KR101275041B1 - 다상 에러 보정을 위한 방법 및 디바이스 - Google Patents
다상 에러 보정을 위한 방법 및 디바이스 Download PDFInfo
- Publication number
- KR101275041B1 KR101275041B1 KR1020107029291A KR20107029291A KR101275041B1 KR 101275041 B1 KR101275041 B1 KR 101275041B1 KR 1020107029291 A KR1020107029291 A KR 1020107029291A KR 20107029291 A KR20107029291 A KR 20107029291A KR 101275041 B1 KR101275041 B1 KR 101275041B1
- Authority
- KR
- South Korea
- Prior art keywords
- bits
- decoding
- data
- subset
- decoded
- Prior art date
Links
Images














Classifications
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M13/00—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes
- H03M13/29—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes combining two or more codes or code structures, e.g. product codes, generalised product codes, concatenated codes, inner and outer codes
- H03M13/2906—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes combining two or more codes or code structures, e.g. product codes, generalised product codes, concatenated codes, inner and outer codes using block codes
- H03M13/2927—Decoding strategies
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M11/00—Coding in connection with keyboards or like devices, i.e. coding of the position of operated keys
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/08—Error detection or correction by redundancy in data representation, e.g. by using checking codes
- G06F11/10—Adding special bits or symbols to the coded information, e.g. parity check, casting out 9's or 11's
- G06F11/1008—Adding special bits or symbols to the coded information, e.g. parity check, casting out 9's or 11's in individual solid state devices
- G06F11/1068—Adding special bits or symbols to the coded information, e.g. parity check, casting out 9's or 11's in individual solid state devices in sector programmable memories, e.g. flash disk
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M13/00—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes
- H03M13/03—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words
- H03M13/05—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words using block codes, i.e. a predetermined number of check bits joined to a predetermined number of information bits
- H03M13/11—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words using block codes, i.e. a predetermined number of check bits joined to a predetermined number of information bits using multiple parity bits
- H03M13/1102—Codes on graphs and decoding on graphs, e.g. low-density parity check [LDPC] codes
- H03M13/1105—Decoding
- H03M13/1111—Soft-decision decoding, e.g. by means of message passing or belief propagation algorithms
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M13/00—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes
- H03M13/03—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words
- H03M13/05—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words using block codes, i.e. a predetermined number of check bits joined to a predetermined number of information bits
- H03M13/13—Linear codes
- H03M13/15—Cyclic codes, i.e. cyclic shifts of codewords produce other codewords, e.g. codes defined by a generator polynomial, Bose-Chaudhuri-Hocquenghem [BCH] codes
- H03M13/151—Cyclic codes, i.e. cyclic shifts of codewords produce other codewords, e.g. codes defined by a generator polynomial, Bose-Chaudhuri-Hocquenghem [BCH] codes using error location or error correction polynomials
- H03M13/152—Bose-Chaudhuri-Hocquenghem [BCH] codes
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M13/00—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes
- H03M13/03—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words
- H03M13/05—Error detection or forward error correction by redundancy in data representation, i.e. code words containing more digits than the source words using block codes, i.e. a predetermined number of check bits joined to a predetermined number of information bits
- H03M13/13—Linear codes
- H03M13/15—Cyclic codes, i.e. cyclic shifts of codewords produce other codewords, e.g. codes defined by a generator polynomial, Bose-Chaudhuri-Hocquenghem [BCH] codes
- H03M13/151—Cyclic codes, i.e. cyclic shifts of codewords produce other codewords, e.g. codes defined by a generator polynomial, Bose-Chaudhuri-Hocquenghem [BCH] codes using error location or error correction polynomials
- H03M13/1545—Determination of error locations, e.g. Chien search or other methods or arrangements for the determination of the roots of the error locator polynomial
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M13/00—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes
- H03M13/29—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes combining two or more codes or code structures, e.g. product codes, generalised product codes, concatenated codes, inner and outer codes
- H03M13/2903—Methods and arrangements specifically for encoding, e.g. parallel encoding of a plurality of constituent codes
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M13/00—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes
- H03M13/29—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes combining two or more codes or code structures, e.g. product codes, generalised product codes, concatenated codes, inner and outer codes
- H03M13/2906—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes combining two or more codes or code structures, e.g. product codes, generalised product codes, concatenated codes, inner and outer codes using block codes
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M13/00—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes
- H03M13/37—Decoding methods or techniques, not specific to the particular type of coding provided for in groups H03M13/03 - H03M13/35
- H03M13/3707—Adaptive decoding and hybrid decoding, e.g. decoding methods or techniques providing more than one decoding algorithm for one code
- H03M13/3715—Adaptation to the number of estimated errors or to the channel state
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M13/00—Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes
- H03M13/63—Joint error correction and other techniques
- H03M13/635—Error control coding in combination with rate matching
- H03M13/6362—Error control coding in combination with rate matching by puncturing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L27/00—Modulated-carrier systems
- H04L27/18—Phase-modulated carrier systems, i.e. using phase-shift keying
Abstract
디코딩되는 데이터 비트는 복수의 부분집합으로 분할된다. 각각의 부분집합은 상응하는 코드워드를 생성하도록 개별적으로 인코딩된다. 선택된 부분집합은 상응하는 코드워드로부터 제거되어 단축된 코드워드를 남기고 압축된 비트로 다 대 일 변형된다. 최종 코드워드는 단축된 코드워드와 압축된 비트의 조합이다. 최종 코드워드의 표현은 선택된 부분집합 및 복수의 나머지 부분집합으로 분할됨으로써 디코딩된다. 각각의 나머지 부분집합은 개별적으로 디코딩된다. 디코딩중 하나가 실패하면, 디코딩이 실패된 나머지 부분집합은 적어도 부분적으로 선택된 부부분집합에 따라 디코딩된다. 인코딩 및 디코딩이 시스테매틱이라면 선택된 부분집합은 패리티 비트이다.
Description
본 발명은 일반적으로 인코딩 및 디코딩 방법에 관한 것이다. 보다 상세하게는, 본 발명은 보다 짧은 서브코드를 인코딩 및 디코딩함으로써 코드의 에러 보정을 제공하는 방법 및 디바이스에 관한 것이다.
현재 이진값, 예를 들어, 1 및 0은 다양한 타입의 정보, 예를 들어, 메모리, 화상, 음성, 통계 정보등을 표현하고 통신하는데 사용된다. 불행하게도, 이진 데이터의 저장, 전송 및/또는 처리 동안, 의도하지 않은 에러가 유입될 수 있다(예를 들어, '1' 비트는 '0' 비트로 또는 그 반대로 변경될 수 있다).
이러한 에러의 존재를 극복하기 위한 당업계에 공지된 다수의 기술은 저장된 정보의 신뢰성을 확실히 하기 위해 에러 보정 코딩 방법을 사용한다. 저장 방법의 특성은 저장 셀 핵 당 정보 비트로서 표현될 수 있는 고정된 용량을 나타낸다. 이러한 고정된 용량은 각 저장 핵 셀내의 신호 대 노이즈 비(SNR)의 직접적인 결과이어서 ("샤논 리미트"로 알려진) 이론적인 상한값을 정의한다.
많은 경우에, 이러한 에러 보정 코딩 방법은 주어진 코드율에 대한 이론적인 보정 능력에 도달하기 위해 매우 긴 코드의 사용을 필요로 한다.
그러나, 코드 길이의 증가는 인코더 및 디코더 회로의 복잡도 및 면적 증가를 유발한다. 그결과, 이러한 에러 보정 코딩 방법을 포함하는 집적 회로를 구현하는 것은 어떤 면에서 더이상 실제적이거나 효율적이지 못하다. 대안으로, 스탠더드 디코딩 기술을 지원하기에는 불충분한 실리콘 밀도가 존재한다.
용어 "에러 보정"(즉, 에러의 검출 및 보정)은 여기에서 데이터 저장에 적용된다. 포워드 에러 보정 코드에 따라 인코딩 및 디코딩하는 단계는 소프트웨어 또는 하드웨어로 수행된다.
일단 샤논 리미트 [1]가 발견되었다면, 샤논의 정보 원리의 성능 리미트에 가까운 코드를 제공할 필요가 있었다. 이러한 리미트에 도달하기 위해 코드 길이를 증가시켜야 하는 [2]-[5]가 주지되어 있다. 1993년에, 베론 [6]은 반복적인 디코딩을 사용하여 근방 커패시티 도달 기술을 제시하는 첫번째였다. 그러나, 오직 긴 코드만이 고려되었다. 저밀도 패리티 체크(LDPC) 코드에 대한 [7]-[11]에 대해서, 이러한 커패시티 리미트에 보다 훨씬 더 가까운 새로운 구조는 긴 코드에 대해서만, 보통 대략 107 비트 길이에 대해서만 성공적으로 제시되었다.
LDPC 반복적 디코더에 기초한 특정 설계는 계산 유닛의 구현 복잡도, 반복수, 요구되는 메모리 사이즈등을 감소시키도록 크게 강조된 [12]-[14]에 설명된다.
이러한 긴 코드를 이들의 성능로부터 장점 및 복잡도 제한된 환경에서 구현하기 위해, 실제적인 보다 짧은 설계가 채용될 수도 있도록 긴 코드의 인코더 및 디코더의 회로 복잡도를 감소시키는 방법을 제공할 필요가 있다.
패리티 오버헤드를 감소시킴으로써 인코더 및 디코더의 회로 복잡도를 감소시키는 펑쳐링 방법을 개시하는 종래 기술이 Dror 등에게 허여된 미국 특허 출원 제 20050160350호에 제시되어 있다.
Dror 특허는 단일 비트 포워드 에러 보정을 제공하는 고속 데이터 인코더/디코더를 개시하고 있다. 이러한 데이터는 직방형 어레이에 보호되도록 배열되어 있어, 단일 비트 에러의 로케이션은 행 및 열 위치에 따라 결정된다. 결과적으로, 에러 신드롬을 에러 로케이션으로 전환하기 위하여 제공된 룩업 테이블의 크기는 감소된다.
그러나, Dror 특허에 개시된 2개의 계산 페이즈의 각각은 제1 페이즈에서 단일 에러를 보정하기 위한 충분한 정보를 제공하지 않기 때문에 자체로는 에러 보정 설계가 아니다. 따라서, 제1 페이즈는 제2 페이즈에서 얻어진 계산에 종속되지 않고 각각의 서브코드내의 단일 에러조차 보정할 수 없다.
본 발명에 따라, (a) 복수의 서브워드의 각각의 비트가 상기 코드워드의 표현의 비트의 진부분집합(proper subset)이 되도록 상기 코드워드의 표현으로부터 상기 복수의 서브워드를 생성하는 단계; (b) 상기 서브워드의 각각을 자체 비트에 따라, 상응하는 디코딩된 서브워드를 생성하도록 디코딩하는 단계; (c) 상기 서브워드중 하나의 서브워드의 디코딩이 실패한다면, 수정된 디코딩된 서브워드를 산출하기 위해, 디코딩이 실패된 상기 하나의 서브워드에 상응하는 상기 디코딩된 서브워드를 수정하는 단계;를 포함하고, 상기 수정하는 단계는 적어도 부분적으로, 적어도 하나의 성공적으로 디코딩된 서브워드의 상기 상응하는 디코딩된 서브워드에 따라 실행되는 코드워드의 표현 디코딩 방법이 제공된다.
본 발명에 따라, (a) N(<M)개의 비트의 워드를 디코딩하는 디코더; 및 (b) 상기 디코더를 M개의 비트의 워드로부터 선택된 N개의 비트의 상이한 부분집합의 각각에 개별적으로 적용하기 위한 매커니즘;을 포함하고, 상기 디코더의 각각의 적용은 상기 각각의 적용이 적용되는 상기 N개의 비트에 단독으로 종속되고, 상기 각각의 적용은 상응하는 디코딩된 데이터를 생성하여, M개의 비트의 워드의 최종 디코딩된 데이터가 적어도 부분적으로 상기 적용의 상기 상응하는 디코딩된 데이터에 따라 생성되고, 상기 적용중 하나가 실패하면, 상기 매커니즘은 적어도 부분적으로, 적어도 하나의 성공적인 적용의 상기 상응하는 디코딩된 데이터에 따라 상기 실패된 적용의 상기 상응하는 디코딩된 데이터의 수정을 행하는 M개의 비트의 워드 디코딩 장치가 제공된다.
본 발명에 따라, (a) N(<M)개의 비트의 워드를 각각 디코딩하는 복수의 디코더; 및 (b) 상기 복수의 디코더의 각각을 M개의 비트의 워드로부터 선택된 N개의 비트의 상이한 부분집합의 각각에 개별적으로 적용하기 위한 매커니즘;을 포함하고, 상기 복수의 디코더의 각각의 적용은 상기 각각의 적용이 적용되는 상기 N개의 비트에 단독으로 종속되고, 상기 각각의 적용은 상응하는 디코딩된 데이터를 생성하여, M개의 비트의 워드의 최종 디코딩된 데이터가 적어도 부분적으로 상기 적용의 상기 상응하는 디코딩된 데이터에 따라 생성되고, 상기 적용중 하나가 실패하면, 상기 매커니즘은 적어도 부분적으로, 적어도 하나의 성공한 디코더의 상기 상응하는 디코딩된 데이터에 따라 상기 실패된 디코더의 상기 상응하는 디코딩된 데이터의 수정을 행하는 M개의 비트의 워드 디코딩 장치가 제공된다.
본 발명에 따라, (a) 제1 그룹의 패리티 비트를 생성하기 위해 제1 인코딩 스킴에 따라 데이터 비트를 인코딩하는 단계; (b) 제2 그룹의 패리티 비트를 생성하기 위해 제2 인코딩 스킴에 따라 데이터 비트를 인코딩하는 단계; (c) 상기 제2 그룹의 패리티 비트를 압축된 그룹의 패리티 그룹으로 변형시키는 단계; 및 (d) 상기 제1 그룹의 패리티 비트를 상기 압축된 그룹의 패리티 비트와 조합하는 단계에 의해 상기 데이터 비트에 대한 최종 그룹의 패리티 비트를 생성하는 단계;를 포함하고, 상기 변형은 다 대 일(many-to-one)인 데이터 비트의 에러 보정 방법이 제공된다.
본 발명에 따라, (a) 데이터 비트의 각각이 복수의 부분집합에서 적어도 한번 나타나도록 상기 데이터 비트로부터 상기 복수의 부분집합의 비트를 생성하는 단계; (b) 상기 부분집합 각각에 대하여, 상응하는 적어도 하나의 제1 패리티 비트를 생성하도록 상응하는 제1 인코딩 스킴에 따라 상기 복수의 부분집합의 각 부분집합을 인코딩하는 단계; (c) 상기 부분집합에 대하여, 상응하는 적어도 하나의 제2 패리티 비트를 생성하기 위하여 상응하는 제2 인코딩 단계에 따라 상기 부분집합 각각을 인코딩하는 단계; (d) 상기 복수의 부분집합의 모두의 적어도 하나의 제2 패리티 비트의 모두를 조인트 압축된 패리티 비트로 변형시키는 단계; 및 (e) 상기 복수의 부분집합의 모두의 상기 적어도 하나의 제1 패리티 비트의 모두와 상기 조인트 압축된 패리티 비트를 조합하는 단계에 의해 데이터 비트에 대한 제1 그룹의 패리티 그룹을 생성하는 단계;를 포함하는 데이터 비트의 에러 보정 방법이 제공된다.
본 발명에 따라, (a) 데이터 비트의 각각이 복수의 부분집합에서 적어도 한번 나타나도록 상기 데이터 비트로부터 상기 복수의 부분집합의 비트를 생성하는 단계; (b) 상기 부분집합 각각에 대하여, 상응하는 적어도 하나의 제1 패리티 비트를 생성하도록 상응하는 인코딩 스킴을 사용하여 상기 복수의 부분집합의 각 부분집합을 인코딩하는 단계; (c) 상기 부분집합에 대하여, 상기 부분집합의 각각의 패리티의 상기 상응하는 적어도 하나의 패리티 비트 및 상기 부분집합의 각각의 비트 사이로부터 상응하는 선택된 부분집합을 선택하는 단계; (d) 상기 복수의 부분집합의 모두의 상기 선택된 부분집합을 조인트 압축된 선택된 비트로 변형시키는 단계; (e) 상기 부분집합의 각각의 비트를 상기 부분집합의 각각의 상기 상응하는 적어도 하나의 패리티 비트와 조합하는 단계 후에 상기 부분집합의 각각의 상기 상응하는 선택된 부분집합의 비트를 제거하는 단계에 의해 상기 부분집합의 각각에 대한 상응하는 단축된 코드워드를 생성하는 단계; 및 (f) 상기 복수의 부분집합의 모두의 상기 상응하는 단축된 코드워드와 상기 조인트 압축된 선택된 비트를 조합하는 단계에 의해 데이터 비트에 대한 코드워드르 생성하는 단계;를 포함하고, 상기 변형시키는 단계는 다 대 일 인 데이터 비트의 에러 보정 방법이 제공된다.
본 발명에 따라, (a) 데이터 비트의 각각이 복수의 부분집합에서 적어도 한번 나타나도록 상기 데이터 비트로부터 상기 복수의 부분집합의 비트를 생성하는 단계; (b) 상기 부분집합 각각에 대하여, 상응하는 코드워드를 생성하도록 상응하는 인코딩 스킴을 사용하여 상기 복수의 부분집합의 각각을 인코딩하는 단계; (c) 상기 부분집합의 각각에 대하여, 상기 상응하는 코드워드의 비트로부터 상응하는 선택된 부분집합을 선택하는 단계; (d) 상기 상응하는 코드워드의 모두의 상기 상응하는 선택된 부분집합을 조인트 압축된 선택된 비트로 변형시키는 단계; (e) 상기 상응하는 코드워드의 각각에 상응하는 상기 선택된 부분집합의 비트를 제거함으로써 상기 상응하는 코드워드의 각각에 대한 상응하는 단축된 코드워드를 생성하는 단계; 및 (f) 상기 복수의 부분집합의 모두의 상기 상응하는 단축된 코드워드를 상기 조인트 압축된 선택된 비트와 조합하는 단계에 의해 데이터 비트에 대한 코드워드를 생성하는 단계;를 포함하고, 상기 변형시키는 단계는 다 대 일인 데이터 비트의 에러 보정 방법이 제공된다.
본 발명에 따라, 상기 표현은 M개의 데이터 비트 및 P개의 패리티 비트를 포함하고, 상기 방법은, (a) P개의 패리티 비트를 제1 그룹의 패리티 그룹과 제2 그룹의 패리티 그룹으로 분할하는 단계; (b) 보정된 데이터 비트를 제공하기 위해 상기 제1 그룹의 패리티 비트만을 사용하여 M개의 데이터 비트를 디코딩하는 단계; 및 (c) 상기 제1 그룹의 패리티 비트만을 사용한 디코딩이 실패한다면, 상기 보정된 데이터 비트를 제공하기 위해 상기 제1 그룹의 패리티 비트 및 상기 제2 그룹의 패리티 비트를 사용하여 상기 M개의 데이터 비트를 디코딩하는 단계;를 포함하는 코드워드의 표현 디코딩 방법이 제공된다.
본 발명에 따라, (a) M개의 데이터 비트를 K(>1)개의 부분집합으로 분할하는 단계; (b) P개의 패리티 비트를 제1 그룹의 패리티 비트 및 제2 그룹의 패리티 비트로 분할하는 단계; (c) 상기 제1 그룹의 패리티 비트를 K개의 부분집합으로 분할하는 단계; (d) M개의 데이터 비트의 각 부분집합의 디코딩된 데이터를 생성하기 위해 상기 제1 그룹의 패리티 비트의 상응하는 부분집합에 따라 상기 M개의 데이터 비트의 상기 부분집합의 각각을 디코딩하는 단계; (e) 상기 M개의 데이터 비트의 상기 K개의 부분집합중 하나의 디코딩이 실패하면, 상기 하나의 부분집합의 상기 디코딩된 데이터를 생성하기 위해 적어도 부분적으로 상기 제2 그룹의 패리티 비트에 따라 상기 하나의 부분집합을 디코딩하는 단계; 및 (f) 상기 M개의 데이터 비트에 대한 전체 디코딩된 데이터를 생성하기 위해 상기 M개의 데이터 비트의 상기 K개의 부분집합 모두의 상기 인코딩된 데이터를 조합하는 단계;를 포함하고, 상기 M개의 데이터 비트의 각각은 상기 K개의 부분집합에 적어도 한번 나타내고, 상기 제1 그룹의 패리티 비트의 부분집합의 각각은 상기 M개의 데이터 비트의 각 부분집합에 상응하는 것을 특징으로 하는 M개의 데이터 비트 및 P개의 패리티 비트를 포함하는 코드워드의 표현 디코딩 방법이 제공된다.
본 발명에 따라, (a) 나머지 비트의 집합을 생성하기 위해 N개의 비트로부터 최대 N-M개의 비트의 선택된 부분집합을 제거하는 단계; (b) 상기 나머지 비트를 상기 나머지 비트의 K(>1)개의 부분집합으로 분할하는 단계; (c) 상기 각 부분집합의 디코딩된 데이터를 생성하기 위해 상기 각 부분집합의 비트만을 따라 상기 K개의 부분집합의 각각을 디코딩하는 단계; (d) 상기 K개의 부분집합중 하나의 디코딩이 실패하면, 상기 하나의 부분집합중 상기 디코딩된 데이터를 생성하기 위해, 적어도 부분적으로, 상기 제거된 선택된 부분집합에 따라 상기 하나의 부분집합을 디코딩하는 단계; 및 (e) 상기 M개의 데이터 비트에 대한 전체 디코딩된 데이터를 생성하기 위해 상기 K개의 부분집합의 모두의 상기 디코딩된 데이터를 조합하는 단계;를 포함하고, 상기 나머지 비트의 각각은 상기 K개의 부분집합의 적어도 하나의 멤버인, N(>M)개의 비트를 갖는 코드워드의 표현으로부터 M개의 데이터 비트를 디코딩하는 방법이 제공된다.
본 발명의 제1 특징은 코드워드의 표현을 디코딩하는 방법이다. 본 발명의 이러한 특징에서 그리고 본 발명의 다른 유사한 특징에서, 코드워드를 기록하고 그후 판독하는 단계가 코드워드에 에러를 도입할 수 있으므로, 저장기에 기록된 코드워드가 디코딩되는 것이 아니라, 코드워드의 표현이 디코딩된다. 코드워드의 기록 및 판독이 코드워드에 에러를 도입시키지 않는다면, 코드워드의 "표현"은 오리지널 코드워드와 동일하다. 코드워드의 기록 및 판독이 코드워드에 에러를 도입시킨다면, 코드워드의 "표현"은 오리지널 코드워드와 동일하지 않지만, 디코딩 프로세스에 의해 오리지널 코드워드로 변환될 수 있을 만큼 오리지널 코드워드와 충분히 유사한 것으로 가정되는 비트의 스트링일 뿐이다. 복수의 서브워드는 이러한 코드워드의 표현으로부터 생성되어 각 서브워드의 비트는 코드워드의 표현의 비트의 진부분집합이다. 각각의 서브워드는 상응하는 디코딩된 서브워드를 생성하도록 자체 비트에 따라 단독으로 디코딩된다. 서브워드중 하나의 디코딩이 실패한다면, 디코딩이 실패한 서브워드에 상응하는 디코딩된 서브워드가 수정되어 수정된 디코딩된 서브워드를 생성한다. 이러한 수정은 적어도 부분적으로, 하나 이상의 성공적으로 디코딩된 서브워드에 상응하는 디코딩된 서브워드에 따라 이루어진다.
하술된 바와 같이, "디코딩된 서브워드"의 용어의 범위는 서브워드를 성공적으로 디코딩함으로써 얻어진 숫자값 및 서브워드를 디코딩하는 시도가 실패하였다는 논리적 지시 모두를 포함한다. 서브워드를 성공적으로 디코딩함으로써 얻어진 숫자값이 오리지널 코드워드 자체의 일부이고, 단지 그 표현이 아니라는 것에 주목해야 한다. 즉, "성공적으로 디코딩된 서브워드"는 서브코드워드이다. 디코딩된 서브워드의 "수정"은 하나의 숫자값으로부터 다른 숫자값으로 또는 디코딩 실패의 논리적 지시로부터 숫자값으로 또는 숫자값으로부터 실패의 논리적 지시값으로부터, 디코딩된 서브워드를 변경시키는 것을 의미한다.
예를 들어, 아래 실시예 1에서, 2개의 서브워드  및
및  는 코드워드의 표현으로부터 생성된다. 각 서브워드는 [11,7,3] 디코더를 사용하여 별개로 디코딩된다.
는 코드워드의 표현으로부터 생성된다. 각 서브워드는 [11,7,3] 디코더를 사용하여 별개로 디코딩된다.  의 디코딩이 실패하고
의 디코딩이 실패하고  의 디코딩이 성공하면,
의 디코딩이 성공하면,  를 디코딩하는 시도가 실패하였다는 논리적 지시는 이러한 논리적 지시를
를 디코딩하는 시도가 실패하였다는 논리적 지시는 이러한 논리적 지시를  으로부터 디코딩된 C 1 으로 대체함으로써 수정된다. 이러한 수정은 성공적으로 디코딩된
으로부터 디코딩된 C 1 으로 대체함으로써 수정된다. 이러한 수정은 성공적으로 디코딩된  에 상응하는 서브코드워드 C 2 short 에 따라 이루어지고, C 2 short 는 P 2 를 생성하기 위해 [15,7,5] 인코더를 사용하여 인코딩되고, P 2 는
에 상응하는 서브코드워드 C 2 short 에 따라 이루어지고, C 2 short 는 P 2 를 생성하기 위해 [15,7,5] 인코더를 사용하여 인코딩되고, P 2 는  을 만들기 위해
을 만들기 위해  와 XOR되고,
와 XOR되고,  및
및  은
은  을 만들기 위해 연결된다.
을 만들기 위해 연결된다.
서브워드중 하나의 디코딩이 실패한다면, 수정된 디코딩된 서브워드로부터의 데이터는, 성공적으로 디코딩된 서브워드에 상응하는 디코딩된 서브워드 모두로부터의 데이터와 조합되는 것이 바람직하다. 예를 들어, 하기 실시예1에서,  의 디코딩이 실패하고
의 디코딩이 실패하고  의 디코딩이 성공한다면,
의 디코딩이 성공한다면,  으로부터 디코딩된 C 1 의 처음 7개의 비트는 헤더를 회복시키기 위해 C 2 short 의 처음 7개의 비트와 연결된다.
으로부터 디코딩된 C 1 의 처음 7개의 비트는 헤더를 회복시키기 위해 C 2 short 의 처음 7개의 비트와 연결된다.
수정된 디코딩된 서브워드로부터의 데이터를 성공적으로 디코딩된 서브워드에 상응하는 디코딩된 서브워드 모두로부터의 데이터와 조합하는 단계는 수정된 디코딩된 서브워드로부터의 데이터를 성공적으로 디코딩된 서브워드에 상응하는 디코딩된 서브워드 모두로부터의 데이터와 어셈블링하는 단계에 의해 수행되는 것이 가장 바람직하다. 2개 이상의 상이한 소스로부터의 데이터를 "어셈블링"하는 것은 여기에서, 가능하게는 변경되는 비트의 순서로, 그리고 가능하게는 적어도 한번 반복되는 하나 이상의 비트와 함께 모든 소스로부터의 비트를 함께 레지스터 또는 저장 로케이션내에 놓는 것으로 정의되어 있다. 그러나, 보통, 하기 실시예 1에서와 같이, 이러한 데이터는 이러한 비트의 순서를 변경하지 않고 그리고 비트를 반복하지 않고, 이러한 데이터의 다양한 소스로부터 비트를 단지 연결함으로써 "어셈블링"된다.
서브워드는 서로소인(disjoint) 것이 바람직하다. 예를 들어, 실시예 1에서,  및
및  는 서로소이다.
는 서로소이다.
서브워드는 모두 동일한 수의 비트를 포함하는 것이 바람직하다. 예를 들어, 하기 실시예 1에서,  및
및  는 11개의 비트를 포함한다.
는 11개의 비트를 포함한다.
본 발명의 제2 특징은 M개의 비트의 워드를 디코딩하기 위한 장치이다. 이 장치는 N(<M)개의 비트의 워드를 디코딩하기 위한 디코더 및 M개의 비트의 워드로부터 선택된 N개의 비트의 상이한 부분집합의 각각에 별개로 디코더를 적용하기 위한 매커니즘을 포함한다. 디코더의 각각의 적용은 적용이 적용되는 N개의 비트에 단독으로 종속된다. 디코더의 각 적용은 상응하는 디코딩된 데이터를 생성하여서, 최종 디코딩된 데이터는 적어도 부분적으로, 디코더의 적용에 의해 생성된 디코딩된 데이터에 따라 생성된다. 만약 디코더의 적용중 하나가 실패하면, 이러한 적용의 디코딩된 데이터는 적어도 부분적으로 디코더의 또 다른 적용에 의해 생성된 디코딩된 데이터에 따라 수정된다.
예를 들어, 하기 실시예 1에서, M=26, N=11 이고 디코더는 [11,7,3] 디코더이다. 11 비트 부분집합은  및
및  이다. [11,7,3] 디코더는 이러한 2개의 부분집합에 개별적으로 적용된다. 최종 디코딩된 데이터는 디코딩된 14-비트 헤더이다. 만약
이다. [11,7,3] 디코더는 이러한 2개의 부분집합에 개별적으로 적용된다. 최종 디코딩된 데이터는 디코딩된 14-비트 헤더이다. 만약  의 디코딩이 실패하고
의 디코딩이 실패하고  의 디코딩이 성공하면,
의 디코딩이 성공하면,  를 디코딩하는 시도가 실패하였다는 논리적 지시는 이러한 논리적 지시를
를 디코딩하는 시도가 실패하였다는 논리적 지시는 이러한 논리적 지시를  으로부터 디코딩된 C 1 으로 대체함으로써 수정된다. 이러한 수정은 성공적으로 디코딩된
으로부터 디코딩된 C 1 으로 대체함으로써 수정된다. 이러한 수정은 성공적으로 디코딩된  에 상응하는 디코딩된 서브워드
에 상응하는 디코딩된 서브워드  에 이루어지고,
에 이루어지고,  는 P 2 를 재생성하기 위해 [15,7,5] 인코더를 사용하여 인코딩되고, P 2 는
는 P 2 를 재생성하기 위해 [15,7,5] 인코더를 사용하여 인코딩되고, P 2 는  을 만들기 위해
을 만들기 위해  와 XOR되고,
와 XOR되고,  및
및  은
은  을 만들기 위해 연결된다.
을 만들기 위해 연결된다.
이러한 부분집합은 서로소인 것이 바람직하다. 예를 들어, 아래 실시예 1에서,  및
및  는 서로소이다.
는 서로소이다.
본 발명의 제3 특징은 M개의 비트의 워드를 디코딩하기 위한 장치이다.
이 장치는 각각 N(<M)개의 비트의 워드를 디코딩하는 복수의 디코더를 포함한다. 이 장치는 또한, M개의 비트의 워드로부터 선택된 N개의 비트의 상이한 부분집합에 별개로 각 디코더를 적용시키기 위한 매커니즘을 포함한다. 디코더의 각 적용은 디코더가 적용되고 있는 N개의 비트에만 단독으로 종속된다. 디코더의 각 적용은 상응하는 디코딩된 데이터를 생성하여서, M개의 비트의 워드의 최종 디코딩된 데이터가 적어도 부분적으로, 디코더를 적용함으로써 산출된 디코딩된 데이터에 따라 생성된다. 디코더중 하나가 실패하면, 상응하는 디코딩된 데이터는 적어도 부분적으로 또 다른 디코더에 의해 산출된 디코딩된 데이터에 따라 수정된다.
예를 들어, 아래 실시예 1에서, M=26, N=11이고 디코더는 [11,7,3] 디코더이다. 11-비트 부분집합은  및
및  이다. 각 [11,7,3] 디코더는 2개의 부분집합중 하나에 적용된다. 최종 디코딩된 데이터가 디코딩된 14 비트 헤더이다.
이다. 각 [11,7,3] 디코더는 2개의 부분집합중 하나에 적용된다. 최종 디코딩된 데이터가 디코딩된 14 비트 헤더이다.  의 디코딩이 실패하고
의 디코딩이 실패하고  의 디코딩이 성공하면,
의 디코딩이 성공하면,  를 디코딩하는 시도가 실패하였다는 논리적 지시는 이러한 논리적 지시를
를 디코딩하는 시도가 실패하였다는 논리적 지시는 이러한 논리적 지시를  으로부터 디코딩되는 C 1 으로 대체됨으로써 수정된다. 이러한 수정은 성공적으로 디코딩된
으로부터 디코딩되는 C 1 으로 대체됨으로써 수정된다. 이러한 수정은 성공적으로 디코딩된  에 상응하는 디코딩된 서브워드
에 상응하는 디코딩된 서브워드  에 따라 이루어지고,
에 따라 이루어지고,  는 P 2 를 재생성하기 위해 [15,7,5] 인코더를 사용하여 인코딩되고, P 2 는
는 P 2 를 재생성하기 위해 [15,7,5] 인코더를 사용하여 인코딩되고, P 2 는 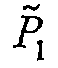 을 만들기 위해
을 만들기 위해  와 XOR되고,
와 XOR되고,  및
및  은
은  을 만들기 위해 연결된다.
을 만들기 위해 연결된다.
부분집합은 서로소인 것이 바람직하다. 예를 들어, 아래 실시예 1에서,  및
및  는 서로소이다.
는 서로소이다.
본 발명의 제4 태양은 데이터 비트의 에러 보정에 대한 스킴을 제공하는 방법이다. 데이터 비트는 제1 그룹의 패리티 비트를 생성하기 위해 제1 인코딩 스킴에 따라 인코딩된다. 이러한 데이터 비트는 제2 그룹의 패리티 비트를 생성하기 위해 제2 인코딩 스킴에 따라 인코딩된다. 제2 그룹의 패리티 비트는 다 대 일 변형에 의해 압축된 그룹의 패리티 비트로 변형된다. 최종 그룹의 패리티 비트는 제1 및 제2 그룹의 패리티 비트를 조합함으로써 생성된다.
예를 들어, 하기 실시예 1에서, 데이터 비트는 헤더의 14개의 비트이다. 제1 인코딩 스킴은  및
및  를 생성하는 [11,7,3] 스킴이다. 제1 그룹의 패리티 비트는
를 생성하는 [11,7,3] 스킴이다. 제1 그룹의 패리티 비트는 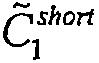 및
및  의 각각의 마지막 4개의 비트이다. 제2 인코딩 스킴은 제2 그룹의 패리티 비트, P 1 , P 2 를 생성하는 [15,7,5] 스킴이다. 제2 그룹의 패리티 비트는 다 대 일 변형 "XOR"에 의해 압축된 그룹 P로 변형된다(8개의 비트 인, 4개의 비트 아웃). 최종 그룹의 패리티 비트는 부재번호 246 및 254에 의해 도 8에 표시된 코드워드의 패리티 비트를 제공하기 위해
의 각각의 마지막 4개의 비트이다. 제2 인코딩 스킴은 제2 그룹의 패리티 비트, P 1 , P 2 를 생성하는 [15,7,5] 스킴이다. 제2 그룹의 패리티 비트는 다 대 일 변형 "XOR"에 의해 압축된 그룹 P로 변형된다(8개의 비트 인, 4개의 비트 아웃). 최종 그룹의 패리티 비트는 부재번호 246 및 254에 의해 도 8에 표시된 코드워드의 패리티 비트를 제공하기 위해 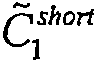 의 마지막 4개의 비트 및
의 마지막 4개의 비트 및  의 마지막 4개의 비트를 P와 조합함으로써 생성된다.
의 마지막 4개의 비트를 P와 조합함으로써 생성된다.
제1 그룹의 패리티 비트는 제1 그룹의 패리티 비트의 적어도 일부를 압축된 그룹의 패리티 비트와 어셈블링함으로써 압축된 그룹의 패리티 비트와 조합되는 것이 바람직하다. 예를 들어, 아래의 실시예1에서,  ,
,  및 P는 플래시 디바이스내의 공통 로케이션에 함께 기록되어
및 P는 플래시 디바이스내의 공통 로케이션에 함께 기록되어  의 마지막 4개의 비트,
의 마지막 4개의 비트,  의 마지막 4개의 비트는 함께 이러한 공통 로케이션에 저장된다.
의 마지막 4개의 비트는 함께 이러한 공통 로케이션에 저장된다.
변형시키는 단계는 제2 그룹의 패리티 비트의 복수의 부분집합을 XOR하는 단계를 포함하는 것이 바람직하다. 예를 들어, 아래의 실시예 1에서, P1 및 P2 는 XOR된다.
본 발명의 제5 특징은 데이터 비트의 에러 보정의 스킴을 제공하는 방법이다. 복수의 부분집합의 비트는 데이터 비트로부터 생성되어서, 각 데이터 비트는 부분집합 내에 적어도 한번 나타난다. 각 부분집합은 하나 이상의 상응하는 제1 패리티 비트를 생성하기 위해 상응하는 제1 인코딩 스킴에 따라 인코딩된다. 각 부분집합은 하나 이상의 상응하는 제2 패리티 비트를 생성하기 위해 상응하는 제2 인코딩 스킴에 따라 인코딩된다. 모든 제2 패리티 비트는 다 대 일 연산에 의해 조인트 압축된 패리티 비트로 변형된다. 최종 그룹의 패리티 비트는 조인트 압축된 패리티 비트와 제1 패리티 비트 모두를 조합함으로써 생성된다.
예를 들어, 하기 실시예 1에서, 데이터 비트는 헤더의 14개의 비트이다. 2개의 부분집합은 헤더의 처음 7개의 비트 및 헤더의 마지막 7개의 비트이다. 각 데이터 비트는 부분집합중 하나에 정확히 한번 나타나고 또 다른 부분집합에서는 전혀 나타나지 않는다. 제1 인코딩 스킴은 모두  및
및  를 생성하는 [11,7,3] 스킴이어서, 제2 부분집합에 대한 4개의 패리티 비트(C1 short 의 마지막 4개의 비트) 및 제2 부분집합에 대한 4개의 패리티 비트(C2 short 의 마지막 4개의 비트)를 생성한다. 제2 인코딩 스킴은 모두 제1 부분집합에 대한 4개의 패리티 비트 P1 및 제2 부분집합에 대한 4개의 패리티 비트 P2 를 생성하는 [15,7,5] 스킴이다. P1 및 P2 는 다 대 일 "XOR" 연산에 의해 압축된 그룹 P로 변형된다(8개의 비트 인, 4개의 비트 아웃). 최종 그룹의 패리티 비트는 C1 short , C2 short 및 P를 플래시 디바이스에 기록함으로써 C1 short 의 마지막 4개의 비트 및 C2 short 의 마지막 4개의 비트는 조합함으로써 생성된다.
를 생성하는 [11,7,3] 스킴이어서, 제2 부분집합에 대한 4개의 패리티 비트(C1 short 의 마지막 4개의 비트) 및 제2 부분집합에 대한 4개의 패리티 비트(C2 short 의 마지막 4개의 비트)를 생성한다. 제2 인코딩 스킴은 모두 제1 부분집합에 대한 4개의 패리티 비트 P1 및 제2 부분집합에 대한 4개의 패리티 비트 P2 를 생성하는 [15,7,5] 스킴이다. P1 및 P2 는 다 대 일 "XOR" 연산에 의해 압축된 그룹 P로 변형된다(8개의 비트 인, 4개의 비트 아웃). 최종 그룹의 패리티 비트는 C1 short , C2 short 및 P를 플래시 디바이스에 기록함으로써 C1 short 의 마지막 4개의 비트 및 C2 short 의 마지막 4개의 비트는 조합함으로써 생성된다.
제1 패리티 비트는 모든 제1 패리티 비트를 압축된 그룹의 패리티 비트와 어셈블링함으로써 압축된 그룹의 패리티 비트와 조합되는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, C 1 short , C 2 short 및 P는 플래시 디바이스에 함께 기록되어 C 1 short 의 마지막 4개의 비트, C 2 short 의 마지막 4개의 비트 및 P는 공통 로케이션에 함께 저장된다.
각각의 데이터 비트는 복수의 부분집합에 한번만 나타나는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, 헤더의 처음 7개의 비트의 각각은 제1 부분집합에 한번 나타나고 제2 부분집합에서는 전혀 나타나지 않고, 헤더의 마지막 7개의 비트의 각각은 제2 부분집합에 한번 나타나고 제1 부분집합에는 전혀 나타나지 않는다. 대안으로, 적어도 하나의 데이터 비트는 복수의 부분집합에서 적어도 2번 나타난다. 예를 들어, 아래의 실시예 2에서, 4096개의 정보 비트를 인코딩하기 위한, 586개의 코드워드내의 586x7=4102 데이터 비트가 존재하여서 예를 들어, 정보 비트중 하나는 6번 중복될 수 있다.
모든 부분집합은 동일한 사이즈를 갖는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, 양측 부분집합은 각각 7개의 비트를 갖는다.
부분집합중 적어도 하나의 부분집합에 대해, 상응하는 제1 및 제2 인코딩 스킴은 공통 인코딩 방법을 사용하여 얻어져서, 제1 인코딩 스킴은 제1 순서에 따라 부분집합의 비트를 인코딩하고 제2 인코딩 스킴은 제2 순서에 따라 부분집합의 비트를 인코딩한다. 예를 들어, 하기의 실시예 1에 대한 대안으로, [11,7,3] 인코딩이 헤더의 첫 7개의 비트 및 마지막 7개의 비트에 제1 인코딩 스킴으로서 개별적으로 적용될 수 있고, 그후에, 헤더의 첫 7개의 비트의 순서 및 헤더의 마지막 7개의 비트의 순서는 변경될 수 있고, 그후에 [11,7,3] 인코딩은 헤더의 변경된 첫 7개의 비트 및 마지막 7개의 비트에 제2 인코딩 스킴로서 개별적으로 적용될 수 있다. 압축된 패리티 비트는 변경된 첫 7개의 헤더 비트를 인코딩함으로써 산출된 코드워드의 마지막 4개의 비트를 변경된 마지막 7개의 헤더 비트에 의해 산출된 코드워드의 마지막 4개의 비트와 XOR함으로써 산출된다.
모든 부분집합은 공통 제1 인코딩 스킴에 따라 인코딩되는 것이 바람직하다. 예를 들어, 아래의 실시예 1에서, 공통 제1 인코딩 스킴은 [11,7,3] 인코딩 스킴이다.
모든 부분집합은 공통 제2 인코딩 스킴에 따라 인코딩되는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, 공통 제2 인코딩 스킴은 [15,7,3] 인코딩 스킴이다.
이러한 제2 패리티 비트를 조인트 압축된 패리티 비트로 변형시키는 단계는 부분집합중 하나에 상응하는 적어도 하나의 제2 패리티 비트를 부분집합의 다른 부분집합에 상응하는 적어도 하나의 제2 패리티 비트와 XOR하는 단계를 포함하는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, "제2 패리티 비트"의 2개의 그룹은 P1 및 P2 이고, P1 은 P2 와 XOR된다.
본 발명의 제6 특징은 데이터 비트에 대한 에러 보정에 대한 스킴을 제공하는 방법이다. 이러한 데이터 비트로부터 복수의 부분집합의 비트가 생성되어 각 데이터 비트는 부분집합에 적어도 한번 나타난다. 각 부분집합은 하나 이상의 상응하는 제1 패리티 비트를 생성하기 위해 상응하는 인코딩 스킴에 따라 인코딩된다. 각 부분집합에 대하여, 상응하는 선택된 부분집합이 부분집합의 비트 및 상응하는 패리티 비트로부터 선택된다. 이러한 선택된 부분집합의 모두는 다 대 일 연산에의해 조인트 압축된 선택된 비트로 변형된다. 각 부분집합에 대하여, 상응하는 단축된 코드워드는 상응하는 패리티 비트와 각 부분집합의 비트를 조합시킨 후에 상응하는 선택된 부분집합의 비트를 제거함으로써 생성된다. 결국, 데이터 비트에대한 코드워드는 모든 단축된 코드워드를 조인트 압축된 선택된 비트와 조합함으로써 생성된다.
예를 들어, 아래 실시예1에서, 데이터 비트는 헤더의 14개의 비트이다. 2개의 부분집합은 헤더의 첫 7개의 비트 및 헤더의 마지막 7개의 비트이다. 각 데이터 비트는 부분집합 중 하나에 정확하게 한번 나타나고 또 다른 부분집합에는 전혀 나타나지 않는다. 각 부분집합은 각각 8개의 패리티 비트를 포함하는 코드워드 C1 및 C2 를 생성하기 위해 [15,7,5] 인코더를 사용하여 인코딩된다. C1 및 C2 의 비트로부터, "선택된" 부분집합 P1 및 P2 는 다 대 일 연산 "XOR"에 의해 P의 조인트 압축된 선택된 비트로 변형된다(8개의 비트 인, 4개의 비트 아웃). 단축된 코드워드 C1 short 및 C2 short 는 완전 코드워드 C1 및 C2를 산출하기 위해 [15,7,5] 인코더에 의해 산출된 패리티 비트와 부분집합의 비트를 조합한 후에 선택된 부분집합 P1 을 C1 으로부터 제거하고 선택된 부분집합 P2 를 C2 로부터 제거함으로써 생성된다. 최종 코드워드는 C1 short 및 C2 short 및 P를 플래시 디바이스에 기록함으로써 C1 short 및 C2 short 및 P를 조합함으로써 생성된다.
각각의 부분집합의 비트는 부분집합의 비트를 상응하는 패리티 비트와 어셈블링함으로써 상응하는 패리티 비트와 조합된다. 예를 들어, 하기 실시예 1에서, 코드워드 C1 은 제1 부분집합을 인코딩함으로써 산출된 패리티 비트와 제1 부분집합을 연결시킴으로써 산출되고, 코드워드 C2 는 제2 부분집합을 인코딩함으로써 산출된 패리티 비트와 제2 부분집합을 연결시킴으로써 산출된다.
단축된 코드워드는 모든 단축된 코드워드를 조인트 선택된 압축된 비트와 어셈블링함으로써 조인트 선택된 압축된 비트와 조합되는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, C 1 short 및 C 2 short 및 P는 플래시 디바이스내의 공통 로케이션에 함께 저장된다.
각 데이터 비트는 복수의 부분집합에서 한번만 나타나는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, 헤더의 처음 7개의 비트의 각각은 제1 부분집합에 한번 나타나고 제2 부분집합에서는 전혀 나타나지 않고, 헤더의 마지막 7개의 비트의 각가은 제2 부분집합에 한번 나타나고 제1 부분집합에서는 전혀 나타나지 않는다. 대안으로, 적어도 하나의 데이터 비트는 복수의 부분집합에 적어도 2번 나타난다. 예를 들어, 하기 실시예 2에서, 4096개의 정보 비트를 인코딩하기 위해 586개의 코드워드내의 586x7=4102개의 데이터 비트가 존재하여서 예를 들어, 정보 비트의 하나가 6번 중복될 수 있다.
모든 부분집합은 동일한 사이즈를 갖는 것이 바람직하다. 예를 들어, 실시예 1에서, 양측 부분집합은 각각 7개의 비트를 갖는다.
모든 부분집합은 공통 인코딩 스킴에 따라 인코딩되는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, 공통 인코딩 스킴은 [15,7,5] 인코딩 스킴이다.
선택된 부분집합을 조인트 압축된 선택된 비트로 변형시키는 단계는 하나의 선택된 부분집합의 비트를 다른 선택된 부분집합의 비트와 XOR하는 단계를 포함한다. 예를 들어, 하기 실시예 1에서, P 1 및 P 2 는 XOR된다.
본 발명의 제7 특징은 데이터 비트의 에러 보정을 제공하는 방법이다. 복수의 부분집합의 비트는 데이터로부터 생성되어 각 데이터 비트는 부분집합에 적어도 한번 나타난다. 각 부분집합은 상응하는 코드워드를 생성하기 위해, 상응하는 인코딩 스킴을 사용하여 인코딩된다. 각 코드워드로부터, 비트의 상응하는 "선택된 부분집합"이 선택된다. 모든 선택된 부분집합은 다 대 일 변형에 의해 조인트 압축된 선택된 비트로 변형된다. 상응하는 단축된 코드워드는 코드워드로부터 상응하는 선택된 부분집합의 비트를 제거함으로써 각 코드워드에 대하여 생성된다. 데이터 비트에 대한 코드워드는 모든 단축된 코드워드를 조인트 압축된 선택된 비트와 조합함으로써 생성된다. 본 발명의 제7 특징이 데이터 비트로부터 구별가능한 패리티 비트를 사용할 필요가 없기 때문에 본 발명의 이러한 특징은 시스테매틱 및 논시스테미틱 인코딩 모두에 적용가능하다는 것에 주목해야 한다.
예를 들어, 하기 실시예 1에서, 데이터 비트는 헤더의 14개의 비트이다. 2개의 부분집합은 헤더의 처음 7개의 비트 및 헤더의 마지막 7개의 비트이다. 각 데이터 비트는 부분집합중 하나에 정확히 한번 나타나고 또 다른 부분집합에서는 전혀 나타나지 않는다. 부분집합은 상응하는 C1 및 C2 를 생성하기 위해 상응하는 [15,7,5] 인코딩 설게를 사용하여 인코딩된다. 선택된 부분집합 P1 은 C1 의 비트로부터 선택되고 선택된 부분집합 P2 는 C2 의 비트로부터 선택된다. P1 및 P2 는 다 대 일 "XOR" 연산에 의해 P로 변형된다(8개의 비트 인, 4개의 비트 아웃). 단축된 코드워드 C1 short 및 C2 short 는 C1 으로부터 P1 을 제거하고 C2 로부터 P2 를 제거함으로써 생성된다. 데이터 비트에 대한 코드워드는 전체로, C1 short, C2 short 및 P를 플래시 디바이스에 기록함으로써 C1 short, C2 short 를 P와 조합함으로써 생성된다,
단축된 코드워드는 모든 단축된 코드워드를 조인트 선택된 압축된 비트와 어셈블링함으로써 조인트 선택된 압축된 비트와 조합되는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, C 1 short , C 2 short 및 P는 플래시 디바이스내의 공통 로케이션에 함께 저장된다.
각 데이터 비트는 복수의 부분집합에 한번만 나타나는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, 헤더의 처음 7개의 비트의 각각은 제1 부분집합에 한번 나타나고 제2 부분집합에는 전혀 나타나지 않고, 헤더의 마지막 7개의 비트의 각각은 제2 부분집합에 한번 나타나고 제1 부분집합에는 전혀 나타나지 않는다. 대안으로, 적어도 하나의 데이터 비트는 복수의 부분집합에 적어도 2번 나타난다.
모든 부분집합은 동일한 사이즈를 갖는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, 양측 부분집합은 각각 7개의 비트를 갖는다.
모든 부분집합은 공통 인코딩 스킴에 따라 인코딩되는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, 공통 인코딩 스킴은 [15,7,5] 인코딩 스킴이다.
선택된 부분집합은 조인트 압축된 선택된 비트로 변형시키는 단계는 하나의 선택된 부분집합의 비트를 다른 선택된 부분집합의 비트와 XOR하는 단계를 포함하는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, P 1 및 P 2 는 XOR된다.
본 발명의 제8 특징은 M개의 데이터 비트 및 P개의 패리티 비트를 포함하는 코드워드의 표현을 디코딩하는 방법이다. P개의 패리티 비트는 제1 그룹의 패리티 비트와 제2 그룹의 패리티 비트로 분할된다. M개의 데이터 비트는 보정된 데이터 비트를 제공하기 위해 제1 그룹의 패리티 비트만을 사용하여 디코딩된다. 오직 제1 그룹의 패리티 비트를 사용하는 디코딩이 실패하면, M개의 비트는 보정된 데이터 비트를 제공하기 위해 양측 그룹의 패리티 비트를 사용하여 디코딩된다.
예를 들어, 하기 실시예 1에서, M=14이고 P=12이다. 14개의 데이터 비트는  의 처음 7개의 비트이고
의 처음 7개의 비트이고  의 처음 7개의 비트이다. 12개의 패리티 비트는
의 처음 7개의 비트이다. 12개의 패리티 비트는  의 마지막 4개의 비트,
의 마지막 4개의 비트,  의 마지막 4개의 비트 및
의 마지막 4개의 비트 및  이다. 제1 그룹의 패리티 비트는
이다. 제1 그룹의 패리티 비트는  의 마지막 4개의 비트 및
의 마지막 4개의 비트 및  의 마지막 4개의 비트이다. 제2 그룹의 패리티 비트는
의 마지막 4개의 비트이다. 제2 그룹의 패리티 비트는  이다. 데이터 비트는
이다. 데이터 비트는  의 처음 7개의 비트 및
의 처음 7개의 비트 및  의 처음 7개의 비트의 디코딩된 표현을 제공하기 위해 오직 제1 그룹의 패리티 비트와 함께 [11,7,3] 디코더를 사용하여 디코딩된다.
의 처음 7개의 비트의 디코딩된 표현을 제공하기 위해 오직 제1 그룹의 패리티 비트와 함께 [11,7,3] 디코더를 사용하여 디코딩된다.  의 디코딩이 실패하고
의 디코딩이 실패하고  의 디코딩이 성공하면, 디코딩된
의 디코딩이 성공하면, 디코딩된  는 P 2 를 재생성하기위해 [15,7,5] 인코더를 사용하여 인코딩되고, P 2 는
는 P 2 를 재생성하기위해 [15,7,5] 인코더를 사용하여 인코딩되고, P 2 는  을 만들기 위해
을 만들기 위해  와 XOR되고,
와 XOR되고,  및
및  은
은  을 만들기 위해 연결되고,
을 만들기 위해 연결되고,  은 [15,7,5] 디코더를 사용하여 디코딩된다.
은 [15,7,5] 디코더를 사용하여 디코딩된다.
본 발명의 제9 특징은 M개의 데이터 비트 및 P개의 패리티 비트를 포함하는 코드워드의 표현을 디코딩하는 방법이다. M개의 데이터 비트는 각각의 데이터 비트가 부분집합에 적어도 한번 나타나도록 2개 이상의 부분집합으로 분할된다. P개의 패리티 비트는 제1 그룹의 패리티 비트 및 제2 그룹의 패리티 비트로 분할된다. 제1 그룹의 패리티 비트는 데이터 비트 부분집합과 제1 그룹의 패리티 비트 부분집합 사이의 1:1 대응을 갖고 분할된다면 데이터 비트와 동일한 수의 부분집합으로 더 분할된다. 각 데이터 비트 부분집합은 상응하는 디코딩된 데이터를 생성하도록 그 상응하는 제1 패리티 비트 부분집합에 따라 디코딩된다. 이러한 디코딩중 하나가 실패하면, 디코딩이 실패한 데이터 비트 부분집합은 상응하는 디코딩된 데이터를 생성하기 위해 적어도 부분적으로 제2 그룹의 패리티 비트에 따라 다시 디코딩된다. 결국, 모든 데이터 비트 부분집합의 디코딩된 데이터는 M개의 데이터 비트에 대하여 전체 디코딩된 데이터를 생성하도록 조합된다.
예를 들어, 하기 실시예 1에서, M=14이고 P=12이다. 14개의 데이터 비트는 2개의 부분집합,  의 처음 7개의 비트 및
의 처음 7개의 비트 및  의 처음 7개의 비트로 분할된다. 제1 그룹의 패리티 비트는
의 처음 7개의 비트로 분할된다. 제1 그룹의 패리티 비트는  의 마지막 4개의비트 및
의 마지막 4개의비트 및  의 마지막 4개의 비트이다. 제2 그룹의 패리티 비트는
의 마지막 4개의 비트이다. 제2 그룹의 패리티 비트는 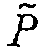 이다.
이다.  의 처음 7개의 비트에 상응하는 제1 패리티 비트의 부분집합은
의 처음 7개의 비트에 상응하는 제1 패리티 비트의 부분집합은  의 마지막 4개의 비트이다.
의 마지막 4개의 비트이다.  의 처음 7개의 비트에 상응하는 제1 패리티 비트의 부분집합은
의 처음 7개의 비트에 상응하는 제1 패리티 비트의 부분집합은  의 마지막 4개의 비트이다.
의 마지막 4개의 비트이다.  의 처음 7개의 비트는
의 처음 7개의 비트는 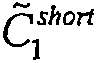 의 마지막 4개의 비트만을 사용하여 [11,7,3] 디코더에 의해 디코딩된다.
의 마지막 4개의 비트만을 사용하여 [11,7,3] 디코더에 의해 디코딩된다.  의 처음 7개의 비트는
의 처음 7개의 비트는  의 마지막 4개의 비트만을 사용하여 [11,7,3] 디코더에 의해 디코딩된다.
의 마지막 4개의 비트만을 사용하여 [11,7,3] 디코더에 의해 디코딩된다.  의 디코딩이 실패하고
의 디코딩이 실패하고  의 디코딩이 성공하면, 디코딩된
의 디코딩이 성공하면, 디코딩된  는 P 2 를 재생성하기 위해 [15,7,5] 인코더를 사용하여 인코딩되고, P 2 는
는 P 2 를 재생성하기 위해 [15,7,5] 인코더를 사용하여 인코딩되고, P 2 는  을 만들기 위해
을 만들기 위해  와 XOR되고,
와 XOR되고,  및
및  은
은  을 만들기 위해 연결되고,
을 만들기 위해 연결되고,  은 [15,7,5] 디코더를 사용하여 디코딩되어서, 코드워드 C 1 을 재생성한다. 반복된 C 1 의 처음 7개의 비트 및 디코딩된
은 [15,7,5] 디코더를 사용하여 디코딩되어서, 코드워드 C 1 을 재생성한다. 반복된 C 1 의 처음 7개의 비트 및 디코딩된  의 처음 7개의 비트는 디코딩된 14-비트 헤더를 생성하기 위해 연결된다.
의 처음 7개의 비트는 디코딩된 14-비트 헤더를 생성하기 위해 연결된다.
데이터 비트 부분집합의 디코딩된 데이터는 데이터 비트 부분집합의 디코딩된 데이터를 어셈블링함으로써 조합된다. 예를 들어, 하기 실시예 1에서, 디코딩된  의 처음 7개의 비트 및 디코딩된
의 처음 7개의 비트 및 디코딩된  의 처음 7개의 비트는 디코딩된 14-비트 헤더를 생성하기 위해 연결된다.
의 처음 7개의 비트는 디코딩된 14-비트 헤더를 생성하기 위해 연결된다.
데이터 비트 부분집합은 서로소인 것이 바람직하다. 예를 들어, 하기 실시예 1에서,  의 처음 7개의 비트 및
의 처음 7개의 비트 및  의 처음 7개의 비트는 2개의 서로소인 부분집합이다.
의 처음 7개의 비트는 2개의 서로소인 부분집합이다.
데이터 비트 부분집합 모두는 동일한 크기를 갖는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, 모든 데이터 비트 부분집합은 7개의 비트를 포함한다.
각각의 데이터 비트 부분집합은 상응하는 제1 디코딩 스킴을 사용하여 상응하는 제1 패리티 비트 부분집합에 따라 디코딩되고, 제2 그룹의 패리티 비트에 따라, 제1 디코딩 스킴에 의한 디코딩이 실패한 데이터 비트 부분집합의 디코딩은 상응하는 제2 디코딩 스킴을 사용하는 단계를 포함한다. 예를 들어, 하기 실시예 1에서, 제1 디코딩 스킴은 [11,7,3] 스킴이고 제2 디코딩 스킴은 [15,7,3] 스킴이다.
데이터 비트 부분집합의 적어도 하나에 대하여, 상응하는 제1 및 제2 디코딩 스킴은 공통 디코딩 방법을 적용한다. 예를 들어, 본 발명의 제5 특징의 실시예 1에 대한 대안에서, 제1 디코딩 스킴 및 제2 디코딩 스킴 모두는 [11,7,3] 스킴이다. 제1 디코딩 스킴은 변경되지 않은 헤더 비트의 인코딩에 의해 생성된 저장된 패리티 비트를 사용한다. 첫 1개의 저장된 데이터 비트의 디코딩이 실패하고 마지막 7개의 저장된 데이터 비트의 디코딩이 성공하면, 성공적으로 디코딩된 데이터 비트는 변경되고 인코딩되어 상응하는 패리티 비트를 재생성하게 된다. 이러한 재생성된 패리티 비트는 첫 7개의 변경된 헤더 비트의 패리티 비트를 재생성하기 위해 마지막 4개의 저장된 패리티 비트와 XOR되고, 이것은 변경된 첫 7개의 저장된 데이터 비트의 [11,7,3] 디코딩을 실행함으로써 첫 7개의 저장된 데이터 비트를 디코딩하는 제2 시도에서 사용된다.
모든 제1 디코딩 스킴은 동일한 것이 바람직하다. 예를 들어, 하기 실시예 1에서, 모든 제1 디코딩 스킴은 동일한 [11,7,3] 스킴이다.
모든 제2 디코딩 스킴은 동일한 것이 바람직하다. 예를 들어, 하기 실시예 1에서, 모든 제2 디코딩 스킴은 동일한 [15,7,5] 스킴이다.
본 발명의 제10 특징은 N(>M)개의 비트를 갖는 코드워드의 표현으로부터 M개의 데이터 비트를 디코딩하는 방법이다. 최대 N-M개의 비트의 선택된 부분집합은 N개의 비트로부터 제거되어, 나머지 비트의 집합을 산출한다. 나머지 비트는 2개 이상의 부분집합으로 분할되어 각 나머지 비트는 부분집합의 적어도 하나의 멤버이다. 각 나머지 비트 부분집합은 상응하는 디코딩된 데이터를 생성하기 위해 오직 자체 비트에 따라서 디코딩된다. 나머지 비트 부분집합중 하나의 디코딩이 실패하면, 나머지 비트 부분집합은 나머지 비트 부분집합의 상응하는 디코딩된 데이터르 생성하도록, 적어도 부분적으로 제거된 선택된 부분집합에 따라 디코딩된다. 결국, 모든 디코딩된 데이터는 M개의 데이터 비트에 대한 전체 디코딩된 데이터를 생성하도록 조합된다. 본 발명의 제10 특징이 데이터 비트로부터 분리되고 구별가능한 패리티 비트를 사용할 필요가 없기 때문에, 본 발명의 이러한 특징은 시스테매틱 인코딩 및 논시스테매틱 인코딩 모두에 적용가능하다는 것에 주목해야 한다.
예를 들어, 하기 실시예 1에서, M=14 이고 N=26이다. 제거된 선택된 부분집합은  이다. 나머지 비트는 2개의 부분집합
이다. 나머지 비트는 2개의 부분집합  및
및  으로 분할된다.
으로 분할된다.  는 다른 정보가 아닌 자체 11개의 비트에 따라서만 디코딩되고, 산출되는 디코딩된 워드의 첫 7개의 비트는
는 다른 정보가 아닌 자체 11개의 비트에 따라서만 디코딩되고, 산출되는 디코딩된 워드의 첫 7개의 비트는  에 상응하는 디코딩된 데이터이다.
에 상응하는 디코딩된 데이터이다.  는 다른 정보가 아닌 자체 11개의 비트에 따라서만 디코딩되고, 산출되는 디코딩된 워드의 첫 7개의 비트는
는 다른 정보가 아닌 자체 11개의 비트에 따라서만 디코딩되고, 산출되는 디코딩된 워드의 첫 7개의 비트는  에 상응하는 디코딩된 데이터이다.
에 상응하는 디코딩된 데이터이다.  의 디코딩이 실패하고
의 디코딩이 실패하고  의 디코딩이 성공하면, 디코딩된
의 디코딩이 성공하면, 디코딩된  는 P 2 를 재생성하기 위해 [15,7,5] 인코더를 사용하여 인코딩되고, P 2 는
는 P 2 를 재생성하기 위해 [15,7,5] 인코더를 사용하여 인코딩되고, P 2 는  을 만들기 위해
을 만들기 위해  와 XOR되고,
와 XOR되고,  및
및  은
은  을 만들기 위해 연결되고,
을 만들기 위해 연결되고,  은 [15,7,5] 디코더를 사용하여 디코딩된다. 디코딩된 C 1 short 의 첫 7개의 비트 및 디코딩된 C 2 short 의 첫 7개의 비트는 디코딩된 14-비트 헤더를 생성하도록 연결된다.
은 [15,7,5] 디코더를 사용하여 디코딩된다. 디코딩된 C 1 short 의 첫 7개의 비트 및 디코딩된 C 2 short 의 첫 7개의 비트는 디코딩된 14-비트 헤더를 생성하도록 연결된다.
나머지 비트 부분집합의 디코딩된 데이터는 나머지 비트 부분집합의 디코딩된 데이터를 어셈블링함으로써 조합된다. 예를 들어, 하기 실시예 1에서, 디코딩된 C 1 short 의 첫 7개의 비트 및 디코딩된 C 2 short 의 첫 7개의 비트는 디코딩된 14-비트 헤더를 생성하기 위해 연결된다.
나머지 비트 부분집합은 서로소인 것이 바람직하다. 예를 들어, 하기 실시예 1에서,  의 처음 7개의 비트 및
의 처음 7개의 비트 및  의 처음 7개의 비트는 2개의 서로소인 부분집합이다.
의 처음 7개의 비트는 2개의 서로소인 부분집합이다.
모든 나머지 비트 부분집합은 동일한 사이즈를 갖는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, 모든 데이터 비트 부분집합은 7개의 비트를 포함한다.
각 나머지 비트 부분집합은 상응하는 제1 디코딩 스킴을 사용하여 자체 비트에 따라 디코딩되고, 제1 디코딩 스킴에 의한 디코딩이 실패한 나머지 비트 부분집합의, 제거된 선택된 부분집합에 따른 디코딩은 상응하는 제2 디코딩 스킴을 사용하는 단계를 포함하는 것이 바람직하다. 예를 들어, 하기 실시예 1에서, 제1 디코딩 스킴은 [11,7,3] 스킴이고 제2 디코딩 스킴은 [15,7,5] 스킴이다.
나머지 비트 부분집합중 적어도 하나에 대하여, 상응하는 제1 및 제2 디코딩 스킴은 공통 디코딩 방법을 적용하는 것이 바람직하다. 예를 들어, 본 발명의 제5 특징의 실시예 1에 대한 대안에서, 제1 디코딩 스킴 및 제2 디코딩 스킴 모두는 [11,7,3] 스킴이다. 제1 디코딩 스킴은 변경되지 않는 헤더 비트의 인코딩에 의해 생성된 저장된 패리티 비트를 사용한다. 첫 7개의 저장된 데이터 비트의 인코딩이 실패하고 마지막 7개의 저장된 데이터 비트의 디코딩이 성공하면, 성공적으로 디코딩된 데이터 비트는 변경되고 인코딩되어 상응하는 패리티 비트를 재생성한다. 이러한 재생성된 패리티 비트는 첫 7개의 변경된 헤더 비트의 패리티 비트를 재생성하도록 마지막 4개의 저장된 패리티 비트와 XOR되고, 변경된 첫 7개의 저장된 데이터 비트의 [11,7,3] 디코딩을 실행함으로써 첫 7개의 저장된 데이터 비트를 디코딩하는 제2 시도에서 사용된다.
모든 제1 디코딩 스킴은 동일한 것이 바람직하다. 예를 들어, 하기 실시예 1에서, 모든 제1 디코딩 스킴은 동일한 [11,7,3] 디코딩 스킴이다.
모든 제2 디코딩 스킴은 동일하다. 예를 들어, 하기 실시예 1에서, 모든 제2 디코딩 스킴은 동일한 [15,7,5] 디코딩 스킴이다.
본 발명의 실시예에 관하여 본 발명을 보다 잘 이해하기 위해, 동일한 부재번호가 상응하는 섹션 또는 요소에 지정된 첨부된 도면에 대하여 설명한다.
도 1은 본 발명의 디바이스의 바람직한 실시예의 블록도이다.
도 2는 도 1의 다상 인코더를 포함하는 컴포넌트의 블록도이다.
도 3은 도 2의 상태 머신 컨트롤 로직 블록에서 수행되는 인코딩 프로세스의 순서도이다.
도 4은 도 1의 다상 디코더를 포함하는 컴포넌트의 블록도이다.
도 5는 도 4의 듀얼 모드 디코더 유닛을 포함하는 컴포넌트의 블록도이다.
도 6은 실시예 1에 관한 디코딩 프로세스의 순서도이다.
도 7은 실시예 2에 관한 디코딩 프로세스의 순서도이다.
도 8은 실시예 1에 관한 인코딩 프로세스의 개략도이다.
도 9는 실시예 2에 관하여 블록 코드[15,7,5]에 대한 생성기 매트릭스의 도면이다.
도 10은 실시예 1 및 실시예 2에 관한, 블록 코드[15,7,5]에 대한 생성기 매트릭스의 도면이다.
도 11은 실시예 1 및 실시예 2에 관한, 브록 코드 [15,7,5]에 대한 패리티 체크 매트릭스 'H'의 도면이다.
도 12은 실시예 1 및 실시예 2에 관한, 블록 코드 [15,7,5]에 대한 듀얼 에러 로케이션의 테이블 도면이다.
도 13은 실시예 1 및 실시예 2에 관한, 블록 코드 [11,7,3]에 대한 패리티 체크 매트릭스 H (1) 의 도면이다.
도 14는 실시예 1에 관한, 블록 코드 [11,7,3]에 대한 단일 에러 로케이션의 테이블 도면이다.
도 1은 본 발명의 디바이스의 바람직한 실시예의 블록도이다.
도 2는 도 1의 다상 인코더를 포함하는 컴포넌트의 블록도이다.
도 3은 도 2의 상태 머신 컨트롤 로직 블록에서 수행되는 인코딩 프로세스의 순서도이다.
도 4은 도 1의 다상 디코더를 포함하는 컴포넌트의 블록도이다.
도 5는 도 4의 듀얼 모드 디코더 유닛을 포함하는 컴포넌트의 블록도이다.
도 6은 실시예 1에 관한 디코딩 프로세스의 순서도이다.
도 7은 실시예 2에 관한 디코딩 프로세스의 순서도이다.
도 8은 실시예 1에 관한 인코딩 프로세스의 개략도이다.
도 9는 실시예 2에 관하여 블록 코드[15,7,5]에 대한 생성기 매트릭스의 도면이다.
도 10은 실시예 1 및 실시예 2에 관한, 블록 코드[15,7,5]에 대한 생성기 매트릭스의 도면이다.
도 11은 실시예 1 및 실시예 2에 관한, 브록 코드 [15,7,5]에 대한 패리티 체크 매트릭스 'H'의 도면이다.
도 12은 실시예 1 및 실시예 2에 관한, 블록 코드 [15,7,5]에 대한 듀얼 에러 로케이션의 테이블 도면이다.
도 13은 실시예 1 및 실시예 2에 관한, 블록 코드 [11,7,3]에 대한 패리티 체크 매트릭스 H (1) 의 도면이다.
도 14는 실시예 1에 관한, 블록 코드 [11,7,3]에 대한 단일 에러 로케이션의 테이블 도면이다.
본 발명은 저장된 정보의 신뢰도를 보장하기 위해 에러 보정 코딩 기술을 제공하는 방법 및 디바이스를 개시하고 있다. 제안된 방법은 긴 코드의 인코더 및 디코더의 회로 복잡성을 피하면서 긴 코드을 실행하게 한다. 그래서, 하드웨어 및 소프트웨어 구현의 사이즈 및 복잡도 감소가 얻어진다.
여기에서, 용어 "디코딩된 데이터의 수정"은 디코딩된 데이터의 제1 값으로부터 디코딩된 데이터의 제2 값으로의 수정을 말한다. 본 발명의 방법에 따라, 특정 짧은 코드 워드 표현의 디코딩된 데이터의 수정은 다른 짧은 코드 워드 표현에 기초하여 이루어진다. 따라서, 디코딩이 실패된 코드 워드 표현에 대한 추가 디코딩 시도는 다른 짧은 코드 워드 표현의 디코딩된 데이터에 따라 수행된다.
여기에서, 용어 "코드 워드의 디코딩된 데이터의 값"은 임의의 유효한 수치값을 말한다. 대안으로, 이러한 용어는 예를 들어, 디코딩이 실패했기 때문에 아무런 현재 공지된 값이 없는 로직 표시를 가리킨다. 그래서, 디코딩된 데이터의 "수정"은 유효한 수치 값으로부터 다른 유효 수치값으로의 수정, 디코딩 실패의 로직 표시로부터 유효 수치값으로의 수정, 또는 유효 수치값으로부터 디코딩 실패의 로직 표시로의 수정일 수 있다.
여기에서, 용어 "부분집합"은 부분집합이 되는 전체 집합보다 작은 진부분집합 및 그 전체 집합 자체를 가리키기도 한다.
다른 짧은 워드의 디코딩된 데이터에 따른 하나의 짧은 워드의 디코딩된 데이터의 수정은 본 발명에서 옵션으로 제공되고 롱 코드 워드를 디코딩하는 각 예 동안 반드시 발생하는 것은 아니라는 것을 이해해야 한다. 특정 에러가 발생하는 롱 워드의 특정 예에 대하여, 상기 수정은 모든 짧은 코드 워드 표현이 제1 시도에서 성공적으로 디코딩되는 케이스일 수 있다. 이러한 경우에, 디코딩된 데이터의 수정은 전혀 적용되지 않는다. 이러한 수정은 적어도 하나의 짧은 워드에 대하여 실패된 디코딩의 경우에만 수행된다. 따라서, 용어 "수정을 행한다"는 "필요에 따라 수정을 선택적으로 행한다"를 의미한다.
본 발명의 방법의 바람직한 실시예는 여기에 실시예 1 및 실시예 2를 통해 설명된다. 이 두가지 실시예는 에러 보정 코딩 기술을 제공하는 디바이스를 개시하는데, 이러한 디바이스는 특히, 데이터 저장의 사용을 적합하다. 그래서, 본 발명의 바람직한 디바이스는 디코딩 프로세스에서 추가 단계를 적용하기 위해 특정 워드에 대한 딜레이를 증가시키도록 제공된 디코더를 포함한다. 피크 딜레이(잘 일어나지 않는다)로 인해, 이러한 에러 보정 코딩 기술은 고정된 제한된 딜레이를 갖고 동기 또는 세미 동기 스트림을 적용시키는 일부 통신 시스템에 적합하지 않을 수도 있다.
본 발명의 방법에 의해 동입된 평균 딜레이는 당업계에 공지된 방법보다 높지 않다는 것을 강조한다. 그러나, 이러한 딜레이가 상당히 증가하는 드문 경우에, 본 발명의 방법은 저장 매체에 특히 적합하고 동기 통신 시스템에 덜 적합하다.
실시예
1
핵셀 당 하나의 비트가 존재하고 셀 에러율(CER)이 4.7×10-5인, 독립 비트를 포함하는 플래시 디바이스가 제공된다. 플래시 메모리가 셀당 하나의 비트를 가지고 있기 때문에, 비트 에러율(BER)은 또한 4.7×10-5이다. 플래시 디바이스의 플래시 메모리는 많은 블록을 포함하고, 각 블록은 다수의 페이지를 가지고 있다. 각 페이지는 각각 512 데이터 바이크 길이를 갖는 다수의 섹터 및 헤더 또는 컨트롤 영역을 포함한다. 14 비트를 포함하는 각 블록의 헤더에 대한 신뢰할만한 저장용량을 제공하고 10-10보다 낮은 헤더 에러율(HER) 성능을 달성하면서(HER < 10-10) 플래시 디바이스에 대한 플래시 컨트롤러내에 에러 보정 코딩 기술을 설계할 필요가 있다.
3 비트 에러 보정 확률이 4.7×10-5의 입력 CER를 가진 14 비트의 세트에 대한 HER < 10-10의 성능 목적을 제공하기 위해 필요하다. 하나의 에러의 보정(즉, t=1)은 HER~3.8×10- 7를 제공하고 2개의 에러의 보정(즉, t=2)은 HER~2.1×10-10을 제공한다.
그래서, 3개의 에러 보정 [229,14] BCH 코드가 필요한데, 코드율 R은 0.4828(즉, 14/29)이고 헤더는 길이 29 비트의 하나의 코드 워드를 사용하여 표현된다.
이러한 회로를 구성하는 방법을 포함하는 BCH 코드의 코딩 및 디코딩의 문헌은 수년동안 철저하게 연구되었다(참조문헌 [16]-[47] 참조). 코딩 및 디코딩의 일예가 본 발명의 방법을 채용하면서 동일한 HER 목표 성능을 얻기 위해 제공된다. 하술된 예는 3개의 에러 대신에 오직 2개의 에러만을 보정할 수 있는 컴포넌트 코드를 포함하는 단순화된 컨트롤러를 사용한다. 또한, 감소된 길이가 반드시 컴포넌트 코드가 보정하는 에러의 수(3보다 2)의 직접적인 결과는 아니고 전체 기술 구조와 주로 관련되어 있기 때문에, 코드 길이는 29 비트 코드 대신에 각 헤드에 대한 오직 26 비트만을 필요로 한다(즉, R의 보다 높은 코드율 = 14/26 = 0.5385가 달성된다). 플래시 헤더 사이즈에서의 이득 감소는 11.54%이다. 이러한 장점은 다음의 제한되지 않는 예에서 달성된다.
[29,14]BCH 코드 대신에, [15,7,5] 블록 코드가 설계된다(그래서 인코더/디코더 하드웨어에 대한 복잡도가 감소된다). 표기 [n,k,d]는 보통 다음과 같이 코드 파라미터를 정의한다: 'n'은 코드 길이를 나타내고, 'k'은 정보 비트의 수를 나타내고, 'd'는 이러한 코드의 최소 해밍 거리를 나타낸다.
이러한 코드를 주의깊게 선택함으로써 3의 최소 해밍 거리를 얻는 (비트 12-15를 추출함으로써) [11,7,3]을 얻는다. 따라서, 이러한 평쳐링된 코드를 사용하여 단일 에러를 보정하는 것이 가능하다. 이러한 관찰에 기초하여, 2 비트의 에러 보정 확률을 갖는 15 비트 코드가 개시된다. 이러한 15 비트 코드는 마지막 4개의 비트르 제거할 때, 즉, 오직 최초 11 비트만을 사용할 때 임의의 단일 에러를 보정하도록 제공된다.
이러한 [15,7,5] 블록 코드에 대한 생성기 매트릭스(270)는 도 10에 도시되어 있다. 인코딩 프로세스, 즉, 7 정보 비트로부터의 8 패리티 비트의 유도는 다음과 같은 GF(2)에 대한 매트릭스 승산 연산을 사용하여 적용된다:
c = m ㆍG, [ c ] = 1×15, [ m ] = 1×7, [G] = 7×15 (1.1)
여기에서, GF(2)는 2개의 요소를 갖는 갈루아 유한 필드(Galois Finite Field)에 대한 표시이고, ' c '는 코드 워드를 포함하는 행 벡터로서 정의되고, ' m '은 7 정보 비트를 포함하는 행 벡터로서 정의되고, 'G'는 시스테메틱 인코딩 매트릭스로서 정의된다.
[15,7,5] 선형 시스테메틱 블록 코드의 디코딩 프로세스는 2개의 단계로 실행된다. 단계 1에서, 8 비트 신드롬은 도 11에 도시된 바와같이 블록 코드 [15,7,5]의 패리티 체크 매트릭스 'H'를 사용하여 계산된다. 이러한 신드롬 계산은 다음과 같이 GF(2)에 대하여 매트릭스 승산 연산을 사용하여 수행된다:
s =Hㆍc T , [ c ]=1×15, [ s ]=8×1, [H]=8×15 (1.2)
여기에서, ' c '는 코드 워드의 행 벡터이고, ' s '는 8 비트 신드롬을 포함하는 열 벡터이고, 'H'는 패리티 체크 매트릭스이고, 표시 () T 는 이항을 의미하여, c T 는 열 벡터이다.
단계 1에서, 8 비트 신드롬은 테이블(290; 도 12 참조)에 액세스하는데 사용된다. 테이블(290)은 2개의 4비트 수들을 제공하여 이러한 4 비트 수의 각각은 15 비트 코드 워드내의 단일 에러의 로케이션을 한정한다.
테이블(290)내의 값 '0'은 '노 에러'의 경우를 나타낸다는 것에 주목해야 한다. 테이블(290)이 그 값의 하나가 제로이고 또 다른 값이 논 제로인 경우에 특정 엔트리내에 2개의 수를 포함하는 경우에는, 2개가 아닌 오직 하나의 에러가 존재함을 지시한다. 또한, 신드롬 자체내의 제로는 전혀 에러가 없음을 나타낸다. 이러한 신드롬 벡터의 최상단 비트가 LSB(최하위 비트)이고, 최하단 비트가 MSB(최상위 비트)임을 가정하여 신드롬 값이 얻어진다. (이러한 신드롬의 256 가능한 값의)오직 121개의 값만이 테이블에 제시되어 있음에 주목해야 한다. 디코더가 또한 에러 검출 기능을 포함하고 있기 때문에, 테이블(290)내에 제시되어 있지 않은 경우에, (도 12 참조) 2개 보다 많은 에러가 존재한다. 그러나, 디코더는 그 에러들의 로케이션를 가리킬 수 없다.
이러한 코드가 생성되는 특별한 방법으로 인해, 단일 비트의 보정에 대한 서브 매트릭스 'H (1) '가 제공된다. 단일 비트의 보정은 동일한 코드 워드의 첫 11개의 비트에 적용된다. 서브 매트릭스 'H (1) '는 "H" 매트릭스의 첫 4개의 행 및 첫 1개의 열을 포함한다. 15 비트 워드의 첫 11개의 비트의 디코딩 프로세스는 다음과 같이 2개의 유사한 단계에서 적용된다.
제1 단계에서, 상술된 바와 같이, 신드롬 계산은 다음과 같이 GF(2)에 대한 매트릭스 승산에 의해 얻어진다.
s =H (1) ㆍc T , [ c ]=1×11, [ s ]=4×1, [H]=4×11 (1.3)
여기에서, ' c '는 판독 워드를 포함하는 행 벡터이고, ' s '는 4 비트 신드롬을 포함하는 열 벡터이고, H (1) 는 매트릭스 'H'의 상기 첫 4개의 행 및 상기 제1 열을 포함하는 "H"의 서브매트릭스이다. 블록 코드 [11,7,3](300)의 매트릭스 H (1) 는 도 13에 도시되어 있다.
디코딩 프로세스의 제2 단계에서, 에러 로케이션은 4 비트 신드롬(310; 도 14 참조)으로부터 추출된다. '0' 값을 갖는 신드롬 비트는 '노 에러'의 경우를 정의한다.
15 비트 코드 워드의 첫 11개의 비트의 성공적인 디코딩시에, (1,1)의 매트릭스 'G'는 15 비트 코드 워드의 마지막 4개의 비트가 디코더에 제공되지 않더라도, 이러한 마지막 4개의 비트를 나타내도록 사용될 수 있다. 첫 11개의 비트가 이미 디코딩되어 있기 때문에, 인코더의 크기는 11개의 디코딩된 비트로중 첫 7개의 비트로부터 직접 마지막 4개의 비트를 재생성하도록 감소된다. 이것은 마지막 4개의 비트의 표시는 단지 매트릭스 'G'의 마지막 4개만을 필요로 한다는 것을 의미한다.
상기 생성된 코드 워드를 사용하여, 단일 [29,14] BCH 코드는 C 1 , C 2 , C 3 , C4로 표시된, 2개의 해체된 워드의 세트로 대체되고, 2개의 시스테메틱 코드 워드이고, 그 각각의 길이는 15이다. 해체된 워드 C 1 은 7개의 정보 비트 및 8개의 패리치 비트를 포함하고, 해체된 워드 C 2 는 나머지 7개의 정보 비트 및 이들과 연관된 8개의 패리티 비트를 포함한다. 따라서, 전체적으로 헤더의 동일한 14개의 정보 비트가 얻어진다. 이러한 인코딩 프로세스는 (1.1)에 설명된 바와 같은 공식에 따라 실행도니다.
이러한 2개의 해체된 워드 C1 , C2 는 부분집합 P1, P2 로 정의된다. 전체 데이터의 함수로서 불리는 상기 부분집합들은 단순히 이러한 부분집합의 (XOR) 연산이다(즉, P=P1 P2; 도 8 참조). 7개의 정보 비트의 각각을 인코딩한 후에, 2개의 부분집합(P1 , P2 )는 C1 및 C2 로부터 추출된다. 그다음, 나머지 비트는 플래시 디바이스에 기록된다(즉, C1 의 첫 11개의 비트 및 C2 의 첫 11개의 비트만이 기록된다). 'P'로 표시된 전체 데이터의 통일된 함수는 해체된 데이터의 부분집합을 통일하기 때문에 통일된 데이터로 정의된다. 이러한 통일된 세트 P는 또한 플래시 디바이스에 기록된다.
P2; 도 8 참조). 7개의 정보 비트의 각각을 인코딩한 후에, 2개의 부분집합(P1 , P2 )는 C1 및 C2 로부터 추출된다. 그다음, 나머지 비트는 플래시 디바이스에 기록된다(즉, C1 의 첫 11개의 비트 및 C2 의 첫 11개의 비트만이 기록된다). 'P'로 표시된 전체 데이터의 통일된 함수는 해체된 데이터의 부분집합을 통일하기 때문에 통일된 데이터로 정의된다. 이러한 통일된 세트 P는 또한 플래시 디바이스에 기록된다.
따라서, 이러한 예의 경우는 26개 (11+11+4) 비트를 모두 통합한다. 플래시 디바이스에 기록된 비트가 비트 P 1 , P 2 를 포함하지 않음이 강조되는데, 그 이유는 이러한 비트들이 코드 워드가 물리적 저장 매체에 전송되기 전에 코드 워드로부터 추출되기 때문이다. 이러한 디코딩 프로세스 동안 재생성된 추출된 비트는 이후로 '감추어진 비트'로 정의된다. 상기 설명된 바와 같이, 첫 1개의 비트가 성공적으로 디코딩된 경우에, 나머지 4개의 비트는 인코딩 프로세스를 통해 재생성될 수 있다. 이러한 디코딩 프로세스는 섹션 "플래시 디바이스로부터 헤더 판독(디코딩)"에서 하술되는 바와같이 이러한 특성의 장점을 가지고 있다.
당업자는 적당한 비교 시나리오가 가능하고 이러한 인코딩 및 디코딩 프로세스의 구현이 가능하다는 것을 이해할 수 있다. 이러한 혁신적인 에러 보정 코딩 설계의 결과는 다음과 같은 기록(인코드) 및 판독(디코드)를 지향하고 있다.
1. 플래시
디바이스로의
헤더 기록(인코딩):
*- 공식 (1.1)에 대하여 상술된 프로세스를 사용하여, C 1 으로부터 정의된 첫 [15,7] 블록 코드를 인코딩하기 위해 헤더의 7개의 정보 비트의 제1 세트를 사용한다. 이러한 15개의 비트 코드 워드 C 1 의 비트 12-15는 P 1 으로서 표시한다.
- 공식 (1.1)에 대하여 상술된 프로세스를 사용하여 C 2 로서 정의된 제2 [15,7] 블록 코드 워드를 인코딩하기 위해 헤더의 7개의 정보 비트의 제2 세트를 사용한다. 이러한 15개의 비트 코드 워드 C 2 의 비트 12-15를 P 2 로서 표시한다.
- 패리티-2 비트 또는 비트 'P'로서 정의된 4개의 비트를 얻기 위하여 세트 P 1 및 P 2 를 각각 비트 단위로 XOR한다.
- 플래시 디바이스에 C 1 의 비트 1-11 및 C 2 의 비트 1-11을 기록한다. C 1 의 비트 1-11를 C 1 short 로 그리고 C 2 의 비트 1-11를 C 2 short 로서 표시한다.
4비트 'P'를 플래시 디바이스에 기록한다.
2. 플래시
디바이스로부터
헤더 판독(디코딩)
- 2개의 11-비트 워드를 판독한다. 그 결과는  및
및  로 표시된 2개의 워드이다. 플래시내에 아무런 에러가 없는 경우에,
로 표시된 2개의 워드이다. 플래시내에 아무런 에러가 없는 경우에,  =C 1 short 및
=C 1 short 및  =C 2 short 이다. 에러의 경우에는,
=C 2 short 이다. 에러의 경우에는,  또는
또는  는 플래시에 처음에 기록된 코드워드 C 1 short 및 C 2 short 에 대한 에러를 포함한다. 에러의 경우에,
는 플래시에 처음에 기록된 코드워드 C 1 short 및 C 2 short 에 대한 에러를 포함한다. 에러의 경우에,  또는
또는  는 각각 워드로서 표시된다는 것에 주목해야 한다(반드시 코드워드일 필요는 없다).
는 각각 워드로서 표시된다는 것에 주목해야 한다(반드시 코드워드일 필요는 없다).
- 공식(1.3)에 대하여 상술된 프로세스에 따라 워드  및
및  를 디코딩한다. 즉, 단일 에러 보정 디코더:
를 디코딩한다. 즉, 단일 에러 보정 디코더:
> ( 가 0 또는 1개의 에러를 가지고 있고
가 0 또는 1개의 에러를 가지고 있고  가 0 또는 1개의 에러를 가지고 있기 때문에) 양측 워드 모두 성공적으로 디코딩된다면, 헤더는 1 비트 디코딩된 워드
가 0 또는 1개의 에러를 가지고 있기 때문에) 양측 워드 모두 성공적으로 디코딩된다면, 헤더는 1 비트 디코딩된 워드  의 첫 7 비트 및 1 비트 디코딩된 워드
의 첫 7 비트 및 1 비트 디코딩된 워드  의 첫 7 비트로서 성공적으로 판독된다. 논-시스테매틱 코드의 경우에, 추가 정보(예를 들어, 테이블 또는 다른 트랜스포메이션)가 헤더를 성공적으로 판독하는데 필요하다.
의 첫 7 비트로서 성공적으로 판독된다. 논-시스테매틱 코드의 경우에, 추가 정보(예를 들어, 테이블 또는 다른 트랜스포메이션)가 헤더를 성공적으로 판독하는데 필요하다.
> ( 가 2 이상의 에러를 가지고 있고
가 2 이상의 에러를 가지고 있고  가 2개 이상의 에러를 가지고 있다면) 양측 워드 모두 디코딩하는데 실패했다면, 헤더는 성공적으로 판독되지 않는다.
가 2개 이상의 에러를 가지고 있다면) 양측 워드 모두 디코딩하는데 실패했다면, 헤더는 성공적으로 판독되지 않는다.
> (하나의 워드가 0 또는 1개의 에러를 가지고 있고 또 다른 워드가 2개 이상의 에러를 가지고 있기 때문에) 하나의 워드가 디코딩하는데 실패하고 또 다른 워드는 디코딩하는데 성공적으로 디코딩되었다면, 디코딩 프로세스는 단계 3으로 진행한다.
3. 정확하게 하나의 서브 코드가 실패하는 경우에 헤더 판독하기:
- 플래시 디바이스로부터 비트 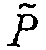 를 판독한다. 이러한 비트는
를 판독한다. 이러한 비트는  와 'P' 사이의 차일 수도 있기 때문에
와 'P' 사이의 차일 수도 있기 때문에  및 not P로서 정의된다.
및 not P로서 정의된다.  비트는 플래시 디바이스로부터 판독됨에 따라, 플래시 디바이스는 에러를 도입하는 것으로 가정된다.
비트는 플래시 디바이스로부터 판독됨에 따라, 플래시 디바이스는 에러를 도입하는 것으로 가정된다.
-  의 디코딩이 실패하고
의 디코딩이 실패하고  의 디코딩이 성공한다면,
의 디코딩이 성공한다면,  은 다음과 같이
은 다음과 같이  및
및  로부터 표현된다.
로부터 표현된다.
> 공식 (1.1)에 대하여 상술된 바와 같이, 인코딩 프로세스를 적용시킴으로써 C 2 의 감추어진 P 2 비트를  로부터 재생성한다.
로부터 재생성한다.
>  을 생성하기 위해 비트
을 생성하기 위해 비트  를 재생성된 감추인 비트 P 2 와 XOR한다.
를 재생성된 감추인 비트 P 2 와 XOR한다.
> 비트 로케이션 1-11에서의  내의 비트
내의 비트  를 배열하고 비트 로케이션 12-15에서의
를 배열하고 비트 로케이션 12-15에서의  내의 비트
내의 비트  을 배열하는 방법에 의해
을 배열하는 방법에 의해  및
및  으로부터
으로부터  을 생성한다.
을 생성한다.
- 공식 (1.2)에 대하여 상술된 디코딩 프로세스를 적용함으로써 2개의 에러 보정 [15,7] 블록 코드로서 모든 15개의 비트를 사용하여  을 디코딩한다.
을 디코딩한다.
- 디코딩이 성공적이라면, 헤더는 성공적으로 판독된다. 그렇지 않으면, 헤더의 판독은 실패하였다.
-  의 디코딩이 실패하고
의 디코딩이 실패하고  의 디코딩이 성공한다면, 다음과같이
의 디코딩이 성공한다면, 다음과같이  및
및  로부터
로부터  를 재생성한다.
를 재생성한다.
> 공식 (1.1)에 대하여 상술된 바와 같이, 인코딩 프로세스를 적용함으로써 C1 의 감춰진 P1 비트를  로부터 재생성한다.
로부터 재생성한다.
>  를 생성하기 위해 비트
를 생성하기 위해 비트  를 재생성된 감춰진 비트 P1 와 XOR한다.
를 재생성된 감춰진 비트 P1 와 XOR한다.
> 비트 로케이션 1-11에서의  내의 비트
내의 비트  를 배열하고 비트 로케이션 12-15에서의
를 배열하고 비트 로케이션 12-15에서의  내의
내의  를 배열하는 방법에 의해
를 배열하는 방법에 의해  및
및  로부터
로부터  를 생성한다.
를 생성한다.
- 공식 (1.2)에 대하여 상술된 디코딩 프로세스를 적용함으로써 2개의 에러 보정 [15,7] 블록 코드로서 모든 15개의 비트를 갖는  를 디코딩한다.
를 디코딩한다.
- 디코딩이 성공적이라면, 헤더는 성공적으로 판독된다. 그렇지 않으면, 헤더의 디코딩은 실패하였다.
실시예
-1의 수학적 분석
다음 섹션은 크기 및 회로 복잡도에 있어 달성된 장점을 평가하기 위해 본 발명의 방법에서 실행되는 수학적 분석을 상세하게 기술한다. 2개의 에러를 보정할 수 있는 디코더의 구현이 3개의 에러를 보정할 수 있는 디코더의 구현보다 더 단순하기 때문에 컨트롤러 복잡도에 관련된 달성된 장점은 명백하다.
기준 스킴을 계산하기 위해, p를 플래시 디바이스 입력 BER로서 정의한다 (즉, 우리의 예에서는 p=4.7×10-5). [n=15, k=7, d=5, t=2]인 디코더의 HER 퍼포먼트는 다음과 같이 이항 분포식에 따라 주어진다.
여기에서, 't'는  와 같이 에러 보정 기능에 관한 것이다(즉, 보정될 수 있는 오류 비트의 최대수). (1.4)에 따라, HER 가 10-10를 초과함에 따라, 2개의 에러를 보정하는데 불충분하기 때문에, 기준 스킴은 3-에러-보정 BCH 코드를 사용해야만한다. 따라서, 본 발명의 스킴을 채용하는 HEER 성능의 계산에서는, 본 발명의 [n=11, k=7, d=3, t=1]인 서브 코드 에러율(SCER)는 다음에 의해 주어진다:
와 같이 에러 보정 기능에 관한 것이다(즉, 보정될 수 있는 오류 비트의 최대수). (1.4)에 따라, HER 가 10-10를 초과함에 따라, 2개의 에러를 보정하는데 불충분하기 때문에, 기준 스킴은 3-에러-보정 BCH 코드를 사용해야만한다. 따라서, 본 발명의 스킴을 채용하는 HEER 성능의 계산에서는, 본 발명의 [n=11, k=7, d=3, t=1]인 서브 코드 에러율(SCER)는 다음에 의해 주어진다:
HER 성능에 대한 제1 컨트리뷰터는 헤더내의 2개의 서브코드의 실패된 디코딩의 경우이다. 이러한 확률은 다음과 같이 계산된다.
HER 성능에 대한 제2 컨트리뷰터는 제1 스테이지내의 하나의 워드의 실패된 디코딩 및 제2 스테이지내의 (2개에 이르는 에러를 15 비트로 디코딩하려고 할 때) 2개 보다 많은 에러의 실패된 디코딩의 경우이다. 이러한 확률은 다음과 같이 계산된다.
이 2개의 확률을 조합하면 다음을 얻을 수 있다.
HER 성능 HER 2 ,2 에 대한 제2 컨트리뷰션은 다음과 같이 계산된다.
좌측 2개의 팩터  는 '2'로 승산되는데, 이는 이것들이 제1 실패된 디코딩 서브 코드 및 제2 성공적인 디코딩 서브 코드에 대한 2개의 가능성이 존재하기 때문이다. 단일 에러 보정 블록 코드에 따라 제1 가능성은 제1 서브 코드의 디코딩이 실패하고 제2 서브 코드의 디코딩이 성공할 때 얻어진다. 제2 가능성은 단일 에러 보정 블록 코드에 따라 제1 서브 코드의 디코딩이 성공하고 제2 서브 코드의 디코딩이 실패할 때 얻어진다.
는 '2'로 승산되는데, 이는 이것들이 제1 실패된 디코딩 서브 코드 및 제2 성공적인 디코딩 서브 코드에 대한 2개의 가능성이 존재하기 때문이다. 단일 에러 보정 블록 코드에 따라 제1 가능성은 제1 서브 코드의 디코딩이 실패하고 제2 서브 코드의 디코딩이 성공할 때 얻어진다. 제2 가능성은 단일 에러 보정 블록 코드에 따라 제1 서브 코드의 디코딩이 성공하고 제2 서브 코드의 디코딩이 실패할 때 얻어진다.
최우측 팩터  는 2개의 값의 디비전의 결과이다. 이러한 결과는 1개의 비트의 부분집합내의 '1' 보다 많은 에러가 존재하는 경우에, 15 비트의 세트내의 2개보다 많은 에러가 존재할 확률에 상응한다. 11개의 비트의 부분집합내의 1 보다 큰 에러의 이벤트를 이벤트 'x'로서 정의하고 15개의 비트의 집합내의 2보다 큰 에러가 존재하는 이벤트를 이벤트 'y'로 정의한다. 따라서, 이벤트
는 2개의 값의 디비전의 결과이다. 이러한 결과는 1개의 비트의 부분집합내의 '1' 보다 많은 에러가 존재하는 경우에, 15 비트의 세트내의 2개보다 많은 에러가 존재할 확률에 상응한다. 11개의 비트의 부분집합내의 1 보다 큰 에러의 이벤트를 이벤트 'x'로서 정의하고 15개의 비트의 집합내의 2보다 큰 에러가 존재하는 이벤트를 이벤트 'y'로 정의한다. 따라서, 이벤트  는 다음과 같이 베이즈 법칙에 따라 얻어진다.
는 다음과 같이 베이즈 법칙에 따라 얻어진다.
이벤트 P(y,x)는 15개의 비트의 세트내에 2개 보다 많은 에러가 존재하고 11개의 비트의 부분집합내에 1보다 많은 에러가 존재하는 것을 말한다. 15개의 비트의 세트내의 2개 보다 많은 에러의 모둔 경우는 이러한 15개의 비트의 부분집합이 1보다 많은 에러가 포함하고 있는 이벤트를 포함한다는 것은 명백하다. 따라서, P(y,x)=P(y)이고, 공식 (1.7)내의 최우측 요소는 P(y)/P(x)이다.
실시예
2:
상기 실시예1에 개시된 것과 동일한 플래시 디바이스가 제공된다. 즉, 셀 당 하나의 비트가 존재하고 셀 에러율(CER)은 4.7×10-5이다. 디코더가 (8개의 비트 각각의) 512 바이트를 포함하는 섹터 데이터 에어리어의 신뢰가능한 기억용량을 제공하기 위해 구현되도록 디코더를 포함하는 플래시 디바이스를 설계하는 것이 필요하다. 이러한 데이터 자체는 각 센터의 헤더보다 덜 중요하기 때문에, 데이터에 대한 타겟 성능, 즉, SER(섹터 에러율)은 5×10-8보다 낮다. 플래시 디바이스의 설계는 단일 ECC(에러 보정 코드) 하드웨어로 제한된다(즉, 상기 헤더에 대해 이미 설계된 바와 같이 15 비트 블록 코드).
t=1 에러의 보정은 SER~1.36×10-4를 얻는다. t=2 에러의 보정은 SER~2.8×10-8를 얻는다. 코드율 R은 코드 길이 n에 의해 분할된 정보 비트의 수 k에 의해 정의된다. 즉, 길이 4096 개의 비트의 섹터를 제시하기 위해 전체  =586개의 코드 워드의 전체를 사용하면 R=512×8/(586×15)=0.466의 전체 코드율을 제공한다. 그래서, 코드율 R=7/15=0.466을 갖는 2개의 에러 보정 [15,7,5] 블록 코드는 충분하다.
=586개의 코드 워드의 전체를 사용하면 R=512×8/(586×15)=0.466의 전체 코드율을 제공한다. 그래서, 코드율 R=7/15=0.466을 갖는 2개의 에러 보정 [15,7,5] 블록 코드는 충분하다.
길이 15의 586개의 코드워드 각각의 설계를 사용하는 대신에, 7개의 정보 비트 및 4개의 패리티 비트의 586개의 펑쳐링된 코드워드를 포함하는 새로운 설계가 제공된다. 모든 서브 코드로부터의 4개의 패리티 비트의 제2 세트는 XOR되고, 4개의 비트 결과는 플래시 디바이스내에 저장된다. 이러한 방식으로, 본 발명의 방법에 의해 동일한 하드웨어 설계를 사용하고 셀당 R=4096/(586×11+4)=0.635 비트의 보다 높은 코드율을 제공하여 SER < 5×10-8의 타겟 성능을 충족할 수 있다. 그래서 플래시 디바이스 크기가 26.6% 만큼 감소되는 장점을 얻을 수 있다. 섹터의 판독 및 기록 연산은 다음과 같이 수행된다.
1. 플래시 디바이스로의 섹터 기록(인코딩):
- 섹터의 4096 정보 비트를 사용하여 [15,7,5] 블록 코드의 586 개의 코드 워드를 인코딩한다.
- 패리티-2 비트로 정의된, 4개의 비트를 얻기 위해 모든 586개의 코드워드의 비트 12-15를 XOR한다.
- 모든 586개의 코드워드의 플래시 디바이스 비트 1-11에 기록한다.
- 플래시 디바이스에 4개의 패리티-2 비트를 기록한다.
2. 플래시 디바이스로부터의 섹터 판독(디코딩):
- 플래시 디바이스로부터 길이 11의 586개의 코드워드를 판독한다.
- [11,7,3] 블록 코드 디코더에 대한 단일 에러 보정 디코더를 사용하여 586개의 워드를 디코딩한다.
- 모든 코드워드가 성공적으로 디코딩되었다면 섹터는 성공적으로 디코딩된다.
- 1개 보다 많은 워드가 디코딩에 실패되었다면, 섹터의 디코딩에는 실패가 존재한다.
- 또 다른 585개의 워드가 성공적으로 디코딩되었다고 단일 워드가 디코딩에 실패하였다면, 다음의 단계를 실행한다.
> 공식 (1.1)에 대하여 상술된 인코딩 프로세스를 적용함으로써 성공적으로 디코딩되었던 모든 585 개의 워드의 감추인 패리티 비트 12-15를 재생성한다.
> 플래시 디바이스로부터 패리티-2 비트를 판독한다.
> 디코딩에 실패된 586번째의 워드의 비트 12-15를 추정하기 위해, 성공적으로 디코딩되었던 모든 585개의 코드워드의 감추인 패리티 비트 12-15와 패리티-2 비트를 XOR한다.
> 공식 (1.2)에 대하여 상술된 듀얼 에러 보정 [15,7,5] 블록 코드 디코더 프로세스로 모든 15비트와 함께 실패된 워드를 다시 디코딩한다. 디코딩이 성공적이라면, 섹터는 성공적으로 판독된다. 그렇지않으면, 섹터의 디코딩에 실패가 존재하였다.
실시예 2를 사용하는 본 발명의 방법은 다음의 장점을 갖는다.
- 감소된 플래시 디바이스 크기(셀의 수가 26% 감소한다) 또는 보다 높은 코드율(0.466 대신에 0.635)
- 동일한 SER 성능 필요조건이 유지된다.
*- 동일한 하드웨어 복잡도-[15,7,5] 블록 코드 인코더/디코더를 사용한다.
- 헤더 및 데이터 인코딩 및 디코딩 프로시져에 대한 통일된 하드웨어.
실시예 2의 수학적 분석
SER 분석은 기준 설계와 본 발명의 설계 사이의 비교를 제공하는데, 이는 도 9에 도시되어 있다. 이러한 값들을 달성하기 위해 사용되는 공식은 다음의 섹션에서 주어진다.
1. 기준 설계(커브 262):
p는 플래시 디바이스의 CER 성능(즉, 본 예에서는 p=4.7×10 -5 )를 나타낸다. [n=15,k=7,t=2] 블록 코드 디코더의 프레임 에러율(FER)은 다음에 의해 주어진다.
기준 설계([n=15,k=7,t=2] 블록 코드의 586개의 코드워드)의 SER 성능은 다음과 같이 주어진다.
2. 본 발명 설계(커브 264):
[n=11,k=7,t=1] 블록 코드 디코더의 프레임 에러율은 다음과 같이 주어진다.
플래시 디바이스의 SER 성능에 대한 제1 컨트리뷰터는 섹터내의 2개 이상의 실패 워드의 경우를 나타낸다. 이러한 확률은 다음에 의해 정의된다.
플래시 디바이스의 SER 성능에 대한 제2 컨트리뷰터는 (2개에 이르는 에러를 디코딩할 수 있는 디코더로써 15개의 비트를 디코딩할 때) 제1 스테이지에서의 단일 워드 실패 및 제2 스테이지에서의 2개보다 많은 에러의 경우를 나타낸다. 이러한 확률은 다음에 의해 정의된다.

2개의 컨트리뷰터를 조합하면 아래의 확률을 얻는다.
이제 도 1를 참조하면, 본 발명의 디바이스의 인코더 및 디코더를 포함하는 블록도가 도시되어 있다. 본 발명의 디바이스(1)는 적용으로부터 정보를 수신하고 이것을 디바이스(1)에 저장하기 위한 호스트 인터페이스 모듈(10)을 포함한다.
호스트 인터페이스(10)는 다상 인코더(20)에 정보를 전송한다. 다상 인코더(20)는 상술되고 도 2 및 도 3에 보다 상세하게 제시된 바와 같이 플래시 디바이스의 프로세스에 헤더 기록을 수행한다. 다상 인코더(20)는 N개의 비트의 코드워드로 K개의 정보 비트의 블록을 전환하는데, N>K이다. 실시예 1에 대하여, K=14 이고 N=26이다.
다음으로 이러한 N-비트 블록은 디지털 프로세싱 유닛(30)에 전송된다. 디지털 프로세싱 유닛(30)은 실시예 2에서 설명된 바와 같이, 데이터 섹터를 이러한 블록에 더하기 위해 그리고, 이러한 블록이 셀에 기록되기 전에 다른 디지털 프로시져를 실행하도록 제공된다. 이러한 디지털 프로시져는 선택적으로 인터리빙 및 그레이 맵핑 프로시져를 포함한다. 이러한 디지털 프로세싱 유닛(30) 당업계에 알려진 임의의 프로세싱 유닛일 수 있다.
그다음, 처리된 N-비트 블록은 물리적인 정보 비트를 저장하기 위해 제공된 저장 디바이스(40)에 전송된다.
저장 디바이스(40)로부터 블록을 판독시에, 이러한 블록은 다상 인코더(20)의 출력부에 나타난 것과 동일한 포맷으로 N-비트 블록을 전환하도록 디지털 리버스 프로세싱 유닛(50)에 전송된다.
그다음, 이러한 N-비트 블록은 디지털 리버스 프로세싱 유닛(50)으로부터 다상 인코더(100)로 전송된다. 다상 디코더(100)는 '플래시 디바이스로부터의 헤더 판독' 섹션에 상술된 바와 같이 그리고 도 4 내지 도 6에 보다 상세하게 설명된 바와같이, 26 비트 헤더 코드워드로부터 헤더의 14개의 정보 비트를 회복시키기 위해 제공된다.
그다음, 헤더의 회복된 정보 비트는 호스트 인터페이스(10)로 재전송된다.
이에 도 2를 참조하면, 도 1의 다상 인코더(20)를 포함하는 컴포넌트의 블록도가 도시되어 있다. 14개의 정보 비트는 호스트 인터페이스(10)로부터 전송되고 램(21)의 상부(분리 섹션)에 저장된다. 램(21)의 분리 섹션은 22 비트에 대한 저장 에어리어를 제공한다.
상태 머신 컨트롤 로직 블록(24)가 [15,7,5] 블록 코드 인코더를 사용하여 14개의 정보 비트중 처음 7개의 정보 비트를 15개의 비트로 인코딩하기 위해 서브코드 인코더(22)를 활성화시키도록 제공된다.
이러한 15개의 비트중 비트 12-15는 조인트 패리티 프로세서(23)에 전송되고, 서브코드 인코더(22)로부터 4개의 새로운 패리티 비트(비트 8-11)는 램(21)의 상부(분리 섹션으로 부른다)에 재전송된다. 조인트 패리티 프로세서(23)는 모든 서브코드의 제2 타입의 패리티 비트에 수학 콤프레션 포뮬레이션(예를 들어, XOR)을 적용하기위해 제공된다.
램(21)로부터, 7개의 정보 비트의 제2 세트가 서브 코드인코더(22)에 전송되고 [15,7,5] 블록 코드워드로 인코딩된다. 이러한 블록 코드워드의 15개의 비트로부터 정보 비트 12-15는 조인트 패리티 프로세서(23)로 전송되고, 추가된 4개의 패리티 비트(비트 8-11)는 서브 코드 인코더(22)로부터 램(21)의 상부에 다시 전송되어 11-정보 비트 [11,7,3] 코드로의 7개의 비트의 제2 세트의 인코딩을 완성한다.
조인트 패리티 프로세서 유닛(23)에서, 이러한 4개의 정보 비트 12-15는 유닛(23)에 이미 저장된 4개의 비트로써 비트 단위로 XOR된다. 그 결과는 램(21)의 하부(조인트 섹션으로 부른다)에 저장된다.
이제 도 3을 참조하면, 도 2의 상태 머신 컨트롤 로직 브록(24)에서 수행되는 인코딩 프로세스의 순서도(31)가 도시되어 있다. 제1 단계(32)에서, 서브 코드 수 'N'이 0으로 시작된다.
다음 단계(33)에서, 가변 'N'의 값은 2의 값, 즉, 실시예 1에 대한 2개의 서브코드로 도달하는지 여부가 체크된다. 인코딩 프로세스의 이러한 단계에서, 'N'=0이고, 'N'의값은 상태 머신 컨트롤 로직 블록(24)이 서브코드(1)를 인코딩하고 있다는 것을 나타내기 위하여 1씩 증가된다(단계 34).
다음 단계(35)에서, 서브 코드 인코더(22; 도 2 참조)는 서브 코드 1을 인코딩하기 위해 활성화된다. DJP1로 정의된 비트 1-11은 램(21)의 상부에 저장된다.
단계(36)에서, JP1으로 정의된 비트 12-15는 조인트 파트 프로세서(JPP) 유닛(23; 도 2 참조)에 저장된다.
단계(37)에서, 이러한 4개의 비트 12-15는 갱신된다(즉, 초기 4개의 제로로 XOR된다). 그다음, 인코딩 프로세스는 단계 33으로 돌아간다.
다음 단계(33)에서, 가변 'N'의 값은 이것이 이러한 루르의 사이클에서 2의 값에 도달하였는지를 판정하기 위해 다시 체크된다. 이러한 단계에서 N=1이기 때문에, 인코딩 프로세스는 루프의 제2 사이클를 실행하기 위해 단계(34)로 진행한다.
단계 34에서, 가변 'N'의 값은 '1'씩 증가되어 N=2가 된다.
단계 35에서, 7개 비트의 제2 그룹은 15개의 비트코드 워드로 인코딩된다. 제1 11개의 비트중 마지막 4개의 비트(DJP2)로 정의된다)는 램(21)의 상부에 저장된다. 15개의 비트중 마지막 4개의 비트는 JP2로서 정의된다.
단계 36에서, JP2 비트는 JPP 유닛(23; 도 2 참조)로 전송된다.
다음 단계 37에서, JP1 비트는 JPP 유닛(23)의 4개의 출력 JPP 비트를 생성하기위해 비트 단위로 JP2로 XOR된다.
이러한 단계에 이어, 인코딩 프로세스는 단계 33으로 돌아간다. 단계 33에 도달시에, 가변 'N'의 값은 2이다. 그래서, 긍정적인 경우에('N'=2), 인코딩 프로세스는 단계 38로 진행한다.
단계 38에서, 산출된 JP 비트는 램(21)의 하부에 기록된다.
마지막 단계 39에서, 인코딩 프로세스는 종료된다.
도 4에 도 1의 다상 디코더(100)를 포함하는 컴포넌트의 블록도가 도시되어 있다. 다상 디코더(100)의 구현예가 조인트 정보(JIR; 110)를 저장하는 램 유닛과 분리 정보(DJIR; 200)를 저장하는 램 유닛을 구별하기 위해 제공된다. 2개의 타입의 정보 사이의 차이는 실제로는, 수학적 분석에서 이전에 JIR 유닛을 사용하는 확률을 고려할 때 이러한 확률이 상당히 작다는 것이 발견되었다는 사실에 기인한다. 따라서, 회로 복잡도를 감소시키기 위해 이러한 2개의 램 유닛을 구별하는 것이 필요하다.
DJIR(200)은 제1 및 제2 분리 정보 워드의 22개의 비트를 저장하기 위해 제공된다. 이러한 워드는 컨트롤 유닛(190)을 통해 이러한 22개의 비트를 판독하는 듀얼 모드 디코더 유닛(130)에 전송된다. 이러한 듀얼 모드 디코더 유닛(130)은 상술된 실시예 1에 대하여 단일 에러 보정 모드에서 활성화된다.
그다음, 제1 워드의 디코딩이 성공하는 경우에, DJIR 유닛(200)은 필요하다면 컨트롤 유닛(190)를 통해, 보정된 비트로써 갱신된다. 이러한 디코딩 프로세스는 다음으로 제2 11-비트 워드에 대해 반복된다.
제1 및 제2 워드의 양측의 디코딩이 성공하는 경우에, JIR 유닛(110)은 비활성화된 상태로 남는다. 양측 워드의 디코딩이 실패한 경우에, 완전한 디코딩 프로세스가 실패한다.
양측 서브 워드가 아닌 어느 하나의 서브워드가(제1 서브 워드 또는 제2 서브워드) 디코딩 실패되는 경우에, 실패한 서브워드를 디코딩하려는 두번째 시도는 성공적으로 디코딩된 서브코드를 사용하여 이루어진다.
예를 들어, 제1 서브코드의 디코딩이 성공하였고 제2 서브코드의 디코딩이 실패하였다면, 제2 시도는 성공적으로 디코딩된 제1 서브코드를 사용하여 제2 서브워드를 디코딩하기 위해 이루어진다. JIR 유닛(110)로부터의 4개의 비트는 컨트롤 유닛(190)을 통하여 판독되고 중간 램(IR) 유닛(170)에 저장된다. 제1 서브코드는 컨트롤 유닛(190)을 통해 다상 인코더(20; 도 2 참조)에 재판독된다. 다상 인코더(20)는 4개의 JP1 비트를 재생성한 후에 이들을 IR 유닛(170)에 전송한다. 조인트 정보 프로세서(JIR) 유닛(180)은 비트 단위로 JP 및 JP1을 XOR하기 위해 제공된다. 그 결과는 [15,7,5] 블록 코드의 로케이션 12-15내의 듀얼 모드 디코더 유닛(130)에 저장된다. 제2 서브코드는 15개의 비트 워드를 생성하기 위해 [15,7,5] 블록 코드의 로케이션 1-11에서 DJIR로부터 듀얼 모드 디코더 유닛(120)으로 재판독된다. 이러한 경우에, 듀얼 모드 디코더 유닛(130)은 듀얼 비트 에러 보정 모드에서 활성화된다. 듀얼 모드 디코더 유닛(130)이 듀얼 에러 보정 모드에서 디코딩에 실패하는 경우에, 완전한 디코딩 프로세스가 실패한다. 그러나, 듀얼 모드 디코더 유닛(130)이 듀얼 에러 보정 모드에서 디코딩에 성공하는 경우에, DJIR 유닛(120)은 보정된 비트로 갱신되고 판독 프로세스는 성공적인 것으로 나타난다.
대안으로, 유사한 디코딩 프로세스가 제2 서브워드(성공적인 디코딩시에 서브코드로서 정의된다)의 디코딩이 성공하였고 제1 서브워드의 디코딩이 실패한 경우에 수행되어, 제1 서브코드와 제2 서브워드 사이의 연산 기능이 상기 예에서 설명된 바와 같이 교환된다.
본 발명이 긴 코드워드를 디코딩하기 위한 단일 디코더를 제공하는 것으로 기술되어 있다. 하지만, 본 발명은 단일 디코더에만 제한되지 않고 긴 코드워드보다 적은 비트를 갖는 코드워드를 각각 디코딩하는 복수의 디코더를 제공하기 위해 동일하게 적용가능하다.
도 5에 도 4의 듀얼 모드 디코더 유닛(130)의 블록도가 도시되어 있다. 상태 머신 유닛(138)은 듀얼 모드 디코더 유닛(130)에 의해 수행되는 디코딩 프로세스를 제어하기 위해 제공된다.
DJIR 유닛(200), JIR 유닛(110), 및 JIP 유닛(180)(도 4 참조)로부터 전송된 정보 비트는 데이터 콜렉터 유닛(132)에 함께 수집된다. 이러한 수집은 상태 머신 유닛(138)에 의해 제어된다.
데이터 콜렉터 유닛(132)으로부터 수신된 정보 비트는 디코더 코어 유닛(134)에서 디코딩된다. 디코딩 프로세스를 위해 필요한 계산을 위해 패리티 체크 매트릭스 유닛(136)은 단일 에러 또는 듀얼 에러 보정 모드에 따라 채용된다. 패리티 체크 매트릭스(136)는 수신된 워드에 대한 패리티 체크를 각 라인에 포함한다. 이러한 매트릭스내의 각 라인은 체크되는 로케이션에 값 '1'을 포함한다. 체킹 프로시져는 패리티 체크 라인이 값 '1'을 포함하였다면 로케이션내의 워드의 엘리먼트를 XOR하는 연산이다. 이러한 체킹 프로시져는 XOR 연산의 결과가 제로가 된다면 성공적이다. 모든 체킹 프로지셔가 제로가 되는 경우에, 수신된 워드는 코드워드로 판정된다. 수신된 워드에 패리티 체크 매트릭스(136)를 적용한 경과는 수신된 워드의 신드롬이다. 논제로 값을 포함하는 수신된 워드의 신드롬은 수신된 워드가 코드워가 아님을 나타낸다. 수신된 워드에 패리티 체크 매트릭스(136)를 적용하는 단계는 등식 (1.2) 또는 등식 (1.3)에 대하여, 상술된 프로시져에 따라 수행된다.
실시예 1에 대하여, 패리티 체크 매트릭스(136; 도 5 참조)에서 구현된 매트릭스는 단일 에러 및 듀얼 에러 보정 모드 모두에 대하여 제공되고서 단일 에러 보정 모드에서 사용되는 매트릭스는 사실 듀얼 에러 보정 모드에서 사용되는 매트릭스의 부분집합이다.
도 6에 실시예 1에 대하여, 디코딩 프로세스의 순서도(140)가 도시되어 있다. 초기 단계(141)에서, 제1 워드는 DJIR(200; 도 4 참조)로부터 판독된다. 그다음, 듀얼 모드 디코더(130)는 단일 에러 보정 모드에서 활성화된다.
다음 단계(142)에서, 상태 머신 유닛(138; 도 5 참조)은 제1 워드의 디코딩이 성공하였는지 여부를 체크한다.
긍정적인 경우에, 디코딩 프로세스는 단계(150)로 진행한다. 단계(150)에서, 제1 워드는 보정이 있는 경우에 보정으로 갱신된다. 이러한 단계에서, 듀얼 모드 디코더(130; 도 4 참조)는 단일 에러 보정 모드에서 DJIR(200; 도 4 참조)로부터 판독된 제2 워드를 디코딩하기 위해 활성화된다. 다음 단계(152)에서, 상태 머신 유닛(138; 도 5 참조)은 제2 워드의 디코딩이 성공하였는지 여부를 체크한다. 부정적인 경우에(즉, 단일 에러 보정 모드에서 제1 워드의 디코딩이 성공하였고 단일 에러 보정 모드에서 제2 워드의 디코딩이 실패한 경우에), 디코딩 프로세스는 단계(153)로 진행한다. 그러나, 긍정적인 경우에, 디코딩 프로세스는 단계(156)로 진행한다. 단계(156)에서, 제2 워드는 보정이 존재하였고 디코딩 프로세스가 성공적으로 종료되는 경우에 보정으로 갱신된다(단계 149).
제1 부정적인 경우에(즉, 제1 워드의 디코딩이 실패하는 경우에), 디코딩 프로세스는 단계(143)로 진행한다. 단계(143)에서, 제2 워드는 DJIR(200; 도 4 참조)로부터 판독되고 단일 에러 보정 모드에서 디코딩된다.
다음 단계(144)에서, 상태 머신 유닛(138; 도 5 참조)은 제2 워드의 디코딩이 성공하였는지 여부를 체크한다. 부정적인 경우에, 완전한 디코딩 프로세스가 실행하고 단계(145)에서 종료된다. 그러나, 긍정적인 경우에(즉, 제2 워드의 디코딩이 성공한 경우에), 디코딩 프로세스는 단계(146)로 진행한다.
단계(153)에서, 추가 디코딩 시도가 성공적으로 디코딩된 제1 워드로부터 그리고 4개의 외부 조인트 비트로부터 얻어진 정보를 사용하여 제2 워드를 디코딩하기 위해 이루어진다. 이러한 단계에서, 제2 워드의 11개의 비트는 DJIR 유닛(200; 도 4 참조)로부터 재판독된다. 제2 워드의 마지막 4개의 비트는 유닛 JIR(110; 도 4 참조)로부터 얻어진 4개의 조인트 비트와 XOR된 제1 워드의 4개의 감추인 비트로부터 재생성된다. 제1 워드의 감추인 비트는 제1 워드로부터 성공적으로 디코딩된 11개의 비트에 인코더를 적용함으로써 얻어진다. 듀얼 모드 디코더(130; 도 4 참조)는 듀얼 에러 보정 모드에서 제2 워드를 디코딩하기 위해 활성화된다. 다음 단계(154)에서, 상태 머신 유닛(138; 도 5 참조)은 제2 워드의 추가 디코딩이 성공하였는지 여부를 체크한다.
*부정적인 경우에, 완전한 디코딩 프로세스가 실패하였고 단계(155)에서 종료된다.
그러나, 긍정적인 경우에, 디코딩 프로세스는 단계(156)로 진행한다. 단계(156)에서, 제2 워드는 제2 워드에 대한 제2 디코딩 시도에서 발견된 보정으로써 DJIR(200; 도 4 참조)로 갱신된다. 제2 디코딩 프로세스는 그다음, 마지막 단계(149)로 진행한다. 마지막 단계(149)에서, 성공적인 디코딩 프로세스가 선언되고 디코딩은 종료된다.
단계 146에서, 실패된 제1 워드를 디코딩하기 위한 제2 시도는 (제1 워드와 제2 사이의 연산 기능이 교환되도록) 단계 153에서 제1 워드에 대하여 수행된 디코딩 프로세스와 유사한 방식으로 이루어진다.
단계 147에서, 상태 머신 유닛(138; 도 5 참조)은 제1 워드의 추가 디코딩이 성공하였는지 여부를 체크한다.
부정적인 경우에, 완전한 디코딩 프로세스가 실패하였고 단계(155)에서 종료된다.
그러나, 긍정적인 경우에, 디코딩 프로세스는 단계 148로 진행한다. 단계 148에서, 제1 워드는 제1 워드에 대한 제2 디코딩 시도에서 발견된 보정으로써 DJIR 유닛(200)에 갱신된다. 마지막 단계 149에서, 성공적인 디코딩 프로세스가 선언되고 디코딩은 종료된다.
도 7에 실시예2에 대한 디코딩 프로세스의 순서도가 도시되어 있다. 도 7에 설명된 디코딩 프로세스는 소프트 디코더의 구현에 보다 적합하다. 소프트 디코더를 구현하기 위한 개별적으로 구현되는 유닛은 점선으로 표시되어 있고 실시예 2에 대하여 사용되지 않는다.
처음 단계(211)에서, 디코딩 프로세스에서 사용되는 다수의 변수에 대해 초기화가 수행된다. 이러한 변수는 성공적으로 디코딩된 서브코드의 수(k), 분리된 서브워드의 수(nc), 처리되는 현 워드의 수(j), 페이즈 카운터(p), 최대 페이즈값(np), 단일 에러 보정 모드에서의 실패 워드의 수(또는 보다 일반적인 경우에서의 제1 디코더)(f), 단일 에러 보정 모드에서의 실패 디코딩의 최대수(또는 보다 일반적인 경우에서의 제1 디코더)(mf)를 포함한다.
벡터 'v'가 벡터 'v'의 상응하는 엘리먼트 로케이션에서 성공적으로 디코딩된 각 서브코드에 대하여 값 '1'을 저장하기 위하여 제공된다. 디코딩 프로세스의 개시시에, 벡터 'v'의 모든 엘리먼트는 '0'으로 초기화되는데, 그 이유는 서브 코드의 어느 하나의 보정도에 대한 아무런 지식이 존재하기 않기 때문이다. 실시예 2에 대하여, 서브워드 nc의 수는 586으로 초기화되어 있어서 벡터 'v'내의 엘리먼트의 수는 586이다.
변수 'j'는 제로로 초기화되어 있다. 변수 'j'는 현재 디코딩된 서브코드의 수이다. 변수 'p'는 디코딩 프로세스에서 현재 실행되는 페이즈수를 정의하고 '0'로 초기화되어 있다.
변수 'np'는 최대 페이즈 수이다. 실시예 2에 대하여, 오직 2개의 페이즈만을 활성화하는데, 즉, 단일 에러 보정 모드를 한정하는 페이즈-0 및 듀얼 에러 보정 모드를 한정하는 페이즈-1만을 활성화하는 것이 가능하다. 소프트 디코더 구현의 경우에는 2개 보다 많은 페이즈가 실행되는 경우이어서 단일 서브코드가 2번 보다 많이 디코딩된다는 것에 주목해야 한다.
변수 'f'는 페이즈-0에서 디코딩하는데 실패한 서브워드의 수이다. 실시예 2에 대하여, 디코딩 프로세스는 페이즈-0에서의 단일 실패보다 많은 경우에 서브워드의 감추인 비트를 재생성할 수 없다. 그러나, 소프트 디코더 구현의 경우에, 변수 'f'는 특정 설계안에 따라 'nc'에 이르는 임의의 값으로 설정될 수 있다.
변수 'k'는 성공적으로 디코딩된 서브 코드의 수이고 일단 페이즈-0가 모든 서브워드에 대해 시도되고 'f'의 값이 세팅되면 k=586-f로 설정된다. 변수 'f'가 갱신될 때마다 변수 'k'의 새로운 계산을 피하기 위해, 변수 'k'는 변수 'f'에 독립적으로 한정된다. 디코딩 프로세스는 일단 변수 'k'가 586값(또는 일반적인 경우에 'nc')에 도달하는 경우에 종료된다.
다음 단계 212에서, 조인트 패리티 비트(JP 비트)는 JIR 유닛(110; 도 4 참조)로부터 중간 램(170; 도 4 참조)로 전송된다. 이어서, 성공적으로 디코딩된 서브코드의 각각에 대하여, JP는 성공적으로 디코딩된 서브코드의 재생성된 감추인 비트로 갱신된다.
단계 213에서, 'j'는 586 값(nc)와 비교된다. 이러한 디코딩 프로세스의 포인트에서 'j'의 값이 586보다 작기 때문에('j=0'), 디코딩 프로세스는 단계 214로 진행한다.
단계 214에서, DJIR 유닛(200; 도 4 참조)으로부터 전송된 분리 워드-0(즉, 루프의 다음 적용내의 워드-j)는 모드-1(즉, 단일 에러 보정 모드는 실시예 2에 대하여 활성화된다)내의 듀얼 모드 디코더(130; 도 4 참조)에서 디코딩된다.
다음 단계 215에서, 상태 머신 유닛(138; 도 5 참조)은 이러한 서브워드의 디코딩이 성공하였는지 여부를 체크한다. 부정적인 경우에, 디코딩 프로세스는 단계 216으로 진행한다. 긍정적인 경우에, 디코딩 프로세스는 단계 219로 진행한다.
단계 219에서, 워드-0의 감추인 비트 JP0는 워드-0(즉, 루프의 다음 적용에서의 워드-j)의 11개의 성공적으로 디코딩된 비트에 인코더를 적용함으로써 그리고 산출된 4개의 패리티 비트를 중간 램(170; 도 5 참조)에 이미 저장된 JP 비트와 XOR함으로써 재구성된다. 엘리먼트 v[0]의 상응하는 값은 워드-0가 성공적으로 디코딩되었고 'k'가 1씩 증가되는 것을 나타내기 위해 '1'로 설정된다. 이러한 변수 설정 동작에 이어, 워드-0(즉, 루프의 다음 적용내의 워드-j)는 보정 결과에 따라 DJIR 유닛(200; 도 4 참조)에서 갱신된다.
단계 221에서, 'j'는 '1'씩 증가되어서, 다음 서브워드의 디코딩을 실행한다. 다음으로 디코딩 프로세스는 단계 213으로 진행한다.
단계 213에서, 변수 'j'의 값은 586보다 작은지 여부가 판정된다.
부정적인 경우에, 디코딩 프로세스는 단계 222로 진행한다. 긍정적인 경우에, 디코딩 프로세스는 변수 'j'에 대해 증가된 값으로 단계 214, 215 및 필요하다면 단계 216을 다시 적용한다.
단계 216에서, 변수 'f'의 값이 체크된다. 이제까지 실패된 서브워드 'f'의 수가 '1' 값을 초과하는 경우에(실시예 2에 대하여), 디코딩 프로세스는 실패를 선언하고 단계 217에서 종료된다. 그렇지 않으면, 디코딩 프로세스는 단계 220 (또는 소프트 디코더가 구현되는 경우에 단계 218)로 진행한다. 소프트 디코더의 경우에, 변수 'f'의 값은 전체 페이지 섹터에 대한 디코딩 실패가 선언되기 전에 '1'의 값을 초과할 수 있다는 것에 주목해야 한다.
단계 218에서, 워드의 감추인 비트에 대하여 수행된 추정치 'j'는 중간 램(170)에 저장된다. 소프트 디코더의 구현을 고려하면, 소프트 디코더가 디코딩에 실패할 지라도 감추인 비트에 새로운 지식, 심지어 부분적으로 제공하는 것이 가능하다. 그러나, 이러한 추정치를 제공하는 것은 실시예 2에 대하여 가능하지 않다. 따라서, 실시예 2에서, 단계 218가 바이패스된다.
단계 220에서, 변수 'f'의 값은 이제까지 실패된 서브워드의 전체수가 증가된 것을 나타내기 위해 하나씩 증가된다. 그다음, 디코딩은 프로세스는 단계 221로 진행하고, 변수 'j'의 값 역시 디코더가 다음 서브코드를 디코딩하기 위해 진행하는 것을 나타내기 위해 하나씩 증가된다.
단계 222에서, 변수 'k'의 값은 586 값에 비교된다. 'k'=586의 경우에, 모든 서브워드의 디코딩은 성공하였고 디코딩 프로세스는 단계 223에서 성공적으로 종료된다. 그렇지 않으면, 실시예 2에 대하여 성공적으로 디코딩되지 않았던 오직 하나의 서브워드가 존재할 수 있고 디코딩 프로세스는 단계 224로 진행한다.
단계 224에서, 페이즈 수'p'의 값은 하나씩 증가된다.
단계 225에서, 변수 'p'의 값이 2 보다 낮은지 여부(또는 일반적인 경우에 'np' 보다 낮은지 여부)가 체크된다. 부정적인 경우에(즉, 'p'가 2이상인 경우에), 전체 디코딩 프로세스는 실패로 선언되고 단계 226에서 종료된다. 그러나, 긍정적인 경우에 단계 227에서, 변수 'j'의 값은 실패된 서브워드를 다시 디코딩하기 위해 '0'으로 리셋팅된다. 단계 227에 이어, 디코딩 프로세스는 단계 228로 진행한다.
단계 228에서, 로케이션 'j'에서의 벡터 'v'의 값(엘리먼트 v[j])이 '0'인지 여부가 체크된다. 긍정적인 경우에, 소프트 디코더의 경우에서, 디코딩 프로세스는 단계 229로 진행하고, 하드 디코더의 경우에, 디코딩 프로세스는 단계 229를 바이패스하고 직접 단계 237로 진행한다. 그러나, 부정적인 경우에, 디코딩 프로세스는 단계 235로 진행한다. 단계 235에서, 변수 'j'의 값은 하나씩 증가되고 디코딩 프로세스는 다음 단계 234로 진행한다. 단계 234에서, 변수 'j'의 값이 586보다 작은지 여부가 체크된다. 부정적인 경우에(즉, 'j'가 586 이상인 경우에), 모든 엘리먼트는 스캐닝되었고 디코딩 프로세스는 단계 222를 적용하도록 다시 진행한다. 그러나, 긍정적인 경우에(즉, 'j'<586인 경우에), 단계 228, 235, 234는 실패된 서브워드가 발견될 때까지 반복된다.
단계 229가 소프트 디코더의 경우에만 수행된다는 것에 주목해야 한다. 소프트 디코더의 경우에, 실패된 서브워드의 감추인 비트는 이제까지 실패된 서브워드의 재구성된 감추인 비트에 대하여 제공된 추정치 및 성공적으로 디코딩된 서브워드의 이제까지 갱신된 JP 비트를 사용하여 재구성된다. 본 발명의 바람직한 방법이 XOR 연산을 사용하여 실패된 서브워드의 재구성된 감추인 비트에 대한 추정치를 제공하지만, 다른 연산이 소프트 디코더의 경우에 또한 고려될 수 있다,
하드 디코더의 경우에, 모든 다른 서브워드는 성공적으로 디코딩되어야 한다. 실시예 2에 대하여, 모든 다른 성공적으로 디코딩된 서브워드로 갱신된 후에, 중간 램(170)에 저장된 JP 비트는 실패된 서브 워드'j'의 감추인 비트에 대한 추정치로서 사용된다. 갱신된 JP 비트는 2개 이상의 에러가 서브 워드'j'의 제1 11개의 비트에 나타나는 경우에 실패된 서브워드'j'의 감추인 비트에 대한 추정치 에 대해서만 사용된다. 서브 워드 'j'를 디코딩하려는 제2 시도가 성공적이라면, 갱신된 JP 비트는 실시예 2에 대하여 단지 추정치가 아니고 재구성된 감추인 비트 자체라는 것에 주목해야 한다. 이것은 제2 디코딩 시도에서의 성공은 15 비트 워드내에 정확하게 2개의 에러가 존재하였다는 것을 의미하기 때문이다. 또한, 제1 시도가 실패하였기 때문에, 15 비트 워드의 첫 11개의 비트에 정확하게 2개의 에러가 존재한다. 그래서, 15 비트 워드의 마지막 4개의 비트는 아무런 에러가 갖지 않고, 정확하게 재구성된 감추인 비트이다.
단계 237에서, 하드 디코더 및 소프트 디코더 모두에 대하여, 워드-'j'는 DJIR(200; 도 4 참조)로부터 듀얼 모드 디코더(130; 도 4 참조)로 판독된다. 그다음, 조인트 정보는 중간 램(170; 도 4 참조)로부터 판독된다. 조인트 정보는 제2 디코딩 모드에서 디코더 코어(134; 도 5 참조)에 디코딩되는 수정된 워드를 형성하기 위해 데이터 콜렉터(132; 도 5 참조)내의 워드-'j'와 결합된다. 실시예 2에 대하여, 조합 연산은 단순 연결이고 제2 디코딩 모드는 [15,7,5] 블록 디코더이다. 일단 수정된 워드-'j'가 디코더 코어(134; 도 5 참조)내에 위치되면, 상태 머신(138; 도 5 참조)은 단계 237의 최종 스테이지에서 디코딩 연산을 개시한다.
단계 230에서, 워드-j가 성공되었는지 여부가 체크된다. 긍정적인 경우에, 디코딩 프로세스는 단계 231을 수행한다. 단계 231에서, 변수 'k'의 값은 하나씩 증가되고, 엘리먼트 v[j]의 값은 '1'로 세팅되고 코드 워드-j는 DJIR(200; 도 4 참조)에서 갱신된다. 소프트 디코더의 경우에, 단계 236에서, 서브워드 'j'의 완전히 재구성된 감추인 비트는 중간 램(17)내에 저장된 조인트 패리티 비트와 조합되고 일한 감추인 비트에 대하여 제공된 추정치는 중간 램(170)으로부터 제거된다. (성공적인 디코딩으로 인해) 완전히 재구성된 감추인 비트를 조인트 패리티 비트와 조합하는 한 방법은 감추인 비트는 조인트 패리티 비트와 비트 단위로 XOR하는 것이다. 단계 231(또는 소프트 디코더의 경우에서의 단계 236)에 이어서,디코딩 프로세스는 단계 23으로 진행한다. 그러나, 부정적인 경우에(즉, 워드-j의 제2 디코딩이 실패한 경우에), 디코딩 프로세스는 단계 233으로 직접 진행한다(또는 소프트 디코더가 구현되는 경우에 단계 232로 진행한다). 단계 232에서, 워드 'j'의 감추인 비트에 대한 갱신된 추정치는 중간 램(170)에 저장된다.
단계 233에서, 변수 'j'의 값은 하나씩 증가하고 디코딩 프로세스는 성공적인 디코딩 (단계 223) 또는 실패된 디코딩 (단계 226)이 선언될 때까지 디코딩 프로세스에 의해 제공된 단계들을 적용시키도록 진행한다.
도 8에서, 실시예 1에 대하여 인코딩 프로세스의 개략도(240)가 도시되어 있다. 숫자(242)에 의해 한정된 7 비트 정보 벡터의 각각은 C 1 및 C 2 로 표시된 15 비트 코드 워드(244)로 전환된다. 이러한 15 비트 코드워드(244) 각각의 첫 1개의 비트는 7개의 정보 비트(242) 및 제1 4개의 패리티 비트(250)를 포함한다. 이러한 첫 11개의 비트(246)은 플래시 디바이스에 기록된다. 각 15 비트 코드워드(244)의 마지막 4개의 패리티 비트(252)는 'P' 비트(254)로 표시된 4개의 패리티 비트의 세트를 생성하도록 비트 단위로 함께 XOR되어 제2 타입의 패리티 비트를 제공한다.
도 9에 실시예 2에 있어서, 입력 CER 성능(x축)와 출력 SER 성능(y축)의 그래프(260)이 도시되어 있다. 그래프(260)에 도시된 바와 같이, 기준 설계(262; 하부 라인)에 의해 얻어진 SER 성능은 본 발명(264; 상부 라인)의 설계에 의해 얻어진 SER 성능와 단지 경미하게 상이하다. SER이 10-10 미만인 환경에서 본 발명의 플래시 메모리 사이즈가 기준 설계의 것보다 상당히 작음에도 불구하고 성능에 있어서 아무런 실제적인 차이가 존재하지 않는다.
본 발명의 디바이스내의 서브코드에 대한 컴포넌트 코어 코드로서 소프트 디코더의 구현이 또한 가능하다. 소프트 디코더는 LDPC(저밀도 패리티 체크), TCM(트렐리스 코디드 모듈레이션), 터보 코드등과 같은 컴포넌트 코드의 사용이 가능하도록 제공된다.
디코딩 프로세스는 다수의 페이즈에서 수행될 수 있고, 각 페이즈에서 소프트 디코더는 (중간 램에 저장된) 조인트 정보를 통해 또 다른 서브워드로부터 전파된 갱신된 정보를 사용하여 일부 서브워드에 대해 활성화된다. 일반적인 경우에, 소프트 디코더는 갱신된 정보의 각 값에 대한 신뢰도 비트를 포함하는 다수의 비트를 수용할 수 있다. 이것은 소프트 디코더에 전송되는 입력 비트값의 표현이 복수의 비트를 더 포함할 수 있다(즉, 갱신된 정보의 각 값은 상기 실시예 1 및 실시예 2에서와 같은 단일 이진 값만을 포함하도록 제한되지 않는다. 이러한 입력 비트 소프트 값은 '0'인 (또는 반대로 '1'인) 입력 비트 i의 이진 값에 대한 신뢰도를 나타내는 확률로서 생각될 수 있고 전환될 수 있다.
아래의 (2.7)에서 정의된 로그 가능성 비(log likelihood ratio; LLR)는 다음에 따라, 이진값 '0' 또는 '1'에 대한 이러한 신뢰도를 나타내기 위해 당업계에서 공지된 코딩 이론에서 널리 사용된다.
통신 도메인과 대조적으로, 이러한 확률은 플래시 디바이스의 저장 제조 프로세스 동안 사전결정된다. 플래시 디바이스내의 저장 유닛은 각 셀내의 비트의 그룹을 포함하여 셀 전압 레벨이 이러한 비트의 그룹을 타나내는 심볼에 상응한다. 따라서, 이러한 심볼의 임의의 세트는 단일 콘스텔레이션으로서 정의된다.
플래시 디바이스는 그 물리적 특성으로 인해 거의 모든 임의의 기록된 전압 레벨이 상이한 전압 레벨로서 판독될 수 있도록 할 수 있다. 전압 레벨 'r' 을 기록하고 상이한 레벨 's'를 판독하는 확률은 크로스 오버 확률 Prs로서 표시한다.
상술된 바와 같이, 플래시 메모리의 특정 제조 프로세스로 인해, 이러한 확률은 고정된 주어진 값이다. (2.7)에서와 같은 이진 값 '0' 및 '1'에 대한 입력 신뢰도는 이러한 크로스 오버 확률(Prs)을 포함하는 상수가 주어진 테이블을 사용하여 계산된다.
제1 페이즈에서, 소프트 디코더는 분리 서브워드 각각을 디코딩하고, "감추인 패리티 비트"의 신뢰도는 제로로 설정된다(소프트 디코더에 의해 이레이저로서 식별된다).
성공 디코딩시에, 이러한 패리티 비트는 성공적으로 재생성된다. 로그 가능성 비(LLR) 포맷으로부터 이진 값 포맷으로서의 변형이 다음과 같이 수행된다.
이러한 이진 값은 LLR 포맷에서 신뢰도의 신호 비트이다. 성공적인 디코딩의 경우에, 이진 감추인 값은 적용(상기 실시예 1 및 실시예 2에서 이것은 분리 서브워드를 인코딩하는데 사용되는 프로세스에 의해 이루어진다)에 따라 재생성된다.그다음, 완전히 재구성된 이진 감추인 값은 플래시 메모리로부터 판독된 분리 정보 비트와 비트 단위로 XOR된다(도 7의 단계 219 및 단계 236 참조). 결과적으로, 조인트 정보 비트 'P'에 대한 "감추인 패리티 비트"의 영향은 제거된다. 이것은 XOR 연산의 특징을 기술하는 프로시져에 기인하는데, 여기에서 A XOR B XOR C XOR B = A XOR C이다.
플래시 디바이스에 저장된 조인트 정보 비트는 또한 고유의 불신뢰도를 포함한다는 것에 주목해야 한다. 따라서, 하나를 제외한 모든 서브워드가 성공적으로 디코딩되는 경우에, 플래시 디바이스에 저장된 조인트 정보 및 또 다른 성공적으로 디코딩된 서브코드의 감추인 비트를 사용하여 실패된 디코딩된 서브워드에 대한 감추인 비트의 재생성시 플래시 디바이스로부터 판독된 조인트 정보로부터의 에러를 포함한다.
소프트 디코더가 실패하는 경우에, 출력 신뢰도는 여전히 "감추인 패리티 비트"에 대한 LLR 포맷으로 생성된다. 이러한 신뢰도는 중간 램에 저장된다. 제1 디코딩 페이즈의 종료시에, 모든 서브코드가 성공적으로 디코딩되는 경우에, 성공적인 디코딩 프로시져가 결정된다.
적어도 하나의 서브워드가 제1 디코딩 페이즈에서 실패하는 경우에, 추가 디코딩 시도가 소프트 디코더에 의해 수행된다. 이러한 각각의 디코딩 시도에 대하여 소프트 디코더는 다른 실패된 서브워드로부터 얻어진 갱신된 조인트 정보 및 신뢰도를 채용한다. 이러한 디코딩 시도는 (도 7의 단계 229, 231, 236 및 232의 소프트 디코더의 경우에서 언급된 바와 같이) 서브워드 사이에 수행된 "메시지-패싱" 프로시져에 의해 지원된다. 이러한 메시지는 중간 램을 통해 서브워드 사이의 통과된 신뢰도를 나타낸다.
이러한 "메시지 패싱" 프로시져를 수행하는 메커니즘을 제공하는 것은 본 발명의 핵심인데, 그 이유는 이러한 매커니즘이 (조인트 정보를 제외하고) 외부 지식을 요구함없이 분리 서브워드의 부분집합에 대한 실패된 디코딩 이벤트를 성공적인 디코딩이 극복할 수 있도록 하는 매커니즘이기 때문이다. LLR 포맷에서 얻어진 이러한 신뢰도는 새로운 외부 정보를 단일 서브워드에 주기 때문에, 이러한 서브워드가 다음 페이즈에서 성공적으로 디코딩될 경우가 될 수도 있다.
서브워드 'y'의 일반적인 디코딩 페이즈 'p'(p>0)에서, 소프트 디코더는 서브워드 'y' 자체의 신뢰도의 컨트리뷰션을 제외하고, 모든 서브워드의 감추인 패리티 비트의 서브워드 신뢰도를 (보통 LLR 포맷으로) 채용한다. 디코딩 페이즈 'p'에서의 서브워드 'y'의 "감추인 패리티 비트"의 추정치에 대한 진폭 Ay 및 기호값 Sy는 동일한 위치내의 "감추인 패리티 비트"이 각 그룹에 대하여 별개로 유도된다. 즉, 진폭 Ay 및 기호값 Sy은 다음과 같이 동일한 서브워드의 다른 감추인 비트로부터 별개로 그리고 독립적으로 동일한 서브워드의 모든 감추인 비트에 대하여 계산된다.
여기에서, ' F'는 외부 갱신된 'P' 비트 및 실패된 디코딩된 서브워드의 감추인 비트를 포함하는 그룹으로서 정의된다. 갱신된 'P' 비트는 디코딩 프로세스내의 모든 이제까지 성공적으로 디코딩된 서브워드의 재생성된 감추인 비트에 의해 갱신된 플래시 디바이스내에 저장된 비트를 말한다. 함수 Ψ는 다수의 방식으로 계산될 수 있는데, 그중 하나는 다음과 같다.
함수 Ψ의 유용한 특성에 주목해야 한다. 함수 Ψ는 자체의 네가티브 역함수이다.
LLR 포맷으로 측정된 신뢰도의 기호로서 한정된 기호 'Sy'는 다음에 따라 진폭 Ay의 계산에서 참여하는 동일한 세트 'F' 에 대한 XOR (배타적 OR) 연산을 적용하는 것으로부터 판정된다.
여기에서, 'F'는 상기 등식(2.8)에서 불리는 그룹으로부터 정의된다.
일단 서브워드 'y'의 감추인 패리티 비트에 대한 갱신된 신뢰도가 계산되면, 동일한 소프트 디코더가 서브워드 'y'를 디코딩하기 위하여 재활성화된다. 디코딩 및 신뢰도 갱신 프로세스는 성공적인 디코딩이 얻어질 때까지 또는 사전한정된 수의 디코딩 시도 및/또는 디코딩 페이즈가 디코딩 설계에 의해 수행될 때까지 반복된다.
성공적인 디코딩 프로세스는 성공적인 디코딩된 서브워드 'y'의 반복된 "감추인 패리티 비트"의 기호 비트르 사용하여 중간 림내에 조인트 정보를 갱신하고 램내의 서브워드 'y'의 비트를 갱신하는 단계를 포함한다. 따라서, 실패된 디코딩 시도에 이어 중간 램내의 서브워드 'y'의 감추인 패리티 비트의 신뢰도를 갱신하는 단계가 이어진다. 갱신된 확률이 실패된 디코딩 시도의 결과로서 얻어지지만, 이러한 확률을 동일한 페이즈 'p'내의 다른 서브워드의 디코딩에서 고려함으로써 이러한 다른 서브워드의 디코딩 효율을 향상시킬 수 있다.
그다음, 소프트 디코더는 모든 서브워드가 성공적으로 디코딩될 때까지 또는 사전하정된 최대 수의 디코딩 페이즈가 특정 서브코드에 대해 수행될 때까지 그다음 서브워드를 디코딩하기 위해 진행한다.
상술된 바와 같이, 중간 램은 각각의 실패된 서브워드에 대한 "감추인 비트"의 신뢰도를 저장한다. 그러나, "감추인 비트"의 추정치에 대한 오직 하나의 비트(즉, 신회도를 LLR 포맷으로 유지하는경우에 기호 비트)를 포함하는 감소된 크기의 중간 램을 구성하는 것이 또한 가능하다. 이러한 경우에, 서브워드 'y'의 감추인 패리티 비트는 또 다른 실패된 서브워드의 현재 추정된 감추인 패리티 비트로부터 그리고 외부 갱신된 'P' 비트로부터 유도된다. 즉, 실패한 서브워드의 감추인 패리티 비트의 신뢰도의 현 추정치(즉, j∈F에 대한 Aj 및 Sj 모두) 이외의 실패한 서브워드의 감추인 패리티 비트의 현 추정치만이(즉, j∈F에 대한 Sj만이) 저장되어 있다.
본 발명의 우수성은 다양한 관점에서 관찰될 수 있다. 제1 관점에서, 본 발명은 복수번 보다 짧은 코드워드를 디코딩함으로써 긴 코드워드의 성공적인 디코딩을 달성하는 방법 및 디바이스를 개시한다. 실시예 1에 대하여, 긴 코드 워드는 [15,7,5] 블록 코드이고 보다 짧은 코드워드는 [11,7,3] 블록 코드이다. 보다 짧은 [11,7,3] 블록 코드는 2번 디코딩된다.
이로 인해, 본 발명의 디바이스는 동일한 출력 BER/SER 성능을 달성하면서 당업계에 공진된 디코더와 연관된 높은 구현 복잡도를 회피하는 것이 가능하다.
이러한 제1 관점에 따라, 고정된 크기의 서브워드를 성공적으로 디코딩함으로써 데이터의 스트림을 디코딩하기 위해 제공된 당업계에 공지된 모든 디코딩 방법이 본 발명에 유사한 방식으로 구현된다고 말할 수 있다.
예를 들어, 데이터의 스트림을 디코딩하는 것이 필요한데, 각각의 코드 워드는 1000 비트이고, 이러한 각 코드워드는 그것의 전후 코드워드에 관계없이 그 자체로 디코딩된다. 당업계에서 알려진 디코딩 방법에 따라, 데이터의 스트림은 N개(예를 들어, N=4) 그룹의 코드워드로 디코딩된다. N 그룹의 전체 스트림이 4000 비트의 단일 긴 코드워드로서 N=4에 대해 한정된다. 짧은 디코딩이 1000의 4개의 짧은 코드 워드의 각각에 대하여 별개로 적용되어 모든 짧은 디코딩의 디코딩된 데이터는 긴 코드워드의 디코딩된 데이터를 생성하도록 연결된다.
그러나, 본 발명의 방법은 상술된 기존의 디코딩 방법과 상이한 에러 보정 코딩 방법을 제공하는데, 그 이유는 본 발명의 방법이 짧은 코드 워드의 디코딩이 실패하는 경우에 다른 짧은 코드워드의 디코딩된 데이터에 따라 짧은 코드 워드의 디코딩된 데이터를 수정하는 스테이지를 더 제공하기 때문이다. 상술된 실시예 1에 대하여, 실패된 짧은 코드워드의 디코딩된 데이터의 감추인 비트는 또 다른 성공적으로 디코딩된 쇼프 코드 워드의 디코딩된 데이터의 재구성된 감추인 비트 및 플래시 디바이스내에 저장된 조인트 패리티(JP) 비트에 따라 대체된다.
상기 종래 방법에 전혀 제시되지 않은 이러한 스테이지는 본 발명에 많은 많은 장점을 부여한다. 이러한 장점은 하나 이상의 짧은 워드에서의 디코딩 실패를 극복하고 있고, 그래서 이러한 보다 짧은 코드워드를 보호하기 위해 보다 적은 패리티 비트를 필요로 한다.
당업계에 공지된 추가 디코딩 방법은 상이한 짧은 코드워드 사이의 연결에 기초하고 있다. 보통 연결된(concatenated) 코딩 설계로 불리는 이러한 방법에 따라, 제1 코드에 의해 인코딩되는 소수의 짧은 코드워드는 함께 그룹핑되고 제2 코드에 의해 다시 인코딩되어 긴 코드워드를 생성한다. 이러한 종래 방법은 보다 긴 코드워드의 디코딩에 따라 여전히 인코딩된 짧은 코드워드의 수정에 영향을 주고, 그후에 비로서 짧은 코드워드를 디코딩한다.
예를 들어, 각각의 기본 코드워드가 1000 비트인 (4000 비트를 포함하는) 4개의 코드워드의 데이터의 스트림은 4500 비트의 하나의 긴 코드워드로서 제1 코드에 의해 인코딩된다. 긴 코드워드의 디코딩은 먼저 제2 코드에 따라 긴 워드를 디코딩하고 그다음 제1 코드워드에 따라 각 짧은 코드워드를 개별적으로 디코딩할 필요가 있다.
그러나, 실시예 1에 대하여, 본 발명의 방법은 이러한 종래의 방법과 상이한데, 그 이유는 본 발명의 방법이 먼저 짧은 코드 워드를 디코딩하고 그다음 다른 짧은 코드워드의 디코딩된 데이터에 따라 디코딩된 데이터의 수정을 행하기 때문이다.
터보 디코딩으로 불리는 다른 디코딩 방법은 소프트 디코딩 방법을 보통 사용하는 "터보 코드"를 채용한다. "터보 코드"는 반복 피드백 알고리즘 플러스 연결된 코드 구조로 구성된 포워드-에러 보정 기술로서 정의된다. 터보 디코딩을 적용시킴으로써 동일한 데이터 비트는 (데이터 비트가 다수의 인코딩 연산에서 상이한 순서를 갖도록 인터리빙되어) 2번 이상 인코딩되어, 코드워드는 모든 인코딩에 의해 생성된 다수의 세트의 패리티 비트 및 데이터 비트 모두를 포함한다. 디코딩시에, 다수의 디코딩 프로세스가 (병렬로 또는 병렬이 아닌 방식으로) 적용된다. 다수의 세트의 패리티 비트중 하나에 따라 적용된 각 디코딩 프로세스는 상이한 패리티 비트를 갖는 동일한 정보 데이터에 대한 이전의 디코딩 페이즈로부터 외부의 정보를 수용한다.
포워드-에러 보정 기술의 장점은 동일한 데이터 비트를 디코딩하기 위해 적용되는 다수의 디코딩 프로세스 사이의 인터랙션("메시지 패싱")에 있다. 이러한 인터랙션은 디코더의 에러 보정 성능을 강화한다. 터보 디코딩을 적용하는 디코더는 오직 하나의 세트의 패리티 비트에 따라 데이터를 디코딩하도록 구성될 수 있어서, 오직 실패된 디코딩의 경우에만 다수의 세트의 패리티 비트가 상술된 바와 같이 디코딩된다.
본 발명의 방법은 소수의 영역에서 당업계에 공지된 터보 디코딩 방법과 상이하다. 먼저, 서브워드 자체의 디코딩과 디코딩된 워드의 수정을 행하는 프로시져 사이에는 명백한 차이가 있다. 본 발명의 방법은 짧은 워드의 각각을 별개로 디코딩한 후에 비로서 디코딩된 데이터의 하나의 부분이 다른 부분에 영향을 주는 프로세스를 적용한다. 그러나, 터보 디코딩 방법에 따라, 서브워드를 디코딩하는 단계와 다른 서브워드의 수정을 행하는 단계 사이에는 이러한 명백한 차이가 존재하지 않는데, 양측 프로시져는 동시에 발생한다.
둘째, 본 발명의 방법에 따라, 각각의 짧은 워드는 또 다른 짧은 워드와 독립적으로 디코딩된다. 따라서, 디코딩된 코드워드는 디코딩된 데이터의 독립 세트를 생성한다. 그러나, 터보 디코딩 방법에 따라, (전형적인 병렬 구현에서의) 짧은 워드의 모두 또는 (2-스테이지 구현에서의) 적어도 하나의 짧은 워드는 디코딩된 비트의 조인트 세트를 생성하기 위해 다른 짧은 코드워드와 직렬로 디코딩된다. 또한, 디코딩된 짧은 코드워드는 반드시 "자체 디코딩된 데이터"로서 식별되지는 않는다(즉, 다른 코드워드에 의존한다).
셋째, 본 발명에 따라, 다수의 짧은 코드워드는 긴 코드워드의 분리 부분집합이다. 그런, 이러한 구현은 터보 디코딩 방법에서 제공되지 않고, 다수의 짧은 코드워드는 모두 동일한 데이터 비트를 인코딩한다.
두번째 관점으로부터, 본 발명의 장점은 2개의 인코딩 설계를 사용하여 데이터 비트를 인코딩하고, 산출된 패리티 비트 모두를 유지하지 않고, 2개의 세트의 패리티 비트 사이의 관계에 의존하여 또 다른 세트가 불충분한 경우에 하나의 세트 "커버업"을 만듬으로써 에러 보정 성능을 향상시키고 있다. 본 발명을 이러한 관점에서 볼 때, 다음 특징이 고려되어야 한다.
a. 이러한 관점의 구별되는 특징은 결국 사용되는 보다 많은 패리티 비트를 계산하는 중간 스테이지이다. 이로 인해 "펑쳐링"의 종래 방법에 주목하게 된다. 에러 보정에서, 이론 용어 "펑쳐링"은 패리티 오버헤드를 감소시키기 위해 일부 계산된 패리티 비트를 드롭핑하고, 이러한 감소된 오버헤드를 보다 낮은 에러 보정 능력과 교환하는 것을 의미한다. 그런, 종래기술에서 이해되는 "펑쳐링"은 본 발명과 매우 상이하다. 본 발명은 그 연산에 대한 기초로서 2개의 에러 보정 인코딩 설계를 채용하지만, 이러한 종류의 설계가 오직 단일 인코딩 설계를 사용하는 종래 기술 평쳐링 방법에는 존재하지 않는다.
b. 2004년 11월 29일에 출원되고, 미국 특허 출원 공개번호 제 2005/016-350으로서 공개되고, Dror 등에게 허여된 "COMPACT HIGH-SPEED SINGLE-BIT ERROR-CORRECTION CIRCUIT"의 제목의 미국 특허 출원 제10/998,003호에는 인코딩 페이즈 동안 계산된 패리티 정보의 일부를 또한 드롭핑하는 에러 보정 방법이 개시되어 있다. Dror 등의 방법은 상술된 펑쳐링 방법보다는 본 발명에 보다 가까운데, 그 이유는 Dror 등의 방법이 겉보기에는 본 발명과 같이 페이즈중 오직 하나의 페이즈의 결과로부터 패리티 정보가 드롭핑되는 2개의 별개의 계산 페이즈를 포함하고 있기 때문이다. 하지만, Dror 등은 상술된 사실로 인해 본 발명과 상이하다. 즉, 본 발명은 2개의 에러 보정 인코딩 스킴을 채용하지만, 이것은 Dror 등에서의 경우가 아니다. Dror등이 2개의 계산 페이즈를 하고 있지만, 각 페이즈는 그 자체로 단일 에러조차 보정할 수 없기 때문에 에러 보정 설계가 아니다. 오직 2개의 계산만이 함께 보정 에러를 위한 충분한 패리티 정보를 제공하고, 따라서, 오직 2개의 계산만이 함께 에러 보정 설계를 구성한다.
본 발명이 시스테매틱 코드에 관한 것이지만, 본 발명의 방법은 시스테매틱 및 논-시스테매틱 에러 보정 코드 모두에 동일하게 적용가능하다는 것을 이해해야 한다. 에러 보정 용어에 따라, 시스테매틱 코드는 인코더에 전송된 입력 데이터 비트의 각각이, 적용가능하다면 펑쳐링하기 전에, 인코딩된 코드워드내의 매칭 비트로의 일대일 상응관계를 갖는 코드로서 정의되어, 인코딩된 코드워드 비트는 2개의 분리부분, 즉, 오리지널 데이터 비트를 포함하는 것과 패리티 비트를 포함하는 또 다른 것으로 분할될 수 있다. 이에 따라, 논-시스테매틱 코드는 상기 상태를 만족시키지 않는 임의의 코드로서 정의된다(즉, 이러한 클리어 분할은 논-시스테매틱 코드에서는 가능하지 않다.).
본 발명의 방법은 하드 인코딩 및 소프트 인코딩 디코더 모두에 동일하게 적용가능하다. 에러 보정 용어에 따라, 소프트 인코딩 디코더는 디코딩 프로세스 동안 고려할 수 있는 입력 비트에 대한 신뢰도 측정치를 수용할 수 있고 이러한 신뢰도 측정치를 디코딩 프로세스 동안 갱신할 수 있는 디코딩 프로세스를 적용한다. 하드 디코딩 디코더는 상기 상태를 만족시키지 않는 디코더이다.
본 발명이 상술된 바와 같이, 단순한 BCH 코드에 기초하고 있지만, 동일한 효율 및 성능 이득을 달성하는 당업계에 공지된 다른 코딩 및 디코딩 기술이 채용될 수 있다.
또한, 본 발명의 디바이스에 의해 채용된 코드 구조는 디지털 저장 매체, 램, 플래시 메모리 및 이이프롬을 포함하는 당업계에서 공지된 임의의 이러한 디바이스에서 채용될 수 있다. 용어 "저장" 및 "메모리"는 여기에 상호교환가능한 것으로 사용되고 이러한 임의의 저장 디바이스를 나타낸다.
본 발명이 여기에 플래시 메모리에 제공되지만, 본 발명의 원리는 통신 시스템(DSL, DVBS, 3G, 4G, CDMA2000, 802.11 및 802.16의 파생을 포함하는 무선, 유선 전화 시스템, 위성, 휴대폰) 및 신호 처리(화상 음성 적용)과 같은 다른 타입의 적용에 사용되도록 적용되어 장점을 제공할 수 있다는 것에 주목해야 한다.
디코딩 프로세스의 제1 페이즈가 불충분한 경우에, 버퍼가 또한, 추가적인 디코딩 시도의 활성화를 위한 데이터를 유지하도록, 당업계에 공지된 통신 시스템에서 구현될 수 있다. 그러나, 아무런 추가 버터가 요구되는 경우가 아닐 수 있는데, 그 이유는 이러한 버퍼가 이미 통신 시스템의 다른 부분에서 채용될 수 있는 반면 디코딩 유닛은 아이들 상태이기 때문이다.
에러 보정 코딩 설계를 제공하는 임의의 방법 및 디바이스에 관련되어 있는 다른 구현이 본 발명의 범위내에서 가능하다는 것을 이해해야 한다.
본 발명이 특정 실시예에 대해 설명되었지만, 이것은 제한하기 위한 것이 아니고, 추가적인 수정이 당업자에게 가능하고 이러한 수정은 첨부된 청구범위내에 있다는 것을 이해해야 한다.
참조


Claims (43)
- 코드워드의 표현(representation)을 디코딩하는 방법으로서,
(a) 복수의 서브워드의 각각의 비트가 상기 코드워드의 표현의 비트의 진부분집합(proper subset)이 되도록 상기 코드워드의 표현으로부터 상기 복수의 서브워드를 생성하는 단계;
(b) 상기 서브워드의 각각을 오직 자체 비트에 따라, 상응하는 디코딩된 서브워드를 생성하도록 디코딩하는 단계; 및
(c) 상기 서브워드중 하나의 서브워드의 디코딩이 실패한다면, 수정된 디코딩된 서브워드를 산출하기 위해, 디코딩이 실패된 상기 하나의 서브워드에 상응하는 상기 디코딩된 서브워드를 수정하는 단계;를 포함하고,
상기 수정하는 단계는 적어도 하나의 성공적으로 디코딩된 서브워드 중 적어도 상기 상응하는 디코딩된 서브워드에 따라 실행되고,
상기 디코딩이 실패된 상기 하나의 서브워드에 상응하는 상기 디코딩된 서브워드를 수정하는 단계는 상기 디코딩이 실패된 하나의 서브워드의 적어도 하나의 비트에 따르고,
상기 디코딩이 실패된 상기 하나의 서브워드에 상응하는 상기 디코딩된 서브워드를 수정하는 단계는:
일세트의 패리티 정보를 구성하기 위해, 상기 성공적으로 디코딩된 서브워드를 인코딩하는 단계;
적어도 상기 구성된 일세트의 패리티 정보를 사용하여, 상기 디코딩이 실패된 서브워드를 위한 패리티 정보를 생성하는 단계;
추출된 상기 패리티 정보를 상기 디코딩된 서브 워드와 관련시키는 단계; 및
상기 디코딩된 서브워드와 상기 관련된 추출 패리티 정보를 이용하여 에러 보정 프로세스를 적용하여 상기 디코딩된 서브 워드를 수정하는 단계에 의해 수행되는 것을 특징으로 하는 코드워드의 표현 디코딩 방법. - 제1항에 있어서,
(d) 상기 서브워드중 하나의 디코딩이 실패한다면, 상기 수정된 디코딩된 서브워드로부터의 데이터와 상기 성공적으로 디코딩된 서브워드의 모두의 상기 상응하는 디코딩된 서브워드로부터의 데이터를 조합하는 단계를 더 포함하는 것을 특징으로 하는 코드워드의 표현 디코딩 방법. - 제2항에 있어서, 상기 수정된 디코딩된 서브워드로부터의 데이터와 상기 성공적으로 디코딩된 서브워드의 모두의 상응하는 디코딩된 서브워드로부터의 데이터를 조합하는 단계는 상기 수정된 디코딩된 서브워드로부터의 데이터를 상기 성공적인 디코딩된 서브워드의 모두의 상기 상응하는 디코딩된 서브워드로부터의 데이터와 어셈블링하는 단계에 의해 실행되는 것을 특징으로 하는 코드워드의 표현 디코딩 방법.
- 제1항에 있어서, 상기 서브워드는 서로소(disjoint)인 것을 특징으로 하는 코드워드의 표현 디코딩 방법.
- 제1항에 있어서, 상기 서브워드는 동일한 수의 비트를 포함하는 것을 특징으로 하는 코드워드의 표현 디코딩 방법.
- 제1항에 있어서, 통합적으로 수집된 상기 서브워드의 상기 비트는 상기 코드워드의 표현의 상기 비트의 진부분집합인 것을 특징으로 하는 코드워드의 표현 디코딩 방법.
- 제6항에 있어서, 상기 디코딩이 실패된 상기 하나의 서브워드에 상응하는 상기 디코딩된 서브워드를 수정하는 단계는 임의의 상기 서브워드의 상기 비트에 속하지 않는 상기 코드워드의 표현의 적어도 하나의 비트에 따르는 것을 특징으로 하는 코드워드의 표현 디코딩 방법.
- 삭제
- 제1항에 있어서, 상기 디코딩이 실패된 상기 하나의 서브워드에 상응하는 상기 디코딩된 서브워드를 수정하는 단계는 상기 디코딩이 실패된 하나의 서브워드의 모든 비트에 따르는 것을 특징으로 하는 코드워드의 표현 디코딩 방법.
- 제1항에 있어서, 상기 수정하는 단계에서, 상기 적어도 하나의 성공적으로 디코딩된 서브워드 중 하나의 상기 상응하는 디코딩된 서브워드의 적어도 하나의 비트는 상기 디코딩이 실패된 하나의 서브워드에 상응하는 상기 디코딩된 서브워드의 복수의 비트에 영향을 주는 것을 특징으로 하는 코드워드의 표현 디코딩 방법.
- M개의 비트의 워드를 디코딩하는 장치로서,
(a) N(<M)개의 비트의 워드를 디코딩하는 디코더; 및
(b) 상기 디코더를 M개의 비트의 워드로부터 선택된 N개의 비트의 상이한 부분집합의 각각에 개별적으로 적용하기 위한 장치;를 포함하고,
상기 디코더의 각각의 적용은 상기 각각의 적용이 적용되는 상기 N개의 비트에 단독으로 종속되고, 상기 각각의 적용은 상응하는 디코딩된 데이터를 생성하여, M개의 비트의 워드의 최종 디코딩된 데이터가 상기 적용의 상기 상응하는 디코딩된 데이터를 포함하는 입력에 따라 생성되고,
상기 적용 중 하나가 실패하면, 상기 장치는 적어도 하나의 성공적인 적용의 상기 상응하는 디코딩된 데이터를 포함하는 입력에 따라 상기 실패된 적용의 상기 상응하는 디코딩된 데이터의 수정을 행하고,
상기 실패된 적용의 상기 상응하는 디코딩된 데이터의 상기 수정의 상기 입력은 또한 상기 실패된 적용이 적용되었던 상기 부분집합의 적어도 하나의 비트를 포함하고,
상기 실패된 적용의 상기 상응하는 디코딩된 데이터의 상기 수정은:
일세트의 패리티 정보를 구성하기 위해, 상기 성공적인 적용에 의해 생성된 데이터를 인코딩하는 단계;
적어도 상기 구성된 일세트의 패리티 정보를 사용하여, 상기 실패된 적용의 상기 상응하는 디코딩된 데이터를 위한 패리티 정보를 생성하는 단계;
추출된 상기 패리티 정보를 상기 실패된 적용의 상기 상응하는 디코딩된 데이터와 관련시키는 단계; 및
상기 실패된 적용의 상기 상응하는 디코딩된 데이터와 상기 관련된 추출 패리티 정보를 이용하여 에러 보정 프로세스를 적용함으로써 상기 실패된 적용의 상기 상응하는 디코딩된 데이터를 수정하는 단계에 의해 수행되는 것을 특징으로 하는 M개의 비트의 워드 디코딩 장치. - 제11항에 있어서, 상기 부분집합은 서로소(disjoint)인 것을 특징으로 하는 M개의 비트의 워드 디코딩 장치.
- 제11항에 있어서, 통합적으로 얻어진, 상기 N비트의 부분집합은 M비트의 진부분집합인 것을 특징으로 하는 M개의 비트의 워드 디코딩 장치.
- 제13항에 있어서, 상기 실패된 적용의 상기 상응하는 디코딩된 데이터의 상기 수정의 상기 입력은 임의의 상기 N개의 비트의 부분집합에 속하지 않는 M개의 비트 중 적어도 하나의 비트를 포함하는 것을 특징으로 하는 M개의 비트의 워드 디코딩 장치.
- 삭제
- 제11항에 있어서, 상기 실패된 적용의 상기 상응하는 디코딩된 데이터의 상기 수정의 상기 입력은 상기 실패된 적용이 적용되었던 상기 부분집합의 모든 비트를 포함하는 것을 특징으로 하는 M개의 비트의 워드 디코딩 장치.
- M개의 비트의 워드를 디코딩하는 장치로서,
(a) N(<M)개의 비트의 워드를 각각 디코딩하는 복수의 디코더; 및
(b) 상기 복수의 디코더의 각각을 M개의 비트의 워드로부터 선택된 N개의 비트의 상이한 부분집합의 각각에 개별적으로 적용하기 위한 장치;를 포함하고,
상기 복수의 디코더의 각각의 적용은 상기 각각의 적용이 적용되는 상기 N개의 비트에 단독으로 종속되고, 상기 각각의 적용은 상응하는 디코딩된 데이터를 생성하여, M개의 비트의 워드의 최종 디코딩된 데이터가 적어도 상기 적용의 상기 상응하는 디코딩된 데이터를 포함하는 입력에 따라 생성되고,
상기 디코더 중 하나가 실패하면, 상기 장치는 적어도 하나의 성공한 디코더의 상기 상응하는 디코딩된 데이터를 포함하는 입력에 따라 실패된 상기 디코더의 상기 상응하는 디코딩된 데이터의 수정을 행하고,
상기 실패된 상기 디코더의 상기 상응하는 디코딩된 데이터의 상기 수정의 상기 입력은 상기 실패된 디코더가 적용되었던 상기 부분집합의 적어도 하나의 비트를 포함하고,
상기 디코딩이 실패된 상기 디코더의 상기 상응하는 디코딩된 데이터의 수정은:
일세트의 패리티 정보를 구성하기 위해, 성공적인 적용에 의해 생성된 상기 상응하는 디코딩된 데이터를 인코딩하는 단계;
적어도 상기 구성된 일세트의 패리티 정보를 사용하여, 실패된 적용의 상기 상응하는 디코딩된 데이터를 위한 패리티 정보를 생성하는 단계;
추출된 상기 패리티 정보를 상기 실패된 적용의 상기 상응하는 디코딩된 데이터와 관련시키는 단계; 및
상기 실패된 적용의 상기 상응하는 디코딩된 데이터와 상기 관련된 추출 패리티 정보를 이용하여 에러 보정 프로세스를 적용함으로써, 상기 실패된 적용의 상기 상응하는 디코딩된 데이터를 수정하는 단계에 의해 수행되는 것을 특징으로 하는 M개의 비트의 워드 디코딩 장치. - 제17항에 있어서, 상기 부분집합은 서로소(disjoint)인 것을 특징으로 하는 M개의 비트의 워드 디코딩 장치.
- 제17항에 있어서, 통합적으로 얻어진, 상기 N개의 비트의 부분집합은 M개의 비트의 진부분집합인 것을 특징으로 하는 M개의 비트의 워드 디코딩 장치.
- 제19항에 있어서, 상기 실패된 적용의 상기 상응하는 디코딩된 데이터의 상기 수정의 상기 입력은 임의의 상기 N개의 비트의 부분집합에 속하지 않는 M개의 비트의 적어도 하나의 비트를 포함하는 것을 특징으로 하는 M개의 비트의 워드 디코딩 장치.
- 삭제
- 제17항에 있어서, 상기 실패된 상기 디코더의 상기 상응하는 디코딩된 데이터의 상기 수정의 상기 입력은 상기 실패된 디코더가 적용되었던 상기 부분집합의 모든 비트를 포함하는 것을 특징으로 하는 M개의 비트의 워드 디코딩 장치.
- 코드워드의 표현 디코딩 방법으로서,
상기 표현은 M개의 데이터 비트 및 P개의 패리티 비트를 포함하고, 상기 방법은,
(a) P개의 패리티 비트를 제1 그룹의 패리티 비트와 제2 그룹의 패리티 비트로 분할하는 단계;
(b) 보정된 데이터 비트를 제공하기 위해 상기 제1 그룹의 패리티 비트만을 사용하여 M개의 데이터 비트를 디코딩하는 단계; 및
(c) 상기 제1 그룹의 패리티 비트만을 사용한 디코딩이 실패한다면, 상기 보정된 데이터 비트를 제공하기 위해 상기 제1 그룹의 패리티 비트 및 상기 제2 그룹의 패리티 비트를 사용하여 상기 M개의 데이터 비트를 디코딩하는 단계를 포함하고,
상기 제2 그룹의 패리티 비트는:
일세트의 패리티 데이터를 생성하기 위해, 디코딩이 성공적인 제2 세트의 M개의 데이터 비트를 인코딩하는 단계; 및
적어도 상기 패리티 데이터 세트를 이용하여 상기 제2 그룹의 패리티 비트를 추출하는 단계에 의해 유도되는 것을 특징으로 하는 코드워드의 표현 디코딩 방법. - M개의 데이터 비트 및 P개의 패리티 비트를 포함하는 코드워드의 표현을 디코딩하는 방법으로서,
(a) M개의 데이터 비트를 K(>1)개의 부분집합으로 분할하는 단계;
(b) P개의 패리티 비트를 제1 그룹의 패리티 비트 및 제2 그룹의 패리티 비트로 분할하는 단계;
(c) 상기 제1 그룹의 패리티 비트를 K개의 부분집합으로 분할하는 단계;
(d) M개의 데이터 비트의 각 부분집합의 디코딩된 데이터를 생성하기 위해 상기 제1 그룹의 패리티 비트의 상응하는 부분집합에 따라 상기 M개의 데이터 비트의 상기 부분집합의 각각을 디코딩하는 단계;
(e) 상기 M개의 데이터 비트의 상기 K개의 부분집합중 하나의 디코딩이 실패하면, 상기 하나의 부분집합의 상기 디코딩된 데이터를 생성하기 위해 적어도 상기 제2 그룹의 패리티 비트에 따라 상기 하나의 부분집합을 디코딩하는 단계; 및
(f) 상기 M개의 데이터 비트에 대한 전체 디코딩된 데이터를 생성하기 위해 상기 M개의 데이터 비트의 상기 K개의 부분집합 모두의 상기 디코딩된 데이터를 조합하는 단계를 포함하고,
상기 M개의 데이터 비트의 각각은 상기 K개의 부분집합에 적어도 한번 나타나고, 상기 제1 그룹의 패리티 비트의 부분집합의 각각은 상기 M개의 데이터 비트의 각 부분집합에 상응하고,
상기 제2 그룹의 패리티 비트는:
일세트의 패리티 데이터 세트를 생성하기 위해, M개의 데이터 비트의 상기 K개의 부분집합 중 디코딩이 성공적인 부분집합을 인코딩하는 단계; 및
적어도 상기 패리티 데이터 세트를 이용하여 제2 그룹의 패리티 비트를 생성하는 단계에 의해 유도되는 것을 특징으로 하는, M개의 데이터 비트 및 P개의 패리티 비트를 포함하는 코드워드의 표현 디코딩 방법. - 제24항에 있어서, 상기 M개의 데이터 비트의 상기 K개의 부분집합 모두의 상기 디코딩된 데이터를 조합하는 단계는 상기 M개의 데이터 비트의 상기 K개의 부분집합 모두의 상기 디코딩된 데이터를 어셈블링하는 단계에 의해 수행되는 것을 특징으로 하는 M개의 데이터 비트 및 P개의 패리티 비트를 포함하는 코드워드 표현 디코딩 방법.
- 제24항에 있어서, 상기 M개의 데이터 비트의 상기 K개의 부분집합은 서로소(disjoint)인 것을 특징으로 하는 M개의 데이터 비트 및 P개의 패리티 비트를 포함하는 코드워드의 표현 디코딩 방법.
- 제24항에 있어서, 상기 M개의 데이터 비트의 상기 K개의 부분집합은 모두 동일한 사이즈를 갖는 것을 특징으로 하는 M개의 데이터 비트 및 P개의 패리티 비트를 포함하는 코드워드의 표현 디코딩 방법.
- 제24항에 있어서, 상기 제1 그룹의 패리티 비트의 상기 상응하는 부분집합에 따라 상기 각각의 부분집합의 데이터 비트를 디코딩하는 단계는 상응하는 제1 디코딩 스킴을 사용하는 단계를 포함하고, 상기 제2 그룹의 패리티 비트에 따라, 디코딩이 실패한, 상기 하나의 부분집합의 데이터 비트를 디코딩하는 단계는 상응하는 제2 디코딩 스킴을 사용하는 단계를 포함하는 것을 특징으로 하는 M개의 데이터 비트 및 P개의 패리티 비트를 포함하는 코드워드의 표현 디코딩 방법.
- 제28항에 있어서, 상기 M개의 데이터 비트의 상기 K개의 부분집합중 적어도 하나에 대해, 상기 상응하는 제1 디코딩 스킴 및 상기 상응하는 제2 디코딩 스킴은 공통인 디코딩 방법을 적용하는 것을 특징으로 하는 M개의 데이터 비트 및 P개의 패리티 비트를 포함하는 코드워드의 표현 디코딩 방법.
- 제28항에 있어서, 상기 제1 디코딩 스킴 모두는 동일한 것을 특징으로 하는 M개의 데이터 비트 및 P개의 패리티 비트를 포함하는 코드워드의 표현 디코딩 방법.
- 제28항에 있어서, 상기 제2 디코딩 스킴 모두는 동일한 것을 특징으로 하는 M개의 데이터 비트 및 P개의 패리티 비트를 포함하는 코드워드의 표현 디코딩 방법.
- 제24항에 있어서, 상기 하나의 부분집합은 상기 하나의 부분집합 중 적어도 하나의 비트에 따라 디코딩되는 것을 특징으로 하는 M개의 데이터 비트 및 P개의 패리티 비트를 포함하는 코드워드의 표현 디코딩 방법.
- 제32항에 있어서, 상기 하나의 부분집합은 상기 하나의 부분집합의 모든 비트에 따라 디코딩되는 것을 특징으로 하는 M개의 데이터 비트 및 P개의 패리티 비트를 포함하는 코드워드의 표현 디코딩 방법.
- N(>M)개의 비트를 갖는 코드워드의 표현으로부터 M개의 데이터 비트를 디코딩하는 방법으로서,
(a) 나머지 비트의 집합을 생성하기 위해 N개의 비트로부터 최대 N-M개의 비트의 선택된 부분집합을 제거하는 단계;
(b) 상기 나머지 비트를 상기 나머지 비트의 K(>1)개의 부분집합으로 분할하는 단계;
(c) 상기 각 부분집합의 디코딩된 데이터를 생성하기 위해 상기 각 부분집합의 비트만을 따라 상기 K개의 부분집합의 각각을 디코딩하는 단계;
(d) 상기 K개의 부분집합중 하나의 디코딩이 실패하면, 상기 하나의 부분집합중 상기 디코딩된 데이터를 생성하기 위해, 적어도 상기 제거된 선택된 부분집합에 따라 상기 하나의 부분집합을 디코딩하는 단계; 및
(e) 상기 M개의 데이터 비트에 대한 전체 디코딩된 데이터를 생성하기 위해 상기 K개의 부분집합의 모두의 상기 디코딩된 데이터를 조합하는 단계;를 포함하고,
상기 나머지 비트의 각각은 적어도 하나의 상기 K개의 부분집합의 멤버이고,
적어도 상기 제거된 선택된 부분집합은 상기 디코딩하는 단계 동안 :
일세트의 패리티 데이터 세트를 생성하기 위해 성공적으로 디코딩된 부분집합을 인코딩하는 단계; 및
적어도 상기 패리티 데이터 세트를 이용하여 상기 K개의 부분집합의 하나에 대해 적어도 상기 제거된 선택된 부분집합을 생성하는 단계에 의해, 생성되는 것을 특징으로 하는, N(>M)개의 비트를 갖는 코드워드의 표현으로부터 M개의 데이터 비트 디코딩 방법. - 제34항에 있어서, 상기 K개의 부분집합의 모두의 상기 디코딩된 데이터를 조합하는 단계는 상기 K개의 부분집합의 모두의 상기 디코딩된 데이터 모두를 어셈블링하는 단계에 의해 수행되는 것을 특징으로 하는 N(>M)개의 비트를 갖는 코드워드의 표현으로부터 M개의 데이터 비트 디코딩 방법.
- 제34항에 있어서, 상기 K개의 부분집합은 서로소(disjoint)인 것을 특징으로 하는 N(>M)개의 비트를 갖는 코드워드의 표현으로부터 M개의 데이터 비트 디코딩 방법.
- 제34항에 있어서, 상기 K개의 부분집합은 모두 동일한 사이즈를 갖는 것을 특징으로 하는 N(>M)개의 비트를 갖는 코드워드의 표현으로부터 M개의 데이터 비트 디코딩 방법.
- 제34항에 있어서, 상기 각각의 부분집합의 상기 비트에 따라 상기 각각의 부분집합의 데이터 비트를 디코딩하는 단계는 상응하는 제1 디코딩 스킴을 사용하는 단계를 포함하고, 상기 제거된 선택된 부분집합에 따라 디코딩이 실패된 상기 하나의 부분집합의 데이터 비트를 디코딩하는 단계는 상응하는 제2 디코딩 스킴을 사용하는 단계를 포함하는 것을 특징으로 하는 N(>M)개의 비트를 갖는 코드워드의 표현으로부터 M개의 데이터 비트 디코딩 방법.
- 제38항에 있어서, 상기 K개의 부분집합중 적어도 하나에 대하여 상기 상응하는 제1 디코딩 스킴 및 상기 상응하는 제2 디코딩 스킴은 공통인 디코딩 방법을 적용하는 것을 특징으로 하는 N(>M)개의 비트를 갖는 코드워드의 표현으로부터 M개의 데이터 비트 디코딩 방법.
- 제38항에 있어서, 상기 제1 디코딩 스킴 모두는 동일한 것을 특징으로 하는 N(>M)개의 비트를 갖는 코드워드의 표현으로부터 M개의 데이터 비트 디코딩 방법.
- 제38항에 있어서, 상기 제2 디코딩 스킴 모두는 동일한 것을 특징으로 하는 N(>M)개의 비트를 갖는 코드워드의 표현으로부터 M개의 데이터 비트 디코딩 방법.
- 제34항에 있어서, 상기 하나의 부분집합은 상기 하나의 부분집합의 적어도 하나의 비트에 따라 디코딩되는 것을 특징으로 하는 N(>M)개의 비트를 갖는 코드워드의 표현으로부터 M개의 데이터 비트 디코딩 방법.
- 제42항에 있어서, 상기 하나의 부분집합은 상기 하나의 부분집합의 모든 비트에 따라 디코딩되는 것을 특징으로 하는 N(>M)개의 비트를 갖는 코드워드의 표현으로부터 M개의 데이터 비트 디코딩 방법.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US73645805P | 2005-11-15 | 2005-11-15 | |
| US60/736,458 | 2005-11-15 | ||
| US11/514,182 | 2006-09-01 | ||
| US11/514,182 US7844877B2 (en) | 2005-11-15 | 2006-09-01 | Method and device for multi phase error-correction |
| PCT/IL2006/001305 WO2007057885A2 (en) | 2005-11-15 | 2006-11-13 | Method and device for multi phase error-correction |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020087014455A Division KR101135425B1 (ko) | 2005-11-15 | 2006-11-13 | 다상 에러 보정을 위한 방법 및 디바이스 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20110014667A KR20110014667A (ko) | 2011-02-11 |
| KR101275041B1 true KR101275041B1 (ko) | 2013-06-14 |
Family
ID=38049059
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020087014455A KR101135425B1 (ko) | 2005-11-15 | 2006-11-13 | 다상 에러 보정을 위한 방법 및 디바이스 |
| KR1020107029291A KR101275041B1 (ko) | 2005-11-15 | 2006-11-13 | 다상 에러 보정을 위한 방법 및 디바이스 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020087014455A KR101135425B1 (ko) | 2005-11-15 | 2006-11-13 | 다상 에러 보정을 위한 방법 및 디바이스 |
Country Status (7)
| Country | Link |
|---|---|
| US (3) | US7844877B2 (ko) |
| EP (1) | EP1949580B1 (ko) |
| JP (1) | JP5216593B2 (ko) |
| KR (2) | KR101135425B1 (ko) |
| CN (2) | CN103023514B (ko) |
| AT (1) | ATE540480T1 (ko) |
| WO (1) | WO2007057885A2 (ko) |
Families Citing this family (163)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006209928A (ja) * | 2005-01-31 | 2006-08-10 | Sony Corp | 光ディスク製造方法及び装置、光ディスク、並びに、光ディスク再生方法及び装置 |
| US7844877B2 (en) * | 2005-11-15 | 2010-11-30 | Ramot At Tel Aviv University Ltd. | Method and device for multi phase error-correction |
| US8271850B2 (en) * | 2005-12-29 | 2012-09-18 | Intel Corporation | Fast low-density parity-check code encoder |
| EP2033368A2 (en) * | 2006-05-01 | 2009-03-11 | Adaptive Spectrum and Signal Alignment, Inc. | Methods and apparatus to combine data from multiple sources to characterize communication systems |
| US7840875B2 (en) * | 2006-05-15 | 2010-11-23 | Sandisk Corporation | Convolutional coding methods for nonvolatile memory |
| US8042029B2 (en) * | 2006-05-21 | 2011-10-18 | Ramot At Tel Aviv University Ltd. | Error correction decoding by trial and error |
| JP4992900B2 (ja) * | 2006-08-02 | 2012-08-08 | 富士通株式会社 | 受信装置及びその復号方法 |
| US7805663B2 (en) * | 2006-09-28 | 2010-09-28 | Sandisk Corporation | Methods of adapting operation of nonvolatile memory |
| US7818653B2 (en) | 2006-09-28 | 2010-10-19 | Sandisk Corporation | Methods of soft-input soft-output decoding for nonvolatile memory |
| US7904783B2 (en) * | 2006-09-28 | 2011-03-08 | Sandisk Corporation | Soft-input soft-output decoder for nonvolatile memory |
| US7904780B2 (en) * | 2006-11-03 | 2011-03-08 | Sandisk Corporation | Methods of modulating error correction coding |
| US7904788B2 (en) * | 2006-11-03 | 2011-03-08 | Sandisk Corporation | Methods of varying read threshold voltage in nonvolatile memory |
| US8001441B2 (en) * | 2006-11-03 | 2011-08-16 | Sandisk Technologies Inc. | Nonvolatile memory with modulated error correction coding |
| US8418023B2 (en) * | 2007-05-01 | 2013-04-09 | The Texas A&M University System | Low density parity check decoder for irregular LDPC codes |
| KR100873824B1 (ko) * | 2007-05-04 | 2008-12-15 | 삼성전자주식회사 | 오류 제어 코드 장치 및 그 방법 |
| US8650352B2 (en) | 2007-09-20 | 2014-02-11 | Densbits Technologies Ltd. | Systems and methods for determining logical values of coupled flash memory cells |
| WO2009095902A2 (en) | 2008-01-31 | 2009-08-06 | Densbits Technologies Ltd. | Systems and methods for handling immediate data errors in flash memory |
| US8694715B2 (en) | 2007-10-22 | 2014-04-08 | Densbits Technologies Ltd. | Methods for adaptively programming flash memory devices and flash memory systems incorporating same |
| WO2009053961A2 (en) | 2007-10-25 | 2009-04-30 | Densbits Technologies Ltd. | Systems and methods for multiple coding rates in flash devices |
| US8453022B2 (en) | 2007-12-05 | 2013-05-28 | Densbits Technologies Ltd. | Apparatus and methods for generating row-specific reading thresholds in flash memory |
| US8335977B2 (en) * | 2007-12-05 | 2012-12-18 | Densbits Technologies Ltd. | Flash memory apparatus and methods using a plurality of decoding stages including optional use of concatenated BCH codes and/or designation of “first below” cells |
| WO2009072105A2 (en) | 2007-12-05 | 2009-06-11 | Densbits Technologies Ltd. | A low power chien-search based bch/rs decoding system for flash memory, mobile communications devices and other applications |
| WO2009074978A2 (en) | 2007-12-12 | 2009-06-18 | Densbits Technologies Ltd. | Systems and methods for error correction and decoding on multi-level physical media |
| US8276051B2 (en) * | 2007-12-12 | 2012-09-25 | Densbits Technologies Ltd. | Chien-search system employing a clock-gating scheme to save power for error correction decoder and other applications |
| US8327246B2 (en) | 2007-12-18 | 2012-12-04 | Densbits Technologies Ltd. | Apparatus for coding at a plurality of rates in multi-level flash memory systems, and methods useful in conjunction therewith |
| JP5522725B2 (ja) * | 2007-12-20 | 2014-06-18 | 日本電気株式会社 | 端末装置、端末装置の制御方法、及び制御プログラム |
| US8301912B2 (en) * | 2007-12-31 | 2012-10-30 | Sandisk Technologies Inc. | System, method and memory device providing data scrambling compatible with on-chip copy operation |
| US8161166B2 (en) * | 2008-01-15 | 2012-04-17 | Adobe Systems Incorporated | Information communication using numerical residuals |
| US20090207725A1 (en) * | 2008-02-11 | 2009-08-20 | Wenfeng Zhang | Method and system for joint encoding multiple independent information messages |
| US8832518B2 (en) * | 2008-02-21 | 2014-09-09 | Ramot At Tel Aviv University Ltd. | Method and device for multi phase error-correction |
| KR20090097673A (ko) * | 2008-03-12 | 2009-09-16 | 삼성전자주식회사 | 연판정 값에 기반하여 메모리에 저장된 데이터를 검출하는장치 |
| WO2009118720A2 (en) | 2008-03-25 | 2009-10-01 | Densbits Technologies Ltd. | Apparatus and methods for hardware-efficient unbiased rounding |
| US20090282267A1 (en) * | 2008-05-09 | 2009-11-12 | Ori Stern | Partial scrambling to reduce correlation |
| US8464131B2 (en) * | 2008-06-23 | 2013-06-11 | Ramot At Tel Aviv University Ltd. | Reading a flash memory by constrained decoding |
| US8458563B2 (en) * | 2008-06-23 | 2013-06-04 | Ramot At Tel Aviv University Ltd. | Reading a flash memory by joint decoding and cell voltage distribution tracking |
| WO2009156877A1 (en) * | 2008-06-24 | 2009-12-30 | Sandisk Il Ltd. | Method and apparatus for error correction according to erase counts of a solid-state memory |
| EP2223431A4 (en) * | 2008-08-15 | 2010-09-01 | Lsi Corp | DECODING LIST OF CODED WORDS CLOSE IN RAM MEMORY |
| US8332725B2 (en) | 2008-08-20 | 2012-12-11 | Densbits Technologies Ltd. | Reprogramming non volatile memory portions |
| US8161345B2 (en) | 2008-10-29 | 2012-04-17 | Agere Systems Inc. | LDPC decoders using fixed and adjustable permutators |
| US9356623B2 (en) | 2008-11-26 | 2016-05-31 | Avago Technologies General Ip (Singapore) Pte. Ltd. | LDPC decoder variable node units having fewer adder stages |
| US8413029B2 (en) * | 2009-01-16 | 2013-04-02 | Lsi Corporation | Error correction capability adjustment of LDPC codes for storage device testing |
| CN101903890B (zh) | 2009-03-05 | 2015-05-20 | Lsi公司 | 用于迭代解码器的改进的turbo均衡方法 |
| JP2010212934A (ja) * | 2009-03-10 | 2010-09-24 | Toshiba Corp | 半導体装置 |
| US8341509B2 (en) * | 2009-03-17 | 2012-12-25 | Broadcom Corporation | Forward error correction (FEC) scheme for communications |
| US8572460B2 (en) * | 2009-03-17 | 2013-10-29 | Broadcom Corporation | Communication device employing binary product coding with selective additional cyclic redundancy check (CRC) therein |
| US8458574B2 (en) | 2009-04-06 | 2013-06-04 | Densbits Technologies Ltd. | Compact chien-search based decoding apparatus and method |
| US8819385B2 (en) | 2009-04-06 | 2014-08-26 | Densbits Technologies Ltd. | Device and method for managing a flash memory |
| CN102077173B (zh) * | 2009-04-21 | 2015-06-24 | 艾格瑞系统有限责任公司 | 利用写入验证减轻代码的误码平层 |
| US8578256B2 (en) * | 2009-04-22 | 2013-11-05 | Agere Systems Llc | Low-latency decoder |
| US8464123B2 (en) * | 2009-05-07 | 2013-06-11 | Ramot At Tel Aviv University Ltd. | Matrix structure for block encoding |
| US8566510B2 (en) | 2009-05-12 | 2013-10-22 | Densbits Technologies Ltd. | Systems and method for flash memory management |
| US8995197B1 (en) | 2009-08-26 | 2015-03-31 | Densbits Technologies Ltd. | System and methods for dynamic erase and program control for flash memory device memories |
| US8914697B2 (en) * | 2009-08-26 | 2014-12-16 | Seagate Technology Llc | Data corruption detection |
| US9330767B1 (en) | 2009-08-26 | 2016-05-03 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Flash memory module and method for programming a page of flash memory cells |
| US8868821B2 (en) | 2009-08-26 | 2014-10-21 | Densbits Technologies Ltd. | Systems and methods for pre-equalization and code design for a flash memory |
| US8305812B2 (en) | 2009-08-26 | 2012-11-06 | Densbits Technologies Ltd. | Flash memory module and method for programming a page of flash memory cells |
| US8730729B2 (en) | 2009-10-15 | 2014-05-20 | Densbits Technologies Ltd. | Systems and methods for averaging error rates in non-volatile devices and storage systems |
| US8724387B2 (en) | 2009-10-22 | 2014-05-13 | Densbits Technologies Ltd. | Method, system, and computer readable medium for reading and programming flash memory cells using multiple bias voltages |
| US8626988B2 (en) | 2009-11-19 | 2014-01-07 | Densbits Technologies Ltd. | System and method for uncoded bit error rate equalization via interleaving |
| US8677209B2 (en) * | 2009-11-19 | 2014-03-18 | Lsi Corporation | Subwords coding using different encoding/decoding matrices |
| US8359515B2 (en) * | 2009-12-02 | 2013-01-22 | Lsi Corporation | Forward substitution for error-correction encoding and the like |
| US9037777B2 (en) | 2009-12-22 | 2015-05-19 | Densbits Technologies Ltd. | Device, system, and method for reducing program/read disturb in flash arrays |
| US8607124B2 (en) | 2009-12-24 | 2013-12-10 | Densbits Technologies Ltd. | System and method for setting a flash memory cell read threshold |
| KR20120137354A (ko) | 2010-01-28 | 2012-12-20 | 샌디스크 아이엘 엘티디 | 슬라이딩-윈도우 에러 정정 |
| US8700970B2 (en) | 2010-02-28 | 2014-04-15 | Densbits Technologies Ltd. | System and method for multi-dimensional decoding |
| DE112011101116B4 (de) * | 2010-03-30 | 2017-09-21 | International Business Machines Corporation | Two-Level BCH-Codes für Solid-State-Speichereinheiten |
| US8527840B2 (en) | 2010-04-06 | 2013-09-03 | Densbits Technologies Ltd. | System and method for restoring damaged data programmed on a flash device |
| US8516274B2 (en) | 2010-04-06 | 2013-08-20 | Densbits Technologies Ltd. | Method, system and medium for analog encryption in a flash memory |
| US8745317B2 (en) | 2010-04-07 | 2014-06-03 | Densbits Technologies Ltd. | System and method for storing information in a multi-level cell memory |
| US8464142B2 (en) | 2010-04-23 | 2013-06-11 | Lsi Corporation | Error-correction decoder employing extrinsic message averaging |
| US9021177B2 (en) | 2010-04-29 | 2015-04-28 | Densbits Technologies Ltd. | System and method for allocating and using spare blocks in a flash memory |
| US8499226B2 (en) | 2010-06-29 | 2013-07-30 | Lsi Corporation | Multi-mode layered decoding |
| US8458555B2 (en) | 2010-06-30 | 2013-06-04 | Lsi Corporation | Breaking trapping sets using targeted bit adjustment |
| US8539311B2 (en) | 2010-07-01 | 2013-09-17 | Densbits Technologies Ltd. | System and method for data recovery in multi-level cell memories |
| US8468431B2 (en) | 2010-07-01 | 2013-06-18 | Densbits Technologies Ltd. | System and method for multi-dimensional encoding and decoding |
| US8504900B2 (en) | 2010-07-02 | 2013-08-06 | Lsi Corporation | On-line discovery and filtering of trapping sets |
| US8467249B2 (en) | 2010-07-06 | 2013-06-18 | Densbits Technologies Ltd. | Systems and methods for storing, retrieving, and adjusting read thresholds in flash memory storage system |
| US8621289B2 (en) | 2010-07-14 | 2013-12-31 | Lsi Corporation | Local and global interleaving/de-interleaving on values in an information word |
| DE102010035210B4 (de) * | 2010-08-24 | 2012-08-30 | Deutsches Zentrum für Luft- und Raumfahrt e.V. | Verfahren zur Rückgewinnung verlorener Daten und zur Korrektur korrumpierter Daten |
| US8964464B2 (en) | 2010-08-24 | 2015-02-24 | Densbits Technologies Ltd. | System and method for accelerated sampling |
| US8879670B2 (en) * | 2010-09-08 | 2014-11-04 | Agence Spatiale Europeenne | Flexible channel decoder |
| US8508995B2 (en) | 2010-09-15 | 2013-08-13 | Densbits Technologies Ltd. | System and method for adjusting read voltage thresholds in memories |
| US9063878B2 (en) | 2010-11-03 | 2015-06-23 | Densbits Technologies Ltd. | Method, system and computer readable medium for copy back |
| US8539321B2 (en) | 2010-11-10 | 2013-09-17 | Infineon Technologies Ag | Apparatus and method for correcting at least one bit error within a coded bit sequence |
| US9450613B2 (en) * | 2010-11-10 | 2016-09-20 | Infineon Technologies Ag | Apparatus and method for error correction and error detection |
| US8850100B2 (en) | 2010-12-07 | 2014-09-30 | Densbits Technologies Ltd. | Interleaving codeword portions between multiple planes and/or dies of a flash memory device |
| US10079068B2 (en) | 2011-02-23 | 2018-09-18 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Devices and method for wear estimation based memory management |
| US8693258B2 (en) | 2011-03-17 | 2014-04-08 | Densbits Technologies Ltd. | Obtaining soft information using a hard interface |
| US8990665B1 (en) | 2011-04-06 | 2015-03-24 | Densbits Technologies Ltd. | System, method and computer program product for joint search of a read threshold and soft decoding |
| US9396106B2 (en) | 2011-05-12 | 2016-07-19 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Advanced management of a non-volatile memory |
| US9195592B1 (en) | 2011-05-12 | 2015-11-24 | Densbits Technologies Ltd. | Advanced management of a non-volatile memory |
| US8996790B1 (en) | 2011-05-12 | 2015-03-31 | Densbits Technologies Ltd. | System and method for flash memory management |
| US9372792B1 (en) | 2011-05-12 | 2016-06-21 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Advanced management of a non-volatile memory |
| US9501392B1 (en) | 2011-05-12 | 2016-11-22 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Management of a non-volatile memory module |
| US9110785B1 (en) | 2011-05-12 | 2015-08-18 | Densbits Technologies Ltd. | Ordered merge of data sectors that belong to memory space portions |
| US8775218B2 (en) * | 2011-05-18 | 2014-07-08 | Rga Reinsurance Company | Transforming data for rendering an insurability decision |
| US8667211B2 (en) | 2011-06-01 | 2014-03-04 | Densbits Technologies Ltd. | System and method for managing a non-volatile memory |
| US9318166B2 (en) * | 2011-07-22 | 2016-04-19 | SanDisk Technologies, Inc. | Systems and methods of storing data |
| CN102323901A (zh) * | 2011-07-28 | 2012-01-18 | 张岭 | 一种提高固态存储系统纠错码使用效率的方法 |
| WO2013018080A1 (en) | 2011-07-31 | 2013-02-07 | Sandisk Technologies, Inc., A Texas Corporation | Error-correction decoding with reduced memory and power requirements |
| US8645810B2 (en) | 2011-07-31 | 2014-02-04 | Sandisk Technologies Inc. | Fast detection of convergence or divergence in iterative decoding |
| US8588003B1 (en) | 2011-08-01 | 2013-11-19 | Densbits Technologies Ltd. | System, method and computer program product for programming and for recovering from a power failure |
| EP2742429A4 (en) | 2011-08-09 | 2015-03-25 | Lsi Corp | I / O DEVICE AND INTERACTION WITH DATA PROCESSING HOST |
| US8553468B2 (en) | 2011-09-21 | 2013-10-08 | Densbits Technologies Ltd. | System and method for managing erase operations in a non-volatile memory |
| US8862960B2 (en) * | 2011-10-10 | 2014-10-14 | Lsi Corporation | Systems and methods for parity shared data encoding |
| US8768990B2 (en) | 2011-11-11 | 2014-07-01 | Lsi Corporation | Reconfigurable cyclic shifter arrangement |
| GB2513749B (en) * | 2011-12-21 | 2014-12-31 | Ibm | Read/write operations in solid-state storage devices |
| US8719677B2 (en) | 2011-12-22 | 2014-05-06 | Sandisk Technologies Inc. | Using ECC encoding to verify an ECC decode operation |
| US8645789B2 (en) | 2011-12-22 | 2014-02-04 | Sandisk Technologies Inc. | Multi-phase ECC encoding using algebraic codes |
| US8947941B2 (en) | 2012-02-09 | 2015-02-03 | Densbits Technologies Ltd. | State responsive operations relating to flash memory cells |
| US8996788B2 (en) | 2012-02-09 | 2015-03-31 | Densbits Technologies Ltd. | Configurable flash interface |
| GB2499424B (en) * | 2012-02-16 | 2016-06-01 | Canon Kk | Methods for decoding, methods for retrieving, method for encoding, method of transmitting, corresponding devices, information storage means and computer |
| US8996793B1 (en) | 2012-04-24 | 2015-03-31 | Densbits Technologies Ltd. | System, method and computer readable medium for generating soft information |
| US8839073B2 (en) * | 2012-05-04 | 2014-09-16 | Lsi Corporation | Zero-one balance management in a solid-state disk controller |
| TW201346922A (zh) | 2012-05-14 | 2013-11-16 | Toshiba Kk | 記憶體控制器、記憶裝置及錯誤修正方法 |
| US8838937B1 (en) | 2012-05-23 | 2014-09-16 | Densbits Technologies Ltd. | Methods, systems and computer readable medium for writing and reading data |
| US8879325B1 (en) | 2012-05-30 | 2014-11-04 | Densbits Technologies Ltd. | System, method and computer program product for processing read threshold information and for reading a flash memory module |
| US9921954B1 (en) | 2012-08-27 | 2018-03-20 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Method and system for split flash memory management between host and storage controller |
| RU2012146685A (ru) | 2012-11-01 | 2014-05-10 | ЭлЭсАй Корпорейшн | База данных наборов-ловушек для декодера на основе разреженного контроля четности |
| US9368225B1 (en) | 2012-11-21 | 2016-06-14 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Determining read thresholds based upon read error direction statistics |
| KR101951663B1 (ko) * | 2012-12-14 | 2019-02-25 | 삼성전자주식회사 | Crc 부호와 극 부호에 의한 부호화 방법 및 장치 |
| US9069659B1 (en) | 2013-01-03 | 2015-06-30 | Densbits Technologies Ltd. | Read threshold determination using reference read threshold |
| US9148252B2 (en) * | 2013-01-11 | 2015-09-29 | Broadcom Corporation | Methods and systems for 2-dimensional forward error correction coding |
| US9124300B2 (en) | 2013-02-28 | 2015-09-01 | Sandisk Technologies Inc. | Error correction coding in non-volatile memory |
| US9407290B2 (en) | 2013-03-15 | 2016-08-02 | Sandisk Technologies Llc | Error-correction decoding with conditional limiting of check-node messages |
| US9136876B1 (en) | 2013-06-13 | 2015-09-15 | Densbits Technologies Ltd. | Size limited multi-dimensional decoding |
| US20150074496A1 (en) * | 2013-09-10 | 2015-03-12 | Kabushiki Kaisha Toshiba | Memory controller, storage device, and memory control method |
| US9413491B1 (en) | 2013-10-08 | 2016-08-09 | Avago Technologies General Ip (Singapore) Pte. Ltd. | System and method for multiple dimension decoding and encoding a message |
| US9786388B1 (en) | 2013-10-09 | 2017-10-10 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Detecting and managing bad columns |
| US9348694B1 (en) | 2013-10-09 | 2016-05-24 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Detecting and managing bad columns |
| US9397706B1 (en) | 2013-10-09 | 2016-07-19 | Avago Technologies General Ip (Singapore) Pte. Ltd. | System and method for irregular multiple dimension decoding and encoding |
| TWI536749B (zh) * | 2013-12-09 | 2016-06-01 | 群聯電子股份有限公司 | 解碼方法、記憶體儲存裝置與記憶體控制電路單元 |
| US9536612B1 (en) | 2014-01-23 | 2017-01-03 | Avago Technologies General Ip (Singapore) Pte. Ltd | Digital signaling processing for three dimensional flash memory arrays |
| US10120792B1 (en) | 2014-01-29 | 2018-11-06 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Programming an embedded flash storage device |
| US9641285B2 (en) | 2014-03-06 | 2017-05-02 | Samsung Electronics Co., Ltd. | Ultra low power (ULP) decoder and decoding processing |
| US9542262B1 (en) | 2014-05-29 | 2017-01-10 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Error correction |
| US9892033B1 (en) | 2014-06-24 | 2018-02-13 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Management of memory units |
| US10089177B2 (en) | 2014-06-30 | 2018-10-02 | Sandisk Technologies Llc | Multi-stage decoder |
| US9614547B2 (en) | 2014-06-30 | 2017-04-04 | Sandisk Technologies Llc | Multi-stage decoder |
| US9972393B1 (en) | 2014-07-03 | 2018-05-15 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Accelerating programming of a flash memory module |
| US9584159B1 (en) | 2014-07-03 | 2017-02-28 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Interleaved encoding |
| US9449702B1 (en) | 2014-07-08 | 2016-09-20 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Power management |
| US9524211B1 (en) | 2014-11-18 | 2016-12-20 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Codeword management |
| KR102254102B1 (ko) * | 2015-01-23 | 2021-05-20 | 삼성전자주식회사 | 메모리 시스템 및 메모리 시스템의 동작 방법 |
| US10305515B1 (en) | 2015-02-02 | 2019-05-28 | Avago Technologies International Sales Pte. Limited | System and method for encoding using multiple linear feedback shift registers |
| KR102305095B1 (ko) | 2015-04-13 | 2021-09-24 | 삼성전자주식회사 | 비휘발성 메모리 컨트롤러의 동작 방법 |
| US10628255B1 (en) | 2015-06-11 | 2020-04-21 | Avago Technologies International Sales Pte. Limited | Multi-dimensional decoding |
| US9851921B1 (en) | 2015-07-05 | 2017-12-26 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Flash memory chip processing |
| US9954558B1 (en) | 2016-03-03 | 2018-04-24 | Avago Technologies General Ip (Singapore) Pte. Ltd. | Fast decoding of data stored in a flash memory |
| US10033407B2 (en) | 2016-04-08 | 2018-07-24 | SK Hynix Inc. | Optimization of low density parity-check code encoder based on a search for an independent set of nodes |
| DE102016107285B4 (de) * | 2016-04-20 | 2019-04-25 | Infineon Technologies Ag | Verfahren zur verwendung einer speichervorrichtung, speichervorrichtung und speichervorrichtungsanordnung |
| US10423500B2 (en) | 2016-06-01 | 2019-09-24 | Seagate Technology Llc | Technologies for limiting performance variation in a storage device |
| US10243591B2 (en) | 2016-08-30 | 2019-03-26 | International Business Machines Corporation | Sequence detectors |
| US9942005B2 (en) * | 2016-08-30 | 2018-04-10 | International Business Machines Corporation | Sequence detector |
| US10025661B1 (en) | 2016-12-27 | 2018-07-17 | Sandisk Technologies Llc | Adaptive hard and soft bit decoding |
| US10855314B2 (en) | 2018-02-09 | 2020-12-01 | Micron Technology, Inc. | Generating and using invertible, shortened Bose-Chaudhuri-Hocquenghem codewords |
| US11146363B2 (en) * | 2018-04-13 | 2021-10-12 | Huawei Technologies Co., Ltd. | Systems and methods for HARQ retransmission using an outer code |
| US10606697B2 (en) * | 2018-06-21 | 2020-03-31 | Goke Us Research Laboratory | Method and apparatus for improved data recovery in data storage systems |
| TWI742371B (zh) * | 2019-05-13 | 2021-10-11 | 義守大學 | 應用單項跡之錯誤更正方法 |
| CN112152751B (zh) * | 2019-06-27 | 2023-09-29 | 义守大学 | 单项迹的计算方法及应用单项迹的错误纠正方法 |
| US11405057B2 (en) | 2019-10-28 | 2022-08-02 | Huawei Technologies Co., Ltd. | System and method for hybrid-ARQ |
| KR20220054096A (ko) | 2020-10-23 | 2022-05-02 | 삼성전자주식회사 | 패리티를 저장하는 메모리 장치 및 이를 포함하는 메모리 시스템 |
| US11481271B2 (en) | 2021-03-16 | 2022-10-25 | Western Digital Technologies, Inc. | Storage system and method for using subcodes and convolutional-based LDPC interleaved coding schemes with read threshold calibration support |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2005022814A1 (en) * | 2003-08-21 | 2005-03-10 | Qualcomm Incorporated | Outer coding methods for broadcast/multicast content and related apparatus |
Family Cites Families (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3546582A (en) * | 1968-01-15 | 1970-12-08 | Ibm | Computer controlled test system for performing functional tests on monolithic devices |
| US4633470A (en) | 1983-09-27 | 1986-12-30 | Cyclotomics, Inc. | Error correction for algebraic block codes |
| US4736376A (en) * | 1985-10-25 | 1988-04-05 | Sequoia Systems, Inc. | Self-checking error correcting encoder/decoder |
| EP0850473B1 (en) * | 1996-06-13 | 2002-11-27 | Koninklijke Philips Electronics N.V. | A method and apparatus for trackwise burst error correction in a multitrack storage format |
| US6088387A (en) * | 1997-12-31 | 2000-07-11 | At&T Corp. | Multi-channel parallel/serial concatenated convolutional codes and trellis coded modulation encoder/decoder |
| US6430722B1 (en) * | 1998-01-23 | 2002-08-06 | Hughes Electronics Corporation | Forward error correction scheme for data channels using universal turbo codes |
| BR9906668A (pt) * | 1998-08-06 | 2000-08-29 | Samsung Electronics Co Ltd | Dispositivo de decodificação de canal, e, processo de decodificação de canal |
| US7356752B2 (en) * | 2000-03-14 | 2008-04-08 | Comtech Telecommunications Corp. | Enhanced turbo product codes |
| US6526531B1 (en) | 2000-03-22 | 2003-02-25 | Agere Systems Inc. | Threshold detection for early termination of iterative decoding |
| US6721373B1 (en) * | 2000-03-29 | 2004-04-13 | Tioga Technologies Ltd. | Multi-tone receiver and a method for operating the same |
| US6516035B1 (en) * | 2000-04-07 | 2003-02-04 | Actisys Corporation | Intelligent encoding method for wireless data communication and control |
| US6865708B2 (en) | 2000-08-23 | 2005-03-08 | Wang Xiao-An | Hybrid early-termination methods and output selection procedure for iterative turbo decoders |
| US7093179B2 (en) | 2001-03-22 | 2006-08-15 | University Of Florida | Method and coding means for error-correction utilizing concatenated parity and turbo codes |
| US6633856B2 (en) | 2001-06-15 | 2003-10-14 | Flarion Technologies, Inc. | Methods and apparatus for decoding LDPC codes |
| WO2004027822A2 (en) * | 2002-09-05 | 2004-04-01 | Nanosys, Inc. | Oriented nanostructures and methods of preparing |
| US7162684B2 (en) | 2003-01-27 | 2007-01-09 | Texas Instruments Incorporated | Efficient encoder for low-density-parity-check codes |
| US7430396B2 (en) | 2003-07-03 | 2008-09-30 | The Directv Group, Inc. | Encoding low density parity check (LDPC) codes through an LDPC decoder |
| US7376883B2 (en) | 2003-10-27 | 2008-05-20 | The Directv Group, Inc. | Method and system for providing long and short block length low density parity check (LDPC) codes |
| US7234098B2 (en) | 2003-10-27 | 2007-06-19 | The Directv Group, Inc. | Method and apparatus for providing reduced memory low density parity check (LDPC) codes |
| US7546510B2 (en) | 2003-12-30 | 2009-06-09 | Sandisk Il Ltd. | Compact high-speed single-bit error-correction circuit |
| US20050193320A1 (en) | 2004-02-09 | 2005-09-01 | President And Fellows Of Harvard College | Methods and apparatus for improving performance of information coding schemes |
| US7441175B2 (en) | 2004-03-12 | 2008-10-21 | Seagate Technology Llc | Turbo product code implementation and decoding termination method and apparatus |
| KR100594818B1 (ko) | 2004-04-13 | 2006-07-03 | 한국전자통신연구원 | 순차적 복호를 이용한 저밀도 패리티 검사 부호의 복호장치 및 그 방법 |
| CN1798012A (zh) * | 2004-12-30 | 2006-07-05 | 松下电器产业株式会社 | 基于低密度奇偶校验码的校验式可信度的纠错方法 |
| US7844877B2 (en) * | 2005-11-15 | 2010-11-30 | Ramot At Tel Aviv University Ltd. | Method and device for multi phase error-correction |
| US8086940B2 (en) * | 2008-04-28 | 2011-12-27 | Newport Media, Inc. | Iterative decoding between turbo and RS decoders for improving bit error rate and packet error rate |
-
2006
- 2006-09-01 US US11/514,182 patent/US7844877B2/en not_active Expired - Fee Related
- 2006-11-13 JP JP2008539611A patent/JP5216593B2/ja not_active Expired - Fee Related
- 2006-11-13 WO PCT/IL2006/001305 patent/WO2007057885A2/en active Application Filing
- 2006-11-13 CN CN201210390594.2A patent/CN103023514B/zh not_active Expired - Fee Related
- 2006-11-13 EP EP06809862A patent/EP1949580B1/en not_active Not-in-force
- 2006-11-13 AT AT06809862T patent/ATE540480T1/de active
- 2006-11-13 CN CN2006800425946A patent/CN101611549B/zh not_active Expired - Fee Related
- 2006-11-13 KR KR1020087014455A patent/KR101135425B1/ko not_active IP Right Cessation
- 2006-11-13 KR KR1020107029291A patent/KR101275041B1/ko not_active IP Right Cessation
-
2009
- 2009-12-29 US US12/648,313 patent/US8086931B2/en not_active Expired - Fee Related
-
2011
- 2011-06-28 US US13/170,193 patent/US8375272B2/en active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2005022814A1 (en) * | 2003-08-21 | 2005-03-10 | Qualcomm Incorporated | Outer coding methods for broadcast/multicast content and related apparatus |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2007057885A3 (en) | 2009-09-03 |
| ATE540480T1 (de) | 2012-01-15 |
| US7844877B2 (en) | 2010-11-30 |
| EP1949580B1 (en) | 2012-01-04 |
| WO2007057885A2 (en) | 2007-05-24 |
| EP1949580A2 (en) | 2008-07-30 |
| US20100169737A1 (en) | 2010-07-01 |
| CN103023514A (zh) | 2013-04-03 |
| US8375272B2 (en) | 2013-02-12 |
| CN101611549A (zh) | 2009-12-23 |
| JP2010509790A (ja) | 2010-03-25 |
| US8086931B2 (en) | 2011-12-27 |
| KR101135425B1 (ko) | 2012-04-23 |
| CN103023514B (zh) | 2016-12-21 |
| JP5216593B2 (ja) | 2013-06-19 |
| KR20110014667A (ko) | 2011-02-11 |
| EP1949580A4 (en) | 2010-03-31 |
| KR20080084970A (ko) | 2008-09-22 |
| US20070124652A1 (en) | 2007-05-31 |
| CN101611549B (zh) | 2012-11-28 |
| US20110276856A1 (en) | 2011-11-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101275041B1 (ko) | 다상 에러 보정을 위한 방법 및 디바이스 | |
| US8832518B2 (en) | Method and device for multi phase error-correction | |
| JP4975301B2 (ja) | 連結された反復型と代数型の符号化 | |
| US8255763B1 (en) | Error correction system using an iterative product code | |
| TWI604698B (zh) | 具有錯誤校正處置之低密度同位檢查解碼器 | |
| US8086945B1 (en) | Tensor product codes containing an iterative code | |
| US8055977B2 (en) | Decoding device, encoding/decoding device and recording/reproducing device | |
| JP4879323B2 (ja) | 誤り訂正復号装置および再生装置 | |
| JP2005528840A (ja) | 線形ブロック符号の軟復号化 | |
| WO2021118395A1 (en) | Spatially coupled forward error correction encoding method and device using generalized error locating codes as component codes | |
| KR20150134505A (ko) | 송신 장치 및 그의 신호 처리 방법 | |
| Han et al. | Dual-mode decoding of product codes with application to tape storage | |
| Tan et al. | A general and optimal framework to achieve the entire rate region for Slepian–Wolf coding | |
| JP4224818B2 (ja) | 符号化方法及び符号化装置並びに復号方法及び復号装置 | |
| Xue et al. | Concatenated Synchronization Error Correcting Code with Designed Markers | |
| Collins | Exploiting the cannibalistic traits of Reed-Solomon codes | |
| JP2004193727A (ja) | 信号処理方法及び信号処理回路 | |
| Hanif | Design of Single Kernel Polar Codes with Exible Lengths | |
| JP2000067531A (ja) | 誤り訂正符号化/復号化方式及び誤り訂正符号化/復号化装置 | |
| Sankaranarayanan et al. | Performance of product codes on channels with memory |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A107 | Divisional application of patent | ||
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| AMND | Amendment | ||
| E601 | Decision to refuse application | ||
| J201 | Request for trial against refusal decision | ||
| AMND | Amendment | ||
| E90F | Notification of reason for final refusal | ||
| B701 | Decision to grant | ||
| GRNT | Written decision to grant | ||
| FPAY | Annual fee payment |
Payment date: 20160517 Year of fee payment: 4 |
|
| LAPS | Lapse due to unpaid annual fee |