WO2006110230A1 - Position-independent microphone system - Google Patents
Position-independent microphone system Download PDFInfo
- Publication number
- WO2006110230A1 WO2006110230A1 PCT/US2006/007800 US2006007800W WO2006110230A1 WO 2006110230 A1 WO2006110230 A1 WO 2006110230A1 US 2006007800 W US2006007800 W US 2006007800W WO 2006110230 A1 WO2006110230 A1 WO 2006110230A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- eigenbeam
- compensation
- distance
- sound source
- microphone array
- Prior art date
Links
Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R3/00—Circuits for transducers, loudspeakers or microphones
- H04R3/005—Circuits for transducers, loudspeakers or microphones for combining the signals of two or more microphones
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S3/00—Systems employing more than two channels, e.g. quadraphonic
- H04S3/002—Non-adaptive circuits, e.g. manually adjustable or static, for enhancing the sound image or the spatial distribution
Definitions
- the present invention relates to acoustics, and, in particular, to microphone arrays. Description of the Related Art
- a microphone array-based audio system typically comprises two units: an arrangement of (a) two or more microphones (i.e., transducers that convert acoustic signals (i.e., sounds) into electrical audio signals) and (b) a beamformer that combines the audio signals generated by the microphones to form an auditory scene representative of at least a portion of the acoustic sound field.
- This combination enables picking up acoustic signals dependent on their direction of propagation.
- microphone arrays are sometimes also referred to as spatial filters.
- Their advantage over conventional directional microphones, such as shotgun microphones, is their high flexibility due to the degrees of freedom offered by the plurality of microphones and the processing of the associated beamformer.
- the directional pattern of a microphone array can be varied over a wide range. This enables, for example, steering the look direction, adapting the pattern according to the actual acoustic situation, and/or zooming in to or out from an acoustic source. All this can be done by controlling the beamformer, which is typically implemented in software, such that no mechanical alteration of the microphone array is needed.
- the beamformer which is typically implemented in software, such that no mechanical alteration of the microphone array is needed.
- the beampattern can be steered to any direction in three- dimensional (3-D) space, without changing the shape of the pattern.
- the spherical array also allows full 3D control of the beampattern.
- Speech pick-up with high signal-to-noise ratio (SNR) is essential for many communication applications. In noisy environments, a common solution is based on farf ⁇ eld microphone array technology. However, for highly noise-contaminated environments, the achievable gain might not be sufficient. In these cases, a close-talking microphone may work better.
- Close-talking microphones also known as noise- canceling microphones, exploit the nearf ⁇ eld effect of a close source and a differential microphone array, in which the frequency response of a differential microphone array to a nearf ⁇ eld source is substantially flat at low frequencies up to a cut-off frequency.
- the frequency response of a differential microphone array to a farfield source shows a high-pass behavior.
- Figs. l(a) and l(b) graphically show the normalized frequency response of a first-order differential microphone array over kd/2, where Ic is the wavenumber (which is equal to 2 ⁇ / ⁇ , where ⁇ is wavelength) and d is the distance between the two microphones in the first-order differential array, for various distances and incidence angles, respectively, where an incidence angle of 0 degrees corresponds to an endfire orientation. All frequency responses are normalized to the sound pressure present at the center of the array.
- the thick curve in each figure corresponds to the farfield response at 0 degrees.
- the other curves in Fig. l(a) are for an incidence angle of 0 degrees, and the other curves in Fig.
- l(b) are for a distance r o ⁇ 2d.
- the improvement in SNR corresponds to the area in the figure between the close-talking response and the farfield response. Note that the improvement is actually higher than can be seen in the figures due to the Hr behavior of the sound pressure from a point source radiator. This effect is eliminated in the figure by normalizing the sound pressure in order to concentrate on the close-talking effect. It can be seen that the noise attenuation as well as the frequency response of the array depend highly on the distance and orientation of the close-taking array relative to the nearf ⁇ eld source.
- the present invention is a method for processing audio signals corresponding to sound received from a sound source.
- a plurality of audio signals are received, where each audio signal has been generated by a different sensor of a microphone array.
- the plurality of audio signals are decomposed into a plurality of eigenbeam outputs, wherein each eigenbeam output corresponds to a different eigenbeam for the microphone array.
- compensation data is generated corresponding to at least one of (i) an estimate of distance between the microphone array and the sound source and (ii) an estimate of orientation of the sound source relative to the microphone array.
- An auditory scene is generated from one or more of the eigenbeam outputs, wherein generation of the auditory scene comprises compensation based on the compensation data.
- the present invention is an audio system for processing audio signals corresponding to sound received from a sound source.
- the audio system comprises a modal decomposer and a modal beamformer.
- the modal decomposer (1) receives a plurality of audio signals, each audio signal having been generated by a different sensor of a microphone array, and (2) decomposes the plurality of audio signals into a plurality of eigenbeam outputs, wherein each eigenbeam output corresponds to a different eigenbeam for the microphone array.
- the modal beamformer (1) generates, based on one or more of the eigenbeam outputs, compensation data corresponding to at least one of (i) an estimate of distance between the microphone array and the sound source and (ii) an estimate of orientation of the sound source relative to the microphone array, and (2) generates an auditory scene from one or more of the eigenbeam outputs, wherein generation of the auditory scene comprises compensation based on the compensation data.
- Figs. l(a) and l(b) graphically show the normalized frequency response of a first-order differential microphone array for various distances and incidence angles;
- Fig. 2 shows a schematic diagram of a four-sensor microphone array
- Fig. 3 graphically represents the spherical coordinate system used in this specification
- Fig. 4 shows a block diagram of a first-order audio system, according to one embodiment of the present invention
- Fig. 6 shows a block diagram of the structure of an exemplary implementation of the modal decomposer of Fig. 4 based on the real and imaginary parts of the spherical harmonics;
- Fig. 7 shows a schematic diagram of a twelve-sensor microphone array; and
- Fig. 8 shows a block diagram of a second-order audio system, according to one embodiment of the present invention.
- a microphone array consisting of a plurality of audio sensors (e.g., microphones) generates a plurality of (time- varying) audio signals, one from each audio sensor in the array.
- the audio signals are then decomposed (e.g., by a digital signal processor or an analog multiplication network) into a (time-varying) series expansion involving discretely sampled (e.g., spherical) harmonics, where each term in the series expansion corresponds to the (time- varying) coefficient for a different three-dimensional eigenbeam.
- the number and location of microphones in the array determine the order of the harmonic expansion, which in turn determines the number and types of eigenbeams in the decomposition. For example, as described in more detail below, an array having four appropriately located microphones supports a discrete first-order harmonic expansion involving one zero-order eigenbeam and three first- order eigenbeams, while an array having nine appropriately located microphones supports a discrete second-order harmonic expansion involving one zero-order eigenbeam, three first-order eigenbeams, and five second-order eigenbeams.
- the set of eigenbeams form an orthonormal set such that the inner-product between any two discretely sampled eigenbeams at the microphone locations, is ideally zero and the inner-product of any discretely sampled eigenbeam with itself is ideally one.
- This characteristic is referred to herein as the discrete orthonormality condition.
- the discrete orthonormality condition may be said to be satisfied when (1) the inner- product between any two different discretely sampled eigenbeams is zero or at least close to zero and (2) the inner-product of any discretely sampled eigenbeam with itself is one or at least close to one.
- the time- varying coefficients corresponding to the different eigenbeams are referred to herein as eigenbeam outputs, one for each different eigenbeam.
- the eigenbeams can be used to generate data corresponding to estimates of the distance and the orientation of the sound source relative to the microphone array.
- the orientation-related data can then be used to process the audio signals generated by the microphone array (either in real-time or subsequently, and either locally or remotely, depending on the application) to form and steer a beam in the estimated direction of the sound source to create an auditory scene that optimizes the signal-to-noise ratio of the processed audio signals.
- Such beamforming creates the auditory scene by selectively applying different weighting factors (corresponding to the estimated direction) to the different eigenbeam outputs and summing together the resulting weighted eigenbeams.
- the distance-related data can be used to compensate the frequency and/or amplitude responses of the microphone array for the estimated separation between the sound source and the microphone array.
- the microphone array and its associated signal processing elements can be operated as a position-independent microphone system that can be steered towards the sound source without having to change the location or the physical orientation of the array, in order to achieve substantially constant performance for a sound source located at any arbitrary orientation relative to the array and located over a relatively wide range of distances from the array spanning from the nearfield to the farfield.
- An extension of the compensation for the nearfield effect as described above is the use of position and orientation information to effect a desired modification of the audio output of the microphone.
- the distance and orientation signals can be used to make desired real-time modifications of the audio stream derived from the microphone distance and orientation of the microphone. For instance, one could control a variable filter that would alter its settings as a function of position or orientation. Also, one could use the distance estimate to control the suppression of the microphone output, thereby increasing the attenuation of the microphone to yield a desired attenuation that could either exceed or lower the attenuation of the microphone output signal.
- embodiments of the present invention are based on microphone arrays in which a sufficient number of audio sensors are mounted on the surface of a suitable structure in a suitable pattern.
- a number of audio sensors are mounted on the surface of an acoustically rigid sphere in a pattern that satisfies or nearly satisfies the above-mentioned discrete orthonormality condition.
- a structure is acoustically rigid if its acoustic impedance is much larger than the characteristic acoustic impedance of the medium surrounding it.
- the highest available order of the harmonic expansion is a function of the number and location of the sensors in the microphone array, the upper frequency limit, and the radius of the sphere.
- the audio sensors are not mounted on the surface of an acoustically rigid sphere.
- the audio sensors could be mounted on the surface of an acoustically soft sphere or even an open sphere.
- Fig. 2 shows a schematic diagram of a four-sensor microphone array 200 having four microphones 202 positioned on the surface of an acoustically rigid sphere 204 at the spherical coordinates specified in Table I, where the origin is at the center of the sphere, the Z axis passes through one of the four microphones (Microphone #1 in Table I), the elevation angle is measured from the Z axis, and the azimuth angle is measured from the X axis in the XY plane, as indicated by the spherical coordinate system represented in Fig. 3.
- Microphone array 200 supports a discrete first-order harmonic expansion involving the zero-order eigenbeam Y 0 and the three first-order eigenbeams [Y 1 ⁇ , Y 1 0 , Y ⁇ ) ⁇
- Fig. 4 shows a block diagram of a first-order audio system 400, according to one embodiment of the present invention, based on microphone array 200 of Fig. 2.
- Audio system 400 comprises the four microphones 202 of Fig. 2 mounted on acoustically rigid sphere 204 (not shown in Fig. 4) in the locations specified in Table I.
- audio system 400 includes a modal decomposer (i.e., eigenbeam former) 402, a modal beamformer 404, and an (optional) audio processor 406.
- modal beamformer 404 comprises distance estimation unit 408, orientation estimation unit 410, direction compensation unit 412, response compensation unit 414, and beam combination unit 416, each of which will be discussed in further detail later in this specification.
- Each microphone 202 in system 400 generates a time-varying analog or digital (depending on the implementation) audio signal X 1 corresponding to the sound incident at the location of that microphone, where audio signal X 1 is transmitted to modal decomposer 402 via some suitable (e.g., wired or wireless) connection.
- Modal decomposer 402 decomposes the audio signals generated by the different microphones to generate a set of time- varying eigenbeam outputs YTM , where each eigenbeam output corresponds to a different eigenbeam for the microphone array.
- These eigenbeam outputs are then processed by beamformer 404 to generate a steered beam 417, which is optionally processed by audio processor 406 to generate an output auditory scene 419.
- auditory scene is used generically to refer to any desired output from an audio system, such as system 400 of Fig. 4.
- the definition of the particular auditory scene will vary from application to application.
- the output generated by beamformer 404 may correspond to a desired beam pattern steered towards the sound source.
- distance estimation unit 408 receives the four eigenbeam outputs from decomposer 402 and generates an estimate of the distance r L between the center of the microphone array and the source of the sound signals received by the microphones of the array. This estimated distance is used to generate filter weights 405, which are applied by response compensation unit 414 to compensate the frequency and amplitude response of the microphone array for the distance between the array and the sound source. In addition, distance estimation unit 408 generates distance information 407, which is applied to both beam combination unit 416 and audio processor 406.
- distance estimation unit 408 determines that the sound source is a nearfield sound source.
- distance estimation unit 408 can compare the difference between beam levels against a suitable threshold value. If the level difference between two different eigenbeam orders is smaller than the specified threshold value, then the sound source is determined to be a nearfield sound source.
- distance estimation unit 408 transmits a control signal 409 to turn on orientation estimation unit 410. Otherwise, distance estimation unit 408 determines that the sound source is a farfield sound source and configures control signal 409 to turn off orientation estimation unit 410. In another possible implementation, orientation estimation unit 410 is always on, and control signal 409 can be omitted.
- orientation estimation unit 410 can be designed to apply a set of default steering weights to form and steer first-order beam 413 in a default direction (e.g., maintain the last direction or steer to a default zero-position marked on the array).
- orientation estimation unit 410 generates direction information 421, which is applied to both beam combination unit 416 and audio processor 406.
- Beam combination unit 416 combines (e.g., sums) the compensated first-order beam 415 generated by response compensation unit 414 with the zero-order beam represented by the eigenbeam output Y 0 to generate steered beam 417.
- beam combination unit 416 may be omitted and first-order beam 415 may be applied directly to audio processor 406.
- the output of beamformer 404 is steered beam 417 generated by the four-sensor microphone array whose sensitivity has been optimized in the estimated direction of the sound source and whose frequency and amplitude response has been compensated based on the estimated distance between the array and the sound source.
- audio processor 406 can be provided to perform suitable audio processing on steered beam 417 to generate the output auditory scene 419.
- Beamformer 404 exploits the geometry of the spherical array and relies on the spherical harmonic decomposition of the incoming sound field by decomposer 402 to construct a desired spatial response.
- Beamformer 404 can provide continuous steering of the beampattern in 3-D space by changing a few scalar multipliers, while the filters determining the beampattern itself remain constant.
- the shape of the beampattern is invariant with respect to the steering direction. Instead of using a filter for each audio sensor as in a conventional f ⁇ lter-and-sum beamformer, beamformer 404 needs only one filter per spherical harmonic, which can significantly reduce the computational cost.
- Audio system 400 with the spherical array geometry of Table I enables accurate control over the beampattem in 3-D space.
- system 400 can also provide multi-direction beampatterns or toroidal beampatterns giving uniform directivity in one plane. These properties can be useful for applications such as general multichannel speech pick-up, video conferencing, or direction of arrival (DOA) estimation. It can also be used as an analysis tool for room acoustics to measure directional properties of the sound field.
- DOA direction of arrival
- Audio system 400 offers another advantage: it supports decomposition of the sound field into mutually orthogonal components, the eigenbeanis (e.g., spherical harmonics) that can be used to reproduce the sound field.
- the eigenbeams are also suitable for wave field synthesis (WFS) methods that enable spatially accurate sound reproduction in a fairly large volume, allowing reproduction of the sound field that is present around the recording sphere. This allows a wide variety of general real-time spatial audio applications.
- Eigenbeam Decomposition e.g., spherical harmonics
- Equation (1) l( ⁇ t-kR)
- Equation (2) Equation (2) where k is the wave number, i is the imaginary constant (i.e., positive root of-1), R is the distance between the source of the sound signals and the measurement point, a ⁇ A is the source dimension (also referred to as the source strength).
- Equation (3) K(*L>9L)C fc.fc).
- the orthonormal component YTM ⁇ 3 S , ⁇ s j corresponding to the spherical harmonic of order n and degree m of the soundfield can be extracted if the spherical microphone involves a continuous aperture sensitivity M($ ⁇ , ⁇ ⁇ J that is proportional to that component.
- Using a microphone with this sensitivity results in an output c nm that represents the corresponding orthonormal component of the soundfield according to Equation (5) as follows:
- the distance r L from the center of the sphere to the sound source is 2a
- r L 8a, where a is the radius of the sphere.
- the distance r L between the sound source and the microphone array can be estimated from the level differences between any two orders at low frequencies.
- the energy of the nth order mode is distributed across the mode's different degrees m.
- the overall energy for a mode of order n can be found using Equation (6) as follows:
- Equation (7) The overall mode strength is determined by combining Equations (5) and (6) to yield Equation (7) as follows:
- the distance r L can be computed using the ratio of the zero- and first-order modes according to Equation (9) as follows:
- the distance r L can be computed using the ratio of the first- and second-order modes according to Equation (10) as follows:
- Equation (11) the contribution of each mode of order n and degree m, represented by the value of the corresponding spherical harmonic, can be found using Equation (11) as follows:
- the phase of the spherical harmonic can be recovered by comparing the phase of the signals c nm . Note that it is not important to know the absolute phase.
- Equation (6) the complex conjugate of the recovered values of the spherical harmonics are the steering coefficients to obtain the maximum output signal y according to Equation (12) as follows: , (12) where ⁇ is the unknown absolute phase.
- the steering operation is analogous to an optimal weight-and-sum beamformer that maximizes the SNR towards the look-direction by compensating for the travel delay (done here using the complex conjugate) and by weighting the signals according to the pressure magnitude.
- the steering weights should be normalized by
- the frequency response of a correction filter for response compensation unit 414 can be computed.
- the ideal compensation is equal to XJV n (kr L , ka) .
- Response compensation unit 414 can then select and switch between different pre-computed filters depending on the estimated distance.
- Temporal smoothing should be implemented to avoid a hard transition from one filter to another.
- Equation (14) ka (ka) 2 b ⁇ (k ⁇ ) ⁇ — for ka ⁇ ⁇ Hi. ka ) a ⁇ ⁇ for ka ⁇ X , (14) where the superscript/ denotes the farfield response.
- the nearfield response can be written as a polynomial.
- Equation (15) the nearfield response may be given by Equation (15) as follows: and, for the first-order mode, the nearf ⁇ eld response may be given by Equation (16) as follows:
- Equations (15) and (16) omit the linear phase component exp(-?7 ⁇ 'i), which is implicitly included in the original nearfield term in Equation (13) within h n .
- beam combination unit 416 generates steered beam 417 by simply adding together the compensated first-order beam 415 generated by response compensation unit 414 and the zero-order beam represented by the eigenbeam output Y 0 .
- the first- and zero-order beams can be combined using some form of weighted summation.
- beam combination unit 416 can be implemented to be adjusted either adaptively or through a computation dependent on the estimation of the direction of a farfield source.
- This computed or adapted farfield beamformer could be operated such that the output power of the microphone array is minimized under a constraint that nearfield sources will not be significantly attenuated. In this way, farfield signal power can be minimized without significantly affecting any nearfield signal power.
- Fig. 4 shows first-order audio system 400, which generates a steered beam 417 having zero-order and first-order components, based on the audio signals generated by the four appropriately located audio sensors 202 of microphone array 200 of Fig. 2.
- higher-order audio systems can be implemented to generate steered beams having higher-order components, based on the audio signals generated by an appropriate number of appropriately located audio sensors.
- Fig. 7 shows a schematic diagram of a twelve-sensor microphone array 700 having twelve microphones 702 positioned on the surface of an acoustically rigid sphere 704 at the spherical coordinates specified in Table II, where the origin is at the center of the sphere, the elevation angle is measured from the Z axis, and the azimuth angle is measured from the X axis in the XY plane, as indicated by the spherical coordinate system represented in Fig. 3.
- Microphone array 700 supports a discrete second-order harmonic expansion involving the zero-order eigenbeam Y 0 , the three first-order eigenbeams
- Fig. 8 shows a block diagram of a second-order audio system 800, according to one embodiment of the present invention, based on microphone array 700 of Fig. 7.
- Audio system 800 comprises the twelve microphones 702 of Fig. 7 mounted on acoustically rigid sphere 704 (not shown in Fig. 8) in the locations specified in Table II.
- audio system 800 includes a modal decomposer (i.e., eigenbeam former) 802, a modal beamformer 804, and an (optional) audio processor 806.
- modal beamformer 804 comprises distance estimation unit 808, orientation estimation unit 810, direction compensation unit 812, response compensation unit 814, and beam combination unit 816.
- second-order audio system 800 shown in Fig. 8 are analogous to corresponding processing units and signals of first-order audio system 400 shown in Fig. 4. Note that, in addition to generating the zero-order eigenbeam Y 0 and the three first-order eigenbeams
- the processing of distance estimation unit 808 is based on Equations (8) and (10), while the processing of orientation estimation unit 810 and direction compensation unit 812 is based on Equations (11) and (12).
- direction compensation unit 812 generates two beams 813: a first-order beam (analogous to first-order beam 413 in Fig. 4) and a second-order beam.
- response compensation unit 814 generates two compensated beams 815: one for the first-order beam received from direction compensation unit 812 and one for the second-order beam received from direction compensation unit 812.
- beam combination unit 816 combines (e.g., sums) the first- and second-order compensated beams 815 received from response compensation unit 814 with the zero-order beam represented by the eigenbeam output Y 0 to generate steered beam 817.
- the processing of response compensation unit 814 is based on Equations (13)-(15).
- Another possible embodiment involves a microphone array having only two audio sensors.
- the two microphone signals can be decomposed into two eigenbeam outputs: a zero-order eigenbeam output corresponding to the sum of the two microphone signals and a first-order eigenbeam output corresponding to the difference between the two microphone signals.
- orientation estimation would not be performed, the distance r L from the midpoint of the microphone array to a sound source can be estimated based on the first expression in Equation (8), where (i) a is the distance between the two microphones in the array and (ii) the two microphones and the sound source are substantially co-linear (i.e., the so-called endfire orientation).
- the estimated distance can be thresholded to determine whether the sound source is a nearfield source or a farfield source. This would enable, for example, farfield signal energy to be attenuated, while leaving nearfield signal energy substantially unattenuated.
- the modal beamformer can be implemented without an orientation estimation unit and a direction compensation unit.
- the results of the previous sections can be modified to be based on the real-valued real and imaginary parts of the spherical harmonics rather than the complex spherical harmonics themselves.
- the eigenbeam weights from Equation (3) are replaced by the real and imaginary parts of the spherical harmonics,
- the structure of modal decomposer 402 of Fig. 4 is shown in Fig. 6.
- the 5 microphone signals x s are applied to decomposer 402, which consists of several weight-and-addbeaniformers.
- the other eigenbeams are generated in an analogous manner.
- all eigenbeams of two different orders n are used, where each order n has 2?z+l components.
- using the zero and first orders involves four eigenbeams: the single zero-order eigenbeam and the three first-order eigenbeams.
- using the first and second orders involves eight eigenbeams: the three first-order eigenbeams and the five second-order eigenbeams.
- the processing of the audio signals from the microphone array comprises two basic stages: decomposition and beamforming. Depending on the application, this signal processing can be implemented in different ways.
- modal decomposer 402 and beamformer 404 are co-located and operate together in real time.
- the eigenbeam outputs generated by modal decomposer 402 are provided immediately to beamformer 404 for use in generating one or more auditory scenes in real time.
- the control of the beamformer can be performed on-site or remotely.
- modal decomposer 402 and beamformer 404 both operate in real time, but are implemented in different (i.e., non-co-located) nodes.
- data corresponding to the eigenbeam outputs generated by modal decomposer 402, which is implemented at a first node are transmitted (via wired and/or wireless connections) from the first node to one or more other remote nodes, within each of which a beamformer 404 is implemented to process the eigenbeam outputs recovered from the received data to generate one or more auditory scenes.
- modal decomposer 402 and beamformer 404 do not both operate at the same time (i.e., beamformer 404 operates subsequent to modal decomposer 402).
- data corresponding to the eigenbeam outputs generated by modal decomposer 402 are stored, and, at some subsequent time, the data is retrieved and used to recover the eigenbeam outputs, which are then processed by one or more beamformers 404 to generate one or more auditory scenes.
- the beamformers may be either co-located or non-co-located with the modal decomposer.
- channels 403 are represented generically in Fig. 4 by channels 403 through which the eigenbeam outputs generated by modal decomposer 402 are provided to beamformer 404.
- channels 403 are represented as a set of parallel streams of eigenbeam output data (i.e., one time-varying eigenbeam output for each eigenbeam in the spherical harmonic expansion for the microphone array).
- a single beamformer such as beamformer 404 of Fig. 4, is used to generate one output beam.
- the eigenbeam outputs generated by modal decomposer 402 may be provided (either in real-time or non-real time, and either locally or remotely) to one or more additional beamformers, each of which is capable of independently generating one output beam from the set of eigenbeam outputs generated by decomposer 402.
- the present invention has been described primarily in the context of a microphone array comprising a plurality of audio sensors mounted on the surface of an acoustically rigid sphere, the present invention is not so limited.
- other acoustic impedances are possible, such as an open sphere or a soft sphere.
- no physical structure is ever perfectly spherical, and the present invention should not be interpreted as having to be limited to such ideal structures.
- the present invention can be implemented in the context of shapes other than spheres that support orthogonal harmonic expansion, such as "spheroidal" oblates and prolates, where, as used in this specification, the term
- “spheroidal” also covers spheres.
- the present invention can be implemented for any shape that supports orthogonal harmonic expansion including cylindrical shapes. It will also be understood that certain deviations from ideal shapes are expected and acceptable in real-world implementations. The same real-world considerations apply to satisfying the discrete orthonormality condition applied to the locations of the sensors. Although, in an ideal world, satisfaction of the condition corresponds to the mathematical delta function, in real-world implementations, certain deviations from this exact mathematical formula are expected and acceptable. Similar real- world principles also apply to the definitions of what constitutes an acoustically rigid or acoustically soft structure.
- the present invention may be implemented as (analog, digital, or a hybrid of both analog and digital) circuit-based processes, including possible implementation on a single integrated circuit.
- the present invention can be implemented in either the time domain or equivalently in the frequency domain.
- various functions of circuit elements may also be implemented as processing steps in a software program.
- Such software may be employed in, for example, a digital signal processor, micro-controller, or general-purpose computer.
- the present invention can be embodied in the form of methods and apparatuses for practicing those methods.
- the present invention can also be embodied in the form of program code embodied in tangible media, such as floppy diskettes, CD-ROMs, hard drives, or any other machine-readable storage medium, wherein, when the program code is loaded into and executed by a machine, such as a computer, the machine becomes an apparatus for practicing the invention.
- the present invention can also be embodied in the form of program code, for example, whether stored in a storage medium, loaded into and/or executed by a machine, or transmitted over some transmission medium or carrier, such as over electrical wiring or cabling, through fiber optics, or via electromagnetic radiation, wherein, when the program code is loaded into and executed by a machine, such as a computer, the machine becomes an apparatus for practicing the invention.
- program code When implemented on a general-purpose processor, the program code segments combine with the processor to provide a unique device that operates analogously to specific logic circuits.
Landscapes
- Physics & Mathematics (AREA)
- Engineering & Computer Science (AREA)
- Acoustics & Sound (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Otolaryngology (AREA)
- Circuit For Audible Band Transducer (AREA)
- Obtaining Desirable Characteristics In Audible-Bandwidth Transducers (AREA)
Abstract
An audio system generates position-independent auditory scenes using harmonic expansions based on me audio signals generated by a microphone array. In one embodiment, a plurality of audio sensors are mounted on the surface of a sphere. The number and location of the audio sensors on the sphere are designed to enable the audio signals generated by those sensors to be decomposed into a set of eigenbeam outputs. Compensation data corresponding to at least one of the estimated distance and the estimated orientation of the sound source relative to the array are generated from eigenbeam outputs and used to generate an auditory scene. Compensation based on estimated orientation involves steering a beam formed from the eigenbeam outputs in the estimated direction of the sound source to increase direction independence, while compensation based on estimated distance involves frequency compensation of the steered beam to increase distance independence.
Description
POSITION-INDEPENDENT MICROPHONE SYSTEM
Cross-Reference to Related Applications
This application claims the benefit of the filing date of U.S. provisional application no. 60/659,787, filed on 03/09/05 as attorney docket no. 1053.005PROV, the teachings of which are incorporated herein by reference.
In addition, this application is a continuation-in-part of U.S. patent application no. 10/500,938, filed on 07/08/04 as attorney docket no. 1053.001B, which is a 371 of PCT/US03/00741, filed on 01/10/03 as attorney docket no. 1053,001PCT, which itself claims the benefit of the filing date of U.S. provisional application no. 60/347,656, filed on 01/11/02 as attorney docket no. 1053.001PROV and U.S. patent application no. 10/315,502, filed on 12/10/02 as attorney docket no. 1053.001, the teachings of all of which are incorporated herein by reference.
BACKGROUND OF THE INVENTION Field of the Invention
The present invention relates to acoustics, and, in particular, to microphone arrays. Description of the Related Art
A microphone array-based audio system typically comprises two units: an arrangement of (a) two or more microphones (i.e., transducers that convert acoustic signals (i.e., sounds) into electrical audio signals) and (b) a beamformer that combines the audio signals generated by the microphones to form an auditory scene representative of at least a portion of the acoustic sound field. This combination enables picking up acoustic signals dependent on their direction of propagation. As such, microphone arrays are sometimes also referred to as spatial filters. Their advantage over conventional directional microphones, such as shotgun microphones, is their high flexibility due to the degrees of freedom offered by the plurality of microphones and the processing of the associated beamformer. The directional pattern of a microphone array can be varied over a wide range. This enables, for example, steering the look direction, adapting the pattern according to the actual acoustic situation, and/or zooming in to or out from an acoustic source. All this can be done by controlling the beamformer, which is typically implemented in software, such that no mechanical alteration of the microphone array is needed. There are several standard microphone array geometries. The most common one is the linear array. Its advantage is its simplicity with respect to analysis and construction. Other geometries include planar arrays, random arrays, circular arrays, and spherical arrays. The spherical array has several advantages over the other geometries. The beampattern can be steered to any direction in three- dimensional (3-D) space, without changing the shape of the pattern. The spherical array also allows full 3D control of the beampattern.
Speech pick-up with high signal-to-noise ratio (SNR) is essential for many communication applications. In noisy environments, a common solution is based on farfϊeld microphone array technology. However, for highly noise-contaminated environments, the achievable gain might not be sufficient. In these cases, a close-talking microphone may work better. Close-talking microphones, also known as noise- canceling microphones, exploit the nearfϊeld effect of a close source and a differential microphone array, in which the frequency response of a differential microphone array to a nearfϊeld source is substantially flat at low frequencies up to a cut-off frequency. On the other hand, the frequency response of a differential microphone array to a farfield source shows a high-pass behavior.
Figs. l(a) and l(b) graphically show the normalized frequency response of a first-order differential microphone array over kd/2, where Ic is the wavenumber (which is equal to 2π/λ , where λ is wavelength) and d is the distance between the two microphones in the first-order differential array, for various distances and incidence angles, respectively, where an incidence angle of 0 degrees corresponds to an endfire orientation. All frequency responses are normalized to the sound pressure present at the center of the array. The thick curve in each figure corresponds to the farfield response at 0 degrees. The other curves in Fig. l(a) are for an incidence angle of 0 degrees, and the other curves in Fig. l(b) are for a distance r oϊ2d. The improvement in SNR corresponds to the area in the figure between the close-talking response and the farfield response. Note that the improvement is actually higher than can be seen in the figures due to the Hr behavior of the sound pressure from a point source radiator. This effect is eliminated in the figure by normalizing the sound pressure in order to concentrate on the close-talking effect. It can be seen that the noise attenuation as well as the frequency response of the array depend highly on the distance and orientation of the close-taking array relative to the nearfϊeld source.
Heinz Teutsch and Gary W. Elko, "An adaptive close-talking microphone array," Proceedings of the WASSPA, New Paltz, NY, Oct. 2001, the teachings of which are incorporated herein by reference, describe an adaptive method that estimates the distances and the orientation of a close-talking array based on time delay of arrival (TDOA) and relative signal level. The estimated parameters are used to generate a correction filter resulting in a flat frequency response for the close-talking array independent of array position. While this method provides a large improvement over conventional close-talking microphone arrays, it does not allow recovering the loss in attenuation of farfϊeld sources due to orientation of the microphone array. As can be seen in Fig. l(b), this loss can be significant. In addition, the array will become more sensitive to the orientation with increasing differential order as the main lobe becomes narrower.
SUMMARY OF THE INVENTION
According to one embodiment, the present invention is a method for processing audio signals corresponding to sound received from a sound source. A plurality of audio signals are received, where each audio signal has been generated by a different sensor of a microphone array. The plurality of audio
signals are decomposed into a plurality of eigenbeam outputs, wherein each eigenbeam output corresponds to a different eigenbeam for the microphone array. Based on one or more of the eigenbeam outputs, compensation data is generated corresponding to at least one of (i) an estimate of distance between the microphone array and the sound source and (ii) an estimate of orientation of the sound source relative to the microphone array. An auditory scene is generated from one or more of the eigenbeam outputs, wherein generation of the auditory scene comprises compensation based on the compensation data.
According to another embodiment, the present invention is an audio system for processing audio signals corresponding to sound received from a sound source. The audio system comprises a modal decomposer and a modal beamformer. The modal decomposer (1) receives a plurality of audio signals, each audio signal having been generated by a different sensor of a microphone array, and (2) decomposes the plurality of audio signals into a plurality of eigenbeam outputs, wherein each eigenbeam output corresponds to a different eigenbeam for the microphone array. The modal beamformer (1) generates, based on one or more of the eigenbeam outputs, compensation data corresponding to at least one of (i) an estimate of distance between the microphone array and the sound source and (ii) an estimate of orientation of the sound source relative to the microphone array, and (2) generates an auditory scene from one or more of the eigenbeam outputs, wherein generation of the auditory scene comprises compensation based on the compensation data.
BRIEF DESCRIPTION OF THE DRAWINGS
Other aspects, features, and advantages of the present invention will become more fully apparent from the following detailed description, the appended claims, and the accompanying drawings in which like reference numerals identify similar or identical elements.
Figs. l(a) and l(b) graphically show the normalized frequency response of a first-order differential microphone array for various distances and incidence angles;
Fig. 2 shows a schematic diagram of a four-sensor microphone array; Fig. 3 graphically represents the spherical coordinate system used in this specification;
Fig. 4 shows a block diagram of a first-order audio system, according to one embodiment of the present invention;
Figs. 5(a) and 5(b) show graphical representations of the magnitudes of the normalized nearfield and farfield mode strengths for spherical harmonic orders «=0,1,2,3 for a continuous spherical microphone covering the surface of an acoustically rigid sphere;
Fig. 6 shows a block diagram of the structure of an exemplary implementation of the modal decomposer of Fig. 4 based on the real and imaginary parts of the spherical harmonics; Fig. 7 shows a schematic diagram of a twelve-sensor microphone array; and Fig. 8 shows a block diagram of a second-order audio system, according to one embodiment of the present invention.
DETAILED DESCRIPTION
According to certain embodiments of the present invention, a microphone array consisting of a plurality of audio sensors (e.g., microphones) generates a plurality of (time- varying) audio signals, one from each audio sensor in the array. The audio signals are then decomposed (e.g., by a digital signal processor or an analog multiplication network) into a (time-varying) series expansion involving discretely sampled (e.g., spherical) harmonics, where each term in the series expansion corresponds to the (time- varying) coefficient for a different three-dimensional eigenbeam.
Note that the number and location of microphones in the array determine the order of the harmonic expansion, which in turn determines the number and types of eigenbeams in the decomposition. For example, as described in more detail below, an array having four appropriately located microphones supports a discrete first-order harmonic expansion involving one zero-order eigenbeam and three first- order eigenbeams, while an array having nine appropriately located microphones supports a discrete second-order harmonic expansion involving one zero-order eigenbeam, three first-order eigenbeams, and five second-order eigenbeams. The set of eigenbeams form an orthonormal set such that the inner-product between any two discretely sampled eigenbeams at the microphone locations, is ideally zero and the inner-product of any discretely sampled eigenbeam with itself is ideally one. This characteristic is referred to herein as the discrete orthonormality condition. Note that, in real- world implementations in which relatively small tolerances are allowed, the discrete orthonormality condition may be said to be satisfied when (1) the inner- product between any two different discretely sampled eigenbeams is zero or at least close to zero and (2) the inner-product of any discretely sampled eigenbeam with itself is one or at least close to one. The time- varying coefficients corresponding to the different eigenbeams are referred to herein as eigenbeam outputs, one for each different eigenbeam.
The eigenbeams can be used to generate data corresponding to estimates of the distance and the orientation of the sound source relative to the microphone array. The orientation-related data can then be used to process the audio signals generated by the microphone array (either in real-time or subsequently, and either locally or remotely, depending on the application) to form and steer a beam in the estimated direction of the sound source to create an auditory scene that optimizes the signal-to-noise ratio of the processed audio signals. Such beamforming creates the auditory scene by selectively applying different weighting factors (corresponding to the estimated direction) to the different eigenbeam outputs and summing together the resulting weighted eigenbeams.
In addition, the distance-related data can be used to compensate the frequency and/or amplitude responses of the microphone array for the estimated separation between the sound source and the microphone array.
In this way, the microphone array and its associated signal processing elements can be operated as a position-independent microphone system that can be steered towards the sound source without having to change the location or the physical orientation of the array, in order to achieve substantially constant performance for a sound source located at any arbitrary orientation relative to the array and located over a relatively wide range of distances from the array spanning from the nearfield to the farfield.
An extension of the compensation for the nearfield effect as described above is the use of position and orientation information to effect a desired modification of the audio output of the microphone. Thus, one can use the distance and orientation signals to make desired real-time modifications of the audio stream derived from the microphone distance and orientation of the microphone. For instance, one could control a variable filter that would alter its settings as a function of position or orientation. Also, one could use the distance estimate to control the suppression of the microphone output, thereby increasing the attenuation of the microphone to yield a desired attenuation that could either exceed or lower the attenuation of the microphone output signal. One could define regions (distance and orientation) of desired signals and regions of suppression of unwanted sources. In order to make a particular-order harmonic expansion practicable, embodiments of the present invention are based on microphone arrays in which a sufficient number of audio sensors are mounted on the surface of a suitable structure in a suitable pattern. For example, in one embodiment, a number of audio sensors are mounted on the surface of an acoustically rigid sphere in a pattern that satisfies or nearly satisfies the above-mentioned discrete orthonormality condition. (Note that the present invention also covers embodiments whose sets of beams are mutually orthogonal without requiring all beams to be normalized.) As used in this specification, a structure is acoustically rigid if its acoustic impedance is much larger than the characteristic acoustic impedance of the medium surrounding it. The highest available order of the harmonic expansion is a function of the number and location of the sensors in the microphone array, the upper frequency limit, and the radius of the sphere. In alternative embodiments, the audio sensors are not mounted on the surface of an acoustically rigid sphere. For example, the audio sensors could be mounted on the surface of an acoustically soft sphere or even an open sphere. First-Order Audio System
Fig. 2 shows a schematic diagram of a four-sensor microphone array 200 having four microphones 202 positioned on the surface of an acoustically rigid sphere 204 at the spherical coordinates specified in Table I, where the origin is at the center of the sphere, the Z axis passes through one of the four microphones (Microphone #1 in Table I), the elevation angle is measured from the Z axis, and the azimuth angle is measured from the X axis in the XY plane, as indicated by the spherical coordinate system represented in Fig. 3. Microphone array 200 supports a discrete first-order harmonic expansion involving the zero-order eigenbeam Y0 and the three first-order eigenbeams [Y1^ , Y1 0, Y\ ) ■

Fig. 4 shows a block diagram of a first-order audio system 400, according to one embodiment of the present invention, based on microphone array 200 of Fig. 2. Audio system 400 comprises the four microphones 202 of Fig. 2 mounted on acoustically rigid sphere 204 (not shown in Fig. 4) in the locations specified in Table I. In addition, audio system 400 includes a modal decomposer (i.e., eigenbeam former) 402, a modal beamformer 404, and an (optional) audio processor 406. In this particular embodiment, modal beamformer 404 comprises distance estimation unit 408, orientation estimation unit 410, direction compensation unit 412, response compensation unit 414, and beam combination unit 416, each of which will be discussed in further detail later in this specification.
Each microphone 202 in system 400 generates a time-varying analog or digital (depending on the implementation) audio signal X1 corresponding to the sound incident at the location of that microphone, where audio signal X1 is transmitted to modal decomposer 402 via some suitable (e.g., wired or wireless) connection. Modal decomposer 402 decomposes the audio signals generated by the different microphones to generate a set of time- varying eigenbeam outputs Y™ , where each eigenbeam output corresponds to a different eigenbeam for the microphone array. These eigenbeam outputs are then processed by beamformer 404 to generate a steered beam 417, which is optionally processed by audio processor 406 to generate an output auditory scene 419. In this specification, the term "auditory scene" is used generically to refer to any desired output from an audio system, such as system 400 of Fig. 4. The definition of the particular auditory scene will vary from application to application. For example, the output generated by beamformer 404 may correspond to a desired beam pattern steered towards the sound source.
As shown in Fig. 4, distance estimation unit 408 receives the four eigenbeam outputs from decomposer 402 and generates an estimate of the distance rL between the center of the microphone array and the source of the sound signals received by the microphones of the array. This estimated distance is used to generate filter weights 405, which are applied by response compensation unit 414 to compensate the frequency and amplitude response of the microphone array for the distance between the array and the
sound source. In addition, distance estimation unit 408 generates distance information 407, which is applied to both beam combination unit 416 and audio processor 406.
In one possible implementation, if the estimated distance rL is less than a specified distance threshold value (e.g., about eight times the radius of the spherical array), then distance estimation unit 408 determines that the sound source is a nearfield sound source. Alternatively, distance estimation unit 408 can compare the difference between beam levels against a suitable threshold value. If the level difference between two different eigenbeam orders is smaller than the specified threshold value, then the sound source is determined to be a nearfield sound source.
In any case, if the sound source is determined to be a nearfield sound source, then distance estimation unit 408 transmits a control signal 409 to turn on orientation estimation unit 410. Otherwise, distance estimation unit 408 determines that the sound source is a farfield sound source and configures control signal 409 to turn off orientation estimation unit 410. In another possible implementation, orientation estimation unit 410 is always on, and control signal 409 can be omitted.
As indicated in Fig. 4, orientation estimation unit 410 receives the three eigenbeam outputs Y" of order «=1 and generates steering weights 411, which depend on the angular orientation of the microphone array to the sound source. These steering weights are used by direction compensation unit 412 to compensate the three eigenbeam outputs Y"' of order n-l for that estimated angular orientation. In effect, direction compensation unit 412 processes the three first-order eigenbeam outputs to form and steer a first- order beam 413 of the microphone array towards the estimated direction of the sound source. It is to this first-order beam that response compensation unit 414 applies its frequency and amplitude compensation based on filter weights 405 received from distance estimation unit 408. Note that, if orientation estimation unit 410 is off, then direction compensation unit 412 can be designed to apply a set of default steering weights to form and steer first-order beam 413 in a default direction (e.g., maintain the last direction or steer to a default zero-position marked on the array). In addition, orientation estimation unit 410 generates direction information 421, which is applied to both beam combination unit 416 and audio processor 406.
Beam combination unit 416 combines (e.g., sums) the compensated first-order beam 415 generated by response compensation unit 414 with the zero-order beam represented by the eigenbeam output Y0 to generate steered beam 417. In applications in which only first-order beam 415 is needed, beam combination unit 416 may be omitted and first-order beam 415 may be applied directly to audio processor 406. The output of beamformer 404 is steered beam 417 generated by the four-sensor microphone array whose sensitivity has been optimized in the estimated direction of the sound source and whose frequency and amplitude response has been compensated based on the estimated distance between the array and the sound source.
As suggested earlier, depending on the particular application, audio processor 406 can be provided to perform suitable audio processing on steered beam 417 to generate the output auditory scene 419.
Beamformer 404 exploits the geometry of the spherical array and relies on the spherical harmonic decomposition of the incoming sound field by decomposer 402 to construct a desired spatial response. Beamformer 404 can provide continuous steering of the beampattern in 3-D space by changing a few scalar multipliers, while the filters determining the beampattern itself remain constant. The shape of the beampattern is invariant with respect to the steering direction. Instead of using a filter for each audio sensor as in a conventional fϊlter-and-sum beamformer, beamformer 404 needs only one filter per spherical harmonic, which can significantly reduce the computational cost. Audio system 400 with the spherical array geometry of Table I enables accurate control over the beampattem in 3-D space. In addition to focused beams, system 400 can also provide multi-direction beampatterns or toroidal beampatterns giving uniform directivity in one plane. These properties can be useful for applications such as general multichannel speech pick-up, video conferencing, or direction of arrival (DOA) estimation. It can also be used as an analysis tool for room acoustics to measure directional properties of the sound field.
Audio system 400 offers another advantage: it supports decomposition of the sound field into mutually orthogonal components, the eigenbeanis (e.g., spherical harmonics) that can be used to reproduce the sound field. The eigenbeams are also suitable for wave field synthesis (WFS) methods that enable spatially accurate sound reproduction in a fairly large volume, allowing reproduction of the sound field that is present around the recording sphere. This allows a wide variety of general real-time spatial audio applications. Eigenbeam Decomposition
This section describes the mathematics underlying the processing of modal decomposer 402 of Fig. 4. A spherical acoustic wave can be described according to Equation (1) as follows: l(ωt-kR)
G{k,R,t)= A — — A ≤ R , (1)
K where k is the wave number, i is the imaginary constant (i.e., positive root of-1), R is the distance between the source of the sound signals and the measurement point, aι\ά A is the source dimension (also referred to as the source strength). Expanding Equation (1) into a series of spherical harmonics yields Equation (2) as follows:
K(*L>9L)C fc.fc). (2)
 n
where the symbol "*" represents complex conjugate, Rs is the sensor position
n
where the symbol "*" represents complex conjugate, Rs is the sensor position
 $( , φλ , RL is the source position Ir1 , &L,φL \ , h^ is the spherical Hankel function of the second kind, Y1"' is the spherical harmonic of order /; and degree m, and b,, is the normalized farfϊeld mode strength. The spherical harmonics Y™ are defined according to Equation (3) as follows:
$( , φλ , RL is the source position Ir1 , &L,φL \ , h^ is the spherical Hankel function of the second kind, Y1"' is the spherical harmonic of order /; and degree m, and b,, is the normalized farfϊeld mode strength. The spherical harmonics Y™ are defined according to Equation (3) as follows:
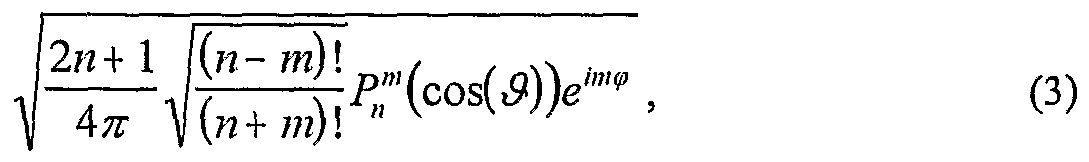
The orthonormal component Y™\ 3S , φsj corresponding to the spherical harmonic of order n and degree m of the soundfield can be extracted if the spherical microphone involves a continuous aperture sensitivity M($Λ , φΛ J that is proportional to that component. Using a microphone with this sensitivity results in an output cnm that represents the corresponding orthonormal component of the soundfield according to Equation (5) as follows:
Cn. = khj?(krL)bn(ka)Y:i$L,φL) = b;,(krL,ka)Y:(3L,φL) where bn s is the normalized nearfield mode strength. Note that the constant factor AmA has been neglected in Equation (5).
Fig. 5 shows graphical representations of the magnitudes of the normalized nearfield mode strength bn" (solid lines) and the farfield mode strength bn (dashed lines) for spherical harmonic orders «=0,1,2,3 for a continuous spherical microphone covering the surface of an acoustically rigid sphere. In particular, for Fig. 5(a), the distance rL from the center of the sphere to the sound source is 2a, while, for Fig. 5(b), rL=8a, where a is the radius of the sphere. Distance Estimation
This section describes the mathematics underlying the processing of distance estimation unit 408 of Fig. 4.
As suggested by Figs. 5(a) and 5(b), the distance rL between the sound source and the microphone array can be estimated from the level differences between any two orders at low frequencies. For a general orientation of the array, the energy of the nth order mode is distributed across the mode's different degrees m. The overall energy for a mode of order n can be found using Equation (6) as follows:
The overall mode strength is determined by combining Equations (5) and (6) to yield Equation (7) as follows:
A low-frequency approximation of the normalized mode strength reveals a relatively simple expression for the ratios that can be used to determine the distance rL. For the modes of order w=0,l,2, these ratios are given by Equations (8) as follows:
H a K a b[ _ 2a_
2 '
X bl- = 3rL (8)
Combining Equations (7) and (8), the distance rL can be computed using the ratio of the zero- and first-order modes according to Equation (9) as follows:

Alternatively, the distance rL can be computed using the ratio of the first- and second-order modes according to Equation (10) as follows:

Orientation Estimation and Direction Compensation
This section describes the mathematics underlying the processing of orientation estimation unit 410 and direction compensation unit 412 of Fig. 4.
For best SNR-gain performance, the maximum sensitivity of the microphone array should be oriented towards the sound source. Once the overall mode strength for order n is determined using Equation (7), the contribution of each mode of order n and degree m, represented by the value of the corresponding spherical harmonic, can be found using Equation (11) as follows:

The steering operation is analogous to an optimal weight-and-sum beamformer that maximizes the SNR towards the look-direction by compensating for the travel delay (done here using the complex conjugate) and by weighting the signals according to the pressure magnitude. In order to maintain the magnitude of the eigenbeams, the steering weights should be normalized by

Response Compensation
This section describes the mathematics underlying the processing of response compensation unit 414 of Fig. 4.
Given the distance n from the microphone array to the sound source, e.g., as estimated using Equation (9) or (10), the frequency response of a correction filter for response compensation unit 414 can be computed. The ideal compensation is equal to XJVn (krL , ka) . However, this might not be practical for some applications, since it could be computationally expensive. One technique is to compute a set of compensation filters in advance for different distances. Response compensation unit 414 can then select and switch between different pre-computed filters depending on the estimated distance. Temporal smoothing should be implemented to avoid a hard transition from one filter to another.
Another technique is to break the frequency response down into several simpler filters. The frequency response of the eigenbeams can be expressed according to Equation (13) as follows:

rL 10L where the superscript n denotes the nearfield response. Note that Equations (15) and (16) omit the linear phase component exp(-?7σ'i), which is implicitly included in the original nearfield term in Equation (13) within hn. Beam Combination
This section describes the processing of beam combination unit 416 of Fig. 4. In one possible implementation, beam combination unit 416 generates steered beam 417 by simply adding together the compensated first-order beam 415 generated by response compensation unit 414 and the zero-order beam represented by the eigenbeam output Y0. In other implementations, the first- and zero-order beams can be combined using some form of weighted summation.
Since the underlying associated signal processing yields distance and direction estimates of the sound source, one could also determine whether the sound source is a nearfield source or a farfield source (e.g., by thresholding the distance estimate). As such, beam combination unit 416 can be implemented to be adjusted either adaptively or through a computation dependent on the estimation of the direction of a farfield source. This computed or adapted farfield beamformer could be operated such that the output power of the microphone array is minimized under a constraint that nearfield sources will not be significantly attenuated. In this way, farfield signal power can be minimized without significantly affecting any nearfield signal power.
Other Exemplary Embodiments
Fig. 4 shows first-order audio system 400, which generates a steered beam 417 having zero-order and first-order components, based on the audio signals generated by the four appropriately located audio sensors 202 of microphone array 200 of Fig. 2. In alternative embodiments of the present invention, higher-order audio systems can be implemented to generate steered beams having higher-order components, based on the audio signals generated by an appropriate number of appropriately located audio sensors.
For example, Fig. 7 shows a schematic diagram of a twelve-sensor microphone array 700 having twelve microphones 702 positioned on the surface of an acoustically rigid sphere 704 at the spherical coordinates specified in Table II, where the origin is at the center of the sphere, the elevation angle is measured from the Z axis, and the azimuth angle is measured from the X axis in the XY plane, as indicated by the spherical coordinate system represented in Fig. 3. Microphone array 700 supports a discrete
second-order harmonic expansion involving the zero-order eigenbeam Y0 , the three first-order eigenbeams
(γ~ι ,Y1 0 ,Y^) , and the five second-order eigenbeams (Y~2 ,Y^1 ,Y° ,Y} ,Y?) . Note that, although nine is the minimum number of appropriately located audio sensors for a second-order harmonic expansion, more than nine appropriately located audio sensors can also be used to support a second-order harmonic expansion.

Fig. 8 shows a block diagram of a second-order audio system 800, according to one embodiment of the present invention, based on microphone array 700 of Fig. 7. Audio system 800 comprises the twelve microphones 702 of Fig. 7 mounted on acoustically rigid sphere 704 (not shown in Fig. 8) in the locations specified in Table II. In addition, audio system 800 includes a modal decomposer (i.e., eigenbeam former) 802, a modal beamformer 804, and an (optional) audio processor 806. In this particular embodiment, modal beamformer 804 comprises distance estimation unit 808, orientation estimation unit 810, direction compensation unit 812, response compensation unit 814, and beam combination unit 816. The various processing units and signals of second-order audio system 800 shown in Fig. 8 are analogous to corresponding processing units and signals of first-order audio system 400 shown in Fig. 4. Note that, in addition to generating the zero-order eigenbeam Y0 and the three first-order eigenbeams
In one possible implementation, the processing of distance estimation unit 808 is based on Equations (8) and (10), while the processing of orientation estimation unit 810 and direction compensation unit 812 is based on Equations (11) and (12). Note that direction compensation unit 812 generates two beams 813: a first-order beam (analogous to first-order beam 413 in Fig. 4) and a second-order beam. Similarly, response compensation unit 814 generates two compensated beams 815: one for the first-order beam received from direction compensation unit 812 and one for the second-order beam received from direction compensation unit 812. Note further that beam combination unit 816 combines (e.g., sums) the first- and second-order compensated beams 815 received from response compensation unit 814 with the zero-order beam represented by the eigenbeam output Y0 to generate steered beam 817. In one possible implementation, the processing of response compensation unit 814 is based on Equations (13)-(15).
Another possible embodiment involves a microphone array having only two audio sensors. In this case, the two microphone signals can be decomposed into two eigenbeam outputs: a zero-order eigenbeam output corresponding to the sum of the two microphone signals and a first-order eigenbeam output corresponding to the difference between the two microphone signals. Although orientation estimation would not be performed, the distance rL from the midpoint of the microphone array to a sound source can be estimated based on the first expression in Equation (8), where (i) a is the distance between the two microphones in the array and (ii) the two microphones and the sound source are substantially co-linear (i.e., the so-called endfire orientation). As before, the estimated distance can be thresholded to determine whether the sound source is a nearfield source or a farfield source. This would enable, for example, farfield signal energy to be attenuated, while leaving nearfield signal energy substantially unattenuated. Note that, for this embodiment, the modal beamformer can be implemented without an orientation estimation unit and a direction compensation unit. Implementation Issues
From an implementation point of view, it may be advantageous to work with real values rather than the complex spherical harmonics. For example, this would enable a straightforward time-domain implementation. The following property of Equation (17) is based on the definition of the spherical harmonics in Equation (3): Y1;"' = (- l)"X"* . (17)
Using this property, which is based on the even and odd symmetry properties of functions, expressions for the real and imaginary parts of the spherical harmonics can be derived according to Equations (18) and (19) as follows:

Using these equations, the results of the previous sections can be modified to be based on the real-valued real and imaginary parts of the spherical harmonics rather than the complex spherical harmonics themselves.
In particular, the eigenbeam weights from Equation (3) are replaced by the real and imaginary parts of the spherical harmonics, In this case, the structure of modal decomposer 402 of Fig. 4 is shown in Fig. 6. As shown in Fig. 6, the 5 microphone signals xs are applied to decomposer 402, which consists of several weight-and-addbeaniformers. Fig. 6 depicts the appropriate weighting for generating Rejl^(Ω)j (i.e., the real part of the eigenbeam of order n=\ and degree m=l), where the symbol Ω v represents the spherical coordinates I i9v, ζ»v | of the location for sensor s. The other eigenbeams are generated in an analogous manner.
For one possible implementation, all eigenbeams of two different orders n are used, where each order n has 2?z+l components. For example, using the zero and first orders involves four eigenbeams: the single zero-order eigenbeam and the three first-order eigenbeams. Alternatively, using the first and second orders involves eight eigenbeams: the three first-order eigenbeams and the five second-order eigenbeams. Applications
Referring again to Fig. 4, the processing of the audio signals from the microphone array comprises two basic stages: decomposition and beamforming. Depending on the application, this signal processing can be implemented in different ways.
In one implementation, modal decomposer 402 and beamformer 404 are co-located and operate together in real time. In this case, the eigenbeam outputs generated by modal decomposer 402 are provided immediately to beamformer 404 for use in generating one or more auditory scenes in real time. The control of the beamformer can be performed on-site or remotely.
In another implementation, modal decomposer 402 and beamformer 404 both operate in real time, but are implemented in different (i.e., non-co-located) nodes. In this case, data corresponding to the eigenbeam outputs generated by modal decomposer 402, which is implemented at a first node, are transmitted (via wired and/or wireless connections) from the first node to one or more other remote nodes,
within each of which a beamformer 404 is implemented to process the eigenbeam outputs recovered from the received data to generate one or more auditory scenes.
In yet another implementation, modal decomposer 402 and beamformer 404 do not both operate at the same time (i.e., beamformer 404 operates subsequent to modal decomposer 402). In this case, data corresponding to the eigenbeam outputs generated by modal decomposer 402 are stored, and, at some subsequent time, the data is retrieved and used to recover the eigenbeam outputs, which are then processed by one or more beamformers 404 to generate one or more auditory scenes. Depending on the application, the beamformers may be either co-located or non-co-located with the modal decomposer.
Each of these different implementations is represented generically in Fig. 4 by channels 403 through which the eigenbeam outputs generated by modal decomposer 402 are provided to beamformer 404. The exact implementation of channels 403 will then depend on the particular application. In Fig. 4, channels 403 are represented as a set of parallel streams of eigenbeam output data (i.e., one time-varying eigenbeam output for each eigenbeam in the spherical harmonic expansion for the microphone array).
In certain applications, a single beamformer, such as beamformer 404 of Fig. 4, is used to generate one output beam. In addition or alternatively, the eigenbeam outputs generated by modal decomposer 402 may be provided (either in real-time or non-real time, and either locally or remotely) to one or more additional beamformers, each of which is capable of independently generating one output beam from the set of eigenbeam outputs generated by decomposer 402.
Although the present invention has been described primarily in the context of a microphone array comprising a plurality of audio sensors mounted on the surface of an acoustically rigid sphere, the present invention is not so limited. For example, other acoustic impedances are possible, such as an open sphere or a soft sphere. Also, in reality, no physical structure is ever perfectly spherical, and the present invention should not be interpreted as having to be limited to such ideal structures. Moreover, the present invention can be implemented in the context of shapes other than spheres that support orthogonal harmonic expansion, such as "spheroidal" oblates and prolates, where, as used in this specification, the term
"spheroidal" also covers spheres. In general, the present invention can be implemented for any shape that supports orthogonal harmonic expansion including cylindrical shapes. It will also be understood that certain deviations from ideal shapes are expected and acceptable in real-world implementations. The same real-world considerations apply to satisfying the discrete orthonormality condition applied to the locations of the sensors. Although, in an ideal world, satisfaction of the condition corresponds to the mathematical delta function, in real-world implementations, certain deviations from this exact mathematical formula are expected and acceptable. Similar real- world principles also apply to the definitions of what constitutes an acoustically rigid or acoustically soft structure.
The present invention may be implemented as (analog, digital, or a hybrid of both analog and digital) circuit-based processes, including possible implementation on a single integrated circuit.
W
-17-
Moreover, the present invention can be implemented in either the time domain or equivalently in the frequency domain. As would be apparent to one skilled in the art, various functions of circuit elements may also be implemented as processing steps in a software program. Such software may be employed in, for example, a digital signal processor, micro-controller, or general-purpose computer. The present invention can be embodied in the form of methods and apparatuses for practicing those methods. The present invention can also be embodied in the form of program code embodied in tangible media, such as floppy diskettes, CD-ROMs, hard drives, or any other machine-readable storage medium, wherein, when the program code is loaded into and executed by a machine, such as a computer, the machine becomes an apparatus for practicing the invention. The present invention can also be embodied in the form of program code, for example, whether stored in a storage medium, loaded into and/or executed by a machine, or transmitted over some transmission medium or carrier, such as over electrical wiring or cabling, through fiber optics, or via electromagnetic radiation, wherein, when the program code is loaded into and executed by a machine, such as a computer, the machine becomes an apparatus for practicing the invention. When implemented on a general-purpose processor, the program code segments combine with the processor to provide a unique device that operates analogously to specific logic circuits.
Unless explicitly stated otherwise, each numerical value and range should be interpreted as being approximate as if the word "about" or "approximately" preceded the value of the value or range.
Reference herein to "one embodiment" or "an embodiment" means that a particular feature, structure, or characteristic described in connection with the embodiment can be included in at least one embodiment of the invention. The appearances of the phrase "in one embodiment" in various places in the specification are not necessarily all referring to the same embodiment, nor are separate or alternative embodiments necessarily mutually exclusive of other embodiments. The same applies to the term "implementation." It will be further understood that various changes in the details, materials, and arrangements of the parts which have been described and illustrated in order to explain the nature of this invention may be made by those skilled in the art without departing from the principle and scope of the invention as expressed in the following claims. Although the steps in the following method claims, if any, are recited in a particular sequence with corresponding labeling, unless the claim recitations otherwise imply a particular sequence for implementing some or all of those steps, those steps are not necessarily intended to be limited to being implemented in that particular sequence.
Claims
1. A method for processing audio signals corresponding to sound received from a sound source, the method comprising: (a) receiving a plurality of audio signals, each audio signal having been generated by a different sensor of a microphone array;
(b) decomposing the plurality of audio signals into a plurality of eigenbeam outputs, wherein each eigenbeam output corresponds to a different eigenbeam for the microphone array;
(c) generating, based on one or more of the eigenbeam outputs, compensation data corresponding to at least one of (i) an estimate of distance between the microphone array and the sound source and (ii) an estimate of orientation of the sound source relative to the microphone array; and
(d) generating an auditory scene from one or more of the eigenbeam outputs, wherein generation of the auditory scene comprises compensation based on the compensation data,
2. The invention of claim 1, wherein: the compensation data comprises distance-based compensation data corresponding to the estimated distance; the compensation comprises frequency response compensation based on the distance-based compensation data.
3. The invention of claim 2, wherein the distance-based compensation data is based on a comparison of overall mode strengths for two or more different mode orders of the eigenbeams.
4. The invention of claim 2, wherein: step (c) further comprises determining whether or not the sound source is a nearfield sound source; and the compensation further comprises direction compensation only if the sound source is determined to be a nearfield sound source.
5. The invention of claim 1, wherein: the compensation data comprises orientation-based compensation data corresponding to the estimated orientation; and the compensation comprises direction compensation based on the orientation-based compensation data.
6. The invention of claim 5, wherein the orientation-based compensation data for an eigenbeam of mode order n and mode degree m is based on a ratio between mode strength of the eigenbeam of degree m and an overall mode strength for mode order n and the relative phase of the eigenbeam of degree m relative to a reference eigenbeam.
7. The invention of claim 5, wherein the direction compensation comprises steering a beam formed from the eigenbeams in a direction based on the estimated orientation.
8. The invention of claim 7, wherein steering the beam comprises: applying a weighting value to each eigenbeam output to form a weighted eigenbeam; and combining the weighted eigenbeams to generate the steered beam.
9. The invention of claim 5, wherein: the direction compensation is applied to eigenbeam outputs of mode order greater than zero to generate a steered beam; and the steered beam is combined with a zero-order eigenbeam output to generate the auditory scene.
10. The invention of claim 9, wherein the combination of the steered beam and the zero-order eigenbeam output attenuates farfϊeld signal energy while leaving nearfield signal energy substantially unattenuated in the auditory scene.
11. The invention of claim 1, wherein: receiving the plurality of audio signals further comprises generating the plurality of audio signals using the microphone array; the eigenbeams correspond to (i) spheroidal harmonics based on a spherical, oblate, or prolate configuration of the sensors in the microphone array or (ii) cylindrical harmonics based on cylindrical configuration of the sensors in the microphone array; and the arrangement of the sensors in the microphone array satisfies a discrete orthogonality condition.
12, The invention of claim 1, further comprising the step of further processing the auditory scene based on at least one of the estimated distance and the estimated orientation.
13. The invention of claim 1, wherein: the plurality of audio signals comprises two audio signals; the two audio signals are decomposed into (i) a zero-order eigenbeam output corresponding to a sum of the two audio signals and (ii) a first-order eigenbeam output corresponding to a difference between the two audio signals; W
-20- the compensation data corresponds to an estimate of the distance between the microphone array and the sound source; and the auditory scene is generated from the zero-order eigenbeam output and the first-order eigenbeam output taking into account the estimated distance.
14. An audio system for processing audio signals corresponding to sound received from a sound source, the audio system comprising: a modal decomposer adapted to:
(1) receive a plurality of audio signals, each audio signal having been generated by a different sensor of a microphone array; and
(2) decompose the plurality of audio signals into a plurality of eigenbeam outputs, wherein each eigenbeam output corresponds to a different eigenbeam for the microphone array; and a modal beamformer adapted to:
(1) generate, based on one or more of the eigenbeam outputs, compensation data corresponding to at least one of (i) an estimate of distance between the microphone array and the sound source and (ii) an estimate of orientation of the sound source relative to the microphone array; and
(2) generate an auditory scene from one or more of the eigenbeam outputs, wherein generation of the auditory scene comprises compensation based on the compensation data.
15. The invention of claim 14, wherein: the compensation data comprises distance-based compensation data corresponding to the estimated distance; the modal beamformer is adapted to perform frequency response compensation based on the distance- based compensation data.
16. The invention of claim 15, wherein the distance-based compensation data is based on a comparison of overall mode strengths for two or more different mode orders of the eigenbeams.
17. The invention of claim 15, wherein the modal beamformer is adapted to: determine whether or not the sound source is a nearfϊeld sound source; and perform direction compensation only if the sound source is determined to be a nearfϊeld sound source.
18. The invention of claim 14, wherein: the compensation data comprises orientation-based compensation data corresponding to the estimated orientation; and the modal beamformer is adapted to perform direction compensation based on the orientation-based compensation data.
19. The invention of claim 18, wherein the orientation-based compensation data for an eigenbeam of mode order n and mode degree m is based on a ratio between mode strength of the eigenbeam of degree m and an overall mode strength for mode order n and the relative phase of the eigenbeam of degree m relative to a reference eigenbeam.
20. The invention of claim 18, wherein the modal beamformer is adapted to perform the direction compensation by steering a beam formed from the eigenbeams in a direction based on the estimated orientation.
21. The invention of claim 20, wherein the modal beamformer is adapted to steer the beam by: applying a weighting value to each eigenbeam output to form a weighted eigenbeam; and combining the weighted eigenbeams to generate the steered beam.
22. The invention of claim 18, wherein the modal beamformer is adapted to: apply the direction compensation to eigenbeam outputs of mode order greater than zero to generate a steered beam; and combine the steered beam with a zero-order eigenbeam output to generate the auditory scene.
23. The invention of claim 22, wherein the modal beamformer is adapted to combine the steered beam and the zero-order eigenbeam output to attenuate farfϊeld signal energy while leaving nearfield signal energy substantially unattenuated in the auditory scene.
24. The invention of claim 14, wherein: the audio system further comprises the microphone array; the eigenbeams correspond to (i) spheroidal harmonics based on a spherical, oblate, or prolate configuration of the sensors in the microphone array or (ii) cylindrical harmonics based on cylindrical configuration of the sensors in the microphone array; and the arrangement of the sensors in the microphone array satisfies a discrete orthogonality condition.
25. The invention of claim 14, wherein the modal beamformer comprises: a distance estimation unit adapted to generate distance-based compensation data from at least some of the eigenbeam outputs; an orientation estimation unit adapted to generate estimated-orientation-based compensation data from at least some of the eigenbeam outputs; a direction compensation unit adapted to perform direction compensation on the eigenbeam outputs based on the estimated-orientation-based compensation data to generate a steered beam; and a response compensation unit adapted to perform distance compensation on the steered beam based on the distance-based compensation data to generate the auditory scene.
26. The invention of claim 25, wherein the distance estimation unit is adapted to control whether the direction compensation is to be based on the estimated-orientation-based compensation data or on default- orientation-based compensation data.
27. The invention of claim 26, wherein: if the distance estimation unit determines that the sound source is a nearfϊeld sound source, then the distance estimation unit controls the direction compensation to be based on the estimated-orientation-based compensation data; and if the distance estimation unit determines that the sound source is a farfield sound source, then the distance estimation unit controls the direction compensation to be based on the default-orientation-based compensation data.
28. The invention of claim 25, wherein the modal beamformer further comprises a beam combination unit adapted to include a zero-order eigenbeam output in the auditory scene.
29. The invention of claim 25, further comprising an audio processor adapted to further process the auditory scene based on at least one of the estimated distance and the estimated orientation.
30. The invention of claim 14, wherein: the plurality of audio signals comprises two audio signals; the modal decomposer is adapted to decompose the two audio signals into (i) a zero-order eigenbeam output corresponding to a sum of the two audio signals and (ii) a first-order eigenbeam output corresponding to a difference between the two audio signals; the modal beamformer is adapted to: generate the compensation data corresponding to an estimate of the distance between the microphone array and the sound source; and generate the auditory scene from the zero-order eigenbeam output and the first-order eigenbeam output taking into account the estimated distance.
31. Apparatus for processing audio signals corresponding to sound received from a sound source, the apparatus comprising:
(a) means for receiving a plurality of audio signals, each audio signal having been generated by a different sensor of a microphone array;
(b) means for decomposing the plurality of audio signals into a plurality of eigenbeam outputs, wherein each eigenbeam output corresponds to a different eigenbeam for the microphone array;
(c) means for generating, based on one or more of the eigenbeam outputs, compensation data corresponding to at least one of (1) an estimate of distance between the microphone array and the sound source and (2) an estimate of orientation of the sound source relative to the microphone array; and
(d) means for generating an auditory scene from one or more of the eigenbeam outputs, wherein generation of the auditory scene comprises compensation based on the compensation data.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP06737030A EP1856948B1 (en) | 2005-03-09 | 2006-03-06 | Position-independent microphone system |
| US11/817,033 US8204247B2 (en) | 2003-01-10 | 2006-03-06 | Position-independent microphone system |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US65978705P | 2005-03-09 | 2005-03-09 | |
| US60/659,787 | 2005-03-09 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2006110230A1 true WO2006110230A1 (en) | 2006-10-19 |
Family
ID=36578793
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2006/007800 WO2006110230A1 (en) | 2003-01-10 | 2006-03-06 | Position-independent microphone system |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US8204247B2 (en) |
| EP (1) | EP1856948B1 (en) |
| WO (1) | WO2006110230A1 (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2114085A1 (en) | 2008-04-28 | 2009-11-04 | Nederlandse Centrale Organisatie Voor Toegepast Natuurwetenschappelijk Onderzoek TNO | Composite microphone, microphone assembly and method of manufacturing those |
| US8120993B2 (en) * | 2008-06-02 | 2012-02-21 | Kabushiki Kaisha Toshiba | Acoustic treatment apparatus and method thereof |
| CN104105049A (en) * | 2014-07-17 | 2014-10-15 | 大连理工大学 | Room impulse response function measuring method allowing using quantity of microphones to be reduced |
| US9025415B2 (en) | 2010-02-23 | 2015-05-05 | Koninklijke Philips N.V. | Audio source localization |
Families Citing this family (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8189807B2 (en) * | 2008-06-27 | 2012-05-29 | Microsoft Corporation | Satellite microphone array for video conferencing |
| WO2010022453A1 (en) | 2008-08-29 | 2010-03-04 | Dev-Audio Pty Ltd | A microphone array system and method for sound acquisition |
| NO332961B1 (en) * | 2008-12-23 | 2013-02-11 | Cisco Systems Int Sarl | Elevated toroid microphone |
| CN102630385B (en) * | 2009-11-30 | 2015-05-27 | 诺基亚公司 | Method, device and system for audio zooming process within an audio scene |
| NO20093511A1 (en) * | 2009-12-14 | 2011-06-15 | Tandberg Telecom As | Toroidemikrofon |
| JPWO2011118218A1 (en) * | 2010-03-26 | 2013-07-04 | パナソニック株式会社 | Speaker device, sound control device, wall with speaker device attached |
| US8855341B2 (en) | 2010-10-25 | 2014-10-07 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for head tracking based on recorded sound signals |
| US9552840B2 (en) * | 2010-10-25 | 2017-01-24 | Qualcomm Incorporated | Three-dimensional sound capturing and reproducing with multi-microphones |
| US9031256B2 (en) | 2010-10-25 | 2015-05-12 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for orientation-sensitive recording control |
| EP2448289A1 (en) * | 2010-10-28 | 2012-05-02 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for deriving a directional information and computer program product |
| EP2905975B1 (en) * | 2012-12-20 | 2017-08-30 | Harman Becker Automotive Systems GmbH | Sound capture system |
| US9706298B2 (en) * | 2013-01-08 | 2017-07-11 | Stmicroelectronics S.R.L. | Method and apparatus for localization of an acoustic source and acoustic beamforming |
| US9591404B1 (en) * | 2013-09-27 | 2017-03-07 | Amazon Technologies, Inc. | Beamformer design using constrained convex optimization in three-dimensional space |
| US9560441B1 (en) * | 2014-12-24 | 2017-01-31 | Amazon Technologies, Inc. | Determining speaker direction using a spherical microphone array |
| US10334390B2 (en) | 2015-05-06 | 2019-06-25 | Idan BAKISH | Method and system for acoustic source enhancement using acoustic sensor array |
| US9479885B1 (en) * | 2015-12-08 | 2016-10-25 | Motorola Mobility Llc | Methods and apparatuses for performing null steering of adaptive microphone array |
| CN106997768B (en) * | 2016-01-25 | 2019-12-10 | 电信科学技术研究院 | Method and device for calculating voice occurrence probability and electronic equipment |
| EP3414919B1 (en) | 2016-02-09 | 2021-07-21 | Zylia Spolka Z Ograniczona Odpowiedzialnoscia | Microphone probe, method, system and computer program product for audio signals processing |
| GB2563670A (en) | 2017-06-23 | 2018-12-26 | Nokia Technologies Oy | Sound source distance estimation |
| WO2019119654A1 (en) * | 2017-12-22 | 2019-06-27 | 北京凌宇智控科技有限公司 | Control method and device for ultrasonic receiving device |
| US10951859B2 (en) | 2018-05-30 | 2021-03-16 | Microsoft Technology Licensing, Llc | Videoconferencing device and method |
| US20220260665A1 (en) * | 2019-06-27 | 2022-08-18 | Rensselaer Polytechnic Institute | Sound source enumeration and direction of arrival estimation using a bayesian framework |
| US11234073B1 (en) * | 2019-07-05 | 2022-01-25 | Facebook Technologies, Llc | Selective active noise cancellation |
| FR3105823B1 (en) * | 2019-12-27 | 2021-12-03 | Fond B Com | Method and system for estimating a quantity representative of sound energy |
| CN117907998B (en) * | 2024-03-20 | 2024-05-28 | 西北工业大学青岛研究院 | Shallow sea broadband sound source ranging method, medium and system |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0381498A2 (en) * | 1989-02-03 | 1990-08-08 | Matsushita Electric Industrial Co., Ltd. | Array microphone |
| WO1995029479A1 (en) * | 1994-04-21 | 1995-11-02 | Brown University Research Foundation | Methods and apparatus for adaptive beamforming |
| EP0869697A2 (en) * | 1997-04-03 | 1998-10-07 | Lucent Technologies Inc. | A steerable and variable first-order differential microphone array |
| JPH11168792A (en) * | 1997-12-03 | 1999-06-22 | Alpine Electron Inc | Sound field controller |
| WO2003061336A1 (en) * | 2002-01-11 | 2003-07-24 | Mh Acoustics, Llc | Audio system based on at least second-order eigenbeams |
| EP1571875A2 (en) * | 2004-03-02 | 2005-09-07 | Microsoft Corporation | A system and method for beamforming using a microphone array |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB1512514A (en) * | 1974-07-12 | 1978-06-01 | Nat Res Dev | Microphone assemblies |
| US5288955A (en) * | 1992-06-05 | 1994-02-22 | Motorola, Inc. | Wind noise and vibration noise reducing microphone |
| JP3541339B2 (en) * | 1997-06-26 | 2004-07-07 | 富士通株式会社 | Microphone array device |
| US6072878A (en) * | 1997-09-24 | 2000-06-06 | Sonic Solutions | Multi-channel surround sound mastering and reproduction techniques that preserve spatial harmonics |
| US6526147B1 (en) | 1998-11-12 | 2003-02-25 | Gn Netcom A/S | Microphone array with high directivity |
| US6239348B1 (en) * | 1999-09-10 | 2001-05-29 | Randall B. Metcalf | Sound system and method for creating a sound event based on a modeled sound field |
| NZ502603A (en) | 2000-02-02 | 2002-09-27 | Ind Res Ltd | Multitransducer microphone arrays with signal processing for high resolution sound field recording |
-
2006
- 2006-03-06 EP EP06737030A patent/EP1856948B1/en active Active
- 2006-03-06 WO PCT/US2006/007800 patent/WO2006110230A1/en active Application Filing
- 2006-03-06 US US11/817,033 patent/US8204247B2/en active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0381498A2 (en) * | 1989-02-03 | 1990-08-08 | Matsushita Electric Industrial Co., Ltd. | Array microphone |
| WO1995029479A1 (en) * | 1994-04-21 | 1995-11-02 | Brown University Research Foundation | Methods and apparatus for adaptive beamforming |
| EP0869697A2 (en) * | 1997-04-03 | 1998-10-07 | Lucent Technologies Inc. | A steerable and variable first-order differential microphone array |
| JPH11168792A (en) * | 1997-12-03 | 1999-06-22 | Alpine Electron Inc | Sound field controller |
| WO2003061336A1 (en) * | 2002-01-11 | 2003-07-24 | Mh Acoustics, Llc | Audio system based on at least second-order eigenbeams |
| EP1571875A2 (en) * | 2004-03-02 | 2005-09-07 | Microsoft Corporation | A system and method for beamforming using a microphone array |
Non-Patent Citations (1)
| Title |
|---|
| PATENT ABSTRACTS OF JAPAN vol. 1999, no. 11 30 September 1999 (1999-09-30) * |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2114085A1 (en) | 2008-04-28 | 2009-11-04 | Nederlandse Centrale Organisatie Voor Toegepast Natuurwetenschappelijk Onderzoek TNO | Composite microphone, microphone assembly and method of manufacturing those |
| WO2009134127A1 (en) | 2008-04-28 | 2009-11-05 | Nederlandse Organisatoe Voor Toegepast Natuurwetenschappelijk Onderzoek Tno | Composite microphone, microphone assembly and method of manufacturing those |
| US8731226B2 (en) | 2008-04-28 | 2014-05-20 | Nederlandse Organisatie Voor Toegepast-Natuurwetenschappelijk Onderzoek Tno | Composite microphone with flexible substrate and conductors |
| US8120993B2 (en) * | 2008-06-02 | 2012-02-21 | Kabushiki Kaisha Toshiba | Acoustic treatment apparatus and method thereof |
| US9025415B2 (en) | 2010-02-23 | 2015-05-05 | Koninklijke Philips N.V. | Audio source localization |
| CN104105049A (en) * | 2014-07-17 | 2014-10-15 | 大连理工大学 | Room impulse response function measuring method allowing using quantity of microphones to be reduced |
Also Published As
| Publication number | Publication date |
|---|---|
| EP1856948B1 (en) | 2011-10-05 |
| EP1856948A1 (en) | 2007-11-21 |
| US20080247565A1 (en) | 2008-10-09 |
| US8204247B2 (en) | 2012-06-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8204247B2 (en) | Position-independent microphone system | |
| EP1466498B1 (en) | Audio system based on at least second order eigenbeams | |
| EP3384684B1 (en) | Conference system with a microphone array system and a method of speech acquisition in a conference system | |
| US9445198B2 (en) | Polyhedral audio system based on at least second-order eigenbeams | |
| US9294838B2 (en) | Sound capture system | |
| US8098844B2 (en) | Dual-microphone spatial noise suppression | |
| KR101555416B1 (en) | Apparatus and method for spatially selective sound acquisition by acoustic triangulation | |
| US10659873B2 (en) | Spatial encoding directional microphone array | |
| KR101456866B1 (en) | Method and apparatus for extracting the target sound signal from the mixed sound | |
| WO2017218399A1 (en) | Spatial encoding directional microphone array | |
| CN101852846A (en) | Signal handling equipment, signal processing method and program | |
| KR20140138907A (en) | A method of applying a combined or hybrid sound -field control strategy | |
| WO2013085605A1 (en) | Near-field null and beamforming | |
| US8615392B1 (en) | Systems and methods for producing an acoustic field having a target spatial pattern | |
| WO2015013058A1 (en) | Adaptive beamforming for eigenbeamforming microphone arrays | |
| Albertini et al. | Two-stage beamforming with arbitrary planar arrays of differential microphone array units | |
| EP2757811B1 (en) | Modal beamforming | |
| Chen et al. | A new approach for speaker tracking in reverberant environment | |
| Haneda et al. | Evaluating small end-fire loudspeaker array under various reverberations | |
| Abe et al. | Estimation of the waveform of a sound source by using an iterative technique with many sensors | |
| Lee et al. | Robust Inverse Filter Design Based on Energy Density Control |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application | ||
| WWE | Wipo information: entry into national phase |
Ref document number: 11817033 Country of ref document: US |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2006737030 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| NENP | Non-entry into the national phase |
Ref country code: RU |