JP6171476B2 - ドキュメント作成支援装置,ドキュメント作成支援プログラム及びドキュメント作成支援方法 - Google Patents
ドキュメント作成支援装置,ドキュメント作成支援プログラム及びドキュメント作成支援方法 Download PDFInfo
- Publication number
- JP6171476B2 JP6171476B2 JP2013069223A JP2013069223A JP6171476B2 JP 6171476 B2 JP6171476 B2 JP 6171476B2 JP 2013069223 A JP2013069223 A JP 2013069223A JP 2013069223 A JP2013069223 A JP 2013069223A JP 6171476 B2 JP6171476 B2 JP 6171476B2
- Authority
- JP
- Japan
- Prior art keywords
- word
- secret
- character string
- replacement
- input character
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images









Landscapes
- Document Processing Apparatus (AREA)
Description
入力された入力文字列に含まれる第1の単語が,秘密ワードデータベース内の秘密ワードと前方一致するか否かの第1の検索を行い,一致した秘密ワードを置換対象候補に登録する置換対象候補検出処理手段と,
前記第1の単語に当該第1の単語に後続する入力文字列に含まれる第2の単語を,前記置換対象候補の秘密ワードの単語構成数に達する数まで結合した結合単語が,前記置換対象候補の秘密ワードと一致するか否かの第2の検索を行い,一致した置換対象候補の秘密ワードを置換対象に登録する置換対象検出処理手段と,
前記入力文字列をそのまま有するオリジナルドキュメントファイル内の前記置換対象の秘密ワードを,前記秘密ワードに対応する置換ワードに置換してマスキングドキュメントファイルを生成するマスキングドキュメント作成手段と
を有する。
図4は,本実施の形態における入力文字列処理とファイル保存処理の概略を説明する図である。図4には,ドキュメント作成中に入力される入力文字列INの一例として図示される以下の文字列が入力されるものとする。
「2000年神奈川県川崎市川崎区B町1丁目1番地(電話044-999-9999)に山田太郎さんと鈴木花子さんが住んでいました。」
この入力文字列について,入力文字列処理部210がどのような処理をするのかについて説明する。まず,入力文字列処理部210では,入力された文字列であって仮名漢字変換で確定した文字列を単語に分解する。
「川崎市川崎区A町1丁目1番地」
「川崎市川崎区B町1丁目1番地」
「川崎市中原区B町1丁目」
「川崎市高津区B町」
その結果,置換対象候補検出処理部211は,秘密ワードデータベース22内の上記4つの秘密ワードについて置換対象候補フラグを「1」にし,それら4つの文字列を置換対象候補の秘密ワードとして登録する。
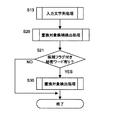
図6は,本実施の形態におけるドキュメント作成支援装置の処理を示すフローチャート図である。既存のドキュメントファイルを編集するか,新規のドキュメントファイルを編集するかによって(S10),ドキュメント作成支援装置は,作成対象の既存のドキュメントファイルを読み込むか(S11),新規にドキュメントファイルを作成する(S12)。
入力される文字列についてドキュメント作成支援処理を行うドキュメント作成支援装置であって,
入力された入力文字列に含まれる第1の単語が,秘密ワードデータベース内の秘密ワードと前方一致するか否かの第1の検索を行い,一致した秘密ワードを置換対象候補に登録する置換対象候補検出処理手段と,
前記第1の単語に当該第1の単語に後続する入力文字列に含まれる第2の単語を,前記置換対象候補の秘密ワードの単語構成数に達する数まで結合した結合単語が,前記置換対象候補の秘密ワードと一致するか否かの第2の検索を行い,一致した置換対象候補の秘密ワードを置換対象の秘密ワードに登録する置換対象検出処理手段と,
前記入力文字列をそのまま有するオリジナルドキュメントファイル内の前記置換対象の秘密ワードを,前記秘密ワードに対応する置換ワードに置換してマスキングドキュメントファイルを生成するマスキングドキュメント作成手段と
を有するドキュメント作成支援装置。
付記1において,
さらに,入力された1つまたは複数の文字を有する入力文字列の仮名漢字変換が確定したときに,前記確定した入力文字列を単語に分解する単語分解手段を有するドキュメント作成支援装置。
付記2において,
前記置換対象検出処理手段は,前記第2の検索において,前記結合単語が前記置換対象候補の秘密ワードと少なくとも前方一致するか否かを行うドキュメント作成支援装置。
入力される文字列についてドキュメント作成支援処理を行うドキュメント作成支援プログラムであって,
前記ドキュメント作成支援処理は,
入力された入力文字列に含まれる第1の単語が,秘密ワードデータベース内の秘密ワードと前方一致するか否かの第1の検索を行い,一致した秘密ワードを置換対象候補に登録する置換対象候補検出処理工程と,
前記第1の単語に当該第1の単語に後続する入力文字列に含まれる第2の単語を,前記置換対象候補の秘密ワードの単語構成数に達する数まで結合した結合単語が,前記置換対象候補の秘密ワードと一致するか否かの第2の検索を行い,一致した置換対象候補の秘密ワードを置換対象の秘密ワードに登録する置換対象検出処理工程と,
前記入力文字列をそのまま有するオリジナルドキュメントファイル内の前記置換対象の秘密ワードを,前記秘密ワードに対応する置換ワードに置換してマスキングドキュメントファイルを生成するマスキングドキュメント作成工程と
を有するドキュメント作成支援プログラム。
入力される文字列についてドキュメント作成支援処理を行うドキュメント作成支援方法であって,
入力された入力文字列に含まれる第1の単語が,秘密ワードデータベース内の秘密ワードと前方一致するか否かの第1の検索を行い,一致した秘密ワードを置換対象候補に登録する置換対象候補検出処理工程と,
前記第1の単語に当該第1の単語に後続する入力文字列に含まれる第2の単語を,前記置換対象候補の秘密ワードの単語構成数に達する数まで結合した結合単語が,前記置換対象候補の秘密ワードと一致するか否かの第2の検索を行い,一致した置換対象候補の秘密ワードを置換対象の秘密ワードに登録する置換対象検出処理工程と,
前記入力文字列をそのまま有するオリジナルドキュメントファイル内の前記置換対象の秘密ワードを,前記秘密ワードに対応する置換ワードに置換してマスキングドキュメントファイルを生成するマスキングドキュメント作成工程と
を有するドキュメント作成支援方法。
211:置換対象候補検出処理部
212:置換対象検出処理部
214:ファイル保存処理部
Claims (3)
- 入力される文字列についてドキュメント作成支援処理を行うドキュメント作成支援装置であって,
入力された1つまたは複数の文字を有する入力文字列の仮名漢字変換が確定したときに,前記確定した入力文字列を単語に分解する単語分解手段と,
前記入力文字列に含まれる第1の単語が,秘密ワードデータベース内の特定の秘密ワードと前方一致するか否かの第1の検索を行い,前方一致した秘密ワードを置換対象候補として登録する置換対象候補検出処理手段と,
前記第1の単語に当該第1の単語に後続する入力文字列に含まれる第2の単語を,前記置換対象候補の秘密ワードの単語構成数に達する数まで結合した結合単語が,前記置換対象候補の秘密ワードと一致するか否かの第2の検索を行い,一致した置換対象候補の秘密ワードを置換対象の秘密ワードとして登録する置換対象検出処理手段と,
前記入力文字列をそのまま有するオリジナルドキュメントファイル内の前記置換対象の秘密ワードとして登録された秘密ワードを,前記秘密ワードに対応する置換ワードに置換してマスキングドキュメントファイルを生成するマスキングドキュメント作成手段と
を有するドキュメント作成支援装置。 - 入力される文字列についてドキュメント作成支援処理を行うドキュメント作成支援プログラムであって,
前記ドキュメント作成支援処理は,
入力された1つまたは複数の文字を有する入力文字列の仮名漢字変換が確定したときに,前記確定した入力文字列を単語に分解する単語分解工程と,
前記入力文字列に含まれる第1の単語が,秘密ワードデータベース内の特定の秘密ワードと前方一致するか否かの第1の検索を行い,前方一致した秘密ワードを置換対象候補として登録する置換対象候補検出処理工程と,
前記第1の単語に当該第1の単語に後続する入力文字列に含まれる第2の単語を,前記置換対象候補の秘密ワードの単語構成数に達する数まで結合した結合単語が,前記置換対象候補の秘密ワードと一致するか否かの第2の検索を行い,一致した置換対象候補の秘密ワードを置換対象の秘密ワードとして登録する置換対象検出処理工程と,
前記入力文字列をそのまま有するオリジナルドキュメントファイル内の前記置換対象の秘密ワードとして登録された秘密ワードを,前記秘密ワードに対応する置換ワードに置換してマスキングドキュメントファイルを生成するマスキングドキュメント作成工程と
を有するドキュメント作成支援プログラム。 - 入力される文字列についてドキュメント作成支援処理を行うドキュメント作成支援方法であって,
入力された1つまたは複数の文字を有する入力文字列の仮名漢字変換が確定したときに,前記確定した入力文字列を単語に分解する単語分解工程と,
前記入力文字列に含まれる第1の単語が,秘密ワードデータベース内の特定の秘密ワードと前方一致するか否かの第1の検索を行い,前方一致した秘密ワードを置換対象候補として登録する置換対象候補検出処理工程と,
前記第1の単語に当該第1の単語に後続する入力文字列に含まれる第2の単語を,前記置換対象候補の秘密ワードの単語構成数に達する数まで結合した結合単語が,前記置換対象候補の秘密ワードと一致するか否かの第2の検索を行い,一致した置換対象候補の秘密ワードを置換対象の秘密ワードとして登録する置換対象検出処理工程と,
前記入力文字列をそのまま有するオリジナルドキュメントファイル内の前記置換対象の秘密ワードとして登録された秘密ワードを,前記秘密ワードに対応する置換ワードに置換してマスキングドキュメントファイルを生成するマスキングドキュメント作成工程と
を有するドキュメント作成支援方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013069223A JP6171476B2 (ja) | 2013-03-28 | 2013-03-28 | ドキュメント作成支援装置,ドキュメント作成支援プログラム及びドキュメント作成支援方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013069223A JP6171476B2 (ja) | 2013-03-28 | 2013-03-28 | ドキュメント作成支援装置,ドキュメント作成支援プログラム及びドキュメント作成支援方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014191778A JP2014191778A (ja) | 2014-10-06 |
| JP6171476B2 true JP6171476B2 (ja) | 2017-08-02 |
Family
ID=51837916
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013069223A Expired - Fee Related JP6171476B2 (ja) | 2013-03-28 | 2013-03-28 | ドキュメント作成支援装置,ドキュメント作成支援プログラム及びドキュメント作成支援方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6171476B2 (ja) |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06149787A (ja) * | 1992-11-12 | 1994-05-31 | Brother Ind Ltd | かな漢字変換装置 |
| JP3983313B2 (ja) * | 1996-01-24 | 2007-09-26 | 富士通株式会社 | 音声合成装置及び音声合成方法 |
| JP2002259368A (ja) * | 2001-03-01 | 2002-09-13 | Nippon Telegr & Teleph Corp <Ntt> | 文書伏字加工方法、文書伏字加工装置、文書伏字加工処理プログラム及びその記録媒体 |
| JP4811557B2 (ja) * | 2005-02-18 | 2011-11-09 | 独立行政法人情報通信研究機構 | 音声再生装置及び発話支援装置 |
| JP2009205647A (ja) * | 2008-02-29 | 2009-09-10 | Softbank Mobile Corp | 住所コード出力装置、及びプログラム |
| JP5224953B2 (ja) * | 2008-07-17 | 2013-07-03 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 情報処理装置、情報処理方法およびプログラム |
| JP5112416B2 (ja) * | 2009-12-28 | 2013-01-09 | ヤフー株式会社 | 用語抽出装置、方法及び用語辞書のデータ構造 |
-
2013
- 2013-03-28 JP JP2013069223A patent/JP6171476B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2014191778A (ja) | 2014-10-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5358549B2 (ja) | 保護対象情報マスキング装置、保護対象情報マスキング方法および保護対象情報マスキングプログラム | |
| CN104424202B (zh) | 对crm系统中的客户信息进行查重的方法及系统 | |
| CN101930524A (zh) | 文档信息创建装置、文档登记系统和文档信息创建方法 | |
| JP6599219B2 (ja) | 読み付与装置、読み付与方法、およびプログラム | |
| JPWO2017017738A1 (ja) | 符号化プログラム、符号化装置、及び符号化方法 | |
| US20150248448A1 (en) | Online radix tree compression with key sequence skip | |
| JP7009802B2 (ja) | 文書管理装置、文書管理システム及びプログラム | |
| JP2008299675A (ja) | かな混在表記抽出装置、方法及びプログラム | |
| KR20230059401A (ko) | 복합 명사 사전 구성 방법 및 그에 기반한 복합 명사 추출 방법 | |
| JP6171476B2 (ja) | ドキュメント作成支援装置,ドキュメント作成支援プログラム及びドキュメント作成支援方法 | |
| JP4807364B2 (ja) | 情報管理装置 | |
| CN115687979A (zh) | 威胁情报中指定技术的识别方法及装置、电子设备、存储介质 | |
| JP6926749B2 (ja) | 文書管理装置、文書管理システム及びプログラム | |
| JP5513953B2 (ja) | テスト用マスキングデータ生成装置及びプログラム | |
| JP2016012271A (ja) | 機密情報隠蔽システム | |
| JP2014186425A (ja) | 文章マスク装置及び文章マスクプログラム | |
| JP5182960B2 (ja) | 店舗名曖昧性解消装置、その方法、プログラム及び記録媒体 | |
| JP2018077604A (ja) | 機能記述からの実現手段・方法の侵害候補を自動特定する人工知能装置 | |
| JP2010146273A (ja) | 文書検索装置およびプログラム | |
| US20250190698A1 (en) | Method of training language model for cybersecurity and system performing the same | |
| CN116150442B (zh) | 一种基于tcam的网络数据检测方法和设备 | |
| JP7718097B2 (ja) | 校正支援装置、校正支援方法、及びプログラム | |
| JP2010182082A (ja) | 出現表記レコード同定装置、削除規則生成装置、その方法、プログラム及び記録媒体 | |
| CN112686024B (zh) | 句法解析方法及装置、电子设备、存储介质 | |
| CN108304401A (zh) | 电子图书搜索方法及系统 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20151204 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20160824 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160830 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20161031 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170228 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170426 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170606 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170619 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6171476 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |