JP6123897B2 - 処理プログラム、処理システムおよび処理方法 - Google Patents
処理プログラム、処理システムおよび処理方法 Download PDFInfo
- Publication number
- JP6123897B2 JP6123897B2 JP2015529259A JP2015529259A JP6123897B2 JP 6123897 B2 JP6123897 B2 JP 6123897B2 JP 2015529259 A JP2015529259 A JP 2015529259A JP 2015529259 A JP2015529259 A JP 2015529259A JP 6123897 B2 JP6123897 B2 JP 6123897B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- query
- node
- engine node
- processing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images


















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/25—Integrating or interfacing systems involving database management systems
- G06F16/258—Data format conversion from or to a database
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2455—Query execution
- G06F16/24553—Query execution of query operations
- G06F16/24561—Intermediate data storage techniques for performance improvement
Landscapes
- Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Devices For Executing Special Programs (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
本発明は、処理プログラム、処理システムおよび処理方法に関する。
従来、大量のイベントデータを複数のクエリで並列して処理し、最終結果を1つにして出力する分散並列型複合イベントプロセッシング(以下、分散並列型CEP(Complex Event Processing)と称する)と呼ばれる技術がある。複数のノードによる分散並列型CEPでは、クエリは複数のノード上に存在するため、ノード間での通信が発生する。
クエリの開発言語としては、開発効率を考慮したオブジェクト指向言語、例えば、Java(登録商標)が採用されることが多い。構造化されたデータを送受信するには、送信側でデータの直列化処理、受信側で直列復元化処理が行われる。オブジェクト指向言語では、構造化データをオブジェクト、直列化処理をシリアライズ、直列化復元処理をデシリアライズと呼んでいる。
分散並列型CEPでは大量のイベントデータが流れるため、各ノードにおけるシリアライズ、デシリアライズにかかる負荷は大きなものとなる。また、クエリは、例えば、前処理と後処理から構成され、前処理において、デシリアライズされたイベントデータを参照して、イベントデータの後処理を実行するか、イベントデータを破棄するかの判断が行われる。
関連する先行技術としては、例えば、直列化された形式を保持するオブジェクトを用いた分散処理システムにおいて、イベントの通知のために、ネットワーク内にある特定のイベントの通知を受信するための装置を登録し、オブジェクトを登録要求とともに転送するものがある。
しかしながら、従来技術によれば、クエリの前処理において破棄されるイベントデータであってもデシリアライズが行われ、ノードにかかる負荷の増大を招くという問題がある。例えば、分散並列型CEPでは、クエリの前処理において多くのイベントデータが破棄される傾向にあり、破棄されるイベントデータが多いにも拘わらず、すべてのイベントデータに対してデシリアライズが行われる。一方で、イベントデータをデシリアライズしなければ、クエリの前処理においてイベントデータを破棄するか否かを判断することができない。
一つの側面では、本発明は、不要なデシリアライズを削減する処理プログラム、処理システムおよび処理方法を提供することを目的とする。
本発明の一側面によれば、データを受信し、クエリの処理対象となるデータを選別するために参照される部分を特定する情報に基づいて、受信した前記データの所定の部分を復元し、復元した前記データの所定の部分と前記処理対象となるデータを選別するための条件とに基づいて、受信した前記データを破棄するか否かを判断し、破棄しないと判断した場合に、受信した前記データを復元する処理プログラム、処理システムおよび処理方法が提案される。
本発明の一態様によれば、不要なデシリアライズを削減することができるという効果を奏する。
以下に図面を参照して、本発明にかかる処理プログラム、処理システムおよび処理方法の実施の形態を詳細に説明する。
(実施の形態1)
図1は、実施の形態1にかかる処理方法の一実施例を示す説明図である。図1において、システム100は、複数のエンジンノード101を含む分散並列型CEPシステムである。システム100では、センサ等で発生したイベントデータがエンジンノード101に送信され、各エンジンノード101がイベントデータを処理し、最終結果が出力される。
図1は、実施の形態1にかかる処理方法の一実施例を示す説明図である。図1において、システム100は、複数のエンジンノード101を含む分散並列型CEPシステムである。システム100では、センサ等で発生したイベントデータがエンジンノード101に送信され、各エンジンノード101がイベントデータを処理し、最終結果が出力される。
エンジンノード101は、データ111を受信して、クエリを実行する情報処理装置である。クエリとは、予め定義されたルールに基づいて記述されたプログラムである。ルールは例えば、EPL(Event Processing Language)等のクエリ記述言語で記述される。ルールをコンパイラで変換することによって、クエリが作成される。
一方、クエリは開発効率性から開発言語として、Javaのようなオブジェクト指向言語により記述されることが多い。オブジェクト指向言語は、オブジェクトと呼ばれる機能の部品でソフトウェアを構成させるプログラミングに適した言語のことである。オブジェクトとは、現実世界に存在する物理的あるいは抽象的な実体を、属性と操作の集合としてモデル化し、コンピュータ上に再現したものである。また、オブジェクトには、C言語等の構造体のような構造化されたデータも含まれる。
データ111は、位置、温度、湿度等の環境情報および時間情報等を、科学的原理を応用して測定するセンサ等で発生したイベントデータを直列化したデータである。構造化されたデータを送受信するには、送信側でデータの直列化処理、受信側で直列復元化処理が行われる。オブジェクト指向言語では、構造化データをオブジェクト、直列化処理をシリアライズ、直列化復元処理をデシリアライズと呼んでいる。以下の説明では、クエリの開発言語の一例として、オブジェクト指向言語を例に挙げて説明する。
シリアライズとは、オブジェクト化されたイベントデータを、ネットワークを介して送受信するために、バイト列に直列化することである。デシリアライズとは、バイト列に直列化したデータをオブジェクト化されたイベントデータに復元することである。オブジェクト化されたイベントデータには、構造化されたイベントデータを含む。
すなわち、エンジンノード101が、他のエンジンノード101にオブジェクト化されたイベントデータを送信する際、イベントデータのシリアライズを実行してデータ111を作成し、他のエンジンノード101に送信する。シリアライズしたデータ111を受信した他のエンジンノード101は、データ111をデシリアライズし、オブジェクト化されたイベントデータを復元する。
例えば、オブジェクト化されたイベントデータには、データ以外にデータ位置を示すポインタ等が含まれる。このため、エンジンノード101は、イベントデータの送信を行う際に、オブジェクト化されたイベントデータからポインタ等を削除して、データを直列に並べるシリアライズを行う。一方、エンジンノード101は、イベントデータを受信した際、シリアライズしたデータ111にポインタ等を追加して、オブジェクト化されたイベントデータを復元するデシリアライズを行う。
ここで、クエリは、前処理と後処理から構成され、前処理において、デシリアライズされたイベントデータを参照して、イベントデータの後処理を実行するか、イベントデータを破棄するかの判断が行われる。イベントデータを破棄するか否かの判断は、デシリアライズされたイベントデータのすべてを参照して行われるのではなく、デシリアライズされたイベントデータの一部を参照して行われる。すなわち、データ111のすべてをデシリアライズすると、参照されない部分までデシリアライズされることになる。
そこで、実施の形態1では、エンジンノード101は、データ111を受信すると、データ111の所定の部分のみを復元し、復元した所定の部分を、クエリの処理対象を選別する条件と比較してデータ111を破棄するか判断する。そして、エンジンノード101は、データ111を破棄しないと判断した場合に、データ111のすべてを復元することにより、不要なデシリアライズを削減する。以下、実施の形態1にかかるエンジンノード101のデータ処理例について説明する。
(1)エンジンノード101は、クエリを実行するための直列化されたデータであるデータ111を受信する。
(2)エンジンノード101は、クエリの処理対象となるデータを選別するために参照される部分を特定する情報114に基づいて、受信したデータ111の所定の部分112をデシリアライズする。ここで、クエリの処理対象となるデータを選別するために参照される部分を特定する情報114とは、クエリごとに存在し、クエリにおいて、イベントデータを破棄するかの判断に使用する情報の位置を特定する情報である。
図1の例では、クエリがデータを選別するための条件であるEPLのフィルタ記述式が、『select a from EventA where b=1』と記述されているとする。この場合、情報114は、データ111の中でbの位置を特定する情報である。エンジンノード101は、情報114に基づいて、受信したデータ111から、所定の部分112をデシリアライズする。
(3)エンジンノード101は、復元した所定の部分112とクエリが処理対象となるデータを選別するための条件とに基づいて、データを破棄するか否かを判断する。データを選別するための条件とは、例えば、数値の一致・不一致、数値の大小、文字列の一致・不一致などを判断する演算子で構成される論理式である。
図1の例では、クエリが処理対象となるデータを選別するための条件は、「b=1」である。従って、エンジンノード101は、復元した所定の部分112が「1」であるか否か確認する。所定の部分112が「1」でない受信したデータ111は、クエリのデータ選別後に使用されないデータである。この場合、エンジンノード101は、受信したデータ111を破棄する。
(4)エンジンノード101は、破棄しないと判断した場合に、受信したデータ111をデシリアライズする。エンジンノード101は、受信したデータ111をデシリアライズし、オブジェクト化されたイベントデータ113を復元する。図1の例では、エンジンノード101は、「int a」、「int b」、「long c」、「long d」を含むデータ111をイベントデータ113にデシリアライズする。
(5)エンジンノード101は、デシリアライズしたイベントデータ113でクエリを実行し、実行結果を出力する。
以上説明したように、エンジンノード101は、クエリを実行するための直列化されたデータ111を受信する。エンジンノード101は、クエリの処理対象となるデータを選別するために参照される部分112を特定する情報に基づいて、受信したデータ111の所定の部分112を復元する。エンジンノード101は、復元したデータ111の所定の部分112と処理対象となるデータを選別するための条件とに基づいて、受信したデータ111を破棄するか否かを判断し、破棄しないと判断した場合に、受信したデータ111を復元する。
これにより、クエリの後処理に渡されるデータ111に対してのみデータ全体のデシリアライズを行い、クエリの前処理において破棄されるデータ111に対してはデータ全体のデシリアライズを行わないようにすることができ、不要なデシリアライズを削減することができる。例えば、分散並列型CEPでは、多くのイベントデータは、所定の部分112を参照後に破棄されるため、不要なデシリアライズを大幅に削減することができる。
(システム200のシステム構成例)
図2は、実施の形態1にかかるシステム200のシステム構成例を示す説明図である。図2において、システム200は、複数のエンジンノード101と、マネージャノード201と、コンパイラノード202と、を有する。エンジンノード101、マネージャノード201およびコンパイラノード202は、有線または無線のネットワーク220を介して接続される。ネットワーク220は、例えば、LAN(Local Area Network)、WAN(Wide Area Network)、インターネットなどである。
図2は、実施の形態1にかかるシステム200のシステム構成例を示す説明図である。図2において、システム200は、複数のエンジンノード101と、マネージャノード201と、コンパイラノード202と、を有する。エンジンノード101、マネージャノード201およびコンパイラノード202は、有線または無線のネットワーク220を介して接続される。ネットワーク220は、例えば、LAN(Local Area Network)、WAN(Wide Area Network)、インターネットなどである。
マネージャノード201は、システム200全体を管理する制御装置である。コンパイラノード202は、EPL等のクエリ記述言語で記述されたルールをコンパイラで変換することによって、クエリを作成するノードである。また、コンパイラノード202は、作成したクエリを各エンジンノード101に分配する機能を有する。マネージャノード201とコンパイラノード202は、図2では、別々のノードであるが、1つのノードとすることもできる。さらに、エンジンノード101と、マネージャノード201と、コンパイラノード202とを1つのノードとすることもできる。
(エンジンノード101のハードウェア構成例)
図3は、エンジンノード101のハードウェア構成例を示すブロック図である。図3において、エンジンノード101は、CPU(Central Processing Unit)301と、メモリ302と、I/F(Interface)303と、磁気ディスクドライブ304と、磁気ディスク305とを有する。また、各構成部は、バス300によってそれぞれ接続される。
図3は、エンジンノード101のハードウェア構成例を示すブロック図である。図3において、エンジンノード101は、CPU(Central Processing Unit)301と、メモリ302と、I/F(Interface)303と、磁気ディスクドライブ304と、磁気ディスク305とを有する。また、各構成部は、バス300によってそれぞれ接続される。
ここで、CPU301は、エンジンノード101の全体の制御を司る。メモリ302は、例えば、ROM(Read Only Memory)、RAM(Random Access Memory)およびフラッシュROMなどを有する。具体的には、例えば、フラッシュROMやROMが各種プログラムを記憶し、RAMがCPU301のワークエリアとして使用される。メモリ302に記憶されるプログラムは、CPU301にロードされることで、コーディングされている処理をCPU301に実行させる。
I/F303は、通信回線を通じてネットワーク220に接続され、ネットワーク220を介して他のコンピュータ(例えば、図2に示したマネージャノード201およびコンパイラノード202)に接続される。そして、I/F303は、ネットワーク220と内部のインターフェースを司り、他のコンピュータからのデータの入出力を制御する。I/F303には、例えば、モデムやLANアダプタなどを採用することができる。
磁気ディスクドライブ304は、CPU301の制御にしたがって磁気ディスク305に対するデータのリード/ライトを制御する。磁気ディスク305は、磁気ディスクドライブ304の制御で書き込まれたデータを記憶する。
上述した構成部のほか、例えば、SSD(Solid State Drive)、キーボード、マウス、ディスプレイなどを有することにしてもよい。また、図2に示したマネージャノード201およびコンパイラノード202についても、上述したエンジンノード101と同様のハードウェア構成例により実現することができる。
(データ111の一例)
図4は、データ111の一例を示す説明図である。図4に示す(1)は、データ111のデータ構造の一例であり、パラメータ長とパラメータデータが順に配置される。データ111のLには、パラメータ長が格納され、この後にパラメータデータが配置される。この場合、エンジンノード101は、クエリの処理対象となるデータを選別するために参照される部分を特定する情報として、パラメータの番号を有する。例えば、図4の例でlong cが、データを選別するために参照される部分である場合、3番目のデータが参照される部分を特定する情報となる。エンジンノード101は、先頭からパラメータ長(L)を読み、Lだけスキップして、再度パラメータ長(L)を読み、Lだけスキップして、目的とする3番目のパラメータに辿り着く。エンジンノード101は、目的のパラメータに辿り着いたら、long cを読み、受信したデータの所定の部分を復元する。
図4は、データ111の一例を示す説明図である。図4に示す(1)は、データ111のデータ構造の一例であり、パラメータ長とパラメータデータが順に配置される。データ111のLには、パラメータ長が格納され、この後にパラメータデータが配置される。この場合、エンジンノード101は、クエリの処理対象となるデータを選別するために参照される部分を特定する情報として、パラメータの番号を有する。例えば、図4の例でlong cが、データを選別するために参照される部分である場合、3番目のデータが参照される部分を特定する情報となる。エンジンノード101は、先頭からパラメータ長(L)を読み、Lだけスキップして、再度パラメータ長(L)を読み、Lだけスキップして、目的とする3番目のパラメータに辿り着く。エンジンノード101は、目的のパラメータに辿り着いたら、long cを読み、受信したデータの所定の部分を復元する。
図4に示す(2)は、データ111のデータ構造の他の例であり、クエリの処理対象となるデータを選別するために参照される部分は最初に配置される。エンジンノード101は、クエリの処理対象となるデータを選別するために参照される部分を特定する情報として、パラメータ長を有する。例えば、図4の例でlong cが、データを選別するために参照される部分である場合、long cのパラメータ長が参照される部分を特定する情報となる。エンジンノード101は、先頭からlong cを読み、受信したデータの所定の部分を復元する。
(エンジンノード101の機能的構成例)
図5は、実施の形態1にかかるエンジンノード101の機能的構成例を示すブロック図である。図5において、エンジンノード101は、受信部501と、復元部502と、選別部503と、処理部504と、変換部505と、送信部506とを含む構成である。各機能部は、具体的には、例えば、図3に示したメモリ302などの記憶装置に記憶されたプログラムをCPU301に実行させることにより、その機能を実現する。各機能部の処理結果は、例えば、図3に示したメモリ302などの記憶装置に記憶される。
図5は、実施の形態1にかかるエンジンノード101の機能的構成例を示すブロック図である。図5において、エンジンノード101は、受信部501と、復元部502と、選別部503と、処理部504と、変換部505と、送信部506とを含む構成である。各機能部は、具体的には、例えば、図3に示したメモリ302などの記憶装置に記憶されたプログラムをCPU301に実行させることにより、その機能を実現する。各機能部の処理結果は、例えば、図3に示したメモリ302などの記憶装置に記憶される。
受信部501は、シリアライズしたデータ111を受信する機能を有する。例えば、受信部501は、センサ等から発生したイベントデータを集約するノードからデータ111を受信する。また、受信部501は、エンジンノード101のクエリより前に実行されるクエリを実行するエンジンノード101からデータ111を受信する。受信部501は、受信したデータ111を復元部502に渡す。
復元部502は、受信したデータ111をデシリアライズする機能を有する。復元部502は、クエリの処理対象となるデータを選別するために参照される部分を特定する情報に基づいて、受信したデータ111の所定の部分112をデシリアライズする。復元部502は、デシリアライズした所定の部分112を選別部503に渡す。また、復元部502は、受信したデータ111をすべてデシリアライズする。復元部502は、すべてデシリアライズしたイベントデータ113を処理部504に渡す。
選別部503は、デシリアライズした所定の部分112と、クエリの処理対象となるデータを選別するための条件とに基づいて、受信したデータ111を破棄するか否かを判断する機能を有する。破棄しないと判断した場合、選別部503は、受信したデータ111を復元部502に渡す。破棄すると判断した場合、選別部503は、受信したデータ111を破棄する。
選別部503は、クエリの処理対象となるデータを選別するための条件を記述する論理式に、所定の部分112の値を代入し、論理式が真であるとき、受信したデータ111を破棄せず、論理式が偽であるとき、受信したデータ111を破棄する。
処理部504は、すべてデシリアライズしたイベントデータ113でクエリを実行する機能を有する。例えば、処理部504は、イベントデータ113のパラメータを加算する等の演算処理を実行する。また、処理部504は、イベントデータ113のパラメータが決められた値以上である時、アラームを発生させる処理等を実行する。処理部504は、クエリの実行により生成したデータを変換部505に渡す。
変換部505は、処理部504が生成したデータをバイト列にシリアライズする機能を有する。変換部505は、シリアライズしたデータを送信部506に渡す。
送信部506は、シリアライズしたデータを他のエンジンノード101に送信する機能を有する。
(エンジンノード101のデータ処理)
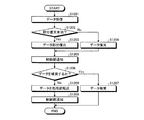
図6は、実施の形態1にかかるエンジンノード101のデータ処理手順の一例を示すフローチャートである。図6のフローチャートにおいて、まず、受信部501は、シリアライズしたデータ111を受信する(ステップS601)。次に、復元部502は、クエリの処理対象となるデータを選別するために参照される部分を特定する情報に基づいて、受信したデータ111の所定の部分112をデシリアライズする(ステップS602)。
図6は、実施の形態1にかかるエンジンノード101のデータ処理手順の一例を示すフローチャートである。図6のフローチャートにおいて、まず、受信部501は、シリアライズしたデータ111を受信する(ステップS601)。次に、復元部502は、クエリの処理対象となるデータを選別するために参照される部分を特定する情報に基づいて、受信したデータ111の所定の部分112をデシリアライズする(ステップS602)。
次に、選別部503は、デシリアライズした所定の部分112と、クエリの処理対象となるデータを選別するための条件とに基づいて、受信したデータ111を破棄するか否かを判断する(ステップS603)。破棄しないと判断した場合(ステップS603:No)、復元部502は、受信したデータ111をすべてデシリアライズする(ステップS605)。処理部504は、デシリアライズしたイベントデータ113でクエリを実行する(ステップS606)。
また、破棄すると判断した場合(ステップS603:Yes)、選別部503は、受信したデータ111を破棄する(ステップS604)。これにより、本フローチャートによる一連の処理は終了する。本フローチャートを実行することにより、選別部503で破棄されないデータ111のみがデシリアライズされる。
以上説明したように、エンジンノード101は、クエリを実行するための直列化されたデータ111を受信する。エンジンノード101は、クエリの処理対象となるデータを選別するために参照される部分112を特定する情報に基づいて、受信したデータ111の所定の部分112を復元する。エンジンノード101は、復元したデータ111の所定の部分112と処理対象となるデータを選別するための条件とに基づいて、受信したデータ111を破棄するか否かを判断し、破棄しないと判断した場合に、受信したデータ111を復元する。
これにより、実施の形態1にかかるエンジンノード101によれば、クエリの前処理において破棄されるデータ111に対してはデータ全体のデシリアライズを行わないようにして不要なデシリアライズを削減することができ、エンジンノード101にかかる負荷の増大を抑制することができる。
(実施の形態2)
次に、実施の形態2にかかる処理方法の一実施例について説明する。実施の形態2では、データ111の所定の部分112のデシリアライズ、およびデータ111のすべてのデシリアライズを行う条件が追加される。なお、実施の形態1で説明した箇所と同一箇所については、図示および説明を省略する。
次に、実施の形態2にかかる処理方法の一実施例について説明する。実施の形態2では、データ111の所定の部分112のデシリアライズ、およびデータ111のすべてのデシリアライズを行う条件が追加される。なお、実施の形態1で説明した箇所と同一箇所については、図示および説明を省略する。
図7は、実施の形態2にかかる処理方法の一実施例を示す説明図である。図7において、エンジンノード101は、クエリの処理対象となるデータを選別するために参照される所定の部分112のデシリアライズの有効または無効を示すフラグ121を有する。エンジンノード101は、フラグ121が有効を示すときに、所定の部分112をデシリアライズする。マネージャノード201およびコンパイラノード202が、フラグ121の有効または無効を判断し、エンジンノード101に通知する。
エンジンノード101は、さらに、データ111の流用が可能または不可能を示すフラグ122を有する。エンジンノード101は、フラグ122が流用不可能を示すときに、データ111をデシリアライズする。コンパイラノード202は、データ111の流用が可能であるか否かを判断してエンジンノード101に通知する。なお、データ111の流用、所定の部分112のデシリアライズの有効または無効の判断、およびデータ111の流用が可能であるか否かの判断についての詳細な説明は後述する。
エンジンノード101は、データ111を受信した回数とデータ111を破棄しない回数を記憶する。エンジンノード101は、記憶したデータ111を受信した回数とデータ111を破棄しない回数に基づいて、クエリ透過率を算出してマネージャノード201に送信する。クエリ透過率とは、データ111を受信した回数に対する、データ111を破棄しないと判断した回数の割合である。
マネージャノード201は、エンジンノード101からクエリ透過率を受信する。マネージャノード201は、受信したクエリ透過率に基づいて、所定の部分112のデシリアライズの有効または無効を判断し、判断結果をエンジンノード101に通知する。例えば、マネージャノード201は、クエリ透過率が所定値α以下である場合、所定の部分112のデシリアライズを有効と判断する。なお、所定値αについての詳細な説明は後述する。
コンパイラノード202は、EPL等のクエリ記述言語を解析し、所定の部分112のデシリアライズの有効または無効を静的に判断する。コンパイラノード202は、判断結果をエンジンノード101に通知する。例えば、コンパイラノード202は、クエリの処理対象となるデータを選別するために参照される部分に含まれるパラメータが、所定の数以下であり、かつ、所定の型である場合に、受信したデータ111の所定の部分112をデシリアライズすると判断する。
ここで、所定の型とは、例えば、string、classのように内部にパラメータを有する型である。また、コンパイラノード202は、クエリの処理対象となるデータを選別するために参照される部分をデシリアライズするコストを算出する。コンパイラノード202は、算出したコストがデータ111をすべてデシリアライズするコスト未満である場合に、受信したデータ111の所定の部分112をデシリアライズすると判断することもできる。ここで、コストとは、エンジンノード101がデシリアライズするために使用するCPU時間、またはメモリのことである。
また、コンパイラノード202は、EPL等のクエリ記述言語を解析し、エンジンノード101のクエリを実行した後に実行される他のエンジンノード101のクエリに参照される情報がデータ111に含まれ、データ111の流用が可能か否かを判断する。コンパイラノード202は、判断結果をエンジンノード101に通知する。以下、実施の形態2にかかるエンジンノード101のデータ処理例について説明する。
(1)エンジンノード101は、シリアライズされたデータ111を受信する。エンジンノード101は、クエリを実行するための直列化されたデータであるデータ111を受信する。
(2)エンジンノード101は、所定の部分112のデシリアライズが有効か無効か判断する。エンジンノード101は、マネージャノード201およびコンパイラノード202から通知された所定の部分112のデシリアライズの有効または無効を示すフラグ121を参照し、所定の部分112のデシリアライズが有効か無効か判断する。
(3)エンジンノード101は、データ111を受信した回数を保存する。エンジンノード101は、クエリ透過率を計算するため、データ111を受信した回数を保存する。
(4)エンジンノード101は、所定の部分112のデシリアライズが有効である場合、受信したデータ111から、クエリの処理対象となるデータを選別するために参照される所定の部分112をデシリアライズする。図7の例では、図1と同様にエンジンノード101は、bの部分を特定する情報に基づいて、受信したデータ111から、所定の部分112をデシリアライズする。また、無効である場合、エンジンノード101は、受信したデータ111をすべてデシリアライズする。
(5)エンジンノード101は、復元した所定の部分112とクエリが処理対象となるデータを選別するための条件とに基づいて、データ111を破棄するか否かを判断する。エンジンノード101は、データ111を破棄しない回数を記憶する。図7の例では、図1と同様に、エンジンノード101は、復元した所定の部分112が1であるか否か確認する。所定の部分112が1でない受信したデータ111は、クエリのデータ選別後に使用されないデータである。この場合、エンジンノード101は、受信したデータ111を破棄する。
(6)エンジンノード101は、データ111を破棄しないと判断した回数を、データ111を受信した回数で割ることによりクエリ透過率を計算し、マネージャノード201に通知する。マネージャノード201が所定の部分112のデシリアライズの有効または無効を動的に判断する情報として、エンジンノード101は、クエリ透過率をマネージャノード201に通知する。
(7)エンジンノード101は、データ111の流用が可能か否かを判断する。コンパイラノード202から通知されたデータ111の流用の可能または不可能を示すフラグ122を参照し、データ111の流用が可能か否かを判断する。
(8)エンジンノード101は、流用が可能と判断した場合、受信したデータ111のデシリアライズを行わない。
(9)エンジンノード101は、受信したデータ111でクエリを実行する。エンジンノード101は、データ111でクエリを実行し、結果を出力する。
以上説明したように、エンジンノード101は、クエリの処理対象となるデータを選別するために参照される部分に含まれるパラメータが、所定の数以下であり、かつ、所定の型である場合に、データ111の所定の部分112をデシリアライズする。また、エンジンノード101は、クエリの処理対象となるデータを選別するために参照される部分をデシリアライズするコストが、データ111をすべてデシリアライズするコスト未満である場合に、データ111の所定の部分112をデシリアライズする。さらに、エンジンノード101は、クエリ透過率が所定値α以下である場合に、データ111の所定の部分112をデシリアライズする。
これにより、不要なデシリアライズを削減する効果が見込まれる場合に、エンジンノード101は、所定の部分112をデシリアライズすることができる。
また、エンジンノード101は、データ111を破棄しないと判断し、かつ、クエリを実行した後に実行される他のクエリに参照される情報がデータ111に含まれる場合は、データ111を復元しない。
これにより、エンジンノード101は、エンジンノード101のクエリを実行した後に実行される他のエンジンノード101までデシリアライズを行わないことが可能になる。このため、エンジンノード101は、デシリアライズを削減することができる。
(マネージャノード201の機能的構成例)
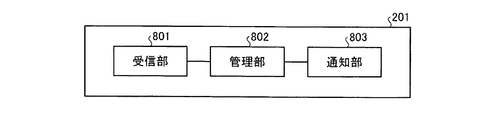
図8は、実施の形態2にかかるマネージャノード201の機能的構成例を示すブロック図である。図8において、マネージャノード201は、受信部801と、管理部802と、通知部803とを含む構成である。各機能部は、具体的には、例えば、図3に示したメモリ302などの記憶装置に記憶されたプログラムをCPU301に実行させることにより、その機能を実現する。各機能部の処理結果は、例えば、図3に示したメモリ302などの記憶装置に記憶される。
図8は、実施の形態2にかかるマネージャノード201の機能的構成例を示すブロック図である。図8において、マネージャノード201は、受信部801と、管理部802と、通知部803とを含む構成である。各機能部は、具体的には、例えば、図3に示したメモリ302などの記憶装置に記憶されたプログラムをCPU301に実行させることにより、その機能を実現する。各機能部の処理結果は、例えば、図3に示したメモリ302などの記憶装置に記憶される。
受信部801は、エンジンノード101からクエリ透過率を受信する機能を有する。受信部801は、受信したクエリ透過率を管理部802に渡す。
管理部802は、受信したクエリ透過率から所定の部分112のデシリアライズの有効または無効を判断する機能を有する。管理部802は、判断した判断結果を通知部803に渡す。例えば、管理部802は、クエリ透過率が所定値α以下である場合、所定の部分112のデシリアライズを有効と判断する。
通知部803は、判断結果をエンジンノード101に通知する機能を有する。具体的には、例えば、通知部803は、管理部802が判断した判断結果を、受信部801が受信したクエリ透過率の送信元のエンジンノード101に通知する。
なお、上述した所定値αは、予め設定されていてもよく、例えば、マネージャノード201が以下のように決定することにしてもよい。
ここで、所定の部分112をデシリアライズした場合のデシリアライズコストは、下記式(1)を用いて表すことができる。また、所定の部分112をデシリアライズしない場合のデシリアライズコストは、下記式(2)を用いて表すことができる。ただし、C1は、所定の部分112をデシリアライズした場合のデシリアライズコストである。C2は、所定の部分112をデシリアライズしない場合のデシリアライズコストである。c1は、所定の部分112をデシリアライズするコストである。c2は、データ111をすべてデシリアライズするコストである。pは、クエリ透過率である。
C1=c1+c2×p ・・・(1)
C2=c2 ・・・(2)
デシリアライズコストC1は、クエリ透過率pがある値より大きくなると、デシリアライズコストC2を超える。すなわち、クエリ透過率pがある値より大きいと、所定の部分112をデシリアライズする場合は、所定の部分112をデシリアライズしない場合と比べてデシリアライズコストが増加する。このため、マネージャノード201は、例えば、デシリアライズコストC1がデシリアライズC2より小さくなるクエリ透過率pの値を所定値αに決定する。
(コンパイラノード202の機能的構成例)
図9は、実施の形態2にかかるコンパイラノード202の機能的構成例を示すブロック図である。図9において、コンパイラノード202は、構文解析部901と、復元コスト検証部902と、分配部903とを含む構成である。各機能部は、具体的には、例えば、図3に示したメモリ302などの記憶装置に記憶されたプログラムをCPU301に実行させることにより、その機能を実現する。各機能部の処理結果は、例えば、図3に示したメモリ302などの記憶装置に記憶される。
図9は、実施の形態2にかかるコンパイラノード202の機能的構成例を示すブロック図である。図9において、コンパイラノード202は、構文解析部901と、復元コスト検証部902と、分配部903とを含む構成である。各機能部は、具体的には、例えば、図3に示したメモリ302などの記憶装置に記憶されたプログラムをCPU301に実行させることにより、その機能を実現する。各機能部の処理結果は、例えば、図3に示したメモリ302などの記憶装置に記憶される。
構文解析部901は、EPL等のクエリ記述言語を解析し、実行可能なクエリに変換する機能を有する。構文解析部901は、変換したクエリを分配部903に渡す。
復元コスト検証部902は、EPL等のクエリ記述言語を解析し、所定の部分112のデシリアライズの有効または無効を判断する機能を有する。復元コスト検証部902は、有効または無効の判断結果を分配部903に渡す。復元コスト検証部902は、例えば、クエリの処理対象となるデータを選別するために参照される部分に含まれるパラメータが、所定の数以下であり、かつ、所定の型である場合に、受信したデータ111の所定の部分112をデシリアライズすると判断する。また、復元コスト検証部902は、クエリの処理対象となるデータを選別するために参照される部分をデシリアライズするコストを算出する。復元コスト検証部902は、算出したコストがデータ111をすべてデシリアライズするコスト未満である場合に、受信したデータ111の所定の部分112をデシリアライズすると判断することもできる。
復元コスト検証部902は、さらに、EPL等のクエリ記述言語を解析し、データ111の流用が可能か否かを判断する機能を有する。復元コスト検証部902は、データ111の流用可能かの判断結果を分配部903に渡す。例えば、エンジンノード101のクエリのEPLが『insert EventB select a,c,d,e,f from EventA where b=100』で記述されているとする。
また、当該クエリを実行した後に、後のエンジンノード101で実行されるクエリのEPLが、『select a,c from EventB where b=100 and e=”AAA”』で記述されているとする。この場合、エンジンノード101のイベントデータであるEventAのパラメータは、そのまま後のエンジンノード101のイベントデータであるEventBのパラメータとして、使用されている。このため、コンパイラノード202はデータ流用が可能であると判断する。
これに対して、エンジンノード101のクエリのEPLが、『insert EventB select a,b,count(a),sum(b) from EventA where b=100』で記述されているとする。この場合、後のエンジンノード101のイベントデータであるEventBのパラメータは、エンジンノード101のイベントデータであるEventAのパラメータに、新しいパラメータを追加したパラメータである。このため、コンパイラノード202はデータ流用が不可能であると判断する。
分配部903は、変換したクエリ、所定の部分112のデシリアライズの有効または無効の判断結果、およびデータ111の流用可能かの判断結果をエンジンノード101に分配する機能を有する。
(エンジンノード101の機能的構成例)
図10は、実施の形態2にかかるエンジンノード101の機能的構成例を示すブロック図である。図10において、エンジンノード101は、受信部501と、復元部502と、選別部503と、処理部504と、変換部505と、送信部506と、制御部1001と、を含む構成である。制御部1001は、具体的には、例えば、図3に示したメモリ302などの記憶装置に記憶されたプログラムをCPU301に実行させることにより、その機能を実現する。各機能部の処理結果は、例えば、図3に示したメモリ302などの記憶装置に記憶される。
図10は、実施の形態2にかかるエンジンノード101の機能的構成例を示すブロック図である。図10において、エンジンノード101は、受信部501と、復元部502と、選別部503と、処理部504と、変換部505と、送信部506と、制御部1001と、を含む構成である。制御部1001は、具体的には、例えば、図3に示したメモリ302などの記憶装置に記憶されたプログラムをCPU301に実行させることにより、その機能を実現する。各機能部の処理結果は、例えば、図3に示したメモリ302などの記憶装置に記憶される。
受信部501は、シリアライズしたデータ111を受信した場合、シリアライズしたデータ111を受信したことを制御部1001に通知する機能をさらに有する。
復元部502は、所定の部分112のデシリアライズの有効または無効を示すフラグ121を参照する機能をさらに有する。復元部502は、所定の部分112のデシリアライズが有効である場合、クエリの処理対象となるデータを選別するために参照される部分を特定する情報に基づいて、受信したデータ111の所定の部分112をデシリアライズする。
選別部503は、データ111を破棄しないと判断した場合、データ111を破棄しないことを制御部1001に通知する機能をさらに有する。
処理部504は、コンパイラノード202から通知されたデータ111の流用の可能または不可能を示すフラグ122を参照する機能をさらに有する。処理部504は、データ111の流用が可能な場合、受信したデータ111のデシリアライズを行わない。
制御部1001は、データ111を破棄しないと判断した回数を、データ111を受信した回数で割ることによりクエリ透過率を計算し、マネージャノード201に通知する機能を有する。また、制御部1001は、マネージャノード201およびコンパイラノード202の通知に基づいて、所定の部分112のデシリアライズの有効または無効を示すフラグ121を更新する機能をさらに有する。さらに、制御部1001は、コンパイラノード202の通知に基づいて、データ111の流用が可能または不可能を示すフラグ122を更新する機能をさらに有する。
(コンパイラノード202の復元コスト検証処理)
図11は、実施の形態2にかかるコンパイラノード202の復元コスト検証処理手順の一例を示すフローチャートである。図11のフローチャートにおいて、まず、復元コスト検証部902は、EPL等のクエリ記述言語を解析する(ステップS1101)。次に、復元コスト検証部902は、クエリの処理対象となるデータを選別するために参照される部分に含まれるパラメータが、所定の数以下であり、かつ、所定の型であるか否かを確認する(ステップS1102)。
図11は、実施の形態2にかかるコンパイラノード202の復元コスト検証処理手順の一例を示すフローチャートである。図11のフローチャートにおいて、まず、復元コスト検証部902は、EPL等のクエリ記述言語を解析する(ステップS1101)。次に、復元コスト検証部902は、クエリの処理対象となるデータを選別するために参照される部分に含まれるパラメータが、所定の数以下であり、かつ、所定の型であるか否かを確認する(ステップS1102)。
パラメータが、所定の数以下であり、かつ、所定の型である場合に(ステップS1102:Yes)、復元コスト検証部902は、所定の部分112のデシリアライズを有効と判断する(ステップS1103)。パラメータが、所定の数より多い、または、所定の型でない場合に(ステップS1102:No)、復元コスト検証部902は、所定の部分112のデシリアライズを無効と判断する(ステップS1104)。
次に、復元コスト検証部902は、EPL等のクエリ記述言語を解析し、データ111の流用が可能か否かを判断する(ステップS1105)。データ流用が可能であると判断した場合(ステップS1105:Yes)、復元コスト検証部902は、データ111の流用転送を可能と判断する(ステップS1106)。データ流用が不可能であると判断した場合(ステップS1105:No)、復元コスト検証部902は、データ111の流用転送を不可能と判断する(ステップS1107)。これにより、本フローチャートによる一連の処理は終了する。本フローチャートを実行することにより、所定の部分112のデシリアライズの有効、無効、およびデータ111の流用転送可能、不可能が判断される。
(エンジンノード101のデータ処理)
図12は、実施の形態2にかかるエンジンノード101のデータ処理手順の一例を示すフローチャート(その1)である。図12のフローチャートにおいて、まず、受信部501は、シリアライズしたデータ111を受信する(ステップS1201)。次に、復元部502は、デシリアライズの有効または無効を示すフラグ121を参照し、所定の部分112のデシリアライズの有効または無効を確認する(ステップS1202)。所定の部分112のデシリアライズが有効である場合(ステップS1202:Yes)、復元部502は、所定の部分112をデシリアライズする(ステップS1203)。所定の部分112のデシリアライズが無効である場合(ステップS1202:No)、復元部502は、受信したデータ111をすべてデシリアライズする(ステップS1204)。
図12は、実施の形態2にかかるエンジンノード101のデータ処理手順の一例を示すフローチャート(その1)である。図12のフローチャートにおいて、まず、受信部501は、シリアライズしたデータ111を受信する(ステップS1201)。次に、復元部502は、デシリアライズの有効または無効を示すフラグ121を参照し、所定の部分112のデシリアライズの有効または無効を確認する(ステップS1202)。所定の部分112のデシリアライズが有効である場合(ステップS1202:Yes)、復元部502は、所定の部分112をデシリアライズする(ステップS1203)。所定の部分112のデシリアライズが無効である場合(ステップS1202:No)、復元部502は、受信したデータ111をすべてデシリアライズする(ステップS1204)。
受信部501は、シリアライズしたデータ111を受信したことを制御部1001に通知する(ステップS1205)。次に、選別部503は、デシリアライズした所定の部分112と、クエリの処理対象となるデータを選別するための条件とに基づいて、受信したデータ111を破棄するか否かを判断する(ステップS1206)。破棄しないと判断した場合(ステップS1206:No)、選別部503は、受信したデータ111を処理部504に転送し(ステップS1208)、データ111を破棄しないことを制御部1001に通知する(ステップS1209)。
また、破棄すると判断した場合(ステップS1206:Yes)、選別部503は、受信したデータ111を破棄する(ステップS1207)。これにより、本フローチャートによる一連の処理は終了する。本フローチャートを実行することにより、所定の部分112のデシリアライズが有効の場合に、所定の部分112がデシリアライズされ、選別部503で破棄されないデータ111のみがデシリアライズされる。
図13は、実施の形態2にかかるエンジンノード101のデータ処理手順の一例を示すフローチャート(その2)である。図13のフローチャートにおいて、まず、処理部504は、デシリアライズの有効または無効を示すフラグ121を参照し、所定の部分112のデシリアライズの有効または無効を確認する(ステップS1301)。所定の部分112のデシリアライズが有効である場合(ステップS1301:Yes)、処理部504は、データ111の流用の可能または不可能を示すフラグ122を参照し、データ111の流用が可能か否かを確認する(ステップS1302)。
流用が可能な場合(ステップS1302:Yes)、処理部504は、受信したデータ111でクエリを実行する(ステップS1304)。この後、ステップS1308に移行する。一方、データ111の流用が不可能な場合(ステップS1302:No)、復元部502は、受信したデータ111をすべてデシリアライズする(ステップS1303)。この後、ステップS1305に移行する。
所定の部分112のデシリアライズが無効である場合(ステップS1301:No)、処理部504は、デシリアライズしたイベントデータ113でクエリを実行する(ステップS1305)。処理部504は、データ処理で生成した新しいパラメータをデータに追加して新データを作成する(ステップS1306)。変換部505は、新データをバイト列にシリアライズする(ステップS1307)。
最後に、送信部506は、シリアライズしたデータを他のエンジンノード101に送信する(ステップS1308)。これにより、本フローチャートによる一連の処理は終了する。本フローチャートを実行することにより、データ111の流用が可能な場合、クエリの選別処理で通過したデータ111はデシリアライズされない。
(エンジンノード101の透過率処理)
図14は、実施の形態2にかかるエンジンノード101の透過率処理手順の一例を示すフローチャートである。図14のフローチャートにおいて、まず、制御部1001は、データ111を破棄しないと判断した回数とデータ111を受信した回数からクエリ透過率を計算する(ステップS1401)。次に、制御部1001は、計算したクエリ透過率をマネージャノード201に通知する(ステップS1402)。これにより、本フローチャートによる一連の処理は終了する。本フローチャートを実行することにより、クエリ透過率がマネージャノード201に通知される。
図14は、実施の形態2にかかるエンジンノード101の透過率処理手順の一例を示すフローチャートである。図14のフローチャートにおいて、まず、制御部1001は、データ111を破棄しないと判断した回数とデータ111を受信した回数からクエリ透過率を計算する(ステップS1401)。次に、制御部1001は、計算したクエリ透過率をマネージャノード201に通知する(ステップS1402)。これにより、本フローチャートによる一連の処理は終了する。本フローチャートを実行することにより、クエリ透過率がマネージャノード201に通知される。
(マネージャノード201の部分復元判断処理)
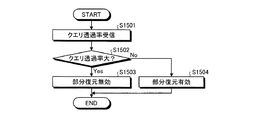
図15は、実施の形態2にかかるマネージャノード201の部分復元判断処理手順の一例を示すフローチャートである。図15のフローチャートにおいて、まず、受信部801は、エンジンノード101からクエリ透過率を受信する(ステップS1501)。次に、管理部802は、クエリ透過率が所定値より大きいかどうか確認する(ステップS1502)。
図15は、実施の形態2にかかるマネージャノード201の部分復元判断処理手順の一例を示すフローチャートである。図15のフローチャートにおいて、まず、受信部801は、エンジンノード101からクエリ透過率を受信する(ステップS1501)。次に、管理部802は、クエリ透過率が所定値より大きいかどうか確認する(ステップS1502)。
クエリ透過率が所定値より大きい場合(ステップS1502:Yes)、管理部802は、所定の部分112のデシリアライズを無効と判断する(ステップS1503)。クエリ透過率が所定値以下である場合(ステップS1502:No)、管理部802は、所定の部分112のデシリアライズを有効と判断する(ステップS1504)。これにより、本フローチャートによる一連の処理は終了する。本フローチャートを実行することにより、所定の部分112のデシリアライズの有効、無効が判断される。
以上説明したように、エンジンノード101は、クエリの処理対象となるデータを選別するために参照される部分に含まれるパラメータが、所定の数以下であり、かつ、所定の型である場合に、データ111の所定の部分112をデシリアライズする。また、エンジンノード101は、クエリの処理対象となるデータを選別するために参照される部分をデシリアライズするコストが、データ111をすべてデシリアライズするコスト未満である場合に、データ111の所定の部分112をデシリアライズする。さらに、エンジンノード101は、透過率が所定値以下である場合に、データ111の所定の部分112をデシリアライズする。
これにより、不要なデシリアライズを削減する効果が見込まれる場合に、エンジンノード101は、所定の部分112をデシリアライズすることができる。
また、エンジンノード101は、データ111を破棄しないと判断し、かつ、クエリを実行した後に実行される他のクエリに参照される情報がデータ111に含まれる場合は、データ111を復元しない。
これにより、エンジンノード101は、エンジンノード101のクエリを実行した後に実行される他のエンジンノード101までデシリアライズを行わないことが可能になる。このため、エンジンノード101は、デシリアライズを削減することができる。
(実施の形態3)
次に、実施の形態3にかかる処理方法の一実施例について説明する。実施の形態3では、クエリを実行するための直列化されたデータをまとめたデータ群単位のクエリ透過率を判断基準にして、データ群の割当先のエンジンノード101を決定する場合について説明する。なお、実施の形態1および実施の形態2で説明した箇所と同一箇所については、図示および説明を省略する。
次に、実施の形態3にかかる処理方法の一実施例について説明する。実施の形態3では、クエリを実行するための直列化されたデータをまとめたデータ群単位のクエリ透過率を判断基準にして、データ群の割当先のエンジンノード101を決定する場合について説明する。なお、実施の形態1および実施の形態2で説明した箇所と同一箇所については、図示および説明を省略する。
図16は、実施の形態3にかかる処理方法の一実施例を示す説明図である。実施の形態3において、同一クエリを並列処理する際、クエリを実行するための直列化された複数のデータは、複数のデータ群に分割される。マネージャノード201は、データ群ごとにデータをエンジンノード101に割り当てる。
例えば、シリアライズされたデータにはid(パラメータ)が付与されており、複数のデータは、各データのidに従って、指定のパラメータ値範囲で複数のデータ群に分割される。なお、idは、シリアライズされたデータの識別子である。ここでは、あるパラメータ値範囲のデータ群を「Vnode」と表記する。
図16の例では、例えば、Vnode1601は、idが「000〜099」のデータ群であり、エンジンノード101−1に割り当てられている。また、例えば、Vnode1604は、idが「300〜399」のデータ群であり、エンジンノード101−2に割り当てられている。
エンジンノード101は、Vnodeごとにデータ111を受信した回数とデータ111を破棄しない回数を記憶する。そして、エンジンノード101は、データ111を受信した回数に対する、データ111を破棄しないと判断した回数の割合であるVnodeごとのクエリ透過率を算出して、マネージャノード201に送信する。
マネージャノード201は、エンジンノード101からVnodeごとのクエリ透過率を受信する。マネージャノード201は、エンジンノード101の負荷が規定値より高くなった場合、例えば、エンジンノード101のCPU使用率またはメモリ使用率が規定値より高くなった場合、Vnodeを他のエンジンノード101に割り当てる。この際、マネージャノード201は、エンジンノード101全体のクエリ透過率とVnodeごとのクエリ透過率に基づいて、移動するVnodeと割当先のエンジンノード101を決定する。
例えば、マネージャノード201は、所定の部分112のデシリアライズの有効であるエンジンノード101、すなわちクエリ透過率が所定値α以下となるエンジンノード101に、クエリ透過率が所定値β以下となるVnodeを割り当てる。また、マネージャノード201は、所定の部分112のデシリアライズの無効であるエンジンノード101、すなわちクエリ透過率が所定値αより大きいエンジンノード101に、クエリ透過率が所定値γ以上のVnodeを割り当てる。所定値βは、所定値α以下の値である。また、所定値γは、所定値α以上の値である。
図16の例で、エンジンノード101−1が所定の部分112のデシリアライズが無効であり、エンジンノード101−2が所定の部分112のデシリアライズが有効であるとする。また、エンジンノード101−1において、Vnode1601のクエリ透過率が所定値β以下であり、Vnode1602のクエリ透過率が所定値γ以上とする。また、エンジンノード101−2において、Vnode1604のクエリ透過率が所定値β以下であり、Vnode1605のクエリ透過率が所定値γ以上とする。
この場合、エンジンノード101−1の負荷が規定値より高くなり、エンジンノード101−1のVnodeをエンジンノード101−2に割り当てる場合、マネージャノード201は、Vnode1602をエンジンノード101−2に割り当てる。一方、エンジンノード101−2の負荷が規定値より高くなり、エンジンノード101−2のVnodeをエンジンノード101−1に割り当てる場合、マネージャノード201は、Vnode1604をエンジンノード101−1に割り当てる。
これにより、マネージャノード201は、クエリ透過率が所定値β以下のVnodeを、所定の部分112のデシリアライズが有効であるエンジンノード101に割り当てることができる。また、マネージャノード201は、クエリ透過率が所定値γ以上のVnodeを、所定の部分112のデシリアライズが無効であるエンジンノード101に割り当てることができる。このため、マネージャノード201は、エンジンノード101での不要なデシリアライズの削減を考慮した負荷均衡化を行うことができる。
(エンジンノードテーブル1700の一例)
図17は、エンジンノードテーブル1700の一例を示す説明図である。図17において、エンジンノードテーブル1700は、エンジンノードID、CPU使用率およびメモリ使用率のフィールドを有し、各フィールドに情報を設定することで、エンジンノード情報(例えば、エンジンノード情報1700−1〜1700−3)をレコードとして記憶する。
図17は、エンジンノードテーブル1700の一例を示す説明図である。図17において、エンジンノードテーブル1700は、エンジンノードID、CPU使用率およびメモリ使用率のフィールドを有し、各フィールドに情報を設定することで、エンジンノード情報(例えば、エンジンノード情報1700−1〜1700−3)をレコードとして記憶する。
ここで、エンジンノードIDは、エンジンノード101の識別子である。CPU使用率は、エンジンノード101のCPUの使用率である。メモリ使用率は、エンジンノード101のメモリの使用率である。例えば、エンジンノード情報1700−1は、エンジンノード101のエンジンノードID「1」、CPU使用率「62%」およびメモリ使用率「45%」を示す。
マネージャノード201は、エンジンノード101から定期的にCPU使用率およびメモリ使用率を受信し、エンジンノードテーブル1700を更新する。マネージャノード201は、エンジンノードテーブル1700に基づいて、エンジンノード101の負荷を判断し、負荷が規定値より高くなったエンジンノード101のデータ群を他のエンジンノード101に割り当てる。
(クエリテーブル1800の一例)
図18は、クエリテーブル1800の一例を示す説明図である。図18において、クエリテーブル1800は、クエリID、エンジンノードID、クエリ透過率、部分復元、および並列可能のフィールドを有し、各フィールドに情報を設定することで、クエリ情報(例えば、クエリ情報1800−1〜1800−5)をレコードとして記憶する。
図18は、クエリテーブル1800の一例を示す説明図である。図18において、クエリテーブル1800は、クエリID、エンジンノードID、クエリ透過率、部分復元、および並列可能のフィールドを有し、各フィールドに情報を設定することで、クエリ情報(例えば、クエリ情報1800−1〜1800−5)をレコードとして記憶する。
ここで、クエリIDは、クエリの識別子である。エンジンノードIDは、クエリIDのクエリが実行されるエンジンノード101の識別子である。クエリ透過率は、エンジンノード101でのデータ111が破棄される割合である。部分復元は、クエリIDのクエリで所定の部分112のデシリアライズが有効であるか無効であるかを示す情報である。並列可能は、クエリIDのクエリが並列クエリであるか否か示す情報である。並列クエリとは、複数のノードで分散して実行可能なクエリである。例えば、クエリ情報1800−1は、クエリID「Q1」のクエリは、エンジンノードID「1」のエンジンノード101で実行され、クエリ透過率「5%」、部分復元「有効」および並列可能「可能」を示す。
マネージャノード201は、クエリ透過率を、クエリを実行するエンジンノード101から取得し、所定の部分112のデシリアライズが有効であるか否かをコンパイラノード202から取得する。マネージャノード201は、クエリテーブル1800に基づいて、Vnodeを移動する際、クエリが並列可能であるか確認し、Vnodeを割り当てるエンジンノード101を決定する。
(Vnode情報テーブル1900の一例)
図19は、Vnode情報テーブル1900の一例を示す説明図である。図19において、Vnode情報テーブル1900は、VnodeID、id、クエリID、およびクエリ透過率のフィールドを有し、各フィールドに情報を設定することで、Vnode情報(例えば、Vnode情報1900−1〜1900−4)をレコードとして記憶する。
図19は、Vnode情報テーブル1900の一例を示す説明図である。図19において、Vnode情報テーブル1900は、VnodeID、id、クエリID、およびクエリ透過率のフィールドを有し、各フィールドに情報を設定することで、Vnode情報(例えば、Vnode情報1900−1〜1900−4)をレコードとして記憶する。
ここで、VnodeIDは、Vnodeの識別子である。idは、データの識別子である。クエリIDは、Vnodeで実行されるクエリの識別子である。クエリ透過率は、VnodeIDでの、データ111が破棄される割合である。例えば、Vnode情報1900−1は、Vnode「D1」が「id=000〜099」のデータを含み、クエリID「Q1」のクエリが実行され、クエリ透過率「7%」を示す。
マネージャノード201は、Vnodeごとに、Vnodeで実行するクエリIDとクエリ透過率を記憶する。マネージャノード201は、Vnodeごとのクエリ透過率を、クエリを実行するエンジンノード101から取得する。マネージャノード201は、Vnodeテーブル1900に基づいて、移動するVnodeを決定する。
(ルーティングテーブル2000の一例)
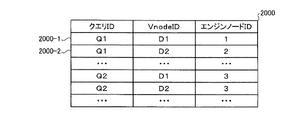
図20は、ルーティングテーブル2000の一例を示す説明図である。図20において、ルーティングテーブル2000は、クエリID、VnodeID、およびエンジンノードIDのフィールドを有し、各フィールドに情報を設定することで、ルーティング情報(例えばルーティング情報2000−1〜2000−2)をレコードとして記憶する。
図20は、ルーティングテーブル2000の一例を示す説明図である。図20において、ルーティングテーブル2000は、クエリID、VnodeID、およびエンジンノードIDのフィールドを有し、各フィールドに情報を設定することで、ルーティング情報(例えばルーティング情報2000−1〜2000−2)をレコードとして記憶する。
ここで、クエリIDは、クエリの識別子である。VnodeIDは、Vnodeの識別子である。エンジンノードIDは、エンジンノード101の識別子である。例えば、ルーティング情報2000−1は、クエリID「Q1」、Vnode「D1]は、エンジンノード101のエンジンノードID「1」に転送されることを示す。
エンジンノード101の送信部506は、ルーティングテーブル2000に基づいて、シリアライズしたデータ111を送信するエンジンノード101を決定する。
(エンジンノード101の機能的構成例)
実施の形態3にかかるエンジンノード101の機能的構成例は、実施の形態2と同じであるため、図示を省略する。また、実施の形態1および実施の形態2で説明した箇所と同一箇所については、説明を省略する。
実施の形態3にかかるエンジンノード101の機能的構成例は、実施の形態2と同じであるため、図示を省略する。また、実施の形態1および実施の形態2で説明した箇所と同一箇所については、説明を省略する。
受信部501は、シリアライズしたデータ111を受信したこと、およびデータ111を含むVnodeを識別する情報を制御部1001に通知する機能をさらに有する。データ111を含むVnodeを識別する情報は、VnodeIDである。
選別部503は、データ111を破棄しないこと、およびデータ111を含むVnodeを識別する情報を制御部1001に通知する機能をさらに有する。
制御部1001は、データ111を破棄しないと判断した回数とデータ111を受信した回数から、Vnodeごとのクエリ透過率を計算し、マネージャノード201に通知する機能をさらに有する。
(マネージャノード201の機能的構成例)
実施の形態3にかかるマネージャノード201の機能的構成例は、実施の形態2と同じであるため、図示を省略する。また、実施の形態1および実施の形態2で説明した箇所と同一箇所については、説明を省略する。
実施の形態3にかかるマネージャノード201の機能的構成例は、実施の形態2と同じであるため、図示を省略する。また、実施の形態1および実施の形態2で説明した箇所と同一箇所については、説明を省略する。
受信部801は、エンジンノード101からVnodeごとのクエリ透過率を受信する機能を有する。受信部801は、受信したVnodeごとのクエリ透過率を管理部802に渡す。
管理部802は、Vnodeごとのクエリ透過率でクエリテーブル1800を更新し、Vnodeを他のエンジンノード101に移動する機能を有する。
(エンジンノード101の透過率処理)
図21は、実施の形態3にかかるエンジンノード101の透過率処理手順の一例を示すフローチャートである。図21のフローチャートにおいて、まず、制御部1001は、データ111を破棄しないと判断した回数とデータ111を受信した回数からエンジンノード101全体のクエリ透過率を計算する(ステップS2101)。次に、制御部1001は、データ111を破棄しないと判断した回数とデータ111を受信した回数から、Vnodeごとのクエリ透過率を計算する(ステップS2102)。
図21は、実施の形態3にかかるエンジンノード101の透過率処理手順の一例を示すフローチャートである。図21のフローチャートにおいて、まず、制御部1001は、データ111を破棄しないと判断した回数とデータ111を受信した回数からエンジンノード101全体のクエリ透過率を計算する(ステップS2101)。次に、制御部1001は、データ111を破棄しないと判断した回数とデータ111を受信した回数から、Vnodeごとのクエリ透過率を計算する(ステップS2102)。
制御部1001は、計算したエンジンノード101全体のクエリ透過率とVnodeごとのクエリ透過率をマネージャノード201に通知する(ステップS2103)。これにより、本フローチャートによる一連の処理は終了する。本フローチャートを実行することにより、エンジンノード101全体のクエリ透過率とVnodeごとのクエリ透過率がマネージャノード201に通知される。
(マネージャノード201のVnode移動処理)
図22は、実施の形態3にかかるマネージャノード201のVnode移動処理手順の一例を示すフローチャートである。図22のフローチャートにおいて、まず、管理部802は、エンジンノードテーブル1700から、CPU使用率またはメモリ使用率が規定値より高くなったエンジンノード101が存在するか否かを確認する(ステップS2201)。CPU使用率またはメモリ使用率が規定値より高くなったエンジンノード101が存在する場合(ステップS2201:Yes)、管理部802は、エンジンノード101で実行しているクエリが並列クエリであるか否かを確認する(ステップS2202)。管理部802は、クエリテーブル1800を参照して、クエリテーブル1800から確認する。
図22は、実施の形態3にかかるマネージャノード201のVnode移動処理手順の一例を示すフローチャートである。図22のフローチャートにおいて、まず、管理部802は、エンジンノードテーブル1700から、CPU使用率またはメモリ使用率が規定値より高くなったエンジンノード101が存在するか否かを確認する(ステップS2201)。CPU使用率またはメモリ使用率が規定値より高くなったエンジンノード101が存在する場合(ステップS2201:Yes)、管理部802は、エンジンノード101で実行しているクエリが並列クエリであるか否かを確認する(ステップS2202)。管理部802は、クエリテーブル1800を参照して、クエリテーブル1800から確認する。
並列クエリである場合(ステップS2202:Yes)、管理部802は、Vnodeの移動先のエンジンノード101を選択する(ステップS2203)。例えば、管理部802は、エンジンノードテーブル1700から、CPU使用率またはメモリ使用率が規定値より低いエンジンノード101を選別する。
管理部802は、選択したエンジンノード101で、所定の部分112のデシリアライズが有効であるか無効であるかを確認する(ステップS2204)。管理部802は、例えば、クエリテーブル1800のクエリ透過率で、所定の部分112のデシリアライズが有効であるか無効であるかを確認する。所定の部分112のデシリアライズが有効である場合(ステップS2204:Yes)、管理部802は、クエリ透過率が所定値β以下のVnodeを選択したエンジンノード101に割り当てる(ステップS2205)。
所定の部分112のデシリアライズが無効である場合(ステップS2204:No)、管理部802は、クエリ透過率が所定値γ以上のVnodeを選択したエンジンノード101に割り当てる(ステップS2206)。管理部802は、例えば、データ群テーブル1902から、Vnodeごとの透過率を参照し、所定値β以下のVnodeおよび所定値γ以上のVnodeを確認する。
また、CPU使用率またはメモリ使用率が規定値より高くなったエンジンノード101が存在しない場合(ステップS2201:No)、および並列クエリでない場合(ステップS2202:No)、管理部802は、処理を終了する。これにより、本フローチャートによる一連の処理は終了する。本フローチャートを実行することにより、Vnodeを適切なエンジンノード101に割り当てることができる。
以上説明したように、エンジンノード101は、データ111を受信した回数に対する、データ111を破棄しないと判断した回数の第1の割合を算出する。また、エンジンノード101は、Vnodeごとに、Vnodeに含まれるデータ111を受信した回数に対する、Vnodeに含まれるデータ111を破棄しないと判断した回数の第2の割合を算出する。マネージャノード201は、複数のエンジンノード101の各々が算出した第1の割合と第2の割合とに基づいて、複数のエンジンノード101に割り当てるVnodeを決定する。例えば、マネージャノード201は、第1の割合が所定値α以下となるエンジンノード101に割り当てるVnodeを、第2の割合が所定値β以下となるVnodeに決定する。また、マネージャノード201は、第1の割合が所定値αより大きいエンジンノード101に割り当てるVnodeを、第2の割合が所定値γ以上となるVnodeに決定する。
これにより、マネージャノード201は、クエリ透過率が所定値β以下のVnodeを、所定の部分112のデシリアライズが有効であるエンジンノード101に割り当てることができる。また、マネージャノード201は、クエリ透過率が所定値γ以上のVnodeを、所定の部分112のデシリアライズが無効であるエンジンノード101に割り当てることができる。このため、マネージャノード201は、エンジンノード101での不要なデシリアライズの削減を考慮した負荷均衡化を行うことができる。
なお、本実施の形態で説明した処理プログラムは、予め用意されたプログラムをパーソナル・コンピュータやワークステーション等のコンピュータで実行することにより実現することができる。本処理プログラムは、ハードディスク、フレキシブルディスク、CD−ROM、MO、DVD等のコンピュータで読み取り可能な記録媒体に記録され、コンピュータによって記録媒体から読み出されることによって実行される。また、本処理プログラムは、インターネット等のネットワークを介して配布してもよい。
上述した実施の形態に関し、さらに以下の付記を開示する。
(付記1)コンピュータに、
データを受信し、
クエリの処理対象となるデータを選別するために参照される部分を特定する情報に基づいて、受信した前記データの所定の部分を復元し、
復元した前記データの所定の部分と前記処理対象となるデータを選別するための条件とに基づいて、受信した前記データを破棄するか否かを判断し、
破棄しないと判断した場合に、受信した前記データを復元する、
処理を実行させることを特徴とする処理プログラム。
データを受信し、
クエリの処理対象となるデータを選別するために参照される部分を特定する情報に基づいて、受信した前記データの所定の部分を復元し、
復元した前記データの所定の部分と前記処理対象となるデータを選別するための条件とに基づいて、受信した前記データを破棄するか否かを判断し、
破棄しないと判断した場合に、受信した前記データを復元する、
処理を実行させることを特徴とする処理プログラム。
(付記2)前記所定の部分を復元する処理は、
前記処理対象となるデータを選別するために参照される部分に含まれるパラメータが、所定の数以下であり、かつ、所定の型である場合に、受信した前記データの所定の部分を復元することを特徴とする付記1に記載の処理プログラム。
前記処理対象となるデータを選別するために参照される部分に含まれるパラメータが、所定の数以下であり、かつ、所定の型である場合に、受信した前記データの所定の部分を復元することを特徴とする付記1に記載の処理プログラム。
(付記3)前記所定の部分を復元する処理は、
前記処理対象となるデータを選別するために参照される部分を復元するコストが、前記処理対象となるデータを復元するコスト未満である場合に、受信した前記データの所定の部分を復元することを特徴とする付記1または2に記載の処理プログラム。
前記処理対象となるデータを選別するために参照される部分を復元するコストが、前記処理対象となるデータを復元するコスト未満である場合に、受信した前記データの所定の部分を復元することを特徴とする付記1または2に記載の処理プログラム。
(付記4)前記データを復元する処理は、
受信した前記データを破棄しないと判断し、かつ、前記クエリを実行した後に実行される他のクエリに参照される情報が前記データに含まれる場合は、当該データを復元しないことを特徴とする付記1〜3のいずれか一つに記載の処理プログラム。
受信した前記データを破棄しないと判断し、かつ、前記クエリを実行した後に実行される他のクエリに参照される情報が前記データに含まれる場合は、当該データを復元しないことを特徴とする付記1〜3のいずれか一つに記載の処理プログラム。
(付記5)前記コンピュータに、
前記データを受信した回数に対する、受信した前記データを破棄しないと判断した回数の割合を算出する処理を実行させ、
前記所定の部分を復元する処理は、
算出した前記割合が所定値以下である場合、受信した前記データの所定の部分を復元することを特徴とする付記1〜4のいずれか一つに記載の処理プログラム。
前記データを受信した回数に対する、受信した前記データを破棄しないと判断した回数の割合を算出する処理を実行させ、
前記所定の部分を復元する処理は、
算出した前記割合が所定値以下である場合、受信した前記データの所定の部分を復元することを特徴とする付記1〜4のいずれか一つに記載の処理プログラム。
(付記6)コンピュータが、
データを受信し、
クエリの処理対象となるデータを選別するために参照される部分を特定する情報に基づいて、受信した前記データの所定の部分を復元し、
復元した前記データの所定の部分と前記処理対象となるデータを選別するための条件とに基づいて、受信した前記データを破棄するか否かを判断し、
破棄しないと判断した場合に、受信した前記データを復元する、
処理を実行することを特徴とする処理方法。
データを受信し、
クエリの処理対象となるデータを選別するために参照される部分を特定する情報に基づいて、受信した前記データの所定の部分を復元し、
復元した前記データの所定の部分と前記処理対象となるデータを選別するための条件とに基づいて、受信した前記データを破棄するか否かを判断し、
破棄しないと判断した場合に、受信した前記データを復元する、
処理を実行することを特徴とする処理方法。
(付記7)データを受信したことに応じて、クエリの処理対象となるデータを選別するために参照される部分を特定する情報に基づいて、受信した前記データの所定の部分を復元し、復元した前記データの所定の部分と前記処理対象となるデータを選別するための条件とに基づいて、前記データを破棄するか否かを判断し、破棄しないと判断した場合に、前記データを復元する情報処理装置を有することを特徴とする処理システム。
(付記8)前記処理対象となるデータを選別するために参照される部分に含まれるパラメータが、所定の数以下であり、かつ、所定の型であるか否かを判定する制御装置をさらに有し、
前記情報処理装置は、
前記パラメータが、所定の数以下であり、かつ、所定の型であると前記制御装置が判定した場合に、前記データの所定の部分を復元することを特徴とする付記7に記載の処理システム。
前記情報処理装置は、
前記パラメータが、所定の数以下であり、かつ、所定の型であると前記制御装置が判定した場合に、前記データの所定の部分を復元することを特徴とする付記7に記載の処理システム。
(付記9)前記処理対象となるデータを選別するために参照される部分を復元するコストが、前記処理対象となるデータを復元するコスト未満であるか否かを判定する制御装置をさらに有し、
前記情報処理装置は、
前記処理対象となるデータを復元するコスト未満であると前記制御装置が判定した場合に、前記データの所定の部分を復元することを特徴とする付記7または8に記載の処理システム。
前記情報処理装置は、
前記処理対象となるデータを復元するコスト未満であると前記制御装置が判定した場合に、前記データの所定の部分を復元することを特徴とする付記7または8に記載の処理システム。
(付記10)前記クエリを実行した後に実行される他のクエリに参照される情報が前記データに含まれるか否かを判定する制御装置をさらに有し、
前記情報処理装置は、
前記データを破棄しないと判断し、かつ、前記他のクエリに参照される情報が前記データに含まれると前記制御装置が判定した場合は、当該データを復元しないことを特徴とする付記7〜9のいずれか一つに記載の処理システム。
前記情報処理装置は、
前記データを破棄しないと判断し、かつ、前記他のクエリに参照される情報が前記データに含まれると前記制御装置が判定した場合は、当該データを復元しないことを特徴とする付記7〜9のいずれか一つに記載の処理システム。
(付記11)前記情報処理装置が前記データを受信した回数に対する、前記情報処理装置が前記データを破棄しないと判断した回数の第1の割合が、第1の閾値以下であるか否かを判定する制御装置をさらに有し、
前記情報処理装置は、
前記第1の割合を算出し、前記第1の割合が前記第1の閾値以下であると前記制御装置が判定した場合に、前記データの所定の部分を復元することを特徴とする付記7〜10のいずれか一つに記載の処理システム。
前記情報処理装置は、
前記第1の割合を算出し、前記第1の割合が前記第1の閾値以下であると前記制御装置が判定した場合に、前記データの所定の部分を復元することを特徴とする付記7〜10のいずれか一つに記載の処理システム。
(付記12)前記情報処理装置は複数存在し、
前記情報処理装置は、
複数のデータから分割されたいずれかのデータ群に含まれるデータを受信したことに応じて、前記データ群に含まれるデータを受信した回数に対する、前記データ群に含まれるデータを破棄しないと判断した回数の第2の割合を算出し、
前記制御装置は、
複数の前記情報処理装置の各々が算出した前記第1の割合と前記第2の割合とに基づいて、複数の前記情報処理装置に割り当てる前記データ群を決定することを特徴とする付記11に記載の処理システム。
前記情報処理装置は、
複数のデータから分割されたいずれかのデータ群に含まれるデータを受信したことに応じて、前記データ群に含まれるデータを受信した回数に対する、前記データ群に含まれるデータを破棄しないと判断した回数の第2の割合を算出し、
前記制御装置は、
複数の前記情報処理装置の各々が算出した前記第1の割合と前記第2の割合とに基づいて、複数の前記情報処理装置に割り当てる前記データ群を決定することを特徴とする付記11に記載の処理システム。
(付記13)前記制御装置は、
前記第1の割合が前記第1の閾値以下となる情報処理装置に割り当てる前記データ群を、前記第2の割合が第2の閾値以下となるデータ群に決定することを特徴とする付記12に記載の処理システム。
前記第1の割合が前記第1の閾値以下となる情報処理装置に割り当てる前記データ群を、前記第2の割合が第2の閾値以下となるデータ群に決定することを特徴とする付記12に記載の処理システム。
(付記14)前記制御装置は、
前記第1の割合が前記第1の閾値より大きい情報処理装置に割り当てる前記データ群を、前記第2の割合が第3の閾値以上となるデータ群に決定することを特徴とする付記12または13に記載の処理システム。
前記第1の割合が前記第1の閾値より大きい情報処理装置に割り当てる前記データ群を、前記第2の割合が第3の閾値以上となるデータ群に決定することを特徴とする付記12または13に記載の処理システム。
101 エンジンノード
201 マネージャノード
202 コンパイラノード
501 受信部
502 復元部
503 選別部
504 処理部
505 変換部
506 送信部
801 受信部
802 管理部
803 通知部
901 構文解析部
902 復元コスト検証部
903 分配部
1001 制御部
201 マネージャノード
202 コンパイラノード
501 受信部
502 復元部
503 選別部
504 処理部
505 変換部
506 送信部
801 受信部
802 管理部
803 通知部
901 構文解析部
902 復元コスト検証部
903 分配部
1001 制御部
Claims (7)
- コンピュータに、
データを受信し、
クエリの処理対象となるデータを選別するために参照される部分を特定する情報に基づいて、受信した前記データの所定の部分を復元し、
復元した前記データの所定の部分と前記処理対象となるデータを選別するための条件とに基づいて、受信した前記データを破棄するか否かを判断し、
破棄しないと判断した場合に、受信した前記データを復元する、
処理を実行させることを特徴とする処理プログラム。 - 前記所定の部分を復元する処理は、
前記処理対象となるデータを選別するために参照される部分に含まれるパラメータが、所定の数以下であり、かつ、所定の型である場合に、受信した前記データの所定の部分を復元することを特徴とする請求項1に記載の処理プログラム。 - 前記所定の部分を復元する処理は、
前記処理対象となるデータを選別するために参照される部分を復元するコストが、前記処理対象となるデータを復元するコスト未満である場合に、受信した前記データの所定の部分を復元することを特徴とする請求項1または2に記載の処理プログラム。 - 前記データを復元する処理は、
受信した前記データを破棄しないと判断し、かつ、前記クエリを実行した後に実行される他のクエリに参照される情報が前記データに含まれる場合は、当該データを復元しないことを特徴とする請求項1〜3のいずれか一つに記載の処理プログラム。 - 前記コンピュータに、
前記データを受信した回数に対する、受信した前記データを破棄しないと判断した回数の割合を算出する処理を実行させ、
前記所定の部分を復元する処理は、
算出した前記割合が所定値以下である場合、受信した前記データの所定の部分を復元することを特徴とする請求項1〜4のいずれか一つに記載の処理プログラム。 - コンピュータが、
データを受信し、
クエリの処理対象となるデータを選別するために参照される部分を特定する情報に基づいて、受信した前記データの所定の部分を復元し、
復元した前記データの所定の部分と前記処理対象となるデータを選別するための条件とに基づいて、受信した前記データを破棄するか否かを判断し、
破棄しないと判断した場合に、受信した前記データを復元する、
処理を実行することを特徴とする処理方法。 - データを受信したことに応じて、クエリの処理対象となるデータを選別するために参照される部分を特定する情報に基づいて、受信した前記データの所定の部分を復元し、復元した前記データの所定の部分と前記処理対象となるデータを選別するための条件とに基づいて、前記データを破棄するか否かを判断し、破棄しないと判断した場合に、前記データを復元する情報処理装置を有することを特徴とする処理システム。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2013/070664 WO2015015574A1 (ja) | 2013-07-30 | 2013-07-30 | 処理プログラム、処理システムおよび処理方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2015015574A1 JPWO2015015574A1 (ja) | 2017-03-02 |
| JP6123897B2 true JP6123897B2 (ja) | 2017-05-10 |
Family
ID=52431155
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015529259A Expired - Fee Related JP6123897B2 (ja) | 2013-07-30 | 2013-07-30 | 処理プログラム、処理システムおよび処理方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US10467242B2 (ja) |
| EP (1) | EP3029581B1 (ja) |
| JP (1) | JP6123897B2 (ja) |
| WO (1) | WO2015015574A1 (ja) |
Families Citing this family (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12013895B2 (en) | 2016-09-26 | 2024-06-18 | Splunk Inc. | Processing data using containerized nodes in a containerized scalable environment |
| US11860940B1 (en) | 2016-09-26 | 2024-01-02 | Splunk Inc. | Identifying buckets for query execution using a catalog of buckets |
| US10956415B2 (en) | 2016-09-26 | 2021-03-23 | Splunk Inc. | Generating a subquery for an external data system using a configuration file |
| US10353965B2 (en) | 2016-09-26 | 2019-07-16 | Splunk Inc. | Data fabric service system architecture |
| US11604795B2 (en) | 2016-09-26 | 2023-03-14 | Splunk Inc. | Distributing partial results from an external data system between worker nodes |
| US11281706B2 (en) | 2016-09-26 | 2022-03-22 | Splunk Inc. | Multi-layer partition allocation for query execution |
| US12118009B2 (en) | 2017-07-31 | 2024-10-15 | Splunk Inc. | Supporting query languages through distributed execution of query engines |
| US11989194B2 (en) | 2017-07-31 | 2024-05-21 | Splunk Inc. | Addressing memory limits for partition tracking among worker nodes |
| US11921672B2 (en) | 2017-07-31 | 2024-03-05 | Splunk Inc. | Query execution at a remote heterogeneous data store of a data fabric service |
| US12248484B2 (en) | 2017-07-31 | 2025-03-11 | Splunk Inc. | Reassigning processing tasks to an external storage system |
| CN108683520B (zh) * | 2018-04-08 | 2021-05-25 | 烽火通信科技股份有限公司 | 一种流输出的过滤方法及系统 |
| US11030019B2 (en) * | 2019-04-09 | 2021-06-08 | International Business Machines Corporation | Deletion of events based on a plurality of factors in a connected car computing environment |
| CN110399415A (zh) * | 2019-07-23 | 2019-11-01 | 江苏鼎速网络科技有限公司 | 一种数据反序列化装置及计算终端 |
| US11494380B2 (en) | 2019-10-18 | 2022-11-08 | Splunk Inc. | Management of distributed computing framework components in a data fabric service system |
| US11922222B1 (en) | 2020-01-30 | 2024-03-05 | Splunk Inc. | Generating a modified component for a data intake and query system using an isolated execution environment image |
| CN111611251B (zh) * | 2020-04-24 | 2021-06-29 | 华智众创(北京)投资管理有限责任公司 | 一种数据处理系统 |
| US12072939B1 (en) | 2021-07-30 | 2024-08-27 | Splunk Inc. | Federated data enrichment objects |
| US12093272B1 (en) | 2022-04-29 | 2024-09-17 | Splunk Inc. | Retrieving data identifiers from queue for search of external data system |
| US12141137B1 (en) | 2022-06-10 | 2024-11-12 | Cisco Technology, Inc. | Query translation for an external data system |
| US12287790B2 (en) | 2023-01-31 | 2025-04-29 | Splunk Inc. | Runtime systems query coordinator |
| US12585638B2 (en) | 2023-07-17 | 2026-03-24 | Cisco Technology, Inc. | Query execution using a data processing scheme of a separate data processing system |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE69903711T2 (de) | 1998-02-26 | 2003-06-26 | Sun Microsystems, Inc. | Hinausgezögerte wiederherstellung von objekten und entfernte ladung für die mitteilung von ereignissen in einem verteilten system |
| US7555506B2 (en) * | 2005-04-05 | 2009-06-30 | Microsoft Corporation | Partial deserialization of complex type objects |
| JP5317017B2 (ja) * | 2009-06-26 | 2013-10-16 | 日本電気株式会社 | 複合イベント配信システム、複合イベント処理装置、複合イベント処理方法、及び複合イベント処理プログラム |
| US8772717B2 (en) * | 2009-08-10 | 2014-07-08 | Drs Rsta, Inc. | Radiation detector having a bandgap engineered absorber |
| WO2011158478A1 (ja) * | 2010-06-17 | 2011-12-22 | 日本電気株式会社 | データ処理システム及びデータ処理方法 |
| US20110314019A1 (en) * | 2010-06-18 | 2011-12-22 | Universidad Politecnica De Madrid | Parallel processing of continuous queries on data streams |
| KR101793683B1 (ko) * | 2010-07-27 | 2017-11-03 | 한화테크윈 주식회사 | 그래핀 제조 방법 |
| US20120254133A1 (en) * | 2011-03-28 | 2012-10-04 | C/O Pontis, Ltd. | Method for binary persistence in a system providing offers to subscribers |
| JP5862245B2 (ja) * | 2011-11-30 | 2016-02-16 | 富士通株式会社 | 配置装置、配置プログラムおよび配置方法 |
| US9177028B2 (en) * | 2012-04-30 | 2015-11-03 | International Business Machines Corporation | Deduplicating storage with enhanced frequent-block detection |
-
2013
- 2013-07-30 EP EP13890829.8A patent/EP3029581B1/en active Active
- 2013-07-30 JP JP2015529259A patent/JP6123897B2/ja not_active Expired - Fee Related
- 2013-07-30 WO PCT/JP2013/070664 patent/WO2015015574A1/ja not_active Ceased
-
2016
- 2016-01-26 US US15/006,518 patent/US10467242B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2015015574A1 (ja) | 2017-03-02 |
| WO2015015574A1 (ja) | 2015-02-05 |
| EP3029581A4 (en) | 2016-07-13 |
| EP3029581B1 (en) | 2019-10-09 |
| US20160140196A1 (en) | 2016-05-19 |
| US10467242B2 (en) | 2019-11-05 |
| EP3029581A1 (en) | 2016-06-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6123897B2 (ja) | 処理プログラム、処理システムおよび処理方法 | |
| TWI620075B (zh) | 用於雲端巨量資料運算架構之伺服器及其雲端運算資源最佳化方法 | |
| JP6825016B2 (ja) | 個人情報の非識別化方法および装置 | |
| US20180189350A1 (en) | Streaming data processing method, streaming data processing device and memory medium | |
| WO2023093689A1 (zh) | 一种计算图优化方法、装置及设备 | |
| CN106557307B (zh) | 业务数据的处理方法及处理系统 | |
| EP3772691B1 (en) | Database server device, server system and request processing method | |
| Kusum et al. | Efficient processing of large graphs via input reduction | |
| CN114416310B (zh) | 一种多处理器负载均衡方法、计算设备及存储介质 | |
| JP2016505956A (ja) | 最適化されたデータサブセット化のための方法、装置及びコンピュータ読み取り可能媒体 | |
| JP2016530584A (ja) | データ操作のための、メモリ及びストレージ空間の管理 | |
| WO2020158347A1 (ja) | 情報処理装置、方法およびプログラム | |
| CN113536040A (zh) | 信息查询方法、装置以及存储介质 | |
| CN111124382A (zh) | Java中的属性赋值方法、装置及服务器 | |
| CN108875317B (zh) | 软件克隆检测方法及装置、检测设备及存储介质 | |
| CN114945898B (zh) | 用于根据TensorFlow图构建编译器中间表示的方法和系统 | |
| Burgueño et al. | On the concurrent execution of model transformations with linda | |
| JP2017073093A (ja) | インデックス生成プログラム、インデックス生成装置、インデックス生成方法、検索プログラム、検索装置および検索方法 | |
| CN107766036A (zh) | 一种模块的构建方法、构建装置及终端设备 | |
| CN103530369A (zh) | 一种去重方法及系统 | |
| JP2016031567A (ja) | パーソナル情報匿名化装置 | |
| JP2024131765A (ja) | 開発支援装置、システム、方法、及び、プログラム | |
| CN106970791A (zh) | 一种线性时态逻辑规范的通用并行挖掘系统 | |
| WO2023221626A1 (zh) | 一种内存分配的方法和装置 | |
| CN104932982A (zh) | 一种消息访存的编译方法及相关装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170307 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170320 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6123897 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |