KR20190110041A - 비디오 신호 처리 방법 및 장치 - Google Patents
비디오 신호 처리 방법 및 장치 Download PDFInfo
- Publication number
- KR20190110041A KR20190110041A KR1020190030052A KR20190030052A KR20190110041A KR 20190110041 A KR20190110041 A KR 20190110041A KR 1020190030052 A KR1020190030052 A KR 1020190030052A KR 20190030052 A KR20190030052 A KR 20190030052A KR 20190110041 A KR20190110041 A KR 20190110041A
- Authority
- KR
- South Korea
- Prior art keywords
- reference sample
- sample
- intra prediction
- current block
- prediction
- Prior art date
Links
Images























Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/103—Selection of coding mode or of prediction mode
- H04N19/105—Selection of the reference unit for prediction within a chosen coding or prediction mode, e.g. adaptive choice of position and number of pixels used for prediction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/132—Sampling, masking or truncation of coding units, e.g. adaptive resampling, frame skipping, frame interpolation or high-frequency transform coefficient masking
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/103—Selection of coding mode or of prediction mode
- H04N19/11—Selection of coding mode or of prediction mode among a plurality of spatial predictive coding modes
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/12—Selection from among a plurality of transforms or standards, e.g. selection between discrete cosine transform [DCT] and sub-band transform or selection between H.263 and H.264
- H04N19/122—Selection of transform size, e.g. 8x8 or 2x4x8 DCT; Selection of sub-band transforms of varying structure or type
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/157—Assigned coding mode, i.e. the coding mode being predefined or preselected to be further used for selection of another element or parameter
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/157—Assigned coding mode, i.e. the coding mode being predefined or preselected to be further used for selection of another element or parameter
- H04N19/159—Prediction type, e.g. intra-frame, inter-frame or bidirectional frame prediction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/176—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a block, e.g. a macroblock
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/189—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the adaptation method, adaptation tool or adaptation type used for the adaptive coding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/593—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving spatial prediction techniques
Abstract
본 발명에 따른 영상 복호화 방법은, 현재 블록의 인트라 예측 모드를 결정하는 단계, 상기 현재 블록에 포함된 예측 대상 샘플에 대한 참조 샘플 라인을 결정하는 단계, 및 상기 인트라 예측 모드 및 상기 참조 샘플 라인을 기초로 상기 예측 대상 샘플의 예측값을 획득하는 단계를 포함할 수 있다.
Description
본 발명은 비디오 신호 처리 방법 및 장치에 관한 것이다.
최근 HD(High Definition) 영상 및 UHD(Ultra High Definition) 영상과 같은 고해상도, 고품질의 영상에 대한 수요가 다양한 응용 분야에서 증가하고 있다. 영상 데이터가 고해상도, 고품질이 될수록 기존의 영상 데이터에 비해 상대적으로 데이터량이 증가하기 때문에 기존의 유무선 광대역 회선과 같은 매체를 이용하여 영상 데이터를 전송하거나 기존의 저장 매체를 이용해 저장하는 경우, 전송 비용과 저장 비용이 증가하게 된다. 영상 데이터가 고해상도, 고품질화 됨에 따라 발생하는 이러한 문제들을 해결하기 위해서는 고효율의 영상 압축 기술들이 활용될 수 있다.
영상 압축 기술로 현재 픽쳐의 이전 또는 이후 픽쳐로부터 현재 픽쳐에 포함된 화소값을 예측하는 화면 간 예측 기술, 현재 픽쳐 내의 화소 정보를 이용하여 현재 픽쳐에 포함된 화소값을 예측하는 화면 내 예측 기술, 출현 빈도가 높은 값에 짧은 부호를 할당하고 출현 빈도가 낮은 값에 긴 부호를 할당하는 엔트로피 부호화 기술 등 다양한 기술이 존재하고 이러한 영상 압축 기술을 이용해 영상 데이터를 효과적으로 압축하여 전송 또는 저장할 수 있다.
한편, 고해상도 영상에 대한 수요가 증가함과 함께, 새로운 영상 서비스로서 입체 영상 컨텐츠에 대한 수요도 함께 증가하고 있다. 고해상도 및 초고해상도의 입체 영상 콘텐츠를 효과적으로 제공하기 위한 비디오 압축 기술에 대하여 논의가 진행되고 있다.
본 발명은 비디오 신호를 부호화/복호화함에 있어서, 부호화/복호화 대상 블록에 대해 효율적으로 인트라 예측을 수행할 수 있는 방법 및 장치를 제공하는 것을 목적으로 한다.
본 발명은 비디오 신호를 부호화/복호화함에 있어서, 복수의 참조 샘플들을 이용하여 인트라 예측을 수행하는 방법 및 장치를 제공하는 것을 목적으로 한다.
본 발명은 비디오 신호를 부호화/복호화함에 있어서, 우측 및 하단 참조 샘플을 이용하여 인트라 예측을 수행하는 방법 및 장치를 제공하는 것을 목적으로 한다.
본 발명은 비디오 신호를 부호화/복호화함에 있어서, 복수의 참조 샘플 라인들 중 적어도 하나를 이용하여 인트라 예측을 수행하는 방법 및 장치를 제공하는 것을 목적으로 한다.
본 발명은 비디오 신호를 부호화/복호화함에 있어서, 현재 블록의 좌/우, 상/하에 인접하는 참조 샘플들을 기초로 복수 참조 샘플들을 구성하는 방법 및 장치를 제공하는 것을 목적으로 한다.
본 발명에서 이루고자 하는 기술적 과제들은 이상에서 언급한 기술적 과제들로 제한되지 않으며, 언급하지 않은 또 다른 기술적 과제들은 아래의 기재로부터 본 발명이 속하는 기술분야에서 통상의 지식을 가진 자에게 명확하게 이해될 수 있을 것이다.
본 발명에 따른 비디오 신호 복호화 방법 및 장치는, 현재 블록의 인트라 예측 모드를 결정하고, 상기 현재 블록에 포함된 예측 대상 샘플에 대한 참조 샘플 라인을 결정하고, 상기 인트라 예측 모드 및 상기 참조 샘플 라인을 기초로 상기 예측 대상 샘플의 예측값을 획득할 수 있다.
본 발명에 따른 비디오 신호 부호화 방법 및 장치는, 현재 블록의 인트라 예측 모드를 결정하고, 상기 현재 블록에 포함된 예측 대상 샘플에 대한 참조 샘플 라인을 결정하고, 상기 인트라 예측 모드 및 상기 참조 샘플 라인을 기초로 상기 예측 대상 샘플의 예측값을 획득할 수 있다.
본 발명에 따른 비디오 신호 부호화/복호화 방법 및 장치에 있어서, 상기 참조 샘플 라인의 결정은 상기 예측 대상 샘플의 위치 또는 상기 예측 대상 샘플이 기 결정된 영역에 포함되어 있는지 여부에 기초하여 수행될 수 있다.
본 발명에 따른 비디오 신호 부호화/복호화 방법 및 장치에 있어서, 상기 참조 샘플 라인의 결정은, 상기 예측 대상 샘플의 위치로부터 제1 참조 샘플 라인에 포함된 제1 참조 샘플까지의 거리 및 상기 예측 대상 샘플의 위치로부터 제2 참조 샘플 라인에 포함된 제2 참조 샘플까지의 거리의 비교 결과에 기초하여 수행될 수 있다.
본 발명에 따른 비디오 신호 부호화/복호화 방법 및 장치에 있어서, 상기 제1 참조 샘플 및 상기 제2 참조 샘플은 상기 인트라 예측 모드에 기초하여 결정될 수 있다.
본 발명에 따른 비디오 신호 부호화/복호화 방법 및 장치에 있어서, 상기 제1 참조 샘플 라인은 상기 현재 블록의 상단에 인접하는 행에 포함된 상단 참조 샘플 및 상기 현재 블록의 좌측에 인접하는 열에 포함된 좌측 참조 샘플을 포함하고, 상기 제2 참조 샘플 라인은 상기 현재 블록의 우측에 인접하는 열에 포함된 우측 참조 샘플 및 상기 현재 블록의 하단에 인접하는 행에 포함된 하단 참조 샘플을 포함할 수 있다.
본 발명에 따른 비디오 신호 부호화/복호화 방법 및 장치에 있어서, 상기 예측값은 제1 참조 샘플 라인에 포함된 제1 참조 샘플과 제2 참조 샘플 라인에 포함된 제2 참조 샘플 사이의 가중합 연산 또는 평균 연산을 기초로 산출될 수 있다.
본 발명에 따른 비디오 신호 부호화/복호화 방법 및 장치에 있어서, 상기 제1 참조 샘플 및 상기 제2 참조 샘플 각각에 적용되는 가중치는, 상기 예측 대상 샘플과의 거리를 기초로 결정될 수 있다.
본 발명에 따른 비디오 신호 부호화/복호화 방법 및 장치에 있어서, 상기 제1 참조 샘플 및 상기 제2 참조 샘플 각각에 적용되는 가중치는, 상기 예측 대상 샘플과의 거리를 기초로 결정될 수 있다.
본 발명에 따른 비디오 신호 부호화/복호화 방법 및 장치에 있어서, 상기 참조 샘플 라인의 결정은, 복수의 참조 샘플 라인을 이용할 것인지 여부의 결정을 포함할 수 있다.
본 발명에 대하여 위에서 간략하게 요약된 특징들은 후술하는 본 발명의 상세한 설명의 예시적인 양상일 뿐이며, 본 발명의 범위를 제한하는 것은 아니다.
본 발명에 의하면, 부호화/복호화 대상 블록에 대해 효율적으로 인트라 예측을 수행할 수 있다.
본 발명에 의하면, 서로 이웃하지 않는 복수의 참조 샘플을 이용하여 인트라 예측을 수행함으로써, 인트라 예측의 효율을 높일 수 있는 이점이 있다.
본 발명에 의하면, 우측 및 하단 참조 샘플을 이용함으로써, 인트라 예측의 효율을 높일 수 있는 이점이 있다.
본 발명에 의하면, 복수의 참조 샘플 라인들 중 적어도 하나를 선택 사용함으로써, 인트라 예측의 효율을 높일 수 있는 이점이 있다.
본 발명에 의하면, 현재 블록의 좌측/상단에 인접하는 참조 샘플들 뿐만 아니라, 우측/하단에 인접하는 참조 샘플들을 이용하여 참조 샘플 라인을 구성함으로써, 인트라 예측의 효율을 높일 수 있는 이점이 있다.
본 발명에서 얻을 수 있는 효과는 이상에서 언급한 효과들로 제한되지 않으며, 언급하지 않은 또 다른 효과들은 아래의 기재로부터 본 발명이 속하는 기술분야에서 통상의 지식을 가진 자에게 명확하게 이해될 수 있을 것이다.
도 1은 본 발명의 일실시예에 따른 영상 부호화 장치를 나타낸 블록도이다.
도 2는 본 발명의 일실시예에 따른 영상 복호화 장치를 나타낸 블록도이다.
도 3은 본 발명이 적용되는 일실시예로서, 트리 구조(tree structure)에 기반하여 코딩 블록을 계층적으로 분할하는 일예를 도시한 것이다.
도 4는 본 발명이 적용되는 일실시예로서, 바이너리 트리 기반의 분할이 허용되는 파티션 형태를 나타낸 도면이다.
도 5는 본 발명이 적용되는 일실시예로서, 특정 형태의 바이너리 트리 기반의 분할만이 허용된 예를 나타낸 도면이다.
도 6은 본 발명이 적용되는 일실시예로서, 바이너리 트리 분할 허용 횟수와 관련된 정보가 부호화/복호화되는 예를 설명하기 위한 도면이다.
도 7은 본 발명이 적용되는 일실시예로서, 코딩 블록에 적용될 수 있는 파티션 모드를 예시한 도면이다.
도 8은 본 발명이 적용되는 일실시예로서, 영상 부호화기/복호화기에 기-정의된 인트라 예측 모드의 종류를 도시한 것이다.
도 9는 본 발명이 적용되는 일실시예로서, 확장된 인트라 예측 모드의 종류를 도시한 것이다.
도 10은 본 발명이 적용되는 일실시예로서, 인트라 예측 방법을 개략적으로 도시한 순서도이다.
도 11은 복수의 참조 샘플 라인을 예시한 도면이다.
도 12는 본 발명이 적용되는 일실시예로서, 주변 샘플들의 차분 정보에 기반하여 현재 블록의 예측 샘플을 보정하는 방법을 도시한 것이다.
도 13 및 도 14는 참조 샘플들이 일렬로 재배열된 일차원 레퍼런스 샘플 그룹을 나타낸 도면이다.
도 15는 복수 참조 샘플을 이용하여, 우측 참조 샘플 또는 하단 참조 샘플을 유도하는 예를 나타낸 도면이다.
도 16 및 도 17은 본 발명의 일 실시예에 따른, 비정방형 블록에 대해 우측 참조 샘플 및 하단 참조 샘플을 유도하는 예를 설명하기 위한 도면이다.
도 18은 복수 참조 샘플 라인을 예시한 도면이다.
도 19는 제1 참조 샘플을 이용하여 적어도 하나의 제2 참조 샘플이 유도되는 예를 설명하기 위한 도면이다.
도 20은 양방향 인트라 예측이 적용되는 영역을 나타낸 예이다.
도 21은 양방향 인트라 예측이 허용되는 방향성 예측 모드를 식별 표시한 예이다.
도 22는 예측 대상 샘플의 위치에 따라 참조 샘플 라인이 결정되는 예를 나타낸 도면이다.
도 23은 예측 대상 샘플의 위치에 따라 참조 샘플 라인의 개수가 결정되는 예를 나타낸 도면이다.
도 2는 본 발명의 일실시예에 따른 영상 복호화 장치를 나타낸 블록도이다.
도 3은 본 발명이 적용되는 일실시예로서, 트리 구조(tree structure)에 기반하여 코딩 블록을 계층적으로 분할하는 일예를 도시한 것이다.
도 4는 본 발명이 적용되는 일실시예로서, 바이너리 트리 기반의 분할이 허용되는 파티션 형태를 나타낸 도면이다.
도 5는 본 발명이 적용되는 일실시예로서, 특정 형태의 바이너리 트리 기반의 분할만이 허용된 예를 나타낸 도면이다.
도 6은 본 발명이 적용되는 일실시예로서, 바이너리 트리 분할 허용 횟수와 관련된 정보가 부호화/복호화되는 예를 설명하기 위한 도면이다.
도 7은 본 발명이 적용되는 일실시예로서, 코딩 블록에 적용될 수 있는 파티션 모드를 예시한 도면이다.
도 8은 본 발명이 적용되는 일실시예로서, 영상 부호화기/복호화기에 기-정의된 인트라 예측 모드의 종류를 도시한 것이다.
도 9는 본 발명이 적용되는 일실시예로서, 확장된 인트라 예측 모드의 종류를 도시한 것이다.
도 10은 본 발명이 적용되는 일실시예로서, 인트라 예측 방법을 개략적으로 도시한 순서도이다.
도 11은 복수의 참조 샘플 라인을 예시한 도면이다.
도 12는 본 발명이 적용되는 일실시예로서, 주변 샘플들의 차분 정보에 기반하여 현재 블록의 예측 샘플을 보정하는 방법을 도시한 것이다.
도 13 및 도 14는 참조 샘플들이 일렬로 재배열된 일차원 레퍼런스 샘플 그룹을 나타낸 도면이다.
도 15는 복수 참조 샘플을 이용하여, 우측 참조 샘플 또는 하단 참조 샘플을 유도하는 예를 나타낸 도면이다.
도 16 및 도 17은 본 발명의 일 실시예에 따른, 비정방형 블록에 대해 우측 참조 샘플 및 하단 참조 샘플을 유도하는 예를 설명하기 위한 도면이다.
도 18은 복수 참조 샘플 라인을 예시한 도면이다.
도 19는 제1 참조 샘플을 이용하여 적어도 하나의 제2 참조 샘플이 유도되는 예를 설명하기 위한 도면이다.
도 20은 양방향 인트라 예측이 적용되는 영역을 나타낸 예이다.
도 21은 양방향 인트라 예측이 허용되는 방향성 예측 모드를 식별 표시한 예이다.
도 22는 예측 대상 샘플의 위치에 따라 참조 샘플 라인이 결정되는 예를 나타낸 도면이다.
도 23은 예측 대상 샘플의 위치에 따라 참조 샘플 라인의 개수가 결정되는 예를 나타낸 도면이다.
본 발명은 다양한 변경을 가할 수 있고 여러 가지 실시예를 가질 수 있는 바, 특정 실시예들을 도면에 예시하고 상세한 설명에 상세하게 설명하고자 한다. 그러나, 이는 본 발명을 특정한 실시 형태에 대해 한정하려는 것이 아니며, 본 발명의 사상 및 기술 범위에 포함되는 모든 변경, 균등물 내지 대체물을 포함하는 것으로 이해되어야 한다. 각 도면을 설명하면서 유사한 참조부호를 유사한 구성요소에 대해 사용하였다.
제1, 제2 등의 용어는 다양한 구성요소들을 설명하는데 사용될 수 있지만, 상기 구성요소들은 상기 용어들에 의해 한정되어서는 안 된다. 상기 용어들은 하나의 구성요소를 다른 구성요소로부터 구별하는 목적으로만 사용된다. 예를 들어, 본 발명의 권리 범위를 벗어나지 않으면서 제1 구성요소는 제2 구성요소로 명명될 수 있고, 유사하게 제2 구성요소도 제1 구성요소로 명명될 수 있다. 및/또는 이라는 용어는 복수의 관련된 기재된 항목들의 조합 또는 복수의 관련된 기재된 항목들 중의 어느 항목을 포함한다.
어떤 구성요소가 다른 구성요소에 "연결되어" 있다거나 "접속되어"있다고 언급된 때에는, 그 다른 구성요소에 직접적으로 연결되어 있거나 또는 접속되어 있을 수도 있지만, 중간에 다른 구성요소가 존재할 수도 있다고 이해되어야 할 것이다. 반면에, 어떤 구성요소가 다른 구성요소에 "직접 연결되어"있다거나 "직접 접속되어"있다고 언급된 때에는, 중간에 다른 구성요소가 존재하지 않는 것으로 이해되어야 할 것이다.
본 출원에서 사용한 용어는 단지 특정한 실시예를 설명하기 위해 사용된 것으로, 본 발명을 한정하려는 의도가 아니다. 단수의 표현은 문맥상 명백하게 다르게 뜻하지 않는 한, 복수의 표현을 포함한다. 본 출원에서, "포함하다" 또는 "가지다" 등의 용어는 명세서상에 기재된 특징, 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것이 존재함을 지정하려는 것이지, 하나 또는 그 이상의 다른 특징들이나 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것들의 존재 또는 부가 가능성을 미리 배제하지 않는 것으로 이해되어야 한다.
이하, 첨부한 도면들을 참조하여, 본 발명의 바람직한 실시예를 보다 상세하게 설명하고자 한다. 이하, 도면상의 동일한 구성요소에 대해서는 동일한 참조부호를 사용하고 동일한 구성요소에 대해서 중복된 설명은 생략한다.
도 1은 본 발명의 일실시예에 따른 영상 부호화 장치를 나타낸 블록도이다.
도 1을 참조하면, 영상 부호화 장치(100)는 픽쳐 분할부(110), 예측부(120, 125), 변환부(130), 양자화부(135), 재정렬부(160), 엔트로피 부호화부(165), 역양자화부(140), 역변환부(145), 필터부(150) 및 메모리(155)를 포함할 수 있다.
도 1에 나타난 각 구성부들은 영상 부호화 장치에서 서로 다른 특징적인 기능들을 나타내기 위해 독립적으로 도시한 것으로, 각 구성부들이 분리된 하드웨어나 하나의 소프트웨어 구성단위로 이루어짐을 의미하지 않는다. 즉, 각 구성부는 설명의 편의상 각각의 구성부로 나열하여 포함한 것으로 각 구성부 중 적어도 두 개의 구성부가 합쳐져 하나의 구성부로 이루어지거나, 하나의 구성부가 복수개의 구성부로 나뉘어져 기능을 수행할 수 있고 이러한 각 구성부의 통합된 실시예 및 분리된 실시예도 본 발명의 본질에서 벗어나지 않는 한 본 발명의 권리범위에 포함된다.
또한, 일부의 구성 요소는 본 발명에서 본질적인 기능을 수행하는 필수적인 구성 요소는 아니고 단지 성능을 향상시키기 위한 선택적 구성 요소일 수 있다. 본 발명은 단지 성능 향상을 위해 사용되는 구성 요소를 제외한 본 발명의 본질을 구현하는데 필수적인 구성부만을 포함하여 구현될 수 있고, 단지 성능 향상을 위해 사용되는 선택적 구성 요소를 제외한 필수 구성 요소만을 포함한 구조도 본 발명의 권리범위에 포함된다.
픽쳐 분할부(110)는 입력된 픽쳐를 적어도 하나의 처리 단위로 분할할 수 있다. 이때, 처리 단위는 예측 단위(Prediction Unit: PU)일 수도 있고, 변환 단위(Transform Unit: TU)일 수도 있으며, 부호화 단위(Coding Unit: CU)일 수도 있다. 픽쳐 분할부(110)에서는 하나의 픽쳐에 대해 복수의 부호화 단위, 예측 단위 및 변환 단위의 조합으로 분할하고 소정의 기준(예를 들어, 비용 함수)으로 하나의 부호화 단위, 예측 단위 및 변환 단위 조합을 선택하여 픽쳐를 부호화 할 수 있다.
예를 들어, 하나의 픽쳐는 복수개의 부호화 단위로 분할될 수 있다. 픽쳐에서 부호화 단위를 분할하기 위해서는 쿼드 트리 구조(Quad Tree Structure)와 같은 재귀적인 트리 구조를 사용할 수 있는데 하나의 영상 또는 최대 크기 부호화 단위(largest coding unit)를 루트로 하여 다른 부호화 단위로 분할되는 부호화 유닛은 분할된 부호화 단위의 개수만큼의 자식 노드를 가지고 분할될 수 있다. 일정한 제한에 따라 더 이상 분할되지 않는 부호화 단위는 리프 노드가 된다. 즉, 하나의 코딩 유닛에 대하여 정방형 분할만이 가능하다고 가정하는 경우, 하나의 부호화 단위는 최대 4개의 다른 부호화 단위로 분할될 수 있다.
이하, 본 발명의 실시예에서는 부호화 단위는 부호화를 수행하는 단위의 의미로 사용할 수도 있고, 복호화를 수행하는 단위의 의미로 사용할 수도 있다.
예측 단위는 하나의 부호화 단위 내에서 동일한 크기의 적어도 하나의 정사각형 또는 직사각형 등의 형태를 가지고 분할된 것일 수도 있고, 하나의 부호화 단위 내에서 분할된 예측 단위 중 어느 하나의 예측 단위가 다른 하나의 예측 단위와 상이한 형태 및/또는 크기를 가지도록 분할된 것일 수도 있다.
부호화 단위를 기초로 인트라 예측을 수행하는 예측 단위를 생성시 최소 부호화 단위가 아닌 경우, 복수의 예측 단위 NxN 으로 분할하지 않고 인트라 예측을 수행할 수 있다.
예측부(120, 125)는 인터 예측을 수행하는 인터 예측부(120)와 인트라 예측을 수행하는 인트라 예측부(125)를 포함할 수 있다. 예측 단위에 대해 인터 예측을 사용할 것인지 또는 인트라 예측을 수행할 것인지를 결정하고, 각 예측 방법에 따른 구체적인 정보(예컨대, 인트라 예측 모드, 모션 벡터, 참조 픽쳐 등)를 결정할 수 있다. 이때, 예측이 수행되는 처리 단위와 예측 방법 및 구체적인 내용이 정해지는 처리 단위는 다를 수 있다. 예컨대, 예측의 방법과 예측 모드 등은 예측 단위로 결정되고, 예측의 수행은 변환 단위로 수행될 수도 있다. 생성된 예측 블록과 원본 블록 사이의 잔차값(잔차 블록)은 변환부(130)로 입력될 수 있다. 또한, 예측을 위해 사용한 예측 모드 정보, 모션 벡터 정보 등은 잔차값과 함께 엔트로피 부호화부(165)에서 부호화되어 복호화기에 전달될 수 있다. 특정한 부호화 모드를 사용할 경우, 예측부(120, 125)를 통해 예측 블록을 생성하지 않고, 원본 블록을 그대로 부호화하여 복호화부에 전송하는 것도 가능하다.
인터 예측부(120)는 현재 픽쳐의 이전 픽쳐 또는 이후 픽쳐 중 적어도 하나의 픽쳐의 정보를 기초로 예측 단위를 예측할 수도 있고, 경우에 따라서는 현재 픽쳐 내의 부호화가 완료된 일부 영역의 정보를 기초로 예측 단위를 예측할 수도 있다. 인터 예측부(120)는 참조 픽쳐 보간부, 모션 예측부, 움직임 보상부를 포함할 수 있다.
참조 픽쳐 보간부에서는 메모리(155)로부터 참조 픽쳐 정보를 제공받고 참조 픽쳐에서 정수 화소 이하의 화소 정보를 생성할 수 있다. 휘도 화소의 경우, 1/4 화소 단위로 정수 화소 이하의 화소 정보를 생성하기 위해 필터 계수를 달리하는 DCT 기반의 8탭 보간 필터(DCT-based Interpolation Filter)가 사용될 수 있다. 색차 신호의 경우 1/8 화소 단위로 정수 화소 이하의 화소 정보를 생성하기 위해 필터 계수를 달리하는 DCT 기반의 4탭 보간 필터(DCT-based Interpolation Filter)가 사용될 수 있다.
모션 예측부는 참조 픽쳐 보간부에 의해 보간된 참조 픽쳐를 기초로 모션 예측을 수행할 수 있다. 모션 벡터를 산출하기 위한 방법으로 FBMA(Full search-based Block Matching Algorithm), TSS(Three Step Search), NTS(New Three-Step Search Algorithm) 등 다양한 방법이 사용될 수 있다. 모션 벡터는 보간된 화소를 기초로 1/2 또는 1/4 화소 단위의 모션 벡터값을 가질 수 있다. 모션 예측부에서는 모션 예측 방법을 다르게 하여 현재 예측 단위를 예측할 수 있다. 모션 예측 방법으로 스킵(Skip) 방법, 머지(Merge) 방법, AMVP(Advanced Motion Vector Prediction) 방법, 인트라 블록 카피(Intra Block Copy) 방법 등 다양한 방법이 사용될 수 있다.
인트라 예측부(125)는 현재 픽쳐 내의 화소 정보인 현재 블록 주변의 참조 픽셀 정보를 기초로 예측 단위를 생성할 수 있다. 현재 예측 단위의 주변 블록이 인터 예측을 수행한 블록이어서, 참조 픽셀이 인터 예측을 수행한 픽셀일 경우, 인터 예측을 수행한 블록에 포함되는 참조 픽셀을 주변의 인트라 예측을 수행한 블록의 참조 픽셀 정보로 대체하여 사용할 수 있다. 즉, 참조 픽셀이 가용하지 않는 경우, 가용하지 않은 참조 픽셀 정보를 가용한 참조 픽셀 중 적어도 하나의 참조 픽셀로 대체하여 사용할 수 있다.
인트라 예측에서 예측 모드는 참조 픽셀 정보를 예측 방향에 따라 사용하는 방향성 예측 모드와 예측을 수행시 방향성 정보를 사용하지 않는 비방향성 모드를 가질 수 있다. 휘도 정보를 예측하기 위한 모드와 색차 정보를 예측하기 위한 모드가 상이할 수 있고, 색차 정보를 예측하기 위해 휘도 정보를 예측하기 위해 사용된 인트라 예측 모드 정보 또는 예측된 휘도 신호 정보를 활용할 수 있다.
인트라 예측을 수행할 때 예측 단위의 크기와 변환 단위의 크기가 동일할 경우, 예측 단위의 좌측에 존재하는 픽셀, 좌측 상단에 존재하는 픽셀, 상단에 존재하는 픽셀을 기초로 예측 단위에 대한 인트라 예측을 수행할 수 있다. 그러나 인트라 예측을 수행할 때 예측 단위의 크기와 변환 단위의 크기가 상이할 경우, 변환 단위를 기초로 한 참조 픽셀을 이용하여 인트라 예측을 수행할 수 있다. 또한, 최소 부호화 단위에 대해서만 NxN 분할을 사용하는 인트라 예측을 사용할 수 있다.
인트라 예측 방법은 예측 모드에 따라 참조 화소에 AIS(Adaptive Intra Smoothing) 필터를 적용한 후 예측 블록을 생성할 수 있다. 참조 화소에 적용되는 AIS 필터의 종류는 상이할 수 있다. 인트라 예측 방법을 수행하기 위해 현재 예측 단위의 인트라 예측 모드는 현재 예측 단위의 주변에 존재하는 예측 단위의 인트라 예측 모드로부터 예측할 수 있다. 주변 예측 단위로부터 예측된 모드 정보를 이용하여 현재 예측 단위의 예측 모드를 예측하는 경우, 현재 예측 단위와 주변 예측 단위의 인트라 예측 모드가 동일하면 소정의 플래그 정보를 이용하여 현재 예측 단위와 주변 예측 단위의 예측 모드가 동일하다는 정보를 전송할 수 있고, 만약 현재 예측 단위와 주변 예측 단위의 예측 모드가 상이하면 엔트로피 부호화를 수행하여 현재 블록의 예측 모드 정보를 부호화할 수 있다.
또한, 예측부(120, 125)에서 생성된 예측 단위를 기초로 예측을 수행한 예측 단위와 예측 단위의 원본 블록과 차이값인 잔차값(Residual) 정보를 포함하는 잔차 블록이 생성될 수 있다. 생성된 잔차 블록은 변환부(130)로 입력될 수 있다.
변환부(130)에서는 원본 블록과 예측부(120, 125)를 통해 생성된 예측 단위의 잔차값(residual)정보를 포함한 잔차 블록을 DCT(Discrete Cosine Transform), DST(Discrete Sine Transform), KLT와 같은 변환 방법을 사용하여 변환시킬 수 있다. 잔차 블록을 변환하기 위해 DCT를 적용할지, DST를 적용할지 또는 KLT를 적용할지는 잔차 블록을 생성하기 위해 사용된 예측 단위의 인트라 예측 모드 정보를 기초로 결정할 수 있다.
양자화부(135)는 변환부(130)에서 주파수 영역으로 변환된 값들을 양자화할 수 있다. 블록에 따라 또는 영상의 중요도에 따라 양자화 계수는 변할 수 있다. 양자화부(135)에서 산출된 값은 역양자화부(140)와 재정렬부(160)에 제공될 수 있다.
재정렬부(160)는 양자화된 잔차값에 대해 계수값의 재정렬을 수행할 수 있다.
재정렬부(160)는 계수 스캐닝(Coefficient Scanning) 방법을 통해 2차원의 블록 형태 계수를 1차원의 벡터 형태로 변경할 수 있다. 예를 들어, 재정렬부(160)에서는 지그-재그 스캔(Zig-Zag Scan)방법을 이용하여 DC 계수부터 고주파수 영역의 계수까지 스캔하여 1차원 벡터 형태로 변경시킬 수 있다. 변환 단위의 크기 및 인트라 예측 모드에 따라 지그-재그 스캔 대신 2차원의 블록 형태 계수를 열 방향으로 스캔하는 수직 스캔, 2차원의 블록 형태 계수를 행 방향으로 스캔하는 수평 스캔이 사용될 수도 있다. 즉, 변환 단위의 크기 및 인트라 예측 모드에 따라 지그-재그 스캔, 수직 방향 스캔 및 수평 방향 스캔 중 어떠한 스캔 방법이 사용될지 여부를 결정할 수 있다.
엔트로피 부호화부(165)는 재정렬부(160)에 의해 산출된 값들을 기초로 엔트로피 부호화를 수행할 수 있다. 엔트로피 부호화는 예를 들어, 지수 골롬(Exponential Golomb), CAVLC(Context-Adaptive Variable Length Coding), CABAC(Context-Adaptive Binary Arithmetic Coding)과 같은 다양한 부호화 방법을 사용할 수 있다.
엔트로피 부호화부(165)는 재정렬부(160) 및 예측부(120, 125)로부터 부호화 단위의 잔차값 계수 정보 및 블록 타입 정보, 예측 모드 정보, 분할 단위 정보, 예측 단위 정보 및 전송 단위 정보, 모션 벡터 정보, 참조 프레임 정보, 블록의 보간 정보, 필터링 정보 등 다양한 정보를 부호화할 수 있다.
엔트로피 부호화부(165)에서는 재정렬부(160)에서 입력된 부호화 단위의 계수값을 엔트로피 부호화할 수 있다.
역양자화부(140) 및 역변환부(145)에서는 양자화부(135)에서 양자화된 값들을 역양자화하고 변환부(130)에서 변환된 값들을 역변환한다. 역양자화부(140) 및 역변환부(145)에서 생성된 잔차값(Residual)은 예측부(120, 125)에 포함된 움직임 추정부, 움직임 보상부 및 인트라 예측부를 통해서 예측된 예측 단위와 합쳐져 복원 블록(Reconstructed Block)을 생성할 수 있다.
필터부(150)는 디블록킹 필터, 오프셋 보정부, ALF(Adaptive Loop Filter)중 적어도 하나를 포함할 수 있다.
디블록킹 필터는 복원된 픽쳐에서 블록간의 경계로 인해 생긴 블록 왜곡을 제거할 수 있다. 디블록킹을 수행할지 여부를 판단하기 위해 블록에 포함된 몇 개의 열 또는 행에 포함된 픽셀을 기초로 현재 블록에 디블록킹 필터 적용할지 여부를 판단할 수 있다. 블록에 디블록킹 필터를 적용하는 경우 필요한 디블록킹 필터링 강도에 따라 강한 필터(Strong Filter) 또는 약한 필터(Weak Filter)를 적용할 수 있다. 또한 디블록킹 필터를 적용함에 있어 수직 필터링 및 수평 필터링 수행시 수평 방향 필터링 및 수직 방향 필터링이 병행 처리되도록 할 수 있다.
오프셋 보정부는 디블록킹을 수행한 영상에 대해 픽셀 단위로 원본 영상과의 오프셋을 보정할 수 있다. 특정 픽쳐에 대한 오프셋 보정을 수행하기 위해 영상에 포함된 픽셀을 일정한 수의 영역으로 구분한 후 오프셋을 수행할 영역을 결정하고 해당 영역에 오프셋을 적용하는 방법 또는 각 픽셀의 에지 정보를 고려하여 오프셋을 적용하는 방법을 사용할 수 있다.
ALF(Adaptive Loop Filtering)는 필터링한 복원 영상과 원래의 영상을 비교한 값을 기초로 수행될 수 있다. 영상에 포함된 픽셀을 소정의 그룹으로 나눈 후 해당 그룹에 적용될 하나의 필터를 결정하여 그룹마다 차별적으로 필터링을 수행할 수 있다. ALF를 적용할지 여부에 관련된 정보는 휘도 신호는 부호화 단위(Coding Unit, CU) 별로 전송될 수 있고, 각각의 블록에 따라 적용될 ALF 필터의 모양 및 필터 계수는 달라질 수 있다. 또한, 적용 대상 블록의 특성에 상관없이 동일한 형태(고정된 형태)의 ALF 필터가 적용될 수도 있다.
메모리(155)는 필터부(150)를 통해 산출된 복원 블록 또는 픽쳐를 저장할 수 있고, 저장된 복원 블록 또는 픽쳐는 인터 예측을 수행 시 예측부(120, 125)에 제공될 수 있다.
도 2는 본 발명의 일실시예에 따른 영상 복호화 장치를 나타낸 블록도이다.
도 2를 참조하면, 영상 복호화기(200)는 엔트로피 복호화부(210), 재정렬부(215), 역양자화부(220), 역변환부(225), 예측부(230, 235), 필터부(240), 메모리(245)가 포함될 수 있다.
영상 부호화기에서 영상 비트스트림이 입력된 경우, 입력된 비트스트림은 영상 부호화기와 반대의 절차로 복호화될 수 있다.
엔트로피 복호화부(210)는 영상 부호화기의 엔트로피 부호화부에서 엔트로피 부호화를 수행한 것과 반대의 절차로 엔트로피 복호화를 수행할 수 있다. 예를 들어, 영상 부호화기에서 수행된 방법에 대응하여 지수 골롬(Exponential Golomb), CAVLC(Context-Adaptive Variable Length Coding), CABAC(Context-Adaptive Binary Arithmetic Coding)과 같은 다양한 방법이 적용될 수 있다.
엔트로피 복호화부(210)에서는 부호화기에서 수행된 인트라 예측 및 인터 예측에 관련된 정보를 복호화할 수 있다.
재정렬부(215)는 엔트로피 복호화부(210)에서 엔트로피 복호화된 비트스트림을 부호화부에서 재정렬한 방법을 기초로 재정렬을 수행할 수 있다. 1차원 벡터 형태로 표현된 계수들을 다시 2차원의 블록 형태의 계수로 복원하여 재정렬할 수 있다. 재정렬부(215)에서는 부호화부에서 수행된 계수 스캐닝에 관련된 정보를 제공받고 해당 부호화부에서 수행된 스캐닝 순서에 기초하여 역으로 스캐닝하는 방법을 통해 재정렬을 수행할 수 있다.
역양자화부(220)는 부호화기에서 제공된 양자화 파라미터와 재정렬된 블록의 계수값을 기초로 역양자화를 수행할 수 있다.
역변환부(225)는 영상 부호화기에서 수행한 양자화 결과에 대해 변환부에서 수행한 변환 즉, DCT, DST, 및 KLT에 대해 역변환 즉, 역 DCT, 역 DST 및 역 KLT를 수행할 수 있다. 역변환은 영상 부호화기에서 결정된 전송 단위를 기초로 수행될 수 있다. 영상 복호화기의 역변환부(225)에서는 예측 방법, 현재 블록의 크기 및 예측 방향 등 복수의 정보에 따라 변환 기법(예를 들어, DCT, DST, KLT)이 선택적으로 수행될 수 있다.
예측부(230, 235)는 엔트로피 복호화부(210)에서 제공된 예측 블록 생성 관련 정보와 메모리(245)에서 제공된 이전에 복호화된 블록 또는 픽쳐 정보를 기초로 예측 블록을 생성할 수 있다.
전술한 바와 같이 영상 부호화기에서의 동작과 동일하게 인트라 예측을 수행시 예측 단위의 크기와 변환 단위의 크기가 동일할 경우, 예측 단위의 좌측에 존재하는 픽셀, 좌측 상단에 존재하는 픽셀, 상단에 존재하는 픽셀을 기초로 예측 단위에 대한 인트라 예측을 수행하지만, 인트라 예측을 수행시 예측 단위의 크기와 변환 단위의 크기가 상이할 경우, 변환 단위를 기초로 한 참조 픽셀을 이용하여 인트라 예측을 수행할 수 있다. 또한, 최소 부호화 단위에 대해서만 NxN 분할을 사용하는 인트라 예측을 사용할 수도 있다.
예측부(230, 235)는 예측 단위 판별부, 인터 예측부 및 인트라 예측부를 포함할 수 있다. 예측 단위 판별부는 엔트로피 복호화부(210)에서 입력되는 예측 단위 정보, 인트라 예측 방법의 예측 모드 정보, 인터 예측 방법의 모션 예측 관련 정보 등 다양한 정보를 입력 받고 현재 부호화 단위에서 예측 단위를 구분하고, 예측 단위가 인터 예측을 수행하는지 아니면 인트라 예측을 수행하는지 여부를 판별할 수 있다. 인터 예측부(230)는 영상 부호화기에서 제공된 현재 예측 단위의 인터 예측에 필요한 정보를 이용해 현재 예측 단위가 포함된 현재 픽쳐의 이전 픽쳐 또는 이후 픽쳐 중 적어도 하나의 픽쳐에 포함된 정보를 기초로 현재 예측 단위에 대한 인터 예측을 수행할 수 있다. 또는, 현재 예측 단위가 포함된 현재 픽쳐 내에서 기-복원된 일부 영역의 정보를 기초로 인터 예측을 수행할 수도 있다.
인터 예측을 수행하기 위해 부호화 단위를 기준으로 해당 부호화 단위에 포함된 예측 단위의 모션 예측 방법이 스킵 모드(Skip Mode), 머지 모드(Merge 모드), AMVP 모드(AMVP Mode), 인트라 블록 카피 모드 중 어떠한 방법인지 여부를 판단할 수 있다.
인트라 예측부(235)는 현재 픽쳐 내의 화소 정보를 기초로 예측 블록을 생성할 수 있다. 예측 단위가 인트라 예측을 수행한 예측 단위인 경우, 영상 부호화기에서 제공된 예측 단위의 인트라 예측 모드 정보를 기초로 인트라 예측을 수행할 수 있다. 인트라 예측부(235)에는 AIS(Adaptive Intra Smoothing) 필터, 참조 화소 보간부, DC 필터를 포함할 수 있다. AIS 필터는 현재 블록의 참조 화소에 필터링을 수행하는 부분으로써 현재 예측 단위의 예측 모드에 따라 필터의 적용 여부를 결정하여 적용할 수 있다. 영상 부호화기에서 제공된 예측 단위의 예측 모드 및 AIS 필터 정보를 이용하여 현재 블록의 참조 화소에 AIS 필터링을 수행할 수 있다. 현재 블록의 예측 모드가 AIS 필터링을 수행하지 않는 모드일 경우, AIS 필터는 적용되지 않을 수 있다.
참조 화소 보간부는 예측 단위의 예측 모드가 참조 화소를 보간한 화소값을 기초로 인트라 예측을 수행하는 예측 단위일 경우, 참조 화소를 보간하여 정수값 이하의 화소 단위의 참조 화소를 생성할 수 있다. 현재 예측 단위의 예측 모드가 참조 화소를 보간하지 않고 예측 블록을 생성하는 예측 모드일 경우 참조 화소는 보간되지 않을 수 있다. DC 필터는 현재 블록의 예측 모드가 DC 모드일 경우 필터링을 통해서 예측 블록을 생성할 수 있다.
복원된 블록 또는 픽쳐는 필터부(240)로 제공될 수 있다. 필터부(240)는 디블록킹 필터, 오프셋 보정부, ALF를 포함할 수 있다.
영상 부호화기로부터 해당 블록 또는 픽쳐에 디블록킹 필터를 적용하였는지 여부에 대한 정보 및 디블록킹 필터를 적용하였을 경우, 강한 필터를 적용하였는지 또는 약한 필터를 적용하였는지에 대한 정보를 제공받을 수 있다. 영상 복호화기의 디블록킹 필터에서는 영상 부호화기에서 제공된 디블록킹 필터 관련 정보를 제공받고 영상 복호화기에서 해당 블록에 대한 디블록킹 필터링을 수행할 수 있다.
오프셋 보정부는 부호화시 영상에 적용된 오프셋 보정의 종류 및 오프셋 값 정보 등을 기초로 복원된 영상에 오프셋 보정을 수행할 수 있다.
ALF는 부호화기로부터 제공된 ALF 적용 여부 정보, ALF 계수 정보 등을 기초로 부호화 단위에 적용될 수 있다. 이러한 ALF 정보는 특정한 파라메터 셋에 포함되어 제공될 수 있다.
메모리(245)는 복원된 픽쳐 또는 블록을 저장하여 참조 픽쳐 또는 참조 블록으로 사용할 수 있도록 할 수 있고 또한 복원된 픽쳐를 출력부로 제공할 수 있다.
전술한 바와 같이 이하, 본 발명의 실시예에서는 설명의 편의상 코딩 유닛(Coding Unit)을 부호화 단위라는 용어로 사용하지만, 부호화뿐만 아니라 복호화를 수행하는 단위가 될 수도 있다.
또한, 현재 블록은, 부호화/복호화 대상 블록을 나타내는 것으로, 부호화/복호화 단계에 따라, 코딩 트리 블록(또는 코딩 트리 유닛), 부호화 블록(또는 부호화 유닛), 변환 블록(또는 변환 유닛) 또는 예측 블록(또는 예측 유닛) 등을 나타내는 것일 수 있다.
하나의 픽쳐는 정방형 또는 비정방형의 기본 블록으로 분할되어 부호화/복호화될 수 있다. 이때, 기본 블록은, 코딩 트리 유닛(Coding Tree Unit)이라 호칭될 수 있다. 코딩 트리 유닛은, 시퀀스 또는 슬라이스에서 허용하는 가장 큰 크기의 부호화 유닛으로 정의될 수도 있다. 코딩 트리 유닛이 정방형 또는 비정방형인지 여부 또는 코딩 트리 유닛의 크기와 관련한 정보는 시퀀스 파라미터 셋트, 픽처 파라미터 셋트 또는 슬라이스 헤더 등을 통해 시그널링될 수 있다. 코딩 트리 유닛은 더 작은 크기의 파티션으로 분할될 수 있다. 이때, 코딩 트리 유닛을 분할함으로써 생성된 파티션을 뎁스 1이라 할 경우, 뎁스 1인 파티션을 분할함으로써 생성된 파티션은 뎁스 2로 정의될 수 있다. 즉, 코딩 트리 유닛 내 뎁스 k인 파티션을 분할함으로써 생성된 파티션은 뎁스 k+1을 갖는 것으로 정의될 수 있다.
코딩 트리 유닛이 분할됨에 따라 생성된 임의 크기의 파티션을 코딩 유닛이라 정의할 수 있다. 코딩 유닛은 재귀적으로 분할되거나, 예측, 양자화, 변환 또는 인루프 필터링 등을 수행하기 위한 기본 단위로 분할될 수 있다. 일 예로, 코딩 유닛이 분할됨에 따라 생성된 임의 크기의 파티션은 코딩 유닛으로 정의되거나, 예측, 양자화, 변환 또는 인루프 필터링 등을 수행하기 위한 기본 단위인 변환 유닛 또는 예측 유닛으로 정의될 수 있다.
코딩 트리 유닛 또는 코딩 유닛의 파티셔닝은, 수직선(Vertical Line) 또는 수평선(Horizontal Line) 중 적어도 하나에 기초하여 수행될 수 있다. 또한, 코딩 트리 유닛 또는 코딩 유닛을 파티셔닝하는 수직선 또는 수평선의 개수는 적어도 하나 이상일 수 있다. 일 예로, 하나의 수직선 또는 하나의 수평선을 이용하여, 코딩 트리 유닛 또는 코딩 유닛을 2개의 파티션으로 분할하거나, 두개의 수직선 또는 두개의 수평선을 이용하여, 코딩 트리 유닛 또는 코딩 유닛을 3개의 파티션으로 분할할 수 있다. 또는, 하나의 수직선 및 하나의 수평선을 이용하여, 코딩 트리 유닛 또는 코딩 유닛을 길이 및 너비가 1/2 인 4개의 파티션으로 분할할 수 있다.
코딩 트리 유닛 또는 코딩 유닛을 적어도 하나의 수직선 또는 적어도 하나의 수평선을 이용하여 복수의 파티션으로 분할하는 경우, 파티션들은 균일한 크기를 갖거나, 서로 다른 크기를 가질 수 있다. 또는, 어느 하나의 파티션이 나머지 파티션과 다른 크기를 가질 수도 있다.
후술되는 실시예들에서는, 코딩 트리 유닛 또는 코딩 유닛이 쿼드 트리, 트리플 트리 또는 바이너리 트리 구조로 분할되는 것으로 가정한다. 그러나, 더 많은 수의 수직선 또는 더 많은 수의 수평선을 이용한 코딩 트리 유닛 또는 코딩 유닛의 분할도 가능하다.
도 3은 본 발명이 적용되는 일실시예로서, 트리 구조(tree structure)에 기반하여 코딩 블록을 계층적으로 분할하는 일예를 도시한 것이다.
입력 영상 신호는 소정의 블록 단위로 복호화되며, 이와 같이 입력 영상 신호를 복호화하기 위한 기본 단위를 코딩 블록이라 한다. 코딩 블록은 인트라/인터 예측, 변환, 양자화를 수행하는 단위가 될 수 있다. 또한, 코딩 블록 단위로 예측 모드(예컨대, 화면 내 예측 모드 또는 화면 간 예측 모드)가 결정되고, 코딩 블록에 포함된 예측 블록들은, 결정된 예측 모드를 공유할 수 있다. 코딩 블록은 8x8 내지 64x64 범위에 속하는 임의의 크기를 가진 정방형 또는 비정방형 블록일 수 있고, 128x128, 256x256 또는 그 이상의 크기를 가진 정방형 또는 비정방형 블록일 수 있다.
구체적으로, 코딩 블록은 쿼드 트리(quad tree), 트리플 트리(triple tree) 및 바이너리 트리(binary tree) 중 적어도 하나에 기초하여 계층적으로 분할될 수 있다. 여기서, 쿼드 트리 기반의 분할은 2Nx2N 코딩 블록이 4개의 NxN 코딩 블록으로 분할되는 방식을, 트리플 트리 기반의 분할은 하나의 코딩 블록이 3개의 코딩 블록으로 분할되는 방식을, 바이너리 트리 기반의 분할은 하나의 코딩 블록이 2개의 코딩 블록으로 분할되는 방식을 각각 의미할 수 있다. 트리플 트리 분할 또는 바이너리 트리 기반의 분할이 수행되었다 하더라도, 하위 뎁스에서는 정방형인 코딩 블록이 존재할 수 있다. 또는, 트리플 트리 분할 또는 바이너리 트리 기반의 분할이 수행된 이후, 하위 뎁스에서는 정방형 코딩 블록이 생성되는 것을 제한할 수도 있다.
바이너리 트리 기반의 분할은 대칭적으로 수행될 수도 있고, 비대칭적으로 수행될 수도 있다. 바이너리 트리 기반으로 분할된 코딩 블록은 정방형 블록일 수도 있고, 직사각형과 같은 비정방형 블록일 수도 있다. 일 예로, 바이너리 트리 기반의 분할이 허용되는 파티션 형태는 도 4에 도시된 예에서와 같이, 대칭형(symmetric)인 2NxN (수평 방향 비 정방 코딩 유닛) 또는 Nx2N (수직 방향 비정방 코딩 유닛), 비대칭형(asymmetric)인 nLx2N, nRx2N, 2NxnU 또는 2NxnD 중 적어도 하나를 포함할 수 있다.
바이너리 트리 기반의 분할은, 대칭형 또는 비대칭 형태의 파티션 중 어느 하나만 제한적으로 허용될 수도 있다. 이 경우, 코딩 트리 유닛을, 정방형 블록으로 구성하는 것은 쿼드 트리 CU 파티셔닝에 해당하고, 코딩 트리 유닛을, 대칭형인 비정방형 블록으로 구성하는 것은 이진 트리 파티셔닝에 해당할 수 있다. 코딩 트리 유닛을 정방형 블록과 대칭형 비정방형 블록으로 구성하는 것은 쿼드 및 바이너리 트리 CU 파티셔닝에 해당할 수 있다.
바이너리 트리 기반의 분할은 쿼드 트리 기반의 분할이 더 이상 수행되지 않는 코딩 블록에 대해서 수행될 수 있다. 바이너리 트리 기반으로 분할된 코딩 블록에 대해서는 쿼드 트리 기반의 분할, 트리플 트리 기반의 분할 또는 바이너리 트리 기반의 분할 중 적어도 하나가 더 이상 수행되지 않도록 설정될 수 있다.
또는, 바이너리 트리 기반으로 분할된 코딩 블록에 대해 트리플 트리 기반의 분할 또는 바이너리 트리 기반의 분할을 허용하되, 수평 방향 또는 수직 방향의 분할 중 어느 하나만을 제한적으로 허용할 수도 있다.
예컨대, 바이너리 트리 기반으로 분할된 코딩 블록의 위치, 인덱스, 형태, 이웃 파티션의 추가 분할 형태 등에 따라, 바이너리 트리 기반으로 분할된 코딩 블록에 대해 추가 분할 또는 추가 분할 방향을 제한할 수도 있다. 일 예로, 바이너리 트리 기반의 분할로 인해 생성된 두 코딩 블록 중 코딩 순서가 앞에 있는 코딩 블록의 인덱스를 0(이하, 코딩 블록 인덱스 0), 코딩 순서가 뒤에 있는 코딩 블록의 인덱스를 1(이하, 코딩 블록 인덱스 1) 이라 할 때, 코딩 블록 인덱스 0 또는 코딩 블록 인덱스 1인 코딩 블록에 모두 바이너리 트리 기반의 분할이 적용되는 경우, 코딩 블록 인덱스가 1인 코딩 블록의 바이너리 트리 기반의 분할 방향은, 코딩 블록 인덱스가 0인 코딩 블록의 바이너리 트리 기반의 분할 방향에 따라 결정될 수 있다. 구체적으로, 코딩 블록 인덱스가 0인 코딩 블록의 바이너리 트리 기반의 분할 방향이 코딩 블록 인덱스가 0인 코딩 블록을 정방형 파티션들로 분할하는 것인 경우, 코딩 블록 인덱스가 1인 코딩 블록의 바이너리 트리 기반의 분할은 코딩 블록 인덱스가 1인 코딩 블록의 바이너리 트리 기반의 분할과 상이한 방향을 갖도록 제한될 수 있다. 즉, 코딩 블록 인덱스 0 및 코딩 블록 인덱스 1인 코딩 블록들이 모두 정방형 파티션들로 분할되는 것이 제한될 수 있다. 이 경우, 코딩 블록 인덱스가 1인 코딩 블록의 바이너리 트리 분할 방향을 나타내는 정보의 부호화/복호화가 생략될 수 있다. 이는, 코딩 블록 인덱스 0 및 코딩 블록 인덱스 1인 코딩 블록들이 모두 정방형 파티션들로 분할되는 것은, 상위 뎁스 블록을 쿼드 트리 기반으로 분할하는 것과 동일한 효과를 나타내는바, 코딩 블록 인덱스 0 및 코딩 블록 인덱스 1을 모두 정방형 파티션들로 분할하는 것을 허용하는 것은 부호화 효율 측면에서 바람직하지 않기 때문이다.
트리플 트리 기반의 분할은, 수평 또는 수직 방향으로 코딩 블록을 3개의 파티션으로 분할하는 것을 의미한다. 트리플 트리 기반의 분할로 인해 생성된 3개의 파티션들 모두는 상이한 크기를 가질 수 있다. 또는, 트리플 트리 기반의 분할로 인해 생성된 파티션들 중 2개는 동일한 크기를 갖고, 나머지 하나가 상이한 크기를 가질수도 있다. 일 예로, 코딩 블록이 분할됨에 따라 생성된 파티션들의 너비비 또는 높이비는 분할 방향에 따라 1:n:1, 1:1:n ,n:1:1 또는 m:n:1 로 설정될 수 있다. 여기서, m과 n은 1 또는 1보다 큰 실수로 예컨대, 2와 같은 정수일 수 있다.
트리플 트리 기반의 분할은 쿼드 트리 기반의 분할이 더 이상 수행되지 않는 코딩 블록에 대해서 수행될 수 있다. 트리플 트리 기반으로 분할된 코딩 블록에 대해서는, 쿼드 트리 기반의 분할, 트리플 트리 기반의 분할 또는 바이너리 트리 기반의 분할 중 적어도 하나가 더 이상 수행되지 않도록 설정될 수 있다.
또는, 트리플 트리 기반으로 분할된 코딩 블록에 대해 트리플 트리 기반의 분할 또는 바이너리 트리 기반의 분할을 허용하되, 수평 방향 또는 수직 방향의 분할 중 어느 하나만을 제한적으로 허용할 수도 있다.
예컨대, 트리플 트리 기반으로 분할된 코딩 블록의 위치, 인덱스, 형태, 크기, 이웃 파티션의 추가 분할 형태 등에 따라, 트리플 트리 기반으로 분할된 코딩 블록에 대한 추가 분할 또는 추가 분할 방향을 제한할 수도 있다. 일 예로, 트리플 트리 기반의 분할로 인해 생성된 코딩 블록들 중 크기가 가장 큰 파티션에 대해서는 수평 방향 분할 또는 수직 방향 분할 중 어느 하나가 제한될 수 있다. 구체적으로, 트리플 트리 기반의 분할로 인해 생성된 코딩 블록들 중 크기가 가장 큰 파티션은 상위 뎁스 파티션의 트리플 트리 분할 방향과 동일한 방향의 바이너리 트리 분할 또는 동일한 방향의 트리플 트리 분할 방향이 허용되지 않을 수 있다. 이 경우, 트리플 트리 기반으로 분할된 코딩 블록 중 가장 큰 파티션에 대해서는 바이너리 트리 분할 방향 또는 트리플 트리 분할 방향을 나타내는 정보의 부호화/복호화가 생략될 수 있다.
현재 블록의 크기 또는 형태에 따라 바이너리 트리 또는 트리플 트리 기반의 분할이 제한될 수 있다. 여기서, 현재 블록의 크기는, 현재 블록의 너비, 높이, 너비/높이 중 최소값/최대값, 너비와 높이의 합, 너비와 높이의 곱 또는 현재 블록에 포함된 샘플의 수 중 적어도 하나를 기초로 표현될 수 있다. 일 예로, 현재 블록의 너비 또는 높이 중 적어도 하나가 기 정의된 값보다 큰 경우, 바이너리 트리 또는 트리플 트리 기반의 분할이 허용되지 않을 수 있다. 여기서, 기 정의된 값은, 16, 32, 64 또는 128 등의 정수일 수 있다. 다른 예로, 현재 블록의 너비와 높이 비율이 기 정의된 값보다 큰 경우 또는 기 정의된 값보다 작은 경우 바이너리 트리 또는 트리플 트리 기반의 분할이 허용되지 않을 수 있다. 기 정의된 값이 1인 경우, 현재 블록이 너비와 높이가 동일한 정방형 블록인 경우에 한하여 바이너리 트리 또는 트리플 트리 기반의 분할이 허용될 수 있다.
하위 뎁스의 분할은 상위 뎁스의 분할 형태에 종속적으로 결정될 수도 있다. 일 예로, 2개 이상의 뎁스에서 바이너리 트리 기반의 분할이 허용된 경우, 하위 뎁스에서는 상위 뎁스의 바이너리 트리 분할 형태와 동일한 형태의 바이너리 트리 기반의 분할만이 허용될 수 있다. 예컨대, 상위 뎁스에서 2NxN 형태로 바이너리 트리 기반의 분할이 수행된 경우, 하위 뎁스에서도 2NxN 형태의 바이너리 트리 기반의 분할이 수행될 수 있다. 또는, 상위 뎁스에서 Nx2N 형태로 바이너리 트리 기반의 분할이 수행된 경우, 하위 뎁스에서도 Nx2N 형태의 바이너리 트리 기반의 분할이 허용될 수 있다.
반대로, 하위 뎁스에서, 상위 뎁스의 바이너리 트리 분할 형태와 상이한 형태의 바이너리 트리 기반의 분할만을 허용하는 것도 가능하다.
시퀀스, 슬라이스, 코딩 트리 유닛 또는 코딩 유닛에 대해, 특정 형태의 바이너리 트리 기반의 분할 또는 특정 형태의 트리플 트리 기반의 분할만이 사용되도록 제한할 수도 있다. 일 예로, 코딩 트리 유닛에 대해 2NxN 또는 Nx2N 형태의 바이너리 트리 기반의 분할만이 허용되도록 제한할 수 있다. 허용되는 파티션 형태는 부호화기 또는 복호화기에 기 정의되어 있을 수도 있고, 허용되는 파티션 형태 또는 허용되지 않는 파티션 형태에 관한 정보를 부호화하여 비트스트림을 통해 시그널링할 수도 있다.
도 5는 특정 형태의 바이너리 트리 기반의 분할만이 허용된 예를 나타낸 도면이다. 도 5의 (a)는 Nx2N 형태의 바이너리 트리 기반의 분할만이 허용되도록 제한된 예를 나타내고, 도 5의 (b)는 2NxN 형태의 바이너리 트리 기반의 분할만이 허용되도록 제한된 예를 나타낸다. 상기 쿼드 트리 또는 바이너리 트리 기반의 적응적 분할을 구현하기 위해 쿼드 트리 기반의 분할을 지시하는 정보, 쿼드 트리 기반의 분할이 허용되는 코딩 블록의 크기/깊이에 관한 정보, 바이너리 트리 기반의 분할을 지시하는 정보, 바이너리 트리 기반의 분할이 허용되는 코딩 블록의 크기/깊이에 대한 정보, 바이너리 트리 기반의 분할이 허용되지 않는 코딩 블록의 크기/깊이에 대한 정보 또는 바이너리 트리 기반의 분할이 세로 방향인지 또는 가로 방향인지에 관한 정보 등이 이용될 수 있다.
또한, 코딩 트리 유닛 또는 소정의 코딩 유닛에 대해, 바이너리 트리 분할/트리플 트리 분할이 허용되는 횟수, 바이너리 트리 분할/트리플 트리 분할이 허용되는 깊이 또는 바이너리 트리 분할/트리플 트리 분할이 허용된 뎁스의 개수 등이 획득될 수 있다. 상기 정보는 코딩 트리 유닛 또는 코딩 유닛 단위로 부호화되어, 비트스트림을 통해 복호화기로 전송될 수 있다.
일 예로, 비트스트림을 통해, 바이너리 트리 분할이 허용되는 최대 뎁스를 나타내는 신택스 'max_binary_depth_idx_minus1'가 비트스트림을 통해 부호화/복호화될 수 있다. 이 경우, max_binary_depth_idx_minus1+1이 바이너리 트리 분할이 허용되는 최대 뎁스를 가리킬 수 있다.
도 6에 도시된 예를 살펴보면, 도 6에서는, 뎁스 2인 코딩 유닛 및 뎁스 3인 코딩 유닛에 대해 바이너리 트리 분할이 수행된 것으로 도시되었다. 이에 따라, 코딩 트리 유닛 내 바이너리 트리 분할이 수행된 횟수(2회)를 나타내는 정보, 코딩 트리 유닛 내 바이너리 트리 분할이 허용된 최대 뎁스(뎁스 3)를 나타내는 정보 또는 코딩 트리 유닛 내 바이너리 트리 분할이 허용된 뎁스의 개수(2개, 뎁스 2 및 뎁스 3)를 나타내는 정보 중 적어도 하나가 비트스트림을 통해 부호화/복호화될 수 있다.
다른 예로, 바이너리 트리 분할/트리플 트리 분할이 허용되는 횟수, 바이너리 트리 분할/트리플 트리 분할이 허용되는 깊이 또는 바이너리 트리 분할/트리플 트리 분할이 허용된 뎁스의 개수 중 적어도 하나는 시퀀스, 픽처 또는 슬라이스별로 획득될 수 있다. 일 예로, 상기 정보는, 시퀀스, 픽처 또는 슬라이스 단위로 부호화되어 비트스트림을 통해 전송될 수 있다. 또는, 시퀀스, 픽처 또는 슬라이스 별로 바이너리 트리 분할/트리플 트리 분할 이 허용되는 깊이 또는 바이너리 트리 분할/트리플 트리 분할 이 허용된 뎁스의 개수가 기 정의되어 있을 수도 있다. 이에 따라, 제1 슬라이스 및 제2 슬라이스의, 바이너리 트리/트리플 트리 분할 횟수, 바이너리 트리/트리플 트리 분할이 허용되는 최대 뎁스 또는 바이너리 트리/트리플 트리 분할이 허용되는 뎁스의 개수 중 적어도 하나가 상이할 수 있다. 일 예로, 제1 슬라이스에서는, 하나의 뎁스에서만 바이너리 트리 분할이 허용되는 반면, 제2 슬라이스에서는, 두개의 뎁스에서 바이너리 트리 분할이 허용될 수 있다.
또 다른 일 예로, 슬라이스 또는 픽쳐의 시간레벨 식별자(TemporalID)에 따라 바이너리 트리/트리플 트리 분할이 허용되는 횟수, 바이너리 트리/트리플 트리 분할이 허용되는 깊이 또는 바이너리 트리/트리플 트리 분할이 허용되는 뎁스의 개수 중 적어도 하나를 상이하게 설정할 수도 있다. 여기서, 시간레벨 식별자(TemporalID)는, 시점(view), 공간(spatial), 시간(temporal) 또는 화질(quality) 중 적어도 하나 이상의 스케일러빌리티(Scalability)를 갖는 영상의 복수개의 레이어 각각을 식별하기 위한 것이다.
도 3에 도시된 바와 같이, 분할 깊이(split depth)가 k인 제1 코딩 블록 300은 쿼드 트리(quad tree)에 기반하여 복수의 제2 코딩 블록으로 분할될 수 있다. 예를 들어, 제2 코딩 블록 310 내지 340은 제1 코딩 블록의 너비와 높이의 절반 크기를 가진 정방형 블록이며, 제2 코딩 블록의 분할 깊이는 k+1로 증가될 수 있다.
분할 깊이가 k+1인 제2 코딩 블록 310은 분할 깊이가 k+2인 복수의 제3 코딩 블록으로 분할될 수 있다. 제2 코딩 블록 310의 분할은 분할 방식에 따라 쿼트 트리 또는 바이너리 트리 중 어느 하나를 선택적으로 이용하여 수행될 수 있다. 여기서, 분할 방식은 쿼드 트리 기반으로의 분할을 지시하는 정보 또는 바이너리 트리 기반의 분할을 지시하는 정보 중 적어도 하나에 기초하여 결정될 수 있다.
제2 코딩 블록 310이 쿼트 트리 기반으로 분할되는 경우, 제2 코딩 블록 310은 제2 코딩 블록의 너비와 높이의 절반 크기를 가진 4개의 제3 코딩 블록 310a으로 분할되며, 제3 코딩 블록 310a의 분할 깊이는 k+2로 증가될 수 있다. 반면, 제2 코딩 블록 310이 바이너리 트리 기반으로 분할되는 경우, 제2 코딩 블록 310은 2개의 제3 코딩 블록으로 분할될 수 있다. 이때, 2개의 제3 코딩 블록 각각은 제2 코딩 블록의 너비와 높이 중 어느 하나가 절반 크기인 비정방형 블록이며, 분할 깊이는 k+2로 증가될 수 있다. 제2 코딩 블록은 분할 방향에 따라 가로 방향 또는 세로 방향의 비정방형 블록으로 결정될 수 있고, 분할 방향은 바이너리 트리 기반의 분할이 세로 방향인지 또는 가로 방향인지에 관한 정보에 기초하여 결정될 수 있다.
한편, 제2 코딩 블록 310은 쿼드 트리 또는 바이너리 트리에 기반하여 더 이상 분할되지 않는 말단 코딩 블록으로 결정될 수도 있고, 이 경우 해당 코딩 블록은 예측 블록 또는 변환 블록으로 이용될 수 있다.
제3 코딩 블록 310a은 제2 코딩 블록 310의 분할과 마찬가지로 말단 코딩 블록으로 결정되거나, 쿼드 트리 또는 바이너리 트리에 기반하여 추가적으로 분할될 수 있다.
한편, 바이너리 트리 기반으로 분할된 제3 코딩 블록 310b은 추가적으로 바이너리 트리에 기반하여 세로 방향의 코딩 블록(310b-2) 또는 가로 방향의 코딩 블록(310b-3)으로 더 분할될 수도 있고, 해당 코딩 블록의 분할 깊이는 k+3으로 증가될 수 있다. 또는, 제3 코딩 블록 310b는 바이너리 트리에 기반하여 더 이상 분할되지 않는 말단 코딩 블록(310b-1)으로 결정될 수 있고, 이 경우 해당 코딩 블록(310b-1)은 예측 블록 또는 변환 블록으로 이용될 수 있다. 다만, 상술한 분할 과정은 쿼드 트리 기반의 분할이 허용되는 코딩 블록의 크기/깊이에 관한 정보, 바이너리 트리 기반의 분할이 허용되는 코딩 블록의 크기/깊이에 대한 정보 또는 바이너리 트리 기반의 분할이 허용되지 않는 코딩 블록의 크기/깊이에 대한 정보 중 적어도 하나에 기초하여 제한적으로 수행될 수 있다.
코딩 블록이 가질 수 있는 크기는 소정 개수로 제한되거나, 소정 단위 내 코딩 블록의 크기는 고정된 값을 가질 수도 있다. 일 예로, 시퀀스 내 코딩 블록의 크기 또는 픽처 내 코딩 블록의 크기는, 256x256, 128x128 또는 32x32로 제한될 수 있다. 시퀀스 또는 픽처 내 코딩 블록의 크기를 나타내는 정보가 시퀀스 헤더 또는 픽처 헤더를 통해 시그널링 될 수 있다.
쿼드 트리, 바이너리 트리 및 트리플 트리에 기반한 분할 결과, 코딩 유닛은, 정방형 또는 임의 크기의 직사각형을 띨 수 있다.
코딩 블록은, 스킵 모드, 화면 내 예측, 화면 간 예측 또는 스킵 방법 중 적어도 하나를 이용하여 부호화/복호화될 수 있다.
다른 예로, 코딩 블록의 분할을 통해 코딩 블록과 동일한 크기 또는 코딩 블록보다 작은 단위로 인트라 예측 또는 인터 예측을 수행할 수 있다. 이를 위해, 코딩 블록이 결정되면, 코딩 블록의 예측 분할을 통해 예측 블록(Prediction Block)을 결정할 수 있다. 코딩 블록의 예측 분할은 코딩 블록의 분할 형태를 나타내는 파티션 모드(Part_mode)에 의해 수행될 수 있다. 예측 블록의 크기 또는 형태는 코딩 블록의 파티션 모드에 따라 결정될 수 있다. 일 예로, 파티션 모드에 따라 결정되는 예측 블록의 크기는 코딩 블록의 크기와 동일하거나 작은 값을 가질 수 있다.
도 7은 코딩 블록이 화면 간 예측으로 부호화되었을 때, 코딩 블록에 적용될 수 있는 파티션 모드를 예시한 도면이다.
코딩 블록이 화면 간 예측으로 부호화된 경우, 코딩 블록에는 도 7에 도시된 예에서와 같이, 8개의 파티션 모드 중 어느 하나가 적용될 수 있다.
코딩 블록이 화면 내 예측으로 부호화된 경우, 코딩 블록에는 파티션 모드 PART_2Nx2N 또는 PART_NxN 이 적용될 수 있다.
PART_NxN은 코딩 블록이 최소 크기를 갖는 경우 적용될 수 있다. 여기서, 코딩 블록의 최소 크기는 부호화기 및 복호화기에서 기 정의된 것일 수 있다. 또는, 코딩 블록의 최소 크기에 관한 정보는 비트스트림을 통해 시그널링될 수도 있다. 일 예로, 코딩 블록의 최소 크기는 슬라이스 헤더를 통해 시그널링되고, 이에 따라, 슬라이스별로 코딩 블록의 최소 크기가 정의될 수 있다.
일반적으로, 예측 블록의 크기는 64x64 부터 4x4의 크기를 가질 수 있다. 단, 코딩 블록이 화면 간 예측으로 부호화된 경우, 움직임 보상을 수행할 때, 메모리 대역폭(memory bandwidth)을 줄이기 위해, 예측 블록이 4x4 크기를 갖지 않도록 할 수 있다.
도 8은 본 발명이 적용되는 일실시예로서, 영상 부호화기/복호화기에 기-정의된 인트라 예측 모드의 종류를 도시한 것이다.
영상 부호화기/복호화기는 기-정의된 인트라 예측 모드 중 어느 하나를 이용하여 인트라 예측을 수행할 수 있다. 인트라 예측을 위한 기-정의된 인트라 예측 모드는 비방향성 예측 모드(예를 들어, Planar mode, DC mode) 및 33개의 방향성 예측 모드(directional prediction mode)로 구성될 수 있다.
또는, 인트라 예측의 정확도를 높이기 위해 33개의 방향성 예측 모드보다 더 많은 개수의 방향성 예측 모드가 이용될 수 있다. 즉, 방향성 예측 모드의 각도(angle)를 더 세분화하여 M개의 확장된 방향성 예측 모드를 정의할 수도 있고(M>33), 기-정의된 33개의 방향성 예측 모드 중 적어도 하나를 이용하여 소정의 각도를 가진 방향성 예측 모드를 유도하여 사용할 수도 있다.
구체적으로, 도 8에 도시된 35개의 인트라 예측 모드 보다 더 많은 수의 인트라 예측 모드를 이용할 수도 있다. 도 8에 도시된 35개의 인트라 예측 모드 보다 더 많은 수의 인트라 예측 모드를 이용하는 것을, 확장된 인트라 예측 모드라 호칭할 수 있다.
도 9는 확장된 인트라 예측 모드의 일예이며, 확장된 인트라 예측 모드는 2개의 비방향성 예측 모드와 65개의 확장된 방향성 예측 모드로 구성될 수 있다. 확장된 인트라 예측 모드는 휘도 성분과 색차 성분에 대해서 동일하게 사용할 수도 있고, 성분 별로 서로 상이한 개수의 인트라 예측 모드를 사용할 수도 있다. 예를 들어, 휘도 성분에서는 67개의 확장된 인트라 예측 모드를 사용하고, 색차 성분에서는 35개의 인트라 예측 모드를 사용할 수도 있다.
또는, 색차 포맷(format)에 따라 서로 다른 개수의 인트라 예측 모드를 사용하여 인트라 예측을 수행할 수도 있다. 예를 들어, 4:2:0 format인 경우에는 휘도 성분에서는 67개의 인트라 예측 모드를 이용하여 인트라 예측을 수행하고 색차 성분에서는 35개의 인트라 예측 모드를 사용할 수 있고, 4:4:4 format인 경우에는 휘도 성분과 색차 성분 모두에서 67개의 인트라 예측 모드를 이용하여 인트라 예측을 사용할 수도 있다.
또는, 블록의 크기 및/또는 형태에 따라 서로 다른 개수의 인트라 예측 모드를 사용하여 인트라 예측을 수행할 수도 있다. 즉, PU 또는 CU의 크기 및/또는 형태에 따라 35개의 인트라 예측 모드 또는 67개의 인트라 예측 모드를 이용하여 인트라 예측을 수행할 수도 있다. 예를 들어, CU 또는 PU의 크기가 64x64보다 작거나 비대칭 파티션(asymmetric partition)인 경우에는 35개의 인트라 예측 모드를 이용하여 인트라 예측을 수행할 수 있고, CU 또는 PU의 크기가 64x64보다 같거나 큰 경우에는 67개의 인트라 예측 모드를 이용하여 인트라 예측을 수행할 수도 있다. Intra_2Nx2N에서는 65개의 방향성 인트라 예측 모드를 허용할 수도 있으며, Intra_NxN에서는 35개의 방향성 인트라 예측 모드만 허용할 수도 있다.
시퀀스, 픽처 또는 슬라이스 별로, 확장된 인트라 예측 모드를 적용하는 블록의 크기를 상이하게 설정할 수도 있다. 일 예로, 제1 슬라이스에서는, 64x64 보다 큰 블록(예컨대, CU 또는 PU)에 확장된 인트라 예측 모드가 적용되도록 설정하고, 제2 슬라이스에서는, 32x32 보다 큰 블록에 확장된 인트라 예측 모드가 적용되도록 설정할 수 있다. 확장된 인트라 예측 모드가 적용되는 블록의 크기를 나타내는 정보는, 시퀀스, 픽처 또는 슬라이스 단위별로 시그널링될 수 있다. 일 예로, 확장된 인트라 예측 모드가 적용되는 블록의 크기를 나타내는 정보는, 블록의 크기에 로그값을 취한 뒤 정수 4를 차감한 'log2_extended_intra_mode_size_minus4'로 정의될 수 있다. 일 예로, log2_extended_intra_mode_size_minus4 의 값이 0인 것은, 16x16 이상의 크기를 갖는 블록 또는 16x16 보다 큰 크기를 갖는 블록에 확장된 인트라 예측 모드를 적용할 수 있음을 나타내고, log2_extended_intra_mode_size_minus4 의 값이 1인 것은, 32x32 이상의 크기를 갖는 블록 또는 32x32 보다 큰 크기를 갖는 블록에 확장된 인트라 예측 모드를 적용할 수 있음을 나타낼 수 있다.
상술한 바와 같이, 색차 성분, 색차 포맷, 블록의 크기 또는 형태 중 적어도 하나를 고려하여, 인트라 예측 모드의 개수가 결정될 수 있다. 설명한 예에 그치지 않고, 부호화/복호화 대상 블록의 인트라 예측 모드를 결정하기 위해 이용되는, 인트라 예측 모드 후보자(예컨대, MPM의 개수)도, 색차 성분, 색차 포맷, 블록의 크기 또는 형태 중 적어도 하나에 따라 결정될 수도 있다. 또한, 도 8에 도시된 것 보다 더 많은 수의 인트라 예측 모드를 이용하는 것도 가능하다. 예컨대, 도 8에 도시된 방향성 예측 모드를 더욱 세분화하여, 129개의 방향성 예측 모드와 2개의 비방향성 예측 모드를 사용하는 것도 가능하다. 도 8에 도시된 것보다 더 많은 수의 인트라 예측 모드를 사용할 것인지 여부는 상술한 예에서와 같이, 색차 성분, 색차 성분, 블록의 크기 또는 형태 중 적어도 하나를 고려하여 결정될 수 있다.
후술되는 도면을 참조하여, 부호화/복호화 대상 블록의 인트라 예측 모드를 결정하는 방법 및 결정된 인트라 예측 모드를 이용하여, 인트라 예측을 수행하는 방법에 대해 살펴보기로 한다.
도 10은 본 발명이 적용되는 일실시예로서, 인트라 예측 방법을 개략적으로 도시한 순서도이다.
먼저, 현재 블록의 참조 샘플 라인 인덱스를 결정할 수 있다(S1010). 참조 샘플 라인 인덱스는, 현재 블록의 인트라 예측을 수행하는데 이용되는 참조 샘플 라인을 결정하는데 이용될 수 있다. 복수의 참조 샘플 라인 중 참조 샘플 라인 인덱스에 지시되는 적어도 하나의 참조 샘플 라인이 현재 블록의 인트라 예측을 수행하는데 이용될 수 있다.
도 11은 복수의 참조 샘플 라인을 예시한 도면이다.
N번째 참조 샘플 라인은, 현재 블록의 최상단 행보다 y좌표가 N만큼 작은 상단 참조 샘플 및 현재 블록의 최좌측 열보다 x좌표가 N만큼 작은 좌측 참조 샘플을 포함할 수 있다. 여기서, N번째 참조 샘플 라인은 도 11에 도시된 예에서 인덱스가 N-1인 참조 샘플 라인을 나타낸다. N번째 참조 샘플 라인은, P(-N, -N)부터 P(2W+N-1, -N)까지의 상단 참조 샘플들 및 P(-N, -N)부터 P(-N, 2H+N-1)까지의 좌측 참조 샘플들을 포함할 수 있다. 일 예로, 참조 샘플 라인 1은 P(-2, _2)부터 P(2W+1, -2) 까지의 상단 참조 샘플들 및 P(-2, -2)부터 P(-2, 2H+1)까지의 좌측 참조 샘플들을 포함할 수 있다.
참조 샘플 라인 후보로 이용될 수 있는 참조 샘플 라인의 개수는 2개, 3개, 4개 혹은 그 이상일 수 있다. 일 예로, 도 11에 도시된 예에서, 참조 샘플 라인 0, 참조 샘플 라인 1 및 참조 샘플 라인 3이 참조 샘플 라인 후보로 이용될 수 있다.
참조 샘플 라인 후보로 이용될 수 있는 참조 샘플 라인의 개수 또는 참조 샘플 라인의 위치는 현재 블록의 크기, 형태, 인트라 예측 모드 또는 위치 중 적어도 하나에 기초하여 결정될 수 있다. 일 예로, 현재 블록이 CTU의 경계 또는 타일의 경계에 인접 위치하는 경우, 참조 샘플 라인 후보의 개수는 1개(예컨대, 참조 샘플 라인 0)로 결정될 수 있다. 현재 블록이 CTU의 경계 또는 타일의 경계에 인접 위치하지 않는 경우, 참조 샘플 라인 후보의 개수는 3개(예컨대, 참조 샘플 라인 0, 참조 샘플 라인 1, 참조 샘플 라인 3)로 결정될 수 있다. 일 예로, 현재 블록의 인트라 예측 모드가 제1 범위에 속하는 경우, 참조 샘플 라인 0, 참조 샘플 라인 1 및 참조 샘플 라인 3이 참조 샘플 라인 후보로서 이용될 수 있다. 현재 블록의 인트라 예측 모드가 제2 범위에 속하는 경우, 참조 샘플 라인 0, 참조 샘플 라인 2 및 참조 샘플 라인 2가 참조 샘플 라인 후보로서 이용될 수 있다.
복수의 참조 샘플 라인 중 적어도 하나를 선택하기 위한 정보가 비트스트림을 통해 시그날링될 수 있다. 상기 인덱스 정보가 부호화되지 않은 경우, 현재 블록에 인접하는 참조 샘플 라인 0이 선택된 것으로 간주될 수 있다.
또는, 현재 블록의 크기, 형태, 위치 또는 인트라 예측 모드에 기초하여, 복수의 참조 샘플 라인 중 적어도 하나가 선택될 수 있다. 일 예로, 현재 블록의 너비, 높이, 크기 중 적어도 하나가 기 정의된 값보다 작은 경우, 참조 샘플 라인 0이 선택될 수 있다. 일 예로, 현재 블록이 CTU 또는 타일의 상단 경계와 접하는 경우, 참조 샘플 라인 0가 선택될 수 있다.
또는, 현재 블록이 서브 블록으로 분할되었는지 여부를 기초로, 참조 샘플 라인을 선택할 수 있다. 일 예로, 현재 블록이 서브 블록으로 분할된 경우, 참조 샘플 라인 0이 선택될 수 있다.
또는, 현재 블록이 복수의 서브 블록들로 분할된 경우, 서브 블록별로 참조 샘플 라인을 결정할 수 있다. 또는, 모든 서브 블록들이 동일한 참조 샘플 라인 인덱스를 갖도록 정의할 수 있다.
현재 블록이 복수의 서브 블록들로 분할된 경우, 서브 블록 단위로 인트라 예측이 수행될 수 있다.
현재 블록에 대해 복수 참조 샘플 라인이 선택될 수 있다. 복수의 참조 샘플 라인을 이용하여 인트라 예측을 수행할 것인지 여부는 현재 블록의 크기, 형태 또는 인트라 예측 모드 등에 따라 적응적으로 결정될 수 있다. 일 예로, 현재 블록의 인트라 예측 모드가 비 방향성 예측 모드인 경우 또는 기 정의된 방향성 인트라 예측 모드인 경우, 복수 참조 샘플 라인을 이용하지 못할 수 있다. 기 정의된 방향성 인트라 예측 모드는, 수직 방향 인트라 예측 모드, 수평 방향 인트라 예측 모드 또는 대각 방향 인트라 예측 모드 중 적어도 하나를 포함할 수 있다.
복수 참조 샘플 라인은, 인덱스 정보에 의해 선택된 참조 샘플 라인 및 상기 참조 샘플 라인의 인덱스에 기 정의된 값을 가산 또는 감산한 참조 샘플 라인을 포함할 수 있다. 여기서, 기 정의된 값은, 1 또는 2일 수 있다.
또는, 복수의 인덱스 정보가 비스스트림을 통해 시그날링될 수 있다. 복수 인덱스 정보 각각은 서로 다른 참조 샘플 라인을 가리킨다.
예측 샘플은 복수 참조 샘플들의 가중합 연산, 평균 연산, 최소값 연산 또는 최대값 연산 중 적어도 하나를 기초로 획득될 수 있다. 여기서, 복수 참조 샘플들 중 적어도 하나를 포함하는 참조 샘플 라인의 인덱스는 나머지를 포함하는 참조 샘플 라인의 인덱스와 상이할 수 있다.
다음으로, 현재 블록의 인트라 예측 모드를 결정할 수 있다(S1020).
현재 블록의 인트라 예측 모드를 결정하기 위해, 현재 블록에 이웃하는 이웃 블록의 인트라 예측 모드를 기초로 MPM(Most Probable Mode) 후보를 유도할 수 있다. 여기서, 이웃 블록은 현재 블록의 상단, 하단, 좌측, 우측 또는 코너에 인접하는 블록 중 적어도 하나를 포함할 수 있다. 일 예로, 상단 이웃 블록의 인트라 예측 모드 및 좌측 이웃 블록의 인트라 예측 모드를 기초로, MPM 후보가 유도될 수 있다. 상단 이웃 블록은 현재 블록의 최상단 행보다 y좌표의 값이 작은 기 정의된 위치의 상단 이웃 샘플을 포함할 수 있다. 기 정의된 위치는 (0, -1), (W/2, -1), (W-1, -1) 또는 (W, -1)일 수 있다. (0, 0)은 현재 블록이 포함하는 좌측 상단 샘플의 위치를 나타내고, W는 현재 블록의 너비를 나타낸다. 좌측 이웃 블록의 현재 블록의 최좌측 열보다 x좌표의 값이 작은 기 정의된 위치의 좌측 이웃 샘플을 포함할 수 있다. 기 정의된 위치는 (-1, 0), (-1, H/2), (-1, H-1) 또는 (-1, H)일 수 있다. H는 현재 블록의 높이를 나타낸다. 만약, 이웃 블록이 인터 예측으로 부호화되었다면, 이웃 블록 또는 현재 블록의 콜로케이티드 블록(Collocated block)의 인트라 예측 모드를 이용하여 MPM 후보를 포함할 수 있다.
후보 리스트가 포함하는 MPM (Most Probable Mode) 후보의 개수는 3개, 4개, 5개, 6개 혹은 그 이상일 수 있다. MPM 후보의 최대 개수는 영상 부호화기/복호화기에 기-설정된 고정된 값일 수 있다. 또는, MPM 후보의 최대 개수는 현재 블록의 속성에 기초하여 결정될 수 있다. 상기 속성은 현재 블록의 위치/크기/형태, 현재 블록이 이용할 수 있는 인트라 예측 모드의 개수/종류, 현재 블록의 컬러 타입(루마/크로마), 현재 블록의 색차 포맷, 현재 블록이 복수의 서브 블록들로 분할되었는지 여부 중 적어도 하나를 포함할 수 있다. 또는, MPM 후보의 최대 개수를 나타내는 정보가 비트스트림을 통해 시그날링될 수 있다. 최대 개수를 나타내는 정보는 시퀀스 레벨, 픽쳐 레벨, 슬라이스 레벨 또는 블록 레벨 중 적어도 하나에서 시그날링될 수 있다.
이웃 블록의 인트라 예측 모드, 이웃 블록과 유사한 방향성 인트라 예측 모드 또는 디폴트 모드 등이 MPM 후보로 설정될 수 있다. 이웃 블록과 유사한 방향성 인트라 예측 모드는, 이웃 블록의 인트라 예측 모드에 기 정의된 값을 가산 또는 감산하여 유도될 수 있다. 기 정의된 값은, 1, 2 또는 그 이상의 정수일 수 있다. 기 정의된 값은 사용 가능한 인트라 예측 모드의 개수에 따라 적응적으로 결정될 수 있다. 일 예로, 사용 가능한 인트라 예측 모드의 개수가 35개인 경우, 기 정의된 값은 1로 설정되고, 사용 가능한 인트라 예측 모드의 개수가 67개인 경우 기 정의된 값은 2로 설정될 수 있다. 나아가, 사용 가능한 인트라 예측 모드의 개수가 131개인 경우, 기 정의된 값은 4로 설정될 수 있다. 제1 이웃 블록의 인트라 예측 모드 및 제2 이웃 블록의 인트라 예측 모드가 모두 방향성 예측 모드인 경우, 제1 이웃 블록의 인트라 예측 모드 및 제2 이웃 블록의 인트라 예측 모드 중 최대값을 기초로, 유사한 방향성 인트라 예측 모드를 유도할 수 있다. 디폴트 모드는, DC 모드, 플래너 모드, 수평 방향 예측 모드, 수직 방향 예측 모드, 우상단 대각방향 모드, 좌하단 대각방향 모드 또는 좌상단 대각방향 모드 중 적어도 하나를 포함할 수 있다.
기 정의된 순서에 따라 MPM 후보 인덱스가 결정될 수 있다. 일 예로, 좌측 이웃 블록의 인트라 예측 모드 및 상단 이웃 블록의 인트라 예측 모드가 상이한 경우, 좌측 이웃 블록의 인트라 예측 모드가 상단 이웃 블록의 인트라 예측 모드보다 작은 인덱스 값을 가질 수 있다.
또는, 현재 블록의 크기/형태에 따라, MPM 후보 인덱스가 결정될 수 있다. 일 예로, 현재 블록이 높이가 너비보다 큰 비정방형인 경우, 상단 이웃 블록의 인트라 예측 모드가 좌측 이웃 블록의 인트라 예측 모드보다 작은 인덱스 값을 가질 수 있다. 현재 블록이 너비가 높이보다 큰 비정방형인 경우, 좌측 이웃 블록의 인트라 예측 모드가 상단 이웃 블록의 인트라 예측 모드보다 작은 인덱스 값을 가질 수 있다.
확장된 인트라 예측 모드와 기-정의된 35개의 인트라 예측 모드가 선택적으로 사용되는 경우, 주변 블록의 인트라 예측 모드를 확장된 인트라 예측 모드에 대응하는 인덱스로 변환하거나, 또는 35개의 인트라 예측 모드에 대응하는 인덱스로 변환하여 MPM 후보를 유도할 수 있다. 인덱스의 변환을 위해 기-정의된 테이블이 이용될 수도 있고, 소정의 값에 기반한 스케일링 연산이 이용될 수도 있다. 여기서, 기-정의된 테이블은 서로 상이한 인트라 예측 모드 그룹 (예를 들어, 확장된 인트라 예측 모드와 35개의 인트라 예측 모드) 간의 매핑 관계를 정의한 것일 수 있다.
예를 들어, 좌측 주변 블록이 35개의 인트라 예측 모드를 사용하고, 좌측 주변 블록의 인트라 예측 모드가 10(horizontal mode)인 경우, 이를 확장된 인트라 예측 모드에서 horizontal mode에 대응하는 인덱스 18로 변환할 수 있다.
또는, 상단 주변 블록이 확장된 인트라 예측 모드를 사용하고, 상단 주변 블록의 인트라 예측 모드 인덱스가 50(vertical mode)인 경우, 이를 35개의 인트라 예측 모드에서 vertical mode에 대응하는 인덱스 26으로 변환할 수 있다.
S1010 단계를 통해 선택된 참조 샘플 라인의 인덱스가 기 정의된 값 이상인 경우, 후보 리스트가 DC 모드 및/또는 플래너 모드를 포함하지 않도록 설정할 수 있다. 기 정의된 값은 1 이상의 정수일 수 있다.
현재 블록이 복수의 서브 블록들로 분할되는 경우, 현재 후보 리스트가 DC 모드를 포함하지 않도록 설정할 수 있다. 또한, 후보 리스트에는 디폴트 모드가 포함될 수 있다. 이때, 현재 블록의 분할 형태에 따라, 디폴트 모드의 개수 또는 종류가 상이할 수 있다.
현재 블록의 인트라 예측 모드와 동일한 MPM 후보가 후보 리스트에 포함되어 있는지 여부를 나타내는 정보가 비트스트림을 통해 시그날링될 수 있다. 상기 정보가 현재 블록의 인트라 예측 모드와 동일한 MPM 후보가 존재함을 지시하는 경우, 후보 리스트에 포함된 MPM 후보 중 어느 하나를 특정하는 인덱스 정보가 비트스트림을 통해 시그날링될 수 있다. 상기 인덱스 정보에 의해 특정된 MPM 후보가 현재 블록의 인트라 예측 모드로 설정될 수 있다. 상기 정보의 부호화/시그날링이 생략된 경우, 상기 현재 블록의 인트라 예측 모드와 동일한 MPM 후보가 후보 리스트에 포함되어 있는 것으로 결정될 수 있다.
반면, 상기 정보가 현재 블록의 인트라 예측 모드와 동일한 MPM 후보가 존재하지 않음을 나타내는 경우, 잔여 모드 정보가 비트스트림을 통해 시그날링될 수 있다. 잔여 모드 정보는 후보 리스트에 포함된 MPM 후보들을 제외한 잔여 인트라 예측 모드들 중 어느 하나를 특정하는데 이용된다. 상기 잔여 모드 정보를 이용하여, 현재 블록의 인트라 예측 모드를 결정할 수 있다. 상기 정보가 현재 블록의 인트라 예측 모드와 동일한 MPM 후보가 존재하지 않음을 나타내는 경우, MPM 후보들을 오름차순으로 재정렬할 수 있다. 이후, 잔여 모드 정보에 의해 지시되는 모드값을 재배열된 MPM 후보들과 순차적으로 비교하여 현재 블록의 인트라 예측 모드를 유도할 수 있다. 일 예로, 잔여 모드 정보에 의해 지시되는 모드값이 재배열된 MPM 후보 이하인 경우, 상기 모드값에 1을 추가할 수 있다. 갱신된 모드값 이하인 MPM 후보가 존재하지 않는 경우, 상기 갱신된 모드값을 현재 블록의 인트라 예측 모드로 결정할 수 있다.
S1010 단계를 통해 선택된 참조 샘플 라인의 인덱스가 기 정의된 값 이상인 경우, 상기 정보의 부호화가 생략될 수 있다. 이에 따라, 참조 샘플 라인의 인덱스가 기 정의된 값 이상인 경우, 현재 블록의 인트라 예측 모드는 인덱스 정보에 의해 지시되는 MPM 후보로 설정될 수 있다.
앞서 살펴본 바와 같이, 참조 샘플 라인의 인덱스가 기 정의된 값 이상인 경우, 후보 리스트가 DC 모드 및/또는 플래너 모드를 포함하지 않도록 설정할 수 있다. 이에 따라, 참조 샘플 라인 인덱스가 기 정의된 값 이상인 경우, DC 모드 및/또는 플래너 모드는 현재 블록에 대해 이용 불가할 수 있다.
현재 블록이 복수의 서브 블록들로 분할된 경우, 복수의 서브 블록들은 현재 블록의 인트라 예측 모드를 공유할 수 있다. 또는, 서브 블록별로 인트라 예측 모드를 결정할 수 있다. 예컨대, 서브 블록별로 상기 정보 및/또는 잔여 모드를 부/복호화할 수 있다. 또는, 서브 블록의 인트라 예측 모드가 이전 부호화/복호화가 완료된 서브 블록과 동일한지 여부를 나타내는 정보를 비트스트림을 통해 시그날링할 수 있다. 또는, 이전 부호화/복호화가 완료된 서브 블록의 인트라 예측 모드에 오프셋을 가산/감산하여 현재 서브 블록의 인트라 예측 모드를 유도할 수 있다.
현재 블록이 복수의 서브 블록들로 분할된 경우, 상기 정보의 부호화가 생략될 수 있다. 이에 따라, 현재 블록들이 복수의 서브 블록들로 분할된 경우, 현재 블록의 인트라 예측 모드는 인덱스 정보에 의해 지시되는 MPM 후보로 설정될 수 있다.
복수의 서브 블록들은 현재 블록의 인트라 예측 모드를 공유할 수 있다.
휘도 성분과 색차 성분 각각의 인트라 예측 모드가 상호 독립적으로 결정될 수 있다. 또는, 휘도 성분의 인트라 예측 모드에 종속하여 색차 성분의 인트라 예측 모드를 결정할 수 있다.
구체적으로, 색차 성분의 인트라 예측 모드는 다음 표 1과 같이 휘도 성분의 인트라 예측 모드에 기반하여 결정될 수 있다.
| Intra_chroma_pred_mode[xCb][yCb] | IntraPredModeY[xCb][yCb] | ||||
| 0 | 26 | 10 | 1 | X(0<=X<=34) | |
| 0 | 34 | 0 | 0 | 0 | 0 |
| 1 | 26 | 34 | 26 | 26 | 26 |
| 2 | 10 | 10 | 34 | 10 | 10 |
| 3 | 1 | 1 | 1 | 34 | 1 |
| 4 | 0 | 26 | 10 | 1 | X |
표 1에서 intra_chroma_pred_mode는 색차 성분의 인트라 예측 모드를 특정하기 위해 시그날링되는 정보를 의미하며, IntraPredModeY는 휘도 성분의 인트라 예측 모드를 나타낸다.
다음으로, 현재 블록에 대한 참조 샘플을 유도할 수 있다(S1030). 일 예로, S1010 단계를 통해 N번째 참조 샘플 라인이 선택된 경우, P(-N, -N)부터 P(2W+N-1, -N)까지의 상단 참조 샘플 및 P(-N, -N)부터 P(-N, 2H+N-1)까지의 좌측 참조 샘플을 유도할 수 있다.
참조 샘플은, 현재 블록보다 먼저 부호화/복호화가 완료된 복원 샘플로부터 유도될 수 있다. 상기 복원 샘플은 인루프 필터가 적용되기 전 상태 또는 인루프 필터가 적용된 이후의 상태의 것을 의미할 수 있다.
참조 샘플들에 소정의 인트라 필터를 적용할 수 있다. 인트라 필터를 이용하여 참조 샘플들을 필터링하는 것을 참조 샘플 스무딩(smoothing)이라 호칭할 수 있다. 상기 인트라 필터는 수평 방향으로 적용되는 제1 인트라 필터 또는 수직 방향으로 적용되는 제2 인트라 필터 중 적어도 하나를 포함할 수 있다. 참조 샘플의 위치에 따라 제1 인트라 필터 또는 제2 인트라 필터 중 어느 하나가 선택적으로 적용될 수 있다. 또는, 하나의 참조 샘플에 2개의 인트라 필터가 중복 적용될 수 있다. 제1 인트라 필터 또는 제2 인트라 필터 중 적어도 하나의 필터 계수는 (1,2,1)일 수 있으나, 이에 한정되지는 않는다.
상기 필터링은 현재 블록의 인트라 예측 모드 또는 현재 블록에 관한 변환 블록의 크기 중 적어도 하나에 기초하여 적응적으로 수행될 수 있다. 예를 들어, 현재 블록의 인트라 예측 모드가 DC 모드, 수직 모드 또는 수평 모드인 경우 필터링은 수행되지 않을 수 있다. 상기 변환 블록의 크기가 NxM인 경우, 필터링은 수행되지 않을 수 있다. 여기서, N과 M은 동일하거나 서로 상이한 값일 수 있고, 4, 8, 16 또는 그 이상의 값 중 어느 하나일 수 있다. 일 예로, 변환 블록의 크기가 4x4인 경우, 필터링은 수행되지 않을 수 있다. 또는, 현재 블록의 인트라 예측 모드와 수직 모드(또는 수평 모드)의 차이와 기-정의된 임계치(threshold) 간의 비교 결과에 기초하여 필터링을 수행 여부를 결정할 수 있다. 예를 들어, 현재 블록의 인트라 예측 모드와 수직 모드의 차이가 임계치보다 큰 경우에 한하여 필터링을 수행할 수 있다. 상기 임계치는 표 2와 같이 변환 블록의 크기 별로 정의될 수 있다.
| 8x8 transform | 16x16 transform | 32x32 transform | |
| Threshold | 7 | 1 | 0 |
상기 인트라 필터는 영상 부호화기/복호화기에 기-정의된 복수의 인트라 필터 후보 중 어느 하나로 결정될 수 있다. 이를 위해 복수의 인트라 필터 후보 중 현재 블록의 인트라 필터를 특정하는 별도의 인덱스가 시그날링될 수 있다. 또는, 현재 블록의 크기/형태, 변환 블록의 크기/형태, 필터 강도(strength)에 관한 정보, 또는 주변 샘플들의 변화량(variation) 중 적어도 하나에 기초하여 인트라 필터가 결정될 수도 있다.다음으로, 현재 블록의 인트라 예측 모드와 참조 샘플을 이용하여 인트라 예측을 수행할 수 있다(S1040).
현재 블록의 인트라 예측 모드와 참조 샘플을 이용하여 예측 샘플을 획득할 수 있다. 복수 참조 샘플 라인이 선택된 경우, 상이한 참조 샘플 라인에 속한 참조 샘플들의 가중합 연산 또는 평균 연산을 기초로 예측 샘플을 획득할 수 있다. 일 예로, 제1 참조 샘플 라인에 속하는 제1 참조 샘플과 제2 참조 샘플 라인에 속하는 제2 참조 샘플의 가중합 연산을 기초로 예측 샘플을 유도할 수 있다. 이때, 제1 참조 샘플과 제2 참조 샘플에 적용되는 가중치는 동일한 값을 가질 수 있다. 또는, 예측 대상 샘플 참조 샘플 사이의 거리에 기초하여 각 참조 샘플에 적용되는 가중치를 결정할 수 있다. 일 예로, 제1 참조 샘플 및 제2 참조 샘플 중 예측 대상 샘플과의 거리가 가까운 참조 샘플에 적용되는 가중치가 다른 참조 샘플에 적용되는 가중치보다 큰 값을 가질 수 있다.
다만, 인트라 예측의 경우 주변 블록의 경계 샘플을 이용하기 때문에 예측 영상의 화질이 떨어지는 문제가 발생할 수 있다. 따라서, 상술한 예측 과정을 통해 생성된 예측 샘플에 대한 보정 과정을 더 수반할 수 있으며, 이하 도 12를 참조하여 자세히 살펴보기로 한다. 다만, 후술할 보정 과정은 인트라 예측 샘플에 대해서만 적용되는 것으로 한정되는 것은 아니며, 인터 예측 샘플 또는 복원 샘플에도 적용될 수 있음은 물론이다.
도 12는 본 발명이 적용되는 일실시예로서, 주변 샘플들의 차분 정보에 기반하여 현재 블록의 예측 샘플을 보정하는 방법을 도시한 것이다.
현재 블록에 대한 복수의 주변 샘플들의 차분 정보에 기반하여 현재 블록의 예측 샘플을 보정할 수 있다. 상기 보정은 현재 블록에 속한 모든 예측 샘플에 대해서 수행될 수도 있고, 소정의 일부 영역에 속한 예측 샘플에 대해서만 수행될 수도 있다. 일부 영역은 하나의 행/열 또는 복수의 행/열일 수 있고, 이는 영상 부호화기/복호화기에서 보정을 위해 기-설정된 영역일 수도 있다. 일 예로, 현재 블록의 경계에 위치한 하나의 행/열 또는 현재 블록의 경계로부터 복수의 행/열에 보정이 수행될 수 있다. 또는, 일부 영역은 현재 블록의 크기/형태 또는 인트라 예측 모드 중 적어도 하나에 기초하여 가변적으로 결정될 수도 있다.
주변 샘플들은 현재 블록의 상단, 좌측, 좌상단 코너에 위치한 주변 블록 중 적어도 하나에 속할 수 있다. 보정을 위해 이용되는 주변 샘플들의 개수는 2개, 3개, 4개 또는 그 이상일 수 있다. 주변 샘플들의 위치는 현재 블록 내 보정 대상인 예측 샘플의 위치에 따라 가변적으로 결정될 수 있다. 또는, 주변 샘플들 중 일부는 보정 대상인 예측 샘플의 위치와 관계없이 고정된 위치를 가지고, 나머지는 보정 대상인 예측 샘플의 위치에 따른 가변적인 위치를 가질 수도 있다.
주변 샘플들의 차분 정보는 주변 샘플들 간의 차분 샘플을 의미할 수도 있고, 상기 차분 샘플을 소정의 상수값(예를 들어, 1, 2, 3 등)으로 스케일링한 값을 의미할 수도 있다. 여기서, 소정의 상수값은 보정 대상인 예측 샘플의 위치, 보정 대상인 예측 샘플이 속한 열 또는 행의 위치, 열 또는 행 내에서 예측 샘플의 위치 등을 고려하여 결정될 수 있다.
예를 들어, 현재 블록의 인트라 예측 모드가 수직 모드인 경우, 현재 블록의 좌측 경계에 인접한 주변 샘플 p(-1,y)과 좌상단 주변 샘플 p(-1,-1) 간의 차분 샘플을 이용하여 다음 수학식 1과 같이 최종 예측 샘플을 획득할 수 있다.
예를 들어, 현재 블록의 인트라 예측 모드가 수평 모드인 경우, 현재 블록의 상단 경계에 인접한 주변 샘플 p(x,-1)과 좌상단 주변 샘플 p(-1,-1) 간의 차분 샘플을 이용하여 다음 수학식 2와 같이 최종 예측 샘플을 획득할 수 있다.
예를 들어, 현재 블록의 인트라 예측 모드가 수직 모드인 경우, 현재 블록의 좌측 경계에 인접한 주변 샘플 p(-1,y)과 좌상단 주변 샘플 p(-1,-1) 간의 차분 샘플을 이용하여 최종 예측 샘플을 획득할 수 있다. 이때, 상기 차분 샘플을 예측 샘플에 가산할 수도 있고, 상기 차분 샘플을 소정의 상수값으로 스케일링한 후, 이를 예측 샘플에 가산할 수도 있다. 스케일링에 이용되는 소정의 상수값은 열 및/또는 행에 따라 상이하게 결정될 수 있다. 일예로, 다음 수학식 3과 수학식 4와 같이 예측 샘플을 보정할 수 있다.
예를 들어, 현재 블록의 인트라 예측 모드가 수평 모드인 경우, 현재 블록의 상단 경계에 인접한 주변 샘플 p(x,-1)과 좌상단 주변 샘플 p(-1,-1) 간의 차분 샘플을 이용하여 최종 예측 샘플을 획득할 수 있으며, 이는 수직 모드에서 상술한 바와 같다. 일예로, 다음 수학식 5와 수학식 6과 같이 예측 샘플을 보정할 수 있다.
현재 블록의 인트라 예측 모드가 방향성 예측 모드인 경우, 현재 블록의 인트라 예측은, 방향성 예측 모드의 방향성에 기초하여 수행될 수 있다. 일 예로, 표 3은, 도 8에 도시된 방향성 인트라 예측 모드인 Mode 2부터 Mode 34까지의 인트라 방향 파라미터(intraPredAng)를 나타낸 것이다.
| predModeIntra | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| intraPredAng | - | 32 | 26 | 21 | 17 | 13 | 9 | 5 | 2 | 0 | -2 | -5 | -9 | -13 | -17 | -21 |
| predModeIntra | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 |
| intraPredAng | -32 | -26 | -21 | -17 | -13 | -9 | -5 | -2 | 0 | 2 | 5 | 9 | 13 | 17 | 21 | 26 |
표 3에서는, 33개의 방향성 인트라 예측 모드를 예시하여 설명하였으나, 이보다 더 많은 수 혹은 이보다 더 적은 수의 방향성 인트라 예측 모드가 정의되는 것도 가능하다. 방향성 인트라 예측 모드와 인트라 방향 파라미터의 매핑 관계를 정의한 룩업 테이블에 기초하여, 현재 블록에 대한 인트라 방향 파라미터를 결정할 수 있다. 또는, 비트스트림을 통해 시그널링되는 정보에 기초하여, 현재 블록에 대한 인트라 방향 파라미터를 결정할 수도 있다.
현재 블록의 인트라 예측은, 방향성 인트라 예측 모드의 방향성에 따라, 좌측 참조 샘플 또는 상단 참조 샘플 중 적어도 하나를 이용하여 수행될 수 있다. 여기서, 상단 참조 샘플은, 현재 블록 내 최상단 행에 포함된 예측 대상 샘플 (x, 0)보다 작은 y축 좌표를 갖는 참조 샘플들(예컨대, (-1, -1) 부터 (2W-1, -1))을 의미하고, 좌측 참조 샘플은, 현재 블록 내 최좌측 열에 포함된 예측 대상 샘플 (0, y)보다 작은 x축 좌표를 갖는 참조 샘플들(예컨대, (-1, -1)부터 (-1, 2H-1))을 의미할 수 있다.
인트라 예측 모드의 방향성에 따라, 현재 블록의 참조 샘플들을 일차원으로 배열할 수도 있다. 구체적으로, 현재 블록의 인트라 예측 시 상단 참조 샘플 및 좌측 참조 샘플을 모두 이용해야 하는 경우, 이들이 수직 또는 수평 방향을 따라 일렬로 배열된 것으로 가정하고, 각 예측 대상 샘플의 참조 샘플을 선정할 수 있다.
일 예로, 인트라 방향 파라미터가 음수인 경우(예컨대, 표 3에서 Mode 11 부터 Mode 25에 해당하는 인트라 예측 모드의 경우), 상단 참조 샘플들 및 좌측 참조 샘플들을 수평 또는 수직 방향을 따라 재배열하여 일차원 레퍼런스 샘플 그룹(P_ref_1D)을 구성할 수 있다.
도 13 및 도 14는 참조 샘플들이 일렬로 재배열된 일차원 레퍼런스 샘플 그룹을 나타낸 도면이다.
참조 샘플들을 수직 방향으로 재배열할 것인지 또는 수평 방향으로 재배열할 것인지는, 인트라 예측 모드의 방향성에 따라 결정될 수 있다. 일 예로, 인트라 예측 모드가 좌측을 향하는 경우(예컨대, 인트라 예측 모드의 인덱스가 도 8에 도시된 예의 11 내지 18 사이), 도 13에 도시된 예에서와 같이, 현재 블록의 상단 참조 샘플들을 반시계 방향으로 회전시켜, 좌측 참조 샘플들 및 상단 참조 샘플들이 수직 방향으로 배열된 일차원 레퍼런스 샘플 그룹을 생성할 수 있다.
반면, 인트라 예측 모드가 상단을 향하는 경우(예컨대, 인트라 예측 모드의 인데ㄱ스가 도 8에 도시된 예의 19 내지 25 사이), 도 14에 도시된 예에서와 같이, 현재 블록의 좌측 참조 샘플들을 좌측 참조 샘플들을 시계 방향으로 회전시켜, 좌측 참조 샘플들 및 상단 참조 샘플들이 수평 방향으로 배열된 일차원 레퍼런스 샘플 그룹을 생성할 수 있다.
현재 블록의 인트라 방향 파라미터가 음수가 아닌 경우, 현재 블록에 대한 인트라 예측은 좌측 참조 샘플들 또는 상단 참조 샘플들만을 이용하여 수행될 수 있다. 이에 따라, 인트라 방향 파라미터가 음수가 아닌 인트라 예측 모드들에 대해서는 좌측 참조 샘플 또는 상단 참조 샘플들만을 이용하여, 일차원 레퍼런스 샘플 그룹을 구성할 수도 있다.
인트라 방향 파라미터에 기초하여, 예측 대상 샘플을 예측하는데 이용되는 적어도 하나의 참조 샘플을 특정하기 위한 참조 샘플 결정 인덱스 iIdx를 유도할 수 있다. 또한, 인트라 방향 파라미터를 기초로 각 참조 샘플에 적용되는 가중치를 결정하는데 이용되는 가중치 관련 파라미터 ifact를 유도할 수 있다. 일 예로, 하기 수학식 7 및 8은 참조 샘플 결정 인덱스 및 가중치 관련 파라미터를 유도하는 예를 나타낸 것이다.
수학식 7에 나타난 바와 같이, iIdx와 ifact는 방향성 인트라 예측 모드의 기울기에 따라 가변적으로 결정된다. 이때, iIdx에 의해 특정되는 참조 샘플은 정수 펠(integer pel)에 해당할 수 있다.
참조 샘플 결정 인덱스에 기초하여, 예측 대상 샘플 별로 적어도 하나 이상의 참조 샘플을 특정할 수 있다. 일 예로, 참조 샘플 결정 인덱스에 기초하여, 현재 블록 내 예측 대상 샘플을 예측하기 위한 일차원 레퍼런스 샘플 그룹 내 참조 샘플의 위치를 특정할 수 있다. 특정된 위치의 참조 샘플을 기초로, 예측 대상 샘플에 대한 예측 영상(즉, 예측 샘플)을 생성할 수 있다.
현재 블록의 인트라 예측 모드에 따라, 하나 또는 복수의 참조 샘플들을 기초로 예측 대상 샘플에 대한 예측 영상을 생성할 수 있다.
일 예로, 예측 대상 샘플로부터 확장되는, 가상의 각도 선(angular line)이 일차원 레퍼런스 샘플 그룹 내 정수 펠(integer pel) 위치(즉, 정수 위치의 참조 샘플)를 지나는 경우, 정수 펠 위치의 참조 샘플을 복사하거나, 정수 펠 위치의 참조 샘플과 예측 대상 샘플 사이의 위치를 고려하여 참조 샘플을 스케일링함으로써, 예측 대상 샘플에 대한 예측 영상을 생성할 수 있다. 가상의 각도 선은 현재 블록의 인트라 예측 모드의 각도 또는 인트라 예측 모드의 기울기를 따라 단방향/양방향 확장된 선을 의미할 수 있다. 일 예로, 하기 수학식 8은 현재 블록의 인트라 예측 모드에 의해 특정되는 참조 샘플 P_ref_1D(x+iIdx+1)을 복사하여, (x, y) 위치의 예측 대상 샘플에 대한 예측 영상 P(x, y)를 생성하는 예를 나타낸 것이다.
반면, 예측 대상 샘플로부터 확장되는 가상의 각도 선이 정수 펠 위치를 지나지 않는 경우, 복수 참조 샘플들을 이용하여, 예측 대상 샘플에 대한 예측 영상을 획득할 수 있다. 예측 대상 샘플에 대한 예측 영상은 상기 가상의 각도 선이 지나는 위치에 인접하는 참조 샘플 및 상기 참조 샘플에 인접하는 적어도 하나의 이웃 참조 샘플을 선형 보간함으로써 생성될 수 있다. 또는, 예측 대상 샘플에 대한 예측 영상은 상기 참조 샘플 및 상기 적어도 하나의 이웃 참조 샘플에 탭 필터(Tap filter) 기반의 보간을 수행함으로써 획득될 수 있다. 보간 필터의 탭수는 2 이상의 자연수일 수 있다. 구체적으로, 보간 대상이 되는 참조 샘플의 개수에 따라, 탭 필터(Tap filter)의 탭수가 2, 3, 4, 5, 6 또는 그 이상의 정수일 수도 있다.
일 예로, 예측 대상 샘플로부터 확장되는 가상의 각도 선이 두 정수 펠 위치 사이를 지나는 경우, 상기 가상의 각도 선이 지나는 위치 양쪽의 참조 샘플들 또는 상기 두 정수 펠 위치의 참조 샘플들 중 적어도 하나와 적어도 하나의 이웃 참조 샘플들을 이용하여 예측 대상 샘플에 대한 예측 영상을 생성할 수 있다. 여기서, 이웃 참조 샘플은, 참조 샘플의 좌/우 또는 상/하에 인접하는 참조 샘플 중 적어도 하나를 포함할 수 있다. 일 예로, 하기 수학식 9는 둘 이상의 참조 샘플을 보간하여, 예측 대상 샘플에 대한 예측 샘플 P(x, y)를 생성하는 예를 나타낸 것이다.
보간 필터의 계수는, 가중치 관련 파라미터 ifact에 기초하여 결정될 수 있다. 일 예로, 보간 필터의 계수는, 각도 선(angular line) 상에 위치한 소수 펠(fractional pel)과 정수 펠(즉, 각 참조 샘플들의 정수 위치) 사이의 거리에 기초하여 결정될 수 있다.
하기 수학식 10은 탭 필터의 탭수가 4인 경우를 예시한 것이다.
상기 수학식 10에 나타난 예와 같이, 연속하는 복수의 참조 샘플들을 보간함으로써, 예측 대상 샘플에 대한 예측 영상을 획득할 수 있다. 이때, 연속하는 N개의 참조 샘플들 중 적어도 하나 이상이 일차원 레퍼런스 샘플 그룹에 포함되어 있지 않는 경우, 해당 참조 샘플의 값을 기 정의된 값 또는 이웃하는 참조 샘플의 값으로 대체할 수 있다. 일 예로, (x+iIdx-1) 위치의 샘플이 일차원 레퍼런스 샘플 그룹에 포함되지 않는 경우, 상기 위치의 참조 샘플의 값을 기 정의된 값 또는 인접하는 참조 샘플의 값(예컨대, P_ref_1D(x+iIdx))으로 대체할 수 있다. 또는, (x+iIdx+2) 위치의 샘플이 일차원 레퍼런스 샘플 그룹에 포함되지 않는 경우, 상기 위치의 참조 샘플의 값을 기 정의된 값, 기 산출된 또는 인접하는 참조 샘플의 값(예컨대, P_ref(x+iIdx+1))으로 대체할 수 있다. 여기서, 기 정의된 값은, 0을 포함하는 정수일 수 있다. 기 산출된 값은 비트 뎁스(Bit depth)에 의해 결정되는 값일 수 있다. 또는, 적어도 하나 이상의 참조 샘플들의 평균값, 최소값 또는 최대값을 기초로 기 정의된 값을 산출할 수 있다.
멀티 탭 필터는 직선 형태일 수 있다. 일 예로, 수평 또는 수직 방향으로 연속하는 복수의 참조 샘플들을 이용하는 직선 형태의 멀티 탭 필터가 적용될 수 있다. 또는, 멀티 탭 필터는 사각형 또는 십자 형태 등 다각형 형태일 수도 있다. 일 예로, 참조 샘플과, 상기 참조 샘플의 사방에 인접하는 참조 샘플들을 이용하는 십자 형태의 멀티 탭 필터가 이용될 수 있다. 멀티 탭 필터의 형태는 현재 블록의 크기, 형태 또는 인트라 예측 모드에 기초하여 가변적으로 결정될 수 있다.
수학식 8 내지 10에 나타난 것과 같이, 인트라 예측의 방향성을 이용하여 참조 샘플을 보간하여 예측 샘플을 생성하는 것을, 인트라 예측 샘플 보간 기법이라 호칭할 수 있다.
인트라 예측 샘플 보간 기법을 이용함에 있어서, 탭 필터의 탭 수가 큰 것이 반드시 예측 정확도 향상을 보장하지는 않는다. 예컨대, 현재 블록의 크기가 2x16과 같이 높이 또는 너비가 다른 하나에 비해 현저히 큰 비대칭 코딩 유닛이거나, 4x4와 같이 작은 크기의 블록이라면, 4 탭 이상의 탭 필터를 사용하는 것은 오히려 예측 영상을 과하게 스무딩하는 결과를 초래할 수 있다. 이에, 현재 블록의 크기, 형태 또는 인트라 예측 모드에 따라, 탭 필터의 종류를 적응적으로 결정할 수 있다. 여기서, 탭 필터의 종류는, 탭 수, 필터 계수, 필터 강도(강/약), 필터링 방향, 필터 형태 중 적어도 하나에 의해 정의될 수 있다. 필터 탭 수 또는 필터 계수 등이 필터 강도에 따라 가변적으로 결정될 수도 있다. 또한, 탭 필터의 종류에 따라, 가로 방향 보간, 세로 방향 보간 또는 가로 및 세로 방향 보간 등 탭 필터의 적용 방향이 결정될 수 있다. 현재 블록 내 라인 단위(행 또는 열) 또는 샘플 단위로 탭 필터의 적용 방향을 가변적으로 설정할 수도 있다.
구체적으로, 현재 블록의 너비 또는 높이에 기초하여 사용하고자 하는 탭 필터의 종류를 결정할 수 있다. 일 예로, 현재 블록의 너비 또는 높이 중 적어도 하나의 값이 기 정의된 값보다 작은 경우, 4탭 필터 대신 2탭 필터를 사용하여 인트라 예측 샘플 보간 기법을 수행할 수 있다. 반면, 현재 블록의 너비 및 높이 모두 기 정의된 값 이상인 경우, 4탭 필터를 사용하여 인트라 예측 샘플 보간 기법을 수행할 수 있다. 여기서, 기 정의된 값은, 4, 8 또는 16 등의 값을 나타낼 수 있다.
또는, 현재 블록의 너비 및 높이가 동일한 값인지 여부에 따라 사용하고자 하는 탭 필터의 종류를 결정할 수 있다. 일 예로, 현재 블록의 너비 및 높이가 상이한 값인 경우, 4탭 필터 대신 2탭 필터를 사용하여 인트라 예측 샘플 보간 기법을 수행할 수 있다. 반면, 현재 블록의 너비 및 높이가 동일한 값을 가질 경우, 4탭 필터를 사용하여 인트라 예측 샘플 보간 기법을 수행할 수 있다.
또는, 현재 블록의 너비와 높이의 비율에 따라 사용하고자 하는 탭 필터의 종류를 결정할 수 있다. 일 예로, 현재 블록의 너비(w)와 높이(h)의 비율(즉, w/h 또는 h/w)이 기 정의된 임계값보다 작은 경우에는 4탭 필터 대신 2탭 필터를 사용하여 인트라 예측 샘플 보간 기법을 수행할 수 있다. 반면, 현재 블록의 너비와 높이의 비율이 기 정의된 임계값 이상인 경우, 4탭 필터를 사용하여 인트라 예측 샘플 보간 기법을 수행할 수 있다.
또는, 현재 블록의 인트라 예측 모드, 형태 또는 크기에 따라 탭 필터의 종류를 결정할 수도 있다. 일 예로, 현재 블록이 2x16 형태의 코딩 유닛이고, 현재 블록의 인트라 예측 모드가 수평 방향 범위에 속하는 인트라 예측 모드일 경우, 탭 수가 n인 탭 필터를 이용하여 인트라 예측 샘플 보간 기법을 수행할 수 있다. 반면, 현재 블록이 2x16 형태의 코딩 유닛이고, 현재 블록의 인트라 예측 모드가 수직 방향 범위에 속하는 인트라 예측 모드일 경우, 탭 수가 m인 탭 필터를 이용하여 인트라 예측 샘플 보간 기법을 수행할 수 있다.
반면, 현재 블록이 16x2 형태의 코딩 유닛이고, 현재 블록의 인트라 예측 모드가 수평 방향 범위에 속하는 인트라 예측 모드일 경우 탭 수가 n인 탭 필터를 이용하여 인트라 예측 샘플 보간 기법을 수행할 수 있다. 반면, 현재 블록이 16x2 형태의 코딩 유닛이고, 현재 블록의 인트라 예측 모드가 수직 방향 범위에 속하는 인트라 예측 모드일 경우, 탭 수가 m인 탭 필터를 이용하여 인트라 예측 샘플 보간 기법을 수행할 수 있다.
여기서, 수평 방향 범위는 수평 방향의 인트라 예측 모드를 포함하는 소정의 범위를 나타낼 수 있고, 수직 방향 범위는 수직 방향의 인트라 예측 모드를 포함하는 소정의 범위를 나타낼 수 있다. 일 예로, 35개의 인트라 예측 모드를 기반으로 하였을 때, 수평 방향 범위는 모드 11부터 모드 18 사이의 인트라 예측 모드를 나타내고, 수직 방향 범위는 모드 19부터 모드 27 사이의 인트라 예측 모드를 나타낼 수 있다.
또한, n과 m은 0보다 큰 상수로, n과 m은 상이한 값을 가질 수 있다. 또는, n과 m이 동일한 값을 갖도록 설정하되, n 탭 필터와 m 탭 필터의 필터 계수 또는 필터 강도 중 적어도 하나를 상이하게 설정할 수도 있다.
방향성 예측 모드 또는 DC 모드를 이용하는 경우, 블록 경계에서 화질 열화가 발생할 염려가 있다. 반면 플래너 모드의 경우, 상기 예측 모드들에 비해 블록 경계의 화질 열화가 상대적으로 적은 장점이 있다.
플래너 예측은, 참조 샘플들을 이용하여, 수평 방향의 제1 예측 영상 및 수직 방향의 제2 예측 영상을 생성한 뒤, 제1 예측 영상 및 제2 예측 영상을 가중 예측함으로써 수행될 수 있다.
여기서, 제1 예측 영상은, 예측 대상 샘플과 동일한 수평선상에 놓인 참조 샘플들을 이용하여 생성될 수 있다. 여기서, 예측 대상 샘플과 동일한 수평선상에 놓인 참조 샘플들은, 예측 대상 샘플과 동일한 y축 좌표를 가질 수 있다. 일 예로, 제1 예측 영상은 예측 대상 샘플의 수평 방향에 놓인 참조 샘플들의 가중합 연산 또는 평균 연산에 기초하여 생성될 수 있다. 이때, 각 참조 샘플들에 적용되는 가중치는 예측 대상 샘플과의 거리 또는 현재 블록의 크기 등을 고려하여 결정될 수 있다. 예측 대상 샘플과 동일한 수평선상에 놓인 참조 샘플들은, 좌측 참조 샘플(즉, 예측 대상 샘플과 동일한 y 좌표를 갖는 좌측 참조 샘플) 및 우측 참조 샘플(즉, 예측 대상 샘플과 동일한 y 좌표를 갖는 우측 참조 샘플)을 포함할 수 있다. 우측 참조 샘플은, 상단 참조 샘플로부터 유도될 수 있다. 일 예로, 우측 참조 샘플과 동일한 수직선상에 놓인 상단 참조 샘플의 값을 복사하거나, 복수 상단 참조 샘플들의 가중합 연산 또는 평균 연산 에 기초하여 우측 참조 샘플을 유도할 수 있다. 여기서, 우측 참조 샘플과 동일한 수직선상에 놓인 상단 참조 샘플은, 우측 참조 샘플과 동일한 x축 좌표를 가질 수 있다. 예컨대, 현재 블록의 우측 상단 코너에 인접한 참조 샘플을 기초로 현재 블록의 우측에 인접한 우측 참조 샘플을 유도할 수 있다. 또는, 현재 블록의 형태, 크기 또는 예측 대상 샘플의 위치에 따라, 우측 참조 샘플을 유도하는데 이용되는 상단 참조 샘플의 위치를 가변적으로 결정할 수도 있다.
제2 예측 영상은, 예측 대상 샘플과 동일한 수직선상에 놓인 참조 샘플들을 이용하여 생성될 수 있다. 여기서, 예측 대상 샘플과 동일한 수직선상에 놓인 참조 샘플들은, 예측 대상 샘플과 동일한 x축 좌표를 가질 수 있다. 일 예로, 제2 예측 영상은 예측 대상 샘플의 수직 방향에 놓인 참조 샘플들의 가중합 연산 또는 평균 연산에 기초하여 생성될 수 있다. 이때, 각 참조 샘플들에 적용되는 가중치는 예측 대상 샘플과의 거리 또는 현재 블록의 크기 등을 고려하여 결정될 수 있다. 예측 대상 샘플과 동일한 수직선상에 놓인 참조 샘플들은, 상단 참조 샘플(즉, 예측 대상 샘플과 동일한 x 좌표를 갖는 상단 참조 샘플) 및 하단 참조 샘플(즉, 예측 대상 샘플과 동일한 x 좌표를 갖는 하단 참조 샘플)을 포함할 수 있다. 하단 참조 샘플은, 좌측 참조 샘플로부터 유도될 수 있다. 일 예로, 하단 참조 샘플과 동일한 수평선상에 놓인 좌측 참조 샘플의 값을 복사하거나, 복수 좌측 참조 샘플들의 가중합 연산 또는 평균 연산에 기초하여 하단 참조 샘플을 유도할 수 있다. 여기서, 하단 참조 샘플과 동일한 수평선상에 놓인 좌측 참조 샘플은, 하단 참조 샘플과 동일한 y축 좌표를 가질 수 있다. 예컨대, 현재 블록의 좌측 하단 코너에 인접한 참조 샘플을 기초로, 현재 블록의 하단에 인접한 하단 참조 샘플을 유도할 수 있다. 또는, 현재 블록의 크기, 형태 또는 예측 대상 샘플의 위치에 따라, 하단 참조 샘플을 유도하는데 이용되는 상단 참조 샘플의 위치를 가변적으로 결정할 수도 있다.
또는, 좌측 참조 샘플 및 상단 참조 샘플 모두를 이용하여 우측 참조 샘플을 유도하거나, 좌측 참조 샘플 및 상단 참조 샘플 모두를 이용하여 하단 참조 샘플을 유도할 수도 있다.
일 예로, 우측 참조 샘플과 동일한 수평선상에 놓인 좌측 참조 샘플 및 우측 참조 샘플과 동일한 수직선상에 놓인 상단 참조 샘플 사이의 가중합 연산, 최소값 연산, 최대값 연산 또는 평균 연산에 기초하여, 우측 참조 샘플을 유도할 수 있다. 하단 참조 샘플과 동일한 수평선상에 놓인 좌측 참조 샘플 및 하단 참조 샘플과 동일한 수직선상에 놓인 상단 참조 샘플 사이의 가중합 연산, 최소값 연산, 최대값 연산 또는 평균 연산에 기초하여, 하단 참조 샘플을 유도할 수 있다.
또는, 좌측 참조 샘플과 상단 참조 샘플을 이용하여, 우측 하단 참조 샘플을 유도한 뒤, 유도된 우측 참조 샘플을 이용하여 우측 참조 샘플과 하단 참조 샘플을 유도할 수도 있다. 우측 하단 참조 샘플은, 우측 하단 참조 샘플과 동일한 수평선상에 위치하는 좌측 참조 샘플 및 우측 하단 참조 샘플과 동일한 수직선상에 위치하는 상단 참조 샘플 사이의 가중합 연산 또는 평균 연산을 기초로 유도될 수 있다. 일 예로, 현재 블록의 우측 하단 코너에 인접하는 우측 하단 참조 샘플 P(W, H)(여기서, W는 현재 블록의 너비, H는 현재 블록의 높이)은, 우측 상단 참조 샘플 P(W, -1) 및 좌측 하단 참조 샘플 P(-1, H) 사이의 가중합 연산 또는 평균 연산을 기초로 유도될 수 있다. 우측 하단 참조 샘플을 유도하기 위해, 우측 상단 참조 샘플 및 좌측 하단 참조 샘플 각각에 적용되는 가중치는 동일한 값을 가질 수도 있고, 현재 블록의 너비/높이에 따라, 상이한 값을 가질 수도 있다. 일 예로, 현재 블록의 너비가 높이보다 큰 경우, 우측 상단 참조 샘플에 적용되는 가중치가 좌측 하단 참조 샘플에 적용되는 가중치보다 큰 값을 가질 수 있다. 반면, 현재 블록의 높이가 너비보다 큰 경우, 좌측 하단 참조 샘플에 적용되는 가중치가 우측 상단 참조 샘플에 적용되는 가중치보다 큰 값을 가질 수 있다.
이후, 우측 하단 참조 샘플과 우측 상단 참조 샘플을 보간(interpolation)하여, 우측 참조 샘플을 유도할 수 있다. 또한, 우측 하단 참조 샘플과 좌측 하단 참조 샘플을 보간하여, 하단 참조 샘플을 유도할 수 있다. 이때, 보간 필터의 계수는, 현재 블록의 크기, 현재 블록의 형태, 우측 참조 샘플로부터 우측 하단 참조 샘플 까지의 거리, 우측 참조 샘플로부터 우측 상단 참조 샘플 까지의 거리, 하단 참조 샘플로부터 우측 하단 참조 샘플 까지의 거리 또는 하단 참조 샘플로부터 좌측 하단 참조 샘플 까지의 거리 중 적어도 하나에 기초하여 결정될 수 있다.
고정된 위치의 참조 샘플 또는 예측 대상 샘플에 종속적으로 결정되는 위치의 참조 샘플을 이용하여, 우측 참조 샘플 또는 하단 참조 샘플을 유도할 수 있다. 예컨대, 우측 참조 샘플은, 예측 대상 샘플의 위치와 무관하게 고정된 위치의 상단 참조 샘플(예컨대, 우측 상단 참조 샘플) 또는 고정된 위치의 좌측 참조 샘플(예컨대, 좌측 하단 참조 샘플) 중 적어도 하나를 이용하여 유도될 수 있다. 또는, 우측 참조 샘플은, 예측 대상 샘플에 따라 선택되는 좌측 참조 샘플(예컨대, 예측 대상 샘플과 동일한 y 축 좌표를 갖는 좌측 참조 샘플) 또는 상단 참조 샘플(예컨대, 예측 대상 샘플과 동일한 x 축 좌표를 갖는 상단 참조 샘플) 중 적어도 하나를 이용하여 유도될 수 있다. 하단 참조 샘플은 예측 대상 샘플의 위치와 무관하게 고정된 위치의 좌측 참조 샘플(예컨대, 좌측 하단 참조 샘플) 또는 고정된 위치의 상단 참조 샘플(예컨대, 우측 상단 참조 샘플) 중 적어도 하나를 이용하여 유도될 수 있다. 또는, 하단 참조 샘플은, 예측 대상 샘플에 따라 선택되는 좌측 참조 샘플(예컨대, 예측 대상 샘플과 동일한 y 축 좌표를 갖는 참조 샘플) 또는 상단 참조 샘플(예컨대, 예측 대상 샘플과 동일한 x 축 좌표를 갖는 참조 샘플) 중 적어도 하나를 이용하여 유도될 수 있다.
도 15는 복수 참조 샘플을 이용하여, 우측 참조 샘플 또는 하단 참조 샘플을 유도하는 예를 나타낸 도면이다. 현재 블록은 WxH의 크기를 갖는 블록이라 가정한다.
도 15의 (a)를 참조하면, 먼저, 현재 블록의 우측 상단 참조 샘플 P(W, -1) 및 좌측 하단 참조 샘플 P(-1, H)의 가중합 연산 또는 평균 연산에 기초하여, 우측 하단 참조 샘플 P(W, H)을 생성할 수 있다. 이때, 우측 상단 참조 샘플 및 좌측 하단 참조 샘플 각각에 적용되는 가중치는 동일한 값을 가질 수 있다. 또는, 우측 상단 참조 샘플 및 좌측 하단 참조 샘플 각각에 적용되는 가중치는 현재 블록의 너비(W) 및 높이(H)에 기초하여 결정될 수 있다. 일 예로, 우측 상단 참조 샘플에 적용되는 가중치는 W/(W+H)로 결정되고, 좌측 하단 참조 샘플에 적용되는 가중치는 H/(W+H)로 결정될 수 있다. 이에 따라, 현재 블록이 정방형인 경우, 우측 상단 참조 샘플 및 좌측 하단 참조 샘플 각각에 동일한 가중치를 적용하여 우측 하단 참조 샘플이 유도될 수 있다. 반면, 현재 블록이 비정방형인 경우, 우측 상단 참조 샘플 및 좌측 하단 참조 샘플 각각에 상이한 가중치를 적용하여 우측 하단 참조 샘플이 유도될 수 있다.
우측 하단 참조 샘플 P(W, H) 및 우측 상단 참조 샘플 P(W, -1)을 기초로, 예측 대상 샘플 (x, y)에 대한 우측 참조 샘플 P(W, y)를 생성할 수 있다. 일 예로, 우측 예측 샘플 P(W, y)은 우측 하단 참조 샘플 P(W, H) 및 우측 상단 참조 샘플 P(W, -1)의 가중합 연산 또는 평균 연산에 기초하여 획득될 수 있다. 또한, 우측 하단 참조 샘플 P(W, H) 및 좌측 하단 참조 샘플 P(-1, H)를 기초로 예측 대상 샘플 (x, y)에 대한 하단 참조 샘플 P(x, H)를 생성할 수 있다. 일 예로, 하단 참조 샘플 P(x, H)는 우측 하단 참조 샘플 P(W, H) 및 좌측 하단 참조 샘플 P(-1, H)의 가중합 연산 또는 평균 연산에 기초하여 획득될 수 있다.
도 15의 (b)에 도시된 바와 같이, 우측 참조 샘플 및 하단 참조 샘플을 이용하여, 예측 대상 샘플에 대한 제1 예측 샘플 Ph(x, y) 및 제2 예측 샘플 Pv(x, y)를 생성할 수 있다. 이때, 제1 예측 샘플 Ph(x, y)는 좌측 참조 샘플 P(-1, y) 및 우측 참조 샘플 P(W, y)의 가중합 연산을 기초로 생성되고, 제2 예측 샘플 Pv(x, y)는 상단 참조 샘플 P(x, -1) 및 하단 참조 샘플 P(x, H)의 가중합 연산을 기초로 생성될 수 있다.
도 16 및 도 17은 본 발명의 일 실시예에 따른, 비정방형 블록에 대해 우측 참조 샘플 및 하단 참조 샘플을 유도하는 예를 설명하기 위한 도면이다.
도 16에 도시된 예에서와 같이, 현재 블록이 (N/2)xN 크기의 비정방형 블록인 경우, 우측 참조 샘플과 동일한 수직선상에 놓인 상단 참조 샘플(예컨대, 우측 상단 참조 샘플 P(N/2, -1))을 기초로, 우측 참조 샘플을 유도하고, 하단 참조 샘플과 동일한 수평선상에 놓인 좌측 참조 샘플(예컨대, 좌측 하단 참조 샘플 P(-1, N))을 기초로 하단 참조 샘플을 유도할 수 있다.
또는, 우측 상단 참조 샘플 P(N/2, -1) 및 좌측 하단 참조 샘플 P(-1, N)의 가중합 연산, 평균 연산, 최소값 연산 또는 최대값 연산 중 적어도 하나에 기초하여, 우측 참조 샘플 또는 하단 참조 샘플을 유도할 수 있다. 예컨대, 우측 상단 참조 샘플 P(N/2, -1) 및 좌측 하단 참조 샘플 P(-1, N)의 가중합 연산 또는 평균 연산을 기초로 우측 참조 샘플을 유도할 수 있다. 또는, 우측 상단 참조 샘플 P(N/2, -1) 및 좌측 하단 참조 샘플 P(-1, N)의 가중합 연산 또는 평균 연산을 기초로 우측 하단 참조 샘플 P(N/2, N)을 유도하고, 우측 하단 참조 샘플 P(N/2, N)과 우측 상단 참조 샘플 P(N/2, -1)을 보간하여 우측 참조 샘플을 유도할 수 있다.
우측 상단 참조 샘플 P(N/2, -1) 및 좌측 하단 참조 샘플 P(-1, N)의 가중합 연산 또는 평균 연산을 기초로 하단 참조 샘플을 유도할 수 있다. 또는, 우측 상단 참조 샘플 P(N/2, -1) 및 좌측 하단 참조 샘플 P(-1, N)의 가중합 연산 또는 평균 연산을 기초로 우측 하단 참조 샘플 P(N/2, N)을 유도하고, 우측 하단 참조 샘플 P(N/2, N)과 좌측 하단 참조 샘플 P(-1, N)을 보간하여 하단 참조 샘플을 유도할 수 있다.
도 17에 도시된 예에서와 같이, 현재 블록이 Nx(N/2) 크기의 비정방형 블록인 경우, 우측 참조 샘플과 동일한 수직선상에 놓인 상단 참조 샘플 (예컨대, 우측 상단 참조 샘플 P(N, -1))을 기초로, 우측 참조 샘플을 유도하고, 하단 참조 샘플과 동일한 수평선상에 놓인 좌측 참조 샘플(예컨대, 좌측 하단 참조 샘플 P(-1, N/2))를 기초로, 하단 참조 샘플을 유도할 수 있다.
또는, 좌측 상단 참조 샘플 P(N, -1) 및 좌측 하단 참조 샘플 P(-1, N/2)의 가중합 연산, 평균 연산, 최소값 연산 또는 최대값 연산 중 적어도 하나에 기초하여, 우측 참조 샘플 또는 하단 참조 샘플을 유도할 수 있다. 예컨대, 우측 상단 참조 샘플 P(N, -1) 및 좌측 하단 참조 샘플 P(-1, N/2)의 가중합 연산 또는 평균 연산을 기초로 우측 참조 샘플을 유도할 수 있다. 또는, 우측 상단 참조 샘플 P(N, -1) 및 좌측 하단 참조 샘플 P(-1, N/2)의 가중합 연산 또는 평균 연산을 기초로 우측 하단 참조 샘플 P(N, N/2)을 유도하고, 우측 하단 참조 샘플 P(N, N/2)과 우측 상단 참조 샘플 P(N, -1)을 보간하여 우측 참조 샘플을 유도할 수 있다.
우측 상단 참조 샘플 P(N, -1) 및 좌측 하단 참조 샘플 P(-1, N/2)의 가중합 연산 또는 평균 연산을 기초로 하단 참조 샘플을 유도할 수 있다. 또는, 우측 상단 참조 샘플 P(N, -1) 및 좌측 하단 참조 샘플 P(-1, N/2)을 기초로 우측 하단 참조 샘플 P(N, N/2)을 유도하고, 우측 하단 참조 샘플 P(N, -1)과 좌측 하단 참조 샘플 P(-1, N/2)을 보간하여 하단 참조 샘플을 유도할 수 있다.
도 15 내지 도 17을 통해 설명한 바에 따르면, 하단 참조 샘플 및 우측 참조 샘플은, 하단 참조 샘플과 동일한 수평선상에 놓인 좌측 참조 샘플 또는 우측 참조 샘플과 동일한 수직선상에 놓인 현재 블록의 상단 참조 샘플 중 적어도 하나를 기초로 유도될 수 있다. 설명한 바와 달리, 상측 중단 참조 샘플 또는 좌측 중단 참조 샘플 중 적어도 하나를 이용하여, 우측 참조 샘플 또는 하단 참조 샘플을 유도할 수도 있다.
일 예로, 상측 중단 참조 샘플을 이용하여, 하측 중단 참조 샘플을 유도할 수 있다. 하측 중단 참조 샘플 및 좌측 하단 참조 샘플 사이의 하단 참조 샘플은 하측 중단 참조 샘플 및 좌측 하단 참조 샘플의 보간을 통해 유도될 수 있다. 하측 중단 참조 샘플 및 우측 하단 참조 샘플 사이의 하단 참조 샘플은 하측 중단 참조 샘플 및 우측 하단 참조 샘플 사이의 보간을 통해 유도될 수 있다. 또는, 하측 중단 참조 샘플 및 우측 하단 참조 샘플 사이의 하단 참조 샘플은 좌측 하단 참조 샘플과 하측 중단 참조 샘플 사이의 외삽(extrapolation)을 통해 유도될 수 있다.
일 예로, 좌측 중단 참조 샘플을 이용하여, 우측 중단 참조 샘플을 유도할 수 있다. 우측 중단 참조 샘플 및 좌측 상단 참조 샘플 사이의 우측 참조 샘플은 우측 중단 참조 샘플 및 우측 상단 참조 샘플의 보간을 통해 유도될 수 있다. 우측 중단 참조 샘플 및 우측 하단 참조 샘플 사이의 우측 참조 샘플은 우측 중단 참조 샘플 및 우측 하단 참조 샘플 사이의 보간을 통해 유도될 수 있다. 또는, 우측 중단 참조 샘플 및 우측 하단 참조 샘플 사이의 우측 참조 샘플은 우측 상단 참조 샘플과 우측 중단 참조 샘플 사이의 외삽을 통해 유도될 수 있다.
우측 중단 참조 샘플 또는 하측 중단 참조 샘플을 이용하여 우측 참조 샘플 또는 하단 참조 샘플을 유도할 것인지 여부는 현재 블록의 크기 또는 형태 중 적어도 하나에 기초하여 결정될 수 있다. 일 예로, 현재 블록의 너비가 기 정의된 값보다 큰 경우 또는 현재 블록이 너비가 높이보다 큰 비정방형 블록인 경우, 하측 중단 참조 샘플을 이용하여 하단 참조 샘플을 유도할 수 있다. 현재 블록의 높이가 기 정의된 값보다 큰 경우 또는 현재 블록이 높이가 너비보다 큰 비정방형 블록인 경우, 우측 중단 중단 참조 샘플을 이용하여 우측 참조 샘플을 유도할 수 있다.
일 예로, 현재 블록이 NxN 크기의 정방형 블록인 경우, 우측 상단 참조 샘플 P(N, -1)을 기초로 우측 참조 샘플을 유도하고, 좌측 하단 참조 샘플 P(-1, N)을 기초로 하단 참조 샘플을 유도할 수 있다. 또는, 현재 블록이 NxN 크기의 정방형 블록인 경우, 우측 상단 참조 샘플 P(N, -1) 및 좌측 하단 참조 샘플 P(-1, N)의 가중합 연산, 평균 연산, 최소값 연산 또는 최대값 연산 중 적어도 하나를 기초로 우측 하단 참조 샘플을 유도하고, 우측 하단 참조 샘플을 이용하여 우측 참조 샘플 및 하단 참조 샘플을 유도할 수도 있다.
반면, 현재 블록이 Nx2/N 크기의 비정방형 블록인 경우, 상측 중단 참조 샘플 P(N/2, -1) 및 좌측 하단 참조 샘플 P(-1, N/2)를 기초로, 하측 중단 참조 샘플 P(N/2, N/2)를 유도할 수 있다. 하단 참조 샘플은, 하측 중단 참조 샘플과 좌측 하단 참조 샘플 사이의 보간/외삽 또는 하측 중단 참조 샘플과 우측 하단 참조 샘플 사이의 보간/외삽에 기초하여 유도될 수 있다. 또는, 현재 블록이 N/2xN 크기의 비정방형 블록인 경우, 우측 상단 참조 샘플 P(N/2, -1) 및 좌측 중단 참조 샘플 P(-1, N/2)를 기초로, 우측 중단 참조 샘플 P(N/2, N/2)를 유도할 수 있다. 우측 참조 샘플은 우측 중단 참조 샘플과 우측 상단 참조 샘플 사이의 보간/외삽 또는 우측 중단 참조 샘플과 우측 하단 참조 샘플 사이의 보간/외삽에 기초하여 유도될 수 있다.
제1 예측 영상은 예측 대상 샘플과 동일한 수평선상에 놓인 참조 샘플들의 가중 예측을 기초로 획득될 수 있다. 또한, 제2 예측 영상은 예측 대상 샘플과 동일한 수직선상에 놓인 참조 샘플들의 가중 예측을 기초로 획득될 수 있다.
또는, 참조 샘플들 사이의 평균 연산, 최소값 연산 또는 최대값 연산 중 적어도 하나에 기초하여 제1 예측 영상 또는 제2 예측 영상을 생성할 수 있다.
참조 샘플의 유도 방법, 또는 제1/제2 예측 영상의 획득 방법은 부호화기/복호화기에서 기 정의되어 있을 수 있다. 또는, 예측 대상 샘플이 현재 블록 내 소정 영역에 포함되어 있는지 여부, 현재 블록의 크기 또는 형태 등에 따라 참조 샘플의 유도 방법, 또는 제1/제2 예측 영상의 획득 방법이 상이하게 설정될 수도 있다. 일 예로, 예측 대상 샘플의 위치에 따라, 우측 또는 하단 참조 샘플을 이용하는데 이용되는 참조 샘플의 개수 또는 참조 샘플의 위치가 상이하게 결정될 수 있다. 또는 예측 대상 샘플의 위치에 따라, 제1 예측 영상 또는 제2 예측 영상을 유도하는데 이용되는 참조 샘플의 수 또는 각 참조 샘플에 부여되는 가중치 등이 상이하게 설정될 수 있다.
일 예로, 소정 영역에 포함된 예측 대상 샘플들에 대한 제1 예측 영상은 상단 참조 샘플(예컨대, 우측 상단 참조 샘플)만을 이용하여 유도된 우측 참조 샘플을 이용하여 획득될 수 있다. 반면, 소정 영역 바깥에 포함된 예측 대상 샘플들에 제1 예측 영상은 상단 참조 샘플 및 좌측 참조 샘플의 가중합 연산 또는 평균 연산을 기초로 유도된 우측 참조 샘플을 이용하여 획득될 수 있다.
소정 영역에 포함된 예측 대상 샘플들에 대한 제2 예측 영상은 좌측 참조 샘플(예컨대, 좌측 하단 참조 샘플)만을 이용하여 유도된 우측 참조 샘플을 이용하여 획득될 수 있다. 반면, 소정 영역 바깥에 포함된 예측 대상 샘플들에 제2 예측 영상은 우측 하단 참조 샘플 및 상단 참조 샘플을 보간하여 유도된 우측 참조 샘플을 이용하여 획득될 수 있다. 여기서, 상기 우측 하단 참조 샘플은 상단 참조 샘플(예컨대, 우측 상단 참조 샘플) 및 좌측 참조 샘플(예컨대, 좌측 하단 참조 샘플)의 가중합 연산 또는 평균 연산에 기초하여 유도될 수 있다.
일 예로, 도 16에 도시된 예에서, 현재 블록이 높이가 너비보다 긴 비정방형 블록인 경우, 현재 블록 내 소정 영역에 포함된 (x, y) 위치의 예측 대상 샘플의 제1 예측 영상은 P(N/2, -1)로부터 유도된 우측 참조 샘플을 기초로 획득될 수 있다. 상기 우측 참조 샘플은 P(N/2, -1) 참조 샘플의 값을 복사하여 생성될 수 있다. 반면, 현재 블록 내 소정 영역 바깥에 포함된 (x', y')위치의 예측 대상 샘플의 제1 예측 영상은 P(N/2, -1) 및 P(-1, N)의 가중합 연산 또는 평균 연산을 기초로 유도된 우측 참조 샘플을 기초로 획득될 수 있다. 상기 우측 참조 샘플은 P(N/2, -1) 및 P(-1, N)을 기초로 유도되는 우측 하단 참조 샘플 P(N/2, N) 및 우측 상단 참조 샘플 P(N/2, -1)을 보간함으로써 획득될 수 있다.
또는, 도 17에 도시된 예에서와 같이, 현재 블록이 너비가 높이보다 긴 비정방형 블록인 경우, 현재 블록 내 소정 영역에 포함된 (x, y) 위치의 예측 대상 샘플의 제2 예측 영상은 P(-1, N/2)로부터 유도되는 하단 참조 샘플을 기초로 획득될 수 있다. 상기 하단 참조 샘플은 P(-1, N/2) 참조 샘플의 값을 복사하여 생성될 수 있다. 반면, 현재 블록 내 소정 영역 바깥에 포함된 (x', y')위치의 예측 대상 샘플의 제2 예측 영상은 P(N, -1) 및 P(-1, N/2)의 가중합 연산 또는 평균 연산에 기초하여 유도된 하단 참조 샘플을 기초로 획득될 수 있다. 상기 하단 참조 샘플은 P(N, -1) 및 P(-1, N/2)를 기초로 유도되는 우측 하단 참조 샘플 P(N, N/2) 및 좌측 하단 참조 샘플 P(-1, N/2)을 보간함으로써 획득될 수 있다.
소정 영역에 포함된 예측 대상 샘플들의 제1 예측 영상 및/또는 제2 예측 영상은, 참조 샘플들의 가중합 연산에 기초하여 생성되고, 소정 영역 바깥의 예측 대상 샘플들의 제1 예측 영상 및/또는 제2 예측 영상은, 참조 샘플들의 평균 연산, 최소값 연산 또는 최대값 연산에 기초하여 생성될 수 있다. 또는, 참조 샘플들 중 기 정의된 위치의 어느 하나만을 이용하여 소정 영역 바깥의 예측 대상 샘플들의 제1 예측 영상 및/또는 제2 예측 영상을 획득할 수도 있다. 일 예로, 도 16에 도시된 예에서, 현재 블록이 높이가 너비보다 긴 비정방형 블록인 경우, 현재 블록 내 소정 영역에 포함된 (x, y) 위치의 예측 대상 샘플의 제1 예측 영상은, P(N/2, -1)로부터 유도된 우측 참조 샘플 P(N/2, y) 및 P(-1, y) 위치의 좌측 참조 샘플의 가중합 연산 또는 평균 연산을 기초로 획득될 수 있다. 반면, 상기 소정 영역에 포함되지 않는 (x', y') 위치의 예측 대상 샘플의 제1 예측 영상은, P(N/2, -1)로부터 유도된 우측 참조 샘플 P(N/2, y') 또는 P(-1, y')위치의 좌측 참조 샘플을 기초로 획득될 수 있다.
또는, 도 17에 도시된 예에서, 현재 블록이 너비가 높이보다 긴 비정방형 블록인 경우, 현재 블록 내 소정 영역에 포함된 (x, y) 위치의 예측 대상 샘플의 제2 예측 영상은, P(-1, N/2)로부터 유도된 하단 참조 샘플 P(x, N/2) 및 P(x, -1) 위치의 상단 참조 샘플의 가중합 연산 또는 평균 연산을 기초로 획득될 수 있다. 반면, 상기 소정 영역에 포함되지 않는 (x', y') 위치의 예측 대상 샘플은, P(-1, N/2)로부터 유도된 하단 참조 샘플 P(x', N/2) 또는 P(-1, y')위치의 상단 참조 샘플을 기초로 획득될 수 있다.
소정 영역은, 현재 블록의 경계에 인접하는 하나 이상의 라인(예컨대, 행 또는 열) 또는 상기 하나 이상의 라인을 제외한 잔여 영역일 수 있다. 소정 영역의 정의 기준이 되는 현재 블록의 경계는, 좌측 경계, 우측 경계, 상단 경계 또는 하측 경계 중 적어도 하나일 수 있다. 또한, 소정 영역을 정의하는데 이용되는 경계의 수 또는 위치는, 현재 블록의 형태에 따라 상이하게 설정될 수 있다. 예컨대, 현재 블록이 너비가 높이보다 큰 비정방형인 경우, 좌측 경계 또는 우측 경계를 기준으로 소정 영역이 정의될 수 있다. 반면, 현재 블록이 높이가 너비보다 큰 비정방형인 경우, 상단 경계 또는 우측 경계를 기준으로 소정 영역이 정의될 수 있다.
또는, 현재 블록의 일코너에 접하는 블록을 소정 영역으로 정의할 수도 있다. 이때, 소정 영역의 크기 및 형태는 현재 블록의 크기 또는 형태 중 적어도 하나를 기초로 결정될 수 있다.
플래너 모드 하에서 최종 예측 영상은, 제1 예측 영상 및 제2 예측 영상의 가중합 연산, 평균 연산, 최소값 연산 또는 최대값 연산을 기초로 유도될 수 있다.
일 예로, 하기 수학식 11은, 제1 예측 영상 Ph 및 제2 예측 영상 Pv의 가중합을 기초로, 최종 예측 영상 P를 생성하는 예를 나타낸 것이다.
상기 수학식 11에서, 예측 가중치 w는 현재 블록의 형태, 크기 또는 예측 대상 샘플의 위치 등에 따라 상이할 수 있다. 구체적으로, 예측 가중치 w는 현재 블록의 너비, 현재 블록의 높이 또는 너비-높이비 중 적어도 하나에 기초하여 결정될 수 있다. 일 예로, 현재 블록이 정방형 블록인 경우, 제1 예측 영상 및 제2 예측 영상에 동일한 가중치가 적용되도록 예측 가중치 w가 설정될 수 있다. 즉, 현재 블록이 정방형인 경우, 예측 가중치 w는 1/2의 값을 가질 수 있다.
반면, 현재 블록이 너비가 높이보다 큰 비정방형 블록인 경우, 제2 예측 영상보다 제1 예측 영상에 더 큰 가중치가 부여되도록 예측 가중치 w가 설정될 수 있다. 예를 들어, 현재 블록이 너비가 높이보다 큰 비정방형 블록(예컨대, Nx(N/2))인 경우, 예측 가중치 w는 3/4로 설정될 수 있다. 이에 따라, 제1 예측 영상 Ph에 3/4의 가중치를 적용하고, 제2 예측 영상 Pv에 1/4의 가중치가 적용될 수 있다. 현재 블록이 높이가 너비보다 큰 비정방형 블록인 경우, 제1 예측 영상보다 제2 예측 영상에 더 큰 가중치가 부여되도록 예측 가중치 w가 설정될 수 있다. 예를 들어, 현재 블록이 높이가 너비보다 큰 비정방형 블록(예컨대, (N/2)xN)인 경우, 예측 가중치 w는 1/4로 설정될 수 있다. 이에 따라, 제1 예측 영상 Ph에 1/4의 가중치를 적용하고, 제2 예측 영상 Pv에 3/4의 가중치가 적용될 수 있다.
도 11에서는, 현재 블록의 최상단 행보다 y좌표 값이 작은 상단 참조 샘플들 및 현재 블록의 최좌측 열보다 x좌표 값이 작은 좌측 참조 샘플들로 참조 샘플 라인이 구성되는 것으로 설명하였다.
본 발명의 일 실시예에 따르면, 복수 참조 샘플 라인 중 적어도 하나가 현재 블록 내 기-복원된 샘플 또는 현재 복원 내 예측 샘플을 포함하도록 설정할 수 있다. 일 예로, 제1 참조 샘플 라인은, 좌측 참조 샘플들 및/또는 상단 참조 샘플들을 포함하고, 제2 참조 샘플 라인은, 현재 블록 내 기-복원되거나 예측된 샘플을 포함할 수 있다.
또는, 복수 참조 샘플 라인 중 적어도 하나가 우측 참조 샘플들 및/또는 하단 참조 샘플들을 포함하도록 설정할 수도 있다. 일 예로, 제1 참조 샘플 라인은, 좌측 참조 샘플들 및/또는 상단 참조 샘플들을 포함하고, 제2 참조 샘플 라인은, 현재 블록의 우측 참조 샘플들 및/또는 하단 참조 샘플들을 포함할 수 있다.
도 18은 복수 참조 샘플 라인을 예시한 도면이다.
제1 참조 샘플 라인은, 현재 블록의 최상단 행에 포함된 예측 대상 샘플보다 y축 좌표값이 작은 참조 샘플들 및 현재 블록의 최좌측 열에 포함된 예측 대상 샘플보다 x축 좌표값이 작은 참조 샘플들을 포함할 수 있다. 제1 참조 샘플 라인이 포함하는 참조 샘플을 '제1 참조 샘플'이라 호칭하기로 한다.
제2 참조 샘플 라인은, 현재 블록의 최하단 행에 포함되는 예측 대상 샘플보다 y축 좌표값이 큰 참조 샘플들 및 현재 블록의 최우측 열에 포함된 예측 대상 샘플보다 x축 좌표값이 큰 참조 샘플들을 포함할 수 있다. 제2 참조 샘플 라인이 포함하는 참조 샘플을 '제2 참조 샘플'이라 호칭하기로 한다.
일 예로, P(-1, -1) 부터 P(2W-1, -1) 까지의 상단 참조 샘플들, P(-1, -1)부터 P(-1, 2H-1) 까지의 좌측 참조 샘플들, P(-W, -1) 부터 P(W, H) 까지의 우측 참조 샘플들, P(-1, H)부터 P(W, H)까지의 하단 참조 샘플들 중 제1 참조 샘플 라인은 P(-1, -1) 부터 P(2W-1, -1)까지의 상단 참조 샘플들 및 P(-1, -1) 부터 P(-1, 2H-1) 까지의 좌측 참조 샘플들을 포함할 수 있다. 제2 참조 샘플 라인은 P(W, -1) 부터 P(2W-1, -1) 까지의 상단 참조 샘플들, P(-1, H) 부터 P(-1, 2H-1) 까지의 좌측 참조 샘플들, P(-W, -1)부터 P(W, H) 까지의 우측 참조 샘플들, P(-1, H)부터 P(W, H)까지의 하단 참조 샘플들을 포함할 수 있다.
도 18에 도시된 예에서와 같이, 적어도 하나의 참조 샘플이 복수의 참조 샘플 라인들에 포함되도록 설정하는 것이 가능하다. 도 18에서는, 제1 참조 샘플 라인 및 제2 참조 샘플 라인이 공통으로 현재 블록의 최하단 행에 포함되는 예측 대상 샘플보다 y축 좌표값이 큰 좌측 참조 샘플들 및 현재 블록의 최우측 열에 포함된 예측 대상 샘플보다 x축 좌표값이 큰 상단 참조 샘플들을 포함하는 것으로 예시되었다.
도시된 예와 달리, 제1 참조 샘플 라인 또는 제2 참조 샘플 라인에만 상기 좌측 참조 샘플들 및/또는 상기 상단 참조 샘플들이 포함되도록 설정할 수도 있다. 일 예로, 제1 참조 샘플 라인은 상기 좌측 참조 샘플들을 포함하도록 구성되고, 제2 참조 샘플 라인은 상기 상단 참조 샘플들을 포함하도록 구성될 수 있다.
현재 블록의 크기, 형태 또는 인트라 예측 모드 중 적어도 하나에 기초하여 복수 참조 샘플 라인들의 구성을 결정할 수 있다. 일 예로, 현재 블록이 너비가 높이보다 큰 비정방형 블록인 경우, 제1 참조 샘플 라인이 상기 상단 참조 샘플들을 포함하고, 제2 참조 샘플 라인이 상기 좌측 참조 샘플들을 포함할 수 있다. 반면, 현재 블록이 높이가 너비보다 큰 비정방형 블록인 경우, 제1 참조 샘플이 상기 좌측 참조 샘플들을 포함하고, 제2 참조 샘플 라인이 상기 상단 참조 샘플들을 포함할 수 있다.
도 18에 도시된 예에서와 같이, 적어도 하나의 참조 샘플이 복수의 참조 샘플 라인들에 포함되도록 설정하는 것이 가능하다.
도 18에 도시된 제1 참조 샘플 라인 및 제2 참조 샘플 라인의 구성은 본 발명의 일 예에 불과하다. 도 18에 도시된 것과 다른 방법으로 제1 참조 샘플 라인 및 제2 참조 샘플 라인을 구성할 수도 있다. 예컨대, 도 18에 도시된 예에서는, 현재 블록에 인접하는 행/열에 포함되는 참조 샘플들로 제1 참조 샘플 라인 및 제2 참조 샘플 라인이 구성되는 것으로 도시되었다. 도시된 예와 달리, 제1 참조 샘플 라인은 현재 블록에 인접하는 행/열에 포함되는 참조 샘플들을 포함하고, 제2 참조 샘플 라인은 현재 블록에 인접하지 않는 행/열에 포함되는 참조 샘플들을 포함하도록 설정될 수 있다.
도 18에는 2개의 참조 샘플 라인이 도시되어 있으나, 이보다 더 많은 수의 참조 샘플 라인을 구성할 수도 있다. 일 예로, 3개 또는 그 이상의 참조 샘플 라인들 중 적어도 하나 이상을 이용하여, 현재 블록의 인트라 예측을 수행할 수 있다.
제2 참조 샘플을 이용하여 인트라 예측을 수행할 것인지 여부는, 현재 블록의 크기, 현재 블록의 형태, 현재 블록의 인트라 예측 모드 또는 예측 대상 샘플의 위치 중 적어도 하나를 기초로 결정될 수 있다. 일 예로, 현재 블록의 인트라 예측 모드가 수직 모드, 수평 모드 또는 대각 방향 모드인지 여부에 따라 제2 참조 샘플의 이용 여부가 결정될 수 있다. 예컨대, 현재 블록의 인트라 예측 모드가 기 정의된 모드인 경우, 제1 참조 샘플 및 제2 참조 샘플의 가중합 연산 또는 평균 연산을 기초로 예측 대상 샘플의 예측 영상을 획득할 수 있다. 기 정의된 모드는 수직 모드, 수평 모드, 대각 방향 모드 또는 플래너 모드 중 적어도 하나를 포함할 수 있다. 반면, 현재 블록의 인트라 예측 모드가 기 정의된 모드가 아닌 경우, 제1 참조 샘플을 기초로 예측 대상 샘플의 예측 영상을 획득할 수 있다.
일 예로, 예측 대상 샘플이 현재 블록 내 소정 영역에 포함되었는지 여부를 기준으로, 제2 참조 샘플의 이용 여부를 결정할 수 있다. 현재 블록 내 소정 영역에 포함된 예측 대상 샘플의 예측 영상은 제1 참조 샘플 및 제2 참조 샘플 사이의 가중 연산 또는 평균 연산을 기초로 유도되거나, 제2 참조 샘플을 기초로 유도될 수 있다. 반면, 현재 블록 내 소정 영역에 포함되지 않는 예측 대상 샘플의 예측 영상은 제1 참조 샘플을 기초로 유도될 수 있다.
또는, 제2 참조 샘플의 이용 여부를 나타내는 정보가 비트스트림을 통해 시그널링될 수 있다. 상기 정보는 1비트의 플래그이거나, 현재 블록의 인트라 예측 모드를 결정하는데 이용되는 인덱스 등일 수 있다.
또는, 현재 블록의 주변 블록에서 제2 참조 샘플을 이용하였는지 여부에 기초하여 제2 참조 샘플 이용 여부를 결정할 수도 있다.
적어도 하나의 제2 참조 샘플은 제1 참조 샘플을 기초로 유도될 수 있다. 일 예로, 제1 참조 샘플들의 순서를 변경하여 제2 참조 샘플들을 구성할 수 있다. 또는, 기 정의된 위치의 제1 참조 샘플을 이용하여 적어도 하나의 제2 참조 샘플을 유도할 수 있다.
도 19는 제1 참조 샘플을 이용하여 적어도 하나의 제2 참조 샘플이 유도되는 예를 설명하기 위한 도면이다. 도 19에는 제2 참조 샘플 라인 중 (W, y) 좌표(여기서, y는 -1 부터 H)를 갖는 우측 참조 샘플 및 (x, H) 좌표(여기서, x는 -1부터 W)를 갖는 하단 참조 샘플을 유도하는 방법이 도시되어 있다. 설명의 편의를 위해, 상단/좌측 참조 샘플은 'r'로 표기하고, 우측/하단 참조 샘플은 'P'로 표기하기로 한다.
먼저, 현재 블록의 우측 상단 참조 샘플 r(W, -1) 및 좌측 하단 참조 샘플 r(-1, H)를 기초로 우측 하단 참조 샘플 P(W, H)를 유도할 수 있다. 구체적으로, 우측 하단 참조 샘플은 우측 상단 참조 샘플 및 좌측 하단 참조 샘플의 가중합 연산 또는 평균 연산을 기초로 유도될 수 있다. 하기 수학식 12는 우측 하단 참조 샘플을 유도하는 예를 나타낸 것이다.
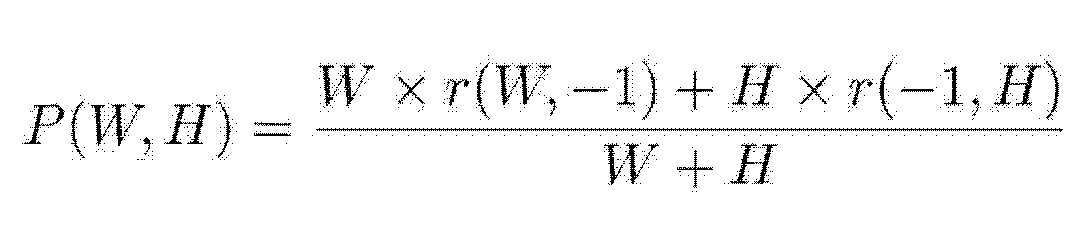
상기 수학식 12에 나타난 바와 같이, 우측 하단 참조 샘플은 우측 상단 참조 샘플 및 좌측 하단 참조 샘플 사이의 가중합을 기초로 계산될 수 있다. 이때, 우측 상단 참조 샘플 및 좌측 하단 참조 샘플에 적용되는 가중치는 현재 블록의 너비 및 높이를 기초로 결정될 수 있다. 수학식 12에 나타난 예에서와 같이, 우측 상단 참조 샘플에는 W/(W+H), 좌측 하단 참조 샘플에는 H/(W+H)의 가중치가 적용될 수 있다. 이에 따라, 현재 블록이 정방형인 경우 우측 상단 참조 샘플 및 좌측 하단 참조 샘플에 적용되는 가중치는 동일한 값을 가질 수 있다. 반면, 현재 블록이 비정방형인 경우 우측 상단 참조 샘플 및 좌측 하단 참조 샘플에 적용되는 가중치는 상이한 값을 가질 수 있다. 단, 수학식 12에 나타난 가중치 설정 방법은 본 발명의 일 예를 나타낸 것일 뿐, 본 발명이 이에 한정되는 것은 아니다. 수학식 12에 나타난 예 이외에도, 현재 블록의 크기, 형태, 인트라 예측 모드, 참조 샘플의 가용성, 주변 블록의 가용성, 주변 블록이 인트라 예측 모드로 부호화되었는지 여부 또는 주변 블록의 인트라 예측 모드 중 적어도 하나에 기초하여 가중치가 결정될 수도 있다.
우측 하단 참조 샘플 P(W, H) 및 우측 상단 참조 샘플 r(W, -1) 사이의 우측 참조 샘플은 우측 하단 참조 샘플 및 우측 상단 참조 샘플을 보간함으로써 획득될 수 있다. 수학식 13은 우측 하단 참조 샘플 및 우측 상단 참조 샘플을 보간하여 우측 참조 샘플이 유도되는 예를 나타낸 것이다.

상기 수학식 13에 나타난 바와 같이, 우측 참조 샘플 Pr(W, y)(이때, y는 0과 CU 높이(cu_height) 사이의 정수)는 우측 상단 참조 샘플 r(W, -1)과 우측 하단 참조 샘플 P(W, H)을 가중 예측하여 획득될 수 있다. 우측 상단 참조 샘플 및 우측 하단 참조 샘플에 적용되는 가중치는 현재 블록의 너비, 높이 또는 우측 참조 샘플의 위치 중 적어도 하나에 기초하여 결정될 수 있다. 수학식 13에 나타난 예에서와 같이, 우측 상단 참조 샘플에는 (H-1-y)/H, 우측 하단 참조 샘플에는 (y+1)/H의 가중치가 적용될 수 있다. 단, 수학식 13에 나타난 가중치 설정 방법은 본 발명의 일 예를 나타낸 것일 뿐, 본 발명이 이에 한정되는 것은 아니다. 수학식 13에 나타난 예 이외에도, 현재 블록의 크기, 형태, 인트라 예측 모드, 참조 샘플의 가용성, 주변 블록의 가용성, 주변 블록이 인트라 예측 모드로 부호화되었는지 여부 또는 주변 블록의 인트라 예측 모드 중 적어도 하나에 기초하여 가중치가 결정될 수도 있다.
우측 하단 참조 샘플 P(W, H) 및 좌측 하단 참조 샘플 r(-1, H) 사이의 하단 참조 샘플은 좌측 우측 하단 참조 샘플 및 좌측 하단 참조 샘플을 보간함으로써 획득될 수 있다. 수학식 14는 우측 하단 참조 샘플 및 좌측 하단 참조 샘플을 보간하여 하단 참조 샘플이 유도되는 예를 나타낸 것이다.

상기 수학식 14에 나타난 바와 같이, 하단 참조 샘플 Pb(x, H)(이때, x는 0과 CU 너비(cu_width) 사이의 정수)는 좌측 하단 참조 샘플 r(-1, H)와 우측 하단 참조 샘플 P(W, H)을 가중 예측하여 획득될 수 있다. 좌측 하단 참조 샘플 및 우측 하단 참조 샘플에 적용되는 가중치는 현재 블록의 너비, 높이 또는 하단 참조 샘플의 위치 중 적어도 하나에 기초하여 결정될 수 있다. 수학식 14에 나타난 예에서와 같이, 좌측 하단 참조 샘플에는 (W-1-x)/W, 우측 하단 참조 샘플에는 (x+1)/W의 가중치가 적용될 수 있다. 단, 수학식 14에 나타난 가중치 설정 방법은 본 발명의 일 예를 나타낸 것일 뿐, 본 발명이 이에 한정되는 것은 아니다. 수학식 14에 나타난 예 이외에도, 현재 블록의 크기, 형태, 인트라 예측 모드, 참조 샘플의 가용성, 주변 블록의 가용성, 주변 블록이 인트라 예측 모드로 부호화되었는지 여부 또는 주변 블록의 인트라 예측 모드 중 적어도 하나에 기초하여 가중치가 결정될 수도 있다.
도 19에 도시된 예 뿐만 아니라, 앞서 도 16 및 도 17을 통해 설명한 실시예를 적용하여 우측 참조 샘플 및 하단 참조 샘플을 유도할 수도 있다.
또는, 현재 블록의 우측, 하단 또는 우하단 중 적어도 하나에 인접한 블록의 기-복원되거나 예측된 샘플을 기초로 적어도 하나의 제2 참조 샘플을 유도할 수도 있다.
또는, 부호화기 및 복호화기에서 기-정의된 디폴트 값(Default value)으로 적어도 하나의 제2 참조 샘플을 설정할 수 있다. 일 예로, 우측 하단 참조 샘플 P(W, H), 우측 중단 샘플 P(W, H/2) 또는 하측 중단 샘플 P(W/2, H) 중 적어도 하나가 디폴트 값으로 설정될 수 있다. 상술한 예에서와 같이, 우측 상단 참조 샘플 및 좌측 하단 참조 샘플 등 고정된 위치의 제1 참조 샘플들을 이용하여 우측 참조 샘플 및 하단 참조 샘플 등 제2 참조 샘플을 유도할 수 있다. 상술한 예와 달리, 우측 상단 참조 샘플 및/또는 좌측 하단 참조 샘플 이외의 제1 참조 샘플을 이용하여 제2 참조 샘플을 유도할 수도 있다. 일 예로, 현재 블록의 상단 중단 참조 샘플 또는 현재 블록의 좌측 중단 샘플 등 제1 참조 샘플을 이용하여 우측 참조 샘플 및 하단 참조 샘플을 유도할 수 있다.
또는, 현재 블록의 인트라 예측 모드에 따라, 제2 참조 샘플을 유도하는데 이용되는 제1 참조 샘플을 결정할 수도 있다. 일 예로, 우측 참조 샘플 및/또는 하단 참조 샘플은 현재 블록의 인트라 예측 모드 방향성에 의해 특정되는 좌측 참조 샘플 및/또는 상단 참조 샘플을 기초로 유도될 수 있다.
또는, 복수의 좌측 참조 샘플 및/또는 복수의 상단 참조 샘플을 이용하여 제2 참조 샘플을 결정할 수도 있다. 일 예로, 우측 참조 샘플, 하단 참조 샘플 또는 우측 하단 참조 샘플 중 적어도 하나는 복수의 좌측 참조 샘플의 가중합, 평균값, 최대값 또는 최소값을 기초로 생성되거나, 복수의 상단 참조 샘플의 가중합, 평균값, 최대값 또는 최소값을 기초로 생성될 수 있다.
또는, 제1 참조 샘플을 복사하여 제2 참조 샘플을 생성할 수 있다. 복사되는 제1 참조 샘플의 위치는 부호화기/복호화기에서 고정된 값을 가질 수 있다. 또는, 복사되는 제1 참조 샘플의 위치는 현재 블록의 크기, 형태, 인트라 예측 모드 또는 제2 참조 샘플의 위치에 따라 적응적으로 결정될 수 있다.
상술한 예에서는, 하단 참조 샘플이 W개이고, 우측 참조 샘플이 H개인 것으로 예시하였으나, 이보다 더 많은 수의 하단 참조 샘플 및/또는 우측 참조 샘플을 유도할 수도 있다. 일 예로, 상단 참조 샘플들의 수와 하단 참조 샘플들의 수가 동일하도록 하단 참조 샘플 라인 구성할 수 있다. 예컨대, 하단 참조 샘플 라인은 P(-1, H), P(2W-1, H) 및 이들 사이의 참조 샘플들을 포함할 수 있다. 좌측 참조 샘플들의 수와 우측 참조 샘플들의 수가 동일하도록 우측 참조 샘플 라인을 구성할 수 있다. 예컨대, 우측 참조 샘플 라인은 P(W, -1), p(W, 2H-1) 및 이들 사이의 참조 샘플들을 포함할 수 있다.
우측 하단 참조 샘플 P(W, H)보다 x 좌표의 값이 큰 갖는 하단 참조 샘플은 좌측 하단 참조 샘플 r(-1, H)과 우측 하단 참조 샘플 P(W, H)를 외삽하거나, 우측 하단 참조 샘플 P(W, H)와 최우측 하단 참조 샘플 P(2W-1, H)를 보간함으로써 생성될 수 있다. 최우측 하단 참조 샘플은 최우측 상단 참조 샘플 r(2W-1, -1)를 복사함으로써 생성되거나, 최우측 상단 참조 샘플과 우측 하단 참조 샘플 사이 또는 최우측 상단 참조 샘플과 좌측 하단 참조 샘플 사이의 가중합 연산 또는 평균 연산에 기초하여 생성될 수 있다. H보다 큰 y 좌표를 갖는 우측 참조 샘플은 우측 상단 참조 샘플과 우측 하단 참조 샘플을 외삽하여 생성되거나, 우측 하단 참조 샘플 P(W, H)와 최하단 우측 참조 샘플 P(W, 2H-1)를 보간하여 생성될 수 있다. 이때, 최하단 우측 참조 샘플은 최하단 좌측 참조 샘플 r(-1, 2H-1)를 복사하여 생성되거나, 최하단 좌측 참조 샘플과 좌측 상단 참조 샘플 사이의 가중합 연산을 통해 생성될 수 있다.
제1 참조 샘플 라인 및/또는 제2 참조 샘플 라인을 일차원으로 배열할 수 있다.
현재 블록의 인트라 예측은, 복수 참조 샘플 라인들 중 적어도 하나를 이용하여 수행될 수 있다.
구체적으로, 복수 참조 샘플 라인들 중 적어도 하나를 선택하고, 선택된 참조 샘플 라인에 포함된 참조 샘플을 이용하여, 예측 대상 샘플의 예측값을 산출할 수 있다.
상기 선택은 비트스트림을 통해 시그날링되는 정보에 기초할 수 있다. 상기 정보는, 복수의 참조 샘플 라인들 중 적어도 하나를 특정하는 인덱스 정보일 수 있다.
또는, 상기 선택은, 현재 블록의 크기, 형태, 위치 또는 인트라 예측 모드에 기초하여, 복수의 참조 샘플 라인 중 적어도 하나에 기초할 수 있다. 일 예로, 현재 블록의 너비, 높이, 크기 중 적어도 하나가 기 정의된 값보다 작은 경우, 제1 참조 샘플 라인이 선택될 수 있다. 일 예로, 현재 블록이 CTU 또는 타일의 상단 경계와 접하는 경우, 제1 참조 샘플 라인이 선택될 수 있다. 일 예로, 기 정의된 인트라 예측 모드가 현재 블록의 인트라 예측 모드로 선택된 경우, 제1 참조 샘플 라인 또는 제2 참조 샘플 라인이 선택될 수 있다.
또는, 복수의 참조 샘플 라인을 선택하여 현재 블록의 인트라 예측을 수행할 수 있다.
예측 대상 샘플의 위치 및/또는 인트라 예측 모드에 기초하여, 예측 대상 샘플의 예측값을 산출하는데 이용될 참조 샘플이 결정될 수 있다. 즉, 예측 대상 샘플의 위치 및/또는 인트라 예측 모드에 기초하여, 상기 예측값을 산출하기 위한 제1 참조 샘플 및 제2 참조 샘플을 결정할 수 있다.
현재 블록 내 예측 대상 샘플의 예측값은 제1 참조 샘플 라인에 포함된 제1 참조 샘플 또는 제2 참조 샘플 라인에 포함된 제2 참조 샘플 중 적어도 하나에 기초하여 획득될 수 있다. 상기 제1 참조 샘플의 위치 및/또는 상기 제2 참조 샘플의 위치는 현재 블록의 형태, 크기, 예측 대상 샘플의 위치 또는 인트라 예측 모드 중 적어도 하나에 기초하여 결정될 수 있다. 일 예로, 현재 블록의 인트라 예측 모드의 정방향을 따라, 예측 대상 샘플에 대한 제1 참조 샘플을 결정할 수 있다. 그리고, 현재 블록의 인트라 예측 모드의 역방향을 따라, 예측 대상 샘플에 대한 제2 참조 샘플을 결정할 수 있다.
또는, 상기 제1 참조 샘플의 위치에 기초하여 상기 제2 참조 샘플의 위치를 결정하거나, 상기 제2 참조 샘플의 위치에 기초하여 상기 제1 참조 샘플의 위치를 결정할 수 있다. 일 예로, 제1 기초 참조 샘플과 동일한 x 좌표 또는 동일한 y 좌표를 갖는 참조 샘플들 중 적어도 하나를 제2 기초 참조 샘플로 결정할 수 있다. 또는, 제1 기초 참조 샘플의 x 좌표 및/또는 y 좌표에 오프셋을 더하여, 제2 기초 참조 샘플을 결정할 수 있다. 여기서, 오프셋은 부호화기/복호화기에서 고정된 값을 가질 수 있다. 또는, 오프셋은 현재 블록의 크기, 형태 또는 인트라 예측 모드에 따라 적응적으로 결정될 수 있다.
또는, 예측 대상 샘플의 위치에 기초하여 예측값을 산출하기 위한 제1 기초 참조 샘플 및/또는 제2 기초 참조 샘플의 위치를 결정할 수 있다. 일 예로, 예측 대상 샘플과 동일한 x 좌표 또는 동일한 y 좌표를 갖는 참조 샘플을 예측값을 산출하기 위한 제1 참조 샘플 및/또는 제2 기초 참조 샘플로 결정할 수 있다. 또는, 예측 대상 샘플의 x 좌표 또는 y 좌표에 오프셋을 가산 또는 감산한 것에 대응되는 위치의 참조 샘플(즉, 예측 대상 샘플의 x좌표에 오프셋을 더한 결과값을 x좌표로 갖는 참조 샘플 또는 예측 대상 샘플의 y좌표에 오프셋을 더한 결과값을 y좌표로 갖는 참조 샘플)을 제1 참조 샘플 및/또는 제2 참조 샘플로 결정할 수 있다. 여기서, 오프셋은 부호화기/복호화기에서 고정된 값을 가질 수 있다. 또는, 오프셋은 현재 블록의 크기, 형태 또는 인트라 예측 모드에 따라 적응적으로 결정될 수 있다.
예측 대상 샘플의 예측값은 제1 참조 샘플을 기초로 획득되는 제1 예측 영상 또는 제2 참조 샘플을 기초로 획득되는 제2 예측 영상 중 적어도 하나를 이용하여 획득될 수 있다. 이때, 제1 예측 영상은 수학식 8 내지 수학식 10을 통해 설명한 실시예에 기초하여 생성될 수 있다.
제2 예측 영상은 현재 블록의 인트라 예측 모드의 기울기에 따라 특정되는 제2 참조 샘플을 보간 또는 복사하여 생성될 수 있다. 일 예로, 수학식 15는 제2 참조 샘플을 복사하여 제2 예측 영상을 유도하는 예를 나타낸 도면이다.
상기 수학식 15에서 P2(x, y)는 제2 예측 영상을 나타내고, P_2nd_1D(x+iIdx+1+f)는 제2 참조 샘플을 나타낸다.
하나의 제2 참조 샘플만으로는 현재 블록의 인트라 예측 모드의 기울기를 표현할 수 없을 때에는, 복수의 제2 참조 샘플들을 보간하여 제2 예측 영상을 생성할 수 있다. 구체적으로, 예측 대상 샘플로부터 확장되는 가장의 각도 선이 정수 펠(integer pel) 위치(즉, 정수 위치의 참조 샘플)를 지나지 않는 경우, 복수 참조 샘플들을 이용하여 제2 예측 영상을 획득할 수 있다. 예측 대상 샘플에 대한 제2 예측 영상은 상기 가상의 각도 선이 지나는 위치에 인접하는 참조 샘플 및 상기 참조 샘플에 인접하는 적어도 하나의 이웃 참조 샘플을 보간하여 획득될 수 있다. 여기서, 이웃 샘플은, 상기 참조 샘플의 상단, 하단, 좌측 또는 우측에 인접하는 것일 수 있다. 수학식 16은 제2 참조 샘플들을 보간하여 제2 예측 영상을 획득하는 예를 나타낸 것이다.
보간 필터의 계수는, 가중치 관련 파라미터 ifact에 기초하여 결정될 수 있다. 일 예로, 보간 필터의 계수는, 각도 선(angular line) 상에 위치하는 소수 펠(fractional pel)과 정수 펠(즉, 참조 샘플의 정수 위치) 사이의 거리에 기초하여 결정될 수 있다.
수학식 16에서는 탭수가 2인 보간 필터를 예시하였으나, 탭수가 2보다 큰 보간 필터를 이용하여 예측값을 산출할 수도 있다.
예측 대상 샘플의 예측값 또는 최종 예측 영상은, 제1 예측 영상 또는 제2 예측 영상 중 적어도 하나에 기초하여 획득될 수 있다. 일 예로, 제1 예측 영상 또는 제2 예측 영상을 예측 대상 샘플의 예측값으로 결정할 수 있다. 또는, 제1 예측 영상과 제2 예측 영상의 가중합 연산 또는 평균 연산에 기초하여 예측 대상 샘플의 예측값을 결정할 수 있다. 수학식 17은 제1 예측 영상 및 제2 예측 영상의 가중합 연산에 기초하여 예측 대상 샘플의 예측값을 산출하는 예를 나타낸 것이다.
상기 수학식 17에서 P(x, y)는 (x, y) 위치의 예측 대상 샘플의 예측값을 나타낸다. 그리고, P1(x, y)는 제1 예측 영상을, P2(x, y)는 제2 예측 영상을 나타낸다. 아울러, w(x, y)는 제1 예측 영상에 부여되는 가중치를 나타낸다.
제1 예측 영상 및 제2 예측 영상에 부여되는 가중치는, 예측 대상 샘플의 위치, 현재 블록의 크기, 형태 또는 인트라 예측 모드 중 적어도 하나에 기초하여 결정될 수 있다. 수학식 18은 현재 블록의 크기 및 예측 대상 샘플의 위치를 기초로 가중치를 결정하는 예를 나타낸 것이다.
상기 수학식 18에서, W 및 H는 각각 현재 블록의 너비 및 높이를 나타내고, (x, y)는 예측 대상 샘플의 좌표를 나타낸다.
상기 수학식 18에 나타난 예에 따르면, 예측 대상 샘플이 현재 블록의 좌측 상단 코너에 인접할수록 제1 예측 영상에 부여되는 가중치가 증가하고, 제2 예측 영상에 부여되는 가중치가 감소할 수 있다. 반면, 예측 대상 샘플이 현재 블록의 우측 하단 코너에 인접할수록 제2 예측 영상에 부여되는 가중치가 증가하고, 제1 예측 영상에 부여되는 가중치가 감소할 수 있다.
또는, 현재 블록의 이웃 블록으로부터 가중치를 유도할 수도 있다. 여기서, 현재 블록의 이웃 블록은, 상단 이웃 블록, 좌측 이웃 블록 또는 현재 블록의 코너에 인접하는 이웃 블록(예컨대, 좌측 상단 이웃 블록, 우측 상단 이웃 블록 또는 좌측 하단 이웃 블록) 중 적어도 하나를 포함할 수 있다.
또는, 가중치를 결정하기 위한 정보가 비트스트림을 통해 시그널링될 수 있다. 상기 정보는 제1 예측 영상 또는 제2 예측 영상에 적용되는 가중치 값을 나타내거나, 현재 블록과 이웃 블록 사이의 가중치 차분값을 나타낼 수 있다.
상술한 예에서와 같이, 제1 예측 영상 및 제2 예측 영상 사이의 가중합 연산 또는 평균 연산을 통해 예측 대상 샘플의 예측값을 획득하는 방법을 양방향 인트라 예측(Bi-intra Prediction)이라 호칭할 수 있다.
양방향 인트라 예측은 현재 블록 내 일부 영역에만 적용될 수 있다. 양방향 인트라 예측의 적용 영역은 부호화기 및 복호화기에서 기 정의되어 있을 수 있다. 일 예로, 현재 블록 내 우측 하단 코너에 인접하는 소정 크기(예컨대, 4x4) 블록에 양방향 인트라 예측을 적용할 수 있다.
또는, 현재 블록의 크기, 형태 또는 인트라 예측 모드 중 적어도 하나에 기초하여, 양방향 인트라 예측의 적용 영역을 결정할 수 있다.
또는, 양방향 인트라 예측이 적용되는 영역을 결정하기 위한 정보(예컨대, 영역의 크기 또는 위치를 나타내는 정보)가 비트스트림을 통해 시그날링될 수 있다.
또는, x좌표, y좌표, x좌표와 y좌표의 합 또는 x좌표와 y좌표의 차분이 기 정의된 값 이상인 예측 대상 샘플에 양방향 인트라 예측을 적용할 수 있다.
도 20은 양방향 인트라 예측이 적용되는 영역을 나타낸 예이다.
도 20의 (a)에 도시된 예에서와 같이, 양방향 인트라 예측의 적용 영역은 사각 형태일 수 있다. 또는, 도 20의 (b)에 도시된 예에서와 같이, 양방향 인트라 예측의 적용 영역은 삼각 형태일 수 있다.
양방향 인트라 예측이 적용되는 영역에 포함된 예측 대상 샘플의 예측값은, 제1 예측 영상과 제2 예측 영상의 가중합 연산 또는 평균 연산에 기초하여 획득될 수 있다. 반면, 양방향 인트라 예측이 적용되지 않는 영역에 포함된 예측 대상 샘플의 예측값은, 제1 예측 영상 또는 제2 예측 영상으로 결정될 수 있다. 양방향 인트라 예측이 적용되지 않는 영역에 포함된 예측 대상 샘플의 예측값을 제1 예측 영상으로 설정할 것인지 또는 제2 예측 영상으로 설정할 것인지 여부는, 현재 블록의 크기, 형태 또는 인트라 예측 모드에 기초하여 결정될 수 있다. 또는, 제1 예측 영상 또는 제2 예측 영상을 선택하기 위한 정보가 비트스트림을 통해 시그날링될 수 있다.
상술한 실시예들에서는, 양방향 인트라 예측을 수행하기 위해, 복수 참조 샘플 라인들이 이용되는 것으로 설명하였다. 설명된 실시예와 달리, 하나의 참조 샘플 라인을 이용하여 양방향 인트라 예측을 수행하는 것도 가능하다. 구체적으로, 제1 참조 샘플 라인에 포함되는 복수의 참조 샘플들을 이용하여 양방향 인트라 예측을 수행하거나, 제2 참조 샘플 라인에 포함되는 복수의 참조 샘플들을 이용하여 양방향 인트라 예측을 수행할 수 있다. 일 예로, 현재 블록의 인트라 예측 모드가 우측 상단 대각 방향 또는 좌측 하단 대각 방향인 경우, 제1 참조 샘플 라인에 포함된 참조 샘플들 중 상단 참조 샘플을 기초로 제1 예측 영상을 유도하고, 좌측 참조 샘플을 기초로 제2 예측 영상을 유도할 수 있다. 또는, 제2 참조 샘플 라인에 포함된 참조 샘플들 중 우측 참조 샘플을 기초로 제1 예측 영상을 유도하고, 하단 참조 샘플을 기초로 제2 예측 영상을 유도할 수 있다. 이후, 제1 참조 영상 및 제2 참조 영상의 가중합 연산 또는 평균 연산에 기초하여, 예측 대상 샘플의 에측값을 획득할 수 있다.
양방향 인트라 예측은 독립적인 인트라 예측 모드로 정의될 수 있다. 일 예로, N개의 방향성 예측 모드와 N개의 방향성 예측 모드에 대응하는 N개의 양방향 인트라 예측 모드를 정의하여, 총 2N+2개의 인트라 예측 모드를 정의할 수 있다. 일 예로, 도 8에 도시된 인트라 예측 모드에 양방향 인트라 예측 모드를 추가하여, 총 68개의 인트라 예측 모드(즉, 2개의 비방향성 인트라 예측 모드, 33개의 방향성 인트라 예측 모드 및 33개의 양방향 인트라 예측 모드)를 정의할 수 있다. 물론, 33개보다 더 많은 수 혹은 더 적은 수의 방향성 인트라 예측 모드 또는 양방향 인트라 예측 모드를 사용하는 것도 가능하다.
또는, 현재 블록의 인트라 예측 모드를 결정한 뒤, 결정된 인트라 예측 모드를 양방향 예측 모드로 전환 이용할 것인지 여부를 결정할 수도 있다. 일 예로, 현재 블록의 인트라 예측 모드가 결정되면, 결정된 인트라 예측 모드를 양방향 인트라 예측 모드로 이용할 것인지 여부에 대한 정보를 복호화할 수 있다. 상기 정보는 1비트의 플래그(예컨대, bi_intra_flag)일 수 있으나, 이에 한정되지 않는다. bi_intra_flag의 값이 0인 것은, 단방향 인트라 예측이 수행됨을 나타내고, bi_intra_flag의 값이 1인 것은, 양방향 인트라 예측이 수행됨을 나타낸다. bi_intra_flag의 값이 0인 경우, 예측 대상 샘플의 예측값은 제1 예측 영상으로 결정될 수 있다. 반면, bi_intra_flag의 값이 1인 경우, 예측 대상 샘플의 예측값은 제1 예측 영상 및 제2 예측 영상의 가중합 연산 또는 평균 연산에 기초하여 획득될 수 있다.
또는, 현재 블록에 이웃하는 주변 블록이 양방향 인트라 예측 모드를 이용했는지 여부에 따라, 현재 블록이 양방향 인트라 예측 모드를 사용하는지 여부를 결정할 수 있다. 일 예로, 현재 블록의 인트라 예측 모드가 주변 블록의 인트라 예측 모드를 기초로 유도된 후보자(즉, MPM 후보)와 동일한 경우, 현재 블록이 양방향 인트라 예측 모드를 사용하는지 여부를 상기 주변 블록이 양방향 인트라 예측 모드를 사용하였는지 여부와 동일하게 결정할 수 있다.
또는, 현재 블록의 크기 및/또는 형태에 기초하여 양방향 인트라 예측 수행 여부를 결정할 수도 있다. 일 예로, 32x32 이상의 블록에서만, 양방향 인트라 예측이 허용되도록 설정될 수 있다. 이에 따라, 현재 블록의 크기가 32x32 보다 작은 경우에는 양방향 인트라 예측이 적용되지 않는 반면, 현재 블록의 크기가 32x32 이상인 경우, 양방향 인트라 예측이 적용될 수 있다.
다른 예로, 정방형 블록에 대해서만 양방향 인트라 예측을 허용하거나, 비정방 형태의 블록에 대해서만 양방향 인트라 예측을 허용할 수도 있다.
또는, 일부 방향성 인트라 예측 모드에 한하여, 양방향 인트라 예측을 적용할 수도 있다. 일 예로, 도 21은 양방향 인트라 예측이 허용되는 방향성 예측 모드를 식별 표시한 예이다. 도 21에 도시된 예에서와 같이, 수평 방향과 수직 방향 사이의 일부 인트라 예측 모드에 한하여 양방향 인트라 예측이 허용되도록 설정할 수 있다. 이때, 상기 범위 내 인트라 예측 모드가 선택되는 경우, 디폴트로 양방향 인트라 예측을 수행할 수도 있고, 상기 범위 내 인트라 예측 모드가 선택되는 경우, 비트스트림을 통해 파싱되는 정보, 현재 블록의 크기 또는 형태 중 적어도 하나에 기초하여 양방향 인트라 예측 모드의 수행 여부를 결정할 수도 있다.
양방향 인트라 예측이 허용되는 인트라 예측 모드는 도 21에 도시된 예에 한정되지 않는다. 양방향 인트라 예측이 허용되는 인트라 예측 모드는 부호화기 및 복호화기에서 기 정의되어 있을 수 있다. 또는, 현재 블록의 크기 및/또는 형태에 따라 양방향 인트라 예측이 허용되는 인트라 예측 모드를 결정할 수 있다. 또는, 양방향 인트라 예측이 허용되는 인트라 예측 모드를 결정하기 위한 정보가 비트스트림을 통해 시그날링될 수도 있다.
복수의 참조 샘플 라인들 중 적어도 하나를 선택하고, 선택된 참조 샘플 라인을 이용하여 인트라 예측을 수행할 수 있다. 상기 선택은, 예측 대상 샘플의 위치, 현재 블록의 인트라 예측 모드, 현재 블록의 크기/형태, 파티션 타입, 스캐닝 순서 또는 플래그 정보 중 적어도 하나에 기초할 수 있다. 일 예로, 현재 블록의 인트라 예측 모드가 방향성인지 여부, 현재 블록의 인트라 예측 모드의 인덱스가 기 정의된 값 이상/이하인지 여부, 현재 블록의 인트라 예측 모드의 인덱스가 기 정의된 범위에 포함되는지 여부 또는 현재 블록의 인트라 예측 모드와 기 정의된 인트라 예측 모드와의 차분값이 기 정의된 값 이상/이하인지 여부 중 적어도 하나에 기초하여, 복수의 참조 샘플 라인 중 적어도 하나를 선택할 수 있다.
또는, 영역별 또는 예측 대상 샘플별로 참조 샘플 라인을 결정할 수 있다.
일 예로, 제1 영역에 포함된 예측 대상 샘플의 인트라 예측은 제1 참조 샘플 라인을 이용하여 수행될 수 있다. 반면, 제2 영역에 포함된 예측 대상 샘플의 인트라 예측은 제2 참조 샘플 라인을 이용하여 수행될 수 있다.
일 예로, x좌표의 값 및 y좌표의 값이 기 정의된 값 이하인 예측 대상 샘플은 제1 참조 샘플 라인을 기초로 인트라 예측을 수행할 수 있다. 반면, x좌표의 값 또는 y좌표의 값 중 적어도 하나가 기 정의된 값보다 큰 예측 대상 샘플은 제2 참조 샘플 라인을 기초로 인트라 예측을 수행할 수 있다.
도 22는 예측 대상 샘플의 위치에 따라 참조 샘플 라인이 결정되는 예를 나타낸 도면이다.
도 22에 도시된 예에서와 같이, P(1, 0) 위치의 예측 대상 샘플에 대한 인트라 예측은, 제1 참조 샘플 라인에 포함된 참조 샘플을 기초로 수행될 수 있다. 반면, P(3, 1) 위치의 예측 대상 샘플에 대한 인트라 예측은, 제2 참조 샘플 라인에 포함된 참조 샘플을 기초로 수행될 수 있다.
예측 대상 샘플과 참조 샘플간의 거리에 기초하여, 참조 샘플 라인을 선택할 수 있다. 일 예로, 예측 대상 샘플과 제1 참조 샘플 라인과의 거리(이하, 제1 참조 거리라 함) 및 예측 대상 샘플과 제2 참조 샘플 라인과의 거리(이하, 제2 참조 거리라 함)를 비교하고, 예측 대상 샘플과의 거리가 더 짧은 참조 샘플 라인을 선택할 수 있다. 즉, 제1 참조 샘플 거리가 제2 참조 샘플 거리보다 작은 경우, 제1 참조 샘플을 사용하여 인트라 예측을 수행할 수 있다. 제2 참조 샘플 거리가 제1 참조 샘플 거리보다 작은 경우, 제2 참조 샘플을 사용하여 인트라 예측을 수행할 수 있다.
예측 대상 샘플과의 거리를 산출하는데 이용되는 참조 샘플의 위치는 현재 블록의 인트라 예측 모드에 기초하여 결정될 수 있다. 일 예로, 상기 참조 샘플은 예측 대상 샘플로부터 확장되는 가상의 각도 선이 지나는 위치에 놓인 참조 샘플 또는 상기 위치에 인접하는 참조 샘플일 수 있다. 또는, 상기 참조 샘플은 예측 대상 샘플과 동일한 x좌표 또는 예측 대상 샘플과 동일한 y좌표를 갖는 참조 샘플일 수 있다. 또는, 제1 참조 샘플 및 제2 참조 샘플 중 어느 하나의 위치는 현재 블록의 인트라 예측 모드를 기초로 결정하고, 다른 하나의 위치는 부호화기/복호화기에서 기 정의된 값 또는 예측 대상 샘플과 동일한 x 좌표 값 또는 동일한 y좌표 값을 기초로 결정할 수 있다.
또는, 기 정의된 위치의 참조 샘플을 이용하여 예측 대상 샘플과의 거리가 산출될 수 있다. 기 정의된 위치는 좌측 상단 참조 샘플, 우측 상단 참조 샘플, 좌측 하단 참조 샘플 또는 우측 하단 참조 샘플 중 적어도 하나를 포함할 수 있다.
수학식 19는 예측 대상 샘플과 참조 샘플 사이의 거리를 산출하는 예를 나타낸 것이다.
상기 수학식 19에서, d(x, y)는 예측 대상 샘플 P(x, y)와 참조 샘플 ref(x0, y0) 사이의 거리를 나타낸다. 수학식 19에 나타나는 예에서와 같이, 샘플 거리 d(x, y)는 두 샘플들의 x 좌표 차분의 절대값 및 y 좌표 차분의 절대값의 합으로 정의될 수 있다.
영역별 또는 예측 대상 샘플별로 선택되는 참조 샘플 라인의 개수가 상이할 수 있다.
일 예로, 제1 영역에 포함된 예측 대상 샘플에 대해서는 1개의 참조 샘플 라인(예컨대, 제1 참조 샘플 라인 또는 제2 참조 샘플 라인)을 이용하여 인트라 예측을 수행할 수 있다. 반면, 제2 영역에 포함된 예측 대상 샘플에 대해서는 2개의 참조 샘플 라인(예컨대, 제1 참조 샘플 라인 및 제2 참조 샘플 라인)을 이용하여 인트라 예측을 수행할 수 있다.
일 예로, x좌표의 값 및 y좌표의 값이 기 정의된 값 이하인 예측 대상 샘플에 대한 인트라 예측은 제1 참조 샘플 라인을 이용하여 수행될 수 있다. 반면, x좌표의 값 또는 y좌표의 값 중 적어도 하나가 기 정의된 값보다 큰 예측 대상 샘플에 대한 인트라 예측은 제1 참조 샘플 라인 및 제2 참조 샘플 라인을 이용하여 수행될 수 있다.
일 예로, x좌표의 값 및 y좌표의 값이 기 정의된 값보다 작은 예측 대상 샘플에 대한 인트라 예측은 제1 참조 샘플 라인을 이용하여 수행될 수 있다. x좌표의 값 또는 y좌표의 값 중 적어도 하나가 기 정의된 값보다 큰 예측 대상 샘플에 대한 인트라 예측은 제2 참조 샘플 라인을 이용하여 수행될 수 있다. x좌표의 값 및 y좌표의 값이 동일한 예측 대상 샘플에 대한 인트라 예측은 제1 참조 샘플 라인 및 제2 참조 샘플 라인을 이용하여 인트라 예측이 수행될 수 있다.
또는, 제1 참조 샘플 거리와 제2 참조 샘플 거리를 비교하여, 복수 참조 샘플 라인의 선택 여부를 결정할 수 있다. 일 예로, 제1 참조 샘플 거리가 제2 참조 샘플 거리보다 짧은 경우, 예측 대상 샘플의 인트라 예측은 제1 참조 샘플 라인을 이용하여 수행될 수 있다. 제2 참조 샘플 거리가 제1 참조 샘플 거리보다 짧은 경우, 예측 대상 샘플의 인트라 예측은 제1 참조 샘플 라인 및 제2 참조 샘플 라인을 이용하여 수행될 수 있다.
복수의 참조 샘플 라인을 이용하여 인트라 예측을 수행하는 경우, 예측 대상 샘플의 예측값은 복수 참조 샘플들의 가중합 연산 또는 평균 연산에 기초하여 획득될 수 있다. 복수 참조 샘플들 중 적어도 하나가 포함된 참조 샘플 라인의 인덱스는 다른 참조 샘플이 포함된 참조 샘플 라인의 인덱스와 상이할 수 있다.
각 참조 샘플에 적용되는 가중치는 부호화기/복호화기에서 기 정의된 것일 수 있다. 또는, 예측 대상 샘플과의 거리를 기초로 가중치를 결정할 수 있다. 또는, 가중치를 결정하기 위한 정보가 비트스트림을 통해 시그날링될 수 있다. 상기 정보는, 복수의 가중치 중 어느 하나를 가리키는 인덱스일 수 있다.
도 23은 예측 대상 샘플의 위치에 따라 참조 샘플 라인의 개수가 결정되는 예를 나타낸 도면이다.
도 23에 도시된 예에서와 같이, P(1, 0) 위치의 예측 대상 샘플에 대한 인트라 예측은 제1 참조 샘플 라인을 이용하여 수행될 수 있다. 반면, P(3, 1) 위치의 예측 대상 샘플에 대한 인트라 예측은, 제1 참조 샘플 라인 및 제2 참조 샘플 라인을 이용하여 수행될 수 있다.
또는, 현재 블록의 인트라 예측이 우상단 방향상 인트라 예측 모드인 경우, 예측 대상 샘플의 위치 P(3, 1)과 예측 대상 샘플로부터 우상단에 위치하는 제1 참조 샘플 P(7, -1)과의 거리 및 예측 대상 샘플의 위치 P(3, 1)과 예측 대상 샘플로부터 우상단에 위치하는 제2 참조 샘플 P(5, 2)와의 거리를 산출할 수 있다. P(1, 0)위치의 예측 대상 샘플의 우상단에는 제1 참조 샘플 P(2, -1)만이 존재한다. 이에 따라, 상기 예측 대상 샘플의 예측값은 상기 제1 참조 샘플을 기초로 획득될 수 있다. P(3, 1) 위치의 예측 대상 샘플의 우상단에는 제1 참조 샘플 P(7, -1)과 제2 참조 샘플 P(5, 2)이 존재한다. 이때, 제2 참조 거리가 제1 참조 거리보다 짧으므로, 상기 예측 대상 샘플의 에측값은 상기 제1 참조 샘플 및 상기 제2 참조 샘플 사이의 가중합 연산 또는 평균 연산에 기초하여 획득될 수 있다.
수학식 20은 제1 참조 샘플과 제2 참조 샘플의 가중합 연산에 기초하여 예측 대상 샘플의 예측값을 산출하는 예를 나타낸 것이다.
상기 수학식 20에서, P(x, y)는 (x, y) 위치의 예측 대상 샘플에 대한 예측값을 나타낸다. Ref_1st(x, y)는 상기 예측 대상 샘플에 대한 제1 참조 샘플을 나타낸다. Ref_2nd(x, y)는 상기 예측 대상 샘플에 대한 제2 참조 샘플을 나타낸다. w는 제1 참조 샘플에 적용되는 가중치를 나타내고, (1-w)는 제2 참조 샘플에 적용되는 가중치를 나타낸다.
복수 참조 샘플은 현재 블록의 인트라 예측 모드에 기초하여 결정될 수 있다. 일 예로, 예측 대상 샘플로부터 확장되는 가상의 각도 선을 기초로 제1 차모 샘플 및 제2 참조 샘플을 결정할 수 있다.
또는, 복수 참조 샘플 중 적어도 하나는 부호화기/복호화기에서 기 약속된 고정된 위치를 가질 수 있다. 상기 고정 위치는 좌측 상단 참조 샘플 P(-1, -1), 우측 상단 참조 샘플 P(W, -1), 좌측 하단 참조 샘플 P(-1, H) 또는 우측 하단 참조 샘플 P(W, H) 중 적어도 하나를 포함할 수 있다.
또는, 복수 참조 샘플 중 적어도 하나는 예측 대상 샘플과 동일한 수직선상 또는 수평선상에 놓인 것일 수 있다. 일 예로, 예측 대상 샘플과 동일한 x좌표를 갖는 참조 샘플 또는 예측 대상 샘플과 동일한 y좌표를 갖는 참조 샘플을 이용하여 예측값을 산출할 수 있다.
전술한 양방향 인트라 예측 방법 또는 영역별/예측 대상 샘플별 참조 샘플 라인/참조 샘플 라인의 수를 상이하게 설정하는 방법은 현재 블록의 인트라 예측 모드가 기 정의된 인트라 예측 모드인 경우에 한하여 수행될 수 있다. 상기 기 정의된 인트라 예측 모드는 방향성 인트라 예측 모드 또는 기 정의된 인덱스 값을 갖는 방향성 인트라 예측 모드일 수 있다.
복호화 과정 또는 부호화 과정을 중심으로 설명된 실시예들을, 부호화 과정 또는 복호화 과정에 적용하는 것은, 본 발명의 범주에 포함되는 것이다. 소정의 순서로 설명된 실시예들을, 설명된 것과 상이한 순서로 변경하는 것 역시, 본 발명의 범주에 포함되는 것이다.
상술한 실시예는 일련의 단계 또는 순서도를 기초로 설명되고 있으나, 이는 발명의 시계열적 순서를 한정한 것은 아니며, 필요에 따라 동시에 수행되거나 다른 순서로 수행될 수 있다. 또한, 상술한 실시예에서 블록도를 구성하는 구성요소(예를 들어, 유닛, 모듈 등) 각각은 하드웨어 장치 또는 소프트웨어로 구현될 수도 있고, 복수의 구성요소가 결합하여 하나의 하드웨어 장치 또는 소프트웨어로 구현될 수도 있다. 상술한 실시예는 다양한 컴퓨터 구성요소를 통하여 수행될 수 있는 프로그램 명령어의 형태로 구현되어 컴퓨터 판독 가능한 기록 매체에 기록될 수 있다. 상기 컴퓨터 판독 가능한 기록 매체는 프로그램 명령어, 데이터 파일, 데이터 구조 등을 단독으로 또는 조합하여 포함할 수 있다. 컴퓨터 판독 가능한 기록 매체의 예에는, 하드 디스크, 플로피 디스크 및 자기 테이프와 같은 자기 매체, CD-ROM, DVD와 같은 광기록 매체, 플롭티컬 디스크(floptical disk)와 같은 자기-광 매체(magneto-optical media), 및 ROM, RAM, 플래시 메모리 등과 같은 프로그램 명령어를 저장하고 수행하도록 특별히 구성된 하드웨어 장치가 포함된다. 상기 하드웨어 장치는 본 발명에 따른 처리를 수행하기 위해 하나 이상의 소프트웨어 모듈로서 작동하도록 구성될 수 있으며, 그 역도 마찬가지이다.
Claims (15)
- 현재 블록의 인트라 예측 모드를 결정하는 단계;
상기 현재 블록에 포함된 예측 대상 샘플에 대한 참조 샘플 라인을 결정하는 단계, 상기 참조 샘플 라인의 결정은 상기 예측 대상 샘플의 위치 또는 상기 예측 대상 샘플이 기 결정된 영역에 포함되어 있는지 여부에 기초하여 수행됨; 및
상기 인트라 예측 모드 및 상기 참조 샘플 라인을 기초로 상기 예측 대상 샘플의 예측값을 획득하는 단계를 포함하는, 영상 복호화 방법. - 제1 항에 있어서,
상기 참조 샘플 라인의 결정은, 상기 예측 대상 샘플의 위치로부터 제1 참조 샘플 라인에 포함된 제1 참조 샘플까지의 거리 및 상기 예측 대상 샘플의 위치로부터 제2 참조 샘플 라인에 포함된 제2 참조 샘플까지의 거리의 비교 결과에 기초하여 수행되는 것을 특징으로 하는, 영상 복호화 방법. - 제2 항에 있어서,
상기 제1 참조 샘플 및 상기 제2 참조 샘플은 상기 인트라 예측 모드에 기초하여 결정되는 것을 특징으로 하는, 영상 복호화 방법. - 제2 항에 있어서,
상기 제1 참조 샘플 라인은 상기 현재 블록의 상단에 인접하는 행에 포함된 상단 참조 샘플 및 상기 현재 블록의 좌측에 인접하는 열에 포함된 좌측 참조 샘플을 포함하고,
상기 제2 참조 샘플 라인은 상기 현재 블록의 우측에 인접하는 열에 포함된 우측 참조 샘플 및 상기 현재 블록의 하단에 인접하는 행에 포함된 하단 참조 샘플을 포함하는, 영상 복호화 방법. - 제1 항에 있어서,
상기 예측값은 제1 참조 샘플 라인에 포함된 제1 참조 샘플과 제2 참조 샘플 라인에 포함된 제2 참조 샘플 사이의 가중합 연산 또는 평균 연산을 기초로 산출되는 것을 특징으로 하는, 영상 복호화 방법. - 제1 항에 있어서,
상기 제1 참조 샘플 및 상기 제2 참조 샘플 각각에 적용되는 가중치는, 상기 예측 대상 샘플과의 거리를 기초로 결정되는, 영상 복호화 방법. - 제6 항에 있어서,
상기 제1 참조 샘플 및 상기 제2 참조 샘플 각각에 적용되는 가중치는, 상기 예측 대상 샘플과의 거리를 기초로 결정되는, 영상 복호화 방법. - 제1 항에 있어서,
상기 참조 샘플 라인의 결정은, 복수의 참조 샘플 라인을 이용할 것인지 여부의 결정을 포함하는, 영상 복호화 방법. - 현재 블록의 인트라 예측 모드를 결정하는 단계;
상기 현재 블록에 포함된 예측 대상 샘플에 대한 참조 샘플 라인을 결정하는 단계, 상기 참조 샘플 라인의 결정은 상기 예측 대상 샘플의 위치 또는 상기 예측 대상 샘플이 기 결정된 영역에 포함되어 있는지 여부에 기초하여 수행됨; 및
상기 인트라 예측 모드 및 상기 참조 샘플 라인을 기초로 상기 예측 대상 샘플의 예측값을 획득하는 단계를 포함하는, 영상 부호화 방법. - 제9 항에 있어서,
상기 참조 샘플 라인의 결정은, 상기 예측 대상 샘플의 위치로부터 제1 참조 샘플 라인에 포함된 제1 참조 샘플까지의 거리 및 상기 예측 대상 샘플의 위치로부터 제2 참조 샘플 라인에 포함된 제2 참조 샘플까지의 거리의 비교 결과에 기초하여 수행되는 것을 특징으로 하는, 영상 부호화 방법. - 제10 항에 있어서,
상기 제1 참조 샘플 및 상기 제2 참조 샘플은 상기 인트라 예측 모드에 기초하여 결정되는 것을 특징으로 하는, 영상 부호화 방법. - 제10 항에 있어서,
상기 제1 참조 샘플 라인은 상기 현재 블록의 상단에 인접하는 행에 포함된 상단 참조 샘플 및 상기 현재 블록의 좌측에 인접하는 열에 포함된 좌측 참조 샘플을 포함하고,
상기 제2 참조 샘플 라인은 상기 현재 블록의 우측에 인접하는 열에 포함된 우측 참조 샘플 및 상기 현재 블록의 하단에 인접하는 행에 포함된 하단 참조 샘플을 포함하는, 영상 부호화 방법. - 제9 항에 있어서,
상기 예측값은 제1 참조 샘플 라인에 포함된 제1 참조 샘플과 제2 참조 샘플 라인에 포함된 제2 참조 샘플 사이의 가중합 연산 또는 평균 연산을 기초로 산출되는 것을 특징으로 하는, 영상 부호화 방법. - 제9 항에 있어서,
상기 제1 참조 샘플 및 상기 제2 참조 샘플 각각에 적용되는 가중치는, 상기 예측 대상 샘플과의 거리를 기초로 결정되는, 영상 부호화 방법. - 현재 블록의 인트라 예측 모드를 결정하고, 상기 현재 블록에 포함된 예측 대상 샘플에 대한 참조 샘플 라인을 결정하고, 상기 인트라 예측 모드 및 상기 참조 샘플 라인을 기초로 상기 예측 대상 샘플의 예측값을 획득하는 인트라 예측부를 포함하되,
상기 참조 샘플 라인의 결정은 상기 예측 대상 샘플의 위치 또는 상기 예측 대상 샘플이 기 결정된 영역에 포함되어 있는지 여부에 기초하여 수행되는, 영상 복호화 장치.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020180031544 | 2018-03-19 | ||
| KR20180031544 | 2018-03-19 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20190110041A true KR20190110041A (ko) | 2019-09-27 |
Family
ID=67987364
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020190030052A KR20190110041A (ko) | 2018-03-19 | 2019-03-15 | 비디오 신호 처리 방법 및 장치 |
Country Status (3)
| Country | Link |
|---|---|
| US (2) | US11483564B2 (ko) |
| KR (1) | KR20190110041A (ko) |
| WO (1) | WO2019182292A1 (ko) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021118309A1 (ko) * | 2019-12-13 | 2021-06-17 | 주식회사 케이티 | 비디오 신호 처리 방법 및 장치 |
| WO2023128489A1 (ko) * | 2021-12-28 | 2023-07-06 | 주식회사 케이티 | 영상 부호화/복호화 방법 및 장치 |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3777169B1 (en) * | 2018-03-28 | 2023-05-03 | Fg Innovation Company Limited | Device and method for decoding video data in multiple reference line prediction |
| US10841575B2 (en) * | 2018-04-15 | 2020-11-17 | Arris Enterprises Llc | Unequal weight planar motion vector derivation |
| AU2019269346B2 (en) * | 2018-05-14 | 2023-07-27 | Interdigital Vc Holdings, Inc. | Block shape adaptive intra prediction directions for quadtree-binary tree |
| US11412211B2 (en) * | 2018-05-23 | 2022-08-09 | Kt Corporation | Method and apparatus for processing video signal |
| WO2020005007A1 (ko) * | 2018-06-29 | 2020-01-02 | 주식회사 케이티 | 비디오 신호 처리 방법 및 장치 |
| WO2020175951A1 (ko) * | 2019-02-28 | 2020-09-03 | 엘지전자 주식회사 | 단일화된 mpm 리스트 기반 인트라 예측 |
| KR102639970B1 (ko) * | 2019-03-11 | 2024-02-22 | 닛폰 호소 교카이 | 화상 부호화 장치, 화상 복호 장치 및 프로그램 |
| WO2021037078A1 (en) * | 2019-08-26 | 2021-03-04 | Beijing Bytedance Network Technology Co., Ltd. | Extensions of intra coding modes in video coding |
| US20220337875A1 (en) * | 2021-04-16 | 2022-10-20 | Tencent America LLC | Low memory design for multiple reference line selection scheme |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3457689B1 (en) | 2010-05-25 | 2020-09-09 | LG Electronics Inc. | New planar prediction mode |
| KR101883932B1 (ko) | 2010-12-22 | 2018-07-31 | 엘지전자 주식회사 | 화면 내 예측 방법 및 이러한 방법을 사용하는 장치 |
| US9420294B2 (en) | 2011-02-23 | 2016-08-16 | Lg Electronics Inc. | Intra-prediction method using filtering, and apparatus using the method |
| DE112012001609B9 (de) | 2011-04-25 | 2021-11-18 | Lg Electronics Inc. | Intra-Prädiktionsverfahren, Kodierer und Dekodierer zur Benutzung desselben |
| WO2014010943A1 (ko) | 2012-07-10 | 2014-01-16 | 한국전자통신연구원 | 영상 부호화/복호화 방법 및 장치 |
| KR20170108367A (ko) * | 2016-03-17 | 2017-09-27 | 세종대학교산학협력단 | 인트라 예측 기반의 비디오 신호 처리 방법 및 장치 |
| US10484712B2 (en) * | 2016-06-08 | 2019-11-19 | Qualcomm Incorporated | Implicit coding of reference line index used in intra prediction |
| KR20180009318A (ko) * | 2016-07-18 | 2018-01-26 | 한국전자통신연구원 | 영상 부호화/복호화 방법, 장치 및 비트스트림을 저장한 기록 매체 |
| CN116506605A (zh) * | 2016-08-01 | 2023-07-28 | 韩国电子通信研究院 | 图像编码/解码方法和设备以及存储比特流的记录介质 |
| CN109565591B (zh) * | 2016-08-03 | 2023-07-18 | 株式会社Kt | 用于对视频进行编码和解码的方法和装置 |
| KR20180029905A (ko) * | 2016-09-13 | 2018-03-21 | 한국전자통신연구원 | 영상 부호화/복호화 방법, 장치 및 비트스트림을 저장한 기록 매체 |
| US10742975B2 (en) * | 2017-05-09 | 2020-08-11 | Futurewei Technologies, Inc. | Intra-prediction with multiple reference lines |
| US10582195B2 (en) * | 2017-06-02 | 2020-03-03 | Futurewei Technologies, Inc. | Intra prediction using unequal weight planar prediction |
-
2019
- 2019-03-15 KR KR1020190030052A patent/KR20190110041A/ko active Search and Examination
- 2019-03-15 WO PCT/KR2019/003044 patent/WO2019182292A1/ko active Application Filing
- 2019-03-15 US US16/981,559 patent/US11483564B2/en active Active
-
2022
- 2022-09-19 US US17/947,552 patent/US20230353742A1/en active Pending
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021118309A1 (ko) * | 2019-12-13 | 2021-06-17 | 주식회사 케이티 | 비디오 신호 처리 방법 및 장치 |
| WO2023128489A1 (ko) * | 2021-12-28 | 2023-07-06 | 주식회사 케이티 | 영상 부호화/복호화 방법 및 장치 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20230353742A1 (en) | 2023-11-02 |
| US11483564B2 (en) | 2022-10-25 |
| WO2019182292A1 (ko) | 2019-09-26 |
| US20210021832A1 (en) | 2021-01-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102416257B1 (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR102410032B1 (ko) | 비디오 신호 처리 방법 및 장치 | |
| CA3065490C (en) | Video signal processing in which intra prediction is performed in units of sub-blocks partitioned from coding block | |
| KR102549178B1 (ko) | 비디오 신호 처리 방법 및 장치 | |
| AU2018327924B2 (en) | Method and device for processing video signal | |
| KR102424419B1 (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR20190110041A (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR102601267B1 (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR102424420B1 (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR102435000B1 (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR20180001478A (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR20200063092A (ko) | 영상 신호 부호화/복호화 방법 및 이를 위한 장치 | |
| KR20190113653A (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR102471207B1 (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR20180059367A (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR20190028324A (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR20190133629A (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR20190139785A (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR20190110044A (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR20190134521A (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR20180103732A (ko) | 비디오 신호 처리 방법 및 장치 | |
| CA3065914A1 (en) | Video signal processing method and device | |
| KR20180056396A (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR20190113652A (ko) | 비디오 신호 처리 방법 및 장치 | |
| KR20200084306A (ko) | 영상 신호 부호화/복호화 방법 및 이를 위한 장치 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination |