WO2009037473A2 - Nucleobase characterisation - Google Patents
Nucleobase characterisation Download PDFInfo
- Publication number
- WO2009037473A2 WO2009037473A2 PCT/GB2008/003185 GB2008003185W WO2009037473A2 WO 2009037473 A2 WO2009037473 A2 WO 2009037473A2 GB 2008003185 W GB2008003185 W GB 2008003185W WO 2009037473 A2 WO2009037473 A2 WO 2009037473A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- pna
- nucleic acid
- modified
- nucleotide
- group
- Prior art date
Links
- 0 *N(CCNP)CC(O)=O Chemical compound *N(CCNP)CC(O)=O 0.000 description 3
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07D—HETEROCYCLIC COMPOUNDS
- C07D239/00—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings
- C07D239/02—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings not condensed with other rings
- C07D239/24—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings not condensed with other rings having three or more double bonds between ring members or between ring members and non-ring members
- C07D239/28—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings not condensed with other rings having three or more double bonds between ring members or between ring members and non-ring members with hetero atoms or with carbon atoms having three bonds to hetero atoms with at the most one bond to halogen, directly attached to ring carbon atoms
- C07D239/32—One oxygen, sulfur or nitrogen atom
- C07D239/34—One oxygen atom
- C07D239/36—One oxygen atom as doubly bound oxygen atom or as unsubstituted hydroxy radical
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07D—HETEROCYCLIC COMPOUNDS
- C07D239/00—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings
- C07D239/02—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings not condensed with other rings
- C07D239/20—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings not condensed with other rings having two double bonds between ring members or between ring members and non-ring members
- C07D239/22—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings not condensed with other rings having two double bonds between ring members or between ring members and non-ring members with hetero atoms directly attached to ring carbon atoms
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07D—HETEROCYCLIC COMPOUNDS
- C07D239/00—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings
- C07D239/02—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings not condensed with other rings
- C07D239/24—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings not condensed with other rings having three or more double bonds between ring members or between ring members and non-ring members
- C07D239/28—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings not condensed with other rings having three or more double bonds between ring members or between ring members and non-ring members with hetero atoms or with carbon atoms having three bonds to hetero atoms with at the most one bond to halogen, directly attached to ring carbon atoms
- C07D239/46—Two or more oxygen, sulphur or nitrogen atoms
- C07D239/47—One nitrogen atom and one oxygen or sulfur atom, e.g. cytosine
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07D—HETEROCYCLIC COMPOUNDS
- C07D239/00—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings
- C07D239/02—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings not condensed with other rings
- C07D239/24—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings not condensed with other rings having three or more double bonds between ring members or between ring members and non-ring members
- C07D239/28—Heterocyclic compounds containing 1,3-diazine or hydrogenated 1,3-diazine rings not condensed with other rings having three or more double bonds between ring members or between ring members and non-ring members with hetero atoms or with carbon atoms having three bonds to hetero atoms with at the most one bond to halogen, directly attached to ring carbon atoms
- C07D239/46—Two or more oxygen, sulphur or nitrogen atoms
- C07D239/52—Two oxygen atoms
- C07D239/54—Two oxygen atoms as doubly bound oxygen atoms or as unsubstituted hydroxy radicals
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07D—HETEROCYCLIC COMPOUNDS
- C07D405/00—Heterocyclic compounds containing both one or more hetero rings having oxygen atoms as the only ring hetero atoms, and one or more rings having nitrogen as the only ring hetero atom
- C07D405/02—Heterocyclic compounds containing both one or more hetero rings having oxygen atoms as the only ring hetero atoms, and one or more rings having nitrogen as the only ring hetero atom containing two hetero rings
- C07D405/12—Heterocyclic compounds containing both one or more hetero rings having oxygen atoms as the only ring hetero atoms, and one or more rings having nitrogen as the only ring hetero atom containing two hetero rings linked by a chain containing hetero atoms as chain links
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07D—HETEROCYCLIC COMPOUNDS
- C07D473/00—Heterocyclic compounds containing purine ring systems
- C07D473/02—Heterocyclic compounds containing purine ring systems with oxygen, sulphur, or nitrogen atoms directly attached in positions 2 and 6
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07D—HETEROCYCLIC COMPOUNDS
- C07D473/00—Heterocyclic compounds containing purine ring systems
- C07D473/02—Heterocyclic compounds containing purine ring systems with oxygen, sulphur, or nitrogen atoms directly attached in positions 2 and 6
- C07D473/18—Heterocyclic compounds containing purine ring systems with oxygen, sulphur, or nitrogen atoms directly attached in positions 2 and 6 one oxygen and one nitrogen atom, e.g. guanine
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07D—HETEROCYCLIC COMPOUNDS
- C07D473/00—Heterocyclic compounds containing purine ring systems
- C07D473/26—Heterocyclic compounds containing purine ring systems with an oxygen, sulphur, or nitrogen atom directly attached in position 2 or 6, but not in both
- C07D473/32—Nitrogen atom
- C07D473/34—Nitrogen atom attached in position 6, e.g. adenine
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07D—HETEROCYCLIC COMPOUNDS
- C07D498/00—Heterocyclic compounds containing in the condensed system at least one hetero ring having nitrogen and oxygen atoms as the only ring hetero atoms
- C07D498/02—Heterocyclic compounds containing in the condensed system at least one hetero ring having nitrogen and oxygen atoms as the only ring hetero atoms in which the condensed system contains two hetero rings
- C07D498/10—Spiro-condensed systems
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10T—TECHNICAL SUBJECTS COVERED BY FORMER US CLASSIFICATION
- Y10T436/00—Chemistry: analytical and immunological testing
- Y10T436/14—Heterocyclic carbon compound [i.e., O, S, N, Se, Te, as only ring hetero atom]
- Y10T436/142222—Hetero-O [e.g., ascorbic acid, etc.]
- Y10T436/143333—Saccharide [e.g., DNA, etc.]
Definitions
- the present invention provides modified nucleobase compounds, modified nucleic acid mimetic compounds and various uses thereof. More specifically, the invention provides methods for nucleobase characterisation, SNP characterisation and nucleic acid sequencing. BACKGROUND
- SNP analysis can be viewed as sequencing a single base.
- SNPs Single nucleotide polymorphisms
- a SNP can constitute a genetic risk factor (or indeed advantage) to specific disease states as well as a host of physical features.
- SNP analysis methods are T/GB2008/003185 many and varied but generally consist of primer extension reactions using polymerases and fluorescently labelled triphosphates, although the methods of capture and analysis vary considerably. SNP analysis is a simple form of DNA sequencing in some respects, in that the identity of a single base is the major concern (although its context is of course crucial).
- DNA and peptide nucleic acid have been used in a number of ligation-based chemical approaches to synthesis (notably the work of D. R. Liu and O. Seitz -X. Li and D.R. Liu, Angew. Chem. Int. Ed., 2004, 43, 4848-4870; S. Ficht et al, ChemBioChem, 2005, 6, 2098-2103).
- Non- enzymatic ligation has also been achieved in a DNA-DNA sense by Kool and Richert (N. Griesang et al, Angew. Chem. Int. Ed., 2006, 45, 6144-6148 and ref therein (e.g. P.
- a “dynamic library” can be prepared by mixing together in solution two complementary components, such as a selection of aldehydes and an amine, or diols and boronic acids, or thiols and disulfides in the presence of a template. Due to the dynamic equilibrium set up in the system (amine/aldehyde/imine) the most strongly bound ligand will predominate and thus in essence the template "builds” and "concentrates” its own partner. Recently, Dawson et al. (J. Am. Chem. Soc, 2006, 128, 15602-15603) showed that equilibrium kinetics of dynamic processes can also be accelerated by catalysts such as aniline.
- the object of the present invention is to obviate or mitigate at least one of the aforementioned problems.
- the invention described herein provides modified bases, modified nucleobases and DNA mimetic compounds which may be used in various nucleic acid sequencing and/or SNP characterisation methods.
- the invention provides clear advantages over the prior art as each of the methods described herein is chemical based and does not require the use of enzymes.
- the present invention provides a modified base comprising a moiety capable of reversible covalent reactions and a detectable tag.
- bases also known as or referred to herein as "nucleobases”
- bases comprise purines and pyrimidines which include, for example the specific bases adenine, guanine, thymine, cytosine and uracil.
- the present invention relates to modified adenine, guanine, thymine, cytosine and/or uracil bases.
- the present invention encompasses variants such as, for example, xanthine, hypoxanthine, isoguanine and uric acid.
- modified base may be taken to encompass bases/nucleobases comprising an alkyl chain further comprising functional groups capable of reversible covalent reactions.
- the heterocycle of the bases may be modified so as to comprise the alkyl chain and functional groups. More specifically a heteroatom or carbon atom of the heterocycle may be modified to comprise the alkyl chain and functional groups.
- the functional groups capable of "reversible covalent reactions” may be, for example, groups comprising aldehydes and/or ketones and in one embodiment, the reversible covalent reactions may involve reactions between the aldehyde/ketone groups of the modified base and amines, hydrazide and hydrazides (A. Dirksen, et al., 7. Am. Chem. Soc, 2006, 128, 15602-15603), alkoxyamine (V.A. Polyakov et al., /. Phys. Org. Chem. 1999, 12, 357-363) or alcohols, diols and/or boronic acids (O. Abed et at. Chem. Mater., 2006, 18, 1247 -1260).
- the group capable of a reversible covalent reaction is not an alcohol.
- detectable tag may be taken to encompass tags or labels which are, for example, distinguishable from one another either optically or otherwise. Many such tags or labels are known to those skilled in this field but, by way of example, tags suitable for use in the present invention may include, for example, fluorescent or mass-tag compounds. More specifically, and in one embodiment, the modified bases/nucleobases of the present invention may comprise one or more detectable tag (such as, for example a fluorophore) selected from a group of tags having optically detectable dyes ranging from, for example, the blue to the far-red spectra.
- detectable tag such as, for example a fluorophore
- tags which may be suitable include, for example, dansyl, fluorescein, rhodamine, texas red, IAEDANS, cyanine dyes (Cy3, Cy3.5, Cy5, Cy5.5, Cy7), Bodipy dyes (Invitrogen) and/or Alexa Fluor dyes (Invitrogen).
- the detectable tag is not ferrocene.
- Suitable "mass-tag” compounds may include, for example, tags which comprise bromide moieties or other compounds, molecules or moieties capable of providing a clear isotopic pattern in mass-spectrometry techniques such as, for example, MALDI-TOF.
- any of the modified nucleobases described herein may be detected by, for example, fluorescent microscopy or mass spectrometry techniques such as MALDI-TOF or the like.
- the heterocycle of each of the modified bases/nucleobases described herein may comprise a detectable tag linked, for example, at any number of positions through a heteroatom or a carbon atom.
- the heteroatom may be modified so as to further comprise suitable spacer/carbon spacer moieties such as, for example an alkyne, alkenylene or alkynylene moiety which may be independently substituted with one or more of the detectable tags noted above.
- the heteroatom and/or modified heteroatom of the heterocycle may comprise one or more fluorophore(s) (T.S. Seo et al, PNAS, 2004, 101, 5488-5493; Z.
- the purine and/or pyrimidine heterocylces may be modified by, for example, cross coupling reactions using palladium catalysts (L. Thoresen et at, Chem. Eur. J. 2003, 9, 4603-4610; N.K. Garg et al. Chem. Commun., 2005, 4551-4553).
- each modified base/nucleobase may comprise a different detectable tag.
- the detectable tag may allow, for example, a modified adenine nucleobase to be distinguished from any other modified nucleobase.
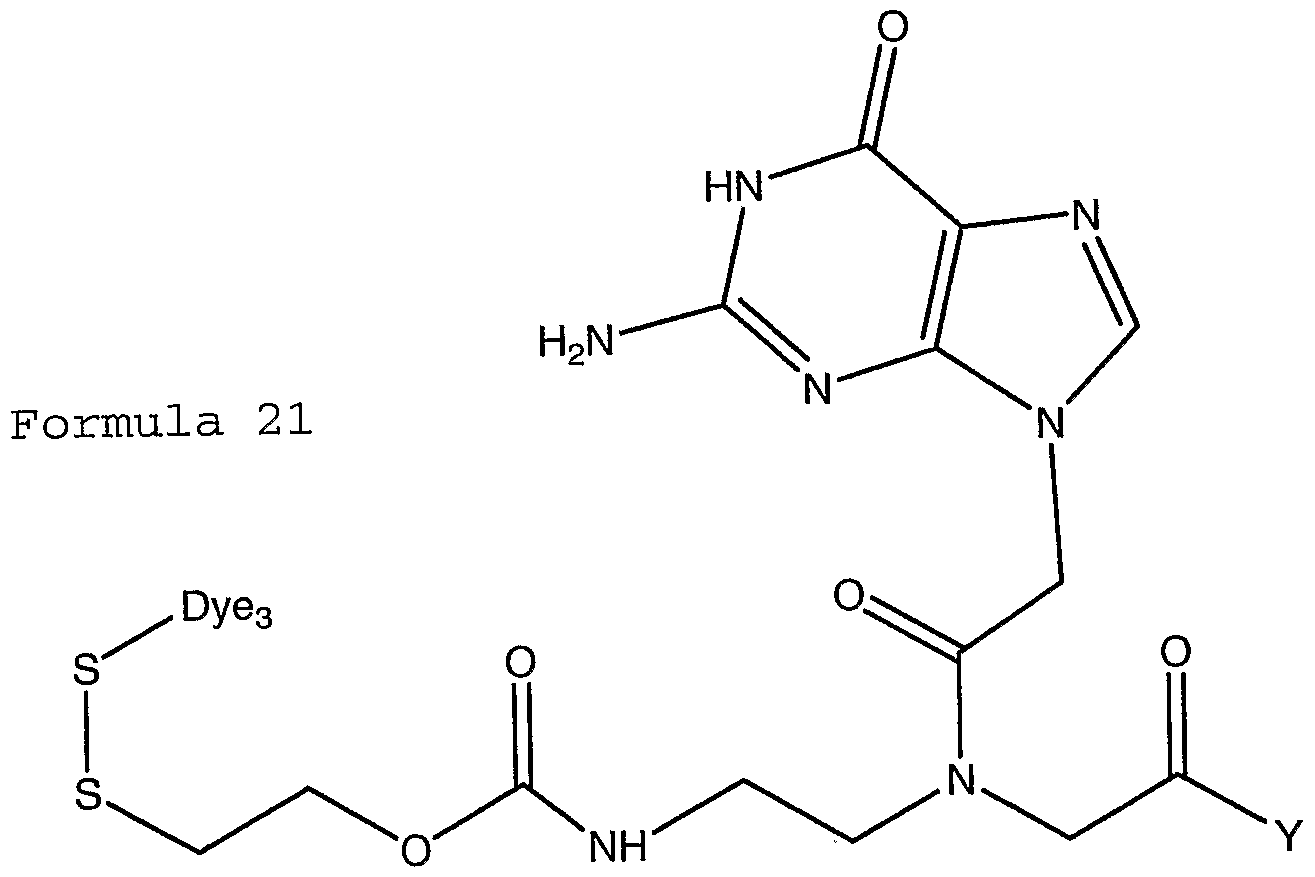
- the present invention provides modified bases selected from the group consisting of:
- Y may comprise a functional group capable of reversible covalent reactions.
- Suitable functional groups may include, for example aldehydes, ketones and/or diols.
- Xi-X 4 may be different detectable tags or spacer-tag combinations or hydrogen.
- Z may be carbon, nitrogen, oxygen and sulphur.
- X may be attached to the heterocycle either through Z, when Z is carbon, or through the carbon moiety at position 8.
- the present invention provides modified bases selected from the group consisting of: Formula 5
- PNA Peptide nucleic acid
- DNA deoxyribonucleic acid
- RNA ribonucleic acid
- the backbone of PNA comprises repeating N-(2-aminoethyl)-glycine units which are linked by peptide bonds.
- the various pyrimidine and/or purine bases (or nucleobases) of PNA are linked to the peptide backbone by amide bond formation.
- a single nucleobase linked via an amide bond to a single N-(2- aminoethyl)-glycine unit may be described as a PNA monomer, but other PNA' s include for example, those containing modified aminoethyl- glycine backbones, such as, for example, pyrrolidine -based (R. J. Worthington et al. Org. Biomol. Chem., 2007, 5, 249-259) and indol-based DNA mimics (Formula 9).
- PNA modified aminoethyl- glycine backbones
- modified PNA monomers having the following general formula:
- heterocycle is a modified base (such as, for example, cytosine, adenine, guanine or thymine/uracil) ) which may comprise a detectable tag, n equals 1, 2 or 3 and further wherein, X represents a way of linkage between the heterocycle and the backbone comprising Ri and Y.
- Ri represents a group capable of reversible covalent reactions.
- Ri may comprise groups such as an amine, a hydrazide, an alkoxymine, a boronic acid, a diol and/or a thiol.
- Y may be a functional group capable of reversible covalent reactions such as, for example, an aldehyde, a ketone, a diol, a boronic acid and a thiol.
- modified PNA monomers having the following general formula:
- heterocycle is a modified base (such as, for example, cytosine, adenine, guanine or thymine/uracil) which may comprise a detectable tag as described above, n equals 1, 2 or 3 and further wherein, R 1 represents a group capable of reversible covalent reactions.
- Ri may comprise groups such as an amine, a hydrazide, an alkoxymine, a boronic acid, a diol and/or a thiol.
- Y may be a functional group capable of reversible covalent reactions such as, for example, an aldehyde, a ketone, a diol, a boronic acid and a thiol.
- R 1 may be derivatised to comprise a protecting group or optionally a protecting group comprising (for example, covalently bound to) one or more of the detectable tags described above.
- Suitable protecting groups for use in further derivatising R 1 may include, for example, protecting groups such as acetyl, N-[l-(4,4-dimethyl-2,6-dioxocyclohex-l- ylidene)ethyl] (Dde), fluorenylmethoxycarbonyl (Fmoc), trityl groups, disulfide (Ardec (aryldithioethyloxycarbonyl)) light cleavage protecting group (nitroveratyl based), butyloxycarbonyl (Boc), benzyloxycarbonyl (Cbz), trifluoroacetyl (Tfa), phthalimide, benzyl, allyloxycarbonyl (Alloc), toluensul
- Ri-R 4 may comprise a group capable of reversible covalent reactions (see above) optionally protected with a protecting group (as described above). Additionally, or alternatively, Ri-R 4 may comprise a protecting group which further comprises (for example covalently bound to) one or more of the detectable tags described herein.
- Xi- X 4 may be one or more of the detectable tags described herein and may be linked to the heterocycle at any number of positions through a heteroatom or a carbon atom.
- the heteroatom may be modified so as to further comprise suitable spacer/carbon spacer moieties such as, for example, an alkyne, alkenylene or alkynylene moiety, which may be independently substituted with one or more of the detectable tags noted above.
- Xi- X 4 is a detectable tag linked to the heterocycles by a cleavable linker or a hydrogen.
- Z may be carbon, nitrogen, oxygen and sulphur and in cases (iii) and (iv) above, X may be linked to the heterocycle either through Z, when Z is carbon, or through the carbon at position 8.
- Y may be a functional group capable of reversible covalent reactions such as, for example, an aldehyde, a ketone, a diol, a boronic acid and a thiol.
- modified PNA monomers selected from the group consisting of:
- Rj may be a hydrocarbon chain, and aryl ring, X may be a hydrocarbon chain and Y may be a hydrocarbon chain or hydrogen.
- the present invention provides modified bases selected from the group consisting of:
- Y may be a hydrogen or a hydrocarbon chain.
- the present invention may relate to PNA dimers or trimers.
- PNA dimers or trimers may relate to PNA dimers or trimers.
- PNA dimer should be understood as relating to two (or three in the case of a PNA “trimer”) PNA monomers which are covalently linked.
- a PNA dimer may comprise at least one nucleobase modified to include any of the detectable tags described herein.
- the PNA dimers may comprise at their N or C terminal ends any one of the detectable tags described herein.
- the other of the N or C terminal end may include a moiety capable of reversible covalent reactions.
- the present invention provides PNA dimers (or trimers) comprising at the N-terminal end a detectable tag and at the C-terminal end, a moiety capable of reversible covalent reactions.
- at least one of the nucleobases of the PNA monomers may further comprise a detectable tag. Exemplary methods of producing PNA dimers (or timers) and examples of specific forms of PNA dimer encompassed by this invention are described in more detail below.
- the present invention also concerns PNA oligomers and one of skill in the art will readily understand that the term "oligomer” may be taken to refer to a molecule comprising at least two PNA monomers linked by, for example, a peptide bond.
- oligomer may be taken to refer to a molecule comprising at least two PNA monomers linked by, for example, a peptide bond.
- the invention also concerns other DNA mimics as noted above.
- NB is a nucleobase (for example a modified nucleobase according to the present invention) and n is at least 2.
- a PNA oligomer typically comprises a continuous peptide backbone with each secondary amine of the peptide backbone being further derivatised to comprise a nucleobase (such as the modified nucleobases described above).
- the present invention may provide a PNA oligomer in which some of the secondary amines of the continuous peptide backbone are not derivatised to comprise a nucleobase and hence are left uncoupled. These oligomers may be referred to as oligomers comprising "blank positions".
- Formula 24 below provides an example of a PNA monomer comprising a blank position (i.e. secondary amine No: 3 is not derivatised to comprise a nucleobase(NB))
- PNA oligomers of the invention may further comprise, at either the N or C-terminal positions, a group capable of reversible covalent reactions.
- the N-terminal position may comprise a free amine group, aldehyde/ketone hydrazide, hydrazine, alkoxyamine, alcohols, diols and/or boronic acids and the C-terminal position may comprise a group capable of forming a reversible covalent reaction with the group at the N-terminal position.
- either of the N-terminal and/or C-terminal positions may be derivatised so as to further comprise a protecting group (as described above).
- the PNA oligomers for use in the methods described herein may be synthesised using N-2aminoethyl-glycine units protected with orthogonal protecting groups. Such units may have the following general formula:
- P 1 and P 2 may be disulfide (Ardec (aryldithioethyloxycarbonyl)), light cleavage protecting group (nitroveratyl based), butyloxycarbonyl (Boc), benzyloxycarbonyl (Cbz), trifluoroacetyl (Tfa), phthalimide, benzyl, allyloxycarbonyl ( Alloc) N- [ l-(4,4-dimethyl-2,6-dioxocyclohex- 1 -ylidene)ethyl] (Dde), 185
- fluorenylmethoxycarbonyl Fmoc
- t-butoxycarbonyl Boc
- trityl groups Green, Wiley-Interscience, New York, 1999
- the present invention provides a use for one or more of the modified bases/nucleobases provided by the first aspect of the present invention and/or the PNA monomers/oligomers described herein, in genetic analysis methods.
- genetic analysis may include, for example, the characterisation, identification and/or sequencing of nucleobases of nucleic acids.
- the methods may be used to characterise single nucleotide polymorphisms and/or to sequencing nucleic acids.
- SNP single nucleotide polymorphism
- a SNP represents a form of variation in a genome wherein a particular nucleotide of the genome varies between members of a population.
- a SNP may comprise two alleles (i.e. one of two possible nucleotides at a particular locus) - and, in such cases some of the individuals within a population may carry one SNP allele at a particular locus while others may carry the other allele at the same locus.
- the phrase "characterising a nucleobase” may be taken to encompass the act of identifying or determining a particular nucleobase of a nucleic acid sequence - in other words, identifying which nucleobase a particular nucleotide comprises.
- the term “characterise” may be taken to encompass the act of determining which particular SNP allele (or nucleobase) is present in a particular nucleic acid sequence.
- the present invention provides a method of characterising a nucleotide in a nucleic acid sequence, said method comprising the steps of:
- a nucleic acid/PNA duplex (a) contacting a nucleic acid with a peptide nucleic acid (PNA) oligomer capable of hybridising to a portion of the nucleic acid and lacking a nucleobase complementary to a nucleobase of the nucleic acid, to form a nucleic acid/PNA duplex; and
- PNA peptide nucleic acid
- nucleic acid/PNA duplex with modified bases according to the first aspect of the invention; wherein the modified nucleobase which integrates with the nucleic acid/PNA duplex is complementary to the nucleobase of the nucleic acid, the nucleotide being characterised by means of the detectable tag of the PNA monomer.
- the part of the PNA oligomer which lacks a base complementary to a nucleobase of the nucleic acid sequence may present a moiety, for example a secondary amine, capable of reacting reversibly with a moiety of the modified bases described above.
- a modified base which is complementary (or matched) to a nucleobase of the nucleic acid may be incorporated into the nucleic acid/PNA duplex by the formation of, for example: (i) a reversible iminium species between the secondary amine of the PNA oligomer and the reacting moiety (aldehyde group) of the modified nucleobase and (ii) the formation of hydrogen bonds between the modified nucleobase and the nucleobase of the nucleic acid.
- the method may comprise the further step of trapping the base integrated with the nucleic acid/PNA duplex and complementary to (i.e. paired with) the nucleotide of the nucleic acid.
- the reversible reaction between 185 and 185 may comprise the further step of trapping the base integrated with the nucleic acid/PNA duplex and complementary to (i.e. paired with) the nucleotide of the nucleic acid.
- the secondary amine of the PNA oligomer and the group capable of reversible covalent reactions of the modified nucleobase may be stopped.
- iminium species may be reduced to give rise to stable tertiary amines using reducing agents such as sodium cyanoborohydride.
- reducing agents such as sodium cyanoborohydride.
- the detectable tag present on each of the modified nucleobases contacted with the nucleic acid/PNA duplex it may be possible to detect which modified base has been incorporated into the nucleic acid/PNA duplex.
- characterisation of the nucleotide of the nucleic acid may easily be achieved.
- the modified nucleobase found to have integrated with the nucleic acid/PNA duplex comprises a tag which indicates that it comprises a thymine nucleobase, in accordance with standard complementary base pairing, the nucleotide of the nucleic acid must comprise an adenine nucleobase.
- the integration of a modified nucleobase which is complementary to a nucleobase of a nucleic acid may represent an example of a dynamic selection process which relates to the various interaction strengths of the complementary (matched) and un-matched nucleobases, as well as the relative concentrations of the four modified nucleobases and may be controlled by changes in the buffer concentrations, pH, temperature and also uses of different catalysts.
- Dynamic selection processes are well known to one of skill in this field and encompass systems in which a number of complementary components are mixed together in the presence of a template (J.M. Lehn, Nat. Rev. Drug Disc, 2002 1, 26- 36). Due to the dynamic equilibrium set up in such a system, the most strongly bound ligand will predominate and thus the template "builds" or selects from the various component parts added, its own “ligand” or "partner".
- the nucleic acid/PNA duplex is contacted with each of the modified nucleobases described above.
- the nucleic acid/PNA duplex will be contacted with modified nucleobases comprising nucleobases complementary to each of the nucleobases likely present in the nucleic acid sample.
- the nucleic acid/PNA duplex may be contacted with the modified adenosine, guanine, cytosine and thymine bases described above.
- each type of modified bases used in the methods described herein comprises a tag which allows it to be separately distinguished from the other modified nucleobases, characterisation of a nucleotide in a nucleic acid sample may be readily achieved.
- the methods described herein may be conducted in solution, it may be advantageous to immobilise or otherwise bind the nucleic acid or PNA oligomer to some form of support substrate, preferably a solid support substrate.
- the support substrate may comprise glass, nitrocellulose, cellulose, plastic, agarose, beads, a metal (such as for example gold) or the like.
- beads sizes of approximately 1 nm to about 2 mm are preferred.
- the present invention provides an alternate method of characterising a nucleotide of a nucleic acid.
- the term "characterise" encompasses the act of identifying a particular nucleobase of a nucleotide.
- the method according to the fifth aspect comprises the step of: (a) hybridising a nucleic acid sequence with a PNA oligomer complementary to a portion of the nucleic acid sequence upstream of the nucleotide to be characterised and further comprising a functional group capable of reversible covalent reactions, to form a nucleic acid/PNA duplex; and (b) contacting the nucleic acid/PNA duplex with modified PNA monomers according to the second aspect of the invention; wherein the modified PNA monomer which integrates with the nucleic acid/PNA duplex is complementary to the nucleobase of the nucleotide, said nucleotide being characterised by means of the detectable tag of the PNA monomer.
- the PNA oligomer hybridises with, or is complementary to, a sequence of the nucleic acid which lies immediately upstream of the nucleotide to be characterised.
- the PNA oligomer may hybridise with or bind to a nucleic acid sequence at a position 3' to the nucleotide of the nucleic acid such that the terminal (or N- et ⁇ i) residue of the PNA oligomer, lies immediately adjacent the nucleotide to be characterised.
- the nucleic acid/PNA duplex is contacted with modified PNA monomers (such as those provided by the second aspect of the invention) comprising nucleobases complementary to each of the nucleobases likely present in the nucleic acid sample.
- modified PNA monomers such as those provided by the second aspect of the invention
- the nucleic acid/PNA duplex may be contacted with modified PNA monomers comprising the adenosine, guanine, cytosine and thymine nucleobases described above.
- the PNA monomers when the PNA monomers are contacted with the nucleic acid/PNA duplex, the PNA monomer comprising the modified nucleobases complementary to the nucleobase of the nucleic acid will, by dynamic selection (as described above), become integrated into the nucleic acid/PNA duplex.
- the methods described herein and particularly the method provided by the fifth aspect of this invention may utilise the PNA dimers provided by this invention.
- the method provided by the fifth aspect may utilise the PNA dimers (or trimers) described herein.
- the PNA oligomer hybridized to the nucleic acid sequence comprising the nucleotide to be characterised may be hybridized in such a way that, while upstream of the nucleotide to be characterised, the terminal (or N- end ) residue of the PNA dimer lies adjacent a nucleotide which is itself immediately adjacent the nucleotide to be characterised.
- the PNA dimer in order to correctly hybridise with the nucleic acid strand containing the nucleotide to be characterised, the PNA dimer must comprise two complementary nucleobases - one complementary to the nucleotide to be characterised and the other complementary to the nucleotide immediately upstream thereof.
- the PNA oligomer may be hybrised to the nucleic acid sequence comprising the nucleotide to be characterised, such that there are two nucleotides of the nucleic acid sequences between the N-terminal end of the PNA oligomer and the nucleotide to be sequenced.
- a correctly integrating PNA trimer must possess three complementary nucleobases; two complementary to the nucleotides immediately upstream of the nucleotide to be characterised and one complementary to the nucleotide to be characterised.
- the method provided by the fifth aspect of this invention may further comprise the step of trapping the modified PNA monomer (or PNA B2008/003185
- each of the modified PNA monomers is labelled with at least one detectable tag which is distinguishable from the detectable tags on other types of PNA monomer (dimer or trimer), detection of the specific monomer (dimer or trimer) which has integrated may be easily achieved.
- PNA dimers there are 16 possible combinations of the four standard nucleotides (A, G, T and C) which must be taken into consideration. As such, when using PNA dimers, the methods described herein may require the addition of all 16 possible PNA dimers. Similarly, when using PNA trimers, there are 64 possible combinations of the four standard nucleotides - as such, when using PNA trimers, the methods described herein may require the addition of all 64 PNA trimers.
- the methods may also permit the user to characterise a SNP present in a nucleic acid sample. For example, if a SNP is known to occur at a particular locus within a gene, by designing PNA oligomers which hybridise either side of the SNP locus or immediately upstream of the SNP locus (as described above) it may be possible to characterise the SNP (i.e. identify which particular SNP allele is present at that locus). Such methods may be particularly useful in detecting mutations associated which particular genetic disorders.
- the present invention provides a method of sequencing a nucleic acid, said method comprising the steps of:
- each PNA monomer may be labelled with a detectable tag which is distinguishable from the detectable tags of PNA monomers comprising another nucleobases, by detecting the tag of the PNA monomer which has integrated into or with the nucleic acid/PNA duplex, it may be possible to sequence a nucleic acid.
- the method provided by the sixth aspect of this invention may, rather than using PNA monomers in step (b), use the PNA dimers and/or trimers provided by this invention.
- each of the PNA monomers (or dimers or trimers) contacted with the nucleic acid/PNA duplex may comprise, at its N-terminal position a blocking group (as described above).
- Such PNA monomers (or dimers or trimers) are referred to hereinafter as "blocked PNA monomers (dimers/trimers)". Methods which use blocked PNA monomers (dimers/trimers) are particularly advantageous as only one PNA monomer can integrate with a nucleic acid/PNA duplex at a time.
- the blocking group of the integrated PNA monomer (dimer or trimer) must first be removed (optionally together with any detectable tag).
- the detectable tag of the integrated modified nucleobase may be identified and the corresponding nucleobase of the nucleic acid determined.
- the techniques which may be used to remove the protecting group are known to one of skill in the art and may include, for example basic-based cleavage, acidic-based cleavage, disulfide reduction, metal-based catalytic reactions, light-based cleavage reactions (Green, Wiley-Interscience, New York, 1999).
- Removal of the protecting group and any tag present on the integrated modified nucleobases may expose or yield a moiety (such as a free amine; group, aldehyde/ketone, hydrazide, hydrazine, alkoxyamine, alcohols, diols and/or boronic acids capable of reacting reversibly with another PNA monomer.
- the method may comprise the further step of trapping the integrated PNA monomer so as to prevent further reversible reactions. For example, reduction of the imine species with sodium cyanoborohydride and further trapping of the generated secondary amine by, for example, an amidation step using acetylchloride. Since each modified nucleobase to integrate with the nucleic acid/PNA duplex binds to a complementary nucleobase of the nucleic acid, the methods described herein render it is possible to sequentially determine the sequence of a nucleic acid.
- the nucleic acid comprising the nucleotide to be characterised may be immobilised on to some form of suitable substrate using, for example, a micro printing system or the like. In this way, a large number of different nucleic acids can be immobilised on to substrates in discrete areas such.
- nucleic acids comprising nucleotides to be characterised may be held in solutions with the other components i.e. the PNA oligomers, modified nucleobases etc. being added in solution also.
- nucleic acids comprising nucleotides to be characterised may be immobilised on to substrates such as, for example, gold surfaces suitable for mass-spectrometry analysis.
- kits comprising the reagents and components required for the methods provided by the fourth, fifth and sixth aspects of this invention.
- the kit may provide reagents and components useful in methods for characterising a nucleotide of a nucleic acid and/or for sequencing a nucleic acid, said kit comprising components selected from the group consisting of:
- a peptide nucleic acid (PNA) oligomer capable of hybridising to a portion of a nucleic acid and lacking a nucleobase complementary to that of the nucleotide to be characterised;
- PNA peptide nucleic acid
- a PNA oligomer complementary to a portion of the nucleic acid sequence upstream of the nucleotide to be characterised and further comprising a functional group capable of reversible covalent reactions.
- modified DNA dimers, trimers and/or oligomers in the methods provided by the fourth, fifth, sixth and seventh aspects of this invention. More specifically, those steps which require the use of a PNA oligomer capable of hybridising to a nucleic acid sequence to be sequenced or comprising a nucleotide to be characterised may, in alternative embodiments utilise
- DNA dimers, trimers and/or oligomers modified to include the requisite functional groups capable of reversible reactions and/or blank positions corresponding to nucleotides to be characterised.
- Figure 1 Structures of PNA and DNA showing PNA-DNA hybridisation.
- Figure 2 Dynamic-based SNP analysis. A complementary PNA sequence lacking a base opposite a SNP location, is hybridised to a nucleic acid sequence comprising a SNP, to form a nucleic acid/PNA duplex. By dynamic attachment, the base complementary to the SNP nucleotide integrates with the nucleic acid/PNA duplex. Each modified base may be labelled with a specific tag which may be a fluorophore (see Figure 1)
- Figure 3 Illustration of the dynamic-based SNP analysis shown in Figure 2.
- Figure 4 Alternative method for dynamic-based SNP analysis - DNA oligomers are hybridised with complementary PNA oligomers having free amino groups at the N-terminus which permit the dynamic attachment of the base complementary to the SNP nucleobase.
- Figure 5 Illustration of the dynamic-based SNP analysis shown in Figure 4.
- Figure 6 Illustration of dynamic-based DNA sequencing, (a) PNA oligomers, which may be attached to surfaces or in solution, containing a free amino group at the N-terminal position (b) DNA templates hybridise to their corresponding "PNA primers" (c) addition of the four N-protected aldehyde PNA monomers (d) dynamic attachment of the corresponding nucleobase (e) removal of both protecting groups and tags "fixing" the growing strand by may be a reduction process and (f) repeat.
- Figure 7 Illustration of dynamic-based DNA sequencing, (a) DNA oligomers, which may be attached to surfaces or in solution (b) "PNA primers" having a free amine group at their N-terminal position hybridise to their corresponding DNA template (c). addition of the four N-protected aldehyde PNA monomers (d) dynamic attachment of the corresponding nucleobase (e) removal of both protecting groups and tags and "fixing" the growing strand by may be a reduction process and (f) repeat.
- DNA oligomers which may be attached to surfaces or in solution
- PNA primers having a free amine group at their N-terminal position hybridise to their corresponding DNA template
- c addition of the four N-protected aldehyde PNA monomers
- e dynamic attachment of the corresponding nucleobase
- removal of both protecting groups and tags and "fixing" the growing strand by may be a reduction process and (f) repeat.
- Figure 8 Dynamic-based DNA sequencing of Figures 6 and 7. 2008/003185
- Figure 9 Synthesis of aldehyde bases (i) N-alkylation of nucleobase using a bromoalkyl acetal (ii) labelling of the nucleobases via Sonogashira reaction (iii) deprotetion of the acetal protecting group.
- Figure 11 Schematic representation of the pattern followed to print 8 DNA oligomers (Table 1) and a fluorescently-labelled marker.
- Figure 12 FITC channel image of slide containing 8 DNA oligomers (Table 1) plus a fluorescent DNA marker hybridized with PNA 13 containing a blank position. Just the fluorescent DNA marker is detected;
- Figure 13 Cy5 channel image of slide containing 8 DNA oligomers (Table 1) plus a fluorescent DNA marker hybridized with PNA 13 containing a blank position, only PNA-DNA antiparallel orientated duplexes were able to hybridise.
- Figure 14 (A) Shows the pattern of amino modified oligonucleotides (Table
- Figure 15 (A) Synthesis of aldehyde dimers for dynamic sequencing where the second nucleobase is defined by a dye. (B) A PNA dimer in which the first nucloebase is identified by a dye.
- Figure 16 (A) Nucleotide characterisation method using PNA dimers in which the second nucleobase of the dimer is labelled with a detectable tag. (B) Alternative method of nucleotide characterisation utilising PNA dimers in which the first nucleobase is labelled with a detectable tag.
- Figure 17 schematic diagram showing a method for mass-spectrometry based
- Figure 18 Shows the general structure of the modified nucleobases for use in mass-spectrometry based SNP analysis.
- Figure 19 Shows the general structures of modified nucleobases which may be useful in mass- spectrometry based nucleic acid sequencing methods.
- PNA-aldehyde monomers and aldehyde bases were prepared as shown in Figures 9 and 10.
- This method is applicable to many protecting groups groups and this includes the Dde group, the Fmoc group, thiol cleaved protecting group (Ardec (aryldithioethyloxycarbonyl) light cleavable protecting groups
- PNA-aldehydes 2 were prepared from PNA carboxylic acids, PNA esters or PNA alcohols following standard chemistries (Scheme 1). 1 was prepared according to a published methods (L. Bialy et al.. Tetrahedron 2005, 61, 8295-8305).
- the resin was then swollen in DMF for approximately 10 min and filtered, then shaken with 20 % v/v piperidine in DMF x2.
- the resin was then shaken with 80 % v/v TFA (trifluoroacetic acid) in DCM, filtered, washed with DCM (1 x) and again shaken with 80 % v/v TFA in DCM.
- the resin was filtered, washed with DCM (5 x) and dried in vacuo at 40 0 C.
- Nucleobases-aldehydes 6 were prepared from commercial available halo-nucleobases by alkylation with 2-(bromomethyl)-l,3-dioxolane (Scheme 5) under microwave irradiation followed by Sonogashira reaction with Tfa protected propargylamine, deprotection of the Tfa protecting group and coupling with a carboxylic acid derivatised dye.
- the labelling of the nucleobases were achieved via Sonogashira cross coupling reaction using aminomethylacetylene.
- Alkylated halobases were subjected to Sonoghasira cross-coupling following a procedure described in N.K. Garg et al. Chem. Commun., 2005, 4551-4553 and using Tfa protected aminomethylacetylene. Deprotecing the Tfa group with ammonia in MeOH, gave rise to a free primary amine which was used to couple dyes containing carboxylic groups. The amide coupling was achieved using HOBt/EDCI HCl coupling agents.
- Acetal deprotection was achieved by treatment with 75% TFA/12.5%H 2 O/12.5%CH 3 CN during 24 hours at room temperature. Alternatively, by heating at 60 0 C under microwave irradiation for 2 hours. Acetals were purified by RP-HPLC.
- RP-HPLC was performed on a HPIlOO system equipped with a Phenomenex Prodigy C18 reverse-phase column (250 mm x 10 mm x 5 mm) with a flow rate of 2.5 mL/min and eluting with (A) 0.1% TFA in H 2 O and (B) 0.042% TFA in acetonitrile, with an initial isocratic period of 4 min at 0% (B) followed by a gradient of 0-50%.(B) over 25 min and 50-100 % (B) over 10 min, holding at 100 % (B) for 5 min.
- ESI-/MS analyses were carried out on an Agilent Technologies LC/MSD Series 1100 quadrupole mass spectrometer (QMS) in a electrospray ionization (ESI) mode. Final aldehydes were identified by NMR and LC-MS (ESI).
- rhodamine-labelled thymine aldehyde (Scheme 9) and fluorescein-labelled cytosine aldehyde (Scheme 10) were produced as described above. Nucleobases modified in this way may be used in any of the methods described herein and in particular, in methods for SNP characterisations and/or analysis.
- halonucleobases are the following: B2008/003185
- PNA oligomer 12 H 2 N-TACTACATC-CTTCC-CONH 2 ) and 13
- PNA 12 MALDI-TOF; calculated mass: 3780, found mass: 3781 (M+l).
- PNA 13 MALDI-TOF; calculated mass: 4244, found mass: 4246 (M+l).
- 8-amino modified oligonucleotides (Table 1) were contact printed onto Code-link (Amersahm) slides for SNP analysis. These oligos were designed to have either a parallel orientation (PNA C-terminal facing DNA 3 '-end) when hybridised with PNA 13 or antiparallel (PNA N-terminal facing DNA 3 '-end).
- Amino modified oligonucleotides (Table 2) were inkjet printed onto aldehyde slides (Genetix) for SNP analysis. These oligos were designed to hybridise following an antiparallel (PNA N-terminal facing DNA 3 '-end) orientation when hybridised with PNA 13
- a A-antipar Oligo 1 TTT TTT GGA AG ⁇ GAT GTA GTA
- aldehyde bases 9 and 10 were incubated with the arrays. Dynamic incorporation was observed when arrays were incubated with 5 ⁇ M of each aldehyde together with ImM of NaBCNH 3 at room temperature for 16h (see Figure 14D) at both pH 6 (0.1M NH 4 OAc) and pH 8.5 (0.2M NaHCO 3 ; 0.3M NaCl). Images obtained using the fluorescein channel (FITC channel) detect DNA oligo 2 (G antiparallel) ( Figure 14D). This signal comes from the base-aldehyde bearing a fluorescein dye, in this case cytosine aldehyde 10, corresponding with the perfect match for G
- FITC channel fluorescein channel
- PNA oligomer 14 (NH 2 -CATTCTTCCTCT-CONH 2 ) was synthesised using Dde protected monomers (L. Bialy et al, Tetrahedron, 2005, 61, 8295-8305) on solid phase (JJ. Diaz-Mochon et al, Org. Lett. 2004, 6, 1127-1129).
- fluorescein-labelled PNA-aldehyde thymine and rhodamine- labelled PNA-aldehyde cytosine were prepared — see scheme 12.
- Aldehydes are prepared by attachment to an additional PNA building block. This necessitates the preparation of a mixture of 16 compounds accomplished by solid phase methods using and split and mix strategy.
- the 4 N-protected aldehydes (A, T, C and G) are immobilised onto either a hydrazine linker (see A. Lee et. al., J. Am. Chem. Soc, 1999, 121, 9907-9914) or threonyl scavenging resin (D.M. Rosenbaum and D.R. Liu, J. Am. Chem. Soc, 2003 125, 13924-13925).
- the protecting groups are then cleaved and the four resins mixed and split into four pools to couple standard protected PNA monomers. Following deprotection and labelling using activated disulfide (Scheme 13) containing a specific dye according to the last nucleobase, a global mixing of the resin and cleavage gives 16 PNA dimers (Figure 15A).
- Figure 16 details methods of characterising SNPs/nucleotides and/or of sequencing which utilise the PNA dimers/trimers provide by this invention.
- the dimers are created such that the first nucleobase is identified by means of a detactable tag and the second is random.
- the first nucloebase has a dye in the ring while the protecting group does not bear any dye.
- Figure 15B shows an example of this form of dimer.
- Gold surfaces with DNA oligos attached through gold-thiol self-assembly monolayers may be used for analysis of genetic material.
- SAM gold-thiol self-assembly monolayers
- dynamic incroporation using aldehyde- modified nucleobases may be used to characterise SNPs/nucleotides and/or to sequence nuclec acids.
- the incorporated base on the PNA strand may be detected by MALDI-TOF (for the use of gold surfaces and detection of PNA- DNA hybridization see Brandt et al/ Nucleic Acid Research, 2003, 31, el 19).
- the nucelobases may either be those modified nucleobases substantially described above i.e. having a dye attached to them, unmodified nucleobases or nucleobases modified to include a mass-tag, such as a bromide tag, to give a clear isotopic pattern (Figure 17).
Landscapes
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Saccharide Compounds (AREA)
- Peptides Or Proteins (AREA)
- Apparatus Associated With Microorganisms And Enzymes (AREA)
- Other Investigation Or Analysis Of Materials By Electrical Means (AREA)
- Investigating Or Analysing Materials By The Use Of Chemical Reactions (AREA)
- Investigating Or Analysing Biological Materials (AREA)
- Nitrogen Condensed Heterocyclic Rings (AREA)
Abstract
Description















































Claims










Priority Applications (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN200880112225.9A CN101827949B (en) | 2007-09-19 | 2008-09-19 | Nucleobase characterisation |
| CA2700082A CA2700082C (en) | 2007-09-19 | 2008-09-19 | Nucleobase characterisation |
| EP08806340.9A EP2195459B1 (en) | 2007-09-19 | 2008-09-19 | Nucleobase characterisation |
| AU2008300432A AU2008300432B2 (en) | 2007-09-19 | 2008-09-19 | Nucleobase characterisation |
| ES08806340.9T ES2532752T3 (en) | 2007-09-19 | 2008-09-19 | Nucleobase characterization |
| US12/679,221 US8716457B2 (en) | 2007-09-19 | 2008-09-19 | Nucleobase characterisation |
| JP2010525429A JP5759723B2 (en) | 2007-09-19 | 2008-09-19 | Nucleobase characterization |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GBGB0718255.3A GB0718255D0 (en) | 2007-09-19 | 2007-09-19 | Nucleobase characterisation |
| GB0718255.3 | 2007-09-19 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2009037473A2 true WO2009037473A2 (en) | 2009-03-26 |
| WO2009037473A3 WO2009037473A3 (en) | 2009-09-11 |
Family
ID=38670145
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/GB2008/003185 WO2009037473A2 (en) | 2007-09-19 | 2008-09-19 | Nucleobase characterisation |
Country Status (10)
| Country | Link |
|---|---|
| US (1) | US8716457B2 (en) |
| EP (1) | EP2195459B1 (en) |
| JP (2) | JP5759723B2 (en) |
| KR (1) | KR101599466B1 (en) |
| CN (1) | CN101827949B (en) |
| AU (1) | AU2008300432B2 (en) |
| CA (1) | CA2700082C (en) |
| ES (1) | ES2532752T3 (en) |
| GB (1) | GB0718255D0 (en) |
| WO (1) | WO2009037473A2 (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8501405B2 (en) | 2009-04-27 | 2013-08-06 | Pacific Biosciences Of California, Inc. | Real-time sequencing methods and systems |
| WO2014191850A1 (en) | 2013-05-29 | 2014-12-04 | Optoelettronica Italia S.R.L | A kit for detecting micro-rna extracted from a samlple of body fluid as well and a method for the detection thereof |
| WO2018011320A1 (en) | 2016-07-12 | 2018-01-18 | Destina Genomica S.L. | Pna probe |
| EP3575414A1 (en) | 2013-05-06 | 2019-12-04 | Pacific Biosciences Of California, Inc. | Real-time electronic sequencing |
| WO2023049108A2 (en) | 2021-09-22 | 2023-03-30 | Illumina, Inc. | Nanopore sequencing |
| WO2024191730A1 (en) | 2023-03-10 | 2024-09-19 | Illumina, Inc. | K-mer-based methods for assembling polynucleotide sequences |
Families Citing this family (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5093661B2 (en) * | 2007-12-06 | 2012-12-12 | 独立行政法人産業技術総合研究所 | Substrates for sensing biological substances and methods for recovering or detecting proteins, metal ions, etc. using the same |
| CN102286081B (en) * | 2011-06-30 | 2013-04-24 | 重庆市畜牧科学院 | Aspirin modified peptide nucleic acid oligomer and preparation method and application thereof |
| US10370415B2 (en) | 2013-04-11 | 2019-08-06 | Carnegie Mellon University | Divalent nucleobase compounds and uses therefor |
| US10221216B2 (en) | 2013-04-11 | 2019-03-05 | Carnegie Mellon University | Template-directed γPNA synthesis process and γPNA targeting compounds |
| JP2019531726A (en) | 2016-09-26 | 2019-11-07 | カーネギー メロン ユニバーシティ | Divalent nucleobase compounds and their use |
| US20200123592A1 (en) * | 2017-05-30 | 2020-04-23 | Quanterix Corporation | Single molecule detection and quantification of nucleic acids with single base specificity |
| JP7373205B2 (en) | 2017-12-21 | 2023-11-02 | カーネギー メロン ユニバーシティ | Template-directed nucleic acid targeting compounds |
| US10784093B1 (en) * | 2019-04-04 | 2020-09-22 | Thermo Finnigan Llc | Chunking algorithm for processing long scan data from a sequence of mass spectrometry ion images |
| CN110568039B (en) * | 2019-09-06 | 2021-05-04 | 中国科学院生物物理研究所 | Amino acid specific real-time detection method using novel electrochemical sensor |
| IT202200010064A1 (en) | 2022-05-16 | 2023-11-16 | Optoelettronica Italia S R L | DEVICE AND METHOD FOR THE DETECTION OF BIOMOLECULES |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2002072865A2 (en) * | 2001-03-09 | 2002-09-19 | Boston Probes, Inc. | Methods, kits and compositions of combination oligomers |
| WO2004022578A2 (en) * | 2002-09-08 | 2004-03-18 | Applera Corporation | Methods, compositions and libraries pertaining pna dimer and pna oligomer synthesis |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE19509038A1 (en) * | 1995-03-14 | 1996-09-19 | Boehringer Mannheim Gmbh | C-nucleoside derivatives and their use in the detection of nucleic acids |
| US20050032069A1 (en) * | 2002-11-05 | 2005-02-10 | Muthiah Manoharan | Oligomeric compounds having modified bases for binding to adenine and guanine and their use in gene modulation |
| WO2003070984A1 (en) * | 2002-02-15 | 2003-08-28 | Somalogic, Inc. | Methods and reagents for detecting target binding by nucleic acid ligands |
| US6054568A (en) * | 1998-01-16 | 2000-04-25 | The Perkin-Elmer Corporation | Nucleobase oligomers |
| CA2426952C (en) * | 2000-11-02 | 2012-06-26 | Sloan-Kettering Institute For Cancer Research | Small molecule compositions for binding to hsp90 |
| US20030207804A1 (en) * | 2001-05-25 | 2003-11-06 | Muthiah Manoharan | Modified peptide nucleic acids |
| US20070048752A1 (en) * | 2004-07-12 | 2007-03-01 | Applera Corporation | Mass tags for quantitative analyses |
| PT1877415E (en) * | 2005-05-02 | 2010-12-09 | Baseclick Gmbh | New labelling strategies for the sensitive detection of analytes |
| WO2006135654A2 (en) * | 2005-06-07 | 2006-12-21 | President And Fellows Of Harvard College | Polymer evolution via templated synthesis related applications |
-
2007
- 2007-09-19 GB GBGB0718255.3A patent/GB0718255D0/en not_active Ceased
-
2008
- 2008-09-19 KR KR1020107008425A patent/KR101599466B1/en active IP Right Grant
- 2008-09-19 CA CA2700082A patent/CA2700082C/en active Active
- 2008-09-19 EP EP08806340.9A patent/EP2195459B1/en active Active
- 2008-09-19 JP JP2010525429A patent/JP5759723B2/en active Active
- 2008-09-19 US US12/679,221 patent/US8716457B2/en active Active
- 2008-09-19 AU AU2008300432A patent/AU2008300432B2/en active Active
- 2008-09-19 ES ES08806340.9T patent/ES2532752T3/en active Active
- 2008-09-19 WO PCT/GB2008/003185 patent/WO2009037473A2/en active Application Filing
- 2008-09-19 CN CN200880112225.9A patent/CN101827949B/en active Active
-
2015
- 2015-03-10 JP JP2015047264A patent/JP2015143698A/en active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2002072865A2 (en) * | 2001-03-09 | 2002-09-19 | Boston Probes, Inc. | Methods, kits and compositions of combination oligomers |
| WO2004022578A2 (en) * | 2002-09-08 | 2004-03-18 | Applera Corporation | Methods, compositions and libraries pertaining pna dimer and pna oligomer synthesis |
Non-Patent Citations (5)
| Title |
|---|
| A. P. MARTINEZ, ET AL.: "DL-Willardiine mustard" JOURNAL OF MEDICINAL CHEMISTRY, vol. 11, no. 1, 1968, pages 60-62, XP002515120 * |
| BECK AND P NIELSEN F ED - KHUDYAKOV YURY E ET AL: "Peptide Nucleic Acid (PNA): A DNA Mimetic with a pseudopeptide backbone" ARTIFICIAL DNA : METHODS AND APPLICATIONS, CRC PRESS, 1 January 2002 (2002-01-01), pages 91-114, XP009119600 ISBN: 978-0-8493-1426-1 * |
| C. AUSÍN, ET AL.: "Synthesis of Amino- and Guanidino-G-clamp PNA Monomers" ORGANIC LETTERS, vol. 4, no. 3, 2002, pages 4073-4075, XP002515121 * |
| See also references of EP2195459A2 * |
| SIPOS F ET AL: "Synthesis of New, Base-Modified PNA Monomers" NUCLEOSIDES, NUCLEOTIDES AND NUCLEIC ACIDS, TAYLOR & FRANCIS, PHILADELPHIA, PA, vol. 26, no. 6/7, 1 June 2007 (2007-06-01), pages 681-685, XP009119646 ISSN: 1525-7770 * |
Cited By (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8501405B2 (en) | 2009-04-27 | 2013-08-06 | Pacific Biosciences Of California, Inc. | Real-time sequencing methods and systems |
| US8940507B2 (en) | 2009-04-27 | 2015-01-27 | Pacific Biosciences Of California, Inc. | Real-time sequencing methods and systems |
| US9200320B2 (en) | 2009-04-27 | 2015-12-01 | Pacific Biosciences Of California, Inc. | Real-time sequencing methods and systems |
| EP3575414A1 (en) | 2013-05-06 | 2019-12-04 | Pacific Biosciences Of California, Inc. | Real-time electronic sequencing |
| WO2014191850A1 (en) | 2013-05-29 | 2014-12-04 | Optoelettronica Italia S.R.L | A kit for detecting micro-rna extracted from a samlple of body fluid as well and a method for the detection thereof |
| CN109790542A (en) * | 2016-07-12 | 2019-05-21 | 德斯蒂娜基因组有限公司 | PNA probe |
| KR20190046787A (en) * | 2016-07-12 | 2019-05-07 | 데스티나 게노미카 에스.엘. | PNA probes |
| WO2018011320A1 (en) | 2016-07-12 | 2018-01-18 | Destina Genomica S.L. | Pna probe |
| KR102356360B1 (en) | 2016-07-12 | 2022-01-26 | 데스티나 게노미카 에스.엘. | PNA probe |
| US11242526B2 (en) | 2016-07-12 | 2022-02-08 | Destina Genomica S.L. | PNA probe |
| CN109790542B (en) * | 2016-07-12 | 2023-01-10 | 德斯蒂娜基因组有限公司 | PNA probe |
| WO2023049108A2 (en) | 2021-09-22 | 2023-03-30 | Illumina, Inc. | Nanopore sequencing |
| WO2024191730A1 (en) | 2023-03-10 | 2024-09-19 | Illumina, Inc. | K-mer-based methods for assembling polynucleotide sequences |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2009037473A3 (en) | 2009-09-11 |
| EP2195459B1 (en) | 2014-12-17 |
| GB0718255D0 (en) | 2007-10-31 |
| ES2532752T3 (en) | 2015-03-31 |
| US8716457B2 (en) | 2014-05-06 |
| CN101827949A (en) | 2010-09-08 |
| KR101599466B1 (en) | 2016-03-03 |
| AU2008300432A1 (en) | 2009-03-26 |
| JP2015143698A (en) | 2015-08-06 |
| CN101827949B (en) | 2014-05-14 |
| AU2008300432B2 (en) | 2015-03-26 |
| CA2700082A1 (en) | 2009-03-26 |
| CA2700082C (en) | 2016-06-14 |
| EP2195459A2 (en) | 2010-06-16 |
| JP2010538673A (en) | 2010-12-16 |
| JP5759723B2 (en) | 2015-08-05 |
| KR20100075506A (en) | 2010-07-02 |
| US20110028337A1 (en) | 2011-02-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP2195459B1 (en) | Nucleobase characterisation | |
| US11939631B2 (en) | Four-color DNA sequencing by synthesis using cleavable fluorescent nucleotide reversible terminators | |
| EP3091026B1 (en) | Disulfide-linked reversible terminators | |
| US8383792B2 (en) | Compound having structure derived from mononucleoside or mononucleotide, nucleic acid, labeling substance, and method and kit for detection of nucleic acid | |
| WO2019105421A1 (en) | Nucleoside analogue, preparation method and application | |
| AU2019203624B2 (en) | Polymethine Compounds and Their Use as Fluorescent Labels | |
| JP2001512131A (en) | Base analog | |
| CN118084996A (en) | Reversible termination nucleotide and application thereof in DNA synthesis sequencing and single molecule sequencing |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 200880112225.9 Country of ref document: CN |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 08806340 Country of ref document: EP Kind code of ref document: A2 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2010525429 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2008300432 Country of ref document: AU Ref document number: 584080 Country of ref document: NZ Ref document number: 2700082 Country of ref document: CA Ref document number: 2008806340 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 1975/CHENP/2010 Country of ref document: IN |
|
| ENP | Entry into the national phase |
Ref document number: 2008300432 Country of ref document: AU Date of ref document: 20080919 Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 20107008425 Country of ref document: KR Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 12679221 Country of ref document: US |