USRE46380E1 - Type inference for datalog with complex type hierarchies - Google Patents
Type inference for datalog with complex type hierarchies Download PDFInfo
- Publication number
- USRE46380E1 USRE46380E1 US14/952,788 US201514952788A USRE46380E US RE46380 E1 USRE46380 E1 US RE46380E1 US 201514952788 A US201514952788 A US 201514952788A US RE46380 E USRE46380 E US RE46380E
- Authority
- US
- United States
- Prior art keywords
- type
- program
- query
- database
- computer
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased, expires
Links
Images













Classifications
-
- G06F17/30421—
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/242—Query formulation
- G06F16/2433—Query languages
- G06F16/2448—Query languages for particular applications; for extensibility, e.g. user defined types
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/40—Transformation of program code
- G06F8/41—Compilation
- G06F8/43—Checking; Contextual analysis
- G06F8/436—Semantic checking
- G06F8/437—Type checking
Definitions
- the present invention relates generally to information retrieval, in particular the way electronically stored data is accessed via queries that are formulated in a programming language.
- the invention concerns both the detection of errors in such queries, and their efficient execution.
- query language Like any other programming task, writing queries is error-prone, and it is helpful if the programming language in which queries are expressed gives assistance in identifying errors while queries are being written, and before they are executed on a database.
- Programming languages often provide “types” for that purpose, indicating for each variable what kind of value it may hold.
- a programming language for expressing queries is usually called a “query language”. The most popular example of a query language is SQL.
- FIG. 1 is an example program written in Datalog with a sequence of rules.
- FIG. 2 is an example of a type hierarchy suitable for the program in FIG. 1 .
- FIG. 3 is a definition listing illustrating the approximation of every use of an extensional relation symbol by the conjunction of its column types.
- FIG. 4 is a diagram illustrating the need for consensus formation when checking type inclusion.
- FIG. 5 is a diagram further illustrating the need for consensus formation when checking type inclusion.
- FIG. 6 is a plot illustrating the type inference time plotted on the y-axis versus the depth (i.e., number of layers) of the program on the x-axis.
- FIG. 7 is a block diagram illustrating how types of database queries are inferred.
- FIG. 10 is a block diagram of a computer system suitable for implementing the various embodiments of the present invention discussed herein according to one embodiment of the present invention.
- FIG. 8 is a flow chart illustrating inclusion testing for types represented by sets of type tuple constraints (TTCs).
- FIG. 9 is a flow chart illustrating saturation of sets of type tuple constraints (TTCs) for inclusion testing.
- FIG. 11 is algorithm 1 of the present invention.
- FIG. 12 is algorithm 2 of the present invention.
- FIG. 13 is algorithm 3 of the present invention.
- FIG. 14 is algorithm 4 of the present invention.
- the present invention infers precise types for queries where the entities in the database satisfy complex conditions regarding subtyping, disjointness and so on.
- bonus(x, y) computes the bonus y that an employee x will get.
- Non-students x get a bonus y that is computed by multiplying x's salary z by a factor f, which is returned by factor(x, f).
- the factor depends on the seniority of the employee. For students, the bonus is always 50, independent of their salary.
- the program defines a query, which is to find the bonus of all senior managers.
- the entity types are expected to satisfy many interesting facts that are useful in reasoning about types, for instance those shown in FIG. 2 .
- the type hierarchy goes well beyond the usual notion of subtyping in traditional programming languages, in that one can state other relationships besides mere implication or equivalence.
- An example of such an interesting fact is the last statement, which says that managers cannot be part-time employees.
- the programmer will have to state these facts as part of the database definition, so that they can be checked when information is entered, and to enable their use in type inference and optimisation.
- extensional relation salary(x, z) ⁇ employee(x) float(z) states that the first column of the extensional relation salary will contain values of type employee, and the second one will contain floating point numbers.
- a database schema provides this column-wise typing information for every extensional relation.
- Type inference will catch errors: when a term is inferred to have the type ⁇ , we know that it denotes the empty relation, independent of the contents of the database. Also, the programmer may wish to declare types for intensional relations in her program, and then it needs to be checked that the inferred type implies the declared type.
- query(x, y) ⁇ manager(x) senior(x) salary(x, z) y 0.15xz
- Section 2 we propose a definition of the class of type programs: any program where all extensionals called are monadic.
- Type programs can, on the other hand, contain (possibly recursive) definitions of intensional predicates of arbitrary arity.
- ⁇ p ⁇ a type inference procedure
- ⁇ p ⁇ the inferred type ⁇ p ⁇ is also optimal: ⁇ p ⁇ is the smallest type program that is an upper bound of p.
- ⁇ p ⁇ is in terms of the semantics of p, so that the syntactic presentation of a query does not affect the inferred type. It follows that the application of logical equivalences by the programmer or by the query optimiser does not affect the result of type inference.
- This logic extends first order logic (including equality) with fixpoint definitions of the form [r(x 1 , . . . , x n ) ⁇ ] ⁇ .
- r is an n-ary relation symbol
- the x i are pairwise different element variables
- ⁇ and ⁇ are formulae.
- the formula defines r by the formula ⁇ , which may contain recursive occurrences of r, and the defined relation can then be used in ⁇ .
- the x i are considered bound in ⁇ and free in ⁇ , whereas the relation r is free in ⁇ and bound in ⁇ .
- free relation symbols are not allowed to occur under a negation, which avoids the problematic case of recursion through negation.
- the formula [s(x, y) ⁇ x ⁇ y ⁇ z.e(x, z) s(z, y)]s(x, y) (1) defines the relation s to be the reflexive transitive closure of e.
- free occurrences of element variables and relation variables have been marked up in bold face. The formula is trivially stratified since no negations occur anywhere.
- relation symbol s is an intensional predicate since it is given a defining equation.
- relation e is an extensional, which we assume to be defined as part of a database on which the program is run. We will denote the set of intensional relation symbols as and that of extensional relation symbols as , and require them to be disjoint.
- the types of the intensional predicates are derived with respect to the types of the extensional predicates. These are provided by a schema which assigns, to every n-ary extensional predicate, an n-tuple of types. As is customary, types are themselves monadic predicates from a set ⁇ of type symbols. For consistency, we require that the schema assigns a type symbol to itself as its type.
- a first order formula likewise denoted as , which expresses this constraint: For every n-ary relation symbol e ⁇ ⁇ and every 1 ⁇ i ⁇ n where u ⁇ is the type assigned to the i-th column of e, the formula contains a conjunct ⁇ x i .( ⁇ x 1 , . . . , x i ⁇ 1 , x i+1 , . . . , x n .e(x 1 , . . . , x n )) u(x i ) (2)
- the hierarchy may stipulate subtyping relations; in our example, the hierarchy could be ⁇ x.a(x) ⁇ b(x), expressing that a is a subtype of b. Perhaps more interestingly, it can also express disjointness of types, e.g. by stating that ⁇ x. a(x) b(x); we could then deduce that in the definition of the reflexive transitive closure e can, in fact, be iterated at most once. Many other kinds of constraints are just as easily expressed, and provide opportunities for advanced optimisations.
- fixpoint definitions can always be eliminated from such type programs, yielding formulae of monadic first order logic.
- Theorem 2 (Optimality). For a negation-free program ⁇ and a type program , if we have , , ⁇ then also , , ⁇
- cart( ) ⁇ ⁇ ⁇ ⁇ (3) for any negation-free formula ⁇ , interpretation and assignment ⁇ whenever . Also, cart( ) if , and cart( ) iff .
- ⁇ ⁇ ⁇ ⁇ ⁇ ⁇ ⁇ ⁇ if ⁇ ⁇ ⁇ ⁇ is ⁇ ⁇ a ⁇ ⁇ type ⁇ ⁇ program ⁇ otherwise
- type propositions which are Boolean combinations of type symbols, all of them applied to the same variable.
- a type proposition is a quantifier-free type program without fixpoint definitions or free relation variables, having precisely one free element variable.
- the subformula h(x) of is a type proposition.
- a type proposition ⁇ behaves essentially the same as the propositional formula
- a(x) b(x) is a type proposition with
- a b.
- fixpoint definitions can be eliminated. To see this, recall that fixpoint definitions can be expanded into infinite disjunctions [10]. It thus suffices to show that the type programs without free relation variables and without fixpoint definitions (which we shall henceforth call flat) form a complete lattice, so that even a prima facie infinite disjunction can in fact be represented by a single formula.
- Lemma 4 The flat type programs form a complete lattice under the order .
- ⁇ ⁇ y 1 , ... ⁇ , y n ⁇ ⁇ ⁇ i ⁇ [ ⁇ 1 ⁇ j ⁇ m ⁇ ⁇ i , j ⁇ ⁇ 1 ⁇ k ⁇ n ⁇ ⁇ i , k ⁇ ( y k ) ⁇ ⁇ ] for a set Y ⁇ y 1 , . . . , y n ⁇ of element variables, where all the ⁇ i,j and X i,k are type propositions, and ⁇ is a conjunction of equations between element variables from X ⁇ Y.
- ⁇ i [ ⁇ 1 ⁇ j ⁇ m ⁇ ⁇ i , j ′ ⁇ ( x j ) ⁇ ⁇ 1 ⁇ k ⁇ n ⁇ ( ⁇ y k ⁇ ⁇ i , k ′ ⁇ ( y k ) ) ⁇ ⁇ ′ ]
- ⁇ ′ now contains only variables from X. We will say that a formula of this shape is in solved form.
- One way of making a set of type propositions lean is to discard its non-minimal elements, which we write as min(C).
- TTC n-ary type tuple constraint
- p is a relation
- p we write p to mean the smallest equivalence relation containing it.
- the equivalence class of an element x under p is written [x] p , where we omit the subscript p if it is clear from context.
- ⁇ i : t i
- a TTC is called degenerate if ⁇ is among its inhabitation constraints; it represents an unsatisfiable formula.
- the equivalence relation is called trivial if it is in fact the identity relation id, and the set of inhabitation constraints is called trivial if it only constrains the component types to be inhabited.
- a lean set of non-degenerate TTCs is called a typing.
- the order ⁇ : is extended to typings by defining T ⁇ :T′ to hold if, for every ⁇ T there is a ⁇ ′ ⁇ T′ with ⁇ : ⁇ ′.
- TTC ⁇ (t 1 , . . . , t n
- ⁇ i (T): max ⁇ ⁇ i ( ⁇ )
- ⁇ be a type program without fixpoint definitions containing the intensional relation variables r 1 , . . . , r m and the element variables x 1 , . . . , x n .
- the individual TTCs then become rectangles in the two-dimensional plain, and it is easy to see that the single TTC in T (depicted by the single rectangle in heavy outline filled with vertical lines) is contained in the union of the TTCs in T′ (the two rectangles filled with slanted lines), but not in either one of them in isolation.
- T ⁇ (a b, a b
- T′ ⁇ (a, a), (b, b) ⁇ .
- the former appears in FIG. 5 as a heavy slanted line, which is not contained in either of the two squares representing the TTCs in T′, but only in their union.
- the problem is that ⁇ : tests containment of TTCs in isolation, whereas the semantic inclusion check considers containments between sets of TTCs.
- mapping [•] is the lower adjoint of a Galois connection, i.e. there is a mapping (
- ) comes directly from the definition of the Galois connection: For any type program , (
- Quine [22] introduces an algorithm whose first part determines the set of prime implicants of a Boolean formula, which are conjunctive formulae such that every conjunctive formula that implies the original formula implies one of the prime implicants.
- u i ⁇ ⁇ j ⁇ J ⁇ t j ⁇ ⁇ j ⁇ J ⁇ t j ′ if ⁇ ⁇ i ⁇ J t i ⁇ t i ′ otherwise
- n-ary typing T is said to be saturated if the consensus of any two TTCs contained in it is covered by the typing; i.e. for any ⁇ , ⁇ ′ ⁇ T and any index set J ⁇ ⁇ 1, . . . , n ⁇ we have ⁇ J ⁇ ′ ⁇ :T and ⁇ ⁇ ⁇ ′ ⁇ :T.
- Every typing T can be converted into a semantically equivalent, saturated typing sat(T) by exhaustive consensus formation.
- a TTC ⁇ is an implicant for a typing T′ if we have [ ⁇ ] [T′]; it is a prime implicant if it is a ⁇ :-maximal implicant.
- TTC ⁇ is a prime implicant for a typing T′ if
- the second condition is equivalent to saying that for any ⁇ with ⁇ : ⁇ and ⁇ : ⁇ we have [ ⁇ ] [T].
- ⁇ i as a disjunction of conjunctions, such that one of its disjuncts, of the form l i, 1 ′ . . . l i, m i′ ′, is satisfied under and ⁇ , meaning that x [i] ⁇ [[l i,j ′]] for all j, so all the l i,j ′ are in fact in L i , so ⁇ i ⁇ : ⁇ i .
- this partition must be finer than the partition of ⁇ .
- the type checker computes typings for programs and immediately proceeds to saturate them to prepare for containment checking. It uses a number of simple heuristics to determine whether a consensus operation needs to be performed. This drastically reduces the over-head of saturation in practice and makes our type inference algorithm practically usable.
- TTCs can be compactly represented by encoding their component type propositions as binary decision diagrams. The same can be done for the hierarchy, so checking containment of type propositions can be done with simple BDD operations.
- C) and ⁇ ′ (t 1 ′, . . . , t n ′
- Algorithm 2 shows in two parts as Algorithm 3 and Algorithm 4, which straightforwardly exploit the above properties to avoid performing useless consensus operations whose result would be discarded by the max ⁇ operator anyway.
- Algorithm 4 we make use of an operation PART( ⁇ , i) which returns the equivalence partition index i belongs to in TTC ⁇ .
- the Datalog programs to be typed arise as an intermediate representation of programs written in a high-level object-oriented query language named .QL [14, 15], which are optimised and then compiled to one of several low-level representations for execution.
- a type inference for the query being compiled is performed at three different points during the optimisation process, giving a total of 267 time measurements. All times were measured on a machine running a Java 1.6 virtual machine under Linux 2.6.28-13 on an Intel Core2 Duo at 2.1 GHz with four gigabytes of RAM, averaging over ten runs, and for each value discarding the lowest and highest reading.
- FIG. 6 shows the type inference time plotted on the y-axis versus the depth (i.e., number of layers) of the program on the x-axis.
- the two cases in which type inference takes longer than four seconds are both of medium size and not among the deepest either.
- the present invention handles negated types accurately. Also, the present invention handles inhabitation constraints (i.e., existentials in type programs) precisely.
- FIG. 7 is a block diagram illustrating how types of database queries are inferred.
- Type inferencer 701 receives database schema 703 and query 704 and infers types from definitions in the program by replacing each use of a database relation in the program by the types in the database schema, resulting in type program 706 as described in the section above entitled “2.
- Type Programs The type inferencer furthermore receives type hierarchy 705 to check types in the type program for inclusion as described in the section above entitled “4. Containment Checking,” generating information about type inclusion 708 .
- the type inferencer also uses the type hierarchy to generate emptiness information 710 indicating which types in the type program are empty as described in the section above entitled “2.
- the inclusion and emptiness information is used by query optimizer 711 to generate an optimized version of the query that can be run on query engine 712 to query relational data source 713 , as described in the section above entitled “1. Introduction,” subsection “Overview.”
- FIG. 8 is a flow chart illustrating inclusion testing for types represented by sets of type tuple constraints (TTCs).
- TTCs type tuple constraints
- TTC Containment Checking,” subsection “Definition 7.” If no such larger TTC is found 809 , the type represented by S 1 is not included in S 2 . Otherwise the TTC is removed from S 1 810 and the next TTC is examined. If a covering TTC is found for every TTC in S 1 806 , then the type represented by S 1 is included in the type represented by S 2 .
- FIG. 9 is a flow chart illustrating saturation of sets of type tuple constraints (TTCs) for inclusion testing.
- TTCs type tuple constraints
- the type inference procedure is itself an extremely simple syntactic mapping.
- the hard work goes into an efficient method of checking containment between type programs.
- the present invention can be realized in hardware or a combination of hardware and software.
- the processing system according to a preferred embodiment of the present invention can be realized in a centralized fashion in one computer system, or in a distributed fashion where different elements are spread across several interconnected computer systems and image acquisition sub-systems. Any kind of computer system—or other apparatus adapted for carrying out the methods described herein—is suited.
- a typical combination of hardware and software is a general-purpose computer system with a computer program that, when loaded and executed, controls the computer system such that it carries out the methods described herein.
- An embodiment of the processing portion of the present invention can also be embedded in a computer program product, which comprises all the features enabling the implementation of the methods described herein, and which—when loaded in a computer system—is able to carry out these methods.
- Computer program means or computer programs in the present context mean any expression, in any language, code or notation, of a set of instructions intended to cause a system having an information processing capability to perform a particular function either directly or after either or both of the following a) conversion to another language, code or, notation; and b) reproduction in a different material form.
- FIG. 10 is a block diagram of a computer system useful for implementing the software steps of the present invention.
- Computer system 1000 includes a display interface 1008 that forwards graphics, text, and other data from the communication infrastructure 1002 (or from a frame buffer not shown) for display on the display unit 1010 .
- Computer system 1000 also includes a main memory 1006 , preferably random access memory (RAM), and optionally includes a secondary memory 1012 .
- the secondary memory 1012 includes, for example, a hard disk drive 1014 and/or a removable storage drive 1016 , representing a floppy disk drive, a magnetic tape drive, an optical disk drive, etc.
- the removable storage drive 1016 reads from and/or writes to a removable storage unit 1018 in a manner well known to those having ordinary skill in the art.
- Removable storage unit 1018 represents a CD, DVD, magnetic tape, optical disk, etc. which is read by and written to by removable storage drive 1016 .
- the removable storage unit 1018 includes a computer usable storage medium having stored therein computer software and/or data.
- the terms “computer program medium,” “computer usable medium,” and “computer readable medium” are used to generally refer to media such as main memory 1006 and secondary memory 1012 , removable storage drive 1016 , a hard disk installed in hard disk drive 1014 , and signals.
- Computer system 1000 also optionally includes a communications interface 1024 .
- Communications interface 1024 allows software and data to be transferred between computer system 1000 and external devices. Examples of communications interface 1024 include a modem, a network interface (such as an Ethernet card), a communications port, a PCM-CIA slot and card, etc.
- Software and data transferred via communications interface 1024 are in the form of signals which may be, for example, electronic, electromagnetic, optical, or other signals capable of being received by communications interface 1024 . These signals are provided to communications interface 1024 via a communications path (i.e., channel) 1026 .
- This channel 1026 carries signals and is implemented using wire or cable, fiber optics, a phone line, a cellular phone link, an RF link, and/or other communications channels.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Mathematical Physics (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
salary(x, z)→employee(x)
states that the first column of the extensional relation salary will contain values of type employee, and the second one will contain floating point numbers. A database schema provides this column-wise typing information for every extensional relation.
bonus(x, y)→employee(x)
factor(x, y)→employee(x)
query(x, y)→senior(x)
query(x, y)←manager(x)
-
- The identification of a language of type programs for Datalog, suitable both for precise error checking and for type-based optimisations.
- The definition of a very simple type inference procedure that is proved sound and optimal.
- A containment check for type programs that relies on a novel generalisation of Quine's method of computing prime implicants.
- Experiments in an industrial database system that show that this containment algorithm is efficient and useful.
[s(x, y)≡x≐y
defines the relation s to be the reflexive transitive closure of e. By way of illustration (and only in this example), free occurrences of element variables and relation variables have been marked up in bold face. The formula is trivially stratified since no negations occur anywhere.
∀xi.(∃x1, . . . , xi−1, xi+1, . . . , xn.e(x1, . . . , xn))
(∀x.(∃y.e(x,y))
[s(x, y)≡x≐y
x≅y
then also
cart(
for any negation-free formula φ, interpretation
[spouse(x, y)≡married(x, y)
(female(x)
for a set Y={y1, . . . , yn} of element variables, where all the ψi,j and Xi,k are type propositions, and ζ is a conjunction of equations between element variables from X ∪ Y.
where ζ′ now contains only variables from X. We will say that a formula of this shape is in solved form.
∃z·a(x)
z≐y
∃z·z≐y
x≐y
-
- each component ti is a type proposition,
- p is an equivalence relation over {1, . . . , n},
- C is a set of type propositions called inhabitation constraints, such that
- for all 1≦i, j≦n with i˜p j (i.e., i and j belong to the same partition of p) we have ti=tj,
- C is lean,
- for all 1≦k≦n we have C<:tk.
∥τ∥:=(∥t1∥
where ∥ti∥q=
-
- for every 1≦i≦n we have ti<:ti′,
- p′ is finer than p,
- C<:C′.
[T]:=
T
and joins are given by
T
∃i(τ):=(t1, . . . , ti−1, ti+1, . . . , tn|p′|min(C∪{ti}))
where p′ is the restriction of p to {1, . . . , i−1, i+1, . . . , n}.
∃i(T):=max⊥{∃i(τ)|τ∈T}
[T]
where C
M:={τ|[τ]
This set is not empty (it contains π by the preceding remark) and it is finite, so we can choose a <:-minimal element ψ∈M.
-
- Assume there is an index i for which ψi≡r′
 r″ for two r′, r″ neither of which equals ψi.
r″ for two r′, r″ neither of which equals ψi.
- Then we form ψ′:=ψi:=r′ and ψ″:=ψi:=r″. Observe that ψ and ψ are strictly smaller than ψ, so they cannot be in M. They both, however, entail π, so there must be φ′, φ″ ∈ T with ψ′<:φ′ and ψ<:φ″.
- Note that ψ=ψ′ ⊕[i] φ″, where [i] is the equivalence class of i in ψ. By
Lemma 11, this means that ψ<:φ′⊕[i]φ″, and since ψ:T we also have φ′⊕[i]φ″ :T, which shows that T is not saturated.
:T, which shows that T is not saturated. - Assume for some c∈C, where C is the set of inhabitation constraints of ψ, we have c≡r′r″ for two r′, r″ neither of which equal c.
- We form ψ from ψ by setting the inhabitation constraints to C\{c} ∪ {r′} and minimising, and similarly for ψ″. As above, those two are strictly smaller than ψ and we can find φ′ and φ″. The proof goes through as in the previous case, since it is easy to see that ψ=ψ′⊕∃ ψ″.
- Otherwise, for any index i and r′, r″ with ψi≡r′r″ we have either ψi≡r′ or ψi≡r″ (i.e. every ψi is join-irreducible) and likewise for all c∈C.
- Assume there is an index i for which ψi≡
for every type symbol b. The assignment is simply defined by σ(xi)=x[i].
-
- 1. If N⊥:={i|ti ti′=⊥} ⊂ J then τ⊕Jτ′ is degenerate.

- 2. If ∈Jtj=⊥ or∈Jtj′=⊥, then τJ′τ′<:{τ, τ′} for any J′⊃J.
- 3. If we have l∉J with j∈Jtj<:tl andj∈Jtj′<:tj′, then τ⊕J∪{l}τ′<:τ⊕Jτ′.
- 4. If j∈Jtj<:j∈Jtj′ or vice versa, then τ⊕Jτ′<:{τ, τ′}.
- 5. For j∈J, j′∉J with j˜
p∪p′ j′ we have τ⊕Jτ′<:τ⊕J∪{j′}τ′. - 6. If N⊥≠∅, then τ⊕∃τ′ is degenerate.
- 1. If N⊥:={i|ti
We prove the individual claims:
-
- 1. Indeed, assume k∈N⊥\J, then uk=tk tk′=⊥.
- 2. Assume, for example, j∈Jtj=⊥ and let J′⊃J be given, then∈J′tj=⊥, so ui=j∈J′t′j′<:ti′ if i∈J, and ui=titi′<:ti′ otherwise, so τ⊕J′τ′<:τ′. If the other disjunct is ⊥, we see that τ⊕J′τ′<:τ by a similar argument.
- 3. Note that j∈J∪{l}tj=j∈J tj andj∈J∪{l}tj′=∈Jtj′, so τ⊕J∪{l}τ′<:τ⊕Jτ′.
- 4. The argument is similar to 2.
- 5. Writing J′ for J ∪ {j′}, we see that the partitioning will be the same for J and J′. Now consider the ith component of τJτ′. If i˜i′ for some i′ ∈ J, then i˜j′, so we have
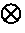
(τJτ′)i=(j∈Jtjj∈Jt′j){tkt′k|k˜i, k∉J}=
(j∈Jtjj∈Jt′j)(tj′t′j′){tkt′k|k˜i, k∉J′}=
(t′j′j∈J′tjtj′j∈J′ t′j){tkt′k|k˜i, k∉J′}<:(j∈J′ tjj∈J′ t′j){tkt′k|k˜i, k∈J′}=(τ⊕J′ τ′)i
- 1. Indeed, assume k∈N⊥\J, then uk=tk
-
- 6. Obvious, since the components of τ⊕∃τ′ are obtained by forming the meet.
- [1] Serge Abiteboul, Georg Lausen, Heinz Uphoff, and Emmanuel Waller. Methods and rules. In ACM SIGMOD International Conference on Management of Data, pages 32-41. ACM Press, 1993.
- [2] Wilhelm Ackermann. Solvable Cases of the Decision Problem. North-Holland Publishing Company, Amsterdam, 1954.
- [3] Leo Bachmair, Harald Ganzinger, and Uwe Waldmann. Set constraints are the monadic class. In Logic in Computer Science, pages 75-83, 1993.
- [4] Leo Bachmair, Harald Ganzinger, and Uwe Waldmann. Superposition with Simplification as a Decision Procedure for the Monadic Class with Equality. In KGC '93: Proceedings of the Third Kurt Gödel Colloquium on Computational Logic and Proof Theory, pages 83-96, London, UK, 1993. Springer-Verlag.
- [5] Sacha Berger, Emmanuel Coquery, Wlodzimierz Drabent, and Artur Wilk. Descriptive Typing Rules for Xcerpt and their soundness. In Francois Fages and Sylvain Soliman, editors, Principles and Practice of Semantic Web Reasoning, volume 3703 of LNCS, pages 85-100. Springer, 2005.
- [6] George S. Boolos and Richard C. Jeffrey. Computability and Logic. Cambridge University Press, 3rd edition, 1989.
- [7] Ashok K. Chandra and Philip M. Merlin. Optimal Implementation of Conjunctive Queries in Relational Data Bases. In STOC '77: Proceedings of the ninth annual ACM symposium on Theory of computing, pages 77-90, New York, N.Y., USA, 1977. ACM.
- [8] Surajit Chaudhuri. Finding nonrecursive envelopes for Datalog predicates. In Principles of Database Systems (PODS), pages 135-146, 1993.
- [9] Surajit Chaudhuri and Phokion G. Kolaitis. Can Datalog be approximated? In Principles of Database Systems (PODS), pages 86-96, 1994.
- [10] Kevin J. Compton. Stratified least fixpoint logic. Theoretical Computer Science, 131(1):95-120, 1994.
- [11] Stavros Cosmadakis, Haim Gaifman, Paris Kanellakis, and Moshe Vardi. Decidable Optimization Problems for Database Logic Programs. In Proceedings of the 20th annual ACM Symposium on Computing, pages 477-490, 1988.
- [12] Olivier Coudert, Christian Berthet, and Jean Christophe Madre. Verification of synchronous sequential machines based on symbolic execution. In Automatic Verification Methods for Finite State Systems, volume 407 of Lecture Notes in Computer Science, pages 365-373. Springer, 1989.
- [13] Oege de Moor, Damien Sereni, Pavel Avgustinov, and Mathieu Verbaere. Type Inference for Datalog and Its Application to Query Optimisation. In PODS '08: Proceedings of the twenty-seventh ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems, pages 291-300, New York, N.Y., USA, 2008. ACM.
- [14] Oege de Moor, Damien Sereni, Mathieu Verbaere, Elnar Hajiyev, Pavel Avgustinov, Torbjörn Ekman, Neil Ongkingco, and Julian Tibble. .QL: Object-oriented queries made easy. In Ralf Lämmel, João Saraiva, and Joost Visser, editors, Generative and Transformational Techniques in Software Engineering, LNCS. Springer, 2007.
- [15] Oege de Moor, Mathieu Verbaere, Elnar Hajiyev, Pavel Avgustinov, Torbjörn Ekman, Neil Ongkingco, Damien Sereni, and Julian Tibble. .QL for source code analysis. In Source Code Analysis and Manipulation (SCAM '07), pages 3-16. IEEE, 2007.
- [16] Thom W. Frühwirth, Ehud Y. Shapiro, Moshe Y. Vardi, and Eyal Yardeni. Logic programs as types for logic programs. In Logic in Computer Science (LICS), pages 300-309. IEEE Computer Society, 1991.
- [17] John P. Gallagher, Kim S. Henriksen, and Gourinath Banda. Techniques for Scaling Up Analyses Based on Pre-Interpretations. In M. Gabbrielli and G. Gupta, editors, International Conference on Logic Programming (ICLP '05), volume 3668 of LNCS, pages 280-296. Springer, 2005.
- [18] John P. Gallagher and Germán Puebla. Abstract Interpretation over Non-deterministic Finite Tree Automata for Set-Based Analysis of Logic Programs. In Practical Aspects of Declarative Languages (PADL), volume 2257 of LNCS, pages 243-261. Springer, 2002.
- [19] Nevin C. Heintze and Joxan Jaffar. A finite presentation theorem for approximating logic programs. In Symposium on Principles of Programming Languages (POPL), pages 197-209, 1990.
- [20] David Hilbert and Wilhelm Ackermann. Grundzüge der Theoretischen Logik. Julius Springer, Berlin, 1928.
- [21] Kim Marriott, Harald Søndergaard, and Neil D. Jones. Denotational Abstract Interpretation of Logic Programs. ACM Transactions on Programming Languages and Systems, 16(3):607-648, 1994.
- [22] Willard V. Quine. On Cores and Prime Implicants of Truth Functions. The American Mathematical Monthly, 66(9):755-760, Nov. 1959.
- [23] Oded Shmueli. Equivalence of Datalog Queries is Undecidable. Journal of Logic Programming, 15(3):231-241, 1993.
- [24] Fang Wei and Georg Lausen. Containment of Conjunctive Queries with Safe Negation. In ICDT '03: Proceedings of the 9th International Conference on Database Theory, pages 346-360, London, UK, 2002. Springer-Verlag.
- [25] John Whaley. JavaBDD. http://javabdd.sourceforge.net/, 2007.
- [26] Bwolen Yang, Randal E. Bryant, David R. O'Halloran, Armin Biere, Olivier Coudert, Geert Janssen, Rajeev K. Ranjan, and Fabio Somenzi. A Performance Study of BDD-Based Model Checking. In 2nd International Conference on Formal Methods in Computer-Aided Design, volume 1522 of Lecture Notes in Computer Science, pages 255-289. Springer, 1998.
- [27] David Zook, Emir Pasalic, and Beata Sarna-Starosta. Typed Datalog. In Practical Aspects of Declarative Languages, pages 168-182. Springer Berlin/Heidelberg, 2009.
Claims (22)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/952,788 USRE46380E1 (en) | 2010-07-15 | 2015-11-25 | Type inference for datalog with complex type hierarchies |
| US15/494,416 USRE48405E1 (en) | 2010-07-15 | 2017-04-21 | Type inference for datalog with complex type hierarchies |
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US36457110P | 2010-07-15 | 2010-07-15 | |
| US13/183,514 US8595213B2 (en) | 2010-07-15 | 2011-07-15 | Type inference for datalog with complex type hierarchies |
| US14/952,788 USRE46380E1 (en) | 2010-07-15 | 2015-11-25 | Type inference for datalog with complex type hierarchies |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/183,514 Reissue US8595213B2 (en) | 2010-07-15 | 2011-07-15 | Type inference for datalog with complex type hierarchies |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/183,514 Continuation US8595213B2 (en) | 2010-07-15 | 2011-07-15 | Type inference for datalog with complex type hierarchies |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| USRE46380E1 true USRE46380E1 (en) | 2017-04-25 |
Family
ID=45467751
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/183,514 Ceased US8595213B2 (en) | 2010-07-15 | 2011-07-15 | Type inference for datalog with complex type hierarchies |
| US14/952,788 Ceased USRE46380E1 (en) | 2010-07-15 | 2015-11-25 | Type inference for datalog with complex type hierarchies |
| US15/494,416 Expired - Fee Related USRE48405E1 (en) | 2010-07-15 | 2017-04-21 | Type inference for datalog with complex type hierarchies |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/183,514 Ceased US8595213B2 (en) | 2010-07-15 | 2011-07-15 | Type inference for datalog with complex type hierarchies |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US15/494,416 Expired - Fee Related USRE48405E1 (en) | 2010-07-15 | 2017-04-21 | Type inference for datalog with complex type hierarchies |
Country Status (1)
| Country | Link |
|---|---|
| US (3) | US8595213B2 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9996583B1 (en) * | 2017-05-25 | 2018-06-12 | Semmle Limited | Differential recursive evaluation of recursive aggregates |
| US10423397B2 (en) * | 2016-12-29 | 2019-09-24 | Grammatech, Inc. | Systems and/or methods for type inference from machine code |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8806451B2 (en) * | 2011-06-16 | 2014-08-12 | Microsoft Corporation | Monad based cloud computing |
| US20140249882A1 (en) * | 2012-10-19 | 2014-09-04 | The Curators Of The University Of Missouri | System and Method of Stochastic Resource-Constrained Project Scheduling |
| JP6551968B2 (en) * | 2015-03-06 | 2019-07-31 | 国立研究開発法人情報通信研究機構 | Implication pair expansion device, computer program therefor, and question answering system |
| US9720961B1 (en) | 2016-09-30 | 2017-08-01 | Semmle Limited | Algebraic data types for database query languages |
| US9633078B1 (en) * | 2016-09-30 | 2017-04-25 | Semmle Limited | Generating identifiers for tuples of recursively defined relations |
| WO2019203779A1 (en) * | 2018-04-16 | 2019-10-24 | Erik Viirre | A human-artificial intelligence hybrid system |
| US11733667B2 (en) | 2019-11-18 | 2023-08-22 | Rockwell Automation Technologies, Inc. | Remote support via visualizations of instructional procedures |
| US11263570B2 (en) * | 2019-11-18 | 2022-03-01 | Rockwell Automation Technologies, Inc. | Generating visualizations for instructional procedures |
| US11455300B2 (en) * | 2019-11-18 | 2022-09-27 | Rockwell Automation Technologies, Inc. | Interactive industrial automation remote assistance system for components |
| US11385874B2 (en) * | 2020-02-03 | 2022-07-12 | Sap Se | Automatic type determination for database programming |
| US12099803B2 (en) * | 2021-05-14 | 2024-09-24 | Microsoft Technology Licensing, Llc | Training a model in a data-scarce environment using added parameter information |
| US11740875B2 (en) * | 2021-07-21 | 2023-08-29 | International Business Machines Corporation | Type inference in dynamic languages |
| CN115840555A (en) * | 2022-12-12 | 2023-03-24 | 大连理工大学 | Small floating point arithmetic unit based on logarithm arithmetic system and application thereof in FPGA |
| US12613680B2 (en) * | 2023-08-28 | 2026-04-28 | Lemon Inc. | Controlling data schema for data oriented architecture |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6006214A (en) * | 1996-12-04 | 1999-12-21 | International Business Machines Corporation | Database management system, method, and program for providing query rewrite transformations for nested set elimination in database views |
| US6338055B1 (en) * | 1998-12-07 | 2002-01-08 | Vitria Technology, Inc. | Real-time query optimization in a decision support system |
| US20020069193A1 (en) * | 2000-12-06 | 2002-06-06 | Beavin Thomas A. | Optimization of SQL queries using filtering predicates |
| US20050086639A1 (en) * | 2003-10-21 | 2005-04-21 | Jun-Ki Min | Method of performing queriable XML compression using reverse arithmetic encoding and type inference engine |
| US7089266B2 (en) * | 2003-06-02 | 2006-08-08 | The Board Of Trustees Of The Leland Stanford Jr. University | Computer systems and methods for the query and visualization of multidimensional databases |
| US20070043702A1 (en) * | 2005-08-19 | 2007-02-22 | Microsoft Corporation | Query expressions and interactions with metadata |
| US20070276787A1 (en) * | 2006-05-15 | 2007-11-29 | Piedmonte Christopher M | Systems and Methods for Data Model Mapping |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7512642B2 (en) * | 2006-01-06 | 2009-03-31 | International Business Machines Corporation | Mapping-based query generation with duplicate elimination and minimal union |
| US8332385B2 (en) * | 2008-03-11 | 2012-12-11 | Semmle Limited | Approximating query results by relations over types for error detection and optimization |
| US20100017395A1 (en) * | 2008-07-16 | 2010-01-21 | Sapphire Information Systems Ltd. | Apparatus and methods for transforming relational queries into multi-dimensional queries |
-
2011
- 2011-07-15 US US13/183,514 patent/US8595213B2/en not_active Ceased
-
2015
- 2015-11-25 US US14/952,788 patent/USRE46380E1/en not_active Ceased
-
2017
- 2017-04-21 US US15/494,416 patent/USRE48405E1/en not_active Expired - Fee Related
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6006214A (en) * | 1996-12-04 | 1999-12-21 | International Business Machines Corporation | Database management system, method, and program for providing query rewrite transformations for nested set elimination in database views |
| US6338055B1 (en) * | 1998-12-07 | 2002-01-08 | Vitria Technology, Inc. | Real-time query optimization in a decision support system |
| US20020069193A1 (en) * | 2000-12-06 | 2002-06-06 | Beavin Thomas A. | Optimization of SQL queries using filtering predicates |
| US7089266B2 (en) * | 2003-06-02 | 2006-08-08 | The Board Of Trustees Of The Leland Stanford Jr. University | Computer systems and methods for the query and visualization of multidimensional databases |
| US20050086639A1 (en) * | 2003-10-21 | 2005-04-21 | Jun-Ki Min | Method of performing queriable XML compression using reverse arithmetic encoding and type inference engine |
| US20070043702A1 (en) * | 2005-08-19 | 2007-02-22 | Microsoft Corporation | Query expressions and interactions with metadata |
| US20070276787A1 (en) * | 2006-05-15 | 2007-11-29 | Piedmonte Christopher M | Systems and Methods for Data Model Mapping |
Non-Patent Citations (25)
| Title |
|---|
| Ashok K. Chandra and Philip M. Merlin, "Optimal Implementation of Conjunctive Queries in Relational Data Bases." In STOC '77: Proceedings of the ninth annual ACM symposium on Theory of computing, pp. 77-90, New York, NY, USA, 1997. ACM. |
| Bowlen Yang, Randal E. Bryant, David R. O'Halloran, Armin Biere, Olivier Coudert, Geert Janssen, Rajeev K. Ranjan, and Fabio Somenzi, "A Performance Study of BDD-Based Model Checking." In 2nd International Conference on Formal Methods in Computer-Aided Design, vol. 1522 of Lecture Notes in Computer Science, pp. 255-289. Springer, 1998. |
| David Zook, Emir Pasalic, and Beata Sarna-Starosta, "Typed Datalog." In Practical Aspects of Declarative Languages, pp. 168-182. Springer Berlin/Heidelberg, 2009. |
| Fang Wei and Georg Lausen, "Containment of Conjunctive Queries with Safe Negation." In ICDT '03: Proceedings of the 9th International Conference on Database Theory, pp. 346-360, London, UK, 2002. Springer-Verlag. |
| John P. Gallagher and Germén Puebla, "Abstract Interpretation over Non-deteriministic Finite Tree Automata for Set-Based Analysis of Logic Programs." In Practical Aspects of Declarative Languages (PADL), vol. 2257 of LNCS, pp. 243-261. Springer, 2002. |
| John P. Gallagher, Kim S. Henriksen, and Gourinath Banda, "Techniques for Scaling Up Analyses Based on Pre-Interpretations." In M. Gabbrielli and G. Gupta, editors, International Conference on Logic Programming (ICLP '05), vol. 3668 of LNCS, pp. 280-296. Springer, 2005. |
| John Whaley. JavaBDD. http://javabdd.sourceforge.net/, 2007. |
| Kevin J. Compton, "Stratified least fixpoint logic." Theoretical Computer Science, 31 (1):95-120, 1994. |
| Kim Marriott, Harald Søndergaard, and Neil D. Jones, "Denotational Abstract Interpretation of Logic Programs." ACM Transactions on Programming Languages and Systems, 16(3):607-648, 1994. |
| Leo Bachmair, Harald Ganzinger, and UweWaldmann, "Set constraints are the monadic class." In Logic in Computer Science, pp. 75-83, 1993. |
| Leo Bachmair, Harald Ganzinger, and UweWaldmann, "Superposition with Simplification as a Decision Procedure for the Monadic Class with Equality." in KGC '93: Proceedings of the Third Kurt Gödel Colloquium on Computational Logic and Proof Theory, pp. 83-96, London, UK, 1993. Springer-Verlag. |
| Max Schafer, Oege de Moor, "Type Inference for Datalog with Complex Type Hierarchies." POPL '10, Jan. 17-23, 2010, Madrid, Spain, copyright 2010 ACM 978-1-60558-479-9/10/01. |
| Nevin C. Heintze and Joxan Jaffar, "A finite presentation theorem for approxmating logic programs." In Symposium on Principles of Programming Languages (POPL), pp. 197-209, 1990. |
| Oded Shmueli, "Equivalence of Datalog Queries is Undecidable." Journal of Logic Programming, 15(3):231-241, 1993. |
| Oege de Moor, Damien Sereni, Mathieu Verbaere, Elnar Hajiyev, Pavel Avgustinov, Torjörn Ekman, Neil Ongkingco, and Julian Tibble, "QL: Object-oriented queries made easy." In Ralf Lämmel, João Saraiva, and Joost Visser, editors, Generative and Transformational Techniques in Software Engineering, LNCS. Springer, 2007. |
| Oege de Moor, Damien Sereni, Pavel Avgustinov, and Mathieu Verbaere, "Type Inference for Datalog and Its Application to Query Optimisation." In PODS '08: Proceedings of the twenty-seventh ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems, pp. 291-300, New York, NY, USA, 2008. ACM. |
| Oege de Moor, Mathieu Verbaere, Elnar Hajiyev, Pavel Avgustinov, Torbjörn Ekman , Neil Ongkingco, Damien Sereni, and Julian Tibble, "QL for source code analysis." In Source Code Analysis and Manipulation (SCAM '07), pp. 3-16, IEEE, 2007. |
| Olivier Coudert, Christian Berthet, and Jean Christophe Madre, "Verification of synchronous sequential machines based on symbolic execution." In Automatic Verification Methods for Finite State Systems, vol. 407 of Lecture Notes in Computer Science, pp. 365-373. Springer, 1989. |
| Sacha Berger, Emmanuel Coquery, Wlodzimierz Drabent, and Artur Wilk, "Descriptive Typing Rules for Xcerpt and their soundness." in François Fages and Sylvain Soliman, editors, Principles and Practice of Semantic Web Reasoning, vol. 3703 of LNCS, pp. 85-100. Springer, 2005. |
| Serge Abiteboul, George Lausen, Heinz Uphoff, and Emmanuel Waller, "Methods and rules". In ACM SIGMOND International Conference on Management of Data, pp. 32-41, ACM Press, 1993. |
| Stavros Cosmadakis, Haim Gaifman, Paris Kanellakis, and Moshe Vardi, "Decidable Optimazation Problems for Database Logic Programs." In Proceedings of the 20th annual ACM Symposium on Computing, pp. 477-490, 1988. |
| Surajit Chaudhuri and Phokion G. Kolaitis, "Can Datalog be approximated?" In Principles of Database Systems (PODS), pp. 86-96, 1994. |
| Surajit Chaudhuri, "Finding nonrecursive envelopes for Datalog predicates." In Principles of Database Systems (PODS), pp. 135-146, 1993. |
| Thom W. Frühwirth, Ehud Y. Shapiro, Moshe Y. Vardi, and Eyal Yardeni, "Logic programs as types for logic programs." In Logic in Computer Science (LICS), pp. 300-309. IEEE Computer Society, 1991. |
| Willard V. Quine, "On Cores and Prime Implicants of Truth Functions." The American Mathematical Monthly, 66(9):755-760, Nov. 1959. |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10423397B2 (en) * | 2016-12-29 | 2019-09-24 | Grammatech, Inc. | Systems and/or methods for type inference from machine code |
| US10942718B2 (en) | 2016-12-29 | 2021-03-09 | Grammatech, Inc | Systems and/or methods for type inference from machine code |
| US9996583B1 (en) * | 2017-05-25 | 2018-06-12 | Semmle Limited | Differential recursive evaluation of recursive aggregates |
Also Published As
| Publication number | Publication date |
|---|---|
| USRE48405E1 (en) | 2021-01-26 |
| US20120016912A1 (en) | 2012-01-19 |
| US8595213B2 (en) | 2013-11-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| USRE46380E1 (en) | Type inference for datalog with complex type hierarchies | |
| Nandi et al. | Rewrite rule inference using equality saturation | |
| van derWerf et al. | Process discovery using integer linear programming | |
| US7346486B2 (en) | System and method for modeling, abstraction, and analysis of software | |
| Fähndrich et al. | Partial online cycle elimination in inclusion constraint graphs | |
| Calcagno et al. | Modular safety checking for fine-grained concurrency | |
| US8332385B2 (en) | Approximating query results by relations over types for error detection and optimization | |
| Ahmetaj et al. | Managing change in graph-structured data using description logics | |
| Larraz et al. | SMT-based array invariant generation | |
| Crawford et al. | Negation and Proof by Contradiction in Access-Limited Logic. | |
| Liu et al. | From datalog rules to efficient programs with time and space guarantees | |
| Schüller | Modeling variations of first-order horn abduction in answer set programming | |
| Calvanese et al. | Verification of evolving graph-structured data under expressive path constraints | |
| Geerts et al. | Expressive power of linear algebra query languages | |
| Khuller et al. | Computing most probable worlds of action probabilistic logic programs: scalable estimation for 1030, 000 worlds | |
| Buneman et al. | Annotations are relative | |
| Bergmann | Incremental model queries in model-driven design | |
| Chabin et al. | Graph rewriting rules for RDF database evolution: optimizing side-effect processing | |
| Schäfer et al. | Type inference for datalog with complex type hierarchies | |
| De Giacomo et al. | Instance-level update in DL-Lite ontologies through first-order rewriting | |
| Dovier et al. | A uniform approach to constraint-solving for lists, multisets, compact lists, and sets | |
| Ozaki et al. | Happy Ever After: Temporally Attributed Description Logics. | |
| De Giacomo et al. | Updating DL-Lite ontologies through first-order queries | |
| Saha et al. | Symbolic support graph: A space efficient data structure for incremental tabled evaluation | |
| Cheney et al. | System description: Alpha-Prolog, a fresh approach to logic programming modulo alpha-equivalence |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| FPAY | Fee payment |
Year of fee payment: 4 |
|
| RF | Reissue application filed |
Effective date: 20170421 |
|
| CC | Certificate of correction | ||
| AS | Assignment |
Owner name: SEMMLE LIMITED, UNITED KINGDOM Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNORS:SCHAEFER, MAX;MOOR, OEGE DE;SIGNING DATES FROM 20110714 TO 20110715;REEL/FRAME:045690/0336 |
|
| AS | Assignment |
Owner name: GITHUB SOFTWARE UK LTD., UNITED KINGDOM Free format text: CHANGE OF NAME;ASSIGNOR:SEMMLE LIMITED;REEL/FRAME:051244/0305 Effective date: 20191129 |
|
| FEPP | Fee payment procedure |
Free format text: ENTITY STATUS SET TO UNDISCOUNTED (ORIGINAL EVENT CODE: BIG.); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY |
|
| AS | Assignment |
Owner name: MICROSOFT TECHNOLOGY LICENSING, LLC, WASHINGTON Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:GITHUB SOFTWARE UK LTD.;REEL/FRAME:051710/0252 Effective date: 20200116 |
|
| MAFP | Maintenance fee payment |
Free format text: PAYMENT OF MAINTENANCE FEE, 8TH YEAR, LARGE ENTITY (ORIGINAL EVENT CODE: M1552); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY Year of fee payment: 8 |
|
| FEPP | Fee payment procedure |
Free format text: MAINTENANCE FEE REMINDER MAILED (ORIGINAL EVENT CODE: REM.); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY |
|
| LAPS | Lapse for failure to pay maintenance fees |
Free format text: PATENT EXPIRED FOR FAILURE TO PAY MAINTENANCE FEES (ORIGINAL EVENT CODE: EXP.); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY |