WO2007089601A2 - Nogo receptor antagonists - Google Patents
Nogo receptor antagonists Download PDFInfo
- Publication number
- WO2007089601A2 WO2007089601A2 PCT/US2007/002199 US2007002199W WO2007089601A2 WO 2007089601 A2 WO2007089601 A2 WO 2007089601A2 US 2007002199 W US2007002199 W US 2007002199W WO 2007089601 A2 WO2007089601 A2 WO 2007089601A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- polypeptide
- seq
- amino acids
- amino acid
- acid sequence
- Prior art date
Links
- 229940116506 Nogo receptor antagonist Drugs 0.000 title abstract description 3
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 611
- 102000004196 processed proteins & peptides Human genes 0.000 claims abstract description 588
- 229920001184 polypeptide Polymers 0.000 claims abstract description 581
- 239000012634 fragment Substances 0.000 claims abstract description 281
- 238000000034 method Methods 0.000 claims abstract description 177
- 102000040430 polynucleotide Human genes 0.000 claims abstract description 86
- 108091033319 polynucleotide Proteins 0.000 claims abstract description 86
- 239000002157 polynucleotide Substances 0.000 claims abstract description 85
- 239000000203 mixture Substances 0.000 claims abstract description 35
- 102000005781 Nogo Receptor Human genes 0.000 claims abstract description 28
- 108020003872 Nogo receptor Proteins 0.000 claims abstract description 28
- 235000001014 amino acid Nutrition 0.000 claims description 405
- 150000001413 amino acids Chemical class 0.000 claims description 336
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 230
- 210000004027 cell Anatomy 0.000 claims description 106
- 241000282414 Homo sapiens Species 0.000 claims description 82
- 238000006467 substitution reaction Methods 0.000 claims description 74
- 239000013598 vector Substances 0.000 claims description 54
- 230000014511 neuron projection development Effects 0.000 claims description 51
- 210000002569 neuron Anatomy 0.000 claims description 50
- 239000004055 small Interfering RNA Substances 0.000 claims description 45
- 230000005764 inhibitory process Effects 0.000 claims description 42
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 claims description 41
- 230000014509 gene expression Effects 0.000 claims description 38
- 230000001404 mediated effect Effects 0.000 claims description 37
- 125000003729 nucleotide group Chemical group 0.000 claims description 30
- -1 amino acids amino acids Chemical class 0.000 claims description 28
- 239000002773 nucleotide Substances 0.000 claims description 28
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 claims description 23
- 108020004459 Small interfering RNA Proteins 0.000 claims description 23
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 23
- 238000011282 treatment Methods 0.000 claims description 23
- 241000124008 Mammalia Species 0.000 claims description 22
- 108091027967 Small hairpin RNA Proteins 0.000 claims description 22
- 210000003169 central nervous system Anatomy 0.000 claims description 18
- 239000002202 Polyethylene glycol Substances 0.000 claims description 17
- 229960004584 methylprednisolone Drugs 0.000 claims description 17
- 229920001223 polyethylene glycol Polymers 0.000 claims description 17
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 16
- 108020004999 messenger RNA Proteins 0.000 claims description 16
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 claims description 15
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 claims description 15
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 claims description 14
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 claims description 14
- 235000004279 alanine Nutrition 0.000 claims description 14
- 125000004122 cyclic group Chemical group 0.000 claims description 14
- 235000018417 cysteine Nutrition 0.000 claims description 14
- 239000003795 chemical substances by application Substances 0.000 claims description 13
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 claims description 13
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 claims description 12
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 claims description 12
- 239000004473 Threonine Substances 0.000 claims description 12
- 208000027418 Wounds and injury Diseases 0.000 claims description 12
- 201000010099 disease Diseases 0.000 claims description 12
- JYGXADMDTFJGBT-VWUMJDOOSA-N hydrocortisone Chemical compound O=C1CC[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 JYGXADMDTFJGBT-VWUMJDOOSA-N 0.000 claims description 12
- 230000002401 inhibitory effect Effects 0.000 claims description 12
- 208000014674 injury Diseases 0.000 claims description 12
- 230000001737 promoting effect Effects 0.000 claims description 12
- 230000000295 complement effect Effects 0.000 claims description 11
- 230000006378 damage Effects 0.000 claims description 11
- 208000035475 disorder Diseases 0.000 claims description 11
- 125000003827 glycol group Chemical group 0.000 claims description 10
- 229920001515 polyalkylene glycol Polymers 0.000 claims description 10
- 208000020431 spinal cord injury Diseases 0.000 claims description 10
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 claims description 9
- 210000004899 c-terminal region Anatomy 0.000 claims description 9
- 229960005205 prednisolone Drugs 0.000 claims description 9
- OIGNJSKKLXVSLS-VWUMJDOOSA-N prednisolone Chemical compound O=C1C=C[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 OIGNJSKKLXVSLS-VWUMJDOOSA-N 0.000 claims description 9
- 239000002294 steroidal antiinflammatory agent Substances 0.000 claims description 9
- 235000020958 biotin Nutrition 0.000 claims description 8
- 229960002685 biotin Drugs 0.000 claims description 8
- 239000011616 biotin Substances 0.000 claims description 8
- 201000006417 multiple sclerosis Diseases 0.000 claims description 8
- 230000028327 secretion Effects 0.000 claims description 7
- 108010011170 Ala-Trp-Arg-His-Pro-Gln-Phe-Gly-Gly Proteins 0.000 claims description 6
- HVLSXIKZNLPZJJ-TXZCQADKSA-N HA peptide Chemical compound C([C@@H](C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 HVLSXIKZNLPZJJ-TXZCQADKSA-N 0.000 claims description 6
- 101710135898 Myc proto-oncogene protein Proteins 0.000 claims description 6
- 102100038895 Myc proto-oncogene protein Human genes 0.000 claims description 6
- MITFXPHMIHQXPI-UHFFFAOYSA-N Oraflex Chemical compound N=1C2=CC(C(C(O)=O)C)=CC=C2OC=1C1=CC=C(Cl)C=C1 MITFXPHMIHQXPI-UHFFFAOYSA-N 0.000 claims description 6
- 102000007562 Serum Albumin Human genes 0.000 claims description 6
- 108010071390 Serum Albumin Proteins 0.000 claims description 6
- 101710150448 Transcriptional regulator Myc Proteins 0.000 claims description 6
- 229940121363 anti-inflammatory agent Drugs 0.000 claims description 6
- 239000002260 anti-inflammatory agent Substances 0.000 claims description 6
- CBGUOGMQLZIXBE-XGQKBEPLSA-N clobetasol propionate Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)CCl)(OC(=O)CC)[C@@]1(C)C[C@@H]2O CBGUOGMQLZIXBE-XGQKBEPLSA-N 0.000 claims description 6
- GAKMQHDJQHZUTJ-ULHLPKEOSA-N fluocortolone Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@@H]1[C@@H]2[C@@H]2C[C@@H](C)[C@H](C(=O)CO)[C@@]2(C)C[C@@H]1O GAKMQHDJQHZUTJ-ULHLPKEOSA-N 0.000 claims description 6
- 229960000890 hydrocortisone Drugs 0.000 claims description 6
- CGIGDMFJXJATDK-UHFFFAOYSA-N indomethacin Chemical compound CC1=C(CC(O)=O)C2=CC(OC)=CC=C2N1C(=O)C1=CC=C(Cl)C=C1 CGIGDMFJXJATDK-UHFFFAOYSA-N 0.000 claims description 6
- 239000000041 non-steroidal anti-inflammatory agent Substances 0.000 claims description 6
- 229940021182 non-steroidal anti-inflammatory drug Drugs 0.000 claims description 6
- 241000712461 unidentified influenza virus Species 0.000 claims description 6
- QWOJMRHUQHTCJG-UHFFFAOYSA-N CC([CH2-])=O Chemical compound CC([CH2-])=O QWOJMRHUQHTCJG-UHFFFAOYSA-N 0.000 claims description 5
- 206010002026 amyotrophic lateral sclerosis Diseases 0.000 claims description 5
- 239000003937 drug carrier Substances 0.000 claims description 5
- 230000011664 signaling Effects 0.000 claims description 5
- 208000024827 Alzheimer disease Diseases 0.000 claims description 4
- 108090000994 Catalytic RNA Proteins 0.000 claims description 4
- 102000053642 Catalytic RNA Human genes 0.000 claims description 4
- 208000023105 Huntington disease Diseases 0.000 claims description 4
- 208000018737 Parkinson disease Diseases 0.000 claims description 4
- 208000006011 Stroke Diseases 0.000 claims description 4
- 208000030886 Traumatic Brain injury Diseases 0.000 claims description 4
- 230000000692 anti-sense effect Effects 0.000 claims description 4
- 108091092562 ribozyme Proteins 0.000 claims description 4
- 230000019491 signal transduction Effects 0.000 claims description 4
- 230000009529 traumatic brain injury Effects 0.000 claims description 4
- 229960005294 triamcinolone Drugs 0.000 claims description 4
- GFNANZIMVAIWHM-OBYCQNJPSA-N triamcinolone Chemical compound O=C1C=C[C@]2(C)[C@@]3(F)[C@@H](O)C[C@](C)([C@@]([C@H](O)C4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 GFNANZIMVAIWHM-OBYCQNJPSA-N 0.000 claims description 4
- RJMIEHBSYVWVIN-LLVKDONJSA-N (2r)-2-[4-(3-oxo-1h-isoindol-2-yl)phenyl]propanoic acid Chemical compound C1=CC([C@H](C(O)=O)C)=CC=C1N1C(=O)C2=CC=CC=C2C1 RJMIEHBSYVWVIN-LLVKDONJSA-N 0.000 claims description 3
- RDJGLLICXDHJDY-NSHDSACASA-N (2s)-2-(3-phenoxyphenyl)propanoic acid Chemical compound OC(=O)[C@@H](C)C1=CC=CC(OC=2C=CC=CC=2)=C1 RDJGLLICXDHJDY-NSHDSACASA-N 0.000 claims description 3
- GUHPRPJDBZHYCJ-SECBINFHSA-N (2s)-2-(5-benzoylthiophen-2-yl)propanoic acid Chemical compound S1C([C@H](C(O)=O)C)=CC=C1C(=O)C1=CC=CC=C1 GUHPRPJDBZHYCJ-SECBINFHSA-N 0.000 claims description 3
- MDKGKXOCJGEUJW-VIFPVBQESA-N (2s)-2-[4-(thiophene-2-carbonyl)phenyl]propanoic acid Chemical compound C1=CC([C@@H](C(O)=O)C)=CC=C1C(=O)C1=CC=CS1 MDKGKXOCJGEUJW-VIFPVBQESA-N 0.000 claims description 3
- FUFLCEKSBBHCMO-UHFFFAOYSA-N 11-dehydrocorticosterone Natural products O=C1CCC2(C)C3C(=O)CC(C)(C(CC4)C(=O)CO)C4C3CCC2=C1 FUFLCEKSBBHCMO-UHFFFAOYSA-N 0.000 claims description 3
- MPDGHEJMBKOTSU-YKLVYJNSSA-N 18beta-glycyrrhetic acid Chemical compound C([C@H]1C2=CC(=O)[C@H]34)[C@@](C)(C(O)=O)CC[C@]1(C)CC[C@@]2(C)[C@]4(C)CC[C@@H]1[C@]3(C)CC[C@H](O)C1(C)C MPDGHEJMBKOTSU-YKLVYJNSSA-N 0.000 claims description 3
- KLIVRBFRQSOGQI-UHFFFAOYSA-N 2-(11-oxo-6h-benzo[c][1]benzothiepin-3-yl)acetic acid Chemical compound S1CC2=CC=CC=C2C(=O)C2=CC=C(CC(=O)O)C=C12 KLIVRBFRQSOGQI-UHFFFAOYSA-N 0.000 claims description 3
- DCXHLPGLBYHNMU-UHFFFAOYSA-N 2-[1-(4-azidobenzoyl)-5-methoxy-2-methylindol-3-yl]acetic acid Chemical compound CC1=C(CC(O)=O)C2=CC(OC)=CC=C2N1C(=O)C1=CC=C(N=[N+]=[N-])C=C1 DCXHLPGLBYHNMU-UHFFFAOYSA-N 0.000 claims description 3
- APBSKHYXXKHJFK-UHFFFAOYSA-N 2-[2-(4-chlorophenyl)-1,3-thiazol-4-yl]acetic acid Chemical compound OC(=O)CC1=CSC(C=2C=CC(Cl)=CC=2)=N1 APBSKHYXXKHJFK-UHFFFAOYSA-N 0.000 claims description 3
- TYCOFFBAZNSQOJ-UHFFFAOYSA-N 2-[4-(3-fluorophenyl)phenyl]propanoic acid Chemical compound C1=CC(C(C(O)=O)C)=CC=C1C1=CC=CC(F)=C1 TYCOFFBAZNSQOJ-UHFFFAOYSA-N 0.000 claims description 3
- JIEKMACRVQTPRC-UHFFFAOYSA-N 2-[4-(4-chlorophenyl)-2-phenyl-5-thiazolyl]acetic acid Chemical compound OC(=O)CC=1SC(C=2C=CC=CC=2)=NC=1C1=CC=C(Cl)C=C1 JIEKMACRVQTPRC-UHFFFAOYSA-N 0.000 claims description 3
- WGDADRBTCPGSDG-UHFFFAOYSA-N 2-[[4,5-bis(4-chlorophenyl)-1,3-oxazol-2-yl]sulfanyl]propanoic acid Chemical compound O1C(SC(C)C(O)=O)=NC(C=2C=CC(Cl)=CC=2)=C1C1=CC=C(Cl)C=C1 WGDADRBTCPGSDG-UHFFFAOYSA-N 0.000 claims description 3
- XKSAJZSJKURQRX-UHFFFAOYSA-N 2-acetyloxy-5-(4-fluorophenyl)benzoic acid Chemical compound C1=C(C(O)=O)C(OC(=O)C)=CC=C1C1=CC=C(F)C=C1 XKSAJZSJKURQRX-UHFFFAOYSA-N 0.000 claims description 3
- FXFBGEDPBBRUFN-UHFFFAOYSA-N 3-chloro-6,6a-dihydro-1ah-indeno[1,2-b]oxirene Chemical compound C12=CC(Cl)=CC=C2CC2C1O2 FXFBGEDPBBRUFN-UHFFFAOYSA-N 0.000 claims description 3
- PJJGZPJJTHBVMX-UHFFFAOYSA-N 5,7-Dihydroxyisoflavone Chemical compound C=1C(O)=CC(O)=C(C2=O)C=1OC=C2C1=CC=CC=C1 PJJGZPJJTHBVMX-UHFFFAOYSA-N 0.000 claims description 3
- BSYNRYMUTXBXSQ-FOQJRBATSA-N 59096-14-9 Chemical compound CC(=O)OC1=CC=CC=C1[14C](O)=O BSYNRYMUTXBXSQ-FOQJRBATSA-N 0.000 claims description 3
- MYYIMZRZXIQBGI-HVIRSNARSA-N 6alpha-Fluoroprednisolone Chemical compound O=C1C=C[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3C[C@H](F)C2=C1 MYYIMZRZXIQBGI-HVIRSNARSA-N 0.000 claims description 3
- OIRAEJWYWSAQNG-UHFFFAOYSA-N Clidanac Chemical compound ClC=1C=C2C(C(=O)O)CCC2=CC=1C1CCCCC1 OIRAEJWYWSAQNG-UHFFFAOYSA-N 0.000 claims description 3
- FBRAWBYQGRLCEK-AVVSTMBFSA-N Clobetasone butyrate Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)CCl)(OC(=O)CCC)[C@@]1(C)CC2=O FBRAWBYQGRLCEK-AVVSTMBFSA-N 0.000 claims description 3
- OMFXVFTZEKFJBZ-UHFFFAOYSA-N Corticosterone Natural products O=C1CCC2(C)C3C(O)CC(C)(C(CC4)C(=O)CO)C4C3CCC2=C1 OMFXVFTZEKFJBZ-UHFFFAOYSA-N 0.000 claims description 3
- MFYSYFVPBJMHGN-ZPOLXVRWSA-N Cortisone Chemical compound O=C1CC[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 MFYSYFVPBJMHGN-ZPOLXVRWSA-N 0.000 claims description 3
- MFYSYFVPBJMHGN-UHFFFAOYSA-N Cortisone Natural products O=C1CCC2(C)C3C(=O)CC(C)(C(CC4)(O)C(=O)CO)C4C3CCC2=C1 MFYSYFVPBJMHGN-UHFFFAOYSA-N 0.000 claims description 3
- 208000032131 Diabetic Neuropathies Diseases 0.000 claims description 3
- HHJIUUAMYGBVSD-YTFFSALGSA-N Diflucortolone valerate Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2C[C@@H](C)[C@H](C(=O)COC(=O)CCCC)[C@@]2(C)C[C@@H]1O HHJIUUAMYGBVSD-YTFFSALGSA-N 0.000 claims description 3
- WYQPLTPSGFELIB-JTQPXKBDSA-N Difluprednate Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2CC[C@@](C(=O)COC(C)=O)(OC(=O)CCC)[C@@]2(C)C[C@@H]1O WYQPLTPSGFELIB-JTQPXKBDSA-N 0.000 claims description 3
- RBBWCVQDXDFISW-UHFFFAOYSA-N Feprazone Chemical compound O=C1C(CC=C(C)C)C(=O)N(C=2C=CC=CC=2)N1C1=CC=CC=C1 RBBWCVQDXDFISW-UHFFFAOYSA-N 0.000 claims description 3
- WJOHZNCJWYWUJD-IUGZLZTKSA-N Fluocinonide Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2C[C@H]3OC(C)(C)O[C@@]3(C(=O)COC(=O)C)[C@@]2(C)C[C@@H]1O WJOHZNCJWYWUJD-IUGZLZTKSA-N 0.000 claims description 3
- MPDGHEJMBKOTSU-UHFFFAOYSA-N Glycyrrhetinsaeure Natural products C12C(=O)C=C3C4CC(C)(C(O)=O)CCC4(C)CCC3(C)C1(C)CCC1C2(C)CCC(O)C1(C)C MPDGHEJMBKOTSU-UHFFFAOYSA-N 0.000 claims description 3
- MUQNGPZZQDCDFT-JNQJZLCISA-N Halcinonide Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H]3OC(C)(C)O[C@@]3(C(=O)CCl)[C@@]1(C)C[C@@H]2O MUQNGPZZQDCDFT-JNQJZLCISA-N 0.000 claims description 3
- YCISZOVUHXIOFY-HKXOFBAYSA-N Halopredone acetate Chemical compound C1([C@H](F)C2)=CC(=O)C(Br)=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2CC[C@](OC(C)=O)(C(=O)COC(=O)C)[C@@]2(C)C[C@@H]1O YCISZOVUHXIOFY-HKXOFBAYSA-N 0.000 claims description 3
- HHZQLQREDATOBM-CODXZCKSSA-M Hydrocortisone Sodium Succinate Chemical compound [Na+].O=C1CC[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)COC(=O)CCC([O-])=O)[C@@H]4[C@@H]3CCC2=C1 HHZQLQREDATOBM-CODXZCKSSA-M 0.000 claims description 3
- BGSOJVFOEQLVMH-UHFFFAOYSA-N Hydrocortisone phosphate Natural products O=C1CCC2(C)C3C(O)CC(C)(C(CC4)(O)C(=O)COP(O)(O)=O)C4C3CCC2=C1 BGSOJVFOEQLVMH-UHFFFAOYSA-N 0.000 claims description 3
- FNFPHNZQOKBKHN-UHFFFAOYSA-N Hydrocortisone tebutate Natural products C1CC2=CC(=O)CCC2(C)C2C1C1CCC(C(=O)COC(=O)CC(C)(C)C)(O)C1(C)CC2O FNFPHNZQOKBKHN-UHFFFAOYSA-N 0.000 claims description 3
- HEFNNWSXXWATRW-UHFFFAOYSA-N Ibuprofen Chemical compound CC(C)CC1=CC=C(C(C)C(O)=O)C=C1 HEFNNWSXXWATRW-UHFFFAOYSA-N 0.000 claims description 3
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 claims description 3
- UETNIIAIRMUTSM-UHFFFAOYSA-N Jacareubin Natural products CC1(C)OC2=CC3Oc4c(O)c(O)ccc4C(=O)C3C(=C2C=C1)O UETNIIAIRMUTSM-UHFFFAOYSA-N 0.000 claims description 3
- SBDNJUWAMKYJOX-UHFFFAOYSA-N Meclofenamic Acid Chemical compound CC1=CC=C(Cl)C(NC=2C(=CC=CC=2)C(O)=O)=C1Cl SBDNJUWAMKYJOX-UHFFFAOYSA-N 0.000 claims description 3
- GZENKSODFLBBHQ-ILSZZQPISA-N Medrysone Chemical compound C([C@@]12C)CC(=O)C=C1[C@@H](C)C[C@@H]1[C@@H]2[C@@H](O)C[C@]2(C)[C@@H](C(C)=O)CC[C@H]21 GZENKSODFLBBHQ-ILSZZQPISA-N 0.000 claims description 3
- CMWTZPSULFXXJA-UHFFFAOYSA-N Naproxen Natural products C1=C(C(C)C(O)=O)C=CC2=CC(OC)=CC=C21 CMWTZPSULFXXJA-UHFFFAOYSA-N 0.000 claims description 3
- JZFPYUNJRRFVQU-UHFFFAOYSA-N Niflumic acid Chemical compound OC(=O)C1=CC=CN=C1NC1=CC=CC(C(F)(F)F)=C1 JZFPYUNJRRFVQU-UHFFFAOYSA-N 0.000 claims description 3
- 208000003435 Optic Neuritis Diseases 0.000 claims description 3
- TVQZAMVBTVNYLA-UHFFFAOYSA-N Pranoprofen Chemical compound C1=CC=C2CC3=CC(C(C(O)=O)C)=CC=C3OC2=N1 TVQZAMVBTVNYLA-UHFFFAOYSA-N 0.000 claims description 3
- HUMXXHTVHHLNRO-KAJVQRHHSA-N Prednisolone tebutate Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(=O)COC(=O)CC(C)(C)C)(O)[C@@]1(C)C[C@@H]2O HUMXXHTVHHLNRO-KAJVQRHHSA-N 0.000 claims description 3
- TZIZWYVVGLXXFV-FLRHRWPCSA-N Triamcinolone hexacetonide Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H]3OC(C)(C)O[C@@]3(C(=O)COC(=O)CC(C)(C)C)[C@@]1(C)C[C@@H]2O TZIZWYVVGLXXFV-FLRHRWPCSA-N 0.000 claims description 3
- FBRAWBYQGRLCEK-UHFFFAOYSA-N [17-(2-chloroacetyl)-9-fluoro-10,13,16-trimethyl-3,11-dioxo-7,8,12,14,15,16-hexahydro-6h-cyclopenta[a]phenanthren-17-yl] butanoate Chemical compound C1CC2=CC(=O)C=CC2(C)C2(F)C1C1CC(C)C(C(=O)CCl)(OC(=O)CCC)C1(C)CC2=O FBRAWBYQGRLCEK-UHFFFAOYSA-N 0.000 claims description 3
- IFXNTPMREPCLFJ-SLPNHVECSA-N [2-[(8s,9s,10r,11s,13s,14s,17r)-11,17-dihydroxy-10,13-dimethyl-16-methylidene-3-oxo-6,7,8,9,11,12,14,15-octahydrocyclopenta[a]phenanthren-17-yl]-2-oxoethyl] 2-(diethylamino)acetate Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC(=C)[C@@](C(=O)COC(=O)CN(CC)CC)(O)[C@@]1(C)C[C@@H]2O IFXNTPMREPCLFJ-SLPNHVECSA-N 0.000 claims description 3
- FNFPHNZQOKBKHN-KAJVQRHHSA-N [2-[(8s,9s,10r,11s,13s,14s,17r)-11,17-dihydroxy-10,13-dimethyl-3-oxo-2,6,7,8,9,11,12,14,15,16-decahydro-1h-cyclopenta[a]phenanthren-17-yl]-2-oxoethyl] 3,3-dimethylbutanoate Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(=O)COC(=O)CC(C)(C)C)(O)[C@@]1(C)C[C@@H]2O FNFPHNZQOKBKHN-KAJVQRHHSA-N 0.000 claims description 3
- 229960004892 acemetacin Drugs 0.000 claims description 3
- FSQKKOOTNAMONP-UHFFFAOYSA-N acemetacin Chemical compound CC1=C(CC(=O)OCC(O)=O)C2=CC(OC)=CC=C2N1C(=O)C1=CC=C(Cl)C=C1 FSQKKOOTNAMONP-UHFFFAOYSA-N 0.000 claims description 3
- 229960005142 alclofenac Drugs 0.000 claims description 3
- ARHWPKZXBHOEEE-UHFFFAOYSA-N alclofenac Chemical compound OC(=O)CC1=CC=C(OCC=C)C(Cl)=C1 ARHWPKZXBHOEEE-UHFFFAOYSA-N 0.000 claims description 3
- 229960001900 algestone Drugs 0.000 claims description 3
- CXDWHYOBSJTRJU-SRWWVFQWSA-N algestone Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1C[C@@H](O)[C@@](C(=O)C)(O)[C@@]1(C)CC2 CXDWHYOBSJTRJU-SRWWVFQWSA-N 0.000 claims description 3
- 229960004663 alminoprofen Drugs 0.000 claims description 3
- FPHLBGOJWPEVME-UHFFFAOYSA-N alminoprofen Chemical compound OC(=O)C(C)C1=CC=C(NCC(C)=C)C=C1 FPHLBGOJWPEVME-UHFFFAOYSA-N 0.000 claims description 3
- 229960003099 amcinonide Drugs 0.000 claims description 3
- ILKJAFIWWBXGDU-MOGDOJJUSA-N amcinonide Chemical compound O([C@@]1([C@H](O2)C[C@@H]3[C@@]1(C[C@H](O)[C@]1(F)[C@@]4(C)C=CC(=O)C=C4CC[C@H]13)C)C(=O)COC(=O)C)C12CCCC1 ILKJAFIWWBXGDU-MOGDOJJUSA-N 0.000 claims description 3
- 229960001671 azapropazone Drugs 0.000 claims description 3
- WOIIIUDZSOLAIW-NSHDSACASA-N azapropazone Chemical compound C1=C(C)C=C2N3C(=O)[C@H](CC=C)C(=O)N3C(N(C)C)=NC2=C1 WOIIIUDZSOLAIW-NSHDSACASA-N 0.000 claims description 3
- 229940092705 beclomethasone Drugs 0.000 claims description 3
- NBMKJKDGKREAPL-DVTGEIKXSA-N beclomethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(Cl)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O NBMKJKDGKREAPL-DVTGEIKXSA-N 0.000 claims description 3
- 229960005430 benoxaprofen Drugs 0.000 claims description 3
- 229960002537 betamethasone Drugs 0.000 claims description 3
- UREBDLICKHMUKA-DVTGEIKXSA-N betamethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O UREBDLICKHMUKA-DVTGEIKXSA-N 0.000 claims description 3
- 229960004311 betamethasone valerate Drugs 0.000 claims description 3
- SNHRLVCMMWUAJD-SUYDQAKGSA-N betamethasone valerate Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)CO)(OC(=O)CCCC)[C@@]1(C)C[C@@H]2O SNHRLVCMMWUAJD-SUYDQAKGSA-N 0.000 claims description 3
- IJTPQQVCKPZIMV-UHFFFAOYSA-N bucloxic acid Chemical compound ClC1=CC(C(=O)CCC(=O)O)=CC=C1C1CCCCC1 IJTPQQVCKPZIMV-UHFFFAOYSA-N 0.000 claims description 3
- 229950005608 bucloxic acid Drugs 0.000 claims description 3
- 229960003184 carprofen Drugs 0.000 claims description 3
- IVUMCTKHWDRRMH-UHFFFAOYSA-N carprofen Chemical compound C1=CC(Cl)=C[C]2C3=CC=C(C(C(O)=O)C)C=C3N=C21 IVUMCTKHWDRRMH-UHFFFAOYSA-N 0.000 claims description 3
- 229950006229 chloroprednisone Drugs 0.000 claims description 3
- 229950010886 clidanac Drugs 0.000 claims description 3
- 229960002842 clobetasol Drugs 0.000 claims description 3
- 229960004703 clobetasol propionate Drugs 0.000 claims description 3
- 229960001146 clobetasone Drugs 0.000 claims description 3
- 229960005465 clobetasone butyrate Drugs 0.000 claims description 3
- 229960004299 clocortolone Drugs 0.000 claims description 3
- 229960002219 cloprednol Drugs 0.000 claims description 3
- YTJIBEDMAQUYSZ-FDNPDPBUSA-N cloprednol Chemical compound O=C1C=C[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3C=C(Cl)C2=C1 YTJIBEDMAQUYSZ-FDNPDPBUSA-N 0.000 claims description 3
- OMFXVFTZEKFJBZ-HJTSIMOOSA-N corticosterone Chemical compound O=C1CC[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@H](CC4)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 OMFXVFTZEKFJBZ-HJTSIMOOSA-N 0.000 claims description 3
- BMCQMVFGOVHVNG-TUFAYURCSA-N cortisol 17-butyrate Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(=O)CO)(OC(=O)CCC)[C@@]1(C)C[C@@H]2O BMCQMVFGOVHVNG-TUFAYURCSA-N 0.000 claims description 3
- ALEXXDVDDISNDU-JZYPGELDSA-N cortisol 21-acetate Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(=O)COC(=O)C)(O)[C@@]1(C)C[C@@H]2O ALEXXDVDDISNDU-JZYPGELDSA-N 0.000 claims description 3
- BGSOJVFOEQLVMH-VWUMJDOOSA-N cortisol phosphate Chemical compound O=C1CC[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)COP(O)(O)=O)[C@@H]4[C@@H]3CCC2=C1 BGSOJVFOEQLVMH-VWUMJDOOSA-N 0.000 claims description 3
- 229960004544 cortisone Drugs 0.000 claims description 3
- 229960003840 cortivazol Drugs 0.000 claims description 3
- RKHQGWMMUURILY-UHRZLXHJSA-N cortivazol Chemical compound C([C@H]1[C@@H]2C[C@H]([C@]([C@@]2(C)C[C@H](O)[C@@H]1[C@@]1(C)C2)(O)C(=O)COC(C)=O)C)=C(C)C1=CC1=C2C=NN1C1=CC=CC=C1 RKHQGWMMUURILY-UHRZLXHJSA-N 0.000 claims description 3
- 229960003662 desonide Drugs 0.000 claims description 3
- WBGKWQHBNHJJPZ-LECWWXJVSA-N desonide Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@@H]2[C@@H]1[C@@H]1C[C@H]3OC(C)(C)O[C@@]3(C(=O)CO)[C@@]1(C)C[C@@H]2O WBGKWQHBNHJJPZ-LECWWXJVSA-N 0.000 claims description 3
- 229960003957 dexamethasone Drugs 0.000 claims description 3
- UREBDLICKHMUKA-CXSFZGCWSA-N dexamethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O UREBDLICKHMUKA-CXSFZGCWSA-N 0.000 claims description 3
- 229960001259 diclofenac Drugs 0.000 claims description 3
- DCOPUUMXTXDBNB-UHFFFAOYSA-N diclofenac Chemical compound OC(=O)CC1=CC=CC=C1NC1=C(Cl)C=CC=C1Cl DCOPUUMXTXDBNB-UHFFFAOYSA-N 0.000 claims description 3
- 229960004154 diflorasone Drugs 0.000 claims description 3
- 229960004091 diflucortolone Drugs 0.000 claims description 3
- OGPWIDANBSLJPC-RFPWEZLHSA-N diflucortolone Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2C[C@@H](C)[C@H](C(=O)CO)[C@@]2(C)C[C@@H]1O OGPWIDANBSLJPC-RFPWEZLHSA-N 0.000 claims description 3
- 229960003970 diflucortolone valerate Drugs 0.000 claims description 3
- 229960000616 diflunisal Drugs 0.000 claims description 3
- HUPFGZXOMWLGNK-UHFFFAOYSA-N diflunisal Chemical compound C1=C(O)C(C(=O)O)=CC(C=2C(=CC(F)=CC=2)F)=C1 HUPFGZXOMWLGNK-UHFFFAOYSA-N 0.000 claims description 3
- 229960004875 difluprednate Drugs 0.000 claims description 3
- 229960003720 enoxolone Drugs 0.000 claims description 3
- 229960001395 fenbufen Drugs 0.000 claims description 3
- ZPAKPRAICRBAOD-UHFFFAOYSA-N fenbufen Chemical compound C1=CC(C(=O)CCC(=O)O)=CC=C1C1=CC=CC=C1 ZPAKPRAICRBAOD-UHFFFAOYSA-N 0.000 claims description 3
- IDKAXRLETRCXKS-UHFFFAOYSA-N fenclofenac Chemical compound OC(=O)CC1=CC=CC=C1OC1=CC=C(Cl)C=C1Cl IDKAXRLETRCXKS-UHFFFAOYSA-N 0.000 claims description 3
- 229950006236 fenclofenac Drugs 0.000 claims description 3
- 229950011481 fenclozic acid Drugs 0.000 claims description 3
- 229960001419 fenoprofen Drugs 0.000 claims description 3
- 229960002679 fentiazac Drugs 0.000 claims description 3
- 229960000489 feprazone Drugs 0.000 claims description 3
- 229950002335 fluazacort Drugs 0.000 claims description 3
- BYZCJOHDXLROEC-RBWIMXSLSA-N fluazacort Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H]3OC(C)=N[C@@]3(C(=O)COC(=O)C)[C@@]1(C)C[C@@H]2O BYZCJOHDXLROEC-RBWIMXSLSA-N 0.000 claims description 3
- 229960004369 flufenamic acid Drugs 0.000 claims description 3
- LPEPZBJOKDYZAD-UHFFFAOYSA-N flufenamic acid Chemical compound OC(=O)C1=CC=CC=C1NC1=CC=CC(C(F)(F)F)=C1 LPEPZBJOKDYZAD-UHFFFAOYSA-N 0.000 claims description 3
- 229950007979 flufenisal Drugs 0.000 claims description 3
- 229960003469 flumetasone Drugs 0.000 claims description 3
- WXURHACBFYSXBI-GQKYHHCASA-N flumethasone Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2C[C@@H](C)[C@@](C(=O)CO)(O)[C@@]2(C)C[C@@H]1O WXURHACBFYSXBI-GQKYHHCASA-N 0.000 claims description 3
- 229940042902 flumethasone pivalate Drugs 0.000 claims description 3
- JWRMHDSINXPDHB-OJAGFMMFSA-N flumethasone pivalate Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2C[C@@H](C)[C@@](C(=O)COC(=O)C(C)(C)C)(O)[C@@]2(C)C[C@@H]1O JWRMHDSINXPDHB-OJAGFMMFSA-N 0.000 claims description 3
- 229960000676 flunisolide Drugs 0.000 claims description 3
- 229960000785 fluocinonide Drugs 0.000 claims description 3
- 229960003973 fluocortolone Drugs 0.000 claims description 3
- 229960001048 fluorometholone Drugs 0.000 claims description 3
- FAOZLTXFLGPHNG-KNAQIMQKSA-N fluorometholone Chemical compound C([C@@]12C)=CC(=O)C=C1[C@@H](C)C[C@@H]1[C@]2(F)[C@@H](O)C[C@]2(C)[C@@](O)(C(C)=O)CC[C@H]21 FAOZLTXFLGPHNG-KNAQIMQKSA-N 0.000 claims description 3
- 229960003590 fluperolone Drugs 0.000 claims description 3
- HHPZZKDXAFJLOH-QZIXMDIESA-N fluperolone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1CC[C@@](C(=O)[C@@H](OC(C)=O)C)(O)[C@@]1(C)C[C@@H]2O HHPZZKDXAFJLOH-QZIXMDIESA-N 0.000 claims description 3
- 229960002650 fluprednidene acetate Drugs 0.000 claims description 3
- DEFOZIFYUBUHHU-IYQKUMFPSA-N fluprednidene acetate Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1CC(=C)[C@@](C(=O)COC(=O)C)(O)[C@@]1(C)C[C@@H]2O DEFOZIFYUBUHHU-IYQKUMFPSA-N 0.000 claims description 3
- 229960000618 fluprednisolone Drugs 0.000 claims description 3
- 229950001284 fluprofen Drugs 0.000 claims description 3
- 229960002390 flurbiprofen Drugs 0.000 claims description 3
- SYTBZMRGLBWNTM-UHFFFAOYSA-N flurbiprofen Chemical compound FC1=CC(C(C(O)=O)C)=CC=C1C1=CC=CC=C1 SYTBZMRGLBWNTM-UHFFFAOYSA-N 0.000 claims description 3
- 229960000671 formocortal Drugs 0.000 claims description 3
- QNXUUBBKHBYRFW-QWAPGEGQSA-N formocortal Chemical compound C1C(C=O)=C2C=C(OCCCl)CC[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H]3OC(C)(C)O[C@@]3(C(=O)COC(=O)C)[C@@]1(C)C[C@@H]2O QNXUUBBKHBYRFW-QWAPGEGQSA-N 0.000 claims description 3
- 229960002383 halcinonide Drugs 0.000 claims description 3
- 229960002475 halometasone Drugs 0.000 claims description 3
- GGXMRPUKBWXVHE-MIHLVHIWSA-N halometasone Chemical compound C1([C@@H](F)C2)=CC(=O)C(Cl)=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2C[C@@H](C)[C@@](C(=O)CO)(O)[C@@]2(C)C[C@@H]1O GGXMRPUKBWXVHE-MIHLVHIWSA-N 0.000 claims description 3
- 229950004611 halopredone acetate Drugs 0.000 claims description 3
- FUZZWVXGSFPDMH-UHFFFAOYSA-N hexanoic acid Chemical compound CCCCCC(O)=O FUZZWVXGSFPDMH-UHFFFAOYSA-N 0.000 claims description 3
- FWFVLWGEFDIZMJ-FOMYWIRZSA-N hydrocortamate Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(=O)COC(=O)CN(CC)CC)(O)[C@@]1(C)C[C@@H]2O FWFVLWGEFDIZMJ-FOMYWIRZSA-N 0.000 claims description 3
- 229950000208 hydrocortamate Drugs 0.000 claims description 3
- 229960001067 hydrocortisone acetate Drugs 0.000 claims description 3
- 229960001524 hydrocortisone butyrate Drugs 0.000 claims description 3
- 229950000785 hydrocortisone phosphate Drugs 0.000 claims description 3
- CYWFCPPBTWOZSF-UHFFFAOYSA-N ibufenac Chemical compound CC(C)CC1=CC=C(CC(O)=O)C=C1 CYWFCPPBTWOZSF-UHFFFAOYSA-N 0.000 claims description 3
- 229950009183 ibufenac Drugs 0.000 claims description 3
- 229960001680 ibuprofen Drugs 0.000 claims description 3
- 229960000905 indomethacin Drugs 0.000 claims description 3
- 229960004187 indoprofen Drugs 0.000 claims description 3
- 230000001939 inductive effect Effects 0.000 claims description 3
- QFGMXJOBTNZHEL-UHFFFAOYSA-N isoxepac Chemical compound O1CC2=CC=CC=C2C(=O)C2=CC(CC(=O)O)=CC=C21 QFGMXJOBTNZHEL-UHFFFAOYSA-N 0.000 claims description 3
- 229950011455 isoxepac Drugs 0.000 claims description 3
- YYUAYBYLJSNDCX-UHFFFAOYSA-N isoxicam Chemical compound OC=1C2=CC=CC=C2S(=O)(=O)N(C)C=1C(=O)NC=1C=C(C)ON=1 YYUAYBYLJSNDCX-UHFFFAOYSA-N 0.000 claims description 3
- 229950002252 isoxicam Drugs 0.000 claims description 3
- DKYWVDODHFEZIM-UHFFFAOYSA-N ketoprofen Chemical compound OC(=O)C(C)C1=CC=CC(C(=O)C=2C=CC=CC=2)=C1 DKYWVDODHFEZIM-UHFFFAOYSA-N 0.000 claims description 3
- 229960000991 ketoprofen Drugs 0.000 claims description 3
- 208000036546 leukodystrophy Diseases 0.000 claims description 3
- CZBOZZDZNVIXFC-VRRJBYJJSA-N mazipredone Chemical compound C1CN(C)CCN1CC(=O)[C@]1(O)[C@@]2(C)C[C@H](O)[C@@H]3[C@@]4(C)C=CC(=O)C=C4CC[C@H]3[C@@H]2CC1 CZBOZZDZNVIXFC-VRRJBYJJSA-N 0.000 claims description 3
- 229950002555 mazipredone Drugs 0.000 claims description 3
- 229960003803 meclofenamic acid Drugs 0.000 claims description 3
- 229960001011 medrysone Drugs 0.000 claims description 3
- 229960003464 mefenamic acid Drugs 0.000 claims description 3
- 229960001810 meprednisone Drugs 0.000 claims description 3
- PIDANAQULIKBQS-RNUIGHNZSA-N meprednisone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@@H]2[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)CC2=O PIDANAQULIKBQS-RNUIGHNZSA-N 0.000 claims description 3
- OJGQFYYLKNCIJD-UHFFFAOYSA-N miroprofen Chemical compound C1=CC(C(C(O)=O)C)=CC=C1C1=CN(C=CC=C2)C2=N1 OJGQFYYLKNCIJD-UHFFFAOYSA-N 0.000 claims description 3
- 229950006616 miroprofen Drugs 0.000 claims description 3
- 229960002744 mometasone furoate Drugs 0.000 claims description 3
- WOFMFGQZHJDGCX-ZULDAHANSA-N mometasone furoate Chemical compound O([C@]1([C@@]2(C)C[C@H](O)[C@]3(Cl)[C@@]4(C)C=CC(=O)C=C4CC[C@H]3[C@@H]2C[C@H]1C)C(=O)CCl)C(=O)C1=CC=CO1 WOFMFGQZHJDGCX-ZULDAHANSA-N 0.000 claims description 3
- 229960002009 naproxen Drugs 0.000 claims description 3
- CMWTZPSULFXXJA-VIFPVBQESA-N naproxen Chemical compound C1=C([C@H](C)C(O)=O)C=CC2=CC(OC)=CC=C21 CMWTZPSULFXXJA-VIFPVBQESA-N 0.000 claims description 3
- 229960000916 niflumic acid Drugs 0.000 claims description 3
- 229960002739 oxaprozin Drugs 0.000 claims description 3
- OFPXSFXSNFPTHF-UHFFFAOYSA-N oxaprozin Chemical compound O1C(CCC(=O)O)=NC(C=2C=CC=CC=2)=C1C1=CC=CC=C1 OFPXSFXSNFPTHF-UHFFFAOYSA-N 0.000 claims description 3
- 229960000649 oxyphenbutazone Drugs 0.000 claims description 3
- HFHZKZSRXITVMK-UHFFFAOYSA-N oxyphenbutazone Chemical compound O=C1C(CCCC)C(=O)N(C=2C=CC=CC=2)N1C1=CC=C(O)C=C1 HFHZKZSRXITVMK-UHFFFAOYSA-N 0.000 claims description 3
- 229960002858 paramethasone Drugs 0.000 claims description 3
- 229960002895 phenylbutazone Drugs 0.000 claims description 3
- VYMDGNCVAMGZFE-UHFFFAOYSA-N phenylbutazonum Chemical compound O=C1C(CCCC)C(=O)N(C=2C=CC=CC=2)N1C1=CC=CC=C1 VYMDGNCVAMGZFE-UHFFFAOYSA-N 0.000 claims description 3
- 229960002702 piroxicam Drugs 0.000 claims description 3
- QYSPLQLAKJAUJT-UHFFFAOYSA-N piroxicam Chemical compound OC=1C2=CC=CC=C2S(=O)(=O)N(C)C=1C(=O)NC1=CC=CC=N1 QYSPLQLAKJAUJT-UHFFFAOYSA-N 0.000 claims description 3
- 229960000851 pirprofen Drugs 0.000 claims description 3
- PIDSZXPFGCURGN-UHFFFAOYSA-N pirprofen Chemical compound ClC1=CC(C(C(O)=O)C)=CC=C1N1CC=CC1 PIDSZXPFGCURGN-UHFFFAOYSA-N 0.000 claims description 3
- 229960003101 pranoprofen Drugs 0.000 claims description 3
- 229960002794 prednicarbate Drugs 0.000 claims description 3
- FNPXMHRZILFCKX-KAJVQRHHSA-N prednicarbate Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(=O)COC(=O)CC)(OC(=O)OCC)[C@@]1(C)C[C@@H]2O FNPXMHRZILFCKX-KAJVQRHHSA-N 0.000 claims description 3
- JDOZJEUDSLGTLU-VWUMJDOOSA-N prednisolone phosphate Chemical compound O=C1C=C[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)COP(O)(O)=O)[C@@H]4[C@@H]3CCC2=C1 JDOZJEUDSLGTLU-VWUMJDOOSA-N 0.000 claims description 3
- 229960002943 prednisolone sodium phosphate Drugs 0.000 claims description 3
- 229960002176 prednisolone sodium succinate Drugs 0.000 claims description 3
- FKKAEMQFOIDZNY-CODXZCKSSA-M prednisolone sodium succinate Chemical compound [Na+].O=C1C=C[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)COC(=O)CCC([O-])=O)[C@@H]4[C@@H]3CCC2=C1 FKKAEMQFOIDZNY-CODXZCKSSA-M 0.000 claims description 3
- 229960004259 prednisolone tebutate Drugs 0.000 claims description 3
- 229960004618 prednisone Drugs 0.000 claims description 3
- XOFYZVNMUHMLCC-ZPOLXVRWSA-N prednisone Chemical compound O=C1C=C[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 XOFYZVNMUHMLCC-ZPOLXVRWSA-N 0.000 claims description 3
- BOFKYYWJAOZDPB-FZNHGJLXSA-N prednival Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(=O)CO)(OC(=O)CCCC)[C@@]1(C)C[C@@H]2O BOFKYYWJAOZDPB-FZNHGJLXSA-N 0.000 claims description 3
- 229950000696 prednival Drugs 0.000 claims description 3
- 229960001917 prednylidene Drugs 0.000 claims description 3
- WSVOMANDJDYYEY-CWNVBEKCSA-N prednylidene Chemical group O=C1C=C[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](C(=C)C4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 WSVOMANDJDYYEY-CWNVBEKCSA-N 0.000 claims description 3
- MIXMJCQRHVAJIO-TZHJZOAOSA-N qk4dys664x Chemical compound O.C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@@H]1[C@@H]2[C@@H]2C[C@H]3OC(C)(C)O[C@@]3(C(=O)CO)[C@@]2(C)C[C@@H]1O.C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@@H]1[C@@H]2[C@@H]2C[C@H]3OC(C)(C)O[C@@]3(C(=O)CO)[C@@]2(C)C[C@@H]1O MIXMJCQRHVAJIO-TZHJZOAOSA-N 0.000 claims description 3
- 239000011734 sodium Substances 0.000 claims description 3
- 229910052708 sodium Inorganic materials 0.000 claims description 3
- RWFZSORKWFPGNE-VDYYWZOJSA-M sodium;3-[2-[(8s,9s,10r,11s,13s,14s,17r)-11,17-dihydroxy-10,13-dimethyl-3-oxo-7,8,9,11,12,14,15,16-octahydro-6h-cyclopenta[a]phenanthren-17-yl]-2-oxoethoxy]carbonylbenzenesulfonate Chemical compound [Na+].O=C([C@@]1(O)CC[C@H]2[C@H]3[C@@H]([C@]4(C=CC(=O)C=C4CC3)C)[C@@H](O)C[C@@]21C)COC(=O)C1=CC=CC(S([O-])(=O)=O)=C1 RWFZSORKWFPGNE-VDYYWZOJSA-M 0.000 claims description 3
- WNIFXKPDILJURQ-UHFFFAOYSA-N stearyl glycyrrhizinate Natural products C1CC(O)C(C)(C)C2CCC3(C)C4(C)CCC5(C)CCC(C(=O)OCCCCCCCCCCCCCCCCCC)(C)CC5C4=CC(=O)C3C21C WNIFXKPDILJURQ-UHFFFAOYSA-N 0.000 claims description 3
- 229960001940 sulfasalazine Drugs 0.000 claims description 3
- NCEXYHBECQHGNR-QZQOTICOSA-N sulfasalazine Chemical compound C1=C(O)C(C(=O)O)=CC(\N=N\C=2C=CC(=CC=2)S(=O)(=O)NC=2N=CC=CC=2)=C1 NCEXYHBECQHGNR-QZQOTICOSA-N 0.000 claims description 3
- NCEXYHBECQHGNR-UHFFFAOYSA-N sulfasalazine Natural products C1=C(O)C(C(=O)O)=CC(N=NC=2C=CC(=CC=2)S(=O)(=O)NC=2N=CC=CC=2)=C1 NCEXYHBECQHGNR-UHFFFAOYSA-N 0.000 claims description 3
- 229960000894 sulindac Drugs 0.000 claims description 3
- MLKXDPUZXIRXEP-MFOYZWKCSA-N sulindac Chemical compound CC1=C(CC(O)=O)C2=CC(F)=CC=C2\C1=C/C1=CC=C(S(C)=O)C=C1 MLKXDPUZXIRXEP-MFOYZWKCSA-N 0.000 claims description 3
- 229960004492 suprofen Drugs 0.000 claims description 3
- 229960001312 tiaprofenic acid Drugs 0.000 claims description 3
- 229950002345 tiopinac Drugs 0.000 claims description 3
- 229950006150 tioxaprofen Drugs 0.000 claims description 3
- 229960004631 tixocortol Drugs 0.000 claims description 3
- YWDBSCORAARPPF-VWUMJDOOSA-N tixocortol Chemical compound O=C1CC[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CS)[C@@H]4[C@@H]3CCC2=C1 YWDBSCORAARPPF-VWUMJDOOSA-N 0.000 claims description 3
- 229960002905 tolfenamic acid Drugs 0.000 claims description 3
- YEZNLOUZAIOMLT-UHFFFAOYSA-N tolfenamic acid Chemical compound CC1=C(Cl)C=CC=C1NC1=CC=CC=C1C(O)=O YEZNLOUZAIOMLT-UHFFFAOYSA-N 0.000 claims description 3
- 229960001017 tolmetin Drugs 0.000 claims description 3
- UPSPUYADGBWSHF-UHFFFAOYSA-N tolmetin Chemical compound C1=CC(C)=CC=C1C(=O)C1=CC=C(CC(O)=O)N1C UPSPUYADGBWSHF-UHFFFAOYSA-N 0.000 claims description 3
- GUYPYYARYIIWJZ-CYEPYHPTSA-N triamcinolone benetonide Chemical compound O=C([C@]12[C@H](OC(C)(C)O1)C[C@@H]1[C@@]2(C[C@H](O)[C@]2(F)[C@@]3(C)C=CC(=O)C=C3CC[C@H]21)C)COC(=O)C(C)CNC(=O)C1=CC=CC=C1 GUYPYYARYIIWJZ-CYEPYHPTSA-N 0.000 claims description 3
- 229950006782 triamcinolone benetonide Drugs 0.000 claims description 3
- 229960004221 triamcinolone hexacetonide Drugs 0.000 claims description 3
- 229950007802 zidometacin Drugs 0.000 claims description 3
- 229960003414 zomepirac Drugs 0.000 claims description 3
- ZXVNMYWKKDOREA-UHFFFAOYSA-N zomepirac Chemical compound C1=C(CC(O)=O)N(C)C(C(=O)C=2C=CC(Cl)=CC=2)=C1C ZXVNMYWKKDOREA-UHFFFAOYSA-N 0.000 claims description 3
- 206010011878 Deafness Diseases 0.000 claims description 2
- 208000010412 Glaucoma Diseases 0.000 claims description 2
- 230000001919 adrenal effect Effects 0.000 claims description 2
- NJNWEGFJCGYWQT-VSXGLTOVSA-N fluclorolone acetonide Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(Cl)[C@@H]2[C@@H]2C[C@H]3OC(C)(C)O[C@@]3(C(=O)CO)[C@@]2(C)C[C@@H]1Cl NJNWEGFJCGYWQT-VSXGLTOVSA-N 0.000 claims description 2
- 229940094766 flucloronide Drugs 0.000 claims description 2
- 230000010370 hearing loss Effects 0.000 claims description 2
- 231100000888 hearing loss Toxicity 0.000 claims description 2
- 208000016354 hearing loss disease Diseases 0.000 claims description 2
- 229960005285 mofebutazone Drugs 0.000 claims description 2
- REOJLIXKJWXUGB-UHFFFAOYSA-N mofebutazone Chemical compound O=C1C(CCCC)C(=O)NN1C1=CC=CC=C1 REOJLIXKJWXUGB-UHFFFAOYSA-N 0.000 claims description 2
- 238000011144 upstream manufacturing Methods 0.000 claims description 2
- VHRSUDSXCMQTMA-PJHHCJLFSA-N 6alpha-methylprednisolone Chemical compound C([C@@]12C)=CC(=O)C=C1[C@@H](C)C[C@@H]1[C@@H]2[C@@H](O)C[C@]2(C)[C@@](O)(C(=O)CO)CC[C@H]21 VHRSUDSXCMQTMA-PJHHCJLFSA-N 0.000 claims 4
- MYQXHLQMZLTSDB-UHFFFAOYSA-N 2-(2-ethyl-2,3-dihydro-1-benzofuran-5-yl)acetic acid Chemical compound OC(=O)CC1=CC=C2OC(CC)CC2=C1 MYQXHLQMZLTSDB-UHFFFAOYSA-N 0.000 claims 2
- SYCHUQUJURZQMO-UHFFFAOYSA-N 4-hydroxy-2-methyl-1,1-dioxo-n-(1,3-thiazol-2-yl)-1$l^{6},2-benzothiazine-3-carboxamide Chemical compound OC=1C2=CC=CC=C2S(=O)(=O)N(C)C=1C(=O)NC1=NC=CS1 SYCHUQUJURZQMO-UHFFFAOYSA-N 0.000 claims 2
- VOVIALXJUBGFJZ-KWVAZRHASA-N Budesonide Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@@H]2[C@@H]1[C@@H]1C[C@H]3OC(CCC)O[C@@]3(C(=O)CO)[C@@]1(C)C[C@@H]2O VOVIALXJUBGFJZ-KWVAZRHASA-N 0.000 claims 2
- MKPDWECBUAZOHP-AFYJWTTESA-N Paramethasone Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@@H]1[C@@H]2[C@@H]2C[C@@H](C)[C@@](C(=O)CO)(O)[C@@]2(C)C[C@@H]1O MKPDWECBUAZOHP-AFYJWTTESA-N 0.000 claims 2
- MDJRZSNPHZEMJH-MTMZYOSNSA-N artisone acetate Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H](C(=O)COC(=O)C)[C@@]1(C)CC2 MDJRZSNPHZEMJH-MTMZYOSNSA-N 0.000 claims 2
- 229960004436 budesonide Drugs 0.000 claims 2
- NPSLCOWKFFNQKK-ZPSUVKRCSA-N chloroprednisone Chemical compound O=C1C=C[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3C[C@H](Cl)C2=C1 NPSLCOWKFFNQKK-ZPSUVKRCSA-N 0.000 claims 2
- YMTMADLUXIRMGX-RFPWEZLHSA-N clocortolone Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(Cl)[C@@H]2[C@@H]2C[C@@H](C)[C@H](C(=O)CO)[C@@]2(C)C[C@@H]1O YMTMADLUXIRMGX-RFPWEZLHSA-N 0.000 claims 2
- WXURHACBFYSXBI-XHIJKXOTSA-N diflorasone Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2C[C@H](C)[C@@](C(=O)CO)(O)[C@@]2(C)C[C@@H]1O WXURHACBFYSXBI-XHIJKXOTSA-N 0.000 claims 2
- FEBLZLNTKCEFIT-VSXGLTOVSA-N fluocinolone acetonide Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2C[C@H]3OC(C)(C)O[C@@]3(C(=O)CO)[C@@]2(C)C[C@@H]1O FEBLZLNTKCEFIT-VSXGLTOVSA-N 0.000 claims 2
- XWTIDFOGTCVGQB-FHIVUSPVSA-N fluocortin butyl Chemical group C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@@H]1[C@@H]2[C@@H]2C[C@@H](C)[C@H](C(=O)C(=O)OCCCC)[C@@]2(C)C[C@@H]1O XWTIDFOGTCVGQB-FHIVUSPVSA-N 0.000 claims 2
- 229950008509 fluocortin butyl Drugs 0.000 claims 2
- 229950010931 furofenac Drugs 0.000 claims 2
- 229950005175 sudoxicam Drugs 0.000 claims 2
- 229960002871 tenoxicam Drugs 0.000 claims 2
- WZWYJBNHTWCXIM-UHFFFAOYSA-N tenoxicam Chemical compound O=C1C=2SC=CC=2S(=O)(=O)N(C)C1=C(O)NC1=CC=CC=N1 WZWYJBNHTWCXIM-UHFFFAOYSA-N 0.000 claims 2
- 229960002117 triamcinolone acetonide Drugs 0.000 claims 2
- YNDXUCZADRHECN-JNQJZLCISA-N triamcinolone acetonide Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H]3OC(C)(C)O[C@@]3(C(=O)CO)[C@@]1(C)C[C@@H]2O YNDXUCZADRHECN-JNQJZLCISA-N 0.000 claims 2
- 230000027455 binding Effects 0.000 abstract description 115
- 239000000427 antigen Substances 0.000 abstract description 89
- 108091007433 antigens Proteins 0.000 abstract description 89
- 102000036639 antigens Human genes 0.000 abstract description 89
- 108010041199 Nogo Receptor 1 Proteins 0.000 abstract description 76
- 102000000343 Nogo Receptor 1 Human genes 0.000 abstract description 76
- 150000007523 nucleic acids Chemical class 0.000 abstract description 47
- 102000039446 nucleic acids Human genes 0.000 abstract description 46
- 108020004707 nucleic acids Proteins 0.000 abstract description 46
- 239000005557 antagonist Substances 0.000 abstract description 45
- 102000037865 fusion proteins Human genes 0.000 abstract description 27
- 108020001507 fusion proteins Proteins 0.000 abstract description 27
- 230000002163 immunogen Effects 0.000 abstract description 18
- 229940024606 amino acid Drugs 0.000 description 265
- 108090000623 proteins and genes Proteins 0.000 description 93
- 102000004169 proteins and genes Human genes 0.000 description 46
- 235000018102 proteins Nutrition 0.000 description 43
- 108020004414 DNA Proteins 0.000 description 41
- 241000700159 Rattus Species 0.000 description 30
- 108091023037 Aptamer Proteins 0.000 description 25
- 230000000694 effects Effects 0.000 description 24
- 108060003951 Immunoglobulin Proteins 0.000 description 23
- 102000018358 immunoglobulin Human genes 0.000 description 23
- 239000013604 expression vector Substances 0.000 description 22
- 230000004048 modification Effects 0.000 description 22
- 238000012986 modification Methods 0.000 description 22
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 21
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 21
- 241001465754 Metazoa Species 0.000 description 21
- 210000004408 hybridoma Anatomy 0.000 description 21
- 101710093481 Reticulon-4 receptor Proteins 0.000 description 20
- 102100029826 Reticulon-4 receptor Human genes 0.000 description 20
- 238000005516 engineering process Methods 0.000 description 20
- 230000035772 mutation Effects 0.000 description 20
- 230000006870 function Effects 0.000 description 19
- 210000000020 growth cone Anatomy 0.000 description 19
- 108091026890 Coding region Proteins 0.000 description 17
- 239000000047 product Substances 0.000 description 17
- 102000006386 Myelin Proteins Human genes 0.000 description 16
- 108010083674 Myelin Proteins Proteins 0.000 description 16
- 238000004519 manufacturing process Methods 0.000 description 16
- 210000005012 myelin Anatomy 0.000 description 16
- 230000015572 biosynthetic process Effects 0.000 description 15
- 230000003376 axonal effect Effects 0.000 description 14
- 238000001727 in vivo Methods 0.000 description 14
- FQISKWAFAHGMGT-SGJOWKDISA-M Methylprednisolone sodium succinate Chemical compound [Na+].C([C@@]12C)=CC(=O)C=C1[C@@H](C)C[C@@H]1[C@@H]2[C@@H](O)C[C@]2(C)[C@@](O)(C(=O)COC(=O)CCC([O-])=O)CC[C@H]21 FQISKWAFAHGMGT-SGJOWKDISA-M 0.000 description 13
- 241000699670 Mus sp. Species 0.000 description 13
- 230000004927 fusion Effects 0.000 description 13
- 230000012010 growth Effects 0.000 description 13
- 239000003446 ligand Substances 0.000 description 13
- 238000013518 transcription Methods 0.000 description 13
- 230000035897 transcription Effects 0.000 description 13
- 241000699666 Mus <mouse, genus> Species 0.000 description 12
- 238000005755 formation reaction Methods 0.000 description 12
- 238000000338 in vitro Methods 0.000 description 12
- 230000001965 increasing effect Effects 0.000 description 12
- 210000002966 serum Anatomy 0.000 description 12
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 11
- 230000008569 process Effects 0.000 description 11
- 235000008521 threonine Nutrition 0.000 description 11
- 230000009368 gene silencing by RNA Effects 0.000 description 10
- 238000002823 phage display Methods 0.000 description 10
- 239000000126 substance Substances 0.000 description 10
- 108091006905 Human Serum Albumin Proteins 0.000 description 9
- 102000008100 Human Serum Albumin Human genes 0.000 description 9
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 9
- 241001529936 Murinae Species 0.000 description 9
- 102000010410 Nogo Proteins Human genes 0.000 description 9
- 108010077641 Nogo Proteins Proteins 0.000 description 9
- 108091030071 RNAI Proteins 0.000 description 9
- 239000002671 adjuvant Substances 0.000 description 9
- 238000012217 deletion Methods 0.000 description 9
- 230000037430 deletion Effects 0.000 description 9
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 9
- 210000004901 leucine-rich repeat Anatomy 0.000 description 9
- 230000004083 survival effect Effects 0.000 description 9
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 8
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 8
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 8
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 8
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 8
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 8
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 8
- 108700026244 Open Reading Frames Proteins 0.000 description 8
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 8
- 241000700605 Viruses Species 0.000 description 8
- 230000007423 decrease Effects 0.000 description 8
- 230000013595 glycosylation Effects 0.000 description 8
- 238000006206 glycosylation reaction Methods 0.000 description 8
- 229960000310 isoleucine Drugs 0.000 description 8
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 8
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 8
- 239000013612 plasmid Substances 0.000 description 8
- 238000012545 processing Methods 0.000 description 8
- 235000004400 serine Nutrition 0.000 description 8
- 230000008685 targeting Effects 0.000 description 8
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 8
- 235000002374 tyrosine Nutrition 0.000 description 8
- 239000004474 valine Substances 0.000 description 8
- 102000004190 Enzymes Human genes 0.000 description 7
- 108090000790 Enzymes Proteins 0.000 description 7
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 7
- 108020004511 Recombinant DNA Proteins 0.000 description 7
- 230000021736 acetylation Effects 0.000 description 7
- 238000006640 acetylation reaction Methods 0.000 description 7
- 238000007792 addition Methods 0.000 description 7
- 239000002299 complementary DNA Substances 0.000 description 7
- 229940088598 enzyme Drugs 0.000 description 7
- 230000001976 improved effect Effects 0.000 description 7
- 230000006576 neuronal survival Effects 0.000 description 7
- 238000007363 ring formation reaction Methods 0.000 description 7
- 230000001225 therapeutic effect Effects 0.000 description 7
- 230000014616 translation Effects 0.000 description 7
- 238000013519 translation Methods 0.000 description 7
- 241000588724 Escherichia coli Species 0.000 description 6
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 6
- 239000004472 Lysine Substances 0.000 description 6
- 241000699660 Mus musculus Species 0.000 description 6
- 102100021831 Myelin-associated glycoprotein Human genes 0.000 description 6
- 108700042240 NgR(310) Ecto-Fc Proteins 0.000 description 6
- 125000000539 amino acid group Chemical group 0.000 description 6
- 230000008499 blood brain barrier function Effects 0.000 description 6
- 210000001218 blood-brain barrier Anatomy 0.000 description 6
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 6
- 238000002649 immunization Methods 0.000 description 6
- 210000004698 lymphocyte Anatomy 0.000 description 6
- 210000004962 mammalian cell Anatomy 0.000 description 6
- 239000000463 material Substances 0.000 description 6
- 239000002953 phosphate buffered saline Substances 0.000 description 6
- 230000026731 phosphorylation Effects 0.000 description 6
- 238000006366 phosphorylation reaction Methods 0.000 description 6
- 230000001323 posttranslational effect Effects 0.000 description 6
- 238000000746 purification Methods 0.000 description 6
- 238000003259 recombinant expression Methods 0.000 description 6
- 230000008929 regeneration Effects 0.000 description 6
- 238000011069 regeneration method Methods 0.000 description 6
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 6
- 230000001105 regulatory effect Effects 0.000 description 6
- 238000012216 screening Methods 0.000 description 6
- 238000010561 standard procedure Methods 0.000 description 6
- 238000011830 transgenic mouse model Methods 0.000 description 6
- 239000004475 Arginine Substances 0.000 description 5
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 5
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 5
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 5
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 5
- 206010028980 Neoplasm Diseases 0.000 description 5
- 108091028043 Nucleic acid sequence Proteins 0.000 description 5
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 5
- 230000002378 acidificating effect Effects 0.000 description 5
- 230000009435 amidation Effects 0.000 description 5
- 238000007112 amidation reaction Methods 0.000 description 5
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 5
- 238000003556 assay Methods 0.000 description 5
- 210000003050 axon Anatomy 0.000 description 5
- 210000003719 b-lymphocyte Anatomy 0.000 description 5
- 230000004071 biological effect Effects 0.000 description 5
- 210000004556 brain Anatomy 0.000 description 5
- 230000001413 cellular effect Effects 0.000 description 5
- 238000001514 detection method Methods 0.000 description 5
- 238000010494 dissociation reaction Methods 0.000 description 5
- 230000005593 dissociations Effects 0.000 description 5
- 239000012636 effector Substances 0.000 description 5
- 238000003197 gene knockdown Methods 0.000 description 5
- 230000028993 immune response Effects 0.000 description 5
- 230000003053 immunization Effects 0.000 description 5
- 230000005847 immunogenicity Effects 0.000 description 5
- 150000002632 lipids Chemical class 0.000 description 5
- 230000004807 localization Effects 0.000 description 5
- 239000003550 marker Substances 0.000 description 5
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 5
- 230000006337 proteolytic cleavage Effects 0.000 description 5
- 238000003786 synthesis reaction Methods 0.000 description 5
- 210000001519 tissue Anatomy 0.000 description 5
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 4
- 241000283690 Bos taurus Species 0.000 description 4
- 241000283086 Equidae Species 0.000 description 4
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 4
- 239000004471 Glycine Substances 0.000 description 4
- 241000282412 Homo Species 0.000 description 4
- 101000727477 Homo sapiens Reticulon-4 receptor Proteins 0.000 description 4
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 4
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 4
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 4
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 4
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 4
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 4
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 4
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 4
- DIBZLYZXTSVGLN-CIUDSAMLSA-N Lys-Ser-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O DIBZLYZXTSVGLN-CIUDSAMLSA-N 0.000 description 4
- 206010035226 Plasma cell myeloma Diseases 0.000 description 4
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 4
- 210000001744 T-lymphocyte Anatomy 0.000 description 4
- 108020004566 Transfer RNA Proteins 0.000 description 4
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 4
- 230000004075 alteration Effects 0.000 description 4
- 125000003118 aryl group Chemical group 0.000 description 4
- 235000009582 asparagine Nutrition 0.000 description 4
- 229960001230 asparagine Drugs 0.000 description 4
- 235000003704 aspartic acid Nutrition 0.000 description 4
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 4
- 150000001720 carbohydrates Chemical group 0.000 description 4
- 238000007385 chemical modification Methods 0.000 description 4
- 238000003776 cleavage reaction Methods 0.000 description 4
- 230000021615 conjugation Effects 0.000 description 4
- 238000001212 derivatisation Methods 0.000 description 4
- 239000003623 enhancer Substances 0.000 description 4
- 230000022244 formylation Effects 0.000 description 4
- 238000006170 formylation reaction Methods 0.000 description 4
- 210000004602 germ cell Anatomy 0.000 description 4
- 229960002989 glutamic acid Drugs 0.000 description 4
- 235000013922 glutamic acid Nutrition 0.000 description 4
- 239000004220 glutamic acid Substances 0.000 description 4
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 4
- 235000004554 glutamine Nutrition 0.000 description 4
- 239000001963 growth medium Substances 0.000 description 4
- 230000016784 immunoglobulin production Effects 0.000 description 4
- 229940072221 immunoglobulins Drugs 0.000 description 4
- 238000005304 joining Methods 0.000 description 4
- 229930182817 methionine Natural products 0.000 description 4
- 238000002703 mutagenesis Methods 0.000 description 4
- 231100000350 mutagenesis Toxicity 0.000 description 4
- 201000000050 myeloid neoplasm Diseases 0.000 description 4
- 230000007935 neutral effect Effects 0.000 description 4
- 230000006320 pegylation Effects 0.000 description 4
- 238000003127 radioimmunoassay Methods 0.000 description 4
- 230000007017 scission Effects 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 238000002560 therapeutic procedure Methods 0.000 description 4
- 241000701161 unidentified adenovirus Species 0.000 description 4
- 230000003612 virological effect Effects 0.000 description 4
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 3
- 108020004705 Codon Proteins 0.000 description 3
- 241000196324 Embryophyta Species 0.000 description 3
- 108010070675 Glutathione transferase Proteins 0.000 description 3
- 102100029100 Hematopoietic prostaglandin D synthase Human genes 0.000 description 3
- 241000238631 Hexapoda Species 0.000 description 3
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 3
- 241000283973 Oryctolagus cuniculus Species 0.000 description 3
- 230000000890 antigenic effect Effects 0.000 description 3
- 239000011324 bead Substances 0.000 description 3
- 230000000903 blocking effect Effects 0.000 description 3
- 229940098773 bovine serum albumin Drugs 0.000 description 3
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- 239000003153 chemical reaction reagent Substances 0.000 description 3
- 238000004587 chromatography analysis Methods 0.000 description 3
- 210000000349 chromosome Anatomy 0.000 description 3
- 238000010367 cloning Methods 0.000 description 3
- 238000004132 cross linking Methods 0.000 description 3
- 231100000599 cytotoxic agent Toxicity 0.000 description 3
- 230000003247 decreasing effect Effects 0.000 description 3
- 239000003814 drug Substances 0.000 description 3
- 210000001671 embryonic stem cell Anatomy 0.000 description 3
- 210000003527 eukaryotic cell Anatomy 0.000 description 3
- 230000002068 genetic effect Effects 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- 238000002955 isolation Methods 0.000 description 3
- 230000011987 methylation Effects 0.000 description 3
- 238000007069 methylation reaction Methods 0.000 description 3
- 210000002241 neurite Anatomy 0.000 description 3
- 210000004248 oligodendroglia Anatomy 0.000 description 3
- 230000036961 partial effect Effects 0.000 description 3
- 230000000069 prophylactic effect Effects 0.000 description 3
- 230000009145 protein modification Effects 0.000 description 3
- 230000002797 proteolythic effect Effects 0.000 description 3
- 230000006798 recombination Effects 0.000 description 3
- 230000003248 secreting effect Effects 0.000 description 3
- 208000024891 symptom Diseases 0.000 description 3
- 230000009261 transgenic effect Effects 0.000 description 3
- 238000010798 ubiquitination Methods 0.000 description 3
- 230000034512 ubiquitination Effects 0.000 description 3
- 238000001262 western blot Methods 0.000 description 3
- HKZAAJSTFUZYTO-LURJTMIESA-N (2s)-2-[[2-[[2-[[2-[(2-aminoacetyl)amino]acetyl]amino]acetyl]amino]acetyl]amino]-3-hydroxypropanoic acid Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O HKZAAJSTFUZYTO-LURJTMIESA-N 0.000 description 2
- VYEWZWBILJHHCU-OMQUDAQFSA-N (e)-n-[(2s,3r,4r,5r,6r)-2-[(2r,3r,4s,5s,6s)-3-acetamido-5-amino-4-hydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-6-[2-[(2r,3s,4r,5r)-5-(2,4-dioxopyrimidin-1-yl)-3,4-dihydroxyoxolan-2-yl]-2-hydroxyethyl]-4,5-dihydroxyoxan-3-yl]-5-methylhex-2-enamide Chemical compound N1([C@@H]2O[C@@H]([C@H]([C@H]2O)O)C(O)C[C@@H]2[C@H](O)[C@H](O)[C@H]([C@@H](O2)O[C@@H]2[C@@H]([C@@H](O)[C@H](N)[C@@H](CO)O2)NC(C)=O)NC(=O)/C=C/CC(C)C)C=CC(=O)NC1=O VYEWZWBILJHHCU-OMQUDAQFSA-N 0.000 description 2
- ODHCTXKNWHHXJC-VKHMYHEASA-N 5-oxo-L-proline Chemical compound OC(=O)[C@@H]1CCC(=O)N1 ODHCTXKNWHHXJC-VKHMYHEASA-N 0.000 description 2
- 230000005730 ADP ribosylation Effects 0.000 description 2
- 241000251468 Actinopterygii Species 0.000 description 2
- 102000007469 Actins Human genes 0.000 description 2
- 108010085238 Actins Proteins 0.000 description 2
- 108090001008 Avidin Proteins 0.000 description 2
- 241000894006 Bacteria Species 0.000 description 2
- 241000345998 Calamus manan Species 0.000 description 2
- 241000282472 Canis lupus familiaris Species 0.000 description 2
- 241000700198 Cavia Species 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- 108020004635 Complementary DNA Proteins 0.000 description 2
- 241000938605 Crocodylia Species 0.000 description 2
- 101710112752 Cytotoxin Proteins 0.000 description 2
- 102000053602 DNA Human genes 0.000 description 2
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 2
- 241000282326 Felis catus Species 0.000 description 2
- 241000724791 Filamentous phage Species 0.000 description 2
- 102100031181 Glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 2
- 102000003886 Glycoproteins Human genes 0.000 description 2
- 108090000288 Glycoproteins Proteins 0.000 description 2
- 101001130250 Homo sapiens Reticulon-4 receptor-like 1 Proteins 0.000 description 2
- 101001130247 Homo sapiens Reticulon-4 receptor-like 2 Proteins 0.000 description 2
- MHAJPDPJQMAIIY-UHFFFAOYSA-N Hydrogen peroxide Chemical compound OO MHAJPDPJQMAIIY-UHFFFAOYSA-N 0.000 description 2
- 102000009786 Immunoglobulin Constant Regions Human genes 0.000 description 2
- 108010009817 Immunoglobulin Constant Regions Proteins 0.000 description 2
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 description 2
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 description 2
- 101001130249 Mus musculus Reticulon-4 receptor-like 1 Proteins 0.000 description 2
- 101001130246 Mus musculus Reticulon-4 receptor-like 2 Proteins 0.000 description 2
- 206010029155 Nephropathy toxic Diseases 0.000 description 2
- 206010069350 Osmotic demyelination syndrome Diseases 0.000 description 2
- 108090000526 Papain Proteins 0.000 description 2
- 241001494479 Pecora Species 0.000 description 2
- 208000017493 Pelizaeus-Merzbacher disease Diseases 0.000 description 2
- 108091093037 Peptide nucleic acid Proteins 0.000 description 2
- 241000276498 Pollachius virens Species 0.000 description 2
- 101710182846 Polyhedrin Proteins 0.000 description 2
- 241000288906 Primates Species 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 2
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 2
- AUNGANRZJHBGPY-SCRDCRAPSA-N Riboflavin Chemical compound OC[C@@H](O)[C@@H](O)[C@@H](O)CN1C=2C=C(C)C(C)=CC=2N=C2C1=NC(=O)NC2=O AUNGANRZJHBGPY-SCRDCRAPSA-N 0.000 description 2
- 101150108294 Rtn4r gene Proteins 0.000 description 2
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 2
- XZKQVQKUZMAADP-IMJSIDKUSA-N Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(O)=O XZKQVQKUZMAADP-IMJSIDKUSA-N 0.000 description 2
- 108091081024 Start codon Proteins 0.000 description 2
- 108010090804 Streptavidin Proteins 0.000 description 2
- 238000000692 Student's t-test Methods 0.000 description 2
- 241000282887 Suidae Species 0.000 description 2
- 108090000373 Tissue Plasminogen Activator Proteins 0.000 description 2
- 102000003978 Tissue Plasminogen Activator Human genes 0.000 description 2
- 241000723873 Tobacco mosaic virus Species 0.000 description 2
- YJQCOFNZVFGCAF-UHFFFAOYSA-N Tunicamycin II Natural products O1C(CC(O)C2C(C(O)C(O2)N2C(NC(=O)C=C2)=O)O)C(O)C(O)C(NC(=O)C=CCCCCCCCCC(C)C)C1OC1OC(CO)C(O)C(O)C1NC(C)=O YJQCOFNZVFGCAF-UHFFFAOYSA-N 0.000 description 2
- 239000002253 acid Substances 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 230000010933 acylation Effects 0.000 description 2
- 238000005917 acylation reaction Methods 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 210000000628 antibody-producing cell Anatomy 0.000 description 2
- 230000010516 arginylation Effects 0.000 description 2
- 230000001580 bacterial effect Effects 0.000 description 2
- 238000006664 bond formation reaction Methods 0.000 description 2
- 235000014633 carbohydrates Nutrition 0.000 description 2
- 210000000170 cell membrane Anatomy 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- 238000012412 chemical coupling Methods 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 238000012258 culturing Methods 0.000 description 2
- 239000002619 cytotoxin Substances 0.000 description 2
- 230000017858 demethylation Effects 0.000 description 2
- 238000010520 demethylation reaction Methods 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- 239000000539 dimer Substances 0.000 description 2
- 201000002491 encephalomyelitis Diseases 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 230000006251 gamma-carboxylation Effects 0.000 description 2
- 238000001415 gene therapy Methods 0.000 description 2
- RWSXRVCMGQZWBV-WDSKDSINSA-N glutathione Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@@H](CS)C(=O)NCC(O)=O RWSXRVCMGQZWBV-WDSKDSINSA-N 0.000 description 2
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 2
- 150000003278 haem Chemical group 0.000 description 2
- 238000002744 homologous recombination Methods 0.000 description 2
- 230000006801 homologous recombination Effects 0.000 description 2
- 102000048720 human RTN4R Human genes 0.000 description 2
- 102000053414 human RTN4RL2 Human genes 0.000 description 2
- 230000033444 hydroxylation Effects 0.000 description 2
- 238000005805 hydroxylation reaction Methods 0.000 description 2
- 230000006698 induction Effects 0.000 description 2
- 239000003112 inhibitor Substances 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- 230000026045 iodination Effects 0.000 description 2
- 238000006192 iodination reaction Methods 0.000 description 2
- 238000012004 kinetic exclusion assay Methods 0.000 description 2
- 230000003902 lesion Effects 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 230000003137 locomotive effect Effects 0.000 description 2
- 210000003141 lower extremity Anatomy 0.000 description 2
- 210000001165 lymph node Anatomy 0.000 description 2
- 230000002503 metabolic effect Effects 0.000 description 2
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 2
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 2
- 230000007498 myristoylation Effects 0.000 description 2
- 230000007694 nephrotoxicity Effects 0.000 description 2
- 231100000417 nephrotoxicity Toxicity 0.000 description 2
- 230000001537 neural effect Effects 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 230000003647 oxidation Effects 0.000 description 2
- 238000007254 oxidation reaction Methods 0.000 description 2
- 229940055729 papain Drugs 0.000 description 2
- 235000019834 papain Nutrition 0.000 description 2
- 210000001428 peripheral nervous system Anatomy 0.000 description 2
- 239000008194 pharmaceutical composition Substances 0.000 description 2
- 230000008488 polyadenylation Effects 0.000 description 2
- 230000001124 posttranscriptional effect Effects 0.000 description 2
- 239000002243 precursor Substances 0.000 description 2
- 230000013823 prenylation Effects 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 206010036807 progressive multifocal leukoencephalopathy Diseases 0.000 description 2
- 210000001243 pseudopodia Anatomy 0.000 description 2
- 229940043131 pyroglutamate Drugs 0.000 description 2
- 230000006340 racemization Effects 0.000 description 2
- 235000012950 rattan cane Nutrition 0.000 description 2
- 102000005962 receptors Human genes 0.000 description 2
- 108020003175 receptors Proteins 0.000 description 2
- 238000005215 recombination Methods 0.000 description 2
- 230000002829 reductive effect Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- 239000000523 sample Substances 0.000 description 2
- 238000002741 site-directed mutagenesis Methods 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 125000006850 spacer group Chemical group 0.000 description 2
- 241000894007 species Species 0.000 description 2
- 210000000278 spinal cord Anatomy 0.000 description 2
- 210000000952 spleen Anatomy 0.000 description 2
- 230000010473 stable expression Effects 0.000 description 2
- 230000019635 sulfation Effects 0.000 description 2
- 238000005670 sulfation reaction Methods 0.000 description 2
- 208000011580 syndromic disease Diseases 0.000 description 2
- 238000010189 synthetic method Methods 0.000 description 2
- 229940124597 therapeutic agent Drugs 0.000 description 2
- 125000003396 thiol group Chemical group [H]S* 0.000 description 2
- 229960000187 tissue plasminogen activator Drugs 0.000 description 2
- 239000003053 toxin Substances 0.000 description 2
- 231100000765 toxin Toxicity 0.000 description 2
- 108700012359 toxins Proteins 0.000 description 2
- 230000002103 transcriptional effect Effects 0.000 description 2
- 238000001890 transfection Methods 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 238000003146 transient transfection Methods 0.000 description 2
- MEYZYGMYMLNUHJ-UHFFFAOYSA-N tunicamycin Natural products CC(C)CCCCCCCCCC=CC(=O)NC1C(O)C(O)C(CC(O)C2OC(C(O)C2O)N3C=CC(=O)NC3=O)OC1OC4OC(CO)C(O)C(O)C4NC(=O)C MEYZYGMYMLNUHJ-UHFFFAOYSA-N 0.000 description 2
- 241001515965 unidentified phage Species 0.000 description 2
- 239000003981 vehicle Substances 0.000 description 2
- LLXVXPPXELIDGQ-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(2,5-dioxopyrrol-1-yl)benzoate Chemical compound C=1C=CC(N2C(C=CC2=O)=O)=CC=1C(=O)ON1C(=O)CCC1=O LLXVXPPXELIDGQ-UHFFFAOYSA-N 0.000 description 1
- DIGQNXIGRZPYDK-WKSCXVIASA-N (2R)-6-amino-2-[[2-[[(2S)-2-[[2-[[(2R)-2-[[(2S)-2-[[(2R,3S)-2-[[2-[[(2S)-2-[[2-[[(2S)-2-[[(2S)-2-[[(2R)-2-[[(2S,3S)-2-[[(2R)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[2-[[(2S)-2-[[(2R)-2-[[2-[[2-[[2-[(2-amino-1-hydroxyethylidene)amino]-3-carboxy-1-hydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1,5-dihydroxy-5-iminopentylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]hexanoic acid Chemical compound C[C@@H]([C@@H](C(=N[C@@H](CS)C(=N[C@@H](C)C(=N[C@@H](CO)C(=NCC(=N[C@@H](CCC(=N)O)C(=NC(CS)C(=N[C@H]([C@H](C)O)C(=N[C@H](CS)C(=N[C@H](CO)C(=NCC(=N[C@H](CS)C(=NCC(=N[C@H](CCCCN)C(=O)O)O)O)O)O)O)O)O)O)O)O)O)O)O)N=C([C@H](CS)N=C([C@H](CO)N=C([C@H](CO)N=C([C@H](C)N=C(CN=C([C@H](CO)N=C([C@H](CS)N=C(CN=C(C(CS)N=C(C(CC(=O)O)N=C(CN)O)O)O)O)O)O)O)O)O)O)O)O DIGQNXIGRZPYDK-WKSCXVIASA-N 0.000 description 1
- ASWBNKHCZGQVJV-UHFFFAOYSA-N (3-hexadecanoyloxy-2-hydroxypropyl) 2-(trimethylazaniumyl)ethyl phosphate Chemical compound CCCCCCCCCCCCCCCC(=O)OCC(O)COP([O-])(=O)OCC[N+](C)(C)C ASWBNKHCZGQVJV-UHFFFAOYSA-N 0.000 description 1
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 1
- UKAUYVFTDYCKQA-UHFFFAOYSA-N -2-Amino-4-hydroxybutanoic acid Natural products OC(=O)C(N)CCO UKAUYVFTDYCKQA-UHFFFAOYSA-N 0.000 description 1
- UFBJCMHMOXMLKC-UHFFFAOYSA-N 2,4-dinitrophenol Chemical compound OC1=CC=C([N+]([O-])=O)C=C1[N+]([O-])=O UFBJCMHMOXMLKC-UHFFFAOYSA-N 0.000 description 1
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- BRMWTNUJHUMWMS-UHFFFAOYSA-N 3-Methylhistidine Natural products CN1C=NC(CC(N)C(O)=O)=C1 BRMWTNUJHUMWMS-UHFFFAOYSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- 229940117976 5-hydroxylysine Drugs 0.000 description 1
- 102100024643 ATP-binding cassette sub-family D member 1 Human genes 0.000 description 1
- 108010042708 Acetylmuramyl-Alanyl-Isoglutamine Proteins 0.000 description 1
- 206010069754 Acquired gene mutation Diseases 0.000 description 1
- 102100029457 Adenine phosphoribosyltransferase Human genes 0.000 description 1
- 108010024223 Adenine phosphoribosyltransferase Proteins 0.000 description 1
- 201000011452 Adrenoleukodystrophy Diseases 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- PEIBBAXIKUAYGN-UBHSHLNASA-N Ala-Phe-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 PEIBBAXIKUAYGN-UBHSHLNASA-N 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 208000011403 Alexander disease Diseases 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 108700028369 Alleles Proteins 0.000 description 1
- 108010032595 Antibody Binding Sites Proteins 0.000 description 1
- 101001084702 Arabidopsis thaliana Histone H2B.10 Proteins 0.000 description 1
- IJYZHIOOBGIINM-WDSKDSINSA-N Arg-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N IJYZHIOOBGIINM-WDSKDSINSA-N 0.000 description 1
- 206010003445 Ascites Diseases 0.000 description 1
- 208000001827 Ataxia with vitamin E deficiency Diseases 0.000 description 1
- 241001203868 Autographa californica Species 0.000 description 1
- 241000271566 Aves Species 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- 208000006373 Bell palsy Diseases 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- 108010075254 C-Peptide Proteins 0.000 description 1
- 125000001433 C-terminal amino-acid group Chemical group 0.000 description 1
- 241000282421 Canidae Species 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 241000701489 Cauliflower mosaic virus Species 0.000 description 1
- 102000016289 Cell Adhesion Molecules Human genes 0.000 description 1
- 108010067225 Cell Adhesion Molecules Proteins 0.000 description 1
- 241000282994 Cervidae Species 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-M Chloride anion Chemical compound [Cl-] VEXZGXHMUGYJMC-UHFFFAOYSA-M 0.000 description 1
- ARPLCFGLEYFDCN-CDACMRRYSA-N Clocortolone acetate Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(Cl)[C@@H]2[C@@H]2C[C@@H](C)[C@H](C(=O)COC(C)=O)[C@@]2(C)C[C@@H]1O ARPLCFGLEYFDCN-CDACMRRYSA-N 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- 239000004971 Cross linker Substances 0.000 description 1
- 241000701022 Cytomegalovirus Species 0.000 description 1
- 101150074155 DHFR gene Proteins 0.000 description 1
- 230000004544 DNA amplification Effects 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 108010016626 Dipeptides Proteins 0.000 description 1
- 206010061818 Disease progression Diseases 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 1
- 241000283074 Equus asinus Species 0.000 description 1
- 108010074860 Factor Xa Proteins 0.000 description 1
- 102000009109 Fc receptors Human genes 0.000 description 1
- 108010087819 Fc receptors Proteins 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 1
- 241000282818 Giraffidae Species 0.000 description 1
- 239000004366 Glucose oxidase Substances 0.000 description 1
- 108010015776 Glucose oxidase Proteins 0.000 description 1
- 108010024636 Glutathione Proteins 0.000 description 1
- 102000002812 Heat-Shock Proteins Human genes 0.000 description 1
- 108010004889 Heat-Shock Proteins Proteins 0.000 description 1
- 102100021519 Hemoglobin subunit beta Human genes 0.000 description 1
- 108091005904 Hemoglobin subunit beta Proteins 0.000 description 1
- 241001272567 Hominoidea Species 0.000 description 1
- 101100017008 Homo sapiens HHAT gene Proteins 0.000 description 1
- 101000998953 Homo sapiens Immunoglobulin heavy variable 1-2 Proteins 0.000 description 1
- 101001008255 Homo sapiens Immunoglobulin kappa variable 1D-8 Proteins 0.000 description 1
- 101001047628 Homo sapiens Immunoglobulin kappa variable 2-29 Proteins 0.000 description 1
- 101001008321 Homo sapiens Immunoglobulin kappa variable 2D-26 Proteins 0.000 description 1
- 101001047619 Homo sapiens Immunoglobulin kappa variable 3-20 Proteins 0.000 description 1
- 101001008263 Homo sapiens Immunoglobulin kappa variable 3D-15 Proteins 0.000 description 1
- 101000727472 Homo sapiens Reticulon-4 Proteins 0.000 description 1
- 101000965724 Homo sapiens Volume-regulated anion channel subunit LRRC8B Proteins 0.000 description 1
- 241000701024 Human betaherpesvirus 5 Species 0.000 description 1
- 101100321817 Human parvovirus B19 (strain HV) 7.5K gene Proteins 0.000 description 1
- PMMYEEVYMWASQN-DMTCNVIQSA-N Hydroxyproline Chemical compound O[C@H]1CN[C@H](C(O)=O)C1 PMMYEEVYMWASQN-DMTCNVIQSA-N 0.000 description 1
- 108010091358 Hypoxanthine Phosphoribosyltransferase Proteins 0.000 description 1
- 102100029098 Hypoxanthine-guanine phosphoribosyltransferase Human genes 0.000 description 1
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 1
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 1
- 102000013463 Immunoglobulin Light Chains Human genes 0.000 description 1
- 108010065825 Immunoglobulin Light Chains Proteins 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 102100036887 Immunoglobulin heavy variable 1-2 Human genes 0.000 description 1
- 102100022964 Immunoglobulin kappa variable 3-20 Human genes 0.000 description 1
- 206010061218 Inflammation Diseases 0.000 description 1
- 108020005350 Initiator Codon Proteins 0.000 description 1
- 229930010555 Inosine Natural products 0.000 description 1
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 1
- 102100034343 Integrase Human genes 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- 102000015696 Interleukins Human genes 0.000 description 1
- 108010063738 Interleukins Proteins 0.000 description 1
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 208000010038 Ischemic Optic Neuropathy Diseases 0.000 description 1
- AHLPHDHHMVZTML-BYPYZUCNSA-N L-Ornithine Chemical compound NCCC[C@H](N)C(O)=O AHLPHDHHMVZTML-BYPYZUCNSA-N 0.000 description 1
- FFFHZYDWPBMWHY-VKHMYHEASA-N L-homocysteine Chemical compound OC(=O)[C@@H](N)CCS FFFHZYDWPBMWHY-VKHMYHEASA-N 0.000 description 1
- UKAUYVFTDYCKQA-VKHMYHEASA-N L-homoserine Chemical compound OC(=O)[C@@H](N)CCO UKAUYVFTDYCKQA-VKHMYHEASA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- 108010006444 Leucine-Rich Repeat Proteins Proteins 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 241000829100 Macaca mulatta polyomavirus 1 Species 0.000 description 1
- 208000030136 Marchiafava-Bignami Disease Diseases 0.000 description 1
- 108010049137 Member 1 Subfamily D ATP Binding Cassette Transporter Proteins 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- 108010052285 Membrane Proteins Proteins 0.000 description 1
- 201000011442 Metachromatic leukodystrophy Diseases 0.000 description 1
- 102000003792 Metallothionein Human genes 0.000 description 1
- 108090000157 Metallothionein Proteins 0.000 description 1
- 101000933447 Mus musculus Beta-glucuronidase Proteins 0.000 description 1
- 101000727479 Mus musculus Reticulon-4 receptor Proteins 0.000 description 1
- 108010013731 Myelin-Associated Glycoprotein Proteins 0.000 description 1
- JDHILDINMRGULE-LURJTMIESA-N N(pros)-methyl-L-histidine Chemical compound CN1C=NC=C1C[C@H](N)C(O)=O JDHILDINMRGULE-LURJTMIESA-N 0.000 description 1
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 1
- 208000012902 Nervous system disease Diseases 0.000 description 1
- 102000000473 Nogo Receptor 2 Human genes 0.000 description 1
- 108010041253 Nogo Receptor 2 Proteins 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 108020005187 Oligonucleotide Probes Proteins 0.000 description 1
- 108010038807 Oligopeptides Proteins 0.000 description 1
- 102000015636 Oligopeptides Human genes 0.000 description 1
- 206010030924 Optic ischaemic neuropathy Diseases 0.000 description 1
- AHLPHDHHMVZTML-UHFFFAOYSA-N Orn-delta-NH2 Natural products NCCCC(N)C(O)=O AHLPHDHHMVZTML-UHFFFAOYSA-N 0.000 description 1
- UTJLXEIPEHZYQJ-UHFFFAOYSA-N Ornithine Natural products OC(=O)C(C)CCCN UTJLXEIPEHZYQJ-UHFFFAOYSA-N 0.000 description 1
- 108010058846 Ovalbumin Proteins 0.000 description 1
- 241000282579 Pan Species 0.000 description 1
- 241000282320 Panthera leo Species 0.000 description 1
- 241000282376 Panthera tigris Species 0.000 description 1
- HYRKAAMZBDSJFJ-LFDBJOOHSA-N Paramethasone acetate Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@@H]1[C@@H]2[C@@H]2C[C@@H](C)[C@@](C(=O)COC(C)=O)(O)[C@@]2(C)C[C@@H]1O HYRKAAMZBDSJFJ-LFDBJOOHSA-N 0.000 description 1
- 241000237988 Patellidae Species 0.000 description 1
- 108090000284 Pepsin A Proteins 0.000 description 1
- 102000057297 Pepsin A Human genes 0.000 description 1
- JEGFCFLCRSJCMA-IHRRRGAJSA-N Phe-Arg-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)O)N JEGFCFLCRSJCMA-IHRRRGAJSA-N 0.000 description 1
- 108010004729 Phycoerythrin Proteins 0.000 description 1
- 241000709664 Picornaviridae Species 0.000 description 1
- 241000282405 Pongo abelii Species 0.000 description 1
- 108010001267 Protein Subunits Proteins 0.000 description 1
- 102000002067 Protein Subunits Human genes 0.000 description 1
- 238000012228 RNA interference-mediated gene silencing Methods 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- 208000019155 Radiation injury Diseases 0.000 description 1
- 101000727470 Rattus norvegicus Reticulon-4 receptor Proteins 0.000 description 1
- 101100364404 Rattus norvegicus Rtn4 gene Proteins 0.000 description 1
- 108091027981 Response element Proteins 0.000 description 1
- 101710095853 Reticulon-4 receptor-like 1 Proteins 0.000 description 1
- 102100031540 Reticulon-4 receptor-like 1 Human genes 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 241000714474 Rous sarcoma virus Species 0.000 description 1
- 238000011579 SCID mouse model Methods 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- NLOAIFSWUUFQFR-CIUDSAMLSA-N Ser-Leu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O NLOAIFSWUUFQFR-CIUDSAMLSA-N 0.000 description 1
- SBMNPABNWKXNBJ-BQBZGAKWSA-N Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](N)CO SBMNPABNWKXNBJ-BQBZGAKWSA-N 0.000 description 1
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 1
- 241000700584 Simplexvirus Species 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- 102220497176 Small vasohibin-binding protein_T47D_mutation Human genes 0.000 description 1
- 241000256251 Spodoptera frugiperda Species 0.000 description 1
- 108020005038 Terminator Codon Proteins 0.000 description 1
- 108090000190 Thrombin Proteins 0.000 description 1
- 102000006601 Thymidine Kinase Human genes 0.000 description 1
- 108020004440 Thymidine kinase Proteins 0.000 description 1
- 108010060804 Toll-Like Receptor 4 Proteins 0.000 description 1
- 102000002689 Toll-like receptor Human genes 0.000 description 1
- 108020000411 Toll-like receptor Proteins 0.000 description 1
- 102100039360 Toll-like receptor 4 Human genes 0.000 description 1
- 108700019146 Transgenes Proteins 0.000 description 1
- 229910052770 Uranium Inorganic materials 0.000 description 1
- 208000036826 VIIth nerve paralysis Diseases 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- 206010047631 Vitamin E deficiency Diseases 0.000 description 1
- 102100040982 Volume-regulated anion channel subunit LRRC8B Human genes 0.000 description 1
- 241000282485 Vulpes vulpes Species 0.000 description 1
- 206010073696 Wallerian degeneration Diseases 0.000 description 1
- RACDDTQBAFEERP-PLTZVPCUSA-N [2-[(6s,8s,9s,10r,13s,14s,17r)-6-chloro-17-hydroxy-10,13-dimethyl-3,11-dioxo-6,7,8,9,12,14,15,16-octahydrocyclopenta[a]phenanthren-17-yl]-2-oxoethyl] acetate Chemical compound C1([C@@H](Cl)C2)=CC(=O)C=C[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@@](C(=O)COC(=O)C)(O)[C@@]2(C)CC1=O RACDDTQBAFEERP-PLTZVPCUSA-N 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- SXEHKFHPFVVDIR-UHFFFAOYSA-N [4-(4-hydrazinylphenyl)phenyl]hydrazine Chemical compound C1=CC(NN)=CC=C1C1=CC=C(NN)C=C1 SXEHKFHPFVVDIR-UHFFFAOYSA-N 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 230000001154 acute effect Effects 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- 150000003862 amino acid derivatives Chemical class 0.000 description 1
- 229940126575 aminoglycoside Drugs 0.000 description 1
- 230000008485 antagonism Effects 0.000 description 1
- 210000004960 anterior grey column Anatomy 0.000 description 1
- 201000007058 anterior ischemic optic neuropathy Diseases 0.000 description 1
- 230000000340 anti-metabolite Effects 0.000 description 1
- 229940100197 antimetabolite Drugs 0.000 description 1
- 239000002256 antimetabolite Substances 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 125000000637 arginyl group Chemical group N[C@@H](CCCNC(N)=N)C(=O)* 0.000 description 1
- 125000000613 asparagine group Chemical group N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- 238000004166 bioassay Methods 0.000 description 1
- 238000010256 biochemical assay Methods 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 238000001815 biotherapy Methods 0.000 description 1
- 210000002459 blastocyst Anatomy 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 108010006025 bovine growth hormone Proteins 0.000 description 1
- 125000000484 butyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 125000000837 carbohydrate group Chemical group 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 230000001925 catabolic effect Effects 0.000 description 1
- 239000006143 cell culture medium Substances 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 208000015114 central nervous system disease Diseases 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 238000010382 chemical cross-linking Methods 0.000 description 1
- 125000003636 chemical group Chemical group 0.000 description 1
- 239000007795 chemical reaction product Substances 0.000 description 1
- 239000005081 chemiluminescent agent Substances 0.000 description 1
- 238000002512 chemotherapy Methods 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 230000001684 chronic effect Effects 0.000 description 1
- 230000009194 climbing Effects 0.000 description 1
- 239000013599 cloning vector Substances 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 150000001875 compounds Chemical class 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 229940127089 cytotoxic agent Drugs 0.000 description 1
- 239000002254 cytotoxic agent Substances 0.000 description 1
- 230000002939 deleterious effect Effects 0.000 description 1
- YSMODUONRAFBET-UHFFFAOYSA-N delta-DL-hydroxylysine Natural products NCC(O)CCC(N)C(O)=O YSMODUONRAFBET-UHFFFAOYSA-N 0.000 description 1
- 210000001787 dendrite Anatomy 0.000 description 1
- 238000000326 densiometry Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 239000000032 diagnostic agent Substances 0.000 description 1
- 229940039227 diagnostic agent Drugs 0.000 description 1
- 238000002405 diagnostic procedure Methods 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- BOBLHFUVNSFZPJ-JOYXJVLSSA-N diflorasone diacetate Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2C[C@H](C)[C@@](C(=O)COC(C)=O)(OC(C)=O)[C@@]2(C)C[C@@H]1O BOBLHFUVNSFZPJ-JOYXJVLSSA-N 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 230000005750 disease progression Effects 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- ZWIBGKZDAWNIFC-UHFFFAOYSA-N disuccinimidyl suberate Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCCC(=O)ON1C(=O)CCC1=O ZWIBGKZDAWNIFC-UHFFFAOYSA-N 0.000 description 1
- 125000002228 disulfide group Chemical group 0.000 description 1
- PMMYEEVYMWASQN-UHFFFAOYSA-N dl-hydroxyproline Natural products OC1C[NH2+]C(C([O-])=O)C1 PMMYEEVYMWASQN-UHFFFAOYSA-N 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 235000013601 eggs Nutrition 0.000 description 1
- 230000005684 electric field Effects 0.000 description 1
- 238000010828 elution Methods 0.000 description 1
- 239000000839 emulsion Substances 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 230000009088 enzymatic function Effects 0.000 description 1
- YSMODUONRAFBET-UHNVWZDZSA-N erythro-5-hydroxy-L-lysine Chemical compound NC[C@H](O)CC[C@H](N)C(O)=O YSMODUONRAFBET-UHNVWZDZSA-N 0.000 description 1
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 201000003264 familial isolated deficiency of vitamin E Diseases 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 239000012530 fluid Substances 0.000 description 1
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 235000013305 food Nutrition 0.000 description 1
- 230000005714 functional activity Effects 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 238000003500 gene array Methods 0.000 description 1
- 230000030279 gene silencing Effects 0.000 description 1
- 230000024924 glomerular filtration Effects 0.000 description 1
- 229940116332 glucose oxidase Drugs 0.000 description 1
- 235000019420 glucose oxidase Nutrition 0.000 description 1
- 229960003180 glutathione Drugs 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- ZJYYHGLJYGJLLN-UHFFFAOYSA-N guanidinium thiocyanate Chemical compound SC#N.NC(N)=N ZJYYHGLJYGJLLN-UHFFFAOYSA-N 0.000 description 1
- 108060003552 hemocyanin Proteins 0.000 description 1
- 230000002949 hemolytic effect Effects 0.000 description 1
- 208000006454 hepatitis Diseases 0.000 description 1
- 231100000283 hepatitis Toxicity 0.000 description 1
- 102000044566 human HHAT Human genes 0.000 description 1
- 210000005260 human cell Anatomy 0.000 description 1
- 210000004754 hybrid cell Anatomy 0.000 description 1
- 238000012872 hydroxylapatite chromatography Methods 0.000 description 1
- 229960002591 hydroxyproline Drugs 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 230000036737 immune function Effects 0.000 description 1
- 238000003119 immunoblot Methods 0.000 description 1
- 238000001114 immunoprecipitation Methods 0.000 description 1
- 230000003308 immunostimulating effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000000099 in vitro assay Methods 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 230000000415 inactivating effect Effects 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 229910052738 indium Inorganic materials 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 230000002757 inflammatory effect Effects 0.000 description 1
- 230000004054 inflammatory process Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 229910052500 inorganic mineral Inorganic materials 0.000 description 1
- 229960003786 inosine Drugs 0.000 description 1
- 102000028416 insulin-like growth factor binding Human genes 0.000 description 1
- 108091022911 insulin-like growth factor binding Proteins 0.000 description 1
- 229940047124 interferons Drugs 0.000 description 1
- 229940047122 interleukins Drugs 0.000 description 1
- 239000007928 intraperitoneal injection Substances 0.000 description 1
- 229940065638 intron a Drugs 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 101150066555 lacZ gene Proteins 0.000 description 1
- 229910052747 lanthanoid Inorganic materials 0.000 description 1
- 150000002602 lanthanoids Chemical class 0.000 description 1
- 230000033001 locomotion Effects 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 210000003563 lymphoid tissue Anatomy 0.000 description 1
- 239000006249 magnetic particle Substances 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 210000001161 mammalian embryo Anatomy 0.000 description 1
- 210000005075 mammary gland Anatomy 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- HPNSFSBZBAHARI-UHFFFAOYSA-N micophenolic acid Natural products OC1=C(CC=C(C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-UHFFFAOYSA-N 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 235000010755 mineral Nutrition 0.000 description 1
- 239000011707 mineral Substances 0.000 description 1
- 230000037230 mobility Effects 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 210000002864 mononuclear phagocyte Anatomy 0.000 description 1
- 230000001459 mortal effect Effects 0.000 description 1
- 210000002161 motor neuron Anatomy 0.000 description 1
- 229960000951 mycophenolic acid Drugs 0.000 description 1
- HPNSFSBZBAHARI-RUDMXATFSA-N mycophenolic acid Chemical compound OC1=C(C\C=C(/C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-RUDMXATFSA-N 0.000 description 1
- 210000004498 neuroglial cell Anatomy 0.000 description 1
- 239000002858 neurotransmitter agent Substances 0.000 description 1
- QJGQUHMNIGDVPM-UHFFFAOYSA-N nitrogen group Chemical group [N] QJGQUHMNIGDVPM-UHFFFAOYSA-N 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 239000002751 oligonucleotide probe Substances 0.000 description 1
- 150000002482 oligosaccharides Polymers 0.000 description 1
- 229960003104 ornithine Drugs 0.000 description 1
- 229940092253 ovalbumin Drugs 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 229910052760 oxygen Inorganic materials 0.000 description 1
- 239000001301 oxygen Substances 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 229940111202 pepsin Drugs 0.000 description 1
- 238000010647 peptide synthesis reaction Methods 0.000 description 1
- 210000005259 peripheral blood Anatomy 0.000 description 1
- 239000011886 peripheral blood Substances 0.000 description 1
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 1
- 239000008177 pharmaceutical agent Substances 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- 229920001983 poloxamer Polymers 0.000 description 1
- 229920000447 polyanionic polymer Polymers 0.000 description 1
- 229920002704 polyhistidine Polymers 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 230000032361 posttranscriptional gene silencing Effects 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 238000004393 prognosis Methods 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 238000000159 protein binding assay Methods 0.000 description 1
- 230000012846 protein folding Effects 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000007115 recruitment Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 210000003705 ribosome Anatomy 0.000 description 1
- 210000003935 rough endoplasmic reticulum Anatomy 0.000 description 1
- 210000004116 schwann cell Anatomy 0.000 description 1
- 239000006152 selective media Substances 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 1
- 238000004513 sizing Methods 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 230000037439 somatic mutation Effects 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 210000003594 spinal ganglia Anatomy 0.000 description 1
- 230000003393 splenic effect Effects 0.000 description 1
- 210000004988 splenocyte Anatomy 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 125000004434 sulfur atom Chemical group 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 1
- 230000000946 synaptic effect Effects 0.000 description 1
- 229960004072 thrombin Drugs 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 230000010474 transient expression Effects 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 208000009174 transverse myelitis Diseases 0.000 description 1
- 206010044652 trigeminal neuralgia Diseases 0.000 description 1
- 125000000430 tryptophan group Chemical group [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C2=C([H])C([H])=C([H])C([H])=C12 0.000 description 1
- 210000004881 tumor cell Anatomy 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 230000008734 wallerian degeneration Effects 0.000 description 1
- 230000003442 weekly effect Effects 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K67/00—Rearing or breeding animals, not otherwise provided for; New or modified breeds of animals
- A01K67/027—New or modified breeds of vertebrates
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K67/00—Rearing or breeding animals, not otherwise provided for; New or modified breeds of animals
- A01K67/027—New or modified breeds of vertebrates
- A01K67/0275—Genetically modified vertebrates, e.g. transgenic
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/177—Receptors; Cell surface antigens; Cell surface determinants
- A61K38/179—Receptors; Cell surface antigens; Cell surface determinants for growth factors; for growth regulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/3955—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against proteinaceous materials, e.g. enzymes, hormones, lymphokines
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P21/00—Drugs for disorders of the muscular or neuromuscular system
- A61P21/02—Muscle relaxants, e.g. for tetanus or cramps
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/14—Drugs for disorders of the nervous system for treating abnormal movements, e.g. chorea, dyskinesia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/14—Drugs for disorders of the nervous system for treating abnormal movements, e.g. chorea, dyskinesia
- A61P25/16—Anti-Parkinson drugs
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/28—Drugs for disorders of the nervous system for treating neurodegenerative disorders of the central nervous system, e.g. nootropic agents, cognition enhancers, drugs for treating Alzheimer's disease or other forms of dementia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P27/00—Drugs for disorders of the senses
- A61P27/02—Ophthalmic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P27/00—Drugs for disorders of the senses
- A61P27/02—Ophthalmic agents
- A61P27/06—Antiglaucoma agents or miotics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P27/00—Drugs for disorders of the senses
- A61P27/16—Otologicals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
- A61P3/10—Drugs for disorders of the metabolism for glucose homeostasis for hyperglycaemia, e.g. antidiabetics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P5/00—Drugs for disorders of the endocrine system
- A61P5/38—Drugs for disorders of the endocrine system of the suprarenal hormones
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/10—Drugs for disorders of the cardiovascular system for treating ischaemic or atherosclerotic diseases, e.g. antianginal drugs, coronary vasodilators, drugs for myocardial infarction, retinopathy, cerebrovascula insufficiency, renal arteriosclerosis
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
- C12N15/1136—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing against growth factors, growth regulators, cytokines, lymphokines or hormones
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
- C12N15/1138—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing against receptors or cell surface proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/8509—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells for producing genetically modified animals, e.g. transgenic
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/05—Animals comprising random inserted nucleic acids (transgenic)
- A01K2217/054—Animals comprising random inserted nucleic acids (transgenic) inducing loss of function
- A01K2217/058—Animals comprising random inserted nucleic acids (transgenic) inducing loss of function due to expression of inhibitory nucleic acid, e.g. siRNA, antisense
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
- A01K2227/105—Murine
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2267/00—Animals characterised by purpose
- A01K2267/03—Animal model, e.g. for test or diseases
- A01K2267/035—Animal model for multifactorial diseases
- A01K2267/0356—Animal model for processes and diseases of the central nervous system, e.g. stress, learning, schizophrenia, pain, epilepsy
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/32—Fusion polypeptide fusions with soluble part of a cell surface receptor, "decoy receptors"
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/33—Fusion polypeptide fusions for targeting to specific cell types, e.g. tissue specific targeting, targeting of a bacterial subspecies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/70—Fusion polypeptide containing domain for protein-protein interaction
- C07K2319/74—Fusion polypeptide containing domain for protein-protein interaction containing a fusion for binding to a cell surface receptor
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/11—Antisense
- C12N2310/111—Antisense spanning the whole gene, or a large part of it
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/14—Type of nucleic acid interfering N.A.
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/50—Physical structure
- C12N2310/53—Physical structure partially self-complementary or closed
Definitions
- This invention relates to neurobiology and molecular biology. More particularly, this invention relates to immunogenic Nogo receptor-1 (NgRl) polypeptides, Nogo receptor-1 antibodies, antigen-binding fragments thereof, soluble Nogo receptors and fusion proteins thereof and nucleic acids encoding the same: This invention further relates to Nogo receptor-1 antagonist polynucleotides. This invention further relates to compositions comprising, and methods for making and using, such Nogo receptor antibodies, antigen-binding fragments thereof, immunogenic Nogo receptor-1 polypeptides, soluble Nogo receptors and fusion proteins thereof, nucleic acids encoding the same and antagonist polynucleotides.
- Axons and dendrites of neurons are long cellular extensions from neurons.
- the distal tip of an extending axon or neurite comprises a specialized region, known as the growth cone.
- Growth cones sense the local environment and guide axonal growth toward the neuron's target cell. Growth cones respond to several environmental cues, for example, surface adhesiveness, growth factors, neurotransmitters and electric fields.
- the guidance of growth at the cone involves various classes of adhesion molecules, intercellular signals, as well as factors that stimulate and inhibit growth cones.
- the growth cone of a growing neurite advances at various rates, but typically at the speed of one to two millimeters per day.
- Growth cones are hand shaped, with broad flat expansion (microspikes or f ⁇ lopodia) that differentially adhere to surfaces in the embryo.
- the f ⁇ lopodia are continually active, some f ⁇ lopodia retract back into the growth cone, while others continue to elongate through the substratum.
- the elongations between different f ⁇ lopodia form lamellipodia.
- the growth cone explores the area that is ahead of it and on either side with its lamellipodia and filopodia. When an elongation contacts a surface that is unfavorable to growth, it withdraws. When an elongation contacts a favorable growth surface, it continues to extend and guides the growth cone in that direction. The growth cone can be guided by small variations in surface properties of the substrata. When the growth cone reaches an appropriate target cell a synaptic connection is created. /
- Nerve cell function is greatly influenced by the contact between the neuron and other cells in its immediate environment (U. Rutishauser, T. M. Jessell, Physiol. Rev. ⁇ JS:819 (1988)). These cells include specialized glial cells, oligodendrocytes in the central nervous system (CNS), and Schwann cells in the peripheral nervous system (PNS), which ensheathe the neuronal axon with myelin (an insulating structure of multi-layered membranes) (G. Lemke, in An Introduction to Molecular Neurobiology, Z. Hall, Ed. (Sinauer, Sunderland, Mass.), p. 281 (1992)).
- CNS central nervous system
- PNS peripheral nervous system
- CNS neurons While CNS neurons have the capacity to regenerate after injury, they are inhibited from doing so because of the presence of inhibitory proteins present in myelin and possibly also by other types of molecules normally found in their local environment (Brittis and Flanagan, Neuron 50:11-14 (2001); Jones et al, J. Neurosc. 22:2792-2803 (2002); Grimpe et al, J. Neurosci. 22:3144-3160 (2002)).
- Each of these proteins has been separately shown to be a ligand for the neuronal Nogo receptor-1 (Wang et al., Nature 417:941-944 (2002); Liu et al, Science 297:1190-93 (2002); Grandpre et al, Nature 403:439-444 (2000); Chen et al, Nature 403:434-439 (2000); Domeniconi et al, Neuron 35:283-90 (2002)).
- Nogo receptor-1 is a GPI-anchored membrane protein that contains 8 leucine rich repeats
- Nogo receptor-1 Upon interaction with an inhibitory protein (e.g., NogoA, MAG and OM-gp), the Nogo receptor-1 complex transduces signals that lead to growth cone collapse and inhibition of neurite outgrowth.
- an inhibitory protein e.g., NogoA, MAG and OM-gp
- the present invention is directed to the use of Nogo receptor-1 antagonists for promoting neurite outgrowth, neuronal survival, and axonal regeneration in CNS neurons.
- the invention features molecules and methods useful for inhibiting neurite outgrowth inhibition, promoting neuronal survival, and/or promoting axonal regeneration in CNS neurons.
- the invention also relates to soluble Nogo receptor-1 polypeptides and fusion proteins comprising them, and antibodies and antigenic fragments thereof directed against specific immunogenic regions of Nogo receptor-1.
- the invention also relates to immunogenic Nogo receptor-1 polypeptides that bind to the antibodies of the invention.
- the invention also relates to Nogo receptor-1 polypeptides that are bound by a monoclonal antibody that binds to Nogo receptor-1.
- Such polypeptides may be used, inter alia, as immunogens or to screen antibodies to identify those with similar specificity to an antibody of the invention.
- the invention further relates to nucleic acids encoding the polypeptides of this invention, vectors and host cells comprising such nucleic acids and methods of making the peptides.
- the antibodies, soluble receptors and receptor fusion proteins of this invention antagonize or block Nogo rece ⁇ tor-1 and are useful for inhibiting binding of Nogo receptor-1 to its ligands, inhibiting growth cone collapse in a neuron and decreasing the inhibition of neurite outgrowth or sprouting in a neuron.
- the invention provides a polypeptide selected from the group consisting of AAAFTGLTLLEQLDLSDNAQLR (SEQ ED NO: 26); LDLSDNAQLR (SEQ ID NO: 27); LDLSDDAELR (SEQ ID NO: 29); LDLASDNAQLR (SEQ ID NO: 30); LDLASDDAELR (SEQ ID NO: 31); LDALSDNAQLR (SEQ ID NO: 32); LD ALSDDAELR (SEQ ID NO: 33); LDLSSDNAQLR (SEQ ED NO: 34); LDLSSDEAELR (SEQ ID NO: 35); DNAQLRWDPTT (SEQ ID NO: 36);
- DNAQLR SEQ ID NO: 37
- ADLSDNAQLRVVDPTT SEQ ID NO: 41
- the invention provides a nucleic acid encoding a polypeptide of the invention.
- the nucleic acid is operably linked to an expression control sequence.
- the invention provides a vector comprising a nucleic acid of the invention.
- the invention provides a host cell comprising a nucleic acid or comprising the vector of the invention.
- the invention provides a method of producing a polypeptide of the invention comprising culturing a host cell comprising a nucleic acid or vector of the invention and recovering the polypeptide from the host cell or culture medium.
- the invention provides a method of producing an antibody comprising the steps of immunizing a host with a polypeptide of the invention or a host cell comprising a nucleic acid or comprising the vector of the invention and recovering the antibody.
- the invention also provides an antibody produced by the method or an antigen-binding fragment thereof.
- the invention provides an antibody or an antigen-binding fragment thereof that specifically binds to a polypeptide of the invention, wherein the antibody is not the monoclonal antibody produced by hybridoma cell line HB 7El 1 (ATCC® accession No. PTA-4587).
- the antibody or antigen-binding fragment (a) inhibits growth cone collapse of a neuron; (b) decreases the inhibition of neurite outgrowth and sprouting in a neuron; and (c) inhibits Nogo receptor-1 binding to a ligand.
- the neurite outgrowth and sprouting is axonal growth.
- the neuron is a central nervous system neuron.
- an antibody of the invention is monoclonal. Ih some embodiments, an antibody of the invention is a murine antibody. In some embodiments, an antibody of the invention is selected from the group consisting of a humanized antibody, a chimeric antibody and a single chain antibody.
- the invention provides a method of inhibiting Nogo receptor-1 binding to a ligand, comprising the step of contacting Nogo receptor-1 with an antibody of the invention or antigen-binding fragment thereof.
- the ligand is selected from the group consisting of N ⁇ goA, NogoB, NogoC, MAG and OM-gp.
- the invention provides a method for inhibiting growth cone collapse in a neuron, comprising the step of contacting the neuron with an antibody of the invention or antigen-binding fragment thereof.
- the invention provides a method for decreasing the inhibition of neurite outgrowth or sprouting in a neuron, comprising the step of contacting the neuron with an antibody of the invention or antigen-binding fragment thereof.
- the neurite outgrowth or sprouting is axonal growth.
- the neuron is a central nervous system neuron.
- the invention provides a composition comprising a pharmaceutically acceptable carrier and an antibody of the invention or an antigen-binding fragment thereof. In some embodiments, the composition further comprises one or more additional therapeutic agents.
- the invention provides a method of promoting survival of a neuron at risk of dying, comprising contacting the neuron with an effective amount of an anti-Nogo receptor-1 antibody of the invention or antigen-binding fragment thereof.
- the neuron is in vitro.
- the neuron is in a mammal.
- the mammal displays signs or symptoms of multiple sclerosis, ALS, Huntington's disease, Alzheimer's disease, Parkinson's disease, diabetic neuropathy, stroke, traumatic brain injuries or spinal cord injury.
- the invention provides a method of promoting survival of a neuron in a mammal, which neuron is at risk of dying, comprising (a) providing a cultured host cell expressing an anti-Nogo receptor-1 antibody of the invention or antigen-binding fragment thereof; and (b) introducing the host cell into the mammal at or near the site of the neuron.
- the invention provides a gene therapy method of promoting survival of a neuron at risk of dying, which neuron is in a mammal, comprising administering at or near the site of the neuron a viral vector comprising a nucleotide sequence that encodes an anti-Nogo receptor- 1 antibody of the invention or an antigen-binding fragment thereof, wherein the anti-Nogo receptor-1 antibody or antigen-binding fragment is expressed from the nucleotide sequence in the mammal in an amount sufficient to promote survival of the neuron.
- the invention provides an isolated polypeptide of 60 residues or less comprising an amino acid sequence selected from the group consisting of: amino acids 309 to 335 of SEQ BD NO:49; amino acids 309 to 336 of SEQ ID NO:49; amino acids 309 to 337 of SEQ ED NO:49; amino acids 309 to 338 of SEQ ID NO:49; amino acids 309 to 339 of SEQ ID NO:49; amino acids 309 to 340 of SEQ ID NO:49; amino acids 309 to 341 of SEQ ID NO:49; amino acids 309 to 342 of SEQ ID NO:49; amino acids 309 to 343 of SEQ ID NO:49; amino acids 309 to 344 of SEQ ID NO:49; amino acids 309 to 345 of SEQ ID NO:49; amino acids 309 to 346of SEQ ID NO:49; amino acids 309 to 347 of SEQ ID NO:49; amino acids 309 to 348 of SEQ DD NO:49; amino acids 309 to
- the invention provides an isolated polypeptide of 60 residues or less comprising an amino acid sequence selected from the group consisting of: amino acids 311-344 of SEQ ED NO:49; amino acids 310-348 of SEQ ID NO:49; amino acids 323-328 of SEQ ID NO:49; amino acids 339-348 of SEQ DD NO:49; amino acids 378-414 of SEQ DD NO:49; amino acids 27-38 of SEQ DD NO:49; amino acids 39-61 of SEQ DD NO:49; amino acids 257-267 of SEQ ED NO:49; amino acids 280- 292 of SEQ ED NO:49; amino acids 301-323 of SEQ ED NO:49; amino acids 335-343 of SEQ DD NO:49; amino acids 310-335 of SEQ ED NO:49; amino acids 326-328 of SEQ DD NO:49; variants or derivatives of any of said polypeptide fragments, and a combination of at least two of any of said polypeptide fragments, and a combination
- the invention provides an isolated polypeptide fragment of 60 residues or less, comprising an amino acid sequence identical to a reference amino acid sequence, except for up to three individual amino acid substitutions, wherein said reference amino acid sequence is selected from the group consisting of: (a) amino acids x to 344 of SEQ ED NO:49, (b) amino acids 309 to y of SEQ DD NO:49, and (c) amino acids x to y of SEQ DD NO:49, wherein x is any integer from 305 to 326, and y is any integer from 328 to 350; and wherein said polypeptide fragment inhibits Nogo- receptor-mediated neurite outgrowth inhibition.
- the invention provides an isolated polypeptide fragment of 60 residues or less, comprising an amino acid sequence identical to a reference amino acid sequence, except for up to three individual amino acid substitutions, wherein said reference amino acid sequence is selected from the group consisting of: (a) amino acids x' to 344 of SEQ ED NO:49, (b) amino acids 309 to y 1 of SEQ ED NO:49, and (c) amino acids x' to y* of SEQ DD NO:49, where x' is any integer from 300 to 326, and y* is any integer from 328 to 360, and wherein said polypeptide fragment inhibits Nogo-receptor-mediated neurite outgrowth inhibition.
- said reference amino acid sequence is selected from the group consisting of: (a) amino acids x' to 344 of SEQ ED NO:49, (b) amino acids 309 to y 1 of SEQ ED NO:49, and (c) amino acids x' to y* of SEQ DD NO:49, where x' is any
- the invention provides an isolated polypeptide fragment of 60 residues or less, comprising an amino acid sequence identical to a reference amino acid sequence, except for up to three individual amino acid substitutions, wherein said reference amino acid sequence is selected from the group consisting of: amino acids 309 to 335 of SEQ ID NO:49; amino acids 309 to 344 of SEQ ID NO:49; amino acids 310 to 335 of SEQ ID NO:49; amino acids 310 to 344 of SEQ ID NO:49; amino acids 309 to 350 of SEQ ID NO:49; amino acids 300 to 344 of SEQ ID NO:49; and amino acids 315 to 344 of SEQ ED NO:49.
- said reference amino acid sequence is selected from the group consisting of: amino acids 309 to 335 of SEQ ID NO:49; amino acids 309 to 344 of SEQ ID NO:49; amino acids 310 to 335 of SEQ ID NO:49; amino acids 310 to 344 of SEQ ID NO:49; amino acids 309 to 350 of SEQ ID NO:49; amino
- the invention provides an isolated polypeptide fragment of 60 residues or less, comprising an amino acid sequence identical to a reference amino acid sequence, except for up to three individual amino acid substitutions, wherein said reference amino acid sequence is amino acids 309 to 344 of SEQ ED NO:49. In some embodiments, the invention provides an isolated polypeptide fragment of 60 residues or less, comprising an amino acid sequence identical to a reference amino acid sequence, except for up to three individual amino acid substitutions, wherein said reference amino acid sequence is amino acids 309 to 335 of SEQ ID NO:49.
- the invention provides a polypeptide of the invention that is cyclic.
- the cyclic polypeptide further comprises a first molecule linked at the N- terminus and a second molecule linked at the C-terminus; wherein the first molecule and the second molecule are joined to each other to form said cyclic molecule.
- the first and second molecules are selected from the group consisting of: a biotin molecule, a cysteine residue, and an acetylated cysteine residue.
- the first molecule is a biotin molecule attached to the N-terminus and the second molecule is a cysteine residue attached to the C-terminus of the polypeptide of the invention.
- the first molecule is an acetylated cysteine residue attached to the N-terminus and the second molecule is a cysteine residue attached to the C-terminus of the polypeptide of the invention. In some embodiments, the first molecule is an acetylated cysteine residue attached to the N-terminus and the second molecule is a cysteine residue attached to the C-terminus of the polypeptide of the invention. In some embodiments, the C-terminal cysteine has an NH2 moiety attached.
- the invention provides an isolated polypeptide comprising a first polypeptide fragment and a second polypeptide fragment, wherein said first polypeptide fragment comprises an amino acid sequence identical to a first reference amino acid sequence, except for up to twenty individual amino acid substitutions, wherein said first reference amino acid sequence is selected from the group consisting of: (a) amino acids a to 445 of SEQ ID NO:49, (b) amino acids 27 to b of SEQ ED NO:49, and (c) amino acids a to b of SEQ ID NO:49, wherein a is any integer from 25 to 35, and b is any integer from 300 to 450; wherein said second polypeptide fragment comprises an amino acid sequence identical to a second reference amino acid sequence, except for up to twenty individual amino acid substitutions, wherein said second reference amino acid sequence is selected from the group consisting of (a) amino acids c to 445 of SEQ ED NO:49, (b) amino acids 27 to d of SEQ ID NO:49, and (c
- the invention further provides an isolated polypeptide comprising a first polypeptide fragment and a second polypeptide fragment, wherein the first polypeptide fragment comprises an amino acid sequence identical to a first reference amino acid sequence, except for up to twenty individual amino acid substitutions, wherein the first reference amino acid sequence is selected from the group consisting of: (a) amino acids 27 to 310 of SEQ ID NO:49 and (b) amino acids 27 to 344 of SEQ ID NO:49.
- the invention further provides an isolated polypeptide comprising a first polypeptide fragment and a second polypeptide fragment, wherein the second polypeptide fragment comprises an amino acid sequence identical to a first reference amino acid sequence, except for up to twenty individual amino acid substitutions, wherein the second reference amino acid sequence is selected from the group consisting of: (a) amino acids 27 to 310 of SEQ ID NO:49 and (b) amino acids 27 to 344 of SEQ ID NO:49.
- the invention further provides an isolated polypeptide comprising a first polypeptide fragment and a second polypeptide fragment, wherein the second polypeptide fragment comprises an amino acid sequence identical to a first reference amino acid sequence, except for up to twenty individual amino acid substitutions, wherein the first polypeptide fragment comprises amino acids 27 to 310 of SEQ ID NO:49 and the second polypeptide fragment comprises amino acids 27 to 310 of SEQ ID NO:49 or wherein the first polypeptide fragment comprises amino acids 27 to 344 of SEQ ID NO:49 and the second polypeptide fragment comprises amino acids 27 to 310 of SEQ ID NO:49 or wherein the first polypeptide fragment comprises amino acids 27 to 344 of SEQ ID NO:49 and the second polypeptide fragment comprises amino acids 27 to 344 of SEQ ID NO:49.
- the invention further provides that the first polypeptide fragment is situated upstream of the second polypeptide fragment. In some embodiments, the invention further provides a peptide linker situated between the first polypeptide fragment and the second polypeptide fragment. In some embodiments, the invention further provides that the peptide linker comprises SEQ ID NO:65 (G4S) 3 . In some embodiments, the invention further provides that the peptide linker comprises SEQ ID NO:66 (G4S) 2 . f0031] In some embodiments, the invention provides a polypeptide of the invention wherein at least one cysteine residue is substituted with a heterologous amino acid. In some embodiments, the at least one cysteine residue is C266.
- the at least one cysteine residue is C309. In some embodiments, the at least one cysteine residue is C335. Ih some embodiments, the at least one cysteine residue is at C336. In some embodiments, the at least one cysteine residue is substituted with a replacement amino acid selected from the group consisting of alanine, serine and threonine. In some embodiments, the replacement amino acid is alanine.
- the invention provides an isolated polypeptide comprising: (a) an amino acid sequence identical to a reference amino acid sequence except that at least one cysteine residue of said reference amino acid sequence is substituted with a different amino acid, wherein said reference amino acid sequence is selected from the group consisting of: (i) amino acids a to 445 of SEQ ID NO:49, (iii) amino acids 27 to b of SEQ ID NO:49, and (iii) amino acids a to b of SEQ ID NO:49, wherein a is any integer from 25 to 35, and b is any integer from 300 to 450; and (b) a heterologous polypeptide; wherein said polypeptide inhibits nogo-receptor-mediated neurite outgrowth inhibition.
- the invention further provides that C266 of said reference amino acid sequence is substituted with a different amino acid. In some embodiments, the invention further provides that C309 of said reference amino acid sequence is substituted with a different amino acid. In some embodiments, the invention further provides that C335 of said reference amino acid sequence is substituted with a different amino acid. Ih some embodiments, the invention further provides that C266 and C309 of said reference amino acid sequence are substituted with different amino acids. In some embodiments, the invention further provides that C309 and C335 of said reference amino acid sequence are substituted with different amino acids. In some embodiments, the invention further provides that the different amino acid is alanine.
- the invention provides an isolated polypeptide comprising: (a) an amino acid sequence identical to a reference amino acid sequence, except for up to twenty individual amino acid substitutions, wherein said reference amino acid sequence is selected from the group consisting of: (i) amino acids a to 445 of SEQ ID NO:49,(ii) amino acids 27 to b of SEQ ID NO:49, and(iii) amino acids a to b of SEQ ID NO:49, wherein a is any integer from 25 to 35, and b is any integer from 300 to 450; and (b) a heterologous polypeptide; wherein said polypeptide inhibits nogo-receptor- mediated neurite outgrowth inhibition.
- the invention provides an isolated polypeptide comprising a first polypeptide fragment and a second polypeptide fragment, wherein said first polypeptide fragment comprises an amino acid sequence identical to a first reference amino acid sequence, except for up to twenty individual amino acid substitutions, wherein said first reference amino acid sequence is selected from the group consisting of: (a) amino acids a to 305 of SEQ ID NO.49, (b) amino acids 1 to b of SEQ ID NO:49, and (c) amino acids a to b of SEQ ID NO:49, wherein a is any integer from 1 to 27, and b is any integer from 264 to 309; and wherein said second polypeptide fragment comprises an amino acid sequence identical to a second reference amino acid sequence, except for up to twenty individual amino acid substitutions, wherein said second reference amino acid sequence is selected from the group consisting of: (a) amino acids c to 332 of SEQ ID NO:60, (b) amino acids 275 to d of SEQ ID NO:60, and (c
- the first reference amino acid sequence is selected from the group consisting of: (a) amino acids 1-274 of SEQ ID NO:49; and (b) amino acids 1-305 of SEQ ID NO:49.
- the second reference amino acid sequence is selected from the group consisting of: (a) amino acids 275-311 of SEQ ID NO:60; (b) amino acids 275-332 of SEQ ID NO:60; (c) amino acids 306-311 of SEQ ID NO:60; (d) amino acids 306-308 of SEQ BD NO:60; and (e) amino acids 306-309 of SEQ ID NO:60.
- the first polypeptide fragment comprises amino acids 1-274 of SEQ ID NO:49 and the second polypeptide fragment comprises amino acids amino acids 275-311 of SEQ ID NO:60. In some embodiments, the first polypeptide fragment comprises amino acids 1-274 of SEQ ID NO:49 and the second polypeptide fragment comprises amino acids 275-332 of SEQ ID NO:60. In some embodiments, the first polypeptide fragment comprises amino acids 1-305 of SEQ ID NO:49 and the second polypeptide fragment comprises amino acids 306-311 of SEQ LD NO:60. In some embodiments, the first polypeptide fragment comprises amino acids 1-305 of SEQ ID NO:49 and the second polypeptide fragment comprises amino acids 306-308 of SEQ BD NO:60.
- the first polypeptide fragment comprises amino acids 1-305 of SEQ ID NO:49 and the second polypeptide fragment comprises amino acids 306-309 of SEQ ID NO:60.
- at least one additional amino acid is added to the C-terminus of the second polypeptide fragment.
- the at least one additional amino acid is tryptophan.
- A269 of the first polypeptide fragment is substituted with a different amino acid.
- the different amino acid is tryptophan.
- the invention provides an isolated polypeptide comprising a first polypeptide fragment and a second polypeptide fragment, wherein said first polypeptide fragment consists of amino acids 1-310 of SEQ ID NO:49, except for up to twenty individual amino acid substitutions; and wherein said second polypeptide fragment consists of amino acids 311 to 318 of SEQ ID NO:60, except for up to five individual amino acid substitutions; and wherein said polypeptide inhibits nogo-receptor-mediated neurite outgrowth inhibition.
- the invention further provides that the heterologous polypeptide is selected from the group consisting of:(a) serum albumin, (b) an Fc region, (c) a signal peptide, (d) a polypeptide tag, and (e) a combination of two or more of said heterologous polypeptides.
- the invention further provides that the Fc region is selected from the group consisting of: an IgA Fc region; an IgD Fc region; an IgG Fc region, an IgEFc region; and an IgM Fc region. In one embodiment, the Fc region is an IgG Fc region.
- the invention further provides that a peptide linker is situated between the amino acid sequence and the IgG Fc region.
- the peptide linker comprises SEQ ID NO:66 (G4S) 2
- the invention further provides that the polypeptide tag is selected from the group consisting of: FLAG tag; Strep tag; poly-histidine tag; VSV-G tag; influenza virus hemagglutinin (HA) tag; and c-Myc tag.
- the invention provides a polypeptide of the invention attached to one or more polyalkylene glycol moieties.
- the invention further provides that the one or more polyalkylene glycol moieties is a polyethylene glycol (PEG) moiety. In some embodiments, the invention further provides a polypeptide of the invention attached to 1 to 5 PEG moieties. [0038] In some embodiments, the invention provides an isolated polynucleotide encoding a polypeptide of the invention. In some embodiments, the invention further provides that the nucleotide sequence is operably linked to an expression control element (e.g. an inducible promoter, a constitutive promoter, or a secretion signal). Additional embodiments include a vector comprising an isolated polynucleotide of the invention and a host cell comprising said vector.
- an expression control element e.g. an inducible promoter, a constitutive promoter, or a secretion signal. Additional embodiments include a vector comprising an isolated polynucleotide of the invention and a host cell comprising said vector.
- the invention provides an isolated polynucleotide selected from the group consisting of :(i) an antisense polynucleotide; (ii) a ribozyme; (iii)a small interfering RNA (siRNA); and (iv) a small-hairpin RNA (shRNA).
- the isolated polynucleotide is an antisense polynucleotide comprising at least 10 bases complementary to the coding portion of the NgRl mRNA. In some embodiments, the polynucleotide is a ribozyme. [0041] In further embodiments, the polynucleotide is a siRNA or a shRNA. In some embodiments, the invention provides that that siRNA or the shRNA inhibits NgRl expression. In some embodiments, the invention further provides that the siRNA or shRNA is at least 90% identical to the nucleotide sequence comprising: CUACUUCUCCCGCAGGCG or CCCGGACCGACGUCUUCAA or CUGACCACUGAGUCUUCCG.
- the siRNA or shRNA nucleotide sequence is CUACUUCUCCCGCAGGCG or CCCGGACCGACGUCUUCAA or CUGACCACUGAGUCUUCCG. [0042] In some embodiments, the invention further provides that the siRNA or shRNA nucleotide sequence is complementary to the xnRNA produced by the polynucleotide sequence GATGAAGAGGGCGTCC GCT or GGGCCTGGCTGCAGAAGTT or GACTGGTGACTCAGAG AAGGC.
- compositions comprising the polypeptides, polynucleotides, vectors or host cells of the invention and in certain embodiments a pharmaceutically acceptable carrier.
- the composition comprises amino acids 27-310 of SEQ DD NO: 7 and an anti-inflammatory agent.
- the composition comprises amino acids 27-310 of SEQ ED NO: 9 and an anti-inflammatory agent.
- the invention further provides that the inflammatory agent is selected from the group consisting of a steroidal anti-inflammatory agent and a non-steroidal anti-inflammatory agent.
- the steroidal anti-inflammatory agent is selected from the group consisting of hydrocortisone, 21-acetoxy ⁇ regnenolone, alclomerasone, algestone, amcinonide, beclomethasone, betamethasone, betamethasone valerate, budeso ⁇ ide, chloroprednisone, clobetasol, clobetasol propionate, clobetasone, clobetasone butyrate, clocortolone, cloprednol, corticosterone, cortisone, cortivazol, deflazacon, desonide, desoximerasone, dexamethasone, diflorasone, diflucortolone, difluprednate, enoxolone, fluazacort, flucloronide, flumethasone, flumethasone pivalate, flunisolide, fiucinolone acetonide, fluocinonide,
- the steroidal anti-inflammatory agent is methylprednisolone.
- the non-steroidal anti-inflammatory agent is selected from the group consisting of alminoprofen, benoxaprofen, bucloxic acid, carprofen, fenbufen, fenoprofen, fluprofen, flurbiprofen, ibuprofen, indoprofen, ketoprofen, miroprofen, naproxen, oxaprozin, pirprofen, pranoprofen, suprofen, tiaprofenic acid, tioxaprofen, indomethacin, acemetacin, alclofenac, clidanac, diclofenac, fenclofenac, fenclozic acid, fentiazac, flirofenac, ibufenac, isoxepac, oxpinac,
- Additional embodiments include compositions where amino acids 27-310 of SEQ ID NO:
- heterologous polypeptide is Fc.
- Embodiments of the invention also include methods for promoting neurite outgrowth, comprising contacting a neuron with an agent which includes polypeptides, polynucleotides or compositions of the invention, wherein said agent inhibits Nogo receptor 1 -mediated neurite outgrowth inhibition.
- Additional embodiments include a method for inhibiting signal transduction by the NgRl signaling complex, comprising contacting a neuron with an effective amount of an agent which includes polypeptide, polynucleotides, or compositions of the invention, wherein said agent inhibits signal transduction by the NgRl signaling complex.
- Other embodiments include a method for treating a central nervous system (CNS) disease, disorder, or injury in a mammal, comprising administering to a mammal in need of treatment an effective amount of an agent which includes polypeptides, polynucleotides, or compositions of the invention, wherein said agent inhibits Nogo Receptor 1-mediated neurite outgrowth inhibition.
- the disease, disorder or injury is selected from the group consisting of multiple sclerosis,
- ALS Huntington's disease
- Alzheimer's disease Parkinson's disease
- diabetic neuropathy stroke
- traumatic brain injuries spinal cord injury
- optic neuritis glaucoma
- hearing loss and adrenal leukodystrophy.
- the invention further provides that the polypeptide is fused to a heterologous polypeptide.
- the heterologous polypeptide is serum albumin.
- the heterologous polypeptide is an Fc region.
- the heterologous polypeptide is a signal peptide.
- the heterologous polypeptide is a polypeptide tag.
- the invention further provides that the Fc region is selected from the group consisting of: an IgA Fc region; an IgD Fc region; an IgG Fc region, an IgEFc region; and an
- the invention further provides that the polypeptide tag is selected from the group consisting of: FLAG tag; Strep tag; poly-histidine tag; VSV-G tag; influenza virus hemagglutinin (HA) tag; and c-Myc tag.
- the polypeptide tag is selected from the group consisting of: FLAG tag; Strep tag; poly-histidine tag; VSV-G tag; influenza virus hemagglutinin (HA) tag; and c-Myc tag.
- Figure 1 is a schematic representation of the structure of Nogo receptor- 1.
- Human sNogoR310 contains residues 26-310 of SEQ ID NO:7 and sNogoR344 contains residues 26-344 of SEQ ID NO:6.
- Rat sNogoR310 contains residues 27-310 of SEQ ED NO:9 and sNogoR344 contains residues
- Figure 2 depicts an antigenicity plot for the Nogo receptor- 1 protein using the Vector
- Rat P-617 is SEQ ID NO: 10 and rat P-618 is SEQ ID NO: 11.
- Human P-617 is SEQ ID NO: 11
- Figure 3 A is a graph depicting the binding activity of anti-Nogo receptor- 1 antibody
- the graph presents the effect of 7El 1 concentration on the binding of Nogo66 to Nogo receptor-1.
- Figure 3B depicts the binding activity of anti-Nogo receptor-1 antibody, 1H2.
- the graph presents the effect of 1H2 concentration on the binding of Nogo66 to sNogoR344-Fc (also referred to herein and in
- Figure 4 depicts the results of an ELISA for anti-Nogo-R-1 antibodies 1H2, 3G5 and
- the effect of the antibodies on OD 4 5 0 in the presence of immobilized antigens was determined.
- the immobilized antigens were sNogoR310-Fc (also referred to herein and in United States patent application
- Figure 5 is a graph depicting the effects of monoclonal antibody, 7El 1, on rat DRG neurite outgrowth in the presence of varying amounts of myelin.
- Figure 6A is a graph depicting the effect of binding of sNogoR310 to l2S I-Nogo66 and
- Figure 6B depicts the binding activity of I25 I-Nogo66 to sNogoR310.
- Figure 7 is a graph depicting the effect of sNogoR310-Fc on I25 I-Nogo40 binding to sNogoR310.
- Figure 8 is a graph depicting the binding activity of sNogoR310-Fc to I25 I-Nogo40.
- Figure 9A is a graph of the effect of sNogoR310 on neurite outgrowth/cell in the presence or absence of myelin.
- Figure 9B is a graph of the effect of sNogoR310 on neurite outgrowth in the presence or absence of myelin.
- Figure 1OA is a graph depicting the effect of sNogoR310-Fc on P4 rat DRG neurite outgrowth in the presence or absence of increasing amounts of myelin.
- Figure 1OB depicts the number of neurites/cell following treatment with PBS, PBS + sNogoR310-Fc, 20ng myelin and myelin + sNogoR310-Fc.
- Figure 11 is a graph depicting the effect of monoclonal antibody 5B10 on DRG neurite outgrowth/cell in the presence of increasing amounts of myelin.
- Figure 12 is a graph depicting the effect of sNogoR310-Fc on the BBB score up to 30 days following induction of injury in a rat spinal cord transection model.
- Figures 13A and 13B report the locomotor BBB score as a function of time after dorsal hemisection in the WT or transgenic mice from Line 08 or Line 01.
- Figure 13C graphs the maximal tolerated inclined plane angle as a function of time after injury for WT and transgenic mice.
- Figure 13D shows hindlimb errors during inclined grid climbing as a function of post-injury time. In all the graphs, means ⁇ s.e.m. from 7-9 mice in each group are reported. The values from transgenic group are statistically different from the WT mice, (double asterisks, P ⁇ 0.01 ; Student's t-test).
- Figure 14A shows the locomotor BBB score as a function of time after dorsal hemisection in vehicle or sNogoR310-Fc treated animals.
- Figure 14B shows hindlimb errors during grid walking as a function of time after injury.
- Figure 14C shows footprint analysis revealing a shorter stride length and a greater stride width in control mice than uninjured or injured + sNogoR310-Fc rats. In all the graphs, means ⁇ s.e.m. from 7-9 rats in each group are reported.
- the values of sNogoR310-Fc group are statistically different from the control ( Figures 14A-B).
- the control values are statistically different from no-SCI or SCI + sNogoR310-Fc rats in Figure 14C. (asterisk, p ⁇ 0.05; double asterisks, p ⁇ 0.01;
- Figure 15 shows a model of the binding of the anti-rNgRl antibody, 1D9, to the soluble fragment of rat NgRl (srNgR310).
- Figure 16A shows the nucleotide sequence of human Nogo receptor cDNA. The start and stop codons are underlined. The selected RNAi target regions are italicized. RNAi-I and RNAi-3 target the human NgR gene specifically, RNAi-2 was designed to target human, mouse and rat NgR genes.
- Figure 16 B shows the nucleotide sequences of the DNA oligonucleotides used for construction of NgR RNAi into expression vector pU6.
- Figure 17 depicts the results of the transient transfection test of RNAi knockdown in mouse L cells.
- Figure 18 shows the transfection of the human NgR expression vector into SKN and 293 cells.
- Figure 19 depicts the transient transfection test of RNAi knockdown in human SKN cells.
- Figure 20 shows a schematic representation of a RNAi lentiviral vector.
- the RNAi expression cassette can be inserted at the Pad site or EcoRI site.
- Figure 21 shows a western blot analysis using 7El 1 antibody to demonstrate NgRl knockdown in cloned Neuroscreen cells.
- Figure 22 shows a summary of NgR expression in cloned NeuroScreen cells transduced with LV (clone # 3G9, 1E5 1E9 IElO), LV-NgR RNAi or na ⁇ ve cells. NgR and GAPDH signals on western blot results were quantified by densitometry scanning.
- Figure 23 shows four NeuroScreen cell clones that were established with different levels of NgR knockdown. NgR expression is shown as the percentage of the NgR:GAPDH signals ratio in na ⁇ ve NeuroScreen cells.
- Figures 24A-B show the effect of ectodomain of the rat NgRl (27-310) fused to a rat
- A BBB score was recorded weekly for 4 weeks.
- B BBB score in MP-treated rats 2 days after SCI.
- C BBB scores normalized to day 2 for individual animals.
- D Frequency of consistent plantar stepping and hindlimb-forelimb coordination, illustrating the proportion of rats in each group that attained a score of 14 or higher 3 and 4 weeks after SCI.
- E Mean stride length in NgR(310)ecto-Fc- and MP + NgR(310)ecto-Fc-treated groups compared with controls.
- Figures 26A-B show the effect of ecto-domain of the rat NgRl (27-310) fused to a rat
- IgG [NgR(310)ecto-Fc] and methylprednisolone (MP) treatment on axon number caudal to the spinal cord lesion.
- Figures 27 shows the effect of ecto-domain of the rat NgRl (27-310) fused to a rat IgG
- a or “an” entity refers to one or more of that entity; for example, “an immunoglobulin molecule,” is understood to represent one or more immunoglobulin molecules.
- the terms “a” (or “an”), “one or more,” and “at least one” can be used interchangeably herein.
- antibody means an intact immunoglobulin, or an antigen-binding fragment thereof.
- Antibodies of this invention can be of any isotype or class (e.g., M, D, G, E and A) or any subclass (e.g., Gl-4, Al-2) and can have either a kappa (K) or lambda ( ⁇ ) light chain.
- Fc means a portion of an immunoglobulin heavy chain that comprises one or more heavy chain constant region domains, CHl 5 CH2 and CH3.
- a portion of the heavy chain constant region of an antibody that is obtainable by papain digestion.
- NogoR fusion protein means a protein comprising a soluble Nogo receptor- 1 moiety fused to a heterologous polypeptide.
- humanized antibody means an antibody in which at least a portion of the non-human sequences are replaced with human sequences. Examples of how to make humanized antibodies may be found in United States Patent Nos. 6,054,297, 5,886,152 and 5,877,293.
- chimeric antibody means an antibody that contains one or more regions from a first antibody and one or more regions from at least one other antibody.
- the first antibody and the additional antibodies can be from the same or different species.
- NogoR NogoR
- NogoR-1 NogoR-1
- NgR nogoR-1
- NgR-I nogo receptor 1
- polypeptide is intended to encompass a singular
- polypeptide as well as plural “polypeptides,” and refers to a molecule composed of monomers (amino acids) linearly linked by amide bonds (also known as peptide bonds).
- polypeptide refers to any chain or chains of two or more amino acids, and does not refer to a specific length of the product.
- peptides, dipeptides, tripeptides, oligopeptides, "protein,” “amino acid chain,” or any other term used to refer to a chain or chains of two or more amino acids are included within the definition of
- polypeptide and the term “polypeptide” may be used instead of, or interchangeably with any of these terms.
- polypeptide is also intended to refer to the products of post-expression modifications of the polypeptide, including without limitation glycosylation, acetylation, phosphorylation, amidation, derivatization by known protecting/blocking groups, proteolytic cleavage, or modification by non- naturally occurring amino acids.
- a polypeptide may be derived from a natural biological source or produced by recombinant technology, but is not necessarily translated from a designated nucleic acid sequence. It may be generated in any manner, including by chemical synthesis.
- a polypeptide of the invention may be of a size of about 3 or more, 5 or more, 10 or more, 20 or more, 25 or more, 50 or more, 75 or more, 100 or more, 200 or more, 500 or more, 1,000 or more, or 2,000 or more amino acids.
- Polypeptides may have a defined three-dimensional structure, although they do not necessarily have such structure. Polypeptides with a defined three-dimensional structure are referred to as folded, and polypeptides which do not possess a defined three-dimensional structure, but rather can adopt a large number of different conformations, and are referred to as unfolded.
- glycoprotein refers to a protein coupled to at least one carbohydrate moiety that is attached to the protein via an oxygen-containing or a nitrogen-containing side chain of an amino acid residue, e.g., a serine residue or an asparagine residue.
- an "isolated" polypeptide or a fragment, variant, or derivative thereof is intended a polypeptide that is not in its natural milieu. No particular level of purification is required.
- an isolated polypeptide can be removed from its native or natural environment.
- Recombinantly produced polypeptides and proteins expressed in host cells are considered isolated for purposed of the invention, as are native or recombinant polypeptides which have been separated, fractionated, or partially or substantially purified by any suitable technique.
- polypeptide fragment refers to a short amino acid sequence of a larger polypeptide. Protein fragments may be "free-standing,” or comprised within a larger polypeptide of which the fragment forms a part of region. Representative examples of polypeptide fragments of the invention, include, for example, fragments comprising about 5 amino acids, about 10 amino acids, about 15 amino acids, about 20 amino acids, about 30 amino acids, about 40 amino acids, about 50 amino acids, about 60 amino acids, about 70 amino acids, about 80 amino acids, about 90 amino acids, and about 100 amino acids or more in length.
- fragment when referring to a polypeptide of the present invention include any polypeptide which retains at least some biological activity.
- Polypeptides as described herein may include fragment, variant, or derivative molecules therein without limitation, so long as the polypeptide still serves its function.
- NgRl polypeptides and polypeptide fragments of the present invention may include proteolytic fragments, deletion fragments and in particular, fragments which more easily reach the site of action when delivered to an animal.
- Polypeptide fragments further include any portion of the polypeptide which comprises an antigenic or immunogenic epitope of the native polypeptide, including linear as well as three-dimensional epitopes.
- NgRl polypeptides and polypeptide fragments of the present invention may comprise variant regions, including fragments as described above, and also polypeptides with altered amino acid sequences due to amino acid substitutions, deletions, or insertions. Variants may occur naturally, such as an allelic variant. By an "allelic variant” is intended alternate forms of a gene occupying a given locus on a chromosome of an organism. Genes H 5 Lewin, B., ed., John Wiley & Sons, New York (1985). Non-naturally occurring variants may be produced using art-known mutagenesis techniques. NgRl polypeptides and polypeptide fragments of the invention may comprise conservative or non-conservative amino acid substitutions, deletions or additions.
- NgRl polypeptides and polypeptide fragments of the present invention may also include derivative molecules.
- Variant polypeptides may also be referred to herein as "polypeptide analogs.”
- a "derivative" of a polypeptide or a polypeptide fragment refers to a subject polypeptide having one or more residues chemically derivatized by reaction of a functional side group. Also included as “derivatives" are those peptides which contain one or more naturally occurring amino acid derivatives of the twenty standard amino acids.
- disulfide bond includes the covalent bond formed between two sulfur atoms.
- the amino acid cysteine comprises a thiol group that can form a disulfide bond or bridge with a second thiol group.
- fusion protein means a protein comprising a first polypeptide linearly connected, via peptide bonds, to a second, polypeptide.
- the first polypeptide and the second polypeptide may be identical or different, and they may be directly connected, or connected via a peptide linker (see below).
- polynucleotide is intended to encompass a singular nucleic acid as well as plural nucleic acids, and refers to an isolated nucleic acid molecule or construct, e.g. , messenger RNA (mRNA) or plasmid DNA (pDNA).
- mRNA messenger RNA
- pDNA plasmid DNA
- a polynucleotide can contain the nucleotide sequence of the full- length cDNA sequence, including the untranslated 5' and 3' sequences, the coding sequences.
- a polynucleotide may comprise a conventional phosphodiester bond or a non-conventional bond (e.g., an amide bond, such as found in peptide nucleic acids (PNA)).
- PNA peptide nucleic acids
- the polynucleotide can be composed of any polyribonucleotide or polydeoxyribonucleotide, which may be unmodified RNA or DNA or modified RNA or DNA.
- polynucleotides can be composed of single- and double-stranded DNA, DNA that is a mixture of single- and double-stranded regions, single- and double-stranded RNA, and RNA that is mixture of single- and double-stranded regions, hybrid molecules comprising DNA and RNA that may be single-stranded or, more typically, double-stranded or a mixture of single- and double- stranded regions.
- polynucleotides can be composed of triple-stranded regions comprising RNA or DNA or both RNA and DNA.
- polynucleotides may also contain one or more modified bases or DNA or RNA backbones modified for stability or for other reasons.
- Modified bases include, for example, tritylated bases and unusual bases such as inosine.
- a variety of modifications can be made to DNA and RNA; thus, "polynucleotide” embraces chemically, enzymatically, or metabolically modified forms.
- nucleic acid refers to any one or more nucleic acid segments, e.g., DNA or
- RNA fragments present in a polynucleotide.
- isolated nucleic acid or polynucleotide is intended a nucleic acid molecule, DNA or RNA, which has been removed from its native environment.
- a recombinant polynucleotide encoding an NgR polypeptide or polypeptide fragment of the invention contained in a vector is considered isolated for the purposes of the present invention.
- Further examples of an isolated polynucleotide include recombinant polynucleotides maintained in heterologous host cells or purified (partially or substantially) polynucleotides in solution.
- Isolated RNA molecules include in vivo or in vitro RNA transcripts of polynucleotides of the present invention. Isolated polynucleotides or nucleic acids according to the present invention further include such molecules produced synthetically. In addition, polynucleotide or a nucleic acid may be or may include a regulatory element such as a promoter, ribosome binding site, or a transcription terminator.
- a "coding region” is a portion of nucleic acid which consists of codons translated into amino acids. Although a “stop codon” (TAG, TGA, or TAA) is not translated into an amino acid, it may be considered to be part of a coding region, but any flanking sequences, for example promoters, ribosome binding sites, transcriptional terminators, introns, and the like, are not part of a coding region. Two or more coding regions of the present invention can be present in a single polynucleotide construct, e.g., on a single vector, or in separate polynucleotide constructs, e.g., on separate (different) vectors.
- any vector may contain a single coding region, or may comprise two or more coding regions, e.g., a single vector may separately encode an immunoglobulin heavy chain variable region and an immunoglobulin light chain variable region.
- a vector, polynucleotide, or nucleic acid of the invention may encode heterologous coding regions, either fused or unfused to a nucleic acid encoding an NgR polypeptide or polypeptide fragment of the present invention.
- Heterologous coding regions include without limitation specialized elements or motifs, such as a secretory signal peptide or a heterologous functional domain.
- the polynucleotide or nucleic acid is DNA.
- a polynucleotide comprising a nucleic acid which encodes a polypeptide normally may include a promoter and/or other transcription or translation control elements operably associated with one or more coding regions.
- An operable association is when a coding region for a gene product, e.g., a polypeptide, is associated with one or more regulatory sequences in such a way as to place expression of the gene product under the influence or control of the regulatory sequence(s).
- Two DNA fragments are "operably associated" if induction of promoter function results in the transcription of mRNA encoding the desired gene product and if the nature of the linkage between the two DNA fragments does not interfere with the ability of the expression regulatory sequences to direct the expression of the gene product or interfere with the ability of the DNA template to be transcribed.
- a promoter region would be operably associated with a nucleic acid encoding a polypeptide if the promoter was capable of effecting transcription of that nucleic acid.
- the promoter may be a cell-specific promoter that directs substantial transcription of the DNA only in predetermined cells.
- transcription control elements besides a promoter, for example enhancers, operators, repressors, and transcription termination signals, can be operably associated with the polynucleotide to direct cell-specific transcription.
- Suitable promoters and other transcription control regions are disclosed herein.
- transcription control regions are known to those skilled in the art. These include, without limitation, transcription control regions which function in vertebrate cells, such as, but not limited to, promoter and enhancer segments from cytomegaloviruses (the immediate early promoter, in conjunction with intron-A), simian virus 40 (the early promoter), and retroviruses (such as Rous sarcoma virus).
- Other transcription control regions include those derived from vertebrate genes such as actin, heat shock protein, bovine growth hormone and rabbit ⁇ -globin, as well as other sequences capable of controlling gene expression in eukaryotic cells. Additional suitable transcription control regions include tissue-specific promoters and enhancers as well as lymphokine-inducible promoters (e.g., promoters inducible by interferons or interleukins).
- translation control elements include, but are not limited to ribosome binding sites, translation initiation and termination codons, and elements derived from picornaviruses (particularly an internal ribosome entry site, or IRES, also referred to as a CITE sequence).
- a polynucleotide of the present invention is RNA, for example, in the form of messenger RNA (mRNA).
- mRNA messenger RNA
- Polynucleotide and nucleic acid coding regions of the present invention may be associated with additional coding regions which encode secretory or signal peptides, which direct the secretion of a polypeptide encoded by a polynucleotide of the present invention.
- proteins secreted by mammalian cells have a signal peptide or secretory leader sequence which is cleaved from the mature protein once export of the growing protein chain across the rough endoplasmic reticulum has been initiated.
- polypeptides secreted by vertebrate cells generally have a signal peptide fused to the N-terminus of the polypeptide, which is cleaved from the complete or "full length" polypeptide to produce a secreted or "mature” form of the polypeptide.
- the native signal peptide e.g., an immunoglobulin heavy chain or light chain signal peptide is used, or a functional derivative of that sequence that retains the ability to direct the secretion of the polypeptide that is operably associated with it.
- a heterologous mammalian signal peptide, or a functional derivative thereof may be used.
- the wild-type leader sequence may be substituted with the leader sequence of human tissue plasminogen activator (TPA) or mouse ⁇ -glucuronidase.
- the term “engineered” includes manipulation of nucleic acid or polypeptide molecules by synthetic means (e.g. by recombinant techniques, in vitro peptide synthesis, by enzymatic or chemical coupling of peptides or some combination of these techniques).
- the terms “linked,” “fused” and “fusion” are used interchangeably. These terms refer to the joining together of two more elements or components, by whatever means including chemical conjugation or recombinant means.
- An “in-frame fusion” refers to the joining of two or more polynucleotide open reading frames (ORFs) to form a continuous longer ORF, in a manner that maintains the correct translational reading frame of the original ORFs.
- a recombinant fusion protein is a single protein containing two ore more segments that correspond to polypeptides encoded by the original ORFs (which segments are not normally so joined in nature.) Although the reading frame is thus made continuous throughout the fused segments, the segments may be physically or spatially separated by, for example, in-frame linker sequence.
- a "linker” sequence is a series of one or more amino acids separating two polypeptide coding regions in a fusion protein.
- a typical linker comprises at least 5 amino acids. Additional linkers comprise at least 10 or at least 15 amino acids.
- the amino acids of a peptide linker are selected so that the linker is hydrophilic.
- the linker (Gly-Gly-Gly-Gly-Ser) 3 (G4S) 3 (SEQ ID NO:65) is a preferred linker that is widely applicable to many antibodies as it provides sufficient flexibility.
- linkers include (Gly-Gly-Gly-Gly-Gly-Ser) 2 (G4S) 2 (SEQ BD NO: 66), GIu Ser GIy Arg Ser GIy GIy GIy GIy Ser GIy GIy GIy GIy Ser (SEQ ID NO:67), GIu GIy Lys Ser Ser GIy Ser GIy Ser GIu Ser Lys Ser Thr (SEQ ID NO:68), GIu GIy Lys Ser Ser GIy Ser GIy Ser GIu Ser Lys Ser Thr GIn (SEQ ID NO:69), GIu GIy Lys Ser Ser GIy Ser GIy Ser GIu Ser Lys VaI Asp (SEQ ID NO:70), GIy Ser Thr Ser GIy Ser GIy Lys Ser Ser GIu GIy Lys GIy (SEQ ID NO:71), Lys GIu Ser GIy Ser VaI Ser Ser Ser GIu GIn Leu Ala GIn
- a “linear sequence” or a “sequence” is an order of amino acids in a polypeptide in an amino to carboxyl terminal direction in which residues that neighbor each other in the sequence are contiguous in the primary structure of the polypeptide.
- the term "expression" as used herein refers to a process by which a gene produces a biochemical, for example, an RNA or polypeptide.
- the process includes any manifestation of the functional presence of the gene within the cell including, without limitation, gene knockdown as well as both transient expression and stable expression. It includes, without limitation, transcription of the gene into messenger RNA (mRNA), transfer RNA (tRNA), small hairpin RNA (shRNA), small interfering RNA (siRNA) or any other RNA product, and the translation of such mRNA into polypeptide(s), as well as any processes which regulate either transcription or translation. If the final desired product is a biochemical, expression includes the creation of that biochemical and any precursors.
- a gene product can be either a nucleic acid, e.g., a messenger RNA produced by transcription of a gene, or a polypeptide which is translated from a transcript.
- Gene products described herein further include nucleic acids with post transcriptional modifications, e.g., polyadenylation, or polypeptides with post translational modifications, e.g., methylation, glycosylation, the addition of lipids, association with other protein subunits, proteolytic cleavage, and the like.
- RNA interference refers to the silencing or decreasing of gene expression by siRNAs. It is the process of sequence-specific, post-transcriptional gene silencing in animals and plants, initiated by siRNA that is homologous in its duplex region to the sequence of the silenced gene.
- the gene may be endogenous or exogenous to the organism, integrated into a chromosome or present in a transfection vector that is not integrated into the genome. The expression of the gene is either completely or partially inhibited.
- RNAi may also be considered to inhibit the function of a target RNA; the function of the target RNA may be complete or partial.
- the terms “treat” or “treatment” refer to both therapeutic treatment and prophylactic or preventative measures, wherein the object is to prevent or slow down (lessen) an undesired physiological change or disorder, such as the progression of multiple sclerosis.
- Beneficial or desired clinical results include, but are not limited to, alleviation of symptoms, diminishment of extent of disease, stabilized (i.e., not worsening) state of disease, delay or slowing of disease progression, amelioration or palliation of the disease state, and remission (whether partial or total), whether detectable or undetectable.
- Treatment can also mean prolonging survival as compared to expected survival if not receiving treatment.
- Those in need of treatment include those already with the condition or disorder as well as those prone to have the condition or disorder or those in which the condition or disorder is to be prevented.
- subject or “individual” or “animal” or “patient” or “mammal,” is meant any subject, particularly a mammalian subject, for whom diagnosis, prognosis, or therapy is desired.
- Mammalian subjects include, but are not limited to, humans, domestic animals, farm animals, zoo animals, sport animals, pet animals such as dogs, cats, guinea pigs, rabbits, rats, mice, horses, cattle, cows; primates such as apes, monkeys, orangutans, and chimpanzees; canids such as dogs and wolves; felids such as cats, lions, and tigers; equids such as horses, donkeys, and zebras; food animals such as cows, pigs, and sheep; ungulates such as deer and giraffes; rodents such as mice, rats, hamsters and guinea pigs; and so on.
- the mammal is a subject, particularly a mamm
- a "therapeutically effective amount” refers to an amount effective, at dosages and for periods of time necessary, to achieve the desired therapeutic result.
- a therapeutic result may be, e.g., lessening of symptoms, prolonged survival, improved mobility, and the like.
- a therapeutic result need not be a "cure” .
- a prophylactically effective amount refers to an amount effective, at dosages and for periods of time necessary, to achieve the desired prophylactic result. Typically, since a prophylactic dose is used in subjects prior to or at an earlier stage of disease, the prophylactically effective amount will be less than the therapeutically effective amount.
- the invention is directed to certain NgRl antagonists that promote neuronal survival, neurite outgrowth and axonal regeneration of neurons, for example, CNS neurons.
- the present invention provides NgRl polypeptides and polypeptide fragments, antibodies and fragments thereof, and polynucleotides which stimulate axonal growth under conditions in which axonal growth is normally inhibited.
- NgRl antagonists of the invention are useful in treating injuries, diseases or disorders that can be alleviated by promoting neuronal survival, or by the stimulation of axonal growth or regeneration in the CNS.
- Exemplary CNS diseases, disorders or injuries include, but are not limited to, multiple sclerosis (MS), progressive multifocal leukoencephalopathy (PML), encephalomyelitis (EPL), central pontine myelolysis (CPM), adrenoleukodystrophy, Alexander's disease, Pelizaeus Merzbacher disease (PMZ), Globoid cell Leucodystrophy (Kxabbe's disease) and Wallerian Degeneration, optic neuritis, transverse myelitis, amyotrophic lateral sclerosis (ALS), Huntington's disease, Alzheimer's disease, Parkinson's disease, spinal cord injury, traumatic brain injury, post radiation injury, neurologic complications of chemotherapy, stroke, acute ischemic optic neuropathy, vitamin E deficiency, isolated vitamin E deficiency syndrome, AR, Bassen-Kornzweig syndrome, Marchiafava-Bignami syndrome, metachromatic leukodystrophy, trigeminal neuralgia, and Bell'
- the present invention relates to Nogo receptor- 1 polypeptides that are immunogenic.
- the immunogenic polypeptide consists essentially of an amino acid sequence selected from the group consisting of: LDLSDNAQLRVVDPTT (rat) (SEQ ED NO: 1); LDLSDNAQLRSVDPAT (human) (SEQ ID NO: 2);
- AVASGPFRPFQTNQLTDEELLGLPKCCQPDAADKA (rat) (SEQ ID NO: 3); AVATGPYHPIWTGRATDEEPLGLPKCCQPDAADKA (human) (SEQ ID NO: 4); and CRLGQAGSGA (mouse) (SEQ ID NO: 5).
- the invention relates to Nogo receptor 1 polypeptides that are bound by a monoclonal antibody that binds to Nogo receptor-1.
- the polypeptide is recognized by the 7El 1 monoclonal antibody.
- the polypeptide is selected from the group consisting of: LDLSDNAQLR (SEQ ID NO: 27); LDLSDDAELR (SEQ ID NO: 29); LDLASDNAQLR (SEQ ID NO: 30); LDLASDD AELR (SEQ ID NO: 31); LDALSDNAQLR (SEQ ID NO: 32); LDALSDDAELR (SEQ ID NO: 33); LDLSSDNAQLR (SEQ ID NO: 34); LDLSSDEAELR (SEQ " ID NO: 35); DNAQLRVVDPTT (SEQ ID NO: 36); DNAQLR (SEQ ID NO: 37); ADLSDNAQLRVVDPTT (SEQ ID NO: 41); LALSDNAQLRVVDPTT (SEQ ID NO: 42); LDLSDNAALRVVDPTT (SEQ ID NO: 43); LDLSDNAQLHVVDPTT (SEQ DD NO: 44); and LDLSDNAQLAVVDPTT (SEQ ID NO: 46).
- the invention relates to a nucleic acid encoding a polypeptide of
- nucleic acid molecule is linked to an expression control sequence (e.g., pCDNA(I)).
- an expression control sequence e.g., pCDNA(I)
- the present invention also relates to a vector comprising a nucleic acid coding for a polypeptide of the invention.
- the vector is a cloning vector.
- the vector is an expression vector.
- the vector contains at least one selectable marker.
- the present invention also relates to host cells comprising the above-described nucleic ' acid or vector.
- the present invention also relates to a method of producing an immunogenic polypeptide of the invention comprising the step of culturing a host cell.
- the host cell is prokaryotic.
- the host cell is eukaryotic.
- the host cell is yeast.
- the present invention is also directed to certain Nogo receptor-1 polypeptides and polypeptide fragments useful, e.g., for promoting neurite outgrowth, promoting neuronal survival, promoting axonal survival, or inhibiting signal transduction by the NgRl signaling complex.
- the polypeptides and polypeptide fragments of the invention act to block NgRl-mediated inhibition of neuronal survival, neurite outgrowth or axonal regeneration of central nervous system (CNS) neurons.
- CNS central nervous system
- the human NgRl polypeptide is shown below as SEQ ID NO:49.
- the rat NgRl polypeptide is shown below as SEQ ID NO:50.
- the mouse NgRl polypeptide is shown below as SEQ ID NO:51.
- the present invention further relates to an antibody or an antigen-binding fragment thereof that specifically binds a Nogo receptor-1 polypeptide of the invention.
- the antibody or antigen-binding fragment binds a polypeptide consisting essentially of an amino acid sequence selected from the group consisting of SEQ ID NOs: 1-5, 26-27, 29-37 and 41-45.
- the antibody or antigen-binding fragment of the present invention may be produced in vivo or in vitro. Production of the antibody or antigen-binding fragment is discussed below.
- An antibody or an antigen-binding fragment thereof of the invention inhibits the binding of Nogo receptor-1 to a ligand (e.g., NogoA, NogoB, NogoC, MAG, OM-gp) and decreases myelin- mediated inhibition of neurite outgrowth and sprouting, particularly axonal growth, and attenuates myelin mediated growth cone collapse.
- a ligand e.g., NogoA, NogoB, NogoC, MAG, OM-gp
- the anti-Nogo receptor-1 antibody or antigen-binding fragment thereof is murine. In some embodiments, the Nogo receptor-1 is from rat. In other embodiments, the Nogo receptor-1 is human. In some embodiments the anti-Nogo receptor-1 antibody or antigen-binding fragment thereof is recombinant, engineered, humanized and/or chimeric.
- the antibody is selected from the group consisting of: monoclonal'
- the antibody is polyclonal antibody 46.
- antigen-binding fragments are, Fab, Fab', F(ab')2, Fv, Fd, dAb, and fragments containing complementarity determining region (CDR) fragments, single-chain antibodies (scFv), chimeric antibodies, diabodies and polypeptides that contain at least a portion of an immunoglobulin that is sufficient to confer specific antigen-binding to the polypeptide (e.g., immunoadhesins).
- Fd means a fragment that consists of the V H and C H i domains
- Fv means a fragment that consists of the V L and V H domains of a single arm of an antibody
- dAb means a fragment that consists of a V H domain (Ward et ai, Nature 341:544-546 (1989)).
- single- chain antibody means an antibody in which, a V L region and a V H region are paired to form a monovalent molecules via a synthetic linker that enables them to be made as a single protein chain (Bird et ah, Science 242:423-426 (1988) and Huston et al, Proc.
- diabody means a bispecific antibody in which V H and V L domains are expressed on a single polypeptide chain, but using a linker that is too short to allow for pairing between the two domains on the same chain, thereby forcing the domains to pair with complementary domains of another chain and creating two antigen-binding sites (see e.g., Holliger, P., et ah, Proc. Natl. Acad. Sd. USA 90:6444-6448 (1993) and Poljak, R. J., et ah, Structure 2:1121-1123 (1994)).
- immunoadhesin that specifically binds an antigen of interest means a molecule in which one or more CDRs may be incorporated, either covalently or noncovalently.
- the invention provides a subunit polypeptide of a Nogo rece ⁇ tor-1 antibody of the invention, wherein the subunit polypeptide is selected from the group consisting of: (a) a heavy chain or a variable region thereof; and (b) a light chain or a variable region thereof.
- the invention provides a nucleic acid encoding the heavy chain or the variable region thereof, or the light chain and the variable region thereof of a subunit polypeptide of a
- Nogo receptor- 1 antibody of the invention Nogo receptor- 1 antibody of the invention.
- the invention provides a hypervariable region (CDR) of a Nogo receptor- 1 antibody of the invention or a nucleic acid encoding a CDR.
- CDR hypervariable region
- Antibodies of the invention can be generated by immunization of a suitable host (e.g., vertebrates, including humans, mice, rats, sheep, goats, pigs, cattle, horses, reptiles, fishes, amphibians, and in eggs of birds, reptiles and fish). Such antibodies may be polyclonal or monoclonal.
- a suitable host e.g., vertebrates, including humans, mice, rats, sheep, goats, pigs, cattle, horses, reptiles, fishes, amphibians, and in eggs of birds, reptiles and fish.
- a suitable host e.g., vertebrates, including humans, mice, rats, sheep, goats, pigs, cattle, horses, reptiles, fishes, amphibians, and in eggs of birds, reptiles and fish.
- Such antibodies may be polyclonal or monoclonal.
- the host is immunized with an immunogenic Nogo receptor- 1 polypeptide of the invention.
- the host is im
- the Nogo receptor-1 antigen is administered with an adjuvant to stimulate the immune response.
- Adjuvants often need to be administered in addition to antigen in order to elicit an immune response to the antigen.
- These adjuvants are usually insoluble or undegradable substances that promote nonspecific inflammation, with recruitment of mononuclear phagocytes at the site of immunization.
- adjuvants include, but are not limited to, Freund's adjuvant, RIBI (muramyl dipeptides), ISCOM (immunostimulating complexes) or fragments thereof.
- Determination of immunoreactivity with an immunogenic Nogo receptor-1 polypeptide of the invention may be made by any of several methods well known in the art, including, e.g., immunoblot assay and ELISA.
- Monoclonal antibodies of the invention can made by standard procedures as described, e.g., in Harlow and Lane, Antibodies, A Laboratory Manual (1988), supra.
- lymph node and/or splenic B-cells are immortalized by any one of several techniques that are well-known in the art, including but not limited to transformation, such as with EBV or fusion with an immortalized cell line, such as myeloma cells. Thereafter, the cells are clonally separated and the supematants of each clone tested for production of an antibody specific for an immunogenic Nogo receptor- 1 polypeptide of the invention. Methods of selecting, cloning and expanding hybridomas are well known in the art. Similarly, methods for identifying the nucleotide and amino acid sequence of the immunoglobulin genes are known in the art.
- Antigens in this case Nogo receptor-1 or an immunogenic polypeptide of the invention
- antibodies can be labeled by joining, either covalently or non-covalently, a substance that provides for a detectable signal.
- Suitable labels include, but are not limited to, radionucleotides, enzymes, substrates, cofactors, inhibitors, fluorescent agents, chemiluminescent agents, magnetic particles and the like. Patents teaching the use of such labels include U.S. Patents 3,817,837; 3,850,752; 3,939,350; 3,996,345; 4,277,437; 4,275,149 and 4,366,241.
- recombinant immunoglobulins may be produced (see U.S. Patent 4,816,567).
- an antibody has multiple binding specificities, such as a bifunctional antibody prepared by any one of a number of techniques known to those of skill in the art including the production of hybrid hybridomas, disulfide exchange, chemical cross-linking, addition of peptide linkers between two monoclonal antibodies, the introduction of two sets of immunoglobulin heavy and light chains into a particular cell line, and so forth (see below for more detailed discussion).
- the antibodies of this invention may also be human monoclonal antibodies, for example those produced by immortalized human cells, by SCID-hu mice or other non-human animals capable of producing "human” antibodies.
- Anti-Nogo receptor-1 antibodies of this invention can be isolated by screening a recombinant combinatorial antibody library.
- exemplary combinatorial libraries are for binding to an immunogenic Nogo receptor-1 polypeptide of the invention, such as a scFv phage display library, prepared using V L and V H cDNAs prepared from mRNA derived an animal immunized with an immunogenic Nogo receptor-1 polypeptide of the invention.
- Methodologies for preparing and screening such libraries are known in the art. There are commercially available methods and materials for generating phage display libraries (e.g., the Pharmacia Recombinant Phage Antibody System, catalog no. 27-9400-01; . the Stratagene SurfZAP TM phage display kit, catalog no.
- nucleic acid encoding the selected antibody can be recovered from the display package (e.g., from the phage genome) and subcloned into other expression vectors by standard recombinant DNA techniques.
- nucleic acid can be further manipulated to create other antibody forms of the invention, as described below.
- DNA encoding the antibody heavy chain and light chain or the variable regions thereof is cloned into a recombinant expression vector and introduced into a mammalian host cell, as described above.
- Anti-Nogo receptor-1 antibodies of the invention can be of any isotype.
- An antibody of any desired isotype can be produced by class switching.
- nucleic acids encoding V L or V H that do not include any nucleotide sequences encoding C L or C H , are isolated using methods well known in the art.
- the nucleic acids encoding V L or V H are then operatively linked to a nucleotide sequence encoding a C L or C H from a desired class of immunoglobulin molecule. This may be achieved using a vector or nucleic acid that comprises a C L or C H chain, as described above.
- an anti- Nogo ⁇ eceptor-1 antibody of the invention that was originally IgM may be class switched to an IgG. Further, the class switching may be used to convert one IgG subclass to another, e.g., from IgGl to IgG2.
- antibodies or antigen-binding fragments of the invention may be mutated in the variable domains of the heavy and/or light chains to alter a binding property of the antibody.
- a mutation may be made in one or more of the CDR regions to increase or decrease the Kd of the antibody for Nogo receptor-1, to increase or decrease K oi ⁇ -, or to alter the binding specificity of the antibody.
- Techniques in site-directed mutagenesis are well known in the art. See e.g., Sambrook et al, Molecular Cloning - A Laboratory Manual, Cold Spring Harbor Laboratory Press (1989) and Ausubel et al, Current Protocols in Molecular Biology (New York: John Wiley & Sons) (1989).
- mutations are made at an amino acid residue that is known to be changed compared to germline in a variable region of an anti-Nogo receptor-1 antibody of the invention.
- mutations are made at one or more amino acid residues that are known to be changed compared to the germline in a variable region of an anti-Nogo receptor-1 antibody of the invention.
- a nucleic acid encoding an antibody heavy chain or light chain variable region is mutated in one or more of the framework regions.
- a mutation may be made in a framework region or constant domain to increase the half-life.
- a mutation in a framework region or constant domain also may be made to alter the immunogenicity of the antibody, to provide a site for covalent or non-covalent binding to another molecule, or to alter such properties as complement fixation. Mutations may be made in each of the framework regions, the constant domain and the variable regions in a single mutated antibody. Alternatively, mutations may be made in only one of the framework regions, the variable regions or the constant domain in a single mutated antibody.
- a fusion antibody or immunoadhesin may be made which comprises all or a portion of an anti-Nogo receptor-1 antibody of the invention linked to another polypeptide.
- only the variable region of the anti-Nogo receptor-1 antibody is linked to the polypeptide.
- the V H domain of an anti-Nogo receptor-1 antibody of this invention is linked to a first polypeptide, while the V L domain of the antibody is linked to a second polypeptide that associates with the first polypeptide in a manner that permits the V H and V L domains to interact with one another to form an antibody binding site.
- the V H domain is separated from the V L domain by a linker that permits the V H and V L domains to interact with one another (see below under Single Chain Antibodies).
- the V H -linker- V L antibody is then linked to a polypeptide of interest.
- the fusion antibody is useful to directing a polypeptide to a cell or tissue that expresses a Nogo receptor-1 ligand.
- the polypeptide of interest may be a therapeutic agent, such as a toxin, or may be a diagnostic agent, such as an enzyme that may be easily visualized, such as horseradish peroxidase, hi addition, fusion antibodies can be created in which two (or more) single-chain antibodies are linked to one another. This is useful if one wants to create a divalent or polyvalent antibody on a single polypeptide chain, or if one wants to create a bispecific antibody.
- the present invention includes a single chain antibody (scFv) that binds a Nogo receptor-
- V H - and V L -encoding DNA is operatively linked to DNA encoding a flexible linker, e.g., encoding the amino acid sequence (Gly 4 -Ser) 3 (SEQ ID NO: 10), such that the V H and V L sequences can be expressed as a contiguous single-chain protein, with the V L and V H regions joined by the flexible linker (see, e.g., Bird et ah, Science 242:423-426 (1988); Huston et ah, Proc. Natl. Acad.
- a flexible linker e.g., encoding the amino acid sequence (Gly 4 -Ser) 3 (SEQ ID NO: 10
- the single chain antibody may be monovalent, if only a single V H and V L are used, bivalent, if two V H and V L are used, or polyvalent, if more than two V H and VL are used.
- the present invention further includes a bispecific antibody or antigen-binding fragment thereof in which one specificity is for a Nogo receptor-1 polypeptide of the invention.
- a chimeric antibody can be generated that specifically binds to a Nogo receptor-1 polypeptide of the invention through one binding domain and to a second molecule through a second binding domain.
- the chimeric antibody can be produced through recombinant molecular biological techniques, or may be physically conjugated together.
- a single chain antibody containing more than one VH and V L may be generated that binds specifically to a polypeptide of the invention and to another molecule that is associated with attenuating myelin mediated growth cone collapse and inhibition of neurite outgrowth and sprouting.
- bispecific antibodies can be generated using techniques that are well known for example, Fanger et al., Immunol Methods 4: 72-81 (1994) and Wright and Harris, supra, and in connection with (iii) see e.g., Traunecker et al. Int. J. Cancer (Suppl.) 7: 51-52 (1992).
- the chimeric antibodies are prepared using one or more of the variable regions from an antibody of the invention. In another embodiment, the chimeric antibody is prepared using one or more CDR regions from said antibody.
- An antibody or an antigen-binding fragment of the invention can be derivatized or linked to another molecule (e.g., another peptide or protein).
- another molecule e.g., another peptide or protein.
- the antibody or antigen-binding fragment is derivatized such that binding to a polypeptide of the invention is not affected adversely by the derivatization or labeling.
- an antibody or antibody portion of the invention can be functionally linked (by chemical coupling, genetic fusion, noncovalent association or otherwise) to one or more other molecular entities, such as another antibody (e.g., a bispecific antibody or a diabody), a detection agent, a cytotoxic agent, a pharmaceutical agent, and/or a protein or peptide that can mediate association of the antibody or antigen-binding fragment with another molecule (such as a streptavidin core region or a polyhistidine tag).
- another antibody e.g., a bispecific antibody or a diabody
- a detection agent e.g., a cytotoxic agent, a pharmaceutical agent
- a protein or peptide that can mediate association of the antibody or antigen-binding fragment with another molecule (such as a streptavidin core region or a polyhistidine tag).
- a derivatized antibody is produced by crosslinking two or more antibodies (of the same type or of different types, e.g., to create bispecific antibodies).
- Suitable crosslinkers include those that are heterobifunctional, having two distinctly reactive groups separated by an appropriate spacer (e.g., m-maleimidobenzoyl-N-hydroxysuccinimide ester) or homobifunctional (e.g., disuccinimidyl suberate).
- an appropriate spacer e.g., m-maleimidobenzoyl-N-hydroxysuccinimide ester
- homobifunctional e.g., disuccinimidyl suberate
- the derivatized antibody is a labeled antibody.
- detection agents with which an antibody or antibody portion of the invention may be derivatized are fluorescent compounds, including fluorescein, fluorescein isothiocyanate, rhodamine, 5-dimethylamine-l-napthalenesulfonyl chloride, phycoerythrin, lanthanide phosphors and the like.
- An antibody also may be labeled with enzymes that are useful for detection, such as horseradish peroxidase, ⁇ -galactosidase, luciferase, alkaline phosphatase, glucose oxidase and the like.
- the antibody is detected by adding additional reagents that the enzyme uses to produce a detectable reaction product.
- additional reagents that the enzyme uses to produce a detectable reaction product.
- an antibody also may be labeled with biotin, and detected through indirect measurement of avidin or streptavidin binding.
- An antibody may also be labeled with a predetermined polypeptide epitopes recognized by a secondary reporter (e.g., leucine zipper pair sequences, binding sites for secondary antibodies, metal binding domains, epitope tags).
- a secondary reporter e.g., leucine zipper pair sequences, binding sites for secondary antibodies, metal binding domains, epitope tags.
- An anti-Nogo receptor-1 antibody or an antigen-fragment thereof also may be labeled with a radio-labeled amino acid.
- the radiolabel may be used for both diagnostic and therapeutic purposes.
- the radio-labeled anti-Nogo receptor-1 antibody may be used diagnostically, for example, for determining Nogo receptor-1 levels in a subject. Further, the radio-labeled anti-Nogo receptor-1 antibody may be used therapeutically for treating spinal cord injury.
- Examples of labels for polypeptides include, but are not limited to, the following radioisotopes or radionucleotides - 3 H, 14 C, 15 N 5 3S S, 90 Y,
- An anti-Nogo receptor-1 antibody or an antigen-fragment thereof may also be derivatized with a chemical group such as polyethylene glycol (PEG), a methyl or ethyl group, or a carbohydrate group. These groups may be useful to improve the biological characteristics of the antibody, e.g., to increase serum half-life or to increase tissue binding.
- a chemical group such as polyethylene glycol (PEG), a methyl or ethyl group, or a carbohydrate group.
- the class and subclass of anti-Nogo receptor-1 antibodies may be determined by any method known in the art.
- the class and subclass of an antibody may be determined using antibodies that are specific for a particular class and subclass of antibody. Such antibodies are available commercially.
- the class and subclass can be determined by ELISA, Western Blot as well as other techniques.
- the class and subclass may be determined by sequencing all or a portion of the constant domains of the heavy and/or light chains of the antibodies, comparing their amino acid sequences to the known amino acid sequences of various class and subclasses of immunoglobulins, and determining the class and subclass of the antibodies.
- the binding affinity and dissociation rate of an anti-Nogo receptor-1 antibody of the invention to a Nogo receptor-1 polypeptide of the invention may be determined by any method known in the art.
- the binding affinity can be measured by competitive ELISAs, RIAs, BIAcore or KinExA technology.
- the dissociation rate also can be measured by BIAcore or KinExA technology.
- the binding affinity and dissociation rate are measured by surface plasmon resonance using, e.g., a BIAcore.
- the K 11 of 7El 1 and 1H2 were determined to be 1 x 10 "7 M and 2 x 10 "8 M, respectively. Inhibition ofNogo receptor-1 activity by anti-Nogo receptor- 1 antibody
- an anti-Nogo receptor-1 antibody or an antigen-binding fragment of the invention thereof inhibits the binding of Nogo receptor-1 to a ligand.
- the IC 50 of such inhibition can be measured by any method known in the art, e.g., by ELISA, RIA, or Functional Antagonism.
- the ICs 0 is between 0.1 and 500 nM.
- the IC 50 is between 10 and 400 nM.
- the antibody or portion thereof has an ICs 0 of between 60 nM and 400 nM.
- the IC 50 of 7El 1 and 1H2 were determined to be 400 nM and 60 nM, respectively, in a binding assay. See also Table 3, infra.
- the present invention also include NgRl-specific antibodies or antigen-binding fragments, variants, or derivatives which are antagonists of NgRl activity.
- NgRl-specific antibodies or antigen-binding fragments, variants, or derivatives which are antagonists of NgRl activity.
- the binding of certain NgRl antibodies to NgRl blocks NgRl -mediated inhibition of neuronal survival, neurite outgrowth or axonal regeneration of central nervous system (CNS) neurons.
- CNS central nervous system
- the present invention includes an antibody, or antigen-binding fragment, variant, or derivative thereof which specifically or preferentially binds to at least one epitope of NgRl, where the epitope comprises, consists essentially of, or consists of at least about four to five amino acids of SEQ ID NO:49, at least seven, at least nine, or between at least about 15 to about 30 amino acids of SEQ ID NO:49.
- the amino acids of a given epitope of SEQ ID NO:49 as described may be, but need not be contiguous or linear.
- the at least one epitope of NgRl comprises, consists essentially of, or consists of a non-linear epitope formed by the extracellular domain of NgRl as expressed on the surface of a cell or as a soluble fragment, e.g., fused to an IgG Fc region.
- the at least one epitope of NgRl comprises, consists essentially of, or consists of at least 4, at least 5, at least 6, at least 7, at least 8, at least 9, at least 10, at least 15, at least 20, at least 25, between about 15 to about 30, or at least 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, or 100 contiguous or non-contiguous amino acids of SEQ ID NO:49, where noncontiguous amino acids form an epitope through protein folding.
- the present invention includes an antibody, or antigen-binding fragment, variant, or derivative thereof which specifically or preferentially binds to at least one epitope of NgRl, where the epitope comprises, consists essentially of, or consists of, in addition to one, two, three, four, five, six or more contiguous or non-contiguous amino acids of SEQ ID NO:49 as described above, and an additional moiety which modifies the protein, e.g., a carbohydrate moiety may be included such that the NgRl antibody binds with higher affinity to modified target protein than it does to an unmodified version of the protein. Alternatively, the NgRl antibody does not bind the unmodified version of the target protein at all.
- an antibody, or antigen-binding fragment, variant, or derivative thereof of the invention binds specifically to at least one epitope of NgRl or fragment or variant described above, i.e., binds to such an epitope more readily than it would bind to an unrelated, or random epitope; binds preferentially to at least one epitope of NgRl or fragment or variant described above, i.e., binds to such an epitope more readily than it would bind to a related, similar, homologous, or analogous epitope; competitively inhibits binding of a reference antibody which itself binds specifically or preferentially to a certain epitope of NgRl or fragment or variant described above; or binds to at least one epitope of NgRl or fragment or variant described above with an affinity characterized by a dissociation constant KD of less than about 5 x 10 '2 M, about 10 "2 M, about 5 x 10 '3 M, about 10
- the term "about” allows for the degree of variation inherent in the methods utilized for measuring antibody affinity. For example, depending on the level of precision of the instrumentation used, standard error based on the number of samples measured, and rounding error, the term “about lO '2 M” might include, for example, from 0.05 M to 0.005 M.
- an antibody, or antigen-binding fragment, variant, or derivative thereof of the invention binds NgRl polypeptides or fragments or variants thereof with an off rate (k(off)) of less than or equal to 5 X 10 "2 sec “1 , 10 "2 sec “1 , 5 X 10 "3 sec “1 or 10 '3 sec “1 .
- an antibody, or antigen-binding fragment, variant, or derivative thereof of the invention binds NgRl polypeptides or fragments or variants thereof with an off rate (k(off)) of less than or equal to 5 X 10 "4 sec “ ', 10 "4 sec “1 , 5 X 10 "s sec “1 , or 10 s sec “1 5 X 10 "6 sec “1 , 10 " ⁇ sec 1 , 5 X 10 "7 sec “1 or 10 "7 sec “1 .
- an antibody, or antigen-binding fragment, variant, or derivative thereof of the invention binds NgRl polypeptides or fragments or variants thereof with an on rate (k(on)) of greater than or equal to 10 3 M "1 sec “1 , 5 X 10 3 M “1 sec “1 , 10 4 M “1 sec “1 or 5 X 10 4 M “1 sec” 1 .
- an antibody, or antigen-binding fragment, variant, or derivative thereof of the invention binds NgRl polypeptides or fragments or variants thereof with an on rate (k(on)) greater than or equal to 10 s M "1 sec “1 , 5 X 10 s M “1 sec “1 , 10 6 M “1 sec “1 , or 5 X 10 6 M “1 sec “1 or 10 7 WT 1 sec “1 .
- a NgRl antagonist for use in the methods of the invention is an antibody molecule, or immunospecific fragment thereof.
- a "fragment thereof in reference to an antibody refers to an immunospecific fragment, i.e., an antigen- specific fragment.
- an antibody of the invention is a bispecif ⁇ c binding molecule, binding polypeptide, or antibody, e.g., a bispecif ⁇ c antibody, minibody, domain deleted antibody, or fusion protein having binding specificity for more than one epitope, e.g., more than one antigen or more than one epitope on the same antigen.
- a bispecif ⁇ c antibody has at least one binding domain specific for at least one epitope on NgRl.
- a bispecif ⁇ c antibody may be a tetravalent antibody that has two target binding domains specific for an epitope of NgRl and two target binding domains specific for a second target.
- a tetravalent bispecif ⁇ c antibody may be bivalent for each specificity.
- an NgRl antagonist antibody or immunospecific fragment thereof, in which at least a fraction of one or more of the constant region domains has been deleted or otherwise altered so as to provide desired biochemical characteristics such as reduced effector functions, the ability to non-covalently dimerize, increased ability to localize at the site of a tumor, reduced serum half-life, or increased serum half-life when compared with a whole, unaltered antibody of approximately the same immunogenicity.
- certain antibodies for use in the treatment methods described herein are domain deleted antibodies which comprise a polypeptide chain similar to an immunoglobulin heavy chain, but which lack at least a portion of one or more heavy chain domains.
- one entire domain of the constant region of the modified antibody will be deleted, for example, all or part of the CH2 domain will be deleted.
- the Fc portion may be mutated to alter, e.g., increase, decrease or modulate effector function using techniques known in the art.
- the deletion or inactivation (through point mutations or other means) of a constant region domain may reduce or alter Fc receptor binding of the circulating modified antibody thereby increasing tumor localization.
- constant region modifications consistent with the instant invention moderate complement binding and thus reduce the serum half life and nonspecific association of a conjugated cytotoxin.
- modifications of the constant region may be used to modify disulfide linkages or oligosaccharide moieties that allow for enhanced localization due to increased antigen specificity or antibody flexibility.
- the resulting physiological profile, bioavailability and other biochemical effects of the modifications, such, as tumor localization, biodistribution and serum half-life, may easily be measured and quantified using well know immunological techniques without undue experimentation.
- variable and constant regions of NgRl antagonist antibodies or immunospecific fragments thereof for use in the treatment methods disclosed herein are fully human.
- Fully human antibodies can be made using techniques that are known in the art and as described herein. For example, fully human antibodies against a specific antigen can be prepared by administering the antigen to a transgenic animal which has been modified to produce such antibodies in response to antigenic challenge, but whose endogenous loci have been disabled.
- NgRl antagonist antibodies or immunospecific fragments thereof for use in the diagnostic and treatment methods disclosed herein can be made or manufactured using techniques that are known in the art.
- antibody molecules or fragments thereof are "recombinantly produced," i.e., are produced using recombinant DNA technology. Exemplary techniques for making antibody molecules or fragments thereof are discussed in more detail elsewhere herein.
- NgRl antagonist antibodies or immunospecific fragments thereof for use in the treatment methods disclosed herein include derivatives that are modified, e.g., by the covalent attachment of any type of molecule to the antibody such that covalent attachment does not prevent the antibody from specifically binding to its cognate epitope.
- the antibody derivatives include antibodies that have been modified, e.g., by glycosylation, acetylation, pegylation, phosphorylation, amidation, derivatization by known protecting/blocking groups, proteolytic cleavage, linkage to a cellular ligand or other protein, etc. Any of numerous chemical modifications may be carried out by known techniques, including, but not limited to specific chemical cleavage, acetylation, formylation, metabolic synthesis of tunicamycin, etc. Additionally, the derivative may contain one or more non-classical amino acids.
- an NgRl antagonist antibody or immunospecific fragment thereof for use in the treatment methods disclosed herein will not elicit a deleterious immune response in the animal to be treated, e.g., in a human.
- NgRl antagonist antibodies or immunospecific fragments thereof for use in the treatment methods disclosed herein may be modified to reduce their immunogenicity using art-recognized techniques.
- antibodies can be humanized, primatized, deimmunized, or chimeric antibodies can be made. These types of antibodies are derived from a non-human antibody, typically a murine or primate antibody, that retains or substantially retains the antigen-binding properties of the parent antibody, but which is less immunogenic in humans.
- CDRs complementarity determining regions
- De-immunization can also be used to decrease the immunogenicity of an antibody.
- the term "de-immunization” includes alteration of an antibody to modify T cell epitopes (see, e.g., WO9852976A1, WO0034317A2).
- VH and VL sequences from the starting antibody are analyzed and a human T cell epitope "map" from each, V region showing the location of epitopes in relation to complementarity-determining regions (CDRs) and other key residues within the sequence.
- CDRs complementarity-determining regions
- VH and VL sequences are designed comprising combinations of amino acid substitutions and these sequences are subsequently incorporated into a range of binding polypeptides, e.g., NgRl antagonist antibodies or irnrnunospecific fragments thereof for use in the diagnostic and treatment methods disclosed herein, which are then tested for function.
- binding polypeptides e.g., NgRl antagonist antibodies or irnrnunospecific fragments thereof for use in the diagnostic and treatment methods disclosed herein, which are then tested for function.
- binding polypeptides e.g., NgRl antagonist antibodies or irnrnunospecific fragments thereof for use in the diagnostic and treatment methods disclosed herein, which are then tested for function.
- binding polypeptides e.g., NgRl antagonist antibodies or irnrnunospecific fragments thereof for use in the diagnostic and treatment methods disclosed herein, which are then tested for function.
- NgRl antagonist antibodies or fragments thereof for use in the methods of the present invention may be generated by any suitable method known in the art.
- Polyclonal antibodies can be produced by various procedures well known in the art.
- a NgRl immunospecific fragment can be administered to various host animals including, but not limited to, rabbits, mice, rats, etc. to induce the production of sera containing polyclonal antibodies specific for the antigen.
- adjuvants may be used to increase the immunological response, depending on the host species, and include but are not limited to, Freund's (complete and incomplete), mineral gels such as aluminum hydroxide, surface active substances such as lysolecithin, pluronic polyols, polyanions, peptides, oil emulsions, keyhole limpet hemocyanins, dinitrophenol, and potentially useful human adjuvants such as BCG (bacille Calmette-Guerin) and Corynebacteriwn parvum. Such adjuvants are also well known in the art.
- Monoclonal antibodies can be prepared using a wide variety of techniques known in the art including the use of hybridoma, recombinant, and phage display technologies, or a combination thereof.
- monoclonal antibodies can be produced using hybridoma techniques including those known in the art and taught, for example, in Harlow et al., Antibodies: A Laboratory Manual, Cold Spring Harbor Laboratory Press, 2nd ed. (1988); Hammerling et al., in: Monoclonal Antibodies and T- CeIl Hybridomas Elsevier, N.Y., 563-681 (1981) (said references incorporated by reference in their entireties).
- the term "monoclonal antibody” as used herein is not limited to antibodies produced through hybridoma technology.
- the term “monoclonal antibody” refers to an antibody that is derived from a single clone, including any eukaryotic, prokaryotic, or phage clone, and not the method by which it is produced. Thus, the term “monoclonal antibody” is not limited to antibodies produced through hybridoma technology.
- Monoclonal antibodies can be prepared using a wide variety of techniques known in the art including the use of hybridoma and recombinant and phage display technology.
- antibodies are raised in mammals by multiple subcutaneous or intraperitoneal injections of the relevant antigen (e.g., purified NgRl antigens or cells or cellular extracts comprising such antigens) and an adjuvant.
- This immunization typically elicits an immune response that comprises production of antigen-reactive antibodies from activated splenocytes or lymphocytes.
- the resulting antibodies may be harvested from the serum of the animal to provide polyclonal preparations, it is often desirable to isolate individual lymphocytes from the spleen, lymph nodes or peripheral blood to provide homogenous preparations of monoclonal antibodies (MAbs).
- the lymphocytes are obtained from the spleen.
- lymphocytes from a mammal which has been injected with antigen are fused with an immortal tumor cell line (e.g. a myeloma cell line), thus, producing hybrid cells or "hybridomas" which are both immortal and capable of producing the genetically coded antibody of the B cell.
- an immortal tumor cell line e.g. a myeloma cell line
- hybrid cells or "hybridomas" which are both immortal and capable of producing the genetically coded antibody of the B cell.
- the resulting hybrids are segregated into single genetic strains by selection, dilution, and regrowth with each individual strain comprising specific genes for the formation of a single antibody. They produce antibodies which are homogeneous against a desired antigen and, in reference to their pure genetic parentage, are termed "monoclonal.”
- Hybridoma cells thus prepared are seeded and grown in a suitable culture medium that preferably contains one or more substances that inhibit the growth or survival of the unfused, parental myeloma cells.
- suitable culture medium that preferably contains one or more substances that inhibit the growth or survival of the unfused, parental myeloma cells.
- reagents, cell lines and media for the formation, selection and growth of hybridomas are commercially available from a number of sources and standardized protocols are well established.
- culture medium in which the hybridoma cells are growing is assayed for production of monoclonal antibodies against the desired antigen.
- the binding specificity of the monoclonal antibodies produced by hybridoma cells is determined by in vitro assays such as immunoprecipitation, radioimmunoassay (RIA) or enzyme-linked immunoabsorbent assay (ELISA).
- in vitro assays such as immunoprecipitation, radioimmunoassay (RIA) or enzyme-linked immunoabsorbent assay (ELISA).
- RIA radioimmunoassay
- ELISA enzyme-linked immunoabsorbent assay
- the monoclonal antibodies secreted by the subclones may be separated from culture medium, ascites fluid or serum by conventional purification procedures such as, for example, protein-A, hydroxylapatite chromatography, gel electrophoresis, dialysis or affinity chromatography.
- Antibody fragments that recognize specific epitopes may be generated by known techniques.
- Fab and F(ab')2 fragments may be produced by proteolytic cleavage of immunoglobulin molecules, using enzymes such as papain (to produce Fab fragments) or pepsin (to produce F(ab')2 fragments).
- F(ab')2 fragments contain the variable region, the light chain constant region and the CHl domain of the heavy chain.
- DNA encoding antibodies or antibody fragments may also be derived from antibody phage libraries.
- phage can be utilized to display antigen-binding domains expressed from a repertoire or combinatorial antibody library (e.g., human or murine).
- Phage expressing an antigen binding domain that binds the antigen of interest can be selected or identified with antigen, e.g., using labeled antigen or antigen bound or captured to a solid surface or bead.
- Phage used in these methods are typically filamentous phage including fd and M 13 binding domains expressed from phage with Fab, Fv or disulfide stabilized Fv antibody domains recombinantly fused to either the phage gene in or gene VIH protein.
- Exemplary methods are set forth, for example, in EP 368 684 Bl; U.S. patent. 5,969,108, Hoogenboom, H.R. and Chames, Immunol. Today 21:371 (2000); Nagy et al. Nat. Med. 5:801 (2002); Huie et al, Proc. Natl. Acad. ScL USA 98:2682 (2001); Lui et al., J. MoI. Biol.
- Ribosomal display can be used to replace bacteriophage as the display platform (see, e.g., Hanes et al., Nat. Biotechnol. 18:1287 (2000); Wilson et al, Proc. Natl. Acad. ScL USA 98:3750 (2001); or Irving et al., J.
- cell surface libraries can be screened for antibodies (Boder et al., Proc. Natl. Acad. ScL USA 97: 10701 (2000); Daugherty et al., J. Immunol. Methods 243:211 (2000)).
- Such procedures provide alternatives to traditional hybridoma techniques for the isolation and subsequent cloning of monoclonal antibodies.
- phage display methods functional antibody domains are displayed on the surface of phage particles which carry the polynucleotide sequences encoding them.
- DNA sequences encoding VH and VL regions are amplified from animal cDNA libraries (e.g., human or murine cDNA libraries of lymphoid tissues) or synthetic cDNA libraries.
- the DNA encoding the VH and VL regions are joined together by an scFv linker by PCR and cloned into a phagemid vector (e.g., p CANTAB 6 or pComb 3 HSS).
- the vector is electroporated in E. coli and the E. coli is infected with helper phage.
- Phage used in these methods are typically filamentous phage including fd and Ml 3 and the VH or VL regions are usually recombinantly fused to either the phage gene III or gene Vm.
- Phage expressing an antigen binding domain that binds to an antigen of interest i.e., a NgRl polypeptide or a fragment thereof
- an antigen of interest i.e., a NgRl polypeptide or a fragment thereof
- can be selected or identified with antigen e.g., using labeled antigen or antigen bound or captured to a solid surface or bead.
- phage display methods that can be used to make the antibodies include those disclosed in Brinkman et al., J. Immunol. Methods 752:41-50 (1995); Ames et al., J. Immunol. Methods 184:177-186 (1995); Kettleborough et al, Eur. J. Immunol 24:952-958 (1994); Persic et al., Gene 187:9-18 (1997); Burton et al, Advances in Immunology 57:191-280 (1994); PCT Application No.
- the antibody coding regions from the phage can be isolated and used to generate whole antibodies, including human antibodies, or any other desired antigen binding fragment, and expressed in any desired host, including mammalian cells, insect cells, plant cells, yeast, and bacteria.
- a chimeric antibody is a molecule in which different portions of the antibody are derived from different animal species, such as antibodies having a variable region derived from a murine monoclonal antibody and a human immunoglobulin constant region.
- Methods for producing chimeric antibodies are known in the art. See, e.g., Morrison, Science 229:1202 (1985); Oi et al, BioTechniques 4:214 (1986); Gillies et al, J. Immunol. Methods 125:191-202 (1989); U.S. Pat. Nos. 5,807,715; 4,816,567; and 4,816397, which are incorporated herein by reference in their entireties.
- Humanized antibodies are antibody molecules from non-human species antibody that binds the desired antigen having one or more complementarity determining regions (CDRs) from the non-human species and framework regions from a human immunoglobulin molecule.
- CDRs complementarity determining regions
- framework residues in the human framework regions will be substituted with the corresponding residue from the CDR donor antibody to alter, preferably improve, antigen binding.
- These framework substitutions are identified by methods well known in the art, e.g., by modeling of the interactions of the CDR and framework residues to identify framework residues important for antigen binding and sequence comparison to identify unusual framework residues at particular positions. (See, e.g., Queen et al, U.S. Pat. No.
- Antibodies can be humanized using a variety of techniques known in the art including, for example, CDR-grafting (EP 239,400; PCT publication WO 91/09967; U.S. Pat. Nos. 5,225,539; 5,530,101; and 5,585,089), veneering or resurfacing (EP 592,106; EP 519,596; Padlan, Molecular Immunology 28(4/5):489-498 (1991); Studnicka et al, Protein Engineering 7 ⁇ :805-814 (1994); Roguska.
- Completely human antibodies are particularly desirable for therapeutic treatment of human patients.
- Human antibodies can be made by a variety of methods known in the art including phage display methods described above using antibody libraries derived from human immunoglobulin sequences. See also, U.S. Pat. Nos. 4,444,887 and 4,716,111; and PCT publications WO 98/46645, WO 98/50433, WO 98/24893, WO 98/16654, WO 96/34096, WO 96/33735, and WO 91/10741; each of which is incorporated herein by reference in its entirety.
- Human antibodies can also be produced using transgenic mice which are incapable of expressing functional endogenous immunoglobulins, but which can express human immunoglobulin genes.
- the human heavy and light chain immunoglobulin gene complexes may be introduced randomly or by homologous recombination into mouse embryonic stem cells.
- the human variable region, constant region, and diversity region may be introduced into mouse embryonic stem cells in addition to the human heavy and light chain genes.
- the mouse heavy and light chain immunoglobulin genes may be rendered non-functional separately or simultaneously with the introduction of human immunoglobulin loci by homologous recombination. In particular, homozygous deletion of the JH region prevents endogenous antibody production.
- the modified embryonic stem cells are expanded and microinjected into blastocysts to produce chimeric mice.
- the chimeric mice are then bred to produce homozygous offspring that express human antibodies.
- the transgenic mice are immunized in the normal fashion with a selected antigen, e.g., all or a portion of a desired target polypeptide.
- Monoclonal antibodies directed against the antigen can be obtained from the immunized, transgenic mice using conventional hybridoma technology.
- the human immunoglobulin transgenes harbored by the transgenic mice rearrange during B-cell differentiation, and subsequently undergo class switching and somatic mutation.
- DNA encoding desired monoclonal antibodies may be readily isolated and sequenced using conventional procedures ⁇ e.g., by using oligonucleotide probes that are capable of binding specifically to genes encoding the heavy and light chains of murine antibodies).
- the isolated and subcloned hybridoma cells serve as a preferred source of such DNA.
- the DNA may be placed into expression vectors, which are then transfected into prokaryotic or eukaryotic host cells such as E. coli cells, simian COS cells, Chinese Hamster Ovary (CHO) cells or myeloma cells that do not otherwise produce immunoglobulins.
- the isolated DNA (which may be synthetic as described herein) may be used to clone constant and variable region sequences for the manufacture antibodies as described in Newman et al., U.S. Pat. No. 5,658,570, filed January 25, 1995, which is incorporated by reference herein. Essentially, this entails extraction of RNA from the selected cells, conversion to cDNA, and amplification by PCR using Ig specific primers. Suitable primers for this purpose are also described in U.S. Pat. No. 5,658,570. As will be discussed in more detail below, transformed cells expressing the desired antibody may be grown up in relatively large quantities to provide clinical and commercial supplies of the immunoglobulin.
- the amino acid sequence of the heavy and/or light chain variable domains may be inspected to identify the sequences of the complementarity determining regions (CDRs) by methods that are well know in the art, e.g., by comparison to known amino acid sequences of other heavy and light chain variable regions to determine the regions of sequence hypervariability.
- CDRs complementarity determining regions
- one or more of the CDRs may be inserted within framework regions, e.g., into human framework regions to humanize a non-human antibody.
- the framework regions may be naturally occurring or consensus framework regions, and preferably human framework regions (see, e.g., Chothia et al, J. MoI Biol.
- the polynucleotide generated by the combination of the framework regions and CDRs encodes an antibody that specifically binds to at least one epitope of a desired polypeptide, e.g., NgRl.
- a desired polypeptide e.g., NgRl.
- one or more amino acid substitutions may be made within the framework regions, and, preferably, the amino acid substitutions improve binding of the antibody to its antigen. Additionally, such methods may be used to make amino acid substitutions or deletions of one or more variable region cysteine residues participating in an intrachain disulfide bond to generate antibody molecules lacking one or more intrachain disulfide bonds.
- Other alterations to the polynucleotide are encompassed by the present invention and within the skill of the art.
- a chimeric antibody is a molecule in which different portions are derived from different animal species, such as those having a variable region derived from a murine monoclonal antibody and a human immunoglobulin constant region, e.g., humanized antibodies.
- NgRl antagonist antibodies may also be human or substantially human antibodies generated in transgenic animals (e.g., mice) that are incapable of endogenous immunoglobulin production (see e.g., U.S. Pat. Nos. 6,075,181, 5,939,598, 5,591,669 and 5,589,369 each of which is incorporated herein by reference).
- transgenic animals e.g., mice
- mice that are incapable of endogenous immunoglobulin production
- the homozygous deletion of the antibody heavy-chain joining region in chimeric and germ-line mutant mice results in complete inhibition of endogenous antibody production. Transfer of a human immunoglobulin gene array to such germ line mutant mice will result in the production of human antibodies upon antigen challenge.
- SCID mice Another preferred means of generating human antibodies using SCID mice is disclosed in U.S. Pat. No. 5,811,524 which is incorporated herein by reference. It will be appreciated that the genetic material associated with these human antibodies may also be isolated and manipulated as described herein.
- lymphocytes can be selected by micromanipulation and the variable genes isolated.
- peripheral blood mononuclear cells can be isolated from an immunized mammal and cultured for about 7 days in vitro. The cultures can be screened for specific
- IgGs that meet the screening criteria. Cells from positive wells can be isolated. Individual Ig- ⁇ roducing
- B cells can be isolated by FACS or by identifying them in a complement-mediated hemolytic plaque assay.
- Ig-producing B cells can be micromanipulated into a tube and the VH and VL genes can be amplified using, e.g., RT-PCR.
- the VH and VL genes can be cloned into an antibody expression vector and transfected into cells (e.g., eukaryotic or prokaryotic cells) for expression.
- antibody-producing cell lines may be selected and cultured using techniques well known to the skilled artisan. Such techniques are described in a variety of laboratory manuals and primary publications. In this respect, techniques suitable for use in the invention as described below are described in Current Protocols in Immunology, Coligan et al., Eds., Green
- Antibodies for use in the therapeutic methods disclosed herein can be produced by any method known in the art for the synthesis of antibodies, in particular, by chemical synthesis or preferably, by recombinant expression techniques as described herein.
- RNA may be isolated from the original hybridoma cells or from other transformed cells by standard techniques, such as guanidinium isothiocyanate extraction and precipitation followed by centrifugation or chromatography. Where desirable, mRNA may be isolated from total RNA by standard techniques such as chromatography on oligo dT cellulose. Suitable techniques are familiar in the art.
- cDNAs that encode the light and the heavy chains of the antibody may be made, either simultaneously or separately, using reverse transcriptase and DNA polymerase in accordance with well known methods.
- PCR may be initiated by consensus constant region primers or by more specific primers based on the published heavy and light chain DNA and amino acid sequences.
- PCR also may be used to isolate DNA clones encoding the antibody light and heavy chains. In this case the libraries may be screened by consensus primers or larger homologous probes, such as mouse constant region probes.
- DNA typically plasmid DNA
- DNA may be isolated from the cells using techniques known in the art, restriction mapped and sequenced in accordance with standard, well known techniques set forth in detail, e.g., in the foregoing references relating to recombinant DNA techniques.
- the DNA may be synthetic according to the present invention at any point during the isolation process or subsequent analysis.
- Recombinant expression of an antibody, or fragment, derivative or analog thereof, e.g., a heavy or light chain of an antibody which is an NgRl antagonist requires construction of an expression vector containing a polynucleotide that encodes the antibody.
- a polynucleotide encoding an antibody molecule or a heavy or light chain of an antibody, or portion thereof (preferably containing the heavy or light chain variable domain), of the invention has been obtained, the vector for the production of the antibody molecule may be produced by recombinant DNA technology using techniques well known in the art.
- methods for preparing a protein by expressing a polynucleotide containing an antibody encoding nucleotide sequence are described herein.
- the invention provides replicable vectors comprising a nucleotide sequence encoding an antibody molecule of the invention, or a heavy or light chain thereof, or a heavy or light chain variable domain, operably linked to a promoter.
- Such vectors may include the nucleotide sequence encoding the constant region of the antibody molecule (see, e.g., PCT Publication WO 86/05807; PCT Publication WO 89/01036; and U.S. Pat. No. 5,122,464) and the variable domain of the antibody may be cloned into such a vector for expression of the entire heavy or light chain.
- the expression vector is transferred to a host cell by conventional techniques and the transfected cells are then cultured by conventional techniques to produce an antibody for use in the methods described herein.
- the invention includes host cells containing a polynucleotide encoding an antibody of the invention, or a heavy or light chain thereof, operably linked to a heterologous promoter.
- vectors encoding both the heavy and light chains may be co-expressed in the host cell for expression of the entire immunoglobulin molecule, as detailed below.
- host-expression vector systems may be utilized to express antibody molecules for use in the methods described herein.
- Such host-expression systems represent vehicles by which the coding sequences of interest may be produced and subsequently purified, but also represent cells which may, when transformed or transfected with the appropriate nucleotide coding sequences, express an antibody molecule of the invention in situ.
- These include but are not limited to microorganisms such as bacteria ⁇ e.g., E. coli, B.
- subtilis transformed with recombinant bacteriophage DNA, plasmid DNA or cosmid DNA expression vectors containing antibody coding sequences; yeast (e.g., Saccharomyces, Pichid) transformed with recombinant yeast expression vectors containing antibody coding sequences; insect cell systems infected with recombinant virus expression vectors (e.g., baculovirus) containing antibody coding sequences; plant cell systems infected with recombinant virus expression vectors (e.g., cauliflower mosaic virus, CaMV; tobacco mosaic virus, TMV) or transformed with recombinant plasmid expression vectors (e.g., Ti plasmid) containing antibody coding sequences; or mammalian cell systems (e.g., COS, CHO, BLK, 293, 3T3 cells) harboring recombinant expression constructs containing promoters derived from the genome of mammalian cells (e.g., metallothionein promoter) or from mamma
- bacterial cells such as Escherichia coli, and more preferably, eukaryotic cells, especially for the expression of whole recombinant antibody molecule, are used for the expression of a recombinant antibody molecule.
- mammalian cells such as Chinese hamster ovary cells (CHO), in conjunction with a vector such as the major intermediate early gene promoter element from human cytomegalovirus is an effective expression system for antibodies (Foecking et ah, Gene 45:101 (1986); Cockett et ah, Bio/Technology 8:2 (1990)).
- a number of expression vectors may be advantageously selected depending upon the use intended for the antibody molecule being expressed. For example, when a large quantity of such a protein is to be produced, for the generation of pharmaceutical compositions of an antibody molecule, vectors which direct the expression of high levels of fusion protein products that are readily purified may be desirable.
- vectors include, but are not limited, to the E. coli expression vector pUR278 (Ruther et ah, EMBO J.
- pGEX vectors may also be used to express foreign polypeptides as fusion proteins with glutathione S-transferase (GST).
- fusion proteins are soluble and can easily be purified from lysed cells by adsorption and binding to a matrix glutathione-agarose beads followed by elution in the presence of free glutathione.
- the pGEX vectors are designed to include thrombin or factor Xa protease cleavage sites so that the cloned target gene product can be released from the GST moiety.
- Autographa californica nuclear polyhidrosis virus (AcNPV) is typically used as a vector to express foreign genes.
- the virus grows in Spodoptera frugiperda cells.
- the antibody coding sequence may be cloned individually into non-essential regions (for example the polyhedrin gene) of the virus and placed under control of an AcNPV promoter (for example the polyhedrin promoter).
- a number of viral-based expression systems may be utilized.
- the antibody coding sequence of interest may be ligated to an adenovirus transcription/translation control complex, e.g., the late promoter and tripartite leader sequence.
- This chimeric gene may then be inserted in the adenovirus genome by in vitro or in vivo recombination. Insertion in a non- essential region of the viral genome (e.g., region El or E3) will result in a recombinant virus that is viable and capable of expressing the antibody molecule in infected hosts.
- a non- essential region of the viral genome e.g., region El or E3
- Specific initiation signals may also be required for efficient translation of inserted antibody coding sequences. These signals include the ATG initiation codon and adjacent sequences. Furthermore, the initiation codon must be in phase with the reading frame of the desired coding sequence to ensure translation of the entire insert. These exogenous translational control signals and initiation codons can be of a variety of origins, both natural and synthetic. The efficiency of expression may be enhanced by the inclusion of appropriate transcription enhancer elements, transcription terminators, etc. (see Bittner et ah, Methods in Enzymol. 755:51-544 (1987)).
- a host cell strain may be chosen which modulates the expression of the inserted sequences, or modifies and processes the gene product in the specific fashion desired. Such modifications (e.g., glycosylation) and processing (e.g., cleavage) of protein products may be important for the function of the protein.
- Different host cells have characteristic and specific mechanisms for the post-translational processing and modification of proteins and gene products. Appropriate cell lines or host systems can be chosen to ensure the correct modification and processing of the foreign protein expressed.
- eukaryotic host cells which possess the cellular machinery for proper processing of the primary transcript, glycosylation, and phosphorylation of the gene product may be used.
- Such mammalian host cells include but are not limited to CHO, VERY, BHK, HeLa, COS, MDCK, 293, 3T3, WI38, and in particular, breast cancer cell lines such as, for example, BT483, Hs578T, HTB2, BT20 and T47D, and normal mammary gland cell line such as, for example, CRL7030 and Hs578Bst.
- breast cancer cell lines such as, for example, BT483, Hs578T, HTB2, BT20 and T47D
- normal mammary gland cell line such as, for example, CRL7030 and Hs578Bst.
- stable expression is preferred.
- cell lines which stably express the antibody molecule may be engineered.
- host cells can be transformed with DNA controlled by appropriate expression control elements (e.g., promoter, enhancer, sequences, transcription terminators, polyadenylation sites, etc.), and a selectable marker.
- appropriate expression control elements e.g., promoter, enhancer, sequences, transcription terminators, polyadenylation sites, etc.
- engineered cells may be allowed to grow for 1-2 days in an enriched media, and then are switched to a selective media.
- the selectable marker in the recombinant plasmid confers resistance to the selection and allows cells to stably integrate the plasmid into their chromosomes and grow to form foci which in turn can be cloned and expanded into cell lines. This method may advantageously be used to engineer cell lines which stably express the antibody molecule.
- a number of selection systems may be used, including but not limited to the herpes simplex virus thymidine kinase (Wigler et al., Cell 77:223 (1977)), hypoxanthine-guanine phosphoribosyltransferase (Szybalska & Szybalski, Proc. Natl. Acad. ScI USA 48:202 (1992)), and adenine phosphoribosyltransferase (Lowy et al., Cell 22:817 1980) genes can be employed in tk-, hgprt- or aprt-cells, respectively.
- antimetabolite resistance can be used as the basis of selection for the following genes: dhfr, which confers resistance to methotrexate (Wigler et al., Proc. Natl. Acad. ScL USA 77:357 (1980); O'Hare et al, Proc. Natl. Acad. ScL USA 78:1527 (1981)); gpt, which confers resistance to mycophenolic acid (Mulligan & Berg, Proc. Natl. Acad.
- the host cell may be co-transfected with two expression vectors of the invention, the first vector encoding a heavy chain derived polypeptide and the second vector encoding a light chain derived polypeptide.
- the two vectors may contain identical selectable markers which enable equal expression of heavy and light chain polypeptides.
- a single vector may be used which encodes both heavy and light chain polypeptides.
- the light chain is advantageously placed before the heavy chain to avoid an excess of toxic free heavy chain (Proudfoot, Nature 322:52 (1986); Kohler, Proc. Natl. Acad. Sd. USA 77:2197 (1980)).
- the coding sequences for the heavy and light chains may comprise cDNA or genomic DNA.
- an antibody molecule of the invention may be purified by any method known in the art for purification of an immunoglobulin molecule, for example, by chromatography (e.g., ion exchange, affinity, particularly by affinity for the specific antigen after Protein A, and sizing column chromatography), centrifugation, differential solubility, or by any other standard technique for the purification of proteins.
- chromatography e.g., ion exchange, affinity, particularly by affinity for the specific antigen after Protein A, and sizing column chromatography
- centrifugation e.g., ion exchange, affinity, particularly by affinity for the specific antigen after Protein A, and sizing column chromatography
- differential solubility e.g., differential solubility
- a binding molecule or antigen binding molecule for use in the methods of the invention comprises a synthetic constant region wherein one or more domains are partially or entirely deleted ("domain-deleted antibodies").
- compatible modified antibodies will comprise domain deleted constructs or variants wherein the entire CH2 domain has been removed ( ⁇ C H 2 constructs).
- ⁇ C H 2 constructs For other embodiments a short connecting peptide may be substituted for the deleted domain to provide flexibility and freedom of movement for the variable region.
- constructs are particularly preferred due to the regulatory properties of the CH2 domain on the catabolic rate of the antibody.
- modified antibodies for use in the methods disclosed herein are minibodies.
- Minibodies can be made using methods described in the art ⁇ see, e.g., US patent 5,837,821 or WO 94/09817Al).
- modified antibodies for use in the methods disclosed herein are:
- a NgRl antagonist antibody or fragment thereof for use in the treatment methods disclosed herein comprises an immunoglobulin heavy chain having deletion or substitution of a few or even a single amino acid as long as it permits association between the monomelic subunits.
- the mutation of a single amino acid in selected areas of the CH2 domain may be enough to substantially reduce Fc binding and thereby increase tumor localization.
- Such partial deletions of the constant regions may improve selected characteristics of the antibody (serum half-life) while leaving other desirable functions associated with the subject constant region domain intact.
- the constant regions of the disclosed antibodies may be synthetic through the mutation or substitution of one or more amino acids that enhances the profile of the resulting construct.
- Ih this respect it may be possible to disrupt the activity provided by a conserved binding site (e.g., Fc binding) while substantially maintaining the configuration and immunogenic profile of the modified antibody.
- Yet other embodiments comprise the addition of one or more amino acids to the constant region to enhance desirable characteristics such as effector function or provide for more cytotoxin or carbohydrate attachment. In such embodiments it may be desirable to insert or replicate specific sequences derived from selected constant region domains.
- the present invention also provides the use of antibodies that comprise, consist essentially of, or consist of, variants (including derivatives) of antibody molecules (e.g., the VH regions and/or VL regions) described herein, which antibodies or fragments thereof immunospecifically bind to a NgRl polypeptide.
- Standard techniques known to those of skill in the art can be used to introduce mutations in the nucleotide sequence encoding a binding molecule, including, but not limited to, site- directed mutagenesis and PCR-mediated mutagenesis which result in amino acid substitutions.
- the variants encode less than 50 amino acid substitutions, less than 40 amino acid substitutions, less than 30 amino acid substitutions, less than 25 amino acid substitutions, less than 20 amino acid substitutions, less than 15 amino acid substitutions, less than 10 amino acid substitutions, less than 5 amino acid substitutions, less than 4 amino acid substitutions, less than 3 amino acid substitutions, or less than 2 amino acid substitutions relative to the reference VH region, VHCDRl, VHCDR2, VHCDR3, VL region, VLCDRl, VLCDR2, or VLCDR3.
- a "conservative amino acid substitution” is one in which the amino acid residue is replaced with an amino acid residue having a side chain with a similar charge.
- Families of amino acid residues having side chains with similar charges have been defined in the art. These families include amino acids with basic side chains (e.g., lysine, arginine, histidine), acidic side chains (e.g., aspartic acid, glutamic acid), uncharged polar side chains (e.g., glycine, asparagine, glutamine, serine, threonine, tyrosine, cysteine), nonpolar side chains (e.g., alanine, valine, leucine, isoleucine, proline, phenylalanine, methionine, tryptophan), beta-branched side chains (e.g., threonine, valine, isoleucine) and aromatic side chains (e.g., tyrosine, phenylalanine, tryptophan, histidine).
- mutations can be introduced randomly along all or part of the coding sequence, such as by saturation mutagenesis, and the resultant mutants
- CDR regions of an antibody molecule may be silent or neutral missense mutations, Le., have no, or little, effect on an antibody's ability to bind antigen. These types of mutations may be useful to optimize codon usage, or improve a hybridoma's antibody production. Alternatively, non-neutral missense mutations may alter an antibody's ability to bind antigen. The location of most silent and neutral missense mutations is likely to be in the framework regions, while the location of most non-neutral missense mutations is likely to be in CDR, though this is not an absolute requirement.
- the encoded protein may routinely be expressed and the functional and/or biological activity of the encoded protein can be determined using techniques described herein or by routinely modifying techniques known in the art.
- compositions comprising, and uses of, the antibodies of the present invention are described below.
- Full-length Nogo receptor- 1 consists of a signal sequence, a N-terminus region (NT), eight leucine rich repeats (LRR), a LRRCT region (a leucine rich repeat domain C-terminal of the eight leucine rich repeats), a C-terminus region (CT) and a GPI anchor (see Fig. 1).
- NT N-terminus region
- LRR leucine rich repeats
- LRRCT region a leucine rich repeat domain C-terminal of the eight leucine rich repeats
- C-terminus region CT
- GPI anchor see Fig. 1
- the NgR domain designations used herein are defined as follows:
- Some embodiments of the invention provide a soluble Nogo receptor-1 polypeptide.
- Soluble Nogo receptor-1 polypeptides of the invention comprise an NT domain; 8 LRRs and an LRRCT domain and lack a signal sequence and a functional GPI anchor (i.e., no GPT anchor or a GPI anchor that lacks the ability to efficiently associate to a cell membrane).
- a soluble Nogo receptor-1 polypeptide comprises a heterologous
- a soluble Nogo receptor-1 polypeptide comprises 2, 3, 4, 5, 6, 1, or 8 heterologous LRRs.
- a heterologous LRR means an LRR obtained from a protein other than Nogo receptor-1.
- Exemplary proteins from which a heterologous LRR can be obtained are toll-like receptor (TLRl .2); T-cell activation leucine repeat rich protein; deceorin; OM-gp; insulin-like growth factor binding protein acidic labile subunit slit and robo; and toll-like receptor 4.
- the invention provides a soluble Nogo receptor-1 polypeptide of
- the invention provides a soluble Nogo receptor-1 polypeptide of 285 amino acids (soluble Nogo receptor-1 310, sNogoRl-310, or sNogoR310) (residues 26-310 of SEQ ID NOs: 7 and 9 or residues 27-310 of SEQ ID NO: 9). See Fig. 1.
- the soluble Nogo receptor-1 polypeptides of the invention are used to inhibit the binding of a ligand to Nogo receptor-1 and act as an antagonist of Nogo receptor-1 ligands. In some embodiments of the invention, the soluble Nogo receptor-1 polypeptides of the invention are used to decrease inhibition of neurite outgrowth and sprouting in a neuron, such as axonal growth and to inhibit myelin mediated growth cone collapse in a neuron. In some embodiments, the neuron is a CNS neuron.
- the present invention provides an isolated polypeptide fragment of 60 residues or less, comprising an amino acid sequence identical to a reference amino acid sequence, except for up to one, two, three, four, ten, or twenty individual amino acid substitutions, wherein said reference amino acid sequence is selected from the group consisting of: (a) amino acids x to 344 of SEQ ID NO:49, (b) amino acids 309 to y of SEQ ID NO:49, and (c) amino acids x to y of SEQ ID NO:49, wherein x is any integer from 305 to 326, and y is any integer from 328 to 350; and wherein said polypeptide fragment inhibits Nogo-receptor-mediated neurite outgrowth inhibition.
- the invention provides an isolated polypeptide fragment of 60 residues or less, comprising an amino acid sequence identical to a reference amino acid sequence, except for up to one, two, three, four, ten or twenty individual amino acid substitutions, wherein said reference amino acid sequence is selected from the group consisting of: (a) amino acids x 1 to 344 of SEQ ID NO:49, (b) amino acids 309 to y' of SEQ ID NO:49, and (c) amino acids x 1 to y' of SEQ ID NO:49, where x' is any integer from 300 to 326, and y' is any integer from 328 to 360, and wherein said polypeptide fragment inhibits Nogo- receptor-mediated neurite outgrowth inhibition.
- an NgRl reference amino acid sequence or “reference amino acid sequence” is meant the specified sequence without the introduction of any amino acid substitutions.
- the “isolated polypeptide” of the invention comprises an amino acid sequence which is identical to the reference amino acid sequence.
- the invention provides an isolated polypeptide fragment of 60 residues or less, comprising an amino acid sequence identical to a reference amino acid sequence, except for up to one, two, or three individual amino acid substitutions, wherein said reference amino acid sequence is selected from the group consisting of: amino acids 309 to 335 of SEQ ID NO:49; amino acids 309 to 344 of SEQ ID NO:49; amino acids 310 to 335 of SEQ ID NO:49; amino acids 310 to 344 of SEQ ID NO:49; amino acids 309 to 350 of SEQ ED NO:49; amino acids 300 to 344 of SEQ EO NO:49; and amino acids 315 to 344 of SEQ ID NO:49.
- the invention provides an isolated polypeptide fragment of 60 residues or less, comprising an amino acid sequence identical to a reference amino acid sequence, except for up to three individual amino acid substitutions, wherein said reference amino acid sequence is amino acids 309 to 344 of SEQ ED NO:49.
- the invention provides an isolated polypeptide fragment of 60 residues or less, comprising an amino acid sequence identical to a reference amino acid sequence, except for up to three individual amino acid substitutions, wherein said reference amino acid sequence is amino acids 309 to 335 of SEQ ED NO:49.
- the invention provides an isolated polypeptide comprising: (a) an amino acid sequence identical to a reference amino acid sequence except that at least one cysteine residue of said reference amino acid sequence is substituted with a different amino acid, wherein said reference amino acid sequence is selected from the group consisting of: (i) amino acids a to 445 of SEQ ID NO:49, (ii) amino acids 27 to b of SEQ BD NO:49, and (iii) amino acids a to b of SEQ ED NO:49, wherein a is any integer from 25 to 35, and b is any integer from 300 to 450; and (b) a heterologous polypeptide; wherein said polypeptide inhibits nogo-receptor-mediated neurite outgrowth inhibition.
- Exemplary amino acid substitutions for polypeptide fragments include substitutions of individual cysteine residues in the polypeptides of the invention with different amino acids. Any different amino acid may be substituted for a cysteine in the polypeptides of the invention. Which different amino acid is used depends on a number of criteria, for example, the effect of the substitution on the conformation of the polypeptide fragment, the charge of the polypeptide fragment, or the hydrophilicity of the polypeptide fragment.
- Amino acid substitutions for the amino acids of the polypeptides of the invention and the reference amino acid sequence can include amino acids with basic side chains ⁇ e.g., lysine, arginine, histidine), acidic side chains (e.g., aspartic acid, glutamic acid), uncharged polar side chains (e.g., glycine, asparagine, glutamine, serine, threonine, tyrosine, cysteine), nonpolar side chains (e.g., alanine, valine, leucine, isoleucine, proline, phenylalanine, methionine, tryptophan), beta-branched side chains (e.g., threonine, valine, isoleucine) and aromatic side chains (e.g., tyrosine,, phenylalanine, tryptophan, histidine).
- basic side chains e.g., lysine, arginine, histidine
- Typical amino acids to substitute for cysteines in the reference amino acid include alanine, serine, threonine, in particular, alanine. Making such substitutions through engineering of a polynucleotide encoding the polypeptide fragment is well within the routine expertise of one of ordinary skill in the art.
- the present invention provides an isolated polypeptide of the invention wherein at least one cysteine residue is substituted with a different amino acid.
- Cysteine residues that can substituted in human NgRl include C27, C31, C33, C43, C80, C140, C264, C266, C287, C309, C335, C336, C419, C429, C455 and C473.
- Cysteine residues that can substituted in rat NgRl include C27, C31, C33, C80, C140, C264, C266, C287, C309, C335, C336, C419, C429, C455 and C473.
- Cysteine residues that can substituted in mouse NgRl include C27, C31, C33, C43, C80, C140, C264, C266, C287, C309, C335, C336, C419, C429, C455 and C473.
- the present invention further provides an isolated polypeptide fragment of 40 residues or less, where the polypeptide fragment comprises an amino acid sequence identical to amino acids 309 to 344 of SEQ ID NO:49, except that: C309 is substituted, C335 is substituted, C336 is substituted, C309 and C335 are substituted, C309 and C336 are substituted, C335 and C336 are substituted, or C309, C335, and C336 are substituted.
- the cysteine residues in the polypeptides of the invention may be substituted with any heterologous amino acid.
- the cysteine is substituted with a small uncharged amino acid which is least likely to alter the three dimensional conformation of the polypeptide, e.g., alanine, serine, threonine, preferably alanine.
- the soluble Nogo receptor-1 polypeptide of the invention is a component of a fusion protein that further comprises a heterologous polypeptide.
- the heterologous polypeptide is an immunoglobulin constant domain.
- the immunoglobulin constant domain is a heavy chain constant domain.
- the heterologous polypeptide is an Fc fragment.
- the Fc is joined to the C-terminal end of the soluble Nogo receptor-1 polypeptide of the invention.
- the fusion Nogo receptor-1 protein is a dimer.
- the invention further encompasses variants, analogs, or derivatives of polypeptide fragments as described above.
- the invention provides an isolated polypeptide comprising: (a) an amino acid sequence identical to a reference amino acid sequence, except for up to twenty individual amino acid substitutions, wherein said reference amino acid sequence is selected from the group consisting of: (i) amino acids a to 445 of SEQ ID NO:49, (ii) amino acids 27 to b of SEQ ID NO:49, and (iii) amino acids a to b of SEQ ID NO:49, wherein a is any integer from 1 to 35, and b is any integer from 300 to 450; and (b) a heterologous polypeptide; wherein said polypeptide inhibits nogo-receptor- mediated neurite outgrowth inhibition.
- the isolated polypeptide is amino acids 1 to 310 Of SEQ ID NO:49, wherein R269 and A310 are substituted with a different amino acid.
- exemplary amino acids that can be substituted in the polypeptide include amino acids with basic side chains (e.g., lysine, arginine, histidine), acidic side chains (e.g., aspartic acid, glutamic acid), uncharged polar side chains (e.g., glycine, asparagine, glutamine, serine, threonine, tyrosine, cysteine), nonpolar side chains (e.g., alanine, valine, leucine, isoleucine, proline, phenylalanine, methionine, tryptophan), beta-branched side chains (e.g., threonine, valine, isoleucine) and aromatic side chains (e.g., tyrosine, phenylalanine, tryptophan, histidine
- Exemplary soluble NgR-Fc fusion proteins with cysteine substitutions are Ala-Ala- human(h)NgRl(310)-Fc which comprises Fc joined to the C-terminal end of a soluble polypeptide with the amino acid sequence of SEQ ID NO:58, Ala-Ala-rat(r)NgRl(310)-Fc which comprises Fc joined to the C-terminal end of a soluble polypeptide with the amino acid sequence of SEQ BD NO:59 and AIa- Ala-human(h)NgRl(344)-Fc which comprises Fc joined to to the C-terminal end of a soluble polypeptide with the amino acid sequence of SEQ DD NO:64.
- a polypeptide in the present invention, can be composed of amino acids joined to each other by peptide bonds or modified peptide bonds, i.e., peptide isosteres, and may contain amino acids other than the 20 gene-encoded amino acids (e.g., non-naturally occurring amino acids).
- the polypeptides of the present invention may be modified by either natural processes, such as posttranslational processing, or by chemical modification techniques which are well known in the art. Such modifications are well described in basic texts and in more detailed monographs, as well as in a voluminous research literature. Modifications can occur anywhere in the polypeptide, including the peptide backbone, the amino acid side-chains and the amino or carboxyl termini.
- polypeptides may be branched, for example, as a result of ubiquitination, and they may be cyclic, with or without branching. Cyclic, branched, and branched cyclic polypeptides may result from natural processes or may be made by synthetic methods.
- Modifications include, but are not limited to, acetylation, acylation, ADP-ribosylation, amidation, covalent attachment of flavin, covalent attachment of a heme moiety, covalent attachment of a nucleotide or nucleotide derivative, covalent attachment of a lipid or lipid derivative, covalent attachment of phosphotidylinositol, cross-linking, cyclization, disulfide bond formation, demethylation, formation of covalent cross-links, formation of cysteine, formation of pyroglutamate, formylation, gamma-carboxylation, glycosylation, GPI anchor formation, hydroxylation, iodination, methylation, myristoylation, oxidation, pegylation, proteolytic processing, phosphorylation, prenylation, racemization, selenoylation, sulfation, transfer-RNA mediated addition of amino acids to proteins such as arginylation, and ubiquitination
- Polypeptides described herein may be cyclic. Cyclization of the polypeptides reduces the conformational freedom of linear peptides and results in a more structurally constrained molecule.
- peptide cyclization by the formation of an amide bond between the N-terminal and the C-terminal amino acid residues of the peptide.
- the "backbone to backbone” cyclization method includes the formation of disulfide bridges between two ⁇ -thio amino acid residues (e.g., cysteine, homocysteine).
- Certain peptides of the present invention include modifications on the N- and C- terminus of the peptide to form a cyclic polypeptide. Such modifications include, but are not limited, to cysteine residues, acetylated cysteine residues, cysteine residues with a NH2 moiety and biotin.
- an NgRl polypeptide or polypeptide fragment of the invention can be administered directly as a preformed polypeptide, or indirectly through a nucleic acid vector.
- an NgRl polypeptide or polypeptide fragment of the invention is administered in a treatment method that includes: (1) transforming or transfecting an implantable host cell with a nucleic acid, e.g., a vector, that expresses an NgRl polypeptide or polypeptide fragment of the invention; and (2) implanting the transformed host cell into a mammal, at the site of a disease, disorder or injury.
- a treatment method that includes: (1) transforming or transfecting an implantable host cell with a nucleic acid, e.g., a vector, that expresses an NgRl polypeptide or polypeptide fragment of the invention.
- the transformed host cell can be implanted at the site of a chronic lesion of MS.
- the implantable host cell is removed from a mammal, temporarily cultured, transformed or transfected with an isolated nucleic acid encoding an NgRl polypeptide or polypeptide fragment of the invention, and implanted back into the same mammal from which it was removed.
- the cell can be, but is not required to be, removed from the same site at which it is implanted.
- Such embodiments sometimes known as ex vivo gene therapy, can provide a continuous supply of the NgRl polypeptide or polypeptide fragment of the invention, localized at the site of action, for a limited period of time.
- NgRl polypeptide that is not the full-length NgRl protein, e.g., polypeptide fragments of NgRl, fused to a heterologous polypeptide moiety to form a fusion protein.
- fusion proteins can be used to accomplish various objectives, e.g., increased serum half-life, improved bioavailability, in vivo targeting to a specific organ or tissue type, improved recombinant expression efficiency, improved host cell secretion, ease of purification, and higher avidity.
- the heterologous moiety can be inert or biologically active.
- NgRl polypeptide moiety of the invention can be chosen to be stably fused to the NgRl polypeptide moiety of the invention or to be cleavable, in vitro or in vivo.
- Heterologous moieties to accomplish these other objectives are known in the art.
- an NgRl polypeptide fragment can be fused to another NgR polypeptide fragment, e.g., an NgR2 or NgR3 polypeptide fragment along with Fc.
- the human NgR2 polypeptide is shown below as SEQ ID NO:60.
- the mouse NgR2 polypeptide is shown below as SEQ ID NO:61.
- the human NgR3 polypeptide is shown below as SEQ ID NO:62.
- the mouse NgR3 polypeptide is shown below as SEQ ID NO:63.
- the invention provides an isolated polypeptide comprising a first polypeptide fragment and a second polypeptide fragment, wherein said first polypeptide fragment comprises an amino acid sequence identical to a first reference amino acid sequence, except for up to one, two, three, four, ten, or twenty individual amino acid substitutions, wherein said first reference amino acid sequence is selected from the group consisting of: (a) amino acids a to 305 of SEQ ED NO:49, (b) amino acids 1 to b of SEQ ID NO:49, and (c) amino acids a to b of SEQ ID NO:49, wherein a is any integer from 1 to 27, and b is any integer from 264 to 309; and wherein said second polypeptide fragment comprises an amino acid sequence identical to a second reference amino acid sequence, except for up to one, two, three, four, ten, or twenty individual amino acid substitutions, wherein said second reference amino acid sequence is selected from the group consisting of (a) amino acids c to 332 of SEQ ID NO
- the invention provides an isolated polypeptide comprising a first polypeptide fragment and a second polypeptide fragment, wherein said first polypeptide fragment comprises an amino acid sequence identical to a first reference amino acid sequence, except for up to one, two, three, four, ten, or twenty individual amino acid substitutions, wherein said first reference amino acid sequence is amino acids 1-274 of SEQ ID NO:49 and wherein said second polypeptide fragment comprises an amino acid sequence identical to a second reference amino acid sequence, except for up to one, two, three, four, ten, or twenty individual amino acid substitutions, wherein said second reference amino acid sequence is amino acids 275-311 of SEQ ID NO:60 and; wherein said polypeptide inhibits nogo-receptor-mediated neurite outgrowth inhibition.
- the invention provides an isolated polypeptide comprising a first polypeptide fragment and a second polypeptide fragment, wherein said first polypeptide fragment comprises an amino acid sequence identical to a first reference amino acid sequence, except for up to one, two, three, four, ten, or twenty individual amino acid substitutions, wherein said first reference amino acid sequence is amino acids 1-274 of SEQ ED NO:49 and wherein said second polypeptide fragment comprises an amino acid sequence identical to a second reference amino acid sequence, except for up to one, two, three, four, ten, or twenty individual amino acid substitutions, wherein said second reference amino acid sequence is amino acids 275-332 of SEQ ID NO:60 and; wherein said polypeptide inhibits nogo-receptor-mediated neurite outgrowth inhibition.
- the invention provides an isolated polypeptide comprising a first polypeptide fragment and a second polypeptide fragment, wherein said first polypeptide fragment comprises an amino acid sequence identical to a first reference amino acid sequence, except for up to one, two, three, four, ten, or twenty individual amino acid substitutions, wherein said first reference amino acid sequence is amino acids 1-305 of SEQ ID NO:49 and wherein said second polypeptide fragment comprises an amino acid sequence identical to a second reference amino acid sequence, except for up to one, two, three, four, ten, or twenty individual amino acid substitutions, wherein said second reference amino acid sequence is amino acids 306-311 of SEQ ID NO:60 and; wherein said polypeptide inhibits nogo-receptor-mediated neurite outgrowth inhibition.
- the invention provides an isolated polypeptide comprising a first polypeptide fragment and a second polypeptide fragment, wherein said first polypeptide fragment comprises an amino acid sequence identical to a first reference amino acid sequence, except for up to one, two, three, four, ten, or twenty individual amino acid substitutions, wherein said first reference amino acid sequence is amino acids 1-305 of SEQ DD NO:49 and wherein said second polypeptide fragment comprises an amino acid sequence identical to a second reference amino acid sequence, except for up to one, two, three, four, ten, or twenty individual amino acid substitutions, wherein said second reference amino acid sequence is amino acids 306-309 of SEQ ID NO:60 and; wherein said polypeptide inhibits nogo-receptor-mediated neurite outgrowth inhibition.
- At least one additional amino acid is added to the C-terminus of the second polypeptide fragment.
- exemplary amino acids that can be added to the polypeptide include amino acids with basic side chains (e.g., lysine, arginine, histidine), acidic side chains ⁇ e.g., aspartic acid, glutamic acid), uncharged polar side chains (e.g., glycine, asparagine, glutamine, serine, threonine, tyrosine, cysteine), nonpolar side chains (e.g., alanine, valine, leucine, isoleucine, proline, phenylalanine, methionine, tryptophan), beta-branched side chains (e.g., threonine, valine, isoleucine) and aromatic side chains (e.g., tyrosine, phenylalanine, tryptophan, histidine).
- basic side chains e.g., lysine,
- the added amino acid is tryptophan.
- the arginine at position 269 of SEQ ID NO:49 is substituted with tryptophan.
- the invention provides an isolated polypeptide comprising a first polypeptide fragment and a second polypeptide fragment, wherein said first polypeptide fragment consists of amino acids 1-310 of SEQ ID NO:49, except for up to one, two, three, four, ten, or twenty individual amino acid substitutions; and wherein said second polypeptide fragment consists of amino acids 311-318 of SEQ ID NO:60 except for up to one, two, three, four, or five individual amino acid substitutions; and wherein said polypeptide inhibits nogo-receptor-mediated neurite outgrowth inhibition.
- the polypeptides of the invention further comprise a heterologous polypeptide.
- the heterologous polypeptide is an immunoglobulin constant domain.
- the immunoglobulin constant domain is a heavy chain constant domain.
- the heterologous polypeptide is an Fc fragment.
- the Fc is joined to the C-terminal end of the polypeptides of the invention.
- the fusion is a dimer.
- the invention further encompasses variants, analogs, or derivatives of polypeptide fragments as described above.
- a chosen heterologous moiety can be preformed and chemically conjugated to the NgR polypeptide moiety of the invention.
- a chosen heterologous moiety will function similarly, whether fused or conjugated to the NgR polypeptide moiety. Therefore, in the following discussion of heterologous amino acid sequences, unless otherwise noted, it is to be understood that the heterologous sequence can be joined to the NgR polypeptide moiety in the form of a fusion protein or as a chemical conjugate.
- NgRl aptamers and antibodies and fragments thereof for use in the treatment methods disclosed herein may also be recombinantly fused to a heterologous polypeptide at the N- or C-terminus or chemically conjugated (including covalent and non-covalent conjugations) to polypeptides or other compositions.
- NgRl antagonist aptamers and antibodies and fragments thereof may be recombinantly fused or conjugated to molecules useful as labels in detection assays and effector molecules such as heterologous polypeptides, drugs, radionuclides, or toxins. See, e.g., PCT publications WO 92/08495; WO 91/14438; WO 89/12624; U.S.
- NgRl antagonist polypeptides, aptamers, and antibodies and fragments thereof for use in the treatment methods disclosed herein include derivatives that are modified, i.e., by the covalent attachment of any typ e °f molecule such that covalent attachment does not prevent the NgRl antagonist polypeptide, aptamer, or antibody from inhibiting the biological function of NgRl.
- the NgRl antagonist polypeptides, aptamers and antibodies and fragments thereof of the present invention may be modified e.g., by glycosylation, acetylation, pegylation, phosphylation, phosphorylation, amidation, derivatization by known protecting/blocking groups, proteolytic cleavage, linkage to a cellular ligand or other protein, etc. Any of numerous chemical modifications may be carried out by known techniques, including, but not limited to specific chemical cleavage, acetylation, formylation, metabolic synthesis of tunicamycin, etc. Additionally, the derivative may contain one or more non-classical amino acids.
- NgRl antagonist polypeptides, aptamers and antibodies and fragments thereof for use in the treatment methods disclosed herein can be composed of amino acids joined to each other by peptide bonds or modified peptide bonds, i.e., peptide isosteres, and may contain amino acids other than the 20 gene-encoded amino acids.
- NgRl antagonist polypeptides, aptamers and antibodies and fragments thereof may be modified by natural processes, such as posttranslational processing, or by chemical modification techniques which are well known in the art. Such modifications are well described in basic texts and in more detailed monographs, as well as in a voluminous research literature.
- Modifications can occur anywhere in the NgRl antagonist polypeptide, aptamer or antibody or fragments thereof, including the peptide backbone, the amino acid side-chains and the amino or carboxyl termini, or on moieties such as carbohydrates. It will be appreciated that the same type of modification may be present in the same or varying degrees at several sites in a given NgRl antagonist polypeptide, aptamer or antibody or fragments thereof. Also, a given NgRl antagonist polypeptide, aptamer or antibody or fragments thereof may contain many types of modifications.
- NgRl antagonist polypeptides, aptamers or antibodies or fragments thereof may be branched, for example, as a result of ubiquiti ⁇ ation, and they may be cyclic, with or without branching. Cyclic, branched, and branched cyclic NgRl antagonist polypeptides, aptamers and antibodies or fragments thereof may result from posttranslational natural processes or may be made by synthetic methods.
- Modifications include acetylation, acylation, ADP-ribosylation, amidation, covalent attachment of flavin, covalent attachment of a heme moiety, covalent attachment of a nucleotide or nucleotide derivative, covalent attachment of a lipid or lipid derivative, covalent attachment of phosphotidylinositol, cross-linking, cyclization, disulfide bond formation, demethylation, formation of covalent cross-links, formation of cysteine, formation of pyroglutamate, formylation, gamma- carboxylation, glycosylation, GPI anchor formation, hydroxylation, iodination, methylation, myristoylation, oxidation, pegylation, proteolytic processing, phosphorylation, prenylation, racemization, selenoylation, sulfation, transfer-RNA mediated addition of amino acids to proteins such as arginylation, and ubiquitination.
- the heterologous polypeptide to which the NgRl antagonist polypeptide, aptamer or antibody or fragments thereof is fused is useful theraeutically or is useful to target the NgRl antagonist polypeptide, aptamer or antibody or fragments thereof.
- NgRl antagonist fusion proteins, aptamers and antibodies or fragments thereof can be used to accomplish various objectives, e.g., increased serum half- life, improved bioavailability, in vivo targeting to a specific organ or tissue type, improved recombinant expression efficiency, improved host cell secretion, ease of purification, and higher avidity.
- the heterologous moiety can be inert or biologically active.
- NgRl antagonist polypeptide aptamer or antibody or fragments thereof or to be cleavable, in vitro or in vivo.
- Heterologous moieties to accomplish these other objectives are known in the art.
- a chosen heterologous moiety can be preformed and chemically conjugated to the antagonist polypeptide, aptamer or antibody. In most cases, a chosen heterologous moiety will function similarly, whether fused or conjugated to the NgRl antagonist polypeptide, aptamer or antibody or fragments thereof. Therefore, in the following discussion of heterologous amino acid sequences, unless otherwise noted, it is to be understood that the heterologous sequence can be joined to the NgRl antagonist polypeptide, aptamer or antibody or fragments thereof in the form of a fusion protein or as a chemical conjugate.
- Pharmacologically active polypeptides such as NgRl antagonist polypeptides, aptamers or antibodies or fragments thereof may exhibit rapid in vivo clearance, necessitating large doses to achieve therapeutically effective concentrations in the body.
- polypeptides smaller than about 60 kDa potentially undergo glomerular filtration, which sometimes leads to nephrotoxicity.
- Fusion or conjugation of relatively small polypeptides such as polypeptide fragments of the NgR signaling domain can be employed to reduce or avoid the risk of such nephrotoxicity.
- heterologous amino acid sequences Le., polypeptide moieties or "carriers,” for increasing the in vivo stability, i.e., serum half-life, of therapeutic polypeptides are known.
- serum albumins such as, e.g., bovine serum albumin (BSA) or human serum albumin (HSA).
- BSA bovine serum albumin
- HSA human serum albumin
- HSA can be used to form a fusion protein or polypeptide conjugate that displays pharmacological activity by virtue of the NgR polypeptide moiety while displaying significantly increased in vivo stability, e.g., 10-fold to 100-fold higher.
- the C-terminus of the HSA can be fused to the N-terminus of the NgR polypeptide moiety. Since HSA is a naturally secreted protein, the HSA signal sequence can be exploited to obtain secretion of the fusion protein into the cell culture medium when the fusion protein is produced in a eukaryotic, e.g., mammalian, expression system.
- NgRl antagonist polypeptides, aptamers, antibodies and antibody fragments thereof for use in the methods of the present invention further comprise a targeting moiety.
- Targeting moieties include a protein or a peptide which directs localization to a certain part of the body, for example, to the brain or compartments therein.
- NgRl antagonist polypeptides, aptamers, antibodies or antibody fragments thereof for use in the methods of the present invention are attached or fused to a brain targeting moiety.
- the brain targeting moieties are attached covalently (e.g., direct, translational fusion, or by chemical linkage either directly or through a spacer molecule, which can be optionally cleavable) or non-covalently attached (e.g., through reversible interactions such as avidin:biotin, protein A:IgG, etc.).
- the NgRl antagonist polypeptides, aptamers, antibodies or antibody fragments thereof for use in the methods of the present invention thereof are attached to one more brain targeting moieties.
- the brain targeting moiety is attached to a plurality of NgRl antagonist polypeptides, aptamers, antibodies or antibody fragments thereof for use in the methods of the present invention.
- a brain targeting moiety associated with an NgRl antagonist polypeptide, aptamer, antibody or antibody fragment thereof enhances brain delivery of such an NgRl antagonist polypeptide, antibody or antibody fragment thereof.
- a number of polypeptides have been described which, when fused to a protein or therapeutic agent, delivers the protein or therapeutic agent through the blood brain barrier (BBB).
- BBB blood brain barrier
- Non-limiting examples include the single domain antibody FC5 (Abulrob et al. (2005) J. Neurochem. 95, 1201-1214); mAB 83-14, a monoclonal antibody to the human insulin receptor (Pardridge et al. (1995) Pharmacol. Res.
- Enhanced brain delivery of an NgRl composition is determined by a number of means well established in the art. For example, administering to an animal a radioactively labelled NgRl antagonist polypeptide, aptamer, antibody or antibody fragment thereof linked to a brain targeting moiety; determining brain localization; and comparing localization with an equivalent radioactively labelled NgRl antagonist polypeptide, aptamer, antibody or antibody fragment thereof that is not associated with a brain targeting moiety. Other means of determining enhanced targeting are described in the above references.
- Some embodiments of the invention employ an NgR polypeptide moiety fused to a hinge and Fc region, i.e., the C-terminal portion of an Ig heavy chain constant region.
- amino acids in the hinge region may be substituted with different amino acids.
- Exemplary amino acid substitutions for the hinge region according to these embodiments include substitutions .of individual cysteine residues in the hinge region with different amino acids. Any different amino acid may be substituted for a cysteine in the hinge region.
- Amino acid substitutions for the amino acids of the polypeptides of the invention and the reference amino acid sequence can include amino acids with basic side chains (e.g., lysine, arginine, histidine), acidic side chains (e.g., aspartic acid, glutamic acid), uncharged polar side chains (e.g., glycine, asparagine, glutamine, serine, threonine, tyrosine, cysteine), nonpolar side chains (e.g., alanine, valine, leucine, isoleucine, proline, phenylalanine, methionine, tryptophan), beta-branched side chains (e.g., threonine, valine, isoleucine) and aromatic side chains (e.g., tyrosine, phenylalanine, tryptophan, histidine).
- basic side chains e.g., lysine, arginine, histidine
- Typical amino acids to substitute for cysteines in the reference amino acid include alanine, serine, threonine, in particular, serine and alanine. Making such substitutions through engineering of a polynucleotide encoding the polypeptide fragment is well within the routine expertise of one of ordinary skill in the art.
- NgR-polypeptide-Fc fusion Potential advantages include solubility, in vivo stability, and multivalency, e.g., dimerization.
- the Fc region used can be an IgA, IgD, or IgG Fc region (hinge-CH2-CH3). Alternatively, it can be an IgE or IgM Fc region (hinge-CH2-CH3-CH4).
- An IgG Fc region is generally used, e.g., an IgGl Fc region or IgG4 Fc region.
- Materials and methods for constructing and expressing DNA encoding Fc fusions are known in the art and can be applied to obtain fusions without undue experimentation. Some embodiments of the invention employ a fusion protein such as those described in Capon et ah, U.S. Patent Nos. 5,428,130 and 5,565,335.
- the signal sequence is a polynucleotide that encodes an amino acid sequence that initiates transport of a protein across the membrane of the endoplasmic reticulum.
- Signal sequences useful for constructing an immunofusin include antibody light chain signal sequences, e.g., antibody 14.18 (Gillies et ah, J. Immunol. Meth., 125:191-202 (1989)), antibody heavy chain signal sequences, e.g., the MOPC141 antibody heavy chain signal sequence (Sakano et ah, Nature 286:5774 (1980)).
- antibody light chain signal sequences e.g., antibody 14.18 (Gillies et ah, J. Immunol. Meth., 125:191-202 (1989)
- antibody heavy chain signal sequences e.g., the MOPC141 antibody heavy chain signal sequence (Sakano et ah, Nature 286:5774 (1980)).
- MOPC141 antibody heavy chain signal sequence e.g
- the signal peptide is usually cleaved in the lumen of the endoplasmic reticulum by signal peptidases. This results in the secretion of an immunofusin protein containing the Fc region and the NgR polypeptide moiety.
- the DNA sequence may encode a proteolytic cleavage site between the secretion cassette and the NgR polypeptide moiety.
- a proteolytic cleavage site may provide, e.g., for the proteolytic cleavage of the encoded fusion protein, thus separating the Fc domain from the target protein.
- Useful proteolytic cleavage sites include amino acid sequences recognized by proteolytic enzymes such as trypsin, plasmin, thrombin, factor Xa, or enterokinase K.
- the secretion cassette can be incorporated into a replicable expression vector.
- Useful vectors include linear nucleic acids, plasmids, phagemids, cosmids and the like.
- An exemplary expression vector is pdC, in which the transcription of the immunofusin DNA is placed under the control of the enhancer and promoter of the human cytomegalovirus. See, e.g., Lo et al, Biochim. Biophys. Acta 1088:112 (1991); and Lo et al, Protein Engineering /7:495-500 (1998).
- An appropriate host cell can be transformed or transfected with a DNA that encodes an NgRl polypeptide or polypeptide fragment of the invention and used for the expression and secretion of the polypeptide.
- Host cells that are typically used include immortal hybridoma cells, myeloma cells, 293 cells, Chinese hamster ovary (CHO) cells, HeIa cells, and COS cells.
- the IgGl Fc region is most often used.
- the Fc region of the other subclasses of immunoglobulin gamma (gamma-2, ga ⁇ nma-3 and gamma-4) can be used in the secretion cassette.
- the IgGl Fc region of immunoglobulin gamma-1 is generally used in the secretion cassette and includes at least part of the hinge region, the CH2 region, and the CH3 region.
- the Fc region of immunoglobulin gamma-1 is a CH2-deleted-Fc, which includes part of the hinge region and the CH3 region, but not the CH2 region.
- a CH2-deleted-Fc has been described by Gillies et al, Hum. Antibod. Hybridomas 1:47 (1990).
- the Fc region of one of IgA, IgD, IgE, or IgM is used.
- NgR-polypeptide-moiety-Fc fusion proteins can be constructed in several different configurations.
- the C-terminus of the NgR polypeptide moiety is fused directly to the N-terminus of the Fc hinge moiety.
- a short polypeptide e.g., 2- 10 amino acids
- the short polypeptide is incorporated into the fusion between the C-terminus of the NgR polypeptide moiety and the N-terminus of the Fc moiety.
- NgRl(310)-2XG4S-Fc which is amino acids 26-310 of SEQ ED NO:49 linked to (Gly-Gly-Gly-GIy-Ser) 2 (SEQ ID NO:66) which is linked to Fc.
- a linker provides conformational flexibility, which may improve biological activity in some circumstances. If a sufficient portion of the hinge region is retained in the Fc moiety, the NgR- polypeptide-moiety-Fc fusion will dimerize, thus forming a divalent molecule. A homogeneous population of monomelic Fc fusions will yield monospecific, bivalent dimers.
- Any of a number of cross-linkers that contain a corresponding amino-reactive group and thiol-reactive group can be used to link an NgRl polypeptide or polypeptide fragment of the invention to serum albumin.
- suitable linkers include amine reactive cross-linkers that insert a thiol- reactive maleimide, e.g., SMCC, AMAS, BMPS, MBS, EMCS, SMPB, SMPH, KMUS, and GMBS.
- Other suitable linkers insert a thiol-reactive haloacetate group, e.g., SBAP, SIA, SIAB.
- Linkers that provide a protected or non-protected thiol for reaction with sulfhydryl groups to product a reducible linkage include SPDP, SMPT, SATA, and SATP. Such reagents are commercially available ⁇ e.g., Pierce Chemical Company, Rockford, IL).
- NgR- polypeptide-albumin fusions can be obtained using genetic engineering techniques, wherein the NgR polypeptide moiety is fused to the serum albumin gene at its N-terminus, C-terminus, or both.
- NgR polypeptides of the invention can be fused to a polypeptide tag.
- polypeptide tag is intended to mean any sequence of amino acids that can be attached to, connected to, or linked to an NgR polypeptide and that can be used to identify, purify, concentrate or isolate the NgR polypeptide.
- the attachment of the polypeptide tag to the NgR polypeptide may occur, e.g., by constructing a nucleic acid molecule that comprises: (a) a nucleic acid sequence that encodes the polypeptide tag, and (b) a nucleic acid sequence that encodes an NgR polypeptide.
- Exemplary polypeptide tags include, e.g., amino acid sequences that are capable of being post-translationally modified, e.g., amino acid sequences that are biotinylated.
- polypeptide tags include, e.g., amino acid sequences that are capable of being recognized and/or bound by an antibody (or fragment thereof) or other specific binding reagent.
- Polypeptide tags that are capable of being recognized by an antibody (or fragment thereof) or other specific binding reagent include, e.g., those that are known in the art as "epitope tags.”
- An epitope tag may be a natural or an artificial epitope tag. Natural and artificial epitope tags are known in the art, including, e.g., artificial epitopes such as FLAG, Strep, or poly-histidine peptides.
- FLAG peptides include the sequence Asp-Tyr-Lys-Asp-Asp-Asp-Asp- Lys (SEQ ID NO:74) or Asp-Tyr-Lys-Asp-Glu-Asp-Asp-Lys (SEQ ID NO:75) (Einhauer, A. and Jungbauer, A., J. Biochem. Biophys. Methods 49: 1-3:455-465 (2001)).
- the Strep epitope has the sequence Ala-Trp-Arg-His-Pro-Gln-Phe-Gly-Gly (SEQ ID NO:76).
- the VSV-G epitope can also be used and has the sequence Tyr-Thr-Asp-He-Glu-Met-Asn-Arg-Leu-Gly-Lys (SEQ ID NO:77).
- Another artificial epitope is a poly-His sequence having six histidine residues (His-His-His-His-His-His (SEQ ID NO: 78).
- Naturally-occurring epitopes include the influenza virus hemagglutinin (HA) sequence Tyr-Pro- Tyr-Asp-Val-Pro-Asp-Tyr-Ala-He-Glu-Gly-Arg (SEQ ID NO: 79) recognized by the monoclonal antibody 12CA5 (Murray et ai, Anal.
- the NgR polypeptide and the polypeptide tag may be connected via a linking amino acid sequence.
- a "linking amino acid sequence” may be an amino acid sequence that is capable of being recognized and/or cleaved by one or more proteases. Amino acid sequences that can be recognized and/or cleaved by one or more proteases are known in the art.
- Exemplary amino acid sequences are those that are recognized by the following proteases: factor VHa, factor IXa, factor Xa, APC, t-PA, u-PA, trypsin, chymotrypsin, enterokinase, pepsin, cathepsin B,H,L,S,D, cathepsin G, renin, angiotensin converting enzyme, matrix metalloproteases (collagenases, stromelysins, gelatinases), macrophage elastase, Cir, and Cis.
- the amino acid sequences that are recognized by the aforementioned proteases are known in the art. Exemplary sequences recognized by certain proteases can be found, e.g., in U.S. Patent No. 5,811,252.
- Polypeptide tags can facilitate purification using commercially available chromatography media.
- an NgR polypeptide fusion construct is used to enhance the production of an NgR polypeptide moiety in bacteria.
- a bacterial protein normally expressed and/or secreted at a high level is employed as the N-terminal fusion partner of an NgRl polypeptide or polypeptide fragment of the invention. See, e.g., Smith et al., Gene 67:31 (1988); Hopp et al, Biotechnology 6:1204 (1988); La Vallie et al, Biotechnology 77:187 (1993).
- an NgR polypeptide moiety can be fused to the amino and carboxy termini of an Ig moiety to produce a bivalent monomelic polypeptide containing two NgR polypeptide moieties. Upon dimerization of two of these monomers, by virtue of the Ig moiety, a tetravalent form of an NgR polypeptide is obtained.
- Such multivalent forms can be used to achieve increased binding affinity for the target.
- Multivalent forms of an NgRl polypeptide or polypeptide fragment of the invention also can be obtained by placing NgR polypeptide moieties in tandem to form concatamers, which can be employed alone or fused to a fusion partner such as Ig or HSA.
- NgRl polypeptide or polypeptide fragment of the invention wherein one or more polymers are conjugated (covalently linked) to the NgR polypeptide.
- polymers suitable for such conjugation include polypeptides (discussed above), sugar polymers and polyalkylene glycol chains.
- a polymer is conjugated to the NgRl polypeptide or polypeptide fragment of the invention for the purpose of improving one or more of the following: solubility, stability, or bioavailability.
- the class of polymer generally used for conjugation to an NgRl polypeptide or polypeptide fragment of the invention is a polyalkylene glycol.
- Polyethylene glycol (PEG) is most frequently used.
- PEG moieties e.g., 1, 2, 3, 4 or 5 PEG polymers, can be conjugated to each NgR polypeptide to increase serum half life, as compared to the NgR polypeptide alone.
- PEG moieties are non-antigenic and essentially biologically inert.
- PEG moieties used in the practice of the invention may be branched or unbranched.
- the number of PEG moieties attached to the NgR polypeptide and the molecular weight of the individual PEG chains can vary. In general, the higher the molecular weight of the polymer, the fewer polymer chains attached to the polypeptide. Usually, the total polymer mass attached to an NgR polypeptide or polypeptide fragment is from 20 kDa to 40 kDa. Thus, if one polymer chain is attached, the molecular weight of the chain is generally 20-40 kDa. If two chains are attached, the molecular weight of each chain is generally 10-20 kDa. If three chains are attached, the molecular weight is generally 7-14 kDa.
- the polymer e.g., PEG
- the exposed reactive group(s) can be, e.g., an N-terminal amino group or the epsilon amino group of an internal lysine residue, or both.
- An activated polymer can react and covalently link at any free amino group on the NgR polypeptide.
- Free carboxylic groups suitably activated carbonyl groups, hydroxyl, guanidyl, imidazole, oxidized carbohydrate moieties and mercapto groups of the NgR polypeptide (if available) also can be used as reactive groups for polymer attachment.
- the polymer can be conjugated to the NgR polypeptide using conventional chemistry.
- a polyalkylene glycol moiety can be coupled to a lysine epsilon amino group of the NgR polypeptide.
- Linkage to the lysine side chain can be performed with an N-hydroxylsuccinimide (NHS) active ester such as PEG succinimidyl succinate (SS-PEG) and succinimidyl propionate (SPA-PEG).
- NHS N-hydroxylsuccinimide
- SS-PEG PEG succinimidyl succinate
- SPA-PEG succinimidyl propionate
- Suitable polyalkylene glycol moieties include, e.g., carboxymethyl-NHS and norleucine-NHS, SC. These reagents are commercially available. Additional amine-reactive PEG linkers can be substituted for the succinimidyl moiety.
- PEGylation can be carried out by any of the PEGylation reactions known in the art. See, e.g., Focus on Growth Factors, 3: 4-10, 1992 and European patent applications EP 0 154 316 and EP 0 401 384. PEGylation may be carried out using an acylation reaction or an alkylation reaction with a reactive polyethylene glycol molecule (or an analogous reactive water-soluble polymer).
- PEGylation by acylation generally involves reacting an active ester derivative of polyethylene glycol. Any reactive PEG molecule can be employed in the PEGylation. PEG esterified to N-hydroxysuccinimide (NHS) is a frequently used activated PEG ester.
- NHS N-hydroxysuccinimide
- acylation includes without limitation the following types of linkages between the therapeutic protein and a water- soluble polymer such as PEG: amide, carbamate, urethane, and the like. See, e.g., Bioconjugate Chem. 5: 133-140, 1994. Reaction parameters are generally selected to avoid temperature, solvent, and pH conditions that would damage or inactivate the NgR polypeptide.
- the connecting linkage is an amide and typically at least 95% of the resulting product is mono-, di- or tri-PEGylated. However, some species with higher degrees of PEGylation may be formed in amounts depending on the specific reaction conditions used.
- purified PEGylated species are separated from the mixture, particularly unreacted species, by conventional purification methods, including, e.g., dialysis, salting-out, ultrafiltration, ion-exchange chromatography, gel filtration chromatography, hydrophobic exchange chromatography, and electrophoresis.
- PEGylation by alkylation generally involves reacting a terminal aldehyde derivative of
- PEG with an NgRl polypeptide or polypeptide fragment of the invention in the presence of a reducing agent can manipulate the reaction conditions to favor PEGylation substantially only at the N-terminal amino group of the NgR polypeptide, i.e. a mono-PEGylated protein.
- the PEG groups are typically attached to the protein via a -CH2- NH- group. With particular reference to the -CH2- group, this type of linkage is known as an "alkyl" linkage.
- PEGylated product exploits differential reactivity of different types of primary amino groups (lysine versus the N-terminal) available for derivatization.
- the reaction is performed at a pH that allows one to take advantage of the pKa differences between the epsilon-amino groups of the lysine residues and that of the N-terminal amino group of the protein.
- a water- soluble polymer that contains a reactive group, such as an aldehyde to a protein is controlled: the conjugation with the polymer takes place predominantly at the N-terminus of the protein and no significant modification of other reactive groups, such as the lysine side chain amino groups, occurs.
- the polymer molecules used in both the acylation and alkylation approaches are selected from among water-soluble polymers.
- the polymer selected is typically modified to have a single reactive group, such as an active ester for acylation or an aldehyde for alkylation, so that the degree of polymerization may be controlled as provided for in the present methods.
- An exemplary reactive PEG aldehyde is polyethylene glycol propionaldehyde, which is water stable, or mono Cl-ClO alkoxy or aryloxy derivatives thereof ⁇ see, e.g., Harris et ah, U.S. Pat. No. 5,252,714).
- the polymer may be branched or unbranched.
- the polymer(s) selected typically have a single reactive ester group.
- the polymer(s) selected typically have a single reactive aldehyde group.
- the water-soluble polymer will not be selected from naturally occurring glycosyl residues, because these are usually made more conveniently by mammalian recombinant expression systems.
- Methods for preparing a PEGylated NgR polypeptides of the invention generally includes the steps of (a) reacting an NgRl polypeptide or polypeptide fragment of the invention with polyethylene glycol (such as a reactive ester or aldehyde derivative of PEG) under conditions whereby the molecule becomes attached to one or more PEG groups, and (b) obtaining the reaction product(s).
- polyethylene glycol such as a reactive ester or aldehyde derivative of PEG
- the optimal reaction conditions for the acylation reactions will be determined case-by-case based on known parameters and the desired result. For example, a larger the ratio of PEG to protein, generally leads to a greater the percentage of poly-PEGylated product.
- Reductive alkylation to produce a substantially homogeneous population of mono- polymer/ NgR polypeptide generally includes the steps of: (a) reacting an NgRl polypeptide or polypeptide fragment of the invention with a reactive PEG molecule under reductive alkylation conditions, at a pH suitable to permit selective modification of the N-terminal amino group of NgR; and (b) obtaining the reaction product(s).
- the reductive alkylation reaction conditions are those that permit the selective attachment of the water- soluble polymer moiety to the N-terminus of an NgRl polypeptide or polypeptide fragment of the invention.
- Such reaction conditions generally provide for pKa differences between the lysine side chain amino groups and the N-terminal amino group.
- the pH is generally in the range of 3-9, typically 3-6.
- NgR polypeptides of the invention can include a tag, e.g., a moiety that can be subsequently released by proteolysis.
- the lysine moiety can be selectively modified by first reacting a His-tag modified with a low-molecular-weight linker such as Traut's reagent (Pierce Chemical Company, Rockford, IL) which will react with both the lysine and N-terminus, and then releasing the His tag.
- the polypeptide will then contain a free SH group that can be selectively modified with a PEG containing a thiol-reactive head group such as a maleimide group, a vinylsulfone group, a haloacetate group, or a free or protected SH.
- a thiol-reactive head group such as a maleimide group, a vinylsulfone group, a haloacetate group, or a free or protected SH.
- Traut's reagent can be replaced with any linker that will set up a specific site for PEG attachment.
- Traut's reagent can be replaced with SPDP, SMPT, SATA, or SATP (Pierce Chemical Company, Rockford, IL).
- SPDP Tinuclear Polypyruvate
- SMPT single-chain polypeptide
- SATA SATA
- SATP Sierce Chemical Company, Rockford, IL
- amine-reactive linker that inserts a maleimide (for example SMCC, AMAS, BMPS, MBS, EMCS, SMPB, SMPH, KMUS, or GMBS), a haloacetate group (SBAP, SIA, SLAB), or a vinylsulfone group and react the resulting product with a PEG that contains a free SH.
- a maleimide for example SMCC, AMAS, BMPS, MBS, EMCS, SMPB, SMPH, KMUS, or
- the polyalkylene glycol moiety is coupled to a cysteine group of the NgR polypeptide.
- Coupling can be effected using, e.g., a maleimide group, a vinylsulfone group, a haloacetate group, or a thiol group.
- the NgR polypeptide is conjugated to the polyethylene-glycol moiety through a labile bond.
- the labile 1 bond can be cleaved in, e.g., biochemical hydrolysis, proteolysis, or sulfhydryl cleavage.
- the bond can be cleaved under in vivo (physiological) conditions.
- the reactions may take place by any suitable method used for reacting biologically active materials with inert polymers, generally at about pH 5-8, e.g., pH 5, 6, 7, or 8, if the reactive groups are on the alpha amino group at the N-terminus.
- the process involves preparing an activated polymer and thereafter reacting the protein with the activated polymer to produce the soluble protein suitable for formulation.
- NgR polypeptides of the invention are soluble polypeptides. Methods for making a polypeptide soluble or improving the solubility of a polypeptide are well known in the art.
- the present invention provide a nucleic acid that encodes a polypeptide of the invention, including the polypeptides of any one of SEQ E) NOs: 1-9, 26-27, 29-37 and 41-45.
- the nucleic acid encodes a polypeptide selected from the group consisting of amino acid residues 26-344 of Nogo receptor-1 as shown in SEQ ID NOs: 6 and 8 or amino acid residues 27-344 of Nogo receptor-1 as shown in SEQ ED NO: 8.
- the nucleic acid molecule encodes a polypeptide selected from the group consisting of amino acid residues 26-310 of Nogo receptor-1 as shown in SEQ ID NOs: 7 and 9 or amino acid residues 27-310 of Nogo receptor-1 as shown in SEQ ID NO: 9.
- nucleic acid means genomic DNA, cDNA, mRNA and antisense molecules, as well as nucleic acids based on alternative backbones or including alternative bases whether derived from natural sources or synthesized.
- the nucleic acid further comprises a transcriptional promoter and optionally a signal sequence each of which is operably linked to the nucleotide sequence encoding the polypeptides of the invention.
- the invention provides a nucleic acid encoding a Nogo receptor-1 fusion protein of the invention, including a fusion protein comprising a polypeptide selected from the group consisting of amino acid residues 26-344 of Nogo receptor-1 as shown in SEQ ID NOs: 6 and 8 or amino acid residues 27-344 of SEQ ID NO: 8 and amino acid residues 26-310 of Nogo receptor-1 as shown in SEQ ID NOs: 7 and 9 or amino acid residues 27-310 of SEQ ID NO: 9.
- the nucleic acid encodes a Nogo receptor-1 fusion protein comprising a polypeptides selected from the group consisting of SEQ ID NOs: 26-27, 29-37 and 41-45.
- the nucleic acid encoding a Nogo receptor-1 fusion protein further comprises a transcriptional promoter and optionally a signal sequence.
- the nucleotide sequence further encodes an immunoglobulin constant region.
- the immunoglobulin constant region is a heavy chain constant region.
- the nucleotide sequence further encodes an immunoglobulin heavy chain constant region joined to a hinge region.
- the nucleic acid further encodes Fc.
- the Nogo receptor-1 fusion proteins comprise an Fc fragment.
- labels include, but are not limited to, biotin, radiolabeled nucleotides and the like. A skilled artisan can employ any of the art known labels to obtain a labeled encoding nucleic acid molecule.
- the present invention also includes polynucleotides that hybridize under moderately stringent or high stringency conditions to the noncoding strand, or complement, of a polynucleotide that encodes any one of the polypeptides of the invention.
- Stringent conditions are known to those skilled in the art and can be found in CURRENT PROTOCOLS IN MOLECULAR BIOLOGY, John Wiley & Sons, N.Y. (1989), 6.3.1-6.3.6.
- the human Nogo rece ⁇ tor-1 polynucleotide is shown below as SEQ ID NO:81.
- the rat Nogo receptor-1 polynucleotide is shown below as SEQ ID NO:82 and is accession number NM_053613 in Genbank. atgaagaggg cgtcctccgg aggaagccgg ctgccgacat gggtgttatg gctacaggcc tggagggtag caacgccctg ccctggtgcc tgtgtgtgct aoaatgagcc caaggtcaca acaagccgccc cccagcaggg cctgcaggct gtacccgctg gcatcccagc ctccagccag agaatcttcc tgcacggcaa ccgaatctct tacgtgccag ccgccagctttccagtcatgc cggaatctca cca cca
- the mouse Nogo receptor-1 polynucleotide is shown below as SEQ ID NO:83 and is accessionnumberNM_022982in Genbank. agccgcagcc cgcgagccca gcccggcccg gtagagcgga gcgccggagc ctcgtcccgc ggccgggccg ggaccgggcc ggagcagcgg cgctggatg cggacccggc cgcgcgcgcaga cgggcgcccgcgcgaagccgcgcccgaagcgcgcgc c ⁇ cgctcgac ccgaagatg aagagggcgt cctccggagg aagcaggctg ctggcatggg tgttatggct aca
- the human Nogo receptor-2 polynucleotide is shown below as SEQ ID NO:84 and is accessionnumber BK001302 in Genbank. atgctgcccg ggctcaggcg cctgctgcaa gctccct cggcctgcct cctgctgatg ctccctggccc tgcccctggc ggccccagc tgctgcacctg ctactcatcc ccgcccaccg tgagctgcca ggccaacaac ttctcctctg tgcctgcaccc agcactcagc gactcttcctgctgctgccaccc agcactcagc gactcttcct gcagaacaac ctcatccgca cgctgcggcc
- the human Nogo receptor-3 polynucleotide is shown below as SEQ ID NO:86 and is accession numberBKOO1305 in Genbank.
- atgcttcgca aagggtgctg tgtggagttg ctgcfcgctgt tggtagctgc ggagctgccc ctgggtggtg gctgcccacg ggactgtgtg tg tgctacccgg cgcccatgac ggtcagctgc caggcgcaca actttgcagc catcccggag ggcatcccg tggacagcga gcgcgtctc ctgcagaaca accgcatcgg cctctccag cccggccact tcagccccccatggtcacc ctgtggatct act
- the mouse Nogo receptor-3 polynucleotide is shown below as SEQ ID NO:87 and is accession number BKOOl 304 in Genbank.
- atgcttcgca aagggtgctg tgtggaattg ctgctgttgc tgctcgctgg agagctacct ctgggtggtg gttgtcctcg agactgtgtg tg tgctaccctg cgcccatgac tgtcagctgc caggcacaca actttgctgc catcccggag ggcatcccag aggacagtgtga gcgcatcttc ctgcagaaca atcgcatcac cttcctccag cagggccact ttcagccccgc catggtcacc ctggatct act
- NgRl polynucleotide antagonists which prevent expression of NgRl (knockdown).
- NgRl polynucleotide antagonists include, but are not limited to antisense molecules, ribozymes, siRNA, shRNA and RNAi.
- binding molecules are separately administered to the animal (see, for example, O'Connor, J. Neurochem. 56:560 (1991), but such binding molecules may also be expressed in vivo from polynucleotides taken up by a host cell and expressed in vivo. See also Oligodeoxynucleotides as Antisense Inhibitors of Gene Expression, CRC Press, Boca Raton, FL (1988).
- RNAi RNA interference
- RNAi refers to the expression of an RNA which interferes with the expression of the targeted mRNA.
- RNAi is a phenomenon in which the introduction of double-stranded RNA (dsRNA) into a cell causes degradation of the homologous mRNA.
- dsRNA double-stranded RNA
- An "RNAi nucleic acid” as used herein is a nucleic acid sequence generally shorter than 50 nucleotides in length, that causes gene silencing at the mRNA level.
- RNA interference provides a mechanism of gene silencing at the mRNA level.
- dsRNA double- stranded RNAs
- RNAi technology can be used for therapeutic purposes.
- RNAi targeting Fas-mediated apoptosis has been shown to protect mice from fulminant hepatitis.
- RNAi technology has been disclosed in numerous publications, such as U.S. Pat. Nos. 5,919,619, 6,506,559 and PCT Publication Nos. WO99/14346, WO01/70949, WO01/36646, WO00/63364, WO00/44895, WO01/75164, WO01/92513, WO01/68836 and WO01/29058.
- RNAi silences a targeted gene via interacting with the specific mRNA
- RNAi molecules include Short hairpin RNA (shRNA); also short interfering hairpin.
- shRNA Short hairpin RNA
- the shRNA molecule contains sense and antisense sequences from a target gene connected by a loop. The shRNA is transported from the nucleus into the cytoplasm, it is degraded along with the mRNA.
- Pol III or V6 promoters can be used to express RNAs for RNAi.
- a sequence capable of inhibiting gene expression by RNA interference can have any length. For instance, the sequence can have at least 10, 15, 20, 25, 30, 35, ' 40, 45, 50, 100 or more consecutive nucleotides.
- the sequence can be dsRNA or any other type of polynucleotide, provided that the sequence can form a functional silencing complex to degrade the target mRNA transcript.
- RNAi is mediated by double stranded RNA (dsRNA) molecules that have sequence- specific homology to their "target" mRNAs (Caplen et al, Proc Natl Acad Sci USA £5:9742-9747, 2001). Biochemical studies in Drosophila cell-free lysates indicates that the mediators of RNA- dependent gene silencing are 18-25 nucleotide "small interfering" RNA duplexes (siRNAs). Accordingly, siRNA molecules are advantageously used in the methods of the present invention. siRNAs can be produced endogenously by degradation of longer dsRNA molecules by an RNase Ill- related nuclease called Dicer.
- Dicer RNase Ill- related nuclease
- siRNAs can also be introduced into a cell exogeno ⁇ sly, or by transcription of an expression construct. Once formed, the siRNAs assemble with protein components into endoribonuclease-containing complexes known as RNA- induced silencing complexes (RISCs). An ATP-generated unwinding of the siRNA activates the RISCs, which in turn target the complementary mRNA transcript by Watson-Crick base-pairing.
- RISCs RNA- induced silencing complexes
- a RISC is guided to a target mRNA, where the siRNA duplex interacts sequence-specifically to mediate cleavage in a catalytic fashion (Bernstein et al, Nature 409:363-366, 2001; Boutla et al, Curr Biol J 1:1776-1780, 2001). Cleavage of the mRNA takes place near the middle of the region bound by the siRNA strand. This sequence specific mRNA degradation results in gene silencing.
- RNAi has been used to analyze gene function and to identify essential genes in mammalian cells (Elbashir et al, Methods 26:199-213, 2002; Harborth et al, J Cell Sci 114:4557-4565, 2001), including by way of non-limiting example neurons (Krichevsky et al, Proc Natl Acad Sci USA 99:11926-11929, 2002).
- RNAi is also being evaluated for therapeutic modalities, such as inhibiting or blocking the infection, replication and/or growth of viruses, including without limitation poliovirus (Gitlin et al, Nature 418:379-380, 2002) and HIV (Capodici et al, J Immunol 169:5196-5201, 2002), and reducing expression of oncogenes (e.g., the bcr-abl gene; Scherr et al, Blood Sep 26 epub ahead of print, 2002).
- viruses including without limitation poliovirus (Gitlin et al, Nature 418:379-380, 2002) and HIV (Capodici et al, J Immunol 169:5196-5201, 2002), and reducing expression of oncogenes (e.g., the bcr-abl gene; Scherr et al, Blood Sep 26 epub ahead of print, 2002).
- RNAi has been used to modulate gene expression in mammalian (mouse) and amphibian (Xenopus) embryos (respectively, Calegari et al, Proc Natl Acad Sci USA 99: 14236-14240, 2002; and Zhou, et al, Nucleic Acids Res 30:1664-1669, 2002), and in postnatal mice (Lewis et al, Nat Genet 32:107-108, 2002), and to reduce trangsene expression in adult transgenic mice (McCaffrey etal, Nature 418:38-39, 2002).
- RNAi molecules that mediate RNAi, including without limitation siRNA
- chemical synthesis Hohjoh, FEBS Lett 527:195-199, 2002
- hydrolysis of dsRNA Yang et al, Proc Natl Acad Sci USA 99:9942-9947, 2002
- T7 RNA polymerase T7 RNA polymerase
- siRNA molecules may also be formed by annealing two oligonucleotides to each other, typically have the following general structure, which includes both double-stranded and single-stranded portions:
- N, X and Y are nucleotides; X hydrogen bonds to Y; ":" signifies a hydrogen bond between two bases; x is a natural integer having a value between 1 and about 100; and m and n are whole integers having, independently, values between 0 and about 100.
- N, X and Y are independently A, G, C and T or U.
- Non-naturally occurring bases and nucleotides can be present, particularly in the case of synthetic siRNA (i.e., the product of annealing two oligonucleotides).
- the double-stranded central section is called the "core” and has base pairs (bp) as units of measurement; the single-stranded portions are overhangs, having nucleotides (nt) as units of measurement.
- the overhangs shown are 3' overhangs, but molecules with 5' overhangs are also within the scope of the invention.
- RNAi technology did not appear to be readily applicable to mammalian systems. This is because, in mammals, dsRNA activates dsRNA-activated protein kinase (PKR) resulting in an apoptotic cascade and cell death (Der et al., Proc. Natl. Acad. Sci. USA 94:3279-3283, 1997). In addition, it has long been known that dsRNA activates the interferon cascade in mammalian cells, which can also lead to altered cell physiology (Colby et al., Annu. Rev. Microbiol. 25:333, 1971; Kleinschmidt et al., Annu. Rev. Biochem.
- dsRNA-mediated activation of the PElR and interferon cascades requires dsRNA longer than about 30 base pairs.
- dsRNA less than 30 base pairs in length has been demonstrated to cause RNAi in mammalian cells (Caplen et al., Proc. Natl. Acad. Sci. USA P5:9742-9747, 2001).
- it is expected that undesirable, non-specific effects associated with longer dsRNA molecules can be avoided by preparing short RNA that is substantially free from longer dsRNAs.
- shRNA short hairpin RNA
- the length of the stem and loop of functional shRNAs varies; stem lengths can range anywhere from about 25 to about 30 nt, and loop size can range between 4 to about 25 nt without affecting silencing activity. While not wishing to be bound by any particular theory, it is believed that these shRNAs resemble the dsRNA products of the DICER RNase and, in any event, have the same capacity for inhibiting expression of a specific gene.
- the invention provides that that siRNA or the shRNA inhibits
- the invention further provides that the siRNA or shRNA is at least 80%, 90%, or 95% identical to the nucleotide sequence comprising: CUACUUCUCCCGCAGGCG (SEQ DD NO:52) or CCCGGACCGACGUCUUCAA (SEQ ID NO:54) or CUGACCACUGAGUCUUCCG (SEQ ID NO:56).
- the siRNA or shRNA nucleotide sequence is CUACUUCUCCCGCAGGCG (SEQ ID NO.52) or CCCGGACCGACGUCUUCAA (SEQ ID NO: 54) or CUGACCACUGAGUCUUCCG (SEQ ID NO:56).
- the invention further provides that the siRNA or shRNA nucleotide sequence is complementary to the mRNA produced by the polynucleotide sequence GATGAAGAGGGCGTCC GCT (SEQ ID NO:53) or GGGCCTGGCTGCAGAAGTT (SEQ ID NO:55) or GACTGGTGACTCAGAG AAGGC (SEQ ID NO:57).
- the shRNA is expressed from a lentiviral vector as described in Example 26.
- nucleic acid molecules with modifications can prevent their degradation by serum ribonucleases, which can increase their potency (see e.g., Eckstein et al, International Publication No. WO 92/07065; Perrault et al, Nature 344:565 (1990); Pieken et al, Science 253:314 (1991); Usman and Cedergren, Trends in Biochem. Sci. 77:334 (1992); Usman et al, International Publication No. WO 93/15187; and Rossi et al, International Publication No. WO 91/03162; Sproat, U.S. Pat. No.
- oligonucleotides are modified to enhance stability and/or enhance biological activity by modification with nuclease resistant groups, for example, 2'-amino, 2'-C-allyl, 2'-flouro, 2'-O-
- the invention features modified siRNA molecules, with phosphate backbone modifications comprising one or more phosphorothioate, phosphorodithioate, methylphosphonate, phosphotriester, morph ' olino, amidate carbamate, carboxymethyl, acetamidate, polyamide, sulfonate, sulfonamide, sulfamate, formacetal, thioformacetal, and/or alkylsilyl, substitutions.
- siRNA molecules having chemical modifications that maintain or enhance activity are provided.
- Such a nucleic acid is also generally more resistant to nucleases than an unmodified nucleic acid. Accordingly, the in vitro and/or in vivo activity should not be significantly lowered.
- therapeutic nucleic acid molecules delivered exogenously should optimally be stable within cells until translation of the target RNA has been modulated long enough to reduce the levels of the undesirable protein. This period of time varies between hours to days depending upon the disease state. Improvements in the chemical synthesis of RNA and DNA (Wincott et al, Nucleic Acids
- Polynucleotides of the present invention can include one or more (e.g., about 1, 2, 3, 4, 5,
- G-clamp nucleotides 6, 7, 8, 9, 10, or more G-clamp nucleotides.
- a G-clamp nucleotide is a modified cytosine analog wherein the modifications confer the ability to hydrogen bond both Watson-Crick and Hoogsteen faces of a complementary guanine within a duplex, see, e.g., Lin and Matteucci, J. Am. Chem. Soc. 120:8531- 8532 (1998).
- a single G-clamp analog substitution within an oligonucleotide can result in substantially enhanced helical thermal stability and mismatch discrimination when hybridized to complementary oligonucleotides.
- Polynucleotides of the present invention can also include one or more (e.g., about 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, or more) LNA "locked nucleic acid" nucleotides such as a 2', 4'-C mythylene bicyclo nucleotide (see, e.g., Wengel et al, International PCT Publication No. WO 00/66604 and WO 99/14226).
- LNA "locked nucleic acid" nucleotides such as a 2', 4'-C mythylene bicyclo nucleotide (see, e.g., Wengel et al, International PCT Publication No. WO 00/66604 and WO 99/14226).
- the present invention also features conjugates and/or complexes of siRNA molecules of the invention.
- conjugates and/or complexes can be used to facilitate delivery of siRNA molecules into a biological system, such as a cell.
- the conjugates and complexes provided by the instant invention can impart therapeutic activity by transferring therapeutic compounds across cellular membranes, altering the pharmacokinetics, and/or modulating the localization of nucleic acid molecules of the invention.
- the present invention encompasses the design and synthesis of novel conjugates and complexes for the delivery of molecules, including, but not limited to, small molecules, lipids, phospholipids, nucleosides, nucleotides, nucleic acids, antibodies, toxins, negatively charged polymers and other polymers, for example proteins, peptides, hormones, carbohydrates, polyethylene glycols, or polyamines, across cellular membranes.
- the transporters described are designed to be used either individually or as part of a multi-component system, with or without degradable linkers. These compounds are expected to improve delivery and/or localization of nucleic acid molecules of the invention into a number of cell types originating from different tissues, in the presence or absence of serum (see Sullenger and Cech, U.S. Pat. No. 5,854,038). Conjugates of the molecules described herein can be attached to biologically active molecules via linkers that are biodegradable, such as biodegradable nucleic acid linker molecules.
- Therapeutic polynucleotides e.g., siRNA molecules
- delivered exogenously optimally are stable within cells until reverse trascription of the RNA has been modulated long enough to reduce the levels of the RNA transcript.
- the nucleic acid molecules are resistant to nucleases in order to function as effective intracellular therapeutic agents. Improvements in the chemical synthesis of nucleic acid molecules described in the instant invention and in the art have expanded the ability to modify nucleic acid molecules by introducing nucleotide modifications to enhance their nuclease stability as described above.
- the present invention also provides for siRNA molecules having chemical modifications that maintain or enhance enzymatic activity of proteins involved in RNAi.
- Such nucleic acids are also generally more resistant to nucleases than unmodified nucleic acids. Thus, in vitro and/or in vivo the activity should not be significantly lowered.
- a siRNA molecule of the invention can comprise one or more 5' and/or a 3'-cap structures, for example on only the sense siRNA strand, antisense siRNA strand, or both siRNA strands.
- cap structure is meant chemical modifications, which have been incorporated at either terminus of the oligonucleotide ( ⁇ ee,for example, Adamic et ah, U.S. Pat. No. 5,998,203, incorporated by reference herein). These terminal modifications protect the nucleic acid molecule from exonuclease degradation, and may help in delivery and/or localization within a cell.
- the cap may be present at the 5'-terrninus (5 1 - cap) or at the 3'-terminal (3'-cap) or may be present on both termini.
- the 5'-cap is selected from the group comprising inverted abasic residue (moiety); 4 1 ,5'-methylene nucleotide; 1- (beta-D-erythrofiiranosyl) nucleotide, 4'-thio nucleotide; carbocyclic nucleotide; 1,5-anhydrohexitol nucleotide; L-nucleotides; alpha-nucleotides; modified base nucleotide; phosphorodithioate linkage; threo-pentofuranosyl nucleotide; acyclic 3',4'-seco nucleotide; acyclic 3,4-dihydroxybutyl nucleotide; acyclic 3,5-dihydroxypentyl nucleotide, 3 '-3 '-inverted nucleotide moiety; 3 '-3 '-inverted abasic moiety; 3'- 2
- the 3 '-cap can be selected from a group comprising, 4',5 '-methylene nucleotide; l-(beta-
- D-erythrofuranosyl) nucleotide 4'-thio nucleotide, carbocyclic nucleotide; 5'-amino-alkyl phosphate; 1,3- diamino-2 -propyl phosphate; 3-aminopropyl phosphate; 6-aminohexyl phosphate; 1 ,2-a ⁇ ninododecyl phosphate; hydroxypropyl phosphate; 1,5-anhydrohexitol nucleotide; L-nucleotide; alpha-nucleotide; modified base nucleotide; phosphorodithioate; threo-pentofuranosyl nucleotide; acyclic 3',4'-seco nucleotide; 3,4-dihydroxybutyl nucleotide; 3,5-dihydroxypentyl nucleotide, 5'-5'-inverted nucleotide moiety; 5'-5'
- nucleic acid siRNA structure can be made to enhance the utility of these molecules. Such modifications will enhance shelf-life, half-life in vitro, stability, and ease of introduction of such oligonucleotides to the target site, e.g., to enhance penetration of cellular membranes, and confer the ability to recognize and bind to targeted cells.
- Antisense technology can be used to control gene expression through antisense DNA or
- RNA or through triple-helix formation.
- Antisense techniques are discussed for example, in Okano, J. Neurochem. 56:560 (1991); Oligodeoxynucleotides as Antisense Inhibitors of Gene Expression, CRC Press, Boca Raton, FL (1988). Triple helix formation is discussed in, for instance, Lee et al., Nucleic Acids Research 10-1573 (1979); Cooney et al., Science 241:456 (1988); and Dervan et al, Science 257:1300 (1991). The methods are based on binding of a polynucleotide to a complementary DNA or RNA.
- the 5' coding portion of a polynucleotide that encodes NgRl may be used to design an antisense RNA oligonucleotide of from about 10 to 40 base pairs in length.
- a DNA oligonucleotide is designed to be complementary to a region of the gene involved in transcription thereby preventing transcription and the production of the target protein.
- the antisense RNA oligonucleotide hybridizes to the mRNA in vivo and blocks translation of the mRNA molecule into the target polypeptide.
- antisense nucleic acids specific for the NgRl gene are produced intracellularly by transcription from an exogenous sequence.
- a vector or a portion thereof is transcribed, producing an antisense nucleic acid (RNA).
- RNA antisense nucleic acid
- Such a vector can remain episomal or become chromosomally integrated, as long as it can be transcribed to produce the desired antisense RNA.
- Such vectors can be constructed by recombinant DNA technology methods standard in the art.
- Vectors can be plasmid, viral, or others known in the art, used for replication and expression in vertebrate cells. Expression of the antisense molecule, can be by any promoter known in the art to act in vertebrate, preferably human cells, such as those described elsewhere herein.
- Absolute complementarity of an antisense molecule is not required.
- a sequence complementary to at least a portion of an RNA encoding NgRl means a sequence having sufficient complementarity to be able to hybridize with the RNA, forming a stable duplex; or triplex formation may be assayed.
- the ability to hybridize will depend on both the degree of complementarity and the length of the antisense nucleic acid. Generally, the larger the hybridizing nucleic acid, the more base mismatches it may contain and still form a stable duplex (or triplex as the case may be).
- One skilled in the art can ascertain a tolerable degree of mismatch by use of standard procedures to determine the melting point of the hybridized complex.
- Oligonucleotides that are complementary to the 5' end of a messenger RNA should work most efficiently at inhibiting translation.
- sequences complementary to the 3' untranslated sequences of mRNAs have been shown to be effective at inhibiting translation of mRNAs as well. See generally, Wagner, R., Nature 372:333-335 (1994).
- oligonucleotides complementary to either the 5'- or 3'- non- translated, non-coding regions could be used in an antisense approach to inhibit translation of NgRl .
- Oligonucleotides complementary to the 5' untranslated region of the mRNA should include the complement of the AUG start codon.
- Antisense oligonucleotides complementary to mRNA coding regions are less efficient inhibitors of translation but could be used in accordance with the invention.
- Antisense nucleic acids should be at least six nucleotides in length, and are preferably oligonucleotides ranging from 6 to about 50 nucleotides in length. In specific aspects the oligonucleotide is at least 10 nucleotides, at least 17 nucleotides, at least 25 nucleotides or at least 50 nucleotides.
- Polynucleotides for use in the therapeutic methods disclosed herein, including aptamers described below, can be DNA or RNA or chimeric mixtures or derivatives or modified versions thereof, single-stranded or double-stranded.
- the oligonucleotide can be modified at the base moiety, sugar moiety, or phosphate backbone, for example, to improve stability of the molecule, hybridization, etc.
- the oligonucleotide may include other appended groups such as peptides (e.g., for targeting host cell receptors in vivo), or agents facilitating transport across the cell membrane (see, e.g., Letsinger et al., Proc. Natl. Acad. ScL U.S.A.
- the oligonucleotide may be conjugated to another molecule, e.g., a peptide, hybridization triggered cross-linking agent, transport agent, hybridization- triggered cleavage agent, etc.
- An antisense oligonucleotide for use in the therapeutic methods disclosed herein may comprise at least one modified base moiety which is selected from the group including, but not limited to, 5-fluorouracil, 5-bromouracil, 5-chlorouracil, 5-iodouracil, hypoxanthine, xantine, 4-acetylcytosine, 5-(carboxyhydroxylmethyl) uracil, 5-carboxymethylaminomethyl-2-thiouridine, 5- carboxymethylaminomethyluracil, dihydrouracil, beta-D-galactosylqueosine, inosine, N-6- isopentenyladenine, 1-methylguanine, 1-methylinosine, 2,2-dimethylguanine, 2-methyladenine, 2- methylguanine, 3-methylcytosine, 5-methylcytosine, N-6-adenine, 7-methylguanine, 5- methylaminomethyluracil, 5-methoxyaminomethyl-2-thi
- 5'methoxycarboxymethyluracil 5-methoxyuracil, 2-rnethylthio-N-6-isopentenyladenine, uracil-5- oxyacetic acid (v), wybutoxosine, pseudouracil, queosine, 2-thiocytosine, 5-methyl-2-thiouracil, 2- thiouracil, 4-thiouracil, 5-methyluracil, uracil-5-oxyacetic acid methylester, uracil-5-oxyacetic acid (v), 5-methyl-2-thiouracil, 3(3-amino-3-N2-carboxypropyl) uracil, (acp3)w, and 2,6-diaminopurine.
- An antisense oligonucleotide for use in the therapeutic methods disclosed herein may also comprise at least one modified sugar moiety selected from the group including, but not limited to, arabinose, 2-fluoroarabinose, xylulose, and hexose.
- an antisense oligonucleotide for use in the therapeutic methods disclosed herein comprises at least one modified phosphate backbone selected from the group including, but not limited to, a phosphorothioate, a phosphorodithioate, a phosphoramidothioate, a phosphoramidate, a phosphordiamidate, a methylphosphonate, an alkyl phosphotriester, and a formacetal or analog thereof.
- an antisense oligonucleotide for use in the therapeutic methods disclosed herein is an ⁇ -anomeric oligonucleotide.
- oligonucleotide forms specific double-stranded hybrids with complementary RNA in which, contrary to the usual situation, the strands run parallel to each other (Gautier et at., Nucl. Acids Res. 75:6625-6641(1987)).
- the oligonucleotide is a 2'-0-methylribonucleotide (Inoue et al., Nucl. Acids Res. 75:6131-6148(1987)), or a chimeric RNA-DNA analogue (Inoue et al., FEBS Lett. 275:327-330(1987)).
- Polynucleotides of the invention including aptamers may be synthesized by standard methods known in the art, e.g. by use of an automated DNA synthesizer (such as are commercially available from Biosearch, Applied Biosystems, etc.).
- an automated DNA synthesizer such as are commercially available from Biosearch, Applied Biosystems, etc.
- phosphorothioate oligonucleotides may be synthesized by the method of Stein et al, Nucl. Acids Res. 16:3209 (1988)
- methylphosphonate oligonucleotides can be prepared by use of controlled pore glass polymer supports (Sarin et al., Proc. Natl. Acad. ScL U.S.A. 55:7448-7451(1988)), etc.
- Polynucleotide compositions for use in the therapeutic methods disclosed herein further include catalytic RNA, or a ribozyme ⁇ See, e.g., PCT International Publication WO 90/11364, published October 4, 1990; Sarver et al., Science 247:1222-1225 (1990).
- the use of hammerhead ribozymes is preferred. Hammerhead ribozymes cleave rnRNAs at locations dictated by flanking regions that form complementary base pairs with the target mRNA. The sole requirement is that the target mRNA have the following sequence of two bases: 5'-UG-3'.
- ribozyme is engineered so that the cleavage recognition site is located near the 5' end of the target mRNA; i.e., to increase efficiency and minimize the intracellular accumulation of nonfunctional mRNA transcripts.
- ribozymes for use in the diagnostic and therapeutic methods disclosed herein can be composed of modified oligonucleotides (e.g. for improved stability, targeting, etc.) and may be delivered to cells which express NgRl in vivo.
- DNA constructs encoding the ribozyme may be introduced into the cell in the same manner as described above for the introduction of antisense encoding DNA.
- a preferred method of delivery involves using a DNA construct "encoding" the ribozyme under the control of a strong constitutive promoter, such as, for example, pol IH or pol II promoter, so that transfected cells will produce sufficient quantities of the ribozyme to destroy endogenous NgRl messages and inhibit translation. Since ribozymes unlike antisense molecules, are catalytic, a lower intracellular concentration is required for efficiency.
- the NgRl antagonist for use in the methods of the present invention is an aptamer.
- An aptamer can be a nucleotide or a polypeptide which has a unique sequence, has the property of binding specifically to a desired target (e.gv, a polypeptide), and is a specific ligand of a given target.
- Nucleotide aptamers of the invention include double stranded DNA and single stranded RNA molecules that bind to NgRl .
- Nucleic acid aptamers are selected using methods known in the art, for example via the
- SELEX Systematic Evolution of Ligands by Exponential Enrichment
- SELEX is a method for the in vitro evolution of nucleic acid molecules with highly specific binding to target molecules as described in e.g. U.S. Pat. Nos. 5,475,096, 5,580,737, 5,567,588, 5,707,796, 5,763,177, 6, 011,577, and 6,699,843, incorporated herein by reference in their entirety.
- Another screening method to identify aptamers is described in U.S. Pat. No. 5,270,163 (also incorporated herein by reference).
- the SELEX process is based on the capacity of nucleic acids for forming a variety of two- and three- dimensional structures, as well as the chemical versatility available within the nucleotide monomers to act as ligands (form specific binding pairs) with virtually any chemical compound, whether monomelic or polymeric, including other nucleic acid molecules and polypeptides. Molecules of any size or composition can serve as targets.
- the SELEX method involves selection from a mixture of candidate oligonucleotides and step-wise iterations of binding, partitioning and amplification, using the same general selection scheme, to achieve desired binding affinity and selectivity.
- the SELEX method includes steps of contacting the mixture with the target under conditions favorable for binding; partitioning unbound nucleic acids from those nucleic acids which have bound specifically to target molecules; dissociating the nucleic acid-target complexes; amplifying the nucleic acids dissociated from the nucleic acid-target complexes to yield a ligand enriched mixture of nucleic acids.
- the steps of binding, partitioning, dissociating and amplifying are repeated through as many cycles as desired to yield highly specific high affinity nucleic acid ligands to the target molecule.
- Nucleotide aptamers may be used, for example, as diagnostic tools or as specific inhibitors to dissect intracellular signaling and transport pathways (James (2001) Curr. Opin. Pharmacol. 1:540-546). The high affinity and specificity of nucleotide aptamers makes them good candidates for drug discovery. For example, aptamer antagonists to the toxin ricin have been isolated and have IC50 values in the nanomolar range (Hesselberth JR et al. (2000) J Biol Chem 275:4937-4942). Nucleotide aptamers may also be used against infectious disease, malignancy and viral surface proteins to reduce cellular infectivity.
- Nucleotide aptamers for use in the methods of the present invention may be modified
- SELEX process would allow for the identification of aptamers that inhibit NgRl -mediated processes (e.g., NgRl -mediated inhibition of axonal regeneration).
- Polypeptide aptamers for use in the methods of the present invention are random peptides selected for their ability to bind to and thereby block the action of NgRl.
- Polypeptide aptamers may include a short variable peptide domain attached at both ends to a protein scaffold. This double structural constraint greatly increases the binding affinity of the peptide aptamer to levels comparable to an antibody's (nanomolar range). See, e.g., Hoppe-Seyler F et al. (2000) J MoI Med 7 ⁇ ?(8):426-430.
- the length of the short variable peptide is typically about 10 to 20 amino acids, and the scaffold may be any protein which has good solubility and compacity properties.
- a scaffold protein is the bacterial protein Thioredoxin-A. See, e.g., Cohen BA et al. (1998) PNAS 95(24): 14272- 14277.
- Polypeptide aptamers are peptides or small polypeptides that act as dominant inhibitors of protein function. Peptide aptamers specifically bind to target proteins, blocking their functional ability (Kolonin et al. (1998) Proc. Natl. Acad. Sd. 95: 14,266-14,271). Peptide aptamers that bind with high affinity and specificity to a target protein can be isolated by a variety of techniques known in the art. Peptide aptamers can be isolated from random peptide libraries by yeast two-hybrid screens (Xu, C.W., et al. (1997) Proc. Natl. Acad.
- peptide aptamers Although the difficult means by which peptide aptamers are synthesized makes their use more complex than polynucleotide aptamers, they have unlimited chemical diversity. Polynucleotide aptamers are limited because they utilize only the four nucleotide bases, while peptide aptamers would have a much-expanded repertoire (i.e., 20 amino acids).
- Peptide aptamers for use in the methods of the present invention may be modified (e.g., conjugated to polymers or fused to proteins) as described for other polypeptides elsewhere herein.
- the invention provides compositions comprising a polypeptide selected from the group consisting of SEQ ID NOs: 1-5, 26-27, 29-37 and 41-45.
- the invention provides compositions comprising an anti-Nogo receptor-1 antibody or an antigen-binding fragment thereof, or a soluble Nogo receptor-1 polypeptide or fusion protein of the present invention.
- the invention provides a composition comprising a polynucleotide of the present invention.
- the invention provides compositions comprising a polypeptide of the present invention and an anti-inflammatory agent.
- the present invention • may contain suitable pharmaceutically acceptable carriers comprising excipients and auxiliaries which facilitate processing of the active compounds into preparations which can be used pharmaceutically for delivery to the site of action.
- Suitable formulations for parenteral administration include aqueous solutions of the active compounds in water-soluble form, for example, water-soluble salts.
- suspensions of the active compounds as appropriate oily injection suspensions may be administered.
- Suitable lipophilic solvents or vehicles include fatty oils, for example, sesame oil, or synthetic fatty acid esters, for example, ethyl oleate or triglycerides.
- Aqueous injection suspensions may contain substances which increase the viscosity of the suspension include, for example, sodium carboxymethyl cellulose, sorbitol and dextran.
- the suspension may also contain stabilizers. Liposomes can also be used to encapsulate the molecules of this invention for delivery into the cell.
- compositions comprise isotonic agents, for example, sugars, polyalcohols such as mannitol, sorbitol, or sodium chloride.
- compositions comprise pharmaceutically acceptable substances such as wetting or minor amounts of auxiliary substances such as wetting or emulsifying agents, preservatives or buffers, which enhance the shelf life or effectiveness of the antibodies, antigen- binding fragments, soluble Nogo receptors or fusion proteins of the invention.
- pharmaceutically acceptable substances such as wetting or minor amounts of auxiliary substances such as wetting or emulsifying agents, preservatives or buffers, which enhance the shelf life or effectiveness of the antibodies, antigen- binding fragments, soluble Nogo receptors or fusion proteins of the invention.
- compositions of the invention may be in a variety of forms, including, for example, liquid, semi -solid and solid dosage forms, such as liquid solutions ⁇ e.g., injectable and infusible solutions), dispersions or suspensions.
- liquid solutions ⁇ e.g., injectable and infusible solutions
- dispersions or suspensions The preferred form depends on the intended mode of administration and therapeutic application.
- compositions are in the form of injectable or infusible solutions, such as compositions similar to those used for passive immunization of humans with other antibodies.
- the composition can be formulated as a solution, micro emulsion, dispersion, liposome, or other ordered structure suitable to high drug concentration.
- Sterile injectable solutions can be prepared by incorporating an anti-Nogo receptor- 1 antibody in the required amount in an appropriate solvent with one or a combination of ingredients enumerated above, as required, followed by filtered sterilization.
- dispersions are prepared by incorporating the active compound into a sterile vehicle that contains a basic dispersion medium and the required other ingredients from those enumerated above.
- the preferred methods of preparation are vacuum drying and freeze-drying that yields a powder of the active ingredient plus any additional desired ingredient from a previously sterile-filtered solution thereof.
- the proper fluidity of a solution can be maintained, for example, by the use of a coating such as lecithin, by the maintenance of the required particle size in the case of dispersion and by the use of surfactants.
- Prolonged absorption of injectable compositions can be brought about by including in the composition an agent that delays absorption, for example, monostearate salts and gelatin.
- the active compound may be prepared with a carrier that will protect the compound against rapid release, such as a controlled release formulation, including implants, transdermal patches, and microencapsulated delivery systems.
- a controlled release formulation including implants, transdermal patches, and microencapsulated delivery systems.
- Biodegradable, biocompatible polymers can be used, such as ethylene vinyl acetate, polyanhydrides, polyglycolic acid, collagen, polyorthoesters, and polylactic acid. Many methods for the preparation of such formulations are patented or generally known to those skilled in the art. See e.g., Sustained and Controlled Release Drug Delivery Systems, J. R. Robinson, ed., Marcel Dekker, Inc., New York (1978).
- Supplementary active compounds also can be incorporated into the compositions.
- a Nogo receptor- 1 antibody or an antigen-binding fragments thereof, or soluble Nogo receptor- 1 polypeptides or fiision proteins of the invention are coformulated with and/or coadministered with one or more additional therapeutic agents, including, for example, an antiinflammatory agent.
- the anti-inflammatory agent is a non-steroidal antiinflammatory agent.
- the anti-inflammatory agent is a steroidal antiinflammatory agent.
- the anti-inflammatory agent is methylprednisolone.
- the present invention is directed to the use of a Nogo receptor antagonist in combination with a non-steroidal anti-inflammatory agent (NSAID), prodrug esters or pharmaceutically acceptable salts thereof.
- NSAIDs which are well-known in the art include propionic acid derivatives (e.g., alminoprofen, benoxaprofen, bucloxic acid, carprofen, fenbufen, fenoprofen, fluprofen, flurbiprofen, ibuprofen, indoprofen, ketoprofen, miroprofen, naproxen, oxaprozin, pirprofen, pranoprofen, suprofen, tiaprofenic acid and tioxaprofen), acetic acid derivatives (e.g., indomethacin, acemetacin, alclofenac, clidanac, diclofenac, fenclofe
- the present invention is directed to the use of a Nogo receptor antagonist in combination with any of one or more steroidal anti-inflammatory agents such as corticosteroids, prodrug esters or pharmaceutically acceptable salts thereof.
- steroidal agents include hydrocortisone and compounds which are derived from hydrocortisone, such as 21-acetoxypregnenolone, alclomerasone, algestone, amcinonide, beclomethasone, betamethasone, betamethasone valerate, budesonide, chloroprednisone, clobetasol, clobetasol propionate, clobetasone, clobetasone butyrate, clocortolone, cloprednol, corticosterone, cortisone, cortivazol, deflazacon, desonide, desoximerasone, dexamethasone, diflorasone, diflucortol
- the pharmaceutical compositions of the invention may include a "therapeutically effective amount” or a “prophylactically effective amount” of an antibody, antigen-binding fragment, polypeptide(s), or fusion protein of the invention.
- a “therapeutically effective amount” refers to an amount effective, at dosages and for periods of time necessary, to achieve the desired therapeutic result.
- a therapeutically effective amount of the Nogo receptor-1 antibody or antigen-binding fragment thereof, soluble Nogo receptor-1 polypeptide or Nogo receptor fusion protein may vary according to factors such as the disease state, age, sex, and weight of the individual.
- a therapeutically effective amount is also one in which any toxic or detrimental effects of the antibody, antigen-binding fragment, soluble Nogo receptor-1 polypeptide or Nogo receptor fusion protein are outweighed by the therapeutically beneficial effects.
- a “prophylactically effective amount” refers to an amount effective, at dosages and for periods of time necessary, to achieve the desired prophylactic result. Typically, since a prophylactic dose is used in subjects prior to or at an earlier stage of disease, the prophylactically effective amount will be less than the therapeutically effective amount.
- Dosage regimens may be adjusted to provide the optimum desired response (e.g., a therapeutic or prophylactic response). For example, a single bolus may be administered, several divided doses may be administered over time or the dose may be proportionally reduced or increased as indicated by the exigencies of the therapeutic situation. It is especially advantageous to formulate parenteral compositions in dosage unit form for ease of administration and uniformity of dosage unit form as used herein refers to physically discrete units suited as unitary dosages for the mammalian subjects to be treated, each unit containing a predetermined quantity of active compound calculated to produce the desired therapeutic effect in association with the required pharmaceutical carrier.
- a therapeutically effective dose range for Nogo receptor-1 antibodies or antigen- binding fragments thereof is 0.1 — 4 mg/Kg per day. In some embodiments a therapeutically effective dose range for Nogo receptor-1 antibodies or antigen-binding fragments thereof is 0.2 - 4 mg/Kg per day.
- a therapeutically effective dose range for Nogo receptor-1 antibodies or antigen- binding fragments thereof is 0.2 mg/Kg per day.
- the NgRl antagonists are generally administered directly to the nervous system, intracerebroventricularly, or intrathecally, e.g. into a chronic lesion of MS.
- Compositions for administration according to the methods of the invention can be formulated so that a dosage of 0.001 — 10 mg/kg body weight per day of the NgRl antagonist is administered. In some embodiments of the invention, the dosage is 0.01 - 1.0 mg/kg body weight per day. In some embodiments, the dosage is 0.001 - 0.5 mg/kg body weight per day.
- the dosage can range, e.g., from about 0.0001 to 100 mg/kg, and more usually 0.01 to 5 mg/kg (e.g., 0.02 mg/kg, 0.25 mg/kg, 0.5 mg/kg, 0.75 mg/kg, lmg/kg, 2 mg/kg, etc.), of the host body weight.
- dosages can be 1 mg/kg body weight or 10 mg/kg body weight or within the range of 1-10 mg/kg, preferably at least 1 mg/kg.
- Doses intermediate in the above ranges are also intended to be within the scope of the invention.
- Subjects can be administered such doses daily, on alternative days, weekly or according to any other schedule determined by empirical analysis.
- An exemplary treatment entails administration in multiple dosages over a prolonged period, for example, of at least six months. Additional exemplary treatment regimes entail administration once per every two weeks or once a month or once every 3 to 6 months. Exemplary dosage schedules include 1-10 mg/kg or 15 mg/kg on consecutive days, 30 mg/kg on alternate days or 60 mg/kg weekly.
- NgRl antagonists are administered simultaneously, in which case the dosage of each antagonist administered falls within the ranges indicated.
- Supplementary active compounds also can be incorporated into the compositions used in the methods of the invention.
- an NgRl antagonist may be coformulated with and/or coadministered with one or more additional therapeutic agents, such as an anti-inflammatory agent, for example, methylprednisolone.
- additional therapeutic agents such as an anti-inflammatory agent, for example, methylprednisolone.
- the invention encompasses any suitable delivery method for an NgRl antagonist to a selected target tissue, including bolus injection of an aqueous solution or implantation of a controlled- release system. Use of a controlled-release implant reduces the need for repeat injections.
- the NgRl antagonists used in the methods of the invention may be directly infused into the brain.
- Various implants for direct brain infusion of compounds are known and are effective in the delivery of therapeutic compounds to human patients suffering from neurological disorders. These include chronic infusion into the brain using a pump, stereotactically implanted, temporary interstitial catheters, permanent intracranial catheter implants, and surgically implanted biodegradable implants. See, e.g., Gill et ah, supra; Scharfen et ah, "High Activity Iodine-125 Interstitial Implant For Gliomas," Int. J. Radiation Oncology Biol. Phys.
- compositions may also comprise an NgRl antagonist of the invention dispersed in a biocompatible carrier material that functions as a suitable delivery or support system for the compounds.
- Suitable examples of sustained release carriers include semipermeable polymer matrices in the form of shaped articles such as suppositories or capsules.
- Implantable or microcapsular sustained release matrices include polylactides (U.S. Patent No.
- an NgRl antagonist of the invention is administered to a patient by direct infusion into an appropriate region of the brain. See, e.g., Gill et al., "Direct brain infusion of glial cell line-derived neurotrophic factor in Parkinson disease," Nature Med. 9: 589-95 (2003).
- Alternative techniques are available and may be applied to administer an NgR antagonist according to the invention. For example, stereotactic placement of a catheter or implant can be accomplished using the Riechert-Mundinger unit and the ZD (Zamorano-Dujovny) multipurpose localizing unit.
- a contrast- enhanced computerized tomography (CT) scan injecting 120 ml of omnipaque, 350 mg iodine/ml, with 2 mm slice thickness can allow three-dimensional multiplanar treatment planning (STP, Fischer, Freiburg, Germany). This equipment permits planning on the basis of magnetic resonance imaging studies, merging the CT and MRI target information for clear target confirmation.
- CT computerized tomography
- the Leksell stereotactic system (Downs Surgical, Inc., Decatur, GA) modified for use with a GE CT scanner (General Electric Company, Milwaukee, WI) as well as the Brown-Roberts-Wells (BRW) stereotactic system (Radionics, Burlington, MA) can be used for this purpose.
- a GE CT scanner General Electric Company, Milwaukee, WI
- BRW Brown-Roberts-Wells
- Radionics Burlington, MA
- serial CT sections can be obtained at 3 mm intervals though the (target tissue) region with a graphite rod localizer frame clamped to the base plate.
- a computerized treatment planning program can be run on a VAX 11/780 computer (Digital Equipment Corporation, Maynard, Mass.) using CT coordinates of the graphite rod images to map between CT space and BRW space.
- the invention provides methods for inhibiting Nogo receptor- 1 activity by administering anti-Nogo receptor- 1 antibodies, antigen-binding fragments of such antibodies, soluble Nogo receptor- 1 polypeptides, or fusion proteins comprising such polypeptides to a mammal in need thereof.
- the invention provides a method of inhibiting Nogo receptor-1 binding to a ligand, comprising the step of contacting Nogo receptor-1 with an antibody or antigen- binding fragment of this invention.
- the ligand is selected from the group consisting of NogoA, NogoB, NogoC, MAG and OM-gp.
- the invention provides a method for inhibiting growth cone collapse in a neuron, comprising the step of contacting the neuron with the antibody or antigen-binding fragment thereof of this invention. In some embodiments, the invention provides a method for decreasing the inhibition of neurite outgrowth or sprouting in a neuron, comprising the step of contacting the neuron with the antibody or antigen-binding fragment of this invention.
- the neuron is a CNS neuron. In some of these methods, the neurite outgrowth or sprouting is axonal growth.
- the invention provides a method of promoting survival of a neuron in a mammal, which neuron is at risk of dying, comprising (a) providing a cultured host cell expressing (i) an anti-Nogo receptor-1 antibody or antigen-binding fragment thereof; or (ii) a soluble Nogo receptor-1 polypeptide; and (b) introducing the host cell into the mammal at or near the site of the neuron.
- a cultured host cell expressing (i) an anti-Nogo receptor-1 antibody or antigen-binding fragment thereof; or (ii) a soluble Nogo receptor-1 polypeptide
- introducing the host cell into the mammal at or near the site of the neuron comprising (a) providing a cultured host cell expressing (i) an anti-Nogo receptor-1 antibody or antigen-binding fragment thereof; or (ii) a soluble Nogo receptor-1 polypeptide; and (b) introducing the host cell into the mammal at or near the site of the neuron.
- the invention provides a gene therapy method of promoting survival of a neuron at risk of dying, which neuron is in a mammal, comprising administering at or near the site of the neuron a viral vector comprising a nucleotide sequence that encodes (a) an anti-Nogo receptor-1 antibody or antigen-binding fragment thereof; or (b) a soluble Nogo receptor-1 polypeptide, wherein the anti-Nogo receptor-1 antibody, antigen-binding fragment, or soluble Nogo receptor-1 polypeptide is expressed from the nucleotide sequence in the mammal in an amount sufficient to promote survival of the neuron.
- Viral vectors and methods useful for these embodiments are described in, e.g., Noel et al, Human Gene Therapy, 73:1483-93 (2002).
- the invention provides a method of inhibiting Nogo receptor-1 binding to a ligand, comprising the step of contacting the ligand with the soluble Nogo receptor-1 polypeptide or the Nogo receptor-1 fusion protein of this invention.
- the invention provides a method of modulating an activity of a
- Nogo ⁇ eceptor-1 ligand comprising the step of contacting the Nogo receptor-1 ligand with a soluble Nogo receptor-1 polypeptide or a Nogo receptor-1 fusion protein of the invention.
- the invention provides a method for inhibiting growth cone collapse in a neuron, comprising the step of contacting a Nogo receptor-1 ligand with a soluble Nogo receptor-1 polypeptide or a Nogo receptor-1 fusion protein of this invention.
- the invention provides a method for decreasing the inhibition of neurite outgrowth or sprouting in a neuron, comprising the step of contacting a Nogo receptor-1 ligand with the soluble Nogo receptor-1 polypeptide or the Nogo receptor-1 fusion protein of this invention.
- the neuron is a CNS neuron.
- the ligand is selected from the group consisting of NogoA, NogoB, NogoC, MAG and OM-gp.
- the neurite outgrowth or sprouting is axonal growth.
- the invention provides a method for promoting neurite outgrowth comprising contacting a neuron with a polypeptide, a polynucleotide, or a composition of the invention.
- the polypeptide, polynucleotide or composition inhibits neurite outgrowth inhibition.
- the neuron is in a mammal. In some embodiments, the mammal is a human.
- the invention provides a method of inhibiting signal transduction by the NgRl signaling complex, comprising contacting a neuron with an effective amount of a polypeptide, a polynucleotide, or a composition of the invention.
- the neuron is in a mammal. In some embodiments, the mammal is a human.
- the invention provides a method of treating a central nervous system (CNS) disease, disorder, or injury in a mammal, comprising administering to a mammal in need of treatment an effective amount of a polypeptide, a polynucleotide, or a composition of the present invention.
- the disease, disorder, or injury is multiple sclerosis, ALS, Huntington's disease, Alzheimer's disease, Parkinson's disease, diabetic neuropathy, stroke, traumatic brain injuries, spinal cord injury, optic neuritis, glaucoma, hearing loss, and adrenal leukodystrophy.
- Any of the types of antibodies or receptors described herein may be used therapeutically.
- the anti-Nogo receptor-1 antibody is a human antibody.
- the mammal is a human patient.
- the antibody or antigen-binding fragment thereof is administered to a non-human mammal expressing a Nogo receptor-1 with which the antibody cross- reacts (e.g., a primate, cynomologous or rhesus monkey) for veterinary purposes or as an animal model of human disease.
- a non-human mammal expressing a Nogo receptor-1 with which the antibody cross- reacts e.g., a primate, cynomologous or rhesus monkey
- Such animal models may be useful for evaluating the therapeutic efficacy of antibodies of this invention.
- administering is used to treat a spinal cord injury to facilitate axonal growth throughout the injured site.
- the anti-Nogo receptor-1 antibodies or antigen-binding fragments, or soluble Nogo receptor-1 polypeptides or fusion proteins of the present invention can be provided alone, or in combination, or in sequential combination with other agents that modulate a particular pathological process.
- anti-inflammatory agents may be co-administered following stroke as a means for blocking further neuronal damage and inhibition of axonal regeneration.
- the Nogo receptor-1 antibodies, antigen-binding fragments, soluble Nogo receptor-1 and Nogo receptor fusion proteins are said to be administered in combination with one or more additional therapeutic agents when the two are administered simultaneously, consecutively or independently.
- Nogo receptor-1 fusion proteins of the present invention can be administered via parenteral, subcutaneous, intravenous, intramuscular, intraperitoneal, transdermal, inhalational or buccal routes.
- an agent may be administered locally to a site of injury via microinfusion. Typical sites include, but are not limited to, damaged areas of the spinal cord resulting from injury.
- the dosage administered will be dependent upon the age, health, and weight of the recipient, kind of concurrent treatment, if any, frequency of treatment, and the nature of the effect desired.
- the compounds of this invention can be utilized in vivo, ordinarily in mammals, such as humans, sheep, horses, cattle, pigs, dogs, cats, rats and mice, or in vitro.
- Vectors of the Invention are also known in the art.
- the invention provides recombinant DNA molecules (rDNA) that contain a coding sequence.
- a rDNA molecule is a DNA molecule that has been subjected to molecular manipulation. Methods for generating rDNA molecules are well known in the art, for example, see Sambrook et al., Molecular Cloning - A Laboratory Manual, Cold Spring Harbor Laboratory Press (1989).
- a coding DNA sequence is operably linked to expression control sequences and vector sequences.
- the invention provides vectors comprising the nucleic acids encoding the polypeptides of the invention.
- the choice of vector and expression control sequences to which the nucleic acids of this invention is operably linked depends directly, as is well known in the art, on the functional properties desired ⁇ e.g., protein expression, and the host cell to be transformed).
- a vector of the present invention may be at least capable of directing the replication or insertion into the host chromosome, and preferably also expression, of the structural gene included in the rDNA molecule.
- Expression control elements that are used for regulating the expression of an operably linked protein encoding sequence are known in the art and include, but are not limited to, inducible promoters, constitutive promoters, secretion signals, and other regulatory elements.
- the inducible promoter is readily controlled, such as being responsive to a nutrient in the host cell's medium.
- the vector containing a coding nucleic acid molecule will include a prokaryotic replicon, i.e., a DNA sequence having the ability to direct autonomous replication and maintenance of the recombinant DNA molecule extra-chromosomally in a prokaryotic host cell, such as a bacterial host cell, transformed therewith.
- vectors that include a prokaryotic replicon may also include a gene whose expression confers a detectable or selectable marker such as a drug resistance.
- a detectable or selectable marker such as a drug resistance.
- Typical of bacterial drug resistance genes are those that confer resistance to ampicillin or tetracycline.
- Vectors that include a prokaryotic replicon can further include a prokaryotic or bacteriophage promoter capable of directing the expression (transcription and translation) of the coding gene sequences in a bacterial host cell, such as E. colt.
- a promoter is an expression control element formed by a DNA sequence that permits binding of RNA polymerase and transcription to occur.
- Promoter sequences compatible with bacterial hosts are typically provided in plasmid vectors containing convenient restriction sites for insertion of a DNA segment of the present invention. Examples of such vector plasmids are pUC8, pUC9, pBR322 and pBR329 (Bio-Rad ® Laboratories), pPL and pKK223 (Pharmacia). Any suitable prokaryotic host can be used to express a recombinant DNA molecule encoding a protein of the invention.
- Expression vectors compatible with eukaryotic cells can also be used to form a rDNA molecules that contains a coding sequence.
- Eukaryotic cell expression vectors are well known in the art and are available from several commercial sources. Typically, such vectors are provided containing convenient restriction sites for insertion of the desired DNA segment. Examples of such vectors are pSVL and pKSV-10 (Pharmacia), pBPV-1, pML2d (International Biotechnologies), pTDTl (ATCC ® 31255) and other eukaryotic expression vectors.
- Eukaryotic cell expression vectors used to construct the rDNA molecules of the present invention may further include a selectable marker that is effective in an eukaryotic cell, preferably a drug resistance selection marker.
- a preferred drug resistance marker is the gene whose expression results in neomycin resistance, i.e., the neomycin phosphotransferase (neo) gene. (Southern et al., J. MoI. Anal. Genet. 7:327-341 (1982)).
- the selectable marker can be present on a separate plasmid, the two vectors introduced by co-transfection of the host cell, and transfectants selected by culturing in the appropriate drug for the selectable marker.
- DNAs encoding partial or full-length light and heavy chains are inserted into expression vectors such that the genes are operatively linked to transcriptional and translational control sequences.
- Expression vectors include plasmids, retroviruses, cosmids, YACs, EBV-derived episomes, and the like.
- the antibody gene is ligated into a vector such that transcriptional and translational control sequences within the vector serve their intended function of regulating the transcription and translation of the antibody gene.
- the expression vector and expression control sequences are chosen to be compatible with the expression host cell used.
- the antibody light chain gene and the antibody heavy chain gene can be inserted into separate vectors. Li some embodiments, both genes are inserted into the same expression vector.
- the antibody genes are inserted into the expression vector by standard methods (e.g., ligation of complementary restriction sites on the antibody gene fragment and vector, or blunt end ligation if no restriction sites are present).
- a convenient vector is one that encodes a functionally complete human C H or C L immunoglobulin sequence, with appropriate restriction sites engineered so that any V H or V L sequence can be easily inserted and expressed, as described above.
- splicing usually occurs between the splice donor site in the inserted J region and the splice acceptor site preceding the human C region, and also at the splice regions that occur within the human C H exons. Polyadenylation and transcription termination occur at native chromosomal sites downstream of the coding regions.
- the recombinant expression vector can also encode a signal peptide that facilitates secretion of the antibody chain from a host cell.
- the antibody chain gene may be cloned into the vector such that the signal peptide is linked in-frame to the amino terminus of the antibody chain gene.
- the signal peptide can be an immunoglobulin signal peptide or a heterologous signal peptide (i.e., a signal peptide from a non- immunoglobulin protein).
- the recombinant expression vectors of the invention carry regulatory sequences that control their expression in a host cell. It will be appreciated by those skilled in the art that the design of the expression vector, including the selection of regulatory sequences may depend on such factors as the choice of the host cell to be transformed, the level of expression of protein desired, etc.
- Preferred regulatory sequences for mammalian host cell expression include viral elements that direct high levels of protein expression in mammalian cells, such as promoters and/or enhancers derived from retroviral LTRs, cytomegalovirus (CIv[V) (such as the CMV promoter/enhancer), Simian Virus 40 (SV40) (such as the SV40 promoter/enhancer), adenovirus, (e.g., the adenovirus major late promoter (AdMLP)), polyoma and strong mammalian promoters such as native immunoglobulin and actin promoters.
- promoters and/or enhancers derived from retroviral LTRs include cytomegalovirus (CIv[V) (such as the CMV promoter/enhancer), Simian Virus 40 (SV40) (such as the SV40 promoter/enhancer), adenovirus, (e.g., the adenovirus major late promoter (AdMLP)
- NEOSPLA (U.S. patent 6,159,730) may be used.
- This vector contains the cytomegalovirus promoter/enhancer, the mouse beta globin major promoter, the SV40 origin of replication, the bovine growth hormone polyadenylation sequence, neomycin phosphotransferase exon 1 and exon 2, the dihydrofolate reductase gene and leader sequence.
- This vector has been found to result in very high level expression upon transfection in CHO cells, followed by selection in G418 containing medium and methotrexate amplification.
- any expression vector which is capable of eliciting expression in eukaryotic cells may be used in the present invention.
- Suitable .vectors include, but are not limited to plasmids pcDNA3, pHCMV/Zeo, pCR3.1, pEFl/His, pIND/GS, pRc/HCMV2, pSV40/Zeo2, pTRACER-HCMV, pUB6/V5-His, pVAXl, and pZeoSV2 (available from Invitrogen, San Diego, CA), and plasmid pCI (available from Promega, Madison, WI).
- Additional eukaryotic cell expression vectors are known in the art and are commercially available. Typically, such vectors contain convenient restriction sites for insertion of the desired DNA segment.
- Exemplary vectors include pSVL and pKSV- 10 (Pharmacia), pBPV-1, pml2d (International Biotechnologies), pTDTl (ATCC 31255), retroviral expression vector pMIG and pLL3.7, adenovirus shuttle vector pDC315, and AAV vectors.
- Other exemplary vector systems are disclosed e.g. , in U.S. Patent 6,413,777.
- lentiviral vectors for expression of the polynucleotides of the invention, e.g., NgR antagonist polynucleotides, e.g., siRNA molecules.
- Lentiviruses can infect noncycling and postmitotic cells, and also provide the advantage of not being silenced during development allowing generation of transgenic animals through infection of embryonic stem cells. Milhavet et al., Pharmacological Rev. 55:629-648 (2003).
- Other polynucleotide expressing viral vectors can be constructed based on, but not limited to, adeno-associated virus, retrovirus, adenovirus, or alphavirus.
- RNA polymerase I eukaryotic RNA polymerase I
- polymerase II RNA polymerase II
- poly III RNA polymerase III
- Transcripts from pol II or pol III promoters are expressed at high levels in all cells; the levels of a given pol II promoter in a given cell type depends on the nature of the gene regulatory sequences (enhancers, silencers, etc.) present nearby.
- Prokaryotic RNA polymerase promoters are also used, providing that the prokaryotic RNA polymerase enzyme is expressed in the appropriate cells (Elroy-Stein and Moss, Proc.
- transcription units such as the ones derived from genes encoding U6 small nuclear (snRNA), transfer RNA (tRNA) and adenovirus VA RNA are useful in generating high concentrations of desired RNA molecules such as siRNA in cells (Thompson et al, supra; Couture and Stinchcomb, 1996, supra; Noonberg et al, Nucleic Acid Res. 22:2830 (1994); Noonberg et al, U.S. Pat. No. 5,624,803; Good et al, Gene Ther. 4:45 (1997); Beigelman et al, International PCT Publication No. WO 96/18736.
- the siRNA transcription units can be incorporated into a variety of vectors for introduction into mammalian cells, including but not restricted to, plasmid DNA vectors, viral DNA vectors (such as adenovirus or adeno- associated virus vectors), or viral RNA vectors (such as retroviral or alphavirus vectors) (for a review see Couture and Stinchcomb, 1996, supra).
- plasmid DNA vectors such as adenovirus or adeno- associated virus vectors
- viral RNA vectors such as retroviral or alphavirus vectors
- the recombinant expression vectors of the invention may carry additional sequences, such as sequences that regulate replication of the vector in host cells (e.g., origins of replication) and selectable marker genes.
- the selectable marker gene facilitates selection of host cells into which the vector has been introduced (see e.g., U.S. Pat. Nos. 4,399,216, 4,634,665 and 5,179,017, all by Axel et al).
- the selectable marker gene confers resistance to drugs, such as G418, hygromycin or methotrexate, on a host cell into which the vector has been introduced.
- Preferred selectable marker genes include the dihydrofolate reductase (DHFR) gene (for use in dhfr " host cells with methotrexate selection/amplification) and the neo gene (for G418 selection).
- DHFR dihydrofolate reductase
- Nucleic acid molecules encoding anti-Nogo receptor-1 antibodies, immunogenic peptides, soluble Nogo receptor-1 polypeptides, soluble Nogo receptor-1 fusion proteins of this invention and vectors comprising these nucleic acid molecules can be used for transformation of a suitable host cell. Transformation can be by any known method for introducing polynucleotides into a host cell.
- nucleic acid molecules may be introduced into mammalian cells by viral vectors.
- Transformation of appropriate cell hosts with a rDNA molecule of the present invention is accomplished by well known methods that typically depend on the type of vector used and host system employed. With regard to transformation of prokaryotic host cells, electroporation and salt treatment methods can be employed (see, for example, Sambrook et al., Molecular Cloning - A Laboratory Manual, Cold Spring Harbor Laboratory Press (1989); Cohen et al, Proc. Natl. Acad. ScL USA 69:2110- 2114 (1972)).
- cationic lipid or salt treatment methods can be employed (see, for example, Graham et al., Virology 52:456-467 (1973); Wigler et al, Proc. Natl. Acad. Sd. USA 7(5: 1373-1376 (1979)).
- Successfully transformed cells i.e., cells that contain a rDNA molecule of the present invention, can be identified by well known techniques including the selection for a selectable marker. For example, cells resulting from the introduction of an rDNA of the present invention can be cloned to produce single colonies.
- Host cells for expression of a polypeptide or antibody of the invention for use in a method of the invention may be prokaryotic or eukaryotic.
- Mammalian cell lines available as hosts for expression are well known in the art and include many immortalized cell lines available from the American Type Culture Collection (ATCC ® ).
- CHO cells Chinese hamster ovary (CHO) cells, NSO, SP2 cells, HeLa cells, baby hamster kidney (BHK) cells, monkey kidney cells (COS), human hepatocellular carcinoma cells (e.g., Hep G2), A549 cells, and a number of other cell lines.
- Cell lines of particular preference are selected through determining which cell lines have high expression levels.
- Other useful eukaryotic host cells include plant cells.
- Other cell lines that may be used are insect cell lines, such as Sf9 cells.
- Exemplary prokaryotic host cells are E. colt and Streptomyces .
- recombinant expression vectors encoding the immunogenic polypeptides, Nogo receptor-1 antibodies or antigen-binding fragments, soluble Nogo receptor-1 polypeptides and soluble Nogo receptor-1 fusion proteins of the invention are introduced into mammalian host cells, they are produced by culturing the host cells for a period of time sufficient to allow for expression of the antibody, polypeptide and fusion polypeptide in the host cells or, more preferably, secretion of the immunogenic polypeptides, Nogo receptor-I antibodies or antigen-binding fragments, soluble Nogo receptor-1 polypeptides and soluble Nogo receptor-1 fusion proteins of the invention into the culture medium in which the host cells are grown.
- Immunogenic polypeptides, Nogo receptor-1 antibodies or antigen-binding fragments, soluble Nogo receptor-1 polypeptides and soluble Nogo receptor-1 fusion proteins of the invention can be recovered from the culture medium using standard protein purification methods.
- the present invention further provides host cells transformed with a nucleic acid molecule that encodes a Nogo receptor-1 antibody, antigen-binding fragment, soluble Nogo receptor-1 polypeptide and/or soluble Nogo receptor-1 fusion protein of the invention.
- the host cell can be either prokaryotic or eukaryotic.
- Eukaryotic cells useful for expression of a protein of the invention are not limited, so long as the cell line is compatible with cell culture methods and compatible with the propagation of the expression vector and expression of the gene product.
- Preferred eukaryotic host cells include, but are not limited to, yeast, insect and mammalian cells, preferably vertebrate cells such as those from a mouse, rat, monkey or human cell line.
- eukaryotic host cells examples include Chinese hamster ovary (CHO) cells available from the ATCC ® as CCL61, NIH Swiss mouse embryo cells NIH-3T3 available from the ATCC as CRL 1658, baby hamster kidney cells (BHK), and the like eukaryotic tissue culture cell lines.
- CHO Chinese hamster ovary
- NIH Swiss mouse embryo cells NIH-3T3 available from the ATCC as CRL 1658
- BHK baby hamster kidney cells
- Other useful eukaryotic host cells include plant cells.
- Other cell lines that may be used are insect cell lines, such as Sf9 cells.
- Exemplary prokaryotic host cells are E. coli and Streptomyces.
- the present invention further provides methods for producing an a Nogo receptor-1 antibody or antigen-binding fragment, soluble Nogo receptor-1 polypeptide and/or soluble Nogo receptor-1 fusion protein of the invention using nucleic acid molecules herein described.
- the production of a recombinant form of a protein typically involves the following steps: [0433] First, a nucleic acid molecule is obtained that encodes a protein of the invention. If the encoding sequence is uninterrupted by introns, it is directly suitable for expression in any host. [0434] The nucleic acid molecule is then optionally placed in operable linkage with suitable control sequences, as described above, to form an expression unit containing the protein open reading frame.
- the expression unit is used to transform a suitable host and the transformed host is cultured under conditions that allow the production of the recombinant protein.
- the recombinant protein is isolated from the medium or from the cells; recovery and purification of the protein may not be necessary in some instances where some impurities may be tolerated.
- the desired coding sequences may be obtained from genomic fragments and used directly in appropriate hosts.
- the construction of expression vectors that are operable in a variety of hosts is accomplished using appropriate replicons and control sequences, as set forth above.
- the control sequences, expression vectors, and transformation methods are dependent on the type of host cell used to express the gene and were discussed in detail earlier.
- Suitable restriction sites can, if not normally available, be added to the ends of the coding sequence so as to provide an excisable gene to insert into these vectors.
- a skilled artisan can readily adapt any host/expression system known in the art for use with the nucleic acid molecules of the invention to produce recombinant protein.
- Anti-Nogo receptor-1 antibodies that specifically bind an immunogenic Nogo receptor-1 polypeptide of the invention were made using the following methods and procedures.
- the rat Nogo receptor-1 gene (GenBankTM No. AF 462390) was subcloned into the mammalian expression vector pEAG1256 (Biogen ® ) that contained the CMV promotor and geneticin resistance gene for drug selection.
- the recombinant plasmid was transfected into COS-7 cells using Superfect (Qiagen ® ). Transfectants were selected using geneticin (GibcoTM, 2 mg/ml), cloned and verified for surface expression of Nogo receptor-1 protein by FACS.
- COS-7 membranes were prepared from these cells according to procedures as described [Wang et al., J. Neurochem.
- Sera from the immunized mice were collected before the first immunization, 7 days after the second and third immunizations, and 38 days after the third immunization and the anti-Nogo receptor-1 antibody titers were measured by ELISA as described below.
- Splenocytes were isolated from the mice and fused to the FL653 myeloma (an APRT- derivative of a Ig-/HGPRT- Balb/c mouse myeloma, maintained in DMEM containing 10% FBS, 4500 mg/L glucose, 4 mM L-glutamine, and 20 mg/ml 8- azaguanine) as described (Kennett et aL, Monoclonal Antibodies: A New Dimension in Biological Analysis, Plenum Press, New York (1993)). Fused cells were plated into 24- or 48-well plates (Corning Glass Works, Corning, NY), and fed with adenine, aminopterin and thymidine containing culture media.
- FL653 myeloma an APRT- derivative of a Ig-/HGPRT- Balb/c mouse myeloma, maintained in DMEM containing 10% FBS, 4500 mg/L glucose, 4 mM L-glutamine, and 20 mg
- AAT resistant cultures were screened by ELISA or flow cytometry for binding to either Nogo receptor-1- COS r 7 cells or to a Nogo receptor-1 antigenic peptide as described below. Cells in the positive wells were further subcloned by limiting dilution.
- the peptides that were used as immunogens were conjugated to BSA.
- 0.5 ⁇ g of the conjugated peptide in 50 ⁇ l of 0.1 M sodium bicarbonate buffer, pH 9.0 was added to each well of a 96-well MaxiSorpTM plate (Nunc TM ). The plate was then incubated at 37°C for 1 hour or 4°C for 16 hours and non-specific binding sites were blocked using 25 mM HEPES, pH 7.4 containing 0.1% BSA, 0.1% ovalbumin, 0.1% blotto and 0.001% azide. Hybridoma supernatant was added and incubated at 25°C for 1 hour.
- Antibodies were screened for binding to full length Nogo receptor-1 as follows.
- COS-7 cells were labeled with 0.1 uM CellTrackerTM Green CMFDA (Molecular Probes, Eugene, OR) as described by the vendor.
- Equal volumes of CellTracker TM labeled control cells were mixed with washed Nogo receptor-1 -COS-7 cells before incubation with anti-Nogo receptor-1 test sera.
- Fifty microliters of the cell mixture was dispensed into each well of a 96-well V-bottom polystyrene plates (Costar ® 3877, Corning, NY) and 100 ⁇ l of hybridoma supernatant or a control anti-Nogo receptor-1 antibody was added.
- the cells were washed and incubated with 50 ⁇ l of R- phycoerythrin-conjugated affinity pure F(ab')2 fragment goat anti-mouse IgG Fc gamma specific second antibody (1:200, Jackson ImmunoResearch Laboratory, West Grove, PA) in PBS.
- the cells were washed twice with PBS and suspended in 200 ⁇ l of PBS containing 1% FBS, and subjected to FACS analyses.
- Nogo receptor-l-COS-7 cells were mixed with hybridoma supernatant and then treated with R-phycoerythrin-conjugated goat anti-mouse secondary antibody and directly subjected to standard FACS analyses.
- primers comprise degenerate nucleotides as follows: S represents G or C; M represents A or C, R represents G or A; W represents A or T; K represents G or T; and Y represents T or C.
- S represents G or C
- M represents A or C
- R represents G or A
- W represents A or T
- K represents G or T
- Y represents T or C.
- the light chains of 7El 1 and 5B10 have 94% amino acid sequence identity and the heavy chains have 91% amino acid sequence identity.
- mAbs 7El 1, 5B10, and 1H2 are of the IgGl isotype and mAbs 3G5 and 2F7 are of the IgG2a isotype. Each of these five mAbs has a light chain of the kappa isotype. We analyze the sequence of the other monoclonal antibodies by this approach. TABLE 2.
- mAb 7El 1 binds both rat and human NgRl . To determine the epitope responsible for
- C- terminal caps (sNgR310) was treated with either acid or cyanogen bromide (CNBr) and separated the fragments by gel electrophoresis. Untreated sNgR310 migrates with an apparent molecular weight of 42 kDa. Acid treatment of sNgR310 produced two major cleavage products of 15 kDa (aa 27-aa 122) and 30 kDa (aa 123-aa 310).
- CNBr treatment generated three fragments, a 33/35 kDa doublet (aa 27-aa 229), which may represent fragments with heterogeneous glycosylation, a 10 kDa product (aa 241-aa 310), and an 11-atnino-acid fragment (aa 230-aa 240), which is not retained on the gel.
- a western blot of the gel was probed with 7El 1 and demonstrated that it bound to intact rat NgRl (aa 27-aa 310), the 15 kDa acid fragment (aa 27-aa 122) and the 35 IcDa CNBr fragment (aa 27-aa 229).
- the 7El 1 binding site was further analyzed by testing tryptic peptide digests of sNgR310. HPLC analyses showed several fragments, indicating that there were several trypsin-sensitive lysine and arginine residues in the NgRl sequence. 7El 1 bound only a single tryptic digest peptide, providing additional evidence that 7El 1 binds to a single epitope on NgRl. Subsequent mass spectroscopy (MS) and sequence analyses identified the bound peptide to be AAAFTGLTLLEQLDLSDNAQLR (SEQ ID NO: 26).
- the LDLSDNAQLRWDPTT peptide (SEQ ID NO: 1) was subjected to further mapping analysis.
- the peptide was digested with trypsin, which yielded two major fragments, LDLSDNAQLR (SEQ ID NO: 27) and WDPTT (SEQ ID NO: 28), and the ability of 7El 1 to bind them was tested.
- MS analysis revealed that the antibody bound peptide LDLSDNAQLR (SEQ ID NO: 27), and therefore this peptide contains the binding epitope for 7El 1.
- the LDLSDNAQLRVVDPTT (SEQ ED NO:1) peptide was also digested with the endoprotease Asp-N and 7El 1 binding was tested. Endoprotease Asp-N cleaved the peptide into 3 peptide fragments, L, DLS and DNAQLRWDPTT (SEQ ED NO: 36). Of these products, 7El 1 bound the DNAQLRWDPTT (SEQ DD NO: 36) peptide. Taken together, the trypsin and Asp-N cleavage data further localize the 7El 1 binding epitope to the sequence shared between them, DNAQLR (SEQ ED NO: 37).
- NgRl, NgR2, and NgR3 were analyzed to predict critical residues in the 7El 1 binding epitope based on the observation that 7El 1 bound rat and human NgRl but not mouse NgRl, human NgR2 or mouse NgR3. Sequence alignment revealed that amino acids 110-125 of rat NgRl and the corresponding sequence of human NgRl are identical and that the mouse NgRl sequence differs only by one amino acid at position 119 (Argl l9 in rat and human NgRl, and Hisl 19 in mouse NgRl; Table 4).
- a ⁇ gl l9 on NgRl contributes to 7E11 binding because it binds well to rat and human
- NgRl but poorly to mouse NgRl.
- Alall ⁇ is involved in the epitope because within the DNAQLR sequence (SEQ ID NO:37) NgR3 only differs from NgRl by an Arginine at the corresponding sequence.
- DNAQLR (SEQ ID NO:37) sequence 4 out of 6 of the residues in NgR2 are identical to rat NgRl. Alal l6 and GIn 117 are replaced with Arginine and Histidine, respectively. This confirms that Alall6 is an important amino acid residue contributing to 7El 1 binding, but does not necessarily preclude the involvement of GIn 117. [0455] To verify these contact points, several peptides containing point mutations within the DNAQLR sequence (SEQ ID NO:37)
- LDLSDNAQLR sequence (SEQ ID NO: 27) were generated and tested for 7El 1 binding.
- the peptides were immobilized on a MaxiSorpTM plate (NuncTM) and serial dilutions of 7El 1 were applied.
- the resulting EC 50 values are shown in Table 5. 7El 1 bound to mutants Leul lOAla and AsplllAla with similar EC 50 values as to the original peptide.
- GIn 117AIa was tested, the EC 50 increased 30-fold and when Argll9His was tested the EC 50 increased 25-fold. The most significant change in EC 50 was observed when Argl 19 was mutated to Alanine.
- the position of the 7El 1 binding epitope was also determined in the recently resolved crystal structure of sNgR310. As expected, the structure shows that the 7El 1 epitope is exposed on the surface of the molecule. Residues Argl 19, Glnll7, Alal l6, and Aspl l4 protrude outward from the structure while Leul 18 and Asn 115 are located inward. The epitope falls on top of an acidic patch within the concave surface of the structure and a basic surface that faces one of the sides.
- sNogoR344-Fc rat Nogo receptor-1 and the hinge and Fc region of the rat IgGl molecule (sNogoR344-Fc) produced as described below was immobilized on 250 ⁇ g of protein-A- or wheatgerm agglutinin- conjugated SPA beads (Amersham Pharmacia Biotech) for 2 hours at 25°C.
- SPA beads coupled with Fc- sNogoR-1, anti-Nogo receptor-1 mAb and l ⁇ l 125 I-Nogo66 (Amersham, 2000 Ci/mmol, InM) in 50 ⁇ l of the HEPES-buffered incubation medium (10 mM HEPES, pH 7.4, 0.1% bovine serum albumin, 0.1% ovalbumin, 2 mM MgCl 2 , 2 mM CaCl 2 and protease inhibitors) was added to each sample well. After 16 hours, radioactivity was measured in quadruplicate samples using a TopCount ® (Packard). ICs 0 values were calculated from a curve-fit analysis (Fig. 3) (PRISM, GraphPad Software, NJ).
- AP-ligand conjugates e.g. AP-Nogo66
- alkaline phosphatase activity we also assayed the ability of the mAbs to block binding of the ligands MAG-Fc and AP-OM-gp to Nogo receptor- 1.
- Anti-Nogo receptor-1 Fab-phage antibodies that specifically bind an immunogenic Nogo receptor-1 polypeptide of the invention were also made by screening a Fab-phage library as follows.
- the MorphoSys Fab-phage library HuCAL ® GOLD was screened against recombinant rat soluble sNogoR310-Fc protein and COS7 cells expressing rat Nogo receptor-1.
- Fab-phages that specifically bound to Nogo receptor-1 were purified and characterized.
- the heavy chain of 14D5 is derived from the V H 2 gene and the light chain is derived from the V K 1 gene.
- the amino acid sequences of the CDRs of the heavy chain and light chain of one of these Fab-phages, 14D5 are shown in Table 7. TABLE 7.
- 14D5 binds to rat Nogo receptor-1 in both monovalent and bivalent forms.
- 14D5 binds to rat Nogo receptor-1 in both monovalent and bivalent forms.
- 14D5 binds to mouse and human Nogo receptor-1 and human Nogo receptor-2 but not mouse Nogo receptor-3.
- Beads were resuspended in 100 ⁇ l of 2X SDS with 10% beta-mercaptoethanol. Samples were incubated at room temperature before being run on a 4-20% Tris-Glycine gel for SDS-PAGE. As determined by SDS-PAGE gel analysis, monoclonal antibodies, 3G5 and 2F7, immunoprecipitate Nogo receptor-1.
- Examples 1 and 2 we performed an ELISA using a panel of Nogo rece ⁇ tor-1 polypeptides.
- the panel consisted of sNogoR310-Fc (a fusion protein comprising amino acids 26-310 of rat Nogo receptor-1 and a rat Fc fragment), sNogoR344-Fc (see supra), polypeptide p-617 (SEQ ID NO: 1), polypeptide ⁇ -618 (a 19-amino acid polypeptide from the LRR7 region of rat Nogo receptor-1; Fig. 2; SEQ ED NO: 11) and polypeptides p-4 and p-5 (polypeptides from the LRR5 and LRRCT regions of Nogo receptor-1 , respectively). Ovalbumin and BSA were used as controls.
- mAbs 1H2, 3G5 and 2F7 all specifically bound to sNogoR344-Fc.
- those antibodies also specifically bound a polypeptide consisting of amino acids 310-344 of rat Nogo receptor-1 (SEQ ED NO: 3) and mAbs 7El 1 and 5B10 specifically bound polypeptide p-617 (SEQ ID NO: 1).
- Nogo66, AP-OM-gp and MAG-Fc ligands were allowed to bind to immobilized sNogoR344-Fc, 1 ⁇ M 14D5 completely inhibited Nogo and MAG binding. 10 ⁇ M of 14D5 was required to completely inhibit the binding of OM-gp to sNogoR344-Fc.
- DRG's Dorsal root ganglions (DRG's) from P3-4 Sprague Dawley rat pups were dissociated with 1 mg/ml collagenase type 1 (Worthington), triturated with fire-polished Pasteur pipettes pre-plated to enrich in neuronal cells and finally plated at 23,000 cells/well on the pre-coated Lab-Tek ® culture slides.
- the culture medium was F12 containing 5% heat inactivated donor horse serum, 5% heat inactivated fetal bovine serum and 50 ng/ml mNGF and incubated at 37°C and 5% CO 2 for 6 hours. Fifteen ⁇ g/ml of mAb 7El 1 was added immediately after plating.
- Nogo receptor-1 transfected and non-transfected cells were plated in 8-well Lab-Tek ® culture slides, fixed with 4% paraformaldehyde for 15 minutes, blocked with 10% normal goat serum, 0.1% Triton X-100 in PBS for 1 hour.
- Mab 7E11 was added at 15 ⁇ g/ml and 1.5 ⁇ g/ml in blocking solution and incubated for 2 hours at room temperature; Alexa ® -conjugated secondary antibody anti- mouse (Molecular Probes) was incubated at a 1:300 dilution in blocking solution for 1 hour; DAPI was added at 5 ⁇ g/ml to the secondary antibody to label all nuclei.
- Transfected and non-transfected cells were plated in 8 well Lab-Tek culture slides, blocked with FACS buffer (containing 4% donor horse serum) for 30 minutes at 4°C, incubated with 7El 1 at 15 ⁇ g/ml and 1.5 ⁇ g/ml in FACS buffer for 1 hour at 4°C, rinsed and incubated with secondary antibody anti-mouse-Alexa ® (1:300 in FACS buffer) for 30 minutes at 4°C.
- FACS buffer containing 4% donor horse serum
- mice (18—22 g) are treated prophylactically with analgesic and antibiotic agents.
- Mice are anesthetized and placed in a stereotaxic apparatus with vertebral column fixation under a stereomicroscope. Trauma to the spinal cord is introduced by a modified version of the weight-drop method (M. Li et al, Neuroscience PP:333-342 (2000).
- a T9 and TlO laminectomy is made and the vertebral column is stabilized using a pair of mouse transverse clamps supporting the T9— TlO transverse processes bilaterally.
- a stainless steel impact rod with a diameter of 1.4 mm and weight of 2 g, is raised 2.5 cm above the dura and dropped onto the spinal cord at the TlO level.
- mice are kept on a 37°C warming blanket and 1 ml of warmed sterile saline is administered subcutaneously to each mouse after surgery to avoid dehydration.
- the bladder is manually expressed once daily until reflexive bladder control is regained.
- Anti-Nogo receptor- 1 antibodies are delivered to the injury site via intrathecal injection for 28 days as described in the rat spinal cord transection model below.
- soluble Nogo receptors sNogoR310-Fc and sNogoR344-Fc were immobilized on 250 ⁇ g WGA-SPA beads and received 0.5 ⁇ L of radioactive ligand (final concentration 0.5 nM) in a final volume of 100 ⁇ L of binding buffer (20 mM HEPES, pH 7.4, 2 mM Ca, 2 mM Mg 5 0.1% BSA, 0.1% ovalbumin and protease inhibitors).
- Ligands included 10 ⁇ M Nogo66, 10 ⁇ M 125 I- Nogo40 (amino acids 1-40 of Nogo A) and 10 ⁇ L of anti-Nogo receptor-1 antibody supernatant for each ligand set.
- Nogo40-A,-B and -C The three tyrosines on Nogo40 were separately iodinated and designated as Nogo40-A,-B and -C respectively. Mean values of triplicates are presented as normalized % bound radioactivity (Figs. 6, 7 and 8). Error bars indicate SEM. Bound radioactivity in the absence of inhibitors was taken as 100% and the lowest bound radioactivity in the presence of 10 ⁇ M Nogo40 was taken as the 0% for data normalization.
- a binding assay similar to the binding assay of Example 8 was used to test the ability of two mAbs produced in Example 1 to inhibit I2S I-Nogo66 binding to sNogoR344-Fc. Mabs 2F7 and 3G5 inhibited 12S I-Nogo66 binding to sNogoR344-Fc.
- CNS myelin alone or mixed with sNogoR310, sNogoR310-Fc fusion protein, mAb 5B10 or control PBS were separately spotted as 3 ⁇ l drops.
- Fluorescent microspheres Polysciences
- Lab- Tek ® slides were then rinsed and coated with 10 ⁇ g/ml laminin (GibcoTM).
- DRG's Dorsal root ganglions (DRG's) from P3-4 Sprague Dawley rat pups were dissociated with 1 mg/ml collagenase type 1 (Worthington), triturated with fire-polished Pasteur pipettes pre-plated to enrich in neuronal cells and finally plated at 23,000 cells/well on the pre-coated Labtek culture slides.
- the culture medium was F12 containing 5% heat inactivated donor horse serum, 5% heat inactivated fetal bovine serum and 50 ng/ml mNGF and incubated at 37 0 C and 5% CO 2 for 6 hours.
- DRG 's were dissected from post-natal day 6-7 rat pups (P6-7), dissociated into single cells and plated on 96-well plates pre-coated with poly-D-lysine as described above. In some wells 2 ⁇ g/ml laminin was added for 2-3 hours and rinsed before the cells were plated. After an 18-20 h incubation the plates were fixed with 4% para-formaldehyde, stained with rabbit anti-Beta-IH-tubulin antibody diluted 1:500 (Covance ® ) and anti-HuC/D diluted 1:100 (Molecular Probes), and fluorescent secondary antibodies (Molecular Probes) were added at 1 :200 dilution.
- the ArrayScan ® ⁇ (Cellomics ® ) was used to capture 5x digital images and to quantify neurite outgrowth as average neurite outgrowth/neuron per well, by using the Neurite outgrowth application. Nine 5x images from 3 wells/condition were analyzed.
- the Neuroscreen TM cells were pre-differentiated for 7 days with 200 ng/ml NGF, detached and replated on 96-well plates pre-coated with poly-D-Iysine. In some wells 5 ⁇ g/ml laminin was added for 2-3 hours and rinsed before the cells were plated. After 2 days incubation the plates were fixed with 4% paraformaldehyde, stained with rabbit anti-Beta-III-tubulin antibody diluted 1:500 (Covance ® ) and Hoechst (nuclear stain). The ArrayScan ® II was used to quantify neurite outgrowth as in the DRG cells. [0492] sNogoR344-Fc or rat IgG were added in solution to P6-7 DRG neurons and to differentiated NeuroscreenTM cells at the time of plating.
- DRG neurons were grown in the absence of laminin. Quantification of neurite outgrowth showed a dose- dependent increase with the addition of sNogoR344-Fc. Addition of sNogoR344-Fc at the same concentrations to DRG neurons growing on a laminin substrate, did not produce any unusual effect, indicating that sNogoR344-Fc is only active on stressed cells. The neuro-protective effect of sNogoR344-Fc at the same concentrations in the absence of laminin also was seen with Neuroscreen TM cells. EXAMPLE 11
- IgGl Fc contained in a mammalian expression vector and this vector was electroporated into Chinese hamster ovary (CHO) (DG44) cells.
- CHO Chinese hamster ovary
- Cells were maintained in alpha-MEM, supplemented with 10% dialyzed fetal bovine serum, 2 mM glutamine and antibiotic-antimycotic reagents. Two days after transfection, the conditioned media was collected and analyzed by Western blot under reducing conditions. A protein band about 60 kDa was detected using a polyclonal rabbit anti-Nogo receptor-1 antibody. Cells were expanded and sorted using a R-PE conjugated goat anti-rat IgG antibody. After the second sorting, cells were plated at a density of one cell/well in 96-well plates.
- CHO cells expressing the sNogoR310-Fc fusion protein were cultured in large scale. 1.7
- the column was washed with 300 mL of 10 mM Tris-HCl, 3 M sodium chloride, 1.5 M glycine, pH 8.9 followed with 120 mL 5 mM Tris-HCl, 3 M sodium chloride, pH 8.9. Protein was eluted with 25 mM sodium phosphate, 100 mM sodium chloride, pH 2.8. 10 mL fractions were collected in tubes containing 1.0 mL of 1.0 M HEPES, pH 8.5. Protein fractions were pooled and dialyzed against 3 x 2 L of 5 mM sodium phosphate, 300 mM NaCl, pH 7.4.
- Alzet ® osmotic pumps were loaded with test solution (sNogoR310-Fc in PBS) made up freshly on the day of use. The loading concentration was calculated to be 5 and 50 ⁇ M. Pumps were primed for >40 hours at 37°C prior to implantation into animals. Female Long Evans rats were given pre-operative analgesia and tranquilizer and anesthetized using isoflurane (3% in O 2 )-
- Rats were allowed to recover and survive up to 28 days after surgery. Behavioral scoring using the BBB system was recorded up to 28 days after induction of injury, just prior to termination of the in-life phase of the study. Following perfusion and fixation, spinal cords were removed, cryoprotected, sectioned, stained and axonal counts performed.
- BBB Basso-Beattie-Bresnahan locomotor rating scale
- mice Female hooded Long Evans rats (170-190 g) are treated prophylactically with analgesic and antibiotic agents. Ten minutes before surgery, animals are tranquilized with 2.5 mg/kg Midazolam i.p. and anesthetized in 2-3% isoflurane in O 2 . Rats are then shaved, wiped down with alcohol and betadine, and ocular lubricant applied to their eyes. Next, an incision is made down the midline and the T7 to T12 vertebrae exposed.
- a dorsal laminectomy is performed at T9 1/2 and TlO to expose the cord.
- the rat is mounted on the Impactor.
- T7 and T8 segments are first clamped and then the TIl and T12 segments are attached to the caudal clamp.
- a soft material is placed underneath the chest of the rat.
- the Impactor rod is set to the zero position and the electrical ground clip is attached to the wound edge.
- the Impactor rod is then raised to 25.0 mm and appropriately adjusted to a position directly above the exposed spinal cord. Next, the Impactor rod is released to hit the exposed cord and the Impactor rod is immediately lifted.
- Soluble Nogo receptor-1 fusion protein (e.g., sNogoR310-Fc) is administered intrathecally as described in the rat spinal cord transection model above. BBB scoring is performed one- day after surgery, then every week thereafter until 4 to 6 weeks.
- Nogo receptor-1) into the Notl site of the C-3123 vector.
- sNogoR310 expression is under the control of the glial fibrillary acidic protein (gfap) gene regulatory elements, which allow high level expression with enhanced secretion from reactive astrocytes at site of injury.
- gfap glial fibrillary acidic protein
- mice used for western blot analysis the spinal cord at a level between T3 and L3 was collected without perfusion 14 days after injury.
- Mice used for Nogo receptor-1 immunohistochernical staining were perfused with 4% paraformaldehyde 10 days after hemisection, and the injured spinal cord was removed for sectioning.
- a cortex stab injury was performed with a number 11 scalpel blade held in a stereotaxic apparatus (David Kopf, Tujunga, CA). A 4 mm parasagittal cut was made, 0.5 mm posterior to Bregma, 1.5 mm laterally from midline and 3.5 mm deep.
- CST corticospinal tracts
- the sections rostral to dorsal hemisection from injured sNogoR310 transgenic mice indicate a quite different BDA labeling pattern.
- a high density of BDA-labeled CST fibers are observed outside of prominent dCST in all the transgenic mice from line TgO8 or line TgOl.
- Ectopic fibers extend throughout the gray matter area, and some fibers reach into lateral and dorsolateral white matter.
- Several fibers (4-12 sprouts per transverse section) are seen on the opposite side of the spinal cord (ipsilateral to the tracer injection site).
- Micro densitometric measurement of the collateral sprouts indicates approximately a tenfold increase in sprouting density in sNogoR310 transgenic mice.
- Transverse sections were collected from the spinal cord 11—16 mm rostral to and 11—16 mm caudal to the injury site.
- To visualize the lesion area we double-stained some sections with antibodies directed against GFAP (Sigma ® , St. Louis, MO). We mounted, dehydrated and covered the sections with mounting medium.
- Collaterals and arborized fibers are most frequently seen in gray matter area of distal spinal cord.
- the reconstructions demonstrate 5-15 BDA-labeled regenerating fibers coursing in the rostral-caudal axis at any level 1-4 mm caudal to the lesion in each transgenic mouse.
- BDA- labeled CST axons are seen in both the gray matter and white matter areas in each transgenic mouse.
- the fiber counts for the transgenic mice indicate approximately a similar number of BDA-labeled CST fibers to the proximal levels in the sagittal sections.
- the other descending tracts such as raphespinal fibers
- the transection injures a majority of the serotonergic fibers, decreasing the density of these fibers by approximately 80% in the ventral horn.
- Analysis of total length of serotonin fibers in the ventral horn of caudal spinal cord indicates a much greater number of these fibers in transgenic mice than WT group, indicating that the growth-promoting effects of sNogoR310 in transgenic mice are not limited to one axon descending pathway.
- mice were employed two more behavioral tests to further characterize the performance of sNogoR310 transgenic mice.
- Bi another behavioral test mice climbed a grid placed at a 45 degree angle to vertical and excursions of the hindlimbs below the plane of the grid were counted (Metz et al., Brain Res. ' 883:165-177 (2000)).
- mice made errors on this test during the pre-injury training. There are numerous foot fault errors with only minimal improvement in WT mice during the period 2-6 weeks post-injury. Ih contrast, the sNogoR310 transgenic mice exhibit a progressive improvement in grid climbing during this period, with the majority of improvement occurring between 1-3 weeks post- injury (Fig. 13D). Thus, transgenic mice secreting sNogoR310 from astrocytes exhibit CST regeneration, raphespinal sprouting and improved motor function after thoracic spinal hemisection.
- 1.2 mg sNogoR310-Fc protein was locally administered in each rat.
- rats receiving the vehicle treatment 1.2 mg rat IgG
- sections rostral to hemisection display the tightly bundled prominent dorsal CST and very few ectopic BDA-labeled CST fibers above the lesion site.
- Sections rostral to lesion from injured rats receiving sNogoR310-Fc protein exhibit a quite different pattern of labeling. Numerous ectopic fibers sprouting from the BDA-labeled CST are observed from transverse and parasagittal sections.
- projections cross from the dCST area near the midline to the circumference of the cord, becoming intermingled with the dorsolateral CST.
- the sprouting axons extend through gray matter to a greater extent than white matter.
- a measure of ectopic sprouting fibers (>100 ⁇ m in transverse sections, >200 ⁇ m in sagittal sections) adjacent to the dCST reveals a greater increase in the sNogoR310-Fc- treated rats.
- An osmotic minipump (Alzet ® 2ML4, 2 ml volume, 2.5 ⁇ l/h, 28 day delivery), which was filled with 1.2 mg rat IgG in PBS or 1.2 mg sNogoR310- Fc fusion protein in PBS, was sutured to muscles under the skin on the back of the animals.
- a catheter connected to the outlet of the minipump was inserted into the intrathecal space of the spinal cord at the T7-8 level through a small hole in the dura.
- Counts of CST fibers from sagittal sections indicate approximately 20 BDA-labeled axons at 1-2 mm caudal to lesion and 15 traced axons at 7-8 mm distal to lesion from each sNogoR310-Fc-treated rat.
- the branching pattern of these fibers is similar to that observed from local
- NEP 1-40 peptide treated animals but more collateral branching in each sprout is seen from the sections treated with sNogoR310-Fc protein.
- a measure of the sprouts from distal spinal cord demonstrates that the total collateral length of each sprout in sNogoR310-Fc-treated rats is twice as great as that from NEP 1-40-treated animals.
- RST fibers are normally located in dorsolateral white matter area of spinal cord, and are transected by the dorsal hemisections of this study.
- transverse sections 11-15 mm rostral to lesion from control rats a small number of short BDA-labeled fibers are seen between the prominent RST and dorsal horn gray matter.
- Sections at same level treated with sNogoR310-Fc exhibit many linking fibers between the main RST and dorsal horn gray matter.
- Transverse sections 11-15 mm distal to SCI no BDA-labeled RST fibers in vehicle-treated rats.
- sections at the same level receiving sNogoR310-Fc treatment display many BDA-labeled RST fibers in both gray and white matter contralateral to tracer injection. Some sprouts with a branching pattern are seen in the gray matter ipsilateral to BDA injection.
- the locomotor BBB score in vehicle-treated rats reaches a stable level of 12 (Fig. 14A).
- most of controls (6 out of 7) have frequent-consistent weight-supported plantar steps and frequent-consistent forelimb-hindlimb coordination, but they have a rotation of predominant paw position when making initial contact with surface.
- the locomotor score continues to improve between 2-4 weeks post-trauma.
- all 9 of the sNogoR310-Fc treated animals had consistent forelimb-hindlimb coordination and a parallel paw position at initial contact with the testing surface.
- Grid walking has been used to assess the deficits in descending fine motor control after spinal cord injury (Metz et ah, Brain Res. 883:165-177 (2000)). This performance requires forelimb- hindlimb coordination and voluntary movement control mediated by ventrolateral, corticospinal and rubrospinal fibers. During the pre-injury training, all the rats accurately place their hindlimbs on the grid bars. At 2-4 weeks post-injury, control rats make 8-9 errors per session with only minimal improvement over time. In contrast, the rats treated with sNogoR310-Fc exhibit a progressive improvement on grid walking and make significant fewer errors (4-7/session on average). The majority of the improvement occurs at 2-3 weeks after injury.
- the complex was prepared at 80 ⁇ M each and mixed at a volumetric ratio of 2:1 with a reservoir solution consisting of 14% Peg3350, 0.4M Zinc Acetate, 0.1M Magnesium Chloride. The solution was incubated at 20 C for 1 hr and centrifiiged at 12,000 x g for 3 minutes to remove precipitate. Crystals were grown by placing 3-5 ⁇ L of the supernatant over wells containing 50% to 100% of the reservoir solution at 20 C. Thin plate-like crystals grew over a period of 1 week at 20 C. The crystals were cryoprotected by quickly transferring into 0.2M Zinc Acetate, 8% Peg3350, 25% Ethylene Glycol for 2 min and then frozen by quick transfer into liquid nitrogen.
- Synchrotron Light Source Upton, NY.
- the crystal structure was solved by utilizing information on multiple isomorphous replacement experiments on soaked crystals to identify common mercury sites bound to the NgR along with molecular replacement.
- Molecular replacement with MOLREP Vagin, A., and Teplyakov, A., J. Appl. Cryst. 30:1022-1025 (1997)
- a rat NgR homology model based on the human NgRl structure (pdb code 1OZN) (He, X.L.
- Table 8 shows the contacts between the 1D9 Fab and rat NgRl . Contacts in which atoms from the Fab are within 3.9 A distance from atoms in rat NgRl are listed and those contacts that could form a hydrogen bond with either the main chain or side chain have an associated asterisk(*).
- RNAi constructs were designed against the human NogoRl ( Figure 16A) transcript.
- RNAi-I and RNAi-3 target the human NgR gene specifically.
- RNAi-2 was designed to target human, mouse, and rat NgR genes.
- Pairs of DNA oligonucleotides were synthesized and constructed into a Poim promoter based RNAi expression vector, pU6 that contained the human U6 promotor, kar resistance gene, and a Pad cloning site.
- Nogor 2m was designed to carry two mismatches to the target sequence and serve as a negative control.
- the nucleotide sequences of these oligonucleotides are shown in Figure 16B.
- RNAi constructs were screened initially by co-transfecting the human NgR expression vector together with the RNAi expression plasmids (phU6NgR-RNAi-l , 2 and 3) in mouse L cells.
- Mouse L cells were plated in 6 well culture plates and then transfected with control GFP reporter plasmid alone or with RNAi vector against GFP, pU6GFPRNAi (lanes 2 and 3). The expression of GFP was monitored as a control for GFP gene silencing.
- Mouse L cells were transfected with 0.5, 1 or 2 ⁇ g of hNgR expression vector (lanes 4-6).
- hNgR vector was co- transfected with 2 ⁇ g NgR RNAi-I, 2, 3, or 2m plasmid (lanes 7-10). Forty eight hours post transfection, cells were harvested in SDS loading buffer and subjected to SDS-PAGE. The expression of hNgR was analyzed by western blot using rabbit serum against polyclonal hNgR antibody Rl 50 (panel A) or monoclonal antibody 7El 1 (panel B).
- the detected signals are specific to hNgR (only in hNgR cDNA transfected cells) with two types of antibodies (Figure 17), the apparent MW of the detected bands ( ⁇ 50kD) was lower than expected. While not being bound by theory, this is probably due to the altered glycosylation of human NgR in mouse L cells.
- hNgR cDNA transfection was carried out again in human SKN cells and 293 cells using Lipofectin. Forty-eight hours post transfection, cells were harvested in SDS loading buffer and subjected to SDS-PAGE. The expression of NgR was detected by Western blot using both 7El 1 and Rl 50 as described above. No hNgR specific signal was detected in parental SKN or 293 cells and the apparent MW of hNgR detected with R150 is of expected in both SKN and 293 cells, >65 IcD ( Figure 18).
- RNAi mediated hNgR silencing was confirmed in SKN cells.
- SKN cells were plated in 6 well culture plates and then transfected with control GFP reporter plasmid alone or with RNAi vector against GFP, pU6GFPRNAi (lanes 2 and 3). The expression of GFP was monitored as a control for GFP gene silencing.
- SKN cells were transfected 2 ⁇ g of hNgR expression vector (lane 4). DNA amount in each well was adjusted to total of 4 ⁇ g DNA by adding pUC19 plasmid DNA.
- hNgR vector 0.5 ⁇ g hNgR vector was co-transfected with 2 ⁇ g NgR RNAi-I, 2, 3 or 2m plasmid (lanes 5-8). Forty-eight hours post transfection, cells were harvested in SDS loading buffer and subjected to SDS-PAGE. The expression of hNgR was analyzed by western blot using rabbit serum against hNgR R150. Again, greater than 90% NgR knockdown was demonstrated in all NgR RNAi-I and -2, but less efficient in NgR RNAi-3 and - 2m ( Figure 19).
- NeuroScreen cells expressing NgR were obtained from Cellomics Inc. for NgR function analysis. In order to achieve stable NgR knockdown in NeuroScreen cells, all RNAi constructs were converted into lentiviral vectors in either beta-gal or GFP backbones. A schematic representation of the lenti viral vector is shown in Figure 20. Lentiviral vectors were generated by transfection of 293 cells with packaging plasmids (Invitrogen).
- the RNAi cassettes consisting of the hU6 promoter that drives the expression of the hairpins (i.e., Nogo-1, Nogo-2, Nogo-2m, and Nogo-3) were excised from the phU6 vector (described in Example 24) by Pad digestion and cloned into the unique Pad site of SSM007 plasmids. See, for e.g., methods described in Robinson et al, Nature Genetics 3.3:401-406 (2003).
- a CBA-GFP expression cassette or CMV-LacZ expression cassette were inserted into SSM007 plasmid at the Xbal site, and the resultant constructs were termed SSM007-BFGW and SSM007-BFZW, respectively.
- the vectors were co-transfected with packaging plasmids, pLPl, pLP2 and pLP/VSVG into FT293 cells for lentiviral vector production (Viropower kit, I ⁇ vitrogen).
- pLPl is a 8889bp construct that contains the HIV-I gag/pol sequence and the rev response element (RRE) expressed from a CMV promoter and with a b-globin poly A
- pLP2 is a 4180 bp construct that expresses Rev from the RSV promoter and with an HIV-I poly A to terminate the transcript
- pLP/VSVG is a 5821 bp plasmid and expresses Vesicular stomatitis virus glycoprotein G from the CMV promoter and beta-globin poly A.
- RNAi interference Due to the self-limiting effect of RNAi interference to lentiviral titer, all viral stock titers appeared lower than regular lentiviral vectors, in the range of 4-5xlO 5 transducing unit in the culture medium.
- NgR RNAi lentivectors (LV-NgR RNAi) were used to transduce NeuroScreen cells at moi (multiplicity of infection) of 1. The transduction efficiency was about 1% as indicated by GFP expression or beta-galatosidase staining.
- NgR RNAi-2 was demonstrated to be effective in NgR silencing and it targets all human, mouse and rat NgR
- LV-NgR RNAi-2 was chosen to transduce NeuroScreen cells. Transduced cells were cloned by limited dilution in 96 well plates. Beta-galactosidase positive or GFP positive clones were identified and expanded for further NgR expression analyses.
- NgR levels of naive NeuroScreen cells are approximately 10% for 3cl2b, 20% for 3c4b, 30% for 5dl2 and 60% for 4al2 of the naive cells, respectively ( Figure 23).
- N56 of the 1D9 heavy chain via computer modeling, can be mutated to serine, glutamic acid, aspartic acid, or glutamine to interact with R78 of the human NgRl.
- R33 of the light chain can be mutated via computer modeling to alanine or serine to avoid the electrostatic and steric clashes with R95 of human NgRl .
- Fc for spinal cord injury we sought to verify that these reagents have independent mechanisms of action.
- myelin was dried overnight in poly-L-lysine-precoated plates (Becton Dickinson, Bedford, MA, USA) at 80 or 400 ng/well (2.5 and 12.7 ng/mm 2 , respectively).
- Wells were then coated with 10 ⁇ g/ml laminin (Calbiochem, La Jolla, CA, USA) for 1 hour at foom temperature (22-24 C).
- Embryonic day 13 chick dorsal root ganglion neurons were dissociated and plated for 6-8 hours as previously described (GrandPre et al., 2000; Fournier et al., 2001).
- PBS phosphate-buffered saline
- a cohort of NgR(Sl O)ecto-Fc treated rats were also treated with MP (Pharmacia; 30 mg/kg iv) and a separatecohort treated with MP alone (30 mg/kg iv)immediately after injury and again 4 and 8 hours later. Functional recovery was assessed using the BBB openfield scoring method (Basso et ah, J.
- BBB scores normalized to day 2 for individual animals illustrate a significant improvement in functional recovery in NgR(310)ecto-Fc-treated rats ⁇ MP 2, 3 and 4 weeks after SCI.
- P ⁇ 0/05 vs control, two-way repeated measure ANOVA with Tukey's posthoc test.
- Figure 25C In combining treatment group normalized BBB scores abrogated the enhancing effect of MP on NgR(310)(ecto)-Fc treatment illustrating that (i) in the combined treatment group the effect of MP occurred early after SCI and (ii) by subtracting out this effect the rate and extent of functional recovery in the combined treatment group and the NgR(310)ecto-Fc group were identical and more pronounced than MP treatment alone.
- a discriminating point on the BBB score is a score of 14, corresponding to consistent weight supported plantar steps and consistent hindlirrib-forelimb coordination.
- Frequency of consistent plantar stepping and hindlimb-forelimb coordination illustrating the proportion of rats in each group that attained a score of 14 or higher 3 and 4 weeks after SCI. Accordingly, results were expressed as the frequency with which rats attained a score of 14 or greater; 50% of control rats attained a score of 14 or greater by 4 weeks after injury (Figure 25D).
- Combined treatment with NgR(310)ecto-Fc and MP significantly improved the rate of functional recovery. P ⁇ 0/05 vs control Fischer exact test.
- Treatment with NgR(310)ecto-Fc or combined treatment with MP and NgR(310)ecto-Fc enhanced axonal plasticity/regeneration after spinal cord transection. Briefly, for histological tracing of the CSTs, 2 weeks after CST transection animals were re-anesthetized and an incision made in the scalp.
- the area around the skin incision was injected with a local anesthetic, the left sensorimotor cortex exposed via a craniotomy and 7 ⁇ L 10% biotin dextran amine (BDA; 10,000 MW; Molcular Probes, Eugene, OR, USA) in PBS injected using a nanoliter injector and micro4 controller at 12 points 0-3.5 mm posterior to Bregma and 0-2.5 mm lateral to the midline at a depth of 1 mm below the surface of the cortex.
- BDA biotin dextran amine
- the CST was labeled bilaterally using the same procedure.
- AlexaFluor-594 (1 :200; Molecular Probes) to visualize labeled CST axons.
- Axon counts were performed on transverse sections taken 10 and 15 mm caudal to the transection site. -All measurements were performed blind. Every eighth section, i.e., sections 400 ⁇ m apart, was counted for each animal at each level of the cord and the values were expressed as mean number of axons per section.
- Anti-vesicular glutamate transporter 1 (vGLUTl) antibody (dilution 1:2500) was used to stain for neuronal cell bodies and ⁇ - and ⁇ -motor neurons in lamina 9 were identified by their size and morphology. The number of axons contacting ⁇ - or ⁇ -motor neurons was significantly increased in the MP + NgR(310)ecto-Fc-treated group compared with control animals, with the most marked and significant effect observed in animals receiving combined treatment with NgR(310)ecto-Fc and MP ( Figure 27). P ⁇ 0/05, one-way ANOVA with Dunnett's posthoc test.
- Hybridomas HB 7El 1 (ATCC ® accession No. PTA-4587), HB 1H2 (ATCC ® accession
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Medicinal Chemistry (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- Biomedical Technology (AREA)
- Zoology (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Molecular Biology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Biotechnology (AREA)
- Immunology (AREA)
- Biochemistry (AREA)
- Biophysics (AREA)
- Wood Science & Technology (AREA)
- General Engineering & Computer Science (AREA)
- Environmental Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Neurology (AREA)
- Microbiology (AREA)
- Neurosurgery (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Gastroenterology & Hepatology (AREA)
- Cell Biology (AREA)
- Endocrinology (AREA)
- Animal Husbandry (AREA)
- Biodiversity & Conservation Biology (AREA)
- Diabetes (AREA)
- Epidemiology (AREA)
- Ophthalmology & Optometry (AREA)
Abstract
Description






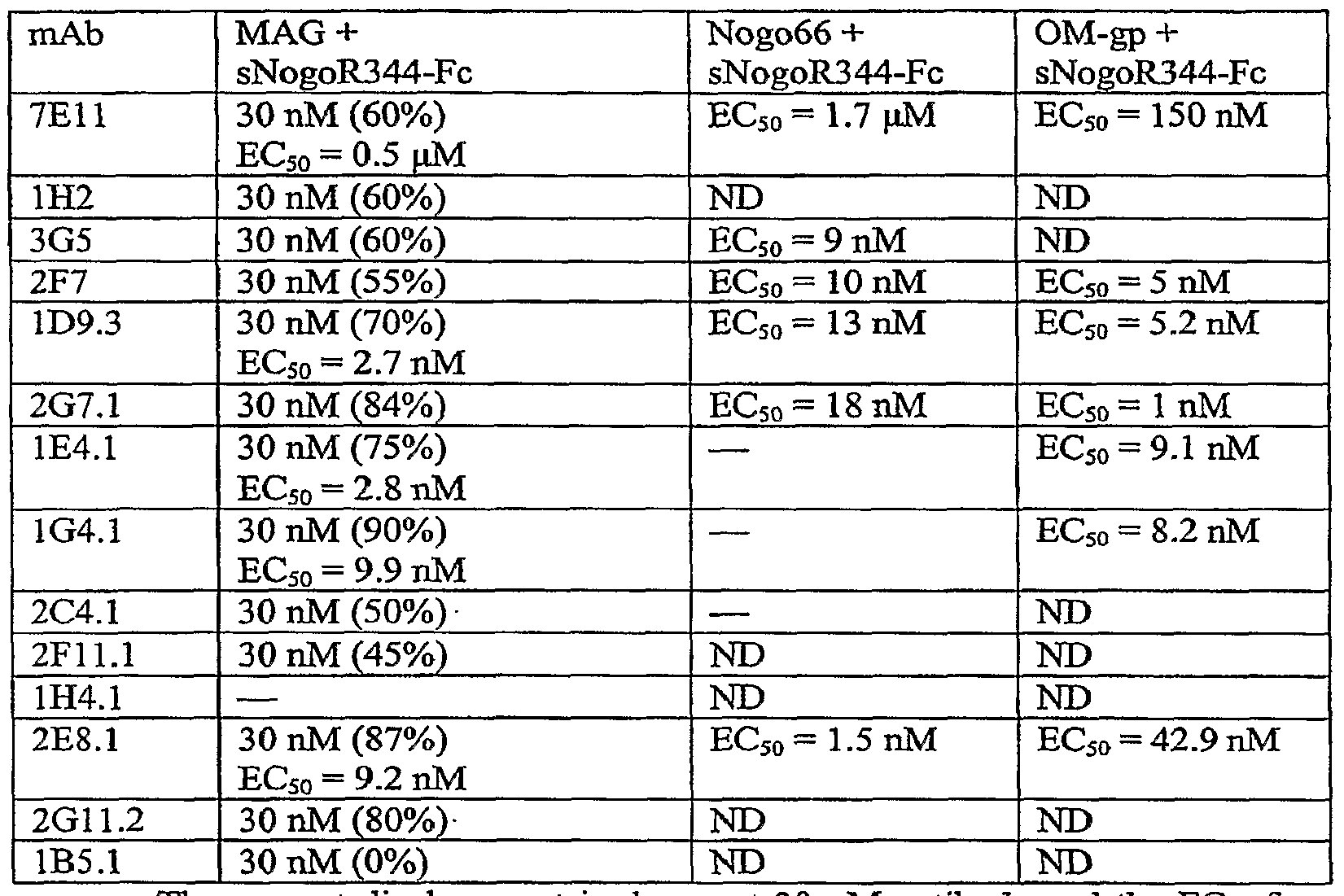



Claims
Priority Applications (11)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008552443A JP5829373B2 (en) | 2006-01-27 | 2007-01-26 | Nogo receptor antagonist |
| CN200780010338.3A CN101420977B (en) | 2006-01-27 | 2007-01-26 | NOGO receptor antagonist |
| EP07762730.5A EP1981902B1 (en) | 2006-01-27 | 2007-01-26 | Nogo receptor antagonists |
| US12/162,256 US8669345B2 (en) | 2006-01-27 | 2007-01-26 | Nogo receptor antagonists |
| ES07762730.5T ES2550099T3 (en) | 2006-01-27 | 2007-01-26 | Nogo receptor antagonists |
| CA2640423A CA2640423C (en) | 2006-01-27 | 2007-01-26 | Nogo receptor antagonists |
| DK07762730.5T DK1981902T3 (en) | 2006-01-27 | 2007-01-26 | Nogo Receptor Antagonists |
| BRPI0707276-7A BRPI0707276B1 (en) | 2006-01-27 | 2007-01-26 | NOGO RECEPTOR ANTAGONIST FUSION POLYPEPTIDE |
| US14/146,345 US9228015B2 (en) | 2006-01-27 | 2014-01-02 | Nogo receptor antagonists and methods of increasing neurite outgrowth |
| HRP20151108TT HRP20151108T1 (en) | 2006-01-27 | 2015-10-20 | Nogo receptor antagonists |
| US14/952,613 US20160159878A1 (en) | 2006-01-27 | 2015-11-25 | NOGO Receptor Antagonists |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US76248706P | 2006-01-27 | 2006-01-27 | |
| US60/762,487 | 2006-01-27 | ||
| US83165906P | 2006-07-19 | 2006-07-19 | |
| US60/831,659 | 2006-07-19 |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US12/162,256 A-371-Of-International US8669345B2 (en) | 2006-01-27 | 2007-01-26 | Nogo receptor antagonists |
| US14/146,345 Continuation US9228015B2 (en) | 2006-01-27 | 2014-01-02 | Nogo receptor antagonists and methods of increasing neurite outgrowth |
Publications (4)
| Publication Number | Publication Date |
|---|---|
| WO2007089601A2 true WO2007089601A2 (en) | 2007-08-09 |
| WO2007089601A8 WO2007089601A8 (en) | 2008-10-02 |
| WO2007089601A3 WO2007089601A3 (en) | 2008-11-06 |
| WO2007089601A9 WO2007089601A9 (en) | 2008-12-18 |
Family
ID=38327911
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2007/002199 WO2007089601A2 (en) | 2006-01-27 | 2007-01-26 | Nogo receptor antagonists |
Country Status (11)
| Country | Link |
|---|---|
| US (3) | US8669345B2 (en) |
| EP (2) | EP2526968A3 (en) |
| JP (4) | JP5829373B2 (en) |
| CN (2) | CN101420977B (en) |
| BR (1) | BRPI0707276B1 (en) |
| CA (2) | CA2640423C (en) |
| DK (1) | DK1981902T3 (en) |
| ES (1) | ES2550099T3 (en) |
| HR (1) | HRP20151108T1 (en) |
| PT (1) | PT1981902E (en) |
| WO (1) | WO2007089601A2 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8992918B2 (en) | 2008-03-13 | 2015-03-31 | Yale University | Reactivation of axon growth and recovery in chronic spinal cord injury |
| WO2021079002A2 (en) | 2019-10-24 | 2021-04-29 | Novago Therapeutics Ag | Novel anti-nogo-a antibodies |
Families Citing this family (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8669345B2 (en) * | 2006-01-27 | 2014-03-11 | Biogen Idec Ma Inc. | Nogo receptor antagonists |
| JP5795072B2 (en) | 2010-10-22 | 2015-10-14 | ソンギュングヮン ユニバーシティ ファウンデーション フォー コーポレート コラボレーション | Nucleic acid molecules that induce RNA interference and uses thereof |
| RS63244B1 (en) | 2011-12-16 | 2022-06-30 | Modernatx Inc | Modified mrna compositions |
| WO2013151664A1 (en) | 2012-04-02 | 2013-10-10 | modeRNA Therapeutics | Modified polynucleotides for the production of proteins |
| US9303079B2 (en) | 2012-04-02 | 2016-04-05 | Moderna Therapeutics, Inc. | Modified polynucleotides for the production of cytoplasmic and cytoskeletal proteins |
| US9283287B2 (en) | 2012-04-02 | 2016-03-15 | Moderna Therapeutics, Inc. | Modified polynucleotides for the production of nuclear proteins |
| DK2853597T3 (en) | 2012-05-22 | 2019-04-08 | Olix Pharmaceuticals Inc | RNA INTERFERENCE-INducing NUCLEIC ACID MOLECULES WITH CELL PENETENING EQUIPMENT AND USE THEREOF |
| US10033029B2 (en) | 2012-11-27 | 2018-07-24 | Apple Inc. | Battery with increased energy density and method of manufacturing the same |
| US10211433B2 (en) | 2012-11-27 | 2019-02-19 | Apple Inc. | Battery packaging |
| US9711770B2 (en) | 2012-11-27 | 2017-07-18 | Apple Inc. | Laminar battery system |
| US9899661B2 (en) | 2013-03-13 | 2018-02-20 | Apple Inc. | Method to improve LiCoO2 morphology in thin film batteries |
| WO2014152211A1 (en) | 2013-03-14 | 2014-09-25 | Moderna Therapeutics, Inc. | Formulation and delivery of modified nucleoside, nucleotide, and nucleic acid compositions |
| US10141600B2 (en) | 2013-03-15 | 2018-11-27 | Apple Inc. | Thin film pattern layer battery systems |
| US9570775B2 (en) | 2013-03-15 | 2017-02-14 | Apple Inc. | Thin film transfer battery systems |
| US9601751B2 (en) | 2013-03-15 | 2017-03-21 | Apple Inc. | Annealing method for thin film electrodes |
| US9887403B2 (en) | 2013-03-15 | 2018-02-06 | Apple Inc. | Thin film encapsulation battery systems |
| US10930915B2 (en) | 2014-09-02 | 2021-02-23 | Apple Inc. | Coupling tolerance accommodating contacts or leads for batteries |
| CA3005411C (en) | 2015-11-16 | 2024-01-09 | Olix Pharmaceuticals, Inc. | Treatment of age-related macular degeneration using rna complexes that target myd88 or tlr3 |
| EP3411481A4 (en) | 2016-02-02 | 2020-02-26 | Olix Pharmaceuticals, Inc. | Treatment of angiogenesis-associated diseases using rna complexes that target angpt2 and pdgfb |
| CN108779463B (en) | 2016-02-02 | 2022-05-24 | 奥利克斯医药有限公司 | Treatment of atopic dermatitis and asthma using RNA complexes targeting IL4R α, TRPA1, or F2RL1 |
| JP7049262B2 (en) | 2016-04-11 | 2022-04-06 | オリックス ファーマシューティカルズ,インコーポレーテッド | Treatment of idiopathic alveolar fibrosis with RNA complexes targeting connective tissue growth factors |
| KR101916652B1 (en) | 2016-06-29 | 2018-11-08 | 올릭스 주식회사 | Compounds improving RNA interference of small interfering RNA and use thereof |
| US11591600B2 (en) | 2017-02-10 | 2023-02-28 | OliX Pharmaceuticals. Inc. | Long double-stranded RNA for RNA interference |
| CN108359011B (en) * | 2017-07-21 | 2019-06-25 | 华博生物医药技术(上海)有限公司 | Target the antibody, preparation method and application of interleukin-17 A |
| CN107522783B (en) * | 2017-09-30 | 2020-07-07 | 华博生物医药技术(上海)有限公司 | Antibody against interleukin 17A, preparation method and application thereof |
| CN111032095B (en) * | 2017-11-22 | 2022-07-01 | 弗门尼舍有限公司 | Method for identifying compounds capable of modulating laundry malodor, mold malodor, and/or sweat malodor |
| US11824220B2 (en) | 2020-09-03 | 2023-11-21 | Apple Inc. | Electronic device having a vented battery barrier |
| KR20240087559A (en) * | 2022-11-29 | 2024-06-19 | 한국생명공학연구원 | Inhibitor of activity or expression of NgR1 protein for improving cytolytic activity by promoting formation of immunological synapse of immune cells |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5252714A (en) | 1990-11-28 | 1993-10-12 | The University Of Alabama In Huntsville | Preparation and use of polyethylene glycol propionaldehyde |
Family Cites Families (159)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| NL154598B (en) | 1970-11-10 | 1977-09-15 | Organon Nv | PROCEDURE FOR DETERMINING AND DETERMINING LOW MOLECULAR COMPOUNDS AND PROTEINS THAT CAN SPECIFICALLY BIND THESE COMPOUNDS AND TEST PACKAGING. |
| US3817837A (en) | 1971-05-14 | 1974-06-18 | Syva Corp | Enzyme amplification assay |
| US3773319A (en) | 1971-12-16 | 1973-11-20 | Fabcor Ind Inc | Corrugated sheet inverting machine |
| US3939350A (en) | 1974-04-29 | 1976-02-17 | Board Of Trustees Of The Leland Stanford Junior University | Fluorescent immunoassay employing total reflection for activation |
| US3996345A (en) | 1974-08-12 | 1976-12-07 | Syva Company | Fluorescence quenching with immunological pairs in immunoassays |
| US4277437A (en) | 1978-04-05 | 1981-07-07 | Syva Company | Kit for carrying out chemically induced fluorescence immunoassay |
| US4275149A (en) | 1978-11-24 | 1981-06-23 | Syva Company | Macromolecular environment control in specific receptor assays |
| US4444887A (en) | 1979-12-10 | 1984-04-24 | Sloan-Kettering Institute | Process for making human antibody producing B-lymphocytes |
| US4634665A (en) | 1980-02-25 | 1987-01-06 | The Trustees Of Columbia University In The City Of New York | Processes for inserting DNA into eucaryotic cells and for producing proteinaceous materials |
| US5179017A (en) | 1980-02-25 | 1993-01-12 | The Trustees Of Columbia University In The City Of New York | Processes for inserting DNA into eucaryotic cells and for producing proteinaceous materials |
| US4399216A (en) | 1980-02-25 | 1983-08-16 | The Trustees Of Columbia University | Processes for inserting DNA into eucaryotic cells and for producing proteinaceous materials |
| US4366241A (en) | 1980-08-07 | 1982-12-28 | Syva Company | Concentrating zone method in heterogeneous immunoassays |
| IE52535B1 (en) | 1981-02-16 | 1987-12-09 | Ici Plc | Continuous release pharmaceutical compositions |
| DE3280400D1 (en) | 1981-10-23 | 1992-06-04 | Molecular Biosystems Inc | OLIGONUCLEOTIDES MEDICINE AND THEIR PRODUCTION METHOD. |
| US4716111A (en) | 1982-08-11 | 1987-12-29 | Trustees Of Boston University | Process for producing human antibodies |
| US4510245A (en) | 1982-11-18 | 1985-04-09 | Chiron Corporation | Adenovirus promoter system |
| GB8308235D0 (en) | 1983-03-25 | 1983-05-05 | Celltech Ltd | Polypeptides |
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| HUT35524A (en) | 1983-08-02 | 1985-07-29 | Hoechst Ag | Process for preparing pharmaceutical compositions containing regulatory /regulative/ peptides providing for the retarded release of the active substance |
| DE3572982D1 (en) | 1984-03-06 | 1989-10-19 | Takeda Chemical Industries Ltd | Chemically modified lymphokine and production thereof |
| US4694778A (en) | 1984-05-04 | 1987-09-22 | Anicon, Inc. | Chemical vapor deposition wafer boat |
| US5807715A (en) | 1984-08-27 | 1998-09-15 | The Board Of Trustees Of The Leland Stanford Junior University | Methods and transformed mammalian lymphocyte cells for producing functional antigen-binding protein including chimeric immunoglobulin |
| US5168062A (en) | 1985-01-30 | 1992-12-01 | University Of Iowa Research Foundation | Transfer vectors and microorganisms containing human cytomegalovirus immediate-early promoter-regulatory DNA sequence |
| GB2183662B (en) | 1985-04-01 | 1989-01-25 | Celltech Ltd | Transformed myeloma cell-line and a process for the expression of a gene coding for a eukaryotic polypeptide employing same |
| US4968615A (en) | 1985-12-18 | 1990-11-06 | Ciba-Geigy Corporation | Deoxyribonucleic acid segment from a virus |
| GB8601597D0 (en) | 1986-01-23 | 1986-02-26 | Wilson R H | Nucleotide sequences |
| GB8607679D0 (en) | 1986-03-27 | 1986-04-30 | Winter G P | Recombinant dna product |
| US5225539A (en) | 1986-03-27 | 1993-07-06 | Medical Research Council | Recombinant altered antibodies and methods of making altered antibodies |
| US4902505A (en) | 1986-07-30 | 1990-02-20 | Alkermes | Chimeric peptides for neuropeptide delivery through the blood-brain barrier |
| US4946778A (en) | 1987-09-21 | 1990-08-07 | Genex Corporation | Single polypeptide chain binding molecules |
| US5116742A (en) | 1986-12-03 | 1992-05-26 | University Patents, Inc. | RNA ribozyme restriction endoribonucleases and methods |
| US5258498A (en) | 1987-05-21 | 1993-11-02 | Creative Biomolecules, Inc. | Polypeptide linkers for production of biosynthetic proteins |
| US4904582A (en) | 1987-06-11 | 1990-02-27 | Synthetic Genetics | Novel amphiphilic nucleic acid conjugates |
| GB8717430D0 (en) | 1987-07-23 | 1987-08-26 | Celltech Ltd | Recombinant dna product |
| US5336603A (en) | 1987-10-02 | 1994-08-09 | Genentech, Inc. | CD4 adheson variants |
| WO1989012624A2 (en) | 1988-06-14 | 1989-12-28 | Cetus Corporation | Coupling agents and sterically hindered disulfide linked conjugates prepared therefrom |
| US5223409A (en) | 1988-09-02 | 1993-06-29 | Protein Engineering Corp. | Directed evolution of novel binding proteins |
| AU4308689A (en) | 1988-09-02 | 1990-04-02 | Protein Engineering Corporation | Generation and selection of recombinant varied binding proteins |
| DE68913658T3 (en) | 1988-11-11 | 2005-07-21 | Stratagene, La Jolla | Cloning of immunoglobulin sequences from the variable domains |
| US5175384A (en) | 1988-12-05 | 1992-12-29 | Genpharm International | Transgenic mice depleted in mature t-cells and methods for making transgenic mice |
| ATE135370T1 (en) | 1988-12-22 | 1996-03-15 | Kirin Amgen Inc | CHEMICALLY MODIFIED GRANULOCYTE COLONY EXCITING FACTOR |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| US5225538A (en) | 1989-02-23 | 1993-07-06 | Genentech, Inc. | Lymphocyte homing receptor/immunoglobulin fusion proteins |
| ZA902949B (en) | 1989-05-05 | 1992-02-26 | Res Dev Foundation | A novel antibody delivery system for biological response modifiers |
| US5413923A (en) | 1989-07-25 | 1995-05-09 | Cell Genesys, Inc. | Homologous recombination for universal donor cells and chimeric mammalian hosts |
| EP0451221B1 (en) | 1989-08-31 | 1994-10-12 | City Of Hope | Chimeric dna-rna catalytic sequences |
| GB8928874D0 (en) | 1989-12-21 | 1990-02-28 | Celltech Ltd | Humanised antibodies |
| WO1991010737A1 (en) | 1990-01-11 | 1991-07-25 | Molecular Affinities Corporation | Production of antibodies using gene libraries |
| US5780225A (en) | 1990-01-12 | 1998-07-14 | Stratagene | Method for generating libaries of antibody genes comprising amplification of diverse antibody DNAs and methods for using these libraries for the production of diverse antigen combining molecules |
| JP3068180B2 (en) | 1990-01-12 | 2000-07-24 | アブジェニックス インコーポレイテッド | Generation of heterologous antibodies |
| US6075181A (en) | 1990-01-12 | 2000-06-13 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| US6150584A (en) | 1990-01-12 | 2000-11-21 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| US5314995A (en) | 1990-01-22 | 1994-05-24 | Oncogen | Therapeutic interleukin-2-antibody based fusion proteins |
| WO1991014438A1 (en) | 1990-03-20 | 1991-10-03 | The Trustees Of Columbia University In The City Of New York | Chimeric antibodies with receptor binding ligands in place of their constant region |
| US5427908A (en) | 1990-05-01 | 1995-06-27 | Affymax Technologies N.V. | Recombinant library screening methods |
| US5962219A (en) | 1990-06-11 | 1999-10-05 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: chemi-selex |
| US5580737A (en) | 1990-06-11 | 1996-12-03 | Nexstar Pharmaceuticals, Inc. | High-affinity nucleic acid ligands that discriminate between theophylline and caffeine |
| EP1493825A3 (en) | 1990-06-11 | 2005-02-09 | Gilead Sciences, Inc. | Method for producing nucleic acid ligands |
| US5567588A (en) | 1990-06-11 | 1996-10-22 | University Research Corporation | Systematic evolution of ligands by exponential enrichment: Solution SELEX |
| US5270163A (en) | 1990-06-11 | 1993-12-14 | University Research Corporation | Methods for identifying nucleic acid ligands |
| US5763177A (en) | 1990-06-11 | 1998-06-09 | Nexstar Pharmaceuticals, Inc. | Systematic evolution of ligands by exponential enrichment: photoselection of nucleic acid ligands and solution selex |
| US5707796A (en) | 1990-06-11 | 1998-01-13 | Nexstar Pharmaceuticals, Inc. | Method for selecting nucleic acids on the basis of structure |
| GB9014932D0 (en) | 1990-07-05 | 1990-08-22 | Celltech Ltd | Recombinant dna product and method |
| GB9015198D0 (en) | 1990-07-10 | 1990-08-29 | Brien Caroline J O | Binding substance |
| AU665190B2 (en) | 1990-07-10 | 1995-12-21 | Cambridge Antibody Technology Limited | Methods for producing members of specific binding pairs |
| US5633425A (en) | 1990-08-29 | 1997-05-27 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5625126A (en) | 1990-08-29 | 1997-04-29 | Genpharm International, Inc. | Transgenic non-human animals for producing heterologous antibodies |
| US5661016A (en) | 1990-08-29 | 1997-08-26 | Genpharm International Inc. | Transgenic non-human animals capable of producing heterologous antibodies of various isotypes |
| ATE158021T1 (en) | 1990-08-29 | 1997-09-15 | Genpharm Int | PRODUCTION AND USE OF NON-HUMAN TRANSGENT ANIMALS FOR THE PRODUCTION OF HETEROLOGUE ANTIBODIES |
| US5814318A (en) | 1990-08-29 | 1998-09-29 | Genpharm International Inc. | Transgenic non-human animals for producing heterologous antibodies |
| US5545806A (en) | 1990-08-29 | 1996-08-13 | Genpharm International, Inc. | Ransgenic non-human animals for producing heterologous antibodies |
| US5698426A (en) | 1990-09-28 | 1997-12-16 | Ixsys, Incorporated | Surface expression libraries of heteromeric receptors |
| EP0552178B1 (en) | 1990-10-12 | 1997-01-02 | Max-Planck-Gesellschaft zur Förderung der Wissenschaften e.V. | Modified ribozymes |
| EP1149913A1 (en) | 1990-11-09 | 2001-10-31 | GILLIES, Stephen D. | Cytokine immunoconjugates |
| DK0564531T3 (en) | 1990-12-03 | 1998-09-28 | Genentech Inc | Enrichment procedure for variant proteins with altered binding properties |
| ATE363532T1 (en) | 1991-03-01 | 2007-06-15 | Dyax Corp | METHOD FOR PRODUCING BINDING MINIPROTEINS |
| ES2315612T3 (en) | 1991-04-10 | 2009-04-01 | The Scripps Research Institute | GENOTECAS OF HETERODYMERIC RECEPTORS USING PHAGEMIDS. |
| DE69233482T2 (en) | 1991-05-17 | 2006-01-12 | Merck & Co., Inc. | Method for reducing the immunogenicity of antibody variable domains |
| WO1992022324A1 (en) | 1991-06-14 | 1992-12-23 | Xoma Corporation | Microbially-produced antibody fragments and their conjugates |
| WO1994004679A1 (en) | 1991-06-14 | 1994-03-03 | Genentech, Inc. | Method for making humanized antibodies |
| DE4216134A1 (en) | 1991-06-20 | 1992-12-24 | Europ Lab Molekularbiolog | SYNTHETIC CATALYTIC OLIGONUCLEOTIDE STRUCTURES |
| DE4122599C2 (en) | 1991-07-08 | 1993-11-11 | Deutsches Krebsforsch | Phagemid for screening antibodies |
| US5756096A (en) | 1991-07-25 | 1998-05-26 | Idec Pharmaceuticals Corporation | Recombinant antibodies for human therapy |
| MX9204374A (en) | 1991-07-25 | 1993-03-01 | Idec Pharma Corp | RECOMBINANT ANTIBODY AND METHOD FOR ITS PRODUCTION. |
| ES2136092T3 (en) | 1991-09-23 | 1999-11-16 | Medical Res Council | PROCEDURES FOR THE PRODUCTION OF HUMANIZED ANTIBODIES. |
| PT1024191E (en) | 1991-12-02 | 2008-12-22 | Medical Res Council | Production of anti-self antibodies from antibody segment repertoires and displayed on phage |
| JPH05244982A (en) | 1991-12-06 | 1993-09-24 | Sumitomo Chem Co Ltd | Humanized b-b10 |
| US5652094A (en) | 1992-01-31 | 1997-07-29 | University Of Montreal | Nucleozymes |
| WO1993016177A1 (en) | 1992-02-11 | 1993-08-19 | Cell Genesys, Inc. | Homogenotization of gene-targeting events |
| US5733743A (en) | 1992-03-24 | 1998-03-31 | Cambridge Antibody Technology Limited | Methods for producing members of specific binding pairs |
| US5639641A (en) | 1992-09-09 | 1997-06-17 | Immunogen Inc. | Resurfacing of rodent antibodies |
| EP0627932B1 (en) | 1992-11-04 | 2002-05-08 | City Of Hope | Antibody construct |
| EP0669986B1 (en) | 1992-11-13 | 2003-04-09 | Idec Pharmaceuticals Corporation | Fully impaired consensus kozac sequences for mammalian expression |
| WO1994016736A1 (en) | 1993-01-22 | 1994-08-04 | University Research Corporation | Localization of therapeutic agents |
| US5624803A (en) | 1993-10-14 | 1997-04-29 | The Regents Of The University Of California | In vivo oligonucleotide generator, and methods of testing the binding affinity of triplex forming oligonucleotides derived therefrom |
| JPH09506262A (en) | 1993-12-08 | 1997-06-24 | ジェンザイム・コーポレイション | Method for producing specific antibody |
| ES2247204T3 (en) | 1994-01-31 | 2006-03-01 | Trustees Of Boston University | BANKS OF POLYCLONAL ANTIBODIES. |
| US5627053A (en) | 1994-03-29 | 1997-05-06 | Ribozyme Pharmaceuticals, Inc. | 2'deoxy-2'-alkylnucleotide containing nucleic acid |
| US5516637A (en) | 1994-06-10 | 1996-05-14 | Dade International Inc. | Method involving display of protein binding pairs on the surface of bacterial pili and bacteriophage |
| US5811252A (en) | 1994-07-07 | 1998-09-22 | Nederlandse Organisatie Voor Toegepast-Natuurwetenschappelijk Onderzoek Tno | Modified proenzymes as substrates for proteolytic enzymes |
| US5716824A (en) | 1995-04-20 | 1998-02-10 | Ribozyme Pharmaceuticals, Inc. | 2'-O-alkylthioalkyl and 2-C-alkylthioalkyl-containing enzymatic nucleic acids (ribozymes) |
| AU4412096A (en) | 1994-12-13 | 1996-07-03 | Ribozyme Pharmaceuticals, Inc. | Method and reagent for treatment of arthritic conditions, induction of graft tolerance and reversal of immune responses |
| US6130364A (en) | 1995-03-29 | 2000-10-10 | Abgenix, Inc. | Production of antibodies using Cre-mediated site-specific recombination |
| DE69637481T2 (en) | 1995-04-27 | 2009-04-09 | Amgen Fremont Inc. | Human antibodies to IL-8 derived from immunized Xenomae |
| AU2466895A (en) | 1995-04-28 | 1996-11-18 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| US6699843B2 (en) | 1995-06-07 | 2004-03-02 | Gilead Sciences, Inc. | Method for treatment of tumors using nucleic acid ligands to PDGF |
| US5811524A (en) | 1995-06-07 | 1998-09-22 | Idec Pharmaceuticals Corporation | Neutralizing high affinity human monoclonal antibodies specific to RSV F-protein and methods for their manufacture and therapeutic use thereof |
| US6068829A (en) | 1995-09-11 | 2000-05-30 | The Burnham Institute | Method of identifying molecules that home to a selected organ in vivo |
| US5998203A (en) | 1996-04-16 | 1999-12-07 | Ribozyme Pharmaceuticals, Inc. | Enzymatic nucleic acids containing 5'-and/or 3'-cap structures |
| WO1997026270A2 (en) | 1996-01-16 | 1997-07-24 | Ribozyme Pharmaceuticals, Inc. | Synthesis of methoxy nucleosides and enzymatic nucleic acid molecules |
| JP2978435B2 (en) | 1996-01-24 | 1999-11-15 | チッソ株式会社 | Method for producing acryloxypropyl silane |
| US5849902A (en) | 1996-09-26 | 1998-12-15 | Oligos Etc. Inc. | Three component chimeric antisense oligonucleotides |
| US5916771A (en) | 1996-10-11 | 1999-06-29 | Abgenix, Inc. | Production of a multimeric protein by cell fusion method |
| US6420140B1 (en) | 1996-10-11 | 2002-07-16 | Abgenix, Inc. | Production of multimeric protein by cell fusion method |
| KR20080059467A (en) | 1996-12-03 | 2008-06-27 | 아브게닉스, 인크. | Transgenic mammals having human ig loci including plural vh and vk regions and antibodies produced therefrom |
| WO1999066041A1 (en) | 1998-06-16 | 1999-12-23 | Human Genome Sciences, Inc. | 94 human secreted proteins |
| PL191251B1 (en) | 1997-03-14 | 2006-04-28 | Idec Pharma Corp | Method for integrating genes at specific sites of mammalian cell genome via honologous recombination and vectors for accomplishing the same |
| WO1998046645A2 (en) | 1997-04-14 | 1998-10-22 | Micromet Gesellschaft Für Biomedizinische Forschung Mbh | Method for the production of antihuman antigen receptors and uses thereof |
| US6235883B1 (en) | 1997-05-05 | 2001-05-22 | Abgenix, Inc. | Human monoclonal antibodies to epidermal growth factor receptor |
| JP2002512624A (en) | 1997-05-21 | 2002-04-23 | バイオベーション リミテッド | Method for producing non-immunogenic protein |
| US6011577A (en) | 1997-06-30 | 2000-01-04 | Polaroid Corporation | Modular optical print head assembly |
| WO1999004705A1 (en) | 1997-07-25 | 1999-02-04 | Tsui Ban C H | Devices, systems and methods for determining proper placement of epidural catheters |
| ES2242291T5 (en) | 1997-09-12 | 2016-03-11 | Exiqon A/S | Bicyclic and tricyclic nucleoside analogs, nucleotides and oligonucleotides |
| AU9319398A (en) | 1997-09-19 | 1999-04-05 | Sequitur, Inc. | Sense mrna therapy |
| US6506559B1 (en) | 1997-12-23 | 2003-01-14 | Carnegie Institute Of Washington | Genetic inhibition by double-stranded RNA |
| US20020072493A1 (en) | 1998-05-19 | 2002-06-13 | Yeda Research And Development Co. Ltd. | Activated T cells, nervous system-specific antigens and their uses |
| EP1051432B1 (en) | 1998-12-08 | 2007-01-24 | Biovation Limited | Method for reducing immunogenicity of proteins |
| US7041474B2 (en) | 1998-12-30 | 2006-05-09 | Millennium Pharmaceuticals, Inc. | Nucleic acid encoding human tango 509 |
| DE19956568A1 (en) | 1999-01-30 | 2000-08-17 | Roland Kreutzer | Method and medicament for inhibiting the expression of a given gene |
| AU781598B2 (en) | 1999-04-21 | 2005-06-02 | Alnylam Pharmaceuticals, Inc. | Methods and compositions for inhibiting the function of polynucleotide sequences |
| ATE356824T1 (en) | 1999-05-04 | 2007-04-15 | Santaris Pharma As | L-RIBO-LNA ANALOGUE |
| WO2001029058A1 (en) | 1999-10-15 | 2001-04-26 | University Of Massachusetts | Rna interference pathway genes as tools for targeted genetic interference |
| GB9927444D0 (en) | 1999-11-19 | 2000-01-19 | Cancer Res Campaign Tech | Inhibiting gene expression |
| US7119165B2 (en) | 2000-01-12 | 2006-10-10 | Yale University | Nogo receptor-mediated blockade of axonal growth |
| AU784349C (en) | 2000-01-12 | 2006-09-28 | Yale University | Nogo receptor-mediated blockade of axonal growth |
| US7378248B2 (en) | 2000-03-06 | 2008-05-27 | Rigel Pharmaceuticals, Inc. | In vivo production of cyclic peptides for inhibiting protein-protein interaction |
| AU2001245793A1 (en) | 2000-03-16 | 2001-09-24 | Cold Spring Harbor Laboratory | Methods and compositions for rna interference |
| WO2001070949A1 (en) | 2000-03-17 | 2001-09-27 | Benitec Australia Ltd | Genetic silencing |
| DK1309726T4 (en) | 2000-03-30 | 2019-01-28 | Whitehead Inst Biomedical Res | RNA Sequence-Specific Mediators of RNA Interference |
| WO2001092513A1 (en) | 2000-05-30 | 2001-12-06 | Johnson & Johnson Research Pty Limited | METHODS FOR MEDIATING GENE SUPPRESION BY USING FACTORS THAT ENHANCE RNAi |
| NZ525422A (en) | 2000-10-06 | 2006-09-29 | Biogen Idec Inc | Isolated polynucleotides comprising a nucleic acid which encodes a polypeptide which modulates axonal growth in CNS neurons |
| WO2002102855A2 (en) | 2000-11-17 | 2002-12-27 | University Of Rochester | In vitro methods of producing and identifying immunoglobulin molecules in eukaryotic cells |
| NZ545176A (en) | 2001-01-29 | 2008-05-30 | Biogen Idec Inc | Modified antibodies reactive with CD20 and methods of use |
| WO2002096948A2 (en) | 2001-01-29 | 2002-12-05 | Idec Pharmaceuticals Corporation | Engineered tetravalent antibodies and methods of use |
| US20040259092A1 (en) | 2001-08-27 | 2004-12-23 | Carmen Barske | Nogo receptor homologues and their use |
| US7129085B2 (en) * | 2001-10-11 | 2006-10-31 | Bristol-Myers Squibb Company | Polynucleotides encoding a human leucine-rich repeat domain containing protein, HLLRCR-1 |
| WO2003035687A1 (en) | 2001-10-22 | 2003-05-01 | Novartis Ag | Nogo receptor homologues and their use |
| US7309485B2 (en) | 2001-12-03 | 2007-12-18 | Children's Medical Center Corporation | Reducing myelin-mediated inhibition of axon regeneration |
| US20030113325A1 (en) | 2001-12-03 | 2003-06-19 | Zhigang He | Reducing myelin-mediated inhibition of axon regeneration |
| EP1354892A1 (en) | 2002-04-19 | 2003-10-22 | Centre National De La Recherche Scientifique (Cnrs) | Peptides capable of inducing attraction of the axonal growth and their use for treating neurodegenerative diseases |
| US7745151B2 (en) | 2002-08-02 | 2010-06-29 | Children's Medical Center Corporation | Methods of determining binding between Nogo receptor and p75 neurotrophin receptor |
| ATE469913T1 (en) | 2002-08-10 | 2010-06-15 | Univ Yale | ANTAGONISTS OF THE NOGO RECEPTOR |
| CN1832752A (en) * | 2003-04-16 | 2006-09-13 | 耶鲁大学 | Nogo-receptor antagonists for the treatment of conditions involving amyloid plaques |
| JP2007501612A (en) | 2003-08-07 | 2007-02-01 | バイオジェン・アイデック・エムエイ・インコーポレイテッド | Nogo receptor antagonist |
| EP1682661A2 (en) | 2003-10-23 | 2006-07-26 | Sirna Therapeutics, Inc. | Rna interference mediated inhibition of gene expression using short interfering nucleic acid (sina) |
| CA2549000A1 (en) * | 2003-12-16 | 2005-06-30 | Children's Medical Center Corporation | Method for treating neurological disorders |
| WO2006124627A2 (en) * | 2005-05-12 | 2006-11-23 | Biogen Idec Ma Inc. | Methods of treating conditions involving neuronal degeneration |
| CA2619406A1 (en) * | 2005-08-25 | 2007-03-01 | Biogen Idec Ma Inc. | Nogo receptor polypeptides and polypeptide fragments and uses thereof |
| US8669345B2 (en) * | 2006-01-27 | 2014-03-11 | Biogen Idec Ma Inc. | Nogo receptor antagonists |
-
2007
- 2007-01-26 US US12/162,256 patent/US8669345B2/en active Active
- 2007-01-26 WO PCT/US2007/002199 patent/WO2007089601A2/en active Application Filing
- 2007-01-26 EP EP12162911.7A patent/EP2526968A3/en not_active Withdrawn
- 2007-01-26 CA CA2640423A patent/CA2640423C/en active Active
- 2007-01-26 CA CA2913655A patent/CA2913655A1/en not_active Abandoned
- 2007-01-26 PT PT77627305T patent/PT1981902E/en unknown
- 2007-01-26 CN CN200780010338.3A patent/CN101420977B/en active Active
- 2007-01-26 ES ES07762730.5T patent/ES2550099T3/en active Active
- 2007-01-26 DK DK07762730.5T patent/DK1981902T3/en active
- 2007-01-26 BR BRPI0707276-7A patent/BRPI0707276B1/en active IP Right Grant
- 2007-01-26 CN CN201210593895.5A patent/CN103215293B/en active Active
- 2007-01-26 EP EP07762730.5A patent/EP1981902B1/en active Active
- 2007-01-26 JP JP2008552443A patent/JP5829373B2/en not_active Expired - Fee Related
-
2012
- 2012-12-05 JP JP2012266674A patent/JP2013048638A/en active Pending
-
2014
- 2014-01-02 US US14/146,345 patent/US9228015B2/en active Active
- 2014-08-21 JP JP2014168201A patent/JP2014221076A/en not_active Withdrawn
-
2015
- 2015-10-20 HR HRP20151108TT patent/HRP20151108T1/en unknown
- 2015-11-25 US US14/952,613 patent/US20160159878A1/en not_active Abandoned
-
2016
- 2016-03-03 JP JP2016040966A patent/JP2016104821A/en not_active Withdrawn
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5252714A (en) | 1990-11-28 | 1993-10-12 | The University Of Alabama In Huntsville | Preparation and use of polyethylene glycol propionaldehyde |
Non-Patent Citations (13)
| Title |
|---|
| BIOCONJUGATE CHEM., vol. 5, 1994, pages 133 - 140 |
| BRITTIS; FLANAGAN, NEURON, vol. 30, 2001, pages 11 - 14 |
| CHEN ET AL., NATURE, vol. 403, 2000, pages 434 - 439 |
| DOMENICONI ET AL., NEURON, vol. 35, 2002, pages 283 - 90 |
| FOUMIER ET AL., NATURE, vol. 409, 2001, pages 341 - 346 |
| GRANDPRE ET AL., NATURE, vol. 403, 2000, pages 439 - 444 |
| GRIMPE ET AL., J. NEUROSCI., vol. 22, 2002, pages 3144 - 3160 |
| JONES ET AL., J. NEUROSC., vol. 22, 2002, pages 2792 - 2803 |
| LIU ET AL., SCIENCE, vol. 297, 2002, pages 1190 - 93 |
| MCKERRACHER ET AL., NEURON, vol. 13, 1994, pages 805 - 811 |
| MIKOL; STEFANSSON, J. CELL. BIOL., vol. 106, 1988, pages 1273 - 1279 |
| MUKHOPADHYAY ET AL., NEURON, vol. 13, 1994, pages 757 - 767 |
| WANG ET AL., NATURE, vol. 417, 2002, pages 941 - 944 |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8992918B2 (en) | 2008-03-13 | 2015-03-31 | Yale University | Reactivation of axon growth and recovery in chronic spinal cord injury |
| WO2021079002A2 (en) | 2019-10-24 | 2021-04-29 | Novago Therapeutics Ag | Novel anti-nogo-a antibodies |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2009524429A (en) | 2009-07-02 |
| ES2550099T3 (en) | 2015-11-04 |
| CA2913655A1 (en) | 2007-08-09 |
| US9228015B2 (en) | 2016-01-05 |
| WO2007089601A3 (en) | 2008-11-06 |
| JP5829373B2 (en) | 2015-12-09 |
| CN103215293A (en) | 2013-07-24 |
| CN103215293B (en) | 2015-10-28 |
| DK1981902T3 (en) | 2015-10-05 |
| JP2014221076A (en) | 2014-11-27 |
| US20160159878A1 (en) | 2016-06-09 |
| WO2007089601A9 (en) | 2008-12-18 |
| WO2007089601A8 (en) | 2008-10-02 |
| CA2640423A1 (en) | 2007-08-09 |
| BRPI0707276A2 (en) | 2011-04-26 |
| JP2013048638A (en) | 2013-03-14 |
| EP1981902A4 (en) | 2009-12-23 |
| US20140227266A1 (en) | 2014-08-14 |
| EP1981902B1 (en) | 2015-07-29 |
| JP2016104821A (en) | 2016-06-09 |
| EP2526968A3 (en) | 2013-05-22 |
| US8669345B2 (en) | 2014-03-11 |
| EP2526968A2 (en) | 2012-11-28 |
| EP1981902A2 (en) | 2008-10-22 |
| HRP20151108T1 (en) | 2015-11-20 |
| US20090099078A1 (en) | 2009-04-16 |
| PT1981902E (en) | 2015-11-02 |
| BRPI0707276B1 (en) | 2021-08-31 |
| CN101420977B (en) | 2016-08-10 |
| CA2640423C (en) | 2016-03-15 |
| CN101420977A (en) | 2009-04-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9228015B2 (en) | Nogo receptor antagonists and methods of increasing neurite outgrowth | |
| US20200297800A1 (en) | Use of lingo-4 antagonists in the treatment of conditions involving demyelination | |
| US8642040B2 (en) | Methods for promoting myelination, neuronal survival and oligodendrocyte differentiation via administration of Sp35 or TrkA antagonists | |
| US8894999B2 (en) | Use of DR6 and p75 antagonists to promote survival of cells of the nervous system | |
| EP2510934A1 (en) | Methods for promoting neurite outgrowth and survival of dopaminergic neurons | |
| CA2576193A1 (en) | Taj in neuronal function | |
| US20110123535A1 (en) | Use of Nogo Receptor-1 (NGR1) for Promoting Oligodendrocyte Survival | |
| MX2008009620A (en) | Nogo receptor antagonists |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application | ||
| WWE | Wipo information: entry into national phase |
Ref document number: 6474/DELNP/2008 Country of ref document: IN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: MX/a/2008/009620 Country of ref document: MX Ref document number: 2008552443 Country of ref document: JP Ref document number: 2640423 Country of ref document: CA |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2007762730 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 200780010338.3 Country of ref document: CN |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 12162256 Country of ref document: US |
|
| ENP | Entry into the national phase |
Ref document number: PI0707276 Country of ref document: BR Kind code of ref document: A2 Effective date: 20080725 |