JP2010044609A - データ改ざん検出装置、データ改ざん検出方法、およびデータ改ざん検出プログラム - Google Patents
データ改ざん検出装置、データ改ざん検出方法、およびデータ改ざん検出プログラム Download PDFInfo
- Publication number
- JP2010044609A JP2010044609A JP2008208480A JP2008208480A JP2010044609A JP 2010044609 A JP2010044609 A JP 2010044609A JP 2008208480 A JP2008208480 A JP 2008208480A JP 2008208480 A JP2008208480 A JP 2008208480A JP 2010044609 A JP2010044609 A JP 2010044609A
- Authority
- JP
- Japan
- Prior art keywords
- data
- nth
- remaining
- composite
- length
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 230000004075 alteration Effects 0.000 title claims abstract description 32
- 238000001514 detection method Methods 0.000 title claims description 37
- 238000000034 method Methods 0.000 claims description 50
- 239000002131 composite material Substances 0.000 claims description 42
- 238000004364 calculation method Methods 0.000 claims description 18
- 238000007493 shaping process Methods 0.000 claims description 18
- 239000000203 mixture Substances 0.000 abstract description 10
- 230000002596 correlated effect Effects 0.000 abstract 1
- 238000013500 data storage Methods 0.000 description 18
- 238000007726 management method Methods 0.000 description 10
- 230000015572 biosynthetic process Effects 0.000 description 9
- 238000003786 synthesis reaction Methods 0.000 description 9
- 230000002194 synthesizing effect Effects 0.000 description 9
- 238000010586 diagram Methods 0.000 description 8
- 238000000605 extraction Methods 0.000 description 8
- 230000006870 function Effects 0.000 description 4
- 238000012790 confirmation Methods 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 239000000284 extract Substances 0.000 description 2
- 238000004590 computer program Methods 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000013523 data management Methods 0.000 description 1
- 238000004321 preservation Methods 0.000 description 1
Images






Landscapes
- Storage Device Security (AREA)
Abstract
【解決手段】本発明に係る改ざん検出装置1は、一意的に関連づけられる必要のある第1および第2のデータ101〜102の改ざんを検出する改ざん検出装置であって、第1のデータと第2のデータとをXOR(排他的論理和)演算して合成データ104を生成する演算部103と、合成データを記憶する記憶部205とを有し、演算部が第1のデータと第2のデータのうち一方のデータと合成データとをXOR演算して他方のデータを生成する。
【選択図】図2
Description
以下、本発明の実施形態の構成について添付図に基づいて説明する。
最初に、本実施形態の基本的な内容について説明し、その後でより具体的な内容について説明する。
本実施形態に係るデータ改ざん検出装置1は、図1〜2に示すように、第1のデータ(文書A101)と第2のデータ(文書B102)とをXOR(排他的論理和)演算して合成データ(COM(A,B)104)を生成する演算部(演算装置103)と、合成データを記憶する記憶部(作業用データ保存部205)とを有する。その上で演算部(演算装置103)は、合成データ(COM(A,B)104)と第1のデータと第2のデータのうちの一方のデータとをXOR演算して他方のデータを生成する。
以後は、nを2以上の自然数とすると、第n−1の残データが一方のデータより長い場合、第n−1の残データから一方のデータ(文書B102)とデータ長が同一の第nの部分データを切り出し、その残りを第nの残データとして、第nの部分データと一方のデータ(文書B102)とをXOR演算して得られた第nの合成データを記憶部に保存するという処理を繰り返す。
第nの部分データが一方のデータ(文書B102)よりも短くなれば一方のデータ(文書B102)から第nの部分データと同一のデータ長を切り出した第n+1の部分データと第nの部分データとをXOR演算して得られた第n+1の合成データを記憶部に保存する。
そして、第1〜第n+1の合成データを切り出し順に従って連結して、合成データ(COM(A,B)104)を生成する。
[基本原理]
関連付けるべき計算機上のデータ対をAおよびBとする。この二つのデータはコンピュータ上では2進数列として表現されている。データA、Bの2進数表現(バイナリデータ)を各々BIN(A)、BIN(B)とする。また、二つのデータの2進数列の長さをLEN(BIN(A))、LEN(BIN(B))とする。説明を容易にするために、LEN(BIN(A))=LEN(BIN(B))であるとする。
このCOM(A、B)を用いて、二つのデータを管理することで、従来の課題を解決する。
f=COM(A、B)= BIN(A) XOR BIN(B)
B=COM(f、A)=COM(A、B) XOR BIN(A)
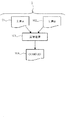
図1は本発明の第1の実施形態に係るデータ改ざん検出装置1の構成を示す概略構成図である。データ改ざん検出装置1は、データ対をなす文書A101と文書B102を管理対象とし、それらから合成データを算出するコンピュータ装置である演算装置103を要部として構成されている。符号104は、演算装置103によって算出された合成データとしてのCOM(A,B)104を示す。この合成データCOM(A,B)は、上述の通りCOM(A、B)=BIN(A) XOR BIN(B)である。
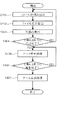
図4は、図1および図2に示した演算装置103が実行する処理を表すフローチャートである。なお、図4では管理対象を2つの文書であるとして説明しているが、3つ以上の管理対象文書に対しては、2つの管理対象に対して実施した本発明の動作の結果得られた合成データをひとつの管理対象文書とみなして、3つ目の文書との間で処理を行い、以降同様に必要な文書数だけ処理を繰り返せばよい。
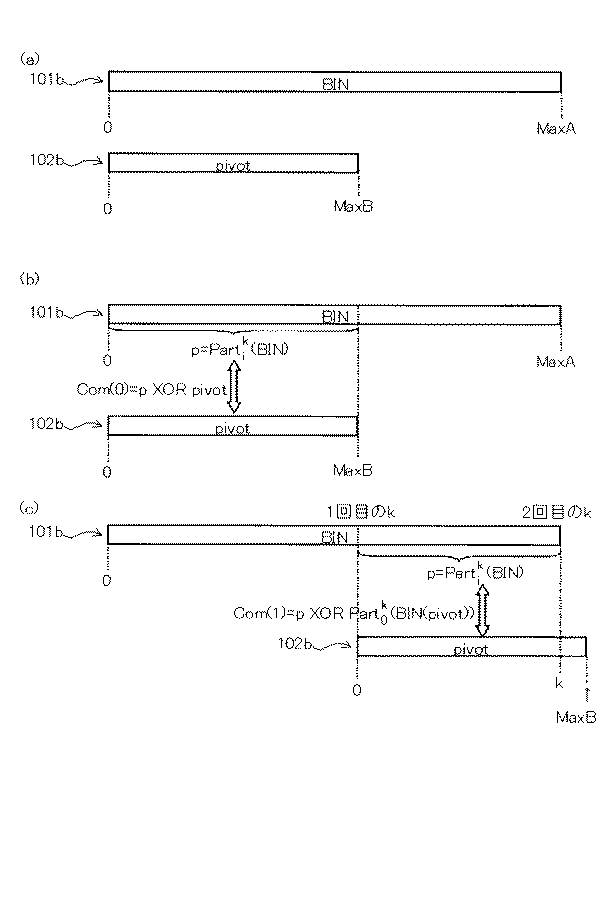
図7は、図4〜5で述べた処理で合成部204によって生成された合成処理結果COM(A、B)104を利用して、図1〜2に示した改ざん検出装置1によって元のデータを復元する処理について説明するフローチャートである。ここでは、文書B102のバイナリデータであるBIN(B)と、合成処理結果COM(A、B)104とを利用して、BIN(A)を再生する。
次に、上記の第1の実施形態の全体的な動作について説明する。本発明の第1の実施形態に係る改ざん検出装置1は、第1のデータ(文書A101)と第2のデータ(文書B102)とをXOR(排他的論理和)演算して合成データ(COM(A,B)104)を生成し、この合成データ(COM(A,B)104)を記憶し、合成データ(COM(A,B)104)と第2のデータ(文書B102)とをXOR演算して第1のデータ(文書A101)を生成するものである。
以後、nを2以上の自然数とすると、第n−1の残データが一方のデータより長い場合、第n−1の残データから一方のデータとデータ長が同一の第nの部分データを切り出し、その残りを第nの残データとして、第nの部分データと一方のデータとをXOR演算して得られた第nの合成データを保存するという処理を繰り返す(図5:ステップS506〜510)。
ここで、第nの残データが一方のデータよりも短くなった場合には(図5:ステップS508)、一方のデータから第nの残データとデータ長が同一の第n+1の部分データを切り出し、これと第nの残データとをXOR演算して得られた第n+1の合成データを保存する(図5:ステップS511)。
そして、これらの第1〜第n+1の合成データを切り出し順に従って連結することによって合成データ(COM(A,B)104)を生成する(図5:ステップS512)。
第1のデータと第2のデータのうち一方のデータをXOR演算して他方のデータを生成することにより、特殊な計算を特に必要とはせずに、記憶保持している他方のデータと生成されたデータとを比較することによって、第1もしくは第2のデータに改ざんがあったことを検出可能である。
図8は、本発明の第2の実施形態に係るデータ改ざん検出装置800を示す概略構成図である。本実施形態に係るデータ改ざん検出装置800は、身分証明書801とそれに対応する生体認証データ802とからなるデータ対を管理対象とする。生体認証データ802としては、たとえば指紋、虹彩などを利用することができる。生成された合成データ804は、身分証明書801に添付される。
101 文書A
102 文書B
101b 整形済文書A
102b 整形済文書B
103 演算装置
104 COM(A,B)
201 列長算出部
202 ファイル名抽出部
203 整形部
204 合成部
205 作業用データ保存部
300 作業用データ
301 列長
302 ファイル名
303 ボディ
801 身分証明書
802 生体認証データ
804 合成データ
Claims (10)
- 一意的に関連づけられるべき第1および第2のデータの改ざんを検出するデータ改ざん検出装置であって、
前記第1のデータと第2のデータとをXOR(排他的論理和)演算して合成データを生成する演算部と、前記合成データを記憶する記憶部とを有し、
前記演算部が、前記第1のデータと第2のデータのうち一方のデータと前記合成データとをXOR演算して前記他方のデータを生成することを特徴とするデータ改ざん検出装置。 - 前記演算部が、前記合成データを生成する際、
前記一方のデータが前記他方のデータより短い場合、前記他方のデータから前記一方のデータと同一のデータ長を第1の部分データとして切り出して残りを第1の残データとし、前記第1の部分データと前記一方のデータとをXOR演算して得られた第1の合成データを前記記憶部に保存し、
以後、nを2以上の自然数とすると、前記第n−1の残データが前記一方のデータより長い場合、前記第n−1の残データから前記一方のデータとデータ長が同一の第nの部分データを切り出し、その残りを第nの残データとして、前記第nの部分データと前記一方のデータとをXOR演算して得られた第nの合成データを前記記憶部に保存する処理を繰り返し、
前記第nの残データが前記一方のデータよりも短くなった場合に、前記一方のデータから前記第nの残データと同一のデータ長を切り出した第n+1の部分データと前記第nの残データとをXOR演算して得られた第n+1の合成データを前記記憶部に保存し、
前記第1ないし第n+1の合成データを切り出し順に従って連結することによって前記合成データを生成する合成部を有する
ことを特徴とする、請求項1に記載のデータ改ざん検出装置。 - 前記合成部が、前記合成データから前記一方のデータと同一のデータ長を切り出して前記一方のデータとXOR演算する処理を繰り返すと共に、前記XOR演算によって得られたデータを切り出し順に従って連結することによって前記他方のデータを生成するデータ復元機能を備えていることを特徴とする、請求項2に記載のデータ改ざん検出装置。
- 前記演算部が、
前記第1および第2の各データに、それぞれのデータ長およびファイル名を表す情報を連結する連結整形部を有し、
この連結整形部によってデータ長およびファイル名を表す情報を連結してなる前記第1および第2のデータに対して前記合成部が前記XOR演算を行うことを特徴とする、請求項2に記載のデータ改ざん検出装置。 - 前記第2のデータが生体認証データであり、前記合成データが前記第1のデータに添付されていることを特徴とする、請求項1に記載のデータ改ざん検出装置。
- 一意的に関連づけられるべき第1および第2のデータの改ざんを検出するデータ改ざん検出方法であって、
前記第1のデータと第2のデータとをXOR(排他的論理和)演算して合成データを生成し、
前記合成データを記憶し、
前記第1のデータと第2のデータのうち一方のデータと前記合成データとをXOR演算して前記他方のデータを生成することを特徴とするデータ改ざん検出方法。 - 前記合成データを生成する処理が、
前記一方のデータが前記他方のデータより短い場合、前記他方のデータから前記一方のデータと同一のデータ長を第1の部分データとして切り出して残りを第1の残データとし、
前記第1の部分データと前記一方のデータとをXOR演算して得られた第1の合成データを保存し、
以後、nを2以上の自然数とすると、前記第n−1の残データが前記一方のデータより長い場合、前記第n−1の残データから前記一方のデータとデータ長が同一の第nの部分データを切り出し、その残りを第nの残データとして、前記第nの部分データと前記一方のデータとをXOR演算して得られた第nの合成データを保存する処理を繰り返し、
前記第nの残データが前記一方のデータよりも短くなった場合に、前記一方のデータから前記第nの残データと同一のデータ長を切り出した第n+1の部分データと前記第nの残データとをXOR演算して得られた第n+1の合成データを保存し、
前記第1ないし第n+1の合成データを切り出し順に従って連結することによって前記合成データを生成する
ことを特徴とする、請求項6に記載のデータ改ざん検出方法。 - 前記合成データから前記一方のデータと同一のデータ長を切り出してXOR演算する処理を繰り返すと共に、
前記XOR演算によって得られたデータを切り出し順に従って連結することによって前記他方のデータを復元することを特徴とする、請求項7に記載のデータ改ざん検出方法。 - 一意的に関連づけられるべき第1および第2のデータの改ざんを検出する改ざん検出装置を形成するコンピュータに、
前記第1のデータと第2のデータとをXOR(排他的論理和)演算して合成データを生成する手順と、
前記合成データを記憶する手順と、
前記第1のデータと第2のデータのうち一方のデータと前記合成データとをXOR演算して前記他方のデータを生成する手順と
を実行させることを特徴とするデータ改ざん検出プログラム。 - 前記合成データを生成する手順が、
前記一方のデータが前記他方のデータより短い場合、前記他方のデータから前記一方のデータと同一のデータ長を第1の部分データとして切り出して残りを第1の残データとする手順と、
前記第1の部分データと前記一方のデータとをXOR演算して得られた第1の合成データを保存する手順と、
以後、nを2以上の自然数とすると、前記第n−1の残データが前記一方のデータより長い場合、前記第n−1の残データから前記一方のデータとデータ長が同一の第nの部分データを切り出し、その残りを第nの残データとして、前記第nの部分データと前記一方のデータとをXOR演算して得られた第nの合成データを保存する処理を繰り返す手順と、
前記第nの残データが前記一方のデータよりも短くなった場合に、前記一方のデータから前記第nの残データと同一のデータ長を切り出した第n+1の部分データと前記第nの残データとをXOR演算して得られた第n+1の合成データを保存する手順と、
前記第1ないし第n+1の合成データを切り出し順に従って連結することによって前記合成データを生成する手順と
を実行させることを特徴とする、請求項9に記載のデータ改ざん検出プログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008208480A JP4924568B2 (ja) | 2008-08-13 | 2008-08-13 | データ改ざん検出装置、データ改ざん検出方法、およびデータ改ざん検出プログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008208480A JP4924568B2 (ja) | 2008-08-13 | 2008-08-13 | データ改ざん検出装置、データ改ざん検出方法、およびデータ改ざん検出プログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010044609A true JP2010044609A (ja) | 2010-02-25 |
| JP4924568B2 JP4924568B2 (ja) | 2012-04-25 |
Family
ID=42015938
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008208480A Expired - Fee Related JP4924568B2 (ja) | 2008-08-13 | 2008-08-13 | データ改ざん検出装置、データ改ざん検出方法、およびデータ改ざん検出プログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4924568B2 (ja) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS63313255A (ja) * | 1987-06-16 | 1988-12-21 | Ricoh Co Ltd | 計算機システムにおけるデ−タ機密保護方法 |
| JPH11203185A (ja) * | 1998-01-13 | 1999-07-30 | Nec Corp | 伝送装置監視装置における二重化データベース比較方法 |
| JP2002084273A (ja) * | 2000-09-07 | 2002-03-22 | Aesop:Kk | 電子認証方式 |
| JP2005100205A (ja) * | 2003-09-26 | 2005-04-14 | Dainippon Printing Co Ltd | 非接触icタグのデータ暗号化・復号化方法およびシステムおよび非接触icタグ |
-
2008
- 2008-08-13 JP JP2008208480A patent/JP4924568B2/ja not_active Expired - Fee Related
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS63313255A (ja) * | 1987-06-16 | 1988-12-21 | Ricoh Co Ltd | 計算機システムにおけるデ−タ機密保護方法 |
| JPH11203185A (ja) * | 1998-01-13 | 1999-07-30 | Nec Corp | 伝送装置監視装置における二重化データベース比較方法 |
| JP2002084273A (ja) * | 2000-09-07 | 2002-03-22 | Aesop:Kk | 電子認証方式 |
| JP2005100205A (ja) * | 2003-09-26 | 2005-04-14 | Dainippon Printing Co Ltd | 非接触icタグのデータ暗号化・復号化方法およびシステムおよび非接触icタグ |
Also Published As
| Publication number | Publication date |
|---|---|
| JP4924568B2 (ja) | 2012-04-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP2105860B1 (en) | Method and apparatus for verifying integrity of redacted documents | |
| US6640294B2 (en) | Data integrity check method using cumulative hash function | |
| CN110457873A (zh) | 一种水印嵌入与检测方法及装置 | |
| CN111475574B (zh) | 一种基于区块链的数据采集装置 | |
| CN113065169B (zh) | 一种文件存证方法、装置及设备 | |
| CN104063731A (zh) | 一种采用数字水印技术的二维码防伪印刷及验证方法 | |
| CN116235169A (zh) | 文本数据的数字水印 | |
| JPH03151738A (ja) | 検証用データ生成装置 | |
| CN112434319A (zh) | 一种用于电子文件的数据加密方法及装置 | |
| Saracevic et al. | Implementation of encryption and data hiding in E-health application | |
| CN112769567A (zh) | 一种区块链hd私钥找回方法 | |
| Mehta et al. | A novel approach as multi-place watermarking for security in database | |
| KR20120055070A (ko) | 영상의 무결성 검증 및 복구 가능한 무손실 디지털 워터마킹 시스템 및 방법 | |
| Kumar et al. | SIGNIFICANCE of hash value generation in digital forensic: A case study | |
| JP4924568B2 (ja) | データ改ざん検出装置、データ改ざん検出方法、およびデータ改ざん検出プログラム | |
| Lin et al. | A copyright protection scheme based on PDF | |
| EP2012269B1 (en) | Method for embedding a multi-bit digital watermark in media data | |
| CN112910638A (zh) | 一种区块链系统密钥的找回方法 | |
| CN114547562B (zh) | 文本水印添加及应用的方法和装置 | |
| CN107291763B (zh) | 电子文档的管理方法及管理装置 | |
| JP6273224B2 (ja) | 暗号化システム、暗号化装置、復号装置、暗号化方法 | |
| Dandass et al. | An empirical analysis of disk sector hashes for data carving | |
| Bellafqira et al. | A blockchain-enhanced reversible watermarking framework for end-to-end data traceability in federated learning systems | |
| Das et al. | A secured key-based digital text passing system through color image pixels | |
| CN118279117B (zh) | 教育考试图像的水印隐写、识别方法及系统 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20110930 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20111011 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20111209 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120110 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120123 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150217 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |