KR20200034918A - 심층 신경망의 가중치에 대한 밸런싱된 프루닝을 제공하는 시스템 및 방법 - Google Patents
심층 신경망의 가중치에 대한 밸런싱된 프루닝을 제공하는 시스템 및 방법 Download PDFInfo
- Publication number
- KR20200034918A KR20200034918A KR1020190024974A KR20190024974A KR20200034918A KR 20200034918 A KR20200034918 A KR 20200034918A KR 1020190024974 A KR1020190024974 A KR 1020190024974A KR 20190024974 A KR20190024974 A KR 20190024974A KR 20200034918 A KR20200034918 A KR 20200034918A
- Authority
- KR
- South Korea
- Prior art keywords
- weights
- weight
- group
- zero
- neural network
- Prior art date
Links
- 238000013138 pruning Methods 0.000 title claims abstract description 18
- 238000000034 method Methods 0.000 title claims description 33
- 238000013528 artificial neural network Methods 0.000 claims abstract description 26
- 230000000873 masking effect Effects 0.000 claims abstract description 25
- 230000006870 function Effects 0.000 description 34
- 238000012545 processing Methods 0.000 description 9
- 238000012549 training Methods 0.000 description 8
- 238000012805 post-processing Methods 0.000 description 6
- 238000005457 optimization Methods 0.000 description 2
- 230000004913 activation Effects 0.000 description 1
- 238000001994 activation Methods 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 230000008094 contradictory effect Effects 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 230000008676 import Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000001537 neural effect Effects 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 229910052709 silver Inorganic materials 0.000 description 1
- 239000004332 silver Substances 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/082—Learning methods modifying the architecture, e.g. adding, deleting or silencing nodes or connections
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/042—Knowledge-based neural networks; Logical representations of neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
- G06N5/022—Knowledge engineering; Knowledge acquisition
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Mathematical Physics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- General Physics & Mathematics (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Feedback Control In General (AREA)
- Complex Calculations (AREA)
- User Interface Of Digital Computer (AREA)
- Scissors And Nippers (AREA)
Abstract
심층 신경망(Deep Neural Network, DNN)의 가중치에 대한 밸런싱된 프루닝(balanced pruning)을 제공하는 시스템이 제공된다. 본 발명의 실시 예에 따른 시스템은, 심층 신경망의 복수의 가중치 그룹들 각각에 포함되는 가중치를 마스킹하는 가중치 마스커(weight masker) 및 심층 신경망의 네트워크 손실에서 복수의 가중치 그룹들 내의 비-제로(non-zero) 가중치의 수에 대한 분산(variance)를 뺀 값에 기초하여, 심층 신경망의 손실을 결정하는 손실 결정기(loss determiner)를 포함한다.
Description
본 발명은 신경망(neural network)에 관한 것으로, 더욱 상세하게는, 심층 신경망(deep neural network, DNN)의 가중치에 대한 밸런싱된 프루닝(balanced pruning)을 제공하는 시스템 및 방법에 관한 것이다.
뉴럴 하드웨어(neural hardware)는 심층 신경망의 계산을 가속화하도록 설계되었다. 그럼에도 불구하고, 하드웨어 가속기(hardware accelerator)는 희소 파라미터(sparse parameter)를 처리하는 데 효율적이지 않고, 병렬 프로세싱 요소가 동일한 양의 작업량(workload)를 갖도록 신경망 파라미터들의 희소성(sparsity)을 밸런싱하는 것은 어려운 문제이다. 희소성은 파라미터의 크기를 줄이고, 심층 신경망의 계산 효율성을 높이는 데 사용된다.
본 발명의 바람직한 실시 예는, 파라미터들을 동시에 트레이닝하고, 비-제로 파라미터들의 수를 감소시키고, 시스템의 프로세싱 요소들의 이용률을 증가시키기 위해 하드웨어 프로세싱 요소들에 대한 비-제로 파라미터들의 수를 밸런싱하는 자동화된(automated) 프루닝 시스템을 제공하고자 한다.
또한, 본 발명의 바람직한 실시 예는, 파라미터들을 동시에 트레이닝하고, 비-제로 파라미터들의 수를 감소시키고, 시스템의 프로세싱 요소들의 이용률을 증가시키기 위해 하드웨어 프로세싱 요소들에 대한 비-제로 파라미터들의 수를 밸런싱하는 자동화된 프루닝 방법을 제공하고자 한다.
본 발명의 몇몇 실시 예에 따라 심층 신경망(Deep Neural Network, DNN)의 가중치에 대한 밸런싱된 프루닝(balanced pruning)을 제공하는 시스템은, 심층 신경망의 복수의 가중치 그룹들 각각에 포함되는 가중치를 마스킹하는 가중치 마스커(weight masker) 및 심층 신경망의 네트워크 손실에서 복수의 가중치 그룹들 내의 비-제로(non-zero) 가중치의 수에 대한 분산(variance)를 뺀 값에 기초하여, 심층 신경망의 손실을 결정하는 손실 결정기(loss determiner)를 포함한다.
본 발명의 몇몇 실시 예에 따라 심층 신경망(Deep Neural Network, DNN)의 가중치에 대한 밸런싱된 프루닝(balanced pruning)을 제공하는 방법은, 심층 신경망의 가중치를 복수의 그룹들로 그룹화(partitioning)하는 단계, 가중치 마스커에 의해, 각각의 그룹의 가중치에 마스킹 함수를 적용하는 단계, 마스킹 함수가 적용된 후, 각각의 그룹 내의 비-제로 가중치의 수를 결정하는 단계, 각각의 그룹 내의 비-제로 가중치의 수의 분산을 결정하는 단계, 손실 결정기에 의해, 각각의 그룹 내의 비-제로 가중치의 수의 분산이 0인 제약을 포함하는 라그랑주 승수를 이용하여 심층 신경망의 손실 함수를 최소화하는 단계 및 BP(back-propagation)에 의해, 가중치 및 라그랑주 승수를 재트레이닝(retraining)하는 단계를 포함한다.
본 발명의 특정 실시 예에 대한 상기 또는 다른 양상들, 특징들 및 이점들은 첨부된 도면들과 관련한 아래의 상세한 설명으로부터 더욱 명백해질 것이다.
도 1은 본 발명의 실시 예에 따른 임계 함수(threshold function)의 예시적인 그래프를 도시한다.
도 2는 본 발명의 실시 예에 따라, 심층 신경망의 밸런싱된 셀프-프루닝(balanced self-pruning) 방법에 대한 순서도이다.
도 3은 본 발명의 실시 예에 따른 후처리(post-processing) 방법에 대한 순서도이다.
도 4는 본 발명의 실시 예에 따른 밸런싱된 셀프-프루너(balanced self-pruner)를 나타내는 도면이다.
설명의 간략화 및 명확화를 위해, 도면에 도시된 요소는 달리 기술되지 않는 한 반드시 축척대로 도시된 것은 아니라는 것이 이해될 것이다. 예를 들어, 일부 요소의 치수는 명확성을 위해 다른 요소에 비해 과장되어 있다. 또한, 적절한 것으로 판단되는 경우, 대응하는 요소 또는 유사한 요소를 나타내기 위해 도면 간에 도면 부호가 반복되어 도시되었다.
도 1은 본 발명의 실시 예에 따른 임계 함수(threshold function)의 예시적인 그래프를 도시한다.
도 2는 본 발명의 실시 예에 따라, 심층 신경망의 밸런싱된 셀프-프루닝(balanced self-pruning) 방법에 대한 순서도이다.
도 3은 본 발명의 실시 예에 따른 후처리(post-processing) 방법에 대한 순서도이다.
도 4는 본 발명의 실시 예에 따른 밸런싱된 셀프-프루너(balanced self-pruner)를 나타내는 도면이다.
설명의 간략화 및 명확화를 위해, 도면에 도시된 요소는 달리 기술되지 않는 한 반드시 축척대로 도시된 것은 아니라는 것이 이해될 것이다. 예를 들어, 일부 요소의 치수는 명확성을 위해 다른 요소에 비해 과장되어 있다. 또한, 적절한 것으로 판단되는 경우, 대응하는 요소 또는 유사한 요소를 나타내기 위해 도면 간에 도면 부호가 반복되어 도시되었다.
다음의 상세한 설명에서, 본 발명의 완전한 이해를 제공하기 위해 다수의 특정 세부 사항들이 설명된다. 그러나, 개시된 본 발명의 양상들이 이러한 특정 세부 사항들 없이 실시될 수 있다는 것이 당업자에 의해 이해될 것이다. 다른 예들에서, 널리 공지된 방법들, 절차들, 구성 요소들 및 회로들은 본 개시를 모호하게 하지 않기 위해 상세하게 설명되지 않았다. 또한, 설명된 진보적인 양상들은, 예를 들어, 스마트 폰, 사용자 단말기(User Equipment, UE), 랩톱 컴퓨터 등을 포함하는 임의의 이미징 장치 또는 시스템에서 저전력, 3D-깊이 측정들을 수행하도록 구현될 수 있다.
본 명세서에서 "일 실시예" 또는 "실시예"는 본 실시예와 관련하여 설명된 특정 특징, 구조 또는 특성이 본 개시의 적어도 하나의 실시예에 포함됨을 의미한다. 따라서, 본 명세서 전체에 걸쳐 다양한 곳에서 "일 실시예에서" 또는 "실시예에서" 또는 "일 실시예에 따라"(또는 유사한 수입 물을 갖는 다른 구들)의 표현은 반드시 동일한 실시예를 지칭하는 것은 아니다. 또한, 특정 특징, 구조 또는 특성은 하나 이상의 실시예에서 임의의 적절한 방식으로 결합될 수 있다. 또한, 여기에서 논의의 문맥에 따라, 단수는 그 복수형을 포함할 수 있고 복수형 용어는 단수형을 포함할 수 있다. 유사하게 하이픈(-)으로 연결된 용어(예를 들어, "2-차원", "미리-결정된", "픽셀-특화된(pixel-specific)" 등)는 때로는 하이픈이 없는 버전(예를 들어, "2 차원", "미리 결정된, 픽셀 특화된 등)으로 이따금 교체되어 사용될 수 있고, 대문자로 시작되는 용어(예를 들어, "카운터 클럭(Counter Clock)", "행 선택(Row Select)", "픽셀 출력(PIXOUT)" 등)은 대문자가 아닌 버전(예를 들어, "카운터 클럭(counter clock)", "행 선택(row select)", "픽셀출력(pixout)"등)으로 이따금 교체되어 사용될 수 있다. 이러한 간헐적 교체 사용은 서로 모순되는 것으로 간주되지 않아야 한다.
"결합된(coupled)", "작용적으로 결합된(operatively coupled)", "연결된(connected)", "연결하는(connecting)", "전기적으로 연결된" 등의 용어는 동작 방식에서 전기적/전자적으로 연결된 상태를 일반적으로 나타내기 위해 상호 교환적으로 사용될 수 있다. 유사하게, 제1 엔티티(entity)가 (유선 또는 무선 수단을 통해) 신호들의 타입(아날로그 또는 디지털)과 무관하게 정보 신호(어드레스, 데이터 또는 제어 정보를 포함하는 지의 여부)를 제2 엔티티(또는 엔티티들)로/로부터 전기적으로 전송 또는 수신할 때, 제1 엔티티가 제2 엔티티와 "통신(communication)"하는 것으로 간주된다.
본 명세서에 사용된 용어 "제1", "제2" 등은 명사들(nouns)에 앞선 레이블들로 사용되며, 명시적으로 정의되지 않는 한, 임의의 순서(예를 들어, 공간적, 시간적, 논리적 등)의 타입을 의미하지 않는다. 또한, 동일하거나 유사한 기능을 갖는 부품들, 구성 요소들, 블록들, 회로들, 유닛들 또는 모듈들을 지칭하기 위해 2개 이상의 도면들에 걸쳐 동일한 참조 번호들이 사용될 수 있다. 그러나, 그러한 사용은 단지 도시의 단순화 및 설명의 용이함을 위한 것으로, 그러한 구성 요소들 또는 유닛들의 구성 또는 구조적 세부 사항들이 모든 실시예들에 걸쳐 동일하거나 또는 그러한 공통으로 참조된 부품들/모듈들이 본 개시의 특정 실시예들의 교시를 구현하는 유일한 방법이라는 것을 의미하지는 않는다. 본 명세서에 사용된 용어 "모듈"은 모듈과 관련하여 여기에 설명된 기능성을 제공하기 위해 구성된 소프트웨어, 펌웨어 및/또는 하드웨어의 임의의 조합을 지칭한다. 소프트웨어는 소프트웨어 패키지, 코드 및/또는 명령 세트 또는 명령들로서 구현될 수 있으며, 여기에 설명된 임의의 구현 예에서 사용되는 "하드웨어"라는 용어는 예를 들어, 단일 또는 임의의 조합, 배선에 의한 회로, 프로그램 가능 회로, 상태 머신 회로, 및/또는 프로그램 가능 회로에 의해 실행되는 명령들을 저장하는 펌웨어를 포함할 수 있다. 모듈들은 집합적으로 또는 개별적으로 예를 들어, 집적 회로(IC), 시스템 온-칩(SoC) 등과 같은 더 큰 시스템의 일부를 형성하는 회로로서 구현될 수 있으나, 여기에 한정되지 않는다.
본 명세서에서 다양한 구성요소 및/또는 기능 블록(functional blocks)은 다양한 구성요소 및/또는 기능 블록과 관련한 기능을 제공하는 소프트웨어, 펌웨어 및/또는 하드웨어를 포함할 수 있는 모듈로서 구현될 수 있다.
본 명세서에서 개시된 주제는, 심층 신경망(DNN)의 가중치를 희생시키는 방법 및 시스템에 관한 것이다. 본 발명의 실시 예에 따라 처리된 DNN 모델의 희소성(sparsity)은 각 그룹에 대해 동일한 수의 비-제로 가중치(non-zero weight)를 갖는다. 상기 그룹은 DNN 하드웨어 아키텍처를 기반으로 생성될 수 있고, 활성화(activation) 및 가중치가 메모리에서 프로세싱 요소로 페치(fetch)되는 방법에 따라 달라질 수 있다. 트레이닝(training) 단계에서, DNN 모델 가중치 및 가중치 임계 파라미터가 동시에 트레이닝되므로, DNN 모델이 최대 트레이닝 정확도(maximum training accuracy) 및 최소 비-제로 가중치에 도달할 수 있다. 동시에, 각 그룹 내의 비-제로 가중치의 수는 그룹들 사이에 비-제로 가중치의 분산을 0에 가깝게 적용하여 거의 동일하게 된다. 트레이닝이 끝나면, 후처리 절차를 적용하여 각 그룹이 완벽하게 밸런싱된 희소성으로서 동일한 수의 비-제로 가중치를 갖는 결과를 얻을 수 있다.
본 명세서에 개시된 주제는, 파라미터들을 동시에 트레이닝하고, 비-제로 파라미터들의 수를 감소시키고, 시스템의 프로세싱 요소들의 이용률을 증가시키기 위해 하드웨어 프로세싱 요소들에 대한 비-제로 파라미터들의 수를 밸런싱하는 자동화된(automated) 프루닝 방법을 제공한다. 트레이닝이 끝난 후의 후처리 단계는, 모든 그룹이 비-제로 가중치의 완벽한 밸런싱을 이루기 위해 정확히 동일한 가중치의 수를 갖도록 가중치를 조정하기 위하여 수행된다.
DNN 모델의 트레이닝은 ground truth와의 차이를 최소화하면서 예측(prediction)을 수행하는 일련의 가중치 파라미터를 찾는 수치 최적화(numerical optimization)의 문제일 수 있다. 최소화 문제(minimization problem)는 아래 수학식 1과 같이 표현될 수 있다.

여기에서,  은 네트워크 오류를 나타낸다. 예를 들어, 예측과 ground truth(t)의 차이는 아래 수학식 2와 같이 표현될 수 있다.
은 네트워크 오류를 나타낸다. 예를 들어, 예측과 ground truth(t)의 차이는 아래 수학식 2와 같이 표현될 수 있다.

여기에서,  은 마지막 레이어의 출력을 나타내고, L은 레이어의 수를 나타낸다.
은 마지막 레이어의 출력을 나타내고, L은 레이어의 수를 나타낸다.
희소성을 강화하기 위해, 임계 값 이하의 크기를 갖는 가중치가 0으로 설정되고 임계 값을 초과하는 가중치가 영향을 받지 않도록, 프루닝 함수(pruning function)가 가중치에 적용될 수 있다. 트레이닝할 수 있는 프루닝 함수를 갖기 위해, 함수를 1차 함수로 미분할 수 있어야 한다. 몇몇 실시 예에 따라, 임계 함수(또는, 프루닝 함수)는 아래 수학식 3으로 표현될 수 있다.
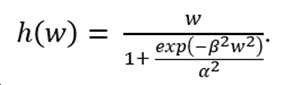
여기에서,  는 신경망의 가중치 값을 나타내고,
는 신경망의 가중치 값을 나타내고,  는 임계 함수
는 임계 함수  의 첨예도(sharpness)를 제어하는 파라미터를 나타내고,
의 첨예도(sharpness)를 제어하는 파라미터를 나타내고,  는 제1 및 제2 엣지(edges) 사이의 거리(distance)(또는, 임계 값의 너비(width))를 제어하는 파라미터를 나타낸다.
는 제1 및 제2 엣지(edges) 사이의 거리(distance)(또는, 임계 값의 너비(width))를 제어하는 파라미터를 나타낸다.
도 1은 수학식 3에 따른 임계 함수(threshold function)의 예시적인 그래프를 도시한다. 수학식 3의 파라미터  는 임계 함수
는 임계 함수  의 엣지(101a) 및 엣지(101b)의 의 첨예도(sharpness)를 제어한다. 즉, 파라미터
의 엣지(101a) 및 엣지(101b)의 의 첨예도(sharpness)를 제어한다. 즉, 파라미터  는
는  = 0 및
= 0 및  = 1 사이의 엣지(101a) 및 엣지(101b)의 변화율(rate of change)을 제어한다. 수학식 3의 파라미터
= 1 사이의 엣지(101a) 및 엣지(101b)의 변화율(rate of change)을 제어한다. 수학식 3의 파라미터  는,
는,  = 0.5에서의 엣지(101a) 및 엣지(101b) 사이의 너비를 제어한다. 도 1에 도시된 바와 같이, 임계 함수
= 0.5에서의 엣지(101a) 및 엣지(101b) 사이의 너비를 제어한다. 도 1에 도시된 바와 같이, 임계 함수  는 0을 중심으로 연속하는 가중치의 제1 세트(103)에 대해 0의 값을 가진다. 또한, 임계 함수
는 0을 중심으로 연속하는 가중치의 제1 세트(103)에 대해 0의 값을 가진다. 또한, 임계 함수  는 연속하는 가중치 중 제1 세트(103)보다 큰 연속하는 가중치 값에 대한 제2 세트(104)에 대해 1의 값을 가진다. 또한, 임계 함수
는 연속하는 가중치 중 제1 세트(103)보다 큰 연속하는 가중치 값에 대한 제2 세트(104)에 대해 1의 값을 가진다. 또한, 임계 함수  는 연속하는 가중치 중 제1 세트(103)보다 작은 연속하는 가중치 값에 대한 제3 세트(105)에 대해 1의 값을 가진다.
는 연속하는 가중치 중 제1 세트(103)보다 작은 연속하는 가중치 값에 대한 제3 세트(105)에 대해 1의 값을 가진다.
임계 함수  의 제1 엣지(101a)는 연속하는 가중치 중 제1 세트(103)과 연속하는 가중치 중 제2 세트(104) 사이에 형성된다. 임계 함수
의 제1 엣지(101a)는 연속하는 가중치 중 제1 세트(103)과 연속하는 가중치 중 제2 세트(104) 사이에 형성된다. 임계 함수  의 제2 엣지(101b)는 연속하는 가중치 중 제1 세트(103)과 연속하는 가중치 중 제3 세트(105) 사이에 형성된다.
의 제2 엣지(101b)는 연속하는 가중치 중 제1 세트(103)과 연속하는 가중치 중 제3 세트(105) 사이에 형성된다.
임계 함수  의 값은, 제1 엣지(101a) 및 제2 엣지(101b)의 영역에서, 0과 1 사이에서 전환된다. 임계 함수
의 값은, 제1 엣지(101a) 및 제2 엣지(101b)의 영역에서, 0과 1 사이에서 전환된다. 임계 함수  가 0 및 1 사이에서 전환될 때의 제1 엣지(101a) 및 제2 엣지(101b) 각각의 첨예도(예를 들어, 임계 함수
가 0 및 1 사이에서 전환될 때의 제1 엣지(101a) 및 제2 엣지(101b) 각각의 첨예도(예를 들어, 임계 함수  의 제1 엣지(101a) 및 제2 엣지(101b)의 첨예도)는 파라미터
의 제1 엣지(101a) 및 제2 엣지(101b)의 첨예도)는 파라미터  의 값에 기초하고,
의 값에 기초하고,  = 0.5에서의 제1 엣지(101a)와 제2 엣지(101b) 사이의 거리(102)는 파라미터
= 0.5에서의 제1 엣지(101a)와 제2 엣지(101b) 사이의 거리(102)는 파라미터  의 값에 기초한다.
의 값에 기초한다.
정규화 항(regularization term)은 손실 함수(loss function)을 보충하기 위해 도입될 수 있다.

여기에서,  는 경험적으로(empirically) 선택된 정규화 파라미터이다. 손실 함수
는 경험적으로(empirically) 선택된 정규화 파라미터이다. 손실 함수  은, DNN 모델의 프루닝에 대한 희소화(sparsification)의 최적화 또는 밸런싱을 위해, 최소화될 수 있다.
은, DNN 모델의 프루닝에 대한 희소화(sparsification)의 최적화 또는 밸런싱을 위해, 최소화될 수 있다.
도 2는 본 발명의 실시 예에 따라, 심층 신경망의 밸런싱된 셀프-프루닝(balanced self-pruning) 방법(200)에 대한 순서도이다. 방법(200)은 201 단계에서 시작한다. 202 단계에서, 희소 가중치(sparse weight)를 다중 프로세싱 요소(PE)에 분배하기 위해, DNN의 가중치가 그룹화된다.
각각의 그룹에서, 비-제로 가중치의 수는 동일해야 한다. 수학식 3과 유사하게 형성되는 분석 마스킹 함수(analytical masking function)  가 DNN의 가중치에 적용된다. 예를 들어, 마스킹 함수는 아래 수학식 5가 사용될 수 있다.
가 DNN의 가중치에 적용된다. 예를 들어, 마스킹 함수는 아래 수학식 5가 사용될 수 있다.

상기 수학식 5의 마스킹 함수는, 가중치의 크기가 임계 값보다 큰 경우 1로 복귀하고, 가중치의 크기가 임계 값보다 작은 경우 0이 된다. 수학식 3 및 수학식 5의 함수들은 미분 가능하고, 따라서, 기능 파라미터들은 트레이닝 가능할 수 있다. 203 단계에서 마스킹 함수가 적용된 후, 204 단계에서, 각각의 그룹 내의 비-제로 가중치의 수가 결정되고, 이 때 비-제로 가중치의 수는 아래 수학식 6으로 표현되는 마스킹 함수의 복귀 값(return value)의 합일 수 있다.
여기에서, i는 그룹 내의 가중치에 대한 인덱스를 의미한다.
모든 그룹들이 동일한 수의 비-제로 가중치를 갖기 위해,  의 분산(variance)은 0이어야 한다. 205 단계에서, 각각의 그룹 내의 비-제로 가중치의 수에 대한 분산이 결정된다. 206 단계에서, 트레이닝 문제(training problem)는 높은 제약(hard constraint)을 갖는 최소화 문제로 아래 수학식 7과 같이 공식화될 수 있다
의 분산(variance)은 0이어야 한다. 205 단계에서, 각각의 그룹 내의 비-제로 가중치의 수에 대한 분산이 결정된다. 206 단계에서, 트레이닝 문제(training problem)는 높은 제약(hard constraint)을 갖는 최소화 문제로 아래 수학식 7과 같이 공식화될 수 있다

높은 제약은 갖는 최소화 문제는, 라그랑주 승수(Lagrange multipliers), dual ascent 방식 또는 ADMM(alternating direction method of multipliers)을 이용하여 해결될 수 있다. 필수적으로, 상기 수학식 7의 2개의 항은, 아래 수학식 8과 같이 라그랑주 승수를 이용하여 결합되어야 한다.

207 단계에서, 파라미터  ,
,  및
및  가 BP(back-propagation)에서 트레이닝되고, 업데이트된다. 파라미터
가 BP(back-propagation)에서 트레이닝되고, 업데이트된다. 파라미터  및
및  는 기울기 하강법(gradient-descent technique)을 이용하여 업데이트되고, 반면에 라그랑주 파라미터는 아래 수학식 9와 같은 기울기 상승법(gradient-ascent technique)을 이용하여 업데이트된다.
는 기울기 하강법(gradient-descent technique)을 이용하여 업데이트되고, 반면에 라그랑주 파라미터는 아래 수학식 9와 같은 기울기 상승법(gradient-ascent technique)을 이용하여 업데이트된다.
수학식 8의 전체 손실이 감소하고, 라그랑주 승수  는 증가하기 때문에, 수학식 7의 높은 제약이 엄격히 요구된다. 208 단계에서, 방법(200)은 종료된다. 상술한 방법(200)을 이용하여, 그룹 사이의 거의 밸런싱된 희소성(sparsity)을 갖는 최소 값(minima)으로, 트레이닝은 결국 수렴될 것이다.
는 증가하기 때문에, 수학식 7의 높은 제약이 엄격히 요구된다. 208 단계에서, 방법(200)은 종료된다. 상술한 방법(200)을 이용하여, 그룹 사이의 거의 밸런싱된 희소성(sparsity)을 갖는 최소 값(minima)으로, 트레이닝은 결국 수렴될 것이다.
정확히 밸런싱된 희소성에 도달하기 위해, 후처리(post-processing) 방법이 적용될 수 있다. 도 2를 참조하여 설명한 밸런싱된 셀프-프루닝 이후, 비-제로 가중치의 수는 부분적인(partially) 희소 패턴을 가질 수 있다. 후처리 프로세스는, 정확한 희소성 밸런싱을 달성하기 위해, 프린지(fringe) 가중치의 마스크를 0 또는 1로 선택적으로 설정하도록 적용될 수 있다
도 3은 본 발명의 실시 예에 따른 후처리(post-processing) 방법(300)에 대한 순서도이다. 방법(300)은 301 단계에서 시작한다. 이 때, 301 단계는 도 2의 방법(200)의 종료 단계인 208 단계일 수 있다. 302 단계에서, 예를 들어, 도 2의 202 단계에서의 그룹 당 가중치의 총 수(total number of weights per group)은 1024라고 가정한다. 207 단계에서의 밸런싱된 셀프-프루닝 결과, 가장 많은 그룹은 500개의 비-제로 가중치의 모드를 가질 수 있고, 반면에 몇몇의 그룹은 모든 가중치가 0일 수 있다.
303 단계에서, 정확한 희소성 밸런싱을 달성하기 위해, 상기 모드보다 많은 비-제로 가중치를 갖는 그룹의 경우, 그룹의 비-제로 가중치의 수가 상기 모드와 동일해질 때까지 그룹의 가장 적은(smallest) 비-제로 가중치에 대한 마스크는, 0으로 설정된다.
304 단계에서, 상기 모드보다 적은 비-제로 가중치를 갖는 그룹의 경우, 가장 큰(largest) 값의 제로 가중치는, 그룹의 비-제로 가중치의 수가 상기 모드와 동일해질 때까지, 비-제로로 리셋(예를 들어, unmasked)된다.
도 4는 본 발명의 실시 예에 따른 밸런싱된 셀프-프루너(balanced self-pruner)(400)를 나타내는 도면이다. 밸런싱된 셀프-프루너(400)은 메모리(401), 마스커(402) 및 손실 결정기(403)을 포함할 수 있다. 몇몇 실시 예에 따라, 밸런싱된 셀프-프루너(400)는 제어 및 반복 유형(iterative-type)의 기능을 제공할 수 있는 컨트롤러(404)를 포함할 수 있다. 다른 실시 예에 따라, 밸런싱된 셀프-프루너는 state machine으로서 구현될 수 있다. 몇몇 실시 예에 따라, 밸런싱된 셀프-프루너는, 최소화(minimization) 및 산술적 기능(arithmetic functionality)을 제공하도록 구성된 소프트웨어, 펌웨어 및/또는 하드웨어의 임의의 조합일 수 있는 최소화 모듈(minimization module)로서 구현될 수 있다. 다른 실시 예에 따라, 밸런싱된 셀프-프루너(400)의 기능 블록들 중 하나 이상은 모듈일 수 있고, 이러한 모듈은 소프트웨어, 펌웨어 및/또는 하드웨어와 관련하여 본 명세서에서 기술된 기능을 제공하도록 구성된 하드웨어의 임의의 조합인 특정 모듈일 수 있다.
메모리(401)는 셀프-프루닝될 DNN의 가중치  를 저장할 수 있다. 또한, 메모리(401)는 마스커(402) 및 손실 결정기(403)에 의해 생성된 중간 값(interim values)르ㄹ 저장할 수 있다. 가중치
를 저장할 수 있다. 또한, 메모리(401)는 마스커(402) 및 손실 결정기(403)에 의해 생성된 중간 값(interim values)르ㄹ 저장할 수 있다. 가중치  는 메모리(401) 내에서 그룹화될 수 있다. 마스커(402)는 제1 곱셈기(multiplier)(405)를 포함할 수 있고, 제1 곱셈기(405)는 가중치
는 메모리(401) 내에서 그룹화될 수 있다. 마스커(402)는 제1 곱셈기(multiplier)(405)를 포함할 수 있고, 제1 곱셈기(405)는 가중치  및 마스킹 함수
및 마스킹 함수  을 입력으로 수신한다. 제1 곱셈기(405)의 출력은, 그룹의 비-제로 가중치의 수를 결정하기 위해 제1 가산기(406)에서 더해진다. 마스커(402)의 출력은 메모리(401)에 저장된다. 마스커(402)는, 마스킹 함수
을 입력으로 수신한다. 제1 곱셈기(405)의 출력은, 그룹의 비-제로 가중치의 수를 결정하기 위해 제1 가산기(406)에서 더해진다. 마스커(402)의 출력은 메모리(401)에 저장된다. 마스커(402)는, 마스킹 함수  가 가중치들의 그룹들 각각에 포함되는 각각의 가중치에 적용되도록, 반복적인 방식(iterative manner)으로 동작할 수 있다.
가 가중치들의 그룹들 각각에 포함되는 각각의 가중치에 적용되도록, 반복적인 방식(iterative manner)으로 동작할 수 있다.
손실 결정기(403)은 제2 가산기(407), 제2 곱셈기(408) 및 제3 가산기(409)를 포함할 수 있다.제2 가산기(407)는 그룹의 비-제로 가중치의 수를 입력으로 수신하고, 모든 그룹의 평균 카운트 값을 감산(subtract)한다. 제2 가산기(407)의 출력은 제2 곱셈기(408)의 입력으로 제공된다. 제2 곱셈기(408)는 제2 가산기(408)의 출력을 제곱(square)하고, 라그랑주 승수  에 의한 결과를 곱한다. 제2 곱셈기(408)의 출력은 네트워크의 손실
에 의한 결과를 곱한다. 제2 곱셈기(408)의 출력은 네트워크의 손실  로부터 감산되고, 손실
로부터 감산되고, 손실  의 최소화를 위한 분석(evaluation)를 위해 메모리(401)에 저장된다. 후처리는, 정확한 희소성 밸런싱을 달성하기 위해 마스커(402)를 이용하여 수행된다.
의 최소화를 위한 분석(evaluation)를 위해 메모리(401)에 저장된다. 후처리는, 정확한 희소성 밸런싱을 달성하기 위해 마스커(402)를 이용하여 수행된다.
일 실시예에 따르면, 상기 설명된 구성 요소들의 각각의 구성 요소(예를 들어, 모듈 또는 프로그램)는 단일 엔티티(entity) 또는 다중 엔티티들을 포함할 수 있다. 하나 이상의 상술한 구성 요소들은 생략될 수 있고, 하나 이상의 다른 구성 요소들이 추가될 수 있다. 대안적으로 또는 추가적으로, 복수의 구성 요소들(예를 들어, 모듈들 또는 프로그램들)은 단일 구성 요소로 통합될(integrated) 수 있다. 이러한 경우, 통합된 구성 요소는 통합 전 하나 이상의 복수의 구성 요소들에 의해서 수행되는 것과 동일하거나 유사한 방식으로 여전히 하나 이상의 복수의 구성 요소들의 하나 이상의 기능을 수행할 수 있다. 모듈, 프로그램, 또는 다른 구성요소에 의해 수행되는 동작은 순차적으로, 병렬적으로, 반복적으로, 또는 휴리스틱하게 수행될 수 있으며, 또한 하나 이상의 동작들이 생략되거나 다른 순서로 수행될 수 있으며, 하나 이상의 다른 동작들이 추가될 수 있다.
이상에서는 본 발명의 바람직한 실시 예에 대하여 도시하고 설명하였지만, 본 발명이 속하는 기술 분야에서 통상의 지식을 가진 자는 본 발명이 아래의 특허청구범위에 의해 정의되는 본 발명의 본질적인 특성에서 벗어나지 않는 범위에서 변형된 형태로 구현될 수 있음을 이해할 수 있을 것이다.
400: 셀프-프루너(self-pruner) 401: 메모리
402: 마스커 403: 손실 결정기
404: 컨트롤러 405: 제1 곱셈기
406: 제1 가산기 407: 제2 가산기
408: 제2 곱셈기 409: 제3 가산기
402: 마스커 403: 손실 결정기
404: 컨트롤러 405: 제1 곱셈기
406: 제1 가산기 407: 제2 가산기
408: 제2 곱셈기 409: 제3 가산기
Claims (12)
- 심층 신경망(Deep Neural Network, DNN)의 가중치에 대한 밸런싱된 프루닝(balanced pruning)을 제공하는 시스템으로서,
상기 심층 신경망의 복수의 가중치 그룹들 각각에 포함되는 가중치를 마스킹하는 가중치 마스커(weight masker); 및
상기 심층 신경망의 네트워크 손실에서 상기 복수의 가중치 그룹들 내의 비-제로(non-zero) 가중치의 수에 대한 분산(variance)를 뺀 값에 기초하여, 상기 심층 신경망의 손실을 결정하는 손실 결정기(loss determiner)를 포함하는 시스템. - 제1항에 있어서,
상기 손실 결정기는, 상기 심층 신경망의 네트워크 손실에서, 라그랑주 승수(Lagrange multiplier)에 의해 곱해진 상기 복수의 가중치 그룹들 내의 비-제로 가중치의 수에 대한 분산을 뺀 값에 기초하여 상기 심층 신경망의 손실을 결정하는 시스템. - 제2항에 있어서,
상기 가중치 마스커는, 마스킹 함수(masking function)에 의해 상기 복수의 가중치 그룹들 각각에 포함되는 가중치를 곱하는 시스템. - 제3항에 있어서,
상기 마스킹 함수는 미분 가능한 함수인, 시스템. - 제4항에 있어서,
상기 마스킹 함수의 첨예도(sharpness)는 선택적으로 제어 가능하고, 상기 마스킹 함수의 너비(width)는 선택적으로 제어 가능한, 시스템. - 심층 신경망(Deep Neural Network, DNN)의 가중치에 대한 밸런싱된 프루닝(balanced pruning)을 제공하는 방법으로서,
상기 심층 신경망의 가중치를 복수의 그룹들로 그룹화(partitioning)하는 단계;
가중치 마스커에 의해, 각각의 그룹의 가중치에 마스킹 함수를 적용하는 단계;
상기 마스킹 함수가 적용된 후, 상기 각각의 그룹 내의 비-제로 가중치의 수를 결정하는 단계;
상기 각각의 그룹 내의 비-제로 가중치의 수의 분산을 결정하는 단계;
손실 결정기에 의해, 상기 각각의 그룹 내의 비-제로 가중치의 수의 분산이 0인 제약을 포함하는 라그랑주 승수를 이용하여 상기 심층 신경망의 손실 함수를 최소화하는 단계; 및
BP(back-propagation)에 의해, 상기 가중치 및 상기 라그랑주 승수를 재트레이닝(retraining)하는 단계를 포함하는 방법. - 제6항에 있어서,
상기 라그랑주 승수는, 상기 각각의 그룹의 비-제로 가중치의 수의 분산을 곱하는데 이용되는, 방법. - 제6항에 있어서,
상기 재트레이닝된 가중치의 모드를 결정하는 단계;
상기 복수의 그룹들 중 제1 그룹이 상기 모드보다 많은 비-제로 가중치를 갖는 경우, 상기 제1 그룹의 비-제로 가중치의 수가 상기 재트레이닝된 가중치의 모드와 동일할 때까지 상기 제1 그룹에 0을 적용하도록 상기 마스킹 함수를 적용하는 단계; 및
상기 복수의 그룹들 중 제2 그룹이 상기 모드보다 적은 비-제로 가중치를 갖는 경우, 상기 제2 그룹의 비-제로 가중치의 수가 상기 재트레이닝된 가중치의 모드와 동일할 때까지 상기 제2 그룹에 1을 적용하도록 상기 마스킹 함수를 적용하는 단계를 더 포함하는, 방법. - 제6항에 있어서,
상기 마스킹 함수는 미분 가능한 함수인, 방법. - 제9항에 있어서,
상기 마스킹 함수의 첨예도는 선택적으로 제어 가능하고, 상기 마스킹 함수의 너비는 선택적으로 제어 가능한, 방법. - 제6항에 있어서,
BP에 의해, 상기 가중치 및 상기 라그랑주 승수를 재트레이닝하는 단계는,
상기 BP에 의해, 상기 가중치, 상기 마스킹 함수의 너비 및 상기 라그랑주 승수를 재트레이닝하는 단계를 더 포함하는, 방법. - 제11항에 있어서,
상기 가중치, 상기 마스킹 함수의 너비 및 상기 라그랑주 승수를 재트레이닝하는 단계는,
기울기 하강 기법(gradient-descent technique)을 이용하여 상기 가중치 및 상기 마스킹 함수의 너비를 업데이트하는 단계; 및
기울기 상승 기법(gradient-ascent technique)을 이용하여 상기 라그랑주 승수를 업데이트하는 단계를 포함하는, 방법.
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862735846P | 2018-09-24 | 2018-09-24 | |
| US62/735,846 | 2018-09-24 | ||
| US16/186,470 US11449756B2 (en) | 2018-09-24 | 2018-11-09 | Method to balance sparsity for efficient inference of deep neural networks |
| US16/186,470 | 2018-11-09 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20200034918A true KR20200034918A (ko) | 2020-04-01 |
Family
ID=69884470
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020190024974A KR20200034918A (ko) | 2018-09-24 | 2019-03-05 | 심층 신경망의 가중치에 대한 밸런싱된 프루닝을 제공하는 시스템 및 방법 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US11449756B2 (ko) |
| KR (1) | KR20200034918A (ko) |
| CN (1) | CN110942135A (ko) |
| TW (1) | TWI801669B (ko) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022145713A1 (ko) * | 2020-12-31 | 2022-07-07 | 주식회사 메이아이 | 인공 신경망 모델을 경량화하기 위한 방법, 시스템 및 비일시성의 컴퓨터 판독 가능한 기록 매체 |
| KR20220143276A (ko) * | 2021-04-16 | 2022-10-25 | 서울시립대학교 산학협력단 | 딥 러닝 모델 학습 방법 및 학습기 |
| KR20230032748A (ko) * | 2021-08-31 | 2023-03-07 | 한국과학기술원 | 심층 강화학습을 위한 심층 신경망 학습 가속 장치 및 그 방법 |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111860568B (zh) * | 2020-05-13 | 2022-02-08 | 北京嘀嘀无限科技发展有限公司 | 数据样本的均衡分布方法、装置及存储介质 |
| CN111950411B (zh) * | 2020-07-31 | 2021-12-28 | 上海商汤智能科技有限公司 | 模型确定方法及相关装置 |
| GB2623044B (en) * | 2020-12-22 | 2024-08-21 | Imagination Tech Ltd | Training a neural network |
| US11895330B2 (en) * | 2021-01-25 | 2024-02-06 | Lemon Inc. | Neural network-based video compression with bit allocation |
| GB202201063D0 (en) * | 2022-01-27 | 2022-03-16 | Samsung Electronics Co Ltd | Method and apparatus for sharpness-aware minimisation |
| WO2023164950A1 (en) * | 2022-03-04 | 2023-09-07 | Intel Corporation | Method and apparatus for accelerating deep leaning inference based on hw-aware sparsity pattern |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20080117231A1 (en) * | 2006-11-19 | 2008-05-22 | Tom Kimpe | Display assemblies and computer programs and methods for defect compensation |
| US8315962B1 (en) * | 2009-11-25 | 2012-11-20 | Science Applications International Corporation | System and method for multiclass discrimination of neural response data |
| US8700552B2 (en) | 2011-11-28 | 2014-04-15 | Microsoft Corporation | Exploiting sparseness in training deep neural networks |
| US10515304B2 (en) * | 2015-04-28 | 2019-12-24 | Qualcomm Incorporated | Filter specificity as training criterion for neural networks |
| US9780985B1 (en) * | 2015-05-11 | 2017-10-03 | University Of South Florida | Suppressing alignment for out-of-band interference and peak-to-average power ratio reduction in OFDM systems |
| CN106599992B (zh) * | 2015-10-08 | 2019-04-09 | 上海兆芯集成电路有限公司 | 以处理单元群组作为时间递归神经网络长短期记忆胞进行运作的神经网络单元 |
| US9946767B2 (en) * | 2016-01-19 | 2018-04-17 | Conduent Business Services, Llc | Smoothed dynamic modeling of user traveling preferences in a public transportation system |
| US10832123B2 (en) * | 2016-08-12 | 2020-11-10 | Xilinx Technology Beijing Limited | Compression of deep neural networks with proper use of mask |
| US10984308B2 (en) | 2016-08-12 | 2021-04-20 | Xilinx Technology Beijing Limited | Compression method for deep neural networks with load balance |
| WO2018058509A1 (en) | 2016-09-30 | 2018-04-05 | Intel Corporation | Dynamic neural network surgery |
| US20180107926A1 (en) * | 2016-10-19 | 2018-04-19 | Samsung Electronics Co., Ltd. | Method and apparatus for neural network quantization |
| US11315018B2 (en) | 2016-10-21 | 2022-04-26 | Nvidia Corporation | Systems and methods for pruning neural networks for resource efficient inference |
| CN107688850B (zh) * | 2017-08-08 | 2021-04-13 | 赛灵思公司 | 一种深度神经网络压缩方法 |
| US10535141B2 (en) * | 2018-02-06 | 2020-01-14 | Google Llc | Differentiable jaccard loss approximation for training an artificial neural network |
| US10977338B1 (en) * | 2018-04-20 | 2021-04-13 | Perceive Corporation | Reduced-area circuit for dot product computation |
| US10977802B2 (en) * | 2018-08-29 | 2021-04-13 | Qualcomm Incorporated | Motion assisted image segmentation |
-
2018
- 2018-11-09 US US16/186,470 patent/US11449756B2/en active Active
-
2019
- 2019-03-05 KR KR1020190024974A patent/KR20200034918A/ko active Search and Examination
- 2019-09-24 TW TW108134461A patent/TWI801669B/zh active
- 2019-09-24 CN CN201910904340.XA patent/CN110942135A/zh active Pending
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022145713A1 (ko) * | 2020-12-31 | 2022-07-07 | 주식회사 메이아이 | 인공 신경망 모델을 경량화하기 위한 방법, 시스템 및 비일시성의 컴퓨터 판독 가능한 기록 매체 |
| KR20220143276A (ko) * | 2021-04-16 | 2022-10-25 | 서울시립대학교 산학협력단 | 딥 러닝 모델 학습 방법 및 학습기 |
| KR20230032748A (ko) * | 2021-08-31 | 2023-03-07 | 한국과학기술원 | 심층 강화학습을 위한 심층 신경망 학습 가속 장치 및 그 방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| US11449756B2 (en) | 2022-09-20 |
| CN110942135A (zh) | 2020-03-31 |
| US20200097830A1 (en) | 2020-03-26 |
| TW202013263A (zh) | 2020-04-01 |
| TWI801669B (zh) | 2023-05-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20200034918A (ko) | 심층 신경망의 가중치에 대한 밸런싱된 프루닝을 제공하는 시스템 및 방법 | |
| Ji et al. | Bridge the gap between neural networks and neuromorphic hardware with a neural network compiler | |
| EP3480690B1 (en) | Error allocation format selection for hardware implementation of deep neural network | |
| CN112085186A (zh) | 一种神经网络的量化参数确定方法及相关产品 | |
| TW202234236A (zh) | 用以最佳化邊緣網路中的資源之方法、系統、製品及設備 | |
| CN112673383A (zh) | 神经网络核中动态精度的数据表示 | |
| KR102181385B1 (ko) | 신경망에서의 무작위성 생성 | |
| CN112785597A (zh) | 识别图像的方法和系统 | |
| DiCecco et al. | FPGA-based training of convolutional neural networks with a reduced precision floating-point library | |
| CN113065997B (zh) | 一种图像处理方法、神经网络的训练方法以及相关设备 | |
| CN108629403B (zh) | 处理脉冲神经网络中的信号饱和 | |
| Kang et al. | An overview of sparsity exploitation in CNNs for on-device intelligence with software-hardware cross-layer optimizations | |
| JP7137067B2 (ja) | 演算処理装置、学習プログラム及び学習方法 | |
| US11615300B1 (en) | System and method for implementing neural networks in integrated circuits | |
| CN111788567B (zh) | 一种数据处理设备以及一种数据处理方法 | |
| CN112232477A (zh) | 图像数据处理方法、装置、设备及介质 | |
| Prono et al. | A Multiply-And-Max/min Neuron Paradigm for Aggressively Prunable Deep Neural Networks | |
| Fraser et al. | A fully pipelined kernel normalised least mean squares processor for accelerated parameter optimisation | |
| CN111930670B (zh) | 异构智能处理量化装置、量化方法、电子设备及存储介质 | |
| US20200371746A1 (en) | Arithmetic processing device, method for controlling arithmetic processing device, and non-transitory computer-readable storage medium for storing program for controlling arithmetic processing device | |
| KR20210116182A (ko) | 소프트맥스 연산 근사화 방법 및 장치 | |
| Kabir et al. | A runtime programmable accelerator for convolutional and multilayer perceptron neural networks on fpga | |
| Gomperts et al. | Implementation of neural network on parameterized FPGA | |
| EP4345692A1 (en) | Methods and systems for online selection of number formats for network parameters of a neural network | |
| KR102695116B1 (ko) | 단조 감소하는 양자화 해상도를 기반으로 하는 기계 학습 장치 및 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination |