JP2010039671A - テキストマイニング装置、方法、プログラム及びその記録媒体 - Google Patents
テキストマイニング装置、方法、プログラム及びその記録媒体 Download PDFInfo
- Publication number
- JP2010039671A JP2010039671A JP2008200574A JP2008200574A JP2010039671A JP 2010039671 A JP2010039671 A JP 2010039671A JP 2008200574 A JP2008200574 A JP 2008200574A JP 2008200574 A JP2008200574 A JP 2008200574A JP 2010039671 A JP2010039671 A JP 2010039671A
- Authority
- JP
- Japan
- Prior art keywords
- word
- frequency
- fixed part
- analysis target
- document
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images









Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
【解決手段】各複数の分析対象文書を複数の単語に分割する。複数の分割された単語のそれぞれが分析対象文書に出現する頻度(以下、単語出現頻度とする。)を求める。ある分析対象文書の定型部をその分析対象文書の主題とは関係がない定型的な部分とし、ある単語の定型部平均単語出現頻度をその単語が各上記複数の分析対象文書の定型部に出現する推定平均頻度として、分割された単語について求まった単語出現頻度からその単語の定型部平均単語出現頻度を減算して、その単語についての定型部影響除去後単語出現頻度を求める。ある単語の文書頻度をその単語を含む上記複数の分析対象文書の数として、定型部影響除去後単語出現頻度が予め定められた頻度よりも高い又は以上である単語のそれぞれについての文書頻度を求める。
【選択図】図1
Description
第1の方法は、定型部に多く現れる単語をストップワードとして登録しておき、このストップワードとして登録された単語を除いて単語ランキングを生成する方法である(例えば、非特許文献1参照。)。ストップワードの例を図8の右上に示す。この例では、文書1,2,3の定型部に多く現れる「電話」「横須賀」「市役所」「市民」「窓口」「ありがとう」「失礼」が、ストップワードとして登録される。そして、これらのストップワードを除いて生成された単語ランキングの例を図8の右下に示す。この単語ランキングは、図6の単語ランキングから、これらのストップワードを除いたものである。
北研二,津田和彦,獅々堀正幹,「情報検索アルゴリズム」,共立出版,p.29−30 Maria A.Hearst. Multi-Paragraph Segmentation of Expository Text.32nd Annual Meeting of the Association for Computation Linguistics. P.9-16. 1944
定型部平均単語出現頻度は単語が定型部に出現する推定平均頻度であるから、単語出現頻度からこの定型部平均単語出現頻度を減算しても、上記第1の方法とは異なり、主題を構成する単語を必要以上に除外することにはならない。また、上記第2の方法とは異なり、上記テキストタイリング法を用いないため、定型部を適切に区切ることができないという問題は生じない。
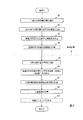
分析対象文書記憶部10に記憶された複数の分析対象文書から一部の分析対象文書が選択される(ステップS1)。そして、これらの選択された分析対象文書のそれぞれから定型部が取り出されて、定型部記憶部20に記憶される。
〔参考文献1〕石崎俊,「自然言語処理」,昭晃堂,P.27−29
定型部形態素解析部30が定型部を分割して単語を出力する際、その分割の方法によっては、助詞、接続詞等の単体で主題を構成しない単語が出力される場合がある。この場合、定型部単語出現頻度計算部40は、名詞、動詞等の単体で主題を構成する単語についての出現頻度を求め、助詞、接続詞等の単体で主題を構成しない単語についての出現頻度を求めなくてもよい。つまり、定型部単語出現頻度計算部40は、定型部形態素解析部30が分割した単語の全部ではなく、一部の単語についての出現頻度を求めてもよい。
−R(Recordable)/RW(ReWritable)等を、光磁気記録媒体として、MO(Magneto-Optical disc)等を、半導体メモリとしてEEP−ROM(Electronically Erasable and Programmable-Read Only Memory)等を用いることができる。
また、上述の各種の処理は、記載に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されてもよい。
その他、本発明の趣旨を逸脱しない範囲で適宜変更が可能であることはいうまでもない。
20 定型部記憶部
30 定型部形態素解析部
40 定型部単語出現頻度計算部
50 定型部平均単語出現頻度計算部
51 定型部平均単語出現頻度記憶部
60 形態素解析部
70 単語出現頻度計算部
80 定型部影響除去部
90 文書頻度計算部
100 単語並替部
Claims (6)
- 複数の分析対象文書を格納する分析対象文書記憶部と、
上記分析対象文書記憶部から読み込んだ各上記複数の分析対象文書を複数の単語に分割する形態素解析部と、
上記複数の分割された単語の全部又は一部のそれぞれが上記読み込んだ分析対象文書に出現する頻度(以下、単語出現頻度とする。)を求める単語出現頻度計算部と、
ある分析対象文書の定型部をその分析対象文書の主題とは関係がない定型的な部分とし、ある単語の定型部平均単語出現頻度をその単語が各上記複数の分析対象文書の定型部に出現する推定平均頻度として、上記分割された単語について求まった上記単語出現頻度からその単語の定型部平均単語出現頻度を減算して、その単語についての定型部影響除去後単語出現頻度を求める定型部影響除去部と、
ある単語の文書頻度をその単語を含む上記複数の分析対象文書の数として、上記複数の分割された単語のうち、定型部影響除去後単語出現頻度が予め定められた頻度よりも高い又は以上である単語のそれぞれについての文書頻度を求める文書頻度計算部と、
を含むテキストマイニング装置。 - 請求項1に記載のテキストマイニング装置において、
上記複数の分析対象文書から選択された一部の分析対象文書のそれぞれの定型部を複数の単語に分割する定型部形態素解析部と、
各上記複数の分割された単語の全部又は一部のそれぞれが、上記定型部に出現する頻度を求める定型部単語出現頻度計算部と、
上記求まった頻度を単語ごとに加算した後に、上記一部の分析対象文書の数で割ることにより、その単語の定型部平均単語出現頻度を求める定型部平均単語出現頻度計算部と、
を更に含むことを特徴とするテキストマイニング装置。 - 請求項1又は2に記載のテキストマイニング装置において、
上記文書頻度が高い順に単語を出力する単語並替部を更に含む、
ことを特徴とするテキストマイニング装置。 - 分析対象文書記憶部には複数の分析対象文書を格納され、
上記分析対象文書記憶部から読み込んだ各上記複数の分析対象文書を複数の単語に分割する形態素解析ステップと、
上記複数の分割された単語の全部又は一部のそれぞれが上記読み込んだ分析対象文書に出現する頻度(以下、単語出現頻度とする。)を求める単語出現頻度計算ステップと、
ある分析対象文書の定型部をその分析対象文書の主題とは関係がない定型的な部分とし、ある単語の定型部平均単語出現頻度をその単語が各上記複数の分析対象文書の定型部に出現する推定平均頻度として、上記分割された単語について求まった上記単語出現頻度からその単語の定型部平均単語出現頻度を減算して、その単語についての定型部影響除去後単語出現頻度を求める定型部影響除去ステップと、
ある単語の文書頻度をその単語を含む上記複数の分析対象文書の数として、上記複数の分割された単語のうち、定型部影響除去後単語出現頻度が予め定められた頻度よりも高い又は以上である単語のそれぞれについての文書頻度を求める文書頻度計算ステップと、
を含むテキストマイニング方法。 - 請求項1から3の何れかに記載のテキストマイニング装置の各部としてコンピュータを機能させるためのプログラム。
- 請求項5に記載のプログラムを記憶したコンピュータ読み取り可能な記録媒体。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008200574A JP5022319B2 (ja) | 2008-08-04 | 2008-08-04 | テキストマイニング装置、方法、プログラム及びその記録媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008200574A JP5022319B2 (ja) | 2008-08-04 | 2008-08-04 | テキストマイニング装置、方法、プログラム及びその記録媒体 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010039671A true JP2010039671A (ja) | 2010-02-18 |
| JP5022319B2 JP5022319B2 (ja) | 2012-09-12 |
Family
ID=42012169
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008200574A Expired - Fee Related JP5022319B2 (ja) | 2008-08-04 | 2008-08-04 | テキストマイニング装置、方法、プログラム及びその記録媒体 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5022319B2 (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109478191A (zh) * | 2016-07-25 | 2019-03-15 | 株式会社斯库林集团 | 文本挖掘方法、文本挖掘程序及文本挖掘装置 |
| JPWO2020230309A1 (ja) * | 2019-05-15 | 2020-11-19 | ||
| US20230196017A1 (en) * | 2021-12-22 | 2023-06-22 | Bank Of America Corporation | Classication of documents |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11282876A (ja) * | 1998-03-28 | 1999-10-15 | Matsushita Electric Ind Co Ltd | 文書検索装置 |
| JP2003296365A (ja) * | 2002-03-29 | 2003-10-17 | Sony Corp | 情報処理装置および方法、記録媒体、並びにプログラム |
-
2008
- 2008-08-04 JP JP2008200574A patent/JP5022319B2/ja not_active Expired - Fee Related
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11282876A (ja) * | 1998-03-28 | 1999-10-15 | Matsushita Electric Ind Co Ltd | 文書検索装置 |
| JP2003296365A (ja) * | 2002-03-29 | 2003-10-17 | Sony Corp | 情報処理装置および方法、記録媒体、並びにプログラム |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109478191A (zh) * | 2016-07-25 | 2019-03-15 | 株式会社斯库林集团 | 文本挖掘方法、文本挖掘程序及文本挖掘装置 |
| JPWO2020230309A1 (ja) * | 2019-05-15 | 2020-11-19 | ||
| JP7338679B2 (ja) | 2019-05-15 | 2023-09-05 | 日本電信電話株式会社 | 業務文書提示装置、業務文書提示方法および業務文書提示プログラム |
| US11874881B2 (en) | 2019-05-15 | 2024-01-16 | Nippon Telegraph And Telephone Corporation | Business documents presentation device, business documents presentation method and business documents presentation program |
| US20230196017A1 (en) * | 2021-12-22 | 2023-06-22 | Bank Of America Corporation | Classication of documents |
| US11977841B2 (en) * | 2021-12-22 | 2024-05-07 | Bank Of America Corporation | Classification of documents |
Also Published As
| Publication number | Publication date |
|---|---|
| JP5022319B2 (ja) | 2012-09-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5775466B2 (ja) | 会話から雑談部分を抽出するための雑談抽出システム、方法、およびプログラム | |
| US10783314B2 (en) | Emphasizing key points in a speech file and structuring an associated transcription | |
| US10831793B2 (en) | Learning thematic similarity metric from article text units | |
| JP6310150B2 (ja) | 意図理解装置、方法およびプログラム | |
| CN104169909B (zh) | 上下文解析装置及上下文解析方法 | |
| KR101768852B1 (ko) | 트리플 데이터의 생성 방법 및 시스템 | |
| JP6812381B2 (ja) | 音声認識精度劣化要因推定装置、音声認識精度劣化要因推定方法、プログラム | |
| WO2019049483A1 (ja) | 同義語辞書作成装置、同義語辞書作成プログラム及び同義語辞書作成方法 | |
| JP6495792B2 (ja) | 音声認識装置、音声認識方法、プログラム | |
| JP5846959B2 (ja) | 基本語彙抽出装置、及びプログラム | |
| JPWO2014133127A1 (ja) | 含意判定装置、含意判定方法及びプログラム | |
| JPWO2018117094A1 (ja) | 音声認識結果リランキング装置、音声認識結果リランキング方法、プログラム | |
| JP5022319B2 (ja) | テキストマイニング装置、方法、プログラム及びその記録媒体 | |
| JP5466575B2 (ja) | 重要語抽出装置とその方法とプログラム | |
| JP2013109635A (ja) | 単語重要度算出装置とその方法とプログラム | |
| JP6259377B2 (ja) | 対話システム評価方法、対話システム評価装置及びプログラム | |
| US9626433B2 (en) | Supporting acquisition of information | |
| KR101646159B1 (ko) | Srl 기반의 문장 분석 방법 및 장치 | |
| JP5670293B2 (ja) | 単語追加装置、単語追加方法、およびプログラム | |
| JP4829910B2 (ja) | 音声認識誤り分析装置、方法、プログラム及びその記録媒体 | |
| Pompili et al. | Topic coherence analysis for the classification of Alzheimer's disease. | |
| JP5441174B2 (ja) | 関係情報抽出装置、その方法及びプログラム | |
| CN110210030B (zh) | 语句分析的方法及装置 | |
| JP6537996B2 (ja) | 未知語検出装置、未知語検出方法、プログラム | |
| JP4769261B2 (ja) | 音声認識誤り分析装置、方法、プログラム及びその記録媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20100726 |
|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20110810 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20120528 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120605 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120615 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150622 Year of fee payment: 3 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |