JP5751537B2 - 国際対応型日本語入力システム - Google Patents
国際対応型日本語入力システム Download PDFInfo
- Publication number
- JP5751537B2 JP5751537B2 JP2008266869A JP2008266869A JP5751537B2 JP 5751537 B2 JP5751537 B2 JP 5751537B2 JP 2008266869 A JP2008266869 A JP 2008266869A JP 2008266869 A JP2008266869 A JP 2008266869A JP 5751537 B2 JP5751537 B2 JP 5751537B2
- Authority
- JP
- Japan
- Prior art keywords
- input
- english
- output
- character string
- conversion
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images













Description
外国人から見ても(本発明は国際対応型であることから)、カタカナ語は、扱い憎く、嫌われている。本来の日本語ではないし、そうかといって、英語とは、かけ離れているからである
(1)新しい動作モードを追加する
本発明では、従来の日本語入力システムに相当する部分は、そのまま、従来と同じモードで実行し、新しく多言語入出力モード(MLモードとも呼ぶ)を追加する。新しい機能はすべてこのモード上で実行する。従来方式のシステムは生かし、それに新しい機能を追加するのは、二つの理由がある。ひとつは、日本人は、現在の入力方式に慣れているので、違う方式に変えるには抵抗があると思われる。もうひとつの理由は、従来式のシステムに新しい機能を追加する方式にしておけば、本発明は、現在使われているすべての方式の日本語入力システムに導入できるということである。本書の説明は、通常のコンピュータで多く使われる仮名漢字変換方式の日本語入力システムに沿って説明しているが、本発明は、すべての方式の日本語入力システムに導入できる。キーボードとボタン入力やタッチパネルの違いはあれ、携帯型コンピュータや携帯電話の日本語入力システムにも、本発明は応用できる。
(2)英語、カタカナ語、ローマ字の3入力方式にする
従来の日本語入力システムでは、仮名またはローマ字入力の仮名変換による日本語入力しかできない。現在、一部の、有料または無料の日本語入力システムでは、英語やカタカナ語で入力できる機能を持つものもあるが、その応用は不十分で、結局は、外来語であるカタカナ語とその他の仮名や漢字を有効に使い分けできていない。そのため、日本語入力システムにおいて、英語やカタカナ語を使って入力するという考えは広まっていない。本発明では、英語入力、カタカナ語入力に加え、ローマ字でも入力できる3入力方式を採用している。ローマ字入力とは、「kiiro」で入力すれば、“黄色”の英語「yellow」を出力できることである。逆に変換もできるので、外国人でも、「yellow」で入力すれば「kiiro」が出力できる。これで、日本語と英語のやりとりが楽になる。
(3)日本語、英語を含む、多言語出力を可能にする
前述のように、入力形態は、従来式の仮名入力や記号での入力のほかに、英語、カタカナ語、ローマ字の3入力が可能であるが、そのために、専用のデータベースを内蔵させている。このデータベースに、日本語、英語のほかに、9カ国語の用語も登録し、多言語出力ができるようにする。入力自体は、日本語(カタカナ語とローマ字)と英語だけであるが、これらも基に、データベースを検索し、登録されている用語を抽出することにより、多言語出力を可能にしている。従って、キーボードは、標準の日本語入力用キーボードがそのまま使える。
現在のように、何が何でも英語の風潮があるから、カタカナ語が増え続けるのではないかとも考える。例えば、中国語では、外国人の名前や地名などは別にして、外来語は、すべて漢字化しているわけである。中国語は、日本人にとって、同じ漢字を扱っている言語なので親しみやすいはずなのだが、発音を聞くとまったく分からない。中国語の発音を身近に聞くことができれば、もっと親しみやすい言語になるはずである。韓国語にも、漢字はあるし、ハングルにも独特の長所がある。また、西洋系言語でも、ラテン語系言語であるスペイン語、ポルトガル語やイタリア語は非常に似ている。発音もどちらかというと、日本人向きである。一つの言語を習得すれば、2〜3ヶ国語を習得するのは、それほど難しくないことがわかる。
(4)音声出力用変換部と音声出力部で、常時、外国語の発音が聞ける
日本人でも、子供の頃から、LとRの音に聞きなれていれば、その違いが分かるようになる。本発明では、音声出力用変換部と音声出力部を内蔵し、キーボードやペン型入力装置からの入力だけでなく、クリップボードやキャプチャー入力した文字列でも直ちに英語(またはその他の言語)で発音できるようにしてある。
英語とカタカナ語の音の違いを常に意識していれば、カナカナ語は必要以上に使えないのである。カタカナ語の語源である外国語(主として英語)の音を簡単に聞けるようになっていないから、カタカナ語は、英語の仮面を被った仮想の言葉として、使われているものと考える。必要限度内で使うならともかく、カタカナ語は乱用されている。カタカナ語を必要以上に使うのは止めるべきである。
(5)クリップボード入力/キャプチャー入力の採用
コンピュータのクリップボードに置かれた文字列データを読み込むことや、キャプチャー入力で文字列データを取り込めるようにする。キャプチャー入力というのは、利用者自身が、キーボードなどの入力装置を使って入力するのではなく、画面上に表示されている各種応用ソフトの文字列を、特殊な通信手段で、その文字列データを取り込む装置である。日本語は、単語の区切り位置を判別するのが難しいが、単語と単語の間にスペースを置いた形で配置しておけば、カタカナ語だけでなく、漢字も読み込める。これは、いわゆる、漢字直接入力方式となる。また、自動取込みもできるので、マウス操作やタッチパネル操作だけで、画面上の文字列や文章を入力することも可能になる。
(1)国際対応型日本語入力システム
従来の日本語入力システムは、日本語を速く、正確に入力することが目的であるが、本発明では、それ以外に、カタカナ語の節度ある使用、日本語と外国語の発音の違いを実感させる、語学学習用にも応用できる、また、単語レベルでは外国人でも扱えることを目的としている。
(2)利用者
本発明の日本語入力システムを使う人または操作する人のことである。
(3)多言語入出力機能実行部と多言語入出力モード(MLモードとも呼ぶ)
本発明の日本語入力システム(図3)は、従来式の日本語入力システム(図2、仮名モードで動作する)に、多言語入出力機能実行部(図1)を追加し、この機能を実行する多言語入出力モード(MLモード)を追加する方式である。新しく追加された機能は、全て、このモード上で動作する。日本語JISキーボード用の標準設定では、Ctrlキーを瞬時的に押すことでMLモードをON/OFFできる。本発明では、英語、カタカナ語およびローマ字での3入力方式が可能で、出力は、英語、日本語を含む11ヶ国語の用語を出力できる。標準設定でのMLモードの動作は次のようになる。
(a)英語またはローマ字を入力する場合、このモードに切り替えると、画面上の入力 位置に黄色のカーソルが現れる。文字を入力すると、背景色が黄色で、下側に点線 が付いた被変換文字列となる。
(b)仮名入力は、従来式の仮名モードで入力し、被変換文字列として表示されている 状態で、このモードに切り替える。モードが切り替わると、被変換文字列が平仮名 の場合は、片仮名に変換され、同時に、文字列の背景色は黄色になる。
(c)変換キーを押し、文字列変換すると、黄色の背景色が消え、変換が成功すると、 被変換文字列が変換文字列に変わり、下側の点線が実線になる。変換が失敗すると 、被変換文字列の中央に二重の取消線が引かれる。
(d)被変換文字列、変換文字列に拘わらず、確定キーを押すと、その文字列が確定し 、確定文字列となる。従って、英数字や記号も入力できる。
(e)確定前で変換文字列が表示されている状態で、変換キーを再度押すと変換候補表 示窓を開くことができる。希望する変換候補を選択し、確定キーを押すと、文字列 が確定する。
(f)被変換文字列または変換文字列が表示されている状態で、左右の矢印キーを押す と、随時、その文字列の英語またはその他の言語の音声を聞くことができる。
変換候補表示窓が開いている場合も、同様に、選択した用語の音声を聞ける。
(g)クリップボード入力やキャプチャー入力を使えば、マウス操作(またはタッチパ ネル操作)だけで、画面上の文字列を取り込むこともできる。自動取込みの場合は 、他の動作と区別するため、被変換文字列の背景色を深紅色にする。
(4)英語1と英語2
米国式英語と英国式英語があり、初期設定では、米国式英語を標準とし、これを英語1とし、英国式英語を英語2とする。そのため、英語という場合、英語1を意味することもある。初期設定を変更して、英語1と英語2を逆にすることもできる。
(5)カタカナ語1とカタカナ語2
カタカナ語は、外国語(主として英語)を語源とする片仮名表記の日本語のことである。技術系用語として使われる長音符なしの短縮型カタカナ語(例えば、プリンタ)を標準とし、これをカタカナ語1とし、雑誌、新聞などで使う長音符付きのカタカナ語(例えば、プリンター)をカタカナ語2とする。そのため、カタカナ語という場合、カタカナ語1を意味することもある。初期設定を変更して、カタカナ語1とカタカナ語2を逆に設定することもできる。
(6)ローマ字
英語の綴りに近いヘボン式ローマ字を使う。分類は日本語であるが、アルファベットで入力されるので、英文字入力でもある。便宜上「ローマ字」と単数で表現するが、実際は、ローマ字の文字列のことである。ローマ字仮名変換表JIS X 4063:2000の表1と表2の内容とは関係ない。本発明では、ローマ字を万能的に使うのではなく、“l”と“r”、“s”と“th”、“b”と“v”など、カタカナ語にすると区別ができなくなるような組み合わせは使わないようにする。例えば、英語の「lamp」を「ranpu」で表現するローマ字表現は使わない。使えない組み合わせのローマ字表現は、カタカナ語のみで使うか、漢字化するか、または、英語そのものを使う。
(7)(文字列)変換または(文字列)変換する
本発明では、変換とは、英語入力を日本語(カタカナ語およびローマ字)または、その他の言語に置き換え、日本語入力(カタカナ語およびローマ字)を英語または、その他の言語に置き換えることを言う。ただし、これは完全一致の場合の変換であり、前方一致入力での変換や、変換候補表示窓を開き、そこから変換候補を選ぶ方法では、あらゆる組み合わせの変換が可能になる。例えば、英語から英語(“telev”から“television”)や、カタカナ語から日本語訳(“ウインター”から“冬”)に変換することもできる。なお、本発明は、従来式の日本語入力システムの部分も含むので、例えば、仮名を漢字に変換する意味で使う場合もある。
(8)被変換文字列と変換文字列
本発明では、前項(7)の説明にあるように、入力された文字列を変換して、それを出力する。入力文字列は、変換される文字列なので、これを被変換文字列とも呼ぶ。本発明の標準設定では、被変換文字列は、文字の下側に点線が引かれた状態(さらに、MLモードでは背景色が黄色)で表示され、変換された変換文字列では、点線が実線になり、利用者が最終的にそれを出力として確定すると、下線のない通常の表示状態になる。
(9)入力または入力する
利用者が、キーボードやペン型入力装置等から文字を入力することである。コンピュータのクリップボードからの文字列データの読み込みやキャプチャー入力で応用ソフト画面上の文字列を取り込むことも入力である。概念的な説明のときは、普通の入力と同じ意味であるが、具体的は動作説明のときは、入力された文字列は、英語版のコンピュータのように、直接入力されるのではなく、日本語入力システムでは、入力文字列は、被変換文字列となり、また文字列変換されても、確定されなければその変換は成立しないので、結局、入力自体もなかったということになる。
(10)出力または出力する
本発明は日本語入力システムであり、広い意味ではすべての文字列は入力として扱われるのだが、本発明は、英語を含む数ヶ国語の言語も扱っており、これらは、入力した文字列を変換して得るものである。従って、本発明では、出力は、文字列変換した出力という意味として使っている。また、本発明には音声出力機能もあるので、音声出力の意味としても使う。
(11)出力対象となる応用ソフトまたは表示装置
本発明の日本語入力システムで得られた変換出力を渡す対象となる応用ソフトや表示装置のことで、ワードプロセッサや携帯電話などである。
(12)検索または検索する
入力した文字列は、内蔵するデータベースに登録されている用語を利用して文字列変換し、それを出力とする。文字列変換するためには、入力した文字列の一部または全部が、データベースに登録されている用語と一致するかどうか調べなければならない。その動作が検索である。完全一致、前方一致および後方一致検索ができる。標準の場合は、前方一致検索で始まり、完全一致したら完全一致に自動的に切り替わる完全一致優先の前方一致検索を行う。後方一致の場合は、ワイルドカード(*)を付けて「*ter」のように入力する。
(13)検索対象項目
入力した文字列が、データベースの登録用語と一致するかどうか検索するときに、その検索の対象となるデータベースの項目である。その項目内の用語を意味することもある。入力文字列が英文字の場合、英語(英語1または英語2)とローマ字の項目が検索対象項目となる。入力文字列がカタカナ語の場合、検索対象項目は、カタカナ語1またはカタカナ語2となる。
(14)出力対象項目
検索対象項目に登録された用語が、入力文字列と一致(完全一致または部分一致)した場合、その一致した用語とデータベース上で同じ行にあり、出力として抽出される項目のことである。その項目内の用語を意味することもある。入力文字列が英語の場合、カタカナ語(カタカナ語1またはカタカナ語2)または、その他の言語が出力対象項目となる。入力文字列が、日本語(カタカナ語またはローマ字)の場合、英語(英語1または英語2)または、その他の言語が出力対象項目となる。ローマ字は登録されていないものもあるので、補助的な項目である。なお、最終出力は、出力対象項目以外からも選べる。
(15)完全一致変換候補表示窓と部分一致変換候補表示窓
文字列を入力し、変換キーを押し、被変換文字列が変換文字列に変換された状態で、再度、変換キーを押すと表示されるのが、変換候補表示窓である。英文字(英語またはローマ字)を入力し、その文字列がデータベースの検索対象項目の用語と完全一致した場合、完全一致変換候補表示窓(図5左側)が表示される。完全一致以外で文字列が一致した場合に表示されるものを、部分一致変換候補表示窓(図5右側および図4の左側[標準]と図4の右側[日英併記])という。カタカナ語の場合、完全一致しても、複数の候補が存在する可能性があるので、部分一致変換候補表示窓が表示される。
(16)登録用語または用語
広い意味では、用語は、ここで説明しているすべての言葉を含むが、本書で使う、狭義の意味の用語は、データベースに登録されている単語または語句のことである。その総称を意味する場合と、個々の単語または語句のことを指す場合がある。また、データベースのセル内がセミコロンで二つに区切られている場合は、その両方を指す場合と、検索が一致した方のみを指す場合がある。
従来式の日本語入力システムと組み合わせた形になるので、まず、日本語入力システムで最も多く使われている仮名漢字変換式日本語入力システムの構成を簡単に説明する。このシステムが使用されている通常のコンピュータには、ステータスバーとか言語バーと呼ばれるソフトウェアで作成されたスイッチ類を備えた帯状の表示部がコンピュータ画面上の右下部分に表示されている。この部分に平仮名入力、片仮名入力などの入力モードの切替えスイッチや各種のツール類の起動用アイコン類が備わっている。本発明のシステムもこの部分は同じように使う。従来式の入力モードは、一般的には、平仮名、片仮名、全角英数、半角片仮名および半角英数モードがあるが、本発明では、これに、多言語入出力モード(MLモード)を追加する。また、この部分に新たに、出力言語選択スイッチも追加する。この出力言語選択スイッチの構成は、下記のようになっている。このスイッチの(1)日英併記は、部分一致変換候補表示窓が、3列構成で、(12)標準は、それが2列構成の表示形式である。これらは、使用言語が日英のみで動作する場合の表示形式で、その他の言語の場合は、3列構成のみとなる。ただし、完全一致変換候補表示窓の場合は、すべて1列構成となる。(11)多言語の場合は、完全一致変換候補窓と同じ1列構成の表示形式となる。
出力言語選択スイッチで選択できる項目
(1)日英併記(2)韓国語(3)中国語(4)フランス語(5)ドイツ語(6)イタリア語(7)スペイン語(8)ポルトガル語(9)ロシア語(10)アラビア語(11)多言語(12)標準
(1)漢字キー
国際対応型日本語入力システムのON/OFFキーとして使う。OFFになると、日本語入力システムは動作しないので、キーボードからは英文字のみ入力ができる。
(2)多言語入出力モード(MLモード)キーまたはCtrlキー
多言語入出力モード(MLモード)のON/OFFキーとして使う。通常は左側のCtrlキーを使う。このキーを操作するには、このキーを0.3秒以内で短く押すこと。長く押し続けると動作しない。これは、このキーの通常用途(長押し)との衝突を避けるためである。また、このキーには変換操作後の確定キーの役目もさせているので、モードの切替えが素早くできる。MLモード時の標準設定では、文字入力位置及び入力された文字列の背景色を黄色に表示させ、モード切替えを利用者が実感できるようにする。入力モード切替えが、素早く、かつ、実感できるのが、本発明の特長である。
(3)変換キー
“変換”キーまたは“スペース”キーを使う。被変換文字列が表示されている状態でこのキーを押すと、変換が始まり、変換が成功すると、被変換文字列が変換文字列に変わる。変換文字列が表示されている状態で、再度押すと、変換候補表示窓が開く。変換候補表示窓が開いている状態で、さらに押すと、画面を上に移動させる役目をする。
(4)確定キー
変換出力の確定キーで、“Enter”キーを使う。被変換文字列が表示されているとき、または文字列変換後、変換候補表示窓を開かない状態で、このキー押すと、画面に表示されている文字列が確定出力となる。完全一致変換候補表示窓が開いている状態で押すと、そのとき選択されている用語が確定出力となり、部分一致変換候補表示窓が開いている状態で押すと、選択されている変換候補の出力対象項目の用語が確定出力となる。
(5)無変換出力キー
文字列変換後の無変換出力用確定キーで、“無変換”キーを使う。部分一致変換候補表示窓が開いている状態で、このキーを押すと、選択されている変換候補の検索対象項目の用語が確定出力となる。
(6)日本語訳出力キー
文字列変換後の日本語訳用確定キーで、“スペース”キーまたは“変換”キーを使う。変換キーに使用するキーと同じであるが、変換キーとして使わない方のキーが自動的にこのキーになる。部分一致変換候補表示窓が開いている状態で、このキーを押すと、選択されている変換候補の日本語訳が確定出力となる。
(7)スペース入力キー
半角スペース(空白)を入力するキーで、“スペース”キー、または“変換”キーを使う。変換キーとして使わない方のキーが自動的にこのキーになる。“無変換”キーでも半角スペースを入力できる。また、変換キーとスペース入力キーを間違って押すこともあるので、仮に、スペース入力キーの代わりに変換キーを押しても、登録されている用語にスペースがある場合は、検索時にこれを自動的に検出して、変換キーを押しても変換はせずに、通常の半角スペース入力用キーとして働くようにしている。
(8)左矢印キー
英語、カタカナ語またはローマ字が、被変換文字列として表示されている状態で、このキーを押すと、音声出力用変換部と音声出力部が動作し、その文字列の英語1、またはその他の言語の音声を出力する。被変換文字列は、音声に対応した文字列に変わる。
変換文字列として表示されている状態、または、変換候補が変換候補表示窓に表示されている状熊で、このキーを押すと、選択された候補の、画面上の左側の文字列の音声を出力する。また、ひとつのセルに二つ用語が登録されている場合は、左側(音声が出た側)が選択されることになる。初期値は左側なので、何もしないと、左側(最初の方)が選択される。
(9)右矢印キー
英語、カタカナ語またはローマ字が、被変換文字列として表示されている状態で、このキーを押すと、音声出力用変換部と音声出力部が動作し、その文字列の英語2、またはその他の言語の音声を出力する。被変換文字列の表示も、音声に対応した文字列に変わる。
変換文字列として表示されている状態、または、変換候補が変換候補表示窓に表示されている状態で、このキーを押すと、選択された候補の、画面上の右側の文字列の音声を出力する。また、ひとつのセルに二つ用語が登録されている場合は、右側(音声が出た側)が選択されることになる。
(10)上矢印キー
変換候補表示窓が開いて状態で押すと、選択されている変換候補行を上に移動(行番号を減らす)し、それにつれて、表示されている変換候補全体を下に移動させる役目をする。
(11)下矢印キー
変換候補表示窓が開いて状態で押すと、選択されている変換候補行を下に移動(行番号を増やす)し、それにつれて、表示されている変換候補全体を上に移動させる役目をする。
(12)Tabキー
出力言語選択スイッチで「多言語」を選択した場合、入力文字列が検索対象項目の用語と完全一致したときのみ、文字列変換処理を行う。英文字(英語、ローマ字)の場合は、完全一致する用語は、一つしかないが、カタカナ語の場合、用語が複数ある場合もある。その場合、用語ごとに変換候補表示窓を開く必要がある。Tabキーは、次の用語に進めるキーとして使う。
(13)F2キー
クリップボードからの文字列データを周期的に読込む操作を開始するキーとして使う。入力するには、他の応用ソフトの画面上の希望する文字列を、ドラッグまたはダブルクリックする。入力文字列の取り込みは、確認取込みと自動取込みの二通りある。
(14)F3キー
キャプチャー入力部操作用キー。キャプチャー入力するためには、専用のソフトウェアが必要なので、そのソフトウェアの操作開始用に使う。このソフトウェアは、本発明の付属ソフトウェアである。キャプチャー入力は、現時点では、クリップボード経由で入力されるので、上記F2と一緒に使わないと動作しない。将来的には、単独で動作できるようにする。
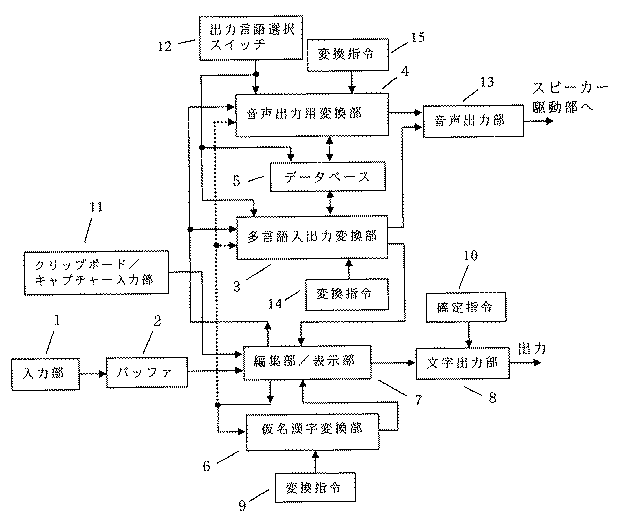
(イ)図3に示す国際対応型日本語入力システムは、図1の多言語入出力機能実行部(MLモードで動作)と、図2に示す従来式の仮名漢字変換式(仮名モードで動作)の日本語入力機能を持つ仮名漢字変換部(6)を組み合わせたものである。MLモードで仮名入力する場合は、図3の点線で示すように、仮名モードで入力した文字列を、内部で、多言語入出力機能実行部に渡し、その文字列が平仮名であれば片仮名に変換することになる。なお、ここでは、多言語入出力機能実行部のうち、多言語入出力変換部(3)部分のみが作用をする。
(ロ)まず、図3の仮名漢字変換部(6)の日本語入力システムの説明をする。このシステムには、英字キーを使うローマ字入力方式と仮名キーを使う仮名入力方式がある。ローマ字入力方式は、JIS X 4063:2000の表1および表2のローマ字仮名変換表またはそれに準拠する変換表に基づきローマ字入力した文字列を仮名に変換し、さらに仮名漢字変換システムで、その一部または全部を漢字に変換し漢字仮名交じり文として、出力対象となる応用ソフトまたは表示装置に渡す。仮名入力方式の場合は、仮名キーで入力した文字列をそのまま仮名漢字変換システムで変換し漢字仮名交じり文とし、出力対象となる応用ソフトまたは表示装置に渡すものである。
(ハ)多言語入出力モード(MLモード)では、入力形態が、英語、カタカナ語およびローマ字の3方式で可能となる。カタカナ語は、仮名モードで入力した後、MLモードに切り替える。その文字列が平仮名であれば片仮名に変換する。この3方式により、日本語と英語間での相互利用が促進される。次に、それぞれの入力形態別に動作を説明する。検索方法も、完全一致、前方一致および後方一致があるので、それらを組み合わせた場合の動作を説明する。図8のデータベースを使用した場合の動作である。図3と連動した動作説明は、段落番号(0010)と段落番号(0011)で説明する。
(1)英語入力
(a)完全一致入力の場合
例えば、図7の例1のように、MLモードで「winter」と入力し、それが被変換文字列として表示されている状態で、変換キーを押せば、被変換文字列「winter」は、出力対象項目の「ウインター;ウィンター」の変換文字列に置き換わり、確定キーを押すと、最初の用語「ウインター」が確定し、出力対象となる応用ソフトや表示装置に「ウインター」を出力する。2番目の用語「ウィンター」を選択するには、確定キーを押す前に、右矢印キーを押す。
変換後、確定キーを押す前に、変換キーを再度押すと、完全一致変換候補表示窓が開き、出力対象項目「ウインター;ウィンター」、検索対象項目「winter」、ローマ字「fuyu」、および日本語訳「冬」が表示され、利用者は、そのなかから希望する出力を選択できる。
(b)前方一致入力の場合
例えば、図7の例3のように、MLモードで「wint」と入力し、それが被変換文字列として表示されている状態で、変換キーを押せば、被変換文字列「wint」は、最初に検出される用語“winter”の検索対象項目「winter」の変換文字列に置き換わり、確定キーを押すと「winter」が確定し、出力対象となる応用ソフトや表示装置に「winter」を出力する。
変換後、確定キーを押す前に、変換キーを再度押すと、部分一致変換候補表示窓が開き、変換候補行ごとに、検索対象項目および日本語訳が表示される。希望する変換候補行を選択し、確定キー、無変換出力キーまたは日本語訳出力キーを押すことにより、利用者は、そのなかから希望する出力を選択できる。
(c)後方一致入力の場合
例えば、図7の例5のように、MLモードで「*ter」と入力し、それが被変換文字列として表示されている状態で、変換キーを押せば、被変換文字列「*ter」は、最初に検出される用語“computer”の検索対象項目「computer」の変換文字列に置き換わり、確定キーを押すと「computer」が確定し、出力対象となる応用ソフトや表示装置に「computer」を出力する。
変換後、確定キーを押す前に、変換キーを再度押すと、部分一致変換候補表示窓が開き、変換候補行ごとに、検索対象項目および日本語訳が表示される。希望する変換候補行を選択し、確定キー、無変換出力キーまたは日本語訳出力キーを押すことにより、利用者は、そのなかから希望する出力を選択できる。
(2)カタカナ語入力
(a)完全一致入力の場合
例えば、図7の例6−1と例6−2のように、従来式の仮名モードで「ういんたー」と入力し、それが被変換文字列として表示されている状態で、MLモードキーを押せば、被変換文字列が「ウインター」になり、続けて、変換キーを押せば、被変換文字列「ウインター」は、最初に検出される“ウインター”の検索対象項目「ウインター」に置き換わり(実際には表示は変化しないように見える)、確定キーを押すと、「ウインター」が確定し、出力対象となる応用ソフトや表示装置に「ウインター」を出力する。
変換後、確定キーを押す前に、変換キーを再度押すと、部分一致変換候補表示窓が開き、検索対象項目および日本語訳が表示される。カタカナ語の場合、完全一致しても、複数の候補が表示される場合もある。その場合は、変換候補行を選択し、確定キー、無変換出力キーまたは日本語訳出力キーを押すことにより、利用者は、そのなかから希望する出力を選択できる。例6−1は、部分一致変換候補表示窓が、2列構成の標準の場合で、例6−2は、3列構成の日英併記の場合の例である。日英併記の方が、表示はわかりやすいが、表示列が多くなると繁雑になるので、表示が2列構成のものを標準にしてある。
(b)前方一致入力の場合
例えば、図7の例7のように、従来式の仮名モードで「ういん」と入力し、それが被変換文字列として表示されている状態で、MLモードキーを押せば、被変換文字列が「ウイン」になり、続けて、変換キーを押せば、被変換文字列「ウイン」は、最初に検出される用語“ウインター”の検索対象項目「ウインター」の変換文字列に置き換わり、確定キーを押すと「ウインター」が確定し、出力対象となる応用ソフトや表示装置に「ウインター」を出力する。
変換後、確定キーを押す前に、変換キーを再度押すと、部分一致変換候補表示窓が開き、変換候補行ごとに、検索対象項目および日本語訳が表示される。希望する変換候補行を選択し、確定キー、無変換出力キーまたは日本語訳出力キーを押すことにより、利用者は、そのなかから希望する出力を選択できる。
(c)後方一致入力の場合
例えば、図7の例8のように、従来式の仮名モードで「*た」と入力し、それが被変換文字列として表示されている状態で、MLモードキーを押せば、被変換文字列が「*タ」になり、続けて、変換キーを押せば、被変換文字列「*タ」は、最初に検出される用語“コンピュータ”の検索対象項目「コンピュータ」の変換文字列に置き換わり、確定キーを押すと「コンピュータ」が確定し、出力対象となる応用ソフトや表示装置に「コンピュータ」を出力する。
変換後、確定キーを押す前に、変換キーを再度押すと、部分一致変換候補表示窓が開き、変換候補行ごとに、検索対象項目および日本語訳が表示される。希望する変換候補行を選択し、確定キー、無変換出力キーまたは日本語訳出力キーを押すことにより、利用者は、そのなかから希望する出力を選択できる。
(3)ローマ字入力
(a)完全一致入力の場合
図7の例9のように、MLモードで「jitensha」と入力すれば、英文字入力で完全一致することになるので、変換キーを押せば、画面表示は、直ちに出力対象項目の「bicycle」に置き換わり、確定キーを押すと「bicycle」が確定し、出力対象となる応用ソフトや表示装置に「bicycle」を出力する。
変換後、確定キーを押す前に、変換キーを再度押すと、完全一致変換候補表示窓が開き、出力対象項目「bicycle」、検索対象項目「jitensha」、カタカナ語「バイシクル」および日本語訳「自転車」が表示され、利用者は、そのなかから希望する出力を選択できる。ローマ字入力の場合は、完全一致入力の場合のみ動作する。
(イ)図3は、図1の多言語入出力機能実行部と、図2の従来の仮名漢字変換方式の日本語入力システムを組み合わせた国際対応型日本語入力システムのブロック図である。ここで示す仮名漢字変換部(6)は、従来の仮名漢字変換システムを概念図として示したものであり、本発明では、あくまで、従来の仮名漢字変換システムはそのまま使用し、それに多言語入出力機能実行部を付加する構成になっている。このシステムを使い、コンピュータ上で動作する日本語ワードプロセッサに日本語を入力する際の動作説明をする。本発明のソフトウェアとコンピュータ内部のソフトウェアおよび応用プログラムであるワードプロセッサのソフトウェアの三つのソフトウェアが、コンピュータ内の通信機能で情報のやりとりすることになる。具体的な動作は、使用するコンピュータにより異なるので、これらの通信方法の動作については省略する。なお、この発明で使うソフトウェア言語は、C言語を含む各種言語で設計可能であるが、ソフトウェア言語で使用する多くの命令や関数は、通常のコンピュータの日本語用オペレーティングシステムが用意している命令や関数のみで設計可能である。特殊の関数を使う必要はない。なお、本発明は多言語入出力を扱うので、使用するコンピュータは、ユニコードを使うものが望ましい。説明文中( )内の番号は、図3の各ブロックの番号である。
(ロ)図3の入力部(1)、バッファ(2)、編集部/表示部(7)および文字出力部(8)は、多言語入出力機能実行部(MLモードで動作)と仮名漢字変換部(仮名モードで動作)の共有である。英数字および記号は、どちらのモードでも扱える。MLモードまたは仮名モードで英数字または記号を入力し、確定キーを押せばよい。このときの動作は、下記に示すそれぞれもモードの該当箇所の動作と同じである。
(ハ)仮名モードでは、英字キーによるローマ字仮名変換したものを入力するか、仮名キーで直接入力して得られた文字列は入力部(1)で必要に応じ片仮名または平仮名に変換され、その仮名の文字列は、バッファ(2)に文節単位で保存され、バッファ(2)から、通信機能を介し、編集部/表示部(7)に送り、コンピュータ内部ソフトウェアの文字列を管理する編集用関数に文字列データを渡し、その文字列は、ワードプロセッサのカーソル位置に表示される。利用者が変換キーを押すと、それが変換指令(9)となり、仮名漢字変換部(6)は、編集用関数の文字列を読み込み、その文字列と内部の辞書を比較しながら、変換候補を抽出し、内部の変換出力用バッファに一時記憶させておく。仮名漢字変換では、殆どの場合、複数の候補が抽出される。変換が終わると、その変換出力を、編集部/表示部(7)に渡す。編集部/表示部(7)は、変換出力の最初の候補を、通信機能を介し、編集用関数に渡し、画面上の表示部にそれを表示させ、同時に、次に変換キーを押したときに全変換候補のデータが、コンピュータ内部ソフトウェアの変換候補表示関数に渡せる状態にしておく。これで、変換が正常に終了したことになる。その状態で、利用者が確定キーを押すと、それが確定指定(10)となり、表示されている最初の変換候補は確定され、通信機能を介し、ワードプロセッサに渡される。確定キーを押さずに、変換キーを押すと、変換候補データが前述の変換候補表示関数に渡り、すぐに変換候補表示窓が開き、変換候補データを表示する。利用者は、希望する変換候補を選び確定キーを押すと、前記と同様に、変換文字列がワードプロセッサに渡される。
(ニ)次に、利用者がMLモードキーを押すと、本システムは、MLモードになり、キーボードやペン型入力装置等から英文字(英語またはローマ字)が入力できるようになる。英文字の綴りを入力すると、変換を始めるまで、文字列として、バッファ(2)に保存される。英文字の文字列であるバッファ(2)の出力は、各文字が入力されるたびに、通信機能を介し、編集部/出力部(7)に送られ、前述の編集用関数に渡される。その文字列は、ワードプロセッサのカーソルの位置に表示される。利用者が変換キーを押すと、それが変換指令(14)となり、多言語入出力変換部(3)は、編集用関数の文字列を読み込み、その文字列がデータベース(5)の検索対象項目の列に登録されているか検索する。英語の場合、文字列が見つかると、その出力対象項目のカタカナ語か、あるいは、出力言語選択スイッチ(12)で、その他の言語が選択されていれば、その用語を抽出し、変換出力用バッファに一時記憶しておく。その際に、検索対象項目の用語、日本語訳、登録されていればローマ字の用語も変換出力データとして変換出力用バッファに記憶しておく。これは、変換候補表示窓を開いたときに必要なデータとなる。
(ホ)ローマ字入力の場合、文字列が見つかると、その出力対象項目の英語、または、その他の言語が選択されていれば、その言語の用語を抽出し、変換出力用バッファに一時記憶しておく。同様に、その際に、検索対象項目の用語、日本語訳、登録されていればローマ字の用語も変換出力データとして変換出力用バッファに記憶しておく。
(ヘ)カタカナ語入力の場合は、一旦、仮名モードで入力し、それからMLモードに切り替える。この時点で、平仮名文字列の場合、片仮名文字列に変換される。文字列が見つかると、その検索対象項目のカタカナ語、出力対象項目の英語(またはその他の言語が選択されていれば、その言語)の用語を抽出し、変換出力用バッファに一時記憶しておく。同様に、その際に、日本語訳も変換出力データとして変換出力用バッファに記憶しておく。
(ト)変換が終わると、その変換出力を、編集部/表示部(7)に渡し、通信機能を介し、前述の編集用関数に送り、変換出力の最初の候補が、画面上の被変換文字列と置き換わるようにし、かつ、次に変換キーを押したときに変換候補データが、前述の変換候補表示関数に渡せる状態にしておく。これで変換が正常に終了したことになる。利用者が確定キーを押すと、表示されている用語が確定され、通信機能を介して、ワードプロセッサに渡される。一方、確定キーを押す前に変換キーを再度押すと、変換出力データが変換候補表示関数に渡る。直後に変換候補表示窓が開き、変換候補表示関数の文字列データが表示される。
(イ)図7の例2で示すように、英語「winter」を入力して、コンピュータ上で動作する日本語ワードプロセッサに、日本語の“冬”を意味するフランス語の「hiver」を出力する際の動作を説明する。図8のデータベースを使った場合の例である。
(ロ)まず、図3の出力言語選択スイッチ(12)をフランス語に設定する。この時に、内部プログラムを自動的に起動させ、データベース(5)の8列目の位置(図8の列番号(8))に、フランス語の登録用語が挿入されるように設計してある。入力部(1)は、利用者がキーボード(ペン型入力装置等でも可能)から入力した英文字を順次受け取り、入力された順に、バッファ(2)に送付し、保存する。バッファ(2)から、通信機能を介し、編集部/表示部(7)に送り、コンピュータ内部ソフトウェアの文字列を管理する編集用関数に文字列データを渡す。変換は、単語または語句(即ち、用語のこと)ごとに処理するので、バッファ(2)および編集用関数には、入力された英文字の用語ごとに保存されることになる。この例の場合、「winter」が保存される。編集用関数の文字列は、ワードプロセッサのカーソルの位置に表示される。この状態で、利用者が確定キーを押すと、それが確定指令(10)となり、表示されている英語の文字列「winter」が確定し、通信機能を介し、ワードプロセッサに渡される。一方、利用者が変換キーを押すと、それが変換指令(14)となり、多言語入出力変換部(3)は、編集用関数の文字列「winter」を読み込み、それが、データベース(5)の検索対象項目である英語1(米国式英語)の列(図8の列番号(1))に登録されているかどうか検索する。(実際には、コンピュータは、英語入力なのかローマ字入力なのか判断できないので、動作は、データベース(5)の1行ごとに、図8の列番号(1)から(8)までの登録用語を、検索用のバッファに一時記憶させ、(1)の列の英語と(3)の列のローマ字が入力文字列と一致するかどうか調べる。)検索は、完全一致優先の前方一致検索を標準とする。詳細は、後述する。この検索は、前方一致検索で始まり、一致した文字列の出力データを、順次、変換出力用のバッファに一時記憶させていく。しかし、「winter」との完全一致文字列が見つかると、それまで記憶していた出力データを捨て、前方一致検索を完全一致検索に切り替え、データベース(5)上の完全一致した検索対象項目と同じ行にある出力対象項目の列(図8の列番号(8))のフランス語の用語「hiver」を抽出する。完全一致した場合は、図5の左側の完全一致変換候補表示窓に表示する文字列データが必要なので、出力対象項目のフランス語「hiver」を抽出すると同時に、検索対象項目の「winter」、ローマ字の「fuyu」および日本語訳の「冬」も出力として抽出し、変換出力バッファに記憶させる(実際には、これらの用語は、前述の検索用バッファに一時記憶させてあるので、このバッファから、これらの用語を抽出する。)変換が終わると、変換出力バッファに記憶されている変換出力は編集部/表示部(7)に渡る。ここで、変換出力の最初の用語「hiver」を、通信機能を介し、前述の編集用関数に渡し、表示されている「winter」を「hiver」に置き換え、同時に、次に変換キーを押したときに変換候補のデータが、コンピュータ内部ソフトウェアの変換候補表示関数に渡せる状態にしておく。これで、変換が正常に終了したことになる。検索文字列が見つからない場合、画面上の被変換文字列に二重取消線が表示され、入力した文字列が見つからないことを利用者に知らせる。利用者は、キーボードの“Backspace”キーを使って入力した英語の文字列を修正し、再度、変換をする。変換が終わり、確定キーを押すと、編集用関数の文字列「hiver」は、通信機能を介し、ワードプロセッサに渡される。英語入力で、かつ、完全一致した文字列が見つかった場合は、変換出力は一つしかなく、かつ、編集用関数の出力文字列は既に画面上に表示されているので、確定キーを押して変換を終了させてもよいが、変換キーを再度押して、変換候補表示窓を開くと次のことができる。
(1)出力データ自体は1種類であるが、変換出力を、データベースの出力対象項目のフランス語「hiver」、検索対象項目の英語「winter」、ローマ字「fuyu」または日本語訳「冬」のいずれかから選ぶことができる。
(2)「hiver」および「winter」の発音を聞くことができる。標準では、日本語の「冬」の発音は出ない。
では、変換キーを再度押して、変換候補表示窓を開いてみる。そうすると、変換出力の文字列データが、前述の変換候補表示関数に渡され、その出力は、変換候補表示窓に表示される。図5の左側の表が完全一致変換候補表示窓である。完全一致した場合は、図7の例2に示すように、用語が縦方法に並ぶ一列表示形式である。1行目が出力対象項目のフランス語「hiver」、2行目が検索対象項目の英語「winter」、3行目がローマ字「fuyu」、4行目が日本語訳「冬」である。選択された項目は、背景色等を変えて選択されたことが分かるようになっている。選択する行を下側に移動させる(選択行番号を大きくする)には、下矢印キーまたは変換キーを押す。上側に移動させる(選択行番号を小さくする)には、上矢印キーを押す。希望する出力項目が選択されている状態で確定キーを押すと、通信機能を介し、その出力がワードプロセッサに渡り、この入力の変換処理が終わる。項目の選択は、矢印キーだけでなく、行番号をキーボードで打つか、またはマウスで希望する行をクリックして選択することもできる。
(ハ)次の例として、図7の例4のように、「winter」の代わりに「wint」を入力し、前方一致検索による変換を行うと、図8のデータベースの場合、最初に前方一致する「winter」に関する用語データが抽出され、変換出力用バッファに一時記憶される。次に前方一致する「winter sports」以降も順次、関連する用語データをバッファに一時記憶される。変換が終わると、変換出力は、表示部/出力部(7)に渡される。ここで、通信機能を介し、コンピュータ内部ソフトウェアの編集用関数に送り、画面上に表示されている「wint」を変換出力バッファの最初に記憶されている検索対象項目の英語「winter」に置換える。前述の完全一致の場合は、この時点で、表示されている文字列が、出力対象項目のフランス語に置き換わっていたが、前方一致の場合は、変換候補が複数あるので、文字列は、一旦、検索対象項目の英語に変換される。同時に、次に変換キーを押したときに変換候補のデータが、コンピュータ内部ソフトウェアの変換候補表示関数に渡せる状態にしておく。これで、変換は正常に終了である。変換候補を表示するために変換キーを再度押すと、通信機能を介し、変換出力が順次、前述の変換候補表示関数に渡され、その出力は変換候補表示窓に表示される。図5の右側の表が、部分一致変換候補表示窓の表示例である。その表示窓の左側の列が、検索対象項目、中央が出力対象項目、右側の列が、日本語訳である。ひとつの変換候補表示窓には、通常のコンピュータの場合、9行まで文字列を表示できる。変換候補が9を超える場合、表示画面を複数ページにし、上下の矢印キーで縦方向に順次画面を移動して、すべてが表示できるようにする。希望する変換候補文字列が選択されている状態で確定キーを押すと、表示窓が消え、通信機能を介し、選択された出力対象項目のフランス語の用語が、前述の編集用関数の出力になり、カーソル位置に表示されている英語の文字列を、そのフランス語の文字列に置き換え、同時に、ワードプロセッサにその文字列出力を渡し、本システムの変換処理が終わる。変換キーの代わりに、無変換出力キーを押すと、出力対象項目のフランス語でなく、検索対象項目の英語を出力させることができる。また、日本語訳出力キーを押すと、日本語訳を出力させることができる。このときの入出力関係を図7の表に示す。完全一致変換候補表示窓の場合は、それぞれの行の文字列が単独で選べるので、無変換出力キーや日本語出力キーを使う必要はない。
(ニ)変換候補表示窓が表示されている状態で、左右の矢印キーを押すと、音声出力部(14)を経由して、その文字列の音声を聞くことができる。左右のキーは、表示窓の表の位置関係に対応している。図5の右側に示す、部分一致変換候補表示窓が表示され、1行目が選択されている場合、左矢印キーを押すと英語の「winter」の音声を出し、右矢印キーを押すとフランス語「hiver」の音声を出す。図4の部分一致変換候補表示窓のように、日本語と英語だけの設定の場合は、左矢印キーを押すと、英語1の音声、右矢印キーを押すと、英語2の音声を聞くことができる。
図8、図9のデータベースの表の上部に示している列番号の順に説明する。下記の内容は、現時点で最適と思われる内容である。細かい内容については、使いやすいように改訂されることはあり得る。
(1)、(2)および(3)列目
1列目、2列目および3列目は、入力文字列が英文字(ローマ字も含む)の場合は、これらの列は検索対象項目となる。一方、入力文字列が日本語(カタカナ語またはローマ字)で、使用言語が日英のみの場合は、1列目または2列目が出力対象項目になる。1列目が、標準英語として使う英語1で、2列目が英語2であるが、逆に設定もできる。次に、それぞれの列ごとに説明する。
(1)列目
米国式英語の用語を登録する。標準では、英語1として設定され、通常の英語として使われる。入力された文字列が、英文字の場合、検索対象項目となり、入力文字列が日本語(カタカナ語またはローマ字)で、使用言語が日英のみの場合は、出力対象項目となる。
(2)列目
英国式英語の用語を登録する。標準では、英語2として設定される。1列目と同じ内容の場合は、空白のままとする。
(3)列目
この列には、ローマ字表記の日本語を登録する。この項目は、カタカナ語の補助的な意味合い持つ。例えば、「comma」のような場合、カタカナ語の「コンマ」または「カンマ」が一般的に使われているので、わざわざ、ローマ字の「konma」や「kanma」を使う必要はない。カタカナ語が適当でない場合は、漢字化したものを使うか、英語そのものを使う。しかし、日本人には必要なくても、外国人には便利な場合がある。「ウインター」はカタカナ語として定着しているが、日本語を学ぶ外国人には、「fuyu」というローマ字があれば便利である。これは「冬」という漢字があるからである。
ローマ字を登録しない場合、空白のままにしておく。入力された文字列が英文字の場合、1列目、2列目と同様に、この列は検索対象項目となる。また、入力文字列が英語で、かつ、完全一致の用語が見つかった場合、出力対象項目と一緒にローマ字も出力用語として抽出される。(図5の左側の表の3行目の「fuyu」と同じ位置に表示される。)
(4)および(5)列目
4列目と5列目は、カタカナ語を登録する。入力文字列が、カタカナ語の場合は、これらの列が検索対象項目となる。入力文字列が英語の場合で、使用言語が日英のみの場合は、これらの列は出力対象項目となる。4列目が、標準として使うカタカナ語1で、5列目がカタカナ語2であるが、逆に設定もできる。次に、それぞれの列ごとに説明する。
(4)列目
技術系の用語として使われる長音符なしの短縮型カタカナ語を登録する。標準では、カタカナ語1として設定され、入力文字列がカタカナ語の場合、この列が検索対象項目となる。入力文字列が英語の場合で、使用言語が日英のみの場合は、この列は出力対象項目となる。
(5)列目
学校での教育用や、雑誌、新聞などで使う長音符付きのカタカナ語を登録する。4列目と同じ内容の場合は、空白のままとする。標準では、カタカナ語2として設定される。
(6)列目
何らかの理由で、4列目、5列目のカタカナ語が本来の英語表現とは異なる場合に、その正式英語を登録する。通常、カタカナ語は外国語(主として英語)をそのまま取り入れているので、その語句の綴りに沿って、それを日本式に表現しているが、何らかの理由で、英語とカタカナ語が対応していないものがある。そのまま英語にすると、いわゆる、和製英語になるので、その場合に、この列に正式英語を登録する。その場合、(1)列目と(2)列目は空白となる。
(7)列目
この列は、英語の日本語訳である。カタカナ語だけでは、英語の本来の意味から外れることがあるので、英語本来の意味を漢字仮名交じり文で登録し、外来語の意味を常に確認できるようにする。ただし、英語を基準にしているので、英語以外の言語からみると、多少意味が違うこともあり得る。句読点を含み、最大12文字以内に限定する。長いと読みづらくなるためである。
(8)列目以降
8列目は、英語以外の言語の用語を登録する。図3の出力言語選択スイッチ(12)で選ばれた言語の用語が、8列目に自動的に登録される。なお、出力言語を「多言語」にした場合、すべての言語の用語が必要になるので、図9のように、データベースの(8)〜(16)列目にすべての言語の用語を登録する。実際には、(1)〜(8)列構成のデータベースと、(1)〜(16)列構成のデータベースの2種類を使い分けている。
図8、図9のデータベースは説明用の構成例であり、実際には、必要な用語をすべて登録する。現在、実際に使うデータベースには、6千語程度のカタカナ語を登録している。これらは、新聞、雑誌などから拾い出し登録したものである。登録語数は多い方が入力するには便利ではあるが、“l”と“r”、“s”と“th”、“b”と“v”など、カタカナ語にすると区別ができなくなるような組み合わせのものは避けるべきであり、今後、登録用語の取捨選択も必要となる。例えば、カタカナ語の「ランプ」は、昔は、英語の「lamp」の意味だけであったが、現在は、「lamp」と「ramp」の両方の意味で使われている。これは、中学生向けの国語辞典にも載っているが、このように、“ラ”の音を“l”と“r”の両方で表す表現は、カタカナ語では、原則的に避けるべきである。日本では、「ランプ」は「lamp」の意味で使われることが少なくなったからであろうか。英語の人名や地名であれば仕方ないが、漢字表現化できるものは漢字化すべきである。このデータベースでは、各カタカナ語に対して、日本語訳が付いているので、漢字化の参考にしてほしい。漢字化されているものでも、最近では、わざわざカタカナ語を使う場合も少なくない。漢字が自然に口に出なくなった用語もある。この日本語入力システムで変換候補窓を開けば、すべてのカタカナ語の漢字表現が出るので、漢字化見直しの参考にしてほしい。
(1)データベースの2列目、6列目は、それぞれ、1列目と5列目と内容が違う用語のみ登録する。
(2)データベースの一つのセルに、「television;TV」のように、二つの単語をセミコロンで区切って登録できる。区切り記号を、セミコロンにしているので、「no−hit,no−run」のように、登録用語にカンマを含ませることができる。
(3)登録できる用語は、一つの単語だけでなく、「compact disk」のように、二つ以上の単語で一つの用語とすることもできる。そのため、半角スペース入力用のキーも用意してある。
(4)カタカナ語の場合、例えば、「ウインター」と「ウィンター」を、両方登録しておくと、どちらで入力しても動作する。現在、両方とも、ほぼ同じぐらい使われている。しかし、本システムでは、英語からカタカナ語に変換する場合は、右矢印キーで選択しない限り、前の方の「ウインター」が選択される。そのため、「ウインター」が標準ということになる。このシステムを使えば、カタカナ表現がどちらかに固定されるので、カタカナ語の揺らぎが少なくなる。
(5)英語の大文字、小文字は区別して登録する。そのため、都市名や人名は、「New York」や「Edison」のように頭文字を大文字で登録する。しかし、クリップボードからの入力やキャプチャー入力の場合、文字の種類やスタイルが違うものが混じっていて、文章の初めの大文字なのか、固有名詞の大文字なのかコンピュータが判別するのは難しい。そのため、登録用語は、大文字と小文字の区別があっても、検索するときに、区別をしないようにする。大文字化したもの同士を比較すれば、大文字と小文字の区別をしない検索ができる。
(イ)本発明では、データベースに登録されている用語の検索方式として、完全一致優先の前方一致検索を標準としている。なお、ワイルドカード(*)記号を使った部分一致検索もできるようにしてある。例えば、「*ター」や「*ter」で検索すると、後方一致検索ができる。
(ロ)完全一致優先の前方一致検索は、日本語と英語の両方の検索を同時に行うために考えた検索方法である。日本語の検索は、仮名漢字変換の検索のように、全文一致で検索するが、英語では、前方一致検索は、完全一致検索と同様に重要な検索手段である。英語とカタカナ語を同時に検索するには、この検索方式が便利である。完全一致とは、二つ以上の文字列が、その文字列の長さ、および内容が全て一致する場合のことであり、前方一致とは、二つ以上の文字列の最初の何文字かが一致することである。本発明では、入力形態が、英語とカタカナ語の場合は、完全一致優先の前方一致検索を適用するが、ローマ字入力の場合は、完全一致検索のみで、前方一致検索は適用しない。ローマ字は、英文字ではあるが、日本語であり、日本語は、前方一致検索には適さないからである。
(ハ)完全一致した場合の処理法は、入力文字列の検索対象となるデータベースの用語登録方法と関係するので、その説明をする。本発明では、英語の場合、用語は常に一つしかないように登録してある。もちろん、英語でも同じ単語で意味の違うものもある。例えば、「close」は、動詞と形容詞で意味および発音が違うが、close[v]、close[a]のように、その単語の後ろに括弧を付け加え、動詞の略号の[v]や形容詞の略号の[a]で区別化して登録してある。また、同じ品詞で意味が違うものがあれば、Maya[1]、maya[2]のように番号で区別し、これらを区別化し、それぞれ、唯一の用語としてデータベースに登録してある。そして検索用プログラミングもそれに合わせた設計にしてある。理由は、このシステムは、辞書ではなく、入力システムなので、操作速度を速くする必要があり、検索して抽出される数はなるべく少なく、一つであるのが理想的だからである。一つであれば、検索用語が見つかると直ちに文字列変換できるが、二つ以上あると、一旦、変換候補表示窓を開いて、それから、希望する変換候補を選ばなければならない。日本語の文章の漢字変換では、変換候補が多くあったとしても、最も適する変換候補は通常一つである。しかし、英語の文字列変換の場合は、どれが最適かは、そのときの状況により違うので、最適な候補をとりあえず表示するというわけにはいかない。
(ニ)一方、日本語(カタカナ語)の場合は、同じカタカナ語でも別の意味を持つものが多い。例えば、「バス」と言っても、乗合自動車の「バス」もあれば、浴槽の「バス」もあり、低音の「バス」、淡水魚の「バス」もあるので、カタカナ語の場合は、完全一致する用語が見つかっても、それが唯一の用語とは見なさないようにしてある。英語、カタカナ語およびローマ字で処理が異なるので、それぞれ別々に説明する。
(1)英語入力の場合
英語で入力し、日本語(カタカナ語とローマ字)またはその他の言語で出力するときの検索方法を説明する。この場合は、完全一致優先の前方一致検索で用語の検索を行う。検索が始まると、入力文字列とデータベースの検索対象項目の用語が一致するかどうか、前方一致方式で検索を開始し、前方一致した用語データを、順次、内部の変換出力バッファに一時記憶させていく。一方、前方一致検索と同時に、完全一致検索も並行して行い、次のように処理する。
(a)前方一致する用語のみ見つかった場合は、最後まで検索し、見つかった全ての用語の検索対象項目、出力対象項目、日本語訳およびローマ字が登録されていれば、ローマ字も抽出する。
(b)完全一致した英語が見つかると、その時点で、一時記憶してある前方一致用語データは捨て、完全一致検索に切り替える。
(c)同時に、英語の場合、完全一致した用語は、データベースに登録されている唯一の用語なので、完全一致した英語の出力対象項目、検索対象項目、日本語訳も必ず抽出し、ローマ字の用語が登録されていれば、その用語も抽出し、検索を終了する。
(2)カタカナ語入力の場合
カタカナ語で入力し、英語(またはその他の言語)を出力するときの検索方法を説明する。この場合も、完全一致優先の前方一致検索で用語の検索を行う。前方一致検索で検索を開始し、前方一致した用語データは、順次、変換出力バッファに一時記憶させていく。一方、前方一致検索と同時に、完全一致検索も並行して行い、次のように処理する。
(a)前方一致する用語のみ見つかった場合は、最後まで検索し、見つかった全ての用語の検索対象項目、出力対象項目、日本語訳を抽出する。
(b)完全一致するものが見つかると、その時点で、一時記憶してある前方一致用語データは捨て、完全一致検索に切り替える。
(c)カタカナ語の場合、完全一致しても、検索は最後まで続け、見つかった完全一致の全ての用語の検索対象項目、出力対象項目、日本語訳を抽出する。
(3)ローマ字入力の場合
ローマ字入力の場合は、完全一致優先の前方一致検索は使わず、完全一致検索のみである。完全一致するものが見つかると、その用語の出力対象項目、検索対象項目、日本語訳を抽出する。英文字なので、完全一致するものは、ひとつだけである。
図3の音声出力用変換部(4)と音声出力部(13)を組み合わせることにより、入力された文字列が、英語、カタカナ語またはローマ字で、その文字列がデータベースに登録されている場合は、左矢印キーを押すと、その文字列の英語1の音声出力を出す。右矢印キーを押すと、英語2の音声出力を出す。図3の出力言語選択スイッチ(12)で英語以外の言語を選んだ場合は、左右の矢印キーを押すと、対応する言語の音声を出力する。なお、多言語入出力変換部(3)でも、文字列変換以降は、文字列変換候補の発音を出せるので、文字列が入力されてから確定される寸前まで、常時、音声が出せることになる。人名や地名で、データベースに登録されていないものは、音は出せないが、必要に応じて合成音声ソフトウェアを準備し、すべての音を出せるようにする。音声出力用変換部(4)の仕様は次のとおりである。
(a)文字入力された状態で、左矢印キーを押すと、データベースに登録されている用語であれば、英語1の音声を出す。英語以外であれば、その言語の音声を出す。
(b)文字入力された状態で、右矢印キーを押すと、データベースに登録されている用語であれば、英語2の音声を出す。英語以外であれば、その言語の音声を出す。
(c)音声を出力すると同時に、被変換文字列は、選択された言語の用語に変換される。
(d)入力文字列が、データベースの検索対象項目の登録用語と完全一致した場合のみ動作する。前方一致などの部分一致では動作しない。
(e)キーボードやペン型入力装置からの英語入力は、大文字、小文字の区別をする。
(f)クリップボード入力と入力キャプチャー入力の場合は、大文字、小文字の区別はしない。また、これらの入力の場合は、現時点では、英語以外の外国語は選択できない。必要性があれば、他の言語も選択できるようにする。
(g)キャプチャー入力の場合は、マウスカーソルによる指定範囲があいまいになることもあるので、単語だけでなく、複数語が入力されることも考えられる。そのため、最初の単語が登録用語と一致したら、音声を出すようにしている。この場合も、現時点では、英語以外の外国語は選択できない。必要性があれば、他の言語も選択できるようにする。
(h)カタカナ語のように、一致する用語が複数ある場合や、データベースの一つのセルに二つ用語が登録されているものもあるので、複数の用語の音声が選ばれることもある。複数ある場合は、矢印キーを押すごとに、次の用語に切り替えて音声を出す。
英語、カタカナ語およびローマ字入力の場合に分けて説明をする。( )内の番号は、図3のブロック番号である。
(1)英語入力の場合
ここでは、英語「computer」を入力して、その音声を出す動作を説明する。まず、MLモードに切り替える。画面上に黄色のカーソルが現れる。入力部(1)は、利用者がキーボード(ペン型入力装置等でも可能)から入力した英語を順次受け取り、入力された順に、バッファ(2)に渡す。バッファ(2)は、その文字列を編集部/表示部(7)に送り、通信機能を介し、コンピュータ内部ソフトウェアの文字列を管理する編集用関数に文字列データを送付する。変換は、単語または語句(即ち、用語)ごとに処理するので、バッファ(2)および編集用関数には、入力された英文字の用語ごとに保存されることになる。この例の場合、「computer」になる。
ここからが音声出力用変換部(4)の動作となる。左矢印キーを押すと、音声出力用変換部(4)は編集用関数の文字列「computer」を読み込み、それが、データベース(5)の検索対象項目である英語1(米国式)の列(図8の列番号(1))に登録されているかどうか検索する。(実際には、コンピュータは、英語入力なのかローマ字入力なのか判断できないので、動作は、データベース(5)の1行ごとに、図8の列番号(1)から(8)までの用語を、検索用のバッファに一時記憶させながら、(1)の列の英語が入力文字列と一致するかどうか調べる。)検索は、完全一致検索のみである。一致したものがあると、英語入力の場合は、完全一致すると、それが唯一の用語とみなすことができるので、検索は終了し、使用言語が日英のみの場合は、その一致した英語の文字列出力を音声出力部に渡し、出力言語選択スイッチ(12)の設定が、その他の言語であれば、列番号(8)の用語を渡す。日英以外の言語が設定されている場合、表示も変えるので、通信機能を介し、コンピュータ内部ソフトウェアの編集用関数の文字列も「computer」に対応する言語の用語に変換し、出力対象となる応用ソフトまたは表示装置の画面上に表示されている用語も変える。
(2)カタカナ語入力の場合
ここでは、「ニューヨーク」と入力して、その音声を出す動作を説明する。従来部の日本語入力モードは、平仮名モードとする。
仮名モードで、「にゅーよーく」と入力する。この操作で、編集用関数には、「にゅーよーく」が保存されていることになる。MLモードに切り替える。被変換文字列「にゅーよーく」は、平仮名からか片仮名に変換され、「ニューヨーク」に変わり、同時に、文字列の背景色は黄色に変わる。
ここからが音声出力用変換部(4)の動作となる。左矢印キーを押すと、音声出力用変換部(4)は編集用関数の文字列「ニューヨーク」を読み込み、それが、データベース(5)の検索対象項目であるカタカナ語(短縮型)の列(図8の列番号(4))に登録されているかどうか検索する。動作は、データベース(5)の1行ごとに、列番号(1)から(8)までの用語を、検索用のバッファに一時記憶させながら、(4)の列のカタカナ語が入力文字列と一致するかどうか調べる。検索は、完全一致検索のみである。完全一致する用語が見つかると、使用言語が日英のみであれば、「ニューヨーク」の出力対象項目である英語(米国式)の「New York」を抽出するが、出力言語選択スイッチ(12)の設定が、その他の言語であれば、列番号(8)の用語を抽出し、順次、変換出力バッファに記憶させていく。実際には、「ニューヨーク」は都市名であり、登録されている用語は一つしかないのだが、カタカナ語は、完全一致しても最後まで検索することになっている。検索はデータベースの最後の行の検索が終わると終了する。日英以外の言語が設定されている場合、表示も変えるので、通信機能を介し、前述の編集用関数の文字列も「ニューヨーク」に対応する言語の用語に変換し、出力対象となる応用ソフトまたは表示装置の画面上に表示されている用語も変える。
(3)ローマ字入力の場合
ここでは、ローマ字「jitensha」を入力して、その音声を出す動作を説明する。
まず、MLモードに切り替える。黄色のカーソルが現れる。入力部(1)は、利用者がキーボード(手書き入力等でも可能)から入力した英文字を順次受け取り、入力された順に、バッファ(2)に渡す。バッファ(2)は、その文字列を編集部/表示部(7)に送り、通信機能を介し、コンピュータ側で文字列を管理する編集用関数に文字列データを送付する。変換は、単語または語句(用語)ごとに処理するので、バッファ(2)および編集用関数には、入力された英文字の用語ごとに保存されることになる。この例の場合、「jitensha」になる。
ここからが音声出力用変換部の動作となる。左矢印キーを押すと、音声出力用変換部(4)は編集用関数の文字列「jitensha」を読み込み、それが、データベース(5)の検索対象項目であるローマ字の列(図8の列番号(2))に登録されているかどうか検索する。(実際には、コンピュータは、英語入力なのかローマ字入力なのか判断できないので、動作は、データベース(5)の1行ごとに、図8の列番号(1)から(8)までの用語を、検索用のバッファに一時記憶させながら、(2)の列の英文字が入力文字列と一致するかどうか調べる。)検索は、完全一致検索のみである。ローマ字入力の場合は、完全一致すると、それが唯一の用語とみなすことができるので、出力言語選択スイッチ(12)の設定により、使用言語が日英のみであれば、その出力対象項目である英語(米国式)の列の英語「bicycle」を抽出し、その他の言語であれば、列番号(8)の用語を抽出し、その文字列を音声出力部に渡す。同時に、ローマ字の場合は、表示も「bicycle」に変えるので、通信機能を介し、コンピュータ側の編集用関数の出力文字列も「bicycle」にし、出力対象となる応用ソフトまたは表示装置の画面上に表示されている「jitensha」を「bicycle」に変える。
(1)概要
夲発明は、発音を語学学習の目的に使うので、基本的には、ネイティブスピーカーが発音したものをディジタル録音しておき、それを再生するのが原則である。人名や地名などで、普通の辞書に載っていない用語の場合もあるので、必要に応じて、図3の音声出力部(13)には、音声合成用ソフトウェアを内蔵させ、合成音で発音できるようにする。音声出力は、コンピュータのスピーカー用駆動部を通して、内蔵または外置きのスピーカーを鳴らす。次に音源について説明をする。
(2)音源について
まず、発音が必要な用語のディジタル音源(WAVやMP3等のファイル)をコンピュータの記憶装置に保存しておく。各音源のファイル名は、データベースに登録されている用語の名前と同じにしておく。ファイル名は、番号やコード名を使ってもよいが、番号を間違えると、別の音になってしまうので、間違いを防ぐためにも、用語名をファイル名として使うようにする。また、英語用の音源はともかく、他の外国語の用語の音源を全部準備するのは手間と費用もかかる。利用者自身がファイルを準備できるようなシステムにしておけば、製作者側の製造費の負担も減り製品も安くできる。日本語版のコンピュータでは、ファイル名として、日本語と英語が使えるが、日本語と英語を一緒に使うと管理上複雑になるので、日本語(カタカナ語)も含み、韓国語、中国語、ロシア語、アラビア語の場合、それに対応する英語の用語名で登録する。その他の西欧の言語はラテン文字なので、その
本発明の日本語入力システムは、従来式の日本語入力システムに相当する部分はそのままで、新しく多言語入出力モード(MLモード)を追加する方式である。このモード切替えが瞬時にできること及び切替わったモードが直観的に把握できることが重要である。本発明では、次に説明するようにモード切替えを瞬時的に、かつ、直観的に把握できるように切り替える。
(1)モード切替え動作
モード切替えは、Ctrlキーを瞬時的に押すことでMLモードをON/OFFできるようにする。また、標準設定では、背景色を黄色にすることで、MLモードに入ったことを実感できるようにする。さらに、文字列変換後であれば、確定キーを押さなくても、モードを切り替えれば、自動的に確定動作を実行するようにしてある。MLモードに切り替わると、次のようになる。
(a)英語またはローマ字入力の場合、画面上の文字入力する位置に黄色のカーソルを表示し、以降、入力する文字列は黄色の背景色で表示される。
(b)仮名入力モードで入力された平仮名が、被変換文字列として表示されている状態で、MLモードに切り替えると、まず、平仮名が片仮名に変換され、文字列の背景色全体が黄色になる。
具体的な操作例は次のとおりである。
(2)モード切替えの具体例
コンピュータ上で動作する日本語ワードプロセッサに、「私はコンピュータを使った」を入力する場合の説明をする。従来方式の仮名漢字変換部の設定は、ローマ字入力方式で、入力モードは平仮名入力モード、出力言語スイッチの設定は、標準(英語)とする。まず、初期状態は、仮名漢字変換部で設定した、ローマ字入力方式、平仮名入力モードで始まる。最初の文節「私は」の部分にはカタカナ語がないので、従来どおり「watashiha」
(1)概要
図3のクリップボード/キャプチャー入力部(11)を通し、任意の応用ソフトの画面上の文字列データを、コンピュータのクリップボードを経由して周期的に読み込むことができる。クリップボードとは、コンピュータ上で、簡易的にデータを保存しておくメモリ領域のことで、キャプチャー入力というのは、利用者自身が、直接、キーボードやペン型入力装置等から入力しなくても、マウスのカーソルを、画面上に表示されている文字列の上、または近くに置くだけで、特殊な通信手段で、そのデータを取り込む入力手法であり、それを実行する応用ソフトでもある。この応用ソフトは、本発明の日本語入力システムの付属ソフトウェアである。このシステムの仕様は次のとおりである。
(a)内蔵タイマー(5秒周期)と連動させて周期的に文字列データを読み込む。
(b)入力文字列が、英語、カタカナ語またはローマ字であれば、読み込むごとに英語の音声を出す。ただし、前回と同じ用語であれば音は出さない。
(c)キャプチャー入力の場合、入力文字列が複数の単語で構成されていれば、最初の単語が用語であるものとし、英語の音を出す。
(d)同じ文字列が続く場合、50秒でタイマーを停止させる。
(e)自動取込みに設定すれば、マウス操作だけで文字列や文章を入力することができる。
(f)画面がタッチパネルに対応するシステムであれば、画面にタッチするだけで文字列を入力できる。
(g)マウスのドラッグ操作は、手間は掛かるが、安定した動作が得られる。文章のように長い文字列を選択するのに適している。単語ごとの選択も可能。
(h)マウスのダブルクリック操作は、単語ごとに選択するのに適している。英語のように、前後にスペースがある場合は、問題なく選択できる。カタカナ語の場合、隣の単語を一緒に選択することもある。その場合は、ドラッグ操作にすること。
(i)キャプチャー入力による、マウスカーソルでの選択は、英語であれば単語の選択はできるが、これも、安定して選択できるかどうかは、応用ソフトによる。現状では、あまり安定した動作は期待できない。しかし、マウスカーソルを置くだけで選択できるので、操作には魅力がある。今後、タッチパネル画面が普及すれば、タッチパネル操作に置換わるのかもしれない。
(2)動作説明
(a)クリップボード入力
クリップボード入力の操作開始キーは、標準では、キーボードのF2キーに割り当てている、MLモード時に、F2キーを押すと5秒周期のタイマーが始動し、クリップボードのテキストデータを、タイマーの周期ごとに、入力として読み込むことができる。入力するには、マウスの機能の一つであるドラッグ(マウスボタンを押したままでマウスの位置を動かす)またはダブルクリックで、画面上に表示されている文字列を選択する。その後は、内部タイマーの周期で、本発明のソフトウェアが自動的に、選択された文字列を読み込むコピー機能(Ctrl+C等)を実行し、その文字列を読み込み、被変換文字列として画面上に表示する。入力文字列が、英語、カタカナ語またはローマ字入力であれば、直ちに音声出力用変換部と音声出力部が動作し、英語の音声出力を出す。英語と、カタカナ語の場合は、表示はそのままであるが、ローマ字入力の場合は、音声出力すると同時に、英語に変換される。機能的には、英語以外の言語に変換することも可能であるが、複雑になりすぎるので、言語は英語だけにしてある。
(b)キャプチャー入力
標準では、キーボードのF3キーを押すと、キャプチャー入力の応用ソフトを起動できるようにしている。キャプチャー入力の場合は、マウスでドラッグ操作をしなくても、画面上の任意の文字列の上またはすぐ近くにマウスのカーソルを置くだけで、その文字列を読み込める。キャプチャー入力で得られた文字列データは、コンピュータの共用メモリ経由で、コンピュータの本体から本システムに直接読み込むことも可能ではあるが、干渉が起きやすいので、現在は、クリップボード経由で間接的にデータを送付する形にしてある。そのため、キャプチャー入力単独では動作せず、キャプチャー入力するときは、F2を押して、クリップボードのタイマーを起動しなければならない。ウェブブラウザも、キャプチャー入力と干渉することがあるので、現在は、操作対象外にしている。キャプチャーの仕組みは、“盗み撮り”の性格があるので、他の応用ソフトと干渉することがあるようだ。ソフトウェアメーカー間の取り決めがないとうまくいかないかも知れない。将来は、すべての応用ソフトで動作するようにする予定である。
(3)入力方法
次に述べるように確認取込みと自動取込みの二通りの入力モードがある。
(a)文字列をマウスで選択し、選択した文字列が、被変換文字列として表示されるので、それを確認し、入力を取り込む確認取込みモード
被変換文字列を確認し、確定キーを押して文字列を取り込む。確認キーを押さないと文字列は取り込めない。一つ一つ文字列の挿入箇所を変える必要がある場合に適する。この場合、マウスで文字列を選択すると、5秒タイマー(1秒周期タイマーで5回数える方式)の動作は次のようになる。
1秒目 選択された文字列を読み込み、被変換文字列として表示する。
2秒目 英語1の音声出力(英語、カタカナ語、ローマ字の用語のみ)
3秒目 (以降、電子音を出す。)
4秒目
5秒目
以降、F2キーを押して停止するまで繰り返す。ただし、同じ文字列が続く場合、50秒で停止させる。
(b)文字列を選択すれば、自動的にその文字列が取り込まれる自動取込みモード
被変換文字列をマウスでクリックすると、このモードになり、標準設定では、被変換文字列の背景色が深紅色になる。このモードの場合、文字列を選択するだけで、連続して文字列を入力できるので、希望する単語、語句、文章の読み込みに適する。この場合、マウスで文字列を選択すると、5秒タイマー(1秒周期タイマーで5回数える方式)の動作は次のようになる。
1秒目 選択された文字列を読み込み、被変換文字列として表示する。
2秒目 英語1の音声出力(英語、カタカナ語、ローマ字の用語のみ)
3秒目 被変換文字列を出力として自動的に確定させる。
4秒目 (以降、電子音を出す。)
5秒目
以降、F2キーを押して停止するまで繰り返す。ただし、同じ文字列が続く場合、50秒で停止させる。
(4)その他の機能
(a)英語、カタカナ語またはローマ字入力が、被変換文字列として表示されているときに、変換キーを押せば、英語はカタカナ語(またはその他の言語)に変換され、カタカナ語およびローマ字入力は、英語(またはその他言語)に変換できる。変換動作自体は、通常の文字列変換と同じである。
(b)同様に、英語、カタカナ語またはローマ字入力が、被変換文字列として表示されているときに、左矢印キーを押せば、音声出力用変換部と音声出力部が動作し、再度、英語1の音声出力を出す。
(c)カタカナ語の場合、複数の英語の発音になることもある。例えば、「バス」と言っても、乗合自動車の「バス」もあれば、浴槽の「バス」もあるので、それらの発音が、キーを押すごとに切り替わって発音される。
(d)右矢印キーを押すと、(b)と同じ内容で、英語2の音声出力をだす。
国際対応型韓国語入力システム
図10の国際対応型韓国語入力システムは、図3の国際対応型日本語入力システムと同様に、従来の韓国語入力システムに相当する韓国語変換部(6)に、図1の多言語入出力機能実行部を組み合わせるものである。そのとき、日本語入力システムでの「カタカナ語」の位置づけを、韓国語入力システムでは、「ハングル」に置換える。韓国語入力システムは、構造的に、日本語入力システムに似ているので、日本語入力システムに準じる形で設計できるはずである。
その他、日本語入力システムとの違いの部分のみ記述する。
データベースの違いは次のとおりである。
(3)列目(ローマ字)
韓国語のローマ字表現は、各種方式があるが、一貫性がないようである。通常は、英語とハングルのみで対応できるので、日本語のローマ字と同じように、必要なもののみ登録すればよい。
(4)列目(ハングル)
ハングル文字は、日本語のカタカナ語に相当する。
(5)列目
不要
(6)列目(正式英語)
韓国語のハングル英語(ハングル表記の英語)は、結構間違っているものが多い。英語から誤って導入されたものや、日本語の和製英語に影響されたものまである。
(7)列目(韓国語訳)
ハングルまたは、漢字で用語の意味を記載する。上記のように、英語とカタカナ語が対応していないものがあるので、英語の意味を正確に訳す必要がある。意味をあらわすには、ハングルだけでなく、漢字も使う。
国際対応型中国語入力システム
図12の国際対応型中国入力システムは、図3の国際対応型日本語入力システムと同様に、従来の中国語入力システムに相当する中国語変換部(6)に、図1の多言語入出力機能実行部を組み合わせるものである。そのとき、日本語入力システムでの「ローマ字」の位置づけを、中国語入力システムでは、「ピンイン(pinyin)」に置換え、日本語入力システムでの「カタカナ語」の位置づけを、中国語入力システムでは、「漢字」に置換える。中国語には、カタカナ語やハングルのような表音文字がないので、漢字から英語に変換する形態は、我々日本人には実感がわかないが、従来の中国語入力モードで漢字を入力し、それを確定させる前に、MLモードに切り替えれば、図12の点線で示すように、多言語入出力変換部(3)に漢字が渡り、その漢字を、多言語入出力変換部(3)で英語(またはその他の言語)に変換できるはずである。また、クリップボード/キャプチャー入力部(11)からマウス操作で漢字を直接、多言語入出力変換部(3)に入力することもできる。中国語では、やはり、漢字から英語の変換もあれば便利なはずである。
その他、日本語入力システムとの違いの部分のみ記述する。
データベースの違いは次のとおりである。
(3)列目(ローマ字)
ピンイン(pinyin)で登録する。
(4)列目
簡体字漢字表記の用語を登録する。
(5)列目
繁体字漢字表記の用語を登録する。
(6)列目(正式英語)
人名とか地名は音訳するが、その他は、外来語を意訳するので、間違い英語という定義はないかも知れないが、何らかの理由で、間違いの英語があるかもしれないので、予備として使う。
(7)列目(中国語訳)
この例では、簡体字を使っているが、必要に応じて繁体字を使う。
(1)日本人の平均的な英語のレベルが向上する
英語の発音や英語の単語に接触する機会が大幅に増えるので、日本人の平均的な英語レベルが上がる。特に、小さい時から英語の発音に接していれば、将来は、英語の得意な日本人が多く出るはずである。今後の世代に期待する。
(2)英語以外の外国語への興味が増す
11ヶ国語の言語が表示できるので、英語以外への興味が増すことも期待できる。外国語は英語だけではなく、選択肢が増えることになる。特に、ラテン系言語を学べば、複数の言語習得も可能であるし、漢字の発音を聞く機会や、その発音の要領がわかれば、中国、台湾、韓国との言語上での交流が増えるはずである。
(3)カタカナ英語乱用の抑制効果
現在は、カタカナ語を、その語源である外国語(主として英語)と対応させて使っていないので乱用されている。また、仮名および漢字で表しにくい微妙な表現の場合、カタカナ語を使うことがよくある。しかし、この発明では、発音を重視し、英語とカタカナ語の発音の差を知らしめ、不適当なカタカナ語は使えなくなるような環境を作ってある。カタカナ語の乱用を抑制する効果が期待できる。
(4)カタカナ語の使用法統一
本発明のシステムで使うデータベースには、カタカナ語が登録されているので、長音符号(ー)を付けるものと付けないものの違いはあるにしても、それ以上の揺らぎは最小限になるはずである。学校教育や新聞記事に書かれる長音符号付きのものと、技術系の資料で使われる長音符なしのものが今でも混在しているのは、なんとかするべきである。この発明がその契機になれば幸いである。
2.文字列データを一時保存するバッファで、文字列を管理する編集用関数にデータを渡す役目をする。
3.編集用関数の文字列を読み込み、一致する用語を探し、見つかれば、その文字列の関連するデータを変換出力として出す。クリップボード/キャプチャー入力からの入力も同様に処理する。文字列変換後および変換候補表示窓が開いているときは、左右の矢印キーを押すと、選択された英語またはその他の言語の音声データを出力する。
4.文字列変換前に、左右の矢印キーを押すと、編集用関数の文字列を読み込み、一致する用語を探し、見つかれば、英語またはその他の言語の音声データを出力する。クリップボード/キャプチャー入力からの入力も同様に処理する。
5.文字列変換用の用語を登録したデータベース。
6.従来式の仮名漢字変換方式の日本語入力システムに相当する部分。
7.キーボードまたはクリップボード/キャプチャー入力からの入力文字列を編集用関数に渡し、その文字列を画面に表示し、さらに多言語入出力部からの変換出力を変換候補表示関数に渡し、変換候補表示窓が開いたときに表示させる。
8.文字列データを受け取り、確定指令が来ると、確定指令に沿った文字列を出力文字列として、出力対象となる応用ソフトまたは表示装置に出力する。
9.利用者が変換キーを押すと、仮名漢字変換部へ変換指令を出す。
10.利用者が確定キーを押すと、文字出力部へ確定指令を出す。
11.クリップボードに保存された文字列データまたはマウス操作等で得られえるキャプチャー入力処理部。
12.出力言語選択用スイッチで、ひとつの言語または11ヶ国語の同時選択も可能。
13.音声出力を作成する装置
14.利用者が変換キーを押すと、多言語入出力変換部へ変換指令を出す。
15.利用者が矢印キーを押すと、音声出力用変換部へ変換指令を出す。
Claims (3)
- 本発明の国際対応型日本語入力システムは、下記(A)から(E)までの5項の内容を含むことを特徴とする日本語入力システム。
(A)本発明は、従来の日本語入力システムの仮名入力や記号での入力に加え、英語、カタカナ語およびローマ字の3入力方式が可能であり、また、出力は、日本語(平仮名、片仮名、漢字および記号)だけでなく、英語、ローマ字に加え、数ヵ国語の多言語出力ができる。
(B)本発明は、日本語と英語の用語の同時検索が可能な完全一致優先の前方一致検索方式を採用している。
(C)本発明は、音声出力用変換部及び音声出力部を内蔵しているので、英語、カタカナ語およびまたはローマ字入力の文字列の英語またはその他の言語の音声を、常時、出力できる。
(D)新規追加したモード(多言語入出力モード)の切替え時に、入力文字列の背景色の色替えをし、モード切替えを利用者に直感的に認識させる。
(E)本発明では、応用ソフト画面上の希望する文字列または文章を、マウス操作(タッチパネル操作)するだけで、本発明のシステムに自動的に取り込むことができる。
同時に、英語の音声も出力できる。 - 本発明の国際対応型韓国語入力システムは、下記(A)から(C)までの3項の内容を含むことを特徴とする韓国語入力システム。国際対応型韓国語入力システムは、従来の韓国語入力システムに相当する韓国語変換部に、多言語入出力機能実行部を組み合わせるものである。
(A)本発明は、英語、ハングルおよびローマ字の3入力方式を採用し、出力は、数ヵ国語の多言語出力ができる。
(B)本発明は、音声出力用変換部及び音声出力部を内蔵しているので、英語、ハングルまたはローマ字入力の文字列の英語またはその他の言語の音声を、常時、出力できる。
(C)本発明では、応用ソフト画面上の希望する文字列または文章を、マウス操作(タッチパネル操作)するだけで、本発明のシステムに自動的に取り込むことができる。同時に、英語の音声も出力できる。 - 本発明の国際対応型中国語入力システムは、下記(A)から(C)までの3項の内容を含むことを特徴とする中国語入力システム。国際対応型中国語入力システムは、従来の中国語入力システムに相当する中国語変換部に、多言語入出力機能実行部を組み合わせるものである。
(A)本発明は、英語、漢字およびピンイン(pinyin)の3入力方式を採用し、出力は、数ヵ国語の多言語出力ができる。
(B)本発明は、音声出力用変換部及び音声出力部を内蔵しているので、英語、漢字またはピンイン(pinyin)の文字列の英語またはその他の言語の音声を、常時、出力できる。
(C)本発明では、応用ソフト画面上の希望する文字列または文章を、マウス操作(タッチパネル操作)するだけで、本発明のシステムに自動的に取り込むことができる。同時に、英語の音声も出力できる。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008266869A JP5751537B2 (ja) | 2008-09-17 | 2008-09-17 | 国際対応型日本語入力システム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008266869A JP5751537B2 (ja) | 2008-09-17 | 2008-09-17 | 国際対応型日本語入力システム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010073177A JP2010073177A (ja) | 2010-04-02 |
| JP5751537B2 true JP5751537B2 (ja) | 2015-07-22 |
Family
ID=42204845
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008266869A Active JP5751537B2 (ja) | 2008-09-17 | 2008-09-17 | 国際対応型日本語入力システム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5751537B2 (ja) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101231438B1 (ko) * | 2011-05-25 | 2013-02-07 | 엔에이치엔(주) | 외래어 발음 검색 서비스를 제공하는 검색결과 제공 시스템 및 방법 |
| US8818791B2 (en) | 2012-04-30 | 2014-08-26 | Google Inc. | Techniques for assisting a user in the textual input of names of entities to a user device in multiple different languages |
| JP6451225B2 (ja) * | 2014-11-06 | 2019-01-16 | セイコーエプソン株式会社 | 表示装置、プロジェクターおよび表示制御方法 |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7260570B2 (en) * | 2002-02-01 | 2007-08-21 | International Business Machines Corporation | Retrieving matching documents by queries in any national language |
| JP2007018468A (ja) * | 2005-07-06 | 2007-01-25 | Shinei Planners:Kk | カタカナ英語変換システム |
| JP4503516B2 (ja) | 2005-09-09 | 2010-07-14 | 株式会社ジェイデータ | 携帯電話 |
-
2008
- 2008-09-17 JP JP2008266869A patent/JP5751537B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2010073177A (ja) | 2010-04-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR100259407B1 (ko) | 중국어 텍스트 입력키보드, 중국어 텍스트 처리 컴퓨터 시스템, 중국어 텍스트 입력장치, 음성 중국어의 음절 및 단어 저장방법 | |
| CN109844696B (zh) | 多语言字符输入装置 | |
| TWI293455B (en) | System and method for disambiguating phonetic input | |
| US8977535B2 (en) | Transliterating methods between character-based and phonetic symbol-based writing systems | |
| KR100930185B1 (ko) | 사전기능을 갖는 전자기기 및 문자입력방법 | |
| JP2010198241A (ja) | 中国語入力装置およびプログラム | |
| JP2008539477A (ja) | すべてより少ない文字、もしくは、与えられた(1つ以上の)文字のすべてより少ないストローク、またはその両方を供給することによる、表意言語の句の省略された手書き入力 | |
| JP2004523034A (ja) | 文字生成システム | |
| JP5751537B2 (ja) | 国際対応型日本語入力システム | |
| JP2007317163A (ja) | 電子辞書及び検索方法 | |
| JP5331654B2 (ja) | 電子機器および電子機器の制御方法 | |
| JP2002207728A (ja) | 表音文字生成装置及びそれを実現するためのプログラムを記録した記録媒体 | |
| JP2010282507A (ja) | 辞書機能を備えた電子機器およびプログラム | |
| KR101018821B1 (ko) | 중국어 문자 생성 방법 및 이에 사용되는 키입력 장치 | |
| JP2009175941A (ja) | 電子辞書装置 | |
| JP5011511B2 (ja) | 辞書機能を備えた電子機器およびプログラム | |
| JP5141130B2 (ja) | 辞書機能を有する電子機器及びプログラム | |
| JP2008217770A (ja) | 言語データ表示システム、言語データ表示方法、及び言語データ表示プログラム | |
| JP2012181654A (ja) | ロシア語検索装置およびプログラム | |
| JP2008140074A (ja) | 例文検索装置および例文検索処理プログラム | |
| KR20080010774A (ko) | 영어-한글 영어 변환 시스템 | |
| JP2021128618A (ja) | 表示装置、及びプログラム | |
| JP5338482B2 (ja) | 漢文例文検索装置およびプログラム | |
| JPH11250048A (ja) | 文字入力装置、文字入力方法および文字入力制御プログラムを記録した記録媒体 | |
| JP5561312B2 (ja) | 辞書機能を備えた電子機器、辞書機能を備えた電子機器における検索文字の入力方法およびプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20110816 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130409 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130604 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20130827 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20150511 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5751537 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |