WO2008087185A1 - Process for selecting individuals and designing a breeding program - Google Patents
Process for selecting individuals and designing a breeding program Download PDFInfo
- Publication number
- WO2008087185A1 WO2008087185A1 PCT/EP2008/050503 EP2008050503W WO2008087185A1 WO 2008087185 A1 WO2008087185 A1 WO 2008087185A1 EP 2008050503 W EP2008050503 W EP 2008050503W WO 2008087185 A1 WO2008087185 A1 WO 2008087185A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- breeding
- genetic
- calculating
- genotype
- generation
- Prior art date
Links
- 0 CC1N(C)C(C)**1 Chemical compound CC1N(C)C(C)**1 0.000 description 1
Classifications
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01H—NEW PLANTS OR NON-TRANSGENIC PROCESSES FOR OBTAINING THEM; PLANT REPRODUCTION BY TISSUE CULTURE TECHNIQUES
- A01H1/00—Processes for modifying genotypes ; Plants characterised by associated natural traits
- A01H1/04—Processes of selection involving genotypic or phenotypic markers; Methods of using phenotypic markers for selection
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/20—Allele or variant detection, e.g. single nucleotide polymorphism [SNP] detection
Definitions
- the presently disclosed subject matter relates to methods for improving the efficacy of a plant breeding program.
- the plant breeding program is aimed at altering phenotypic traits for which associations with genetic markers can be established. Genetic values of individuals can be computed based on the individuals' marker genotypes and the associations established between genetic markers and phenotypic traits. Individuals and mating schemes can then be selected based both on the individuals' genome-wide genetic value and on the distributions of these genetic values for the potential progenies derived through the mating schemes under evaluation.
- the presently disclosed subject matter also relates to systems and computer program products for performing the disclosed methods as well as plants selected, provided, or produced by, and transgenic plants created by, the disclosed methods.
- Selective breeding has been employed for centuries to improve, or attempt to improve, phenotypic traits of agronomic and economic interest in plants, such as yield, percentage of grain oil, etc.
- selective breeding involves the selection of individuals to serve as parents of the next generation on the basis of one or more phenotypic traits of interest.
- phenotypic selection is frequently complicated by non-genetic factors that can impact the phenotype(s) of interest.
- Non-genetic factors that can have such effects include, but are not limited to environmental influences such as soil type and quality, rainfall, temperature range, and others.
- phenotypic traits of interest are controlled by more than one genetic locus, each of which typically influences the given trait to a greater or lesser degree.
- U.S. Patent No. 6,399,855 to Beavis suggests that the vast majority of economically important phenotypic traits in domesticated plants are so-called quantitative traits.
- quantitative traits have been used to describe a phenotype that exhibits continuous variability in expression and is the net result of multiple genetic loci presumably interacting with each other and/or with the environment.
- complex trait has atso been broadly used to describe any trait that does not exhibit classic Mendelian inheritance, which generally is attributable to a single genetic locus (Lander & Schork, 1994).
- QTL quantitative trait loci
- QTLs see e.g., U.S. Patent Nos. 5,385,835; 5,492,547; and 5,981 ,832.
- One such approach involves crossing two inbred iines to produce F 1 single cross hybrid progeny, selfing the F 1 hybrid progeny to produce segregating F 2 progeny, genotyping multiple marker loci, and evaluating one to several quantitative phenotypic traits among the segregating progeny.
- the QTLs are then identified on the basis of significant statistical associations between the genotypic values and the phenotypic variability among the segregating progeny.
- the parental lines of the F 1 generation have known linkage phases, all of the segregating loci in the progeny are informative, and linkage disequilibrium between the marker loci and the genetic loci affecting the phenotypic traits is maximized.
- considerable resources must be devoted to determining the phenotypic performance of large numbers of hybrid and/or inbred progeny.
- this approach can only detect the trait loci (e.g., the QTLs) for which the two parents are polymorphic.
- This set of trait loci might only represent a fraction of the loci segregating in breeding populations of interest (e.g., breeding populations of maize, sorghum, soybean, canola, etc.).
- these progeny show variation for only one or a small number of the phenotypic traits that are of interest in applied breeding programs. This means that separate populations might need to be developed, scored for marker loci, and grown in replicated field experiments and scored for the phenotypic traits of interest. Additionally, methods used to detect QTLs can produce biased estimates of the QTLs that are identified (see e.g. , Beavis, 1994). Additional imprecision can be introduced in extrapolating the identification of QTLs to the progeny of genetically different parents within a breeding population. Furthermore, many if not all traits are affected by environmental factors, which can also introduce imprecision.
- the presently disclosed subject matter provides methods for calculating a distribution of a probability or frequency of occurrence of one or more potential genotypes.
- the presently disclosed methods comprise (a) providing a first breeding partner and a second breeding partner, wherein (i) the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers, each of which is linked to a genetic locus; and (ii) a genetic distance between each genetic marker and the genetic locus to which it is linked is known or can be assigned; (b) calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner to generate a subsequent generation, each member of the subsequent generation comprising a genotype; and (c) calculating a distribution of a probability or a frequency of occurrence for one or more of the genotypes of one or more members of the subsequent generation.
- the presently disclosed subject matter also provides methods for calculating a genetic value distribution.
- the presently disclosed methods comprise (a) providing a first breeding partner and a second breeding partner, wherein (i) the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers linked to one or more genetic loci; (ii) a genetic distance between each genetic marker and the genetic locus to which it is linked is known or can be assigned; and (iii) each genotype is associated with a genetic value; (b) calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner to generate a subsequent generation, each member of the subsequent generation comprising a genotype; and (c) calculating a genetic value distribution for one or more of the genotypes.
- the presently disclosed subject matter also provides methods for choosing a breeding pair for producing a progeny having a desired genotype.
- the presently disclosed methods comprise (a) providing a first breeding partner and a second breeding partner, wherein (i) the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers, each of which is linked to a genetic locus; and (ii) a genetic distance between each genetic marker and the genetic locus to which it is linked is known or can be assigned; (b) calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner to generate a subsequent generation, each member of the subsequent generation comprising a genotype; (c) calculating a distribution of a probability or a frequency of occurrence for one or more of the genotypes of one or more members of the subsequent generation; (d) repeating steps (a) through (c) with a different first, different second, or both different first and different second potential breeding partners;
- the presently disclosed methods for choosing a breeding pair for producing a progeny having a desired genotype comprise (a) providing a first breeding partner and a second breeding partner, wherein (i) the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers linked to one or more genetic loci; (ii) a genetic distance between each genetic marker and the genetic locus to which it is linked is known or can be assigned; and (iii) each genotype is associated with a genetic value; (b) calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner to generate a subsequent generation, each member of the subsequent generation comprising a genotype; (c) calcuiating a distribution of genetic values associated with one or more of the genotypes of one or more members of the subsequent generation; (d) repeating steps (a) through (c) with a different first, different second, or both different first and different second potential breeding partners; (e
- the presently disclosed subject matter also provides methods for generating a progeny individual having a desired genotype.
- the presently disclosed methods comprise (a) providing a first breeding partner and a second breeding partner, wherein (i) the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers, each of which is linked to a genetic locus; and (ii) a genetic distance between each genetic marker and the genetic locus to which it is linked is known or can be assigned; (b) calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner to generate a subsequent generation, each member of the subsequent generation comprising a genotype; (c) calculating a distribution of a probability or a frequency of occurrence for one or more of the genotypes of one or more members of the subsequent generation; (d) repeating steps (a) through (c) with a different first, different second, or both different first and different second potential breeding partners; (e)
- the presently disclosed methods for generating a progeny individual having a desired genotype comprises (a) providing a first breeding partner and a second breeding partner, wherein (i) the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers linked to one or more genetic loci; (ii) a genetic distance between each genetic marker and the genetic locus to which it is linked is known or can be assigned; and (iii) each genotype is associated with a genetic value; (b) calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner to generate a subsequent generation, each member of the subsequent generation comprising a genotype; (c) calculating a distribution of genetic values associated with one or more of the genotypes of one or more members of the subsequent generation; (d) repeating steps (a) through (c) with a different first, different second, or both different first and different second potential breeding partners; (e) comparing the genetic value distribution
- the presently disclosed methods further com prise generating one or more further generation progeny, wherein each further generation progeny is generated by one or more rounds of calculating, simulating, or combinations of calculating and simulating a breeding of at least one member of the subsequent generation or a later generation with an individual selected from the group consisting of itself, a member of the immediately prior generation, another individual from the same generation, another individual from a previous generation, the first breeding partner, the second breeding partner, and doubled haploid derivatives thereof.
- the further generation progeny are generated by one or more successive generations of crossings, selfings, doubled haploid derivative generation, or combinations thereof of one or more individuals from a preceding generation.
- the further generation progeny are generated by three successive generations of crossings, selfings, doubled hapioid derivative generation, or combinations thereof of one or more individuals of a preceding generation. In some embodiments, the further generation progeny are generated by four successive generations of crossings, selftngs, doubled hapioid derivative generation, or combinations thereof of one or more individuals from a preceding generation. In some embodiments, the further generation is generated by at least two, three, or four successive generations of selfing of one or more members of a preceding generation.
- the one or more genetic markers are selected from the group consisting of a single nucleotide polymorphism (SNP), an indel (i.e., insertion/deletion), a simple sequence repeat (SSR), a restriction fragment length polymorphism (RFLP), a random amplified polymorphic DNA (RAPD), a cleaved amplified polymorphic sequence (CAPS) marker, a Diversity Arrays Technology (DArT) marker, an amplified fragment length polymorphism (AFLP), and combinations thereof.
- the one or more genetic markers comprise between one and ten markers. In some embodiments, the one or more genetic markers comprise more than ten genetic markers.
- the calculating, simulating, or combinations of calculating and simulating a breeding includes calculating, simulating, or combinations of calculating and simulating an expected rate of recombination between at least one of the one or more genetic markers and a genetic locus associated with expression of a phenotypic trait.
- the phenotypic trait is selected from the group consisting of a qualitative trait and a quantitative trait.
- the one or more genetic markers are linked to one or more quantitative trait loci associated with expression of the phenotypic trait.
- the genetic locus associated with expression of the phenotypic trait encodes a gene product that is associated with expression of the phenotypic trait.
- the rate of recombination between the at least one of the one or more genetic markers and the genetic locus associated with expression of the phenotypic trait is zero.
- the breeding partners are the same individual.
- each calculated or simulated breeding comprises selfing an individual from the immediately prior generation.
- the breeding pair comprises a pool of male genotypes, a pool of female genotypes, or both a pool of male and a pool of female genotypes.
- the presently disclosed subject matter also provides individuals generated by the presently disclosed methods.
- an individual so generated is a plant.
- the presently disclosed subject matter also provides cells, seed, and/or progeny from the plant generated by the presently disclosed methods.
- Figure 1 illustrates an exemplary general purpose computing platform 100 upon which the methods and systems of the presently disclosed subject matter can be implemented.
- Figure 2 is a flowchart of a process 200 for implementing a method for calculating a distribution of a probability or a frequency of occurrence of one or more potential genotypes as disclosed herein.
- Figure 3 is a flowchart of a process 300 for implementing a method for calculating a genetic value distribution as disclosed herein.
- Figure 4 is a flowchart of a process 400 for implementing a method for choosing a breeding pair for producing a progeny having a desired genotype as disclosed herein.
- Figure 5 is a flowchart of a process 500 for implementing a method for generating a progeny individual having a desired genotype as disclosed herein.
- Figure 6 is a plot depicting agronomic performance of marker-based-selection- derived material, compared to reference material.
- Figure 6 shows grain yield (in quintals per hectare) and grain moisture at harvest of hybrids made from two marker-based- selection-derived lines, MDL53 and MDL54, crossed onto four testers, T41 , T42, T51 , and T58, and grown at five locations in Europe in 2006. The results shown are the averages over all five locations.
- the figure also shows performance of reference commercial hybrids (identified as "check") as well as performance of one parental line, BFP57, crossed onto T41 , T42, and T51.
- Check hybrids are represented by white squares.
- Marker-based- selection-derived hybrids are represented by black squares. The hybrids that show high grain yield and low grain moisture at harvest are positioned in the upper left corner of Figure 6.
- Figure 7 is a plot depicting agronomic performance of marker-based-selection- derived material, compared to reference material.
- Figure 7 shows grain yield (in quintals per hectare) and grain moisture at harvest of hybrids made from two marker-based- selection-derived lines, MDL53 and MDL54, crossed onto two testers, T11 and T15, and grown at four locations in Europe in 2006. The results shown are the averages over all four locations.
- the figure also shows performance of reference commercial hybrids (identified as "check") as well as performance of experimental hybrids derived through conventional breeding. Check hybrids are represented by white squares. Marker-based-seiection- derived hybrids are represented by black squares. Conventional-breeding-derived hybrids are represented by crosses. The hybrids that show high grain yield and low grain moisture at harvest are positioned in the upper left comer of Figure 7.
- the presently disclosed subject matter relates to virtually (theoretically) deriving the progeny of interest (through modeling of selfing, crossing, or combinations thereof) and computing their probabilities of occurrence and their genome-wide genetic values.
- the presently disclosed subject matter can consider, in some embodiments, the entire genome simultaneously, thereby taking into account linkage disequilibrium and leading to realistic predictions. As such, the presently disclosed subject matter can provide for the development of more efficient marker- and/or QTL-based breeding than existing technologies.
- the presently disclosed subject matter relates in some embodiments to selecting individuals (e.g., plants) or groups (e.g., pairs) of individuals based on the genetic values and genetic characteristics of their progeny, rather than on their own genetic values and genetic characteristics.
- progeny are not actually derived and assessed but only "theoretically" derived through analytical computations (exact or approximate) or simulations. Based on these "theoretical" genetic values, progeny may or may not be actually derived (as desired) through specific breeding schemes (including, but not limited to selfing, crossing, and combinations thereof). Genetic values and characteristics of the progeny depend on the genetic characteristics of their parents after the action of meiosis and fertilization.
- the presently disclosed subject matter relates to calculating and/or simulating how genetic characteristics of individuals pass meiosis and fertilization to create new individuals (progeny), and assessing genome-wide genetic values of these progeny.
- calculations and/or simulations can take into account genetic markers and all linkages between them, as well as the characteristics of the associations between genetic markers and phenotypic traits.
- allele and “allelic variant” refer to any of one or more alternative forms of a gene or genetic marker.
- the two alleles of a given gene (or marker) typically occupy corresponding loci on a pair of homologous chromosomes.
- association refers to a definable relationship between two or more entities.
- the relationship can be of any type and scope based on the nature of the entities and the context in which the terms appear.
- a genotype can be associated with a probability of occurrence or a frequency of occurrence.
- This usage refers to the fact that a probability or a frequency of occurrence of a particular genotype can be calculated and/or otherwise determined based on knowledge, testing, calculation, simulation, or any other manipulation of other genotypes that are related to the particular genotype as parent, sib, or progeny.
- the fact that the probability of occurrence or the frequency of occurrence of the particular genotype can be determined from the other genotypes means that there is an association (i.e., a relationship) between the various genotypes.
- each genotype can be associated with a genetic value.
- a genotype is associated with a genetic value when one or more alleles that comprise the genotype are assigned a genetic value and the genetic values so assigned are summed or otherwise calculated for each individual allele that makes up the genotype to arrive at a genetic value for the genotype as a whole.
- the genetic values that are assigned to each allele can be assigned based on whatever criteria the assignor deems important, once genetic values are assigned to one or more alleles, a given genotype that is made up of combinations of these alleles will have a specific genetic value based on the individual genetic values so assigned.
- a genotype can be considered to be associated with a genetic value based on the calculation employed for the individual alleles.
- a genetic locus can also be associated with expression of a phenotypic trait.
- the genetic locus is understood to influence the expression of the phenotypic trait.
- a genetic locus that is associated with expression of a phenotypic trait is a locus (e.g. , a QTL) for which the various alleles that can be present at that locus affect some aspect of the phenotype.
- associations can exist between genetic markers and phenotypic traits, particularly when the presence of a genetic marker is indicative and/or predictive of the presence of an allele that itself is associated with expression of the phenotypic trait.
- breeding refers to any process that generates a progeny individual. Breedings can be sexual or asexual, or any combination thereof. Exemplary non-limiting types of breedings include crossings, settings, doubled haploid derivative generation, and combinations thereof. As disclosed herein, these breedings need not be performed to generate physical progeny, but can be modeled using, for example, the predictive calculations and/or simulations disclosed herein.
- diploid individual refers to an individual that has two sets of chromosomes, typically one from each of its two parents. However, it is understood that in some embodiments a diploid individual can receive its "maternal” and “paternal” sets of chromosomes from the same single organism, such as when a plant is selfed to produce a subsequent generation of plants.
- the phrase "established breeding population" refers to a collection of potential breeding partners produced by and/or used as parents in a breeding program; e.g., a commercial breeding program.
- the members of the established breeding population are typically welt-characterized genetically and/or phenotypically. For example, several phenotypic traits of interest might have been evaluated, e.g., under different environmental conditions, at multiple locations, and/or at different times.
- one or more genetic loci associated with expression of the phenotypic traits might have been identified and one or more of the members of the breeding population might have been genotyped with respect to the one or more genetic loci as well as with respect to one or more genetic markers that are associated with the one or more genetic loci.
- the term "F 0" refers to an initial individual or plurality of individuals (e.g., a first and a second breeding partner) that are used to generate the subsequent generations as set forth herein. It is noted that while an F 0 individual is in some embodiments an inbred individual and thus additional genetically identical individuals exist, it is not necessary that this be the case. In some embodiments, therefore, the term “F 0 " is a relative term that is employed herein to refer to an individual or plurality of individuals that are bred or that otherwise donate genetic information to subsequent generations (e.g. , Fi , F 2 , F 3 , F n-I , F n , etc.).
- Fo can in some embodiments refer to an individual of a generation that produces an Fi generation, even if there are one or more generations that actually precede the generation of which the designated Fo individual is a member.
- F 1 refers to the first filial generation, the progeny of a breeding between, for example, two Fo individuals (e.g., a first and a second breeding partner) or between two Fo inbred lines as defined herein. It is also possible to generate an F- I individual or generation by selfing an Fo individual or by other techniques that are known in the art of husbandry.
- the term "advanced generation” refers to the second and subsequent filial generations (e.g., the F 2 , F 3 , and later generations) produced from the Fi progeny by seifing or sexual crosses (e.g., with other Fi progeny, with an inbred line, etc.).
- the term "founder” refers to an inbred or single cross Fi hybrid that contains one or more alleles (e.g., genetic marker alleles) that can be tracked through the founder's descendents in a pedigree of a population; e.g., a breeding population.
- the founders are typically (but not necessarily) the earliest developed lines.
- Gene is used broadly to refer to any nucleic acid associated with a biological function. Genes typically include coding sequences and/or regulatory sequences required for expression of such coding sequences.
- the phrase "genetic marker” refers to a feature of an individual's genome (e.g., a nucleotide or a polynucleotide sequence that is present in an individual's genome) that is associated with one or more loci of interest.
- a genetic marker is polymorphic in a population of interest, or the locus occupied by the polymorphism, depending on context.
- Genetic markers include, for example, single nucleotide polymorphisms (SNPs), indels (i.e., insertions/deletions), simple sequence repeats (SSRs), restriction fragment length polymorphisms (RFLPs), random amplified polymorphic DNAs (RAPDs) 1 cleaved amplified polymorphic sequence (CAPS) markers, Diversity Arrays Technology (DArT) markers, and amplified fragment length polymorphisms (AFLPs), among many other examples. Genetic markers can, for example, be used to locate genetic loci containing alleles that contribute to variability in expression of phenotypic traits on a chromosome.
- genetic marker can also refer to a polynucleotide sequence complementary to a genomic sequence, such as a sequence of a nucleic acid used as probes.
- a genetic marker can be physically located in a position on a chromosome that is within or outside of to the genetic locus with which it is associated (i.e., is intragenic or extragenic, respectively).
- the presently disclosed subject matter can also employ genetic markers that are physically within the boundaries of a genetic locus (e.g., inside a genomic sequence that corresponds to a gene such as, but not limited to a polymorphism within an intron or an exon of a gene).
- the one or more genetic markers comprise between one and ten markers, and in some embodiments the one or more genetic markers comprise more than ten genetic markers.
- the term "genotype” refers to the genetic constitution of a cell or organism.
- An individual's "genotype for a set of genetic markers” includes the specific alleles, for one or more genetic marker loci, present in the individual.
- a genotype can relate to a single locus or to multiple loci, whether the loci are related or unrelated and/or are linked or unlinked.
- an individual's genotype relates to one or more genes that are related in that the one or more of the genes are involved in the expression of a phenotype of interest ⁇ e.g., a quantitative trait as defined herein).
- a genotype comprises a summary of one or more alleles present within an individual at one or more genetic loci of a quantitative trait.
- a genotype is expressed in terms of a haplotype (defined herein below).
- the term “germplasm” refers to the totality of the genotypes of a population or other group of individuals (e.g., a species).
- the term “germplasm” can also refer to plant material; e.g., a group of plants that act as a repository for various alleles.
- adapted germplasm refers to plant materials of proven genetic superiority; e.g., for a given environment or geographical area
- non-adapted germplasm refers to plant materials of unknown or unproven genetic value; e.g., fora given environment or geographical area; as such, the phrase “non-adapted germplasm” refers in some embodiments to plant materials that are not part of an established breeding population and that do not have a known relationship to a member of the established breeding population.
- haplotype refers to the set of alleles an individual inherited from one parent. A diploid individual thus has two haplotypes.
- haplotype can be used in a more limited sense to refer to physically linked and/or unlinked genetic markers (e.g., sequence polymorphisms) associated with a phenotypic trait.
- haplotype block (sometimes also referred to in the literature simply as a haplotype) refers to a group of two or more genetic markers that are physically linked on a single chromosome (or a portion thereof). Typically, each block has a few common haplotypes, and a subset of the genetic markers (i.e., a "haplotype tag”) can be chosen that uniquely identifies each of these haplotypes.
- high throughput screening refers to assays in which the format allows large numbers of samples to be screened.
- high throughput screening refers to assays in which the format allows large numbers of genetic markers (e.g., nucleic acid sequences), large numbers of individual or pools of genotypes, or both, to be screened.
- high throughput screening refers in some embodiments to the screening of large numbers of genotypes as individuals or pools for nucleic acid sequences of the genome of an individual to identify the presence of genetic marker alleles.
- pool of genotypes refers to male gametes, which are pooled from several male individuals.
- This pool may be used to fertilize a number of female gametes which may be derived from different female individuals. If the progeny of these fertilizations are harvested ail together without tracing female parent origin, a collection of progeny results for which the specific male parent or female parent is unknown. Yet, it is known that the male parent is one of a number of male parents (those used to pool male gametes), and that their female parent is one of a number of female parents (those fertilized with the pooled male gametes).
- hybrid As used herein, the terms “hybrid”, “hybrid plant,” and “hybrid progeny” refers to an individual produced from genetically different parents (e.g., a genetically heterozygous or mostly heterozygous individual).
- the alleles are termed "identical by descent” if the alleles were inherited from one common ancestor (i.e., the alleles are copies of the same parental allele).
- the alternative is that the alleles are "identical by state” (i.e., the alleles appear the same but are derived from two different copies of the allele).
- Identity by descent information is useful for linkage studies; both identity by descent and identity by state information can be used in association studies such as those described herein, although identity by descent information can be particularly useful.
- inbred line refers to a genetically homozygous or nearly homozygous population.
- An inbred line for example, can be derived through several cycles of brother/sister breedings or of selfing. in some embodiments, inbred lines breed true for one or more phenotypic traits of interest.
- An "inbred”, “inbred individual”, or “inbred progeny” is an individual sampled from an inbred line.
- linkage refers to the tendency of alleles at different loci on the same chromosome to segregate together more often than would be expected by chance if their transmission were independent, in some embodiments as a consequence of their physical proximity.
- linkage disequilibrium refers to a phenomenon wherein particular alleles at two or more loci tend to remain together in linkage groups when segregating from parents to offspring with a greater frequency than expected from their individual frequencies in a given population.
- a genetic marker allele and a QTL allele can show linkage disequilibrium when they occur together with frequencies greater than those predicted from the individual allele frequencies.
- Linkage disequilibrium can occur for several reasons including, but not limited to the alleles being in close proximity on a chromosome
- locus refers to a position on a chromosome (e.g., of a gene, a genetic marker, or the like).
- nucleic acid refers to any physical string of monomer units that can be corresponded to a string of nucleotides, including a polymer of nucleotides (e.g., a typical DNA or RNA polymer), modified oligonucleotides (e.g., oligonucleotides comprising bases that are not typical to biological RNA or DNA, such as 2'-O-methy!ated oligonucleotides), and the like.
- a nucleic acid can be single-stranded, double-stranded, multi-stranded, or combinations thereof.
- a particular nucleic acid sequence of the presently disclosed subject matter optionally comprises or encodes complementary sequences, in addition to any sequence explicitly indicated.
- phenotypic trait refers to the appearance or other detectable characteristic of an individual, resulting from the interaction of its genome with the environment.
- plality refers to more than one.
- a “plurality of individuals” refers to at least two individuals.
- the term plurality refers to more than half of the whole.
- a “plurality of a population” refers to more than half the members of that population.
- progeny refers to the descendant(s) of a particular cross. Typically, progeny result from breeding of two individuals, although some species (particularly some plants and hermaphroditic animals) can be selfed (i.e., the same plant acts as the donor of both male and female gametes).
- the descendant(s) can be, for example, of the F-i, the F 2 , or any subsequent generation.
- the phrase "qualitative trait” refers to a phenotypic trait that is controlled by one or a few genes that exhibit major phenotypic effects. Because of this, qualitative traits are typically simply inherited. Examples in plants include, but are not limited to, flower color, cob color, and disease resistance such as Northern corn leaf blight resistance.
- the term "quantile” refers to a point along a probability or frequency curve below which a desired percentage of the events fall.
- the "50% quantile” corresponds to that point on a probability or frequency curve below which 50% of the events fall.
- the "95% quantile” corresponds to that point on a probability or frequency curve below which 95% of the events fall.
- a 50% quantile or a 95% quantile relates to that point on a plot of genetic values versus probability or frequency of occurrence as calculated, simulated, or combinations of calculated and simulated using the presently disclosed methods that is greater than 50% or 95%, respectively, of the possible genetic values that can be generated by the calculating, simulating, or combinations of calculating and simulating.
- a 50% quantile or a 95% quantile relates to the genetic value that corresponds to that point on a plot of genetic values versus probability or frequency of occurrence as calculated, simulated, or combinations of calculated and simulated using the presently disclosed methods that is greater than 50% or 95%, respectively, of the possible genetic values that can be generated by the calculating, simulating, or combinations of calculating and simulating.
- the term "combination of quantiles" refers to the average (Q95% +
- the phrase "quantitative trait” refers to a phenotypic trait that can be described numerically (i.e., quantitated or quantified).
- a quantitative trait typically exhibits continuous variation between individuals of a population; that is, differences in the numerical value of the phenotypic trait are slight and grade into each other. Frequently, the frequency distribution in a population of a quantitative phenotypic trait exhibits a bell- shaped curve (i.e., exhibits a normal distribution between two extremes).
- a quantitative trait is typically the result of a genetic locus interacting with the environment or of multiple genetic loci (QTL) interacting with each other and/or with the environment. Examples of quantitative traits include plant height and yield.
- QTL quantitative trait locus
- marker trait association refers to an association between a genetic marker and a chromosomal region and/or gene that affects the phenotype of a trait of interest. Typically, this is determined statistically; e.g. , based on one or more methods published in the literature.
- a QTL can be a chromosomal region and/or a genetic locus with at least two alleles that differentially affect the expression of a phenotypic trait (either a quantitative trait or a qualitative trait).
- the phrases "sexually crossed” and “sexual reproduction” in the context of the presently disclosed subject matter refers to the fusion of gametes to produce progeny (e.g., by fertilization, such as to produce seed by pollination in plants).
- a "sexual cross” or “cross-fertilization” is in some embodiments fertilization of one individual by another (e.g., cross-pollination in plants).
- selfing refers in some embodiments to the production of seed by self-fertilization or self-pollination; i.e., pollen and ovule are from the same plant.
- the phrase “single cross F 1 hybrid” refers to an F 1 hybrid produced from a cross between two inbred lines.
- tester refers to a line or individual with a standard genotype, known characteristics, and established performance.
- a "tester parent” is an individual from a tester line that is used as a parent in a sexual cross. Typically, the tester parent is unrelated to and genetically different from the individual to which it is crossed.
- a tester is typically used to generate F 1 progeny when crossed to individuals or inbred lines for phenotypic evaluation.
- topcross combination refers to the process of crossing a single tester line to multiple lines. The purpose of producing such crosses is to determine phenotypic performance of hybrid progeny; that is, to evaluate the ability of each of the multiple lines to produce desirable phenotypes in hybrid progeny derived from the line by the tester cross.
- transgenic refers to a cell or an individual into which one or more exogenous polynucleotides have been introduced by any technique other than sexual cross or selfing. Examples of techniques by which this can be accomplished are known in the art.
- a transgenic individual is a transgenic plant, and the technique employed to create the transgenic plant is selected from the group consisting of Agrobacteriurn-me ⁇ iated transformation, biolistic methods, electroporation, in plants techniques, and the like.
- Transgenic individuals can also arise from sexual crosses or by selfing of transgenic individuals into which exogenous polynucleotides have been introduced.
- the presently disclosed subject matter provides methods for calculating a distribution of a probability or frequency of occurrence of one or more potential genotypes.
- the methods comprise (a) providing a first breeding partner and a second breeding partner, wherein (i) the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers, each of which is linked to a genetic locus; and (ii) a genetic distance between each genetic marker and the genetic locus to which it is linked is known or can be assigned; (b) calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner to generate a subsequent generation, each member of the subsequent generation comprising a genotype; and (c) calculating a distribution of a probability or a frequency of occurrence for one or more of the genotypes of one or more members of the subsequent generation.
- calculating or simulating a progeny starts from the genotype(s) of the parent(s) and results in genotype(s) of progeny. Frequencies or probabilities of occurrence of these genotypes are derived from genetic distances. Progeny of a cross between breeding parents is described herein as genotype(s). Since each genotype can be associated to a probability or frequency of occurrence, a distribution of such statistics can be constructed. ll.A.2, II.A.3, and II.A.IV show one way of calculating progeny from breeding parents by detailing the three consecutive steps involved: recombination, segregation, and fertilization. The formula at the bottom of page 24 shows the probability of one progeny genotype that can be obtained from the cross between two breeding parents.
- Example 5 provides an example of how genotypes and genetic distances are used to compute progeny distributions.
- the phrase "calculating a distribution of a probability or frequency of occurrence of one or more potential genotypes” refers to methods for generating probabilities and/or frequencies of occurrence for one or more genotypes that can be produced when an individual with a known or predictable genotype is selfed, crossed to another individual with a known or predictable genotype, or generated by calculating or simulating a doubled haploid breeding of an individual from a prior generation (e.g., from the immediately prior generation).
- the phrase refers to methods for generating probabilities and/or frequencies of occurrence for all possible genotypes that can be produced when an individual with a known or predictable genotype is selfed, crossed to another individual with a known or predictable genotype, or generated by calculating or simulating a doubled haploid breeding of an individual from a prior generation (e.g., from the immediately prior generation).
- the phrase refers to determining all or a subset of all potential genotypes that can be produced when a progeny individual is produced from one or more known or predictable genotypes as well as determining an expected probability and/or frequency at which each such genotype would be expected to occur.
- the phrase "known" in the context of a genotype of an individual with respect to one or more genetic markers refers to a genotype for which the presence or absence and/or the identity of the one or more genetic markers has been ascertained for an individual (e.g., has been determined experimentally or otherwise).
- the phrase "predictable” in the context of a genotype of an individual with respect to one or more genetic markers refers to a genotype for which the presence or absence and/or the identity of the one or more genetic markers can be calculated or otherwise predicted for an individual, for example by comparison to one or more related individuals (e.g., progenitors or offspring of any generation) for which the genotypes are known.
- a genotype with respect to one or more genetic markers is deemed to be predictable when the genotype of the individual can be determined with reference to the genotypes of one or more progenitors and/or one or more progeny, with either or both of the progenitors and progeny being 1 , 2, or more generations removed from the individual itself.
- a genetic distance between each genetic marker and the genetic locus to which it is linked is known or can be assigned.
- a genetic distance refers to an absolute or a relative distance between a genetic marker and a genetic locus to which it is associated.
- a genetic distance is a physical distance, and can be expressed in term such as, but not limited to, bases, kilobases, megabases, etc.
- a genetic distance is a relative distance, and can be expressed in terms such as, but not limited to, a recombination rate between the genetic marker and the genetic locus.
- Terms that can be employed to express genetic distances that are based on recombination rates include, but are not limited to percent recombination and its associated term centiMorgan (cM). It is understood that recombination occurs at different rates or frequencies in different species and also in different regions of different chromosomes in the same species, and thus a centiMorgan can refer to a different absolute number of bases in different contexts.
- centiMorgan centiMorgan
- genetic distances between genetic markers and genetic loci can be known or can be assigned.
- a genetic distance is "known”, it has been determined experimentally to have a particular value.
- a genetic distance can be "assigned”, it may not have been precisely determined experimentally, but can be predicted based on whatever information might be available.
- first breeding partner and second breeding partner refer to any individuals that can provide male gametes and female gametes. Accordingly, in some embodiments the first breeding partner and the second breeding partner can be different members of the same species.
- the individuals that comprise the breeding partners, the breeding pairs, and the progeny can be of any species.
- each breeding partner is a plant. Any plant species can be employed.
- the plant is selected from the group consisting of maize, wheat, barley, rice, sugar beet, sunflower, winter oilseed rape, canola, tomato, pepper, melon, watermelon, broccoli, cauliflower, Brussel sprouts, lettuce, spinach, sugar cane, coffee, cocoa, pine, poplar, eucalyptus, apple tree, and grape.
- the plant is a maize plant.
- the individuals that comprise the breeding partners, the breeding pairs, and the progeny can be inbred or outbred.
- the individuals that comprise the breeding partners, the breeding pairs, and the progeny are inbred individuals or are the F 1 progeny of one or two inbred individuals.
- the species is one that can be bred by selfing. Therefore, in these embodiments the first and the second breeding partners can be the same individual.
- the future generation is generated by at least two successive generations of seifing of one or more members of a preceding generation. In some embodiments, the future generation is generated by three successive generations of selfing of one or more members of a preceding generation. In some embodiments, the future generation is generated by four successive generations of selfing of one or more members of a preceding generation.
- the presently disclosed methods employ doubled haploid derivatives of an individual of a previous generation.
- Doubled haploid derivatives of an individual are produced by the doubling of a set of chromosomes (1 N) from a heterozygous plant to produce a completely homozygous individual.
- Methods for producing doubled hapioid derivatives are known in the art (see e.g., Wan ef a/., 1989; U.S. Application Publication No. 20030005479; U.S. Patent No. 7,135,615). This can be advantageous because the process omits the generations of selfing needed to obtain a homozygous plant from a heterozygous source.
- the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers, each of which is linked to a genetic locus; and (ii) a genetic distance between each genetic marker and the genetic locus to which it is linked is known or can be assigned.
- Methods for genotyping individuals with respect to one or more genetic loci are known, as are methods for identifying distances between genetic markers and genetic loci to which the markers are linked.
- the one or more genetic markers are selected from the group consisting of a single nucleotide polymorphism (SNP), an indel (i.e., insertion/deletion), a simple sequence repeat (SSR), a restriction fragment length polymorphism (RFLP), a random amplified polymorphic DNA (RAPD), a cleaved amplified polymorphic sequence (CAPS) marker, a Diversity Arrays Technology (DArT) marker, an amplified fragment length polymorphism (AFLP), and combinations thereof.
- the one or more genetic markers comprise between one and ten markers, and in some embodiments the one or more genetic markers comprise more than ten genetic markers.
- the calculating, simulating, or combinations of calculating and simulating a breeding includes calculating, simulating, or combinations of calculating and simulating an expected rate of recombination between at least one of the one or more genetic markers and a genetic locus associated with expression of a phenotypic trait.
- a representative method for calculating, simulating, or combinations of calculating and simulating an expected rate of recombination between at least one of the one or more genetic markers and a genetic locus associated with expression of a phenotypic trait is set forth hereinbelow.
- the phenotypic trait is a quantitative trait
- the one or more genetic markers are linked to one or more quantitative trait loci associated with expression of the phenotypic trait.
- the genetic locus associated with expression of the phenotypic trait encodes a gene product that is associated with expression of the phenotypic trait.
- the rate of recombination between the at least one of the one or more genetic markers and the genetic locus associated with expression of the phenotypic trait is zero.
- the presently disclosed methods employ calculating, simulating, or combinations of calculating and simulating of a breeding of the first breeding partner and the second breeding partner to generate a subsequent generation.
- subsequent generation refers to a generation of one or more progeny that results from the calculated, simulated, or combinations of both calculated and simulated breeding of the first breeding partner and the second breeding partner.
- the first and second breeding partners can be assigned to be the F 0 generation, which are then bred by calculating, simulating, or combinations of calculating and simulating a breeding to produce an Fi generation that is referred to herein as the "subsequent generation", individuals of which can optionally be bred for one or more additional generations to produce one or more "further generations” (i.e., the F 2 , F 3 , F 4 , Fs, ..., F n generations).
- breedings that are calculated and/or simulated can include breedings of any combinations of individuals from any of these generations as well as derivatives thereof
- the presently disclosed methods comprise calculating a distribution of a probability or frequency of occurrence of one or more of the potential genotypes that can be calculated.
- the presently disclosed subject matter provides methods that relate to calculating and/or predicting a distribution of a probability or a frequency of occurrence of one or more potential genotypes.
- the distribution of a probability or a frequency of occurrence of one or more potential genotypes relates to a distribution of a probability or a frequency of occurrence of one or more potential genotypes in a progeny individual based on knowledge of parental genotypes (i.e., the first breeding partner and the second breeding partner, which in some embodiments are the same individual such as when plants are selfed).
- a genotype can be considered and assigned the symbol .
- This genotype is described as the pairing of two chromosomes: chromosomes are assumed with L loci and a chromosome is represented by a vector g) with L components taking binary values on ⁇ 0,1 ⁇ . Symbol o represents the ordered (from top to bottom) pairing operator of two chromosomes. Taking all this into account, genotypes and can be written as:
- Recombination designates the genotype obtained after recombination operation on genotype ⁇ 1 [G ⁇ .
- the event probability is then: where the writing Pr ⁇ x ⁇ y ⁇ expresses the occurrence probability of event y conditioned to event x.
- the probability of event can be developed into the sum below:
- conditional probability can be facto rized as:
- genotype is the ranked juxtaposition ⁇ g). o of two chromosomes, by convention the upper one being first, the lower one second. Since the coding requires their separate consideration, it is necessary to be able to differentiate them. Therefore, H) designates the upper haplotype, and ⁇ S) the lower haplotype.
- each ⁇ g) vector is the sequence of L ⁇ 0,1 ⁇ binary values.
- the coding of the genotype is therefore the juxtaposition of two vectors of this type.
- a coding operator can be defined which, applied to a genotype, reduces the juxtaposition of both vectors to a single vector .
- This vector which summarizes without information loss the genotype state, is obtained by the following operation:
- Coding of states with phases implies a four-modality coding for distinguishing types (0,0) and (1,1 ) homozygous states and of types (0,1 ) and (1 ,0) heterozygous states. Approaches for choosing this coding are disclosed herein.
- Coding operato is insensitive to the allele phase and generates a 3-modaiity coding for distinguishing types (0,0) and (1 ,1 ) homozygous states from heterozygous ones. It generates a vector using the operation:
- This coding is obtained from relation: where ⁇ and g / , as set forth hereinabove, are respectively the allele state coding vectors of the upper and lower haplotypes.
- the upper and lower chromosome coding can also be retrieved if the genotype coding is known by the relations:
- a vector is defined of length L 1 where the elements are binary values that contain the recombination information according to the following mode: Recombination between loci (I -1 ) and / . No recombination
- one of the roles assigned to the recombination process in the model is chromosome rank mixing before releasing the gametes.
- the recombination process includes the possibility of recombination before the first locus (with Yn probability)
- Value 1 for locus / corresponds to an allele flip at the level of this locus, while value 0 refers to an unchanged situation, an even number of recombination between loci (I - 1) and / being without effect on the locus configuration.
- the necessary and sufficient condition for realizing the translation is that the homologous loci must be homozygous and identical, or heterozygous.
- the filtering function is equal to:
- the f w/ ⁇ y filtration function expression established above can be used to derive the set of necessary and sufficient conditions for a feasible transition.
- an index resulting from the binary code corresponding to this signature can be defined. IfW is this index; it is then computed by:
- a first condition is therefore expresse by:
- the integers corresponding to the homozygous part of each haplotype can be identical. If 1 on the other hand, the sum of the two integers corresponding to the heterozygous part of each haplotype is conserved by the recombination, the recombination operation conserves the sum of the indexes.
- a class can be defined as a set of genotypes where each genotype (ij) in this set can be linked to any other of this same set through a recombination operation.
- the individuals present in each class they can be assigned through one of these two indexes, the sum of both being known.
- ⁇ f value indicating or not an allele change at locus /
- Lh heterozygous loci there will thus be 2 L"L * terms to sum, which can represent an important use of computation time.
- Another way to take into account the degeneration introduced by the presence of homozygous loci is to reduce the genotype to heterozygous loci only, compute the equivalent recombination coefficients, and then compute the recombination probability. The summation occurs therefore in an implicit way.
- the reduction of the genotype occurs very easily: having vector
- the probability computation is then carried out by using the expression set forth hereinabove.
- the factor F ⁇ / +j > u ⁇ has the following meaning: by extending function F definition, this factor is non null and equal to a unit if and only if condition / +/ > u is verified. This factor comes from the constraint m > 0 imposed implicitly by a summation on this index beginning with the unit value. This constraint is contained in the constraint imposing an identical heterozygous signature. Given
- each factor represents the probabiiity to generate a gamete provided by a given parent:
- the presently disclosed subject matter also provides methods for calculating a genetic value distribution.
- the presently disclosed subject matter provides methods for calculating a genetic value distribution.
- the methods comprise (a) providing a first breeding partner and a second breeding partner, wherein (i) the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers linked to one or more genetic loci; (ii) a genetic distance between each genetic marker and the genetic locus to which it is linked is known or can be assigned; and (iii) each genotype is associated with a genetic value; (b) calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner to generate a subsequent generation, each member of the subsequent generation comprising a genotype; and (c) calculating a genetic value distribution for one or more of the genotypes.
- the phrase “genetic value” refers to a value assigned to a particular allele at a locus.
- the phrase “genetic value” can refer to a value assigned to a genotype and/or haplotype.
- the genetic value of a genotype and/or a haplotype is calculated by adding together one or more of the individual genetic values that have been assigned for those alleles that make up the genotype and/or the haplotype.
- the genetic values for each allele at each locus is assigned a value of -1 if the allele is desirable in the progeny, a value of -1 if the allele is undesirable in the progeny, and a value of 0 if the allele is neither desirable nor undesirable in the progeny.
- the total genetic value that each individual might have at a given genetic locus will be selected from among -2, -1, 0, 1 , and 2.
- a genetic value for an allele at each locus is assigned based on a qualitative assessment of the desirability of a given allele being present in a progeny individual.
- a genetic value can have any value (e.g., a positive value, a negative value, or zero) including whole numbers, fractional values, decimal values (e.g., numbers with 1, 2, 3, 4, or more decimal places), etc.
- values can be assigned in any manner, and can, for example, take into account a degree of contribution that an allele has on the expression of a quantitative trait. In some embodiments, the degree of contribution is determined experimentally by examination of individuals with known genotypes.
- a plant is represented by a set of genotypes, each one being affected by an occurrence probability measurement.
- a genotype including all marker loci and QTLs was considered. This genotype was noted as G and a particular state of it as G,y. Henceforth, each type of iocus wili be distinguished.
- the set of marker ioci can be noted E while that of QTLs will be noted U.
- ( ⁇ ) the name given to a specific plant, given the probability of occurrence associated to genotype G ⁇ .
- the expression of probabilities can be denoted Py . In order to avoid index multiplication, it can be assumed that the experimental plant ( ⁇ ) comes from the generic plant of order (0); so, the probabilities Pij are deducted from probabilities p#
- the probability under evaluation can be completely determined when the conditional probability Pr ⁇ E ⁇ G ol is actualized. This probability will be null if and will be equal to unity on the contrary. Using once more function F, this probability can be written as:
- an index distribution associated with plant crossings and/or self-fertilizations can be computed as set forth hereinbeiow.
- a simple index ft can be defined wherein a subset of QTLs intervenes among the set of the K QTLs, by calculating the following weighted sum:
- the index value can be independent of the phase at the loci. Therefore, all the genotypes of a same class will have the same index values. Consequently, a maximum of 3 A r distinct index values can exist if K ⁇ v> is the number of QTLs intervening in the evaluation of index / ⁇ ) .
- Vecto is defined as follow: If is defined as the position signature vector of K
- index definition can be rewritten by revisiting the genotypic representation by a unique vector.
- index value can be expressed as:
- each haplotype can be expressed as carrying an index value, which can be defined by:
- This additivity property can be used advantageously and widely to select plants according to the index distribution of their gametes, and therefore avoid progeny simulations that have little value in terms of the distribution of the index value sums.
- the second step aims at generating a population integrated with the phase states.
- this comes to compound individuals belonging to a same class: with [R 11 I 1 ), (/c2,/z), ..., (&,mon ,/,cite ) as individual indexes of a class c including m c of them; the indexes of the various genotypes of the class are then such as: Consequently, the coding of the summation is: So, the index distribution calculation from probabilities /> « entails the operations:
- Genotype The presently disclosed subject matter also provides methods for choosing a breeding pair for producing a progeny having a desired genotype.
- the methods comprise (a) providing a first breeding partner and a second breeding partner, wherein (i) the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers, each of which is [inked to a genetic locus; and (fi) a genetic distance between each genetic marker and the genetic locus to which it is linked is known or can be assigned; (b) calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner to generate a subsequent generation, each member of the subsequent generation comprising a genotype; (c) calculating a distribution of a probability or a frequency of occurrence for one or more of the genotypes of one or more members of the subsequent generation; (d) repeating steps (a) through (c) with a different first, different second, or both different first and different second potential breeding partners
- the presently disclosed methods for choosing a breeding pair for producing a progeny having a desired genotype comprise (a) providing a first breeding partner and a second breeding partner, wherein (i) the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers linked to one or more genetic loci; (ii) a genetic distance between each genetic marker and the genetic locus to which it is linked is known or can be assigned; and (iii) each genotype is associated with a genetic value; (b) calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner to generate a subsequent generation, each member of the subsequent generation comprising a genotype; (c) calculating a distribution of genetic values associated with one or more of the genotypes of one or more members of the subsequent generation; (d)repeating steps (a) through (c) with a different first, different second, or both different first and different second potential breeding partners; (e)
- Add/tfo ⁇ ady in some embodiments the presently disclosed methods further comprise generating one or more further generation progeny, wherein each further generation progeny is generated by one or more rounds of calculating, simulating, or combinations of calculating and simulating a breeding of at least one member of the subsequent generation or a later generation with an individual selected from the group consisting of itself, a member of the immediately prior generation, another individual from the same generation, another individual from a previous generation, the first breeding partner, the second breeding partner, and doubled haploid derivatives thereof.
- Distributions of probabilities and/or frequencies of occurrence for one or more of the genotypes of one or more members of any such further generation, and/or distributions of genetic values associated with one or more of the genotypes of one or more members of any of the further generations can also bee calculated and compared.
- the presently disclosed methods allow for the selection of breedjng pairs based on a comparison of the distributions of the probability or frequency of occurrence of one or more of the genotypes and/or of the distributions of the genetic values associated with these genotypes in the subsequent generation and/or of any further generation.
- the choice of a breeding pair based on comparing one or more of these distributions can include any criteria deemed relevant, and can include, but is not limited to the number of generations required to produce an individual with a genotype having a desired minimum genetic value, the extent to which genetic values can be increased by increasing the number of generations, and judgments that take into account both probabilities and/or frequencies of generating desirable genotypes in conjunction with the genetic vafues of the desirable genotypes, ft is understood that the presently disclosed subject matter is not limited to any single criterion in the comparing step leading to the choice of breeding partners.
- an exemplary approach to selecting breeding pairs is to stochastically simulate progeny frequency or index distributions through the simulation of meiosis (the creation of gametes) and fertilization (the union of gametes).
- Meiosis can be seen as a series of recombination events along a given chromosome happening either at random or not while homologous chromosomes separate into gametic sets.
- Progeny genotype, GEN then results from the union of two gametic sets of chromosomes, respectively with genotypes GEH1 and GEH2, through fertilization.
- progeny genotypes each with an associated frequency or probability of occurrence. All progeny genotypes, with their associated frequency or probability of occurrence, can be represented by a frequency or probability distribution.
- genotypes can be diploid, with two alleles, "a” and "A".
- GEN phased genotypes
- phased genotypes there are up to three possible "unphased" genotypes: aa, a A (which is equivalent to Aa), and AA. Because there can be more phased than unphased genotypes at a given iocus, several phased genotypes can correspond to an unphased genotype (heterozygous loci). When considering several loci, one individual can be represented by more than one phased, multi-locus, genotype, each genotype being referred to as a sample genotype.
- GEN GEH1 + 2 x GEH2
- Experimental genotypes are in some embodiments unphased. In order to simulate progeny genotypes, it can first be necessary to simulate frequency distributions of phased genotypes underlying unphased (experimental) genotypes. This can be achieved in some embodiments by simulating meiosis and fertilization of individuals.
- ns12 sample genotypes for any individual.
- Sample genotypes for the first breeding partner can be stored in a vector pal of length N (N being the size of a linkage group, in terms of number of marker loci) x ns12
- Each pal vector can be a series of ns12 subgroups of N values, stored one after another, each subgroup containing values for one sample genotype.
- Sample genotypes for the second breeding partner can also be stored in a vector pal , having the same attributes as that of the first breeding partner.
- simulating meiosis can comprise simulating recombination ⁇ i.e., crossing-overs) between homologous chromosomes. Recombination can be viewed as "walking" on homologous chromosomes and "jumping" from one to the other or vice- versa.
- homologous chromosomes can be defined as one being on the "top” and the other on the "bottom”.
- Indicator variables sw1 and sw2 can be defined to indicate "walking" on either the "top” or the "bottom” chromosome. In some embodiments, these indicator variables can take the following values:
- the first step in simulating meiosis is to pick a random sample genotype from among the ns12 samples for the first breeding partner.
- a random number e.g., "Iran”
- the sample genotype at position iran in the vector pal can then be picked.
- the same procedure can be applied to pick a sample genotype for the second breeding partner.
- a "test" recombination distance rj * can be sampled from a normalized uniform distribution. If this test recombination distance is smaller than the known recombination distance, rn j , between marker loci nn and nn + 1 (here ⁇ ⁇ r1 jv where r1j is the known recombination distance between marker locus 1 and marker locus 2), the vatue of indicator variable sw1 changes from 1 to 2 (or 2 to 1 - here from 1 to 2).
- GEN a progeny genotype
- GEN GEH1 + 2 x GEH2
- the output vector is of size N x ns (ns being the pre-defined target number of sample genotypes).
- Each of the N marker loci can be approached in the same fashion, starting at the step where a "test" recombination distance r j * is sampled when moving to the subsequent marker locus. These steps can then be repeated ns times to obtain ns sample genotypes.
- Simulating future progeny The process to simulate future progeny can be essentially the same, without the comparison between sample genotype and experimental genotype since no experimental genotype is available for future progeny. Also, in some embodiments initial sample genotypes are not chosen randomly but rather the sample genotypes created above are used.
- QTL genotypes can be computed from sample genotypes using the matrices proposed by Fisch et a/., 1996. Genetic values can then be computed based on QTL genotypes using economic indices such as: where ⁇ t is the weight (economic value) of trait t, ⁇ r/l is the effect of the favorable allele at QTL q of trait t (usually the additive value of the QTL), ⁇ i ⁇ is the probability of occurrence of genotype i at QTL q of trait t, and S 10 is the selection value of QTL genotype i at QTL q of trait t.
- V 1 Methods for Generating a Progeny Individual Having a Desired Genotype
- the methods comprise (a) providing a first breeding partner and a second breeding partner, wherein (i) the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers, each of which is linked to a genetic locus; and (ii) a genetic distance between each genetic marker and the genetic locus to which it is linked is known or can be assigned; (b) calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner to generate a subsequent generation, each member of the subsequent generation comprising a genotype; (c) calculating a distribution of a probability or a frequency of occurrence for one or more of the genotypes of one or more members of the subsequent generation; (d) repeating steps (a) through (c) with a different first, different second, or both different first and different second potential breeding partners; (e) comparing the probability
- the presently disclosed methods for generating a progeny individual having a desired genotype comprises (a) providing a first breeding partner and a second breeding partner, wherein (i) the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers linked to one or more genetic loci; (ii) a genetic distance between each genetic marker and the genetic locus to which it is linked is known or can be assigned; and (iii) each genotype is associated with a genetic value; (b) calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner to generate a subsequent generation, each member of the subsequent generation comprising a genotype; (c) calculating a distribution of genetic values associated with one or more of the genotypes of one or more members of the subsequent generation; (d) repeating steps (a) through (c) with a different first, different second, or both different first and different second potential breeding partners; (e) comparing the genetic value distribution
- the presently disclosed methods are designed to produce the desired progeny individual itself by performing the series of breeding steps that were modeled by the methods of the presently disclosed subject matter and that employ the breeding partners through the presently disclosed methods.
- the phrase "breeding the breeding pair in accordance with the calculating, simulating, or combinations of calculating and simulating as set forth in step (b)" refers to actually performing the series of breeding steps that the presently disclosed methods indicate would result in producing the desired progeny individual.
- the presently disclosed subject matter also provides methods, systems, and computer program products that can be employed in the general methods disclosed herein. tn some embodiments, the methods of the presently disclosed subject matter can be implemented in hardware, firmware, software, or any combination thereof. In some embodiments, the methods and data structures for calculating a distribution of a probability or a frequency of occurrence of one or more potential genotypes, for calculating a genetic value distribution, for choosing a breeding pair for producing a progeny having a desired genotype, and/or for generating a progeny individual having a desired genotype can be implemented at (east / ⁇ part as computer readable instructions and data structures embodied in a computer-readable medium.
- an exemplary system for implementing the presently disclosed subject matter includes a general purpose computing device in the form of a conventional personal computer 100, including a processing unit 101, a system memory 102, and a system bus 103 that couples various system components including the system memory to the processing unit 101.
- System bus 103 can be any of several types of bus structures including a memory bus or memory controller, a peripheral bus, and a local bus using any of a variety of bus architectures.
- the system memory includes read only memory (ROM) 104 and random access memory (RAM) 105.
- ROM read only memory
- RAM random access memory
- a basic input/output system (BIOS) 106 containing the basic routines that help to transfer information between elements within personal computer 100, such as during start-up, is stored in ROM 104.
- Personai computer 100 further includes a hard disk drive 107 for reading from and writing to a hard disk (not shown), a magnetic disk drive 108 for reading from or writing to a removable magnetic disk 109, and an optical disk drive 110 for reading from or writing to a removable optical disk 111 such as a CD ROM or other optical media.
- a hard disk drive 107 for reading from and writing to a hard disk (not shown)
- a magnetic disk drive 108 for reading from or writing to a removable magnetic disk 109
- an optical disk drive 110 for reading from or writing to a removable optical disk 111 such as a CD ROM or other optical media.
- Hard disk drive 107, magnetic disk drive 108, and optica! disk drive 110 are connected to system bus 103 by a hard disk drive interface 112, a magnetic disk drive interface 113, and an optical disk drive interface 114, respectively.
- the drives and their associated computer-readable media provide nonvolatile storage of computer readable instructions, data structures, program modules, and other data for personal computer 100.
- a number of program modules can be stored on the hard disk, magnetic disk 109, optical disk 111, ROM 104, or RAM 105, including an operating system 115, one or more applications programs 116, other program modules 117, and program data 118.
- a user can enter commands and information into personal computer 100 through input devices such as a keyboard 120 and a pointing device 122.
- Other input devices can include a microphone, touch panel, joystick, game pad, satellite dish, scanner, or the like.
- processing unit 101 can be connected by other interfaces, such as a parallel port, game port or a universal serial bus (USB).
- a monitor 127 or other type of display device is also connected to system bus 103 via an interface, such as a video adapter 128.
- personai computers typically include other peripheral output devices, not shown, such as speakers and printers.
- the user can use one of the input devices to input data indicating the user's preference between alternatives presented to the user via monitor 127.
- Personal computer 100 can operate in a networked environment using logical connections to one or more remote computers, such as a remote computer 129.
- Remote computer 129 can be another personal computer, a server, a router, a network PC, a peer device or other common network node, and typically includes many or all of the elements described above relative to personal computer 100, although only a memory storage device 130 has been illustrated in Figure 1.
- the logical connections depicted in Figure 1 include a local area network (LAN) 131, a wide area network (WAN) 132, and a system area network (SAN) 133.
- LAN local area network
- WAN wide area network
- SAN system area network
- System area networking environments are used to interconnect nodes within a distributed computing system, such as a cluster.
- personal computer 100 can comprise a first node in a cluster and remote computer 129 can comprise a second node in the cluster.
- remote computer 129 it is preferable that personal computer 100 and remote computer 129 be under a common administrative domain.
- computer 129 is labeled "remote"
- computer 129 can be in close physical proximity to personal computer 100.
- personal computer 100 When used in a LAN or SAN networking environment, personal computer 100 is connected to local network 131 or system network 133 through network interface adapters 134 and 134a.
- Network interface adapters 134 and 134a can include processing units 135 and 135a and one or more memory units 136 and 136a.
- personal computer 100 When used in a WAN networking environment, personal computer 100 typically includes a modem 138 or other device for establishing communications over WAN 132.
- Modem 138 which can be internal or external, is connected to system bus 103 via serial port interface 126.
- program modules depicted relative to personal computer 100, or portions thereof can be stored in the remote memory storage device. It will be appreciated that the network connections shown are exemplary and other approaches to establishing a communications link between the computers can be used.
- a representative example of an embodiment of the presently disclosed subject matter for calculating a distribution of a probability or a frequency of occurrence of one or more potential genotypes as disclosed herein is referred to generally at 200 in Figure 2.
- a first breeding partner and a second breeding partner are provided, wherein the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers, each of which is linked to a genetic locus.
- a genetic distance between each genetic marker and the genetic locus to which it is linked is known.
- a plurality of subsequent generation genotypes is established by calculating, simulating, or combinations of calculating and simulating a breeding of the First breeding partner and the second breeding partner
- step ST205 in Figure 2 can be repeated one or more times to generate a plurality of further generation genotypes, each of which is associated with a probability of occurrence or a frequency of occurrence.
- a distribution of a probability or a frequency of occurrence for each of the plurality of subsequent and/or further generation genotypes is calculated.
- step ST208 in Figure 2 in some embodiments of the presently disclosed subject matter the results of the calculation in step ST206.can be displayed, it is noted that this step is optional.
- a representative example of an embodiment of the presently disclosed subject matter for calculating a genetic value distribution as disclosed herein is referred to generally at 300 in Figure 3.
- a first breeding partner and a second breeding partner are provided, wherein the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers, each of which is linked to a genetic locus, and each genotype is associated with a genetic value.
- a genetic distance between each genetic marker and the genetic locus to which it is linked is known.
- a plurality of subsequent generation genotypes is established by calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner.
- step ST305 in Figure 3 further generations can be generated as shown in step ST305 in Figure 3, which can be repeated one or more times to generate a plurality of further generation genotypes, each of which is associated with a probability of occurrence or a frequency of occurrence.
- step ST306 in Figure 3 a genetic value distribution of one or more of the subsequent and/or further generation genotypes is calculated.
- step ST308 in Figure 3 the results of the calculation in step ST310 in Figure 3 are displayed.
- a representative example of an embodiment of the presently disclosed subject matter for producing a progeny having a desired genotype as disclosed herein is referred to generally at 400 in Figure 4.
- a first breeding partner and a second breeding partner are provided, wherein the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers, each of which is linked to a genetic iocus.
- a genetic distance between each genetic marker and the genetic locus to which it is linked is known.
- each genotype can be associated with a genetic value, if desired. It is noted that the in addition to associating genetic values to the genotypes of the first and second breeding partners, genetic values can also be associated to any of the genotypes established in the subsequent generation, one or more of the further generations, or combinations thereof.
- a plurality of subsequent generation genotypes are established by calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner.
- a distribution of a probability or a frequency of occurrence and/or of a genetic value for one or more of the plurality of subsequent generation genotypes is calculated.
- step ST407 in Figure 4 can be repeated one or more times to generate a plurality of further generation genotypes, each of which is associated with a probability of occurrence or a frequency of occurrence and/or with a genetic value.
- steps ST402 through ST407 in Figure 4 can be repeated one or more times in step ST408 of Figure 4 to generate one or more additional subsequent generations and/or further generations.
- step ST410 in Figure 4 the distributions calculated in one or more iterations of step ST406 are compared to each other.
- step ST412 in Figure 4 a breeding pair is chosen based on comparing step ST410.
- a representative example of an embodiment of the presently disclosed subject matter for generating a progeny individual having a desired genotype as disclosed herein is referred to generally at 500 in Figure 5.
- a first breeding partner and a second breeding partner is provided, wherein the genotype of each of the first breeding partner and the second breeding partner is known or is predictable with respect to one or more genetic markers, each of which is linked to a genetic locus.
- a genetic distance between each genetic marker and the genetic iocus to which it is linked is known.
- each genotype can be associated with a genetic value, if desired. It is noted that the in addition to associating genetic values to the genotypes of the first and second breeding partners, genetic values can also be associated to any of the genotypes established in the subsequent generation, one or more of the further generations, or combinations thereof.
- a plurality of subsequent generation genotypes is established by calculating, simulating, or combinations of calculating and simulating a breeding of the first breeding partner and the second breeding partner.
- a distribution of a probability or a frequency of occurrence and/or of a genetic value for one or more of the plurality of subsequent generation genotypes is calculated.
- step ST507 in Figure 5 further generations can be generated as shown in step ST507 in Figure 5, which can be repeated one or more times to generate a plurality of further generation genotypes, each of which is associated with a probability of occurrence or a frequency of occurrence and/or with a genetic value.
- steps ST502 through ST507 in Figure 5 can be repeated one or more times in step ST508 in Figure 5 to generate one or more additional subsequent generations and/or further generations.
- step ST510 in Figure 5 the distributions calculated in one or more iterations of step ST506 are compared to each other.
- step ST512 in Figure 5 a breeding pair is chosen based on comparing step ST510.
- step ST514 in Figure 5 the breeding pair and subsequent generations (if employed) are bred in accordance with the calculated or simulated breedings as set forth in steps ST506 and ST508.
- a progeny individual having a desired genotype is identified.
- the methods can also further comprise generating one or more further generation progeny, wherein each further generation progeny is generated by one or more rounds of calculating, simulating, or combinations of calculating and simulating a breeding of at least one member of the subsequent generation or a later generation with an individual selected from the group consisting of itself, a member of the immediately prior generation, another individual from the same generation, another individual from a previous generation, the first breeding partner, the second breeding partner, and doubled haploid derivatives thereof.
- Strategies that can be employed for generating the further generation(s) can include, but are not limited to one or more successive generations of crossings, selfings, doubled haploid derivative generation, or combinations thereof of one or more individuals from a preceding generation, ⁇ e.g., one, two, three, four, or more successive generations of such crossings, selfings, doubled haploid derivative generation, or combinations thereof); at least one, two, three, four, or more successive generations of selfing of one or more members of a preceding generation.
- the presently disclosed subject matter also encompasses individuals generated by the presently disclosed methods, as well as cells, parts, tissues, gametes, and progeny thereof. In some embodiments, the individuals are plants.
- Parental material included two maize inbred lines: BFP57 and BMP34, both from the Stiff-Stalk Synthetic heterotic group. These lines were crossed with one another to produce
- Fi seed Fi kernels were planted and the resulting Fi plants were self-fertilized to produce
- F2 seed About 500 F 2 kernels were planted. The resulting F2 plants were self-fertilized to produce F 3 seed.
- F 3 kernel was harvested on each F 2 plant, a commonly-used generation advancement procedure known as single kernel descent (SKD). The almost 500 F 3 kernels so harvested were planted, and the resulting F 3 plants self-fertilized to produce F 4 seed. All F 4 kernels produced on each F 3 plant were harvested, keeping all F 4 kernels harvested separated by F 3 plant of origin, and thereby constituting F 4 families.
- SMD single kernel descent
- Testcross seed from 229 F 4 families was planted at 6 field locations in two-row plots.
- the experimental design was a lattice design with one replication.
- Several other hybrids, used as checks, were also planted in the same trials.
- a molecular marker map was constructed using the commonly used software MapMaker and JoinMap. This molecular marker map had a total length of 1674 centiMorgans (cM), with a marker density of one marker every 19 cM. Joint-analysis of genotypic and phenotypic data was performed using the software QTLCartographer and PlabGTL Sixty-one QTLs were identified, for all traits. In particular, 14 QTLs were identified for grain yield, and 17 for grain moisture. QTLs are characterized by their position on the genetic map, and their additive and dominance effects. Positions are defined as a genetic distances between the most likely position of the QTLs (usually the position of the peak LOD score value) and flanking marker loci (in cM).
- Additive and dominance effects are defined as deviations from the mean and are expressed in the same unit as the trait they refer to.
- Additive values define which of the two parental lines carries the favorable allele at the QTL.
- additive values represent the effect of the BMP34 allele, whether positive or negative.
- a positive additive value means that BMP34 carries the favorable allele while a negative additive value means that BFP57 carries the favorable allele.
- EXAMPLE 4 Selection Indices, Genetic Values, and Ideal Genotype - Maize Based on the QTLs identified, selection indices were defined. These selection indices were then applied to the plants' QTL genotypes, to compute these plants' genetic values. Genetic value (GV) of a plant was computed as follows, based on the plant's QTL genotype: where ⁇ s is the weight (econom c value) of trait t, a ⁇ is the effect of the favorable allele at QTL q of trait t (usually the additive value of the QTL), p k ⁇ is the probability of occurrence of genotype i at QTL q of trait t, and ⁇ lql is the selection value of QTL genotype i at QTL q of trait t. can ⁇ e considered as the QTL genetic value (QTL q of trait t).
- IND One index (called IND) was based on 14 QTL for grain yield, 17 QTL for grain moisture at harvest, 13 QTL for root lodging, 7 QTL for common smut incidence, and 5
- QTL for Helminthospo ⁇ um incidence QTL parameters were as defined in Tables 1-5 below. Additive effects were used as allele effects ⁇ a qt ). Trait weights ( ⁇ t ) were 1.2 for grain yield, -8.5 for grain moisture at harvest, -1.2 for root lodging, -9.6 for common smut incidence, and -78.1 for Helminthosporium incidence.
- index IND Genetic values for index IND were computed for all 229 F 3 plants for which genotypes had been previously obtained. None of the 229 F3 plants matched the ideal genotype.
- 229 crosses can be made, given that each plant produces on average only one ear. Which are the best 229 crosses out of the 26,106 theoretically possible ones is the question that needed to be answered. Each cross, if made, would produce a number of different genotypes. These genotypes and their probability of occurrence can be computed from the genotypes of the plants to be crossed. Marker genotypes of the 229 F 3 plants were known therefore whole-genome marker genotypes of the potential progeny of crosses among these F 3 plants can be predicted. The probability of occurrence of each one of these whole-genome progeny genotypes can be computed from recombination distances between marker loci provided by the genetic map. Index values of these whole-genome progeny genotypes can also be computed.
- frequency distributions of index values of progenies can be constructed. These frequency distributions can be used to identify breedings (self-fertilizations or crosses) with high probabilities of generating high genetic value progeny. Quantile values of the frequency distributions are used to compared distributions and identify superior breedings.
- the first round of marker-based selection operated on F 3 plants, for which marker genotypes were generated for the QTL mapping step. Since F 3 plants were not any longer available, hypothetical crosses (or selfs) among F 4 families were evaluated by computing frequency distributions of their progeny's genetic values and the associated quantile values. Seven different indices were used in the selection process.
- An assessment of the F 3 plants involved in the selected crosses (selfs) allowed for the identification of the 12 F 3 plants involved in the largest number of highest value hypothetical crosses (selfs). This completed the first round of marker-based selection. Since F 3 plants were not available any longer F 3 progeny of these 12 selected F 3 plants was used to initiate the second round of marker-based selection.
- EXAMPLE 7 Marker-Based Selection - Maize Round 2 About 45 kernels of each of the 12 selected F 4 families were planted, leaf sampled and genotyped with molecular markers flanking QTLs involved in the selection indices. There were a total of 531 F 4 plants.
- F 4 plants proceeded in a similar manner as selection of F 3 plants.
- Hypothetical crosses (selfs) among the 531 F 4 plants were generated, the genetic value and frequency of occurrence of their progeny computed, and frequency distributions constructed and their quantile values computed. These calculations were done for each of the seven indices (the same as in Round 1 ) used in the selection process. Any hypothetical cross (self) that showed a negative 50% quantife value, for any index, was discarded. This resulted in about 60,000 hypothetical crosses being pre-selected. Genetically similar crosses (selfs), Ae. involving F 4 plants from the same two F 4 families (or single F 4 family in case of selfs) were identified and those with low quantile values were discarded.
- EXAMPLE 8 Marker-Based Selection - Maize Round 3 A total of 551 kernels from the 9 selected Ci families were planted, leaf sampled and genotyped with molecular markers flanking QTLs involved in the selection indices.
- Ci plants proceeded in a similar manner as selection of F 4 plants.
- EXAMPLE 9 Marker-Based Selection - Maize Round 4 A total of 519 kernels from the 9 selected C 2 families were planted, leaf sampled and genotyped with molecular markers flanking QTLs involved in the selection indices.
- C 2 plants proceeded in a similar manner as selection of C 1 plants.
- Hypothetical crosses (selfs) among the 519 C2 plants were generated, the genetic value and frequency of occurrence of their progeny computed, and frequency distributions constructed and their quantile values computed. These calculations were done for each of the seven indices (the same as in previous rounds) used in the selection process. Any hypothetical cross (self) that showed a negative 50% quantile value, for any index, was discarded. This resulted in about 55,000 hypothetical crosses being pre-selected. Genetically similar crosses (selfs), i.e. involving C 2 plants from the same two C 2 families (or single C 2 family in case of selfs) were identified and those with low quantile values were discarded.
- EXAMPLE 10 Plant Material - Wheat A segregating population was created from crossing two wheat inbred lines, BR25 and FO71. Several plants of one line were crossed with several plants of the other line to produce Fi seed. F 1 kernels were planted. The resulting Fi plants were self-fertilized to produce F 2 seed. About 400 F 2 kernels were planted and F 2 plants were self-fertilized to produce F 3 seed. One and only one F 3 kernel was harvested on each F 2 plant, a commonly-used generation advancement procedure known as single kernel descent (SKD) resulting in a bulk of 400 F 3 kernels. These 400 F3 kernels were planted, and F 3 plants self-fertilized to produce F 4 seed. All F 4 kernels produced on each F 3 plant were harvested, keeping all F 4 kernels harvested separated by F 3 plant of origin, and thereby constituting F 4 families (400).
- SSD single kernel descent
- F 4 plants One row kernels of each F 4 family was planted and F 4 plants self-fertilized in order to increase seed quantities.
- the harvested seed consisted of the F5 generation.
- FsiFs families were available. Leaf tissue of each F3:Fs family was sampled by bulking leaf disk samples from 12 F 5 plants per F 3 :F 5 family. These leaf samples were later used for DNA extraction and genotyping. The genotyped obtained represented the genotypes of the F 3 plants.
- a molecular marker map was constructed using the commonly used software Mapmaker. Joint-analysis of genotypic and phenotypic data was performed using the software QTLCartographer and PlabQTL. More than fifty QTLs were identified for all traits. In particular, 11 QTLs were identified for grain yield, and 12 for the SDS sedimentation test. QTLs were characterized by their position on the genetic map, and their additive effect. Positions were defined as genetic distances (in centimorgans - cM) between the most likely position of the QTLs (usually the position of the peak LOD score value) and flanking marker loci. Additive effects are defined as deviations from the mean and are expressed in the same unit as the trait they refer to.
- Additive values define which of the two parental lines carries the favorable allele at the QTL.
- additive values represent the effect of the allele carried by FO71 , whether positive or negative.
- a positive additive value means that FO71 carries the favorable allele and BR25 the unfavourable one.
- a negative additive value means that BR25 carries the favorable allele and FO71 the unfavourable one.
- EXAMPLE 13 Selection Indices, Genetic Values, and ideal Genotype - Wheat Based on the QTLs identified, selection indices were defined. These selection indices were then applied to the plants' QTL genotypes, to compute these plants' genetic values. Genetic value (GV) of a plant was computed as follows, based on the plant's QTL genotype: where ⁇ , is the weight (economic value) of trait t, a ⁇ is the effect of the favorable allele at QTL q of trait t (usually the additive value of the QTL), p ⁇ is the probability of occurrence of genotype i at QTL q of trait t, and ⁇ i ⁇ is the selection value of QTL genotype i at QTL q of trait t. c an be considered as the QTL genetic value (QTL q of trait t). c a ⁇ be considered as the trait value (trait t).
- Selection values of the QTL genotypes can be given arbitrary values.
- selection values of the QTLs were assigned the following values:
- index IND Genetic values for index IND were computed for ail 400 F 3 plants for which genotypes had been previously obtained. None of the plants matched the ideal genotype.
- genotypes of these 400 F 3 plants indicated that the ideal genotype could be obtained by successive cycles of crosses among plants.
- the challenge was to identify the crosses, from all possible ones, which would be the best crosses in terms of allowing individuals having genotypes identical or similar to that of the ideal genotype to develop.
- Each cross, if made, would produce a number of different genotypes.
- These genotypes and their probability of occurrence can be computed from the genotypes of the plants to be crossed.
- Marker genotypes of the 400 F 3 plants were known therefore whole-genome marker genotypes of the potential progeny of crosses among these F 3 plants can be predicted.
- the probability of occurrence of each one of these whole-genome progeny genotypes can be computed from recombination distances between marker loci provided by the genetic map. Index values of these whole-genome progeny genotypes can also be computed. Once these index vales are taken into consideration with their probabilities of occurrence, frequency distributions of index values of progenies can be constructed. These frequency distributions can be used to identify matings (self-fertilizations or crosses) with high probabilities of generating high genetic value progeny. Quantile values of the frequency distributions are used to compared distributions and identify superior matings.
- EXAMPLE 15 Marker-Based Selection - Wheat Round 1 The first round of marker-based selection operated on F 3 plants, for which marker genotypes were generated for the QTL mapping step. Since F 3 plants were not any longer available, hypothetical crosses (or selfs) among F 4 or Fg families were evaluated by computing frequency distributions of their progeny's genetic values and the associated quantile values. One index, IND was used in the selection process.
- Any hypothetical cross (self) that showed a negative 50% quantile value for index IND was discarded resulting in several hypothetical crosses being pre-selected. Preselected hypothetical crosses (selfs) with the highest values for index IND were further selected, resulting in 40 final selections.
- An assessment of the F 3 plants involved in the selected crosses (selfs) allowed for the identification of the 15 F 3 plants involved in the largest number of highest value hypothetical crosses (selfs). This completed the first round of marker-based selection. Since F3 plants were not available any longer F 5 progeny of these 15 selected F 3 plants was used to initiate the second round of marker-based selection.
- a total of 540 kernels from the 18 selected Ci families were planted, leaf sampled and genotyped with molecular markers flanking QTLs involved in the selection index.
- Ci plants proceeded in a similar manner as selection of F 5 plants.
- the presently disclosed subject matter relates in some embodiments to the selection of plants to be crossed or selfed based on the characteristics of their potential progeny.
- Progeny characteristics include their individual genotypes, probabilities of occurrence of these individual genotypes, and genetic values of these genotypes, as well as overall progeny characteristics such as the frequency distribution of genetic values and corresponding quantiie values.
- Progeny characteristics can be calculated rather than estimated through simulation.
- Progeny can be the immediate product of a specific cross or self or the product of a specific cross or self followed by several generations of self- fertilizing or crossing. Marker-trait associations are not limited to QTL but also include genes.
- the population to which the presently disclosed subject matter can be applied can be any type of population, in some embodiments a bi-parental (bi-allelic) population, although this is not necessary.
- a bi-parental population in some embodiments a bi-parental population, although this is not necessary.
- various algorithms and software have been developed for the bi-allelic situation, but development of algorithms and software for rnulti- allelic situations are also provided in accordance with the presently disclosed subject matter.
- the population can be F 2 individuals or any F n generation.
- C1 and C2 plants as illustrated in the above EXAMPLES, constitute segregating populations where individuals can have either homozygous or heterozygous genotypes at any locus.
- the population of plants to which marker-based selection is applied can be the same generation as that used to establish marker-trait (genotype- phenotype) associations.
- the presently disclosed methods also apply to situations where the marker-trait associations have been established on populations independent from those where marker-based selection is applied. Marker-trait associations can even come from several independent populations. For instance, one might have conducted QTL mapping projects which have resulted in marker-trait associations. Published experiments run at public institutions might have also resulted in marker-trait associations. Finally, information about genes, including map positions and sequence polymorphism (haplotypes) might also be available. All this information, marker-trait associations from internal experiments, external experiments, as well as gene information, can be used to conduct marker-based selection in another population. The number of consecutive generations to which the presently disclosed subject matter can be applied is unlimited.
- the presently disclosed subject matter can be applied to any species, not limited to plants.
- references listed in the instant disclosure including but not limited to all patents, patent applications and publications thereof, scientific journal articles, and database entries (e.g., GENBANK® database entries and all annotations available therein) are incorporated herein by reference in their entireties to the extent that they supplement, explain, provide a background for, or teach methodology, techniques, and/or compositions employed herein.
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Physics & Mathematics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Theoretical Computer Science (AREA)
- Analytical Chemistry (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Biophysics (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Medical Informatics (AREA)
- Biotechnology (AREA)
- Chemical & Material Sciences (AREA)
- Botany (AREA)
- Developmental Biology & Embryology (AREA)
- Environmental Sciences (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Breeding Of Plants And Reproduction By Means Of Culturing (AREA)
Abstract
Description












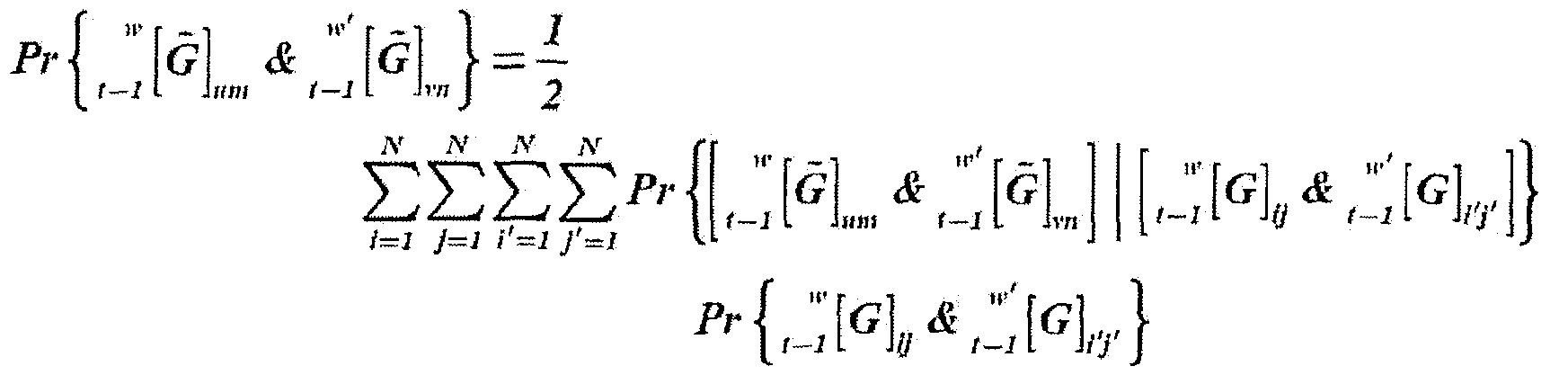





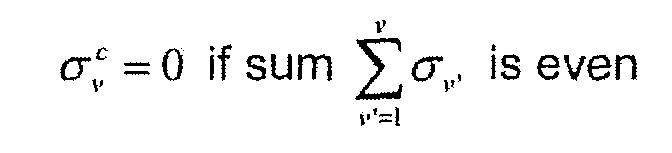





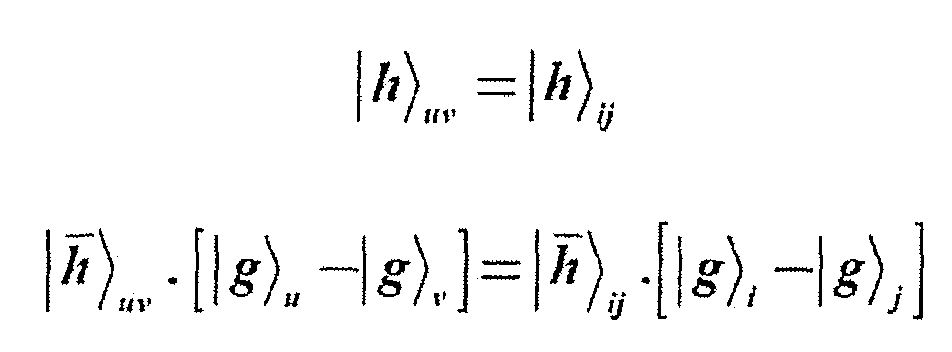



















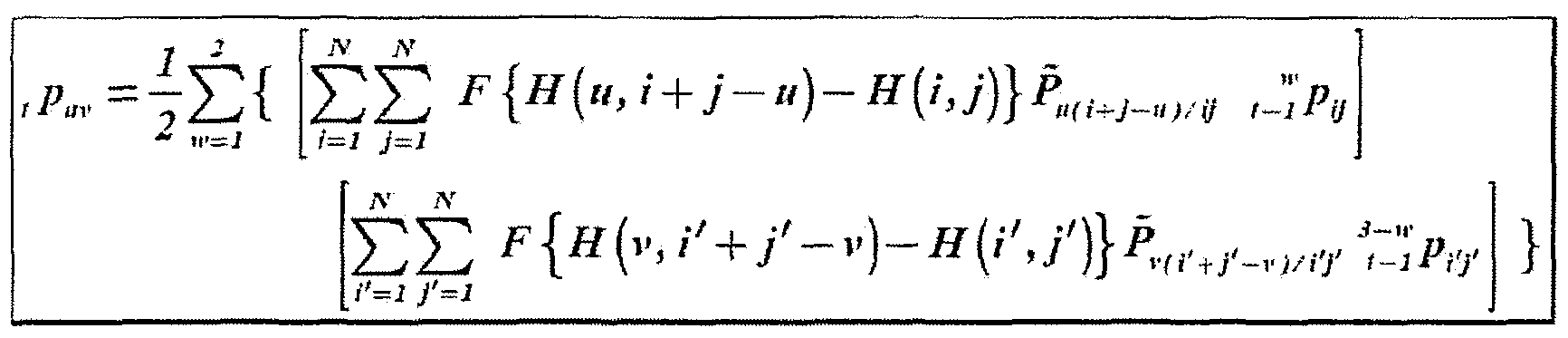









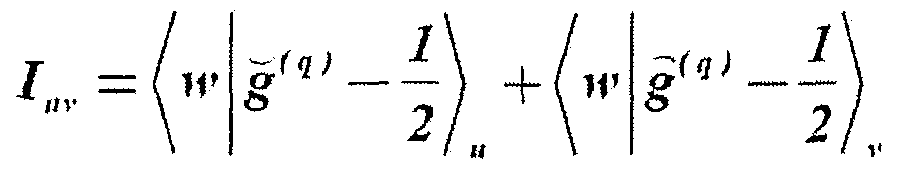

















Claims
Priority Applications (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| MX2009007371A MX2009007371A (en) | 2007-01-17 | 2008-01-17 | Process for selecting individuals and designing a breeding program. |
| CA002674791A CA2674791A1 (en) | 2007-01-17 | 2008-01-17 | Process for selecting individuals and designing a breeding program |
| EP08707951A EP2140388A1 (en) | 2007-01-17 | 2008-01-17 | Process for selecting individuals and designing a breeding program |
| AU2008206924A AU2008206924B2 (en) | 2007-01-17 | 2008-01-17 | Process for selecting individuals and designing a breeding program |
| BRPI0806919-0A BRPI0806919A2 (en) | 2007-01-17 | 2008-01-17 | PROCESS TO SELECT INDIVIDUALS AND DESIGN A REPRODUCTION PROGRAM |
| CN2008800024634A CN101583956B (en) | 2007-01-17 | 2008-01-17 | Process for selecting individuals and designing a breeding program |
| ZA2009/04441A ZA200904441B (en) | 2007-01-17 | 2009-06-25 | Process for selecting individuals and designing a breeding program |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP07290060A EP1962212A1 (en) | 2007-01-17 | 2007-01-17 | Process for selecting individuals and designing a breeding program |
| EP07290060.8 | 2007-01-17 | ||
| EP07002818 | 2007-02-09 | ||
| EP07002818.8 | 2007-02-09 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2008087185A1 true WO2008087185A1 (en) | 2008-07-24 |
Family
ID=39635674
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/EP2008/050503 WO2008087185A1 (en) | 2007-01-17 | 2008-01-17 | Process for selecting individuals and designing a breeding program |
Country Status (7)
| Country | Link |
|---|---|
| EP (2) | EP2140388A1 (en) |
| AU (1) | AU2008206924B2 (en) |
| BR (1) | BRPI0806919A2 (en) |
| CA (1) | CA2674791A1 (en) |
| MX (1) | MX2009007371A (en) |
| WO (1) | WO2008087185A1 (en) |
| ZA (1) | ZA200904441B (en) |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102242186A (en) * | 2010-05-11 | 2011-11-16 | 山东省果树研究所 | Two color-related mutations in apple MdMYB1 gene and detection method thereof |
| EP2491170A1 (en) * | 2009-10-20 | 2012-08-29 | Genepeeks, Inc. | Methods and systems for pre-conceptual prediction of progeny attributes |
| CN102952851A (en) * | 2011-08-23 | 2013-03-06 | 中国检验检疫科学研究院 | Primer for detecting kind and/or purity of malting barley, and kit and method thereof |
| CN103614373A (en) * | 2013-10-16 | 2014-03-05 | 山东省果树研究所 | Mutation, relevant to precocity fruiting character, in Malus domestica Borkh MdMYB1 genes, and identification method of mutation |
| US8874420B2 (en) | 2010-11-30 | 2014-10-28 | Syngenta Participations Ag | Methods for increasing genetic gain in a breeding population |
| EP3158486A4 (en) * | 2014-06-17 | 2018-02-14 | Genepeeks, Inc. | Evolutionary models of multiple sequence alignments to predict offspring fitness prior to conception |
| CN112126699A (en) * | 2020-09-15 | 2020-12-25 | 中国农业大学 | Malus plant complete genome InDel marker genotype database and application thereof in germplasm resource specificity identification |
| CN112514790A (en) * | 2020-11-27 | 2021-03-19 | 上海师范大学 | Rice molecular navigation breeding method and application |
| US11627710B2 (en) | 2017-12-10 | 2023-04-18 | Monsanto Technology Llc | Methods and systems for identifying hybrids for use in plant breeding |
| CN117133354A (en) * | 2023-08-29 | 2023-11-28 | 北京林业大学 | Method for efficiently identifying key breeding gene modules of forest tree |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5492547A (en) * | 1993-09-14 | 1996-02-20 | Dekalb Genetics Corp. | Process for predicting the phenotypic trait of yield in maize |
| US20050144664A1 (en) * | 2003-05-28 | 2005-06-30 | Pioneer Hi-Bred International, Inc. | Plant breeding method |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0306139A3 (en) | 1987-08-04 | 1989-09-27 | Native Plants Incorporated | Identification, localization and introgression into plants of desired multigenic traits |
| US6399855B1 (en) | 1997-12-22 | 2002-06-04 | Pioneer Hi-Bred International, Inc. | QTL mapping in plant breeding populations |
| AU2002346242A1 (en) | 2001-06-05 | 2002-12-16 | The Curators Of The University Of Missouri | Chromosome doubling method |
-
2008
- 2008-01-17 WO PCT/EP2008/050503 patent/WO2008087185A1/en active Application Filing
- 2008-01-17 MX MX2009007371A patent/MX2009007371A/en active IP Right Grant
- 2008-01-17 AU AU2008206924A patent/AU2008206924B2/en not_active Ceased
- 2008-01-17 EP EP08707951A patent/EP2140388A1/en not_active Ceased
- 2008-01-17 BR BRPI0806919-0A patent/BRPI0806919A2/en not_active IP Right Cessation
- 2008-01-17 EP EP12161199A patent/EP2541451A3/en not_active Withdrawn
- 2008-01-17 CA CA002674791A patent/CA2674791A1/en not_active Abandoned
-
2009
- 2009-06-25 ZA ZA2009/04441A patent/ZA200904441B/en unknown
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5492547A (en) * | 1993-09-14 | 1996-02-20 | Dekalb Genetics Corp. | Process for predicting the phenotypic trait of yield in maize |
| US5492547B1 (en) * | 1993-09-14 | 1998-06-30 | Dekalb Genetics Corp | Process for predicting the phenotypic trait of yield in maize |
| US20050144664A1 (en) * | 2003-05-28 | 2005-06-30 | Pioneer Hi-Bred International, Inc. | Plant breeding method |
Non-Patent Citations (5)
| Title |
|---|
| FRISCH M ET AL: "PLABSIM: Software for Simulation of Marker-Assisted Backcrossing", JOURNAL OF HEREDITY, OXFORD UNIVERSITY PRESS, CARY, GB, vol. 91, 1 January 2000 (2000-01-01), pages 86 - 87, XP007902079, ISSN: 0022-1503 * |
| HOSPITAL F ET AL: "A GENERAL ALGORITHM TO COMPUTE MULTILOCUS GENOTYPE FREQUENCIES UNDER VARIOUS MATING SYSTEMS", CABIOS COMPUTER APPLICATIONS IN THE BIOSCIENCES, IRL PRESS,OXFORD, GB, vol. 12, no. 6, 1 January 1996 (1996-01-01), pages 455 - 462, XP009082303, ISSN: 0266-7061 * |
| MATTHIAS FRISCH ET AL: "Marker-Based Prediction of the Parental Genome Contribution to Inbred Lines Derived From Biparental Crosses", GENETICS, GENETICS SOCIETY OF AMERICA, AUSTIN, TX, US, vol. 174, 1 October 2006 (2006-10-01), pages 795 - 803, XP007902081, ISSN: 0016-6731 * |
| MAURER H P ET AL: "PLABSOFT: SOFTWARE FOR SIMULATION AND DATA ANALYSIS IN PLANT BREEDING", PROCEEDINGS OF THE EUCARPIA GENERAL CONGRESS, X, XX, no. 17TH, 1 January 2004 (2004-01-01), pages 359 - 362, XP009083615 * |
| SERVIN B ET AL: "MDM: A Program to Compute Fully Informative Genotype Frequencies in Complex Breeding Schemes", JOURNAL OF HEREDITY, OXFORD UNIVERSITY PRESS, CARY, GB, vol. 93, no. 3, 1 January 2002 (2002-01-01), pages 227 - 228, XP007902080, ISSN: 0022-1503 * |
Cited By (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10916332B2 (en) | 2009-10-20 | 2021-02-09 | Ancestry.Com Dna, Llc | Methods and systems for generating a virtual progeny genome |
| EP2491170A1 (en) * | 2009-10-20 | 2012-08-29 | Genepeeks, Inc. | Methods and systems for pre-conceptual prediction of progeny attributes |
| EP2491170A4 (en) * | 2009-10-20 | 2014-10-22 | Genepeeks Inc | Methods and systems for pre-conceptual prediction of progeny attributes |
| CN102242186B (en) * | 2010-05-11 | 2013-06-26 | 山东省果树研究所 | Two color-related mutations in apple MdMYB1 gene and detection method thereof |
| CN102242186A (en) * | 2010-05-11 | 2011-11-16 | 山东省果树研究所 | Two color-related mutations in apple MdMYB1 gene and detection method thereof |
| US8874420B2 (en) | 2010-11-30 | 2014-10-28 | Syngenta Participations Ag | Methods for increasing genetic gain in a breeding population |
| CN102952851A (en) * | 2011-08-23 | 2013-03-06 | 中国检验检疫科学研究院 | Primer for detecting kind and/or purity of malting barley, and kit and method thereof |
| CN103614373A (en) * | 2013-10-16 | 2014-03-05 | 山东省果树研究所 | Mutation, relevant to precocity fruiting character, in Malus domestica Borkh MdMYB1 genes, and identification method of mutation |
| CN103614373B (en) * | 2013-10-16 | 2017-11-17 | 山东省果树研究所 | The mutation related to precocity fruiting character and its authentication method in apple MdMYB1 genes |
| EP3158486A4 (en) * | 2014-06-17 | 2018-02-14 | Genepeeks, Inc. | Evolutionary models of multiple sequence alignments to predict offspring fitness prior to conception |
| US11627710B2 (en) | 2017-12-10 | 2023-04-18 | Monsanto Technology Llc | Methods and systems for identifying hybrids for use in plant breeding |
| CN112126699A (en) * | 2020-09-15 | 2020-12-25 | 中国农业大学 | Malus plant complete genome InDel marker genotype database and application thereof in germplasm resource specificity identification |
| CN112126699B (en) * | 2020-09-15 | 2022-03-01 | 中国农业大学 | Malus plant complete genome InDel marker genotype database and application thereof in germplasm resource specificity identification |
| CN112514790A (en) * | 2020-11-27 | 2021-03-19 | 上海师范大学 | Rice molecular navigation breeding method and application |
| CN112514790B (en) * | 2020-11-27 | 2022-04-01 | 上海师范大学 | Rice molecular navigation breeding method and application |
| CN117133354A (en) * | 2023-08-29 | 2023-11-28 | 北京林业大学 | Method for efficiently identifying key breeding gene modules of forest tree |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2008206924B2 (en) | 2013-02-07 |
| EP2541451A2 (en) | 2013-01-02 |
| ZA200904441B (en) | 2011-11-30 |
| EP2541451A3 (en) | 2013-03-13 |
| BRPI0806919A2 (en) | 2014-04-29 |
| AU2008206924A1 (en) | 2008-07-24 |
| MX2009007371A (en) | 2009-07-16 |
| EP2140388A1 (en) | 2010-01-06 |
| CA2674791A1 (en) | 2008-07-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20150080238A1 (en) | Process for selecting individuals and designing a breeding program | |
| AU2008206924B2 (en) | Process for selecting individuals and designing a breeding program | |
| Slater et al. | Improving genetic gain with genomic selection in autotetraploid potato | |
| Austerlitz et al. | Using genetic markers to estimate the pollen dispersal curve | |
| Heffner et al. | Genomic selection accuracy using multifamily prediction models in a wheat breeding program | |
| Hung et al. | The relationship between parental genetic or phenotypic divergence and progeny variation in the maize nested association mapping population | |
| CA2750225C (en) | Method for selecting statistically validated candidate genes | |
| US8874420B2 (en) | Methods for increasing genetic gain in a breeding population | |
| Jia et al. | Genomic prediction for 25 agronomic and quality traits in alfalfa (Medicago sativa) | |
| Pace et al. | Genomic prediction of seedling root length in maize (Zea mays L.) | |
| Vinson et al. | Using molecular markers to investigate genetic diversity, mating system and gene flow of Neotropical trees | |
| Souza et al. | Genomic selection in rubber tree breeding: a comparison of models and methods for managing G× E interactions | |
| Matsubara et al. | Improvement of rice biomass yield through QTL-based selection | |
| EP2577536A2 (en) | Methods and compositions for predicting unobserved phenotypes (pup) | |
| Colicchio et al. | Individualized mating system estimation using genomic data | |
| Kong et al. | Transmission genetics of a Sorghum bicolor× S. halepense backcross populations | |
| Pégard et al. | Genome-wide genotyping data renew knowledge on genetic diversity of a worldwide alfalfa collection and give insights on genetic control of phenology traits | |
| Oztolan-Erol et al. | Unraveling genetic diversity amongst European hazelnut (Corylus avellana L.) varieties in Turkey | |
| Odell et al. | Modeling allelic diversity of multiparent mapping populations affects detection of quantitative trait loci | |
| Alvarez-Castro et al. | Modelling of genetic interactions improves prediction of hybrid patterns–a case study in domestic fowl | |
| Zhang et al. | Telomere-to-telomere Citrullus super-pangenome provides direction for watermelon breeding | |
| Sleper et al. | Genomewide selection for unfavorably correlated traits in maize | |
| Wu | Mapping quantitative trait loci by genotyping haploid tissues | |
| Ledesma et al. | Molecular characterization of doubled haploid lines derived from different cycles of the Iowa Stiff Stalk Synthetic (BSSS) maize population | |
| Hasan et al. | Reticulate Evolution in AA-Genome Wild Rice in Australia |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 200880002463.4 Country of ref document: CN |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 08707951 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2008206924 Country of ref document: AU |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2674791 Country of ref document: CA |
|
| WWE | Wipo information: entry into national phase |
Ref document number: MX/A/2009/007371 Country of ref document: MX |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2008206924 Country of ref document: AU Date of ref document: 20080117 Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2008707951 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: PI0806919 Country of ref document: BR Kind code of ref document: A2 Effective date: 20090717 |