. TPAMI, vol.33, no.1, pp.117-128, 2011参照)。最近傍候補の選択精度を向上させるには空間を細かく分割する(Gを大きくする)必要がある。しかし、最近傍候補選択の計算コストはO(G)となり、大きな値をとることができない。従って、最近傍候補選択の精度が十分に得られないという問題がある。
2.IMIの最近傍候補選択
そこでIVFADVの改良手法として提案されたのがIMIである(例えば、A. Babenko and V. Lempitsky, "The inverted multi-index," Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp.3069-3076, 2012参照)。粗量子化ではベクトルxを2つの部分ベクトルU1(x),U2(x)に分割するプロダクト量子化を行う。得られた部分セントロイドの集合をC1,C2、その要素数|C1|=|C2|=をgとする。セントロイドの集合はC=C1×C2で得られ、その数はG=g2となる。C1のi番目とC2のj番目の要素を並べてできるセントロイドをcij={ci 1,cj 2}と定義すると、クエリqとcijに属する点までの推定二乗距離Fij(q)は、クエリから第m部分セントロイドのi番目の要素までの距離を

として、次式で表される。

従って、セントロイドをクエリに近い順に選択する問題は、2つの部分距離リスト

の中から1つずつ選択して、その和Fijが小さくなるiとjの組み合わせを探索する問題に帰着する。IMIではこの問題を Multi-Sequenceアルゴリズムと呼ばれる組み合わせ探索法を用いて解く。このアルゴリズムは、ある時点で最も距離が小さい添え字の組み合わせを生成する毎に、次に小さい距離の組み合わせを生成する可能性がある添え字の組としての添え字候補を追加し、その中から次の組み合わせを選択する処理を繰り返す。そして、得られた最近傍候補数がL点に達した時点で探索を終了する。
空間の分割数Gが等しいとき、プロダクト量子化はベクトル量子化に比べて精度は悪くなる。しかし、プロダクト量子化を用いることでMulti-Sequence アルゴリズムが適用でき、計算コストが

で最近傍候補を得られるため、探索の高速化が実現できる。上述の文献"The inverted multi-index,"では、IVFADCに比べて高速に解を得られることが報告されている。
以上、従来の代表的な近似最近傍探索手法について述べた。
〈6.IVFADCとIMI〉
Inverted File with Asymmetric Distance Calculation(IVFADC)やその改良手法であるInveted Multi-Index(IMI)は、k-means法によってデータ空間を粗く量子化(粗量子化)することで、空間を分割(インデクシング)する。このとき粗量子化により得られる各クラスター(分割された領域)の代表値(セントロイド)の集合をCとし、クラスターの総数、即ちセントロイドの総数を|C|=Gとする。このとき、クエリから各領域に属する点までの距離の期待値(推定距離)はその領域のセントロイドまでの距離である。従って、クエリに近いセントロイドを求め、その領域に属する点を最近傍候補とすれば効率がよい。
1.IVFADCの最近傍候補選択
IVFADCは粗量子化に単純なベクトル量子化を用いる(例えば、H. Jegou, M. Douze, and C. Schmid, "Product quantization for nearest neighbor search," IEEE Trans. TPAMI, vol.33, no.1, pp.117-128, 2011参照)。最近傍候補の選択精度を向上させるには空間を細かく分割する(Gを大きくする)必要がある。しかし、最近傍候補選択の計算コストはO(G)となり、大きな値をとることができない。従って、最近傍候補選択の精度が十分に得られないという問題がある。
2.IMIの最近傍候補選択
そこでIVFADVの改良手法として提案されたのがIMIである(例えば、A. Babenko and V. Lempitsky, "The inverted multi-index," Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp.3069-3076, 2012参照)。粗量子化ではベクトルxを2つの部分ベクトルU1(x),U2(x)に分割するプロダクト量子化を行う。得られた部分セントロイドの集合をC1,C2、その要素数|C1|=|C2|=をgとする。セントロイドの集合はC=C1×C2で得られ、その数はG=g2となる。C1のi番目とC2のj番目の要素を並べてできるセントロイドをcij={ci 1,cj 2}と定義すると、クエリqとcijに属する点までの推定二乗距離Fij(q)は、クエリから第m部分セントロイドのi番目の要素までの距離を
空間の分割数Gが等しいとき、プロダクト量子化はベクトル量子化に比べて精度は悪くなる。しかし、プロダクト量子化を用いることでMulti-Sequence アルゴリズムが適用でき、計算コストが
以上、従来の代表的な近似最近傍探索手法について述べた。
《この発明に係る距離推定の手法》
以下、図面を用いてこの発明をさらに詳述する。なお、以下の説明は、すべての点で例示であって、この発明を限定するものと解されるべきではない。
近似最近傍探索が高精度かつ高速であるためには、最近傍候補の抽出において真の最近傍点を漏らさずに候補を減らし、またこの処理自体が高速であることが重要となる。このとき、クエリを中心とする超球領域を探索して最近傍候補とすることができれば真の最近傍点を漏らすことがなく理想である。しかし、データ空間が高次元である場合、距離計算を行わずにこれを実現するのは容易ではない。ハッシュのインデックスに基づく概算距離が元の空間での距離をうまく保持していれば、インデックスに基づいてクエリからの距離を推定できる可能性がある。しかし、従来手法の多くは射影後の空間における距離が元の空間における距離を十分に保持することができず、推定距離が真の距離の大小関係を十分に保持することができない。その場合、探索の精度を上げるためには多くの最近傍候補を確保する必要があり、高速に解を得ることができない。
以下、図面を用いてこの発明をさらに詳述する。なお、以下の説明は、すべての点で例示であって、この発明を限定するものと解されるべきではない。
近似最近傍探索が高精度かつ高速であるためには、最近傍候補の抽出において真の最近傍点を漏らさずに候補を減らし、またこの処理自体が高速であることが重要となる。このとき、クエリを中心とする超球領域を探索して最近傍候補とすることができれば真の最近傍点を漏らすことがなく理想である。しかし、データ空間が高次元である場合、距離計算を行わずにこれを実現するのは容易ではない。ハッシュのインデックスに基づく概算距離が元の空間での距離をうまく保持していれば、インデックスに基づいてクエリからの距離を推定できる可能性がある。しかし、従来手法の多くは射影後の空間における距離が元の空間における距離を十分に保持することができず、推定距離が真の距離の大小関係を十分に保持することができない。その場合、探索の精度を上げるためには多くの最近傍候補を確保する必要があり、高速に解を得ることができない。
そこで、発明者らは、概算距離が真の距離の大小関係をよく反映している佐藤らの手法に着目し、さらに改良された近似最近傍探索手法を提案する。これによって、従来の手法と比べて高精度かつ高速な距離推定が可能になり、ひいては近似最近傍探索の処理全体の高速化が実現される。
この発明は、近似最近傍探索の一段目の処理における最近傍候補の選択精度を向上させ、最近傍候補の選択を高速に実行するために、距離推定の手法および適応的な探索範囲の決定手法に特に着目している。
この発明は、近似最近傍探索の一段目の処理における最近傍候補の選択精度を向上させ、最近傍候補の選択を高速に実行するために、距離推定の手法および適応的な探索範囲の決定手法に特に着目している。
佐藤らの手法における距離推定に対する第1の改良点は、ハッシュに基づき点対バケットで距離を推定する手法である。第2の改良点は、分割されたハッシュテーブルを用いる手法である。そして、第3の改良点は、距離推定に適した空間分割の手法である。第4の改良点は、確率密度関数に基づく距離推定の手法である。さらに、第5の改良点は適応的探索範囲に係るものであり、クエリ周辺のデータ密度を考慮した探索領域の拡張である。各手法は、単独で適用することもできるが、全部または一部を組み合わせて適用することができる。以下、各手法の詳細について述べる。併せて、各手法の有効性を示す実験例について述べる。
以下の説明では、前述した改良点のうち第1の点対バケットの距離推定および第2のハッシュテーブルの分割を適用した近似最近傍探索手法をBucket Distance HashingあるいはBDHと呼ぶ。さらに、BDHに第3の改良点である距離推定に適した空間分割を組み合わせた手法をk-means BDHと呼ぶ。そして、さらにk-means BDHに第4の改良点である確率密度関数に基づく距離推定を組み合わせた手法をk-means BDH Pと呼ぶ。また、k-means BDH Pに第5の改良点である適応的探索範囲を組み合わせた手法をk-means BDH PCと呼ぶ。
〈第1の改良点:ハッシュに基づく点対バケットの距離推定〉
1つ目の改良された手法は、主として距離推定の精度向上に係るものである。佐藤らの手法ではクエリとデータのそれぞれが属するバケット間の距離、すなわちバケット対バケットの距離を推定した。ここでは厳密なクエリの位置から各データが属するバケットへの距離、すなわち点対バケットの距離を推定することにより、同じデータ構造のまま距離推定の精度を向上させる手法を提案する。
1つ目の改良された手法は、主として距離推定の精度向上に係るものである。佐藤らの手法ではクエリとデータのそれぞれが属するバケット間の距離、すなわちバケット対バケットの距離を推定した。ここでは厳密なクエリの位置から各データが属するバケットへの距離、すなわち点対バケットの距離を推定することにより、同じデータ構造のまま距離推定の精度を向上させる手法を提案する。
この手法は、ハッシュ関数として佐藤らの手法と同じ式(5)を用いる。つまり、2点p1,p2についてp1の座標とp2と同じバケットに属する点の座標の期待値を計算して代表点を定める。具体的には、代表点の座標がバケットに属する点の座標の期待値になるように代表点を定める。すなわち、代表点はバケットの重心になる。そして、p1の座標と
p2が属するバケットの代表点の座標の2点間のユークリッド距離を計算し、これを概算距離とする。まず、基底i方向のユークリッド2乗距離の期待値を考えると次のようになる。

また,各基底が独立であるという仮定からv 次元空間におけるユークリッド2乗距離の期待値は次のようになる。
p2が属するバケットの代表点の座標の2点間のユークリッド距離を計算し、これを概算距離とする。まず、基底i方向のユークリッド2乗距離の期待値を考えると次のようになる。

点p1とp2が属するバケットB(p2)の間の距離、つまり点対バケットの距離は次のように表される。

式(7)で、(hi(p2)+1/2)はバケットB(p2)の重心のΨi方向の座標を表しており、式(7)の距離はクエリとバケット重心の距離に等しい。クエリの位置が特定されている分、式(6)よりも精度の高い距離推定を実現している。推定距離の誤差分散は、バケット対バケットの距離を推定する佐藤らの手法に比べて1/W2となる。
ここで後の説明のために式(7)の距離をW倍して次式のように置き直す。

ここで、BDi(p1,B(p2))は、点p1とバケットB(p2)の重心との第i次元の基底方向における距離を表す。
この置き直しによって推定される距離がW倍されることになるが、最近傍候補の選択は相対的な距離に基づいて行われるため、結果は変わらない。
この置き直しによって推定される距離がW倍されることになるが、最近傍候補の選択は相対的な距離に基づいて行われるため、結果は変わらない。
図2は、この実施形態に係る距離推定の一例を示す説明図である。従来の佐藤らの手法における距離推定を示す図1に対応する図である。図1と同様に、図2中の星印はクエリを表す。バケットの中心間の距離を1とすれば、左右方向については、クエリは左のバケットの中心から0.6、右のバケットの中心から0.4の位置にあり、上下方向については上のバケットの中心から0.7、下のバケットの中心から0.3の位置にある。軸の数字(2.56, 0.36など)は左右方向および上下方向のバケット距離の重みを表し、バケット内の数字(3.05, 0.85など)は推定されたクエリと各バケットとの距離の重みを表す。重みはユークリッド2乗距離としている。
図3は、この実施形態に係る距離推定の異なる一例を示す説明図である。図3でハッシュ関数の次元数ν=2である。図2とは別の探索空間とクエリを表した例である。図3のクエリを中心とした円が探索半径の大きさを表しており、バケット中心が円内にあるバケットを探索領域とし、その探索領域を灰色で示している。探索時にはパラメータとして与えられた探索半径R以内のバケットを参照する。クエリの入ったバケットの中心ではなくクエリを中心とした円内(ハッシュの次元数νを任意の自然数に拡張した場合は超球)を探索範囲とするので、バケット対バケットの距離推定を行う佐藤らの方法に比べて高い精度で距離推定を行うことができる。
このように探索半径R以内のバケットを選択する処理は佐藤らの手法に比べて複雑になる。その理由は、佐藤らの手法では推定距離が整数に限定されていたのに対して、BDHでは実数であるため、推定距離を厳密に扱おうとすれば計算時間がかかる。この問題を避けるために、この発明では探索半径R以内のバケットを高速に特定するアルゴリズムを提案する。図18は、この実施形態において探索半径R以内のバケットを高速に特定する分枝限定法に基づく2つのアルゴリズムを示している。「アルゴリズム1」および「アルゴリズム2」である。ただし、これらのアルゴリズム1、2は、いずれも特徴ベクトルの次元数をdとし、クエリをq={q1,q2,…,qd}として、BDij=BDi(q,j)とする。BDij(p1,B(p2))は、クエリとj番目のバケットの重心との第i次元の基底方向における距離を表す。
ハッシュ関数の次元数がνの場合、クエリからあるバケットの代表点までの距離を求めるにはそれぞれν個の座標値が必要である。バケットの代表点の座標値はν個のハッシュ値、H(x)={h1(x),h2(x)…hν(x)}を使って求められる。これらが決まると,ν回の足し算によってバケットまでの距離がわかる。
ここでν個の基底は主成分分析によって選ばれ、固有値の降順に並んでいるため、データは(添字の番号が若い)上位の基底方向に大きな分散を持っている。従って、最も効率的な半径R以内のバケットの探索方法は以下で述べるように添字の番号順に評価することである。
ここでν個の基底は主成分分析によって選ばれ、固有値の降順に並んでいるため、データは(添字の番号が若い)上位の基底方向に大きな分散を持っている。従って、最も効率的な半径R以内のバケットの探索方法は以下で述べるように添字の番号順に評価することである。
ν個のハッシュ値のうち上位i個のハッシュ値h1(x),h2(x)…hi(x)が既に決定したとすれば、残りν-i個のハッシュ値を選択することによって半径R以内のバケットを探索することになる。ここで上位i個のハッシュ値で計算される距離をDiとおくと、ν-i個の各ハッシュ関数において取りうる最小値を足して得られる距離mDiとDiの和が探索半径Rを超えれば、上位i個のハッシュ値を使用する限りクエリから半径R以内という条件を満たす事はできない。このようにしてクエリから半径R以内に存在するバケットを順次探索する。
アルゴリズム1では1~3行目で、上位i次元分のハッシュ値が決定したとき,残りのν-i個のハッシュ値を自由に選べるとして,ν-i次元分の距離の最小値mDiを算出する。4~6行目ではクエリから最も近いバケットまでの距離Σνb=1minjBDbjが探索半径Rより小さければアルゴリズム2の関数を呼び出す。
アルゴリズム2は2つの引数を取る。何次元目のハッシュ値を決定するかを表すiと既に確定したi-1次元分の距離Dである。1~7行目では、最後の基底(ν番目のハッシュ値を決める段階)に到達していなければ(1行目)、ki個(第i基底の分割数、即ち第i基底方向のバケットを構成するビンの数)のハッシュ値(インデックス)を試す(2行目)。BDijはハッシュ値j(第j番目のビン)を選択したときの第i基底における1次元分の距離(第i基底方向の距離成分)であるので、D+BDij+mDiはi個のハッシュ値が決まった段階で最も近いバケットまでの距離であり、これが探索半径Rよりも小さい場合のみ自分自身を再帰呼び出しして次の基底に進む(3~5行目)。9~13行目では、最後であるν番目の基底に到達したときのみ実行され、探索半径以内のバケットがあればそのハッシュを引く。
〈第2の改良点: ハッシュテーブルの分割〉
佐藤らの手法には高次元データに対して、高速な探索を行うことができないという問題がある。これはハッシュの次元数とハッシュテーブルに含まれるバケット数(以後ハッシュサイズ)の関係で生じる問題である。2点間の距離を低次元の部分空間に射影して計算する場合、部分空間の次元数が低い程推定された距離の精度は低くなる。従って、一定の推定精度を維持するためにはそれに応じた次元数の部分空間が必要になる。ハッシュを用いて距離推定する場合も同じで、推定距離の精度を維持するためにはデータの次元数に合わせてハッシュの次元数νを大きくする必要がある。しかし、ハッシュの次元数νを大きくするとハッシュサイズが膨大になり、メモリに収まりきらないといった事態に陥る。
佐藤らの手法には高次元データに対して、高速な探索を行うことができないという問題がある。これはハッシュの次元数とハッシュテーブルに含まれるバケット数(以後ハッシュサイズ)の関係で生じる問題である。2点間の距離を低次元の部分空間に射影して計算する場合、部分空間の次元数が低い程推定された距離の精度は低くなる。従って、一定の推定精度を維持するためにはそれに応じた次元数の部分空間が必要になる。ハッシュを用いて距離推定する場合も同じで、推定距離の精度を維持するためにはデータの次元数に合わせてハッシュの次元数νを大きくする必要がある。しかし、ハッシュの次元数νを大きくするとハッシュサイズが膨大になり、メモリに収まりきらないといった事態に陥る。
例えば、1つの基底の分割数、即ちビンの数をsとすると、ハッシュテーブルとしてはs個のビンに対応するデータ格納領域をν組用意する必要がある。よって、ハッシュテーブルのサイズ(ハッシュサイズ)のオーダーはO(sν)となる。仮にビンの数sを最小の2に抑えたとしてもν=30次元のハッシュを構成するには約10億のデータ格納領域が必要となる。
そこでデータの次元数の増大に対するハッシュサイズの増加を抑制するために、高次元のハッシュテーブルを分割し、低次元のハッシュテーブルから得られる推定距離を統合することによって高次元ハッシュの推定距離を求める手法を提案する。ν次元ハッシュテーブルをM個に分割する場合、次のようにν個のハッシュ関数をM個の組に分ける。

ただし、j=1,…,M、かつΣjtj=νある。即ち、Hj(x)はM組に分割されたハッシュ関数の各組のハッシュ関数群であり、分割されたハッシュ関数Hj(x)の次元数の総和はνである。
そして、クエリqから任意の点pへの推定距離を

で表すことができる。これはν次元ハッシュによって求められる推定距離に等しい。ここで距離計算の対象となるのはいずれかのハッシュテーブルでクエリから探索半径R以内に存在した点である。距離計算対象の点がj番目のハッシュテーブルでクエリから探索半径R以内に存在した場合はその距離をDj(q,Bj(p))とし、存在しなかった場合はDj(q,Bj(p))=Rとする。ハッシュテーブルを分割する利点は、同じ次元数のハッシュを表現する場合でも1つのハッシュテーブルを用いる場合に比べて飛躍的にハッシュサイズが小さくなることにある。一つの基底方向にそれぞれs分割されている場合を考えると、1つのハッシュテーブルによってν次元ハッシュを表現する場合、ハッシュサイズはO(sν)あるのに対し、M個のハッシュテーブルに分割してν次元ハッシュを表現する場合、分割された1つのハッシュテーブルのサイズはO(sν/M)となり、Mに対して指数関数的に減少することが分かる。ハッシュ全体としてもその高々M倍に留まる。従って、ハッシュテーブルを分割して多次元ハッシュを表現することにより、高次元データに対しても最近傍候補の抽出速度を落とすことなく、距離推定の精度を向上させることができる。
〈第1、第2の改良点に係る実験例〉
前述の第1および第2の改良点について、その有効性を確認する実験を行った。以下に実験の内容とその結果を記す。
〈1. 予備実験〉
図4は、従来の佐藤らの手法の多次元ハッシュの次元数νを変化させたときの、精度と処理時間の関係を示すグラフである。ここで用いたデータは64次元または128次元であり、図4(a)は64次元、図4(b)は128次元の場合を示す。1000万点の正規分布に基づく人工データおよびクエリは、どちらも同じ条件で生成した2000点である。用いた計算機はCPUがOpteron(tm)6174(2.2GHz)、メモリは256[GB]であり、実験はシングル・コアで行った。
人工データにおいては佐藤らの手法と図示していないBDH共にν=24が最も精度と処理時間の関係が良かったので、以降、本節での人工データを用いた実験においてはν=24とする。
前述の第1および第2の改良点について、その有効性を確認する実験を行った。以下に実験の内容とその結果を記す。
〈1. 予備実験〉
図4は、従来の佐藤らの手法の多次元ハッシュの次元数νを変化させたときの、精度と処理時間の関係を示すグラフである。ここで用いたデータは64次元または128次元であり、図4(a)は64次元、図4(b)は128次元の場合を示す。1000万点の正規分布に基づく人工データおよびクエリは、どちらも同じ条件で生成した2000点である。用いた計算機はCPUがOpteron(tm)6174(2.2GHz)、メモリは256[GB]であり、実験はシングル・コアで行った。
人工データにおいては佐藤らの手法と図示していないBDH共にν=24が最も精度と処理時間の関係が良かったので、以降、本節での人工データを用いた実験においてはν=24とする。
〈2. 実験〉
本節では提案したBDHの性能を評価するため、前節で紹介した従来手法とこの発明の比較実験を行う。計算機は予備実験と同じものを用いた。佐藤らの手法及びBDHで用いる基底は、人工データでは元の基底を分散の大きいものからν個選び、実データでは主成分分析で得られた主成分を分散の大きい方からν個を選んだ。
本節では提案したBDHの性能を評価するため、前節で紹介した従来手法とこの発明の比較実験を行う。計算機は予備実験と同じものを用いた。佐藤らの手法及びBDHで用いる基底は、人工データでは元の基底を分散の大きいものからν個選び、実データでは主成分分析で得られた主成分を分散の大きい方からν個を選んだ。
図5、図6および表1に、ANN、SH、佐藤らの手法およびこの発明に係るBDHにおいて、最適なパラメータにおける精度(真の最近傍点が得られた割合)と処理時間(クエリを与えてから解を得るまでの時間の平均)の関係と、そのときのメモリ使用量を示す。ここでの最適とは同一精度で比較したときに処理時間が最も小さくなる状態を指す。予備実験の結果、パラメータとしてSHはビット長がlog2nであるとき、佐藤らの手法、BDHでは次元数ν=log2n×M、分割幅W={max(Ψν・p)-min(Ψν・p)}/2であるときが最適であることがわかっている。これらのパラメータはハッシュサイズがデータ数nと同程度になる値である。
データは64次元、128次元、256次元の正規分布に従う人工データ(各基底で分散は100~400で一様に選ばれる)と、TRECVID2010のInstance Searchタスクで配布された動画の各フレーム画像から抽出したSIFT特徴量(128次元、なお、SIFTについては、例えばD.G. Lowe, "Distinctive image features from scale-invariant keypoints," International journal of computer vision, vol.60, no.2, pp.91-110, 2004.参照)の4種類をそれぞれ1000万点用意した。クエリはデータベースと同じ条件でつくられた2000点を用い、その平均を結果とする。
人工データの結果については、精度と処理時間の関係を図5に示す。図5(a)は64次元の人工データ、図5(b)は128次元の人工データ、図5(c)は256次元の人工データの実験結果である。このときのメモリ使用量を表1に示す。画像データの結果については、図6に示す。なお、図5および図6では横軸を精度、縦軸を処理時間としている。凡例の単一ハッシュはこの発明においてハッシュテーブルを分割しなかった場合であり、分割ハッシュはハッシュテーブルを分割した場合である。
以上の実験の結果、全てのデータにおいて同一精度で比較したときにBDHが最も高速であった。人工データにおいて、単一ハッシュと分割ハッシュを比べると低次元のデータに対しては単一ハッシュの方がわずかに良い結果が得られているが、次元数が大きくなると、分割ハッシュの有効性が現れる。これは、ハッシュテーブル分割により探索の考慮に入る基底の数が増え、これによって推定距離の精度の低下を抑えることができたからである。故に、高次元データに対してハッシュテーブル分割が有効であるといえる。
SIFT特徴量(128次元)に対する結果を見ると、単一ハッシュが優勢である。処理時間を見ると、同精度で比べたときに64次元の人工データよりも高速に解を得られていることが分かる。つまり、SIFT特徴量は見かけ上128次元であるが、実質的な次元数は半分以下であり、それ故に単一ハッシュが優勢になったと考えられる。
SIFT特徴量(128次元)に対する結果を見ると、単一ハッシュが優勢である。処理時間を見ると、同精度で比べたときに64次元の人工データよりも高速に解を得られていることが分かる。つまり、SIFT特徴量は見かけ上128次元であるが、実質的な次元数は半分以下であり、それ故に単一ハッシュが優勢になったと考えられる。

〈第3の改良点:距離推定に適したデータ空間の分割〉
BDHはデータの一様分布を仮定して各基底を等分割し、その領域の中心をバケットに属する点の代表ベクトルとしたが、一般に実データは一様でなく、このような方法では距離推定の誤差が大きい。そこで発明者らは、図7のように各基底の要素の代表値をk-means法によって求め、データの分布に合わせた適応的な分割を施すことで推定誤差を最小化する。このアプローチにより、距離推定の精度が向上し、より効率的に最近傍候補を得ることができる。この発明では、第i基底をki分割することを考え、各基底に適切な代表値をそれぞれki個用意し、誤差Eを最小化する。第i基底のj番目の代表値をCijとおく。ハッシュ関数は次式で表される。
BDHはデータの一様分布を仮定して各基底を等分割し、その領域の中心をバケットに属する点の代表ベクトルとしたが、一般に実データは一様でなく、このような方法では距離推定の誤差が大きい。そこで発明者らは、図7のように各基底の要素の代表値をk-means法によって求め、データの分布に合わせた適応的な分割を施すことで推定誤差を最小化する。このアプローチにより、距離推定の精度が向上し、より効率的に最近傍候補を得ることができる。この発明では、第i基底をki分割することを考え、各基底に適切な代表値をそれぞれki個用意し、誤差Eを最小化する。第i基底のj番目の代表値をCijとおく。ハッシュ関数は次式で表される。

すると基底の代表値Cijの組み合わせによりベクトルを表すことができるので、このベクトルによってバケットが定義されるものとする。すなわち、あるベクトルが最近傍となる領域をバケットの範囲と定める。このベクトルのことを代表ベクトルと呼ぶことにする。このようにしてデータ空間はΠi vki個の領域に分割される。従って、点pと代表値Cijとの第i基底方向における距離成分、即ち基底距離BDiは

ただし、Xはデータの集合、Xnはn番目のデータを、BEiは第i主成分方向の誤差を表している。この発明では、各基底における代表値{Cij}をこの発明と同じ目的関数を持つk-means法によって求める。
ここで重要となるのは、各基底における代表値の数をいくらに設定するかということである。このような問題に対してはよく全基底を同数で分割するが、実際のデータにおいては主成分基底に射影されたデータの分散は主成分基底毎に大きく異なり、等価に扱うことは効率的でない。当然のことながら同じ代表ベクトル数ならば推定誤差が小さい方がよい。
ここで重要となるのは、各基底における代表値の数をいくらに設定するかということである。このような問題に対してはよく全基底を同数で分割するが、実際のデータにおいては主成分基底に射影されたデータの分散は主成分基底毎に大きく異なり、等価に扱うことは効率的でない。当然のことながら同じ代表ベクトル数ならば推定誤差が小さい方がよい。
ここで、ある基底の代表値の数をn倍する場合を考えると、代表ベクトル数もn倍となる。一様分布を仮定すると、量子化の影響からこのときの推定誤差は1/n2倍となる。
分散の大きい基底ほど代表ベクトルの増加によって誤差が大きく減少すると期待されるため、分散の大きい基底から順に代表値を増やし、全ての基底の誤差が与えられた閾値Mより小さくなった時点で分割を終了することが効率的と考えられる。これは各基底の距離計算への寄与率を考慮した適応的な分割となっている。図7は、この実施形態に係る等分割と適応的な基底分割の比較例を示す説明図である。
分散の大きい基底ほど代表ベクトルの増加によって誤差が大きく減少すると期待されるため、分散の大きい基底から順に代表値を増やし、全ての基底の誤差が与えられた閾値Mより小さくなった時点で分割を終了することが効率的と考えられる。これは各基底の距離計算への寄与率を考慮した適応的な分割となっている。図7は、この実施形態に係る等分割と適応的な基底分割の比較例を示す説明図である。
〈第4の改良点:確率密度関数に基づく距離推定〉
前節では一様分布の制約を緩和するために空間分割の構造を提案した。これに対して、本節では各区間の確率密度関数を仮定し、より一般の分布に対して柔軟に対応できる距離推定法を提案する。以下、手法の詳細を示す。
この発明では、各主成分方向に対してhi(p)=jを満たす領域(ti(j-1)≦Vi・p<tij)にあるサンプル(ベクトルデータ)の分布をヒストグラムで表し、これを正規化した後に最小二乗法によって確率密度関数Pij(y)に変換する。ただし、tijは次のように表される。
前節では一様分布の制約を緩和するために空間分割の構造を提案した。これに対して、本節では各区間の確率密度関数を仮定し、より一般の分布に対して柔軟に対応できる距離推定法を提案する。以下、手法の詳細を示す。
この発明では、各主成分方向に対してhi(p)=jを満たす領域(ti(j-1)≦Vi・p<tij)にあるサンプル(ベクトルデータ)の分布をヒストグラムで表し、これを正規化した後に最小二乗法によって確率密度関数Pij(y)に変換する。ただし、tijは次のように表される。


〈第5の改良点:クエリ周辺のデータ密度を考慮した探索半径の拡張〉
ハッシュを用いる手法では一般にパラメータとして与えられた探索半径Rに従って探索領域を決定する。しかし、公知の文献(例えば、W. Dong, Z. Wang, W. Josephson, M. Charikar, and K. Li, "Modeling LSH for performance tuning," Proceeding of the 17th ACM conference on Information and knowledge management, pp.669-678 2008.参照)で述べられているように、近似最近傍探索において真の最近傍点が得られる確率や処理時間はパラメータによって大きく左右される。従って、全てのクエリを共通のRで処理する場合、十分な精度を得るためにはクエリが疎な領域にある場合も最近傍点が得られるようにある程度大きなRを与える必要がある。その結果としてクエリが密な領域にある場合には探索領域が必要以上に広く、距離計算が過剰になるという現象が起こる。つまり、データ空間内のクエリ位置によって望ましいRは大きく異なる。
ハッシュを用いる手法では一般にパラメータとして与えられた探索半径Rに従って探索領域を決定する。しかし、公知の文献(例えば、W. Dong, Z. Wang, W. Josephson, M. Charikar, and K. Li, "Modeling LSH for performance tuning," Proceeding of the 17th ACM conference on Information and knowledge management, pp.669-678 2008.参照)で述べられているように、近似最近傍探索において真の最近傍点が得られる確率や処理時間はパラメータによって大きく左右される。従って、全てのクエリを共通のRで処理する場合、十分な精度を得るためにはクエリが疎な領域にある場合も最近傍点が得られるようにある程度大きなRを与える必要がある。その結果としてクエリが密な領域にある場合には探索領域が必要以上に広く、距離計算が過剰になるという現象が起こる。つまり、データ空間内のクエリ位置によって望ましいRは大きく異なる。
そこで発明者らは探索半径Rではなく最近傍候補数cをパラメータとすることで、探索半径を適応的に変化させ、クエリに依らず処理時間を安定して軽減する方法を提案する。これは、推定距離の小さい所から段階的に探索領域を拡張していき、最近傍候補数cを満たした時点で探索領域拡張を打ち切るというものである。図8は、この実施形態の例として、クエリ周辺の密度に応じて探索半径を変化させる様子を示す説明図である。なお、ハッシュの次元数ν=2の例である。この手法により、図8(a)のようにクエリ周辺が疎な場合には広い範囲を、図8(b)のようにクエリ周辺が密な場合は狭い範囲を探索することができる。密な領域に入ったクエリに対する過剰な距離計算を抑えることができるために結果として平均パフォーマンスが向上する。なお、図8(a)(b)で灰色の領域は参照バケットを示しており、共に9点を最近傍候補としている。
次に、この実施形態の手法に係る、効率的な近傍バケットの参照アルゴリズムについて述べる。従来の手法では、全てのバケットに対してハッシュ上の距離を計算して参照バケットを求めるもの(例えば、H. Jegou, M. Douze, and C. Schmid, "Product quantization for nearest neighbor search," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol.33, no.1, pp.117-128, 2011.参照)や、実装上ハッシュ構造を持たずに全サンプル点に対してハッシュ上の距離を計算することで探索半径以下の点を割り出すもの(SHやその改良手法)など、最近傍候補の特定にも処理時間を要していた。
そこで各バケットを推定距離の小さい所から厳密に参照するという条件を緩和する。つまり、推定距離の上限を段階的に大きくし、上限以下のバケットの順位を無視して参照する。すると、複雑なデータ構造やソートといった処理が必要なくなり、高速に探索バケットを特定することができる。図19は、この実施形態において探索半径を適応的に変化させる2つのアルゴリズムを示している。「アルゴリズム3」および「アルゴリズム4」である。ただし、これらのアルゴリズムは何れもクエリをqとして、BDij=BDi(q,j)である。L,Uは、探索半径の下限および上限をそれぞれ表し、Δは探索半径を拡張するときの前回との半径の差分である。このような最近傍候補数を基準とした段階的な処理により、前述の従来手法や「アルゴリズム1」、「アルゴリズム2」よりも効率的な探索が可能になる。
「アルゴリズム1」および「アルゴリズム2」では、ν-i個の各ハッシュ関数において取りうる最小値を足して得られる距離mDiを算出してクエリから半径R以内に存在するバケットを探索したが、「アルゴリズム3」および「アルゴリズム4」ではそれに加えて、取りうる最大値を足して得られる距離MDiを算出してクエリから半径L以遠に存在するという条件も使用する。
アルゴリズム3では1~4行目で、ν-i次元分の距離の最小値mDiと取りうる最大値を足して得られる距離MDiを算出する。5~6行目では探索半径の下限および上限であるLとUの初期値を設定する。7~11行目では最近傍候補がc点以上になるまで探索半径をΔずつ拡張しながらアルゴリズム4の関数を呼び出して探索を続ける。
アルゴリズム3では1~4行目で、ν-i次元分の距離の最小値mDiと取りうる最大値を足して得られる距離MDiを算出する。5~6行目では探索半径の下限および上限であるLとUの初期値を設定する。7~11行目では最近傍候補がc点以上になるまで探索半径をΔずつ拡張しながらアルゴリズム4の関数を呼び出して探索を続ける。
アルゴリズム4の2つの引数はアルゴリズム2と同じである。1~7行目では、最後の基底(ν番目のハッシュ値を決める段階)に到達していなければ(1行目),ki個(第i基底の分割数)のハッシュ値を試す(2 行目)。BDijはハッシュ値jを選択した時の第i基底における1次元分の距離であるので、D+BDij+mDiはi個のハッシュ値が決まった段階で最も近いバケットまでの距離であり、D+BDij+MDiは最も遠いバケットまでの距離である。前者が探索半径の上限Uよりも小さく、かつ後者が探索半径の下限Lよりも大きい場合のみ自分自身を再帰呼び出しして次の基底に進む(3~5行目)。9~13行目では、最後であるν番目の基底に到達したときのみ実行され,探索半径の上限以内かつ下限以遠のバケットがあればそのハッシュを引く。
〈第3~5の改良点に係る実験〉
前述の第3~5の改良点について、その有効性を確認する実験を行った。以下に実験の内容とその結果を記す。
実験において、インプリメントは全てC++で行った。ANNはANN Library(URL:http://www.cs.umd.edu/ mount/ANN/参照)を用い、SHは著者のMATLABのソースコード(URL: http://www.cs.huji.ac.il/yweiss/SpectralHashing/参照)とLSH-KIT(URL: http://lshkit.sourceforge.net/参照)を参考にして発明者らが実装した。実験に用いた計算機は、CPUがOpteron(tm)6174(2.2GHz)、メモリは256[GB]であり、実験はシングル・コアで行った。データベースにはTRECVID2010のInstance Searchタスクで配布された動画から10秒おきに得た画像よりSIFT特徴量を抽出し、重複するベクトルを取り除いた。
前述の第3~5の改良点について、その有効性を確認する実験を行った。以下に実験の内容とその結果を記す。
実験において、インプリメントは全てC++で行った。ANNはANN Library(URL:http://www.cs.umd.edu/ mount/ANN/参照)を用い、SHは著者のMATLABのソースコード(URL: http://www.cs.huji.ac.il/yweiss/SpectralHashing/参照)とLSH-KIT(URL: http://lshkit.sourceforge.net/参照)を参考にして発明者らが実装した。実験に用いた計算機は、CPUがOpteron(tm)6174(2.2GHz)、メモリは256[GB]であり、実験はシングル・コアで行った。データベースにはTRECVID2010のInstance Searchタスクで配布された動画から10秒おきに得た画像よりSIFT特徴量を抽出し、重複するベクトルを取り除いた。
〈1. 実験1〉
符号長を変化させたときの推定距離と実際のユークリッド距離の相関係数を示す。この結果は、推定距離がどの程度真の距離を反映しているかを表す。比較するハッシュ構造はSH、BDH、k-means BDH(第3の改良点:距離推定に適したデータ空間の分割)であり、SIFT特徴量100万点に対して1000点のクエリを入力し、相関係数の平均を結果とした。この実験においてSHの推定距離はバイナリ符号のハミング距離であり、BDH、k-means BDHの符号長はbをバケット数(ハッシュサイズ)として[log2(b)]である。推定距離の精度を示す結果を図9に示す。横軸が符号長[bit]、縦軸が相関係数である。k-means法による分布を考慮した分割により、同じ符号長で比較してBDHよりも高い相関係数が得られている。符号長を大きくしてもSHの相関係数が大きくならないのは、SHが一様分布を仮定した空間分割をしていることや、ハミング距離とユークリッド距離の距離尺度としてのずれが原因である。
参考までに符号長を120bitとしたときの推定距離と真の距離の関係を図10に示す。やはり、相関係数の結果が示すようにk-means BDHの推定距離が真の距離よく反映しているのがわかる。
符号長を変化させたときの推定距離と実際のユークリッド距離の相関係数を示す。この結果は、推定距離がどの程度真の距離を反映しているかを表す。比較するハッシュ構造はSH、BDH、k-means BDH(第3の改良点:距離推定に適したデータ空間の分割)であり、SIFT特徴量100万点に対して1000点のクエリを入力し、相関係数の平均を結果とした。この実験においてSHの推定距離はバイナリ符号のハミング距離であり、BDH、k-means BDHの符号長はbをバケット数(ハッシュサイズ)として[log2(b)]である。推定距離の精度を示す結果を図9に示す。横軸が符号長[bit]、縦軸が相関係数である。k-means法による分布を考慮した分割により、同じ符号長で比較してBDHよりも高い相関係数が得られている。符号長を大きくしてもSHの相関係数が大きくならないのは、SHが一様分布を仮定した空間分割をしていることや、ハミング距離とユークリッド距離の距離尺度としてのずれが原因である。
参考までに符号長を120bitとしたときの推定距離と真の距離の関係を図10に示す。やはり、相関係数の結果が示すようにk-means BDHの推定距離が真の距離よく反映しているのがわかる。
〈2. 実験2〉
符号長を変化させたときのハッシュ上の距離における最近傍点の平均順位を示す。つまりこれは最近傍点を発見するために最低限必要な計算量を示していて、この値が小さいほど良い。この実験はk-近傍探索における符号長-Precision曲線による評価に相当する。ただし、BDHやk-means BDHの符号長はcをバケット数(ハッシュサイズ)として[log2(c)]と定義した。また、SIFT特徴量100万点に対して1000点のクエリを入力し、その平均を結果とした。符号長を変化させたときのハッシュ上の距離における最近傍点の平均順位を図11に示す。
横軸が符号長[bit]、縦軸が最近傍点の順位である。どの符号長においてもBDHがSHに比べて最近傍点の平均順位が高くなっていることがわかる。最近傍点の順位はSHに比べて20bitで約1/8、40bitで約1/8、80bitで約1/13となった。
符号長を変化させたときのハッシュ上の距離における最近傍点の平均順位を示す。つまりこれは最近傍点を発見するために最低限必要な計算量を示していて、この値が小さいほど良い。この実験はk-近傍探索における符号長-Precision曲線による評価に相当する。ただし、BDHやk-means BDHの符号長はcをバケット数(ハッシュサイズ)として[log2(c)]と定義した。また、SIFT特徴量100万点に対して1000点のクエリを入力し、その平均を結果とした。符号長を変化させたときのハッシュ上の距離における最近傍点の平均順位を図11に示す。
横軸が符号長[bit]、縦軸が最近傍点の順位である。どの符号長においてもBDHがSHに比べて最近傍点の平均順位が高くなっていることがわかる。最近傍点の順位はSHに比べて20bitで約1/8、40bitで約1/8、80bitで約1/13となった。
〈3. 実験3〉
探索パラメータを変化させたときの、最近傍探索問題における精度(真の最近傍点が得られた割合)と処理時間(クエリを与えてから解を得るまでの時間の平均)の関係を示す。本実験ではデータベースとしてSIFT特徴量1000万点、クエリとしてデータベースと同じ条件でつくられた1000点を用いた。SH及びBDHの符号長nは24[bit]とした。n=24としたのは実験的にハッシュサイズ224データ数107となるときが最適であると分かっている為である。
探索パラメータを変化させたときの、最近傍探索問題における精度(真の最近傍点が得られた割合)と処理時間(クエリを与えてから解を得るまでの時間の平均)の関係を示す。本実験ではデータベースとしてSIFT特徴量1000万点、クエリとしてデータベースと同じ条件でつくられた1000点を用いた。SH及びBDHの符号長nは24[bit]とした。n=24としたのは実験的にハッシュサイズ224データ数107となるときが最適であると分かっている為である。
まず初めに、探索半径Rを固定した場合のデータ分布に適応した距離推定の有効性を確認する。比較の結果を図12に示す。k-means BDHは第3の改良点に係るk-meansを用いた空間分割法を適用したもの、k-means BDH Pはk-means BDHに第4の改良点である確率密度関数を用いた距離推定を適用したものである。k-meansのみを適応すると、BDHよりも性能が落ちるが、確率密度関数を組み合わせることで改善が見られた。
次に、図12で最も高速であった第4の改良点(確率密度関数に基づく距離推定)のみのk-means BDH P(探索半径Rを固定する方法)と、第4の改良点に第5の改良点(最近傍候補数cを固定する方法)を加えたk-means BDH PCの比較を行う。比較の結果を図13に示す。クエリ周辺のデータ密度を反映させることにより、概ね2倍程度の高速化が確認され、十分な効果が得られることが分かった。
最後に代表的既存手法であるANNとSHとの比較を行う。また、それぞれの探索パラメータはANNがε、SHがハミング距離R、k-means BDH PC最近傍候補数cである。比較結果を図14に示す。k-means BDH PCの処理時間は同一精度で比較して、ANNに対して約1/10、SHに対して約1/6~1/12となっており、大幅な高速化がなされていることが分かる。
〈4.実験4〉
次にこの発明のパラメータチューニングに関する実験を行う。探索を実行する際に、入力するパラメータとそのときに得られる性能の関係を知ることは実用上非常に重要であり、この発明は容易にこの関係を知ることができる。入力した最近傍候補数のパラメータcと処理時間、精度の関係をそれぞれ図15、16に示す。図15から処理時間はパラメータcに対してほぼ線形であり、処理時間T=tcで表すことができる。また、図16は縦横軸をlogスケールで示しており、精度20%~90%の範囲でグラフがほぼ直線を描いており、この範囲において精度A=caが成り立つことを示している。20%以下の範囲でグラフが直線から離れるのは、図17に示されるようにcが小さいとほとんどのクエリは一回目の探索でc個の最近傍候補を確保する為に、実際に得られる最近傍候補数が変わらないためである。従って、ある程度のサンプルクエリを入力しておけば、パラメータcから精度と処理時間を予め知ることができ、パラメータチューニングが容易である。
次にこの発明のパラメータチューニングに関する実験を行う。探索を実行する際に、入力するパラメータとそのときに得られる性能の関係を知ることは実用上非常に重要であり、この発明は容易にこの関係を知ることができる。入力した最近傍候補数のパラメータcと処理時間、精度の関係をそれぞれ図15、16に示す。図15から処理時間はパラメータcに対してほぼ線形であり、処理時間T=tcで表すことができる。また、図16は縦横軸をlogスケールで示しており、精度20%~90%の範囲でグラフがほぼ直線を描いており、この範囲において精度A=caが成り立つことを示している。20%以下の範囲でグラフが直線から離れるのは、図17に示されるようにcが小さいとほとんどのクエリは一回目の探索でc個の最近傍候補を確保する為に、実際に得られる最近傍候補数が変わらないためである。従って、ある程度のサンプルクエリを入力しておけば、パラメータcから精度と処理時間を予め知ることができ、パラメータチューニングが容易である。
前述した実施の形態の他にも、この発明について種々の変形例があり得る。それらの変形例は、この発明の範囲に属さないと解されるべきものではない。この発明には、請求の範囲と均等の意味および前記範囲内でのすべての変形とが含まれるべきである。
例えば、この発明は、距離尺度にマンハッタン距離(L1ノルム)を用いた場合にも、あるいはユークリット距離(L2ノルム)を用いた場合にも、また、それ以外の距離を用いた場合にも適用可能である。
例えば、この発明は、距離尺度にマンハッタン距離(L1ノルム)を用いた場合にも、あるいはユークリット距離(L2ノルム)を用いた場合にも、また、それ以外の距離を用いた場合にも適用可能である。
〈第6の改良点〉
第3の改良点の「距離推定に適したデータ空間の分割」に係るインデクシングと第4の改良点の「確率密度関数に基づく距離推定」を発展させた第6の改良点を述べる。この方法を第5の改良点の「クエリ周辺のデータ密度を考慮した探索半径の拡張」に係る探索方式と組み合わせて使用することで高い探索性能を実現できることを実験で確認する。
第3の改良点の「距離推定に適したデータ空間の分割」に係るインデクシングと第4の改良点の「確率密度関数に基づく距離推定」を発展させた第6の改良点を述べる。この方法を第5の改良点の「クエリ周辺のデータ密度を考慮した探索半径の拡張」に係る探索方式と組み合わせて使用することで高い探索性能を実現できることを実験で確認する。
1.データ空間のインデクシング
第3の改良ではデータ空間を分割(インデクシング)する際に、選択した基底によって張られるM次元空間をスカラ量子化によって粗量子化している。しかし、実データにおいては基底が直交していてもそれらが必ずしも互いに独立とはいえず、スカラ量子化では量子化効率が悪い。
第3の改良ではデータ空間を分割(インデクシング)する際に、選択した基底によって張られるM次元空間をスカラ量子化によって粗量子化している。しかし、実データにおいては基底が直交していてもそれらが必ずしも互いに独立とはいえず、スカラ量子化では量子化効率が悪い。
ここでハッシュ関数をhm(x)、データが存在する範囲を覆うのに十分なハッシュ値の個数をgmとすることで、バケット数Gは

のようにMに対して指数的に大きくなる。バケットの数が大きくなれば、精度は上がるが隣接バケットを探索する処理に時間がかかるようになる。従って、安易に大きなMを用いることはできず、ベクトルが高次元であった場合には全次元数に対してインデクシングに使うMが相対的に小さくなり、距離推定の精度が得られずに近似最近傍探索全体の性能の低下を招く。経験的にバケット数がデータセットサイズ
そこで、第6の改良点では直交基底Vの中から、P本の直交基底からなるセットをM組選択し、データ空間をM個のP次元部分空間の直積で表現する。ここで、Vmをm番目の部分空間を張るP個の直交基底とする。インデクシングの際には部分空間毎にk-meansアルゴリズムを用いてセントロイドの集合Cmを求め、量子化誤差の最小化を図る。これは上記の基底によって張られたPM次元空間に射影されたベクトルを、M個のP次元部分ベクトルに分けてプロダクト量子化することに等しい。Cmのi番目の部分セントロイドをCi
mと表せば、ハッシュ関数H(・)は次のようになる。

2.バケット距離
ここでは推定誤差が最小となるような距離の推定量を導き、バケット距離を定義する。各基底間に相関がないと仮定(主成分基底を用いれば2次までの無相関が保障される)すれば、各基底方向の推定距離の誤差を独立に最小化すればよいので、1次元の二乗距離の誤差を最小化することを考える。
最小化問題を次のように定義する。データxは確率密度関数P(x)に従うものとし、xがある領域zに存在する事象をZとすれば、領域z内にあるデータの分布はP(x|Z)と表される。このとき、
ここでは推定誤差が最小となるような距離の推定量を導き、バケット距離を定義する。各基底間に相関がないと仮定(主成分基底を用いれば2次までの無相関が保障される)すれば、各基底方向の推定距離の誤差を独立に最小化すればよいので、1次元の二乗距離の誤差を最小化することを考える。
最小化問題を次のように定義する。データxは確率密度関数P(x)に従うものとし、xがある領域zに存在する事象をZとすれば、領域z内にあるデータの分布はP(x|Z)と表される。このとき、

式(24)で、Var[]は、引数を母集団の標本とみなして不偏分散を返す関数である。ここで得られる推定量は領域の重心との距離ではないことに注意べきである。
以上の結果から、ハッシュ値リストがHであるようなバケット距離FHを次のように定義する。なお、下記式(26)で、um pは第m番目の部分空間の第p番目の主成分基底である。

以上の結果から、ハッシュ値リストがHであるようなバケット距離FHを次のように定義する。なお、下記式(26)で、um pは第m番目の部分空間の第p番目の主成分基底である。
3.部分セントロイドの数
次に各部分空間に与えるセントロイドの数gmを考える。一般的なプロダクト量子化では、gmは各部分空間で共通の値を用いるが、PCAを用いた場合など、各部分空間のデータの広がりに偏りがある場合は量子化効率が悪く、図24のように量子化誤差を最小化するにはgmを各部分空間の広がりに合わせて調節する必要がある。具体的な説明をする。図24はデータ空間中の点の分布の様子、u1,u2は第1、第2主成分基底を表す。図24(a)のNormalのように、基の基底を独立に量子化すると、これらは相関を持っている場合が多く量子化に無駄が生じる。そこで図24(b)のPCAのように、主成分方向に射影すれば、2次以下の相関を打ち消すことができる。しかし、この場合基底間の分散に偏りが生じるため分割される領域がある方向に長くなるような形になる。一般的にこのような領域分割は各領域が球に近づくことが理想であるため、これも誤差を大きくする原因となる。従って、図24(c)の“PCA+bit coordination”のように、点の分布を考慮して分割数を変動させればよい。
次に、gmを分配する基準について考える。式(23)の誤差を式(24)の推定量eを用いて計算し直すと、次のようになる。
次に各部分空間に与えるセントロイドの数gmを考える。一般的なプロダクト量子化では、gmは各部分空間で共通の値を用いるが、PCAを用いた場合など、各部分空間のデータの広がりに偏りがある場合は量子化効率が悪く、図24のように量子化誤差を最小化するにはgmを各部分空間の広がりに合わせて調節する必要がある。具体的な説明をする。図24はデータ空間中の点の分布の様子、u1,u2は第1、第2主成分基底を表す。図24(a)のNormalのように、基の基底を独立に量子化すると、これらは相関を持っている場合が多く量子化に無駄が生じる。そこで図24(b)のPCAのように、主成分方向に射影すれば、2次以下の相関を打ち消すことができる。しかし、この場合基底間の分散に偏りが生じるため分割される領域がある方向に長くなるような形になる。一般的にこのような領域分割は各領域が球に近づくことが理想であるため、これも誤差を大きくする原因となる。従って、図24(c)の“PCA+bit coordination”のように、点の分布を考慮して分割数を変動させればよい。
次に、gmを分配する基準について考える。式(23)の誤差を式(24)の推定量eを用いて計算し直すと、次のようになる。

最後の近似は

は領域z内に縛られているためにqに対して分散が小さく、E[q2]が他の要素に比べて非常に大きくなるため為された。従って空間インデクシングの際には、分割された領域内の分散

に注意すればよく、これは各部分空間の量子化誤差に相当する。以上から、BDHでは各部分空間の量子化誤差の最大値が最も小さくなるように、分散が大きい基底セットほどgmを大きく設定する。
〈第6の改良点に係る実験〉
ここでは、初めにメモリ使用量を制限せずに精度と処理時間の関係を検証し、次にメモリ削減を適用して、使用できるメモリ使用量に上限を設けた場合の精度と処理時間の関係を検証した。問題設定はクエリに近いK点を探索するK近傍探索問題とした。
ここでは、初めにメモリ使用量を制限せずに精度と処理時間の関係を検証し、次にメモリ削減を適用して、使用できるメモリ使用量に上限を設けた場合の精度と処理時間の関係を検証した。問題設定はクエリに近いK点を探索するK近傍探索問題とした。
1.実験条件
実験にはBIGANNデータセット("Datasets for approximate nearest neighbor search," http://corpus-texmex.irisa.fr/.参照)のSIFT特徴量と80 million tiny images("Tiny Images Dataset," http://groups.csail.mit.edu/vision/TinyImages/.参照)のGIST特徴量を用いた。クエリはともに1000個とし、探索精度は平均再現率、処理時間はクエリベクトル1個当たりの処理時間の平均である。SIFTの学習にはデータセットの初めの100万点、GISTの学習には10万点を用いた。実験に用いたCPUはOpteron(tm)6174(2.2GHz)であり、実験は全てシングルコアで行った。
実験にはBIGANNデータセット("Datasets for approximate nearest neighbor search," http://corpus-texmex.irisa.fr/.参照)のSIFT特徴量と80 million tiny images("Tiny Images Dataset," http://groups.csail.mit.edu/vision/TinyImages/.参照)のGIST特徴量を用いた。クエリはともに1000個とし、探索精度は平均再現率、処理時間はクエリベクトル1個当たりの処理時間の平均である。SIFTの学習にはデータセットの初めの100万点、GISTの学習には10万点を用いた。実験に用いたCPUはOpteron(tm)6174(2.2GHz)であり、実験は全てシングルコアで行った。
2.処理時間と精度の関係
本節ではこの実施形態による提案手法と各比較手法の処理時間と精度の関係を示す。K=1とした。ここではメモリ削減をしないため、どの手法も探索領域を広げることで必ず100%の精度を達成できる。実験にはSIFTが100万点(学習データ)、1000万点、1億点、GISTが10万点(学習データ)、100万点、1000万点のデータベースを用いた。比較手法は木構造を用いた手法としてRandamized kd-tree(C. Silpa-Anan and R. Hartley, "Optimised kd-trees for fast image descriptor matching," Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp.1-8, 2008.参照)、階層的k-means(D. Nister and H. Stewenius, "Scalable recognition with a vocabulary tree," Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol.2, pp.2161-2168, 2006.参照)、ハッシュ法を用いたものとしてIVFADC,IMIを用いた。結果を図25~図30に示す。また、実験に用いたパラメータを表2に示す。図の縦軸は探索処理に要した時間を、横軸は精度をそれぞれ表している。グラフの凡例のうち"BDH"はこの実施形態による提案手法を示している。これに対して、"Multi"はIMI、"IVF"はIVFADC、"RKD"はRandamized kd-tree、"HKM"は階層的k-meansの比較手法をそれぞれ示している。
本節ではこの実施形態による提案手法と各比較手法の処理時間と精度の関係を示す。K=1とした。ここではメモリ削減をしないため、どの手法も探索領域を広げることで必ず100%の精度を達成できる。実験にはSIFTが100万点(学習データ)、1000万点、1億点、GISTが10万点(学習データ)、100万点、1000万点のデータベースを用いた。比較手法は木構造を用いた手法としてRandamized kd-tree(C. Silpa-Anan and R. Hartley, "Optimised kd-trees for fast image descriptor matching," Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp.1-8, 2008.参照)、階層的k-means(D. Nister and H. Stewenius, "Scalable recognition with a vocabulary tree," Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol.2, pp.2161-2168, 2006.参照)、ハッシュ法を用いたものとしてIVFADC,IMIを用いた。結果を図25~図30に示す。また、実験に用いたパラメータを表2に示す。図の縦軸は探索処理に要した時間を、横軸は精度をそれぞれ表している。グラフの凡例のうち"BDH"はこの実施形態による提案手法を示している。これに対して、"Multi"はIMI、"IVF"はIVFADC、"RKD"はRandamized kd-tree、"HKM"は階層的k-meansの比較手法をそれぞれ示している。

図25~図30のグラフからわかるように、提案手法はいずれの特徴量で比較しても、常に既存手法に比べて高速に解を得られることが確認できた。精度が90%を超えるような高精度帯においては各手法間にそれほど大きな違いは見られないが、50%以下の低精度帯においては提案手法が明らかに他と比べて高速である。特に点数の多い図27で顕著である。
この原因は最近候補選択のオーバーヘッドである。IVFADCは近傍セントロイドの探索にG回の距離計算を行い、IMIは部分距離リスト{fi m}の生成に2G1/2回の距離計算とそのソートを必要とする為、低精度であっても処理時間が小さくならない。しかし、空間インデクシングの量子化精度はBDHに比べて高いので、精度に対するグラフの上昇は緩やかになる。
この原因は最近候補選択のオーバーヘッドである。IVFADCは近傍セントロイドの探索にG回の距離計算を行い、IMIは部分距離リスト{fi m}の生成に2G1/2回の距離計算とそのソートを必要とする為、低精度であっても処理時間が小さくならない。しかし、空間インデクシングの量子化精度はBDHに比べて高いので、精度に対するグラフの上昇は緩やかになる。
11:特徴点抽出部、 13:探索範囲決定部、 15:画像データベース、 15h:ハッシュテーブル、 17:最近傍点決定部、 19:投票部、 21:投票テーブル、 23:画像選択部
Claims (12)
- ベクトルデータで表現される複数の点が入力されたとき、多次元ハッシュテーブルのインデックス算出用のハッシュ関数をそれぞれ適用して各点についてハッシュインデックスを算出し、前記多次元ハッシュテーブルのビンによって複数の領域に分割された多次元空間内の前記ハッシュインデックスに応じた領域に各点を射影することにより各点を多次元ハッシュテーブルに格納してなるデータベース格納部と、
クエリが入力されたとき、そのクエリに前記ハッシュ関数を適用して前記多次元空間内でのクエリの位置を決定し、クエリと前記空間内の各領域との距離の推定値を決定し、その推定値に基づいて少なくとも1つの探索すべき領域を決定する探索範囲決定部と、
前記探索すべき領域内の各点とクエリとの距離を計算し、クエリに最も近い点をクエリの最近傍点として算出する最近傍点決定部とを備え、
前記探索範囲決定部は、各領域のインデックスを参照してその領域の代表点を求め、前記クエリと各代表点との距離に基づいて前記推定値を決定し、分枝限定法を適用して前記探索すべき領域になり得ない領域を除外して前記探索すべき領域を決定することを特徴とする近似最近傍探索装置。 - 前記データベース格納部は、M組(Mは2以上の自然数)のハッシュ関数群を用いてM組の多次元ハッシュテーブルに各点をそれぞれ登録してなる請求項1に記載の近似最近傍探索装置。
- M組の多次元ハッシュテーブルは、各組の次元数が略等しい請求項2に記載の近似最近傍探索装置。
- 前記多次元ハッシュテーブルは、各次元に対応するハッシュテーブルを組み合わせてなり、各ハッシュテーブルは各次元に対応する基底をビンで分割し、各ビンの幅は、すべてのビンが等幅とした場合に各ビンに登録されることになる点と、各ビンを代表する代表点との位置の誤差を各ビンについて求め、それらの誤差の和がより小さくなるように各ビンの幅が調整されてなる請求項1~3の何れか一つに記載の近似最近傍探索装置。
- 各ハッシュテーブルは、各点を予め定められたn個のクラスタにクラスタリングしてクラスタごとの代表点を算出し、それぞれのクラスタに属する各点からそのクラスタの代表点までの平均距離を表す分散が予め定められた閾値よりも小さくなるように各ビンの幅が決定されてなる請求項4に記載の近似最近傍探索装置。
- 前記探索範囲決定部は、各基底の方向におけるベクトルデータの分布から確率密度関数を求め、その確率密度関数を距離の重み付けに用いて前記推定値を決定する請求項4または5に記載の近似最近傍探索装置。
- 前記探索範囲決定部は、クエリを中心として予め定められた探索半径Rの範囲内に代表点がある領域を前記探索すべき領域とする請求項1~6の何れか一つに記載の近似最近傍探索装置。
- 前記探索範囲決定部は、クエリを中心として探索半径Rの範囲内に代表点のある領域を前記探索すべき領域とし、その領域に含まれる点の数が予め定められた数に達するまで探索半径Rを漸次大きくする請求項1~6の何れか一つに記載の近似最近傍探索装置。
- 前記データベース格納部は、ν次元空間に各点が射影され、
前記多次元ハッシュテーブルは、前記ν次元空間を張るν本の直交基底のうちP本の直交基底が張る部分空間をM組選択し、各部分空間にk-means法を用いてその部分空間が分割され、かつ、各領域内の分散が大きい部分空間ほど分割の数が大きく設定されてなり、
前記検索範囲決定部は、各基底の方向におけるベクトルデータの分布から求めた確率密度関数に従って各領域に存在する点とクエリとの二乗距離の推定誤差が各基底方向においてそれぞれ最小化されるように前記推定値を決定する請求項1~8の何れか一つに記載の近似最近傍探索装置。 - 前記データベース格納部は、主成分分析により基底が決定されたν次元空間に各点が射影されてなり、
前記探索範囲決定部は、前記クエリと各代表点との距離の各基底の方向における距離成分をそれぞれ算出して前記推定値とし、
前記分枝限定法は、各距離成分の算出の過程において、各距離成分の和が定められた探索半径R内であることを制約条件とし、前記主成分分析において大きな固有値を有する基底の順に各領域の代表点が半径R内にあるかを判断する請求項1~9の何れか一つに記載の近似最近傍探索装置。 - コンピュータが、
ベクトルデータで表現される複数の点が入力されたとき、多次元ハッシュテーブルのインデックス算出用のハッシュ関数をそれぞれ適用して各点についてハッシュインデックスを算出し、前記多次元ハッシュテーブルのビンによって複数の領域に分割された多次元空間内の前記ハッシュインデックスに応じた領域に各点を射影することにより各点を多次元ハッシュテーブルに格納してなるデータベース格納部にアクセスするステップと、
クエリが入力されたとき、そのクエリに前記ハッシュ関数を適用して前記空間内でのクエリの位置を決定し、クエリと前記空間内の各領域との距離の推定値を決定し、その推定値に基づいて少なくとも1つの探索すべき領域を決定する探索範囲決定ステップと、
前記探索すべき領域内の各点とクエリとの距離を計算し、クエリに最も近い点をクエリの最近傍点として算出するステップとを備え、
前記探索範囲決定ステップは、各領域のインデックスを参照してその領域の代表点を求め、前記クエリと各代表点との距離に基づいて前記推定値を決定し、分枝限定法を適用して前記探索すべき領域になり得ない領域を除外して前記探索すべき領域を決定することを特徴とする近似最近傍探索方法。 - ベクトルデータで表現される複数の点が入力されたとき、多次元ハッシュテーブルのインデックス算出用のハッシュ関数をそれぞれ適用して各点についてハッシュインデックスを算出し、前記多次元ハッシュテーブルのビンによって複数の領域に分割された多次元空間内のハッシュインデックスに応じた領域に各点を射影することにより各点を多次元ハッシュテーブルに格納してなるデータベース格納部にアクセスする処理と、
クエリが入力されたとき、そのクエリに前記ハッシュ関数を適用して前記空間内でのクエリの位置を決定し、クエリと前記空間内の各領域との距離の推定値を決定し、その推定値に基づいて少なくとも1つの探索すべき領域を決定する探索範囲決定部としての処理と、
前記探索すべき領域内の各点とクエリとの距離を計算し、クエリに最も近い点をクエリの最近傍点として算出する最近傍点決定部としての処理をコンピュータに実行させ、
前記探索範囲決定部は、各領域のインデックスを参照してその領域の代表点を求め、前記クエリと各代表点との距離に基づいて前記推定値を決定し、分枝限定法を適用して前記探索すべき領域になり得ない領域を除外して前記探索すべき領域を決定することを特徴とする近似最近傍探索プログラム。
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012-042172 | 2012-02-28 | ||
| JP2012042172 | 2012-02-28 | ||
| US201261684911P | 2012-08-20 | 2012-08-20 | |
| US61/684,911 | 2012-08-20 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2013129580A1 true WO2013129580A1 (ja) | 2013-09-06 |
Family
ID=49082771
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2013/055440 WO2013129580A1 (ja) | 2012-02-28 | 2013-02-28 | 近似最近傍探索装置、近似最近傍探索方法およびそのプログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JPWO2013129580A1 (ja) |
| WO (1) | WO2013129580A1 (ja) |
Cited By (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101721114B1 (ko) * | 2016-06-27 | 2017-03-30 | 서울대학교산학협력단 | 위치정보가 포함된 포인트 데이터를 다축척의 웹 지도상에 클러스터링하기 위하여 격자의 크기를 결정하는 방법 |
| WO2017065795A1 (en) * | 2015-10-16 | 2017-04-20 | Hewlett Packard Enterprise Development Lp | Incremental update of a neighbor graph via an orthogonal transform based indexing |
| WO2017072890A1 (ja) * | 2015-10-28 | 2017-05-04 | 株式会社東芝 | データ管理システム、データ管理方法およびプログラム |
| CN106897258A (zh) * | 2017-02-27 | 2017-06-27 | 郑州云海信息技术有限公司 | 一种文本差异性的计算方法及装置 |
| GB2551504A (en) * | 2016-06-20 | 2017-12-27 | Snell Advanced Media Ltd | Image Processing |
| WO2018159690A1 (ja) * | 2017-02-28 | 2018-09-07 | 国立研究開発法人理化学研究所 | 点群データの抽出方法、及び点群データの抽出装置 |
| WO2019200264A1 (en) * | 2018-04-12 | 2019-10-17 | Georgia Tech Research Corporation | Privacy preserving face-based authentication |
| CN110377681A (zh) * | 2019-07-11 | 2019-10-25 | 拉扎斯网络科技(上海)有限公司 | 一种数据查询的方法、装置、可读存储介质和电子设备 |
| CN110569244A (zh) * | 2019-08-30 | 2019-12-13 | 深圳计算科学研究院 | 一种海明空间近似查询方法及存储介质 |
| CN111033495A (zh) * | 2017-08-23 | 2020-04-17 | 谷歌有限责任公司 | 用于快速相似性搜索的多尺度量化 |
| CN111859192A (zh) * | 2020-07-28 | 2020-10-30 | 科大讯飞股份有限公司 | 搜索方法、装置、电子设备及存储介质 |
| CN111881767A (zh) * | 2020-07-03 | 2020-11-03 | 深圳力维智联技术有限公司 | 高维特征的处理方法、装置、设备及计算机可读存储介质 |
| CN112241475A (zh) * | 2020-10-16 | 2021-01-19 | 中国海洋大学 | 基于维度分析量化器哈希学习的数据检索方法 |
| CN112860758A (zh) * | 2019-11-27 | 2021-05-28 | 阿里巴巴集团控股有限公司 | 搜索方法、装置、电子设备及计算机存储介质 |
| CN113542750A (zh) * | 2021-05-27 | 2021-10-22 | 绍兴市北大信息技术科创中心 | 采用两套及两套以上哈希表进行搜索的数据编码方法 |
| CN113868291A (zh) * | 2021-10-21 | 2021-12-31 | 深圳云天励飞技术股份有限公司 | 一种最近邻搜索方法、装置、终端和存储介质 |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113157688A (zh) * | 2020-01-07 | 2021-07-23 | 四川大学 | 一种基于空间索引及相邻点信息的最近邻点搜索方法 |
-
2013
- 2013-02-28 JP JP2014502374A patent/JPWO2013129580A1/ja active Pending
- 2013-02-28 WO PCT/JP2013/055440 patent/WO2013129580A1/ja active Application Filing
Non-Patent Citations (2)
| Title |
|---|
| NAOTO MASUYAMA ET AL.: "Acceleration of the k- Nearest Neighbor Algorithm by Addition of Termination Conditions in Pattern Recognition Problems", THE TRANSACTIONS OF THE INSTITUTE OF ELECTRONICS, INFORMATION AND COMMUNICATION ENGINEERS, vol. J84-D-II, no. 3, 1 March 2001 (2001-03-01), pages 439 - 447 * |
| TOMOKAZU SATO ET AL.: "Gaisan Kyori no Seido Kojo ni yoru Kinji Saikinbo Tansaku no Kosokuka", IPSJ SIG NOTES, 15 October 2011 (2011-10-15), pages 1 - 6 * |
Cited By (27)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2017065795A1 (en) * | 2015-10-16 | 2017-04-20 | Hewlett Packard Enterprise Development Lp | Incremental update of a neighbor graph via an orthogonal transform based indexing |
| US11361195B2 (en) | 2015-10-16 | 2022-06-14 | Hewlett Packard Enterprise Development Lp | Incremental update of a neighbor graph via an orthogonal transform based indexing |
| WO2017072890A1 (ja) * | 2015-10-28 | 2017-05-04 | 株式会社東芝 | データ管理システム、データ管理方法およびプログラム |
| JPWO2017072890A1 (ja) * | 2015-10-28 | 2018-05-17 | 株式会社東芝 | データ管理システム、データ管理方法およびプログラム |
| US11281645B2 (en) | 2015-10-28 | 2022-03-22 | Kabushiki Kaisha Toshiba | Data management system, data management method, and computer program product |
| GB2551504A (en) * | 2016-06-20 | 2017-12-27 | Snell Advanced Media Ltd | Image Processing |
| KR101721114B1 (ko) * | 2016-06-27 | 2017-03-30 | 서울대학교산학협력단 | 위치정보가 포함된 포인트 데이터를 다축척의 웹 지도상에 클러스터링하기 위하여 격자의 크기를 결정하는 방법 |
| CN106897258A (zh) * | 2017-02-27 | 2017-06-27 | 郑州云海信息技术有限公司 | 一种文本差异性的计算方法及装置 |
| US11204243B2 (en) | 2017-02-28 | 2021-12-21 | Topcon Corporation | Point cloud data extraction method and point cloud data extraction device |
| JP2018141757A (ja) * | 2017-02-28 | 2018-09-13 | 国立研究開発法人理化学研究所 | 点群データの抽出方法、及び点群データの抽出装置 |
| WO2018159690A1 (ja) * | 2017-02-28 | 2018-09-07 | 国立研究開発法人理化学研究所 | 点群データの抽出方法、及び点群データの抽出装置 |
| EP3531068A4 (en) * | 2017-02-28 | 2020-04-01 | Riken | METHOD FOR THE EXTRACTION OF POINT CLOUD DATA AND DEVICE FOR THE EXTRACTION OF POINT CLOUD DATA |
| CN111033495A (zh) * | 2017-08-23 | 2020-04-17 | 谷歌有限责任公司 | 用于快速相似性搜索的多尺度量化 |
| US11874911B2 (en) | 2018-04-12 | 2024-01-16 | Georgia Tech Research Corporation | Privacy preserving face-based authentication |
| US11494476B2 (en) | 2018-04-12 | 2022-11-08 | Georgia Tech Research Corporation | Privacy preserving face-based authentication |
| WO2019200264A1 (en) * | 2018-04-12 | 2019-10-17 | Georgia Tech Research Corporation | Privacy preserving face-based authentication |
| CN110377681A (zh) * | 2019-07-11 | 2019-10-25 | 拉扎斯网络科技(上海)有限公司 | 一种数据查询的方法、装置、可读存储介质和电子设备 |
| CN110569244A (zh) * | 2019-08-30 | 2019-12-13 | 深圳计算科学研究院 | 一种海明空间近似查询方法及存储介质 |
| CN112860758A (zh) * | 2019-11-27 | 2021-05-28 | 阿里巴巴集团控股有限公司 | 搜索方法、装置、电子设备及计算机存储介质 |
| CN111881767A (zh) * | 2020-07-03 | 2020-11-03 | 深圳力维智联技术有限公司 | 高维特征的处理方法、装置、设备及计算机可读存储介质 |
| CN111881767B (zh) * | 2020-07-03 | 2023-11-03 | 深圳力维智联技术有限公司 | 高维特征的处理方法、装置、设备及计算机可读存储介质 |
| CN111859192B (zh) * | 2020-07-28 | 2023-01-17 | 科大讯飞股份有限公司 | 搜索方法、装置、电子设备及存储介质 |
| CN111859192A (zh) * | 2020-07-28 | 2020-10-30 | 科大讯飞股份有限公司 | 搜索方法、装置、电子设备及存储介质 |
| CN112241475B (zh) * | 2020-10-16 | 2022-04-26 | 中国海洋大学 | 基于维度分析量化器哈希学习的数据检索方法 |
| CN112241475A (zh) * | 2020-10-16 | 2021-01-19 | 中国海洋大学 | 基于维度分析量化器哈希学习的数据检索方法 |
| CN113542750A (zh) * | 2021-05-27 | 2021-10-22 | 绍兴市北大信息技术科创中心 | 采用两套及两套以上哈希表进行搜索的数据编码方法 |
| CN113868291A (zh) * | 2021-10-21 | 2021-12-31 | 深圳云天励飞技术股份有限公司 | 一种最近邻搜索方法、装置、终端和存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2013129580A1 (ja) | 2015-07-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2013129580A1 (ja) | 近似最近傍探索装置、近似最近傍探索方法およびそのプログラム | |
| CN105912611B (zh) | 一种基于cnn的快速图像检索方法 | |
| He et al. | Scalable similarity search with optimized kernel hashing | |
| Zhang et al. | Supervised hashing with latent factor models | |
| Wang et al. | Order preserving hashing for approximate nearest neighbor search | |
| Wu et al. | Online multi-modal distance metric learning with application to image retrieval | |
| Wang et al. | Query-specific visual semantic spaces for web image re-ranking | |
| CN109271486B (zh) | 一种相似性保留跨模态哈希检索方法 | |
| Rafailidis et al. | A unified framework for multimodal retrieval | |
| Tiakas et al. | MSIDX: multi-sort indexing for efficient content-based image search and retrieval | |
| CN113961528A (zh) | 基于知识图谱的文件语义关联存储系统及方法 | |
| CN109145143A (zh) | 图像检索中的序列约束哈希算法 | |
| CN106570173B (zh) | 一种基于Spark的高维稀疏文本数据聚类方法 | |
| Pedronette et al. | Exploiting contextual information for image re-ranking and rank aggregation | |
| Dharani et al. | Content based image retrieval system using feature classification with modified KNN algorithm | |
| US9104946B2 (en) | Systems and methods for comparing images | |
| Ła̧giewka et al. | Distributed image retrieval with colour and keypoint features | |
| JP6017277B2 (ja) | 特徴ベクトルの集合で表されるコンテンツ間の類似度を算出するプログラム、装置及び方法 | |
| JP5833499B2 (ja) | 高次元の特徴ベクトル集合で表現されるコンテンツを高精度で検索する検索装置及びプログラム | |
| JP5971722B2 (ja) | ハッシュ関数の変換行列を定める方法、該ハッシュ関数を利用するハッシュ型近似最近傍探索方法、その装置及びそのコンピュータプログラム | |
| Zhang et al. | FRWCAE: joint faster-RCNN and Wasserstein convolutional auto-encoder for instance retrieval | |
| Yang et al. | Submodular reranking with multiple feature modalities for image retrieval | |
| KR102590388B1 (ko) | 영상 컨텐츠 추천 장치 및 방법 | |
| Antaris et al. | Similarity search over the cloud based on image descriptors' dimensions value cardinalities | |
| Hua et al. | Cross-modal correlation learning with deep convolutional architecture |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 13755813 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2014502374 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 13755813 Country of ref document: EP Kind code of ref document: A1 |