RU2595616C1 - Method for prediction of efficiency of speech action of fragments of discourse in different languages - Google Patents
Method for prediction of efficiency of speech action of fragments of discourse in different languages Download PDFInfo
- Publication number
- RU2595616C1 RU2595616C1 RU2015101668/08A RU2015101668A RU2595616C1 RU 2595616 C1 RU2595616 C1 RU 2595616C1 RU 2015101668/08 A RU2015101668/08 A RU 2015101668/08A RU 2015101668 A RU2015101668 A RU 2015101668A RU 2595616 C1 RU2595616 C1 RU 2595616C1
- Authority
- RU
- Russia
- Prior art keywords
- fragments
- parameters
- erv
- languages
- fragment
- Prior art date
Links
- 239000012634 fragment Substances 0.000 title claims abstract description 186
- 238000000034 method Methods 0.000 title claims description 42
- 238000010219 correlation analysis Methods 0.000 claims abstract description 14
- 238000010835 comparative analysis Methods 0.000 claims abstract description 7
- 206010028916 Neologism Diseases 0.000 claims description 5
- 230000000694 effects Effects 0.000 abstract description 10
- 238000012545 processing Methods 0.000 abstract description 9
- 238000012986 modification Methods 0.000 abstract description 3
- 230000004048 modification Effects 0.000 abstract description 3
- 238000004321 preservation Methods 0.000 abstract description 2
- 239000000969 carrier Substances 0.000 abstract 1
- 239000000126 substance Substances 0.000 abstract 1
- 238000013459 approach Methods 0.000 description 12
- 230000008859 change Effects 0.000 description 12
- 238000004891 communication Methods 0.000 description 12
- 230000001149 cognitive effect Effects 0.000 description 10
- 238000009826 distribution Methods 0.000 description 8
- 238000011160 research Methods 0.000 description 7
- 230000004044 response Effects 0.000 description 7
- 230000001419 dependent effect Effects 0.000 description 5
- 230000008707 rearrangement Effects 0.000 description 5
- 238000011161 development Methods 0.000 description 4
- 230000003340 mental effect Effects 0.000 description 4
- 230000008569 process Effects 0.000 description 4
- 238000013519 translation Methods 0.000 description 4
- 238000012790 confirmation Methods 0.000 description 3
- 238000010276 construction Methods 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- 230000008450 motivation Effects 0.000 description 3
- 238000002360 preparation method Methods 0.000 description 3
- UUKWKUSGGZNXGA-UHFFFAOYSA-N 3,5-dinitrobenzamide Chemical compound NC(=O)C1=CC([N+]([O-])=O)=CC([N+]([O-])=O)=C1 UUKWKUSGGZNXGA-UHFFFAOYSA-N 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 238000005755 formation reaction Methods 0.000 description 2
- 238000012417 linear regression Methods 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 230000007935 neutral effect Effects 0.000 description 2
- VYZAMTAEIAYCRO-UHFFFAOYSA-N Chromium Chemical compound [Cr] VYZAMTAEIAYCRO-UHFFFAOYSA-N 0.000 description 1
- MMOXZBCLCQITDF-UHFFFAOYSA-N N,N-diethyl-m-toluamide Chemical compound CCN(CC)C(=O)C1=CC=CC(C)=C1 MMOXZBCLCQITDF-UHFFFAOYSA-N 0.000 description 1
- 230000001174 ascending effect Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 238000004422 calculation algorithm Methods 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 230000019771 cognition Effects 0.000 description 1
- 230000000052 comparative effect Effects 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 238000013525 hypothesis research Methods 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 238000000691 measurement method Methods 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 230000006996 mental state Effects 0.000 description 1
- 230000008447 perception Effects 0.000 description 1
- 238000003825 pressing Methods 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 230000035807 sensation Effects 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 238000000844 transformation Methods 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
- 230000001755 vocal effect Effects 0.000 description 1
Images


Landscapes
- Machine Translation (AREA)
Abstract
Description
Изобретение относится к области лингвистики, психолингвистики и социолингвистики и может быть использовано при составлении речей различного характера, в т.ч. рассчитанных на массового адресата, при формировании паттернов, концептов и др. ментальных образований мышления, пропаганде, рекламе, средствах массовой информации, дипломатическом общении, бизнес-коммуникации и др.The invention relates to the field of linguistics, psycholinguistics and sociolinguistics and can be used in the compilation of speeches of various nature, including designed for the mass addressee, in the formation of patterns, concepts, and other mental formations of thinking, propaganda, advertising, the media, diplomatic communication, business communication, etc.
Определения ключевых понятий.Definitions of key concepts.
Дискурс - сложно-структурированная динамичная коммуникативно-знаковая система, взаимодействующая с объективной реальностью по диалектическому принципу; обладающая шестью основными планами: интенциональным, актуальным, виртуальным, контекстуальным, психологическим и «осадочным».Discourse is a complex-structured dynamic communicative-sign system that interacts with objective reality according to the dialectical principle; having six main plans: intentional, relevant, virtual, contextual, psychological and "sedimentary".
Отрезок дискурса - часть дискурса объемом не менее 30000-40000 словA discourse segment is a part of a discourse of at least 30000-40000 words
Фрагмент дискурса - совокупность нескольких сегментов дискурса, границами которых могут выступать союзы, пунктуационные знаки или атрибутивные предложения.A discourse fragment is a combination of several discourse segments, the boundaries of which can be unions, punctuation marks or attribute sentences.
Контрольный фрагмент - фрагмент дискурса, ответ респондента на который исследователем предполагается как очевидный; используется для того, чтобы фильтровать выборку респондентов по определенному критерию.Control fragment - a fragment of discourse, the respondent’s response to which is supposed to be obvious by the researcher; used to filter the sample of respondents according to a specific criterion.
Экстралингвистический фактор (ЭЛФ) - свойство или характеристика внеязыковой социальной действительности, обусловливающее изменения в языке как глобального, так и частного характера.Extralinguistic factor (ELF) is a property or characteristic of extralinguistic social reality that causes changes in the language of both global and private nature.
Эффективность речевого воздействия (ЭРВ) - результативное достижение регуляции поведения реципиента, осуществляемой с помощью обращенной к нему речи (устной, письменной, через средства массовой информации и др.) и с минимально возможными издержками.The effectiveness of speech exposure (ERV) is the effective achievement of the regulation of recipient behavior, carried out using speech addressed to him (oral, written, through the media, etc.) and with the lowest possible costs.
Потенциал речевого воздействия (РВ) - возможности лингвистических средств оказывать речевое воздействие.Speech Impact Potential (RV) - the ability of linguistic means to exert a speech effect.
Эталон нормы речевого воздействия - мера-ориентир, служащая для определения отклонения определенной величины РВ от исходной величины РВ, вычисляемой для фрагмента, обладаемого наименьшим РВ.The standard of the norm of speech exposure is a landmark measure that serves to determine the deviation of a certain value of RV from the initial value of RV, calculated for the fragment with the smallest RV.
Адресант - отправитель; который в процессах социальной коммуникации при помощи передачи сообщения стремится вызвать определенное поведение у реципиента.Addressee - sender; which in the processes of social communication through the transmission of messages tends to cause a certain behavior in the recipient.
Реципиент - субъект социальной коммуникации, воспринимающий адресованное ему сообщение.The recipient is the subject of social communication, perceiving the message addressed to him.
Риторический прием - мотивированное условиями речевого общения отклонение от языковой нормы.A rhetorical device is a deviation from the language norm motivated by the conditions of verbal communication.
Плотность риторических приемов - величина, описывающая наличие определенного количества риторических приемов в определенном объеме дискурса.Density of rhetorical devices - a value that describes the presence of a certain number of rhetorical devices in a certain volume of discourse.
Непараметр - характеристика лингвистического объекта, представляющая собой отсутствие в нем параметров, предусмотренных гипотезой исследования.Nonparameter is a characteristic of a linguistic object, which is the absence of parameters in it provided for by the research hypothesis.
Когнитивный подход - подход, основанный на положениях когнитивной психологии и предусматривающий опору на принцип сознательности, учет различных когнитивных стилей и стратегий, связанных с познанием и мышлением.Cognitive approach - an approach based on the provisions of cognitive psychology and providing for the support of the principle of consciousness, taking into account various cognitive styles and strategies associated with cognition and thinking.
Семиотика - наука о знаках и знаковых системах, знаковом (использующем знаки) поведении и знаковой - лингвистической и нелингвистической - коммуникации.Semiotics is the science of signs and sign systems, sign (using signs) behavior and sign - linguistic and non-linguistic - communication.
Фиктивная переменная - качественная переменная, принимающая значения 0 и 1 (бинарная), и большее количество значений (многозначная), включаемая в эконометрическую модель для учета влияния качественных признаков и событий на объясняемую переменную.A dummy variable is a qualitative variable that takes values 0 and 1 (binary), and a larger number of values (multi-valued), which is included in the econometric model to take into account the influence of qualitative features and events on the variable being explained.
Коэффициент Пирсона - мера тесноты связи двух признаков при наличии линейной зависимости между ними.The Pearson coefficient is a measure of the tightness of the relationship between two signs in the presence of a linear relationship between them.
Уравнение множественной линейной регрессии - математическое уравнение, устанавливающее линейную зависимость между результирующим признаком и рядом независимых параметров.The multiple linear regression equation is a mathematical equation that establishes a linear relationship between the resulting attribute and a number of independent parameters.
Приблизительное уравнение регрессии - математическое уравнение, устанавливающее линейную зависимость между результирующим признаком и рядом независимых параметров; при этом коэффициенты уравнения могут варьироваться в ограниченном диапазоне в зависимости от репрезентативности и объема выборки.An approximate regression equation is a mathematical equation that establishes a linear relationship between the resulting attribute and a number of independent parameters; however, the coefficients of the equation can vary in a limited range depending on the representativeness and size of the sample.
Проблема поиска оптимальных, максимально эффективных форм выражения мысли, форм внедрения определенной концепции мироустройства в сознание человека и форм воздействия на последнего - одна из наиболее актуальных на сегодняшний день. Существует множество лингвистических и психолингвистических работ по описанию и оценке ЭРВ, как отечественных (О.С. Иссерс, В.Е. Чернявская, К.В. Никитина, Ю.И. Плахотная, С.А. Виноградова, М.Р. Желтухина, И.А. Скрипак и др.), так и зарубежных (Т.А. van Dijk, W. Ladov, D. Franchel, G. Kress, T. Zheng, P. DiMaggio, P. Catellani, M. Dertolotti et al.), однако во всех работах дискурс и, в частности, ЭРВ его фрагментов изучаются с помощью собственно филологических методов (контент-анализ, когнитивный анализ, сравнительный, сопоставительный анализ, ранжирование и др.) или психолингивстических (дискурс-анализ и др.).The problem of finding optimal, most effective forms of expression of thought, forms of introducing a certain concept of world order into the human mind and forms of influence on the latter is one of the most relevant today. There are many linguistic and psycholinguistic works on describing and evaluating ERV as domestic ones (O.S. Issers, V.E. Chernyavskaya, K.V. Nikitina, Yu.I. Plahotnaya, S.A. Vinogradova, M.R. Zheltukhina , I.A. Skripak et al.) And foreign (T.A. van Dijk, W. Ladov, D. Franchel, G. Kress, T. Zheng, P. DiMaggio, P. Catellani, M. Dertolotti et al.), however, in all works, discourse and, in particular, the ERV of its fragments are studied using proper philological methods (content analysis, cognitive analysis, comparative, comparative analysis, ranking, etc.) or psycholinguistic (disc with analysis and others.).
Основные направления в области изучения речевого воздействия (РВ) включают в себя исследования РВ как психологического, когнитивного и коммуникативного феномена.The main directions in the study of speech exposure (RV) include studies of RV as a psychological, cognitive and communicative phenomenon.
Психологический подход рассматривает РВ как определенные манипуляции, целью которых является изменение поведения и мышления человека путем мотивации или демотивации, путем удовлетворения основных потребностей: физиологических, потребностей в самосохранении, любви, уважении, самоутверждении. Этот подход оценивает ЭРВ через изменения в мышлении и поведении человека, абстрактные критерии.The psychological approach considers the RV as certain manipulations, the purpose of which is to change a person’s behavior and thinking through motivation or demotivation, by satisfying basic needs: physiological, self-preservation, love, respect, self-affirmation. This approach evaluates the ERV through changes in human thinking and behavior, abstract criteria.
Недостатками подхода являются субъективность оценки ЭРВ вследствие разного оценивания изменений в мышлении и поведении человека; несистемность набора критериев оценки ЭРВ, их неконкретность, неточность и зависимость от различных субъектных и несубъектных ЭЛФ; невозможность какой-либо количественной оценки ЭРВ; невозможность сравнения различных отрезков дискурса, если неизвестно, насколько и как изменилось мышление или поведение человека после восприятия фрагмента дискурса (прослушивания, просматривания, чтения и др.)The disadvantages of the approach are the subjectivity of the ERV assessment due to the different assessment of changes in thinking and human behavior; unsystematic set of criteria for evaluating ERV, their lack of specificity, inaccuracy and dependence on various subject and non-subject ELFs; the impossibility of any quantitative assessment of the ERV; the impossibility of comparing different sections of the discourse, if it is not known how much and how the thinking or behavior of a person has changed after perceiving a fragment of the discourse (listening, viewing, reading, etc.)
Когнитивный подход рассматривает РВ как модификацию когнитивной модели мира реципиента, воспринимающего фрагмент дискурса. Модификация происходит в результате интенсификации (например, преувеличения положительных характеристик) или преуменьшения (умолчания, сокрытия негативных характеристик). Эти две стратегии РВ осуществляются с помощью различных преобразований: аннулирующего (например, полуправды), фингирующего (например, «заговаривания зубов»), индефинитизирующего (например, изменения уровня абстракции явлений или объектов). Все стратегии основаны на введении новых знаний в когнитивную модель мира реципиента или индуцирования представления уже имеющихся знаний в искаженном виде.The cognitive approach considers RV as a modification of the cognitive model of the world of the recipient, perceiving a fragment of discourse. Modification occurs as a result of intensification (for example, exaggeration of positive characteristics) or understatement (default, concealment of negative characteristics). These two strategies of real estate are implemented using various transformations: annihilating (for example, half-truths), finging (for example, “raising teeth”), indefinite (for example, changing the level of abstraction of phenomena or objects). All strategies are based on the introduction of new knowledge into the cognitive model of the world of the recipient or inducing the representation of existing knowledge in a distorted form.
Недостатками подхода являются невозможность определения степени достоверности или искаженности когнитивной модели мира реципиента до и после восприятия последним фрагмента дискурса; невозможность определения или точного определения того, сколько реципиент приобрел знаний и сколько утратил; субъективность оценивания того или иного фрагмента дискурса как, например, полуправды или изменения уровня абстракции: один исследователь считает, что уровень абстракции изменился, другой считает, что нет, т.е. отсутствуют критерии однозначной детерминации параметров, приводящих к изменению когнитивной модели мира реципиента.The disadvantages of the approach are the inability to determine the degree of reliability or distortion of the cognitive model of the world of the recipient before and after the perception of the last fragment of the discourse; the impossibility of determining or accurately determining how much the recipient has acquired knowledge and how much has lost; the subjectivity of evaluating one or another fragment of the discourse, such as half-truths or changes in the level of abstraction: one researcher believes that the level of abstraction has changed, another believes that not, i.e. there are no criteria for the unambiguous determination of parameters leading to a change in the cognitive model of the recipient's world.
Коммуникативный подход к РВ связан с семиотикой и моделью коммуникативного акта, предопределяющими потенциал РВ и условия его эффективной реализации. Согласно подходу ЭРВ увеличивается при изменении ментального образа адресанта, образа реципиента, при выборе кода сообщения, канала связи и при наличии обратной связи. Основу ЭРВ коммуникативный подход видит в асимметрии языкового знака.The communicative approach to real estate is connected with semiotics and the model of a communicative act, predetermining the potential of real estate and the conditions for its effective implementation. According to the approach, the ERV increases with a change in the mental image of the addressee, the image of the recipient, when choosing a message code, a communication channel, and in the presence of feedback. The communicative approach sees the basis of the ERV in the asymmetry of the linguistic sign.
Однако недостатками этого подхода является невозможность объективной и точной диагностики каких-либо изменений в ментальном образе адресанта, образе реципиента: дляHowever, the disadvantages of this approach are the impossibility of objective and accurate diagnosis of any changes in the mental image of the addressee, the image of the recipient: for
этого не разработано специальное техническое оборудование. О выборе коде сообщения и канале связи имеется только общая информация: определенный код сообщения или канал связи обладает наибольшей ЭРВ (по мнению большинства ученых). Соответственно, оценить, сравнить ЭРВ различных фрагментов дискурса, а тем более, в точных величинах в рамках данного подхода невозможно. Кроме того, в класс определенного кода сообщения и канала связи, даже при определенном ментальном образе адресанта и реципиента, попадают тысячи фрагментов дискурса - в связи с чем, исследователь вынужден считать их ЭРВ одинаковыми. В свою очередь, для того, чтобы выделить такие классы исследователю необходимо учесть все комбинации типичных образов адресанта и реципиента, кодов сообщения, каналов связи и видов обратной связи, что является трудоемкой работой, на которую могут уйти десятилетия.this is not developed special technical equipment. There is only general information about the choice of a message code and a communication channel: a certain message code or communication channel has the highest ERV (according to most scientists). Accordingly, it is impossible to evaluate, compare the ERV of various fragments of discourse, and even more so, in exact terms within the framework of this approach. In addition, thousands of fragments of discourse fall into the class of a certain message code and communication channel, even with a certain mental image of the addressee and the recipient - in connection with which, the researcher is forced to consider their ERV to be the same. In turn, in order to distinguish such classes, the researcher must take into account all combinations of typical images of the addressee and the recipient, message codes, communication channels and types of feedback, which is a laborious job that can take decades.
Ни в одном из известных исследований РВ не делается попытки объективно оценить его эффективность, тем более, ее измерить. Все труды находят косвенные доказательства (например, из импликаций текстов, опираясь на здравый смысл и логику) наличия или отсутствия РВ. Если это и возможно сделать более-менее объективно - хотя опосредованные методы изучения РВ через исключительно содержание дискурса не учитывают большое количество привходящих факторов, которые могут повлиять на результаты исследования - то сравнение фрагментов дискурса и других лингвистических данных между собой, т.е. оценка их ЭРВ относительно друг друга в подобных работах субъективна, поскольку невозможно только филологическими методами и подсчетом частотности и процентных значений оценить разницу между ЭРВ одного фрагмента и другого. Кроме того, если нет точных величин, у каждого исследователя может быть свое мнение насчет того, насколько сильно воздействует тот или иной фрагмент; мнение исследователя может зависеть от его принадлежности к какой-либо лингвистической школе, направлению, культуре (славянской, западной, восточной и др.) и т.д., тем более, если исследование осуществляется на материале языков из разных языковых групп. Следовательно, такое исследование в большой степени будет субъективным.None of the known studies of RS makes an attempt to objectively evaluate its effectiveness, let alone measure it. All works find indirect evidence (for example, from the implications of texts, based on common sense and logic) of the presence or absence of real estate. If this is possible to do more or less objectively - although the indirect methods of studying the RS through exclusively the content of the discourse do not take into account a large number of contributing factors that may affect the results of the study - then comparing fragments of the discourse and other linguistic data among themselves, i.e. the assessment of their ERV relative to each other in such works is subjective, since it is impossible only by philological methods and by calculating the frequency and percentage values to estimate the difference between the ERV of one fragment and another. In addition, if there are no exact values, each researcher may have his own opinion about how strongly this or that fragment affects; the opinion of the researcher may depend on his belonging to any linguistic school, direction, culture (Slavic, Western, Eastern, etc.), etc., especially if the study is carried out on the basis of languages from different language groups. Consequently, such a study will be subjective to a large extent.
Основной путь повышения объективности и точности исследования ЭРВ лежит через непосредственное получение данных от большого количества потенциальных реципиентов, на которых может быть направлено РВ, с помощью онлайн-анкетирования, преобразования качественных параметров и показателей в количественные и статистической обработки. Реципиентами являются носители языка, поскольку именно на них направлено РВ.The main way to increase the objectivity and accuracy of ERV research lies through the direct receipt of data from a large number of potential recipients to whom RV can be sent, using online questioning, converting qualitative parameters and indicators into quantitative and statistical processing. Recipients are native speakers, since it is on them that RV is directed.
Технической задачей изобретения является точное измерение, сравнение и прогнозирование ЭРВ фрагмента дискурса на любом языке за счет преобразования качественных параметров в количественные, в т.ч. путем приписывания значений фиктивным переменным согласно поставленным гипотезам и введения количественной оценки степени убедительности фрагмента; возможность проведения одним человеком недорогостоящегоAn object of the invention is the accurate measurement, comparison and prediction of the ERV of a discourse fragment in any language by converting qualitative parameters into quantitative ones, including by assigning values to dummy variables according to the hypotheses put forward and introducing a quantitative assessment of the degree of persuasiveness of the fragment; the possibility of one-person low-cost
исследования на основе ответов неограниченного количества респондентов (онлайн-анкетирование) в короткие сроки и автоматической статистической обработки.research based on the responses of an unlimited number of respondents (online questionnaires) in a short time and automatic statistical processing.
Поставленная задача достигается тем, что способ прогнозирования эффективности речевого воздействия (ЭРВ) фрагмента включает в себя отбор параметров ЭРВ в исследуемых языках, отбор фрагментов дискурса с данными параметрами, определение ЭЛФ, влияющих на ЭРВ, нивелирование влияния этих ЭЛФ в отобранных фрагментах, составление онлайн-анкеты и проведение онлайн-анкетирования на исследуемых языках (перевод осуществляется с сохранением потенциала РВ), проведение корреляционного и сравнительного анализа результатов онлайн-анкетирования с составлением уравнения регрессии, позволяющего прогнозировать ЭРВ в зависимости от наличия и количества параметров ЭРВ, ранжирование данных параметров согласно значениям стандартизированных Beta-коэффициентов.The problem is achieved in that the method for predicting the effectiveness of speech exposure (ERV) of a fragment includes selecting ERV parameters in the languages studied, selecting fragments of discourse with these parameters, determining ELFs that affect ERV, leveling the effect of these ELFs in selected fragments, compiling online questionnaires and conducting online questionnaires in the languages studied (translation is carried out while preserving the potential of RS), conducting a correlation and comparative analysis of the results of online questioning with representation of the regression equation to predict the ERV depending on the presence and quantity of ERV parameters ranking parameter data according to the standardized values Beta-coefficients.
Категоричный вывод о том, насколько эффективен тот или иной фрагмент с точки зрения речевого воздействия, формулируют в соответствии с составленным уравнением регрессии, если коэффициент Пирсона для данной модели не менее 0,1, что говорит о наличие связи включенных в модель параметров и ЭРВ.A definitive conclusion about how effective a particular fragment is from the point of view of speech exposure is formulated in accordance with the compiled regression equation if the Pearson coefficient for this model is not less than 0.1, which indicates the presence of a connection between the parameters included in the model and the EDS.
Способ позволяет объективно оценить и точно измерить ЭРВ фрагмента дискурса за счет непосредственного оценивания убедительности фрагмента носителями языка по 5-балльной шкале путем онлайн-анкетирования и за счет преобразования качественных параметров в количественные, в т.ч. приписывания значений фиктивным переменным.The method allows you to objectively assess and accurately measure the ERV of a discourse fragment by directly assessing the persuasiveness of a fragment by native speakers on a 5-point scale by online questioning and by converting qualitative parameters into quantitative ones, including assigning values to dummy variables.
В качестве параметров ЭРВ рассматриваем все возможные в дискурсе риторические приемы, которые способны влиять на ЭРВ фрагмента: метафора, сравнение, повтор, стилистический контраст, нестилистический контраст, эпитет, ирония/сатира, риторический вопрос, преувеличение/преуменьшение, каламбур (игра слов), неологизм, аллюзия, перестановка частей слова/предложения, замена слова/структуры другим словом/структурой, олицетворение, зевгма, градация, плотность риторических приемов (18 параметров).As the parameters of the ERV, we consider all possible rhetorical techniques in the discourse that can influence the ERV of a fragment: metaphor, comparison, repetition, stylistic contrast, non-stylistic contrast, epithet, irony / satire, rhetorical question, exaggeration / understatement, pun (wordplay), neologism, allusion, rearrangement of parts of a word / sentence, replacing a word / structure with another word / structure, personification, zevgma, gradation, density of rhetorical devices (18 parameters).
При этом из массива параметров исключаются те, которые являются видом или подвидом выделенных выше параметров. Так, метонимию и синекдоху относят к параметру «метафора», поскольку все три риторических приема основаны на сходстве признака(-ов) двух объектов действительности и переносе этого признака на другой объект.At the same time, those that are a type or subspecies of the parameters highlighted above are excluded from the array of parameters. So, metonymy and synecdoch are referred to the “metaphor” parameter, since all three rhetorical devices are based on the similarity of the sign (s) of two objects of reality and the transfer of this sign to another object.
Дополнительно в анализ могут быть включены и другие параметры, специфичные для определенных языков. При этом все остальные процедуры способа измерения ЭРВ остаются теми же.Additionally, other parameters specific to specific languages may be included in the analysis. In this case, all other procedures of the method of measuring the electric propulsion are the same.
Из массива полученных онлайн-анкет исключаются незаполненные анкеты, т.к. не дают общей картины ответов, а также те онлайн-анкеты, которые заполнялись в течение периода не менее 1,5 минут и не более 10 минут. Поскольку задаче соответствует измерение только ЭРВ, то автоматическое или бездумное заполнение онлайн-анкет (как в случае, если те заполнялисьUnfilled questionnaires are excluded from the array of received online profiles. do not give a general picture of the answers, as well as those online questionnaires that were filled out over a period of at least 1.5 minutes and no more than 10 minutes. Since the task corresponds to measuring only the electric propulsion, then automatically or thoughtlessly filling out online questionnaires (as if they were filled out
в течение периода менее 1,5 минут) или, наоборот, слишком глубокое вникание в суть фрагмента (как в случае, если те заполнялись в течение периода более 10 мин.), а не быстрая реакция респондента с последующим кликом на одну из категорий 5-балльной шкалы ответов, могут в сумме дать необъективную картину результатов, особенно если количество таких онлайн-анкет превышает 5% от общего количества. Среднее время заполнения онлайн анкет равняется 4-6 мин. и рассчитывается исходя из количества фрагментов в онлайн-анкете и их длины. Наиболее оптимальное количество фрагментов для лингвистических Интернет-опросов - 8, а длина каждого фрагмента - 300 печатных знаков.within a period of less than 1.5 minutes) or, conversely, a deeper understanding of the essence of the fragment (as if they were filled over a period of more than 10 minutes), rather than a quick reaction of the respondent with a subsequent click on one of the categories 5- A scale of answers can add up to a biased picture of the results, especially if the number of such online profiles exceeds 5% of the total. The average time for filling out online profiles is 4-6 minutes. and is calculated based on the number of fragments in the online application and their length. The most optimal number of fragments for linguistic Internet surveys is 8, and the length of each fragment is 300 characters.
Для увеличения точности и объективности заявленного способа косвенным подтверждением правильности составленных уравнений регрессии для ЭРВ является дополнительный анализ среднеарифметических значений ЭРВ, а проверкой уравнения служит анализ пропорций значений ЭРВ, вычисленных с помощью уравнения и с помощью анализа среднеарифметических значений реальных ответов респондентов на определенные фрагменты, выбираемые случайно. Если разница между значениями, полученных делением значений, полученных с помощью уравнения, на значения, полученные с помощью анализа среднеарифметических значений, не превышает 0,1, то уравнение регрессии для данного языка считается точным; если эта разница находится в диапазоне 0,1-0,3 - то приблизительным; если разница составляет более 0,3 - то неточным. Получение приблизительного уравнения может быть вызвано влиянием факторов, которые не были учтены на предыдущих этапах способа измерения.In order to increase the accuracy and objectivity of the claimed method, an indirect analysis of the arithmetic mean values of the ERV is an indirect confirmation of the correctness of the compiled regression equations for the ERW, and the equation is verified by analyzing the proportions of the ERV values calculated using the equation and by analyzing the arithmetic mean values of the respondents' real answers to certain fragments randomly selected . If the difference between the values obtained by dividing the values obtained using the equation by the values obtained using the analysis of arithmetic mean values does not exceed 0.1, then the regression equation for this language is considered accurate; if this difference is in the range of 0.1-0.3 - then approximate; if the difference is more than 0.3, then it is inaccurate. Obtaining an approximate equation can be caused by the influence of factors that were not taken into account in the previous steps of the measurement method.
Однако признание уравнения приблизительным не означает неуспех в плане общей оценки ЭРВ и сравнения параметров ЭРВ. Надежные коэффициенты корреляции, вычисленные для проверки выдвинутых гипотез, - достаточное основание для выводов о частичном подтверждении гипотез и наличии тенденций в исследуемых языках. Также данные коэффициенты для разных языков могут сравниваться между собой.However, the recognition of the equation approximate does not mean failure in terms of the overall assessment of the ERV and comparison of the parameters of the ERV. Reliable correlation coefficients calculated to test the hypotheses put forward are sufficient grounds for conclusions about partial confirmation of hypotheses and the presence of trends in the languages being studied. Also, these coefficients for different languages can be compared with each other.
Сущность изобретения заключается в способе измерения, сравнения и прогнозирования ЭРВ фрагмента дискурса в разных языках путем онлайн-анкетирования и корреляционного и сравнительного анализа его результатов; для проведения онлайн-анкетирования разрабатывается специальное программное обеспечение, в т.ч. автоматическая запись ответов респондентов в специализированную базу данных, пригодную для последующей фильтрации на выделенные параметры ЭРВ, а также социологические параметры: пол, возраст, образование, и для последующей автоматической статистической обработки в специализированных программных пакетах Microsoft Excel, STATISTICA, UNISTAT 6.5, MedCalc, SPSS 20, SAS и др.; при этом статистическая обработка предоставляет данные, пригодные для сравнительного анализа значений ЭРВ и ее параметров в исследуемых языках, а именно: вычисляются коэффициенты корреляции Пирсона и стандартизированные коэффициенты Beta, составляютсяThe invention consists in a method for measuring, comparing and predicting an ERV fragment of a discourse in different languages by means of an online questionnaire and a correlation and comparative analysis of its results; special software is being developed for conducting online questionnaires, including automatic recording of respondents' answers in a specialized database suitable for subsequent filtering on the selected EW parameters, as well as sociological parameters: gender, age, education, and for subsequent automatic statistical processing in specialized software packages Microsoft Excel, STATISTICA, UNISTAT 6.5, MedCalc, SPSS 20, SAS et al .; in this case, statistical processing provides data suitable for a comparative analysis of the ERV values and its parameters in the studied languages, namely: Pearson correlation coefficients and standardized Beta coefficients are calculated, and
уравнения регрессии для измерения и прогнозирования ЭРВ фрагмента в определенном языке, проверяются уравнения регрессии пропорциональным анализом значений ЭРВ, полученных с помощью уравнения и с помощью неопосредованного анализа среднеарифметических значений ответов респондентов, сравниваются значения ЭРВ одних и тех же фрагментов на разных языках, подтверждаются или опровергаются выдвинутые гипотезы исследования, ранжируются параметры ЭРВ согласно значениям стандартизированных Beta-коэффициентов (см. Таблица Coefficients » ниже).regression equations for measuring and predicting the ERV of a fragment in a particular language, checking the regression equations by proportional analysis of the ERV values obtained using the equation and using a non-mediated analysis of the arithmetic mean values of the respondents' answers, comparing the ERV values of the same fragments in different languages, confirming or refuting the advanced research hypotheses, ERV parameters are ranked according to the values of standardized Beta coefficients (see the Coefficients table "below).
Предлагаемый способ поясняется скриншотами с сайта, где находится онлайн-анкета:The proposed method is illustrated by screenshots from the site where the online application is located:
Фиг. 1 Главная веб-страница онлайн-анкеты;FIG. 1 Main page of the online application form;
Фиг. 2 Веб-страница онлайн-анкеты с одним из фрагментов;FIG. 2 Web page of an online questionnaire with one of the fragments;
Фиг. 3 Скриншот фрагмента онлайн-анкеты на иврите;FIG. 3 Screenshot of a fragment of an online questionnaire in Hebrew;
Фиг. 4 Блок схема устройства для реализации способа.FIG. 4 Block diagram of a device for implementing the method.
Способ заключается в следующем.The method is as follows.
Для повышения объективности случайной выборки выбирают вид дискурса для анализа и на одном из исследуемых языков подбирают материал (книги, речи, выступления и т.д.) объемом не менее 40000 слов в рамках этого вида дискурса. Методом случайной выборки отбирают фрагменты дискурса, поскольку любой из них оказывает какое-либо РВ. РВ равняться нулю не может, может только стремиться к нулю. Из каждого фрагмента выделяют параметры, связанные с РВ. Из всех параметров отбирают те, которые способны воздействовать на реципиента. Это те параметры, благодаря которым элементы фрагмента дискурса (слова, словосочетания и т.д.) переходят из нейтрального стиля в другой (официально-деловой, разговорный, жаргон и т.п.), а именно: метафора, сравнение, повтор, стилистический контраст, нестилистический контраст, эпитет, ирония/сатира, риторический вопрос, преувеличение/преуменьшение, каламбур (игра слов), неологизм, аллюзия, перестановка частей слова/предложения, замена слова/структуры другим словом/структурой, олицетворение, зевгма, градация. Это т.н. риторические приемы, цель которых является повысить ЭРВ фрагмента. Отдельно выделяют параметр плотности риторических приемов.To increase the objectivity of a random sample, choose the type of discourse for analysis and select material (books, speeches, speeches, etc.) with a volume of at least 40,000 words within this type of discourse in one of the languages studied. Fragments of discourse are selected by random sampling, since any of them has some kind of real-life discourse. RV cannot be zero, it can only tend to zero. From each fragment, parameters associated with PB are distinguished. Of all the parameters, those that are able to act on the recipient are selected. These are the parameters due to which the elements of the discourse fragment (words, phrases, etc.) move from a neutral style to another (official business, conversational, jargon, etc.), namely: metaphor, comparison, repetition, stylistic contrast, non-stylistic contrast, epithet, irony / satire, rhetorical question, exaggeration / understatement, pun (wordplay), neologism, allusion, rearrangement of parts of a word / sentence, replacing a word / structure with another word / structure, personification, zevgma, gradation. This is the so-called rhetorical techniques, the purpose of which is to increase the ERV of the fragment. Separately, the density parameter of rhetorical devices is distinguished.
После отбора параметров выделяют большие отрезки дискурса из подобранного материала на одном из исследуемых языков.After selecting the parameters, large sections of the discourse are distinguished from the selected material in one of the languages studied.
Составляют стандартный список ЭЛФ, выделенных из больших отрезков дискурса: ЭЛФ пространства, времени, социальные ЭЛФ (принадлежность к социальному классу, социальные потребности, количество адресатов речи, социальные задачи исторического периода, активность общественной жизни и степень участия в ней), собственно политические ЭЛФ (интенсивность связи с историей общества, политические цели и задачи исторического периода), психологические ЭЛФ (личные отношений между субъектами дискурса, психического состояния).They compile a standard list of ELFs selected from large sections of the discourse: ELFs of space, time, social ELFs (belonging to the social class, social needs, the number of speech recipients, social tasks of the historical period, the activity of public life and the degree of participation in it), actually political ELFs ( the intensity of communication with the history of society, political goals and objectives of the historical period), psychological ELF (personal relations between subjects of discourse, mental state).
На основании стандартного списка ЭЛФ выделяют ЭЛФ, влияющие именно на ЭРВ в исследуемых языках путем пропорционального анализа параметров в фрагментах дискурса; получают специализированный список ЭЛФ.On the basis of the standard ELF list, ELFs are distinguished that affect specifically the ERW in the studied languages by proportional analysis of the parameters in the discourse fragments; get a specialized ELF list.
Составляют таблицу, где указывают пропорции одного параметра к общему числу параметров в конкретном фрагменте дискурса:They compose a table where they indicate the proportions of one parameter to the total number of parameters in a particular fragment of the discourse:

Так может быть определена относительная величина присутствия параметра в фрагменте дискурса. Соотнесение выделенных параметров с фрагментами дискурса позволяет ранжировать последние согласно любому из этих параметров. Подобное ранжирование при распределении каждого ЭЛФ, например, по убыванию позволяет при сопоставительном анализе ранжирования фрагментов дискурса и распределения ЭЛФ выделить между ними зависимости.In this way, the relative magnitude of the presence of a parameter in a discourse fragment can be determined. Correlation of selected parameters with discourse fragments allows ranking the latter according to any of these parameters. Such a ranking in the distribution of each ELF, for example, in decreasing order, allows for a comparative analysis of the ranking of fragments of discourse and distribution of ELF to distinguish between them.
Пример: согласно Табл. 1 распределяют фрагменты дискурса по убыванию ЭЛФ пространства, т.е. по уменьшению объема пространства (стадион (фрагмент А) - площадь (фрагмент Б) - официальная трибуна (фрагмент В). Добавляют столбец с указанным ЭЛФ и сопоставляют значения на предмет устойчивой зависимости (корреляции) между указанным ЭЛФ и параметрами:Example: according to Tab. 1 distribute fragments of discourse in descending order of ELF space, i.e. to reduce the volume of space (stadium (fragment A) - area (fragment B) - official tribune (fragment C). Add a column with the specified ELF and compare the values for a stable relationship (correlation) between the specified ELF and the parameters:
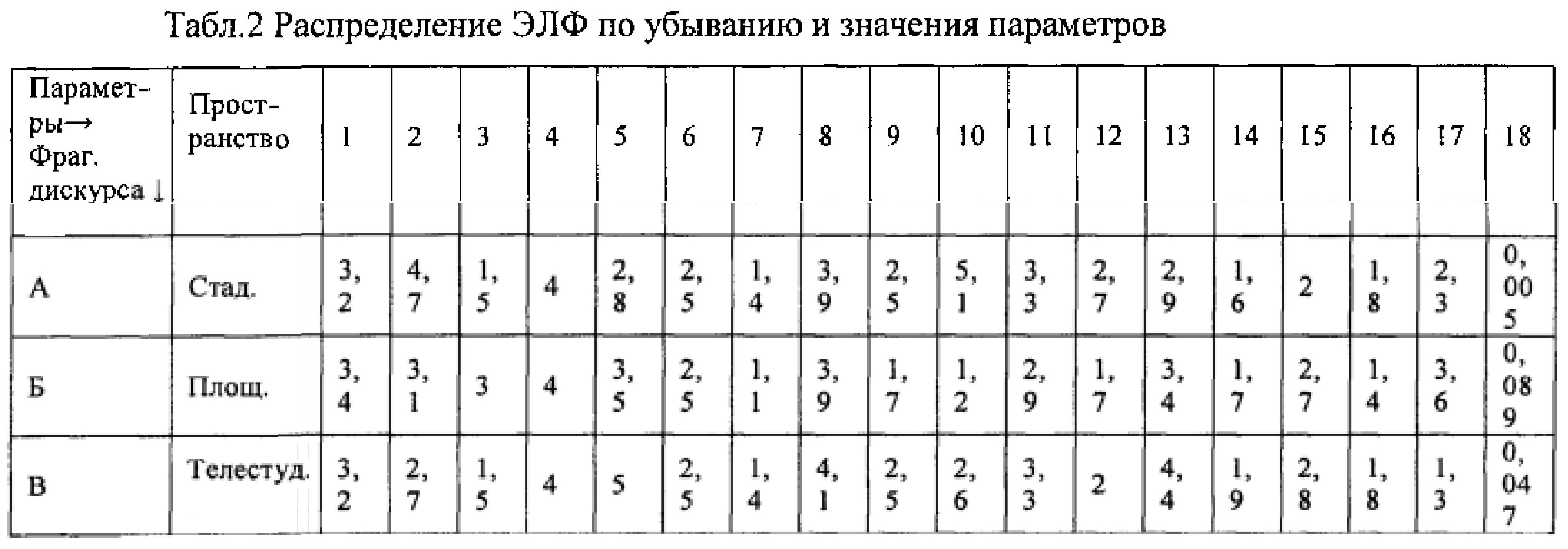
Под устойчивой зависимостью понимается такое ранжирование фрагментов дискурса по одному из параметров, которое полностью коррелирует с распределением ЭЛФ, и ни одно из значений параметра или распределения ЭЛФ не нарушает общую тенденцию.A stable dependence refers to such a ranking of discourse fragments according to one of the parameters that completely correlates with the distribution of ELF, and none of the values of the parameter or distribution of ELF violates the general tendency.
Получают устойчивые зависимости между ЭЛФ и параметрами. Если устанавливают устойчивые зависимости между определенным ЭЛФ и хотя бы одним из параметров, то данные ЭЛФ относят к ЭЛФ, влияющим на ЭРВ. В случае с Табл.2 существуют устойчивые зависимости между объемом пространства дискурса и параметрами 2, 14, 15 (прямо пропорциональные); 5, 13 (обратно пропорциональные).Stable relationships between ELF and parameters are obtained. If stable relationships are established between a certain ELF and at least one of the parameters, then the ELF data are referred to as ELFs affecting the ERV. In the case of Table 2, there are stable relationships between the amount of discourse space and parameters 2, 14, 15 (directly proportional); 5, 13 (inversely proportional).
С помощью подобной процедуры проверяются все ЭЛФ из стандартного списка и все параметры на наличие устойчивых зависимостей между ними. Составляют специализированный список ЭЛФ (тех, которые влияют на ЭРВ).Using a similar procedure, all ELFs from the standard list and all parameters are checked for stable dependencies between them. Make a specialized list of ELF (those that affect the ERV).
В целях проведения психолингвистического исследования ЭРВ, максимально свободного от вмешательства привходящих факторов экстралингвистического характера, нивелируют влияние ЭЛФ из специализированного списка. Другими словами, при проведении исследования оставляют фрагменты с одинаковыми ЭЛФ из специализированного списка. Например, все фрагменты дискурса произносились в телестудии.In order to conduct a psycholinguistic study of the ERV, which is as free as possible from interference of extralinguistic factors, the influence of ELF from a specialized list is leveled. In other words, when conducting the study, fragments with the same ELF are left from the specialized list. For example, all fragments of the discourse were pronounced in a television studio.
Исследователем могут вводиться дополнительные экстралингвистические критерии отбора, если их влияние на ЭРВ очевидно. К таким критериям относится, например, авторство.The researcher may introduce additional extralinguistic selection criteria, if their effect on the ERV is obvious. These criteria include, for example, authorship.
Таким образом получают набор фрагментов дискурса с одинаковыми ЭЛФ: все фрагменты находятся в равных экстралингвистических условиях.Thus, a set of discourse fragments with the same ELF is obtained: all fragments are in equal extra-linguistic conditions.
Далее из этого набора фрагментов отбирают фрагменты с выделенными 18 параметрами в соответствии с количеством параметров - 18 фрагментов, добавляют 2 фрагмента, необходимых для сравнения плотностей риторических приемов, 2 фрагмента, в которых риторические приемы отсутствуют, и 1 контрольный фрагмент. Итого 23 фрагмента. Контрольный фрагмент подбирают так, чтобы он содержал 100%-но логичную, энциклопедическую и доступную всем информацию. Контрольный фрагмент выявляет тех респондентов, которые посчитали его нелогичным и неубедительным, что означает, что они не вдавались в суть фрагмента, а оценивали свои мнения и ощущения, насколько убедительно этот фрагмент звучит. Это и является одной из задач исследования - собрать ответы респондентов, которые не вдавались в суть фрагмента и при ответе руководствовались не логикой, своимиThen, fragments with 18 parameters selected in accordance with the number of parameters — 18 fragments are selected from this set of fragments, 2 fragments are needed to compare the densities of rhetorical devices, 2 fragments in which there are no rhetorical devices, and 1 control fragment. Total 23 fragments. The control fragment is selected so that it contains 100% logical, encyclopedic and accessible to all information. The control fragment identifies those respondents who considered it illogical and unconvincing, which means that they did not go into the essence of the fragment, but assessed their opinions and feelings about how convincing this fragment sounds. This is one of the objectives of the study - to collect the answers of respondents who did not go into the essence of the fragment and were guided not by logic, by their answers.
знаниями, а ощущениями, психологической реакцией и быстро сформированным мнением о содержимом фрагмента.knowledge, and sensations, psychological reaction and quickly formed opinion about the contents of the fragment.
Для оценки параметра «плотность риторических приемов» необходимо ввести 3 фрагмента с наиболее разными плотностями: низкой, средней и высокой: 0,005; 0,01; 0,02. Указанные плотности могут варьироваться от языка к языку от одного массива фрагментов к другому. Таким образом, получают набор оригинальных фрагментов дискурса, в которых перемешаны выделенные параметры и последние содержатся в различном количестве. Для повышения объективности исследования уравнивают объемы фрагментов и количество параметров. Объем фрагмента, равный 400 печатным знакам - достаточное количество для реализации любого риторического приема. Количество параметров уравнивают путем оставления в каждом фрагменте по 1 параметру. В итоге, получают набор из 18 модифицированных фрагментов, содержащих 18 выделенных параметров, а также 2 дополнительных фрагмента для сравнения плотностей контраста при корреляционном анализе, 2 фрагмента без параметров в качестве эталона нормы РВ и 1 контрольный фрагмент. Фрагменты с эталоном нормы РВ вводятся, во-первых, для того, чтобы полностью убедиться, что наличие параметров РВ приводит к отклонению от нормы и последующему повышению ЭРВ, а во-вторых, чтобы определить насколько ЭРВ фрагментов без выделенных параметров отличается от фрагментов с ними.To evaluate the parameter “density of rhetorical devices”, it is necessary to introduce 3 fragments with the most different densities: low, medium and high: 0.005; 0.01; 0.02. The indicated densities can vary from language to language from one array of fragments to another. Thus, a set of original discourse fragments is obtained in which the selected parameters are mixed and the latter are contained in various quantities. To increase objectivity, studies equalize the volume of fragments and the number of parameters. The volume of the fragment equal to 400 printed characters is a sufficient amount for the implementation of any rhetorical device. The number of parameters is equalized by leaving 1 parameter in each fragment. As a result, a set of 18 modified fragments containing 18 selected parameters is obtained, as well as 2 additional fragments for comparing contrast densities in the correlation analysis, 2 fragments without parameters as a reference standard for RV, and 1 control fragment. Fragments with a standard of standard RV are introduced, firstly, in order to fully verify that the presence of parameters of the RV leads to a deviation from the norm and a subsequent increase in the ERV, and secondly, to determine how much the ERV of fragments without selected parameters differs from fragments with them .
Затем из полученных фрагментов составляют онлайн-анкету. Данный процесс включает в себя как составление анкеты, так и разработку специального программного обеспечения для ее вывешивания в сети Интернет. Для получения хорошего процента заполненных анкет делят набор фрагментов на 3 примерно равные части и получают по 7+7+6 (20) фрагментов в онлайн-анкетах и добавляют в каждую из них 2 фрагмента без риторических приемов (т.е. без параметров) и 1 контрольный фрагмент. Соответственно, приходят к следующему: 10+10+9 фрагментов в 3 онлайн-анкетах.Then, from the fragments obtained, an online questionnaire is compiled. This process includes both the preparation of the questionnaire and the development of special software for posting it on the Internet. To obtain a good percentage of completed questionnaires, divide the set of fragments into 3 approximately equal parts and get 7 + 7 + 6 (20) fragments in online questionnaires and add 2 fragments to each of them without rhetorical techniques (i.e. without parameters) and 1 control fragment. Accordingly, they come to the following: 10 + 10 + 9 fragments in 3 online profiles.
Все фрагменты в онлайн-анкетах организованы по следующим двум принципам. В основной части (т.е. в середине анкеты с 3-го по 7-й фрагменты) располагают самые трудные для восприятия фрагменты. Трудные для восприятия фрагменты чередуют с более простыми.All fragments in online profiles are organized according to the following two principles. In the main part (i.e., in the middle of the questionnaire from the 3rd to the 7th fragments), the most difficult to understand fragments are located. Difficult to perceive fragments alternate with simpler ones.
Устанавливают период проведения онлайн-анкетирования в пределах максимально сжатых сроков - 3 месяца, поскольку в течение более длинных периодов могут появиться ЭЛФ, не зависящие ни от исследователя, ни от условий в которых проводится исследование.The period for conducting an online questionnaire is set within the shortest possible time — 3 months, since ELFs may appear over longer periods that are independent of the researcher or the conditions under which the study is conducted.
Устанавливают диапазон времени, в течение которого онлайн-анкета должна быть заполнена: максимальный диапазон от -60% (в мин.) до +50% (в мин.) от общего количества фрагментов в этой онлайн-анкете. Соответственно, для онлайн-анкеты в 9-10 фрагментов, этот диапазон равняется 4-15 минут. Ограничение диапазона времени вводится как во избежание быстрого автоматического заполнения онлайн-анкеты, так и во избежание анкет, гдеSet the time range during which the online application should be filled: the maximum range is from -60% (in min.) To + 50% (in min.) Of the total number of fragments in this online application. Accordingly, for an online questionnaire in 9-10 fragments, this range is 4-15 minutes. The time range limitation is introduced both to avoid the quick automatic filling of the online questionnaire and to avoid questionnaires, where
респонденты слишком глубоко пытались вникнуть в суть фрагмента, что не соответствует задачам исследования и инструкции к онлайн-анкете, которую респонденты читают перед ее заполнением. Онлайн-анкета проверяет и регистрирует убедительность фрагментов - их ЭРВ - а не их логичность, моральность и т.п.the respondents tried too deeply to understand the essence of the fragment, which does not correspond to the objectives of the study and the instructions for the online questionnaire that the respondents read before filling it out. An online questionnaire checks and records the credibility of fragments - their ERV - and not their logic, morality, etc.
В фрагментах используются грамматические конструкции не выше средней сложности, может использоваться небольшое количество специфической терминологии изучаемого вида дискурса. Для снижения сложности восприятия в фрагментах избегаются пассивные конструкции, жаргон, аббревиатуры и сложные/редкие слова.The fragments use grammatical constructions of no higher than average complexity, a small amount of specific terminology of the studied type of discourse can be used. Passive constructions, jargon, abbreviations, and complex / rare words are avoided in fragments to reduce perceptual complexity.
Каждая онлайн-анкета состоит из вводной, реквизитной классификационной и информационной частей и повторной благодарности.Each online questionnaire consists of an introductory, requisite classification and information part and a second thanks.
- Вводная часть содержит общую информацию об исследовательском институте, о цели исследовании, практическом применении результатов исследования, а также информацию о полезности данной анкеты, что повышает мотивацию респондентов.- The introductory part contains general information about the research institute, the purpose of the study, the practical application of the research results, as well as information about the usefulness of this questionnaire, which increases the motivation of respondents.
- В реквизитной части даются данные об учреждении, проводящем анкетирование, названии анкеты, времени проведения, теме.- The requisite part provides information about the institution conducting the survey, the name of the questionnaire, time, topic.
- Классификационная часть (паспортичка) запрашивает данные о респонденте: пол, возраст, образование и электронный адрес (опционально для тех, кто хотел бы получить результаты исследования на свой адрес электронной почты)- The classification part (passport) requests information about the respondent: gender, age, education and email address (optional for those who would like to receive the results of the study to their email address)
- Информационная часть содержит вводные инструкции по заполнению, 6 основных вопросов-фрагментов (4 с параметрами, 2 без и 1 контрольный фрагмент)- The information part contains introductory instructions for completing, 6 basic questions-fragments (4 with parameters, 2 without and 1 control fragment)
- Повторная благодарность за прохождение анкеты находится в ее конце.- Repeated gratitude for passing the questionnaire is at its end.
Любые элементы в фрагментах, способные склонить респондента к тому или иному варианту ответа были максимально элиминированы. Такие элементы широко известны под названием эффектов (в зарубежной литературе - biases). Ниже представлена таблица со всеми возможными в онлайн-анкете эффектами и способами их нейтрализации, которые применяют при составлении онлайн-анкеты для точного измерения ЭРВ:Any elements in fragments that could incline the respondent to one or another variant of the answer were eliminated as much as possible. Such elements are widely known under the name of effects (in foreign literature - biases). Below is a table with all the possible effects in the online questionnaire and ways to neutralize them, which are used in the preparation of the online questionnaire for accurate measurement of the ERV:

В качестве вариантов ответа применяют сбалансированную 5-балльную шкалу: 2 позитивных ответа («убедительно» и «абсолютно убедительно»), 2 негативных («неубедительно», «совершенно неубедительно») и 1 нейтральный («затрудняюсь ответить»). Наличие в фрагментах дискуссионных тем сделало все варианты ответа равновозможными, что крайне важно для получения объективных результатов.As a response option, a balanced 5-point scale is used: 2 positive answers (“convincingly” and “absolutely convincing”), 2 negative (“unconvincing”, “completely unconvincing”) and 1 neutral (“difficult to answer”). The presence of discussion topics in fragments made all possible answers equally possible, which is extremely important for obtaining objective results.
Кроме того, фрагменты в каждой из 3-х онлайн-анкет не взаимосвязаны ни тематически, ни логически. В анкетах учитывают специфику культуры и используют реалии, понятные большинству респондентов, говорящих на том или ином языке. В онлайн-анкете повсеместно используются иллюстрации. При заполнении онлайн-анкеты предусмотрена полная анонимность. Программа ЭВМ для онлайн-анкет разработана под цель и задачи исследования.In addition, fragments in each of the 3 online profiles are not related either thematically or logically. The questionnaires take into account the specifics of culture and use realities that are understandable to most respondents who speak a particular language. The online application is widely used illustrations. When filling out an online application, complete anonymity is provided. The computer program for online questionnaires is designed for the purpose and objectives of the study.
Она написана на языках HTML и Javascript с применением РНР для обработки данных на сервере. Также используется библиотека jQuery для динамического отображения контента: загрузка новых фрагментов анкеты без перезагрузки страницы. Данные об ответах респондентов записываются в базу данных MySQL для дальнейшей работы с полученным набором данных.It is written in HTML and Javascript using PHP to process data on the server. The jQuery library is also used to dynamically display content: loading new fragments of the questionnaire without reloading the page. Data on the responses of the respondents is recorded in the MySQL database for further work with the obtained data set.
Новые технические решения, предпринятые при разработке программного обеспечения для онлайн-анкеты.New technical solutions undertaken in the development of software for online profiles.
1. Анкеты чередуются с каждым новым посещением сайта с цикличностью: анкета №1, 2, 3. В итоге, количество респондентов, ответивших на каждую из 3 онлайн-анкет будет, примерно одинаковым.1. Questionnaires alternate with each new visit to the site in cycles: questionnaire No. 1, 2, 3. As a result, the number of respondents who answered each of the 3 online questionnaires will be approximately the same.
Для этого в таблице choose_tbl в базе данных SQL есть столбец с названием ′number′, который принимает значения 1-3. После того как респондент нажимает «Перейти к анкете», программа обращается к базе данных, чтобы выбрать следующую по счету анкету.To do this, in the choose_tbl table in the SQL database, there is a column called 'number', which takes values 1-3. After the respondent clicks “Go to the questionnaire”, the program contacts the database to select the next questionnaire.
После этого программа обновляет значение в столбце ′number′, чтобы следующему опрашиваемому была показана другая анкета. Всего имеется 3 онлайн-анкеты.After that, the program updates the value in the column 'number' so that the next respondent is shown a different questionnaire. There are 3 online profiles in total.
Код программы выглядит так:The program code looks like this:

2. Найдено решение для отображения текста на языках, графически сильно отличающихся от европейских: иврит, китайский, японский и др.2. A solution was found for displaying text in languages that are graphically very different from European ones: Hebrew, Chinese, Japanese, etc.
Представим простую запись части программы на русском языке:Imagine a simple record of a part of the program in Russian:

![]()
![]()
![]()
![]()
Наша страна - это страна для великих дел. Это страна неограниченных возможностей.»Our country is a country for great things. This is a country of unlimited possibilities. ”
![]()
![]()
В иврите в отличие от русского языка направление текста обратное, т.е. справа налево. Большинство браузеров, отображающих веб-страницы и доступных обычным пользователям, разработаны в Америке или Европе: Internet Explorer (США), Google Chrome (США), Safari (США), Opera (Норвегия) - следовательно преимущественно рассчитаны на европейские языки. Поэтому при попытке простой записи в HTML документе абзаца на иврите слова в предложениях переставлены местами:In Hebrew, in contrast to the Russian language, the direction of the text is opposite, i.e. from right to left. Most browsers that display web pages and are accessible to ordinary users are developed in America or Europe: Internet Explorer (USA), Google Chrome (USA), Safari (USA), Opera (Norway) - therefore, they are mainly designed for European languages. Therefore, when trying to simply write a paragraph in an Hebrew HTML document, the words in sentences are rearranged:

Любой символ - в нашем случае буква языка - может быть закодирован, и если закодировать каждую букву цифрой, цепочка цифр записывается в HTML документе в корректно читаемом браузером направлении, т.е. слева направо. Поэтому запись была представлена в кодировке Unicode:Any character — in our case, a language letter — can be encoded, and if you encode each letter with a number, the string of numbers is written in the HTML document in the direction that the browser reads correctly, i.e. from left to right. Therefore, the record was presented in Unicode encoding:

Полученный результат демонстрирует Фиг. 3.The result obtained is shown in FIG. 3.
Более того, такая форма записи решает проблему разнонаправленного текста: например, когда одна часть предложения записывается на языке, где направление текста справа налевоMoreover, this form of writing solves the problem of multidirectional text: for example, when one part of a sentence is written in a language where the direction of the text is from right to left
(семито-хамитская языковая семья), а другая часть - на языке, где направление текста слева направо (славянская, романо-германская группа), или сверху вниз (алтайская языковая семья (японский, корейский и др.) и сино-тибетскаясемья (китайский и др.).(Semitic-Hamitic language family), and the other part is in a language where the direction of the text is from left to right (Slavic, Romano-Germanic group), or from top to bottom (Altai language family (Japanese, Korean, etc.) and Sino-Tibetan family (Chinese and etc.).
3. Для исключения незаполненных анкет (тем самым повышается качество всех полученных данных), а также тех онлайн-анкет, которые заполнялись в течение периода не менее 4 минут и не более 15 минут, в программу введен таймер входа и выхода респондента с сайта. Запись времени входа на сайт производится в момент нажатия кнопки «Перейти к анкете». Программа вставляет в таблицу базы данных соответствующую данной анкете (survey_1, survey_2, survey_3) новую строку с выбранными параметрами (дата и время начала прохождения и завершения онлайн-анкеты, язык).3. To exclude unfilled questionnaires (thereby improving the quality of all received data), as well as those online questionnaires that were filled in for a period of at least 4 minutes and no more than 15 minutes, a responder logged in and out of the site was entered into the program. The entry time to the site is recorded at the moment you click the "Go to profile" button. The program inserts into the database table corresponding to this questionnaire (survey_1, survey_2, survey_3) a new row with the selected parameters (date and time of the beginning of the passage and completion of the online questionnaire, language).
В базу данных SQL записывается новый порядковый номер респондента (его уникальный идентификационный номер), время и дата начала заполнения анкеты и язык, на котором заполнялась анкета. Далее, после ответа на последний вопрос, записывается время и дата завершения заполнения анкеты. Тем самым исследователь получает набор респондентов, заполнивших анкету полностью.The respondent’s new serial number (his unique identification number), the time and date of the start of filling out the questionnaire, and the language in which the questionnaire was filled out are recorded in the SQL database. Further, after answering the last question, the time and date of completion of filling out the questionnaire is recorded. Thus, the researcher receives a set of respondents who fill out the questionnaire completely.
Дату начала заполнения мы получаем с помощью встроенной функции MySQL ′NOW()′.We get the filling start date using the built-in MySQL ′ NOW () ′ function.
Код программы приведен ниже:The program code is shown below:

4. Каждый фрагмент респонденту показывается на как будто отдельной вебстранице. «Как будто», поскольку смена фрагментов производится при помощи JavaScript (библиотека jQuery) без перезагрузки новой веб-страницы. Т.е. в реальности в коде программы4. Each fragment to the respondent is shown on a separate web page. “As if,” because the change of fragments is done using JavaScript (jQuery library) without reloading a new web page. Those. in reality in program code
записаны все фрагменты в одном файле, но при отображении в браузере часть скрыта для респондента, поэтому он видит веб-страницу частично - единовременно для него показывается только один фрагмент. Соответственно, браузер загружает на веб-страницу все 8-9 фрагментов одновременно, но фрагменты показываются по очереди, и только при ответе на текущий фрагмент следующий будет показан, а текущий скрыт. Код программы выглядит так:all fragments are recorded in one file, but when displayed in the browser, part is hidden for the respondent, so he sees the web page partially - at a time only one fragment is displayed for him. Accordingly, the browser uploads to the web page all 8-9 fragments at a time, but the fragments are displayed in turn, and only when the current fragment is answered the next one will be shown and the current one will be hidden. The program code looks like this:

Для получения объективных результатов и точной статистики необходимо, по крайней мере, 200-300 ответов по каждому из параметров и на каждом изучаемом языке. В нашем примере с 18 различными параметрами и 2 дополнительными фрагментами это 900 (300*3) заполненных онлайн-анкет на каждом изучаемом языке.To obtain objective results and accurate statistics, you need at least 200-300 answers for each of the parameters and in each language studied. In our example, with 18 different parameters and 2 additional fragments, these are 900 (300 * 3) completed online profiles in each language studied.
Итак, составлены 3 онлайн-анкеты для оценки, измерения, сравнения и прогнозирования ЭРВ. Пример фрагментов из одной онлайн-анкеты:So, 3 online questionnaires have been compiled for assessing, measuring, comparing and predicting ERV. Example fragments from one online application:
1. (без параметра): «Хотелось бы сказать, что выборы - одно из проявлений демократии, и личное участие в них может решить, каким будет новый парламент. Примите взвешенное решение и приходите на выборы».1. (without parameter): “I would like to say that elections are one of the manifestations of democracy, and personal participation in them can decide what the new parliament will be like. Make an informed decision and come to the polls. ”
2. (повтор): «Когда вы сегодня говорите, что вы построили заводы. Их строили заключенные и солдаты Советской армии. 75%! А Беломорканал - только заключенные. Давайте посадим два миллиона в тюрьмы и бросим на строительство заводов, они нам построят тысячи заводов, тысячи заводов!»2. (repeat): “When you say today that you have built factories. They were built by prisoners and soldiers of the Soviet army. 75% off! And Belomorkanal - only prisoners. Let’s put two million in jail and throw in the construction of factories, they will build thousands of factories, thousands of factories! ”
3. (сравнение): «Наша страна должна конкурировать не за государственный бюджет, который ограничен и мал, а за те средства, которые есть у частного и международного бизнеса. Поэтому мы в дальнейшем будем рассматривать эти вопросы: судебная система, конкурентная среда и частный бизнес как двигатель перемен»;3. (comparison): “Our country should not compete for the state budget, which is limited and small, but for the funds that private and international business has. Therefore, we will continue to consider these issues: the judicial system, the competitive environment and private business as an engine of change ”;
4. (риторический вопрос): «Если исходить из того, что сказал предыдущий оратор, то сто лет назад также было: все выступали. Хорошо, мы пошли по левому пути. Ночью в4. (rhetorical question): “Based on what the previous speaker said, a hundred years ago it was also: everyone spoke. Ok, we went on the left path. At night in
октябре 17-го левые взяли власть. Шли 75 лет. Ну и где результат? При этом у этой власти было все в руках»;On October 17th, the left took power. They walked 75 years. Well, where is the result? Moreover, this power had everything in its hands ”;
5. (стилистический контраст): «Я участвовал в президентских выборах и писал не раз. И вот новый президент, перезагрузилась вся страна, и все думали, каким будет новый президент, он такой у него Iphone есть, он сейчас твиттернет куда-нибудь, погуглит, все решит. И ничего не изменилось»;5. (stylistic contrast): “I participated in the presidential election and wrote more than once. And now the new president, the whole country rebooted, and everyone thought what the new president would be, he has such an Iphone, he’ll now tweet the Internet somewhere, google it, it will solve everything. And nothing has changed ”;
6. (контрольный фрагмент): «Нужно усилить роль институтов государства в жизни общества. Устойчивое развитие общества невозможно без дееспособного государства. Сильное государство - государство, цель которого - создание лучших, наиболее комфортных условий для жизни, творчества и предпринимательства»;6. (control fragment): “We need to strengthen the role of state institutions in society. Sustainable development of society is impossible without a capable state. A strong state is a state whose goal is to create the best, most comfortable conditions for life, creativity and entrepreneurship ”;
7. (метафора): «Я - доктор наук, и понимаю что-нибудь в науке! Сейчас нахожусь во главе партии, и не нужно меня учить. Вот вы на наследстве Маркса едете. Вам должно быть стыдно: вы проедаете наследство партии, которой уже нет. Вот та была партия!»;7. (metaphor): “I am a doctor of science, and I understand something in science! Now I am at the head of the party, and there is no need to teach me. Here you are on the legacy of Marx. You should be ashamed: you are eating the inheritance of a party that is no longer there. That was the party! ”;
8. (нестилистический контраст): «Мы понимаем, что есть люди, у которых имеются интересы в том, чтобы какая-то часть территории нашей страны отделилась. Мы хотели бы объединять вокруг себя, в том числе других людей, для которых целостность страны является действительно безусловным приоритетом»;8. (non-stylistic contrast): “We understand that there are people who have interests in having some part of the territory of our country separate. We would like to unite around ourselves, including other people for whom the integrity of the country is really an absolute priority ”;
9. (без параметра): «Что касается базовых специальностей: учитель, врач, инженер, ученый и военный и другие, зарплата должна быть удвоена. Я сделаю все необходимое для того, чтобы восстановить отношения с соседними государствами. Для молодежи гарантирую бесплатное образование вплоть до высшего.»;9. (without parameter): “As for the basic specialties: teacher, doctor, engineer, scientist and military and others, the salary should be doubled. I will do everything necessary to restore relations with neighboring states. For young people I guarantee free education up to higher education. ”;
10. (эпитет): «Нельзя просто обсуждать в парламентах. Я объявляю войну вранью, популизму и пустым обязательствам. Я независимый политик, и могу говорить о том, что происходит на самом деле… Нам нужно решать проблемы, оставшиеся после трудного периода истории страны.»10. (epithet): “You can’t just discuss in parliaments. I declare war on lies, populism and empty obligations. I’m an independent politician, and I can talk about what really happens ... We need to solve the problems that remain after a difficult period in the history of the country. ”
Все 3 онлайн-анкеты переводят на исследуемые языки с сохранением потенциала РВ. Чтобы потенциал РВ был одинаковым в фрагментах на разных языках сохраняют количественные и качественные характеристики дискурса. К количественным характеристикам относятся: частотность употребления слова, их совместная встречаемость и распределение в дискурсе, объем фрагмента. К качественным характеристикам относится наличие риторических приемов. Для сохранения качественных характеристик фрагмента исключают и/или добавляют, или заменяют риторические приемы с одинаковыми ЭРВ. Например:All 3 online questionnaires are translated into the studied languages while maintaining the potential of the real estate. In order for the potential of the RW to be the same in fragments in different languages, the quantitative and qualitative characteristics of the discourse are preserved. Quantitative characteristics include: the frequency of use of the word, their joint occurrence and distribution in the discourse, the volume of the fragment. Qualitative characteristics include the presence of rhetorical devices. To preserve the qualitative characteristics of the fragment, rhetorical techniques with the same ERV are excluded and / or added, or replaced. For example:
«Столыпин выступал здесь, центристы и правые поддерживали, левые не поддерживали»;“Stolypin spoke here, the centrists and the right supported, the left did not support”;
«Stolypin spoke here, the centrists and the rightists supported him, the leftists did not.» (лексический повтор заменяют на эллипсис);"Stolypin spoke here, the centrists and the rightists supported him, the leftists did not." (Lexical repetition replaced with an ellipsis);
Как известно, нарушение принятой в языке конструкции используется как стилистический прием, поэтому при переводе предложения с русского языка, где использован один прием, в нашем случае лексический повтор, на английский язык оказывается, что в тексте перевода указанного предложения два приема: лексический повтор и нарушение принятой в языке конструкции.As you know, a violation of a design accepted in the language is used as a stylistic device, therefore, when translating a sentence from Russian, where one technique is used, in our case, lexical repetition, into English, it turns out that the text of the translation of this sentence has two methods: lexical repetition and violation accepted in the design language.
Поэтому вместо лексического повтора используем эллипсис. В этом случае количество употреблений эллипсиса возрастает, компенсируя снижение количества лексического повтора. Эллипсис относится к риторическому приему замены структуры другой структурой.Therefore, instead of lexical repetition, we use an ellipse. In this case, the number of uses of the ellipsis increases, compensating for the decrease in the number of lexical repetition. Ellipsis refers to the rhetorical method of replacing a structure with another structure.
Таким образом, при переводе максимально сохраняют потенциал РВ фрагмента, чтобы процесс перевода с одного языка на другой имел наименьшее влияние на результаты исследования.Thus, when translating, the potential of the RV fragment is maximally preserved, so that the process of translation from one language to another has the least impact on the results of the study.
После перевода онлайн-анкеты на исследуемые языки проводят онлайн-анкетирование носителей языка. Все ответы автоматически регистрируются в специализированной базе данных:After the translation of the online questionnaire into the studied languages, an online survey of native speakers is carried out. All answers are automatically registered in a specialized database:

Итак, каждому параметру соответствует 1 фрагмент, а на каждый этот фрагмент есть, допустим, 300 ответов респондентов, оценивших его ЭРВ от 1 до 5; причем 300 ответов на каждом из исследуемых языков. Также есть 300 ответов на 2 фрагмента, в которых выделенные параметры отсутствуют.So, each parameter corresponds to 1 fragment, and for each this fragment there are, say, 300 responses from respondents who rated its ERV from 1 to 5; with 300 answers in each of the studied languages. There are also 300 answers to 2 fragments in which the selected parameters are missing.
С помощью оператора [select * from survey_1 (2, 3) timediff (end_date, start_date) > 240 and timediff (end_date, start_date) < 900] исключают из базы данных онлайн-анкеты, заполненные менее, чем за 4 минуты и более, чем за 15 минут. С помощью дополнительного фильтра [where lang = ru (eng, hebr и т.д.)] отбирают онлайн-анкеты на одном из исследуемых языков.Using the [select * from survey_1 (2, 3) timediff (end_date, start_date)> 240 and timediff (end_date, start_date) <900 operator, exclude online profiles filled out in less than 4 minutes or more than in 15 minutes. Using an additional filter [where lang = ru (eng, hebr, etc.)], online questionnaires in one of the studied languages are selected.
Затем выбирают совокупность всех полученных в результате фильтрации ответов на 3 онлайн-анкеты (на которые ранее поделили изначальные 20 фрагментов) с помощью оператора [union all]. Экспортируют базу данных в формате Microsoft Excel. Соединяют 3 таблицы, полученные в соответствии с ответами на 3 онлайн-анкеты, в одну, где оказываются 18 столбцов с ответов, соответствующими 18 выделенным параметрам, 2 столбца - с дополнительными плотностями риторических приемов (средней и высокой), 2 столбца с ответами респондентов на фрагмент, в котором выделенные параметры отсутствуют (непараметры) и 1 столбец с ответами на контрольный фрагмент - см. Табл. 5.Then select the totality of all the answers received as a result of filtering to 3 online profiles (which were previously divided into the original 20 fragments) using the [union all] operator. Export the database in Microsoft Excel format. Combine 3 tables obtained in accordance with the answers to 3 online questionnaires, into one, where there are 18 columns with answers corresponding to 18 selected parameters, 2 columns with additional rhetorical densities (medium and high), 2 columns with respondents' answers a fragment in which the selected parameters are absent (nonparameters) and 1 column with answers to the control fragment - see Table. 5.


Однако анализ САЗ ЭРВ поверхностный, поскольку не учитывает т.н. «тяжелых хвостов», при наличии которых распределение значений ЭРВ не подчиняется нормальному закону. Поэтому результаты анализа САЗ ЭРВ подтверждаются, корректируются корреляционным анализом на коэффициент Пирсона, который представляет из себя множественную линейную регрессию. В соответствии с этим анализом находят корреляции между зависимой и независимыми переменными, где зависимой переменной выступает ЭРВ фрагмента, а независимыми - 23 параметра и непараметра. Значения зависимой переменной определяют респонденты; значения независимых переменных оценивает исследователь, преобразуя качественные параметры (метафора и др. риторические приемы) в количественные (0,1). По сути вводятся 20 двузначных фиктивных переменных со значениями 0 для непараметров и 1 для параметров. Фиктивная переменная, представляющая плотность риторических приемов, является многозначной и принимает следующие значения: 0 - если параметр плотности отсутствует в фрагменте, 1 - если плотность низкая (в нашем примере - 0,005), 2 - если плотность средняя (в примере - 0,01), 3 - если плотность высокая (в примере более - 0,02).However, the analysis of SAV ERV is superficial, since it does not take into account the so-called “Heavy tails”, in the presence of which the distribution of the ERV values does not obey the normal law. Therefore, the results of the analysis of SAS ERV are confirmed, corrected by correlation analysis for the Pearson coefficient, which is a multiple linear regression. In accordance with this analysis, correlations between the dependent and independent variables are found, where the ERV of the fragment acts as the dependent variable, and 23 parameters and nonparameter are independent. The values of the dependent variable are determined by the respondents; the values of the independent variables are evaluated by the researcher, transforming the qualitative parameters (metaphor and other rhetorical techniques) into quantitative (0.1). In fact, 20 two-digit dummy variables with values of 0 for non-parameters and 1 for parameters are introduced. The dummy variable representing the density of rhetorical devices is ambiguous and takes the following values: 0 - if the density parameter is not in the fragment, 1 - if the density is low (in our example - 0.005), 2 - if the density is average (in the example - 0.01) , 3 - if the density is high (in the example, more than 0.02).
Все приведенные значения зависимой и независимой переменной записываются в таблице в виде пригодном для автоматического вычисления коэффициента корреляции Пирсона и составления уравнения множественной регрессии с данными переменными:All the given values of the dependent and independent variable are written in the table in the form suitable for automatically calculating the Pearson correlation coefficient and compiling the multiple regression equation with these variables:

Номера параметров и непараметров см. Табл.5.Parameter and non-parameter numbers see Table 5.


Все вычисления проводят с помощью программных пакетов Microsoft Excel, STATISTICA, UNISTAT 6.5, MedCalc, SPSS 20, SAS на уровне значимости p<0,05 (вероятность 95%). Другими словами, все полученные результаты с вероятностью 95% будут верны для других репрезентативных выборок в пределах исследуемых языков и видов дискурса (если изначально фрагменты отбирались только из одного вида дискурса).All calculations are performed using the Microsoft Excel, STATISTICA, UNISTAT 6.5, MedCalc, SPSS 20, SAS software packages at a significance level of p <0.05 (95% probability). In other words, all the results obtained with a probability of 95% will be true for other representative samples within the studied languages and types of discourse (if initially fragments were selected from only one type of discourse).
С помощью корреляционного анализа получают следующие данные: коэффициент корреляции Пирсона для всей модели регрессии, для частных корреляций между ЭРВ и параметрами/непараметрами и для частных корреляций между параметрами/непараметрами; переменные, включенные в анализ (поскольку в анализ включают переменные, значения которых имеют нормальное распределение); коэффициент детерминации для всей модели (этот коэффициент определяет качество модели) и его изменение (определяет надежность результатов анализа); F change (также определяет надежность результатов анализа); F-отношение (показывает, насколько случайна связь между переменными); нестандартизированные коэффициенты В для уравнения регрессии; стандартизированные коэффициенты Beta (определяют вклад каждого параметра в величину ЭРВ); диагностики коллинеарности (проверка модели на коллинеарность осуществляется для выявления тесной корреляционной взаимосвязи между отбираемыми для анализа параметрами, совместно воздействующими на величину ЭРВ, которая затрудняет объективное оценивание каждого параметра в отдельности).Using the correlation analysis, the following data are obtained: Pearson's correlation coefficient for the entire regression model, for partial correlations between the ERA and parameters / non-parameters, and for partial correlations between parameters / non-parameters; variables included in the analysis (since the analysis includes variables whose values have a normal distribution); the coefficient of determination for the entire model (this coefficient determines the quality of the model) and its change (determines the reliability of the analysis results); F change (also determines the reliability of the analysis results); F-ratio (shows how random the relationship between the variables is); non-standard coefficients B for the regression equation; standardized Beta coefficients (determine the contribution of each parameter to the ERV value); collinearity diagnostics (checking the model for collinearity is carried out to identify a close correlation between the parameters selected for analysis, which jointly affect the ERV value, which makes it difficult to objectively evaluate each parameter individually).
Для данных в Табл. 7 результаты корреляционного анализа выглядят следующим образом:For the data in Table 7, the results of correlation analysis are as follows:
Descriptive StatisticsDescriptive statistics



Анализируют полученные данные.Analyze the data.
С помощью коэффициента корреляции R для всей модели определяют, существует ли связь между ЭРВ и параметрами и насколько она сильная. Так, в нашем примере самый высокий R в модели 3 - R=0,476, что констатирует существование слабой корреляции между ЭРВ и включенными в анализ переменными 2, 10, 13, а именно: риторическими приемами сравнения, каламбура и перестановки частей слова/предложения. В модель 3 входят данные три параметра.Using the correlation coefficient R for the entire model, it is determined whether there is a relationship between the ERA and the parameters and how strong it is. So, in our example, the highest R in model 3 is R = 0.476, which indicates the existence of a weak correlation between the ERV and the variables 2, 10, 13 included in the analysis, namely, rhetorical methods of comparison, puns and permutation of parts of a word / sentence. Model 3 includes these three parameters.
Коэффициент Пирсона для частных корреляций между ЭРВ и конкретным параметром/непараметром позволяет определить, есть ли между ними связь, направление этой связи и силу. В нашем примере не выявлены такие корреляции.The Pearson coefficient for particular correlations between the EDS and a specific parameter / non-parameter allows us to determine whether there is a connection between them, the direction of this connection, and the strength. In our example, no such correlations were revealed.
Коэффициент детерминации R2 показывает качество всей модели регрессии: чем больше R2, тем качество модели выше. Так, в нашем примере модель 3 является наиболее качественной, поскольку R2=0,227.The determination coefficient R 2 shows the quality of the entire regression model: the larger R 2 , the higher the quality of the model. So, in our example, model 3 is the highest quality, since R 2 = 0.227.
Изменение R2 (R2 change) происходит в результате добавления/удаления из уравнения регрессии того или иного параметра. Соответственно, если величина изменения R2 достаточно большая, то эта модель - хороший предиктор. В нашем примере это модель 3, R2 change = 0,084.A change in R 2 (R 2 change) occurs as a result of adding / removing a parameter from the regression equation. Accordingly, if the magnitude of the change in R 2 is large enough, then this model is a good predictor. In our example, this is model 3, R 2 change = 0.084.
F Change, т.е отношение доли вариации зависимой переменной (ЭРВ) к ее доли вариации, приходящейся на остатки, демонстрирует, что коэффициент Пирсона R для модели 3 с 3 параметрами надежнее, чем для модели 1 с параметром «сравнение», или модели 2 с параметрами «каламбур» и «перестановка частей слова/предложения».F Change, that is, the ratio of the proportion of variation of the dependent variable (ERV) to its fraction of variation attributable to the residuals, demonstrates that the Pearson coefficient R for model 3 with 3 parameters is more reliable than for model 1 with the parameter “comparison”, or model 2 with the parameters "pun" and "permutation of parts of the word / sentence."
С помощью F-отношения, или т.н. F-статистики, определяют носит ли установленная корреляционная связь между переменными случайный или неслучайный характер. F-отношение для всех 3 моделей незначительно, что не позволяет с уверенностью отвергнуть нулевую гипотезу о том, что связь параметров «сравнение», «каламбур» и «перестановка частей слова/предложения» с ЭРВ случайна. Соответственно, связь между данными параметрами и ЭРВ может быть случайной.Using the F-relation, or the so-called F-statistics determine whether the established correlation between variables is random or non-random. The F-ratio for all 3 models is insignificant, which does not allow us to confidently reject the null hypothesis that the connection between the parameters “comparison”, “pun” and “rearrangement of parts of a word / sentence” with EER is random. Accordingly, the relationship between these parameters and the EDS may be random.
В соответствии с нестандартизированными коэффициентами составляют уравнение регрессии, которое при подстановке значений параметров/непараметров (а в нашем случае эти значения 0,1 или 0-4 (плотность риторических приемов)) позволяет измерить ЭРВ конкретного фрагмента, а также прогнозировать ЭРВ при, например, моделировании идеального с точки зрения ЭРВ фрагмента:In accordance with non-standardized coefficients, they compose a regression equation, which, when substituting parameter / non-parameter values (in our case, these values are 0.1 or 0-4 (the density of rhetorical devices)), allows to measure the ERV of a particular fragment, as well as to predict the ERV for, for example, modeling an ideal fragment from the point of view of ERV:
ЭРВ(фр.)=1,574а+1,574b+1,574с+3,426,ERV (fr.) = 1,574a + 1,574b + 1,574s + 3,426,
где а - значение параметра «сравнение», b - значение параметра «каламбур», с - значение параметра «перестановка частей слова/предложения».where a is the value of the parameter “comparison”, b is the value of the parameter “pun”, c is the value of the parameter “permutation of parts of the word / sentence”.
При прогнозировании и моделировании важное значение имеет знание того, какие параметры являются основополагающими и оказывают наибольшее влияние на величину ЭРВ. Для этого вычисляют стандартизированные коэффициенты уравнения регрессии. Так, в нашем примере все 3 параметра осуществляют одинаковый вклад в величину ЭРВ (0,29).In predicting and modeling, it is important to know which parameters are fundamental and have the greatest influence on the magnitude of the ERV. To do this, calculate the standardized coefficients of the regression equation. So, in our example, all 3 parameters make the same contribution to the ERV value (0.29).
Диагностики коллинеарности выявляют наличие взаимосвязей между переменными, т.е. параметрами/непараметрами. Такие связи могут влиять на результаты всего корреляционного анализа, поэтому важно диагностировать отсутствие мультиколлинеарности в модели регрессии. В нашем примере показатели коллинеарности имеют следующие значения: Eigenvalue (собственное значение коллинеарности) = 1,378; 1; 1; 0,622 (меньше критического значения 13) и Condition index (показатель обусловленности) = 1; 1,174; 1,174; 1,488 (меньше критического значения 15). Следовательно, констатируют отсутствие мультиколлинеарности в модели регрессии 3.Diagnostics of collinearity reveal the presence of relationships between variables, i.e. parameters / nonparameters. Such relationships can affect the results of the entire correlation analysis, therefore it is important to diagnose the absence of multicollinearity in the regression model. In our example, collinearity indicators have the following meanings: Eigenvalue (eigenvalue of collinearity) = 1,378; one; one; 0.622 (less than the critical value of 13) and Condition index (conditionality indicator) = 1; 1.174; 1.174; 1,488 (less than the critical value of 15). Therefore, the absence of multicollinearity in the regression model 3 was noted.
Проверка уравнения регрессии осуществляется с помощью реальных совокупностей ответов респондентов - пропорционального анализа, где сравниваются отношения среднеарифметических значений ЭРВ (в т.ч. фрагмента 22, не участвовавшего вVerification of the regression equation is carried out using real sets of respondents' answers - a proportional analysis, which compares the ratios of the arithmetic mean values of the ERV (including fragment 22, which did not participate in
корреляционном анализе) и значений ЭРВ этих же фрагментов, полученных с помощью уравнения регрессии. Если разница между полученными значениями пропорций больше 0,2, то данное уравнение не считается точным. Согласно уравнению регрессии:correlation analysis) and the ERV values of the same fragments obtained using the regression equation. If the difference between the obtained proportions is greater than 0.2, then this equation is not considered accurate. According to the regression equation:
1. Фрагмент №1 анкеты 1 (1 параметр): ЭРВ=1,574*0+1,574*0+1,574*0+3,426=3,4261. Fragment No. 1 of questionnaire 1 (1 parameter): ERV = 1.574 * 0 + 1.574 * 0 + 1.574 * 0 + 3.426 = 3.426
2. Фрагмент №4 анкеты 2 (10 параметр): ЭРВ=1,574*0+1,574*1+1,574*0+3,426=52. Fragment No. 4 of questionnaire 2 (10 parameter): ERV = 1.574 * 0 + 1.574 * 1 + 1.574 * 0 + 3.426 = 5
3. Фрагмент №3 анкеты 3 (15 параметр): ЭРВ=1,574*0+1,574*0+1,574*0+3,426=3,4263. Fragment No. 3 of questionnaire 3 (15 parameters): ERV = 1.574 * 0 + 1.574 * 0 + 1.574 * 0 + 3.426 = 3.426
4. Фрагмент №10 анкеты 3 (22 параметр): 1,574*0+1,574*0+1,574*0+3,426=3,4264. Fragment No. 10 of questionnaire 3 (22 parameters): 1.574 * 0 + 1.574 * 0 + 1.574 * 0 + 3.426 = 3.426
Согласно САЗ ЭРВ:According to the SAZ ERV:
1. Фрагмент №1 анкеты 1: ЭРВ=8:3=2,667, где 8 - суммарное значение ЭРВ, 3 - количество онлайн-анкет1. Fragment No. 1 of questionnaire 1: ERV = 8: 3 = 2.667, where 8 is the total ERV value, 3 is the number of online profiles
2. Фрагмент №4 анкеты 2: ЭРВ=15:3=52. Fragment No. 4 of questionnaire 2: ERV = 15: 3 = 5
3. Фрагмент №3 анкеты 3: ЭРВ=8:3=2,6673. Fragment No. 3 of questionnaire 3: ERV = 8: 3 = 2,667
4. Фрагмент №10 анкеты 3: ЭРВ=9:3=34. Fragment No. 10 of questionnaire 3: ERV = 9: 3 = 3
Полученные пропорции:The resulting proportions:
1. 3,426:2,667=1,31.3.426: 2.667 = 1.3
2. 5:5=12.5: 5 = 1
3. 3,426:2,667=1,33.4.426: 2.667 = 1.3
4. 3,426: 3=1,14.3.426: 3 = 1.1
Таким образом, устанавливают, что связь между ЭРВ и параметрами «сравнение», «каламбур» и «перестановка частей слова/предложения» существует и является прямо пропорциональной, что подтверждает изначальную гипотезу о том, что фрагменты дискурса с риторическими приемами имеют более высокую ЭРВ, чем фрагменты без них, в отношении сравнения, каламбура и перестановки частей слова/предложения.Thus, it is established that the relationship between the ERV and the parameters “comparison”, “pun” and “rearrangement of parts of the word / sentence” exists and is directly proportional, which confirms the initial hypothesis that fragments of discourse with rhetorical devices have a higher ERV, than fragments without them, in terms of comparison, pun and permutation of parts of a word / sentence.
Однако большая разница между пропорциями значений ЭРВ, полученных с помощью корреляционного анализа и анкетирования, свидетельствует о приблизительности уравнения. Поэтому добавление остальных параметров в уравнение не считаем критическим, тем более, что в отношение некоторых из параметров поставленная гипотеза подтвердилась и менее вероятно, что фрагмент №10 анкеты 3 (22 параметр) имеет такую же ЭРВ, как фрагмент №1 анкеты 1 (1 параметр) и фрагмент №3 анкеты 3(15 параметр), хотя согласно уравнению это так.However, the large difference between the proportions of the ERV values obtained using the correlation analysis and questionnaire indicates the approximation of the equation. Therefore, we do not consider the addition of the remaining parameters to the equation to be critical, especially since the hypothesis was confirmed for some of the parameters and it is less likely that fragment No. 10 of questionnaire 3 (parameter 22) has the same ERV as fragment No. 1 of questionnaire 1 (1 parameter ) and fragment No. 3 of questionnaire 3 (parameter 15), although according to the equation this is so.
В связи с этим вводят остальные параметры в уравнение регрессии с вычисленными для них нестандартизированными коэффициентами, которые были исключены ранее шаговым отбором, поскольку их распределение не соответствовало нормальному.In this regard, the remaining parameters are introduced into the regression equation with non-standardized coefficients calculated for them, which were previously excluded by step selection, since their distribution did not correspond to the normal one.
ЭРВ(фр.)=0,148а+1,574b+0,177с+0,112d+0,018е+0,177f+0,083g+0,018h+0,177i+1,574j+0,112k+0,083l+1,574m+0,112n+0,148o+0,083p+0,083q+0,171r+3,426, где буквы,ERV (fr.) = 0.148a + 1.574b + 0.177s + 0.112d + 0.018e + 0.177f + 0.083g + 0.018h + 0.177i + 1.574j + 0.112k + 0.083l + 1.574m + 0.112n + 0.148o + 0.083p + 0.083q + 0.171r + 3.426, where the letters,
обозначают значение параметра, все буквы а-r соответствуют 1-18 параметрам в возрастающем порядке.indicate the value of the parameter, all letters a-r correspond to 1-18 parameters in ascending order.
Итак, чтобы измерить ЭРВ фрагмента, необходимо подставить значения в фиктивные переменные уравнения. Если константа в уравнении намного больше, чем вся сумма переменных, то выделенные параметры - только небольшая часть тех факторов, которые влияют на ЭРВ фрагмента. Чем меньше константа в уравнении, тем больше объективность и точность самого уравнения, т.к. это означает, что все основные факторы влияния присутствуют в уравнении.So, in order to measure the ERV of a fragment, it is necessary to substitute the values in the dummy variables of the equation. If the constant in the equation is much larger than the total sum of the variables, then the selected parameters are only a small part of those factors that affect the ERV of the fragment. The smaller the constant in the equation, the greater the objectivity and accuracy of the equation itself, because this means that all the main influence factors are present in the equation.
В нашем примере в полном уравнении регрессии константа равна 3,426, а максимальная сумма всех значений равна 6,406. Полагаем, что данная величина константы большая (составляет более 0,5 от максимальной величины совокупности всех параметров ЭРВ) и что в изначальной гипотезе остались некоторые существенные факторы влияния неучтенными.In our example, in the full regression equation, the constant is 3.426, and the maximum sum of all values is 6.406. We believe that this constant value is large (more than 0.5 of the maximum value of the aggregate of all parameters of the electric propulsion) and that in the initial hypothesis some significant influence factors remained unaccounted for.
При этом, в основном, можно констатировать большую надежность составленных уравнений регрессии, поскольку мультиколлинеарность в них отсутствует.In this case, basically, we can state the greater reliability of the compiled regression equations, since there is no multicollinearity in them.
Сравнивают результаты анализа САЗ ЭРВ с результатами корреляционного анализа. Определяют наличие полностью и частично подтвержденных гипотез и тенденций. Под гипотезой в данном случае понимается предположение о том, что, например, фрагмент с риторическим приемом «метафора» имеет большую ЭРВ, чем без него. Отсюда значения фиктивной переменной (ЭРВ): с метафорой - 1, без - 0.Compare the results of the analysis of SAZ ERV with the results of the correlation analysis. The presence of fully and partially confirmed hypotheses and trends is determined. In this case, a hypothesis is understood as an assumption that, for example, a fragment with a rhetorical method “metaphor” has a larger ERV than without it. Hence the values of the dummy variable (ERV): with a metaphor - 1, without - 0.
Градация гипотез на полностью и частично подтвержденные и тенденции осуществляется на основе совокупности данных анализа среднеарифметических значений и корреляционного анализа:The gradation of hypotheses to fully and partially confirmed and trends is based on a combination of data from the analysis of arithmetic mean values and correlation analysis:
к полностью подтвержденным относим гипотезы, подтвердившиеся в ходе анализа среднеарифметических значений ЭРВ и имеющие коэффициент корреляции не меньше 0,1 при условии, что этот коэффициент надежен;we refer to fully confirmed hypotheses, which were confirmed during the analysis of the arithmetic mean values of the electric propulsion and have a correlation coefficient of at least 0.1, provided that this coefficient is reliable;
к частично подтвержденным - гипотезы, подтвердившиеся в ходе анализа среднеарифметических значений ЭРВ и имеющие коэффициент корреляции меньше 0,1, но больше 0,05 при условии, что этот коэффициент надежен; если коэффициент не надежен, то те гипотезы, которые имеют коэффициент корреляции не меньше 0,1;partially confirmed - hypotheses that were confirmed in the analysis of the arithmetic mean values of the electric propulsion and having a correlation coefficient less than 0.1, but more than 0.05, provided that this coefficient is reliable; if the coefficient is not reliable, then those hypotheses that have a correlation coefficient of at least 0.1;
к тенденциям - гипотезы, либо подтвердившиеся в ходе анализа среднеарифметических значений ЭРВ и имеющие коэффициент корреляции меньше 0,1, либо имеющие коэффициент корреляции не меньше 0,1.to trends - hypotheses, either confirmed during the analysis of arithmetic mean values of the electric propulsion and having a correlation coefficient less than 0.1, or having a correlation coefficient not less than 0.1.
Согласно указанной градации выявляем в примере:According to the indicated gradation, we identify in the example:
- полностью подтвержденные гипотезы: фрагменты дискурса, содержащие риторические приемы сравнения, и/или каламбура, и/или перестановки частей слова/предложения, и/или со- fully confirmed hypotheses: fragments of discourse containing rhetorical methods of comparison, and / or pun, and / or rearrangement of parts of a word / sentence, and / or
средней или высокой плотностью риторических приемов имеют значительно большую ЭРВ, чем фрагменты, содержащие другие риторические приемы, а, тем более, без них;medium or high density rhetorical devices have a significantly higher ERV than fragments containing other rhetorical devices, and, especially, without them;
- частично подтвержденные гипотезы (в соответствии с частичными корреляциями в таблице Excluded Variables, столбец Partial correlation): параметры 3, 4, 6, 9, 11, 14 имеют САЗ ЭРВ выше 3,0 и значение частичной корреляции выше 0,1, т.е. фрагменты дискурса, содержащие риторические приемы повтора, стилистического контраста, эпитета, преувеличения/преуменьшения, неологизма и замены слова/структуры другим словом/структурой, имеют большую ЭРВ, чем фрагменты, содержащие другие риторические приемы (кроме тех, указанных в полностью подтвердившихся гипотезах), а, тем более, без них;- partially confirmed hypotheses (in accordance with the partial correlations in the Excluded Variables table, the Partial correlation column):
- тенденции: в отношении параметров 5, 7, 8 была опровергнута изначальная гипотеза и выдвинута обратная ей, поскольку коэффициенты частичных корреляций имеют отрицательный знак, а значит, корреляция является обратной. Другими словами, в исследуемом языке существует тенденция снижения ЭРВ фрагментов в случае содержания в фрагменте параметров 5 (нестилистический контраст), 7 (ирония/сатира) и 8 (риторический вопрос).. Следует отметить, что весь анализ проводился на показательном примере из 3 респондентов, поэтому в полной статистически значимой выборке результаты исследования будут другими.- trends: in relation to parameters 5, 7, 8, the initial hypothesis was refuted and the opposite was put forward, since the partial correlation coefficients have a negative sign, which means that the correlation is inverse. In other words, in the language under study there is a tendency for the ERV fragments to decrease if the fragment contains parameters 5 (non-stylistic contrast), 7 (irony / satire) and 8 (rhetorical question) .. It should be noted that the whole analysis was carried out on a representative example of 3 respondents , therefore, in a full statistically significant sample, the results of the study will be different.
Достоверность частично подтвержденных гипотез и тенденций может быть проверена только дополнительным исследованием, учитывающим факторы, из-за которых происходит исключение переменных из уравнения регрессии.The reliability of partially confirmed hypotheses and trends can only be verified by additional research that takes into account the factors that cause the exclusion of variables from the regression equation.
После подтверждения/опровержения (в т.ч. частичного) поставленных гипотез сравнивают результаты анализа САЗ ЭРВ и корреляционного анализа для всех исследуемых языков и представляют это сравнение в табличной форме для удобства восприятия сжатой информации:After confirmation / refutation (including partial) of the hypotheses put forward, the results of the analysis of the SAZ ERV and the correlation analysis for all the languages studied are compared and presented in tabular form for the convenience of comprehension of compressed information:


Составляют список общих и уникальных для исследуемых языков черт и закономерностей:Make a list of common and unique for the studied languages traits and patterns:
![]()
![]()
чем больше в фрагменте риторического приема «повтор» (параметр 3), тем выше ЭРВ фрагмента;the more “repeat” in the fragment of the rhetorical device (parameter 3), the higher the ERV of the fragment;
чем больше в фрагменте риторического приема «стилистический контраст» (параметр 4), тем выше ЭРВ фрагмента;the more “stylistic contrast” in the fragment of the rhetorical device (parameter 4), the higher the fragment's ERV;
чем больше в фрагменте риторического приема «нестилистический контраст» (параметр 5), тем выше ЭРВ фрагмента;the more “non-stylistic contrast” in the fragment of the rhetorical device (parameter 5), the higher the ERV of the fragment;
чем больше в фрагменте риторического приема «неологизм» (параметр 11), тем выше ЭРВ фрагмента;the more “neologism” in the fragment of the rhetorical device (parameter 11), the higher the ERV of the fragment;
чем выше плотность риторических приемов (параметр 18) в фрагменте, тем выше его ЭРВ.the higher the density of rhetorical devices (parameter 18) in the fragment, the higher its ERV.
![]()
![]()
Блок ввода и блок вывода осуществляют взаимодействие ПАК с респондентами и оператором. Через блок ввода (онлайн-анкету) осуществляется ввод ответов респондентов. Блок вывода (программа MySQL Workbench 5.2 СЕ) осуществляет вывод данных в формате, удобном для последующей обработки оператором (в табличных форматах CSV, Excel Spreadsheet и др.).The input unit and the output unit interact with the PAC respondents and the operator. The input block (online questionnaire) is used to enter the responses of respondents. The output block (MySQL Workbench 5.2 CE program) carries out data output in a format convenient for subsequent processing by the operator (in table formats CSV, Excel Spreadsheet, etc.).
База данных (БД) ПАК содержит информацию об отобранных параметрах и их значениях, информацию о респондентах и др. Блок обработки данных взаимодействует с БД программно-аппаратного комплекса, блоками ввода и вывода, производящих программную обработку информацию из БД и сохраняет в БД результаты обработки.The PAK database (DB) contains information about the selected parameters and their values, information about respondents, etc. The data processing unit interacts with the database of the hardware and software complex, input and output blocks that perform software processing of information from the database, and stores the processing results in the database.
В качестве ПАК может быть использован персональный компьютер с оперативной системой Windows 7, содержащий центральный процессор, оперативное запоминающее устройство, накопитель на жестком диске, клавиатуру, монитор, сетевую карту, и/или модель для обеспечения работы с интернет-ресурсом. Алгоритм работы ПАК представлен на Фиг. 1. Респондент оценивает каждый из параметров по выделенному критерию - в соответствии с предложенной шкалой из 5 вариантов ответа. Данную оценку направляют в БД программно-аппаратного комплекса, имеющего массив информации для оценки параметра по выделенному критерию - эффективности речевого воздействия - в 5-балльной системе. При этом производится обработка массива информации в соответствии с видами загружаемой информации: информации о респонденте, онлайн-анкете и ответах респондента, - каждую из которых ПАК классифицирует на информационные элементы, записываемые в отдельных ячейках БД. К примеру, информация о респонденте включает в себя следующие информационные элементы: имя респондента, фамилия, электронный адрес, возраст, пол, образование. Каждому ответу респондента присваивается соответствующее значение по 5-балльной системе. Например, ответу «совершенно неубедительно» ПАК приписывает значение «1», «совершенно убедительно» - значение «5». Таким образом, получают значение эффективности речевого воздействия для каждого фрагмента в отдельности, а также для каждого параметра в целом после сортировки БД с помощью функции «select concat (наименование информационного элемента) from "наименование онлайн-анкеты" where lang = ′наименование языка онлайн-анкеты′» в блоке вывода (программа MySQL Workbench 5.2 СЕ).As a PAC, a personal computer with the Windows 7 operating system can be used, containing a central processor, random access memory, a hard disk drive, a keyboard, a monitor, a network card, and / or a model for providing work with an Internet resource. The PAK operation algorithm is shown in FIG. 1. The respondent evaluates each of the parameters according to the selected criterion - in accordance with the proposed scale of 5 answer options. This assessment is sent to the database of the hardware-software complex, which has an array of information for evaluating the parameter according to the selected criterion - the effectiveness of speech exposure - in a 5-point system. At the same time, an array of information is processed in accordance with the types of downloaded information: information about the respondent, online questionnaire and respondent's answers, each of which the PAC classifies into information elements recorded in separate database cells. For example, information about the respondent includes the following information elements: respondent's name, last name, email address, age, gender, education. Each response of the respondent is assigned a corresponding value according to a 5-point system. For example, the PAK attributes the value “1” to the answer “completely unconvincing”, and the value “5” ascribes “absolutely convincing”. Thus, we obtain the value of the effectiveness of speech exposure for each fragment separately, as well as for each parameter as a whole, after sorting the database using the function "select concat (name of the information element) from" name of the online questionnaire "where lang = ′ name of the language online profiles' ”in the output block (MySQL Workbench 5.2 CE program).
На следующем этапе работы способа производится извлечение имеющейся в БД информации путем нажатия оператором ПАК кнопки «Export» и экспортирования данной информации в форматах CSV, Excel Spreadsheet, HTML, XML и др., пригодных для последующего составления уравнения регрессии и прогнозирования эффективности речевого воздействия (ЭРВ). Кроме того, ПАК может содержать дополнительные функции и информационные элементы, обеспечивающие ранжирование фрагментов дискурса по ЭРВ и прогнозирование ЭРВ этих фрагментов.At the next stage of the method’s work, the information available in the database is extracted by pressing the “Export” button by the PAC operator and exporting this information in CSV, Excel Spreadsheet, HTML, XML, and other formats suitable for the subsequent preparation of the regression equation and prediction of the effectiveness of speech exposure (ERV) ) In addition, the PAC may contain additional functions and information elements that provide ranking of fragments of the discourse according to the EDS and prediction of the ERA of these fragments.
Заявленный способ был апробирован при оценке ЭРВ 19 фрагментов 450 респондентами. Каждый фрагмент оценивался по выделенным параметрам и критерию - ЭРВ (степени убедительности). Полученная совокупность количественных оценок по каждому параметру позволила ранжировать параметры и сами фрагменты по ЭРВ и составить уравнение регрессии, способное прогнозировать ЭРВ любого фрагмента подстановкой значений параметров в данное уравнение.The claimed method was tested in evaluating the ERV of 19 fragments by 450 respondents. Each fragment was evaluated according to the selected parameters and criteria - ERV (degree of persuasiveness). The resulting set of quantitative estimates for each parameter made it possible to rank the parameters and the fragments themselves by the EDS and compose a regression equation capable of predicting the ERA of any fragment by substituting the parameter values into this equation.
Преимуществами заявленного способа являются:The advantages of the claimed method are:
1. высокая степень точности и достоверности;1. a high degree of accuracy and reliability;
2. надежность и валидность;2. reliability and validity;
3. возможность проверки главного результата, получаемого в ходе исследования - уравнения регрессии3. the ability to verify the main result obtained during the study - the regression equation
4. возможность непосредственного изучения эффективности речевого воздействия в разных языках и на различных этапах их развития;4. the ability to directly study the effectiveness of speech exposure in different languages and at different stages of their development;
5. возможность измерения и моделирования идеального с точки зрения ЭРВ фрагмента дискурса для разных целей;5. the possibility of measuring and modeling the ideal from the point of view of the ERV fragment of the discourse for different purposes;
6. возможность автоматизировать процессы сбора, хранения и анализа результатов исследования;6. the ability to automate the collection, storage and analysis of research results;
7. заявленный способ является открытой системой, может сочетаться с другими способами (например, с обычным бумажным анкетированием) и формировать гибридный способ;7. The claimed method is an open system, can be combined with other methods (for example, with ordinary paper questionnaires) and form a hybrid method;
8. оперативность способа;8. the speed of the method;
9. возможность дистанционного изучения ЭРВ и отсутствие контакта с анкетером-исследователем;9. the possibility of remote study of the ERV and the lack of contact with the questionnaire researcher;
10. отсутствие сложного оборудования для получения необходимой информации;10. lack of sophisticated equipment to obtain the necessary information;
11. невысокая стоимость (окупает себя, если выборка превышает 300 респондентов);11. low cost (pays off if the sample exceeds 300 respondents);
12. анонимность онлайн-анкет;12. anonymity of online profiles;
13. удобство респондента (заполнение в любом месте, где есть сеть интернет, в любое удобное время и т.п.);13. convenience of the respondent (filling in at any place where there is an Internet network, at any convenient time, etc.);
14. возможность использования мультимедиа (повышает процент до конца заполненных анкет и мотивацию респондентов).14. the possibility of using multimedia (increases the percentage to the end of the completed questionnaires and the motivation of respondents).
Claims (2)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| RU2015101668/08A RU2595616C1 (en) | 2015-01-21 | 2015-01-21 | Method for prediction of efficiency of speech action of fragments of discourse in different languages |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| RU2015101668/08A RU2595616C1 (en) | 2015-01-21 | 2015-01-21 | Method for prediction of efficiency of speech action of fragments of discourse in different languages |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| RU2595616C1 true RU2595616C1 (en) | 2016-08-27 |
Family
ID=56892236
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| RU2015101668/08A RU2595616C1 (en) | 2015-01-21 | 2015-01-21 | Method for prediction of efficiency of speech action of fragments of discourse in different languages |
Country Status (1)
| Country | Link |
|---|---|
| RU (1) | RU2595616C1 (en) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2136038C1 (en) * | 1992-09-04 | 1999-08-27 | Катерпиллар Инк. | Computer system and method for preparing texts in source language and their translation into foreign languages |
| RU2345416C1 (en) * | 2007-05-31 | 2009-01-27 | НАСЫПНАЯ Галина Анатольевна | Method of synthesis of self-trained analytical question-answer system with extraction of knowledge from texts |
| CN102629156A (en) * | 2012-03-06 | 2012-08-08 | 上海大学 | Method for achieving motor imagery brain computer interface based on Matlab and digital signal processor (DSP) |
| CN102662776A (en) * | 2012-04-01 | 2012-09-12 | 杭州格畅科技有限公司 | Inter-application communication method, client side and application process manager of online application platform |
-
2015
- 2015-01-21 RU RU2015101668/08A patent/RU2595616C1/en active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2136038C1 (en) * | 1992-09-04 | 1999-08-27 | Катерпиллар Инк. | Computer system and method for preparing texts in source language and their translation into foreign languages |
| RU2345416C1 (en) * | 2007-05-31 | 2009-01-27 | НАСЫПНАЯ Галина Анатольевна | Method of synthesis of self-trained analytical question-answer system with extraction of knowledge from texts |
| CN102629156A (en) * | 2012-03-06 | 2012-08-08 | 上海大学 | Method for achieving motor imagery brain computer interface based on Matlab and digital signal processor (DSP) |
| CN102662776A (en) * | 2012-04-01 | 2012-09-12 | 杭州格畅科技有限公司 | Inter-application communication method, client side and application process manager of online application platform |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Dewaele et al. | Does multilingualism shape personality? An exploratory investigation | |
| Bali et al. | Communicating forensic science opinion: An examination of expert reporting practices | |
| Rybinski et al. | Will artificial intelligence revolutionise the student evaluation of teaching? A big data study of 1.6 million student reviews | |
| Tabak et al. | Mock jury attitudes towards credibility, age, and guilt in a fictional child sexual assault scenario | |
| Dohmen et al. | Willingness to take risk: The role of risk conception and optimism | |
| Kraft | Measuring morality in political attitude expression | |
| Notestine et al. | Counselors' attributions of blame toward female survivors of battering | |
| Nanda et al. | Diagnostics for pretesting questionnaires: a comparative analysis | |
| Titzmann et al. | Friendship homophily among diaspora migrant adolescents in Germany and Israel | |
| Peterson | Certainty or accessibility: Attitude strength in candidate evaluations | |
| Körner et al. | It’s all about power | |
| Ziegler | A text-as-data approach for using open-ended responses as manipulation checks | |
| Gonzalez et al. | The experience and perception of corruption: A comparative study in 34 societies | |
| Biancarosa et al. | Constructing subscores that add validity: A case study of identifying students at risk | |
| Pu et al. | Do peers affect undergraduates’ decisions to switch majors? | |
| Doornkamp et al. | Understanding the symbolic effects of gender representation: A multi-source study in education | |
| Youk et al. | Measures of argument strength: a computational, large-scale analysis of effective persuasion in real-world debates | |
| Niederberger et al. | Argument-based QUalitative Analysis strategy (AQUA) for analyzing free-text responses in health sciences Delphi studies | |
| Sarafoglou et al. | Subjective evidence evaluation survey for many-analysts studies | |
| Verkoeijen et al. | A practical illustration of methods to deal with potential outliers: a multiverse outlier analysis of study 3 from Brummelman, Thomaes, Orobio de Castro, Overbeek, and Bushman | |
| Whittingham | Impact of personality on academic performance of MBA students: Qualitative versus quantitative courses | |
| von der Heyde et al. | Vox populi, vox ai? using large language models to estimate german vote choice | |
| FINNILÄ‐TUOHIMAA et al. | Expert judgment in cases of alleged child sexual abuse: Clinicians’ sensitivity to suggestive influences, pre‐existing beliefs and base rate estimates | |
| Leifker et al. | Suicide as an interpersonal phenomenon: Dyadic methodological and statistical considerations in suicide research | |
| Newbury et al. | Measurement of child-directed speech: A survey of clinical practice |