以下、本発明の実施の形態について、図面を参照しながら説明する。なお、同一部分には同一符号を付し、図面で同一の符号が付いたものは、説明を省略する場合もある。
(実施の形態1)
(文字列生成装置30の構成)
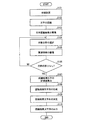
図1は、本発明の実施の形態1にかかる文字列生成装置30の概略構成を示すブロック図である。図1において、本実施の形態にかかる文字列生成装置30は、制御部1と、文字認識部2と、候補蓄積部3と、算出部(算出手段)4と、関連情報蓄積部5と、文字列結合部(文字列結合手段)6と、決定部(決定手段)7と、入力部8と、出力部9と、を備えている。
文字列生成装置30において、制御部1は入力部8から入力される画像から認識対象文字列の各文字を文字認識し、最終結果である認識結果文字列を出力部9から出力するまでの全体の処理を制御する。制御部1は文字認識部2、候補蓄積部3、算出部4、関連情報蓄積部5、文字列結合部6及び決定部7の各々と接続されており、例えば、各部間における各種のデータのやり取りを制御し、それら各種のデータを一時的に記憶する。また、制御部1は、各部の処理に必要となる基準、ルール等も適宜記憶する。制御部1は、例えば、CPU及び、RAM、ROM等のメモリから構成すればよい。
入力部8は、例えば、スキャナであるが、画像を取得できるものであれば、どのようなものであってもよい。
文字認識部2は、入力部8を用いて入力された画像(入力画像)に含まれる認識対象文字列を構成するの各認識対象文字を認識する。この入力画像には、少なくとも1つの文字列が含まれており、入力画像に含まれる文字列のうちの、認識対象となる文字列が、認識対象文字列である。
この文字認識処理では、まず、入力画像から、認識対象文字列を構成する各認識対象文字列を構成する各認識対象文字を1つずつ含む文字画像が切り出され、その切り出された文字画像に含まれる認識対象文字ごとに特徴量が算出される。
次に、その算出された特徴量に基づいて、あらかじめ用意された標準パターンの認識辞書から1文字当たり単数または複数の認識候補文字が選出される。
換言すれば、文字認識部2は、認識対象文字に対応する1つ以上の候補文字からなる候補文字群を、各認識対象文字について生成する。
各認識候補文字には、各々の候補順位及び類似度が付与される。この類似度とは、切り出された認識対象文字と選出された認識候補文字とがどれだけ近いかを表わす割合を示すものであり、例えば、最も近いものが第1候補とされる。文字認識部2は認識対象文字列の1文字ごとに認識候補文字とその候補順位、及び、各々に対応する類似度を互いに関連付けて候補蓄積部3に蓄積する。
候補蓄積部3は、例えばフラッシュメモリ、USB、ROM等の半導体メモリ、ハードディスク、CD、DVD等のDVD磁気メモリから構成されており、文字認識部2の認識結果を順次蓄積する。
算出部4は、認識対象文字の認識結果としての確からしさを表す評価値を各候補文字について算出する。具体的には、算出部4は、候補蓄積部3に蓄積された各認識候補文字の類似度に加えて、関連情報蓄積部5にあらかじめ蓄積された分野別の関連情報(関連度)も利用し、認識対象文字列に含まれる各認識候補文字に対して上記評価値を算出する。
関連情報蓄積部5は、例えば、あらかじめ選定された分野において出現する頻度の高い順に並べられた多数の文字のリストを上記の関連情報として蓄積している。この関連情報とは、選定された分野において、当該分野と各文字との関連性の強さを表わすものである。換言すれば、関連情報とは、分野という所定の概念を表現する場合にその文字が使用される頻度を示す指標である。
上記のリストにおいては、より高い順位の文字ほど、当該分野との関連性が強い、つまり、当該分野に関する文書等において出現する頻度が高いことを意味する。あらかじめ選定される分野(所定の概念)は単数であっても複数であってもよく、例えば、「住所」、「姓」、「名」、「技術」、「科学」、「文学」、「一般」等が挙げられる。もちろん、これらは一例に過ぎず、他の分野であっても構わない。
文字列結合部6は、算出部4による認識候補文字列の妥当性の評価結果に基づいて認識結果文字列を生成する。具体的には、文字列結合部6は認識対象文字列の各文字に対する認識候補文字の妥当性の評価結果(すなわち、各認識候補文字に対して付与された評価値)を算出部4から取得する。そして、文字列結合部6は認識対象文字の1文字ごとに、候補蓄積部3に蓄積された、各認識対象文字の認識候補文字の群のうちから認識結果文字として出力すべき文字を1つずつ決定し、それらを結合することにより認識候補文字列を生成する。
決定部7は、文字列結合部6が生成した認識候補文字列の中から、認識対象文字列の認識結果となる認識結果文字列を決定する。決定部7によって決定された認識結果文字列は出力部9に出力される。
出力部9は、液晶、有機EL等のディスプレイを有しており、そのディスプレイ上に決定部7から出力された認識結果文字列を表示させる。もちろん、出力部9はこの構成に限られるものではなく、例えば、識結果文字列を紙面上に印刷する印刷機能を有していても構わない。要は、出力部9が、文字列生成装置30の利用者が認識結果文字列を視認可能とするディスプレイ装置、プリンタ装置等を有していればよい。
なお、文字認識部2、算出部4、文字列結合部6及び決定部7は、例えば、個別の汎用の論理素子、機能素子等を組み合わせて実現すればよい。あるいは、ASIC等の専用素子で実現しても構わない。また、本実施の形態においては、図1にも示したように、制御部1、文字認識部2、算出部4、文字列結合部6及び決定部7は、それぞれ、別体としているが、例えば、制御部1のCPUが所定の実行ファイルを実行することにより文字認識部2、算出部4、文字列結合部6及び決定部7の各々の機能が実施されるようにしても構わない。もちろん、文字認識部2、算出部4、文字列結合部6及び決定部7の各々の機能を実施するCPUは、制御部1のCPUと同一であっても、異なるものであっても構わない。
(文字列生成装置30の動作)
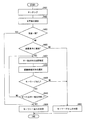
次に、文字列生成装置30の動作の一例について説明する。図2は、文字列生成装置30における処理手順の一例を示すフローチャートである。以下では、上記分野(所定の概念)として、「住所」、「姓」、「名」、「一般」を用いる場合について説明する。もちろん、本発明はこの4種類の分野に限定されるものではなく、文字列生成装置30の利用形態に応じて増やすことも減らすことも可能である。
図2に示すように、まず、制御部1は、利用者の指示に基づいて文字列生成装置30に対する初期設定を実行する(ステップS101)。具体的には、利用者による各種のパラメータの設定が行われる。このパラメータとしては、例えば、この文字列生成装置30を用いて利用者が実施する「業務」の種類が挙げられる。
複数設定された「分野(所定の概念)」は、互いに関連する「分野」を含む集合(分野集合(概念集合))のいずれかに分類されている。上記「業務」の種類とは、上記分野集合のひとつであり、上記「業務」の種類を設定することは、複数設定された分野集合のうちのひとつを選択することを意味する。選択された分野集合に含まれる「分野」を「対象分野」と称する。
この「業務」の種類が設定されると、この種類に応じた設定が算出部4及び関連情報蓄積部5に対して実行される。例えば、制御部1は、関連情報蓄積部5に対して、あらかじめ蓄積されている各分野の関連情報のうち、利用者が指定した「業務」に含まれる分野(対象分野)の関連情報を利用するよう指示する。また、制御部1は、算出部4に対して、利用者が指定した「業務」に含まれる対象分野ごとに、認識候補文字の評価値を算出するよう指示する。
換言すれば、算出部4は、どの分野についての関連度を、評価値の算出のために用いればよいかを示すユーザの指示を、制御部1を介して取得する。これにより、算出部4は、取得した指示が示す関連度を用いて評価値を算出することになる。
次に、文字認識部2が、文字の認識を実行する(ステップS102)。この文字認識ステップS102では、入力部8を介して入力された入力画像に含まれる認識対象文字列を構成する各認識対象文字の認識が実行される。具体的には、入力画像から切り出された各文字画像について、当該各文字画像に含まれる認識対象文字の特徴を数十次元の数値列に変換した特徴ベクトルが生成される。この特徴ベクトルの生成には種々の公知手法があるが、例えば、文字画像を64×64個の要素に分割し、各要素で白が多ければ0、黒が多ければ1として64×64個の要素を持つ特徴ベクトルを作成すればよい。
そして、文字画像から生成された特徴ベクトルと、辞書に登録されている文字ごとにあらかじめ生成されている辞書特徴ベクトルの各々との間で内積をとる。この辞書特徴ベクトルは、文字認識部2が利用可能な記憶部に格納されている。文字の形状が互いに似通っていれば、特徴ベクトル間の対応する要素が同じになるため、内積の値が高くなる。この内積の値が各認識候補文字の認識対象文字に対する類似度を表わしており、各認識対象文字において類似度の高い認識候補文字ほどその候補順位が上位となる。
次に、文字認識部2は、文字認識結果の蓄積を実行する(ステップS103)。この文字認識結果蓄積ステップS103では、文字認識ステップS102において認識された各認識候補文字と、その候補順位及び類似度とを対応付け、候補順位及び類似度と対応付けられた認識候補文字を含む候補文字群を候補蓄積部3に蓄積する。
次に、制御部1は、初期設定ステップS101において設定された「業務」が示す複数の対象分野のひとつを選択する(ステップS104)。
次に、制御部1は、関連情報の蓄積を実行する(ステップS105)。この関連情報蓄積ステップS105では、文字認識結果蓄積ステップS103において蓄積された認識候補文字の各々に対し、対象分野決定ステップS104において選択された対象分野の関連情報を付与し、再び、候補蓄積部3に蓄積する。
上記の対象分野決定ステップS104及び関連情報蓄積ステップS105が、関連情報蓄積部5にあらかじめ蓄積されている分野別関連情報の分野のうち、対象分野のすべてについて実行されるまで(S106にてNO)、上記の対象分野決定ステップS104及び関連情報蓄積ステップS105が繰り返される。すなわち、制御部1は、候補蓄積部3に蓄積された認識候補文字のそれぞれに対して、当該認識候補文字に関する、すべての対象分野の関連情報を対応付ける。
対象分野のすべてについて上記の対象分野決定ステップS104及び関連情報蓄積ステップS105が実行されると(S106にてYES)、次に、算出部4は、認識候補文字の妥当性評価を実行する(ステップS107)。この認識候補文字妥当性評価ステップS107では、認識対象文字列の各認識候補文字のうち、いずれの認識候補文字を認識結果文字として選択すべきかを判断するための評価値を算出する。
具体的には、算出部4は、上記の文字認識結果蓄積ステップS103及び関連情報蓄積ステップS105において候補蓄積部3に蓄積された各認識候補文字の類似度及び関連情報を用いて、あらかじめ設定された基準に基づき、各認識候補文字の妥当性を表わす評価値を算出する。この基準は、各認識候補文字の類似度及び関連情報から評価値を決めるための基準である。その内容としては、例えば、後述するように、各認識候補文字の類似度と関連情報とを単純に加算して評価値を算出する、あるいは、単純には加算せずに、類似度、関連情報に対して重み付けを行った後に加算し、評価値を算出する等である。
より詳細には、算出部4は、認識対象文字に対応する1つ以上の候補文字からなる候補文字群を、各認識対象文字について取得し、上記関連情報および類似度を用いて、分野という所定の概念を表現する場合の、認識対象文字の認識結果としての確からしさを表す評価値を各認識候補文字について、対象分野ごとに算出する。算出部4は、算出した評価値を文字列結合部6へ出力する。
次に、文字列結合部6は、算出部4から出力された評価値を用いて、各認識対象文字に対応する候補文字群からそれぞれ1つずつ選ばれた候補文字を、認識対象文字列における認識対象文字の配列と同じ配列で結合することによって、認識候補文字列を、対象分野ごとに生成する(ステップS108)。文字列結合部6は、生成した認識候補文字列を決定部7へ出力する。
次に、決定部7は、文字列結合部6から出力された複数の認識候補文字列の中から、認識対象文字列の認識結果となる認識結果文字列を決定する(ステップS109)。決定部7は、決定した認識結果文字列を出力部9へ出力する。この決定部7における処理の詳細については後述する。
最後に、出力部9は、決定部7によって決定された認識結果文字列の出力(例えば、表示)を実行する(ステップS110)。
このようにして、本実施の形態にかかる文字列生成装置30の動作が終了する。
(文字認識結果の具体例)
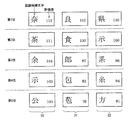
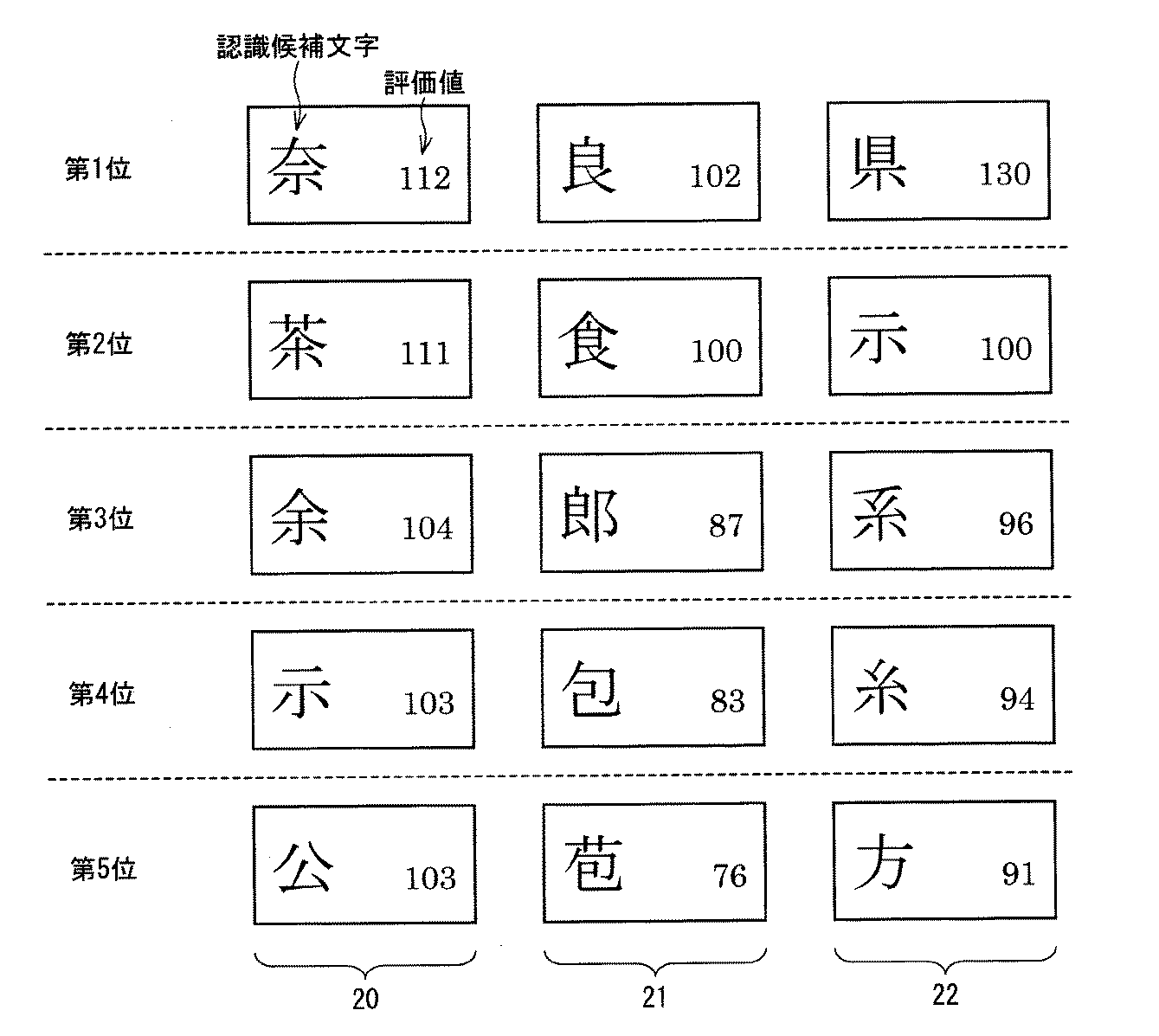
次に、図2の関連情報蓄積ステップS105における処理内容について、さらに詳しく説明する。図3に、図2の文字認識ステップS102における処理結果の一例を示す。図3の処理結果例は、認識対象文字列として「奈良県」を用いた場合である。図3に示すように、認識対象文字列「奈良県」を構成する文字「奈」、「良」、「県」のそれぞれに対して、第1〜第5位までの認識候補文字10、11、12が挙げられている。そして、各認識候補文字には類似度が付与されている。例えば、文字「奈」の第1位の認識候補文字は「茶」であり、その類似度は「110」である。文字認識ステップS102において、各認識対象文字の認識候補文字には、その類似度の高い順に従って候補順位が設定されている。
なお、図3では、認識対象文字列の文字数は3個、候補順位は第1〜第5位までを示しているが、認識対象文字数は、1〜2個でもよいし、4個以上でもよく、候補順位として出力される順位の数も、1つ以上4つ以下でもよく、6つ以上でもよい。また、「奈良県」の各認識候補文字に設定された類似度も単なる一例であり、文字認識によって必ずしもこの順序や、数値になるものではない。
(関連情報の具体例)
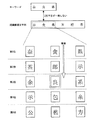
図4に、図2の関連情報蓄積ステップS105における処理結果の一例を示す。図4の処理結果例では、図3の処理結果例における各認識候補文字に対して、関連情報蓄積部5にあらかじめ蓄積されている関連情報が分野ごとに付与されている。図4の処理結果例では、上述したように、対象分野として「住所」、「姓」、「名」、「一般」の4分野が選択されている。
対象分野ごとに、認識対象文字「奈」の認識候補文字13、認識対象文字「良」の認識候補文字14、及び、認識対象文字「県」の認識候補文字15の各々に対して、各文字と各分野との関連性の強さを表わす関連情報が付与されている。ここでは、各分野において、その分野との関連性が強い文字ほど、関連情報の数値が大きくなるようになっている。
なお、図1の関連情報蓄積部5にあらかじめ蓄積されている分野別の関連情報は、分野ごとに、文字認識され得る文字候補の分だけ関連情報が存在する。したがって、関連情報蓄積部5には、仮にJIS第一、第二水準の漢字を全て認識対象文字とした場合、3000〜4000文字分程度の関連情報が分野ごとに蓄積されていることになる。
また、図4の例では、関連情報の一例として、各認識対象文字と各分野との間の関連性の強さを数値で示している。各数値は、例えば、各認識対象文字が各分野との関連性として、各分野という概念を表現する場合にその文字を用いる頻度で表わす。数値自体は、類似度との間で桁数の違いが大きいと文字認識の結果とほとんど同じになる場合、あるいは逆に、全く異なる場合が想定されるため、類似度に合わせて関連情報に重み付けを行う(正規化する)場合も想定される。
例えば、図5の例1で示すように、文字認識の類似度の範囲が0〜20000であり、関連情報の範囲が0〜50である場合、類似度に対して、関連情報の値がほとんど影響を与えず、図3の処理結果例がほとんど変わらないことが予想される。
逆に、図5の例2で示すように、文字認識の類似度の範囲が0〜20000であり、関連情報の範囲が0〜5000である場合、図3の処理結果が関連情報の影響を受けすぎて、図3の処理結果例が意味をなさなくなる可能性がある。
本発明では、関連情報は文字認識の誤りを訂正し、認識結果の順位を入れ替えるためのものである。このため、類似度と関連情報とのバランスを考慮し、例えば「関連情報の最大値は類似度の最大値の5%にする」というルールを設定しておけばよい。そうすることにより、図5の例1の場合であれば関連情報の値を一律20倍し、図5の例2の場合であれば関連情報の値を一律5分の1に減少させる(正規化する)ことで、類似度と関連情報を適正な範囲にすることが可能である。
なお、本発明は上記の「5%」に限定されるものではない。要は、本発明は、文字認識で得られた類似度に対して補正的な意味合いで各分野との関連性を用いており、このため、関連情報の割合を大きくしすぎると文字認識の結果が意味をなさなくなってしまう。したがって、関連情報の影響を受けすぎないような値であればよい。
また、本実施の形態では、上述したように、関連情報として、各分野における、各認識候補文字の出現頻度を主に想定している。例えば「住所」の場合、住所を表すテキストを大量に収集し、そのテキストの中で各認識候補文字が現れる頻度を数え、関連情報とするものである。ただし、本実施の形態の関連情報は上記の出現頻度に限定されるものではなく、例えばシソーラス上における、「住所」と各認識候補文字の距離など、「住所」と各認識候補文字間の意味的な距離を関連情報として用いることも可能である。すなわち、上記関連情報は、認識候補文字と所定の概念との関連性の度合いを表す関連度であってもよい。
(認識候補文字列妥当性評価ステップの詳細)
次に、図2の認識候補文字妥当性評価ステップS107についてさらに詳しく説明する。図6に、図2の認識候補文字妥当性評価ステップS107における処理結果の一例を示す。図6の処理結果例では、図3の処理結果例における各認識候補文字に、図4の処理結果例における分野「住所」の各認識候補文字に付与された関連情報が加算され、各評価値が算出されている。
例えば、認識候補文字「奈」の場合、図3の類似度「110」に図4の関連情報「7」が加算され、評価値「112」が算出されている。同様にして、認識対象文字列「奈良県」の各文字「奈」、「良」、「県」に対する認識候補文字20、21、22の各々に対して、各評価値が算出されている。そして、図3及び図6から明らかなように、この算出された評価値の大きさに従って各認識候補文字20、22、21の候補順位の入れ替えが行われている。
図6の処理結果例では、単純に認識候補文字の類似度と分野別関連情報とを加算して評価値を算出しているが、他にも類似度、関連情報の各々の数値に重みを付けて、評価値を算出する等、評価値の算出方法については様々な方法が考えられる。
すなわち、算出部4は、関連情報の値または類似度に対して重み付けを行った後に、関連情報の値と類似度とを加算することにより評価値を算出してもよい。
例えば、類似度の範囲が0〜150の時に、ある認識対象文字についての認識候補文字列のうち、最大の類似度が80であった場合、その文字に対する文字認識処理の信頼性には問題があると考えられる。その場合、関連情報を重み付けして2倍した値と類似度を加算し、類似度に対する関連情報の影響の度合いを大きくすることにより、各分野との関連性の高い文字を上位に上げてもよい。そうすることにより、文字認識処理の低信頼性の影響を低減することができる。
図6の処理結果例により、認識対象文字「奈」の認識候補文字20のうち、「奈」の評価値が最高の112となり、同様に、認識対象文字「良」の認識候補文字21のうち、「良」の評価値が最高の102、認識対象文字「県」の認識候補文字22のうち、「県」の評価値が最高の130となる。ここでは、この結果を便宜的に、住所Max(112(奈)、102(良)、130(県))と表わす。
図2の認識候補文字妥当性評価ステップS107においては、「住所」以外の「姓」、「名」、「一般」の各分野に対しても、図6の処理結果例と同様な処理結果を得る。すなわち、分野「姓」の場合であれば、認識対象文字「奈」の認識候補文字のうち、「奈」の評価値が最高の112となり、認識対象文字「良」の認識候補文字のうち、「食」の評価値が最高の101、認識対象文字「県」の認識候補文字のうち、「県」の評価値が最高の120となる。したがって、この結果は、姓Max(112(奈)、101(食)、120(県))となる。
次に、分野「名」の場合であれば、認識対象文字「奈」の認識候補文字のうち、「茶」及び「奈」の評価値が最高の111となり、認識対象文字「良」の認識候補文字のうち、「食」の評価値が最高の101、認識対象文字「県」の認識候補文字のうち、「県」の評価値が最高の120となる。したがって、この結果は、名Max(111(茶、奈)、101(食)、120(県))となる。なお、認識対象文字「奈」の認識候補文字のうち、「茶」及び「奈」の評価値が同一となってしまうが、この場合、例えば、算出部4は類似度の高いほうを優先するようにすればよい。
次に、分野「一般」の場合であれば、認識対象文字「奈」の認識候補文字のうち、「茶」の評価値が最高の115となり、認識対象文字「良」の認識候補文字のうち、「食」の評価値が最高の107、認識対象文字「県」の認識候補文字のうち、「県」の評価値が最高の123となる。したがって、この結果は一般Max(115(茶)、107(食)、123(県))となる。
このようにして、図2の認識候補文字妥当性評価ステップS107において、算出部4は、分野ごとに、各認識候補文字の妥当性を表わす評価値を算出する。
(認識候補文字列生成ステップ及び認識結果文字列決定ステップの詳細)
図2の認識候補文字列生成ステップS108においては、分野ごとに、上記の最高の評価値を持つ認識候補文字からなる認識候補文字列が生成される。具体的には、文字列結合部6は、認識対象文字列に含まれる各認識対象文字について、対応する認識候補文字の群から最高の評価値を有する認識候補文字(最高評価文字)を選択し、選択した最高評価文字を、認識対象文字列における認識対象文字の配列と対応する配列で結合することにより、認識候補文字列を生成する。文字列結合部6は、この処理を分野ごとに行う。それゆえ、分野の数と同数の認識候補文字列が生成される。
認識結果文字列決定ステップS109では、決定部7が、認識候補文字列生成ステップS108において生成された各分野の認識候補文字列のうちから、出力すべき認識候補文字列を選択し、認識結果文字列を決定する。例えば、分野ごとに、認識候補文字列に含まれる認識候補文字の評価値を加算し、その加算値が最大の認識候補文字列を認識結果文字列として決定すればよい。この場合、上述の例では、各分野の最高評価値の加算値は、「住所」、「姓」、「名」、「一般」の順に、344、333、333、345となる。したがって、単純に類似度と分野別関連情報を加算して求めた評価値の場合、分野「一般」の認識候補文字列である「茶良県」が認識結果文字列として決定される。
すなわち、決定部7は、分野ごとに生成した認識候補文字列に含まれる認識候補文字が有する評価値を当該認識候補文字列ごとに加算し、最高の評価値の合計を有する認識候補文字列を、認識対象文字列の認識結果として決定する。
以上説明したように、本発明の実施の形態1によれば、図6に示した認識候補文字の評価値を用いることにより、図3に示した認識候補文字の類似度のみから認識結果文字列を決定した場合と比べて、認識対象文字列「奈良県」により近い認識結果文字列を出力することができる。
なお、上述の例では、認識対象文字列と認識結果文字列とは完全には一致していないが、両者が完全に一致する場合もある。それゆえ、文字列生成装置30が発明として未完成なわけではない。
(実施の形態2)
次に、本発明の実施の形態2について説明する。上記の実施の形態1では、認識候補文字の類似度に加えて分野ごとの関連情報を用いることにより、類似度のみを用いた場合と比べて認識対象文字列により近い認識結果文字列を出力するものであった。
しかしながら、図6から明らかなように、必ずしも認識対象文字列と完全に一致するとは限らない。すなわち、上記の実施の形態1においては、認識候補文字列と各分野との関連性の強さを表わす関連情報の評価値への寄与度や、類似度と関連情報との間における正規化処理の有無により、認識対象文字列とは完全に一致しない文字列が生成される場合がある。
そこで、本実施の形態は、算出部4が、図2の認識候補文字妥当性評価ステップS107における評価値算出の際に、初期設定ステップS101において設定されたパラメータ(ここでは、「業務」の種類)に基づいて、各認識候補文字に付与された関連情報の評価値への寄与度を分野毎に変化させる形態である。以下、上記の実施の形態1と異なる点について、図2を用いて説明する。
例えば、利用者が図1の文字列生成装置30を用いて実施する「業務」の種類が「住所録」であるとする。この場合、初期設定ステップS101において制御部1が初期設定を実行する際、利用者がこの文字列生成装置30を用いて実施する「業務」の種類として「住所録」が設定される。そして、制御部1は、対象とすべき分野のすべてについて対象分野決定ステップS104及び関連情報蓄積ステップS105を実行する。
算出部4は、「住所録」に対応する対象分野「住所」、「姓」、「名」、「一般」の各々について、各認識候補文字の評価値を算出するときの関連情報の寄与度を用いて、認識候補文字妥当性評価ステップS107における評価値算出を実行する。
具体的には、算出部4は、上記の「業務」の種類である「住所録」に対応する対象分野「住所」、「姓」、「名」、「一般」ごとに各認識候補文字列の評価値を算出するときに、「住所」、「姓」、「名」についての評価値を算出するときには関連情報の寄与を相対的に大きくし、「一般」についての評価値を算出するときには関連情報の寄与を相対的に小さくする。ここでは、対象分野「住所」、「姓」、「名」、「一般」のうち、上記の「住所録」との関連性が相対的に強い分野「住所」、「姓」、「名」の関連情報を例えば2倍とし、上記の「住所録」との関連性が相対的に弱い分野「一般」の関連情報を1倍としている。算出部4は、例えば、制御部1のメモリに、「業務」に含まれる分野(対象分野)のうち、いずれの分野が当該「業務」との関連性が強く、いずれの分野が比較的弱いかを表わす情報があらかじめ蓄積しておき、算出部4がその情報に基づいて、関連情報を変更すればよい。
そうすることにより、各分野の最高評価値の加算値は、「住所」、「姓」、「名」、「一般」の順に、368、334、347、345となる。したがって、この場合であれば、分野「住所」の認識候補文字列である「奈良県」が認識結果文字列として出力されることになる。
上記の場合、分野関連情報の寄与度のみを設定したが、類似度の寄与度についても、評価値に対する寄与度を設定してもよい。文字認識部2の精度にも依存するが、例えば、図3に示した類似度のみに従って認識結果文字列を生成した場合に、その認識結果文字列と認識対象文字列とが一致する割合が60〜80%程度であれば、類似度及び関連情報の各々の寄与度を、関連情報が類似度に対して10〜35%程度評価値に寄与するように設定すればよい。そうすることにより、類似度のみに従って認識結果文字列を生成する場合と比べて、類似度に要求される精度を低下させることができる。このため、文字認識部2が文字認識する際に処理すべきデータ量が低減され、文字認識部2が必要とするメモリ容量が小さくなる。
(実施の形態3)
(文字列生成装置31の構成)
次に、本発明の実施の形態3について説明する。図7は、本発明の実施の形態3にかかる文字列生成装置31の概略構成を示すブロック図である。図7において、本実施の形態にかかる文字列生成装置31は、上記の実施の形態1の文字列生成装置30と同様に、制御部1と、文字認識部2と、候補蓄積部3と、算出部4と、関連情報蓄積部5と、文字列結合部6と、決定部7と、入力部8と、出力部9と、を備えている。
本実施の形態にかかる文字列生成装置はさらに、照合部60と、キーワード辞書61と、備えている。照合部60は、制御部1と接続されており、文字列結合部6が生成する認識候補文字列をキーワード辞書61にあらかじめ蓄積されているキーワードと照合を行うものである。以下においては、この照合部60及びキーワード辞書61について主として説明するものとし、その他については上記の実施の形態1と同様であるので説明は繰り返さない。
照合部60は文字列結合部6が生成する認識候補文字列をキーワード辞書61と照合する。キーワード辞書61は分野別のキーワードをあらかじめ蓄積している。キーワード辞書61として、選定された対象分野の各々に対応する辞書が用意されており、各辞書には、それぞれに対応する分野において利用される頻度の高いキーワードがあらかじめ選定され、記載されている。ここでは、上記の実施の形態1と同様、分野として「住所」、「姓」、「名」、「一般」が設定され、キーワード辞書61としては、「住所キーワード辞書」、「姓キーワード辞書」、「名キーワード辞書」、「一般キーワード辞書」の4種類があるものとする。
次に、本実施の形態にかかる文字列生成装置31の動作について説明する。図8は、本実施の形態にかかる文字列生成装置31の文字列生成方法の処理手順の一例を示すフローチャートである。図2に示した上記実施の形態1のフローチャートと同一のステップには、同一の番号が付されている。ここでは、上述したように、実施の形態1とは異なる点のみ説明する。
文字列生成装置31の文字列生成方法の処理手順においては、図2の認識候補文字列生成ステップS108と認識結果文字列決定ステップS109との間にキーワード辞書との照合ステップS201が追加されている。
また、文字列結合部6は、生成した認識候補文字列を、当該認識候補文字列の分野および当該認識候補文字列が含む各認識候補文字列の最高評価値の加算値と対応付けて、制御部1を介して決定部7へ出力する。
例えば、上記の実施の形態1においては、認識候補文字列生成ステップS108において分野ごとに生成された認識候補文字列「奈良県」、「奈食県」、「茶食県、奈食県」、「茶食県」のうち、各認識候補文字の最高評価値を加算した結果が最大であるのは分野「一般」の認識候補文字列「茶良県」であった。
しかし、本実施の形態のキーワード辞書照合ステップS201においては、照合部60が、文字列結合部6が対象分野「一般」について生成した認識候補文字列がその対象分野と対応付けられて入力されると、まず、当該認識候補文字列と対応付けられた対象分野「一般」に対応する、キーワード辞書61の一般キーワード辞書を用いて「茶良県」をキーワード照合する。
次に、一般キーワード辞書に「茶良県」は無いので、最高評価値を加算した結果が次に高い分野「住所」についての認識候補文字列「奈良県」が、その分野についての住所キーワード辞書と照合され、照合に成功する。
決定部7は、この照合成功の結果に基づき、認識結果文字列決定ステップS109において、分野「住所」の認識候補文字列である「奈良県」を認識結果文字列として決定し、出力部9が、認識結果文字列出力ステップS110において、決定部7によって決定された認識結果文字列の出力を実行する。
すなわち、照合部60は、文字列結合部6が生成した認識候補文字列と、キーワード辞書61が有する、上記認識候補文字列の分野についてのキーワード辞書に含まれるキーワードとを照合する処理を、分野ごとに生成された認識候補文字列のそれぞれについて、当該認識候補文字列の最高評価値の加算値が大きい順に行い、決定部7は、照合部60が最初に照合に成功した認識候補文字列を認識結果文字列として決定する。
(実施の形態4)
次に、本発明の実施の形態4について説明する。上記の実施の形態3においては、評価値の加算値が一番高い認識候補文字列から順に(換言すれば、評価値の加算値が一番高い分野から順に)と、その認識候補文字列の分野についてのキーワード辞書との照合によって認識結果文字列を決定している。このとき処理時間が長くかかるのは、キーワード辞書61のオープン、クローズ及び、認識候補文字列とキーワード辞書との照合との照合である。上記の実施の形態3では、まず評価値の加算値が一番高い一般分野で照合し、次に住所分野で照合した結果、正解文字列を得ている。もし、住所分野から照合処理に入ったら正しい文字列生成に要する時間は大幅に縮小される。
この問題を解決するため、本実施の形態では、制御部1が分野特徴文字を用いて照合部60の照合順を決定する。この分野特徴文字とは、対応する分野に特徴的な文字のことであり、例えば、住所分野であれば、「都」、「道」、「府」、「県」、「市」、「区」、「群」、「町」、「村」、「丁」、「目」、「番」、「地」、「棟」、「号」、「室」等、姓分野であれば「佐」、「斎」、「藤」等の文字が該当する。これら分野特徴文字は、制御部1を構成するメモリにあらかじめ記憶しておけばよい。
図9は、本実施の形態にかかる文字列生成装置31の文字列生成方法の処理手順を示すフローチャートである。図8に示した上記実施の形態3のフローチャートと同一のステップには、同一の番号が付されている。ここでは、実施の形態3とは異なる点のみ説明する。
図9に示すように、キーワード辞書照合ステップS201の前に、制御部1は、キーワード辞書の照合順決定ステップS301を実行する。このキーワード辞書照合順決定ステップS301では、制御部1が、照合部60がどの分野からキーワード辞書61との照合を行うべきかを照合順序ルールを参照することによって決定する。この照合の順序は、例えば、制御部1のメモリに蓄積された照合順序ルールによって決定される。
この照合順序ルールとしては、例えば、上記の実施の形態1のように各認識候補文字の類似度及び関連情報の各寄与度に差をつける方法の場合であれば、「各認識候補文字としての分野特徴文字の評価値を、分野特徴文字が属する認識候補文字列の文字数で割った値が43以上である同一の分野の分野特徴文字の数が、認識候補文字列の文字数の30%を超える場合は、当該分野特徴文字に対応する分野から照合する」ルールが挙げられる。図6に示した上記の実施の形態1の場合、「県」の評価値が130となっており、認識候補文字列が3文字なので、1文字当たりでは43.3となる。このため、「県」が文字列全体に占める割合は3文字中1文字のため、30%以上となり、このルールが適用される。つまり、住所分野の上記分野特徴文字として「県」を選定した場合に、評価値43.3/文字となる「県」の分野である「住所」が照合の第1候補に変わる。
すなわち、制御部1は、ある分野について生成された認識候補文字列を、どの分野のキーワード辞書と最初に照合するかを、当該認識候補文字列に含まれる分野特徴文字の割合に基づいて決定する。
その結果、キーワード辞書照合ステップS201においては、照合部60が、最高評価値の加算値で最高となった一般分野で得られた「茶良県」を、最初に、住所キーワード辞書と照合することになる。この例では、照合の結果は不成功に終わり(ステップS302にてNO)、照合部(置換部)60は、一般分野の認識候補文字列「茶良県」の先頭の認識候補文字を類似度の高い順に置き換え(ステップS303)、照合部(置換部)60はは、認識候補文字がなくなるまでキーワード辞書と照合する(ステップS303及び304にてNO)。この例では、一般分野における認識候補文字列の先頭の認識候補文字は「奈」が第2候補であるので、「奈良県」と住所キーワード辞書が照合され、照合に成功する(ステップS302にてYES)。
決定部7は、この照合成功の結果に基づき、認識結果文字列決定ステップS109において、「奈良県」を認識結果文字列として決定し、出力部9が、認識結果文字列出力ステップS110において、決定部7によって決定された認識結果文字列の出力を実行する。
本実施の形態によれば、キーワード辞書61のキーワード辞書のオープン、クローズの回数を減らすことができるので、照合部60による照合時間を削減し、照合部60による照合処理に必要なメモリ容量を削減することができる。
なお、上記の実施の形態3及び4において各分野のキーワード辞書を用いて認識候補文字列との照合を行うのは、上記の実施の形態1及び2において生成される認識候補文字列が現実にありえる文字列か否かを判定するためである。現実にありえない文字列を生成しても意味がないため、各分野のキーワードを含むか否かのチェックを行っている。
(実施の形態5)
次に、本発明の実施の形態5について説明する。上記の実施の形態3及び4では、キーワード辞書との照合は完全一致の場合を想定して説明されている。これに対し、本実施の形態は、完全一致はしないが部分一致する場合にも適合するように、図8及び図9のキーワード辞書照合ステップS201の処理内容を拡張した形態である。
本実施の形態においては、照合部60が、キーワード辞書からキーワードを取り出し、認識候補文字列と照合し、認識候補文字列にキーワードが含まれるか否かを調べる。キーワードが認識候補文字列に含まれていれば、キーワードは認識候補文字列に含まれるという判定結果が得られる。認識候補文字列よりキーワードの文字列長の方が長い場合は認識候補文字列にワイルドカードを付けてキーワードの文字数と合うようにして照合を行う。ワイルドカードはどんな文字でも一致することを示す。照合部60による照合結果には、追加したワイルドカードの文字数を記録しておき、結果を使用する際に用いられるようにする。照合部60による上記の照合結果は、適宜、制御部1のメモリに記憶される。
図10は、分野「住所」のキーワード辞書のキーワード「奈良県」に対して、認識候補文字列が「奈食県天理市」だった場合の例である。この状態で認識候補文字列の先頭から照合を行うと、キーワードの1文字目、3文字目は一致するが、2文字目は一致しないという結果になる。上記の実施の形態3及び4では、判定結果はキーワードなしという判定結果になる。しかし、認識候補文字列に間違いがあり、間違いを直せば一致するという場合は、掘り下げて調べる必要がある。
そこで、本実施の形態では、最初の単純照合を行った際の結果に関して設定条件を決めておく。この条件は、例えば「キーワード長の80%以上が一致している」、「不一致文字がキーワード長2文字、3文字の場合で1文字以内、6文字以下で2文字以内、7文字以上は3文字以内」といった形式であらかじめ設定しておく。最初の単純照合の際に完全一致でなくても、上記の設定条件を満たす範囲で一致している場合に、照合部60は、認識候補文字列の間違いの可能性を調査する。
図10の例では、2文字目の認識候補文字は、文字認識処理の際、正しい文字「良」が第1候補にならなかった例である。上記の設定条件を満たした場合、照合部60は、第2候補以降の認識候補文字を参照し、不一致位置にあるべき正しい認識候補文字があるかどうかを調べる。図10の例では、2文字目の認識対象文字についての候補文字群に含まれる認識候補文字と対応するキーワードの文字「良」との一致を順に調べていくと、第3位に「良」があり、一致する。このため、キーワード「奈良県」は認識対象文字列内にあると判定される。上記の類似度または評価値について閾値を設定し、探索する範囲を閾値以上のものに限定することも可能である。
図11は、図8及び図9のキーワード辞書照合ステップS201における処理手順を示すフローチャートである。キーワード辞書照合ステップS201の処理が部分一致まで拡張されている。ここでは、あるキーワードとある認識候補文字列のある位置でマッチングした際の動作を述べる。実際には、認識候補文字列のマッチング位置ごと、及び、キーワードごとに図11の処理を呼び出す。
図11に示すように、まず、照合部60がマッチングステップを実行する(ステップS401)。このマッチングステップS401では、キーワードと認識候補文字列のある位置で通常のマッチングを行う。
次に、照合部60が文字数の集計ステップを実行する(ステップS402)。この文字数集計ステップ402では、マッチングステップS401におけるマッチング結果から、キーワードと認識候補文字列との間で一致した文字数(一致文字数)を集計する。
そして、キーワードの文字数と一致文字数とが一致した場合には(ステップS403YES)、照合部60はキーワードありと判定する(ステップS404)。このキーワードあり判定ステップS404では、認識候補文字列中に現在マッチング対象にしているキーワードがあると判定する。
一方、キーワードと認識候補文字列とが完全に一致しない場合には(ステップS403NO)、照合部60はあらかじめ設定された上記の設定条件を満足するか否かを判断する(ステップS405)。そして、満足しない場合には(ステップS405NO)、照合部60は、キーワードなしと判定する(ステップS406)。このキーワードなし判定ステップ406では、認識候補文字列中に現在マッチング対象にしているキーワードはないと判定する。
また、上記の設定条件を満足する場合には(ステップS405YES)、照合部60は不一致文字の位置を特定する(ステップS407)。この不一致文字位置特定ステップS407では、キーワードと認識候補文字列とで一致しない文字の位置を特定する。
次に、照合部60は、不一致文字が属する候補文字群に含まれる他の認識候補文字を参照する(ステップS408)。この認識候補文字参照ステップS408では、不一致文字位置特定ステップS407において特定された不一致文字位置のうちの1つにおける上記他の認識候補文字の1つを選択する。
そして、認識候補文字参照ステップS408において選択された認識候補文字と上記不一致文字とを入れ替えた認識候補文字列中におけるキーワードの有無が判断される(ステップS409)。そして、キーワードが無ければ(ステップS409NO)、照合部60はキーワードなしと判定する(ステップS406)。
一方、キーワードが有れば(ステップS409YES)、照合部60は、マッチング時の全ての不一致文字をステップS407〜ステップS409の手順で処理したかどうかを判断する(ステップS410)。認識結果によっては、複数の不一致文字が存在する場合もあるためである。不一致文字がまだある場合には(ステップS410NO)、ステップS407に戻って不一致文字の検出を続ける。不一致文字がない場合には(ステップS410YES)、キーワードありと判定する(ステップS404)。
図12に、本実施の形態のキーワード辞書照合ステップS201の処理結果例を示す。図10に示した認識候補文字列「奈食県天理市」に対し、「住所」、「姓」、「名」、「一般」の各辞書中のキーワードとマッチングした際の結果を示している。分野ごとに、上記の認識候補文字列とキーワードをマッチングさせた際に、一致したキーワードとその一致した認識候補文字列中の位置を記録する。認識候補文字列中の位置は、認識候補文字列の先頭を基準としてキーワードの開始位置を表示している。また、出力文字数よりキーワードの方が長く、出力文字列にワイルドカードを付けてキーワードとマッチした場合は追加したワイルドカードの数も記録する。図12の例では、住所辞書にキーワード「奈良」、「奈良県」、「天理市」があり、姓辞書にキーワード「奈良」がある場合で、認識候補文字列とのマッチングでこれらのキーワードが発見された場合である。内容はマッチしたキーワード、キーワードの出力文字列中での位置、マッチング時に追加したワイルドカードの個数である。
なお、これらの情報は、例えば、出力部9から出力された認識結果文字列に含まれるキーワードに関する情報として、利用者に提供してもよい。
(実施の形態6)
(文字列生成装置32の構成)
次に、本発明の実施の形態6について説明する。図13は、本実施の形態にかかる文字列生成装置32の概略構成を示すブロック図である。図13において、本実施の形態にかかる文字列生成装置32は、上記の実施の形態5の文字列生成層と同様、制御部1と、文字認識部2と、候補蓄積部3と、算出部4と、関連情報蓄積部5と、文字列結合部6と、決定部7と、入力部8と、出力部9と、照合部60と、キーワード辞書61と、を備えている。
本実施の形態にかかる文字列生成装置32はさらに、分野解析部(キーワード解析手段)130と、書き換え規則記憶部131と、備えている。分野解析部130は、制御部1と接続されており、文字列結合部6が生成する認識候補文字列に含まれるキーワードの分野を解析し、その解析結果に基づいて、その認識候補文字列の確度(確実さの程度)を付加する。書き換え規則記憶部131は、分野解析部130がキーワード解析の際に利用するキーワード分野の書き換え規則をあらかじめ記憶している。なお、分野解析部130は、算出部4や、照合部60と同じ技術で実現可能であり、書き換え規則記憶部131はキーワード辞書と同様の蓄積部で実現可能である。
(分野解析部130及び書き換え規則記憶部131の詳細)
次に、分野解析部130及び書き換え規則記憶部131について説明する。図14は、上記の実施の形態5のキーワード辞書照合ステップS201の処理結果例を示す。図14の処理結果例は、認識候補文字列「奈良県警」をキーワード辞書で照合した場合の結果である。図14に示すように、「奈良県警」の分野が住所であるとすると、住所キーワード辞書との照合により「奈良県」がマッチし、「警」はどの辞書ともマッチしない状況になる。一方、「奈良」が住所あるいは「姓」とすると、一般分野のキーワード辞書にエントリされている「県警」との組み合わせになる。
生成された認識候補文字列が同じ分野の部分文字列の組み合わせで生成されていれば認識対象文字列の分野依存が確認でき、且つ、生成された文字列も正しい確率が高くなる。しかし、上記の場合のように、どの辞書ともマッチしない文字列を含む場合や、分野の違う文字列の組み合わせの場合には、生成された文字列は正しい確率が低くなってしまう。
本実施の形態は、上記のような場合でも、生成される認識候補文字列に、その認識候補文字列の確からしさを示す精度情報を、評価値とは別に付加することにより、正しい認識結果文字列が生成される確率を高くするものである。
図15に、図13に示した書き換え規則記憶部131に記憶された書き換え規則の内容の一例を示す。図15において、左側の要素は文字または分野である。「+」記号は、文字または分野どうしを結合可能であることを示している。〔〕は分野を示している。〔〕の付かない文字は単なる文字で、〔〕の中の文字は分野を表わしている。したがって、〔住所〕は分野「住所」という意味である。図15では、複数の文字列の組み合わせからなる認識候補文字列の各文字列の分野からその認識候補文字列全体としての分野を解析するための、分野「住所」についての書き換え規則を中心に示している。ここで、〔数〕は分野「数字」で、算用数字、漢数字、ローマ数字などが該当する。〔未〕はいずれのキーワード辞書ともマッチしない場合に付けられる未定義の分野を持つ文字あるいは文字列という意味であり、文字列全体の結果が〔未〕の場合であれば分野解析不能ということである。〔*〕はキーワード辞書のいずれかとマッチすることを意味し、〔姓名〕は〔姓〕と〔名〕をつないだ姓名という分野である。また、「→」は書き換えが可能であることを示している。
図16は、本発明の実施の形態6にかかる文字列生成装置の文字列生成方法の処理手順を示すフローチャートである。図9及び図11に示した上記実施の形態5のフローチャートと同一のステップには、同一の番号が付されている。ここでは、上記の実施の形態5とは異なる点のみ説明する。
図16において、分野解析部130は、図14に示した処理結果例に対して分野解析を行う(ステップS501)。例えば、認識候補文字列が「奈良県警」の場合、この「奈良県警」は、〔住所〕の「奈良県」と〔未〕との組み合わせであると、分野解析部130が判定した場合、図15の書き換え規則120により解析不能という結果になる。
解析不能の場合には(ステップS502NO)、分野解析部130は、照合部60の照合結果(ここでは、図14の処理結果例)に基づいて、〔住所〕を含めて他の分野のキーワードの組み合わせが無いかを調べ(ステップS504)、あれば(ステップS504YES)、異なる分野候補に対し再度「奈良県警」についての分野解析を行う(ステップS501)。図14の処理結果例であれば、「奈良県警」について(「奈良県」〔住所〕)(「警」〔未〕)→〔未〕という書き換え規則が適用されるのであれば、上記と同じ結果となるが、(「奈良」〔住所〕)(「県警」(一般))→〔一般〕という書き換え規則が適用されれば、解析成功という結果となる(S502にてYES)。
すなわち、分野解析部130は、認識候補文字列が、所定のキーワードの組み合わせから構成されているかどうかを判定するキーワード判定のための複数の判定基準(書き換え規則)のうちの1つである第1の判定基準(第1の書き換え規則)を用いてキーワード判定を行い、当該認識候補文字列が所定のキーワードの組み合わせから構成されていないと第1の判定基準に基づいて判定した場合に、第1の判定基準とは異なる第2の判定基準(第2の書き換え規則)を用いてキーワード判定を行う。
分野解析部130は、解析成功との結果に基づき、確度が高いという情報(+確度情報)を認識候補文字列である「奈良県警」に付加する(ステップS503)。一方、他の分野候補の組み合わせが無く(ステップS504にてNO)、分野解析不成功で終わる場合は、確度が低いという情報(−確度情報)を、その認識候補文字列に付加する(ステップS506)。
決定部7は、この確度情報に基づき、認識結果文字列決定ステップS109において、+確度情報が付加された認識候補文字列である「奈良県警」を認識結果文字列として決定し、出力部9が、認識結果文字列出力ステップS110において、決定部7によって決定された認識結果文字列の出力を実行する。
このように、分野解析を行うことによって、生成された文字列の確度を判定し、+確度情報が付加された認識候補文字列を認識結果文字列として決定し、出力することにより、認識結果文字列の認識精度を高めることができる。
なお、本発明は、上述した各実施形態に限定されるものではなく、請求項に示した範囲で種々の変更が可能であり、異なる実施形態にそれぞれ開示された技術的手段を適宜組み合わせて得られる実施形態についても本発明の技術的範囲に含まれる。
最後に、各実施の形態にかかる文字列生成装置の各ブロック、特に制御部1は、ハードウェアロジックによって構成してもよいし、次のようにCPUを用いてソフトウェアによって実現してもよい。
すなわち、各実施の形態にかかる文字列生成装置は、各機能を実現する制御プログラムの命令を実行するCPU(central processing unit)、前記プログラムを格納したROM(read only memory)、前記プログラムを展開するRAM(random access memory)、前記プログラム及び各種データを格納するメモリ等の記憶装置(記録媒体)などを備えている。そして、本発明の目的は、上述した機能を実現するソフトウェアである光ディスク装置の制御プログラムのプログラムコード(実行形式プログラム、中間コードプログラム、ソースプログラム)をコンピュータで読み取り可能に記録した記録媒体を、前記光ディスク装置に供給し、そのコンピュータ(又はCPUやMPU)が記録媒体に記録されているプログラムコードを読み出し実行することによっても、達成可能である。
前記記録媒体としては、例えば、磁気テープやカセットテープ等のテープ系、フロッピー(登録商標)ディスク/ハードディスク等の磁気ディスクやコンパクトディスク−ROM/MO/MD/デジタルビデオデイスク/コンパクトディスク−R等の光ディスクを含むディスク系、ICカード(メモリカードを含む)/光カード等のカード系、あるいはマスクROM/EPROM/EEPROM/フラッシュROM等の半導体メモリ系などを用いることができる。
また、各実施の形態にかかる文字列生成装置を通信ネットワークと接続可能に構成し、前記プログラムコードを、通信ネットワークを介して、供給してもよい。この通信ネットワークとしては、特に限定されず、例えば、インターネット、イントラネット、エキストラネット、LAN、ISDN、VAN、CATV通信網、仮想専用網(virtual private network)、電話回線網、移動体通信網、衛星通信網等が利用可能である。また、通信ネットワークを構成する伝送媒体としては、特に限定されず、例えば、IEEE1394、USB、電力線搬送、ケーブルTV回線、電話線、ADSL回線等の有線でも、IrDAやリモコンのような赤外線、Bluetooth(登録商標)、802.11無線、HDR、携帯電話網、衛星回線、地上波デジタル網等の無線でも利用可能である。なお、本発明は、前記プログラムコードが電子的な伝送で具現化された、搬送波に埋め込まれたコンピュータデータ信号の形態でも実現され得る。
なお、本発明は、以下のようにも表現することができる。すなわち、本発明にかかる文字列生成装置は、文字認識の候補の列から認識結果としての文字列を生成する文字列生成装置であって、文字認識候補を類似度とともに蓄積する候補蓄積手段と、各文字と予め定められた分野間の関連性を示す情報を蓄積する分野別関連情報蓄積手段と、生成する文字列の信頼度を表す評価値を算出する算出手段と、上記評価値に基づいて文字列を結合する文字列結合手段を備え、上記算出手段によって類似度と分野別関連情報に基づいて認識対象の各文字の分野毎の評価値を求め、最大評価値分野の文字列を結合した文字列を生成する。
上記算出手段は評価値の算出に際して文字認識候補の類似度又は分野別関連情報を正規化した数値を用いることが好ましい。
上記算出手段は評価値の算出に際して適用する業務の種類に応じて文字認識候補の類似度又は分野別関連情報の分野寄与度に基づいた数値を用いることが好ましい。
上記文字列生成装置はさらに、上記各分野に対応したキーワードを蓄積したキーワード辞書蓄積手段と、上記生成された文字列とキーワード辞書のキーワードとのマッチングをとる照合手段を備え、上記評価値が最大となる文字列が上記照合手段により照合された上記キーワードと一致し、当該キーワード辞書の分野が前記分野と同一の場合に、上記分野別に結合した文字列を認識結果として生成することが好ましい。
上記評価値が最大となる文字列が上記照合手段により照合されたいずれのキーワードともその一部が一致せず、当該不一致文字の認識の他の候補の中に当該不意一文字と置き換えることによって上記文字列がキーワード一致する場合は、当該文字部分を他の候補で置き換えた文字列を認識結果として生成することが好ましい。
上記文字列生成装置はさらに、上記各分野に対応したキーワードを蓄積したキーワード辞書蓄積手段と、上記生成された文字列とキーワード辞書のキーワードとのマッチングをとる照合手段と、分野項目間の結合による分野項目書き換え規則を蓄積する書き換え規則蓄積手段と、上記分野項目書き換え規則を適用して分野項目を決定する分野解析手段を備え、上記評価値が最大となる文字列の分野が上記書き換え規則を適用することにより、文字列全体が分野解析可能な否かに基づいて生成した文字列の確度情報を付加することが好ましい。
対象とする文字列に対し上記書き換え規則を再帰的に適用し分野解析手段で解析した結果解析不能の場合、他の分野属性の候補に対し分野解析を行うことが好ましい。
上記分野解析の結果、分野解析可能な場合は生成された文字列の確度を上げ、解析不能の場合生成された文字列の確度を下げることが好ましい。
本発明にかかる文字列生成プログラムは、上記の文字列分類装置の上記各手段としてコンピュータを動作させるための文字列生成プログラムである。
本発明にかかるコンピュータ読み取り可能な記録媒体は、上記の文字列生成プログラムを記録した、コンピュータ読み取り可能な記録媒体である。
本発明にかかる文字列生成方法は、文字認識の候補の列から認識結果としての文字列を生成する文字列生成装置を用いた文字列生成方法であって、文字認識候補を類似度とともに蓄積する候補蓄積ステップと、各文字と予め定められた分野間の関連性を示す情報を蓄積する分野別関連情報蓄積ステップと、生成する文字列の信頼度を表す評価値を算出する算出ステップと、上記評価値に基づいて文字列を結合する文字列結合ステップを備え、上記算出ステップによって求めた類似度と分野別関連情報に基づいて認識対象の各文字の分野毎の評価値を求めるステップと、最大評価値分野の文字列を結合した文字列を生成するステップを備える。