WO2009054863A2 - Human antibodies that bind cd19 and uses thereof - Google Patents
Human antibodies that bind cd19 and uses thereof Download PDFInfo
- Publication number
- WO2009054863A2 WO2009054863A2 PCT/US2007/087393 US2007087393W WO2009054863A2 WO 2009054863 A2 WO2009054863 A2 WO 2009054863A2 US 2007087393 W US2007087393 W US 2007087393W WO 2009054863 A2 WO2009054863 A2 WO 2009054863A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- seq
- variable region
- chain variable
- antibody
- amino acid
- Prior art date
Links
- 241000282414 Homo sapiens Species 0.000 title claims abstract description 342
- 210000004027 cell Anatomy 0.000 claims abstract description 175
- 108091007433 antigens Proteins 0.000 claims abstract description 108
- 102000036639 antigens Human genes 0.000 claims abstract description 108
- 239000000427 antigen Substances 0.000 claims abstract description 107
- 238000000034 method Methods 0.000 claims abstract description 97
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 68
- 210000003719 b-lymphocyte Anatomy 0.000 claims abstract description 36
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 claims abstract description 21
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 claims abstract description 21
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 claims abstract description 8
- 230000036210 malignancy Effects 0.000 claims abstract description 8
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 294
- 230000027455 binding Effects 0.000 claims description 196
- 108090000623 proteins and genes Proteins 0.000 claims description 138
- 239000003814 drug Substances 0.000 claims description 104
- 102000004169 proteins and genes Human genes 0.000 claims description 81
- 239000000203 mixture Substances 0.000 claims description 59
- 239000002619 cytotoxin Substances 0.000 claims description 49
- 231100000599 cytotoxic agent Toxicity 0.000 claims description 48
- 238000001727 in vivo Methods 0.000 claims description 41
- 210000004881 tumor cell Anatomy 0.000 claims description 41
- 101710112752 Cytotoxin Proteins 0.000 claims description 39
- OAKJQQAXSVQMHS-UHFFFAOYSA-N hydrazine Substances NN OAKJQQAXSVQMHS-UHFFFAOYSA-N 0.000 claims description 32
- 229940124597 therapeutic agent Drugs 0.000 claims description 32
- 239000000126 substance Substances 0.000 claims description 29
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 claims description 24
- 201000011510 cancer Diseases 0.000 claims description 22
- 230000012010 growth Effects 0.000 claims description 14
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 9
- 239000003937 drug carrier Substances 0.000 claims description 8
- 230000002285 radioactive effect Effects 0.000 claims description 5
- 101150096316 5 gene Proteins 0.000 claims description 3
- 101150044182 8 gene Proteins 0.000 claims description 3
- 230000002401 inhibitory effect Effects 0.000 claims description 3
- 208000025205 Mantle-Cell Lymphoma Diseases 0.000 claims 2
- 101000934356 Homo sapiens CD70 antigen Proteins 0.000 claims 1
- 230000000779 depleting effect Effects 0.000 claims 1
- 102000053826 human CD70 Human genes 0.000 claims 1
- 108700026220 vif Genes Proteins 0.000 claims 1
- 102000039446 nucleic acids Human genes 0.000 abstract description 23
- 150000007523 nucleic acids Chemical class 0.000 abstract description 23
- 108020004707 nucleic acids Proteins 0.000 abstract description 23
- 239000013604 expression vector Substances 0.000 abstract description 18
- 239000008194 pharmaceutical composition Substances 0.000 abstract description 10
- 208000034578 Multiple myelomas Diseases 0.000 abstract description 8
- 230000001419 dependent effect Effects 0.000 abstract description 7
- 208000031671 Large B-Cell Diffuse Lymphoma Diseases 0.000 abstract description 6
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 abstract description 6
- 201000003444 follicular lymphoma Diseases 0.000 abstract description 6
- 230000005889 cellular cytotoxicity Effects 0.000 abstract description 4
- 125000000217 alkyl group Chemical group 0.000 description 128
- 101100112922 Candida albicans CDR3 gene Proteins 0.000 description 120
- 125000005647 linker group Chemical group 0.000 description 120
- 125000004404 heteroalkyl group Chemical group 0.000 description 106
- 102100035361 Cerebellar degeneration-related protein 2 Human genes 0.000 description 95
- 101000737796 Homo sapiens Cerebellar degeneration-related protein 2 Proteins 0.000 description 95
- -1 type 2) Proteins 0.000 description 87
- 150000001875 compounds Chemical class 0.000 description 80
- 125000003118 aryl group Chemical group 0.000 description 79
- 210000004602 germ cell Anatomy 0.000 description 76
- 235000018102 proteins Nutrition 0.000 description 76
- 229940079593 drug Drugs 0.000 description 72
- 108090000765 processed proteins & peptides Proteins 0.000 description 68
- 235000001014 amino acid Nutrition 0.000 description 66
- 239000000562 conjugate Substances 0.000 description 59
- 125000001072 heteroaryl group Chemical group 0.000 description 59
- 239000003795 chemical substances by application Substances 0.000 description 56
- 229940024606 amino acid Drugs 0.000 description 53
- 150000001413 amino acids Chemical group 0.000 description 53
- 125000000592 heterocycloalkyl group Chemical group 0.000 description 53
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 47
- 102000004190 Enzymes Human genes 0.000 description 42
- 108090000790 Enzymes Proteins 0.000 description 42
- 229940088598 enzyme Drugs 0.000 description 42
- 230000004048 modification Effects 0.000 description 36
- 238000012986 modification Methods 0.000 description 36
- 239000000758 substrate Substances 0.000 description 35
- 229910052739 hydrogen Inorganic materials 0.000 description 34
- 238000003776 cleavage reaction Methods 0.000 description 33
- 230000007017 scission Effects 0.000 description 33
- 239000012634 fragment Substances 0.000 description 32
- QTBSBXVTEAMEQO-UHFFFAOYSA-N acetic acid Substances CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 31
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 31
- 241000699666 Mus <mouse, genus> Species 0.000 description 30
- 125000000524 functional group Chemical group 0.000 description 30
- 230000008685 targeting Effects 0.000 description 29
- 125000006850 spacer group Chemical group 0.000 description 28
- 125000001424 substituent group Chemical group 0.000 description 28
- 125000000547 substituted alkyl group Chemical group 0.000 description 28
- 230000000694 effects Effects 0.000 description 27
- 241000699670 Mus sp. Species 0.000 description 25
- 125000005842 heteroatom Chemical group 0.000 description 25
- 229920001223 polyethylene glycol Polymers 0.000 description 25
- 102000035195 Peptidases Human genes 0.000 description 24
- 108091005804 Peptidases Proteins 0.000 description 24
- 229940127121 immunoconjugate Drugs 0.000 description 24
- 239000003550 marker Substances 0.000 description 24
- 230000001225 therapeutic effect Effects 0.000 description 24
- 108020004414 DNA Proteins 0.000 description 23
- 239000002202 Polyethylene glycol Substances 0.000 description 23
- 239000004365 Protease Substances 0.000 description 23
- 230000013595 glycosylation Effects 0.000 description 23
- 238000006206 glycosylation reaction Methods 0.000 description 23
- 229910052736 halogen Inorganic materials 0.000 description 23
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 23
- 241000894007 species Species 0.000 description 23
- 238000006467 substitution reaction Methods 0.000 description 23
- 108060003951 Immunoglobulin Proteins 0.000 description 22
- 201000010099 disease Diseases 0.000 description 22
- 102000018358 immunoglobulin Human genes 0.000 description 22
- 125000000539 amino acid group Chemical group 0.000 description 21
- 238000003556 assay Methods 0.000 description 21
- 150000002367 halogens Chemical class 0.000 description 21
- 229910052757 nitrogen Inorganic materials 0.000 description 21
- 125000004122 cyclic group Chemical group 0.000 description 20
- 230000014509 gene expression Effects 0.000 description 20
- 210000004408 hybridoma Anatomy 0.000 description 20
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 19
- 125000002252 acyl group Chemical group 0.000 description 19
- 230000006870 function Effects 0.000 description 19
- 238000011282 treatment Methods 0.000 description 19
- 239000012636 effector Substances 0.000 description 18
- 238000005516 engineering process Methods 0.000 description 18
- 239000000047 product Substances 0.000 description 18
- 241001529936 Murinae Species 0.000 description 17
- 238000007792 addition Methods 0.000 description 17
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 17
- 238000006243 chemical reaction Methods 0.000 description 17
- 238000000338 in vitro Methods 0.000 description 17
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 16
- 239000002253 acid Substances 0.000 description 16
- 238000004519 manufacturing process Methods 0.000 description 16
- 230000035772 mutation Effects 0.000 description 16
- 229910052760 oxygen Inorganic materials 0.000 description 16
- 229910052717 sulfur Inorganic materials 0.000 description 16
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 15
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 15
- JCXJVPUVTGWSNB-UHFFFAOYSA-N Nitrogen dioxide Chemical compound O=[N]=O JCXJVPUVTGWSNB-UHFFFAOYSA-N 0.000 description 15
- 125000004432 carbon atom Chemical group C* 0.000 description 15
- 238000009795 derivation Methods 0.000 description 15
- 229910052731 fluorine Inorganic materials 0.000 description 15
- 239000002773 nucleotide Substances 0.000 description 15
- 125000003729 nucleotide group Chemical group 0.000 description 15
- 235000019419 proteases Nutrition 0.000 description 15
- 102000005962 receptors Human genes 0.000 description 15
- 108020003175 receptors Proteins 0.000 description 15
- 102000001400 Tryptase Human genes 0.000 description 14
- 108060005989 Tryptase Proteins 0.000 description 14
- 229940027941 immunoglobulin g Drugs 0.000 description 14
- 239000003446 ligand Substances 0.000 description 14
- 102000004196 processed proteins & peptides Human genes 0.000 description 14
- 108700022150 Designed Ankyrin Repeat Proteins Proteins 0.000 description 13
- 150000001412 amines Chemical class 0.000 description 13
- 239000013598 vector Substances 0.000 description 13
- 238000002965 ELISA Methods 0.000 description 12
- 108010073807 IgG Receptors Proteins 0.000 description 12
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 12
- 238000013459 approach Methods 0.000 description 12
- 229940002612 prodrug Drugs 0.000 description 12
- 239000000651 prodrug Substances 0.000 description 12
- 108700019146 Transgenes Proteins 0.000 description 11
- 230000037396 body weight Effects 0.000 description 11
- 230000000295 complement effect Effects 0.000 description 11
- 150000002148 esters Chemical class 0.000 description 11
- 238000002360 preparation method Methods 0.000 description 11
- 238000007363 ring formation reaction Methods 0.000 description 11
- 150000003839 salts Chemical class 0.000 description 11
- 239000000243 solution Substances 0.000 description 11
- 125000003107 substituted aryl group Chemical group 0.000 description 11
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 10
- 206010035226 Plasma cell myeloma Diseases 0.000 description 10
- 230000004913 activation Effects 0.000 description 10
- 229910052799 carbon Inorganic materials 0.000 description 10
- 125000001559 cyclopropyl group Chemical group [H]C1([H])C([H])([H])C1([H])* 0.000 description 10
- 230000007423 decrease Effects 0.000 description 10
- 230000001404 mediated effect Effects 0.000 description 10
- 125000004433 nitrogen atom Chemical group N* 0.000 description 10
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 9
- 238000011579 SCID mouse model Methods 0.000 description 9
- 230000002776 aggregation Effects 0.000 description 9
- 238000004220 aggregation Methods 0.000 description 9
- 230000021615 conjugation Effects 0.000 description 9
- 238000012217 deletion Methods 0.000 description 9
- 230000037430 deletion Effects 0.000 description 9
- 208000035475 disorder Diseases 0.000 description 9
- 238000000684 flow cytometry Methods 0.000 description 9
- 238000009472 formulation Methods 0.000 description 9
- 230000004927 fusion Effects 0.000 description 9
- 230000003053 immunization Effects 0.000 description 9
- 125000001151 peptidyl group Chemical group 0.000 description 9
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 9
- 150000003254 radicals Chemical class 0.000 description 9
- 230000001105 regulatory effect Effects 0.000 description 9
- 238000010561 standard procedure Methods 0.000 description 9
- 125000003396 thiol group Chemical class [H]S* 0.000 description 9
- 210000001519 tissue Anatomy 0.000 description 9
- 241001465754 Metazoa Species 0.000 description 8
- 108091028043 Nucleic acid sequence Proteins 0.000 description 8
- 238000004458 analytical method Methods 0.000 description 8
- 230000008901 benefit Effects 0.000 description 8
- 210000004369 blood Anatomy 0.000 description 8
- 239000008280 blood Substances 0.000 description 8
- 239000000460 chlorine Substances 0.000 description 8
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 8
- 230000000875 corresponding effect Effects 0.000 description 8
- 125000000753 cycloalkyl group Chemical group 0.000 description 8
- 230000001472 cytotoxic effect Effects 0.000 description 8
- 238000001802 infusion Methods 0.000 description 8
- 238000002347 injection Methods 0.000 description 8
- 239000007924 injection Substances 0.000 description 8
- 230000000670 limiting effect Effects 0.000 description 8
- 238000002703 mutagenesis Methods 0.000 description 8
- 231100000350 mutagenesis Toxicity 0.000 description 8
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 8
- 230000000087 stabilizing effect Effects 0.000 description 8
- 230000005740 tumor formation Effects 0.000 description 8
- 102000009109 Fc receptors Human genes 0.000 description 7
- 108010087819 Fc receptors Proteins 0.000 description 7
- 230000009471 action Effects 0.000 description 7
- 239000004480 active ingredient Substances 0.000 description 7
- 125000003545 alkoxy group Chemical group 0.000 description 7
- 125000003277 amino group Chemical group 0.000 description 7
- 230000003247 decreasing effect Effects 0.000 description 7
- 239000001177 diphosphate Substances 0.000 description 7
- XPPKVPWEQAFLFU-UHFFFAOYSA-J diphosphate(4-) Chemical compound [O-]P([O-])(=O)OP([O-])([O-])=O XPPKVPWEQAFLFU-UHFFFAOYSA-J 0.000 description 7
- 235000011180 diphosphates Nutrition 0.000 description 7
- 238000012377 drug delivery Methods 0.000 description 7
- 230000002255 enzymatic effect Effects 0.000 description 7
- 238000002649 immunization Methods 0.000 description 7
- 230000001976 improved effect Effects 0.000 description 7
- 239000011159 matrix material Substances 0.000 description 7
- 229920001184 polypeptide Polymers 0.000 description 7
- 230000002829 reductive effect Effects 0.000 description 7
- 210000002966 serum Anatomy 0.000 description 7
- 208000024891 symptom Diseases 0.000 description 7
- 238000011830 transgenic mouse model Methods 0.000 description 7
- 239000001226 triphosphate Substances 0.000 description 7
- 235000011178 triphosphate Nutrition 0.000 description 7
- 230000004614 tumor growth Effects 0.000 description 7
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 7
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 6
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 6
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 6
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 6
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 6
- 102000019298 Lipocalin Human genes 0.000 description 6
- 108050006654 Lipocalin Proteins 0.000 description 6
- 206010025323 Lymphomas Diseases 0.000 description 6
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 6
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 6
- 108010076504 Protein Sorting Signals Proteins 0.000 description 6
- 125000002947 alkylene group Chemical group 0.000 description 6
- 150000001371 alpha-amino acids Chemical class 0.000 description 6
- 235000008206 alpha-amino acids Nutrition 0.000 description 6
- 125000004429 atom Chemical group 0.000 description 6
- 150000001720 carbohydrates Chemical class 0.000 description 6
- 230000015556 catabolic process Effects 0.000 description 6
- 239000003153 chemical reaction reagent Substances 0.000 description 6
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 6
- 229910052801 chlorine Inorganic materials 0.000 description 6
- 125000004093 cyano group Chemical group *C#N 0.000 description 6
- 235000018417 cysteine Nutrition 0.000 description 6
- 229960002433 cysteine Drugs 0.000 description 6
- 231100000433 cytotoxic Toxicity 0.000 description 6
- 238000006731 degradation reaction Methods 0.000 description 6
- 238000002474 experimental method Methods 0.000 description 6
- 125000004474 heteroalkylene group Chemical group 0.000 description 6
- 239000001257 hydrogen Substances 0.000 description 6
- 230000028993 immune response Effects 0.000 description 6
- 230000005847 immunogenicity Effects 0.000 description 6
- 239000000463 material Substances 0.000 description 6
- 230000007246 mechanism Effects 0.000 description 6
- TWXDDNPPQUTEOV-FVGYRXGTSA-N methamphetamine hydrochloride Chemical compound Cl.CN[C@@H](C)CC1=CC=CC=C1 TWXDDNPPQUTEOV-FVGYRXGTSA-N 0.000 description 6
- 125000000956 methoxy group Chemical group [H]C([H])([H])O* 0.000 description 6
- 201000000050 myeloid neoplasm Diseases 0.000 description 6
- 238000002823 phage display Methods 0.000 description 6
- 210000002381 plasma Anatomy 0.000 description 6
- 238000000159 protein binding assay Methods 0.000 description 6
- 238000012216 screening Methods 0.000 description 6
- 238000007920 subcutaneous administration Methods 0.000 description 6
- 238000012360 testing method Methods 0.000 description 6
- 230000009261 transgenic effect Effects 0.000 description 6
- 206010069754 Acquired gene mutation Diseases 0.000 description 5
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 5
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 description 5
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 5
- 101000878602 Homo sapiens Immunoglobulin alpha Fc receptor Proteins 0.000 description 5
- 238000012450 HuMAb Mouse Methods 0.000 description 5
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 5
- 102000009490 IgG Receptors Human genes 0.000 description 5
- 102100038005 Immunoglobulin alpha Fc receptor Human genes 0.000 description 5
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 5
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 5
- 102100029185 Low affinity immunoglobulin gamma Fc region receptor III-B Human genes 0.000 description 5
- 206010057249 Phagocytosis Diseases 0.000 description 5
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 description 5
- KAESVJOAVNADME-UHFFFAOYSA-N Pyrrole Chemical compound C=1C=CNC=1 KAESVJOAVNADME-UHFFFAOYSA-N 0.000 description 5
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 5
- 150000007513 acids Chemical class 0.000 description 5
- 239000002671 adjuvant Substances 0.000 description 5
- 230000015572 biosynthetic process Effects 0.000 description 5
- 229910052794 bromium Inorganic materials 0.000 description 5
- 150000001721 carbon Chemical group 0.000 description 5
- 230000001413 cellular effect Effects 0.000 description 5
- 238000012512 characterization method Methods 0.000 description 5
- 230000001268 conjugating effect Effects 0.000 description 5
- GLNDAGDHSLMOKX-UHFFFAOYSA-N coumarin 120 Chemical compound C1=C(N)C=CC2=C1OC(=O)C=C2C GLNDAGDHSLMOKX-UHFFFAOYSA-N 0.000 description 5
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 5
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 5
- 239000006185 dispersion Substances 0.000 description 5
- 150000002019 disulfides Chemical class 0.000 description 5
- 239000007850 fluorescent dye Substances 0.000 description 5
- 125000001188 haloalkyl group Chemical group 0.000 description 5
- 230000036541 health Effects 0.000 description 5
- 230000002209 hydrophobic effect Effects 0.000 description 5
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 5
- 238000001990 intravenous administration Methods 0.000 description 5
- 125000001570 methylene group Chemical group [H]C([H])([*:1])[*:2] 0.000 description 5
- 230000008782 phagocytosis Effects 0.000 description 5
- 239000002953 phosphate buffered saline Substances 0.000 description 5
- 238000003127 radioimmunoassay Methods 0.000 description 5
- 230000019491 signal transduction Effects 0.000 description 5
- 230000037439 somatic mutation Effects 0.000 description 5
- 238000012289 standard assay Methods 0.000 description 5
- 238000003786 synthesis reaction Methods 0.000 description 5
- 230000009885 systemic effect Effects 0.000 description 5
- 230000001988 toxicity Effects 0.000 description 5
- 231100000419 toxicity Toxicity 0.000 description 5
- 125000002264 triphosphate group Chemical class [H]OP(=O)(O[H])OP(=O)(O[H])OP(=O)(O[H])O* 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- 208000009746 Adult T-Cell Leukemia-Lymphoma Diseases 0.000 description 4
- 208000016683 Adult T-cell leukemia/lymphoma Diseases 0.000 description 4
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 4
- 241000588724 Escherichia coli Species 0.000 description 4
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 4
- 101000913074 Homo sapiens High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 description 4
- 108010042653 IgA receptor Proteins 0.000 description 4
- 208000002971 Immunoblastic Lymphadenopathy Diseases 0.000 description 4
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 4
- 238000012449 Kunming mouse Methods 0.000 description 4
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical compound C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 description 4
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 4
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 4
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 4
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 4
- 208000032004 Large-Cell Anaplastic Lymphoma Diseases 0.000 description 4
- 241000124008 Mammalia Species 0.000 description 4
- 102000003729 Neprilysin Human genes 0.000 description 4
- 108090000028 Neprilysin Proteins 0.000 description 4
- 108010029485 Protein Isoforms Proteins 0.000 description 4
- 102000001708 Protein Isoforms Human genes 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- 206010042971 T-cell lymphoma Diseases 0.000 description 4
- 102100031293 Thimet oligopeptidase Human genes 0.000 description 4
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 4
- 238000010521 absorption reaction Methods 0.000 description 4
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 4
- 206010002449 angioimmunoblastic T-cell lymphoma Diseases 0.000 description 4
- 239000003963 antioxidant agent Substances 0.000 description 4
- 235000006708 antioxidants Nutrition 0.000 description 4
- 239000011324 bead Substances 0.000 description 4
- 239000011230 binding agent Substances 0.000 description 4
- 125000001589 carboacyl group Chemical group 0.000 description 4
- 235000014633 carbohydrates Nutrition 0.000 description 4
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 4
- 229940127089 cytotoxic agent Drugs 0.000 description 4
- 239000000032 diagnostic agent Substances 0.000 description 4
- 229940039227 diagnostic agent Drugs 0.000 description 4
- 229960004679 doxorubicin Drugs 0.000 description 4
- 210000003630 histaminocyte Anatomy 0.000 description 4
- 230000001900 immune effect Effects 0.000 description 4
- 230000002163 immunogen Effects 0.000 description 4
- 229940099472 immunoglobulin a Drugs 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- 239000002502 liposome Substances 0.000 description 4
- 210000002540 macrophage Anatomy 0.000 description 4
- 239000012528 membrane Substances 0.000 description 4
- 210000004379 membrane Anatomy 0.000 description 4
- 102000006240 membrane receptors Human genes 0.000 description 4
- 229960000485 methotrexate Drugs 0.000 description 4
- 238000001823 molecular biology technique Methods 0.000 description 4
- 210000001616 monocyte Anatomy 0.000 description 4
- 150000004712 monophosphates Chemical class 0.000 description 4
- 229920000642 polymer Polymers 0.000 description 4
- 125000006239 protecting group Chemical group 0.000 description 4
- 238000003259 recombinant expression Methods 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 230000004044 response Effects 0.000 description 4
- 239000000523 sample Substances 0.000 description 4
- 230000035945 sensitivity Effects 0.000 description 4
- 238000002741 site-directed mutagenesis Methods 0.000 description 4
- 238000003860 storage Methods 0.000 description 4
- 235000000346 sugar Nutrition 0.000 description 4
- 150000003871 sulfonates Chemical class 0.000 description 4
- 238000013268 sustained release Methods 0.000 description 4
- 238000002560 therapeutic procedure Methods 0.000 description 4
- 108010073106 thimet oligopeptidase Proteins 0.000 description 4
- 125000002023 trifluoromethyl group Chemical group FC(F)(F)* 0.000 description 4
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 3
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 3
- 102100033400 4F2 cell-surface antigen heavy chain Human genes 0.000 description 3
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 3
- 102100021266 Alpha-(1,6)-fucosyltransferase Human genes 0.000 description 3
- 208000023275 Autoimmune disease Diseases 0.000 description 3
- 208000003950 B-cell lymphoma Diseases 0.000 description 3
- 241000283690 Bos taurus Species 0.000 description 3
- 208000011691 Burkitt lymphomas Diseases 0.000 description 3
- 108010001857 Cell Surface Receptors Proteins 0.000 description 3
- 229930186147 Cephalosporin Natural products 0.000 description 3
- 102000004127 Cytokines Human genes 0.000 description 3
- 108090000695 Cytokines Proteins 0.000 description 3
- 102000053602 DNA Human genes 0.000 description 3
- 108010092160 Dactinomycin Proteins 0.000 description 3
- 229920002307 Dextran Polymers 0.000 description 3
- 238000012286 ELISA Assay Methods 0.000 description 3
- 108010037362 Extracellular Matrix Proteins Proteins 0.000 description 3
- 102000010834 Extracellular Matrix Proteins Human genes 0.000 description 3
- PNNNRSAQSRJVSB-SLPGGIOYSA-N Fucose Natural products C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C=O PNNNRSAQSRJVSB-SLPGGIOYSA-N 0.000 description 3
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 3
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 3
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 3
- 108090001101 Hepsin Proteins 0.000 description 3
- 102000004989 Hepsin Human genes 0.000 description 3
- 101000800023 Homo sapiens 4F2 cell-surface antigen heavy chain Proteins 0.000 description 3
- 101000627872 Homo sapiens 72 kDa type IV collagenase Proteins 0.000 description 3
- 101000990902 Homo sapiens Matrix metalloproteinase-9 Proteins 0.000 description 3
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 3
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 3
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 3
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 3
- 241000829100 Macaca mulatta polyomavirus 1 Species 0.000 description 3
- 102100030412 Matrix metalloproteinase-9 Human genes 0.000 description 3
- 102000005741 Metalloproteases Human genes 0.000 description 3
- 108010006035 Metalloproteases Proteins 0.000 description 3
- 241000699660 Mus musculus Species 0.000 description 3
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 3
- 102000005348 Neuraminidase Human genes 0.000 description 3
- 108010006232 Neuraminidase Proteins 0.000 description 3
- 108010039918 Polylysine Proteins 0.000 description 3
- 241000288906 Primates Species 0.000 description 3
- 241000700159 Rattus Species 0.000 description 3
- 108020004511 Recombinant DNA Proteins 0.000 description 3
- 102000012479 Serine Proteases Human genes 0.000 description 3
- 108010022999 Serine Proteases Proteins 0.000 description 3
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 3
- 108010022394 Threonine synthase Proteins 0.000 description 3
- 102000014384 Type C Phospholipases Human genes 0.000 description 3
- 108010079194 Type C Phospholipases Proteins 0.000 description 3
- 108090000435 Urokinase-type plasminogen activator Proteins 0.000 description 3
- 102000003990 Urokinase-type plasminogen activator Human genes 0.000 description 3
- 241000700605 Viruses Species 0.000 description 3
- 150000001266 acyl halides Chemical class 0.000 description 3
- 238000001042 affinity chromatography Methods 0.000 description 3
- 150000001299 aldehydes Chemical class 0.000 description 3
- 125000004390 alkyl sulfonyl group Chemical group 0.000 description 3
- 230000004075 alteration Effects 0.000 description 3
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 3
- 238000010171 animal model Methods 0.000 description 3
- 239000003242 anti bacterial agent Substances 0.000 description 3
- 230000000259 anti-tumor effect Effects 0.000 description 3
- 230000009830 antibody antigen interaction Effects 0.000 description 3
- 238000011091 antibody purification Methods 0.000 description 3
- 239000002246 antineoplastic agent Substances 0.000 description 3
- 125000004391 aryl sulfonyl group Chemical group 0.000 description 3
- 235000003704 aspartic acid Nutrition 0.000 description 3
- 230000001580 bacterial effect Effects 0.000 description 3
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 3
- 230000008499 blood brain barrier function Effects 0.000 description 3
- 210000001218 blood-brain barrier Anatomy 0.000 description 3
- 125000002915 carbonyl group Chemical group [*:2]C([*:1])=O 0.000 description 3
- 230000010261 cell growth Effects 0.000 description 3
- 229940124587 cephalosporin Drugs 0.000 description 3
- 150000001780 cephalosporins Chemical class 0.000 description 3
- 229960004316 cisplatin Drugs 0.000 description 3
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 3
- 238000000576 coating method Methods 0.000 description 3
- 238000002648 combination therapy Methods 0.000 description 3
- 230000008878 coupling Effects 0.000 description 3
- 238000010168 coupling process Methods 0.000 description 3
- 238000005859 coupling reaction Methods 0.000 description 3
- 238000004132 cross linking Methods 0.000 description 3
- 239000002254 cytotoxic agent Substances 0.000 description 3
- 230000006378 damage Effects 0.000 description 3
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 238000001514 detection method Methods 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 230000018109 developmental process Effects 0.000 description 3
- 102000004419 dihydrofolate reductase Human genes 0.000 description 3
- 238000010790 dilution Methods 0.000 description 3
- 239000012895 dilution Substances 0.000 description 3
- 239000002612 dispersion medium Substances 0.000 description 3
- 125000002228 disulfide group Chemical group 0.000 description 3
- 229930184221 duocarmycin Natural products 0.000 description 3
- 229960005501 duocarmycin Drugs 0.000 description 3
- 230000008030 elimination Effects 0.000 description 3
- 238000003379 elimination reaction Methods 0.000 description 3
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 3
- 210000002744 extracellular matrix Anatomy 0.000 description 3
- 108020001507 fusion proteins Proteins 0.000 description 3
- 102000037865 fusion proteins Human genes 0.000 description 3
- 235000013922 glutamic acid Nutrition 0.000 description 3
- 239000004220 glutamic acid Substances 0.000 description 3
- 238000004128 high performance liquid chromatography Methods 0.000 description 3
- 150000002429 hydrazines Chemical class 0.000 description 3
- 230000007062 hydrolysis Effects 0.000 description 3
- 238000006460 hydrolysis reaction Methods 0.000 description 3
- 210000000987 immune system Anatomy 0.000 description 3
- 239000007943 implant Substances 0.000 description 3
- 239000004615 ingredient Substances 0.000 description 3
- 238000007918 intramuscular administration Methods 0.000 description 3
- 229910052740 iodine Inorganic materials 0.000 description 3
- 239000007951 isotonicity adjuster Substances 0.000 description 3
- 239000000787 lecithin Substances 0.000 description 3
- 229940067606 lecithin Drugs 0.000 description 3
- 235000010445 lecithin Nutrition 0.000 description 3
- 210000004698 lymphocyte Anatomy 0.000 description 3
- 210000004962 mammalian cell Anatomy 0.000 description 3
- 239000002609 medium Substances 0.000 description 3
- 230000003278 mimic effect Effects 0.000 description 3
- QJGQUHMNIGDVPM-UHFFFAOYSA-N nitrogen group Chemical group [N] QJGQUHMNIGDVPM-UHFFFAOYSA-N 0.000 description 3
- 231100000252 nontoxic Toxicity 0.000 description 3
- 230000003000 nontoxic effect Effects 0.000 description 3
- 230000000704 physical effect Effects 0.000 description 3
- 229920000656 polylysine Polymers 0.000 description 3
- 229920005862 polyol Polymers 0.000 description 3
- 150000003077 polyols Chemical class 0.000 description 3
- 230000003389 potentiating effect Effects 0.000 description 3
- 239000000843 powder Substances 0.000 description 3
- 230000002265 prevention Effects 0.000 description 3
- 230000000069 prophylactic effect Effects 0.000 description 3
- 230000009257 reactivity Effects 0.000 description 3
- 230000000717 retained effect Effects 0.000 description 3
- 238000012552 review Methods 0.000 description 3
- 206010039073 rheumatoid arthritis Diseases 0.000 description 3
- 150000003335 secondary amines Chemical group 0.000 description 3
- 229910052710 silicon Inorganic materials 0.000 description 3
- 150000003384 small molecules Chemical class 0.000 description 3
- 239000007787 solid Substances 0.000 description 3
- 239000002904 solvent Substances 0.000 description 3
- 238000012409 standard PCR amplification Methods 0.000 description 3
- 239000007858 starting material Substances 0.000 description 3
- 150000008163 sugars Chemical class 0.000 description 3
- 125000004434 sulfur atom Chemical group 0.000 description 3
- 239000012730 sustained-release form Substances 0.000 description 3
- 231100000331 toxic Toxicity 0.000 description 3
- 230000002588 toxic effect Effects 0.000 description 3
- 238000013519 translation Methods 0.000 description 3
- 230000014616 translation Effects 0.000 description 3
- 238000001262 western blot Methods 0.000 description 3
- AGGWFDNPHKLBBV-YUMQZZPRSA-N (2s)-2-[[(2s)-2-amino-3-methylbutanoyl]amino]-5-(carbamoylamino)pentanoic acid Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(O)=O)CCCNC(N)=O AGGWFDNPHKLBBV-YUMQZZPRSA-N 0.000 description 2
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 2
- YJCJVMMDTBEITC-UHFFFAOYSA-N 10-hydroxycapric acid Chemical compound OCCCCCCCCCC(O)=O YJCJVMMDTBEITC-UHFFFAOYSA-N 0.000 description 2
- HZAXFHJVJLSVMW-UHFFFAOYSA-N 2-Aminoethan-1-ol Chemical compound NCCO HZAXFHJVJLSVMW-UHFFFAOYSA-N 0.000 description 2
- WNZQDUSMALZDQF-UHFFFAOYSA-N 2-benzofuran-1(3H)-one Chemical compound C1=CC=C2C(=O)OCC2=C1 WNZQDUSMALZDQF-UHFFFAOYSA-N 0.000 description 2
- VXPSQDAMFATNNG-UHFFFAOYSA-N 3-[2-(2,5-dioxopyrrol-3-yl)phenyl]pyrrole-2,5-dione Chemical compound O=C1NC(=O)C(C=2C(=CC=CC=2)C=2C(NC(=O)C=2)=O)=C1 VXPSQDAMFATNNG-UHFFFAOYSA-N 0.000 description 2
- SGYIRNXZLWJMCR-UHFFFAOYSA-M 3-methyl-1,3-benzothiazol-3-ium;iodide Chemical compound [I-].C1=CC=C2[N+](C)=CSC2=C1 SGYIRNXZLWJMCR-UHFFFAOYSA-M 0.000 description 2
- JJMDCOVWQOJGCB-UHFFFAOYSA-N 5-aminopentanoic acid Chemical compound [NH3+]CCCCC([O-])=O JJMDCOVWQOJGCB-UHFFFAOYSA-N 0.000 description 2
- SLXKOJJOQWFEFD-UHFFFAOYSA-N 6-aminohexanoic acid Chemical compound NCCCCCC(O)=O SLXKOJJOQWFEFD-UHFFFAOYSA-N 0.000 description 2
- 102100024406 60S ribosomal protein L15 Human genes 0.000 description 2
- 102100026802 72 kDa type IV collagenase Human genes 0.000 description 2
- NGNQZCDZXSOVQU-UHFFFAOYSA-N 8,16,18,26,34,36-hexahydroxyhentetracontane-2,6,10,14,24,28,32-heptone Chemical compound CCCCCC(O)CC(O)CC(=O)CCCC(=O)CC(O)CC(=O)CCCCCC(O)CC(O)CC(=O)CCCC(=O)CC(O)CC(=O)CCCC(C)=O NGNQZCDZXSOVQU-UHFFFAOYSA-N 0.000 description 2
- 101001023095 Anemonia sulcata Delta-actitoxin-Avd1a Proteins 0.000 description 2
- 101000641989 Araneus ventricosus Kunitz-type U1-aranetoxin-Av1a Proteins 0.000 description 2
- 101000939689 Araneus ventricosus U2-aranetoxin-Av1a Proteins 0.000 description 2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 2
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 2
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 description 2
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 2
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 2
- 108010006654 Bleomycin Proteins 0.000 description 2
- 208000031648 Body Weight Changes Diseases 0.000 description 2
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 2
- 101000633673 Buthacus arenicola Beta-insect depressant toxin BaIT2 Proteins 0.000 description 2
- 239000004322 Butylated hydroxytoluene Substances 0.000 description 2
- NLZUEZXRPGMBCV-UHFFFAOYSA-N Butylhydroxytoluene Chemical compound CC1=CC(C(C)(C)C)=C(O)C(C(C)(C)C)=C1 NLZUEZXRPGMBCV-UHFFFAOYSA-N 0.000 description 2
- 241000282472 Canis lupus familiaris Species 0.000 description 2
- 201000009030 Carcinoma Diseases 0.000 description 2
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 description 2
- 102000014914 Carrier Proteins Human genes 0.000 description 2
- 101001028691 Carybdea rastonii Toxin CrTX-A Proteins 0.000 description 2
- 208000005024 Castleman disease Diseases 0.000 description 2
- 108010084457 Cathepsins Proteins 0.000 description 2
- 102000005600 Cathepsins Human genes 0.000 description 2
- 101000685083 Centruroides infamatus Beta-toxin Cii1 Proteins 0.000 description 2
- 101000654318 Centruroides noxius Beta-mammal toxin Cn2 Proteins 0.000 description 2
- 101000685085 Centruroides noxius Toxin Cn1 Proteins 0.000 description 2
- 101001028688 Chironex fleckeri Toxin CfTX-1 Proteins 0.000 description 2
- 101001028695 Chironex fleckeri Toxin CfTX-2 Proteins 0.000 description 2
- 108010035532 Collagen Proteins 0.000 description 2
- 102000008186 Collagen Human genes 0.000 description 2
- 101000644407 Cyriopagopus schmidti U6-theraphotoxin-Hs1a Proteins 0.000 description 2
- 241000701022 Cytomegalovirus Species 0.000 description 2
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 2
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 2
- 238000005698 Diels-Alder reaction Methods 0.000 description 2
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 2
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 2
- 201000009051 Embryonal Carcinoma Diseases 0.000 description 2
- 102100031940 Epithelial cell adhesion molecule Human genes 0.000 description 2
- 241000283086 Equidae Species 0.000 description 2
- 108090000371 Esterases Proteins 0.000 description 2
- 241000282326 Felis catus Species 0.000 description 2
- 241000287828 Gallus gallus Species 0.000 description 2
- 108010010803 Gelatin Proteins 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 102100026122 High affinity immunoglobulin gamma Fc receptor I Human genes 0.000 description 2
- 241000282412 Homo Species 0.000 description 2
- 101000819490 Homo sapiens Alpha-(1,6)-fucosyltransferase Proteins 0.000 description 2
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 2
- 101000920667 Homo sapiens Epithelial cell adhesion molecule Proteins 0.000 description 2
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 2
- 101000798702 Homo sapiens Transmembrane protease serine 4 Proteins 0.000 description 2
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 2
- VAXBXNPRXPHGHG-BJDJZHNGSA-N Ile-Ala-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)O)N VAXBXNPRXPHGHG-BJDJZHNGSA-N 0.000 description 2
- 206010053574 Immunoblastic lymphoma Diseases 0.000 description 2
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 2
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 2
- 208000007766 Kaposi sarcoma Diseases 0.000 description 2
- 125000000998 L-alanino group Chemical group [H]N([*])[C@](C([H])([H])[H])([H])C(=O)O[H] 0.000 description 2
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 2
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 2
- 125000000393 L-methionino group Chemical group [H]OC(=O)[C@@]([H])(N([H])[*])C([H])([H])C(SC([H])([H])[H])([H])[H] 0.000 description 2
- 125000000174 L-prolyl group Chemical group [H]N1C([H])([H])C([H])([H])C([H])([H])[C@@]1([H])C(*)=O 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- 125000000510 L-tryptophano group Chemical group [H]C1=C([H])C([H])=C2N([H])C([H])=C(C([H])([H])[C@@]([H])(C(O[H])=O)N([H])[*])C2=C1[H] 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- 241000270322 Lepidosauria Species 0.000 description 2
- LSPYFSHXDAYVDI-SRVKXCTJSA-N Leu-Ala-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(C)C LSPYFSHXDAYVDI-SRVKXCTJSA-N 0.000 description 2
- GQYIWUVLTXOXAJ-UHFFFAOYSA-N Lomustine Chemical compound ClCCN(N=O)C(=O)NC1CCCCC1 GQYIWUVLTXOXAJ-UHFFFAOYSA-N 0.000 description 2
- 241000282567 Macaca fascicularis Species 0.000 description 2
- 108010091175 Matriptase Proteins 0.000 description 2
- 102000002274 Matrix Metalloproteinases Human genes 0.000 description 2
- 108010000684 Matrix Metalloproteinases Proteins 0.000 description 2
- 108010052285 Membrane Proteins Proteins 0.000 description 2
- 206010027476 Metastases Diseases 0.000 description 2
- 241001494479 Pecora Species 0.000 description 2
- 208000027190 Peripheral T-cell lymphomas Diseases 0.000 description 2
- 101000679608 Phaeosphaeria nodorum (strain SN15 / ATCC MYA-4574 / FGSC 10173) Cysteine rich necrotrophic effector Tox1 Proteins 0.000 description 2
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 2
- 108091000080 Phosphotransferase Proteins 0.000 description 2
- 241000235648 Pichia Species 0.000 description 2
- 102000013566 Plasminogen Human genes 0.000 description 2
- 108010051456 Plasminogen Proteins 0.000 description 2
- 206010065857 Primary Effusion Lymphoma Diseases 0.000 description 2
- ZTHYODDOHIVTJV-UHFFFAOYSA-N Propyl gallate Chemical compound CCCOC(=O)C1=CC(O)=C(O)C(O)=C1 ZTHYODDOHIVTJV-UHFFFAOYSA-N 0.000 description 2
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 2
- 229920002684 Sepharose Polymers 0.000 description 2
- 102100037942 Suppressor of tumorigenicity 14 protein Human genes 0.000 description 2
- 208000031673 T-Cell Cutaneous Lymphoma Diseases 0.000 description 2
- 208000031672 T-Cell Peripheral Lymphoma Diseases 0.000 description 2
- 201000011176 T-cell adult acute lymphocytic leukemia Diseases 0.000 description 2
- 208000000389 T-cell leukemia Diseases 0.000 description 2
- 208000028530 T-cell lymphoblastic leukemia/lymphoma Diseases 0.000 description 2
- 208000027585 T-cell non-Hodgkin lymphoma Diseases 0.000 description 2
- 206010042987 T-cell type acute leukaemia Diseases 0.000 description 2
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 2
- 210000001744 T-lymphocyte Anatomy 0.000 description 2
- KKEYFWRCBNTPAC-UHFFFAOYSA-N Terephthalic acid Chemical compound OC(=O)C1=CC=C(C(O)=O)C=C1 KKEYFWRCBNTPAC-UHFFFAOYSA-N 0.000 description 2
- 102100036494 Testisin Human genes 0.000 description 2
- 108050003829 Testisin Proteins 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- 102100032471 Transmembrane protease serine 4 Human genes 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- JKHXYJKMNSSFFL-IUCAKERBSA-N Val-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(O)=O)CCCCN JKHXYJKMNSSFFL-IUCAKERBSA-N 0.000 description 2
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 2
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 2
- 208000033559 Waldenström macroglobulinemia Diseases 0.000 description 2
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 2
- 238000005917 acylation reaction Methods 0.000 description 2
- 201000006966 adult T-cell leukemia Diseases 0.000 description 2
- 150000001298 alcohols Chemical class 0.000 description 2
- 125000003342 alkenyl group Chemical group 0.000 description 2
- 125000003282 alkyl amino group Chemical group 0.000 description 2
- 125000000304 alkynyl group Chemical group 0.000 description 2
- 102000012086 alpha-L-Fucosidase Human genes 0.000 description 2
- 108010061314 alpha-L-Fucosidase Proteins 0.000 description 2
- 150000001408 amides Chemical class 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 125000002490 anilino group Chemical group [H]N(*)C1=C([H])C([H])=C([H])C([H])=C1[H] 0.000 description 2
- 230000000844 anti-bacterial effect Effects 0.000 description 2
- 230000005875 antibody response Effects 0.000 description 2
- 239000003429 antifungal agent Substances 0.000 description 2
- 229940121375 antifungal agent Drugs 0.000 description 2
- 230000030741 antigen processing and presentation Effects 0.000 description 2
- 125000003710 aryl alkyl group Chemical group 0.000 description 2
- 235000009582 asparagine Nutrition 0.000 description 2
- 229960001230 asparagine Drugs 0.000 description 2
- 230000005784 autoimmunity Effects 0.000 description 2
- 238000000376 autoradiography Methods 0.000 description 2
- 150000001540 azides Chemical group 0.000 description 2
- 239000002585 base Substances 0.000 description 2
- IQFYYKKMVGJFEH-UHFFFAOYSA-N beta-L-thymidine Natural products O=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1 IQFYYKKMVGJFEH-UHFFFAOYSA-N 0.000 description 2
- UCMIRNVEIXFBKS-UHFFFAOYSA-N beta-alanine Chemical compound NCCC(O)=O UCMIRNVEIXFBKS-UHFFFAOYSA-N 0.000 description 2
- 108091008324 binding proteins Proteins 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 230000008033 biological extinction Effects 0.000 description 2
- 230000008827 biological function Effects 0.000 description 2
- 229960002685 biotin Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 239000011616 biotin Substances 0.000 description 2
- 230000004579 body weight change Effects 0.000 description 2
- GDTBXPJZTBHREO-UHFFFAOYSA-N bromine Chemical compound BrBr GDTBXPJZTBHREO-UHFFFAOYSA-N 0.000 description 2
- 239000007853 buffer solution Substances 0.000 description 2
- 235000010354 butylated hydroxytoluene Nutrition 0.000 description 2
- 229940095259 butylated hydroxytoluene Drugs 0.000 description 2
- 210000004899 c-terminal region Anatomy 0.000 description 2
- AIYUHDOJVYHVIT-UHFFFAOYSA-M caesium chloride Chemical compound [Cl-].[Cs+] AIYUHDOJVYHVIT-UHFFFAOYSA-M 0.000 description 2
- 229930195731 calicheamicin Natural products 0.000 description 2
- 238000005251 capillar electrophoresis Methods 0.000 description 2
- 229960005243 carmustine Drugs 0.000 description 2
- 239000000969 carrier Substances 0.000 description 2
- 239000006285 cell suspension Substances 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 238000002512 chemotherapy Methods 0.000 description 2
- 235000013330 chicken meat Nutrition 0.000 description 2
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 2
- 229960004630 chlorambucil Drugs 0.000 description 2
- OSASVXMJTNOKOY-UHFFFAOYSA-N chlorobutanol Chemical compound CC(C)(O)C(Cl)(Cl)Cl OSASVXMJTNOKOY-UHFFFAOYSA-N 0.000 description 2
- 210000000349 chromosome Anatomy 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 238000011260 co-administration Methods 0.000 description 2
- 239000011248 coating agent Substances 0.000 description 2
- 229920001436 collagen Polymers 0.000 description 2
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 238000013270 controlled release Methods 0.000 description 2
- 239000003431 cross linking reagent Substances 0.000 description 2
- 230000009260 cross reactivity Effects 0.000 description 2
- 125000000113 cyclohexyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C([H])([H])C1([H])[H] 0.000 description 2
- UFULAYFCSOUIOV-UHFFFAOYSA-N cysteamine Chemical compound NCCS UFULAYFCSOUIOV-UHFFFAOYSA-N 0.000 description 2
- 229960000640 dactinomycin Drugs 0.000 description 2
- 229960000975 daunorubicin Drugs 0.000 description 2
- 230000006240 deamidation Effects 0.000 description 2
- CFCUWKMKBJTWLW-UHFFFAOYSA-N deoliosyl-3C-alpha-L-digitoxosyl-MTM Natural products CC=1C(O)=C2C(O)=C3C(=O)C(OC4OC(C)C(O)C(OC5OC(C)C(O)C(OC6OC(C)C(O)C(C)(O)C6)C5)C4)C(C(OC)C(=O)C(O)C(C)O)CC3=CC2=CC=1OC(OC(C)C1O)CC1OC1CC(O)C(O)C(C)O1 CFCUWKMKBJTWLW-UHFFFAOYSA-N 0.000 description 2
- 238000003745 diagnosis Methods 0.000 description 2
- 239000000539 dimer Substances 0.000 description 2
- 125000000118 dimethyl group Chemical group [H]C([H])([H])* 0.000 description 2
- BFMYDTVEBKDAKJ-UHFFFAOYSA-L disodium;(2',7'-dibromo-3',6'-dioxido-3-oxospiro[2-benzofuran-1,9'-xanthene]-4'-yl)mercury;hydrate Chemical compound O.[Na+].[Na+].O1C(=O)C2=CC=CC=C2C21C1=CC(Br)=C([O-])C([Hg])=C1OC1=C2C=C(Br)C([O-])=C1 BFMYDTVEBKDAKJ-UHFFFAOYSA-L 0.000 description 2
- 238000010494 dissociation reaction Methods 0.000 description 2
- 230000005593 dissociations Effects 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 239000002552 dosage form Substances 0.000 description 2
- VQNATVDKACXKTF-XELLLNAOSA-N duocarmycin Chemical class COC1=C(OC)C(OC)=C2NC(C(=O)N3C4=CC(=O)C5=C([C@@]64C[C@@H]6C3)C=C(N5)C(=O)OC)=CC2=C1 VQNATVDKACXKTF-XELLLNAOSA-N 0.000 description 2
- 239000012893 effector ligand Substances 0.000 description 2
- 238000001962 electrophoresis Methods 0.000 description 2
- 239000003623 enhancer Substances 0.000 description 2
- 210000003527 eukaryotic cell Anatomy 0.000 description 2
- 125000001153 fluoro group Chemical group F* 0.000 description 2
- 125000002446 fucosyl group Chemical group C1([C@@H](O)[C@H](O)[C@H](O)[C@@H](O1)C)* 0.000 description 2
- 238000002825 functional assay Methods 0.000 description 2
- 101150023212 fut8 gene Proteins 0.000 description 2
- 238000001502 gel electrophoresis Methods 0.000 description 2
- 229920000159 gelatin Polymers 0.000 description 2
- 239000008273 gelatin Substances 0.000 description 2
- 235000019322 gelatine Nutrition 0.000 description 2
- 235000011852 gelatine desserts Nutrition 0.000 description 2
- 125000003827 glycol group Chemical group 0.000 description 2
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 2
- 210000003714 granulocyte Anatomy 0.000 description 2
- 239000005090 green fluorescent protein Substances 0.000 description 2
- 239000001963 growth medium Substances 0.000 description 2
- 125000005843 halogen group Chemical group 0.000 description 2
- 125000000623 heterocyclic group Chemical group 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 229940096329 human immunoglobulin a Drugs 0.000 description 2
- 238000009396 hybridization Methods 0.000 description 2
- 150000002430 hydrocarbons Chemical group 0.000 description 2
- 125000004435 hydrogen atom Chemical class [H]* 0.000 description 2
- 210000002865 immune cell Anatomy 0.000 description 2
- 238000003018 immunoassay Methods 0.000 description 2
- 229940072221 immunoglobulins Drugs 0.000 description 2
- 238000003364 immunohistochemistry Methods 0.000 description 2
- 239000003018 immunosuppressive agent Substances 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 210000004185 liver Anatomy 0.000 description 2
- 238000012423 maintenance Methods 0.000 description 2
- 210000003622 mature neutrocyte Anatomy 0.000 description 2
- 238000002844 melting Methods 0.000 description 2
- 230000008018 melting Effects 0.000 description 2
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 2
- 230000009401 metastasis Effects 0.000 description 2
- OSDXSOSJRPQCHJ-XVNBXDOJSA-N methyl 3-(3,4-dihydroxyphenyl)-3-[(E)-3-(3,4-dihydroxyphenyl)prop-2-enoyl]oxypropanoate Chemical compound C=1C=C(O)C(O)=CC=1C(CC(=O)OC)OC(=O)\C=C\C1=CC=C(O)C(O)=C1 OSDXSOSJRPQCHJ-XVNBXDOJSA-N 0.000 description 2
- CFCUWKMKBJTWLW-BKHRDMLASA-N mithramycin Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@H]1O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@H](O)[C@H](O[C@@H]3O[C@H](C)[C@@H](O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@H]1C[C@@H](O)[C@H](O)[C@@H](C)O1 CFCUWKMKBJTWLW-BKHRDMLASA-N 0.000 description 2
- 229960004857 mitomycin Drugs 0.000 description 2
- 125000004573 morpholin-4-yl group Chemical group N1(CCOCC1)* 0.000 description 2
- 238000010172 mouse model Methods 0.000 description 2
- 230000000869 mutational effect Effects 0.000 description 2
- 208000014761 nasopharyngeal type undifferentiated carcinoma Diseases 0.000 description 2
- 210000001989 nasopharynx Anatomy 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 210000004940 nucleus Anatomy 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 230000003204 osmotic effect Effects 0.000 description 2
- CTSLXHKWHWQRSH-UHFFFAOYSA-N oxalyl chloride Chemical compound ClC(=O)C(Cl)=O CTSLXHKWHWQRSH-UHFFFAOYSA-N 0.000 description 2
- 125000004430 oxygen atom Chemical group O* 0.000 description 2
- 230000036961 partial effect Effects 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- 244000052769 pathogen Species 0.000 description 2
- 230000006320 pegylation Effects 0.000 description 2
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 2
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 2
- 102000020233 phosphotransferase Human genes 0.000 description 2
- 229940012957 plasmin Drugs 0.000 description 2
- 229960003171 plicamycin Drugs 0.000 description 2
- 229910052700 potassium Inorganic materials 0.000 description 2
- MFDFERRIHVXMIY-UHFFFAOYSA-N procaine Chemical compound CCN(CC)CCOC(=O)C1=CC=C(N)C=C1 MFDFERRIHVXMIY-UHFFFAOYSA-N 0.000 description 2
- 229960004919 procaine Drugs 0.000 description 2
- 230000035755 proliferation Effects 0.000 description 2
- 230000002035 prolonged effect Effects 0.000 description 2
- AQHHHDLHHXJYJD-UHFFFAOYSA-N propranolol Chemical compound C1=CC=C2C(OCC(O)CNC(C)C)=CC=CC2=C1 AQHHHDLHHXJYJD-UHFFFAOYSA-N 0.000 description 2
- 229960004063 propylene glycol Drugs 0.000 description 2
- 235000013772 propylene glycol Nutrition 0.000 description 2
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 2
- 108010073863 saruplase Proteins 0.000 description 2
- 230000028327 secretion Effects 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- DAEPDZWVDSPTHF-UHFFFAOYSA-M sodium pyruvate Chemical compound [Na+].CC(=O)C([O-])=O DAEPDZWVDSPTHF-UHFFFAOYSA-M 0.000 description 2
- GEHJYWRUCIMESM-UHFFFAOYSA-L sodium sulfite Chemical compound [Na+].[Na+].[O-]S([O-])=O GEHJYWRUCIMESM-UHFFFAOYSA-L 0.000 description 2
- 210000001082 somatic cell Anatomy 0.000 description 2
- 239000000600 sorbitol Substances 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 230000003393 splenic effect Effects 0.000 description 2
- 210000004988 splenocyte Anatomy 0.000 description 2
- 230000003335 steric effect Effects 0.000 description 2
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 2
- 239000006228 supernatant Substances 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 229960000814 tetanus toxoid Drugs 0.000 description 2
- 230000004797 therapeutic response Effects 0.000 description 2
- 150000007970 thio esters Chemical class 0.000 description 2
- 125000005309 thioalkoxy group Chemical group 0.000 description 2
- FYSNRJHAOHDILO-UHFFFAOYSA-N thionyl chloride Chemical compound ClS(Cl)=O FYSNRJHAOHDILO-UHFFFAOYSA-N 0.000 description 2
- 229940104230 thymidine Drugs 0.000 description 2
- WYWHKKSPHMUBEB-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 description 2
- 230000007838 tissue remodeling Effects 0.000 description 2
- 230000000699 topical effect Effects 0.000 description 2
- 238000012448 transchromosomic mouse model Methods 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- 230000002103 transcriptional effect Effects 0.000 description 2
- 238000001890 transfection Methods 0.000 description 2
- 230000032258 transport Effects 0.000 description 2
- 239000013638 trimer Substances 0.000 description 2
- UNXRWKVEANCORM-UHFFFAOYSA-N triphosphoric acid Chemical compound OP(O)(=O)OP(O)(=O)OP(O)(O)=O UNXRWKVEANCORM-UHFFFAOYSA-N 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 241000701161 unidentified adenovirus Species 0.000 description 2
- 125000004417 unsaturated alkyl group Chemical group 0.000 description 2
- 229960005356 urokinase Drugs 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- 108010073969 valyllysine Proteins 0.000 description 2
- 229960003048 vinblastine Drugs 0.000 description 2
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 2
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 2
- 229960004528 vincristine Drugs 0.000 description 2
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 2
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 2
- QIJRTFXNRTXDIP-UHFFFAOYSA-N (1-carboxy-2-sulfanylethyl)azanium;chloride;hydrate Chemical compound O.Cl.SCC(N)C(O)=O QIJRTFXNRTXDIP-UHFFFAOYSA-N 0.000 description 1
- FLCQLSRLQIPNLM-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 2-acetylsulfanylacetate Chemical compound CC(=O)SCC(=O)ON1C(=O)CCC1=O FLCQLSRLQIPNLM-UHFFFAOYSA-N 0.000 description 1
- JWDFQMWEFLOOED-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(pyridin-2-yldisulfanyl)propanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCSSC1=CC=CC=N1 JWDFQMWEFLOOED-UHFFFAOYSA-N 0.000 description 1
- RVCHDOICLURXLG-WCCKRBBISA-N (2s)-2-(dimethylamino)propanoic acid;hydrazine Chemical compound NN.CN(C)[C@@H](C)C(O)=O RVCHDOICLURXLG-WCCKRBBISA-N 0.000 description 1
- KQRHTCDQWJLLME-XUXIUFHCSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-aminopropanoyl]amino]-4-methylpentanoyl]amino]propanoyl]amino]-4-methylpentanoic acid Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)N KQRHTCDQWJLLME-XUXIUFHCSA-N 0.000 description 1
- QPUQFUKWLQUBQJ-ZQIUZPCESA-N (2s)-2-[[2-[[(2s)-2-[[(2s)-1-(2-aminoacetyl)pyrrolidine-2-carbonyl]amino]-4-methylpentanoyl]amino]acetyl]amino]-3-methylbutanoic acid Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1C(=O)CN QPUQFUKWLQUBQJ-ZQIUZPCESA-N 0.000 description 1
- NXLNNXIXOYSCMB-UHFFFAOYSA-N (4-nitrophenyl) carbonochloridate Chemical compound [O-][N+](=O)C1=CC=C(OC(Cl)=O)C=C1 NXLNNXIXOYSCMB-UHFFFAOYSA-N 0.000 description 1
- MWWSFMDVAYGXBV-MYPASOLCSA-N (7r,9s)-7-[(2r,4s,5s,6s)-4-amino-5-hydroxy-6-methyloxan-2-yl]oxy-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-4-methoxy-8,10-dihydro-7h-tetracene-5,12-dione;hydrochloride Chemical compound Cl.O([C@@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 MWWSFMDVAYGXBV-MYPASOLCSA-N 0.000 description 1
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 1
- GVJHHUAWPYXKBD-IEOSBIPESA-N (R)-alpha-Tocopherol Natural products OC1=C(C)C(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-IEOSBIPESA-N 0.000 description 1
- IAKHMKGGTNLKSZ-INIZCTEOSA-N (S)-colchicine Chemical compound C1([C@@H](NC(C)=O)CC2)=CC(=O)C(OC)=CC=C1C1=C2C=C(OC)C(OC)=C1OC IAKHMKGGTNLKSZ-INIZCTEOSA-N 0.000 description 1
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- HNSDLXPSAYFUHK-UHFFFAOYSA-N 1,4-bis(2-ethylhexyl) sulfosuccinate Chemical compound CCCCC(CC)COC(=O)CC(S(O)(=O)=O)C(=O)OCC(CC)CCCC HNSDLXPSAYFUHK-UHFFFAOYSA-N 0.000 description 1
- BOKGTLAJQHTOKE-UHFFFAOYSA-N 1,5-dihydroxynaphthalene Chemical compound C1=CC=C2C(O)=CC=CC2=C1O BOKGTLAJQHTOKE-UHFFFAOYSA-N 0.000 description 1
- ASOKPJOREAFHNY-UHFFFAOYSA-N 1-Hydroxybenzotriazole Chemical class C1=CC=C2N(O)N=NC2=C1 ASOKPJOREAFHNY-UHFFFAOYSA-N 0.000 description 1
- FPIRBHDGWMWJEP-UHFFFAOYSA-N 1-hydroxy-7-azabenzotriazole Chemical compound C1=CN=C2N(O)N=NC2=C1 FPIRBHDGWMWJEP-UHFFFAOYSA-N 0.000 description 1
- 125000001637 1-naphthyl group Chemical group [H]C1=C([H])C([H])=C2C(*)=C([H])C([H])=C([H])C2=C1[H] 0.000 description 1
- 125000001462 1-pyrrolyl group Chemical group [*]N1C([H])=C([H])C([H])=C1[H] 0.000 description 1
- KGLPWQKSKUVKMJ-UHFFFAOYSA-N 2,3-dihydrophthalazine-1,4-dione Chemical class C1=CC=C2C(=O)NNC(=O)C2=C1 KGLPWQKSKUVKMJ-UHFFFAOYSA-N 0.000 description 1
- 150000003923 2,5-pyrrolediones Chemical class 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- 125000004174 2-benzimidazolyl group Chemical group [H]N1C(*)=NC2=C([H])C([H])=C([H])C([H])=C12 0.000 description 1
- 125000002941 2-furyl group Chemical group O1C([*])=C([H])C([H])=C1[H] 0.000 description 1
- 125000001622 2-naphthyl group Chemical group [H]C1=C([H])C([H])=C2C([H])=C(*)C([H])=C([H])C2=C1[H] 0.000 description 1
- 125000000094 2-phenylethyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000003903 2-propenyl group Chemical group [H]C([*])([H])C([H])=C([H])[H] 0.000 description 1
- 125000004105 2-pyridyl group Chemical group N1=C([*])C([H])=C([H])C([H])=C1[H] 0.000 description 1
- 125000000389 2-pyrrolyl group Chemical group [H]N1C([*])=C([H])C([H])=C1[H] 0.000 description 1
- 125000000175 2-thienyl group Chemical group S1C([*])=C([H])C([H])=C1[H] 0.000 description 1
- KIUMMUBSPKGMOY-UHFFFAOYSA-N 3,3'-Dithiobis(6-nitrobenzoic acid) Chemical compound C1=C([N+]([O-])=O)C(C(=O)O)=CC(SSC=2C=C(C(=CC=2)[N+]([O-])=O)C(O)=O)=C1 KIUMMUBSPKGMOY-UHFFFAOYSA-N 0.000 description 1
- ZJGBFJBMTKEFNQ-UHFFFAOYSA-N 3-(2,5-dioxopyrrol-1-yl)benzoic acid Chemical compound OC(=O)C1=CC=CC(N2C(C=CC2=O)=O)=C1 ZJGBFJBMTKEFNQ-UHFFFAOYSA-N 0.000 description 1
- GFZXQBDELXEPTQ-UHFFFAOYSA-N 3-[(3-carboxy-2-nitrophenyl)disulfanyl]-2-nitrobenzoic acid Chemical compound OC(=O)C1=CC=CC(SSC=2C(=C(C(O)=O)C=CC=2)[N+]([O-])=O)=C1[N+]([O-])=O GFZXQBDELXEPTQ-UHFFFAOYSA-N 0.000 description 1
- WUIABRMSWOKTOF-OYALTWQYSA-N 3-[[2-[2-[2-[[(2s,3r)-2-[[(2s,3s,4r)-4-[[(2s,3r)-2-[[6-amino-2-[(1s)-3-amino-1-[[(2s)-2,3-diamino-3-oxopropyl]amino]-3-oxopropyl]-5-methylpyrimidine-4-carbonyl]amino]-3-[(2r,3s,4s,5s,6s)-3-[(2r,3s,4s,5r,6r)-4-carbamoyloxy-3,5-dihydroxy-6-(hydroxymethyl)ox Chemical compound OS([O-])(=O)=O.N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1NC=NC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C WUIABRMSWOKTOF-OYALTWQYSA-N 0.000 description 1
- 125000000474 3-butynyl group Chemical group [H]C#CC([H])([H])C([H])([H])* 0.000 description 1
- 125000003682 3-furyl group Chemical group O1C([H])=C([*])C([H])=C1[H] 0.000 description 1
- DKIDEFUBRARXTE-UHFFFAOYSA-N 3-mercaptopropanoic acid Chemical compound OC(=O)CCS DKIDEFUBRARXTE-UHFFFAOYSA-N 0.000 description 1
- 125000003349 3-pyridyl group Chemical group N1=C([H])C([*])=C([H])C([H])=C1[H] 0.000 description 1
- 125000001397 3-pyrrolyl group Chemical group [H]N1C([H])=C([*])C([H])=C1[H] 0.000 description 1
- 125000001541 3-thienyl group Chemical group S1C([H])=C([*])C([H])=C1[H] 0.000 description 1
- XZKIHKMTEMTJQX-UHFFFAOYSA-N 4-Nitrophenyl Phosphate Chemical compound OP(O)(=O)OC1=CC=C([N+]([O-])=O)C=C1 XZKIHKMTEMTJQX-UHFFFAOYSA-N 0.000 description 1
- FJKROLUGYXJWQN-UHFFFAOYSA-N 4-hydroxybenzoic acid Chemical compound OC(=O)C1=CC=C(O)C=C1 FJKROLUGYXJWQN-UHFFFAOYSA-N 0.000 description 1
- 125000000339 4-pyridyl group Chemical group N1=C([H])C([H])=C([*])C([H])=C1[H] 0.000 description 1
- KDDQRKBRJSGMQE-UHFFFAOYSA-N 4-thiazolyl Chemical group [C]1=CSC=N1 KDDQRKBRJSGMQE-UHFFFAOYSA-N 0.000 description 1
- QRXMUCSWCMTJGU-UHFFFAOYSA-N 5-bromo-4-chloro-3-indolyl phosphate Chemical compound C1=C(Br)C(Cl)=C2C(OP(O)(=O)O)=CNC2=C1 QRXMUCSWCMTJGU-UHFFFAOYSA-N 0.000 description 1
- ODHCTXKNWHHXJC-VKHMYHEASA-N 5-oxo-L-proline Chemical compound OC(=O)[C@@H]1CCC(=O)N1 ODHCTXKNWHHXJC-VKHMYHEASA-N 0.000 description 1
- CWDWFSXUQODZGW-UHFFFAOYSA-N 5-thiazolyl Chemical group [C]1=CN=CS1 CWDWFSXUQODZGW-UHFFFAOYSA-N 0.000 description 1
- SUTWPJHCRAITLU-UHFFFAOYSA-N 6-aminohexan-1-ol Chemical compound NCCCCCCO SUTWPJHCRAITLU-UHFFFAOYSA-N 0.000 description 1
- UGZAJZLUKVKCBM-UHFFFAOYSA-N 6-sulfanylhexan-1-ol Chemical compound OCCCCCCS UGZAJZLUKVKCBM-UHFFFAOYSA-N 0.000 description 1
- CJIJXIFQYOPWTF-UHFFFAOYSA-N 7-hydroxycoumarin Natural products O1C(=O)C=CC2=CC(O)=CC=C21 CJIJXIFQYOPWTF-UHFFFAOYSA-N 0.000 description 1
- ZCYVEMRRCGMTRW-UHFFFAOYSA-N 7553-56-2 Chemical group [I] ZCYVEMRRCGMTRW-UHFFFAOYSA-N 0.000 description 1
- 241000242759 Actiniaria Species 0.000 description 1
- 208000008190 Agammaglobulinemia Diseases 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- 241000607620 Aliivibrio fischeri Species 0.000 description 1
- 101710146120 Alpha-(1,6)-fucosyltransferase Proteins 0.000 description 1
- 208000024827 Alzheimer disease Diseases 0.000 description 1
- 108010079054 Amyloid beta-Protein Precursor Proteins 0.000 description 1
- 102000014303 Amyloid beta-Protein Precursor Human genes 0.000 description 1
- 102000008102 Ankyrins Human genes 0.000 description 1
- 241000239290 Araneae Species 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 241000186063 Arthrobacter Species 0.000 description 1
- 241000228212 Aspergillus Species 0.000 description 1
- 108091008875 B cell receptors Proteins 0.000 description 1
- 230000003844 B-cell-activation Effects 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- COVZYZSDYWQREU-UHFFFAOYSA-N Busulfan Chemical compound CS(=O)(=O)OCCCCOS(C)(=O)=O COVZYZSDYWQREU-UHFFFAOYSA-N 0.000 description 1
- 241000208199 Buxus sempervirens Species 0.000 description 1
- 101150013553 CD40 gene Proteins 0.000 description 1
- 102100027221 CD81 antigen Human genes 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- BVKZGUZCCUSVTD-UHFFFAOYSA-L Carbonate Chemical compound [O-]C([O-])=O BVKZGUZCCUSVTD-UHFFFAOYSA-L 0.000 description 1
- 108010078791 Carrier Proteins Proteins 0.000 description 1
- 108090000712 Cathepsin B Proteins 0.000 description 1
- 102000004225 Cathepsin B Human genes 0.000 description 1
- 241000700199 Cavia porcellus Species 0.000 description 1
- KZBUYRJDOAKODT-UHFFFAOYSA-N Chlorine Chemical compound ClCl KZBUYRJDOAKODT-UHFFFAOYSA-N 0.000 description 1
- 241000243321 Cnidaria Species 0.000 description 1
- 108091026890 Coding region Proteins 0.000 description 1
- 108020004705 Codon Proteins 0.000 description 1
- 108060005980 Collagenase Proteins 0.000 description 1
- 102000029816 Collagenase Human genes 0.000 description 1
- 102100032768 Complement receptor type 2 Human genes 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- 241000192700 Cyanobacteria Species 0.000 description 1
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 1
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 1
- IGXWBGJHJZYPQS-SSDOTTSWSA-N D-Luciferin Chemical compound OC(=O)[C@H]1CSC(C=2SC3=CC=C(O)C=C3N=2)=N1 IGXWBGJHJZYPQS-SSDOTTSWSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- 101150074155 DHFR gene Proteins 0.000 description 1
- WEAHRLBPCANXCN-UHFFFAOYSA-N Daunomycin Natural products CCC1(O)CC(OC2CC(N)C(O)C(C)O2)c3cc4C(=O)c5c(OC)cccc5C(=O)c4c(O)c3C1 WEAHRLBPCANXCN-UHFFFAOYSA-N 0.000 description 1
- CYCGRDQQIOGCKX-UHFFFAOYSA-N Dehydro-luciferin Natural products OC(=O)C1=CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 CYCGRDQQIOGCKX-UHFFFAOYSA-N 0.000 description 1
- FEWJPZIEWOKRBE-JCYAYHJZSA-N Dextrotartaric acid Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O FEWJPZIEWOKRBE-JCYAYHJZSA-N 0.000 description 1
- YMWUJEATGCHHMB-UHFFFAOYSA-N Dichloromethane Chemical compound ClCCl YMWUJEATGCHHMB-UHFFFAOYSA-N 0.000 description 1
- QEVGZEDELICMKH-UHFFFAOYSA-N Diglycolic acid Chemical compound OC(=O)COCC(O)=O QEVGZEDELICMKH-UHFFFAOYSA-N 0.000 description 1
- 108090000204 Dipeptidase 1 Proteins 0.000 description 1
- LVGKNOAMLMIIKO-UHFFFAOYSA-N Elaidinsaeure-aethylester Natural products CCCCCCCCC=CCCCCCCCC(=O)OCC LVGKNOAMLMIIKO-UHFFFAOYSA-N 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- MBYXEBXZARTUSS-QLWBXOBMSA-N Emetamine Natural products O(C)c1c(OC)cc2c(c(C[C@@H]3[C@H](CC)CN4[C@H](c5c(cc(OC)c(OC)c5)CC4)C3)ncc2)c1 MBYXEBXZARTUSS-QLWBXOBMSA-N 0.000 description 1
- 102000010911 Enzyme Precursors Human genes 0.000 description 1
- 108010062466 Enzyme Precursors Proteins 0.000 description 1
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 1
- PIICEJLVQHRZGT-UHFFFAOYSA-N Ethylenediamine Chemical compound NCCN PIICEJLVQHRZGT-UHFFFAOYSA-N 0.000 description 1
- 108091029865 Exogenous DNA Proteins 0.000 description 1
- 206010015866 Extravasation Diseases 0.000 description 1
- 206010016654 Fibrosis Diseases 0.000 description 1
- BJGNCJDXODQBOB-UHFFFAOYSA-N Fivefly Luciferin Natural products OC(=O)C1CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 BJGNCJDXODQBOB-UHFFFAOYSA-N 0.000 description 1
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 1
- PXGOKWXKJXAPGV-UHFFFAOYSA-N Fluorine Chemical compound FF PXGOKWXKJXAPGV-UHFFFAOYSA-N 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- 108010019236 Fucosyltransferases Proteins 0.000 description 1
- 101150074355 GS gene Proteins 0.000 description 1
- 102100021792 Gamma-sarcoglycan Human genes 0.000 description 1
- 241000237858 Gastropoda Species 0.000 description 1
- CEAZRRDELHUEMR-URQXQFDESA-N Gentamicin Chemical compound O1[C@H](C(C)NC)CC[C@@H](N)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](NC)[C@@](C)(O)CO2)O)[C@H](N)C[C@@H]1N CEAZRRDELHUEMR-URQXQFDESA-N 0.000 description 1
- 229930182566 Gentamicin Natural products 0.000 description 1
- INKFLNZBTSNFON-CIUDSAMLSA-N Gln-Ala-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O INKFLNZBTSNFON-CIUDSAMLSA-N 0.000 description 1
- 239000004366 Glucose oxidase Substances 0.000 description 1
- 108010015776 Glucose oxidase Proteins 0.000 description 1
- 102000053187 Glucuronidase Human genes 0.000 description 1
- 108010060309 Glucuronidase Proteins 0.000 description 1
- YLEIWGJJBFBFHC-KBPBESRZSA-N Gly-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 YLEIWGJJBFBFHC-KBPBESRZSA-N 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 102000005744 Glycoside Hydrolases Human genes 0.000 description 1
- 108010031186 Glycoside Hydrolases Proteins 0.000 description 1
- 108700023372 Glycosyltransferases Proteins 0.000 description 1
- 108010026389 Gramicidin Proteins 0.000 description 1
- 102000004269 Granulocyte Colony-Stimulating Factor Human genes 0.000 description 1
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 description 1
- 102000004457 Granulocyte-Macrophage Colony-Stimulating Factor Human genes 0.000 description 1
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 239000007995 HEPES buffer Substances 0.000 description 1
- 102100021519 Hemoglobin subunit beta Human genes 0.000 description 1
- 108091005904 Hemoglobin subunit beta Proteins 0.000 description 1
- 241000545744 Hirudinea Species 0.000 description 1
- 101100383038 Homo sapiens CD19 gene Proteins 0.000 description 1
- 101000914479 Homo sapiens CD81 antigen Proteins 0.000 description 1
- 101000941929 Homo sapiens Complement receptor type 2 Proteins 0.000 description 1
- 101000616435 Homo sapiens Gamma-sarcoglycan Proteins 0.000 description 1
- 101000917826 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-a Proteins 0.000 description 1
- 101000917824 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-b Proteins 0.000 description 1
- 101000904196 Homo sapiens Pancreatic secretory granule membrane major glycoprotein GP2 Proteins 0.000 description 1
- 241000714260 Human T-lymphotropic virus 1 Species 0.000 description 1
- 102000004157 Hydrolases Human genes 0.000 description 1
- 108090000604 Hydrolases Proteins 0.000 description 1
- 229920001612 Hydroxyethyl starch Polymers 0.000 description 1
- AVXURJPOCDRRFD-UHFFFAOYSA-N Hydroxylamine Chemical group ON AVXURJPOCDRRFD-UHFFFAOYSA-N 0.000 description 1
- VSNHCAURESNICA-UHFFFAOYSA-N Hydroxyurea Chemical compound NC(=O)NO VSNHCAURESNICA-UHFFFAOYSA-N 0.000 description 1
- 206010020983 Hypogammaglobulinaemia Diseases 0.000 description 1
- 102100026120 IgG receptor FcRn large subunit p51 Human genes 0.000 description 1
- 101710177940 IgG receptor FcRn large subunit p51 Proteins 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 1
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 1
- 102000013463 Immunoglobulin Light Chains Human genes 0.000 description 1
- 108010065825 Immunoglobulin Light Chains Proteins 0.000 description 1
- 206010061218 Inflammation Diseases 0.000 description 1
- 102000004310 Ion Channels Human genes 0.000 description 1
- 241000235649 Kluyveromyces Species 0.000 description 1
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 1
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- 239000011786 L-ascorbyl-6-palmitate Substances 0.000 description 1
- QAQJMLQRFWZOBN-LAUBAEHRSA-N L-ascorbyl-6-palmitate Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](O)[C@H]1OC(=O)C(O)=C1O QAQJMLQRFWZOBN-LAUBAEHRSA-N 0.000 description 1
- 229930182816 L-glutamine Natural products 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- WUFYAPWIHCUMLL-CIUDSAMLSA-N Leu-Asn-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O WUFYAPWIHCUMLL-CIUDSAMLSA-N 0.000 description 1
- IDGZVZJLYFTXSL-DCAQKATOSA-N Leu-Ser-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IDGZVZJLYFTXSL-DCAQKATOSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 108010006444 Leucine-Rich Repeat Proteins Proteins 0.000 description 1
- NNJVILVZKWQKPM-UHFFFAOYSA-N Lidocaine Chemical compound CCN(CC)CC(=O)NC1=C(C)C=CC=C1C NNJVILVZKWQKPM-UHFFFAOYSA-N 0.000 description 1
- 102100029204 Low affinity immunoglobulin gamma Fc region receptor II-a Human genes 0.000 description 1
- DDWFXDSYGUXRAY-UHFFFAOYSA-N Luciferin Natural products CCc1c(C)c(CC2NC(=O)C(=C2C=C)C)[nH]c1Cc3[nH]c4C(=C5/NC(CC(=O)O)C(C)C5CC(=O)O)CC(=O)c4c3C DDWFXDSYGUXRAY-UHFFFAOYSA-N 0.000 description 1
- LJADEBULDNKJNK-IHRRRGAJSA-N Lys-Leu-Val Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O LJADEBULDNKJNK-IHRRRGAJSA-N 0.000 description 1
- NVGBPTNZLWRQSY-UWVGGRQHSA-N Lys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(O)=O)CCCCN NVGBPTNZLWRQSY-UWVGGRQHSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- FYYHWMGAXLPEAU-UHFFFAOYSA-N Magnesium Chemical compound [Mg] FYYHWMGAXLPEAU-UHFFFAOYSA-N 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 108010016165 Matrix Metalloproteinase 2 Proteins 0.000 description 1
- 102000000424 Matrix Metalloproteinase 2 Human genes 0.000 description 1
- 102000001776 Matrix metalloproteinase-9 Human genes 0.000 description 1
- 108010015302 Matrix metalloproteinase-9 Proteins 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- 238000006845 Michael addition reaction Methods 0.000 description 1
- 238000006957 Michael reaction Methods 0.000 description 1
- 241001314546 Microtis <orchid> Species 0.000 description 1
- VFKZTMPDYBFSTM-KVTDHHQDSA-N Mitobronitol Chemical compound BrC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CBr VFKZTMPDYBFSTM-KVTDHHQDSA-N 0.000 description 1
- 229930192392 Mitomycin Natural products 0.000 description 1
- 101000822667 Mus musculus Something about silencing protein 10 Proteins 0.000 description 1
- QCYOIFVBYZNUNW-BYPYZUCNSA-N N,N-dimethyl-L-alanine Chemical compound CN(C)[C@@H](C)C(O)=O QCYOIFVBYZNUNW-BYPYZUCNSA-N 0.000 description 1
- NQTADLQHYWFPDB-UHFFFAOYSA-N N-Hydroxysuccinimide Chemical class ON1C(=O)CCC1=O NQTADLQHYWFPDB-UHFFFAOYSA-N 0.000 description 1
- OVRNDRQMDRJTHS-UHFFFAOYSA-N N-acelyl-D-glucosamine Natural products CC(=O)NC1C(O)OC(CO)C(O)C1O OVRNDRQMDRJTHS-UHFFFAOYSA-N 0.000 description 1
- OVRNDRQMDRJTHS-FMDGEEDCSA-N N-acetyl-beta-D-glucosamine Chemical compound CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-FMDGEEDCSA-N 0.000 description 1
- MBLBDJOUHNCFQT-LXGUWJNJSA-N N-acetylglucosamine Natural products CC(=O)N[C@@H](C=O)[C@@H](O)[C@H](O)[C@H](O)CO MBLBDJOUHNCFQT-LXGUWJNJSA-N 0.000 description 1
- 150000001199 N-acyl amides Chemical class 0.000 description 1
- MBBZMMPHUWSWHV-BDVNFPICSA-N N-methylglucamine Chemical compound CNC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO MBBZMMPHUWSWHV-BDVNFPICSA-N 0.000 description 1
- PAYRUJLWNCNPSJ-UHFFFAOYSA-N N-phenyl amine Natural products NC1=CC=CC=C1 PAYRUJLWNCNPSJ-UHFFFAOYSA-N 0.000 description 1
- BVMWIXWOIGJRGE-UHFFFAOYSA-N NP(O)=O Chemical class NP(O)=O BVMWIXWOIGJRGE-UHFFFAOYSA-N 0.000 description 1
- 241001045988 Neogene Species 0.000 description 1
- 102000003797 Neuropeptides Human genes 0.000 description 1
- 108090000189 Neuropeptides Proteins 0.000 description 1
- JZFPYUNJRRFVQU-UHFFFAOYSA-N Niflumic acid Chemical class OC(=O)C1=CC=CN=C1NC1=CC=CC(C(F)(F)F)=C1 JZFPYUNJRRFVQU-UHFFFAOYSA-N 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- 108091005461 Nucleic proteins Proteins 0.000 description 1
- 229910003849 O-Si Inorganic materials 0.000 description 1
- 206010061535 Ovarian neoplasm Diseases 0.000 description 1
- 229910003872 O—Si Inorganic materials 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 229930012538 Paclitaxel Natural products 0.000 description 1
- 102100024019 Pancreatic secretory granule membrane major glycoprotein GP2 Human genes 0.000 description 1
- 229930182555 Penicillin Natural products 0.000 description 1
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 1
- 108700020962 Peroxidase Proteins 0.000 description 1
- 102000003992 Peroxidases Human genes 0.000 description 1
- MIDZLCFIAINOQN-WPRPVWTQSA-N Phe-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 MIDZLCFIAINOQN-WPRPVWTQSA-N 0.000 description 1
- FADYJNXDPBKVCA-STQMWFEESA-N Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 FADYJNXDPBKVCA-STQMWFEESA-N 0.000 description 1
- RBRNEFJTEHPDSL-ACRUOGEOSA-N Phe-Phe-Lys Chemical compound C([C@@H](C(=O)N[C@@H](CCCCN)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 RBRNEFJTEHPDSL-ACRUOGEOSA-N 0.000 description 1
- YGYAWVDWMABLBF-UHFFFAOYSA-N Phosgene Chemical compound ClC(Cl)=O YGYAWVDWMABLBF-UHFFFAOYSA-N 0.000 description 1
- 108700019535 Phosphoprotein Phosphatases Proteins 0.000 description 1
- ABLZXFCXXLZCGV-UHFFFAOYSA-N Phosphorous acid Chemical class OP(O)=O ABLZXFCXXLZCGV-UHFFFAOYSA-N 0.000 description 1
- 108010053210 Phycocyanin Proteins 0.000 description 1
- 108010004729 Phycoerythrin Proteins 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- 229920002732 Polyanhydride Polymers 0.000 description 1
- 239000004698 Polyethylene Substances 0.000 description 1
- 229920002873 Polyethylenimine Polymers 0.000 description 1
- 229920000954 Polyglycolide Polymers 0.000 description 1
- 229920001710 Polyorthoester Polymers 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- 239000004793 Polystyrene Substances 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- 241001415846 Procellariidae Species 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- OFOBLEOULBTSOW-UHFFFAOYSA-N Propanedioic acid Natural products OC(=O)CC(O)=O OFOBLEOULBTSOW-UHFFFAOYSA-N 0.000 description 1
- 102000001253 Protein Kinase Human genes 0.000 description 1
- 102100037132 Proteinase-activated receptor 2 Human genes 0.000 description 1
- 101710121435 Proteinase-activated receptor 2 Proteins 0.000 description 1
- ODHCTXKNWHHXJC-GSVOUGTGSA-N Pyroglutamic acid Natural products OC(=O)[C@H]1CCC(=O)N1 ODHCTXKNWHHXJC-GSVOUGTGSA-N 0.000 description 1
- 108091008103 RNA aptamers Proteins 0.000 description 1
- 230000010799 Receptor Interactions Effects 0.000 description 1
- 108010073443 Ribi adjuvant Proteins 0.000 description 1
- AUVVAXYIELKVAI-UHFFFAOYSA-N SJ000285215 Natural products N1CCC2=CC(OC)=C(OC)C=C2C1CC1CC2C3=CC(OC)=C(OC)C=C3CCN2CC1CC AUVVAXYIELKVAI-UHFFFAOYSA-N 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- 241000607142 Salmonella Species 0.000 description 1
- 239000002262 Schiff base Substances 0.000 description 1
- 150000004753 Schiff bases Chemical class 0.000 description 1
- 241000239226 Scorpiones Species 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 241000270295 Serpentes Species 0.000 description 1
- 201000004283 Shwachman-Diamond syndrome Diseases 0.000 description 1
- XUIMIQQOPSSXEZ-UHFFFAOYSA-N Silicon Chemical compound [Si] XUIMIQQOPSSXEZ-UHFFFAOYSA-N 0.000 description 1
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 1
- 108010088160 Staphylococcal Protein A Proteins 0.000 description 1
- 101000677856 Stenotrophomonas maltophilia (strain K279a) Actin-binding protein Smlt3054 Proteins 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- 241000133426 Streptomyces zelensis Species 0.000 description 1
- ZSJLQEPLLKMAKR-UHFFFAOYSA-N Streptozotocin Natural products O=NN(C)C(=O)NC1C(O)OC(CO)C(O)C1O ZSJLQEPLLKMAKR-UHFFFAOYSA-N 0.000 description 1
- KDYFGRWQOYBRFD-UHFFFAOYSA-N Succinic acid Natural products OC(=O)CCC(O)=O KDYFGRWQOYBRFD-UHFFFAOYSA-N 0.000 description 1
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 1
- OUUQCZGPVNCOIJ-UHFFFAOYSA-M Superoxide Chemical compound [O-][O] OUUQCZGPVNCOIJ-UHFFFAOYSA-M 0.000 description 1
- 241000200270 Symbiodinium sp. Species 0.000 description 1
- 241000192707 Synechococcus Species 0.000 description 1
- FEWJPZIEWOKRBE-UHFFFAOYSA-N Tartaric acid Natural products [H+].[H+].[O-]C(=O)C(O)C(O)C([O-])=O FEWJPZIEWOKRBE-UHFFFAOYSA-N 0.000 description 1
- 108090000190 Thrombin Proteins 0.000 description 1
- 102000004357 Transferases Human genes 0.000 description 1
- 108090000992 Transferases Proteins 0.000 description 1
- 241000223259 Trichoderma Species 0.000 description 1
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 1
- GBOGMAARMMDZGR-UHFFFAOYSA-N UNPD149280 Natural products N1C(=O)C23OC(=O)C=CC(O)CCCC(C)CC=CC3C(O)C(=C)C(C)C2C1CC1=CC=CC=C1 GBOGMAARMMDZGR-UHFFFAOYSA-N 0.000 description 1
- VGQOVCHZGQWAOI-UHFFFAOYSA-N UNPD55612 Natural products N1C(O)C2CC(C=CC(N)=O)=CN2C(=O)C2=CC=C(C)C(O)=C12 VGQOVCHZGQWAOI-UHFFFAOYSA-N 0.000 description 1
- 108090000848 Ubiquitin Proteins 0.000 description 1
- 102000044159 Ubiquitin Human genes 0.000 description 1
- 229910052770 Uranium Inorganic materials 0.000 description 1
- HSRXSKHRSXRCFC-WDSKDSINSA-N Val-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(O)=O HSRXSKHRSXRCFC-WDSKDSINSA-N 0.000 description 1
- QRZVUAAKNRHEOP-GUBZILKMSA-N Val-Ala-Val Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O QRZVUAAKNRHEOP-GUBZILKMSA-N 0.000 description 1
- 108010003205 Vasoactive Intestinal Peptide Proteins 0.000 description 1
- 102400000015 Vasoactive intestinal peptide Human genes 0.000 description 1
- 238000012452 Xenomouse strains Methods 0.000 description 1
- 108091027569 Z-DNA Proteins 0.000 description 1
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 1
- 230000001594 aberrant effect Effects 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 239000003070 absorption delaying agent Substances 0.000 description 1
- 230000035508 accumulation Effects 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 150000001241 acetals Chemical class 0.000 description 1
- WETWJCDKMRHUPV-UHFFFAOYSA-N acetyl chloride Chemical compound CC(Cl)=O WETWJCDKMRHUPV-UHFFFAOYSA-N 0.000 description 1
- 239000012346 acetyl chloride Substances 0.000 description 1
- ODHCTXKNWHHXJC-UHFFFAOYSA-N acide pyroglutamique Natural products OC(=O)C1CCC(=O)N1 ODHCTXKNWHHXJC-UHFFFAOYSA-N 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 125000003647 acryloyl group Chemical group O=C([*])C([H])=C([H])[H] 0.000 description 1
- 229930183665 actinomycin Natural products 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 230000010933 acylation Effects 0.000 description 1
- 125000005041 acyloxyalkyl group Chemical group 0.000 description 1
- 102000035181 adaptor proteins Human genes 0.000 description 1
- 108091005764 adaptor proteins Proteins 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 229940009456 adriamycin Drugs 0.000 description 1
- 238000001261 affinity purification Methods 0.000 description 1
- 238000000246 agarose gel electrophoresis Methods 0.000 description 1
- 230000032683 aging Effects 0.000 description 1
- 230000001270 agonistic effect Effects 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 108010054982 alanyl-leucyl-alanyl-leucine Proteins 0.000 description 1
- HAXFWIACAGNFHA-UHFFFAOYSA-N aldrithiol Chemical compound C=1C=CC=NC=1SSC1=CC=CC=N1 HAXFWIACAGNFHA-UHFFFAOYSA-N 0.000 description 1
- 150000001335 aliphatic alkanes Chemical class 0.000 description 1
- 125000001931 aliphatic group Chemical group 0.000 description 1
- 229910052784 alkaline earth metal Inorganic materials 0.000 description 1
- 150000001342 alkaline earth metals Chemical class 0.000 description 1
- 150000001336 alkenes Chemical class 0.000 description 1
- 150000005303 alkyl halide derivatives Chemical class 0.000 description 1
- 125000004414 alkyl thio group Chemical group 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- 238000005804 alkylation reaction Methods 0.000 description 1
- 125000005237 alkyleneamino group Chemical group 0.000 description 1
- 125000005238 alkylenediamino group Chemical group 0.000 description 1
- 125000005530 alkylenedioxy group Chemical group 0.000 description 1
- 125000005529 alkyleneoxy group Chemical group 0.000 description 1
- 208000026935 allergic disease Diseases 0.000 description 1
- 230000000172 allergic effect Effects 0.000 description 1
- 230000008850 allosteric inhibition Effects 0.000 description 1
- 101150087698 alpha gene Proteins 0.000 description 1
- 229940087168 alpha tocopherol Drugs 0.000 description 1
- HSFWRNGVRCDJHI-UHFFFAOYSA-N alpha-acetylene Natural products C#C HSFWRNGVRCDJHI-UHFFFAOYSA-N 0.000 description 1
- 229960002684 aminocaproic acid Drugs 0.000 description 1
- MDFFNEOEWAXZRQ-UHFFFAOYSA-N aminyl Chemical compound [NH2] MDFFNEOEWAXZRQ-UHFFFAOYSA-N 0.000 description 1
- 230000033115 angiogenesis Effects 0.000 description 1
- 150000008064 anhydrides Chemical class 0.000 description 1
- MWPLVEDNUUSJAV-UHFFFAOYSA-N anthracene Chemical compound C1=CC=CC2=CC3=CC=CC=C3C=C21 MWPLVEDNUUSJAV-UHFFFAOYSA-N 0.000 description 1
- 229940045799 anthracyclines and related substance Drugs 0.000 description 1
- VGQOVCHZGQWAOI-HYUHUPJXSA-N anthramycin Chemical compound N1[C@@H](O)[C@@H]2CC(\C=C\C(N)=O)=CN2C(=O)C2=CC=C(C)C(O)=C12 VGQOVCHZGQWAOI-HYUHUPJXSA-N 0.000 description 1
- 230000036436 anti-hiv Effects 0.000 description 1
- 230000000340 anti-metabolite Effects 0.000 description 1
- 230000000845 anti-microbial effect Effects 0.000 description 1
- 230000003097 anti-respiratory effect Effects 0.000 description 1
- 230000002096 anti-tetanic effect Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 239000000611 antibody drug conjugate Substances 0.000 description 1
- 229940049595 antibody-drug conjugate Drugs 0.000 description 1
- 210000000628 antibody-producing cell Anatomy 0.000 description 1
- 238000011319 anticancer therapy Methods 0.000 description 1
- 229940019748 antifibrinolytic proteinase inhibitors Drugs 0.000 description 1
- 210000000612 antigen-presenting cell Anatomy 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 229940100197 antimetabolite Drugs 0.000 description 1
- 239000002256 antimetabolite Substances 0.000 description 1
- 239000003080 antimitotic agent Substances 0.000 description 1
- 229940034982 antineoplastic agent Drugs 0.000 description 1
- 230000003078 antioxidant effect Effects 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 238000000149 argon plasma sintering Methods 0.000 description 1
- 159000000032 aromatic acids Chemical class 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 125000005165 aryl thioxy group Chemical group 0.000 description 1
- 125000004104 aryloxy group Chemical group 0.000 description 1
- 235000010323 ascorbic acid Nutrition 0.000 description 1
- 229960005070 ascorbic acid Drugs 0.000 description 1
- 239000011668 ascorbic acid Substances 0.000 description 1
- 235000010385 ascorbyl palmitate Nutrition 0.000 description 1
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 1
- 230000001363 autoimmune Effects 0.000 description 1
- 150000001541 aziridines Chemical class 0.000 description 1
- WZSDNEJJUSYNSG-UHFFFAOYSA-N azocan-1-yl-(3,4,5-trimethoxyphenyl)methanone Chemical compound COC1=C(OC)C(OC)=CC(C(=O)N2CCCCCCC2)=C1 WZSDNEJJUSYNSG-UHFFFAOYSA-N 0.000 description 1
- 210000002469 basement membrane Anatomy 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- WPYMKLBDIGXBTP-UHFFFAOYSA-N benzoic acid group Chemical group C(C1=CC=CC=C1)(=O)O WPYMKLBDIGXBTP-UHFFFAOYSA-N 0.000 description 1
- 125000001797 benzyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])* 0.000 description 1
- 102000005936 beta-Galactosidase Human genes 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 229940000635 beta-alanine Drugs 0.000 description 1
- 102000006635 beta-lactamase Human genes 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- 238000004166 bioassay Methods 0.000 description 1
- 229920000249 biocompatible polymer Polymers 0.000 description 1
- 239000013060 biological fluid Substances 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 229960000074 biopharmaceutical Drugs 0.000 description 1
- 125000000319 biphenyl-4-yl group Chemical group [H]C1=C([H])C([H])=C([H])C([H])=C1C1=C([H])C([H])=C([*])C([H])=C1[H] 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 229960004395 bleomycin sulfate Drugs 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 230000036765 blood level Effects 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- RSIHSRDYCUFFLA-DYKIIFRCSA-N boldenone Chemical compound O=C1C=C[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 RSIHSRDYCUFFLA-DYKIIFRCSA-N 0.000 description 1
- 229940098773 bovine serum albumin Drugs 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 229960002092 busulfan Drugs 0.000 description 1
- DQXBYHZEEUGOBF-UHFFFAOYSA-N but-3-enoic acid;ethene Chemical compound C=C.OC(=O)CC=C DQXBYHZEEUGOBF-UHFFFAOYSA-N 0.000 description 1
- KDYFGRWQOYBRFD-NUQCWPJISA-N butanedioic acid Chemical compound O[14C](=O)CC[14C](O)=O KDYFGRWQOYBRFD-NUQCWPJISA-N 0.000 description 1
- 235000019282 butylated hydroxyanisole Nutrition 0.000 description 1
- 238000012410 cDNA cloning technique Methods 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 229960005069 calcium Drugs 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229960001714 calcium phosphate Drugs 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- HXCHCVDVKSCDHU-LULTVBGHSA-N calicheamicin Chemical compound C1[C@H](OC)[C@@H](NCC)CO[C@H]1O[C@H]1[C@H](O[C@@H]2C\3=C(NC(=O)OC)C(=O)C[C@](C/3=C/CSSSC)(O)C#C\C=C/C#C2)O[C@H](C)[C@@H](NO[C@@H]2O[C@H](C)[C@@H](SC(=O)C=3C(=C(OC)C(O[C@H]4[C@@H]([C@H](OC)[C@@H](O)[C@H](C)O4)O)=C(I)C=3C)OC)[C@@H](O)C2)[C@@H]1O HXCHCVDVKSCDHU-LULTVBGHSA-N 0.000 description 1
- 238000000533 capillary isoelectric focusing Methods 0.000 description 1
- 150000004657 carbamic acid derivatives Chemical class 0.000 description 1
- 235000013877 carbamide Nutrition 0.000 description 1
- 150000001718 carbodiimides Chemical class 0.000 description 1
- CREMABGTGYGIQB-UHFFFAOYSA-N carbon carbon Chemical compound C.C CREMABGTGYGIQB-UHFFFAOYSA-N 0.000 description 1
- 239000011203 carbon fibre reinforced carbon Substances 0.000 description 1
- 150000004649 carbonic acid derivatives Chemical class 0.000 description 1
- 150000001732 carboxylic acid derivatives Chemical class 0.000 description 1
- 239000012876 carrier material Substances 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 238000003352 cell adhesion assay Methods 0.000 description 1
- 230000011712 cell development Effects 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 230000007910 cell fusion Effects 0.000 description 1
- 230000022534 cell killing Effects 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 239000002738 chelating agent Substances 0.000 description 1
- NDAYQJDHGXTBJL-MWWSRJDJSA-N chembl557217 Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](C(C)C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](C(C)C)NC(=O)[C@H](C)NC(=O)[C@H](NC(=O)CNC(=O)[C@@H](NC=O)C(C)C)CC(C)C)C(=O)NCCO)=CNC2=C1 NDAYQJDHGXTBJL-MWWSRJDJSA-N 0.000 description 1
- 238000012412 chemical coupling Methods 0.000 description 1
- 238000001311 chemical methods and process Methods 0.000 description 1
- 239000007795 chemical reaction product Substances 0.000 description 1
- 238000006757 chemical reactions by type Methods 0.000 description 1
- FZFAMSAMCHXGEF-UHFFFAOYSA-N chloro formate Chemical compound ClOC=O FZFAMSAMCHXGEF-UHFFFAOYSA-N 0.000 description 1
- 229960004926 chlorobutanol Drugs 0.000 description 1
- VDANGULDQQJODZ-UHFFFAOYSA-N chloroprocaine Chemical compound CCN(CC)CCOC(=O)C1=CC=C(N)C=C1Cl VDANGULDQQJODZ-UHFFFAOYSA-N 0.000 description 1
- 229960002023 chloroprocaine Drugs 0.000 description 1
- OEYIOHPDSNJKLS-UHFFFAOYSA-N choline Chemical compound C[N+](C)(C)CCO OEYIOHPDSNJKLS-UHFFFAOYSA-N 0.000 description 1
- 229960001231 choline Drugs 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 208000023819 chronic asthma Diseases 0.000 description 1
- 238000002983 circular dichroism Methods 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 238000011220 combination immunotherapy Methods 0.000 description 1
- 108010047295 complement receptors Proteins 0.000 description 1
- 102000006834 complement receptors Human genes 0.000 description 1
- 230000004154 complement system Effects 0.000 description 1
- 238000013329 compounding Methods 0.000 description 1
- 239000003636 conditioned culture medium Substances 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 239000013068 control sample Substances 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 239000007822 coupling agent Substances 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 230000001186 cumulative effect Effects 0.000 description 1
- 238000006352 cycloaddition reaction Methods 0.000 description 1
- 125000000392 cycloalkenyl group Chemical group 0.000 description 1
- 125000000582 cycloheptyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])([H])C([H])(*)C([H])([H])C1([H])[H] 0.000 description 1
- 125000001511 cyclopentyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- 229960004397 cyclophosphamide Drugs 0.000 description 1
- 125000004186 cyclopropylmethyl group Chemical group [H]C([H])(*)C1([H])C([H])([H])C1([H])[H] 0.000 description 1
- 229960001305 cysteine hydrochloride Drugs 0.000 description 1
- 150000001945 cysteines Chemical class 0.000 description 1
- 229960000684 cytarabine Drugs 0.000 description 1
- GBOGMAARMMDZGR-TYHYBEHESA-N cytochalasin B Chemical compound C([C@H]1[C@@H]2[C@@H](C([C@@H](O)[C@@H]3/C=C/C[C@H](C)CCC[C@@H](O)/C=C/C(=O)O[C@@]23C(=O)N1)=C)C)C1=CC=CC=C1 GBOGMAARMMDZGR-TYHYBEHESA-N 0.000 description 1
- GBOGMAARMMDZGR-JREHFAHYSA-N cytochalasin B Natural products C[C@H]1CCC[C@@H](O)C=CC(=O)O[C@@]23[C@H](C=CC1)[C@H](O)C(=C)[C@@H](C)[C@@H]2[C@H](Cc4ccccc4)NC3=O GBOGMAARMMDZGR-JREHFAHYSA-N 0.000 description 1
- 108010057085 cytokine receptors Proteins 0.000 description 1
- 102000003675 cytokine receptors Human genes 0.000 description 1
- 238000007822 cytometric assay Methods 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 1
- 230000003013 cytotoxicity Effects 0.000 description 1
- 231100000135 cytotoxicity Toxicity 0.000 description 1
- 125000001295 dansyl group Chemical group [H]C1=C([H])C(N(C([H])([H])[H])C([H])([H])[H])=C2C([H])=C([H])C([H])=C(C2=C1[H])S(*)(=O)=O 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 230000006735 deficit Effects 0.000 description 1
- RSIHSRDYCUFFLA-UHFFFAOYSA-N dehydrotestosterone Natural products O=C1C=CC2(C)C3CCC(C)(C(CC4)O)C4C3CCC2=C1 RSIHSRDYCUFFLA-UHFFFAOYSA-N 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 210000004443 dendritic cell Anatomy 0.000 description 1
- 238000001212 derivatisation Methods 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 125000004663 dialkyl amino group Chemical group 0.000 description 1
- VILAVOFMIJHSJA-UHFFFAOYSA-N dicarbon monoxide Chemical compound [C]=C=O VILAVOFMIJHSJA-UHFFFAOYSA-N 0.000 description 1
- 150000001991 dicarboxylic acids Chemical class 0.000 description 1
- ZBCBWPMODOFKDW-UHFFFAOYSA-N diethanolamine Chemical compound OCCNCCO ZBCBWPMODOFKDW-UHFFFAOYSA-N 0.000 description 1
- 229940043237 diethanolamine Drugs 0.000 description 1
- 238000000113 differential scanning calorimetry Methods 0.000 description 1
- UGMCXQCYOVCMTB-UHFFFAOYSA-K dihydroxy(stearato)aluminium Chemical compound CCCCCCCCCCCCCCCCCC(=O)O[Al](O)O UGMCXQCYOVCMTB-UHFFFAOYSA-K 0.000 description 1
- RXKJFZQQPQGTFL-UHFFFAOYSA-N dihydroxyacetone Chemical class OCC(=O)CO RXKJFZQQPQGTFL-UHFFFAOYSA-N 0.000 description 1
- 125000002147 dimethylamino group Chemical group [H]C([H])([H])N(*)C([H])([H])[H] 0.000 description 1
- 230000003292 diminished effect Effects 0.000 description 1
- 235000021158 dinner Nutrition 0.000 description 1
- 150000002009 diols Chemical class 0.000 description 1
- 239000002270 dispersing agent Substances 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 238000007876 drug discovery Methods 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 230000005684 electric field Effects 0.000 description 1
- 238000007336 electrophilic substitution reaction Methods 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- AUVVAXYIELKVAI-CKBKHPSWSA-N emetine Chemical compound N1CCC2=CC(OC)=C(OC)C=C2[C@H]1C[C@H]1C[C@H]2C3=CC(OC)=C(OC)C=C3CCN2C[C@@H]1CC AUVVAXYIELKVAI-CKBKHPSWSA-N 0.000 description 1
- 229960002694 emetine Drugs 0.000 description 1
- AUVVAXYIELKVAI-UWBTVBNJSA-N emetine Natural products N1CCC2=CC(OC)=C(OC)C=C2[C@H]1C[C@H]1C[C@H]2C3=CC(OC)=C(OC)C=C3CCN2C[C@H]1CC AUVVAXYIELKVAI-UWBTVBNJSA-N 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 150000002081 enamines Chemical class 0.000 description 1
- 230000002124 endocrine Effects 0.000 description 1
- 238000012407 engineering method Methods 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- 210000003979 eosinophil Anatomy 0.000 description 1
- 230000002327 eosinophilic effect Effects 0.000 description 1
- 150000002118 epoxides Chemical class 0.000 description 1
- BEFDCLMNVWHSGT-UHFFFAOYSA-N ethenylcyclopentane Chemical compound C=CC1CCCC1 BEFDCLMNVWHSGT-UHFFFAOYSA-N 0.000 description 1
- RTZKZFJDLAIYFH-UHFFFAOYSA-N ether Substances CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 1
- 150000002170 ethers Chemical class 0.000 description 1
- ZMMJGEGLRURXTF-UHFFFAOYSA-N ethidium bromide Chemical compound [Br-].C12=CC(N)=CC=C2C2=CC=C(N)C=C2[N+](CC)=C1C1=CC=CC=C1 ZMMJGEGLRURXTF-UHFFFAOYSA-N 0.000 description 1
- 229960005542 ethidium bromide Drugs 0.000 description 1
- LVGKNOAMLMIIKO-QXMHVHEDSA-N ethyl oleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC LVGKNOAMLMIIKO-QXMHVHEDSA-N 0.000 description 1
- 229940093471 ethyl oleate Drugs 0.000 description 1
- 239000005038 ethylene vinyl acetate Substances 0.000 description 1
- 229940012017 ethylenediamine Drugs 0.000 description 1
- 125000002534 ethynyl group Chemical group [H]C#C* 0.000 description 1
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 1
- 229960005420 etoposide Drugs 0.000 description 1
- 230000029142 excretion Effects 0.000 description 1
- 210000001723 extracellular space Anatomy 0.000 description 1
- 230000036251 extravasation Effects 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 239000012894 fetal calf serum Substances 0.000 description 1
- 230000001605 fetal effect Effects 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 230000004761 fibrosis Effects 0.000 description 1
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 1
- 108091006047 fluorescent proteins Proteins 0.000 description 1
- 102000034287 fluorescent proteins Human genes 0.000 description 1
- 239000011737 fluorine Substances 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- 229940014144 folate Drugs 0.000 description 1
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 1
- 235000019152 folic acid Nutrition 0.000 description 1
- 239000011724 folic acid Substances 0.000 description 1
- 150000002224 folic acids Chemical class 0.000 description 1
- 125000002485 formyl group Chemical group [H]C(*)=O 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 238000004108 freeze drying Methods 0.000 description 1
- 238000007306 functionalization reaction Methods 0.000 description 1
- 108010062699 gamma-Glutamyl Hydrolase Proteins 0.000 description 1
- 210000001035 gastrointestinal tract Anatomy 0.000 description 1
- 229960003297 gemtuzumab ozogamicin Drugs 0.000 description 1
- 238000012637 gene transfection Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 238000010362 genome editing Methods 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 239000003862 glucocorticoid Substances 0.000 description 1
- 235000019420 glucose oxidase Nutrition 0.000 description 1
- 229940116332 glucose oxidase Drugs 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 150000002310 glutaric acid derivatives Chemical class 0.000 description 1
- 102000045442 glycosyltransferase activity proteins Human genes 0.000 description 1
- 108700014210 glycosyltransferase activity proteins Proteins 0.000 description 1
- 239000010931 gold Substances 0.000 description 1
- 229910052737 gold Inorganic materials 0.000 description 1
- 230000009036 growth inhibition Effects 0.000 description 1
- 229940093915 gynecological organic acid Drugs 0.000 description 1
- 150000004820 halides Chemical class 0.000 description 1
- 125000005179 haloacetyl group Chemical group 0.000 description 1
- 125000004366 heterocycloalkenyl group Chemical group 0.000 description 1
- XXMIOPMDWAUFGU-UHFFFAOYSA-N hexane-1,6-diol Chemical compound OCCCCCCO XXMIOPMDWAUFGU-UHFFFAOYSA-N 0.000 description 1
- 210000005260 human cell Anatomy 0.000 description 1
- 229940098197 human immunoglobulin g Drugs 0.000 description 1
- 150000007857 hydrazones Chemical class 0.000 description 1
- BHEPBYXIRTUNPN-UHFFFAOYSA-N hydridophosphorus(.) (triplet) Chemical compound [PH] BHEPBYXIRTUNPN-UHFFFAOYSA-N 0.000 description 1
- 150000002433 hydrophilic molecules Chemical class 0.000 description 1
- 229960001330 hydroxycarbamide Drugs 0.000 description 1
- 229940050526 hydroxyethylstarch Drugs 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 150000002466 imines Chemical class 0.000 description 1
- 239000012642 immune effector Substances 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 230000000984 immunochemical effect Effects 0.000 description 1
- 238000010166 immunofluorescence Methods 0.000 description 1
- 229940121354 immunomodulator Drugs 0.000 description 1
- 229960003444 immunosuppressant agent Drugs 0.000 description 1
- 230000001861 immunosuppressant effect Effects 0.000 description 1
- 229940125721 immunosuppressive agent Drugs 0.000 description 1
- 230000001771 impaired effect Effects 0.000 description 1
- 238000000099 in vitro assay Methods 0.000 description 1
- 238000005462 in vivo assay Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 125000001041 indolyl group Chemical group 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 208000027866 inflammatory disease Diseases 0.000 description 1
- 230000004054 inflammatory process Effects 0.000 description 1
- 230000000198 inhibitory effect on lymphoma Effects 0.000 description 1
- 239000007972 injectable composition Substances 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 230000009545 invasion Effects 0.000 description 1
- VBUWHHLIZKOSMS-RIWXPGAOSA-N invicorp Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC=1NC=NC=1)C(C)C)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=C(O)C=C1 VBUWHHLIZKOSMS-RIWXPGAOSA-N 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- 230000001788 irregular Effects 0.000 description 1
- 125000000959 isobutyl group Chemical group [H]C([H])([H])C([H])(C([H])([H])[H])C([H])([H])* 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 125000000468 ketone group Chemical group 0.000 description 1
- 239000004816 latex Substances 0.000 description 1
- 229920000126 latex Polymers 0.000 description 1
- 150000002611 lead compounds Chemical class 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- 210000000265 leukocyte Anatomy 0.000 description 1
- 229960004194 lidocaine Drugs 0.000 description 1
- 108020001756 ligand binding domains Proteins 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 229960002247 lomustine Drugs 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- HWYHZTIRURJOHG-UHFFFAOYSA-N luminol Chemical compound O=C1NNC(=O)C2=C1C(N)=CC=C2 HWYHZTIRURJOHG-UHFFFAOYSA-N 0.000 description 1
- 210000002751 lymph Anatomy 0.000 description 1
- 210000001165 lymph node Anatomy 0.000 description 1
- 230000001926 lymphatic effect Effects 0.000 description 1
- 230000002132 lysosomal effect Effects 0.000 description 1
- 108010054155 lysyllysine Proteins 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 239000011777 magnesium Substances 0.000 description 1
- 229910052749 magnesium Inorganic materials 0.000 description 1
- VZCYOOQTPOCHFL-UPHRSURJSA-N maleic acid Chemical compound OC(=O)\C=C/C(O)=O VZCYOOQTPOCHFL-UPHRSURJSA-N 0.000 description 1
- 239000011976 maleic acid Substances 0.000 description 1
- 125000005439 maleimidyl group Chemical group C1(C=CC(N1*)=O)=O 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 238000001906 matrix-assisted laser desorption--ionisation mass spectrometry Methods 0.000 description 1
- 229960004961 mechlorethamine Drugs 0.000 description 1
- HAWPXGHAZFHHAD-UHFFFAOYSA-N mechlorethamine Chemical compound ClCCN(C)CCCl HAWPXGHAZFHHAD-UHFFFAOYSA-N 0.000 description 1
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 1
- 229960001924 melphalan Drugs 0.000 description 1
- 108020004084 membrane receptors Proteins 0.000 description 1
- 229960003151 mercaptamine Drugs 0.000 description 1
- 229960001428 mercaptopurine Drugs 0.000 description 1
- 230000004060 metabolic process Effects 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- HRDXJKGNWSUIBT-UHFFFAOYSA-N methoxybenzene Chemical group [CH2]OC1=CC=CC=C1 HRDXJKGNWSUIBT-UHFFFAOYSA-N 0.000 description 1
- 239000004530 micro-emulsion Substances 0.000 description 1
- 238000001471 micro-filtration Methods 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 150000007522 mineralic acids Chemical class 0.000 description 1
- 229960005485 mitobronitol Drugs 0.000 description 1
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 1
- 229960001156 mitoxantrone Drugs 0.000 description 1
- 239000003068 molecular probe Substances 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 125000006682 monohaloalkyl group Chemical group 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 150000002772 monosaccharides Chemical class 0.000 description 1
- 125000004572 morpholin-3-yl group Chemical group N1C(COCC1)* 0.000 description 1
- 108091005763 multidomain proteins Proteins 0.000 description 1
- 230000036457 multidrug resistance Effects 0.000 description 1
- ACTNHJDHMQSOGL-UHFFFAOYSA-N n',n'-dibenzylethane-1,2-diamine Chemical compound C=1C=CC=CC=1CN(CCN)CC1=CC=CC=C1 ACTNHJDHMQSOGL-UHFFFAOYSA-N 0.000 description 1
- 229950006780 n-acetylglucosamine Drugs 0.000 description 1
- 125000004108 n-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000003136 n-heptyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000001280 n-hexyl group Chemical group C(CCCCC)* 0.000 description 1
- 125000000740 n-pentyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000004123 n-propyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 210000000822 natural killer cell Anatomy 0.000 description 1
- 101150091879 neo gene Proteins 0.000 description 1
- 230000003472 neutralizing effect Effects 0.000 description 1
- 210000000440 neutrophil Anatomy 0.000 description 1
- 230000003448 neutrophilic effect Effects 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- 125000006574 non-aromatic ring group Chemical group 0.000 description 1
- 230000009871 nonspecific binding Effects 0.000 description 1
- 238000010534 nucleophilic substitution reaction Methods 0.000 description 1
- 238000011580 nude mouse model Methods 0.000 description 1
- 235000008390 olive oil Nutrition 0.000 description 1
- 239000004006 olive oil Substances 0.000 description 1
- 230000006548 oncogenic transformation Effects 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 150000002894 organic compounds Chemical class 0.000 description 1
- 150000002895 organic esters Chemical class 0.000 description 1
- 229940127084 other anti-cancer agent Drugs 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 230000002018 overexpression Effects 0.000 description 1
- SOWBFZRMHSNYGE-UHFFFAOYSA-N oxamic acid Chemical compound NC(=O)C(O)=O SOWBFZRMHSNYGE-UHFFFAOYSA-N 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 150000002923 oximes Chemical class 0.000 description 1
- 239000001301 oxygen Substances 0.000 description 1
- 125000000636 p-nitrophenyl group Chemical group [H]C1=C([H])C(=C([H])C([H])=C1*)[N+]([O-])=O 0.000 description 1
- 229960001592 paclitaxel Drugs 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 230000007170 pathology Effects 0.000 description 1
- 230000007310 pathophysiology Effects 0.000 description 1
- 229940049954 penicillin Drugs 0.000 description 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 1
- 125000005010 perfluoroalkyl group Chemical group 0.000 description 1
- KHIWWQKSHDUIBK-UHFFFAOYSA-N periodic acid Chemical compound OI(=O)(=O)=O KHIWWQKSHDUIBK-UHFFFAOYSA-N 0.000 description 1
- 210000001539 phagocyte Anatomy 0.000 description 1
- 230000003285 pharmacodynamic effect Effects 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- 108010024607 phenylalanylalanine Proteins 0.000 description 1
- 125000005506 phthalide group Chemical group 0.000 description 1
- 108060006184 phycobiliprotein Proteins 0.000 description 1
- 125000000587 piperidin-1-yl group Chemical group [H]C1([H])N(*)C([H])([H])C([H])([H])C([H])([H])C1([H])[H] 0.000 description 1
- 125000004483 piperidin-3-yl group Chemical group N1CC(CCC1)* 0.000 description 1
- 230000003169 placental effect Effects 0.000 description 1
- 229920003023 plastic Polymers 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 229920001200 poly(ethylene-vinyl acetate) Polymers 0.000 description 1
- 229920000747 poly(lactic acid) Polymers 0.000 description 1
- 229920002401 polyacrylamide Polymers 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 125000003367 polycyclic group Chemical group 0.000 description 1
- 229920000570 polyether Polymers 0.000 description 1
- 229920000573 polyethylene Polymers 0.000 description 1
- 239000004633 polyglycolic acid Substances 0.000 description 1
- 125000006684 polyhaloalkyl group Polymers 0.000 description 1
- 239000004626 polylactic acid Substances 0.000 description 1
- 229920001155 polypropylene Polymers 0.000 description 1
- 229920001451 polypropylene glycol Polymers 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 229920002223 polystyrene Polymers 0.000 description 1
- 238000010837 poor prognosis Methods 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000009465 prokaryotic expression Effects 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 238000011321 prophylaxis Methods 0.000 description 1
- 229960003712 propranolol Drugs 0.000 description 1
- 239000000473 propyl gallate Substances 0.000 description 1
- 235000010388 propyl gallate Nutrition 0.000 description 1
- 229940075579 propyl gallate Drugs 0.000 description 1
- 210000002307 prostate Anatomy 0.000 description 1
- 108020001580 protein domains Proteins 0.000 description 1
- 108060006633 protein kinase Proteins 0.000 description 1
- 230000009145 protein modification Effects 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 230000004850 protein–protein interaction Effects 0.000 description 1
- 230000002797 proteolythic effect Effects 0.000 description 1
- 230000006337 proteolytic cleavage Effects 0.000 description 1
- 229940024999 proteolytic enzymes for treatment of wounds and ulcers Drugs 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 125000000561 purinyl group Chemical group N1=C(N=C2N=CNC2=C1)* 0.000 description 1
- 229950010131 puromycin Drugs 0.000 description 1
- 125000003373 pyrazinyl group Chemical group 0.000 description 1
- 125000005344 pyridylmethyl group Chemical group [H]C1=C([H])C([H])=C([H])C(=N1)C([H])([H])* 0.000 description 1
- 150000003233 pyrroles Chemical class 0.000 description 1
- 125000000719 pyrrolidinyl group Chemical group 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 125000001453 quaternary ammonium group Chemical group 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 239000002287 radioligand Substances 0.000 description 1
- 231100000336 radiotoxic Toxicity 0.000 description 1
- 230000001690 radiotoxic effect Effects 0.000 description 1
- 231100001258 radiotoxin Toxicity 0.000 description 1
- 238000002708 random mutagenesis Methods 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 230000019705 regulation of vascular permeability Effects 0.000 description 1
- 208000023504 respiratory system disease Diseases 0.000 description 1
- 238000004007 reversed phase HPLC Methods 0.000 description 1
- 229960004641 rituximab Drugs 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 238000003118 sandwich ELISA Methods 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 229930195734 saturated hydrocarbon Natural products 0.000 description 1
- 125000002914 sec-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 239000006152 selective media Substances 0.000 description 1
- 150000007659 semicarbazones Chemical class 0.000 description 1
- 230000008054 signal transmission Effects 0.000 description 1
- 239000010703 silicon Substances 0.000 description 1
- 210000003491 skin Anatomy 0.000 description 1
- 229940126586 small molecule drug Drugs 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- WBHQBSYUUJJSRZ-UHFFFAOYSA-M sodium bisulfate Chemical compound [Na+].OS([O-])(=O)=O WBHQBSYUUJJSRZ-UHFFFAOYSA-M 0.000 description 1
- 229910000342 sodium bisulfate Inorganic materials 0.000 description 1
- 229940100996 sodium bisulfate Drugs 0.000 description 1
- HRZFUMHJMZEROT-UHFFFAOYSA-L sodium disulfite Chemical compound [Na+].[Na+].[O-]S(=O)S([O-])(=O)=O HRZFUMHJMZEROT-UHFFFAOYSA-L 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- 229940001584 sodium metabisulfite Drugs 0.000 description 1
- 235000010262 sodium metabisulphite Nutrition 0.000 description 1
- 229940054269 sodium pyruvate Drugs 0.000 description 1
- 229940001482 sodium sulfite Drugs 0.000 description 1
- 235000010265 sodium sulphite Nutrition 0.000 description 1
- 230000000392 somatic effect Effects 0.000 description 1
- 235000010199 sorbic acid Nutrition 0.000 description 1
- 239000004334 sorbic acid Substances 0.000 description 1
- 229940075582 sorbic acid Drugs 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 230000001954 sterilising effect Effects 0.000 description 1
- 238000004659 sterilization and disinfection Methods 0.000 description 1
- 238000012414 sterilization procedure Methods 0.000 description 1
- 229960005322 streptomycin Drugs 0.000 description 1
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 description 1
- 229960001052 streptozocin Drugs 0.000 description 1
- 150000005846 sugar alcohols Polymers 0.000 description 1
- 229940124530 sulfonamide Drugs 0.000 description 1
- 150000003456 sulfonamides Chemical class 0.000 description 1
- 150000003459 sulfonic acid esters Chemical group 0.000 description 1
- 150000003461 sulfonyl halides Chemical class 0.000 description 1
- 239000011593 sulfur Substances 0.000 description 1
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 1
- 108010033090 surfactant protein A receptor Proteins 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 229940037128 systemic glucocorticoids Drugs 0.000 description 1
- 239000003826 tablet Substances 0.000 description 1
- 239000011975 tartaric acid Substances 0.000 description 1
- 235000002906 tartaric acid Nutrition 0.000 description 1
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 1
- NRUKOCRGYNPUPR-QBPJDGROSA-N teniposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@@H](OC[C@H]4O3)C=3SC=CC=3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 NRUKOCRGYNPUPR-QBPJDGROSA-N 0.000 description 1
- 229960001278 teniposide Drugs 0.000 description 1
- 125000000999 tert-butyl group Chemical group [H]C([H])([H])C(*)(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- IHMQNZFRFVYNDS-UHFFFAOYSA-N tert-butyl n-amino-n-methylcarbamate Chemical compound CN(N)C(=O)OC(C)(C)C IHMQNZFRFVYNDS-UHFFFAOYSA-N 0.000 description 1
- 229960002372 tetracaine Drugs 0.000 description 1
- GKCBAIGFKIBETG-UHFFFAOYSA-N tetracaine Chemical compound CCCCNC1=CC=C(C(=O)OCCN(C)C)C=C1 GKCBAIGFKIBETG-UHFFFAOYSA-N 0.000 description 1
- 125000004192 tetrahydrofuran-2-yl group Chemical group [H]C1([H])OC([H])(*)C([H])([H])C1([H])[H] 0.000 description 1
- MPLHNVLQVRSVEE-UHFFFAOYSA-N texas red Chemical compound [O-]S(=O)(=O)C1=CC(S(Cl)(=O)=O)=CC=C1C(C1=CC=2CCCN3CCCC(C=23)=C1O1)=C2C1=C(CCC1)C3=[N+]1CCCC3=C2 MPLHNVLQVRSVEE-UHFFFAOYSA-N 0.000 description 1
- 231100001274 therapeutic index Toxicity 0.000 description 1
- 230000008719 thickening Effects 0.000 description 1
- 150000003585 thioureas Chemical class 0.000 description 1
- 229960004072 thrombin Drugs 0.000 description 1
- 229960003087 tioguanine Drugs 0.000 description 1
- 239000003104 tissue culture media Substances 0.000 description 1
- AOBORMOPSGHCAX-DGHZZKTQSA-N tocofersolan Chemical compound OCCOC(=O)CCC(=O)OC1=C(C)C(C)=C2O[C@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C AOBORMOPSGHCAX-DGHZZKTQSA-N 0.000 description 1
- 229960000984 tocofersolan Drugs 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 230000002110 toxicologic effect Effects 0.000 description 1
- 231100000759 toxicological effect Toxicity 0.000 description 1
- 238000012549 training Methods 0.000 description 1
- VZCYOOQTPOCHFL-UHFFFAOYSA-N trans-butenedioic acid Natural products OC(=O)C=CC(O)=O VZCYOOQTPOCHFL-UHFFFAOYSA-N 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000014723 transformation of host cell by virus Effects 0.000 description 1
- 238000012451 transgenic animal system Methods 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 150000008648 triflates Chemical class 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
- 238000009966 trimming Methods 0.000 description 1
- 230000004565 tumor cell growth Effects 0.000 description 1
- 238000013413 tumor xenograft mouse model Methods 0.000 description 1
- 231100000588 tumorigenic Toxicity 0.000 description 1
- 230000000381 tumorigenic effect Effects 0.000 description 1
- ORHBXUUXSCNDEV-UHFFFAOYSA-N umbelliferone Chemical compound C1=CC(=O)OC2=CC(O)=CC=C21 ORHBXUUXSCNDEV-UHFFFAOYSA-N 0.000 description 1
- HFTAFOQKODTIJY-UHFFFAOYSA-N umbelliferone Natural products Cc1cc2C=CC(=O)Oc2cc1OCC=CC(C)(C)O HFTAFOQKODTIJY-UHFFFAOYSA-N 0.000 description 1
- 150000003672 ureas Chemical class 0.000 description 1
- 238000001291 vacuum drying Methods 0.000 description 1
- 238000009777 vacuum freeze-drying Methods 0.000 description 1
- 235000015112 vegetable and seed oil Nutrition 0.000 description 1
- 239000008158 vegetable oil Substances 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 125000000391 vinyl group Chemical group [H]C([*])=C([H])[H] 0.000 description 1
- 229920002554 vinyl polymer Polymers 0.000 description 1
- 230000007502 viral entry Effects 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 238000007794 visualization technique Methods 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
- 229920003169 water-soluble polymer Polymers 0.000 description 1
- 230000003442 weekly effect Effects 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 239000002023 wood Substances 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- 108091005957 yellow fluorescent proteins Proteins 0.000 description 1
- 229910052725 zinc Inorganic materials 0.000 description 1
- 239000011701 zinc Substances 0.000 description 1
- 239000002076 α-tocopherol Substances 0.000 description 1
- 235000004835 α-tocopherol Nutrition 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6849—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a receptor, a cell surface antigen or a cell surface determinant
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- A61P35/02—Antineoplastic agents specific for leukemia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/545—Medicinal preparations containing antigens or antibodies characterised by the dose, timing or administration schedule
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/40—Immunoglobulins specific features characterized by post-translational modification
- C07K2317/41—Glycosylation, sialylation, or fucosylation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/732—Antibody-dependent cellular cytotoxicity [ADCC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/77—Internalization into the cell
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
Definitions
- CD 19 is a 95 kDa membrane receptor that is expressed early in B cell differentiation and continues to be expressed until the B cells are triggered to terminally differentiate (Pezzutto et al., (1987) J Immunol. 138:2793; Tedder et al. (1994) Immunol Today iJ>:437).
- the CD 19 extracellular domain contains two C2-type immunoglobulin (IG)-like domains separated by a smaller potentially disulfi de-linked domain.
- the CD 19 cytoplasmic domain is structurally unique, but highly conserved between human, mouse, and guinea pig (Fujimoto et al., (1998) Semin Immunol. JjO:267).
- CD 19 is part of a protein complex found on the cell surface of B lymphocytes.
- the protein complex includes CD 19, CD21 (complement receptor, type 2), CD81 (TAPA-I), and CD225 (Leu- 13) (Fujimoto, supra).
- CD 19 is an important regulator of transmembrane signals in B cells. An increase or decrease in the cell surface density of CD 19 affects B cell development and function, resulting in diseases such as autoimmunity or hypogammaglobulinemia (Fujimoto, supra).
- the CD 19 complex potentiates the response of B cells to antigen in vivo through cross-linking of two separate signal transduction complexes found on B cell membranes.
- CD 19 and B cell receptor cross-linking reduces the number of IgM molecules required to activate PLC (Fujimoto, supra; Ghetie, supra). Additionally, CD 19 functions as a specialized adapter protein for the amplification of Arc family kinases (Hasegawa et al. , (2001 ) J Immunol 167:3190). CD 19 binding has been shown to both enhance and inhibit B-cell activation and proliferation, depending on the amount of cross-linking that occurs (Tedder, supra).
- CD 19 is expressed on greater than 90% of B-cell lymphomas and has been predicted to affect growth of lymphomas in vitro and in vivo (Ghetie, supra).
- Antibodies generated to CD 19 have been murine antibodies.
- a disadvantage of using a murine antibody in treatment of human subjects is the human anti-mouse (HAMA) response on administration to the patient. Accordingly, the need exists for improved therapeutic antibodies against CD 19 which are more effective for treating and/or preventing diseases mediated by CD 19.
- the present disclosure provides isolated monoclonal antibodies, in particular human monoclonal antibodies, that specifically bind to CD 19 and that exhibit numerous desirable properties. These properties include high affinity binding to human CDl 9, internalization by cells expressing CD 19, and/or the ability to mediate antigen depu-uci > cellular cytotoxicity.
- the antibodies of the invention can be used, for example, to detect CD 19 protein or to inhibit the growth of cells expressing CD 19, such as tumor cells that express CD 19. Also provided are methods for treating a variety CD 19 mediated diseases using the antibodies and compositions of this disclosure.
- this disclosure pertains to an isolated monoclonal human or an antigen binding portion thereof, wherein the antibody binds human CD 19 and exhibits at least one of the following properties: (a) binds to human CD 19 with a K 0 of 1 x 10 "7 M or less;
- ADCC antibody dependent cellular cytotoxicity
- the antibody exhibits at least two of properties (a), (b), (c), (d), and (e). More preferably, the antibody exhibits at least three of properties (a), (b), (c), (d), and (e). More preferably, the antibody exhibits four of properties (a), (b), (c), (d), and (e). Even, more preferably, the antibody exhibits all five of properties (a), (b), (c), (d),
- the antibody inhibits growth of CDl 9- expressing tumor cells in vivo when the antibody is conjugated to a cytotoxin.
- the antibody binds to human CD 19 with a Kp of 5 x 10 ⁇ 8 M or less, binds to human CD 19 with a K D of 2 x 10 "8 M or less, binds to human CD 19 with a K D of 1 x 10 "8 M or less, binds to human CD 19 with a K D of 5x 10 ⁇ 9 M or less, binds to human CD 19 with a K D of 4x10 "9 M or less, binds to human CD 19 with a KQ of 3xlO "9 M or less, or binds to human CD 19 with a K 0 of 2 x 10 ⁇ 9 M or less.
- the antibody is a human antibody, although in alternative embodiments the antibody can be a murine antibody, a chimeric antibody or humanized antibody.
- the invention pertains to an isolated human monoclonal antibody, or antigen binding portion thereof, wherein the antibody cross-competes for binding to an epitope on human CD 19 which is recognized by a reference antibody, wherein the reference antibody comprises:
- the reference antibody comprises: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 1 ; and (b) a light chain variable region comprising the amino acid sequence of SEQ ID NO: 8; or the reference antibody comprises: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 1; and (b) a light chain variable region comprising the amino acid sequence of SEQ ID NO: 9; or the reference antibody comprises: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 2; and (b) a light chain variable region comprising the amino acid sequence of SEQ ID NO: 10; or the reference antibody comprises: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 3; and (b) a light chain variable region comprising the amino acid sequence of SEQ ID NO: 1 1 ; or the reference antibody comprises: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 4; and (b) a light chain variable region compris
- this disclosure pertains to an isolated monoclonal antibody, or antigen binding portion thereof, wherein the antibody comprises a heavy chain variable region that is the product of or derived from a human V H 5-51 gene, wherein the antibody specifically binds CD 19.
- This disclosure also provides an isolated human monoclonal antibody, or antigen binding portion thereof, wherein the antibody comprises a heavy chain variable region that is the product of or derived from a human V H 1-69 gene, wherein the antibody specifically binds CD 19.
- This disclosure still further provides an isolated human monoclonal antibody, or antigen binding portion thereof comprising a light chain variable region that is the product of or derived from a human V ⁇ Ll 8 gene, wherein the antibody specifically binds CD 19.
- This disclosure even further provides an isolated human monoclonal antibody, or antigen binding portion thereof, wherein the antibody comprises a light chain variable region that is the product of or derived from a human V K A27 gene, wherein the antibody specifically binds CD 19.
- This disclosure even further provides an isolated human monoclonal antibody, or antigen binding portion thereof, wherein the antibody comprises a light chain variable region that is the product of or derived from a human V K L15 gene, wherein the antibody specifically binds CD19.
- this disclosure provides an isolated human monoclonal antibody, or antigen binding portion thereof, wherein the antibody comprises (a) a heavy chain variable region of a human V H 5-51 or 1-69 gene; and (b) a light chain variable region of a human V ⁇ Ll 8, A27 or V K L 15; wherein the antibody specifically binds to CD 19.
- this disclosure provides an isolated human monoclonal antibody, or antigen binding portion thereof, wherein the antibody comprises a heavy chain variable region that comprises CDRl, CDR2, and CDR3 sequences; and a light chain variable region that comprises CDRl, CDR2, and CDR3 sequences, wherein: (a) the heavy chain variable region CDR3 sequence comprises an amino acid sequence selected from the group consisting of amino acid sequences of SEQ ID NOs: 30, 31, 32, 33, 34, 35 and 36, and conservative modifications thereof; (b) the light chain variable region CDR3 sequence comprises an amino acid sequence selected from the group consisting of amino acid sequence of SEQ ID NOs: 51, 52, 53, 54, 55, 56, 57 and 58, and conservative modifications thereof; (c) the antibody binds to human CD 19 with a Kp of IxI(T 7 M or less; and (d) binds to Raji and Daudi B-cell tumor cells.
- the antibody comprises a heavy chain variable region that comprises CDRl, CDR2, and CDR3 sequences
- the heavy chain variable region CDR2 sequence comprises an amino acid sequence selected from the group consisting of amino acid sequences of SEQ ID NOs: 23, 24, 25, 26, 27, 28 and 29, and conservative modifications thereof; and the light chain variable region CDR2 sequence comprises an amino acid sequence selected from the group consisting of amino acid sequences of SEQ ID NOs: 44, 45, 46, 47, 48, 49 and 50, and conservative modifications thereof.
- the heavy chain variable region CDRl sequence comprises an amino acid sequence selected from the group consisting of amino acid sequences of SEQ ID NOs: 16, 17, 18, 19, 20, 21 and 22, and conservative modifications thereof; and the light chain variable region CDRl sequence comprises an amino acid sequence selected from the group consisting of amino acid sequences of SEQ ID NOs: 37, 38, 39, 40, 41, 42 and 43, and conservative modifications thereof.
- a preferred combination comprises: (a) a heavy chain variable region CDRl comprising SEQ ID NO: 16;
- Another preferred combination comprises:
- a light chain variable region CDR3 comprising SEQ ID NO: 53.
- Another preferred combination comprises: (a) a heavy chain variable region CDRl comprising SEQ ID NO: 18;
- Another preferred combination comprises:
- Another preferred combination comprises:
- a heavy chain variable region comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 1, 2, 3, 4, 5, 6 and 7;
- a light chain variable region comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 8, 9, 10, 1 1, 12, 13, 14 and 15; wherein the antibody specifically binds CD 19.
- a preferred combination comprises: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 1; and (b) a light chain variable region comprising the amino acid sequence of SEQ ID NO: 8.
- Another preferred combination comprises: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 1 ; and (b) a light chain variable region comprising the amino acid sequence of SEQ ID NO: 9.
- Another preferred combination comprises: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 2; and (b) a light chain variable region comprising the amino acid sequence of SEQ ID NO: 10.
- Another preferred combination comprises: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 3; and (b) a light chain variable region comprising the amino acid sequence of SEQ ID NO: 1 1.
- Another preferred combination comprises: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 4; and (b) a light chain variable region comprising the amino acid sequence of SEQ ID NO: 12.
- Another preferred combination comprises: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 5; and (b) a light chain variable region comprising the amino acid sequence of SEQ ID NO: 13.
- Another preferred combination comprises: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 6; and (b) a light chain variable region comprising the amino acid sequence of SEQ ID NO: 14.
- Another preferred combination comprises: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 7; and (b) a light chain variable region comprising the amino acid sequence of SEQ ID NO: 15.
- antibodies, or antigen-binding portion or fragments thereof are provided that compete for binding to CD 19 with any of the aforementioned antibodies.
- the antibodies of this disclosure can be, for example, full-length antibodies, for example of an IgGl or IgG4 isotype.
- the antibodies can be antibody fragments, such as Fab, Fab' or Fab'2 fragments, or single chain antibodies.
- This disclosure also provides an immunoconjugate comprising an antibody of this disclosure, or antigen-binding portion thereof, linked to a therapeutic agent, such as a cytotoxin or a radioactive isotope.
- a therapeutic agent such as a cytotoxin or a radioactive isotope.
- the invention provides an immunoconjugate comprising an antibody of this disclosure, or antigen-binding portion thereof, linked to a cytotoxin (for example, a cytotoxin described herein or in U.S. Pat. App. No. 60/882,461, filed on December 28, 2006 or U.S. Pat. App. No. 60/991,300, filed on November 30, 2007, which are hereby incorporated by reference in their entirety) (e.g., via a thiol linkage).
- a cytotoxin for example, a cytotoxin described herein or in U.S. Pat. App. No. 60/882,461, filed on December 28, 2006 or U.S. Pat. App. No. 60/991,300, filed on November 30, 2007, which are hereby incorporated by reference in their entirety
- the invention provides the following preferred immunoconjugates:
- an immunoconjugate comprising an antibody, or antigen-binding portion thereof, comprising: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 1 and a light chain variable region comprising the amino acid sequence of SEQ ID NO: 8.
- an immunoconjugate comprising an antibody, or antigen-binding portion thereof, comprising:
- a light chain variable region CDR3 comprising SEQ ID NO: 51; an antibody, or antigen-binding portion thereof, comprising:
- a light chain variable region CDR3 comprising SEQ ID NO: 52; an antibody, or antigen-binding portion thereof, comprising:
- a light chain variable region CDR3 comprising SEQ ID NO: 53; an antibody, or antigen-binding portion thereof, comprising:
- a light chain variable region CDR3 comprising SEQ ID NO: 54; an antibody, or antigen-binding portion thereof, comprising: (a) a heavy chain variable region CDRl comprising SEQ ID NO: 19;
- a light chain variable region CDR2 comprising SEQ ID NO: 47
- a light chain variable region CDR3 comprising SEQ ID NO: 55
- an antibody, or antigen-binding portion thereof comprising: (a) a heavy chain variable region CDRl comprising SEQ ID NO: 20;
- a light chain variable region CDR3 comprising SEQ ID NO: 56; an antibody, or antigen-binding portion thereof, comprising:
- a light chain variable region CDR3 comprising SEQ ID NO: 57; or an antibody, or antigen-binding portion thereof, comprising: (a) a heavy chain variable region CDRl comprising SEQ ID NO: 22;
- an immunoconjugate comprising an antibody, or antigen-binding portion thereof, that binds to the same epitope that is recognized by (e.g., cross-competes for binding to human CD 19 with) an antibody comprising: (a) a heavy chain variable region comprising the amino acid sequence of SEQ ID NO:
- a heavy chain variable region comprising the amino acid sequence of SEQ ID NO: 7 and a light chain variable region comprising the amino acid sequence of SEQ ID NO: 15, linked to a cytotoxin.
- This disclosure also provides a bispecific molecule comprising an antibody, or antigen-binding portion or fragment thereof, of this disclosure, linked to a second functional moiety having a different binding specificity than said antibody, or antigen binding portion thereof.
- compositions comprising an antibody, or antigen-binding portion thereof, or immunoconjugate or bispecific molecule of this disclosure and a pharmaceutically acceptable carrier are also provided.
- Nucleic acid molecules encoding the antibodies, or antigen-binding portions thereof, of this disclosure are also encompassed by this disclosure, as well as expression vectors comprising such nucleic acids and host cells comprising such expression vectors.
- Methods for preparing anti-CD 19 antibodies using the host cells comprising such expression vectors are also provided and may include the steps of (i) expressing the antibody in the host cell and (ii) isolating the antibody from the host cell.
- the invention pertains to a method for preparing an anti- CD 19 antibody.
- the method comprises: (a) providing: (i) a heavy chain variable region antibody sequence comprising a
- the present disclosure also provides isolated anti-CD 19 antibody-partner molecule conjugates that specifically bind to CD 19 with high affinity, particularly those comprising human monoclonal antibodies. Certain of such antibody-partner molecule conjugates are capable of being internalized into CD19-expressing cells and are capable of mediating antigen dependent cellular cytotoxicity. This disclosure also provides methods for treating cancers, such as treat B cell malignancies, including non-Hodgkin's lymphoma, chronic lymphocytic leukemias, follicular lymphomas, diffuse large cell lymphomas of B lineage, and multiple myelomas, using an anti-CD 19 antibody-partner molecule conjugate disclosed herein.
- compositions comprising an antibody, or antigen-binding portion thereof, conjugated to a partner molecule of this disclosure are also provided.
- Partner molecules that can be advantageously conjugated to an antibody in an antibody partner molecule conjugate as disclosed herein include, but are not limited to, molecules as drugs, cytotoxins, marker molecules (e.g., radioisotopes), proteins and therapeutic agents.
- Compositions comprising antibody-partner molecule conjugates and pharmaceutically acceptable earners are also disclosed herein.
- such antibody-partner molecule conjugates are conjugated via chemical linkers.
- the linker is a peptidyl linker, and is depicted herein as (L 4 ) p — F — (L 1 ), thinking.
- Other linkers include hydrazine and disulfide linkers, and is depicted herein as (L 4 ) p — H — (L') m or (L 4 ) p — J — (L') m , respectively.
- the present invention also provides cleavable linker arms that are appropriate for attachment to essentially any molecular species.
- the invention pertains to a method of inhibiting growth of a CD 19-expressing tumor cell.
- the method comprises contacting the CD 19-expressing tumor cell with an antibody-partner molecule conjugate of the disclosure such that growth of the CDl 9-expressing tumor cell is inhibited.
- the partner molecule is a therapeutic agent, such as a cytotoxin.
- Particularly preferred CD 19- expressing tumor cells are B-cell tumor cells.
- the invention pertains to a method of treating cancer in a subject. The method comprises administering to the subject an antibody-partner molecule conjugate of the disclosure such that the cancer is treated in the subject.
- the partner molecule is a therapeutic agent, such as a cytotoxin.
- Particularly preferred cancers for treatment are B cell malignancies, for example, non- Hodgkin's lymphoma, chronic lymphocytic leukemias, follicular lymphomas, diffuse large cell lymphomas of B lineage, and multiple myelomas.
- B cell malignancies for example, non- Hodgkin's lymphoma, chronic lymphocytic leukemias, follicular lymphomas, diffuse large cell lymphomas of B lineage, and multiple myelomas.
- Figure IA shows the nucleotide sequence (SEQ ID NO: 59) and amino acid sequence (SEQ ID NO: 1) of the heavy chain variable region of the 21D4 and 21 D4a human monoclonal antibodies.
- the CDRl (SEQ ID NO: 16), CDR2 (SEQ ID NO: 23) and CDR3 (SEQ ID NO: 30) regions are delineated and the V, D and J germline derivations are indicated.
- Figure IB shows the nucleotide sequence (SEQ ID NO: 66) and amino acid sequence (SEQ ID NO: 8) of the light chain variable region of the 21D4 human monoclonal antibody.
- the CDRl (SEQ ID NO: 37), CDR2 (SEQ ID NO: 44) and CDR3 (SEQ ID NO: 51) regions are delineated and the V and J germline derivations are indicated.
- Figure 1 C shows the nucleotide sequence (SEQ ID NO: 67) and amino acid sequence (SEQ ID NO: 9) of the light chain variable region of the 21D4a human monoclonal antibody.
- the CDRl (SEQ ID NO: 37), CDR2 (SEQ ID NO: 44) and CDR3 (SEQ ID NO: 52) regions are delineated and the V and J germline derivations are indicated.
- Figure 2A shows the nucleotide sequence (SEQ ID NO: 60) and amino acid sequence (SEQ ID NO: 2) of the heavy chain variable region of the 47G4 human monoclonal antibody.
- the CDRl (SEQ ID NO: 17), CDR2 (SEQ ID NO: 24) and CDR3 (SEQ ID NO: 31) regions are delineated and the V, D and J germline derivations are indicated.
- Figure 2B shows the nucleotide sequence (SEQ ID NO: 68) and amino acid sequence (SEQ ID NO: 10) of the light chain variable region of the 47G4 human monoclonal antibody.
- the CDRl (SEQ ID NO: 38), CDR2 (SEQ ID NO: 45) and CDR3 (SEQ ID NO: 53) regions are delineated and the V and J germline derivations are indicated.
- Figure 3 A shows the nucleotide sequence (SEQ ID NO: 61) and amino acid sequence (SEQ ID NO: 3) of the heavy chain variable region of the 27F3 human monoclonal antibody.
- the CDRl (SEQ ID NO: 18), CDR2 (SEQ ID NO: 25) and CDR3 (SEQ ID NO: 32) regions are delineated and the V, D and J germline derivations are indicated.
- Figure 3B shows the nucleotide sequence (SEQ ID NO: 69) and amino acid sequence (SEQ ID NO: 11) of the light chain variable region of the 27F3 human monoclonal antibody.
- the CDRl (SEQ ID NO: 39), CDR2 (SEQ ID NO: 46) and CDR3 (SEQ ID NO: 54) regions are delineated and the V and J germline derivations are indicated.
- Figure 4A shows the nucleotide sequence (SEQ ID NO: 62) and amino acid sequence (SEQ ID NO: 4) of the heavy chain variable region of the 3C10 human monoclonal antibody.
- the CDRl (SEQ ID NO: 19), CDR2 (SEQ ID NO: 26) and CDR3 (SEQ ID NO: 33) regions are delineated and the V, D and J germline derivations are indicated.
- Figure 4B shows the nucleotide sequence (SEQ ID NO: 70) and amino acid sequence (SEQ ID NO: 12) of the light chain variable region of the 3C10 human monoclonal antibody.
- the CDRl (SEQ ID NO: 40), CDR2 (SEQ ID NO: 47) and CDR3 (SEQ ID NO: 55) regions are delineated and the V and J germline derivations are indicated.
- Figure 5A shows the nucleotide sequence (SEQ ID NO: 63) and amino acid sequence (SEQ ID NO: 5) of the heavy chain variable region of the 5G7 human monoclonal antibody.
- the CDRl (SEQ ID NO: 20), CDR2 (SEQ ID NO: 27) and CDR3 (SEQ ID NO: 34) regions are delineated and the V, D and J ge ⁇ nline derivations are indicated.
- Figure 5B shows the nucleotide sequence (SEQ ID NO: 71) and amino acid sequence (SEQ ID NO: 13) of the light chain variable region of the 5G7 human monoclonal antibody.
- the CDRl (SEQ ID NO: 41), CDR2 (SEQ ID NO: 48) and CDR3 (SEQ ID NO: 56) regions are delineated and the V and J ge ⁇ nline derivations are indicated.
- Figure 6A shows the nucleotide sequence (SEQ ID NO: 64) and amino acid sequence (SEQ ID NO: 6) of the heavy chain variable region of the 13Fl human monoclonal antibody.
- the CDRl (SEQ ID NO: 21), CDR2 (SEQ ID NO: 28) and CDR3 (SEQ ID NO: 35) regions are delineated and the V, D and J germline derivations are indicated.
- Figure 6B shows the nucleotide sequence (SEQ ID NO: 72) and amino acid sequence (SEQ ID NO: 14) of the light chain variable region of the 13Fl human monoclonal antibody.
- the CDRl (SEQ ID NO: 42), CDR2 (SEQ ID NO: 49) and CDR3 (SEQ ID NO: 57) regions are delineated and the V and J germline derivations are indicated.
- Figure 7 A shows the nucleotide sequence (SEQ ID NO: 65) and amino acid sequence (SEQ ID NO: 7) of the heavy chain variable region of the 46E8 human monoclonal antibody.
- the CDRl SEQ ID NO: 22
- CDR2 SEQ ID NO: 29
- CDR3 (SEQ ID NO: 36) regions are delineated and the V, D and J germiine derivations are indicated.
- Figure 7B shows the nucleotide sequence (SEQ ID NO: 73) and amino acid sequence (SEQ ID NO: 15) of the light chain variable region of the 46E8 human monoclonal antibody.
- the CDRl SEQ ID NO: 43
- CDR2 SEQ ID NO: 50
- CDR3 (SEQ ID NO: 58) regions are delineated and the V and J ge ⁇ nline derivations are indicated.
- Figure 8 shows the alignment of the amino acid sequence of the heavy chain variable region of 21D4 (SEQ ID NO: 1) and 21D4a (SEQ ID NO: 1), with the human ge ⁇ nline V H 5-51 amino acid sequence (SEQ ID NO: 74).
- the JH4b germline is disclosed as SEQ ID NO: 80.
- Figure 9 shows the alignment of the amino acid sequence of the heavy chain variable region of 47G4 (SEQ ID NO: 2) with the human ge ⁇ nline Vn 1-69 amino acid sequences (SEQ ID NO: 75).
- the JH5b germline is disclosed as SEQ ID NO: 81.
- Figure 10 shows the alignment of the amino acid sequence of the heavy chain variable region of 27F3 (SEQ ID NO: 3), with the human germline Vn 5-51 amino acid sequence (SEQ ID NO: 74).
- the JH6b ge ⁇ nline is disclosed as SEQ ID NO: 82.
- Figure 11 shows the alignment of the amino acid sequence of the heavy chain variable region of 3C10 (SEQ ID NO: 4) with the human germline V H 1-69 amino acid sequences (SEQ ID NO: 75).
- the JH6b germline is disclosed as SEQ ID NO: 82.
- Figure 12 shows the alignment of the amino acid sequence of the heavy chain variable region of 5G7 (SEQ ID NO: 5), with the human ge ⁇ nline V H 5-51 amino acid sequence (SEQ ID NO: 74).
- the JH6b ge ⁇ nline is disclosed as SEQ ID NO: 83.
- Figure 13 shows the alignment of the amino acid sequence of the heavy chain variable region of 13Fl (SEQ ID NO: 6), with the human germline V H 5-51 amino acid sequence (SEQ ID NO: 74).
- the JH6b ge ⁇ nline is disclosed as SEQ ID NO: 82.
- Figure 14 shows the alignment of the amino acid sequence of the heavy chain variable region of 46E8 (SEQ ID NO: 7), with the human germline V H 5-51 amino acid sequence (SEQ ID NO: 74).
- the JH6b germline is disclosed as SEQ ID NO: 82.
- Figure 15 shows the alignment of the amino acid sequence of the light chain variable region of 21D4 (SEQ ID NO: 8) with the human germline V k L18 amino acid sequence (SEQ ID NO:76).
- the JK2 ge ⁇ nline is disclosed as SEQ ID NO: 84.
- Figure 16 shows the alignment of the amino acid sequence of the light chain variable region of 21D4a (SEQ ID NO: 9) with the human ge ⁇ nline Vt- LlS amino acid sequence (SEQ ID NO:76).
- the JK3 germline is disclosed as SEQ ID NO: 85.
- Figure 17 shows the alignment of the amino acid sequence of the light chain variable region of 47G4 (SEQ ID NO: 10) with the human germline V k A27 amino acid sequence (SEQ ID NO:77).
- the JK3 ge ⁇ nline is disclosed as SEQ ID NO: 85.
- Figure 18 shows the alignment of the amino acid sequence of the light chain variable region of 27F3 (SEQ ID NO: 1 1 ) with the human germline V k L18 amino acid sequence (SEQ ID NO:76).
- the JK2 germline is disclosed as SEQ ID NO: 84.
- Figure 19 shows the alignment of the amino acid sequence of the light chain variable region of 3C10 (SEQ ID NO: 12) with the human germline Vk L15 amino acid sequence (SEQ ID NO:78).
- the JK2 germline is disclosed as SEQ ID NO: 84.
- Figure 20 shows the alignment of the amino acid sequence of the light chain variable region of 5G7 (SEQ ID NO: 13) with the human germline V k Ll 8 amino acid sequence (SEQ ID NO:76).
- the JKl ge ⁇ nline is disclosed as SEQ ID NO: 86.
- Figure 21 shows the alignment of the amino acid sequence of the light chain variable region of 13Fl (SEQ ID NO: 14) with the human germline V k Ll 8 amino acid sequence (SEQ ID NO:76).
- the JK2 ge ⁇ nline is disclosed as SEQ ID NO: 87.
- Figure 22 shows the alignment of the amino acid sequence of the light chain variable region of 46E8 (SEQ ID NO: 15) with the human germline V k Ll 8 amino acid sequence (SEQ ID NO:76).
- the JK2 germline is disclosed as SEQ ID NO: 87.
- Figure 23 is a graph showing the results of experiments demonstrating that the human monoclonal antibody 47 G4, directed against human CD 19, specifically binds to human CD 19.
- Figure 24 A and B are graphs showing the results of experiments demonstrating that the human monoclonal antibodies against CD 19 compete for binding on Raji cells.
- Figure 25A-D shows the results of flow cytometry experiments demonstrating that the human monoclonal antibodies 21 D4, 21 D4a, 47G4, 3Cl 0, 5G7 and 13F 1 , directed against human CD 19, binds the cell surface of B-cell tumor cell lines.
- A Flow cytometry of HuMAbs 21D4 and 47G4 on CHO cells transfected with human CD 19.
- B Flow cytometry of HuMAb 47G4 on Daudi B tumor cells.
- C Flow cytometry of HuMAbs 21 D4 and 47G4 on Raji B tumor cells.
- D Flow cytometry of HuMAbs 21 D4, 21D4a, 3C10, 5G7 and 13Fl on Raji B tumor cells.
- Figures 26A-B shows the results of internalization experiments demonstrating that the human monoclonal antibodies 21D4 and 47G4, directed against human CD 19, enters CHO-CD 19 and CD19-expressing Raji B tumor cells by a 3H-thymidine release assay.
- HuMAb 47G4 internalization into CHO-CD 19 cells.
- Figure 27A and B shows the results of a thymidine incorporation assay demonstrating that human monoclonal antibodies directed against human CD 19 kill Raji B cell tumor cells.
- Figure 28 shows a Kaplan-Meier plot of mouse survival in a Ramos systemic model.
- Figure 29A-B shows the body weight change in mice in a Ramos systemic model.
- Figure 30A-B shows the results of an in vivo mouse tumor model study demonstrating that treatment with naked anti-CD 19 antibody 21D4 has a direct inhibitory effect on lymphoma tumors in vivo.
- A ARH-77 tumors
- B Raji tumors.
- Figure 31 shows the results of an antibody dependent cellular cytotoxicity (ADCC) assay demonstrating that nonfucosylated human monoclonal anti-CD 19 antibodies have increased cell cytotoxicity on human leukemia cells in an ADCC dependent manner.
- ADCC antibody dependent cellular cytotoxicity
- Figure 32 shows the results of an in vivo mouse tumor model study demonstrating that cytotoxin-conjugated anti-CD19 antibodies reduce tumor volume.
- Toxin 1 is cytotoxin Nl and toxin 2 is cytotoxin N2.
- Figure 33 shows the body weight change in mice in a Raji tumor model study. Toxin 1 is cytotoxin Nl and toxin 2 is cytotoxin N2.
- Figure 34 shows the results of a cynomolgus monkey study showing a decreased population of CD20+ cells following treatment of iucosylated or nonfucosylated anti- CD 19 HuMAbS.
- Figure 35 shows the results of individual cynomolgus monkeys following treatment with fucosylated or nonfucosylated anti-CD 19 HuMAbs.
- Figure 36A-C shows the results of a thymidine incoiporation assay demonstrating that human monoclonal antibodies directed against human CD 19 alone or cytotoxin- conjugated kill Raji and SU-DHL-6 B cell tumor cells.
- Figure 37 shows the in vivo efficacy of immunoconjugate anti-CD 19-N2 against tumor formation in a subcutaneous xenograft SCID mouse model.
- Figure 38 shows the in vivo efficacy of immunoconjugate anti-CD 19-N2 against tumor formation in a subcutaneous Burkitt's lymphoma SCID mouse model.
- Figure 39 shows the in vivo efficacy of immunoconjugate anti-CD 19-N2 against tumor formation in a systemic SCID mouse model.
- Figure 4OA shows that B cells (CD20 + ) were decreased in a dose-dependent manner after administration of 21D4 with minimal or no depletion at 0.01 mg/kg. B cells decreased to 16% to 32% of baseline after administration of 0.1 mg/kg.
- Figure 4OB illustrates that the magnitude and length of B-cell depletion after administration of 21D4 was similar to that of a 0.1 mg/kg injection of rituximab.
- Figure 41 shows the in vivo efficacy of a single dose of anti-CD 19-cytotoxin A against tumor formation in a Raji xenograft SCID mouse model.
- Figure 42 shows the in vivo efficacy of a single dose of anti-CD 19-cytotoxin A against tumor formation in a Raji xenograft SClD mouse model, including an isotype control.
- Figure 43 shows the in vivo efficacy of a single dose and repeat doses of anti- CD 19-cytotoxin A against tumor formation in a Ramos xenograft Es l e nude mouse model.
- Figure 44 shows the in vivo efficacy of a single dose of anti-CD 19-cytotoxin A against tumor formation in a Daudi xenograft SCID mouse model.
- Figure 45 shows the in vivo efficacy of a single dose of anti-CD 19-N2 against tumor formation in a SU-DHL6 xenograft SClD mouse model.
- N2 cytotoxin B.
- Figure 46 is the structure of cytotoxin A.
- the present disclosure relates to isolated monoclonal antibodies, particularly human monoclonal antibodies which bind specifically to human' CD 19 with high affinity and that have desirable functional properties.
- the antibodies of this disclosure are derived from particular heavy and light chain germline sequences and/or comprise particular structural features such as CDR regions comprising particular amino acid sequences.
- This disclosure provides isolated antibodies, methods of making such antibodies, antibody-partner molecule conjugates, and bispecific molecules comprising such antibodies and pharmaceutical compositions containing the antibodies, antibody-partner molecule conjugates or bispecific molecules of this disclosure.
- This disclosure also relates to methods of using the antibodies, such as to detect CD 19, as well as to treat diseases associated with expression of CD19, such as B cell malignancies that express CD 19.
- this disclosure also provides methods of using the anti- CD 19 antibodies and antibody-partner molecule conjugates of this disclosure to treat B cell malignancies, for example, in the treatment of non-Hodgkin " s lymphoma, chronic lymphocytic leukemias, follicular lymphomas, diffuse large cell lymphomas of B lineage, and multiple myelomas.
- CD 19 refers to, for example, variants, iso forms, homologs, orthologs and paralogs of human CD 19. Accordingly, human antibodies of this disclosure may, in certain cases, cross-react with CD 19 from species other than human. In certain embodiments, the antibodies may be completely specific for one or more human CD 19 proteins and may not exhibit species or other types of non-human cross-reactivity, or may cross-react with CD 19 from certain other species but not all other species (e.g., cross-react with a primate CD 19 but not mouse CD 19).
- human CD 19 refers to human sequence CD 19, such as the complete amino acid sequence of human CD 19 having Genbank Accession Number NM_001770 (SEQ ID NO: 79).
- mouse CD 19 refers to mouse sequence CD 19, such as the complete amino acid sequence of mouse CD 19 having Genbank Accession Number AAA37390.
- the human CD 19 sequence may differ from human CD 19 of Genbank Accession Number NM_001770 by having, for example, conserved mutations or mutations in non- conserved regions and the CD 19 has substantially the same biological function as the human CD 19 of Genbank Accession Number NMJ301770.
- a particular human CD 19 sequence will generally be at least 90% identical in amino acids sequence to human CD 19 of Genbank Accession Number NIvIJ)01770 and contains amino acid residues that identify the amino acid sequence as being human when compared to CD 19 amino acid sequences of other species (e.g., murine).
- a human CD 19 may be at least 95%, or even at least 96%, 97%, 98%, or 99% identical in amino acid sequence to CD 19 of Genbank Accession Number NM_001770.
- a human CD 19 sequence will display no more than 10 amino acid differences from the CD 19 sequence of Genbank Accession Number NM_001770.
- the human CD 19 may display no more than 5, or even no more than 4, 3, 2, or 1 amino acid difference from the CD 19 sequence of Genbank Accession Number NMJ301770. Percent identity can be determined as described herein.
- immune response refers to the action of, for example, lymphocytes, antigen presenting cells, phagocytic cells, granulocytes, and soluble macromolecules produced by the above cells or the liver (including antibodies, cytokines, and complement) that results in selective damage to, destruction of, or elimination from the human body of invading pathogens, cells or tissues infected with pathogens, cancerous cells, or, in cases of autoimmunity or pathological inflammation, normal human cells or tissues.
- a “signal transduction pathway” refers to the biochemical relationship between a variety of signal transduction molecules that play a role in the transmission of a signal from one portion of a cell to another portion of a cell.
- the phrase “cell surface receptor” includes, for example, molecules and complexes of molecules capable of receiving a signal and the transmission of such a signal across the plasma membrane of
- a cell An example of a "cell surface receptor" of the present disclosure is the CD 19 receptor.
- antibody' * as referred to herein includes whole antibodies and any antigen binding fragment (i.e., "antigen-binding portion") or single chains thereof.
- An “antibody” refers to a glycoprotein comprising at least two heavy (H) chains and two light (L) chains inter-connected by disulfide bonds, or an antigen binding portion thereof.
- Each heavy chain is comprised of a heavy chain variable region (abbreviated herein as V H ) and a heavy chain constant region.
- the heavy chain constant region is comprised of three domains, C H I , C H 2 and C H 3.
- Each light chain is comprised of a light chain variable region (abbreviated herein as V L ) and a light chain constant region.
- the light chain constant region is comprised of one domain, C L .
- the V H and V L regions can be further subdivided into regions of hypervariability, termed complementarity determining regions (CDR), interspersed with regions that are more conserved, termed framework regions (FR).
- CDR complementarity determining regions
- FR framework regions
- Each V H and V L is composed of three CDRs and four FRs, arranged from amino- terminus to carboxy-te ⁇ ninus in the following order: FRl, CDRl, FR2, CDR2, FR3,
- variable regions of the heavy and light chains contain a binding domain that interacts with an antigen.
- the constant regions of the antibodies may mediate the binding of the immunoglobulin to host tissues or factors, including various cells of the immune system (e.g., effector cells) and the first component (CIq) of the classical complement system.
- antibody fragment ' ' and "antigen-binding portion" of an antibody refer to one or more fragments of an antibody that retain the ability to specifically bind to an antigen (eg., CD 19). It has been shown that the antigen-binding function of an antibody can be performed by fragments of a full- length antibody.
- binding fragments encompassed within the term "antigen- binding portion" of an antibody include (i) a Fab fragment, a monovalent fragment consisting of the V L , VH, C 1 and C H I domains; (ii) a F(ab')2 fragment, a bivalent fragment comprising two Fab fragments linked by a disulfide bridge at the hinge region; (iii) a Fab 1 fragment, which is essentially an Fab with part of the hinge region (see, FUNDAMENTAL IMMUNOLOGY, Paul ed., 3rd ed. 1993); (iv) a Fd fragment consisting of the V H and Ci
- -21- domains of a single arm of an antibody (vi) a dAb fragment (Ward et al., (1989) Nature 341:544-546), which consists of a V n domain; (vii) an isolated complementarity determining region (CDR); and (viii) a nanobody, a heavy chain variable region containing a single variable domain and two constant domains.
- a dAb fragment Ward et al., (1989) Nature 341:544-546
- CDR complementarity determining region
- nanobody a heavy chain variable region containing a single variable domain and two constant domains.
- the two domains of the Fv fragment, V 1 and Vn are coded for by separate genes, they can be joined, using recombinant methods, by a synthetic linker that enables them to be made as a single protein chain in which the V L and V H regions pair to form monovalent molecules (known as single chain Fv (scFv); see e.g., Bird et al. (1988) Science 242:423- 426; and Huston et al. (1988) Proc. Natl. Acad. ScL USA 85:5879-5883).
- single chain Fv single chain Fv
- Such single chain antibodies are also intended to be encompassed within the term "antigen-binding portion" of an antibody.
- an "isolated antibody”, as used herein, is intended to refer to an antibody that is substantially free of other antibodies having different antigenic specificities (e.g., an isolated antibody that specifically binds CD 19 is substantially free of antibodies that specifically bind antigens other than CD 19).
- An isolated antibody that specifically binds CD 19 may, however, have cross-reactivity to other antigens, such as CD 19 molecules from other species.
- an isolated antibody may be substantially free of other cellular material and/or chemicals.
- the terms “monoclonal antibody” or “monoclonal antibody composition” as used herein refer to a preparation of antibody molecules of single molecular composition.
- a monoclonal antibody composition displays a single binding specificity and affinity for a particular epitope.
- the term "human antibody”, as used herein, is intended to include antibodies having variable regions in which both the framework and CDR regions are derived from human germline immunoglobulin sequences. Furthermore, if the antibody contains a constant region, the constant region also is derived from human germline immunoglobulin sequences.
- the human antibodies of this disclosure may include amino acid residues not encoded by human germline immunoglobulin sequences (e.g., mutations introduced by random or site-specific mutagenesis in vitro or by somatic mutation in vivo).
- the tenn "human antibody”, as used herein, is not intended to include antibodies in which CDR sequences derived from the germline of another mammalian species, such as a mouse, have been grafted onto human framework sequences.
- the tenn "human monoclonal antibody” refers to antibodies displaying a single binding specificity which have variable regions in which both the framework and CDR regions are derived from human germline immunoglobulin sequences.
- the human monoclonal antibodies are produced by a hybridoma which includes a B cell obtained from a transgenic nonhuman animal, e.g., a transgenic mouse, having a genome comprising a human heavy chain transgene and a light chain transgene fused to an immortalized cell.
- recombinant human antibody includes all human antibodies that are prepared, expressed, created or isolated by recombinant means, such as (a) antibodies isolated from an animal ⁇ e.g., a mouse) that is transgenic or transchromosomal for human immunoglobulin genes or a hybridoma prepared therefrom (described further below), (b) antibodies isolated from a host cell transformed to express the human antibody, e.g., from a transfectoma, (c) antibodies isolated from a recombinant, combinatorial human antibody library, and (d) antibodies prepared, expressed, created or isolated by any other means that involve splicing of human immunoglobulin gene sequences to other DNA sequences.
- recombinant means such as (a) antibodies isolated from an animal ⁇ e.g., a mouse) that is transgenic or transchromosomal for human immunoglobulin genes or a hybridoma prepared therefrom (described further below), (b) antibodies isolated from a host cell transformed to express the human antibody, e.
- Such recombinant human antibodies have variable regions in which the framework and CDR regions are derived from human germline immunoglobulin sequences.
- such recombinant human antibodies can be subjected to in vitro mutagenesis (or, when an animal transgenic for human Ig sequences is used, in vivo somatic mutagenesis) and thus the amino acid sequences of the V H and V ( regions of the recombinant antibodies are sequences that, while derived from and related to human germline V H and Vi sequences, may not naturally exist within the human antibody germline repertoire in vivo.
- isotype refers to the antibody class (e.g., IgM or IgGl) that is encoded by the heavy chain constant region genes.
- the phrases “an antibody recognizing an antigen” and “an antibody specific for an antigen” are used interchangeably herein with the term “an antibody which binds specifically to an antigen.”
- human antibody derivatives refers to any modified form of the human antibody, e.g., a conjugate of the antibody and another agent or antibody.
- humanized antibody is intended to refer to antibodies in which CDR sequences derived from the germline of another mammalian species, such as a mouse, have been grafted onto human framework sequences. Additional framework region modifications may be made within the human framework sequences.
- chimeric antibody is intended to refer to antibodies in which the variable region sequences are derived from one species and the constant region sequences are derived from another species, such as an antibody in which the variable region sequences are derived from a mouse antibody and the constant region sequences are derived from a human antibody.
- antibody mimetic is intended to refer to molecules capable of mimicking an antibody's ability to bind an antigen, but which are not limited to native antibody structures.
- antibody mimetics include, but are not limited to, Aff ⁇ bodies, DARPins, Anticalins, Avimers, and Versabodies, all of which employ binding structures that, while they mimic traditional antibody binding, are generated from and function via distinct mechanisms.
- partner molecule refers to the entity which is conjugated to an antibody in an antibody-partner molecule conjugate.
- partner molecules include drags, cytotoxins, marker molecules (including, but not limited to peptide and small molecule markers such as fluorochrome markers, as well as single atom markers such as radioisotopes), proteins and therapeutic agents.
- an antibody that "specifically binds to human CD 19" is intended to refer to an antibody that binds to human CD 19 with a K D of I x 10 "7 M or less, more preferably 5 x 1O *8 M or less, more preferably 3 x 10 s M or less, more preferably 1 x 1(T 8 M or less, even more preferably 5 x 10 "9 M or less.
- the term "does not substantially bind" to a protein or cells means does not bind or does not bind with a high affinity to the protein or cells, i.e.
- K assoc or "K a ", as used herein, is intended to refer to the association rate of a particular antibody-antigen interaction
- K dis or "'K d ,” as used herein, is intended to refer to the dissociation rate of a particular antibody- antigen interaction
- 'K D is intended to refer to the dissociation constant, which is obtained from the ratio of K d to K a (i.e., K d /K a ) and is expressed as a molar concentration (M).
- K D values for antibodies can be determined using methods well established in the art.
- a preferred method for determining the KQ of an antibody is by using surface plasmon resonance, preferably using a biosensor system such as a Biacore" system.
- the term ''high affinity" for an IgG antibody refers to an antibody having a Kp of 1 x 10 "7 M or less, more preferably 5 x 10 "8 M or less and even more preferably 1 x 10 "9 M or less and even more preferably 5 x 10 "9 M or less for a target antigen.
- ''high affinity” binding can vary for other antibody isotypes.
- "high affinity” binding for an IgM isotype refers to an antibody having a K D of 10 "6 M or less, more preferably 10 "7 M or less, even more preferably 10 s M or less.
- the term “subject” includes any human or nonhuman animal.
- nonhuman animal includes all vertebrates, e.g., mammals and non-mammals, such as nonhuman primates, sheep, dogs, cats, horses, cows, chickens, amphibians, reptiles, etc.
- alkyl by itself or as part of another substituent, means, unless otherwise stated, a straight or branched chain, or cyclic hydrocarbon radical, or combination thereof, which may be fully saturated, mono- or polyunsaturated and can include di- and multivalent radicals, having the number of carbon atoms designated (i.e., C
- saturated hydrocarbon radicals include, but are not limited to, groups such as methyl, ethyl, n-propyl, isopropyl.
- An unsaturated alkyl group is one having one or more double bonds or triple bonds.
- alkyl groups examples include, but are not limited to, vinyl, 2-propenyl, crotyl, 2-isopentenyl, 2-(butadienyl), 2,4-pentadienyl, 3-(l,4-pentadienyl). ethynyl, 1- and 3-propynyl, 3-butynyl, and the higher homologs and isomers.
- alkyl unless otherwise noted, is also meant to include those derivatives of alkyl defined in more detail below, such as “heteroalkyl.”
- Alkyl groups, which are limited to hydrocarbon groups are termed "homoalkyl".
- alkylene by itself or as part of another substituent means a divalent radical derived from an alkane, as exemplified, but not limited, by -CHiCH 2 CH 2 CH?-, and further includes those groups described below as “heteroalkylene.”
- an alkyl (or alkylene) group will have from 1 to 24 carbon atoms, with those groups ha ⁇ ing 10 or fewer carbon atoms being preferred in the present invention.
- a '"lower alkyl” or “lower alkylene” is a shorter chain alkyl or alkylene group, generally having eight or fewer carbon atoms.
- heteroalkyl by itself or in combination with another term, means, unless otherwise stated, a stable straight or branched chain, or cyclic hydrocarbon radical, or combinations thereof, consisting of the stated number of carbon atoms and at least one heteroatom selected from the group consisting of O, N, Si, and S, and wherein the nitrogen, carbon and sulfur atoms may optionally be oxidized and the nitrogen heteroatom may optionally be quaternized.
- the heteroatom(s) O, N, S, and Si may be placed at any interior position of the heteroalkyl group or at the position at which the alkyl group is attached to the remainder of the molecule.
- heteroalkylene by itself or as part of another substituent means a divalent radical derived from heteroalkyl, as exemplified, but not limited by, -CH2-CH2-S-CH2-CH2- and --CH 2 -S-CH 2 -CH 2 -NH-CH 2 -.
- heteroatoms can also occupy either or both of the chain termini (e.g., alkyleneoxy, alkylenedioxy, alkyleneamino, alkylenediamino, and the like).
- heteroalkyl and “heteroalkylene” encompass poly(ethylene glycol) and its derivatives (see, for example, Shearwater Polymers Catalog, 2001). Still further, for alkylene and heteroalkylene linking groups, no orientation of the linking group is implied by the direction in which the formula of the linking group is written. For example, the formula -C(O) 2 R * - represents both -C(O) 2 R'- and -R 1 C(O) 2 -.
- lower in combination with the terms “alkyl” or “heteroalkyl " refers to a moiety having from 1 to 6 carbon atoms.
- alkylamino alkylsulfonyl
- alkylthio or thioalkoxy
- arylsulfonyl refers to an aryl group attached to the remainder of the molecule via an SO 2 group
- sulfhydryl refers to an SH group.
- an "acyl substituent" is also selected from the group set forth above.
- acyl substituent refers to groups attached to, and fulfilling the valence of a carbonyl carbon that is either directly or indirectly attached to the polycyclic nucleus of the compounds of the present invention.
- cycloalkyl and “heterocycloalkyl”, by themselves or in combination with other terms, represent, unless otherwise stated, cyclic versions of substituted or unsubstituted “alkyl” and substituted or unsubstituted “heteroalkyl”, respectively. Additionally, for heterocycloalkyl, a heteroatom can occupy the position at which the heterocycle is attached to the remainder of the molecule. Examples of cycloalkyl include, but are not limited to, cyclopentyl, cyclohexyl, 1-cyclohexenyl, 3-cyclohexenyl, cycloheptyl, and the like.
- heterocycloalkyl examples include, but are not limited to, 1 -(1,2,5,6-tetrahydropyridyl), 1-piperidinyl, 2-piperidinyl, 3-piperidinyl, 4-morpholinyl, 3-morpholinyl, tetrahydrofuran-2-yl, tetrahydrofuran-3-yl, tetrahydrothien-2-yl, tetrahydrothien-3-yl, 1 -piperazinyl, 2-piperazinyl, and the like.
- the heteroatoms and carbon atoms of the cyclic structures are optionally oxidized.
- halo or halogen
- haloalkyl by themselves or as part of another substituent, mean, unless otherwise stated, a fluorine, chlorine, bromine, or iodine atom.
- terms such as “haloalkyl,” are meant to include monohaloalkyl and polyhaloalkyl.
- 'halo(Ci-C 4 )alkyr is meant to include, but not be limited to, trifluoromethyl, 2,2,2-trifluor ⁇ ethyl, 4-chlorobutyl, 3-bromopropyl, and the like.
- aryl means, unless otherwise stated, a substituted or unsubstituted polyunsaturated, aromatic, hydrocarbon substituent which can be a single ring or multiple rings (preferably from 1 to 3 rings) which are fused together or linked covalently.
- heteroaryl refers to aryl groups (or rings) that contain from one to four heteroatoms selected from N, O, and S, wherein the nitrogen, carbon and sulfur atoms are optionally oxidized, and the nitrogen atom(s) are optionally quatemized.
- a heteroaryl group can be attached to the remainder of the molecule through a heteroatom.
- Non- limiting examples of aryl and heteroaryl groups include phenyl, 1-naphthyl, 2-naphthyl, 4-biphenyl, 1-pyrrolyl, 2-pyrrolyl, 3-pyrrolyl, 3-pyrazolyl, 2-imidazolyl, 4-imidazolyl, pyrazinyl, 2-oxazolyl, 4-oxazolyl, 2-phenyl-4-oxazolyl, 5-oxazolyl, 3-isoxazolyl, A- isoxazolyl, 5-isoxazolyl, 2-thiazolyl, 4-thiazolyl, 5-thiazolyl, 2-furyl, 3-furyl, 2-thienyl, 3-thienyl, 2-pyridyl, 3-pyridyl, 4-pyridyl, 2-pyrimidyl, 4-pyrimidyl, 5-benzothiazolyl, purinyl, 2-benzimidazolyl, 5-indolyl, 1-iso
- aryl and heteroaryl ring systems are selected from the group of acceptable substituents described below.
- Aryl and “heteroaryl” also encompass ring systems in which one or more non-aromatic ring systems are fused, or otherwise bound, to an aryl or heteroaryl system.
- aryF when used in combination with other terms (e.g., aryloxy, arylthioxy, arylalkyl) includes both aryl and heteroaryl rings as defined above.
- arylalkyP is meant to include those radicals in which an aryl group is attached to an alkyl group (e.g., benzyl, phenethyl, pyridylmethyl and the like) including those alkyl groups in which a carbon atom (e.g., a methylene group) has been replaced by, for example, an oxygen atom (e.g., phenoxymethyl, 2-pyridyloxymethyl, 3-(l- naphthyloxy)propyl, and the like).
- alkyl group e.g., benzyl, phenethyl, pyridylmethyl and the like
- oxygen atom e.g., phenoxymethyl, 2-pyridyloxymethyl, 3-(l- naphthyloxy)
- R', R", R"' * and R" each preferably independently refer to hydrogen, substituted or unsubstituted heteroalkyl, substituted or unsubstituted aryl, e.g., aryl substituted with 1-3 halogens, substituted or unsubstituted alkyl, alkoxy or thioalkoxy groups, or arylalkyl groups.
- each of the R groups is independently selected as are each R ⁇ R", R 1 " and R'"' groups when more than one of these groups is present.
- R' and R" are attached to the same nitrogen atom, they can be combined with the nitrogen atom to form a 5, 6, or 7-membered ring.
- -NR'R is meant to include, but not be limited to, l ⁇ pyrrolidinyl and 4- morpholinyl.
- alkyl is meant to include groups including carbon atoms bound to groups other than hydrogen groups, such as haloalkyl (e.g., -CF 3 and -CH 2 CF 3 ) and acyl (e.g., -C(O)CH 3 , -C(O)CF 3 , -C(O)CH 2 OCH 3 , and the like).
- -NR-C(NR " R") NR'",.-S(O)R ⁇ -S(O) 2 R 5 , -S(O) 2 NR 5 R", -NRSO 2 R', -CN and -NO 2 , - R', -Nj, -CH(Ph)O, fluoro(C r C 4 )alkoxy, and fluoro(C
- R group for example
- Two of the aryl substituents on adjacent atoms of the aryl or heteroaryl ring may optionally be replaced with a substituent of the formula -T-C(O)-(CRR' ) q - U-, wherein T and U are independently -NR-, -O-, -CRR'- or a single bond, and q is an integer of from 0 to 3.
- two of the substituents on adjacent atoms of the aryl or heteroaryl ring may optionally be replaced with a substituent of the formula -A-(CHo) 1 -B-, wherein A and B are independently -CRR'-, -O-, -NR-, -S-, -S(O)-, -S(O) 2 -, -S(O) 2 NR 1 - or a single bond, and r is an integer of from 1 to 4.
- One of the single bonds of the new ring so formed may optionally be replaced with a double bond.
- two of the substituents on adjacent atoms of the aryl or heteroaryl ring may optionally be replaced with a substituent of the formula -(CRR') s -X-(CR"R “ ")d-, where s and d are independently integers of from 0 to 3, and X is -O-, -NR'-, -S-, -S(O)-, -S(O) 2 -, or -- S(O) 2 NR'-.
- the substituents R, R', R" and R"" are preferably independently selected from hydrogen or substituted or unsubstituted (Ci-C 6 ) alkyl.
- diphosphate includes but is not limited to an ester of phosphoric acid containing two phosphate groups.
- triphosphate includes but is not limited to an ester of phosphoric acid containing three phosphate groups.
- drugs having a diphosphate or a triphosphate include:
- heteroatom includes oxygen (O), nitrogen (N), sulfur (S) and silicon (Si).
- R is a general abbreviation that represents a substituent group that is selected from substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl, and substituted or unsubstituted heterocyclyl groups.
- the antibodies of this disclosure are characterized by particular functional features or properties of the antibodies.
- the antibodies specifically bind to human CD 19.
- an antibody of this disclosure binds to CD 19 with high affinity, for example with a K D of 1 x 10 " M or less.
- the anti-CD 19 antibodies of this disclosure preferably exhibit one or more of the following characteristics:
- the antibody exhibits at least two of properties (a), (b), (c), (d), and (e). More preferably, the antibody exhibits at least three of properties (a), (b), (c), (d), and (e). More preferably, the antibody exhibits four of properties (a), (b), (c), (d), and (e). Even, more preferably, the antibody exhibits all five of properties (a), (b), (c), (d), and (e). In another preferred embodiment, the antibody inhibits growth of CD 19- expressing tumor cells in vivo when the antibody is conjugated to a cytotoxin.
- the antibody binds to human CD 19 with a K D of 5 x 10 s M or less, binds to human CD 19 with a K 0 of 1 x 10 "8 M or less, binds to human CD 19 with a K D of 5 x 10 "9 M or less, binds to human CD 19 with a K D of 4 X 10 "9 M or less, binds to human CD 19 with a K D of 3 x 10 "9 M or less, or binds to human CD 19 with a Kp of 2 x 10 "9 M or less, or binds to human CD 19 with a K D of 1 x l ⁇ " ⁇ M or less.
- an antibody of the invention can be assessed using one or more techniques well established in the art.
- an antibody can be tested by a flow cytometry assay in which the antibody is reacted with a cell line that expresses human CD 19, such as CHO cells that have been transfected to express CD 19 on their cell surface or CD19-expressing cell lines such as OVCAR3, NCI- H226, CFPAC-I and/or KB (see, e.g., Example 3 A for a suitable assay and further description of cell lines).
- the binding of the antibody can be tested in BIAcore binding assays (see , e.g., Example 3B for suitable assays).
- BIAcore binding assays see , e.g., Example 3B for suitable assays.
- Still other suitable binding assays include ELISA assays, for example using a recombinant CD 19 protein see, e.g., Example 1 for a suitable assay).
- an antibody of this disclosure binds to a CD 19 protein with a KD of 5 x 10-8 M or less, binds to a CD 19 protein with a KD of 3 x 10-8 M or less, binds to a
- CD 19 protein with a KD of 1 x 10-8 M or less binds to a CD 19 protein with a KD of 7 x 10-9 M or less, binds to a CD 19 protein with a KD of 6 x 10-9 M or less or binds to a CD 19 protein with a KD of 5 x 10-9 M or less.
- the binding affinity of the antibody for CD 19 can be evaluated, for example, by standard BIACORE analysis, (see e.g., Example 3B).
- Standard assays for evaluating internalization of anti-CD 19 antibodies by CD 19- expressing cells are known in the art (see e.g., the Hum-ZAP and immunofluorescence assays described in Example 5).
- Standard assays for evaluating binding of CD 19 to CAl 25, and inhibition thereof by anti-CD 19 antibodies also are known in the art (see e.g., the OVCAR3 cell adhesion assay described in Example 6).
- Standard assays for evaluating ADCC against CD19-expressing cells also are known in the art (see e.g., the ADCC assay described in Example 7).
- Preferred antibodies of the invention are human monoclonal antibodies. Additionally or alternatively, the antibodies can be, for example, chimeric or humanized monoclonal antibodies.
- Preferred antibodies of this disclosure are the human monoclonal antibodies 21D4, 2lD4a, 47G4, 27F3, 3ClO, 5G7, 13Fl and 46E8, isolated and structurally characterized as described in Examples 16, 17, 18, 19, 20, 21 and 22.
- the Vn amino acid sequences of 21D4, 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl and 46E8 are shown in SEQ ID NOs: 1, 1, 2, 3, 4, 5, 6 and 7, respectively.
- 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl and 46E8 are shown in SEQ ID NOs: 8, 9, 10, 1 1, 12, 13, 14 and 15, respectively.
- sequences can be "mixed and matched" to create other anti-CD 19 binding molecules of this disclosure.
- CD 19 binding of such "mixed and matched” antibodies can be tested using the binding assays described above and in the Examples (e.g., ELISAs).
- a V H sequence from a particular Vn/V ⁇ pairing is replaced with a structurally similar V H sequence.
- a V 1 sequence from a particular V 5 /V L pairing is replaced with a structurally similar V L sequence.
- this disclosure provides an isolated monoclonal antibody, or antigen binding portion thereof comprising:
- a heavy chain variable region comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 1, 2, 3, 4, 5, 6 and 7; and (b) a light chain variable region comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 8, 9, 10, 1 1, 12, 13, 14 and 15; wherein the antibody specifically binds CD 19, preferably human CD 19.
- Preferred heavy and light chain combinations include:
- this disclosure provides antibodies that comprise the heavy chain and light chain CDRIs, CDR2s and CDR3s of 21D4, 21D4a, 47G4, 27F3, 3ClO, 5G7, 13Fl and 46E8, or combinations thereof.
- the amino acid sequences of the V H CDRIs of 21D4, 21D4a, 47G4, 27F3, 3ClO, 5G7, 13Fl and 46E8 are shown in SEQ ID NOs: 16, 17, 18, 19, 20, 21 and 22.
- the amino acid sequences of the V H CDR2s of 21D4, 21D4a, 47G4, 27F3, 3ClO, 5G7, 13Fl and 46E8 are shown in SEQ ID NOs: 23, 24, 25, 26, 27, 28 and 29.
- amino acid sequences of the Vn CDR3s of 21D4, 21D4a, 47G4, 27F3, 3ClO, 5G7, 13Fl and 46E8 are shown in SEQ ID NOs: 30, 31, 32, 33, 34, 35 and 36.
- amino acid sequences of the V k CDRIs of 21D4, 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl and 46E8 are shown in SEQ ID NOs: 37, 38, 39, 40, 41, 42 and 43.
- the amino acid sequences of the V k CDR2s of 21 D4, 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl and 46E8 are shown in SEQ ID NOs: 44, 45, 46, 47, 48, 49 and 50.
- the amino acid sequences of the V k CDR3s of 21D4, 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl and 46E8 are shown in SEQ ID NOs: 51, 52, 53, 54, 55, 56, 57 and 58.
- the CDR regions are delineated using the Kabat system (Kabat, E. A., et ai (1991) Sequences of Proteins of Immunological Interest, Fifth Edition, U.S. Department of Health and Human Services, NIH Publication No. 91-3242).
- Vn CDRl, CDR2, and CDR3 sequences and V k CDRl, CDR2, and CDR3 sequences can be "mixed and matched" ⁇ i.e., CDRs from different antibodies can be mixed and match, although each antibody must contain a V H CDRl, CDR2, and CDR3 and a V k CDRl, CDR2, and CDR3) to create other anti-CD 19 binding molecules of this disclosure.
- CD 19 binding of such "mixed and matched" antibodies can be tested using the binding assays described above and in the Examples ⁇ e.g., ELISAs, Biacore* analysis).
- V H CDR sequences are mixed and matched
- the CDR 1 , CDR2 and/or CDR3 sequence from a particular V H sequence is replaced with a structurally similar CDR sequence(s).
- V k CDR sequences are mixed and matched
- the CDRl, CDR2 and/or CDR3 sequence from a particular V ⁇ sequence preferably is replaced with a structurally similar CDR sequence(s).
- this disclosure provides an isolated monoclonal antibody, or antigen binding portion thereof comprising:
- a heavy chain variable region CDRl comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 16, 17, 18, 19, 20, 21 and 22;
- a heavy chain variable region CDR2 comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 23, 24, 25, 26, 27, 28 and 29
- a heavy chain variable region CDR3 comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 30, 31, 32, 33, 34, 35 and 36;
- a light chain variable region CDRl comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 37, 38, 39, 40, 41, 42 and 43;
- a light chain variable region CDR2 comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 44, 45, 46, 47, 48, 49 and 50;
- a light chain variable region CDR3 comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 51, 52, 53, 54, 55, 56, 57 and 58; wherein the antibody specifically binds CD 19, preferably human CD 19.
- the antibody comprises:
- the antibody comprises:
- the antibody comprises: (a) a heavy chain variable region CDRl comprising SEQ ID NO: 17;
- the antibody comprises: (a) a heavy chain variable region CDR 1 comprising SEQ ID NO: 18;
- the antibody comprises:
- the antibody comprises: (a) a heavy chain variable region CDR 1 comprising SEQ ID NO: 20;
- the antibody comprises:
- the antibody comprises:
- the CDR3 domain independently from the CDRl and/or CDR2 domain(s), alone can determine the binding specificity of an antibody for a cognate antigen and that multiple antibodies can predictably be generated having the same binding specificity based on a common CDR3 sequence. See, for example, Klimka et al., British J. of Cancer 83(2):252-260 (2000) (describing the production of a humanized anti-CD30 antibody using only the heavy chain variable domain CDR3 of murine anti-CD30 antibody Ki-4); Beiboer et al, J. MoL Biol.
- Biochem (Tokyo) 117:452-7 (1995) (describing a 12 amino acid synthetic polypeptide corresponding to the CDR3 domain of an anti-phosphatidylserine antibody); Bourgeois et al, J. Virol 72:807- 10 (1998) (showing that a single peptide derived from the heavy chain CDR3 domain of an anti-respiratory syncytial virus (RSV) antibody was capable of neutralizing the virus in vitro); Levi et uL, Proc. Natl. Acad. Sci. U.S.A. 90:4374-8 (1993) (describing a peptide based on the heavy chain CDR3 domain of a murine anti-HIV antibody); Polymenis and Stoller, J.
- RSV anti-respiratory syncytial virus
- the present disclosure provides monoclonal antibodies comprising one or more heavy and/or light chain CDR3 domains from an antibody derived from a human or non-human animal, wherein the monoclonal antibody is capable of specifically binding to CD 19.
- the present disclosure provides monoclonal antibodies comprising one or more heavy and/or light chain CDR3 domain from a non- human antibody, such as a mouse or rat antibody, wherein the monoclonal antibody is capable of specifically binding to CD 19.
- inventive antibodies comprising one or more heavy and/or light chain CDR3 domain from a non- human antibody (a) are capable of competing for binding with; (b) retain the functional characteristics; (c) bind to the same epitope; and/or (d) have a similar binding affinity as the corresponding parental non-human antibody.
- the present disclosure provides monoclonal antibodies comprising one or more heavy and/or light chain CDR3 domain from a human antibody, such as, for example, a human antibody obtained from a non-human animal, wherein the human antibody is capable of specifically binding to CD 19.
- a human antibody such as, for example, a human antibody obtained from a non-human animal
- the present disclosure provides monoclonal antibodies comprising one or more heavy and/or light chain CDR3 domain from a first human antibody, such as, for example, a human antibody obtained from a non-human animal, wherein the first human antibody is capable of specifically binding to CD 19 and wherein the CDR3 domain from the first human antibody replaces a CDR3 domain in a human antibody that is lacking binding specificity for CD 19 to generate a second human antibody that is capable of specifically binding to CD 19.
- inventive antibodies comprising one or more heavy and/or light chain CDR3 domain from the first human antibody (a) are capable of competing for binding with; (b) retain the functional characteristics; (c) bind to the same epitope: and/or (d) have a similar binding affinity as the corresponding parental first human antibody.
- an antibody of this disclosure comprises a heavy chain variable region from a particular germline heavy chain immunoglobulin gene and/or a light chain variable region from a particular germline light chain immunoglobulin gene.
- this disclosure provides an isolated monoclonal antibody, or an antigen-binding portion thereof, comprising a heavy chain variable region that is the product of or derived from a human V H 5-51 gene, wherein the antibody specifically binds CD 19.
- this disclosure provides an isolated monoclonal antibody, or an antigen-binding portion thereof, comprising a heavy chain variable region that is the product of or derived from a human V H 1-69 gene, wherein the antibody specifically binds CD 19.
- this disclosure provides an isolated monoclonal antibody, or an antigen- binding portion thereof, comprising a light chain variable region that is the product of or derived from a human V K Ll 8 gene, wherein the antibody specifically binds CD 19.
- this disclosure provides an isolated monoclonal antibody, or an antigen-binding portion thereof, comprising a light chain variable region that is the product of or derived from a human V K A27 gene, wherein the antibody specifically binds CD 19.
- this disclosure provides an isolated monoclonal antibody, or an antigen-binding portion thereof, comprising a light chain variable region that is the product of or derived from a human V K Ll 5 gene, wherein the antibody specifically binds CD 19.
- this disclosure provides an isolated monoclonal antibody, or antigen-binding portion thereof, wherein the antibody: (a) comprises a heavy chain variable region that is the product of or derived from a human Vn 5-51 or 1-69 gene (which genes encode the amino acid sequences set forth in SEQ ID NOs: 74 and 75, respectively);
- (b) comprises a light chain variable region that is the product of or derived from a human V K L 18, V ⁇ A27 or V ⁇ Ll 5 gene (which genes encode the amino acid sequences set forth in SEQ ID NOs: 76, 77 and 78, respectively); and
- (c) specifically binds to CD 19, preferably human CD 19.
- Such antibodies also may possess one or more of the functional characteristics described in detail above, such as high affinity binding to human CD 19, internalization by CD 19-expressing cells, the ability to mediate ADCC against CD 19-expressing cells and/or the ability to inhibit tumor growth of CDl 9-expressing tumor cells in vivo when conjugated to a cytotoxin.
- Examples of antibodies having V H and V ⁇ of V H 5-51 and V K L18, respectively. are 21D4, 21D4a, 27F3, 5G7, 13Fl and 46E8.
- An example of an antibody having V H and V ⁇ of V H 1-69 and V K A27, respectively, is 47G4.
- An example of an antibody having Vn and V ⁇ of Vn 1-69 and V ⁇ L15, respectively, is 3C10.
- a human antibody comprises heavy or light chain variable regions that is "the product of or '"derived from” a particular germline sequence if the variable regions of the antibody are obtained from a system that uses human germline immunoglobulin genes.
- Such systems include immunizing a transgenic mouse carrying human immunoglobulin genes with the antigen of interest or screening a human immunoglobulin gene library displayed on phage with the antigen of interest.
- a human antibody that is "the product of” or “derived from” a human germline immunoglobulin sequence can be identified as such by comparing the amino acid sequence of the human antibody to the amino acid sequences of human germline immunoglobulins and selecting the human germline immunoglobulin sequence that is closest in sequence (i.e., greatest % identity) to the sequence of the human antibody.
- a human antibody that is "the product of or "derived from” a particular human germline immunoglobulin sequence may contain amino acid differences as compared to the gennline sequence, due to, for example, naturally-occurring somatic mutations or intentional introduction of site- directed mutation.
- a selected human antibody typically is at least 90% identical in amino acids sequence to an amino acid sequence encoded by a human germline immunoglobulin gene and contains amino acid residues that identify the human antibody as being human when compared to the germline immunoglobulin amino acid sequences of other species (e.g., murine germline sequences).
- a human antibody may be at least 95%, or even at least 96%, 97%, 98%, or 99% identical in amino acid sequence to the amino acid sequence encoded by the germline immunoglobulin gene.
- a human antibody derived from a particular human germline sequence will display no more than 10 amino acid differences from the amino acid sequence encoded by the human germline immunoglobulin gene.
- the human antibody may display no more than 5, or even no more than 4, 3, 2, or 1 amino acid difference from the amino acid sequence encoded by the germline immunoglobulin gene.
- an antibody of this disclosure comprises heavy and light chain variable regions comprising amino acid sequences that are homologous to the amino acid sequences of the preferred antibodies described herein, and wherein the antibodies retain the desired functional properties of the anti-CD 19 antibodies of this disclosure.
- this disclosure provides an isolated monoclonal antibody, or antigen binding portion thereof, comprising a heavy chain variable region and a light chain variable region, wherein:
- the heavy chain variable region comprises an amino acid sequence that is at least 80% homologous to an amino acid sequence selected from the group consisting of SEQ ID NOs: 1, 2, 3, 4, 5, 6 and 7;
- the light chain variable region comprises an amino acid sequence that is at least 80% homologous to an amino acid sequence selected from the group consisting of
- the antibody may possess one or more of the following functional properties discussed above, such as high affinity binding to human CD 19, internalization by CD19-expressing cells, the ability to mediate ADCC against CD 19-expressing cells and/or the ability to inhibit tumor growth of CD 19-expressing tumor cells in vivo when conjugated to a cytotoxin.
- the antibody can be, for example, a human antibody, a humanized antibody or a chimeric antibody.
- the V H and/or V L amino acid sequences may be 85%, 90%,
- An antibody having V H and V L regions having high (i.e., 80% or greater) homology to the Vn and V L regions of the sequences set forth above can be obtained by mutagenesis (e.g., site- directed or PCR-mediated mutagenesis) of nucleic acid molecules encoding SEQ ID NOs: 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72 or 73, followed by testing of the encoded altered antibody for retained function (i.e., the functions set forth in (c) through (d) above) using the functional assays described herein.
- mutagenesis e.g., site- directed or PCR-mediated mutagenesis
- the percent homology between two amino acid sequences is equivalent to the percent identity between the two sequences.
- the comparison of sequences and determination of percent identity between two sequences can be accomplished using a mathematical algorithm, as described in the non-limiting examples below.
- the percent identity between two amino acid sequences can be determined using the algorithm of E. Meyers and W. Miller (Comput. Appl. Biosci., 4: 1 1-17 (1988)) which has been incorporated into the ALIGN program (version 2.0), using a PAM 120 weight residue table, a gap length penalty of 12 and a gap penalty of 4.
- the percent identity between two amino acid sequences can be determined using the Needleman and Wunsch (J. MoI. Biol.
- the protein sequences of the present disclosure can further be used as a "query sequence" to perform a search against public databases to, for example, identify related sequences. Such searches can be performed using the XBLAST program (version 2.0) of Altschul, et al. (1990) J. MoI. Biol. 215:403-10.
- Gapped BLAST can be utilized as described in Altschul et al., (1997) Nucleic Acids Res. 25(17):3389-3402.
- the default parameters of the respective programs e.g., XBLAST and NBLAST are useful. See www.ncbi.nlm.nih.gov.
- an antibody of this disclosure comprises a heavy chain variable region comprising CDRl, CDR2 and CDR3 sequences and a light chain variable region comprising CDRl , CDR2 and CDR3 sequences, wherein one or more of these CDR sequences comprise specified amino acid sequences based on known anti-CD 19 antibodies, or conservative modifications thereof, and wherein the antibodies retain the desired functional properties of the anti-CD 19 antibodies of this disclosure. It is understood in the art that certain conservative sequence modification can be made which do not remove antigen binding. See, for example, Brummell et al. (1993) Biochem 32:1180-8 (describing mutational analysis in the CDR3 heavy chain domain of antibodies specific for Salmonella); de Wildt et al.
- this disclosure provides an isolated monoclonal antibody, or antigen binding portion thereof, comprising a heavy chain variable region comprising CDRl, CDR2, and CDR3 sequences and a light chain variable region comprising CDRl, CDR2, and CDR3 sequences, wherein: (a) the heavy chain variable region CDR3 sequence comprises an amino acid sequence selected from the group consisting of amino acid sequences of SEQ ID NOs: 30, 31, 32, 33, 34, 35 and 36, and conservative modifications thereof;
- the light chain variable region CDR3 sequence comprises an amino acid sequence selected from the group consisting of amino acid sequence of SEQ ID NOs: 51 , 52, 53, 54, 55, 56, 57 and 58, and conservative modifications thereof;
- the antibody may possess one or more of the following functional properties described above, such as high affinity binding to human CD 19, internalization by CD19-expressing cells, the ability to mediate ADCC against CD19-expressing cells and/or the ability to inhibit tumor growth of CD19-expressing tumor cells in vivo when conjugated to a cytotoxin.
- the heavy chain variable region CDR2 sequence comprises an amino acid sequence selected from the group consisting of amino acid sequences of SEQ ID NOs: 23, 24, 25, 26, 27, 28 and 29, and conservative modifications thereof; and the light chain variable region CDR2 sequence comprises an amino acid sequence selected from the group consisting of amino acid sequences of SEQ ID NOs: 44, 45, 46, 47, 48, 49 and 50, and conservative modifications thereof.
- the heavy chain variable region CDRl sequence comprises an amino acid sequence selected from the group consisting of amino acid sequences of SEQ ID NOs: 16, 17, 18, 19, 20, 21 and 22, and conservative modifications thereof; and the light chain variable region CDRl sequence comprises an amino acid sequence selected from the group consisting of amino acid sequences of SEQ ID NOs: 37, 38, 39, 40, 41, 42 and 43, and conservative modifications thereof.
- the antibody can be, for example, human antibodies, humanized antibodies or chimeric antibodies.
- conservative sequence modifications are intended to refer to amino acid modifications that do not significantly affect or alter the binding characteristics of the antibody containing the amino acid sequence. Such conservative modifications include amino acid substitutions, additions and deletions. Modifications can be introduced into an antibody of this disclosure by standard techniques known in the art, such as site-directed mutagenesis and PCR-mediated mutagenesis. Conservative amino acid substitutions are ones in which the amino acid residue is replaced with an amino acid residue having a similar side chain. Families of amino acid residues having similar side chains have been defined in the art.
- amino acids with basic side chains e.g., lysine, arginine, histidine
- acidic side chains e.g., aspartic acid, glutamic acid
- uncharged polar side chains e.g., glycine, asparagine, glutamine, serine, threonine, tyrosine, cysteine, tryptophan
- nonpolar side chains e.g., alanine, valine, leucine, isoleucine, proline, phenylalanine, methionine
- beta-branched side chains e.g., threonine, valine, isoleucine
- aromatic side chains e.g., tyrosine, phenylalanine, tryptophan, histidine
- one or more amino acid residues within the CDR regions of an antibody of this disclosure can be replaced with other amino acid residues from the same side chain family and the altered antibody can be tested for retained function (/ e , the functions set forth in (c) through (d) above) using the functional assays described herein.
- this disclosure provides antibodies that bind an epitope on human CD 19 recognized by any of the CD 19 monoclonal antibodies of this disclosure (i.e., antibodies that have the ability to cross-compete for binding to CD 19 with any of the monoclonal antibodies of this disclosure).
- the reference antibody for cross-competition studies can be the monoclonal antibody 21D4 (having V H and V L sequences as shown in SEQ ID NOs: 1 and 8, respectively), or the monoclonal antibody 21D4a (having V H and V L sequences as shown in SEQ ID NOs: 1 and 9, respectively), or the monoclonal antibody 47G4 (having V H and V L sequences as shown in SEQ ID NOs: 2 and 10, respectively), or the monoclonal antibody 27F3 (having Vn and V L sequences as shown in SEQ ID NOs: 3 and 1 1, respectively), or the monoclonal antibody 3C10 (having V H and V L sequences as shown in SEQ ID NOs: 4 and 12, respectively), or the monoclonal antibody 5G7 (having V H and V L sequences as shown in SEQ ID NOs: 5 and 13, respectively), or the monoclonal antibody 13Fl (having V H and V L sequences as shown in SEQ ID NOs: 6 and 14, respectively
- cross-competing antibodies can be identified based on their ability to cross-compete with 21D4, 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl or 46E8 in standard CD 19 binding assays.
- Standard ELISA assays can be used in which a recombinant human CD 19 protein is immobilized on the plate, one of the antibodies is fluorescently labeled and the ability of non-labeled antibodies to compete off the binding of the labeled antibody is evaluated.
- BIAcore analysis can be used to assess the ability of the antibodies to cross-compete.
- test antibody to inhibit the binding of, for example, 21D4, 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl or 46E8, to human CD 19 demonstrates that the test antibody can compete with 21D4, 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl or 46E8 for binding to human CD19 and thus binds to the same epitope on human CD 19 as 21D4, 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl or 46E8.
- the antibody that binds to the same epitope on human CD 19 as 21D4, 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl or 46E8 is a human monoclonal antibody.
- human monoclonal antibodies can be prepared and isolated as described in the Examples.
- An antibody of the invention can further be prepared using an antibody having one or more known CDl 9 antibody V H and/or V 1 sequences can be used as starting material to engineer a modified antibody, which modified antibody may have altered properties as compared to the starting antibody.
- An antibody can be engineered by modifying one or more amino acids within one or both variable regions (i.e., V H and/or V L ), for example, within one or more CDR regions and/or within one or more framework regions. Additionally or alternatively, an antibody can be engineered by modifying residues within the constant region(s), for example, to alter the effector function(s) of the antibody.
- CDR grafting can be used to engineer variable regions of antibodies.
- Antibodies interact with target antigens predominantly through amino acid residues that are located in the six heavy and light chain complementarity determining regions (CDRs). For this reason, the amino acid sequences within CDRs are more diverse between individual antibodies than sequences outside of CDRs. Because CDR sequences are responsible for most antibody-antigen interactions, it is possible to express recombinant antibodies that mimic the properties of specific naturally occurring antibodies by constructing expression vectors that include CDR sequences from the specific naturally occurring antibody grafted onto framework sequences from a different antibody with different properties (see, e.g., Riechmann, L. et al. (1998) Nature 332:323- 327; Jones, P.
- an isolated monoclonal antibody, or antigen binding portion thereof comprising a heavy chain variable region comprising CDRl, CDR2, and CDR3 sequences comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 16, 17, 18, 19, 20, 21 and 22, SEQ ID NOs: 23, 24, 25, 26, 27, 28 and 29, and SEQ ID NOs: 30, 31, 32, 33, 34, 35 and 36, respectively, and a light chain variable region comprising CDRl, CDR2, and CDR3 sequences comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 37, 38, 39, 40, 41, 42 and 43, SEQ ID NOs: 44, 45, 46, 47, 48, 49 and 50, and SEQ ID NOs: 51, 52, 53, 54, 55, 56, 57 and 58, respectively.
- such antibodies contain the V H and V L CDR
- Such framework sequences can be obtained from public DNA databases or published references that include germline antibody gene sequences.
- germline DNA sequences for human heavy and light chain variable region genes can be found in the "VBase" human germline sequence database (available on the Internet at www.mrc-cpe.cam.ac.uk/vbase), as well as in Kabat, E. A., et al. (1991) Sequences of Proteins of Immunological Interest, Fifth Edition, U.S. Department of Health and Human Services, NIH Publication No. 91-3242; Tomlinson, I. M., et al.
- NG_0010109, NTJ)24637 and BC070333 3-33 (NG_0010109 and NTJ)24637) and 3- 7 (NGJ3O1O1O9 and NT_024637).
- the following heavy chain germline sequences found in the HCo 12 HuMAb mouse are available in the accompanying Genbank accession numbers: 1-69 (NGJ)OlO 109, NT_024637 and BC070333), 5-51 (NGJ)OlO 109 and NTJ)24637), 4-34 (NGJ)010109 and NT_024637), 3-30.3 (CAJ556644) and 3-23 (A.T406678).
- Yet another source of human heavy and light chain germline sequences is the database of human immunoglobulin genes available from IMGT (http://imgt.cines.fr).
- Antibody protein sequences are compared against a compiled protein sequence database using one of the sequence similarity searching methods called the Gapped BLAST (Altschul et al. (1997) Nucleic Acids Research 25:3389-3402), which is well known to those skilled in the art.
- BLAST is a heuristic algorithm in that a statistically significant alignment between the antibody sequence and the database sequence is likely to contain high-scoring segment pairs (HSP) of aligned words. Segment pairs whose scores cannot be improved by extension or trimming is called a hit.
- HSP high-scoring segment pairs
- nucleotide sequences of VBASE origin ⁇ http://vbase.mrc-cpe.cam.ac.uk/vbase 1 /Iist2.php
- the database sequences have an average length of 98 residues.
- Duplicate sequences which are exact matches over the entire length of the protein are removed.
- the nucleotide sequences are translated in all six frames and the frame with no stop codons in the matching segment of the database sequence is considered the potential hit.
- BLAST program tblastx which translates the antibody sequence in all six frames and compares those translations to the VBASE nucleotide sequences dynamically translated in all six frames.
- Other human germline sequence databases such as that available from IMGT (http://imgt.cines.fr), can be searched similarly to VBASE as described above.
- the identities are exact amino acid matches between the antibody sequence and the protein database over the entire length of the sequence.
- the positives are not identical but amino acid substitutions guided by the BLOSUM62 substitution matrix. If the antibody sequence matches two of the database sequences with same identity, the hit with most positives would be decided to be the matching sequence hit.
- Preferred framework sequences for use in the antibodies of this disclosure are those that are structurally similar to the framework sequences used by selected antibodies of this disclosure, e.g., similar to the Vn 5-51 framework sequences (SEQ ID NO: 74) and/or the V H 1-69 framework sequences (SEQ ID NO: 75) and/or the V K L 18 framework sequences (SEQ ID NO: 76) and/or the V ⁇ A27 framework sequence (SEQ ID NO: 77) and/or the V ⁇ Ll 5 framework sequence (SEQ ID NO: 78) used by preferred monoclonal antibodies of this disclosure.
- V H CDRl, CDR2, and CDR3 sequences, and the V K CDRl, CDR2, and CDR3 sequences can be grafted onto framework regions that have the identical sequence as that found in the germline immunoglobulin gene from which the framework sequence derive, or the CDR sequences can be grafted onto framework regions that contain one or more mutations as compared to the germline sequences.
- variable region modification is to mutate amino acid residues within the V H and/or V K CDRl, CDR2 and/or CDR3 regions to thereby improve one or more binding properties ⁇ e.g., affinity) of the antibody of interest.
- Site-directed mutagenesis or PCR-mediated mutagenesis can be performed to introduce the mutation(s) and the effect on antibody binding, or other functional property of interest, can be evaluated in in vitro or in vivo assays as described herein and provided in the Examples.
- Preferably conservative modifications are introduced.
- the mutations may be amino acid substitutions, additions or deletions, but are preferably substitutions.
- typically no more than one, two, three, four or five residues within a CDR region are altered.
- the instant disclosure provides isolated anti- CD 19 monoclonal antibodies, or antigen binding portions thereof, comprising a heavy chain variable region comprising: (a) a Vu CDRl region comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 16, 17, 18, 19, 20, 21 and 22, or an amino acid sequence having one, two, three, four or five amino acid substitutions, deletions or additions as compared to SEQ ID NOs: 16, 17, 18, 19, 20, 21 and 22; (b) a Vn CDR2 region comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 23, 24, 25, 26, 27, 28 and 29, or an amino acid sequence having one, two, three, four or five amino acid substitutions, deletions or additions as compared to SEQ ID NOs: 23, 24, 25, 26, 27, 28 and 29; (c) a V H CDR3 region comprising an amino acid sequence selected from the group consisting of SEQ ID NOs: 30, 31, 32, 33, 34, 35 and 36, or an amino acid sequence having one, two
- Engineered antibodies of this disclosure include those in which modifications have been made to framework residues within V H and/or V «, e.g. to improve the properties of the antibody. Typically such framework modifications are made to decrease the immunogenicity of the antibody. For example, one approach is to "backmutate' ' one or more framework residues to the corresponding germline sequence. More specifically, an antibody that has undergone somatic mutation may contain framework residues that differ from the germline sequence from which the antibody is derived. Such residues can be identified by comparing the antibody framework sequences to the germline sequences from which the antibody is derived.
- Table 1 shows a number of amino acid changes in the framework regions of the anti-PD-1 antibodies 17D8, 2D3, 4Hl, 5C4, 4Al 1, 7D3 and 5F4 that differ from the heavy chain parent germline sequence.
- somatic mutations can be "backmutated" to the germline sequence by, for example, site-directed mutagenesis or PCR-mediated mutagenesis.
- Ant ⁇ -CD19 Ab Amino acid position Amino acid of Original amino acid of germline antibody configuration
- Another type of framework modification involves mutating one or more residues within the framework region, or even within one or more CDR regions, to remove T cell epitopes to thereby reduce the potential immunogenicity of the antibody. This approach is also referred to as "deimmunization" and is described in further detail in U.S. Patent Publication No. 20030153043 by Can- et al.
- antibodies of this disclosure may be engineered to include modifications within the Fc region, typically to alter one or more functional properties of the antibody, such as serum half-life, complement fixation, Fc receptor binding, and/or antigen-dependent cellular cytotoxicity.
- an antibody of this disclosure may be chemically modified (e.g., one or more chemical moieties can be attached to the antibody) or be modified to alter its glycosylation, again to alter one or more functional properties of the antibody.
- chemically modified e.g., one or more chemical moieties can be attached to the antibody
- modify its glycosylation again to alter one or more functional properties of the antibody.
- the hinge region of CHl is modified such that the number of cysteine residues in the hinge region is altered, e.g., increased or decreased.
- This approach is described further in U.S. Patent No. 5,677,425 by Bodmer et al.
- the number of cysteine residues in the hinge region of CHl is altered to, for example, facilitate assembly of the light and heavy chains or to increase or decrease the stability of the antibody.
- the Fc hinge region of an antibody is mutated to decrease the biological half life of the antibody. More specifically, one or more amino acid mutations are introduced into the CH2-CH3 domain interface region of the Fc -hinge fragment such that the antibody has impaired Staphylococcyl protein A (SpA) binding relative to native Fc-hinge domain SpA binding.
- SpA Staphylococcyl protein A
- the antibody is modified to increase its biological half life.
- the antibody is modified to increase its biological half life.
- Various approaches are possible. For example, one or more of the following mutations can be introduced: T252L, T254S, T256F, as described in U.S. Patent No.
- the antibody can be altered within the CHl or C t . region to contain a salvage receptor binding epitope taken from two loops of a CH2 domain of an Fc region of an IgG, as described in U.S. Patent Nos. 5,869,046 and 6, 121,022 by Presta et al.
- the Fc region is altered by replacing at least one amino acid residue with a different amino acid residue to alter the effector function(s) of the antibody.
- one or more amino acids selected from amino acid residues 234, 235, 236, 237, 297, 318, 320 and 322 can be replaced with a different amino acid residue such that the antibody has an altered affinity for an effector ligand but retains the antigen- binding ability of the parent antibody.
- the effector ligand to which affinity is altered can be, for example, an Fc receptor or the Cl component of complement. This approach is described in further detail in U.S. Patent Nos. 5,624,821 and 5,648,260, both by Winter et al.
- one or more amino acids selected from amino acid residues 329, 331 and 322 can be replaced with a different amino acid residue such that the antibody has altered CIq binding and/or reduced or abolished complement dependent cytotoxicity (CDC).
- CDC complement dependent cytotoxicity
- one or more amino acid residues within amino acid positions 2316, 17, 18, 19, 20, 21 and 2239 are altered to thereby alter the ability of the antibody to fix complement. This approach is described further in PCT Publication WO 94/29351 by Bodmer et al.
- the Fc region is modified to increase the ability of the antibody to mediate antibody dependent cellular cytotoxicity (ADCC) and/or to increase the affinity of the antibody for an Fc ⁇ receptor by modifying one or more amino acids at the following positions: 238, 239. 248, 249, 252, 254, 255, 256, 258, 265, 267, 268, 269, 270, 272, 276, 278, 280, 283, 285, 286, 289, 290, 292, 293, 294, 295, 296, 298, 301, 303, 305, 307, 309, 312, 315, 320, 322, 324, 326, 327, 329, 330.
- ADCC antibody dependent cellular cytotoxicity
- the C-terminal end of an antibody of the present invention is modified by the introduction of a cysteine residue as is described in U.S. Provisional Application Serial No. 60/957,271, which is hereby incorporated by reference in its entirety.
- Such modifications include, but are not limited to, the replacement of an existing amino acid residue at or near the C-terminus of a full-length heavy chain sequence, as well as the introduction of a cysteine-containing extension to the c-terminus of a full-length heavy chain sequence.
- the cysteine-containing extension comprises the sequence alanine-alanine-cysteine (from N-terminal to C- terminal).
- the presence of such C-te ⁇ ninal cysteine modifications provide a location for conjugation of a partner molecule, such as a therapeutic agent or a marker molecule.
- a partner molecule such as a therapeutic agent or a marker molecule.
- the presence of a reactive thiol group, due to the C- terminal cysteine modification can be used to conjugate a partner molecule employing the disulfide linkers described in detail below. Conjugation of the antibody to a partner molecule in this manner allows for increased control over the specific site of attachment.
- conjugation can be optimized such that it reduces or eliminates interference with the antibody's functional properties, and allows for simplified analysis and quality control of conjugate preparations.
- the glycosylation of an antibody is modified.
- an aglycoslated antibody can be made (i.e., the antibody lacks glycosylation).
- Glycosylation can be altered to, for example, increase the affinity of the antibody for antigen.
- carbohydrate modifications can be accomplished by, for example, altering one or more sites of glycosylation within the antibody sequence.
- one or more amino acid substitutions can be made that result in elimination of one or more variable region framework glycosylation sites to thereby eliminate glycosylation at that site.
- Such aglycosylation may increase the affinity of the antibody for antigen.
- an antibody can be made that has an altered type of glycosylation, such as a hypofucosylated antibody having reduced amounts of fucosyl residues or an antibody having increased bisecting GlcNac structures.
- altered glycosylation patterns have been demonstrated to increase the ADCC ability of antibodies.
- carbohydrate modifications can be accomplished by, for example, expressing the antibody in a host cell with altered glycosylation machinery. Cells with altered glycosylation machinery have been described in the art and can be used as host cells in which to express recombinant antibodies of this disclosure to thereby produce an antibody with altered glycosylation.
- the cell lines Ms704, Ms705, and Ms709 lack the fucosyltransferase gene, FUT8 (alpha ( 1 ,6) fucosyltransferase), such that antibodies expressed in the Ms704, Ms705, and Ms709 cell lines lack fucose on their carbohydrates.
- the Ms704, Ms705, and Ms709 FUT8 ⁇ ; ⁇ cell lines were created by the targeted disruption of the FUT8 gene in CHO/DG44 cells using two replacement vectors (see U.S. Patent Publication No. 20040110704 by Yamane et al. and Yamane-Ohnuki et al. (2004) Biotechnol Bioeng 87:614-22).
- EP 1 , 176, 195 by Hanai et al. describes a cell line with a functionally disrupted FUT8 gene, which encodes a fuc ⁇ sv i transferase, such that antibodies expressed in such a cell line exhibit hypo fixcosylat ion by reducing or eliminating the alpha 1,6 bond-related enzyme.
- Hanai et al. also describe cell lines which have a low enzyme activity for adding fucose to the N-acetylglucosamine that binds to the Fc region of the antibody or does not have the enzyme activity, for example the rat myeloma cell line YB2/0 (ATCC CRL 1662).
- PCT Publication WO 03/035835 by Presta describes a variant CHO cell line, Lee 13 cells, with reduced ability to attach fucose to Asn(297)-linked carbohydrates, also resulting in hypofucosylation of antibodies expressed in that host cell (see also Shields, R.L. et al. (2002) J. Biol. Client. 277:26733-26740).
- PCT Publication WO 99/54342 by Umana et al.
- glycoprotein-modifying glycosyl transferases ⁇ e.g., beta( l,4)-N- acetylglucosaminyltransferase III (GnTIII)
- GnTIII glycoprotein-modifying glycosyl transferases
- the fucose residues of the antibody may be cleaved off using a fucosidase enzyme.
- the fucosidase alpha-L-fucosidase removes fucosyl residues from antibodies (Tarentino, A.
- an antibody can be made that has an altered type of glycosylation, wherein that alteration relates to the level of sialyation of the antibody.
- Such alterations are described in PCT Publication No. WO/2007/084926 to Dickey et al , and PCT Publication No. WO/2007/055916 to Ravetch et al., both of which are incorporated by reference in their entirety.
- sialidase such as, for example, Arthrobacter ureafacens sialidase. The conditions of such a reaction are generally described in the U.S. Patent No.
- Suitable enzymes are neuraminidase and N-GIycosidase F, as described in Schloemer et al . , ]. Virology, 15(4), 882-893 (1975) and in Leibiger et al . , Biochem J., 338, 529-538 (1999), respectively. Desialylated antibodies may be further purified by using affinity chromatography. Alternatively, one may employ methods to increase the level of sialyation, such as by employing sialytransferase enzymes. Conditions of such a reaction are generally described in Basset et al., Scandinavian Journal of Immunology, 51(3), 307-31 1 (2000).
- An antibody can be pegylated to, for example, increase the biological (e.g., serum) half life of the antibody.
- the antibody, or fragment thereof typically is reacted with polyethylene glycol (PEG), such as a reactive ester or aldehyde derivative of PEG, under conditions in which one or more PEG groups become attached to the antibody or antibody fragment.
- PEG polyethylene glycol
- the pegylation is earned out via an acylation reaction or an alkylation reaction with a reactive PEG molecule (or an analogous reactive water-soluble polymer).
- polyethylene glycol is intended to encompass any of the forms of PEG that have been used to derivatize other proteins, such as mono (Cl-Cl 0) alkoxy- or aryloxy- polyethylene glycol or polyethylene glycol-maleirnide.
- the antibody to be pegylated is an aglycosylated antibody. Methods for pegylating proteins are known in the art and can be applied to the antibodies of this disclosure. See for example, EP 0 154 316 by Nishimura et al. and EP 0401 384 by Ishikawa et al.
- Antibody Fragments and Antibody Mimetics The instant invention is not limited to traditional antibodies and may be practiced through the use of antibody fragments and antibody mimetics.
- antibody fragment and antibody mimetic technologies have now been developed and are widely known in the art. While a number of these technologies, such as domain antibodies, Nanobodies, and UniBodies make use of fragments of, or other modifications to, traditional antibody structures, there are also alternative technologies, such as Affibodies, DARPins, Anticalins, Avimers, and Versabodies that employ binding structures that, while they mimic traditional antibody binding, are generated from and function via distinct mechanisms.
- Domain Antibodies are the smallest functional binding units of antibodies, corresponding to the variable regions of either the heavy (VH) or light (VL) chains of human antibodies. Domain Antibodies have a molecular weight of approximately 13 kDa. Domantis has developed a series of large and highly functional libraries of fully human VH and VL dAbs (more than ten billion different sequences in each library), and uses these libraries to select dAbs that are specific to therapeutic targets. In contrast to many conventional antibodies, Domain Antibodies are well expressed in bacterial, yeast, and mammalian cell systems. Further details of domain antibodies and methods of production thereof may be obtained by reference to U.S.
- Nanobodies are antibody-derived therapeutic proteins that contain the unique structural and functional properties of naturally-occurring heavy-chain antibodies. These heavy-chain antibodies contain a single variable domain (VHH) and two constant domains (CH2 and CH3). Importantly, the cloned and isolated VHH domain is a perfectly stable polypeptide harboring the full antigen-binding capacity of the original heavy-chain antibody. Nanobodies have a high homology with the VH domains of human antibodies and can be further humanized without any loss of activity. Importantly, Nanobodies have a low immunogenic potential, which has been confirmed in primate studies with Nanobody lead compounds. Nanobodies combine the advantages of conventional antibodies with important features of small molecule drags.
- Nanobodies Like conventional antibodies, Nanobodies show high target specificity, high affinity for their target and low inherent toxicity. However, like small molecule drugs they can inhibit enzymes and readily access receptor clefts. Furthermore, Nanobodies are extremely stable, can be administered by means other than injection (see, e.g., WO 04/041867, which is herein incoiporated by reference in its entirety) and are easy to manufacture. Other advantages of Nanobodies include recognizing uncommon or hidden epitopes as a result of their small size, binding into cavities or active sites of protein targets with high affinity and selectivity due to their unique 3 -dimensional, drug format flexibility, tailoring of half-life and ease and speed of drug discovery.
- Nanobodies are encoded by single genes and are efficiently produced in almost all prokaryotic and eukaryotic hosts, e.g., E. coli (see, e.g., U.S. 6,765,087, which is herein incorporated by reference in its entirety), molds (for example Aspergillus or Trichoderma) and yeast (for example Saccharomyces, Kluyveromyces, Hansenula or Pichia) (see, e.g., U.S. 6,838,254, which is herein incoiporated by reference in its entirety).
- the production process is scalable and multi-kilogram quantities of
- Nanobodies have been produced. Because Nanobodies exhibit a superior stability compared with conventional antibodies, they can be formulated as a long shelf-life, ready-to-use solution.
- the Nanoclone method (see, e.g., WO 06/079372, which is herein incoiporated by reference in its entirety) is a proprietary method for generating Nanobodies against a desired target, based on automated high-throughout selection of B-cells and could be used in the context of the instant invention.
- UniBodies are another antibody fragment technology, however this one is based upon the removal of the hinge region of IgG4 antibodies. The deletion of the hinge region results in a molecule that is essentially half the size of traditional IgG4 antibodies and has a univalent binding region rather than the bivalent binding region of IgG4 antibodies. It is also well known that IgG4 antibodies are inert and thus do not interact with the immune system, which may be advantageous for the treatment of diseases where an immune response is not desired, and this advantage is passed onto UniBodies. For example, UniBodies may function to inhibit or silence, but not kill, the cells to which they are bound. Additionally, UniBody binding to cancer cells do not stimulate them to proliferate.
- UniBodies are about half the size of traditional IgG4 antibodies, they may show better distribution over larger solid tumors with potentially advantageous efficacy. UniBodies are cleared from the body at a similar rate to whole IgG4 antibodies and are able to bind with a similar affinity for their antigens as whole antibodies. Further details of UniBodies may be obtained by reference to patent application WO2007/059782, which is herein incorporated by reference in its entirety.
- Affibody molecules represent a new class of affinity proteins based on a 58-amino acid residue protein domain, derived from one of the igG-binding domains of staphylococcal protein A. This three helix bundle domain has been used as a scaffold for the construction of combinatorial phagemid libraries, from which Affibody valiants that target the desired molecules can be selected using phage display technology (Nord K, Gunneriusson E, Ringdahl J, Stahl S, Uhlen M, Nygren PA, Binding proteins selected from combinatorial libraries of an ⁇ -helical bacterial receptor domain, Nat Biotechnol 1997; 15:772-7.
- Affibody molecules in combination with their low molecular weight (6 kDa), make them suitable for a wide variety of applications, for instance, as detection reagents (Ronmark J, Hansson M, Nguyen T, et al, Construction and characterization of affibody-Fc chimeras produced in Escherichia coli, J Immunol Methods 2002;261 : 199-21 1 ) and to inhibit receptor interactions (Sandstorai K, Xu Z, Forsberg G, Nygren PA, Inhibition of the CD28-CD80 co-stimulation signal by a CD28-binding Affibody ligand developed by combinatorial protein engineering, Protein Eng 2003;16:691-7). Further details of Affi
- Labeled Affibodies may also be useful in imaging applications for determining abundance of Isoforms.
- DARPins Designed Ankyrin Repeat Proteins
- Repeat proteins such as ankyrin or leucine-rich repeat proteins, are ubiquitous binding molecules, which occur, unlike antibodies, intra- and extracellularly.
- Their unique modular architecture features repeating structural units (repeats), which stack together to form elongated repeat domains displaying variable and modular target-binding surfaces. Based on this modularity, combinatorial libraries of polypeptides with highly diversified binding specificities can be generated. This strategy includes the consensus design of self- compatible repeats displaying variable surface residues and their random assembly into repeat domains.
- DARPins can be produced in bacterial expression systems at very high yields and they belong to the most stable proteins known. Highly specific, high-affinity DARPins to a broad range of target proteins, including human receptors, cytokines, kinases, human proteases, viruses and membrane proteins, have been selected. DARPins having affinities in the single-digit nanomolar to picomolar range can be obtained.
- DARPins have been used in a wide range of applications, including ELISA, sandwich ELISA, flow cytometric analysis (FACS), immunohistochemistry (IHC), chip applications, affinity purification or Western blotting. DARPins also proved to be highly active in the intracellular compartment for example as intracellular marker proteins fused to green fluorescent protein (GFP). DARPins were further used to inhibit viral entry with IC50 in the pM range. DARPins are not only ideal to block protein-protein interactions, but also to inhibit enzymes. Proteases, kinases and transporters have been successfully inhibited, most often an allosteric inhibition mode. Very fast and specific enrichments on the tumor and very favorable tumor to blood ratios make DARPins well suited for in vivo diagnostics or therapeutic approaches.
- Anticalins are an additional antibody mimetic technology, however in this case the binding specificity is derived from lipocalins, a family of low molecular weight proteins that are naturally and abundantly expressed in human tissues and body fluids. Lipocalins have evolved to perform a range of functions in vivo associated with the physiological transport and storage of chemically sensitive or insoluble compounds. Lipocalins have a robust intrinsic structure comprising a highly conserved ⁇ -barrel which supports four loops at one terminus of the protein. These loops form the entrance to a binding pocket and conformational differences in this part of the molecule account for the variation in binding specificity between individual lipocalins.
- lipocalins differ considerably from antibodies in terms of size, being composed of a single polypeptide chain of 160-180 amino acids which is marginally larger than a single immunoglobulin domain.
- Lipocalins are cloned and their loops are subjected to engineering in order to create Anticalins. Libraries of structurally diverse Anticalins have been generated and Anticalin display allows the selection and screening of binding function, followed by the expression and production of soluble protein for further analysis in prokaryotic or eukaryotic systems. Studies have successfully demonstrated that Anticalins can be developed that are specific for virtually any human target protein can be isolated and binding affinities in the nanomolar or higher range can be obtained.
- Anticalins can also be formatted as dual targeting proteins, so-called Duocalins.
- a Duocalin binds two separate therapeutic targets in one easily produced monomeric protein using standard manufacturing processes while retaining target specificity and affinity regardless of the structural orientation of its two binding domains. Modulation of multiple targets through a single molecule is particularly advantageous in diseases known to involve more than a single causative factor.
- bi- or multivalent binding formats such as Duocalins have significant potential in targeting cell surface molecules in disease, mediating agonistic effects on signal transduction pathways or inducing enhanced internalization effects via binding and clustering of cell surface receptors.
- the high intrinsic stability of Duocalins is comparable to monomeric Anticalins, offering flexible formulation and delivery potential for Duocalins.
- Anticalins can be found in U.S. Patent No. 7,250,297 and International Patent Application Publication No. WO 99/16873, both of which are hereby incorporated by reference in their entirety.
- Another antibody mimetic technology useful in the context of the instant invention are Avimers.
- Avimers are evolved from a large family of human extracellular receptor domains by in vitro exon shuffling and phage display, generating multidomain proteins with binding and inhibitory properties. Linking multiple independent binding domains has been shown to create avidity and results in improved affinity and specificity compared with conventional single-epitope binding proteins.
- Other potential advantages include simple and efficient production of multitarget-specific molecules in Escherichia coli, improved thermostability and resistance to proteases.
- Avimers with sub-nanomolar affinities have been obtained against a variety of targets. Additional information regarding Avimers can be found in U.S. Patent
- Versabodies are another antibody mimetic technology that could be used in the context of the instant invention.
- Versabodies are small proteins of 3-5 kDa with >15% cysteines, which form a high disulfide density scaffold, replacing the hydrophobic core that typical proteins have.
- antibody fragment and antibody mimetic technologies are not intended to be a comprehensive list of all technologies that could be used in the context of the instant specification.
- additional technologies including alternative polypeptide-based technologies, such as fusions of complimentary determining regions as outlined in Qui et al., Nature Biotechnology, 25(8) 921-929 (2007), which is hereby incorporated by reference in its entirety, as well as nucleic acid-based technologies, such as the RNA aptamer technologies described in U.S. Patent Nos.
- the antibodies of the present disclosure may be further characterized by the various physical properties of the anti-CD 19 antibodies.
- Various assays may be used to detect and/or differentiate different classes of antibodies based on these physical properties.
- antibodies of the present disclosure may contain one or more glycosylation sites in either the light or heavy chain variable region.
- the presence of one or more glycosylation sites in the variable region may result in increased immunogenicity of the antibody or an alteration of the pK of the antibody due to altered antigen binding (Marshall et al (1972) Annu Rev Biochem 41:673-702; Gala FA and Morrison SL (2004) J Immunol 172:5489-94; Wallick et al (1988) J Exp Med 168: 1099- 109; Spiro RG (2002) Glycobiology I2:43R-56R; Parekh et al (1985) Nature 316:452-7; Mimura et al.
- variable region glycosylation may be tested using a Glycoblot assay, which cleaves the antibody to produce a Fab, and then tests for glycosylation using an assay that measures periodate oxidation and Schiff base formation.
- variable region glycosylation may be tested using Dionex light chromatography (Dionex-LC), which cleaves saccharides from a Fab into monosaccharides and analyzes the individual saccharide content.
- Dionex-LC Dionex light chromatography
- the antibodies of the present disclosure do not contain asparagine isomerism sites.
- a deamidation or isoaspartic acid effect may occur on N-G or D-G sequences, respectively.
- the deamidation or isoaspartic acid effect results in the creation of isoaspartic acid which decreases the stability of an antibody by creating a kinked structure off a side chain carboxy terminus rather than the main chain.
- the creation of isoaspartic acid can be measured using an iso-quant assay, which uses a reverse-phase HPLC to test for isoaspartic acid.
- Each antibody will have a unique isoelectric point (pi), but generally antibodies will fall in the pH range of between 6 and 9.5.
- the pi for an IgGl antibody typically falls within the pH range of 7-9.5 and the pi for an IgG4 antibody typically falls within the pH range of 6-8.
- Antibodies may have a pi that is outside this range. Although the effects are generally unknown, there is speculation that antibodies with a pi outside the normal range may have some unfolding and instability under in vivo conditions.
- the isoelectric point may be tested using a capillary isoelectric focusing assay, which creates a pH gradient and may utilize laser focusing for increased accuracy (Janini et al (2002) Electrophoresis 23: 1605-1 1 ; Ma et al.
- an anti- CD 19 antibody that contains a pi value that falls in the normal range. This can be achieved either by selecting antibodies with a pi in the normal range, or by mutating charged surface residues using standard techniques well known in the art.
- each antibody will have a melting temperature that is indicative of thermal stability (Krishnamurthy R and Manning MC (2002) Curr Pharm Biotechnol 3:361-71). A higher thermal stability indicates greater overall antibody stability in vivo.
- the melting point of an antibody may be measured using techniques such as differential scanning calorimetry (Chen et al (2003) Pharm Res 20: 1952-60; Ghirlando et al (1999) Immunol Lett 68:47-52).
- T M I indicates the temperature of the initial unfolding of the antibody.
- T M2 indicates the temperature of complete unfolding of the antibody.
- the T M i of an antibody of the present disclosure is greater than 60 0 C, preferably greater than 65°C, even more preferably greater than 7O 0 C.
- the thermal stability of an antibody may be measured using circular dichroism (Murray et al. (2002) J. Chromatogr Sci 40:343-9).
- antibodies are selected that do not rapidly degrade. Fragmentation of an anti-CD 19 antibody may be measured using capillary electrophoresis (CE) and MALDI-MS, as is well understood in the art (Alexander AJ and Hughes DE (1995) Anal Chem 67:3626-32).
- CE capillary electrophoresis
- MALDI-MS MALDI-MS
- antibodies are selected that have minimal aggregation effects. Aggregation may lead to triggering of an unwanted immune response and/or altered or unfavorable pharmacokinetic properties. Generally, antibodies are acceptable with aggregation of 25% or less, preferably 20% or less, even more preferably 15% or less, even more preferably 10% or less and even more preferably 5% or less. Aggregation may be measured by several techniques well known in the art, including size-exclusion column (SEC) high performance liquid chromatography (HPLC), and light scattering to identify monomers, dinners, trimers or multimers.
- SEC size-exclusion column
- HPLC high performance liquid chromatography
- the anti-CD 19 antibodies having V H and V K sequences disclosed herein can be used to create new anti-CD 19 antibodies by modifying the V H and/or V K sequences, or the constant region(s) attached thereto.
- the staictural features of an anti-CD 19 antibody of this disclosure e.g. 21 D4, 21 D4a, 47G4, 27F3, 3C10, 5G7, 13Fl or 46E8, are used to create structurally related anti-CD 19 antibodies that retain at least one functional property of the antibodies of this disclosure, such as binding to human CD 19.
- one or more CDR regions of 21 D4, 21 D4a, 47G4, 27F3, 3ClO, 5G7, 13Fl or 46E8, or mutations thereof can be combined recombinantly with known framework regions and/or other CDRs to create additional, recombinantly-engineered, anti-CD 19 antibodies of this disclosure, as discussed above.
- Other types of modifications include those described in the previous section.
- the starting material for the engineering method is one or more of the V H and'or V K sequences provided herein, or one or more CDR regions thereof.
- this disclosure provides a method for preparing an anti-CD 19 antibody comprising:
- the altered antibody sequence as a protein.
- Standard molecular biology techniques can be used to prepare and express the altered antibody sequence.
- the antibody encoded by the altered antibody sequence(s) is one that retains one, some or all of the functional properties of the anti-CD 19 antibodies described herein, which functional properties include, but are not limited to:
- the functional properties of the altered antibodies can be assessed using standard assays available in the art and/or described herein, such as those set forth in the Examples (e.g.. flow cytometry, binding assays).
- mutations can be introduced randomly or selectively along all or part of an anti-CD 19 antibody coding sequence and the resulting modified anti-CD 19 antibodies can be screened for binding activity and/or other functional properties as described herein.
- Mutational methods have been described in the art.
- PCT Publication WO 02/092780 by Short describes methods for creating and screening antibody mutations using saturation mutagenesis, synthetic ligation assembly, or a combination thereof.
- PCT Publication WO 03/074679 by Lazar et al. describes methods of using computational screening methods to optimize physiochemical properties of antibodies.
- nucleic Acid Molecules Encoding Antibodies of this Disclosure Another aspect of this disclosure pertains to nucleic acid molecules that encode the antibodies of this disclosure.
- the nucleic acids may be present in whole cells, in a cell lysate, or in a partially purified or substantially pure form.
- a nucleic acid is "isolated” or “rendered substantially pure” when purified away from other cellular components or other contaminants, e.g., other cellular nucleic acids or proteins, by standard techniques, including alkaline/SDS treatment, CsCl banding, column chromatography, agarose gel electrophoresis and others well known in the art. See, F. Ausubel, et ai, ed.
- a nucleic acid of this disclosure can be, for example, DNA or RNA and may or may not contain intronic sequences.
- the nucleic acid is a cDNA molecule.
- Nucleic acids of this disclosure can be obtained using standard molecular biology techniques. For antibodies expressed by hybridomas (e.g., hybridomas prepared from transgenic mice carrying human immunoglobulin genes as described further below), cDNAs encoding the light and heavy chains of the antibody made by the hybridoma can be obtained by standard PCR amplification or cDNA cloning techniques. For antibodies obtained from an immunoglobulin gene library (e.g., using phage display techniques), one or more nucleic acids encoding the antibody can be recovered from the library.
- hybridomas e.g., hybridomas prepared from transgenic mice carrying human immunoglobulin genes as described further below
- cDNAs encoding the light and heavy chains of the antibody made by the hybridoma can be obtained by standard PCR amplification or cDNA clon
- Preferred nucleic acids molecules of this disclosure are those encoding the Vn and V L sequences of the 21 D4, 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl or 46E8 monoclonal antibodies.
- DNA sequences encoding the Vn sequences of 21D4, 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl and 46E8 are shown in SEQ ID NOs: 59, 60, 61, 62, 63, 64 and 65, respectively.
- DNA sequences encoding the V L sequences of 21D4, 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl and 46E8 are shown in SEQ ID NOs: 66, 67, 68, 69, 70, 71, 72 and 73, respectively.
- Vn and V L segments are obtained, these DNA fragments can be further manipulated by standard recombinant DNA techniques, for example to convert the variable region genes to full-length antibody chain genes, to Fab fragment genes or to a scFv gene.
- a V L - or Vn-encoding DNA fragment is operatively linked to another DNA fragment encoding another protein, such as an antibody constant region or a flexible linker.
- the term "operatively linked”, as used in this context, is intended to mean that the two DNA fragments are joined such that the amino acid sequences encoded by the two DNA fragments remain in-frame.
- the isolated DNA encoding the V H region can be converted to a full-length heavy chain gene by operatively linking the VH-encoding DNA to another DNA molecule encoding heavy chain constant regions (CHl, CH2 and CH3).
- CHl heavy chain constant regions
- the sequences of human heavy chain constant region genes are known in the art (see e.g., Kabat, E. A., el al.
- the heavy chain constant region can be an IgGl, IgG2, IgG3, IgG4, IgA, IgE, IgM or IgD constant region, but most preferably is an IgG 1 or IgG4 constant region.
- the V ⁇ -encoding DNA can be operatively linked to another DNA molecule encoding only the heavy chain CH 1 constant region.
- the isolated DNA encoding the V L region can be converted to a full-length light chain gene (as well as a Fab light chain gene) by operatively linking the V L -encoding DNA to another DNA molecule encoding the light chain constant region, CL.
- the sequences of human light chain constant region genes are known in the art (see e.g., Kabat, E. A., et al. (1991) Sequences of Proteins of Immunological Interest, Fifth Edition, U.S. Department of Health and Human Services, NIH Publication No. 91-3242) and DNA fragments encompassing these regions can be obtained by standard PCR amplification.
- the light chain constant region can be a kappa or lambda constant region.
- V H - and V t -encoding DNA fragments are operatively linked to another fragment encoding a flexible linker, e.g., encoding the amino acid sequence (GIy 4 -Ser) 3 , such that the V H and V] sequences can be expressed as a contiguous single-chain protein, with the V 1 and V H regions joined by the flexible linker (see e.g., Bird et al. (1988) Science 242:423-426; Huston et al. (1988) Proc. Natl. Acad. ScL USA 85:5879-5883; McCafferty et al., (1990) Nature 348:552-554).
- a flexible linker e.g., encoding the amino acid sequence (GIy 4 -Ser) 3 , such that the V H and V] sequences can be expressed as a contiguous single-chain protein, with the V 1 and V H regions joined by the flexible linker (see e.g., Bird
- Monoclonal antibodies (mAbs) of the present disclosure can be produced by a variety of techniques, including conventional monoclonal antibody methodology e.g., the standard somatic cell hybridization technique of Kohler and Milstein (1975) Nature 256:
- hybridomas The preferred animal system for preparing hybridomas is the murine system.
- Hybridoma production in the mouse is a very well-established procedure. Immunization protocols and techniques for isolation of immunized splenocytes for fusion are known in
- Fusion partners e.g., murine myeloma cells
- fusion procedures are also known.
- Chimeric or humanized antibodies of the present disclosure can be prepared based on the sequence of a non-human monoclonal antibody prepared as described above.
- DNA encoding the heavy and light chain immunoglobulins can be obtained from the non- human hybridoma of interest and engineered to contain non-murine (e.g., human) immunoglobulin sequences using standard molecular biology techniques.
- murine variable regions can be linked to human constant regions using methods known in the art (see e.g., U.S. Patent No. 4,816,567 to Cabilly et a L).
- murine CDR regions can be inserted into a human framework using methods known in the art (see e.g., U.S. Patent No. 5,225,539 to Winter, and U.S. Patent Nos. 5,530,101 ; 5,585,089; 5,693,762 and 6, 180,370 to Queen et al.).
- the antibodies of this disclosure are human monoclonal antibodies.
- Such human monoclonal antibodies directed against CD 19 can be generated using transgenic or transchromosomic mice carrying parts of the human immune system rather than the mouse system.
- These transgenic and transchromosomic mice include mice referred to herein as the HuMAb Mouse* and KM Mouse* ' , respectively, and are collectively referred to herein as '"human Ig mice.”
- the HuMAb Mouse* (Medarex ® , Inc.) contains human immunoglobulin gene miniloci that encode unrearranged human heavy ( ⁇ and ⁇ ) and K light chain immunoglobulin sequences, together with targeted mutations that inactivate the endogenous ⁇ and K chain loci (see e.g., Lonberg, et al.
- mice exhibit reduced expression of mouse IgM or K, and in response to immunization, the introduced human heavy and light chain transgenes undergo class switching and somatic mutation to generate high affinity human IgG ⁇ monoclonal antibodies (Lonberg, N. et al. (1994), supra; reviewed in Lonberg, N. (1994) Handbook of Experimental Pharmacology 113 :49- 101 ; Lonberg, N. and Huszar, D. (1995) Intern. Rev. Immunol. L3: 65-93, and Harding, F. and Lonberg, N. (1995) Ann. N. Y. Acad. Sci. 764:536-546).
- a mouse carrying a human lambda light chain transgene can be crossbred with a mouse carrying a human heavy chain transgene (e.g., HCo7), and optionally also carrying a human kappa light chain transgene (e.g., KCo5) to create a mouse carrying both human heavy and light chain transgenes (see e.g.. Example 1).
- a human heavy chain transgene e.g., HCo7
- a human kappa light chain transgene e.g., KCo5
- human antibodies of this disclosure can be raised using a mouse that carries human immunoglobulin sequences on transgenes and transchomosomes, such as a mouse that carries a human heavy chain transgene and a human light chain transchromosome.
- This mouse is referred to herein as a '"KM mouse ® ", and is described in detail in PCT Publication WO 02/43478 to Ishida et al.
- transgenic animal systems expressing human immunoglobulin genes are available in the art and can be used to raise anti-CD 19 antibodies of this disclosure.
- an alternative transgenic system referred to as the Xenomouse (Abgenix, Inc.) can be used; such mice are described in, for example, U.S. Patent Nos. 5,939,598; 6,075, 181; 6,114,598; 6,150,584 and 6, 162,963 to Kucherlapati et al.
- mice carrying both a human heavy chain transchromosome and a human light chain tranchromosome referred to as "TC mice” can be used; such mice are described in Tomizuka et al. (2000) Proc. Natl. Acad. Sci. USA 92:122-121.
- cows carrying human heavy and light chain transchromosomes have been described in the art ⁇ e.g., Kuroiwa et al. (2002) Nature Biotechnology 20:889-894 and PCT application No. WO 2002/092812) and can be used to raise anti-CD 19 antibodies of this disclosure.
- Human monoclonal antibodies of this disclosure can also be prepared using phage display methods for screening libraries of human immunoglobulin genes.
- phage display methods for isolating human antibodies are established in the art. See for example: U.S. Patent Nos. 5,223,409; 5,403,484; and 5,571,698 to Ladner et al; U.S. Patent Nos. 5,427,908 and 5,580,717 to Dower et al.; U.S. Patent Nos. 5,969,108 and 6,172,197 to McCafferty et al.; and U.S. Patent Nos. 5,885,793; 6,521,404; 6,544,731; 6,555,313; 6,582,9130, 6,582,915 and 6,593,081 to Griffiths et al.
- Human monoclonal antibodies of this disclosure can also be prepared using SCID mice into which human immune cells have been reconstituted such that a human antibody response can be generated upon immunization.
- SCID mice into which human immune cells have been reconstituted such that a human antibody response can be generated upon immunization.
- Such mice are described in, for example, U.S. Patent Nos. 5,476,996 and 5,698,767 to Wilson et al.
- human anti-CD 19 antibodies are prepared using a combination of human Ig mouse and phage display techniques, as described in U.S. Patent No. 6,794,132 by Buechler et al. More specifically, the method first involves raising an anti-CD 19 antibody response in a human Ig mouse (such as a HuMab mouse or KM mouse as described above) by immunizing the mouse with one or more CD 19 antigens, followed by isolating nucleic acids encoding human antibody chains from lymphatic cells of the mouse and introducing these nucleic acids into a display vector ⁇ e.g., phage) to provide a library of display packages.
- a human Ig mouse such as a HuMab mouse or KM mouse as described above
- each library member comprises a nucleic acid encoding a human antibody chain and each antibody chain is displayed from the display package.
- the library then is screened with CD 19 protein to isolate library members that specifically bind to CD 19.
- Nucleic acid inserts of the selected library members then are isolated and sequenced by standard methods to determine the light and heavy chain variable sequences of the selected CD 19 binders.
- the variable regions can be converted to full-length antibody chains by standard recombinant DNA techniques, such as cloning of the variable regions into an expression vector that carries the human heavy and light chain constant regions such that the Vn region is operatively linked to the Cn region and the V 1 region is operatively linked to the C L region.
- mice When human Ig mice are used to raise human antibodies of this disclosure, such mice can be immunized with a purified or enriched preparation of CD 19 antigen and/or recombinant CD 19, or cells expressing a CD 19 protein, or a CD 19 fusion protein, as described by Lonberg, N. et al. (1994) Nature 368(6474): 856-859; Fishwild, D. et al. (1996) Nature Biotechnology W: 845-851 ; and PCT Publication WO 98/24884 and WO 01/14424.
- the mice will be 6-16 weeks of age upon the first infusion.
- a purified or recombinant preparation (5-50 ⁇ g) of CD 19 antigen can be used to immunize the human Ig mice intraperitoneally and/or subcutaneously.
- the immunogen used to raise the antibodies of this disclosure is a CD 19 fusion protein comprising the extracellular domain of a CD 19 protein, fused at its N-terminus to a non- CD ⁇ polypeptide (e.g., a His tag) (described further in Example 1).
- Example I Detailed procedures to generate fully human monoclonal antibodies that bind to human CD 19 are described in Example I below. Cumulative experience with various antigens has shown that the transgenic mice respond when initially immunized intraperitoneally (IP) with antigen in complete Freund's adjuvant, followed by every other week IP immunizations (up to a total of 6) with antigen in incomplete Freund's adjuvant. However, adjuvants other than Freund's are also found to be effective (e.g., RIBI adjuvant). In addition, whole cells in the absence of adjuvant are found to be highly immunogenic. The immune response can be monitored over the course of the immunization protocol with plasma samples being obtained by retroorbital bleeds.
- mice with sufficient titers of anti-CD 19 human immunoglobulin can be used for fusions.
- Mice can be boosted intravenously with antigen, for example 3 days before sacrifice and removal of the spleen. It is expected that 2-3 fusions for each immunization may need to be performed. Between 6 and 24 mice are typically immunized for each antigen.
- HCo7 and HCo 12 strains are used.
- both HCo7 and HCo 12 transgene can be bred together into a single mouse having two different human heavy chain transgenes (HCo7/HCol2).
- the KM Mouse 1 " strain can be used..
- splenocytes and/or lymph node cells from immunized mice can be isolated and fused to an appropriate immortalized cell line, such as a mouse myeloma cell line.
- an appropriate immortalized cell line such as a mouse myeloma cell line.
- the resulting hybridomas can be screened for the production of antigen-specific antibodies.
- single cell suspensions of splenic lymphocytes from immunized mice can be fused to one-sixth the number of P3X63-Ag8.653 nonsecreting mouse myeloma cells (ATCC, CRL 1580) with 50% PEG.
- the single cell suspension of splenic lymphocytes from immunized mice can be fused using an electric field based electrofusion method, using a CytoPulse large chamber cell fusion electroporator (CytoPulse Sciences, Inc., Glen Burnie Maryland).
- Cells are plated at approximately 2 x 10 in flat bottom microti ter plate, followed by a two week incubation in selective medium containing 20% fetal Clone Serum, 18% "653" conditioned media, 5% origen (IGEN), 4 mM L-glutamine, 1 mM sodium pyruvate, 5mM HEPES, 0.055 mM 2-mercaptoethanol, 50 units/ml penicillin, 50 mg/ml streptomycin, 50 mg/ml gentamycin and IX HAT (Sigma; the HAT is added 24 hours after the fusion). After approximately two weeks, cells can be cultured in medium in which the HAT is replaced with HT.
- selective medium containing 20% fetal Clone Serum, 18% "653" conditioned media, 5% origen (IGEN), 4 mM L-glutamine, 1 mM sodium pyruvate, 5mM HEPES, 0.055 mM 2-mercaptoethanol, 50 units/ml penicillin,
- selected hybridomas can be grown in two-liter spinner-flasks for monoclonal antibody purification.
- Supernatants can be filtered and concentrated before affinity chromatography with protein A-sepharose (Pharmacia, Piscataway, NJ.).
- Eluted IgG can be checked by gel electrophoresis and high performance liquid chromatography to ensure purity.
- the buffer solution can be exchanged into PBS, and the concentration can be determined by OD280 using 1.43 extinction coefficient.
- the monoclonal antibodies can be aliquoted and stored at -80° C.
- Antibodies of this disclosure also can be produced in a host cell transfectoma using, for example, a combination of recombinant DNA techniques and gene transfection methods as is well known in the art (e.g., Morrison, S. (1985) Science 229: 1202).
- DNAs encoding partial or full-length light and heavy chains can be obtained by standard molecular biology techniques (e.g., PCR amplification or cDNA cloning using a hybridoma that expresses the antibody of interest) and the DNAs can be inserted into expression vectors such that the genes are operatively linked to transcriptional and translational control sequences.
- operatively linked is intended to mean that an antibody gene is ligated into a vector such that transcriptional and translational control sequences within the vector serve their intended function of regulating the transcription and translation of the antibody gene.
- the expression vector and expression control sequences are chosen to be compatible with the expression host cell used.
- the antibody light chain gene and the antibody heavy chain gene can be inserted into separate vector or, more typically, both genes are inserted into the same expression vector.
- the antibody genes are inserted into the expression vector by standard methods (e.g., ligation of complementary restriction sites on the antibody gene fragment and vector, or blunt end ligation if no restriction sites are present).
- the light and heavy chain variable regions of the antibodies described herein can be used to create full-length antibody genes of any antibody isotype by inserting them into expression vectors already encoding heavy chain constant and light chain constant regions of the desired isotype such that the V H segment is operatively linked to the C M segment(s) within the vector and the V K segment is operatively linked to the C 1 . segment within the vector.
- the recombinant expression vector can encode a signal peptide that facilitates secretion of the antibody chain from a host cell.
- the antibody chain gene can be cloned into the vector such that the signal peptide is linked in-frame to the amino terminus of the antibody chain gene.
- the signal peptide can be an immunoglobulin signal peptide or a heterologous signal peptide (i.e., a signal peptide from a non- immunoglobulin protein).
- the recombinant expression vectors of this disclosure carry regulatory sequences that control the expression of the antibody chain genes in a host cell.
- the term "regulatory sequence” is intended to include promoters, enhancers and other expression control elements (e.g., polyadenylation signals) that control the transcription or translation of the antibody chain genes.
- Such regulatory sequences are described, for example, in Goeddel (Gene Expression Technology. Methods in Enzymology 185, Academic Press, San Diego, CA (1990)). It will be appreciated by those skilled in the art that the design of the expression vector, including the selection of regulatory sequences, may depend on such factors as the choice of the host cell to be transformed, the level of expression of protein desired, etc.
- Preferred regulatory sequences for mammalian host cell expression include viral elements that direct high levels of protein expression in mammalian cells, such as promoters and/or enhancers derived from cytomegalovirus (CMV), Simian Virus 40 (SV40), adenovirus, (e.g., the adenovirus major late promoter (AdMLP)) and polyoma.
- CMV cytomegalovirus
- SV40 Simian Virus 40
- AdMLP adenovirus major late promoter
- nonviral regulatory sequences may be used, such as the ubiquitin promoter or ⁇ -globin promoter.
- regulatory elements composed of sequences from different sources such as the SRa promoter system, " which contains sequences from the SV40 early promoter and the long terminal repeat of human T cell leukemia virus type 1 (Takebe, Y. et al. (1988) MoL Cell. Biol. 8:466-472).
- the recombinant expression vectors of this disclosure may carry additional sequences, such as sequences that regulate replication of the vector in host cells (e.g., origins of replication) and selectable marker genes.
- the selectable marker gene facilitates selection of host cells into which the vector has been introduced (see, e.g., U.S. Pat. Nos. 4,399,216, 4,634,665 and 5,179,017, all by Axel et al ).
- the selectable marker gene confers resistance to drugs, such as G418, hygromycin or methotrexate, on a host cell into which the vector has been introduced.
- Preferred selectable marker genes include the dihydrofolate reductase (DHFR) gene (for use in dhfr- host cells with methotrexate selection/amplification) and the neo gene (for G418 selection).
- DHFR dihydrofolate reductase
- neo gene for G418 selection.
- the expression vector(s) encoding the heavy and light chains is transfected into a host cell by standard techniques.
- the various forms of the term "transfection" are intended to encompass a wide variety of techniques commonly used for the introduction of exogenous DNA into a prokaryotic or eukaryotic host cell, e.g., electroporation, calcium-phosphate precipitation, DEAE- dextran transfection and the like.
- Preferred mammalian host cells for expressing the recombinant antibodies of this disclosure include Chinese Hamster Ovary (CHO cells) (including dhfr ' CHO cells, described in Urlaub and Chasin, (1980) Proc. Natl. Acad. Sci. USA 77:4216-4220, used with a DHFR selectable marker, e.g., as described in R. J. Kaufman and P. A. Sharp (1982) J. MoL Biol. 159:601-621), NSO myeloma cells, COS cells and SP2 cells.
- Chinese Hamster Ovary CHO cells
- dhfr ' CHO cells described in Urlaub and Chasin, (1980) Proc. Natl. Acad. Sci. USA 77:4216-4220, used with a DHFR selectable marker, e.g., as described in R. J. Kaufman and P. A. Sharp (1982) J. MoL Biol. 159:601-621
- another preferred expression system is the GS gene expression system disclosed in WO 87/04462 (to Wilson), WO 89/01036 (to Bebbington) and EP 338,841 (to Bebbington).
- the antibodies are produced by culturing the host cells for a period of time sufficient to allow for expression of the antibody in the host cells or, more preferably, secretion of the antibody into the culture medium in which the host cells are grown.
- Antibodies can be recovered from the culture medium using standard protein purification methods.
- Antibodies of this disclosure can be tested for binding to human CD 19 by, for example, standard ELISA. Briefly, microtiter plates are coated with purified at 0.25 ⁇ g/ml in PBS, and then blocked with 5% bovine serum albumin in PBS. Dilutions of antibody (e.g., dilutions of plasma from CD19-immunized mice) are added to each well and incubated for 1-2 hours at 37 0 C. The plates are washed with PBS/Tween and then incubated with secondary reagent (e.g., for human antibodies, a goat-anti-human IgG Fc- specific polyclonal reagent) conjugated to alkaline phosphatase for 1 hour at 37°C. After washing, the plates are developed with pNPP substrate (1 mg/ml), and analyzed at OD of 405-650. Preferably, mice which develop the highest titers will be used for fusions.
- secondary reagent e.g., for human antibodies
- An ELISA assay as described above can also be used to screen for hybridomas that show positive reactivity with CD 19 immunogen.
- Hybridomas that bind with high avidity and/or affinity to a CD 19 protein are subcloned and further characterized.
- One clone from each hybridoma, which retains the reactivity of the parent cells (by ELISA) can be chosen for making a 5-10 vial cell bank stored at -140 0 C, and for antibody purification.
- selected hybridomas can be grown in two-liter spinner-flasks for monoclonal antibody purification.
- Supernatants can be filtered and concentrated before affinity chromatography with protein A-sepharose (Pharmacia, Piscataway, NJ).
- Eluted IgG can be checked by gel electrophoresis and high performance liquid chromatography to ensure purity.
- the buffer solution can be exchanged into PBS, and the concentration can be determined by OD280 using 1.43 extinction coefficient.
- the monoclonal antibodies can be aliquoted and stored at -80 0 C. To determine if the selected anti-CD 19 monoclonal antibodies bind to unique epitopes, each antibody can be biotinylated using commercially available reagents
- isotype ELISAs can be performed using reagents specific for antibodies of a particular isotype. For example, to determine the isotype of a human monoclonal antibody, wells of microtiter plates can be coated with 1 ⁇ g/ml of anti-human immunoglobulin overnight at 4°C.
- the plates After blocking with 1% BSA, the plates are reacted with 1 ⁇ g /ml or less of test monoclonal antibodies or purified isotype controls, at ambient temperature for one to two hours. The wells can then be reacted with either human IgGl or human IgM-specific alkaline phosphatase-conjugated probes. Plates are developed and analyzed as described above.
- Anti-CD 19 human IgGs can be further tested for reactivity with CD 19 antigen by Western blotting. Briefly, CD 19 can be prepared and subjected to sodium dodecyl sulfate polyacrylamide gel electrophoresis. After electrophoresis, the separated antigens are transferred to nitrocellulose membranes, blocked with 10% fetal calf serum, and probed with the monoclonal antibodies to be tested. Human IgG binding can be detected using anti-human IgG alkaline phosphatase and developed with BCIP/NBT substrate tablets (Sigma Chem. Co., St. Louis, Mo.).
- the binding specificity of an antibody of this disclosure may also be determined by monitoring binding of the antibody to cells expressing a CD 19 protein, for example by flow cytometry.
- Cells or cell lines that naturally expresses CD 19 protein such OVCAR3, NCI-H226, CFPAC-I or KB cells (described further in Example 3) may be used or a cell line, such as a CHO cell line, may be transfected with an expression vector encoding CD 19 such that CD 19 is expressed on the surface of the cells.
- the transfected protein may comprise a tag, such as a myc-tag or a his-tag, preferably at the N-terminus, for detection using an antibody to the tag.
- Binding of an antibody of this disclosure to a CD 19 protein may be determined by incubating the transfected cells with the antibody, and detecting bound antibody. Binding of an antibody to the tag on the transfected protein may be used as a positive control.
- the present disclosure features bispecific molecules comprising an anti-CD 19 antibody, or a fragment thereof, of this disclosure.
- An antibody of this disclosure, or antigen-binding portions thereof can be derivatized or linked to another functional molecule, e.g., another peptide or protein (e.g., another antibody or ligand for a receptor) to generate a bispecific molecule that binds to at least two different binding sites or target molecules.
- the antibody of this disclosure may in fact be derivatized or linked to more than one other functional molecule to generate multispecific molecules that bind to more than two different binding sites and/or target molecules; such multispecific molecules are also intended to be encompassed by the term "bispecific molecule" as used herein.
- an antibody of this disclosure can be functionally linked (e.g., by chemical coupling, genetic fusion, noncovalent association or otherwise) to one or more other binding molecules, such as another antibody, antibody fragment, peptide or binding mimetic, such that a bispecific molecule results.
- the present disclosure includes bispecific molecules comprising at least one first binding specificity for CD 19 and a second binding specificity for a second target epitope.
- the second target epitope is an Fc receptor, e.g., human Fc ⁇ RI (CD64) or a human Fc ⁇ receptor (CD89). Therefore, this disclosure includes bispecific molecules capable of binding both to Fc ⁇ R or Fc ⁇ R expressing effector cells (e.g., monocytes, macrophages or polymorphonuclear cells
- the molecule can further include a third binding specificity, in addition to an anti-Fc binding specificity and an anti-CD 19 binding specificity.
- the third binding specificity is an anti-enhancement factor (EF) portion, e.g..
- the "anti-enhancement factor portion” can be an antibody, functional antibody fragment or a ligand that binds to a given molecule, e.g., an antigen or a receptor, and thereby results in an enhancement of the effect of the binding determinants for the Fc receptor or target cell antigen.
- the "anti-enhancement factor portion” can bind an Fc receptor or a target cell antigen.
- the anti- enhancement factor portion can bind to an entity that is different from the entity to which the first and second binding specificities bind.
- the anti-enhancement factor portion can bind a cytotoxic T-cell (e.g., via CD2, CD3, CD8, CD28, CD4, CD40, ICAM-I or other immune cell that results in an increased immune response against the target cell).
- the bispecific molecules of this disclosure comprise as a binding specificity at least one antibody, or an antibody fragment thereof, including, e.g., an Fab, Fab', F(ab') 2 , Fv, Fd, dAb or a single chain Fv.
- the antibody may also be a light chain or heavy chain dimer, or any minimal fragment thereof such as a Fv or a single chain construct as described in U.S. Patent No.
- the binding specificity for an Fc ⁇ receptor is provided by a monoclonal antibody, the binding of which is not blocked by human immunoglobulin G (IgG).
- IgG receptor refers to any of the eight ⁇ -chain genes located on chromosome 1. These genes encode a total of twelve transmembrane or soluble receptor isoforms which are grouped into three Fc ⁇ receptor classes: Fc ⁇ RI (CD64), Fc ⁇ RII(CD32), and Fc ⁇ RIII (CD 16).
- the Fc ⁇ receptor a human high affinity Fc ⁇ RI.
- the human Fc ⁇ RI is a 72 kDa molecule, which shows high affinity for monomeric IgG (10 b - 10 ⁇ M "1 ).
- the hybridoma producing mAb 32 is available from the American Type Culture Collection, ATCC Accession No. HB9469.
- the anti-Fc ⁇ receptor antibody is a humanized form of monoclonal antibody 22 (H22).
- H22 monoclonal antibody 22
- the production and characterization of the H22 antibody is described in Graziano, R. F. et al. (1995) J. Immunol 155 (10): 4996-5002 and PCT Publication WO 94/10332 to Tempest et al..
- the H22 antibody producing cell line was deposited at the American Type Culture Collection under the designation HA022CL1 and has the accession no. CRL 1 1 177.
- the binding specificity for an Fc receptor is provided by an antibody that binds to a human IgA receptor, e.g., an Fc-alpha receptor (Fc ⁇ RI (CD89)), the binding of which is preferably not blocked by human immunoglobulin A (IgA).
- IgA receptor is intended to include the gene product of one ⁇ -gene (Fc ⁇ RI) located on chromosome 19. This gene is known to encode several alternatively spliced transmembrane isoforms of 55 to 1 10 kDa.
- Fc ⁇ RI (CD89) is constitutively expressed on monocytes/macrophages, eosinophilic and neutrophilic granulocytes, but not on non-effector cell populations.
- Fc ⁇ RI has medium affinity (« 5 ⁇ 10 7 M "1 ) for both IgAl and IgA2, which is increased upon exposure to cytokines such as G-CSF or GM-CSF (Morton, H.C. et al. ( 1996) Critical Reviews in Immunology J_6:423-440).
- cytokines such as G-CSF or GM-CSF
- Fc ⁇ RI and Fc ⁇ RI are preferred trigger receptors for use in the bispecific molecules of this disclosure because they are ( 1 ) expressed primarily on immune effector cells, e.g., monocytes, PMNs, macrophages and dendritic cells; (2) expressed at high levels (e.g., 5,000-100,000 per cell); (3) mediators of cytotoxic activities (e.g., ADCC, phagocytosis); and (4) mediate enhanced antigen presentation of antigens, including self- antigens, targeted to them. While human monoclonal antibodies are preferred, other antibodies which can be employed in the bispecific molecules of this disclosure are murine, chimeric and humanized monoclonal antibodies.
- the bispecific molecules of the present disclosure can be prepared by conjugating the constituent binding specificities, e.g., the anti-FcR and anti-CD 19 binding specificities, using methods known in the art. For example, each binding specificity of the bispecific molecule can be generated separately and then conjugated to one another. When the binding specificities are proteins or peptides, a variety of coupling or cross- linking agents can be used for covalent conjugation.
- cross-linking agents examples include protein A, carbodiimide, N-succinimidyl-S-acetyl-thioacetate (SATA), 5,5'- dithiobis(2-nitrobenzoic acid) (DTNB), o-phenylenedimaleimide (oPDM), N- succinimidyl-3-(2-pyridyldithio)propionate (SPDP), and sulfosuccinimidyl 4-(N- maleimidomethyl) cyclohaxane-1-carboxylate (sulfo-SMCC) (see e.g., Karpovsky et al. (1984) J. Exp. Med.
- Preferred conjugating agents are SATA and sulfo-SMCC, both available from Pierce Chemical Co. (Rockford, IL).
- the binding specificities are antibodies, they can be conjugated via sulfhydryl bonding of the C-terminus hinge regions of the two heavy chains.
- the hinge region is modified to contain an odd number of sulfhydryl residues, preferably one, prior to conjugation.
- both binding specificities can be encoded in the same vector and expressed and assembled in the same host cell.
- This method is particularly useful where the bispecific molecule is a mAb x mAb, mAb x Fab, Fab x F(ab') 2 or ligand x Fab fusion protein.
- a bispecific molecule of this disclosure can be a single chain molecule comprising one single chain antibody and a binding determinant, or a single chain bispecific molecule comprising two binding determinants. Bispecific molecules may comprise at least two single chain molecules. Methods for preparing bispecific molecules are described for example in U.S.
- Binding of the bispecific molecules to their specific targets can be confirmed by, for example, enzyme-linked immunosorbent assay (ELISA), radioimmunoassay (RIA), FACS analysis, bioassay (e.g., growth inhibition), or Western Blot assay.
- ELISA enzyme-linked immunosorbent assay
- RIA radioimmunoassay
- FACS fluorescence-activated cell sorting
- bioassay e.g., growth inhibition
- Western Blot assay Western Blot assay.
- Each of these assays generally detects the presence of protein-antibody complexes of particular interest by employing a labeled reagent (e.g., an antibody) specific for the complex of interest.
- a labeled reagent e.g., an antibody
- the FcR-antibody complexes can be detected using e.g., an enzyme-linked antibody or antibody fragment which recognizes and specifically binds to the antibody- FcR complexes.
- the antibody can be radioactively labeled and used in a radioimmunoassay (RIA) (see, for example, Weintraub, B., Principles of Radioimmunoassays, Seventh Training Course on Radioligand Assay Techniques, The Endocrine Society, March, 1986, which is incorporated by reference herein).
- RIA radioimmunoassay
- the radioactive isotope can be detected by such means as the use of aycounter or a scintillation counter or by autoradiography.
- the present invention provides for antibody-partner conjugates where the antibody is linked to the partner through a chemical linker.
- the linker is a peptidyl linker, and is depicted herein as (L 4 ) p — F — (L 1 ) m .
- Other linkers include hydrazine and disulfide linkers, and is depicted herein as (L 4 ) p — H — (L 1 ) m or (L 4 ) p — J— (L 1 ) m , respectively.
- the present invention also provides cleavable linker arms that are appropriate for attachment to essentially any molecular species.
- linker arm aspect of the invention is exemplified herein by reference to their attachment to a therapeutic moiety. It will, however, be readily apparent to those of skill in the art that the linkers can be attached to diverse species including, but not limited to, diagnostic agents, analytical agents, biomolecules, targeting agents, detectable labels and the like.
- the present invention relates to linkers that are useful to attach targeting groups to therapeutic agents and markers.
- the invention provides linkers that impart stability to compounds, reduce their in vivo toxicity, or otherwise favorably affect their pharmacokinetics, bioavailability and/or pharmacodynamics. It is generally preferred that in such embodiments, the linker is cleaved, releasing the active drug, once the drug is delivered to its site of action.
- the linkers of the invention are traceless, such that once removed from the therapeutic agent or marker (such as during activation), no trace of the linker's presence remains.
- the linkers are characterized by their ability to be cleaved at a site in or near the target cell such as at the site of therapeutic action or marker activity. Such cleavage can be enzymatic in nature. This feature aids in reducing systemic activation of the therapeutic agent or marker, reducing toxicity and systemic side effects. Preferred cleavable groups for enzymatic cleavage include peptide bonds, ester linkages, and disulfide linkages.
- the linkers are sensitive to pH and are cleaved through changes in pH. An important aspect of the current invention is the ability to control the speed with which the linkers cleave. Often a linker that cleaves quickly is desired.
- a linker that cleaves more slowly may be preferred.
- WO 02/096910 provides several specific ligand-drug complexes having a hydrazine linker.
- the linker composition dependent upon the rate of cyclization required, and the particular compounds described cleave the ligand from the drug at a slower rate than is preferred for many drug-linker conjugates.
- the hydrazine linkers of the current invention provide for a range of cyclization rates, from very fast to very slow, thereby allowing for the selection of a particular hydrazine linker based on the desired rate of cyclization.
- very fast cyclization can be achieved with hydrazine linkers that produce a single 5-membered ring upon cleavage.
- Preferred cyclization rates for targeted delivery of a cytotoxic agent to cells are achieved using hydrazine linkers that produce, upon cleavage, either two 5-membered rings or a single 6-membered ring resulting from a linker having two methyls at the geminal position.
- the gx-w-dimethyl effect has been shown to accelerate the rate of the cyclization reaction as compared to a single 6- membered ring without the two methyls at the geminal position. This results from the strain being relieved in the ring.
- substitutents may slow down the reaction instead of making it faster. Often the reasons for the retardation can be traced to steric hindrance.
- the gem dimethyl substitution allows for a much faster cyclization reaction to occur compared to when the geminal carbon is a CHi.
- a linker that cleaves more slowly may be preferred.
- a linker which cleaves more slowly may be useful.
- a slow rate of cyclization is achieved using a hydrazine linker that produces, upon cleavage, either a single 6-membered ring, without the gem-dimethyl substitution, or a single 7-membered ring.
- the linkers also serve to stabilize the therapeutic agent or marker against degradation while in circulation. This feature provides a significant benefit since such stabilization results in prolonging the circulation half-life of the attached agent or marker.
- the linker also serves to attenuate the activity of the attached agent or marker so that the conjugate is relatively benign while in circulation and has the desired effect, for example is toxic, after activation at the desired site of action.
- this feature of the linker serves to improve the therapeutic index of the agent.
- the stabilizing groups are preferably selected to limit clearance and metabolism of the therapeutic agent or marker by enzymes that may be present in blood or non-target tissue and are further selected to limit transport of the agent or marker into the cells.
- the stabilizing groups serve to block degradation of the agent or marker and may also act in providing other physical characteristics of the agent or marker.
- the stabilizing group may also improve the agent or marker's stability during storage in either a formulated or non-formulated form.
- the stabilizing group is useful to stabilize a therapeutic agent or marker if it serves to protect the agent or marker from degradation when tested by storage of the agent or marker in human blood at 37°C for 2 hours and results in less than 20%, preferably less than 10%, more preferably less than 5% and even more preferably less than 2%, cleavage of the agent or marker by the enzymes present in the human blood under the given assay conditions.
- the present invention also relates to conjugates containing these linkers. More particularly, the invention relates to prodrugs that may be used for the treatment of disease, especially for cancer chemotherapy. Specifically, use of the linkers described herein provide for prodrugs that display a high specificity of action, a reduced toxicity, and an improved stability in blood relative to prodrugs of similar structure.
- linkers of the present invention as described herein may be present at a variety of positions within the partner molecule.
- linker that may contain any of a variety of groups as part of its chain that will cleave in vivo, e.g., in the blood stream, at a rate which is enhanced relative to that of constructs that lack such groups.
- conjugates of the linker amis with therapeutic and diagnostic agents are useful to form prodrug analogs of therapeutic agents and to reversibly link a therapeutic or diagnostic agent to a targeting agent, a detectable label, or a solid support.
- the linkers may be incorporated into complexes that include a cytotoxin.
- Activation of a prodrug may be achieved by an esterase, both within tumor cells and in several normal tissues, including plasma.
- the level of relevant esterase activity in humans has been shown to be very similar to that observed in rats and non-human primates, although less than that observed in mice.
- Activation of a prodrug may also be achieved by cleavage by glucuronidase.
- one or more self-immolative linker groups L 1 are optionally introduced between the cytotoxin and the targeting agent.
- linker groups may also be described as spacer groups and contain at least two reactive functional groups.
- one chemical functionality of the spacer group bonds to a chemical functionality of the therapeutic agent, e.g., cytotoxin, while the other chemical functionality of the spacer group is used to bond to a chemical functionality of the targeting agent or the cleavable linker.
- Examples of chemical functionalities of spacer groups include hydroxy, mercapto, carbonyl, carboxy, amino, ketone, and mercapto groups.
- the self-immolative linkers represented by L 1 , are generally a substituted or unsubstituted alkyl, substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl or substituted or unsubstituted heteroalkyl group.
- the alkyl or aryl groups may comprise between 1 and 20 carbon atoms. They may also comprise a polyethylene glycol moiety.
- Exemplary spacer groups include, for example, 6-aminohexanol, 6- mercaptohexanol, 10-hydroxydecanoic acid, glycine and other amino acids, 1 ,6- hexanediol, ⁇ -alanine, 2-aminoethanol, cysteamine (2-aminoethanethiol), 5- aminopentanoic acid, 6-aminohexanoic acid, 3-maleimidobenzoic acid, phthalide, ⁇ - substituted phthalides, the carbonyl group, aminal esters, nucleic acids, peptides and the like.
- the spacer can serve to introduce additional molecular mass and chemical functionality into the cytotoxin-targeting agent complex. Generally, the additional mass and functionality will affect the serum half-life and other properties of the complex. Thus, through careful selection of spacer groups, cytotoxin complexes with a range of serum half-lives can be produced.
- the spacer(s) located directly adjacent to the drug moiety is also denoted as (L 1 ),,,, wherein m is an integer selected from 0, 1, 2, 3, 4, 5, and 6.
- L 1 may be any self- immolative group.
- L 4 is a linker moiety that preferably imparts increased solubility or decreased aggregation properties to conjugates utilizing a linker that contains the moiety or modifies the hydrolysis rate of the conjugate.
- the L 4 linker does not have to be self immolative.
- the L 4 moiety is substituted alkyl, unsubstituted alkyl, substituted aryl, unsubstituted aryl, substituted heteroalkyl, or unsubstituted heteroalkyl, any of which may be straight, branched, or cyclic.
- the substitutions may be, for example, a lower (C '-C 6 ) alkyl, alkoxy, aklylthio, alkylamino, or dialkylamino.
- L comprises a non-cyclic moiety.
- L comprises any positively or negatively charged amino acid polymer, such as polylysine or polyargenine.
- L 4 can comprise a polymer such as a polyethylene glycol moiety.
- the L 4 linker can comprise, for example, both a polymer component and a small chemical moiety.
- L 4 comprises a polyethylene glycol (PEG) moiety.
- the PEG portion of L 4 may be between 1 and 50 units long.
- the PEG will have 1-12 repeat units, more preferably 3-12 repeat units, more preferably 2-6 repeat units, or even more preferably 3-5 repeat units and most preferably 4 repeat units.
- L 4 may consist solely of the PEG moiety, or it may also contain an additional substituted or unsubstituted alkyl or heteroalkyl. It is useful to combine PEG as part of the L 4 moiety to enhance the water solubility of the complex. Additionally, the PEG moiety reduces the degree of aggregation that may occur during the conjugation of the drug to the antibody.
- L comprises
- R 20 is a member selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, and acyl.
- Each R 25 , R 25 , R 26 , and R 26 is independently selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl, and substituted or unsubstituted heterocycloalkyl; and s and t are independently integers from 1 to 6.
- R " °.
- R 2 ⁇ R 2 * , R 26 and R 26 are hydrophobic.
- R 20 is H or alkyl (preferably, unsubstituted lower alkyl).
- R 25 , R 25 , R 26 and R 26 are independently H or alkyl (preferably, unsubstituted C 1 to C 4 alkyl).
- R 23 , R 23 , R 26 and R 26 are all H.
- t is 1 and s is 1 or 2.
- the peptidyl linkers of the invention can be represented by the general formula: (L 4 ) p — F — (L 1 ) m , wherein F represents the linker portion comprising the peptidyl moiety.
- the F portion comprises an optional additional self-immolative linker(s), L 2 , and a carbonyl group.
- the F portion comprises an amino group and an optional spacer group(s), L 3 .
- the conjugate comprising the peptidyl linker comprises a structure of the following formula (a):
- L 1 is a self-immolative linker, as described above, and L 4 is a moiety that preferably imparts increased solubility, or decreased aggregation properties, or modifies the hydrolysis rate, as described above.
- L 2 represents a self-immolative linker(s).
- m is 0, 1, 2, 3, 4, 5, or 6; and o and p are independently 0 or 1.
- AA 1 represents one or more natural amino acids, and/or unnatural ⁇ -amino acids; c is an integer from 1 and 20. In some embodiments, c is in the range of 2 to 5 or c is 2 or 3.
- AA 1 is linked, at its amino terminus, either directly to L 4 or, when L 4 is absent, directly to the X 4 group (i.e., the targeting agent, detectable label, protected reactive functional group or unprotected reactive functional group).
- L 4 when L is present, L 4 does not comprise a carboxylic acyl group directly attached to the N-terminus of (AA ') c .
- there it is not necessary in these embodiments for there to be a carboxylic acyl unit directly between either L 4 or X 4 and AA 1 , as is necessary in the peptidic linkers of U.S. Patent No. 6,214,345.
- the conjugate comprising the peptidyl linker comprises a structure of the following formula (b):
- L 4 is a moiety that preferably imparts increased solubility, or decreased aggregation properties, or modifies the hydrolysis rate, as described above;
- L 3 is a spacer group comprising a primary or secondary amine or a carboxyl functional group, and either the amine of L 3 forms an amide bond with a pendant carboxyl functional group of D or the carboxyl of L 3 forms an amide bond with a pendant amine functional group of D; and o and p are independently 0 or 1.
- AA 1 represents one or more natural amino acids, and/or unnatural ⁇ -amino acids;
- c is an integer from 1 and 20.
- L is absent (i.e., m is 0 in the general formula).
- AA is linked, at its amino terminus, either directly to L 4 or, when L 4 is absent, directly to the X 4 group (i.e., the targeting agent, detectable label, protected reactive functional group or unprotected reactive functional group).
- L 4 when L 4 is present, L 4 does not comprise a carboxylic acyl group directly attached to the N-terminus of (AA ') c .
- carboxylic acyl unit directly between either L 4 or X 4 and AA 1 , as is necessary in the peptidic linkers of U.S. Patent No. 6,214,345.
- the self-immolative linker L 2 is a bifunctional chemical moiety which is capable of covalently linking together two spaced chemical moieties into a normally stable tripartate molecule, releasing one of said spaced chemical moieties from the tripartate molecule by means of enzymatic cleavage; and following said enzymatic cleavage, spontaneously cleaving from the remainder of the molecule to release the other of said spaced chemical moieties.
- the self-immolative spacer is covalently linked at one of its ends to the peptide moiety and covalently linked at its other end to the chemically reactive site of the drug moiety whose derivatization inhibits pharmacological activity, so as to space and covalently link together the peptide moiety and the drug moiety into a tripartate molecule which is stable and pharmacologically inactive in the absence of the target enzyme, but which is enzymatically cleavable by such target enzyme at the bond covalently linking the spacer moiety and the peptide moiety to thereby affect release of the peptide moiety from the tripartate molecule.
- Such enzymatic cleavage will activate the self-immolating character of the spacer moiety and initiate spontaneous cleavage of the bond covalently linking the spacer moiety to the drug moiety, to thereby affect release of the drug in pharmacologically active form.
- the self-immolative linker L 2 may be any self-immolative group.
- L 2 is a substituted alkyl, unsubstituted alkyl, substituted heteroalkyl, unsubstituted heteroalkyl, unsubstituted heterocycloalkyl, substituted heterocycloalkyl, substituted and unsubstituted aryl, and substituted and unsubstituted heteroaryl.
- One particularly preferred seif-immolative spacer L 2 may be represented by the formula (c):
- the aromatic ring of the aminobenzyl group may be substituted with one or more "K" groups.
- a “K” group is a substituent on the aromatic ring that replaces a hydrogen otherwise attached to one of the four non-substituted carbons that are part of the ring structure.
- the "K” group may be a single atom, such as a halogen, or may be a multi- atom group, such as alkyl, heteroalkyl, amino, nitro, hydroxy, alkoxy, haloalkyl, and cyano.
- Each K is independently selected from the group consisting of substituted alkyl, unsubstituted alkyl, substituted heteroalkyl, unsubstituted heteroalkyl, substituted aryl, unsubstituted aryl, substituted heteroaryl, unsubstituted heteroaryl, substituted heterocycloalkyl, unsubstituted heterocycloalkyl, halogen, NO 2 , NR 21 R 22 , NR 21 COR 22 , OCONR 21 R 22 , OCOR 21 , and OR 21 , wherein R 21 and R 22 are independently selected from the group consisting of H, substituted alkyl, unsubstituted alkyl, substituted heteroalkyl, unsubstituted heteroalkyl, substituted aryl, unsubstituted aryl, substituted heteroaryl, unsubstituted heteroaryl, substituted heterocycloalkyl and unsubstituted heterocycloalkyl.
- K substituents include, but are not limited to, F, Cl, Br, I, NO 2 , OH, OCH 3 , NHCOCH 3 , N(CHj) 2 , NHCOCF 3 and methyl.
- K 1 is an integer of O, 1 , 2, 3, or 4. In one preferred embodiment, / is O.
- the ether oxygen atom of the structure shown above is connected to a carbonyl group.
- the line from the NR 24 functionality into the aromatic ring indicates that the amine functionality may be bonded to any of the five carbons that both form the ring and are not substituted by the -CH 2 -O- group.
- the NR 24 functionality of X is covalently bound to the aromatic ring at the para position relative to the -CH 2 -O- group.
- R 24 is a member selected from the group consisting of H, substituted alkyl, unsubstituted alkyl, substituted heteroalkyl, and unsubstituted heteroalkyl. In a specific embodiment, R 24 is hydrogen.
- the invention provides a peptide linker of formula (a) above, wherein F comprises the structure:
- R 24 is selected from the group consisting of H, substituted alkyl, unsubstituted alkyl, substituted heteroalkyl, and unsubstituted heteroalkyl.
- Each K is a member independently selected from the group consisting of substituted alkyl, unsubstituted alkyl, substituted heteroalkyl, unsubstituted heteroalkyl, substituted aryl, unsubstituted aryl, substituted heteroaryl, unsubstituted heteroaryl, substituted heterocycloalkyl, unsubstituted heterocycloalkyl, halogen, NO 2 , NR 21 R 22 , NR 21 COR 22 , OCONR 21 R 22 , OCOR 21 , and OR 21 where R 21 and R 22 are independently selected from the group consisting of H, substituted alkyl, unsubstituted alkyl, substituted heteroalkyl, unsubstituted heteroalkyl, substituted aryl, unsubstituted
- the peptide linker of formula (a) above comprises a -F- (L 1 ),,,- that comprises the structure:
- each R » 2"4 i • s a member independently selected from the group consisting of H, substituted alkyl, unsubstituted alkyl, substituted heteroalkyl, and unsubstituted heteroalkyl.
- the self-immolative spacer L 1 or L " includes
- each R 17 , R 18 , and R 19 is independently selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl and substituted or unsubstituted aryl, and w is an integer from 0 to 4.
- R 17 and R 18 are independently H or alkyl (preferably, unsubstituted C 1-4 alkyl).
- R 17 and R are Cl -4 alkyl, such as methyl or ethyl.
- w is 0. While not wishing to be bound to any particular theory, it has been found experimentally that this particular self-immolative spacer cyclizes relatively quickly.
- L 1 or L 2 includes
- the spacer group L J is characterized in that it comprises a primary or secondary amine or a carboxyl functional group, and either the amine of the L group forms an amide bond with a pendant carboxyl functional group of D or the carboxyl of L J forms an amide bond with a pendant amine functional group of D.
- L 3 can be selected from the group consisting of substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, substituted or unsubstituted aryl, substituted or unsubstituted hteroaryl, or substituted or unsubstituted heterocycloalkyl.
- L 3 comprises an aromatic group. More preferably, L 3 comprises a benzoic acid group, an aniline group or indole group.
- Non-limiting examples of structures that can serve as an -L 3 -NH- spacer include the following structures:
- Z is a member selected from O, S and NR 23
- R 23 is a member selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, and acyl.
- the IS moiety Upon cleavage of the linker of the invention containing L 3 , the IS moiety remains attached to the drug, D. Accordingly, the L/ moiety is chosen such that its presence attached to D does not significantly alter the activity of D.
- a portion of the drug D itself functions as the L 3 spacer.
- the drug, D is a duocarmycin derivative in which a portion of the drug functions as the L spacer
- Non-hmiting examples of such embodiments include those in which NHo- (L 3 )-D has a structure selected fiom the group consisting of
- Z is a member selected fiom O, S and NR 2 ⁇ where R 2 ⁇ is a member selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, and acyl; and where the NH 2 group on each structure reacts with (AA ') c to form -(AA') C -NH-.
- the Peptide Sequence AA represents a single amino acid or a plurality of ammo acids that are joined together by amide bonds.
- the amino acids may be natural amino acids and/or unnatui al ⁇ -amino acids
- the peptide of the current invention is selected for directing enzyme-catalyzed cleavage of the peptide by an enzyme in a location of interest in a biological system.
- a peptide is chosen that is cleaved by one or more proteases that may exist in the extracellular matrix, e.g., due to release of the cellular contents of nearby dying cells, such that the peptide is cleaved extracellularly.
- the number of amino acids within the peptide can range from 1 to 20; but more preferably there will be 1-8 amino acids, 1-6 amino acids or 1, 2, 3 or 4 amino acids comprising (AA ') c .
- Peptide sequences that are susceptible to cleavage by specific enzymes or classes of enzymes are well known in the art. Many peptide sequences that are cleaved by enzymes in the serum, liver, gut, etc. are known in the art.
- An exemplary peptide sequence of the invention includes a peptide sequence that is cleaved by a protease. The focus of the discussion that follows on the use of a protease-sensitive sequence is for clarity of illustration and does not serve to limit the scope of the present invention.
- the linker When the enzyme that cleaves the peptide is a protease, the linker generally includes a peptide containing a cleavage recognition sequence for the protease.
- a cleavage recognition sequence for a protease is a specific amino acid sequence recognized by the protease during proteolytic cleavage.
- Many protease cleavage sites are known in the art, and these and other cleavage sites can be included in the linker moiety. See, e.g., Matayoshi et al. Science 2Al ⁇ 954 ( 1990); Dunn et al. Meth. Enzymol. 241 : 254 (1994); Seidah et al. Meth. Enzymol.
- the amino acids of the peptide sequence (AA') C are chosen based on their suitability for selective enzymatic cleavage by particular molecules such as tumor- associated protease.
- the amino acids used may be natural or unnatural amino acids. They may be in the L or the D configuration. In one embodiment, at least three different amino acids are used. In another embodiment, only two amino acids are used.
- the peptide sequence (AA') C is chosen based on its ability to be cleaved by a lysosomal proteases, non-limiting examples of which include cathepsins B, C, D, H, L and S.
- the peptide sequence (AA 1 ) c is capable of being cleaved by cathepsin B in vitro, which can be tested using in vitro protease cleavage assays known in the art.
- the peptide sequence (AA ') c is chosen based on its ability to be cleaved by a tumor-associated protease, such as a protease that is found extracellularly in the vicinity of tumor cells, non-limiting examples of which include thimet oligopeptidase (TOP) and CD 10.
- TOP thimet oligopeptidase
- the ability of a peptide to be cleaved by TOP or CD 10 can be tested using in vitro protease cleavage assays known in the art.
- Suitable, but non-limiting, examples of peptide sequences suitable for use in the conjugates of the invention include Val-Cit, Cit-Cit, Val-Lys, Phe-Lys, Lys-Lys, AIa- Lys, Phe-Cit, Leu-Cit, Ile-Cit, Tip, Gt, Phe-Ala, Phe-N 9 -tosyl-Arg, Phe-N 9 -nitro-Arg, Phe-Phe-Lys, D-Phe-Phe-Lys, Gly-Phe-Lys, Leu-Ala-Leu, Ile-Ala-Leu, Val-Ala-Val, Ala-Leu- Ala-Leu (SEQ ID NO:88), ⁇ -Ala-Leu- Ala-Leu (SEQ ID NO:89), Gly-Phe-Leu- GIy (SEQ ID NO:90), Val-Ala, Leu-Leu-Gly-Leu (SEQ
- the amino acid located the closest to the drug moiety is selected from the group consisting of: Ala, Asn, Asp, Cit, Cys, GIn, GIu, GIy, He, Leu, Lys, Met, Phe, Pro, Ser, Thr, Trp, Tyr, and VaL
- the amino acid located the closest to the drug moiety is selected from the group consisting of: Ala, Asn, Asp, Cys, GIn, GIu, GIy, He, Leu, Met, Phe, Pro, Ser, Thr, Trp, Tyr, and VaL
- Proteases have been implicated in cancer metastasis. Increased synthesis of the protease urokinase was correlated with an increased ability to metastasize in many cancers.
- Urokinase activates plasmin from plasminogen, which is ubiquitously located in the extracellular space and its activation can cause the degradation of the proteins in the extracellular matrix through which the metastasizing tumor cells invade. Plasmin can also activate the collagenases thus promoting the degradation of the collagen in the basement membrane surrounding the capillaries and lymph system thereby allowing tumor cells to invade into the target tissues (Dano, et al. Adv. Cancer. Res., 44: 139 (1985)).
- the invention also provides the use of peptide sequences that are sensitive to cleavage by tryptases.
- Human mast cells express at least four distinct tryptases. designated ⁇ ⁇ l, ⁇ lf, and ⁇ lll. These enzymes are not controlled by blood plasma proteinase inhibitors and only cleave a few physiological substrates in vitro.
- the tryptase family of serine proteases has been implicated in a variety of allergic and inflammatory diseases involving mast cells because of elevated tryptase levels found in biological fluids from patients with these disorders. However, the exact role of tryptase in the pathophysiology of disease remains to be delineated. The scope of biological functions and coi ⁇ esponding physiological consequences of tryptase are substantially defined by their substrate specificity.
- Tryptase is a potent activator of pro-urokinase plasminogen activator (uPA) the zymogen form of a protease associated with tumor metastasis and invasion. Activation of the plasminogen cascade, resulting in the destruction of extracellular matrix for cellular extravasation and migration, may be a function of tryptase activation of pro-urokinase plasminogen activator at the P4-P1 sequence of Pro-Arg-Phe-Lys (SEQ ID NO:91) (Stack, et al., Journal of Biological Chemistry 269 (13): 9416-9419 (1994)).
- uPA pro-urokinase plasminogen activator
- Vasoactive intestinal peptide a neuropeptide that is implicated in the regulation of vascular permeability, is also cleaved by tryptase, primarily at the Thr-Arg-Leu-Arg (SEQ ID NO:92) sequence (Tarn, et al., Am. J. Respir. Cell MoL Biol. 3: 27-32 (1990)).
- the G- protein coupled receptor PAR-2 can be cleaved and activated by tryptase at the Ser-Lys- GIy- Arg (SEQ ID NO:93) sequence to drive fibroblast proliferation, whereas the thrombin activated receptor PAR-I is inactivated by tryptase at the Pro-Asn-Asp-Lys (SEQ ID NO:94) sequence (Molino et al., Journal of Biological Chemistry 272(7): 4043- 4049 (1997)).
- SEQ ID NO:94 Pro-Asn-Asp-Lys
- the antibody-partner conjugate of the current invention may optionally contain two or more linkers. These linkers may be the same or different. For example, a peptidyl linker may be used to connect the drug to the ligand and a second peptidyl linker may attach a diagnostic agent to the complex. Other uses for additional linkers include linking analytical agents, biomolecules, targeting agents, and detectable labels to the antibody- partner complex.
- compounds of the invention that are poly- or multi-valent species, including, for example, species such as dimers, trimers, tetramers and higher homologs of the compounds of the invention or reactive analogues thereof.
- the poly- and multi-valent species can be assembled from a single species or more than one species of the invention.
- a dimeric construct can be "homo-dimeric" or 'lieterodimeric.' ' '
- poly- and multi-valent constructs in which a compound of the invention or a reactive analogue thereof, is attached to an oligomeric or polymeric framework are within the scope of the present invention.
- the framework is preferably polyfunctional (i.e. having an array of reactive sites for attaching compounds of the invention).
- the framework can be derivatized with a single species of the invention or more than one species of the invention.
- the present invention includes compounds that are functionalized to afford compounds having water-solubility that is enhanced relative to analogous compounds that are not similarly functionalized.
- any of the substituents set forth herein can be replaced with analogous radicals that have enhanced water solubility.
- additional water solubility is imparted by substitution at a site not essential for the activity towards the ion channel of the compounds set forth herein with a moiety that enhances the water solubility of the parent compounds.
- Such methods include, but are not limited to, functionalizing an organic nucleus with a permanently charged moiety, e.g., quaternary ammonium, or a group that is charged at a physiologically relevant pH, e.g. carboxylic acid, amine.
- Other methods include, appending to the organic nucleus hydroxyl- or amine-containing groups, e.g. alcohols, polyols, polyethers, and the like.
- Representative examples include, but are not limited to, polylysine, polyethyleneimine, poly(ethyleneglycol) and poly(propyleneglycol). Suitable functionalization chemistries and strategies for these compounds are known in the art.
- the conjugate of the invention comprises a hydrazine self-immolative linker, wherein the conjugate has the structure:
- nj is an integer from 1 - 10; n 2 is 0, 1, or 2; each R 24 is a member independently selected from the group consisting of H, substituted alkyl, unsubstituted alkyl, substituted heteroalkyl, and unsubstituted heteroalkyl; and I is either a bond (i.e., the bond between the carbon of the backbone and the adjacent nitrogen) or:
- n 3 is 0 or 1 , with the proviso that when n ⁇ is 0, n 2 is not 0; and 11 4 is I, 2, or 3, wherein when I is a bond, ni is 3 and n 2 is 1 , D can not be
- R is Me or CH 2 - CH 2 -NMe 2 .
- the substitution on the phenyl ring is a para substitution.
- n> is 2, 3, or 4 or ni is 3.
- n 2 is 1.
- I is a bond (i.e., the bond between the carbon of the backbone and the adjacent nitrogen).
- the hydrazine linker, H can form a 6- membered self immolative linker upon cleavage, for example, when n 3 is 0 and 11 4 is 2.
- the hydrazine linker, H can form two 5-membered self immolative linkers upon cleavage.
- H forms a 5-membered self immolative linker
- H forms a 7-membered self immolative linker
- H forms a 5-membered self immolative linker and a 6-membered self immolative linker, upon cleavage.
- the rate of cleavage is affected by the size of the ring formed upon cleavage. Thus, depending upon the rate of cleavage desired, an appropriate size ring to be formed upon cleavage can be selected.
- the hydrazine linker comprises a 5-membered hydrazine linker, wherein H comprises the structure:
- ni is 2, 3, or 4. In another preferred embodiment, ni is 3.
- each R 24 is a member independently selected from the group consisting of H, substituted alkyl, unsubstituted alkyl, substituted heteroalkyl, and unsubstituted heteroalkyl.
- each R 24 is independently H or a Ci - C 6 alkyl.
- each R 24 is independently H or a Ci - C 3 alkyl, more preferably H or CH 3 .
- at least one R 24 is a methyl group.
- each R 24 is H.
- Each R 24 is selected to tailor the compounds steric effects and for altering solubility.
- the 5-membered hydrazine linkers can undergo one or more cyclization reactions that separate the drug from the linker, and can be described, for example, by:
- An exemplary synthetic route for preparing a five membered linker of the invention is:
- the Cbz-protected DMDA b is reacted with 2,2-Dimethyl-makmic acid a in solution vvitli thionyl chloride to form a Cbz-DMDA-2,2-dimethylmalonic acid c.
- Compound c is reacted with Boc-N-methyl hydrazine d in the presence of EDC to form DMDA-2,2- dimetylmalonic-Boc-N-methylhydrazine e.
- the hydrazine linker comprises a 6-membered hydrazine linker, wherein H comprises the structure:
- each R 24 is a member independently selected from the group consisting of H, substituted alkyl, unsubstituted alkyl, substituted heteroalkyl, and unsubstituted heteroalkyl.
- each R 24 is independently H or a Ci - Ce alkyl.
- each R 24 is independently H or a Ct - C 3 alkyl, more preferably H or CH 3 .
- at least one R " is a methyl group.
- each R24 is H.
- Each R "4 is selected to tailor the compounds steric effects and for altering solubility.
- H comprises the structure:
- H comprises a geminal dimethyl substitution.
- each R 24 is independently an H or a substituted or unsubstituted alkyl.
- the 6-membered hydrazine linkers will undergo a cyclization reaction that separates the drug from the linker, and can be described as:
- An exemplary synthetic route for preparing a six membered linker of the invention is:
- the invention comprises a linker having seven members. This linker would likely not cyclize as quickly as the five or six membered linkers, but this may be preferred for some antibody-partner conjugates.
- the hydrazine linker may comprise two six membered rings or a hydrazine linker having one six and one five membered cyclization products. A five and seven membered linker as well as a six and seven membered linker are also contemplated.
- Another hydrazine structure, H has the formula:
- each R 24 is a member independently selected from the group consisting of H, substituted alkyl, unsubstituted alkyl, substituted heteroalkyl, and unsubstituted heteroalkyl.
- This hydrazine structure can also form five-, six-, or seven-membered rings and additional components can be added to form multiple rings.
- the linker comprises an enzymatically cleavable disulfide group.
- the invention provides a cytotoxic antibody-partner compound having a structure according to Formula (d): wherein D, L 1 , L 4 , and X 4 are as defined above and described further herein, and J is a disulfide linker comprising a group having the structure:
- the aromatic ring of the disulfides linker may be substituted with one or more "K" groups.
- a “K” group is a substituent on the aromatic ring that replaces a hydrogen otherwise attached to one of the four non-substituted carbons that are part of the ring structure.
- the "K” group may be a single atom, such as a halogen, or may be a multi- atom group, such as alkyl, heteroalkyl, amino, nitro, hydroxy, alkoxy, haloalkyl, and cyano.
- K substituents independently include, but are not limited to, F, Cl, Br, I, NO 2 , OH, OCH 3 , NHCOCH 3 , N(CHj) 2 , NHCOCF . , and methyl.
- K 1 is an integer of O, 1 , 2, 3, or 4. In a specific embodiment, / is O.
- the linker comprises an enzymatically cleavable disulfide group of the following formula:
- L 4 , X 4 , p, and R 24 are as described above, and d is O, 1, 2, 3, 4, 5, or 6. In a particular embodiment, d is 1 or 2.
- d is 1 or 2.
- d is 1 or 2.
- the disulfides are ortho to the amine.
- a is 0.
- R 24 is independently selected from H and CH 3 .
- An exemplary synthetic route for preparing a disulfide linker of the invention is as follows:
- a solution of 3-mercaptopropionic acid a is reacted with aldrithiol-2 to form 3- methyl benzothiazolium iodide b.
- 3-methylbenzothiazolium iodide c is reacted with sodium hydroxide to form compound d.
- a solution of compound d with methanol is further reacted with compound b to form compound e.
- the present invention features an antibody conjugated to a partner molecule, such as a cytotoxin, a drug (e.g., an immunosuppressant) or a radiotoxin.
- a partner molecule such as a cytotoxin, a drug (e.g., an immunosuppressant) or a radiotoxin.
- cytotoxin e.g., an immunosuppressant
- radiotoxin e.g., an immunosuppressant
- immunocytotoxins e.g., an immunosuppressant
- a cytotoxin or cytotoxic agent includes any agent that is detrimental to (e.g., kills) cells.
- partner molecules of the present invention include taxol, cytochalasin B, gramicidin D, ethidium bromide, emetine, mitomycin, etoposide, tenoposide, vincristine, vinblastine, colchicin, doxorubicin, daunorubicin, dihydroxy anthracin dione, mitoxantrone, mithramycin, actinomycin D, 1 -dehydrotestosterone, glucocorticoids, procaine, tetracaine, lidocaine, propranolol, and puromycin and analogs or homologs thereof.
- partner molecules also include, for example, antimetabolites (e.g., methotrexate, 6-mercaptopurine, 6-thioguanine, cytarabine, 5- fluorouracil decarbazine), alkylating agents (e.g., mechlorethamine, thioepa chlorambucil, melphalan, carmustine (BSNU) and lomustine (CCNU), cyclothosphamide, busulfan, dibromomannitol, streptozotocin, mitomycin C, and cis- dichlorodiamine platinum (II) (DDP) cisplatin), anthracyclines (e.g., daunorubicin (formerly daunomycin) and doxorubicin), antibiotics (e.g., dactinomycin (formerly actinomycin), bleomycin, mithramycin, and anthramycin (AMC)), and anti-mitotic agents (e.g., vin,
- An example of a calicheamicin antibody conjugate is commercially available (Mylotarg ⁇ ; American Home Products).
- Preferred examples of partner molecule are CC- 1065 and the duocarmycins. CC-
- the Upjohn Company (Pharmacia Upjohn) has also been active in preparing derivatives of CC- 1065. See, for example, U.S. Patent No. 5,739,350; 4,978,757, 5,332, 837 and 4,912,227.
- a particularly preferred aspect of the current invention provides a cytotoxic compound having a structure according to the following formula (e):
- ring system A is a member selected from substituted or unsubstituted aryl substituted or unsubstituted heteroaryl and substituted or unsubstituted heterocycloalkyl groups.
- exemplary ring systems include phenyl and pyrrole.
- E and G are independently selected from H, substituted or unsubstituted alkyl, substituted or unsubslituted heteroalkyl, a heteroatom, a single bond or E and G are optionally joined to form a ring system selected from substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl and substituted or unsubstituted heterocycloalkyl.
- R 23 is a member selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, and acyl.
- R 12 , R 13 , and R 14 independently represent H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl and substituted or unsubstituted aryl, where R 12 and R 13 together with the nitrogen or carbon atom to which they are attached are optionally joined to form a substituted or unsubstituted heterocycloalkyl ring system having from 4 to 6 members, optionally containing two or more heteroatoms.
- R 12 , R l ⁇ or R 14 can include a cleavable group within its structure.
- R 4 , R 4 ⁇ R 5 and R 5 ' are members independently selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl, substituted or unsubstituted heterocycloalkyl, halogen, NO 2 , NR 15 R 16 , NC(O)R 15 , OC(O)NR 15 R 16 , OC(O)OR 15 , C(O)R 15 , SR 15 , OR 15 , CR 15 ⁇ NR 16 , and
- n is an integer from 1 to 20, or any adjacent pair of R 4 , R 4 ', R 3 and R 5 ⁇ together with the carbon atoms to which they are attached, are joined to form a substituted or unsubstituted cycloalkyl or heterocycloalkyl ring system having from 4 to 6 members.
- R 15 and R 16 independently represent H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl, substituted or unsubstituted heterocycloalkyl and substituted or unsubstituted peptidyl, where R 15 and R 16 together with the nitrogen atom to which they are attached are optionally joined to form a substituted or unsubstituted heterocycloalkyl ring system having from 4 to 6 members, optionally containing two or more heteroatoms.
- One exemplary structure is aniline.
- R 4 , R 4 ⁇ R 5 , R 5 ⁇ R 1 ', R 12 , R 13 , R 15 and R 16 optionally contain one or more cleavable groups within their structure, such as a cleavable linker or cleavable substrate.
- cleavable groups include, but are not limited to peptides, amino acids, hydrazines, disulfides, and cephalosporin derivatives.
- At least one of R 4 , R 4 ', R ⁇ R 5 ⁇ R 1 1 , R 12 , R 13 , R 15 and R 16 is used to join the drug to a linker or enzyme cleavable substrate of the present invention, as described herein, for example to L 1 , if present or to F, H, J, or X", or J.
- R 4 , R 4 ⁇ R 5 , R 5' , R 11 , R 12 , R 13 , R 15 and R 16 bears a reactive group appropriate for conjugating the compound.
- R 4 , R 4 ', R 5 , R 5 ', R 1 ', R 12 , R 13 , R 15 and R 16 are independently selected from H, substituted alkyl and substituted heteroalkyl and have a reactive functional group at the free terminus of the alkyl or heteroalkyl moiety.
- R 4 , R 4 ', R 5 , R 5 ', R 1 ', R 12 , R 13 , R 15 and R 16 may be conjugated to another species, e.g, targeting agent, detectable label, solid support, etc.
- R 6 is a single bond which is either present or absent. When R 6 is present, R 6 and
- R 7 are joined to form a cyclopropyl ring.
- R 7 is CH 2 -X 1 or -CH 2 -.
- X 1 represents a leaving group such as a halogen, for example Cl, Br or F.
- the combinations of R 6 and R 7 are interpreted in a manner that does not violate the principles of chemical valence.
- X 1 may be any leaving group.
- Useful leaving groups include, but are not limited to, halogens, azides, sulfonic esters (e.g., alkylsulfonyl, arylsulfonyl), oxonium ions, alkyl perchlorates, ammonioalkanesulfonate esters, alkylfluorosulfonates and fluorinated compounds (e.g., triflates, nonaflates, tresylates) and the like.
- Particular halogens useful as leaving groups are F, Cl and Br.
- At least one of R , R '. R 3 , and R 5 ' links said drug to L , if present, or to F, H, J, or X 2 , and includes
- v is an integer from 1 to 6; and each R 27 , R 27 , R 28 , and R 28 is independently selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl, and substituted or unsubstituted heterocycloalkyl.
- R 27 , R 27 , R 2S , and R *" are all H.
- v is an integer from 1 to 3 (preferably, 1 ). This unit can be used to separate aryl substituents from the drug and thereby resist or avoid generating compounds that are substrates for multi-drug resistance.
- R 1 ' includes a moiety, X 5 , that does not self-cyclize and links the drug to L 1 , if present, or to F, H, J, or X 2 .
- the moiety, X ⁇ is preferably cleavable using an enzyme and, when cleaved, provides the active drug.
- R can have the following structure (with the right side coupling to the remainder of the drug):
- ring system A of fonnula (e) is a substituted or unsubstituted phenyl ring.
- Ring system A may be substituted with one or more aryl group substituents as set forth in the definitions section herein.
- the phenyl ring is substituted with a CN or methoxy moiety.
- R 4 , R 4 ', R 5 , and R 3 ' links said drug to L 1 , if present, or to F, H, J, or X 2 , and R 3 is selected from SR 1 1 , NHR 1 1 and OR".
- R 1 1 is selected from -SO(OH) 2 , -PO(OH) 2 , -AA n , -Si(CH 3 ) 2 C(CH 3 ) 3 , -C(O)OPhNH(AA) 1n ,
- n is any integer in the range of 1 to 10
- m is any integer in the range of 1 to 4
- p is any integer in the range of 1 to 6
- AA is any natural or non-natural amino acid.
- AA n or AA 1n is selected from the same amino acid sequences described above for the peptide linkers (F) and optionally is the same as the amino acid sequence used in the linker portion of R 4 , R 4 ', R , or R '.
- R" is cleavable in vivo to provide an active drug compound.
- R 3 increases in vivo solublility of the compound.
- the rate of decrease of the concentration of the active drug in the blood is substantially faster than the rate of cleavage of R ' to provide the active drug. This may be particularly useful where the toxicity of the active drag is substantially higher than that of the prodrug fo ⁇ n. In other embodiments, the rate of cleavage of R " to provide the active drug is faster than the rate of decrease of concentration of the active drug in the blood.
- the invention provides a compound having a structure according to Formula (g):
- the identities of the substituents R 3 , R 4 , R 4 ', R 5 , R 5 ⁇ R 6 , R 7 and X are substantially as described above for Formula (a), as well as preferences for particular embodiments.
- the symbol Z is a member independently selected from O, S and NR" J .
- the symbol R 23 represents a member selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, and acyl. Each R 23 is independently selected.
- the symbol R 1 represents H, substituted or unsubstituted lower alkyl, or C(O)R 8 or CO 2 R 8 .
- R 8 is a member selected from substituted alkyl, unsubstituted alkyl, NR 9 R 10 , NR 9 NHR 10 and OR 9 .
- R 9 and R 10 are independently selected from H, substituted or unsubstituted alkyl and substituted or unsubstituted heteroalkyl.
- R 2 is H, or substituted or unsubstituted lower alkyl. It is generally preferred that when R 2 is substituted alkyl, it is other than a perfluoroalkyl, e.g., CF 3 .
- R 2 is a substituted alkyl wherein the substitution is not a halogen.
- R 2 is an unsubstituted alkyl.
- R 1 is an ester moiety, such as CO2CH3.
- R 2 is a lower alkyl group, which may be substituted or unsubstituted. A presently preferred lower alkyl group is CH 3 .
- R 1 is CO 2 CH 3 and R 2 is CH 3 .
- R 4 , R 4 ', R 5 , and R 5 ' are members independently selected from H, halogen, NH 2 , OMe, O(CH 2 ) 2 N(R 29 ) 2 and NO 2 .
- Each R 2q is independently H or lower alkyl (e.g., methyl).
- the drug is selected such that the leaving group X 1 is a member selected from the group consisting of halogen, alkylsulfonyl, arylsulfonyl, and azide. In some embodiments, X 1 is F, Cl, or Br.
- Z is O or NH.
- X is O.
- the invention provides compounds having a structure according to Formula (h) or (i):
- duocarmycin analog of Formula (e) is a structure in which the ring system A is an unsubstituted or substituted phenyl ring.
- the preferred substituents on the drug molecule described hereinabove for the structure of Formula 7 when the ring system A is a pyrrole are also preferred substituents when the ring system A is an unsubstituted or substituted phenyl ring.
- the drug (D) comprises a structure (j):
- R 3 , R 6 , R 7 , X are as described above for Formula (e).
- Z is a member selected from O, S and NR 23 , wherein R 23 is a member selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, and acyl;
- R 1 is H, substituted or unsubstituted lower alkyl, C(O)R 8 , or CO 2 R 8 , wherein R 8 is a member selected from NR 9 R 10 and OR 9 , in which R 9 and R 10 are members independently selected from H, substituted or unsubstituted alkyl and substituted or unsubstituted heteroalkyl;
- R 1 is H, substituted or unsubstituted lower alkyl, or C(O)R 8 , wherein R 8 is a member selected from NR R 1 and OR , in which R y and R 10 are members independently selected from H, substituted or unsubstituted alkyl and substituted or unsubstituted heteroalkyl;
- R " is H, or substituted or unsubstituted lower alkyl or unsubstituted heteroalkyl or cyano or alkoxy; and R 2 is H, or substituted or unsubstituted lower alkyl or unsubstituted heteroalkyl.
- At least one of R 4 , R »4- , R", R , R" , R . 1 1 2', R 1'3 J , R , 1"5 or R l b links the drug to L 1 , if present, or to F, H, J, or X 2 .
- Another embodiment of the drug (D) comprises a structure (k) where R 4 and R 4 have been joined to from a heterocycloalkyl:
- R 3 , R 5 , R 5 , R 6 , R 7 , X are as described above for Formula (e).
- Z is a member selected from O, S and NR 23 , wherein R 23 is a member selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, and acyl;
- R 15 and R 16 independently represent H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl, substituted or unsubstituted heterocycloalkyl and substituted or unsubstituted peptidyl, where R 15 and R 16 together with the nitrogen atom to which they are attached are optionally joined to form a substituted or unsubstituted heterocycloalkyl ring system having from 4 to 6 members, optionally containing two or more heteroatoms.
- R 32 optionally contains one or more cleavable groups within its structure, such as a cleavable linker or cleavable substrate.
- cleavable groups include, but are not limited to, peptides, amino acids, hydrazines, disulfides, and cephalosporin derivatives. Moreover, any selection of substituents described herein for R 4 , R 4 , R 5 , R 5 ', R' ⁇ and R 16 is also applicable to R ".
- At least one of R 5 , R 5 ', R 1 ' 'R 12 , R 13 , R 15 , R 16 , or R 32 links the drug to L 1 , if present, or to F, H, J, or X 2 .
- R 32 links the drug to L 1 , if present, or to F, H, J, or X 2 .
- R is H, substituted or unsubstituted lower alkyl, C(O)R 8 , or CO 2 R , wherein R 8 is a member selected from NR 0 R 10 and OR 9 , in which R 9 and R 10 are members independently selected from H, substituted or unsubstituted alkyl and substituted or unsubstituted heteroalkyl;
- R 1 is H, substituted or unsubstituted lower alkyl, or C(O)R 8 , wherein R 8 is a member selected from NR 9 R 10 and OR 9 , in which R 9 and R 10 are members independently selected from H, substituted or unsubstituted alkyl and substituted or unsubstituted heteroalkyl;
- R" is H, or substituted or unsubstituted lower alkyl or unsubstituted heteroalkyl or cyano or alkoxy; and R ⁇ is H, or substituted or unsubstituted lower alkyl or unsubstituted heteroalkyl.
- A, R 6 , R 7 , X, R 4 , R 4 , R 5 , and R 5 are as described above for Formula (e).
- Z is a member selected from O, S and NR 23 , where R 23 is a member selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, and acyl;
- R is selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl, substituted or unsubstituted heterocycloalkyl, halogen, NO 2 , NR 15 R 16 , NC(O)R 15 , OC(O)NR 15 R 16 , OC(O)OR 15 ,
- R 13 and R 16 independently represent H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl, substituted or unsubstituted heterocycloalkyl and substituted or unsubstituted peptidyl, where R 15 and R 16 together with the nitrogen atom to which they are attached are optionally joined to form a substituted or unsubstituted heterocycloalkyl ring system having from 4 to 6 members, optionally containing two or more heteroatoms.
- R 33 links the drug to L 1 , if present, or to F, H, J, or X 2 .
- A is substituted or unsubstituted phenyl or substituted or unsubstituted pyrrole.
- any selection of substituents described herein for R is also applicable to R 33 .
- X 4 represents a ligand selected from the group consisting of protected reactive functional groups, unprotected reactive functional groups, detectable labels, and targeting agents.
- Preferred ligands are targeting agents, such as antibodies and fragments thereof.
- the group X can be described as a member selected from R 29 , COOR 29 , C(O)NR 29 , and C(O)NNR 29 wherein R 29 is a member selected from substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl and substituted or unsubstituted heteroaryl.
- R 29 is a thiol reactive member.
- R 29 is a thiol reactive member selected from haloacetyl and alkyl halide derivatives, maleimides, aziridines, and acryloyl derivatives.
- the above thiol reactive members can act as reactive protective groups that can be reacted with, for example, a side chain of an amino acid of a targeting agent, such as an antibody, to thereby link the targeting agent to the linker-drug moiety.
- Detectable Labels The particular label or detectable group used in conjunction with the compounds and methods of the invention is generally not a critical aspect of the invention, as long as it does not significantly interfere with the activity or utility of the compound of the invention.
- the detectable group can be any material having a detectable physical or chemical property.
- a label is any composition detectable by spectroscopic, photochemical, biochemical, immunochemical, electrical, optical or chemical means.
- Useful labels in the present invention include magnetic beads (e.g., DYNABEADS ⁇ M ), fluorescent dyes (e.g., fluorescein isothiocyanate, Texas red, rhodamine, and the like), radiolabels (e.g., 3 H, 125 1, 35 S, 14 C, or 32 P), enzymes (e.g., horse radish peroxidase, alkaline phosphatase and others commonly used in an ELISA), and colorimetric labels such as colloidal gold or colored glass or plastic beads (e.g., polystyrene, polypropylene, latex, etc.).
- the label may be coupled directly or indirectly to a compound of the invention according to methods well known in the art.
- the label is preferably a member selected from the group consisting of radioactive isotopes, fluorescent agents, fluorescent agent precursors, chromophores, enzymes and combinations thereof.
- a detectable label that is frequently conjugated to an antibody is an enzyme, such as horseradish peroxidase, alkaline phosphatase, ⁇ - galactosidase, and glucose oxidase.
- Non-radioactive labels are often attached by indirect means.
- a ligand molecule e.g., biotin
- the ligand then binds to another molecules (e.g., streptavidin) molecule, which is either inherently detectable or covalently bound to a signal system, such as a detectable enzyme, a fluorescent compound, or a chemiluminescent compound.
- a signal system such as a detectable enzyme, a fluorescent compound, or a chemiluminescent compound.
- Components of the conjugates of the invention can also be conjugated directly to signal generating compounds, e.g., by conjugation with an enzyme or fluorophore.
- Enzymes of interest as labels will primarily be hydrolases, particularly phosphatases, esterases and glycosidases, or oxidotases, particularly peroxidases.
- Fluorescent compounds include fluorescein and its derivatives, rhodamine and its derivatives, dansyl, umbel liferone, etc.
- Chemiluminescent compounds include luciferin, and 2,3- dihydrophthalazinediones, e.g., luminol.
- Means of detecting labels are well known to those of skill in the art.
- means for detection include a scintillation counter or photographic film as in autoradiography.
- the label is a fluorescent label, it may be detected by exciting the fluorochrome with the appropriate wavelength of light and detecting the resulting fluorescence. The fluorescence may be detected visually, by means of photographic film, by the use of electronic detectors such as charge coupled devices (CCDs) or photomultipliers and the like.
- CCDs charge coupled devices
- enzymatic labels may be detected by providing the appropriate substrates for the enzyme and detecting the resulting reaction product.
- simple colorimetric labels may be detected simply by observing the color associated with the label. Thus, in various dipstick assays, conjugated gold often appears pink, while various conjugated beads appear the color of the bead.
- Fluorescent labels are presently preferred as they have the advantage of requiring few precautions in handling, and being amenable to high-throughput visualization techniques (optical analysis including digitization of the image for analysis in an integrated system comprising a computer).
- Preferred labels are typically characterized by one or more of the following: high sensitivity, high stability, low background, low environmental sensitivity and high specificity in labeling.
- Many fluorescent labels are commercially available from the SIGMA chemical company (Saint Louis, MO), Molecular Probes (Eugene, OR), R&D systems (Minneapolis, MN), Pharmacia LKB Biotechnology (Piscataway, NJ), CLONTECH Laboratories, Inc.
- fluorescent proteins include, for example, green fluorescent proteins of cnidarians (Ward et ai, Photochem. Photobiol. 35:803-808 (1982); Levine et al, Comp. Biochem. Physiol,
- the chemical functionalities Prior to forming the linkage between the cytotoxin and the targeting (or other) agent, and optionally, the spacer group, at least one of the chemical functionalities will be activated.
- the chemical functionalities including hydroxy, amino, and carboxy groups, can be activated using a variety of standard methods and conditions.
- a hydroxyl group of the cytotoxin or targeting agent can be activated through treatment with phosgene to form the corresponding chloroformate, or p-nitrophenylchloroformate to form the corresponding carbonate.
- the invention makes use of a targeting agent that includes a carboxyl functionality.
- Carboxyl groups may be activated by, for example, conversion to the corresponding acyl halide or active ester. This reaction may be performed under a variety of conditions as illustrated in March, supra pp. 388-89.
- the acyl halide is prepared through the reaction of the carboxyl- containing group with oxalyl chloride. The activated agent is reacted with a cytotoxin or cytotoxin-linker arm combination to form a conjugate of the invention.
- carboxyl-containing targeting agents is merely illustrative, and that agents having many other functional groups can be conjugated to the linkers of the invention.
- Exemplary compounds of the invention bear a reactive functional group, which is generally located on a substituted or unsubstituted alkyj.or heteroalkyl chain, allowing their facile attachment to another species.
- a convenient location for the reactive group is the terminal position of the chain.
- Reactive groups and classes of reactions useful in practicing the present invention are generally those that are well known in the art of bioconjugate chemistry.
- the reactive functional group may be protected or unprotected, and the protected nature of the group may be changed by methods known in the art of organic synthesis.
- Preferred classes of reactions available with reactive cytotoxin analogues are those which proceed under relatively mild conditions. These include, but are not limited to nucleophilic substitutions (e.g., reactions of amines and alcohols with acyl halides, active esters), electrophilic substitutions (e.g., enamine reactions) and additions to carbon-carbon and carbon- heteroatom multiple bonds (e.g., Michael reaction, Diels-Alder addition).
- Exemplary reaction types include the reaction of carboxyl groups and various derivatives thereof including, but not limited to, N-hydroxysuccinimide esters, N- hydroxybenztriazole esters, acid halides, acyl imidazoles, thioesters, p-nitrophenyl esters, alkyl, alkenyl, alkynyl and aromatic esters.
- Hydroxyl groups can be converted to esters, ethers, aldehydes, etc.
- Haloalkyl groups are converted to new species by reaction with, for example, an amine, a carboxylate anion, thiol anion, carbanion, or an alkoxide ion.
- Dienophile (e.g., maleimide) groups participate in Diels-Alder.
- Aldehyde or ketone groups can be converted to imines, hydrazones, semicarbazones or oximes, or via such mechanisms as Grignard addition or alkyllithium addition.
- Sulfonyl halides react readily with amines, for example, to form sulfonamides.
- Amine or sulfhydryl groups are, for example, acylated, alkylated or oxidized.
- Alkenes can be converted to an array of new species using cycloadditions, acylation, Michael addition, etc. Epoxides react readily with amines and hydroxyl compounds.
- the reactive functional groups can be unprotected and chosen such that they do not participate in, or interfere with, the reactions. Alternatively, a reactive functional group can be protected from participating in the reaction by the presence of a protecting group. Those of skill in the art will understand how to protect a particular functional group from interfering with a chosen set of reaction conditions. For examples of useful protecting groups, See Greene et al., Protective Groups in Organic Synthesis, John Wiley & Sons, New York, 1991.
- the targeting agent is linked covalently to a cytotoxin using standard chemical techniques through their respective chemical functionalities.
- the linker or agent is coupled to the agent through one or more spacer groups.
- the spacer groups can be equivalent or different when used in combination.
- the invention comprises a carboxyl functionality as a reactive functional group.
- Carboxyl groups may be activated as described hereinabove.
- the cleavable substrates of the current invention are depicted as "X 2 ".
- the cleavable substrate is a cleavable enzyme substrate that can be cleaved by an enzyme.
- the enzyme is preferentially associated, directly or indirectly, with the tumor or other target cells to be treated.
- the enzyme may be generated by the tumor or other target cells to be treated.
- the cleavable substrate can be a peptide that is preferentially cleavable by an enzyme found around or in a tumor or other target cell.
- the enzyme can be attached to a targeting agent that binds specifically to tumor cells, such as an antibody specific for a tumor antigen.
- the peptide is cleavable by an enzyme, such as a trouase (such as thimet oligopeptidase), CDlO (neprilysin), a matrix metal lopro tease (such as MMP2 or MMP9), a type II transmembrane serine protease (such as Hepsin, testisin, TMPRSS4, or matriptase/MT- SPl), or a cathepsin, associated with a tumor.
- a prodrug includes the drug as described above, a peptide, a stabilizing group, and optionally a linking group between the drug and the peptide.
- the stabilizing group is attached to the end of the peptide to protect the prodrug from degradation before arriving at the tumor or other target cell.
- suitable stabilizing groups include non-amino acids, such as succinic acid, diglycolic acid, maleic acid, polyethylene glycol, pyroglutamic acid, acetic acid, naphthylcarboxylic acid, terephthalic acid, and glutaric acid derivatives; as well as non-genetically-coded amino acids or aspartic acid or glutamic acid attached to the N- terminus of the peptide at the ⁇ -carboxy group of aspartic acid or the ⁇ -carboxyl group of glutamic acid.
- the peptide typically includes 3-12 (or more) amino acids.
- amino acids will depend, at least in part, on the enzyme to be used for cleaving the peptide, as well as, the stability of the peptide in vivo.
- a suitable cleavable peptide is ⁇ -AlaLeuAlaLeu (SEQ ID NO: 102). This can be combined with a stabilizing group to form succinyl- ⁇ -AlaLeuAlaLeu (SEQ ID NO: 102).
- SEQ ID NO: 102 ⁇ -AlaLeuAlaLeu
- CDlO also known as neprilysin, neutral endopeptidase (NEP), and common acute lymphoblastic leukemia antigen (CALLA)
- NEP neutral endopeptidase
- CALLA common acute lymphoblastic leukemia antigen
- Cleavable substrates suitable for use with CDlO include LeuAlaLeu and IleAlaLeu.
- Other known substrates for CDlO include peptides of up to 50 amino acids in length, although catalytic efficiency often declines as the substrate gets larger.
- MMP matrix metalloproteases
- Suitable sequences for use with MMPs include, but are not limited to, ProValGlyLeuIleGly (SEQ ID NO: 95), GlyProLeuGlyVal (SEQ ID NO:96), GlyProLeuGlylleAlaGlyGln (SEQ ID NO: 97), ProLeuGlyLeu (SEQ ID NO: 98), GlyProLeuGlyMetLeuSerGln (SEQ ID NO: 99), and GlyProLeuGlyLeuTrpAlaGln (SEQ ID NO: 100).
- ProValGlyLeuIleGly SEQ ID NO: 95
- GlyProLeuGlyVal SEQ ID NO:96
- GlyProLeuGlylleAlaGlyGln SEQ ID NO: 97
- ProLeuGlyLeu SEQ ID NO: 98
- GlyProLeuGlyMetLeuSerGln SEQ ID NO: 99
- type II transmembrane serine proteases This group of enzymes includes, for example, hepsin, testisin, and TMPRSS4.
- GlnAlaArg is one substrate sequence that is useful with matriptase/MT-SPl (which is over-expressed in breast and ovarian cancers) and LeuSerArg is useful with hepsin (over-expressed in prostate and some other tumor types).
- Other cleavable substrates can also be used.
- Another type of cleavable substrate arrangement includes preparing a separate enzyme capable of cleaving the cleavable substrate that becomes associated with the tumor or cells.
- an enzyme can be coupled to a tumor-specific antibody (or other entity that is preferentially attracted to the tumor or other target cell such as a receptor ligand) and then the enzyme-antibody conjugate can be provided to the patient.
- the enzyme-antibody conjugate is directed to, and binds to, antigen associated with the tumor.
- the drug-cleavable substrate conjugate is provided to the patient as a prodrug.
- the drug is only released in the vicinity of the tumor when the drug-cleavable substrate conjugate interacts with the enzyme that has become associated with the tumor so that the cleavable substrate is cleaved and the drug is freed.
- suitable enzymes and substrates include, but are not limited to, ⁇ -lactamase and cephalosporin derivatives, carboxypeptidase G2 and glutamic and aspartic folate derivatives.
- the enzyme-antibody conjugate includes an antibody, or antibody fragment, that is selected based on its specificity for an antigen expressed on a target cell, or at a target site, of interest.
- an antibody or antibody fragment, that is selected based on its specificity for an antigen expressed on a target cell, or at a target site, of interest.
- a discussion of antibodies is provided hereinabove.
- One example of a suitable cephalosporin-cleavable substrate is
- linkers and cleavable substrates of the invention can be used in conjugates containing a variety of partner molecules. Examples of conjugates of the invention are described in further detail below. Unless otherwise indicated, substituents are defined as set forth above in the sections regarding cytotoxins, linkers, and cleavable substrates.
- Linker Conjugates One example of a suitable conjugate is a compound of the formula:
- L 1 is a self-immolative linker
- m is an integer 0, 1, 2, 3, 4, 5, or 6
- F is a linker comprising the structure:
- AA 1 is one or more members independently selected from the group consisting of natural amino acids and unnatural ⁇ - amino acids; c is an integer from 1 to 20; L 2 is a self-immolative linker and comprises
- each R . 17 , R , 18 , and R , 19 i •s independently selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl and substituted or unsubstituted aryi, and w is an integer from 0 to 4; o is 1; L 4 is a linker member; p is 0 or 1; X 4 is a member selected from the group consisting of protected reactive functional groups, unprotected reactive functional groups, detectable labels, and targeting agents; and D comprises a structure:
- ring system A is a member selected from substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl and substituted or unsubstituted heterocycloalkyl groups
- E and G are members independently selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, a heteroatom, a single bond, or E and G are joined to form a ring system selected from substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl and substituted or unsubstituted heterocycloalkyl
- X is a member selected from O, S and NR 23
- R 23 is a member selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, and acyl
- R J is OR 1 ', wherein R 1 1 is a member selected from the group consisting of H, substituted alkyl, unsubsti
- the drug has structure (c) or (f) above.
- One specific example of a compound suitable for use as a conjugate is
- L 1 is a self-immolative linker
- m is an integer 0, 1, 2, 3, 4, 5, or 6
- F is a linker comprising the structure: wherein AA is one or more members independently selected from the group consisting of natural amino acids and unnatural ⁇ -amino acids; c is an integer from 1 to 20; L 2 is a self-immolative linker; o is 0 or 1 ; L 4 is a linker member; p is 0 or 1 ; X 4 is a member selected from the group consisting of protected reactive functional groups, unprotected reactive functional groups, detectable labels, and targeting agents; and D comprises a structure:
- ring system A is a member selected from substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl and substituted or unsubstituted heterocycloalkyl groups
- E and G are members independently selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, a heteroatom, a single bond, or E and G are joined to form a ring system selected from substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl and substituted or unsubstituted heterocycloalkyl
- X is a member selected from O, S and NR 23
- R 23 is a member selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, and acyl
- R 27 , R 27 , R 2S , and R 28 is independently selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl, and substituted or unsubstituted heterocycloalkyl;
- R 6 is a single bond which is either present or absent and when present R and R are joined to form a cyclopropyl ring; and R is CH 2 -X 1 or -CH 2 - joined in said cyclopropyl ring with R 6 , wherein X 1 is a leaving group.
- the drug has structure (c) or (f) above.
- r is an integer in the range from 0 to 24.
- Another example of a suitable conjugate is a compound of the formula
- L 4 is a linker member, wherein L 4 comprises
- R >20 is a member selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, and acyl
- each R 25 , R 25 , R 26 , and R 26 is independently selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl, and substituted or unsubstituted heterocycloalkyl
- s and t are independently integers from 1 to 6
- p is 1
- X 4 is a member selected from the group consisting of protected reactive functional groups, unprotected reactive functional groups, detectable labels, and targeting agents
- D comprises a structure:
- ring system A is a member selected from substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl and substituted or unsubstituted heterocycloalkyl groups
- E and G are members independently selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, a heteroatom, a single bond, or E and G are joined to form a ring system selected from substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl and substituted or unsubstituted heterocycloalkyl
- X is a member selected from O, S and NR 23
- R 23 is a member selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, and acyl
- the drug has structure (c) or (f) above.
- One specific example of a compound suitable for use as conjugate is
- r is an integer in the range from 0 to 24.
- Suitable compounds for use as conjugates include:
- R is oorr and r is an integer in the range from 0 to 24.
- Conjugates can also be formed using the drugs having structure (g), such as the following compounds:
- Conjugates can also be fo ⁇ ned using the drugs having the following structures:
- the anti-CD 19 is conjugated to the linker and therapeutic agent of structure N 1 :
- the anti-CD 19 is conjugated to the linker and therapeutic agent of structure N2: O
- a suitable conjugate is a compound having the following structure: wherein L 1 is a self-immolative spacer; m is an integer of 0, 1, 2, 3, 4, 5, or 6; X 2 is a cleavable substrate; and D comprises a structure:
- ring system A is a member selected from substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl and substituted or unsubstituted heterocycloalkyl groups
- E and G are members independently selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, a heteroatom, a single bond, or E and G are joined to form a ⁇ ng system selected from substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl and substituted or unsubstituted heterocycloalkyl
- X is a member selected from O, S and NR 2 '
- R 2 ' is a member selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, and acyl
- R 1 1 is a member selected from the group consisting of H, substituted alkyl, unsubstituted alkyl, substituted heteroalkyl, unsubstituted heteroalkyl, diphosphates, triphosphates, acyl, C(O)R 12 R 13 , C(O)OR 12 , C(O)NR 12 R 13 .
- R 12 , R 13 , and R 14 are members independently selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl and substituted or unsubstituted aryl, wherein R 12 and R 13 together with the nitrogen or carbon atom to which they are attached are optionally joined to form a substituted or unsubstituted heterocycloalkyl ring system having from 4 to 6 members, optionally containing two or more heteroatoms; R 6 is a single bond which is either present or absent and when present R 6 and R 7 are joined to fo ⁇ n a cyclopropyl ring; and R 7 is CH 2 -X 1 or -CH 2 - joined in said cyclopropyl ring with R 6 , wherein X 1 is a leaving group, R 4 , R 4 ', R 5
- R 15 and R 16 are independently selected from H, substituted or unsubstituted alkyl, substituted or unsubstituted heteroalkyl, substituted or unsubstituted aryl, substituted or unsubstituted heteroaryl, substituted or unsubstituted heterocycloalkyl, and substituted or unsubstituted peptidyl, wherein R 15 and R 16 together with the nitrogen atom to which they are attached are optionally joined to form a substituted or
- cleavable linkers examples include ⁇ -AlaLeuAlaLeu (SEQ ID NO: 102) and
- the present disclosure provides a composition, e.g., a pharmaceutical composition, containing one or a combination of monoclonal antibodies, or antigen-binding portion(s) thereof, of the present disclosure, formulated together with a pharmaceutically acceptable carrier.
- Such compositions may include one or a combination of ⁇ e.g., two or more different) antibodies, or immunoconjugates or bispecific molecules of this disclosure.
- a pharmaceutical composition of this disclosure can comprise a combination of antibodies (or immunoconjugates or bispecifics) that bind to different epitopes on the target antigen or that have complementary activities.
- Pharmaceutical compositions of this disclosure also can be administered in combination therapy, i.e., combined with other agents.
- the combination therapy can include an anti-CD 19 antibody of the present disclosure combined with at least one other anti-cancer agent. Examples of therapeutic agents that can be used in combination therapy are described in greater detail below in the section on uses of the antibodies of this disclosure.
- pharmaceutically acceptable earner includes any and all solvents, dispersion media, coatings, antibacterial and antifungal agents, isotonic and absorption delaying agents, and the like that are physiologically compatible.
- the carrier is suitable for intravenous, intramuscular, subcutaneous, parenteral, spinal or epidermal administration (e.g., by injection or infusion).
- the active compound i.e., antibody, immunoconjugate, or bispecific molecule
- the pharmaceutical compounds of this disclosure may include one or more pharmaceutically acceptable salts.
- a “pharmaceutically acceptable salt” refers to a salt that retains the desired biological activity of the parent compound and does not impart any undesired toxicological effects (see e.g.. Berge, S. M., et al. (1977) J. Pharm. Sci. 66: 1-19). Examples of such salts include acid addition salts and base addition salts.
- Acid addition salts include those derived from nontoxic inorganic acids, such as hydrochloric, nitric, phosphoric, sulfuric, hydrobromic, hydroiodic, phosphorous and the like, as well as from nontoxic organic acids such as aliphatic mono- and dicarboxylic acids, phenyl- substituted alkanoic acids, hydroxy alkanoic acids, aromatic acids, aliphatic and aromatic sulfonic acids and the like.
- nontoxic inorganic acids such as hydrochloric, nitric, phosphoric, sulfuric, hydrobromic, hydroiodic, phosphorous and the like
- nontoxic organic acids such as aliphatic mono- and dicarboxylic acids, phenyl- substituted alkanoic acids, hydroxy alkanoic acids, aromatic acids, aliphatic and aromatic sulfonic acids and the like.
- Base addition salts include those derived from alkaline earth metals, such as sodium, potassium, magnesium, calcium and the like, as well as from nontoxic organic amines, such as N.N'-dibenzylethylenediamine, N-methylglucamine, chloroprocaine, choline, diethanolamine, ethylenediamine, procaine and the like.
- a pharmaceutical composition of this disclosure also may include a pharmaceutically acceptable anti-oxidant.
- pharmaceutically acceptable antioxidants include: (1) water soluble antioxidants, such as ascorbic acid, cysteine hydrochloride, sodium bisulfate, sodium metabisulfite, sodium sulfite and the like; (2) oil-soluble antioxidants, such as ascorbyl palmitate, butylated hydroxyanisole (BHA) 5 butylated hydroxytoluene (BHT), lecithin, propyl gallate, alpha-tocopherol, and the like; and (3) metal chelating agents, such as citric acid, ethylenediamine tetraacetic acid (EDTA), sorbitol, tartaric acid, phosphoric acid, and the like.
- water soluble antioxidants such as ascorbic acid, cysteine hydrochloride, sodium bisulfate, sodium metabisulfite, sodium sulfite and the like
- oil-soluble antioxidants such as ascorbyl palmitate, butylated
- aqueous and nonaqueous carriers examples include water, ethanol, polyols (such as glycerol, propylene glycol, polyethylene glycol, and the like), and suitable mixtures thereof, vegetable oils, such as olive oil, and injectable organic esters, such as ethyl oleate.
- polyols such as glycerol, propylene glycol, polyethylene glycol, and the like
- vegetable oils such as olive oil
- injectable organic esters such as ethyl oleate.
- Proper fluidity can be maintained, for example, by the use of coating materials, such as lecithin, by the maintenance of the required particle size in the case of dispersions, and by the use of surfactants.
- compositions may also contain adjuvants such as preservatives, wetting agents, emulsifying agents and dispersing agents. Prevention of presence of microorganisms may be ensured both by sterilization procedures, supra, and by the inclusion of various antibacterial and antifungal agents, for example, paraben, chlorobutanol, phenol sorbic acid, and the like. It may also be desirable to include isotonic agents, such as sugars, sodium chloride, and the like into the compositions. In addition, prolonged absorption of the injectable pharmaceutical form may be brought about by the inclusion of agents which delay absorption such as aluminum monostearate and gelatin.
- Pharmaceutically acceptable carriers include sterile aqueous solutions or dispersions and sterile powders for the extemporaneous preparation of sterile injectable solutions or dispersion.
- sterile aqueous solutions or dispersions and sterile powders for the extemporaneous preparation of sterile injectable solutions or dispersion.
- the use of such media and agents for pharmaceutically active substances is known in the art. Except insofar as any conventional media or agent is incompatible with the active compound, use thereof in the pharmaceutical compositions of this disclosure is contemplated. Supplementary active compounds can also be incorporated into the compositions.
- compositions typically must be sterile and stable under the conditions of manufacture and storage.
- the composition can be formulated as a solution, microemulsion, liposome, or other ordered structure suitable to high drug concentration.
- the carrier can be a solvent or dispersion medium containing, for example, water, ethanol, polyol (for example, glycerol, propylene glycol, and liquid polyethylene glycol, and the like), and suitable mixtures thereof.
- the proper fluidity can be maintained, for example, by the use of a coating such as lecithin, by the maintenance of the required particle size in the case of dispersion and by the use of surfactants.
- isotonic agents for example, sugars, polyalcohols such as mannitol, sorbitol, or sodium chloride in the composition.
- Prolonged absorption of the injectable compositions can be brought about by including in the composition an agent that delays absorption, for example, monostearate salts and gelatin.
- Sterile injectable solutions can be prepared by incoiporating the active compound in the required amount in an appropriate solvent with one or a combination of ingredients enumerated above, as required, followed by sterilization microfiltration.
- dispersions are prepared by incorporating the active compound into a sterile vehicle that contains a basic dispersion medium and the required other ingredients from those enumerated above.
- the preferred methods of preparation are vacuum drying and freeze-drying (lyophilization) that yield a powder of the active ingredient plus any additional desired ingredient from a previously sterile-filtered solution thereof.
- the amount of active ingredient which can be combined with a carrier material to produce a single dosage form will vary depending upon the subject being treated, and the particular mode of administration.
- the amount of active ingredient which can be combined with a earner material to produce a single dosage form will generally be that amount of the composition which produces a therapeutic effect. Generally, out of one hundred per cent, this amount will range from about 0.01 per cent to about ninety-nine percent of active ingredient, preferably from about 0.1 per cent to about 70 per cent, most preferably from about 1 per cent to about 30 per cent of active ingredient in combination with a pharmaceutically acceptable carrier.
- Dosage regimens are adjusted to provide the optimum desired response (e.g., a therapeutic response). For example, a single bolus may be administered, several divided doses may be administered over time or the dose may be proportionally reduced or increased as indicated by the exigencies of the therapeutic situation. It is especially advantageous to formulate parenteral compositions in dosage unit form for ease of administration and uniformity of dosage.
- Dosage unit form as used herein refers to physically discrete units suited as unitary dosages for the subjects to be treated; each unit contains a predetermined quantity of active compound calculated to produce the desired therapeutic effect in association with the required pharmaceutical carrier.
- the dosage unit forms of this disclosure are dictated by and directly dependent on (a) the unique characteristics of the active compound and the particular therapeutic effect to be achieved, and (b) the limitations inherent in the art of compounding such an active compound for the treatment of sensitivity in individuals.
- the dosage ranges from about 0.0001 to 100 mg/kg, and more usually 0.01 to 5 mg/kg, of the host body weight.
- dosages can be 0.3 mg/kg body weight, 1 mg/kg body weight, 3 mg/kg body weight, 5 mg/kg body weight or 10 mg/kg body weight or within the range of 1-10 mg/kg.
- An exemplary treatment regime entails administration once per week, once every two weeks, once every three weeks, once every four weeks, once a month, once every 3 months or once every three to 6 months.
- Preferred dosage regimens for an anti-CD 19 antibody of this disclosure include 1 mg/kg body weight or 3 mg/kg body weight via intravenous administration, with the antibody being given using one of the following dosing schedules: (i) every four weeks for six dosages, then every three months; (ii) every three weeks; (iii) 3 mg/kg body weight once followed by 1 mg/kg body weight every three weeks.
- two or more monoclonal antibodies with different binding specificities are administered simultaneously, in which case the dosage of each antibody administered falls within the ranges indicated.
- Antibody is usually administered on multiple occasions. Intervals between single dosages can be, for example, weekly, monthly, every three months or yearly. Intervals can also be irregular as indicated by measuring blood levels of antibody to the target antigen in the patient.
- dosage is adjusted to achieve a plasma antibody concentration of about 1-1000 ⁇ g /ml and in some methods about 25-300 ⁇ g /ml.
- antibody can be administered as a sustained release formulation, in which case less frequent administration is required. Dosage and frequency vary depending on the half-life of the antibody in the patient. In general, human antibodies show the longest half life, followed by humanized antibodies, chimeric antibodies, and nonhuman antibodies. The dosage and frequency of administration can vary depending on whether the treatment is prophylactic or therapeutic. In prophylactic applications, a relatively low dosage is administered at relatively infrequent intervals over a long period of time. Some patients continue to receive treatment for the rest of their lives. In therapeutic applications, a relatively high dosage at relatively short intervals is sometimes required until progression of the disease is reduced or terminated, and preferably until the patient shows partial or complete amelioration of symptoms of disease. Thereafter, the patient can be administered a prophylactic regime. For use in the prophylaxis and/or treatment of diseases related to abnormal cellular proliferation, a circulating concentration of administered compound of about 0.001 ⁇ M to 20 ⁇ M is preferred, with about 0.01 ⁇ M to 5 ⁇ M being preferred.
- Patient doses for oral administration of the compounds described herein typically range from about 1 mg/day to about 10,000 mg/day, more typically from about 10 mg/day to about 1,000 mg/day, and most typically from about 50 mg/day to about 500 mg/day. Stated in terms of patient body weight, typical dosages range from about 0.01 to about 150 mg/kg/day, more typically from about 0.1 to about 15 mg/kg/day, and most typically from about 1 to about 10 mg/kg/day, for example 5 mg/kg/day or 3 mg/kg/day. In at least some embodiments, patient doses that retard or inhibit tumor growth can be 1 ⁇ mol/kg/day or less.
- the patient doses can be 0.9, 0.8, 0.7, 0.6, 0.5, 0.45, 0.3, 0.2, 0.15, 0.1, 0.09, 0.08, 0.07, 0.06, 0.05, 0.04, 0.03, 0.02, 0.01, or 0.005 ⁇ mol/kg or less (referring to moles of the drag).
- the antibody-drug conjugate retards growth of the tumor when administered in the daily dosage amount over a period of at least five days.
- the tumor is a human-type tumor in a SCID mouse.
- the SCID mouse can be a CB 17.SCID mouse (available from Taconic, Ge ⁇ nantown, NY).
- Actual dosage levels of the active ingredients in the pharmaceutical compositions of the present disclosure may be varied so as to obtain an amount of the active ingredient which is effective to achieve the desired therapeutic response for a particular patient, composition, and mode of administration, without being toxic to the patient.
- the selected dosage level will depend upon a variety of pharmacokinetic factors including the activity of the particular compositions of the present disclosure employed, or the ester, salt or amide thereof, the route of administration, the time of administration, the rate of excretion of the particular compound being employed, the duration of the treatment, other drugs, compounds and/or materials used in combination with the particular compositions employed, the age, sex, weight, condition, general health and prior medical history of the patient being treated, and like factors well known in the medical arts.
- a "therapeutically effective dosage" of an anti-CD 19 antibody of this disclosure preferably results in a decrease in severity of disease symptoms, an increase in frequency and duration of disease symptom-free periods, or a prevention of impairment or disability due to the disease affliction.
- a "therapeutically effective dosage" of an anti-CD 19 antibody of this disclosure preferably results in a decrease in severity of disease symptoms, an increase in frequency and duration of disease symptom-free periods, or a prevention of impairment or disability due to the disease affliction.
- a "therapeutically effective dosage" of an anti-CD 19 antibody of this disclosure preferably results in a decrease in severity of disease symptoms, an increase in frequency and duration of disease symptom-free periods, or a prevention of impairment or disability due to the disease affliction.
- therapeutically effective dosage preferably inhibits cell growth or tumor growth by at least about 20%, more preferably by at least about 40%, even more preferably by at least about 60%, and still more preferably by at least about 80% relative to untreated subjects.
- the ability of a compound to inhibit tumor growth can be evaluated in an animal model system predictive of efficacy in human tumors. Alternatively, this property of a composition can be evaluated by examining the ability of the compound to inhibit cell growth, such inhibition can be measured in vitro by assays known to the skilled practitioner.
- a therapeutically effective amount of a therapeutic compound can decrease tumor size, or otherwise ameliorate symptoms in a subject.
- One of ordinary skill in the art would be able to determine such amounts based on such factors as the subject's size, the severity of the subject's symptoms, and the particular composition or route of administration selected.
- a composition of the present disclosure can be administered via one or more routes of administration using one or more of a variety of methods known in the art.
- routes and/or mode of administration will vary depending upon the desired results.
- Preferred routes of administration for antibodies of this disclosure include intravenous, intramuscular, intradermal, intraperitoneal, subcutaneous, spinal or other parenteral routes of administration, for example by injection or infusion.
- parenteral administration means modes of administration other than enteral and topical administration, usually by injection, and includes, without limitation, intravenous, intramuscular, intraarterial, intrathecal, intracapsular, intraorbital, intracardiac, intradermal, intraperitoneal, transtracheal, subcutaneous, subcuticular, intraarticular, subcapsular, subarachnoid, intraspinal, epidural and intrasternal injection and infusion.
- an antibody of this disclosure can be administered via a non- parenteral route, such as a topical, epidermal or mucosal route of administration, for example, intranasally, orally, vaginally, rectally, sublingually or topically.
- a non- parenteral route such as a topical, epidermal or mucosal route of administration, for example, intranasally, orally, vaginally, rectally, sublingually or topically.
- the active compounds can be prepared with carriers that will protect the compound against rapid release, such as a controlled release formulation, including implants, transde ⁇ nal patches, and microencapsulated delivery systems.
- a controlled release formulation including implants, transde ⁇ nal patches, and microencapsulated delivery systems.
- Biodegradable, biocompatible polymers can be used, such as ethylene vinyl acetate, polyanhydrides, polyglycolic acid, collagen, polyorthoesters, and polylactic acid. Many methods for the preparation of such formulations are patented or generally known to those skilled in the art. See, e.g., Sustained and Controlled Release Drug Delivery Systems, J. R. Robinson, edL, Marcel Dekker, Inc., New York, 1978.
- Therapeutic compositions can be administered with medical devices known in the art.
- a therapeutic composition of this disclosure can be administered with a needleless hypodermic injection device, such as the devices disclosed in U.S. Patent Nos. 5,399,163; 5,383,851; 5,312,335; 5,064,413; 4,941,880; 4,790,824; or 4,596,556.
- a needleless hypodermic injection device such as the devices disclosed in U.S. Patent Nos. 5,399,163; 5,383,851; 5,312,335; 5,064,413; 4,941,880; 4,790,824; or 4,596,556.
- Examples of well-known implants and modules useful in the present disclosure include: U.S. Patent No. 4,487,603, which discloses an implantable micro-infusion pump for dispensing medication at a controlled rate; U.S. Patent No. 4,486, 194, which discloses a therapeutic device for administering medicants through the skin; U.S. Patent No.
- the blood-brain barrier excludes many highly hydrophilic compounds.
- the therapeutic compounds of this disclosure cross the BBB (if desired)
- they can be formulated, for example, in liposomes.
- liposomes For methods of manufacturing liposomes, see, e.g., U.S. Patents 4,522,81 1 ; 5,374,548; and 5,399,331.
- the liposomes may comprise one or more moieties which are selectively transported into specific cells or organs, thus enhance targeted drug delivery (see, e.g., V. V. Ranade (1989) J. Clin. Pharmacol. 29:685).
- Exemplary targeting moieties include folate or biotin (see, e.g., U.S.
- Patent 5,416,016 to Low et al. marmosides (Umezawa et ai, (1988) Biochem. Biophys. Res. Comrnun. 153:1038); antibodies (P.G. Bloeman et al. (1995) FEBS Lett. 357: 140; M. Owais et al (1995) Antimicrob. Agents Chemother. 39: 180); surfactant protein A receptor (Briscoe et al.
- the antibodies particularly the human antibodies, antibody compositions antibody-partner molecule conjugate compositions and methods of the present disclosure have numerous in vitro and in vivo diagnostic and therapeutic utilities involving the diagnosis and treatment of CD 19 mediated disorders.
- these molecules can be administered to cells in culture, in vitro or ex vivo, or to human subjects, e.g., in vivo, to treat, prevent and to diagnose a variety of disorders.
- the term "subject" is intended to include human and non-human animals.
- Non-human animals include all vertebrates, e.g., mammals and non-mammals, such as non-human primates, sheep, dogs, cats, cows, horses, chickens, amphibians, and reptiles.
- Preferred subjects include human patients having disorders mediated by CD 19 activity.
- the methods are particularly suitable for treating human patients having a disorder associated with aberrant CD 19 expression.
- antibody-partner molecule conjugates to CD 19 are administered together with another agent, the two can be administered in either order or simultaneously.
- the antibodies of this disclosure can be used to specifically detect CD 19 expression on the surface of cells and, moreover, can be used to purify CD 19 via immunoaff ⁇ nity purification.
- the human antibody-partner molecule conjugate compositions and methods of the present disclosure can be used to treat a subject with a tumorigenic disorder, e.g., a disorder characterized by the presence of tumor cells expressing CD19 including, for example, non-Hodgkin's lymphoma (NHL), acute lymphocytic leukemia (ALL), chronic lymphocytic leukemia (CLL), Burkitt's lymphoma, anaplastic large-cell lymphomas (ALCL), multiple myeloma, cutaneous T-cell lymphomas, nodular small cleaved-cell lymphomas, lymphocytic lymphomas, peripheral T-cell lymphomas, Lennert's lymphomas, immunoblastic lymphomas, T-cell leukemia/lymphomas (ATLL), adult T-cell leukemia (T-ALL), entroblastic/centrocytic (cb/cc) follicular lymphomas cancers
- a tumorigenic disorder e.g
- CD 19 may lead to loss of B-cell tolerance and generation of autoimmune disorders (Tedder et al. (2005) Curr Dir Autoimmun 8:55). This autoimmune effect has been seen by the accumulation of CD 19+ B-cells in the inflamed joints of rheumatoid arthritis patients (He et al. (2001 ) J Rheumatol 28:2168).
- the human antibodies, antibody compositions and methods of the present disclosure can be used to treat a subject with an autoimmune disorder, e.g., a disorder characterized by the presence of B-cells expressing CD 19 including, for example, rheumatoid arthritis.
- the antibodies e.g., human monoclonal antibodies, multispecific and bispecific molecules and compositions
- the antibodies can be used to detect levels of CD 19, or levels of cells which contain CD 19 on their membrane surface, which levels can then be linked to certain disease symptoms.
- the antibodies can be used to inhibit or block CD 19 function which, in turn, can be linked to the prevention or amelioration of certain disease symptoms, thereby implicating CD 19 as .a mediator of the disease. This can be achieved by contacting a sample and a control sample with the anti-CD 19 antibody under conditions that allow for the formation of a complex between the antibody and CD 19. Any complexes formed between the antibody and CD 19 are detected and compared in the sample and the control.
- the antibodies (e.g., human antibodies, multispecif ⁇ c and bispecific molecules and compositions) of this disclosure can be initially tested for binding activity associated with therapeutic or diagnostic use in vitro.
- compositions of this disclosure can be tested using the flow cytometric assays described in the Examples below.
- the antibodies (e.g., human antibodies, multispecific and bispecific molecules, immunoconjugates and compositions) of this disclosure have additional utility in therapy and diagnosis of CD19-related diseases.
- the human monoclonal antibodies, the multispecific or bispecific molecules and the immunoconjugates can be used to elicit in vivo or in vitro one or more of the following biological activities: to inhibit the growth of and/or kill a cell expressing CDl 9; to mediate phagocytosis or ADCC of a cell expressing CD 19 in the presence of human effector cells, or to block CD 19 ligand binding to CD 19.
- the antibodies are used in vivo to treat, prevent or diagnose a variety of CD 19-related diseases.
- CD 19-related diseases include, among others, autoimmune disorders, rheumatoid arthritis, cancer, non-Hodgkin's lymphoma, acute lymphocytic leukemia (ALL), chronic lymphocytic leukemia (CLL), Burkitt's lymphoma, anaplastic large-cell lymphomas (ALCL), multiple myeloma, cutaneous T- cell lymphomas, nodular small cleaved-cell lymphomas, lymphocytic lymphomas, peripheral T-cell lymphomas, Lennert's lymphomas, immunoblastic lymphomas, T-cell leukemia/lymphomas (ATLL), adult T-cell leukemia (T-ALL), entroblastic/centrocytic (cb/cc) follicular lymphomas
- ALL acute lymphocytic leukemia
- CLL chronic lymphocytic leuk
- Suitable routes of administering the antibody compositions of this disclosure e.g., human monoclonal antibodies, multispecific and bispecific molecules and immunoconjugates
- the antibody compositions can be administered by injection (e.g., intravenous or subcutaneous).
- Suitable dosages of the molecules used will depend on the age and weight of the subject and the concentration and/or formulation of the antibody composition.
- human anti-CD 19 antibodies of this disclosure can be co-administered with one or other more therapeutic agents, e.g., a cytotoxic agent, a radiotoxic agent or an immunosuppressive agent.
- the antibody can be linked to the agent (as an immunocomplex) or can be administered separate from the agent. In the latter case (separate administration), the antibody can be administered before, after or concurrently with the agent or can be co-administered with other known therapies, e.g., an anti-cancer therapy, e.g., radiation.
- Such therapeutic agents include, among others, anti-neoplastic agents such as doxorubicin (adriamycin), cisplatin bleomycin sulfate, carmustine, chlorambucil, and cyclophosphamide hydroxyurea which, by themselves, are only effective at levels which are toxic or subtoxic to a patient.
- anti-neoplastic agents such as doxorubicin (adriamycin), cisplatin bleomycin sulfate, carmustine, chlorambucil, and cyclophosphamide hydroxyurea which, by themselves, are only effective at levels which are toxic or subtoxic to a patient.
- Cisplatin is intravenously administered as a 100 mg/ dose once every four weeks and adriamycin is intravenously administered as a 60-75 mg/ml dose once every 21 days.
- Co-administration of the human anti-CD 19 antibodies, or antigen binding fragments thereof, of the present disclosure with chemotherapeutic agents provides two anti-cancer agents which operate via different mechanisms which yield a cytotoxic effect to human tumor cells.
- Such co-administration can solve problems due to development of resistance to drugs or a change in the antigenicity of the tumor cells which would render them unreactive with the antibody.
- Target-specific effector cells e.g., effector cells linked to compositions (e.g., human antibodies, multispecific and bispecific molecules) of this disclosure can also be used as therapeutic agents.
- Effector cells for targeting can be human leukocytes such as macrophages, neutrophils or monocytes.
- effector cells can be obtained from the subject to be treated.
- the target-specific effector cells can be administered as a suspension of cells in a physiologically acceptable solution.
- the number of cells administered can be in the order of 10 s - 10 9 but will vary depending on the therapeutic purpose. In general, the amount will be sufficient to obtain localization at the target cell, e.g., a tumor cell expressing CD 19, and to effect cell killing by, e.g., phagocytosis. Routes of administration can also vary. Therapy with target-specific effector cells can be performed in conjunction with other techniques for removal of targeted cells.
- anti-tumor therapy using the compositions (e.g., human antibodies, multispecif ⁇ c and bispecific molecules) of this disclosure and/or effector cells armed with these compositions can be used in conjunction with chemotherapy.
- combination immunotherapy may be used to direct two distinct cytotoxic effector populations toward tumor cell rejection.
- anti-CD 19 antibodies linked to anti-Fc-gamma RI or anti-CD3 may be used in conjunction with IgG- or IgA-receptor specific binding agents.
- Bispecific and multispecific molecules of this disclosure can also be used to modulate Fc ⁇ R or Fc ⁇ R levels on effector cells, such as by capping and elimination of receptors on the cell surface. Mixtures of anti-Fc receptors can also be used for this purpose.
- compositions ⁇ e.g., human antibodies, multispecific and bispecific molecules and immunoconjugates) of this disclosure which have complement binding sites, such as portions from IgGl, -2, or -3 or IgM which bind complement, can also be used in the presence of complement.
- ex vivo treatment of a population of cells comprising target cells with a binding agent of this disclosure and appropriate effector cells can be supplemented by the addition of complement or serum containing complement.
- Phagocytosis of target cells coated with a binding agent of this disclosure can be improved by binding of complement proteins.
- target cells coated with the compositions (e.g., human antibodies, multispecific and bispecific molecules) of this disclosure can also be lysed by complement.
- the compositions of this disclosure do not activate complement.
- compositions of this disclosure can also be administered together with complement.
- the instant disclosure provides compositions comprising human antibodies, multispecific or bispecific molecules and serum or complement. These compositions can be advantageous when the complement is located in close proximity to the human antibodies, multispecific or bispecific molecules.
- the human antibodies, multispecific or bispecific molecules of this disclosure and the complement or serum can be administered separately.
- kits which comprise the antibody compositions of this disclosure (e.g., human antibodies, bispecific or multispecific molecules, or immunoconjugates), and instructions for its use.
- the kit can further contain one or more additional reagents, such as an immunosuppressive reagent, a cytotoxic agent or a radiotoxic agent, or one or more additional human antibodies of this disclosure (e.g., a human antibody having a complementary activity which binds to an epitope in the CD 19 antigen distinct from the first human antibody).
- additional reagents such as an immunosuppressive reagent, a cytotoxic agent or a radiotoxic agent, or one or more additional human antibodies of this disclosure (e.g., a human antibody having a complementary activity which binds to an epitope in the CD 19 antigen distinct from the first human antibody).
- patients treated with antibody compositions of this disclosure can be additionally administered (prior to, simultaneously with, or following administration of a human antibody of this disclosure) with another therapeutic agent, such as a cytotoxic or radiotoxic agent, which enhances or augments the therapeutic effect of the human antibodies.
- another therapeutic agent such as a cytotoxic or radiotoxic agent, which enhances or augments the therapeutic effect of the human antibodies.
- the subject can be additionally treated with an agent that modulates, e.g., enhances or inhibits, the expression or activity of Fc ⁇ or Fc ⁇ receptors by, for example, treating the subject with a cytokine.
- cytokines for administration during treatment with the multispecific molecule include of granulocyte colony-stimulating factor (G-CSF), granulocyte- macrophage colony-stimulating factor (GM-CSF), interferon- ⁇ (IFN- ⁇ ), and tumor necrosis factor (TNF).
- G-CSF granulocyte colony-stimulating factor
- GM-CSF granulocyte- macrophage colony-stimulating factor
- IFN- ⁇ interferon- ⁇
- TNF tumor necrosis factor
- compositions e.g., human antibodies, multispecific and bispecific molecules
- the compositions can also be used to target cells expressing Fc ⁇ R or CD 19, for example for labeling such cells.
- the binding agent can be linked to a molecule that can be detected.
- this disclosure provides methods for localizing ex vivo or in vitro cells expressing Fc receptors, such as Fc ⁇ R, or CD 19.
- the detectable label can be, e.g., a radioisotope, a fluorescent compound, an enzyme, or an enzyme co-factor.
- this disclosure provides methods for detecting the presence of CD 19 antigen in a sample, or measuring the amount of CD 19 antigen, comprising contacting the sample, and a control sample, with a human monoclonal antibody, or an antigen binding portion thereof, which specifically binds to CD 19, under conditions that allow for formation of a complex between the antibody or portion thereof and CD 19. The formation of a complex is then detected, wherein a difference complex formation between the sample compared to the control sample is indicative the presence of CD 19 antigen in the sample.
- this disclosure provides methods for treating an CD 19 mediated disorder in a subject, e.g., autoimmune disorder, rheumatoid arthritis, cancer, non-Hodgkin's lymphoma, acute lymphocytic leukemia (ALL), chronic lymphocytic leukemia (CLL), Burkitt's lymphoma, anaplastic large-cell lymphomas (ALCL), cutaneous T-cell lymphomas, nodular small cleaved-cell lymphomas, lymphocytic lymphomas, peripheral T-cell lymphomas, Lennert's lymphomas, immunoblastic lymphomas, T-cell leukemia/lymphomas (ATLL), adult T-cell leukemia (T-ALL), entroblastic/centrocytic (cb/cc) follicular lymphomas cancers, diffuse large cell lymphomas of B lineage, angioimmunoblastic lymphadenopathy (AILD)-like T cell lymphoma, HIV associated
- ALL acute
- Such antibodies and derivatives thereof are used to inhibit CD 19 induced activities associated with certain disorders, e.g., proliferation and differentiation.
- CD 19 By contacting the antibody with CD 19 (e.g., by administering the antibody to a subject), the ability of CD 19 to induce such activities is inhibited and, thus, the associated disorder is treated.
- the antibody composition can be administered alone or along with another therapeutic agent, such as a cytotoxic or a radiotoxic agent which acts in conjunction with or synergistically with the antibody composition to treat or prevent the CD 19 mediated disease.
- immunoconjugates of this disclosure can be used to target compounds (e.g., therapeutic agents, labels, cytotoxins, radiotoxins immunosuppressants, etc.) to cells which have CD 19 cell surface receptors by linking such compounds to the antibody.
- compounds e.g., therapeutic agents, labels, cytotoxins, radiotoxins immunosuppressants, etc.
- an anti-CD 19 antibody can be conjugated to any of the toxin compounds described in US Patent Nos. 6, 281, 354 and 6,548,530, US patent publication Nos. 20030050331, 20030064984, 20030073852, and 20040087497, or published in WO 03/022806.
- this disclosure also provides methods for localizing ex vivo or in vivo cells expressing CD 19 (e.g., with a detectable label, such as a radioisotope, a fluorescent compound, an enzyme, or an enzyme co- factor).
- a detectable label such as a radioisotope, a fluorescent compound, an enzyme, or an enzyme co- factor.
- the immunoconjugates can be used to kill cells which have CD 19 cell surface receptors by targeting cytotoxins or radiotoxins to CD 19.
- the B cell tumor cell lines Raji (ATCC Accession #CCL-86) and Daudi (ATCC Accession #CCL-213) were used as antigen for immunization.
- Fully human monoclonal antibodies to CD 19 were prepared using the KM strain of transgenic transchromosomic mice, which expresses human antibody genes.
- the endogenous mouse kappa light chain gene has been homozygously disrupted as described in Chen et al. ( 1993) EMBO J. 12:81 1 -820 and the endogenous mouse heavy chain gene has been homozygously disrupted as described in Example 1 of PCT Publication WO 01/09187 for HuMab mice.
- the mouse carries a human kappa light chain transgene, KCo5, as described in Fishwild et al. (1996) Nature Biotechnology 14:845-851.
- the mouse also carries a human heavy chain transchromosome, SC20, as described in PCT Publication WO 02/43478.
- mice were 6-16 weeks of age upon the first infusion of antigen.
- a cell preparation was used to immunize the mice (KM-MOUSE ® ) intraperitonealy (IP).
- mice were immunized twice with antigen in complete Freund's adjuvant or Ribi adjuvant IP, followed by 3-21 days IP (up to a total of 1 1 immunizations) with the antigen in incomplete Freund's or Ribi adjuvant.
- the immune response was monitored by retroorbital bleeds.
- the plasma was screened by ELISA (as described below), and mice with sufficient titers of anti-CD 19 human immunogolobulin were used for fusions. Mice were boosted intravenously with antigen 3 days before sacrifice and removal of the spleen. Selection of a KM-MOUSE ® Producing Anti-CD 19 Antibodies:
- the plates were washed with PBS/Tween and then incubated with a goat- anti-human kappa light chain polyclonal antibody conjugated with alkaline phophatase for 1 hour at room temperature. After washing, the plates were developed with pNPP substrate and analyzed by spectrophotometer at OD 415-650. Mice that developed the highest titers of anti-CD 19 antibodies were used for fusions. Fusions were performed as described below and hybridoma supernatants were tested for anti-CD 19 activity by ELISA. Generation of Hybridomas Producing Human Monoclonal Antibodies to CD 19:
- mice splenocytes isolated from a KM-MOUSE* " , were fused with PEG to a mouse myeloma cell line either using PEG based upon standard protocols or electric field based electrofusion using a Cyto Pulse large chamber cull fusion electroporator (Cyto Pulse Sciences, Inc., Glen Burnie, MD). The resulting hybridomas were then screened for the production of antigen-specific antibodies. Single cell suspensions of splenic lymphocytes from immunized mice were fused to one-fourth the number of SP2/0 nonsecreting mouse myeloma cells (ATCC, CRL 1581) with 50% PEG (Sigma).
- Cells were plated at approximately lxlO 5 /well in flat bottom microtiter plate, followed by about two week incubation in selective medium containing 10% fetal bovine serum, 10% P388D1 (ATCC, CRL TIB-63) conditioned medium, 3-5% origen (IGEN) in DMEM (Mediatech, CRL 10013, with high glucose, L-glutamine and sodium pyruvate) plus 5 mM HEPES, 0.055 mM 2-mercaptoethanol, 50 mg/ml gentamycin and Ix HAT (Sigma, CRL P-7185). After 1-2 weeks, cells were cultured in medium in which the HAT was replaced with HT.
- selective medium containing 10% fetal bovine serum, 10% P388D1 (ATCC, CRL TIB-63) conditioned medium, 3-5% origen (IGEN) in DMEM (Mediatech, CRL 10013, with high glucose, L-glutamine and sodium pyruvate) plus 5 mM HEPES,
- Example 2 Structural Characterization of Human Monoclonal Antibodies 21D4, 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl and 46E8
- the cDNA sequences encoding the heavy and light chain variable regions of the 21D4 and 21D4a monoclonal antibodies were obtained from the 21D4 hybridoma using standard PCR techniques and were sequenced using standard DNA sequencing techniques. It is noted that the 21D4 hybridoma produces antibodies having a heavy chain that pairs with one of two light chains (SEQ ID NOs: 8 and 9). Both antibodies (i.e., 21D4 with V H and V L sequences of SEQ ID NOs: 1 and 8, respectively, and 21D4a with V H and V 1 sequences of SEQ ID NOs: 1 and 9, respectively) bind to CD 19.
- the cDNA sequences encoding the heavy and light chain variable regions of the 47G4, 27F3, 3C10, 5G7, 13Fl and 46E8 monoclonal antibodies were obtained from the 21D4, 21D4a, 47G4, 27F3, 3C10, 5G7, 13Fl and 46E8 hybridomas, respectively, using standard PCR techniques and were sequenced using standard DNA sequencing techniques.
- 21D4 are shown in Figure IA and in SEQ ID NO: 59 and 1, respectively.
- nucleotide and amino acid sequences of the light chain variable region of 21D4 are shown in Figure IB and in SEQ ID NO: 66 and 8, respectively.
- 21D4 heavy chain immunoglobulin sequence Comparison of the 21D4 heavy chain immunoglobulin sequence to the known human germline immunoglobulin heavy chain sequences demonstrated that the 21 D4 heavy chain utilizes a V H segment from human germline V H 5-51, a D segment from the human germline 3-10, and a J H segment from human germline JH 4b.
- the alignment of the 21D4 V H sequence to the germline V H 5-51 sequence is shown in Figure 8.
- Further analysis of the 21D4 Vn sequence using the Kabat system of CDR region determination led to the delineation of the heavy chain CDRl, CDR2 and CD3 regions as shown in Figures IA and 8, and in SEQ ID NOs: 16, 23 and 30, respectively.
- nucleotide and amino acid sequences of the heavy chain variable region of 21D4a are shown in Figure IA and in SEQ ID NO: 59 and 1, respectively.
- the nucleotide and amino acid sequences of the light chain variable region of 21D4a are shown in Figure 1C and in SEQ ID NO: 67 and 9, respectively.
- Comparison of the 21D4a heavy chain immunoglobulin sequence to the known human germline immunoglobulin heavy chain sequences demonstrated that the 21D4a heavy chain utilizes a Vn segment from human germline V H 5-51, a D segment from the human germline 3-10, and a J H segment from human germline JH 4b.
- the alignment of the 21D4a V H sequence to the germline V ( 1 5-51 sequence is shown in Figure 8.
- the nucleotide and amino acid sequences of the light chain variable region of 47G4 are shown in Figure 2B and in SEQ ID NO: 68 and 10, respectively. Comparison of the 47G4 heavy chain immunoglobulin sequence to the known human germline immunoglobulin heavy chain sequences demonstrated that the 47G4 heavy chain utilizes a V H segment from human germline V H 1-69, a D segment from the human germline 6-19, and a J H segment from human germline JH 5b. The alignment of the 47G4 V H sequence to the germline V H 1 -69 sequence is shown in Figure 9.
- nucleotide and amino acid sequences of the heavy chain variable region of 27F3 are shown in Figure 3A and in SEQ ID NO: 61 and 3, respectively.
- the nucleotide and amino acid sequences of the light chain variable region of 27F3 are shown in Figure 3B and in SEQ ID NO: 69 and 1 1, respectively.
- Comparison of the 27F3 heavy chain immunoglobulin sequence to the known human germline immunoglobulin heavy chain sequences demonstrated that the 27F3 heavy chain utilizes a V H segment from human germline V H 5-51, a D segment from the human germline 6-19, and a J H segment from human germline JH 6b.
- the alignment of the 27F3 V H sequence to the germline V H 5-51 sequence is shown in Figure 10.
- nucleotide and amino acid sequences of the heavy chain variable region of 3C10 are shown in Figure 4A and in SEQ ID NO: 62 and 4, respectively.
- the nucleotide and amino acid sequences of the light chain variable region of 3ClO are shown in Figure 4B and in SEQ ID NO: 70 and 12, respectively.
- Comparison of the 3C10 heavy chain immunoglobulin sequence to the known human germline immunoglobulin heavy chain sequences demonstrated that the 3C10 heavy chain utilizes a V H segment from human germline VH 1-69, a D segment from the human germline 1-26, and a J H segment from human germline JH 6b.
- the alignment of the 3C10 V H sequence to the ge ⁇ nline V H 1-69 sequence is shown in Figure 1 1.
- the nucleotide and amino acid sequences of the light chain variable region of 5G7 are shown in Figure 5B and in SEQ ID NO: 71 and 13, respectively. Comparison of the 5G7 heavy chain immunoglobulin sequence to the known human germline immunoglobulin heavy chain sequences demonstrated that the 5G7 heavy chain utilizes a V H segment from human germline V H 5-51, a D segment from the human germline 3-10, and a J H segment from human germline JH 6b. The alignment of the 5G7 V H sequence to the germline V H 5-51 sequence is shown in Figure 12.
- nucleotide and amino acid sequences of the heavy chain variable region of 13Fl are shown in Figure 6A and in SEQ ID NO: 64 and 6, respectively.
- the nucleotide and amino acid sequences of the light chain variable region of 13Fl are shown in Figure 6B and in SEQ ID NO: 72 and 14, respectively. Comparison of the 13Fl heavy chain immunoglobulin sequence to the known human germline immunoglobulin heavy chain sequences demonstrated that the 13Fl heavy chain utilizes a V H segment from human germline V H 5-51, a D segment from the human germline 6-19, and a Jn segment from human germline JH 6b. The alignment of the 13Fl V H sequence to the germline Vn 5-51 sequence is shown in Figure 13.
- nucleotide and amino acid sequences of the heavy chain variable region of 46E8 are shown in Figure 7A and in SEQ ID NO: 65 and 7, respectively.
- the nucleotide and amino acid sequences of the light chain variable region of 46E8 are shown in Figure 7B and in SEQ ID NO: 73 and 15, respectively. Comparison of the 46E8 heavy chain immunoglobulin sequence to the known human germline immunoglobulin heavy chain sequences demonstrated that the 46E8 heavy chain utilizes a V H segment from human germline V H 5-51 , a D segment from the human germline 6-19, and a J H segment from human germline JH 6b. The alignment of the 46E8 Vn sequence to the germline V H 5-51 sequence is shown in Figure 14.
- binding affinity of the anti-CD 19 antibodies 21D4 and 47G4 were examined by ELISA analysis. Binding specificity by ELISA
- Microtiter plates were coated with 50 ⁇ l purified full-length CD 19-Fc fusion protein at 1.0 ⁇ g/ml in PBS, and then blocked with 150 ⁇ l of 1% bovine serum albumin in PBS. The plates were allowed to incubate for 30 minutes to 1 hour and washed three times. Dilutions of the HuMAb anti-CD 19 antibody 47G4 was added to each well and incubated for 1 hour at 37 0 C. A known murine anti-CD 19 antibody was used as a positive control. The plates were washed with PBS/Tween and then incubated with a goat anti-human IgG Kappa-specific secondary reagent conjugated to horseradish peroxidase for 1 hour at 37 0 C.
- Flow cytometry was used to determine epitope grouping of anti-CD 19 HuMAbs.
- Epitope binding of the anti-CD 19 human monoclonal antibodies 21D4, 21D4a, 3C10, 5G7, 5G7-N19K, 5G7-N19Q and 13Fl was assessed by incubating Raji B tumor cells with 0.3 ⁇ g/ml of either biotinylated 21 D4 or 21 D4a anti-CD 19 human monoclonal antibody, washed, and followed by the addition of a cold anti-CD 19 human monoclonal antibody.
- An isotype control antibody was used as a negative control. Binding was detected with a FITC-labeled anti-human IgG Ab.
- CD 19 HuMAbs Binding of the CD 19 HuMAbs by flow cytometry to the B cell tumor lines Raji and Daudi, or to a CHO-CD 19 transfected cell line was assessed.
- CHO cells were transfected with an expression plasmid containing the full length cDNA encoding the transmembrane form of CD 19.
- the Raji, Daudi, and CD19-CHO cell lines were incubated with one of the following CD 19 HuMAbs: 21D4, 21D4a, 47G4, 5G7, 5G7- N 19K, 5G7-N19Q, 3C10 or 13Fl .
- a known murine anti-CD 19 antibody was used as a positive control.
- the cells were washed and detected by either a phycoerythrin-labeled anti-human or anti-mouse secondary antibody and analyzed by flow cytometry.
- the results for binding to the CHO-CD 19 cell line, Daudi B cell line, Raji B cell line and an expanded binding set against the Raji B cell line are shown in Figures 25 A, 25B, 25C and 25D, respectively.
- the human anti-CD 19 monoclonal antibodies, 21D4 and 47G4 bound to the CHO-CD 19 cell line.
- the anti-CD19 HuMAb antibodies 21 D4, 21D4a, 3C10, 5G7, 5G7-N19K, 5G7- N19Q, and 13Fl had calculated EC 50 values of 0.1413, 0.1293, 0.2399, 0.1878. 0.2240, 0.2167 and 0.2659, respectively. 47G4 was also shown to bind the Daudi B tumor cell line. AU results are shown as measured by the geometric mean fluorescent intensity (GMFI) of staining.
- GMFI geometric mean fluorescent intensity
- CD 19 protein is expressed on the surface of tumor cell lines of B cell origin and that the anti-CD 19 HuMAb antibodies 21D4, 21D4a, 47G4, 5G7, 5G7-N19K, 5G7-N19Q, 3C10 and 13Fl bind to CD19 expressed on the cell surface.
- Raji cells were obtained from ATCC (Accession #CCL-86) and grown in RPMI containing 10% fetal bovine serum (FBS). The cells were washed twice with RPMI containing 10% FBS at 4 0 C and the cells were adjusted to 4x10 7 cells/ml in RPMI media containing 10% fetal bovine serum (binding buffer containing 24mM Tris pH 7.2, 137mM NaCl, 2.7mN KCl, 2mM glucose, ImM CaCl 2 , ImM MgCl 2 , 0.1% BSA). Millipore plates (MAFB NOB) were coated with 1% nonfat dry milk in water and stored a 4 0 C overnight.
- FBS fetal bovine serum
- the plates were washed with binding buffer and 25 ⁇ l of unlabeled antibody (1000-fold excess) in binding buffer was added to control wells in a Millipore 96 well glass fiber filter plate (non-specific binding NSB). Twenty-five microliters of buffer alone was added to the maximum binding control well (total binding). Twenty- five microliters of varying concentrations of l2:> I-anti-CD19 antibody 21D4 or 47G4 and 25 ⁇ l of Raji cells (4 X 10 7 cells/ml) in binding buffer were added. The plates were incubated for 2 hours at 200 RPM on a shaker at 4 0 C.
- the Millipore plates were washed three times with 0.2 ml of cold wash buffer (24mM Tris pH 7.2, 50OmM NaCl, 2.7mN KCl, 2mM glucose, ImM CaCl 2 , ImM MgCl 2 , 0.1% BSA). The filters were removed and counted in a gamma counter. Evaluation of equilibrium binding was performed using single site binding parameters with the Prism software (San Diego, CA). Using the above scatchard binding assay, the K D of the antibody for Raji cells was approximately 2.14 nM for 21D4 and 12.02 nM for 47G4.
- Anti-CD 19 HuMAbs were tested for the ability to internalize into CD 19- expressing Raji B tumor cells or human CHO cells transfected with CD 19 using a Hum- Zap internalization assay.
- Hum-Zap tests for internalization of a primary human antibody through binding of a secondary antibody with affinity for human IgG conjugated to the toxin saporin.
- the CHO-CD 19 or Raji B tumor cell line was seeded at 1.0x10 4 cells/well in 100 ⁇ l wells either overnight or the following day for a two hour period. Either the anti- CD 19 antibody 21 D4 or 47G4 were added to the wells at a starting concentration of 30 nM and titrated down at 1:3 serial dilutions. A human isotype control antibody that is non-specific for CD 19 was used as a negative control.
- the Hum-Zap Advanced Targeting Systems, IT-22-25
- anti-CD 19 monoclonal antibodies conjugated to a cytotoxin were tested for the ability to kill CD 19+ cell lines in a thymidine incorporation assay. Cytotoxin N 1 was used in this experiment. An anti-CD 19 monoclonal antibody was conjugated to a cytotoxin via a linker, such as a peptidyl, hydrazone or disulfide linker. The CD 19+ expressing Raji cell line was seeded at 2.5x10 4 cells/wells for 3 hours. An anti-CD 19 antibody-cytotoxin conjugate was added to the wells at a starting concentration of 30 nM and titrated down at 1 :3 serial dilutions.
- An isotype control antibody that is non-specific for CDl 9 was used as a negative control. Ten-fold excess cold antibody, either 21 D4a or an isotype control antibody is used to compete binding. Plates were allowed to incubate for 69 hours. The plates were then pulsed with 1.0 ⁇ Ci of 3 H-thymidine for 24 hours, harvested and read in a Top Count Scintillation Counter (Packard Instruments, Meriden, CT). The results are shown in Figure 27A and B along with the EC50 values. This data demonstrates that the anti-CD 19 antibody 21 D4 kills Raji B-cell tumor cells.
- Example 8 Treatment of in vivo B cell Tumors Using Anti-CD19 Antibodies
- SCID mice implanted with cancerous B cell tumors were treated in vivo with either naked anti-CD19 21D4 antibodies or cytotox in-conjugated anti-CD19 antibody 21D4 to examine the in vivo effect of the antibodies on tumor growth.
- Cytotoxin N 1 was used in this experiment.
- Cytotoxin-conjugated anti-CD 19 antibodies were prepared as described above. Severe combined immune deficient (SCID) mice, which lack functional B and T lymphocytes were used to study B-cell malignancies. Cells from the Ramos B tumor cell line were injected intravenously. The mice were treated either with 19.6 mg/kg of cytotox in-conjugate anti-CD 19 antibody or 30 mg/kg naked anti-CD 19 antibody. An isotype control antibody or formulation buffer was used as a negative control. The isotype control was conjugated to the free toxin released by cleavage of the linker in Nl. The animals were dosed by intraperitoneal injection with approximately 200 ⁇ l of PBS containing antibody or vehicle.
- SCID Severe combined immune deficient mice, which lack functional B and T lymphocytes were used to study B-cell malignancies. Cells from the Ramos B tumor cell line were injected intravenously. The mice were treated either with 19.6 mg/kg of cytotox in-conjugate anti
- the antibody-cytotoxin conjugate was injected as a single dose on day 7, while the naked antibody was either injected as a single dose prophylactic model on day 1 or as a treatment model on days 7, 14 and 21.
- the mice were monitored daily for hind leg paralysis for approximately 6 weeks. Using an electronic caliper, the tumors were measured three dimensionally (height x width x length) and tumor volume was calculated. Mice were euthanized when there was hindleg paralysis.
- the change in body weight was also measured and calculated as percent change in weight.
- the data is shown in Figures 29A and B. Over a 30 day period, there was a net increase change in body weight with one cytotoxin-conjugate antibody and a net decrease change in body weight with antibody and cytotoxin (not conjugate). There was a net increase change in body weight with either the prophylactic naked anti-CD 19 antibody or the anti-CD 19 antibody treatment regimen.
- mice implanted with a lymphoma tumor were treated in vivo with naked anti- CD ⁇ antibodies to examine the in vivo effect of the antibodies on tumor growth.
- ARH-77 human B lymphoblast leukemia; ATCC Accession No. CRL- 1621
- Raji human B lymphocyte Burkitt's lymphoma; ATCC Accession No. CCL-86 cells were expanded in vitro using standard laboratory procedures.
- SCID mice Teconic, Hudson, NY
- Mice were weighed and measured for tumors three dimensionally using an electronic caliper twice weekly after implantation. Tumor volumes were calculated as height x width x length/2.
- mice with ARH-77 tumors averaging 80 mm 3 or Raji tumors averaging 170 mm 3 were randomized into treatment groups.
- the mice were dosed intraperitoneal Iy with PBS vehicle, isotype control antibody or naked anti-CD 19 HuMAb 2H5 on Day 0. Mice were euthanized when the tumors reached tumor end point (2000 mm 3 ).
- the results are shown in Figure 30A (ARH-77 tumors) and 30B (Raji tumors).
- the naked anti-CD 19 antibody 21 D4 extended the mean time to reaching the tumor end point volume (2000 mm 3 ) and slowed tumor growth progression.
- treatment with an anti-CD 19 antibody alone has a direct in vivo inhibitory effect on tumor growth.
- Antibodies with reduced amounts of fucosyl residues have been demonstrated to increase the ADCC ability of the antibody.
- the anti-CD 19 HuMAb 21D4 has been produced that is lacking in fucosyl residues.
- the CHO cell line Ms704-PF which lacks the fucosyltransferase gene, FUT 8 (Biowa, Inc., Princeton, NJ) was electroporated with a vector which expresses the heavy and light chains of antibody 21 D4. Drug-resistant clones were selected by growth in Ex- Cell 325-PF CHO media (JRH Biosciences, Lenexa, KS) with 6 mM L-glutamine and
- the N-linked glycans from the Fc portion of HuMAb 21 D4 expressed in CHO fucosylating and non-fucosylating cells were released.
- the supernatant containing the glycans was dried by vacuum centrifugation and resuspended in 19mM 8-aminopyrene- 1,3,6- trisulfonate (APTS) (Beckman) under mild reductive amination conditions in which desialylation and loss of fucose residues was minimized (15% acetic acid and 1 M sodium cyanoborohydride in THF (Sigma)).
- APTS 19mM 8-aminopyrene- 1,3,6- trisulfonate
- the glycan labeling reaction was allowed to continue overnight at 40°C followed by 25-fold dilution of sample in water.
- APTS- labeled glycans were applied to capillary electrophoresis with laser induced fluorescence on a P/ACE MDQ CE system (Beckman) with reverse polarity, using a 50 ⁇ m internal diameter N-CHO coated capillary (Beckman) with 50 cm effective length. Samples were pressure (8 sec.) injected and separation was carried out at 20°C using Carbohydrate Separation Gel Buffer (Beckman) at 25 kV for 20 min.
- IgG samples (200 ⁇ g) were subjected to acid hydrolysis using either 2 N TFA (for estimating neutral sugars) or 6 N HCl (for estimating amino sugars) at 100°C for 4 h. Samples were dried by vacuum centrifugation at ambient temperature and were reconstituted in 200 ⁇ l water prior to analysis by HPAE-PAD (Dionex). Monosaccharides were separated using a CarboPac PAlO 4 x 250 mm column with pre- column Amino Trap and Borate Trap (Dionex). Procedures were followed according to Dionex Technical Note 53. Monosaccharide peak identity and relative abundance were determined using monosaccharide standards (Dionex).
- the nonfucosylated anti-CD 19 21 D4 antibody was also tested using a standard capillary isoelectric focusing kit assay (Beckman Coulter). The assay returned observed pi values of pH 8.45 for fucosylated 21D4, 8.44 and 8.21 for fucosylated 21D4a, and 8.52 and 8.30 for the nonfucosylated 21D4 antibodies.
- ADCC antibody dependent cellular cytotoxicity
- Nonfucosylated human Anti-CD 19 monoclonal antibody 21 D4 was prepared as described above.
- Human effector cells were prepared from whole blood as follows. Human peripheral blood mononuclear cells were purified from heparinized whole blood by standard Ficoll-paque separation. The cells were resuspended in RPMI 1640 media containing 10% FBS (culture media) and 200 U/ml of human IL-2 and incubated overnight at 37°C. The following day, the cells were collected and washed once in culture media and resuspended at 2 x 10 7 cells/ml.
- Target CD 19+ cells were incubated with BATDA reagent (Perkin Elmer, Wellesley, MA) at 2.5 ⁇ l BATDA per 1 x 10 6 target cells/mL in culture media supplemented with 2.5mM probenecid (assay media) for 20 minutes at 37° C.
- BATDA reagent Perkin Elmer, Wellesley, MA
- the target cells were washed four times in PBS with 2OmM HEPES and 2.5mM probenecid, spun down and brought to a final volume of 1x10 " cells/ml in assay media.
- the CD 19+ cell line ARH-77 human B lymphoblast leukemia; ATCC Accession
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Immunology (AREA)
- Engineering & Computer Science (AREA)
- Medicinal Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Organic Chemistry (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Epidemiology (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- General Chemical & Material Sciences (AREA)
- Cell Biology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Hematology (AREA)
- Oncology (AREA)
- Microbiology (AREA)
- Mycology (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
Abstract
Description














































































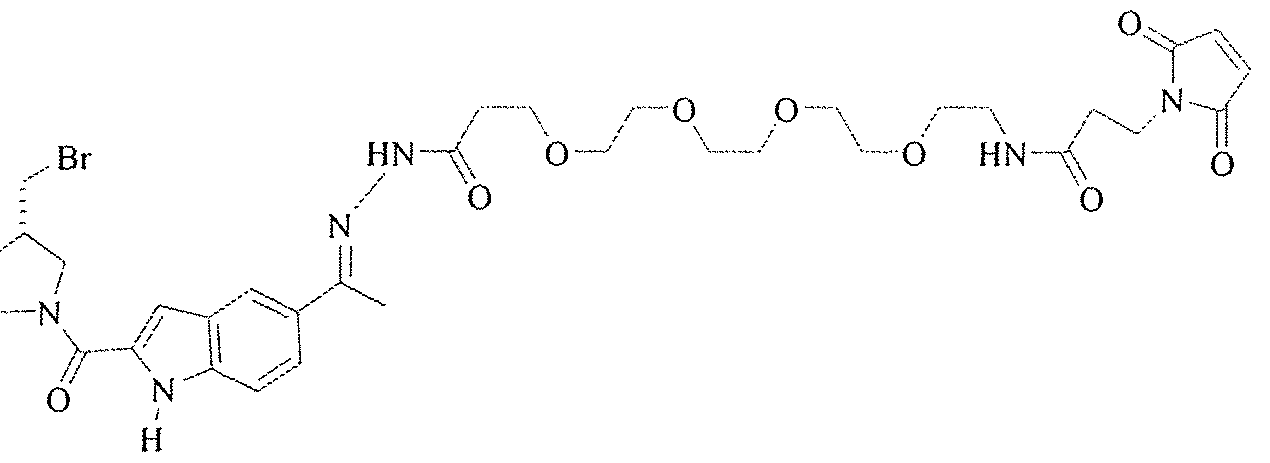







Claims
Priority Applications (8)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| BRPI0718349-6A2A BRPI0718349A2 (en) | 2006-12-13 | 2007-12-13 | CONJUGATED ANTIBODY PARTNERSHIP COMPOSITION, METHOD OF INHIBITING THE GROWTH OF A TUMOR CELL EXPRESSING CD19, B-CELL EXHAUST METHOD IN A SUBJECT AND METHOD OF TREATMENT OF A SUBJECT TO A CANCER |
| EP07875235.9A EP2101817A4 (en) | 2006-12-13 | 2007-12-13 | Human antibodies that bind cd19 and uses thereof |
| MX2009006275A MX2009006275A (en) | 2006-12-13 | 2007-12-13 | Human antibodies that bind cd19 and uses thereof. |
| JP2009541583A JP5517626B2 (en) | 2006-12-13 | 2007-12-13 | Human antibodies that bind to CD19 and uses thereof |
| CN200780050552.1A CN101636502B (en) | 2006-12-13 | 2007-12-13 | Human antibodies that bind cd19 and uses thereof |
| CA002672800A CA2672800A1 (en) | 2006-12-13 | 2007-12-13 | Human antibodies that bind cd19 and uses thereof |
| US12/519,149 US20100104509A1 (en) | 2006-12-13 | 2007-12-13 | Human antibodies that bind cd19 and uses thereof |
| AU2007360636A AU2007360636A1 (en) | 2006-12-13 | 2007-12-13 | Human antibodies that bind CD19 and uses thereof |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US86990406P | 2006-12-13 | 2006-12-13 | |
| US60/869,904 | 2006-12-13 | ||
| US99170007P | 2007-11-30 | 2007-11-30 | |
| US60/991,700 | 2007-11-30 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2009054863A2 true WO2009054863A2 (en) | 2009-04-30 |
| WO2009054863A3 WO2009054863A3 (en) | 2009-09-24 |
Family
ID=40580273
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2007/087393 WO2009054863A2 (en) | 2006-12-13 | 2007-12-13 | Human antibodies that bind cd19 and uses thereof |
Country Status (13)
| Country | Link |
|---|---|
| US (1) | US20100104509A1 (en) |
| EP (1) | EP2101817A4 (en) |
| JP (1) | JP5517626B2 (en) |
| KR (1) | KR20090088940A (en) |
| CN (1) | CN101636502B (en) |
| AR (1) | AR064337A1 (en) |
| AU (1) | AU2007360636A1 (en) |
| BR (1) | BRPI0718349A2 (en) |
| CA (1) | CA2672800A1 (en) |
| CL (1) | CL2007003622A1 (en) |
| MX (1) | MX2009006275A (en) |
| TW (1) | TW200833713A (en) |
| WO (1) | WO2009054863A2 (en) |
Cited By (35)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2409712A1 (en) | 2010-07-19 | 2012-01-25 | International-Drug-Development-Biotech | Anti-CD19 antibody having ADCC and CDC functions and improved glycosylation profile |
| EP2409993A1 (en) | 2010-07-19 | 2012-01-25 | International-Drug-Development-Biotech | Anti-CD19 antibody having ADCC function with improved glycosylation profile |
| WO2014008218A1 (en) | 2012-07-02 | 2014-01-09 | Bristol-Myers Squibb Company | Optimization of antibodies that bind lymphocyte activation gene-3 (lag-3), and uses thereof |
| EP2905030A1 (en) | 2008-08-11 | 2015-08-12 | E. R. Squibb & Sons, L.L.C. | Human antibodies that bind lymphocyte activation gene-3 (LAG-3) and uses thereof |
| WO2015187835A2 (en) | 2014-06-06 | 2015-12-10 | Bristol-Myers Squibb Company | Antibodies against glucocorticoid-induced tumor necrosis factor receptor (gitr) and uses thereof |
| WO2016033570A1 (en) * | 2014-08-28 | 2016-03-03 | Juno Therapeutics, Inc. | Antibodies and chimeric antigen receptors specific for cd19 |
| WO2016081748A2 (en) | 2014-11-21 | 2016-05-26 | Bristol-Myers Squibb Company | Antibodies against cd73 and uses thereof |
| WO2017087678A2 (en) | 2015-11-19 | 2017-05-26 | Bristol-Myers Squibb Company | Antibodies against glucocorticoid-induced tumor necrosis factor receptor (gitr) and uses thereof |
| WO2017152085A1 (en) | 2016-03-04 | 2017-09-08 | Bristol-Myers Squibb Company | Combination therapy with anti-cd73 antibodies |
| WO2018083535A1 (en) * | 2016-11-04 | 2018-05-11 | Novimmune Sa | Anti-cd19 antibodies and methods of use thereof |
| WO2018151821A1 (en) | 2017-02-17 | 2018-08-23 | Bristol-Myers Squibb Company | Antibodies to alpha-synuclein and uses thereof |
| WO2018213297A1 (en) | 2017-05-16 | 2018-11-22 | Bristol-Myers Squibb Company | Treatment of cancer with anti-gitr agonist antibodies |
| WO2018218056A1 (en) | 2017-05-25 | 2018-11-29 | Birstol-Myers Squibb Company | Antibodies comprising modified heavy constant regions |
| WO2019243626A1 (en) | 2018-06-22 | 2019-12-26 | Genmab A/S | Method for producing a controlled mixture of two or more different antibodies |
| WO2019215510A3 (en) * | 2018-05-09 | 2020-01-09 | Legochem Biosciences, Inc. | Compositions and methods related to anti-cd19 antibody drug conjugates |
| WO2020154889A1 (en) * | 2019-01-29 | 2020-08-06 | 上海鑫湾生物科技有限公司 | Combination of antibody having fc mutant and effector cell, use thereof and preparation method therefor |
| EP3789399A1 (en) | 2014-11-21 | 2021-03-10 | Bristol-Myers Squibb Company | Antibodies comprising modified heavy constant regions |
| WO2021067598A1 (en) | 2019-10-04 | 2021-04-08 | Ultragenyx Pharmaceutical Inc. | Methods for improved therapeutic use of recombinant aav |
| US10980890B2 (en) | 2014-05-28 | 2021-04-20 | Legochem Biosciences, Inc. | Compounds comprising self-immolative group |
| EP3684820A4 (en) * | 2017-09-21 | 2021-05-26 | Wuxi Biologics (Cayman) Inc. | Novel anti-cd19 antibodies |
| US11059910B2 (en) | 2012-12-03 | 2021-07-13 | Novimmune Sa | Anti-CD47 antibodies and methods of use thereof |
| US11167040B2 (en) | 2015-11-25 | 2021-11-09 | Legochem Biosciences, Inc. | Conjugates comprising peptide groups and methods related thereto |
| US11173214B2 (en) | 2015-11-25 | 2021-11-16 | Legochem Biosciences, Inc. | Antibody-drug conjugates comprising branched linkers and methods related thereto |
| CN113840841A (en) * | 2019-05-20 | 2021-12-24 | 南京驯鹿医疗技术有限公司 | Fully human antibody targeting CD19 and application thereof |
| US11236161B2 (en) | 2014-06-02 | 2022-02-01 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Chimeric antigen receptors targeting CD-19 |
| US11286300B2 (en) | 2015-10-01 | 2022-03-29 | Hoffmann-La Roche Inc. | Humanized anti-human CD19 antibodies and methods of use |
| US11299551B2 (en) | 2020-02-26 | 2022-04-12 | Biograph 55, Inc. | Composite binding molecules targeting immunosuppressive B cells |
| US11413353B2 (en) | 2015-11-25 | 2022-08-16 | Legochem Biosciences, Inc. | Conjugates comprising self-immolative groups and methods related thereto |
| US11654197B2 (en) | 2017-03-29 | 2023-05-23 | Legochem Biosciences, Inc. | Pyrrolobenzodiazepine dimer prodrug and ligand-linker conjugate compound of the same |
| US11707533B2 (en) | 2019-09-04 | 2023-07-25 | Legochem Biosciences, Inc. | Antibody-drug conjugate comprising antibody against human ROR1 and use for the same |
| EP4249066A2 (en) | 2014-12-23 | 2023-09-27 | Bristol-Myers Squibb Company | Antibodies to tigit |
| WO2023198744A1 (en) | 2022-04-13 | 2023-10-19 | Tessa Therapeutics Ltd. | Therapeutic t cell product |
| US11793834B2 (en) | 2018-12-12 | 2023-10-24 | Kite Pharma, Inc. | Chimeric antigen and T cell receptors and methods of use |
| RU2806333C2 (en) * | 2018-05-09 | 2023-10-31 | Легокем Байосайенсиз, Инк. | Compositions and methods relating to drug conjugates with anti-cd19 antibodies |
| WO2023245106A1 (en) * | 2022-06-16 | 2023-12-21 | Abbvie Biotherapeutics Inc. | Anti-cd19 antibody drug conjugates |
Families Citing this family (45)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| LT2211904T (en) | 2007-10-19 | 2016-11-25 | Seattle Genetics, Inc. | Cd19 binding agents and uses thereof |
| US8852599B2 (en) | 2011-05-26 | 2014-10-07 | Bristol-Myers Squibb Company | Immunoconjugates, compositions for making them, and methods of making and use |
| CA2876730A1 (en) | 2012-07-13 | 2014-01-16 | The Trustees Of The University Of Pennsylvania | Enhancing activity of car t cells by co-introducing a bispecific antibody |
| CN105837689B (en) * | 2015-01-13 | 2020-06-19 | 博生吉安科细胞技术有限公司 | anti-CD19 monoclonal antibody and preparation method thereof |
| MA44909A (en) | 2015-09-15 | 2018-07-25 | Acerta Pharma Bv | THERAPEUTIC ASSOCIATION OF A CD19 INHIBITOR AND A BTK INHIBITOR |
| CN106554414B (en) * | 2015-09-18 | 2019-04-23 | 上海科济制药有限公司 | Anti- CD19 human antibody and the immune effector cell for targeting CD19 |
| WO2017075465A1 (en) | 2015-10-28 | 2017-05-04 | The Broad Institute Inc. | Compositions and methods for evaluating and modulating immune responses by detecting and targeting gata3 |
| WO2017075451A1 (en) | 2015-10-28 | 2017-05-04 | The Broad Institute Inc. | Compositions and methods for evaluating and modulating immune responses by detecting and targeting pou2af1 |
| HUE063911T2 (en) * | 2016-06-02 | 2024-02-28 | Bristol Myers Squibb Co | Use of an anti-pd-1 antibody in combination with an anti-cd30 antibody in lymphoma treatment |
| WO2018049025A2 (en) | 2016-09-07 | 2018-03-15 | The Broad Institute Inc. | Compositions and methods for evaluating and modulating immune responses |
| WO2018183908A1 (en) | 2017-03-31 | 2018-10-04 | Dana-Farber Cancer Institute, Inc. | Compositions and methods for treating ovarian tumors |
| EP3606518A4 (en) | 2017-04-01 | 2021-04-07 | The Broad Institute, Inc. | Methods and compositions for detecting and modulating an immunotherapy resistance gene signature in cancer |
| US20200071773A1 (en) | 2017-04-12 | 2020-03-05 | Massachusetts Eye And Ear Infirmary | Tumor signature for metastasis, compositions of matter methods of use thereof |
| JOP20180042A1 (en) * | 2017-04-24 | 2019-01-30 | Kite Pharma Inc | Humanized Antigen-Binding Domains and Methods of Use |
| WO2018232195A1 (en) | 2017-06-14 | 2018-12-20 | The Broad Institute, Inc. | Compositions and methods targeting complement component 3 for inhibiting tumor growth |
| US11634488B2 (en) | 2017-07-10 | 2023-04-25 | International—Drug—Development—Biotech | Treatment of B cell malignancies using afucosylated pro-apoptotic anti-CD19 antibodies in combination with anti CD20 antibodies or chemotherapeutics |
| WO2019014581A1 (en) | 2017-07-14 | 2019-01-17 | The Broad Institute, Inc. | Methods and compositions for modulating cytotoxic lymphocyte activity |
| WO2019070755A1 (en) | 2017-10-02 | 2019-04-11 | The Broad Institute, Inc. | Methods and compositions for detecting and modulating an immunotherapy resistance gene signature in cancer |
| EP3710039A4 (en) | 2017-11-13 | 2021-08-04 | The Broad Institute, Inc. | Methods and compositions for treating cancer by targeting the clec2d-klrb1 pathway |
| US11994512B2 (en) | 2018-01-04 | 2024-05-28 | Massachusetts Institute Of Technology | Single-cell genomic methods to generate ex vivo cell systems that recapitulate in vivo biology with improved fidelity |
| US11957695B2 (en) | 2018-04-26 | 2024-04-16 | The Broad Institute, Inc. | Methods and compositions targeting glucocorticoid signaling for modulating immune responses |
| US20210371932A1 (en) | 2018-06-01 | 2021-12-02 | Massachusetts Institute Of Technology | Methods and compositions for detecting and modulating microenvironment gene signatures from the csf of metastasis patients |
| US12036240B2 (en) | 2018-06-14 | 2024-07-16 | The Broad Institute, Inc. | Compositions and methods targeting complement component 3 for inhibiting tumor growth |
| CN111019905A (en) * | 2018-09-12 | 2020-04-17 | 上海斯丹赛生物技术有限公司 | CAR modified cell and application thereof in preparation of autoimmune disease drugs |
| CN112955172A (en) * | 2018-09-17 | 2021-06-11 | 美国卫生和人力服务部 | Bicistronic chimeric antigen receptor targeting CD19 and CD20 and uses thereof |
| US20210382068A1 (en) | 2018-10-02 | 2021-12-09 | Dana-Farber Cancer Institute, Inc. | Hla single allele lines |
| WO2020081730A2 (en) | 2018-10-16 | 2020-04-23 | Massachusetts Institute Of Technology | Methods and compositions for modulating microenvironment |
| US20220170097A1 (en) | 2018-10-29 | 2022-06-02 | The Broad Institute, Inc. | Car t cell transcriptional atlas |
| WO2020131586A2 (en) | 2018-12-17 | 2020-06-25 | The Broad Institute, Inc. | Methods for identifying neoantigens |
| US11739156B2 (en) | 2019-01-06 | 2023-08-29 | The Broad Institute, Inc. Massachusetts Institute of Technology | Methods and compositions for overcoming immunosuppression |
| US20220154282A1 (en) | 2019-03-12 | 2022-05-19 | The Broad Institute, Inc. | Detection means, compositions and methods for modulating synovial sarcoma cells |
| US20220142948A1 (en) | 2019-03-18 | 2022-05-12 | The Broad Institute, Inc. | Compositions and methods for modulating metabolic regulators of t cell pathogenicity |
| WO2020236967A1 (en) | 2019-05-20 | 2020-11-26 | The Broad Institute, Inc. | Random crispr-cas deletion mutant |
| WO2020236792A1 (en) * | 2019-05-21 | 2020-11-26 | Novartis Ag | Cd19 binding molecules and uses thereof |
| US20220282333A1 (en) | 2019-08-13 | 2022-09-08 | The General Hospital Corporation | Methods for predicting outcomes of checkpoint inhibition and treatment thereof |
| US20220298501A1 (en) | 2019-08-30 | 2022-09-22 | The Broad Institute, Inc. | Crispr-associated mu transposase systems |
| US11981922B2 (en) | 2019-10-03 | 2024-05-14 | Dana-Farber Cancer Institute, Inc. | Methods and compositions for the modulation of cell interactions and signaling in the tumor microenvironment |
| US11793787B2 (en) | 2019-10-07 | 2023-10-24 | The Broad Institute, Inc. | Methods and compositions for enhancing anti-tumor immunity by targeting steroidogenesis |
| US11844800B2 (en) | 2019-10-30 | 2023-12-19 | Massachusetts Institute Of Technology | Methods and compositions for predicting and preventing relapse of acute lymphoblastic leukemia |
| CN112679612B (en) * | 2021-01-29 | 2022-07-01 | 武汉华美生物工程有限公司 | anti-CD 19 humanized antibody and preparation method and application thereof |
| WO2022165419A1 (en) | 2021-02-01 | 2022-08-04 | Kyverna Therapeutics, Inc. | Methods for increasing t-cell function |
| US20230210900A1 (en) | 2022-01-04 | 2023-07-06 | Kyverna Therapeutics, Inc. | Methods for treating autoimmune diseases |
| WO2024077256A1 (en) | 2022-10-07 | 2024-04-11 | The General Hospital Corporation | Methods and compositions for high-throughput discovery ofpeptide-mhc targeting binding proteins |
| WO2024124044A1 (en) | 2022-12-07 | 2024-06-13 | The Brigham And Women’S Hospital, Inc. | Compositions and methods targeting sat1 for enhancing anti¬ tumor immunity during tumor progression |
| US20240285762A1 (en) | 2023-02-28 | 2024-08-29 | Juno Therapeutics, Inc. | Cell therapy for treating systemic autoimmune diseases |
Citations (165)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4391904A (en) | 1979-12-26 | 1983-07-05 | Syva Company | Test strip kits in immunoassays and compositions therein |
| US4399216A (en) | 1980-02-25 | 1983-08-16 | The Trustees Of Columbia University | Processes for inserting DNA into eucaryotic cells and for producing proteinaceous materials |
| US4439196A (en) | 1982-03-18 | 1984-03-27 | Merck & Co., Inc. | Osmotic drug delivery system |
| US4447224A (en) | 1982-09-20 | 1984-05-08 | Infusaid Corporation | Variable flow implantable infusion apparatus |
| US4447233A (en) | 1981-04-10 | 1984-05-08 | Parker-Hannifin Corporation | Medication infusion pump |
| US4475196A (en) | 1981-03-06 | 1984-10-02 | Zor Clair G | Instrument for locating faults in aircraft passenger reading light and attendant call control system |
| US4486194A (en) | 1983-06-08 | 1984-12-04 | James Ferrara | Therapeutic device for administering medicaments through the skin |
| US4487603A (en) | 1982-11-26 | 1984-12-11 | Cordis Corporation | Implantable microinfusion pump system |
| US4522811A (en) | 1982-07-08 | 1985-06-11 | Syntex (U.S.A.) Inc. | Serial injection of muramyldipeptides and liposomes enhances the anti-infective activity of muramyldipeptides |
| EP0154316A2 (en) | 1984-03-06 | 1985-09-11 | Takeda Chemical Industries, Ltd. | Chemically modified lymphokine and production thereof |
| US4596556A (en) | 1985-03-25 | 1986-06-24 | Bioject, Inc. | Hypodermic injection apparatus |
| US4634665A (en) | 1980-02-25 | 1987-01-06 | The Trustees Of Columbia University In The City Of New York | Processes for inserting DNA into eucaryotic cells and for producing proteinaceous materials |
| WO1987004462A1 (en) | 1986-01-23 | 1987-07-30 | Celltech Limited | Recombinant dna sequences, vectors containing them and method for the use thereof |
| WO1988000052A1 (en) | 1986-07-07 | 1988-01-14 | Trustees Of Dartmouth College | Monoclonal antibodies to fc receptor |
| US4790824A (en) | 1987-06-19 | 1988-12-13 | Bioject, Inc. | Non-invasive hypodermic injection device |
| WO1989001036A1 (en) | 1987-07-23 | 1989-02-09 | Celltech Limited | Recombinant dna expression vectors |
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| EP0338841A1 (en) | 1988-04-18 | 1989-10-25 | Celltech Limited | Recombinant DNA methods, vectors and host cells |
| US4881175A (en) | 1986-09-02 | 1989-11-14 | Genex Corporation | Computer based system and method for determining and displaying possible chemical structures for converting double- or multiple-chain polypeptides to single-chain polypeptides |
| US4912227A (en) | 1984-02-21 | 1990-03-27 | The Upjohn Company | 1,2,8,8A-tetrahydrocyclopropa(c)pyrrolo(3,2-e)-indol-4-(5H)-ones and related compounds |
| EP0368684A1 (en) | 1988-11-11 | 1990-05-16 | Medical Research Council | Cloning immunoglobulin variable domain sequences. |
| US4941880A (en) | 1987-06-19 | 1990-07-17 | Bioject, Inc. | Pre-filled ampule and non-invasive hypodermic injection device assembly |
| US4946778A (en) | 1987-09-21 | 1990-08-07 | Genex Corporation | Single polypeptide chain binding molecules |
| US4975278A (en) | 1988-02-26 | 1990-12-04 | Bristol-Myers Company | Antibody-enzyme conjugates in combination with prodrugs for the delivery of cytotoxic agents to tumor cells |
| EP0401384A1 (en) | 1988-12-22 | 1990-12-12 | Kirin-Amgen, Inc. | Chemically modified granulocyte colony stimulating factor |
| US4978757A (en) | 1984-02-21 | 1990-12-18 | The Upjohn Company | 1,2,8,8a-tetrahydrocyclopropa (C) pyrrolo [3,2-e)]-indol-4(5H)-ones and related compounds |
| US5013653A (en) | 1987-03-20 | 1991-05-07 | Creative Biomolecules, Inc. | Product and process for introduction of a hinge region into a fusion protein to facilitate cleavage |
| US5064413A (en) | 1989-11-09 | 1991-11-12 | Bioject, Inc. | Needleless hypodermic injection device |
| US5070092A (en) | 1989-07-03 | 1991-12-03 | Kyowa Hakko Kogyo Co., Ltd. | Pyrroloindole derivatives related to dc-88a compound |
| US5084468A (en) | 1988-08-11 | 1992-01-28 | Kyowa Hakko Kogyo Co., Ltd. | Dc-88a derivatives |
| US5091513A (en) | 1987-05-21 | 1992-02-25 | Creative Biomolecules, Inc. | Biosynthetic antibody binding sites |
| WO1992003918A1 (en) | 1990-08-29 | 1992-03-19 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5101038A (en) | 1988-12-28 | 1992-03-31 | Kyowa Hakko Kogyo Co., Ltd. | Novel substance dc 113 and production thereof |
| US5132405A (en) | 1987-05-21 | 1992-07-21 | Creative Biomolecules, Inc. | Biosynthetic antibody binding sites |
| US5179017A (en) | 1980-02-25 | 1993-01-12 | The Trustees Of Columbia University In The City Of New York | Processes for inserting DNA into eucaryotic cells and for producing proteinaceous materials |
| US5187186A (en) | 1989-07-03 | 1993-02-16 | Kyowa Hakko Kogyo Co., Ltd. | Pyrroloindole derivatives |
| EP0537575A1 (en) | 1991-10-07 | 1993-04-21 | Kyowa Hakko Kogyo Co., Ltd. | Hydrobromide of DC-89 derivative having antitumor activity |
| WO1993012227A1 (en) | 1991-12-17 | 1993-06-24 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5223409A (en) | 1988-09-02 | 1993-06-29 | Protein Engineering Corp. | Directed evolution of novel binding proteins |
| US5225539A (en) | 1986-03-27 | 1993-07-06 | Medical Research Council | Recombinant altered antibodies and methods of making altered antibodies |
| US5258498A (en) | 1987-05-21 | 1993-11-02 | Creative Biomolecules, Inc. | Polypeptide linkers for production of biosynthetic proteins |
| US5260203A (en) | 1986-09-02 | 1993-11-09 | Enzon, Inc. | Single polypeptide chain binding molecules |
| WO1994010332A1 (en) | 1992-11-04 | 1994-05-11 | Medarex, Inc. | HUMANIZED ANTIBODIES TO Fc RECEPTORS FOR IMMUNOGLOBULIN G ON HUMAN MONONUCLEAR PHAGOCYTES |
| US5312335A (en) | 1989-11-09 | 1994-05-17 | Bioject Inc. | Needleless hypodermic injection device |
| US5332837A (en) | 1986-12-19 | 1994-07-26 | The Upjohn Company | CC-1065 analogs |
| EP0616640A1 (en) | 1991-12-02 | 1994-09-28 | Medical Research Council | Production of anti-self antibodies from antibody segment repertoires and displayed on phage |
| WO1994025585A1 (en) | 1993-04-26 | 1994-11-10 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5374548A (en) | 1986-05-02 | 1994-12-20 | Genentech, Inc. | Methods and compositions for the attachment of proteins to liposomes using a glycophospholipid anchor |
| WO1994029351A2 (en) | 1993-06-16 | 1994-12-22 | Celltech Limited | Antibodies |
| US5383851A (en) | 1992-07-24 | 1995-01-24 | Bioject Inc. | Needleless hypodermic injection device |
| US5399331A (en) | 1985-06-26 | 1995-03-21 | The Liposome Company, Inc. | Method for protein-liposome coupling |
| US5416016A (en) | 1989-04-03 | 1995-05-16 | Purdue Research Foundation | Method for enhancing transmembrane transport of exogenous molecules |
| US5427908A (en) | 1990-05-01 | 1995-06-27 | Affymax Technologies N.V. | Recombinant library screening methods |
| US5476996A (en) | 1988-06-14 | 1995-12-19 | Lidak Pharmaceuticals | Human immune system in non-human animal |
| US5476786A (en) | 1987-05-21 | 1995-12-19 | Creative Biomolecules, Inc. | Biosynthetic antibody binding sites |
| WO1996010405A1 (en) | 1994-09-30 | 1996-04-11 | Kyowa Hakko Kogyo Co., Ltd. | Antitumor agent |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| US5545806A (en) | 1990-08-29 | 1996-08-13 | Genpharm International, Inc. | Ransgenic non-human animals for producing heterologous antibodies |
| US5545807A (en) | 1988-10-12 | 1996-08-13 | The Babraham Institute | Production of antibodies from transgenic animals |
| US5587161A (en) | 1992-07-23 | 1996-12-24 | Zeneca Limited | Prodrugs for antibody directed enzyme prodrug therapy |
| WO1997013852A1 (en) | 1995-10-10 | 1997-04-17 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5625126A (en) | 1990-08-29 | 1997-04-29 | Genpharm International, Inc. | Transgenic non-human animals for producing heterologous antibodies |
| US5624821A (en) | 1987-03-18 | 1997-04-29 | Scotgen Biopharmaceuticals Incorporated | Antibodies with altered effector functions |
| US5633425A (en) | 1990-08-29 | 1997-05-27 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5641780A (en) | 1994-04-22 | 1997-06-24 | Kyowa Hakko Kogyo Co., Ltd. | Pyrrolo-indole derivatives |
| US5661016A (en) | 1990-08-29 | 1997-08-26 | Genpharm International Inc. | Transgenic non-human animals capable of producing heterologous antibodies of various isotypes |
| US5677425A (en) | 1987-09-04 | 1997-10-14 | Celltech Therapeutics Limited | Recombinant antibody |
| US5703080A (en) | 1994-05-20 | 1997-12-30 | Kyowa Hakko Kogyo Co., Ltd. | Method for stabilizing duocarmycin derivatives |
| US5712375A (en) | 1990-06-11 | 1998-01-27 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: tissue selex |
| US5714350A (en) | 1992-03-09 | 1998-02-03 | Protein Design Labs, Inc. | Increasing antibody affinity by altering glycosylation in the immunoglobulin variable region |
| US5739350A (en) | 1990-04-25 | 1998-04-14 | Pharmacia & Upjohn Company | CC-1065 analogs |
| US5760185A (en) | 1992-11-28 | 1998-06-02 | Juridical Foundation The Chemo-Sero-Therapeutic Research Institute | Anti-feline herpes virus-1 recombinant antibody and gene fragment coding for said antibody |
| US5763566A (en) | 1990-06-11 | 1998-06-09 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: tissue SELEX |
| US5762905A (en) | 1992-09-16 | 1998-06-09 | The Scripps Research Institute | Human neutralizing monoclonal antibodies to respiratory syncytial virus |
| WO1998024884A1 (en) | 1996-12-02 | 1998-06-11 | Genpharm International | Transgenic non-human animals capable of producing heterologous antibodies |
| US5773435A (en) | 1987-08-04 | 1998-06-30 | Bristol-Myers Squibb Company | Prodrugs for β-lactamase and uses thereof |
| US5789157A (en) | 1990-06-11 | 1998-08-04 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: tissue selex |
| US5789650A (en) | 1990-08-29 | 1998-08-04 | Genpharm International, Inc. | Transgenic non-human animals for producing heterologous antibodies |
| US5814318A (en) | 1990-08-29 | 1998-09-29 | Genpharm International Inc. | Transgenic non-human animals for producing heterologous antibodies |
| US5831077A (en) | 1993-12-09 | 1998-11-03 | Redmond; John William | Glycosylhydrazines, preparation, immobilization and reactions of: glycoprotein analysis and O-glycan removal |
| US5831012A (en) | 1994-01-14 | 1998-11-03 | Pharmacia & Upjohn Aktiebolag | Bacterial receptor structures |
| US5833943A (en) | 1991-04-23 | 1998-11-10 | Cancer Therapeutics Limited | Minimum recognition unit of a pem mucin tandem repeat specific monoclonal antibody |
| US5864026A (en) | 1990-06-11 | 1999-01-26 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: tissue selex |
| US5869046A (en) | 1995-04-14 | 1999-02-09 | Genentech, Inc. | Altered polypeptides with increased half-life |
| US5874299A (en) | 1990-08-29 | 1999-02-23 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5877397A (en) | 1990-08-29 | 1999-03-02 | Genpharm International Inc. | Transgenic non-human animals capable of producing heterologous antibodies of various isotypes |
| US5885793A (en) | 1991-12-02 | 1999-03-23 | Medical Research Council | Production of anti-self antibodies from antibody segment repertoires and displayed on phage |
| WO1999016873A1 (en) | 1997-09-26 | 1999-04-08 | Arne Skerra | Anticalins |
| US5939598A (en) | 1990-01-12 | 1999-08-17 | Abgenix, Inc. | Method of making transgenic mice lacking endogenous heavy chains |
| WO1999045962A1 (en) | 1998-03-13 | 1999-09-16 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5969108A (en) | 1990-07-10 | 1999-10-19 | Medical Research Council | Methods for producing members of specific binding pairs |
| WO1999054342A1 (en) | 1998-04-20 | 1999-10-28 | Pablo Umana | Glycosylation engineering of antibodies for improving antibody-dependent cellular cytotoxicity |
| US6013443A (en) | 1995-05-03 | 2000-01-11 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: tissue SELEX |
| WO2000026373A1 (en) | 1998-11-03 | 2000-05-11 | Babraham Institute | MURINE EXPRESSION OF HUMAN Igμ LOCUS |
| US6075181A (en) | 1990-01-12 | 2000-06-13 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| WO2000033888A2 (en) | 1998-12-11 | 2000-06-15 | Coulter Pharmaceutical, Inc. | Prodrug compounds and process for preparation thereof |
| US6090382A (en) | 1996-02-09 | 2000-07-18 | Basf Aktiengesellschaft | Human antibodies that bind human TNFα |
| WO2000042072A2 (en) | 1999-01-15 | 2000-07-20 | Genentech, Inc. | Polypeptide variants with altered effector function |
| US6114120A (en) | 1995-05-03 | 2000-09-05 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: tissue selex |
| US6121022A (en) | 1995-04-14 | 2000-09-19 | Genentech, Inc. | Altered polypeptides with increased half-life |
| US6132722A (en) | 1997-05-07 | 2000-10-17 | Bristol-Myers Squibb Company | Recombinant antibody-enzyme fusion proteins |
| US6150584A (en) | 1990-01-12 | 2000-11-21 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| US6156313A (en) | 1994-01-04 | 2000-12-05 | The Scripps Research Institute | Human monoclonal antibodies to herpes simplex virus and methods therefor |
| US6162963A (en) | 1990-01-12 | 2000-12-19 | Abgenix, Inc. | Generation of Xenogenetic antibodies |
| US6165745A (en) | 1992-04-24 | 2000-12-26 | Board Of Regents, The University Of Texas System | Recombinant production of immunoglobulin-like domains in prokaryotic cells |
| US6172197B1 (en) | 1991-07-10 | 2001-01-09 | Medical Research Council | Methods for producing members of specific binding pairs |
| WO2001009187A2 (en) | 1999-07-29 | 2001-02-08 | Medarex, Inc. | Human monoclonal antibodies to her2/neu |
| US6194551B1 (en) | 1998-04-02 | 2001-02-27 | Genentech, Inc. | Polypeptide variants |
| WO2001014424A2 (en) | 1999-08-24 | 2001-03-01 | Medarex, Inc. | Human ctla-4 antibodies and their uses |
| US6214345B1 (en) | 1993-05-14 | 2001-04-10 | Bristol-Myers Squibb Co. | Lysosomal enzyme-cleavable antitumor drug conjugates |
| US6261774B1 (en) | 1990-06-11 | 2001-07-17 | Gilead Sciences, Inc. | Truncation selex method |
| US6277375B1 (en) | 1997-03-03 | 2001-08-21 | Board Of Regents, The University Of Texas System | Immunoglobulin-like domains with increased half-lives |
| US6281354B1 (en) | 1997-05-22 | 2001-08-28 | The Scripps Research Institute | Analogs of duocarmycin and cc-1065 |
| US6291158B1 (en) | 1989-05-16 | 2001-09-18 | Scripps Research Institute | Method for tapping the immunological repertoire |
| WO2001095943A2 (en) | 2000-06-14 | 2001-12-20 | Medarex, Inc. | Prodrug compounds with an oligopeptide having an isoleucine residue |
| WO2001095945A2 (en) | 2000-06-14 | 2001-12-20 | Medarex, Inc. | Prodrug compounds cleavable by thimet oligopeptidase |
| WO2002000263A2 (en) | 2000-06-14 | 2002-01-03 | Medarex, Inc. | Tripeptide prodrug compounds |
| EP1176195A1 (en) | 1999-04-09 | 2002-01-30 | Kyowa Hakko Kogyo Co., Ltd. | Method for controlling the activity of immunologically functional molecule |
| WO2002020565A2 (en) | 2000-09-08 | 2002-03-14 | Universität Zürich | Collections of repeat proteins comprising repeat modules |
| US6387620B1 (en) | 1999-07-28 | 2002-05-14 | Gilead Sciences, Inc. | Transcription-free selex |
| WO2002043478A2 (en) | 2000-11-30 | 2002-06-06 | Medarex, Inc. | Transgenic transchromosomal rodents for making human antibodies |
| WO2002083180A1 (en) | 2001-03-23 | 2002-10-24 | Syntarga B.V. | Elongated and multiple spacers in activatible prodrugs |
| WO2002092812A1 (en) | 2001-05-11 | 2002-11-21 | Kirin Beer Kabushiki Kaisha | ARTIFICIAL HUMAN CHROMOSOME CONTAINING HUMAN ANTIBODY μ LIGHT CHAIN GENE |
| WO2002092780A2 (en) | 2001-05-17 | 2002-11-21 | Diversa Corporation | Novel antigen binding molecules for therapeutic, diagnostic, prophylactic, enzymatic, industrial, and agricultural applications, and methods for generating and screening thereof |
| WO2002096910A1 (en) | 2001-05-31 | 2002-12-05 | Medarex, Inc. | Cytotoxins, prodrugs, linkers and stabilizers useful therefor |
| WO2002100353A2 (en) | 2001-06-11 | 2002-12-19 | Medarex, Inc. | Cd10-activated prodrug compounds |
| WO2003002609A2 (en) | 2001-06-28 | 2003-01-09 | Domantis Limited | Dual-specific ligand and its use |
| WO2003022806A2 (en) | 2001-09-07 | 2003-03-20 | The Scripps Research Institute | Cbi analogues of cc-1065 and the duocarmycins |
| US6548530B1 (en) | 1995-10-03 | 2003-04-15 | The Scripps Research Institute | CBI analogs of CC-1065 and the duocarmycins |
| WO2003035835A2 (en) | 2001-10-25 | 2003-05-01 | Genentech, Inc. | Glycoprotein compositions |
| US20030096743A1 (en) | 2001-09-24 | 2003-05-22 | Seattle Genetics, Inc. | p-Amidobenzylethers in drug delivery agents |
| US20030153043A1 (en) | 1997-05-21 | 2003-08-14 | Biovation Limited | Method for the production of non-immunogenic proteins |
| WO2003074679A2 (en) | 2002-03-01 | 2003-09-12 | Xencor | Antibody optimization |
| WO2004003019A2 (en) | 2002-06-28 | 2004-01-08 | Domantis Limited | Immunoglobin single variant antigen-binding domains and dual-specific constructs |
| US6696245B2 (en) | 1997-10-20 | 2004-02-24 | Domantis Limited | Methods for selecting functional polypeptides |
| US6737056B1 (en) | 1999-01-15 | 2004-05-18 | Genentech, Inc. | Polypeptide variants with altered effector function |
| WO2004041867A2 (en) | 2002-11-08 | 2004-05-21 | Ablynx N.V. | Camelidae antibodies against imminoglobulin e and use thereof for the treatment of allergic disorders |
| US20040110704A1 (en) | 2002-04-09 | 2004-06-10 | Kyowa Hakko Kogyo Co., Ltd. | Cells of which genome is modified |
| WO2004058821A2 (en) | 2002-12-27 | 2004-07-15 | Domantis Limited | Dual specific single domain antibodies specific for a ligand and for the receptor of the ligand |
| US6765087B1 (en) | 1992-08-21 | 2004-07-20 | Vrije Universiteit Brussel | Immunoglobulins devoid of light chains |
| US20040175756A1 (en) | 2001-04-26 | 2004-09-09 | Avidia Research Institute | Methods for using combinatorial libraries of monomer domains |
| US6794132B2 (en) | 1999-10-02 | 2004-09-21 | Biosite, Inc. | Human antibodies |
| WO2004081026A2 (en) | 2003-06-30 | 2004-09-23 | Domantis Limited | Polypeptides |
| US6818216B2 (en) | 2000-11-28 | 2004-11-16 | Medimmune, Inc. | Anti-RSV antibodies |
| WO2004101790A1 (en) | 2003-05-14 | 2004-11-25 | Domantis Limited | A process for recovering polypeptides that unfold reversibly from a polypeptide repertoire |
| US6827925B1 (en) | 1998-07-02 | 2004-12-07 | Cambridge Antibody Technology Limited | Specific binding proteins including antibodies which bind to the necrotic center of tumors, and uses thereof |
| US6838254B1 (en) | 1993-04-29 | 2005-01-04 | Conopco, Inc. | Production of antibodies or (functionalized) fragments thereof derived from heavy chain immunoglobulins of camelidae |
| US20050048512A1 (en) | 2001-04-26 | 2005-03-03 | Avidia Research Institute | Combinatorial libraries of monomer domains |
| US20050053973A1 (en) | 2001-04-26 | 2005-03-10 | Avidia Research Institute | Novel proteins with targeted binding |
| US20050089932A1 (en) | 2001-04-26 | 2005-04-28 | Avidia Research Institute | Novel proteins with targeted binding |
| US6914128B1 (en) | 1999-03-25 | 2005-07-05 | Abbott Gmbh & Co. Kg | Human antibodies that bind human IL-12 and methods for producing |
| US20050164301A1 (en) | 2003-10-24 | 2005-07-28 | Avidia Research Institute | LDL receptor class A and EGF domain monomers and multimers |
| US6951646B1 (en) | 1998-07-21 | 2005-10-04 | Genmab A/S | Anti hepatitis C virus antibody and uses thereof |
| US20050221384A1 (en) | 2001-04-26 | 2005-10-06 | Avidia Research Institute | Combinatorial libraries of monomer domains |
| US20060008844A1 (en) | 2004-06-17 | 2006-01-12 | Avidia Research Institute | c-Met kinase binding proteins |
| WO2006079372A1 (en) | 2005-01-31 | 2006-08-03 | Ablynx N.V. | Method for generating variable domain sequences of heavy chain antibodies |
| WO2006089294A2 (en) | 2005-02-18 | 2006-08-24 | Origen Therapeutics, Inc. | Tissue specific expression of antibodies in chickens |
| US20060223114A1 (en) | 2001-04-26 | 2006-10-05 | Avidia Research Institute | Protein scaffolds and uses thereof |
| US20060234299A1 (en) | 2004-11-16 | 2006-10-19 | Avidia Research Institute | Protein scaffolds and uses thereof |
| US20060286603A1 (en) | 2001-04-26 | 2006-12-21 | Avidia Research Institute | Combinatorial libraries of monomer domains |
| WO2007055916A2 (en) | 2005-11-07 | 2007-05-18 | The Rockefeller University | Reagents, methods and systems for selecting a cytotoxic antibody or variant thereof |
| WO2007059404A2 (en) | 2005-11-10 | 2007-05-24 | Medarex, Inc. | Duocarmycin derivatives as novel cytotoxic compounds and conjugates |
| WO2007059782A1 (en) | 2005-11-28 | 2007-05-31 | Genmab A/S | Recombinant monovalent antibodies and methods for production thereof |
| WO2007084926A2 (en) | 2006-01-17 | 2007-07-26 | Biolex Therapeutics, Inc. | Compositions and methods for humanization and optimization of n-glycans in plants |
| US20070191272A1 (en) | 2005-09-27 | 2007-08-16 | Stemmer Willem P | Proteinaceous pharmaceuticals and uses thereof |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11505704A (en) * | 1995-05-17 | 1999-05-25 | リージェンツ・オブ・ザ・ユニバーシティ・オブ・ミネソタ | Immunoconjugates Containing Single Chain Variable Region Fragments of Anti-CD-19 Antibodies |
| EP1073464B1 (en) * | 1998-04-28 | 2004-10-06 | Smithkline Beecham Corporation | Monoclonal antibodies with reduced immunogenicity |
| US7595378B2 (en) * | 2001-06-13 | 2009-09-29 | Genmab A/S | Human monoclonal antibodies to epidermal growth factor receptor (EGFR) |
| US7135174B2 (en) * | 2002-01-07 | 2006-11-14 | Amgen Fremont, Inc. | Antibodies directed to PDGFD and uses thereof |
| US20040258678A1 (en) * | 2002-02-22 | 2004-12-23 | Genentech, Inc. | Compositions and methods for the treatment of immune related diseases |
| AU2003295411A1 (en) * | 2002-11-07 | 2004-06-03 | Celltech R & D | Human monoclonal antibodies to heparanase |
| CA2534639C (en) * | 2003-07-31 | 2013-07-30 | Immunomedics, Inc. | Anti-cd19 antibodies |
| EP2360186B1 (en) * | 2004-04-13 | 2017-08-30 | F. Hoffmann-La Roche AG | Anti-P-selectin antibodies |
| CN102863532A (en) * | 2004-06-21 | 2013-01-09 | 米德列斯公司 | Interferon alpha receptor 1 antibodies and their uses |
| AU2006214121B9 (en) * | 2005-02-15 | 2013-02-14 | Duke University | Anti-CD19 antibodies and uses in oncology |
| JP3857712B2 (en) * | 2005-05-20 | 2006-12-13 | 株式会社コナミデジタルエンタテインメント | Game system |
| EP1899379B1 (en) * | 2005-06-20 | 2018-04-11 | E. R. Squibb & Sons, L.L.C. | Cd19 antibodies and their uses |
| CN100543035C (en) * | 2006-09-14 | 2009-09-23 | 中国医学科学院血液学研究所 | Be used for the treatment of bone-marrow-derived lymphocyte leukemia, lymphadenomatous B7.1-CD19scFv fusion gene engineering albumen and uses thereof |
-
2007
- 2007-12-12 CL CL2007003622A patent/CL2007003622A1/en unknown
- 2007-12-13 US US12/519,149 patent/US20100104509A1/en not_active Abandoned
- 2007-12-13 JP JP2009541583A patent/JP5517626B2/en active Active
- 2007-12-13 KR KR1020097014232A patent/KR20090088940A/en not_active Application Discontinuation
- 2007-12-13 AR ARP070105603A patent/AR064337A1/en not_active Application Discontinuation
- 2007-12-13 EP EP07875235.9A patent/EP2101817A4/en not_active Withdrawn
- 2007-12-13 CN CN200780050552.1A patent/CN101636502B/en active Active
- 2007-12-13 AU AU2007360636A patent/AU2007360636A1/en not_active Abandoned
- 2007-12-13 CA CA002672800A patent/CA2672800A1/en not_active Abandoned
- 2007-12-13 TW TW096147760A patent/TW200833713A/en unknown
- 2007-12-13 BR BRPI0718349-6A2A patent/BRPI0718349A2/en not_active IP Right Cessation
- 2007-12-13 WO PCT/US2007/087393 patent/WO2009054863A2/en active Application Filing
- 2007-12-13 MX MX2009006275A patent/MX2009006275A/en not_active Application Discontinuation
Patent Citations (203)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4391904A (en) | 1979-12-26 | 1983-07-05 | Syva Company | Test strip kits in immunoassays and compositions therein |
| US4634665A (en) | 1980-02-25 | 1987-01-06 | The Trustees Of Columbia University In The City Of New York | Processes for inserting DNA into eucaryotic cells and for producing proteinaceous materials |
| US4399216A (en) | 1980-02-25 | 1983-08-16 | The Trustees Of Columbia University | Processes for inserting DNA into eucaryotic cells and for producing proteinaceous materials |
| US5179017A (en) | 1980-02-25 | 1993-01-12 | The Trustees Of Columbia University In The City Of New York | Processes for inserting DNA into eucaryotic cells and for producing proteinaceous materials |
| US4475196A (en) | 1981-03-06 | 1984-10-02 | Zor Clair G | Instrument for locating faults in aircraft passenger reading light and attendant call control system |
| US4447233A (en) | 1981-04-10 | 1984-05-08 | Parker-Hannifin Corporation | Medication infusion pump |
| US4439196A (en) | 1982-03-18 | 1984-03-27 | Merck & Co., Inc. | Osmotic drug delivery system |
| US4522811A (en) | 1982-07-08 | 1985-06-11 | Syntex (U.S.A.) Inc. | Serial injection of muramyldipeptides and liposomes enhances the anti-infective activity of muramyldipeptides |
| US4447224A (en) | 1982-09-20 | 1984-05-08 | Infusaid Corporation | Variable flow implantable infusion apparatus |
| US4487603A (en) | 1982-11-26 | 1984-12-11 | Cordis Corporation | Implantable microinfusion pump system |
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US4486194A (en) | 1983-06-08 | 1984-12-04 | James Ferrara | Therapeutic device for administering medicaments through the skin |
| US4978757A (en) | 1984-02-21 | 1990-12-18 | The Upjohn Company | 1,2,8,8a-tetrahydrocyclopropa (C) pyrrolo [3,2-e)]-indol-4(5H)-ones and related compounds |
| US4912227A (en) | 1984-02-21 | 1990-03-27 | The Upjohn Company | 1,2,8,8A-tetrahydrocyclopropa(c)pyrrolo(3,2-e)-indol-4-(5H)-ones and related compounds |
| EP0154316A2 (en) | 1984-03-06 | 1985-09-11 | Takeda Chemical Industries, Ltd. | Chemically modified lymphokine and production thereof |
| US4596556A (en) | 1985-03-25 | 1986-06-24 | Bioject, Inc. | Hypodermic injection apparatus |
| US5399331A (en) | 1985-06-26 | 1995-03-21 | The Liposome Company, Inc. | Method for protein-liposome coupling |
| WO1987004462A1 (en) | 1986-01-23 | 1987-07-30 | Celltech Limited | Recombinant dna sequences, vectors containing them and method for the use thereof |
| US5225539A (en) | 1986-03-27 | 1993-07-06 | Medical Research Council | Recombinant altered antibodies and methods of making altered antibodies |
| US5374548A (en) | 1986-05-02 | 1994-12-20 | Genentech, Inc. | Methods and compositions for the attachment of proteins to liposomes using a glycophospholipid anchor |
| WO1988000052A1 (en) | 1986-07-07 | 1988-01-14 | Trustees Of Dartmouth College | Monoclonal antibodies to fc receptor |
| US4954617A (en) | 1986-07-07 | 1990-09-04 | Trustees Of Dartmouth College | Monoclonal antibodies to FC receptors for immunoglobulin G on human mononuclear phagocytes |
| US4881175A (en) | 1986-09-02 | 1989-11-14 | Genex Corporation | Computer based system and method for determining and displaying possible chemical structures for converting double- or multiple-chain polypeptides to single-chain polypeptides |
| US5455030A (en) | 1986-09-02 | 1995-10-03 | Enzon Labs, Inc. | Immunotheraphy using single chain polypeptide binding molecules |
| US5260203A (en) | 1986-09-02 | 1993-11-09 | Enzon, Inc. | Single polypeptide chain binding molecules |
| US5332837A (en) | 1986-12-19 | 1994-07-26 | The Upjohn Company | CC-1065 analogs |
| US5624821A (en) | 1987-03-18 | 1997-04-29 | Scotgen Biopharmaceuticals Incorporated | Antibodies with altered effector functions |
| US5648260A (en) | 1987-03-18 | 1997-07-15 | Scotgen Biopharmaceuticals Incorporated | DNA encoding antibodies with altered effector functions |
| US5013653A (en) | 1987-03-20 | 1991-05-07 | Creative Biomolecules, Inc. | Product and process for introduction of a hinge region into a fusion protein to facilitate cleavage |
| US5258498A (en) | 1987-05-21 | 1993-11-02 | Creative Biomolecules, Inc. | Polypeptide linkers for production of biosynthetic proteins |
| US5482858A (en) | 1987-05-21 | 1996-01-09 | Creative Biomolecules, Inc. | Polypeptide linkers for production of biosynthetic proteins |
| US5091513A (en) | 1987-05-21 | 1992-02-25 | Creative Biomolecules, Inc. | Biosynthetic antibody binding sites |
| US5476786A (en) | 1987-05-21 | 1995-12-19 | Creative Biomolecules, Inc. | Biosynthetic antibody binding sites |
| US5132405A (en) | 1987-05-21 | 1992-07-21 | Creative Biomolecules, Inc. | Biosynthetic antibody binding sites |
| US4790824A (en) | 1987-06-19 | 1988-12-13 | Bioject, Inc. | Non-invasive hypodermic injection device |
| US4941880A (en) | 1987-06-19 | 1990-07-17 | Bioject, Inc. | Pre-filled ampule and non-invasive hypodermic injection device assembly |
| WO1989001036A1 (en) | 1987-07-23 | 1989-02-09 | Celltech Limited | Recombinant dna expression vectors |
| US5773435A (en) | 1987-08-04 | 1998-06-30 | Bristol-Myers Squibb Company | Prodrugs for β-lactamase and uses thereof |
| US5677425A (en) | 1987-09-04 | 1997-10-14 | Celltech Therapeutics Limited | Recombinant antibody |
| US4946778A (en) | 1987-09-21 | 1990-08-07 | Genex Corporation | Single polypeptide chain binding molecules |
| US4975278A (en) | 1988-02-26 | 1990-12-04 | Bristol-Myers Company | Antibody-enzyme conjugates in combination with prodrugs for the delivery of cytotoxic agents to tumor cells |
| EP0338841A1 (en) | 1988-04-18 | 1989-10-25 | Celltech Limited | Recombinant DNA methods, vectors and host cells |
| US5476996A (en) | 1988-06-14 | 1995-12-19 | Lidak Pharmaceuticals | Human immune system in non-human animal |
| US5698767A (en) | 1988-06-14 | 1997-12-16 | Lidak Pharmaceuticals | Human immune system in non-human animal |
| US5084468A (en) | 1988-08-11 | 1992-01-28 | Kyowa Hakko Kogyo Co., Ltd. | Dc-88a derivatives |
| US5223409A (en) | 1988-09-02 | 1993-06-29 | Protein Engineering Corp. | Directed evolution of novel binding proteins |
| US5571698A (en) | 1988-09-02 | 1996-11-05 | Protein Engineering Corporation | Directed evolution of novel binding proteins |
| US5403484A (en) | 1988-09-02 | 1995-04-04 | Protein Engineering Corporation | Viruses expressing chimeric binding proteins |
| US5545807A (en) | 1988-10-12 | 1996-08-13 | The Babraham Institute | Production of antibodies from transgenic animals |
| EP0368684A1 (en) | 1988-11-11 | 1990-05-16 | Medical Research Council | Cloning immunoglobulin variable domain sequences. |
| US20040110941A2 (en) | 1988-11-11 | 2004-06-10 | Medical Research Council | Single domain ligands, receptors comprising said ligands, methods for their production, and use of said ligands and receptors |
| EP0401384A1 (en) | 1988-12-22 | 1990-12-12 | Kirin-Amgen, Inc. | Chemically modified granulocyte colony stimulating factor |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| US6180370B1 (en) | 1988-12-28 | 2001-01-30 | Protein Design Labs, Inc. | Humanized immunoglobulins and methods of making the same |
| US5585089A (en) | 1988-12-28 | 1996-12-17 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| US5101038A (en) | 1988-12-28 | 1992-03-31 | Kyowa Hakko Kogyo Co., Ltd. | Novel substance dc 113 and production thereof |
| US5693762A (en) | 1988-12-28 | 1997-12-02 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| US5416016A (en) | 1989-04-03 | 1995-05-16 | Purdue Research Foundation | Method for enhancing transmembrane transport of exogenous molecules |
| US6291158B1 (en) | 1989-05-16 | 2001-09-18 | Scripps Research Institute | Method for tapping the immunological repertoire |
| US5070092A (en) | 1989-07-03 | 1991-12-03 | Kyowa Hakko Kogyo Co., Ltd. | Pyrroloindole derivatives related to dc-88a compound |
| US5187186A (en) | 1989-07-03 | 1993-02-16 | Kyowa Hakko Kogyo Co., Ltd. | Pyrroloindole derivatives |
| US5064413A (en) | 1989-11-09 | 1991-11-12 | Bioject, Inc. | Needleless hypodermic injection device |
| US5312335A (en) | 1989-11-09 | 1994-05-17 | Bioject Inc. | Needleless hypodermic injection device |
| US6150584A (en) | 1990-01-12 | 2000-11-21 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| US5939598A (en) | 1990-01-12 | 1999-08-17 | Abgenix, Inc. | Method of making transgenic mice lacking endogenous heavy chains |
| US6162963A (en) | 1990-01-12 | 2000-12-19 | Abgenix, Inc. | Generation of Xenogenetic antibodies |
| US6075181A (en) | 1990-01-12 | 2000-06-13 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| US6114598A (en) | 1990-01-12 | 2000-09-05 | Abgenix, Inc. | Generation of xenogeneic antibodies |
| US5739350A (en) | 1990-04-25 | 1998-04-14 | Pharmacia & Upjohn Company | CC-1065 analogs |
| US5580717A (en) | 1990-05-01 | 1996-12-03 | Affymax Technologies N.V. | Recombinant library screening methods |
| US5427908A (en) | 1990-05-01 | 1995-06-27 | Affymax Technologies N.V. | Recombinant library screening methods |
| US5712375A (en) | 1990-06-11 | 1998-01-27 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: tissue selex |
| US5864026A (en) | 1990-06-11 | 1999-01-26 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: tissue selex |
| US5789157A (en) | 1990-06-11 | 1998-08-04 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: tissue selex |
| US6261774B1 (en) | 1990-06-11 | 2001-07-17 | Gilead Sciences, Inc. | Truncation selex method |
| US5763566A (en) | 1990-06-11 | 1998-06-09 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: tissue SELEX |
| US5969108A (en) | 1990-07-10 | 1999-10-19 | Medical Research Council | Methods for producing members of specific binding pairs |
| EP1433846A2 (en) | 1990-07-10 | 2004-06-30 | Cambridge Antibody Technology LTD | Phagemid-based method of producing filamentous bacteriophage particles displaying antibody molecules and the corresponding bacteriophage particles. |
| US5545806A (en) | 1990-08-29 | 1996-08-13 | Genpharm International, Inc. | Ransgenic non-human animals for producing heterologous antibodies |
| US5633425A (en) | 1990-08-29 | 1997-05-27 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| WO1992003918A1 (en) | 1990-08-29 | 1992-03-19 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5625126A (en) | 1990-08-29 | 1997-04-29 | Genpharm International, Inc. | Transgenic non-human animals for producing heterologous antibodies |
| US5877397A (en) | 1990-08-29 | 1999-03-02 | Genpharm International Inc. | Transgenic non-human animals capable of producing heterologous antibodies of various isotypes |
| US5569825A (en) | 1990-08-29 | 1996-10-29 | Genpharm International | Transgenic non-human animals capable of producing heterologous antibodies of various isotypes |
| US5874299A (en) | 1990-08-29 | 1999-02-23 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5814318A (en) | 1990-08-29 | 1998-09-29 | Genpharm International Inc. | Transgenic non-human animals for producing heterologous antibodies |
| US5661016A (en) | 1990-08-29 | 1997-08-26 | Genpharm International Inc. | Transgenic non-human animals capable of producing heterologous antibodies of various isotypes |
| US5789650A (en) | 1990-08-29 | 1998-08-04 | Genpharm International, Inc. | Transgenic non-human animals for producing heterologous antibodies |
| US5770429A (en) | 1990-08-29 | 1998-06-23 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5833943A (en) | 1991-04-23 | 1998-11-10 | Cancer Therapeutics Limited | Minimum recognition unit of a pem mucin tandem repeat specific monoclonal antibody |
| US6172197B1 (en) | 1991-07-10 | 2001-01-09 | Medical Research Council | Methods for producing members of specific binding pairs |
| EP0537575A1 (en) | 1991-10-07 | 1993-04-21 | Kyowa Hakko Kogyo Co., Ltd. | Hydrobromide of DC-89 derivative having antitumor activity |
| US6555313B1 (en) | 1991-12-02 | 2003-04-29 | Medical Research Council | Production of anti-self antibodies from antibody segment repertoires and displayed on phage |
| US6593081B1 (en) | 1991-12-02 | 2003-07-15 | Medical Research Council | Production of anti-self antibodies from antibody segment repertoires and displayed on phage |
| US6521404B1 (en) | 1991-12-02 | 2003-02-18 | Medical Research Council | Production of anti-self antibodies from antibody segment repertoires and displayed on phage |
| EP0616640A1 (en) | 1991-12-02 | 1994-09-28 | Medical Research Council | Production of anti-self antibodies from antibody segment repertoires and displayed on phage |
| US6582915B1 (en) | 1991-12-02 | 2003-06-24 | Medical Research Council | Production of anti-self bodies from antibody segment repertories and displayed on phage |
| US5885793A (en) | 1991-12-02 | 1999-03-23 | Medical Research Council | Production of anti-self antibodies from antibody segment repertoires and displayed on phage |
| US6544731B1 (en) | 1991-12-02 | 2003-04-08 | Medical Research Council | Production of anti-self antibodies from antibody segment repertories and displayed on phage |
| WO1993012227A1 (en) | 1991-12-17 | 1993-06-24 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5714350A (en) | 1992-03-09 | 1998-02-03 | Protein Design Labs, Inc. | Increasing antibody affinity by altering glycosylation in the immunoglobulin variable region |
| US6350861B1 (en) | 1992-03-09 | 2002-02-26 | Protein Design Labs, Inc. | Antibodies with increased binding affinity |
| US6165745A (en) | 1992-04-24 | 2000-12-26 | Board Of Regents, The University Of Texas System | Recombinant production of immunoglobulin-like domains in prokaryotic cells |
| US5660829A (en) | 1992-07-23 | 1997-08-26 | Zeneca Limited | Process for antibody directed enzyme prodrug therapy |
| US5587161A (en) | 1992-07-23 | 1996-12-24 | Zeneca Limited | Prodrugs for antibody directed enzyme prodrug therapy |
| US5399163A (en) | 1992-07-24 | 1995-03-21 | Bioject Inc. | Needleless hypodermic injection methods and device |
| US5383851A (en) | 1992-07-24 | 1995-01-24 | Bioject Inc. | Needleless hypodermic injection device |
| US6765087B1 (en) | 1992-08-21 | 2004-07-20 | Vrije Universiteit Brussel | Immunoglobulins devoid of light chains |
| US5762905A (en) | 1992-09-16 | 1998-06-09 | The Scripps Research Institute | Human neutralizing monoclonal antibodies to respiratory syncytial virus |
| WO1994010332A1 (en) | 1992-11-04 | 1994-05-11 | Medarex, Inc. | HUMANIZED ANTIBODIES TO Fc RECEPTORS FOR IMMUNOGLOBULIN G ON HUMAN MONONUCLEAR PHAGOCYTES |
| US5760185A (en) | 1992-11-28 | 1998-06-02 | Juridical Foundation The Chemo-Sero-Therapeutic Research Institute | Anti-feline herpes virus-1 recombinant antibody and gene fragment coding for said antibody |
| WO1994025585A1 (en) | 1993-04-26 | 1994-11-10 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US6838254B1 (en) | 1993-04-29 | 2005-01-04 | Conopco, Inc. | Production of antibodies or (functionalized) fragments thereof derived from heavy chain immunoglobulins of camelidae |
| US6214345B1 (en) | 1993-05-14 | 2001-04-10 | Bristol-Myers Squibb Co. | Lysosomal enzyme-cleavable antitumor drug conjugates |
| WO1994029351A2 (en) | 1993-06-16 | 1994-12-22 | Celltech Limited | Antibodies |
| US5831077A (en) | 1993-12-09 | 1998-11-03 | Redmond; John William | Glycosylhydrazines, preparation, immobilization and reactions of: glycoprotein analysis and O-glycan removal |
| US6156313A (en) | 1994-01-04 | 2000-12-05 | The Scripps Research Institute | Human monoclonal antibodies to herpes simplex virus and methods therefor |
| US5831012A (en) | 1994-01-14 | 1998-11-03 | Pharmacia & Upjohn Aktiebolag | Bacterial receptor structures |
| US5641780A (en) | 1994-04-22 | 1997-06-24 | Kyowa Hakko Kogyo Co., Ltd. | Pyrrolo-indole derivatives |
| US5703080A (en) | 1994-05-20 | 1997-12-30 | Kyowa Hakko Kogyo Co., Ltd. | Method for stabilizing duocarmycin derivatives |
| WO1996010405A1 (en) | 1994-09-30 | 1996-04-11 | Kyowa Hakko Kogyo Co., Ltd. | Antitumor agent |
| US5869046A (en) | 1995-04-14 | 1999-02-09 | Genentech, Inc. | Altered polypeptides with increased half-life |
| US6121022A (en) | 1995-04-14 | 2000-09-19 | Genentech, Inc. | Altered polypeptides with increased half-life |
| US6114120A (en) | 1995-05-03 | 2000-09-05 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: tissue selex |
| US6613526B2 (en) | 1995-05-03 | 2003-09-02 | Gilead Sciences, Inc. | Systematic evolution of ligands by exponential enrichment: tissue selex |
| US6376474B1 (en) | 1995-05-03 | 2002-04-23 | Gilead Sciences, Inc. | Systematic evolution of ligands by exponential enrichment: tissue SELEX |
| US6013443A (en) | 1995-05-03 | 2000-01-11 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: tissue SELEX |
| US6548530B1 (en) | 1995-10-03 | 2003-04-15 | The Scripps Research Institute | CBI analogs of CC-1065 and the duocarmycins |
| WO1997013852A1 (en) | 1995-10-10 | 1997-04-17 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US6090382A (en) | 1996-02-09 | 2000-07-18 | Basf Aktiengesellschaft | Human antibodies that bind human TNFα |
| WO1998024884A1 (en) | 1996-12-02 | 1998-06-11 | Genpharm International | Transgenic non-human animals capable of producing heterologous antibodies |
| US6277375B1 (en) | 1997-03-03 | 2001-08-21 | Board Of Regents, The University Of Texas System | Immunoglobulin-like domains with increased half-lives |
| US6132722A (en) | 1997-05-07 | 2000-10-17 | Bristol-Myers Squibb Company | Recombinant antibody-enzyme fusion proteins |
| US20030153043A1 (en) | 1997-05-21 | 2003-08-14 | Biovation Limited | Method for the production of non-immunogenic proteins |
| US6281354B1 (en) | 1997-05-22 | 2001-08-28 | The Scripps Research Institute | Analogs of duocarmycin and cc-1065 |
| US7250297B1 (en) | 1997-09-26 | 2007-07-31 | Pieris Ag | Anticalins |
| WO1999016873A1 (en) | 1997-09-26 | 1999-04-08 | Arne Skerra | Anticalins |
| US6696245B2 (en) | 1997-10-20 | 2004-02-24 | Domantis Limited | Methods for selecting functional polypeptides |
| WO1999045962A1 (en) | 1998-03-13 | 1999-09-16 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US6194551B1 (en) | 1998-04-02 | 2001-02-27 | Genentech, Inc. | Polypeptide variants |
| WO1999054342A1 (en) | 1998-04-20 | 1999-10-28 | Pablo Umana | Glycosylation engineering of antibodies for improving antibody-dependent cellular cytotoxicity |
| US6827925B1 (en) | 1998-07-02 | 2004-12-07 | Cambridge Antibody Technology Limited | Specific binding proteins including antibodies which bind to the necrotic center of tumors, and uses thereof |
| US6951646B1 (en) | 1998-07-21 | 2005-10-04 | Genmab A/S | Anti hepatitis C virus antibody and uses thereof |
| WO2000026373A1 (en) | 1998-11-03 | 2000-05-11 | Babraham Institute | MURINE EXPRESSION OF HUMAN Igμ LOCUS |
| WO2000033888A2 (en) | 1998-12-11 | 2000-06-15 | Coulter Pharmaceutical, Inc. | Prodrug compounds and process for preparation thereof |
| US6737056B1 (en) | 1999-01-15 | 2004-05-18 | Genentech, Inc. | Polypeptide variants with altered effector function |
| WO2000042072A2 (en) | 1999-01-15 | 2000-07-20 | Genentech, Inc. | Polypeptide variants with altered effector function |
| US6914128B1 (en) | 1999-03-25 | 2005-07-05 | Abbott Gmbh & Co. Kg | Human antibodies that bind human IL-12 and methods for producing |
| EP1176195A1 (en) | 1999-04-09 | 2002-01-30 | Kyowa Hakko Kogyo Co., Ltd. | Method for controlling the activity of immunologically functional molecule |
| US7214775B2 (en) | 1999-04-09 | 2007-05-08 | Kyowa Hakko Kogyo Co., Ltd. | Method of modulating the activity of functional immune molecules |
| US6387620B1 (en) | 1999-07-28 | 2002-05-14 | Gilead Sciences, Inc. | Transcription-free selex |
| WO2001009187A2 (en) | 1999-07-29 | 2001-02-08 | Medarex, Inc. | Human monoclonal antibodies to her2/neu |
| WO2001014424A2 (en) | 1999-08-24 | 2001-03-01 | Medarex, Inc. | Human ctla-4 antibodies and their uses |
| US6794132B2 (en) | 1999-10-02 | 2004-09-21 | Biosite, Inc. | Human antibodies |
| WO2001095943A2 (en) | 2000-06-14 | 2001-12-20 | Medarex, Inc. | Prodrug compounds with an oligopeptide having an isoleucine residue |
| WO2002000263A2 (en) | 2000-06-14 | 2002-01-03 | Medarex, Inc. | Tripeptide prodrug compounds |
| WO2001095945A2 (en) | 2000-06-14 | 2001-12-20 | Medarex, Inc. | Prodrug compounds cleavable by thimet oligopeptidase |
| WO2002020565A2 (en) | 2000-09-08 | 2002-03-14 | Universität Zürich | Collections of repeat proteins comprising repeat modules |
| US20040132028A1 (en) | 2000-09-08 | 2004-07-08 | Stumpp Michael Tobias | Collection of repeat proteins comprising repeat modules |
| US6818216B2 (en) | 2000-11-28 | 2004-11-16 | Medimmune, Inc. | Anti-RSV antibodies |
| WO2002043478A2 (en) | 2000-11-30 | 2002-06-06 | Medarex, Inc. | Transgenic transchromosomal rodents for making human antibodies |
| WO2002083180A1 (en) | 2001-03-23 | 2002-10-24 | Syntarga B.V. | Elongated and multiple spacers in activatible prodrugs |
| US20060223114A1 (en) | 2001-04-26 | 2006-10-05 | Avidia Research Institute | Protein scaffolds and uses thereof |
| US20050048512A1 (en) | 2001-04-26 | 2005-03-03 | Avidia Research Institute | Combinatorial libraries of monomer domains |
| US20060286603A1 (en) | 2001-04-26 | 2006-12-21 | Avidia Research Institute | Combinatorial libraries of monomer domains |
| US20050221384A1 (en) | 2001-04-26 | 2005-10-06 | Avidia Research Institute | Combinatorial libraries of monomer domains |
| US20050089932A1 (en) | 2001-04-26 | 2005-04-28 | Avidia Research Institute | Novel proteins with targeted binding |
| US20040175756A1 (en) | 2001-04-26 | 2004-09-09 | Avidia Research Institute | Methods for using combinatorial libraries of monomer domains |
| US20050053973A1 (en) | 2001-04-26 | 2005-03-10 | Avidia Research Institute | Novel proteins with targeted binding |
| WO2002092812A1 (en) | 2001-05-11 | 2002-11-21 | Kirin Beer Kabushiki Kaisha | ARTIFICIAL HUMAN CHROMOSOME CONTAINING HUMAN ANTIBODY μ LIGHT CHAIN GENE |
| WO2002092780A2 (en) | 2001-05-17 | 2002-11-21 | Diversa Corporation | Novel antigen binding molecules for therapeutic, diagnostic, prophylactic, enzymatic, industrial, and agricultural applications, and methods for generating and screening thereof |
| US20030073852A1 (en) | 2001-05-31 | 2003-04-17 | Medarex, Inc. | Disulfide prodrugs and linkers and stabilizers useful therefor |
| WO2002096910A1 (en) | 2001-05-31 | 2002-12-05 | Medarex, Inc. | Cytotoxins, prodrugs, linkers and stabilizers useful therefor |
| US6989452B2 (en) | 2001-05-31 | 2006-01-24 | Medarex, Inc. | Disulfide prodrugs and linkers and stabilizers useful therefor |
| US20030050331A1 (en) | 2001-05-31 | 2003-03-13 | Medarex Inc. | Cytotoxic agents |
| US20030064984A1 (en) | 2001-05-31 | 2003-04-03 | Medarex, Inc. | Peptidyl prodrugs and linkers and stabilizers useful therefor |
| WO2002100353A2 (en) | 2001-06-11 | 2002-12-19 | Medarex, Inc. | Cd10-activated prodrug compounds |
| US20040087497A1 (en) | 2001-06-11 | 2004-05-06 | Bebbington Christopher R. | CD10-activated prodrug compounds |
| WO2003002609A2 (en) | 2001-06-28 | 2003-01-09 | Domantis Limited | Dual-specific ligand and its use |
| WO2003022806A2 (en) | 2001-09-07 | 2003-03-20 | The Scripps Research Institute | Cbi analogues of cc-1065 and the duocarmycins |
| US20030096743A1 (en) | 2001-09-24 | 2003-05-22 | Seattle Genetics, Inc. | p-Amidobenzylethers in drug delivery agents |
| US20030130189A1 (en) | 2001-09-24 | 2003-07-10 | Senter Peter D. | P-amidobenzylethers in drug delivery agents |
| US20070020260A1 (en) | 2001-10-25 | 2007-01-25 | Genentech, Inc. | Glycoprotein compositions |
| WO2003035835A2 (en) | 2001-10-25 | 2003-05-01 | Genentech, Inc. | Glycoprotein compositions |
| WO2003074679A2 (en) | 2002-03-01 | 2003-09-12 | Xencor | Antibody optimization |
| US20040110704A1 (en) | 2002-04-09 | 2004-06-10 | Kyowa Hakko Kogyo Co., Ltd. | Cells of which genome is modified |
| WO2004003019A2 (en) | 2002-06-28 | 2004-01-08 | Domantis Limited | Immunoglobin single variant antigen-binding domains and dual-specific constructs |
| WO2004041867A2 (en) | 2002-11-08 | 2004-05-21 | Ablynx N.V. | Camelidae antibodies against imminoglobulin e and use thereof for the treatment of allergic disorders |
| WO2004058821A2 (en) | 2002-12-27 | 2004-07-15 | Domantis Limited | Dual specific single domain antibodies specific for a ligand and for the receptor of the ligand |
| WO2004101790A1 (en) | 2003-05-14 | 2004-11-25 | Domantis Limited | A process for recovering polypeptides that unfold reversibly from a polypeptide repertoire |
| WO2004081026A2 (en) | 2003-06-30 | 2004-09-23 | Domantis Limited | Polypeptides |
| WO2005035572A2 (en) | 2003-10-08 | 2005-04-21 | Domantis Limited | Antibody compositions and methods |
| US20050164301A1 (en) | 2003-10-24 | 2005-07-28 | Avidia Research Institute | LDL receptor class A and EGF domain monomers and multimers |
| US20060177831A1 (en) | 2004-06-17 | 2006-08-10 | Avidia Research Institute | c-MET kinase binding proteins |
| US20060008844A1 (en) | 2004-06-17 | 2006-01-12 | Avidia Research Institute | c-Met kinase binding proteins |
| US20060234299A1 (en) | 2004-11-16 | 2006-10-19 | Avidia Research Institute | Protein scaffolds and uses thereof |
| WO2006079372A1 (en) | 2005-01-31 | 2006-08-03 | Ablynx N.V. | Method for generating variable domain sequences of heavy chain antibodies |
| WO2006089294A2 (en) | 2005-02-18 | 2006-08-24 | Origen Therapeutics, Inc. | Tissue specific expression of antibodies in chickens |
| US20070191272A1 (en) | 2005-09-27 | 2007-08-16 | Stemmer Willem P | Proteinaceous pharmaceuticals and uses thereof |
| WO2007055916A2 (en) | 2005-11-07 | 2007-05-18 | The Rockefeller University | Reagents, methods and systems for selecting a cytotoxic antibody or variant thereof |
| WO2007059404A2 (en) | 2005-11-10 | 2007-05-24 | Medarex, Inc. | Duocarmycin derivatives as novel cytotoxic compounds and conjugates |
| WO2007059782A1 (en) | 2005-11-28 | 2007-05-31 | Genmab A/S | Recombinant monovalent antibodies and methods for production thereof |
| WO2007084926A2 (en) | 2006-01-17 | 2007-07-26 | Biolex Therapeutics, Inc. | Compositions and methods for humanization and optimization of n-glycans in plants |
Non-Patent Citations (171)
| Title |
|---|
| "Current Protocols in Molecular Biology", 1987, GREENE PUBLISHING AND WILEY INTERSCIENCE |
| "FUNDAMENTAL IMMUNOLOGY", 1993 |
| "POLYMERIC DRUGS AND DRUG DELIVERY SYSTEMS", vol. 469, 1991, AMERICAN CHEMICAL SOCIETY |
| "Sustained and Controlled Release Drug Delivery Systems", 1978, MARCEL DEKKER, INC. |
| ADIB-CONQUY ET AL., INT. IMMUNOL., vol. 10, 1998, pages 341 - 6 |
| ALEXANDER AJ; HUGHES DE, ANAL CHEM, vol. 67, 1995, pages 3626 - 32 |
| ALLEN, T.M., NAT. REV. CANCER, vol. 2, 2002, pages 750 - 763 |
| ALTSCHUL ET AL., J MOL. BIOL., vol. 215, 1990, pages 403 - 10 |
| ALTSCHUL ET AL., NUCLEIC ACIDS RES., vol. 25, no. 17, 1997, pages 3389 - 3402 |
| ALTSCHUL ET AL., NUCLEIC ACIDS RESEARCH, vol. 25, 1997, pages 3389 - 3402 |
| BAE ET AL., DRUGS EXP. CLIN. RES., vol. 29, 2004, pages 15 - 23 |
| BALDWIN ET AL., BIOCHEMISTRY, vol. 29, 1990, pages 5509 - 15 |
| BARBAS ET AL., J AM. CHEM. SOC., vol. 116, 1994, pages 2161 - 2162 |
| BARBAS ET AL., PROC. NATL. ACAD. SCI. U.S.A., vol. 92, 1995, pages 2529 - 2533 |
| BASSET ET AL., SCANDINAVIAN JOURNAL OF IMMUNOLOGY, vol. 51, no. 3, 2000, pages 307 - 311 |
| BEERS ET AL., CLIN. CAN. RES., vol. 6, 2000, pages 2835 - 43 |
| BEIBOER ET AL., J MOL. BIOL., vol. 296, 2000, pages 833 - 849 |
| BEREZOV ET AL., BIAJOURNAL 8: SCIENTIFIC REVIEW, 2001, pages 8 |
| BERGE, S.M. ET AL., J PHARM. SCI., vol. 66, 1977, pages 1 - 19 |
| BIRD ET AL., SCIENCE, vol. 242, 1988, pages 423 - 426 |
| BOGER ET AL., ANGEW. CHEM. INT. ED. ENGL., vol. 35, 1996, pages 1438 |
| BOGER ET AL., CHEM. REV., vol. 97, 1997, pages 787 |
| BOSS, M. A.; WOOD, C. R., IMMUNOLOGY TODAY, vol. 6, 1985, pages 12 - 13 |
| BOURGEOIS ET AL., J VIROL, vol. 72, 1998, pages 807 - 10 |
| BOUVIER ET AL., METH. ENZYMOL., vol. 248, 1995, pages 614 |
| BRENNAN ET AL., SCIENCE, vol. 229, 1985, pages 81 - 83 |
| BRISCOE ET AL., AM. J PHYSIOL., vol. 123, no. 3, 1995, pages 13 4 |
| BRUMMELL ET AL., BIOCHEM, vol. 32, 1993, pages 1180 - 8 |
| BUNDGAARD ET AL., J MED. CHEM., vol. 31, 1988, pages 2066 |
| CARL ET AL., J. MED. CHEM. LETT., vol. 24, 1981, pages 479 |
| CHAU ET AL., BIOCONJUGATE CHEM., vol. 15, 2004, pages 931 - 941 |
| CHEN ET AL., EMBO J., vol. 12, 1993, pages 811 - 820 |
| CHEN ET AL., PHARM RES, vol. 20, 2003, pages 1952 - 60 |
| CHEN, J. ET AL., EMBO J., vol. 12, 1993, pages 821 - 830 |
| CHEN, J. ET AL., INTERNATIONAL IMMUNOLOGY, vol. 5, 1993, pages 647 - 656 |
| CHOI ET AL., NATURE GENETICS, vol. 4, 1993, pages 117 - 123 |
| COUSSENS ET AL., GENES AND DEVELOPMENT, vol. 13, no. 11, 1999, pages 1382 - 97 |
| COX, J. P. L. ET AL.: "A Directory of Human Germ-line VH Segments Reveals a Strong Bias in their Usage", EUR. J IMMUNOL., vol. 24, 1994, pages 827 - 836 |
| DANO ET AL., ADV. CANCER. RES., vol. 44, 1985, pages 139 |
| DE GROOT ET AL., J. MED. CHEM., vol. 42, 1999, pages 5277 |
| DE GROOT ET AL., J. MED. CHEM., vol. 66, 2001, pages 8815 |
| DE GROOT ET AL., J. ORG. CHEM., vol. 43, 2000, pages 3093 |
| DE WILDT ET AL., PROTO ENG., vol. 10, 1997, pages 835 - 41 |
| DITZEL ET AL., J IMMUNOL., vol. 157, 1996, pages 739 - 749 |
| DUBOWCHIK ET AL., BIOORG & MED. CHEM. LETT., vol. 8, 1998, pages 3347 |
| DUNN ET AL., METH. ENZYMOL., vol. 241, 1994, pages 254 |
| E. MEYERS; W. MILLER, COMPUT. APPL. BIOSCI., vol. 4, 1988, pages 11 - 17 |
| FEENEY ET AL.: "Modification of Proteins; Advances in Chemistry Series", vol. 198, 1982, AMERICAN CHEMICAL SOCIETY |
| FISHWILD ET AL., NATURE BIOTECHNOLOGY, vol. 14, 1996, pages 845 - 851 |
| FISHWILD, D. ET AL., NATURE BIOTECHNOLOGY, vol. 14, 1996, pages 845 - 851 |
| FUJIMOTO ET AL., SEMIN IMMUNOL., vol. 10, 1998, pages 267 |
| GALA FA; MORRISON SL, JLMMUNOL, vol. 172, 2004, pages 5489 - 94 |
| GHIRLANDO ET AL., IMMUNOL LETT, vol. 68, 1999, pages 47 - 52 |
| GLENNIE ET AL., J IMMUNOL., vol. 139, 1987, pages 2367 - 2375 |
| GRAZIANO, R.F. ET AL., J IMMUNOL, vol. 155, no. 10, 1995, pages 4996 - 5002 |
| GREENE ET AL.: "Protective Groups in Organic Synthesis", 1991, JOHN WILEY & SONS |
| HALL ET AL., J IMMUNOL., vol. 149, 1992, pages 1605 - 12 |
| HANKA ET AL., J. ANTIBIOT., vol. 31, 1978, pages 1211 |
| HARDING, F.; LONBERG, N., ANN. N.Y. ACAD SCI., vol. 764, 1995, pages 536 - 546 |
| HARDY ET AL.: "Amyloid Protein Precursor in Development, Aging, and Alzheimer's Disease", 1994, pages: 190 - 198 |
| HASEGAWA ET AL., JLMMUNOL, vol. 167, 2001, pages 3190 |
| HE ET AL., JRHEUMATOL, vol. 28, 2001, pages 2168 |
| HERMANSON: "Bioconjugate Techniques", 1996, ACADEMIC PRESS |
| HUNT ET AL., J CHROMATOGR A, vol. 800, 1998, pages 355 - 67 |
| HURLEY ET AL., SCIENCE, vol. 226, 1984, pages 843 |
| HUSTON ET AL., PROC. NATL. ACAD. SCI. USA, vol. 85, 1988, pages 5879 - 5883 |
| IGARASHI ET AL., J BIOCHEM (TOKYO), vol. 117, 1995, pages 452 - 7 |
| J.J. KILLION; I.J. FIDLER, IMMUNOMETHODS, vol. 4, 1994, pages 273 |
| JANINI ET AL., ELECTROPHORESIS, vol. 23, 2002, pages 1605 - 11 |
| JONES, P. ET AL., NATURE, vol. 321, 1986, pages 522 - 525 |
| K. KEINANEN; M.L. LAUKKANEN, FEBS LETT., vol. 346, 1994, pages 123 |
| KABAT, E. A. ET AL.: "Sequences of Proteins of Immunological Interest", 1991, U.S. DEPARTMENT OF HEALTH AND HUMAN SERVICES |
| KARPOVSKY ET AL., J EXP. MED., vol. 160, 1984, pages 1686 |
| KELLEY; O'CONNELL, BIOCHEM., vol. 32, 1993, pages 6862 - 35 |
| KLIMKA ET AL., BRITISH J OF CANCER, vol. 83, no. 2, 2000, pages 252 - 260 |
| KLINE ET AL., MOL. PHARMACEUT., vol. 1, 2004, pages 9 - 22 |
| KOHLER; MILSTEIN, NATURE, vol. 256, 1975, pages 495 |
| KOMISSAROV ET AL., J BIOL. CHEM., vol. 272, 1997, pages 26864 - 26870 |
| KRATZ ET AL., BIOORG. MED. CHEM. LETT., vol. 11, 2001, pages 2001 - 2006 |
| KRISHNAMURTHY R; MANNING MC, CURR PHARM BIOTECHNOL, vol. 3, 2002, pages 361 - 71 |
| KURACHI; YAMAMOTO: "Handbook of Proeolytic Enzymes", vol. 2, 2004, pages: 1699 - 1702 |
| KUROIWA ET AL., NATURE BIOTECHNOLOGY, vol. 20, 2002, pages 889 - 894 |
| LEE, D. ET AL., BIOORGANIC AND MEDICINAL CHEMISTRY LETTERS, vol. 9, 1999, pages 1667 - 72 |
| LEE, J BIOL. CHEM., vol. 275, pages 36720 - 36725 |
| LEIBIGER ET AL., BIOCHEM J., vol. 338, 1999, pages 529 - 538 |
| LEVI ET AL., PROC. NATL. ACAD. SCI. USA., vol. 90, 1993, pages 4374 - 8 |
| LEVINE ET AL., COMP. BIOCHEM. PHYSIOL., vol. 72B, 1982, pages 77 - 85 |
| LI ET AL., CANCER RES., vol. 42, 1982, pages 999 |
| LIU ET AL., CANCER RES., vol. 60, 2000, pages 6061 - 6067 |
| LIU, MA ET AL., PROC. NATL. ACAD. SCI. USA, vol. 82, 1985, pages 8648 |
| LONBERG ET AL., NATURE, vol. 368, no. 6474, 1994, pages 856 - 859 |
| LONBERG, N. ET AL., NATURE, vol. 368, no. 6474, 1994, pages 856 - 859 |
| LONBERG, N.: "Handbook of Experimental Pharmacology", vol. 113, 1994, pages: 49 - 101 |
| LONBERG, N.; HUSZAR, D., INTERN. REV. IMMUNOL., vol. 13, 1995, pages 65 - 93 |
| M. OWAIS ET AL., ANTIMICROB. AGENTS CHEMOTHER., vol. 39, 1995, pages 180 |
| MA ET AL., CHROMATOGRAPHIA, vol. 53, 2001, pages 75 - 89 |
| MARCH J: "Advanced Organic Chemistry", 1992, JOHN WILEY AND SONS |
| MARCH: "Advanced Organic Chemistry", 1985, JOHN WILEY & SONS |
| MARSHALL ET AL., ANNU REV BIOCHEM, vol. 41, 1972, pages 673 - 702 |
| MARTIN ET AL., J. ANTIBIOT., vol. 33, 1980, pages 902 |
| MARTIN ET AL., J. ANTIBIOT., vol. 34, 1981, pages 1119 |
| MATAYOSHI ET AL., SCIENCE, vol. 247, 1990, pages 954 |
| MCCAFFERTY ET AL., NATURE, vol. 348, 1990, pages 552 - 554 |
| MIMURA ET AL., MOL IMMUNOL, vol. 37, 2000, pages 697 - 706 |
| MOLINO ET AL., JOURNAL OFBIOLOGICAL CHEMISTRY, vol. 272, no. 7, 1997, pages 4043 - 4049 |
| MONTEIRO, R.C. ET AL., J IMMUNOL., vol. 148, 1992, pages 1764 |
| MORRIS ET AL., PLANT MOLECULAR BIOLOGY, vol. 24, no. 673, 1994, pages 77 |
| MORRISON, S., SCIENCE, vol. 229, 1985, pages 1202 |
| MORTON, H.C. ET AL., CRITICAL REVIEWS IN IMMUNOLOGY, vol. 16, 1996, pages 423 - 440 |
| MURRAY ET AL., J CHROMATOGR SCI, vol. 40, 2002, pages 343 - 9 |
| NEEDLEMAN; WUNSCH, J MOL. BIOL., vol. 48, 1970, pages 444 - 453 |
| NORD K ET AL.: "Binding proteins selected from combinatorial libraries of an a-helical bacterial receptor domain", NAT BIOTECHNOL, vol. 15, 1997, pages 772 - 7 |
| P.G. BLOEMAN ET AL., FEBSLETT., vol. 357, 1995, pages 140 |
| PAREKH ET AL., NATURE, vol. 316, 1985, pages 452 - 7 |
| PASTAN, I.; KREITMAN, R. J., CURR. OPIN. INVESTIG. DRUGS, vol. 3, 2002, pages 1089 - 1091 |
| PAULUS, BEHRING INS. MITT., no. 78, 1985, pages 118 - 132 |
| PAYNE, G., CANCER CELL, vol. 3, 2003, pages 207 - 212 |
| PETRACEK ET AL., ANNALS NYACAD SCI., vol. 507, 1987, pages 353 - 54 |
| PEZZUTTO ET AL., JLMMUNOL., vol. 138, 1987, pages 2793 |
| POLYMENIS; STOLLER, J IMMUNOL., vol. 152, 1994, pages 5218 - 5329 |
| QUEEN, C. ET AL., PROC. NATL. ACAD. SEE. USA., vol. 86, 1989, pages 10029 - 10033 |
| QUI ET AL., NATURE BIOTECHNOLOGY, vol. 25, no. 8, 2007, pages 921 - 929 |
| R. J. KAUFMAN; P. A. SHARP, J MOL. BIOL., vol. 159, 1982, pages 601 - 621 |
| RADER ET AL., PROC. NATL. ACAD. SCI. USA., vol. 95, 1998, pages 8910 - 8915 |
| RANO, T.A. ET AL., CHEMISTRY AND BIOLOGY, vol. 4, 1997, pages 149 - 55 |
| RIBATTI ET AL., INTERNATIONAL JOURNAL OF CANCER, vol. 85, no. 2, 2000, pages 171 - 5 |
| RIECHMANN, L. ET AL., NATURE, vol. 332, 1998, pages 323 - 327 |
| RONMARK J ET AL.: "Human immunoglobulin A (IgA)-specific ligands from combinatorial engineering of protein A", EUR J BIOCHEM, vol. 269, 2002, pages 2647 - 55 |
| RONMARK J; HANSSON M; NGUYEN T ET AL.: "Construction and characterization of affibody-Fc chimeras produced in Escherichia coli", J IMMUNOL METHODS, vol. 261, 2002, pages 199 - 211 |
| SAITO, G. ET AL.: "Cytotoxic Compounds And Conjugates", ADV. DRUG DELIV. REV., vol. 55, 2003, pages 199 - 215 |
| SANDLER SR; KARO W: "Organic Functional Group Preparations", 1983, ACADEMIC PRESS, INC. |
| SANDSTORM K ET AL.: "Inhibition of the CD28-CD80 co-stimulation signal by a CD28- binding Affibody ligand developed by combinatorial protein engineering", PROTEIN ENG, vol. 16, 2003, pages 691 - 7 |
| SCHLOEMER ET AL., J. VIROLOGY, vol. 15, no. 4, 1975, pages 882 - 893 |
| SCHREIER ET AL., J BIOL. CHEM., vol. 269, 1994, pages 9090 |
| SEIDAH ET AL., METH. ENZYMOL., vol. 244, 1994, pages 175 |
| SENTER, P.D.; SPRINGER, C.J., ADV. DRUG DELIV. REV., vol. 53, 2001, pages 247 - 264 |
| SHEARWATER POLYMERS CATALOG, 2001 |
| SHIELDS, R.L. ET AL., J BIOL. CHEM., vol. 276, 2001, pages 6591 - 6604 |
| SHIELDS, R.L. ET AL., J BIOL. CHEM., vol. 277, 2002, pages 26733 - 26740 |
| SMITH ET AL., METH. ENZYMOL., vol. 244, 1994, pages 412 |
| SPIRO RG, GLYCOBIOLOGY, vol. 12, 2002, pages 43R - 56R |
| STACK ET AL., JOURNAL OFBIOLOGICAL CHEMISTRY, vol. 269, no. 13, 1994, pages 9416 - 9419 |
| SWENSON ET AL., CANCER RES., vol. 42, 1982, pages 2821 |
| TAKANAMI ET AL., CANCER, vol. 88, no. 12, 2000, pages 2686 - 92 |
| TAKEBE, Y. ET AL., MOL. CELL. BIOL., vol. 8, 1988, pages 466 - 472 |
| TAM ET AL., AM. J RESPIR. CELL MOL. BIOL., vol. 3, 1990, pages 27 - 32 |
| TARENTINO, A.L. ET AL., BIOCHEM., vol. 14, 1975, pages 5516 - 23 |
| TAYLOR, L. ET AL., INTERNATIONAL IMMUNOLOGY, vol. 6, 1994, pages 579 - 591 |
| TAYLOR, L. ET AL., NUCLEIC ACIDS RESEARCH, vol. 20, 1992, pages 6287 - 6295 |
| TEDDER ET AL., CURR DIR AUTOIMMUN, vol. 8, 2005, pages 55 |
| TEDDER ET AL., IMMUNOL TODAY, vol. 15, 1994, pages 437 |
| THORNBERRY, METH. ENZYMOL., vol. 244, 1994, pages 615 |
| TOMIZUKA ET AL., PROC. NATL. ACAD. SCI. USA, vol. 97, 2000, pages 722 - 727 |
| TOMLINSON, I. M. ET AL.: "The Repertoire of Human Germline VH Sequences Reveals about Fifty Groups of VH Segments with Different Hypervariable Loops", J MOL. BIOL., vol. 227, 1992, pages 776 - 798 |
| TOTH-JAKATICS ET AL., HUMAN PATHOLOGY, vol. 31, no. 8, 2000, pages 955 - 960 |
| TRAIL, P.A. ET AL., CANCER IMMUNOL. IMMUNOTHER., vol. 52, 2003, pages 328 - 337 |
| TUAILLON ET AL., J IMMUNOL., vol. 152, 1994, pages 2912 - 2920 |
| TUAILLON ET AL., PROC. NATL. ACAD. SCI. USA, vol. 90, 1993, pages 3720 - 3724 |
| UMANA ET AL., NAT. BIOTECH., vol. 17, 1999, pages 176 - 180 |
| UMEZAWA ET AL., BIOCHEM. BIOPHYS. RES. COMMUN., vol. 153, 1988, pages 1038 |
| URLAUB; CHASIN, PROC. NATL. ACAD. SCI. USA, vol. 77, 1980, pages 4216 - 4220 |
| V.V. RANADE, J CLIN. PHARMACOL., vol. 29, 1989, pages 685 |
| WADE LG: "Compendium of Organic Synthetic Methods", 1980, JOHN WILEY AND SONS |
| WALLICK ET AL., JEXP MED, vol. 168, 1988, pages 1099 - 109 |
| WARD ET AL., NATURE, vol. 341, 1989, pages 544 - 546 |
| WARD ET AL., PHOTOCHEM. PHOTOBIOL., vol. 35, 1982, pages 803 - 808 |
| WEBER ET AL., METH. ENZYMOL., vol. 244, 1994, pages 595 |
| WILBANKS ET AL., J BIOL. CHEM., vol. 268, 1993, pages 1226 - 35 |
| XU; DAVIS, IMMUNITY, vol. 13, 2000, pages 37 - 45 |
| YAMANE-OHNUKI ET AL., BIOTECHNOL BIOENG, vol. 87, 2004, pages 614 - 22 |
| ZIMMERMAN, M. ET AL., ANALYTICAL BIOCHEMISTRY, vol. 78, 1977, pages 47 - 51 |
Cited By (62)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3597216A1 (en) | 2008-08-11 | 2020-01-22 | E. R. Squibb & Sons, L.L.C. | Human antibodies that bind lymphocyte activation gene-3 (lag-3) and uses thereof |
| EP2905030A1 (en) | 2008-08-11 | 2015-08-12 | E. R. Squibb & Sons, L.L.C. | Human antibodies that bind lymphocyte activation gene-3 (LAG-3) and uses thereof |
| EP4147714A1 (en) | 2008-08-11 | 2023-03-15 | E. R. Squibb & Sons, L.L.C. | Human antibodies that bind lymphocyte activation gene-3 (lag-3) and uses thereof |
| EP2409712A1 (en) | 2010-07-19 | 2012-01-25 | International-Drug-Development-Biotech | Anti-CD19 antibody having ADCC and CDC functions and improved glycosylation profile |
| EP2409993A1 (en) | 2010-07-19 | 2012-01-25 | International-Drug-Development-Biotech | Anti-CD19 antibody having ADCC function with improved glycosylation profile |
| WO2012010562A1 (en) | 2010-07-19 | 2012-01-26 | International - Drug - Development - Biotech | Anti-cd19 antibody having adcc and cdc functions and improved glycosylation profile |
| WO2012010561A1 (en) | 2010-07-19 | 2012-01-26 | International - Drug - Development - Biotech | Anti-cd19 antibody having adcc function with improved glycosylation profile |
| WO2014008218A1 (en) | 2012-07-02 | 2014-01-09 | Bristol-Myers Squibb Company | Optimization of antibodies that bind lymphocyte activation gene-3 (lag-3), and uses thereof |
| EP3275899A1 (en) | 2012-07-02 | 2018-01-31 | Bristol-Myers Squibb Company | Optimization of antibodies that bind lymphocyte activation gene-3 (lag-3), and uses thereof |
| EP3795592A1 (en) | 2012-07-02 | 2021-03-24 | Bristol-Myers Squibb Company | Optimization of antibodies that bind lymphocyte activation gene-3 (lag-3), and uses thereof |
| US11059910B2 (en) | 2012-12-03 | 2021-07-13 | Novimmune Sa | Anti-CD47 antibodies and methods of use thereof |
| US11840553B2 (en) | 2012-12-03 | 2023-12-12 | Novimmune Sa | Anti-CD47 antibodies and methods of use thereof |
| US10980890B2 (en) | 2014-05-28 | 2021-04-20 | Legochem Biosciences, Inc. | Compounds comprising self-immolative group |
| US11236161B2 (en) | 2014-06-02 | 2022-02-01 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Chimeric antigen receptors targeting CD-19 |
| WO2015187835A2 (en) | 2014-06-06 | 2015-12-10 | Bristol-Myers Squibb Company | Antibodies against glucocorticoid-induced tumor necrosis factor receptor (gitr) and uses thereof |
| EP3998079A1 (en) | 2014-06-06 | 2022-05-18 | Bristol-Myers Squibb Company | Antibodies against glucocorticoid-induced tumor necrosis factor receptor (gitr) and uses thereof |
| EP3610924A1 (en) | 2014-06-06 | 2020-02-19 | Bristol-Myers Squibb Company | Antibodies against glucocorticoid-induced tumor necrosis factor receptor (gitr) and uses thereof |
| EP3805267A1 (en) * | 2014-08-28 | 2021-04-14 | Juno Therapeutics, Inc. | Antibodies and chimeric antigen receptors specific for cd19 |
| TWI805109B (en) * | 2014-08-28 | 2023-06-11 | 美商奇諾治療有限公司 | Antibodies and chimeric antigen receptors specific for cd19 |
| TWI751102B (en) * | 2014-08-28 | 2022-01-01 | 美商奇諾治療有限公司 | Antibodies and chimeric antigen receptors specific for cd19 |
| IL250831B2 (en) * | 2014-08-28 | 2023-11-01 | Juno Therapeutics Inc | Antibodies and chimeric antigen receptors specific for cd19, compositions containing same and uses thereof |
| IL250831B1 (en) * | 2014-08-28 | 2023-07-01 | Juno Therapeutics Inc | Antibodies and chimeric antigen receptors specific for cd19, compositions containing same and uses thereof |
| WO2016033570A1 (en) * | 2014-08-28 | 2016-03-03 | Juno Therapeutics, Inc. | Antibodies and chimeric antigen receptors specific for cd19 |
| RU2741105C2 (en) * | 2014-08-28 | 2021-01-22 | Джуно Терапьютикс, Инк. | Antibodies and chimeric antigenic receptors specific to cd19 |
| US10533055B2 (en) | 2014-08-28 | 2020-01-14 | Juno Therapeutics, Inc. | Antibodies and chimeric antigen receptors specific for CD19 |
| US11827714B2 (en) | 2014-08-28 | 2023-11-28 | Juno Therapeutics, Inc. | Antibodies and chimeric antigen receptors specific for CD19 |
| EP3789399A1 (en) | 2014-11-21 | 2021-03-10 | Bristol-Myers Squibb Company | Antibodies comprising modified heavy constant regions |
| EP3725808A1 (en) | 2014-11-21 | 2020-10-21 | Bristol-Myers Squibb Company | Antibodies against cd73 and uses thereof |
| WO2016081748A2 (en) | 2014-11-21 | 2016-05-26 | Bristol-Myers Squibb Company | Antibodies against cd73 and uses thereof |
| EP4249066A2 (en) | 2014-12-23 | 2023-09-27 | Bristol-Myers Squibb Company | Antibodies to tigit |
| US11286300B2 (en) | 2015-10-01 | 2022-03-29 | Hoffmann-La Roche Inc. | Humanized anti-human CD19 antibodies and methods of use |
| WO2017087678A2 (en) | 2015-11-19 | 2017-05-26 | Bristol-Myers Squibb Company | Antibodies against glucocorticoid-induced tumor necrosis factor receptor (gitr) and uses thereof |
| US11173214B2 (en) | 2015-11-25 | 2021-11-16 | Legochem Biosciences, Inc. | Antibody-drug conjugates comprising branched linkers and methods related thereto |
| US11167040B2 (en) | 2015-11-25 | 2021-11-09 | Legochem Biosciences, Inc. | Conjugates comprising peptide groups and methods related thereto |
| US11413353B2 (en) | 2015-11-25 | 2022-08-16 | Legochem Biosciences, Inc. | Conjugates comprising self-immolative groups and methods related thereto |
| US11975076B2 (en) | 2015-11-25 | 2024-05-07 | Legochem Biosciences, Inc. | Antibody-drug conjugates comprising branched linkers and methods related thereto |
| WO2017152085A1 (en) | 2016-03-04 | 2017-09-08 | Bristol-Myers Squibb Company | Combination therapy with anti-cd73 antibodies |
| WO2018083535A1 (en) * | 2016-11-04 | 2018-05-11 | Novimmune Sa | Anti-cd19 antibodies and methods of use thereof |
| US11142570B2 (en) | 2017-02-17 | 2021-10-12 | Bristol-Myers Squibb Company | Antibodies to alpha-synuclein and uses thereof |
| WO2018151821A1 (en) | 2017-02-17 | 2018-08-23 | Bristol-Myers Squibb Company | Antibodies to alpha-synuclein and uses thereof |
| US11827695B2 (en) | 2017-02-17 | 2023-11-28 | Bristol-Myers Squibb Company | Antibodies to alpha-synuclein and uses thereof |
| US11654197B2 (en) | 2017-03-29 | 2023-05-23 | Legochem Biosciences, Inc. | Pyrrolobenzodiazepine dimer prodrug and ligand-linker conjugate compound of the same |
| WO2018213297A1 (en) | 2017-05-16 | 2018-11-22 | Bristol-Myers Squibb Company | Treatment of cancer with anti-gitr agonist antibodies |
| EP4098662A1 (en) | 2017-05-25 | 2022-12-07 | Bristol-Myers Squibb Company | Antibodies comprising modified heavy constant regions |
| WO2018218056A1 (en) | 2017-05-25 | 2018-11-29 | Birstol-Myers Squibb Company | Antibodies comprising modified heavy constant regions |
| TWI812645B (en) * | 2017-09-21 | 2023-08-21 | 中國大陸商上海藥明生物技術有限公司 | Novel Anti-CD19 Antibody |
| EP3684820A4 (en) * | 2017-09-21 | 2021-05-26 | Wuxi Biologics (Cayman) Inc. | Novel anti-cd19 antibodies |
| US11497769B2 (en) | 2017-09-21 | 2022-11-15 | WuXi Biologics Ireland Limited | Anti-CD19 antibodies |
| WO2019215510A3 (en) * | 2018-05-09 | 2020-01-09 | Legochem Biosciences, Inc. | Compositions and methods related to anti-cd19 antibody drug conjugates |
| RU2806333C2 (en) * | 2018-05-09 | 2023-10-31 | Легокем Байосайенсиз, Инк. | Compositions and methods relating to drug conjugates with anti-cd19 antibodies |
| US11827703B2 (en) | 2018-05-09 | 2023-11-28 | Legochem Biosciences, Inc. | Compositions and methods related to anti-CD19 antibody drug conjugates |
| WO2019243626A1 (en) | 2018-06-22 | 2019-12-26 | Genmab A/S | Method for producing a controlled mixture of two or more different antibodies |
| US11793834B2 (en) | 2018-12-12 | 2023-10-24 | Kite Pharma, Inc. | Chimeric antigen and T cell receptors and methods of use |
| WO2020154889A1 (en) * | 2019-01-29 | 2020-08-06 | 上海鑫湾生物科技有限公司 | Combination of antibody having fc mutant and effector cell, use thereof and preparation method therefor |
| CN113840841B (en) * | 2019-05-20 | 2023-03-07 | 南京驯鹿医疗技术有限公司 | Fully human antibody targeting CD19 and application thereof |
| CN113840841A (en) * | 2019-05-20 | 2021-12-24 | 南京驯鹿医疗技术有限公司 | Fully human antibody targeting CD19 and application thereof |
| US11707533B2 (en) | 2019-09-04 | 2023-07-25 | Legochem Biosciences, Inc. | Antibody-drug conjugate comprising antibody against human ROR1 and use for the same |
| WO2021067598A1 (en) | 2019-10-04 | 2021-04-08 | Ultragenyx Pharmaceutical Inc. | Methods for improved therapeutic use of recombinant aav |
| US11299551B2 (en) | 2020-02-26 | 2022-04-12 | Biograph 55, Inc. | Composite binding molecules targeting immunosuppressive B cells |
| WO2023198744A1 (en) | 2022-04-13 | 2023-10-19 | Tessa Therapeutics Ltd. | Therapeutic t cell product |
| WO2023245106A1 (en) * | 2022-06-16 | 2023-12-21 | Abbvie Biotherapeutics Inc. | Anti-cd19 antibody drug conjugates |
| US12121589B2 (en) | 2023-06-15 | 2024-10-22 | Abbvie Biotherapeutics Inc. | Anti-CD19 antibody drug conjugates |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2010513303A (en) | 2010-04-30 |
| WO2009054863A3 (en) | 2009-09-24 |
| BRPI0718349A2 (en) | 2014-01-14 |
| CA2672800A1 (en) | 2009-04-30 |
| EP2101817A2 (en) | 2009-09-23 |
| AU2007360636A1 (en) | 2009-04-30 |
| EP2101817A4 (en) | 2013-05-01 |
| AR064337A1 (en) | 2009-04-01 |
| TW200833713A (en) | 2008-08-16 |
| US20100104509A1 (en) | 2010-04-29 |
| MX2009006275A (en) | 2009-07-22 |
| CN101636502A (en) | 2010-01-27 |
| KR20090088940A (en) | 2009-08-20 |
| JP5517626B2 (en) | 2014-06-11 |
| CN101636502B (en) | 2014-06-04 |
| CL2007003622A1 (en) | 2009-08-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5517626B2 (en) | Human antibodies that bind to CD19 and uses thereof | |
| US9499632B2 (en) | Human antibodies that bind CD22 and uses thereof | |
| AU2008308956B2 (en) | Human antibodies that bind mesothelin, and uses thereof | |
| US20100150950A1 (en) | Human antibodies that bind cd70 and uses thereof | |
| AU2008334063A1 (en) | Anti-B7H4 monoclonal antibody-drug conjugate and methods of use | |
| EP2229187A2 (en) | Monoclonal antibody partner molecule conjugates directed to protein tyrosine kinase 7 (ptk7) | |
| SG173742A1 (en) | Fully human antibodies specific to cadm1 | |
| AU2007329529B2 (en) | Human antibodies that bind CD22 and uses thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 578353 Country of ref document: NZ Ref document number: 200780050552.1 Country of ref document: CN |
|
| ENP | Entry into the national phase |
Ref document number: 2009541583 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2672800 Country of ref document: CA Ref document number: MX/A/2009/006275 Country of ref document: MX |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2007360636 Country of ref document: AU |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 07875235 Country of ref document: EP Kind code of ref document: A2 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2007875235 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2460/KOLNP/2009 Country of ref document: IN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 1020097014232 Country of ref document: KR |
|
| ENP | Entry into the national phase |
Ref document number: 2007360636 Country of ref document: AU Date of ref document: 20071213 Kind code of ref document: A |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01E Ref document number: PI0718349 Country of ref document: BR Free format text: SOLICITA-SE A REGULARIZACAO DA PROCURACAO, UMA VEZ QUE A PROCURACAO APRESENTADA NAO POSSUI DATA. |
|
| ENP | Entry into the national phase |
Ref document number: PI0718349 Country of ref document: BR Kind code of ref document: A2 Effective date: 20090612 |