EP4174759A1 - Method of reflection removal based on a generative adversarial network used for training of an adas camera of a vehicle - Google Patents
Method of reflection removal based on a generative adversarial network used for training of an adas camera of a vehicle Download PDFInfo
- Publication number
- EP4174759A1 EP4174759A1 EP22201878.0A EP22201878A EP4174759A1 EP 4174759 A1 EP4174759 A1 EP 4174759A1 EP 22201878 A EP22201878 A EP 22201878A EP 4174759 A1 EP4174759 A1 EP 4174759A1
- Authority
- EP
- European Patent Office
- Prior art keywords
- image
- reflection
- images
- block
- transmission image
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T5/00—Image enhancement or restoration
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T5/00—Image enhancement or restoration
- G06T5/77—Retouching; Inpainting; Scratch removal
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/50—Context or environment of the image
- G06V20/56—Context or environment of the image exterior to a vehicle by using sensors mounted on the vehicle
- G06V20/58—Recognition of moving objects or obstacles, e.g. vehicles or pedestrians; Recognition of traffic objects, e.g. traffic signs, traffic lights or roads
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B60—VEHICLES IN GENERAL
- B60W—CONJOINT CONTROL OF VEHICLE SUB-UNITS OF DIFFERENT TYPE OR DIFFERENT FUNCTION; CONTROL SYSTEMS SPECIALLY ADAPTED FOR HYBRID VEHICLES; ROAD VEHICLE DRIVE CONTROL SYSTEMS FOR PURPOSES NOT RELATED TO THE CONTROL OF A PARTICULAR SUB-UNIT
- B60W40/00—Estimation or calculation of non-directly measurable driving parameters for road vehicle drive control systems not related to the control of a particular sub unit, e.g. by using mathematical models
- B60W40/12—Estimation or calculation of non-directly measurable driving parameters for road vehicle drive control systems not related to the control of a particular sub unit, e.g. by using mathematical models related to parameters of the vehicle itself, e.g. tyre models
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0475—Generative networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/082—Learning methods modifying the architecture, e.g. adding, deleting or silencing nodes or connections
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/094—Adversarial learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T11/00—Two-dimensional [2D] image generation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T3/00—Geometric image transformations in the plane of the image
- G06T3/04—Context-preserving transformations, e.g. by using an importance map
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T5/00—Image enhancement or restoration
- G06T5/60—Image enhancement or restoration using machine learning, e.g. neural networks
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B60—VEHICLES IN GENERAL
- B60W—CONJOINT CONTROL OF VEHICLE SUB-UNITS OF DIFFERENT TYPE OR DIFFERENT FUNCTION; CONTROL SYSTEMS SPECIALLY ADAPTED FOR HYBRID VEHICLES; ROAD VEHICLE DRIVE CONTROL SYSTEMS FOR PURPOSES NOT RELATED TO THE CONTROL OF A PARTICULAR SUB-UNIT
- B60W2420/00—Indexing codes relating to the type of sensors based on the principle of their operation
- B60W2420/40—Photo, light or radio wave sensitive means, e.g. infrared sensors
- B60W2420/403—Image sensing, e.g. optical camera
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10024—Color image
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/30—Subject of image; Context of image processing
- G06T2207/30248—Vehicle exterior or interior
- G06T2207/30252—Vehicle exterior; Vicinity of vehicle
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02T—CLIMATE CHANGE MITIGATION TECHNOLOGIES RELATED TO TRANSPORTATION
- Y02T10/00—Road transport of goods or passengers
- Y02T10/10—Internal combustion engine [ICE] based vehicles
- Y02T10/40—Engine management systems
Definitions
- the present invention relates to removing window reflection from the images acquired by cameras mounted in the interior of a vehicle, the images used in advanced driver assistance systems ADAS.
- the present invention relates to a method of reflection removal based on Generative Adversarial Networks used for training of the ADAS camera of the vehicle.
- the I and T images aren't aligned at pixel level, but they represent the same environment, either taken at 2 different moments in time, in one moment when there is a glass in front of the camera as to have the reflection present, and in another moment when there is no reflection present.
- CNNs Convolution Neural Networks
- Document [14] refers to a method of single image reflection removal by exploiting targeted network enhancements and by the novel use of misaligned data.
- document [14] discloses augmenting a baseline network architecture by embedding context encoding modules that are capable of leveraging high-level contextual clues to reduce indeterminacy within areas containing strong reflections.
- document [14] introduces an alignment-invariant loss function that facilitates exploiting misaligned real-world training data that is much easier to collect.
- GANs Generative Adversarial Networks
- ERRNet Single Image Reflection Removal Exploiting Misaligned Training Data and Network Enhancements
- This architecture is designed so as to work towards the goal of reflection removal. It does this by learning from unaligned pairs of images with and without reflection. At the same time, it uses random images without reflection from which it synthesizes reflection and learns how to remove the generated reflection.
- First training step comprises receiving a randomly sampled pair of images from the first image dataset by a first images acquisition block, carrying out a first altering of the images by a data augmentation and reflection synthesis block, generating a first transmission image, a first synthetical reflection, and a first mixed image, Simultaneously, it is carried out a second altering of the images by the data augmentation and reflection synthesis block, generating: a second transmission image, a second synthetical reflection, and a second mixed image.
- the first transmission image, the first synthetical reflection, the first mixed image, the second transmission image, the second synthetical reflection and the second mixed image are sent to a Generative Adversarial Network machine learning block.
- a third aspect of the invention it is presented an ADAS camera of a vehicle, provided with the machine learning model of the invention, trained in accordance with the training steps of the method in any of its preferred embodiments and configured to carry out the inference step of the method in any of its preferred embodiments.
- the second ADAS camera images - namely the ones with the natural reflection present - are sent to a second image dataset 2, comprising naturally mixed images I3i having natural reflection.
- the first image dataset 1 is synchronized with the second image dataset 2 by the timestamps of the two ADAS cameras.
- the two ADAS cameras used in the acquisition steps are used solely for providing respective images for the respective image datasets used in the training step for the training of the machine learning module. For this reason, it is not necessary that the two ADAS cameras used in the acquisition steps be provided with the machine learning module.
- the modified reflection synthesis generating block C2 comprises three blocks: a modified Gaussian blurring block C21, a varying reflection 2 nd pass block C22, and a vertical flip block C23.
- the vertical flip block C23 outputs a low blurred image R as being the second synthetical reflection R2, together with the second mixed image 12 and a second transmission image T2.
- the second transmission image T2 is the one that corresponds to the first image P2 which is a real image, that is not generated synthetically and only augmented by resizing, cropping and horizontal flipping in half of the cases.
- the second mixed image 12 and the first mixed image 11 differ in the sharpness and, possibly, in the vertical rotation of their corresponding reflections, while at the same time the augmentations of the first transmission image T1, the first synthetical reflection R1, the second transmission image T2, and the second synthetical reflection R2, are different because of the sampling with randomly chosen different values from the same distributions mentioned before.
- the third training step is carried out by the Generative Adversarial Network GAN machine learning block E, based on the machine learning model running on the data processing hardware.
- the preset number of iterations for the adjusting of the machine learning model is 1, that is the adjusting of the plurality of parameters is carried out after each iteration. This has the advantage of better adjusting the process of learning.
- the machine learning model generates an approximation of the image without reflection for each image with reflection.
- the ADAS camera acquires images I from the real-life context, that are the equivalent of the mixed images of the training step because they do contain reflection.
- the training method has the advantage that, when compared with the training method of prior art, generalizes better what is and what is not a reflection in the images acquired by the ADAS camera yielding better results than the training methods of prior art for the particular case of ADAS cameras used in the vehicles, while at the same time not altering the non-reflection part of images.
- a data processing hardware configured to carry out the training steps of the method in any of its preferred embodiments, comprising: a first images acquisition block, a second images acquisition block, a data augmentation and reflection synthesis block, a data augmentation block specific to image pairs, and a Generative Adversarial Network machine learning block.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Biophysics (AREA)
- Data Mining & Analysis (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Biomedical Technology (AREA)
- General Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Computing Systems (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Mechanical Engineering (AREA)
- Automation & Control Theory (AREA)
- Transportation (AREA)
- Multimedia (AREA)
- Image Analysis (AREA)
- Image Processing (AREA)
Abstract
Description
- The present invention relates to removing window reflection from the images acquired by cameras mounted in the interior of a vehicle, the images used in advanced driver assistance systems ADAS. In particular the present invention relates to a method of reflection removal based on Generative Adversarial Networks used for training of the ADAS camera of the vehicle.
- Throughout this invention the following terms have the following corresponding meanings:
Advanced driver assistance systems ADAS cameras, hereafter alternatively called ADAS cameras, or, alternatively cameras, are used in the automotive industry for the purpose to provide quick and accurate detection and recognize of objects and persons from the exterior of the vehicle such as other vehicles, pedestrians, obstacles, traffic signs, lane markers, etc. The information captured by cameras is then analyzed by an ADAS processing chain and used to trigger a response by the vehicle. - The ADAS camera shall be understood as including the hardware and the software needed to carry out the respective steps of the method, according to the invention. Vehicle is, in this invention, any road vehicle provided with at least one ADAS camera acquiring pictures through at least one window of the vehicle.
- Reflection, alternatively called window reflection, is used throughout this invention with the meaning of a light in the ADAS camera, which was not intended when the ADAS camera as optical system was designed.
- Other terms that shall be used interchangeably in this invention are: picture(s), image(s), frame(s), having the same meaning of picture(s) acquired by the ADAS camera. The picture(s) acquired by the ADAS camera include the video frames, as the difference between picture and video is only a matter of frame rate.
- The problem of reflection removal using only one image is addressed in the literature. There are more than a few methods that solve the problem under different constraints, or only in a subset of situations.
- The mechanical ways to remove the reflection generally consist in placing some kind of plastic around the camera in order to mechanically remove the reflection.
- The first successful methods require additional contextual information or make assumptions that don't hold for all reflections or environmental situations. Such are the methods disclosed in documents [1], [4] that require capturing the same scene from different viewpoints, [1] assumes the reflection will change, and as such considers it dynamic between the frames, and what is static is considered as background with useful information.
- The method disclosed in document [2] assumes that the reflection layer is blurred, while in document [3] the proposed method considers that the reflection layer has a ghosting effect, and what that means is that there is a second shifted and attenuated reflection of the objects on the same side of the glass as the camera.
- Document [5] makes use of the depth of field of the image in order to determine the reflection layer which is considered closer.
- Document [6] proposes to not remove the reflection layer but to suppress it by making use of a Laplacian data fidelity term and gradient sparsity. In document [6] the suppression of the reflection, without its removal, can still affect the interpretability of the occluded scene behind the reflection.
- More recent breakthroughs were achieved by making use of Deep Learning, such are the cases presented in the documents [7],[8],[9],[10],[11],[12],[13],[14],[15] and [16] which make use of convolutional neural networks in order to learn a mapping between the initial image, henceforward referred as I, which has a reflection overlapping the information layer, and the transmission image T, which is the expected image with information and without reflection.
- In some cases, the reflection is generated synthetically as to obtain a pixel level alignment between I and T. Then, for each pixel, the difference made by the reflection layer, - which consists of the reflection image and is referred as R when obtruding the information layer, can be calculated.
- In other cases, the I and T images aren't aligned at pixel level, but they represent the same environment, either taken at 2 different moments in time, in one moment when there is a glass in front of the camera as to have the reflection present, and in another moment when there is no reflection present.
- In other cases, there are 2 cameras present arranged side by side, one having a reflective layer in front of it, while the other doesn't, as to capture the same scene at the same moment. In both cases there won't be a pixel alignment between the image pairs and the solution is to compare the images at the feature level.
- Convolution Neural Networks (CNNs) can be used for automating the feature learning such that to allow the calculation of the difference between the two layers at the feature level when it is not relevant to compare at pixel level.
- Some of the solutions, such as the documents [7], [9], [10], [11], [12], [13], [14], [15], and [17] include the use of the Generative Adversarial Networks GANs because of the advantage these networks have as they include a Discriminator component, which takes the resulting image from a Generator, that is usually based on CNNs, and tries to determine how realistic the predicted image with the removed reflection is compared to the reference image with no reflection.
- There are two major categories of difficulties when making use of CNNs for image reflection removal.
- Firstly, a loss function that encapsulates the perceptual difference between the image pairs R and T is hard to define as it is hard to mathematically encapsulate the realistic perception of an image. The fact that in some cases the pairs R and T, that represent the same scene, are unaligned makes it an even harder task.
- Secondly, having a good network architecture that can distinguish and remove the reflection layer requires training on a wide variety of images with reflection layers that are dynamic, vary in intensity, blurring, transparency and other factors. Having a dataset of diverse reflections implies either having a lot of paired images with and without reflection that are diverse, which are hard to collect, or to have a method of generating realistic and diverse reflections.
- Document [14] refers to a method of single image reflection removal by exploiting targeted network enhancements and by the novel use of misaligned data. When it comes to the targeted network enhancements, document [14] discloses augmenting a baseline network architecture by embedding context encoding modules that are capable of leveraging high-level contextual clues to reduce indeterminacy within areas containing strong reflections. When it comes to the novel use of misaligned data, document [14] introduces an alignment-invariant loss function that facilitates exploiting misaligned real-world training data that is much easier to collect.
- The experiments are carried out using Generative Adversarial Networks (GANs), the relevant being here the Single Image Reflection Removal Exploiting Misaligned Training Data and Network Enhancements or ERRNet of document [14]. This architecture is designed so as to work towards the goal of reflection removal. It does this by learning from unaligned pairs of images with and without reflection. At the same time, it uses random images without reflection from which it synthesizes reflection and learns how to remove the generated reflection.
- The generation of the synthetical reflections using a type of Generative Adversarial Networks GAN is disclosed in article [15].
- The mechanical methods for reflection removal have the disadvantage that they impair the camera field of view. None of the non-mechanical methods of prior art specifically addresses the reflection removal for the images acquired by the ADAS cameras of the vehicle. They address reflection removal in general.
- The methods of prior art do not work properly in the case of the images acquired by the ADAS cameras of the vehicle for one or more from the following reasons: ADAS cameras are placed in the interior of the vehicle in specific fixed places, being many times subject to restrictions, such as for example the inclination of the windshield which favors more types of reflection: from the outside of the vehicle and from the interior of the vehicle (dashboard).
- In case of ADAS cameras, many of the methods of prior art require additional contextual information which is hard if not impossible to obtain at runtime when the vehicle is in motion.
- Some of the methods of prior art consider the reflection to be blurred. Experience of the person skilled in the art shows that there is almost no blurring present in case of ADAS cameras, which means that making use of the methods of articles [15] and [16] for generating synthetical reflection does not yield satisfactory results, because the two afore-mentioned methods generate reflections that are too blurred on one hand and the real reflections are in many cases too hard to distinguish without contextual information on the other hand.
- Other methods of prior art start from the hypothesis that the reflection layer has a ghosting effect, which in general does not apply to the reflection through the windows of the vehicles, thus this hypothesis is of no use for the removal of the reflection on the images captured by the ADAS cameras.
- ADAS cameras provide, in general images of lower quality in respect to other categories of cameras, such as the cameras of the mobile phones. Lower quality in this context means that the negative influence of the noise when capturing the images on ADAS cameras is more significant than the negative influence on said other categories of cameras. Given that the images captured by the ADAS cameras are further processed by an ADAS processing chain, if the input image is damaged by the noise, the output- namely the processed image is most likely to be damaged as well.
- The technical problem to be solved is to find a method for reflection removal using a single image, the method adapted for the specific context when said single image is acquired by an ADAS camera of a vehicle without the need of additional contextual information.
- In order to overcome the disadvantages of prior art, in a first aspect of the invention it is presented a method of reflection removal based on a Generative Adversarial Network used for training of an ADAS camera of a vehicle. It comprises the following steps: an acquisition step, training steps and an inference step.
- Acquisition Step comprises capturing simultaneously first ADAS camera images by a first ADAS camera and second ADAS camera images from a second ADAS camera, the first ADAS camera identical with the second ADAS camera and identical with the ADAS camera of the vehicle, and the first ADAS camera further comprising a physical reflection removal filter. The first ADAS camera and the second ADAS camera are aligned such that to have essentially the same field of view, the first ADAS camera and the second ADAS camera capturing in their respective images essentially the same content at the same time. The captured images are sent to two respective image datasets:
the first ADAS camera images to a first image dataset, comprising images without reflection, the second ADAS camera images to a second image dataset, the second image dataset comprising naturally mixed images having natural reflection. The acquisition step is followed by training steps carried out by a data processing hardware. First training step comprises receiving a randomly sampled pair of images from the first image dataset by a first images acquisition block, carrying out a first altering of the images by a data augmentation and reflection synthesis block, generating a first transmission image, a first synthetical reflection, and a first mixed image, Simultaneously, it is carried out a second altering of the images by the data augmentation and reflection synthesis block, generating: a second transmission image, a second synthetical reflection, and a second mixed image. The first transmission image, the first synthetical reflection, the first mixed image, the second transmission image, the second synthetical reflection and the second mixed image are sent to a Generative Adversarial Network machine learning block. - Second training step comprises receiving by a second images acquisition block the first image from the first image dataset and a third mixed image from the second image dataset having the same content with the first image, carrying out by a data augmentation specific to image pairs block augmentation of the first image, generating a third transmission image and augmentation of the third mixed image, using third augmentation parameters, and sending the third transmission image and the third mixed image to the Generative Adversarial Network GAN machine learning block. Third training step is carried out by the Generative Adversarial Network GAN machine learning block, and comprises: generating at each iteration, based on a machine learning model comprising a plurality of parameters, corresponding predicted transmission images by a Generator of the Generative Adversarial Network GAN machine learning block, calculating at each iteration by a Discriminator of the Generative Adversarial Network GAN machine learning block a certainty score for respective pair of images of predicted transmission image and transmission image: calculating at each iteration: an Adversarial loss based on the certainty score, a pixel level loss for the pairs of the respective predicted transmission image and its corresponding transmission image, a feature level loss and an alignment invariant loss for all three pairs of images; optimizing after a preset number of iterations the machine learning model including adjusting the plurality of parameters, such that to optimize the generation of predicted transmission images as close as possible to the respective transmission images, compressing said optimized machine learning model and sending the compressed machine learning model to a GAN machine learning block of the ADAS camera.
- Inference Step is carried out by the ADAS camera of the vehicle and comprises acquiring an image by the ADAS camera, the image containing reflection; suppressing, by the GAN machine learning block of the reflection and generating a predicted transmission image, having the reflection suppressed; making the predicted transmission image available to an ADAS processing chain.
- In a second aspect of the invention, it is presented a data processing hardware configured to carry out the training steps of the method in any of its preferred embodiments. The data processing hardware comprises: a first images acquisition block, a second images acquisition block, a data augmentation and reflection synthesis block, a data augmentation block specific to image pairs, and a Generative Adversarial Network machine learning block.
- In a third aspect of the invention, it is presented an ADAS camera of a vehicle, provided with the machine learning model of the invention, trained in accordance with the training steps of the method in any of its preferred embodiments and configured to carry out the inference step of the method in any of its preferred embodiments.
- In a fourth aspect of the invention, it is presented a first computer program comprising instructions which, when executed by the data processing hardware of the invention, causes the respective data processing hardware to perform the training steps of the method in any of its preferred embodiments.
- In a fifth aspect of the invention, it is presented a second computer program comprising instructions which when executed by the ADAS camera of the invention, causes the respective ADAS camera to perform the inference step IS of the method in any of its preferred embodiments.
- In a sixth aspect of the invention, it is presented a first computer readable medium having stored thereon instructions of the first computer program of the invention.
- Finally, in a seventh aspect of the invention, it is presented a second computer readable medium having stored thereon instructions of the second computer program of the invention.
- Further advantageous embodiments are the subject matter of the dependent claims.
- The main advantages of using the invention are as follows:
The method of the invention provides a better removal of the reflection from the images acquired by the ADAS camera of a vehicle as compared with the mechanical methods of prior art because the field of view of the camera is not impaired. - The method works without the need of additional contextual information.
- The training method of the invention has the advantage that, when compared with the training method of prior art, generalizes better what is and what is not a reflection in the images acquired by the ADAS camera yielding better results than the training methods of prior art for the particular case of ADAS cameras used in the vehicles, while at the same time not altering the non-reflection part of images.
- The method of the invention yields excellent results in the very frequent context when the reflection is not blurred, which happens in most cases when the reflection is strong, and the window glass is close to the ADAS camera.
- Further special features and advantages of the present invention can be taken from the following description of an advantageous embodiment by way of the accompanying drawings:
-
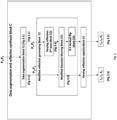
Fig. 1 illustrates a schematic representation of the method of the invention and of the components of the data processing hardware -
Fig. 2 illustrates a schematic detailed representation of thetraining step 1 of the method and of the components of the data processing hardware involved in this step -
Fig. 3.1 illustrates the resulting images outputted by the data augmentation block -
Fig. 3.2 illustrates the three images outputted by the modified Gaussian blurring block corresponding to the first mixed image -
Fig. 3.3 illustrates the three images outputted by the modified Gaussian blurring block after processing by the varying reflection opacity block, corresponding to the first mixed image -
Fig. 3.4 illustrates the three images outputted by the varying reflection pass block corresponding to the second mixed image -
Fig. 3.5 illustrates the three images outputted by the modified Gaussian blurring block after processing by the varying reflection opacity block corresponding to the second mixed image -
Fig. 3.6 illustrates an example of reflection removal in the inference step. - The method of the invention starts from the inventors' idea that the method for reflection removal using a single image should be based on artificial intelligence, "teaching" the ADAS camera of the vehicle how to remove the reflection based on two corresponding pluralities of images taken by two other ADAS cameras of the same type. In this way it is removed the need to have additional contextual information at the moment of the use of a single image for reflection removal.
- The method has three steps: an acquisition step AS, a training step TS and an inference step IS.
- The inference step corresponds to the day-to-day use of the method in the ADAS camera of a vehicle, the ADAS camera provided with a graphical processing unit GPU.
- For the purpose of adapting the removal of the reflection to the specific context when the single image is acquired by the ADAS camera of a vehicle, the inventors thought to use a Generative Adversarial Network GAN machine learning module F integrated in the graphical processing unit GPU of the ADAS camera to train the graphical processing unit GPU of the ADAS camera to carry out the removal reflection of the single image
- Thus, in the invention, the graphical processing unit GPU of the ADAS camera is adapted to integrate the Generative Adversarial Network GAN machine learning module F such that to allow running in the inference step of a Generative Adversarial Network GAN machine learning model, hereafter for simplicity called "the machine learning model" on the machine learning module F. Hereafter, the reference to the training of the ADAS camera of the vehicle shall be read as reference to the training of the graphical processing unit GPU of the ADAS camera.
- The machine learning model is trained in the training step using the data acquired in the acquisition step.
- In the acquisition step, two ADAS cameras are used: a first ADAS camera and a second ADAS camera. The two ADAS cameras have identical configurations between themselves and identical configuration with the ADAS camera used in the inference step, with one exception: the first ADAS camera is provided with a physical reflection removal filter, whereas the second ADAS camera is not provided with any reflection removal filter. Both ADAS cameras are provided with respective timestamps.
- The first ADAS camera captures first ADAS camera images, whereas the second ADAS camera captures second ADAS camera images.
- The two ADAS cameras are positioned on a training vehicle, the training vehicle having similar overall size with the vehicle of the inference step, the windows of the training vehicle having similar characteristics with the windows of the vehicle of the inference step, and the positioning of the two cameras being similar with the ones of the vehicle of the inference step. For example, if the ADAS camera of the inference step is to be used to capture images through the windscreen, the two ADAS cameras used in the acquisition step will be placed such that to capture images through the windscreen and not through the rear window.
- The two ADAS cameras are positioned within the training vehicle aligned such that to have essentially the same field of view and such that the two cameras capture in their respective images essentially the same content- that is viewed from essentially the same perspective and at the same time. One preferred example of positioning is stacking vertically one of the two ADAS cameras above the other one, being vertically aligned. Due to the small size of the ADAS cameras as compared with the content of the images, there is no substantial impact on the content of the fact that the cameras are placed one above the other.
- The two ADAS cameras with the configuration described above capture images of the environment according to prior art: the first ADAS camera images have the reflection removed by means of the physical reflection removal filter, the second ADAS camera images have the natural reflection present.
- Throughout the invention, the images containing reflection are called "mixed images". The captured images of the two ADAS cameras are sent to two respective image datasets stored in a non-volatile datasets memory:
The first ADAS camera images- namely the ones with the reflection removed - are sent to afirst image dataset 1, comprising images Pi without reflection. - The second ADAS camera images - namely the ones with the natural reflection present - are sent to a
second image dataset 2, comprising naturally mixed images I3i having natural reflection. - The
first image dataset 1 is synchronized with thesecond image dataset 2 by the timestamps of the two ADAS cameras. - For the sake of simplicity,
Fig. 1 illustrates from the acquisition step only thefirst image dataset 1 and thesecond image dataset 2. - The two ADAS cameras used in the acquisition steps are used solely for providing respective images for the respective image datasets used in the training step for the training of the machine learning module. For this reason, it is not necessary that the two ADAS cameras used in the acquisition steps be provided with the machine learning module.
- The training step is carried out by a data processing hardware comprising:
a first images acquisition block A configured to receive images from thefirst image dataset 1, a second images acquisition block B configured to receive images from thesecond image dataset 2, a data augmentation and reflection synthesis block C, a data augmentation block D specific to image pairs, and a Generative Adversarial Network machine learning block E. - The first images acquisition block A receives a randomly sampled pair of images P1 and P2 from the
first image dataset 1. The first images acquisition block A is a buffer having the role to prepare the images received from thefirst image dataset 1 for the further processing detailed in the subsequent training sub-steps. The random sampling is according to prior art. - Both the first image P1 and the second image P2 are without reflection, because they were sampled from the
first image dataset 1. The first image P1 is selected to be used as transmission layer, referred to in this invention as a first transmission image T1, having the meaning of "reference" or, alternatively called "true" image. - The selection of the image used as "true" image is also random, that is, it can be any of P1 and P2. For the sake of ease of understanding, in this invention it was used the first image P1.
- With reference to
Fig. 2 , the data augmentation and reflection synthesis block C comprises three blocks: a data augmentation block C1, a modified reflection synthesis generating block C2, a varying reflection opacity block C3. - The modified reflection synthesis generating block C2 comprises three blocks:
a modified Gaussian blurring block C21, a varyingreflection 2nd pass block C22, and a vertical flip block C23. - Generically, as prior art teaches, the pair of randomly sampled images P1 and P2 are used as input into some kind of reflection processing block, outputting a mixed image, where the mixed image is considered as a per channel pixel-wise sum of T and R and can be expressed as:

- The expression "per channel" refers to the channels of
color 1 channel in case of grayscale images, Red Blue Green RBG or Blue Green Red BGR in case of 3-channel images; or Red Green Green Blue RGGB in case of 4-channel images. Thus, generically, after processing, P1 will become T and P2 will become R. - In the method of the invention, based on each pair of randomly sampled images P1 and P2 used as input to the data augmentation and reflection synthesis block C, there are two mixed images instead of one: a first mixed image 11 and a second mixed image 12.
- The data augmentation block C1 augments the first image P1 and the second image P2 using a pair of corresponding augmentation parameters: first augmentation parameters result from sampling firstly for the first image P1 and second augmentation parameters result from sampling secondly for the second image P2.
- Non-limiting examples of augmentation operations are resizing, cropping and horizontal flipping,
- The sample resizing and cropping parameters are uniformly distributed in pre-set resizing and cropping intervals, in order to obtain a specific target size of the image. For example, the resizing is done so as to have an increase of the size with 0% to 20% than the expected shape of the image as the initial imagine is about two times bigger than the resolution used for training, whereas the cropping interval is between 0 and 20% inclusively depending on the dimensions of the images after resizing. Or, in other words, the resizing parameters may be uniformly sampled from the range [0, 0.2] increase of size, individually for the first image P1, respectively for the second image P2, and the cropping parameters may be uniformly sampled from the range [0,0.2] crop of size individually for the resized first image P1, respectively for the second image P2.
- After resizing and the cropping of the first image P1 and of the second image P2, the first data augmentation block C flips the resized and cropped images. For example, the flip can be a horizontal flip of 50% for both images. In other words, the horizontal flip parameter is uniformly sampled from the range [0,0.5] for both resized and cropped images P1, P2.
- The resizing, the cropping and the flipping are carried out for the purpose of increasing the number of training examples while making use of the same images received from the
first image dataset 1. - The augmentation operations applied to each of the first image P1 and the second image P2 are selected randomly, for example the flipping applied to the first image P1 can be of 180°, whereas there is no flipping for the second image P2.
- An example of the resulting images after resizing, cropping and flipping is depicted in
Fig. 3.1 . - The first mixed image 11 is obtained by a first altering of the images P1 and P2, which become T1 and R1, respectively, and then overlapping the first synthetical reflection R1 by the modified Gaussian blurring block C21 over the first transmission image T1. The inventors observed that, when first training only with synthetical data - that is only with the first mixed images 11, the results were poor, that is the reflection was poorly removed. By comparing the synthetical reflections with the reflections from the real world in the specific context of the images provided by the ADAS cameras, the inventors observed that there was a significative difference in luminosity and blurring level of the reflections. Namely the reflections from the real world were only slightly blurred, whereas the synthetical reflections used initially in the training of the machine learning model generated quite blurred images.
- For this reason, the inventors decided to modify the blurring block of the prior art (i.e., an image-blurring filter that uses a Gaussian function) by introducing two additional features: by using in the modified Gaussian blurring block C21 a kernel of 1 for the Gaussian blurring, while keeping the standard deviation close to 0, sampled uniformly from the interval [0.0001,0.001] in order to always obtain a reflection by slightly blurring the R1 image, and by increasing the intensity of the reflection by adding an opacity parameter in the varying reflection opacity block C3.
- Thus, the modified Gaussian blurring block C21 is different from the blurring block of the prior art. Due to the above-captioned enhancements, the modified Gaussian blurring block C21 outputs a sharp R image as being the first synthetical reflection R1, together with the first mixed image 11 and a first transmission image T1. The first transmission image T1 is the one that corresponds to the first image P1 which is a real image, that is not generated synthetically, and the only difference is that the first transmission image T1 was obtained from augmenting P1 by resizing, cropping and horizontal flipping in half of the cases.
- Thus, the first mixed image 11 is expressed as:

-
Fig. 3.2 . illustrates the three images outputted by the modified Gaussian blurring block C21: 11, T1, Sharp R = R1. - The inventors equally decided to introduce the second mixed image 12 which is outputted at the end of processing through the three blocks, as it can be seen in
Fig.2 : the varyingreflection 2nd pass block C22, the modified Gaussian blurring block C21 and the vertical flip block C23. - The first image P1 and the second image P2 undergo in the varying
reflection 2nd pass block C22 the same operations of altering and overlapping as the first mixed image 11 but applying the second augmentation parameters. For example, the second augmentation parameters can be: resizing, cropping, horizontal flipping. Then they undergo the adding of a second synthetical reflection R2 generated by the modified Gaussian blurring block C21. - In order to have a varying reflection between the first synthetical reflection R1 as sharp R and the second synthetical reflection R2 as low blurred R, the standard deviation of the Gaussian blurring convolution, in the case of the second synthetical reflection R2, was uniformly sampled from the range [0.0001, 0.25], while keeping the
kernel size 1, as part of the modified Gaussian blurring block C21. The range of the standard deviation accommodates the need of some variance in the blurring while still maintaining a low blurring level of the reflections. - Then, the second image P2 as outputted by the modified Gaussian blurring block C21 undergoes a vertical flipping carried out by the vertical flip block C23, half of the times.
- This means that the reflection is vertically flipped half of the times in such way to produce illuminated reflections in the bottom side of the frame, by considering the sky as the source of reflection. Here it was decided to flip vertically the reflection layer in half of the cases so as to have the sky, from the upper part of the image, as reflection for both the upper and lower part of the reflection layer. This choice can be explained by the fact that the reflection of the sky is generally bright and similar to other strong reflections.
- Consequently, the vertical flip block C23 outputs a low blurred image R as being the second synthetical reflection R2, together with the second mixed image 12 and a second transmission image T2. The second transmission image T2 is the one that corresponds to the first image P2 which is a real image, that is not generated synthetically and only augmented by resizing, cropping and horizontal flipping in half of the cases.
- Thus, the second mixed image 12 is expressed as follows:

-
Fig. 3.4 . illustrates the three images outputted by the varyingreflection 2nd pass block C22: 12, T2, Low blurred R, where Low blurred R = R2. - As it can be seen in
Fig. 3.1 ,Fig.3.2 andFig.3.4 , the first transmission image T1 and the second transmission image T2 are both generated from the first image P1, and the only difference between them is that they are generated using different randomly sampled parameters for the augmentation: the first augmentation parameters for the first transmission image T1 and the second augmentation parameters for the second transmission image T2. As such, it is possible that, for example one of them is resized to a bigger dimension or is horizontally flipped, while the other isn't. - The first synthetical reflection R1 and the second synthetical reflection R2 are then processed by the varying reflection opacity block C3 by adding the opacity parameter, used to improve the realism of the reflection by creating stronger or weaker reflections. The reflection opacity parameter is uniformly sampled from the range [0.7, 0.85] individually for the first synthetical reflection R1, respectively the second synthetical reflection R2. The adding of the opacity parameter, when applied to first synthetical reflection R1 and the second synthetical reflection R2 ends up affecting the first mixed image 11 and correspondingly the second mixed image 12. The explanation of the afore-mentioned sampling range of is that it helps to have certain degree of varying opacity, while at the same time allowing good visibility of the shape and color of objects behind the reflection. In cases where the reflection is strong and occludes the perspective behind it, when removing the reflection, much of the content is also removed, thus the quality of the picture provide to the ADAS processing chain is poor.
- Two sets of images are outputted by the data augmentation and reflection synthesis block C at the end of TS1: the first set of images containing I1, T1, R1 =Sharp R, and the second set of images containing 12, T2, and R2=Low blurred R.
- The difference between Sharp R and Low blurred R represents a slight variation of the reflection blurring parameter.
-
Fig. 3.3 . illustrates the three images outputted by the modified Gaussian blurring block C21: 11, T1, R1 = Sharp R after processing by the varying reflection opacity block C3 but without the processing by the varyingreflection 2nd pass block C22 and the vertical flip block C23, whereasFig. 3.5 illustrates the three images outputted by the varying Gaussian blurring block C21: 12, T2, R2 = Low blurred R after processing by the varying reflection opacity block C3, with the processing by the varyingreflection 2nd pass block C22 and the vertical flip block C23. The main differences between the two sets of I, T and R are that R1 is a sharper reflection and the second synthetical reflection R2 can be vertically flipped half of the times. As a consequence, the second mixed image 12 and the first mixed image 11 differ in the sharpness and, possibly, in the vertical rotation of their corresponding reflections, while at the same time the augmentations of the first transmission image T1, the first synthetical reflection R1, the second transmission image T2, and the second synthetical reflection R2, are different because of the sampling with randomly chosen different values from the same distributions mentioned before. - For the sake of easing the understanding, the references to the components of the first mixed image 11 and of the second mixed image 12 throughout the processing carried out by each of the components of the data augmentation and reflection synthesis block C are maintained the same, as the person skilled in the art understands that each of the images is subject to processing in each of the blocks of the data augmentation and reflection synthesis block C.
- In the literature there is a method presented in document [17], where the mixed image is reintroduced multiple times in the neural network as to iteratively remove the reflection.
- The advantage of generating simultaneously two mixed images 11 and 12 having a slightly altered version of the synthetical reflection - as the invention teaches in this step instead of reintroducing the same mixed images multiple times, is that it provides the machine learning model with more diversified data obtained based on the same number of captured images, while altering the generated reflection. Reintroducing the mixed images multiple times leads to overfitting the same type of reflection by processing it twice or more times.
- At the end of the first training step, the first transmission image T1, the first synthetical reflection R1, the first mixed image 11, the second transmission image T2, the second synthetical reflection R2 and the second mixed image 12 are sent to a Generative Adversarial Network GAN machine learning block E.
- The second images acquisition block B receives the first image P1 from the
first image dataset 1 and a third mixed image 13 from thesecond image dataset 2. - The second images acquisition block B, like the first images acquisition block A is a buffer, with the role to prepare the images received from the
first image dataset 1 and from thesecond image dataset 2 for the further processing detailed in the subsequent training sub-steps. - The first image P1 from the
first image dataset 1 has the same content with the third mixed image 13 from thesecond image dataset 2. It is required a geometrical alignment of the first image P1 and the third mixed image 13, preferably vertical, which corresponds to the vertical alignment of the first ADAS camera and of the second ADAS camera. The vertical alignment is preferred to the horizontal alignment because it is better adapted to solve the problem of the invention for the following reasons: - due to the small size of the ADAS cameras as compared with the content of the images, there is no substantial impact on the content of the fact that the cameras are placed one above the other; the small difference between the first image P1 and the third mixed image 13 refer to the upper and the lower margin of the pictures. The upper margin of all ADAS camera pictures depict the sky whereas the lower margin of all ADAS camera pictures usually depict the hood of the vehicle. Both the sky and the hood are of less interest for the ADAS processing chain which is the beneficiary of the pictures. The small difference between the respective images from thefirst image dataset 1 and from thesecond image dataset 2 can be further reduced following the augmentation carried out by the data augmentation block C1, respectively by the data augmentation block D specific to image pairs. Specificity of data augmentation block D consists in performing data augmentation dedicated to pairs of images, namely the pair of images P1 and the third mixed image 13 enter the data augmentation block D, where they will be processed. - The third mixed image 13 - that is the one with the natural reflection - will be used in the next step to infer a corresponding image without reflection.
- The data augmentation block D specific to image pairs is identical to the data augmentation block C1, with the only difference being that the augmentation parameters are sampled only once for the pairs 13 and P1, and, as such, they are identically augmented. Thus, the processing of the pair of images P1 and the third mixed image 13 is similar with the processing of the pair of images P1 and P2 by said data augmentation block C1, that is augmenting the image P1, transforming it into a third transmission image T3 and the third mixed image 13 using third augmentation parameters. In this sub-step neither synthetic generation, nor opacity, nor vertical flipping are applied.
- For the sake of easing the understanding, the references to the components of the third mixed image 13 and of the third transmission image T3 throughout the processing carried out by the data augmentation block D specific to image pairs are maintained the same, as the person skilled in the art understands that each of the images is subject to processing in the data augmentation block D specific to image pairs.
- As seen in
Fig. 1 , the output of this stage is the pair of images consisting in the third transmission image T3 and the third mixed image 13, which is sent to the Generative Adversarial Network GAN machine learning block E. - The third training step is carried out by the Generative Adversarial Network GAN machine learning block E, based on the machine learning model running on the data processing hardware.
- The input, as shown in
Fig. 1 , comes from the data augmentation and reflection synthesis block C and from the data augmentation block D specific to image pairs. - In essence, in this stage, at each iteration, the machine learning model learns to suppress the reflection from each of the three mixed images, 11, 12, 13.
- The machine learning model uses the Generative Adversarial Network GAN which basically comprises a Generator and a Discriminator and a plurality of parameters. In the training stage, at each iteration, the Generator is provided with the images containing reflection, that is with the three mixed images, 11, 12, 13. The Generator generates corresponding predicted transmission images T': a first predicted transmission image T'1 corresponding to the first transmission image T1, a second predicted transmission image T'2 corresponding to the second transmission image T2, and a third predicted transmission image T'3 corresponding to the third transmission image T3.
- The predicted transmission images T '1...T'n , considered after a preset number of iterations, approximate the corresponding transmission images T1....Tn, said corresponding transmission images T1....Tn being based on real images and not on synthetical images. The corresponding transmission images T1....Tn have the value of reference images. The predicted transmission images T '1...T'n have the reflection suppressed. A full removal of the reflection is an aim of all removal methods; however, it is very difficult to obtain.
- Then, the Discriminator is provided in the current iteration with three pairs of images: the first, second and third predicted transmission images T '1...T'3 and the corresponding first, second and third transmission images T1....T3, the latter having the value of reference images. The Discriminator is not aware which one of the two images of each pair is the reference image, and which one is the generated image. As such, for each image of the pair, the Discriminator calculates a certainty score that corresponds to the realism of the image.
- Thus, at each iteration, the score is computed for each of the three predicted transmission images T '1...T'3 and for each of the three corresponding transmission images T1....T3.
- This score is compared with a reference score, as the data processing hardware knows which one of the images is the reference image and which is not and then, the error of the Discriminator is quantified for each of the three predicted transmission images T '1...T'3 and for each of the corresponding three transmission images T1....T3 and an adversarial loss is calculated.
- After calculating the adversarial loss, at each iteration, a pixel level loss is calculated between the first predicted transmission image T'1 and the first transmission image T1 as well as between the second predicted transmission image T'2 and the second transmission image T2.
- The reason for not calculating the pixel level loss for the third predicted transmission image T'3 and its corresponding third transmission image T3 pair of images is the two images of the pair are obtained from two different cameras, preferably stacked vertically as it was disclosed previously, the third predicted transmission image T'3 being obtained from the third mixed image 13 after being processed by the Generator. As such, there is a slight shift between the resulting pairs of images which makes impossible a pixel level comparison. While for T'1 - T2 and T'2 - T2 pairs the pixel level comparison is possible as they all are obtained from the same camera.
- Then, an alignment invariant loss and a feature level loss are added by the Generative Adversarial Network GAN machine learning block E, the calculation of the two losses being outside the scope of the invention.
- Then, based on said calculated losses, a backward pass adapted to the neural network needed to correct the errors. The calculation of the differences and the backwards pass is outside the scope of the invention.
- The result is the optimization of the machine learning model by adjusting, after the preset number of iterations, the plurality of parameters of the machine learning model including adjusting the plurality of parameters, such that to optimize the generation of predicted transmission images T' as close as possible to the respective transmission images T according to the result of the calculated losses and the backward pass the preset number of iterations.
- In a preferred embodiment, the preset number of iterations for the adjusting of the machine learning model is 1, that is the adjusting of the plurality of parameters is carried out after each iteration. This has the advantage of better adjusting the process of learning.
- This is the end of one iteration of the training step TS. A plurality of iterations is carried out during the training step TS in a similar way with the iteration described above.
- Thus, in each iteration, the machine learning model generates an approximation of the image without reflection for each image with reflection.
- The machine learning model is trained to generalize in order to suppress the reflection from the images containing reflection. This generalization expects the model to be invariant to the type of reflection that it "sees". As such, during training the machine learning model "sees" reflections that vary in sharpness and opacity, while, at the same time, being generated from diverse images so as to have diverse resulting reflections. The expected generalization aims to an optimal removal of future reflections, during the inference step, reflections that were not present in the training data, while at the same time not altering the non-reflection part of images. The simultaneous generation in TS1 of two mixed images - the first mixed image 11 and the second mixed image 12, having a slightly altered version of the synthetical reflection as well as increased intensity of the reflection by adding the opacity parameter have the advantage of feeding the machine learning model with a more diversified type of images-The images are closer to the reality of the images acquired by the ADAS cameras as compared with the machine learning models of prior art. For this reason, the expected generalization of what is and what is not a reflection in the images acquired by the ADAS camera yields better results for the particular case of ADAS cameras used in the vehicles, without getting stuck on the blurring level of each element of each image or being unable to see the same combination of the first image P1 and the second image P2 as they were sampled from the
first image dataset 1. - The machine learning model is then optimized in order to run on the graphical processing unit GPU of the ADAS camera and then it is sent to a GAN machine learning block F of said graphical processing unit GPU of the ADAS camera. The optimization of the machine learning model as well as the details of sending it to the GAN machine learning block F of said graphical processing unit GPU are outside the scope of this invention.
- With reference to
Fig.1 , in the inference step, the ADAS camera acquires images I from the real-life context, that are the equivalent of the mixed images of the training step because they do contain reflection. - The images I are processed by the GAN machine learning block F, that is already trained to suppress the reflection. Consequently, in the inference step, the GAN machine learning block F will output a predicted transmission image T', having the reflection suppressed.
- An example of the images of the inference step is depicted in
Fig. 3.6 . - At the end of the inference step IS, the predicted transmission image T' is made available to the ADAS processing chain.
- In a preferred embodiment, the Generative Adversarial Network is Single Image Reflection Removal Exploiting Misaligned Training Data and Network Enhancements, ERRNet.
- The Generator and the Discriminator of the ERRNet used in the invention are similar to the one disclosed in paper [14].
- The Discriminator has ten 2D Convolutions for the base processing. Each layer has
kernel 3,padding 1 andstride - After the ten convolutions, there is an Adaptive Average Pooling 2D layer that reduces each feature field of the 512 to the dimension 1x1, which results in 1x1x512. After this, two Convolutional 2D layers are included, with
kernel size 1 andstride 1, in between being a Leaky RELU with alpha 0.02. These convolutions change the feature fields as follows [512, 1024], and then [1024, 1], so as to end up extracting only the relevant information that is put on 1 channel. Over this channel a Sigmoid layer is applied in order to determine the final prediction in the interval [0.0, 1.0]. This represents how realistic the discriminator finds the given image. This Discriminator is used only for training, and at each iteration it is applied on both the predicted transmission images T '1...T'n generated by the Generator, as well as on the images without reflection, that is the transmission images T1...Tn, so as to better learn what a real image looks like. - For the Generator, there are quite a few more layers in its implementation but 3 structures should be noted as being the most relevant. The Generator takes as input each of the given images, that is the transmission images T1...Tn, with not only its original channels, but additionally some ~1000 channels concatenated to it after the image is processed by a VGG-19 which is frozen after training on ImageNet, where ImageNet is a reference dataset for images when training 2D object detection and VGG-19 is a general architecture used as backbone for feature extraction. The channels represent the hyper-column features of the activation of specific layers of the VGG-19. Both ImageNet and VGG-19 are described in detail in document No. [18].
- The Generator initially contains three convolutional layers, each followed by a RELU activation. This is followed by thirteen residual blocks, then another convolutional layer with RELU, and then a Pyramid Pooling block followed by a last Convolutional layer.
- Important notice should be given to the thirteen residual blocks and the Pyramid Pooling block. The residual structures have the role of processing the image at different depths by increasing the number of feature fields resulting from multiple Convolutional layers. Residual blocks are known in the literature for using the information from previous layers so as to combine different layers of abstraction. The convolutional layer that follows the thirteen residual blocks has the role of trying to compress the information by reducing the dimensionality of the data. This in turn is given to the Pyramid Pooling block. Here, the feature fields are processed at four different resolutions so as to remove the reflection at different scales. The results of each scale are resized to the initial resolution that was given to the block, and all the feature fields are concatenated together. Afterwards, the last convolutional layer has the role of combining all of this information into one single image of the initial resolution- in this case of 224x224x3, which is supposed to have the reflection optimally removed. The resulting image is the predicted transmission image T '1...T'n, which is then sent to the Discriminator for evaluation.
- Although the architecture of the Generator and the Discriminator of the ERRNet used in the invention is similar to the one disclosed in paper [14], the machine training model of the invention is significantly improved in respect to the one disclosed in said paper [14], because the input data of the machine training model of the invention is significantly different from the input data of the prior art for the reasons disclosed in detail above, namely the simultaneous generation in TS1 of two mixed images - the first mixed image 11 and the second mixed image 12, having a slightly altered version of the synthetical reflection as well as varying the intensity of the reflection by adding the opacity parameter.
- In this preferred embodiment using the ERRNet, the adjustment of the plurality of parameters is carried out after each iteration. This has the advantage that noise might be introduced alongside learning how to remove the reflection of each image. The noise originates from adjusting the plurality of parameters depending only on the error of the reflection removal on one image and not over multiple images.
- The training method has the advantage that, when compared with the training method of prior art, generalizes better what is and what is not a reflection in the images acquired by the ADAS camera yielding better results than the training methods of prior art for the particular case of ADAS cameras used in the vehicles, while at the same time not altering the non-reflection part of images.
- The trained machine learning model of the invention has the advantage that is significantly improved in respect to prior art because the input data of the machine training model of the invention is improved in respect to the input data of the prior art for the reasons disclosed in detail above, namely the simultaneous generation in TS1 of two mixed images - the first mixed image 11 and the second mixed image 12, having a slightly altered version of the synthetical reflection as well as increased intensity of the reflection by adding the opacity parameter.
- In a second aspect of the invention, it is presented a data processing hardware configured to carry out the training steps of the method in any of its preferred embodiments, comprising: a first images acquisition block, a second images acquisition block, a data augmentation and reflection synthesis block, a data augmentation block specific to image pairs, and a Generative Adversarial Network machine learning block.
- In a preferred embodiment, the data augmentation and reflection synthesis block comprises a data augmentation block, and a modified reflection synthesis generating block.
- The data processing hardware comprises at least one computer processing unit core at least one volatile memory RAM and at least one non-volatile memory ROM, the respective configuration of which is according to prior art.
- Non limiting examples of data processing hardware are: servers, laptops, computers or controllers, electronic control units.
- In a preferred embodiment, all blocks of the data processing hardware are comprised in a single hardware entity, as this has the advantage of reducing latency when it comes to the continuous fetching of the training data at each iteration of the training process.
- In another preferred embodiment, the blocks of the data processing hardware are comprised in separated individual hardware entities communicating between themselves by communication protocols. This embodiment is used in the cases when it is not possible to comprise all blocks of the data processing hardware in the same single hardware entity.
- In a preferred embodiment, the non-volatile datasets memory is part of the data processing hardware, whereas, in another preferred embodiment, the non-volatile datasets memory is part of another processing hardware, communicating with the data processing hardware by communication protocols. Including the non-volatile datasets memory in the data processing hardware is more advantageous than placing it in the other processing hardware because it reduces latency when it comes to the continuous fetching of the training data at each iteration of the training process. In a third aspect of the invention, it is presented an ADAS camera of a vehicle, provided with the machine learning model of the invention, trained in accordance with the training steps of the method in any of its preferred embodiments and configured to carry out the inference step of the method in any of its preferred embodiments. The ADAS camera of the invention has the advantage that provides better quality images after the removal of the reflection by applying the method of the invention and as a result of the training of the machine learning model according to the training steps of the invention.
- In a fourth aspect of the invention, it is presented a first computer program comprising instructions which, when executed by the data processing hardware of the invention, causes the respective data processing hardware to perform the training steps of the method in any of its preferred embodiments.
- In a fifth aspect of the invention, it is presented a second computer program comprising instructions which when executed by the ADAS camera of the invention, causes the respective ADAS camera to perform the inference step IS of the method in any of its preferred embodiments.
- In a sixth aspect of the invention, it is presented a first computer readable medium having stored thereon instructions of the first computer program of the invention. Finally, in a seventh aspect of the invention, it is presented a second computer readable medium having stored thereon instructions of the second computer program of the invention.
- While certain embodiments of the present invention have been described in detail, those familiar with the art to which this invention relates will recognize various alternative designs and embodiments for practicing the invention as defined by the following claims.
-
- [1] You LI and Michael S. Brown, Exploiting Reflection Change for Automatic Reflection Removal, 2013 IEEE International Conference on Computer Vision, 1-8 December 2013, https://ieeexplore.ieee.org/document/6751413, available online as of 03 March 2014
- [2] Qiang Wen et al, Single Image Reflection Removal Beyond Linearity, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 15-20 June 2019, https://openaccess.thecvf.com/content CVPR 2019/html/Wen Single Image Reflec tion Removal Beyond Linearity CVPR 2019 paper.html, available online as of 09 January 2020
- [3] YiChang Shih et al, Reflection removal using ghosting cues, 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 7-12 June 2015, https://ieeexplore.ieee.org/document/7298939, available online as of 15 October 2015
- [4] Tianfan Xue et al, A Computational Approach for Obstruction-Free Photography, ACM Transactions on Graphics (Proc. SIGGRAPH), 2015, https://people.csail.mit.edu/mrub/papers/ObstructionFreePhotography SIGGRAPH2 015.pdf
- [5] Renjie Wan et al, Depth of field guided reflection removal, 2016 IEEE International Conference on Image Processing (ICIP), 25-28 September 2016, https://ieeexplore.ieee.org/document/7532311
- [6] Nikolaos Arvanitopoulos, Radhakrishna Achanta and Sabine Süsstrunk, Single Image Reflection Suppression, 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 21-26 July 2017, https://ieeexplore.ieee.org/document/8099673 , available online as of 09 November 2017
- [7] Donghoon Lee, Ming-Hsuan Yang and Songhwai Oh ,Generative Single Image Reflection Separation, arXiv:1801.04102v1 [cs.CV], 12 January 2018, https://arxiv.org/pdf/1801.04102.pdf
- [8] Huaidong Zang et al, Fast User-Guided Single Image Reflection Removal via Edge-Aware Cascaded Networks, IEEE Transactions on Multimedia (Volume: 22, Issue: 8, Aug. 2020), pages 2012 - 2023, 04 November 2019, https://ieeexplore.ieee.org/document/8890835
- [9] Yu Li et al, Single Image Layer Separation using Relative Smoothness, 2014 IEEE Conference on Computer Vision and Pattern Recognition, 23-28 June 2014, https://openaccess.thecvf.com/content cvpr 2014/papers/Li , available online as of 25 September 2014
- [10] Daiqian Ma et al, Learning to Jointly Generate and Separate Reflections, 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 27 October-2 November 2019, https://openaccess.thecvf.com/content ICCV 2019/papers/Ma Learning to Jointly Generate and Separate Reflections ICCV 2019 paper.pdf , available online as of 27 February 2020
- [11] Meiguang Jin; Sabine Süsstrunk and Paolo Favaro, Learning to see through reflections, 2018 IEEE International Conference on Computational Photography (ICCP), 4-6 May 2018, https://ieeexplore.ieee.org/document/8368464 , available online as of 31 May 2018
- [12] Ryo Abiko and Masaaki Ikehara, Single Image Reflection Removal Based on GAN With Gradient Constraint, IEEE Access (Volume: 7), pages 148790 - 148799, October 14, 2019, https://ieeexplore.ieee.org/document/8868089
- [13] Chao Li et al, Single Image Reflection Removal through Cascaded Refinement, arXiv:1911.06634v2 [cs.CV], 5 April, 2020 https://arxiv.org/abs/1911.06634
- [14] Kaixuan Wei et al, Single Image Reflection Removal Exploiting Misaligned Training Data and Network Enhancements, arXiv:1904.00637v1 [cs.CV], 1 April 2019, https://arxiv.org/pdf/1904.00637.pdf
- [15] Xuaner Zhang et al, Single Image Reflection Separation with Perceptual Losses, arXiv:1806.05376v1 [cs.CV], 14 June 2018, https://arxiv.org/abs/1806.05376
- [16] Qingnan Fan et al, A Generic Deep Architecture for Single Image Reflection Removal and Image Smoothing, arXiv:1708.03474v2 [cs.CV] 10 June 2018, https://arxiv.org/abs/1708.034-74
- [17] Jie Yang et al, Seeing Deeply and Bidirectionally: A Deep Learning Approach for Single Image Reflection Removal, Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 654-669, https://link.springer.com/conference/eccv
- [18] Olga Russakovsky et al, ImageNet Large Scale Visual Recognition Challenge arXiv:1409.0575v3, 30 January 2015, https://arxiv.org/pdf/1409.0575.pdf
-
- A - first images acquisition block
- B - second images acquisition block
- C data augmentation and reflection synthesis block
- C1 - data augmentation block
- C2 - modified reflection synthesis generating block
- C21 - modified Gaussian blurring block
- C22 -varying
reflection 2nd pass block - C23 vertical flip block
- C3 - varying reflection opacity block
- D - data augmentation block specific to image pairs
- E - Generative Adversarial Network machine learning block,
- F Generative Adversarial Network GAN machine learning module of the ADAS camera
-
- 11
- first mixed image
- R1
- first synthetical reflection
- T1
- first transmission image
- 12
- second mixed image
- R2
- second synthetical reflection
- T2
- second transmission image
- 13
- third mixed image having natural reflection
- T3
- third transmission image
- T'1
- predicted transmission image corresponding to the first mixed image 11,
- T'2
- predicted transmission image corresponding to the second mixed image 12,
- T'3
- predicted transmission image corresponding to the third mixed image 13,
-
- I
- image from real-life (mixed image)
- T'
- predicted transmission image
Claims (10)
- Method of reflection removal based on a Generative Adversarial Network GAN used for training of an ADAS camera of a vehicle, characterized in that it comprises the following steps:a. an Acquisition Step (AS) of a1. capturing simultaneously first ADAS camera images by a first ADAS camera and second ADAS camera images from a second ADAS camera,the first ADAS camera identical with the second ADAS camera and identical with the ADAS camera of the vehicle, and the first ADAS camera further comprising a physical reflection removal filter, the first ADAS camera and the second ADAS camera aligned such that to have essentially the same field of view,the first ADAS camera and the second ADAS camera capturing in their respective images essentially the same content at the same time,
anda2. sending the captured images to two respective image datasets:the first ADAS camera images to a first image dataset (1), comprising images (Pi) without reflection,the second ADAS camera images to a second image dataset (2), the second image dataset (2) comprising naturally mixed images (I3i) having natural reflection,training steps (TS) carried out by a data processing hardware,b. a first training step (TS1) ofb1.1. receiving a randomly sampled pair of images P1 and P2 from the first image dataset (1) by a first images acquisition block (A),b1.2. carrying out a first altering of the images P1 and P2 by a data augmentation and reflection synthesis block (C), generating: a first transmission image T1, a first synthetical reflection R1, and a first mixed image 11 generated by overlapping the first synthetical reflection R1 over the first transmission image T1
and, simultaneously, carrying out a second altering of the images P1 and P2 by the data augmentation and reflection synthesis block (C), generating: a second transmission image T2, a second synthetical reflection (R2), and a second mixed image 12 generated by overlapping the second synthetical reflection R2 over the second transmission image T2,b1.3. sending the first transmission image T1, the first synthetical reflection R1, the first mixed image 11, the second transmission image T2, the second synthetical reflection R2 and the second mixed image 12 to a Generative Adversarial Network GAN machine learning block (E),
wherein the first transmission image T1, the first reflection R1, and the first mixed image 11 are generated as follows:augmenting the first image P1 and the second image P2 by a data augmentation block (C1) using first augmentation parameters, adding the first synthetical reflection R1 by a modified Gaussian blurring block (C21), adding an opacity parameter to the first synthetical reflection R1 by a varying reflection opacity block (C3),
andwherein the second transmission image T2, the second synthetical reflection R2 and the second mixed image 12 are generated as follows: augmenting the first image P1 and the second image P2 by a varying reflection 2nd pass block (C22) using second augmentation parameters, adding the second synthetical reflection R2 generated by the modified Gaussian blurring block (C21), vertical flipping of the second image P2 by a vertical flip block (C23), adding the opacity parameter to the second synthetical reflection (R2) by the varying reflection opacity block (C3),a second training step (TS2) ofb2.1 receiving by a second images acquisition block (B): the first image P1 from the first image dataset (1) and a third mixed image 13 from the second image dataset (2) having the same content with the first image P1,b2.2 carrying out, by a data augmentation block (D) specific to image pairs, augmentation of the first image P1 generating a third transmission image (T3), and augmentation of the third mixed image 13 using third augmentation parameters,b2.3 sending the third transmission image T3 and the third mixed image 13 to the Generative Adversarial Network GAN machine learning block (E),
a third training Step (TS3) carried out by the Generative Adversarial Network GAN machine learning block (E), ofb3.1 generating at each iteration, based on a machine learning model comprising a plurality of parameters, corresponding predicted transmission images T' by a Generator of the Generative Adversarial Network GAN machine learning block (E): a first predicted transmission image T'1 corresponding to the first transmission image T1, a second predicted transmission image T'2 corresponding to the second transmission image T2, a third predicted transmission image T'3 corresponding to the third transmission image T3, b3.2 calculating, at each iteration, by a Discriminator of the Generative Adversarial Network GAN machine learning block (E) a certainty score for each pair of images:the first predicted transmission image T'1 and the first transmission image T1,the second predicted transmission image (T'2) and the second transmission image (T2), the third predicted transmission image (T'3) and the third transmission image (T3),b3.3 calculating, at each iteration, an Adversarial loss based on the certainty score, a pixel level loss for the pairs of the first predicted transmission image T'1 and its corresponding first transmission image T1, the second predicted transmission image T'2 and its corresponding second transmission image T2, a feature level loss and an alignment invariant loss for all three pairs of images,b3.4 optimizing, after a preset number of iterations, the machine learning model, including adjusting the plurality of parameters, such that to optimize the generation of predicted transmission images T' as close as possible to the respective transmission images T,b3.5 compressing said optimized machine learning model and sending the compressed machine learning model to a GAN machine learning block (F) of the ADAS camera, andc. an inference Step (IS) carried out by the ADAS camera of the vehicle (IS), ofc1. Acquiring, by the ADAS camera, an image I, the image I containing reflection,c2. suppressing, by the GAN machine learning block (F) of the reflection and generating a predicted transmission image T', having the reflection suppressed,c3. making the predicted transmission image T' available to an ADAS processing chain. - The method of Claim 1, characterized in that the Generative Adversarial Network is Single Image Reflection Removal Exploiting Misaligned Training Data and Network Enhancements ERRNet.
- A data processing hardware comprising: a first images acquisition block (A), a second images acquisition block (B), a data augmentation and reflection synthesis block (C), a data augmentation block (D) specific to image pairs, and a Generative Adversarial Network machine learning block (E), characterized in that it is configured to carry out the training steps (TS) of claims 1 or 2.
- Data processing hardware according to claim 3, characterized in that the data augmentation and reflection synthesis block (C) comprises: a data augmentation block (C1), a modified reflection synthesis generating block (C2), and a varying reflection opacity block (C3).
- Data processing hardware according to claims 3 and 4, characterized in that the modified reflection synthesis generating block (C2) comprises: a modified Gaussian blurring block (C21), a varying reflection 2nd pass block (C22) and a vertical flip block (C23).
- An ADAS camera of a vehicle, characterized in that it is provided with the machine learning model trained in accordance with the training steps (TS) of claims 1 or 2 and configured to carry out the inference step (IS) of claims 1 or 2.
- A first computer program characterized in that it comprises instructions which, when executed by the data processing hardware of claim 3, causes the respective data processing hardware to perform the training steps (TS) of claims 1 or 2.
- A second computer program characterized in that it comprises instructions which when executed by the ADAS camera of claim 6, causes the respective ADAS camera to perform the inference step (IS) of claims 1 or 2.
- A first computer readable medium having stored thereon instructions of the first computer program of claim 7.
- A second computer readable medium having stored thereon instructions of the second computer program of claim 8.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP21465557 | 2021-11-01 | ||
| GB2115714.4A GB2612581B (en) | 2021-11-02 | 2021-11-02 | Method of reflection removal based on a Generative Adversarial Network used for training of an ADAS camera of a vehicle |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP4174759A1 true EP4174759A1 (en) | 2023-05-03 |
| EP4174759B1 EP4174759B1 (en) | 2025-12-10 |
Family
ID=83598367
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP22201878.0A Active EP4174759B1 (en) | 2021-11-01 | 2022-10-17 | Method of reflection removal based on a generative adversarial network used for training of an adas camera of a vehicle |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US12475713B2 (en) |
| EP (1) | EP4174759B1 (en) |
| CN (1) | CN116091334A (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20250111488A1 (en) * | 2023-09-28 | 2025-04-03 | Apple Inc. | Enhanced Detection or Repair of Unwanted Reflection Artifacts in Digital Images |
| EP4614454A1 (en) * | 2024-03-05 | 2025-09-10 | Robert Bosch GmbH | Method for enhancing object detection |
| CN119205551A (en) * | 2024-09-23 | 2024-12-27 | 景德镇学院 | An image acquisition device for computer vision |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105008857A (en) * | 2013-02-25 | 2015-10-28 | 大陆汽车有限责任公司 | Intelligent video navigation for automobiles |
| KR20170010645A (en) * | 2015-07-20 | 2017-02-01 | 엘지전자 주식회사 | Autonomous vehicle and autonomous vehicle system including the same |
| KR102261329B1 (en) * | 2015-07-24 | 2021-06-04 | 엘지전자 주식회사 | Antenna, radar for vehicle, and vehicle including the same |
| US10145951B2 (en) * | 2016-03-30 | 2018-12-04 | Aptiv Technologies Limited | Object detection using radar and vision defined image detection zone |
| WO2019094843A1 (en) * | 2017-11-10 | 2019-05-16 | Nvidia Corporation | Systems and methods for safe and reliable autonomous vehicles |
| CN111861894B (en) * | 2019-04-25 | 2023-06-20 | 上海理工大学 | Image motion blur removing method based on generation type countermeasure network |
| KR102921223B1 (en) * | 2019-05-17 | 2026-02-02 | 삼성전자주식회사 | Advanced driver assist device and method of detecting object in the same |
| US11244500B2 (en) * | 2019-12-31 | 2022-02-08 | Woven Planet North America, Inc. | Map feature extraction using overhead view images |
| US11288522B2 (en) * | 2019-12-31 | 2022-03-29 | Woven Planet North America, Inc. | Generating training data from overhead view images |
| US20210199446A1 (en) * | 2019-12-31 | 2021-07-01 | Lyft, Inc. | Overhead view image generation |
| US11869208B2 (en) * | 2020-03-16 | 2024-01-09 | Taipei Veterans General Hospital | Methods, apparatuses, and computer programs for processing pulmonary vein computed tomography images |
| US11768504B2 (en) * | 2020-06-10 | 2023-09-26 | AI Incorporated | Light weight and real time slam for robots |
| CN111899176B (en) * | 2020-07-31 | 2022-08-12 | 罗雄彪 | A video image enhancement method |
| CN112102182B (en) * | 2020-08-31 | 2022-09-20 | 华南理工大学 | Single image reflection removing method based on deep learning |
| CN112581396A (en) * | 2020-12-18 | 2021-03-30 | 南京邮电大学 | Reflection elimination method based on generation countermeasure network |
| US11688041B2 (en) * | 2021-03-02 | 2023-06-27 | International Business Machines Corporation | System and method of automatic image enhancement using system generated feedback mechanism |
-
2022
- 2022-10-17 EP EP22201878.0A patent/EP4174759B1/en active Active
- 2022-10-31 CN CN202211345913.8A patent/CN116091334A/en active Pending
- 2022-11-01 US US18/051,747 patent/US12475713B2/en active Active
Non-Patent Citations (21)
| Title |
|---|
| ABIKO RYO ET AL: "Single Image Reflection Removal Based on GAN with Gradient Constraint", 23 February 2020, ARXIV.ORG, CORNELL UNIVERSITY LIBRARY, 201 OLIN LIBRARY CORNELL UNIVERSITY ITHACA, NY 14853, PAGE(S) 609 - 624, XP047536367 * |
| CHAO LI ET AL.: "Single Image Reflection Removal through Cascaded Refinement", ARXIV:1911.06634V2, 5 April 2020 (2020-04-05) |
| DAIQIAN MA ET AL.: "Learning to Jointly Generate and Separate Reflections", 2019 IEEE/CVF INTERNATIONAL CONFERENCE ON COMPUTER VISION (ICCV, 27 October 2019 (2019-10-27) |
| DONGHOON LEEMING-HSUAN YANGSONGHWAI OH: "Generative Single Image Reflection Separation", ARXIV: 1801.04102V1, 12 January 2018 (2018-01-12), Retrieved from the Internet <URL:https://arxiv.org/pdf/1801.04102.pd> |
| HUAIDONG ZANG ET AL.: "Fast User-Guided Single Image Reflection Removal via Edge-Aware Cascaded Networks", IEEE TRANSACTIONS ON MULTIMEDIA, vol. 22, 4 November 2019 (2019-11-04), pages 2012 - 2023, XP011800680, DOI: 10.1109/TMM.2019.2951461 |
| JIE YANG ET AL.: "Seeing Deeply and Bidirectionally: A Deep Learning Approach for Single Image Reflection Removal", PROCEEDINGS OF THE EUROPEAN CONFERENCE ON COMPUTER VISION (ECCV, 2018, pages 654 - 669 |
| KAIXUAN WEI ET AL: "Single Image Reflection Removal Exploiting Misaligned Training Data and Network Enhancements", ARXIV.ORG, CORNELL UNIVERSITY LIBRARY, 201 OLIN LIBRARY CORNELL UNIVERSITY ITHACA, NY 14853, 1 April 2019 (2019-04-01), XP081163226 * |
| KAIXUAN WEI: "Single Image Reflection Removal Exploiting Misaligned Training Data and Network Enhancements", ARXIV:1904.00637V1, 1 April 2019 (2019-04-01), Retrieved from the Internet <URL:https://arxiv.org/pdf/1904.00637.pdf> |
| MEIGUANG JINSABINE SUSSTRUNKPAOLO FAVARO: "Learning to see through reflections", 2018 IEEE INTERNATIONAL CONFERENCE ON COMPUTATIONAL PHOTOGRAPHY (ICCP, 31 May 2018 (2018-05-31), Retrieved from the Internet <URL:https://ieeexplore.ieee.org/document/8368464> |
| NIKOLAOS ARVANITOPOULOSRADHAKRISHNA ACHANTASABINE SUSSTRUNK: "Single Image Reflection Suppression", 2017 IEEE CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR, 21 July 2017 (2017-07-21) |
| OLGA RUSSAKOVSKY ET AL.: "ImageNet Large Scale Visual Recognition Challenge", ARXIV:1409.0575V3, 30 January 2015 (2015-01-30), Retrieved from the Internet <URL:https://arxiv.org/pdf/1409.0575.pdf> |
| QIANG WEN ET AL.: "Single Image Reflection Removal Beyond Linearity", PROCEEDINGS OF THE IEEE/CVF CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR, 15 June 2019 (2019-06-15) |
| QINGNAN FAN ET AL.: "A Generic Deep Architecture for Single Image Reflection Removal and Image Smoothing", ARXIV:1708.03474V2, 10 June 2018 (2018-06-10), Retrieved from the Internet <URL:https://arxiv.org/abs/1708.03474> |
| RENJIE WAN ET AL.: "Depth of field guided reflection removal", 2016 IEEE INTERNATIONAL CONFERENCE ON IMAGE PROCESSING (ICIP, 25 September 2016 (2016-09-25), Retrieved from the Internet <URL:https://ieeexplore.ieee.org/document/7532311> |
| RYO ABIKOMASAAKI IKEHARA: "Single Image Reflection Removal Based on GAN With Gradient Constraint", IEEE ACCESS, vol. 7, 14 October 2019 (2019-10-14), pages 148790 - 148799, XP011751487, Retrieved from the Internet <URL:https://ieeexplore.ieee.org/document/8868089> DOI: 10.1109/ACCESS.2019.2947266 |
| TIANFAN XUE ET AL.: "A Computational Approach for Obstruction-Free Photography", ACM TRANSACTIONS ON GRAPHICS (PROC. SIGGRAPH, 2015, Retrieved from the Internet <URL:https://people.csail.mit.edu/mrub/papers/ObstructionFreePhotographySIGGRAPH2015.pdf> |
| XUANER ZHANG ET AL: "Single Image Reflection Separation with Perceptual Losses", ARXIV.ORG, CORNELL UNIVERSITY LIBRARY, 201 OLIN LIBRARY CORNELL UNIVERSITY ITHACA, NY 14853, 14 June 2018 (2018-06-14), XP080890574 * |
| XUANER ZHANG: "Single Image Reflection Separation with Perceptual Losses", ARXIV:1806.05376V1, 14 June 2018 (2018-06-14), Retrieved from the Internet <URL:https://arxiv.org/abs/1806.05376> |
| YICHANG SHIH ET AL.: "Reflection removal using ghosting cues", 2015 IEEE CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR, 7 June 2015 (2015-06-07), Retrieved from the Internet <URL:https://ieeexplore.ieee.org/document/7298939> |
| YOU LIMICHAEL S. BROWN: "Exploiting Reflection Change for Automatic Reflection Removal", 2013 IEEE INTERNATIONAL CONFERENCE ON COMPUTER VISION, vol. 1-8, 3 March 2014 (2014-03-03) |
| YU LI ET AL.: "Single Image Layer Separation using Relative Smoothness", 2014 IEEE CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION, 23 June 2014 (2014-06-23) |
Also Published As
| Publication number | Publication date |
|---|---|
| US12475713B2 (en) | 2025-11-18 |
| EP4174759B1 (en) | 2025-12-10 |
| US20230135636A1 (en) | 2023-05-04 |
| CN116091334A (en) | 2023-05-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP4174759B1 (en) | Method of reflection removal based on a generative adversarial network used for training of an adas camera of a vehicle | |
| CN112233038B (en) | True image denoising method based on multi-scale fusion and edge enhancement | |
| US11017586B2 (en) | 3D motion effect from a 2D image | |
| CN110324664B (en) | A neural network-based video frame supplementation method and its model training method | |
| CN111028177A (en) | Edge-based deep learning image motion blur removing method | |
| KR20210012009A (en) | Apparatus and method for image processing, and system for training neural networks | |
| GB2612581A (en) | Method of reflection removal based on a Generative Adversarial Network used for training of an ADAS camera of a vehicle | |
| US20110176722A1 (en) | System and method of processing stereo images | |
| EP4149110B1 (en) | Virtual viewpoint synthesis method, electronic device and computer readable medium | |
| WO2016050729A1 (en) | Face inpainting using piece-wise affine warping and sparse coding | |
| JP7787704B2 (en) | Method and system for removing scene text from an image | |
| CN115965531A (en) | Model training method, image generation method, device, equipment and storage medium | |
| EP4468698A1 (en) | Artistically controllable stereo conversion | |
| US20250285304A1 (en) | Image processing apparatus, image processing method, and storage medium | |
| CN119169180B (en) | NeRF three-dimensional reconstruction method based on deformable pose blur kernel | |
| CN120471801A (en) | An event-driven image motion deblurring method | |
| CN117710868B (en) | Optimized extraction system and method for real-time video target | |
| EP3879495A1 (en) | Image generation for training a neural network | |
| CN119299645A (en) | A 3D image generation method, device, equipment and storage medium | |
| Ahalya et al. | Deep Learning for Single Image Deblurring | |
| Li et al. | A position-enhanced attention framework for video deblurring | |
| US20260073625A1 (en) | Image processing apparatus and operating method thereof | |
| CN114202651A (en) | Image over-segmentation method, system and medium for enhancing interested region | |
| CN114782941B (en) | Video OSD character recognition method, device and medium | |
| CN113902786B (en) | Depth image preprocessing method, system and related device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION HAS BEEN PUBLISHED |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC ME MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: REQUEST FOR EXAMINATION WAS MADE |
|
| 17P | Request for examination filed |
Effective date: 20240129 |
|
| RBV | Designated contracting states (corrected) |
Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC ME MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: GRANT OF PATENT IS INTENDED |
|
| RAP3 | Party data changed (applicant data changed or rights of an application transferred) |
Owner name: AUMOVIO AUTONOMOUS MOBILITY GERMANY GMBH |
|
| INTG | Intention to grant announced |
Effective date: 20250724 |
|
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE PATENT HAS BEEN GRANTED |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC ME MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: F10 Free format text: ST27 STATUS EVENT CODE: U-0-0-F10-F00 (AS PROVIDED BY THE NATIONAL OFFICE) Effective date: 20251210 Ref country code: GB Ref legal event code: FG4D |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R096 Ref document number: 602022026499 Country of ref document: DE |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: FG4D |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: ES Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20251210 |
|
| REG | Reference to a national code |
Ref country code: LT Ref legal event code: MG9D |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: NO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20260310 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: FI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20251210 Ref country code: HR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20251210 |
|
| REG | Reference to a national code |
Ref country code: NL Ref legal event code: MP Effective date: 20251210 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: RS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20260310 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LV Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20251210 |