JP5376795B2 - 画像処理装置、画像処理方法、そのプログラム及び記憶媒体 - Google Patents
画像処理装置、画像処理方法、そのプログラム及び記憶媒体 Download PDFInfo
- Publication number
- JP5376795B2 JP5376795B2 JP2007321283A JP2007321283A JP5376795B2 JP 5376795 B2 JP5376795 B2 JP 5376795B2 JP 2007321283 A JP2007321283 A JP 2007321283A JP 2007321283 A JP2007321283 A JP 2007321283A JP 5376795 B2 JP5376795 B2 JP 5376795B2
- Authority
- JP
- Japan
- Prior art keywords
- character
- data
- electronic document
- image
- document
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images














Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/103—Formatting, i.e. changing of presentation of documents
- G06F40/109—Font handling; Temporal or kinetic typography
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/123—Storage facilities
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T11/00—2D [Two Dimensional] image generation
- G06T11/60—Editing figures and text; Combining figures or text
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/14—Image acquisition
- G06V30/148—Segmentation of character regions
- G06V30/158—Segmentation of character regions using character size, text spacings or pitch estimation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/24—Character recognition characterised by the processing or recognition method
- G06V30/242—Division of the character sequences into groups prior to recognition; Selection of dictionaries
- G06V30/244—Division of the character sequences into groups prior to recognition; Selection of dictionaries using graphical properties, e.g. alphabet type or font
- G06V30/245—Font recognition
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/28—Character recognition specially adapted to the type of the alphabet, e.g. Latin alphabet
- G06V30/287—Character recognition specially adapted to the type of the alphabet, e.g. Latin alphabet of Kanji, Hiragana or Katakana characters
Description
以下、本発明の一実施形態について図面を用いて説明する。
・文字列の縦書き/横書きを示す属性Direction(なお、Directionが指定されていない場合は、デフォルトで横書きとする)
・文字の開始位置の座標を指定する属性X,Y
・文字を描画する際に適用されるフォントデータのIDを指定する属性Font
・フォントサイズを指定する属性Size
・描画時の文字色を、R成分値、G成分値、B成分値、透過度を表すアルファチャネル値の4値の組で指定する属性Color
・文字列の内容(文字コード列)を指定する属性String
・String内の各文字から次の文字までの送り幅を指定する属性CWidth
・String内の各文字が描画の際に使用する字形データすなわちグリフのIDを指定する属性CGlyphId
「原点(0,0)にMOVE,上方向に1024単位縦線を描画、右方向に1024単位横線を描画、下方向に1024単位縦線を描画、現在の点から開始点まで線を描画して囲まれた範囲を塗りつぶす。」
すなわち、1024×1024を塗りつぶす正方形のグリフを表現する記述となっている。
「原点(0,0)にMOVE,上方向に64単位縦線を描画、右方向に1024単位横線を描画、下方向に64単位縦線を描画、現在の点から開始点まで線を描画して囲まれた範囲を塗りつぶす。」
すなわち、描画矩形単位内下部の1024×64の領域を塗りつぶす水平方向直線状のグリフを表現する記述となっている。
・グリフ二値画像の画素値が0に対応する画素の場合:
(r’,g’,b’)=(r,g,b)
・グリフ二値画像の画素値が1に対応する画素の場合:
(r’,g’,b’)=(F(r,Cr),F(g,Cg),F(b,Cb))
ここで、F(r,Cr)=(r×A+Cr×(255−A))/255、F(g,Cg)=(g×A+Cg×(255−A))/255、F(b,Cb)=(b×A+Cb×(255−A))/255とする。また、Aは文字色Cのアルファチャネル値、Cr,Cg,Cbは文字色CのそれぞれRGB値である。なお、アルファチャネル値として255が指定されている場合は、当該グリフ二値画像は透明であるので、グリフ二値画像の画素値が1に対応する画素についても、(r’,g’,b’)=(r,g,b)となる。
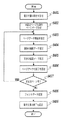
ステップS515では、処理中の文字が検索文字列として検出された範囲内にあることを示すための強調処理を行う。具体的には、対応するグリフ二値画像の画素値が0である画素はそのままに、対応するグリフ二値画像の画素値が1である画素に対しては各画素値(r,g,b)を以下の(r’,g’,b’)へと各々変化させる
(r’,g’,b’)=(G(r),G(g),G(b))
ここで、G(r)=255−r,G(g)=255−g,G(b)=255−bであるとする。
次に、本発明の第2の実施形態(実施形態2)について図面を用いて説明する。
また、上述した実施形態では、スキャン画像に対してJPEG圧縮等を行った全面イメージを<Image>要素に記述し、透明テキストを<Text>要素に記述した電子文書を生成することとしたが、これに限るものではない。
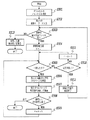
また、上述した実施形態では、図3及び図5で説明したように、検索を行う際は、キーワードに一致する文字列を文書の先頭から順に検索していき、最初に検索された文字列を強調表示した。そして、「次を検索」の指示があれば、順次、次に一致する文字列を検索して強調表示するように構成した。このように、上述した実施形態では、検索キーワードに一致する文字列を先頭から順に検索をおこない、検索キーワードがヒットするごとに順次強調表示を行っていたが、これに限るものではない。例えば、電子文書内に含まれる全ての文字列について、検索キーワードと比較を行い、全ての一致する文字列を特定し、そのキーワードに一致した全ての文字列を同時に強調表示するような構成にしてもよい。
この場合、記憶媒体から読み出されたプログラムコード自体が、コンピュータに、上述した実施形態の機能を実現させることになる。そのため、このプログラムコード及びプログラムコードを記憶/記録したコンピュータ読み取り可能な記憶媒体も本発明の一つを構成することになる。
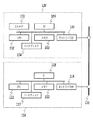
101 スキャナ
102,111 CPU
103,112 メモリ
104,113 ハードディスク
105,114 ネットワークI/F
106,115 UI
120 ネットワーク
Claims (12)
- 文書画像内の複数の文字画像に対して文字認識処理を行うことにより、それぞれの文字画像に対応する文字コードを得る文字認識手段と、
前記文書画像と、前記文字認識手段で得た複数の文字コードと、複数の異なる文字コードの描画において共通で利用する字形データと、どの字形データを使用すべきかを各アプリケーションで判断するための判断基準の情報とを格納した電子文書を生成する生成手段と、
を有する画像処理装置であって、
前記複数の異なる文字コードの描画において共通で利用する字形データとして、複数種類の字形データが前記電子文書に格納され、
前記判断基準の情報は、前記複数種類の字形データそれぞれの属性データとして各字形データの形状の特徴を記述した情報であり、
前記電子文書に格納されている前記文書画像と前記文字コードとを描画することによって前記電子文書の閲覧処理を行うアプリケーションは、当該電子文書に格納されている前記複数種類の字形データの中から、前記複数種類の字形データそれぞれの属性データに記述されている各字形データの形状の特徴に基づいて、当該アプリケーションで強調表示するのに適した形状の特徴が前記属性データに記述されている字形データを自動的に1つ選択し、当該選択した1つの字形データを用いて当該電子文書に格納されている前記複数の異なる文字コードの描画を行う
ことを特徴とする画像処理装置。 - 文書画像内の複数の文字画像に対して文字認識処理を行うことにより、それぞれの文字画像に対応する文字コードを得る文字認識手段と、
前記文書画像と、前記文字認識手段で得た複数の文字コードと、複数の異なる文字コードの描画において共通で利用する字形データと、どの字形データを使用すべきかを各アプリケーションで判断するための判断基準の情報とを格納した電子文書を生成する生成手段と、
を有する画像処理装置であって、
前記複数の異なる文字コードの描画において共通で利用する字形データとして、複数種類の字形データが前記電子文書に格納され、
前記判断基準の情報は、前記複数種類の字形データそれぞれの属性データとしてアプリケーションの名前または種類を記述した情報であり、
前記電子文書に格納されている前記文書画像と前記文字コードとを描画することによって前記電子文書の閲覧処理を行うアプリケーションは、当該電子文書に格納されている前記複数種類の字形データの中から、当該閲覧処理を行うアプリケーションの名前または種類が前記属性データに記述されている字形データを自動的に1つ選択し、当該選択した1つの字形データを用いて当該電子文書に格納されている前記複数の異なる文字コードの描画を行う
ことを特徴とする画像処理装置。 - 前記電子文書に格納される複数種類の字形データのうちの1つは、矩形の形状を有する字形データであることを特徴とする請求項1または2に記載の画像処理装置。
- 前記電子文書に格納される複数種類の字形データのうちの1つは、下線の形状を有する字形データであることを特徴とする請求項1または2に記載の画像処理装置。
- 前記電子文書に格納される複数種類の字形データのうちの1つは、波線、点線、三角、丸、四角形の形状のうちの少なくともいずれかの形状を有する字形データであることを特徴とする請求項1または2に記載の画像処理装置。
- 前記生成手段で生成された電子文書には、前記複数の文字コードに対応させた字形データを、前記文書画像内の各文字画像の位置に対応する位置に透明色で描画させるための記述が含まれることを特徴とする請求項1または2に記載の画像処理装置。
- 前記電子文書は、XMLフォーマット或いはXPSフォーマットで記述された電子文書であることを特徴とする請求項1または2に記載の画像処理装置。
- 前記画像処理装置は、前記文書画像を圧縮する圧縮手段を更に有し、
前記電子文書に格納される文書画像は、前記圧縮手段で圧縮処理が施された文書画像であることを特徴とする請求項1または2に記載の画像処理装置。 - 前記圧縮手段は、前記文書画像内に含まれる領域を解析して適応的に圧縮することを特徴とする請求項8に記載の画像処理装置。
- 前記アプリケーションは、前記生成された電子文書に格納されている複数の文字コードに対して、入力された検索キーワードに一致する部分を前記選択した1つの字形データを用いて強調表示させることを特徴とする請求項1乃至9のいずれか1項に記載の画像処理装置。
- 文字認識手段が、文書画像内の複数の文字画像に対して文字認識処理を行うことにより、それぞれの文字画像に対応する文字コードを得る文字認識ステップと、
生成手段が、前記文書画像と、前記文字認識手段で得た複数の文字コードと、複数の異なる文字コードの描画において共通で利用する字形データと、どの字形データを使用すべきかを各アプリケーションで判断するための判断基準の情報とを格納した電子文書を生成する生成ステップと、を有する画像処理方法であって、
前記複数の異なる文字コードの描画において共通で利用する字形データとして、複数種類の字形データが前記電子文書に格納され、
前記判断基準の情報は、前記複数種類の字形データそれぞれの属性データとして各字形データの形状の特徴を記述した情報であり、
前記電子文書に格納されている前記文書画像と前記文字コードとを描画することによって前記電子文書の閲覧処理を行うアプリケーションは、当該電子文書に格納されている前記複数種類の字形データの中から、前記複数種類の字形データそれぞれの属性データに記述されている各字形データの形状の特徴に基づいて、当該アプリケーションで強調表示するのに適した形状の特徴が前記属性データに記述されている字形データを自動的に1つ選択し、当該選択した1つの字形データを用いて当該電子文書に格納されている前記複数の異なる文字コードの描画を行う
ことを特徴とする画像処理方法。 - コンピュータを、請求項1乃至10のいずれか1項に記載の画像処理装置として機能させるためのプログラム。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007321283A JP5376795B2 (ja) | 2007-12-12 | 2007-12-12 | 画像処理装置、画像処理方法、そのプログラム及び記憶媒体 |
| US12/331,330 US8396294B2 (en) | 2007-12-12 | 2008-12-09 | Image processing device, image processing method, and program and recording medium thereof |
| EP08171347.1A EP2071493B1 (en) | 2007-12-12 | 2008-12-11 | Image processing device, image processing method, and program and recording medium thereof |
| CN200810183281.3A CN101458699B (zh) | 2007-12-12 | 2008-12-12 | 图像处理装置和图像处理方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007321283A JP5376795B2 (ja) | 2007-12-12 | 2007-12-12 | 画像処理装置、画像処理方法、そのプログラム及び記憶媒体 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2009146064A JP2009146064A (ja) | 2009-07-02 |
| JP2009146064A5 JP2009146064A5 (ja) | 2011-02-03 |
| JP5376795B2 true JP5376795B2 (ja) | 2013-12-25 |
Family
ID=40469995
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007321283A Expired - Fee Related JP5376795B2 (ja) | 2007-12-12 | 2007-12-12 | 画像処理装置、画像処理方法、そのプログラム及び記憶媒体 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US8396294B2 (ja) |
| EP (1) | EP2071493B1 (ja) |
| JP (1) | JP5376795B2 (ja) |
| CN (1) | CN101458699B (ja) |
Families Citing this family (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20080313036A1 (en) * | 2007-06-13 | 2008-12-18 | Marc Mosko | System and method for providing advertisements in online and hardcopy mediums |
| US7949560B2 (en) * | 2007-06-13 | 2011-05-24 | Palo Alto Research Center Incorporated | System and method for providing print advertisements |
| JP4402138B2 (ja) | 2007-06-29 | 2010-01-20 | キヤノン株式会社 | 画像処理装置、画像処理方法、コンピュータプログラム |
| JP4590433B2 (ja) * | 2007-06-29 | 2010-12-01 | キヤノン株式会社 | 画像処理装置、画像処理方法、コンピュータプログラム |
| US8031366B2 (en) * | 2007-07-31 | 2011-10-04 | Canon Kabushiki Kaisha | Control apparatus, controlling method, program and recording medium |
| US9092668B2 (en) * | 2009-07-18 | 2015-07-28 | ABBYY Development | Identifying picture areas based on gradient image analysis |
| KR20110051052A (ko) * | 2009-11-09 | 2011-05-17 | 삼성전자주식회사 | 인쇄 제어 방법 및 인쇄 제어 단말장치 |
| US8571270B2 (en) * | 2010-05-10 | 2013-10-29 | Microsoft Corporation | Segmentation of a word bitmap into individual characters or glyphs during an OCR process |
| US20110280481A1 (en) * | 2010-05-17 | 2011-11-17 | Microsoft Corporation | User correction of errors arising in a textual document undergoing optical character recognition (ocr) process |
| JP5676942B2 (ja) | 2010-07-06 | 2015-02-25 | キヤノン株式会社 | 画像処理装置、画像処理方法、及びプログラム |
| JP5249387B2 (ja) | 2010-07-06 | 2013-07-31 | キヤノン株式会社 | 画像処理装置、画像処理方法、及びプログラム |
| US8781152B2 (en) * | 2010-08-05 | 2014-07-15 | Brian Momeyer | Identifying visual media content captured by camera-enabled mobile device |
| JP5716328B2 (ja) * | 2010-09-14 | 2015-05-13 | 株式会社リコー | 情報処理装置、情報処理方法、および情報処理プログラム |
| CN102456040A (zh) * | 2010-10-28 | 2012-05-16 | 上海中晶科技有限公司 | 影像管理系统及方法 |
| CN103765449B (zh) * | 2011-09-08 | 2018-03-27 | 惠普发展公司,有限责任合伙企业 | 生成增量信息对象 |
| CN103186911B (zh) * | 2011-12-28 | 2015-07-15 | 北大方正集团有限公司 | 一种处理扫描书数据的方法及装置 |
| JP2013238933A (ja) * | 2012-05-11 | 2013-11-28 | Sharp Corp | 画像処理装置、画像形成装置、プログラムおよびその記録媒体 |
| JP5950700B2 (ja) | 2012-06-06 | 2016-07-13 | キヤノン株式会社 | 画像処理装置、画像処理方法及びプログラム |
| US10552717B2 (en) * | 2016-03-16 | 2020-02-04 | Canon Kabushiki Kaisha | Image processing apparatus, control method thereof, and storage medium |
| CN112118307B (zh) * | 2020-09-14 | 2022-03-15 | 珠海格力电器股份有限公司 | 设备数据的下载方法 |
| JP7049010B1 (ja) * | 2021-03-02 | 2022-04-06 | 株式会社インタラクティブソリューションズ | プレゼンテーション評価システム |
| CN114020006B (zh) * | 2021-09-26 | 2023-04-07 | 佛山中科云图智能科技有限公司 | 无人机辅助降落方法、装置、存储介质以及电子设备 |
Family Cites Families (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| IT1234357B (it) | 1989-04-17 | 1992-05-15 | Nordica Spa | Dispositivo di bloccaggio del piede, particolarmente per scarponi da sci |
| JP3376129B2 (ja) | 1993-12-27 | 2003-02-10 | キヤノン株式会社 | 画像処理装置及びその方法 |
| US5689620A (en) * | 1995-04-28 | 1997-11-18 | Xerox Corporation | Automatic training of character templates using a transcription and a two-dimensional image source model |
| JP3606401B2 (ja) * | 1995-11-30 | 2005-01-05 | 富士通株式会社 | 文書検索装置および方法 |
| JP4235286B2 (ja) | 1998-09-11 | 2009-03-11 | キヤノン株式会社 | 表認識方法及び装置 |
| AUPP702498A0 (en) * | 1998-11-09 | 1998-12-03 | Silverbrook Research Pty Ltd | Image creation method and apparatus (ART77) |
| JP2000322417A (ja) | 1999-05-06 | 2000-11-24 | Canon Inc | 画像ファイリング装置及び方法及び記憶媒体 |
| JP4454789B2 (ja) | 1999-05-13 | 2010-04-21 | キヤノン株式会社 | 帳票分類方法及び装置 |
| JP4366003B2 (ja) | 2000-08-25 | 2009-11-18 | キヤノン株式会社 | 画像処理装置及び画像処理方法 |
| US7133565B2 (en) * | 2000-08-25 | 2006-11-07 | Canon Kabushiki Kaisha | Image processing apparatus and method |
| JP3826221B2 (ja) | 2002-04-24 | 2006-09-27 | 国際技術開発株式会社 | 真空太陽熱収集装置の製造方法及びその製造装置 |
| US7228501B2 (en) * | 2002-11-01 | 2007-06-05 | Microsoft Corporation | Method for selecting a font |
| US7310769B1 (en) * | 2003-03-12 | 2007-12-18 | Adobe Systems Incorporated | Text encoding using dummy font |
| JP2005259017A (ja) * | 2004-03-15 | 2005-09-22 | Ricoh Co Ltd | 画像処理装置、画像処理用プログラム及び記憶媒体 |
| US7707039B2 (en) * | 2004-02-15 | 2010-04-27 | Exbiblio B.V. | Automatic modification of web pages |
| JP2005275863A (ja) | 2004-03-25 | 2005-10-06 | Murata Mach Ltd | 複合機 |
| JP2006092027A (ja) * | 2004-09-21 | 2006-04-06 | Fuji Xerox Co Ltd | 文字認識装置、文字認識方法および文字認識プログラム |
| JP2007058605A (ja) * | 2005-08-24 | 2007-03-08 | Ricoh Co Ltd | 文書管理システム |
-
2007
- 2007-12-12 JP JP2007321283A patent/JP5376795B2/ja not_active Expired - Fee Related
-
2008
- 2008-12-09 US US12/331,330 patent/US8396294B2/en not_active Expired - Fee Related
- 2008-12-11 EP EP08171347.1A patent/EP2071493B1/en not_active Expired - Fee Related
- 2008-12-12 CN CN200810183281.3A patent/CN101458699B/zh not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| CN101458699A (zh) | 2009-06-17 |
| EP2071493A3 (en) | 2013-08-14 |
| CN101458699B (zh) | 2015-11-25 |
| EP2071493B1 (en) | 2019-05-15 |
| US20090154810A1 (en) | 2009-06-18 |
| US8396294B2 (en) | 2013-03-12 |
| JP2009146064A (ja) | 2009-07-02 |
| EP2071493A2 (en) | 2009-06-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5376795B2 (ja) | 画像処理装置、画像処理方法、そのプログラム及び記憶媒体 | |
| JP4590433B2 (ja) | 画像処理装置、画像処理方法、コンピュータプログラム | |
| JP4402138B2 (ja) | 画像処理装置、画像処理方法、コンピュータプログラム | |
| JP5111268B2 (ja) | 画像処理装置、画像処理方法、そのプログラムおよび記憶媒体 | |
| US8954845B2 (en) | Image processing device, method and storage medium for two-way linking between related graphics and text in an electronic document | |
| CN101820489B (zh) | 图像处理设备及图像处理方法 | |
| JP5197694B2 (ja) | 画像処理装置、画像処理方法、コンピュータプログラム | |
| JP5098614B2 (ja) | 文章処理装置の制御方法および文章処理装置 | |
| JP2000322417A (ja) | 画像ファイリング装置及び方法及び記憶媒体 | |
| JP4892600B2 (ja) | 画像処理装置 | |
| JPH05324717A (ja) | 対訳画像形成装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20101106 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20101209 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20101209 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20121011 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20121023 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20121221 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130618 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130808 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20130827 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20130924 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 5376795 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |
|
| LAPS | Cancellation because of no payment of annual fees |