JP2010054588A - 音響モデル作成装置、その装置を用いた音声認識装置、これらの方法、これらのプログラム、およびこれらの記録媒体 - Google Patents
音響モデル作成装置、その装置を用いた音声認識装置、これらの方法、これらのプログラム、およびこれらの記録媒体 Download PDFInfo
- Publication number
- JP2010054588A JP2010054588A JP2008216640A JP2008216640A JP2010054588A JP 2010054588 A JP2010054588 A JP 2010054588A JP 2008216640 A JP2008216640 A JP 2008216640A JP 2008216640 A JP2008216640 A JP 2008216640A JP 2010054588 A JP2010054588 A JP 2010054588A
- Authority
- JP
- Japan
- Prior art keywords
- acoustic model
- parameter
- posterior probability
- distribution
- probability distribution
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images














Abstract
【解決手段】今回の適応用音声データの特徴量系列を抽出し、音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布をガウス分布で表現した際の、当該事後確率分布の平均ベクトルパラメータ、共分散行列パラメータに対するスケーリング因子、初期の共分散行列で表されることに基づき、前回のガウス分布の平均ベクトルパラメータの事後確率分布、今回まで累積された特徴量系列の一部を用い、今回の音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布をガウス分布で表現した際の、当該事後確率分布の平均ベクトルパラメータ及び、スケーリング因子を計算することで、今回の音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布を求め、今回の音響モデルパラメータの事後確率分布を新たな音響モデルパラメータに変換して更新する。
【選択図】図3
Description
従来の音声認識装置の機能構成例を図1に示し、従来の音声認識装置の処理の主な流れを図2に示す。音声認識装置2は主に、特徴抽出部4と単語列探索部6と音響モデル記憶部8と言語モデル記憶部10とで構成されている。
次に、音響モデルの作成方法について説明する。音響モデルは、音声の音響的特徴をモデル化したものであり、認識用音声データと音響モデルを参照することにより、音声データを音素や単語といったシンボルに変換する。そのため、音響モデルの作成は、音声認識装置の性能を大きく左右する。通常、音声認識用音響モデルでは、各音素をLeft to rightの隠れマルコフモデル(HMM)で、HMM状態の出力確率分布を混合ガウス分布モデル(GMM)で表現する。そのため、実際に音響モデルとして記憶部に記憶されているのは、音素などの各シンボルにおける、HMMの状態遷移確率a,GMMの混合重み因子w、及び音響モデル中のガウス分布の平均ベクトルパラメータμ、及び音響モデル中のガウス分布の共分散行列パラメータΣとなる。これらを音響モデルパラメータと呼びその集合をθとする。つまり、θ={a,w,μ,Σ}とする。音響モデルパラメータθの値を正確に求めるのが音響モデルの作成過程となり、この過程を音響モデル作成方法と呼ぶ。
音響モデルパラメータに対しての適応学習は、パラメータあたりの学習データ量が少ない場合に初期モデルを先験知識として用い、少ないデータで学習を行う手法である。通常の学習方法との違いは学習データのみならず初期モデルを用いて音響モデルを構築する点である。このように初期モデルと学習データから新たに音響モデルを構築する学習方法を適応学習と呼ぶ。
適応学習の中では、音響モデル中のガウス分布の平均ベクトルパラメータμに対する線形回帰行列を推定する手法が広く用いられている(非特許文献1、2参照)。線形回帰行列を用いた場合の音響モデル作成装置の機能構成例を図5に示し、この場合の音響モデル作成装置の主な処理の流れを図6に示す。この手法を用いた音響モデル作成装置21は、特徴抽出部4、特徴量記憶部5、パラメータ適応部22、とで構成されており、パラメータ適応部22は変換パラメータ推定部24、変換パラメータ記憶部26、モデルパラメータ変換部28、とで構成されている。
μ=Aμ0+ν (1)
ここで、AはD×Dの行列であり、平均ベクトルパラメータμ0の回転、伸縮をさせる行列である。νはD次元ベクトルであり平均ベクトルパラメータμ0の平行移動をさせるベクトルを表す。このとき、変換パラメータW=(ν,A)である。変換パラメータWは特徴量系列Oから期待値最大化(Expectation Maximization)アルゴリズム(以下EMアルゴリズムという)やその一種であるMLLR(Maximum Likelihood Linear Regression)アルゴリズムを用いて繰り返し計算により効率よく求められる(ステップS46)。推定すべき変換パラメータWのパラメータ数はD2+D=D(D+1)となる。何故なら、行列Aの要素数はD2であり、ベクトルνの要素数はDであるからである。平均ベクトルのパラメータ数Dよりもパラメータ数が多いが、複数のガウス分布で同一の変換パラメータを共有することにより、推定すべきパラメータ数を減らすことが可能である。推定された変換パラメータWは一旦変換パラメータ記憶部26に記憶される。
以上までは、一まとまりの特徴量系列O={o1,o2,…,on,…,oN}(ただし、Nはフレーム数である)に対しての適応学習を考えた。しかし、音声は雑音などの外的要因や発声のなまり等の内的要因によって、時々刻々その音響的特徴を大きく変化させている。このような変化に追随していくためには、時系列的に与えられるまとまった量の音声データに対して逐次モデルを適応させる逐次適応学習が有効である。このとき、特徴量系列を1まとまりとして捉えず、複数のまとまりが時系列的に与えられる場合の適応を考える。つまり以下の式(2)(3)のように考える。

θt+1=f(θt,Ot+1) (4)
このとき、変換パラメータ推定法の逐次適応への適用を考察する(非特許文献2参照)。先ほどは、変換パラメータWは全ての特徴量系列から推定されたとしたが、逐次適応においては各まとまりごと(tごと)にWを推定する。それをWt={νt,At}とすれば、パラメータ変換に基づく逐次適応法における平均パラメータの更新式(前記式(4)に示す)は前記式(1)を基に、以下の式(5)のように漸化式で表現することができる。
μt+1=At+1μt+νt+1 (5)
これによって、パラメータ変換に基づく逐次適応が実現される。以下の説明では、At+1は「今回の音響モデルパラメータ中の平均の確率的ダイナミクスを線形表現した時の係数行列」といい、νt+1は「今回の音響モデルパラメータ中の平均の確率的ダイナミクスを線形表現した時の係数ベクトル」という。
次に、本発明の基本概念となる「分布変換にもとづく逐次適応法」について説明する。本手法では、音響モデルパラメータθtそのものの推定を考えるのではなく、音響モデルパラメータの分布p(θt)を考える(特許文献1、非特許文献3、4参照)。
p(θt+1|Ot+1)=F[p(θt|Ot)] (8)
を用いて時間発展、つまり、音声の音響的特徴の変化として対応した漸化式を記述することにより、前記式(4)で注目した音響モデルパラメータθではなく、音響モデルパラメータの事後確率分布p(θ|O)に基づく逐次適応を実現することができる。ここで、F[・]はp(θ|O)を引数として持つ汎関数である。また、F[・]は今回まで累積された特徴量系列Ot+1の一部の特徴量系列に基づいて表現されるものである。以下の説明では、F[・]は、今回まで累積された特徴量系列Ot+1に基づいて、表現されるものとする。このとき、F[・]をパラメトリックに表現し、その変換パラメータWを例えば特徴量Otから適切に推定することにより前記式(8)で表現される逐次適応を実現できる。ただし、変換パラメータの推定は、特徴量Otのみではなく、特徴量系列O1,O2,…,Otのうちの一部を用いてもよく、特徴量系列Otを用いてもよい。
p(θt+1|Ot)=∫p(θt+1|θt,Ot)p(θt|Ot)dθt (10)
従って式(10)を式(9)に代入することにより次式(11)のような漸化式を導出することができる。
)を推定する通常の適応を示している。つまり、本発明は逐次適応のみならず通常の適応においてもその効果を与えることができる。
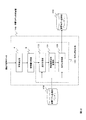
モデル更新部56で、音響モデル記憶部58内の音響モデルとしての前回の事後確率分布p(θt|Ot)が、今回の音響モデルパラメータの事後確率分布p(θt+1|Ot+1)に新たな音響モデルとして更新する(ステップS70)。
次に前記式(11)の演算処理をマルコフ過程を仮定することで簡単にする手法を説明する。p(Ot+1|θt+1,Ot)及びp(θt+1|θt,Ot)は累積された特徴量系列に直接依存する。これらを全ての累積特徴量系列から推定しようとした場合、時が経つにつれ累積データは多くなるため、その推定は大変計算量が多くなり現実的でない。そこで、マルコフ過程を仮定すると、p(Ot+1|θt+1,Ot)とp(θt+1|θt,Ot)はそれぞれ式(13)のように近似される。
p(Ot+1|θt+1,Ot)≒p(Ot+1|θt+1),
p(θt+1|θt,Ot) ≒p(θt+1|θt) (13)
p(θt+1|Ot+1)∝p(Ot+1|θt+1)∫p(θt+1|θt)p(θt|Ot)dθt (14)
ここで、A∝BはAとBは比例しているということを表す。前記式(14)によって、シンプルな出力分布及び確率的ダイナミクスを設定することができる。図8中の逐次学習部52は、この式(14)を計算することになる。
以上の議論では、HMMの状態遷移確率a,GMMの混合重み因子w、及びガウス分布の平均ベクトルパラメータμ及び共分散行列パラメータΣといった全ての音響モデルパラメータθの事後確率分布p(θ|O)についての処理を行った。一般に、音響モデルにおいて最も性能を左右するパラメータはガウス分布の平均ベクトルパラメータμであり、またそれ以外のパラメータの事後確率分布を推定対象とした場合、分布変換関数Fの推定すべきパラメータ数が多くなるため、少量データ適応において効果が十分でなくなる。そのため、以降ではガウス分布の平均ベクトルパラメータμのみに焦点を当て、つまり、音響モデルパラメータθに代えて、ガウス分布の平均ベクトルパラメータμを用いて、図8の逐次学習部52では演算する。演算された事後確率分布p(μ|O)の時間発展について考察する。つまり、前記式(14)においてガウス分布の平均ベクトルパラメータμのみを考えるため時間発展は次式(15)を逐次学習部52で演算する。
p(μt+1|Ot+1)∝p(Ot+1|μt+1)∫p(μt+1|μt)p(μt|Ot)dμt (15)
なお、式(15)は音響モデル中の各ガウス分布の平均ベクトルパラメータに独立に与えられる。その際の各ガウス分布のインデックスは文中では省略する。
次に、前記式(15)の解析解を導出することを考える。これを用いて、逐次学習を行う。式(15)にはさまざまな解析解が存在するが、最も単純な解析解として確率的ダイナミクスが線形で表現される場合を考える。つまり、確率的ダイナミクスとして、以下の式(16)を仮定することが出来る。
μt+1=At+1μt+νt+1+εt+1 (16)
p(μt+1|μt)=N(μt+1|At+1μt+νt+1,U) (17)
p(μt│Ot)=N(μt│μ^t、Q^t) (19)
p(μt+1│Ot+1)=N(μt+1│μ^t+1、Q^t+1) (20)
ここで、
Q^t+1=((U+At+1Q^tAt+1’)−1+ζt+1Σ―1)−1
(21)
K^t+1=Q^t+1ζt+1Σ―1 (22)
μ^t+1=At+1μ^t+νt+1
+K^t+1(Mt+1/ζt+1−At+1μ^t−νt+1) (23)
Q^更新部520では前記式(21)が計算され、K^更新部522では前記式(22)が計算され、μ^更新部524では前記式(23)が計算され、事後確率計算部526では前記式(20)が計算される。
Q^t+1=(((u0)−1Σ+At+1Q^tAt+1’)−1+ζt+1Σ―1)−1 (25)
K^t+1=Q^t+1ζt+1Σ―1 (26)
μ^t+1=At+1μ^t+νt+1+K^t+1(Mt+1/ζt+1−At+1μ^t−νt+1) (27)
以上によってパラメータu0によって制御される分布変換にもとづく逐次適応法を実現できる。
前記線形ダイナミクスの式(16)の平均ベクトルμtの平行移動νt+1にだけ注目することにより、推定すべきパラメータを少なくしてより少量データでの適応を実現できる。このとき、前記式(25)(26)(27)における行列At+1を単位行列Iとする、つまり、At+1=Iとすると、Q^、K^、μ^は以下の式(28)(29)(30)で計算される。
K^t+1=Q^t+1ζt+1Σ―1 (29)
μ^t+1=μ^t+νt+1+Q^t+1ζt+1Σ―1(Mt+1/ζt+1−μ^t−νt+1) (30)
この場合、Q^更新部520では前記式(28)が計算され、K^更新部522では前記式(29)が計算され、μ^更新部524では前記式(30)が計算される。
C.J.Leggetter and P.C.Woodland,Maximum likelihood linear regression for speaker adaptation of continuous density hidden Markov models. Computer Speech and Language,Vol.9,pp.171-185,1995. C.J.Leggetter and P.C.Woodland,Maximum.Flexible speaker using maximum likehood linear regression In Proc ARPA Spoken Language Technology Work-shop,pp.104-109,1995. 渡部晋治、中村篤、確率分布の巨視的な時間発展システムに基づく逐次モデル適応.秋季音響学会講演論文集、2−2−10,pp.71−72,2006. 渡部晋治、中村篤、確率分布の巨視的な時間発展系に基づくモデル適応との従来型適応との関係の考察.秋季音響学会講演論文集2−3−12、2007.
また分布パラメータQ^tはモデルの更新に必要なため、それらを音響モデルパラメータ記憶部58に記憶する必要がある。しかし、Q^tは非対角成分が0でない全共分散行列(ただし、対称行列)であり、それが音響モデル中のガウス分布数分存在するため、大量のメモリを消費する。例えば、音響モデルは39次元のガウス分布数万個で表現される音響モデルが数メガバイト程度なのに対し、Q^tだけで、音響モデルの10倍以上のメモリ(数10メガバイト)を消費する。
Q^t=(r^t)−1Σ (31)
これにより、式(28)〜(30)はスカラー演算に直すことができるため、計算量の削減および安定性の確保を実現することができる。また、記憶すべき更新パラメータが対称行列Q^tからr^tとなるため音響モデル記憶部中のメモリ容量を削減できる。
μt 前回の音響モデル中のガウス分布の平均ベクトルパラメータ
Σt 前回の音響モデル中のガウス分布の共分散行列パラメータ
p(μt│Ot) 前回の音響モデル中のガウス分布の平均ベクトルパラメータμtの事後分布確率
μ^t 音響モデル中のガウス分布の平均ベクトルパラメータμtの事後確率分布p(μt│Ot)をガウス分布で表現した際の平均ベクトルパラメータ、もしくは、p(μt│Ot)の平均ベクトルパラメータ
Q^t 音響モデル中のガウス分布の平均ベクトルパラメータμtの事後確率分布p(μt│Ot)をガウス分布で表現した際の共分散行列パラメータ、もしくは、p(μt│Ot)の共分散行列パラメータ
r^t 音響モデル中のガウス分布の平均ベクトルパラメータμtの事後確率分布p(μt│Ot)をガウス分布で表現した際の共分散行列パラメータQ^tに対するスケーリング因子、もしくは、p(μt│Ot)の共分散行列パラメータQ^tに対するスケーリング因子
前記式(28)〜(30)について、式(29)に示すK^t+1を式(30)に代入した式を以下に示す。
Q^t+1=(((u0)−1Σ+Q^t)−1+ζt+1Σ―1)−1(32)
μ^t+1=μ^t+νt+1+Q^t+1ζt+1Σ―1(Mt+1/ζt+1−μ^t−νt+1) (33)
Q^t=(r^t)−1Σ (31)
この式(31)を式(32)に代入するとQ^t+1の更新式はそれぞれ以下のように表現できる。
Q^t+1=(((μ0)−1Σ+(r^t)−1Σ)−1+ζt+1Σ−1)−1
=(((μ0)−1+(r^t)−1)−1+ζt+1)−1Σ
(34)
r^t+1=((μ0)−1+(r^t)−1)−1+ζt+1 (35)
つまり、式(32)に示すQ^t+1の更新式を式(35)に示すr^t+1に書き直すことができる。
p(μt+1│Ot+1)=N(μt+1│μ^t+1、(r^t+1)−1Σ)
(37)
p(μt│Ot)=N(μt│μ^t、(r^t)−1Σ) (37’)
により表される。従って、前回の平均ベクトルパラメータμ^t、前回のスケーリング因子r^tを用いるということは、事後分布確率p(μt│Ot)を用いているということになる。
また、式(35)(36)を用いることにより、逐次適応において、図9中の音響モデル記憶部58記載のように、分布パラメータの共分散行列Q^tと平均ベクトルパラメータμ^tを記録するのではなく、図12、図13中の音響モデル記憶部158記載のようにスケーリング因子r^tと平均ベクトルμ^tを記録することにより、大幅にメモリ量を削減できる。
∫p(xτ|μt)p(μt|Ot)dμt (40)
ここでp(xτ|μt)は音響モデルの出力分布である。μt以外のパラメータはここでは省略する。従って、p(μt|Ot)について検討すれば良い。単語列探索部6による複数フレームの音響スコア算出に関しては前記式(40)をもとに動的計画法(DP:Dynamic Programming マッチング)を行えばよい。音響スコアを最大とする単語列を認識単語列として出力する(ステップS84)。なお、この場合はステップS80におけるモデル更新は、音響モデルとして事後確率分布p(μτ|Ot)の更新を行う(ステップS80a)。前記式(40)の積分は数値的に解くことも可能であるが、次のような2種類の解析解が存在する。
Plug-in法では、積分をまともに扱うのではなく、p(μt|Ot)の事後確率最大化(MAP)値(以下の式(41)の右辺)は、前記式(36)のμ^tである事を利用する。つまり、以下の式(41)になる。
周辺化法は、Plug-in法と違い積分を解析的に解く方法である。この積分をとく方法が、平均ベクトルパラメータμtについての周辺化にあたる。周辺化法は、Plug-in法と比較して、平均ベクトルパラメータの事後確率分布p(μt|Ot)の分散を考慮することになる。このようにすれば、積分計算によるスコア計算は以下の式(43)で表せることになる。
ASJ(日本音響学会)読み上げ音声データベース100時間分を用いてトライフォンHMMの総状態数2000、HMM状態あたりの混合数16の不特定話者音響モデルを構築し、日本語模擬ニュース音声に対し、逐次適応実験を行った。特徴量は12次元MFCC(メルフレクエンシイペプストラム係数)と、そのフレームのエネルギーと、MFCCのフレーム間差分Δと、その差分MFCCのフレーム間差分デルタΔΔとして、語彙サイズ70万語のトライアングルを用いて大語彙連続音声認識実験を行った。逐次適応を行わない通常の音声認識の場合の音声認識率は81.3%であった。
また、この発明の音響モデル作成装置における処理をコンピュータによって実現する場合、音響モデル作成装置が有すべき機能の処理内容はプログラムによって記述される。そして、このプログラムをコンピュータで実行することにより、音響モデル作成装置における処理機能がコンピュータ上で実現される。
Claims (10)
- 適応用音声データの特徴量系列を抽出する特徴抽出部と、
音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布をガウス分布で表現した際の、当該事後確率分布の平均ベクトルパラメータ、当該事後確率分布の共分散行列パラメータに対するスケーリング因子、初期音響モデルパラメータ中の共分散行列で表されることに基づき、前回までの累積された特徴量系列が加味された、前回求めた音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布及び今回まで累積された特徴量系列の一部を用いて、今回の音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布をガウス分布で表現した際の、当該事後確率分布の平均ベクトルパラメータ及び当該事後確率分布の共分散行列パラメータのスケーリング因子を計算することで、今回の音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布を求める逐次学習部と、
前記今回の音響モデルパラメータの事後確率分布を新たな音響モデルパラメータに変換して更新するモデル更新部と、を具備する音響モデル作成装置。 - 請求項1記載の音響モデル作成装置であって、
前記逐次学習部は、音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布の共分散ベクトルパラメータに対する今回のスケーリング因子r^t+1を、前回のスケーリング因子r^t、今回の事後占有確率値の和ζt+1とから求め、
音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布の今回の平均ベクトルパラメータμ^t+1を、前回の平均ベクトルパラメータμ^t、今回の音響モデルパラメータ中の平均の確率的ダイナミクスを線形表現した時の係数ベクトルνt+1、今回の事後占有確率値の和ζt+1、今回の各時点におけるζと特徴量との積和Mt+1、今回のスケーリング因子r^t+1とから求めることを特徴とする音響モデル作成装置。 - 請求項2記載の音響モデル作成装置であって、
前記逐次学習部は、今回の音響モデルパラメータのスケーリング因子r^t+1および今回の音響モデルパラメータの平均ベクトルパラメータμ^t+1を以下の式により求め、
- 認識用音声データの音響的特徴を持つ適応用音声データに適応化させた音響モデルを、請求項1〜3何れかに記載した音響モデル作成装置により作成して、音響モデルを更新する認識用モデル更新部と、
前記更新された音響モデルを用いて、前記音響的特徴を持った入力音声データに対する音声認識を行う認識部とを具備する音声認識装置。 - 適応用音声データの特徴量系列を抽出する特徴抽出過程と、
音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布をガウス分布で表現した際の、当該事後確率分布の平均ベクトルパラメータ、当該事後確率分布の共分散行列パラメータに対するスケーリング因子、初期音響モデルパラメータ中の共分散行列で表されることに基づき、前回までの累積された特徴量系列が加味された、前回求めた音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布及び今回まで累積された特徴量系列の一部を用いて、今回の音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布をガウス分布で表現した際の、当該事後確率分布の平均ベクトルパラメータ及び当該事後確率分布の共分散行列パラメータのスケーリング因子を計算することで、今回の音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布を求める逐次学習過程と、
前記今回の音響モデルパラメータの事後確率分布を新たな音響モデルパラメータに変換して更新するモデル更新過程と、を有する音響モデル作成方法。 - 請求項5記載の音響モデル作成方法であって、
前記逐次学習過程は、音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布の共分散ベクトルパラメータに対する今回のスケーリング因子r^t+1を、前回のスケーリング因子r^t、今回の事後占有確率値の和ζt+1とから求め、
音響モデル中のガウス分布の平均ベクトルパラメータの事後確率分布の今回の平均ベクトルパラメータμ^t+1を、前回の平均ベクトルパラメータμ^t、今回の音響モデルパラメータ中の平均の確率的ダイナミクスを線形表現した時の係数ベクトルνt+1、今回の事後占有確率値の和ζt+1、今回の各時点におけるζと特徴量との積和Mt+1、今回のスケーリング因子r^t+1とから求めることを特徴とする音響モデル作成方法。 - 請求項6記載の音響モデル作成方法であって、
前記逐次学習過程は、今回の音響モデルパラメータのスケーリング因子r^t+1および今回の音響モデルパラメータの平均ベクトルパラメータμ^t+1を以下の式により求め、
- 認識用音声データの音響的特徴を持つ適応用音声データに適応化させた音響モデルを、請求項5〜7何れかに記載した音響モデル作成方法により作成して、音響モデルを更新する認識用モデル更新過程と、
前記更新された音響モデルを用いて、前記音響的特徴を持った入力音声データに対する音声認識を行う認識過程とを有する音声認識方法。 - 請求項1〜3何れかに記載の音響モデル作成装置または、請求項4記載の音声認識装置としてコンピュータを動作させるプログラム。
- 請求項9記載のプログラムを記録したコンピュータ読み取り可能な記録媒体。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008216640A JP4881357B2 (ja) | 2008-08-26 | 2008-08-26 | 音響モデル作成装置、その装置を用いた音声認識装置、これらの方法、これらのプログラム、およびこれらの記録媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008216640A JP4881357B2 (ja) | 2008-08-26 | 2008-08-26 | 音響モデル作成装置、その装置を用いた音声認識装置、これらの方法、これらのプログラム、およびこれらの記録媒体 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010054588A true JP2010054588A (ja) | 2010-03-11 |
| JP4881357B2 JP4881357B2 (ja) | 2012-02-22 |
Family
ID=42070622
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008216640A Active JP4881357B2 (ja) | 2008-08-26 | 2008-08-26 | 音響モデル作成装置、その装置を用いた音声認識装置、これらの方法、これらのプログラム、およびこれらの記録媒体 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4881357B2 (ja) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9251784B2 (en) | 2013-10-23 | 2016-02-02 | International Business Machines Corporation | Regularized feature space discrimination adaptation |
| KR20200063315A (ko) * | 2018-11-20 | 2020-06-05 | 한국전자통신연구원 | 음성 인식을 위한 음향 모델 학습 장치 및 그 학습 방법 |
| CN114067834A (zh) * | 2020-07-30 | 2022-02-18 | 中国移动通信集团有限公司 | 一种不良前导音识别方法、装置、存储介质和计算机设备 |
| CN116978368A (zh) * | 2023-09-25 | 2023-10-31 | 腾讯科技(深圳)有限公司 | 一种唤醒词检测方法和相关装置 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004117503A (ja) * | 2002-09-24 | 2004-04-15 | Nippon Telegr & Teleph Corp <Ntt> | 音声認識用音響モデル作成方法、その装置、そのプログラムおよびその記録媒体、上記音響モデルを用いる音声認識装置 |
| JP2006053431A (ja) * | 2004-08-13 | 2006-02-23 | Nippon Telegr & Teleph Corp <Ntt> | 音声認識用音響モデル作成方法、音声認識用音響モデル作成装置、音声認識用音響モデル作成プログラム及びこのプログラムを記録した記録媒体 |
| JP2008064849A (ja) * | 2006-09-05 | 2008-03-21 | Nippon Telegr & Teleph Corp <Ntt> | 音響モデル作成装置、その装置を用いた音声認識装置、これらの方法、これらのプログラム、およびこれらの記録媒体 |
-
2008
- 2008-08-26 JP JP2008216640A patent/JP4881357B2/ja active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004117503A (ja) * | 2002-09-24 | 2004-04-15 | Nippon Telegr & Teleph Corp <Ntt> | 音声認識用音響モデル作成方法、その装置、そのプログラムおよびその記録媒体、上記音響モデルを用いる音声認識装置 |
| JP2006053431A (ja) * | 2004-08-13 | 2006-02-23 | Nippon Telegr & Teleph Corp <Ntt> | 音声認識用音響モデル作成方法、音声認識用音響モデル作成装置、音声認識用音響モデル作成プログラム及びこのプログラムを記録した記録媒体 |
| JP2008064849A (ja) * | 2006-09-05 | 2008-03-21 | Nippon Telegr & Teleph Corp <Ntt> | 音響モデル作成装置、その装置を用いた音声認識装置、これらの方法、これらのプログラム、およびこれらの記録媒体 |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9251784B2 (en) | 2013-10-23 | 2016-02-02 | International Business Machines Corporation | Regularized feature space discrimination adaptation |
| KR20200063315A (ko) * | 2018-11-20 | 2020-06-05 | 한국전자통신연구원 | 음성 인식을 위한 음향 모델 학습 장치 및 그 학습 방법 |
| KR102418887B1 (ko) | 2018-11-20 | 2022-07-11 | 한국전자통신연구원 | 음성 인식을 위한 음향 모델 학습 장치 및 그 학습 방법 |
| CN114067834A (zh) * | 2020-07-30 | 2022-02-18 | 中国移动通信集团有限公司 | 一种不良前导音识别方法、装置、存储介质和计算机设备 |
| CN116978368A (zh) * | 2023-09-25 | 2023-10-31 | 腾讯科技(深圳)有限公司 | 一种唤醒词检测方法和相关装置 |
| CN116978368B (zh) * | 2023-09-25 | 2023-12-15 | 腾讯科技(深圳)有限公司 | 一种唤醒词检测方法和相关装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP4881357B2 (ja) | 2012-02-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9460711B1 (en) | Multilingual, acoustic deep neural networks | |
| Najkar et al. | A novel approach to HMM-based speech recognition systems using particle swarm optimization | |
| US8515758B2 (en) | Speech recognition including removal of irrelevant information | |
| US20170040016A1 (en) | Data augmentation method based on stochastic feature mapping for automatic speech recognition | |
| CN107615376B (zh) | 声音识别装置及计算机程序记录介质 | |
| Lu et al. | Acoustic data-driven pronunciation lexicon for large vocabulary speech recognition | |
| JP5249967B2 (ja) | 音声認識装置、重みベクトル学習装置、音声認識方法、重みベクトル学習方法、プログラム | |
| CN113674733A (zh) | 用于说话时间估计的方法和设备 | |
| Mirsamadi et al. | A study on deep neural network acoustic model adaptation for robust far-field speech recognition. | |
| JPWO2007105409A1 (ja) | 標準パタン適応装置、標準パタン適応方法および標準パタン適応プログラム | |
| US8078462B2 (en) | Apparatus for creating speaker model, and computer program product | |
| JP4881357B2 (ja) | 音響モデル作成装置、その装置を用いた音声認識装置、これらの方法、これらのプログラム、およびこれらの記録媒体 | |
| JP4829871B2 (ja) | 学習データ選択装置、学習データ選択方法、プログラムおよび記録媒体、音響モデル作成装置、音響モデル作成方法、プログラムおよび記録媒体 | |
| JP4964194B2 (ja) | 音声認識モデル作成装置とその方法、音声認識装置とその方法、プログラムとその記録媒体 | |
| JP3920749B2 (ja) | 音声認識用音響モデル作成方法、その装置、そのプログラムおよびその記録媒体、上記音響モデルを用いる音声認識装置 | |
| JP6158105B2 (ja) | 言語モデル作成装置、音声認識装置、その方法及びプログラム | |
| JP5079760B2 (ja) | 音響モデルパラメータ学習装置、音響モデルパラメータ学習方法、音響モデルパラメータ学習プログラム | |
| JP4891806B2 (ja) | 適応モデル学習方法とその装置、それを用いた音声認識用音響モデル作成方法とその装置、及び音響モデルを用いた音声認識方法とその装置、及びそれら装置のプログラムと、それらプログラムの記憶媒体 | |
| JP4950600B2 (ja) | 音響モデル作成装置、その装置を用いた音声認識装置、これらの方法、これらのプログラム、およびこれらの記録媒体 | |
| JP4705557B2 (ja) | 音響モデル生成装置、方法、プログラム及びその記録媒体 | |
| JP6542823B2 (ja) | 音響モデル学習装置、音声合成装置、それらの方法、及びプログラム | |
| JP7259988B2 (ja) | 検知装置、その方法、およびプログラム | |
| JP5457999B2 (ja) | 雑音抑圧装置とその方法とプログラム | |
| JP4801108B2 (ja) | 音声認識装置、方法、プログラム及びその記録媒体 | |
| JP4801107B2 (ja) | 音声認識装置、方法、プログラム及びその記録媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20100726 |
|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20110810 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20111024 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20111122 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20111202 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 Ref document number: 4881357 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20141209 Year of fee payment: 3 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| S533 | Written request for registration of change of name |
Free format text: JAPANESE INTERMEDIATE CODE: R313533 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |