Methods and Compositions for Reducing Screening in Oligonucleotide-Directed Nucleic Acid Sequence Alteration
CROSS-REFERENCE TO RELATED APPLICATIONS
[0001] This application claims the benefit of U.S. provisional applications nos. 60/453,360, filed March 7, 2003, and 60/416,983, filed October 7, 2002, the disclosures of which are incorporated herein by reference in their entireties.
FIELD OF THE INVENTION
[0002] The technical field of the invention relates to oligonucleotide-directed alteration of nucleic acid sequence.
BACKGROUND OF THE INVENTION
[0003] A number of methods have been developed to alter specific nucleotides within both isolated DNA molecules and DNA present within intact cells of bacteria, plants, fungi and animals, including humans.
[0004] In one approach, genomic sequences are targeted for alteration by homologous recombination using duplex fragments. The duplex fragments are large, having several hundred basepairs. See, e.g., Kunzelmann et al., Gene Ther. 3:859-867 (1996).
[0005] In another approach, oligonucleotides are used to effect targeted genetic changes.
[0006] In early experiments, oligonucleotide-directed sequence changes were typically effected in yeast, Moerschell et al., 1988, Proc. Natl. Acad. Sci. 85:524 and Yamamoto et al., Yeast 8:935
(1992), which among eukaryotes are known to have high recombinogenic activity, although one series of experiments were attempted in human cells, Campbell et al., The New Biologist 1 : 223-227 (1989).
[0007] More recently, a number of different types of polynucleotides and oligonucleotides have been described that permit targeted alteration of genetic material in cells of higher 5 eukaryotes, including (i) triplex-forming oligonucleotides; (ii) chimeric RNA-DNA oligonucleotides that are internally duplexed, notably in the region containing the nucleotide that directs the sequence alteration; and (iii) terminally modified single-stranded oligonucleotides having an internally unduplexed DNA domain and modified ends.
[0008] Sequence-altering triplexing oligonucleotides are described, for example, in U.S. 0 Pat. Nos. 6,303,376, 5,962,426, and 5,776,744.
[0009] Triplex-forming oligonucleotides require a structural domain that binds to a DNA helical duplex through Hoogsteen interactions between the major groove of the DNA duplex and the oligonucleotide. The binding domain must typically target polypurine or polypyrimidine tracts. These sequence requirements limit the usefulness of triplex-forming oligonucleotides for targeted sequence . 5 alteration, requiring that the target sequence to be modified be situated in proximity to such polypurine or polypyrimidine tract. Triplex-forming oligonucleotides may also require an additional DNA reactive moiety, such as psoralen, to be covalently linked to the oligonucleotide, in order to stabilize the interactions between the triplex-forming domain of the oligonucleotide and the DNA double helix if the Hoogsteen interactions from the oligonucleotide/target base composition are insufficient. See, e.g., U.S. Patent o 5,422,251. Such DNA-reactive moieties can, however, be indiscriminately mutagenic.
[0010] In more recent work with sequence-altering triplexing oligonucleotides, the triplex-forming domain is linked or tethered to a domain that effects targeted alteration, Culver et al., Na Biotechnology 17: 989-93 (1999), relaxing somewhat the permissible distance between target sequence and polypurine/polypyrimidine stretch. 5 [0011] , Internally duplexed, hairpin- and double-hairpin-containing chimeric RNA-DNA oligonucleotides are described, inter alia, in U.S. Pat. Nos. 6,573,046; 5,888,983; 5,871 ,984; 5,795,972; 5,780,296; 5,760,012; 5,756,325; 5,731 ,181 , and 5,565,350. Such chimeric RNA-DNA oligonucleotides are reportedly capable of directing targeted alteration of single base pairs, as well as introducing frameshift alterations, in cells and cell-free extracts from a variety of host organisms, including bacteria, o fungi, plants and animals. The oligonucleotides are reportedly able to operate on almost any target sequence.
[0012] Such chimeric molecules have significant structural requirements, however, including a requirement for both ribonucleotides and deoxyribonucleotides, and typically also a requirement that the oligonucleotide adopt a double-hairpin conformation. Even when such double hairpins are not required, however, significant structural constraints remain. 5 [0013] Single-stranded oligonucleotides having modified ends and an internally unduplexed DNA domain that directs sequence alteration are described in copending international patent applications published as WO 03/027265; WO 02/10364; WO 01/92512; WO 01/87914; and WO 01/73002, as well as in U.S. Pat. Nos. 6,479,292 and 6,271 ,360, the disclosures of which are incorporated herein by reference in their entireties. o [0014] These single-stranded oligonucleotides have fewer structural requirements than chimeric oligonucleotides and are capable of directing sequence alteration, including introduction of frameshift mutations, in cells and cell-free extracts from a variety of host organisms, including bacteria, fungi, plants and animals, in episomal and in chromosomal targets, often at alteration efficiencies that exceed those observed with hairpin-containing, internally duplexed, chimeric oligonucleotides. 5 [0015] The usefulness of oligonucleotide-mediated nucleic acid sequence alteration — as a means, for example, for manipulating cloned DNA, for generating agricultural products with enhanced traits, for generating cellular models for laboratory use, or for generating animal models or animals with desired traits — is affected by its frequency. The usefulness of oligonucleotide-mediated nucleic acid sequence alteration as an ex vivo or in vivo therapeutic method would also be enhanced by increasing its o efficiency.
[0016] A need exists, therefore, for methods to enhance the efficiency of targeted alteration of genetic material.
SUMMARY OF THE INVENTION 5 [0017] The invention provides methods, compositions and kits for enhancing oligonucleotide-directed nucleic acid sequence alteration by reducing the number of target nucleic acid molecules required to be screened during oligonucleotide-directed targeted nucleic acid sequence alteration. The methods, compositions and kits involve using at least two oligonucleotides, where at least one of the oligonucleotides directs alteration of a selectable target. o [0018] In one aspect, the invention provides methods for reducing the number of target nucleic acid molecules required to be screened during oligonucleotide-directed nucleic acid sequence alteration comprising combining a nucleic acid molecule in the presence of repair proteins with at least two
oligonucleotides capable of directing alteration in at least two nucleic acid targets, where alteration by at least one oligonucleotide confers a selectable phenotype which is selected for, and selecting or screening for a nucleic acid molecule having the alteration directed by the other oligonucleotide in a composition having the selectable phenotype. 5 [0019] In other aspects, the invention provides compositions and kits for oligonucleotide-directed nucleic acid sequence alteration comprising at least two oligonucleotides, where at least one of the oligonucleotides directs an alteration which confers a selectable phenotype.
[0020] Other embodiments of the invention are set forth in the following numbered items: o [0021] 1. A method for reducing the number of target nucleic acid molecules required to be screened during oligonucleotide-directed nucleic acid sequence alteration of a first nucleic acid target in a composition comprising said first nucleic acid target and a second nucleic acid target,
[0022] wherein alteration of said first nucleic acid target is effected by combining, in the presence of cellular repair proteins, a nucleic acid molecule comprising said first nucleic acid target with a 5 first oligonucleotide and a second oligonucleotide,
[0023] wherein said first oligonucleotide is capable of effecting alteration of said first nucleic acid target and said second oligonucleotide is capable of effecting alteration of said second nucleic acid target, and wherein alteration of said second nucleic acid target confers a selectable phenotype, 0 [0024] said method comprising:
[0025] (a) selecting for alteration of said second nucleic acid target and [0026] (b) screening for a nucleic acid molecule comprising an alteration of said first nucleic acid target.
5 [0027] 2. A method for targeted alteration of a first nucleic acid target in a composition comprising said first nucleic acid target and a second nucleic acid target, comprising:
[0028] (a) combining, in the presence of cellular repair proteins, a nucleic acid molecule comprising said first nucleic acid target with a first oligonucleotide and a second oligonucleotide, [0029] wherein said first oligonucleotide is capable of effecting alteration of said o first nucleic acid target and said second oligonucleotide is capable of effecting alteration of said second nucleic acid target, and wherein alteration of said second nucleic acid target confers a selectable phenotype; and
[0030] (b) identifying a nucleic acid molecule comprising an alteration of said first nucleic acid target in a composition in which alteration of the second nucleic acid target has occurred.
[0031] 3. The method of item 1 or 2, wherein alteration of the selectable 5 phenotype is selected from the group consisting of: antibiotic resistance, prototrophy, expression of a fluorescent protein, presence of an epitope and resistance to an apoptotic signal.
[0032] 4. The method of any one of items 1-3, wherein the alteration of the first nucleic acid target is a substitution, deletion or insertion of at least one base. 0
[0033] 5. The method of item 4, wherein the alteration of the second nucleic acid target is a substitution, deletion or insertion of at least one base.
[0034] 6. The method of any one of items 1-5, wherein the nucleic acid molecule 5 comprising the first nucleic acid target does not comprise the second nucleic acid target.
[0035] 7. The method of any one of items 1-5, wherein the nucleic acid molecule comprising the first nucleic acid target comprises the second nucleic acid target.
o [0036] 8. The method of any one of items 1-7, wherein the nucleic acid molecule comprising the first nucleic acid target is a DNA molecule.
[0037] 9. The method of item 8, wherein the DNA molecule is selected from the group consisting of: a chromosome, a plasmid, a YAC, a BAC, a PLAC, a MAC, and a PAC. 5
[0038] 10. The method of item 8 or 9, wherein the DNA molecule is present in a cell.
[0039] 11. The method of item 10, wherein the cell is selected from the group o consisting of: a prokaryotic cell, a fungal cell, a plant cell, and an animal cell.
[0040] 12. The method of item 11 , wherein the cell is prokaryotic cell.
[0041] 13. The method of item 12, wherein the prokaryotic cell is an Escherichia coli cell.
[0042] 14. The method of item 11 , wherein the cell is a fungal cell.
[0043] 15. The method of item 14, wherein the fungal cell is selected from the group consisting of: a Saccharomyces cerevisiae cell, an Ustilago maydis cell, a Neurospora crassa cell and a Candida albicans cell.
[0044] 16. The method of item 11, wherein the cell is a plant cell.
[0045] 17. The method of item 16, wherein the plant cell is selected from the group consisting of: an angiosperm cell, a gymnosperm cell and a moss cell.
[0046] 18. The method of item 16, wherein the cell is a Chlamydomonas rheinhardtii cell.
[0047] 19. The method of item 17, wherein the angiosperm cell is an Arabidopsis thaliana cell.
[0048] 20. The method of item 17, wherein the moss cell is a Physcomitrella patens cell.
[0049] 21. The method of item 11 , wherein the cell is an animal cell.
[0050] 22. The method of item 21 , wherein the animal cell is a mammalian cell.
[0051] 23. The method of item 22, wherein the mammalian cell is selected from the group consisting of: a human cell, a rodent cell, a mouse cell, a hamster cell, a rat cell, and a monkey cell.
[0052] 24. The method of item 23, wherein the human cell is selected from the group consisting of: a liver cell, a lung cell, a colon cell, a cervical cell, a kidney cell, an epithelial cell, a blood cell, a cancer cell, and a stem cell.
5 [0053] 25. The method of any one of items 1 -24, wherein the first oligonucleotide has a region that is fully complementary in sequence to the first nucleic acid target, but for one or more mismatches as between the sequences of the first oligonucleotide and its complement on the first nucleic acid target, and wherein the first oligonucleotide has at least one terminal modification.
o [0054] 26. The method of item 25, wherein the at least one terminal modification is selected from the group consisting of: at least one terminal locked nucleic acid (LNA), at least one terminal 2'-0-Me base analog, and at least three terminal phosphorothioate linkages.
[0055] 27. The method of item 26, wherein the first oligonucleotide is a single- 5 stranded oligonucleotide 15 - 121 nucleotides in length, has an internally unduplexed domain of at least 8 contiguous deoxyribonucleotides, and wherein the one or more mismatches are positioned exclusively in the oligonucleotide DNA domain and at least 7 nucleotides from said oligonucleotide's 5' and 3' termini.
[0056] 28. The method of item 27, wherein the first oligonucleotide has at least one o terminal locked nucleic acid (LNA).
[0057] 29. The method of item 1 or 2, wherein the first oligonucleotide is at least 25 nucleotides in length.
5 [0058] 30. The method of item 1 or 2, wherein the first oligonucleotide is no more than 121 nucleotides in length.
[0059] 31. The method of item 30, wherein the first oligonucleotide is no more than 74 nucleotides in length. 0
[0060] 32. A composition for targeted alteration of a first nucleic acid target, comprising:
[0061] a first oligonucleotide and a second oligonucleotide, wherein the oligonucleotides are capable, in the presence of cellular repair proteins, of effecting targeted alteration of a first nucleic target and a second nucleic acid target, respectively; and
[0062] wherein alteration of the second nucleic acid target confers a selectable phenotype.
[0063] 33. The composition of item 32 further comprising cellular repair proteins.
[0064] 34. The composition of item 33, wherein said cellular proteins are purified.
[0065] 35. The composition of item 33, wherein said cellular proteins are present in a cell-free protein extract.
[0066] 36. The composition of item 33, wherein said cellular proteins are present within an intact cell.
[0067] 37. The composition of any one of items 33 - 36, wherein the cell is selected from the group consisting of: a prokaryotic cell, a fungal cell, a plant cell, and an animal cell.
[0068] 38. The composition of any one of items 33 - 37, further comprising lambda beta protein.
[0069] 39. The composition of any one of items 33 - 37, wherein the cellular proteins are derived from a cell prior-contacted with hydroxyurea.
[0070] 40. The composition of any one of items 33 - 37, wherein the cellular proteins are derived from a cell prior-contacted with a histone deacetylase inhibitor.
[0071] 41. The composition of item 37, wherein the cell is prokaryotic cell.
[0072] 42. The composition of item 41 , wherein the prokaryotic cell is an E. coli cell.
[0073] 43. The composition of item 37, wherein the cell is a fungal cell.
[0074] 44. The composition of item 43, wherein the fungal cell is selected from the group consisting of: a Saccharomyces cerevisiae cell, an Ustilago maydis cell, a Neurospora crassa cell 5 and a Candida albicans cell.
[0075] 45. The composition of item 37, wherein the cell is a plant cell.
[0076] 46. The composition of item 45, wherein the plant cell is selected from the o group consisting of: an angiosperm cell, a gymnosperm cell and a moss cell.
[0077]
[0078] 47. The composition of item 45, wherein the cell is a Chlamydomonas rheinhardtii cell.
[0079] 5 [0080] 48. The composition of item 46, wherein the angiosperm cell is an
Arabidopsis thaliana cell.
[0081] 49. The composition of item 46, wherein the moss cell is a Physcomitrella patens cell. 0
[0082] 50. The composition of item 37, wherein the cell is an animal cell.
[0083] 51. The composition of item 50, wherein the animal cell is a mammalian cell.
5 [0084] 52. The composition of item 51 , wherein the mammalian cell is selected from the group consisting of: a human cell, a rodent cell, a mouse cell, a hamster cell, a rat cell, and a monkey cell.
[0085] 53. The composition of item 52, wherein the human cell is selected from the o group consisting of: a liver cell, a lung cell, a colon cell, a cervical cell, a kidney cell, an epithelial cell, a blood cell, a cancer cell, and a stem cell. [0086]
[0087] 54. The composition of any one of items 32 - 53, wherein the first oligonucleotide is fully complementary in sequence to the first nucleic acid target, but for one or more mismatches as between the sequences of the first oligonucleotide and its complement on the first nucleic acid target, and wherein the first oligonucleotide has at least one terminal modification.
[0088] 55. The composition of item 54, wherein the at least one terminal modification is selected from the group consisting of; at least one terminal locked nucleic acid (LNA), at least one terminal 2'-0-Me base analog, and at least three terminal phosphorothioate linkages.
[0089] 56. The composition of item 55, wherein the first oligonucleotide is a single- stranded oligonucleotide 15 - 121 nucleotides in length, has an internally unduplexed domain of at least 7 contiguous deoxyribonucleotides, and wherein the one or more mismatches are positioned exclusively in the oligonucleotide DNA domain and at least 8 nucleotides from said oligonucleotide's 5' and 3' termini.
[0090] 57. The composition of item 55, wherein the first oligonucleotide has at least one terminal locked nucleic acid (LNA).
[0091] 58. The composition of any one of items 32 - 57, wherein said oligonucleotide is at least 25 nucleotides in length.
[0092] 59. The composition of any one of items 32 - 57, wherein said oligonucleotide is no more than 121 nucleotides in length.
[0093] 60. The composition of item 59, wherein said oligonucleotide is no more than 74 nucleotides in length.
[0094] 61. A kit for targeted alteration of nucleic acid sequence comprising: [0095] a first oligonucleotide and a second oligonucleotide, wherein the oligonucleotides are capable, in the presence of cellular repair proteins, of effecting targeted alteration of a first nucleic target and a second nucleic acid target, respectively; and
[0096] wherein alteration of the second nucleic acid target confers a selectable phenotype.
[0097] 62. The kit of item 61 further comprising a cellular repair protein.
[0098] 63. The kit of item 62, wherein the cellular repair protein is from a cell precontacted with an HDAC inhibitor; hydroxyurea or lambda phage beta protein.
[0099] 64. The kit of item 62, wherein the cellular repair protein is selected from the group consisting of: RAD10, RAD51 , RAD52, RAD54, RAD55, MRE11 , PMS1 and XRS2.
[0100] 65. The kit of any one of items 61 - 64 further comprising an HDAC inhibitor; hydroxyurea or lambda phage beta protein.
[0101] 66. The kit of item 65 further comprising a cell.
[0102] 67. The kit of item 66, wherein the cell has increased levels or activity of at least one protein selected from the group consisting of: RAD10, RAD51 , RAD52, RAD54, RAD55, MRE11 , PMS1 and XRS2.
[0103] 68. The kit of item 66 or 67, wherein the cell has decreased levels or activity of at least one protein selected from the group consisting of: RAD10, RAD51 , RAD52, RAD54, RAD55, MRE11 , PMS1 and XRS2.
[0104] 69. The kit of any one of items 66 - 68, wherein the cell comprises a target nucleic acid sequence, wherein alteration of said target nucleic acid sequence by said second oligonucleotide confers a selectable phenotype.
[0105] 70. The kit of any one of items 61-69, wherein the kit further comprises instructions for performing the method of item 1 or item 2.
BRIEF DESCRIPTION OF THE DRAWINGS
[0106] Figure 1. Diagram of pAURHYG(x)eGFP target plasmids. Sequences are shown for the normal hygromycin resistance allele (SEQ ID NO: _) and the mutant alleles present in
pAURHYG(rep)eGFP (SEQ ID NO: J, pAURHYG(ins)eGFP (SEQ ID NO: J and pAURHYG(Δ)eGFP (SEQ ID NO: J.
[0107] FIG. 2. Dual targeting protocol. (A) Schematic diagram of the generalized strategy for dual targeting. (B) Sequences of the hygromycin-resistance gene and its mutation. (C) Schematic of the YAC containing the human β-globin locus and the βThall and βTha!2 sequences that are changed by the corresponding oligonucleotides.
[0108] FIG. 3. Dual targeting results. (A) Efficiency of gene editing of hygromycin mutation using the dual targeting protocol. For these experiments, YAC-containing LSY678lntHyg(rep)β cells are grown in the presence of HU, electroporated with the selectable and nonselectable oligonucleotides, and allowed to recover in the presence of TSA. (B) Gene editing of the human β-globin gene directed by the βThall oligonucleotide, including the sequence of the altered segment before (SEQ ID NO: _) and after (SEQ ID NO: _) the conversion.
[0109] FIG. 4. Dual targeting and Rad51. (A) Efficiency of gene editing of hygromycin mutation using the dual targeting protocol in combination with overexpression of yeast Rad51. For these experiments, YAC-containing LSY678lntHyg(rep)β cells are grown in the presence of HU, electroporated with the selectable and nonselectable oligonucleotides, and allowed to recover in the presence of TSA. (B) Gene editing of the human β-globin gene directed by the βThal2 oligonucleotide, including the sequence of the altered segment before (SEQ ID NO: _) and after (SEQ ID NO: _) the conversion.
DETAILED DESCRIPTION
[0110] We have discovered, surprisingly, that the frequency of oligonucleotide-directed sequence alterations at a first nucleic acid target site is higher in a population of cells that has been selected for concurrent alteration at a second nucleic acid target site, as compared to a population of cells that has not been selected for concurrent alteration at a second nucleic acid target site. [0111] Accordingly, in a first aspect the invention provides a method for identifying cells having a desired oligonucleotide-directed sequence alteration at a first nucleic acid target site within the cell. The method comprises identifying the desired sequence alteration in cells that have been selected for the presence of a selectable phenotype conferred upon the cell by a concurrent oligonucleotide- directed sequence alteration at a second nucleic acid target site within the cell. [0112] In a second aspect, the invention provides a method for effecting a desired sequence alteration at a first nucleic acid target site within a cell, the method comprising concurrently targeting first and second nucleic acid sites within the cell for sequence alteration with respective first and
second sequence-altering oligonucleotides, the second alteration conferring a selectable phenotype upon the cell; selecting cells having the selectable phenotype; and then identifying among the selected cells those having the desired sequence alteration at the first nucleic acid target site.
[0113] The methods of the present invention increase the efficiency with which 5 bacteria, plant, fungi and animal cells having a desired genotypic change at the first target site may be identified. In related aspects, the invention provides compositions and kits for effecting or facilitating practice of the methods of the present invention.
[0114] Either or both of the first and second nucleic acid target sites within the cell may be in genomic double-stranded DNA. 0 [0115] The targeted genomic DNA can be normal, cellular chromosomal DNA; organellar DNA, such as mitochondrial or plastid DNA; or extrachromosomal DNA present in cells in different forms including, e.g., mammalian artificial chromosomes (MACs), PACs from P-1 vectors, yeast artificial chromosomes (YACs), bacterial artificial chromosomes (BACs), plant artificial chromosomes (PLACs), BiBACS, as well as episomal DNA, including episomal DNA from an exogenous source such as 5 a plasmid or recombinant vector. Many of these artificial chromosome constructs containing human DNA can be obtained from a variety of sources, including, e.g., the Whitehead Institute, and are described, e.g., in Cohen et al., Nature 336: 698-701 (1993) and Chumakov, et al., Nature 377: 175-297 (1995).
[0116] The first targeted nucleic acid site may be in a part of the DNA that is transcriptionally silent or transcriptionally active; typically, the second targeted nucleic acid site will be in a o part of the DNA that is transcriptionally active so as to confer a selectable phenotype upon the cell. The first and second targeted sites may be in any part of a gene including, for example, an exon, an intron, a promoter, an enhancer or a 3'- or 5'- untranslated region, and may be in intergenic regions, with the second targeted site typically being in an exon so as to confer a selectable phenotype upon the cell.
[0117] In some embodiments, the first and/or second sequence-altering oligonucleotide 5 is designed to direct alteration of the transcribed strand of the target sequence; in other embodiments, the first and/or second oligonucleotide is designed to direct alteration of nucleic acid sequence targeting the non-transcribed strand of the target sequence. The targeted strand may differ as between first and second target sites.
[0118] The first and second oligonucleotides may independently be selected from any o type of sequence-altering oligonucleotide known in the art, including (i) triplex-forming oligonucleotides; (ii) chimeric RNA-DNA oligonucleotides that are internally duplexed, notably in the region containing the
nucleotide that directs the sequence alteration; and (iii) terminally modified single-stranded oligonucleotides having an internally unduplexed DNA domain and modified ends.
[0119] Sequence-altering triplexing oligonucleotides useful in the methods, compositions, and kits of the present invention are described, for example, in U.S. Pat. Nos. 6,303,376, 5 5,962,426, and 5,776,744, the disclosures of which are incorporated herein by reference in their entireties. Bifunctional oligonucleotides having a triplex-forming domain linked or tethered to a domain that effects targeted alteration, useful in the methods, compositions, and kits of the present invention, are described in Culver et al., Nat Biotechnology 17: 989-93 (1999), the disclosure of which is incorporated herein by reference in its entirety. o [0120] Internally duplexed, hairpin- and double-hairpin-containing chimeric RNA-DNA oligonucleotides useful in the methods, compositions, and kits of the present invention are described, inter alia, in U.S. Pat. Nos. 6,573,046; 5,888,983; 5,871 ,984; 5,795,972; 5,780,296; 5,760,012; 5,756,325; 5,731 ,181 , and 5,565,350, the disclosures of which are incorporated herein by reference in their entireties.
[0121] In preferred embodiments, at least one of the first and second oligonucleotides 5 is a single-stranded oligonucleotide having modified ends and an internally unduplexed DNA domain that directs sequence alteration.
[0122] Such oligonucleotides are further described in copending international patent applications published as WO 03/027265; WO 02/10364; WO 01/92512; WO 01/87914; and WO 01/73002, as well as in U.S. Pat. Nos. 6,479,292 and 6,271 ,360, the disclosures of which are o incorporated herein by reference in their entireties.
[0123] In typical embodiments, the oligonucleotide is 17 - 121 nucleotides in length and "has an internally unduplexed domain (that is, a nonhairpin domain) of at least 8 contiguous deoxyribonucleotides. The oligonucleotide is fully complementary in sequence to the sequence of a first strand of the respective nucleic acid target, but for one or more mismatches as between the sequences of 5 the oligonucleotide internally unduplexed deoxyribonucleotide domain and its complement on the target nucleic acid first strand. Each of the mismatches is positioned at least 8 nucleotides from each of the oligonucleotide's 5' and 3' termini. The oligonucleotide has at least one terminal modification.
[0124] In some embodiments, the at least one terminal modification may be selected from the group consisting of 2'-0-alkyl, such as 2'-0-methyl, residue; phosphorothioate internucleoside o linkage; and locked nucleic acid (LNA) residue. The basic structural and functional characteristics of
LNAs and related analogues are disclosed in various publications and patents, including WO 99/14226, WO 00/56748, WO 00/66604, WO 98/39352, United States Patent No. 6,043,060, and United States
Patent No. 6,268,490, the disclosures of which are incorporated herein by reference in their entireties. In some embodiments, the terminal modification comprises a plurality of adjacent phosphorothioate internucleoside linkages, such as three phosphorothioate linkages at the 3' terminus of the oligonucleotide. 5 [0125] In certain preferred embodiments, both of the first and second sequence-altering oligonucleotides are single-stranded oligonucleotides having modified ends and an internally unduplexed DNA domain that directs sequence alteration.
[0126] In some embodiments, a plurality of single-stranded oligonucleotides having modified ends and an internally unduplexed DNA domain that directs sequence alteration can be used to o effect either or both of the first and second sequence alterations. Use of such plural oligonucleotides is described in copending U.S. patent application no. 10/623,107, filed July 18, 2003 ("Targeted Nucleic Acid Sequence Alteration Using Plural Oligonucleotides"), the disclosure of which is incorporated herein by reference in its entirety.
[0127] In the methods, compositions, and kits of the present invention, at least the 5 second oligonucleotide directs a sequence alteration that produces a selectable phenotype. Although the first oligonucleotide may also direct an alteration that produces a selectable phenotype, generally the first oligonucleotide directs an alteration that must be identified by screening, e.g., by determining the corresponding nucleic acid sequence or by assaying a non-selectable phenotype that is generated by the alteration event. o [0128] The selectable phenotype chosen will depend on the host cell chosen and whether the selection is effected in vitro or in vivo. As is well known in the art, exemplary selectable phenotypes include, e.g., antibiotic or other chemical resistance, ability to use a nutrient source, expression of a fluorescent protein, presence of an epitope or resistance to an apoptotic signal. The selectable phenotype chosen may be selectable based on preferential growth of a cell with the desired 5 sequence alteration. Examples of such selectable phenotypes include, e.g., the ability to grow in the presence of a compound that either kills or prevents the growth of the cell such as an apoptotic signal or an antibiotic, the ability to grow in the absence of a nutrient that is required prior to the sequence alteration, or the ability to utilize a particular resource that is not usable prior to the sequence alteration. The selectable phenotype may also be selected mechanically. Examples of phenotypes that may be o selected mechanically include, e.g., expression of a fluorescent protein or a particular epitope.
Mechanical selection may be by any means known to one of skill in the art including, e.g., FACS (directly in the case of a fluorescent protein or using a labeled antibody for an epitope), column chromatography,
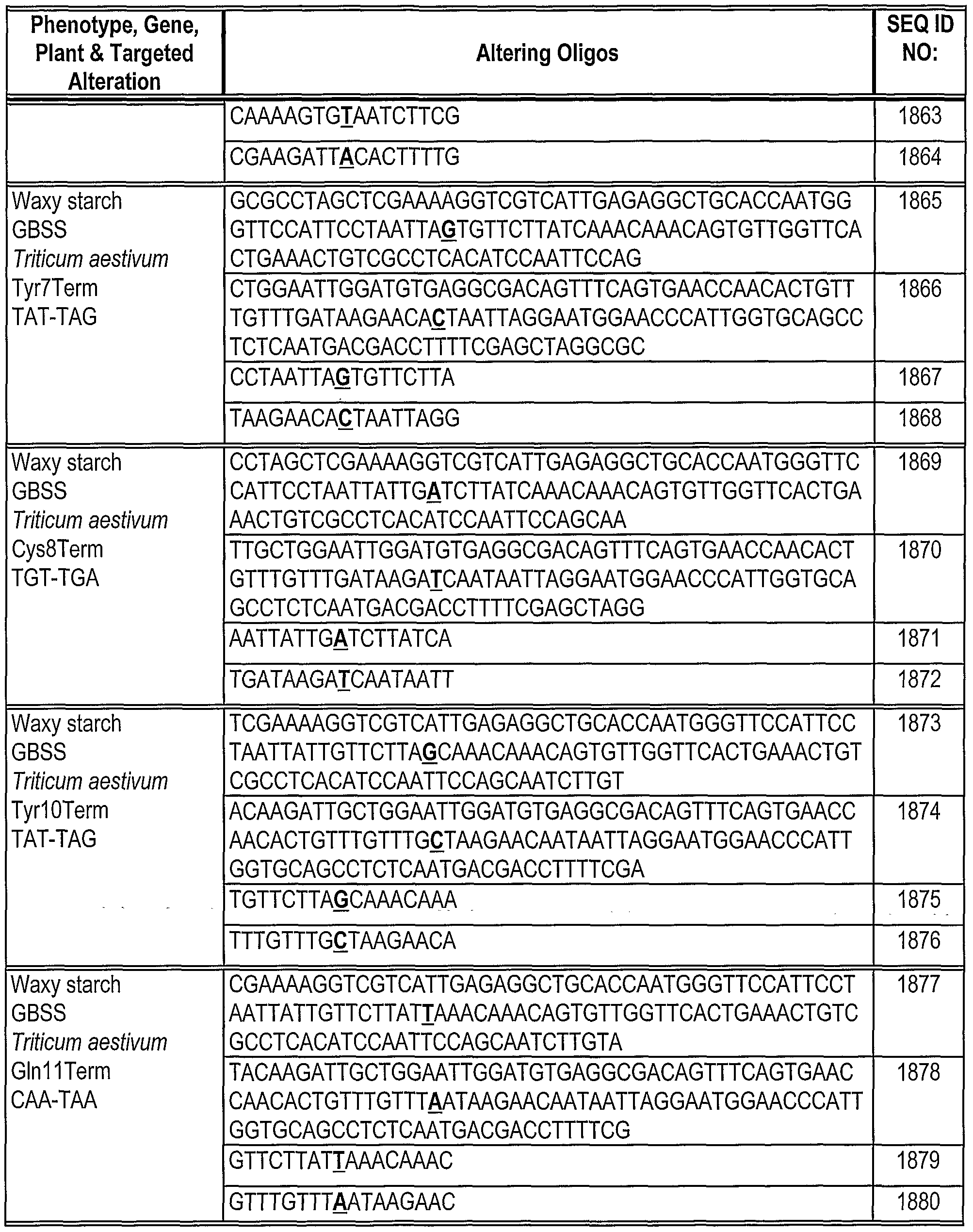
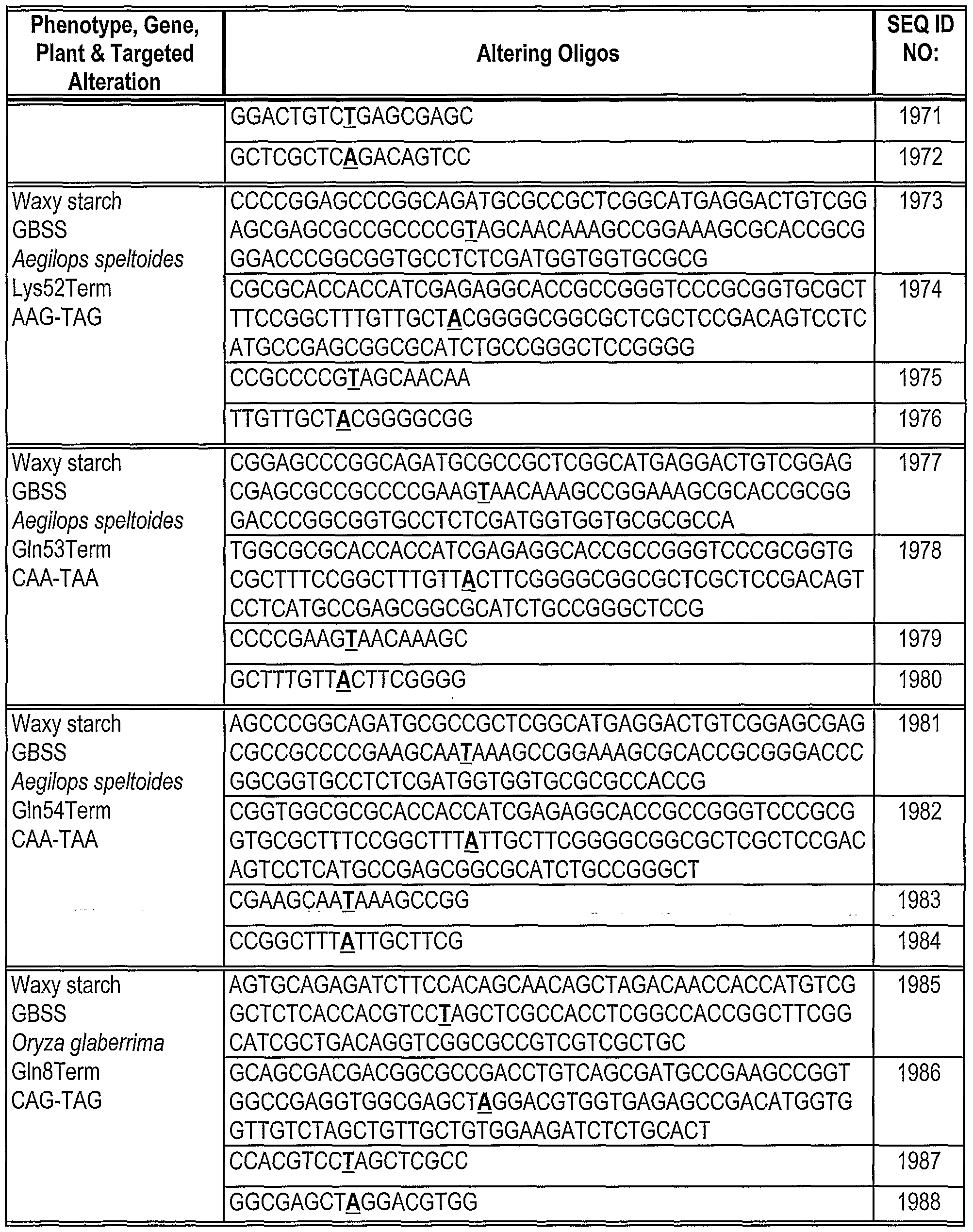
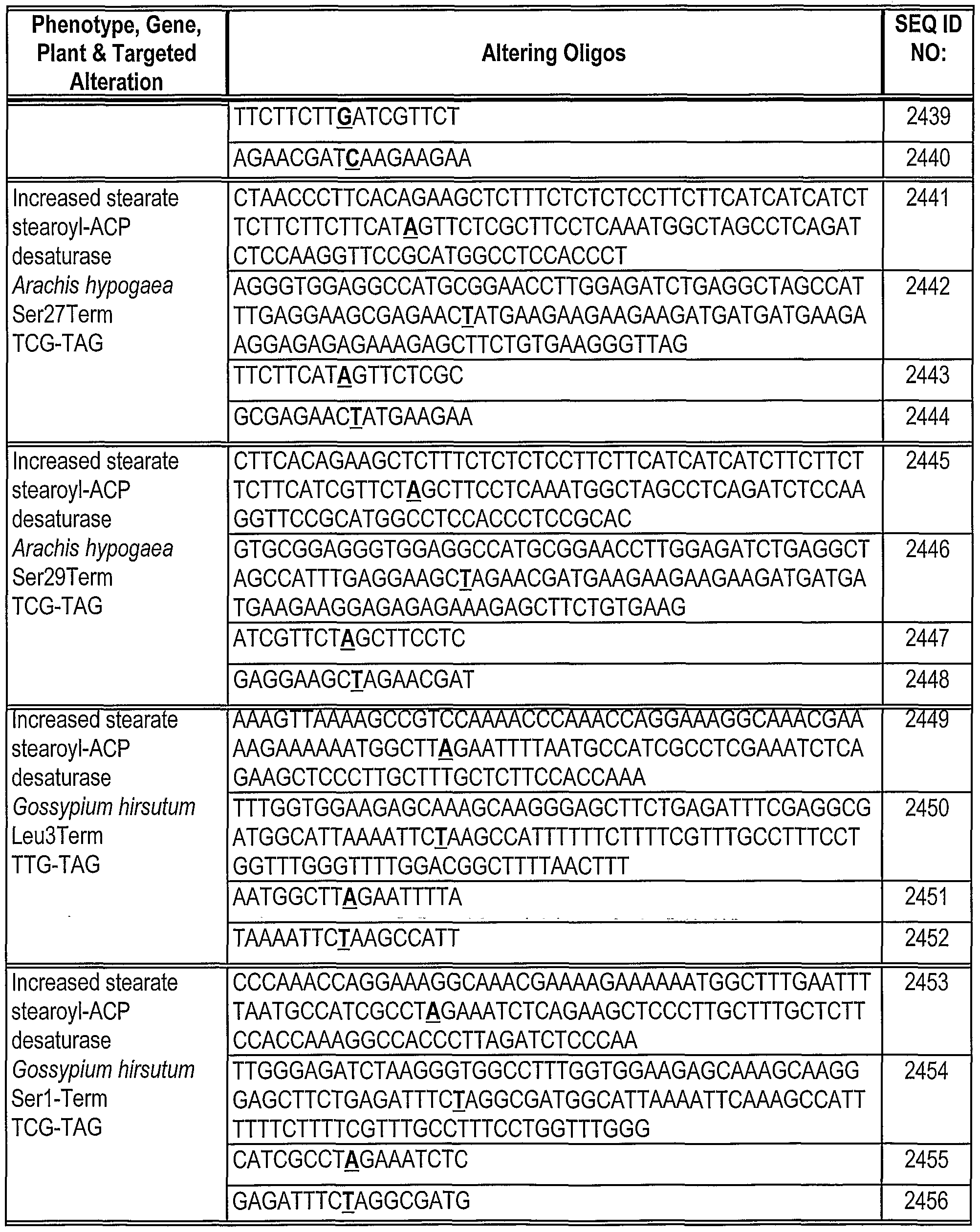
or using paramagnetic beads produced by, e.g., Miltenyi Biotec. Selection also does not require intact cells. For example, a single nucleotide change (SNP) in a nucleic acid molecule may be detected and isolated in vitro using methods such as are described in WO 03/027640. In such cases, the first oligonucleotide effects a change in the selected molecule. 5 [0129] The methods, compositions and kits of the invention typically reduce the number of cells required to be screened by at least about two-fold relative to the number that must be screened in a population of targeted cells that has not previously been selected for an oligonucleotide-directed nucleic acid sequence alteration that confers a selectable phenotype. The reduction can be by at least about two, three, four, five, six, seven, eight, nine, ten, twelve, fifteen, twenty, thirty, and fifty or more fold. o [0130] The methods, compositions and kits of the invention may be used with any oligonucleotide that directs targeted alteration of nucleic acid sequence. For example, oligonucleotides may be desined to alter sequences in many human genes including, e.g., ADA, p53, beta-globin, RB, BRCA1 , BRCA2, CFTR, CDKN2A, APC, Factor V, Factor VIII, Factor IX, hemoglobin alpha 1 , hemoglobin alpha 2, MLH1 , MSH2, MSH6, ApoE, LDL receptor, UGT1 , APP, PSEN1, and PSEN2. These genes are 5 described in greater detail in Examples 5 to 22. In the examples and in Tables 6 to 20 herein, correcting oligonucleotides of defined sequence are provided for alteration of plant genes. Each of these oligonucleotides may be a first sequence-altering oligonucleotide as defined herein. Certain of these oligonucleotides may also be a second sequence-altering oligonucleotide as defined herein, e.g., where the oligonucleotide effects a nucleic acid sequence alteration that confers a selectable phenotype such as o herbicide resistance. In the tables of these examples, the oligonucleotides are not limited to the particular sequences disclosed. The oligonucleotides include extensions of the appropriate sequence of the longer 121 base oligonucleotides which can be added base by base to the smallest disclosed oligonucleotides of 17 bases. Some oligonucleotides may be 15 or 16 bases which can be obtained by subtraction or one or two bases from the smallest disclosed oligonucleotides of 17 bases. Thus the representative 5 oligonucleotides include for each correcting change, oligonucleotides of length 15, 16, 17, 18, 19, 20, 21 ,
22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35, 36, 37, 38, 39, 40, 41 , 42, 43, 44, 45, 46, 47, 48, 49, 50, 51 , 52, 53, 54, 55, 56, 57, 58, 59, 60, 61 , 62, 63, 64, 65, 66, 67, 68, 69, 70, 71 , 72, 73, 74, 75, 76, 77, 78, 79, 80, 81 , 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101 , 102, 103, 104, 105, 106, 107, 108, 109, 110, 111 , 112, 113, 114, 115, 116, 117, 118, 119, or 120 with further single- o nucleotide additions up to the longest sequence disclosed. These oligonucleotide sequences can be used to design first oligonucleotides, or, where the oligonucleotide directs an alteration that confers a selectable phenotype, first and/or second oligonucleotides. Moreover, the oligonucleotides of the
invention do not require a symmetrical extension on either side of the central DNA domain. Similarly, the oligonucleotides designed using the sequences of oligonucleotides disclosed in the various tables for correction of human diseases or for directing specific alterations in plant genes comprise structures or modifications that enable them to effect oligonucleotide-directed nucleic acid sequence alteration, such 5 as, e.g., phosphorothioate linkages, LNA residues or chimeric RNA-DNA internally duplexed structure. [0131] Efficiency of conversion is defined herein as the percentage of recovered substrate target molecules that have undergone a conversion event. Depending on the nature of the target genetic material, e.g. an extrachromosomal element in a cell, efficiency could be represented as the proportion of cells or clones containing an extrachromosomal element that exhibit a particular phenotype. o Alternatively, representative samples of the target genetic material can be analyzed, e.g. by sequencing, allele-specific PCR or comparable techniques, to determine the percentage that have acquired the desired change. This latter method of determining efficiency is most frequently applied where the phenotype conferred by the alteration is a non-selectable phenotype.
[0132] Each of the first and second oligonucleotides can direct any kind of alteration, 5 including, for example, deletion, insertion or replacement of 1 , 2 or 3 nucleotides in the target sequence. These altered nucleotides may be contiguous or non-contiguous to each other. Multiple alterations can be directed to each of the first and second target sites by a single oligonucleotide or by 1 , 2 or 3 separate oligonucleotides. In some embodiments, the multiple alterations are directed by a single oligonucleotide. In some embodiments, the multiple alterations are within 1 to 10 nucleotides of each other. o [0133] The methods, compositions and kits of the invention can be combined with one or more other methods of enhancing the efficiency of oligonucleotide-directed alteration of nucleic acid sequence known in the art.
[0134] Such methods are described, e.g., in copending International patent applications published as WO 02/10364 ("Methods for Enhancing Targeted Gene Alteration Using Oligonucleotides,"); 5 WO 03/027265 ("Composition and Methods for Enhancing Oligonucleotide-Directed Sequence Alteration"); and WO 03/075856 ("Methods, Compositions, and Kits for Enhancing Oligonucleotide- Mediated Nucleic Acid Sequence Alteration Using Compositions Comprising a Histone Deacetylase Inhibitor, Lambda Phage Beta Protein, or Hydroxyurea"), the disclosures of which are incorporated herein by reference in their entireties. o [0135] For example, in typical embodiments of this aspect of the invention, the methods comprise treating a cell or tissue from a bacterium, a fungus, a plant, or an animal with a histone deacetylase (HDAC) inhibitor or hydroxyurea (HU), and then administering to the treated cell or tissue at
- li
least first and second oligonucleotides having nucleic acid sequence alteration activity. In other embodiments, the HDAC inhibitor or hydroxyurea, respectively, may be added contemporaneously with oligonucleotide addition or even following oligonucleotide addition. [0136] The HDAC inhibitor can be trichostatin A. [0137] One of skill in the art will appreciate, however, that other HDAC inhibitors may be suitable for these purposes. For example, U.S. Patent Application Publication No. 2002/0143052, which is hereby incorporated by reference in its entirety, discloses compounds having HDAC inhibitor activity due to the presence of a zinc-binding moiety. Other examples of HDAC inhibitors suitable for purposes of the invention include butyric acid, MS-27-275, suberoylanilide hydroxamic acid (SAHA), oxamflatin, trapoxin A, depudecin, FR901228 (also known as depsipeptide), apicidin, m-carboxy-cinnamic acid bishydroxamic acid (CBHA), suberic bishydroxamic acid (SBHA), and pyroxamide. See Marks et a/., J. Natl. Cane. Inst 92(15):1210-1216 (2000), which is hereby incorporated by reference in its entirety. Yet other examples of suitable HDAC inhibitors are chlamydocin, HC-toxin, Cyl-2, WF-3161 , and radicicol, as disclosed in WO 00/23567, which is hereby incorporated by reference in its entirety. [0138] When administering an HDAC inhibitor or HU to cells or cell extracts, the dosage to be administered and the timing of administration will depend on various factors, including cell type.
[0139] In the case of TSA, the dosage may be 10 nM, 100 nM, 1 μM, 10 μM, 100 μM, 1 mM, 10 mM, or even higher, or as little as 1 mM, 100 μM, 10 μM, 1 μM, 100 nM, 10 nM, 1 nM, or even lower. In the case of HU, the dosage may be 100 nM, 1 μM, 10 μM, 100 μM, 1 mM, 10 mM, 100 mM, 1 M or even higher, or as little as 100 mM, 10 mM, 1 mM, 100 μM, 10 μM, 1 μM, 100 nM, 10 nM, or even lower.
[0140] In the case of HU, treatment may be with 100 mM, 75 mM, 50 mM, 40 mM, 20 mM, 10 mM, 2 mM, 1 mM, 100 microM, 10 microM, 1 microM, 100 nM, 10 nM or lower. The dosage is preferably from about 4 to 100 mM for yeast cells and from about 0.05 mM to 3 mM for mammalian cells. The dosage may be at least 0.05 mM, 0.10 mM, 0.15 mM, 0.20 mM, 0.25 mM, 0.30 mM, 0.35 mM, 0.40 mM, 0.50 mM or more, including at least 0.55 mM, 0.60 mM, 0.65 mM, 0.70 mM, 0.75 mM, 0.80 mM, 0.85 mM, 0.90 mM, 0.95 mM or even 1 mM, 1.1 mM, 1.2 mM, 1.3 mM, 1.4 mM, 1.4 mM, 1.5 mM, 1.6 mM, 1.7 mM, 1.8 mM, 1.9 mM, 2.0 mM, 2.5 mM, 3 mM, or more. Typically, the dosage for mammalian cells is less than about 3.0 mM, and can be less than 2.5 mM, 2.0 mM, 1.5 mM, 1.0 mM, even less than 0.90, 0.85, 0.80, 0.75, 0.70, 0.65, 0.60, 0.55, 0.50, 0.45, 0.40, and even less than about 0.35 or 0.30 mM.
[0141] Cells may be grown in the presence of an HDAC inhibitor or HU, and cell extracts may be treated with the HDAC inhibitor or HU, for various times prior to combination with a
sequence-altering oligonucleotide. Growth or treatment may be as long as 1 h, 2 h, 3 h, 4 h, 6 h, 8 h, 12 h, 20 h, or even longer, including up to 28 days, 14 days, 7 days, or shorter, or as short as 12 h, 8 h, 6 h, 4 h, 3 h, 2 h, 1 h, or even shorter. Alternatively, treatment of cells or cell extracts with HDAC inhibitor or HU and the sequence-altering oligonucleotide may occur simultaneously, or the HDAC inhibitor or HU, 5 respectively, may be added after oligonucleotide addition.
[0142] Cells may further be allowed to recover from treatment with an HDAC inhibitor or HU by growth in the absence of the HDAC inhibitor or HU for various times prior to treatment with a sequence-altering oligonucleotide. Recovery may be as long as 10 min, 20 min, 40 min, 60 min, 90 min, 2 h, 4 h, or even longer, or as short as 90 min, 60 min, 40 min, 20 min, 10 min, or even shorter. Cells may o also be allowed to recover following their treatment with a sequence-altering oligonucleotide. This recovery period may be as long as 1 h, 2 h, 4 h, 6 h, 8 h, 12 h, or even longer, or as short as 8 h, 6 h, 4 h, 2 h, 1 h, or even shorter. The HDAC inhibitor or HU may either be present in or absent from the cell medium during the recovery period.
[0143] Optimum dosages and the timing and duration of administration of HDAC 5 inhibitors and HU to cells or cell extracts can be determined by routine experimentation. For example, optimized dosage and timing of treatment with an HDAC inhibitor, such as TSA, can be determined using the assay system described in WO 03/075856.
[0144] Cultured cells (such as yeast cells) are treated with varying concentrations of HDAC inhibitor for a varying number of hours prior to electroporation with the sequence altering o oligonucleotide. After recovery for varying periods, the cells are plated and tested for efficiency of sequence alteration. Parameters are then selected that provide the highest efficiency of correction. The method may then be repeated, as necessary, further to optimize dosage, duration of pretreatment, duration of recovery period, if any, and the like.
[0145] A similar approach for HU can be determined using the assay system set forth in 5 WO 03/075856.
[0146] The methods, compositions, and kits of the instant invention comprising either an HDAC inhibitor, such as trichostatin A, or HU typically increase nucleic acid sequence alteration efficiency by at least two fold relative to the same method respectively lacking the HDAC inhibitor or HU. The increase in nucleic acid sequence alteration efficiency can also be about three, four, five, six, seven, o eight, nine, ten, twelve, fifteen, twenty, thirty, and fifty or more fold. The methods, compositions, and kits of the instant invention comprising beta protein increase the efficiency of altering a DNA sequence, as compared to the same method lacking beta protein, typically at least 2 fold, and can increase the
efficiency 5 fold, 10 fold, 15 fold, 20 fold, 25 fold, 30 fold, 40 fold, 50 fold, 60 fold, 70 fold, 80 fold, 90 fold, 100 fold, 250 fold, 500 fold, 1000 fold, or more; in certain embodiments, the methods, compositions, and kits of the instant invention that comprise beta protein increase efficiency less than two-fold as compared to comparable methods lacking beta protein, such as 1.9 fold, 1.5 fold, or even by 10%, 20%, 30%, 40%. [0147] The cells in which targeted nucleic acid sequence alterations may usefully be made according to the methods of the present invention include mammalian cells, including human cells, such as liver, lung, colon, cervix, kidney, and epithelium cells.
[0148] Cultured mammalian cells that usefully may be targeted for desired sequence alteration according to the methods of the present invention include HT1080 cells (human epithelial fibrosarcoma), COS-1 and COS-7 cells (African green monkey), CHO-K1 cells (Chinese hamster ovary), H1299 cells (human epithelial carcinoma, non-small cell lung cancer), C127I (immortal murine mammary epithelial cells), MEF (mouse embryonic fibroblasts), HEC-1-A (human uterine carcinoma), HCT15 (human colon cancer), HCT116 (human colon carcinoma), LoVo (human colon adenocarcinoma), and HeLa (human cervical carcinoma) cancer cells as well as PC12 cells (rat pheochromocytoma). [0149] Alterations in cultured mammalian cells may usefully be made to create coisogenic cell collections, as described in copending international patent application published as WO 03/027264 and U.S. patent application no. 10/260,638, the disclosures of which are incorporated herein by reference in their entireties. Genes usefully targeted in such coisogenic collections include loci affecting drug resistance (equivalent^, drug sensitivity) or drug metabolism, including: CYP1A2, CYP2C17, CYP2D6, CYP2E, CYP3A4, CYP4A11 , CYP1 B1 , CYP1A1 , CYP2A6, CYP2A13, CYP2B6, CYP2C8, CYP2C9, CYP11A, CYP2C19, CYP2F1 , CYP2J2, CYP3A5, CYP3A7, CYP4B1 , CYP4F2, CYP4F3, CYP6D1 , CYP6F1 , CYP7A1 , CYP8, CYP11A, CYP11 B1 , CYP11 B2 , CYP17, CYP19, CYP21A2, CYP24, CYP27A1 , CYP51 , ABCB1 , ABCB4, ABCC1, ABCC2, ABCC3, ABCC4, ABCC5, ABCC6, MRP7, ABCC8, ABCC9, ABCC10, ABCC11 , ABCC12, EPHX1 , EPHX2, LTA4H, TRAG3, GUSB, TMPT, BCRP, HERG, hKCNE2, UDP glucuronosyl transferase (UGT), sulfotransferase, sulfatase, glutathione S-transferase (GST) -alpha, glutathione S-transferase -mu, glutathione S-transferase -pi, ACE, and KCHN2.
[0150] In other embodiments, cells within which targeted alterations may usefully be effected according to the methods of the present invention include progenitor and stem cells — both embryonic (ES) stem cells and non-ES cells such as hematopoietic progenitor or stem cells, including CD34+CD38- hematopoietic progenitor and stem cells and muscle-derived stem cells.
[0151] ES cells can be mammalian ES cells, either non-human mammalian ES cells or human ES cells; human ES cells may, e.g., be from a cell line approved for use in the jurisdiction in which the methods, compositions and kits of the present invention are to be used. For example, for use in the United States, any human stem cell line that does not violate state or federal law may be used, such as 5 those cell lines that meet United States federal funding criteria; the National Institutes of Health is currently compiling a list of these existing stem cell lines (http://escr.nih.gov) which includes those held by the following: BresaGen, Inc., Athens, Georgia (4 lines); CyThera, Inc., San Diego, California (9 lines); Karolinska Institute, Stockholm, Sweden (5 lines); Monash University, Melbourne, Australia (6 lines); National Center for Biological Sciences, Bangalore, India (3 lines); Reliance Life Sciences, Mumbai, India 0 (7 lines); Technion-lsrael Institute of Technology, Haifa, Israel (4 lines); University of California, San Francisco, California (2 lines); Goteborg University, Gόteborg, Sweden (19 lines); Wisconsin Alumni Research Foundation, Madison, Wisconsin (5 lines).
[0152] In yet other embodiments, the cells within which targeted alterations are made are plant cells. 5 [0153] Particularly useful plants from which the cells to be used may be drawn include, for example, experimental model plants such as Chlamydomonas reinhardtii, Physcomitrella patens, and Arabidopsis thaliana in addition to crop plants such as cauliflower (Brassica oleracea), artichoke (Cynara scolymus), fruits such as apples (Malus, e.g. domesticus), mangoes (Mangifera, e.g. indica), banana (Musa, e.g. acuminata), berries (such as currant, Ribes, e.g. rubrum), kiwifruit (Actinidia, e.g. chinensis), o grapes (Vitis, e.g. vinifera), bell peppers (Capsicum, e.g. annuum), cherries (such as the sweet cherry, Prunus, e.g. avium), cucumber (Cucumis, e.g. sativus), melons (Cucumis, e.g. melo), nuts (such as walnut, Juglans, e.g. regie; peanut, Arachis hypogeae), orange (Citrus, e.g. maxima), peach (Prunus, e.g. persica), pear (Pyra, e.g. communis), plum (Prunus, e.g. domestica), strawberry (Fragaria, e.g. moschata or vesca), tomato (Lycopersicon, e.g. esculentum); leaves and forage, such as alfalfa (Medicago, e.g. 5 sativa or truncatula), cabbage (e.g. Brassica oleracea), endive (Cichoreum, e.g. endivia), leek (Allium, e.g. porrum), lettuce (Lactuca, e.g. sativa), spinach (Spinacia, e.g. oleraceae), tobacco (Nicotiana, e.g. tabacum); roots, such as arrowroot (Maranta, e.g. arundinacea), beet (Beta, e.g. vulgaris), carrot (Daucus, e.g. carota), cassava (Manihot, e.g. esculenta), turnip (Brassica, e.g. rapa), radish (Raphanus, e.g. sativus), yam (Dioscorea, e.g. esculenta), sweet potato (Ipomoea batatas); seeds, including oilseeds, o such as beans (Phaseolus, e.g. vulgaris), pea (Pisum, e.g. sativum), soybean (Glycine, e.g. max), cowpea
(Vigna unguiculata), mothbean (Vigna aconitifolia), wheat (Triticum, e.g. aestivum), sorghum (Sorghum e.g. bicolor), barley (Hordeum, e.g. vulgare), corn (lea, e.g. mays), rice (Oryza, e.g. sativa), rapeseed
(Brassica napus), millet (Panicum sp.), sunflower (Helianthus annuus), oats (Avena sativa), chickpea (Cicer, e.g. arietinum); tubers, such as kohlrabi (Brassica, e.g. oleraceae), potato (Solanum, e.g. tuberosum) and the like; fiber and wood plants, such as flax (Linum e.g. usitatissimum), cotton (Gossypium e.g. hirsutum), pine (P/'nt/s sp.), oak (Quercus sp.), eucalyptus (Eucalyptus sp.), and the like 5 and ornamental plants such as turfgrass (Lolium, e.g. rigidum), petunia (Petunia, e.g. x hybrida), hyacinth (Hyacinthus ohentalis), carnation (Dianthus e.g. caryophyllus), delphinium (Delphinium, e.g. a/ac/'s), Job's tears (Coix lacryma-jobi), snapdragon (Antirrhinum majus), poppy (Papaver, e.g. nudicaule), lilac (Syringa, e.g. vulgaris), hydrangea (Hydrangea e.g. macrophylla), roses (including Gallicas, Albas, Damasks, Damask Perpetuals, Centifolias, Chinas, Teas and Hybrid Teas) and ornamental goldenrods (e.g. 0 Solidago spp.).
[0154] Generally, the oligonucleotides are administered to isolated plant cells or protoplasts according to a method of the present invention and the resulting cells are used to regenerate whole plants according to any method known in the art.
[0155] Relatively few specific plant mutations that produce desirable phenotypes have 5 been described for plant species or cultivars.
[0156] However, the methods, compositions and kits of the instant invention may be used to identify a desirable mutation in one species, for example an experimental model plant, and the desirable mutation can then be introduced in the homologous genes of other species using the kits, compositions and methods of the invention. Further, the methods, compositions and kits of the invention o can be used to produce "knock out" mutations by modification of specific amino acid codons to produce stop codons (e.g., a CAA codon specifying glutamine can be modified at a specific site to TAA; a AAG codon specifying lysine can be modified to TAG at a specific site; and a CGA codon for arginine can be modified to a TGA codon at a specific site). Such base pair changes will terminate the reading frame and produce a truncated protein shortened at the site of the stop codon, which truncated protein may be 5 defective or have an altered function. Alternatively, frameshift additions or deletions can be directed at a specific sequence to interrupt the reading frame and produce a garbled downstream protein. Such stop or frameshift mutations can be introduced to determine the effect of knocking out the protein in either plant or animal cells.
[0157] Desirable phenotypes that may be obtained in plants by known nucleic acid o sequence alterations include, for example, herbicide resistance; male- or female-sterility; salt, drought, lead, freezing and other stress tolerances; altered amino acid content; altered levels or composition of
starch; altered levels or composition of oils; and elimination of epitopes in gluten that are known to instigate autoimmune responses in individuals with celiac disease.
[0158] The cells within which targeted alterations are effected according to the methods of the present invention can be primary isolated cells, selectively enriched cells, cultured cells, or tissue 5 explants.
[0159] In certain ex vivo embodiments of the methods of the present invention, in which targeted sequence alterations are made in non-human cells, such as non-human mammalian ES cells or plant cells, the sequence-altered cells can be used to generate intact organisms, which can thereafter be propagated. o [0160] For example, the methods of the present invention can be used to create genetically altered animals, including livestock — such as cattle, bison, horses, goats, sheep, pigs, chickens, geese, ducks, turkeys, pheasant, ostrich and pigeon — to enhance expression of desirable traits, and/or decrease expression of undesirable traits, by first creating genetically altered cells. In other embodiments, the methods of the present invention can be used to create genetically altered animals 5 useful as laboratory models, such as rodents, including mice, rats, guinea pigs; lagomorphs, such as rabbits; monkeys; apes; dogs; and cats. Methods for producing transgenic animals comprising genetically modified cells are known in the art, and are disclosed, for example, in WO 00/51424, "Genetic Modification of Somatic Cells and Uses Thereof," the disclosure of which is hereby incorporated herein by reference in its entirety. o [0161] Further aspects of the present invention are the non-human animals produced thereby.
[0162] In other ex vivo embodiments of the methods of the present invention, the targeted sequence alterations are made in human ES cells, which are thereafter used, where legally permissible, to generate tissue or, where permitted, a viable embryo. 5 [0163] In other ex vivo embodiments of the methods of the present invention, in which targeted sequence alterations are made in human non-ES cells, such as hematopoietic progenitor or stem cells, such as CD34+CD38- hematopoietic stem cells, the sequence-altered cells can be reintroduced into a human subject for ex vivo gene therapies.
[0164] In certain particularly useful embodiments of the methods of the present o invention, the first and second oligonucleotides are designed to alter the nucleic acid sequence of an expressed human gene or a plant gene.
[0165] The oligonucleotides used in the methods, compositions and kits of the invention can be introduced into cells or tissues by any technique known to one of skill in the art. Such techniques include, for example: electroporation; carrier-mediated delivery using, e.g., liposomes, aqueous-cored lipid vesicles, lipid nanospheres or polycations; naked nucleic acid insertion; particle bombardment and 5 calcium phosphate precipitation. In some embodiments, the oligonucleotides are introduced using electroporation, for example using a BTX ECM® 830 Square Wave electroporator. In other embodiments the transfection is performed with a liposomal transfer compound, for example, DOTAP (N-1-(2,3- Dioleoyloxy)propyl-N,N,N-trimethylammonium methylsulfate, Boehringer-Mannheim) or an equivalent, such as LIPOFECTIN®. In other embodiments, the transfection technique uses cationic lipids. In some 0 embodiments, transfection is performed with Lipofectamine™ 2000 (Invitrogen Corporation, Carlsbad, CA).
[0166] The methods of the invention can be used with a wide range of concentrations of oligonucleotides. For example, good results can be achieved with 10 nM/105 cells. A ratio of about 500 ng of oligonucleotide in 3 μg of DOTAP per 105 cells can be used. The transfected cells may be cultured 5 in different media, including, for example, in serum-free media, media supplemented with fetal calf serum, human serum albumin, or human serum. The first and second oligonucleotides are typically used in a 1:1 stoichiometric ratio, but other ratios including, e.g., 1 :2, 1 :3, 1 :4 and 1 :5, may be used in the methods, composition and kits of the invention. In some embodiments, the first and second oligonucleotides used in the methods and compositions of the invention are administered simultaneously; in other embodiments o the oligonucleotides are adjunctively administered.
[0167] Further embodiments of the invention are compositions and kits comprising a cell, cell-free extract, or cellular repair protein and at least one oligonucleotide which is capable of effecting a desired sequence alteration at a nucleic acid target site, which sequence alteration confers a selectable phenotype. In some embodiments, the compositions and kits also comprise a second 5 oligonucleotide that is capable of effecting a desired sequence alteration, typically a sequence alteration that is frequently desired and/or is not selectable. In some embodiments the compositions or kits comprise a nucleic acid molecule comprising a nucleic acid sequence which is the target for the at least one oligonucleotide which capable of effecting a desired sequence alteration at a nucleic acid target site, which sequence alteration confers a selectable phenotype. o [0168] A cell, cell-free extract, or cellular repair protein for a composition or kit of the invention may be derived from any organism. Compositions and kits of the invention and may comprise any combination of cells, cell-free extracts, or cellular repairs proteins and the cells, cell-free extracts, or
cellular repair proteins may be from the same organism or from different organisms. Cellular repair proteins that may be used include, for example, proteins from the RAD52 epistasis group, the mismatch repair group, or the nucleotide excision repair group. In some embodiments, the cell, cell-free extract, or cellular repair protein is or is from a eukaryotic cell or tissue. In some embodiments, the eukaryotic cell is 5 a fungal cell, e.g. a yeast cell. In other embodiments, the cell is a plant cell, e.g., a maize, rice, wheat, barley, soybean, cotton, potato or tomato cell. Other exemplary plant cells include those described elsewhere herein. In some embodiments, the kits comprise a chemical compound selected from the group consisting of: a trichostatin, a histone deacetylase inhibitor and the lambda beta protein. In some embodiments such kits also include instructions for use. o [0169] Other embodiments of the invention relate to kits comprising a nucleic acid molecule the nucleic acid sequence of which has been altered according to a method of the invention or using a composition or kit of the invention. In some embodiments, the invention relates to kits comprising a cell comprising a nucleic acid molecule the nucleic acid sequence of which has been altered according to the methods of the invention or using a composition or kit of the invention. In some embodiments, the 5 nucleic acid molecule is selected from the group consisting of: mammalian artificial chromosomes
(MACs), PACs from P-1 vectors, yeast artificial chromosomes (YACs), bacterial artificial chromosomes (BACs), plant artificial chromosomes (PLACs), plasmids, viruses or other recombinant vectors.
[0170] The purified oligonucleotides compositions may be formulated in accordance with routine procedures as a pharmaceutical composition adapted for bathing cells in culture, for o microinjection into cells in culture, and for intravenous administration to human beings or animals.
Typically, compositions for cellular administration or for intravenous administration into animals, including humans, are solutions in sterile isotonic aqueous buffer. Where necessary, the composition may also include a solubilizing agent and a local anaesthetic such as lignocaine to ease pain at the site of the injection. Generally, the ingredients will be supplied either separately or mixed together in unit dosage 5 form, for example, as a dry, lyophilized powder or water-free concentrate, The composition may be stored in a hermetically sealed container such as an ampule or sachette indicating the quantity of active agent in activity units. Where the composition is administered by infusion, it can be dispensed with an infusion bottle containing sterile pharmaceutical grade "water for injection" or saline. Where the composition is to be administered by injection, an ampule of sterile water for injection or saline may be provided so that the o ingredients may be mixed prior to administration.
[0171] Pharmaceutical compositions of this invention comprise the oligonucleotides used in the methods of the present invention and pharmaceutically acceptable salts thereof, with any pharmaceutically acceptable ingredient, excipient, carrier, adjuvant or vehicle.
[0172] The oligonucleotides of the invention are preferably administered to the subject 5 in the form of an injectable composition. The composition is preferably administered parenterally, meaning intravenously, intraarterially, intrathecally, interstitially or intracavitarilly. Pharmaceutical compositions of this invention can be administered to mammals including humans in a manner similar to other diagnostic or therapeutic agents. The dosage to be administered, and the mode of administration will depend on a variety of factors including age, weight, sex, condition of the subject and genetic factors, o and will ultimately be decided by medical personnel subsequent to experimental determinations of varying dosage as described herein. In general, dosage required for targeted nucleic acid sequence alteration and therapeutic efficacy will range from about 0.001 to 50,000 μg/kg, e.g. between 1 to 250 μg/kg of host cell or body mass or a concentration of between 30 and 60 micromolar.
[0173] For cell administration, direct injection into the nucleus, biolistic bombardment, 5 electroporation, liposome transfer and calcium phosphate precipitation may be used. In yeast, lithium acetate or spheroplast transformation may also be used. In one method, the administration is performed with a liposomal transfer compound, e.g., DOTAP (Boehringer-Mannheim), Lipofectamine™ 2000 (Invitrogen™) or an equivalent such as lipofectin. The amount of the oligonucleotide pair used, for example, is about 500 nanograms in 3 micrograms of DOTAP per 100,000 cells or about 1 microgram o with 1 microliter Lipofectamine™ 2000 per 1 ,000,000 cells. For electroporation, between 20 nanograms and 30 micrograms of oligonucleotide per million cells to be electroporated is an appropriate range of dosages which can be increased to improve efficiency of genetic alteration upon review of the appropriate sequence according to the methods described herein.
[0174] In order that this invention may be better understood, the following examples are 5 set forth. These examples are for purposes of illustration only, and are not to be construed as limiting the scope of the invention in any manner.
EXAMPLE 1
Yeast Cell Targeting Assay Method for Nucleic Acid Sequence o Alteration and Preferred Oligonucleotide Selection
[0175] In this example, we use single-stranded oligonucleotides to measure oligonucleotide-directed nucleic acid sequence alteration using a Mata wild-type yeast strain with an
integrated plasmid with a fusion between a hygromycin resistance gene and eGFP as a target for gene repair (Mata+lntHYG(x)eGFP). Modifications to the oligonucleotides and construction of target vectors are disclosed in WO 01/73002, the disclosure of which is hereby incorporated by reference.
[0176] In vivo assay systems. We monitor targeted alteration of genetic material in 5 yeast using both episomal and chromosomal targets. To monitor gene alteration of episomal targets, we employ a yeast system using the plasmids pAURHYG(rep)eGFP, which contains a point mutation in the hygromycin resistance gene, pAURHYG(ins)eGFP, which contains a single-base insertion in the hygromycin resistance gene and pAURHYG(Δ)eGFP which has a single base deletion (shown in Figure 1). We also use the same plasmid containing a functional copy of the hygromycin-eGFP fusion gene, 0 designated pAURHYG(wt)eGFP, as a control. These plasmids are collectively designated pAURHYG(x)eGFP. These plasmids also contain an aureobasidinA resistance gene. In pAURHYG(rep)eGFP, hygromycin resistance gene function and green fluorescence from the eGFP protein are restored when a G at position 137, in codon 46 of the hygromycin B coding sequence, is converted to a C thus removing a premature stop codon in the hygromycin resistance gene coding region, 5 In pAURHYG(ins)eGFP, hygromycin resistance gene function and green fluorescence from the eGFP protein are restored when an A inserted between nucleotide positions 136 and 137, in codon 46 of the hygromycin B coding sequence, is deleted and a C is substituted for the T at position 137, thus correcting a frameshift mutation and restoring the reading frame of the hygromycin-eGFP fusion gene. In pAURHYG(Δ)eGFP, hygromycin resistance gene function and green fluorescence from eGFP are o restored when a C is inserted at the site of the single nucleotide deletion.
[0177] We synthesize the set of three yeast expression constructs pAURHYG(rep)eGFP, pAURHYG(Δ)eGFP, pAURHYG(ins)eGFP, that contain a point mutation at nucleotide 137 of the hygromycin-B coding sequence as follows: (rep) indicates a T137G replacement, (Δ) represents a deletion of G137 and (ins) represents an A insertion between nucleotides 136 and 137. 5 We construct this set of plasmids by excising the respective expression cassettes by restriction digest from pHyg(x)eGFP and ligation into pAUR123 (Panvera, CA). We digest 10 μg pAUR123 vector DNA as well as 10 μg of each pHyg(x)EGFP construct with Kpnl and Sail (NEB). We gel purify each of the DNA fragments and prepare them for enzymatic ligation. We ligate each mutated insert into pAUR123 vector at a 3:1 molar ratio using T4 DNA ligase (Roche). We screen clones by restriction digest, confirm by Sanger o dideoxy chain termination sequencing and purify plasmid DNA using a Qiagen maxiprep kit.
[0178] To monitor oligonucleotide-directed alteration of chromosomal nucleic acid sequence targets, we typically employ a yeast system in which we monitor chromosomal genes or we use
integrational plasmids such as those designated pAUR101-HYG(x)eGFP. These plasmids do not replicate in yeast. These plasmids comprise the HYG(x)eGFP fusion proteins used in the pAURHYG(x)eGFP episomal plasmid system (shown in Figure 1) and an aureobasidinA resistance gene. Therefore, like pAURHYG(x)eGFP, these constructs can also be used to monitor all types of gene alterations, i.e. replacements, insertions and deletions. We designate yeast strains into which the pAUR101-HYG(x)eGFP plasmid integrates as "+lntHYG(x)eGFP." In addition to this construct, we monitor gene alteration of specific yeast genes including, for example, CYC1.
[0179] Oligonucleotide synthesis and cells. We synthesize and purify the chimeric, RNA-DNA oligonucleotides with internally duplexed conformation and single-stranded oligonucleotides (including those with the indicated modifications) using available phosphoramidites on controlled pore glass supports. After deprotection and detachment from the solid support, the oligonucleotides are gel- purified using, for example, procedures such as those described in Gamper et al., Biochem. 39, 5808- 5816 (2000), or the oligonucleotides are ion-exchange HPLC-purified. We determine the concentration of the oligonucleotides spectrophotometrically (33 or 40 μg/ml per A260 unit of single-stranded or hairpin oligonucleotide, respectively). We introduce the oligonucleotides into yeast cells by electroporation as follows: we prepare electrocompetent yeast cells by inoculating 10 ml of YPD media supplemented with 250 μg/ml aureobasidin from a single colony and grow the cultures overnight with shaking at 300 rpm at 30°C. We pellet the cells from the overnight culture by centrifuging at 3000 rpm for 5 minutes, resuspend the cells in 40 ml YPD media (ODβoo approximately 0.2). We incubate the cells with shaking at 30°C until the OD600 is between 0.5 and 1.0 (3-5 hours). We wash the cells by centrifuging at 4°C at 3000 rpm for 5 minutes and twice resuspending the cells in 25 ml ice-cold distilled water. We centrifuge at 4°C at 3000 rpm for 5 minutes and resuspend in 1 ml ice-cold 1 M sorbitol and then finally centrifuge the cells at 4°C at 5000 rpm for 5 minutes and resuspend the cells in 120 μl 1M sorbitol. To transform electrocompetent cells with plasmids or oligonucleotides, we mix 40 μl of cells with oligonucleotide (typically 5 μg or amounts as indicated) and incubate on ice for 5 minutes. We transfer the mixture to a 0.2 cm electroporation cuvette and electroporate with a BIO-RAD Gene Pulser apparatus at 1.5 kV, 25 μF, 200 Ω for one five-second pulse. We then immediately resuspend the cells in 3 ml YPD media supplemented with 2M sorbitol and incubate the cultures at 30°C with shaking at 300 rpm for 6 hours. We spread 200 μl of this culture on selective plates containing 300 μg/ml hygromycin and spread 200 μl of a 105 dilution of this culture on selective plates containing 500 ng/ml aureobasidinA and/or and incubate at 30°C for 3 days to allow individual yeast colonies to grow. We count the colonies on the plates and calculate the
gene conversion efficiency by determining the number of hygromycin resistance colonies per 105 aureobasidinA resistant colonies.
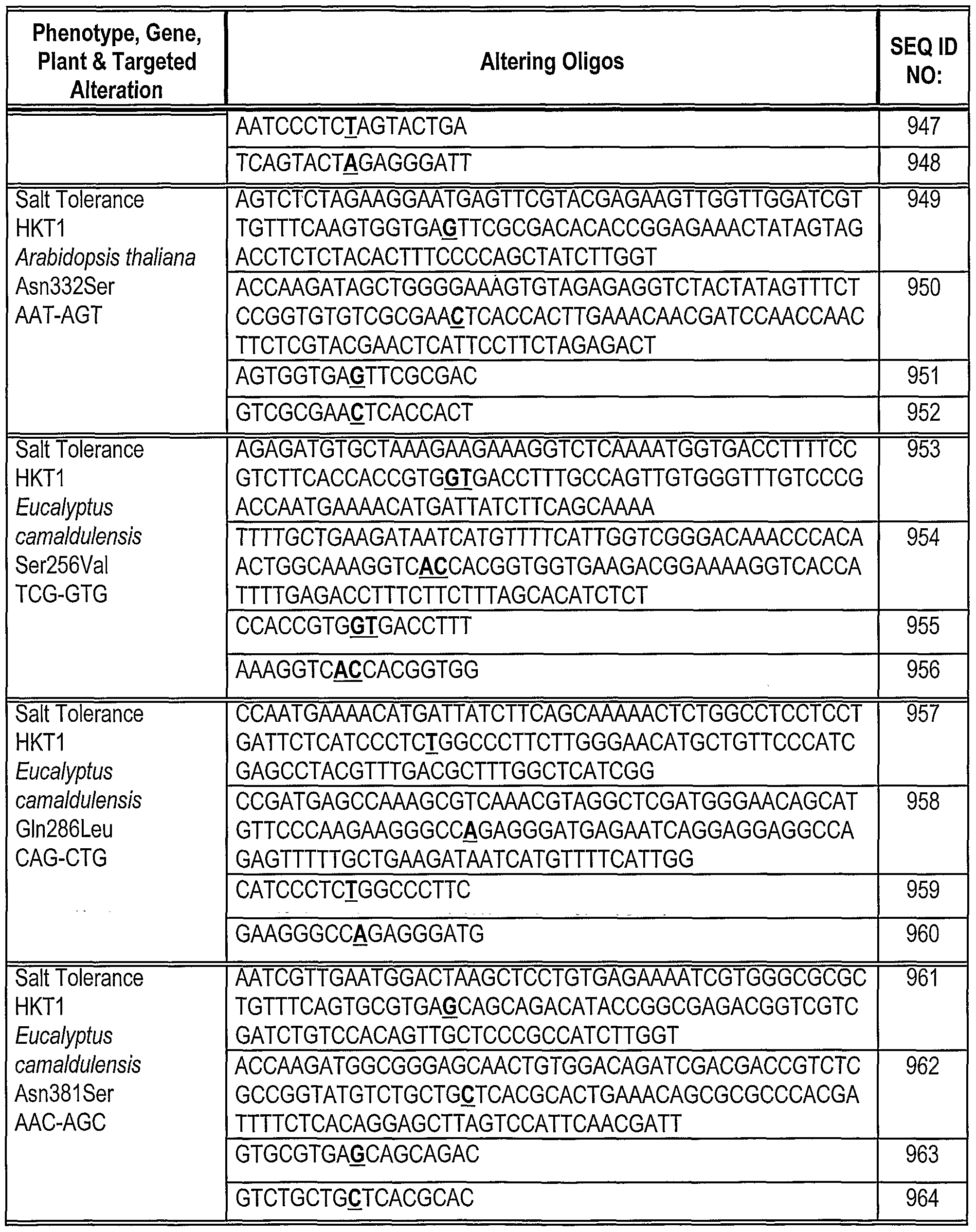
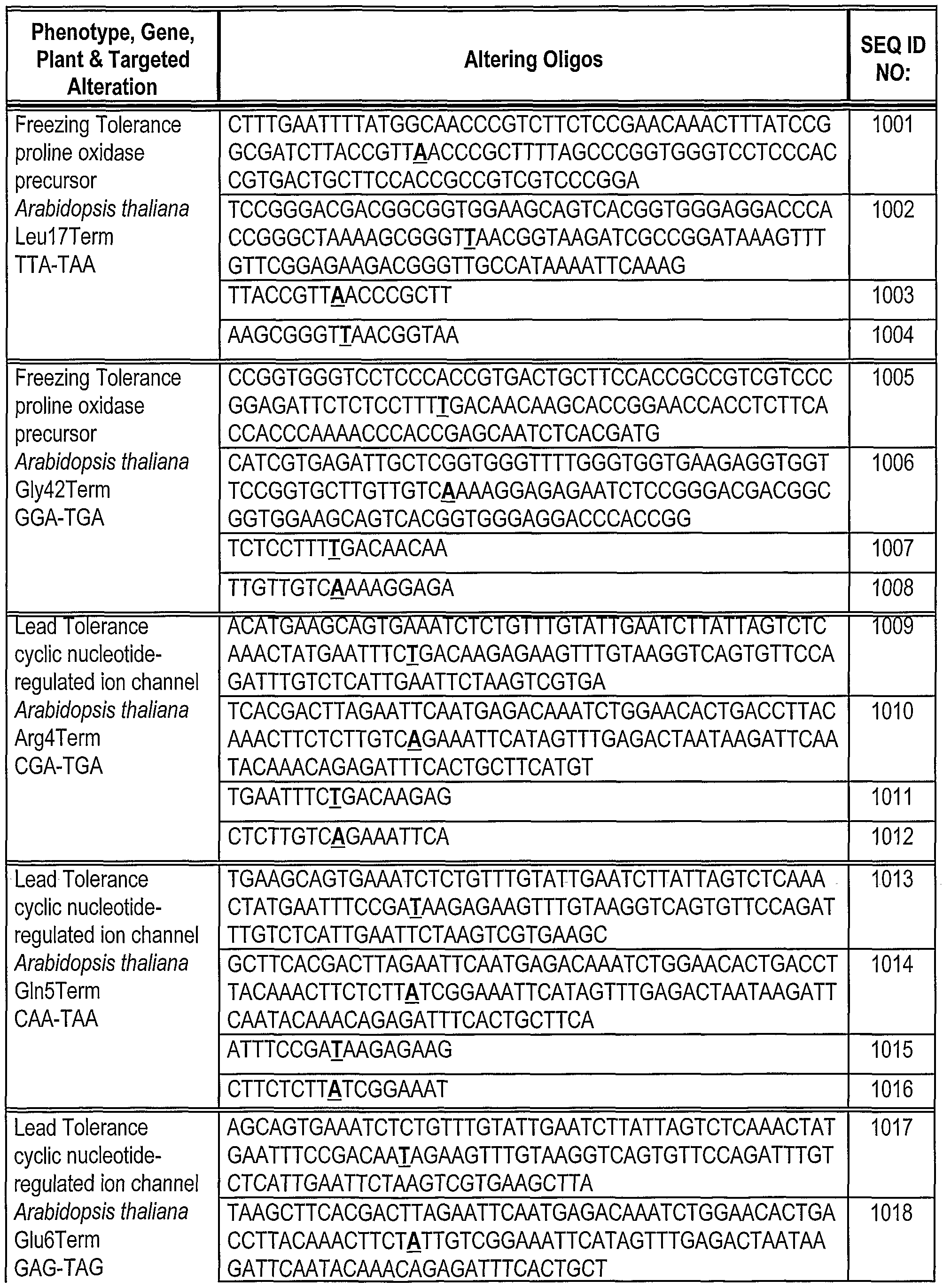
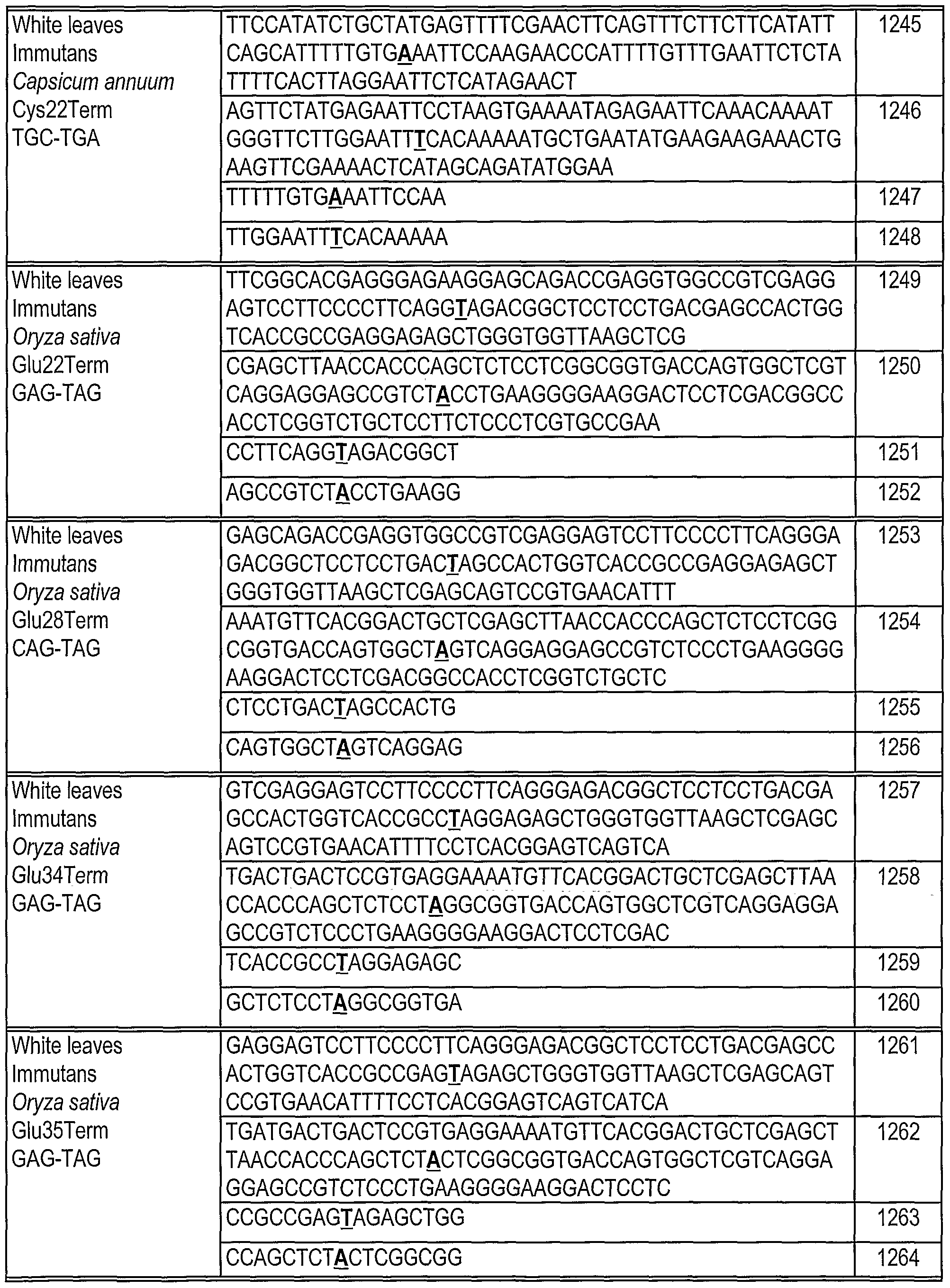
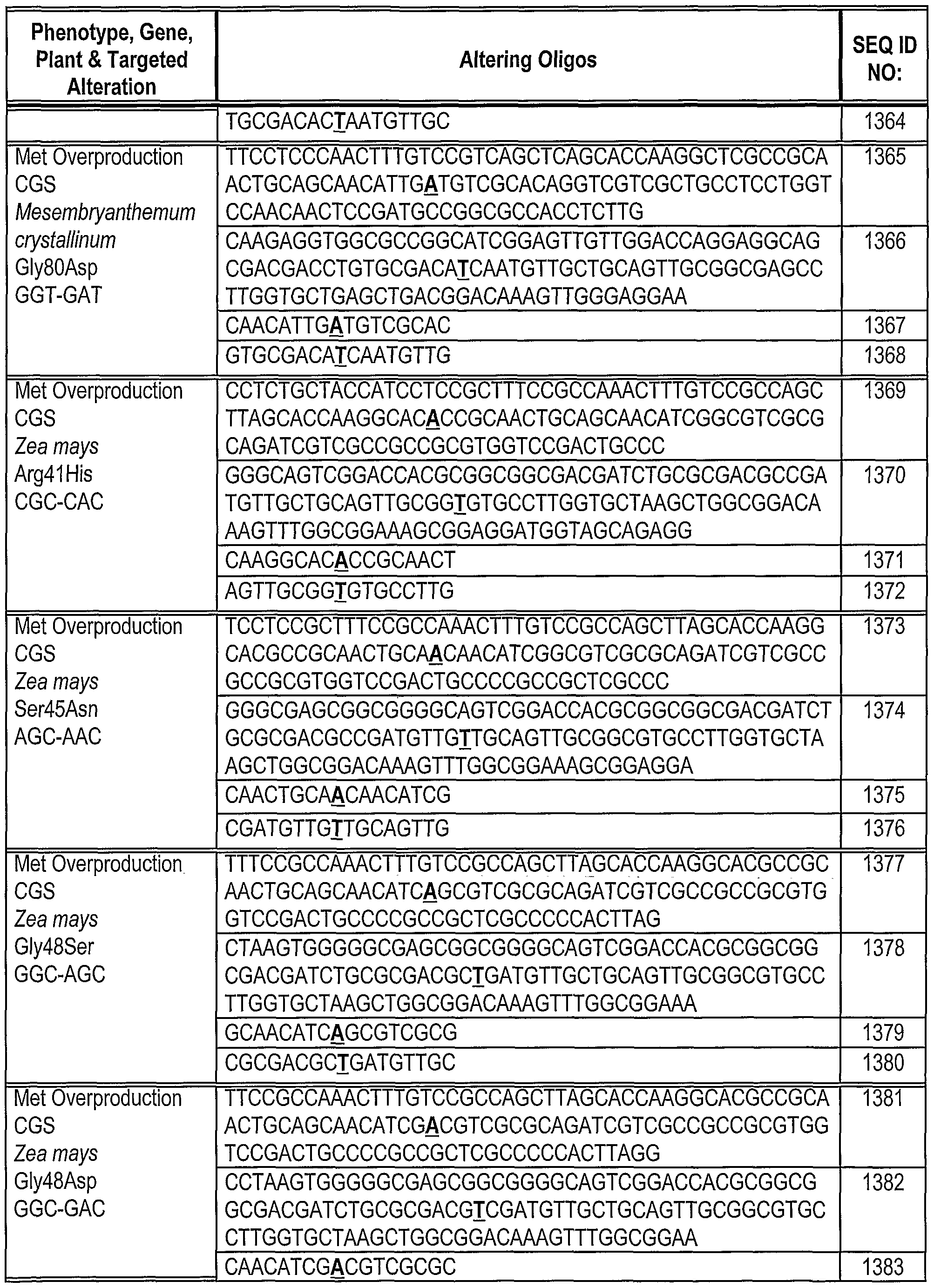
[0180] Oligonucleotides direct gene alteration. We use this system to assay the ability of various oligonucleotides (sequences shown in Table 1) to support correction under a variety of conditions. The oligonucleotides are designed so that they can direct correction of the replacement, insertion and deletion mutations in Mata+lntHYG(x)eGFP. The oligonucleotides generally are centered around the base targeted for alteration. In this example, we test the ability of these oligonucleotides to direct alteration of nucleic acid sequence in Mata+lntHYG(rep)eGFP (see Table 2).
[0181] We also use additional oligonucleotides to assay the ability of individual oligonucleotides to correct multiple mutations in both the pAURHYG(x)eGFP plasmid and in yeast strains with integrated copies of pAUR101-HYG(x)eGFP. These include, for example, an oligonucleotide that alters two basepairs that are 3 nucleotides apart with the sequence 5'-CTC GTG CTT TCA GCT TCG ATG TAG GAG GGC GTG GGT ACG TCC TGC GGG TAA ATA GCT GCG CCG ATG GTT TCT AC-3' (SEQ ID NO: _); a 74-mer that alters two basepairs that are 15 nucleotides apart with the sequence 5'- CTC GTG CTT TCA GCT TCG ATG TAG GAG GGC GTG GAT ACG TCC TGC GGG TAA ACA GCT GCG CCG ATG GTT TCT AC-3' (SEQ ID NO: J; and a 74-mer that alters two basepairs that are 27 nucleotides apart with the sequence 5'-CTC GTG CTT TCA GCT TCG ATG TAG GAG GGC GTG GAT ACG TCC TGC GGG TAA ATA GCT GCG CCG ACG GTT TCT AC (SEQ ID NO: J. The nucleotides in these oligonucleotides that direct alteration of the target sequence are in boldface. These oligonucleotides are chemically modified to enable them to effect oligonucleotide-directed nucleic acid sequence alteration.
Table 1 : Oligonucleotides used in Examples 1 and 2
Phosphorothioate linkages are indicated as "*" between the bases. The base corresponding to the location of the replacement mutation in the Hyg(rep) target is in bold.
Table 2: Gene alteration in Mata+lntHYG(rep)eGFP
1These numbers represent an average of four experiments with the standard deviation indicated for alteration efficiency.
5 EXAMPLE 2
Selection for a First Alteration Reduces Screening Required to Identify a Second Alteration in the Same Cell
[0182] In this example we demonstrate that the efficiency of alteration of nucleic acid sequence at a second site is enhanced in a population of nucleic acid molecules that have been o previously selected for alteration at a first target site. We use yeast strains having an integrated copy of the pAUR101-HYG(rep)eGFP plasmid described in Example 1 that also contain the βS YAC (230 kb YAC comprising the human β-globin gene). In some experiments, the yeast strains also contain a plasmid that overexpresses yeast Rad51 , designated pYNARadδl We use several oligonucleotides: Hyg3S/74NT, which, as described in Example 1 , is capable of directing alteration of the mutated Hyg(x)eGFP target to 5 confer hygromycin resistance; and βS-386m and βS-378m, each of which is a 71 -mer oligonucleotide with 3 phosphorothioate linkages on each end, which is capable of directing a mutation in the human β- globin gene. The sequence of βS-386m is 5' - G*C*C* TCA CCA CCA ACT TCA TCC ACG TTC ACC TTG CCT CAC AGG GCA GTA ACG GCA GAC TTC TCC ACA GG*A *G*T - 3' (SEQ ID NO: _) and the sequence of βS-378m is 5' - T*A*A* CGG CAG ACT TCT CCA CAG GAG TCA GGT GCA CCG TGG 0 TGT CTG TTT GAG GTT GCT AGT GAA CAC AG*T *T*G - 3' (SEQ ID NO: J. βS-386m and βS-378m both hybridize to the non-transcribed sequence of the human β-globin gene and direct a nucleic acid sequence alteration that creates a β-thalassemia mutation: βS-386m converts a TGG codon to a stop codon (TGA) and βS-378m converts the ATG start codon to ACG.
[0183] We introduce the oligonucleotides into the yeast cells by electroporation as follows: we prepare electrocompetent yeast cells by inoculating a single colony into 10 ml of appropriate media supplemented with 250 μg/ml aureobasidin and grow the cultures overnight with shaking at 300 rpm at 30°C. In this Example, we use YPD media unless the cells contain a plasmid to overexpress a repair protein when we use SC-ade media. We dilute the cells into 40 ml media to an initial ODβoo of approximately 0.15. We incubate the cells with shaking at 30°C until the OD600 is approximately 0.25 and,
in some experiments, we add 100 mM hydroxyurea (HU). We continue to incubate the cells with shaking at 30°C until the ODδoo is approximately 0.6. We spin down the cells at 3000 rpm for 5 minutes and resuspend in 1 ml YPD supplemented with 25 μl 1M DTT and incubate the culture with shaking at 30°C for 20 minutes. We wash the cells four times by centrifuging at 4°C at 3000 rpm for 5 minutes and 5 resuspending the cells twice in 25 ml ice-cold distilled water; once in 25 ml ice-cold 1 M sorbitol; and once in 1 ml ice-cold 1M sorbitol. We centrifuge the cells at 4°C at 5000 rpm for 5 minutes and resuspend the cells in 120 μl 1 M sorbitol. We transform the electrocompetent cells with Hyg3S/74NT and either βS- 386m or βS-378m by mixing 40 μl of cells with 30 μg oligonucleotide (or 30 μg of each oligonucleotide) and incubate on ice for 5 minutes. We transfer the mixture to a 0.2 cm electroporation cuvette and o electroporate with a BIO-RAD® Gene Pulser® apparatus at 1.5 kV, 25 μF, 200 Ω for one approximately five-second pulse. We then resuspend the cells in 3 ml YPD media supplemented with Aureobasidin and allow the cells to recover by incubating them overnight at 30°C with shaking at 300 rpm. In some experiments, we supplement the culture with 50 mg/ml Trichostatin A (TSA) during this recovery phase. We spin down the cells, resuspend in 1 ml YPD and spread 100 μl of this culture (and/or 100 μl of 101 or 5 102 dilutions) on selective plates containing 300 μg/ml hygromycin and spread 200 μl of a 105 dilution of this culture on selective plates containing 500 ng/ml aureobasidinA and incubate at 30°C for 3 days to allow individual yeast colonies to grow. We count the colonies on the plates and calculate the conversion efficiency for the hygromycin target by determining the number of hygromycin resistance colonies per 105 aureobasidinA resistant colonies. We pick individual colonies from YPD-hygromycin plates into 96-well o plates with 150 μl YPD/well and allow the cells to grow overnight at 30°C. We screen individual wells for alteration of the β-globin target in the βS YAC as follows: we PCR amplify a 345 bp fragment of the β- globin gene using forward primer PC02; 5'- TCC TAA GCC AGT GCC AGA AGA -3' (SEQ ID NO: J and reverse primer PC05; 5'- CTA TTG GTC TCC TTA AAC CTG -3' (SEQ ID NO: J and purify the PCR product. We analyze the sequence at the target nucleotide in the PCR products by SNaPshot™ analysis 5 on an ABI3100 (Applied Biosystems™) using primers corresponding to the different alterations directed by βS-386m and βS-378m as follows: 386RC; 5'- CCC CCC CCC CCC CCC CCA AGT CTG CCG TTA CTG CCC TGT G -3' (SEQ ID NO: _) and 378MF; 5'- TTT TTT TTT TTT TTT TTT TTT TTT TTT TTT TTT TGC AAC CTC AAA CAG ACA CCA -3' (SEQ ID NO: J.
[0184] As shown in Tables 3 and 4, we observe that the alteration efficiency of the β- o globin gene is approximately 10-fold higher than for alteration of the hygromycin target. We observe this result with both βS-386m and βS-378m as well as in the presence or absence of additional factors that
enhance oligonucleotide-directed nucleic acid sequence alteration such as, e.g., overexpression of Rad51.
[0185] In other experiments, we do the experiments in yeast strains overexpressing other repair protein(s) in place of or in addition to Rad51 and/or yeast strains with one or more mutations in repair proteins. We also do experiments where we add other compounds that enhance oligonucleotide- directed nucleic acid sequence alteration such as histone deacetylase inhibitors and the bacteriophage lambda beta protein.
Table 3: βS-386m Experiment
Table 4: βS-378m Experiment
NA = not applicable; ND = not determined; KanUD3/71 is a negative control oligonucleotide
EXAMPLE 3
Selection for a First Alteration Reduces Screening Required to Identify a Second Alteration in Human Blood Cells
[0001] Assay system. We monitor targeted alteration of genetic material in human blood cells using the chromosomal gene encoding the beta subunit of hemoglobin as the target. We 5 cointroduce two oligonucleotides with a plasmid comprising a mutant copy of the green fluorescent protein (GFP) gene. The second oligonucleotide is designed to direct an alteration which repairs the mutant GFP resulting in fluorescence. The first oligonucleotide is designed to convert the wild-type allele to the sickle allele. We use first oligonucleotides that correspond in sequence to the wild-type allele at all positions except the single nucleotide position designed to introduce the sickle mutation into the gene. Therefore, o these oligonucleotides are identical to the oligonucleotides described in Example 6 and shown in Table 7 except for a single base. For example, we use first oligonucleotides selected from: 5'- C*A*A* CCT CAA ACA GAC ACC ATG GTG CAC CTG ACT CCT GtG GAG AAG TCT GCC GTT ACT GCC CTG TGG GGC AA*G *G*T -3'; SEQ ID NO: _; 5'- A*C*C* TTG CCC CAC AGG GCA GTA ACG GCA GAC TTC TCC aCA GGA GTC AGG TGC ACC ATG GTG TCT GTT TGA GG*T *T*G-3'; SEQ ID NO: _; 5'-ACC 5 TCA AAC AGA CAC CAT GGT GCA CCT GAC TCC TGt GGA GAA GTC TGC CGT TAG TGC CCT GTG GGG CAA GG -3'; SEQ ID NO: _; 5'- G*A*C* ACC ATG GTG CAC CTG ACT CCT GtG GAG AAG TCT GCC GTT ACT GCC *C*T*G -3'; SEQ ID NO: _; and 5'- A*C*C* TCA AAC AGA CAC CAT GGT GCA CCT GAC TCC TGt GGA GAA GTC TGC CGT TAC TGC CCT GTG GGG CA*A *G*G -3'. The bases in the oligonucleotides which are mismatched to the wild-type allele are shown in lowercase. The o oligonucleotides are synthesized with three phosphorothioate linkages on each end (represented with asterisks) or with a single LNA base at each end (bold).
[0187] Preparation and treatment of cells. We thaw and electroporate cells as follows. We warm QBSF-60 medium (Quality Bio) containing 10% FCS (StemCell Technologies) to 37°C. We quickly thaw frozen G-CSF mobilized peripheral blood CD-34+ cells (BioWhittaker) in a 37°C water bath, 5 wipe the outside of the tube with 70% ethanol and aseptically transfer about 2 ml (approximately 1 x 106 cells) of cell suspension to a 15 ml or 50 ml conical tube. We rinse the vial in 1 ml of medium and add it dropwise to the cells, gently swirling the conical tube every few drops. We slowly add medium dropwise until the volume is about 5 ml, still gently swirling the conical tube every few drops, and then slowly bring the volume up to fill the tube by adding 1-2 ml of medium dropwise, swirling after every addition. We o centrifuge the cell suspension at 200 x g (1500 rpm) for 15 minutes at room temperature. We use a pipet to remove most of the wash to a second tube, leaving a few ml behind to avoid disturbing the cell pellet. We resuspend the pellet in the remaining medium and transfer to a 15 ml conical tube. We rinse the
original tube with 5 ml medium and add the wash to the cells dropwise, swirling gently after each addition, and recentrifuge at 200 x g for 15 minutes. We pipet off all but 2 ml of the wash and gently resuspend the cells in the remaining medium and count them. We rest the cells at 37°C and 5% CO2 for 1 hour and then recount the cells. We add 5 ml QBSF-60 medium without FCS containing the cytokines flt-3, SCF and TPO at 100 ng/ml final concentration (Stem Cell Technologies), repellet the cells at 200 x g (1500 rpm for 15 min), and gently remove as much liquid volume as possible without disturbing the pellet. We resuspend the cells at about 5 x 10 - 1 x 106 cells/ml and transfer them to 6-well tissue culture treated dishes. We stimulate the cells for three days with cytokines (QBSF-60 medium without FCS containing the cytokines flt-3, SCF and TPO at 100 ng/ml final concentration) and perform a cell count using trypan blue exclusion staining. We centrifuge the cells at 200 x g (1500 rpm) for 15 minutes. We remove the excess volume by pipet and resuspend the cells in the same medium at 2 x 106 cells/ml.
[0188] We electroporate the oligonucleotides and the GFP plasmid into the cells under square wave conditions as follows. We add 250 μl cell suspension, 5 μg GFP plasmid and 30 μg each oligonucleotide to a 2 mm gap cuvette and electroporate for one 19 msec pulse at 220 V. We then add 750 μl Iscove's Medium (Invitrogen™), 10% FCS (StemCell Technologies) and the cytokines flt-3, SCF, TPO at 100 ng/ml final concentration, glutamine and penicillin/streptomycin. Alternatively, we add 250 μl cell suspension, 250 μl QBSF-60 medium supplemented with flt-3, SCF and TPO and 30 μg oligonucleotide to a 4 mm gap cuvette and electroporate for five 19 msec pulse at 220 V with a pulse interval of 1 sec. We then add 500 μl Iscove's Medium (Invitrogen™), 10% FCS (StemCell Technologies) and the cytokines flt-3, SCF and TPO at 100 ng/ml final concentration. We select for the repair of the mutant GFP protein using by FACS and analyze the sequence of the hemoglobin target by PCR amplification and analysis on the SNapShot™ device using two oligonucleotides: 5'- TTT TTT TTT TTT TTT GAC ACC ATG GTG CAC CTG ACT CCT G -3'; SEQ ID NO _; and 5'- TTT TTT TTT TTT TTT TTT TTC AGT AAC GGC AGA CTT CTC C -3'; SEQ ID NO _. As we see in other cells, these oligonucleotides direct targeted alteration in human blood cells.
EXAMPLE 4 Use of HU and TSA in Dual Targeting Experiments
[0189] The efficiency of targeted alteration can be increased and the cost decreased by using at least two unrelated oligonucleotides simultaneously in dual targeting experiments. In this approach, alteration by a first oligonucleotide confers a selectable phenotype that is selected for.
Alterations directed by a second oligonucleotide are then screened for from within this selected population. Because the population identified by selective pressure is enriched for cells that bear an edited base at the non-selective site, the approach is useful as a method, termed gene editing, for rapidly and efficiently introducing a single nucleotide polymorphism of choice into virtually any gene at any 5 desired location using modified single-stranded oligonucleotides.
[0190] The dual targeting strategy is illustrated in FIG. 2A. The LSY678lntHyg(rep)β strain (Table 5) contains a 240 kb human βs-globin YAC and a cassette containing a chromosomal hygromycin-resistance gene inactivated by a single base mutation and a functional aureobasidin- resistance gene. See Liu et al., Nucleic Acids Res. 31 :2742-2750 (2002); Parekh-Olmedo et al., Chem. o Biol. 9:1073-1084 (2002); and Liu et al., Mol. Cell Biol. 22:3852-3863 (2002). FIG. 2B shows the oligonucleotide that is used to direct editing of the chromosomal hygromycin mutant gene. Hyg3S/74NT
(SEQ ID NO: ) is a 74-mer that is specific for inding to the nontranscribed strand and contains three terminal phosphorothioate linkages. Id. Also shown is the target sequence of the mutant, which contains a TAG stop codon. FIG. 2C illustrates the structure of the β-globin YAC and nucleotides targeted for 5 editing are specified. The two nonselectable changes are directed by different oligonucleotides, βThall (SEQ ID NO: _) and βThal2 (SEQ ID NO: _), in separate experiments. The YAC contains approximately 230 kb of genomic DNA from human chromosome 11, indicated by the shaded region. The unshaded regions represent the yeast sequences that are on either end of the YAC (not drawn to scale). Yu et al., Proc. Natl. Acad. Sci. USA 97:5978-5983 (2000). A portion of the β-globin sequence is shown, o beginning with the start codon. βThall directs a change from a G to an A while βThal2 directs a change from a T to a C. The sequences of the oligonucleotides having nucleic acid sequence alteration activity are shown and are designed to bind to the non-transcribed strand, relative to human transcription of the β- globin locus. Both changes result in single-base substitutions that have been documented to result in β- thalassemia in humans. 5 [0191] For editing experiments, YAC-containing LSY678lntHyg(rep)β cells (Table 5) are grown in the presence of HU, electroporated with the selectable and nonselectable oligonucleotides, and allowed to recover in the presence of TSA (FIG. 2A). Because the human β-globin gene is likely to be transcriptionally inactive in yeast, HU and TSA are especially important in increasing target accessibility. The results of dual targeting experiments are presented in FIG. 3A. Hygromycin-resistant colonies are o observed when the oligonucleotide, Hyg3S/74NT, is used. The ratio of hygromycin-resistant colonies to aureobasidin-resistant colonies is referred to as the correction efficiency (C.E.). The presence of HU and TSA leads to an increase in the CE. of the hygromycin mutation, here about 4- to 6-fold. In this
experiment, hygromycin-resistant colonies are found at roughly 1 per 3000 aureobasidin-resistant colonies. Hygromycin-resistant colonies are then analyzed for second-site editing in the YAC β-globin gene. The βThall oligonucleotide is designed to direct the replacement of a G in TGG codon 16 of exon 1 with an A, giving the stop codon TGA (FIG. 2C). FIG. 3B shows an ABI SNaPshot (middle panels) and 5 direct DNA sequence (bottom panel) of a region of the b-globin gene in a corrected colony from this experiment; in both, the G to A change is evident. Of those colonies that are corrected in the hygromycin mutation, 1 in 325 also contain the second change in the YAC β-globin sequence. Thus, approximately 10% of the cells with the corrected hygromycin-resistance gene also contain the edited β-globin gene.
[0192] As shown in various experiments above, overexpression of RAD51 consistently o increases the frequency of chromosomal gene editing. Accordingly, we introduce an expression plasmid containing the yeast RAD51 gene into LSY678lntHyg(rep)β cells (Table 5). FIG. 4 shows results of dual targeting in this strain and, as expected, expression of RAD51 increases the hygromycin correction efficiency of oligonucleotide Hyg3S/74NT (compare with FIG. 3). For these editing experiments, YAC- containing LSY678lntHyg(rep)β cells (Table 5) are grown in the presence of HU, electroporated with the 5 selectable and nonselectable oligonucleotides, and allowed to recover in the presence of TSA (FIG, 2A). Here too, addition of a second oligonucleotide, βThal2, increases the correction efficiency further, to roughly 1 hygromycin-resistant colony per 800 aureobasidin-resistant colonies.
[0193] The βThal2 oligonucleotide is designed to direct the replacement of a T in the initiator ATG codon of exon 1 with a C, giving the non-initiator codon ACG (FIG. 2). FIG. 4B shows an ABI o SNaPshot (middle panels) and direct DNA sequence (bottom panel) of the β-globin gene from a corrected
Hygr colony; the T to C change is evident in both analytical panels. Importantly, of those colonies that are corrected in the hygromycin mutation, 1 in 70 also contain the second single-base change in the YAC β- globin sequence. Thus, the dual targeting approach is again successful; approximately 10% of the cells bearing the corrected hygromycin also contain the edited β-globin gene, In addition, in the presence of 5 high levels of Rad51 , gene editing occurs at a higher level, indicating that the presence of HU, TSA, and RAD51 overexpression exhibit synergistic effects on the overall process.
Table 5 Genotype of yeast strains
[0194] Strains. The genotypes of the yeast strains used in these studies are listed in Table 5. Details of the LSY678lntHyg(rep) strain are published in Liu et al., Mol. Cell Biol. 22:3852-3863 (2002). [0195] YAC Manipulations. The β-globin YAC is isolated from a preparative pulsed- field gel as described in Gnirke et al., Genomics 15:659-667 (1993). Briefly, concentrated chromosomal DNA from the β S-YAC strain (AB1380 background, see Chang et al„ Proc. Natl. Acad. Sci. USA 95:14886-14890 (1998)) is prepared and resolved on a 1 % low-melt agarose pulsed-field gel at 200V, 14°C, 20-50s, 33 hours. The YAC is isolated, equilibrated with a modified agarase buffer (10mM BisTris- HCI pH6.5, 1 mM EDTA, 100mM NaCl), treated with β-agarase 1 (New England Biolabs), and concentrated to a final volume of -200 μl. Thirty μl of the purified YAC are introduced into competent LSY678IntHyg(rep) cells by spheroplast transformation and selection on agar/sorbitol plates lacking tryptophan. Transformants are restreaked and confirmed by pulsed-field gel electrophoresis, PCR, and sequence analysis for a fragment of the human β-globin gene. [0196] The pYNARad51 episomal expression plasmid is constructed by replacing the
TRP1 gene of pYNRad51 (see Liu et al., Nucleic Acids Res. 31, 2742-2750 (2002)) with the ADE2 gene. pYNARad51 is introduced into LSY678lntHyg(rep)β by electroporation and selection on agar plates lacking adenine.
[0197] Oligonucleotides. Hyg3S/74NT (SEQ ID NO: _), βThall (SEQ ID NO: _), and βThal2 (SEQ ID NO: _) are ordered from IDT with HPLC purification. Hyg3S/74NT is a 74mer and both βThall and βTha!2 are 71 mers; all three oligonucleotides have three phosphorothioate linkages at the 5' and 3' ends (FIG. 2).
[0198] Dual Targeting. The dual targeting protocol is outlined in FIG. 2A. LSY678lntHyg(rep)β cells are grown overnight in 10 ml YPD media at 30°C. The culture is diluted to ODeoo -0.15-0.20 in 40 ml YPD media and grown for one doubling time to ODeoo -0.3-0.4. 100mM HU is added to the culture and the cells are grown for one doubling time to ODeoo -0,6-0.8. Cells are harvested and resuspended in 1 ml YPD containing 25 μl 1M DTT and grown for an additional 20 minutes at 30°C, The cells are washed twice with 25 ml cold dH20 and once with 25 ml cold 1M sorbitol. The cells are
resuspended gently in 1 ml cold 1 M sorbitol, spun for 5 minutes at 5000 rpm in a microcentrifuge, and resuspended in 120μl 1 M sorbitol. Forty microliters of cells are electroporated with 30 μg of each oligonucleotide in a 2 mm gap cuvette using a Bio-Rad Gene Pulser apparatus (Richmond, CA) with 1.5 kV, 25μF, 200Ω, 1 pulse, 5s/pulsed length. The cells are immediately resuspended in 3 ml YPD with 0.8 5 μg/ml aureobasidin A and 50 μg/ml TSA and recovered overnight at 30°C. The cells are spun down and resuspended in 1 ml fresh YPD. Dilutions are plated on YPD agar plates containing either hygromycin (300μg/ml) or aureobasidin A (0.5 μg/ml). Correction efficiencies (C.E.s) are determined based on the number of hygromycin-resistant colonies per aureobasidin-resistant colonies,
[0199] Individual colonies are picked from the hygromycin agar plates into 96-well o plates (Corning) containing 150 μl YPD and grown overnight at 30°C with shaking. A 345 bp PCR product specific for the human β-globin locus is amplified from each of the 96 wells using the primers PC02 (5- TCCTAAGCCAGTGCCAGAAG-3' (SEQ ID NO.: _)) and PC05 (5'-CTATTGGTCTCCTTAAACCTG-3' (SEQ ID NO.: _)) in order to screen for the βThall or βThal2 conversion. The PCR reactions are performed by adding 8 pmoles of each primer and 2.5 μl yeast cell culture into pre-aliquoted PCR reaction 5 mixes (Marsh/Abgene). The PCR reactions use an annealing temperature of 45.8°C and an extension time of 1 min for 35 cycles. The PCR reactions are purified using a QiaQuick PCR 96-well purification kit (Qiagen) and eluted in a volume of 80 μl. One microliter of the purified PCR product is used as a template for the ABI SNaPshot reaction. The sequence of the SNaPshot primer used to screen for the βThall conversion is: 5'-CCCCCCCCCCCCCCCCCAAGTCTGCCGTTACTGCCCTGTG-3' (SEQ ID NO: _). 0 The sequence of the SNaPshot primer used to screen for the βThal2 conversion is: 5'-
TTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTCCACAGGAGTCAGGTGCACC-3' (SEQ ID NO: __). The SNaPshot reactions are performed Using an ABI Prism SNaPshot Multiplex Kit, as specified by the manufacturer, and analyzed on an ABI 3100 Genetic Analyzer.
[0200] Sequence Analysis. Any potential converted clones from the SNaPshot 5 reactions are confirmed by sequence analysis. Both strands of the PCR products are sequenced using primers PC02 and PC05 by Sanger dideoxy sequencing using an ABI Prism kit, as specified by the manufacturer, on an automated ABI 3100 Genetic Analyzer.
EXAMPLE 5 o Adenosine Deaminase (ADA)
[0201] Adenosine deaminase (ADA, EC 3.5.4.4) catalyses the deamination of adenosine and 2'-deoxyadenosine to inosine or 2'-deoxyinosine respectively. ADA deficiency has been
identified as the metabolic basis for 20-30% of cases with recessively inherited severe combined immunodeficiency (SCID). Affected infants are subject to recurrent chronic viral, fungal, protozoa!, and bacterial infections and frequently present with persistent diarrhea, failure to thrive and candidiasis. In patients homozygous for ADA deficiency, 2'-deoxyadenosine accumulating during the rapid turnover of 5 cells rich in DNA is converted back to dATP, either by adenosine kinase or deoxycytidine kinase. Many hypotheses have been advanced to explain the specific toxicity to the immune system in ADA deficiency, The apparently selective accumulation of dATP in thymocytes and peripheral blood B cells, with resultant inhibition of ribonucleotide reductase and DNA synthesis is probably the principal mechanism.
[0202] The structural gene for ADA is encoded as a single 32 kb locus containing 12 o exons. Studies of the molecular defect in ADA-deficient patients have shown that mRNA is usually detectable in normal or supranormal amounts. Specific base substitution mutations have been detected in the majority of cases with the complete deficiency, A C-to-T base substitution mutation in exon 11 accounts for a high proportion of these, whilst a few patients are homozygous for large deletions encompassing exon I. A common point mutation resulting in a heat-labile ADA has been characterised in 5 some patients with partial ADA deficiency, a disorder with an apparently increased prevalence in the Caribbean.
[0203] As yet no totally effective therapy for ADA deficiency has been reported, except in those few cases where bone marrow from an HLA/MLR compatible sibling donor was available.
[0204] Two therapeutic approaches have provided long-term benefit in specific o instances. First, reconstitution using T cell depleted mismatched sibling marrow has been encouraging, particularly in early presenters completely deficient in ADA. Secondly, therapy with polyethylene glycol-modified adenosine deaminase (PEG-ADA) for more than 5 years has produced a sustained increase in lymphocyte numbers and mitogen responses together with evidence of in vivo B cell function. Success has generally been achieved in late presenters with residual ADA activity in mononuclear cells. 5 [0205] ADA deficiency has been chosen as the candidate disease for gene replacement therapy and the first human experiment commenced in 1990. The clinical consequences of overexpression of ADA activity — one of the potential hazards of gene implant — are known and take the form of an hereditary haemolytic anaemia associated with a tissue-specific increase in ADA activity. The genetic basis for the latter autosomal dominant disorder seemingly relates to markedly increased levels of o structurally normal ADA mRNA.
EXAMPLE 6
P53 Mutations
[0206] The p53 gene codes for a protein that acts as a transcription factor and serves as a key regulator of the cell cycle. Mutation in this gene is probably the most significant genetic change characterizing the transformation of cells from normalcy to malignancy, 5 [0207] Inactivation of p53 by mutation disrupts the cell cycle which, in turn, sets the stage for tumor formation. Mutations in the p53 gene are among the most commonly diagnosed genetic disorders, occuring in as many as 50% of cancer patients. For some types of cancer, most notably of the breast, lung and colon, p53 mutations are the predominant genetic alternations found thus far. These mutations are associated with genomic instability and thus an increased susceptibility to cancer. Some o p53 lesions result in malignancies that are resistant to the most widely used therapeutic regimens and therefore demand more aggressive treatment.
[0208] That p53 is associated with different malignant tumors is illustrated in the Li-Fraumeni autosomal dominant hereditary disorder characterized by familial multiple tumors due to mutation in the p53 gene. Affected individuals can develop one or more tumors, including: brain (12%); 5 soft-tissue sarcoma (12%); breast cancer (25%); adrenal tumors (1 %); bone cancer (osteosarcoma) (6%); cancer of the lung, prostate, pancreas, and colon as well as lymphoma and melanoma can also occur. Certain of the most frequently mutated codons are codons 175, 248 and 273.
EXAMPLE 9 0 BRCA1 and BRCA2
[0209] Breast cancer is the second major cause of cancer death in American women, with an estimated 44,190 lives lost (290 men and 43,900 women) in the US in 1997. While ovarian cancer accounts for fewer deaths than breast cancer, it still represents 4% of all female cancers. In 1994, two breast cancer susceptibility genes were identified: BRCA1 on chromosome 17 and BRCA2 on 5 chromosome 13. When a woman carries a mutation in either BRCA1 or BRCA2, she is at increased risk of being diagnosed with breast or ovarian cancer at some point in her life.
[0210] Ford ef a/., Am. J. Hum. Genet 62: 676-689 (1998) assessed the contribution of BRCA1 and BRCA2 to inherited breast cancer by linkage and mutation analysis in 237 families, each with at least 4 cases of breast cancer. Families were included without regard to the occurrence of ovarian or o other cancers. Overall, disease was linked to BRCA1 in an estimated 52% of families, to BRCA2 in 32% of families, and to neither gene in 16%, suggesting other predisposition genes. The majority (81%) of the breast-ovarian cancer families were due to BRCA1 , with most others (14%) due to BRCA2. Conversely,
the majority (76%) of families with both male and female breast cancer were due to BRCA2. The largest proportion (67%) of families due to other genes were families with 4 or 5 cases of female breast cancer only,
[0211] More than 75% of the reported mutations in the BRCA1 gene result in truncated proteins. Couch et al., Hum. Mutat 8: 8-18, 1996. (1996) reported a total of 254 BRCA1 mutations, 132 (52%) of which were unique. A total of 221 (87%) of all mutations or 107 (81 %) of the unique mutations are small deletions, insertions, nonsense point mutations, splice variants, and regulatory mutations that result in truncation or absence of the BRCA1 protein. A total of 11 disease-associated missense mutations (5 unique) and 21 variants (19 unique) as yet unclassified as missense mutations or polymorphisms had been detected. Thirty-five independent benign polymorphisms had been described. The most common mutations were 185delAG and 5382insC, which accounted for 30 (11.7%) and 26 (10.1%), respectively, of all the mutations.
[0212] Most BRCA2 mutations are predicted to result in a truncated protein product. The smallest known cancer-associated deletion removes from the C terminus only 224 of the 3,418 residues constituting BRCA2, suggesting that these terminal amino acids are critical for BRCA2 function. Studies (Spain et al., Proc, Natl. Acad. Sci. 96:13920-13925 (1999)) suggest that such truncations eliminate or interfere with 2 nuclear localization signals that reside within the final 156 residues of BRCA2, suggesting that the vast majority of BRCA2 mutants are nonfunctional because they are not translocated into the nucleus.
EXAMPLE 10
Cystic Fibrosis - CFTR
[0213] Cystic fibrosis is a lethal disease affecting approximately one in 2,500 live Caucasian births and is the most common autosomal recessive disease in Caucasians. Patients with this disease have reduced chloride ion permeability in the secretory and absorptive cells of organs with epithelial cell linings, including the airways, pancreas, intestine, sweat glands and male genital tract. This, in turn, reduces the transport of water across the epithelia. The lungs and the Gl tract are the predominant organ systems affected in this disease and the pathology is characterized by blocking of the respiratory and Gl tracts with viscous mucus. The chloride impermeability in affected tissues is due to mutations in a specific chloride channel, the cystic fibrosis transmembrane conductance regulator protein
(CFTR), which prevents normal passage of chloride ions through the cell membrane (Welsh et al., Neuron, 8:821-829 (1992)). Damage to the lungs due to mucus blockage, frequent bacterial infections
and inflammation is the primary cause of morbidity and mortality in CF patients and, although maintenance therapy has improved the quality of patients' lives, the median age at death is still only around 30 years, There is no effective treatment for the disease, and therapeutic research is focused on gene therapy using exogenous transgenes in viral vectors and/or activating the defective or other chloride 5 channels in the cell membrane to normalize chloride permeability (Tizzano et al., J. Pediat., 120:337-349 (1992)). However, the death of a teenage patient treated with an adenovirus vector carrying an exogenous CFTR gene in clinical trials in the late 1990's has impacted this area of research.
EXAMPLE 11 o Cyclin-dependent kinase inhibitor 2A - CDKN2A
[0214] The human CDKN2A gene was also designated MTS-1 for multiple tumor suppressor-1 and has been implicated in multiple cancers including, for example, malignant melanoma. Malignant melanoma is a cutaneous neoplasm of melanocytes. Melanomas generally have features of asymmetry, irregular border, variegated color, and diameter greater than 6 mm. The precise cause of 5 melanoma is unknown, but sunlight and heredity are risk factors. Melanoma has been increasing during the past few decades.
[0215] The CDKN2A gene has been found to be homozygously deleted at high frequency in cell lines derived from tumors of lung, breast, brain, bone, skin, bladder, kidney, ovary, and lymphocyte. Melanoma cell lines carried at least one copy of CDKN2A in combination with a deleted o allele. Melanoma cell lines that carried at least 1 copy of CDKN2A frequently showed nonsense, missense, or frameshift mutations in the gene. Thus, CDKN2A may rival p53 (see Example 6) in the universality of its involvement in tumorigenesis.
EXAMPLE 12 5 Adenomatous polyposis of the colon - APC
[0216] Adenomatous polyposis of the colon is characterized by adenomatous polyps of the colon and rectum; in extreme cases the bowel is carpeted with a myriad of polyps. This is a viciously premalignant disease with one or more polyps progressing through dysplasia to malignancy in untreated gene carriers with a median age at diagnosis of 40 years. o [0217] Mutations in the APC gene are an initiating event for both familial and sporadic colorectal tumorigenesis and many alleles of the APC gene have been identified. Carcinoma may arise at
any age from late childhood through the seventh decade with presenting features including, for example, weight loss and inanition, bowel obstruction, or bloody diarrhea. Cases of new mutation still present in these ways but in areas with well organized registers most other gene carriers are detected.
EXAMPLE 13
Parahemophilia and Hemophilia - Factor V, Factor VIII and Factor IX Deficiencies
[0218] Deficiency in clotting Factor V is associated with a lifelong predisposition to thrombosis. The disease typically manifests itself with usually mild bleeding, although bleeding times and clotting times are consistently prolonged. Individuals that are heterozygous for a mutation in Factor V have lowered levels of factor V but probably never have abnormal bleeding. A large number of alleles with a range of presenting symptoms have been identified,
EXAMPLE 14
Alpha thalassemia - Hemoglobin alpha loci 1 and 2 [0219] The thalassemia syndromes are a heterogeneous group of inherited anemias characterized by defects in the synthesis of one or more globin chain subunits. For example, beta- thalassemia discussed in Example 6, is caused by a decrease in beta-chain production relative to alpha- chain production; the converse is the case for alpha-thalassemia.
EXAMPLE 15
Human mismatch repair - MLH1
[0220] The human MLH1 gene is homologous to the bacterial mutL gene, which is involved in mismatch repair. Mutations in the MLH1 gene have been identified in many individuals with hereditary nonpolyposis colorectal cancer (HNPCC). Mutations in the MLH1 gene are also implicated in predisposition to a variety of cancers associated with, for example, Muir-Torre syndrome and Turcot syndrome.
EXAMPLE 16 Human mismatch repair - MSH2
[0221] The human MSH2 gene is homologous to the bacterial mutS gene, which is involved in mismatch repair. Mutations in the MSH2 gene have been identified in a variety of cancers, including, for example, ovarian tumors, colorectal cancer, endometrial cancer, uterine cancer.
EXAMPLE 18
Human mismatch repair - MSH6
[0222] The human MSH6 gene is homologous to the bacterial mutS gene, which is involved in mismatch repair. Mutations in the MSH6 gene have been identified in a variety of cancers, including particularly hereditary nonpolyposis colorectal cancer. 0
EXAMPLE 19
Hyperlipidemia - APOE
[0223] Hyperlipidemia is the abnormal elevation of plasma cholesterol and/or triglyceride levels and it is one of the most common diseases, The human apolipoprotein E protein is 5 involved in the transport of endogenous lipids and appears to be crucial for both the direct removal of cholesterol-rich LDL from plasma and conversion of IDL particles to LDL particles. Individuals who either lack apolipoprotein E or who are homozygous for particular alleles of apoE may have have a condition known as dysbetalipoproteinemia, which is characterized by elevated plasma cholesterol and triglyceride levels and an increased risk for atherosclerosis. o [0224] In a comprehensive review of apoE variants, de Knijff et al., Hum. Mutat
4:178-194 (1994) found that 30 variants had been characterized, including the most common variant, apoE3. To that time, 14 apoE variants had been found to be associated with familial dysbetalipoproteinemia.
5 EXAMPLE 20
Familial hypercholesterolemia - LDLR
[0225] Familial hypercholesterolemia is characterized by elevation of serum cholesterol bound to low density lipoprotein (LDL) and is, hence, one of the conditions producing a hyperlipoproteinemia phenotype. Familial hypercholesterolemia is an autosomal dominant disorder o characterized by elevation of serum cholesterol bound to low density lipoprotein (LDL). Mutations in the
LDL receptor (LDLR) gene cause this disorder.
EXAMPLE 21
UDP-glucuronosyltransferase - UGT1
[0226] Mutations in the human UGT1 gene result in a range of disease syndromes, 5 ranging from relatively common diseases such as Gilbert's syndrome, which effects up to 7% of the population, to rare disorders such as Crigler-Najjar syndrome. Symptoms of these diseases are the result of diminished bilirubin conjugation and typically present with jaundice or, when mild, as an incidental finding during routing laboratory analysis. Severe cases of Crigler-Najjar syndrome are caused by an absence of UGT1 activity and the majority of these patients die in the neonatal period. The only known o treatment is liver transplant.
EXAMPLE 22
Alzheimer's Disease - Amyloid precursor protein (APP)
[0227] Over the past few decades Alzheimer's disease (AD), once considered a rare 5 disorder, has become recognized as a major public health problem. Although there is no agreement on the exact prevalence of Alzheimer's disease, in part due to difficulties of diagnosis, studies consistently point to an exponential rise in prevalence of this disease with age. After age 65, the percentage of affected people approximately doubles with every decade of life, regardless of definition. Among people age 85 or older, studies suggest that 25 to 35 percent have dementia, including Alzheimer's disease; one o study reports that 47.2 percent of people over age 85 have Alzheimer's disease, exclusive of other dementias.
[0228] Alzheimer's disease progressively destroys memory, reason, judgment, language, and, eventually, the ability to carry out even the simplest tasks. Anatomic changes associated with Alzheimer's disease begin in the entorhinal cortex, proceed to the hippocampus, and then gradually 5 spread to other regions, particularly the cerebral cortex. Chief among such anatomic changes are the presence of characteristic extracellular plaques and internal neurofibrillary tangles.
[0229] At least four genes have been identified to date that contribute to development of Alzheimer's disease: AD1 is caused by mutations in the amyloid precursor gene (APP); AD2 is associated with a particular allele of APOE (see Example 20); AD3 is caused by mutation in a gene o encoding a 7-transmembrane domain protein, presenilin-1 (PSEN1), and AD4 is caused by mutation in a gene that encodes a similar 7-transmembrane domain protein, presenilin-2 (PSEN2).
Example 23 Engineering herbicide resistant plants
[230] Chemical weed control is an important tool of modern agriculture and many herbicides have been developed for this purpose. Their use has resulted in substantial increases in the yields of many crops, including, for example, maize, soybeans, and cotton. Thus while the use of fertilizers and new high-yielding crop varieties have contributed greatly to the "green revolution," chemical weed control has also been at the forefront of technological achievement.
[231] Herbicides having broad-spectrum activity are particularly useful because they obviate the need for multiple herbicides targeting different classes of weeds. The problem with such herbicides is that they typically also affect crops which are exposed to the herbicide. One way to overcome this is to generate plants which are resistant to one or more broad-spectrum herbicides. Such herbicide-tolerant plants may reduce the need for tillage to control weeds, thereby effectively reducing soil erosion and can reduce the quantity and number of different herbicides applied in the field.
[232] Common herbicides used, for example, include those that inhibit the enzyme 5-enolpyruvyl-3-phosphoshikimic acid synthase (EPSPS), for example N-phosphonomethyl-glycine (e.g. glyphosate), those that inhibit acetolactate synthase (ALS) activity, for example the sulfonylureas and related herbicides, and those that inhibit dihydropteroate synthase, for example methyl[(4-amino- phenyl)sulfonyl]carbamate (e.g. Asulam). Herbicide-tolerant plants can be produced by several methods, including, for example, introducing into the genome of the plant the ability to degrade the herbicide, the capacity to produce a higher level of the targeted enzyme, and/or expressing an herbicide-tolerant allele of the enzyme.
[233] The attached tables disclose exemplary oligonucleotides base sequences which can be used to generate site-specific mutations in plant genes that confer herbicide resistance.
Table 6 Genome-Altering Oligos Conferring Glyphosate Resistance
Table 7 Genome-Altering Oligos Conferring Imidazolinone and Sulfonylurea Herbicide Resistance
Table 8 Genome-Altering Oligos Conferring Porphyric Herbicide Resistance
Table 9 Genome-Altering Oligos Conferring Triazine Resistance
Example 24 Engineering male- or female-sterile plants
[234] Flower development in distantly related dicot plant species is increasingly better understood and appears to be regulated by a family of genes which encode regulatory proteins. These genes include, for example, AGAMOUS (AG), APETALA1 (AP1), and APETALA3 (AP3) and PISTILLATA (PI) in Arabidopsis thaliana, and DEFICIENS A (DEFA), GLOBOSA (GLO), SQUAMOSA (SQUA), and PLENA (PLE) in Antirrhinum majus. Genetic studies have shown that the DEFA, GLO and AP3 genes are essential for petal and stamen development. Sequence analysis of these genes revealed that the gene products contain a conserved MADS box region, a DNA-binding domain. Using these clones as probes, MADS box genes have also been isolated from other species including tomato, tobacco, petunia, Brassica napus, and maize.
[235] Altering the expression of these genes results in altered floral morphology. For example, mutations in AP3 and PI result in male-sterile flowers because petals develop in place of stamens.
[236] The attached tables disclose exemplary oligonucleotide base sequences which can be used to generate site-specific mutations that confer altered floral structures in plants.
Table 10 Oligonucleotides to produce male-sterile plants
Table 11 Oligonucleotides to produce male-sterile plants
Table 12 Oligonucleotides to produce male-sterile plants
Example 25 Engineering plants for abiotic stress tolerance
[237] Environmental stresses, such as drought, increased soil salinity, soil contamination with heavy metals, and extreme temperature, are major factors limiting plant growth and productivity. The worldwide loss in yield of three major cereal crops, rice, maize, and wheat due to water stress (drought) has been estimated to be over ten billion dollars annually and many currently marginal soils could be brought into cultivation if suitable plant varieties were available.
[238] Physiological and biochemical responses to high levels of ionic or nonionic solutes and decreased water potential have been studied in a variety of plants. It is known, for example, that increasing levels of alcohol dehydrogenase can confer enhances flooding resistance in plants. There are also several possible mechanisms to enhance plant salt tolerance. For example, one mechanism underlying the adaptation or tolerance of plants to osmotic stresses is the accumulation of compatible, low molecular weight osmolytes such as sugar alcohols, special amino acids, and glycinebetaine. Such accumulation can be engineered, for example, by removing feedback inhibition on 1-pyrroline-t-carboxylate synthetase, which results in accumulation of proline. Additionally, recent experiments suggest that altering the expression or activity of specific sodium or potassium transporters can confer enhanced salt tolerance.
[239] Plant tolerance of contamination by heavy metals such as lead and aluminum in soils has also been investigated and one mechanism underlying tolerance is the production of dicarboxylic acids such as oxalate and citrate. In addition, individual genes involved in heavy metal sensitivity have been identified.
[240] The attached tables disclose exemplary oligonucleotide base sequences which can be used to generate site-specific mutations that confer stress tolerance in plants.
Table 13 Genome-Altering Oligos Conferring Stress Tolerance
Example 26 Production of albino mutants for the analysis of photosynthetic processes
[241] Plant productivity is limited by resources available and the ability of plants to harness these resources. The conversion of light to chemical energy, which is then used to synthesize carbohydrates, fatty acids, sugars, amino acids and other compounds, requires a complex system which combines the light harvesting apparatus of pigments and proteins. The value of light energy to the plant can only be realized when it is efficiently converted into chemical energy by photosynthesis and fed into various biochemical processes. Significant effort has therefore been directed at studying photosynthetic processes in plants in order to improve productivity and/or the efficiency of photosynthesis. The analysis of the photosynthetic process is substantially aided by the ability to produce albino plants.
[242] The attached table discloses exemplary oligonucleotide base sequences which can be used to generate site-specific mutations in genes involved in starch metabolism.
Table 14 Oligonucleotides to produce albino plants
Example 27 Altering amino acid content of plants
[243] Another aim of biotechnology is to generate plants, especially crop plants, with added value traits. An example of such a trait is improved nutritional quality in food crops. For example, lysine, tryptophan and threonine, which are essential amino acids in the diet of humans and many animals, are limiting nutrients in most cereal crops. Consequently, grain-based diets, such as those based on corn, barley, wheat, rice, maize, millet, sorghum, and the like, must be supplemented with more expensive synthetic amino acids or amino-acid-containing oilseed protein meals. Increasing the lysine content of these grains or of any of the feed component crops would result in significant added value.
[244] Naturally occurring mutants of plants that have different levels of particular essential amino acids have been identified. However, these mutants are generally not the result of increased free amino acid, but are instead the result of shifts in the overall protein profile of the grain. For example, in maize, reduced levels of lysine-deficient endosperm proteins (prolamines) are complemented by elevated levels of more lysine-rich proteins (albumins, globulins and glutelins). While nutritionally superior, these mutants are associated with reduced yields and poor grain quality, limiting their agronomic usefulness.
[245] An alternative approach is to generate plants with mutations that render key amino acid biosynthetic enzymes insensitive to feedback inhibition. Many such mutations are known and mutation results in increased free amino acid. The increased production can optionally be coupled to increased expression of an abundant storage protein comprising the chosen amino acid. Alternatively, a normally abundant protein can be engineered to contain more of the target amino acid.
[246] The attached table discloses exemplary oligonucleotide base sequences which can be used to generate site-specific mutations that remove feedback inhibition in plant amino acid biosynthetic enzymes.
Table 15 Genome-Altering Oligos Conferring Amino Acid Overproduction
Example 28 Production of modified starch in plants
[247] A principal aim of biotechnology is the improvement of crop plants for food value, agriculture, and to produce a range of plant-derived raw materials. Along with oils, fats and proteins, polysaccharides constitute the main raw materials derived from plants, and apart from cellulose, the storage polymer starch is the most important polysaccharide raw material. Starch is derived from a range of plants, but maize is the most important cultivated plant for the production of starch.
[248] The polysaccharide starch is a polymer made up of glucose molecules. However, starch is not a homogeneous raw material and is, in fact, a highly complex mixture of various types of molecules which differ from each other, for example, in their degree of polymerization and in the degree of branching of the glucose chains. For example, amylose-starch is a basically non-branched polymer made up of α-1 ,4-glycosidically branched glucose molecules, and amylopectin-starch is a complex mixture of variously branched glucose chains. The branching results from additional α-1 ,6-glycosidic linkages. In plants from which starch is typically isolated, for example maize or potato, the starch is approximately 25% amylose-starch and 75% amylopectin-starch.
[249] In maize, various mutants in starch metabolism are known, for example waxy, sugary, shrunken and opaque-2. In addition to producing a modified starch, these mutations greatly improve grain quality in maize, and thus expand the use of maize not only as the food but also for the important industrial materials in food chemistry. It would therefore be advantageous to be able readily to obtain mutants in these genes in particular maize genotypes as well as other plants. Such plants can be obtained, for example, using traditional breeding methods and through specific genetic modification by means of recombinant DNA techniques.
[250] The attached tables disclose exemplary oligonucleotide base sequences which can be used to generate site-specific mutations in genes involved in starch metabolism.
Table 16 Genome-Altering Oligos Conferring Increased Starch
Table 17 Oligonucleotides to produce plants with waxy starch
Example 29 Altering fatty acid content of plants
[251] Improved means to manipulate fatty acid compositions, from biosynthetic or natural plant sources, are needed. For example, oils containing reduced saturated fatty acids are desired for dietary reasons and oils containing increased saturated fatty acids are also needed as alternatives to current sources of highly saturated oil products, such as tropical oils or chemically hydrogenated oils. It would therefore be advantageous to influence directly the production and composition of fatty acids in crop plants.
[252] Higher plants synthesize fatty acids, primarily palmitic, stearic and oleic acids, in the plastids (i.e., chloroplasts, proplastids, or other related organelles) as part of the Fatty Acid Synthase (FAS) complex, Fatty acid synthesis is the result of the three enzymatic activities: acyl-ACP elongase, acyl-ACP desaturase and acyl-ACP thioesterases specific for each of palmitoyl-, stearoyl- and oleoyl-ACP.
[253] A variety of enzymes have been identified that influence the relative levels of saturated vs. unsaturated fatty acids in plants. For example, the enzymes stearoyl-acyl carrier protein (stearoyl-ACP) desaturase, oleoyl desaturase and linoleate desaturase produce unsaturated fatty acids from saturated precursors. Similarly, relative enzymatic activities of the various acyl-ACP thioesterases influences the relative acyl-chain composition of the resultant fatty acids. Consequently a reduction or an increase of the activity of these enzymes can alter the properties of oils produced in a plant. In fact, specific targeting of particular enzymatic activities can results in altered levels of particular fatty acids.
[254] The attached tables disclose exemplary oligonucleotides base sequences which can be used to generate site-specific mutations in plant genes encoding proteins involved in fatty acid biosynthesis.
Table 18 Oligonucleotides to produce plants with reduced palmitate
Phenotype, Gene, SEQ ID
Plant & Targeted Altering Oligos NO:
Alteration
Reduced palmitate ATTCTTCTTCTATAAACCAAAACCTCAGGAACCATAAAAAAAAAAGG "22 Acyl-ACP-thioesterase GCATCAAAAATGTAGAAGCTTTCGTGTAATGTGACTAACAACTTAC Brassica napus ACACCTTCTCCTTCTTCTCCGATTCCTC Leu2Term GAGGAATCGGAGAAGAAGGAGAAGGTGTGTAAGTTGTTAGTCACA 2210 TTG-TAG TTACACGAAAGCTTCIACATTTTTGATGCCCTTTTTTTTTTATGGTTC CTGAGGTTTTGGTTTATAGAAGAAGAAT
AAAAATGTAGAAGCTTT 2211
AAAGCTTCTACATTTTT 2212
Reduced palmitate TCTTCTTCTATAAACCAAAACCTCAGGAACCATAAAAAAAAAAGGG 2213 Acyl-ACP-thioesterase CATCAAAAATGTTGIAGCTTTCGTGTAATGTGACTAACAACTTACAC Brassica napus ACCTTCTCCTTCTTCTCCGATTCCTCCC Lys3Term GGGAGGAATCGGAGAAGAAGGAGAAGGTGTGTAAGTTGTTAGTCA 2214 AAG-TAG CATTACACGAAAGCTACAACATTTTTGATGCCCTTTTTTTTTTATGG
TTCCTGAGGTTTTGGTTTATAGAAGAAGA
AAATGTTGTAGCTTTCG 2215
CGAAAGCTACAACATTT 2216
Reduced palmitate CTATAAACCAAAACCTCAGGAACCATAAAAAAAAMGGGCATCAAA 2217 Acyl-ACP-thioesterase AATGTTGAAGCTTTAGTGTAATGTGACTAACAACTTACACACCTTCT Brassica napus CCTTCTTCTCCGATTCCTCCCTTTTCAT SerδTerm ATGAAAAGGGAGGAATCGGAGAAGAAGGAGAAGGTGTGTAAGTT 2218 TCG-TAG GTTAGTCACATTACACIAAAGCTTCAACATTTTTGATGCCCTTTTTT TTTTATGGTTCCTGAGGTTTTGGTTTATAG
GAAGCTTTAGTGTAATG 2219
CATTACACTAAAGCTTC 2220
Reduced palmitate AAACCAAAACCTCAGGAACCATAAAAAAAAAAGGGCATCAAAAATG 2221 Acyl-ACP-thioesterase TTGAAGCTTTCGTGAAATGTGACTAACAACTTACACACCTTCTCCTT Brassica napus CTTCTCCGATTCCTCCCTTTTCATCCCG Cys6Term CGGGATGAAAAGGGAGGAATCGGAGAAGAAGGAGAAGGTGTGTA 2222 TGT-TGA AGTTGTTAGTCACATTICACGAAAGCTTCAACATTTTTGATGCCCTT TTTTTTTTATGGTTCCTGAGGTTTTGGTTT
CTTTCGTGAAATGTGAC 2223
GTCACATTTCACGAAAG 2224
Table 19 Oligonucleotides to produce plants with increased stearate
Table 20 Oligonucleotides to produce plants with reduced linolenic acid
[255] Although a number of embodiments and features are described herein, it will be understood by those skilled in the art that modification and variations of the described embodiments and features may be made without departing from either the spirit of the invention or the scope of the appended claims. All publications and patents cited herein are incorporated by reference in their entireties.