CN113707136B - 服务型机器人语音交互的音视频混合语音前端处理方法 - Google Patents
服务型机器人语音交互的音视频混合语音前端处理方法 Download PDFInfo
- Publication number
- CN113707136B CN113707136B CN202111258776.XA CN202111258776A CN113707136B CN 113707136 B CN113707136 B CN 113707136B CN 202111258776 A CN202111258776 A CN 202111258776A CN 113707136 B CN113707136 B CN 113707136B
- Authority
- CN
- China
- Prior art keywords
- voice
- image
- signal
- time
- speech
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/14—Speech classification or search using statistical models, e.g. Hidden Markov Models [HMMs]
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/20—Speech recognition techniques specially adapted for robustness in adverse environments, e.g. in noise, of stress induced speech
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/24—Speech recognition using non-acoustical features
- G10L15/25—Speech recognition using non-acoustical features using position of the lips, movement of the lips or face analysis
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
- G10L25/84—Detection of presence or absence of voice signals for discriminating voice from noise
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
- G10L2015/0631—Creating reference templates; Clustering
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Artificial Intelligence (AREA)
- Probability & Statistics with Applications (AREA)
- Circuit For Audible Band Transducer (AREA)
Abstract
本发明公开了一种服务型机器人语音交互的音视频混合语音前端处理方法,具体步骤如下:(1)通过视频处理手段捕获期望说话人嘴部动作信息;(2)根据期望说话人嘴部动作信息获得准确的语音激活检测结果;(3)根据语音活动检测结果,优化机器人传声器阵列的波束算法;(4)通过阵列传声器实现语音增强,抑制环境噪声,提升机器人采集语音的信噪比。本发明在机器人所处复杂声场环境中可以有效提升机器人采集语音的信号质量。
Description
技术领域
本发明属于语音信号处理的技术领域,具体涉及一种复杂环境中使用传声器阵列的语音前端,用于提升服务型机器人的语音采集质量。
背景技术
语音交互系统,作为最快捷有效的智能人机交互系统,在我们的生活中无处不在。语音交互系统需要在不同的场景下捕捉使用者的说话音频,在语音增强与分离等预处理步骤后进行自动语音识别(automatic speech recognition, ASR)。在远场、嘈杂等声学环境恶劣的情况下,识别准确率迅速下降。为了提高系统的鲁棒性,需要利用各种算法进行语音增强以提高语音的质量和可靠度。语音增强主要包括:语音分离、语音去混响和语音降噪,三者要解决的干扰分别来源于其他说话人的声音信号、空间环境对声音信号反射产生的混响和各种环境噪声。语音增强通过有效抑制这些噪声或人声来提高语音质量,现已应用于语音识别、助听器以及电话会议等。
传声器阵列指两个或以上的传声器单元以特定空间位置排列组成的声学系统,配合信号处理方法,能够达到声源定位、盲源分离、声全息和语音增强等目的。此技术在传统的通信、生物医学工程等领域以及最近热门的虚拟现实(VR)、增强现实(AR)和人工智能(AI)领域皆有广泛的应用前景。基于阵列的增强方案包括阵列波束形成(beamforming)与盲源分离(HIGUCHI T, ITO N, YOSHIOKA T, et al. Robust MVDR beamforming usingtimefrequency masks for online/offline ASR in noise[C] // 2016 IEEEInternational Conference on Acoustics, Speech and Signal Processing (ICASSP).2016 :5210 – 5214.)等。
传声器阵列波束形成,即按照阵列和声源的相关空间位置的导向矢量(steeringvector)设计空间滤波器。按照空间滤波器参数可变与否,分为固定波束形成和自适应波束形成。固定波束由于滤波器参数不可调整,具有相对自适应波束更差的抗干扰能力和分辨率。当声源位置时变时,固定波束性能显著下降。但是其运算量较小、易于实现、且对传声器和声源位置的准确性有更好的鲁棒性。
固定波束设计的设计目标是使波束主瓣指向目标声源,达到增强声源信号,抑制其他方向噪声信号的目的。延时求和(delay and sum, DS)波束(BRANDSTEIN M, WARD D.Microphone arrays: signal processing techniques and applications[M]. [S.l.] :Springer Science & Business Media, 2013.)是最常用的固定波束算法,它对于扰动鲁棒性好,但是主瓣随频率升高而变窄,即频率越高指向性越强,导致信号低通畸变。另外,延时求和波束要获得好的指向,需要足够多的单元数量。固定波束算法难以设计具有任意指向性的波束,而宽带波束的方法可以根据不同的代价函数和滤波求和结构,设计满足空间特征的波束:最小二乘法(least square, LS)、特征滤波器法(eigenfilter method)、基于阵列特征参数的方法、非线性优化波束(DOCLO S. Multimicrophone noise reductionand dereverberation techniques for speech applications[J], 2003.)等。
自适应波束设计结合了波束指向性和空间信息自适应的特点,通过一定的迭代方式使实际响应接近期望响应。自适应波束根据不同的策略,如线性约束最小化方差(linearly constrained minimum variance, LCMV)策略、广义旁瓣抵消(generalizedsidelobe cancellation, GSC)策略等。其中,LCMV的应用之一最小方差无失真响应(minimum variance distortionless response, MVDR)波束是应用得最广泛的自适应波束之一,也是本发明阵列的波束形成策略。
常用的语音增强算法一般将处理重点放在音频信号本身。而人脑在处理别人传达的信息时,往往是将多种模态的信息,例如肢体语言、嘴唇动作和面部表情等,融合在一起处理的。与之类似,在设计语音增强解决方案时,若能充分关注这些多模特征,有望进一步提升系统性能。另外,在机器人人机交互、车载交互、视频会议等语音交互系统中,信息的传入设备同时包含传声器(阵列)和摄像头,这也为结合视频信息处理语音增强问题提供了基本的硬件条件。
图像序列的行为识别任务有一个通用的框架,即用卷积神经网络(convolutionalneural networks, CNN)提取特征,再通过几层循环神经网络(recurrent neuralnetwork, RNN)以方便利用帧与帧之间的关联信息(DONAHUE J, ANNE HENDRICKS L,GUADARRAMA S, et al. Longterm recurrent convolutional networks for visualrecognition and description[C]// Proceedings of the IEEE conference oncomputer vision and pattern recognition.2015 : 2625 – 2634.)。本发明也采取类似的网络设置来对唇部图像的VAD判决进行预测,以期望达到图像唇读VAD的SOTA方案的准确性。
发明内容
发明目的:传统只依赖音频信息的语音增强方法在对低信噪比、非稳态噪声、强混响环境下的语音进行增强时往往难以去除噪声成分,这对后续机器人的语音识别和语义理解造成了巨大的困难,本发明提供一种服务型机器人语音交互的音视频混合语音前端处理方法,本发明提出结合图像和视频分析的多模语音增强方案,其具有不错的鲁棒性,并且在低信噪比时对语音识别效果提升很明显。
技术方案:为实现上述目的,本发明采用的技术方案为:
一种服务型机器人语音交互的音视频混合语音前端处理方法,包括以下步骤:
步骤1,模型训练:采集训练音视频样本,将训练音视频样本中视频部分按帧分成图像,将训练音视频样本中语音部分按对应帧图像进行标签,得到对应帧的干净语音VAD标签。将图像和对应帧的干净语音VAD标签导入CNN-RNN图像分类网络中,对图像中的唇动状态和应帧的干净语音VAD标签进行训练,得到训练好的CNN-RNN图像分类网络。
步骤2,采集目标说话人嘴部动作视频和对应的含噪语音。嘴部动作视频用卷积神经网络方法标记出目标说话人人脸五官定位,并裁出嘴唇区域图像。嘴唇区域图像逐帧进行灰度图重塑得到嘴唇区域灰度图像,将嘴唇区域灰度图像输入到图像活动语音检测器。
步骤3,图像活动语音检测器根据输入的嘴唇区域灰度图像检测到目标说话人正在说话,则将嘴唇区域灰度图像输入到训练好的CNN-RNN图像分类网络中,得到此帧嘴唇区域灰度图对应的图像语音VAD概率。
步骤4,对含噪语音做短时傅里叶变换得到短时傅里叶频谱。
使用清晰视频数据集的音频、多通道噪声数据集,并根据相应的传声器空间位置以及随机声源位置模拟出相应传声器采集到的含噪语音。
步骤5,将图像语音VAD概率通过非线性的映射函数得到映射后图像语音概率,映射后图像语音概率与相应帧的所对应音频信号的短时傅里叶频谱进行时域上的加权操作,进行图像VAD和传声器阵列信号的多模融合,得到图像VAD加权后的传声器阵列信号频谱。
本发明相比现有技术,具有以下有益效果:
本发明从传声器阵列和声源的相对空间位置入手,利用复高斯混合模型(CGMM),期望最大化(EM)方法以及最小方差无失真响应(MVDR)波束来增强目标源方向的语音。其中时频掩模的使用能够避免使用不准确的先验知识,例如阵列几何和平面波传播假设,从而提供稳健的导向矢量估计。在此基础上,为了提高在低信噪比、非稳态噪声等多种复杂噪声场景下算法的有效性,采用了对噪声不敏感的图像模态的信息作为补充,用唇部图像生成可靠的VAD判决。在 CGMM分类系统的前端融合 VAD 可有效提高语音时频掩膜的准确性,从而得到更好的音质和语音可懂度,为后续语音识别任务提供更优质的前端输入。
附图说明
图1是本发明的结合图像和视频处理的多模语音增强处理流程图。
图2是用卷积神经网络方法标记出目标说话人人脸的五官定位,并裁出嘴唇区域的处理结果。
图3为嘴唇图像处理部分的2D CNN-RNN神经网络的框架,其中包括二维卷积层组成的编码器,随后经过长短期记忆网络块,接着得到此刻唇动状态VAD的预测。
图4为一个声源时的问题框架示意图。
图5为模拟含噪语音生成的空间示意图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
一种服务型机器人语音交互的音视频混合语音前端处理方法,如图1所示,包括以下步骤:
步骤1,模型训练:采集训练音视频样本,将训练音视频样本中视频部分按帧分成图像,将训练音视频样本中语音部分按对应帧图像进行标签,得到对应帧的干净语音VAD标签。将图像和对应帧的干净语音VAD标签导入CNN-RNN图像分类网络中,对图像中的唇动状态和应帧的干净语音VAD标签进行训练,得到训练好的CNN-RNN图像分类网络。
步骤2,采集目标说话人嘴部动作视频和对应的含噪语音。嘴部动作视频用卷积神经网络方法标记出目标说话人人脸五官定位,并裁出嘴唇区域图像,截取如图2所示。嘴唇区域图像逐帧进行90×110像素的灰度图重塑,并归一化数据格式到16位浮点数,得到嘴唇区域灰度图像,将嘴唇区域灰度图像输入到图像活动语音检测器。
步骤3,图像活动语音检测器根据输入的嘴唇区域灰度图像检测到目标说话人正在说话,则将嘴唇区域灰度图像输入到训练好的CNN-RNN图像分类网络中,得到此帧嘴唇区域灰度图对应的图像语音VAD概率,如图3所示,首先第一列嘴唇区域灰度图序列经过二维卷积层组成的编码器,随后经过长短期记忆网络块,接着得到此刻唇动状态的预测,输出根据图像信息判决此帧为图像语音VAD概率。
步骤4,使用清晰视频数据集的音频、多通道噪声数据集,并根据相应的传声器空间位置以及随机声源位置模拟出相应传声器采集到的含噪语音,如图5所示,对含噪语音做短时傅里叶变换得到短时傅里叶频谱,其中信号处理的参数设置见表1。
表1 音频算法的实验参数

步骤5,将图像语音VAD概率通过非线性的映射函数得到映射后图像语音概率,映射后图像语音概率与相应帧的所对应音频信号的短时傅里叶频谱进行时域上的加权操作,进行图像VAD和传声器阵列信号的多模融合,得到图像VAD加权后的传声器阵列信号频谱。
其中映射函数的定义域和值域都在[0,1],可以理解为一种额外设计的激活函数,目的是为了让加权操作更加平滑。映射具体函数关系见式(1),加权方式见式(2):

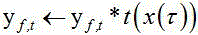
其中,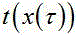 表示映射后图像语音概率,
表示映射后图像语音概率, 是图像语音VAD概率,即CNN-RNN图
像分类网络预测结果,
是图像语音VAD概率,即CNN-RNN图
像分类网络预测结果,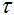 是图像的时间帧索引,
是图像的时间帧索引, 表示短时傅里叶频谱,
表示短时傅里叶频谱, 表示频域,
表示频域,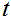 表
示时刻。
表
示时刻。
步骤6,将得到的图像VAD加权后的传声器阵列信号频谱输入基于复数高斯混合模型CGMM的时频掩模估计器,然后用最大似然法估计CGMM 参数,得到时频掩膜序列。然后对于所有频域点数,依次在线递归更新空间相关矩阵,含噪语音和噪声的协方差矩阵,以及聚类的混合权重。最后更新所有源的期望协方差矩阵并作时间平滑,分离它们的特征向量作为对应源导向矢量的估计,用MVDR波束的空间最优权矢量滤波器得到目标方向增强的语音信号。
一、问题框架
k ∈ {1, ..., K}是源索引,K表示源信号个数,m ∈ {1, ..., M} 是传声器索
引,M表示传声器个数。在时域中,第 m 个传声器的语音信号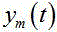 可以写为:
可以写为:

其中,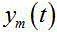 表示第 m 个传声器的语音信号,
表示第 m 个传声器的语音信号, 表示第 k 个源信号的噪声
信号,
表示第 k 个源信号的噪声
信号, 表示第 m 个传声器采集到的噪声信号,
表示第 m 个传声器采集到的噪声信号, 表示对应于第k 个源和第 m
个传声器之间的脉冲响应,如图4所示,
表示对应于第k 个源和第 m
个传声器之间的脉冲响应,如图4所示, 是图像的时间帧索引,
是图像的时间帧索引, 表示时刻。
表示时刻。
第 m 个传声器的语音信号 通过应用短时傅立叶变换(shorttime Fourier
transform, STFT),公式 (3)可以在频域中表示为:
通过应用短时傅立叶变换(shorttime Fourier
transform, STFT),公式 (3)可以在频域中表示为:

其中, 为
为 的频域表示,
的频域表示, 为
为 的频域表示,
的频域表示, 为
为 的频域表示,
的频域表示, 为
为 的频域表示。
的频域表示。
这里我们假设脉冲响应的长度远小于 STFT 窗口的长度,因此,脉冲响应和源信号在时域中的卷积表示为时不变频率响应和时变源信号在频域中的乘积,引入矢量符号,式(4)可以改写为:

其中:
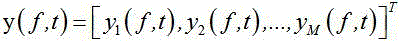


其中, 表示被噪声混合的观测信号,
表示被噪声混合的观测信号, 表示第 k 个信号源和各个传
声器之间的频率响应,
表示第 k 个信号源和各个传
声器之间的频率响应,  是导向矢量,
是导向矢量, 表示源信号的短时傅立叶变换,
表示源信号的短时傅立叶变换, 表示噪声信号的短时傅立叶变换,T 表示非共轭转置。
表示噪声信号的短时傅立叶变换,T 表示非共轭转置。
源分离 (或语音增强) 问题的目标是凭借被噪声混合的观测信号 估计每
个目标源信号
估计每
个目标源信号 。
。
二、结合图像信息的CGMM-MVDR在线方法:
初始化协方差矩阵 ,掩膜和
,掩膜和 ,聚类的混合权重
,聚类的混合权重 ,
取前1000ms作为空间相关矩阵
,
取前1000ms作为空间相关矩阵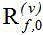 的粗略估计。
的粗略估计。 分别表示含噪语音、噪
声、干净语音。
分别表示含噪语音、噪
声、干净语音。
首先通过基于复数高斯混合模型CGMM的时频掩模估计器进行CGMM的EM方法掩膜估计,在掩膜估计期望步骤(E step)中后验概率用以下式子计算:

其中, 表示
表示 类的掩膜,
类的掩膜, 表示
表示 类的混合权重,
类的混合权重, 表示条件概率,
表示条件概率, 表示含噪
语音、噪声、干净语音中的任意一类,
表示含噪
语音、噪声、干净语音中的任意一类, 表示一系列CGMM参数。
表示一系列CGMM参数。
步骤5得到的图像VAD加权后的传声器阵列信号频谱得到混合权重为 的复高
斯混合模型,如下所示:
的复高
斯混合模型,如下所示:

其中, 表示复数高斯混合分布,
表示复数高斯混合分布, 表示时频点的信号方差,
表示时频点的信号方差,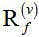 表示
表示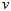 类的空
间相关矩阵。
类的空
间相关矩阵。
具有均值µ和协方差矩阵Σ的多元复高斯分布为:

其中, 表示随机变量为X均值为
表示随机变量为X均值为 方差为
方差为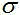 的复数高斯混合分布,
的复数高斯混合分布,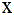 表示随机变量,
表示随机变量, 表示均值,
表示均值, 表示方差,
表示方差, 表示共轭转置。
表示共轭转置。
在掩膜估计最大化步骤(M step)中,CGMM 参数用以下式子更新:

其中, 表示
表示 类时频点的信号方差,
类时频点的信号方差, 表示空间相关矩阵的维度,
表示空间相关矩阵的维度, 表示取矩
阵的迹,
表示取矩
阵的迹, 表示含噪语音的观测信号的时频点,
表示含噪语音的观测信号的时频点,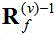 表示空间相关矩阵取逆。
表示空间相关矩阵取逆。
在每个 EM 迭代步骤里被最大化的 Q 函数为:

直至EM方法迭代达到指定次数。
EM方法迭代指定次数后,第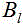 批处的空间相关矩阵由下式递归估计:
批处的空间相关矩阵由下式递归估计:
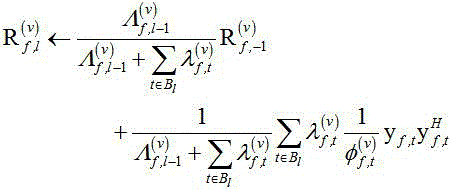
含噪语音和噪声的协方差矩阵被在线递归更新为:
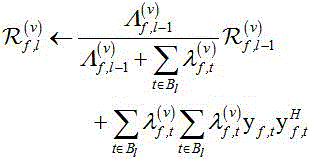
递归更新混合权重:

以上步骤对于所有频率点都更新完,随后进行导向矢量的估计。
通过导向向量估计器进行导向向量估计:
先计算含噪语音 和噪声
和噪声 的协方差矩阵估计:
的协方差矩阵估计:

得到k-th语音信号协方差矩阵估计:

然后对 执行特征向量分解,提取最大特征值相关联的特征向量作为导向向量
执行特征向量分解,提取最大特征值相关联的特征向量作为导向向量 的估计。
的估计。
最后进行MVDR波束形成,得到增强语音。
MVDR波束的k-th源的滤波器系数:
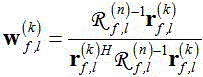
得到增强的k-th源信号估计:
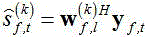

由于是在线算法,故以上操作都只针对某一批次的每个时间点 ,结束这一批
次以后,需要更新掩膜和:
,结束这一批
次以后,需要更新掩膜和:
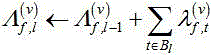
然后进行下次批次的更新,直到音频结束。
三、.数据集与评价指标
噪声来自DEMAND多通道噪声库,纯净目标源来自 TIMIT 库。共模拟数据 120(干净音频)*12(噪声种类)=1440(组)。对于在线处理,每个音频的前 1000ms,约31帧作为训练数据以估计可靠的初始空间相关矩阵。由于 TIMIT 库的音频说话开始时间皆小于1000ms,这样做是可行的。
评价指标包括经常被用来衡量语音分离效果的尺度不变的信号失真比(SI-SDR),其定义为

其中, 和
和 分别是干净语音和估计的目标语音,它们被零均值归一化以保证尺度
不变性。
分别是干净语音和估计的目标语音,它们被零均值归一化以保证尺度
不变性。 表示干净语音在干净语音和估计语音相关系数的归一化的方向的投影,
表示干净语音在干净语音和估计语音相关系数的归一化的方向的投影, 表示编程语言里的赋值语句的符号,
表示编程语言里的赋值语句的符号, 表示估计的噪声信号。
表示估计的噪声信号。
除了SI-SDR之外,评价指标还有语音质量客观评价指标PESQ。
四、实验结果
对比是否结合图像信息的CGMM-MVDR在线算法,对不同信噪比混合语音处理前后的效果用处理前后指标的差值表示,数值越大代表改善越大,测试结果如表2所示:
表2 测试结果

标准CGMM-MVDR算法不含图像的多模处理,为混合处理为否的部分。它在含噪语音为0dB左右的时候SI-SDR改善最多,而PESQ则是含噪语音信噪比越低处理前后改善越多。因为含噪语音信噪比越低,初始分数越低。
多模混合处理方案在极低信噪比SNR=-10dB时,相对于标准方案,SI-SDR还能再提高1.06dB,Babble类人声噪音此提高幅度更甚。由于多模融合时粗暴的幅度加权,PESQ效果略逊色。但是实际在使用时,由于多模检测为不说话的时间段上本来就不需要语音识别,所以PESQ的逊色只会影响听感,而不影响后续语音识别。反而准确的图像VAD判决会为后续的语音识别任务强调重点识别的地方,在目标说话人闭嘴时忽略其他类似的人声噪声。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
Claims (5)
1.一种服务型机器人语音交互的音视频混合语音前端处理方法,其特征在于,包括以下步骤:
步骤1,模型训练:采集训练音视频样本,将训练音视频样本中视频部分按帧分成图像,将训练音视频样本中语音部分按对应帧图像进行标签,得到对应帧的干净语音VAD标签;将图像和对应帧的干净语音VAD标签导入CNN-RNN图像分类网络中,对图像中的唇动状态和应帧的干净语音VAD标签进行训练,得到训练好的CNN-RNN图像分类网络;
步骤2,采集目标说话人嘴部动作视频和对应的含噪语音;嘴部动作视频用卷积神经网络方法标记出目标说话人人脸五官定位,并裁出嘴唇区域图像;嘴唇区域图像逐帧进行灰度图重塑得到嘴唇区域灰度图像,将嘴唇区域灰度图像输入到图像活动语音检测器;
步骤3,图像活动语音检测器根据输入的嘴唇区域灰度图像检测到目标说话人正在说话,则将嘴唇区域灰度图像输入到训练好的CNN-RNN图像分类网络中,得到此帧嘴唇区域灰度图对应的图像语音VAD概率;
步骤4,对含噪语音做短时傅里叶变换得到短时傅里叶频谱;
对含噪语音做短时傅里叶变换得到短时傅里叶频谱的方法:
k ∈ {1, ..., K}是源索引,K表示源信号个数,m ∈ {1, ..., M} 是传声器索引,M
表示传声器个数;在时域中,第 m 个传声器的语音信号 写为:
写为:

其中, 表示第 m 个传声器的语音信号,
表示第 m 个传声器的语音信号,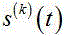 表示第 k 个源信号的噪声信号,
表示第 k 个源信号的噪声信号,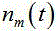 表示第 m 个传声器采集到的噪声信号,
表示第 m 个传声器采集到的噪声信号, 表示对应于第k 个源和第 m 个传
声器之间的脉冲响应,
表示对应于第k 个源和第 m 个传
声器之间的脉冲响应, 是图像的时间帧索引,
是图像的时间帧索引,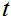 表示时刻;
表示时刻;
第 m 个传声器的语音信号 通过应用短时傅立叶变换在频域中表示为:
通过应用短时傅立叶变换在频域中表示为:

其中,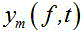 为
为 的频域表示,
的频域表示, 为
为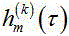 的频域表示,
的频域表示, 为
为 的频域表示,
的频域表示, 为
为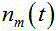 的频域表示;
的频域表示;
脉冲响应的长度远小于 STFT 窗口的长度,因此,脉冲响应和源信号在时域中的卷积表示为时不变频率响应和时变源信号在频域中的乘积,引入矢量符号,将应用短时傅立叶变换在频域中表示改写为:

其中:
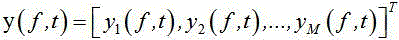

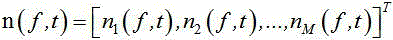
其中, 表示含噪语音的观测信号,
表示含噪语音的观测信号,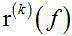 表示第 k 个信号源和各个传声器之
间的频率响应,
表示第 k 个信号源和各个传声器之
间的频率响应, 表示源信号的短时傅立叶变换,
表示源信号的短时傅立叶变换, 表示噪声信号的短时傅
立叶变换,T 表示非共轭转置;
表示噪声信号的短时傅
立叶变换,T 表示非共轭转置;
步骤5,将图像语音VAD概率通过非线性的映射函数得到映射后图像语音概率,映射后图像语音概率与相应帧的所对应音频信号的短时傅里叶频谱进行时域上的加权操作,进行图像VAD和传声器阵列信号的多模融合,得到图像VAD加权后的传声器阵列信号频谱;
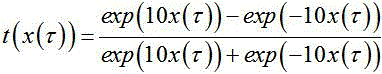

其中, 表示映射后图像语音概率,
表示映射后图像语音概率, 是图像语音VAD概率,
是图像语音VAD概率, 是图像的时间帧
索引,
是图像的时间帧
索引,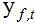 表示短时傅里叶频谱,
表示短时傅里叶频谱, 表示频域,
表示频域,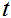 表示时刻;
表示时刻;
步骤6,将得到的图像VAD加权后的传声器阵列信号频谱输入基于复数高斯混合模型CGMM的时频掩模估计器,然后用最大似然法估计CGMM 参数,得到时频掩膜序列;然后对于所有频域点数,依次在线递归更新空间相关矩阵,含噪语音和噪声的协方差矩阵,以及聚类的混合权重;最后更新所有源的期望协方差矩阵并作时间平滑,分离它们的特征向量作为对应源导向矢量的估计,用MVDR波束的空间最优权矢量滤波器得到目标方向增强的语音信号;
基于复数高斯混合模型CGMM的时频掩模估计器采用结合图像信息的CGMM-MVDR在线方法:
初始化协方差矩阵 ,掩膜和
,掩膜和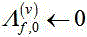 ,聚类的混合权重
,聚类的混合权重 ,
,  分别表示含噪语音、噪声、干净语音;
分别表示含噪语音、噪声、干净语音;
首先通过基于复数高斯混合模型CGMM的时频掩模估计器进行CGMM的EM方法掩膜估计,在掩膜估计期望步骤中后验概率用以下式子计算:
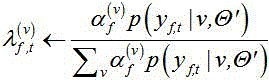
其中,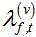 表示
表示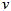 类的掩膜,
类的掩膜, 表示
表示 类的混合权重,
类的混合权重,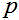 表示条件概率,
表示条件概率, 表示含噪语音、
噪声、干净语音中的任一一类,
表示含噪语音、
噪声、干净语音中的任一一类, 表示一系列CGMM参数;
表示一系列CGMM参数;
步骤5得到的图像VAD加权后的传声器阵列信号频谱得到混合权重为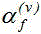 的复高斯混
合模型:
的复高斯混
合模型:

其中, 表示复数高斯混合分布,
表示复数高斯混合分布, 表示时频点的信号方差,
表示时频点的信号方差,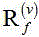 表示
表示 类的空间相
关矩阵;
类的空间相
关矩阵;
具有均值µ和协方差矩阵Σ的多元复高斯分布为:

其中, 表示随机变量为X均值为
表示随机变量为X均值为 方差为
方差为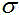 的复数高斯混合分布,
的复数高斯混合分布, 表示
随机变量,
表示
随机变量, 表示均值,
表示均值, 表示方差,
表示方差, 表示共轭转置;
表示共轭转置;
在掩膜估计最大化步骤中,CGMM 参数用以下式子更新:

其中, 表示
表示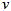 类时频点的信号方差,
类时频点的信号方差, 表示传声器个数,
表示传声器个数, 表示取矩阵的迹,
表示取矩阵的迹, 表
示含噪语音的观测信号的时频点,
表
示含噪语音的观测信号的时频点,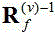 表示空间相关矩阵取逆;
表示空间相关矩阵取逆;
被最大化的 Q 函数为:

直至EM方法迭代达到指定次数。
2.根据权利要求1所述服务型机器人语音交互的音视频混合语音前端处理方法,其特征在于:
EM方法迭代指定次数后,第 批处的空间相关矩阵由下式递归估计:
批处的空间相关矩阵由下式递归估计:

含噪语音和噪声的协方差矩阵被在线递归更新为:
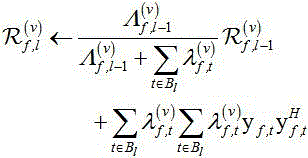
递归更新混合权重:

更新所有源的期望协方差矩阵。
3.根据权利要求2所述服务型机器人语音交互的音视频混合语音前端处理方法,其特征在于:通过导向向量估计器进行导向向量估计:
先计算含噪语音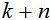 和噪声
和噪声 的协方差矩阵估计:
的协方差矩阵估计:

得到k-th语音信号协方差矩阵估计:

然后对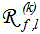 执行特征向量分解,提取最大特征值相关联的特征向量作为导向向量
执行特征向量分解,提取最大特征值相关联的特征向量作为导向向量 的估计;
的估计;
最后进行MVDR波束形成,得到增强语音;
MVDR波束的k-th源的滤波器系数:

得到增强的k-th源信号估计:

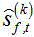
4.根据权利要求3所述服务型机器人语音交互的音视频混合语音前端处理方法,其特
征在于:由于只针对某一批次的每个时间点 ,结束这一批次以后,需要更新掩膜和:
,结束这一批次以后,需要更新掩膜和:

然后进行下次批次的更新,直到音频结束。
5.根据权利要求4所述服务型机器人语音交互的音视频混合语音前端处理方法,其特征在于:步骤4中使用清晰视频数据集的音频、多通道噪声数据集,并根据相应的传声器空间位置以及随机声源位置模拟出相应传声器采集到的含噪语音。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111258776.XA CN113707136B (zh) | 2021-10-28 | 2021-10-28 | 服务型机器人语音交互的音视频混合语音前端处理方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202111258776.XA CN113707136B (zh) | 2021-10-28 | 2021-10-28 | 服务型机器人语音交互的音视频混合语音前端处理方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN113707136A CN113707136A (zh) | 2021-11-26 |
| CN113707136B true CN113707136B (zh) | 2021-12-31 |
Family
ID=78647121
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202111258776.XA Active CN113707136B (zh) | 2021-10-28 | 2021-10-28 | 服务型机器人语音交互的音视频混合语音前端处理方法 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN113707136B (zh) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114093380B (zh) * | 2022-01-24 | 2022-07-05 | 北京荣耀终端有限公司 | 一种语音增强方法、电子设备、芯片系统及可读存储介质 |
| CN114999522B (zh) * | 2022-05-31 | 2025-09-23 | 平安科技(深圳)有限公司 | 基于说话人辅助信息的特定说话人语音提取方法及装置 |
| CN115691544A (zh) * | 2022-10-31 | 2023-02-03 | 广州方硅信息技术有限公司 | 虚拟形象口型驱动模型的训练及其驱动方法、装置和设备 |
| CN117935835B (zh) * | 2024-03-22 | 2024-06-07 | 浙江华创视讯科技有限公司 | 音频降噪方法、电子设备以及存储介质 |
| CN118298792A (zh) * | 2024-04-08 | 2024-07-05 | 哈尔滨工程大学 | 一种基于深度学习的船舶声纳平台自噪声抑制方法 |
| CN120410919B (zh) * | 2025-07-01 | 2025-09-12 | 汕头市超声仪器研究所股份有限公司 | 一种超声图像噪声抑制算法 |
| CN120496510B (zh) * | 2025-07-14 | 2025-09-19 | 广东九四智能科技有限公司 | 一种用于语音识别的人机交互方法及系统 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110931036A (zh) * | 2019-12-07 | 2020-03-27 | 杭州国芯科技股份有限公司 | 一种麦克风阵列波束形成方法 |
| CN111599371A (zh) * | 2020-05-19 | 2020-08-28 | 苏州奇梦者网络科技有限公司 | 语音增加方法、系统、装置及存储介质 |
| CN112735460A (zh) * | 2020-12-24 | 2021-04-30 | 中国人民解放军战略支援部队信息工程大学 | 基于时频掩蔽值估计的波束成形方法及系统 |
| CN113030862A (zh) * | 2021-03-12 | 2021-06-25 | 中国科学院声学研究所 | 一种多通道语音增强方法及装置 |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1883040A1 (en) * | 2006-07-28 | 2008-01-30 | IEE International Electronics & Engineering S.A.R.L. | Pattern classification method |
| CN100495537C (zh) * | 2007-07-05 | 2009-06-03 | 南京大学 | 强鲁棒性语音分离方法 |
| KR102236471B1 (ko) * | 2018-01-26 | 2021-04-05 | 서강대학교 산학협력단 | 재귀적 최소 제곱 기법을 이용한 온라인 cgmm에 기반한 방향 벡터 추정을 이용한 음원 방향 추정 방법 |
| KR102475989B1 (ko) * | 2018-02-12 | 2022-12-12 | 삼성전자주식회사 | 오디오 신호의 주파수의 변화에 따른 위상 변화율에 기반하여 노이즈가 감쇠된 오디오 신호를 생성하는 장치 및 방법 |
| KR102478393B1 (ko) * | 2018-02-12 | 2022-12-19 | 삼성전자주식회사 | 노이즈가 정제된 음성 신호를 획득하는 방법 및 이를 수행하는 전자 장치 |
| WO2020121545A1 (ja) * | 2018-12-14 | 2020-06-18 | 日本電信電話株式会社 | 信号処理装置、信号処理方法、およびプログラム |
| CN110400572B (zh) * | 2019-08-12 | 2021-10-12 | 思必驰科技股份有限公司 | 音频增强方法及系统 |
| CN112509564B (zh) * | 2020-10-15 | 2024-04-02 | 江苏南大电子信息技术股份有限公司 | 基于连接时序分类和自注意力机制的端到端语音识别方法 |
| CN112951263B (zh) * | 2021-03-17 | 2022-08-02 | 云知声智能科技股份有限公司 | 语音增强方法、装置、设备和存储介质 |
-
2021
- 2021-10-28 CN CN202111258776.XA patent/CN113707136B/zh active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110931036A (zh) * | 2019-12-07 | 2020-03-27 | 杭州国芯科技股份有限公司 | 一种麦克风阵列波束形成方法 |
| CN111599371A (zh) * | 2020-05-19 | 2020-08-28 | 苏州奇梦者网络科技有限公司 | 语音增加方法、系统、装置及存储介质 |
| CN112735460A (zh) * | 2020-12-24 | 2021-04-30 | 中国人民解放军战略支援部队信息工程大学 | 基于时频掩蔽值估计的波束成形方法及系统 |
| CN113030862A (zh) * | 2021-03-12 | 2021-06-25 | 中国科学院声学研究所 | 一种多通道语音增强方法及装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN113707136A (zh) | 2021-11-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113707136B (zh) | 服务型机器人语音交互的音视频混合语音前端处理方法 | |
| CN107452389B (zh) | 一种通用的单声道实时降噪方法 | |
| US7383178B2 (en) | System and method for speech processing using independent component analysis under stability constraints | |
| Wang et al. | Deep learning assisted time-frequency processing for speech enhancement on drones | |
| CN108417224B (zh) | 双向神经网络模型的训练和识别方法及系统 | |
| Zhang et al. | Multi-channel multi-frame ADL-MVDR for target speech separation | |
| CN118486318B (zh) | 一种户外直播环境杂音消除方法、介质及系统 | |
| CN103258533B (zh) | 远距离语音识别中的模型域补偿新方法 | |
| CN113870893B (zh) | 一种多通道双说话人分离方法及系统 | |
| CN112735460A (zh) | 基于时频掩蔽值估计的波束成形方法及系统 | |
| CN115620739A (zh) | 指定方向的语音增强方法及电子设备和存储介质 | |
| CN113223552A (zh) | 语音增强方法、装置、设备、存储介质及程序 | |
| CN118899005B (zh) | 一种音频信号处理方法、装置、计算机设备及存储介质 | |
| WO2019014890A1 (zh) | 一种通用的单声道实时降噪方法 | |
| Cherukuru et al. | CNN-based noise reduction for multi-channel speech enhancement system with discrete wavelet transform (DWT) preprocessing | |
| CN105957536B (zh) | 基于通道聚合度频域回声消除方法 | |
| Kothapally et al. | Monaural speech dereverberation using deformable convolutional networks | |
| Chen | Noise reduction of bird calls based on a combination of spectral subtraction, Wiener filtering, and Kalman filtering | |
| Pertilä et al. | Time difference of arrival estimation with deep learning–from acoustic simulations to recorded data | |
| CN110838307B (zh) | 语音消息处理方法及装置 | |
| CN115802245B (zh) | 一种自适应麦克风阵列分离增强方法及系统 | |
| CN115421099B (zh) | 一种语音波达方向估计方法及系统 | |
| CN117711422A (zh) | 一种基于压缩感知空间信息估计的欠定语音分离方法和装置 | |
| Taghia et al. | Dual-channel noise reduction based on a mixture of circular-symmetric complex Gaussians on unit hypersphere | |
| Malek et al. | Speaker extraction using LCMV beamformer with DNN-based SPP and RTF identification scheme |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |