US9360888B2 - System and method for motion detection and interpretation - Google Patents
System and method for motion detection and interpretation Download PDFInfo
- Publication number
- US9360888B2 US9360888B2 US13/890,709 US201313890709A US9360888B2 US 9360888 B2 US9360888 B2 US 9360888B2 US 201313890709 A US201313890709 A US 201313890709A US 9360888 B2 US9360888 B2 US 9360888B2
- Authority
- US
- United States
- Prior art keywords
- reflected
- camera
- computer
- view
- coordinate system
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active, expires
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F1/00—Details not covered by groups G06F3/00 - G06F13/00 and G06F21/00
- G06F1/16—Constructional details or arrangements
- G06F1/1601—Constructional details related to the housing of computer displays, e.g. of CRT monitors, of flat displays
- G06F1/1605—Multimedia displays, e.g. with integrated or attached speakers, cameras, microphones
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/011—Arrangements for interaction with the human body, e.g. for user immersion in virtual reality
- G06F3/012—Head tracking input arrangements
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/017—Gesture based interaction, e.g. based on a set of recognized hand gestures
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/03—Arrangements for converting the position or the displacement of a member into a coded form
- G06F3/0304—Detection arrangements using opto-electronic means
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/03—Arrangements for converting the position or the displacement of a member into a coded form
- G06F3/041—Digitisers, e.g. for touch screens or touch pads, characterised by the transducing means
- G06F3/0416—Control or interface arrangements specially adapted for digitisers
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/03—Arrangements for converting the position or the displacement of a member into a coded form
- G06F3/041—Digitisers, e.g. for touch screens or touch pads, characterised by the transducing means
- G06F3/042—Digitisers, e.g. for touch screens or touch pads, characterised by the transducing means by opto-electronic means
- G06F3/0425—Digitisers, e.g. for touch screens or touch pads, characterised by the transducing means by opto-electronic means using a single imaging device like a video camera for tracking the absolute position of a single or a plurality of objects with respect to an imaged reference surface, e.g. video camera imaging a display or a projection screen, a table or a wall surface, on which a computer generated image is displayed or projected
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/03—Arrangements for converting the position or the displacement of a member into a coded form
- G06F3/041—Digitisers, e.g. for touch screens or touch pads, characterised by the transducing means
- G06F3/042—Digitisers, e.g. for touch screens or touch pads, characterised by the transducing means by opto-electronic means
- G06F3/0425—Digitisers, e.g. for touch screens or touch pads, characterised by the transducing means by opto-electronic means using a single imaging device like a video camera for tracking the absolute position of a single or a plurality of objects with respect to an imaged reference surface, e.g. video camera imaging a display or a projection screen, a table or a wall surface, on which a computer generated image is displayed or projected
- G06F3/0426—Digitisers, e.g. for touch screens or touch pads, characterised by the transducing means by opto-electronic means using a single imaging device like a video camera for tracking the absolute position of a single or a plurality of objects with respect to an imaged reference surface, e.g. video camera imaging a display or a projection screen, a table or a wall surface, on which a computer generated image is displayed or projected tracking fingers with respect to a virtual keyboard projected or printed on the surface
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N23/00—Cameras or camera modules comprising electronic image sensors; Control thereof
- H04N23/60—Control of cameras or camera modules
- H04N23/61—Control of cameras or camera modules based on recognised objects
-
- H04N5/2254—
Definitions
- This disclosure relates to the field of automated motion detection. More particularly this disclosure relates to computer vision systems registering body motion inputs and translating such inputs into computer instructions.
- Interactive motion detection and interpretation is useful in many modern computing applications such as gaming, retail, bank teller machines, and communications.
- a video camera, an infrared (IR) emitter/detector, a display screen and a computer processor are required to translate body motion inputs into computer instructions.
- IR infrared
- a single camera only works sufficiently in applications that recognize broad movements, such as gaming, but not in applications that require inputs from small or discrete movements or that require an obstructed view of the user.
- the display may block some portion of the camera's view of the user.
- bank teller machines physical security of the system often times requires an obstructed view of the user.
- the prior art requires additional cameras placed behind, above, or to the side of the display to provide an unobstructed view of the user.
- multiple cameras increase complexity and cost.
- U.S. Pat. No. 7,598,942 to Underkoffler, et al. discloses a gestural interface to visually presented elements on a display screen.
- Multiple cameras capture movement and detect location and orientation and generate output signals to processors connected to a computer.
- the processors translate the camera outputs into gestural signals which are interpreted as input information.
- the computer uses the input information to generate commands to control computer functions.
- U.S. Pat. No. 7,034,807 to Maggioni discloses a system for interaction with a display.
- the system includes a recording unit for recording a pointer object in the vicinity of the display.
- a computer is connected to the recording unit and is used to determine a position of the pointer object.
- the system requires multiple cameras and multiple reflective surfaces.
- U.S. Patent Application Publication No. 2012/0212413 to Plagemann, et al. discloses a system for receiving image information and translating it into computer instructions. Image information is received for a single predetermined action space to identify motion. A camera combined with mirrors, prisms, or optic cables is used to gather the image information. However, only one action area is monitored at any given time.
- U.S. Patent Application Publication No. 2012/0162077 to Sze, et al. discloses an input device used to detect locations and motions of objects in a virtual working area.
- a camera is directed to a region of interest.
- a region of interest is illuminated by a “flat” beam of light.
- An object is placed in the region of interest and illuminated.
- the camera captures an image of the object and sends it to the processor.
- the processor processes the image to obtain locations and movements. Based on the movements, the processor produces computer instructions.
- the system disclosed gathers video data and depth information from around an obstruction with a single camera.
- a single mirror is geometrically positioned in such a way as to provide the camera a reflected view around the obstruction.
- the system creates a virtual touch screen for interaction with the computer from behind a glass barrier which prevents any physical contact between the user and the system.
- the single camera of the system disclosed has an unobstructed view of the user.
- a novel positioning of the camera and the mirror provides a view of body movements and image recognition and a view around the obstruction to capture fine motor movements of, for example, a user's hands interacting with a virtual touch screen.
- the system also provides a novel component positioning which allows the components of the system to be protected behind glass, while still being accessible to the user via the virtual touch screen.
- the system can simultaneously react to fine motor inputs and perform facial recognition. For example, it is possible for the system to identify a user by his facial characteristics and query the user for a manually entered personal identification number (PIN) at the same time.
- PIN personal identification number
- Other examples of useful embodiments include adaptive advertising displays in store windows, automatic teller machines requiring secure financial transactions, and building entrance security.
- the virtual touch screen is a predefined three dimensional set of coordinates in which movements and positions behind an obstruction are recognized.
- the action area can be comprised of a plurality of separately defined actions areas each corresponding to a different function. When an object is detected in the action area, it is recognized and interpreted as a set of specific computer instructions. In one embodiment, a signal is sent to a display screen that confirms the interpretations to the user as they are being made.
- FIG. 1 is a schematic diagram of the components of a preferred embodiment.
- FIG. 2A is an elevation view of a preferred embodiment.
- FIG. 2B is an elevation view of a preferred embodiment.
- FIG. 2C is an elevation view of a preferred embodiment.
- FIG. 3 is a ray diagram of a preferred embodiment.
- FIG. 4 is a schematic of a field of view of a camera of a preferred embodiment.
- FIG. 5 is an isometric view of an action area of a preferred embodiment.
- FIG. 6 is a flow chart of steps involved in the setup of a preferred embodiment.
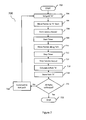
- FIG. 7 is a flow chart of the steps involved in the use of a preferred embodiment.
- FIG. 8 is a flow chart of the steps involved in the facial recognition routine of a preferred embodiment.
- FIG. 9 is a flow chart of the steps involved for interaction with a virtual touch screen in a preferred embodiment.
- FIG. 10 is an elevation view of a display screen of a preferred embodiment.
- aspects of the present disclosure may be illustrated and described herein in any of a number of patentable classes or context including any new and useful process, machine, manufacture, or composition of matter, or any new and useful improvement thereof. Therefore, aspects of the present disclosure may be implemented entirely in hardware or combining software and hardware implementation that may all generally be referred to herein as a “circuit,” “module,” “component,” or “system” (including firmware, resident software, micro-code, etc.). Further, aspects of the present disclosure may take the form of a computer program product embodied in one or more computer readable media having computer readable program code embodied thereon.
- the computer readable media may be a computer readable signal medium or a computer readable storage medium.
- a computer readable storage medium may be, but not limited to, an electronic, magnetic, optical, electromagnetic, or semiconductor system, apparatus, or device, or any suitable combination of the foregoing.
- a computer readable storage medium may be any tangible medium that can contain, or store a program for use by or in connection with an instruction execution system, apparatus, or device.
- a computer readable signal medium may include a propagated data signal with computer readable program code embodied therein, for example, in baseband or as part of a carrier wave.
- the propagated data signal may take any of a variety of forms, including, but not limited to, electro-magnetic, optical, or any suitable combination thereof.
- a computer readable signal medium may be any computer readable medium that is not a computer readable storage medium and that can communicate, propagate, or transport a program for use by or in connection with an instruction execution system, apparatus, or device.
- Program code embodied on a computer readable signal medium may be transmitted using any appropriate medium, including but not limited to wireless, wire line, optical fiber cable, RF, or any suitable combination thereof.
- Computer program code for carrying out operations for aspects of the present disclosure may be written in any combination of one or more programming languages, including an object oriented programming language such as Java, Scala, Smalltalk, Eiffel, JADE, Emerald, C++, C#, VB.NET, Python or the like, conventional procedural programming languages, such as the “C” programming language, Visual Basic, Fortran 2003, Perl, COBOL 2002, PHP, ABAP, dynamic programming languages such as Python, Ruby and Groovy, or other programming languages.
- object oriented programming language such as Java, Scala, Smalltalk, Eiffel, JADE, Emerald, C++, C#, VB.NET
- Python or the like
- conventional procedural programming languages such as the “C” programming language, Visual Basic, Fortran 2003, Perl, COBOL 2002, PHP, ABAP, dynamic programming languages such as Python, Ruby and Groovy, or other programming languages.
- These computer program instructions may also be stored in a computer readable medium that when executed can direct a computer, other programmable data processing apparatus, or other devices to function in a particular manner, such that the instructions when stored in the computer readable medium produce an article of manufacture including instructions which when executed, cause a computer to implement the function/act specified in the flowchart and/or block diagram block or blocks.
- the computer program instructions may also be loaded onto a computer, other programmable instruction execution apparatus, or other devices to cause a series of operational steps to be performed on the computer, other programmable apparatuses or other devices to produce a computer implemented process such that the instructions which execute on the computer or other programmable apparatus provide processes for implementing the functions/acts specified in the flowchart and/or block diagram block or blocks.
- components of motion detection and interpretation system 100 include computer 101 connected to camera 102 .
- Camera 102 is known in the art and includes firmware for movement interpretation and image recognition.
- An example is the Carmine 1.08 3D sensor from PrimeSense of Tel-Aviv, Israel.
- Another example is the Xbox Kinect from Microsoft of Redmond, Wash.
- Camera 102 provides image data in the form of streaming video at the rate of 30 frames per second in a standard 640 ⁇ 480 VGA.
- the focal length of the camera is 525 pixels with a field of view of approximately 63°.
- the camera also provides distance-to-target information from an on-board infrared transmitter/receiver pair.
- the focal length of the infrared transmitter/receiver is 580 pixels with a field of view of approximately 58°.
- the infrared data is provided as a 16 bit number at a refresh rate of 200 ⁇ s.
- Computer 101 contains processor 104 , memory 105 , and software module 107 .
- Software module 107 includes hardware drivers 108 .
- hardware drivers include an image capturing program such as Kinect for Windows available from Microsoft in Software Development Kit 1.7.
- Software module 107 includes executable routine 109 for coordination and execution of the system functions as will be further described.
- the software module includes a database 110 .
- the database is a SQL database which resides in memory.
- the software module also includes facial recognition routine 111 .
- Computer 101 is connected to display 106 .
- Display 106 in the preferred embodiment is a flat panel LCD screen provided by LG Electronics of South Korea.
- Mirror 112 is positioned within view of camera 102 as will be further described.
- camera 102 is positioned to achieve field of view 220 .
- field of view 220 can range from 55°-110°.
- Glass 208 separates the user from camera 102 and display 106 .
- Mirror 112 is positioned behind glass 208 . In other preferred embodiments, when security is of lesser concern, mirror 112 can be positioned in front of glass 208 .
- the mirror is a front silvered planar mirror having an optical coating to prevent distortion.
- Display 106 is positioned a typical distance above the ground, usually about eye level. In order to be at eye level, the display necessarily blocks a portion of field of view 220 , as shown by obstructed view 216 . In an alternate preferred embodiment, field of view 220 may be narrow and/or the position of the camera relative to the display may be situated such that field of view 220 is not obstructed by the display. Partial field of view 222 represents the limited unobstructed view from camera 102 . Reflected field of view 217 represents the portion of the total field returned by mirror 112 .
- reflected field of view 217 allows the camera to compensate for the obstructed field of view 216 adjacent the display, thereby allowing actions that take place in the obstructed field of view to be recognized.
- Overlap area 234 represents the field of view visible to the camera that otherwise would be obstructed. It is also important to note that overlap area 234 is directly adjacent the display.
- the camera is mounted a distance “g” from the floor and a distance “h” from the display.
- the visual axis of the camera is maintained at an angle ⁇ with respect to horizontal.
- the mirror is typically positioned a distance “i” from the camera and a distance “j” from the floor.
- the mirror is mounted at a fixed angle ⁇ from horizontal.
- the display is typically mounted at about eye level, at a distance “k” from the floor.
- the display is typically a distance “l” from the glass.
- the camera and mirror are shown positioned above the display; however, the camera and the mirror may also be positioned below or to the side of the display and still function as intended, so long as the relative positions of the devices provide for the overlap area. Table 1 summarizes the angles and distances as approximate ranges of the preferred embodiments:
- Curved mirror 212 is a curved mirror having a focal length f and a center curvature 2 f .
- the curved mirror has a focal length of between about 1 and 4 inches.
- the curved mirror may be convex or concave. Further, the curved mirror may be curved in one or more planes, that is, it may spherical or cylindrical.
- the convex mirror in these embodiments is a front silvered mirror having an optical coating to reduce distortion.
- Curved mirror 212 provides the camera with a reflected field of view 217 . Reflected field of view 217 results in overlap area 254 .
- overlap area 254 is significantly larger and overlap area 234 .
- the larger overlap enables the system to track gross motor movements over a larger area.
- overlap area 274 is significantly smaller, thus allowing the system to track fine motor movements more accurately than the prior art as will be further described.
- Action area 214 is a 3-dimensional space defined by the software module.
- the action area is positioned adjacent glass 208 and between user 210 and display 106 .
- the action area is located in the overlap area, that is both in the reflected field of view and the obstructed field of view.
- a ray diagram shows incident light 302 reflected from user 210 into camera 102 .
- incident light 304 is reflected from hand 306 of user 210 to mirror 112 where it is further reflected to camera 102 .
- Camera 102 reports distance “A+A” as the distance to hand 306 and distance “B” as the distance from the facial image of user 210 to the computer, as will be further described.
- the image data gathered by camera 102 includes image 450 .
- Image 450 also includes reflected image 460 .
- Reflected image 460 reflects light from mirror 112 .
- image 450 includes that portion of the user not blocked by display 106 .
- reflected image 460 includes both a view of the user's hands (which are obstructed from the view of the camera) and action area 214 .
- the reflected image alters the reference coordinates in the image data gathered by the camera.
- the camera receives data according to coordinate system reference 455 for the image 450 .
- the x axis represents horizontal. They axis represents vertical and the z axis is out of the page.
- reflected image 460 is reported to the camera according to coordinate system 465 .
- the x axis is horizontal, the y axis is out of the page and the z axis is vertical.
- Action area 214 is defined in reflected image 460 .
- Facial recognition area 215 is defined in image 450 .
- Action area 214 is described in more detail.
- Action area 214 is sub-divided into a series of three-dimensional geometric shapes within coordinate system 465 .
- Each of the geometric shapes is bounded by a series of points which form lines enclosing certain discrete volumes.
- sub-action area 214 A is bounded by a set of points including X 1 , Y 1 , Z 1 ; X 2 , Y 1 , Z 1 ; X 1 , Y 2 , Z 1 ; X 2 , Y 2 , Z 1 ; and function 505 .
- Function 505 in this example, is a hyperbolic function defined by the equation C ⁇ x 2 +y 2 (1)
- hyperbolic functions or linear functions may be used to define any set of points, in the X, Y, or Z directions, defining a general shape, so long as the function is closed with respect to the discrete area.
- sub-action area 214 B comprises a relatively “shallow” depth. Such shallow depths are useful to directly “mimic” a prior art touch screen, thereby conveying to the user a sensation that touching the glass surface causes the interaction.
- Sub-action areas 214 C and 214 D comprise “medium” depth areas. The medium depth areas convey to the user a sense that a computer function can be activated without actually touching the glass surface.
- Sub-action areas 214 E and 215 F comprise relatively “deep” action areas. Deep action areas, such as are shown in 214 E and 214 F are useful to record 3-dimensional paths indicated by a user, such as path 510 .
- method 600 of calibrating the system is described.
- the following preferred method is used by the system to calibrate the boundaries of action area 214 and facial recognition area 215 .
- the method begins at step 602 .
- the processor is instructed to set an initial point X, Y, Z in the obstructed view to define a corner of the action area.
- a pointer such as a finger or stylus, is moved to the actual location X, Y, Z.
- the processor queries the camera for the perceived image location X′, Y′, Z′.
- the processor calculates the difference between the actual location X, Y, Z and the perceived location at X′, Y′, Z′ to arrive at a difference ⁇ X, ⁇ Y, ⁇ Z.
- ⁇ X, ⁇ Y, and ⁇ Z are used to derive a translation function.
- the translation function is stored.
- the processor sets X, Y, Z in the reflected view.
- the pointer is moved to the corresponding physical location in the reflected view.
- the camera queried for the X, Y, Z location of the image.
- a transform function is derived. Calibration of additional points is required if the transform function is nonlinear.
- Nonlinear transform functions may arise in embodiments where concave, convex or non-planar mirrors are used. If so, at step 624 , the processor increments to the next point to be calibrated, and returns to step 616 . If not, the processor moves to step 625 and stores the transform function. At step 626 , the process is complete.
- step 700 method 700 of calibrating a path is described.
- the method begins at step 702 .
- the chosen predefined path such as path 510 , is loaded into memory by the processor.
- a pointer is moved to the start of the path.
- the processor activates the camera and begins recording video data and storing it in memory.
- the processor starts an internal timer to record the time it takes for the pointer to move along the path.
- the pointer is moved through the path in action area 112 from the beginning of the path to the end of the path within a time “t”.
- the processor stops the timer upon the arrival of the pointer at the end of the path.
- the processor then stops recording video images from the camera.
- the processor calculates the equation of the path of “A” over the variables X, Y, Z and t, based on the recorded pointer movements.
- the processor calculates the difference between the original path A and the stored path A′.
- the new path A′ is stored in memory.
- the processor determines if all paths have been calibrated. If not, at step 724 , the processor increments to the next path to be calibrated and returns to step 704 . If all paths have been calibrated at step 720 , the processor proceeds to step 722 and the process of path calibration is complete.
- facial recognition routine 800 will be described.
- the process starts.
- the camera is queried for the locations of facial features including eye location and color, ear location, chin location and hair color.
- the query is accommodated by Microsoft SKD Rel. 7.1 .LIB file Microsoft.Kinect.Toolkit.FaceTracking. In a preferred embodiment, at least 121 different locations are determined.
- the distances between facial features are measured.
- a “facial map” is created at step 806 .
- the facial map includes a table of the facial features and the distances between them.
- the facial map is compared to a set of digital images stored in database 110 . If the map is not recognized, then the process returns to step 801 . If the facial map is recognized, then the process moves to step 810 .
- the user identification demographic is returned.
- the process concludes.
- the processor is activated and loads the executable routine.
- a display signal is sent to the display at step 903 by the executable routine.
- the display signal includes a graphical and text picture which corresponds to a two-dimensional representation of the access area and sub-areas.
- the camera is queried for motion presence in facial recognition area.
- the processor returns to step 904 . If a presence is detected, the process moves to step 906 and initiates the facial recognition routine to determine the identity of the user.
- the facial recognition routine sorts through the database to identify facial features which match a predetermined pattern. The database then is queried for associated user information, such as the user's name, and account status, which is stored in the memory for later use by the processor.
- the processor then moves to step 908 where it begins monitoring the action area.
- the camera is queried for image data within the action area.
- step 912 image data and distance data are perceived in the action area and returned from the camera as coordinates X, Y, Z.
- the processor executes the translation function to translate the perceived coordinates into the actual coordinates.
- step 916 the processor executes the translation function to interpret the coordinates of the reflected view into the coordinates of the unobstructed view so that “Y” and “Z” dimension information is accurately reported to the processor.
- step 918 if the action position is no in a sub-action area then the process returns to step 912 . If it is in a sub-action area, then the processor proceeds to step 920 .
- the processor receives path data from the action area including a set of path variables X, Y, Z over a defined time period, ⁇ t.
- the processor executes the translation function to translate the perceived path to the actual path.
- the processor executes the transform function to change the coordinates of the reflected view into the coordinates of the unobstructed view so that the path information is accurately reported to the processor.
- the processor determines if a path defined by the action position corresponds to a path within a predefined tolerance and predefined time period. If the path is not within a predefined tolerance and a predefined time period, the processor returns to step 912 .
- step 928 a look-up table is queried for a predetermined instruction, if an action is within an action area and/or a motion is within a predefined path tolerance and time period.
- the processor performs the instruction according to the look-up table.
- step 932 the processor displays the results of and feedback from the instruction. After the instruction is displayed, the processor returns to step 904 and again queries the camera for the presence of a subject in the facial recognition area.
- FIG. 10 shows display 106 as viewed by a user outside glass 208 .
- Selections 1016 A-F are shown on display 106 .
- a user can see the selections available on the display but cannot physically touch the display because it is behind glass 208 .
- Feedback display 1017 provides visual confirmation of the system interface to the user. Confirming, that is, that actions have been recognized and correctly interpreted by the system. For example, an interaction with sub-action area 214 B results in selection 1016 B shown to the user to be selected as a radio button.
Landscapes
- Engineering & Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Computer Hardware Design (AREA)
- User Interface Of Digital Computer (AREA)
Abstract
Description
| TABLE 1 | ||||
| Range | Preferred | |||
| g | 3.5-14 | ft. | 7 | |
| h |
| 1 in.-8 ft. | 14 | in. | ||
| i | 1 in.-2 ft. | 4 | in. |
| j | 6-14 | ft. | 7 ft. 1 in. |
| k | 3-9 | ft. | 6 | ft. | |
| l | 1-6 | in. | 2 | in. |
| α | (−27)°-27° | −5° | ||
| β | 0°-110° | 45° | ||
C≈x 2 +y 2 (1)
Of course, other hyperbolic functions or linear functions may be used to define any set of points, in the X, Y, or Z directions, defining a general shape, so long as the function is closed with respect to the discrete area.
X=X′+ΔX (2)
Y=Y′+ΔY (3)
Z=Z′+ΔZ (4)
At
Claims (26)
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/890,709 US9360888B2 (en) | 2013-05-09 | 2013-05-09 | System and method for motion detection and interpretation |
| US14/535,823 US9465488B2 (en) | 2013-05-09 | 2014-11-07 | System and method for motion detection and interpretation |
| US15/258,973 US20160378267A1 (en) | 2013-05-09 | 2016-09-07 | System and Method for Motion Detection and Interpretation |
| US15/394,799 US10891003B2 (en) | 2013-05-09 | 2016-12-29 | System, method, and apparatus for an interactive container |
| US16/810,799 US20200312080A1 (en) | 2013-05-09 | 2020-03-05 | Method, System and Apparatus for a Gambling System |
| US17/138,208 US20210117040A1 (en) | 2013-05-09 | 2020-12-30 | System, method, and apparatus for an interactive container |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/890,709 US9360888B2 (en) | 2013-05-09 | 2013-05-09 | System and method for motion detection and interpretation |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US14/985,044 Continuation-In-Part US11233981B2 (en) | 2013-05-09 | 2015-12-30 | System and method for interactive projection |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US14/535,823 Continuation-In-Part US9465488B2 (en) | 2013-05-09 | 2014-11-07 | System and method for motion detection and interpretation |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| US20140333745A1 US20140333745A1 (en) | 2014-11-13 |
| US9360888B2 true US9360888B2 (en) | 2016-06-07 |
Family
ID=51864503
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/890,709 Active 2033-09-23 US9360888B2 (en) | 2013-05-09 | 2013-05-09 | System and method for motion detection and interpretation |
Country Status (1)
| Country | Link |
|---|---|
| US (1) | US9360888B2 (en) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20160085518A1 (en) * | 2014-09-21 | 2016-03-24 | Jang Hee I | Systems and methods for imaging and generation of executable processor instructions based on ordered objects |
| US10398855B2 (en) | 2017-11-14 | 2019-09-03 | William T. MCCLELLAN | Augmented reality based injection therapy |
| US11582425B2 (en) | 2020-06-10 | 2023-02-14 | Magna Electronics Inc. | Driver monitoring system using camera with adjustable mirror |
| US12340546B2 (en) | 2021-11-19 | 2025-06-24 | Magna Electronics Inc. | Vehicular occupant monitoring system using centralized camera with expanded view |
| DE102022112930A1 (en) * | 2022-05-23 | 2023-11-23 | Gestigon Gmbh | CAPTURE SYSTEM AND METHOD FOR COLLECTING CONTACTLESS DIRECTED USER INPUTS AND METHOD FOR CALIBRATION OF THE CAPTURE SYSTEM |
Citations (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5528263A (en) * | 1994-06-15 | 1996-06-18 | Daniel M. Platzker | Interactive projected video image display system |
| US6339748B1 (en) * | 1997-11-11 | 2002-01-15 | Seiko Epson Corporation | Coordinate input system and display apparatus |
| US6512536B1 (en) * | 1999-02-09 | 2003-01-28 | The United States Of America As Represented By The United States National Aeronautics And Space Administration | Cable and line inspection mechanism |
| US6759979B2 (en) * | 2002-01-22 | 2004-07-06 | E-Businesscontrols Corp. | GPS-enhanced system and method for automatically capturing and co-registering virtual models of a site |
| US7034807B2 (en) * | 2000-02-21 | 2006-04-25 | Siemens Aktiengesellschaft | Method and configuration for interacting with a display visible in a display window |
| US7046838B1 (en) * | 1999-03-30 | 2006-05-16 | Minolta Co., Ltd. | Three-dimensional data input method and apparatus |
| US7084857B2 (en) | 2000-05-29 | 2006-08-01 | Vkb Inc. | Virtual data entry device and method for input of alphanumeric and other data |
| US20060249679A1 (en) * | 2004-12-03 | 2006-11-09 | Johnson Kirk R | Visible light and ir combined image camera |
| US20070217042A1 (en) * | 2004-10-14 | 2007-09-20 | Prefix Suffix | Rectilinear Mirror and Imaging System Having the Same |
| US20080029691A1 (en) | 2006-08-03 | 2008-02-07 | Han Jefferson Y | Multi-touch sensing display through frustrated total internal reflection |
| USRE40368E1 (en) | 2000-05-29 | 2008-06-10 | Vkb Inc. | Data input device |
| US7598942B2 (en) | 2005-02-08 | 2009-10-06 | Oblong Industries, Inc. | System and method for gesture based control system |
| EP2210532A2 (en) | 2008-11-14 | 2010-07-28 | N.V. Nederlandsche Apparatenfabriek NEDAP | Smart full-length mirror |
| US20100302138A1 (en) * | 2009-05-29 | 2010-12-02 | Microsoft Corporation | Methods and systems for defining or modifying a visual representation |
| EP2397932A1 (en) | 2010-06-18 | 2011-12-21 | Nlighten Trading (Shanghai) Co. | Light uniforming system for projecting type touch control apparatus |
| US8094129B2 (en) | 2006-11-27 | 2012-01-10 | Microsoft Corporation | Touch sensing using shadow and reflective modes |
| US20120044141A1 (en) * | 2008-05-23 | 2012-02-23 | Hiromu Ueshima | Input system, input method, computer program, and recording medium |
| US20120162077A1 (en) | 2010-01-06 | 2012-06-28 | Celluon, Inc. | System and method for a virtual multi-touch mouse and stylus apparatus |
| US20120212413A1 (en) | 2011-02-17 | 2012-08-23 | The Board of Trustees of the Leland Stanford, Junior, University | Method and System for Touch-Free Control of Devices |
| US20120262366A1 (en) * | 2011-04-15 | 2012-10-18 | Ingeonix Corporation | Electronic systems with touch free input devices and associated methods |
| US20120268372A1 (en) | 2011-04-19 | 2012-10-25 | Jong Soon Park | Method and electronic device for gesture recognition |
| US20120299879A1 (en) | 2009-12-11 | 2012-11-29 | Kim Sung-Han | Optical touch screen |
| US8331998B2 (en) | 2000-03-22 | 2012-12-11 | Akihabara Limited Llc | Combined rear view mirror and telephone |
| US20120326958A1 (en) | 2006-12-08 | 2012-12-27 | Johnson Controls Technology Company | Display and user interface |
-
2013
- 2013-05-09 US US13/890,709 patent/US9360888B2/en active Active
Patent Citations (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5528263A (en) * | 1994-06-15 | 1996-06-18 | Daniel M. Platzker | Interactive projected video image display system |
| US6339748B1 (en) * | 1997-11-11 | 2002-01-15 | Seiko Epson Corporation | Coordinate input system and display apparatus |
| US6512536B1 (en) * | 1999-02-09 | 2003-01-28 | The United States Of America As Represented By The United States National Aeronautics And Space Administration | Cable and line inspection mechanism |
| US7046838B1 (en) * | 1999-03-30 | 2006-05-16 | Minolta Co., Ltd. | Three-dimensional data input method and apparatus |
| US7034807B2 (en) * | 2000-02-21 | 2006-04-25 | Siemens Aktiengesellschaft | Method and configuration for interacting with a display visible in a display window |
| US8331998B2 (en) | 2000-03-22 | 2012-12-11 | Akihabara Limited Llc | Combined rear view mirror and telephone |
| US7084857B2 (en) | 2000-05-29 | 2006-08-01 | Vkb Inc. | Virtual data entry device and method for input of alphanumeric and other data |
| USRE40368E1 (en) | 2000-05-29 | 2008-06-10 | Vkb Inc. | Data input device |
| US6759979B2 (en) * | 2002-01-22 | 2004-07-06 | E-Businesscontrols Corp. | GPS-enhanced system and method for automatically capturing and co-registering virtual models of a site |
| US20070217042A1 (en) * | 2004-10-14 | 2007-09-20 | Prefix Suffix | Rectilinear Mirror and Imaging System Having the Same |
| US20060249679A1 (en) * | 2004-12-03 | 2006-11-09 | Johnson Kirk R | Visible light and ir combined image camera |
| US7598942B2 (en) | 2005-02-08 | 2009-10-06 | Oblong Industries, Inc. | System and method for gesture based control system |
| US20080029691A1 (en) | 2006-08-03 | 2008-02-07 | Han Jefferson Y | Multi-touch sensing display through frustrated total internal reflection |
| US8094129B2 (en) | 2006-11-27 | 2012-01-10 | Microsoft Corporation | Touch sensing using shadow and reflective modes |
| US20120326958A1 (en) | 2006-12-08 | 2012-12-27 | Johnson Controls Technology Company | Display and user interface |
| US20120044141A1 (en) * | 2008-05-23 | 2012-02-23 | Hiromu Ueshima | Input system, input method, computer program, and recording medium |
| EP2210532A2 (en) | 2008-11-14 | 2010-07-28 | N.V. Nederlandsche Apparatenfabriek NEDAP | Smart full-length mirror |
| US20100302138A1 (en) * | 2009-05-29 | 2010-12-02 | Microsoft Corporation | Methods and systems for defining or modifying a visual representation |
| US20120299879A1 (en) | 2009-12-11 | 2012-11-29 | Kim Sung-Han | Optical touch screen |
| US20120162077A1 (en) | 2010-01-06 | 2012-06-28 | Celluon, Inc. | System and method for a virtual multi-touch mouse and stylus apparatus |
| EP2397932A1 (en) | 2010-06-18 | 2011-12-21 | Nlighten Trading (Shanghai) Co. | Light uniforming system for projecting type touch control apparatus |
| US20120212413A1 (en) | 2011-02-17 | 2012-08-23 | The Board of Trustees of the Leland Stanford, Junior, University | Method and System for Touch-Free Control of Devices |
| US20120262366A1 (en) * | 2011-04-15 | 2012-10-18 | Ingeonix Corporation | Electronic systems with touch free input devices and associated methods |
| US20120268372A1 (en) | 2011-04-19 | 2012-10-25 | Jong Soon Park | Method and electronic device for gesture recognition |
Also Published As
| Publication number | Publication date |
|---|---|
| US20140333745A1 (en) | 2014-11-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9465488B2 (en) | System and method for motion detection and interpretation | |
| US12353646B2 (en) | Augmented reality eyewear 3D painting | |
| US12256211B2 (en) | Immersive augmented reality experiences using spatial audio | |
| CN204480228U (en) | motion sensing and imaging device | |
| US12299933B2 (en) | Collaborative augmented reality eyewear with ego motion alignment | |
| US20180012074A1 (en) | Safety for wearable virtual reality devices via object detection and tracking | |
| US9602806B1 (en) | Stereo camera calibration using proximity data | |
| WO2020076396A1 (en) | Real-world anchor in a virtual-reality environment | |
| US20150379770A1 (en) | Digital action in response to object interaction | |
| US20170277259A1 (en) | Eye tracking via transparent near eye lens | |
| US20140317576A1 (en) | Method and system for responding to user's selection gesture of object displayed in three dimensions | |
| US20160371886A1 (en) | System and method for spawning drawing surfaces | |
| US9106903B2 (en) | Head tracking eyewear system | |
| US9360888B2 (en) | System and method for motion detection and interpretation | |
| KR102032662B1 (en) | Human-computer interaction with scene space monitoring | |
| US10878285B2 (en) | Methods and systems for shape based training for an object detection algorithm | |
| US20170256073A1 (en) | Minimizing variations in camera height to estimate distance to objects | |
| US10437342B2 (en) | Calibration systems and methods for depth-based interfaces with disparate fields of view | |
| US20200103959A1 (en) | Drift Cancelation for Portable Object Detection and Tracking | |
| CA2955072C (en) | Reflection-based control activation | |
| US9122346B2 (en) | Methods for input-output calibration and image rendering | |
| WO2018161564A1 (en) | Gesture recognition system and method, and display device | |
| US20190155380A1 (en) | Slippage Compensation in Eye Tracking | |
| Piérard et al. | I-see-3D! An interactive and immersive system that dynamically adapts 2D projections to the location of a user's eyes | |
| US9465483B2 (en) | Methods for input-output calibration and image rendering |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| STCF | Information on status: patent grant |
Free format text: PATENTED CASE |
|
| AS | Assignment |
Owner name: OMNI CONSUMER PRODUCTS, LLC, TEXAS Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:HOWARD, STEPHEN;REEL/FRAME:040575/0995 Effective date: 20161103 |
|
| MAFP | Maintenance fee payment |
Free format text: PAYMENT OF MAINTENANCE FEE, 4TH YR, SMALL ENTITY (ORIGINAL EVENT CODE: M2551); ENTITY STATUS OF PATENT OWNER: SMALL ENTITY Year of fee payment: 4 |
|
| FEPP | Fee payment procedure |
Free format text: MAINTENANCE FEE REMINDER MAILED (ORIGINAL EVENT CODE: REM.); ENTITY STATUS OF PATENT OWNER: SMALL ENTITY |
|
| FEPP | Fee payment procedure |
Free format text: 7.5 YR SURCHARGE - LATE PMT W/IN 6 MO, SMALL ENTITY (ORIGINAL EVENT CODE: M2555); ENTITY STATUS OF PATENT OWNER: SMALL ENTITY |
|
| MAFP | Maintenance fee payment |
Free format text: PAYMENT OF MAINTENANCE FEE, 8TH YR, SMALL ENTITY (ORIGINAL EVENT CODE: M2552); ENTITY STATUS OF PATENT OWNER: SMALL ENTITY Year of fee payment: 8 |
|
| AS | Assignment |
Owner name: WISNIEWSKI, SCOTT, TEXAS Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:OMNI CONSUMER PRODUCTS, LLC;REEL/FRAME:072153/0001 Effective date: 20241125 |
|
| AS | Assignment |
Owner name: HOVERTOUCH TECHNOLOGIES, INC., TEXAS Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:WISNIEWSKI, SCOTT;REEL/FRAME:072164/0669 Effective date: 20250904 |
|
| AS | Assignment |
Owner name: SPACEE, INC., TEXAS Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:HOVERTOUCH TECHNOLOGIES, INC.;REEL/FRAME:072440/0879 Effective date: 20251001 |